| Issue |
A&A
Volume 595, November 2016
|
|
|---|---|---|
| Article Number | A93 | |
| Number of page(s) | 15 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/201628846 | |
| Published online | 07 November 2016 | |
Systematic tests for position-dependent additive shear bias
1 University College London, Gower Street, London WC1E 6BT, UK
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2 Argelander-Institut für Astronomie, Auf dem Hügel 71, 53121 Bonn, Germany
Received: 3 May 2016
Accepted: 11 August 2016
Abstract
We present new tests to identify stationary position-dependent additive shear biases in weak gravitational lensing data sets. These tests are important diagnostics for currently ongoing and planned cosmic shear surveys, as such biases induce coherent shear patterns that can mimic and potentially bias the cosmic shear signal. The central idea of these tests is to determine the average ellipticity of all galaxies with shape measurements in a grid in the pixel plane. The distribution of the absolute values of these averaged ellipticities can be compared to randomised catalogues; a difference points to systematics in the data. In addition, we introduce a method to quantify the spatial correlation of the additive bias, which suppresses the contribution from cosmic shear and therefore eases the identification of a position-dependent additive shear bias in the data. We apply these tests to the publicly available shear catalogues from the Canada-France-Hawaii Telescope Lensing Survey (CFHTLenS) and the Kilo Degree Survey (KiDS) and find evidence for a small but non-negligible residual additive bias at small scales. As this residual bias is smaller than the error on the shear correlation signal at those scales, it is highly unlikely that it causes a significant bias in the published cosmic shear results of CFHTLenS. In CFHTLenS, the amplitude of this systematic signal is consistent with zero in fields where the number of stars used to model the point spread function (PSF) is higher than average, suggesting that the position-dependent additive shear bias originates from undersampled PSF variations across the image.
Key words: gravitational lensing: weak / methods: observational
© ESO 2016
1. Introduction
Cosmic shear, the coherent distortion of the observed shapes of distant galaxies by the gravitational field of intervening matter distributions, is one of the most powerful tools to constrain cosmological parameters (Albrecht et al. 2006). Since its first detection in the early 2000s, the field has rapidly expanded and matured (see Kilbinger 2015, for a recent review). Several large and deep optical imaging surveys are currently ongoing (KiDS, DES and HSC, see Kuijken et al. 2015; Jarvis et al. 2016; Miyazaki et al. 2015, respectively) or will begin in the near future (e.g. Euclid, LSST and WFIRST, see Laureijs et al. 2011; Abell et al. 2009; Spergel et al. 2015, respectively) that are designed to measure cosmic shear. These surveys will map large portions of sky to great depths, increasing the number of galaxies usable for weak lensing by a factor of 100−1000 compared to the current state-of-the-art in cosmic shear: the Canada-France-Hawaii Lensing Survey (CFHTLenS; Heymans et al. 2012), an analysis of 139 deg2 of high-quality optical imaging data, which yielded the tightest lensing constraints on cosmological parameters to date (Kilbinger et al. 2013; Heymans et al. 2013; Kitching et al. 2014). Consequently, the precision of the shear measurements in these new surveys will be pushed down by orders of magnitude. Demonstrating that systematic errors in the lensing measurements are under control is imperative before the data can be exploited for cosmology.
The accuracy of weak-lensing shape measurements is commonly quantified with two numbers, the multiplicative bias m and the additive bias c, following ⟨ ϵg ⟩ = (1 + m) × γ + c (Heymans et al. 2006). In an unbiased shape measurement method, m = c = 0, such that the observed galaxy ellipticities ϵg form an unbiased estimate of the shear γ. No shear measurement method to date has proven to be unbiased when tested under realistic conditions. Even worse, m and c are generally not constant, but depend on the flux of a galaxy, its size, the ellipticity of the point spread function (PSF), the Strehl-ratio, the sky background, etc. The dependencies on these parameters need to be extremely well calibrated to enable an unbiased cosmological exploitation of the data.
There are several causes for additive and multiplicative shear biases (see e.g. Massey et al. 2013). Multiplicative biases are mainly caused by noise: measuring an ellipticity generally involves a non-linear transformation of pixel data, a process in which pixel noise enters non-linearly and does not average out (Melchior & Viola 2012; Refregier et al. 2012). Another source of multiplicative bias is model bias: the implicit or explicit use of incorrect galaxy shape models to fit to the observed galaxies (Bernstein 2010). Additive biases can be caused by elliptical PSFs or by charge transfer inefficiencies that have not been completely accounted for. The magnitude of these biases generally depends on the shape measurement method that is employed. How these shape measurement biases propagate in cosmic shear studies is investigated in several works (see e.g. Massey et al. 2013; Cropper et al. 2013; Kitching et al. 2016, and references therein).
There are different strategies to determine m and c: m is usually determined by applying the shape measurement method to simulated data that mimics the real data as closely as possible. By comparing the recovered shear for different known input shear values, m can be determined. Alternatively, cross-correlations of the lensing maps with galaxy density and cosmic microwave background lensing maps can be used (Das et al. 2013; Liu et al. 2016), as well as cross-correlations with weak lensing magnification (Rozo & Schmidt 2010; Vallinotto et al. 2011) or generalised shear-ratio tests (Schneider 2016). Additive shear bias can be determined from the data itself. Since galaxies do not have a preferred direction on the sky, their mean ellipticity should average to zero. Hence by determining the mean galaxy ellipticity, additive biases can be identified and subsequently removed by subtracting it from the observed galaxy ellipticities.
Additive biases are usually determined as a function of galaxy property and observing condition, but not as a function of position on the camera. PSF ellipticities and star densities usually vary in the field-of-view and could cause a position-dependent additive bias that is stationary between exposures. Previously employed correction schemes that only measured a field-averaged additive bias would miss position-dependent residuals and these could still be present in the data. A coherent additive bias pattern is problematic as it might mimic the real, physical correlation between galaxy shapes due to cosmic shear, and could therefore bias cosmic shear analyses (Kitching et al. 2016). Motivated by this concern, we develop tests to identify whether a position-dependent additive shear bias (which we refer to as position-dependent c from here on) is present in weak lensing data sets.
In Sect. 2 we present a method to identify position-dependent c. We apply it to data from CFHTLenS in Sect. 3. In Sect. 4, we study the spatial correlation of the additive bias and investigate its dependence on position in the field, stellar density and photometric redshift. We repeat our analysis on KiDS data in Sect. 5 and conclude in Sect. 6. We assume that the reader is familiar with the basics of gravitational lensing. For a general introduction, please see Bartelmann & Schneider (2001).
