| Issue |
A&A
Volume 669, January 2023
|
|
|---|---|---|
| Article Number | A69 | |
| Number of page(s) | 18 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202244673 | |
| Published online | 10 January 2023 | |
KiDS-1000 cosmology: Constraints from density split statistics
1
Argelander-Institut für Astronomie, Auf dem Hügel 71, 53121 Bonn, Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Universitäts-Sternwarte, Fakultät für Physik, Ludwig-Maximilians-Universität München, Scheinerstr.1, 81679 München, Germany
3
School of Mathematics, Statistics and Physics, Newcastle University, Newcastle upon Tyne NE1 7RU, UK
4
E.A Milne Centre, University of Hull, Cottingham Road, Hull HU6 7RX, UK
5
Center for Theoretical Physics, Polish Academy of Sciences, al. Lotników 32/46, 02-668 Warsaw, Poland
6
Ruhr University Bochum, Faculty of Physics and Astronomy, Astronomical Institute (AIRUB), German Centre for Cosmological Lensing, 44780 Bochum, Germany
7
INAF – Istituto Nazionale di Astrofisica, Osservatorio Astronomico di Trieste, Via Tiepolo 11, 34143 Trieste, Italy
8
INFN – Istituto Nazionale di Fisica Nucleare, Sezione di Trieste, Via Valerio 2, 34127 Trieste, Italy
9
Institute for Fundamental Physics of the Universe, Via Beirut 2, 34151 Trieste, Italy
10
Germany Max-Planck-Institut für Astrophysik, Karl-Schwarzschild-Straße 1, 85741 Garching, Germany
11
Institute for Astronomy, University of Edinburgh, Royal Observatory, Blackford Hill, Edinburgh EH9 3HJ, UK
12
Department of Physics and Astronomy, University College London, Gower Street, London WC1E 6BT, UK
13
Leiden Observatory, Leiden University, PO Box 9513, 2300 RA Leiden, The Netherlands
14
Laboratoire d’Astrophysique de Marseille, Aix-Marseille Univ., Rue Frédéric Joliot-Curie 38, 13388 Marseille, France
15
Shanghai Astronomical Observatory (SHAO), Nandan Road 80, Shanghai 200030, PR China
16
University of Chinese Academy of Sciences, Yuquan Road 19A, Beijing 100049, PR China
17
Institute for Particle Physics and Astrophysics, ETH Zürich, Wolfgang-Pauli-Strasse 27, 8093 Zürich, Switzerland
Received:
3
August
2022
Accepted:
28
October
2022
Abstract
Context. Weak lensing and clustering statistics beyond two-point functions can capture non-Gaussian information about the matter density field, thereby improving the constraints on cosmological parameters relative to the mainstream methods based on correlation functions and power spectra.
Aims. This paper presents a cosmological analysis of the fourth data release of the Kilo Degree Survey based on the density split statistics, which measures the mean shear profiles around regions classified according to foreground densities. The latter is constructed from a bright galaxy sample, which we further split into red and blue samples, allowing us to probe their respective connection to the underlying dark matter density.
Methods. We used the state-of-the-art model of the density splitting statistics and validated its robustness against mock data infused with known systematic effects such as intrinsic galaxy alignment and baryonic feedback.
Results. After marginalising over the photometric redshift uncertainty and the residual shear calibration bias, we measured for the full KiDS-bright sample a structure growth parameter of 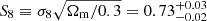 that is competitive and consistent with two-point cosmic shear results, a matter density of Ωm = 0.27 ± 0.02, and a constant galaxy bias of b = 1.37 ± 0.10.
that is competitive and consistent with two-point cosmic shear results, a matter density of Ωm = 0.27 ± 0.02, and a constant galaxy bias of b = 1.37 ± 0.10.
Key words: cosmological parameters / large-scale structure of Universe / gravitational lensing: weak / methods: statistical
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe-to-Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Gravitational lensing, the theory that describes the deflection of light by massive objects, reveals a wealth of information about the evolution of matter structure in the Universe (see, e.g. Hamana et al. 2020; Asgari et al. 2021; Amon et al. 2022, for recent cosmic shear analyses). Due to the accurate theoretical description and control over systematic inaccuracies, the most commonly used methods focus on two-point statistics, namely the two-point correlation functions and their Fourier counterparts called power spectra. These statistics are excellent for capturing the Gaussian information contained in the data and are complete if the data are Gaussian-distributed, such as the cosmic microwave background (CMB; e.g. Planck Collaboration V 2020). In the late Universe, however, non-linear gravitational instabilities generate a significant amount of non-Gaussian features, whose information can only be accessed with higher-order statistics. Furthermore, since higher-order statistics scale differently with cosmology and are affected differently by residual systematic effects, the constraining power on cosmological parameters increases by jointly investigating second- and higher-order statistics (see, e.g. Kilbinger & Schneider 2005; Bergé et al. 2010; Pires et al. 2012; Fu et al. 2014; Pyne & Joachimi 2021).
As the current analysis of the estimation of cosmological parameters reaches the per cent level, tensions arise between observations of the early and late or local Universe. A famous tension is the one for the Hubble parameter H0 (Di Valentino et al. 2021a) but it is not the subject of this work. More interesting for us is the tension in the matter clustering parameter 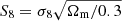 , where it seems that the local Universe is less clustered than observations of the CMB suggest (Hildebrandt et al. 2017; Joudaki et al. 2020; Heymans et al. 2021; Di Valentino et al. 2021b).
, where it seems that the local Universe is less clustered than observations of the CMB suggest (Hildebrandt et al. 2017; Joudaki et al. 2020; Heymans et al. 2021; Di Valentino et al. 2021b).
A recent development in analysis methods has enabled the joint investigation of weak lensing and galaxy clustering data (van Uitert et al. 2018; Joudaki et al. 2018; Abbott et al. 2018; DES Collaboration 2022), yielding significantly better constraints, especially along the σ8 − Ωm degeneracy axis. Even though foreground clustering data introduces largely uncertain astrophysical parameters, such as the galaxy bias, that complicate the analysis, these joint analyses inform us better about the correlation between galaxies and the underlying matter distribution (Sánchez et al. 2017). Here again, two-point statistics have been favoured so far for the reasons mentioned above, such that the combination of all measurements (cosmic shear, galaxy clustering, and galaxy-galaxy lensing) are generally referred to as ‘3×2pts’ statistics.
To access the additional information contained in the non-Gaussian features, a competitive statistic to the 3×2pts method was recently proposed in Gruen et al. (2016), coined the ‘density-split statistics’ (DSS hereafter). This technique measures the tangential shear on the full pixelated survey footprint and bins the resulting shear profiles as a function of the foreground mass density. For example, high galaxy density regions generally trace large matter over-density regions, in which the tangential shear is expected to be larger, and this varies with cosmology. The DSS, therefore, captures information both from the shape and amplitude of the shear profiles and from the number of foreground galaxies in each density bin, with the latter helping to measure the galaxy bias significantly.
The first ingredient needed is a prediction model to interpret the measurements and constrain cosmological and astrophysical parameters. This can be constructed either from simulations (see, e.g., Harnois-Déraps et al. 2021; Zürcher et al. 2022, for examples of simulation-based inference using the lensing peak count) or from analytical calculations, where for instance Reimberg & Bernardeau (2018) and Barthelemy et al. (2021) made use of large deviation theory (LDT) to model the reduced-shear correction to the aperture mass probability distribution function (PDF). Another approach to access higher-order moments is discussed in Halder et al. (2021), Halder & Barreira (2022), and Heydenreich et al. (2022), where third-order cosmic shear statistics were modelled directly from the bispectrum. Although, the simulation-based approach has advantages regarding the numerical incorporation of critical systematic effects such as the intrinsic alignment (IA) of galaxies (see, e.g. Harnois-Déraps et al. 2022, hereafter HD22) and baryonic processes extracted from hydrodynamical simulations. However, it typically requires large simulation suites that jointly vary all the parameters under consideration. On the other hand, analytical modelling of the DSS can better dissect the basic underlying properties of the LSS, and it can be computed sufficiently fast enough at any point in the cosmological parameter space. Such a model was derived in Friedrich et al. (2018, hereafter F18), based on non-perturbative modelling of the matter density PDF. For a given cosmology, mean foreground galaxy density, and redshift distributions of the foreground and background galaxies, the F18 model predicts the mean tangential shear profiles and the PDF of the galaxy counts in each mass density bin. In Gruen et al. (2018, hereafter G18), the F18 model was used to constrain cosmological parameters from measurements of the Dark Energy Survey (DES) First Year and Sloan Digital Sky Survey (SDSS) data, yielding results competitive with the main DES 3×2 pt analysis (Abbott et al. 2018).
To date, no cosmological constraints from DSS exist, except that of G18. However, the methods have been improved significantly. In particular, Brouwer et al. (2018) have presented a contemporary measurement of the DSS extracted from the third data release of the Kilo-Degree Survey data (KiDS), wherein the foreground galaxies were selected to mimic the spectroscopic Galaxy And Mass Assembly survey (hereafter GAMA; Driver et al. 2011). They developed an optimal methodology in their work, notably showing how the resulting signal-to-noise ratio (S/N) depends on the smoothing scale for the density map of foreground galaxies.
Burger et al. (2022, hereafter B22) modified the analytical model by F18 for an application to galaxy density fields smoothed with general filters. As discussed in Burger et al. (2020), compensated filter functions outperform the previously used top-hat filter functions in terms of the overall S/N of the shear signals and in recovering the correlation between the galaxy and matter density contrast. B22 mention another advantage of compensated filter functions: they are more compact in Fourier space and, therefore, can better suppress large-ℓ modes where baryonic effects play an important role, as studied in Asgari et al. (2020). On the downside, compensated filters complicate the LDT-like calculations (Barthelemy et al. 2021). Nevertheless, B22 show that the density split statistics with compensated filters can still be accurately modelled in a computationally tractable manner after calibrating residual inaccuracies at large and small scales on the simulations of Takahashi et al. (2017).
The current paper presents the first cosmological inference based on a DSS analysis of the KiDS data. We exploited the model advances presented in B22, using the dense sample of bright galaxies presented in Bilicki et al. (2021), to construct our foreground density maps and compute the tangential shear from the lensing catalogue constructed from the fourth KiDS data release. Our inference includes a marginalisation over several residual systematic uncertainties. We verified with numerical N-body and hydrodynamical simulations that our measurements are robust against the IA of galaxies and baryonic feedback.
This work is structured as follows. In Sect. 2 we review the basics of the DSS and introduce small modifications made to our model compared to the one from B22. In Sect. 3 we present the observed data used in our analysis, and then we describe in Sect. 4 the simulations needed for the validation of our inference pipeline which is described in Sect. 5. In Sect. 6 we perform our validation of the model together with an investigation on IA and baryonic physics which could potentially contaminate our results. In Sect. 7 we finally present our main results and conclude with a discussion and summary in Sect. 8.
2. Theoretical background
The DSS essentially measures the tangential shear around sub-areas of the sky that are assigned according to the galaxy foreground density. It is therefore closely related to aperture statistics, which we introduce here first. Given a convergence field κ(θ), the aperture mass map is defined as
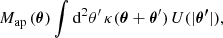 (1)
(1)
where θ is the position on the flat sky, and U(ϑ) is a compensated, axisymmetric filter function, such that ∫ϑ U(ϑ) dϑ = 0. The aperture mass, Map, can also be expressed in terms of the tangential shear γt (Schneider 1996) and a second filter function Q as
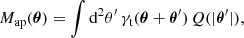 (2)
(2)
where
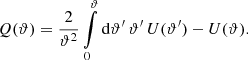 (3)
(3)
The above relation between the two filters U and Q can be inverted,
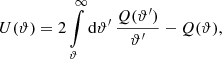 (4)
(4)
allowing us to work either with convergence maps or shear catalogues. Replacing the convergence by the foreground galaxy number counts n(θ) in Eq. (1), we define the aperture number counts, or simply aperture number, as (Schneider 1998)
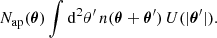 (5)
(5)
This definition is equivalent to the ‘Counts-in-Cell’ (CiC) statistics mentioned in Gruen et al. (2016) if the filter U is defined as a top-hat. In that case, however, U is not compensated; hence, one can not relate the filters U and Q.
