| Issue |
A&A
Volume 666, October 2022
|
|
|---|---|---|
| Article Number | A162 | |
| Number of page(s) | 19 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202141847 | |
| Published online | 24 October 2022 | |
ShapePipe: A new shape measurement pipeline and weak-lensing application to UNIONS/CFIS data
1
AIM, CEA, CNRS, Université Paris-Saclay, Université de Paris, 91191 Gif-sur-Yvette, France
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Université de Paris, CNRS, Astroparticule et Cosmologie, 75013 Paris, France
3
Institut d’Astrophysique de Paris, UMR7095 CNRS, Université Pierre & Marie Curie, 98 bis boulevard Arago, 75014 Paris, France
4
Institute of Physics, Laboratory of Astrophysics, Ecole Polytechnique Fédérale de Lausanne (EPFL), Observatoire de Sauverny, 1290 Versoix, Switzerland
5
Institut d’Estudis Espacials de Catalunya (IEEC), 08034 Barcelona, Spain
6
Institute of Space Sciences (ICE, CSIC), 08193 Barcelona, Spain
7
Department of Astrophysical Sciences, Princeton University, 4 Ivy Ln., Princeton 08544, USA
8
Department of Physics and Astronomy, University of Waterloo, Waterloo, ON N2L 3G1, Canada
9
Waterloo Centre for Astrophysics, Waterloo, ON N2L 3G1, Canada
10
Perimeter Institute for Theoretical Physics, 31 Caroline St. N., Waterloo, ON N2L 2Y5, Canada
11
Argelander Institute for Astronomy, University of Bonn, Auf dem Hügel 71, 53121 Bonn, Germany
12
NRC Herzberg Astronomy and Astrophysics, 5071 West Saanich Road, Victoria, BC V9E 2E7, Canada
13
Ruhr University Bochum, Faculty of Physics and Astronomy, Astronomical Institute (AIRUB), German Centre for Cosmological Lensing, 44780 Bochum, Germany
14
Department of Physics and Astronomy, University of British Columbia, 6224 Agricultural Road, Vancouver, V6T 1Z1 BC, Canada
15
Department of Physics, University of Oxford, Denys Wilkinson Building, Keble Road, Oxford OX1 3RH, UK
16
Canadian Astronomy Data Centre, Herzberg Astronomy and Astrophysics, National Research Council, 5071 West Saanich Rd, Victoria, BC V9E 2E7, Canada
17
Institute of Astronomy, University of Cambridge, Madingley Road, Cambridge CB30HA, UK
Received:
21
July
2021
Accepted:
5
May
2022
Abstract
Context. The Ultraviolet Near-Infrared Optical Northern Survey (UNIONS) is an ongoing collaboration that will provide the largest deep photometric survey of the northern sky in four optical bands to date. As part of this collaboration, the Canada-France Imaging Survey (CFIS) is observing r-band data with an average seeing of 0.65 arcsec, which is complete to magnitude 24.5 and thus ideal for weak-lensing studies.
Aims. We perform the first weak-lensing analysis of CFIS r-band data over an area spanning 1700 deg2 of the sky. We create a catalogue with measured shapes for 40 million galaxies, corresponding to an effective density of 6.8 galaxies per square arcminute, and demonstrate a low level of systematic biases. This work serves as the basis for further cosmological studies that will use the full UNIONS survey of 4800 deg2 when completed.
Methods. Here we present SHAPEPIPE, a newly developed weak-lensing pipeline. This pipeline makes use of state-of-the-art methods such as NGMIX for accurate galaxy shape measurement. Shear calibration is performed with metacalibration. We carry out extensive validation tests on the point spread function (PSF) and on the galaxy shapes. In addition, we create realistic image simulations to validate the estimated shear.
Results. We quantify the PSF model accuracy and show that the level of systematics is low as measured by the PSF residuals. Their effect on the shear two-point correlation function is sub-dominant compared to the cosmological contribution on angular scales < 100′. The additive shear bias is below 5 × 10−4, and the residual multiplicative shear bias is at most 10−3 as measured on image simulations. Using complete orthogonal sets of E-/B-mode integrals (COSEBIs), we show that there are no significant B-modes present in second-order shear statistics. We present convergence maps and see clear correlations of the E-mode with known cluster positions. We measure the stacked tangential shear profile around Planck clusters at a significance higher than 4σ.
Key words: cosmology: observations / gravitational lensing: weak / techniques: image processing
© A. Guinot et al. 2022
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe-to-Open model.
1. Introduction
Weak gravitational lensing, the apparent distortion of the shapes of galaxies by foreground matter, is today one of the primary probes of cosmology. The ability to trace the total matter distribution, including dark matter, makes weak lensing an indispensable tool in the modern era of precision cosmology (see e.g., Kilbinger 2015 or Mandelbaum 2018 for reviews). Weak-lensing distortions of galaxy images induced by large-scale structure are very small and prone to a number of systematic errors. In addition, for the cosmological interpretation of the measured gravitational shear, photometric redshifts of the lensed galaxies need to be known to a high precision. For these reasons, weak-lensing studies require a very large observed area, high image quality in multiple bands for photometric redshifts, and a significant depth.
Previous experiments have studied weak lensing in great detail, such as the Canada-France-Hawai’i Telescope Legacy Survey (CFHTLS; Erben et al. 2013), the Kilo-Degree Survey (KiDS; Kuijken et al. 2019), the Hyper Suprime Cam (HSC) survey (Mandelbaum et al. 2018), and the Dark Energy Survey (DES; Gatti et al. 2021).
In this paper we focus on the ongoing Ultraviolet Near-Infrared Optical Northern Survey (UNIONS). UNIONS is a collaboration between the Canada-France Imaging Survey (CFIS), the Panoramic Survey And Rapid Response System (Pan-STARRS; Chambers et al. 2016), and WISHES (Wide Imaging with Subaru HSC of the Euclid Sky). It aims to provide the largest (4800 deg2) multi-band optical photometric survey of the northern hemisphere. CFIS provides r-band images observed with the Canada-France-Hawai’i Telescope (CFHT) with excellent image quality, ideal for weak-lensing purposes (the average seeing is ≈0.65 arcsec in the r-band). CFHT has a proven track record of providing images for state-of-the-art weak-lensing studies. Wide surveys with CFHT started with CFHTLS/CFHTLenS and were followed by RCSLenS (Hildebrandt et al. 2016) and now CFIS. In addition to the large area and small seeing, CFIS area overlaps with very wide spectroscopic surveys such as SDSS’s Baryon Oscillation Spectroscopic Survey (SDSS-BOSS, Eisenstein et al. 2011), extended Baryon Oscillation Spectroscopic Survey (eBOSS, Dawson et al. 2016), and soon the Dark Energy Spectroscopic Instrument (DESI) survey (DESI Collaboration 2016). This combination of surveys provides a unique dataset for weak-lensing studies.
Central to all weak-lensing analyses is a robust and efficient data processing pipeline. To extract the weak-lensing signal from the distorted shapes of the galaxies, one has to be particularly meticulous through the entire chain of processing. The main piece of such a pipeline is the shape measurement algorithm used to capture the shear signal from the noisy, pixelised, and blurred images of galaxies. This signal is subject to a number of systematic errors. Every step requires a specific calibration and validation to reach the level of precision required for the cosmological analysis.
In this paper we present a new pipeline architecture designed to handle the large area of a stage-III (Albrecht et al. 2006) survey. The pipeline presents a balance of well-established methods and newly developed algorithms. Our goal is to develop a framework that is capable of handling CFIS data but flexible enough to allow for the evolution of the current methods and the addition of new ones in the future.
This paper is organised as follows. In Sect. 2 we present the UNIONS survey with a focus on the CFIS r-band, which was used for the shape measurement presented here. In this section we also detail how we estimate the redshift distribution for this first study. In Sect. 3 we introduce the modular design of our pipeline. In Sect. 4 we discuss the modelling of the point spread function (PSF), a key part for any weak-lensing pipeline. In Sect. 5 we present the multi-epoch shape measurement method. Sect. 6 shows the numerous diagnostics we carry out to validate our measurements on the data. We also perform tests on simulated images to validate our implementation of the shape measurement. These tests are presented in Sect. 7. Finally, we show our scientific results in Sect. 8 before presenting our conclusions in Sect. 9.
2. Data
CFIS is a large imaging survey observing the northern hemisphere with the wide-field imager MEGACAM on CFHT (pixel scale of 0.187 arcsec). CFIS started observations in 2017 and has (as of early 2021) reached a coverage of around 3000 deg2, 60% of the planned final area of 4800 deg2. The survey will reach completion by 2025. CFIS takes deep images in the r-band (640 nm) and u-band (355 nm). It takes advantage of the excellent sky quality of Mauna Kea, with an average seeing of 0.65 arcsec in the r-band. These conditions make CFIS ideally suited for weak-lensing studies.
