| Issue |
A&A
Volume 619, November 2018
|
|
|---|---|---|
| Article Number | A125 | |
| Number of page(s) | 11 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/201833099 | |
| Published online | 14 November 2018 | |
Dissecting stellar chemical abundance space with t-SNE
1
Leibniz-Institut für Astrophysik Potsdam (AIP), An der Sternwarte 16, 14482
Potsdam, Germany
2
Laboratório Interinstitucional de e-Astronomia, LIneA, Rua Gal. José Cristino 77, Rio de Janeiro, RJ, 20921-400
Brazil
e-mail: fanders@aip.de
3
Instituto de Física, Universidade Federal do Rio Grande do Sul, Caixa Postal 15051, Porto Alegre, RS, 91501-970
Brazil
Received:
25
March
2018
Accepted:
28
August
2018
In the era of large-scale Galactic astronomy and multi-object spectroscopic stellar surveys, the sample sizes and the number of available stellar chemical abundances have reached dimensions in which it has become difficult to process all the available information in an effective manner. In this paper we demonstrate the use of a dimensionality-reduction technique (t-distributed stochastic neighbour embedding; t-SNE) for analysing the stellar abundance-space distribution. While the non-parametric non-linear behaviour of this technique makes it difficult to estimate the significance of any abundance-space substructure found, we show that our results depend little on parameter choices and are robust to abundance errors. By reanalysing the high-resolution high-signal-to-noise solar-neighbourhood HARPS-GTO sample with t-SNE, we find clearer chemical separations of the high- and low-[α/Fe] disc sequences, hints for multiple populations in the high-[α/Fe] population, and indications that the chemical evolution of the high-[α/Fe] metal-rich stars is connected with the super-metal-rich stars. We also identify a number of chemically peculiar stars, among them a high-confidence s-process-enhanced abundance-ratio pair (HD 91345/HD 126681) with very similar ages and v X and v Y velocities, which we suggest have a common birth origin, possibly a dwarf galaxy. Our results demonstrate the potential of abundance-space t-SNE and similar methods for chemical-tagging studies with large spectroscopic surveys.
Key words: solar neighborhood / Galaxy: abundances / Galaxy: disk / Galaxy: stellar content / stars: abundances
© ESO 2018
1. Introduction
One of the major goals of modern Galactic astrophysics is to infer the formation history of our Milky Way. To achieve this aim it is necessary to obtain precise six-dimensional (6D) stellar phase-space positions, detailed chemical abundance patterns, and reliable age estimates for large stellar samples. This chrono-chemo-kinematical map of the Galactic stellar populations can then be compared to predictions of various Milky-Way models, eventually unveiling the star-formation and dynamical history of our Galaxy.
Massive spectroscopic observing campaigns such as RAVE (Steinmetz et al. 2006), SEGUE (Yanny et al. 2009), the Gaia-ESO survey (Gilmore et al. 2012), LAMOST (Deng et al. 2012), APOGEE (Majewski et al. 2017), and GALAH (Martell et al. 2017) have in the past decade increased both the volume coverage and the statistical sample sizes by more than two orders of magnitude, to 5 × 106 stars distributed from the solar vicinity to the far side of the Galactic bulge and the outer halo. In spite of this recent conquest of the Milky Way in terms of the number of spectroscopically analysed stars, detailed multi-abundance chemo-kinematical studies of the immediate solar vicinity (e.g. Edvardsson et al. 1993; Fuhrmann 1998, 2011; Fuhrmann et al. 2017; Adibekyan et al. 2012; Bensby et al. 2014; Nissen 2015, 2016; Delgado Mena et al. 2017) remain at least equally important for Galactic Archaeology (see Lindegren & Feltzing 2013 for a quantitative analysis). Also, before Gaia’s second data release (DR2; Gaia Collaboration 2018), reliable stellar ages were still mostly confined to the solar vicinity (for exceptions using asteroseismology see Chiappini et al. 2015; Martig et al. 2015; Casagrande et al. 2016; Anders et al. 2017; Rodrigues et al. 2017; Miglio et al. 2017).
The wealth of new data, especially the high dimensionality of chemo-kinematics space, requires new statistical analysis methods to efficiently constrain detailed Milky-Way formation models (including e.g. stellar evolution, stellar chemical feedback, chemical evolution, and dynamical evolution). Traditionally, the metallicity distribution function and two-dimensional (2D) chemical-abundance diagrams ([X/Fe] vs. [Fe/H]), and abundance gradients have been used to constrain the chemical evolution of stellar populations (e.g. Pagel 2009). On the other hand, it is also possible to define stellar populations by chemistry (e.g. carbon-enhanced metal-poor stars – Beers & Christlieb 2005; the chemical thick disc – Fuhrmann 1998; high-[α/Fe] metal-rich stars – Adibekyan et al. 2011), and then to study their structural and chemo-kinematic properties in detail. Abundance-space populations are usually defined in a simple fashion, by dissecting only one 2D abundance diagram.
More thorough multi-dimensional abundance-space studies using data-mining techniques have emerged over the past years. In a pioneer study, Ting et al. (2012) used principal-component analysis (PCA) to determine the effective dimensionality of abundance space accessible by spectroscopic surveys. Da Silva et al. (2012, 2015), and Jofré et al. (2017) used tree clustering to find groups of stars with similar abundance patterns. Recently, Boesso & Rocha-Pinto (2018) studied a solar-vicinity literature compilation and combined hierarchical clustering with PCA to find peculiar chemical subgroups that do not follow the chemical-enrichment flow of the Galactic disc. Their results also suggest that 90% of the variance in the abundance data can be explained by two principal components that capture the main contributions to chemical enrichment. This is slightly at odds with the earlier work of Ting et al. (2012) who suggest that spectroscopic abundance space has at least an effective dimension of 4.
In this paper we explore the possibility of combining the information contained in various measured abundance ratios using the dimensionality reduction technique t-SNE (t-distributed stochastic neighbour embedding) to define more robust sub-populations and better identify outliers. In astronomical applications, t-SNE has mainly been used to identify objects with peculiar spectra (e.g. Matijevič et al. 2017; Valentini et al. 2017; Traven et al. 2017; Anders et al. 2018; Reis et al. 2018). Jofré et al. (2017) employed t-SNE to identify spectral twins in the RAVE database. Recently, Kos et al. (2018) demonstrated in a complementary analysis that t-SNE can also be used as a chemical-tagging tool in chemical-abundance space: the authors were able to recover seven out of nine known open and globular clusters with high efficiency and low contamination using 13 chemical abundances from the GALAH survey (Martell et al. 2017), and they also found two new field member stars to known clusters with this technique.
Here we apply abundance-space t-SNE to the high-resolution solar-vicinity HARPS-GTO survey data of Delgado Mena et al. (2017), and demonstrate that this method provides a powerful visualisation and clustering tool also for field-star chemical-tagging studies. We identify, in a robust way, several distinct chemical-abundance substructures of the solar-vicinity disc population, as well as some peculiar stars. In a subsequent paper that extends our analysis to other surveys (Chiappini et al., in prep.) we discuss the main result: the detection of distinct chemical sub-populations in the high-[α/Fe] regime that points to a different origin of the metal-poor and metal-rich part of the high-[α/Fe] disc.
The paper is structured as follows: Sect. 2 introduces t-SNE. Section 3 describes the t-SNE results for the high-resolution spectroscopic solar-vicinity survey of Delgado Mena et al. (2017), considering possible caveats in our analysis and characterising each of the found sub-populations. We finish with a discussion and conclusions in Sect. 4.