2. Methodology
The central idea of our tests is to determine the average ellipticities of galaxies in a pixel grid on the detector and analyse their properties. If a position-dependent c is present that is stationary between exposures (e.g. in one corner of the image where the PSF ellipticity is always large), this both affects the distribution of absolute values of the averaged ellipticities, and also causes a positive correlation between the average ellipticities of neighbouring grid cells at small separations. We started with defining a regularly spaced grid in the pixel plane. For a single image (i.e. a pointing on the sky) called S, we determined the average ellipticity of all galaxies in each grid cell: 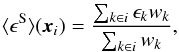 (1)with xi the position of grid cell i, ϵk the complex ellipticity and wk the lensing weight of galaxy k. The sums run over all galaxies k in image S that fall inside grid cell i. Next, we determined the mean ellipticity in each grid cell averaged over all images:
(1)with xi the position of grid cell i, ϵk the complex ellipticity and wk the lensing weight of galaxy k. The sums run over all galaxies k in image S that fall inside grid cell i. Next, we determined the mean ellipticity in each grid cell averaged over all images: 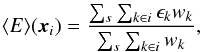 (2)which explicitly sums over all images s. We also defined the average ellipticity of all images except one, image S:
(2)which explicitly sums over all images s. We also defined the average ellipticity of all images except one, image S: 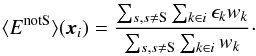 (3)Using these average ellipticities, we defined two systematic shear correlation functions:
(3)Using these average ellipticities, we defined two systematic shear correlation functions: 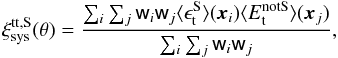 (4)and
(4)and 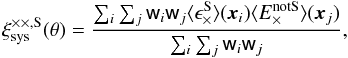 (5)with i and j denoting different grid cells,
(5)with i and j denoting different grid cells, 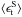 and
and 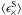 the tangential and cross component of ⟨ ϵS ⟩ measured relative to the separation vector between xi and xj, and
the tangential and cross component of ⟨ ϵS ⟩ measured relative to the separation vector between xi and xj, and 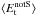 and
and 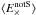 the tangential and cross component of ⟨ EnotS ⟩. For the definition of tangential and cross shear, please see for example Kilbinger (2015). θ is the pixel separation between grid cell i and j. wi and wj are weight factors, which equal the sum of the weights wk of galaxies that went into computing
the tangential and cross component of ⟨ EnotS ⟩. For the definition of tangential and cross shear, please see for example Kilbinger (2015). θ is the pixel separation between grid cell i and j. wi and wj are weight factors, which equal the sum of the weights wk of galaxies that went into computing 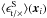 and
and 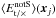 , respectively. The sum runs over the grid cells whose separation falls inside a θ bin. From these we formed
, respectively. The sum runs over the grid cells whose separation falls inside a θ bin. From these we formed 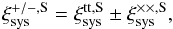 (6)which is our estimator for position-dependent c for a single image S. We note that
(6)which is our estimator for position-dependent c for a single image S. We note that 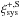 is equal to the correlation of the two grid-averaged ellipticities,
is equal to the correlation of the two grid-averaged ellipticities, ![Mathematical equation: \hbox{$\xi_{\rm sys}^{+, {\rm S}}=\langle \Re \left[\epsilon^{\rm S}E^{\rm notS*}\right] \rangle=$}](/articles/aa/full_html/2016/11/aa28846-16/aa28846-16-eq36.png)
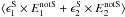 . We also measured the complex part of the systematic shear correlation function:
. We also measured the complex part of the systematic shear correlation function: 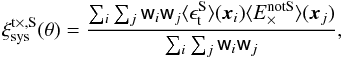 (7)and
(7)and 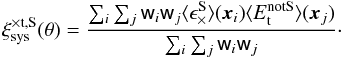 (8)Their equivalents in cosmic shear studies are usually not measured, since they are expected to vanish from parity symmetry. In the presence of systematics, that is no longer necessarily the case.
(8)Their equivalents in cosmic shear studies are usually not measured, since they are expected to vanish from parity symmetry. In the presence of systematics, that is no longer necessarily the case.
To estimate a survey-averaged systematic shear signal, 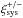 , we used a bootstrap technique. For a survey of N images, we randomly drew N systematic correlation functions (
, we used a bootstrap technique. For a survey of N images, we randomly drew N systematic correlation functions (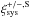 ) from the full set with replacement. For each bootstrap realisation we determined the average systematic correlation function, . In total, we created 10 000 bootstrap realisations. Their mean is our systematic signal, the scatter between the bootstrap realisations forms the error.
) from the full set with replacement. For each bootstrap realisation we determined the average systematic correlation function, . In total, we created 10 000 bootstrap realisations. Their mean is our systematic signal, the scatter between the bootstrap realisations forms the error. 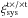 was determined in a similar fashion.
was determined in a similar fashion.
The reason why we correlate the average ellipticity of galaxies in a single image to the average ellipticity of all other images, is that it suppresses the contribution from cosmic shear. Had we instead correlated the average ellipticities of all images, the galaxies in neighbouring grid cells from the same image would be subject to the same cosmic shear field, “contaminating” with a real, cosmic shear signal. We demonstrate in Sect. 4.5 that this effect is small but not entirely negligible. The remaining cosmic shear contribution to our estimator, which is only present at scales larger than the size of an image, is even smaller and can be safely ignored. In principle, it could be further suppressed by excluding not only image S in 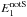 , but also its neighbours.
, but also its neighbours.
We note that alternative estimators of the systematic correlation functions could be formed as well; one could, for example, correlate the average ellipticities of pairs of images S and T (for S≠T), and randomly draw from those correlation functions to form a survey average. Alternatively, one could determine the average ellipticities of two images, and correlate that to the average ellipticities of the other images. This effectively boils down to adjusting the weighting scheme, which we plan to explore in a future work.
3. 1-point statistics
 |
Fig. 1 Left-hand panel: whisker plot showing the average galaxy ellipticity as a function of field position in the 128 CFHTLenS “pass” fields for the G2 grid (16 × 16). The sticks indicate the size and orientation of the averaged ellipticities. The grey-scale of the sticks indicate the number of galaxies in a grid cell. The range of the horizontal and vertical axis corresponds to the size of a CFHTLenS image. Right-hand panel: whisker plot of the average model PSF in CFHTLenS obtained by averaging the model PSFs at the location of the galaxies for the same grid. |
We tested our estimator on the publicly available shape measurements catalogues from CFHTLenS (Heymans et al. 2012). The catalogues are based on 139 deg2 of imaging data in the ugrzi-bands from the CFHT Legacy Survey, obtained with MegaPrime, a multi-chip camera that consists of 9 × 4 CCDs of 2048 × 4096 pixels each with a pixel scale of 0.187 arcsec. The total field-of-view is roughly 1 deg2. The lensing measurements were performed on the i-band data, using a shape measurement method called lensfit (Miller et al. 2013), a Bayesian forward-modelling technique which models galaxies as a bulge plus disc, applies a shear and convolves them with a model PSF that is determined from the stars in the images (Miller et al. 2007; Kitching et al. 2008). The inverse variance weights provided by lensfit are applied when we compute the mean ellipticities. The five-band photometry was used to derive photometric redshifts of galaxies with the BPZ method (Benítez 2000). The photometric redshifts were found to be robust in the range 0.2 < zB < 1.3 (Hildebrandt et al. 2012), with zB the peak of the posterior redshift distribution. We use all galaxies with a non-zero lensfit weight and with a photometric redshift 0.2 < zB < 1.3; the effective weighted galaxy number density is 11 arcmin-2. We limit ourselves to the 128 fields that passed the systematic test of Heymans et al. (2012); the 43 fields that did not pass this test are analysed separately in Sect. 4.1.
The shape measurement catalogues from CFHTLenS have a non-zero multiplicative and additive shear bias. The multiplicative bias is determined by applying lensfit to image simulations that mimic the actual observations. We ignore it here as we only focus on the additive bias. The additive bias in CFHTLenS is negligible in ϵ1 (c1 = 0.0001 ± 0.0001) but not in ϵ2, where it has a value of c2 = 0.0020 ± 0.0001. This bias is found to scale with galaxy size r and signal-to-noise νSN, but not with PSF size, PSF ellipticity and galaxy type. Heymans et al. (2012) fit a functional form to model the dependence on r and νSN: ![Mathematical equation: \begin{equation} c_2=\max \left[\frac{11.910\times \log_{10}(\nu_{\rm SN})-12.715}{1+\left(\frac{r}{0.01''}\right)^{2.458}} , 0\right]. \end{equation}](/articles/aa/full_html/2016/11/aa28846-16/aa28846-16-eq60.png) (9)The bias is predicted on a galaxy-by-galaxy basis and is provided as a separate column in the public catalogue. We corrected the ellipticities with this correction factor by subtracting it before we started our tests.
