| Issue |
A&A
Volume 692, December 2024
|
|
|---|---|---|
| Article Number | A186 | |
| Number of page(s) | 17 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202452334 | |
| Published online | 12 December 2024 | |
Optimizing redshift distribution inference through joint self-calibration and clustering-redshift synergy
1
School of Physics and Astronomy, Sun Yat-Sen University, 2 Daxue Road, Tangjia, Zhuhai 519082, China
2
CSST Science Center for the Guangdong-Hongkong-Macau Greater Bay Area, SYSU, Zhuhai 519082, China
3
Shanghai Astronomical Observatory, Chinese Academy of Sciences, Nandan Road 80, Shanghai 200240, China
4
Department of Astronomy, Shanghai Jiao Tong University, Shanghai 200240, China
5
Key Laboratory for Particle Astrophysics and Cosmology (MOE)/Shanghai Key Laboratory for Particle Physics and Cosmology, Shanghai 200240, China
6
Peng Cheng Laboratory, No. 2, Xingke 1st Street, Shenzhen 518000, China
⋆ Corresponding author; chankc@mail.sysu.edu.cn
Received:
21
September
2024
Accepted:
12
November
2024
Context. Accurately characterizing the true redshift (true-z) distribution of a photometric redshift (photo-z) sample is critical for cosmological analyses in imaging surveys. Clustering-based techniques, which include clustering-redshift (CZ) and self-calibration (SC) methods–depending on whether external spectroscopic data are used–offer powerful tools for this purpose.
Aims. In this study, we explore the joint inference of the true-z distribution by combining SC and CZ (denoted as SC+CZ).
Methods. We derived simple multiplicative update rules to perform the joint inference. By incorporating appropriate error weighting and an additional weighting function, our method shows significant improvement over previous algorithms. We validated our approach using a DES Y3 mock catalog.
Results. The true-z distribution estimated through the combined SC+CZ method is generally more accurate than using SC or CZ alone. To account for the different constraining powers of these methods, we assigned distinct weights to the SC and CZ contributions. The optimal weights, which minimize the distribution error, depend on the relative constraining strength of the SC and CZ data. Specifically, for a spectroscopic redshift sample that amounts to 1% of the photo-z sample, the optimal combination reduces the total error by 20% (40%) compared to using CZ (SC) alone, and it keeps the bias in mean redshift [Δ͞z/(1+z)] at the level of 0.003. Furthermore, when CZ data are only available in the low-z range and the high-z range relies solely on SC data, SC+CZ enables consistent estimation of the true-z distribution across the entire redshift range.
Conclusions. Our findings demonstrate that SC+CZ is an effective tool for constraining the true-z distribution, paving the way for clustering-based methods to be applied at z ≳ 1.
Key words: cosmology: observations / large-scale structure of Universe
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1. Introduction
Wide-area imaging surveys provide powerful cosmological probes to constrain cosmology. Weak lensing is a prime example (Bartelmann & Schneider 2001; Heymans et al. 2013; Hildebrandt et al. 2017; Troxel et al. 2018; Asgari et al. 2021; Hikage et al. 2019; Amon et al. 2022; Secco et al. 2022; Li et al. 2023; Dalal et al. 2023). In particular, cosmic shear is often bundled in 3 × 2 point analysis, which includes cosmic shear, galaxy-galaxy lensing, and galaxy clustering (Abbott et al. 2018, 2022a; Heymans et al. 2021; Miyatake et al. 2023; Sugiyama et al. 2023). These analyses offer a strong constraint on S8, and the tightest uncertainty level (∼2%) is already comparable to that from the Planck Satellite’s study of the cosmic microwave background (Planck Collaboration VI 2020). Because the lensing results are consistently lower than those from the cosmic microwave background, there is heated discussion regarding the S8 tension. Moreover, imaging surveys also enable measurements of the transverse baryon acoustic oscillations (BAO) (Padmanabhan et al. 2007; Estrada et al. 2009; Hütsi 2010; Seo et al. 2012; Carnero et al. 2012; de Simoni et al. 2013; Abbott et al. 2019, 2024, 2022b; Chan et al. 2022; Song et al. 2024). The latest transverse BAO measurements, such as Abbott et al. (2024), are yielding constraints competitive with those from spectroscopic surveys (DESI Collaboration 2024). Upcoming stage IV surveys, such as from the Rubin Observatory Legacy Survey of Space and Time (LSST) (Ivezić et al. 2019; Mandelbaum et al. 2018), Euclid (Laureijs et al. 2011), Chinese Space Station Telescope (CSST) (Zhan 2011; Gong et al. 2019), and Roman Space Telescope (WFIRST) (Spergel et al. 2015; Eifler et al. 2021), are expected to deliver even more enormous photometric data and hence more exquisite results.
In imaging surveys, the redshifts (photo-z’s) are derived from the photometry information measured from a few broadband filters. The template fitting and training methods are commonly used to infer the photo-z’s of the galaxies (see Salvato et al. (2019), Newman & Gruen (2022) for a review). The template fitting method (e.g. Arnouts et al. 1999; Bolzonella et al. 2000; Benítez 2000; Ilbert et al. 2006) fits a model derived from known spectral energy distribution SED) templates, which includes the photo-z as a fitting parameter, to the color or magnitude data. The prior information can also be included in the fitting. This method is limited by the accuracy and representativeness of the templates and the accuracy of the prior information. Training methods often make use of tools from machine learning (Collister & Lahav 2004; Sadeh et al. 2016; De Vicente et al. 2016; Zhou et al. 2021; Li et al. 2022). A spectroscopic redshift (spec-z) sample is required to train the machine learning algorithm, so its accuracy depends on the abundance and the completeness or representativity of the spec-z sample.
In cosmological applications, accurate true redshift (true-z) distribution of the photo-z sample must be obtained to avoid biasing the cosmological results. Using a weighted spec-z sample is a viable approach. The effectiveness of this method hinges on the availability of the spec-z sample or sometimes a high-quality photo-z sample with numerous photo-z bands. The weighted spec-z sample can be constructed using a k-nearest neighbor search (Lima et al. 2008; Cunha et al. 2009; Bonnett et al. 2016) or a self-organizing map (Carrasco Kind & Brunner 2014; Masters et al. 2015; Buchs et al. 2019; Wright et al. 2020; Campos et al. 2024).
The clustering-based methods provide an independent way to calibrate the true-z distribution of the photo-z sample. Unlike photometry-based methods, this approach uses the clustering information, which can be traced back to gravity. Depending on the utilization of the external spec-z sample, it can be further categorized into the clustering-z (hereafter CZ) and self-calibration (SC) methods. In CZ, the true-z distribution is determined by cross correlating the photo-z sample with an external spec-z sample (Newman 2008; Matthews & Newman 2010; McQuinn & White 2013; Ménard et al. 2013; Schmidt et al. 2013; Morrison et al. 2017; van den Busch et al. 2020). This requires the spec-z sample to overlap with the photo-z one spatially, but the spec-z sample does not need to be representative. CZ has been routinely used to calibrate the true-z distribution in real data (e.g., Gatti et al. 2018, 2022; Cawthon et al. 2022; Hildebrandt et al. 2021; Rau et al. 2023). On the other hand, the SC method relies solely on the clustering information, both the auto and cross bin correlation function, of the photometric sample itself. (Schneider et al. 2006; Zhang et al. 2010; Benjamin et al. 2010; Zhang et al. 2017; Peng et al. 2022; Xu et al. 2023). Although SC has also been used for weak lensing (Benjamin et al. 2013) and BAO (Song et al. 2024) measurements, it is less frequently used than CZ. This may be because the redshift range explored in current surveys are still relatively low (z ≲ 1), and hence the spec-z sample is still sufficient for the calibration purpose. However, even in present surveys, the high redshift portion of the sample cannot be calibrated using CZ due to the absence of spec-z galaxies at high redshifts (e.g., Rau et al. 2023; Abbott et al. 2024). Consequently, we expect the SC method to play a more prominent role in upcoming surveys.
In this paper we explore combining the information of CZ and SC to simultaneously constrain the true-z distribution of a photo-z sample. As far as we know, this is the first time that these two methods have been jointly applied to constrain the true-z distribution in realistic mock data (see the Fisher forecast in McQuinn & White 2013). We anticipate that this synergy in redshift calibration is particularly fruitful in the high redshift regime, where the spec-z sample is scarce. The rest of the paper is organized as follows. We first review the SC and CZ formalism in Sect. 2.1 and then present the algorithm to jointly solve the SC and CZ equations in Sect. 2.2. We test our method using a DES Y3 mock catalog in Sect. 3. In particular, we contrast the true-z inference results from SC, CZ, and SC+CZ, and we demonstrate that our improved algorithm is superior to the old algorithm. Moreover, we study the scenarios when the number of spec-z bins is equal to and less than the number of photo-z bins respectively, and show that SC+CZ can effectively extend the clustering-based method to a higher redshift. We conclude in Sect. 4. In Appendix A, we present the derivation of the update rules. We investigate the impact of outlying spec-z galaxies in Appendix B and the impact of setting the negative measurements to a tiny positive value in Appendix C.
2. The joint calibration method
2.1. Derivation of the SC and CZ equations
In this subsection, we show how the correlation function of the photo-z sample and the cross correlation function between the photo-z and spec-z sample are related to the true-z distribution. Our convention follows that of Song et al. (2024), and the meaning for the key notations used in Sect. 2.1 are summarized in Table 1.
Because of photo-z uncertainties, galaxies within a photo-z bin may originate from multiple spec-z bins:
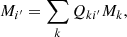
where M is the angular galaxy number density, Qki′ represents the probability that a galaxy in spec-z bin k leaks into photo-z bin i′. The index with (without) a prime denotes the photo-z (spec-z) bin index.
The correlation function of the photo-z sample can be written as
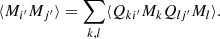
By expressing 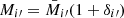 and
and 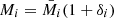 in terms of their respective means
in terms of their respective means 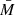 and fluctuations δ, we can write the angular overdensity correlation function as
and fluctuations δ, we can write the angular overdensity correlation function as
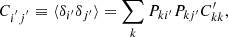
where C′kk = ⟨δkδk⟩ is the spec-z angular overdensity correlation function of the photo-z sample in the spec-z bin k. We have defined Pki′ as
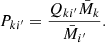
From Eq. (4), it is evident that Pki′ satisfies the normalization condition
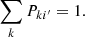
Thus Pki′ represents the fraction of galaxies in photo-z bin i′ coming from spec-z bin k.
By expressing Mi′ and Mi in Eq. (1) in terms of their fluctuations and then invoking Eq. (5), we get the following relation
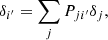
which is the analogous relation to Eq. (1). In fact, Pji′ is the true-z distribution of the photo-z sample, which is often denoted as n(z). In this paper, we use these two notations interchangeably.