2. Dissecting chemistry space with t-SNE
Interpreting multi-dimensional abundance distributions determined by spectroscopic surveys is not a trivial task, since different elements originate in different astrophysical sites and at different rates, and their abundance determination is affected by variable observational errors. A convenient way to simplify this problem is dimensionality reduction, i.e. the projection of the N-dimensional abundance space onto a lower-dimensional space in which the chemical similarity between two stars is reflected by their distance in that space. Possibly the best-known such method is PCA, widely used also in astronomical literature. For highly-correlated datasets such as spectral pixel spaces or chemical-abundance spaces, however, more sophisticated non-linear methods like IsoMap or locally linear embedding are known to perform much better (e.g. Matijevič et al. 2012; Ivezić et al. 2013).
In this paper, we reanalyse the high-resolution spectroscopic solar-vicinity survey of Delgado Mena et al. (2017) using a machine-learning algorithm called t-distributed stochastic neighbour embedding (t-SNE; Hinton & Roweis 2003; van der Maaten & Hinton 2008). This method is widely used in big-data analytics, and is able to efficiently project complex datasets onto a 2D plane in which the proximity between similar data points is preserved. We use the python implementation of t-SNE included in the scikit-learnpackage (Pedregosa et al. 2012) and refer to the original papers and the online documentation for details about the method and code. In short, the advantage of using t-SNE over other manifold-learning techniques is that it performs much better in revealing structure at many different scales (van der Maaten & Hinton 2008; Matijevič et al. 2017), which is a necessary feature when looking for chemical substructure in the Galactic disc.
How t-SNE works. For a given set of N high-dimensional datapoints x 1, …, x N (images, spectra, or in our case chemical-abundance vectors), t-SNE first computes pairwise similarity probabilities p i j for the points x i and x j :
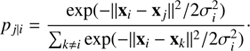
To circumvent problems with outliers, the symmetrised similarity of x j and x i is defined as
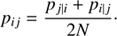
In the next step, t-SNE attempts to learn a d-dimensional map y 1, …, y N (in general d = 2) that reflects the similarities p i j between two points y i and y j in the low-dimensional map, defined as
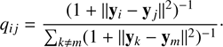
This metric uses Student’s t distribution to avoid crowding problems in the low-dimensional map (van der Maaten & Hinton 2008). Starting from a random Gaussian distribution in the d-dimensional map, the locations of the points y i are determined by minimising the Kullback–Leibler divergence (Kullback & Leibler 1951) between the low- and high-dimensional similarity distributions Q and P,

using a gradient-descent method. The result of this optimization is a 2D (or 3D) map that reflects the similarities between the high-dimensional inputs (see Figs. 1 and 2).
 |
Fig. 1. Illustration of how t-SNE works in abundance space, using the Delgado Mena et al. (2017) sample. The small panels show eleven of the possible ∼20 000 abundance diagrams that can be created from 13 elements. The resulting reference t-SNE projection of the full abundance space is shown in the big panel, and several identified sub-groups are indicated. For reference, the Sun would be found very close to the solar-abundance twin HD 212036 ([Fe/H] = −0.01, [X/Fe] = 0 + −0.05 for all measured elements X), which is located at (Xt − SNE, Yt − SNE) = (−4.57, 1.46). |
 |
Fig. 2. Fiducial t-SNE projection of the Delgado Mena et al. (2017) sample (see big panel in Fig. 1), colour-coded by chemical abundances (top three rows), spectroscopic parameters (effective temperature T eff, surface gravity logg, microturbulence ξ, and signal-to-noise ratio logS/N; fourth row), age τ (fifth row, first panel) and space velocities (fifth row). We note that only [Fe/H] and the [X/Fe] ratios were used as input for the t-SNE run. |
The method has one main parameter, the so-called perplexity, p, which governs the bandwidth of the Gaussian kernels σ i appearing in the similarities p i j . As a result, the bandwidth is adapted to the density of the data: smaller values of σ i are used in denser parts of the data space. The perplexity parameter can be thought of as a guess about the number of close neighbours each point has, and therefore the ideal value for p depends on the sample size. A change in perplexity has in many cases a complex effect on the resulting map, and different values for p should be explored (Wattenberg et al. 2016).
Recently, Linderman & Steinerberger (2017) demonstrated that two other hyper-parameters of t-SNE can be chosen optimally: the learning rate should be set to ∼1, and the early-exaggeration parameter should be set to ∼0.1 times the sample size. In the following, we use these recommendations.
In addition, t-SNE, as a genuine machine-learning technique, does have two drawbacks that are relevant for our science case. First, it does not account for individual uncertainties, and may therefore be affected by extremely heteroscedastic errors. We mitigate this shortcoming by performing a simple Monte-Carlo experiment (Sect. 3.2) to show that our results are robust to abundance uncertainties. Secondly, its current implementations do not allow us to treat missing data, so that any star with a missing individual abundance measurement has to be excluded. We therefore decided to focus on the most inclusive set of chemical abundances (see Sect. 3).
3. Re-analysing the HARPS GTO sample
In an extensive series of papers, Adibekyan et al. (2011, 2012); Delgado Mena et al. (2014, 2015, 2017, 2018), Bertran de Lis et al. (2015), and Suárez-Andrés et al. (2017) studied the chemical abundances of a sample of 1111 solar-vicinity FGK stars using the very high resolution of the HARPS spectrograph (R ∼ 115 000). This sample mostly contains metal-rich warm dwarf and sub-giant stars, but also includes a wide range of effective temperatures, gravities and metallicities. The HARPS sample initially served to detect and characterise exoplanets is volume-complete within 60 pc and was selected in such a way that metallicity biases are avoided (Adibekyan et al. 2013). The HARPS metallicity distribution (MDF) agrees well with the MDF of the 25 pc volume-complete sample of Fuhrmann (2011) and the high-quality local (d < 1 kpc) APOGEE DR10 red-giant sample of Anders et al. (2014).
Delgado Mena et al. (2017) recently reanalysed this sample, employing a revised linelist (Tsantaki et al. 2013), improving the effective temperature calibration, and correcting spectroscopic gravities using the HIPPARCOS parallaxes of van Leeuwen (2007). They report chemical abundances for Mg, Al, Si, Ca, Ti, Fe, Cu, Zn, Sr, Y, Zr, and Ba for 1059 stars (Ce, Nd and Eu are available for a substantial subset of these), derived using standard local thermodynamic equilibrium (LTE) analysis using ARES (Sousa et al. 2007, 2015) to measure equivalent widths and MOOG (Sneden 1973) to measure abundances by comparing to Kurucz ATLAS9 atmospheres (Kurucz 1993). These chemical abundances were complemented by photometry from APASS DR9 (Henden & Munari 2014) and 2MASS (Cutri et al. 2003), and by astrometry (parallaxes, proper motions) from the Gaia DR1/TGAS catalogue (Michalik et al. 2015; Gaia Collaboration 2016), or when these were unavailable (135/1059 stars), from the re-reduced HIPPARCOS data (van Leeuwen 2007). Using the combined spectroscopic, photometric, and astrometric data, we computed precise stellar masses, ages, distances, and extinctions using the StarHorse code (Queiroz et al. 2018). For this run, we employed a fine grid (Δlogτ = 0.01 dex, Δ[Z/H] = 0.02 dex) of PARSEC 1.2S stellar models (Bressan et al. 2012; Tang et al. 2014; Chen et al. 2015), which significantly improved the precision of our ages with respect to the default grid (Δlogτ = 0.05 dex, Δ[Z/H] = 0.05 dex). The median age precision of the final t-SNE sample is 14%.