The general idea of the DSS is to divide the survey area into quantiles 𝒬 according to the aperture number Nap and then measure the mean tangential shear in the corresponding quantiles ⟨γt|𝒬⟩. We detail in Sect. 2.1 how we achieve this in the data and in Sect. 2.2 how we predict it analytically.
2.1. Measuring the DSS vector
We followed several ordered pipeline steps to extract the DSS data vector for the cosmological inference. First, we distributed the foreground (lens) galaxies onto a HEALPix (Górski et al. 2005) grid n(θ) of nside = 4096, which resulted in a pixel area of AHP ≈ 0.74 arcmin2. Second, we determined the aperture number field Nap with a filter function U, with a finite filter radius Θ and maximal one transition from positive to negative values at θtr. This was achieved with the healpy function smoothing, with a beam window function that is the U-filter in the spherical harmonic space determined with healpy function beam2bl. Since Eq. (5) assumes full knowledge of n(θ) on the sky which has to be modified in the presence of a mask m(θ) as
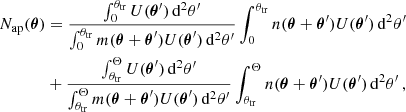 (6)
(6)
where in this work m(θ) was the KiDS-1000 mask. For example, the second part of this equation vanishes for a top-hat filter. We divided the filter in this way to prevent the masked area from entering the positive part to decrease Nap systematically and artificially increase the aperture number when entering the negative filter region. By separating the compensated filter into its positive and negative parts, we could correct both individually. Furthermore, since this correction became less accurate in heavily masked regions, we included only those pixels where the number of unmasked pixels within the given filter radius (effective area) was greater than 50% of the total number of pixels inside the same circle (maximal area), which we treated as our ‘good’ pixels. This can change from pixel to pixel because our HEALPix map originated from a flat sky mask. To avoid a pixel being considered good, yet for more than 50% of pixels to be missing in the negative part, we included for compensated filters only those pixels where the effective area for the positive and the negative part was greater than 50% of their individual maximal area. With our choice of the 50% threshold, we attempted to achieve a compromise between statistical power and falsely measured Nap values. G18 considered only regions with at least 80% coverage, but since the KiDS footprint is very narrow, we had to relax that threshold to avoid shot noise-dominated data vectors. Therefore, we decided to use the highest threshold that yielded shear profiles that do not deviate significantly from shear profiles with smaller threshold values. The result is shown in Fig. A.1, where it is seen that the shear profiles with threshold values of 50% or smaller are quite similar and start to deviate for higher threshold values. Next, we allocated those good pixels to five quantiles 𝒬 according to their Nap value. The pixels from each quantile are then correlated with the tangential shear information from the source catalogues using the treecorr (Jarvis et al. 2004) software in ten log-spaced bins with angular separation 10 arcmin < ϑ < 120 arcmin. This resulted in measurements of the five tangential shear profiles ⟨γt|𝒬⟩, that is, one per quantile. For all measured profiles, the shear around random points is subtracted, which ensures that the average overall quantiles vanish by definition. Finally, we constructed our data vector, which consists of the shear profiles from the highest two and lowest two quantiles, plus the mean of the aperture number values in the same four quantiles. We must exclude the information of one quantile 𝒬 since the other four quantiles fully determine it by construction, for the reason explained above. The same is true for mean aperture number values in those quantiles, whose average is fixed by the total galaxy number density measured in the data. This results in ten θ bins, four quantiles and two source bins in a data vector of 80 + 4 = 84 elements. Although the information content is independent of which quantile is removed, we exclude the middle quantile for the whole analysis since it would have the least cosmological information, if the quantiles were analysed separately.
2.2. Modelling the DSS vector
Our modelling of the DSS signal is inspired by the LDT approach and builds from the original F18 model and the subsequent improvements presented in B22. We refer the reader to these two references for the complete details of the model calculations and highlight here only the broad principles and the minor modifications we have made. Briefly, the model consists of three key ingredients: (i) the PDF of the matter density contrast, smoothed with the filter function U, labelled δm, U; (ii) the expectation value of the convergence inside a radius ϑ given the smoothed matter density contrast defined above; (iii) the distribution of Nap values given δm, U. B22 shows how these are computed for arbitrary filter functions and quantile counts. We, however, focus here on the ‘adapted compensated’ filter case, introduced in B20 and shown in Fig. 3 in B22, and five quantiles. As in B22, the model was calibrated using the full-sky simulations described in Takahashi et al. (2017) to suppress the residual differences of the modelled and measured data vector. The KiDS-1000 lens distribution used in the current paper peaks at a lower redshift than that in B22, and we know that the DSS model is slightly less accurate in that case, but we subsequently show that the calibration is accurate enough to yield unbiased results.
Since real galaxies are not expected to be perfectly Poisson-distributed, we modified the distribution of the aperture number computed in the B22 model in a way that allows for super-Poissonian shot noise. Inspired by F18, we achieved this by scaling the galaxy number density n0 with a free parameter α > 0, such that n0 α−1 can be interpreted as an effective number density of Poissonian tracers. This implies that the quantity p(Nap α−1|δm, U) follows a log-normal distribution, instead of p(Nap|δm, U) as in B22. Consequently, the characteristic function Ψ, determining the parameters of the log-normal distribution, must be modified to (see Eq. (36) of B22)
![Mathematical equation: $$ \begin{aligned} \Psi (t)=&\exp \left(2\pi \frac{n_0}{\alpha } \int _0^\infty {\mathrm{d}} \vartheta \;\vartheta \; \left(1+b\, \langle { w}_\vartheta |\delta _{\mathrm{m} ,U}\rangle \right) \left[\mathrm{e} ^{\mathrm{i} t U(\vartheta )} -1\right]\right), \end{aligned} $$](/articles/aa/full_html/2023/01/aa44673-22/aa44673-22-eq9.gif) (7)
(7)
where wϑ is the mean 2D density contrast on a circle at ϑ (see Eq. (37) in B22), and b is the linear galaxy bias. Moreover, to ensure that the mean aperture number remains constant, we further modified the calculation of p(Nap|δm, U) as (see Eq. (A39) of B22):
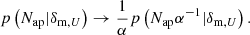 (8)
(8)
Since the expectation value ⟨Nap|δm, U⟩∝α and the variance ⟨(Nap − ⟨Nap|δm, U⟩)2|δm, U⟩∝α2 we see that the ratio of variance to expectation value is proportional to α as required to describe deviations from Poissonian samples. Similar to Friedrich et al. (2018), we require α > 0.1 in our parameter sampling for numerical reasons. We also compared our definition of this α parameter to the one implemented in Friedrich et al. (2018) and found no differences in the predictions.
Compared with numerical simulations, this model has been shown in B22 to be accurate, with residual inaccuracies to be everywhere significantly smaller than the statistical noise of the KiDS-1000 data. We, therefore, do not need to include a modelling error in our uncertainty budget. Furthermore, we also tested a non-linear galaxy bias model, where we exchanged the constant galaxy bias b with b = b1 + b2δm, U > 0. However, b2 was highly correlated with other parameters such as Ωm which prevented our parameter estimation from converging and therefore had to be excluded for this analysis. We also tested if the assumption of a linear galaxy bias is satisfied (see Fig. A.2 and its description), and the results of that test can be summarised as follows: a linear galaxy bias model is sufficient if an analysis using shear and Nap information gives similar cosmological results as using only shear information since the shear profiles are basically insensitive to the galaxy bias model.
3. Observational data
In our analysis, we exploit the fourth data release of the KiDS (Kuijken et al. 2015, 2019; de Jong et al. 2015, 2017), which is a public survey carried out at the European Southern Observatory1. KiDS was designed for weak lensing applications, producing high-quality images with VST-OmegaCAM camera. Thanks to the infrared data from its overlapping partner survey VIKING (VISTA Kilo-degree Infrared Galaxy survey, Edge et al. 2013), galaxies are observed in nine optical and near-infrared bands, u, g, r, i, Z, Y, J, H, Ks, allowing for better control over redshift uncertainties (Hildebrandt et al. 2021, hereafter H21) to earlier releases. The weak lensing data in KiDS DR4 are collectively called ‘KiDS-1000’ as they cover ∼1000 deg2 of images; this reduces to 777.4 deg2 of the effective area after masking. These galaxies are further split into lens and source samples, which we discuss in more detail in the following sections, with properties summarised in Table 1.
Overview of the observational KiDS-1000 data.
3.1. Lens catalogues
Our primary lens catalogue is the ‘KiDS-bright’ sample described in Bilicki et al. (2021, hereafter Bi21), a flux-limited galaxy catalogue with accurate and precise photometric redshifts, zph, derived using the nine photometric bands available in the KiDS-1000 data. This highly pure and complete2 galaxy dataset was selected to match the properties of the partly overlapping Galaxy And Mass Assembly (GAMA, Driver et al. 2011) spectroscopic redshift, zsp, dataset. KiDS-bright is limited to r < 20 mag, covers ∼1000 deg2 and contains about one million galaxies after artefact masking. To obtain photometric redshift estimates, Bi21 took advantage of the large amount of spectroscopic calibration data measured by GAMA and trained a supervised machine-learning neural network algorithm implemented in the ANNz2 software (Sadeh et al. 2016) to map an input space of 9-band magnitudes to an output redshift. The ANNz2 training sample consists of matched KiDS galaxies with spectroscopic redshifts from the GAMA equatorial fields, where that survey is the most complete and provides representative training data. The trained model was subsequently applied to the entire inference dataset, the photometrically selected KiDS galaxies with the same r < 20 cut and magnitudes detected in the same nine bands. This sample spans the redshift range of 0 < z ≲ 0.6; however, since our analytical DSS model is less accurate for very small redshifts, we further exclude all galaxies with zph < 0.1. This cut only slightly lowers the number of lenses and results in a projected number density of 0.325 arcmin−2, as summarised in the first row of Table 1.
The main properties of interest to us are the galaxy bias, which has not been measured before for the KiDS-bright sample, the galaxy number density, and the redshift distribution, which is needed in the modelling. As shown in Bi21, the photometric redshift distribution of the full KiDS-bright sample is measured with high precision: jackknife sub-sampling reveals negligible mean bias, with a small overall scatter of σz ≈ 0.018(1 + z). However, for our theoretical model, we need to estimate our newly selected foreground sample’s true n(z) distribution. We take advantage of the very good match between the GAMA spectroscopic sample and the KiDS-bright dataset, allowing us to build an accurate model of the photometric redshift error distribution, as discussed in Bi21. Following the description in Peacock & Bilicki (2018), the best-estimated nbe(z) of the true n(z) can be obtained from a convolution between the normalised photometric redshift distribution of all the galaxies in our selected sample, nph(z), and a photo-z error model pδz(Δz),
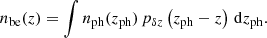 (9)
(9)
Following Bilicki et al. (2014), we adopted a ‘modified Lorentzian’,
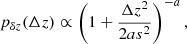 (10)
(10)
which was shown in Bi21 to reproduce the photo-z errors better than a Gaussian error model. To estimate the parameters a and s, Eq. (10) is fitted to the KiDS-bright galaxies that also have GAMA spectroscopic redshifts, where Δz = zph − zsp. The best-fit a and s values for our selection are provided in the top row of Table 1, and the resulting nbe(z) is shown in black in Fig. 1.
 |
Fig. 1. Redshift distributions, n(z), of the galaxy samples. The lens sample is obtained from the KiDS-bright galaxies described in Bi21. The blue line shows nsp(z), i.e. the redshift distribution of KiDS galaxies for which we have spectra from the GAMA survey. The red line shows nph(z), the distribution of the full KiDS-bright sample as estimated by ANNz2 with a photometric redshift cut of zph < 0.1. The black line shows our best-estimated nbe(z): a smoothed version of nph(z) that better accounts for photometric redshift errors. The cyan, orange, and brown lines show the third, fourth and fifth redshift bins of the KiDS-1000 data, as estimated in H21. As the third bin strongly overlaps the sources, it is excluded from the analysis. |
In order to estimate the uncertainty on our n(z) estimate, we notice that Eq. (9) has two ingredients: the photometric redshift distribution nph(z), which is ‘exact’ in the sense that they are directly measured, and the photo-z error model pδz. Putting aside possible systematic effects related to adopting this machine learning approach in this framework, we only need to quantify the uncertainty associated with our choice of the error model. To account for this, we measured how much the output n(z) changes when the a and s parameters are determined from different sub-samples on the sky. For this, we split the KiDS-bright × GAMA matched sample into ten sub-samples along the right ascension, where each sub-sample has the same number of objects. We fitted a and s to each sub-sample with Eq. (10) and convolve the resulting pδz with the full p(zph) of the KiDS-bright sample. The resulting ten n(z) distributions are almost indistinguishable from our best estimate, as displayed in Fig. A.3. We, therefore, conclude that we can safely neglect the error coming from the Lorentzian fit.
