| Issue |
A&A
Volume 611, March 2018
|
|
|---|---|---|
| Article Number | A50 | |
| Number of page(s) | 18 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201731222 | |
| Published online | 23 March 2018 | |
Anisotropy of the galaxy cluster X-ray luminosity–temperature relation
Argelander-Institut für Astronomie,
Universität Bonn,
Auf dem Hügel 71,
53121 Bonn, Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
23
May
2017
Accepted:
30
October
2017
Abstract
We introduce a new test to study the cosmological principle with galaxy clusters. Galaxy clusters exhibit a tight correlation between the luminosity and temperature of the X-ray-emitting intracluster medium. While the luminosity measurement depends on cosmological parameters through the luminosity distance, the temperature determination is cosmology-independent. We exploit this property to test the isotropy of the luminosity distance over the full extragalactic sky, through the normalization a of the LX–T scaling relation and the cosmological parameters Ωm and H0. To this end, we use two almost independent galaxy cluster samples: the ASCA Cluster Catalog (ACC) and the XMM Cluster Survey (XCS-DR1). Interestingly enough, these two samples appear to have the same pattern for a with respect to the Galactic longitude. More specifically, we identify one sky region within l ~ (−15°, 90°) (Group A) that shares very different best-fit values for the normalization of the LX–T relation for both ACC and XCS-DR1 samples. We use the Bootstrap and Jackknife methods to assess the statistical significance of these results. We find the deviation of Group A, compared to the rest of the sky in terms of a, to be ~2.7σ for ACC and ~3.1σ for XCS-DR1. This tension is not significantly relieved after excluding possible outliers and is not attributed to different redshift (z), temperature (T), or distributions of observable uncertainties. Moreover, a redshift conversion to the cosmic microwave background (CMB) frame does not have an important impact on our results. Using also the HIFLUGCS sample, we show that a possible excess of cool-core clusters in this region, is not able to explain the obtained deviations. Furthermore, we tested for a dependence of the results on supercluster environment, where the fraction of disturbed clusters might be enhanced, possibly affecting the LX–T relation. We indeed find a trend in the XCS-DR1 sample for supercluster members to be underluminous compared to field clusters. However, the fraction of supercluster members is similar in the different sky regions, so this cannot explain the observed differences, either. Constraining Ωm and H0 via the redshift evolution of LX–T and the luminosity distance via the flux–luminosity conversion, we obtain approximately the same deviation amplitudes as for a. It is interesting that the general observed behavior of Ωm for the sky regions that coincide with the CMB dipole is similar to what was found with other cosmological probes such as supernovae Ia. The reason for this behavior remains to be identified.
Key words: cosmology: observations / X-rays: galaxies: clusters / galaxies: clusters: general / methods: statistical
© ESO 2018
1 Introduction
The cosmological principle (CP) is considered to be the foundation of modern cosmology, stating that the Universe must be isotropic and homogeneous on sufficiently large scales. It is robustly supported by various cosmological probes such as the cosmic microwave background observed by Wilkinson Microwave Anisotropy Probe (WMAP; Bennett et al. 2013) and Planck (Planck Collaboration XVI 2016) satellites, the distribution of distant radio sources (Blake & Wall 2002) and the large scale distribution of galaxies (Marinoni et al. 2012; Appleby & Shafieloo 2014; Alonso et al. 2015; Pandey & Sarkar 2015).
However, several studies, using the magnitude-redshift relation of Type Ia supernovae (SNIa), have reported mild-significance anisotropic signals of the Hubble expansion, mostly correlated with the cosmic microwave background (CMB) dipole (Schwarz & Weinhorst 2007; Antoniou & Perivolaropoulos 2010; Mariano & Perivolaropoulos 2012; Appleby et al. 2015; Bengaly et al. 2015; Javanmardi et al. 2015; Migkas & Plionis 2016), even if the redshifts of the SNIa have been adjusted to the CMB rest frame prior to the analysis. However, such signals can be attributed to single SNIa acting as outliers, that can affect the cosmological parameters derived from smaller subsamples, as shown in Migkas & Plionis (2016).
Furthermore, a similar dipole anisotropy has been found in the X-ray background from previous studies (Shafer & Fabian 1983; Plionis & Georgantopoulos 1999), that could again be attributed to the local motions of the Local Group.
Of course, the consistency of the pinpointed anisotropy signal in different SNIa samples and other independent probes must be further investigated. A systematic finding of a dipole anisotropy that coincides with the CMB dipole direction could indicate that the reason behind the latter is not exclusively due to the Doppler shift caused by our own bulk motion.
The CPmust be valid not only for cosmological parameters, but for the properties of astrophysical objects as well. Javanmardi & Kroupa (2017) found a significant hemisphere anisotropy in the galaxy morphological types aligned with the rotational axis of the Earth, arguing that is probably caused by a systematic bias in the classification of galaxy types.
Some of the most interesting objects to study and use in order to trace the behavior of the large-scale structure are galaxy clusters. They are the largest gravitationally bound systems in the Universe, easily detected in the X-ray regime due to the large amounts of hot gas they contain(~10% of their total mass) in the intracluster medium (ICM). One of the most crucial properties of galaxy clusters are their scalingrelations, correlating important physical quantities such as luminosity, temperature, and mass with each other. Kaiser (1986), based on the self-similar model, provided a theoretical prediction for these scaling laws.
Specifically, the relation between the X-ray luminosity and the temperature of the ICM gas is given by 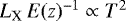 , where
, where 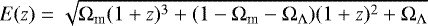 takes into account the redshift evolution of the relation (Giodini et al. 2013). This is derived under the assumption that gravitational energy is the only source of energy transferred to the ICM. The LX –T relation has been well-investigated (Edge & Stewart 1991; Markevitch 1998; Vikhlinin et al. 2002; Pacaud et al. 2007; Pratt et al. 2009; Eckmiller et al. 2011; Mittal et al. 2011; Hilton et al. 2012; Maughan et al. 2012; Takey et al. 2011; Connor et al. 2014; Bharadwaj et al. 2015; Lovisari et al. 2015). The observed slope of the power-law is systematically steeper than the predicted one, indicating the existence of different energy sources contributing to the ICM. Such sources are active Galactic nuclei feedback, supernovae-driven winds, and so on.
takes into account the redshift evolution of the relation (Giodini et al. 2013). This is derived under the assumption that gravitational energy is the only source of energy transferred to the ICM. The LX –T relation has been well-investigated (Edge & Stewart 1991; Markevitch 1998; Vikhlinin et al. 2002; Pacaud et al. 2007; Pratt et al. 2009; Eckmiller et al. 2011; Mittal et al. 2011; Hilton et al. 2012; Maughan et al. 2012; Takey et al. 2011; Connor et al. 2014; Bharadwaj et al. 2015; Lovisari et al. 2015). The observed slope of the power-law is systematically steeper than the predicted one, indicating the existence of different energy sources contributing to the ICM. Such sources are active Galactic nuclei feedback, supernovae-driven winds, and so on.
While the LX –T slope heavily depends on the physical processes that heat the gas in the ICM, differences in the normalization of the relation can potentially reflect any differences that might exist in the cosmological parameters for different directions on the sky. This is due to the fact that H0, Ωm, ΩΛ, and so on, enter through the conversion of the observed X-ray flux to the X-ray luminosity, as well as from the E(z) factor. Therefore, for fixed values of redshift and temperature, a higher value for Ω m towards a sky region would lead to lower luminosity distances, thus to lower X-ray luminosities, and eventually to lower normalization values. At the same time, the temperature determination is cosmology-independent, something that motivates the use of the LX –T relation for anisotropy studies. Assuming fixed values for the cosmological parameters, one could precisely determine the normalization and slope of LX –T or vice versa. All these make galaxy clusters excellent tools for constraining the cosmological parameters and studying their underlying physics.
Previous studies have used the kinematic Sunyaev–Zeldovic effect of galaxy clusters to trace the large scale peculiar motions up to ~ 600 h−1 Mpc, reporting challenging results for the Λ cold dark matter (Λ CDM) model (Kashlinsky et al. 2008, 2010, 2011; Atrio-Barandela et al. 2015). However, the significance of these results has been a topic of some controversy (Keisler 2009; Atrio-Barandela et al. 2010; Osborne et al. 2011; Atrio-Barandela 2013; Planck Collaboration Int. XIII 2014). Moreover, the X-ray flux-weighted method has been used for galaxy cluster luminosity functions (Plionis & Kolokotronis 1998; Kocevski et al. 2004), finding consistent results with the concordance cosmology.
In addition, Bengaly et al. (2017) used the Planck measurements of the Sunyaev–Zeldovic effect (Planck Collaboration XXVII 2016; Planck Collaboration XXIV 2016) to probe the angular distribution of clusters in antipodal patches of the sky, finding fully consistent results with the statistical isotropy assumption.
In this study, we introduce a new method to test the validity of the CP, namely the isotropy of the LX –T scaling relation of galaxy clusters. To this end, we use two almost independent galaxy cluster samples. The first is contained in the Advanced Satellite for Cosmology and Astrophysics (ASCA; Tanaka et al. 1994) catalog and was compiled by Horner (2001) under the name ASCA Cluster Catalog (ACC); the second is the first data release from the XMM-Newton Cluster Survey (XCS-DR1; Mehrtens et al. 2012). Throughout this paper, we correct LX values, as given by the data samples, to a ΛCDM cosmology with H0 = 70 km s−1 Mpc−1, Ω m = 0.28 and ΩΛ = 0.72. Finally, logx is used as log10x.
2 Data samples
2.1 ACC
We use all the 272 galaxy clusters and groups contained in ACC, for which we have information for their right ascension, declination, redshift (z), bolometric X-ray luminosity (LX), correction factor lvir to apply to LX to obtain the luminosity within the virial radius r200 (the radius inside which the mean density of the cluster is 200 times greater than the critical density of the Universe, e.g., the radius where we consider the virialized halo to extend) and X-ray temperature (T) with its 90%-confidence levels. The confidence levels for LX are not given. The extraction region of the spectra and LX, was chosen such that the radial profile of cluster counts was at least 5σ greater than the background signal; for the vast majority of the objects, this corresponds to a radius of ~0.8r200–1.05r200. In order to be consistent for all the clusters of the sample, we use the bolometric LX emitted from within r200. Moreover, while the absorbed LX is given for all the 272 objects, only 230 clusters are also given with their LX values corrected for the neutral hydrogen column density absorption. Therefore, using xspec (Arnaud 1996) we correct the LX values ourselves for the remaining 42 galaxy clusters and groups.
For these 272 objects, the median relative temperature uncertainty is 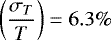 , demonstrating the spectroscopic precision of the observations.
, demonstrating the spectroscopic precision of the observations.
A specific selection function has not been applied to the ASCA clusters, since the final sample is an archival one composed of observations obtained for the needs of different projects at different times and not by one full-sky survey. To this preliminary catalog, Horner (2001) applied a homogeneous data reduction pipeline to obtain the final ACC sample. The spatial distribution of the ACC clusters is displayed in Fig. 1. Finally, the cosmology used to derive LX was an EdS Universe with H0 = 50 km s−1 Mpc−1, Ωm = 1, and ΩΛ = 0, which we convert to our default cosmology.
 |
Fig. 1 Positions of the galaxy clusters contained in ACC (blue) and XCS-DR1 (red) at the Galactic sky map. |
2.2 XCS-DR1
This sampleconsists of 503 optically confirmed X-ray galaxy clusters, serendipitously detected by the XMM-Newton telescope (Jansen et al. 2001) and drawn from publicly available data (Mehrtens et al. 2012). The galaxy clusters were homogeneously selected, covering the full sky (except for the Galactic latitudes |b| ≤ 20°). Out of these 503 clusters, 356 are observed in X-rays for the first time and 255 are newly discovered.
We make use of the 364 clusters for which the above-mentioned information plus the uncertainties of LX (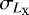 ) are given. In this case, we use the bolometric X-ray luminosity LX emitted from within r500. We excluded two clusters that appear to have a “negative” upper-limit LX uncertainty (LX,max < LX). For these 364 galaxy clusters, the median relative uncertainties for LX and T are
) are given. In this case, we use the bolometric X-ray luminosity LX emitted from within r500. We excluded two clusters that appear to have a “negative” upper-limit LX uncertainty (LX,max < LX). For these 364 galaxy clusters, the median relative uncertainties for LX and T are 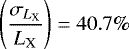 and
and 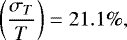 respectively, which are considerably larger than the relative T-uncertainty of ACC. Most of these clusters (214, ~60%) have a spectroscopically determined redshift (~10% of them are X-ray redshifts) while the remaining 150 have photometrically determined redshifts. The redshift uncertainty was assumed to be zero during the derivation of LX (Lloyd-Davies et al. 2011).
respectively, which are considerably larger than the relative T-uncertainty of ACC. Most of these clusters (214, ~60%) have a spectroscopically determined redshift (~10% of them are X-ray redshifts) while the remaining 150 have photometrically determined redshifts. The redshift uncertainty was assumed to be zero during the derivation of LX (Lloyd-Davies et al. 2011).