The kinematic results are based on Gaia DR1/TGAS positions and proper motions, radial velocities from Adibekyan et al. (2012), our StarHorse distances, and the orbit-integration tool galpy (Bovy 2015), using the new Staeckel approximation implementation of Mackereth & Bovy (2018) to determine orbital eccentricities e and maximum heights above the plane Z max. Galactic space velocities were estimated adopting a solar Galactocentric distance of 8.3 kpc, a local standard-of-rest velocity of 220 km s−1, and solar peculiar velocities as in Piffl et al. (2014).
In this section we test the performance of abundance-space t-SNE on this most recent HARPS GTO sample compilation. The high number of measured abundances, in conjunction with the high precision of the measurements and the easily tractable sample size, makes the HARPS sample an ideal test case for machine-learning algorithms. Our first tests showed that, in order to obtain reliable t-SNE abundance maps, the sample needed to be analysed in a more restricted temperature range, because certain abundance trends seem to be dominated by underlying temperature trends. Therefore, similar to Delgado Mena et al. (2017), we chose an effective temperature range of 5300 K < T eff< 6000 K (satisfied for 539 stars) for our analysis. We furthermore excluded one star with log gHIP < 3, and required successful abundance determination for Mg, Al, Si, Ca, TiI, Fe, Cu, Zn, Sr, Y, ZrII, Ce, and Ba that we use as input for t-SNE, leaving us with 533 stars1. To compensate for the fact that t-SNE does not take into account individual (heteroscedastic) uncertainties in the data, we followed the approach of Hogg et al. (2016) and rescaled each abundance by the median uncertainty in that element, assuming an abundance uncertainty floor of 0.03 dex. In our final sample of 530 stars we also discarded three stars for which our age determination code, StarHorse (Santiago et al. 2016; Queiroz et al. 2018), did not converge. We verified that these choices do not significantly affect the resulting t-SNE maps.
The result of our reference t-SNE projection (perplexity p = 40) is illustrated in Fig. 1. The figure shows how the neighbourhood of points in several abundance diagrams (small panels) is reflected in the t-SNE map (big panel). In Fig. 1 we also identified and named some substructures that clearly emerge from the t-SNE projection. The groupings were visually defined by jointly analysing t-SNE projections with different hyper-parameters (most importantly, perplexity). The robustness of each of the substructures and groups is discussed extensively below. The naming of the subgroups was inspired by previous knowledge about the chemo-chrono-kinematic relations of Galactic stellar populations.
Figure 2 again shows our reference t-SNE map for the HARPS sample, but now colour-coded by chemical-abundance ratios, stellar parameters, ages, and kinematics. The panels in the first three rows show how t-SNE groups the stars with similar abundances in the two-dimensional plane. The panels coloured as a function of stellar parameters demonstrate that the sample is not subject to major systematic abundance shifts, but does show some residual trends with effective temperature, since it preferentially groups cooler stars in slightly different regions of the t-SNE map from hotter ones. Because part of this effect may be due to chemical evolution rather than systematic abundance errors, we refrained from applying ad-hoc corrections to the abundances.
Figure 3 shows the corresponding [X/Fe] abundance trends versus proton number for each of the substructures identified in Fig. 1. We now proceed to the discussion of these results.
 |
Fig. 3. Chemical-abundance patterns relative to iron for the t-SNE-selected subsamples of the HARPS survey, using the same symbols and colours as in Fig. 1. For each population we show the median abundance trend, as well as the full abundance distribution (for the top two panels). For visibility, we divided the sample into three groups that are shown separately in the three panels. The “thin disc” population (black circles) is shown in all panels for comparison. |
3.1. The overall appearance of the t-SNE map
Our reference t-SNE projection shown in Figs. 1 and 2 reveals significant amounts of substructure in the local chemical-abundance space. The non-linearity of the method makes it difficult to attribute the overall appearance of the map to specific elemental abundances, which is why we limit this discussion to a qualitative level. In accordance with earlier studies of the dimensionality of abundance space (e.g. Ting et al. 2012; Boesso & Rocha-Pinto 2018), our results suggest that most of the variance of the data is in the metallicity and [α/Fe] abundance dimensions, corresponding to the different timescales of supernovae type Ia and type II. In fact, the X dimension of the t-SNE map correlates very well with metallicity (Pearson’s correlation coefficient r = −0.95; see Fig. 2, top left panel), which means that a lot of information about the chemical pattern of a star is already given by its metallicity. The t-SNE X dimension is also highly correlated with [α/Fe] (e.g., r = 0.92 for [Ca/Fe] and r = 0.87 for [TiI/Fe]).
Figure 2 also demonstrates that the t-SNE map’s Y dimension, although it also correlates with [α/Fe] and [Zn/Fe] abundances, encodes information on s-process abundances, for example [Ba/Fe] and [Y/Zn], and consequently stellar age, a variable that was not included in the inference. In principle this opens up the possibility for calibrating multi-element chemical clocks.
The fourth row of Fig. 2 also shows that the t-SNE projection responds to elemental-abundance trends with stellar parameters, although they have not been included as input parameters, and although we work in a narrow effective-temperature bin: t-SNE places stars with slightly different stellar parameters in slightly different places on the map. For example, we see some residual abundance trends with T eff (fourth row, left panel), which may either be due to possible systematic abundance errors (see also Delgado Mena et al. 2017), or due to real stellar population trends (with stellar mass). In the case of logg (fourth row, second panel), the trends are likely not due to systematic errors, but due to stellar and chemical evolution: at fixed T eff on the main sequence, logg is a proxy for stellar age, and the abundance patterns are expected to vary with age.
By construction, t-SNE clusters similar-abundance stars in different places on the map. The several discernible islands on the map suggest that we are able to identify stars that were formed from gas with significantly different chemical enrichment than the bulk of the disc stars that live on the “main island” of the map. In the following subsection, we will show that most of the substructures identified in Fig. 1 are robust to abundance uncertainties and reasonable variations in our analysis.
3.2. The robustness of the t-SNE results
As discussed in Sect. 2, the overall appearance of the maps produced by t-SNE depends mainly on the perplexity parameter p, as well as on the chosen parameter space. In Fig. 4, we show the t-SNE maps for different perplexity values and different sets of input parameters, using the same colours and symbols as in Fig. 1. This experiment shows that:
-
The main features (i.e. neighbourhood relations between points) of the map are preserved (modulo map rotations and/or reflections) for a wide range of perplexities,.
-
The groups defined in Fig. 1 are also robustly recovered for different perplexities.
-
Using only [X/Fe] abundance ratios results in slightly different maps, which can be explained by the higher abundance precision of [Fe/H] with respect to the [X/Fe], and the thus higher weight of this dimension in the t-SNE projection. The [Fe/H] dimension alone, however, is not responsible for the emergence of the prominent subgroups.
