| Issue |
A&A
Volume 699, July 2025
|
|
|---|---|---|
| Article Number | A118 | |
| Number of page(s) | 15 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202453215 | |
| Published online | 01 July 2025 | |
A statistical study of lopsided galaxies using random forests
Departamento de Astronomía, Universidad de La Serena, av. Raul Bitrán, La Serena, Chile
⋆ Corresponding author: valentina.fontirroig@userena.cl
Received:
28
November
2024
Accepted:
21
May
2025
Context. Lopsided galaxies are late-type galaxies that feature a non-axisymmetric disk caused by an uneven distribution of their stellar mass or light. Despite being a relatively common perturbation, there are still several questions regarding its origin and the information that can be extracted from them about the evolutionary history of late-type galaxies. Previous observational and numerical studies have suggested a correlation between lopsidedness and galaxy assembly history and internal structure.
Aims. The advent of several large multiband photometric surveys will allow us to statistically analyze this perturbation, with information that was not previously available. This paper aims to develop a method of rapidly and automatically pre-classifying late-type galaxies as lopsided and symmetric, purely based on the galaxies’ internal parameters. This method allows us to test the hypothesis that lopsidedness is a strong indicator of peculiar internal galaxy properties, rather than an indicator of the present-day environment they are hosted in.
Methods. We selected a sample of ≈8000 late type galaxies from the Illustris TNG50 simulation. A Fourier decomposition of their stellar mass surface density was used to label galaxies as lopsided and symmetric. We trained a random forest binary classifier to rapidly and automatically identify this type of perturbation, exclusively using galaxies’ internal properties. We explored different algorithms to deal with the imbalance nature of our data, and selected the most suitable approach based on the considered metrics.
Results. We show that our trained algorithm can provide a very accurate and rapid pre-classification of lopsided galaxies. The excellent results obtained by our classifier, trained with features that do not account for the galaxies environment, strongly support the hypothesis that lopsidedness is mainly a tracer of galaxies’ internal structures. We also show that similar results can be obtained when considering as input features observable quantities that are readily obtainable from multiband photometric surveys.
Conclusions. Our results show that algorithms such as the ones considered allow for the rapid and accurate pre-classification of lopsided galaxies from large multiband photometric surveys, allowing us to explore whether lopsidedness in present-day disk galaxies is connected to galaxies’ specific evolutionary histories.
Key words: methods: data analysis / methods: statistical / galaxies: evolution / galaxies: formation / galaxies: spiral / galaxies: structure
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1. Introduction
Lopsided galaxies feature a non-axisymmetric disk, caused by an uneven distribution of stellar mass or light. Observational studies have shown that up to 30% of nearby galaxies display a certain degree of lopsidedness (Zaritsky & Rix 1997; Rudnick & Rix 1998; Bournaud et al. 2005; van Eymeren et al. 2011). The term “lopsidedness” was first coined by Baldwin et al. (1980) to refer to those galaxies in their sample for which there was a strong asymmetry in the HI gas density distribution between the opposite sides. As was discussed in Jog & Combes (2009, and references therein), this asymmetry can significantly impact the dynamical structure and evolution of the host galaxy, causing enhanced star-forming regions, fueling the central active galactic nucleus, and redistributing matter, among other matters.
Despite lopsided galaxies being an ubiquitous object in the nearby Universe, this asymmetry has received less attention than other commonly studied perturbations (e.g., Sellwood 2013; Conselice 2014; Erwin 2019). Moreover, the origin of this asymmetry is not quite well understood, as both galaxies in the field and in denser environments present lopsidedness. Different mechanisms have been proposed as the main driver of this asymmetry, such as asymmetric gas accretion (Phookun et al. 1993; Bournaud et al. 2005), tidal encounters (Weinberg 1994; Rudnick et al. 2000; Gómez et al. 2016), satellite accretion (Walker et al. 1996; Zaritsky & Rix 1997), the response of the disk to the distorted dark matter halo (Jog 1997, 2002), and off-centered disk (Noordermeer et al. 2001), among others.