It is difficult to estimate all uncertainties accurately on the n(z) estimate since, for this, we would need to test the ANN2z algorithm on another spectroscopic survey with the same selection. We investigate this further and study the impact of changing the shape and the mean of the n(z). Therefore, besides the best-estimated nbe(z), we also consider using the nph(z) directly, as well as the spectroscopic redshift distribution nsp(z) itself, coming from the matched KiDS-bright × GAMA galaxies; both also shown in Fig. 1. We further allow the n(z) to shift along the redshift direction to give the analysis some flexibility, where the shift value δ⟨z⟩ is drawn from a Gaussian with a standard deviation of 0.01 and vanishing mean, motivated by the uncertainty on the mean of the source redshift distribution.
In addition to the full lens sample described above, we take advantage of the colour information contained in the KiDS-bright data to construct colour-selected sub-samples. This allows us to constrain the bias of blue and red galaxy populations separately from the DSS signal. Following Bi21, we use an empirical split between red and blue galaxies based on their location on the absolute r-band magnitude Mr and the rest-frame u − g colour diagram. The rest-frame quantities are based on LePhare (Arnouts et al. 1999) with the derivations presented in Bi21. We apply a cut through the green valley in the colour-magnitude diagram, which results in a line that delimits the red and blue samples that satisfy
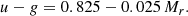 (11)
(11)
We identify those galaxies that are at least 0.05 mag above (below ) the cut line as red (blue) galaxies. We estimate their underlying redshift distributions following the same approach as for the full sample, and the resulting n(z) are shown in Fig. B.1. The effective number densities and best-fit parameters of the modified Lorentzian redshift error model are also listed in the second and third rows of Table 1. We finally note that, while these colour-selected sub-samples are particularly interesting from a galaxy formation perspective, our main cosmological results are obtained from the full lens sample, which has the highest signal-to-noise.
3.2. Source catalogues
The fiducial KiDS-1000 cosmic shear catalogue consists of five tomographic bins, whose redshifts are calibrated using the self-organising map (SOM) method3 of Wright et al. (2020) and presented in Hildebrandt et al. (2021). Although the five bins can be exploited in a cosmic shear analysis as in Asgari et al. (2021), for the DSS analyses, one must also be cautious about source-lens coupling, which arises if sources and lenses belong to the same gravitational potential. This can significantly affect our signal and bias our cosmological inference if left unmodelled. A significant redshift overlap between the source and lens distribution can result in further contamination by the IA of source galaxies that are tidally connected with the foreground lenses. We measure this effect in Sect. 4.2 from IA-infused weak lensing simulations and show that, given the KiDS-bright n(z), this can be avoided by excluding the first three tomographic bins of the KiDS-1000 sources from the analysis. An additional lens-source coupling complication is the so-called boost factor, which arises due to the clustering of sources with over-dense and the anti-correlation of sources with under-dense regions. This can be taken into account by modifying the source n(z) depending on clustering properties (Gruen et al. 2018). Since we exclude the third bin, we do not need to consider this further complication. The fourth and fifth redshift bins, shown as the orange and brown lines in Fig. 1, are separate enough from the lens n(z) to avoid any appreciable lens-source coupling and are therefore used in our cosmological analysis. The uncertainty on the redshift distribution and the residual systematic offsets are very small, as listed in the last two rows of Table 1. The galaxy shear estimates are provided by the lensfit tool (Miller et al. 2013; Fenech Conti et al. 2017) and are described in more detail in Giblin et al. (2021), where it is shown that shear-related systematic effects do not cause more than a 0.1σ shift in S8 ≡ σ8(Ωm/0.3)0.5 when measured by cosmic shear two-point functions.
4. Simulated data
Besides the real KiDS-1000 data, we validate our inference pipeline on several simulated data sets, study the impact of key systematic uncertainties and carry out the cosmological inference. We use the publicly available FLASK tool (Full-sky Log-normal Astro-fields Simulation Kit) described in Xavier et al. (2016) to estimate the covariance of errors in the DSS data vector of the KiDS-1000; the cosmo-SLICS+IA simulations, described in HD22, to quantify the impact of IA on our measurements and to validate the new Nap segment in our pipeline (see the end of Sect. 2) that was not present in the B22 model; and the Magneticum lensing simulations, first introduced in Hirschmann et al. (2014), to investigate the impact of stellar and AGN feedback. More details are provided in the following sections.
4.1. FLASK log-normal simulations
Our cosmological inference analysis requires an estimate of the error covariance of the DSS data vector. Since an analytical covariance matrix for the DSS is challenging to compute, we make use instead of an ensemble of log-normal simulations produced with the publicly available FLASK tool4 (Xavier et al. 2016). In Hilbert et al. (2011) it is shown that log-normal random fields are a good approximation to the 1-point PDF of the weak lensing convergence and shear field, and Friedrich et al. (2020) show that they are in fact accurate enough to estimate the covariance matrix for higher-order statistics in Stage-III lensing surveys (see their Fig. 4)5. Compared to full N-body simulations, FLASK log-normal random fields are computationally cheap to create. The fact that FLASK outputs full-sky maps has the advantage that it can easily be masked to match the footprint of the data, making area re-scaling unnecessary. For the creation of our mock catalogues, we use the cosmological parameters that approximately match current cosmological analyses and fixed the matter density parameter to Ωm = 0.3, the normalisation of the matter power spectrum to σ8 = 0.74, the dimensionless Hubble parameter to h = 0.7, the dark energy equation-of-state parameter to w0 = −1 and the power spectrum power-law index to ns = 0.97. Furthermore, we provide FLASK with the angular power spectrum of the projected matter density field, the convergence power spectrum for both source bins, and the two matter-lensing cross-spectra. By assuming a flat universe throughout this paper, given the n(z) shown in Fig. 1, and using the PYCCL software package6 (Chisari et al. 2019) to get the 3D matter density contrast power spectrum Pδ(ℓ/χ, χ), we calculate the angular power spectrum by use of the Limber-approximated projection (Kaiser 1992) as
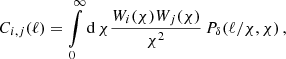 (12)
(12)
where i, j are placeholder for either the galaxy or convergence projection, such that ![Mathematical equation: $ W_g(\chi) = n_{\mathrm{l}}(z[\chi])\frac{{\mathrm{d}} z(\chi)}{{\mathrm{d}} \chi} $](/articles/aa/full_html/2023/01/aa44673-22/aa44673-22-eq15.gif) for the lenses with redshift distribution nl, while for the source with redshift distribution ns we have instead
for the lenses with redshift distribution nl, while for the source with redshift distribution ns we have instead
![Mathematical equation: $$ \begin{aligned} W_{\rm s}(\chi ) = \frac{3\Omega _{\rm m}H_0^2}{2c^2}\int _\chi ^\infty {\mathrm{d}} \chi^\prime \, \frac{\chi (\chi^\prime -\chi )}{\chi^\prime a(\chi )}\, n_{\rm s}(z[\chi^\prime ])\frac{{\mathrm{d}} z[\chi^\prime ]}{{\mathrm{d}} \chi^\prime } \;. \end{aligned} $$](/articles/aa/full_html/2023/01/aa44673-22/aa44673-22-eq16.gif) (13)
(13)
Besides these angular power spectra, FLASK needs the log-normal shift parameters κ0 and δ0, where −κ0 and −δ0 defining the lower limits of the log-normal random variable of the convergence and matter density fields, respectively. Whereas the shift parameter κ0 = {0.02, 0.03} for the convergence power spectra for the two source bins can be determined directly from the fitting formula Eq. (38) in Hilbert et al. (2011), we estimated the shift parameter δ0 = {0.57, 0.59, 0.56} for the three lens samples (full, red, blue), as described in Gruen et al. (2016), by assuming that it can be approximated by the shift parameter of the smoothed density contrast, which in turn is calculated from our model for a top-hat filter function (see Eq. (23) in B22). Given this setup, FLASK returns a foreground density map δm,2D(θ) and two sets of correlated shear and convergence grids γ1,2(θ),κ(θ), one per tomographic source bin. We populate our mock KiDS-bright galaxies on the density map by sampling, for each pixel θ, a Poisson distribution with mean parameter λ = neff[1+b δm,2D(θ)], where b = 1.4 is the (constant) linear galaxy bias estimated from preliminary analyses with only some realisations7 and neff = 0.325 arcmin−2 is the mean galaxy density of the KiDS-bright sample. Similarly, we populate the two source planes by Poisson-sampling for each pixel a number of source galaxies npix with parameter λ = neffApix, where Apix is the area of the pixel under consideration8, and the effective number density neff is taken from Table 1. We finally combine the two shear components of each object with their convergence to construct reduced shear components g1, 2, and further combine these with a shape noise contribution ϵs taken from sampling a Gaussian distribution with vanishing mean and deviation σϵ also taken from Table 1. This results in catalogues containing observed ellipticities ϵobs transformed as (Seitz & Schneider 1997)
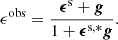 (14)
(14)
The quantities in bold here are all complex numbers, and the asterisk ‘’ indicates complex conjugation. This procedure ensures that we match the number of foreground and background galaxies in the data and the associated shape noise level.
4.2. cosmo-SLICS+IA
As mentioned earlier, the second suite of simulations is used to validate the inference pipeline and study the impact of IA on our DSS measurements. We use for this the fiducial suite of the cosmo-SLICS presented in Harnois-Déraps et al. (2019), which consists of a set of 50 simulated light cones of 100 deg2 each, run in a ΛCDM universe with Ωm = 0.2905, ΩΛ = 0.7095, Ωb = 0.0473, h = 0.6898, σ8 = 0.836 and ns = 0.969. The mocks follow the non-linear evolution of 15363 particles up to z = 0, computed by the cubep3mN-body code (Harnois-Déraps et al. 2013). For Fourier modes of comoving wave number k < 2.0 h Mpc−1, the cosmo-SLICS three-dimensional dark matter power spectrum P(k) agrees within 2% with the predictions from the Extended Cosmic Emulator (Heitmann et al. 2014), followed by a progressive deviation for higher k-modes (Harnois-Déraps et al. 2019), offering a sufficient resolution to model Stage-III galaxy surveys. The particle data were assigned onto mass sheets at 18 redshifts and then post-processed into 10 × 10 deg2 light cones. Lensing maps were produced at 18 source redshift planes for each cosmo-SLICS light cone and used to interpolate lensing information onto galaxy catalogues.
Similar to B22, we construct cosmo-SLICS mock source samples that reproduce a number of key data properties, including the tomographic n(z), the galaxy number density neff and the shape noise levels. As for the FLASK simulations, we use Eq. (14) to add shape noise to the reduced shear signal. Source galaxies are placed at random positions on the light cones, and the shear quantities (γ1/2, κ) are interpolated at these positions from the enclosing lensing maps.
We also construct mock KiDS-bright samples by populating the light cone mass maps with galaxies that trace the underlying dark matter field linearly, following the method presented in Harnois-Déraps et al. (2018). We here again fix the galaxy bias to 1.4 and an effective number density of neff = 0.325 arcmin−2.