In 2018 the UNIONS survey collaboration was created to gather in a single scientific group the various multi-band surveys that cover the planned Euclid footprint in the northern hemisphere. CFIS will provide the r- and u-bands, while Pan-STARRS will observe the i- and z-band, and Subaru HSC will complement the z-band through WISHES.
2.1. The UNIONS/CFIS survey
CFIS single-exposure images are taken with a large dither between each exposure, which is around one-third of the focal plane, or 0.33 deg. This survey strategy was chosen to maximise the total area covered. Three exposures (of ∼200 s each) are necessary to reach the planned depth of r = 24.1 at S/N = 10 for extended sources observed in the stacked images. The decision was made to have an exposure time that varies (between 100s and 300s) according to observing conditions (sky brightness, image quality, sensitivity of the system telescope+camera) to achieve a constant magnitude depth across the survey footprint (Cuillandre et al. 2014).
2.2. Pre-processing steps
The pre-processing of the data is a key step in the processing chain. For CFIS, CFHT images are calibrated using the MegaPipe pipeline (Gwyn 2008). An astrometric calibration within 20 mas was achieved using the Gaia DR2 observations (Brown et al. 2018) of 1.7 billions stars. The photometric calibration relies on observations from the Pan-STARRS PS1 survey (Chambers et al. 2016) providing a photometric solution as good as 1 milli-magnitude in the r-band internally (camera field of view), and 4 milli-magnitudes in absolute with respect to an all-sky reference. Both of these steps are important for shape measurement as the gravitational lensing signal is extremely sensitive to astrometric and photometric calibrations. The level of calibration achieved by CFIS can reduce systematic effects (Mandelbaum 2018).
After the single exposures have been calibrated, stacked images are created. This step allows one to increase the signal-to-noise ratio by combining several images together. For CFIS, the images are combined with SWARP1 using a weighted average. This method has the advantage of preserving point-source-like objects, but it does not behave as well as a median average regarding outliers. This choice was motivated by the small number of single exposures (three on average), which is not enough to properly remove time-dependent artefacts even with a median stacking.
2.3. Galaxy redshift distribution
As mentioned above, the UNIONS survey will be composed of several photometric bands, making it possible to compute photometric redshifts (photo-z’s) for all observed galaxies. However, at present time only the r-band data have reached a sufficiently large area and depth to obtain reliable photo-z’s. For our science analysis (Sect. 8) we need an estimate for the redshift distribution N(z) of our weak-lensing galaxies over the processed area.
Here, we make use of the overlapping area with the CFHTLS-W3 field analysed by the CFHTLenS survey (Erben et al. 2013). We match our galaxies (see below) to the public CFHTLenS-W3 catalogue, within a 0.72 arcsec radius (≈4 pixels) on the sphere. We use their best-fit redshift measures Hildebrandt et al. (2012, Z_B) of the 576 000 matched galaxies to get an estimate for the redshift distribution N(z) of our r-band catalogue. We then use this N(z) for the entire galaxy sample. Given the observing strategy used for CFIS, which provides a constant depth over the observed area, this extrapolation seems justified. The distribution is shown in Fig. 1.
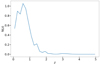 |
Fig. 1. Redshift distribution inferred from matching CFIS with CFHTLenS Z_BEST over the CFHTLS-W3 area. |
This extrapolation introduces sample variance to the redshift distribution. Van Waerbeke et al. (2006) estimated the variance that is added to the cosmic-shear covariance. In our case, this variance is sub-dominant compared to shape noise and cosmic variance, with the strongest contribution at scales of around 2′.
3. The SHAPEPIPE weak-lensing processing pipeline
ShapePipe is a modular weak-lensing processing and analysis pipeline written in Python. The package itself is composed of two principal sub-packages: one that constitutes the core pipeline architecture, and a second part that contains the various modules that account for each of the steps in the pipeline.
ShapePipe makes use of the open-source package management system Conda2 to provide a version-controlled environment for each pipeline release. This ensures consistency in the versions of third-party packages employed by ShapePipe including those not written in Python (e.g., SEXTRACTOR, PSFEx, etc.). This in turn ensures a level of reproducibility of ShapePipe results on different processing platforms.
The core pipeline sub-package (hereafter referred to as the ShapePipe core) manages basic operations such as argument parsing, logging, dependence handling, and reading and writing FITS files. In addition to this, the pipeline core is responsible for parallel processing and module handling.
The ShapePipe core operates under the assumption that a series of input products can be handled in an embarrassingly parallel manner via a series of independent jobs. The package uses two different methods for distributing jobs. On shared memory systems the ShapePipe core uses Joblib (Joblib Development Team 2020) to implement a form of symmetric multi-processing (SMP), while on larger clusters a message passing interface (MPI) is implemented via MPI for Python (Dalcin et al. 2005, 2008, 2011). This enables ShapePipe to be run with as many CPU cores as are available on a given platform.
The ShapePipe core was designed to be as modular as possible, meaning that various processing steps could be updated, supplemented or replaced as new advances are made. A series of modules and the order in which they should be run can be specified in the configuration file before launching the pipeline. This enables ShapePipe to better adapt to data sets coming from different surveys.
The ShapePipe core has been optimised to minimise the amount of memory used. This ensures that the majority of system resources are available for the modules.
Finally, the ShapePipe core makes use of the following third-party packages to provide extra funcitonality: Astropy (Astropy Collaboration 2018), ModOpt (Farrens et al. 2020), and Numpy (Harris et al. 2020).
4. PSF modelling
The estimation of the PSF is a critical step for weak-lensing shape measurement. The PSF encompasses all aberrations induced in galaxy images due to optical imperfections and, most importantly, atmospheric effects such as refraction or turbulence. In the following section we describe how we model the PSF and its variations on the CFIS single-exposure images. The resulting model is used in Sect. 5 to correct for PSF effects in galaxy shapes.
To model the PSF one needs to have a selection of stars, which should be as pure as possible and homogeneously distributed over the area of interest. Given the large dither and different observation periods between overlapping exposures, we decided to perform star selection at the single-exposure level. Despite their lower signal-to-noise ratio, the single exposures provide a more spatially stable distribution of stars. The star selection, as well as the PSF modelling, is performed independently on each of the 40 chips that constitute the MEGACAM CCD mosaic.
4.1. Star selection
The star selection is a challenging step for UNIONS because, to date, only the r-band has been observed over an area and depth large enough to accurately model the PSF. Therefore, we select star candidates by identifying the stellar locus in a size-magnitude diagram, using the fact that the observed size of stars does not correlate with their luminosity.
The selection is done in two steps. We first run SEXTRACTOR3 (Bertin & Arnouts 1996) with a relatively large area threshold to avoid polluting the star candidate sample with artefacts (bad pixels, cosmic ray hits, etc.). For that we fix the value DETECT_MINAREA = 10 pixels. This corresponds to a circular aperture with a radius of ≈2 pixels.
Next, we select stars in a size-magnitude plane. We first pre-select a sample of objects with FWHM (full-width half maximum) between 0.3 and 1.5 arcsec, and compute the mode of the FWHM distribution, which provides us with an estimate of the stellar locus. From this pre-selection we keep objects for which the FWHM is within 0.04 arcsec of the mode. In addition to these size cuts, we only use star candidates in the magnitude range 18 < r < 22. These limits remove saturated stars, and faint, noisy objects that might be galaxies. This selection is carried out independently for each field of view, and also on each CCD. This accounts for the varying seeing between single exposures, and for the PSF size that changes with position on the focal plane. The star selection for one CCD is shown in Fig. 2. The stellar locus is clearly visible (in orange) and there are enough stars to reliably estimate the mode. The distribution of the number of selected stars per CCD is shown in the top panel of Fig. 3. We set a threshold of 22 stars, below which a CCD will not be considered for PSF modelling, and consequently will not contribute to the multi-epoch shape measurements of galaxies imaged by this CCD. Only a small fraction of CCDs have a number of stars smaller than this threshold. The computation of the mode and star selection is performed automatically by the pipeline.
 |
Fig. 2. Size-magnitude diagram for one CCD. In orange we show the selected stars. The dashed line represents the mode of the stellar locus at 0.59 arcsec, which is automatically estimated by SHAPEPIPE. |
 |
Fig. 3. Distribution of selected stars over all 208 000 CCDs. Top: number of stars per CCD. The dashed line represents the cut at 22 stars/CCD, below which the CCD is discarded for the PSF estimation. Bottom: mode (per CCD exposure) of the FHWM of stars. |
The bottom panel of Fig. 3 shows the FWHM distribution over all 208 000 CCDs, demonstrating the excellent image quality of CFHT/MEGACAM. With an average seeing of 0.65 arcsec, UNIONS is at the same level as the HSC survey (Mandelbaum et al. 2017) and substantially better than what was achieved by DECam (Zuntz et al. 2018).
