| Issue |
A&A
Volume 659, March 2022
|
|
|---|---|---|
| Article Number | A166 | |
| Number of page(s) | 21 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202141538 | |
| Published online | 22 March 2022 | |
A novel cosmic filament catalogue from SDSS data⋆
1
Dipartimento di Fisica, Università di Roma Tor Vergata, via della Ricerca Scientifica, 1, 00133 Roma, Italy
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
INFN, Sezione di Roma 2, Università di Roma Tor Vergata, via della Ricerca Scientifica, 1, 00133 Roma, Italy
3
Dipartimento di Matematica, Universitá di Roma Tor Vergata, via della Ricerca Scientifica, 1, 00133 Roma, Italy
Received:
14
June
2021
Accepted:
2
November
2021
Abstract
Aims. In this work we present a new catalogue of cosmic filaments obtained from the latest Sloan Digital Sky Survey (SDSS) public data.
Methods. In order to detect filaments, we implement a version of the Subspace-Constrained Mean-Shift algorithm that is boosted by machine learning techniques. This allows us to detect cosmic filaments as one-dimensional maxima in the galaxy density distribution. Our filament catalogue uses the cosmological sample of SDSS, including Data Release 16, and therefore inherits its sky footprint (aside from small border effects) and redshift coverage. In particular, this means that, taking advantage of the quasar sample, our filament reconstruction covers redshifts up to z = 2.2, making it one of the deepest filament reconstructions to our knowledge. We follow a tomographic approach and slice the galaxy data in 269 shells at different redshift. The reconstruction algorithm is applied to 2D spherical maps.
Results. The catalogue provides the position and uncertainty of each detection for each redshift slice. The quality of our detections, which we assess with several metrics, show improvement with respect to previous public catalogues obtained with similar methods. We also detect a highly significant correlation between our filament catalogue and galaxy cluster catalogues built from microwave observations of the Planck Satellite and the Atacama Cosmology Telescope.
Key words: large-scale structure of Universe / catalogs / methods: data analysis
A copy of the catalogue is available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/cat/J/A+A/659/A166
© ESO 2022
1. Introduction
It has long been recognised that matter in the Universe is arranged along an intricate pattern known as the cosmic web (Joeveer & Einasto 1978; Bond et al. 1996). This highly structured web results from the anisotropic gravitational collapse and hosts four main classes of substructures: massive halos, long filaments, sheets, and vast low-density regions known as cosmic voids (Zeldovich et al. 1982). Filaments are highly defining features in this network, as they delimit voids and provide bridges along which matter is expected to be channelled towards halos and galaxy clusters.
Filamentary structures in the large-scale distribution of galaxies were originally observed with the Center for Astrophysics (CfA) galaxy survey (de Lapparent et al. 1986). Since then, ample evidence for such structures has been gathered by galaxy redshift surveys, such as the Sloan Digital Sky Survey (SDSS, York et al. 2000), the Two-degree-Field Galaxy Redshift Survey (2dFGRS, Cole et al. 2005), the Six-degree-Field Galaxy Survey (6dFGS, Jones et al. 2004), the Cosmic Evolution Survey (COSMOS, Scoville et al. 2007), the Galaxy and Mass Assembly (GAMA, Driver et al. 2011), the Two Micron All Sky Survey (2MASS, Huchra et al. 2012), and the VIMOS Public Extragalactic Redshift Survey (VIPERS, Guzzo et al. 2014). Concurrently, further corroboration of the filamentary arrangement of matter also came from cosmological N-body simulations (e.g., Springel 2005; Vogelsberger et al. 2014).
Nevertheless, detecting and reconstructing cosmic filaments still poses some challenges due to the lack of a standard and unique definition. As a consequence, a variety of approaches and algorithms have been explored in the literature. Among these there are multiscale morphology filters, such as MMF (Aragón-Calvo et al. 2007, 2010b) or NEXUS (Cautun et al. 2013); segmentation-based approaches, such as the Candy model (Stoica et al. 2005) or the watershed method implemented in SpineWeb (Aragón-Calvo et al. 2010a); skeleton analyses (Novikov et al. 2006; Sousbie et al. 2008); tessellations, as in DisPerSE (Sousbie 2011); the Bisous model (Tempel et al. 2016); methods based on graph theory such as T-Rex (Bonnaire et al. 2020) or minimal spanning trees (Pereyra et al. 2020); or methods based on machine learning classification algorithms, such as random forests (Buncher & Carrasco Kind 2020) or convolutional neural networks (CNNs; as in Aragon-Calvo 2019). Comparisons between different methods can be found in Libeskind et al. (2017) and Rost et al. (2020), for example. All these methods rely on different assumptions and can be more or less advantageous depending on the specific application.
In the present paper, we adopt and extend the technique proposed by Chen et al. (2015a, hereafter C15), who implement the Subspace-Constrained Mean-Shift (SCMS) algorithm to identify the filamentary structure in the distribution of galaxies. This technique is based on a modified gradient ascent method that models filaments as ridges in the galaxy density distribution. It has already been successfully applied to SDSS data (Chen et al. 2016), providing a filament catalogue which has been used to study the effect of filaments on galaxy properties, such as colour and mass (Chen et al. 2017), or orientation (Chen et al. 2019; Krolewski et al. 2019). The catalogue also allowed the first detection of cosmic microwave background (CMB) lensing by cosmic filaments (He et al. 2018) and has been used to study the possible effect of cosmic strings on cosmic filaments (Fernandez et al. 2020). Our implementation of the algorithm presents two main differences with respect to C15. In their work, the filament finder is applied on 2D galaxy density maps which are built from the original catalogue assuming a flat-sky approximation. Here, we extend the formalism to work on spherical coordinates, as we expect this approach to be less sensitive to projection effects, especially for wide surveys. Secondly, we complement the method with a machine learning technique that combines information from different smoothing scales in the density field. This procedure has been designed to be robust against the choice of a particular smoothing scale, and allows the algorithm to exploit the information present at lower redshift (with more available galaxies) in order to robustly predict the filaments at higher redshift (with fewer available galaxies).
We apply this new implementation of the algorithm to the DR16 SDSS data (Ahumada et al. 2020) from BOSS (Baryon Oscillation Spectroscopic Survey) and eBOSS (extended BOSS) clustering surveys. The latter, in particular, has not been used in previous filament-extraction studies. eBOSS creates the largest volume survey to date and, thanks to its sample of quasars, we have been able to build a filament catalogue that extends to very high redshifts of up to z = 2.2. In our approach, we divide the data into 269 redshift shells of 20 Mpc in width, and provide the filament reconstruction in 2D spherical slices. We also deliver the uncertainties associated to the filament positions, which have been estimated with a bootstrap method.
There are several advantages to using this tomographic approach to filament reconstruction. For example, the 2D filament maps can be directly employed in cross-correlation studies with maps of the CMB lensing convergence or thermal Sunyaev-Zel’dovich signal (see e.g., Tanimura et al. 2020). We also expect this method to be particularly suitable for the extraction of filament maps from future wide photometric surveys, such as Euclid (Laureijs et al. 2011) and the Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST, Ivezić et al. 2019), where uncertainties on redshift estimates might limit the applicability of 3D methods. The tomographic approach has also been shown to provide more robust detection near galaxy clusters and to be less sensitive to the Finger of God effect, even when it is statistically corrected (Kuchner et al. 2021). Moreover, the tomographic catalogue will naturally trace the evolution of the filamentary structure of the Universe as a function of redshift and can therefore be used to test structure formation history and cosmological models. On the other hand, the tomographic approach reduces the sensitivity to filaments at angles close to the line of sight and may split long filaments across two or more slices. Different applications will benefit from different approaches.
The paper is organised as follows. We start by providing a detailed description of the methodology and the algorithm in Sect. 2. In Sect. 3 we introduce the data sets used in our analysis, while in Sect. 4 we present the results of the filament extraction. In Sect. 5 we compare the results with the catalogue from C15. In Sect. 6 we discuss the validation of the catalogue through several metrics. Finally, in Sect. 7 we draw our conclusions.
2. Methodology
In this section, we explain the theoretical framework that we use and the complete methodology that we implement. The scheme of this section is as follows. In Sect. 2.1 we explain our working definition of cosmic filaments. In Sect. 2.2 we introduce our tomographic strategy. In Sect. 2.3 we explain the basis of the SCMS algorithm used to detect these filaments from galaxy distribution maps. In Sect. 2.4 we study how this algorithm can be extended to yield an estimation of the error of the detection. In Sect. 2.5 we introduce the two methods (based on SCMS) that we implement to detect filaments, including a version of SCMS boosted by machine learning techniques. Finally, in Sect. 2.6 we discuss the strengths and limitations of our methodology. All the details explaining the training of the machine learning step and the procedure to clean the final filament catalogue and remove outliers can be found in Appendices A and C, respectively.
2.1. Definition of cosmic filaments
Cosmic filaments can be defined in multiple ways. In this work, we adopt the mathematical framework of the Ridge formalism (Eberly 1996). This formalism has been widely studied in the mathematical literature, for example by Ozertem & Erdogmus (2011) and Genovese et al. (2014). We refer the reader to these references for a more complete overview of the properties of ridges. Here, we summarise the definition and some key properties.
A ridge of a density field d(x) in D dimensions is defined as follows. Let g(x) and H(x) be the gradient and the Hessian of d(x). Let λ1 ≥ ⋯ ≥ λD be the eigenvalues of H(x), with associated eigenvectors v1, ..., vD. We define V(x) as the subspace spanned by all eigenvectors except v1 (therefore perpendicular to it). We define the gradient projected into this subspace as G(x). Finally, the ridges of the density field d(x) are defined as
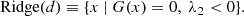 (1)
(1)
This definition is conceptually analogous to the criteria for maxima of a one-dimensional function: ‘first derivative equals 0’ and ‘second derivative is negative’. In the case of higher dimensions, one has to restrict those criteria to the subspace perpendicular to the filament. The largest eigenvalue λ1 corresponds to an eigenvector v1 parallel to the filament, given that the density decreases with the distance to a filament, but not in the direction of the filament (or not as quickly). We note that the gradient on a point of the ridge is always parallel to the direction of the ridge. Not only is this observation important for the algorithm we use to find the filaments, but it also provides a method for calculating the direction of a filament in a point.
By definition, ridges are one-dimensional, overdense structures, the two properties that define cosmic filaments. We note that other cosmological structures are given by slightly modified definitions. If the subspace V(x) is the whole space and λ1 < 0, we obtain overdense zero-dimensional structures, similar to nodes in the cosmic web, or halos. If the subspace V(x) is the whole space and λ3 > 0, we obtain underdense zero-dimensional structures similar to void centres. Finally, if the subspace V(x) is spanned only by v3 and λ3 < 0, we obtain overdense two-dimensional structures similar to cosmic walls. It is important to note that these definitions always include the lower dimension objects: this means that filaments include nodes of the cosmic web (and therefore galaxy clusters) by definition.
Alternative definitions of cosmic filaments can be found in the literature. In particular, it is common to classify the cosmic web according only to the eigenvalues of the hessian (Aragón-Calvo et al. 2007; Cautun et al. 2013, 2014): all positive for halos, two positive for cosmic walls, one positive for filaments, and all negative for voids. Therefore, the space is completely divided into these four classes. This definition implies that regions classified as filaments are more clumpy, and are not one dimensional. In other words, it does not provide information about the centre of the filaments, which may be relevant for some applications. We note that ridges satisfy this definition, while also being local maxima in the direction perpendicular to the filament. Another common approach is to detect filaments with graph-based tools, such in Bonnaire et al. (2020) and Pereyra et al. (2020). These methods do not define filaments using an underlying physical quantity such as density. Instead, they try to connect most galaxies with links subject to some regularising criteria. They result in a one-dimensional network, but they are usually sensitive to a range of parameters which must be tuned.
