| Issue |
A&A
Volume 646, February 2021
|
|
|---|---|---|
| Article Number | A67 | |
| Number of page(s) | 19 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/202039852 | |
| Published online | 09 February 2021 | |
Weighing the Galactic disk in sub-regions of the solar neighbourhood using Gaia DR2
1
Dark Cosmology Centre, Niels Bohr Institute, University of Copenhagen, Jagtvej 128, 2200 Copenhagen N, Denmark
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
The Oskar Klein Centre for Cosmoparticle Physics, Department of Physics, Stockholm University, AlbaNova, 10691 Stockholm, Sweden
3
Université de Strasbourg, CNRS UMR 7550, Observatoire astronomique de Strasbourg, 11 rue de l’Université, 67000 Strasbourg, France
Received:
5
November
2020
Accepted:
26
November
2020
Abstract
Aims. We infer the gravitational potential of the Galactic disk by analysing the phase-space densities of 120 stellar samples in 40 spatially separate sub-regions of the solar neighbourhood, using Gaia’s second data release (DR2), in order to quantify spatially dependent systematic effects that bias this type of measurement.
Methods. The gravitational potential was inferred under the assumption of a steady state in the framework of a Bayesian hierarchical model. We performed a joint fit of our stellar tracers’ three-dimensional velocity distribution, while fully accounting for the astrometric uncertainties of all stars as well as dust extinction, and we also masked angular areas of known open clusters. The inferred gravitational potential is compared, post-inference, to a model for the baryonic matter and halo dark matter components.
Results. We see an unexpected but clear trend for all 40 spatially separate sub-regions: Compared to the potential derived from the baryonic model, the inferred gravitational potential is significantly steeper close to the Galactic mid-plane (≲60 pc), but flattens such that the two agree well at greater distances (∼400 pc). The inferred potential implies a total matter density distribution that is highly concentrated to the Galactic mid-plane and decays quickly with height. We see a dependence on the Galactic radius that is consistent with a disk scale length of a few kiloparsecs. Apart from this, there are discrepancies between stellar samples, implying spatially dependent systematic effects which are, at least in part, explained by substructures in the phase-space distributions.
Conclusions. In terms of the inferred matter density distribution, the very low matter density that is inferred at greater heights (≳300 pc) is inconsistent with the observed scale height and matter distribution of the stellar disk, which cannot be explained by a misunderstood density of cold gas or other hidden mass. Our interpretation is that these results must be biased by a time-varying phase-space structure, possibly a breathing mode, that is large enough to affect all stellar samples in the same manner.
Key words: Galaxy: kinematics and dynamics / Galaxy: disk / solar neighborhood / astrometry
© ESO 2021
1. Introduction
Dynamical mass measurements of the solar neighbourhood and Galactic disk are of great importance for constraining properties of the Milky Way (Dehnen & Binney 1998; Klypin et al. 2002; Widrow et al. 2008; Weber & de Boer 2010; McMillan 2011, 2017; Kafle et al. 2014; Cole & Binney 2017; Nitschai et al. 2020; Cautun et al. 2020; Li et al. 2020), and this has implications for the dark sector, for direct and indirect dark matter detection experiments (Jungman et al. 1996; Klasen et al. 2015), as well as for dark substructures (Read et al. 2008; Purcell et al. 2009; Fan et al. 2013a; Ruchti et al. 2014). Dynamical mass measurements are often performed under the assumption of a steady state by isolating a stellar tracer population and fitting its phase-space distribution or through Jeans analysis (Kapteyn 1922; Oort 1932; Bahcall 1984a,b; Kuijken & Gilmore 1989a,b,c, 1991; Crézé et al. 1998; Holmberg & Flynn 2000; Bienayme et al. 2006; Garbari et al. 2012; Bovy & Tremaine 2012; Zhang et al. 2013; Bienaymé et al. 2014; Widmark & Monari 2018; Schutz et al. 2018; Buch et al. 2019; Widmark 2019; Salomon et al. 2020; Guo et al. 2020). With the depth and precision of the astrometric Gaia mission (Gaia Collaboration 2016), which had its second data release (DR2) in April 2018 (Gaia Collaboration 2018b), it is possible to fit more complicated dynamical models than ever before, calling for more sophisticated statistical methods and modelling techniques.
The solar neighbourhood and the Galactic mid-plane is believed to be dominated by baryons with roughly equal matter densities of stars and gas (Flynn et al. 2006; McKee et al. 2015; Kramer & Randall 2016a). Precise dynamical mass measurements of the Galactic disk can constrain the distribution of baryons, supplementing other observations, as well as the local density of dark matter. In the standard scenario, the cold dark matter halo would constitute about 10% of the mid-plane matter density (Salomon et al. 2020; Guo et al. 2020). A more exotic possibility has been proposed by Fan et al. (2013a,b), whereby a thin dark disk, co-planar with and embedded in the stellar disk of the Milky Way, would form from a dark matter sub-component with strong dissipative self-interactions. The possibility of a thin dark disk was constrained by Kramer & Randall (2016b) using interstellar gas, by Caputo et al. (2018) using binary pulsars, and by Schutz et al. (2018) and Buch et al. (2019) using Gaia observations. The studies based on Gaia set the most stringent upper bounds to such a surface density surplus, of approximately 7 M⊙ pc−2. However, a third Gaia based study by Widmark (2019) infers an over-density in the Galactic plane that is on par with these upper bounds.
This paper is largely a follow-up on the analysis made in Widmark (2019). Following the approach of that work, we formulated our statistical model in the framework of a Bayesian hierarchical model and utilised the six-dimensional phase-space information of all stars in our stellar samples, while fully accounting for the astrometric uncertainties of all stars. We performed a joint fit of the gravitational potential and the full three-dimensional velocity distribution (rather than just the vertical velocities, as in previous work). We also accounted for dust extinction and masked the angular areas where open clusters are known to be present. We divided the solar neighbourhood into 120 stellar samples, using 40 spatially separate area cells in the directions parallel to the Galactic plane, and three different cuts in the vertical direction (200, 300, and 400 pc above and below the Sun). The main reason for this division was to quantify possible systematic effects, which would reveal themselves if they affect the stellar samples differently, depending on their spatial position. Such effects could be associated with substructures and time-variations of the phase-space distribution, breaking the steady state assumption. Many such features have already been revealed by Gaia, such as moving groups in the solar neighbourhood and phase-space spirals and ridges (Gaia Collaboration 2018c; Antoja et al. 2018). It is an open question to what extent such time-varying features can affect this type of local dynamical mass measurement. The main focus of this work is to quantify such biases and determine whether they have a spatial dependence.
This article is structured in the following way. In Sect. 2, we present our model for the dynamics of the solar neighbourhood as well as the expected gravitational potential coming from baryonic observations. In Sect. 3, we discuss the data of Gaia DR2 and explain how the stellar samples are constructed. The statistical model is present in Sect. 4, and the inferred results are found in in Sect. 5. In Sects. 6 and 7, we discuss and conclude.
2. Galactic model
2.1. Coordinate system
In order to describe the phase-space density of stars in the local neighbourhood, we use the following system of coordinates. The spatial coordinates X ≡ {X, Y, Z} denote the position of a star as seen from the Sun, where positive X corresponds to the direction of the Galactic centre, positive Y corresponds to the direction of Galactic rotation, and positive Z corresponds to the direction of Galactic north. Their respective time derivatives correspond to velocities V ≡ {U, V, W}, whose origin is that of the solar rest frame.
Furthermore, the quantities z and w correspond to position and velocity as seen from the rest-frame of the Galactic mid-plane. They are equal to
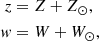 (1)
(1)
where Z⊙ is the vertical position of the Sun with respect to the Galactic mid-plane and W⊙ is the vertical velocity of the Sun in the rest-frame of the Galactic disk.
2.2. Gravitational potential
In this work we considered stellar tracer populations in the solar neighbourhood, out to a distance of a few hundred parsecs from the Sun. We constructed a total of 120 stellar samples (see Sect. 3 for a detailed description) whose spatial volumes are elongated in the direction of Z (extending 400–800 pc), and comparatively narrow in X and Y (50–100 pc). In these column-like volumes, we made the assumption that the gravitational potential only depends on Z and is invariant with respect to X and Y.
The gravitational potential was modeled as
![Mathematical equation: $$ \begin{aligned} \Phi (z) = 4 \pi G \sum _{h} \; \rho _h\, \mathrm{log} \Bigg [ \mathrm{cosh} \Bigg ( \frac{z}{h~\mathrm{pc} } \Bigg ) \Bigg ] \, (h~\mathrm{pc} )^2, \end{aligned} $$](/articles/aa/full_html/2021/02/aa39852-20/aa39852-20-eq2.gif) (2)
(2)
where h iterates over the numbers {40, 80, 160, 320}.
Given the one-dimensional Poisson equation,
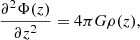 (3)
(3)
the four parameters ρ{40, 80, 160, 320} correspond to a sum of matter density components with scale heights of 40, 80, 160, and 320 pc respectively, according to
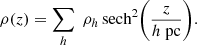 (4)
(4)
This model form assumes mirror symmetry of the Galactic plane and that the matter density decreases monotonically with distance from the Galactic mid-plane, but is otherwise quite free to vary in shape.
The one-dimensional Poisson equation neglects contributions from the other two spatial dimensions. Likely, the most important contribution is in the direction of Galactocentric radius R, which gives a matter density correction equal to
![Mathematical equation: $$ \begin{aligned} \Delta \rho = \frac{1}{4\pi G R}\frac{\partial }{\partial R} \left[ R \frac{\partial \Phi (R,z)}{\partial R} \right], \end{aligned} $$](/articles/aa/full_html/2021/02/aa39852-20/aa39852-20-eq5.gif) (5)
(5)
where the quantity in the large square brackets is equal to the square of the Galactic circular velocity (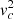 ). Because the circular velocity curve is close to flat in the solar neighbourhood, this correction is likely small. According to recent studies, the local slope of the circular velocity is roughly ∂vc/∂R = −1.5 km s−1 kpc−1 (−1.7 ± 0.1 km s−1 kpc−1 in Eilers et al. 2019; −1.33 ± 0.1 km s−1 kpc−1 in Ablimit et al. 2020), giving a negligible correction of Δρ ≃ −0.0016 M⊙ pc−3.
). Because the circular velocity curve is close to flat in the solar neighbourhood, this correction is likely small. According to recent studies, the local slope of the circular velocity is roughly ∂vc/∂R = −1.5 km s−1 kpc−1 (−1.7 ± 0.1 km s−1 kpc−1 in Eilers et al. 2019; −1.33 ± 0.1 km s−1 kpc−1 in Ablimit et al. 2020), giving a negligible correction of Δρ ≃ −0.0016 M⊙ pc−3.