4.2. PSF estimation and interpolation
In this section we describe how we model the PSF on each single exposure. We make use of the PSFEx software package4 (Bertin 2011). Since we carry out our own star selection (see Sect. 4.1), we disable the internal PSFEx pre-selection, and the PSF is thus obtained using the entire star sample. We ran PSFEx in PIXEL basis mode. This means that no assumptions are made regarding the parametric profile for the PSF. Rather, the pixels themselves are fitted in real space. This fit is initialised using the median profile of the sources provided in the field. The parameters fitted by PSFEx are the pixels that make up a set of PSF basis functions, 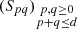 , each of which is an image of the same size as the desired PSF model. These are then combined as a polynomial function of the position (x, y) (here chosen to be the pixel position) to capture the spatial variations of the PSF:
, each of which is an image of the same size as the desired PSF model. These are then combined as a polynomial function of the position (x, y) (here chosen to be the pixel position) to capture the spatial variations of the PSF:
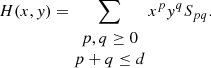 (1)
(1)
The maximal degree of the polynomials, d, is chosen through the PSFEx parameter PSFVAR_DEGREES, which we set to two.
PSFEx runs an iterative χ2 fit that allows for the removal of potential outliers at each iteration. This outlier rejection method removes around 0.08% of all stars from the final PSF sample, demonstrating that our star selection (Sect. 4.1) is robust.
The PSFEx parameters we used are presented in Table 1. We have chosen not to over-sample the PSF models. This choice of parameters was driven by a comparison of PSF model performance using different sets of parameters and repeating the validation tests of Sect. 6.2 on a large subset of the CFIS data.
PSFEx parametrisation.
The computation of the PSFEx model at any given position (as in Eq. (1)) is normally carried out by SEXTRACTOR. However, since we perform our own shape measurement rather than relying on SEXTRACTOR, we use our own Python module to recombine the PSFEx basis functions.
5. Shape measurement
In this section we first describe how the galaxy sample is selected using the spread model. Then, we present the method we used for measuring galaxy shapes. To calibrate the estimated shear, we make use of the metacalibration framework. The shape measurement is based on a joint multi-epoch5 model fitting and makes use of the NGMIX software package6 (Sheldon & Huff 2017).
5.1. Source extraction
We start the processing by extracting all the sources using SEXTRACTOR, with the parametrisation presented in Table 2. We extract sources for which the pixel values are above 1.5 times the noise variance. This is set with both parameters THRESH_TYPE and DETECT_THRESH. We do the extraction on stacked images, which provide a better signal-to-noise ratio, and most artefacts have a reduced amplitude with respect to single exposures (due to time or position dependence). The detection is performed on a filtered image, for which we used the default 3 × 3 Gaussian kernel. This filtering smoothes the image and makes the detection less sensitive to noise fluctuation. As was done for the stars, we do not include sources that are too small (DETECT_MINAREA = 10, see Sect. 4.1). This choice could lead to a detection bias, but overall we are more confident that our sample contains astrophysical sources and not artefacts.
SEXTRACTOR parametrisation.
5.2. Galaxy selection
Among the several techniques available to select galaxies we use the spread model introduced in Mohr et al. (2012) and Desai et al. (2012). This method proposes to compare each extracted source to a point-source-like and an extended object. Sources with a spread model equal to zero are considered as point sources. A spread model larger than zero corresponds to extended objects, while values below zero corresponds to objects smaller than the PSF (i.e. artefacts). As the spread model is noisy, we can construct an error for this measure, σs, which we use as a relaxation parameter to do the final classification. We do not consider the spread model to be sufficiently robust to classify PSF stars, which is why it is only used to pre-select our galaxy sample. Here we encounter the same difficulty as for the star selection, in that we do not have access to colour information which would help to more accurately select our galaxy sample. However, as we demonstrate below, a conservative spread-model classification based on a single band is sufficiently accurate to yield a pure galaxy sample. Another difficulty at this stage is the handling of the PSF model. Indeed, as discussed in Sect. 4.2, PSF models extracted from stacked images proved to be unreliable. Instead, we extrapolate the PSF information from the measurement on the single exposures to the stacked images. This implementation has been tested on a set of simulated images of stars and galaxies (which will be described in more detail in a future paper). The results show that only 0.7% of the objects in our galaxy sample are stars that have been misclassified as galaxies. Here we present the equations of the spread model, s, and the spread model error, σs:
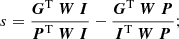 (2)
(2)
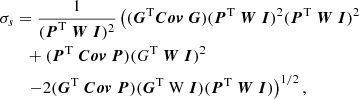 (3)
(3)
where P is the PSF represented by an isotropic Gaussian with sigma equal to the mean sigma of the PSF model of the single epoch images interpolated to the position of the object detected on the stack. We represent an extended source, G, approximated by an exponential profile with a scale radius of 1/16 PSFFWHM convolved by the PSF P. The object image postage stamp is represented by I and the weight image postage stamp by W. The noise covariance matrix is described by Cov, assumed to be diagonal, with 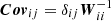 .
.
We then use the spread model to make the selection presented in Eqs. (4)–(6) below:
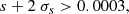 (4)
(4)
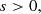 (5)
(5)
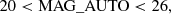 (6)
(6)
where s is given by Eq. (2), and σs by Eq. (3). The cuts are illustrated in Fig. 4.
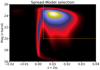 |
Fig. 4. Spread model classification. The orange area corresponds to the objects that have been selected for the galaxy sample. (The yellow contours represent a density 8 times larger than red). |
In addition to the spread model, we also apply cuts based on quantities derived from the model fitting described in Sect. 5.4. The spread model gives a sample of extended sources, which needs to be refined. We apply additional cuts to the ratio between the size of the galaxies, Tgal, and the size of the PSF, TPSF. We also remove objects that have a low S/N, which we defined as the ratio between the measured flux of the galaxies, F, and the error on the flux, σF. The cuts are in Eqs. (7) and (8)
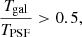 (7)
(7)
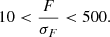 (8)
(8)
5.3. Metacalibration
Metacalibration is a method introduced by Huff & Mandelbaum (2017) and was used in the DES collaboration (Zuntz et al. 2018). This method allows one to calibrate shear measurements without the need to create a large number of time-consuming image simulations. It consists in measuring the response, R, of a shape measurement algorithm to a shear artificially applied to an image. To introduce this response we start with the classic equation in the weak-lensing limit used to estimate the mean shear, γ, from an ensemble of galaxies. With i∈ Planck Collaboration XIII (2016), Albrecht et al. (2006) denoting the ellipticity component, the observed ellipticity, 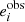 , is given as
, is given as
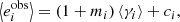 (9)
(9)
with mi and ci being the multiplicative and additive bias for component i. This relation assumes that the intrinsic ellipticity of galaxies vanishes on average.
The shear response generalises this equation and relates the observed ellipticity to shear for an individual galaxy of intrinsic ellipticity, 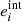 , as
, as
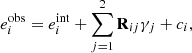 (10)
(10)
where R is the response matrix, which can be described as
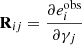 (11)
(11)
and approximated to
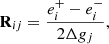 (12)
(12)
where 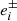 represents the ith component of ellipticity measured on an image with added shear component ±Δgi.
represents the ith component of ellipticity measured on an image with added shear component ±Δgi.
To apply an artificial shear, the image needs to be first deconvolved by its original PSF. The deconvolution is performed by a division in Fourier space. We can then apply an artificial shear and reconvolve the object by a larger PSF7. Finally, we generate a noise image (i.e. a postage stamp of the same size as the original observation but containing only noise) with the same variance as the original image to cancel the correlations created by the shearing process. To cancel the correlations, the noise image undergoes the same process of deconvolution, shearing and reconvolution. The difference being in the shearing. To cancel the correlations created in the image we apply the shear on a 90deg rotated version of the noise image, which is then rotated back, and applied to our science image (for a more in-depth description of the noise handling we refer the reader to Sect. 4.2 of Sheldon & Huff 2017). In this work, we use the NGMIX software package to handle the metacalibration steps.
This method creates four images used for the calibration, and one for the measurement. The response is composed of two components, R = ⟨Rshear⟩+⟨Rselection⟩. The corrections of the shear bias is handled by ⟨Rshear⟩, which here encompass model bias and noise bias. The biases due to selection cuts (e.g., on magnitude or object size) are handled by ⟨Rselection⟩. To correct for these selection effects, the cuts have to be performed on parameters obtained from the sheared images. We refer to these cuts as the selection mask, M±. Both ⟨Rshear⟩ and ⟨Rselection⟩ can be defined as follows:
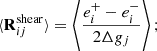 (13)
(13)
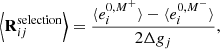 (14)
(14)
where 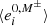 represents the average ellipticity measured on the image with no shear applied but using the selection mask (described in Sect. 5.2), M±, from the images with a small shear ±Δgi applied. Since the quantities to which we apply cuts are correlated to the shear, we will obtain different values for
represents the average ellipticity measured on the image with no shear applied but using the selection mask (described in Sect. 5.2), M±, from the images with a small shear ±Δgi applied. Since the quantities to which we apply cuts are correlated to the shear, we will obtain different values for 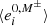 depending on which sheared version of the image we apply the cuts. This leads to a non-zero selection response. Finally, we have Δgj = | ± gj|, with gj = 0.01, according to Sheldon et al. (2020).
depending on which sheared version of the image we apply the cuts. This leads to a non-zero selection response. Finally, we have Δgj = | ± gj|, with gj = 0.01, according to Sheldon et al. (2020).