(9)The bias is predicted on a galaxy-by-galaxy basis and is provided as a separate column in the public catalogue. We corrected the ellipticities with this correction factor by subtracting it before we started our tests.
We defined three regularly spaced grids on each field that contain 8 × 8, 16 × 16 and 32 × 32 grid cells. In what follows, we refer to these as the G1, G2 and G3 grids, respectively. These grids were designed to enable us to roughly trace the chip gaps. To define the grid, we used the minimum and maximum x- and y-positions of all galaxies that passed our selection criteria. As the i-band data consists of seven dithered exposures on average, with a dithering step that is larger in the vertical direction (up to ~3 arcmin) than in the horizontal direction (up to ~0.5 arcmin) to fill in the larger gap between the chip rows, our grid is slightly rectangular. The horizontal axis spans a range of 58.8 arcmin, whilst the vertical axis spans a range of 62.5 arcmin.
The whisker plot of ⟨ E ⟩ (xi) for the G2 grid is shown in Fig. 1. The bins at the edges contain roughly half the number of galaxies compared to the central ones and therefore have a larger scatter. In the absence of a position-dependent c, there should be no pattern in this plot. By eye, we can identify a number of suspicious features, such as at the bottom right-hand corner, where several grid cells have a similar ⟨ E2 ⟩ component, and at y-values just below 20 arcmin, where we observe a row of grid cells with similar ⟨ E1 ⟩ values.
To check whether these features are significant, we first quantified the distribution of the absolute values of the average ellipticities in the grid cells, 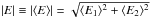 . We show the histogram of | E | in the left-hand panel of Fig. 2. To see if they are suspiciously large, we randomised the ellipticities: every galaxy in our sample was assigned the ellipticity and weight of another galaxy that was randomly drawn from the full CFHTLenS catalogue. We remeasured | E | using the same grid and determined the histogram. The advantage of this procedure is that it uses the true observed ellipticity distribution of CFHTLenS, and that the density of galaxies in each bin is preserved. We repeated this procedure 10 000 times. The mean of these randomised histograms is shown with red circles in the left-hand panel of Fig. 2, the error bars indicate the scatter.
. We show the histogram of | E | in the left-hand panel of Fig. 2. To see if they are suspiciously large, we randomised the ellipticities: every galaxy in our sample was assigned the ellipticity and weight of another galaxy that was randomly drawn from the full CFHTLenS catalogue. We remeasured | E | using the same grid and determined the histogram. The advantage of this procedure is that it uses the true observed ellipticity distribution of CFHTLenS, and that the density of galaxies in each bin is preserved. We repeated this procedure 10 000 times. The mean of these randomised histograms is shown with red circles in the left-hand panel of Fig. 2, the error bars indicate the scatter.
The histogram of | E | for the original CFHTLenS catalogues differs from the mean of the randomised ones. We find fewer bins with | E | < 4 × 10-3 in the original histogram and more bins with | E | > 5 × 10-3. If a position-dependent c is present, these tend to increase the average ellipticity of galaxies in certain regions and one expects an increase of bins with large mean ellipticity and a corresponding decrease of bins with small ellipticities. In the random catalogues, any position-dependent c is averaged out. Hence our results are indicative of a position-dependent c.
To quantify the difference between the histograms, we computed the reduced χ2 between the observed and the mean of the randomised histograms, using the scatter between the random realisations as errors. We find that 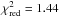 (with 23 deg of freedom). The corresponding probability to exceed (p-value) is 0.08, which provides weak evidence that the observed distribution is not a random realisation.
(with 23 deg of freedom). The corresponding probability to exceed (p-value) is 0.08, which provides weak evidence that the observed distribution is not a random realisation.
The 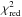 test is ignorant about the sign of the difference between the two samples (a systematic decrease of the number of bins at | E | < 4 × 10-3 and a systematic excess at | E | > 5 × 10-3). A more sensitive test is the Kolmogorov-Smirnov (KS) statistic on two samples. We determined the cumulative probability of the two histograms and show it in the right-hand panel of Fig. 2. We measured the KS statistic, which is the maximum distance between the cumulative probability distributions, to check whether the two distributions are drawn from the same reference distribution. The KS statistic has a value of 0.097, with a corresponding p-value of 0.015, which shows that the two distributions are different.
test is ignorant about the sign of the difference between the two samples (a systematic decrease of the number of bins at | E | < 4 × 10-3 and a systematic excess at | E | > 5 × 10-3). A more sensitive test is the Kolmogorov-Smirnov (KS) statistic on two samples. We determined the cumulative probability of the two histograms and show it in the right-hand panel of Fig. 2. We measured the KS statistic, which is the maximum distance between the cumulative probability distributions, to check whether the two distributions are drawn from the same reference distribution. The KS statistic has a value of 0.097, with a corresponding p-value of 0.015, which shows that the two distributions are different.
 |
Fig. 2 Left-hand panel: histogram of mean ellipticity values in the G2 grid. The black line shows the distribution for the original CFHTLenS catalogue, the red dots indicate the mean and scatter of 10 000 realisations where the ellipticities were randomised. Right-hand panel: cumulative probability distribution of the observed and randomised histograms. |
If galaxies at the edge of the field are systematically noisier and more elliptical, we may overestimate how odd/unlikely the observed distribution is. We therefore also made random catalogues by only rotating the galaxy ellipticities with random amounts (but keeping the magnitude of the ellipticity fixed to the input value). We made 10 000 random catalogues and assessed the difference between the original distribution and the mean of the random distributions as before. In this case, the reduced χ2 between the observed and the mean of the randomised histograms has a value of 1.39 and the corresponding KS statistic has a value of 0.096. Our results therefore do not depend on how we create the random catalogues.
4. 2-point statistics
 |
Fig. 3
|
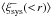
We quantified the presence of position-dependent c using the systematic correlation functions from Eq. (6) as a function of separation between the grid cells. We used 12, 24 and 48 radial bins between (0,60] arcmin for the G1, G2 and G3 grids, respectively. The first bin contains 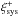 at zero lag.
at zero lag. 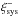 is not defined at zero lag and hence not shown. The remaining radial bins are evenly spaced up to 60 arcmin. The correlation functions are shown in Fig. 3, where the three columns correspond to the three grids. The middle panel shows the value of a constant fitted to , using scales up to that radius (e.g. the third radial bin includes the measurements of the first, second and third radial bins; the final point is the weighted mean of averaged over the entire range). The absence of a position-dependent c would result in a constant that is consistent with zero on all scales. When we fit the constant we use the covariance matrix of , determined from the bootstrap realisations. is weakly correlated between neighbouring radial bins and is practically uncorrelated. We corrected the inverse of the covariance matrix with a correction factor that accounts for a bias in the inversion that arises from noise (Kaufmann 1967; Hartlap et al. 2007). Finally, in the third row we show the p-values that correspond to the χ2 of the null hypothesis. A p-value that is much smaller than 1 indicates that the data is not consistent with zero. Here and in the following, we calculate the p-values using a calibration described in Appendix A.
is not defined at zero lag and hence not shown. The remaining radial bins are evenly spaced up to 60 arcmin. The correlation functions are shown in Fig. 3, where the three columns correspond to the three grids. The middle panel shows the value of a constant fitted to , using scales up to that radius (e.g. the third radial bin includes the measurements of the first, second and third radial bins; the final point is the weighted mean of averaged over the entire range). The absence of a position-dependent c would result in a constant that is consistent with zero on all scales. When we fit the constant we use the covariance matrix of , determined from the bootstrap realisations. is weakly correlated between neighbouring radial bins and is practically uncorrelated. We corrected the inverse of the covariance matrix with a correction factor that accounts for a bias in the inversion that arises from noise (Kaufmann 1967; Hartlap et al. 2007). Finally, in the third row we show the p-values that correspond to the χ2 of the null hypothesis. A p-value that is much smaller than 1 indicates that the data is not consistent with zero. Here and in the following, we calculate the p-values using a calibration described in Appendix A.
is significantly non-zero at small separations. The first bin, which shows the correlation at zero lag, deviates from zero with 2.9σ, 2.6σ and 0.7σ for the G1, G2 and G3 grids, respectively. This shows that most of the power of the small-scale additive bias has a scale-length that corresponds to the size of the G1 grid-cell, 60/8 = 7.5 arcmin, roughly the width of a chip. Our results therefore point to an additive bias that is constant per chip, but varies between chips. This suggests that the bias originates from the constant term in the PSF modelling that is fit per chip (see also Sect. 4.3).
