| Issue |
A&A
Volume 610, February 2018
|
|
|---|---|---|
| Article Number | A59 | |
| Number of page(s) | 20 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201731685 | |
| Published online | 28 February 2018 | |
The VIMOS Public Extragalactic Redshift Survey (VIPERS)★
An unbiased estimate of the growth rate of structure at 〈z〉 = 0.85 using the clustering of luminous blue galaxies
1
INAF–Osservatorio Astronomico di Brera, via Brera 28, 20122 Milano – via E. Bianchi 46,
23807
Merate, Italy
e-mail: faizan.mohammad@brera.inaf.it
2
Dipartimento di Scienza e Alta Tecnologia, Università degli studi dell’Insubria,
via Valleggio 11,
22100
Como, Italy
3
Università degli Studi di Milano,
via G. Celoria 16,
20133
Milano, Italy
4
Aix-Marseille Univ., Université Toulon, CNRS, CPT,
13288
Marseille, France
5
Dipartimento di Matematica e Fisica, Università degli Studi Roma Tre,
via della Vasca Navale 84,
00146
Roma, Italy
6
INFN, Sezione di Roma Tre,
via della Vasca Navale 84,
00146
Roma, Italy
7
INAF–Osservatorio Astronomico di Roma,
via Frascati 33,
00040
Monte Porzio Catone (RM), Italy
8
Aix-Marseille Univ., CNRS, LAM, Laboratoire d’Astrophysique de Marseille,
13388
Marseille, France
9
Dipartimento di Fisica e Astronomia, Alma Mater Studiorum Università di Bologna,
via Gobetti 93/2,
40129
Bologna, Italy
10
INFN, Sezione di Bologna,
viale Berti Pichat 6/2,
40127
Bologna, Italy
11
INAF–Osservatorio Astronomico di Bologna,
via Gobetti 93/3,
40129
Bologna, Italy
12
Institute for Astronomy, University of Edinburgh, Royal Observatory,
Blackford Hill,
Edinburgh
EH9 3HJ, UK
13
INAF–Istituto di Astrofisica Spaziale e Fisica Cosmica Milano,
via Bassini 15,
20133
Milano, Italy
14
INAF–Osservatorio Astrofisico di Torino,
10025
Pino Torinese, Italy
15
Laboratoire Lagrange, UMR},7293, Université de Nice Sophia Antipolis, CNRS, Observatoire de la Côte dAzur,
06300
Nice, France
16
Institute of Physics, Jan Kochanowski University,
ul. Swietokrzyska 15,
25-406
Kielce, Poland
17
National Centre for Nuclear Research,
ul. Hoza 69,
00-681
Warszawa, Poland
18
Aix-Marseille Universit, Jardin du Pharo,
58 bd Charles Livon,
13284
Marseille Cedex 7, France
19
IRAP, 9 Av. du colonel Roche, BP 44346,
31028
Toulouse Cedex 4, France
20
Astronomical Observatory of the Jagiellonian University,
Orla 171,
30-001
Cracow, Poland
21
School of Physics and Astronomy, University of St Andrews,
St Andrews
KY16 9SS, UK
22
INAF–Istituto di Astrofisica Spaziale e Fisica Cosmica Bologna,
via Gobetti 101,
40129
Bologna, Italy
23
INAF–Istituto di Radioastronomia,
via Gobetti 101,
40129
Bologna, Italy
24
Canada-France-Hawaii Telescope,
65–1238 Mamalahoa Highway,
Kamuela,
HI 96743, USA
25
Department of Astronomy, University of Geneva,
ch. dEcogia 16,
1290
Versoix, Switzerland
26
INAF–Osservatorio Astronomico di Trieste,
via G. B. Tiepolo 11,
34143
Trieste, Italy
27
Department of Astronomy & Physics, Saint Mary’s University,
923 Robie Street,
Halifax,
Nova Scotia
B3H 3C3, Canada
Received:
31
July
2017
Accepted:
5
October
2017
We used the VIMOS Public Extragalactic Redshift Survey (VIPERS) final data release (PDR-2) to investigate the performance of colour-selected populations of galaxies as tracers of linear large-scale motions. We empirically selected volume-limited samples of blue and red galaxies as to minimise the systematic error on the estimate of the growth rate of structure fσ8 from the anisotropy of the two-point correlation function. To this end, rather than rigidly splitting the sample into two colour classes we defined the red or blue fractional contribution of each object through a weight based on the (U − V) colour distribution. Using mock surveys that are designed to reproduce the observed properties of VIPERS galaxies, we find the systematic error in recovering the fiducial value of fσ8 to be minimised when using a volume-limited sample of luminous blue galaxies. We modelled non-linear corrections via the Scoccimarro extension of the Kaiser model (with updated fitting formulae for the velocity power spectra), finding systematic errors on fσ8 of below 1–2%, using scales as small as 5 h−1 Mpc. We interpret this result as indicating that selection of luminous blue galaxies maximises the fraction that are central objects in their dark matter haloes; this in turn minimises the contribution to the measured ξ(rp,π) from the 1-halo term, which is dominated by non-linear motions. The gain is inferior if one uses the full magnitude-limited sample of blue objects, consistent with the presence of a significant fraction of blue, fainter satellites dominated by non-streaming, orbital velocities. We measured a value of f σ8 = 0.45 ± 0.11 over the single redshift range 0.6 ≤ z ≤ 1.0, corresponding to an effective redshift for the blue galaxies 〈z〉=0.85. Including in the likelihood the potential extra information contained in the blue-red galaxy cross-correlation function does not lead to an appreciable improvement in the error bars, while it increases the systematic error.
Key words: cosmology: observations / large-scale structure of Universe / galaxies: high-redshift / galaxies: statistics
Based on observations collected at the European Southern Observatory, Cerro Paranal, Chile, using the Very Large Telescope under programs 182.A-0886 and partly 070.A-9007. Also based on observations obtained with MegaPrime/MegaCam, a joint project of CFHT and CEA/DAPNIA, at the Canada-France-Hawaii Telescope (CFHT), which is operated by the National Research Council (NRC) of Canada, the Institut National des Sciences de l’Univers of the Centre National de la Recherche Scientifique (CNRS) of France, and the University of Hawaii. This work is based in part on data products produced at TERAPIX and the Canadian Astronomy Data Centre as part of the Canada-France-Hawaii Telescope Legacy Survey, a collaborative project of NRC and CNRS. The VIPERS web site is http://www.vipers.inaf.it/
© ESO 2018
1 Introduction
Over the past two decades, observations have established that the Universe is undergoing a period of accelerated expansion. The expansion history H(z) is now well constrained by geometrical probes such as Type-1a supernovae (Riess et al. 1998; Perlmutter et al. 1999), baryon acoustic oscillations (BAO; e.g. Anderson et al. 2014) in the clustering of galaxies and anisotropies in the cosmic microwave background (CMB; e.g. Planck Collaboration XIII 2016). In the framework of Einstein’s General Relativity (GR), the observed H(z) requires the inclusion of an extra contribution in the cosmic budget, in the form of a fluid with negative pressure, dubbed “dark energy”. Current observations are compatible with the simplest form for this fluid, coinciding with Einstein’s cosmological constant. Alternatively, however, one could also match the data by modifying the very nature of the gravitational equations. These two alternatives are degenerate when considering the expansion history of the Universe alone. Such a degeneracy can be lifted, in principle, by measurements of the growth rate of cosmological structure, which is sensitive to the gravity theory.
As the motions of galaxies respond to the gravitational potential, the velocity field can be used as a powerful probe of the growth of structure. In galaxy redshift surveys, the line-of-sight velocity information becomes encoded in the redshift through the Doppler component which combines with the cosmological redshift, radially distorting galaxy positions in what is called “redshift space”. The amplitude of such “redshift-space distortions” (RSD; Kaiser 1987) can be quantified statistically by modelling their effect on two-point statistics. The linear component of the distortion is directly proportional to the linear growth rate of structure, f(z), and motivates the interest in RSD as a powerful way to break the degeneracy between GR and alternative theories of gravity (Guzzo et al. 2008).
Measuring f from RSD is however complicated by the non-linear component of the velocity field, which dominates on small scales (< 3 h−1 Mpc) and is produced by high-velocity galaxies inside virialised structures, such as groups and clusters. This component has to be properly modelled if one wants to extract the linear growth rate signal, fully exploiting the data (e.g. Reid et al. 2014). To this end, early measurements used a modification of the original linear model for the redshift-space power spectrum derived by Kaiser (1987), empirically accounting for non-linear contributions through a Lorenzian (or exponential in configuration space) damping (the “dispersion model”, Peacock & Dodds 1994). Numerical tests have shown that for galaxy-sized haloes this model tends in general to deliver biased estimates of f(z), up to ~10% (Okumura & Jing 2011; Bianchi et al. 2012). This is clearly incompatible with the percent precision goals of modern redshift surveys, motivating extensive work on improved RSD models extending into the non-linear regime (e.g. Scoccimarro 2004; Taruya et al. 2010; Reid & White 2011; Bianchi et al. 2015, Bianchi et al. 2016; Uhlemann et al. 2015). Some of these models have been applied to real data, with positive results (e.g. Pezzotta et al. 2017; de la Torre et al. 2017, and references therein).
Given the challenge of modelling the non-linear regime, we can attempt to reduce the importance of these regimes in the data. One way to achieve this is through a linearisation of the density field by thresholding density peaks using the “clipping” technique. We study this approach in a parallel work (Wilson et al., in prep.).
Another way is to identify, if they exist, sub-populations of galaxies that by their very nature are less affected by non-linear motions. In Mohammad et al. (2016), for example, we used numerical simulations to explore the use of galaxy groups and clusters as tracers of large-scale linear motions, modelling their redshift-space auto and cross-correlation functions. Although the group auto-correlation function yields the least biased results, it is penalised by the reduced statistics, due to the inevitably smaller number of galaxy groups that can be identified in a survey catalogue. The best compromise between statistical and systematic errors was obtained using the group-galaxy cross-correlation function, with systematic errors remaining smaller than 5% also when including measurements down to 5 h−1 Mpc. The idea beyond these experiments is that of eliminating or reducing the weight of high-velocity galaxies in virialised structures in the computed two-point function. In the language of the halo model (Cooray & Sheth 2002), these are the objects defined as satellites, in contrast to central halo galaxies. In this picture, auto-correlating groups enhances the large-scale halo-halo term, minimising the contribution of 1-halo pairs affected by high relative velocities.
Going beyond this would require identifying a sub-class of galaxies that are more numerous than groups, while still being objects that are central galaxies in a halo. One way to look for such a sample is to start from the observed colour dichotomy of galaxies. It is well known since almost forty years (e.g. Dressler 1980) that high density regions, where random high-velocity motions dominate, are preferentially inhabited by red galaxies. Conversely, blue galaxies tend to avoid these regions (at least out to z ≃ 1) and as such should be less affected by the non-streaming motions typical of groups and clusters. Several works in the literature have compared the clustering of active (blue) and passive (red) galaxies at z ≃ 0 (Madgwick et al. 2003; Zehavi et al. 2005). Quantitatively, halo occupation distribution (HOD) models indicate that red galaxies are likely to be satellites in massive dark matter haloes, while blue galaxies are typically central galaxies in haloes of lower mass (Guo et al. 2014). It is also well known that the segregation of galaxy colours and morphologies is mirrored by the kinematics of red and blue galaxies (Guzzo et al. 1997). In the local Universe, early-type (i.e. red S0s and elliptical) galaxies show larger random velocities and prominent “fingers-of-God” features than late-type (blue spiral and irregular) galaxies.
In this paper we exploit this dichotomy using the newly released data of the VIMOS Public Extragalactic Redshift Survey(VIPERS; Guzzo et al. 2014; Scodeggio et al. 2018). Measurements of the growth rate from RSD out to z = 1 using the VIPERS final data release have been presented recently using complementary techniques (Pezzotta et al. 2017; de la Torre et al. 2017; Hawken et al. 2017). The selection of a catalogue of galaxy groups is under way (Iovino et al., in preparation) and is limited by the VIPERS angular mask. Given its broad selection function (essentially flux-limited), high sampling rate and extended photometric information, VIPERS is ideal to select sub-samples of galaxies based on properties such as luminosity and colour.
Here we perform joint analyses of the auto-correlation and cross-correlation statistics of the sub-samples. The study is focussed on two populations selected by colour, red and blue, and further selected by luminosity to form volume-limited samples.
In Sect. 2 we describe the VIPERS dataset and the methodology used for sample selection. In Sect. 3 we describe the construction of the mock catalogues that we used for building covariance matrices and testing the accuracy of the estimators. The computation of the correlation function statistics is described in Sect. 4. In Sect. 5 we present the redshift-space distortion models that we use to fit the data in Sects. 6 and 7. The results and final conclusions are given in Sects. 8 and 9. Throughout the work we adopted the standard flat Λ cold dark matter (CDM) cosmological model with parameters (Ωb, Ωm, h, ns, σ8) = (0.045, 0.30, 0.7, 0.96, 0.80).
2 Observational data
2.1 The VIPERS survey
The VIPERS survey extends over an area of 23.5 deg2 within the W1 and W4 fields of the Canada-France-Hawaii Telescope Legacy Survey Wide (CFHTLS-Wide). The VIMOS multi-object spectrograph (Le Fèvre et al. 2003) was used to cover these two fields with a mosaic of 288 pointings, 192 in W1 and 96 in W4. Galaxies were selected from the CFHTLS-Wide catalogue to a faint limit of iAB = 22.5, applying an additional (r − i) vs. (u − g) colour pre-selection that efficiently and robustlyremoves galaxies at z < 0.5. Coupled with a highly optimised observing strategy (Scodeggio et al. 2009), this doubles the mean galaxy sampling efficiency in the redshift range of interest, compared to a purely magnitude-limited sample, bringing it to 47%.
Spectra were collected at moderate resolution (R ≃ 220) using the LR Red grism, providing a wavelength coverage of 5500–9500. The typical redshift error for the sample of reliable redshifts is σz = 0.00054(1 + z), which corresponds to an error on a galaxy peculiar velocity at any redshift of 163 km s−1. These and other details are given in the PDR-2 release paper (Scodeggio et al. 2018). A discussion of the data reduction and management infrastructure was presented in Garilli et al. (2014), while a complete description of the survey design and target selection was given in Guzzo et al. (2014). The dataset used in this paper is an early version of the PDR-2 data, from which it differs by a few hundred redshifts revised during the very last period before the release. In total it includes 89 022 objects with measured redshifts. As in all statistical analyses of the VIPERS data, only measurements with quality flags2 to 9 inclusive are used, corresponding to a sample with a redshift confirmation rate of 96.1% (for a description of the quality flag scheme, see Scodeggio et al. 2018). In this work we used the absolute magnitudes derived for the VIPERS sample in Davidzon et al. (2016), where spectral energy distributions (SED) were fitted to the extensive multi-band ancillary photometry available for the survey, as part of the VIPERS Multi-Lambda Survey (Moutard et al. 2016).