Here we measure the selection effects due to the different cuts one can apply to the shape catalogue. The cuts use the same criteria for all the sheared versions but they might give a different selection for each sheared version of the objects. The differences account for this effect, which is the selection effect we want to capture. It is important to note that only effects due to cuts on quantities measured on the sheared images can be accounted for. For example, it is not possible to correct for detection effects at this stage (Sheldon et al. 2020).
5.4. Multi-epoch model fitting shape measurement
To measure the shapes of objects we use NGMIX, a model-fitting technique. This method consists in finding the best-fit parameters for a model that minimises the function:
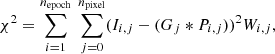 (15)
(15)
where Ii, j corresponds to the vectorised image and Wi, j to the weight describing noise variations in the image, for the single exposure i and pixel index j. Gj is the vectorised modelled image convolved (*) with the PSF of the corresponding single exposure i, Pi, j. Here, we model the galaxies with a simple Gaussian profile. Despite being very simple, the model bias (Kacprzak et al. 2014) is small. Furthermore, since this bias is calibrated to a large extent by the metacalibration framework. We quantify this in Sect. 7. The minimisation (Eq. (15)) is performed in Fourier space for computational reasons.
The model is created using GALSIM8 (Rowe et al. 2015). Six parameters are used to describe the model: Δx and Δy for centroid shifts, e1 and e2 the two ellipticity components, r50 the half-light radius, and the flux F. The model takes into account the optical distortions in all single exposures through the WCS (World Coordinates System) framework.
For the minimisation of χ2, a least-square algorithm is used with the priors presented in Table 3.
Priors used for the model fitting.
Finally, in order to reach convergence during the fitting operation we have to provide accurate initial values for the size and the flux. We thus run first an adaptive moments algorithm to initialise the least-square operation. In order to avoid any bias due to the choice of the initialisation, this is performed on each sheared version of the object. The initial values are chosen as presented in Eqs. (16)–(20):
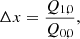 (16)
(16)
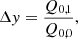 (17)
(17)
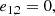 (18)
(18)
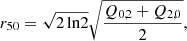 (19)
(19)
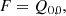 (20)
(20)
where
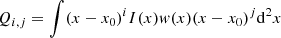 (21)
(21)
represent the moments of the light profile I(x) of order i + j and weighted by a Gaussian window w(x). The moments are computed using the HSM algorithm (Hirata & Seljak 2003) from the GALSIM software package.
We need to apply weights to the ellipticity values in order to take into account the measurement uncertainties. These weights are computed as
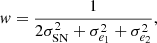 (22)
(22)
where σSN represents the raw shape noise, which has been measured from data to be 0.34 (here we used a simple variance estimator, a more precise estimate is given by Eq. (37)). σe1, 2 is the variance of the ellipticity parameters estimated during the model fitting.
6. Diagnostics
Here we present the validation tests performed on the PSF model and on the shape measurements. These tests are crucial to demonstrate a low enough level of systematics for reliable science applications of the weak-lensing data.
First, we present two sets of tests of the PSF model, some qualitative and some quantitative. For the shape measurement we focused on the PSF residuals propagated to the galaxy shapes. Since no cosmological requirements are defined yet in the UNIONS collaboration, we took other surveys as a reference.
6.1. Ellipticity correlation functions
Some diagnostics of the impact of the PSF on shape measurements concern the correlation between the measured ellipticities of different galaxy and star samples. First, we define the two-point correlation function ρ of the ellipticity e, written as a complex number e = e1 + ie2, of two samples. We consider two samples A and B. If their ellipticities, as random fields on the sky at positions θ, eA(θ) and eB(θ), respectively, are statistically homogeneous and isotropic, their two-point function only depends on a scalar distance θ, ρ = ρ(θ) = ⟨eA*eB⟩(θ). Here, the asterisk ‘*’ denotes complex conjugation. Replacing the ensemble average by a spatial average over positions θ′, we can write ρ(θ) = ⟨eA*(θ′)eB(θ′+θ)⟩. An unbiased estimator of ρ is
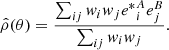 (23)
(23)
The weighted sum is carried out over pairs (ij) of objects at sky positions θi, θj, whose distance θij = |θi − θj| is close to θ. We use logarithmic bins, and therefore the angular bin is given by lnθ − Δlnθ/2 < lnθij < lnθ + Δlnθ/2. The weights wi are defined in Eq. (22).
In the case of cosmic-shear, where the ellipticity samples A and B are galaxy shear estimates, the correlation function ρ defined above is represented by ξ+. In addition, ξ− is defined as ξ−(θ) = ℜ[⟨eA(θ′)eB(θ′+θ)exp(−4iφ)⟩], where φ is the polar angle of θij (Schneider et al. 2002). We make use of both functions in Sects. 6.3.3 and 8.4.
6.2. PSF validation tests
In this section we present the tests we have performed on our PSF model to quantify the systematics. To be able to perform these tests properly, our star sample has been randomly divided in two. We use 80% of the stars to create the model and we keep the remaining 20% for the validation. For the following validation tests we only use the test sample. In doing so, we can test the interpolation of the PSF model and at the same time be less sensitive to over-fitting.
6.2.1. Focal-plane PSF residuals
To estimate the errors due to the PSF modelling, we first look at the ellipticity and size residuals between the model and the stars. In this work we define the residuals as δePSF = ePSF − estar with ePSF and estar being the ellipticity of the PSF at the star positions and the ellipticity of stars, respectively, and δTPSF = TPSF − Tstar where TPSF and Tstar are the size of the PSF and the size of the star, respectively. The size is defined as follows:
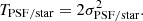 (24)
(24)
The ellipticity and the size (σPSF/star) here are measured using the adaptive moments implementation from the HSM module in the GALSIM software package. The model ellipticity and residuals are plotted in Fig. 5 while Fig. 6 presents the same statistics for the size. Each panel shows the average over all exposures as a function of position on the focal plane. For each of the 40 MEGACAM CCDs, values are averaged over pixels of size 20 arcsec2.
 |
Fig. 5. PSF ellipticity (upper panels), ePSF, and PSF ellipticity residual (lower panels), δePSF, maps of the 40 CCDs of the MEGACAM focal plane. |
 |
Fig. 6. PSF size (left panel), TPSF, and PSF size residual (in pixels2; right panel), δTPSF/Tstar, maps of the 40 CCDs of the MEGACAM focal plane. |
The PSF ellipticity residuals typically are a factor of 10 smaller than the PSF amplitude, which indicates an accurate PSF model on average. The PSF size is more uniform and reproduced by the model to a higher accuracy, with the highest residual being situated at the CCD edges.
In the figure large circular patterns in the residuals can be seen. This could be caused by the low degree (2 in our case) of the polynomial used to construct the model. In this case, the patterns would reflect higher-order spatial variations. We did, however, try to increase the degree of the polynomial and, due to the small number of selected stars, the resulting model was too noisy to be used. Another possibility is that this is caused by the PSF model being limited to each inidividual CCD. Since the patterns are larger than the size of one CCD, they might not be captured by this model. In upcoming work we will use the multi-CCD method presented in Liaudat et al. (2021), which produces smaller residual errors with respect to PSFEx.
6.2.2. ρ-statistics
Another test one can do is to use the metrics proposed by Rowe (2010) and Jarvis et al. (2016). This consists in computing the spatial correlations between the ellipticities of the PSF model and residuals. For that purpose, the two-point correlation functions defined in Sect. 6.1 are used. The different ρ-statistics correlation functions are given as follows:
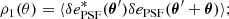 (25)
(25)
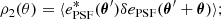 (26)
(26)
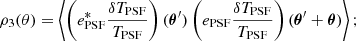 (27)
(27)
 (28)
(28)
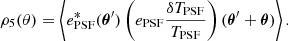 (29)
(29)
It should be noted that some of these correlation functions use ellipticities weighted by the relative size residuals, δTPSF/TPSF.