Refining the grid reveals more features which are smoothed out in the more crudely sampled grids. Furthermore, the finer grids appear to reveal the presence of additional structure, most noticeably a negative dip at a radial separation of ~20 arcmin. Interestingly, ~20 arcmin is not obviously related to a structure of the camera such as the size of a chip.
In contrast to , depends on the direction of the separation vector between the grid cells. We therefore might expect to see some differences between the trends in the three grids. In all cases, does not show an obvious trend; the incremental weighted mean is consistent with zero when averaged over the full radial range.
 |
Fig. 4
|
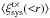
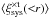
The complex part of the systematic shear correlation functions is shown in Fig. 4. The 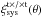 measurements do not show a clear trend. The incremental weighted mean of
measurements do not show a clear trend. The incremental weighted mean of 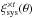 is consistent with zero for the three grids.
is consistent with zero for the three grids. 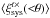 , however, prefers a negative value for G2 and G3 when averaged over all scales at the 3σ level, but the actual values are very small (~−5 × 10-8). Hence these correlation functions also indicate that systematics may be present in the data.
, however, prefers a negative value for G2 and G3 when averaged over all scales at the 3σ level, but the actual values are very small (~−5 × 10-8). Hence these correlation functions also indicate that systematics may be present in the data.
The systematic correlation functions are in line with our results from the previous section and point at the presence of a position-dependent c that is unaccounted for in the public CFHTLenS catalogues. In the next section we repeat our test on the CFHTLenS fields that did not pass the systematic tests of Heymans et al. (2012). In Sects. 4.2−4.4 we investigate the source of the position-dependent c, and in Sect. 4.5 we illustrate how our correlation functions suppress the contribution from cosmic shear. It is important to stress that the amplitude of is much smaller than the shear correlation function. For example, Kilbinger et al. (2013) measure a ξ+ of ~5 × 10-5 at a separation of a few arcmin, roughly 50 times larger than at those scales. Since the amplitude of the systematics is smaller than the error bars on the cosmic shear measurements when averaged over all fields, it seems highly unlikely that these systematics cause a significant bias on cosmological parameters estimates from CFHTLenS. However, as pointed out before, our test is only sensitive to an additive bias that is coherent over all pointings in the survey. An additive bias that varies between pointings would remain undetected by our method.
Unfortunately, correcting for a stationary position-dependent c is not trivial. The averaged ellipticity in each grid cell is a combination of an intrinsic shape dispersion component and a stationary systematic ellipticity component, whose relative contributions are unknown. Fitting a functional form to the averaged ellipticities as a function of grid position does not exclusively capture the additive bias contribution, as the regions where the additive bias originates are very localised (as is most discrepant from zero at small separations) but a priori unknown. Subtracting the mean ellipticity in each grid cell also removes real signal which is undesirable (but we note that this also happens, albeit to a lesser extent, in the common correction schemes for additive bias in which the average ellipticity per image is subtracted). Only if one is willing to make an assumption on the origin of the bias, for example that it is related to the PSF anisotropy, one can in principle devise a correction scheme. We recommend our tests as diagnostic tools rather than converting it into a method to correct for a position-dependent c.
4.1. CFHTLenS fail fields
 |
Fig. 5 Left-hand panel: whisker plot showing the average galaxy ellipticity as a function of field position for the CFHTLenS fail fields. Middle/right-hand panel: the |
 |
Fig. 6
|
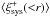
Heymans et al. (2012) developed a novel methodology to identify fields with spurious PSF anisotropy contamination, enabling them to exclude those from their cosmological analyses. Their method consists of measuring the cross-correlation of the (PSF-corrected) shapes of galaxies with the shapes of stars in individual fields. The distribution of the magnitudes of these cross-correlations is compared to a model distribution that accounts for noise and chance alignments of the PSF with cosmic shear and intrinsic galaxy alignments. Problematic fields are identified as outliers from this model distribution. In total, 43 outliers were identified and removed from the cosmic shear analyses.
We repeated our position-dependent c tests on these so-called “fail” fields. In the left-hand panel of Fig. 5 we show the whisker plot and in the middle panel the systematic correlation functions from Eq. (6). We find a very strong correlation for that is nearly independent of scale. This is suggestive of a constant additive bias. Note that neighbouring radial bins are highly correlated.
The whisker plot suggests the presence of an overall c2-term. We determined the average ellipticities of all galaxies in these fields, which are ⟨ E1 ⟩ = 0.0016 ± 0.0003 and ⟨ E2 ⟩ = 0.0016 ± 0.0003, and recalibrated these fields by subtracting ⟨ E1,2 ⟩ from the galaxy ellipticities in the catalogue. The resulting systematic correlation functions are shown in the right-hand panel of Fig. 5. This correction removes the constant, scale-independent part of . However, the correlation function still deviates from zero with a magnitude that is worse than for the CFHTLenS “pass” fields (shown in Fig. 3; the y-axis has a different scaling). Furthermore, we note that the bootstrap errors of become noticeably smaller after the recalibration.
4.2. Edge removal
To investigate whether the position-dependent c originates from a particular part of the image, we performed two tests. In Fig. 1 we found that some of the suspicious looking grid cells are located at the edge of the grid. Hence we removed the columns and rows near the edge of the grid and measured with the remaining grid cells. In Fig. 6, we show the signal after removing either 1 or 2 columns/rows near the edge of the field, for the G2 (16 × 16) grid. The left-hand panel shows the signal for the full grid for reference.
Excluding the grid cells near the edge of the field does not lead to a large decrease of the small-scale signal of the 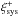 correlation function. The dip at ~20 arcmin, however, becomes more pronounced, especially in the case where we exclude the two rows and columns near the grid edge. This shows that this dip is somehow related to a feature in the central part of the image. becomes increasingly noisy at large separations when we remove the rows and columns at the edge, because we have fewer grid cell pairs left to compute the correlation.
correlation function. The dip at ~20 arcmin, however, becomes more pronounced, especially in the case where we exclude the two rows and columns near the grid edge. This shows that this dip is somehow related to a feature in the central part of the image. becomes increasingly noisy at large separations when we remove the rows and columns at the edge, because we have fewer grid cell pairs left to compute the correlation.
Next, we measured on the left, right, bottom or top half of the grid. This allowed us to test whether certain parts of the image contain more systematics than others. If, for example, PSF residuals are larger in one of the corners, for example because of on average larger PSF anisotropies at that location, we would expect to find a larger systematic correlation function using that part of the image only. The correlation functions are shown in Fig. 7. Comparing the results of the left-hand part of the grid with the right-hand part, we find that the signals look comparable. Both sides show the small-scale correlation and the dip near ~20 arcmin. Comparing the top half with the bottom half, we find that the bottom half has a somewhat larger signal at small scales.
