| Issue |
A&A
Volume 671, March 2023
|
|
|---|---|---|
| Article Number | A100 | |
| Number of page(s) | 25 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202244674 | |
| Published online | 14 March 2023 | |
Euclid preparation
XXIV. Calibration of the halo mass function in Λ(ν)CDM cosmologies
1
INAF-Osservatorio Astronomico di Trieste, Via G. B. Tiepolo 11, 34143 Trieste, Italy
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
INFN, Sezione di Trieste, Via Valerio 2, 34127 Trieste TS, Italy
3
IFPU, Institute for Fundamental Physics of the Universe, Via Beirut 2, 34151 Trieste, Italy
4
Dipartimento di Fisica – Sezione di Astronomia, Universitá di Trieste, Via Tiepolo 11, 34131 Trieste, Italy
5
Donostia International Physics Center (DIPC), Paseo Manuel de Lardizabal, 4, 20018 Donostia-San Sebastián, Guipuzkoa, Spain
6
IKERBASQUE, Basque Foundation for Science, 48013 Bilbao, Spain
7
University Observatory, Faculty of Physics, Ludwig-Maximilians-Universität, Scheinerstr. 1, 81679 Munich, Germany
8
INAF-IASF Milano, Via Alfonso Corti 12, 20133 Milano, Italy
9
Department of Physics and Astronomy, University of Aarhus, Ny Munkegade 120, 8000 Aarhus C, Denmark
10
Universitäts-Sternwarte München, Fakultät für Physik, Ludwig-Maximilians-Universität München, Scheinerstrasse 1, 81679 München, Germany
11
Max-Planck-Institut für Astrophysik, Karl-Schwarzschild Str. 1, 85741 Garching, Germany
12
Istituto Nazionale di Astrofisica (INAF) – Osservatorio di Astrofisica e Scienza dello Spazio (OAS), Via Gobetti 93/3, 40127 Bologna, Italy
13
Istituto Nazionale di Fisica Nucleare, Sezione di Bologna, Via Irnerio 46, 40126 Bologna, Italy
14
Dipartimento di Fisica e Astronomia, Universitá di Bologna, Via Gobetti 93/2, 40129 Bologna, Italy
15
Laboratoire Univers et Théorie, Observatoire de Paris, Université PSL, Université Paris Cité, CNRS, 92190 Meudon, France
16
Institute of Cosmology and Gravitation, University of Portsmouth, Portsmouth PO1 3FX, UK
17
Institut für Theoretische Physik, University of Heidelberg, Philosophenweg 16, 69120 Heidelberg, Germany
18
INAF-Osservatorio di Astrofisica e Scienza dello Spazio di Bologna, Via Piero Gobetti 93/3, 40129 Bologna, Italy
19
INFN-Sezione di Bologna, Viale Berti Pichat 6/2, 40127 Bologna, Italy
20
Max Planck Institute for Extraterrestrial Physics, Giessenbachstr. 1, 85748 Garching, Germany
21
Dipartimento di Fisica, Università di Genova, Via Dodecaneso 33, 16146 Genova, Italy
22
INFN-Sezione di Roma Tre, Via della Vasca Navale 84, 00146 Roma, Italy
23
Department of Physics “E. Pancini”, University Federico II, Via Cinthia 6, 80126 Napoli, Italy
24
INAF-Osservatorio Astronomico di Capodimonte, Via Moiariello 16, 80131 Napoli, Italy
25
Dipartimento di Fisica, Universitá degli Studi di Torino, Via P. Giuria 1, 10125 Torino, Italy
26
INFN-Sezione di Torino, Via P. Giuria 1, 10125 Torino, Italy
27
INAF-Osservatorio Astrofisico di Torino, Via Osservatorio 20, 10025 Pino Torinese (TO), Italy
28
Institut de Física d’Altes Energies (IFAE), The Barcelona Institute of Science and Technology, Campus UAB, 08193 Bellaterra (Barcelona), Spain
29
Port d’Informació Científica, Campus UAB, C. Albareda s/n, 08193 Bellaterra (Barcelona), Spain
30
INAF-Osservatorio Astronomico di Roma, Via Frascati 33, 00078 Monteporzio Catone, Italy
31
INFN section of Naples, Via Cinthia 6, 80126 Napoli, Italy
32
Dipartimento di Fisica e Astronomia “Augusto Righi” – Alma Mater Studiorum Universitá di Bologna, Viale Berti Pichat 6/2, 40127 Bologna, Italy
33
INAF-Osservatorio Astrofisico di Arcetri, Largo E. Fermi 5, 50125 Firenze, Italy
34
Centre National d’Etudes Spatiales – Centre spatial de Toulouse, 18 avenue Edouard Belin, 31401 Toulouse Cedex 9, France
35
Institut national de physique nucléaire et de physique des particules, 3 rue Michel-Ange, 75794 Paris Cedex 16, France
36
Institute for Astronomy, University of Edinburgh, Royal Observatory, Blackford Hill, Edinburgh EH9 3HJ, UK
37
ESAC/ESA, Camino Bajo del Castillo, s/n., Urb. Villafranca del Castillo, 28692 Villanueva de la Cañada, Madrid, Spain
38
European Space Agency/ESRIN, Largo Galileo Galilei 1, 00044 Frascati, Roma, Italy
39
Univ Lyon, Univ Claude Bernard Lyon 1, CNRS/IN2P3, IP2I Lyon, UMR 5822, 69622 Villeurbanne, France
40
Institute of Physics, Laboratory of Astrophysics, Ecole Polytechnique Fédérale de Lausanne (EPFL), Observatoire de Sauverny, 1290 Versoix, Switzerland
41
Departamento de Física, Faculdade de Ciências, Universidade de Lisboa, Edifício C8, Campo Grande, 1749-016 Lisboa, Portugal
42
Instituto de Astrofísica e Ciências do Espaço, Faculdade de Ciências, Universidade de Lisboa, Campo Grande, 1749-016 Lisboa, Portugal
43
Department of Astronomy, University of Geneva, ch. dÉcogia 16, 1290 Versoix, Switzerland
44
Université Paris-Saclay, CNRS, Institut d’astrophysique spatiale, 91405 Orsay, France
45
Department of Physics, Oxford University, Keble Road, Oxford OX1 3RH, UK
46
Jodrell Bank Centre for Astrophysics, Department of Physics and Astronomy, University of Manchester, Oxford Road, Manchester M13 9PL, UK
47
Université Paris-Saclay, Université Paris Cité, CEA, CNRS, Astrophysique, Instrumentation et Modélisation Paris-Saclay, 91191 Gif-sur-Yvette, France
48
Institute of Space Sciences (ICE, CSIC), Campus UAB, Carrer de Can Magrans, s/n, 08193 Barcelona, Spain
49
Institut d’Estudis Espacials de Catalunya (IEEC), Carrer Gran Capitá 2-4, 08034 Barcelona, Spain
50
INAF-Osservatorio Astronomico di Padova, Via dell’Osservatorio 5, 35122 Padova, Italy
51
Institute of Theoretical Astrophysics, University of Oslo, PO Box 1029 Blindern, 0315 Oslo, Norway
52
von Hoerner & Sulger GmbH, SchloßPlatz 8, 68723 Schwetzingen, Germany
53
Technical University of Denmark, Elektrovej 327, 2800 Kgs. Lyngby, Denmark
54
Institut d’Astrophysique de Paris, 98bis Boulevard Arago, 75014 Paris, France
55
Max-Planck-Institut für Astronomie, Königstuhl 17, 69117 Heidelberg, Germany
56
Aix-Marseille Univ., CNRS/IN2P3, CPPM, Marseille, France
57
Mullard Space Science Laboratory, University College London, Holmbury St Mary, Dorking, Surrey RH5 6NT, UK
58
Université de Genève, Département de Physique Théorique and Centre for Astroparticle Physics, 24 quai Ernest-Ansermet, 1211 Genève 4, Switzerland
59
Department of Physics and Helsinki Institute of Physics, Gustaf Hällströmin katu 2, 00014 University of Helsinki, Finland
60
NOVA optical infrared instrumentation group at ASTRON, Oude Hoogeveensedijk 4, 7991 PD Dwingeloo, The Netherlands
61
Argelander-Institut für Astronomie, Universität Bonn, Auf dem Hügel 71, 53121 Bonn, Germany
62
Dipartimento di Fisica e Astronomia “Augusto Righi” – Alma Mater Studiorum Università di Bologna, via Piero Gobetti 93/2, 40129 Bologna, Italy
63
European Space Agency/ESTEC, Keplerlaan 1, 2201 AZ Noordwijk, The Netherlands
64
AIM, CEA, CNRS, Université Paris-Saclay, Université de Paris, 91191 Gif-sur-Yvette, France
65
Space Science Data Center, Italian Space Agency, Via del Politecnico snc, 00133 Roma, Italy
66
Institute of Space Science, Bucharest 077125, Romania
67
Instituto de Astrofísica de Canarias, Calle Vía Láctea s/n, 38204 San Cristóbal de La Laguna, Tenerife, Spain
68
Departamento de Astrofísica, Universidad de La Laguna, 38206 La Laguna, Tenerife, Spain
69
Dipartimento di Fisica e Astronomia “G.Galilei”, Universitá di Padova, Via Marzolo 8, 35131 Padova, Italy
70
INFN-Padova, Via Marzolo 8, 35131 Padova, Italy
71
Jet Propulsion Laboratory, California Institute of Technology, 4800 Oak Grove Drive, Pasadena, CA 91109, USA
72
Departamento de Física, FCFM, Universidad de Chile, Blanco Encalada, 2008 Santiago, Chile
73
Centro de Investigaciones Energéticas, Medioambientales y Tecnológicas (CIEMAT), Avenida Complutense 40, 28040 Madrid, Spain
74
Universidad Politécnica de Cartagena, Departamento de Electrónica y Tecnología de Computadoras, 30202 Cartagena, Spain
75
Kapteyn Astronomical Institute, University of Groningen, PO Box 800 9700 AV Groningen, The Netherlands
76
Infrared Processing and Analysis Center, California Institute of Technology, Pasadena, CA 91125, USA
77
INAF-Osservatorio Astronomico di Brera, Via Brera 28, 20122 Milano, Italy
78
INAF-Istituto di Astrofisica e Planetologia Spaziali, Via del Fosso del Cavaliere, 100, 00100 Roma, Italy
79
Junia, EPA department, 41 Bd Vauban, 59000 Lille, France
80
SISSA, International School for Advanced Studies, Via Bonomea 265, 34136 Trieste TS, Italy
81
Dipartimento di Fisica e Scienze della Terra, Universitá degli Studi di Ferrara, Via Giuseppe Saragat 1, 44122 Ferrara, Italy
82
Istituto Nazionale di Fisica Nucleare, Sezione di Ferrara, Via Giuseppe Saragat 1, 44122 Ferrara, Italy
83
Institut de Physique Théorique, CEA, CNRS, Université Paris-Saclay, 91191 Gif-sur-Yvette Cedex, France
84
Institut de Recherche en Astrophysique et Planétologie (IRAP), Université de Toulouse, CNRS, UPS, CNES, 14 Av. Edouard Belin, 31400 Toulouse, France
85
NASA Ames Research Center, Moffett Field, CA 94035, USA
86
INAF, Istituto di Radioastronomia, Via Piero Gobetti 101, 40129 Bologna, Italy
87
INFN-Bologna, Via Irnerio 46, 40126 Bologna, Italy
88
Université Côte d’Azur, Observatoire de la Côte d’Azur, CNRS, Laboratoire Lagrange, Bd de l’Observatoire, CS 34229, 06304 Nice Cedex 4, France
89
Instituto de Astrofísica e Ciências do Espaço, Faculdade de Ciências, Universidade de Lisboa, Tapada da Ajuda, 1349-018 Lisboa, Portugal
90
Institute for Theoretical Particle Physics and Cosmology (TTK), RWTH Aachen University, 52056 Aachen, Germany
91
Department of Physics & Astronomy, University of California Irvine, Irvine, CA 92697, USA
92
University of Lyon, UCB Lyon 1, CNRS/IN2P3, IUF, IP2I Lyon, 4 rue Enrico Fermi, 69622 Villeurbanne, France
93
INFN-Sezione di Genova, Via Dodecaneso 33, 16146 Genova, Italy
94
Université Paris Cité, CNRS, Astroparticule et Cosmologie, 75013 Paris, France
95
Instituto de Física Teórica UAM-CSIC, Campus de Cantoblanco, 28049 Madrid, Spain
96
Department of Physics, PO Box 64 00014 University of Helsinki, Finland
97
Ruhr University Bochum, Faculty of Physics and Astronomy, Astronomical Institute (AIRUB), German Centre for Cosmological Lensing (GCCL), 44780 Bochum, Germany
98
Department of Physics, Lancaster University, Lancaster LA1 4YB, UK
99
Université Paris-Saclay, CNRS/IN2P3, IJCLab, 91405 Orsay, France
100
Department of Physics and Astronomy, University College London, Gower Street, London WC1E 6BT, UK
101
Astrophysics Group, Blackett Laboratory, Imperial College London, London SW7 2AZ, UK
102
Univ. Grenoble Alpes, CNRS, Grenoble INP, LPSC-IN2P3, 53, Avenue des Martyrs, 38000 Grenoble, France
103
Dipartimento di Fisica, Sapienza Università di Roma, Piazzale Aldo Moro 2, 00185 Roma, Italy
104
University of Applied Sciences and Arts of Northwestern Switzerland, School of Engineering, 5210 Windisch, Switzerland
105
Aix-Marseille Univ, CNRS, CNES, LAM, Marseille, France
106
Zentrum für Astronomie, Universität Heidelberg, Philosophenweg 12, 69120 Heidelberg, Germany
107
Department of Mathematics and Physics E. De Giorgi, University of Salento, Via per Arnesano, CP-I93, 73100 Lecce, Italy
108
INAF-Sezione di Lecce, c/o Dipartimento Matematica e Fisica, Via per Arnesano, 73100 Lecce, Italy
109
INFN, Sezione di Lecce, Via per Arnesano, CP-193, 73100 Lecce, Italy
110
Observatoire de Sauverny, Ecole Polytechnique Fédérale de Lau- sanne, 1290 Versoix, Switzerland
111
Institute for Computational Science, University of Zurich, Winterthurerstrasse 190, 8057 Zurich, Switzerland
112
Higgs Centre for Theoretical Physics, School of Physics and Astronomy, The University of Edinburgh, Edinburgh EH9 3FD, UK
113
Université St Joseph; Faculty of Sciences, Beirut, Lebanon
114
Department of Astrophysical Sciences, Peyton Hall, Princeton University, Princeton, NJ 08544, USA
115
Helsinki Institute of Physics, Gustaf Hällströmin katu 2, University of Helsinki, Helsinki, Finland
116
Department of Mathematics and Physics, Roma Tre University, Via della Vasca Navale 84, 00146 Rome, Italy
Received:
3
August
2022
Accepted:
21
November
2022
Abstract
Euclid’s photometric galaxy cluster survey has the potential to be a very competitive cosmological probe. The main cosmological probe with observations of clusters is their number count, within which the halo mass function (HMF) is a key theoretical quantity. We present a new calibration of the analytic HMF, at the level of accuracy and precision required for the uncertainty in this quantity to be subdominant with respect to other sources of uncertainty in recovering cosmological parameters from Euclid cluster counts. Our model is calibrated against a suite of N-body simulations using a Bayesian approach taking into account systematic errors arising from numerical effects in the simulation. First, we test the convergence of HMF predictions from different N-body codes, by using initial conditions generated with different orders of Lagrangian Perturbation theory, and adopting different simulation box sizes and mass resolution. Then, we quantify the effect of using different halo finder algorithms, and how the resulting differences propagate to the cosmological constraints. In order to trace the violation of universality in the HMF, we also analyse simulations based on initial conditions characterised by scale-free power spectra with different spectral indexes, assuming both Einstein–de Sitter and standard ΛCDM expansion histories. Based on these results, we construct a fitting function for the HMF that we demonstrate to be sub-percent accurate in reproducing results from 9 different variants of the ΛCDM model including massive neutrinos cosmologies. The calibration systematic uncertainty is largely sub-dominant with respect to the expected precision of future mass–observation relations; with the only notable exception of the effect due to the halo finder, that could lead to biased cosmological inference.