The approximation of separability also neglects some corrections, which in Jeans theory are known as the “axial” and “tilt” terms, which have been measured to be small this close to the Galactic plane (Büdenbender et al. 2015; Sivertsson et al. 2018). As discussed by Binney & Tremaine (2008) and Zhang et al. (2013), and also tested on simulations by Garbari et al. (2011), the assumption of separability for the gravitational potential should be valid at least to heights comparable to the disk’s scale height (|z| ≲ 300 pc).
There can potentially be smaller scale fluctuations in the potential due to substructures in the Galactic disk. If such fluctuations do exist and are large enough to produce a significant bias, this could cause a discrepancy in the results of the stellar samples. Identifying and quantifying such spatially dependent systematic effects was the main reason for dividing the local neighbourhood into sub-regions.
2.3. Phase-space density
In our model of inference we performed a joint fit of the gravitational potential and the full three-dimensional velocity distribution. Although our stellar tracer phase-space distribution was modeled to vary only as a function of distance from the Galactic mid-plane, the full three-dimensional velocity distribution was fitted for the following reason. While the majority of stars included in our stellar samples have high quality data which constrains their three-dimensional velocity very well, a significant subset of stars have missing radial velocity information and/or high astrometric uncertainties. The available information of such stars is still informative and helps constrain the population model, but their missing components need to be marginalised over. For example, for a star with missing radial velocity information, this velocity component is constrained by the overall population of stars; at the same time, the star’s more precise data components are used to constrain the other two directions of the velocity distribution.
For the velocity distribution we assumed mirror symmetry across the Galactic plane (i.e. invariance with respect to w → −w). For the directions parallel to the plane (U and V), no such symmetry was imposed. In this sense, our model assumed that the phase-space distribution is well phase-mixed in the vertical direction, but not in the directions parallel to the Galactic plane. This is to be expected because the vertical oscillation frequency is comparatively high, especially for stars with low vertical energies, and therefore associated with a short relaxation time. Observations also indicate better phase-mixing in the vertical direction, whereas the U–V plane is more structured (see for example Fig. 22 in Gaia Collaboration 2018c). The U–V distribution is largely distorted by the presence of several moving groups, many of which could have origin in resonances between the stars and the non-axisymmetric components of the Galaxy, like the bar and the spiral arms (see for example Monari et al. 2019).
We modeled the three-dimensional velocity distribution as a Gaussian mixture model, parametrised by Gaussian weights ak, mean values 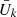 and
and 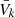 (due to mirror symmetry across the plane,
(due to mirror symmetry across the plane, 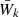 is fixed), and dispersions σU, k, σV, k, and σW, k. The index k is only ever used to label the respective Gaussians of this mixture model. The velocity distribution in the Galactic mid-plane is proportional to
is fixed), and dispersions σU, k, σV, k, and σW, k. The index k is only ever used to label the respective Gaussians of this mixture model. The velocity distribution in the Galactic mid-plane is proportional to
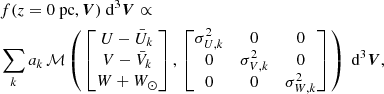 (6)
(6)
where ℳ represents the multivariate Gaussian distribution, defined
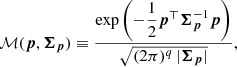 (7)
(7)
where q is the number of dimensions of the column vector p, and Σp is a covariance matrix.
Because the phase-space distribution was assumed to be separable in the vertical direction and in a steady state configuration, the phase-space density at any height z has the same distribution of vertical energy:
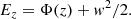 (8)
(8)
Thus the phase-space density at any height z is related to that of the mid-plane according to
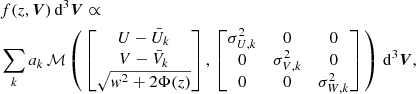 (9)
(9)
where it is implicit that w = W + W⊙ and z = Z + Z⊙. The peculiar velocities of the Sun in the directions parallel to the Galactic plane (U⊙ and V⊙) can be ignored, as the phase-space density is assumed to be invariant in these directions.
If we integrate the phase-space density over the velocities, we get the stellar number density in units of inverse volume, which is proportional to
![Mathematical equation: $$ \begin{aligned} n(z) \propto \sum _k a_k \exp \left[-\frac{\Phi (z)}{\sigma _{W,k}^2}\right]. \end{aligned} $$](/articles/aa/full_html/2021/02/aa39852-20/aa39852-20-eq14.gif) (10)
(10)
2.4. Expected density and gravitational potential
In this work, our approach was to produce results that are data-driven and as model independent as possible. For this reason, the gravitational potential in our model of inference did not rely on any a priori expectations for the baryonic and halo dark matter density profiles. However, we do compare our end result with the expected gravitational potential, which is presented here.
The baryonic matter density profile comes from Schutz et al. (2018), who compiled a table of baryonic components using results from Flynn et al. (2006), McKee et al. (2015), and Kramer & Randall (2016a). This density profile has also been used in for example Sivertsson et al. (2018), Buch et al. (2019), and Widmark (2019).
The baryonic components are listed in Table 1. They are presented in terms of their mid-plane densities (a total of 0.0889 ± 0.0071 M⊙ pc−3) and their respective velocity dispersions. Their respective vertical velocity distributions were assumed to be Gaussian and in equilibrium (i.e. iso-thermal), such that their matter densities (labelled by index t) varies with z according to
![Mathematical equation: $$ \begin{aligned} \rho _b = \sum _{t} \rho _{t}\exp \left[ -\frac{\Phi (z)}{\sigma _{t}^2} \right]. \end{aligned} $$](/articles/aa/full_html/2021/02/aa39852-20/aa39852-20-eq15.gif) (11)
(11)
Mid-plane densities ρt and vertical velocity dispersions σt of the baryonic matter components.
In addition to the baryonic components, we also added a homogeneous dark matter halo density of 0.011 ± 0.003 M⊙ pc−3, with a conservatively large uncertainty (Read 2014).1 The density components and how they vary with z are summarised in Fig. 1.
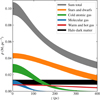 |
Fig. 1. Expected total matter density shown as a 1σ band, also broken down into components of stars, cold atomic gas, molecular gas, hot gas, and halo dark matter. |
An important property of the expected matter density is that the shape of the baryonic density profiles are extrapolated using the components’ observed vertical velocity dispersions. The vertical velocity distribution is also assumed to be Gaussian, which is a dubious assumption and somewhat discrepant with respect to this work’s observed population of stars. In Appendix A we compare the expected stellar density profile for stars with those of the stellar samples used in this work. Even larger systematic issues are associated with the baryonic gas components of the Galactic disk. Cold gas is difficult to observe and depends on some quite uncertain quantities: measurements of molecular hydrogen depend on the CO-to-H2 conversion factor and 21 cm based measurements of atomic hydrogen depend on corrections for optical depth (see for example Hessman 2015 for an instructive discussion). The contribution of the gaseous components to the gravitational potential is further complicated by the gas’ non-uniform spatial structure in density and ionisation fraction; for example, the very local volume within roughly 100 pc has a very low density of gas and dust (Lallement et al. 2003). In summary, the baryonic model presented here suffers from some potentially quite severe shortcomings and the systematic error could well be significantly larger than the statistical uncertainty. In Sects. 6 and 7 we discuss the need to update the baryonic model using more recent survey data.
3. Data and sample construction
In this work we used data from Gaia DR2. The data of a single star is written 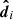 , labelled by the index i, and is listed in Table 2. It consists of the following information: apparent magnitude,
, labelled by the index i, and is listed in Table 2. It consists of the following information: apparent magnitude, 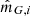 ; Galactic longitude and latitude,
; Galactic longitude and latitude, 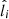 and
and 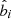 ; parallax,
; parallax, 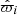 ; proper motions in the latitudinal and longitudinal directions,
; proper motions in the latitudinal and longitudinal directions, 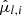 and
and 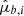 ; error covariance matrix for parallax and proper motions,
; error covariance matrix for parallax and proper motions, 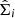 ; radial velocity,
; radial velocity, 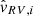 ; and radial velocity uncertainty,
; and radial velocity uncertainty, 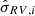 . The radial velocity is available only for a subset of stars in Gaia DR2. For
. The radial velocity is available only for a subset of stars in Gaia DR2. For 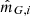 ,
, 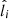 , and
, and 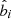 , the observational uncertainties are small and can safely be neglected.
, the observational uncertainties are small and can safely be neglected.
Population parameters, stellar parameters, and data of our Bayesian hierarchical model.
We made no cuts on the quality of the data (such as removing stars with poor astrometric precision, for example). Rather, our model fully accounted for all significant observational uncertainties. For the parallax measurements, the zero-point offset of −0.03 mas was subtracted from the catalogue values (Lindegren et al. 2018).
In this paper, the data is always written with hats (for example 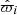 ). A quantity written without a hat (for example ϖi) always refers to the true property of the star.
). A quantity written without a hat (for example ϖi) always refers to the true property of the star.
The stellar samples were constructed using cuts in spatial position and absolute magnitude. We made cuts in the spatial coordinates X and Y according to Fig. 2. This gave a total of 40 area cells, constructed to have roughly the same area in the X–Y plane. They are labelled by a letter and a number, where the letter corresponds to the range in heliocentric cylindrical radius. The spatial volume of our stellar samples were limited in the vertical direction by a maximum height of Zlim. above and below the Sun, which took values of 200, 300, and 400 pc. This gave a total of 120 stellar samples (although samples that share area cell, and differ only in Zlim., are not statistically independent because they have a stellar membership overlap).
 |
Fig. 2. Area cells in the X-Y plane by which we constructed our data samples. The point in the centre of the plot corresponds to the position of the Sun. For each area cell, we constructed three stellar samples reaching Zlim. = {200, 300, 400} pc above and below the Sun. |
Each stellar sample has a shorthand name consisting of it’s area cell followed by it’s value of Zlim. in units of parsecs, for example A1-200. We also use the term region to refer to the area covered by all area cells beginning with the same letter, for example region A.
Because the true properties of the stars in the Gaia DR2 catalogue are not perfectly known, the stellar sample had to be constructed using cuts on the data. Therefore, our volume cuts corresponded to the following criteria:
![Mathematical equation: $$ \begin{aligned} \begin{aligned}&\hat{l} \in \Big [ (q-1) \frac{360^{\circ }}{4P},\, q \frac{360^{\circ }}{4P} \Big ], \\&\cos {\hat{b}}\,\frac{\mathrm{mas} }{\hat{\varpi }} \in \Big [ P \times 0.05,\, (P+1) \times 0.05 \Big ], \\&\sin {\hat{b}}\,\frac{\mathrm{mas} }{\hat{\varpi }} \in \Big [ -\frac{Z_{\mathrm{lim.} }}{\mathrm{kpc} },\, \frac{Z_{\mathrm{lim.} }}{\mathrm{kpc} } \Big ], \\ \end{aligned} \end{aligned} $$](/articles/aa/full_html/2021/02/aa39852-20/aa39852-20-eq41.gif) (12)
(12)
where P = {1, 2, 3, 4} for stellar sample names beginning with the letter {A,B,C,D}, and q is the number in the sample name.