From these, only three are already contained in the ACC sample, making the two catalogs almost independent. The cosmological parameters used to derive LX were H0 = 70 km s−1 Mpc−1, Ωm = 0.3, and ΩΛ = 0.7.
3 Analysis method
As previously stated, we use a new method to try to identify anisotropies of the extragalactic sky properties using the LX –T relation. The fact that LX heavily depends on the cosmological parameters through the luminosity distance, and that T can be measured regardless of the cosmology, is of crucial importance.
3.1 Formof the X-ray luminosity–temperature relation
The power-law form of the LX –T scaling relation that we use, following Mittal et al. (2011), is given by
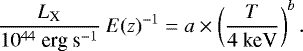 (1)
(1)
The parameter fitting is performed using the χ2 -minimization method, using the logarithmic form of the LX –T relation. Additionally, we use the reversed T–LX relation as well when the σT values are larger than the 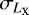 ones. Both of these cases are displayed in Eq. (2).
ones. Both of these cases are displayed in Eq. (2).
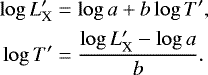 (2)
(2)
3.2 Fitting procedure
The constraining of a and b is performed by minimizing χ2 as displayed in Eq. (3) for LX –T or T–LX fitting, respectively, for N data1 :
![Mathematical equation: \begin{align*} &\chi^2_L=\sum\limits_{i=1}^N\left(\frac{\log{(L'_{\textrm{X,obs}})}-\log{[L'_{\textrm{X,th}}(T',\mathbf{p})]}}{\sigma _{\log{L},i}}\right)^2,\\ &\chi^2_T=\sum\limits_{i=1}^N\left(\frac{\log{(T'_{\textrm{obs}})}-\log{[T'_{\textrm{th}}(L'_{\textrm{X}},\mathbf{p})]}}{\sigma _{\log{T,i}}}\right)^2,\end{align*}](/articles/aa/full_html/2018/03/aa31222-17/aa31222-17-eq10.png) (3) (4)
(3) (4)
where the numerator represents the difference between the measured value of 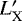 (or T′ ) with respect to the theoretical prediction of the quantity based on Eq. (2). The expected value is based on the measured value of T′ (or
(or T′ ) with respect to the theoretical prediction of the quantity based on Eq. (2). The expected value is based on the measured value of T′ (or 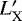 ) of the cluster as well as on the free parameters p. Also, σlog L,T,i are the Gaussian logarithmic uncertainties which are derived as indicated in Reiprich & Böhringer (2002)2. The derivation of the 3σ uncertainties that are displayed with every best-fit value, is based on the usual
) of the cluster as well as on the free parameters p. Also, σlog L,T,i are the Gaussian logarithmic uncertainties which are derived as indicated in Reiprich & Böhringer (2002)2. The derivation of the 3σ uncertainties that are displayed with every best-fit value, is based on the usual  limits (Δ χ2 ≤ 9 or 11.83 for 1 or 2 fitted parameters, respectively).
limits (Δ χ2 ≤ 9 or 11.83 for 1 or 2 fitted parameters, respectively).
In order to account for the uncertainties of the data in both axes, we consider a purely geometrical reasoning. Firstly, we perform the fitting considering only the y-axis uncertainties, obtaining the best-fit value for the slope, b1. Then, we project the x-axis uncertainty to the y-axis, adding it to the already existing uncertainty of the y-axis quantity. For the LX –T case, this reads as 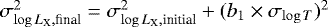 , while for T–LX fitting, we have
, while for T–LX fitting, we have 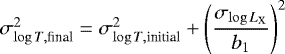 . Eventually, we repeat the procedure with the new y-uncertainties to obtain the final constraints of a and b of Eq. (1). This fitting method is equivalent to the one described by Akritas & Bershady (1996) and has been used by several studies; for example Zhang et al. (2017). Moreover, a ~ 100% change of b1 would cause a ~6% shift of the final best-fit values, suggesting that the obtained results are not sensitive to the uncertainty conversion that we apply.
. Eventually, we repeat the procedure with the new y-uncertainties to obtain the final constraints of a and b of Eq. (1). This fitting method is equivalent to the one described by Akritas & Bershady (1996) and has been used by several studies; for example Zhang et al. (2017). Moreover, a ~ 100% change of b1 would cause a ~6% shift of the final best-fit values, suggesting that the obtained results are not sensitive to the uncertainty conversion that we apply.
3.3 Identification of anisotropies
In order to pinpoint the solid angles in the sky that seem to share the largest deviation between them, we “scan” the sky as following: we consider the sky region with the Galactic coordinates l ∈ [−45°, +45°] (here we avoid the notationl ∈ [315°, 45°]) and b ∈ [−90°, +90°]. We obtain the best-fit value for the fitted parameters. Subsequently, we shift this region by 5° towards larger values of l (keeping the same size Δl = 90°), obtaining again the best-fit values. We repeat until the entire sky is scanned, returning to the initial position of the sky region. Each region contains 19%–30% of all the clusters for ACC and 14%–43% for XCS-DR1.
Moreover, we follow the same steps to scan the sky in terms of the Galactic latitude b, where we consider regions with a width of Δb = 40°, with a shift of 10° every time. The fewer clusters there are in a region, the larger the uncertainty in the derived result. We do not use smaller solid angles, sincethey contain fewer data and eventually they are heavily affected by individual clusters that can act as outliers, making the results untrustworthy.
3.4 Statistical significance and outliers
We need a valid expression for the statistical significance of the results that can be applied to both cluster samples. For this purpose, we use the Bootstrap resampling method. In detail, we consider the remaining sample, after excluding the clusters contained in the sky region, for which we want to express the statistical significance of its best-fit results. Then, we randomly draw 10 000 different groups of clusters with the same number of data as the excluded one, fitting the parameters we are interested in for each group. Consequently, we obtain the mean values and the standard deviation of the results, allowing us to express the frequency with which the best-fit values of the excluded subsample could randomly appear.
If we identify inconsistencies between different subsamples, we need to clarify whether or not this inconsistency is caused by certain outliers; to do this we exclude them and check to see if the inconsistency disappears. To this end, we apply the Jackknife resampling method to identify such possible data with strong effects in the final best-fit solutions. The procedure we follow is similar to that described in Migkas & Plionis (2016). For a given subsample with N galaxy clusters, we exclude one cluster each time, calculating the best-fit values of the parameters of our choice. Thus, we obtain N different best-fit values for N different subsamples, containing N − 1 clusters each time. If the best-fit values do not change significantly regardless of the excluded cluster, then we conclude that the peculiar behavior of the subsample is systematic and not caused by individual data.
Finally, we highlight the pair of independent solid angles with the largest tension, that does not depend on only a few cluster measurements.
4 Results
4.1 ACC
As explained in Sect. 2.1, in order to correct the X-ray luminosities of 230 objects (out of 272 in total), Horner (2001) used the HI column density values (NHI) as given by Dickey & Lockman (1990), based on 21 cm measurements. The X-ray luminosities for the last 42 objects were corrected by us using the same method. As shown in Fig. 2, NHI promptly increases for the Galactic latitudes b ≤|20°|, while it appears to have a mild structure with respect to the Galactic longitude l (small peaks every Δ l ~ 90°). This of course also depends on the b-distribution of the clusters for every l region.
However, Baumgartner & Mushotzky (2006) and Schellenberger et al. (2015) have showed that the X-ray/total hydrogen column density (NH,tot) roughly doubles compared to the HI column density, for NHI > 1021 cm−2. If this increase of the absorption is not taken into account, it could lead to an underestimation of the X-ray luminosities of clusters near the Galactic plane as well as towards any direction with a HI column density of NHI > 1021 cm−2. In order to obtain the correct NH,tot values for the sky position of every of these clusters, we use an online tool3 which uses the method of Willingale et al. (2013). Finally, using xspec, we correct the LX values for all the respective clusters, prior to our analysis.
 |
Fig. 2 HI column density as given by Dickey & Lockman (1990), as a function of the Galactic longitude (top) and latitude (bottom). |
4.1.1 General solution
Since ACC does not come with LX uncertainties, we use the T–LX fitting procedure, based on Eq. (4). However, the initially obtained normalization is not representative of the sample. This is due to the “overfitting” of some clusters with large LX and very low T-uncertainties that dominate the χ2-fit.
With the purpose of applying a more realistic approach, we insert an extra 5% LX uncertainty to every data point, converting it to a y-axis uncertainty as described in Sect. 3, with b1 = 3.405 (the best-fit value considering only σT). We choose this value for 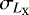 because we want it to be small compared tothe median σT; additionally, it is the minimum value of inserted
because we want it to be small compared tothe median σT; additionally, it is the minimum value of inserted 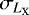 that does not affect our result significantly, but allows us to obtain a more representative fitting of the data. Compared to the case with only σT , the slope changes by ~1%, the normalization by ~15% and the reduced
that does not affect our result significantly, but allows us to obtain a more representative fitting of the data. Compared to the case with only σT , the slope changes by ~1%, the normalization by ~15% and the reduced 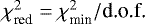 by ~50%. To ensure that our method does not bias our results, we always check whether or not the behaviors that we identify during the analysis exist also for the
by ~50%. To ensure that our method does not bias our results, we always check whether or not the behaviors that we identify during the analysis exist also for the 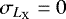 case. We should note that Horner (2001) uses an inserted 20% uncertainty for LX for all clusters, in order to constrain the LX –T, stating that this has a minimum effect on the results. He also argues that the best-fit results do not significantly depend on the fitting method. We consider the case of the 20% LX uncertainty as well, every time we have an interesting finding, in order to see how (and if) it is affected by the different value of
case. We should note that Horner (2001) uses an inserted 20% uncertainty for LX for all clusters, in order to constrain the LX –T, stating that this has a minimum effect on the results. He also argues that the best-fit results do not significantly depend on the fitting method. We consider the case of the 20% LX uncertainty as well, every time we have an interesting finding, in order to see how (and if) it is affected by the different value of 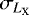 .
.
The best-fit values with their 3σ credibility intervals for the 272 objects of ACC that we use are:
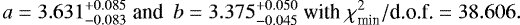 (5)
(5)
While the normalization value is considered to be typical, the slope is slightly large for typical galaxy cluster samples. Using the same sample, Horner (2001) found b = 3.49 ± 0.1, fully consistent with our result, despite the different fitting procedures. Fukazawa et al. (2004) also considered some massive elliptical galaxies along with the galaxy clusters and groups of ASCA, finding b = 3.17 ± 0.15 for objects with a gas temperature of 1.5–15 keV and b = 3.74 ± 0.72 for 1.5–5 keV (90% C.I.), which is again consistent with our derived value. Generally, the slope obtained by the T–LX fitting is expected to be somewhat different from the corresponding LX –T fitting value. Furthermore, the best-fit values of the 3σ uncertainties we recover are quite small due to the considerably large 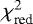 . The latter emerges because the LX –T relation has significant intrinsic scatter and because the statistical uncertainty of LX is likely underestimated.
. The latter emerges because the LX –T relation has significant intrinsic scatter and because the statistical uncertainty of LX is likely underestimated.
4.1.2 Different sky solid angles
The main goal of this project is to test the isotropy of the LX –T scaling relation. Before we apply the method described in Sect. 3.3, we divide the sky into hemispheres and derive the best-fit values for a and b. The results are shown in Table 1.
The northern and southern hemispheres do not appear to have significant deviations. For ACC, we do not display the probability contours of the a–b solution space, since the reduced 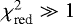 and as a result, the real uncertainties should be larger than the ones derived by the usual Δ χ2 limits. On the other hand, for the second pair of hemispheres, it is easily seen that there is a modest apparent inconsistency in the normalization value. In addition, it is noteworthy that the slope b is similar for all the Galactic hemispheres except for the southern, which seems to have a slightly increased b value. Since the southern Galactic hemisphere contains relatively few clusters, it is more easily affected by outliers. In fact, if we exclude its most extreme outlier, galaxy cluster 2A 0335+096 (we analytically explain why this is so further below), its slope shifts to
and as a result, the real uncertainties should be larger than the ones derived by the usual Δ χ2 limits. On the other hand, for the second pair of hemispheres, it is easily seen that there is a modest apparent inconsistency in the normalization value. In addition, it is noteworthy that the slope b is similar for all the Galactic hemispheres except for the southern, which seems to have a slightly increased b value. Since the southern Galactic hemisphere contains relatively few clusters, it is more easily affected by outliers. In fact, if we exclude its most extreme outlier, galaxy cluster 2A 0335+096 (we analytically explain why this is so further below), its slope shifts to 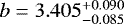 , becoming more consistent with the all the other Galactic hemispheres. Moreover, its normalization also shifts to
, becoming more consistent with the all the other Galactic hemispheres. Moreover, its normalization also shifts to 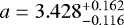 , becoming totally consistent with the northern Galactic hemisphere.