2.2. Tomographic analysis
The above definition of filaments can be applied to the cosmic web with D = 3 dimensions by converting redshift into distance; or with D = 2 dimensions by taking redshift slices and applying it independently to each slice.
Using a 3D galaxy distribution presents the problem of an asymmetric uncertainty, as the uncertainty in redshift is much larger than the uncertainty in sky position. This can generate false detections in the line-of-sight direction, especially near galaxy clusters (Kuchner et al. 2021). It is also more computationally expensive in general, as the number of points that need to be stored in memory increases significantly. On the other hand, a tomographic approach is less sensitive to filaments with their axis aligned close to the line-of-sight direction. The angle between these directions will have an impact on the likeliness of a correct detection. Additionally, slicing the redshift range may produce border effects, such as the splitting of a long filament across two or more slices, or the detection of a filament in two consecutive slices when its redshift is close to the limit between slices. Depending on the goal, one method will be more suitable than the other.
In this work, we use the second approach with thin slices in order to obtain tomographic information on the filament network. In principle, this means that we lose the ability to detect some of the filaments in exchange for a lower number of false detections, especially around clusters. Given that we work on spherical slices, all computations are done by taking into account the spherical geometry of the space, that is, the computation of the gradient, the hessian, and the definition of the density estimate d.
There are different techniques to slice the redshift information. An important aspect to take into account is that the width of the shells needs to be thin enough to avoid the case where different filaments overlap in a single slice; while it needs to be thick enough to include a large number of galaxies so we can detect the filaments in each slice. Additionally, we ensure that this width is larger than the redshift uncertainty of the galaxies within it by at least a factor of five.
2.3. Subspace-Constrained Mean Shift
The SCMS algorithm exploits the previous definition of a ridge in order to find one-dimensional maxima. It has been used in cosmology to obtain cosmic filaments in galaxy catalogues (Chen et al. 2014a,b) and simulations (Chen et al. 2015b). This algorithm has also been applied to weak lensing maps by the Dark Energy Survey (Moews et al. 2020); to galactic simulations in order to study filaments formed in interactions with satellite galaxies (Hendel et al. 2019); and even in the analysis of the location of crimes in cities (Moews et al. 2021).
SCMS is an iterative algorithm. We start with a set of test points that uniformly fill the analysed area and at each step they move towards the filaments. In order to do that, we first compute an estimate of the galaxy density, and obtain its gradient and hessian. These points move in the direction given by the eigenvector of the hessian with the smallest eigenvalue. The magnitude of the movement is given by the projection of the gradient onto this eigenvector. In a ridge, the gradient is parallel to the direction of the ridge by definition, while this eigenvector is always perpendicular. This means that points remain fixed in place once they reach a ridge.
A detailed description of the algorithm can be found in Chen et al. (2015a). Here, we reproduce the steps as we have implemented them:
Algorithm 1 (filament detection).
-
In:
A collection of points on the sphere, {xi}≡{(θi, ϕi)}, representing the galaxies observed within a given redshift slice.
-
1.
Obtain a density function d(θ, ϕ) (defined over the sphere) by smoothing the point distribution with a certain kernel.
-
2.
Calculate the gradient of the density: g(θ, ϕ)≡∇d(θ, ϕ)
-
3.
Calculate the hessian of the density: ℋ(θ, ϕ)
-
4.
Diagonalize the hessian (2 × 2 matrix) at every point and find the eigenvectors v1(θ, ϕ), v2(θ, ϕ), with the smallest eigenvalue corresponding to v2
-
5.
Project the gradient g onto the eigenvector v2. Let p(θ, ϕ) be this projection.
-
6.
Select a set of points {yj} that will be used to search for the filaments. In our case, it will be a uniform grid over the sphere. Iterate until convergence:
-
(a)
At step s, move every point
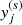 in the direction of the projection at that point
in the direction of the projection at that point 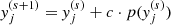 1.
1. -
7.
When the points do not move between steps, they have reached a filament.
-
Out:
A collection of points on the sphere
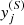 placed on the filaments.
placed on the filaments.
Figure 1 illustrates several steps of this algorithm.
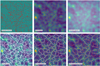 |
Fig. 1. Different steps of the algorithms. Top left: initial distribution of galaxies in a redshift slice. Top centre: a density distribution is estimated from the galaxies. Top right: a grid of points {yj} is selected as the initial positions of the iterative steps; they correspond to the centres of HEALPix pixels. Bottom left: the positions of the points after one step of the iteration. Bottom centre: the positions of the points after they converge, with the initial galaxy distribution overlapped. Bottom right: same as bottom centre, but the uncertainty of each point in the filaments is calculated with Algorithm 2; a redder colour represents a lower certainty. All images are gnomic projections centred at RA = 180°, Dec = 40° with a side size of 60°. The data used in this example corresponds to BOSS data at z = 0.570 (see Sect. 3). |
All quantities defined over the sky (d, g, ℋ, v1, v2 and p) are computed using the HEALPix pixelisation scheme at resolution Nside = 1024 (Górski et al. 2005). This corresponds to pixels with an approximate size of 3.44′. This is chosen to be much lower than the expected scales of any of the fields of interest (typically in the order of degrees) so as to avoid pixelisation effects.
In order to implement the algorithm, we must choose the kernel to be used in the density estimation: in this work, we use a spherical Gaussian kernel (i.e. a Gaussian kernel evaluated on the geodesic distance). This requires the choice of a free parameter: the full width at half maximum (FWHM) of the kernel. The relation between the size of the kernel and the number of points can significantly affect the quality of the reconstruction in a redshift slice. To mitigate this effect, we implement two independent solutions:
-
(a)
Adapt the FWHM of the kernel to the number of points of each redshift slice;
-
(b)
Combine the results of the algorithm at different scales using a machine learning approach. Both approaches are explained in Sect. 2.5.
2.4. Estimate of the uncertainty
We measure the robustness of each detection as explained in Chen et al. (2015a). This method is designed to simulate different realisations of the galaxy distribution using bootstrapping: for each simulation, we take a random sample of the real galaxies in order to obtain a modified realisation of galaxies. We then compare the filaments obtained in the real data with the filaments obtained in this new realisation of galaxies. In practice, we do this in the following way:
Algorithm 2 (uncertainty of the detection).
-
1.
The true filaments are computed on all the real data, yj.
-
2.
A new set of simulated galaxies is generated by bootstrapping the original galaxy catalogue. The new set has the same number of galaxies, but with possible repetitions.
-
3.
Algorithm 1 is run on these galaxies to obtain a new set of simulated filaments
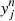 .
. -
4.
For every point on the true filament, we compute the minimum distance to the closest new filament
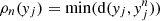 . Small distances correspond to more consistent detections.
. Small distances correspond to more consistent detections. -
5.
We repeat steps 2–4 a total of N = 100 times. For every point of the true filament, we have a minimum distance for each simulation; we find the (quadratic) mean of all simulations
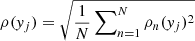 .
. -
Out:
A single error estimate (average minimum distance) for every point in the true filaments, ρ(yj).
The value of ρ(yj) has a natural interpretation: it is the typical error in the location of a particular point in a filament, when the galaxy distribution changes slightly. As it is given in degrees, is can be readily represented as a confidence region on the sky. This is illustrated on the left image of Fig. 2. We note that most filaments are determined with an accuracy well below 1°, while the ends of filaments and smaller filaments present higher uncertainties. This uncertainty estimate may be very useful in applications where the user needs a certain position accuracy, as they can keep only the filaments that satisfy their criteria.
 |
Fig. 2. Representations of the uncertainty of the detection. On the left, we plot a circle around each point of the filament with a radius equal to the uncertainty; this is a way of visualising the regions of the sky where a certain filament is expected to be. On the right, we apply the uncertainty estimate to each pixel of the map, and obtain an average distance to bootstrapped filaments for every pixel; actual filaments are found mostly where the mean distances are low. In both cases, colour represents uncertainty in degrees, and filaments found with real data are represented in white. Both figures are gnomic projections centred at RA = 180°, Dec = 40° with a side size of 60°. The data used in this example correspond to BOSS data z = 0.570 (see Sect. 3). |
We note that Algorithm 2 can be run on any set of points yj, not necessarily the filament points. In this case, one obtains the typical distance to a filament for any point on the sky, averaged over the 100 bootstrapping realisations. We use this approach to construct full maps of the regions of interest, setting yj to be the set of all pixels in the region of interest. This will be the basis of the second method to obtain filaments, as explained in the following section. An example of such a map can be seen in the right image of Fig. 2. It can be seen that filaments are mostly detected in regions with minimum uncertainty. This figure also presents some spurious detections, which are characterised by high uncertainty and can be removed a posteriori.
2.5. Choice and combination of scales
As mentioned before, the shape and size of the filter kernel is a free parameter of Algorithm 1. We use a Gaussian kernel to perform this step. We use two independent methods in order to select the best FWHM for each redshift slice, and mitigate the importance of this parameter; these will be explained in the following section.
We note that we also tested the Mexican needlets of different orders (see Narcowich et al. 2006; Geller & Mayeli 2008; Marinucci et al. 2008), as they have yielded better results than Gaussian profiles in several applications in cosmology (e.g., Oppizzi et al. 2020; Planck Collaboration XLVIII 2016). However, in this particular case, they did not improve the results. This is due to the oscillating shape of these filters in pixel space, which may introduce artificial ridges in the maps.
2.5.1. Method A: optimise the FWHM
The first method consists of finding an optimal value for the FWHM at each redshift slice. In order to avoid dependence on any theoretical model, we do not use the possible evolution of filaments as information to find them. The only parameter we consider is the number of galaxies per unit area within each redshift slice. Slices with a low density number do not have enough reliable information to reconstruct smaller filaments, and so the kernel has to be wider in order to compensate for this. On the other hand, highly populated slices contain enough information to reconstruct both large and small filaments, and so a narrower kernel can be used.
The goal of changing the FWHM with redshift is to obtain the most complete reconstruction possible at each redshift, while maintaining a similar quality of the reconstruction in terms of accuracy and error.
In practice, we scale the FWHM with the number of galaxies using the following expression:
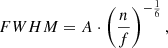 (2)
(2)
where n is the number of galaxies within a redshift slice, f is the observed sky fraction, and A is a constant parameter. The exponent −1/6 is a common scaling factor for kernel density estimators in two dimensions, and is used for example in the Silverman’s rule of thumb (Silverman 1998). This is proven to be optimal in the case of reconstruction of a Gaussian profile, in which case A can be optimally calculated. However, as we do not expect a Gaussian profile, we tune the prefactor A of this rule of thumb to
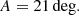 (3)
(3)
We tested different values in simulations with filaments and noise. This value yields better results than higher (28, 35) or lower (14, 7) values; with a false detection rate below 15% and discovery power above 90%. This value seems to perform better with real data as well. We refer to the filament catalogue obtained with method A as Catalogue A.
2.5.2. Method B: combine the information at different scales
The alternative method aims to eliminate the choice of a FWHM by combining different scales. It combines the results of filtering at different scales in order to obtain a single predictor of the filament locations. The key idea is that the quantities computed in Algorithm 1 at different scales (density, gradient, Hessian, etc.) contain enough information in order to be able to distinguish a point in a filament from a point far from it. By combining these quantities, we may be able to predict the location of filaments more accurately than applying the algorithm on a single scale. Multiscale approaches have been used before in the literature (Aragón-Calvo et al. 2007); in this work we develop a powerful new method to combine the information into a single output.