Key words: galaxies: clusters: general / cosmology: theory / large-scale structure of Universe
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Structure formation in the Universe follows a hierarchical process, with larger structures forming from the collapse of smaller ones. Galaxy clusters sit at the top of this hierarchy as the most massive virialized objects in the Universe. Their cosmological abundance and evolution make them competitive cosmological probes of both the geometry of our Universe and the growth of density perturbations (Allen et al. 2011; Kravtsov & Borgani 2012, for reviews).
Number-counts experiments represent the main cosmological probe from cluster surveys (Holder et al. 2001; Rozo et al. 2010; Hasselfield et al. 2013; Planck Collaboration XX 2014; Planck Collaboration XXIV 2016; Bocquet et al. 2015; Mantz et al. 2015; Bocquet et al. 2019; Abbott et al. 2020; Costanzi et al. 2021; Lesci et al. 2022). The idea behind number counts is remarkable in its simplicity; assuming the halo mass function (HMF) is precisely predicted in a given cosmological model, one can confront the number of observed clusters in a survey with this theoretical prediction and, from this, constrain cosmological parameters.
Press & Schechter (1974) presented the first theoretical model for the HMF based on mapping the peaks of a primordial, Gaussian density field to the number of collapsed structures at low redshift. Later, Bond et al. (1991) introduced the excursion-set formalism that embedded the Press–Schechter derivation in a more rigorous and rich mathematical framework. Despite the success of these models in providing an insightful, qualitative description of the abundance of halos, their agreement with increasingly accurate N-body simulations is quantitatively poor (see, e.g. Sheth & Tormen 1999). Later, Maggiore & Riotto (2010a,b,c) extended the excursion-set solution to more realist collapse barriers leading to better agreement with N-body simulations (see also Corasaniti & Achitouv 2011a,b).
Several works presented semi-analytical extensions of the Press–Schechter formalism calibrated to reproduce the results of numerical simulations (see, e.g. Sheth & Tormen 1999; Sheth et al. 2001; Jenkins et al. 2001; Warren et al. 2006; Tinker et al. 2008; Watson et al. 2013; Despali et al. 2016). These extensions rely on the feature of the HMF being predominantly universal, that is, being independent of the underlying cosmological model, if expressed as a function of the Gaussian density field statistics.
The departure of the HMF from universality depends on several aspects, and modelling it is a daunting task. Recent works have started using emulators to circumvent the complex analytical modelling to predict the HMF (McClintock et al. 2019; Nishimichi et al. 2019; Bocquet et al. 2020). Although practical and straightforward, this strategy has limitations as emulators are not rigorously supported by a robust underlying model and are known to perform poorly outside the regime in which they have been built. Furthermore, building an emulator does not necessarily lead to a better understanding of nature, lacking a theoretical legacy. Still, it is essential to note that emulators have pushed the precision and accuracy of the HMF predictions to a few percent, outperforming fitting functions, which range in accuracy from 10 to 30 percent.
N-body simulations are central to both approaches as they are the only theoretical tool to with which to stringently assess the non-linear regime where galaxy clusters are deep-seated. The ever-increasing requirements for larger and high-resolution simulations pushed the development of fast and efficient gravity solvers, each of them relying on different algorithms with different approximations. Keeping the validity, accuracy, and precision of those approximations under control is utterly necessary in order to guarantee the robustness of the final HMF model (see e.g. Angulo & Hahn 2022, for a detailed discussion of the methodology).
The luminous matter composition of our Universe, although subdominant, is known to impact the formation of structure in a significant way (Cui et al. 2014; Velliscig et al. 2014; Bocquet et al. 2016; Castro et al. 2020). The modelling of the baryonic feedback in hydrodynamical simulations is a controversial subject in vogue. However, at the scales of galaxy clusters, it is well established that baryonic feedback cannot disrupt structures; instead, its net effect is to rearrange the halo composition, changing its mass with respect to the same object simulated using a collisionless scheme. As hydrodynamical simulations are thousands of times more expensive than purely gravitational N-body simulations, the standard approach is to characterise the HMF using the latter and model how baryonic physics changes the mass of halos in post-processing (see, e.g. Schneider & Teyssier 2015; Aricò et al. 2021). This method will not be addressed in this paper.
The impact of systematic effects in determining the HMF has already been addressed. For instance, Knebe et al. (2011) and Garcia & Rozo (2019) showed that differences in the halo finder algorithm result in changes in the HMF that can be as large as several percent. Salvati et al. (2020) and Artis et al. (2021) claimed that such discrepancies on the HMF model in future surveys could lead to severe biases in the cosmological constraints, raising awareness of the degree of accuracy required by the quality of next generation data.
In the present work, we aim to calibrate an HMF fitting function with a target accuracy of 1 percent for objects more massive than a few times 1013 h−1 M⊙, as demanded by the large number of galaxy clusters expected to be observed by the ESA Euclid satellite (see Sartoris et al. 2016). In particular, the wide, Euclid survey will cover 15 000 deg2 of the extra-galactic sky (Laureijs et al. 2011) in optical and near-infrared (NIR) bands. By relying on suitable algorithms to identify galaxy clusters as galaxy concentrations in photometric redshift space (Euclid Collaboration 2019), Euclid will provide a survey of optically identified clusters that is unique in terms of the depth and area covered, and that has the potential to provide tight constraints on cosmological models (Sartoris et al. 2016).
To fully exploit the cosmological potential of the Euclid Cluster Survey, several observational and theoretical systematic effects must be controlled. As for the latter, we concentrate in this paper on an accurate calibration of the HMF. To this purpose, we follow the approach of Ondaro-Mallea et al. (2021) and explicitly model the non-universality of the HMF. To guarantee the robustness of our results, we start by presenting a detailed study of the numerical systematic errors on N-body simulations and how they impact the HMF. We then employ a suite of N-body simulations and calibrate a model to predict the abundance of halos as a function of mass, cosmology, and redshift. Lastly, we forecast the impact of numerical and systematic uncertainties on Euclid’s number counts analysis.
This paper is organised as follows: in Sect. 2 we present our methodology. The study of the convergence of the simulation setup used in this work is presented in detail in Sect. 3. In Sect. 4, we present our modelling of the HMF. Our results are presented in Sect. 5. Finally, concluding remarks are provided in Sect. 6. Additionally, in Appendices A–C, we present further numerical convergence tests for our adopted setup, a comparison between the HMF calibrated in different halo finders, and the robustness of our calibration as a function of redshift, respectively.
2. Methodology
In this section, we present a short overview of the main concepts of the HMF (Sect. 2.1), a description of the sets of simulations carried out for our analysis (Sect. 2.2), the halo finders adopted (Sect. 2.3), the Bayesian framework used for the HMF calibration (Sect. 2.4), and the pipeline to forecast the effects of uncertainties on the HMF calibration on the cosmological constraints from the Euclid photometric survey of galaxy clusters (Sect. 2.5).
2.1. The halo mass function
The comoving number density of halos with mass in the range [M, M + dM] is given by:
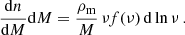 (1)
(1)
Equation (1) is known as the differential halo mass function, where ρm is the comoving cosmic mean matter density, ν is the peak height, and the function νf(ν) is known as the multiplicity function. The peak height ν is a measure of how rare a halo is and is defined as ν = δc/σ(M, z), where δc is the critical density for spherical halo collapse extrapolated to z = 0 (Peebles 2020) and σ2(M, z) is the mass variance at redshift z, which can be expressed in terms of the linear matter power spectrum Pm(k, z) as:
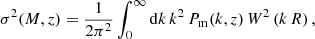 (2)
(2)
where R(M) = [3 M / (4 π ρm)]1/3 is the Lagrangian radius of a sphere containing the mass M, and W(k R) is the top-hat filter in k-space.
The multiplicity function is said to be universal if its cosmological dependence comes only through its dependence on the peak height ν, with the functional form of this dependence being independent of cosmology. While this assumption of HMF universality holds to first approximation, a number of independent analyses based on N-body simulations have demonstrated that the HMF systematically deviates from universality at late times (Crocce et al. 2010; Courtin et al. 2011; Watson et al. 2013; Diemer 2020; Ondaro-Mallea et al. 2021).
The non-universality of the HMF has been observed to depend on both the halo definition (Watson et al. 2013; Despali et al. 2016; Diemer 2020; Ondaro-Mallea et al. 2021) and the residual dependence of δc on cosmology. For instance, although several works have used the mass variance σ2(M, z) as a characteristic parameter (Jenkins et al. 2001; Reed et al. 2003; Warren et al. 2006; Tinker et al. 2008; Crocce et al. 2010; Watson et al. 2013; Bocquet et al. 2016; Castro et al. 2020), it has been shown by Courtin et al. (2011) that correctly using the peak height ν(M, z) = δc/σ(M, z), thus including the cosmological dependence of the linear collapse barrier δc, provides more universal results. The effect is more prominent at high masses, which is the regime relevant for cluster cosmology and where we dedicate particular attention in this paper.
In our analysis, halos are defined as spherical overdensities with average enclosed density equal to Δvir(z) times the background density, where Δvir(z) is the non-linear density contrast of virialized structures as predicted by spherical collapse (see, e.g. Eke et al. 1996; Bryan & Norman 1998). In the following, we parameterize the HMF for a given cosmology at a given redshift according to the fitting function introduced by Bhattacharya et al. (2011),
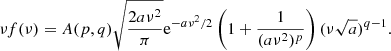 (3)
(3)
The dependence of the fitting parameters {a, p, q} on cosmology is presented in Sect. 4. As for δc, we use the fitting formula presented by Kitayama & Suto (1996).
According to the Halo Model (see e.g. Cooray & Sheth 2002, and references therein), all matter in the Universe is contained in halos. Thus, the integral of the HMF should be normalised to unity. In the case where a, p, and q do not depend on ν, this condition is satisfied by:
![Mathematical equation: $$ \begin{aligned} A(p,q) = \Bigg \{ \frac{2^{-1/2-p+q/2}}{\sqrt{\pi }} \, \left[ 2^p \, \Gamma \left(\frac{q}{2}\right)+ \Gamma \left(-p+\frac{q}{2}\right) \right] \Bigg \}^{-1}\, , \end{aligned} $$](/articles/aa/full_html/2023/03/aa44674-22/aa44674-22-eq4.gif) (4)
(4)
where Γ denotes the Gamma function. However, we note that not all HMF models presented in the literature obey this condition. Furthermore, this normalisation is not likely to hold in our Universe (see e.g. Angulo & White 2010). As discussed below, we write the parameters {a, p, q} explicitly as functions of the matter power spectrum shape and background evolution; thus, our model violates the condition of normalisation to unity even if it formally uses Eq. (4). In this sense, Eq. (4) is used here only to guarantee an asymptotic behaviour to the HMF when extrapolated to lower masses.
2.2. Simulations
Due to its intrinsically non-linear dynamics, the formation of virialized halos can only be studied in detail by resorting to cosmological simulations. The need for an accurate N-body simulation to numerically solve the evolution of billions of particles during many dynamical time scales entails the design and development of high performance and scalable algorithms and codes. Each gravity solver algorithm comes with different technical aspects characterising its validity, accuracy, and precision. A comprehensive comparison of the publicly available codes is beyond the scope of this paper (see e.g. Angulo & Hahn 2022, and references therein). Still, understanding and quantifying differences in the HMFs predicted by different, and widely used, N-body codes is key to establishing confidence in the convergence and robustness of the N-body solution of the HMF.
The HMF analysis that we present in this paper is based on three sets of simulations specifically designed for this purpose and which are summarised in Table 1. The TEsting simulAtion SEt (TEASE) is used in Sects. 3 and 4 to quantify the aforementioned impact of numerical systematic effects on the HMF. The set consists of simulations of 500 h−1 Mpc cosmological boxes run with different setups and different codes. We used the codes: Open-GADGET, GADGET-41, PKDGRAV-32, CONCEPT3, and RAMSES4, which respectively deploy the following gravity solver algorithms: tree-particle mesh (tree-PM; Xu 1995; Bagla 2002; Springel 2005), fast multipole method-particle mesh (FMM-PM; Springel et al. 2021; FMM; Potter et al. 2017), particle particle – particle mesh (P3M; Dakin et al. 2022), and adaptive mesh refinement (AMR; Teyssier 2002). Initial conditions have been generated using either the Zeldovich approximation (Zeldovich 1970) at z = 99 with MUSIC (Hahn & Abel 2011)5 or third-order Lagrangian perturbation theory (3LPT) at z = 24 with monofonIC (Michaux et al. 2020)6. For this simulation set, the background expansion history and linear matter power spectrum are both kept fixed, while resolution is varied (see Table 1).
The suite of simulations.
The scAle frEe simulaTIons fOr cLuster cOsmoloGY (AETIOLOGY) set of simulations is used in Sect. 4 to model the departure of the HMF from universality. The set consists of simulations with 10243 particles in boxes of 1000 h−1 Mpc on a side. The simulations and the initial conditions (2LPT at z = 99) were run with GADGET-4. This set is specifically designed to discriminate between the non-universality arising from the presence of characteristic timescales in the background expansion history, and from the presence of characteristic length scales in the matter power spectrum. For this purpose, the set combines simulations with either power-law or ΛCDM linear power spectrum on a background that is either Einstein–de Sitter – that is (Ωm, ΩΛ) = (1, 0); EdS hereafter – or ΛCDM. The self-similarity of scale-free simulations has been extensively used by Leroy et al. (2021), Garrison et al. (2021a,b), Joyce et al. (2021), and Maleubre et al. (2022) to carry out controlled tests of numerical convergence for several cosmological algorithms. Here, instead, we focus on self-similarity to isolate the effect of the power spectrum shape from the effect of the background evolution on the HMF universality. We note that the idea of carrying out simulations with independent background and power spectrum parameters was also used by Ondaro-Mallea et al. (2021).
Lastly, the PathfInder Cluster COsmoLOgy (PICCOLO) set is used in Sect. 5 to calibrate our HMF model. The set comprises 26 cosmological boxes of 2000 h−1 Mpc in size and 4 × 12803 particles. These simulations were carried out with Open-GADGET. Initial conditions were generated using monofonIC according to 3LPT at z = 24. The set of cosmological parameters for this set are varied by uniformly drawing them from the 95 percent confidence level hyper-volume of the joint SPT and DES cluster abundance constraints presented by Costanzi et al. (2021; see Table 2). Two realisations were simulated for each cosmology, with the exception of the reference C0 model, for which ten realisations were carried out.
In this paper, we deliberately ignored the effect of massive neutrinos in the simulations. Castorina et al. (2014) showed that the effects of massive neutrinos on the HMF are mostly absorbed into the computation of the mass variance once the cold-dark-matter power spectrum is considered instead of the total matter power (see also Costanzi et al. 2013). We will rely on this approach to extend our modelling to scenarios with massive neutrinos; however, as we recognise the importance of validating this approach ensuring it provides the accuracy required for the application to the Euclid cluster survey, in Sect. 5.2 we compare our model to two external sets of simulations that include neutrinos at the particle level.