4.2.1. IA infusion
The impact of galaxy IA is a known secondary signal to the cosmic shear measurements that have been neglected in past DSS studies. In this paper, we verify the validity of this assumption by measuring our statistics in simulated source data that are infused with IA. We find that IA influences our data vector only if the lenses’ n(z) overlap with that of the sources. Following the methods described in HD22, the IA properties of these galaxies are computed as
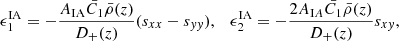 (15)
(15)
where sij = ∂ijϕ are the Cartesian components of the projected tidal field tensors interpolated at their positions, with ϕ being the gravitational potential. In the above expression, AIA captures the strength of the coupling between the ellipticities and the tidal field, 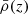 is the matter density, D+(z) is the linear growth factor,
is the matter density, D+(z) is the linear growth factor, 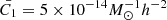 Mpc3, as calibrated in Brown et al. (2002). These intrinsic ellipticity components
Mpc3, as calibrated in Brown et al. (2002). These intrinsic ellipticity components 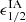 are then combined with the cosmic shear signal by Eq. (14), resulting in an IA-contaminated weak lensing sample that is consistent with the NLA model of Bridle & King (2007). We refer the reader to HD22 for full details about the IA infusion method. We test several values of AIA, more precisely, we infused AIA = {1, 1.5, 2}, and inspect in each case the impact on the DSS data vector.
are then combined with the cosmic shear signal by Eq. (14), resulting in an IA-contaminated weak lensing sample that is consistent with the NLA model of Bridle & King (2007). We refer the reader to HD22 for full details about the IA infusion method. We test several values of AIA, more precisely, we infused AIA = {1, 1.5, 2}, and inspect in each case the impact on the DSS data vector.
4.3. Magneticum
Baryon feedback is also known to affect the distribution of the large-scale structure significantly, as the sustained outflows of energy arising from stellar winds, supernovae and AGN reduce the clustering on intra-cluster scales by up to tens of per cent (van Daalen et al. 2011). The exact strength of this suppression is still largely uncertain, with different hydro-dynamical simulations predicting different redshift and scale dependencies (see, e.g. Chisari et al. 2015, for a review of recent results). Without consensus, we opted to measure the DSS in one of these hydro-dynamical simulations for which the impact is quite high and inspect how an extreme baryon impact would affect our data vector.
The Magneticum lensing simulations were first introduced in Hirschmann et al. (2014) and used to mock up KiDS-450 and Stage-IV cosmic shear data (Martinet et al. 2021), and subsequently in Harnois-Déraps et al. (2021) to study the impact of baryons in the peak count analysis of the Dark Energy Survey Y1 data. The underlying matter field is constructed from the Magneticum Pathfinder simulations9, more specifically by the Run-2 and Run-2b data described in Hirschmann et al. (2014) and Ragagnin et al. (2017). These are based on the GADGET3 smoothed particle hydrodynamical code (Springel 2005) and are able to reproduce a large number of observations (see Castro et al. 2021, for more details). These both co-evolve dark matter particles of mass 6.9 × 108h−1 M⊙ and gas particles with mass 1.4 × 108h−1 M⊙, in comoving volumes of side 352 and 640 h−1 Mpc, respectively. Included key mechanisms are radiative cooling, star formation, supernovae, AGN, and their associated feedback on the matter density field. From sequences of projected mass planes, we use the procedure outlined above for the cosmo-SLICS simulations to generate KiDS-1000 sources and KiDS-bright lenses for ten pseudo-independent light cones, each covering 100 deg2. We repeat the same procedure on dark matter-only light cones, such that any difference is caused by the presence of baryons.
The cosmo-SLICS+IA and Magneticum light cones are square-shaped, a geometry that accentuates the edge effects when the aperture filter overlaps with the light cone boundaries. One could, in principle, weight the outer rims for each Nap map, such that the whole map can be used; although this would increase our statistical power, it could also introduce a systematic offset. We opted instead to exclude the outer rim for each realisation, resulting in an effective area of 36 deg2, where a 2 deg band has been removed, matching the size of the adapted filter. This procedure also ensures that roughly the same number of background galaxies are used to calculate the shear profile around each pixel.
5. Cosmological parameter inference
Before performing several Markov chain Monte Carlo (MCMC) samplings in the following two sections, we describe here the pipeline of our Monte-Carlo sampler. In our different MCMC runs, the model vector, the data vector and the covariance matrix are varied, but the overall pipeline stays the same.
Our statistical analysis has the following two free cosmological parameters that we fitted for: the matter density parameter Ωm and the normalisation of the power spectrum σ8. We additionally vary the galaxy bias term b and the super-Poisonnian shot-noise parameter α (see Eq. (7)). We detail the prior ranges of all parameters in Table 2, where we also show the Gaussian priors for the nuisance parameters used in the data analysis (but not in the simulation-based validation runs).
All varied parameters and their prior knowledge.
For the estimated covariance matrix 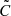 , which itself is a random variable, Percival et al. (2022) suggested a procedure that uses a more general joint prior of the mean and covariance matrix as the Jeffreys prior proposed in Eq. (6) in Sellentin & Heavens (2016). The method by Percival et al. (2022) leads to credible intervals that can also be interpreted as confidence intervals with approximately the same coverage probability. From a data vector d and a covariance matrix
, which itself is a random variable, Percival et al. (2022) suggested a procedure that uses a more general joint prior of the mean and covariance matrix as the Jeffreys prior proposed in Eq. (6) in Sellentin & Heavens (2016). The method by Percival et al. (2022) leads to credible intervals that can also be interpreted as confidence intervals with approximately the same coverage probability. From a data vector d and a covariance matrix 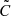 measured from nr simulated survey realisations, the posterior distribution of a model vector m that depends on nθ parameters Θ is
measured from nr simulated survey realisations, the posterior distribution of a model vector m that depends on nθ parameters Θ is
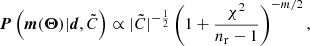 (16)
(16)
where
![Mathematical equation: $$ \begin{aligned} \chi ^2 = \left[\boldsymbol{m}(\boldsymbol{\Theta })-\boldsymbol{d}\right]^\mathrm{T} \tilde{C}^{-1} \left[\boldsymbol{m}(\boldsymbol{\Theta })-\boldsymbol{d}\right]. \end{aligned} $$](/articles/aa/full_html/2023/01/aa44673-22/aa44673-22-eq25.gif) (17)
(17)
The power-law index m is
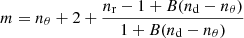 (18)
(18)
with nd being the number of data points and
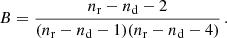 (19)
(19)
By setting m = nr the formalism of Sellentin & Heavens (2016) is recovered.
Finally, since the model prediction is too slow for our MCMC, we use the emulation tool contained in CosmoPower (Spurio Mancini et al. 2022), which was first developed to emulate power spectra but can easily be adapted for arbitrary vectors. We trained the emulator on 4000 model points in the parameter space {Ωm, σ8, b, α} distributed in a Latin hypercube, where we also included δ⟨z⟩ Gaussian distributed values with the mean as shown in Table 2 but twice the standard deviation10. To quantify the accuracy of the emulator, we calculated the model at 500 independent points in the same parameter space, as determined with the emulator or directly with the model and show the model vector accuracy in Fig. A.4. The fractional error is better than 2% (95% confidence level).
5.1. Reporting parameter constraints and goodness of fit
In this work, we followed the approach of Joachimi et al. (2021) to report our parameter constraints. In particular, we seek to report the global best fit to the data, that is the set of parameter values that provide the maximum a posteriori (MAP) distribution, computed as
![Mathematical equation: $$ \begin{aligned} \boldsymbol{\Theta }_{\rm MAP} = \underset{\boldsymbol{\Theta }}{\mathrm{argmax} } \left[\boldsymbol{P}(\boldsymbol{m}(\boldsymbol{\Theta })|\boldsymbol{d},\tilde{C})\right], \end{aligned} $$](/articles/aa/full_html/2023/01/aa44673-22/aa44673-22-eq28.gif) (20)
(20)
where we found the maximum by running several minimisation processes. To estimate the resulting uncertainties around the MAP, we use the suggested projected-joint-highest-posterior-density (PJ-HPD) method, which calculates the parameter ranges that encompass the 68% and 95% credible intervals.
Furthermore, with the degrees of freedom (d.o.f.), we also report the reduced χ2/d.o.f. to quantify the goodness of fit, where the χ2 results from the point in the high-dimensional parameter space that has the highest posterior probability. To unbias the covariance matrix 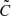 , which is used to estimate the χ2-values, we instead of inverting
, which is used to estimate the χ2-values, we instead of inverting  with the known Hartlap factor (Hartlap et al. 2007) defined as h = (nr − 1)/(nr − nd − 2), but rather use
with the known Hartlap factor (Hartlap et al. 2007) defined as h = (nr − 1)/(nr − nd − 2), but rather use
![Mathematical equation: $$ \begin{aligned} \tilde{C}^\prime = \frac{(n_{\rm r}-1)\left[1+B(n_{\rm d}-n_{\theta })\right]}{n_{\rm r}-n_{\rm d}+n_\theta -1}\tilde{C}. \end{aligned} $$](/articles/aa/full_html/2023/01/aa44673-22/aa44673-22-eq31.gif) (21)
(21)
To estimate the d.o.f. we measure for 1000 mock data vectors the best χ2 and fit a χ2 distribution to it. The 1000 mock data vectors are drawn from a multivariate Gaussian distribution, where the mean is the model prediction at the MAP values, and the covariance is the corresponding covariance matrix for that particular model. As we have only four free parameters and the rest are fixed by prior knowledge, we expect that the resulting d.o.f. is only slightly less than the raw number of elements in the data vector. Lastly, we report the p-value in each case, which provides the probability of finding a χ2 that is more extreme for the given d.o.f., and therefore indicates the goodness of fit. For our analysis, we choose a significance level of 0.01 to be a reliable fit. We have verified with some selected cosmo-SLICS nodes that the theoretical model for the KiDS-bright sample is valid and accurate for σ8 < 1.0, with indications that it loses accuracy for larger values of σ8. This does not affect our results, given that the preferred values of σ8 are well below this limit.
6. Validating the model on simulations
In this section, we validate our model on simulated measurements, several of which are infused with known and controlled systematic effects. The first (fiducial) test establishes that our model is unbiased in the simplest setup, where lens galaxies linearly trace the pure dark matter density maps, while source galaxies are given by the noise-free pure gravitational shear. The second test verifies that our results are unchanged in the presence of IA, as described in Sect. 4.2, while, lastly, we investigate the impact of baryonic physics on our statistics. The fiducial and the IA tests use 20 light cones, which have an unmasked area close to that of the KiDS-1000 footprint11. The measurements on the Magneticum mocks use the ten available light cones. Furthermore, we measured the shear profiles from KiDS-like mocks with shape noise to validate our model on a realistic data vector.
6.1. Validation on intrinsic alignment
To quantify the influence of IA on our results, we performed an MCMC analysis on the mock infused with a strong IA amplitude (AIA = 2.0) and compared it to our fiducial model (AIA = 0). For this, we used the mocks described in Sect. 4.2, excluding the third source tomographic bin due to the lens-source coupling. The resulting profiles and mean relative number counts that are used for our pipeline validation are shown in Figs. 2 and 3, respectively. Although the aperture number is not affected by IA, it has a slight effect on the profiles, and hence we verify how it impacts the full data analysis. Although the fourth quantile in Nap has 2 σ deviation, the p-value is approximately 0.2, which shows that this is consistent with being a statistical fluctuation. We performed this validation test for the adapted and top-hat filters but show the resulting shear signals, and the corresponding mean aperture number values only for the adapted filter since those of the top-hat filter are very similar and would not yield more insights.
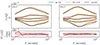 |
Fig. 2. Shear profiles measured with the adapted filter for the KiDS-bright-like lenses and sources from the cosmo-SLICS+IA simulations for two different IA amplitudes (see the legend). The orange regions are estimated from the covariance matrix, while the black dashed lines are obtained from our IA-free analytical predictions at the input cosmology and using the n(z) shown in Fig. 1. As the differences between the shear profiles with varying IA amplitude can barely be seen, we display the relative difference between them in the bottom panels for the highest and lowest two quantiles. |
 |
Fig. 3. Relative difference between the mean ⟨Nap⟩ measured in the cosmo-SLICS+IA bright mocks for four quantiles, and the value of ⟨Nap⟩ predicted by the model at the same cosmology. The blue error bars show the KiDS-1000 statistical uncertainty measured from FLASK. |
To quantify our decision to discard the third source tomographic bin from our analysis, we show in Fig. A.5 the same shear profiles as in Fig. 2 but also the ones resulting from the third redshift bin, where we clearly see the third tomographic bin is heavily affected by IA, due to a significant overlap in redshift between the lens and source populations, and therefore would need additional modelling of IA, which we disregard for this work, and thus we exclude the third bin.