In order to obtain a homogeneous population of tracer stars, we also made cuts in absolute magnitude. The stellar sample should be homogeneous in the sense that the same cuts are applied to the stars’ intrinsic properties, regardless of their phase-space coordinates. When constructing the stellar sample, we accounted for dust extinction using the three-dimensional maps of Capitanio et al. (2017), and a conversion factor of 3.1 for going from E(B − V) reddening to Gaia G-band extinction (Fitzpatrick 1999; Danielski et al. 2018). The Gaia G-band dust extinction as a function of spatial position is written 𝒟(l, b, ϖ). In terms of the data, the cut in absolute magnitude corresponded to the criteria
 (13)
(13)
where IMG is the interval of allowed absolute magnitudes. Because the data quality of Gaia DR2 is optimal in the range of apparent magnitudes of roughly 8–13 (mainly due to the availability of radial velocity information), the different area cells have slightly different absolute magnitude intervals, according to
-
region A: IMG = [4.6, 5.5],
-
region B: IMG = [3.7, 5.0],
-
region C: IMG = [3.0, 4.7],
-
region D: IMG = [3.0, 4.5].
For each stellar sample, we also masked regions in l and b where there is an open cluster inside or in the vicinity of the sample volume, in order to avoid contamination from their peculiar spatial and kinematic properties. We used the catalogue of open clusters by Cantat-Gaudin et al. (2018). A mask was applied if the centre of the cluster was within the stellar sample volume or less than 50 pc from its spatial boundaries. Each masked region corresponded to a circular area on the sky, centred on the open cluster and with a radius of 5 × r50, where r50 is the angular radius that contains 50 % of the open cluster’s members. In terms of the data, the mask criteria can be stated like
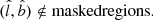 (14)
(14)
The percentage of the angular area that was masked by open clusters is listed in Table 3. A star in the Gaia DR2 catalogue was included in the stellar sample if and only if all of the criteria in Eqs. (12)–(14) were fulfilled.
Percentage of angular area that was masked due to open clusters.
The spatial volume closest to the Sun (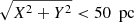 ) was ignored altogether in order to avoid systematic errors. A crucial requirement when constructing a sample of tracers is to select a population of stars that is uniform over the sample’s spatial volume. Firstly, the completeness of Gaia is poorly modeled for bright objects due to a lower number count, and bright objects are included by necessity in a volume that has no lower distance boundary. Secondly, multiple stellar systems, which are ubiquitous in the Milky Way (Moe & Di Stefano 2017), can bias the observed number density of the tracer stars. A binary stellar system with a fixed orbital separation can be unresolved in outskirts of the sample volume, but resolved and seen as two stars in the Sun’s immediate vicinity, breaking the requirement of homogeneity. For these reasons, it was safer to construct stellar samples with a small ratio between their most distant and nearest spatial points (a ratio which is infinite in the absence of a lower distance boundary).
) was ignored altogether in order to avoid systematic errors. A crucial requirement when constructing a sample of tracers is to select a population of stars that is uniform over the sample’s spatial volume. Firstly, the completeness of Gaia is poorly modeled for bright objects due to a lower number count, and bright objects are included by necessity in a volume that has no lower distance boundary. Secondly, multiple stellar systems, which are ubiquitous in the Milky Way (Moe & Di Stefano 2017), can bias the observed number density of the tracer stars. A binary stellar system with a fixed orbital separation can be unresolved in outskirts of the sample volume, but resolved and seen as two stars in the Sun’s immediate vicinity, breaking the requirement of homogeneity. For these reasons, it was safer to construct stellar samples with a small ratio between their most distant and nearest spatial points (a ratio which is infinite in the absence of a lower distance boundary).
The total number of stars in our stellar samples, for the different regions and values of Zlim., are presented in Table 4. The stellar samples belonging to region D has a slightly lower number count, partly due to a lower stellar density for stars with brighter magnitudes. The outer regions also have a higher variance in the number counts, which is due to a higher rate of open cluster masks.
Number of stars in the stellar samples used in this work.
4. Statistical model
In this section we present our statistical model of inference. It is a Bayesian hierarchical model, which in this case has a hierarchy of two levels: the top level of population parameters Ψ, which describe the population of tracer stars as a whole; and the bottom level of stellar parameters ψi, which describe the properties of individual stars.
The population parameters Ψ are listed in Table 2, and include: four parameters ρh = {40, 80, 160, 320}, which determine the gravitational potential according to Eq. (2); 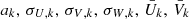 are the weights, dispersions, and mean values of the three-dimensional velocity distribution, described in Eq. (9); Z⊙ is the height of the Sun with respect to the Galactic plane; and W⊙ is the vertical velocity of the Sun in the Galactic rest frame. The weights ak are constrained to sum to unity. The population parameters have 5 + 6K degrees of freedom, where K is the number of Gaussians in the velocity distribution Gaussian mixture model.
are the weights, dispersions, and mean values of the three-dimensional velocity distribution, described in Eq. (9); Z⊙ is the height of the Sun with respect to the Galactic plane; and W⊙ is the vertical velocity of the Sun in the Galactic rest frame. The weights ak are constrained to sum to unity. The population parameters have 5 + 6K degrees of freedom, where K is the number of Gaussians in the velocity distribution Gaussian mixture model.
The stellar parameters ψi, also listed in Table 2, are unique for each star and consist of: three-dimensional position, Xi; three-dimensional velocity, Vi; and absolute magnitude in the Gaia G-band, MG, i. The stellar parameters have a total of 7N degrees of freedom, where N is the number of stars in the stellar sample.
The posterior density is the probability of Ψ and ψi given 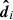 , and is proportional to
, and is proportional to
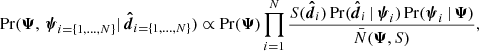 (15)
(15)
where Pr(Ψ) is the prior probability of the population parameters, 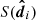 is the selection function,
is the selection function, 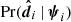 is the data likelihood, Pr(ψi | Ψ) is the stellar parameter probability density, and
is the data likelihood, Pr(ψi | Ψ) is the stellar parameter probability density, and 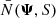 is a normalisation factor to the density distribution of stellar parameters. These five factors are described in detail in Sects. 4.1–4.5 below. When sampling the posterior using Markov chain Monte Carlo (MCMC), only the relative fraction between different posterior values are relevant, such that any constant factors can be ignored. For this reason, many factors in the posterior density are written with a proportionality sign.
is a normalisation factor to the density distribution of stellar parameters. These five factors are described in detail in Sects. 4.1–4.5 below. When sampling the posterior using Markov chain Monte Carlo (MCMC), only the relative fraction between different posterior values are relevant, such that any constant factors can be ignored. For this reason, many factors in the posterior density are written with a proportionality sign.
The statistical model is also represented in Fig. 3 as a directed acyclic graph, illustrating how the top level population parameters set the probability distribution by which the bottom level stellar parameters are generated, which in turn generate the data. Because both Ψ and ψi are free parameters, this model fully accounted for the uncertainties associated with the observation of each star.
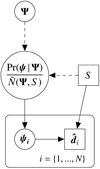 |
Fig. 3. Directed acyclic graph representing the Bayesian hierarchical model. Quantities inscribed in circles (squares) are free to vary (fixed) during the inference. Arrows with dashed (solid) lines represent deterministic (probabilistic) dependencies. The large square with rounded corners represents iteration over the stars in the stellar sample. |
The statistical model has a high number of free parameters (typically several 104); to make it computationally tractable, it was implemented in TENSORFLOW which allows for auto-differentiation and posterior sampling using an MCMC algorithm called Hamiltonian Monte-Carlo. Further details on this can be found in Appendix B.
4.1. Prior
The prior over the population parameters Pr(Ψ) is a uniform box, although with the additional constraint that
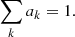 (16)
(16)
The bounds for the parameters are the following:
-
ρh ∈ [0, 0.3] M⊙ pc−3,
-
ak ∈ [0, 1],
-
σU, k, σV, k, σW, k ∈ [0, 250] km s−1,
-
![Mathematical equation: $ \bar{U}_k,\, \bar{V}_k \in [-250,\, 250]~{\text{ km}\,\text{ s}^{-1}} $](/articles/aa/full_html/2021/02/aa39852-20/aa39852-20-eq52.gif) ,
, -
Z⊙ ∈ [ − 50, 50] pc,
-
W⊙ ∈ [ − 20, 20] km s−1.
This uniform box prior is wide enough for the posterior densities not to be affected by the specific position of its boundaries (with the exception of some bounds which prevent negative values).
4.2. Selection function
The selection function models the probability that a star will be included in the stellar sample. It is a function of data, written
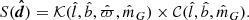 (17)
(17)
The factor 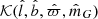 corresponds to the data cuts by which the stellar samples are constructed; it includes the cuts in
corresponds to the data cuts by which the stellar samples are constructed; it includes the cuts in 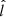 ,
, 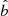 ,
, 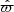 , and
, and 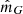 that define the stellar sample, and also the open cluster masked regions in
that define the stellar sample, and also the open cluster masked regions in 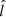 and
and 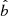 , as described in Sect. 3. The function
, as described in Sect. 3. The function 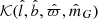 takes a value of one when all criteria are fulfilled, and is otherwise zero. The factor
takes a value of one when all criteria are fulfilled, and is otherwise zero. The factor 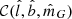 is the completeness of Gaia DR2; it is a function of angular position and apparent magnitude, calculated using a cross-match with the 2MASS catalogue (Rybizki & Drimmel 2018). The average completeness in the relevant range of apparent magnitudes is evaluated to around 99%.
is the completeness of Gaia DR2; it is a function of angular position and apparent magnitude, calculated using a cross-match with the 2MASS catalogue (Rybizki & Drimmel 2018). The average completeness in the relevant range of apparent magnitudes is evaluated to around 99%.