In arriving at Eq. (3), we have assumed that 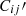 is diagonal. In other words, the correlation between spec-z bins is non-zero only when they are within the same bin. This is an excellent approximation and it is exact under Limber approximation (e.g. Simon 2007). Eq. (3) is the essence of the SC method, and it enables us to extract Pki′ using the clustering information of the photo-z data alone (Schneider et al. 2006; Zhang et al. 2010).
is diagonal. In other words, the correlation between spec-z bins is non-zero only when they are within the same bin. This is an excellent approximation and it is exact under Limber approximation (e.g. Simon 2007). Eq. (3) is the essence of the SC method, and it enables us to extract Pki′ using the clustering information of the photo-z data alone (Schneider et al. 2006; Zhang et al. 2010).
Assuming linear galaxy bias, we can further write Eq. (3) in terms of the underlying spec-z matter power spectrum 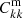 as
as
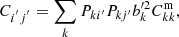
where bk′ is the bias parameter of the photo-z sample in kth spec-z bin.
From Eqs. (1) to (3), we implicitly assume that the leakage due to photo-z is universal irrespective of the galaxy type composition in the spec-z bin. To illustrate this point, let us assume that there are two types of galaxies in a spec-z bin, say blue and red galaxies. The universal leakage assumption asserts that both types of galaxies leak to different photo-z bins in the same proportion. Given photo-z estimation is based on the photometry information, which is closely related to the galaxy types, this assumption can only hold approximately.
For the present work, the violation of the universal leakage assumption manifests as the dependence of the bias parameter on the photo-z bin index i′. Without the universal leakage assumption, Eq. (7) would be generalized to
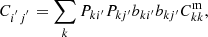
where bki′ is the bias parameter of the i′th photo-z sample in the kth spec-z bin. In this work, we assume that the leakage is universal.
Suppose now we have another spec-z sample with number density in spec-z bin i, Ni, which is related to its mean number density 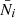 and density fluctuation ϵi by the relation
and density fluctuation ϵi by the relation 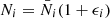 . We note that Ni and ϵi are in general different from the corresponding quantities for the photo-z sample in spec-z bin, Mi and δi. The spec-z sample is often much less abundant than the photo-z sample, and it tends to be brighter, and hence the linear bias of the spec-z sample is likely to be higher.
. We note that Ni and ϵi are in general different from the corresponding quantities for the photo-z sample in spec-z bin, Mi and δi. The spec-z sample is often much less abundant than the photo-z sample, and it tends to be brighter, and hence the linear bias of the spec-z sample is likely to be higher.
The cross correlation function between the spec-z and photo-z sample reads
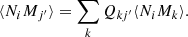
Similar to the derivation of the SC results, we have the corresponding CZ equation:
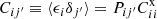
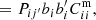
where 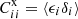 is the cross angular correlation function between the spec-z sample in bin i with the photo-z sample in spec-z bin i, and bi is the bias parameter of the spec-z sample in ith spec-z bin. For completeness, without the universal leakage assumption, we would instead have
is the cross angular correlation function between the spec-z sample in bin i with the photo-z sample in spec-z bin i, and bi is the bias parameter of the spec-z sample in ith spec-z bin. For completeness, without the universal leakage assumption, we would instead have
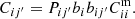
Unlike the SC case, which is quadratic in P, CZ is a linear problem. In the usual CZ method, the bias parameter of the spec-z sample, bj can be measured easily but it is difficult to get bj′. Thus CZ only directly constrains Pij′bi′ if we assume some theoretical matter correlation function model. Moreover, since Pij′ is normalized, if bi′ is a constant, it has no effect on the estimation of Pij′. However, if bi′ evolves with redshift (or index i), its evolution is degenerate with Pij′. Indirect methods have been proposed to mitigate the impact of bias evolution (Schmidt et al. 2013; Davis et al. 2018; van den Busch et al. 2020; Cawthon et al. 2022; Gatti et al. 2022). From Eq. (7), it is clear that the bias evolution issue also affects the SC problem. When we allow the correlation function in the spec-z bin to be a free parameter (called P method below), the degree of freedom due to bias evolution is taken into account.
We shall test different approaches to solve the system of SC and CZ equations. First we regard Pij′, 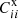 , and C′ii as unknowns, denoted as the P method. This is the most general parameterization, but the constraint is slightly weakened. Similar approach is taken in SC, e.g. Zhang et al. (2017). On the other hand, analogous to the approach in CZ, we take Rij′ ≡ Pij′bi′ as the variable and abbreviate it as the R method. We note that there is no normalization constraint on Rij′. If we assume that bi is known from measurement and
, and C′ii as unknowns, denoted as the P method. This is the most general parameterization, but the constraint is slightly weakened. Similar approach is taken in SC, e.g. Zhang et al. (2017). On the other hand, analogous to the approach in CZ, we take Rij′ ≡ Pij′bi′ as the variable and abbreviate it as the R method. We note that there is no normalization constraint on Rij′. If we assume that bi is known from measurement and 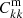 can be computed theoretically, then we only need to solve for R in the system:
can be computed theoretically, then we only need to solve for R in the system:
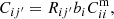
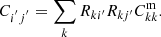
As a side note, in terms of the variable Rij′ ≡ Pij′bij′, it is easy to see that the non-universality issue does not introduce extra complications in the case of CZ.
2.2. Solution to the SC and CZ equations
2.2.1. Cost function and multiplicative update rules
Our goal is to develop an efficient method to solve Eq. (3) and (10) simultaneously for Pij′, C′ii, and 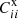 . Here we use the P method as an example and comment on the R method later on. In particular, because Eq. (3) is a system of coupled quadratic equations, it is challenging to solve. Several studies have been devoted to solving the SC equation (Erben et al. 2009; Benjamin et al. 2010, 2013; Zhang et al. 2017). Unlike prior researches, Zhang et al. (2017) solves Eq. (3) in full generality, without limiting the analysis to a two-bin scenario (Erben et al. 2009) or relying on a linear coupling (in P) approximation as done by Benjamin et al. (2010). In this work, inspired by Zhang et al. (2017), we construct multiplicative update rules to solve Eqs. (3) and (10) jointly.
. Here we use the P method as an example and comment on the R method later on. In particular, because Eq. (3) is a system of coupled quadratic equations, it is challenging to solve. Several studies have been devoted to solving the SC equation (Erben et al. 2009; Benjamin et al. 2010, 2013; Zhang et al. 2017). Unlike prior researches, Zhang et al. (2017) solves Eq. (3) in full generality, without limiting the analysis to a two-bin scenario (Erben et al. 2009) or relying on a linear coupling (in P) approximation as done by Benjamin et al. (2010). In this work, inspired by Zhang et al. (2017), we construct multiplicative update rules to solve Eqs. (3) and (10) jointly.
We aim to derive an iterative update rule to minimize the sum of the SC and CZ cost functions:1
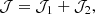
where 𝒥1 and 𝒥2 are the contributions from SC and CZ respectively. They are given by
![$$ \begin{aligned} \mathcal{J} _{1}&=\frac{1}{2} \sum _{i^{^{\prime }},j^{^{\prime }}, \mu } \frac{ W_1(\theta _\mu ) }{ \sigma _{i^{\prime }j^{\prime }}^2 (\theta _\mu ) } \Bigg [ D_{i^{^{\prime }}j^{^{\prime }}}(\theta _\mu )-\sum _{k}P_{ki^{^{\prime }}}P_{kj^{^{\prime }}}C^{\prime }_{kk}(\theta _\mu ) \Bigg ]^{2} ,\end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq34.gif)
![$$ \begin{aligned} \mathcal{J} _{2}&=\frac{1}{2} \sum _{i,j^{^{\prime }}, \mu } \frac{ W_2(\theta _\mu ) }{ \sigma _{ij^{\prime }}^2 (\theta _\mu ) } \Bigg [ D_{ij^{^{\prime }}}(\theta _\mu )-P_{ij^{^{\prime }}}C_{ii}^\mathrm{x}(\theta _\mu ) \Bigg ]^{2} , \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq35.gif)
where D denotes the data measurement (angular correlation function in our case), σ is the error bar of the measurement, and W1 and W2 are the weight functions. We consider weight function of the form θn in this work (see also Ménard et al. 2013). Here we use Latin indices for the redshift bins and Greek indices for the angular bins. The update rule will update Pij′, 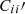 , and
, and 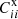 iteratively to look for a minimum of 𝒥. Additionally, we will consider assigning different weights to 𝒥1 and 𝒥2 later on.
iteratively to look for a minimum of 𝒥. Additionally, we will consider assigning different weights to 𝒥1 and 𝒥2 later on.
By minimizing the cost function with respect to Pab′, a multiplicative update rule (Eq. (A.9)) for Pab′ can be derived. Upon multiplying the factor in Eq. (A.9) to Pab′ repeatedly, Pab′ converges to the solution. This method can be viewed as a variant of the gradient decent (Lee & Seung 2000). Similar update rule can also be established for 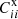 and C′ii (Eq. (A.10)). The details of the derivation are relegated to Appendix A. A few comments of the multiplicative rules are in order.
and C′ii (Eq. (A.10)). The details of the derivation are relegated to Appendix A. A few comments of the multiplicative rules are in order.
First, Zhang et al. (2017) employed the non-negative matrix factorization (NMF) algorithm, originally proposed by Lee & Seung (2000), to address the SC problem. This approach has been adopted in subsequent studies (Peng et al. 2022; Xu et al. 2023; Song et al. 2024; Peng & Yu 2024). Due to the non-negativity constraint inherent in the SC model, the NMF method offers an elegant and efficient solution. NMF assumes that the model can be factorized into a product form WH, where W and H are distinct matrices. To apply this framework to the SC model, Zhang et al. (2017) reformulated it as WHθ, with W = PT and Hθ = C(θ)P. However, this splitting is somewhat artificial for the SC problem and may cause difficulty in including the CZ information due to its rigid structure. To further optimize and generalize the approach for solving the SC model, we bypass the NMF interpretation and instead treat it directly as a minimization problem with respect to Pab′. By employing a specialized parameter update scheme inspired by the NMF approach, our simplified interpretation allows for an efficient combination of information from both SC and CZ models.
Secondly, the cost function for the multiplicative update rule is often taken to be the mean squared error without the inverse error bar weighting, e.g. Lee & Seung (2000), Zhang et al. (2017). Treating all the data on equal footing is at best sub-optimal. We have to include the error bar to down-weight the contribution of the poor measurements and up-weight the good ones, and to eliminate the impact of missing data measurements. Here we have improved over previous treatments by taking into account the error of measurements and the inclusion of additional weighting functions. The proper treatment should include the full covariance matrix. However, in the derivation of the multiplicative rule, we have to separate the positive part of the gradient from the negative one. Usage of the full covariance will hinder this separation. Thus for simplicity, we opt to use diagonal error bars in Eqs. (16) and (17). Under the diagonal covariance approximation, the data points are taken to be independent. This may seem a poor approximation, but we observed that the overall performance of the algorithm is good. We mention that Xu et al. (2023) used χ2 as the stopping criterion of the iteration process, but the update rule is still based on the cost function without the inverse error weighting. Recently, Peng & Yu (2024) independently proposed to include error weighting in the NMF algorithm to solve the SC problem. They adopted the improved NMF algorithm of Zhu (2016), Green & Bailey (2023), which generalizes the Lee & Seung (2000) NMF update rule to account for the data measurement error. We expect its performance to be similar to our SC results.