-
Adding ages and/or kinematics to the input parameter space does not significantly improve the t-SNE projection, at least in this special case of very local, high-resolution, and high-signal-to-noise data. In the case of moving groups or globular clusters, however, adding kinematic dimensions to chemical tagging exercises does seem to help the recovery of known clusters (Chen et al. 2018).
 |
Fig. 4. t-SNE representations of the chrono-chemo-kinematics space spanned by the Delgado Mena et al. (2017) sample. Each column represents a combination of input information (only [X/Fe], [X/Fe] + [Fe/H], [X/Fe] + [Fe/H] + age, and [X/Fe] + [Fe/H] + age + space velocities, respectively), while each row corresponds to a particular perplexity value, as indicated on the right side of the figure. The panel highlighted in yellow represents the results that we analyse in detail in this paper by defining chemical sub-populations based on this map. |
 |
Fig. 5. Robustness test of our t-SNE-selected subsamples to abundance errors. The left panel shows the fiducial map, while the right panel shows the result of our Monte-Carlo test. For each star, 50 random stars were drawn from a Gaussian centred on the measured abundance, and with dispersions corresponding to the measured uncertainties. t-SNE was then run on this artificially increased sample. The resulting map (for p = 40) shows the positions of each Monte-Carlo realisation as faint grey dots, and the median position of each star as the same big symbol as in the fiducial map. The experiment demonstrates that most of our selected subgroups are robust to doubling the observational errors of the HARPS sample. |
3.3. Disc sub-populations
In this subsection, we discuss the main groups and features identified in Fig. 1 in more detail.
The thin-thick disc dichotomy. As discussed in the works of Adibekyan et al. (2011, 2012) and Delgado Mena et al. (2017), the HARPS-GTO data confirm the clear discontinuity between the high- and the low-[α/Fe] sequences in the [Mg/Fe]–[Fe/H] diagram (e.g. Edvardsson et al. 1993; Fuhrmann 1998, 2011; Fuhrmann et al. 2017). This discontinuity is reflected in a very clear manner in the t-SNE projection: we find a clear and obvious gap between the chemical thin- and thick-disc populations in the t-SNE diagram that remains very robust for different choices of the t-SNE hyper-parameters. Primarily, this means that the chemical patterns of thin and thick disc are indeed distinct, and can be disentangled by high-resolution spectroscopy. Secondly, our analysis of the full chemical information results in a much more accurate division of the chemical thin and thick populations. Indeed, if one only relies on one diagnostic, such as the [Mg/Fe]–[Fe/H] diagram (Adibekyan et al. 2011; Delgado Mena et al. 2017), some thick-disc stars would (probably incorrectly) be identified as belonging to the chemical thin disc (see Fig. 1).
H i g h − [α/F e]s u b − p o p u l a t i o n s. Adibekyan et al. (2011) first discovered a clear discontinuity between the metal-poor and metal-rich [α/Fe]-enhanced disc populations (although there are earlier indications in the literature, e.g. Fuhrmann 2008, Fig. 30). In our t-SNE analysis of the Delgado Mena et al. (2017) sample, similar to the original paper, we also see a clear difference between at least two, maybe three or four populations (dubbed Thick Disc I/II and Inner Disc I/II in Fig. 1). Even if ages and/or kinematics are included as additional dimensions in the analysis, this picture does not change much. The implications of this result, which we can also confirm with other high-resolution data covering larger volumes, will be discussed in depth in a companion paper (Chiappini et al., in prep.).
The middle panel of Fig. 3 shows the abundance profile with respect to iron for each of the four [α/Fe]-rich populations, compared to the chemical thin disc. The figure suggests that most of the abundance variance among the four groups can be captured by one parameter (e.g. metallicity). There are, however, subtle deviations from this pattern: for example, group Thick Disc II is more enhanced in [Al/Fe] than group Thick Disc I. Figure 6 shows that the Inner Disc populations I–IV form a rather tight chemical-evolution sequence in many abundance versus age diagrams, separated from the Thick-Disc I/II by a jump in [α/Fe] abundances.
 |
Fig. 6. Abundance trends of the HARPS-GTO abundances with stellar age, measured with the StarHorse code (Queiroz et al. 2018). |
Super-metal-rich stars. The Inner Disc IV population (western-most stars in the t-SNE plane; orange stars in Fig. 1) encompasses super-metal-rich stars (SMR; [Fe/H] ≳ 0.3; see Grenon et al. 1972; Grenon 1989, 1999; Chiappini et al. 2009). They have only slightly different abundance patterns from the bulk of the thin-disc stars (black dots; see Fig. 3, top panel); however, Fig. 2 shows that they are enhanced in [Y/Ba] and [Cu/Fe] with respect to the local thin disc, indicative of an origin in the inner Milky Way disc. Figures 6 and 7 show that most of these stars have ages between 4 and 8 Gyr (Trevisan et al. 2011; Casagrande et al. 2011; Anders et al. 2017), and are on cold orbits (e < 0.12; e.g. Kordopatis et al. 2015), which again supports the idea that they have radially migrated from the inner disc (see e.g. Minchev et al. 2012, 2013, 2014; Vera-Ciro et al. 2014; Grand & Kawata 2016).
 |
Fig. 7. Kinematic trends of the HARPS-GTO sample. The upper panels show the distribution of the sample in the v X − v Y (or U V) and v Y − v Z (V W) planes. We note that the 1σ errorbars are in most cases smaller than the symbols. The middle left panel shows the classic Toomre diagram (e.g. Feltzing et al. 2003), and the middle right panel shows a diagram of orbital heating (as measured by v X and v − Z) as a function of age. The bottom panels display the orbital eccentricities and maximum heights above the Galactic plane, respectively, as a function of age. |
T h e t r a n s i t i o n f r o m h α m r t o S M R s t a r s. Most literature measurements agree that the high- and low-[α/Fe] sequences in the [α/Fe]–[Fe/H] diagram merge at super-solar metallicities (e.g. Adibekyan et al. 2011; Anders et al. 2014; Hayden et al. 2015). In other words, the upper metallicity limit of the high-[α/Fe]/hαmr population is not yet firmly established. Our analysis shows that even when including the full chemistry information, the high-[α/Fe]-like and SMR population still form a sequence in the t-SNE projection (e.g. the dark yellow triangles in Fig. 1 have intermediate characteristics between the red triangles and the orange stars). This is why we named the hαmr groups “Inner Disc I/II” in Fig. 1, meaning that they do not belong to the genuine thick disc. In fact, they are slightly younger and kinematically colder than the “Thick Disc” populations. This is shown in Fig. 7, which shows different projections of our sample in velocity-age space, as well as orbital parameters as a function of age (more discussion in Chiappini et al., in prep.).
The outer disc population. The green squares and circles in Fig. 1 correspond to the metal-poor thin disc ([Fe/H] ∼ − 0.5). Apart from metallicity, its main abundance differences with respect to the bulk of the chemical thin-disc population are: 1) a slight elevation in all [α/Fe] ratios as a consequence of the later onset of star formation in the outer disc, from which this population is most likely to originate (e.g. Nordström et al. 2004; Anders et al. 2014; Hayden et al. 2015; see also kinematic diagnostics in Fig. 7), 2) a slight underabundance of [Sr/Fe] and [Y/Fe] with respect to the thin-disc population, but solar-like second s-process peak abundances, and 3) a hint of a systematic r-process ([Eu/Fe] ∼ 0.2) enhancement (consistent with that in [α/Fe] with respect to the local disc.
The young locally born disc. The grey circles in Fig. 1 denote a population that we call young local disc, because 1) they are among the youngest stars (∼1 Gyr; see Fig. 6), and 2) they follow the local rotation curve with a very low velocity dispersion (see Fig. 7, top panels). The young local disc stars have near-solar metallicities and are slightly deficient in [Mg/Fe], [Al/Fe], and [Si/Fe] with respect to the Sun and the rest of the thin disc, as expected for young stars from the stronger contribution of SN Ia yields. They are also systematically deficient in [Cu/Fe] and [Zn/Fe], while being moderately enhanced ([s/Fe]∼0.15) in s-process elements (see Figs. 3 and 6). In fact, these stars occupy the upper boundary in the [Ba/Fe]-age and [Ba/Y]-age relations of the thin disc (see also Spina et al. 2018), but are still roughly consistent with the trends set by chemical-evolution models with metallicity-dependent yields from intermediate- and low-mass AGB stars (e.g. Cristallo et al. 2009 2015; Da Silva et al. 2016; Delgado Mena et al. 2017).