Interestingly, several works have found differences in the structural properties of lopsided galaxies with respect to the ones of more symmetrical late-type galaxies. In particular, Reichard et al. (2008) studied a sample of 25 155 low-redshift (z < 0.06) galaxies in the Sloan Digital Sky Survey (SDSS, Kollmeier et al. 2019), and showed that lopsided galaxies tend to have a lower concentration and stellar mass density within their half light radius than symmetrical galaxies. This suggests that there is a correlation between lopsidedness and the structural properties of the galaxies. Using a sample of late-type galaxies from the Illustris TNG50 simulation, Varela-Lavin et al. (2023) found a similar strong correlation between lopsidedness and the internal properties of galaxies. Specifically, they found an anticorrelation between lopsidedness and the tidal force exerted by the inner regions on the outskirts of their galactic disk. This result indicates that less gravitationally cohesive disk galaxies are more susceptible to developing this asymmetry when exposed to external perturbations. Indeed, these results, based on numerical models, are in agreement with Jog (1999, 2000), who studied the self-consistent response of an axisymmetric galactic disk perturbed by a constant lopsided halo potential. They showed that the disk self-gravity plays a crucial role in the determination of the net lopsided distribution in the disk. Dolfi et al. (2023) extended this study by considering a larger sample of z = 0 TNG50 disk-like galaxies, located in different environments. They showed that, independently of the environment, while symmetric galaxies are typically assembled at early times (∼8 − 6 Gyr ago), with a relatively short and intense burst of central star formation, lopsided galaxies assembled over a longer time periods, with less prominent initial bursts and a subsequent milder and constant star formation rate up to z = 0.
Large current and upcoming observational surveys, such as S-Plus (Mendes de Oliveira et al. 2019), J-Plus (Cenarro et al. 2019), J-PAS (Benitez et al. 2014), and LSST (Ivezić et al. 2019), will enable us to identify and characterize lopsidedness in a very large number of well-resolved galaxies in the local Universe. This will be crucial to further study the connection between such perturbation and the internal galaxy properties, and to test current model predictions and understand the origin of lopsidedness considering their star formation history in relation with the environment. However, as the volume of data increases, using traditional approaches to study and characterize this non-axisymmetry, such as visual inspection (e.g., Baldwin et al. 1980; Richter & Sacisi 1994), the identification of surface brightness residuals with respect to unperturbed distributions (e.g., Conselice et al. 2000), and Fourier decomposition (e.g., Zaritsky & Rix 1997; Reichard et al. 2008), can become a limiting task. All these techniques require human supervision and intervention (such as visual inspection), and thus result in cumbersome and slow approach to study lopsidedness in larger volumes of data, which could also result in missing important information or discoveries.
To avoid this problem, machine learning algorithms are a helpful tool used to automate and speed up the classification of objects such as galaxies. Different algorithms can be used for different tasks depending on the problem to solve. In particular, some methods are defined as supervised, as they require a subsample of already labeled data to train and test a model, generally referred as training set. A few of these algorithms consist of ensemble methods, such as random forests (Breiman 2001) and gradient boosting (Friedman 2001), artificial neural networks, such as convolutional neural networks (O’Shea & Nash 2015) and recurrent neural networks (Rumelhart & McClelland 1987), distance-based algorithms, such as nearest-neighbor algorithms (Cover & Hart 1967), among others. Some examples of their application are morphological classification of galaxies (Ball et al. 2004; Dieleman et al. 2015; Huertas-Company et al. 2015; Farias et al. 2020), classification of variable stars using time-domain (Aguirre et al. 2019; Monsalves et al. 2024), and the estimation of photometric redshifts (Zhang et al. 2013; Lee & Shin 2021). On the other hand, unsupervised algorithms such as clustering, such as k-means (Lloyd 1982) and hierarchical clustering (Guha et al. 2000), and dimensional reduction algorithms, for example principal component analysis (Jolliffe 2002), are trained with unlabeled data. They are typically employed for anomaly detection (Baron & Poznanski 2017; Giles & Walkowicz 2019; Sarkar et al. 2022), feature selection (Zheng & Zhang 2008) and extraction (Wang et al. 2017), and even galaxy classification (Hocking et al. 2018).