The MCMC results for the two IA amplitudes (no IA and IA = 2.0) are shown in Fig. 4. First, it is clearly shown that changing the IA amplitude does not affect the posterior at all. Second, and very importantly, the input cosmology is recovered. We observe a small offset on the parameter α, but the other parameters are all recovered within the 1 σ region. This confirms that the < 6% deviations seen on the aperture number count presented in Fig. 4 do not impact our cosmological inference. Finally, we observe an anti-correlation between the S8 or σ8 parameter and the galaxy bias b parameter, which is expected since all three parameters are directly correlated with the amplitude of the shear signal. This correlation and the correlation of S8 and σ8 to the α parameter could potentially impair the robustness of the later constrained parameters. However, these parameters are particularly important for our model and, therefore, cannot be ignored. The same validation is done for the top-hat filter in Appendix C.
 |
Fig. 4. Pipeline validation: cosmological inference with the adapted filter using the cosmo-SLICS simulations with and without IA infusion, analysed with our model that ignores IA. The posteriors are almost indistinguishable from each other. |
6.2. Validation on baryonic feedback
As a last important verification, we investigate for the first time the impact of baryons on the DSS with the Magneticum simulations described in Sect. 4.3. By combining the different DM-only and Hydro mock data for the lenses and sources, we end up with four scenarios (lens-source = DM-DM, DM-Hydro, Hydro-DM and Hydro-Hydro). Figure 5 shows the residuals between the shear profiles measured from dark matter-only mocks (DM-DM) to the other three combinations for each quantile. Clearly, the deviations are well inside the expected KiDS-1000 uncertainty. The biggest differences are seen if baryonic feedback processes are included in the lens mocks: some pixels, close to the Nap threshold between two quantiles, are shifted to another quantile by the presence of baryons. This is in concordance with the mean aperture numbers reported in Fig. 6, which shows that the mean aperture numbers with baryons are slightly lower. Different to our studies of baryonic feedback such as Heydenreich et al. (2022) or Harnois-Déraps et al. (2021), the inclusion of baryons in the sources has only a minor impact on the DSS, but as expected, becoming more important at small scales. In light of this, we can safely neglect the impact of baryons in our real data analysis.
 |
Fig. 5. Absolute differences between the mean shear profiles for all quantiles using either dark matter-only or full hydrodynamical Magneticum simulations. The residuals are with respect to the dark matter-only mocks for the lenses and sources and are always within the expected statistical uncertainty shown as the orange bands. |
 |
Fig. 6. Relative difference between the mean ⟨Nap⟩ to compare measurements from the hydro and dark matter-only Magneticum simulations. The relative difference is always well inside the expected statistical uncertainty of KiDS-1000. |
7. Results and discussion
After validating our model to simulations in B22 and our additional testing on the impact of IA and baryonic physics, we are well equipped to analyse real lensing data accurately. As described in Sect. 3, we use the KiDS-bright sample as our foreground lenses and the fourth and fifth KiDS-1000 tomographic bins as our cosmic shear data.
To recap, in our fiducial analysis, we used the n(z) shown as the black solid line in Fig. 1, we varied the two cosmological parameters Ωm and σ8 as well as the two astrophysical parameters b and α. We marginalised over the systematic effects parameters describing the δ⟨z⟩ and m-bias uncertainty. In Figs. 7 and 8 we display the resulting shear profiles and mean aperture number. The model shown in these figures is computed at the best-fit MAP values, listed in the first column of Table 3. In that table, the p-values indicate that the data are well fitted by the model, being all well above our threshold value fixed at p = 0.01. The d.o.f. are estimated as described in Sect. 5, where we show in Fig. A.6 the distribution of χ2 values and for which a χ2-distribution with 81 d.o.f. fits well. As expected, the resulting d.o.f. is slightly lower than the raw number of elements. The reduced χ2 values are slightly below the expectation of 1.0, potentially indicating that the uncertainties could be slightly overestimated, although they are well inside the expected reduced χ2 scatter of 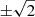 , hence do not warrant further investigation.
, hence do not warrant further investigation.
 |
Fig. 7. Shear profiles measured in the data, compared to the best-fit predictions (MAP) obtained with values listed in Table 3, for the adapted filter. The shaded region shows the statistical uncertainty estimated from 1000 FLASK realisations. |
 |
Fig. 8. Relative difference between the mean ⟨Nap⟩ to compare measurements from the KiDS-bright sample and our model, evaluated at the MAP values shown in Table 3. The measured ⟨Nap⟩ are all greater than the predicted ⟨Nap⟩ at MAP just indicating that the measured p(Nap) is broader than the predicted one. |
Marginalised MAP values and their 68% confidence intervals for the different lens n(z) of the full sample.
Using the approach described in Sect. 5 to estimate the uncertainty around the MAP, we find
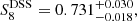 (22)
(22)
which is consistent with and competitive to the KiDS-1000 cosmic shear constraints from Asgari et al. (2021),
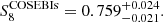 (23)
(23)
We present the posterior of these two analyses in Fig. 9, where the consistency between the two probes is obvious. The DSS has a slightly lower constraining power on S8; however, the Ωm–σ8 degeneracy is broken, thanks to the additional information provided by the foreground data. But even for the shear-only case shown in green in Fig. 9, the DSS has better constraining power for the Ωm and σ8 parameters, although the lower bound should be taken with caution as we excluded all Ωm < 0.2, as the model does not agree with the cosmo-SLICS for smaller Ωm values. Furthermore, although the results of Fig. A.2 show that the inferred S8 might be smaller compared to the truth if a linear galaxy bias model is not sufficient, the consistency between the shear-only DSS analysis to the complete DSS analysis supports the robustness of our inferred parameters with respect to the galaxy bias model (see the discussion at the end of Sect. 2.2). The comparison to the COSEBIs analysis reveals competitive S/N for the S8 parameter while using only a fraction of the lensing sources (tomographic bins four and five). Caution should be taken when comparing their respective constraining power, as the COSEBIs analysis marginalises over more cosmological parameters and samples the parameter space differently. Nevertheless, it seems that a joint COSEBIs-DSS analysis could further improve the constraints, which we leave for future work. Lastly, as the DSS estimates of S8 are slightly lower but with higher uncertainty, we measure a similar tension to the CMB results as the COSEBIs analysis.
 |
Fig. 9. Cosmological posteriors for the adapted filter for the best-estimated nbe(z) in black using the full data vector and in green using only shear information compared to the COSEBIs posteriors in orange presented in Asgari et al. (2021) and to the (TT, TE, EE+lowE) results of Planck Collaboration V (2020) in red. The sharp cut of the green posterior is due to the conservative prior of Ωm > 0.2, as the model does not agree with the cosmo-SLICS for smaller Ωm values. The shear-only posterior is shown in this figure to support the assumption of using a linear galaxy bias model. |
In the next section, we investigate the robustness of our results with respect to the lens redshift distribution n(z), of varying the covariance matrix. We further present our galaxy colour-split analysis and additionally discuss the galaxy bias b and α results.
7.1. Impact of lens redshift distribution
To estimate the impact of the shape of the lens galaxy redshift distribution (on top of shifting the mean by δ⟨z⟩ in the sampling), we repeat the analysis for the three n(z) shown in Fig. 1. These are the smoothed version of the photometric redshift distribution nbe(z), the photometric redshift distribution nph(z) itself without any smoothing, and the spectroscopic redshift nsp(z) from those GAMA galaxies that are also in the KiDS-bright sample. Although Bi21 showed that GAMA is representative and that mismatches should be rare, the results from the GAMA spectroscopic nsp(z) should be taken with caution because the equatorial fields have a relatively small sky coverage, leading to features in the nsp(z) that are caused by the large-scale structure present in these fields. For this investigation, we use the same setup as for the fiducial analysis, varying the two cosmological parameters Ωm and σ8 together with the α and the linear galaxy bias b parameter. We also marginalised over the nuisance parameters shown bottom half of Table 2. In Fig. 10 we display the different posteriors following from the three alternatives n(z). It is clearly seen that the posteriors are shifted along the Ωm − σ8 degeneracy axis, whereas these shifts partially cancel out for S8. Due to the different lens n(z), the amplitude and the slope of the shear signal predictions are slightly different. In particular, higher amplitude and steeper slope of the shear profiles result in larger σ8 and smaller Ωm, and vice-versa. Furthermore, we notice that the linear galaxy bias b and the noise α are stable against changes in the n(z).
 |
Fig. 10. Posteriors of the full DSS vector resulting from using the different lens n(z) shown in Fig. 1. The n(zphot) and n(z) have, by construction, the same mean redshift, while the mean redshift of the spectroscopic redshift estimate is ∼0.015 lower. The main DSS results include a marginalisation over our uncertainty in the mean redshifts of both the lens and source samples, which partially compensates for some of these differences. The posterior obtained using the GAMA spectroscopic n(z), shown in blue, should be taken with caution as it is estimated from a smaller sky coverage and, as such, contains larger statistical fluctuations. |
Lastly, in order to investigate the impact of our photometric redshift cut at zph = 0.1 (see Sect. 3.1), we perform two additional analyses, this time modifying the photometric redshift threshold to zph > 0.15 and zph > 0.2. We find that the posteriors shifts are smaller than the 68% credibility region, indicating that removing low-redshift galaxies does not result in systematically different Ωm or σ8.
7.2. Cosmology scaling of the covariance matrix
The covariance matrix used in the main analysis is determined at a specific point in the parameter space (see Sect. 4.1), which is not identical to the MAP. However, assuming the MAP values are the true parameters, the most robust likelihood analysis would be achieved with a data covariance matrix estimated at the MAP values. This section, therefore, explores the impact of considering a cosmology-dependent covariance matrix.
In the related literature, there are two common approaches on whether the cosmology should be kept fixed in the covariance matrix (van Uitert et al. 2018) or varied at each point sampled by the MCMC, as in Eifler et al. (2009). It is argued in Carron (2013) that the latter could result in over-constraints, whereas Kodwani et al. (2019) argues that the effect is small. We, therefore, explore both methods here.
We achieve our cosmology rescaling by assuming that the covariance matrix scales quadratically with the signal. This is only strictly true in the Gaussian regime; nevertheless, it is a good first approximation, even though the impact on the non-linear mode coupling is neglected in this approach.
To achieve the rescaling, we compute at a new cosmology Θ the ratio between the predicted model m(Θ) and the model predicted at the FLASK cosmology m(ΘF),
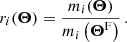 (24)
(24)
We then multiply each element of the fiducial covariance matrix, 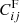 , by the scaling factors,
, by the scaling factors,
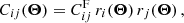 (25)
(25)
and obtain a cosmology-rescaled covariance matrix.
As explained in Eifler et al. (2009), this method is only valid for a noise-free covariance matrix since it wrongly rescales the shape-noise component and possibly over-estimates the cosmology changes. Finally, we note that in Eq. (16) the determinant of the covariance matrix changes with cosmology as well and needs to be recalculated.
Using our fiducial setup, we determine the posterior distribution in two distinct ways: first, by varying the covariance matrix alongside the model vector at each step of the MCMC, and second, by scaling the covariance matrix to the MAP value. For the latter approach, we use an iterative process, where we first estimate the MAP with the fiducial covariance matrix, then use the MAP parameters to scale the covariance matrix and find new MAP parameters; we repeated that process 100 times. As seen in Fig. A.7 after approximately 20 iterations the MAP values converged. The results are shown in Fig. 11, where the red posteriors used a covariance rescaled to the converged MAP value; the blue posteriors are for a full parameter-dependent covariance matrix varied in the MCMC; the black posteriors show the fiducial covariance. The red and black posteriors are almost identical, which is not surprising given the fact that the MAP values are very close to the parameters used to determine the covariance matrix. However, the blue contours slightly differ from the other two but are still within half 1 σ; we are therefore not concerned about the impact on our constraints of this analysis choice. In Stage IV surveys, this is even less important due to the tighter posterior and the, therefore, smaller cosmology variation.
 |
Fig. 11. Comparison between the posteriors obtained from our fiducial setup (with the covariance matrix calculated at the initial cosmology, see the black contours), with those obtained after scaling the covariance at the best-fit parameters (red) and to those obtained by varying the covariance with the parameters (blue). |
7.3. Red and blue split
In this section, we present our final investigation, dividing the KiDS-bright sample into red and blue galaxies according to their colour as described in Sect. 3.1, and carry out a joint analysis. The motivation for this is to learn more about the behaviour of different galaxy types and as a cosmological robustness check. As for the main analysis, we use the best-estimated nbe(z), resulting from smoothing the photometric redshifts after applying a zph > 0.1 cut. In this setup, our data vector has 168 elements. But given the likelihood modelling described in Sect. 5, we are still confident in our results with respect to the remaining noise in the covariance matrix. As shown in Table 4, the reduced χ2/d.o.f. = 1.00 indicates a valid fit. The resulting posteriors are shown in Fig. 12 and the MAP values are stated in Table 4.
 |
Fig. 12. Posterior for the full KiDS-bright sample shown in green, while the joint red+blue posteriors represent the results of the colour-selected samples. In the latter case, the red and blue samples share the same cosmology (the dark blue contours) by construction. The resulting measured and best-fit predicted shear profiles for the red and blue samples are displayed in Fig. B.2 and the corresponding mean aperture number values are seen in Fig. B.3. |
Marginalised MAP values and their 68% confidence intervals for the different lens samples.