4.3. Likelihood
The likelihood of the data, given a set of stellar parameters (here parametrised in the space of observables and denoted by quantities without hats), is proportional to
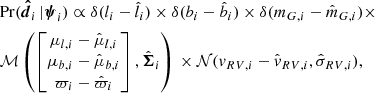 (18)
(18)
where δ is the Dirac delta function (uncertainties for 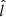 ,
, 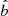 , and
, and 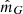 are neglected), and
are neglected), and
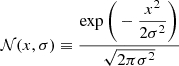 (19)
(19)
is the one-dimensional Gaussian distribution. The error covariance matrix
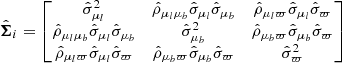 (20)
(20)
accounts for all uncertainties 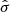 and uncertainty correlations
and uncertainty correlations 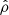 between the measured parallax and proper motions of the ith star (for shorthand, the index i is dropped in the right-hand side of the above expression). If radial velocity information is not available, the factor
between the measured parallax and proper motions of the ith star (for shorthand, the index i is dropped in the right-hand side of the above expression). If radial velocity information is not available, the factor 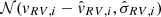 is dropped from Eq. (18).
is dropped from Eq. (18).
4.4. Stellar parameter probability density
The stellar parameter probability density for a star, labelled by the index i, is equal to
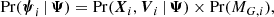 (21)
(21)
where Pr(Xi, Vi | Ψ) the phase-space probability density, and Pr(MG, i) is the probability of its absolute magnitude (which is independent of Ψ).
For almost all stars in our stellar samples the distance is constrained well enough such that their inferred absolute magnitude varies only minimally. Hence, including Pr(MG, i) in the posterior density grants no significant power of inference for such stars. It is relevant only for the few stars with very poor parallax precision, in order to suppress the probability that they are extremely bright objects very far away. For this reason we modeled the distribution of magnitudes in our stellar parameter probability density according to the following simple form,
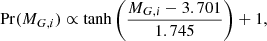 (22)
(22)
which was fitted to the distribution of solar neighbourhood stars with MG < 7.
The phase-space probability is given by Eq. (9), according to
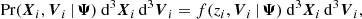 (23)
(23)
where we now write f(zi, vi | Ψ) with an explicit dependence on Ψ. The differential factors are written in order to be explicit that the above expression is written in terms of the phase-space coordinates X and V.
When we sampled our posterior probability density, we reparametrised the phase space coordinates Xi and Vi to the space of observables (li, bi, ϖi, μl, i, μb, i, vRV, i). Because uncertainties on l and b are neglected, those coordinates are fixed by the data. Combined with the angle factors of the data likelihood, the phase-space density can be reformulated like
![Mathematical equation: $$ \begin{aligned} \begin{aligned}&\delta (l_i-\hat{l}_i) \times \delta (b_i-\hat{b}_i) \times f(Z_i+Z_\odot ,\boldsymbol{V}_i \, | \, \boldsymbol{\Psi }) ~ \mathrm{d} ^3\boldsymbol{X}_i \, \mathrm{d} ^3\boldsymbol{V}_i \propto \\&f[ Z_i(\ldots )+Z_\odot ,\boldsymbol{V}_i(\ldots ) \, | \, \boldsymbol{\Psi }]\, \varpi _i^{-6} ~ \mathrm{d} \varpi _i \, \mathrm{d} \mu _{l,i} \, \mathrm{d} \mu _{b,i}\, \mathrm{d} v_{RV,i}, \end{aligned}\end{aligned} $$](/articles/aa/full_html/2021/02/aa39852-20/aa39852-20-eq75.gif) (24)
(24)
where the additional factor 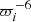 comes from the Jacobian of the coordinate transformation (constant factors neglected). In this expression it is implicit that Zi(…) and Vi(…) depend on the observables and angular data, according to
comes from the Jacobian of the coordinate transformation (constant factors neglected). In this expression it is implicit that Zi(…) and Vi(…) depend on the observables and angular data, according to
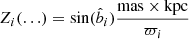 (25)
(25)
and
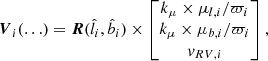 (26)
(26)
where kμ = 4.74057 yr × km s−1 and
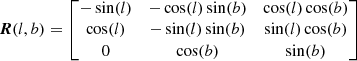 (27)
(27)
is a rotational matrix that transforms the longitudinal-latitudinal-radial directions to those of V.
4.5. Normalisation
Because there are two levels in our Bayesian hierarchical model, there are two levels of normalisation. The normalisation to the population parameters is fixed and therefore ignored, as any constant factor can be dropped from the posterior probability density. Conversely, the normalisation to the distribution of stellar parameters will vary, dependent on the population parameters. This normalisation factor is included in the denominator of Eq. (15), written 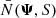 . It ensures that a star, randomly generated from the population model, has an integrated probability of one to be included in the stellar sample. It is equal to
. It ensures that a star, randomly generated from the population model, has an integrated probability of one to be included in the stellar sample. It is equal to
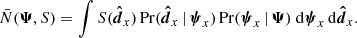 (28)
(28)
The stellar parameters and data, ψx and 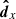 , have an index x in order to highlight that this object is hypothetical and generated from the population model set by Ψ.
, have an index x in order to highlight that this object is hypothetical and generated from the population model set by Ψ.
The integral in Eq. (28) is high dimensional and expensive to compute. However, because the phase-space probability density is invariant with respect to X and Y, and because the selection function does not depend on velocity, most of this integral only needs to be computed once. The normalisation factor can be reformulated like
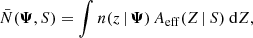 (29)
(29)
where Aeff(Z | S) is an effective area which depends on the selection function S and varies with Z. It is equal to
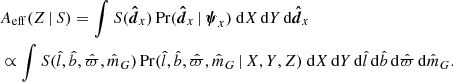 (30)
(30)
In the second row of this expression, only the data components relevant for the selection function are integrated over. The effective area does not depend on the population parameters Ψ, which means it can be computed separately and catalogued before computing the full posterior probability density.
The expression 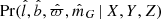 is the probability of generating a certain set of data given a star’s true properties. The angles
is the probability of generating a certain set of data given a star’s true properties. The angles 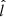 and
and 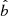 are given directly by the spatial position. The apparent magnitude
are given directly by the spatial position. The apparent magnitude 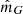 is also given directly once we also generate the absolute magnitude, which is done from the observed distribution of absolute magnitudes in the solar neighbourhood, written F(MG) (this distribution is the same as used in Widmark 2019, see Sect. 2.4 in that paper for more details). Finally, the parallax
is also given directly once we also generate the absolute magnitude, which is done from the observed distribution of absolute magnitudes in the solar neighbourhood, written F(MG) (this distribution is the same as used in Widmark 2019, see Sect. 2.4 in that paper for more details). Finally, the parallax 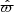 has significant uncertainties, which are generated from the distribution of parallax uncertainties in the specific volume of the stellar sample. It is modeled as a function of apparent magnitude and latitude, written
has significant uncertainties, which are generated from the distribution of parallax uncertainties in the specific volume of the stellar sample. It is modeled as a function of apparent magnitude and latitude, written 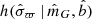 , given by a two-dimensional histogram with bin sizes of ∼0.2 mag and ∼10 degrees.
, given by a two-dimensional histogram with bin sizes of ∼0.2 mag and ∼10 degrees.
Thus we have that
![Mathematical equation: $$ \begin{aligned} \begin{aligned}&\mathrm{Pr} (\hat{l}, \hat{b}, \hat{\varpi }, \hat{m}_G \, | \, X,Y,Z) = \delta [ l(X,Y,Z) - \hat{l} ] \times \delta [ b(X,Y,Z) - \hat{b} ] \\&\times \int \delta \Bigg [M_G + 5\log _{10}\Bigg ( \dfrac{{100~\mathrm{mas} }}{\varpi (X,Y,Z)} \Bigg ) -\hat{m}_G \Bigg ] \, F(M_G) \, \mathrm{d} M_G \\&\times \int \mathcal{N} (\varpi -\hat{\varpi },\hat{\sigma }_\varpi )\, h(\hat{\sigma }_\varpi \, |\, \hat{m}_G,\hat{b})\, \mathrm{d} \hat{\sigma }_\varpi , \end{aligned}\end{aligned} $$](/articles/aa/full_html/2021/02/aa39852-20/aa39852-20-eq91.gif) (31)
(31)
where δ is the Dirac delta function.
In practice, we calculated Aeff(Z | S) numerically by rejection sampling. This was done by randomly generating a star’s position, given a uniform stellar number density, and the observational data according to the distribution of absolute magnitudes and parallax uncertainties described above. We took care to randomise stars whose true properties lied outside the region of the stellar sample, as stars can be scattered into the sample region through observational errors.
An example of a stellar sample’s effective area is shown in Fig. 4. It differs from the idealised flat box of the stellar sample’s geometric volume due to the completeness of Gaia DR2, data uncertainties, and open cluster masks.
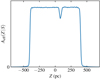 |
Fig. 4. Effective area of stellar sample B5-400. The depression around Z = 80 pc is due to an open cluster mask. |
5. Results
In this section we discuss our results, mainly in terms of the inferred posterior probability densities. How the posterior density was sampled is discussed in more detail in Appendix B. For the velocity distribution we used a Gaussian mixture model consisting of 10 Gaussians, giving a total of 65 degrees of freedom for the population model. This number of Gaussians gave enough flexibility to produce good phase-space distribution fits. We also ran our inference using 20 Gaussians but the results did not change notably.
The results in this work are mainly presented in terms of the gravitational potential rather than the inferred matter density profiles. The gravitational potential is arguably the quantity that was actually being measured from which the matter density could be calculated via the Poisson equation (see Eq. (3)). Because the Poisson equation contains a second derivative, the matter density was not as robustly inferred; it is more dependent on the choice of parametrisation and priors, and suffers from strong degeneracies, especially between its mid-plane amplitude and profile shape. For this reason, the gravitational potential is the more illustrative quantity, and easier to compare with the expected result.
The inferred gravitational potentials of stellar samples A1-200, A1-300, and A1-400 are shown in Fig. 5, and the three samples agree well with each other. They are consistent with the expected potential (see Sect. 2.4) at larger distances from the mid-plane, around |z|≃400 pc. However, the potential is significantly steeper at small distances of |z| ≲ 60 pc, implying a high mid-plane matter density that quickly decreases with z. In the top panel of Fig. 5, we also show the inferred potential of Widmark (2019). That work used different cuts in spatial volume and absolute magnitude2, but the results agree well with this work.
 |
Fig. 5. Inferred gravitational potential of stellar samples A1-200, A1-300, and A1-400, in the top, middle, and bottom panel, plotted in terms of its square root as a function of z. The width of the blue band shows the 16th to 84th percentile of the inferred posterior density of the respective stellar samples. The band has a lighter colour for z > Zlim., indicating that this is an extrapolation outside the spatial volume of the stellar sample. The 1σ band of the expected gravitational potential is shown in grey (identical in all panels). The black dash-dotted and dotted lines show the gravitational potential in case of a homogeneous matter density of 0.2 and 0.1 M⊙ pc−3. Top panel: we also plot the inferred potential of Widmark (2019) in red, where the dot indicates the median and the error bars cover the 10th and 90th percentiles of that work’s eight stellar sample posterior densities. |
The inferred total matter density as a function of z, for stellar sample A1-400, is shown in Fig. 6. The inferred matter density is very strongly concentrated to the Galactic mid-plane and decays quickly with height. As such, it does not imply a total matter density surplus if we consider the total surface density within a sufficiently large distance from the mid-plane. The inferred distribution is at odds with the expected matter density, as described in Sect. 2.4, which does not decay as quickly with height |z|; hence, this result cannot be reconciled, at least not completely, by including some kind of hidden over-density. If we use the expected gravitational potential, while keeping other population parameters fixed, we obtain a normalised stellar tracer density, 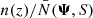 , that is ∼5% higher in the mid-plane and ∼5% lower at |z|≃200 pc. This demonstrates that our result can be explained by a comparatively small time-varying feature in the stellar tracer density, rather than the dramatic difference in the total matter density seen in Fig. 6. See Sect. 6 for further discussion on the likelihood that the assumption of a steady state is broken. Similar matter density profiles are obtained for practically all stellar samples.