The remaining thin-disc component. The black dots in Fig. 1 stand for the remaining parts of the low-[α/Fe] solar-vicinity disc (7 kpc ≲R guide ≲ 9 kpc). The morphology of this population in the t-SNE map confirms that this reference “thin disc” is not a homogeneous monolithic population either (possibly more substructure could be defined, although less robustly; see Fig. 5). Within the scope of this paper we define the thin disc as a broad component that has a wide range of ages and birth places, and therefore could in principle also cover a wider range of chemical abundances. Figure 3 shows, however, that our “thin disc” population, while covering a considerable metallicity range from −0.3 to 0.24, has quite small spreads in each elemental abundance relative to iron, and closely follows the solar abundance pattern. This suggests that the chemical evolution of the interstellar medium in the disc must have been slow and very homogeneous for the past ≲10 Gyr (e.g. Nissen 2016). The significant spread in the age-metallicity relation of the solar-neighbourhood thin disc (Fig. 6) can be explained by the presence of a strong radial metallicity gradient, together with radial mixing (e.g. Haywood 2006; Minchev et al. 2013, 2018; Anders et al. 2017).
3.4. Chemically peculiar stars
In addition to the main disc populations discussed in the previous subsection, Fig. 1 also highlights a number of outliers and chemically peculiar stars revealed by the t-SNE projection. Some of them are known peculiar objects, some are solid, and some are dubious candidates. Their abundance patterns relative to iron are shown in the bottom panel of Fig. 3. Here we discuss each of them briefly.
s-process-enhanced stars. Our method clearly singles out a small group of stars with dwarf-galaxy- or globular-cluster-like, and s-process-enhanced abundance patterns (a few more were lost due to the temperature and abundance quality cuts). These seven stars (yellow points in Fig. 1) are all enhanced in the measured s-process elements with respect to both the thin and thick disc populations (see Fig. 3, bottom panel). They are also old (see Fig. 6), enhanced in [α/Fe] – although there is considerable star-to-star variance –, and all of them are [Al/Mg]-poorer than the thick-disc populations, placing them in an abundance regime somewhere in-between Galactic thick disc, the halo, and massive dwarf-galaxies.
The most extreme abundance outlier in this group, as already noted by Delgado Mena et al. (2017), is HD 11397 (yellow hexagon), which shows the highest s-process abundances of the entire sample ([s/Fe]∼0.7). It was classified as a so-called mild barium star by Pompéia & Allen (2008) who also showed that its s-process abundance pattern is compatible with typical AGB stellar yields, possibly accreted from an unseen companion. Another star that was noted as a mildly s-enhanced thick-disc star by Delgado Mena et al. (2017) is HD 126803 (yellow square). The last mild s-enhancement candidate of Delgado Mena et al. (2017), CD–436810, did not satisfy our T eff criterion, and was therefore not included in our analysis.
s-process-enhanced stars with halo kinematics. HD 175179 (yellow pentagon) as well as BD+083095 and CD–4512460 (yellow diamonds) are mildly [s/Fe]-enhanced, old halo-kinematic stars with very similar abundance patterns and metallicities between −0.66 and −0.86. BD+083095 and CD–4512460 are shown with the same symbol in all figures because they also have similar kinematics.
A high-confidence s-process-enhanced abundance pair. The yellow triangles in all figures correspond to the nearby high proper-motion stars HD 91345 and HD 1266812. We find that the HARPS-derived abundances of Delgado Mena et al. (2017) are so similar for these two stars that they can be considered abundance-ratio twins (see Table 1). With the exception of metallicity (2σ-deviation), all [X/Fe] abundances are consistent with each other within the respective 1σ uncertainties. They have the two highest [Si/Fe] enrichments of the sample. In connection with their similar ages and space velocities (except for the discrepant v Z component and the slightly different [Fe/H] abundances), and considering the rareness of [s/Fe]-enhanced metal-poor disc stars, we propose that the two stars could have been born in the same stellar system (possibly a massive globular cluster or a dwarf galaxy) that has long since been disrupted by the Milky Way (see e.g. Bekki & Tsujimoto 2016).
Another debris candidate at higher metallicity. HD 28701 (brown diamond in Fig. 1) is another interesting object with similar s-process enhancements as the [s/Fe]-enhanced stars discussed above, but at higher metallicity ([Fe/H] = −0.32). Like the group of yellow stars, it shows mildly enhanced ([s/Fe]∼0.2) abundances of Sr, Y and Zr when compared to thick-disc stars of similar metallicity, and not as much enhancement in the second s-process peak elements Ba, Ce and Nd. It is also enhanced in the r-process element europium ([Eu/Fe] = 0.30 ± 0.06). Bensby et al. (2014) and Battistini & Bensby (2016) report very similar abundances for this star.
High-[Ti/Fe] candidate. HD 14452 (lime-green pentagon, S/N HARPS = 89) has possibly the most extraordinary abundance pattern of the Delgado Mena et al. (2017) sample. It has a metallicity of [Fe/H] = −0.16 ± 0.02 and seems to be highly enriched in the heavier α-elements titanium and calcium ([TiI/Fe] = 0.52 ± 0.05, [Ca/Fe] = 0.37 ± 0.10), while being only slightly enhanced in [Mg/Fe], and not at all in [Si/Fe]. Also the elevated [Al/Mg] ratio is puzzling. However, a reanalysis of the equivalent widths used for the TiI abundance determination has shown that the high [TiI/Fe] value measured in Delgado Mena et al. (2017) should be revised to a lower value (Delgado-Mena, priv. comm.). If an abundance pattern with extreme Ca and Ti enrichment like the one for HD 14452 shown in Fig. 3 were confirmed, this would have made the star a very interesting object: this abundance pattern would suggest a peculiar chemical enrichment, for example by a ∼15 M ⊙ type-II supernova that did not produce light α elements but large amounts of Ca and Ti (e.g. Ritter et al. 2018, Fig. 26). A further interesting point is its rather young age (∼4 ± 2 Gyr), which would have made the star an extreme outlier to the age-[Ti/Fe] relation (Fig. 6, third panel) and a (metal-rich) candidate young [α/Fe]-rich star (Chiappini et al. 2015; Martig et al. 2015). A plausible explanation for such an object could be that it is the surviving secondary star of an old binary system whose much more massive primary exploded in a type-II supernova that polluted the atmosphere of the companion.
Low-[Mg/Fe] candidate. HD 113513 (black square) is not really an outlier in the t-SNE map, but the star with the lowest [α/Fe] ratios of the sample, and it also sticks out in several of the abundance diagrams shown in Fig. 1. Its abundance profile is similar to the “young local disc” population defined above, except for its higher metallicity and the elevated [Al/Mg] ratio. We note the low signal-to-noise ratio (S/N HARPS = 26) of the spectrum, and the consequently higher abundance uncertainties, which make this star a lower confidence outlier.
High-[Al/Mg] candidate. HD 29428 (blue octogon) is most likely not a truly anomalous star, but a typical youngish thin-disc star with a very uncertain Al measurement ([Al/Fe] = 0.43 ± 0.46) that ended up as an outlier in the t-SNE map because the method cannot account for heteroscedastic errors.