In order to combine the information at different scales, we deploy a machine learning algorithm: Gradient Boosting. This algorithm generates a series of decision trees based on the input values for each quantity. The first tree will be trained to predict the desired output, the second tree is trained to learn the error caused by the first, the nth tree is trained to predict the error of the sum of the first n − 1. By generating a large number of these trees and combining their predictions in this way, the ensemble prediction is greatly improved. For more information about the algorithm, see Ho (1995), Friedman (2001), and Géron (2019). The choices for some of the most important hyperparameters are the following: number of trees (100), learning rate (0.1), loss function (least squares), and maximum depth of each tree (3 layers). These are the baseline settings for this algorithm and we have verified results are stable when faced with small changes in these parameters. This would resolve the problem of fixing the FWHM and eliminate the dependence with redshift. Additionally, the algorithm should be able to learn the typical characteristics of filaments in the most populated redshift slices at low redshift, where filaments are easier to detect. It can then use this learnt information in order to identify filaments at higher redshift or less populated slices. Galaxies at lower redshift (red galaxies) and higher redshift (quasars) are tracers with different characteristics: quasars have a higher value of the bias (Laurent et al. 2017). In order to train and apply the algorithm on the whole redshift range, we must ensure that the algorithm is flexible enough to accommodate both datasets. We confirm that this is the case in Appendix B.
The idea of this algorithm is similar to the well-established technique of convolutional neural networks (see Krachmalnicoff & Tomasi (2019) for an implementation of convolutional neural networks compatible with the HEALPix pixelisation). These networks typically convolve the map with a series of stacked layers; each layer containing a number of small filters trained to maximise the information extracted from the map. In order to extract information from a large area around a pixel, a large number of layers must be stacked. However, in our case, we can extract more useful information from the density map by obtaining relevant quantities such as the modulus of the gradient or the eigenvalues of the hessian at different scales, as these are very good indicators of the location of ridges. These quantities cannot be easily reproduced by training linear filters. Computing these quantities also implies isotropic filters, as opposed to trained filters, where the orientation is important. Lastly, extracting these features explicitly allows us to use different fixed scales; these scales are much larger than the pixel size (∼50 to 100 times larger), which can usually only be obtained by stacking a large number of convolutional layers.
The input of the Gradient Boosting is some of the quantities computed in Algorithm 1 at each pixel. We select five quantities that could be physically correlated (positively or negatively) with the presence of a filament: the density estimate d, the magnitude of the gradient ∥g∥, the magnitude of the projection ∥p∥, the value of the second eigenvalue of the Hessian of the density λ2, and its eigengapλ1 − λ2. We compute these quantities for each pixel at several smoothing scales. For example, for the data we analyse here, we verified that four scales provide a stable reconstruction, while adding more scales does not carry any significant improvement. In particular, we use FWHM = 2.7 deg, 3.4 deg, 4.1 deg and 4.8 deg. Therefore, there are 20 input features (5 quantities times 4 scales) and as many points as pixels in the region of interest.
As output of the Gradient Boosting, we want a measure of the ‘filament-ness’ for each pixel. In order to do this, we exploit the method to estimate the error described in the last paragraph of Sect. 2.4. There we derived a map in which the value of each pixel is the average distance to a filament in the bootstrapping simulations, as in the right image of Fig. 2. The machine learning algorithm uses the value of the quantities at each pixel to predict the typical distance of a filament from a pixel with certain characteristics. In particular, the algorithm learns the characteristics of the pixels with filaments. The exact procedure to produce the training maps is explained in Appendix A.
After the algorithm is trained, we obtain a prediction of the estimated error map for each redshift slice. In order to compare with the previous method, we obtain a filament distribution by applying Algorithm 1 again on these maps. We report the filament catalogue, which we call Catalogue B.
There are three key advantages to making the prediction with the Gradient Boosting algorithm:
-
It generalises better. The algorithm is able to learn what range of values are expected at a filament, close to a filament, and far from a filament. This means that results from redshift slices with a greater number of observed galaxies will improve the algorithm at all redshift slices. In particular, the algorithm becomes more robust at higher redshifts where there are fewer observations.
-
It reduces the impact of anomalies. For the same reason, spurious detections become less likely, as they are sometimes caused by local ridges that do not correspond to values expected from real filaments (e.g., produced by a small number of galaxies).
-
It is much faster than computing the real scale-combined estimated uncertainty maps, as explained in Appendix A.
2.6. Strengths and limitations
Given the choices explained in this section and the algorithms used, we identify the following strengths (+) and limitations (−) of our methodology:
-
+
The implementation works natively in the surface of the sphere, taking into account its geometry, and is compatible with the widely used HEALPix scheme. This also makes the implementation rotationally invariant and independent of the chosen reference system.
-
+
We reduce the sensitivity to the density estimate thanks to the development of a boosted version of the standard SCMS algorithm with machine learning (Method B).
-
+
The approach provides a tomographic catalogue. This eases the study of the evolution of different parameters or characteristics of filaments as a function of redshift. Additionally, it avoids or reduces artefacts due to the conversion from redshift to distance, such as the Finger of God effect or the asymmetrical error in the 3D location.
-
+
The method provides uncertainty estimates for each detection using bootstrapping simulations (see Sect. 2.4).
-
+
The algorithm is fast, it takes only a few seconds per redshift slice on a laptop.
-
±
Physical centre and width: the ridge definition applies to the centre of the filaments, and so the algorithm is able to locate the 1D centre; however, it gives no direct information about its physical width.
-
−
This methodology is most sensitive to filaments perpendicular to the line of sight direction. Filaments with directions close to the line of sight will not be detected by this methodology.
-
−
The ridge definition does not determine the individual filaments, it only determines which points are in a filament; filament separation needs to be done afterwards using another method.
3. Data
The Sloan Digital Sky Survey (SDSS, Blanton et al. 2017) is currently the largest and most complete spectroscopic galaxy catalogue. In particular, we use two of its surveys: BOSS (Baryon Oscillation Spectroscopic Survey) and eBOSS (extended BOSS). Both of these surveys report a specific catalogue tailored to the study of large-scale structure. They are divided into different samples, each optimised to a specific redshift range. In this section we briefly describe the different samples and how we use and combine them.
3.1. BOSS
BOSS maps the distribution of luminous red galaxies (LRG) and quasars (QSO) on the sky and in redshift. The final data release is part of the SDSS DR12 (see Dawson et al. 2013; Alam et al. 2015; Anderson et al. 2014). They report two samples:
-
LOWZ: Galaxies in this sample are mostly located in the range of 0.05 < z < 0.5 in both the north and south Galactic cap. The sky footprint can be seen in Fig. 3 (top row). The sky fraction is approximately 17.0% and 7.5% for the north and south Galactic caps, respectively. The north Galactic cap presents an unobserved region; we note that we remove all filaments detected close to this region in order to avoid border effects, see Appendix C.
-
CMASS: Galaxies in this sample are mostly located in the range of 0.4 < z < 0.8 in both the north and south Galactic caps. The sky footprint can be seen in Fig. 3 (second row). The sky fraction is approximately 19.0% and 7.5% for the north and south Galactic caps, respectively.
 |
Fig. 3. Sky footprint of the data reported by BOSS LOWZ (top), BOSS CMASS (second), and the three eBOSS samples: LRG and QSO (third), and ELG (bottom). The representation uses a mollweide projection in equatorial coordinates (J2000), with a rotation of 90° along the z axis. The footprints on the left and right sides correspond to the north and south Galactic caps, respectively. |
3.2. eBOSS
The eBOSS survey uses three different tracers: LRGs, emission line galaxies (ELGs), and QSOs. The most recent data are reported in SDSS DR16 (see Dawson et al. 2016; Ahumada et al. 2020; Ross et al. 2020). Catalogues for each type are reported separately:
-
LRGs: Galaxies in this sample are located in the range of 0.6 < z < 1.0 in both the north and south Galactic cap. The sky footprint can be seen in Fig. 3 (third row). The sky fraction is approximately 8.4% and 6.0% for the north and south Galactic caps, respectively. The north Galactic cap is a subregion of the BOSS footprint; it is around half the size of this latter and is very regular. The south Galactic cap is irregular and presents a gap. Given that the area close to borders may introduce spurious detections (Appendix C), the region available for the analysis is too small to be used for our filament-finding algorithm: we do not include this cap.
-
ELGs: Galaxies in this sample are located in the range of 0.6 < z < 1.1 in both the north and south Galactic cap. The sky footprint can be seen in Fig. 3 (bottom row). The sky fraction is 1.6% and 2.0% for the north and south Galactic caps, respectively. Both of these caps are too small and irregular for the algorithm, so we do not use this sample.
-
QSOs: Quasars in this sample are located in the range of 0.8 < z < 2.2 in the north and south Galactic cap. The sky footprint is identical to the one for LRG, which can be seen in Fig. 3 (third row). The sky fraction is approximately 8.4% and 6.0% for the north and south Galactic caps, respectively. As before, we are unable to use the data in the south Galactic cap, and so we use only the north Galactic cap.
3.3. Combining data
In order to produce the best possible filament catalogue, we carefully combine the previous data, maximising the density of galaxies and the covered sky fraction. Combining different samples by simply merging the catalogues may generate an inhomogeneous sample on the sky. This would introduce artefacts in the regions when the number of galaxies varies abruptly due to sampling inhomogeneities. Therefore, when combining samples with different footprints, we need to select the most restrictive footprint. This means that there is a natural trade-off between the observed number of galaxies and the sky footprint to be considered.
In practice, we combine the data into the following Blocks (i.e. data samples), each with a different mask:
-
Block 1: 0.05 < z < 0.45. Data from LOWZ and CMASS; in the sky footprint from LOWZ, which is the most restrictive of the two. The number of galaxies per redshift bin and the ratio of both samples can be seen in Fig. 4. We note that this block is dominated by LOWZ, with CMASS data providing a relevant contribution (more than 10% of the galaxies) only at z > 0.4. At the higher redshift end, the majority of galaxies come from the CMASS sample. However, there are a large number of LOWZ galaxies which we decide not to neglect as they improve the filament reconstruction, although this does reduce the sky region slightly.
-
Block 2: 0.45 < z < 0.7. Data from CMASS only. The number of galaxies per redshift bin can be seen in Fig. 5.
-
Block 3: 0.6 < z < 2.2. Data from CMASS, LRG and QSO; in the footprint from LRG (equal to the QSO footprint), the most restrictive of the two regions. There are no QSO data below z = 0.8, while all filaments above z = 1.0 are detected using QSO data exclusively. The number of galaxies per redshift bin and the fraction of each sample can be seen in Fig. 6.
 |
Fig. 4. Galaxy distribution in Block 1. Top: stacked number of galaxies per redshift bin from both the used surveys. Bottom: fraction of galaxies corresponding to each survey as a function of redshift. |
 |
Fig. 5. Galaxy distribution in Block 2. Number of galaxies per redshift bin. All galaxies correspond to the CMASS sample. |
 |
Fig. 6. Galaxy distribution in Block 3. Top: stacked number of galaxies per redshift bin from all of the used surveys. Bottom: fraction of galaxies corresponding to each sample as a function of redshift. |
We note that the redshift range 0.6 < z < 0.7 is covered by two Blocks: Block 2 which is made up only by CMASS data in a larger sky region; and Block 3 which is made up by CMASS+LRG data, but in a smaller region given by LRG. We perform the filament reconstruction in this redshift range separately for the two Blocks. This is done in order to extract the most information out of the samples, while ensuring that the entire region is homogeneously sampled in order to avoid the introduction of artefacts. As an interesting byproduct, we are able to compare filaments extracted from BOSS alone and from BOSS+eBOSS.
4. The filament catalogue
4.1. Filament reconstruction
We apply Methods A and B, as explained in Sect. 2.5, to extract the cosmic filaments catalogues from the three Blocks of data introduced in Sect. 3.3. These three Blocks correspond to three different redshift ranges and sky fractions f inherited from the used SDSS data: (a) Block 1 (0.05 < z < 0.45), with 78 bins and f1 = 0.186; (b) Block 2 (0.45 < z < 0.7), with 40 bins and f2 = 0.219; and (c) Block 3 (0.6 < z < 2.2), with 166 bins and f3 = 0.062.