We emphasise that, in order to guarantee a fair comparison between the different gravity solvers, we proceeded as follows.
-
We carried out convergence tests for the adopted setup of Open-GADGET and GADGET-4 (see Sect. 3).
-
We used the default setup of the CONCEPT code. The default setup of CONCEPT was extensively tested and compared with other codes by Dakin et al. (2022).
-
We used the conservative PKDGRAV-3 example setup (D. Potter, 2021, priv. comm.).
-
We used the recommended RAMSES setup suggested by the MUSIC and monofonIC initial conditions generators.
2.3. Halo finders
For the purpose of testing the HMF calibration against the choice of the halo finder, we used AHF7, SUBFIND8, VELOCIraptor9, DENHF, and ROCKSTAR10 to extract halo catalogues from the different simulation sets. While all these algorithms are based on a spherical overdensity (SO) method to define halo boundaries, they differ in the method applied to identify the centre from which spheres are grown. For each of these halo finders, we provide a very short description of their main characteristics below, while we refer to the original papers where they have been presented. We further refer to Knebe et al. (2011) for an extensive and detailed comparison of the different halo finders.
-
AHF (Gill et al. 2004; Knollmann & Knebe 2009) deploys an AMR algorithm to identify prospective halos centres as density peaks on the end-leaves of the refined tree.
-
DENHF (Despali et al. 2016) determines prospective halo centres as peaks of the density field estimated using the inverse of the cubic distance to the n-th closest neighbours.
-
SUBFIND (Springel et al. 2001, 2021) determines halo centres by first executing a parallel implementation of the 3D friends-of-friends (FOF, see e.g. Davis et al. 1985) algorithm and then by assigning it to the position of the particle with the lowest potential.
-
VELOCIraptor (Elahi et al. 2019) can operate very similarly to SUBFIND if required. Additionally, the user can choose three group finders: 3DFOF, 6DFOF (see e.g. Diemand et al. 2006), and a 6DFOF with adaptive velocity scale. Lastly, halo centres are defined as the group’s centre of mass.
-
ROCKSTAR (Behroozi et al. 2013a) starts by partitioning the simulation volume into 3DFOF groups for straightforward parallelization. An adaptive and recursive 6DFOF algorithm is then run for each group, creating a hierarchical set of FOF subgroups. Halo centres are computed by averaging the positions of the particles belonging to the innermost subgroup in the hierarchy. We run the CONSISTENT11 algorithm on top of the previously extracted ROCKSTAR catalogues. CONSISTENT was shown in Behroozi et al. (2013b) to improve the consistency of the halo catalogues using a dynamical tracking of halo progenitors.
It is important to note that we employ the same halo mass definition; thus, the algorithms above will differ only in the centring definition and, more importantly, in their hierarchical conditions, that is, the requirements to discriminate between structures and substructures. Unless stated otherwise, we only consider inclusive SO masses, that is, including all particles inside the virial radius regardless of whether they are gravitationally bound.
All halo catalogues have been logarithmically binned according to the number of halo particles to minimise the effect of mass discretization. This effect and the adopted binning are further discussed in Sect. 4.1.
2.4. HMF calibration: maximum likelihood approach
In the Press–Schechter formalism, halos are assumed to form due to the gravitational collapse of matter over-densities, filtered over a given mass scale M, above the linear collapse threshold δc. The unconditional distribution of the number of excursions above a given threshold on a Gaussian field follows a Poisson distribution. This motivates us to write the likelihood ℒ(Ni|θ, z) for the number of halos 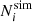 with masses Mhalo ∈ [Mi, Mi + 1) in the snapshot at redshift z as:
with masses Mhalo ∈ [Mi, Mi + 1) in the snapshot at redshift z as:
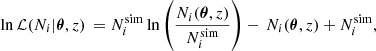 (5)
(5)
where Ni(θ, z) is the theoretical expectation of halos computed by integrating Eq. (1) and multiplying it by the volume of the simulated cosmological box. Lastly, θ is the vector of parameters of Eq. (3) including their dependency on cosmology.
However, numerical systematic effects, such as round-off errors, can affect the distribution of halos introducing further scatter between the predicted HMFs. This problem is more prominent for low-mass halos as the abundance of halos quickly grows with decreasing mass and Poisson errors under-predict the total error budget. In this paper, we use the composite likelihood instead:
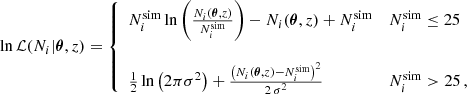 (6)
(6)
where  is the standard deviation resulting from the convolution of the Gaussian approximation to the Poisson distribution with a noise distribution assumed to be Gaussian with zero mean and variance
is the standard deviation resulting from the convolution of the Gaussian approximation to the Poisson distribution with a noise distribution assumed to be Gaussian with zero mean and variance 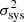 . We note that our likelihood presents a discontinuity at
. We note that our likelihood presents a discontinuity at 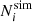 = 25. The impact of the discontinuity is two-fold. Firstly, the discontinuity amplitude depends on the chosen value for σsys. As we discuss here below, we assume σsys ≲ 1 percent, thus minimising the impact on the transition regime. Secondly, there is the transition from the purely Poisson error to a symmetric Gaussian approximation. The chosen transition value for
= 25. The impact of the discontinuity is two-fold. Firstly, the discontinuity amplitude depends on the chosen value for σsys. As we discuss here below, we assume σsys ≲ 1 percent, thus minimising the impact on the transition regime. Secondly, there is the transition from the purely Poisson error to a symmetric Gaussian approximation. The chosen transition value for 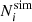 guarantees that the transition is again smooth as the Poisson contribution largely dominates the total error budget while negative values for Ni(θ, z) are very rare (≳5σ) fluctuations of a Gaussian distribution. We also checked a more complex composite likelihood function with a two-sided σ following Watson et al. (2013):
guarantees that the transition is again smooth as the Poisson contribution largely dominates the total error budget while negative values for Ni(θ, z) are very rare (≳5σ) fluctuations of a Gaussian distribution. We also checked a more complex composite likelihood function with a two-sided σ following Watson et al. (2013):
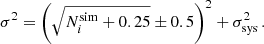 (7)
(7)
The relative difference in the log-likelihood between the two functional forms is below 10−5 around the best-fit values and provides statistically indistinguishable results. We stick to the functional form presented in Eq. (6) for simplicity.
The final log-likelihood is computed by summing Eq. (6) over all redshifts, mass bins, and simulations. This amounts to assuming that different mass bins at fixed redshift and simulation outputs at different redshifts are independent of each other. However, we note that when using the output of the same simulation at different redshifts, the results are clearly not independent, as the binning in a given redshift will contain the progenitors or descendants of the object in another redshift. To minimise the impact of the correlation, we follow Bocquet et al. (2016) and use a time-spacing of roughly 1.7 Gyr; such spacing is larger than the characteristic dynamical time of galaxy clusters.
2.5. Forecasting Euclid’s cluster counts observations
To understand the impact of the HMF systematic errors on cosmological constraints it is important to realistically forecast the cosmological information to be extracted from the Euclid photometric cluster survey. Synthetic cluster abundance data are generated in the following way: we consider a Euclid-like light cone covering 15 000 deg2, with redshift range z = [0, 2] (Laureijs et al. 2011). As discussed in detail by Euclid Collaboration (2019), clusters from the Euclid Wide Survey (Euclid Collaboration 2022) will be identified as overdensities in photometric redshift space by applying two cluster finders, which have been demonstrated to be the most accurate in terms of completeness and purity among those considered, namely AMICO (Bellagamba et al. 2018) and PZWav (Gonzalez 2014). Once clusters are identified an optical richness is assigned to them.
The abundance of halos is sampled assuming our primary calibration for the HMF presented in Sect. 5. Optical richness λ is assigned to the halos according to the richness–mass relation ⟨λ|Mvir, z⟩ (see e.g. Saro et al. 2015):
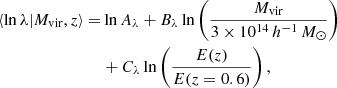 (8)
(8)
where E(z) is the ratio of the Hubble parameter at redshift z and 0. We assume a richness range λ = [20, 2000] and a log-normal scatter given by:
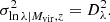 (9)
(9)
We use the following fiducial values for the parameters of Eqs. (8) and (9) Aλ = 37.8, Bλ = 1.16, Cλ = 0.91, Dλ = 0.15. These parameter values were determined by converting the richness–mass relation presented by Saro et al. (2015) for M500c (presented in their Table 2) to the virial mass definition, assuming that halos have a Navarro–Frenk–White (NFW) profile (Navarro et al. 1997) and follow the mass–concentration relation given by Diemer & Joyce (2019). The adopted values are in agreement with the results presented by Castignani & Benoist (2016).
Lastly, Poisson and sample variance fluctuations are added through a multivariate Gaussian distribution with amplitude given by the covariance model of Hu & Kravtsov (2003), which was validated by Euclid Collaboration (2021).
3. Setup of N-body simulations
In this section, we define an accurate and precise numerical setup for our primary N-body code, Open-GADGET. We present convergence tests for the adopted configuration and parameter values (Sect. 3.1), and the simulation resolution (Sect. 3.2). Lastly, we compare the convergence of our configuration setup to other N-body solvers (Sect. 3.3).
3.1. Parameter and configuration setting
The chosen values for the internal key simulation parameters used within Open-GADGET are presented in Table 3. Parameter file variables are set at run time, controlling time integration accuracy, the maximum time step allowed, the tree opening criterion, the value of the critical angle for tree opening, and the force accuracy. The configuration file parameters are set at compilation time. These latter control the maximum distance used to compute short-range forces (RCUT) and the matching region between short-range and long-range forces (ASMTH). See details of the implementation in Springel (2005) and in the official user guide12.
Chosen values for the Open-GADGET runs.
We checked that our parameter set provides sub-Poisson differences relative to higher precision sets (see Appendix A for details), deviating by less than a fraction of a percent in the abundance of halos more massive than 3 × 1013 h−1 M⊙. In this test and the following ones, we use the cumulative HMF as a test for the convergence instead of the differential HMF for three reasons: firstly, the cumulative version presents less noise than the differential HMF; secondly, we do not want to assume a binning to compute the differential HMF at this stage before discussing the impact of binning (see Sect. 4.1 below); lastly, for cluster cosmology, most of the constraining power comes from measuring the total number of objects above a given mass threshold; the cumulative mass function is the limit where the mass–observable relation tends to a Dirac delta function. We assessed the numerical convergence of the results by directly comparing it to more precise setups where each parameter was set to to half the value presented in Table 3.
Testing the convergence of the simulation results to the configuration settings of parameters presented in Table 1 is slightly more delicate than the parameter settings as the configuration variables control the raw structure of the gravity solver algorithm. For instance, if one selects very large values for RCUT in Open-GADGET, the tree-PM algorithm results will converge to the tree. The tree algorithm struggles to provide accurate force calculations if the particle distribution is close to a regular uniform grid, as is commonly the case for initial conditions generated with low-order LPT. In this latter case, tweaking the parameters in order to search for a stable point does not guarantee convergence to accurate results (see e.g. Springel et al. 2021).
Instead, we test the accuracy of our configuration set through a comparison with GADGET-4. The rationale for this approach is that the fifth order FMM-PM algorithm deployed in GADGET-4 delivers more accurate force calculations than the tree-PM algorithm deployed in Open-GADGET at fixed accuracy parameters and has smaller error correlations due to the possibility of randomising the box centre at every domain decomposition step. We assessed the convergence of the results for three different initial conditions: 5123 particles displaced from a uniform regular grid according to 3LPT at z = 24, the same number of particles using Zeldovich at z = 99, and 4 × 3203 particles displaced from a face centred cubic (FCC) grid according to 3LPT at z = 24. In all configurations, we verified that the agreement between Open-GADGET and GADGET-4 is better than a fraction of a percent for all masses of interest. However, due to the higher degree of symmetry, the FCC configuration shows even better agreement between the two codes. In this configuration, the standard tree algorithm delivers accurate forces from the simulation start, suppressing the spatial correlations of the force calculation errors.
3.2. Resolution convergence
Previous works (see e.g. Joyce et al. 2005; Marcos 2008; Garrison et al. 2016) showed that the mass element discretization and their departure from the fluid limit at initial conditions introduces transient systematic effects on N-body simulations. Michaux et al. (2020) showed that the impact of these transient effects is significantly suppressed if simulations start from initial conditions generated with higher order Lagrangian perturbation theory using a grid of elements with more planes of symmetry at the closest redshift prior to shell-crossing.
In Fig. 1, we present the convergence test for the cumulative mass function concerning both transients and modes sampled in the initial conditions. We consider five resolutions, corresponding to particle masses: {6.50 × 1011, 8.13 × 1010, 1.02 × 1010, 5.08 × 109, 1.27 × 109} h−1 M⊙; these values for the particle masses correspond to {4 × 1603, 4 × 3203, 4 × 6403, 12803, 4 × 12803} particles in a box of 500 h−1 Mpc, respectively. The rationale behind such choices for the number of particles is that 4 × 1603 differs by ∼2 percent from 2563, thus one can directly compare with other commonly used particle numbers at similar computational cost. The gravitational softening is set to one-fortieth of the mean inter-particle distance in all simulations. Initial conditions are created by monofonIC using 3LPT at z = 24 and FCC grid for all simulations but the simulation with 12803 particles, which uses a standard equally spaced grid. The reference in all redshift panels is the simulation run at the highest resolution. For easier inspection, we add the moving average over five bins for each case. We note that the lower resolution simulation tends to suppress the formation of halos at all masses at z = 0, with a more severe effect at low masses. At z = 0.14, we observe good agreement with higher resolution simulations for objects more massive than 5 × 1013 h−1 M⊙. For the other redshifts, the lower resolution simulation presents either deviations or fluctuations comparable to the Poisson noise (shown in red). However, we note that the Poisson noise was computed assuming no correlation between the simulations, which is not true as the simulations share the same initial conditions. However, as assessing the correlation between the simulations would require many more realisations, we still decided to present the Poisson estimates, considering that they represent a very conservative estimation of the true scatter.
 |
Fig. 1. Convergence test for the cumulative mass function with respect to the effects of both transients and modes sampled in the initial conditions, at fixed box size. In each panel, we report results for five particle masses: {6.50 × 1011, 8.13 × 1010, 1.02 × 1010, 5.08 × 109, 1.27 × 109} h−1 M⊙; respectively {4 × 1603, 4 × 3203, 4 × 6403, 12803, 4 × 12803} particles in a box of 500 h−1 Mpc. The rationale for the chosen number of particles is that 4 × 1603 differs by ∼2 percent from 2563, and therefore one can directly compare the results presented here with Fig. A.3 at similar computational cost. The filled region in grey represents the 1 percent region around unity and the filled region in red marks the 68 percent confidence level assuming Poisson distribution for the abundance of halos in both simulations. Each panel shows the comparison for a different redshift, as labelled. |
From the next simulation in resolution order, we see a subpercent agreement in the number of objects more massive than 5 × 1013 h−1 M⊙. At the same computational cost, the simulation with 4 × 3203 (Fig. 1) particles presents a slightly better convergence than 5123 (Fig. A.3) at z = 0. Lastly, comparing the two most costly simulations at z = 1.98, we observe that the simulation 4 × 6403 has a more stable agreement with the higher resolution simulation than the simulation with 12803 particles, despite the factor of two increase in the total number of particles; this illustrates one of the advantages of using FCC grids instead of the standard ones for creating initial conditions.