Details of the s-process-enhanced abundance-ratio pair HD 91345 and HD 126681.
4. Discussion and conclusions
The solar vicinity comprises a well-established mixture of stellar populations, among them halo stars, thick- and thin-disc stars, stars in streams, stars passing by on eccentric orbits, stars on circular orbits that have radially migrated, chemically peculiar stars, and even stars with possibly extragalactic origins (e.g. members of disrupted dwarf galaxies or globular clusters). In this paper we have demonstrated the use of the dimensionality reduction algorithm t-SNE to better define sub-populations in abundance space. While the non-parametric, non-linear behaviour of the technique makes it difficult to estimate the significance of subgroups or clusters that are found, we have verified that our results depend little on the t-SNE parameter choices and are robust to abundance errors. As in other differential abundance studies, it is important to confine the analysis to narrow regions in atmospheric-parameter space to avoid spurious abundance trends induced by differences in atmospheric parameters. The t-SNE method could in principle even be coupled to a genuine cluster finding algorithm.
Our approach allowed us to define chemical sub-populations in the solar vicinity in a more reliable way than by just looking at 2D abundance diagrams. The gap between the chemical thin and thick discs is much more prominent, as is the separation between the genuine thick-disc and the high-α metal-rich population. The high-[α/Fe] population may even be composed of more than two distinct populations, but this affirmation is not as robust to abundance uncertainties. The metal-rich end of the high-α metal-rich population and the super-metal-rich thin-disc stars are not clearly separated in our t-SNE map, which suggests that their chemical evolution is connected (both have origins in the inner disc, (Adibekyan et al. 2012; Haywood et al. 2018, see also Chiappini et al., in prep.).
We also re-characterise the chemical thin-disc component, even excluding the metal-poor and super-metal-rich parts corresponding to stars originating from the outer and inner disc, respectively. This broad component still covers a considerable metallicity range (∼− 0.3 to +0.25) and a wide range of ages (∼10 Gyr), but has surprisingly similar abundances to the Sun, and very small spreads in the α abundances (σ[α i /Fe]≃0.03 – smaller than the individual abundance uncertainties except for [Mg/Fe]), while [s/Fe] abundances dispersions (∼0.08 dex) are slightly higher than the observational uncertainties (e.g. ∼0.04 dex for [Ba/Fe]) because s-process elements are more sensitive to age and birth radius. In accordance with previous literature, we attribute these facts to a slow and homogeneous chemical evolution in the disc that is mainly characterised by a negative radial metallicity gradient, as well as strong radial migration that brought stars from various Galactic radii into the solar vicinity.
We found several chemically peculiar stars and candidates, of which most are s-process enhanced stars. Other outliers, such as the intriguing high-[Ti/Fe] candidate HD 14452, are more likely to be due to erroneous abundance measurements.
Our identification of the s-process-rich abundance pair HD 91345/HD 126681 in Sect. 3.4 demonstrates the potential of abundance-space t-SNE for chemical tagging. The viability of t-SNE for strong chemical tagging (finding dispersed members of open clusters) is still not completely clear, though. The GALAH results of Kos et al. (2018) suggest that it is possible to recover a large fraction of open clusters with abundance-space t-SNE, and to even find extra-tidal cluster members with this technique. On the other hand, the recent APOGEE paper by Ness et al. (2018) adopts a more pessimistic view on strong chemical tagging: the authors find that most 0.03-dex level abundance pairs (at solar metallicity) were probably not born in the same cluster, but are rather “doppelgänger-abundance” stars than actual twins. Our abundance pair is arguably a rarer case than a solar-abundance pair, and may well be a real abundance-ratio twin, as also suggested by the very similar (and precise) ages, as well as v X and v Y space velocities. The slightly (2σ) discrepant [Fe/H] abundances could be explained naturally if the progenitor system was a massive (ω Cen-like) globular cluster or a dwarf galaxy. The question why the v Z velocities are so different remains to be resolved, as well as the question of whether we can find more stars with similar abundance patterns.
Carbon and oxygen abundances are available from previous studies (Suárez-Andrés et al. 2017; Bertran de Lis et al. 2015), but since they are based on previous stellar parameter estimates, we decided not to include them in the t-SNE runs and only use them in the interpretation. We also did not use Nd and Eu in the t-SNE run, because they were only available for about half of the sample (stars with the highest signal-to-noise ratios).
Both stars were observed by various solar-vicinity spectroscopic surveys such as RAVE (Steinmetz et al. 2006; Kunder et al. 2017) and GCS (Nordström et al. 2004; Casagrande et al. 2011), resulting in compatible spectroscopic parameter determinations (although of lower quality). Using high-resolution spectroscopy, Bensby et al. (2014) measured a slightly lower metallicity for HD 126681 ([Fe/H] = −1.3), but a very similar abundance profile to the HARPS one analysed here.
Acknowledgments
We thank the referee for comments and suggestions that helped to improve the quality of this work. F.A. would like to thank Elisa Delgado-Mena for sharing the re-reduced HARPS-GTO data prior to publication and for carefully reinspecting the spectrum of HD 14452. He also thanks Katia Cunha, Ivan Minchev, Paula Jofré, Bertrand Lemasle, and the other participants of the IAU symposium 334 in Potsdam, as well as David W. Hogg and Roland Drimmel, for encouragement and critical thoughts.