Thirdly, the multiplicative update rule ensures that the estimated values are non-negative provided that the measurements are non-negative2. This is less likely to hold for Cij′ (see Fig. 1 below) due to its larger covariance. Negative measurements may spoil the update rule and result in negative estimated value. To mitigate this problem, in Xu et al. (2023), negative measurements are set to small positive values by hand, and a more refined process is applied in Peng & Yu (2024). In Appendix C, we test the impact of setting the negative measurements to a tiny positive value.
 |
Fig. 1. Sample of the photo-z angular correlation function between the photo-z bin i′ and j′, Ci′j′ (blue) and the cross angular correlation function between the spec-z bin i and photo-z bin j′, Cij′ (red) to be used for true-z inference. The line and its associated color band are the median and 16 and 84 percentile among 100 mock runs. The whole redshift range [0.6,1.1] is divided into 10 photo-z bins, each of width Δzp = 0.05. This results in a true-z distribution with resolution of Δz = 0.05. The label i-j represents i′j′ for photo-z correlation function and ij′ for spec-z-photo-z cross correlation function respectively. We only show the odd bin results for clarity. |
Finally, we mention that our update rule is also applicable when 𝒥1 or 𝒥2 are missing. In particular it can be used for the SC method. We will contrast ours against the results from Xu et al. (2023) below.
Before closing this section, we comment on the solution of the system Eqs. (13) and (14) in the R method. Basically it is the same as the P method, except that Rij′ is solved without the normalization constraint, viz. Eq. (A.4). From Rij′, if we assume that there is no bias evolution, then using Eq. (5), we have3
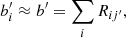
and it follows that
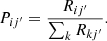
2.2.2. Numerical implementation
Because our method is rooted in the previous works and we shall contrast the old result with ours, it is helpful to review the algorithm of Zhang et al. (2017) and its improvements in Xu et al. (2023). We shall denote this as the “Old NMF” and use it as a benchmark for comparison.
The algorithm starts by initializing Pij′ randomly as a diagonally dominant matrix. The initialization procedure assumes that the true-z distribution peaks at the photo-z estimate and decreases monotonically on both sides. The initial C′ii and 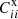 are obtained from Eqs. (3) or (10) using the initial Pij′. Before applying the multiplicative update rule, Zhang et al. (2017) found that it was necessary to get a preliminary solution using a fixed-point method for the NMF step to be successful. Using this preliminary solution as the initial trial solution, the NMF update rule is applied until a minimum of the cost function is attained. Zhang et al. (2017) writes the SC model as WHθ with W = PT and Hθ = C(θ)P. In each step, the update rule analogous to that in Lee & Seung (2000) is applied to W with Hθ fixed. The P in Hθ is then replaced with the new W, and with P held fixed C(θ) is subsequently solved by the least square solution. To estimate the error bar on Pij′, Xu et al. (2023) generates 100 sets of Pij′ and for each set, the measurement Ci′j′ is perturbed by adding a Gaussian perturbation obtained by sampling the covariance of Ci′j′. We call this set random runs to distinguish them from the mock realizations. The best fit and the 1σ error are estimated by the median and the half width between the 16 and 84 percentile, respectively.
are obtained from Eqs. (3) or (10) using the initial Pij′. Before applying the multiplicative update rule, Zhang et al. (2017) found that it was necessary to get a preliminary solution using a fixed-point method for the NMF step to be successful. Using this preliminary solution as the initial trial solution, the NMF update rule is applied until a minimum of the cost function is attained. Zhang et al. (2017) writes the SC model as WHθ with W = PT and Hθ = C(θ)P. In each step, the update rule analogous to that in Lee & Seung (2000) is applied to W with Hθ fixed. The P in Hθ is then replaced with the new W, and with P held fixed C(θ) is subsequently solved by the least square solution. To estimate the error bar on Pij′, Xu et al. (2023) generates 100 sets of Pij′ and for each set, the measurement Ci′j′ is perturbed by adding a Gaussian perturbation obtained by sampling the covariance of Ci′j′. We call this set random runs to distinguish them from the mock realizations. The best fit and the 1σ error are estimated by the median and the half width between the 16 and 84 percentile, respectively.
We shall contrast three different setups: SC, CZ, and the joint inference by SC and CZ, denoted as SC+CZ. For SC and SC+CZ, the default method uses Pij′ and 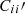 (and
(and 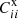 ) as unknowns (abbreviated as P method), while for CZ, we use Rij′ as variables (denoted as R method). The reason for these differences is related to the error estimation and we shall comment on it later on. For the P method, we initialize Pij′ and C′ii (and
) as unknowns (abbreviated as P method), while for CZ, we use Rij′ as variables (denoted as R method). The reason for these differences is related to the error estimation and we shall comment on it later on. For the P method, we initialize Pij′ and C′ii (and 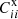 ) as in the Old NMF, but we then feed the initial guess to the multiplicative update rule (Eqs. (A.9) and (A.10)) directly because we find that our algorithm no longer requires the intermediate solution from the fixed point method. We take the weighting function to be θn with n = −1. Similar to Xu et al. (2023), we generate 100 random runs to estimate the best fit and 1σ error bar. The best fit and 1σ error bar are estimated by the median and half width of the 68-percentile about the median. In each run, we also perturb the measurement using a Gaussian perturbation derived from the mock covariance.
) as in the Old NMF, but we then feed the initial guess to the multiplicative update rule (Eqs. (A.9) and (A.10)) directly because we find that our algorithm no longer requires the intermediate solution from the fixed point method. We take the weighting function to be θn with n = −1. Similar to Xu et al. (2023), we generate 100 random runs to estimate the best fit and 1σ error bar. The best fit and 1σ error bar are estimated by the median and half width of the 68-percentile about the median. In each run, we also perturb the measurement using a Gaussian perturbation derived from the mock covariance.
For the R method, the procedures are similar. To initialize Rij′ we generate the initial Pij′ as above, but we find that the result is sensitive to the trial bi′. Thus we perform a grid search on bi′ to find the one that gives rise to the minimum 𝒥 and use it as the final solution. We then get Pij′ from the best fit Rij′ using Eq. (19).
3. Mock test results
In this section, we apply our algorithm to the mock catalog to test its performance.
3.1. Description of the mock catalog
We shall test and validate our results using mock catalogs. For this purpose, we employ the ICE-COLA mocks (Ferrero et al. 2021), which is a specialized mock catalog tailored for the DES Y3 BAO analyses (Abbott et al. 2022b). A brief overview is provided here, with further details available in Ferrero et al. (2021).
The ICE-COLA mocks are derived from the COLA simulations, built upon the COLA method (Tassev et al. 2013), and executed through the ICE-COLA code (Izard et al. 2016). The COLA method combines the second-order Lagrangian perturbation theory with the particle-mesh simulation technique, ensuring the preservation of accuracy in large-scale modes despite the utilization of coarse simulation time steps. In each simulation, there are 20483 particles in a cube measuring side length of 1536 Mpc h−1. The comoving simulation is transformed to a lightcone simulation extending up to z ∼ 1.4. The cosmology adopted by the mock catalog follows that in the MICE simulation (Fosalba et al. 2015; Crocce et al. 2015), which is a flat ΛCDM with Ωm = 0.25, ΩΛ = 0.75, h = 0.7, and σ8 = 0.8. Each mock occupies a DES Y3 footprint, covering 4180 deg2 in area. We make use of 100 mock catalogs to estimate the covariance. The same set of mocks are also used to estimate the ensemble mean and its associated error.
The mock galaxies are allocated to the ICE-COLA halos through a hybrid method combining Halo Occupation Distribution and Halo Abundance Matching, mirroring the technique outlined in Avila et al. (2018). These mock galaxies resemble the red galaxy sample in DES Y3 (see Carnero et al. 2012 for more details on this sample). The mock galaxies are equipped with realistic photo-z. To do so, a 2D joint probability distribution in the photo-z and spec-z space is constructed using a sample of actual galaxies possessing both types of redshifts. Through sampling this distribution, the candidate mock galaxies are assigned the appropriate photo-z’s.
Because the galaxies have both photo-z and spec-z labels, we can use them to create photo-z and spec-z samples. As in DES Y3, we select galaxies in the photo-z range [0.6,1.1] and divide them into five tomographic bins, each of width 0.1. Our goal is to determine the true-z distribution of the samples in these tomographic bins using clustering-based methods. To model the fact that the spec-z galaxies are generally few and bright, we approximate it by selecting the most massive galaxies from the mock. In this case we expect the clustering amplitude of the spec-z sample to be higher than the intrinsic clustering of the photo-z sample since the linear bias increases with mass. We consider samples containing the most massive p% of the galaxies with p = 5, 1, and 0.5.
When we restrict the sample to the photo-z range [0.6,1.1], a small fraction of the galaxies will possess spec-z values outside this range. This implies that there are reductions in correlation signal from SC and CZ. This problem can be alleviated by considering the redshift range of data, both photo-z and spec-z data, to be sufficiently wide relative to the redshift range of interest. Because the mock data are only available in the photo-z range [0.6,1.1], this is not possible. Here we clean the sample by removing the galaxies with spec-z values outside of the range [0.6,1.1], and this effectively forces the true-z distribution to vanish outside the range [0.6,1.1]. This cleaning cannot be done in real data. In Appendix B, we study the impact of the outlying galaxies on the true-z estimation.
3.2. Clustering measurements
The data for inference are the angular correlation functions. While the bin width of the target photo-z sample is Δzp = 0.1, to increase the redshift resolution of the true-z distribution, we divided the sample into ten photo-z bins, each with bin width of Δzp = 0.05. From the true-z inference code, we ended up with ten true-z distributions with a redshift resolution of Δz = 0.05 for these ten photo-z samples. We then combined every two true-z distributions to get the weighted mean for our target photo-z samples, e.g., the first and second true-z distributions are combined to get the one for the first target photo-z sample.
In Fig. 1, we show a sample of the angular correlation function w(θ) to be used in true-z inference. The plot shows the photo-z angular correlation function Ci′j′ and the cross angular correlation between the spec-z and photo-z sample Cij′. In this plot, the spec-z sample consists of the most massive 1% galaxies. We have plotted the median and the 1σ band estimated by the 16 and 84 percentile among 100 mock runs. We only show the results for i-j with i and j being odd for clarity.
These angular correlation function measurements are performed using CUTE (Alonso 2012) with the grid method. We compute them in the angular range of [0.2, 5]° with linear binning of width 0.2°.
3.3. Inference of the true-z distribution
We show the results on the inference of the true-z distribution in Fig. 2. We compare the results obtained with SC, CZ, and SC+CZ against the true-z distribution measurement from the mock catalog. Here we show the results from a single mock. They are produced using the fiducial setup, and the spec-z sample is the most massive 1%.
 |
Fig. 2. True-z distribution inferred by the clustering-based estimators [CZ (red), SC (orange), and SC+CZ (blue)] are compared with the direct mock measurement (green bars). The clustering-based estimator data points are offset horizontally for clarity. The results for five tomographic bins are shown (from top to bottom). |
In order to quantify the accuracy of the results, we use all 100 mocks and consider the metric 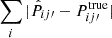 , the absolute difference between the mock measurement Pij′true and the estimated result
, the absolute difference between the mock measurement Pij′true and the estimated result 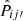 . We show this in the upper panel of Fig. 3. The line corresponds to the median and the color band demarcates the 16 and 84 percentile lines among 100 mock runs.