The width of the slices in the line-of-sight direction is taken as 20 Mpc, computed with the ΛCDM parameters obtained by Planck (Planck Collaboration VI 2020); in particular, 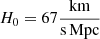 . We note that the exact parameters to be used have a limited impact, as small variations of this width do not significantly alter our results. This width is chosen to be small enough to avoid several overlapping filaments in a single slice, but large enough to be several times larger than the uncertainty on the galaxy measured redshift.
. We note that the exact parameters to be used have a limited impact, as small variations of this width do not significantly alter our results. This width is chosen to be small enough to avoid several overlapping filaments in a single slice, but large enough to be several times larger than the uncertainty on the galaxy measured redshift.
Method A requires the choice of the size of the smoothing kernel. As explained in Sect. 2.5.1, this is taken to be a function of the number of galaxies within a redshift slice. The value of FWHM of the Gaussian kernel, in degrees, can be seen in Fig. 7. Method B uses four fixed scales which can also be seen in the figure (2.7 deg, 3.4 deg, 4.1 deg, 4.8 deg); they contain the range of sizes used for Method A.
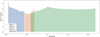 |
Fig. 7. Value of the FWHM of the Gaussian kernel chosen for Method A as a function of redshift for each block. The scales that are combined in Method B are fixed and can be seen with markers on both redshift ends. |
We compare the results obtained with both methods in Sect. 4.2. We see that Method B generally outperforms Method A. Therefore, we recommend the use of the catalogue produced with Method B, which is publicly available online2. The catalogue produced with Method A is also available upon request. The columns of the catalogues are explained in Table 1.
Columns in the catalogues.
4.2. Comparison between methods
In this section we present and compare the catalogues obtained with Methods A and B explained in Sect. 2.5. We use the final results in the complete redshift range 0.05 < z < 2.2 and all available sky.
The first difference between the two catalogues is that Method B is able to detect more filaments. An example at z = 0.20 can be seen in the top row of Fig. 8; this is representative of the results at lower redshift (z < 0.5). It can be seen that most filaments in Catalogue A are also detected in Catalogue B. The latter have a slightly larger associated uncertainty. However, more importantly, there is an additional filament population in Catalogue B, which is detected at lower significance. These additional filaments are not detected with Method A because they are erased when smoothing the galaxy density map at a single scale. On the other hand, as expected, Method B is able to correctly recover the same filaments detected with method A, plus additional filaments from other (usually smaller) scales.
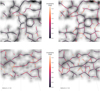 |
Fig. 8. Example of reconstructed filaments at z = 0.20 (top) and z = 1.00 (bottom); with Method A (left) and Method B (right). The colour of the points represents the error estimate in degrees. Grey points correspond to galaxies, while the background map represents the galaxy density, smoothed at 3°, for visualisation purposes. The visualisation is a gnomonic projection around the point (RA = 140°, δ = 40°) with a side size of 60°. Meridians and parallels are both represented at a step of 20 deg. |
At higher redshift (z > 0.7), we continue to observe an additional filament population for the same reason. However, the filaments which are observed in both catalogues are detected with a significantly lower uncertainty estimate in Catalogue B. A representative example at z = 1.00 can be seen in the bottom row of Fig. 8. At this redshift, the number of galaxies is lower; Method A only uses the information at the given slice, and so it is more sensitive to noise and incomplete information. On the other hand, the machine learning algorithm in Method B is able to ‘learn’ the typical characteristics of filaments in slices where there are more galaxies and less noise. It is then able to use some of this information in all redshift slices to obtain a more confident and uniform reconstruction of the filaments.
4.2.1. Distance from galaxies to filaments
The filament catalogues are built to trace the regions with a galaxy number overdensity. Consequently, there is a correlation between filaments and galaxies by construction. We use this correlation as a proxy to study the quality of the reconstruction and to quantify the differences between the two methods. We consider the distance from every galaxy to its closest filament. Galaxies are typically not located at the exact centre of the filaments, and so this distance will have a dispersion around zero. In general, the main causes for this dispersion are the following:
-
(a)
distribution of matter and galaxies along the whole size of the filament, not exclusively on the central spine,
-
(b)
error in the location of the centre of the filament, and
-
(c)
non-detection of actual filaments, so the galaxies in that filament will appear to be far from detected filaments.
The second point can be approximated with the estimated uncertainty of the detections. The third point is not significant in the full catalogue, but could be relevant if one takes a small subset, such as a strong threshold in the uncertainty of the detection. In our analysis, we consider the full catalogue.
We compute the distance between galaxies and their closest filament for the two methods. A comparison of the median distance over redshift can be seen in Fig. 9 both in degrees and proper distance. We choose to use the median as it is more robust in slices with a lower number of galaxies (especially at high and very low redshift). This distance is lower overall in Method B, partly due to the fact that it reports a higher number of filaments.
 |
Fig. 9. Mean distance between galaxies and their closest filament as a function of redshift. Blue corresponds to Method A, and orange corresponds to Method B. Different shades of colour correspond to the three different Blocks with different masks. Top: angular distance in degrees; bottom: proper distance in megaparsecs. |
Another way to analyse the distance between galaxies and filaments is to look at their distribution compared to that obtained from a random distribution of points. In this case, we partially mitigate the effect induced by having a larger number of filaments in method B, as it also decreases the overall distance from random points to filaments. The number of galaxies at a distance r from a filament, with respect to the number of random points at the same distance, 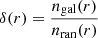 , can be seen in Fig. 10 for both catalogues. Both catalogues present a similar ratio, although Catalogue A produces a slightly higher peak at a very close distance to the filaments.
, can be seen in Fig. 10 for both catalogues. Both catalogues present a similar ratio, although Catalogue A produces a slightly higher peak at a very close distance to the filaments.
 |
Fig. 10. Average distribution of distances between galaxies and their closest filament divided by the same distribution for random points, as described in the text. Left: Method A. Right: Method B. Different colours correspond to the three different Blocks. |
Both methods yield significant detection levels throughout the entire redshift range. This includes z > 1, where data come from QSO detections only. The quality of the reconstruction in this range remains roughly constant. Distances from galaxies to filaments are significantly lower than for random points.
This distance between galaxies and filaments can be understood as a typical width of the filament and is compatible with values in the literature. This quantity has been studied in hydrodynamical simulations by Galárraga-Espinosa et al. (2020) using Illustris-TNG, Illustris, and Magneticum simulations. These authors observe that the radii of filaments are typically ∼3 to ∼5 Mpc at z = 0. Although the radius definition is different and we do not reach z = 0, we verified that our measurement in the lowest redshift bins is compatible with the measurement of these latter authors in simulations. This is also compatible with other simulations in the literature, such as Colberg et al. (2005), where the typical radius of a filament is between 1.5h−1 and 2h−1 Mpc.
4.2.2. Uncertainty of the detections
The second metric we use in the comparison is the estimated uncertainty of the detections. This is calculated using bootstrapping of the original galaxies, as explained in Algorithm 2. This procedure estimates the variability in the location of the detected filaments, given in degrees, and is therefore a measure of the robustness of the results.
We compute the median of the estimated uncertainty of detection. A comparison can be seen in Fig. 11 in degrees and proper distance. The median uncertainty for Method B is approximately constant over z. As mentioned before, at low redshift, the higher median uncertainty with respect to method A is mainly driven by the additional population of detected filaments with higher uncertainty. This effect is also seen at higher redshift, but it is compensated by a much lower estimated uncertainty for the filaments found in both catalogues.
 |
Fig. 11. Mean uncertainty estimate for the detected filaments as a function of redshift. Blue corresponds to Method A, orange corresponds to Method B. Different shades of colour correspond to the three different Blocks with different masks. Top: angular distance in degrees; bottom: proper distance in megaparsecs. |
It is important to note that, at low redshift, Method B yields a result of similar quality to Method A (as measured with galaxy–filament distances), even if Method A reports a lower estimated uncertainty. At higher redshift (z > 1), Method B yields both lower distances and lower uncertainty estimates.
We note that we expect most applications of these catalogues to require an additional threshold, for example on the limit of the estimated uncertainty required3. After a cut of this kind (for example using Catalogue B while removing points with an estimated uncertainty over 1 deg), the described results would be slightly modified in the following way: (a) the median distance would increase overall by around 0.05 deg, (b) the peak in δ would increase to be very similar to the one in Catalogue A, and (c) the estimated uncertainty would be very uniform in z at a value of (0.55 ± 0.02) deg. This is a consequence of the natural trade-off between the confidence of detections and the number of filaments detected that arises when imposing a threshold of this kind. Different applications will require different choices.
5. Comparison with previous work
As stated above, this work follows a similar framework as the one described in Chen et al. (2015a, 2016) (C15). In this section, we explore the improvements in the catalogues obtained by our implementation. A first improvement concerns the data themselves. In this work we perform the reconstruction on a wider sky region encompassing both the north and south Galactic caps, while the C15 catalogue is produced only in the north Galactic cap. We also include the eBOSS sample, which allows a deeper reconstruction in redshift. However, to make a fairer comparison of the methodologies, in the rest of the section we restrict to the redshift range given by C15: 0.05 < z < 0.7, equivalent to Block 1 and Block 2 of our catalogues. These two Blocks are produced only with BOSS data. Additionally, in C15 the authors use the NYU Value Added Catalogue (Blanton et al. 2005) to have more data in the lowest redshift bins. We decided against using these data in order to have a consistent dataset over the whole redshift range, produced only by SDSS. This means that comparisons at the lowest redshift bins (z ≲ 0.2) will be affected by the difference in the data being used, and so we do not consider them in the comparison.
We use our Catalogue A in the comparisons, as it is the most similar to the methodology followed to produce C15. The main difference is the spherical treatment of the sky; other minor differences are the binning strategy (20 Mpc instead of Δz = 0.005) and slightly different criterion for the smoothing kernel. In Sect. 4.2 we compare the results obtained using our two methods: Method A, our implementation of the SCMS algorithm, and Method B, a version boosted with a machine learning approach.
5.1. Uncertainty of the detections
The first metric we use to compare our Catalogue with the C15 catalogue is the estimated uncertainty for each point in a filament; this is the same metric we used to compare our two catalogues in Sect. 4.2.2. This is calculated using bootstrapping of the original galaxies, as explained in Algorithm 2. This estimates the variability in the location of the detected filaments, given in degrees and is therefore a measure of the robustness of the results.
For each redshift, we compute the average uncertainty estimate. This can be seen in Fig. 12. We observe that the estimated uncertainty is lower in our catalogue over the entire redshift range, by a factor of approximately two. It is also more uniform with redshift. We stress that the uncertainty was estimated using the same method adopted in C15 (Algorithm 2), and therefore the difference we find comes from the reconstruction of filaments.
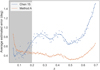 |
Fig. 12. Average estimated uncertainty of the detected filaments as a function of redshift. Orange corresponds to our Method A, blue corresponds to C15. For z < 0.2 (grey band), filaments are reconstructed from different data in the two catalogues. Lines are non-linear fits shown for visualisation only. |
5.2. Distance from galaxies to filaments
The second metric we use to compare the catalogues is the distance between galaxies and their closest filament. As explained in Sect. 4.2.1, this quantity is mainly determined by the physical width of the filaments and the error in their detected positions.