2.2 Colour classification
To split the VIPERS sample into two blue and red sub-samples, we used the observed bimodal distribution of galaxy properties. Haines et al. (2017) give an extensive discussion of bimodality in the final VIPERS data as a function of spectral properties. Here we used a criterion based on photometry, following Fritz et al. (2014), where UV = (MU − MV) colours and their dependence on redshift are described (see also Siudek et al. 2017).
We modelled the UV colour distribution with three Gaussian components. We note that the details of this split are not crucial for this work since our goal is essentially to separate a population dominating the high-density regions (the “red” galaxies) from the remaining class of bluer objects that should mostly populate the “field” and not to assess the reality of a third population with intermediate properties. Thus, the three-Gaussian fit simply characterises the three main populations of galaxies evident in the colour-magnitude diagram: the “red sequence”, “green valley” and the “blue cloud”. We performed the fit in redshift slices with width Δz = 0.1 to account for redshift evolution. In each redshift bin, the measured UV colour distribution was fitted with the three-Gaussian model
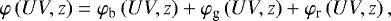 (1)
(1)
where 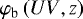 ,
, 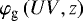 and
and 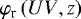 model the contribution to the overall colour distribution from the blue, green and red classes, respectively. Each term
model the contribution to the overall colour distribution from the blue, green and red classes, respectively. Each term 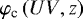 on the right side of Eq. (1) was modelled as a Gaussian distribution,
on the right side of Eq. (1) was modelled as a Gaussian distribution,
![\begin{equation*} \varphi_{\textrm{c}}\left({UV},z\right) = \frac{{A}_{\textrm{c}}\left(z\right)}{\sqrt{2\pi}\sigma_{\textrm{c}}\left(z\right)}\exp{\left[-\frac{\left({UV}-\mu_{\textrm{c}}\left(z\right)\right)^2}{2\sigma_{\textrm{c}}^2\left(z\right)}\right]}\cdot\end{equation*}](/articles/aa/full_html/2018/02/aa31685-17/aa31685-17-eq7.png) (2)
(2)
In Eq. (2), Ac, μc and σc are respectively the normalization factor, the mean and the dispersion of the Gaussian distribution. Figure 1 shows the histograms of the UV colour distribution in different redshift bins along with the related best-fitting models. In computing the normalised distributions of the UV colour, we weighted each galaxy to correct for the target sampling rate TSR and spectroscopic success rate SSR (both quantities are defined and discussed in details in Sect. 4.2). We assigned a red and blue weight to each galaxy based upon the model fit to quantify the likelihood of being a member of the red or blue classes. The weight is normalised such that wb +wr = 1, with
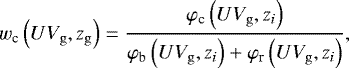 (3)
(3)
where UVg and zg are the galaxy colour and redshift while zi is the corresponding redshift bin, that is zi − Δz∕2 ≤ zg ≤ zi + Δz∕2 and the subscript -c denotes the blue or red colour type.
We stress here that in this analysis only two classes are considered. Galaxies with intermediate “green” colours contribute to the red and bluesamples with their corresponding weights. In practice, the result is similar to the usual binary blue-red classification based upon UV colour. However, here green galaxies are not discarded but enter the measurements proportionally to their blue or red fractions. The advantage is twofold. We avoid introducing a sharp, arbitrary cut to separate red from blue objects and we keep all the objects of the catalogue. In this work, we weighted each galaxy by its corresponding colour weight wb or wr when computing statistics on the blue or red samples, respectively.
The redshift distributions resulting from this classification are shown in Fig. 2 for the blue and red weighted samples along with the full sample of galaxies in VIPERS. The smoothed distribution using a Gaussian filter with width σz = 0.07 are also shown in the same figure.
 |
Fig. 1 Normalised distribution of galaxy rest-frame UV colour in VIPERS in the redshift range 0.5 ≤ z ≤ 1.2 (points). Statistical uncertainties include contributions from Poissonian shot noise and cosmic variance, estimated using the linear bias relation with b = 1.4 (see Appendix D). The best-fit models (Eq. (1)) are shown as black continuous lines. Contributions to the model from the galaxies belonging to the blue cloud, red sequence and green valley are plotted as blue dashed, red dash-dotted and green dotted lines, respectively. |
2.3 Volume-limited samples
Selecting volume-limited samples from a flux-limited survey that covers an extended redshift range entails making assumptions on how galaxies evolve within the redshift range. In the past this has been usually modelled through an empirical luminosity evolution of the form
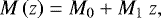 (4)
(4)
where M0 is the absolute magnitude threshold one would assume at z = 0, and, for the B band and redshifts between 0 and ~1, a slope M1 ≃−1 was adopted to describe the average luminosity evolution of the full population of galaxies (e.g. zCOSMOS: Lilly et al. 2009). This was empirically motivated by the observed evolution of the characteristic luminosity M* in the same surveys, under the assumption of a pure luminosity evolution.
Here we need to estimate the evolution parameters in Eq. (4) for each of our colour-selected sub-classes. From now on, we restricted our analysesto 0.6 ≤ z ≤ 1.0, a range which allowed us to build sufficiently large and fully complete volume-limited samples, given the VIPERS apparent magnitude limit. We worked under the same assumption that the comoving number density of galaxies in each class is preserved. This is clearly not strictly true as over the restricted redshift range considered, 0.6 ≤ z ≤ 1.0, (a) we expect some objects to migrate from the blue cloud to the red sequence (e.g. Gargiulo et al. 2017; Haines et al. 2017; Cucciati et al. 2017) and (b) the merger rate is small but non-zero (e.g. Fritz et al. 2014). In practice, these approximations have no impact on our conclusions, as our broad goal, as we shall show, is to maximize the fraction of central galaxies of galaxy-sized haloes.
Under these assumptions, we required the resulting comoving number density of galaxies in the selected samples to be constant with redshift, and computed the parameter values (M0, M1) that give the corresponding integration limit of the luminosity function in Eq. (4). We worked in bins of width Δz = 0.05, fixing the luminosity threshold  to match the 90% completeness value in the highest-redshift bin (i.e. 0.95 ≤ z ≤ 1.0) and computed the related reference comoving number density nref. The luminosity threshold
to match the 90% completeness value in the highest-redshift bin (i.e. 0.95 ≤ z ≤ 1.0) and computed the related reference comoving number density nref. The luminosity threshold 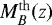 over the full range was then estimated as the one that keeps the comoving number density equal to this value: n(z) = nref. We assumed
over the full range was then estimated as the one that keeps the comoving number density equal to this value: n(z) = nref. We assumed 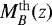 to evolve linearly with redshift according to Eq. (4).
to evolve linearly with redshift according to Eq. (4).
The measured luminosity evolution function 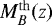 is shown in Fig. 3 and Fig. 4 for blue and red galaxy samples, respectively, along with the related best-fit models. The error budget σn(z) on n(z) takes contributions from the Poissonian shot-noise and the sample variance terms. The latter was estimated through linear theory predictions (see Appendix D) assuming a linear local and scale-independent bias b = 1.6. With respect to the discussion in Sect. 2.2 we used a higher value here as the bias is known to be larger for more luminous galaxies (Marulli et al. 2013; Granett et al. 2015; Cappi et al. 2015; Di Porto et al. 2016). The errors on the luminosity threshold
is shown in Fig. 3 and Fig. 4 for blue and red galaxy samples, respectively, along with the related best-fit models. The error budget σn(z) on n(z) takes contributions from the Poissonian shot-noise and the sample variance terms. The latter was estimated through linear theory predictions (see Appendix D) assuming a linear local and scale-independent bias b = 1.6. With respect to the discussion in Sect. 2.2 we used a higher value here as the bias is known to be larger for more luminous galaxies (Marulli et al. 2013; Granett et al. 2015; Cappi et al. 2015; Di Porto et al. 2016). The errors on the luminosity threshold 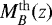 in each redshift bin were obtained by considering the values
in each redshift bin were obtained by considering the values 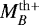 and
and 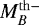 corresponding to a comoving number density
corresponding to a comoving number density 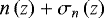 and
and 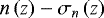 , respectively. The error on
, respectively. The error on 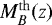 was then obtained as
was then obtained as 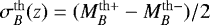 . We finally fit the values of
. We finally fit the values of 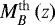 inferred from the data with a linear model for the luminosity evolution in Eq. (4).
inferred from the data with a linear model for the luminosity evolution in Eq. (4).
The best-fit evolution coefficients for the cases of red and blue galaxies, together with the main properties of the resulting volume-limited samples are listed in Table 1. In this work we defined the effective redshift zeff as the median of the distribution of the average redshift of all galaxy pairs with separations 3 h−1 Mpc < s < 50 h−1 Mpc.
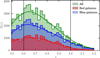 |
Fig. 2 Un-normalised redshift distributions of VIPERS galaxies in the redshift range 0.5 ≤ z ≤ 1.2. The red and blue filled histograms show the observed number of blue and red galaxies respectively, i.e. when each galaxy is weighted by its blue wb or red wr colour weight only (see Eq. (3)), resulting from our classification scheme (Sect. 2). Thedistribution of all galaxies is also shown with green filled histogram. The continuous lines superposedon the histograms show the same distributions after convolving with a Gaussian kernel with σz = 0.07. Vertical black lines delimit the redshift range used in this analysis. |
 |
Fig. 3 Magnitude-redshift diagram of VIPERS blue galaxies. Top panel: scatter plot in the magnitude (MB)-redshift plane. Dark dots represent galaxies included in the volume-limited sample while the light dots show the ones excluded due to the luminosity threshold. Points show the luminosity threshold |
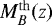
Parameters characterising the volume-limited samples of red and blue galaxies in VIPERS within 0.6 ≤ z ≤ 1.0.
3 VIPERS mock surveys
We used a set of 153 independent VIPERS mock catalogues both to estimate the covariance matrix of clustering measurements and to test the impact of systematics arising from observational issues and RSD modelling. In our analysis we used two types of mock samples:
- i)
parent mocks – the light-cone galaxy catalogues with the VIPERS redshift distribution and rectangular sky coverage;
- ii)
VIPERS-like mocks – the parent mocks with VIPERS survey geometry and application of the slit-assignment algorithm and redshift measurement error.
3.1 Mock construction
The mocks were constructed from the Big MultiDark Planck (BigMDPL; Prada et al. 2012) dark matter N-body simulation using HOD prescriptions to populate dark matter haloes with galaxies. The HOD parameters were calibrated using luminosity-dependent clustering measurements from the preliminary data release of VIPERS. The detailed procedure is described in de la Torre et al. (2013, de la Torre et al. 2017).
The simulations were carried out in the flat ΛCDM cosmological model with parameters:
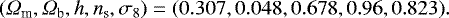
Since the resolution is not sufficient to match the typical halo masses probed by VIPERS, low mass haloes were added following the recipe proposed in de la Torre & Peacock (2013).
Central galaxies were placed at the halo centre with no peculiar velocities in the rest frame of the hosting halo. Satellite galaxies were distributed within dark matter haloes according to an NFW profile (Navarro et al. 1997). In addition to the hosting halo peculiar velocity, an additional random velocity component, drawn from a Gaussian distribution along each Cartesian direction, was assigned to the satellite galaxies. The velocity dispersion along each axis was computed following van den Bosch et al. (2004) under the assumption of spherical symmetry and isotropy within dark matter haloes obeying an NFW density profile. This is clearly a delicate aspect in the case in which the mocks are used to test models of redshift-space distortions, as done for VIPERS, since the non-linear component of the velocity field is the most critical part of RSD modelling. We shall discuss this point further in this paper, when comparing results from the mocks and the real data.
Galaxy B-band luminosities and colours were assigned following the methods presented in Skibba et al. (2006) and Skibba (2009). To summarise, halo occupation distribution model fits were carried out on the observed projected correlation functions measured in luminosity threshold samples, leading to an analytical luminosity- and redshift-dependent HOD parametrization (de la Torre et al. 2013). The observed conditional colour bimodality ⟨UV |MB⟩ in VIPERS was fitted with a double Gaussian distribution function. Using these fits, galaxies were placed in the simulation with the following recipe:
- 1.
For halo mass m at redshift z, compute ⟨Ncen(m| > MB,cut, z)⟩ and ⟨Nsat(m| > MB,cut, z)⟩, where MB,cut is the absolute magnitude limit corresponding to i = 22.5 at redshift z, and populate the given halo accordingly.
- 2.
Draw values of MB for the central and satellite galaxies by sampling from the cumulative distribution. This is done by solving ⟨Ntype(m| > MB, z)⟩∕⟨Ntype(m| > MB,cut, z)⟩ = u for MB, where u is a uniform random number between 0 and 1 and the subscript “type” stands for “cen” or “sat” depending on the type of galaxy.
- 3.
The rest-frame colour of the satellite and central galaxies is assigned with the relations (Skibba 2009)
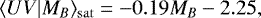 (5)
(5)
![\begin{align*}\nonumber \langle UV | M_B\rangle_{\mathrm{cen}}& = \langle UV | M_B\rangle_{\mathrm{all}} \\ &\quad+ \frac{n_{\mathrm{sat}}(M_B)}{n_{\mathrm{cen}}(M_B)}\left[\langle UV|M_B\rangle_{\mathrm{all}} - \langle UV | M_B\rangle_{\mathrm{sat}} \right]. \end{align*}](/articles/aa/full_html/2018/02/aa31685-17/aa31685-17-eq24.png)
Similarly to Skibba (2009), the coefficients in Eq. (5) have been set by trial and error, as to reproduce the observed segregation in the projected correlation function of red and blue galaxies.