Given the strong previously reported correlation between lopsidedness and the structural properties of galaxies, this paper aims to use using machine learning techniques to automatically classify galaxies as lopsided and symmetric by only using their internal properties. Our goal is to develop a machine learning classifier algorithm designed as a fast preselection tool rather than a replacement for other methods that provide crucial information such as a Fourier decomposition. We also seek to explore whether an accurate classification of this asymmetry can be obtained without including any direct information regarding the environment inhabited by the galaxies. Our selected machine learning algorithms were trained and tested over a large sample of galaxies obtained from the IllustrisTNG simulation. We also determined the key parameters that enable the correct classification of lopsided galaxies. The organization of this paper is as follows. In Sect. 2 we list the selection criteria to obtain the internal and observational parameters of disk-like galaxies extracted from the TNG50-1 simulation. In Sect. 3 we describe the procedure we follow to implement the classification algorithms. In Sect. 4 we list and analyze our results. The conclusions and discussion are finally presented in Sect. 5.
2. Data
In this section we present the criteria to select the necessary dataset to train and test our selected pre-classification models, discussed in Sect. 3.2. In particular, we use galaxy models extracted from the fully cosmological simulation, Illustris TNG50 (Nelson et al. 2019a; Pillepich et al. 2019). For each galaxy model, we compute internal parameters that are commonly measured in observational studies to classify galaxies’ morphology.
2.1. The IllustrisTNG project
IllustrisTNG (hereafter TNG), successor of the Illustris project (Genel et al. 2014; Vogelsberger et al. 2014; Nelson et al. 2015), is a set of cosmological, gravo-magnetohydrodynamical simulation run with the moving-mesh code AREPO (Springel 2010). IllustisTNG builds upon its predecessor model (Genel et al. 2014) by incorporating an updated physical model (Pillepich et al. 2018) which accounts for stellar evolution, gas cooling, feedback and growth from supermassive blackholes, among others. In particular, the improved model for the feedback of the low accretion mode in supermassive black holes resulted in a reduction of the discrepancies with observational constraints identified in the original Illustris simulations, such as the galaxy color bimodality (Nelson et al. 2018). These improvements make IllustrisTNG a powerful tool for comparisons with observational data.
TNG consists of three simulations with different volumes: 503 Mpc, 1003 Mpc, and 3003 Mpc, referred as TNG50, TNG100, and TNG300, respectively. Each simulation was run with different mass and spatial resolution. As a result, the three realizations complement each other. The largest simulation box, TNG300, enables the study of galaxy clustering and provides the largest statistical galaxy sample. On the other hand, TNG50 provides the smallest galaxy sample at the high mass end, but it has the highest mass resolution overall. Therefore, it enables a more detailed look at the morphology of galaxies and its structural properties. TNG-100 falls somewhere in between these two other simulations.
In this work, due to its mass and spatial resolution, we make use of the publicly available TNG50-1 model (Pillepich et al. 2019; Nelson et al. 2019a). Having a dark matter and baryonic mass resolution of 4.5 × 105 M⊙ and 8.5 × 104 M⊙, respectively, TNG50-1 allow us to resolve the structure of 109 M⊙ stellar disk with at least 104 stellar particles, enabling a better characterization of their morphology (Nelson et al. 2019b).
The cosmological model adopted in IllustrisTNG is a flat ΛCDM Universe with the following parameters: Hubble constant H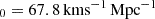 , total matter density Ωm = 0.3089, dark energy density ΩΛ = 0.6911, baryonic matter density Ωb = 0.0486, rms of mass fluctuations at a scale of 8
, total matter density Ωm = 0.3089, dark energy density ΩΛ = 0.6911, baryonic matter density Ωb = 0.0486, rms of mass fluctuations at a scale of 8 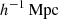 σ8 = 0.8159, and a primordial spectral index ns = 0.9667 (Planck Collaboration XIII 2016).
σ8 = 0.8159, and a primordial spectral index ns = 0.9667 (Planck Collaboration XIII 2016).
2.2. Selection criteria
We focus our study on central and satellite disk-like galaxies, identified within the redshift range z = 0 to z = 0.5. The z range considered allow us to obtain a large number of galaxy models to train our classification algorithm. Note that, even though a given galaxy will be present at different snapshots of the simulation, their detailed structure will evolve (see e.g., Varela-Lavin et al. 2023) and, thus, it will serve as input for the training process.
Following Dolfi et al. (2023) based on our selection criteria, we consider galaxies with:
-
Ntot,stars ≥ 104, where Ntot, stars represents the number of bound stellar particles. This is used to make sure that galaxies have enough stellar particles to be reasonably well resolved. Considering that the baryonic mass resolution is ∼ 105 M⊙, as mentioned before, the minimum stellar mass considered is ≳109 M⊙.