, becoming totally consistent with the northern Galactic hemisphere.
Furthermore, we are more interested in expressing any occurring deviations in terms of the normalization a, since the latter is more closely related to the cosmological parameters than to the slope (Sect. 1). We are not interested in the true values of a for every region, but in comparing the consistency between different sky patches. Since the obtained a value for a subsample clearly depends on the corresponding b value, we prefer to use the same slope value for every subsample so that the comparison is not biased. Even if two subsamples have significantly different slope values (being inconsistent in that manner) but similar a values, this discrepancy will propagate in the a values whenwe use the same slope for both, not allowing the deviation to be ignored. Thus, we fix the slope to b = 3.375 and we only fit the normalization a when we look for anisotropies with the “scanning” method.
As displayed in the left panel of Fig. 3, the normalization of the LX –T relation strongly fluctuates with the Galactic longitude, while surprisingly, the highest and lowest peaks are separated by Δ l ≈ 90°. Another interesting feature is the smooth transition to the peaks for l ~ 30° and l ~ 270°. This indicates that clustersin these regions have a systematic behavior towards higher/lower normalization values and they do not cause random fluctuations of the derived a value.
Additionally, from the right panel of Fig. 3, we can see that the normalization heavily drops as we move towards the Galactic plane, suggesting that the X-ray luminosities of these low-b clusters have likely not been properly derived. Here it is essential to remind the reader that we correct the LX values for the total hydrogen column density absorption, since the given LX are supposed to be corrected for the absorption only due to the neutral atomic hydrogen column density. This “dip” in the a value is not relieved even for the most extreme case for which we assume that no absorption correction has been applied to the data (knowing this is not the case, since the catalog contains both the absorbed and the unabsorbed flux and luminosity values). Applying the correction ourselves (practically “overcorrecting” for the absorption twice in a row), the lowest point at b = 0° ± 20° shifts to 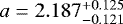 . After using the Jackknife method, we realize that this behavior cannot be entirely attributed to outliers. Consequently, when looking for possible anisotropies, we have to be careful with the consequences of clusters with |b| ≤ 20° in our subsamples. Additionally, we see that when we exclude all (16) clusters within |b| ≤ 20°, a increases significantly for b ∈ [−40°, 30°]. The lowest a in this case appears for b ∈ [20°, 30°] (25 clusters), with a = 2.31 ± 0.209. The error bars displayed are obtained from the Δχ2 limits and since
. After using the Jackknife method, we realize that this behavior cannot be entirely attributed to outliers. Consequently, when looking for possible anisotropies, we have to be careful with the consequences of clusters with |b| ≤ 20° in our subsamples. Additionally, we see that when we exclude all (16) clusters within |b| ≤ 20°, a increases significantly for b ∈ [−40°, 30°]. The lowest a in this case appears for b ∈ [20°, 30°] (25 clusters), with a = 2.31 ± 0.209. The error bars displayed are obtained from the Δχ2 limits and since 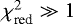 , they are not representative of the true uncertainties.
, they are not representative of the true uncertainties.
In order to put a proper probabilistic value on the deviations, we use the Bootstrap method as described in Sect. 3.4, where we consider 10 000 random subsamples every time, after we have excluded the subsample of interest. The σ value in the parentheses henceforth represents the Gaussian deviation of the result as derived from the Bootstrap, with respect to the rest of the sample. According to this method, the region within b ∈ [20°, 30°] is consistent at ~ 2σ with the rest of the sample (excluding low-b clusters) and therefore is not considered as statistically significant. However, when we use the entire sample, the 16 clusters within |b| ≤ 20° have a ~ 2.4σ deviation from the rest.
For the left panel of Fig. 3 again, the peaks at l ~ 120° and l ~ 215° have the maximum deviation between them, but due to the sudden transition of their values, it is indicated that this is caused by single clusters acting as outliers. In order to confirm this, we again use the Jackknife method. In fact, the normalization of the region with central l ∈ [165°, 260°] (66 clusters) shifts from 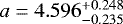 (2.68σ) to
(2.68σ) to 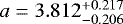 (0.87σ) when we exclude the galaxy cluster 2A 0335+096, making the behavior of the region consistent with the rest of the sample. In particular, 2A 0335+096 has a temperature and a bolometric X-ray luminosity of T = 2.86 ± 0.03 and LX = 1.095 × 1045 erg s−1, respectively. However, this specific cluster has been found to have a higher temperature by Ikebe et al. (2002) (
(0.87σ) when we exclude the galaxy cluster 2A 0335+096, making the behavior of the region consistent with the rest of the sample. In particular, 2A 0335+096 has a temperature and a bolometric X-ray luminosity of T = 2.86 ± 0.03 and LX = 1.095 × 1045 erg s−1, respectively. However, this specific cluster has been found to have a higher temperature by Ikebe et al. (2002) (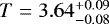 keV) and Hudson et al. (2010) (
keV) and Hudson et al. (2010) (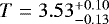 keV), who both used a double thermal modeling with ASCA and Chandra (Weisskopf et al. 2000), respectively, while Horner (2001) uses a single thermal modeling.
keV), who both used a double thermal modeling with ASCA and Chandra (Weisskopf et al. 2000), respectively, while Horner (2001) uses a single thermal modeling.
Therefore, the region with practically the largest normalization is the one with l ∈ [−20°, 75°] (75 clusters,where we consider as one the regions expressed by the two data points with the largest a), which has 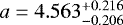 (2.65σ). Applying the Jackknife, the minimum value
(2.65σ). Applying the Jackknife, the minimum value 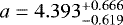 (2.28σ) occurs when we exclude A2052 while the largest is
(2.28σ) occurs when we exclude A2052 while the largest is 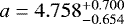 (3.10σ), obtained after excluding the Ophiuchus cluster. As shown in the top left panel of Fig. 4, this region does not contain any significant outliers. Furthermore, if low-b clusters are excluded from the whole sample, the deviation between l ∈ [−20°, 75°] and the rest slightly decreases to 2.09σ. From now on, we will call this region Group A. However, in this case the region with the maximum deviation from the rest of the sample is l ∈ [−10°, 90°], with
(3.10σ), obtained after excluding the Ophiuchus cluster. As shown in the top left panel of Fig. 4, this region does not contain any significant outliers. Furthermore, if low-b clusters are excluded from the whole sample, the deviation between l ∈ [−20°, 75°] and the rest slightly decreases to 2.09σ. From now on, we will call this region Group A. However, in this case the region with the maximum deviation from the rest of the sample is l ∈ [−10°, 90°], with 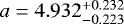 (2.47σ).
(2.47σ).
On the other hand, the lowest normalization is the one for the region with l ∈ [75°, 175°] (82 clusters) which rises from 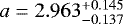 (2.06σ) to
(2.06σ) to 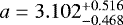 (1.77σ) when we exclude the galaxy cluster 3C 129, which is not such a big effect. Furthermore, excluding only A1885, we obtain
(1.77σ) when we exclude the galaxy cluster 3C 129, which is not such a big effect. Furthermore, excluding only A1885, we obtain 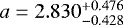 (2.34σ). If we entirely exclude clusters with |b|≤ 20°, the normalization of the region changes to
(2.34σ). If we entirely exclude clusters with |b|≤ 20°, the normalization of the region changes to 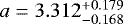 while the deviation of this region remains the same (2.04σ). We refer to this region as Group C.
while the deviation of this region remains the same (2.04σ). We refer to this region as Group C.
For the other low-a region with l ∈ [215°, 310°] which contains 63 clusters, a shifts from 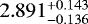 (1.86σ) to
(1.86σ) to 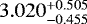 (1.65σ) after excluding AS636. However, it also shifts to
(1.65σ) after excluding AS636. However, it also shifts to 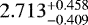 (2.16σ) when we only exclude the galaxy cluster PKS 0745-19. Excluding, once more, all the clusters with |b| ≤ 20°, we obtain
(2.16σ) when we only exclude the galaxy cluster PKS 0745-19. Excluding, once more, all the clusters with |b| ≤ 20°, we obtain 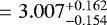 and the deviation of this region shifts to 2.36σ, becoming less consistent with the general solution. From now on we refer to this region as Group B.
and the deviation of this region shifts to 2.36σ, becoming less consistent with the general solution. From now on we refer to this region as Group B.
All these results show that there is a strong tension mainly between Group A and the rest of the sample, as well as between Group A and Groups B and C. If we exclude both Groups A and C from the sample and we apply the Bootstrap method, we find that the deviation of Group A from the rest of the sample is still at 2.21σ, while Group C is at 2.07σ. However, it is necessary to point out here that now the remaining sample, from which we draw the 10 000 random subsamples of the same size as the groups, consists of 115 clusters. Hence, the 75 or 82 clusters of Groups A and C, respectively, constitute a large fraction of the remaining 115. Therefore, the 10 000 random subsamples will be highly correlated and this could lead to a decreased standard deviation of the Gaussian results, eventually leading to an overestimation of the tension between the groups and the rest. Therefore, we must be cautious about the deviations that occur in the case where the size of the subsamples is >50% of the sample from where we draw them.
Moreover, since we are dealing with small subsamples with large scatter, we must be very careful with the effect that outliers have on the results. Consequently, we apply the Jackknife method again to the rest of the sample, finding that the biggest effect comes from the galaxy cluster 2A 0335+096, as it was for the sky region within l ∈ (165°, 260°). If we also exclude this cluster, the deviation for Group C heavily drops to 1.07σ while for Group A this increases to 3.71σ. As expected, if we now compare Group A with the rest of the sample including Group C, the deviation is at 3.64σ, much higher than the case where we include 2A 0335+096 in the rest of the sample. Accordingly, comparing Group C with the rest of the sample (including Group A) we find a tension of 1.90σ, slightly lower than the original case.
Assuming a typical subsample size of 77 galaxy clusters and considering the whole sample, we obtain that the deviation between Groups A and C is 3.84σ4, which is statistically very significant, although we stress again our reservations for this result, based on the sizes of the samples used. If we take the most conservative values excluding the two most important clusters for each group (as we identified them from the Jackknife), the tension is still at 3.11σ. Excluding 2A 0335+096, the deviation between Groups A and C becomes 4.75σ, and 3.88σ when we again exclude the most extreme cluster of each group. This increased tension is obtained due to the lower scatter of the best-fit values of the normalization when 2A 0335+096 is not included, leading to a lower standard deviation of the Gaussian results.
Excluding only Groups A and B this time and applying the Bootstrap to the rest of the sample, we find that Group B deviates by only 1.36σ, while Group A deviates by 1.83σ, mainly because the standard deviation is large. If we also exclude just 2A 0335+096, the deviation of Group A rapidly increases to 3.28σ. All these firmly indicate the large effect of this particular galaxy cluster and how sensitive our results are to outliers when we consider small samples.
Additionally, we test the case with no inserted 5% LX uncertainty, but only accounting for the temperature uncertainties. The values of the normalization slightly change (no more than 15%). When we consider Group A and the rest of the sample, we obtain a deviation of 1.02σ which is relatively low. If we now exclude 2A 0335+096 from the rest of the sample the deviation boosts to 2.88σ. The deviation values derived for Group C and the rest of the sample for these two cases are 1.72σ and 1.69σ.
For the case where we exclude both Groups A and C from the sample and compare with the rest, the deviation for Group C slightly decreases to 1.81σ. On the contrary, the deviation of Group A drops from 2.21σ to 0.78σ, due to the very large standard deviation of the results (114% larger). However, we have to consider the reason for which we initially inserted this extra uncertainty and this is to avoid the overfitting of some clusters with very low σT that dominate the results. Thus, by only excluding the galaxy cluster 2A 0335+096 once more, the normalization of the rest of the sample drops by 28% and the deviation of Group A rockets to 2.72σ while Group C is now at 1.27σ. Consequently, we conclude that this small inserted luminosity uncertainty is necessary to derive trustworthy results, even if the deviation remains roughly the same without it.