, that is ∼5% higher in the mid-plane and ∼5% lower at |z|≃200 pc. This demonstrates that our result can be explained by a comparatively small time-varying feature in the stellar tracer density, rather than the dramatic difference in the total matter density seen in Fig. 6. See Sect. 6 for further discussion on the likelihood that the assumption of a steady state is broken. Similar matter density profiles are obtained for practically all stellar samples.
 |
Fig. 6. Inferred total matter density profile of stellar sample A1-400. The width of the blue band shows the 16th to 84th percentile of the inferred posterior density. The 1σ band of the expected gravitational potential is shown in grey. |
In Fig. 7, we show the inferred potential of our 120 stellar samples, for heights z = {100, 200, 300, 400} pc. For almost all stellar samples, we see the same general behaviour as for area cell A1, with a steep potential close to the Galactic mid-plane, but consistent with the expected potential at greater |z|. There are discrepancies between the inferred potential of the stellar samples, where B8-200 stands out with low values, and to a lesser extent also area cells D7, D9, D12, D13, and D16. The spatial dependence of the inferred potentials is illustrated in Fig. 8, where the area cells are colour coded according to the median posterior value of Φ(z = 400 pc), for samples with Zlim. = 400 pc. Our model for the expected potential is evaluated at the Sun’s position, but our stellar samples do span a significant range in the Galactic radius (i.e. X), over which the total matter density is expected to vary. We fitted the variation of Φ(z = 400 pc) with respect to X for the stellar samples of region C, accounting for the statistical variance of the stellar samples’ posterior densities, and obtain a disk scale length of a few kiloparsecs; the maximum likelihood is for 3.7 kpc, but this is associated with a large uncertainty, allowing 2.6 kpc within 1σ (similar results are found for region D, for which 2.6 kpc is consistent within 1.5σ). This is consistent with recent studies: see for example the review by Bland-Hawthorn & Gerhard (2016), that report scale lengths for the thin and thick disks of ∼2.6 kpc and ∼2kpc, where the former is dominant in our case.3 We do not see a statistically significant variation in the azimuthal direction (i.e. Y).
 |
Fig. 7. Inferred potential for the 120 stellar samples, presented in terms of |
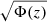
 |
Fig. 8. Inferred gravitational potential at z = 400 pc for different area cells, presented in terms of the posterior distribution median, using stellar samples with Zlim. = 400 pc. |
In Figs. 9 and 10 we show the inferred values for Z⊙ and W⊙ of our 120 stellar samples. There are discrepancies between stellar samples for both Z⊙ and W⊙, larger than statistical errors can account for, as well as a spatial dependence. For Z⊙, the mean values of all stellar samples is 2.8 pc, and {0.4, 2.0, 6.0} pc when grouping them by Zlim. = {200, 300, 400} pc, which is indicative of a broken Galactic plane mirror symmetry. Furthermore, these values are low with respect to some other studies that reach kiloparsec distances from the Galactic plane (25 ± 5 pc, 13.4 ± 4.4 pc, and 20.8 ± 0.3 pc, for Juric et al. 2008, Yao et al. 2017, and Bennett & Bovy 2019). For W⊙, the mean value of all stellar samples is 7.3 km s−1 (also with some dependence on region and Zlim.). Again, we see outliers for both Z⊙ and W⊙ especially for area cell B8, and to a lesser extent also for some samples in region D. In the posterior densities, there are no strong correlations between ρh and Z⊙ or between ρh and W⊙; the correlation values are typically a few percent.
 |
Fig. 9. Inferred height of the Sun, Z⊙, for the 120 stellar samples. The samples are listed vertically according to area cell, in groups of three for different Zlim. in descending order, which are labelled by colour according to the legend. The horizontal lines represent the posterior widths, whose endpoints are equal to the 16th and 84th percentile of the posterior distribution. |
 |
Fig. 10. Inferred vertical velocity of the Sun, W⊙, for the 120 stellar samples. The samples are listed vertically according to area cell, in groups of three for different Zlim. in descending order, which are labelled by colour according to the legend. The horizontal lines represent the posterior widths, whose endpoints are equal to the 16th and 84th percentile of the posterior distribution. |
In Appendix D, we show control plots for a number of stellar samples, where we compare the inferred population model with the distribution of stars in the Z–w plane. Control plots are shown for a few representative samples, for which the population model and distribution of stars agree reasonable well. We also show the control plots for stellar samples B8-200 and B8-400, which are obviously poor fits. There is a clear over-dense feature in the Z–w plane of the B8 stellar samples, possibly the remnant of a dissolved open cluster, which our statistical model mistakenly infers to correspond to the Galactic mid-plane. This substructure is diffuse in the space of angular coordinates, which is probably why it was not included in the open cluster catalogue of Cantat-Gaudin et al. (2018) and therefore not masked. The same substructure also seems to be present, although to a lesser extent, in the neighbouring area cell B7, which exhibits similar outlier values for Z⊙ and W⊙.
The area cells with the largest open cluster masks are D7, D12, C10, C5, and D16 (in descending order, see Table 3 for more details). Many of these stellar samples contain a lower number of stars, especially close to the mid-plane, which is essential to inferring the shape of the potential at low |z|. This is, at least to some extent, reflected in larger uncertainties to the inferred potential of these stellar samples (for example D7-200, D12-200, D16-200). Not only is the statistical uncertainty larger but potentially also the systematic error, as the steady state assumption is more questionable in spatial volumes where large and/or numerous open clusters are present.
In Appendix C, we inferred the gravitational potential using a very simple Jeans analysis. Despite the crude nature of this analysis, it reproduced the general trends of our results: a gravitational potential that is significantly steeper than expected close to the Galactic mid-plane.
6. Discussion
We have inferred the gravitational potential of the Galactic disk for 120 stellar samples in the solar neighbourhood, in 40 separate spatial volumes, under the assumption of a steady state and separability of the gravitational potential in the vertical direction. The main reason for dividing the local volume into sub-regions was to ascertain whether spatially dependent systematic errors would affect our results. We see a spatial dependence with respect to the Galactic radius, which is consistent with a disk scale length of a few kiloparsecs. Apart from this, we see an unexpected but nonetheless clear trend, present in almost all stellar samples: The inferred vertical gravitational potential, normalised to Φ(0 pc) = 0 km2s−2, agrees well with the expectation at large distances from the mid-plane (|z|≃400 pc) but is significantly steeper than expected close to the Galactic mid-plane (|z| ≲ 60 pc). If this result is taken at face value, it implies a total matter density that is highly concentrated to the mid-plane, but decays quickly with height. This is inconsistent with the observed distribution of baryons. The high mid-plane matter density itself could potentially be explained by an excess of cold gas or other hidden matter density (see Sect. 2.4 for a discussion on systematics associated with the local density of gas and Sect. 1 about the possibility of dark sector over-densities in the Galactic disk). However, even if we allow for such hidden matter densities, the low matter density inferred at greater heights (|z|≳300 pc, see Fig. 6) leaves little to no room for any matter density other than halo dark matter, which is irreconcilable with the matter density distribution and scale height of the stellar disk.
We consider time-varying dynamical effects, breaking the assumption of a steady state, to be the most probable reason for this unexpected result. We do see how local phase-space substructures can bias our result for individual stellar samples, most clearly for those of area cell B8. However, explaining the steep gravitational potential close to the Galactic mid-plane, inferred for almost all stellar samples, requires a phase-space structure that spans the whole spatial volume that is studied in this work. Indeed, spatially large time-varying phase-space structures are present in the Galaxy, for example in the form of phase-space spirals and ridges (Gaia Collaboration 2018c; Antoja et al. 2018), and Galactic plane mirror asymmetries (Bennett & Bovy 2019, especially prominent for heights |z|≳400 pc). In order to produce a steep gravitational potential at low |z|, there could be a breathing mode in the stellar disk (Widrow et al. 2014; Monari et al. 2016) which is currently in its most compressed state. Such a configuration would not be detectable by comparing the mean vertical velocities above and below the mid-plane, because the breathing oscillation would be at a turning point between contraction and expansion. Mass estimates close to the mid-plane and under the steady state assumption would be biased towards more massive results, as the stellar disk would have a smaller scale height and larger vertical velocities. In order to explain our results, such a breathing mode would have to be large enough for the stellar number density in the mid-plane to oscillate with a relative amplitude of ∼5%. Monari et al. (2016 see for example Fig. 4) have shown that a local breathing mode could be created by a spiral arm that passes close enough to the Sun, inducing a net motion away from (towards) the Galactic mid-plane for stars on the outside (inside) of the spiral arm. Furthermore, such a close passage of a spiral arm is indicated by some dynamical models of the horizontal motions within the Galactic disk (for example Siebert et al. 2012). The dynamics of the Galactic disk are very complex and probably contains a combination of breathing and bending modes created by the last impact of the Sagittarius dwarf galaxy (for example Laporte et al. 2019); it is very plausible to think that the famous phase-space spirals in the z–w plane are a local manifestation of these larger scale perturbations. The phase-space spiral structure could have an effect on our analysis, especially for the stellar samples with higher Zlim.. On a larger scale, the bending and breathing modes of the Galaxy have been shown to affect dynamical mass measurements of the Galactic disk, especially at greater heights (Banik et al. 2017; Haines et al. 2019).