3.2 Volume-limited mock samples
Although the mock catalogues are found to be a good representation of the observed properties of the global galaxy population surveyed by VIPERS, they do not necessarily accurately reproduce the distributions of colour-selected galaxy samples. We found that by following the procedure to construct volume limited samples described in Sect. 2.3, we were unable to match both the number density and clustering amplitude of the blue and red samples in the mocks and data. The main consequence of this mismatch is inaccuracy in the covariance matrices that we derive from the mocks. As a compromise, we set the luminosity threshold to match the clustering amplitude. This guarantees the accuracy of the cosmic variance contribution in covariance matrices. This lead to a ~ 15% deficit in the galaxy number density in the mocks with respect to the corresponding VIPERS samples. However, we accounted for this mismatch of shot noise by modifying the covariance matrix (see Sect. 6).
To draw volume-limited mock samples from the flux-limited ones, we followed the same procedure adopted for real catalogues in Sect. 2.3. We adopted a second-order polynomial in z to better reproduce the mean luminosity evolution measured from our 153 mocks,
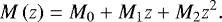 (7)
(7)
To match the clustering amplitude of red and blue galaxies in VIPERS we set the luminosity threshold for mock galaxies (both blue and red) to 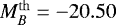 in the last redshift bin (see Fig. 15 where the measurements of the 2PCF multipoles of the luminous blue galaxies in VIPERS-like mocks and VIPERS data are plotted together).
in the last redshift bin (see Fig. 15 where the measurements of the 2PCF multipoles of the luminous blue galaxies in VIPERS-like mocks and VIPERS data are plotted together).
4 Two-point correlations
The anisotropic two-point correlation function was measured as a function of two variables, namely the angle-averaged pair separation s and μ, the cosine of the angle between the line of sight and the direction of pair separation. We describe here the estimator used to measure the anisotropic two-point correlation functions 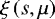 and the method used to correct the measurements against different observational systematics.
and the method used to correct the measurements against different observational systematics.
4.1 Estimator
We used the minimum variance estimator proposed by Landy & Szalay (1993),
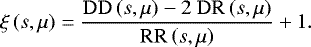 (8)
(8)
In Eq. (8) DD, DR and RR are respectively the data-data, data-random and random-random normalised pair counts. The random sample consists of points drawn uniformly from the survey volume characterised by the same radial and angular selection functions affecting the galaxy sample.
We obtained the cross-correlation function between volume-limited samples of blue and red galaxies by replacing the galaxy-galaxy pair count DD with the blue-red galaxy cross-pair count DbDr and the galaxy-random cross-pair count 2DR with DbR + DrR with the subscript -b (-r) denoting the blue (red) galaxy type. The use of volume-limited samples allowed us to build a single random catalogue characterised by a comoving number density constant with redshift to probe the survey volume in virtue of the fact that both blue and red samples are affected by the same angular and radial selection functions.
In particular we used 200 linear bins in μ between [0, 1] with measurements sampled at the mid point of each bin in μ. The pair separation s was binned using logarithmic bins,
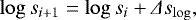 (9)
(9)
with Δslog = 0.1. The value of s to which the measured correlation in each bin is referenced was defined using the logarithmic mean1,
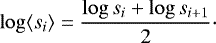 (10)
(10)
The measured anisotropic two-point correlation function 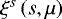 was then projected on the Legendre polynomials
was then projected on the Legendre polynomials 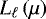 in order to obtain the multipole moments of the two-point correlation function
in order to obtain the multipole moments of the two-point correlation function 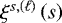 . However, given the discrete bins in μ we replaced the integral by the Riemann sum,
. However, given the discrete bins in μ we replaced the integral by the Riemann sum,
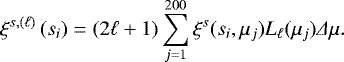 (11)
(11)
The number of bins in μ was deliberately taken high in order to have a good sensitivity to the direction of the pair separation, crucial for estimates of the quadrupole.
4.2 Corrections for incompleteness
The target sampling rate (TSR) and spectroscopic success rate (SSR) result in incompleteness in the observed galaxy distribution with respectto the underlying one that systematically biases the two-point correlation function on large scales. In particular, due to the slit placement constraints, the target sampling rate is lower in regions with a high density of galaxies on the sky. This leads to a systematic reduction in the clustering amplitude. The effect is even stronger for the more strongly clustered luminosity and colour sub-samples that we consider. Following the procedure presented in de la Torre et al. (2013), we corrected for the sampling effects by applying weights. Each galaxy was weighted by the inverse of the effective sampling rate, wESR = TSR−1 ×SSR−1 in addition to the colour weight corresponding to the blue or red sample selection, wb or wr.
The proper computation of the target sampling rate requires having the photometric parent sample. However, for sub-samples selected by luminosity, the parent sample is not known since it is defined using spectroscopic redshift. Due to this limitation, we used the same target sampling rate estimated on the full flux-limited sample and used by Pezzotta et al. (2017) to analyse the full VIPERS sample.
The effective sampling rate affects the amplitude of the correlation function on large scales as shown in Figs. 5 and 6 for the multipoles of the auto correlation of blue galaxies and blue-red cross correlation respectively in the volume-limited mock samples. We do not show results for the auto-correlation of red galaxies, as the tests on the parent mocks will show that this class of galaxies produced very biased results (see Sect. 7), and so will not be used to draw our final conclusions. However, we found that, in the case of volume-limited sample of red galaxies, the performance of the correction method was similar to the cases shown in Figs. 5 and 6. The application of the weights corrected the monopole and quadrupole within ~ 5−7% with the exception of the zero-crossing region for the quadrupole.
We found that the weights do not perform as well as shown in the full-sample analysis (Pezzotta et al. 2017). This is due to the higher clustering of volume-limited samples, together with the fact that the weights are computed based upon the full sample. The correction acts by upweighting galaxies according to the local projected density in the full sample, but since the sub-samples we considered are more clustered than in the full sample the weights do not fully account for the galaxies that were missed.
The pairs that are lost due to the slit placement constraints preferentially remove power on scales < 1 h−1 Mpc. As described in de la Torre et al. (2013) this bias may be corrected by the application of a weighting function to galaxy pairs that depends on angular separation (see Appendix A). We tested the application of angular weights using mock catalogues on the colour- and luminosity-selected samples and found no significant change in the measured monopole and quadrupole on the scales considered. We found that, as expected, the sparseness of our sub-samples amplifies the shot noise error and the uncertainties in the weight correction degrading the measurement. Therefore, for the subsequent analyses we did not apply the angular weights.
Taking into account the sampling rate corrections, the final pair counts are,
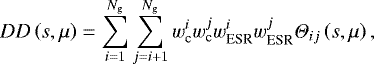 (12a)
(12a)
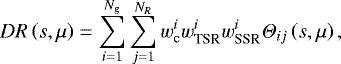 (12b)
(12b)
 |
Fig. 5 Impact of different corrections on the measured multipole moments of the two-point correlation function of blue galaxies in volume-limited mock samples. Top panel shows the measurements, while middle and bottom panels contain the relative systematic error on the monopole and quadrupole, respectively. Black continuous lines result from parent mocks. Red dotted lines are the raw estimates from VIPERS-like mocks. Blue dashed lines result from correcting the multipoles for TSR only (also, no SSR correction is needed for the mocks). Green dash-dotted lines are the case when both TSR (wTSR) and angular (wA) weights are applied. Horizontal grey shaded bands in the middle and bottom panels delimit the 1% and 5% regions, while blue shaded regions show the 1σ error on the mean estimates of the multipole in parent mocks. |
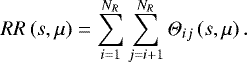 (12c)
(12c)
In Eq. (12) wc is the galaxy colour weight related to the colour type c (blue or red) and 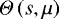 is a step function equal to unity if logs ∈ [logsi − Δslog∕2, logsi + Δslog∕2] and μ ∈ [μj − Δμ∕2, μj + Δμ∕2] and zero otherwise.
is a step function equal to unity if logs ∈ [logsi − Δslog∕2, logsi + Δslog∕2] and μ ∈ [μj − Δμ∕2, μj + Δμ∕2] and zero otherwise.
In flux-limited galaxy samples, the radial selection function drops as one moves to higher redshifts. As a result the pair counts are dominated by the nearby galaxies with limited contribution from the more distant ones, even though the latter probe larger volumes. This motivates the use of J3 weights (Hamilton 1993) in configuration space, or equivalently FKP weights (Feldman et al. 1994) in Fourier space, to give an optimum balance between cosmic variance and shot noise in the two-point statistics. But the J3 weighting scheme is found in practice to be ineffective for the flux-limited sample in VIPERS (de la Torre et al. 2013) and only makes the measurements noisier; we therefore did not include these weights in our measurements. In any case, the optimal weights are proportional to the inverse of the selection function except where shot noise dominates. Since we restricted the redshift range of our analysis to exclude the low-density tails, volume-limited samples should therefore give the main advantage claimed for optimal weighting, maximizing the effective volume and minimizing the sampling errors.
Figure 7 shows the redshift-space two-point correlation functions ξs (rp, π) for the blue and red populations both in the flux- and volume-limited sub-samples, computed applying the methodology and correction discussed above. The reduced small-scale FoG stretching for blue galaxies is evident. In the top panels we have also over-plotted the correlation function estimates obtained respectively from the mean of the blue and red mock samples. The agreement between data and mock samples for the blue population is remarkable on all scales. This is not true for the red galaxies: first, the mock sample shows a higher amplitude, which was expected given its slightly higher linear bias. Secondly, the small-scale stretch of the contours produced by high-velocity dispersion pairs is significantly stronger. We will have to keep this in mind when discussing the growth rate estimates based on the mock red galaxies; however, as we shall see, this difference will not change the main conclusions when comparing the blue and red samples.
 |
Fig. 6 Same as in Fig. 5 but for the multipole moments of the blue-red two-point cross-correlation function. |
5 Theoretical models for RSD
In large redshift surveys, observed redshifts result from a combination of the cosmological ones with the Doppler effect due to the line-of-sight component of the galaxy peculiar velocities. As a result the galaxy apparent positions s are distorted in the radial direction with respect to the real ones r if cosmological distances are inferred by means of observed redshifts,
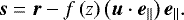 (13)
(13)
In Eq. (13) f(z) is the linear growth rate of structure, e|| is the unit vector along the line of sight and u is the scaledvelocity field,
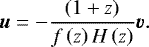 (14)
(14)
In terms of the overall matter density contrast 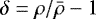 the mass conservation between true δ and redshift-space δs reads
the mass conservation between true δ and redshift-space δs reads
![\begin{equation*} \left[1+\delta^s\right]=\left[1+\delta\right]\left|\frac{\textrm{d}^3\vec{s}}{\textrm{d}^3\vec{r}}\right|^{-1}\cdot\end{equation*}](/articles/aa/full_html/2018/02/aa31685-17/aa31685-17-eq42.png) (15)
(15)
In Eq. (15) 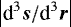 is the Jacobian of the coordinate transformation in Eq. (13),
is the Jacobian of the coordinate transformation in Eq. (13),
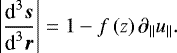 (16)
(16)
Under the small-angle plane-parallel approximation in the regime where the density contrast and the velocity gradients are much smaller than unity, that is δ ≪ 1 and ∂∥u∥≪ 1 respectively,and the velocity field is irrotational, the mass conservation in Eq. (15) takes a much simpler form in Fourier space,
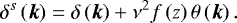 (17)
(17)
In Eq. (17) ν is the cosine of the angle between the wavevector k and the line of sight and θ = ∇⋅u is the velocity divergence.
The galaxy bias b is assumed here to be linear, local and scale-independent. Furthermore, the galaxy peculiar velocity field is assumed unbiased with respect to that of the overall matter. Equation (17) can thus be written as
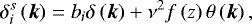 (18)
(18)
where the subscript -i denotes the specific galaxy type considered.
In the large-scale limit where δ = θ, Eq. (18) becomes
![\begin{equation*} \delta_{{i}}^s\left(\vec{k}\right) = \left[b_{{i}}+\nu^2f\left(z\right)\right]\delta\left(\vec{k}\right).\end{equation*}](/articles/aa/full_html/2018/02/aa31685-17/aa31685-17-eq47.png) (19)
(19)
In the most general case of blue-red cross correlation explored in this work, the linear Kaiser model (Kaiser 1987) for the redshift-space cross power spectrum 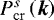 follows directly from Eq. (19),
follows directly from Eq. (19),
![\begin{equation*} P^s_{\mathrm{cr}}\left(k,\nu\right)=\left[b_{\mathrm{b}}+\nu^2f\right]\left[b_{\mathrm{r}}+\nu^2f\right]P_{\delta\delta}\left(k\right).\end{equation*}](/articles/aa/full_html/2018/02/aa31685-17/aa31685-17-eq49.png) (20)
(20)
In Eq. (20) Pδδ is the real-space matter power spectrum. The linear Kaiser model captures the enhancement in the galaxy clustering at very large scales. However it is not able to model the apparent clustering at smaller scales. Peacock & Dodds (1994) proposed the dispersion model, an empirical correction to the linear Kaiser model which accounts for the effect of fingers of God at small scales,
![\begin{equation*} P^s_{\textrm{cr}}\left(k,\nu\right)=D\left(k\nu\sigma_{12}\right)\times\left[b_{\mathrm{b}}+\nu^2f\right]\left[b_{\mathrm{r}}+\nu^2f\right]P_{\delta\delta}\left(k\right).\end{equation*}](/articles/aa/full_html/2018/02/aa31685-17/aa31685-17-eq50.png) (21)
(21)
The damping factor 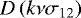 in Eq. (21) mimics the effect of pairwise velocity dispersion by suppressing the clustering power predicted by the linear Kaiser model. Here σ12 is a scale-independent nuisance parameter which can be regarded as an effective pairwise velocity dispersion.
in Eq. (21) mimics the effect of pairwise velocity dispersion by suppressing the clustering power predicted by the linear Kaiser model. Here σ12 is a scale-independent nuisance parameter which can be regarded as an effective pairwise velocity dispersion.