Finally, we use an inserted LX uncertainty of 20%, following Horner (2001). Now, in the cases that we include or not 2A 0335+096 in the rest of the sample, Group A deviates by 3.42σ and 3.84σ, respectively. On the other hand, Group C deviates by 2.26σ and 2.14σ for these two cases, respectively. All these show that the apparent deviations between these groups do not strongly depend on the inserted LX uncertainty.
In Fig. 5, the LX –T plane for Groups A and C is displayed.
Best-fit values of the fitted parameters with their 3σ credibility ranges for the four Galactic hemispheres of ACC.
 |
Fig. 3 Best-fit value of the normalization for every sky region of ACC with: left: Δ l = 90°, Δb = 180° as a functionof its central Galactic longitude and right: Δl = 360°, Δb = 40° as a function of its central Galactic latitude. Given the bin widths, the data points are obviously strongly correlated. |
 |
Fig. 4 Distribution of the best-fit value of the normalization as obtained by the Jackknife resampling method, for the sky regions with 75 clusters within l ∈ (−20°, 75°) (top left), 82 clusters within l ∈ (75°, 175°) (top right), 66 clusters within l ∈ (165°, 260°) (bottom left)and 63 clusters within l ∈ (215°, 310°) (bottom right). |
 |
Fig. 5 Bolometric luminosity LX as a functionof temperature T for the sky regions within l ∈ (−20°, 75°) (Group A, red) and l ∈ (75°, 175°) (Group C, blue). The best-fit functions (with a fixed slope of b = 3.375) are also displayed with green for Group A (a = 4.563) and with purple for Group C (a = 2.963). |
4.1.3 Possible causes
Distributions of T,
z and
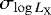
Since ACC does not have a specific selection function, it is necessary to test if these apparent anisotropies are caused by different temperature, redshift, or uncertainty distributions in the different sky regions.
If the LX –T relation were not described well by a power-law for the whole temperature range (from groups to clusters), then having relatively more clusters with higher temperatures in one subsample compared to another could potentially bias the results. Similarly, if the redshift evolution of the LX –T relation were not satisfyingly described by the self-similar E(z) factor, more high-z data in one subsample than in another one would also add a bias in our derived normalization values.
In Fig. 6, these distributions for Groups A, C, and the rest of the sample are displayed.
The temperature and the uncertainty distributions of the three subsamples are very similar. Furthermore, the redshift distributions of Groups A and C are comparable, while the rest of the sample has a higher fraction of low-z clusters than the two groups. However, this does not seem to play any role, since the two groups with similar distributions have such different best-fit values. This implies that the observed deviation is not the result of different selection effects.
In order to further investigate the reason for the behavior of the two different sky regions, we compare the best-fit normalization values of these three subsamples as they occur for low and high T and z. The results are shown in Table 2.
The tension between the Groups A, C, and the rest of the sample persists in both the low- and high-T regimes. The relatively high value of the rest of the sample for the low-T data is mainly caused by 2A 0335+096 and without it, it decreases to a = 3.729 ± 0.175. Therefore, the strong deviation seems to be consistent for all temperatures.
In the high-z regime, there is only a small discrepancy in a between the two groups, while the rest of the sample has a larger a than Group A. In the low-z data however, the discrepancy is ~3σ. We have to take into account though that the large uncertainties of the derived results do not allow us to draw robust conclusions for the galaxy clusters with z > 0.1. Moreover, since the number of data is very small for these T and z ranges, the best-fit values are very sensitive to the exact limits of the different ranges. Nevertheless, one could conclude that the apparent deviation seems to be stronger in the local Universe, something that could potentially be attributed to differences in the local structure, such as the existence of superclusters. This will be further investigated for the XCS-DR1 sample, as described in Sect. 4.2.4. In addition, clusters with |b| ≤ 20° do not change the results of the rest of the sample to an important degree, while excluding them shifts a for Group C (z ≤ 0.1) to 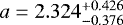 and for Group A to
and for Group A to 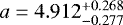 .
.
 |
Fig. 6 Distribution of the temperature (left), redshift (center) and temperature uncertainties (right) of the galaxy clusters contained inGroup A (red), Group C (black) and the rest of the sample (blue). |
Best-fit normalization values with their 3σ credibility ranges for Group A, Group C, and the rest of the sample of the ACC sample, for low and high temperature and redshift ranges.
Redshift correction to the CMB frame and peculiar velocities
Another test is to check if the (conservatively assumed) heliocentric redshifts of the data affect the final normalization and if we need to use the redshifts of the clusters with respect to the CMB frame. To this end, we properly convert the redshifts of all the clusters in a way so to account for a bulk velocity of 371 km s−1 towards (l, b) ~ (270°, 35°). The direction of our bulk motion within the CMB frame has been previously found by Fixsen et al. (1996) to be towards (l, b) ~ (264.14° ± 0.30°, 48.26° ± 0.30°) with a velocity of 371 ± 1 km s−1. Also, Bennett et al. (2003) found the same values for the direction and velocity and Watkins et al. (2009) found a bulk velocity of 407 ± 81 km s−1 towards (l, b) ~ (287° ± 9°, 8° ± 6°). Thus, we adopt values for the direction in between the results of these three studies. We should note that the obtained results are not at all sensitive to the exact direction and amplitude of the relative motion.
Such a motion could lead us to observe smaller redshifts in this direction than the ones only due to the Hubble flow. Consequently, an underestimation of the distance and equivalently of the luminosity would take place, resulting in a lower normalization value.
Repeating the analysis up to now considering the CMB redshift correction, we see that this does not significantly affect the apparent deviation. The incompatibility between Groups A and C becomes somewhat smaller (4.16σ), while the one between Group A and the rest of the sample also slightly decreases (2.56σ). On the other hand, Group C has now a deviation of 2.53σ with the rest of the sample. Finally, it is remarkable that by only excluding galaxy cluster 2A 0335+096, the deviation of Group A becomes 3.45σ while the one of Group C remains almost constant.
In order for the tension between Group A and the rest of the sample to drop below 2σ, the velocity of our bulk motion towards (l, b) ~ (270°, 35°) would need to be ubulk ≳ 3030 km s−1, which is obviously out of the question. The lowest possible bulk velocity that could decrease the above mentioned tension by same level is ubulk ≳ 415 km s−1 towards (l, b) ~ (210°, 0°) (the antipodal point of the center of Group A in the sky). However, all these cases would induce a dipole-like apparent anisotropy with the normalization maxima and minima separated by ~ 180°, and this does not seem to be the case, as shown in the left panel of Fig. 3.
The obtained redshifts of all the galaxy clusters are more or less affected by their local motions. If we assume that all the clusters contained in the most extreme sky region (Group A), have roughly the same peculiar velocity amplitude projected to our line-of-sight and towards the same direction (which is of course not to be expected), this projected peculiar velocity still needs to be ~430 km s−1 (moving away from us, or, in other words, all the redshifts of the Group A clusters need to be reduced by this velocity value) in order to explain the apparent anisotropy of Group A at a 2σ level. Finally, in all these cases, low-redshift samples such as ACC would be much more sensitive than high-redshift ones, such as XCS-DR1, which would not be significantly affected by such velocity amplitudes.
Possibly different NHI structure
Keeping in mind that clusters with large NH,tot in their direction tend to have lower measured LX values, an uneven distribution of these clusters between Groups A and C could cause such a behavior. We should point out here that we do not claim a physical reason behind this; rather we state an observational result, as shown in the right panel of Fig. 3. As displayed in Fig. 2 though, such an uneven distribution does not seem to be the case. The two groups have the same percentage of clusters with NHI > 1021 cm−2 (~ 6%) and the rest of the clusters of the two groups have similar NHI values. Finally, the dependence of the derived T on NH,tot will be tested in future work. In the case where a multitemperature structure model needs to be considered, a significant Galactic absorption would unevenly affect the cold and hot thermal component, potentially biasing the measurement of T.
Cool-core clusters
A possible excess of cool-core clusters towards the Group A region could potentially result in higher a values compared tosky regions with less cool-core clusters. Furthermore, a higher fraction of mergers towards a region could alter the obtained results for different regions as well. To this end, as a first test, we use the HIFLUGCS sample (Reiprich & Böhringer 2002; Hudson et al. 2010; Mittal et al. 2011) which contains all the necessary information, including cool-core X-ray luminosities Lcool for the 64 brightest galaxy clusters in the sky. For these clusters, 56 are also contained in ACC. Moreover, 46 clusters in total (72% of the sample) have a cool-core, 16 of them lying within the Group A region (80% of the total 20 clusters in Group A). Thus, the rest of the sample has 30 cool-core clusters out of a total of 46 members (68%). At the same time, 60% (9 out of 15) of Group C clusters contain a cool-core. Group A contains 31% of all the sample’s clusters and 35% of the cool-core ones.
These small differences are not sufficient to explain the ≥ 3σ deviations that we found for ACC. Moreover, these statistics are limited to a small fraction of the ACC clusters. Hence, they could be considered indicative for explaining these deviations only if the cool-core related results changed significantly compared to the general solution. When we consider the bolometric LX for the entire sample, the deviation between Group A and the rest of the sample is surprisingly high (3.39σ, using again the Bootstrap method), while Group C is totally consistent (< 1σ) with the rest of the sample for HIFLUGCS. Considering the cool-core-corrected luminosity L = LX − Lcool for the 46 clusters, the deviation between Group A and the rest persists with the same significance (3.28σ). However, these deviation amplitudes are biased because of the quite different temperature distribution of Group A compared to the rest of the sky. Nonetheless, this strongly demonstrates that the obtained deviations are not the result of a possible bias added by an uneven distribution of cool-core clusters.
Environmental effects, mergers, and superclusters
The properties of galaxy clusters, and particularly the LX –T scaling relation, may depend on the environment in which the clusters are formed. Studies have shown that disturbed clusters tend to be less luminous than undisturbed clusters, for the same X-ray temperatures (Pratt et al. 2009; Chon et al. 2012). Therefore, a larger number of disturbed systems in the rest of the sky than in the Group A sky region could result in a lower normalization value of the LX –T relation, causing the tension between the two subsamples. On the other hand, a significant difference in the number of these systems between Group A and the rest would be necessary to account for ~ 3σ anisotropies. If this were actually the case, another form of an anisotropy would occur, since there are no obvious reasons why such a difference should occur.
Disturbed clusters are expected to coincide with mergers and, in general, to be found in overdense regions, such as superclusters (Schuecker et al. 2001). With the purpose of applying a first test, we now look attwo subsamples from the 400d catalog, as given in Vikhlinin et al. (2009). There are 49 low-z and 36 high-z galaxy clusters, all observed with Chandra (while the 400d catalog was constructed by ROSAT (Truemper 1993, archival data). The low-z part is basically a subsample of the HIFLUGCS catalog, from where the 15 clusters with the lowest z were excluded. All clusters come with an estimation of their dynamical state; for example, if they are relaxed or if they are merging systems. The vast majority of the low-z clusters (45 or 92%) are included in ACC as well. We see that for the low-z systems, Group A region contains ~30% of all the clusters and ~25% of all the mergers (covering 25% of the whole sky). This shows that for this limited subsample, there are no obvious significant differences from the rest of the sky. From the 36 high-z clusters, only 2 are lying within Group A, preventing us from comparing the number of mergers with the rest of the sample.
Anothertest that could be applied is to look for superclusters in the sample and test the behavior of their cluster members, as well as theirposition in the sky. However, our ability to perform such a test is limited by the fact that ACC is mainly compiled byarchival data from pointing observations of clusters, which were conducted for the purposes of different projects. This would add a significant bias in the process of finding superclusters, since some clusters could in fact be members of superclusters, but we would not identify them as such, since the other members of the supercluster would not have been included in the ACC catalog. This problem would be even more severe in the case where the linking length of the members of a supercluster were greater than the ASCA (GIS) field of view (FOV), namely 50 arcmin (Tanaka et al. 1994). Considering that ACC is a low-z sample, the vast majority of the supercluster members would be at distances greater than that (for the median z = 0.09, the distance covered by the FOV of ASCA would be ~5.5 Mpc).
4.2 XCS-DR1
In order to verify this peculiar behavior of the specific sky regions as they have been identified for the ACC sample, we need to cross check our results with another, independent sample, namely XCS-DR1.
4.2.1 General solution and hemispheres
For this sample of galaxy clusters, the luminosity uncertainties 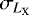 are more important than the temperatureuncertainties σT. Consequently, we now use Eq. (3) for the fitting procedure. We consider the log -uncertainties as described in Sect. 3.2, where b1 = 2.220 is the best-fit value for the slope when we do not consider σlog T.
are more important than the temperatureuncertainties σT. Consequently, we now use Eq. (3) for the fitting procedure. We consider the log -uncertainties as described in Sect. 3.2, where b1 = 2.220 is the best-fit value for the slope when we do not consider σlog T.