We compute the distribution of these distances and obtain the average for each redshift slice. The comparison of average distances can be seen in Fig. 13. Our catalogue produces lower distances between galaxies and filaments for z < 0.45. C15 presents a sharp decrease at redshift z ≈ 0.45, corresponding to the transition from LOWZ data to CMASS data. As we explore in Sect. 5.3, this is mainly driven by artefacts at high latitudes, where the flat sky approach is less accurate. We observe a smoother curve with less dispersion in our catalogue, corresponding to more consistent detections across redshifts.
 |
Fig. 13. Average distance between galaxies and their closest filament as a function of redshift. Orange corresponds to our Method A, blue corresponds to C15. For z < 0.2 (grey band) filaments are reconstructed from different data in the two catalogues. Lines are non-linear fits shown for visualisation only. |
Additionally, we can compare the average distances between filaments and galaxies with the estimated uncertainties for the centre of the filaments. These two quantities are comparable for C15, whereas in our Catalogue A the uncertainty is lower by a factor of approximately two. This means that, in our case, the dispersion in distances is not dominated by the uncertainty in the location of filament centres, although this effect cannot be neglected.
5.3. Isotropy
One of the main differences between our work and C15 is the full treatment of the spherical geometry of the sky. The catalogue in C15 is obtained by approximating the observed area to a flat sky using spherical coordinates as euclidean. As a consequence, there is some risk that results could show anisotropic features at high latitudes. On the other hand, as we do not apply such an approximation, the algorithm is expected to behave isotropically.
We test this expectation by considering two stripes at different latitudes4:
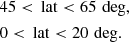 (4)
(4)
We look at the same metrics discussed above, restricting the analysis to these stripes. The estimated uncertainty and the galaxy–filament distance can be seen in Fig. 14. The first thing to notice is that our catalogue reports highly compatible results at high and low latitudes, both for the estimated uncertainty and the galaxy–filament distance. Our algorithm is performing isotropically, as expected.
 |
Fig. 14. Top: average distance from galaxies to their closest filaments, in degrees. Bottom: average estimated uncertainty on the location of the centre of the filaments, in degrees. Both metrics are calculated separately for high- and low-latitude filaments. For z < 0.2 (grey band), filaments are reconstructed from different data in the two catalogues. Lines are non-linear fits shown for visualisation only. |
The C15 catalogue on the other hand shows a slightly different behaviour for results at higher and lower latitudes. An example of this difference can be seen in Fig. 15, where we compare the filaments obtained at z = 0.510 for both catalogues. It can be seen that the filaments at low latitudes are similar, while there is a larger discrepancy at high latitudes. In that region, C15 produces a larger number of filaments, with a preferred vertical orientation. This is an artefact due to the flat sky approximation and indeed is hidden when looking at the filaments in a flat sky, because this region gets dilated (e.g., see Fig. 4 in Chen et al. 2016). This anisotropic feature artificially reduces the distances from galaxies to filaments in this region compared to low-latitude results with no anisotropic effects. This reduction can be up to 25% in the average distance. Heuristically, it seems that the intrinsic physical meaning of the derivative in the ϕ direction is altered by flat sky projection effects at high latitudes and this has an effect on the features of the algorithm.
 |
Fig. 15. Example of obtained filaments at z = 0.510 for C15 (left) and our result (right). The colour of the points represents the uncertainty estimate, in degrees. Grey points correspond to galaxies, while the background map represents the galaxy density smoothed at 3° for visualisation purposes. The visualisation is a gnomonic projection around the point (RA = 140, δ = 40) with a side size of 60°. Meridians and parallels are both represented in steps of 20 deg. |
Similarly, the estimated uncertainty reported by C15 is also affected by this anisotropy. Estimated uncertainties are calculated as an average of distances between real filaments and simulated filaments (as explained in Algorithm 2). However, distances calculated in flat space are artificially increased at high latitudes. This implies an increased value of the estimated uncertainty for this region. Indeed, this is the observed effect, as presented in Fig. 14.
This effect can be quantified by defining Δdist and Δunc as the average difference between values at high and low latitudes of the distance and the estimated uncertainty. For Method A we have the following results:
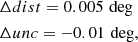 (5)
(5)
while for C15 we obtain the following:
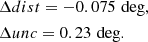 (6)
(6)
We note that this anisotropy is only relevant at high latitudes. At low and intermediate latitudes, our catalogue reports similar results to those of C15. Therefore, this effect does not invalidate the multiple results in the literature based on this catalogue. If anything, we expect these results to be more significant when this anisotropy is corrected.
6. Validation of the catalogue
In this section, we evaluate the quality of the reconstruction in several respects: we check that the results are isotropic, that the catalogue is strongly correlated to independent galaxy cluster catalogues, that the results are stable even if new data are included, and that the length distribution of filaments is compatible with other works in the literature.
6.1. Isotropy
An interesting aspect related to the isotropy of our catalogue is the result at both hemispheres. For 0.05 < z < 0.7 (i.e. Block 1 and 2), we have data at both the southern and northern hemispheres. The sky fractions5 are fS = 0.054, fN = 0.132 for Block 1, and fS = 0.054, fN = 0.165 for Block 2. As a sanity check, we test that the results at both hemispheres are similar.
On each redshift slice and each hemisphere, we compute the mean distance from galaxies to filaments, and the mean estimated uncertainty. We then compute the difference between the metrics at both hemispheres (north minus south). The average differences for Method A are
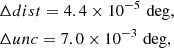 (7)
(7)
and the average differences for Method B are
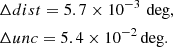 (8)
(8)
We see that none of these differences are significant: all of them are below 1 arcminute, except the difference in estimated error with Method B, which is 3.2′. Additionally, we do not observe trends with redshift. The algorithms is performing isotropically, yielding compatible results at both hemispheres.
6.2. Galaxy clusters
According to the evolution of the cosmic web, the largest overdensities are located in the cosmic halos, which are usually located at the intersection of several filaments. These overdensitites can seed the formation of galaxy clusters. Therefore, known galaxy clusters are expected to be located at a small distance from cosmic filaments (Hahn et al. 2007; Aragón-Calvo et al. 2010b).
We test this expectation with two catalogues of galaxy clusters available in the literature, listed below. Both catalogues were built using the Sunyaev-Zel’dovich effect as a tracer. Therefore, the detection of these galaxy clusters is completely independent of the SDSS data we use to detect the filaments. The catalogues are the following:
-
Planck galaxy cluster catalogue: Planck Collaboration XXVII (2016). This catalogue presents a total of 1653 clusters, mainly at z < 0.6, corresponding to our Blocks 1 and 2. They are reported to have a S/N ≥ 4.5. They are distributed over the full sky; a total of 301 clusters are located within the region where we extract the filaments (254 for Block 1 and 47 in Block 2).
-
Atacama Cosmology Telescope (ACT) galaxy cluster catalogue: Hilton et al. (2021). This catalogue presents a total of 4195 clusters, with S/N ≥ 4.0. This catalogue covers a restricted sky area, as it presents clusters with latitudes up to 20°. Therefore, there is some overlap with the footprints for our Blocks 1 and 2. Unfortunately, there is no overlap with Block 3. In order to minimise possible systematic errors, we select the subsample of clusters with spectroscopic determination of redshift. The number of selected clusters in the footprint of the filaments is 951 (479 in Block 1 and 472 in Block 2).
Two examples of the location of clusters and filaments can be found in Fig. 16 for z = 0.249 (Method A) and z = 0.552 (Method B). All clusters are found to be close to filaments and in particular they tend to be close to intersections of filaments. We observe this trend for both catalogues and throughout the entire redshift range. In some rare instances, a cluster seems to be far from any filament; this can be seen in the bottom image of Fig. 16 for the cluster at lat = 17.5°, lon = 169.0°, apparently located in a cosmic void. A closer examination of this individual cluster reveals that its redshift (z = 0.553) is very close to the lower limit of the slice (z = 0.552). Indeed, it is located in the intersection of filaments in the previous redshift slice, hinting at a possible small error in its redshift determination.
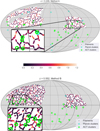 |
Fig. 16. Example of filament maps at different redshift slices with the two methods. The colours of the filaments represent the estimated uncertainty of the detection, in degrees. Independently-measured galaxy clusters from Planck and ACT are also represented. The grey area is excluded from the catalogue due to lack of data and border effects. |
In order to test the statistical significance of the correlation between these clusters and our filaments, we produce 500 random mocks for each cluster catalogue. For each simulation, we take all the clusters located in the footprint of our filaments and randomly place them in a different location, keeping their original redshift. The location is sampled uniformly from the intersection between the cluster catalogue footprint and the filaments footprint. We compute the average distance from these new points to the filaments. We repeat this calculation for the actual data and see how different it is from the random realisations. We can see the result in Fig. 17. It can be seen that the actual clusters are much closer to the filaments than the random catalogue. In particular, the average distance with actual data is between 14σ and 23σ lower than random realisations.
 |
Fig. 17. Distribution of the average distance between clusters and filaments for random realisations and real data. In the y-axis, the average distance, in degrees; different histograms for the two cluster catalogues and methods are represented. The average distance for real data is represented with squares. |
The average distance between clusters and the closest filaments is 0.54° for ACT and 0.62° for Planck. There is therefore a strong correlation between the filament catalogues presented in this work and cluster catalogues in the literature. We emphasise that the detection of these clusters is obtained with a different physical observable and they are independent from our data.
6.3. Stability when faced with new data
One question that arises when analysing the results is how robust these filaments are with respect to new data. If a future survey is able to detect more galaxies at a certain redshift, we would like to know whether we would obtain a similar set of filaments. Equivalently, this can be seen as the predictive power of the filaments: whether new observations of galaxies will be located in the regions predicted by the detected filaments.
We can test this exact situation in the redshift range of 0.6 < z < 0.7. In this range, we have data coming from BOSS that we use in our Block 2, but we also have more recent data coming from eBOSS; we use an aggregation of both in the Block 3. The two Blocks overlap in this redshift range, and so we can test how much the filaments differ when adding the more recent eBOSS data. We note that eBOSS sky coverage is smaller, so we limit this comparison to the common sky region.
In order to compute the difference, we take the filaments obtained with BOSS data only and consider an area around them with a radius of 1°. We then take the filaments obtained with BOSS+eBOSS data and compute the fraction of filament points that lay inside this region. This procedure is done for all redshift slices in 0.6 < z < 0.7. Slices at lower redshift have a higher percentage of common galaxies; that is, new data coming from eBOSS are less important here, and we expect to find similar filaments. At higher redshift, the majority of galaxies come from new data, and we expect the filaments to differ more.
We can see the fraction of common filaments as a function of the fraction of common galaxies in Fig. 18. Each point corresponds to a single redshift slice, and the two curves correspond to Method A and B. The grey region corresponds to the expected results when carrying out this procedure with uncorrelated slices. The fraction of common filaments (alternatively, the fraction of filaments that are correctly predicted by older data) is between 72% and 96%, even when the fraction of shared galaxies goes below 40%.
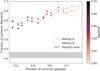 |
Fig. 18. Stability of the results to new data. On the y-axis, the fraction of filaments found using all data (older and newer) which were also found using only older data. On the x-axis, the fraction of galaxies corresponding to older data. Each point corresponds to the result for a single redshift slice. See text. |
This means that new observations in this range are unlikely to change the results significantly: duplicating the number of galaxies only produced 25% more filaments. New data may have a greater effect if a different tracer is used, or with further improvements to the algorithms.
6.4. Length distribution of the cosmic filaments
The study of the topology of the cosmic web is highly non-trivial and is an active topic in the literature; see, for example Neyrinck et al. (2018) and Wilding et al. (2021). This is in part due to the difficulty of defining a single filament. In this work, we use a definition of filaments that is based on the ridge formalism, which is very useful to find the network of filaments, but does not provide information about individual filaments (see Sect. 2.1).
For this section, in order to provide example, we consider that every intersection of the web is the starting point of a filament, regardless of the angle or density of such intersections. The filament ends at another intersection or an end point. We note that this kind of definition is sensitive to the depth of the detection: detection of fainter and shorter filaments will of course increase the number of shorter filaments, but it will also increase the number intersections and split longer filaments into shorter ones.