References
- Adibekyan, V. Z., Santos, N. C., Sousa, S. G., & Israelian, G. 2011, A&A, 535, L11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Adibekyan, V. Z., Sousa, S. G., Santos, N. C., et al. 2012, A&A, 545, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Adibekyan, V. Z., Figueira, P., Santos, N. C., et al. 2013, A&A, 554, A44 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Anders, F., Chiappini, C., Santiago, B. X., et al. 2014, A&A, 564, A115 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Anders, F., Chiappini, C., Minchev, I., et al. 2017a, A&A, 600, A70 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Anders, F., Chiappini, C., Rodrigues, T. S., et al. 2017b, A&A, 597, A30 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Anders, F., Queiroz, A. B., Chiappini, C., et al. 2018, in Rediscovering Our Galaxy, eds. C. Chiappini, I. MinchevE. Starkenburg, & M. Valentini, IAU Symp., 334, 153 [NASA ADS] [Google Scholar]
- Battistini, C., & Bensby, T. 2016, A&A, 586, A49 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Beers, T. C., & Christlieb, N. 2005, ARA&A, 43, 531 [NASA ADS] [CrossRef] [Google Scholar]
- Bekki, K., & Tsujimoto, T. 2016, ApJ, 831, 70 [NASA ADS] [CrossRef] [Google Scholar]
- Bensby, T., Feltzing, S., & Oey, M. S. 2014, A&A, 562, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bertran de Lis, S., Delgado Mena, E., Adibekyan, V.Z., Santos, N.C., & Sousa, S.G. 2015, A&A, 576, A89 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Boesso, R., & Rocha-Pinto, H. J. 2018, MNRAS, 474, 4010 [NASA ADS] [CrossRef] [Google Scholar]
- Bovy, J. 2015, ApJS, 216, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Bressan, A., Marigo, P., Girardi, L., et al. 2012, MNRAS, 427, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Casagrande, L., Schönrich, R., Asplund, M., et al. 2011, A&A, 530, A138 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casagrande, L., Silva Aguirre, V., Schlesinger, K. J., et al. 2016, MNRAS, 455, 987 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, B., D’Onghia, E., Pardy, S. A., et al. 2018, ApJ, 860, 70 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, Y., Bressan, A., Girardi, L., et al. 2015, MNRAS, 452, 1068 [NASA ADS] [CrossRef] [Google Scholar]
- Chiappini, C. 2009, in IAU Symp., eds. J. Andersen,B. Nordström, & J. Bland-Hawthorn, 254, 191 [Google Scholar]
- Chiappini, C., Anders, F., Rodrigues, T. S., et al. 2015, A&A, 576, L12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cristallo, S., Straniero, O., Gallino, R., et al. 2009, ApJ, 696, 797 [NASA ADS] [CrossRef] [Google Scholar]
- Cristallo, S., Straniero, O., Piersanti, L., & Gobrecht, D. 2015, ApJS, 219, 40 [NASA ADS] [CrossRef] [Google Scholar]
- Cutri, R. M., Skrutskie, M. F., & van Dyk, S. 2003, 2MASS All Sky Catalog of Point Sources [Google Scholar]
- Da Silva, R., Porto de Mello, G. F., Milone, A. C., et al. 2012, A&A, 542, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Da Silva, R., Milone, A. D. C., & Rocha-Pinto, H. J. 2015, A&A, 580, A24 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Da Silva, R., Lemasle, B., Bono, G., et al. 2016, A&A, 586, A125 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Delgado Mena, E., Israelian, G., González Hernández, J. I., et al. 2014, A&A, 562, A92 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Delgado Mena, E., Bertrán de Lis, S., Adibekyan, V. Z., et al. 2015, A&A, 576, A69 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Delgado Mena, E., Tsantaki, M., Adibekyan, V. Z., et al. 2017, A&A, 606, A94 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Delgado Mena, E., Tsantaki, M., Adibekyan, Z. V., et al. 2018, in IAU Symp., eds. A. Recio-Blanco,P. de Laverny, A. G. A. Brown, & T. Prusti, 330, 156 [NASA ADS] [Google Scholar]
- Deng, L.-C., Newberg, H. J., Liu, C., et al. 2012, Res. Astron. Astrophys., 12, 735 [NASA ADS] [CrossRef] [Google Scholar]
- Edvardsson, B., Andersen, J., Gustafsson, B., et al. 1993, A&A, 275, 101 [NASA ADS] [Google Scholar]
- Feltzing, S., Bensby, T., & Lundström, I. 2003, A&A, 397, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fuhrmann, K. 1998, A&A, 338, 161 [NASA ADS] [Google Scholar]
- Fuhrmann, K. 2008, MNRAS, 384, 173 [NASA ADS] [CrossRef] [Google Scholar]
- Fuhrmann, K. 2011, MNRAS, 414, 2893 [NASA ADS] [CrossRef] [Google Scholar]
- Fuhrmann, K., Chini, R., Kaderhandt, L., & Chen, Z. 2017, MNRAS, 464, 2610 [NASA ADS] [CrossRef] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2016, A&A, 595, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2018, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gilmore, G. 2012, in in Galactic Archaeology: Near-field Cosmology and the Formation of the Milky Way, eds. W. Aoki,M. Ishigaki,T. Suda,T. Tsujimoto, & N. Arimoto, ASP Conf. Ser., 147 [Google Scholar]
- Grand, R. J. J., & Kawata, D. 2016, Astron. Nachr., 337, 957 [NASA ADS] [CrossRef] [Google Scholar]
- Grenon, M. 1972, in in IAU Colloq. 17: Age des Etoiles, eds. G. Cayrel de Strobel, & A. M. Delplace, 55 [Google Scholar]
- Grenon, M. 1989, Ap&SS, 156, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Grenon, M. 1999, Ap&SS, 265, 331 [NASA ADS] [CrossRef] [Google Scholar]
- Hayden, M. R., Bovy, J., Holtzman, J. A., et al. 2015, ApJ, 808, 132 [NASA ADS] [CrossRef] [Google Scholar]
- Haywood, M. 2006, MNRAS, 371, 1760 [NASA ADS] [CrossRef] [Google Scholar]
- Haywood, M., Di Matteo, P., & Lehnert, M. 2018, A&A, in press, DOI 10.1051/0004-6361/201731363 [Google Scholar]
- Henden, A., & Munari, U. 2014, Contrib. Astron. Observat. Skalnate Pleso, 43, 518 [Google Scholar]
- Hinton, G. E., & Roweis, S. T. 2003, Advances in Neural Information Processing Systems, 857 [Google Scholar]
- Hogg, D. W., Casey, A. R., Ness, M., et al. 2016, ApJ, 833, 262 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Ż., Connolly, A., VanderPlas, J., & Gray, A. 2013, Statistics, Data Mining, and Machine Learning in Astronomy (Princeton NJ: Princeton University Press) [Google Scholar]
- Jofré, P., Das, P., Bertranpetit, J., & Foley, R. 2017a, MNRAS, 467, 1140 [NASA ADS] [CrossRef] [Google Scholar]
- Jofré, P., Traven, G., Hawkins, K., et al. 2017b, MNRAS, 472, 2517 [NASA ADS] [CrossRef] [Google Scholar]
- Kordopatis, G., Binney, J., Gilmore, G., et al. 2015, MNRAS, 447, 3526 [NASA ADS] [CrossRef] [Google Scholar]
- Kos, J., Bland-Hawthorn, J., Freeman, K., et al. 2018, MNRAS, 473, 4612 [NASA ADS] [CrossRef] [Google Scholar]
- Kullback, S., & Leibler, R. A. 1951, Ann. Math. Stat., 22, 79 [CrossRef] [Google Scholar]
- Kunder, A., Kordopatis, G., Steinmetz, M., et al. 2017, AJ, 153, 75 [NASA ADS] [CrossRef] [Google Scholar]
- Kurucz, R. 1993, ATLAS9 Stellar Atmosphere Programs and 2 km/s Grid. Kurucz CD-ROM No. 13, (Cambridge, MA: Smithsonian Astrophysical Observatory), 13 [Google Scholar]
- Lindegren, L., & Feltzing, S. 2013, A&A, 553, A94 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Linderman, G. C., & Steinerberger, S. 2017, Clustering with t-SNE, Provably [Google Scholar]
- Mackereth, J. T., & Bovy, J. 2018, ASP Conf. Ser., 130, 114501 [Google Scholar]
- Majewski, S. R., Schiavon, R. P., Frinchaboy, P. M., et al. 2017, AJ, 154, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Martell, S. L., Sharma, S., Buder, S., et al. 2017, MNRAS, 465, 3203 [NASA ADS] [CrossRef] [Google Scholar]
- Martig, M., Rix, H.-W., Aguirre, V. S., et al. 2015, MNRAS, 451, 2230 [NASA ADS] [CrossRef] [Google Scholar]
- Matijevič, G., Zwitter, T., Bienaymé, O., et al. 2012, ApJS, 200, 14 [NASA ADS] [CrossRef] [Google Scholar]