First, we notice that the cosmological parameters of the full KiDS-bright sample analysis and the joint red and blue analysis are consistent and within 0.48 σ in σ8 and almost identical in Ωm. Of particular interest in this investigation are the results obtained for the two astrophysical parameters, where we see that, as expected, the blue (red) sample prefers a smaller (larger) linear galaxy bias b compared to the full sample. This is in line with the fact that red galaxies are known to be more strongly clustered than blue galaxies and therefore have a larger galaxy bias (Mo et al. 2010). Furthermore, we find that the α parameter for the blue sample is significantly larger than unity, whereas the red sample tends to be below one. This shows that blue galaxies follow a super-Poisson distribution and red galaxies a sub-Poisson distribution. Following the results of Friedrich et al. (2022) who found that a higher satellite fraction leads to a higher α value, the blue sample has more satellites. The full sample overlaps with the blue and red posteriors and is consistent with a normal-Poisson distribution (α = 1.0).
8. Summary and conclusions
In this work, we present an unblinded density split statistic analysis of the fourth data release of the Kilo-Degree survey (KiDS-1000). The analytical model used to infer cosmological and astrophysical parameters was first developed in Friedrich et al. (2018) and then modified in Burger et al. (2022), and we further validated it on realistic simulated data. The lenses used to construct the foreground density map are taken from the KiDS-bright sample described in Bi21, while for our sources, we used the fourth and fifth tomographic redshift bins of the KiDS-1000 data described in H21.
We investigated for the first time the impact of baryons and IA on the DSS. While the effect of the former is suppressed due to the implied smoothing of the density map, IA can have an important role if the redshift distributions of the lenses and sources overlap. We carried out a full analysis on contaminated mock data without overlapping redshift distributions and found that for our selected data, we are immune to both of the systematic effects at the level of the inferred posteriors.
We explored the uncertainty of the redshift distribution of the lenses by investigating the impact on the posterior of changing the mean and the shape of the nph(z). In particular, for this, we used the photometric redshift distribution nph(z) with and without smoothing, as well as the distribution obtained directly from the overlapping spectroscopic GAMA galaxies. We found that the posteriors vary by less than ∼0.5 σ. Notably, we observed that of all parameters, Ωm is the most affected and is generally lower for broader n(z); in contrast, σ8 increased, leaving S8 values changed by ∼0.5 σ. We assigned an extra error term to this uncertainty, resulting in 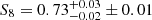 for the n(z) shape after marginalising over the other systematic effects. These constraints are competitive and consistent with the KiDS-1000 cosmic shear constraints from Asgari et al. (2021).
for the n(z) shape after marginalising over the other systematic effects. These constraints are competitive and consistent with the KiDS-1000 cosmic shear constraints from Asgari et al. (2021).
Furthermore, we investigated the impact of varying the covariance matrix with cosmological parameters, where we used an iterative process once to scale the covariance matrix to the MAP best-fit parameters, and we varied them alongside the parameters in the MCMC process once as well; for all cases, we recorded no significant deviations.
As our final result, we divided the full KiDS-bright sample into red and blue galaxies as a cosmology robustness check and to learn more about different galaxy types. For this, we performed a joint analysis of the red and blue samples with a joint covariance matrix with the smoothed version of nph(z) as our best redshift estimate. The resulting posteriors of the full and joint red+blue analyses agree as to the cosmological parameters within 0.35 σ. Furthermore, this shows the expected behaviour of the linear galaxy bias, where blue (red) galaxies have a lower (higher) bias than the full sample. The α parameter, which accounts for super-Poisson or sub-Poisson shot noise, also revealed interesting results. Whereas red galaxies have an α value that tends to be smaller than one (≈2 σ), blue galaxies have an α value significantly larger than one (≈6 σ), meaning that blue galaxies are super-Poisson distributed and red galaxies are sub-Poisson distributed. According to Friedrich et al. (2020), this reveals information about the halo occupation distribution, with samples with a larger fraction of satellite galaxies tending to have larger α values.
We conclude from our results that the density split statistic is a valuable tool with a major advantage in the Ωm-σ8 degeneracy breaking. In addition to this, it also yields a new way to measure the galaxy bias on linear scales and the Poissanity of different galaxy types. We save the inference of the dark-energy-equation of state w for future analysis; this can be achieved by a tomographic analysis of high-precision lensing and clustering data. Other aspects for future analysis include the modelling of a more complex galaxy bias model, and lastly, the impact of the filter size, where we expect smaller filter sizes to be more constraining yet also more sensitive to non-linear scales and baryonic analysis.
The KiDS data products are public and available through http://kids.strw.leidenuniv.nl/DR4
By purity, we mean very low fractions of stars and quasars (point sources) or artefacts. Completeness is evaluated with respect to GAMA.
The SOM method organises galaxies into groups based on their nine-band photometry and finds matches within spectroscopic samples. Galaxies for which no matches are found are removed from the catalogue.
We tested that an area-rescaled covariance matrix coming from over 600 fully independent N-body simulations (see Harnois-Déraps et al. 2018, for a description of the SLICS simulation suite) results in similar constraints.
Currently available here: https://github.com/LSSTDESC/CCL
Also different values would not affect the posteriors as we discuss in Sect. 7.2.
The public KiDS-1000 mask is provided on a flat sky with a resolution of 0.01 arcmin2. This results in a HEALPix mask that varies from pixel to pixel given the fact that the pixelation is different and has a size of 0.74 arcmin2.
For the validation analysis we used only 2000 nodes as for that analysis the nuisance parameters were not modelled.
After removing the outer strip, each light cone has an effective area of 36 deg2, which roughly matches the unmasked area of the KiDS-1000 data if 20 light cones are added.
Acknowledgments
We thank the anonymous referee for the very constructive and fruitful comments. This paper went through the KiDS review process, where we especially want to thank the KiDS-internal referee Benjamin Joachimi for his fruitful comments to improve this work. Further, we would like to thank Mike Jarvis for maintaining treecorr, and Alessio Mancini to develop the CosmoPower emulator, which improved our work significantly. Lastly, we thank Sven Heydenreich, Laila Linke, Patrick Simon and Jan Luca van den Busch for very valuable discussions. PAB acknowledges support by the German Academic Scholarship Foundation. JHD acknowledges support from an STFC Ernest Rutherford Fellowship (project reference ST/S004858/1). OF gratefully acknowledges support by the Kavli Foundation and the International Newton Trust through a Newton-Kavli-Junior Fellowship and by Churchill College Cambridge through a postdoctoral By-Fellowship. MB is supported by the Polish National Science Center through grants no. 2020/38/E/ST9/00395, 2018/30/E/ST9/00698, 2018/31/G/ST9/03388 and 2020/39/B/ST9/03494, and by the Polish Ministry of Science and Higher Education through grant DIR/WK/2018/12. HH is supported by a Heisenberg grant of the Deutsche Forschungsgemeinschaft (Hi 1495/5-1) as well as an ERC Consolidator Grant (No. 770935). AHW is supported by a European Research Council Consolidator Grant (No. 770935). TC is supported by the INFN INDARK PD51 grant and the FARE MIUR grant ‘ClustersXEuclid’ R165SBKTMA. KD acknowledges support by the COMPLEX project from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program grant agreement ERC-2019-AdG 882679 and by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy – EXC-2094 – 390783311. The calculations for the Magneticum simulations were carried out at the Leibniz Supercomputer Center (LRZ) under the project pr83li and with the support by M. Petkova through the Computational Center for Particle and Astrophysics (C2PAP). CH acknowledges support from the European Research Council under grant number 647112, and support from the Max Planck Society and the Alexander von Humboldt Foundation in the framework of the Max Planck-Humboldt Research Award endowed by the Federal Ministry of Education and Research. BJ acknowledges support by STFC Consolidated Grant ST/V000780/1. KK acknowledges support from the Royal Society, and Imperial College. NM acknowledges support from the Centre National d’Études Spatiales (CNES) fellowship. HYS acknowledges the support from CMS-CSST-2021-A01 and CMS-CSST-2021-B01, NSFC of China under grant 11973070, the Shanghai Committee of Science and Technology grant No.19ZR1466600 and Key Research Program of Frontier Sciences, CAS, Grant No. ZDBS-LY-7013. TT acknowledges support from the Leverhulme Trust. Author contributions: all authors contributed to the development and writing of this paper. The authorship list is given in three groups: the lead authors (PAB, OF, JHD, PS), where we ordered (OF, JHD, PS) alphabetically. PAB led the paper, JHD provided all necessary simulations, OF and PS contributed to the modelling, and all four helped in the development of the analysis. The first author group is followed by two further alphabetical groups. The first alphabetical group includes those who are key contributors to both the scientific analysis and the data products. The second group covers those who have either made a significant contribution to the data products or to the scientific analysis.