The ρ-statistics can be related to cosmology. They add directly to the measured shear two-point correlation function ξ+. To constrain cosmological parameters from ξ+ at a given precision, the amplitude of the ρ-statistics should not exceed an amount that can be computed as follows (Jarvis et al. 2016):
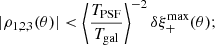 (30)
(30)
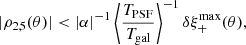 (31)
(31)
where 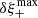 is the sensitivity of ξ+ with respect to cosmology. The PSF leakage α can be introduced as an additive bias in Eq. (9), leading to
is the sensitivity of ξ+ with respect to cosmology. The PSF leakage α can be introduced as an additive bias in Eq. (9), leading to
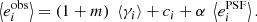 (32)
(32)
Following Zuntz et al. (2018), we consider only one cosmological parameter here, namely σ8, and get
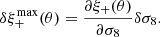 (33)
(33)
As shown in Eq. (33), the requirements are defined with respect to σ8. Since this paper does not make any claims on cosmology, this analysis is qualitative and we set a soft requirement of 3% error on σ8, which means δσ8/σ8 < 0.03 (based on Zuntz et al. 2018). To estimate the theoretical shear-shear correlation we make use of the CCL software package9 (Chisari et al. 2019) with the estimated N(z) described in Sect. 2.3. The results are presented in Fig. 7. The PSF residuals are sub-dominant at scales smaller than around 100′. We can see that the model performs worse on the largest scales. This might be related to the issues raised regarding the PSF residuals (Fig. 5). The inconsistency of the model for large spatial variations is also reflected in these statistics.
 |
Fig. 7. PSF residual ρ-statistics. The grey area is the requirement described in Sect. 6.2.1. Here we set TPSF/Tgal = 1 and α = 0.1. |
6.3. Shear validation tests
This section presents the tests we perform on our shape catalogue to estimate the systematics on the data. First, we compute the additive shear bias. Next, we consider the residual correlation of galaxy shapes with the PSF, which is a main concern for shear estimation. To quantify this effect we carry out three tests, presented below. To perform our tests we use the definition for the PSF leakage, α, presented in Eq. (32).
6.3.1. Additive shear bias
To estimate the additive bias, ci defined in Eq. (9), we compute the weighted average of both components of the galaxy ellipticity using a jackknife estimator. Since our data are observed over a very large area, we can safely assume that the average shear and intrinsic ellipticity are very close to zero. With this assumption, we measure c1 = ( − 4.95 ± 0.58)×10−4, and c2 = (4.66 ± 0.59)×10−4 for the two ellipticity components. These numbers are of the same order of magnitude compared to previous measurements for this shape measurement method (Sheldon & Huff 2017). It is important to note that a small additive bias does not imply zero PSF leakage, as we have observed.
6.3.2. Global PSF leakage
In the first test, for which the results are shown in Fig. 8, we estimate the global PSF leakage by measuring the galaxy ellipticies in bins of PSF ellipticity. For this test we use the PSF ellipticity measured at the position of galaxies averaged over the contributing single exposures. For each of the equi-populated bins we estimate the weighted average via a jackknife, where the error bars represent the standard deviation. The weights are defined in Eq. (22). We find correlations between 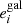 and
and 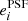 of less than 2% for both components i = 1, 2. The cross-correlation between different components is close to 0. No correlations are observed with the PSF size as presented in Fig. 9. To compute the correlations we fit a linear model on the unbinned data.
of less than 2% for both components i = 1, 2. The cross-correlation between different components is close to 0. No correlations are observed with the PSF size as presented in Fig. 9. To compute the correlations we fit a linear model on the unbinned data.
 |
Fig. 8. PSF leakage using the averaged galaxy shape in bins of PSF ellipticity component 1 (left panel) and component 2 (right panel). For the figure on the left, we find |
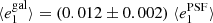
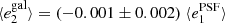
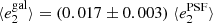
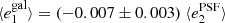
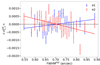 |
Fig. 9. PSF leakage using the averaged galaxy shape in bins of PSF size. The slopes are |
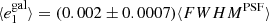
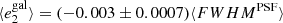
6.3.3. Scale-dependent PSF leakage
Another test we perform to estimate the leakage was presented in Jarvis et al. (2016). The leakage α can be written as the ratio between the star-galaxy cross-correlation, 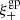 , and the star-star auto-correlation,
, and the star-star auto-correlation, 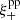 . For this test, we use the ellipticity of the PSF model at the position of the stars (test sample only). It is defined as follows:
. For this test, we use the ellipticity of the PSF model at the position of the stars (test sample only). It is defined as follows:
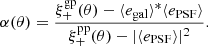 (34)
(34)
The variations of α in the range [2, 200] arcmin is presented in Fig. 10. The all-scale average gives α = 0.033 for the model-fitting method. α is in agreement with the test presented above when θ → 0.
Finally, we look at ξsys, which was introduced in Bacon et al. (2003) and used in Heymans et al. (2012) for the CFHTLenS survey. This consists in comparing the signal of the shear-PSF correlation to the shear-shear correlation. If the PSF is well corrected for, the former (systematic) has an amplitude that is much lower than the latter (signal), such that it does not contaminate the cosmological interpretation of the latter. The systematic correlation function can be written as
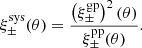 (35)
(35)
Results are shown in Fig. 11. To see the impact of our systematics we used a theoretical prediction for the shear-shear correlations,  , using the CCL library and cosmological parameters from Planck (Planck Collaboration VI 2020). We see that on small scales we have a signal free from systematics, which are two orders of magnitudes smaller. However, on large scales ξsys reaches 10–20% of the shear-shear correlation, and contributions from residual PSF correlations to the cosmological signal might not be negligible.
, using the CCL library and cosmological parameters from Planck (Planck Collaboration VI 2020). We see that on small scales we have a signal free from systematics, which are two orders of magnitudes smaller. However, on large scales ξsys reaches 10–20% of the shear-shear correlation, and contributions from residual PSF correlations to the cosmological signal might not be negligible.
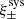
Overall, the different tests performed on our shape catalogue show very small correlations with the PSF of the order of a few percent. The large scales are still impacted by our PSF modelling. We believe that this problem can be solved by having a more accurate PSF model at all scales. For the purposes of the work presented here, we have neglected the impact of blends, which will be the main concern for the future development of the weak-lensing analysis of CFIS data.
7. Image simulations
In this section we present the set of image simulations we use to validate the shape measurements. The simulations have been created to test the implementation of the model-fitting method. We implement all effects that need to be accounted for during the shape measurement, that is: transformations between a planar and spherical world coordinate system (WCS), mis-centering, spatial noise and PSF variation. We used the simulations to quantify the PSF leakage and the additive and multiplicative biases. Only the multiplicative bias will be detailed here since it is not available from the data only. The other tests show results consistent with those obtained from the data.
7.1. Simulated PSF
The PSF can be separated in two parts: the optical distortions and the atmospheric turbulence. To simulate the optical variations of the telescope we use a Moffat profile for which we fix the atmospheric scattering coefficient β = 4.765 (Trujillo et al. 2001), and the ellipticity is drawn from the real optical variations of CFHT (Canada-France-Hawaii Telescope) derived from the CFIS data shown in Fig. 5. To model the atmospheric turbulence we use a Kolmogorov profile (Buscher et al. 1995) with random ellipticity drawn from a Gaussian distribution with mean μ = 0 and standard deviation σ = 0.01. Both models are convolved to create the final PSF. The average size of the simulated PSFs is set to 0.65 arcsec, which corresponds to the mean seeing of CFIS (see Sect. 4.1). This model is a simple but accurate enough description of the real PSF obtained from the data. Since we are working on small postage stamps, the spatial variations across the postage stamp have been neglected. This process is repeated for each simulated observation of each object. This allows us to quantify the PSF leakage in the simulations. We also applied WCS transformations to the PSF used for the shape measurement, which were randomly selected among the real images.
7.2. Real galaxies
Our set of simulations is based on the real galaxy images from the COSMOS catalogue. Here, the deconvolved images are used10. The flux is rescaled in order to reproduce a 300s exposure at the 3.6m CFHT telescope. The image is resampled at the pixel scale of the CFIS survey, 0.187 arcsec. Finally, Gaussian noise with σ = 14.5 is added on top of the image to replicate the S/N on the CFIS data. We also include WCS transformations on the images by random draws from the real data. We create three epochs of observations for each object. Between epochs we vary the centring (intra-pixel shifts), the noise realisation, and the PSF.
The galaxies are created in batches of 10 000 postage stamps with the same constant shear applied to them. One half of the galaxies are copies of the other half but rotated by 90° to cancel out shape noise. The rotation is applied before the shear is added. We simulate 200 batches with 200 different shear values.