For a first exploration of the matter, we find the individual filaments on each redshift slice as follows:
-
(a)
A binary HEALPix map of nside = 256 is created with value of 0 everywhere,
-
(b)
The values of the pixels close6 to a filament point in the catalogue are changed to 1,
-
(c)
The skeleton of this map is extracted7,
-
(d)
Pixels in the skeleton are divided into filaments, ends, or intersections depending on the number of neighbours, and
-
(e)
Filaments are considered to be the connected set of pixels between intersections or ends.
Using this procedure, we obtain the distribution of filament lengths of filaments in Catalogue B, which can be seen in Fig. 19. It is characterised by a redshift-dependent peak followed by a power-law decrease. This distribution is also observed in Malavasi et al. (2020) (see their Figs. 18–22); the length distribution found by these latter authors is almost exactly the same as our result for Block 1, even though the method they use to find filaments is completely different (i.e. 3D reconstruction with the DisPerSE scheme). For Blocks 2 and 3, at higher redshifts, we notice that there are fewer shorter filaments; this could be an observational effect (shorter filaments are more difficult to detect at higher redshifts). We note that a similar effect has been observed in simulations: less densely populated simulations report longer filaments (Galárraga-Espinosa et al. 2020); although these simulations report shorter filaments overall. Further investigation is needed to further investigate these trends.
 |
Fig. 19. Distribution of the lengths of the filaments in the catalogues, for the three different Blocks (Block 1: 0.05 < z < 0.45, Block 2: 0.45 < z < 0.7, Block 3: 0.6 < z < 2.2). The dotted line represents the results when we impose an additional threshold on the catalogue, considering only points with uncertainty of the detection under 0.8°. |
Finally, we also report the length distribution when imposing an additional threshold to the catalogue. The fainter lines in Fig. 19 represent the result when considering only points with associated uncertainty lower than 0.8°. As expected, the number of shorter filaments decreases, which decreases the number of intersections, increasing the number of longer filaments. We note that this threshold provides a similar result to that produced using Method A because this method is less sensitive to short filaments, as explained in Sect. 4.2.
7. Conclusions
In this work we present a new catalogue of cosmic filaments found with the SDSS Data Release 16. We implemented a version of the Subspace Constrained Mean Shift algorithm on spherical coordinates and applied it to thin redshift slices in order to obtain a tomographic reconstruction of the cosmic web. We boosted the algorithm with machine learning techniques, which improves the results at higher redshifts. Our main results can be summarised as follows:
-
We report a new public catalogue of cosmic filaments, which inherits the sky footprint of SDSS, and its redshift coverage from z = 0.05 up to z = 2.2. All detected points of the cosmic web come with an associated uncertainty.
-
We study the distances from galaxies to cosmic filaments, and the uncertainty associated with the filament detections, both as a function of redshift. We use these as metrics to assess the goodness of the reconstruction. Both metrics remain within reasonable bounds even at high redshift.
-
We build upon the SCMS algorithm, which has already proven useful for filament detection and cosmological applications (Chen et al. 2015a). We show improvements in the isotropy of our results and we extend the coverage to higher redshift and the southern Galactic hemisphere thanks to more recent data.
-
We additionally boost the algorithm with a machine learning algorithm that ‘learns’ the characteristics of filaments from the most populated redshift slices and use that knowledge to better detect filaments at less populated redshift slices. This proves especially useful when extending the reconstruction to higher redshift slices. We show that, according to the metrics above, this approach also provides more uniform results across redshifts.
-
We study the correlation between our cosmic filament catalogue and external galaxy cluster catalogues from Planck and ACT as part of the validation of our catalogue. These galaxy cluster catalogues are built using the Sunyaev-Zel’dovich effect, a completely independent physical probe. We show a very strong correlation with both catalogues, up to more than 20σ compared to random points.
-
We study the filament persistence with a realistic example by comparing the filaments found with older data (BOSS) and with all data (BOSS+eBOSS) at redshift slices between z = 0.6 and z = 0.7. We show that excluding the new data (up to 60% of total points) only results in a loss of less than 25% of the reconstructed cosmic web.
-
Although the algorithm is not designed to isolate single filaments, we performed a first analysis of the filament length distribution assuming that filament endpoints are in the intersections. We find similar trends to those obtained in other works (Malavasi et al. 2020; Galárraga-Espinosa et al. 2020)
The catalogue is publicly available online8, along with Python codes that can be used to perform standard operations.
We hope that this new catalogue opens the door to more complete studies of the cosmic web. In particular, we are currently working on the extension and validation of previously found correlations between filaments and weak lensing of the cosmic microwave background and the Sunyaev-Zeldovich effect in order to constrain mass profiles and their hot gas content (He et al. 2018; Tanimura et al. 2020). The methodology in this work can also be applied to N-body simulations in order to assess the feasibility of using cosmic filaments as cosmological probes. Finally, we believe that the tomographic reconstruction of the cosmic web will be extremely valuable for upcoming wide photometric galaxy surveys like those expected from Euclid and LSST, for which three-dimensional reconstruction is more difficult.
The value of c for optimal convergence varies with the pixel, and can be calculated with the derivative of the smoothing kernel. See Comaniciu & Meer (2002).
This can be done manually on the catalogue or with the Python functions that we provide at javiercarron.com/catalogue
We are always working in an equatorial reference system, so the latitude of the sphere corresponds to the declination δ.
The sky fraction is defined as the observed area over the total sky area; the maximum value of f for a hemisphere is therefore 0.5.
At a distance of 4 pixels or fewer from the filament point.
This is done with the software Scikit-image (van der Walt et al. 2014), which uses the algorithm described in Zhang & Suen (1984), iteratively removing pixels from the borders without creating gaps or disconnections.
Acknowledgments
We thank Yen-Chi Chen for the valuable discussions regarding the SCMS algorithm and the comparison of the catalogues. We are grateful to the referee for very useful comments and suggestions, which helped improve the manuscript. We have developed the code used in this work using Python 3.8 (available at python.org) with the JupyterLab environment (Kluyver et al. 2016), and the following packages. For numerical computations, we use NumPy (Harris et al. 2020), SciPy (Virtanen et al. 2020), and Astropy (Astropy Collaboration 2018). For treatment of the spherical maps, we use healpy (Górski et al. 2005; Zonca et al. 2019) and MTNeedlet (Carrón Duque et al. 2019). For treatment of tables and databases, we use pandas (Wes McKinney 2010). For parallelization of the code, we use Ray (Moritz et al. 2018). For visualisation, we use Matplotlib (Hunter 2007) and seaborn (Waskom 2021). We thank the developers of these pieces of software and their contributors. We acknowledge support from INFN through the InDark initiative. This work was also supported by ASI/COSMOS grant n. 2016-24-H.0 and ASI/LiteBIRD grant n. 2020-9-HH.0. M.M. is supported by the program for young researchers “Rita Levi Montalcini” year 2015. D.M. acknowledges support from the MIUR Excellence Project awarded to the Department of Mathematics, Università di Roma Tor Vergata, CUP E83C18000100006. Funding for the Sloan Digital Sky Survey IV has been provided by the Alfred P. Sloan Foundation, the U.S. Department of Energy Office of Science, and the Participating Institutions. SDSS acknowledges support and resources from the Center for High-Performance Computing at the University of Utah. The SDSS web site is www.sdss.org. SDSS is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS Collaboration including the Brazilian Participation Group, the Carnegie Institution for Science, Carnegie Mellon University, Center for Astrophysics, Harvard & Smithsonian (CfA), the Chilean Participation Group, the French Participation Group, Instituto de Astrofísica de Canarias, The Johns Hopkins University, Kavli Institute for the Physics and Mathematics of the Universe (IPMU)/University of Tokyo, the Korean Participation Group, Lawrence Berkeley National Laboratory, Leibniz Institut für Astrophysik Potsdam (AIP), Max-Planck-Institut für Astronomie (MPIA Heidelberg), Max-Planck-Institut für Astrophysik (MPA Garching), Max-Planck-Institut für Extraterrestrische Physik (MPE), National Astronomical Observatories of China, New Mexico State University, New York University, University of Notre Dame, Observatório Nacional/MCTI, The Ohio State University, Pennsylvania State University, Shanghai Astronomical Observatory, United Kingdom Participation Group, Universidad Nacional Autónoma de México, University of Arizona, University of Colorado Boulder, University of Oxford, University of Portsmouth, University of Utah, University of Virginia, University of Washington, University of Wisconsin, Vanderbilt University, and Yale University. Based on observations obtained with Planck (http://www.esa.int/Planck), an ESA science mission with instruments and contributions directly funded by ESA Member States, NASA, and Canada. This work used the public data produced by the Atacama Cosmology Telescope (https://act.princeton.edu).