The inferred potential of our stellar samples agrees well with the results of Widmark (2019), where a similar method but different stellar sample cuts were used. Due to the smaller heights considered in that work (|Z|< 200 pc), there did seem to be a surplus of matter in the Galactic disk. In a similar study by Buch et al. (2019), also using Gaia DR2, they set an upper bound to a surface density surplus (7.5 M⊙ pc−2 for a scale height of ∼40 pc, 95 % confidence region limit) that roughly correspond to the preferred model of Widmark (2019). Interestingly, the most stringent bound in Buch et al. (2019) come from their sample of A-type stars, which is a stellar population with a comparatively small scale height. The fact that their other stellar samples (G-type and F-type) produced weaker limits could possibly be explained by a time-varying dynamical structure, which could produce a different bias depending on the scale height of the stellar tracer population. The stellar samples in Widmark (2019) did not include stars that were quite as bright as A-type, but still saw some anti-correlation between the inferred matter density surplus and the brightness of the stellar samples.
Apart from the overall trend of our results, we do see discrepancies larger than expected from statistical variance, especially for Z⊙ and W⊙. One especially noteworthy outlier is area cell B8, which appears to host a previously unknown spatially diffuse remnant of a dissolved open cluster. In this case, the population model is obviously a poor fit, as can be seen in Appendix D and Figs. D.4 and D.5. This demonstrates that stellar phase-space substructures are present and can produce biases, despite masking previously identified open clusters.
The shape of the inferred gravitational potential cannot be explained, at least not completely, by adding some kind of hidden matter density to the observed distribution of baryons and halo dark matter. We infer a matter density that is strongly concentrated to the Galactic mid-plane, but decays quickly with height; the baryonic distribution is inconsistent with such a rapidly decaying matter density, mainly due to the observed scale height of the stellar disk. With that said, the distribution of baryons could, to some extent, be misunderstood. As we demonstrate in Appendix A, the baryonic model from which the expected gravitational potential is derived does not agree very well with the stellar number density profiles of our stellar samples. Most importantly, its dependence on z relies on extrapolations using the different components’ vertical velocity distributions, under the erroneous assumption that those velocity distributions are Gaussian (i.e. iso-thermal). It is less likely that the stellar densities in the mid-plane are significantly biased, but an update to the baryonic model could improve especially on the shape of the matter density profiles of the stellar components.
Likely, only a small bias to the results of this study could be caused by data systematics. In terms of the astrometric data of Gaia DR2, systematic errors are probably small: ≲0.01 mag for the apparent magnitudes (Gaia Collaboration 2018a), ≲0.1 mas for the parallax, and ≲0.1 mas yr−1 for the proper motions (Luri et al. 2018, corresponding to velocity errors ≲0.2 km s−1 at the distance scales of this study). Dust corrections are insignificant for the closest samples, but a poorly modeled dust map could potentially have some effect on the more distant stellar samples, especially region D. The median and 90th percentile values to the 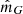 dust corrections are roughly 0.02 and 0.06 mag for region A, and roughly 0.1 and 0.2 mag for region D. In summary, data and dust effects could potentially produce a small bias, but likely only for the most distant stellar samples, especially in region D. It could be worth revisiting these stellar samples with future Gaia data releases and a more accurate dust map.
dust corrections are roughly 0.02 and 0.06 mag for region A, and roughly 0.1 and 0.2 mag for region D. In summary, data and dust effects could potentially produce a small bias, but likely only for the most distant stellar samples, especially in region D. It could be worth revisiting these stellar samples with future Gaia data releases and a more accurate dust map.
In summary, we consider the gravitational potential inferred in this work to be strongly biased by a spatially large time-varying dynamical structure, such as a breathing mode of the Galactic disk. Such a bias could potentially be diagnosed by jointly analysing a multitude of stellar populations with different dynamical properties and vertical scale heights. Another complementary measurement is explored in Widmark et al. (2020), where they demonstrate that a cold stellar stream passing through or close to the Galactic plane could provide competitive constraints to the disk’s potential, which would also be independent of the steady state assumption for the stellar disk. In a more general sense, modelling time-varying dynamical systems in order to extract information about their gravitational potential and mass distribution becomes all the more interesting and necessary, not only for weighing the Galactic disk. For the solar neighbourhood, relaxing the steady state assumption is a natural next step, and this relatively compact and well-defined problem could be a good testing ground for developing such methods.
7. Conclusion
In this work we have inferred the gravitational potential of the Galactic disk, under the assumption of a steady state and separability in the vertical direction. We did so for 120 stellar samples, for 40 spatially separate area cells in the directions parallel to the Galactic plane, and three different spatial ranges in the vertical direction. For the inferred gravitational potentials of our stellar samples, we see a dependence on the Galactic radius that is consistent with a disk scale length of a few kiloparsecs. In addition to this, a general trend is that the gravitational potential is significantly steeper than expected close to the Galactic mid-plane (|z| ≲ 60 pc), but agrees well at greater heights (|z|≃400 pc). The trend is in agreement with Widmark (2019), which uses different cuts in spatial volume and absolute magnitude, and also the simple Jeans analysis carried out in Appendix C. Our result does not imply a surface density surplus in the Galactic disk but rather a mass distribution that is highly concentrated to the Galactic mid-plane; this is inconsistent with the observed distribution of baryons, mainly because the observed scale height of the stellar disk cannot be reconciled with such a small total matter density at |z|≳300 pc. Our inferred gravitational potentials must be affected by a significant systematic bias; we consider a time-varying dynamical structure to be the most likely explanation. For example, our results could be explained by a breathing mode that is currently in its most compressed state, corresponding to a temporary ∼5% increase of the mid-plane stellar number density. This dynamical structure must also be spatially large, as it affects the full volume of all stellar samples in practically the same manner.
We will investigate the possibility of time-varying structures in future work. With future Gaia data releases, we plan to perform the same analysis in other spatial volumes further away from the Sun, and for other stellar populations such as the brighter A-type stars studied by Schutz et al. (2018) and Buch et al. (2019). We will also explore in more detail what kind of vibrational mode of the Galactic disk would be needed to produce our result, and how to diagnose such a feature.
Furthermore, we plan to update the baryonic matter density model in future work, using upcoming Gaia data releases. The expected gravitational potential used in this work (as well as for example Schutz et al. 2018; Sivertsson et al. 2018; Buch et al. 2019, and Widmark 2019) is based on observations of the different baryonic components’ mid-plane densities and mid-plane vertical velocity distributions. As demonstrated in Appendix A, this baryonic model could be improved using the stellar number density profiles of current or future Gaia data releases.
The exact value of the local dark matter density is still under debate. Although most results are in agreement with a value of 0.011 M⊙ pc−3, they do differ somewhat depending on the method, for example global Galactic mass modelling (Cautun et al. 2020), rotation curve fitting (Karukes et al. 2019; de Salas et al. 2019; Benito et al. 2020) or vertical Jeans analysis of different regions and stellar populations (Sivertsson et al. 2018; Salomon et al. 2020).
In Widmark (2019), all stellar samples were constructed from a spatial volume consisting of a spherical shell defined by a heliocentric distance between 100 and 200 pc. The eight samples had non-overlapping cuts in absolute magnitude, with MG ranging from 3 to 6.3.
The scale length of the Galactic disk also varies depending on the stellar population. For example, Bovy et al. (2012) show a clear dependence on metallicity, where the most metal rich stars have scale lengths up to ∼4 kpc.
Acknowledgments
We would like to thank the anonymous referee for their insightful and constructive review. AW acknowledges support from the Carlsberg Foundation via a Semper Ardens grant (CF15-0384). PFdS acknowledges support by the Vetenskapsrådet (Swedish Research Council) through contract No. 638-2013-8993 and the Oskar Klein Centre for Cosmoparticle Physics. This work made use of an HPC facility funded by a grant from VILLUM FONDEN (projectnumber 16599). This work has made use of data from the European Space Agency (ESA) mission Gaia (https://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC, https://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement. This research utilised the following open-source Python packages: MATPLOTLIB (Hunter 2007), NUMPY (Harris et al. 2020), SCIPY (Virtanen et al. 2020), PANDAS (McKinney et al. 2010), TENSORFLOW (Abadi et al. 2015), Gaia DR2 completeness (Rybizki & Drimmel 2018).