7.3. Shear bias estimation
The main purpose of our image simulations is to quantify the residual shear bias after calibration. For this reason, only the shape measurement is performed. We neglect all biases coming from detection or the pre-selection cuts. The results are presented in Fig. 12, showing that, after calibration, we are left with a residual multiplicative bias of the order 10−3, and an additive bias of at most 10−4.
 |
Fig. 12. Residual multiplicative bias after calibration and weighting. Dashed lines represent the best linear fit (mgtrue + c) to the points. |
As mentioned previously, we can use the image simulations to perform an independent consistency check of the PSF leakage created by our analysis. Here we measure the global PSF leakage presented in Sect. 6.3.2. We find a leakage compatible with zero for both components of the ellipticity, as shown in Figs. A.1 and A.2. Since the PSF in the image simulations is perfectly known, this is a strong indication that the leakage stems from an imperfect modelling of the PSF variation across the focal plane. This has been discussed in Zuntz et al. (2018).
8. Science results
In this section we present the first science results obtained with our shear catalogue. This section serves as a proof of concept of the results achievable in the future with the full CFIS data and processing with our pipeline, SHAPEPIPE. We focus here on convergence maps, cluster lensing, and second-order cosmic shear statistics.
8.1. Shear catalogue
The catalogue used here is constructed from an effective (after masking) area of A = 1565 square degrees. We measure the shape of Ngal = 40 151 119 galaxies. The data are divided in four fields, named P1 to P4, which are presented in Fig. 13. The effective density is derived from the formula proposed in Heymans et al. (2012):
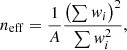 (36)
(36)
 |
Fig. 13. Four patches of the CFIS dataset processed in this work. From left to right: P3, P4, P1, and P2. |
and the corresponding shape noise is given by
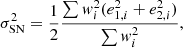 (37)
(37)
where the sum is carried out over all objects in the catalogue. We find neff = 6.76 gal arcmin−2, compared to a raw, unweighted density of nraw = Ngal/A = 7.13 gal arcmin−2, and σSN = 0.35. The magnitude distribution is presented in Fig. 14. Due to our conservative detection criteria, this distribution does not reflect the true depth of the survey. With a selection aimed at completeness, we should be able to obtain a complete sample at magnitude 23.5 in the r-band.
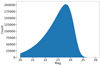 |
Fig. 14. Magnitude distribution on the r-band for weak-lensing selected source galaxies. |
8.2. Convergence mass maps
Convergence maps can be interpreted as 2D projected distributions of matter fluctuations. To compute the convergence from the shear catalogue we perform a Kaiser-Squires inversion (Kaiser & Squires 1993) using the LENSPACK software package11. The ellipticities are binned in 40 × 40 arcsec2 pixels. The masked regions have an ϵ set to 0. The convergence map is then smoothed by applying a Gaussian kernel with a standard deviation of 16 pixels.
In Fig. 15 we show patch P1, the other three patches are presented in Appendix B. Overplotted are the positions of known clusters detected via the Sunyaev-Zel’dovich (SZ) effect (Sunyaev & Zel’dovich 1970; Sunyaev & Zel’dovich 1980), presented in Planck Collaboration XIII (2016).
 |
Fig. 15. Mass map for the patch P1. The black circles represent the positions of Planck clusters. The value on top of each cross is the cluster redshift, and the bottom value indicates the SZ cluster mass (1014 M⊙). The top (bottom) panel shows the E-mode (B-mode). |
In the E-mode map, we see that most of the clusters match with an overdense region. On the other hand, in the B-mode, we do not see a correlation between the peaks and the cluster positions, as expected. To confirm this result, we show the convergence E- and B-mode maps stacked around the cluster positions. For this stack, we select source galaxies in a 5 Mpc projected radius around each cluster. We then shift all galaxies to have the centre of every cluster at the same effective position, and we compute the Kaiser-Squires inversion from the joint galaxy ellipticities. The resulting maps are shown in Fig. 16. In this plot we can clearly see that we obtain a strong signal in the E-mode, and only noise for the B-mode.
 |
Fig. 16. Mass maps stacked on the Planck cluster positions for P1. The galaxies for the tangential shear stacks are selected in a radius of 5 Mpc around each cluster, where this distance is computed at the cluster redshift. |
8.3. Galaxy cluster stacked profiles
To evaluate the performance of our pipeline for future cluster science, we measured the tangential shear profile around the clusters used in the previous section (36 clusters fall within the processed area after masking). To assess the significance of the signal we compare it to what we measure at random positions. The box plot presented in Fig. 17 is constructed from random catalogues. We create catalogues that have the same size as the real one (36 here) with random positions. We repeat this process 5000 times. We can then derive the variance and the median of the tangential shear around these random positions. In this figure we see that the random positions produce a signal compatible with 0. In comparison, the tangential shear signal around the true cluster positions is detected at a high significance. The tangential shear at a given angular scale exceeds the random signal on average by 4 σ, which can be seen as a conservative, lower bound of the overall detection significance.
 |
Fig. 17. Stacked tangential shear around 36 clusters in the CFIS footprint. The box plot represents the result around 5000 × 36 random points. |
In a separate analysis, we (Spitzer et al., in prep.) have analysed the weak-lensing masses of redMapper clusters (Rykoff et al. 2014) using this ShapePipe catalogue and find good agreement with previous results from weak lensing with SDSS (Simet et al. 2017).
8.4. Second-order shear statistics: COSEBI B-modes
One of the main weak-lensing observables for cosmology are the second-order cosmic shear correlations. One such measure are the Complete Orthogonal Sets of E-/B-mode Integrals (COSEBIs), introduced in Schneider et al. (2010). These modes are linear functions of the measured two-point correlation functions ξ+ and ξ− (Sect. 6.1).
First, we compute the shear-shear correlation functions between θmin = 2 arcmin and θmax = 200 arcmin with 1000 bins using the TREECORR12 software package (Jarvis 2015). Next, we derive the COSEBIs using NICAEA13 (Kilbinger et al. 2009). This results in E- and B-modes, Em and Bm, respectively, where each of these modes is an integral over ξ+(θ) and ξ−(θ) filtered with a polynomial in log θ of order m + 1.
To construct the error bars, we first assume a Gaussian covariance for ξ±, derived from the COSMOCOV software package14 (Krause & Eifler 2017, Fang et al. 2020a,b). As a fiducial model for the covariance we use a Planck cosmology (Planck Collaboration VI 2020), and ignore intrinsic galaxy alignment. Next, we re-sample the shear-shear correlations 1000 times from this covariance, and re-compute the COSEBIs for each simulated ξ±. The results are presented in Fig. 18. We see that the B-modes are consistent with 0, which indicates a low level of systematics present at second order in our shear data.
 |
Fig. 18. COSEBIs for modes m between 1 and 16. This test was performed to quantify the impact of potential systematics on the B-mode, which are consistent with 0 for our study. |
9. Conclusion
In this paper we have introduced a new weak-lensing pipeline, SHAPEPIPE. This pipeline relies on well-tested tools such as SEXTRACTOR, PSFEx, and NGMIX. These tools have been adapted to suit the demanding constraints on memory and CPU time imposed by the large area of the CFIS survey. We have demonstrated that our pipeline is able to handle such large datasets. The modularity of the pipeline makes it easy to adapt it to new datasets and to update it to include new state-of-the-art shape measurement and analysis tools.
This first analysis of 1700 deg2 of CFIS data presented in this work shows the high quality of the images as well as the quality of both pre-processing and processing. The most well-known systematics that create biases in the shear estimated from galaxy shape measurements have been addressed in this work. Our modelling of the PSF captures the measured PSF accurately, with typical residuals an order of magnitude smaller than the focal-plane PSF variations, and showing remaining coherent patterns at only a very small amplitude. The PSF residual angular correlations (ρ statistics) are sub-dominant to the shear two-point correlation function on scales up to 100′. This corresponds to a sub-dominant contribution to a potential measurement of σ8 to 3% accuracy.
We also have quantified the contamination of galaxy ellipticities by the PSF shape, the so-called PSF leakage. The global leakage is below 2%, which we measure using two different methods. For larger angular distances the scale-dependent leakage increases to 4%. Through comparison with galaxy shapes measured on simulations, we have established this leakage is caused by the remaining PSF residuals.
Our preliminary science analysis shows that the pipeline is well suited for cluster lensing or mass mapping science. The COSEBIs confirmed the low level of systematics for shear-shear correlations observed on our different validation tests.
Our main remaining source of systematic seems to come from the PSF modelling. In a future analysis we will employ a new approach based on the work from Liaudat et al. (2021), with the objective to reduce the residuals at large scales. Finally, we have ignored the effect of blending for this first analysis. This will be addressed in more detail in future works.
Uses several observation of the same object from different single exposures.
Using a larger PSF for the reconvolution ensures that the artefacts created by the deconvolution due to the presence of noise in the images are smoothed out.
This step creates artefacts and correlated noise residuals. However, after reconvolution with a larger PSF (described above), and with the addition of noise, it can be considered that these spurious correlations have been removed from the final image.