The dip at ~20 arcmin disappears in the bottom half and is less prominent in the top half. Hence this dip is at least partly the result of a pattern in the bottom half of the grid that is anti-correlated (i.e. oriented at a relative angle of ~90 deg) with a pattern in the top-half. We also note that becomes negative at large scales in the bottom and top half of the field, but not in the other two halves, indicating the presence of an overall anti-correlation in residual c on large scales between the left-hand side and the right-hand side of the grid.
4.3. Star density
One of the main causes of additive bias is thought to be the inaccurate removal of PSF anisotropies in the shape measurement process. Problems can occur at several stages: the star catalogue can be contaminated with galaxies; the model fit to the brightness profiles of stars can be inaccurate (e.g. missing the wings); the models used to capture the spatial variations of the PSF can be inadequate. The latter can occur when the PSF varies rapidly and the number of stars is insufficient to capture its small-scale variation. This would result in correlated additive biases at small scales and hence might partly explain what we observe.
To test this, we divided all CFHTLenS pass fields in two samples, based on the density of stars used to model the PSF. PSF modelling in CFHTLenS starts with identifying star candidates from the stacked image from their location in a size-magnitude diagram. The selection is refined using the stellar loci in the gri bands. The PSF is represented as a set of pixels at the same resolution of the data. The pixel values are modelled in every exposure separately, by fitting a third-order polynomial plus an additional parameter per chip, which allows for discontinuities between chips. For more details on the PSF modelling we refer to Miller et al. (2013).
 |
Fig. 7
|
 |
Fig. 8
|
Due to seeing variations between exposures and the dithering pattern, the number of stars used to model the PSF changes somewhat between the different exposures of the same field. The variation between exposures is typically smaller than the variation between different fields. Hence we determined the average number of stars per field by counting the stars from all exposures and dividing that by the number of exposures and used that as a proxy of star density in the field. We split the CFHTLenS pass fields in a low-stellar density and a high-stellar density sample. The number of stars used in the low-stellar density sample ranges from ~2300 to ~3100, with a mean of ~2830 stars per image. The average effective area of these images is 0.81 deg2, hence this corresponds to a PSF star density of 0.97 arcmin-2. For the high-stellar density sample, the number of stars ranges up to ~9600, and the mean number of stars is ~5910 per image. The average effective area of these images is 0.72 deg2, hence the corresponding PSF star density is 2.28 arcmin-2. The effective area is likely lower in the high-stellar density sample as more stars are saturated and causing reflections, which have been masked.
We repeated the systematic tests on the two samples. The resulting systematic correlation functions are shown in Fig. 8. For the high-stellar density fields, is consistent with zero on all scales. For the low-stellar density fields, the systematics are enhanced. This strongly suggests that the small-scale additive bias is caused by undersampling of the spatial variation of the PSF. Since the systematics have a typical scale-length of the width of a chip (~7.5 arcmin) and not that of the average separation between stars (~1 arcmin) we suspect that the parameter fitted to each chip separately in the PSF model is causing the trouble.
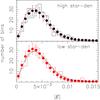 |
Fig. 9 Histogram of mean ellipticity values in the G2 grid for the samples with higher than average (top) and lower than average (bottom) stellar density. The solid histogram shows the distribution for the original CFHTLenS catalogue, whilst the dots indicate the mean and scatter of 10 000 realisations where the ellipticities were randomised. The solid red line in the top panel indicates the mean of the randomised histograms of the bottom panel, and the black line in the bottom panel shows the mean of the randomised histograms of the top panel. |
 |
Fig. 10
|
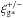
Motivated by this difference, we repeated the 1-point statistic tests on the two samples. The whisker plots are not particularly revealing and hence not shown. We do show the histograms of the ellipticity values of the whisker plots in Fig. 9. For the low-stellar-density sample, there are several bins at | E | > 6 × 10-3 higher than the mean of the randomised histograms; this it not the case for the high-stellar-density sample. The reduced χ2 between the observed and the mean of the randomised histograms is 1.64 and 0.94 for the low- and high-stellar-density sample, respectively, with corresponding p-values of 0.028 and 0.537. The KS statistic of the two samples are 0.085 and 0.057, respectively, with corresponding p-values of 0.048 and 0.368. In Fig. 9 we also show the mean of the randomised histogram of the lower-stellar density sample in the higher-stellar density panel, and vice versa. This shows that the dispersion of the average galaxy ellipticities in the lower-stellar-density sample is smaller than in the higher-stellar-density sample, suggesting that errors in the PSF model tend to make galaxies rounder on average.
We also computed the systematic correlation function of the average galaxy ellipticities and the averaged PSF model ellipticities, ⟨ E∗ ,m ⟩, of the same galaxies (as shown in the right-hand panel of Fig. 1): 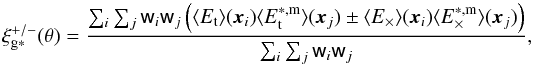 (10)with
(10)with 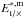 the tangential and cross component of E∗ ,m. Since ⟨ E∗ ,m ⟩ is not subject to cosmic shear, we can create bootstrap realisations by randomly drawing 128 fields from the full sample with replacement. The result is shown in Fig. 10. At separations below 10 arcmin, the average galaxy ellipticity and the average PSF model ellipticity are correlated, whilst at separations of 40 arcmin they are anti-correlated. Neighbouring radial bins are highly correlated, however, which is reflected in the bottom row of Fig. 10: when including the covariance,
the tangential and cross component of E∗ ,m. Since ⟨ E∗ ,m ⟩ is not subject to cosmic shear, we can create bootstrap realisations by randomly drawing 128 fields from the full sample with replacement. The result is shown in Fig. 10. At separations below 10 arcmin, the average galaxy ellipticity and the average PSF model ellipticity are correlated, whilst at separations of 40 arcmin they are anti-correlated. Neighbouring radial bins are highly correlated, however, which is reflected in the bottom row of Fig. 10: when including the covariance, 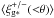 is consistent with zero for all values of θ.
is consistent with zero for all values of θ.
Finally, we compared the star density distribution of the CFHTLenS pass and fail fields. Both distributions are similar. The fail fields do not have a spuriously low star density, and undersampling of the PSF model is not likely to be the cause of the systematics in these fields.
4.4. Photometric redshift
Most cosmic shear analyses are performed in tomographic bins, that is in narrow bins of (photometric) redshift. The average size and brightness of galaxies change with redshift. Residual PSF systematics may have different magnitudes for different populations of galaxies, and could therefore be a function of redshift as well. To test this, we measured the position-dependent c as a function of redshift.
 |
Fig. 11
|
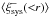
In CFHTLenS, photometric redshift of galaxies are considered reliable for galaxies with 0.2 < zB < 1.3. We split this range into two parts, 0.2 < zB < 0.7 and 0.7 < zB < 1.3 and show the systematic correlation functions in the top panel of Fig. 11. is consistent with zero for the 0.2 < zB < 0.7 sample on all scales, but the systematic correlation function of the 0.7 < zB < 1.3 sample is predominantly positive (with 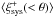 larger than zero at the 2−2.5σ level at θ < 40 arcmin). However, given the larger errors, the results of 0.2 < zB < 0.7 and 0.7 < zB < 1.3 are consistent. Since of the full galaxy sample is only positive on small scales (see Fig. 3), but appears to be positive on most scales for the two redshift subsamples, we suspect that the systematics affecting galaxies at low and high redshift have a different pattern, such that they more or less average out for the full sample. is consistent with zero for most radial bins, except for a few bins around ~10 arcmin for the 0.2 < zB < 0.7 subsample, where
larger than zero at the 2−2.5σ level at θ < 40 arcmin). However, given the larger errors, the results of 0.2 < zB < 0.7 and 0.7 < zB < 1.3 are consistent. Since of the full galaxy sample is only positive on small scales (see Fig. 3), but appears to be positive on most scales for the two redshift subsamples, we suspect that the systematics affecting galaxies at low and high redshift have a different pattern, such that they more or less average out for the full sample. is consistent with zero for most radial bins, except for a few bins around ~10 arcmin for the 0.2 < zB < 0.7 subsample, where 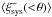 reaches a ~2.8σ deviation from zero.
reaches a ~2.8σ deviation from zero.