References
- Abadi, M., Agarwal, A., Barham, P., et al. 2015, TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems, software available from https://www.tensorflow.org/ [Google Scholar]
- Ablimit, I., Zhao, G., Flynn, C., & Bird, S. A. 2020, ApJ, 895, L12 [Google Scholar]
- Antoja, T., Helmi, A., Romero-Gómez, M., et al. 2018, Nature, 561, 360 [NASA ADS] [CrossRef] [Google Scholar]
- Bahcall, J. N. 1984a, ApJ, 287, 926 [NASA ADS] [CrossRef] [Google Scholar]
- Bahcall, J. N. 1984b, ApJ, 276, 169 [NASA ADS] [CrossRef] [Google Scholar]
- Banik, N., Widrow, L. M., & Dodelson, S. 2017, MNRAS, 464, 3775 [NASA ADS] [CrossRef] [Google Scholar]
- Benito, M., Iocco, F., & Cuoco, A. 2020, ArXiv e-prints [arXiv:2009.13523] [Google Scholar]
- Bennett, M., & Bovy, J. 2019, MNRAS, 482, 1417 [NASA ADS] [CrossRef] [Google Scholar]
- Bienayme, O., Soubiran, C., Mishenina, T. V., Kovtyukh, V. V., & Siebert, A. 2006, A&A, 446, 933 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bienaymé, O., Famaey, B., Siebert, A., et al. 2014, A&A, 571, A92 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Binney, J., & Tremaine, S. 2008, Galactic Dynamics, Second Edition (Princeton University Press) [Google Scholar]
- Bland-Hawthorn, J., & Gerhard, O. 2016, ARA&A, 54, 529 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bovy, J., & Tremaine, S. 2012, ApJ, 756, 89 [Google Scholar]
- Bovy, J., Rix, H.-W., Liu, C., et al. 2012, ApJ, 753, 148 [NASA ADS] [CrossRef] [Google Scholar]
- Buch, J., Leung, J. S. C., & Fan, J. 2019, J. Cosmol. Astropart. Phys., 2019, 026 [Google Scholar]
- Büdenbender, A., van de Ven, G., & Watkins, L. L. 2015, MNRAS, 452, 956 [NASA ADS] [CrossRef] [Google Scholar]
- Cantat-Gaudin, T., Jordi, C., Vallenari, A., et al. 2018, A&A, 618, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Capitanio, L., Lallement, R., Vergely, J. L., Elyajouri, M., & Monreal-Ibero, A. 2017, A&A, 606, A65 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Caputo, A., Zavala, J., & Blas, D. 2018, Phys. Dark Univ., 19, 1 [CrossRef] [Google Scholar]
- Cautun, M., Benítez-Llambay, A., Deason, A. J., et al. 2020, MNRAS, 494, 4291 [Google Scholar]
- Cole, D. R., & Binney, J. 2017, MNRAS, 465, 798 [NASA ADS] [CrossRef] [Google Scholar]
- Crézé, M., Chereul, E., Bienayme, O., & Pichon, C. 1998, A&A, 329, 920 [NASA ADS] [Google Scholar]
- Danielski, C., Babusiaux, C., Ruiz-Dern, L., Sartoretti, P., & Arenou, F. 2018, A&A, 614, A19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dehnen, W., & Binney, J. 1998, MNRAS, 294, 429 [NASA ADS] [CrossRef] [Google Scholar]
- de Salas, P. F., Malhan, K., Freese, K., Hattori, K., & Valluri, M. 2019, J. Cosmol. Astropart. Phys., 2019, 037 [Google Scholar]
- Eilers, A.-C., Hogg, D. W., Rix, H.-W., & Ness, M. K. 2019, ApJ, 871, 120 [NASA ADS] [CrossRef] [Google Scholar]
- Fan, J., Katz, A., Randall, L., & Reece, M. 2013a, Phys. Rev. Lett., 110, 211302 [Google Scholar]
- Fan, J., Katz, A., Randall, L., & Reece, M. 2013b, Phys. Dark Univ., 2, 139 [CrossRef] [Google Scholar]
- Fitzpatrick, E. L. 1999, PASP, 111, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Flynn, C., Holmberg, J., Portinari, L., Fuchs, B., & Jahreiss, H. 2006, MNRAS, 372, 1149 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Babusiaux, C., et al.) 2018a, A&A, 616, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2018b, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Katz, D., et al.) 2018c, A&A, 616, A11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garbari, S., Read, J. I., & Lake, G. 2011, MNRAS, 416, 2318 [NASA ADS] [CrossRef] [Google Scholar]
- Garbari, S., Liu, C., Read, J. I., & Lake, G. 2012, MNRAS, 425, 1445 [NASA ADS] [CrossRef] [Google Scholar]
- Gelman, A., Carlin, J., Stern, H., et al. 2013, Bayesian Data Analysis, Third Edition (CRC Press) [Google Scholar]
- Guo, R., Liu, C., Mao, S., et al. 2020, MNRAS, 495, 4828 [Google Scholar]
- Haines, T., D’Onghia, E., Famaey, B., Laporte, C., & Hernquist, L. 2019, ApJ, 879, L15 [NASA ADS] [CrossRef] [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [CrossRef] [PubMed] [Google Scholar]
- Hessman, F. V. 2015, A&A, 579, A123 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Holmberg, J., & Flynn, C. 2000, MNRAS, 313, 209 [NASA ADS] [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Jungman, G., Kamionkowski, M., & Griest, K. 1996, Phys. Rept., 267, 195 [Google Scholar]
- Juric, M., Ivezic, Z., Brooks, A., et al. 2008, ApJ, 673, 864 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Kafle, P. R., Sharma, S., Lewis, G. F., & Bland-Hawthorn, J. 2014, ApJ, 794, 59 [NASA ADS] [CrossRef] [Google Scholar]
- Kapteyn, J. C. 1922, ApJ, 55, 302 [NASA ADS] [CrossRef] [Google Scholar]
- Karukes, E. V., Benito, M., Iocco, F., Trotta, R., & Geringer-Sameth, A. 2019, J. Cosmol. Astropart. Phys., 2019, 046 [Google Scholar]
- Klasen, M., Pohl, M., & Sigl, G. 2015, Prog. Part. Nucl. Phys., 85, 1 [Google Scholar]
- Klypin, A., Zhao, H., & Somerville, R. S. 2002, ApJ, 573, 597 [Google Scholar]
- Kramer, E. D., & Randall, L. 2016a, ApJ, 829, 126 [NASA ADS] [CrossRef] [Google Scholar]
- Kramer, E. D., & Randall, L. 2016b, ApJ, 824, 116 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K., & Gilmore, G. 1989a, MNRAS, 239, 605 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K., & Gilmore, G. 1989b, MNRAS, 239, 651 [NASA ADS] [Google Scholar]
- Kuijken, K., & Gilmore, G. 1989c, MNRAS, 239, 571 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K., & Gilmore, G. 1991, ApJ, 367, L9 [NASA ADS] [CrossRef] [Google Scholar]
- Lallement, R., Welsh, B. Y., Vergely, J. L., Crifo, F., & Sfeir, D. 2003, A&A, 411, 447 [EDP Sciences] [Google Scholar]
- Laporte, C. F. P., Minchev, I., Johnston, K. V., & Gómez, F. A. 2019, MNRAS, 485, 3134 [Google Scholar]
- Li, Z.-Z., Qian, Y.-Z., Han, J., et al. 2020, ApJ, 894, 10 [Google Scholar]
- Lindegren, L., Hernández, J., Bombrun, A., et al. 2018, A&A, 616, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Luri, X., Brown, A. G. A., Sarro, L. M., et al. 2018, A&A, 616, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- McKee, C. F., Parravano, A., & Hollenbach, D. J. 2015, ApJ, 814, 13 [NASA ADS] [CrossRef] [Google Scholar]
- McKinney, W. 2010, in Proceedings of the 9th Python in Science Conference, eds. S. van der Walt, & J. Millman, 56 [Google Scholar]
- McMillan, P. J. 2011, MNRAS, 414, 2446 [NASA ADS] [CrossRef] [Google Scholar]
- McMillan, P. J. 2017, MNRAS, 465, 76 [NASA ADS] [CrossRef] [Google Scholar]
- Moe, M., & Di Stefano, R. 2017, ApJS, 230, 15 [Google Scholar]
- Monari, G., Famaey, B., & Siebert, A. 2016, MNRAS, 457, 2569 [NASA ADS] [CrossRef] [Google Scholar]
- Monari, G., Famaey, B., Siebert, A., Wegg, C., & Gerhard, O. 2019, A&A, 626, A41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nitschai, M. S., Cappellari, M., & Neumayer, N. 2020, MNRAS, 494, 6001 [CrossRef] [Google Scholar]
- Oort, J. H. 1932, Bull. Astron. Inst. Netherlands, 6, 249 [Google Scholar]
- Purcell, C. W., Bullock, J. S., & Kaplinghat, M. 2009, ApJ, 703, 2275 [NASA ADS] [CrossRef] [Google Scholar]
- Read, J. I. 2014, J. Phys. G Nucl. Phys., 41, 063101 [NASA ADS] [CrossRef] [Google Scholar]
- Read, J. I., Lake, G., Agertz, O., & Debattista, V. P. 2008, MNRAS, 389, 1041 [NASA ADS] [CrossRef] [Google Scholar]
- Ruchti, G. R., Read, J. I., Feltzing, S., Pipino, A., & Bensby, T. 2014, MNRAS, 444, 515 [Google Scholar]
- Rybizki, J., & Drimmel, R. 2018, gdr2_completeness: Gaia DR2 Data Retrieval and Manipulation [Google Scholar]
- Salomon, J.-B., Bienaymé, O., Reylé, C., Robin, A. C., & Famaey, B. 2020, A&A, 643, A75 [EDP Sciences] [Google Scholar]
- Schutz, K., Lin, T., Safdi, B. R., & Wu, C.-L. 2018, Phys. Rev. Lett., 121, 081101 [NASA ADS] [CrossRef] [Google Scholar]
- Siebert, A., Famaey, B., Binney, J., et al. 2012, MNRAS, 425, 2335 [NASA ADS] [CrossRef] [Google Scholar]
- Sivertsson, S., Silverwood, H., Read, J. I., Bertone, G., & Steger, P. 2018, MNRAS, 478, 1677 [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Weber, M., & de Boer, W. 2010, A&A, 509, A25 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Widmark, A. 2019, A&A, 623, A30 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Widmark, A., & Monari, G. 2018, MNRAS, sty2400 [Google Scholar]
- Widmark, A., Malhan, K., de Salas, P. F., & Sivertsson, S. 2020, MNRAS, 496, 3112 [Google Scholar]
- Widrow, L. M., Barber, J., Chequers, M. H., & Cheng, E. 2014, MNRAS, 440, 1971 [Google Scholar]
- Widrow, L. M., Pym, B., & Dubinski, J. 2008, ApJ, 679, 1239 [Google Scholar]
- Yao, J. M., Manchester, R. N., & Wang, N. 2017, MNRAS, 468, 3289 [Google Scholar]
- Zhang, L., Rix, H.-W., van de Ven, G., et al. 2013, ApJ, 772, 108 [Google Scholar]
Appendix A: Expected baryonic density comparison
In this section we compare the observed number density profiles of stars in regions A, B, C, and D, with the stellar density profiles of the baryonic model described in Sect. 2.4.
This comparison is visible in Fig. A.1. Regions A–D contain stars with different intervals in absolute magnitude MG (regions A and D have no overlap, with IMG = [4.6, 5.5] and IMG = [3.0, 4.5], respectively); in terms of intrinsic brightness, they correspond roughly to the baryonic model’s stellar density components with absolute magnitude ranges MV ∈ [4, 5] and MV ∈ [3, 4]. Evident from the figure is that neither profile of the expected density has a shape that agrees well with regions A–D. This discrepancy is explained, at least in part, by the fact that the distribution of vertical velocities is not Gaussian, as is assumed in the baryonic model, but rather a distribution with significantly heavier tails. Furthermore, the stellar regions A–D all have similar number density profiles, unlike the expected baryonic model for which the two absolute magnitude ranges have quite different profiles.
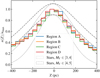 |
Fig. A.1. Stellar number densities for the stars of regions A, B, C, and D, normalised to unity for their maximum values. The number densities of two stellar components of the baryonic model are shown in terms of their 1σ bands, in dashed and dotted grey, where Z⊙ = 10 pc. |
Appendix B: HMC sampling
In this work, our statistical model of inference was a Bayesian hierarchical model with a high number of free parameters. Using a velocity distribution Gaussian mixture model consisting of 10 Gaussians, we had 65 degrees of freedom in the population parameters. For a stellar sample with N stars, there was also a total of 7N degrees of freedom for the stellar parameters. However, due to the Dirac functions in the data likelihood, see Eq. (18), the degrees of freedom were effectively reduced to 4N. Because our stellar samples each had roughly 5000 stars, the number of free parameters was typically around 2 × 104.
We sampled our posterior probability distribution, as described in Sect. 4, using a Markov chain Monte Carlo (MCMC) algorithm (Gelman et al. 2013). In order to sample a function with such a high number of dimensions, we implemented our model in TENSORFLOW (Abadi et al. 2015), which allows for auto-differentiation of the posterior density function with respect to the model’s free parameters. By utilising the posterior derivatives, sampling of the posterior was made computationally tractable using Hamiltonian Monte Carlo (HMC). In addition to what is described in Sect. 4, we applied the constraint that the velocity dispersions σW, k must be in ascending order, in order to avoid multiplicity in our velocity Gaussian mixture model.