However, when we try to fit the model to the data, we notice the same behavior as in ACC. The normalization is fairly high (a ~ 3) and does not represent the sample well. This is again caused by the very low σlog L and σlog T values of some high-LX clusters (LX > 1044 erg s−1). As a result, χ2 is once again overfitting these data, leading to a rather high normalization. To fix this, we follow a similar approach as in ACC, adding an extra “false” uncertainty to the 5% of the sample with the lowest 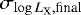 5. These clusters initially have
5. These clusters initially have 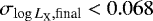 and we apply the “correction” such that they eventually have
and we apply the “correction” such that they eventually have 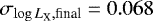 . These galaxy clusters also correspond to ~ 4–7% of every subsample that we analyze later. The relative plot is shown in the left panel of Fig. 7. From the right panel of the same figure, we can see the rapid change of the best-fit a value once we add this extra LX uncertainty.
. These galaxy clusters also correspond to ~ 4–7% of every subsample that we analyze later. The relative plot is shown in the left panel of Fig. 7. From the right panel of the same figure, we can see the rapid change of the best-fit a value once we add this extra LX uncertainty.
The final results for the entire XCS-DR1 sample and the four main Galactic hemispheres are shown in Table 3. The noticeable features here are the much less steep slope compared to the ACC sample, the large uncertainties of the best-fit values, and the much lower 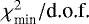 value, all because of the large uncertainties of the observations. Our results for the entire sample are in total agreement with those of Hilton et al. (2012) (if one corrects for the redshift evolution that they fit), indicating the validity of our method.
value, all because of the large uncertainties of the observations. Our results for the entire sample are in total agreement with those of Hilton et al. (2012) (if one corrects for the redshift evolution that they fit), indicating the validity of our method.
Comparing the sky hemispheres, we do not find any deviations in their solutions (not larger than ~ 1.5σ).
 |
Fig. 7 Left panel: logarithmic luminosity uncertainty |
4.2.2 Different sky solid angles
We repeat the steps we applied during the ACC analysis, scanning the sky as described in Sect. 3.3, obtaining the normalization. During this, we fix the slope to b = 2.388. The results are displayed in Fig. 8.
The clusters of the XCS-DR1 sample are not evenly distributed throughout the Galactic longitudes, since all the regions which are entirely included within l ∈ (90°, 240°) contain more than 140 members each. At the same time, the rest of the regions could contain as few as 52 clusters. Groups A and B contain 78 and 83 objects, respectively.
As shown in the top right panel of Fig. 8, in the case of XCS-DR1, a does not appear to have large differences for different Galactic latitude regions. The only region that could imply an inconsistent behavior is the one with b ∈ (−70°, −30°), which ends up having a 2.01σ tension with the rest of the sample. At the same time, all the other regions have a < 1σ tension with the rest of the sample. XCS-DR1 does not contain any clusters with |b| < 20°.
The most characteristic feature of Fig. 8 (bottom right panel) is the very similar fluctuation of a with the Galactic longitude as in ACC. The normalization value follows approximately the same fluctuation pattern as in ACC, with the highest normalization being found in the sky region within l ∈ (−5°, 95°), which we will also refer to as Group A for the XCS-DR1 sample. The corresponding region for ACC was lying within l ∈ (−20°, 75°) while the lowest values were found within l ∈ (75°, 175°) and l ∈ (255°, 340°). We remind the reader that XCS-DR1 shares only three common clusters with ACC, while only one is within the Group A regions, not causing a significant effect. Therefore, the two samples do not have an obvious reason to have the same behavior.
For XCS-DR1, the lowest a value belongs to the sky region within l ∈ (265°, 355°), almost identically with ACC. However, its statistical significance, which we obtain after the performed analysis, is not sufficiently high (1.99σ), due to the few cluster members it contains (60). Therefore, practically the lowest a belongs to the region within l ∈ (200°, 310°), which we will refer to as Group B. The region within l ∈ (95°, 155°) (which we call Group C for XCS-DR1), which is a subpart of the Group C region as defined for the ACC sample, has also a low normalization, with a somewhat lower statistical significance than Group B. Originally, the region with the lowest a at that part of the sky, was l ∈ (65°, 155°) (Δ l = 90°). However, since we do not wish this region to overlap with Group A, we set the low limit to l = 95°, which in fact, gives a stronger deviation. Nevertheless, the main low-a sky part of XCS-DR1, remains Group B.
The large uncertainties of this sample lead to a 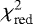 of ~ 3, significantly lower than the one of ACC. However, this again does not allow us to directly infer the deviations between subsamples only by the 3σ uncertainties of their derived best-fit results (using the Δχ2 limits), since this would require
of ~ 3, significantly lower than the one of ACC. However, this again does not allow us to directly infer the deviations between subsamples only by the 3σ uncertainties of their derived best-fit results (using the Δχ2 limits), since this would require 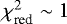 . Moreover, different scatter for different subsamples would cause
. Moreover, different scatter for different subsamples would cause 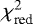 to vary, affecting the best-fit values of uncertainties derived from the Δ χ2 limits. This could sometimes result in similar (or even smaller) 3σ uncertainties for the best-fit values of subsamples with significantly less clusters than others. Hence, we again apply the Bootstrap and Jackknife methods to ensure that there are no outliers causing this behavior and to properly assess the statistical significance of any deviation.
to vary, affecting the best-fit values of uncertainties derived from the Δ χ2 limits. This could sometimes result in similar (or even smaller) 3σ uncertainties for the best-fit values of subsamples with significantly less clusters than others. Hence, we again apply the Bootstrap and Jackknife methods to ensure that there are no outliers causing this behavior and to properly assess the statistical significance of any deviation.
Due to the larger number of clusters XCS-DR1 contains and the nearly ten times larger uncertainties than ACC, the results are not affected by single data, as shown in Fig. 9.
For Group A, we obtain 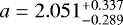 , which intensely deviates by 3.12σ from the rest of the sample. If we exclude the galaxy cluster with the most strong effect on the Group A behavior, cluster XMMXCS J2339.8-1213, the deviation shifts to 2.73σ.
, which intensely deviates by 3.12σ from the rest of the sample. If we exclude the galaxy cluster with the most strong effect on the Group A behavior, cluster XMMXCS J2339.8-1213, the deviation shifts to 2.73σ.
Group B has 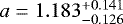 and a discrepancy of 2.67σ with the rest of the sample. Excluding XMMXCS J0056.0-3732, the discrepancy moves to 2.44σ.
and a discrepancy of 2.67σ with the rest of the sample. Excluding XMMXCS J0056.0-3732, the discrepancy moves to 2.44σ.
If we consider the rest of the sample subtracting both Groups A and B, the deviation of Group A is now 1.69σ, while for Group B it is 2.22σ. Considering a typical size for the random subsamples of 80 clusters while we apply the Bootstrap method, we find that the tension between Group A and Group B is at 3.89σ, for which the statistical significance is impressively large (again bearing in mind the small sample size). Even if we exclude the two above-mentioned galaxy clusters, the deviation is no less than 3.34σ. A comparison of the most extreme sky regions of ACC and XCS-DR1, is displayed in Table 4.
In the bottom-left panel of Fig. 8 we also display the results for the T–LX fitting, which gives us a slope of b = 3.066 ± 0.137. In this case, the sensitivity to individual clusters is larger, making the dispersion and the uncertainties of the derived best-fit values also larger. Due to these uncertainties, all the deviations we refer to between Group A, Group B, and the rest of the sample drop to 45%–65% for the T–LX fitting. However, since the luminosity uncertainties are much larger than the temperature uncertainties, the LX –T fitting is more appropriate here.
 |
Fig. 8 Best-fit value of the normalization with its 3σ uncertainty for every sky region of XCS-DR1: Top left: with Δl = 90°, Δb = 180° as a function of its central Galactic longitude, with the best-fit normalization value for the whole sample (purple). Top right: with Δl = 360°, Δb = 40° as a functionof its central Galactic latitude. Bottom left: for the LX–T (blue) and T–LX (red) fitting. Bottom right: for XCS-DR1 (blue) and ACC (red) with their best-fit values for the whole sample (green line for ACC and purple line for XCS-DR1). Given the bin widths, the data points are obviously strongly correlated. |
 |
Fig. 9 Distribution of the best-fit values of the normalization as obtained by the Jackknife resampling method, for Group A (red), Group B (blue), and the rest of the sample (black). |
Galactic longitude l limits for Groups A, B, and C as they are defined for ACC and XCS-DR1.
4.2.3 Free slope
Now we consider the slope as a free parameter, in order to compare the a–b solution space between the two groups and the rest of the sample. In Table 5 the results of the fit are displayed, where we see that the slope of Group A also differs to a large degree.
As shown in Fig. 10, despite the large uncertainties in log LX (in the order of ~ 100% adding σlog T as explained), Group A does not share any common 3σ solution space with Group B or the rest of the sample in general. Additionally, Groups A and B share very limited 3σ common solution space with the rest of the sample when both are excluded from it.
In Fig. 11, the LX –T plot of the two groups is displayed.
 |
Fig. 10 1σ (green, light blue and purple) and 3σ (red, black and blue) contour plots, where the intrinsic scatter is not considered. Left: for Group A and the rest of the sample, including Group B. Right: Group A, Group B, and the rest of the sample, excluding Group B. |
 |
Fig. 11 Bolometric luminosity LX as a functionof temperature T for Group A (red) and Group B (blue). The best-fit functions are also displayed for Group A [a = 2.051, b = 2.512 (fixed) with green and a = 1.742, b = 2.032 (free) with black] and for Group B [a = 1.183, b = 2.512 (fixed) with light blue]. |
4.2.4 Possible causes
Distributions of T, z,
and 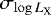
As we did for ACC, we test if the apparent anisotropy is caused by different distributions of the temperatures, redshifts, or uncertainties of the groups or by a specific temperature or redshift range. From Table 6, we see that the tension between the two groups and the rest of the sample is consistent for all the redshift ranges. However, Group B and the rest of the sample have the same solution for high-z clusters. Furthermore, this is also the case for Group A and the rest of the sample, but for high-T clusters. Therefore, the deviation seems to be due to the low-T clusters.
As argued above, such a behavior could also be caused by a different redshift, temperature, or observable uncertainties distribution of the subsamples. XCS-DR1 is a homogeneous sample though, with the same selection functions towards all sky directions.
As illustrated in Fig. 12, and as it was expected, this does not seem to be the case. All the distributions of Group A and the rest of the sample without Group B, are quite similar. On the contrary, Group B has more low-z galaxy clusters than Group A, but this is not the cause of the deviation between the two groups, since the latter is relatively consistent throughout all the redshift ranges, as shown in Table 6.
Thus, the reason for the strong deviation of mainly the Group A region and secondarily the Group B and C regions, that exists in both samples, remains to be found.
Best-fit normalization values with their 3σ credibility ranges for Group A, Group B, and the rest of the sample of the XCS-DR1 sample, for low and high temperature and redshift ranges.
 |
Fig. 12 Distribution of the temperature (left), redshift (center) and final luminosity uncertainties (right) of the galaxy clusters contained in Group A (red), Group B (blue), and the rest of the sample (black). |
Redshift correction to the CMB frame and peculiar velocities
XCS-DR1 mostly contains clusters at high redshifts and thus their measured redshift values are not practically affected by the bulk motionof our Galaxy or the peculiar velocities of the clusters. With the purpose of demonstrating this analytically, we repeat the tests we performed for ACC. In order for Group A and the rest of the sample to be consistent at a 2σ level, the bulk velocity of our Galaxy would need to be ubulk ≳ 11 000 km s−1 towards (l, b) ~ (270°, 35°) or ubulk ≳ 3800 km s−1 (the minimum possible) towards (l, b) ~ (210°, 0°). Moreover, ifwe again make the same assumption (as we also did for ACC), where we consider that all the Group A clusters have the same projected peculiar velocity to our line-of-sight, this velocity needs to be ~ 2800 km s−1 in order to decrease the tension at 2σ (instead of 3.12σ that it was originally). Obviously all these peculiar velocity values are unreasonable in almost all cosmological models, meaning that the explanation for the obtained deviation does not seem to be based on the wrongly determined cosmological redshifts due to peculiar motions of the objects.