A more sophisticated model was derived by Scoccimarro (2004) to extend the description of RSD at mildly non-linear regime treating separately the density and velocity divergence fields. In particular, dropping the approximation δ = θ, it follows from Eq. (18) that
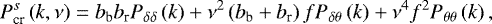 (22)
(22)
where Pδθ and Pθθ are respectively the density-velocity divergence and velocity divergence-velocity divergence power spectra. However, the Scoccimarromodel in Eq. (22) fails in the description of small-scale motions within massive virialised structures dominated by high velocity galaxies with orbits that cross each other. This effect is included in the modelling in a similar way to the dispersion model by means of a damping factor,
![\begin{align*}\nonumber P^s_{\textrm{cr}}\left(k,\nu\right) &= D\left(k\nu\sigma_{12}\right)\times\left[b_{\textrm{b}}b_{\textrm{r}}P_{\delta\delta}\left(k\right)+\nu^2\left(b_{\textrm{b}}+b_{\textrm{r}}\right)fP_{\delta\theta}\left(k\right) \right.\\ &\left.\quad +\nu^4 f^2P_{\theta\theta}\left(k\right)\right].\end{align*}](/articles/aa/full_html/2018/02/aa31685-17/aa31685-17-eq53.png) (23)
(23)
Although an improvement over the Kaiser model, the model in Eq. (22) is still an approximation. It is derived in the large-scale limit in the Gaussian case, while the probability distribution function (PDF) for the pairwise velocities is expected to be non-Gaussian at all scales. Furthermore, it neglects the scale dependence of the pairwise velocity PDF. Nevertheless, our tests in the following sections show that this model is able to capture the main effects in redshift space even at small scales provided that an appropriate galaxy sample, less affected by non-linear motions, is selected from the full galaxy population.
In Pezzotta et al. (2017), where all galaxies are considered in the analysis, the modelling included the even more advanced extension represented by the so called Taruya or TNS model (Taruya et al. 2010), which takes into account the non-linear mode coupling between the density and velocity fields through additional corrections to the Scoccimarro model of Eq. (22) (which has the drawback of having extra degrees of freedom in the fit). Our goal here is complementary, that is to keep the modelling at a simpler possible level, but reducing the systematic biases through an optimised choice of galaxy tracers. For this reason we did not consider the TNS model.
The previous models also describe auto-correlation when bb = br = b. RSD in the linear regime are degenerate with the linear growth rate f, the linear bias parameters b and the amplitude of the linear matter power spectrum σ8, so that one can constrain combinations of these parameters. Here we consider the combinations fσ8 and bσ8 once the input power spectra Pδδ, Pδθ and Pθθ are renormalised by  .
.
The input model for the linear matter power spectrum 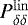 was obtained using the code for anisotropies in the microwave background (CAMB; Lewis et al. 2000) which was then combined with the HALOFIT tool (Takahashi et al. 2012) to predict the non-linear matter power spectrum Pδδ at the effective redshift of the galaxy sample. The density-velocity divergence cross power spectrum Pδθ and the velocity divergence-velocity divergence auto power spectrum Pθθ were obtained using the new fitting formulae calibrated on a large set of N-body simulations with various cosmologies (DEMNUni; Carbone et al. 2016) which are described in a companion work (Bel et al., in prep.),
was obtained using the code for anisotropies in the microwave background (CAMB; Lewis et al. 2000) which was then combined with the HALOFIT tool (Takahashi et al. 2012) to predict the non-linear matter power spectrum Pδδ at the effective redshift of the galaxy sample. The density-velocity divergence cross power spectrum Pδθ and the velocity divergence-velocity divergence auto power spectrum Pθθ were obtained using the new fitting formulae calibrated on a large set of N-body simulations with various cosmologies (DEMNUni; Carbone et al. 2016) which are described in a companion work (Bel et al., in prep.),
![\begin{align*} \pdt &=\left[P_{\delta\delta}^{\textrm{lin}}\left(k\right)P_{\delta\delta}\left(k\right)\exp\left(-\frac{k}{k_{\delta\theta}^{\textrm{cut}}}\right) \right]^{1/2},\\ \ptt &=\left[P_{\delta\delta}^{\textrm{lin}}\left(k\right)\exp\left(-\frac{k}{k_{\theta\theta}^{\textrm{cut}}}\right)\right]\cdot \end{align*}](/articles/aa/full_html/2018/02/aa31685-17/aa31685-17-eq56.png)
In Eq. (24) 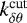 and
and 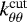 are defined as
are defined as

with σ8 being the amplitude of the linear matter power spectrum. These formulae are more general and represent an improvement over the previous expressions provided by Jennings et al. (2011).
We adopted a Lorentzian functional form for the damping factor as it is found to provide the best description of N-body simulations and observations (Zurek et al. 1994; de la Torre & Guzzo 2012; Pezzotta et al. 2017),
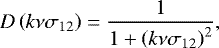 (26)
(26)
with σ12 being a free fitting parameter. The multipole moments of the anisotropic power spectrum 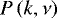 are given by
are given by
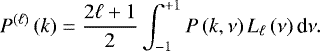 (27)
(27)
In Eq. (27) Lℓ is the Legendre polynomial of order ℓ. The corresponding multipoles of the two-point correlation function can be easily obtained from 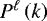 through
through
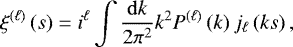 (28)
(28)
with jℓ(x) being the spherical Bessel functions.
The dispersion and Scoccimarro models (Eqs. (21) and (23) respectively) for the blue-red cross-correlation depend on four fitting parameters, namely {fσ8, bbσ8, brσ8, σ12}. However, both models present a degeneracy between the three parameters fσ8, bb σ8 and br σ8. One way to break such a degeneracy is to estimate the relative bias b12 = br∕bb from the ratio of the projected two-point correlation functions at large scales (Mohammad et al. 2016). But in our case the statistical errors on the measurements are sufficiently large that this approach does not give a stable estimate of b12. Alternatively, one can jointly fit the blue-red two-point cross-correlation function and one of the auto-correlation statistics. The price to pay is that the number of fitting parameters is increased to include the dispersion parameter σ12 for the auto-correlation statistic 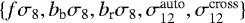 . It is important to stress here that the previous considerations are valid only if redshift distributions of the blue and red samples have the same shape, resulting in the same effective redshift.
. It is important to stress here that the previous considerations are valid only if redshift distributions of the blue and red samples have the same shape, resulting in the same effective redshift.
We fixed the redshift-distance relation to the fiducial model and neglected geometric distortions arising from the Alcock-Paczynski (AP) effect (Alcock & Paczynski 1979). Including the AP effect would add two additional fitting parameters in the RSD model, the angular-diameter distance DA and the Hubble parameter H(z), at the expenses of significantly larger statistical errors on the measurements of the cosmological parameters (see e.g. Wilson et al., in prep.). However, as shown in de la Torre et al. (2013), a change in the fiducial cosmology from WMAP9 to the Planck one results in a marginal variation in the estimates of fσ8 of less than 1%, small enough to be neglected in the total error budget of our analysis.
 |
Fig. 7 Redshift-space two-point correlation function ξs(rp, π), measured at 0.6 ≤ z ≤ 1.0 from flux-limited (top row) and volume-limited samples (bottom row) of blue (left) and red (right) VIPERS galaxies (colour scale and solid contours). The measurements are binned in 1 h−1 Mpc bins in both directions and have been smoothed with a Gaussian filter with dispersion σ = 0.8 h−1 Mpc. The more prominent small-scale stretching along the line of sight is clear in the clustering of red galaxies (right panels), which is almost absent for the blue galaxies (left panels). The dotted lines overplotted on the two top panels report instead for comparison the corresponding (un-smoothed) estimates from the mean of the 153 blue and red mock samples. The agreement of the blue mocks with the data is excellent. Conversely, the red mocks show, in addition to their known slightly larger linear bias value, a significantly stronger small-scale stretching, indicating a higher non-linear velocity component with respect to the data (see text for discussion). In the two bottompanels the look-up table has been normalised as to get the same top colour at the peak value of ξs (rp, π), while settingthe bottom limit to ξs(rp, π) = 0.01. |
 |
Fig. 8 Joint data correlation matrix |
6 Fittingmethod and data covariance matrix
We fitted only the first two multipole moments of the redshift-space two-point correlation function, namely the monopole 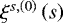 and quadrupole
and quadrupole 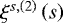 , to estimate the linear growth rate of structure. However, rather than using the multipoles themselves, we considered the quantity
, to estimate the linear growth rate of structure. However, rather than using the multipoles themselves, we considered the quantity
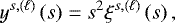 (29)
(29)
that has a smaller dynamical range and, therefore, easier to fit in the range of separations we consider here (de la Torre et al. 2013).
6.1 Data covariance matrix
The clustering measurements in configuration space show a strong bin-to-bin correlation that needs to be taken into account when comparing data with theoretical models. This is quantified by means of the covariance matrix and its off-diagonal terms. To estimate the covariance matrix of the monopole and quadrupole moments of the auto- and cross-correlation functions we have used the 153 VIPERS mock catalogues. The covariance of a given quantity y in two different measurement bins i and j is estimated as
![\begin{equation*} C_{ij} = \frac{1}{N_{\textrm{s}}-1}\sum_{k=1}^{N_{\textrm{s}}}\left[y_i^k-\langle y_i\rangle\right]\left[y_j^k-\langle y_j\rangle\right],\end{equation*}](/articles/aa/full_html/2018/02/aa31685-17/aa31685-17-eq69.png) (30)
(30)
where Ns is the number of mocks, 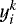 is the measurement in bin i drawn from the kth mock while ⟨yi⟩ denotes the mean of yi among its Ns measurements. We fitted both the monopole and quadrupole of the two-point correlation function; thus, we also computed the cross-covariance of the multipoles.
is the measurement in bin i drawn from the kth mock while ⟨yi⟩ denotes the mean of yi among its Ns measurements. We fitted both the monopole and quadrupole of the two-point correlation function; thus, we also computed the cross-covariance of the multipoles.
The quantity of interest in our case is not the covariance matrix itself but rather its inverse matrix C−1, in other words the precision matrix. Noise in the covariance matrix is amplified by the inversion process and leads to a biased estimate of the precision matrix (Hartlap et al. 2007). To account for this systematic error we followed Percival et al. (2014) and multiplied the generic element of the precision matrix by the factor (1 − D), with,
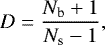 (31)
(31)
where Nb is the number of measurement bins. In the case of the correlation matrix shown in Fig. 8, Nb = 44, Ns = 153 and 1 − D = 0.71.
The construction of the mock samples allowed us to match the clustering amplitude, but not the number density of VIPERS galaxies (see Sect. 3.2). This means that the shot noise contribution in the covariance is not accurate. We modelled the covariance as the sum of two terms, the sample variance and shot noise,
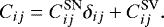 (32)
(32)
The shot noise contribution was assumed to arise from a Poisson sampling process and is diagonal. We estimated this term using Monte Carlo realizations of a Poisson random field. We generated a set of 153 un-clustered random samples containing a number of particles equal to the one in the galaxy catalogue under consideration. Then using the monopole and quadrupole correlation functions measured in each Poisson random field we estimated the shot noise term of the covariance matrix. The covariance matrix derived from the mocks was then modified by subtracting the shot noise term expected in the mocks and then adding the term corresponding to the number density of the VIPERS sample under consideration.
The estimated covariance matrix was rather noisy because of the limited number and the sparseness of the mock catalogues. To improve the estimation we used a box-car smoothing algorithm (Mandelbaum et al. 2013) with a kernel of size 3 × 3 bins centred on the bin in consideration to smooth the off-diagonal terms of the covariance matrices. Each sub-block of the covariance matrix was smoothed independently. This smoothing operation reduces the noise in the covariance matrix so the correction in Eq. (31) becomes only an approximation. In practice, the smoothed covariance matrix would be equivalent to using a larger number of mocks (Dodelson & Schneider 2013). Nevertheless, based on the tests shown in Appendix B, we kept the correction factor as defined earlier. This was a conservative choice as the correction acts to enlarge the error bars and Fig. B.1 confirms that this procedure further stabilizes the systematic errors in our range of interest. The condition number of the covariance matrix used for our reference estimate of the growth rate in Sect. 8 is ~ 10−3, well above the machine precision. Figure 8 shows the correlation matrix 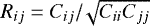 before and after smoothing.
before and after smoothing.
6.2 Fitting method
In Sect. 7 we fit jointly the measured 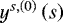 and
and 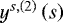 (see Eq. (29)) to estimate the parameters of both the dispersion and Scoccimarro models with a Monte Carlo Markov Chain (MCMC) algorithm. The Markov chain explores the posterior distribution in the parameter space constrained by the data likelihood and parameter priors. The data likelihood is given by
(see Eq. (29)) to estimate the parameters of both the dispersion and Scoccimarro models with a Monte Carlo Markov Chain (MCMC) algorithm. The Markov chain explores the posterior distribution in the parameter space constrained by the data likelihood and parameter priors. The data likelihood is given by
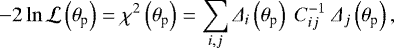 (33)
(33)
where χ2 is the goodness of fit, θp contains the set of model parameters and Δi is the difference between the measurement and the model predictions in bin i. The data vector yi is a concatenation of the monopole 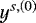 and quadrupole
and quadrupole 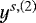 , restricted to the scales of interest. In particular, in Sect. 7 we fit the measured multipoles between a varying minimum fitting scale smin up to a maximum scale of smax ≃ 50 h−1 Mpc. Measurements on scales larger than smax are affected by large statistical errors due to finite-volume effects. The performance of the RSD models was tested by gradually increasing the minimum fitting scale between smin ≃ 3 h−1 Mpc up to smin = 10 h−1 Mpc.
, restricted to the scales of interest. In particular, in Sect. 7 we fit the measured multipoles between a varying minimum fitting scale smin up to a maximum scale of smax ≃ 50 h−1 Mpc. Measurements on scales larger than smax are affected by large statistical errors due to finite-volume effects. The performance of the RSD models was tested by gradually increasing the minimum fitting scale between smin ≃ 3 h−1 Mpc up to smin = 10 h−1 Mpc.
We adopted flat priors on each model parameter with bounds listed in Table 2. As usual with an MCMC exploration of parameter space, marginalization over uninteresting degrees of freedom is achieved by ignoring those parameter values and simply dealing with the distribution of the MCMC samples over the parameter of interest – namely fσ8.
7 Testing models on colour and luminosity mock VIPERS sub-samples
We used theVIPERS mock catalogues to test and optimise our RSD analysis applied to various galaxy sub-samples.
 |
Fig. 9 Systematic errors on the estimates of the growth rate fσ8 when using the full parent mock flux-limited samples of blue and red galaxies in the redshift range 0.6 ≤ z ≤ 1.0. The statistical errors, corresponding to the mean among 153 realizations, are also shown as vertical error bars although for the blue galaxies these are smaller than the size of points. The shaded regions correspond to 1% and 5% intervals on the growth rate, after marginalization over the hidden parameters of bias and velocity dispersion. We recall here that the apparent lack of red squares for smin < 10 h−1 Mpc is due to the large systematic errors from the red galaxies which are always greater than 45%. Here, as in the following plots, points at the same smin are slightly displaced for clarity. |
7.1 Ideal case
The first test used ideal mock VIPERS catalogues with no selection effects and observational errors to assess the importance of non-linear corrections. We refer to these ideal mocks as the VIPERS “parent” mock samples.