References
- Ahumada, R., Prieto, C. A., Almeida, A., et al. 2020, ApJS, 249, 3 [Google Scholar]
- Alam, S., Albareti, F. D., Prieto, C. A., et al. 2015, ApJS, 219, 12 [NASA ADS] [CrossRef] [Google Scholar]
- Anderson, L., Aubourg, E., Bailey, S., et al. 2014, MNRAS, 441, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Aragon-Calvo, M. A. 2019, MNRAS, 484, 5771 [CrossRef] [Google Scholar]
- Aragón-Calvo, M. A., Jones, B. J. T., van de Weygaert, R., & van der Hulst, J. M. 2007, A&A, 474, 315 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Aragón-Calvo, M. A., van de Weygaert, R., & Jones, B. J. T. 2010a, MNRAS, 408, 2163 [CrossRef] [Google Scholar]
- Aragón-Calvo, M. A., Platen, E., van de Weygaert, R., & Szalay, A. S. 2010b, ApJ, 723, 364 [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Blanton, M. R., Schlegel, D. J., Strauss, M. A., et al. 2005, AJ, 129, 2562 [NASA ADS] [CrossRef] [Google Scholar]
- Blanton, M. R., Bershady, M. A., Abolfathi, B., et al. 2017, AJ, 154, 28 [Google Scholar]
- Bond, J. R., Kofman, L., & Pogosyan, D. 1996, Naature, 380, 603 [NASA ADS] [CrossRef] [Google Scholar]
- Bonnaire, T., Aghanim, N., Decelle, A., & Douspis, M. 2020, A&A, 637, A18 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Buncher, B., & Carrasco Kind, M. 2020, MNRAS, 497, 5041 [NASA ADS] [CrossRef] [Google Scholar]
- Carrón Duque, J., Buzzelli, A., Fantaye, Y., et al. 2019, Astron. Comput., 28, 100310 [CrossRef] [Google Scholar]
- Cautun, M., van de Weygaert, R., & Jones, B. J. T. 2013, MNRAS, 429, 1286 [NASA ADS] [CrossRef] [Google Scholar]
- Cautun, M., van de Weygaert, R., Jones, B. J. T., & Frenk, C. S. 2014, MNRAS, 441, 2923 [Google Scholar]
- Chen, Y.-C., Genovese, C. R., & Wasserman, L. 2014a, Ann. Stat., 43, 1896 [Google Scholar]
- Chen, Y. C., Genovese, C. R., & Wasserman, L. 2014b, ArXiv e-prints [arXiv:1406.1803] [Google Scholar]
- Chen, Y.-C., Ho, S., Tenneti, A., et al. 2015a, MNRAS, 454, 3341 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, Y.-C., Ho, S., Freeman, P. E., Genovese, C. R., & Wasserman, L. 2015b, MNRAS, 454, 1140 [CrossRef] [Google Scholar]
- Chen, Y.-C., Ho, S., Brinkmann, J., et al. 2016, MNRAS, 461, 3896 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, Y.-C., Ho, S., Mandelbaum, R., et al. 2017, MNRAS, 466, 1880 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, Y.-C., Ho, S., Blazek, J., et al. 2019, MNRAS, 485, 2492 [NASA ADS] [CrossRef] [Google Scholar]
- Colberg, J. M., Krughoff, K. S., & Connolly, A. J. 2005, MNRAS, 359, 272 [NASA ADS] [CrossRef] [Google Scholar]
- Cole, S., Percival, W. J., Peacock, J. A., et al. 2005, MNRAS, 362, 505 [Google Scholar]
- Comaniciu, D., & Meer, P. 2002, IEEE Trans. Pattern Anal. Mach. Intell., 24, 603 [CrossRef] [Google Scholar]
- Dawson, K. S., Schlegel, D. J., Ahn, C. P., et al. 2013, AJ, 145, 10 [Google Scholar]
- Dawson, K. S., Kneib, J.-P., Percival, W. J., et al. 2016, AJ, 151, 44 [Google Scholar]
- de Lapparent, V., Geller, M. J., & Huchra, J. P. 1986, ApJ, 302, L1 [Google Scholar]
- Driver, S. P., Hill, D. T., Kelvin, L. S., et al. 2011, MNRAS, 413, 971 [Google Scholar]
- Eberly, D. 1996, Ridges in Image and Data Analysis, Computational Imaging and Vision (The Netherlands: Springer) [Google Scholar]
- Fernandez, M., Bird, S., & Cui, Y. 2020, Phys. Rev. D, 102, 043509 [NASA ADS] [CrossRef] [Google Scholar]
- Friedman, J. H. 2001, Ann. Stat., 29, 1189 [Google Scholar]
- Galárraga-Espinosa, D., Aghanim, N., Langer, M., Gouin, C., & Malavasi, N. 2020, A&A, 641, A173 [EDP Sciences] [Google Scholar]
- Geller, D., & Mayeli, A. 2008, Math. Z., 262, 895 [Google Scholar]
- Genovese, C. R., Perone-Pacifico, M., Verdinelli, I., & Wasserman, L. 2014, Ann. Stat., 42, 1511 [CrossRef] [Google Scholar]
- Guzzo, L., Scodeggio, M., Garilli, B., et al. 2014, A&A, 566, A108 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Géron, A. 2019, Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd edn. (O’Reilly Media, Inc.) [Google Scholar]
- Górski, K. M., Hivon, E., Banday, A. J., et al. 2005, ApJ, 622, 759 [Google Scholar]
- Hahn, O., Porciani, C., Carollo, C. M., & Dekel, A. 2007, MNRAS, 375, 489 [NASA ADS] [CrossRef] [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- He, S., Alam, S., Ferraro, S., Chen, Y.-C., & Ho, S. 2018, Nat. Astron., 2, 401 [NASA ADS] [CrossRef] [Google Scholar]
- Hendel, D., Johnston, K. V., Patra, R. K., & Sen, B. 2019, MNRAS, 486, 3604 [NASA ADS] [CrossRef] [Google Scholar]
- Hilton, M., Sifón, C., Naess, S., et al. 2021, ApJS, 253, 3 [Google Scholar]
- Huchra, J. P., Macri, L. M., Masters, K. L., et al. 2012, ApJS, 199, 26 [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Joeveer, M., & Einasto, J. 1978, Symposium-International Astronomical Union (Cambridge University Press), 79, 241 [CrossRef] [Google Scholar]
- Jones, D. H., Saunders, W., Colless, M., et al. 2004, MNRAS, 355, 747 [NASA ADS] [CrossRef] [Google Scholar]
- Kluyver, T., Ragan-Kelley, B., Pérez, F., et al. 2016, in Positioning and Power in Academic Publishing: Players, Agents and Agendas, eds. F. Loizides, B. Scmidt, et al. (The Netherlands: IOS Press), 87 [Google Scholar]
- Krachmalnicoff, N., & Tomasi, M. 2019, A&A, 628, A129 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Krolewski, A., Ho, S., Chen, Y.-C., et al. 2019, ApJ, 876, 52 [NASA ADS] [CrossRef] [Google Scholar]
- Kuchner, U., Aragón-Salamanca, A., Rost, A., et al. 2021, MNRAS, 503, 2065 [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Laurent, P., Eftekharzadeh, S., Goff, J.-M. L., et al. 2017, JCAP, 2017, 017 [CrossRef] [Google Scholar]
- Libeskind, N. I., van de Weygaert, R., Cautun, M., et al. 2017, MNRAS, 473, 1195 [Google Scholar]
- Malavasi, N., Aghanim, N., Douspis, M., Tanimura, H., & Bonjean, V. 2020, A&A, 642, A19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Marinucci, D., Pietrobon, D., Balbi, A., et al. 2008, MNRAS, 383, 539 [NASA ADS] [CrossRef] [Google Scholar]
- Moews, B., Schmitz, M. A., Lawler, A. J., et al. 2020, MNRAS, 500, 859 [CrossRef] [Google Scholar]
- Moews, B., Argueta, J. R., & Gieschen, A. 2021, Decis. Support Syst., 144, 113518 [CrossRef] [Google Scholar]
- Moritz, P., Nishihara, R., Wang, S., et al. 2018, in 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18) (Carlsbad, CA: USENIX Association), 561 [Google Scholar]
- Narcowich, F. J., Petrushev, P., & Ward, J. D. 2006, SIAM J. Math. Anal., 38, 574 [CrossRef] [Google Scholar]
- Neyrinck, M. C., Hidding, J., Konstantatou, M., & van de Weygaert, R. 2018, R. Soc. Open Sc., 5, 171582 [NASA ADS] [CrossRef] [Google Scholar]
- Novikov, D., Colombi, S., & Doré, O. 2006, MNRAS, 366, 1201 [NASA ADS] [Google Scholar]
- Oppizzi, F., Renzi, A., Liguori, M., et al. 2020, JCAP, 2020, 054 [CrossRef] [Google Scholar]
- Ozertem, U., & Erdogmus, D. 2011, J. Mach. Learn. Res., 12, 1249 [Google Scholar]
- Pereyra, L. A., Sgró, M. A., Merchán, M. E., Stasyszyn, F. A., & Paz, D. J. 2020, MNRAS, 499, 4876 [Google Scholar]
- Planck Collaboration XXVII. 2016, A&A, 594, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XLVIII. 2016, A&A, 596, A109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ross, A. J., Bautista, J., Tojeiro, R., et al. 2020, MNRAS, 498, 2354 [NASA ADS] [CrossRef] [Google Scholar]
- Rost, A., Stasyszyn, F., Pereyra, L., & Martínez, H. J. 2020, MNRAS, 493, 1936 [Google Scholar]
- Scoville, N., Abraham, R. G., Aussel, H., et al. 2007, ApJS, 172, 38 [NASA ADS] [CrossRef] [Google Scholar]
- Silverman, B. W. 1998, Density Estimation for Statistics and Data Analysis (Routledge) [Google Scholar]
- Sousbie, T. 2011, MNRAS, 414, 350 [NASA ADS] [CrossRef] [Google Scholar]
- Sousbie, T., Pichon, C., Colombi, S., Novikov, D., & Pogosyan, D. 2008, MNRAS, 383, 1655 [Google Scholar]
- Springel, V. 2005, MNRAS, 364, 1105 [Google Scholar]
- Stoica, R. S., Martínez, V. J., Mateu, J., & Saar, E. 2005, A&A, 434, 423 [CrossRef] [EDP Sciences] [Google Scholar]
- Tanimura, H., Aghanim, N., Bonjean, V., Malavasi, N., & Douspis, M. 2020, A&A, 637, A41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tempel, E., Stoica, R. S., Kipper, R., & Saar, E. 2016, Astron. Comput., 16, 17 [NASA ADS] [CrossRef] [Google Scholar]
- Ho, T. K. 1995, in Proceedings of 3rd International Conference on Document Analysis and Recognition (IEEE), 1, 278 [Google Scholar]
- van der Walt, S., Schönberger, J. L., Nunez-Iglesias, J., et al. 2014, scikit-image: Image processing in Python (PeerJ Inc.) [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Vogelsberger, M., Genel, S., Springel, V., et al. 2014, MNRAS, 444, 1518 [Google Scholar]
- Waskom, M. L. 2021, J. Open Source Softw., 6, 3021 [CrossRef] [Google Scholar]
- Wes McKinney, 2010, in Proceedings of the 9th Python in Science Conference, eds. S. van der Walt, & J. Millman, 56 [CrossRef] [Google Scholar]
- Wilding, G., Nevenzeel, K., van de Weygaert, R., et al. 2021, MNRAS, 507, 2968 [NASA ADS] [CrossRef] [Google Scholar]
- York, D. G., Adelman, J., Anderson, J. E. Jr., et al. 2000, AJ, 120, 1579 [Google Scholar]
- Zeldovich, I. B., Einasto, J., & Shandarin, S. F. 1982, Nature, 300, 407 [Google Scholar]
- Zhang, T. Y., & Suen, C. Y. 1984, Commun. ACM, 27, 236 [CrossRef] [Google Scholar]
- Zonca, A., Singer, L., Lenz, D., et al. 2019, J. Open Source Softw., 4, 1298 [Google Scholar]
Appendix A: Training of the gradient boosting method
As explained in Section 2.5.2, we use a gradient boosting algorithm as a part of Method B. The input corresponds to five quantities computed at four scales each, for each pixel. This means that the input corresponds to 20 features and as many points as pixels in the observed region. The algorithm uses the value of the quantities at each pixel to predict the typical distance of a filament from a pixel with certain characteristics.
In order to create the training maps, we proceed as follows. We select an intermediate value of redshift and obtain the estimated uncertainty map for each of the four smoothing scales mentioned above. The uncertainty map is obtained by applying Algorithm 2 to all pixels in the observed sky. This map represents the typical distance from each pixel to filaments of the bootstrapping simulation, when using the algorithm at a certain smoothing scale. Let xn, s be the value of this typical distance at the pixel n = 1...N and smoothing scale labelled by s = 1...S, where S = 4 in our case. We combine all the maps into 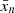 with the following expression:
with the following expression:
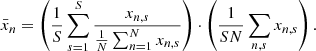 (A.1)
(A.1)
This expression can be understood as an arithmetic average of the four scales, where each size is normalised to unit mean in order to give the same importance to all scales. Then, the result of the average is denormalised to the original scale by multiplying it with the global average, so that the final result  is given in units of degrees, as in the original xn, s. More complex expressions are possible, such as giving different weights to different scales; however, in practice they do not significantly affect the filament reconstruction.
is given in units of degrees, as in the original xn, s. More complex expressions are possible, such as giving different weights to different scales; however, in practice they do not significantly affect the filament reconstruction.
In principle, this procedure could be done for all 284 redshift slices instead of using it to train a gradient boosting algorithm. However, this would be computationally unfeasible, because it requires the application of Algorithm 1 a total of 401 times per redshift slice (100 different bootstrap simulation times 4 scales, and 1 final computation in order to obtain the filaments), plus the computation of millions of pair-wise distances between points on the sphere. By training a machine learning algorithm, we reduce this computation to only 5 per slice (1 times 4 scales in order to compute the input values and 1 final computation in order to obtain the filaments). Training the algorithm has other advantages, such as a more robust detection at higher redshift, with less data.
In order to have training data representing all the redshift region, we repeat the previous computation for a redshift slice in each of the different sets of data. In practice, we select the slices starting at z = 0.239 for LOWZ, z = 0.570 for CMASS, 0.803 for LRG, and z = 1.394 for QSO. Then, we apply the trained gradient boosting to all slices. We note that the results for a single slice interpolate very well within the same survey and even to the different surveys at different redshift values. However, we use a slice from each survey as this approach is more general and could include particular effects from all surveys, making it more robust.
The mean squared error of the predictor is 0.047 deg on the test dataset. We note that the exact predicted values are not critical, as we are interested in the ridges of the map. The results concerning the filaments reconstructed with this method are reported in Section 4 under the label of Method B.