We also measured the correlation functions in the range where the photometric redshifts are not reliable, zB < 0.2 and zB > 1.3. We show the results in the lower panels of Fig. 11. The range of the vertical axis has been increased. For zB < 0.2, we find a highly significant at zero-lag. For zB > 1.3, there is also a significant signal at small separations, with a magnitude that is larger than for the galaxies in the reliable photometric redshift range. Additionally, there is a hint for a negative correlation at separations larger than half a degree.
Although the galaxies with zB < 0.2 and zB > 1.3 are excluded in all CFHTLenS analyses, we note that the additive and multiplicative shear calibration schemes do not depend on photometric redshift. Unless the photometric redshifts in these ranges are completely bogus, the photometric redshifts are correlated to observable galaxy properties (galaxies with zB < 0.2 being larger and brighter on average, whilst those at zB > 1.3 smaller and fainter). This could mean that the position-dependent c depends on observed galaxy properties. However, we were pointed to the fact that the model PSF ellipticity was highly correlated with the photometric redshifts if the photometry was not regaussianised. This motivated the use of regaussianised photometry in CFHTLenS. Hence it is possible that some residual correlation remains and that photometric errors in some bands places galaxies at certain redshifts (e.g. at zB < 0.2). The systematics for these two redshift bins might therefore be related to PSF modelling issues and not to galaxy properties (L. Miller, priv. comm.). Such a correlation between PSF properties and zB was also listed in Asgari et al. (2016) as a potential cause of the B-modes found in their analysis of CFHTLenS data. We postpone a further investigation of the dependence of position-dependent c on galaxy properties to future work.
4.5. Impact of cosmic shear
 |
Fig. 12
|
Our method of correlating the average ellipticities of one image with the average ellipticities of the galaxies of all other images suppresses the contribution from cosmic shear. To illustrate how much cosmic shear can contribute, we correlated the average ellipticities of all images, ⟨ E ⟩, with itself: ![Mathematical equation: \begin{eqnarray} \xi_{\rm sys}^{+, {\rm A}} && (\theta)= \nonumber\\ && \frac{\sum_{i} \sum_{j} {\sf w}_i {\sf w}_j \left [\langle E_{\rm t}\rangle (\vec{x}_i) \langle E_{\rm t}\rangle (\vec{x}_j) + \langle E_\times\rangle (\vec{x}_i) \langle E_\times\rangle (\vec{x}_j)\right] }{\sum_{i} \sum_{j} {\sf w}_i {\sf w}_j}, \end{eqnarray}](/articles/aa/full_html/2016/11/aa28846-16/aa28846-16-eq116.png) (11)with Et, × the tangential and cross components of E, respectively. We show
(11)with Et, × the tangential and cross components of E, respectively. We show 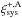 together with the reference in Fig. 12. At large separations, the two correlation functions have similar signals, but at small scales, is systematically larger than , as is clear from the lower inset of Fig. 12 which shows
together with the reference in Fig. 12. At large separations, the two correlation functions have similar signals, but at small scales, is systematically larger than , as is clear from the lower inset of Fig. 12 which shows 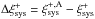 . The difference is caused by cosmic shear, which causes an additional correlation between the averaged ellipticities, as neighbouring grid cells contain galaxies from the same image that are subject to the same cosmic shear field. The zero-lag point of has a value of ~4.5 × 10-5, much higher than the rest. Since it includes the auto-correlation of galaxy ellipticities, this number is not meaningful.
. The difference is caused by cosmic shear, which causes an additional correlation between the averaged ellipticities, as neighbouring grid cells contain galaxies from the same image that are subject to the same cosmic shear field. The zero-lag point of has a value of ~4.5 × 10-5, much higher than the rest. Since it includes the auto-correlation of galaxy ellipticities, this number is not meaningful.
Even though our estimator suppresses the contribution from cosmic shear, there may still be some signal left from modes that stretch over several degrees. In principle, these could be further suppressed by excluding the neighbouring fields when computing ⟨ EnotS ⟩ (xi). However, the contribution should be small (much smaller than the difference between and ), so we consider it safe to ignore it here.
5. KiDS
 |
Fig. 13 Average galaxy ellipticity whisker for the G2 grid (16 × 16) for KiDS. The sticks indicate the size and orientation of the averaged ellipticities. The grey-scale of the sticks indicate the number of galaxies in a grid cell. The range of the horizontal and vertical axis corresponds to the size of a KiDS image. |
We repeated our systematic tests on data from the Kilo Degree Survey (KiDS; de Jong et al. 2013). KiDS is an ongoing lensing survey that will eventually cover 1500 deg2 in the ugri-bands. KiDS is observed with the VLT survey telescope (VST) using the OmegaCAM imager, a 1 deg2 CCD camera that consists of 8 × 4 CCDs. Each chip has 2048 × 4096 pixels and the pixel scale is 0.21 arcsec. 109 KiDS tiles have been released as part of the first and second data release to ESO and made publicly available. The effective area after removing the data that is masked and in the overlap between tiles is 75.4 deg2.
The shear measurement procedure for KiDS is outlined in Kuijken et al. (2015) and is very similar to the analysis of CFHTLenS. Galaxy shapes are measured in the r-band data with lensfit and photometric redshifts are estimated from the ugri photometry using BPZ; the range where the redshifts are considered reliable is 0.005 < zB < 1.2. As for CFHTLenS, the additive bias is determined by averaging the ellipticities of galaxies as a function of their observed properties, but not as a function of position in the field. The additive bias is non-zero for ϵ1 and ϵ2. A strong dependence is found between c1 and the Strehl ratio of the PSF, which could indicate a problem with undersampling of the PSF brightness profile (not an undersampling of the spatial variation; see Sect. 5.4 in Kuijken et al. 2015). The additive bias is characterised by binning the galaxies in signal-to-noise, size and Strehl ratio, to which a 3D second-order polynomial is fit. The correction factors are computed on a galaxy-by-galaxy basis and are provided as separate columns in the catalogue.
We repeated our systematic tests on these catalogues. We applied the additive bias correction and only used galaxies from unmasked areas, with a non-zero lensfit weight and with 0.005 < zB < 1.2. We used the same grids as before. The whisker plot for G2 is shown in Fig. 13 and the measurements in Fig. 14. appears to be systematically larger than zero around scales of ~10 arcmin. is positive at zero lag, followed by a negative dip around ~20 arcmin. Furthermore, we find a negative dip at scales ~50 arcmin, which has to originate from regions close to the boundaries of the images. We therefore also measured the tangential shear signal around the image centres and show it in Fig. 15. It clearly shows a negative dip at separations of half a degree. The systematic signal is more clearly visible in the tangential shear than in the measurements. The tangential shear is optimised to detect tangential trends, so any systematic that is roughly tangential with respect to the image centre is more easily detected. It shows that both tests need to be done.
 |
Fig. 14
|
Another large ongoing lensing survey is the Dark Energy Survey (DES; Diehl et al. 2014), whichs aims to observe 5000 deg2 in the griz-bands. DES recently released their shear catalogues of their science verification data (Jarvis et al. 2016), which covers 139 deg2 up to full depth. Unfortunately, neither the pixel positions of the galaxies, nor a field-identifier were included in their catalogues, meaning that we could not repeat our systematic tests on their data1.