-
fe > 0.4, where fe represents the circularity fraction, defined as the fractional mass of the stellar particles with circularity ϵ > 0.7. The latter has previously shown to reliably select orbits confined to a disk (Aumer et al. 2013). fe kinematically quantifies the disk’s shape, thus ensuring that the galaxies selected are considered “disky” (Joshi et al. 2020).
-
R90 ≥ 3 kpc. This ensures that the structure of the galactic disk is clearly resolved.
These criteria result in a sample of 7919 late-type galaxies. In Table 1 we list the parameters measured from each galaxy that are later used to train our pre-classification models. These parameters are computed as described in Dolfi et al. (2023), and references there in. Note that all selected parameters characterize galaxies internal properties and do not explicitly account for the environment in which the galaxies are located. Moreover, previous works have shown that some of these parameters, such as the disk central stellar density, μ*, and its extension, Rext, are expected to be strongly linked to the occurrence of lopsided perturbations. In Fig. 1 we quantify the Pearson Correlation Coefficient between the listed parameters. Checking the parameters’ correlation is an important first step to ensure an accurate representation of the classifier’s results, as having highly correlated data (Pearson correlation values of 1 and −1) can lead to a misinterpretation of the importance of some parameters. In our case, we note that our parameters do not show a strong correlation, with the exception of R50 and Rext, which have a score of 0.88. This suggests that there is no issue in applying all the selected parameters in our classifier.
List of the internal parameters of the 7919 disk-like galaxies obtained from TNG50-1.
3. Methods
In this work we make use of the random forest (hereafter RF; Breiman 2001) algorithm and its variations to study our selected dataset. Since we deal with a supervised algorithm, it is necessary to count with a training and testing set where galaxies are already labeled as lopsided or symmetric galaxies. A Fourier decomposition of the light/mass distribution is often used to quantify asymmetries (Zaritsky & Rix 1997; Reichard et al. 2008; Varela-Lavin et al. 2023; Dolfi et al. 2023). We used the radial distribution of the m = 1 mode to label our dataset. To prepare our data before applying it to the models, we partitioned the dataset into a training set and a testing set comprising 70% and 30% of the total sample, respectively. To do so, we employed STRATIFIEDSHUFFLESPLIT from SCIKIT-LEARN1.
In this section we first discuss how lopsidedness is measured in our models, and then introduce and summarize the main characteristics of random forests and its variations. We also discuss our particular application and the metrics used to measure its performance.
3.1. Measuring lopsidedness
To label the galaxies in our sample between lopsided and symmetric, we applied a Fourier decomposition. To do so, we measure the amplitude of the first mode m = 1 of the stellar disk density distribution, A1, which quantifies the asymmetry of the stellar mass distribution. Before doing so, we took into account a few considerations. First, it is crucial to ensure that each galaxy is projected face-on, as the Fourier decomposition is highly sensitive to the disk inclination. To do so, we rotated each galaxy such as the z axis was aligned with the disk angular momentum vector. Secondly, to focus our analysis on stellar disks, we consider only stellar participles located within a cylinder of width equal to 1.4R90, and a height equal to 2h90. Here, h90 is defined as the vertical distance above and below the disk plane enclosing 90% of the total galaxy stellar mass. The adopted definition for the disk extent allows us to reach their outer regions without introducing contamination from the stellar halo. We have tested several definitions for the disk extent, and found that, overall, the results are not significantly affected by our definition.
The Fourier decomposition for the stellar mass distribution was calculated as follows:
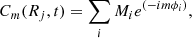
where Mi and ϕi are the mass and the azimuthal coordinate of the i-th stellar particle, respectively. The A1 radial profile is then calculated as follows:
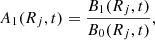
where B1(Rj, t) and B0(Rj, t) are the amplitude, or strength, of the m = 1 and m = 0 mode, respectively, within a certain radius, Rj, and a certain snapshot, t. In general, the amplitude of the Fourier decomposition is given by:
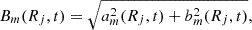
where am(Rj, t) and bm(Rj, t) are defined as the real and imaginary values of Cm(Rj, t) for the m-th mode, respectively.