Environmental effects and superclusters
As explained before for the ACC sample, identifying clusters that belong in rich environments such as superclusters (and are possibly disturbed), and studying their LX –T behavior, could indicate if these systems could cause the apparent deviations we observe between Group A and the rest of the sky. Since the XCS-DR1 sample is composed of clusters that were serendipitously detected on the archival observations of XMM-Newton data bases, there is a higher probability of identifying multiple members of the same supercluster, than in ACC. Of course the selection bias which was described in Sect. 4.1.3 will again affect our results, but to a lesser degree. This bias is eliminated in the case in which the supercluster members are separated by less than the FOV of XMM-Newton, namely ~ 30 arcmin. Moreover, one has to consider that XCS-DR1 is a high-z sample, and thus the FOV covers greater proper distances at the cluster redshifts (~ 10 Mpc for the median z = 0.315); however still not enough for the vast majority of superclusters.
To this end, we perform a first, simple test to try to identify superclusters and investigate if they have any effect on the apparent anisotropy we obtain from the data. Using the coordinates and the redshifts of the clusters as well as a specific linking length R of our choice, we identify all cluster pairs separated by distances ≤ R. Then, starting from a pair, we find all the clusters which are connected to that pair, iteratively adding clusters until no more can be found at distances ≤ R. This is considered an isolated supercluster structure. Repeating these steps for all the initial pairs, we finally obtain all the clusters that belong to such structures. Of course, the number of such structures heavily depends on our choice of R.
Starting with R = 20 Mpc, we only find 10 superstructures, containing 21 clusters in total. It is rather obvious that the number of clusters is too small to properly evaluate their behavior, since the statistical uncertainties are quite large. Thus, we increase the linking length to R = 50 Mpc, this time obtaining 22 superstructures containing 48 galaxy clusters (most of them in pairs). For these clusters, we obtain a = 1.603 ± 0.311 and b = 2.969 ± 0.222, and if we fix the slope to b = 2.512, we then obtain a = 1.274 ± 0.234. This clearly shows that supercluster members are underluminous compared to field clusters. However, their sky distribution is not quite uniform, since 10 out of the 48 clusters are found in the XXL North part of the sky, a 25 deg2 area fully observed by XMM-Newton with high exposure times, for the needs of the XXL survey (Pierre et al. 2016). Moreover, out of these 48 clusters, only 5 lie within Group A, which is 6.5% of all the clusters of this group. At the same time, for the rest of the sky, 15% of all the clusters belong to superclusters. If we exclude the clusters contained in the XXL north region, which clearly adds a bias since 65% of its clusters belong to superclusters, then for the rest of the sky we find a fraction of 12.5%. There is a slight difference between Group A and the rest, but the statistics are too limited to derive a conclusive result. Nevertheless, the clusters that appear to belong in superclusters, seem to be significantly more luminous for Group A (5 clusters with a = 2.001 ± 1.143) compared to the rest (43 clusters with a = 1.197 ± 0.230). If we entirely exclude all the 48 clusters that seem to belong in superclusters and redo the analysis, the deviation of Group A decreases from 3.12σ to 2.50σ, which is still statistically significant. Finally, Groups B and C have once more the most underluminous clusters that belong to superstructures.
We now increase the linking length of the superclusters to R = 70 Mpc, finding 29 superclusters, containing in total 63 galaxy clusters. For these, we obtain a = 1.517 ± 0.240 and b = 2.804 ± 0.212. Fixing the slope to b = 2.512, we obtain a = 1.346 ± 0.195, so, again supercluster members appear underluminous compared to field clusters. Out of these 63 clusters, 11 belong to Group A (14% of all its clusters) and 52 to the rest of the sky (18%). Once again, the XXL North region contains 18 supercluster members, that is, 85% of its clusters. Excluding once again this region, the rest of the sky has a supercluster-members fraction of 13%. For this R, we see that the Group A region has practically the same fraction of supercluster members as the rest of the sky does, excluding ornot the XXL North region. It is noteworthy that when we fit the 11 clusters of Group A, we obtain a = 2.285 ± 0.889, which is consistent with the general behavior of the Group A region, while for the rest of the sky we obtain a = 1.188 ± 0.217. For these clusters, Groups B and C have a = 0.953 ± 0.285 (13 clusters) and 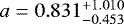 (11 clusters), respectively. All in all, even the clusters that belong to rich environments such as superclusters, and are possibly disturbed, seem to share the same behavior trends for all the different sky patches, returning the similar differences in the normalization value as the ones we obtained during the initial analysis. If we once again exclude these 63 clusters from our analysis, the deviation between Group A and the rest of the sky shifts to 2.32σ. This small drop of the statistical significance is mostly due to the smaller size of Group A this time (67 clusters instead of 78) rather than the more consistent a values between the two subsamples. The interpretation from all these could be that the cause of the deviation of Group A compared to the rest of the sky, is also affecting the clusters located within rich environments, rather than be caused by them. This could also be seen by the similar fraction of such clusters between Group A and the rest.
(11 clusters), respectively. All in all, even the clusters that belong to rich environments such as superclusters, and are possibly disturbed, seem to share the same behavior trends for all the different sky patches, returning the similar differences in the normalization value as the ones we obtained during the initial analysis. If we once again exclude these 63 clusters from our analysis, the deviation between Group A and the rest of the sky shifts to 2.32σ. This small drop of the statistical significance is mostly due to the smaller size of Group A this time (67 clusters instead of 78) rather than the more consistent a values between the two subsamples. The interpretation from all these could be that the cause of the deviation of Group A compared to the rest of the sky, is also affecting the clusters located within rich environments, rather than be caused by them. This could also be seen by the similar fraction of such clusters between Group A and the rest.
4.3 Cosmological constraints
During our analysis up to now, we assumed fixed cosmological parameters towards all the directions in the sky in order to derive the normalization and slope of the LX –T relation. If this time we assume that the normalization and slope should be the same for every subsample of galaxy clusters (using the best-fit value for the whole sample), we can express any deviation that occurs in terms of the cosmological parameters, that is, Ω m and H0 . These enter through the conversion of the X-ray flux to luminosity (via the luminosity distance) while Ω m also enters through the redshift correction factor E(z), as in Eq. (1). We should note that we do not care about the actual values of the cosmological parameters, since they will be biased due to the a, b values which were determined using a specific cosmological model. Furthermore, we do not know precisely whether the actual intrinsic evolution is indeed self-similar. What we aim to compare are simply the occurring deviations between the Ω m and H0 values for different subsamples. Generally, these parameters are strongly correlated with the normalization.
4.3.1 Ωm fitting
Repeating all the steps firstly with respect to the Ωm fitting, we find the Ωm deviations to be roughly of the same amplitude as for the normalization. In fact, for the XCS-DR1 sample the Ω m deviations are slightly larger, while for ACC, the Bootstrap results are not Gaussian and the exact statistical deviation cannot be determined.
Towards Group A region, we obtain a much higher Ωm value than for the rest of the sky. This could indicate the need for smaller cosmological distances for a fixed redshift towards this sky region, leading to lower LX values of the clusters, and eventually alleviating the tension in the normalization of LX –T between this region and the rest of the sky.
For instance, for the entire XCS-DR1 sample, we obtain Ω m = 0.300 ± 0.061, while for Group A this is Ω m = 0.581 ± 0.242 and for the rest of the sample this is Ωm = 0.264 ± 0.064, giving us a 3.02σ tension. More specifically, Group B has Ωm = 0.150 ± 0.098 (2.28σ from the rest of the sample) and Group C gives 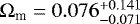 (2.05σ), not being as statistically significant as Group B. The Galactic coordinates map of these regions together with the results are shown in the left panel of Fig. 13. Additionally, in the right panel of Fig. 13, the best-fit values for Ω m are displayed for different patches of the sky. Interestingly, the lowest value in the right panel occurs from the sky region in which the axis for the maximum acceleration (minimum Ωm) of the Hubble expansion has been detected by several authors and methods (see references in Sect. 1), usually with low to mild statistical significance. Moreover, the “warm” end of the CMB dipole roughly coincides with the center of this region. The higher Ω m occurs from the same l in the southern Galactic hemisphere, but it contains very few clusters in order to draw a trustworthy result.
(2.05σ), not being as statistically significant as Group B. The Galactic coordinates map of these regions together with the results are shown in the left panel of Fig. 13. Additionally, in the right panel of Fig. 13, the best-fit values for Ω m are displayed for different patches of the sky. Interestingly, the lowest value in the right panel occurs from the sky region in which the axis for the maximum acceleration (minimum Ωm) of the Hubble expansion has been detected by several authors and methods (see references in Sect. 1), usually with low to mild statistical significance. Moreover, the “warm” end of the CMB dipole roughly coincides with the center of this region. The higher Ω m occurs from the same l in the southern Galactic hemisphere, but it contains very few clusters in order to draw a trustworthy result.
Repeating the “scanning” of the sky for Ωm as we previously did for a, we obtain the results shown in Fig. 14. From this, we see that the largest deviation for Ω m does not occur for what we defined as Group A for XCS-DR1, but is found within l ∈ [−15°, 75°], which is almost the same sky region with Group A as defined for ACC. The Ω m value for this sky patch is Ω m = 0.650 ± 0.262 and it appears to have a 3.53σ tension with the rest of the sample (which has Ωm = 0.258 ± 0.067), according tothe Bootstrap results.
Moreover, the lowest Ωm = 0.120 ± 0.120 appears for the sky region within l ∈ [265°, 345°] (where we “cut” the region l ∈ (345°, 355°] so it does not overlap with the highest-a region). However, it has a low statistical significance (1.44σ) due to its limited number of clusters (50). Thus, the lowest-Ωm region turns out to be l ∈ [75°, 155°] (where we excluded the first 10° to avoid overlapping regions), which has 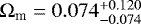 with a deviation of 3.03σ from the rest of the sample. Therefore, the general sky region of Group A remains the one with the most intense inconsistency for the Ωm fitting as well.
with a deviation of 3.03σ from the rest of the sample. Therefore, the general sky region of Group A remains the one with the most intense inconsistency for the Ωm fitting as well.
XCS-DR1 is more suitable than ACC for the Ωm fitting, due to its larger z distribution. For clusters with low-z, such as those contained in ACC, the Ωm value cannot be easily constrained, since it does not change significantly the LX or the E(z) factor of a cluster.
With this in mind, for the entire ACC sample, we obtain a value of Ω m = 0.412 ± 0.091, while for Group A we get 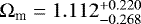 . At the same time, for the rest of the sample we obtain
. At the same time, for the rest of the sample we obtain 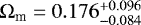 . Group A’s value is greater than all of the results derived by Bootstrap. Group C returns a value of
. Group A’s value is greater than all of the results derived by Bootstrap. Group C returns a value of 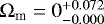 while Group B gives
while Group B gives 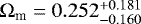 .
.
 |
Fig. 13 Best-fit value of Ωm for XCS-DR1, with its 3σ uncertainty and the number of clusters in each region. Different uncertainty magnitudes for similar numbers of clusters are caused by the different scatter of the LX –T relation. Leftpanel: for Groups A and B. The rest of the sky has Ωm = 0.318 ± 0.071. Right panel:for the four “usual” quarters of the Galactic sky. |
 |
Fig. 14 Best-fit value of Ωm for every skyregion of XCS-DR1 with Δl = 90°, Δb = 180° as a function of its central Galactic longitude. |
4.3.2 H0 fitting
If one wishes to study the apparent deviations based on a purely kinematic approach, the most obvious option would be to only fit H0 , which directly probes the expansion rate of the local Universe. Since the effect of H0 on LX through the luminosity distance does not depend on the redshift, both ACC and XCS-DR1 samples can be used to give us valuable results.
For the entire XCS-DR1 sample, we obtain H0 = 69.32 ± 2.32 km s−1 Mpc−1, while the results from the sky “scanning” are shown in the left panel of Fig. 15. As expected, we obtain the same fluctuation pattern for H0 as we did before for the normalization as well as for Ωm. Once again, Group A returns the largest value, namely 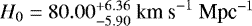 , which deviates by 2.76σ from the rest of the sample (H0 = 67.09 ± 2.45 km s−1 Mpc−1). At the same time, for Group B we obtain
, which deviates by 2.76σ from the rest of the sample (H0 = 67.09 ± 2.45 km s−1 Mpc−1). At the same time, for Group B we obtain 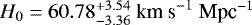 (2.74σ) and for Group C
(2.74σ) and for Group C 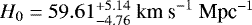 (2.41σ). We see that Groups A and B have a similar statistical significance, with the difference that the Group A region has a consistent behavior regardless of the fitted parameter or the galaxy cluster sample used, unlike Group B region (although its statistical significance is > 1.5σ in all cases).
(2.41σ). We see that Groups A and B have a similar statistical significance, with the difference that the Group A region has a consistent behavior regardless of the fitted parameter or the galaxy cluster sample used, unlike Group B region (although its statistical significance is > 1.5σ in all cases).