. We show this in the upper panel of Fig. 3. The line corresponds to the median and the color band demarcates the 16 and 84 percentile lines among 100 mock runs.
 |
Fig. 3. Comparison of the accuracy of the true-z distribution inferred using CZ (red), SC (orange), and SC+CZ (blue). Upper panel: |
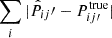
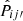
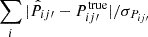
We find that for the first two bins, SC and CZ results are similar with SC marginally better, and the accuracy of CZ remains good for the high z bins while SC deteriorates. In reality, the number of spec-z galaxies may plummet faster than the constant fraction selection assumed here, and thus the performance of CZ in the high z bins may not be as good as the case shown here. The combination SC+CZ achieves the minimal error, and performs better than SC or CZ alone.
To go on to check the accuracy of the error estimate on Pij′, σPij′, we plot the absolute difference normalized by the estimated error, 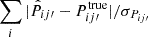 in the lower panel of Fig. 3. A rough estimate is that the difference should be of order σPij′, and so the sum is ∼5. We find that the result are generally larger than this simple estimate by a factor of ∼1.5, and it gets larger for the last bin. The large fluctuation of the 1σ band especially for the last bin is caused by the occasionally too small error bar estimation in the tail of true-z distribution.
in the lower panel of Fig. 3. A rough estimate is that the difference should be of order σPij′, and so the sum is ∼5. We find that the result are generally larger than this simple estimate by a factor of ∼1.5, and it gets larger for the last bin. The large fluctuation of the 1σ band especially for the last bin is caused by the occasionally too small error bar estimation in the tail of true-z distribution.
Bias in the mean redshift ez obtained with various methods.
To determine the true-z distribution, all the cross bin clustering information is used; thus the information is not localized to a particular bin and it is hard to get a “simple” explanation of the trend seen in Fig. 3. For CZ, all the spec-z sample is used to cross correlate with a photo-z sample. Thus we argue that the photo-z sample property could give a better estimate of the quality of the CZ inference. After cleaning, the number of photo-z galaxies in the photo-z bins are 1228413, 1576759, 1683208, 1266897, and 708319 respectively. The effective bias parameters of the photo-z sample in the tomographic bins are similar (about 1.1), but at both ends the bias is ∼1.3. The rise at both ends is caused by the cleaning process, which cuts off the true-z distribution and hence increases the clustering amplitude (Chan et al. 2024). Nonetheless the biases in the true-z bins, bi′ are quite constant (see Fig. 6). Hence the number of photo-z galaxies in the tomographic bins can qualitatively explain the trend of CZ in Fig. 3. The trend of the SC is even harder to interpret as it relies on the auto and cross clustering information all the bins.
The bias in the mean of the true-z distribution is commonly used as an indicator for the accuracy of the characterization of the true-z distribution4. In Table 2, we show bias in the mean redshift:
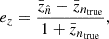
where 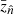 (
(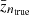 ) denotes the mean redshift computed using the true-z distribution from the estimator (direct measurement).
) denotes the mean redshift computed using the true-z distribution from the estimator (direct measurement).
For SC the biases are about 0.5%, and are positive for all the tomographic bins. The CZ results show larger variation and the bias goes from positive to negative as the redshift increases. The patterns for the three mass samples are similar. Although the first bin is relatively inaccurate, the others are good. In fact, the bias in the third bin is the smallest among all the entries. But this could be a particularity of the mock as the bias remains 0.05% even for the 0.5% sample. In contrast, the SC+CZ results are stable across the tomographic bins with bias about 0.3% for most of the entries. Although SC+CZ bias values are systematically lower than SC in all the tomographic bins, somewhat surprisingly they are larger than CZ for the last three bins. Nonetheless, if we take the bias of all the bins into account by adding up the absolute value of the biases in all five bins, SC+CZ gives a smaller total bias. For example, for the 1% sample, the total bias is reduced by about 31% and 48% relative to the CZ and SC bias, respectively. It seems that adding SC to CZ spoils some of the “accidentally” accurate bin results for CZ, but it makes the overall results more stable. Here we avoid overinterpreting the results, and leave it to future mock tests to settle the some of the subtle trends.
3.4. Comparison of different implementations
In this subsection, we compare the results obtained with different implementations. Using SC as an example, in Fig. 4, we compare the true-z distribution obtained with different algorithms for a single mock. In Fig. 5, we plot the absolute error and the normalized absolute error of these estimators computed with the 100-mock ensemble.
 |
Fig. 4. Comparison of the true-z distribution obtained by different implementations of the SC method with the direct measurement on the mock (green bars). The results obtained using the R method (red), P method (orange), and the Old NMF (blue) are compared. Because the Old NMF is not stable when it is run with resolution Δz = 0.05, we can only produce the results with Δz = 0.1. |
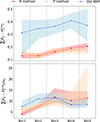 |
Fig. 5. Comparison of the accuracy of the estimated true-z distribution obtained with different SC algorithms. Upper panel: |
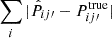
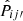
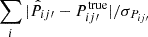
Recall that for SC, our fiducial method is the P method, for which both Pij′ and  are the fitting parameters. Alternatively, in the R method, the only unknown is Rij′. For the best fit value, P and R method give pretty similar results, but R method tends to give smaller error estimates thanks to less unknowns.
are the fitting parameters. Alternatively, in the R method, the only unknown is Rij′. For the best fit value, P and R method give pretty similar results, but R method tends to give smaller error estimates thanks to less unknowns.
It seems that R method is more constraining, but we find that it gives too small error bar too often in the case of SC+CZ. On the other hand, P method also tends to give too small error bars in the case of CZ. Because CZ is a linear problem, the computation of error bars is straightforward. We find that R method yields error bars consistent with the simple error propagation result. These considerations motivate the adoption of P method for SC and SC+CZ, while R method for CZ.
We further contrast our results against the one obtained with the Old NMF method, for which we use the default setting in Xu et al. (2023). In particular the best fit is estimated using 100 random runs, and the best fit and the 1σ error bar are the median and the half width of the 68 percentile about the median. The stopping criterion is based on minimal χ2 although its update rule is still rooted in the old 𝒥. For each random run, a Gaussian perturbation is added to the measurement by sampling the covariance. We note that the covariance adopted here is derived from 100 mocks rather than the jackknife covariance as in Xu et al. (2023). The adoption of the mock covariance here is driven by the observation that there is a significant difference between the mock covariance and the jackknife covariance computed using the method in Xu et al. (2023). By definition, the covariance is estimated by the ensemble mean among realizations; thus the mock covariance is the correct one to use. Furthermore, the negative measurements are set to a small positive value. We tried to run the old NMF with Δz = 0.05, but it is not stable in this case and we have to settle with resolution Δz = 0.1. Song et al. (2024) also found that the old NMF fails to produce the true-z distribution with a fine resolution, and used a coarse resolution of Δz = 0.1 although that did not impair the final BAO measurement there.
Fig. 4 and the top panel of Fig. 5 demonstrate that our improved algorithm results in a much more accurate estimation of the true-z distribution than the Old NMF method. The Old NMF tends to give excessively large error bars in the central region of the true-z distribution, while too small error estimate in the tail. We note that when the jackknife covariance is used instead, the error bars would be smaller.
Table 2 also displays the bias from the old NMF method, and we find that our updated algorithm reduces the bias by more than a factor of 2 in almost all the bins.
3.5. Estimation of the clustering amplitudes
Although our primary target is the true-z distribution Pij′, the accuracy of the best fit correlation function serves an important cross-check and it reflects the consistency of the algorithm.
In Fig. 6, we plot the galaxy bias parameter of the photo-z sample in the spec-z bin i, bi′ in 10 spec-z bins. Here we illustrate the results from SC+CZ using the massive 1% sample. The bias bi′ is estimated by the following means:
 |
Fig. 6. Galaxy bias parameter of the photo-z sample in the spec-z bin i, bi′ estimated by various methods. The estimate by |
-
From the best fit
 , we have
, we have 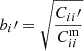 .
. -
Using the best fit
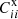 , we get
, we get 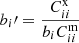 , where bi is measured using the auto angular correlation function of the spec-z sample.
, where bi is measured using the auto angular correlation function of the spec-z sample. -
Under the universal leakage assumption and no bias evolution approximation, b′≈∑iRij′, which predicts that the bias is constant across all the photo-z bins. If we employ the generalized bias form, bj′ ≈ ∑ibij′Pij′, the resultant bias is redshift dependent albeit on index j′. Because the true-z distribution peaks about the photo-z estimate, bj′ ≈ bj. In Fig. 6, we have plotted bj′ as black dashed line.
-
By dividing the whole photo-z sample into ten spec-z bins, we can measure their correlation functions to directly get bi′.
Different estimates are in agreement with each other within 10% in most of the bins in the range θ ≲ 1°. The estimate from 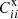 has larger error bar because it also requires the estimation of bi from the angular correlation function of the spec-z sample. Moreover, bi′ from Rij′ is almost constant across all the spec-z bins. It is remarkable that it is in nice agreement with other estimates except for the last bin given there are a few approximations made.
has larger error bar because it also requires the estimation of bi from the angular correlation function of the spec-z sample. Moreover, bi′ from Rij′ is almost constant across all the spec-z bins. It is remarkable that it is in nice agreement with other estimates except for the last bin given there are a few approximations made.
In principle, to check the universal leakage assumption, for data in each photo-z bin j′, we could divide the sample into 10 true-z bins and measure the bias bij′. Under the universal leakage assumption, we anticipate bij′ to be independent of j′. However, in creating the mocks, photo-z’s are assigned to galaxies based on the spec-z and photo-z probability distribution only, without the photometry information. Thus the universal leakage assumption is built in during mock construction.
3.6. Optimal weighting for SC and CZ
While σ2 takes into account the measurement error of the correlation function, the theoretical uncertainties of the method are not included. Simply adding up 𝒥1 and 𝒥2 implicitly assumes that they have equal constraining power and this may not lead to optimal results because SC and CS have different level of degeneracy. A simple way to tackle this issue is to assign different weights to their cost functions. We consider two scenarios: (i) the number of spec-z bins with spec-z data is equal to the number of photo-z bins or (ii) the number of spec-z bins with spec-z data is less than the number of photo-z bins. The second setup is particularly interesting because the lack of spec-z data at high z limits the application of the clustering-based method to the high z regime.
3.6.1. Full spec-z data
Here we focus on the scenario when the number of spec-z bin is the same as the number of photo-z bins. For this full spec-z bin data case, we consider the joint cost function:
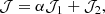
where 𝒥1 and 𝒥2 are given by Eqs. (16) and (17) respectively, and the weight α adjusts their relative importance.