7.1.1 Flux-limited samples
Using the ensemble of flux-limited mock samples, we measured the monopole and quadrupole correlation function for red and blue samples. We fixed the redshift range to z = [0.6, 1.0] that will also be used for the volume limited samples. We fitted the measurements with the dispersion and Scoccimarro models and tested the dependence on the minimum scale used in the fit smin. The results are plotted in Fig. 9, in which we show the relative difference between the measured and expected values of fσ8 as a function of smin. Since we are interested in estimating the systematic error, we consider the best estimate of fσ8 that can be obtained from our 153 mocks and compare its deviations from the expected value. In principle, we should treat each mock as an independent realization to estimate the growth rate. The best estimate is then the mean of such 153 measurements of fσ8. However, due to computational requirements we carried out a single fit on the mean correlation function multipoles of the mocks with appropriate covariance matrix. As shown in Appendix C, both methods agree.
When using the red population, we measured a value of fσ8 that is ≳30% below the true one. The blue galaxy sample performed better, but required the exclusion of scales below smin = 10 h−1 Mpc in order to achieve a systematic error of ~ 5% using the Scoccimarro model, which is consistent with previous works (de la Torre & Guzzo 2012; Pezzotta et al. 2017). The dispersion model is more biased than the Scoccimaro model at all scales.
For the flux-limited samples we did not considered combining these results with the blue-red cross-correlation since the blue and red populations are characterised by different effective redshifts. If we were to do so, the number of free parameters would increase to seven: 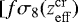 ,
, 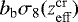 ,
, 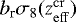 ,
, ![$\sigma_{12}^{\mathrm{cr}},f\sigma_8(z^{b}_{\mathrm{eff}}),b_{\textrm{b}}\sigma_8(z^{b}_{\mathrm{eff}}),\sigma_{12}^{b}]$](/articles/aa/full_html/2018/02/aa31685-17/aa31685-17-eq82.png) (see Sect. 5). This increase in the degrees of freedom fully erases the potential gain of the combination, which we shall explore only for the case of volume-limited samples.
(see Sect. 5). This increase in the degrees of freedom fully erases the potential gain of the combination, which we shall explore only for the case of volume-limited samples.
 |
Fig. 10 Same as in Fig. 9 but now using volume-limited samples drawn from the parent mock catalogues. Empty and filled markers distinguish the dispersion and Scoccimarro models, respectively, as in Fig. 9. The green diamonds correspond to the joint fit of the blue galaxy auto-correlation and the cross-correlation of the two populations. |
7.1.2 Volume-limited samples
The tests using the flux-limited samples clearly suggest that we can reduce the weight of non-linearities by excluding red galaxies. Still, even when using blue galaxies alone a significant systematic under-estimate is evident, indicating a remaining non-negligible role of high-velocity-dispersion objects, that we interpret as the presence of “blue satellites” in dark matter haloes. We then considered luminosity-selected blue and red samples to try to maximise the fraction of central galaxies within this population since the intrinsic luminosity cut excludes faint objects that are commonly satellite galaxies.
The corresponding results are plotted in Fig. 10, in the same form of the previous case. We also show results for the joint fit of the blue auto-correlation function with the blue-red cross-correlation. As before, red galaxies strongly underestimate the input growth rate parameter, although non-linear effects seem to be reduced when limiting the fit to scales larger than smin = 10 h−1 Mpc. The volume-limited sample of blue objects, instead, yielded systematic errors within ± 5% down to the smallest explored scales, when the Scoccimarro correction (filled circles) was used. Also the simpler dispersion model delivered fairly good results downto smin ≃ 6 h−1 Mpc. The joint fit “blue + cross” also provided us with improved systematic errors (below − 5% for smin > 6 h−1 Mpc). In all cases,as for the flux-limited samples presented in Sect. 7.1.1, the relative difference between the dispersion and Scoccimarro models decreases considering higher values of smin.
Our modelling assumes that the galaxy distribution traces the overall matter density field through a local, linear and scale-independent bias parameter b. One may wonder whether the excellent performance of the adopted RSD model for luminous blue galaxies could be due to an accidental cancellation of systematics from an inadequate dynamical model and a simplistic bias model. In the mock catalogues we can measure the galaxy bias as a function of scale,
![\begin{equation*} b\left(r\right)= \left[\frac{\xi_{\textrm{g}}\left(r\right)}{\xi_{\textrm{m}}\left(r\right)}\right]^{1/2},\end{equation*}](/articles/aa/full_html/2018/02/aa31685-17/aa31685-17-eq83.png) (34)
(34)
where ξg(r) is the galaxy real-space correlation function and ξm(r) is the non-linear matter correlation function used in the RSD model (see Sect. 5). We measured the bias of the luminous blue galaxy sample using the parent mock catalogues. The mean measurement of b(r) in the mocks isplotted in Fig. 11. The best-fitting bias inferred from the RSD analysis using scales down to 5 h−1 Mpc is over-plotted. It is remarkable that the inferred bias matches the real space measurement within ~2%. This agreement gives us confidence that the local and scale independent bias assumption is justified and does not introduce a significant systematic error in the RSD analysis.
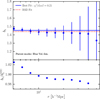 |
Fig. 11 Linear galaxy bias of luminous blue galaxies in VIPERS parent mocks. Top panel: points with error bars show the mean measurement and the related 1σ error of the linear galaxy bias for the luminous blue galaxies in the 153 parent mocks, together with their best-fit with a constant value over r = [5, 50] h−1 Mpc (blue solid line). The red dashed line corresponds instead to the value yielded by MCMC using the Scoccimarro model, over the same rage of fitting scales. Bottom panel: the ratio of the measurements and the red dashed line in the top panel. |
7.2 Understanding the performances of volume-limited samples
These results clearly show that luminous blue galaxies preferentially trace large-scale, coherent, linear flows with little velocity dispersion, yielding the least biased estimates of fσ8 that we could obtain. This is consistent with our conjecture that the colour and luminosity selections we have applied mainly select galaxies that are likely to be central objects of their dark matter haloes in the halo occupation distribution picture. We can verify this hypothesis by analysing the details of our mock samples which were built using a HOD model to reproduce the joint distribution of luminosity, colour and clustering amplitude in VIPERS (de la Torre et al. 2013).
In the mock catalogues more luminous galaxies tend to be centrals for both blue and red classes. Consequently the satellite fractions are lower in the volume-limited samples with respect to the flux-limited samples, which is what we were aiming for to minimise the non-linear contribution to the velocity field. This effect is clearly illustrated in Fig. 12 which plots the satellite fraction fsat as a function of redshift in the two cases. A large fraction of the red satellite galaxies are faint and so are effectively removed by the luminosity threshold. However, in absolute terms this fraction is still much higher than for the blue galaxies (40% vs. 7%), showing the predominance of red satellites in group environments. Evidently, to select red galaxies that are mostly centrals, one should select at an even higher luminosity threshold, which would make the sample very sparse and too small for a quantitative analysis. On the other hand, for the blue galaxies, the VIPERS HOD analysis that was used to build the mock samples predicts that a large fraction are central galaxies of their haloes. The difference in fsat between the flux- and volume-limited samples reduces at high redshifts since the luminosity cut there is closer to the original flux cut of the parent sample.
We then made the assumption that this interpretation applies equally well to the VIPERS data, which is reasonable given that the HOD fit used in the mocks was calibrated using the VIPERS dataset. This choice is further corroborated by more recent HOD analyses that are ongoing with the VIPERS data.
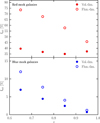 |
Fig. 12 Satellite fraction of colour selected blue and red galaxies in VIEPRS-like mocks. The halo occupation distribution (HOD) model used to build the mock catalogues identifies galaxies as either satellite or central. Plotted are the fraction of satellite galaxies fsat in the flux- (empty markers) and volume-limited (filled markers) VIPERS-like mock samples for red (top panel) and blue (bottom panel) galaxies. In both panels fsat is measured in redshift bins of width Δz = 0.1 between 0.6 ≤ z ≤ 1.0. |
7.3 Test on full VIPERS-like mocks
Before proceeding to the analysis of the luminous galaxy samples from VIPERS, we performed a final test of the modelling when all observational effects are included (masks, TSR and redshift measurement errors), analysing the fully realistic VIPERS-like mocks. Following de la Torre et al. (2017) and Pezzotta et al. (2017), redshift errors were accounted for in the RSD modelling through an extra Gaussian damping factor, whose dispersion is fixed to the known rms value of the VIPERS redshift errors. In the mocks, this value is σz = 4.7 × 10−4(1 + z), corresponding to the first estimate from the PDR-1 (Guzzo et al. 2014), while when fitting the data we used the most updated estimate from PDR-2 that is σz = 5.4 × 10−4(1 + z) (Scodeggio et al. 2018). We also stress that, based on the results of Sect. 4, in all computations (on the mocks, and in the following, on the data), we did not applied the small-scale angular correction using the wA weights.
The results are plotted in Fig. 13, where top panel clearly indicates that blue galaxies in the volume-limited sample trace the quasi-linear RSD better than objects in the flux-limited sample, yielding with both models systematic errors within 5% down to very small scales. The Scoccimarro model, in particular, provided virtually unbiased estimates when using scales smin ≥ 5 h−1 Mpc. This furtherregularisation could be interpreted as due to a further depletion of galaxy pairs with high velocity differences, which cannot be observed after applying SPOC, the VIPERS slit assignment scheme.
In the same figure we also show the results for the joint fit of the blue auto-correlation and the blue-red cross-correlation, which gave again less satisfactory results. This combination is clearly affected by the poor performances of the red population. The interestin adding this combination was clearly stimulated by the hope to reduce statistical errors. This is in fact the case, as shown the bottom panel of the same figure, where statistical errors expected for a single VIPERS-like realisation using the Scoccimarro model are shown. However, the gain is marginal when compared to the increase in the systematic bias with respect to the use of blue galaxies alone.
Based on these results, in the application to the real VIPERS data we will therefore not use red galaxy data (auto- and cross-correlation) as a contribution to our main conclusions regarding fσ8. Nevertheless, we will report the measurements for the VIPERS real red galaxy data as it is interesting to see how the consistency of the growth-rate measurements compares with what is seen in the mocks, and discuss this comparison in Appendix E.
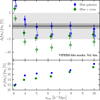 |
Fig. 13 Top panel: same as in Fig. 10 but now using the volume-limited samples in fully VIPERS-like mocks. Filled points result from using the Scoccimarro model while the empty markers show the growth rate estimates adopting the dispersion model. Both models adopt a second Gaussian damping factor to mimic the effect of spectroscopic redshift errors in the galaxy redshifts (see Sect. 7.3). The shaded regions are the 5% and 1% intervals around the unbiased case. Bottom panel: relative statistical uncertainties expected for a single VIPERS-like realisation. For clarity, only the Scoccimarro model case is shown. |
 |
Fig. 14 Dependence on the minimum fitted scale, smin, of the estimate of fσ8 from the VIPERS PDR-2 data, using a volume-limited sample of luminous blue galaxies (blue circles). We also show for comparison, for the reference smin =5 h−1 Mpc, estimates based on the auto-correlation of VIPERS luminous red galaxies (red square) and from the blue+cross joint fit (green diamond). All estimates use the Scoccimarro model. |
8 Results on the VIPERS data
Our detailed mock experiments suggest that an analysis of the blue luminous galaxy sample using the Scoccimarro RSD model should allow us to obtain unbiased measurements of fσ8 from the data, down to s = 5 h−1 Mpc (Fig. 13). But although the mock samples are realistic in many respects, they cannot be expected to match all aspects of the real VIPERS sample. We therefore performed an additional robustness test to check the stability of the values of fσ8 measured from the data as a function of smin, as was done with the mocks.
The results are shown in Fig. 14. The recovered values of fσ8 are very stable, down to the minimum scales considered, with some oscillation around smin = 4 h−1 Mpc, which we know coincides with the scale where the quadrupole changes sign and is intrinsically difficult to fit. Based on the mock results, however, we preferred to be conservative and excluded from our reference estimate measurements below smin ≃ 5 h−1 Mpc, since this is the range where non-linear effects and non-linear bias might not have been fully captured by our VIPERS mocks. For this same minimum scale smin, we have also plotted in the same figure the estimate one obtains by modelling the auto-correlation of the luminous red sample and from a joint fit of the blue auto-correlation and the cross-correlation function. The red galaxy estimate is 13% lower than the blue galaxy value, which is in agreement with the results of the mock catalogues, but in a less dramatic way (see Fig. 10). For the chosen reference value of smin we plot in Fig. 15 the monopole 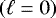 and quadrupole
and quadrupole 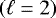 of the VIPERS luminous blue galaxy sample, together with their best fit models. The close agreement between the data and the mocks is impressive – especially so for the quadrupole, given that the HOD mocks were not built with any requirement to match this moment of the two-point correlation function. Even though we have used simple probabilistic algorithms to mimic colour sub-classes of galaxies, it seems that the resulting galaxy catalogues are reassuringly realistic in their redshift-space properties. For comparison, the accuracy of the mock red galaxy sample in reproducing the real data is discussed in Appendix E.
of the VIPERS luminous blue galaxy sample, together with their best fit models. The close agreement between the data and the mocks is impressive – especially so for the quadrupole, given that the HOD mocks were not built with any requirement to match this moment of the two-point correlation function. Even though we have used simple probabilistic algorithms to mimic colour sub-classes of galaxies, it seems that the resulting galaxy catalogues are reassuringly realistic in their redshift-space properties. For comparison, the accuracy of the mock red galaxy sample in reproducing the real data is discussed in Appendix E.
The results of the joint fit to monopole and quadrupole of the luminous blue galaxies yielded
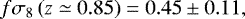 (35)
(35)
which agrees very well with the complementary VIPERS measurements based on the full PDR-2 sample (Pezzotta et al. 2017), its combination with galaxy-galaxy lensing (de la Torre et al. 2017), and using galaxy outflows from cosmic voids (Hawken et al. 2017). All these measurements are shown in Fig. 16. Such an agreement provides a posteriori reassurance of the quality of non-linear corrections applied in all these different analyses. We stress that the sample used here differs significantly from the full-survey samples used in Pezzotta et al. (2017) and de la Torre et al. (2017). In this respect, the measurement based on galaxy outflows from voids (Hawken et al. 2017) is the most novel technique, for which systematic biases are still to be fully explored. Nevertheless, the value obtained using voids remains within ~ 2σ of the other estimates.