For the full ACC sample, we find H0 = 70.06 ± 0.84 km s−1 Mpc−1 while the results from the sky “scanning” are shown in the right panel of Fig. 15. Group A appears to have the largest value (that does not depend on single outliers) with H0 = 78.30 ± 1.82 km s−1 Mpc−1 (2.36σ), while Group C is the sky region with the most statistically significant small value of H0 = 63.12 ± 1.51 km s−1 Mpc−1 (2.17σ). Additionally, for Group B we obtain H0 = 62.34 ± 1.52 km s−1 Mpc−1 (1.84σ). Now, once more, we exclude the most extreme outlier (galaxy cluster 2A 0335+096) which, as we showed in Sect. 4.1.2, has the strongest effect on the entire sample due to its “problematic” temperature determination. As a result, the deviation of Group A shifts to (3.34σ), while the one for Group C remains relatively constant.
From all the obtained results, we see that the Group A sky region is mimicking the behavior of the minimum acceleration axis in a supposedly anisotropic Universe, with a ≳ 2.5σ statistical significance in all cases. Generally, H0 deviations are of slightly smaller amplitude than the ones of the normalization and Ω m .
 |
Fig. 15 Best-fit value of H0 for every skyregion of XCS-DR1 (left) and ACC (right) with Δl = 90°, Δb = 180° as a function of its central Galactic longitude. |
5 Discussion
While the LX –T relation has been analyzed in several previous studies using different samples, there has not been an extensive analysis of the isotropy of this scaling relation for different sky directions. The main advantage of such an application, is the ability of directly measuring the X-ray flux, temperature, and redshift of the clusters, without the use of (cosmological) assumptions (unlike the mass determination). This classifies the LX –T relation as avery effective tool with which we can test the validity of the CP, totally independently from all the other cosmological probes used for this purpose. In addition, the almost entire independence of the two galaxy cluster samples used here gives us the opportunity to verify if a detected behavior of a sky region is consistent for every sample or if it the result of one sample’s systematics.
The main finding of this project is the existence of an apparent anisotropy in the LX –T scaling relation between the so-called Group A sky region within l ~ (−15°, 90°) and the rest of the sky, and especially the sky regions within l ~ (200°, 310°) (Group B) and l ~ (90°, 160°) (Group C). The regions are slightly different for the two samples but are towards the same directions. We calculate the deviation using the Bootstrap method with 10 000 random, non-identical samples every time. The deviation of the normalization of Group A (as defined in every sample separately) is 2.65σ for ACC and 3.12σ for XCS-DR1 when compared to the rest of the sample, while it shifts to ~ 4σ when compared to other coherent and independent sky patches.
Another very noteworthy result is the striking similarity of the normalization trend as a function of the Galactic longitude between the two independent samples, following a pattern where high and low peaks are separated by Δ l ~ 90°. This could point to the need for an explanation that does not emanate from systematic behaviors of the samples but rather from independent factors, such as large-scale effects.
Moreover, using the Jackknife resampling method, we try to identify possible outliers that could be responsible for the deviations between subsamples. From this procedure, we see that single clusters can heavily affect the obtained result when the size of the subsample is not sufficient. However, for the specific groups, the tension is not significantly broken when we exclude their most “extreme” clusters. Other factors that were proven unable to explain the derived results were a redshift conversion to the CMB rest frame, a bulk flow motion of our Galaxy towards any direction and for any velocity amplitude, an exclusion of the galaxy clusters within |b| ≤ 20°, a possible difference in the NHI values of different sky regions, or different T and z distributions. Furthermore, using the HIFLUGCS sample, we saw that the deviation of Group A is even stronger for the brightest clusters and is not at all affected by the cool-cores of many of the members. Another possible cause that has to be tested in more detail, is the effect that nearby structures, such as superclusters, could have on the LX –T behavior of the member clusters. The simple test that we applied, indeed shows that clusters found in rich environments such as superclusters tend to have lower X-ray luminosities for the same temperature than clusters that are more isolated. However, as we pointed out,this does not seem to be the cause of the apparent deviation between Group A and the rest of the sky. The sky distribution of such structures, is roughly uniform between the two subsamples. In addition, the differences in the normalization between Group A and the rest of the sky can be also identified in the clusters that belong in superclusters (with large uncertainties of course due to the limited number of such clusters). Moreover, the dependence of the T measurement on different NHI values, in the case when a double thermal model fitting is needed, has to be studied in the future.
When we fix the normalization and slope to the same values for the entire sky, the behavior of the fitted cosmological parameters Ω m and H0 is almost identical with the behavior that the normalization appeared to have before, having the same trends and deviation amplitudes. This indicates the effectiveness with which one can trace the differences in the obtained cosmological parameter values by only studying the normalization of the LX –T scaling relation. If one considers an anisotropic Hubble expansion to be the reason behind these statistically significant discrepancies between different sky regions, then Group A seems to have the minimum expansion rate, in contrast with Groups B (mainly) and C that appear to have the opposite behavior.
On the other hand, it should be pointed out here that galaxy clusters are driven by complex physical processes while the LX –T relation generally suffers from a large intrinsic scatter, and therefore other physical reasons for these apparent deviations must be examined. A future comparison with a large number of data from cosmological simulations would give us a better idea of how likely these deviations are to occur within a cosmologically isotropic frame.
Additionally, future all-sky samples such as eeHIFLUGCS (Reiprich 2017) and the one that will be constructed with the eROSITA telescope (Merloni et al. 2012; Pillepich et al. 2012; Borm et al. 2014; Predehl et al. 2016), would be extremely useful to further investigate this phenomenon in depth. Finally, since the new method that we introduce in this paper is used for the first time, more work is needed to properly assess the significance of the obtained results.
6 Conclusions
In this study, we suggest a new method which takes advantage of the LX –T scaling relation of galaxy clusters in order to investigate the validity of the CP. Based on the fact that cosmological parameters enter the relation only through the luminosity distance and the redshift evolution of the LX –T relation, any deviations in the normalization of the latter will be strongly correlated with deviations in the cosmological parameters.
For this purpose, we use two full-sky galaxy cluster samples, ACC and XCS-DR1, which share less than 1% of their clusters. Remarkably, we find that the two samples have their higher and lower normalization values at similar Galactic longitudes, showing the same fluctuation tendency. The sky region that stands out the most in both samples is the one within l ~ (−15°, 90°) (Group A) that appears to have a statistically significant deviation from the rest of the sample (~ 3σ). This behavior is consistent in both ACC and XCS-DR1 samples. More specifically, if one compares the regions with the lowest a values, Group A seems to have a ~4σ deviation.
Several possible reasons for these inconsistencies were considered. Firstly, we demonstrated that single clusters that act as outliers are not the reason for the peculiar behavior of Group A region. Excluding clusters in low Galactic latitudes that could suffer from an improper LX derivation due to absorption did not alleviate the tension between the best-fit results of the independent subsamples. Furthermore, using the HIFLUGCS sample whose vast majority of clusters are contained in ACC, we saw that cool-core clusters are not responsible for the differences between Group A and the rest of the sky. A specific structure in the hydrogen column densities of different sky directions and its effects on the obtained LX values does not seem to be the case either, although the same remains to be verified for T measurements also. A redshift conversion from heliocentric with respect to the CMB frame as well as redshift conversions to account for possible bulk flows of the clusters, were also applied to both samples, without significantly changing the results. Moreover, Group A has similar T, z and 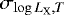 distributions to the rest of the sky and to the lowest-a regions, for both ACC and XCS-DR1. Another reason that was tested is the effect of the environment on the LX –T behavior of galaxy clusters. While we found that clusters that appear to belong to superclusters tend to have lower LX values compared to field clusters, this cannot explain the observed deviations.
distributions to the rest of the sky and to the lowest-a regions, for both ACC and XCS-DR1. Another reason that was tested is the effect of the environment on the LX –T behavior of galaxy clusters. While we found that clusters that appear to belong to superclusters tend to have lower LX values compared to field clusters, this cannot explain the observed deviations.
The reason behind this apparent mild anisotropy in the normalization value of the LX –T relation remains to be identified. This could also be expressed as a difference in the luminosity distance, for example, cosmological parameters of different sky regions. The same fluctuation trend as for the normalization has been obtained for Ω m and H0 for both samples, while the statistical significance of Group A is similar in all cases (~ 3σ). Of course, in order for such an extreme scenario to be considered, the statistical significance of the results must be higher and all the possible physical reasons for such a deviation must be examined and eventually rejected. Comparisons with isotropic cosmological simulations of > 106 galaxy clusters will also be made in future work. Finally, next-generation samples that will cover the full sky, such as eeHIFLUGCS and the eROSITA all-sky survey sample, containing large amounts of data with exceptional accuracy, will allow us to further investigate these interesting behaviors.
Acknowledgements
We thank the anonymous referee for their useful and constructive comments which helped us improve the quality of the paper. Moreover, we thank Florian Pacaud for providing us with the supercluster detection results using his code, as well as for his very helpful advice. K.M. is a member of the Bonn-Cologne Graduate School for Physics and Astronomy (BCGS), and thanks for its support. THR acknowledges support by the German Research Association (DFG) through grant RE 1462/6 and through the Transregional Collaborative Research Centre TRR33 The Dark Universe (project B18) as well as by the German Aerospace Agency (DLR) with funds from the Ministry of Economy and Technology (BMWi) through grant 50 OR 1608. This research has made use of the NASA/IPAC Extragalactic Database which is operated by the Jet Propulsion Laboratory, California Institute of Technology, under contract with the National Aeronautics and Space Administration.