Appendix B: LRG and QSO in the training sample
We used a training sample representing all the different surveys we are using. However, we know that LRGs and QSOs are different tracers of the large-scale structure. In particular, QSOs are known to present a higher value of the bias (Laurent et al. 2017), meaning that they tend to be more clustered along dark matter overdensities than LRGs.
In principle, this means that the training sample could be inhomogeneous and the training could be affected, or even impossible. On the other hand, the fact that QSOs are better tracers of the cosmic web could be balanced by the lower number of them. Additionally, the underlying cosmic web traced by both populations is the same, so the algorithm may be flexible enough to learn some characteristics linked to the web itself rather than its tracers.
In order to test possible effects caused by the differences between LRGs and QSOs, we train the Gradient Boosting step (as explained in Section 2.5.2) on both populations independently. For LRGs, we restrict the training sample to the LOWZ and CMASS training slices (z = 0.239 and z = 0.570), while for QSOs, we only use the eBOSS QSO training sample (z = 1.394).
After training the algorithm on both populations independently, we apply it to a sample slice at z = 0.803. We can see the filaments obtained in both cases in Figure B.1: the filament network reconstruction is almost identical in both cases, and they are well inside the confidence region of each other. We checked that this result is consistent in the whole redshift range.
 |
Fig. B.1. Comparison of the reconstructions obtained by training the algorithm only with LRGs (red) and only with QSOs (orange). The coloured region is the confidence region of the LRG-reconstructed filaments. The figure is a gnomic projection centred at RA = 180°, dec = 40° with a side size of 45°. The data used in this example correspond to data at z = 0.803. |
We also analyse the similarity between the Gradient Boosting algorithm trained in these two sets. A way to do this is to give them the same input and analysing the similarity among the results. We feed them with the real inputs for several redshift slices and we see a very high correlation between both outputs (R = 0.97). It has to be noted that the training on QSOs yields slightly higher predictions than when training on LRGs, perhaps because of the larger uncertainties driven by the lower number of QSOs. This means that the uncertainty estimates of the detections are slightly larger if we only use QSOs in the training (∼10′ larger); however, the positions of the detected filaments, presents no difference.
Appendix C: Filament catalogue cleaning
Once the filaments have been obtained by either of the two methods explained in Section 3.3, we apply a series of filters to remove spurious or unclear detections. All the thresholds adopted in this work are very conservative in order to remove only the outliers and problematic regions, preserving a very large sample. However, we recommend imposing more aggressive thresholds depending on the specific application of the catalogue. An especially useful threshold may be in the estimated uncertainty of the detections. These filters can easily be performed with the code provided with the catalogue at javiercarron.com/catalogue.
-
Initial density estimate: step 6 of Algorithm 1 introduces an initial set of points yj that are used to start the iterative algorithm. In practise, we remove the points with a density estimate lower than a threshold K. This is a common criterion in filament-searching algorithms (Cautun et al. 2013; Chen et al. 2015a) as it helps with the stability of the results and minimises spurious detections. In our case, we define K to be the 10% percentile of the value of the density estimate in the region of interest.
-
Border effects: some artefacts may arise in the areas of the sky near the border of the surveyed regions. In order to remove these areas, we establish a buffer of 2deg: the reported filaments are the detections that are further than this distance from a border.
-
Threshold in estimated uncertainty: the location of spurious filaments may vary significantly if the initial set of points vary slightly. This is estimated through Algorithm 2. We remove detections whose estimated uncertainty is in the top 2% of the slice (corresponding to an estimated uncertainty of 1.0 deg to 1.5 deg). We note that most applications of the catalogue will require a more strict threshold or a threshold in units of proper distance.
-
Isolated points: the algorithms sometimes detect spurious ridges that consist in a few points, not connected to any other structure. By contrast, typical filaments are detected by hundreds or thousands of points. This effect is rare but can be easily removed: detections are only reported if they have other detections nearby. In practice, we consider a coarser pixelisation (with Nside = 128) and count the detections in each pixel; in order to be reported, a point must be in a pixel with at least 15 detections or adjacent to one of such pixels.
These filters are applied consecutively in the listed order.
The average number of points excluded by each filter in each block can be seen in Table C.1. Within Blocks, there are only weak trends with redshift, as every filter has a similar effect regardless of redshift.
Average number of points excluded due to each of the preprocessing filters applied in order, see text.
Additionally, we reduce the size of the catalogue by removing most points. The original search of filaments is done with a uniform grid in the sky (the grid {yj} in Algorithm 1); in particular, we use the centres of the pixels in the HEALPix scheme with nside = 256. For example, this translates into more than 210000 points per redshift slice for Block 2. Considering all the 284 redshift slices, we have more 34.9 million points (more than 24.2 after the filters above). However, this set of points is highly redundant, because each filament is detected by hundreds or thousands of points. It is possible to reduce the size of the catalogue without losing any information. We sample 20% of this initial set of points to obtain 4862353 points for Catalogue A and 4460054 points for Catalogue B. This is performed as a final step after all other filters have been applied.
All Tables
Average number of points excluded due to each of the preprocessing filters applied in order, see text.
All Figures
|
Fig. 1. Different steps of the algorithms. Top left: initial distribution of galaxies in a redshift slice. Top centre: a density distribution is estimated from the galaxies. Top right: a grid of points {yj} is selected as the initial positions of the iterative steps; they correspond to the centres of HEALPix pixels. Bottom left: the positions of the points after one step of the iteration. Bottom centre: the positions of the points after they converge, with the initial galaxy distribution overlapped. Bottom right: same as bottom centre, but the uncertainty of each point in the filaments is calculated with Algorithm 2; a redder colour represents a lower certainty. All images are gnomic projections centred at RA = 180°, Dec = 40° with a side size of 60°. The data used in this example corresponds to BOSS data at z = 0.570 (see Sect. 3). |
| In the text | |
|
Fig. 2. Representations of the uncertainty of the detection. On the left, we plot a circle around each point of the filament with a radius equal to the uncertainty; this is a way of visualising the regions of the sky where a certain filament is expected to be. On the right, we apply the uncertainty estimate to each pixel of the map, and obtain an average distance to bootstrapped filaments for every pixel; actual filaments are found mostly where the mean distances are low. In both cases, colour represents uncertainty in degrees, and filaments found with real data are represented in white. Both figures are gnomic projections centred at RA = 180°, Dec = 40° with a side size of 60°. The data used in this example correspond to BOSS data z = 0.570 (see Sect. 3). |
| In the text | |
|
Fig. 3. Sky footprint of the data reported by BOSS LOWZ (top), BOSS CMASS (second), and the three eBOSS samples: LRG and QSO (third), and ELG (bottom). The representation uses a mollweide projection in equatorial coordinates (J2000), with a rotation of 90° along the z axis. The footprints on the left and right sides correspond to the north and south Galactic caps, respectively. |
| In the text | |
|
Fig. 4. Galaxy distribution in Block 1. Top: stacked number of galaxies per redshift bin from both the used surveys. Bottom: fraction of galaxies corresponding to each survey as a function of redshift. |
| In the text | |
|
Fig. 5. Galaxy distribution in Block 2. Number of galaxies per redshift bin. All galaxies correspond to the CMASS sample. |
| In the text | |
|
Fig. 6. Galaxy distribution in Block 3. Top: stacked number of galaxies per redshift bin from all of the used surveys. Bottom: fraction of galaxies corresponding to each sample as a function of redshift. |
| In the text | |
|
Fig. 7. Value of the FWHM of the Gaussian kernel chosen for Method A as a function of redshift for each block. The scales that are combined in Method B are fixed and can be seen with markers on both redshift ends. |
| In the text | |
|
Fig. 8. Example of reconstructed filaments at z = 0.20 (top) and z = 1.00 (bottom); with Method A (left) and Method B (right). The colour of the points represents the error estimate in degrees. Grey points correspond to galaxies, while the background map represents the galaxy density, smoothed at 3°, for visualisation purposes. The visualisation is a gnomonic projection around the point (RA = 140°, δ = 40°) with a side size of 60°. Meridians and parallels are both represented at a step of 20 deg. |
| In the text | |
|
Fig. 9. Mean distance between galaxies and their closest filament as a function of redshift. Blue corresponds to Method A, and orange corresponds to Method B. Different shades of colour correspond to the three different Blocks with different masks. Top: angular distance in degrees; bottom: proper distance in megaparsecs. |
| In the text | |
|
Fig. 10. Average distribution of distances between galaxies and their closest filament divided by the same distribution for random points, as described in the text. Left: Method A. Right: Method B. Different colours correspond to the three different Blocks. |
| In the text | |
|
Fig. 11. Mean uncertainty estimate for the detected filaments as a function of redshift. Blue corresponds to Method A, orange corresponds to Method B. Different shades of colour correspond to the three different Blocks with different masks. Top: angular distance in degrees; bottom: proper distance in megaparsecs. |
| In the text | |
|
Fig. 12. Average estimated uncertainty of the detected filaments as a function of redshift. Orange corresponds to our Method A, blue corresponds to C15. For z < 0.2 (grey band), filaments are reconstructed from different data in the two catalogues. Lines are non-linear fits shown for visualisation only. |
| In the text | |
|
Fig. 13. Average distance between galaxies and their closest filament as a function of redshift. Orange corresponds to our Method A, blue corresponds to C15. For z < 0.2 (grey band) filaments are reconstructed from different data in the two catalogues. Lines are non-linear fits shown for visualisation only. |
| In the text | |
|
Fig. 14. Top: average distance from galaxies to their closest filaments, in degrees. Bottom: average estimated uncertainty on the location of the centre of the filaments, in degrees. Both metrics are calculated separately for high- and low-latitude filaments. For z < 0.2 (grey band), filaments are reconstructed from different data in the two catalogues. Lines are non-linear fits shown for visualisation only. |
| In the text | |
|
Fig. 15. Example of obtained filaments at z = 0.510 for C15 (left) and our result (right). The colour of the points represents the uncertainty estimate, in degrees. Grey points correspond to galaxies, while the background map represents the galaxy density smoothed at 3° for visualisation purposes. The visualisation is a gnomonic projection around the point (RA = 140, δ = 40) with a side size of 60°. Meridians and parallels are both represented in steps of 20 deg. |
| In the text | |
|
Fig. 16. Example of filament maps at different redshift slices with the two methods. The colours of the filaments represent the estimated uncertainty of the detection, in degrees. Independently-measured galaxy clusters from Planck and ACT are also represented. The grey area is excluded from the catalogue due to lack of data and border effects. |
| In the text | |
|
Fig. 17. Distribution of the average distance between clusters and filaments for random realisations and real data. In the y-axis, the average distance, in degrees; different histograms for the two cluster catalogues and methods are represented. The average distance for real data is represented with squares. |
| In the text | |
|
Fig. 18. Stability of the results to new data. On the y-axis, the fraction of filaments found using all data (older and newer) which were also found using only older data. On the x-axis, the fraction of galaxies corresponding to older data. Each point corresponds to the result for a single redshift slice. See text. |
| In the text | |
|
Fig. 19. Distribution of the lengths of the filaments in the catalogues, for the three different Blocks (Block 1: 0.05 < z < 0.45, Block 2: 0.45 < z < 0.7, Block 3: 0.6 < z < 2.2). The dotted line represents the results when we impose an additional threshold on the catalogue, considering only points with uncertainty of the detection under 0.8°. |
| In the text | |
|
Fig. B.1. Comparison of the reconstructions obtained by training the algorithm only with LRGs (red) and only with QSOs (orange). The coloured region is the confidence region of the LRG-reconstructed filaments. The figure is a gnomic projection centred at RA = 180°, dec = 40° with a side size of 45°. The data used in this example correspond to data at z = 0.803. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.