In the same figure we also report previous measurements from other large galaxy redshift surveys. The value obtained here using luminous blue galaxies confirms the agreement of the VIPERS estimates and of virtually all recent surveys with the standard ΛCDM model with cosmological parameters set to the Planck values (solid line).
 |
Fig. 15 Monopole (filled circles) and quadrupole (empty circles) of the two-point correlation function of VIPERS luminous blue galaxies; the measurements are shown together with the corresponding best-fit model multipoles (thick lines), corresponding to the smin =5 h−1 Mpc estimate of Fig. 14. The quadrupole points are slightly shifted along the separation axis for clarity. The cyan thin continuous and dashed lines show for comparison the corresponding measurements from the 153 mock samples. A version of this plot for the red population is discussed in Appendix E. |
 |
Fig. 16 Estimate of the linear growth rate fσ8 obtained here from the luminous blue galaxy sample (red circle), compared to other VIPERS measurements using different techniques, together with those from other surveys. The black solid curve shows the predictions of General Relativity with a ΛCDM model with parameters set to Planck 2016 (Planck Collaboration XIII 2016) results and the shaded band corresponds to the related 1σ error. |
9 Discussion and conclusions
The relative clustering signal of red and blue galaxies was used in previous works as a way to reduce statistical errors on the growth rate (Blake et al. 2013; Ross et al. 2014; Pearson et al. 2016) following the idea of McDonald & Seljak (2009). A prerequisite for these multi-tracer analyses is that there is no systematic difference in the inferred growth rate from the individual populations. This was explicitly verified in the analysis by Ross et al. (2014) who find that the growth rate measurements from blue and red sub-samples in the CMASS BOSS survey are compatible with each other with a minimum fitting scale of 30 h−1 Mpc.
Pushing the RSD analysis to smaller scales reveals systematic differences in the velocity fields traced by red and blue galaxies (Guzzo et al. 1997). In this paper we have taken advantage of these differences in order to minimise the systematic uncertainties in the measurement of the growth rate. We have benefited from the VIPERS broad (essentially flux-limited) selection function, which targeted galaxies uniformly and with high sampling rate, independently of type and colour. We used the rest-frame UV colours to select sub-samples of blue and red galaxies which largely coincide with active and passive galaxy types. We modelled the luminosity evolution of each class to high precision, defining samples that we argue are homogeneously selected in colour and luminosity over the range 0.6 ≤ z ≤ 1.0.
A clear trend is seen in the data that the red sample has higher velocity dispersion evident by the fingers-of-God feature (see Fig. 7). Red galaxies are typically found in high density regions while blue galaxies tend to populate low density environments. This difference is accounted for in the halo occupation distribution (HOD) framework, in which the red sample has a higher satellite fraction characteristic of massive dark matter haloes, while the blue sample is predominantly made up of central galaxies in lower mass haloes. Guided by this idea, we have explored the possibility of selecting blue objects as preferential RSD tracers in the linear regime. We tested this hypothesis using a set of VIPERS mock catalogues that were built within the same HOD theoretical framework.
The main findings of the analysis on mock catalogues is that the accuracy of the growth-rate fσ8 measurement can be improved by using sub-samples of galaxies. Blue galaxies, which are more likely to be central galaxies in low mass haloes, give less biased measurements of fσ8. Furthermore, by constructing volume limited samples, and in general by applying a luminosity cut, we can reduce the satellite fraction and further reduce the non-linear motions.
The mock experiments additionally show that the auto-correlation of the volume-limited blue galaxy sample provides the best estimate of the growth rate while maintaining a small statistical error. In fact, the statistical error we find matches that for the full galaxy sample (Pezzotta et al. 2017) despite using a sample that is half the size. This is consistent with the expectations from Bianchi et al. (2012), who show that the error is driven by volume and scales weakly with number density. An additional consideration that can affect the error is the number of free parameters in the model. In the full analysis of Pezzotta et al. (2017) the parameters σ8 and f were allowed to vary independently. This freedom is needed in the Taruya et al. (2010) parametrization but not for the Scoccimarro (2004) model adopted here. As long as a good fit can be found, reducing the number of model degrees of freedom should lead to stronger constraints. In making this argument, we do have to be aware of potential biases from effects that are omitted from both mocks and theory; in that case, recovery of the true growth rate from simulated data need not imply that unbiased results will also result from the same method applied to actual observations. Indeed, Reid et al. (2014) pointed out that different models of aligned peculiar velocities of central galaxies in massive structures may have significant impact on the RSD signal at separations of a few Mpc. The corrections seen by Reid et al. are not significant in comparison with the random errors in the current VIPERS work, which is why we have been content to construct mocks using the simple assumption that central galaxies sit at rest in their haloes. But the challenge of constructing full realistic mocks will only increase as RSD studies move into regimes of higher precision.
Applying our current methodology to the VIPERS data, we produced a new measurement of the growth rate at the effective redshift z = 0.85 using the auto-correlation of the volume-limited blue galaxy sample alone: fσ8 (z = 0.85) = 0.45 ± 0.11. The estimate is consistent at the 1-σ level with those obtained from the full galaxy sample from the VIPERS dataset, and is fully consistent with the ΛCDM model constrained by the Planck data.
This work demonstrates that improved accuracy in RSD measurements can be achieved by identifying appropriate galaxy tracers. By selecting particular galaxy samples by colour and luminosity we are able to use relatively straightforward theoretical models without compromising the systematic and statistical precision on the estimates of the cosmological parameters. Furthermore, the use of this technique helps us in pushing the statistical analysis of RSD to relatively lower scales where the clustering signal is measured with higher statistical precision. We look forward to seeing this robust technique applied to forthcominglarge surveys where the statistical precision on the growth rate is capable of reaching the few percent level.
Acknowledgements
We acknowledge the crucial contribution of the ESO staff for the management of service observations. In particular, we are deeply grateful to M. Hilker for his constant help and support of this programme. Italian participation to VIPERS has been funded by INAF through PRIN 2008, 2010, 2014 and 2015 programs. L.G., F.G.M.,B.R.G. and J.B. acknowledge support from the European Research Council through grant No. 291521. O.L.F. acknowledges support from the European Research Council through grant No. 268107. J.A.P. acknowledges support of the European Research Council through the COSFORM ERC Advanced Research Grant (# 670193). G.D.L. acknowledges financial support from the European Research Council through grant No. 202781. R.T. acknowledges financial support from the European Research Council through grant No. 202686. A.P., K.M., and J.K. have been supported by the National Science Centre (grants UMO-2012/07/B/ST9/04425 and UMO-2013/09/D/ST9/04030). E.B., F.M. and L.M. acknowledge the support from grants ASI-INAF I/023/12/0 and PRIN MIUR 2010-2011. L.M. also acknowledges financial support from PRIN INAF 2012. S.D.L.T. and M.P. acknowledge the support of the OCEVU Labex (ANR-11-LABX-0060) and the A*MIDEX project (ANR-11-IDEX-0001-02) funded by the “Investissements d’Avenir” French government programme managed by the ANR. T.M. and S.A. acknowledge financial support from the ANR Spin(e) through the French grant ANR-13-BS05-0005. The Big MultiDark Database used in this paper and the web application providing online access to it were constructed as part of the activities of the German Astrophysical Virtual Observatory as result of a collaboration between the Leibniz-Institute for Astrophysics Potsdam (AIP) and the Spanish MultiDark Consolider Project CSD2009-00064. The Bolshoi and MultiDark simulations were run on the NASA’s Pleiades supercomputer at the NASA Ames Research Center. We thank the reviewer for the insightful comments that led us to improve the overall message of this work.
Appendix A: Angular weights
The instrumental constraints of placing slits on the galaxies imposes a systematic exclusion of pairs with small angular separations. The effect is important on scales < 1 h−1 Mpc in VIPERS (de la Torre et al. 2013). To account for the missing power, we weighted galaxy pairs according to the angular separation with the function 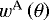 (Hawkins et al. 2003) defined as
(Hawkins et al. 2003) defined as
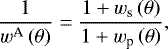 (A.1)
(A.1)
where 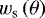 and
and 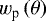 are the angular two-point correlation function of the spectroscopically observed and underlying parent samples of galaxies and θ is the pair separation angle.
are the angular two-point correlation function of the spectroscopically observed and underlying parent samples of galaxies and θ is the pair separation angle.
 |
Fig. A.1 Angular completeness |
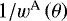
As with the target sampling rate (Sect. 4.2), the application of the angular weight requires having the photometricparent sample in hand. However, using mock catalogues we demonstrated that the weight does not depend on the sample (see Fig. A.1). Thus we applied the angular weights computed for the flux-limited sample.
The effect of the angular weights together with the sampling weights is shown in Fig. 6. We see that the target sampling rate produces the largest systematic effect. The angular correction does not further improve the measurement. For this reason we decided to not to use this correction when analysing the VIPERS data.
Appendix B: Impact of smoothing the data covariance matrix on the estimates of fσ8
In Sect. 6 we used the boxcar algorithm (Mandelbaum et al. 2013) to smooth the off-diagonal elements of the data covariance matrix. The visual analysis of Fig. 8 shows that the smoothing does not alter the global structure of the correlation (or equivalently covariance) matrix. When smoothing the covariance matrix, it is crucial that such a scheme does not alter the estimated values of the fitting parameters. In Fig. B.1 we show the impact of the smoothing of data covariance matrix on the measurements of the linear growth rate fσ8 with respect to the use of the raw estimates of the covariance matrix. It is clear that the smoothing scheme does not have a statistically significant effect on the best estimates of fσ8 while it only makes the results more stable in the range of minimum fitting scales of interest, which is 5 h−1 Mpc ≲ smin ≲ 8 h−1 Mpc.
 |
Fig. B.1 Impact of the smoothing of the data covariance matrix on the systematic errors on fσ8 (filled circles, same as the filled blue circles in Fig. 13) when fitting the auto-correlation function of luminous blue galaxies in VIPERS-like mock samples. Measurements obtained using the raw estimates of the data covariance matrix are also shown as empty circles. In both cases error bars give the errors on the mean of the 153 mock samples. Fits are performed using the Scoccimarro model. |
Appendix C: Dependence of results on the fitting method
In Sect. 7 we explored the parameter space through a Monte Carlo Markov chain (MCMC) technique where the measured multipole moments ys,(0)(s) and ys,(2)(s) averaged over 153 mock samples were fitted with the theoretical models using the related covariance matrix. The best-fit estimate for a given fitting parameter was taken as its value corresponding to the maximum of the one-dimensional marginalised posterior likelihood with the statistical error given by the corresponding 68% confidence level. But ideally one would like to apply the same procedure, adopted in the case of real data, to the measurements from each mock and take the mean of the best-fit estimates as the best estimate of the fitting parameter with its dispersion among 153 mocks as the statistical 1σ error. However, the latter method is computationally time consuming given the large set of cases we explored in this work, in terms of different theoretical models, fitting scales and tracers. Here we show that these methods both yield to the same results in terms of thebest estimate and statistical errors of the fitting parameters. In order to fairly compare the two fitting methods, when using the MCMC technique, here we fit the mean estimate of the multipole moments among 153 mocks with the data covariance matrix related to a single realization. The results are shown in Fig. C.1. In particular, the distribution of the best fit values among 153 mock realisations qualitatively agrees with the 68% and 95% confidence levels of the two-dimensional marginalised posterior likelihoods obtained using the MCMC technique in the 2D plots. Furthermore, the marginalised one-dimensional posterior provides a good match to the frequency histograms. Also the best-fit estimates and the related 1σ statistical errors obtained from the two methods are in a very good agreement. Overall we conclude that the results obtained in this work do not depend on the specific technique used here. In Sect. 7 we therefore used the Monte Carlo approach to fit the mean estimates of the 2PCF multipoles among our 153 mocks with the related covariance matrix.
 |
Fig. C.1 Results of fitting the auto-correlation of blue galaxies in the volume-limited VIPERS-like mocks between 5 h−1 Mpc < s < 50 h−1 Mpc with the Scoccimarro model. In all panels, blue colour shows results using the MCMC technique while red colour represents results obtained fitting single mocks. The blue smooth curves and coloured contours show respectively the one- and two-dimensional marginalised posterior likelihood distributions obtained running an MCMC algorithm. The red points and the histograms correspond to the best-fit values obtained from each of the 153 VIPERS mocks. For each single-parameter distribution, the vertical thick solid blue and red dashed lines show the best-fit values, while the vertical shaded blue stripes and thin dashed red lines give the corresponding 1σ statistical errors, respectively. |
Appendix D: Errors on the number counts
The covariance matrix of the number counts is computed assuming a linear bias relation between galaxies and the overall matter distribution (see e.g. Crocce et al. 2010; Hoffmann et al. 2015). The number count of galaxies Ni in bin i (e.g. a bin of UV colour) measured in a volume V centred on position r can be written as
![\begin{equation*} N_i\left(\vec{r}\right)=\bar{N}_i\left[1+\delta_i\left(\vec{r}\right)\right]+\delta N_i^{\textrm{sn}}.\end{equation*}](/articles/aa/full_html/2018/02/aa31685-17/aa31685-17-eq91.png) (D.1)
(D.1)
The mean number count in the bin is 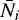 , δi is the mean density contrast of the galaxy field in the volume and
, δi is the mean density contrast of the galaxy field in the volume and 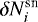 is the noise which we assume to be Poissonian.
is the noise which we assume to be Poissonian.
In the approximation of the linear, local and scale-independent galaxy bias bi, we can rewrite Eq. (D.1) as
![\begin{equation*} N_i\left(\vec{r}\right)=\bar{N}_i\left[1+b_i\delta_{\textrm{m}}\left(\vec{r}\right)\right]+\delta N_i^{\textrm{sn}},\end{equation*}](/articles/aa/full_html/2018/02/aa31685-17/aa31685-17-eq94.png) (D.2)
(D.2)
where δm is the density contrast related to the overall matter in the volume V around r. The covariance matrix Cij of the number counts in the measurement bins i and j is defined as
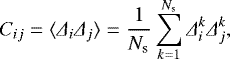 (D.3)
(D.3)
where Ns is the number of independent realisations and 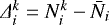 is the difference between the measurement in bin i drawn from the kth realisation and the corresponding mean value. The covariance matrix in Eq. (D.3) results from a combination of two terms
is the difference between the measurement in bin i drawn from the kth realisation and the corresponding mean value. The covariance matrix in Eq. (D.3) results from a combination of two terms
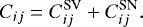 (D.4)
(D.4)
In Eq. (D.4) 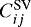 is the contribution from the sample variance,
is the contribution from the sample variance,
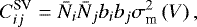 (D.5)
(D.5)
where  is the variance of the matter density contrast in the volume V. Having at disposal only one realisation of our dataset, we replace
is the variance of the matter density contrast in the volume V. Having at disposal only one realisation of our dataset, we replace  with the value directly measured from data.
with the value directly measured from data.