References
- Akritas, M. G., & Bershady, M. A. 1996, ApJ, 470, 706 [NASA ADS] [CrossRef] [Google Scholar]
- Alonso, D., Salvador, A. I., Sánchez, F. J., et al. 2015, MNRAS, 449, 670 [NASA ADS] [CrossRef] [Google Scholar]
- Antoniou, I., & Perivolaropoulos, L. 2010, JCAP, 12, 012 [NASA ADS] [CrossRef] [Google Scholar]
- Appleby, S., & Shafieloo, A. 2014, JCAP, 10, 070 [NASA ADS] [CrossRef] [Google Scholar]
- Appleby, S., Shafieloo, A., & Johnson, A. 2015, ApJ, 801, 76 [NASA ADS] [CrossRef] [Google Scholar]
- Arnaud, K. A. 1996, in Astronomical Data Analysis Software and Systems V, eds. G. H. Jacoby, & J. Barnes, ASP Conf. Ser., 101, 17 [NASA ADS] [Google Scholar]
- Atrio-Barandela, F. 2013, A&A, 557, A116 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Atrio-Barandela, F., Kashlinsky, A., Ebeling, H., Kocevski, D., & Edge, A. 2010, ApJ, 719, 77 [NASA ADS] [CrossRef] [Google Scholar]
- Atrio-Barandela, F., Kashlinsky, A., Ebeling, H., Fixsen, D. J., & Kocevski, D. 2015, ApJ, 810, 143 [NASA ADS] [CrossRef] [Google Scholar]
- Baumgartner, W. H., & Mushotzky, R. F. 2006, ApJ, 639, 929 [NASA ADS] [CrossRef] [Google Scholar]
- Bengaly, Jr., C. A. P., Bernui, A., & Alcaniz, J. S. 2015, ApJ, 808, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Bengaly, C. A. P., Bernui, A., Ferreira, I. S., & Alcaniz, J. S. 2017, MNRAS, 466, 2799 [NASA ADS] [CrossRef] [Google Scholar]
- Bennett, C. L., Halpern, M., Hinshaw, G., et al. 2003, ApJS, 148, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Bennett, C. L., Larson, D., Weiland, J. L., et al. 2013, ApJS, 208, 20 [Google Scholar]
- Bharadwaj, V., Reiprich, T. H., Lovisari, L., & Eckmiller, H. J. 2015, A&A, 573, A75 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blake, C., & Wall, J. 2002, Nature, 416, 150 [NASA ADS] [CrossRef] [Google Scholar]
- Borm, K., Reiprich, T. H., Mohammed, I., & Lovisari, L. 2014, A&A, 567, A65 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chon, G., Böhringer, H., & Smith, G. P. 2012, A&A, 548, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Connor, T., Donahue, M., Sun, M., et al. 2014, ApJ, 794, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Dickey, J. M.,& Lockman, F. J. 1990, ARA&A, 28, 215 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Eckmiller, H. J., Hudson, D. S., & Reiprich, T. H. 2011, A&A, 535, A105 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Edge, A. C., & Stewart, G. C. 1991, MNRAS, 252, 414 [NASA ADS] [CrossRef] [Google Scholar]
- Fixsen, D. J., Cheng, E. S., Gales, J. M., et al. 1996, ApJ, 473, 576 [NASA ADS] [CrossRef] [Google Scholar]
- Fukazawa, Y., Makishima, K., & Ohashi, T. 2004, PASJ, 56, 965 [NASA ADS] [Google Scholar]
- Giodini, S., Lovisari, L., Pointecouteau, E., et al. 2013, Space Sci. Rev., 177, 247 [NASA ADS] [CrossRef] [Google Scholar]
- Hilton, M., Romer, A. K., Kay, S. T., et al. 2012, MNRAS, 424, 2086 [NASA ADS] [CrossRef] [Google Scholar]
- Horner, D. J. 2001, Ph.D. Thesis, University of Maryland, College Park, USA [Google Scholar]
- Hudson, D. S., Mittal, R., Reiprich, T. H., et al. 2010, A&A, 513, A37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ikebe, Y., Reiprich, T. H., Böhringer, H., Tanaka, Y., & Kitayama, T. 2002, A&A, 383, 773 endrefcommentnewpage [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jansen, F., Lumb, D., Altieri, B., et al. 2001, A&A, 365, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Javanmardi, B., & Kroupa, P. 2017, A&A, 597, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Javanmardi, B., Porciani, C., Kroupa, P., & Pflamm-Altenburg, J. 2015, ApJ, 810, 47 [NASA ADS] [CrossRef] [Google Scholar]
- Kaiser, N. 1986, MNRAS, 222, 323 [NASA ADS] [CrossRef] [Google Scholar]
- Kashlinsky, A., Atrio-Barandela, F., Kocevski, D., & Ebeling, H. 2008, ApJ, 686, L49 [NASA ADS] [CrossRef] [Google Scholar]
- Kashlinsky, A., Atrio-Barandela, F., Ebeling, H., Edge, A., & Kocevski, D. 2010, ApJ, 712, L81 [NASA ADS] [CrossRef] [Google Scholar]
- Kashlinsky, A., Atrio-Barandela, F., & Ebeling, H. 2011, ApJ, 732, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Keisler, R. 2009, ApJ, 707, L42 [NASA ADS] [CrossRef] [Google Scholar]
- Kocevski, D. D., Mullis, C. R., & Ebeling, H. 2004, ApJ, 608, 721 [NASA ADS] [CrossRef] [Google Scholar]
- Lloyd-Davies, E. J., Romer, A. K., Mehrtens, N., et al. 2011, MNRAS, 418, 14 [NASA ADS] [CrossRef] [Google Scholar]
- Lovisari, L., Reiprich, T. H., & Schellenberger, G. 2015, A&A, 573, A118 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mariano, A., & Perivolaropoulos, L. 2012, Phys. Rev. D, 86, 083517 [NASA ADS] [CrossRef] [Google Scholar]
- Marinoni, C., Bel, J., & Buzzi, A. 2012, JCAP, 10, 036 [NASA ADS] [CrossRef] [Google Scholar]
- Markevitch, M. 1998, ApJ, 504, 27 [NASA ADS] [CrossRef] [Google Scholar]
- Maughan, B. J., Giles, P. A., Randall, S. W., Jones, C., & Forman, W. R. 2012, MNRAS, 421, 1583 [NASA ADS] [CrossRef] [Google Scholar]
- Mehrtens, N., Romer, A. K., Hilton, M., et al. 2012, MNRAS, 423, 1024 [NASA ADS] [CrossRef] [Google Scholar]
- Merloni, A., Predehl, P., Becker, W., et al. 2012, ArXiv e-prints [arXiv:1209.3114] [Google Scholar]
- Migkas, K., & Plionis, M. 2016, RMXAA, 52, 133 [Google Scholar]
- Mittal, R., Hicks, A., Reiprich, T. H., & Jaritz, V. 2011, A&A, 532, A133 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Osborne, S. J., Mak, D. S. Y., Church, S. E., & Pierpaoli, E. 2011, ApJ, 737, 98 [NASA ADS] [CrossRef] [Google Scholar]
- Pacaud, F., Pierre, M., Adami, C., et al. 2007, MNRAS, 382, 1289 [NASA ADS] [CrossRef] [Google Scholar]
- Pandey, B., & Sarkar, S. 2015, MNRAS, 454, 2647 [NASA ADS] [CrossRef] [Google Scholar]
- Pierre, M., Pacaud, F., Adami, C., et al. 2016, A&A, 592, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pillepich, A., Porciani, C., & Reiprich, T. H. 2012, MNRAS, 422, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration Int XIII. 2014, A&A, 561, A97 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XVI. 2016, A&A, 594, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXVII. 2016, A&A, 594, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XXIV. 2016, A&A, 594, A24 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Plionis, M., & Georgantopoulos, I. 1999, MNRAS, 306, 112 [NASA ADS] [CrossRef] [Google Scholar]
- Plionis, M., & Kolokotronis, V. 1998, ApJ, 500, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Pratt, G. W., Croston, J. H., Arnaud, M., & Böhringer, H. 2009, A&A, 498, 361 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Predehl, P., Andritschke, R., Babyshkin, V., et al. 2016, in Space Telescopes and Instrumentation 2016: Ultraviolet to Gamma Ray, Proc. SPIE, 9905, 99051 [Google Scholar]
- Reiprich, T. H. 2017, Astron. Nachr., 338, 349 [NASA ADS] [CrossRef] [Google Scholar]
- Reiprich, T. H., & Böhringer, H. 2002, ApJ, 567, 716 [NASA ADS] [CrossRef] [Google Scholar]
- Schellenberger, G., Reiprich, T. H., Lovisari, L., Nevalainen, J., & David, L. 2015, A&A, 575, A30 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schuecker, P., Böhringer, H., Reiprich, T. H., & Feretti, L. 2001, A&A, 378, 408 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schwarz, D. J., & Weinhorst, B. 2007, A&A, 474, 717 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shafer, R. A., & Fabian, A. C. 1983, in Early Evolution of the Universe and Its Present Structure, eds. G. O. Abell, & G. Chincarini, IAU Symp., 104,333 [Google Scholar]
- Takey, A., Schwope, A., & Lamer, G. 2011, A&A, 534, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tanaka, Y., Inoue, H., & Holt, S. S. 1994, PASJ, 46, L37 [NASA ADS] [Google Scholar]
- Truemper, J. 1993, Science, 260, 1769 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Vikhlinin, A., van Speybroeck, L., Markevitch, M., Forman, W. R., & Grego, L. 2002, ApJ, 578, L107 [NASA ADS] [CrossRef] [Google Scholar]
- Vikhlinin, A., Burenin, R. A., Ebeling, H., et al. 2009, ApJ, 692, 1033 [NASA ADS] [CrossRef] [Google Scholar]
- Watkins, R., Feldman, H. A., & Hudson, M. J. 2009, MNRAS, 392, 743 [NASA ADS] [CrossRef] [Google Scholar]
- Weisskopf, M. C., Tananbaum, H. D., Van Speybroeck, L. P., & O’Dell, S. L. 2000, in X-Ray Optics, Instruments, and Missions III, eds. J. E. Truemper, & B. Aschenbach, Proc. SPIE, 4012, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Willingale, R., Starling, R. L. C., Beardmore, A. P., Tanvir, N. R., & O’Brien, P. T. 2013, MNRAS, 431, 394 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, Y.-Y., Reiprich, T. H., Schneider, P., et al. 2017, A&A, 599, A138 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
We set as 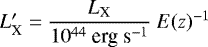 and
and 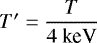 .
.
 ,
where x+ and
x− are the upper and lower
limits of the main value x
of a quantity, considering its uncertainty.
,
where x+ and
x− are the upper and lower
limits of the main value x
of a quantity, considering its uncertainty.
Here we divide the difference between the best-fit a
values for the two groups with the standard deviation obtained by the random subsamples,
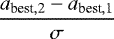 .
.
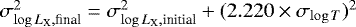 .
.
All Tables
Best-fit values of the fitted parameters with their 3σ credibility ranges for the four Galactic hemispheres of ACC.
Best-fit normalization values with their 3σ credibility ranges for Group A, Group C, and the rest of the sample of the ACC sample, for low and high temperature and redshift ranges.
Galactic longitude l limits for Groups A, B, and C as they are defined for ACC and XCS-DR1.
Best-fit normalization values with their 3σ credibility ranges for Group A, Group B, and the rest of the sample of the XCS-DR1 sample, for low and high temperature and redshift ranges.
All Figures
|
Fig. 1 Positions of the galaxy clusters contained in ACC (blue) and XCS-DR1 (red) at the Galactic sky map. |
| In the text | |
|
Fig. 2 HI column density as given by Dickey & Lockman (1990), as a function of the Galactic longitude (top) and latitude (bottom). |
| In the text | |
|
Fig. 3 Best-fit value of the normalization for every sky region of ACC with: left: Δ l = 90°, Δb = 180° as a functionof its central Galactic longitude and right: Δl = 360°, Δb = 40° as a function of its central Galactic latitude. Given the bin widths, the data points are obviously strongly correlated. |
| In the text | |
|
Fig. 4 Distribution of the best-fit value of the normalization as obtained by the Jackknife resampling method, for the sky regions with 75 clusters within l ∈ (−20°, 75°) (top left), 82 clusters within l ∈ (75°, 175°) (top right), 66 clusters within l ∈ (165°, 260°) (bottom left)and 63 clusters within l ∈ (215°, 310°) (bottom right). |
| In the text | |
|
Fig. 5 Bolometric luminosity LX as a functionof temperature T for the sky regions within l ∈ (−20°, 75°) (Group A, red) and l ∈ (75°, 175°) (Group C, blue). The best-fit functions (with a fixed slope of b = 3.375) are also displayed with green for Group A (a = 4.563) and with purple for Group C (a = 2.963). |
| In the text | |
|
Fig. 6 Distribution of the temperature (left), redshift (center) and temperature uncertainties (right) of the galaxy clusters contained inGroup A (red), Group C (black) and the rest of the sample (blue). |
| In the text | |
|
Fig. 7 Left panel: logarithmic luminosity uncertainty |
| In the text | |
|
Fig. 8 Best-fit value of the normalization with its 3σ uncertainty for every sky region of XCS-DR1: Top left: with Δl = 90°, Δb = 180° as a function of its central Galactic longitude, with the best-fit normalization value for the whole sample (purple). Top right: with Δl = 360°, Δb = 40° as a functionof its central Galactic latitude. Bottom left: for the LX–T (blue) and T–LX (red) fitting. Bottom right: for XCS-DR1 (blue) and ACC (red) with their best-fit values for the whole sample (green line for ACC and purple line for XCS-DR1). Given the bin widths, the data points are obviously strongly correlated. |
| In the text | |
|
Fig. 9 Distribution of the best-fit values of the normalization as obtained by the Jackknife resampling method, for Group A (red), Group B (blue), and the rest of the sample (black). |
| In the text | |
|
Fig. 10 1σ (green, light blue and purple) and 3σ (red, black and blue) contour plots, where the intrinsic scatter is not considered. Left: for Group A and the rest of the sample, including Group B. Right: Group A, Group B, and the rest of the sample, excluding Group B. |
| In the text | |
|
Fig. 11 Bolometric luminosity LX as a functionof temperature T for Group A (red) and Group B (blue). The best-fit functions are also displayed for Group A [a = 2.051, b = 2.512 (fixed) with green and a = 1.742, b = 2.032 (free) with black] and for Group B [a = 1.183, b = 2.512 (fixed) with light blue]. |
| In the text | |
|
Fig. 12 Distribution of the temperature (left), redshift (center) and final luminosity uncertainties (right) of the galaxy clusters contained in Group A (red), Group B (blue), and the rest of the sample (black). |
| In the text | |
|
Fig. 13 Best-fit value of Ωm for XCS-DR1, with its 3σ uncertainty and the number of clusters in each region. Different uncertainty magnitudes for similar numbers of clusters are caused by the different scatter of the LX –T relation. Leftpanel: for Groups A and B. The rest of the sky has Ωm = 0.318 ± 0.071. Right panel:for the four “usual” quarters of the Galactic sky. |
| In the text | |
|
Fig. 14 Best-fit value of Ωm for every skyregion of XCS-DR1 with Δl = 90°, Δb = 180° as a function of its central Galactic longitude. |
| In the text | |
|
Fig. 15 Best-fit value of H0 for every skyregion of XCS-DR1 (left) and ACC (right) with Δl = 90°, Δb = 180° as a function of its central Galactic longitude. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.