Before running our MCMC chains, we ran an initial minimisation algorithm for each stellar sample, in order to locate the approximate mode of the population model. During this minimisation the stellar parameters were fixed and only the velocity information of stars with high data quality were used (meaning 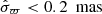 and
and 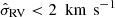 ). In order to avoid getting stuck in a local minimum far from the global minimum, this minimisation was run from 10 randomly chosen initial points in the space of the population parameters, out of which the minimum posterior value was chosen.
). In order to avoid getting stuck in a local minimum far from the global minimum, this minimisation was run from 10 randomly chosen initial points in the space of the population parameters, out of which the minimum posterior value was chosen.
After this, we ran a thorough burn-in phase for the full posterior probability density, where its mode was located and the diagonal step-size matrix of the HMC algorithm was tuned. We then ran the chain for long enough to obtain a minimum of 2500 independently drawn posterior realisations for each stellar sample. This was tested by calculating the auto-correlation of each individual free parameter of our model. For each free parameter, we counted the number of alternating crossings of the 16th and 84th percentiles of the obtained posterior density, in order to ensure that the full parameter space was well sampled.
The TENSORFLOW code written for this work is open source and can be found online4.
Appendix C: Comparison with Jeans analysis
The statistical method used in this work is rather complicated, and yields an unexpected result. In this section we present a similar but significantly simpler analysis, which used an easily reproducible method based on the Jeans equations. Despite the crude nature of this approach, it reproduces the general trend of our results.
Using the assumption of separability of the gravitational potential, reducing the problem to the vertical dimension only, the vertical Jeans equation states that
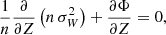 (C.1)
(C.1)
where 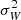 refers the variance of the vertical velocity distribution.
refers the variance of the vertical velocity distribution.
We applied the Jeans analysis to the four regions A, B, C, and D (defined by the rings formed by area cells A1–A4, B1–B8, C1–C12, and D1–D16), with a height limit of Zlim. = 400 pc above and below the Sun. We did not apply any masks for the open clusters and accounted for no Gaia DR2 incompleteness effects or observational uncertainties.
Each respective region was divided into bins with a height of 80 pc. For each bin, labelled with an index l, the stellar number density nl was given by the number of stars in that bin, and the variance 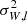 was calculated from the stars in that bin with sufficient data quality (requiring that
was calculated from the stars in that bin with sufficient data quality (requiring that 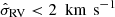 and
and 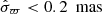 ). By using a discretised version of Eq. (C.1), the difference in the gravitational potential of two neighbouring bins with indices l + 1 and l is equal to
). By using a discretised version of Eq. (C.1), the difference in the gravitational potential of two neighbouring bins with indices l + 1 and l is equal to
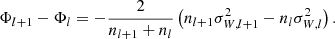 (C.2)
(C.2)
For the inferred gravitational potential of each respective bin, we estimated the statistical error by jackknifing. The number of stars in each respective region is presented in Table C.1.
Number of stars in the regions used for Jeans analysis.
The inferred gravitational potentials of regions A–D are visible in Fig. C.1, where they are normalised such that that their minimum values are equal to zero. The inferred potential is close to the expectation at higher values of |z|, but is significantly steeper close to the mid-plane, in agreement with the main analysis of this work. The inferred potential becomes increasingly noisy if choosing smaller bins (< 80 pc), especially for region A which has comparatively few stars, but still tends to the same overall result.
 |
Fig. C.1. Inferred gravitational potential using the simple Jeans analysis, for regions A–D. The grey line represents the expected case described in Sect. 2.4, where Z⊙ = 10 pc. The errorbars represent 1σ statistical uncertainties. |
Appendix D: Control plots
In this section, we compare the inferred population model with the distribution of stars, in terms of their phase-space distributions in vertical position and vertical velocity. The difference in the stellar number counts between the two are quantified in terms of a residual in the Z–w plane. It is defined
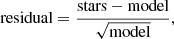 (D.1)
(D.1)
where ‘model’ refers to the number of stars in a pixel as predicted by the population model, and ‘stars’ refers to the number of stars according to the stellar parameters. The latter could in principle be called ‘data’, as the phase-space position is strongly constrained by the data for the majority of stars in our stellar samples. In the limit of high numbers, the residuals should be distributed according to a Gaussian with a standard deviation of one; however, because some pixels have a small number count, especially at the sample boundary around |Z|≃Zlim., the distribution of residuals is skewed.
Control plots are shown in Figs. D.1–D.5, for samples A1-200, C1-400, C5-400, B8-200, and B8-400. The first three are included as representative examples, where the distribution of stars in Z and w are reasonably well fitted by the population model. There is some structure that our model does not capture, for example in the form of slight asymmetries with respect the Galactic plane. Apart from this asymmetry there are no obvious phase-space features that are shared between all area cells. Stellar sample C5-400 is an example of a sample with significant open cluster masks. The latter two, B8-200 and B8-400, are special cases. As discussed in Sect. 5, area cell B8 has a substructure in the Z–w plane which our model mistakenly infers to correspond to the Galactic mid-plane, and Figs. D.4 and D.5 clearly shows that the inferred phase-space distributions are poor fits.
 |
Fig. D.1. Control plot for sample A1-200, showing the distribution of vertical position Z and vertical velocity w in one-dimensional and two-dimensional histograms, for a randomly drawn realisation of the posterior probability density. The colour bars of panels a and b show the number of stars in each respective pixel in the Z–w plane, and use the same normalisation. The colour bar in panel c shows the residuals of each respective pixel, which is the tension between the phase-space number count according to the population model and the stellar parameters (which is strongly constrained by the data). Panel d: the dashed and dotted black lines correspond to the stellar number density according to the population model, where the former includes the effective area. Similarly, the dashed black line in panel e shows the distribution of vertical velocities (marginalised over Z) according to the population model. |
The control plots of all 120 stellar samples can be found online5.
All Tables
Mid-plane densities ρt and vertical velocity dispersions σt of the baryonic matter components.
Population parameters, stellar parameters, and data of our Bayesian hierarchical model.
All Figures
|
Fig. 1. Expected total matter density shown as a 1σ band, also broken down into components of stars, cold atomic gas, molecular gas, hot gas, and halo dark matter. |
| In the text | |
|
Fig. 2. Area cells in the X-Y plane by which we constructed our data samples. The point in the centre of the plot corresponds to the position of the Sun. For each area cell, we constructed three stellar samples reaching Zlim. = {200, 300, 400} pc above and below the Sun. |
| In the text | |
|
Fig. 3. Directed acyclic graph representing the Bayesian hierarchical model. Quantities inscribed in circles (squares) are free to vary (fixed) during the inference. Arrows with dashed (solid) lines represent deterministic (probabilistic) dependencies. The large square with rounded corners represents iteration over the stars in the stellar sample. |
| In the text | |
|
Fig. 4. Effective area of stellar sample B5-400. The depression around Z = 80 pc is due to an open cluster mask. |
| In the text | |
|
Fig. 5. Inferred gravitational potential of stellar samples A1-200, A1-300, and A1-400, in the top, middle, and bottom panel, plotted in terms of its square root as a function of z. The width of the blue band shows the 16th to 84th percentile of the inferred posterior density of the respective stellar samples. The band has a lighter colour for z > Zlim., indicating that this is an extrapolation outside the spatial volume of the stellar sample. The 1σ band of the expected gravitational potential is shown in grey (identical in all panels). The black dash-dotted and dotted lines show the gravitational potential in case of a homogeneous matter density of 0.2 and 0.1 M⊙ pc−3. Top panel: we also plot the inferred potential of Widmark (2019) in red, where the dot indicates the median and the error bars cover the 10th and 90th percentiles of that work’s eight stellar sample posterior densities. |
| In the text | |
|
Fig. 6. Inferred total matter density profile of stellar sample A1-400. The width of the blue band shows the 16th to 84th percentile of the inferred posterior density. The 1σ band of the expected gravitational potential is shown in grey. |
| In the text | |
|
Fig. 7. Inferred potential for the 120 stellar samples, presented in terms of |
| In the text | |
|
Fig. 8. Inferred gravitational potential at z = 400 pc for different area cells, presented in terms of the posterior distribution median, using stellar samples with Zlim. = 400 pc. |
| In the text | |
|
Fig. 9. Inferred height of the Sun, Z⊙, for the 120 stellar samples. The samples are listed vertically according to area cell, in groups of three for different Zlim. in descending order, which are labelled by colour according to the legend. The horizontal lines represent the posterior widths, whose endpoints are equal to the 16th and 84th percentile of the posterior distribution. |
| In the text | |
|
Fig. 10. Inferred vertical velocity of the Sun, W⊙, for the 120 stellar samples. The samples are listed vertically according to area cell, in groups of three for different Zlim. in descending order, which are labelled by colour according to the legend. The horizontal lines represent the posterior widths, whose endpoints are equal to the 16th and 84th percentile of the posterior distribution. |
| In the text | |
|
Fig. A.1. Stellar number densities for the stars of regions A, B, C, and D, normalised to unity for their maximum values. The number densities of two stellar components of the baryonic model are shown in terms of their 1σ bands, in dashed and dotted grey, where Z⊙ = 10 pc. |
| In the text | |
|
Fig. C.1. Inferred gravitational potential using the simple Jeans analysis, for regions A–D. The grey line represents the expected case described in Sect. 2.4, where Z⊙ = 10 pc. The errorbars represent 1σ statistical uncertainties. |
| In the text | |
|
Fig. D.1. Control plot for sample A1-200, showing the distribution of vertical position Z and vertical velocity w in one-dimensional and two-dimensional histograms, for a randomly drawn realisation of the posterior probability density. The colour bars of panels a and b show the number of stars in each respective pixel in the Z–w plane, and use the same normalisation. The colour bar in panel c shows the residuals of each respective pixel, which is the tension between the phase-space number count according to the population model and the stellar parameters (which is strongly constrained by the data). Panel d: the dashed and dotted black lines correspond to the stellar number density according to the population model, where the former includes the effective area. Similarly, the dashed black line in panel e shows the distribution of vertical velocities (marginalised over Z) according to the population model. |
| In the text | |
 |
Fig. D.2. Same as Fig. D.1, but for stellar sample C1-400. |
| In the text | |
 |
Fig. D.3. Same as Fig. D.1, but for stellar sample C5-400. |
| In the text | |
 |
Fig. D.4. Same as Fig. D.1, but for stellar sample B8-200. |
| In the text | |
 |
Fig. D.5. Same as Fig. D.1, but for stellar sample B8-400. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.