The second term  in Eq. (D.4) is related to the noise on the measurements. This is assumed to be Poissonian and thus independent of the position r. The Poissonian shot-noise contribution to Cij is diagonal and given by
in Eq. (D.4) is related to the noise on the measurements. This is assumed to be Poissonian and thus independent of the position r. The Poissonian shot-noise contribution to Cij is diagonal and given by
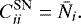 (D.6)
(D.6)
The estimation of 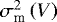 requires the knowledge of the window function which describes the peculiar geometry of the survey. Alternatively, rather than computing directly the window function, one can use a catalogue of randomly distributed points within the survey, with the same radial and angular selection function of the galaxy sample under consideration, to probe the related volume. Another ingredient to compute the variance
requires the knowledge of the window function which describes the peculiar geometry of the survey. Alternatively, rather than computing directly the window function, one can use a catalogue of randomly distributed points within the survey, with the same radial and angular selection function of the galaxy sample under consideration, to probe the related volume. Another ingredient to compute the variance 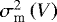 is the matter two-point correlation function ξm which we compute using the publicly available CAMB code (Lewis et al. 2000) for the reference cosmological model. Once the volume V is populated with a sufficiently dense catalogue of NR random points, the variance
is the matter two-point correlation function ξm which we compute using the publicly available CAMB code (Lewis et al. 2000) for the reference cosmological model. Once the volume V is populated with a sufficiently dense catalogue of NR random points, the variance  can be computed as
can be computed as
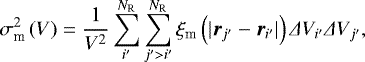 (D.7)
(D.7)
with 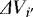 being the volume probed by the i′th random particle. We approximate
being the volume probed by the i′th random particle. We approximate 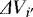 with
with
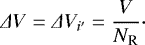 (D.8)
(D.8)
The error covariance matrix in Eq. (D.4) then can be written as
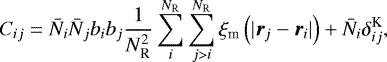 (D.9)
(D.9)
where the shot noise term is written with the Kronecker delta  . The biases bi and bj of galaxies in bins i and j are, in practice difficult to infer directly from data. We thus approximate them with a constant bias value.
. The biases bi and bj of galaxies in bins i and j are, in practice difficult to infer directly from data. We thus approximate them with a constant bias value.
Appendix E: Performances of the Scoccimarro model for simulated and real red galaxies
Our measurements from the mock samples show that red galaxies alone gave rather biased estimates of the growth rate when using the Scoccimarro model (see Sect. 7.1). However, the application of the same model to the real red galaxy data yieldeda value that, still underestimated, is much closer to the one obtained from the blue galaxies. In this appendix we investigate the issue in greater detail and discuss the extent to which the mocks are representative of the VIPERS sample. Figure E.1 is the analogue of Fig. 15, showing the monopole and quadrupole of the correlation function of the VIPERS red galaxy sample, compared to those from the ensemble of red galaxy mocks; both refer to volume-limited samples as defined in the main text. The Scoccimarro model best fit to the data points is overplotted, using smin = 5 h−1 Mpc as done for the blue galaxy data. This corresponds to 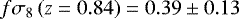 , which is 13% lower than the corresponding value obtained fitting the blue population. This difference, while still indicating the tendency of the red population to deliver lower values of the growth rate, is significantly smaller than what the mocks experiments indicated. It is interesting to understand why, given that the overall agreement of the mocks with the data shown in the figure would seem qualitatively good (in particular once a small difference in the linear bias between the red data and mocks is taken into account).
, which is 13% lower than the corresponding value obtained fitting the blue population. This difference, while still indicating the tendency of the red population to deliver lower values of the growth rate, is significantly smaller than what the mocks experiments indicated. It is interesting to understand why, given that the overall agreement of the mocks with the data shown in the figure would seem qualitatively good (in particular once a small difference in the linear bias between the red data and mocks is taken into account).
 |
Fig. E.2 Behaviour of the Scoccimarro model when varying the dispersion parameter σ12. Points with error bars show the monopole (ℓ = 0) and quadrupole (ℓ = 2) measured using the volume-limited ideal parent mock samples of red galaxies. We show the errors corresponding to a single realisation to highlight the relative difference of precision at different scales as the errors on the mean are too small to appreciate their scale dependence. Black continuous and dashed thick lines show the best-fit Scoccimarro model with smin =5 h−1 Mpc. Thin continuous and dashed lines with colour spanning from blue to red are obtained fixing the growth rate to its fiducial value fσ8 = 0.46 and the dispersion parameter varying from σ12 = 0 to 10 h−1 Mpc. The linear bias parameter is set to match the amplitude of the monopole at large scales. |
Let us then look in more detail into the measurements on the volume-limited samples obtained from the ideal parent mocks, which were used toproduce Fig. 10. Figure E.2 shows the mean monopole and quadrupole of the correlation function. We stress here that these are precise values obtained by averaging the 153 mock realisations, since the aim of our mock experiments is to evidence systematic limitations in the accuracy of the applied model. The best-fit model to these mean measurements for smin = 5 h−1 Mpc is also shown in Fig. E.2 that corresponds to the following set of parameters: 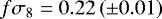 ,
, 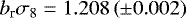 and
and 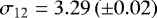 . As extensively discussed in the main text, the recovered fσ8 is significantly biased low, compared to the fiducial value of the mocks, fσ8= 0.46, corresponding to a − 52% systematic error. The figure shows more clearly what happens: the fit is substantially driven by the points at small separations (s < 8 h−1 Mpc), due to their small error bars, and the same model cannot fit both small and large scales adequately. We explore the sensitivity to the differentparameters by overplotting a range of models when we fixed the growth rate to the fiducial value, fσ8= 0.46, and varied the pairwise dispersion σ12 over the range [0, 10] h−1 Mpc; we also set the bias to brσ8 = 1.0, to match the monopole at large scales. What the curves show is that when the fiducial growth rate is fixed, the model can reproduce the measured monopole with a virtually null pairwise dispersion, but it is not capable of fitting the quadrupole particularly at small scales. We also note from Fig. 10 that if separations smaller than smin = 10 h−1 Mpc are excluded, then the systematic error estimated from the red mocks volume-limited sample becomes negligible (the full magnitude-limited sample still gives a large systematic even for such large values of smin as shown in Fig. 9).
. As extensively discussed in the main text, the recovered fσ8 is significantly biased low, compared to the fiducial value of the mocks, fσ8= 0.46, corresponding to a − 52% systematic error. The figure shows more clearly what happens: the fit is substantially driven by the points at small separations (s < 8 h−1 Mpc), due to their small error bars, and the same model cannot fit both small and large scales adequately. We explore the sensitivity to the differentparameters by overplotting a range of models when we fixed the growth rate to the fiducial value, fσ8= 0.46, and varied the pairwise dispersion σ12 over the range [0, 10] h−1 Mpc; we also set the bias to brσ8 = 1.0, to match the monopole at large scales. What the curves show is that when the fiducial growth rate is fixed, the model can reproduce the measured monopole with a virtually null pairwise dispersion, but it is not capable of fitting the quadrupole particularly at small scales. We also note from Fig. 10 that if separations smaller than smin = 10 h−1 Mpc are excluded, then the systematic error estimated from the red mocks volume-limited sample becomes negligible (the full magnitude-limited sample still gives a large systematic even for such large values of smin as shown in Fig. 9).
The conclusion is that the higher non-linear velocity component in the mock samples, which is stronger than in the real data (see Fig. 7) exacerbates the limitations of the model, evidencing where its weaknesses lie. The increasingly better performances obtained with the volume-limited sample of real red galaxy data (which clearly show a smaller contribution from non-linear motions than the mocks) and the blue galaxy experiments are all consistent with the main result of this paper: that relatively simple RSD models can be applied including measurements down to scales as small as 5 h−1 Mpc to obtain virtually unbiased results, provided that the non-linear small-scale component of the velocity field is minimised. We have shown that an effective way to obtain this is to work with volume-limited samples of blue luminous galaxies.
References
- Alcock, C., & Paczynski, B. 1979, Nature, 281, 358 [NASA ADS] [CrossRef] [Google Scholar]
- Anderson, L., Aubourg, É., Bailey, S., et al. 2014, MNRAS, 441, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Beutler, F., Blake, C., Colless, M., et al. 2012, MNRAS, 423, 3430 [NASA ADS] [CrossRef] [Google Scholar]
- Beutler, F., Seo, H.-J., Saito, S., et al. 2017, MNRAS, 466, 2242 [NASA ADS] [CrossRef] [Google Scholar]
- Bianchi, D., Guzzo, L., Branchini, E., et al. 2012, MNRAS, 427, 2420 [NASA ADS] [CrossRef] [Google Scholar]
- Bianchi, D., Chiesa, M., & Guzzo, L. 2015, MNRAS, 446, 75 [NASA ADS] [CrossRef] [Google Scholar]
- Bianchi, D., Percival, W. J., & Bel, J. 2016, MNRAS, 463, 3783 [NASA ADS] [CrossRef] [Google Scholar]
- Blake, C., Brough, S., Colless, M., et al. 2012, MNRAS, 425, 405 [NASA ADS] [CrossRef] [Google Scholar]
- Blake, C., Baldry, I. K., Bland-Hawthorn, J., et al. 2013, MNRAS, 436, 3089 [NASA ADS] [CrossRef] [Google Scholar]
- Cappi, A., Marulli, F., Bel, J., et al. 2015, A&A, 579, A70 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carbone, C., Petkova, M., & Dolag, K. 2016, J. Cosmol. Astropart. Phys., 7, 034 [NASA ADS] [CrossRef] [Google Scholar]
- Cooray, A., & Sheth, R. 2002, Phys. Rep., 372, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Crocce, M., Fosalba, P., Castander, F. J., & Gazta naga E. 2010, MNRAS, 403, 1353 [Google Scholar]
- Cucciati, O., Davidzon, I., Bolzonella, M., et al. 2017, A&A, 602, A15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Davidzon, I., Cucciati, O., Bolzonella, M., et al. 2016, A&A, 586, A23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de la Torre, S., & Guzzo, L. 2012, MNRAS, 427, 327 [NASA ADS] [CrossRef] [Google Scholar]
- de la Torre, S., & Peacock, J. A. 2013, MNRAS, 435, 743 [NASA ADS] [CrossRef] [Google Scholar]
- de la Torre, S., Guzzo, L., Peacock, J. A., et al. 2013, A&A, 557, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de la Torre, S., Jullo, E., Giocoli, C., et al. 2017, A&A, 608, A44 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Di Porto, C., Branchini, E., Bel, J., et al. 2016, A&A, 594, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dodelson, S., & Schneider, M. D. 2013, Phys. Rev. D, 88, 063537 [NASA ADS] [CrossRef] [Google Scholar]
- Dressler, A. 1980, ApJ, 236, 351 [NASA ADS] [CrossRef] [Google Scholar]
- Feldman, H. A., Kaiser, N., & Peacock, J. A. 1994, ApJ, 426, 23 [NASA ADS] [CrossRef] [Google Scholar]
- Fritz, A., Scodeggio, M., Ilbert, O., et al. 2014, A&A, 563, A92 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gargiulo, A., Bolzonella, M., Scodeggio, M., et al. 2017, A&A, 606, A113 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garilli, B., Guzzo, L., Scodeggio, M., et al. 2014, A&A, 562, A23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Granett, B. R., Branchini, E., Guzzo, L., et al. 2015, A&A, 583, A61 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Guo, H., Zheng, Z., Zehavi, I., et al. 2014, MNRAS, 441, 2398 [NASA ADS] [CrossRef] [Google Scholar]
- Guzzo, L., Strauss, M. A., Fisher, K. B., Giovanelli, R., & Haynes, M. P. 1997, ApJ, 489, 37 [NASA ADS] [CrossRef] [Google Scholar]
- Guzzo, L., Pierleoni, M., Meneux, B., et al. 2008, Nature, 451, 541 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Guzzo, L., Scodeggio, M., Garilli, B., et al. 2014, A&A, 566, A108 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Haines, C. P., Iovino, A., Krywult, J., et al. 2017, A&A, 605, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hamilton, A. J. S. 1993, ApJ, 417, 19 [NASA ADS] [CrossRef] [Google Scholar]
- Hartlap, J., Simon, P., & Schneider, P. 2007, A&A, 464, 399 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hawken, A. J., Granett, B. R., Iovino, A., et al. 2017, A&A, 607, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hawkins, E., Maddox, S., Cole, S., et al. 2003, MNRAS, 346, 78 [NASA ADS] [CrossRef] [Google Scholar]
- Hoffmann, K., Bel, J., & Gazta naga E. 2015, MNRAS, 450, 1674 [NASA ADS] [CrossRef] [Google Scholar]
- Howlett, C., Ross, A. J., Samushia, L., Percival, W. J., & Manera, M. 2015, MNRAS, 449, 848 [NASA ADS] [CrossRef] [Google Scholar]
- Jennings, E., Baugh, C. M., & Pascoli, S. 2011, MNRAS, 410, 2081 [NASA ADS] [Google Scholar]
- Kaiser, N. 1987, MNRAS, 227, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Landy, S. D., & Szalay, A. S. 1993, ApJ, 412, 64 [NASA ADS] [CrossRef] [Google Scholar]
- Le Fèvre, O., Saisse, M., Mancini, D., et al. 2003, in Proc. SPIE, eds. M. Iye, & A. F. M. Moorwood, 4841, 1670 [NASA ADS] [CrossRef] [Google Scholar]
- Lewis, A., Challinor, A., & Lasenby, A. 2000, ApJ, 538, 473 [NASA ADS] [CrossRef] [Google Scholar]