6. Conclusions
Various potential sources of additive shear bias in weak lensing data sets are a function of pixel position, such as a varying PSF anisotropy. Consequently, the additive bias itself can depend on pixel position too. Previously applied correction schemes for additive bias used field-averaged correction factors, ignoring any spatial variation that is stationary between exposures. We have developed new tests for identifying such stationary position-dependent additive shear biases. Our main test consists of determining the average galaxy ellipticities on a grid for a single image, and correlating that with the average, gridded ellipticities of the galaxies from all other fields. This test is designed to suppress the contribution from cosmic shear and hence to enhance potential remaining systematics.
We have applied our method to the publicly available CFHTLenS shear catalogues. After correcting the catalogues with the field-averaged additive bias corrections from Heymans et al. (2012), we found that the resulting shear whisker plot revealed some suspicious features. We first analysed the distribution of the absolute values of the ellipticities by comparing it with a randomised version of the catalogue and found that the two were significantly different.
We quantified the positional dependence of the additive bias by measuring the systematic correlation functions, (based on Eq. (6)). is not consistent with zero on all scales and shows a number of features. At small scales, we find that it is positive, whilst at larger scales, there is a negative dip around ~20 arcmin. The level of spurious signal is much smaller than the cosmological signal on all scales and is not expected to significantly bias the published cosmic shear results from CFHTLenS.
To investigate the origin of the position-dependent additive shear bias, we studied its dependence on regions in the field, on the density of stars used in the PSF modelling and on photometric redshift. We found a strong correlation with stellar density: the fields with higher than average stellar density have a systematic correlation function that is consistent with zero on all scales. This suggests that for the fields with lower than average stellar density, the number of stars used to model the spatial variation of the PSF is too low.
Our systematic test can be trivially extended along various routes and could include trends with observed galaxy properties such as galaxy size and brightness. Another interesting option is to combine fields with similar PSF properties, such as those with a similar average seeing or with similar PSF patterns.
 |
Fig. 15 Average tangential shear pattern around the centre of the KiDS-DR2 images. |
Future lensing surveys will contain hundreds to thousands times more galaxies than currently used in state-of-the-art surveys like CFHTLenS. The increase of statistical power of the lensing signal needs to be matched with new methods to detect and remove ever smaller systematics in the catalogues. Identifying the positional dependence of additive shear bias is an essential one, as these can mimic and hence bias cosmic shear measurements.
Note, however, that whisker plots for the DES-SV catalogues are presented in Fig. 14 of Jarvis et al. (2016) and seem to suggest the presence of an overall ϵ2-trend and correlated structures at small scales.
Acknowledgments
We would like to thank Ludovic van Waerbeke and Lance Miller for providing the lists of stars used in the PSF modelling, and Lance Miller in addition for providing valuable feedback on this draft. E.v.U. acknowledges support from a grant from the German Space Agency DLR and from an STFC Ernest Rutherford Research Grant, grant reference ST/L00285X/1. This work is supported by the Deutsche Forschungsgemeinschaft in the framework of the TR33 “The Dark Universe”. This work is based on observations obtained with MegaPrime/MegaCam, a joint project of CFHT and CEA/DAPNIA, at the Canada-France-Hawaii Telescope (CFHT) which is operated by the National Research Council (NRC) of Canada, the Institut National des Sciences de l’Univers of the Centre National de la Recherche Scientifique (CNRS) of France, and the University of Hawaii. This research used the facilities of the Canadian Astronomy Data Centre operated by the National Research Council of Canada with the support of the Canadian Space Agency. CFHTLenS data processing was made possible thanks to significant computing support from the NSERC Research Tools and Instruments grant programme. This work is based on data products from observations made with ESO Telescopes at the La Silla Paranal Observatory under programme IDs 177.A-3016, 177.A-3017 and 177.A-3018.
References
- Abell, P. A., Allison, J., et al. (LSST Science Collaboration) 2009, ArXiv e-prints [arXiv:0912.0201] [Google Scholar]
- Albrecht, A., Bernstein, G., Cahn, R., et al. 2006, ArXiv e-prints [arXiv:astro-ph/0609591] [Google Scholar]
- Asgari, M., Heymans, C., Blake, C., et al. 2016, MNRAS, submitted [arXiv:1601.00115] [Google Scholar]
- Bartelmann, M., & Schneider, P. 2001, Phys. Rep., 340, 291 [NASA ADS] [CrossRef] [Google Scholar]
- Benítez, N. 2000, ApJ, 536, 571 [NASA ADS] [CrossRef] [Google Scholar]
- Bernstein, G. M. 2010, MNRAS, 406, 2793 [NASA ADS] [CrossRef] [Google Scholar]
- Cropper, M., Hoekstra, H., Kitching, T., et al. 2013, MNRAS, 431, 3103 [NASA ADS] [CrossRef] [Google Scholar]
- Das, S., Errard, J., & Spergel, D. 2013, ArXiv e-prints [arXiv:1311.2338] [Google Scholar]
- de Jong, J. T. A., Kuijken, K., Applegate, D., et al. 2013, The Messenger, 154, 44 [NASA ADS] [Google Scholar]
- Diehl, H. T., Abbott, T. M. C., Annis, J., et al. 2014, in Observatory Operations: Strategies, Processes, and Systems V, Proc. SPIE, 9149, 91490 [Google Scholar]
- Hartlap, J., Simon, P., & Schneider, P. 2007, A&A, 464, 399 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heymans, C., Van Waerbeke, L., Bacon, D., et al. 2006, MNRAS, 368, 1323 [NASA ADS] [CrossRef] [Google Scholar]
- Heymans, C., Van Waerbeke, L., Miller, L., et al. 2012, MNRAS, 427, 146 [NASA ADS] [CrossRef] [Google Scholar]
- Heymans, C., Grocutt, E., Heavens, A., et al. 2013, MNRAS, 432, 2433 [NASA ADS] [CrossRef] [Google Scholar]
- Hildebrandt, H., Erben, T., Kuijken, K., et al. 2012, MNRAS, 421, 2355 [NASA ADS] [CrossRef] [Google Scholar]
- Jarvis, M., Sheldon, E., Zuntz, J., et al. 2016, MNRAS, 460, 2245 [NASA ADS] [CrossRef] [Google Scholar]
- Kaufmann, G. M. 1967, Some Bayesian Moment Formulae, Report No. 6710, Centre for Operations Research and Econometrics (Catholic University of Louvain, Heverlee) [Google Scholar]
- Kilbinger, M. 2015, Rep. Prog. Phys., 78, 086901 [Google Scholar]
- Kilbinger, M., Fu, L., Heymans, C., et al. 2013, MNRAS, 430, 2200 [NASA ADS] [CrossRef] [Google Scholar]
- Kitching, T. D., Miller, L., Heymans, C. E., van Waerbeke, L., & Heavens, A. F. 2008, MNRAS, 390, 149 [NASA ADS] [CrossRef] [Google Scholar]
- Kitching, T. D., Heavens, A. F., Alsing, J., et al. 2014, MNRAS, 442, 1326 [NASA ADS] [CrossRef] [Google Scholar]
- Kitching, T. D., Taylor, A. N., Cropper, M., et al. 2016, MNRAS, 455, 3319 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K., Heymans, C., Hildebrandt, H., et al. 2015, MNRAS, 454, 3500 [NASA ADS] [CrossRef] [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, ArXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Liu, J., Ortiz-Vazquez, A., & Hill, J. C. 2016, Phys. Rev. D, 93, 103508 [NASA ADS] [CrossRef] [Google Scholar]
- Massey, R., Hoekstra, H., Kitching, T., et al. 2013, MNRAS, 429, 661 [Google Scholar]
- Melchior, P., & Viola, M. 2012, MNRAS, 424, 2757 [NASA ADS] [CrossRef] [Google Scholar]
- Miller, L., Kitching, T. D., Heymans, C., Heavens, A. F., & van Waerbeke, L. 2007, MNRAS, 382, 315 [NASA ADS] [CrossRef] [Google Scholar]