3.3. Comparison of different N-body solvers
To gain insight into the impact of the different gravity solvers on the halo statistics, in Fig. 2 we present the matter density contrast of the 2D projection of a zoomed-in volume of (15.37 h−1 Mpc)3 around the position of the most massive halo found by AHF. The box size of this volume corresponds to six times the virial radius of the central halo. The corresponding mass of the central halo in each simulation is {2.007, 1.904, 2.029, 1.887, 1.975}× 1015 h−1 M⊙ for Open-GADGET, GADGET-4, PKDGRAV-3, CONCEPT, and RAMSES. Silver and cyan circles denote the virial radius of halos and subhalos identified in this region, respectively. For the sake of clarity, a mass threshold of (1012) 1013 h−1 M⊙ was imposed to select the (sub)halos presented in Fig. 2. We observe that all N-body codes produce similar distributions of the most massive objects, however, due to slight differences in the evolution, the relation between a large halo and its surrounding depends on the N-body code as some structures are detected as an isolated halo in a simulation but as a subhalo in others.
 |
Fig. 2. Matter density contrast in a 2D projection of a zoomed-in volume of (15.37 h−1 Mpc)3 around the position of the most massive halo found by AHF in the corresponding Open-GADGET simulation. The box size of this volume corresponds to six times the virial radius of the Open-GADGET central halo. Silver and cyan circles denote the virial radius of halos and subhalos identified in this region, respectively. For the sake of clarity, a mass threshold of (1012) 1013 h−1 M⊙ was imposed to select the (sub)halos presented. |
Figure 2 also shows a stronger code signature on the distribution of substructures identified by AHF. While in this paper we are not interested in any detailed analysis of substructures, we trace them here for the sole purpose of comparing different N-body solvers in detail. Open-GADGET, GADGET-4, PKDGRAV-3, and CONCEPT produce similar numbers of substructures in large objects, but a very heterogeneous spatial distribution of them. On the other hand, we observe that RAMSES produces a smoother mass distribution than the other codes, significantly reducing the number of detected substructures. Similar results were previously reported by Elahi et al. (2016). The tendency of RAMSES to give a smoother mass distribution is also confirmed by measuring the NFW concentration parameter c of the central object: c = {5.587, 5.283, 6.170, 5.007, 4.610} for Open-GADGET, GADGET-4, PKDGRAV-3, CONCEPT, and RAMSES.
The impact of different N-body solvers on the final results is expected to depend on the simulation resolution as critical parameters are usually set as a function of the number of particles; for example the softening length, the maximum refinement level, and the refinement strategy. Figure 3 presents the ratio of the cumulative mass function at z = 0 to that observed in Open-GADGET. The three panels correspond to three different mass resolutions of {6.35 × 1011, 7.94 × 1010, 9.92 × 109} h−1 M⊙; respectively {2563, 5123, 10243} particles in a box of 500 h−1 Mpc. For reference, we present the 68 percent confidence level for the CONCEPT case assuming that the number of halos observed in the two simulations is described by a Poisson realization of the mass function.
 |
Fig. 3. Ratio of the cumulative mass function at z = 0 to that measured from the Open-GADGET simulation. From top to bottom, the panels correspond to a particle mass resolution of {6.35 × 1011, 7.94 × 1010, 9.92 × 109} h−1 M⊙; respectively, {2563, 5123, 10243} particles in a box of 500 h−1 Mpc. The red filled area represents the 68 percent confidence level for the CONCEPT case assuming that the number of halos observed in the two simulations follows an uncorrelated Poisson distribution. |
While the differences of the other codes with respect to Open-GADGET are stable and at the few-percent level for all resolutions for halos more massive than 3 × 1013 h−1 M⊙, the difference between RAMSES and Open-GADGET is quite sensitive to resolution. At the lowest resolution considered in Fig. 3, RAMSES agrees with the other codes for halos more massive than ≈ 3 × 1014 h−1 M⊙ while producing a significantly smaller number of less massive objects. At the highest resolution considered, this difference is partially reduced and RAMSES agrees to better than 1 percent with the other codes for halos more massive than ≈ 4 × 1013 h−1 M⊙. The suppression in the halo abundance and the production of smoother density fields are known signatures of the RAMSES AMR gravity solver. As the adaptive refinement cannot be repeated indefinitely as it is bound to stop before producing empty voxels, the total number of particles in the simulation also sets the maximum force resolution achievable in RAMSES. Lastly, from Figs. 1 and 3, we conclude that the HMF convergence with respect to particle mass is achieved first for the other codes before RAMSES.
4. Modelling
In this section, we present our modelling for the HMF and the numerical and theoretical systematic effects that influence its assessment, including their dependence on initial conditions (Sect. 4.1) and the impact of the simulated volume (Sect. 4.2). We revisit the implications of assuming different halo definitions (Sect. 4.3); globally, comparing different halo finders (Sect. 4.3.1) and internally to a single halo finder (AHF), using different centring (Sect. 4.3.2) and different halo mass assignment (Sect. 4.3.3). Lastly, we present our modelling for the non-universality of the HMF (Sect. 4.4), modelling it as a function of the shape of the power spectrum (Sect. 4.4.1) and the background evolution Sect. 4.4.2).
4.1. Sensitivity of the HMF to initial conditions
In Fig. 4, we present the ratio of the cumulative mass function computed from simulations started with the same seed, but different LPT orders and redshifts. We consider the 3LPT and Zeldovich approximation and the following starting redshifts: z = 24, z = 49, and z = 99. The rationale for the chosen starting redshifts is two-fold: z = 99 and z = 49 have been extensively used in the literature to start simulations using Zeldovich and high-order LPT, respectively. Furthermore, Michaux et al. (2020) showed that starting the simulation at z = 24 using 3LPT is a good compromise between the convergence of the LPT (see, for instance, their Fig. 4) and the effect of particle discreteness on several summary statistics. While third-order LPT gives percent-level accuracy on the cumulative mass function for objects more massive than 5 × 1013 h−1 M⊙ independent of the starting redshift considered, setting initial conditions at z = 99 using the Zeldovich approximation suppresses the formation of structures by ≳1 percent with respect to 3LPT. Our results are in agreement with previous studies (Crocce et al. 2006; Reed et al. 2013; Michaux et al. 2020). We also note that, for objects less massive than 5 × 1013 h−1 M⊙, the 3LPT initial conditions set at z = 24 slightly boosts the formation of structures. The reason for this is two-fold: firstly, as discussed in Sect. 3, there is a difference in the tree force accuracy calculations when the particle distribution is close to the initial grid. Secondly, shell crossing is known to artificially boost the formation of smaller objects (Power et al. 2016). In summary, although we have not run tests for 2LPT, from Fig. 4 we infer that the configuration used for the AETIOLOGY set, that is, 2LPT at z = 99, provides results that agree to better than ≲2% with 3LPT at z = 24 as it should range between the green and red lines.
 |
Fig. 4. Ratio of the cumulative mass function measured from simulations started with same seed, but different LPT order (3LPT vs. Zeldovich approximation) and starting redshifts (z = 24, z = 49, and z = 99), as indicated by the different coloured lines in the legend. |
Besides the sensitivity to the LPT order used to generate initial conditions, structure formation is also sensitive to small perturbations in the initial positions of particles, such as those caused by round-off errors. This is due to the intrinsically chaotic dynamics obeyed by the several thousands of particles whose orbits are integrated by an N-body solver during many dynamical times as they follow the collapse of a halo. The variation of a simulation result on small perturbations in the initial conditions is dubbed the butterfly effect. Genel et al. (2019) thoroughly discuss this effect and how it is amplified in hydrodynamic simulations by thermal processes. Correspondingly, to assess the dependence of the HMF on small perturbations to the initial conditions in purely collisionless simulations, we ran ten simulations for which the initial positions of the particles were randomly displaced by a single unit in the last significant single-precision digit. For the box size of 500 h−1 Mpc, this perturbation corresponds to a random displacement of ≲1 pc. We note that, for isolating the effect of perturbing initial conditions from round-off errors due to the use of single precision, those simulations were run using GADGET-4 with long integer (i.e., 64 bit) positions. The fluctuations in the HMF caused by the perturbation in initial positions are due to the increasing sensitivity of the non-linear structure formation to initial conditions. However, such small fluctuations cannot disrupt large groups. Instead, they can cause differences in the history of these objects that grow in time resulting in particles accreted by a given group in one simulation ending in a different group in another. In Fig. 5, we present the distribution of the mass of halos with similar mass matched by their position between different simulations at z = 0. In the top panel, we present the distribution of the relative mass difference for halos with masses residing in six intervals, each of 0.3 dex width, between 1013 and 1015 h−1 M⊙. We observe that the impact on halo masses depends strongly on the object mass; whereas halos with masses of a few times 1013 h−1 M⊙ can have their masses affected by several percent, the impact reduces to ≈1 percent for the most massive objects. In the bottom panel, we repeat the former exercise scaling the distribution by the number of particles Np, corresponding to the object mass: Np = Mvir/mp, where mp is the particle mass. We note that the effect is rather universal if presented in these terms, and agrees with a Gaussian distribution of zero mean and standard deviation 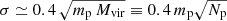 . Thus, the limited precision in the initial conditions propagates to a sub-Poisson fluctuation in the number of particles belonging to a given halo at low redshift. In relative terms, the effect is larger for objects with fewer particles and represents only a subpercent effect for objects with more than 1500 particles.
. Thus, the limited precision in the initial conditions propagates to a sub-Poisson fluctuation in the number of particles belonging to a given halo at low redshift. In relative terms, the effect is larger for objects with fewer particles and represents only a subpercent effect for objects with more than 1500 particles.
 |
Fig. 5. Distribution of the relative difference between masses of halos at z = 0 matched between different simulations with initial conditions perturbed by ≲1 pc. Top: Distribution of the relative mass difference. Bottom: Same distribution scaled by the number of particles corresponding to the object mass. |
Figure 6 presents the results of the same analysis, when double precision (i.e., 64 bit floating-point) is used. For double precision the effect is not only strongly suppressed, but is also no longer universal when scaled by the number of particles. The significant suppression in the scatter of the mass of the objects indicates that double precision should be used to setup initial conditions of cosmological simulations and internally by the gravity solver, assuming one can afford the factor two increase in the memory and storage. As storing double-precision outputs is not the default option for several codes, the propagation of double-precision round-off errors will not be further discussed in this work.
The mass fluctuations presented in Fig. 5 can be strongly amplified in binned statistics depending on the bin width. In Fig. 7, we show the rms variation in the HMF induced by the noise in the initial conditions, normalised to the expected Poisson noise, as a function of halo mass. Different curves correspond to different binnings of halo masses. As is commonly done for the calibration of the HMF, we considered logarithmically spaced mass bins. The results shown in Fig. 7 were obtained by creating a synthetic halo catalogue with masses distributed according to the HMF presented by Tinker et al. (2008). After that, several halo catalogues were created by perturbing the halo masses according to the distribution presented in Fig. 5. Lastly, the HMF was extracted from these catalogues binning the halos in mass and dividing by the volume times the mass bin width. Although we have to tacitly assume a volume in the previous exercise, we have observed negligible impact of the nominal volume assumed by considering two different volumes: (2000 h−1 Mpc)3 and (500 h−1 Mpc)3.
 |
Fig. 7. The rms variation in the HMF induced by the noise in the initial conditions, normalised to the expected Poisson noise, as a function of halo mass. Curves with different colours correspond to different binnings of halo masses, as indicated in the legend. |
From Fig. 7 it is clear that the binning has to be carefully chosen to reduce the butterfly impact. Ideally, the bin width should be much larger than the scatter caused by the round-off errors. This leads to the condition:
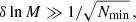 (10)
(10)
where Nmin is the number of particles of the smallest object of interest.
4.2. Impact of the simulated volume
The effect of the simulation volume on the HMF is two-fold: firstly, the computation of the mass variance σ2(M) presented in Eq. (2) has to be truncated to the fundamental mode of the cosmological box; secondly, by construction, only a few independent modes are contained in the simulated volume for the first multiples of the fundamental mode, thus introducing an effect of sample variance into the computation of the mass variance at large halo masses.
Quantifying the effect of the simulated volume in the HMF directly with simulations would require a much more extensive set of simulations than the ones used in this paper. Instead, we assess the impact of the simulated volume through its impact on the mass variance calculation and propagate this effect to the HMF, assuming the analytical prescription.
In Fig. 8, we present the impact of the simulation box size L on the HMF for three different cases L = {500, 1000, 2000} h−1 Mpc shown in red, blue, and green, respectively. Solid lines represent the mean effect due to the truncation of the mass variance integration to the fundamental mode. The corresponding shaded regions correspond to the 68 percent interval due to the sample variance. In the top panel, we present the effect on the calculation of the mass variance itself, while in the bottom we propagate the impact on the mass variance to the differential HMF. The 68 percent regions were determined creating 1000 synthetic realisations of a matter power spectrum assuming the C0 cosmology for each box. The matter power spectrum was sampled between the fundamental and the 4096th modes. Sample variance was added to the power spectrum perturbing it with a Gaussian fluctuation of amplitude σP(k) given by:
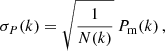 (11)
(11)
 |
Fig. 8. Impact of the simulation box size L on the mass variance (top panel) and the differential HMF (bottom panel) for three different cases L = {500, 1000, 2000} h−1 Mpc depicted in red, blue, and green, respectively. Solid lines represent the mean effect due to the truncation of the mass variance integration to the fundamental mode. The corresponding shaded regions correspond to the 68 percent interval due to the sample variance. |
where N(k) = 2π (δk/k)2 is the number of independent modes inside the bin with width δk in k-space. Finally, the differential HMF in the bottom panel of Fig. 8 has been calculated using the model of Tinker et al. (2008).
In Fig. 8, we observe that the exponential dependence of the HMF on the mass variance at high-masses significantly amplify the impact of both the truncation and sample-variance impact on the mass variance. The absence of modes larger than 500 h−1 Mpc causes the suppression of the formation of objects more massive than 8 × 1014 h−1 M⊙. No significant suppression on the formation of objects is observed for the two larger box sizes. On the other hand, the impact of sample variance on the HMF is below one percent for all boxes considered for halos lighter than 3 × 1014 h−1 M⊙. For the 1000 h−1 Mpc and 2000 h−1 Mpc box sizes, the 1 percent threshold is exceeded for halos more massive than 8 × 1014 h−1 M⊙ and 2 × 1015 h−1 M⊙, respectively.
One way of taking into account the effect of the box size on the calibration of the HMF is to calculate the mass variance, using the matter power spectrum computed from the initial conditions (see e.g. Despali et al. 2016). This approach presents a few challenges: for instance, the computation of the power spectrum at initial conditions might be affected by the mesh used to create the initial displacement field – assuming one has not used a ‘glass’13 unstructured mesh from which to displace particles. Also, one has to choose the k-binning for the computation of the matter power spectrum wisely, as an overly thin shell would produce a noisy measurement, while an excessively broad shell would affect the mass variance integral accuracy. We instead advocate that to keep the impact of sample variance to a minimum, one should use boxes larger than 1000 h−1 Mpc and produce initial conditions with fixed amplitudes of the initial conditions random field to the desired theoretical power spectrum, as presented in Angulo & Pontzen (2016). Following this approach one circumvents the above-mentioned challenges as the realised and theoretical power spectrum match exactly.