- Matijevič, G., Chiappini, C., Grebel, E. K., et al. 2017, A&A, 603, A19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Michalik, D., Lindegren, L., & Hobbs, D. 2015, A&A, 574, A115 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Miglio, A., Chiappini, C., Mosser, B., et al. 2017, Astron. Nachr., 338, 644 [NASA ADS] [CrossRef] [Google Scholar]
- Minchev, I., Famaey, B., Quillen, A. C., et al. 2012, A&A, 548, A127 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Minchev, I., Chiappini, C., & Martig, M. 2013, A&A, 558, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Minchev, I., Chiappini, C., & Martig, M. 2014, A&A, 572, A92 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Minchev, I., Anders, F., Recio-Blanco, A., et al. 2018, MNRAS, 481, 1645 [NASA ADS] [CrossRef] [Google Scholar]
- Ness, M., Rix, H.-W., Hogg, D. W., et al. 2018, ApJ, 853, 198 [NASA ADS] [CrossRef] [Google Scholar]
- Nissen, P. E. 2015, A&A, 579, A52 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nissen, P. E. 2016, A&A, 593, A65 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nordström, B., Mayor, M., Andersen, J., et al. 2004, A&A, 418, 989 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pagel, B. E. J. 2009, Nucleosynthesis and Chemical Evolution of Galaxies (Cambridge: Cambridge University Press) [CrossRef] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2012, ArXiv e-prints [arXiv:1201.0490] [Google Scholar]
- Piffl, T., Scannapieco, C., Binney, J., et al. 2014, A&A, 562, A91 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pompéia, L., & Allen, D. M. 2008, A&A, 488, 723 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Queiroz, A. B. A., Anders, F., Santiago, B. X., et al. 2018, MNRAS, 476, 2556 [NASA ADS] [CrossRef] [Google Scholar]
- Reis, I., Poznanski, D., Baron, D., Zasowski, G., & Shahaf, S. 2018, MNRAS, 476, 2117 [NASA ADS] [CrossRef] [Google Scholar]
- Ritter, C., Herwig, F., Jones, S., et al. 2018, MNRAS, 455, 3848 [Google Scholar]
- Rodrigues, T. S., Bossini, D., Miglio, A., et al. 2017, MNRAS, 467, 1433 [NASA ADS] [Google Scholar]
- Santiago, B. X., Brauer, D. E., Anders, F., et al. 2016, A&A, 585, A42 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sneden, C.A. 1973, PhD Thesis, University of Texas at Austin [Google Scholar]
- Sousa, S. G., Santos, N. C., Israelian, G., Mayor, M., & Monteiro, M. J. P. F. G. 2007, A&A, 469, 783 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sousa, S. G., Santos, N. C., Adibekyan, V., Delgado-Mena, E., & Israelian, G. 2015, A&A, 577, A67 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Spina, L., Meléndez, J., Karakas, A. I., et al. 2018, MNRAS, 474, 2580 [NASA ADS] [Google Scholar]
- Steinmetz, M., Zwitter, T., Siebert, A., et al. 2006, AJ, 132, 1645 [NASA ADS] [CrossRef] [Google Scholar]
- Suárez-Andrés, L., Israelian, G., González Hernández, J. I., et al. 2017, A&A, 599, A96 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tang, J., Bressan, A., Rosenfield, P., et al. 2014, MNRAS, 445, 4287 [NASA ADS] [CrossRef] [Google Scholar]
- Ting, Y.-S., Freeman, K. C., Kobayashi, C., De Silva, G. M., & Bland-Hawthorn, J. 2012, MNRAS, 421, 1231 [NASA ADS] [CrossRef] [Google Scholar]
- Traven, G., Matijevič, G., Zwitter, T., et al. 2017, ApJS, 228, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Trevisan, M., Barbuy, B., Eriksson, K., et al. 2011, A&A, 535, A42 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tsantaki, M., Sousa, S. G., Adibekyan, V. Z., et al. 2013, A&A, 555, A150 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Valentini, M., Chiappini, C., Davies, G. R., et al. 2017, A&A, 600, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- van der Maaten, L., & Hinton, G. 2008, J. Mach. Learn. Res., 9, 85 [Google Scholar]
- van Leeuwen, F. 2007, Hipparcos, the New Reduction of the Raw Data, Astrophysics and Space Science Library, 350 [CrossRef] [Google Scholar]
- Vera-Ciro, C., D’Onghia, E., Navarro, J., & Abadi, M. 2014, ApJ, 794, 173 [NASA ADS] [CrossRef] [Google Scholar]
- Wattenberg, M., Viégas, F., & Johnson, I. 2016, Distill, DOI 10.23915/distill.00002 [Google Scholar]
- Yanny, B., Rockosi, C., Newberg, H. J., et al. 2009, AJ, 137, 4377 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
All Figures
|
Fig. 1. Illustration of how t-SNE works in abundance space, using the Delgado Mena et al. (2017) sample. The small panels show eleven of the possible ∼20 000 abundance diagrams that can be created from 13 elements. The resulting reference t-SNE projection of the full abundance space is shown in the big panel, and several identified sub-groups are indicated. For reference, the Sun would be found very close to the solar-abundance twin HD 212036 ([Fe/H] = −0.01, [X/Fe] = 0 + −0.05 for all measured elements X), which is located at (Xt − SNE, Yt − SNE) = (−4.57, 1.46). |
| In the text | |
|
Fig. 2. Fiducial t-SNE projection of the Delgado Mena et al. (2017) sample (see big panel in Fig. 1), colour-coded by chemical abundances (top three rows), spectroscopic parameters (effective temperature T eff, surface gravity logg, microturbulence ξ, and signal-to-noise ratio logS/N; fourth row), age τ (fifth row, first panel) and space velocities (fifth row). We note that only [Fe/H] and the [X/Fe] ratios were used as input for the t-SNE run. |
| In the text | |
|
Fig. 3. Chemical-abundance patterns relative to iron for the t-SNE-selected subsamples of the HARPS survey, using the same symbols and colours as in Fig. 1. For each population we show the median abundance trend, as well as the full abundance distribution (for the top two panels). For visibility, we divided the sample into three groups that are shown separately in the three panels. The “thin disc” population (black circles) is shown in all panels for comparison. |
| In the text | |
|
Fig. 4. t-SNE representations of the chrono-chemo-kinematics space spanned by the Delgado Mena et al. (2017) sample. Each column represents a combination of input information (only [X/Fe], [X/Fe] + [Fe/H], [X/Fe] + [Fe/H] + age, and [X/Fe] + [Fe/H] + age + space velocities, respectively), while each row corresponds to a particular perplexity value, as indicated on the right side of the figure. The panel highlighted in yellow represents the results that we analyse in detail in this paper by defining chemical sub-populations based on this map. |
| In the text | |
|
Fig. 5. Robustness test of our t-SNE-selected subsamples to abundance errors. The left panel shows the fiducial map, while the right panel shows the result of our Monte-Carlo test. For each star, 50 random stars were drawn from a Gaussian centred on the measured abundance, and with dispersions corresponding to the measured uncertainties. t-SNE was then run on this artificially increased sample. The resulting map (for p = 40) shows the positions of each Monte-Carlo realisation as faint grey dots, and the median position of each star as the same big symbol as in the fiducial map. The experiment demonstrates that most of our selected subgroups are robust to doubling the observational errors of the HARPS sample. |
| In the text | |
|
Fig. 6. Abundance trends of the HARPS-GTO abundances with stellar age, measured with the StarHorse code (Queiroz et al. 2018). |
| In the text | |
|
Fig. 7. Kinematic trends of the HARPS-GTO sample. The upper panels show the distribution of the sample in the v X − v Y (or U V) and v Y − v Z (V W) planes. We note that the 1σ errorbars are in most cases smaller than the symbols. The middle left panel shows the classic Toomre diagram (e.g. Feltzing et al. 2003), and the middle right panel shows a diagram of orbital heating (as measured by v X and v − Z) as a function of age. The bottom panels display the orbital eccentricities and maximum heights above the Galactic plane, respectively, as a function of age. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.