In Fig. 7, we show the absolute error of the estimated distribution. We note that we have summed over both indices i and j′. We have shown the results for three spec-z samples, which respectively consist of the most massive 5%, 1%, and 0.5% of the galaxies. The best fit and the 1σ error band are derived from 100 mocks. For α ≳ 100, we see that the curves are convergent because the information is dictated by SC in this limit. On the other hand, in the low α limit, the result is determined by CZ. As expected, if the fraction of galaxies in the spec-z sample is higher, the signal-to-noise of the cross correlation function is higher, and hence the absolute error is smaller.
 |
Fig. 7. Accuracy of the true-z estimation characterized by |
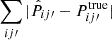
In the intermediate range, for the 0.5% sample, there is a dip roughly around α ∼ 0.7, implying that this weight optimally combines the information. As the mass fraction increases, dip becomes much broader and shallower but the dip position remains nearly unchanged with very mild shift towards a smaller α. These indicate that the SC information helps little and the signal is largely dominated by CZ. We note that the from 0.5% to 1%, the optimal α seems to increase, but this is not expected and should be interpreted as statistical fluctuations. For the 1% spec-z sample, the optimal combination of SC+CZ reduces the total error by 20% relative to CZ and 40% relative to SC.
3.6.2. Missing spec-z data
Often the spec-z data are only available in the relatively low redshift range. Thus it is of interest to consider the situation in which the low z part of the true-z distribution is simultaneously constrained by both SC and CZ, while the high z part relies solely on SC.
For notational convenience, let S be the set of all the bins of interest, {1, 2, …, N}, T be the set of the bins with spec-z data available, {1, 2, ,…,Ns} with Ns ≤ N, and S ∖ T be the set of bins without spec-z info, {Ns + 1, …, N}. T⨂T denotes the tuple {(i, j)| i ∈ Tandj ∈ T}, and its complement (T⨂T)C represents {(i, j)| i ∈ S ∖ Torj ∈ S ∖ T}. With these notations defined, the total cost function with two weight adjustment factors α1 and α2 is written as
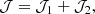
where 𝒥1 is given by
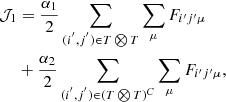
with Fi′j′μ denoting
![$$ \begin{aligned} F_{i^{\prime }j^{\prime }\mu } = \frac{ W_1(\theta _\mu ) }{ \sigma ^2_{i^{\prime } j^{\prime }}(\theta _\mu ) } \bigg [ D_{i^{^{\prime }}j^{^{\prime }}}(\theta _\mu ) - \sum _{k}P_{ki^{^{\prime }}}P_{kj^{^{\prime }}}C_{kk}^{\prime }( \theta _\mu ) \bigg ]^{2}, \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq72.gif)
and 𝒥2 by
![$$ \begin{aligned} \mathcal{J} _{2} =\frac{1}{2} \sum _{(i,j^{^{\prime }}) \in T \bigotimes T} \sum _\mu \frac{ W_2(\theta _\mu ) }{ \sigma _{ij^{\prime }}^2 (\theta _\mu ) } \Bigg [ D_{ij^{^{\prime }}}(\theta _\mu )-P_{ij^{^{\prime }}}C_{ii}^\mathrm{x}(\theta _\mu ) \Bigg ]^{2} . \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq73.gif)
In words, the weight α1 is to adjust the importance of the SC part with respect to the CZ counterpart, while the additional weight α2 in 𝒥1 allows for the possibility to leverage the weight of the SC contribution from the S ∖ T bins to compensate the missing CZ contribution.
In the left panel of Fig. 8, we show the results when the ninth and tenth spec-z bin data are missing. We contrasted the cases with α1 fixed to be 0.1, 1, and 10, corresponding to the CZ information being dominant, similar to, and subdominant to the matching SC bins. The accuracy of the inference is presented as a function of α2. In addition, we have compared the results from the spec-z samples consisting of the most massive 5%, 1%, and 0.5% of the galaxies.
 |
Fig. 8. Accuracy of the true-z inference by SC+CZ in the absence of the high z spec-z data. In the left panel, the spec-z data for the last two bins, bins 9 and 10, are missing; In the right panel, the spec-z data from bins 7 to 10 are missing. We have contrasted the cases with α1 = 0.1, 1, and 10, which controls the importance of the preceding SC bins with CZ counterpart. The total absolute difference is plotted as a function of α2, which adjusts the weight of the SC bin without CZ counterpart. Shown are the results from spec-z samples consisting of the most massive 5%, 1%, and 0.5%, respectively. |
First, for α1 = 0.1, CZ information is determinant in the first 8 bins. For large α2, the importance of SC bin 9 and 10 is inflated and becomes dominant so that the overall accuracy decreases. The error is minimized at a trough varying from α2 ∼ 0.2 to 0.5, depending on the fraction of the spec-z sample. The optimal α2 is less than unity reflects that the constraining power of the SC in 9th and 10th bin is bin-wisely weaker than CZ in the bins 1 to 8. The accuracy also deteriorates in the limit of small α2 because the missing bins become less and less constrained in this case. The optimal α2 for higher mass sample is slightly higher in order to balance the greater CZ constraint from the lower redshift bins. The differences among the three spec-z samples diminish at α2 ≲ 0.1, and this reflects that the CZ information is saturated and the missing bin is the bottleneck in enhancing the accuracy of the true-z inference.
The overall trend with α2 is similar for α1 = 1 and 10, but the shape generally shifts to a larger α2 to be in line with α1. For α1 = 1, the CZ and SC information has comparable weight for the first 8 bins, we find that the minimal error occurs around α2 ∼ 1 for 0.5% spec-z sample and ∼2 for 5%. The differences among the spec-z samples are less pronounced than α1 = 0.1 case because larger α1 value reduces the weight of CZ. Finally, when SC information is dominant in the first 8 bins (α1 = 10), the optimal α2 moves to ∼9 because the constraining power of SC bins are roughly similar.
It is worth summarizing the roles of the weight factors. α1 adjusts the weight of the SC bins relative to their CZ counterpart. The SC and CZ part compete with each other and they have equal weights when α1 = 1. α2 controls the weight of the SC part without CZ information. Through the above exercise, we see that α2 is in the same order of magnitude as the dominating part of the lower redshift bins.
In addition, we present the missing spec-z data in bin 7-10 case in the right panel of Fig. 8. They are qualitatively similar to the no bin 9 and 10 case. In particular, the optimal α2 is quite similar to the no bin 9 and 10 case. However, in contrast, the minimal error increases in the CZ dominating case (α1 = 0.1) by a small amount, while the SC dominated case (α1 = 10) is the least affected. This can be attributed to the fact that the CZ information is more constraining than SC. For the same reason, in the small α2 limit, we find that the accuracy is generally lower than the no bin 9 and 10 case.
Although the precise weights depend on the relative constraining power of the SC and CZ data, our test suggests that there is generally a set of optimal α1 and α2 minimizing the error.
We show the bias in the mean redshift in Table 2 for missing spec-z bin data 9-10 and 7-10. Even with missing spec-z bin data, SC+CZ is stable and the results are similar to the full bin case. Sometimes, the mean value in missing bin case is even lower than the full bin case although the difference is statistically insignificant. Only when the bin 7-10 are missing, we notice systematic increase in bias in the tomographic bin 4 and 5 (by about half σ).
Finally, for completeness, we plot the true-z distribution estimated by various number of spec-z bin data for a single mock in Fig. 9 and the absolute error estimated from 100 mocks in Fig. 10. In these plots, we assume α1 = 1 and α2 = 1, which are close to the optimal weights for the 1% sample used here. We have shown the results obtained with full spec-z bins, no spec-z bin 9 and 10, no spec-z bin 7 to 10, and SC only. We indeed see that as the number of spec-z bins decreases, the constraining power weakens. The true-z distribution for lower tomographic bins 1 and 2 are almost unaffected for the missing spec-z bin cases, while the higher tomographic bin ones are more affected. In summary, we have demonstrated that by incorporating the SC information with CZ, we are able to extend the constraint on the true-z distribution to higher redshift where spec-z data are missing, and the constraint is better than SC alone.
 |
Fig. 9. Comparison of the true-z distribution obtained by different number of spec-z bins with spec-z data available against the direct measurement on the mock (green bars) for a single mock. We have presented the results from full spec-z bins (violet), no spec-z bin 9 and 10 (red), no spec-z bin 7 to 10 (blue), and SC only (orange). |
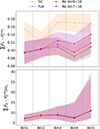 |
Fig. 10. The absolute error of the true-z distribution estimated by different amount of spec-z bin data. Upper panel: |
4. Conclusions
Characterization of the true-z distribution is crucial in the science of the wide-field imaging surveys such as weak lensing and BAO. A valuable avenue to calibrate the true-z distribution of a photo-z sample is to make use of the clustering information. Clustering-z (CZ) has been widely used in the cosmological analyses in imaging surveys. However, a limitation of this method is that the spec-z sample is often only available in relatively low redshift regime. The self-calibration (SC) method relying solely on the clustering information of the photometric sample is gaining popularity. In this work we develop a method to jointly constrain the true-z distribution of a photo-z sample using the information of SC and CZ simultaneously. We use the DES Y3 catalog to test our method and find that it can effectively infer the true-z distribution. The codes performing the SC+CZ inference can be downloaded on GitHub5.
Previous SC analyses often rely on the non-negative matrix factorization (NMF) algorithm. Such an interpretation becomes a burden when we want to generalize the method to combine SC with CZ. Inspired by the NMF method, we construct multiplicative update rules to directly solve for the true-z distribution. It is worth stressing that we have avoided the NMF interpretation altogether. Our straightforward analysis enables us to easily combine the information of SC with CZ.
Our formalism has improved upon the previous approach by taking the weighting functions into account. We have included the inverse error weighting and an additional weighting function. The inverse error weighting allows us to downweight the impact of the poor measurements and upweight the good ones. The additional weighting function give the freedom to put more weight on the constraining part of the correlation function, and we take it to be the form θ−n with n = 1. We demonstrate that our improved algorithm results in a much more accurate estimation of the true-z distribution compared to the previous method in the case of SC (Figs. 4 and 5). Moreover, our algorithm gives more stable results and allows us to have a true-z distribution with higher resolution. This bias in the mean redshift is reduced by more than a factor of two.
We employ our algorithm to show that SC+CZ improves the constraint relative to using SC or CZ alone (Figs. 2 and 3). SC+CZ gives a stable bias on the mean redshift, keeping it at a level of ∼0.3%, even though it sometimes fairs worst than CZ. The clustering-based methods also yield estimates of the intrinsic clustering amplitude. We find that various clustering measurements are consistent with each other (Fig. 6). To optimize the constraining power of SC and CZ data, we assign extra weight factors to the SC cost function. We consider the scenario with the number of spec-z bins with spec-z data equal to the number of photo-z bins and the more interesting one with the spec-z bin data only available in the low z bins. We find that there generally exist some weights that minimize the total error (Figs. 7 and 8). The precise weights depend on the constraining power of the SC and CZ data, and detailed mock tests are required to locate the optimal values. To highlight the improvement, we quote the 1% spec-z sample result with full spec-z bins here. In this case we find that the optimal combination reduces the total error by 20% and 40% compared to using respectively CZ and SC only. The test with spec-z data restricted to the low z range demonstrates that by incorporating with the SC information, we can extend the utility of the clustering-based method to higher redshift.