The averaged value of A1(R, t) (hereafter A1) at a given time, t, and over a certain radial interval is then used as the global or large-scale lopsidedness indicator. In general, if A1 > 0.1, the galaxy is considered lopsided. For values of A1 < 0.1 galaxies are considered symmetric. This threshold has been widely adopted in the literature, where both large observational and simulated galaxies were considered (e.g., Jog & Combes 2009; Reichard et al. 2008; Varela-Lavin et al. 2023; Dolfi et al. 2023). The radial interval considered to calculate the global A1 parameter has varied between different works. For instance, Zaritsky & Rix (1997) studied the lopsidedness distribution of a sample of 60 field spiral galaxies, using the radial interval of (1.5−2.5) disk scale lengths. On the other hand, Reichard et al. (2008) measured the lopsidedness of a sample obtained from SDSS in the radial interval R50–R90. van Eymeren et al. (2011) reached distances up to 4–5 disk scale lengths to study the asymmetries of the disks’ outer regions. In our case, we use R50 − 1.4R90, as we find that this radial interval best represent the non-axisymmetry of the sample.
As an example of the classification made by A1, Fig. 2 shows the face-on projections of the surface brightness distribution in the V-band of two clearly classified cases. Here the dashed and cyan lines indicate the lower and upper radial limits, respectively, considered to compute A1. Considering their respective A1 values, the galaxy on the left is classified as a strong symmetric example with A1 = 0.02, while the galaxy on the right is classified as a strong lopsided example with a value of A1 = 0.36.
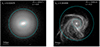 |
Fig. 2. V-band face-on projected surface brightness distribution of a symmetric (left) and lopsided (right) galaxy, considered as examples of the classification made by A1. Their respective A1 value, ID (as in TNG50-1), and redshift snapshot are plotted on the upper side. On the lower left, the box size considered for each galaxy is also plotted. For both images, the dashed cyan line represents the radius R50 and the solid cyan line represents the radius 1.4R90, which are the limits of the radial interval used in the Fourier decomposition. |
The resulting A1 distribution of our sample is shown in Fig. 3. The light blue and orange shaded areas indicate the distribution for symmetric and lopsided classified galaxies, based on the selected A1 threshold (black line). Notably, our sample is imbalanced; meaning that we have a higher quantity of lopsided galaxies with respect to the symmetric cases. Out of the total sample size of 7919 galaxies, 5273 (i.e., ∼65%) are classified as lopsided, while 2646 (i.e., ∼35%) as symmetric. We note that we find a larger fraction of lopsided galaxies than observations in the local Universe (e.g., ∼30%; Zaritsky & Rix 1997; Reichard et al. 2008). As previously discussed in Dolfi et al. (2023), this difference can be likely attributed to the different radial interval used to measure the global lopsidedness A1. For this reason, we are finding a larger fraction of lopsided galaxies than observations, due to the fact that we are reaching out to larger galactocentric radii where the lopsided amplitude is stronger (see also Varela-Lavin et al. 2023). The resulting imbalance imposes a great challenge for the training and testing of our selected machine learning algorithms. In the following section, we dive deeper into this issue and describe the methods we use to address it.
 |
Fig. 3. A1 distribution of our total sample. A1 is defined as the averaged strength of the m = 1 mode of the Fourier decomposition for each stellar particle within the radial range R50 − 1.4R90. The black line represents the threshold used to distinguish between lopsided (orange) and symmetric galaxies (blue). The dashed distributions represent the incorrect classifications of the galaxies made by SMOTE + RF for testing set, as we discuss later in Sect. 4. The dashed purple distribution represents the actual symmetric galaxies classified by the model as lopsided galaxies |


Lastly, Fig. 4 shows the distribution of our selected parameters, subdividing both types of galaxies to stress their differences. The dashed lines indicate the median of the corresponding distributions. The first and second top panels show the distributions of μ* and TP. It is evident that the two galaxy types show the largest differences in these two parameters. As expected, lopsided galaxies typically show significantly smaller μ* than their symmetric counterparts. Similarly, lopsided galaxies exhibit smaller values of TP. This trends are in agreement with previous results (Reichard et al. 2008; Zaritsky et al. 2013; Varela-Lavin et al. 2023) that highlighted that both types of galaxies are indeed characterized by different internal structures.