Acknowledgments
We would like to thank Catherine Heymans, Mike Jarvis, François Lanusse, Erin Sheldon, and Florent Sureau for helpful discussions. This work is based on data obtained as part of the Canada- France Imaging Survey, a CFHT large program of the National Research Council of Canada and the French Centre National de la Recherche Scientifique. Based on observations obtained with MegaPrime/MegaCam, a joint project of CFHT and CEA Saclay, at the Canada-France-Hawaii Telescope (CFHT) which is operated by the National Research Council (NRC) of Canada, the Institut National des Science de l’Univers (INSU) of the Centre National de la Recherche Scientifique (CNRS) of France, and the University of Hawaii. Pan-STARRS is a project of the Institute for Astronomy of the University of Hawaii, and is supported by the NASA SSO Near Earth Observation Program under grants 80NSSC18K0971, NNX14AM74G, NNX12AR65G, NNX13AQ47G, NNX08AR22G, and by the State of Hawaii. We also acknowledge the support from the French national program for cosmology and galaxies (PNCG). This work is supported by Région d’Île-de-France in the framework of DIM-ACAV thesis fellowship. This work was supported in part by the Canadian Advanced Network for Astronomical Research (CANFAR) and Compute Canada facilities. This work has made use of the CANDIDE Cluster at the Institut d’Astrophysique de Paris and made possible by grants from the PNCG and the DIM-ACAV. We gratefully acknowledge support from the CNRS/IN2P3 Computing Center (Lyon - France) for providing computing and data-processing resources. This research made use of Astropy (http://www.astropy.org), a community-developed core Python package for Astronomy (Astropy Collaboration 2013, 2018). Arnau Pujol acknowledges support from a European Research Council Starting Grant (LENA-678282) and Juan de la Cierva fellowship. Hendrik Hildebrandt is supported by a Heisenberg grant of the Deutsche Forschungsgemeinschaft (Hi 1495/5-1) as well as an ERC Consolidator Grant (No. 770935). Raphael Gavazzi thanks IoA and the Churchill College in Cambridge for their hospitality and acknowledges local support from the French government. Mike Hudson acknowledges support from an NSERC Discovery Grant.
References
- Albrecht, A., Bernstein, G., Cahn, R., et al. 2006, ArXiv e-prints [arXiv:astro-ph/0609591] [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Bacon, D. J., Massey, R. J., Refregier, A. R., & Ellis, R. S. 2003, MNRAS, 344, 673 [NASA ADS] [CrossRef] [Google Scholar]
- Bernstein, G. M., & Armstrong, R. 2014, MNRAS, 438, 1880 [NASA ADS] [CrossRef] [Google Scholar]
- Bertin, E. 2011, in Astronomical Data Analysis Software and Systems XX, eds. I. N. Evans, A. Accomazzi, D. J. Mink, & A. H. Rots, ASP Conf. Ser., 442, 435 [Google Scholar]
- Bertin, E., & Arnouts, S. 1996, A&AS, 117, 393 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Brown, A. G. A., Vallenari, A., Prusti, T., et al. 2018, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Buscher, D. F., Armstrong, J. T., Hummel, C. A., et al. 1995, Appl. Opt., 34, 1081 [NASA ADS] [CrossRef] [Google Scholar]
- Chambers, K. C., Magnier, E. A., Metcalfe, N., et al. 2016, The Pan-STARRS1 Surveys [Google Scholar]
- Chisari, N. E., Alonso, D., Krause, E., et al. 2019, ApJS, 242, 2 [Google Scholar]
- Cuillandre, J., Mahoney, B., & Withington, K. 2014, in Astronomical Data Analysis Software and Systems XXIII, eds. N. Manset, & P. Forshay, ASP Conf. Ser., 485, 81 [NASA ADS] [Google Scholar]
- Dalcin, L. D., Paz, R., & Storti, M. 2005, J. Parallel Distrib. Comput., 65, 1108 [CrossRef] [Google Scholar]
- Dalcin, L. D., Paz, R., Storti, M., & D’Elía, J. 2008, J. Parallel Distrib. Comput., 68, 655 [CrossRef] [Google Scholar]
- Dalcin, L. D., Paz, R. R., Kler, P. A., & Cosimo, A. 2011, Adv. Water Resources, 34, 1124 [NASA ADS] [CrossRef] [Google Scholar]
- Dawson, K. S., Kneib, J.-P., Percival, W. J., et al. 2016, AJ, 151, 44 [Google Scholar]
- Desai, S., Armstrong, R., Mohr, J. J., et al. 2012, ApJ, 757, 83 [Google Scholar]
- DESI Collaboration (Aghamousa, A., et al.) 2016, ArXiv e-prints [arXiv:1611.00036] [Google Scholar]
- Eisenstein, D. J., Weinberg, D. H., Agol, E., et al. 2011, AJ, 142, 72 [Google Scholar]
- Erben, T., Hildebrandt, H., Miller, L., et al. 2013, MNRAS, 433, 2545 [Google Scholar]
- Fang, X., Eifler, T., & Krause, E. 2020a, MNRAS, 497, 2699 [NASA ADS] [CrossRef] [Google Scholar]
- Fang, X., Krause, E., Eifler, T., & MacCrann, N. 2020b, JCAP, 2020, 010 [CrossRef] [Google Scholar]
- Farrens, S., Grigis, A., El Gueddari, L., et al. 2020, Astron. Comput., 32, 100402 [Google Scholar]
- Gatti, M., Sheldon, E., Amon, A., et al. 2021, MNRAS, 504, 4312 [NASA ADS] [CrossRef] [Google Scholar]
- Gwyn, S. D. J. 2008, PASP, 120, 212 [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Heymans, C., Van Waerbeke, L., Miller, L., et al. 2012, MNRAS, 427, 146 [Google Scholar]
- Hildebrandt, H., Erben, T., Kuijken, K., et al. 2012, MNRAS, 421, 2355 [Google Scholar]
- Hildebrandt, H., Choi, A., Heymans, C., et al. 2016, MMNRS, 463, 635 [NASA ADS] [CrossRef] [Google Scholar]
- Hirata, C., & Seljak, U. 2003, MNRAS, 343, 459 [Google Scholar]
- Huff, E., & Mandelbaum, R. 2017, ArXiv e-prints [arXiv:1702.02600] [Google Scholar]
- Jarvis, M. 2015, TreeCorr: Two-point Correlation Functions [Google Scholar]
- Jarvis, M., Sheldon, E., Zuntz, J., et al. 2016, MNRAS, 460, 2245 [Google Scholar]
- Joblib Development Team 2020, Joblib: running Python functions as pipeline jobs [Google Scholar]
- Kacprzak, T., Bridle, S., Rowe, B., et al. 2014, MNRAS, 441, 2528 [NASA ADS] [CrossRef] [Google Scholar]
- Kaiser, N., & Squires, G. 1993, ApJ, 404, 441 [Google Scholar]
- Kilbinger, M. 2015, Rep. Prog. Phys., 78, 086901 [Google Scholar]
- Kilbinger, M., Benabed, K., Guy, J., et al. 2009, A&A, 497, 677 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Krause, E., & Eifler, T. 2017, MMNRAS, 470, 2100 [CrossRef] [Google Scholar]
- Kuijken, K., Heymans, C., Dvornik, A., et al. 2019, A&A, 625, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Liaudat, T., Bonnin, J., Starck, J. L., et al. 2021, A&A, 646, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mandelbaum, R. 2018, ARA&A, 56, 393 [Google Scholar]
- Mandelbaum, R., Miyatake, H., Hamana, T., et al. 2017, PASJ, 70, S25 [NASA ADS] [Google Scholar]
- Mandelbaum, R., Miyatake, H., Hamana, T., et al. 2018, PASJ, 70, S25 [Google Scholar]
- Mohr, J. J., Armstrong, R., Bertin, E., et al. 2012, Software and Cyberinfrastructure for Astronomy II, Proceedings of SPIE, 8451 [Google Scholar]
- Planck Collaboration XIII. 2016, A&A, 594, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rowe, B. 2010, MNRAS, 404, 350 [NASA ADS] [Google Scholar]
- Rowe, B. T. P., Jarvis, M., Mandelbaum, R., et al. 2015, Astron. Comput., 10, 121 [Google Scholar]
- Rykoff, E. S., Rozo, E., Busha, M. T., et al. 2014, ApJ, 785, 104 [Google Scholar]
- Schneider, P., Van Waerbeke, L., Kilbinger, M., & Mellier, Y. 2002, A&A, 396, 1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schneider, P., Eifler, T., & Krause, E. 2010, A&A, 520, A116 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sheldon, E. S., & Huff, E. M. 2017, ApJ, 841, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Sheldon, E. S., Becker, M. R., MacCrann, N., & Jarvis, M. 2020, ApJ, 902, 138 [CrossRef] [Google Scholar]
- Simet, M., McClintock, T., Mandelbaum, R., et al. 2017, MNRAS, 466, 3103 [NASA ADS] [CrossRef] [Google Scholar]
- Sunyaev, R. A., & Zel’dovich, Y. B. 1970, Ap&SS, 7, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Sunyaev, R. A., & Zel’dovich, I. B. 1980, ARA&A, 18, 537 [NASA ADS] [CrossRef] [Google Scholar]
- Trujillo, I., Aguerri, J. A. L., Cepa, J., & Gutiérrez, C. M. 2001, MNRAS, 328, 977 [NASA ADS] [CrossRef] [Google Scholar]
- Van Waerbeke, L., White, M., Hoekstra, H., & Heymans, C. 2006, Astropart. Phys., 26, 91 [NASA ADS] [CrossRef] [Google Scholar]
- Zuntz, J., Sheldon, E., Samuroff, S., et al. 2018, MNRAS, 481, 1149 [Google Scholar]
Appendix A: Leakage PSF in simulation
We present here the PSF leakage measured on the simulated data. In this particular case the PSF used during the shape measurement is the true model used to create the simulated images. This allows us to quantify the leakage from the shape measurement only, disregarding potential errors due to the modelling as we likely have on real data. In Fig. A.1 we do not observe any measurable dependences between the PSF and galaxy ellipticities. The same conclusion is obtained with the PSF size as shown in Fig. A.2. These results reinforce our hypothesis that the leakage observed in the real data are coming mainly from the errors in the PSF model.