After successfully demonstrating the power of the SC+CZ method via mock catalogs, it is desirable to apply it to real data, such as the DES Y6 BAO data (Abbott et al. 2024; Mena-Fernández et al. 2024). For this dataset, only the portion of data with z < 1 is calibrated with CZ, while the data in the range 1 < z < 1.2 have to be calibrated with a spec-z sample from a small sky area. A few caveats need to keep in mind when applying the method to real data. In this work we have used Δz = 0.05, but this is still larger than the redshift bin width often taken in CZ analysis (e.g. Δz = 0.03). We have also assumed no bias evolution, at least in the CZ case. We leave it to future work to test the impact of these setups, and study possible improvements. We have not considered the magnification bias in this paper because the redshift range of the data is still small and the mock does not include this effect. For larger redshift extent, magnification bias correction must be made. Furthermore, the photometric data are more prone to observational systematics, which must be treated before SC. Compared to the applications to the clustering samples such as the lens sample in weak lensing and the BAO sample mentioned above, the application of the SC method to the source sample in weak lensing is more challenging simply because it is not constructed for clustering analysis. The source sample is often inhomogeneous and the random catalog is likely missing in standard analysis, so it must be built with great care. Moreover, the systematics mitigation is designed for the shear measurements, and so it remains to show that the existing mitigation efforts are sufficient or additional clustering weight needs to be created. Nevertheless, our work paves the way to calibrate the true-z distribution in high redshift using the clustering information.
This is actually the χ2 with the regularization by the weight function W, but here we follow the previous convention (Lee & Seung 2000; Zhang et al. 2017) to call it 𝒥.
We mention that the suppressed Gaussian process can also be tuned to return non-negative estimated values (Naidoo et al. 2023).
In Eq. (18) the indices on both sides do not match. It will look more pleasant if we employ the general bias form bij′.
For example, the target bias level of Euclid is less than 0.002(1 + z) (Laureijs et al. 2011) and Rubin aims for bias less than 0.003(1 + z) (Ivezić et al. 2019).
Acknowledgments
We thank the anonymous referee for his/her insightful comments that improve the presentation of the manuscript. WZ, KCC, and RS are supported by the National Science Foundation of China under the grant number 12273121 and the science research grants from the China Manned Space Project with NO.CMS-CSST-2021-B01. HX is supported by the National SKA Program of China (grant No. 2020SKA0110100), the National Natural Science Foundation of China (Nos. 11922305, 11833005) and the science research grants from the China Manned Space Project with NOs. CMS-CSST-2021-A02. LZ is supported by National SKA Program of China (2020SKA0110401, 2020SKA0110402, 2020SKA0110100), the National Key R&D Program of China (2020YFC2201600), the China Manned Space Project with No. CMS-CSST-2021 (A02, A03), and Guangdong Basic and Applied Basic Research Foundation (2024A1515012309).
References
- Abbott, T. M. C., Abdalla, F. B., Alarcon, A., et al. 2018, Phys. Rev. D, 98, 043526 [NASA ADS] [CrossRef] [Google Scholar]
- Abbott, T., Abdalla, F. B., Alarcon, A., et al. 2019, MNRAS, 483, 4866 [NASA ADS] [CrossRef] [Google Scholar]
- Abbott, T., Aguena, M., Alarcon, A., et al. 2022a, Phys. Rev. D, 105, 023520 [NASA ADS] [CrossRef] [Google Scholar]
- Abbott, T. M. C., Aguena, M., Allam, S., et al. 2022b, Phys. Rev. D, 105, 043512 [CrossRef] [Google Scholar]
- Abbott, T. M. C., Adamow, M., Aguena, M., et al. 2024, Phys. Rev. D, 110, 063515 [NASA ADS] [CrossRef] [Google Scholar]
- Alonso, D. 2012, arXiv e-prints [arXiv:1210.1833] [Google Scholar]
- Amon, A., Gruen, D., Troxel, M. A., et al. 2022, Phys. Rev. D, 105, 023514 [NASA ADS] [CrossRef] [Google Scholar]
- Arnouts, S., Cristiani, S., Moscardini, L., et al. 1999, MNRAS, 310, 540 [Google Scholar]
- Asgari, M., Lin, C.-A., Joachimi, B., et al. 2021, A&A, 645, A104 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Avila, S., Crocce, M., Ross, A. J., et al. 2018, MNRAS, 479, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Bartelmann, M., & Schneider, P. 2001, Phys. Rep., 340, 291 [Google Scholar]
- Benítez, N. 2000, ApJ, 536, 571 [Google Scholar]
- Benjamin, J., van Waerbeke, L., Ménard, B., & Kilbinger, M. 2010, MNRAS, 408, 1168 [NASA ADS] [CrossRef] [Google Scholar]
- Benjamin, J., Van Waerbeke, L., Heymans, C., et al. 2013, MNRAS, 431, 1547 [Google Scholar]
- Bolzonella, M., Miralles, J. M., & Pelló, R. 2000, A&A, 363, 476 [NASA ADS] [Google Scholar]
- Bonnett, C., Troxel, M. A., Hartley, W., et al. 2016, Phys. Rev. D, 94, 042005 [Google Scholar]
- Buchs, R., Davis, C., Gruen, D., et al. 2019, MNRAS, 489, 820 [Google Scholar]
- Campos, A., Yin, B., Dodelson, S., et al. 2024, arXiv e-prints [arXiv:2408.00922] [Google Scholar]
- Carnero, A., Sánchez, E., Crocce, M., Cabré, A., & Gaztañaga, E. 2012, MNRAS, 419, 1689 [NASA ADS] [CrossRef] [Google Scholar]
- Carrasco Kind, M., & Brunner, R. J. 2014, MNRAS, 438, 3409 [NASA ADS] [CrossRef] [Google Scholar]
- Cawthon, R., Elvin-Poole, J., Porredon, A., et al. 2022, MNRAS, 513, 5517 [NASA ADS] [CrossRef] [Google Scholar]
- Chan, K. C., Avila, S., Carnero Rosell, A., et al. 2022, Phys. Rev. D, 106, 123502 [NASA ADS] [CrossRef] [Google Scholar]
- Chan, K. C., Lu, G., & Wang, X. 2024, MNRAS, 529, 1667 [NASA ADS] [CrossRef] [Google Scholar]
- Choi, S. 2008, in 2008 IEEE International Joint Conference on NeuralNetworks (IEEE World Congress on Computational Intelligence), 1828 [Google Scholar]
- Collister, A. A., & Lahav, O. 2004, PASP, 116, 345 [NASA ADS] [CrossRef] [Google Scholar]
- Crocce, M., Castander, F. J., Gaztañaga, E., Fosalba, P., & Carretero, J. 2015, MNRAS, 453, 1513 [NASA ADS] [CrossRef] [Google Scholar]
- Cunha, C. E., Lima, M., Oyaizu, H., Frieman, J., & Lin, H. 2009, MNRAS, 396, 2379 [Google Scholar]
- Dalal, R., Li, X., Nicola, A., et al. 2023, Phys. Rev. D, 108, 123519 [CrossRef] [Google Scholar]
- Davis, C., Rozo, E., Roodman, A., et al. 2018, MNRAS, 477, 2196 [Google Scholar]
- de Simoni, F., Sobreira, F., Carnero, A., et al. 2013, MNRAS, 435, 3017 [NASA ADS] [CrossRef] [Google Scholar]
- De Vicente, J., Sánchez, E., & Sevilla-Noarbe, I. 2016, MNRAS, 459, 3078 [NASA ADS] [CrossRef] [Google Scholar]
- DESI Collaboration (Adame, A. G., et al.) 2024, arXiv e-prints [arXiv:2404.03000] [Google Scholar]
- Eifler, T., Miyatake, H., Krause, E., et al. 2021, MNRAS, 507, 1746 [NASA ADS] [CrossRef] [Google Scholar]
- Erben, T., Hildebrandt, H., Lerchster, M., et al. 2009, A&A, 493, 1197 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Estrada, J., Sefusatti, E., & Frieman, J. A. 2009, ApJ, 692, 265 [NASA ADS] [CrossRef] [Google Scholar]
- Ferrero, I., Crocce, M., Tutusaus, I., et al. 2021, A&A, 656, A106 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fosalba, P., Crocce, M., Gaztañaga, E., & Castander, F. J. 2015, MNRAS, 448, 2987 [NASA ADS] [CrossRef] [Google Scholar]
- Gatti, M., Vielzeuf, P., Davis, C., et al. 2018, MNRAS, 477, 1664 [Google Scholar]
- Gatti, M., Giannini, G., Bernstein, G. M., et al. 2022, MNRAS, 510, 1223 [Google Scholar]
- Gong, Y., Liu, X., Cao, Y., et al. 2019, ApJ, 883, 203 [NASA ADS] [CrossRef] [Google Scholar]
- Goodfellow, I. J., Bengio, Y., & Courville, A. 2016, Deep Learning (Cambridge, MA, USA: MIT Press) [Google Scholar]
- Green, D., & Bailey, S. 2023, IEEE Transactions on Signal Processing, 72, 5187 [Google Scholar]
- Heymans, C., Grocutt, E., Heavens, A., et al. 2013, MNRAS, 432, 2433 [Google Scholar]
- Heymans, C., Tröster, T., Asgari, M., et al. 2021, A&A, 646, A140 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hikage, C., Oguri, M., Hamana, T., et al. 2019, PASJ, 71, 43 [Google Scholar]
- Hildebrandt, H., Viola, M., Heymans, C., et al. 2017, MNRAS, 465, 1454 [Google Scholar]
- Hildebrandt, H., van den Busch, J. L., Wright, A. H., et al. 2021, A&A, 647, A124 [EDP Sciences] [Google Scholar]
- Hütsi, G. 2010, MNRAS, 401, 2477 [CrossRef] [Google Scholar]
- Ilbert, O., Arnouts, S., McCracken, H. J., et al. 2006, A&A, 457, 841 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Izard, A., Crocce, M., & Fosalba, P. 2016, MNRAS, 459, 2327 [NASA ADS] [CrossRef] [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, arXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Lee, D., & Seung, H. S. 2000, Adv. Neural Inf. Process. Syst., 13 [Google Scholar]
- Li, R., Napolitano, N. R., Roy, N., et al. 2022, ApJ, 929, 152 [NASA ADS] [CrossRef] [Google Scholar]
- Li, X., Zhang, T., Sugiyama, S., et al. 2023, Phys. Rev. D, 108, 123518 [CrossRef] [Google Scholar]
- Lima, M., Cunha, C. E., Oyaizu, H., et al. 2008, MNRAS, 390, 118 [Google Scholar]
- Mandelbaum, R., Eifler, T., Hložek, R., et al. 2018, arXiv e-prints [arXiv:1809.01669] [Google Scholar]
- Masters, D., Capak, P., Stern, D., et al. 2015, ApJ, 813, 53 [Google Scholar]
- Matthews, D. J., & Newman, J. A. 2010, ApJ, 721, 456 [Google Scholar]
- McQuinn, M., & White, M. 2013, MNRAS, 433, 2857 [Google Scholar]
- Mena-Fernández, J., Rodríguez-Monroy, M., Avila, S., et al. 2024, Phys. Rev. D, 110, 063514 [CrossRef] [Google Scholar]
- Ménard, B., Scranton, R., Schmidt, S., et al. 2013, arXiv e-prints [arXiv:1303.4722] [Google Scholar]
- Miyatake, H., Sugiyama, S., Takada, M., et al. 2023, Phys. Rev. D, 108, 123517 [NASA ADS] [CrossRef] [Google Scholar]