- Miller, L., Heymans, C., Kitching, T. D., et al. 2013, MNRAS, 429, 2858 [Google Scholar]
- Miyazaki, S., Oguri, M., Hamana, T., et al. 2015, ApJ, 807, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Refregier, A., Kacprzak, T., Amara, A., Bridle, S., & Rowe, B. 2012, MNRAS, 425, 1951 [NASA ADS] [CrossRef] [Google Scholar]
- Rozo, E., & Schmidt, F. 2010, ArXiv e-prints [arXiv:1009.5735] [Google Scholar]
- Schneider, P. 2016, A&A, 592, L6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Spergel, D., Gehrels, N., Baltay, C., et al. 2015, ArXiv e-prints [arXiv:1503.03757] [Google Scholar]
- Vallinotto, A., Dodelson, S., & Zhang, P. 2011, Phys. Rev. D, 84, 103004 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Estimating p-values
 |
Fig. A.1 Cumulative distribution of the occurence of p-values corresponding to the χ2 value of the null hypothesis for the systematic shear correlation functions, determined using a large set of randomised catalogues. The different panels correspond, from left to right and top to bottom, to the increasing number of radial bins included in the fit (indicated in each panel). The black line shows the p-values of |
To estimate the probability that the systematic correlation functions are consistent with zero, we computed the χ2 value of the null hypothesis, taking into account the correlation between the radial bins. The p-value corresponding to this χ2 value does not exactly correspond to the probability that 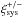 is zero. At small scales, the number of radial bins is small and the probability derived from the χ2 is inaccurate. In addition, the errors on may not follow Gaussian statistics, which would also lead to differences between the p-values and the actual probabilities.
is zero. At small scales, the number of radial bins is small and the probability derived from the χ2 is inaccurate. In addition, the errors on may not follow Gaussian statistics, which would also lead to differences between the p-values and the actual probabilities.
To analyse how the p-values relate to the actual probabilities of being zero, we created random realisations of the data. We rotated the ellipticities of all galaxies by a random amount (different from galaxy to galaxy). Next, we analysed this randomised catalogue exactly as the real data: we measured the average ellipticities on the 16 × 16 grid, correlated the average ellipticities of one image to the average of all the others, and estimated the covariances of the correlation functions using bootstrapping. The expectation value of of these randomised catalogues is zero by construction. We determined the χ2 value of the null hypothesis for increasing radial scales using the covariance matrix estimated from the bootstraps, and computed the corresponding p-value.
We repeated this procedure 1000 times. Then we determined the distribution of p-values for each radialbin. The results are shown in Fig. A.1. The horizontal axis of this figure shows the observed p-value, the vertical axis the number of times a p-value smaller than the observed one was found in the randomised catalogues (i.e. the real probability). If the measured p-values would correspond to the actual probability of being consistent with zero, one would expect a one-to-one correspondence. For 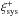 , the p-value generally overestimates the probability, particularly for low p-values (more random realisations have low p-values than you would expect). For
, the p-value generally overestimates the probability, particularly for low p-values (more random realisations have low p-values than you would expect). For 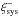 , the p-values agree fairly well with the probability if we only include small radial scales, but slightly overestimates the probability towards an increasing number of radial bins.
, the p-values agree fairly well with the probability if we only include small radial scales, but slightly overestimates the probability towards an increasing number of radial bins.
We used this result to convert the p-values that correspond to the χ2 values of the null hypothesis in our measurement, to the actual probability that is consistent with zero. All p-values that are shown in this work have been converted like this. We derived separate conversions for each measurement. In particular, the conversion of the CFHTLenS fail fields, as well as the one of the low/high-stellar density fields, differs slightly from the one shown in Fig. A.1 (although the main trends are the same). The conversion scheme for differs as well, such that the p-value that corresponds to the χ2 value of the null hypothesis, is closer to the actual probability. Finally, we note that for the CFHTLenS fail fields and for the zB< 0.2 sample, we used ten times more random realisations, which we needed to ensure that the conversion at low p-values was robust.
All Figures
|
Fig. 1 Left-hand panel: whisker plot showing the average galaxy ellipticity as a function of field position in the 128 CFHTLenS “pass” fields for the G2 grid (16 × 16). The sticks indicate the size and orientation of the averaged ellipticities. The grey-scale of the sticks indicate the number of galaxies in a grid cell. The range of the horizontal and vertical axis corresponds to the size of a CFHTLenS image. Right-hand panel: whisker plot of the average model PSF in CFHTLenS obtained by averaging the model PSFs at the location of the galaxies for the same grid. |
| In the text | |
|
Fig. 2 Left-hand panel: histogram of mean ellipticity values in the G2 grid. The black line shows the distribution for the original CFHTLenS catalogue, the red dots indicate the mean and scatter of 10 000 realisations where the ellipticities were randomised. Right-hand panel: cumulative probability distribution of the observed and randomised histograms. |
| In the text | |
|
Fig. 3
|
| In the text | |
|
Fig. 4
|
| In the text | |
|
Fig. 5 Left-hand panel: whisker plot showing the average galaxy ellipticity as a function of field position for the CFHTLenS fail fields. Middle/right-hand panel: the |
| In the text | |
|
Fig. 6
|
| In the text | |
|
Fig. 7
|
| In the text | |
|
Fig. 8
|
| In the text | |
|
Fig. 9 Histogram of mean ellipticity values in the G2 grid for the samples with higher than average (top) and lower than average (bottom) stellar density. The solid histogram shows the distribution for the original CFHTLenS catalogue, whilst the dots indicate the mean and scatter of 10 000 realisations where the ellipticities were randomised. The solid red line in the top panel indicates the mean of the randomised histograms of the bottom panel, and the black line in the bottom panel shows the mean of the randomised histograms of the top panel. |
| In the text | |
|
Fig. 10
|
| In the text | |
|
Fig. 11
|
| In the text | |
|
Fig. 12
|
| In the text | |
|
Fig. 13 Average galaxy ellipticity whisker for the G2 grid (16 × 16) for KiDS. The sticks indicate the size and orientation of the averaged ellipticities. The grey-scale of the sticks indicate the number of galaxies in a grid cell. The range of the horizontal and vertical axis corresponds to the size of a KiDS image. |
| In the text | |
|
Fig. 14
|
| In the text | |
|
Fig. 15 Average tangential shear pattern around the centre of the KiDS-DR2 images. |
| In the text | |
|
Fig. A.1 Cumulative distribution of the occurence of p-values corresponding to the χ2 value of the null hypothesis for the systematic shear correlation functions, determined using a large set of randomised catalogues. The different panels correspond, from left to right and top to bottom, to the increasing number of radial bins included in the fit (indicated in each panel). The black line shows the p-values of |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.