 |
Fig. A.1. PSF leakage using the averaged galaxy shape in bins of PSF ellipticity component 1 (left panel) and component 2 (right panel). For the figure on the left, we find |
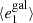
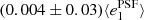
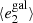
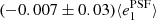
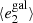
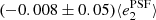
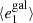
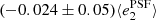
 |
Fig. A.2. PSF leakage using the averaged galaxy shape in bins of PSF size. The slopes are |
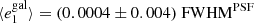
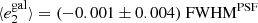
Appendix B: Convergence maps
In this section we show the convergence maps obtained through the method detailed in Sect. 8.2 for the 3 other patches that have been processed. At some cluster positions it is difficult to see a correlation with an over-density on the projected convergence maps. Yet, the stacked profiles shown in Figs. B.2, B.4 and B.6 all shows a very clear signal on the E-mode while only noise is present on B-mode. This analysis tend to confirm the ability of our pipeline to accurately measure shapes with a low level of systematics.
 |
Fig. B.1. Mass map for the patch P2. The black circles represent the positions of Planck clusters. The value on top of each cross is the cluster redshift, and the bottom value indicates the SZ cluster mass (1014 M⊙). The top (bottom) panel shows the E-mode (B-mode). |
 |
Fig. B.2. Mass maps stacked on the Planck cluster positions for P2. The galaxies for the tangential shear stacks are selected in a radius of 5 Mpc around each cluster, where this distance is computed at the cluster redshift. |
 |
Fig. B.3. Mass map for the patch P3. The black circles represent the positions of Planck clusters. The value on top of each cross is the cluster redshift, and the bottom value indicates the SZ cluster mass (1014 M⊙). The top (bottom) panel shows the E-mode (B-mode). |
 |
Fig. B.4. Mass maps stacked on the Planck cluster positions for P3. The galaxies for the tangential shear stacks are selected in a radius of 5 Mpc around each cluster, where this distance is computed at the cluster redshift. |
 |
Fig. B.5. Mass map for the patch P4. The black circles represent the positions of Planck clusters. The value on top of each cross is the cluster redshift, and the bottom value indicates the SZ cluster mass (1014 M⊙). The top (bottom) panel shows the E-mode (B-mode). |
 |
Fig. B.6. Mass maps stacked on the Planck cluster positions for P4. The galaxies for the tangential shear stacks are selected in a radius of 5 Mpc around each cluster, where this distance is computed at the cluster redshift. |
All Tables
All Figures
|
Fig. 1. Redshift distribution inferred from matching CFIS with CFHTLenS Z_BEST over the CFHTLS-W3 area. |
| In the text | |
|
Fig. 2. Size-magnitude diagram for one CCD. In orange we show the selected stars. The dashed line represents the mode of the stellar locus at 0.59 arcsec, which is automatically estimated by SHAPEPIPE. |
| In the text | |
|
Fig. 3. Distribution of selected stars over all 208 000 CCDs. Top: number of stars per CCD. The dashed line represents the cut at 22 stars/CCD, below which the CCD is discarded for the PSF estimation. Bottom: mode (per CCD exposure) of the FHWM of stars. |
| In the text | |
|
Fig. 4. Spread model classification. The orange area corresponds to the objects that have been selected for the galaxy sample. (The yellow contours represent a density 8 times larger than red). |
| In the text | |
|
Fig. 5. PSF ellipticity (upper panels), ePSF, and PSF ellipticity residual (lower panels), δePSF, maps of the 40 CCDs of the MEGACAM focal plane. |
| In the text | |
|
Fig. 6. PSF size (left panel), TPSF, and PSF size residual (in pixels2; right panel), δTPSF/Tstar, maps of the 40 CCDs of the MEGACAM focal plane. |
| In the text | |
|
Fig. 7. PSF residual ρ-statistics. The grey area is the requirement described in Sect. 6.2.1. Here we set TPSF/Tgal = 1 and α = 0.1. |
| In the text | |
|
Fig. 8. PSF leakage using the averaged galaxy shape in bins of PSF ellipticity component 1 (left panel) and component 2 (right panel). For the figure on the left, we find |
| In the text | |
|
Fig. 9. PSF leakage using the averaged galaxy shape in bins of PSF size. The slopes are |
| In the text | |
 |
Fig. 10. PSF leakage α (Eq. (34)) shown as a function of scale θ. |
| In the text | |
 |
Fig. 11. Systematic signal |
| In the text | |
|
Fig. 12. Residual multiplicative bias after calibration and weighting. Dashed lines represent the best linear fit (mgtrue + c) to the points. |
| In the text | |
|
Fig. 13. Four patches of the CFIS dataset processed in this work. From left to right: P3, P4, P1, and P2. |
| In the text | |
|
Fig. 14. Magnitude distribution on the r-band for weak-lensing selected source galaxies. |
| In the text | |
|
Fig. 15. Mass map for the patch P1. The black circles represent the positions of Planck clusters. The value on top of each cross is the cluster redshift, and the bottom value indicates the SZ cluster mass (1014 M⊙). The top (bottom) panel shows the E-mode (B-mode). |
| In the text | |
|
Fig. 16. Mass maps stacked on the Planck cluster positions for P1. The galaxies for the tangential shear stacks are selected in a radius of 5 Mpc around each cluster, where this distance is computed at the cluster redshift. |
| In the text | |
|
Fig. 17. Stacked tangential shear around 36 clusters in the CFIS footprint. The box plot represents the result around 5000 × 36 random points. |
| In the text | |
|
Fig. 18. COSEBIs for modes m between 1 and 16. This test was performed to quantify the impact of potential systematics on the B-mode, which are consistent with 0 for our study. |
| In the text | |
|
Fig. A.1. PSF leakage using the averaged galaxy shape in bins of PSF ellipticity component 1 (left panel) and component 2 (right panel). For the figure on the left, we find |
| In the text | |
|
Fig. A.2. PSF leakage using the averaged galaxy shape in bins of PSF size. The slopes are |
| In the text | |
|
Fig. B.1. Mass map for the patch P2. The black circles represent the positions of Planck clusters. The value on top of each cross is the cluster redshift, and the bottom value indicates the SZ cluster mass (1014 M⊙). The top (bottom) panel shows the E-mode (B-mode). |
| In the text | |
|
Fig. B.2. Mass maps stacked on the Planck cluster positions for P2. The galaxies for the tangential shear stacks are selected in a radius of 5 Mpc around each cluster, where this distance is computed at the cluster redshift. |
| In the text | |
|
Fig. B.3. Mass map for the patch P3. The black circles represent the positions of Planck clusters. The value on top of each cross is the cluster redshift, and the bottom value indicates the SZ cluster mass (1014 M⊙). The top (bottom) panel shows the E-mode (B-mode). |
| In the text | |
|
Fig. B.4. Mass maps stacked on the Planck cluster positions for P3. The galaxies for the tangential shear stacks are selected in a radius of 5 Mpc around each cluster, where this distance is computed at the cluster redshift. |
| In the text | |
|
Fig. B.5. Mass map for the patch P4. The black circles represent the positions of Planck clusters. The value on top of each cross is the cluster redshift, and the bottom value indicates the SZ cluster mass (1014 M⊙). The top (bottom) panel shows the E-mode (B-mode). |
| In the text | |
|
Fig. B.6. Mass maps stacked on the Planck cluster positions for P4. The galaxies for the tangential shear stacks are selected in a radius of 5 Mpc around each cluster, where this distance is computed at the cluster redshift. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.