4.3. Impact of the halo definition
4.3.1. Sensitivity to different halo finders
For a visual inspection of the effect of different halo finders on the HMF, Fig. 9 shows a comparison between AHF and SUBFIND halos identified within a (26.65 h−1 Mpc)3 volume extracted from a 500 h−1 Mpc box with 5123 particles started at z = 99 using the Zeldovich approximation. The mass of the largest halo located at the centre is 2 × 1015 h−1 M⊙ while the smallest halo marked in each panel is 1013 h−1 M⊙. Whereas AHF and SUBFIND both find the same large groups, for smaller groups, we notice a non-negligible suppression on the number of objects, with SUBFIND tending to group together smaller objects into a larger one. The effect is more evident along the stream on the centre left of the larger object presented in Fig. 9. The tendency of pure FOF-based methods to merger smaller, dynamically distinct objects along tidal streams, building ‘particle bridges’ between structures, is well known (see e.g. Knebe et al. 2011, and references therein).
 |
Fig. 9. Comparison between AHF and SUBFIND halos extracted from the same (26.65 h−1 Mpc)3 volume. The largest and smallest halo masses depicted are 2 × 1015 h−1 M⊙ and 1013 h−1 M⊙, respectively. The cyan circles denote the virial radius of halos identified in this region. |
Figure 10 presents the ratio of the cumulative mass functions extracted from AHF, SUBFIND, VELOCIraptor, and DENHF to that extracted from ROCKSTAR. The filled regions in red and purple represent the 68 percent confidence level region, for AHF and VELOCIraptor (6DFOF Adaptive), respectively, assuming that the number of objects in each catalogue follows a Poisson distribution.
 |
Fig. 10. Ratio of the cumulative mass function extracted from AHF, SUBFIND, VELOCIraptor, and DENHF to that extracted from ROCKSTAR. The filled regions in red and purple represent the 68% confidence regions for the AHF and VELOCIraptor (6DFOF Adaptive), respectively, assuming that the number of objects in each catalogue follows a Poisson distribution. |
Figure 10 clearly shows a separation of the algorithms considered here into two groups, with the 3DFOF and non-adaptive 6DFOF suppressing the number of halos less massive than 1014 h−1 M⊙.
We caution that it is not our goal here to model the specifics of each halo finder. The reason is two-fold; firstly, this is a complex task, as many parameters control the different algorithms. Secondly, investigating how the results from different finders compare to each other when changing the respective parameters, even in great detail, would not address the fundamental question of how does the definition of a halo adopted in simulations compares with the observed clusters. The analysis presented is simply designed to deliver a flexible model for the HMF that can accommodate different halo definitions. With such a model calibrated against different halo catalogues, we will assess the impact of different definitions of halos in the HMF calibration on Euclid’s cluster counts analysis.
4.3.2. Impact of the halo centre
We assessed the impact of the choice for the halo centre on the cumulative mass function using AHF on one of the TEASE simulations. AHF allows the user to choose the prospective halo centre alternatively as the geometrical centre of the refinement patch, the cell with the lowest potential, the cell with the highest density, or the centre of mass of the particles inside the refinement patch. The latter is our default choice, following the official AHF documentation.
We verified that the AHF cumulative mass function has a percent-level robustness to the choice of the halo centre. We remind that VELOCIraptor (based on a 3DFOF) and SUBFIND differ only for the choice of the halo centre. Nevertheless, they differ from each other (see Fig. 10) by an amount that is larger than the differences between different halo centres in the AHF. This is, again, due to particle bridges that connect two dynamically distinct objects, which causes a stronger impact on the halo centre choice.
4.3.3. Total halo mass versus bound mass
All halo finders considered in this paper include all particles within a given radius, when computing the spherical overdensity masses, regardless of whether the particles are bound to a halo or not. In order to test the effect of this assumption, in Fig. 11, we present the difference in the cumulative HMF between including all particles inside the spherical overdensity and only the contribution from bound particles. AHF determines as bound the particles with velocities smaller than the local escape velocity multiplied by a constant parameter VescTune which we set to unity. The simulation used for this test is the same as the one used in Sect. 4.3.2. Not surprisingly, assigning to halos only bound particles reduces the cumulative mass function by about 5 percent. That is due to the fact that the gravitationally bound mass within a fixed halo radius is by construction smaller than the total mass within the same radius. It is important to note that both are valid definitions to weigh a halo. The most adequate choice will depend on the method used to measure cluster masses from observations. Arguably, if one works with, for instance, masses obtained from the gravitational lensing, the total mass definition should be adopted, as this is the one that contributes to the lensing signal. In the remainder of this paper, we refer only to the total mass definition.
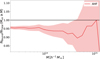 |
Fig. 11. Difference in the cumulative mass function when all particles inside the spherical overdensity are considered versus just the bound particles. |
4.4. Non-universality of the virial mass function
Despali et al. (2016), Diemer (2020), Ondaro-Mallea et al. (2021) showed that the HMF preserves most of its universality when described as a function of the virial mass, as predicted by the spherical collapse model (Eke et al. 1996; Bryan & Norman 1998). Still, departure from universality can reach up to 20 percent for the high-end tail of the mass function (see e.g. Diemer 2020).
In the following sections, and for the specific purpose of tracing the origin of any departure from universality, we use the AETIOLOGY set of simulations to model the dependence of the virial HMF both as a function of the shape of the matter power spectrum and of the background evolution. Unless stated otherwise, the simulations used here were run using GADGET-4 with initial conditions generated at z = 99 according to 2LPT. Halo catalogues were extracted on the fly with the GADGET-4 SUBFIND implementation. Halos were binned according to their mass using 50 log-spaced intervals in the number of particles.
For the calibration of the HMF, we impose a mass cut that corresponds to a minimum number of 300 particles so as to minimise the noise in the identification of low-mass halos (see e.g. Leroy et al. 2021). We assume the likelihood presented in Sect. 2.4 with σsys = 0.01 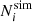 . This choice for the systematic error means that the relative error has a floor of 1 percent in the total error budget, thus avoiding over-weighting mass bins with many halos, for which the purely Poisson error under-predicts the true data variance, as discussed in Sects. 4.1 and 4.2. Its value was chosen so that the best-fit neither over- nor under-fits the simulations over the entire redshift range considered, that is, keeping the fit-quality constant. We use the snapshots at z = {2.00, 1.25, 0.90, 0.52, 0.29, 0.14, 0.0}.
. This choice for the systematic error means that the relative error has a floor of 1 percent in the total error budget, thus avoiding over-weighting mass bins with many halos, for which the purely Poisson error under-predicts the true data variance, as discussed in Sects. 4.1 and 4.2. Its value was chosen so that the best-fit neither over- nor under-fits the simulations over the entire redshift range considered, that is, keeping the fit-quality constant. We use the snapshots at z = {2.00, 1.25, 0.90, 0.52, 0.29, 0.14, 0.0}.
4.4.1. Dependence on the power spectrum slope
In order to understand the dependence of the HMF parameters on the power spectrum shape, in Fig. 12, we present the 68 and 95 percent confidence level contours of the calibration carried out independently in several simulations assuming a power-law linear power spectrum in an EdS background, that is, Pm(k)∝kns and (Ωm, ΩΛ) = (1, 0).
 |
Fig. 12. The 68% and 95% confidence level contours of the calibration carried out independently in several simulations assuming a power-law linear power spectrum in an EdS background, i.e., Pm(k)≈kns and Ωm = 1. |
The first interesting result is that, even for self-similar cosmologies, the HMF is not universal against changing the spectral index. While the parameters {p, q} of Eq. (3) seem to have a linear dependence on ns, the parameter a exhibits a non-monotonic dependence with a local minimum around ns = −1.75. The overall simple and well-behaved dependence of the parameters of the HMF on the spectral index over a range of values covering all the relevant regimes for structure formation motivates our approach to select a flexible fitting function that precisely accommodates the HMF shape on a self-similar cosmology. At the same time, the non-universality is modelled through the explicit dependence of the HMF parameters on cosmology.
4.4.2. Dependence on the background evolution
In order to understand the dependence of the HMF parameters on the background evolution we follow an approach similar to that presented in Ondaro-Mallea et al. (2021). In Fig. 13, we present the 68 and 95 percent confidence level contours of the calibration carried out independently in simulations with ns = { − 2.0, −2.5} and background evolution given by either a cosmology in agreement with the Planck 2018 (P18) results for the cosmological parameters (Planck Collaboration VI 2020) or EdS. For the specific purpose of this exercise, the chosen values for the spectral index are not important, and other combinations produce similar trends; still, we choose ns = { − 2.0, −2.5} as this range corresponds roughly to the slope of the ΛCDM matter power spectrum on cluster scales.
 |
Fig. 13. The 68% and 95% confidence level contours of the calibration carried out independently in simulations with ns = { − 2.0, −2.5} and background evolution given by either a cosmology in agreement with Planck Collaboration VI (2020) or EdS. |
At fixed ns, we note that p is consistent with being independent of the background evolution. On the other hand, the parameters {a, q} consistently show a dependence on the chosen background, with departures from the EdS scenario providing smaller values of such parameters.
4.4.3. The HMF model
From the above results, we define the following model to capture the dependence of the multiplicity function on redshift and power spectrum shape as:
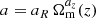 (12)
(12)
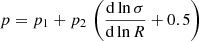 (13)
(13)
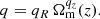 (14)
(14)
where:
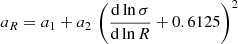 (15)
(15)
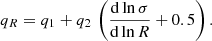 (16)
(16)
The growth rate, that is, dlnG/dln(1 + z)−1 where G(z) is the linear growth of density perturbations, was used by Ondaro-Mallea et al. (2021) to characterise the non-universality of the HMF instead of Ωm(z). For the cosmological models considered here this is well approximated by (see e.g. Amendola & Tsujikawa 2010):
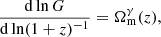 (17)
(17)
with γ = 0.55. Therefore, Eqs. (12)–(16) produce exactly the same results for the cosmological models studied here once one substitutes:
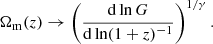 (18)
(18)
Whether such a substitution leads to universal extensions of the model to cosmologies with growth histories given by modified gravity theories is left for further investigation. We concentrate here on the description as a function of Ωm, as it is more straightforward to compute and produces the same results.
Regarding the characterisation of the dependence of the multiplicity function on the shape of the power spectrum, the first obvious choice is to use its logarithmic slope dlnPm(k)/dlnk which reduces to the spectral index ns for power-law cosmologies. However, in more realistic cosmologies, the logarithmic slope of the power spectrum contains fluctuations due to the baryonic acoustic oscillations (BAOs) for the characteristic length of the most massive halos. One can circumvent this problem by smoothing the BAO before the computation of the slope, as was done in Diemer & Kravtsov (2015). Conversely, we propose the logarithmic slope of the mass variance dlnσ(R)/dln R. For the power-law cosmologies this reduces to:
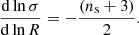 (19)
(19)
5. Results
In this section, we present the calibration of the HMF model (Sect. 5.1), compare it with previous works (Sect. 5.3), and forecast the impact of numerical and statistical uncertainties related to our calibration on Euclid’s cluster counts analysis (Sect. 5.4).
5.1. Calibration of the HMF
First, we provide a short recap of the rationale behind the setup of the PICCOLO simulations. Before presenting the calibration of the HMF model validated in the AETIOLOGY suite, we present a summary of the numerical and theoretical systematic effects on the HMF and how the PICCOLO suite was designed to address them. The PICCOLO simulations were run with Open-GADGET set according to the parameters presented in Table 1. This choice of the parameters is shown in Sects. 3.1 and 3.2 to produce results of subpercent accuracy and the robustness of the results is assessed by code-comparison in Sect. 3.3. This suite of simulations uses FCC grids as pre-initial conditions to mitigate the impact of transients due to fluid discretization (see Michaux et al. 2020). The FCC pre-initial conditions and initial displacements computed with 3LPT at z = 24 also reduce the impact of correlated errors on the force computations at early redshifts. We refer to Fig. A.2, where we compare Open-GADGET and GADGET-4, and to the discussion of force accuracy presented by Springel et al. (2021). To mitigate the effect of round-off errors on the HMF, we use the binning condition presented at the end of Sect. 4.1. To minimise the impact of sample-variance, box sizes are 2000 h−1 Mpc and initial conditions have been created with fixed amplitudes of initial density perturbations (Angulo & Pontzen 2016) as discussed in Sect. 4.2.
In order to calibrate the parameters in Eqs. (12)–(16), we use the PICCOLO set of simulations presented in Table 1. The halo catalogues were binned in 50 logarithmically spaced bins in number of particles, corresponding to roughly δlnM ≈ 0.15. We assumed the likelihood presented in Sect. 2.4 with σsys = 0.005 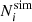 . As for the AETIOLOGY fit, its value was chosen such that the best-fit neither over- nor under-fits the simulations and this value is in agreement with the expected non-Poisson scatter caused by round-off errors discussed in Sect. 4.1 for the most populated bin considered in the calibration. Its impact is rapidly diluted as the Poisson contribution grows quickly with mass and redshift. Lastly, we imposed a mass cut below which a halo is not considered as resolved, which corresponds to a minimum of 300 particles. Finally, we analyzed the outputs of simulations at redshifts z = {2.00, 1.25, 0.90, 0.52, 0.29, 0.14, 0.0}.
. As for the AETIOLOGY fit, its value was chosen such that the best-fit neither over- nor under-fits the simulations and this value is in agreement with the expected non-Poisson scatter caused by round-off errors discussed in Sect. 4.1 for the most populated bin considered in the calibration. Its impact is rapidly diluted as the Poisson contribution grows quickly with mass and redshift. Lastly, we imposed a mass cut below which a halo is not considered as resolved, which corresponds to a minimum of 300 particles. Finally, we analyzed the outputs of simulations at redshifts z = {2.00, 1.25, 0.90, 0.52, 0.29, 0.14, 0.0}.
In Table 4, we present the best fitting parameters of our calibration for our primary halo finder (ROCKSTAR) and three other auxiliary halo finders (AHF, SUBFIND, and VELOCIraptor). Details of the difference between the calibrations for different halo finders are further discussed in Appendix B. The AHF, SUBFIND, and VELOCIraptor fits were performed using one simulation for each cosmology presented in Table 2. For the ROCKSTAR fit, we used two simulations for each cosmology including C0 with which we carried out ten realisations. We decided not use the remaining eight C0 simulations for calibration in order to avoid over-weighting this cosmology in our derivation of the HMF fit; we only use them to reduce the Poisson fluctuations of rare halos, which allows us to assess our uncertainty in the calibration at this regime.
In Fig. 14, we present the HMF for ROCKSTAR halos and the prediction of the respective best fit from the PICCOLO simulations at z = 0. The vertical dotted line represents the cut in mass corresponding to the cut in the minimum number of 300 particles for the C0 runs. Figure 15 presents the ratio of ROCKSTAR best-fit to the mean abundance of halos extracted from the simulations at z = {0.0, 0.5, 1.0, 2.0}. As in Fig. 14, the vertical dotted line represents the cut in mass corresponding to the cut in the minimum number of 300 particles for the C0 runs. The regions in grey represent the relative 1 percent and 2.5 percent regions. For the sake of illustration, we present the Poisson error bars corresponding to the C0 and C3 (our cosmology with fewer halos) – the former counts with ten realisations while the latter counts with two.
 |
Fig. 14. HMF at z = 0 for the PICCOLO cosmologies and the ROCKSTAR best-fit prediction. The vertical dotted line represents the cut in mass corresponding to the minimum number of 300 particles for the C0 runs. Error bars are shown assuming a Poisson distribution of the expected number of objects. |
Quite remarkably, our model shows a percent-level agreement with the simulations over the entire mass and redshift ranges considered in the calibration despite the much larger difference between the cosmological models presented in Fig. 14. This result demonstrates that our model HMF is capable of accurately describing the cosmology dependence of the deviations from universality, for a given set of simulations and for a given choice of the halo finder. In Appendix C, we present further tests of the robustness of our calibration as a function of redshift.