- Morrison, C. B., Hildebrandt, H., Schmidt, S. J., et al. 2017, MNRAS, 467, 3576 [Google Scholar]
- Naidoo, K., Johnston, H., Joachimi, B., et al. 2023, A&A, 670, A149 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Newman, J. A. 2008, ApJ, 684, 88 [Google Scholar]
- Newman, J. A., & Gruen, D. 2022, ARA&A, 60, 363 [NASA ADS] [CrossRef] [Google Scholar]
- Padmanabhan, N., Schlegel, D. J., Seljak, U., et al. 2007, MNRAS, 378, 852 [NASA ADS] [CrossRef] [Google Scholar]
- Peng, H., & Yu, Y. 2024, JCAP, 2024, 025 [CrossRef] [Google Scholar]
- Peng, H., Xu, H., Zhang, L., Chen, Z., & Yu, Y. 2022, MNRAS, 516, 6210 [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rau, M. M., Dalal, R., Zhang, T., et al. 2023, MNRAS, 524, 5109 [NASA ADS] [CrossRef] [Google Scholar]
- Sadeh, I., Abdalla, F. B., & Lahav, O. 2016, PASP, 128, 104502 [NASA ADS] [CrossRef] [Google Scholar]
- Salvato, M., Ilbert, O., & Hoyle, B. 2019, Nat. Astron., 3, 212 [NASA ADS] [CrossRef] [Google Scholar]
- Schmidt, S. J., Ménard, B., Scranton, R., Morrison, C., & McBride, C. K. 2013, MNRAS, 431, 3307 [Google Scholar]
- Schneider, M., Knox, L., Zhan, H., & Connolly, A. 2006, ApJ, 651, 14 [Google Scholar]
- Secco, L. F., Samuroff, S., Krause, E., et al. 2022, Phys. Rev. D, 105, 023515 [NASA ADS] [CrossRef] [Google Scholar]
- Seo, H.-J., Ho, S., White, M., et al. 2012, ApJ, 761, 13 [NASA ADS] [CrossRef] [Google Scholar]
- Simon, P. 2007, A&A, 473, 711 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Song, R., Chan, K. C., Xu, H., & Zheng, W. 2024, MNRAS, 530, 881 [NASA ADS] [CrossRef] [Google Scholar]
- Spergel, D., Gehrels, N., Baltay, C., et al. 2015, arXiv e-prints [arXiv:1503.03757] [Google Scholar]
- Sugiyama, S., Miyatake, H., More, S., et al. 2023, Phys. Rev. D, 108, 123521 [NASA ADS] [CrossRef] [Google Scholar]
- Tassev, S., Zaldarriaga, M., & Eisenstein, D. J. 2013, JCAP, 2013, 036 [Google Scholar]
- Troxel, M. A., MacCrann, N., Zuntz, J., et al. 2018, Phys. Rev. D, 98, 043528 [Google Scholar]
- van den Busch, J. L., Hildebrandt, H., Wright, A. H., et al. 2020, A&A, 642, A200 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wright, A. H., Hildebrandt, H., van den Busch, J. L., & Heymans, C. 2020, A&A, 637, A100 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Xu, H., Zhang, P., Peng, H., et al. 2023, MNRAS, 520, 161 [Google Scholar]
- Zhan, H. 2011, Sci. Sin. Phys. Mech. Astron., 41, 1441 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, P., Pen, U.-L., & Bernstein, G. 2010, MNRAS, 405, 359 [NASA ADS] [Google Scholar]
- Zhang, L., Yu, Y., & Zhang, P. 2017, ApJ, 848, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Zhou, R., Newman, J. A., Mao, Y.-Y., et al. 2021, MNRAS, 501, 3309 [NASA ADS] [CrossRef] [Google Scholar]
- Zhu, G. 2016, arXiv e-prints [arXiv:1612.06037] [Google Scholar]
- Zhu, Z., Yang, Z., & Oja, E. 2013, in 18th conference Scandinavian Conferences on Image Analysis (SCIA 2013) Espoo, Finland, June 17–20, 2013 (Germany: Springer Gabler), 143 [Google Scholar]
Appendix A: Derivation of the multiplicative update rule
In general, a multiplicative update rule is a set of iterative instructions to update a function by multiplying it with some factor to search for the minimum of the cost function. The most influential multiplicative update rule for non-negative matrix factorization (NMF) is presented by Lee & Seung (2000). This multiplicative update rule can be interpreted as a special kind of gradient descent rule with variable step size. A distinguishing feature of the NMF update rule is the non-negativity of the solution. This has been adopted in Zhang et al. (2017) to solve the SC equation. The update rule in Lee & Seung (2000) can be easily derived by splitting the gradient of the cost function into the positive and negative parts (Choi 2008). Inspired by this derivation, we derive multiplicative update rules for the joint inference by SC and CZ.
A.1. P method
In P method, we aim to derive multiplicative rules for Pij′, 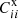 , and C′ii so that the cost function 𝒥 [Eq. (15)] is minimized. If we take Pab′ as the independent variable, we also need to account for the normalization constraint Eq. (5). This can be implemented by introducing the Lagrange multipliers into the cost function as
, and C′ii so that the cost function 𝒥 [Eq. (15)] is minimized. If we take Pab′ as the independent variable, we also need to account for the normalization constraint Eq. (5). This can be implemented by introducing the Lagrange multipliers into the cost function as
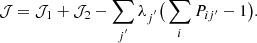
We first computed the derivative with respect to Pab′ and then to the Lagrange multipliers.
The derivative of 𝒥1 with respect to Pab′ reads
![$$ \begin{aligned} \frac{\partial \mathcal{J} _{1}}{\partial P_{ab^{^{\prime }}}} = -2\sum _{j^{^{\prime }}, \mu }&\frac{ W_1(\theta _\mu ) }{\sigma _{b^{\prime } j^{\prime }}^2( \theta _\mu ) } \Big [ D_{b^{^{\prime }}j^{^{\prime }}}(\theta _\mu )-\sum _{k}P_{kb^{^{\prime }}}P_{kj^{^{\prime }}}C^{\prime }_{kk}(\theta _\mu ) \Big ] \nonumber \\&\times P_{aj^{^{\prime }}}C^{\prime }_{aa} (\theta _\mu ) , \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq79.gif)
and for 𝒥2, we have
![$$ \begin{aligned} \frac{\partial \mathcal{J} _{2}}{\partial P_{ab^{^{\prime }}}}&=- \sum _\mu \frac{ W_2(\theta _\mu ) }{ \sigma _{ab^{\prime }}^2(\theta _\mu ) } [ D_{ab^{^{\prime }}}(\theta _\mu )-P_{ab^{^{\prime }}}C_{aa}^\mathrm{x}(\theta _\mu )]C_{aa}^\mathrm{x}(\theta _\mu ). \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq80.gif)
Without the constraint, following Lee & Seung (2000), the update rule is given by
![$$ \begin{aligned} P_{ab^{^{\prime }}}\xleftarrow P_{ab^{^{\prime }}}\frac{ [\partial _{P_{ab^{\prime }}} \mathcal{J} ]^-}{[\partial _{P_{ab^{\prime }}} \mathcal{J} ]^+}, \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq81.gif)
where [∂Pab′𝒥]− ([∂Pab′𝒥]+) denotes the unsigned negative (positive) part of the derivative of ∂Pab′𝒥. We can contrast this with the usual additive gradient descent (Goodfellow et al. 2016). The term [∂Pab′𝒥]− tends to increase the value of Pab′, while [∂Pab′𝒥]+ tends to decrease it, so they play the same role as in the usual gradient descent. When the minimum is reached, ∇𝒥 vanishes and the multiplicative factor becomes unity. Moreover, the factor [∂Pab′𝒥]−/[∂Pab′𝒥]+ is non-negative, and so it does not flip the sign of Pab′.
When the normalization constraint is included, we have
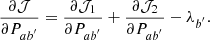
For the treatment of the Lagrange multiplier part, we follow the procedures in Zhu et al. (2013). We can first establish a preliminary update rule in terms of λb′, and then demand the resultant Pab′ to satisfy the normalization constraint. This enabled us to solve for λb′. It is convenient to include a negative sign for λb′ and assume λb′to be positive. However, this assumption does not always hold and so Zhu et al. (2013) consider a “moving term” trick to alleviate this problem.
The preliminary update rule is
![$$ \begin{aligned} P_{ab^{^{\prime }}}\xleftarrow P_{ab^{^{\prime }}}\frac{ [\partial _{P_{ab^{\prime }}} \mathcal{J} ]^- +\lambda _{b^{^{\prime }}}}{[\partial _{P_{ab^{\prime }}} \mathcal{J} ]^+}. \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq83.gif)
The new P is also demanded to meet the normalization constraint:
![$$ \begin{aligned} \sum _{a}&P_{ab^{^{\prime }}}\frac{ [\partial _{P_{ab^{\prime } }} \mathcal{J} ]^- +\lambda _{b^{^{\prime }}}}{[\partial _{P_{ab^{\prime }}} \mathcal{J} ]^+ } = 1 . \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq84.gif)
Solving for λb′, the update rule becomes
![$$ \begin{aligned} P_{ab^{^{\prime }}}\xleftarrow P_{ab^{^{\prime }}} \frac{ [\partial _{P_{ab^{\prime }} }\mathcal{J} ]^- \sum _{c}\frac{P_{cb^{^{\prime }}}}{ [\partial _{P_{cb^{\prime }} }\mathcal{J} ]^+ }+1-\sum _{c}P_{cb^{^{\prime }}}\frac{ [\partial _{P_{cb^{\prime }} }\mathcal{J} ]^- }{ [\partial _{P_{cb^{\prime }} }\mathcal{J} ]^+}}{[\partial _{P_{ab^{\prime }} }\mathcal{J} ]^+\sum _{c}\frac{P_{cb^{^{\prime }}}}{ [\partial _{P_{cb^{\prime }} }\mathcal{J} ]^+ }}. \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq85.gif)
To make the numerator always positive, we applied the “moving trick” to get
![$$ \begin{aligned} P_{ab^{^{\prime }}}\xleftarrow P_{ab^{^{\prime }}}\frac{ [\partial _{P_{ab^{\prime }} }\mathcal{J} ]^- \sum _{c}\frac{P_{cb^{^{\prime }}}}{ [\partial _{P_{cb^{\prime }} }\mathcal{J} ]^+ }+1}{[\partial _{P_{ab^{\prime }} }\mathcal{J} ]^+ \sum _{c}\frac{P_{cb^{^{\prime }}}}{ [\partial _{P_{cb^{\prime }} }\mathcal{J} ]^+}+\sum _{c}P_{cb^{^{\prime }}}\frac{[\partial _{P_{cb^{\prime }} }\mathcal{J} ]^-}{[\partial _{P_{cb^{\prime }} }\mathcal{J} ]^+}}. \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq86.gif)
We also update Caa′ [in Eq. (16)] and 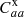 [in Eq. (17)] using the multiplicative rule although this is not necessary. Because they are linear parameters, direct analytic minimization is possible as was done in Zhang et al. (2017). The update rule for Caa′ reads
[in Eq. (17)] using the multiplicative rule although this is not necessary. Because they are linear parameters, direct analytic minimization is possible as was done in Zhang et al. (2017). The update rule for Caa′ reads
![$$ \begin{aligned} C_{aa}^{\prime }(\theta )\xleftarrow C_{aa}^{\prime }(\theta ) \frac{ [\partial _{C^{\prime }_{aa}(\theta ) } \mathcal{J} ]^- }{ [\partial _{C^{\prime }_{aa}(\theta ) } \mathcal{J} ]^+ }. \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq88.gif)
A similar update rule for  can be derived.
can be derived.