- Lilly, S. J., Le Brun, V., Maier, C., et al. 2009, ApJS, 184, 218 [Google Scholar]
- Madgwick, D. S., Hawkins, E., Lahav, O., et al. 2003, MNRAS, 344, 847 [NASA ADS] [CrossRef] [Google Scholar]
- Mandelbaum, R., Slosar, A., Baldauf, T., et al. 2013, MNRAS, 432, 1544 [NASA ADS] [CrossRef] [Google Scholar]
- Marulli, F., Bolzonella, M., Branchini, E., et al. 2013, A&A, 557, A17 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- McDonald, P., & Seljak, U. 2009, J. Cosmol. Astropart. Phys., 10, 007 [NASA ADS] [CrossRef] [Google Scholar]
- Mohammad, F. G., de la Torre, S., Bianchi, D., Guzzo, L., & Peacock, J. A. 2016, MNRAS, 458, 1948 [NASA ADS] [CrossRef] [Google Scholar]
- Moutard, T., Arnouts, S., Ilbert, O., et al. 2016, A&A, 590, A102 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [NASA ADS] [CrossRef] [Google Scholar]
- Okumura, T., & Jing, Y. P. 2011, ApJ, 726, 5 [NASA ADS] [CrossRef] [Google Scholar]
- Okumura, T., Hikage, C., Totani, T., et al. 2016, PASJ, 68, 38 [NASA ADS] [Google Scholar]
- Peacock, J. A., & Dodds, S. J. 1994, MNRAS, 267, 1020 [NASA ADS] [Google Scholar]
- Pearson, D. W., Samushia, L., & Gagrani, P. 2016, MNRAS, 463, 2708 [NASA ADS] [CrossRef] [Google Scholar]
- Percival, W. J., Ross, A. J., Sánchez, A. G., et al. 2014, MNRAS, 439, 2531 [NASA ADS] [CrossRef] [Google Scholar]
- Perlmutter, S., Aldering, G., Goldhaber, G., et al. 1999, ApJ, 517, 565 [NASA ADS] [CrossRef] [Google Scholar]
- Pezzotta, A., de la Torre, S., Bel, J., et al. 2017, A&A, 604, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration XIII. 2016, A&A, 594, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Prada, F., Klypin, A. A., Cuesta, A. J., Betancort-Rijo, J. E., & Primack, J. 2012, MNRAS, 423, 3018 [NASA ADS] [CrossRef] [Google Scholar]
- Reid, B. A., & White, M. 2011, MNRAS, 417, 1913 [NASA ADS] [CrossRef] [Google Scholar]
- Reid, B. A., Seo, H.-J., Leauthaud, A., Tinker, J. L., & White, M. 2014, MNRAS, 444, 476 [NASA ADS] [CrossRef] [Google Scholar]
- Riess, A. G., Filippenko, A. V., Challis, P., et al. 1998, AJ, 116, 1009 [NASA ADS] [CrossRef] [Google Scholar]
- Ross, A. J., Samushia, L., Burden, A., et al. 2014, MNRAS, 437, 1109 [NASA ADS] [CrossRef] [Google Scholar]
- Scoccimarro, R. 2004, Phys. Rev. D, 70, 083007 [NASA ADS] [CrossRef] [Google Scholar]
- Scodeggio, M., Franzetti, P., Garilli, B., Le Fèvre, O., & Guzzo, L. 2009, The Messenger, 135, 13 [NASA ADS] [Google Scholar]
- Scodeggio, M., Guzzo, L., Garilli, B., et al. 2018, A&A, 609, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Siudek, M., Małek, K., Scodeggio, M., et al. 2017, A&A, 597, A107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Skibba, R. A. 2009, MNRAS, 392, 1467 [NASA ADS] [CrossRef] [Google Scholar]
- Skibba, R., Sheth, R. K., Connolly, A. J., & Scranton, R. 2006, MNRAS, 369, 68 [NASA ADS] [CrossRef] [Google Scholar]
- Takahashi, R., Sato, M., Nishimichi, T., Taruya, A., & Oguri, M. 2012, ApJ, 761, 152 [NASA ADS] [CrossRef] [Google Scholar]
- Taruya, A., Nishimichi, T., & Saito, S. 2010, Phys. Rev. D, 82, 063522 [NASA ADS] [CrossRef] [Google Scholar]
- Uhlemann, C., Kopp, M., & Haugg, T. 2015, Phys. Rev. D, 92, 063004 [NASA ADS] [CrossRef] [Google Scholar]
- van den Bosch, F. C., Norberg, P., Mo, H. J., & Yang, X. 2004, MNRAS, 352, 1302 [NASA ADS] [CrossRef] [Google Scholar]
- Zehavi, I., Zheng, Z., Weinberg, D. H., et al. 2005, ApJ, 630, 1 [Google Scholar]
- Zurek, W. H., Quinn, P. J., Salmon, J. K., & Warren, M. S. 1994, ApJ, 431, 559 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
Parameters characterising the volume-limited samples of red and blue galaxies in VIPERS within 0.6 ≤ z ≤ 1.0.
All Figures
|
Fig. 1 Normalised distribution of galaxy rest-frame UV colour in VIPERS in the redshift range 0.5 ≤ z ≤ 1.2 (points). Statistical uncertainties include contributions from Poissonian shot noise and cosmic variance, estimated using the linear bias relation with b = 1.4 (see Appendix D). The best-fit models (Eq. (1)) are shown as black continuous lines. Contributions to the model from the galaxies belonging to the blue cloud, red sequence and green valley are plotted as blue dashed, red dash-dotted and green dotted lines, respectively. |
| In the text | |
|
Fig. 2 Un-normalised redshift distributions of VIPERS galaxies in the redshift range 0.5 ≤ z ≤ 1.2. The red and blue filled histograms show the observed number of blue and red galaxies respectively, i.e. when each galaxy is weighted by its blue wb or red wr colour weight only (see Eq. (3)), resulting from our classification scheme (Sect. 2). Thedistribution of all galaxies is also shown with green filled histogram. The continuous lines superposedon the histograms show the same distributions after convolving with a Gaussian kernel with σz = 0.07. Vertical black lines delimit the redshift range used in this analysis. |
| In the text | |
|
Fig. 3 Magnitude-redshift diagram of VIPERS blue galaxies. Top panel: scatter plot in the magnitude (MB)-redshift plane. Dark dots represent galaxies included in the volume-limited sample while the light dots show the ones excluded due to the luminosity threshold. Points show the luminosity threshold |
| In the text | |
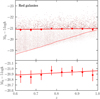 |
Fig. 4 Same as in Fig. 3 but here for red galaxies. |
| In the text | |
|
Fig. 5 Impact of different corrections on the measured multipole moments of the two-point correlation function of blue galaxies in volume-limited mock samples. Top panel shows the measurements, while middle and bottom panels contain the relative systematic error on the monopole and quadrupole, respectively. Black continuous lines result from parent mocks. Red dotted lines are the raw estimates from VIPERS-like mocks. Blue dashed lines result from correcting the multipoles for TSR only (also, no SSR correction is needed for the mocks). Green dash-dotted lines are the case when both TSR (wTSR) and angular (wA) weights are applied. Horizontal grey shaded bands in the middle and bottom panels delimit the 1% and 5% regions, while blue shaded regions show the 1σ error on the mean estimates of the multipole in parent mocks. |
| In the text | |
|
Fig. 6 Same as in Fig. 5 but for the multipole moments of the blue-red two-point cross-correlation function. |
| In the text | |
|
Fig. 7 Redshift-space two-point correlation function ξs(rp, π), measured at 0.6 ≤ z ≤ 1.0 from flux-limited (top row) and volume-limited samples (bottom row) of blue (left) and red (right) VIPERS galaxies (colour scale and solid contours). The measurements are binned in 1 h−1 Mpc bins in both directions and have been smoothed with a Gaussian filter with dispersion σ = 0.8 h−1 Mpc. The more prominent small-scale stretching along the line of sight is clear in the clustering of red galaxies (right panels), which is almost absent for the blue galaxies (left panels). The dotted lines overplotted on the two top panels report instead for comparison the corresponding (un-smoothed) estimates from the mean of the 153 blue and red mock samples. The agreement of the blue mocks with the data is excellent. Conversely, the red mocks show, in addition to their known slightly larger linear bias value, a significantly stronger small-scale stretching, indicating a higher non-linear velocity component with respect to the data (see text for discussion). In the two bottompanels the look-up table has been normalised as to get the same top colour at the peak value of ξs (rp, π), while settingthe bottom limit to ξs(rp, π) = 0.01. |
| In the text | |
|
Fig. 8 Joint data correlation matrix |
| In the text | |
|
Fig. 9 Systematic errors on the estimates of the growth rate fσ8 when using the full parent mock flux-limited samples of blue and red galaxies in the redshift range 0.6 ≤ z ≤ 1.0. The statistical errors, corresponding to the mean among 153 realizations, are also shown as vertical error bars although for the blue galaxies these are smaller than the size of points. The shaded regions correspond to 1% and 5% intervals on the growth rate, after marginalization over the hidden parameters of bias and velocity dispersion. We recall here that the apparent lack of red squares for smin < 10 h−1 Mpc is due to the large systematic errors from the red galaxies which are always greater than 45%. Here, as in the following plots, points at the same smin are slightly displaced for clarity. |
| In the text | |
|
Fig. 10 Same as in Fig. 9 but now using volume-limited samples drawn from the parent mock catalogues. Empty and filled markers distinguish the dispersion and Scoccimarro models, respectively, as in Fig. 9. The green diamonds correspond to the joint fit of the blue galaxy auto-correlation and the cross-correlation of the two populations. |
| In the text | |
|
Fig. 11 Linear galaxy bias of luminous blue galaxies in VIPERS parent mocks. Top panel: points with error bars show the mean measurement and the related 1σ error of the linear galaxy bias for the luminous blue galaxies in the 153 parent mocks, together with their best-fit with a constant value over r = [5, 50] h−1 Mpc (blue solid line). The red dashed line corresponds instead to the value yielded by MCMC using the Scoccimarro model, over the same rage of fitting scales. Bottom panel: the ratio of the measurements and the red dashed line in the top panel. |
| In the text | |
|
Fig. 12 Satellite fraction of colour selected blue and red galaxies in VIEPRS-like mocks. The halo occupation distribution (HOD) model used to build the mock catalogues identifies galaxies as either satellite or central. Plotted are the fraction of satellite galaxies fsat in the flux- (empty markers) and volume-limited (filled markers) VIPERS-like mock samples for red (top panel) and blue (bottom panel) galaxies. In both panels fsat is measured in redshift bins of width Δz = 0.1 between 0.6 ≤ z ≤ 1.0. |
| In the text | |
|
Fig. 13 Top panel: same as in Fig. 10 but now using the volume-limited samples in fully VIPERS-like mocks. Filled points result from using the Scoccimarro model while the empty markers show the growth rate estimates adopting the dispersion model. Both models adopt a second Gaussian damping factor to mimic the effect of spectroscopic redshift errors in the galaxy redshifts (see Sect. 7.3). The shaded regions are the 5% and 1% intervals around the unbiased case. Bottom panel: relative statistical uncertainties expected for a single VIPERS-like realisation. For clarity, only the Scoccimarro model case is shown. |
| In the text | |
|
Fig. 14 Dependence on the minimum fitted scale, smin, of the estimate of fσ8 from the VIPERS PDR-2 data, using a volume-limited sample of luminous blue galaxies (blue circles). We also show for comparison, for the reference smin =5 h−1 Mpc, estimates based on the auto-correlation of VIPERS luminous red galaxies (red square) and from the blue+cross joint fit (green diamond). All estimates use the Scoccimarro model. |
| In the text | |
|
Fig. 15 Monopole (filled circles) and quadrupole (empty circles) of the two-point correlation function of VIPERS luminous blue galaxies; the measurements are shown together with the corresponding best-fit model multipoles (thick lines), corresponding to the smin =5 h−1 Mpc estimate of Fig. 14. The quadrupole points are slightly shifted along the separation axis for clarity. The cyan thin continuous and dashed lines show for comparison the corresponding measurements from the 153 mock samples. A version of this plot for the red population is discussed in Appendix E. |
| In the text | |
|
Fig. 16 Estimate of the linear growth rate fσ8 obtained here from the luminous blue galaxy sample (red circle), compared to other VIPERS measurements using different techniques, together with those from other surveys. The black solid curve shows the predictions of General Relativity with a ΛCDM model with parameters set to Planck 2016 (Planck Collaboration XIII 2016) results and the shaded band corresponds to the related 1σ error. |
| In the text | |
|
Fig. A.1 Angular completeness |
| In the text | |
|
Fig. B.1 Impact of the smoothing of the data covariance matrix on the systematic errors on fσ8 (filled circles, same as the filled blue circles in Fig. 13) when fitting the auto-correlation function of luminous blue galaxies in VIPERS-like mock samples. Measurements obtained using the raw estimates of the data covariance matrix are also shown as empty circles. In both cases error bars give the errors on the mean of the 153 mock samples. Fits are performed using the Scoccimarro model. |
| In the text | |
|
Fig. C.1 Results of fitting the auto-correlation of blue galaxies in the volume-limited VIPERS-like mocks between 5 h−1 Mpc < s < 50 h−1 Mpc with the Scoccimarro model. In all panels, blue colour shows results using the MCMC technique while red colour represents results obtained fitting single mocks. The blue smooth curves and coloured contours show respectively the one- and two-dimensional marginalised posterior likelihood distributions obtained running an MCMC algorithm. The red points and the histograms correspond to the best-fit values obtained from each of the 153 VIPERS mocks. For each single-parameter distribution, the vertical thick solid blue and red dashed lines show the best-fit values, while the vertical shaded blue stripes and thin dashed red lines give the corresponding 1σ statistical errors, respectively. |
| In the text | |
 |
Fig. E.1 Same as in Fig. 15 but here for the volume-limited samples of red galaxies in VIPERS. |
| In the text | |
|
Fig. E.2 Behaviour of the Scoccimarro model when varying the dispersion parameter σ12. Points with error bars show the monopole (ℓ = 0) and quadrupole (ℓ = 2) measured using the volume-limited ideal parent mock samples of red galaxies. We show the errors corresponding to a single realisation to highlight the relative difference of precision at different scales as the errors on the mean are too small to appreciate their scale dependence. Black continuous and dashed thick lines show the best-fit Scoccimarro model with smin =5 h−1 Mpc. Thin continuous and dashed lines with colour spanning from blue to red are obtained fixing the growth rate to its fiducial value fσ8 = 0.46 and the dispersion parameter varying from σ12 = 0 to 10 h−1 Mpc. The linear bias parameter is set to match the amplitude of the monopole at large scales. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.