5.2. Cosmologies with massive neutrinos
The response of the HMF to neutrinos ℛ is defined as
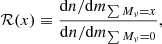 (20)
(20)
where ∑Mν is the sum of the masses of the three neutrino species.
In Figs. 16 and 17, we present the response of the HMF to massive neutrinos and the accuracy of the model presented in Castorina et al. (2014) in order to take this latter into account. Briefly, the model assumes that neutrinos impact the HMF passively, that is, through its effect on the background evolution. Operationally, implementation of the model only requires that we replace the total matter power spectrum Pm in the computation of the mass variance (Eq. (2)) with the cold dark matter plus baryons power spectrum and that we ignore the contribution of neutrinos to the mass of the Lagrangian patch corresponding to a given halo. To assess the accuracy of the model, we compare the response ℛ predicted by the model and from simulations. The rationale for using ℛ to assess the accuracy of the model is to mitigate the impact of systematic effects due to differences in the setup between the external simulations and the ones used for the calibration of the HMF in this work.
We used two independent external simulations: the DEMNUni (see Carbone et al. 2016, for details of the simulation)14 and the Open-GADGET subset of the Euclid’s neutrino code comparison simulations (Euclid Collaboration 2022). Halos were extracted in both sets using SUBFIND. Thus, the results presented in this subsection rely on our SUBFIND calibration presented in Table 4.
The DEMNUni set consists of three simulations of 2000 h−1 Mpc boxes assuming a cosmology in agreement with Planck 2013 results for the cosmological parameters (Planck Collaboration XVI 2014)15. The reference simulation considers massless neutrinos, while the other two simulations use the particle-based implementation of neutrinos, assuming a total neutrino masses of 0.16 and 0.32 eV, respectively. The reference simulations include 20483 dark matter particles, while the latter includes the same number of dark matter particles and as many 20483 neutrino particles.
The Open-GADGET subset of the Euclid’s neutrino code comparison shares the same implementation, a similar mass resolution, and a similar cosmological parameters as the DEMNUni but in 1000 h−1 Mpc boxes. Instead, the total neutrino masses simulated are 0.0, 0.15, 0.30, and 0.60 eV. These simulations have been extensively compared with different neutrino implementations. The agreement for the power spectrum, bispectrum, and HMF was observed to be better than 1 percent for the range of interest.
In Fig. 16, we observe the well-established suppression in the cluster abundance caused by massive neutrinos and its dependence on the total neutrino mass. In Fig. 17, we observe that, for total neutrino masses smaller than 0.32 eV and for both simulations, the model of Castorina et al. (2014) agrees with simulations to better than 1 percent (dark shaded area) over the entire mass range of validity of our calibration; as in Fig. 15, the dotted line represents the 300-particle mass cut used for the calibration. We only note that at lower masses, below ∼ 3 × 1013 h−1 M⊙ the model HMF tends to underestimate the effect of massive neutrinos, an effect that increases with neutrino masses. While we are not interested in the HMF calibration in this mass range, we ascribe this difference to the effect of neutrino free-streaming on the growth of CDM perturbations, which cannot be captured by simply ignoring the neutrino component in the linear matter power spectrum.
 |
Fig. 15. Ratio of ROCKSTAR best-fit to the mean abundance of halos extracted from the simulations at z = {0, 0.5, 1.0, 2.0}. The vertical dotted line represents the cut in mass corresponding to the minimum number of 300 particles for the C0 runs. The regions in grey represent the relative 1% and 2.5% regions. The Poisson error bars correspond to the C0 and C3 (our cosmology with fewer halos), which count with ten and two realisations, respectively. We only show mass bins with more than 50 halos for improved readability. |
 |
Fig. 16. Impact of massive neutrinos on the HMF. We present the ratio of the HMF with massive neutrinos to the corresponding massless neutrinos counterpart as observed in two independent external simulations DEMNUni (top) and the Open-GADGET subset of Euclid’s neutrino code comparison simulations (bottom). See the definition of ℛ in Eq. (20). |
 |
Fig. 17. Accuracy of the model presented in Castorina et al. (2014) in accounting for the impact of massive neutrinos on the HMF. We compare the ratio of the HMF with massive neutrinos to the corresponding massless neutrinos counterpart, assuming the model of Castorina et al. (2014) divided by the same quantity as observed in two independent external simulations: DEMNUni (top) and the Open-GADGET subset of Euclid’s neutrino code comparison simulations (bottom). See the definition of ℛ in Eq. (20). |
For the most massive neutrinos considered, we only rely on the simulations carried out for the code comparison. Due to its smaller volume, larger fluctuations are observed with respect to the DEMNUni, but at the mass threshold of validity of our calibration, we nevertheless observe that the model agrees with the simulation within a few percent, and for lower masses the model starts to over-predict the impact of neutrinos. The agreement for masses larger than 4 × 1013 h−1 M⊙ is again consistent with 1 percent scatter.
5.3. Comparison to other works
In Fig. 18, we compare our HMF model to the works of Tinker et al. (2008), Despali et al. (2016), and Ondaro-Mallea et al. (2021). We use our ROCKSTAR calibration as a reference and present our SUBFIND calibration as our SUBFIND setup matches those used by Ondaro-Mallea et al. (2021), making the comparison easier. WE note that, in Fig. 10, we present a comparison of the cumulative mass function produced with ROCKSTAR with that produced by DENHF. The latter, used by Despali et al. (2016), differs from the former by roughly 1 percent. Lastly, Behroozi et al. (2013a) compared ROCKSTAR catalogues with the prediction of Tinker et al. (2008) and presented an agreement within 5 percent at z = 0. We also present the mean of the multiplicity function νf(ν) measured from the ten PICCOLO C0 runs. The grey areas depict the 1 and 5 percent regions. To embed the significant differences with respect to the other works, we adopted a symmetric log scale on the y-axis, where the region between the dotted lines is presented in a linear scale.
 |
Fig. 18. Comparison of our HMF model to the works of Tinker et al. (2008), Despali et al. (2016), and Ondaro-Mallea et al. (2021). We use our ROCKSTAR calibration as the reference and present our SUBFIND calibration for easy comparison with Ondaro-Mallea et al. (2021). We also present the mean of the multiplicity function νf(ν) measured from the ten PICCOLO C0 runs. The grey regions depict the 1 and 5 percent regions. We adopted a symmetric-log scale on the y-axis, where the region between the dashed lines is presented in a linear scale. |
As already shown in Fig. 15, our model accurately reproduces results from simulations over fairly large ranges of masses and redshifts. Globally, the differences are larger at both large masses and high redshifts, where the statistics are poorer. At z = 0, the model of Tinker et al. (2008) differs from ours by a maximum of 3 percent for halos less massive than 1015 h−1 M⊙; it crosses the 5 percent threshold at 2 × 1015 h−1 M⊙, and beyond that it deviates from our model, predicting significantly fewer halos. The model of Despali et al. (2016) crosses the 5 percent threshold over a narrower mass range; it deviates from our model by more than 5 percent beyond 4 × 1014 h−1 M⊙, and over-predicts the number of halos more massive than 1015 h−1 M⊙ by more than 20 percent. Comparing the model by Ondaro-Mallea et al. (2021) to our HMF calibration based on SUBFIND we note that they start differing by more than 5 percent for halos more massive than 7 × 1014 h−1 M⊙, above which the model of these latter starts to follow the same trend as the model of Despali et al. (2016). The picture at z = 1 and z = 2 are similar; at smaller masses, all models tend to predict fewer halos than observed in our simulations and predicted by our model. For Despali et al. (2016) and Ondaro-Mallea et al. (2021), the trend flips at intermediate masses and starts to over-predict the abundance of the most massive halos. Similar results were obtained by comparing our calibration directly with the simulations used and made available by Ondaro-Mallea et al. (2021), which reassures us of the robustness of our calibration.
5.4. Impact on cluster counts analysis
In this subsection, we forecast the impact of the uncertainties on the HMF calibration on the cosmological constraints to be derived from the Euclid cluster counts.
5.4.1. Impact of the halo finder
In Table 5, we summarise the impact of the different halo finders on the inference of the marginalised cosmological parameters Ωm and σ8. To do so, we compare the results obtained when one assumes VELOCIraptor, SUBFIND or AHF calibrations to create the synthetic catalogue while the fiducial ROCKSTAR calibration is used for the analysis. We perform this forecast following the methodology described in Sect. 2.5. For the likelihood analysis, we assume flat priors on the cosmological parameters and Gaussian priors with amplitudes on the mass–observable parameters of 1, 3, and 5 percent. The likelihood sampling is performed with ZEUS (see Karamanis & Beutler 2021; Karamanis et al. 2021). The impact of the different halo finders’ calibrations is quantified using the index of inconsistency (IOI; Lin & Ishak 2017), which is calculated as
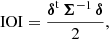 (21)
(21)
Summary statistics for the forecast of the impact of different halo finders and calibration errors on Euclid cluster counts cosmological constraints on Ωm and σ8.
where δ is the two-dimensional difference vector between the best-fit and the assumed cosmological parameters {Ωm, σ8}={0.30711, 0.8288}. Additionally, Σ is the covariance matrix between these parameters, which we assume to be Gaussian distributed. In all cases, the tension in the (Ωm, σ8) plane increases monotonically as the priors on the richness–mass relation tightens. For both VELOCIraptor and SUBFIND the tension goes from ≲1 σ for 5 and 3 percent priors to ≲2 σ when the prior tightens to 1 percent. The tension for the AHF case is ≲1 σ for all priors considered, which is a result of the similarity observed in Figs. 10 and B.1 between AHF and ROCKSTAR calibrations.
Therefore, we conclude that differences in the HMF calibration associated with different choices of the halo finder propagate into systematic effects in the measurements of cosmological parameters that are comparable to the formal uncertainties on such parameters. For instance, if the cluster richness–mass relation from Euclid data could be calibrated at < 3 percent precision, then a crucial factor in deriving cosmological constraints from cluster number counts would become the way in which a halo is defined and identified in simulations in the process of the HMF calibration. Lastly, if one increases the error budget for the HMF calibration until it comprises the different halo-finder prescriptions studied here, the IOI presented in Table 5 also provides the expected reduction factor in the FOM of the cosmological constraining power of the Euclid cluster counts.
5.4.2. Impact of the calibration error
In Table 5, we also summarise the impact of the systematic and statistical errors of our main (ROCKSTAR) calibration and one of the auxiliary calibrations (VELOCIraptor) on the marginalised uncertainties in the cosmological parameters Ωm and σ8. We only consider one calibration of each group of halo finders, as this test is dominated by the number of simulations used in the HMF calibration. As VELOCIraptor, SUBFIND, and AHF all use the same number of simulations – equal to half of the set used for the ROCKSTAR calibration – they present very similar results. We compare the FOM change in the (Ωm, σ8) plane obtained by fixing the halo mass function parameters to the calibrated values with the ones obtained by marginalizing over such parameters using a multi-variate Gaussian with covariance given by the fit uncertainties. We consider again 1, 3, and 5 percent priors on the richness–mass scaling relations. For ROCKSTAR the statistical uncertainty only marginally affects the cosmological inference. For VELOCIraptor, we observe that the only significant impact is seen for the 1 percent prior, where the FOM is over-estimated by ∼10 percent when the HMF parameters are left fixed. Therefore, from this test, we conclude that the residual uncertainties in the HMF parameters have a negligible impact on the corresponding cosmological constraints.
6. Conclusions
In this paper, we carried out a detailed analysis to assess the numerical robustness of the halo mass function (HMF) predicted by N-body simulations, and to quantify and model its deviation from universality. The variety of tests that we carried out include changing the prescription for generating initial conditions, the effect of resolution and of round-off errors in particle positions in the initial conditions, the N-body integrator, the definition of a halo, and the halo finder. While our reference analysis were carried out assuming a vanilla ΛCDM cosmology, we also simulated the effect on the HMF of including massive neutrinos. Furthermore, in order to trace the origin of departures from universality, we also ran simulations with a purely scale-free power spectrum, both assuming Einstein–de Sitter and ΛCDM expansion histories. Finally, with the resulting high-resolution calibration of the HMF, we assess the impact of systematic effects in the cosmological parameters inference from an idealized Euclid cluster number counts experiment. Our main conclusions can be summarised as follows.
-
The different gravity solvers considered in this paper agree better than 1 percent on the HMF of cluster-sized halos for particle masses smaller than 1010 h−1 M⊙. Interestingly, the N-body integrator of RAMSES, the only code based on adaptive mesh refinement among those considered here, seems to systematically predict a lower number of halos with M ≲ 1014 h−1 M⊙ an effect that is more apparent at lower mass resolutions.
-
Our adopted setup for the PICCOLO set, which includes simulations for nine different cosmological models, provides a percent-level convergence on the HMF model when compared to higher resolution simulations.
-
Numerical artifacts, such as round-off errors, add non-Poisson fluctuations to the mass-binned distribution of halos. Choosing the mass binning accordingly mitigates the problem.
-
The differences in the abundance of halos coming from different halo finders largely dominate all the other numerical systematic errors considered here. The final impact on cosmological constraints depends on how well the mass–observable relation is kept under control, which highlights the need of a better understanding of how halos identified in simulations are related to clusters identified in an optical/NIR photometric survey, such as those provided by Euclid.
-
The HMF non-universality of virial halos depends on both the background evolution and the power spectrum shape, confirming the results of Ondaro-Mallea et al. (2021).
-
Our HMF model was calibrated against nine ΛCDM cosmologies evenly covering the 95 percent confidence level constraints on cosmological parameters from DES+SPT cluster counts (Costanzi et al. 2021) and four different halo finders (ROCKSTAR, AHF, SUBFIND, VELOCIraptor). Our HMF calibration reproduces the abundance of virial halos more massive than 3 × 1013 h−1 M⊙ with a precision of better than 1 percent for the range of cosmological parameters studied here. However, our calibration is expected to retain its accuracy beyond this range, as the HMF modelling was validated on a more extreme set of simulations (AETIOLOGY).
-
Using two external sets of simulations that include massive neutrinos, we validated the model presented in Castorina et al. (2014). Jointly with our calibration, the model by Castorina et al. (2014) reproduces the abundance of virial halos more massive than 4 × 1013 h−1 M⊙ for a total neutrino mass in the range [0.0 − 0.6] eV with a precision of better than 1 percent.
-
The statistical uncertainties on the HMF calibration presented in our analysis are significantly smaller than the expected accuracy for the mass–observational relation of Euclid. However, the difference between the HMF of the halo finders studied here is comparable to the expected accuracy for the mass–observational relation of Euclid and, as such, could lead to a biased inference of cosmological parameters.
One of the results of our analysis is that the main source of uncertainty in the calibration of the HMF from N-body simulations is related to the definition of halos and to the finder used to identify them. Reassuringly, the differences we found by applying four different halo finders do not compromise the accuracy of the HMF required by the Euclid cluster survey. Still, our analysis does not provide information as to the correspondence between a halo identified in an N-body simulation and a cluster identified in a photometric survey, and how uncertain knowledge of this correspondence will impact on the derivation of cosmological posteriors remains an open question. Indeed, uncertainties in the relation between richness and mass enclosed within a suitably defined (and cosmology-dependent) radius, projection effects in the selection function of the cluster sample, and miscentring, are all effects that need to be controlled and convolved with the predicted HMF. While all such issues need to be addressed one by one, the analysis presented here demonstrates that the precision in the definition of a fitting function for the HMF predicted by N-body simulations of Λ(ν)CDM cosmologies is not a limiting factor for cluster cosmology with Euclid. In forthcoming analyses we will verify whether a similar precision can be maintained when including uncertainties related to the astrophysics of baryons and departures from the standard Λ(ν)CDM framework.