References
- Abbott, T. M. C., Abdalla, F. B., Alarcon, A., et al. 2018, Phys. Rev. D, 98, 043526 [NASA ADS] [CrossRef] [Google Scholar]
- Amon, A., Gruen, D., Troxel, M. A., et al. 2022, Phys. Rev. D, 105, 023514 [NASA ADS] [CrossRef] [Google Scholar]
- Arnouts, S., Cristiani, S., Moscardini, L., et al. 1999, MNRAS, 310, 540 [Google Scholar]
- Asgari, M., Tröster, T., Heymans, C., et al. 2020, A&A, 634, A127 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Asgari, M., Lin, C.-A., Joachimi, B., et al. 2021, A&A, 645, A104 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Barthelemy, A., Codis, S., & Bernardeau, F. 2021, MNRAS, 503, 5204 [Google Scholar]
- Bergé, J., Amara, A., & Réfrégier, A. 2010, ApJ, 712, 992 [CrossRef] [Google Scholar]
- Bilicki, M., Jarrett, T. H., Peacock, J. A., Cluver, M. E., & Steward, L. 2014, ApJS, 210, 9 [Google Scholar]
- Bilicki, M., Dvornik, A., Hoekstra, H., et al. 2021, A&A, 653, A82 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bridle, S., & King, L. 2007, New J. Phys., 9, 444 [Google Scholar]
- Brouwer, M. M., Demchenko, V., Harnois-Déraps, J., et al. 2018, MNRAS, 481, 5189 [NASA ADS] [CrossRef] [Google Scholar]
- Brown, M. L., Taylor, A. N., Hambly, N. C., & Dye, S. 2002, MNRAS, 333, 501 [NASA ADS] [CrossRef] [Google Scholar]
- Burger, P., Schneider, P., Demchenko, V., et al. 2020, A&A, 642, A161 [EDP Sciences] [Google Scholar]
- Burger, P., Friedrich, O., Harnois-Déraps, J., & Schneider, P. 2022, A&A, 661, A137 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carron, J. 2013, A&A, 551, A88 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Castro, T., Borgani, S., Dolag, K., et al. 2021, MNRAS, 500, 2316 [Google Scholar]
- Chisari, N., Codis, S., Laigle, C., et al. 2015, MNRAS, 454, 2736 [NASA ADS] [CrossRef] [Google Scholar]
- Chisari, N. E., Alonso, D., Krause, E., et al. 2019, ApJS, 242, 2 [Google Scholar]
- de Jong, J. T. A., Verdoes Kleijn, G. A., Boxhoorn, D. R., et al. 2015, A&A, 582, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de Jong, J. T. A., Verdoes Kleijn, G. A., Erben, T., et al. 2017, A&A, 604, A134 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- DES Collaboration (Abbott, T. M. C., et al.) 2022, Phys. Rev. D, 105, 023520 [CrossRef] [Google Scholar]
- Di Valentino, E., Anchordoqui, L. A., Akarsu, Ö., et al. 2021a, Astropart. Phys., 131, 102605 [NASA ADS] [CrossRef] [Google Scholar]
- Di Valentino, E., Anchordoqui, L. A., Akarsu, Ö., et al. 2021b, Astropart. Phys., 131, 102604 [NASA ADS] [CrossRef] [Google Scholar]
- Driver, S. P., Hill, D. T., Kelvin, L. S., et al. 2011, MNRAS, 413, 971 [Google Scholar]
- Edge, A., Sutherland, W., Kuijken, K., et al. 2013, The Messenger, 154, 32 [NASA ADS] [Google Scholar]
- Eifler, T., Schneider, P., & Hartlap, J. 2009, A&A, 502, 721 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fenech Conti, I., Herbonnet, R., Hoekstra, H., et al. 2017, MNRAS, 467, 1627 [NASA ADS] [Google Scholar]
- Friedrich, O., Gruen, D., DeRose, J., et al. 2018, Phys. Rev. D, 98, 023508 [Google Scholar]
- Friedrich, O., Uhlemann, C., Villaescusa-Navarro, F., et al. 2020, MNRAS, 498, 464 [NASA ADS] [CrossRef] [Google Scholar]
- Friedrich, O., Halder, A., Boyle, A., et al. 2022, MNRAS, 510, 5069 [NASA ADS] [CrossRef] [Google Scholar]
- Fu, L., Kilbinger, M., Erben, T., et al. 2014, MNRAS, 441, 2725 [Google Scholar]
- Giblin, B., Heymans, C., Asgari, M., et al. 2021, A&A, 645, A105 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Górski, K. M., Hivon, E., Banday, A. J., et al. 2005, ApJ, 622, 759 [Google Scholar]
- Gruen, D., Friedrich, O., Amara, A., et al. 2016, MNRAS, 455, 3367 [Google Scholar]
- Gruen, D., Friedrich, O., Krause, E., et al. 2018, Phys. Rev. D, 98, 023507 [Google Scholar]
- Halder, A., & Barreira, A. 2022, MNRAS, 515, 4639 [NASA ADS] [CrossRef] [Google Scholar]
- Halder, A., Friedrich, O., Seitz, S., & Varga, T. N. 2021, MNRAS, 506, 2780 [CrossRef] [Google Scholar]
- Hamana, T., Shirasaki, M., Miyazaki, S., et al. 2020, PASJ, 72, 16 [Google Scholar]
- Harnois-Déraps, J., Pen, U.-L., Iliev, I. T., et al. 2013, MNRAS, 436, 540 [Google Scholar]
- Harnois-Déraps, J., Amon, A., Choi, A., et al. 2018, MNRAS, 481, 1337 [Google Scholar]
- Harnois-Déraps, J., Giblin, B., & Joachimi, B. 2019, A&A, 631, A160 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Harnois-Déraps, J., Martinet, N., Castro, T., et al. 2021, MNRAS, 506, 1623 [CrossRef] [Google Scholar]
- Harnois-Déraps, J., Martinet, N., & Reischke, R. 2022, MNRAS, 509, 3868 [Google Scholar]
- Hartlap, J., Simon, P., & Schneider, P. 2007, A&A, 464, 399 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heitmann, K., Lawrence, E., Kwan, J., Habib, S., & Higdon, D. 2014, ApJ, 780, 111 [Google Scholar]
- Heydenreich, S., Brück, B., Burger, P., et al. 2022, A&A, 667, A125 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heymans, C., Tröster, T., Asgari, M., et al. 2021, A&A, 646, A140 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hilbert, S., Hartlap, J., & Schneider, P. 2011, A&A, 536, A85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hildebrandt, H., Viola, M., Heymans, C., et al. 2017, MNRAS, 465, 1454 [Google Scholar]
- Hildebrandt, H., van den Busch, J. L., Wright, A. H., et al. 2021, A&A, 647, A124 [EDP Sciences] [Google Scholar]
- Hirschmann, M., Dolag, K., Saro, A., et al. 2014, MNRAS, 442, 2304 [Google Scholar]
- Jarvis, M., Bernstein, G., & Jain, B. 2004, MNRAS, 352, 338 [Google Scholar]
- Joachimi, B., Lin, C. A., Asgari, M., et al. 2021, A&A, 646, A129 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Joudaki, S., Blake, C., Johnson, A., et al. 2018, MNRAS, 474, 4894 [NASA ADS] [CrossRef] [Google Scholar]
- Joudaki, S., Hildebrandt, H., Traykova, D., et al. 2020, A&A, 638, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kaiser, N. 1992, ApJ, 388, 272 [Google Scholar]
- Kilbinger, M., & Schneider, P. 2005, A&A, 442, 69 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kodwani, D., Alonso, D., & Ferreira, P. 2019, Open J. Astrophys., 2, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K., Heymans, C., Hildebrandt, H., et al. 2015, MNRAS, 454, 3500 [Google Scholar]
- Kuijken, K., Heymans, C., Dvornik, A., et al. 2019, A&A, 625, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Martinet, N., Castro, T., Harnois-Déraps, J., et al. 2021, A&A, 648, A115 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Miller, L., Heymans, C., Kitching, T. D., et al. 2013, MNRAS, 429, 2858 [Google Scholar]
- Mo, H., van den Bosch, F. C., & White, S. 2010, Galaxy Formation and Evolution, (Cambridge, UK: Cambridge University Press) [Google Scholar]
- Peacock, J. A., & Bilicki, M. 2018, MNRAS, 481, 1133 [Google Scholar]
- Percival, W. J., Friedrich, O., Sellentin, E., & Heavens, A. 2022, MNRAS, 510, 3207 [NASA ADS] [CrossRef] [Google Scholar]
- Pires, S., Leonard, A., & Starck, J.-L. 2012, MNRAS, 423, 983 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration V. 2020, A&A, 641, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pyne, S., & Joachimi, B. 2021, MNRAS, 503, 2300 [NASA ADS] [CrossRef] [Google Scholar]
- Ragagnin, A., Dolag, K., Biffi, V., et al. 2017, Astron. Comput., 20, 52 [Google Scholar]
- Reimberg, P., & Bernardeau, F. 2018, Phys. Rev. D, 97, 023524 [NASA ADS] [CrossRef] [Google Scholar]
- Sadeh, I., Abdalla, F. B., & Lahav, O. 2016, PASP, 128, 104502 [NASA ADS] [CrossRef] [Google Scholar]
- Sánchez, A. G., Scoccimarro, R., Crocce, M., et al. 2017, MNRAS, 464, 1640 [Google Scholar]
- Schneider, P. 1996, MNRAS, 283, 837 [Google Scholar]
- Schneider, P. 1998, ApJ, 498, 43 [Google Scholar]
- Seitz, C., & Schneider, P. 1997, A&A, 318, 687 [NASA ADS] [Google Scholar]
- Sellentin, E., & Heavens, A. F. 2016, MNRAS, 456, L132 [Google Scholar]
- Smith, A., Cole, S., Baugh, C., et al. 2017, MNRAS, 470, 4646 [NASA ADS] [CrossRef] [Google Scholar]
- Springel, V. 2005, MNRAS, 364, 1105 [Google Scholar]
- Spurio Mancini, A., Piras, D., Alsing, J., Joachimi, B., & Hobson, M. P. 2022, MNRAS, 511, 1771 [NASA ADS] [CrossRef] [Google Scholar]
- Takahashi, R., Hamana, T., Shirasaki, M., et al. 2017, ApJ, 850, 24 [Google Scholar]
- van Daalen, M. P., Schaye, J., Booth, C. M., & Dalla Vecchia, C. 2011, MNRAS, 415, 3649 [Google Scholar]
- van den Busch, J. L., Wright, A. H., Hildebrandt, H., et al. 2022, A&A, 664, A170 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- van Uitert, E., Joachimi, B., Joudaki, S., et al. 2018, MNRAS, 476, 4662 [NASA ADS] [CrossRef] [Google Scholar]
- Wright, A. H., Hildebrandt, H., van den Busch, J. L., et al. 2020, A&A, 640, L14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Xavier, H. S., Abdalla, F. B., & Joachimi, B. 2016, MNRAS, 459, 3693 [NASA ADS] [CrossRef] [Google Scholar]
- Zürcher, D., Fluri, J., Sgier, R., et al. 2022, MNRAS, 511, 2075 [CrossRef] [Google Scholar]
Appendix A: Additional plots
 |
Fig. A.1. Residual shear profiles of the highest quantile filter for different threshold values that the effective area must exceed to be used with respect to the shear profiles with a 0.5 threshold. It is seen that for threshold values above 0.6 the shear profiles deviate more than one standard deviation (grey band) due to decreasing remaining area. |
 |
Fig. A.2. Posterior distributions, using different b2 values to distribute galaxies to the same density contrast, from which a data vector is measured. The lower right panel shows the posterior results from simulations, where galaxies are distributed with a HOD. The model vector uses for all four cases a linear galaxy bias model. |
In this section, we show additional plots which belong to the main text. We start by visualising the shear profiles that result in different threshold values for the effective area above which pixels are used for the analysis in Fig. A.1.
In Fig. A.2 we show different posterior distributions, to test whether our analytical model with a linear galaxy bias model gives robust cosmological results even if galaxies are placed with a Poisson process with mean ![Mathematical equation: $ \lambda=n_{\mathrm{eff}}\big[1+b_{\mathrm{1}}\,\delta_{\mathrm{m,2D}}({\boldsymbol \theta})+b_{\mathrm{2}}\,(\delta_{\mathrm{m,2D}}^2({\boldsymbol \theta})-\langle\delta_{\mathrm{m,2D}}^2)\rangle\big] $](/articles/aa/full_html/2023/01/aa44673-22/aa44673-22-eq65.gif) , where δm, 2D is the projected density contrast or with a halo occupation distribution (HOD) description (Smith et al. 2017). For the Poisson process test, we use the simulation of Takahashi et al. (2017) with sources that mimic the fourth and fifth KiDS-1000 bins and lenses that mimic the KiDS-bright sample. For the HOD analysis, we measure the data vector, and the covariance from 614 SLICS realisations with noisy KiDS-1000 sources and GAMA lens mocks (see Harnois-Déraps et al. 2018, for a detailed description), where the covariance is scaled to approximately match the KIDS-1000 footprint. It is clearly seen that the posterior for b2 > 0 is strongly biased if shear and Nap information are used. In contrast, using only shear information, the posterior is unbiased as they are almost insensitive to the galaxy bias model. Although the HOD analysis already shows that the linear galaxy bias assumption is sufficient, if the posterior using shear and Nap information is consistent with the posterior using only shear information gives additional confidence that b2 ≈ 0.