A.2. R method
In R method, only Rij′ is the unknown. Explicitly the cost functions read
![$$ \begin{aligned} \mathcal{J} _{1}&=\frac{1}{2} \sum _{i^{\prime },j^{\prime }, \mu } \frac{ W_1(\theta _\mu ) }{ \sigma _{i^{\prime }j^{\prime }}^2 (\theta _\mu ) } \Big [ D_{i^{^{\prime }}j^{^{\prime }}}(\theta _\mu ) - \sum _k R_{ki^{\prime }} R_{kj^{\prime }} C_{kk}^\mathrm{m} (\theta _\mu ) \Big ]^{2} , \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq90.gif)
![$$ \begin{aligned} \mathcal{J} _{2}&=\frac{1}{2} \sum _{i,j^{\prime }, \mu } \frac{ W_2(\theta _\mu ) }{ \sigma _{ij^{\prime }}^2 (\theta _\mu ) } \Big [ D_{ij^{^{\prime }}}(\theta _\mu ) - R_{ij^{\prime }} b_i C_{ii}^\mathrm{m} (\theta _\mu ) \Big ]^{2} . \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq91.gif)
The derivative of the cost functions with respect to Rab′ are given by
![$$ \begin{aligned} \frac{\partial \mathcal{J} _{1}}{\partial R_{ab^{\prime }}} = -2\sum _{j^{\prime }, \mu }&\frac{ W_1(\theta _\mu ) }{\sigma _{b^{\prime } j^{\prime }}^2( \theta _\mu ) } \Big [ D_{b^{\prime }j^{\prime }}(\theta _\mu )- \sum _{k}R_{kb^{\prime }}R_{kj^{\prime }}C^\mathrm{m}_{kk}(\theta _\mu ) \Big ] \nonumber \\&\times R_{aj^{\prime }}C^\mathrm{m}_{aa} (\theta _\mu ) , \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq92.gif)
and
![$$ \begin{aligned} \frac{\partial \mathcal{J} _{2}}{\partial R_{ab^{\prime }}}&=- \sum _\mu \frac{ W_2(\theta _\mu ) }{ \sigma _{ab^{\prime }}^2(\theta _\mu ) } [ D_{ab^{\prime }}(\theta _\mu )- b_a R_{ab^{\prime }}C_{aa}^\mathrm{m}(\theta _\mu )] b_a C_{aa}^\mathrm{m}(\theta _\mu ). \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq93.gif)
The update rule for Rab′ can then be constructed:
![$$ \begin{aligned} R_{ab^{^{\prime }}}\xleftarrow R_{ab^{\prime }}\frac{ [\partial _{R_{ab^{\prime }}} \mathcal{J} ]^-}{[\partial _{R_{ab^{\prime }}} \mathcal{J} ]^+}. \end{aligned} $$](/articles/aa/full_html/2024/12/aa52334-24/aa52334-24-eq94.gif)
We note that Pij′ follows from Eq. (19) if we assume that there is no galaxy bias evolution.
Appendix B: Impact of outlying galaxies
When the photo-z galaxies are present only in the redshift range [0.6, 1.1], the true-z distribution of this sample can extend outside it. In this work, we restrict both photo-z and spec-z range of the galaxies to [0.6,1.1], and this effectively assumes that Pij′ vanishes outside this range. In practice, however, this kind of cleaning is not possible.
To test the impact of the outlying galaxies on the estimation of the true-z distribution, we apply the algorithm to the raw photo-z sample, which contains the galaxies with spec-z values lying outside the range [0.6,1.1]. When the outlying galaxies are not removed, this additional component does not correlate with the ones inside, and this causes a reduction in the correlation signals in general. We compare the resulting distributions from the raw sample against the ones from the cleaned sample in Fig. B.1. Overall, we find that the impact of the outlying galaxies is pretty small for our sample.
We note that, as expected, the distributions for the boundary bins are more affected, i.e. bin 1 and 5. This is because the outlying spec-z galaxies are mainly located in the photo-z bins near the boundaries. We further note that CZ is more strongly affected than SC, and thus SC+CZ is in between. This can be explained by the fact that in CZ, the correlation is localized in the precise redshift of the spec-z bin, while the information in SC is more distributed, and hence CZ is more affected by the reduction in correlation with the boundary bins.
 |
Fig. B.1. Test of the impact of the galaxies with spec-z values lying outside the redshift range [0.6,1.1]. The true-z distribution from the raw sample, which contains the outlying spec-z galaxies (unfilled markers), are compared with the cleaned sample results (filled markers). The results from SC (red), CZ (orange), and SC+CZ (blue) are displayed. The direct mock measurements (green bars) are from the cleaned sample. |
Appendix C: Impact of setting negative measurements to a tiny positive value
In the main text, we mention that the multiplicative rule implicitly assumes that the measurements are positive. A quick fix is to set the negative measurements to a tiny positive value, for which we take it to be 10−5. Here we test the impact of such a modification on the true-z inference results.
Fig. C.1 showcases the true-z distribution from a mock. While there are only small fluctuations in the best fit value, without the modification, the estimated error bars from SC and SC+CZ appear to be larger, but the CZ error bars are little affected. We further examine the accuracy of the estimated distribution in Fig. C.2. The central value and the 1σ error bound are estimated from 100 mock catalogs. From the top panel, we see that nulling the negative measurements seems to increase the accuracy of SC and SC+CZ in most of the bins albeit by a statistically insignificant amount, but the modification also causes the SC bin 1 result to degrade. The impact on the estimated error bar is more apparent. The modification homogenizes the range of 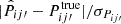 across tomographic bins.
across tomographic bins.
There seem to be benefits, especially on the error bar estimation, in doing such a modification, and thus we may consider adopting it in future.
 |
Fig. C.1. Comparison of the true-z distribution obtained by setting the negative measurements to a tiny positive value (empty markers) or not (filled markers). We have presented the results from SC (orange), CZ (red), and SC+CZ (blue). |
 |
Fig. C.2. Absolute error of the true-z distribution estimated using samples processed by setting the negative measurements to a tiny positive value (empty markers) or not (filled markers). Shown are the results from SC (orange), CZ (red), and SC+CZ (blue). Upper panel: |
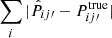
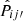
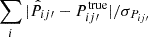
All Tables
All Figures
|
Fig. 1. Sample of the photo-z angular correlation function between the photo-z bin i′ and j′, Ci′j′ (blue) and the cross angular correlation function between the spec-z bin i and photo-z bin j′, Cij′ (red) to be used for true-z inference. The line and its associated color band are the median and 16 and 84 percentile among 100 mock runs. The whole redshift range [0.6,1.1] is divided into 10 photo-z bins, each of width Δzp = 0.05. This results in a true-z distribution with resolution of Δz = 0.05. The label i-j represents i′j′ for photo-z correlation function and ij′ for spec-z-photo-z cross correlation function respectively. We only show the odd bin results for clarity. |
| In the text | |
|
Fig. 2. True-z distribution inferred by the clustering-based estimators [CZ (red), SC (orange), and SC+CZ (blue)] are compared with the direct mock measurement (green bars). The clustering-based estimator data points are offset horizontally for clarity. The results for five tomographic bins are shown (from top to bottom). |
| In the text | |
|
Fig. 3. Comparison of the accuracy of the true-z distribution inferred using CZ (red), SC (orange), and SC+CZ (blue). Upper panel: |
| In the text | |
|
Fig. 4. Comparison of the true-z distribution obtained by different implementations of the SC method with the direct measurement on the mock (green bars). The results obtained using the R method (red), P method (orange), and the Old NMF (blue) are compared. Because the Old NMF is not stable when it is run with resolution Δz = 0.05, we can only produce the results with Δz = 0.1. |
| In the text | |
|
Fig. 5. Comparison of the accuracy of the estimated true-z distribution obtained with different SC algorithms. Upper panel: |
| In the text | |
|
Fig. 6. Galaxy bias parameter of the photo-z sample in the spec-z bin i, bi′ estimated by various methods. The estimate by |
| In the text | |
|
Fig. 7. Accuracy of the true-z estimation characterized by |
| In the text | |
|
Fig. 8. Accuracy of the true-z inference by SC+CZ in the absence of the high z spec-z data. In the left panel, the spec-z data for the last two bins, bins 9 and 10, are missing; In the right panel, the spec-z data from bins 7 to 10 are missing. We have contrasted the cases with α1 = 0.1, 1, and 10, which controls the importance of the preceding SC bins with CZ counterpart. The total absolute difference is plotted as a function of α2, which adjusts the weight of the SC bin without CZ counterpart. Shown are the results from spec-z samples consisting of the most massive 5%, 1%, and 0.5%, respectively. |
| In the text | |
|
Fig. 9. Comparison of the true-z distribution obtained by different number of spec-z bins with spec-z data available against the direct measurement on the mock (green bars) for a single mock. We have presented the results from full spec-z bins (violet), no spec-z bin 9 and 10 (red), no spec-z bin 7 to 10 (blue), and SC only (orange). |
| In the text | |
|
Fig. 10. The absolute error of the true-z distribution estimated by different amount of spec-z bin data. Upper panel: |
| In the text | |
|
Fig. B.1. Test of the impact of the galaxies with spec-z values lying outside the redshift range [0.6,1.1]. The true-z distribution from the raw sample, which contains the outlying spec-z galaxies (unfilled markers), are compared with the cleaned sample results (filled markers). The results from SC (red), CZ (orange), and SC+CZ (blue) are displayed. The direct mock measurements (green bars) are from the cleaned sample. |
| In the text | |
|
Fig. C.1. Comparison of the true-z distribution obtained by setting the negative measurements to a tiny positive value (empty markers) or not (filled markers). We have presented the results from SC (orange), CZ (red), and SC+CZ (blue). |
| In the text | |
|
Fig. C.2. Absolute error of the true-z distribution estimated using samples processed by setting the negative measurements to a tiny positive value (empty markers) or not (filled markers). Shown are the results from SC (orange), CZ (red), and SC+CZ (blue). Upper panel: |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.