See footnote 1
Glass pre-initial conditions are random samples that are dynamically evolved assuming a gravitational interaction with reversed sign until they settle in a quasi-equilibrium state.
Acknowledgments
It is a pleasure to thank Valerio Marra for constructive comments during the production of this work, Renate Mauland-Hus and Hans Winter for the support with RAMSES simulations, Peter Berhoozi for the support with ROCKSTAR, Oliver Hahn for the support with monofonIC and MUSIC, and Douglas Potter for the support with PKDGRAV-3 set up. Lourdes Ondaro-Mallea and Matteo Zennaro for sharing their HMF data. TC, SB, and AS are supported by the INFN INDARK PD51 grant. TC and AS are also supported by the FARE MIUR grant ‘ClustersXEuclid’ R165SBKTMA. AS is also supported by the ERC ‘ClustersXCosmo’ grant agreement 716762. KD acknowledges support by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy – EXC-2094 – 390783311 as well as support through the COMPLEX project from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program grant agreement ERC-2019-AdG 882679. AR is supported by the PRIN-MIUR 2017 WSCC32 ZOOMING grant. We acknowledge the computing centre of CINECA and INAF, under the coordination of the “Accordo Quadro (MoU) per lo svolgimento di attività congiunta di ricerca Nuove frontiere in Astrofisica: HPC e Data Exploration di nuova generazione”, for the availability of computing resources and support. We acknowledge the use of the HOTCAT computing infrastructure of the Astronomical Observatory of Trieste – National Institute for Astrophysics (INAF, Italy; see Bertocco et al. 2020; Taffoni et al. 2020). The Euclid Consortium acknowledges the European Space Agency and a number of agencies and institutes that have supported the development of Euclid, in particular the Academy of Finland, the Agenzia Spaziale Italiana, the Belgian Science Policy, the Canadian Euclid Consortium, the French Centre National d’Etudes Spatiales, the Deutsches Zentrum für Luft- und Raumfahrt, the Danish Space Research Institute, the Fundação para a Ciência e a Tecnologia, the Ministerio de Ciencia e Innovación, the National Aeronautics and Space Administration, the National Astronomical Observatory of Japan, the Netherlandse Onderzoekschool Voor Astronomie, the Norwegian Space Agency, the Romanian Space Agency, the State Secretariat for Education, Research and Innovation (SERI) at the Swiss Space Office (SSO), and the United Kingdom Space Agency. A complete and detailed list is available on the Euclid web site (http://www.euclid-ec.org).
References
- Abbott, T. M. C., Aguena, M., Alarcon, A., et al. 2020, PRD, 102, 023509 [NASA ADS] [CrossRef] [Google Scholar]
- Allen, S. W., Evrard, A. E., & Mantz, A. B. 2011, ARA&A, 49, 409 [Google Scholar]
- Amendola, L., & Tsujikawa, S. 2010, Dark Energy: Theory and Observations (Cambridge University Press) [Google Scholar]
- Angulo, R. E., & Hahn, O. 2022, Liv. Rev. Comput. Astrophys., 8, 1 [CrossRef] [Google Scholar]
- Angulo, R. E., & Pontzen, A. 2016, MNRAS, 462, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Angulo, R. E., & White, S. D. M. 2010, MNRAS, 401, 1796 [NASA ADS] [CrossRef] [Google Scholar]
- Aricò, G., Angulo, R. E., Contreras, S., et al. 2021, MNRAS, 506, 4070 [CrossRef] [Google Scholar]
- Artis, E., Melin, J.-B., Bartlett, J. G., & Murray, C. 2021, A&A, 649, A47 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bagla, J. S. 2002, J. Astrophys. Astron., 23, 185 [NASA ADS] [CrossRef] [Google Scholar]
- Behroozi, P. S., Wechsler, R. H., & Wu, H.-Y. 2013a, ApJ, 762, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Behroozi, P. S., Wechsler, R. H., Wu, H.-Y., et al. 2013b, ApJ, 763, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Bellagamba, F., Roncarelli, M., Maturi, M., & Moscardini, L. 2018, MNRAS, 473, 5221 [NASA ADS] [CrossRef] [Google Scholar]
- Bertocco, S., Goz, D., Tornatore, L., et al. 2020, ASP Conf. Ser., 527, 303 [NASA ADS] [Google Scholar]
- Bhattacharya, S., Heitmann, K., White, M., et al. 2011, ApJ, 732, 122 [NASA ADS] [CrossRef] [Google Scholar]
- Bocquet, S., Saro, A., Mohr, J. J., et al. 2015, ApJ, 799, 214 [NASA ADS] [CrossRef] [Google Scholar]
- Bocquet, S., Saro, A., Dolag, K., & Mohr, J. J. 2016, MNRAS, 456, 2361 [Google Scholar]
- Bocquet, S., Dietrich, J. P., Schrabback, T., et al. 2019, ApJ, 878, 55 [Google Scholar]
- Bocquet, S., Heitmann, K., Habib, S., et al. 2020, ApJ, 901, 5 [Google Scholar]
- Bond, J. R., Cole, S., Efstathiou, G., & Kaiser, N. 1991, ApJ, 379, 440 [NASA ADS] [CrossRef] [Google Scholar]
- Bryan, G. L., & Norman, M. L. 1998, ApJ, 495, 80 [NASA ADS] [CrossRef] [Google Scholar]
- Carbone, C., Petkova, M., & Dolag, K. 2016, JCAP, 07, 034 [CrossRef] [Google Scholar]
- Castignani, G., & Benoist, C. 2016, A&A, 595, A111 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Castorina, E., Sefusatti, E., Sheth, R. K., Villaescusa-Navarro, F., & Viel, M. 2014, JCAP, 2014, 049 [Google Scholar]
- Castro, T., Borgani, S., Dolag, K., et al. 2020, MNRAS, 500, 2316 [Google Scholar]
- Cooray, A., & Sheth, R. K. 2002, Phys. Rept., 372, 1 [Google Scholar]
- Corasaniti, P. S., & Achitouv, I. 2011a, PRD, 84, 023009 [Google Scholar]
- Corasaniti, P. S., & Achitouv, I. 2011b, PRL, 106, 241302 [Google Scholar]
- Costanzi, M., Villaescusa-Navarro, F., Viel, M., et al. 2013, JCAP, 12, 012 [Google Scholar]
- Costanzi, M., Saro, A., Bocquet, S., et al. 2021, PRD, 103, 043522 [NASA ADS] [CrossRef] [Google Scholar]
- Courtin, J., Rasera, Y., Alimi, J. M., et al. 2011, MNRAS, 410, 1911 [NASA ADS] [Google Scholar]
- Crocce, M., Pueblas, S., & Scoccimarro, R. 2006, MNRAS, 373, 369 [NASA ADS] [CrossRef] [Google Scholar]
- Crocce, M., Fosalba, P., Castander, F. J., & Gaztanaga, E. 2010, MNRAS, 403, 1353 [NASA ADS] [CrossRef] [Google Scholar]
- Cui, W., Borgani, S., & Murante, G. 2014, MNRAS, 441, 1769 [NASA ADS] [CrossRef] [Google Scholar]
- Dakin, J., Hannestad, S., & Tram, T. 2022, MNRAS, 513, 991 [CrossRef] [Google Scholar]
- Davis, M., Efstathiou, G., Frenk, C. S., & White, S. D. M. 1985, ApJ, 292, 371 [Google Scholar]
- Despali, G., Giocoli, C., Angulo, R. E., et al. 2016, MNRAS, 456, 2486 [NASA ADS] [CrossRef] [Google Scholar]
- Diemand, J., Kuhlen, M., & Madau, P. 2006, ApJ, 649, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Diemer, B. 2020, ApJ, 903, 87 [NASA ADS] [CrossRef] [Google Scholar]
- Diemer, B., & Joyce, M. 2019, ApJ, 871, 168 [NASA ADS] [CrossRef] [Google Scholar]
- Diemer, B., & Kravtsov, A. V. 2015, ApJ, 799, 108 [Google Scholar]
- Eke, V. R., Cole, S., & Frenk, C. S. 1996, MNRAS, 282, 263 [CrossRef] [Google Scholar]
- Elahi, P. J., Knebe, A., Pearce, F. R., et al. 2016, MNRAS, 458, 1096 [Google Scholar]
- Elahi, P. J., Cañas, R., Poulton, R. J. J., et al. 2019, PASA, 36, e021 [NASA ADS] [CrossRef] [Google Scholar]
- Euclid Collaboration (Adam, R., et al.) 2019, A&A, 627, A23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Euclid Collaboration (Fumagalli, A., et al.) 2021, A&A, 652, A21 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Euclid Collaboration (Scaramella, R., et al.) 2022, A&A, 662, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Euclid Collaboration (Adamek, J., et al.) 2022, https://doi.org/10.5281/zenodo.7297976 [Google Scholar]
- Garcia, R., & Rozo, E. 2019, MNRAS, 489, 4170 [NASA ADS] [CrossRef] [Google Scholar]
- Garrison, L. H., Eisenstein, D. J., Ferrer, D., Metchnik, M. V., & Pinto, P. A. 2016, MNRAS, 461, 4125 [NASA ADS] [CrossRef] [Google Scholar]
- Garrison, L. H., Abel, T., & Eisenstein, D. J. 2021a, MNRAS, 509, 2281 [NASA ADS] [CrossRef] [Google Scholar]
- Garrison, L. H., Joyce, M., & Eisenstein, D. J. 2021b, MNRAS, 504, 3550 [CrossRef] [Google Scholar]
- Genel, S., Bryan, G. L., Springel, V., et al. 2019, ApJ, 871, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Gill, S. P. D., Knebe, A., & Gibson, B. K. 2004, MNRAS, 351, 399 [Google Scholar]
- Gonzalez, A. 2014, in Building the Euclid Cluster Survey - Scientific Program, 7 [Google Scholar]
- Hahn, O., & Abel, T. 2011, MNRAS, 415, 2101 [Google Scholar]
- Hasselfield, M., Hilton, M., Marriage, T. A., et al. 2013, JCAP, 07, 008 [CrossRef] [Google Scholar]
- Holder, G., Haiman, Z., & Mohr, J. 2001, ApJ, 560, L111 [NASA ADS] [CrossRef] [Google Scholar]
- Hu, W., & Kravtsov, A. V. 2003, ApJ, 584, 702 [Google Scholar]
- Jenkins, A., Frenk, C. S., White, S. D. M., et al. 2001, MNRAS, 321, 372 [Google Scholar]
- Joyce, M., Marcos, B., Gabrielli, A., Baertschiger, T., & Labini, F. S. 2005, PRL, 95, 011304 [Google Scholar]
- Joyce, M., Garrison, L., & Eisenstein, D. 2021, MNRAS, 501, 5051 [CrossRef] [Google Scholar]
- Karamanis, M., & Beutler, F. 2021, Stat. Comput., 31, 61 [Google Scholar]
- Karamanis, M., Beutler, F., & Peacock, J. A. 2021, MNRAS, 508, 3589 [NASA ADS] [CrossRef] [Google Scholar]
- Kitayama, T., & Suto, Y. 1996, ApJ, 469, 480 [CrossRef] [Google Scholar]
- Knebe, A., Knollmann, S. R., Muldrew, S. I., et al. 2011, MNRAS, 415, 2293 [Google Scholar]
- Knollmann, S. R., & Knebe, A. 2009, ApJS, 182, 608 [Google Scholar]
- Kravtsov, A. V., & Borgani, S. 2012, ARA&A, 50, 353 [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv eprints [arXiv:1110.3193] [Google Scholar]
- Leroy, M., Garrison, L., Eisenstein, D., Joyce, M., & Maleubre, S. 2021, MNRAS, 501, 5064 [NASA ADS] [CrossRef] [Google Scholar]
- Lesci, G. F., Marulli, F., Moscardini, L., et al. 2022, A&A, 659, A88 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lin, W., & Ishak, M. 2017, PRD, 96, 023532 [Google Scholar]
- Maggiore, M., & Riotto, A. 2010a, ApJ, 711, 907 [NASA ADS] [CrossRef] [Google Scholar]
- Maggiore, M., & Riotto, A. 2010b, ApJ, 717, 515 [NASA ADS] [CrossRef] [Google Scholar]
- Maggiore, M., & Riotto, A. 2010c, ApJ, 717, 526 [NASA ADS] [CrossRef] [Google Scholar]
- Maleubre, S., Eisenstein, D., Garrison, L. H., & Joyce, M. 2022, MNRAS, 512, 1829 [CrossRef] [Google Scholar]
- Mantz, A. B., von der Linden, A., Allen, S. W., et al. 2015, MNRAS, 446, 2205 [Google Scholar]
- Marcos, B. 2008, PRD, 78, 043536 [Google Scholar]
- McClintock, T., Rozo, E., Becker, M. R., et al. 2019, ApJ, 872, 53 [NASA ADS] [CrossRef] [Google Scholar]
- Michaux, M., Hahn, O., Rampf, C., & Angulo, R. E. 2020, MNRAS, 500, 663 [NASA ADS] [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [Google Scholar]
- Nishimichi, T., Takada, M., Takahashi, R., et al. 2019, ApJ, 884, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Ondaro-Mallea, L., Angulo, R. E., Zennaro, M., Contreras, S., & Aricò, G. 2021, MNRAS, 509, 6077 [NASA ADS] [CrossRef] [Google Scholar]
- Peebles, P. J. E. 2020, The large-scale structure of the universe (Princeton University Press), 98 [Google Scholar]
- Planck Collaboration XVI. 2014, A&A, 571, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XX. 2014, A&A, 571, A20 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXIV. 2016, A&A, 594, A24 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6; Erratum: 2021, 652, C4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Potter, D., Stadel, J., & Teyssier, R. 2017, Comput. Astrophys. Cosmol., 4, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Power, C., Robotham, A. S. G., Obreschkow, D., Hobbs, A., & Lewis, G. F. 2016, MNRAS, 462, 474 [NASA ADS] [CrossRef] [Google Scholar]
- Press, W. H., & Schechter, P. 1974, ApJ, 187, 425 [Google Scholar]
- Reed, D., Gardner, J., Quinn, T. R., et al. 2003, MNRAS, 346, 565 [NASA ADS] [CrossRef] [Google Scholar]
- Reed, D. S., Smith, R. E., Potter, D., et al. 2013, MNRAS, 431, 1866 [NASA ADS] [CrossRef] [Google Scholar]
- Rozo, E., Wechsler, R. H., Rykoff, E. S., et al. 2010, ApJ, 708, 645 [Google Scholar]
- Salvati, L., Douspis, M., & Aghanim, N. 2020, A&A, 643, A20 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Saro, A., Bocquet, S., Rozo, E., et al. 2015, MNRAS, 454, 2305 [Google Scholar]
- Sartoris, B., Biviano, A., Fedeli, C., et al. 2016, MNRAS, 459, 1764 [Google Scholar]
- Schneider, A., & Teyssier, R. 2015, JCAP, 12, 049 [Google Scholar]
- Sheth, R. K., & Tormen, G. 1999, MNRAS, 308, 119 [Google Scholar]
- Sheth, R. K., Mo, H. J., & Tormen, G. 2001, MNRAS, 323, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Springel, V. 2005, MNRAS, 364, 1105 [Google Scholar]
- Springel, V., White, S. D. M., Tormen, G., & Kauffmann, G. 2001, MNRAS, 328, 726 [Google Scholar]
- Springel, V., Pakmor, R., Zier, O., & Reinecke, M. 2021, MNRAS, 506, 2871 [NASA ADS] [CrossRef] [Google Scholar]
- Taffoni, G., Becciani, U., Garilli, B., et al. 2020, ASP Conf. Ser., 527, 307 [NASA ADS] [Google Scholar]
- Teyssier, R. 2002, A&A, 385, 337 [CrossRef] [EDP Sciences] [Google Scholar]
- Tinker, J. L., Kravtsov, A. V., Klypin, A., et al. 2008, ApJ, 688, 709 [NASA ADS] [CrossRef] [Google Scholar]
- Velliscig, M., van Daalen, M. P., Schaye, J., et al. 2014, MNRAS, 442, 2641 [Google Scholar]
- Warren, M. S., Abazajian, K., Holz, D. E., & Teodoro, L. 2006, ApJ, 646, 881 [NASA ADS] [CrossRef] [Google Scholar]
- Watson, W. A., Iliev, I. T., D’Aloisio, A., et al. 2013, MNRAS, 433, 1230 [Google Scholar]
- Xu, G.-H. 1995, ApJS, 98, 355 [NASA ADS] [CrossRef] [Google Scholar]
- Zeldovich, Y. B. 1970, A&A, 5, 84 [Google Scholar]
Appendix A: Convergence tests
In Fig. A.1, we test the sensitivity and convergence of the cumulative HMF extracted from AHF catalogues to the accuracy parameters of Open-GADGET for one of the TEASE simulations of 5123 particles displaced from an equally spaced grid according to the Zeldovich approximation at z = 99. Each line corresponds to the ratio of the cumulative HMF obtained setting one of the accuracy parameters to half the value presented in Table 3. For comparison, we also add the 68 percent confidence level in red for the ErrTolForceAcc assuming that the number of halos in the simulations are distributed according to a Poisson distribution. Fig. A.1 shows that our parameter set provide sub-Poisson differences to higher precision sets, deviating by less than a fraction of a percent in the abundance of halos more massive than 3 × 1013 h−1 M⊙.