, where δm, 2D is the projected density contrast or with a halo occupation distribution (HOD) description (Smith et al. 2017). For the Poisson process test, we use the simulation of Takahashi et al. (2017) with sources that mimic the fourth and fifth KiDS-1000 bins and lenses that mimic the KiDS-bright sample. For the HOD analysis, we measure the data vector, and the covariance from 614 SLICS realisations with noisy KiDS-1000 sources and GAMA lens mocks (see Harnois-Déraps et al. 2018, for a detailed description), where the covariance is scaled to approximately match the KIDS-1000 footprint. It is clearly seen that the posterior for b2 > 0 is strongly biased if shear and Nap information are used. In contrast, using only shear information, the posterior is unbiased as they are almost insensitive to the galaxy bias model. Although the HOD analysis already shows that the linear galaxy bias assumption is sufficient, if the posterior using shear and Nap information is consistent with the posterior using only shear information gives additional confidence that b2 ≈ 0.
 |
Fig. A.3. Redshift distribution of the full KiDS-bright sample resulting from Lorentzian fitting parameters (a and s), which in turn are determined from different patches on the sky. In the bottom panel, the absolute differences to the best-estimated nbe(z) are shown. |
 |
Fig. A.4. Difference between the true and emulated model data vector m(Θ) scaled by the standard deviation of the measured data estimated with the FLASK. |
 |
Fig. A.5. Shear profiles of the cosmo-SLICS for the bright lens and all three source mocks with the n(z) shown in Fig. 1 for two different IA amplitudes for the adapted filter. The third source tomographic bin is strongly contaminated by IA due to the significant overlap with the lens n(z) and is therefore excluded from this analysis. |
In Fig. A.3 we show the negligible difference of the lens n(z) if the Lorentzian fitting parameters (a and s) are estimated from different patches of the sky. In Fig. A.4 we display the accuracy of the emulator, and in Fig. A.5, that the third tomographic bin is indeed contaminated by IA, in Fig. A.6 the χ2 distribution of mock data vectors around the MAP for the adapted filter with the best-estimated nbe(z), and lastly in Fig. A.7 the iterative process to find the optimal MAP values by scaling the covariance matrix to the previously found MAP.
 |
Fig. A.6. Distribution of χ2 values of mock data vectors that follow from multivariate Gaussian distributions, where the mean is the model prediction at MAP and the covariance is the corresponding covariance for that particular model. The red line shows the χ2 values using the real data vector. The orange line is a χ2 distribution with d.o.f. = 81, which is slightly smaller than the 84 elements of the data vector. |
 |
Fig. A.7. Change of MAP values due to scaling of the covariance to the previously measured MAP values. Roughly after ten iterations, the process converged, where the occasional outliers happened if the minimisation process stopped to early by coincidence. |
Appendix B: Additional material for the red and blue analysis
Here in this chapter, we show the complementary plots for the joint red+blue analysis. In Fig. B.1 the redshift distribution for the red and blue samples is shown, resulting from the smoothing method described in Sect. 3.1. In Fig. B.2 we show the shear profiles; in Fig. B.3 the mean aperture number values for both samples which are used as the model and data vectors.
 |
Fig. B.1. Best estimated redshift distributions of the red and blue KiDS-bright samples in red and blue, with the full KiDS-bright sample in green. |
 |
Fig. B.2. Measured and predicted shear profiles at the MAP values for the adapted filter for the red and blue samples. The shaded region is the expected KiDS-1000 uncertainty estimated from the 1000 FLASK realisations with shape noise. |
 |
Fig. B.3. Mean aperture number of the red and blue sample, where the predictions follow from a joint minimisation process. Different to the full bright sample the measured p(Nap) is smaller than the predicted Map, resulting in the measured ⟨Nap⟩ being smaller. |
Appendix C: Top-hat filter analysis
 |
Fig. C.1. MCMC results for the top-hat filter using the model and simulations where we infused the pure shear signal with different amplitudes of IA. |
Marginalised MAP values and their 68% confidence intervals for the different lens n(z) of the full sample.
This section shows the corresponding plots that belong to the analysis with the top-hat filter. We start by showing in Fig. C.1 the validation for the top-hat with the cosmo-SLICS, which shows that the true parameters are always inside 1 σ. The discussion from Sect. 7.1 about the impact of different redshifts distributions is summarised for the top-hat filter in Table C.1, which shows with the given reduced χ2 and corresponding p-value that the model is well fitted to the data given the covariance matrix, and result in parameters that are consistent to the ones constrained with the adapted filter.
Finally we show in Fig. C.2 and Table C.2 the analogous results for the top-hat filter to the adapted filter as shown in Fig. 12 and Table 4. The p-value for the joint red+blue indicates that the given d.o.f. has a significant tension between the measured data and the best fit model. Although this reduced χ2 is not ideal for the given d.o.f., we still perform the analysis, but the posteriors should be taken with caution, which is already true because we are uncertain about the true n(z) of the sub-samples. Overall the results show the same trends as for the adapted filter, where the blue galaxies result in smaller bias b and larger α than the red galaxies. The reason for the top-hat filter performing worse than the adapted filter is unclear. Nevertheless, besides the fact that the n(z) of the red and blue sample is quite uncertain, both filters are probing on fundamentally different scales so that different behaviours are not surprising.
 |
Fig. C.2. Posterior for the full KiDS-bright sample shown in green, and the joint red+blue posteriors that represent the results of the individual colour-selected samples. In the latter case, by construction, the red and blue samples share the same cosmology (the dark blue contours). |
Marginalised MAP values and their 68% confidence intervals for the different lens samples.
All Tables
Marginalised MAP values and their 68% confidence intervals for the different lens n(z) of the full sample.
Marginalised MAP values and their 68% confidence intervals for the different lens samples.
Marginalised MAP values and their 68% confidence intervals for the different lens n(z) of the full sample.
Marginalised MAP values and their 68% confidence intervals for the different lens samples.
All Figures
|
Fig. 1. Redshift distributions, n(z), of the galaxy samples. The lens sample is obtained from the KiDS-bright galaxies described in Bi21. The blue line shows nsp(z), i.e. the redshift distribution of KiDS galaxies for which we have spectra from the GAMA survey. The red line shows nph(z), the distribution of the full KiDS-bright sample as estimated by ANNz2 with a photometric redshift cut of zph < 0.1. The black line shows our best-estimated nbe(z): a smoothed version of nph(z) that better accounts for photometric redshift errors. The cyan, orange, and brown lines show the third, fourth and fifth redshift bins of the KiDS-1000 data, as estimated in H21. As the third bin strongly overlaps the sources, it is excluded from the analysis. |
| In the text | |
|
Fig. 2. Shear profiles measured with the adapted filter for the KiDS-bright-like lenses and sources from the cosmo-SLICS+IA simulations for two different IA amplitudes (see the legend). The orange regions are estimated from the covariance matrix, while the black dashed lines are obtained from our IA-free analytical predictions at the input cosmology and using the n(z) shown in Fig. 1. As the differences between the shear profiles with varying IA amplitude can barely be seen, we display the relative difference between them in the bottom panels for the highest and lowest two quantiles. |
| In the text | |
|
Fig. 3. Relative difference between the mean ⟨Nap⟩ measured in the cosmo-SLICS+IA bright mocks for four quantiles, and the value of ⟨Nap⟩ predicted by the model at the same cosmology. The blue error bars show the KiDS-1000 statistical uncertainty measured from FLASK. |
| In the text | |
|
Fig. 4. Pipeline validation: cosmological inference with the adapted filter using the cosmo-SLICS simulations with and without IA infusion, analysed with our model that ignores IA. The posteriors are almost indistinguishable from each other. |
| In the text | |
|
Fig. 5. Absolute differences between the mean shear profiles for all quantiles using either dark matter-only or full hydrodynamical Magneticum simulations. The residuals are with respect to the dark matter-only mocks for the lenses and sources and are always within the expected statistical uncertainty shown as the orange bands. |
| In the text | |
|
Fig. 6. Relative difference between the mean ⟨Nap⟩ to compare measurements from the hydro and dark matter-only Magneticum simulations. The relative difference is always well inside the expected statistical uncertainty of KiDS-1000. |
| In the text | |
|
Fig. 7. Shear profiles measured in the data, compared to the best-fit predictions (MAP) obtained with values listed in Table 3, for the adapted filter. The shaded region shows the statistical uncertainty estimated from 1000 FLASK realisations. |
| In the text | |
|
Fig. 8. Relative difference between the mean ⟨Nap⟩ to compare measurements from the KiDS-bright sample and our model, evaluated at the MAP values shown in Table 3. The measured ⟨Nap⟩ are all greater than the predicted ⟨Nap⟩ at MAP just indicating that the measured p(Nap) is broader than the predicted one. |
| In the text | |
|
Fig. 9. Cosmological posteriors for the adapted filter for the best-estimated nbe(z) in black using the full data vector and in green using only shear information compared to the COSEBIs posteriors in orange presented in Asgari et al. (2021) and to the (TT, TE, EE+lowE) results of Planck Collaboration V (2020) in red. The sharp cut of the green posterior is due to the conservative prior of Ωm > 0.2, as the model does not agree with the cosmo-SLICS for smaller Ωm values. The shear-only posterior is shown in this figure to support the assumption of using a linear galaxy bias model. |
| In the text | |
|
Fig. 10. Posteriors of the full DSS vector resulting from using the different lens n(z) shown in Fig. 1. The n(zphot) and n(z) have, by construction, the same mean redshift, while the mean redshift of the spectroscopic redshift estimate is ∼0.015 lower. The main DSS results include a marginalisation over our uncertainty in the mean redshifts of both the lens and source samples, which partially compensates for some of these differences. The posterior obtained using the GAMA spectroscopic n(z), shown in blue, should be taken with caution as it is estimated from a smaller sky coverage and, as such, contains larger statistical fluctuations. |
| In the text | |
|
Fig. 11. Comparison between the posteriors obtained from our fiducial setup (with the covariance matrix calculated at the initial cosmology, see the black contours), with those obtained after scaling the covariance at the best-fit parameters (red) and to those obtained by varying the covariance with the parameters (blue). |
| In the text | |
|
Fig. 12. Posterior for the full KiDS-bright sample shown in green, while the joint red+blue posteriors represent the results of the colour-selected samples. In the latter case, the red and blue samples share the same cosmology (the dark blue contours) by construction. The resulting measured and best-fit predicted shear profiles for the red and blue samples are displayed in Fig. B.2 and the corresponding mean aperture number values are seen in Fig. B.3. |
| In the text | |
|
Fig. A.1. Residual shear profiles of the highest quantile filter for different threshold values that the effective area must exceed to be used with respect to the shear profiles with a 0.5 threshold. It is seen that for threshold values above 0.6 the shear profiles deviate more than one standard deviation (grey band) due to decreasing remaining area. |
| In the text | |
|
Fig. A.2. Posterior distributions, using different b2 values to distribute galaxies to the same density contrast, from which a data vector is measured. The lower right panel shows the posterior results from simulations, where galaxies are distributed with a HOD. The model vector uses for all four cases a linear galaxy bias model. |
| In the text | |
|
Fig. A.3. Redshift distribution of the full KiDS-bright sample resulting from Lorentzian fitting parameters (a and s), which in turn are determined from different patches on the sky. In the bottom panel, the absolute differences to the best-estimated nbe(z) are shown. |
| In the text | |
|
Fig. A.4. Difference between the true and emulated model data vector m(Θ) scaled by the standard deviation of the measured data estimated with the FLASK. |
| In the text | |
|
Fig. A.5. Shear profiles of the cosmo-SLICS for the bright lens and all three source mocks with the n(z) shown in Fig. 1 for two different IA amplitudes for the adapted filter. The third source tomographic bin is strongly contaminated by IA due to the significant overlap with the lens n(z) and is therefore excluded from this analysis. |
| In the text | |
|
Fig. A.6. Distribution of χ2 values of mock data vectors that follow from multivariate Gaussian distributions, where the mean is the model prediction at MAP and the covariance is the corresponding covariance for that particular model. The red line shows the χ2 values using the real data vector. The orange line is a χ2 distribution with d.o.f. = 81, which is slightly smaller than the 84 elements of the data vector. |
| In the text | |
|
Fig. A.7. Change of MAP values due to scaling of the covariance to the previously measured MAP values. Roughly after ten iterations, the process converged, where the occasional outliers happened if the minimisation process stopped to early by coincidence. |
| In the text | |
|
Fig. B.1. Best estimated redshift distributions of the red and blue KiDS-bright samples in red and blue, with the full KiDS-bright sample in green. |
| In the text | |
|
Fig. B.2. Measured and predicted shear profiles at the MAP values for the adapted filter for the red and blue samples. The shaded region is the expected KiDS-1000 uncertainty estimated from the 1000 FLASK realisations with shape noise. |
| In the text | |
|
Fig. B.3. Mean aperture number of the red and blue sample, where the predictions follow from a joint minimisation process. Different to the full bright sample the measured p(Nap) is smaller than the predicted Map, resulting in the measured ⟨Nap⟩ being smaller. |
| In the text | |
|
Fig. C.1. MCMC results for the top-hat filter using the model and simulations where we infused the pure shear signal with different amplitudes of IA. |
| In the text | |
|
Fig. C.2. Posterior for the full KiDS-bright sample shown in green, and the joint red+blue posteriors that represent the results of the individual colour-selected samples. In the latter case, by construction, the red and blue samples share the same cosmology (the dark blue contours). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.