 |
Fig. A.1. Sensitivity of the cumulative mass function to the accuracy parameters of Open-GADGET. Each line corresponds to the ratio of the cumulative mass function obtained setting one of the accuracy parameters to half the value presented in Table 3 with respect to the fiducial set. For comparison, we add the 68% confidence level in red for the ErrTolForceAcc assuming that halos in the simulations are distributed according to a Poisson distribution. |
In Fig. A.2, we present the comparison between the cumulative mass function extracted with AHF from cosmological simulations run with Open-GADGET and GADGET-4. We tested the convergence of the results for three different initial conditions: 5123 particles displaced from an equally spaced grid according to 3LPT at z = 24, the same number of particles using Zeldovich at z = 99, and 4 × 3203 particles displaced from a face centred cubic (FCC) grid according to 3LPT at z = 24. The box size is 500 h−1 Mpc. In all configurations, the agreement between Open-GADGET and GADGET-4 is better than a fraction of percent for all masses considered. Due to the higher degree of planes of symmetry, the FCC configuration shows an even better agreement between the two codes, as in this configuration the usual tree algorithm delivers more accurate forces from the simulation start.
 |
Fig. A.2. Comparison between the cumulative mass function extracted from Open-GADGET and GADGET-4 for three different initial conditions: 5123 displaced from a equally spaced grid according to 3LPT at z = 24, the same number of particles using Zeldovich at z = 99, and 4 × 3203 particles displaced from a FCC grid at z = 24. |
In Fig. A.3, we present a convergence test for the cumulative mass function computed from AHF halo catalogue for different particle masses and spatial resolutions. We consider three mass resolutions, corresponding to the following particle masses: {6.35 × 1011, 7.94 × 1010, 9.92 × 109} h−1 M⊙; respectively {2563, 5123, 10243} particles in a box of 500 h−1 Mpc. For the gravitational softening we consider: ϵ = {l/20, l/40, l/80}, where l is the mean interparticle distance. For reference, the 1 percent region is shown with the grey-shaded area, while the 68 percent confidence level assuming Poisson distribution for the halo distribution of the simulations with 10243 particles with ϵ = l/40 and ϵ = l/80 is depicted in red. We note that a particle mass of few times 1010 h−1 M⊙ is enough to have a cumulative mass function that agrees to within 1 percent with the higher resolution simulation for halos more massive than 1014 h−1 M⊙. Lighter objects are more strongly affected by both the mass and spatial resolutions. For the simulation with 2563 particles, even the formation of very massive objects is suppressed by ≈4 percent.
 |
Fig. A.3. Convergence test for the cumulative mass function for different particle mass ({6.35 × 1011, 7.94 × 1010, 9.92 × 109} h−1 M⊙, respectively, {2563, 5123, 10243} particles in a box of 500 h−1 Mpc) and spatial resolution set by the gravitational softening (ϵ = {l/20, l/40, l/80}, where l is the mean interparticle distance). The filled region in grey represents the 1 percent region around unity and the filled region in red represent the 68 percent confidence level assuming Poisson distribution for the abundance of halos in both simulations. |
Appendix B: Comparison between the different halo finder calibrations
The ratio of the multiplicity function as a function of the halo virial mass for the different calibrations with respect to ROCKSTAR is shown in Fig. B.1 colour coded by the redshift. Fig. B.1 confirms the trends at low redshift presented in Fig. 10, but also shows their dependence with redshift. Despite the very different algorithm, AHF and ROCKSTAR provide a multiplicity function that agrees within 10 percent up to Mvir ∼ 1015 h−1 M⊙ for the redshift range considered.
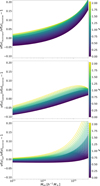 |
Fig. B.1. Ratio of the multiplicity function as a function of the halo virial mass for the different calibrations to ROCKSTAR colour coded according to redshift. From top to bottom, we present the results for VELOCIraptor, SUBFIND, and AHF. |
ROCKSTAR’s agreement with VELOCIraptor is worse than the agreement with AHF, depending more strongly on both mass and redshifts. At low redshift, VELOCIraptor tends to suppress the number of halos with mass Mvir ≲ 1014 h−1 M⊙ by few percents.
ROCKSTAR’s worst agreement is with respect to SUBFIND, with SUBFIND suppressing the number of objects with mass Mvir ≲ 1015 h−1 M⊙ at all redshifts.
Appendix C: Assessment of the fit-quality dependence on redshift
In Fig. C.1, we present the ROCKSTAR fit quality dependence with redshift. The fit-quality (p-value) in Fig. C.1 was estimated from sampling 1000 points from the likelihood used for the calibration assuming the best-fit parameters. On the right panel, we present the histogram projection of the left panel. The p-value is the fraction of random catalogues that had a residual higher than the original catalogue fit. While all the PICCOLO snapshots were used to produce the left panel of the Fig. C.1, only the specific snapshots used for the calibration were used to present the histogram on the right panel so as to avoid using strongly correlated snapshots. Figure C.1 shows that our model provides robust results for the redshift range [0, 2] and confirms that our choice of σsys is reasonable.
 |
Fig. C.1. Dependence of ROCKSTAR fit quality as a function of redshift. The fit quality (p-value) was estimated from sampling from the likelihood used for the calibration assuming the best-fit parameters. The p-value is the fraction of random catalogues that had a residual higher than the original catalogue. On the right panel, we present the histogram projection of the left panel. |
All Tables
Summary statistics for the forecast of the impact of different halo finders and calibration errors on Euclid cluster counts cosmological constraints on Ωm and σ8.
All Figures
|
Fig. 1. Convergence test for the cumulative mass function with respect to the effects of both transients and modes sampled in the initial conditions, at fixed box size. In each panel, we report results for five particle masses: {6.50 × 1011, 8.13 × 1010, 1.02 × 1010, 5.08 × 109, 1.27 × 109} h−1 M⊙; respectively {4 × 1603, 4 × 3203, 4 × 6403, 12803, 4 × 12803} particles in a box of 500 h−1 Mpc. The rationale for the chosen number of particles is that 4 × 1603 differs by ∼2 percent from 2563, and therefore one can directly compare the results presented here with Fig. A.3 at similar computational cost. The filled region in grey represents the 1 percent region around unity and the filled region in red marks the 68 percent confidence level assuming Poisson distribution for the abundance of halos in both simulations. Each panel shows the comparison for a different redshift, as labelled. |
| In the text | |
|
Fig. 2. Matter density contrast in a 2D projection of a zoomed-in volume of (15.37 h−1 Mpc)3 around the position of the most massive halo found by AHF in the corresponding Open-GADGET simulation. The box size of this volume corresponds to six times the virial radius of the Open-GADGET central halo. Silver and cyan circles denote the virial radius of halos and subhalos identified in this region, respectively. For the sake of clarity, a mass threshold of (1012) 1013 h−1 M⊙ was imposed to select the (sub)halos presented. |
| In the text | |
|
Fig. 3. Ratio of the cumulative mass function at z = 0 to that measured from the Open-GADGET simulation. From top to bottom, the panels correspond to a particle mass resolution of {6.35 × 1011, 7.94 × 1010, 9.92 × 109} h−1 M⊙; respectively, {2563, 5123, 10243} particles in a box of 500 h−1 Mpc. The red filled area represents the 68 percent confidence level for the CONCEPT case assuming that the number of halos observed in the two simulations follows an uncorrelated Poisson distribution. |
| In the text | |
|
Fig. 4. Ratio of the cumulative mass function measured from simulations started with same seed, but different LPT order (3LPT vs. Zeldovich approximation) and starting redshifts (z = 24, z = 49, and z = 99), as indicated by the different coloured lines in the legend. |
| In the text | |
|
Fig. 5. Distribution of the relative difference between masses of halos at z = 0 matched between different simulations with initial conditions perturbed by ≲1 pc. Top: Distribution of the relative mass difference. Bottom: Same distribution scaled by the number of particles corresponding to the object mass. |
| In the text | |
 |
Fig. 6. Same as Fig. 5 but with double precision. |
| In the text | |
|
Fig. 7. The rms variation in the HMF induced by the noise in the initial conditions, normalised to the expected Poisson noise, as a function of halo mass. Curves with different colours correspond to different binnings of halo masses, as indicated in the legend. |
| In the text | |
|
Fig. 8. Impact of the simulation box size L on the mass variance (top panel) and the differential HMF (bottom panel) for three different cases L = {500, 1000, 2000} h−1 Mpc depicted in red, blue, and green, respectively. Solid lines represent the mean effect due to the truncation of the mass variance integration to the fundamental mode. The corresponding shaded regions correspond to the 68 percent interval due to the sample variance. |
| In the text | |
|
Fig. 9. Comparison between AHF and SUBFIND halos extracted from the same (26.65 h−1 Mpc)3 volume. The largest and smallest halo masses depicted are 2 × 1015 h−1 M⊙ and 1013 h−1 M⊙, respectively. The cyan circles denote the virial radius of halos identified in this region. |
| In the text | |
|
Fig. 10. Ratio of the cumulative mass function extracted from AHF, SUBFIND, VELOCIraptor, and DENHF to that extracted from ROCKSTAR. The filled regions in red and purple represent the 68% confidence regions for the AHF and VELOCIraptor (6DFOF Adaptive), respectively, assuming that the number of objects in each catalogue follows a Poisson distribution. |
| In the text | |
|
Fig. 11. Difference in the cumulative mass function when all particles inside the spherical overdensity are considered versus just the bound particles. |
| In the text | |
|
Fig. 12. The 68% and 95% confidence level contours of the calibration carried out independently in several simulations assuming a power-law linear power spectrum in an EdS background, i.e., Pm(k)≈kns and Ωm = 1. |
| In the text | |
|
Fig. 13. The 68% and 95% confidence level contours of the calibration carried out independently in simulations with ns = { − 2.0, −2.5} and background evolution given by either a cosmology in agreement with Planck Collaboration VI (2020) or EdS. |
| In the text | |
|
Fig. 14. HMF at z = 0 for the PICCOLO cosmologies and the ROCKSTAR best-fit prediction. The vertical dotted line represents the cut in mass corresponding to the minimum number of 300 particles for the C0 runs. Error bars are shown assuming a Poisson distribution of the expected number of objects. |
| In the text | |
|
Fig. 15. Ratio of ROCKSTAR best-fit to the mean abundance of halos extracted from the simulations at z = {0, 0.5, 1.0, 2.0}. The vertical dotted line represents the cut in mass corresponding to the minimum number of 300 particles for the C0 runs. The regions in grey represent the relative 1% and 2.5% regions. The Poisson error bars correspond to the C0 and C3 (our cosmology with fewer halos), which count with ten and two realisations, respectively. We only show mass bins with more than 50 halos for improved readability. |
| In the text | |
|
Fig. 16. Impact of massive neutrinos on the HMF. We present the ratio of the HMF with massive neutrinos to the corresponding massless neutrinos counterpart as observed in two independent external simulations DEMNUni (top) and the Open-GADGET subset of Euclid’s neutrino code comparison simulations (bottom). See the definition of ℛ in Eq. (20). |
| In the text | |
|
Fig. 17. Accuracy of the model presented in Castorina et al. (2014) in accounting for the impact of massive neutrinos on the HMF. We compare the ratio of the HMF with massive neutrinos to the corresponding massless neutrinos counterpart, assuming the model of Castorina et al. (2014) divided by the same quantity as observed in two independent external simulations: DEMNUni (top) and the Open-GADGET subset of Euclid’s neutrino code comparison simulations (bottom). See the definition of ℛ in Eq. (20). |
| In the text | |
|
Fig. 18. Comparison of our HMF model to the works of Tinker et al. (2008), Despali et al. (2016), and Ondaro-Mallea et al. (2021). We use our ROCKSTAR calibration as the reference and present our SUBFIND calibration for easy comparison with Ondaro-Mallea et al. (2021). We also present the mean of the multiplicity function νf(ν) measured from the ten PICCOLO C0 runs. The grey regions depict the 1 and 5 percent regions. We adopted a symmetric-log scale on the y-axis, where the region between the dashed lines is presented in a linear scale. |
| In the text | |
|
Fig. A.1. Sensitivity of the cumulative mass function to the accuracy parameters of Open-GADGET. Each line corresponds to the ratio of the cumulative mass function obtained setting one of the accuracy parameters to half the value presented in Table 3 with respect to the fiducial set. For comparison, we add the 68% confidence level in red for the ErrTolForceAcc assuming that halos in the simulations are distributed according to a Poisson distribution. |
| In the text | |
|
Fig. A.2. Comparison between the cumulative mass function extracted from Open-GADGET and GADGET-4 for three different initial conditions: 5123 displaced from a equally spaced grid according to 3LPT at z = 24, the same number of particles using Zeldovich at z = 99, and 4 × 3203 particles displaced from a FCC grid at z = 24. |
| In the text | |
|
Fig. A.3. Convergence test for the cumulative mass function for different particle mass ({6.35 × 1011, 7.94 × 1010, 9.92 × 109} h−1 M⊙, respectively, {2563, 5123, 10243} particles in a box of 500 h−1 Mpc) and spatial resolution set by the gravitational softening (ϵ = {l/20, l/40, l/80}, where l is the mean interparticle distance). The filled region in grey represents the 1 percent region around unity and the filled region in red represent the 68 percent confidence level assuming Poisson distribution for the abundance of halos in both simulations. |
| In the text | |
|
Fig. B.1. Ratio of the multiplicity function as a function of the halo virial mass for the different calibrations to ROCKSTAR colour coded according to redshift. From top to bottom, we present the results for VELOCIraptor, SUBFIND, and AHF. |
| In the text | |
|
Fig. C.1. Dependence of ROCKSTAR fit quality as a function of redshift. The fit quality (p-value) was estimated from sampling from the likelihood used for the calibration assuming the best-fit parameters. The p-value is the fraction of random catalogues that had a residual higher than the original catalogue. On the right panel, we present the histogram projection of the left panel. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.