 |
Fig. 4. Distribution of parameters selected to characterize our galaxy sample. These parameters are used as features by the random forest classifier. The orange and blue distributions represent lopsided and symmetric galaxies, respectively. The dashed colored lines represent their respective median. |
3.2. Classification algorithms
RF is a type of supervised algorithm that poses a great advantage in the automation of different classification and regression tasks. For instance, it can describe different complexity relations between the parameters, or features, of a sample considering their assigned label. It can also works with a wide variety of different datasets and sizes, among other advantages. In the case of astronomy, it is clear that the use of machine learning algorithms, such as random forests, have grown as a result of the exponential increase in data with the current and next-generation surveys and telescopes. As application examples, random forests pose a great alternative to classify different sources in different wavelengths (Gao et al. 2009), estimation of photometric redshifts (Carliles et al. 2010), perform automatic classification of light curves of variable stars (Sánchez-Sáez et al. 2021), predict underlying gas conditions of the circumgalactic medium (Appleby et al. 2023), identify galaxy mergers (Guzmán-Ortega et al. 2023) and estimate different galaxies’ physical properties (Mucesh et al. 2021), among other applications.
RF consists of an ensemble, or collection, of decision trees. A decision tree is a tree-like predictive model composed of nodes, where the sample is recursively divided by conditions in the form of xi(j) < Xj, the latter being the j-th feature and xi(j) a certain threshold based on the j-th feature. In other words, decision trees divide the input space, which depends on the selected feature/s by the decision tree, to create subspaces that are able to differentiate between the different classes. The quality of this division is measured by the “purity” of the subspace, where the purer it is, the more datapoints from the same class are assigned. The final nodes, called leaves or terminal nodes, result from either fully partitioning the sample or until all leaves have less than the minimum quantity to split a node, which is determined by a certain parameter in the tuning process, discussed below. For classification tasks, these final nodes provide predictions of a certain class based on the resulting probability or, in the case of regression tasks, they provide a numeric value. This process is done firstly on a learning set, or training set, where then a new unseen dataset is propagated over the tree to predict the corresponding class or numeric value.
Although decision trees have numerous advantages due to their intrinsic nature (e.g., they can be used by any kind of sample, they have an easy hyperparameter customization or tuning, and they also estimate the feature importance aside from class predictions), they are easy to overfit. This means that a decision tree may be less accurate when predicting unseen data during testing, as the model tends to overly fit to the training set. RF avoids this issue by training non-correlated decision trees, each on a subsample with replacement of the training set, thus reducing the variance while maintaining high accuracy. For a binary classification task, which is our focus, each decision tree classifies the data as either positive or negative class. Then, the final prediction of the RF is the class predicted by more than half of the trees. This method is called bagging or bootstrap aggregating (Breiman 1996).
Due to our dataset being imbalanced, as seen in Fig. 3, using a RF classifier could lead to an inaccurate classification. The training and testing of the random forests are performed considering bootstrapped samples of the corresponding data sets. As each sample follows the same distribution as the original dataset, the majority class would have more predictions in favor, thus having more accurate results than the minority class. To avoid this issue affecting our results, we employ two different algorithms. The first one consists on oversampling the minority class of the training set and then apply it to a RF classifier. To do the oversampling, we use SMOTE (Bowyer et al. 2011) from IMBALANCED-LEARN2. This method creates new “synthetic” data by interpolation between two close datapoints in the multidimensional feature space; in our case, a 10 dimensional feature space. The second algorithm consists of using Balanced Random Forests (hereafter BRF; Chen & Breiman 2004), where we use the BALANCEDRANDOMFORESTCLASSIFIER method from IMBALANCED-LEARN. In this case, the bootstrapped sample is only considered for the minority class, whereas the majority class is randomly sampled with replacement, matching the size of the minority class. This avoids manually oversampling the dataset and it is directly performed by each decision tree.
To have an optimal performance of both classifiers using our datasets, we perform an hyperparameter tuning. This involves finding the best combination of parameters from the models to yield the best results. The hyperparameters involved in the fitting of the RF classifiers are listed in Table 2 with their respective results. To tune both models, we use RANDOMIZEDSEARCHCV with number of iterations niter = 10 and, as cross-validation, REPEATEDSTRATIFIEDKFOLD with number of repeats nrepeat = 10 and number of splits nsplits = 5. For SMOTE + RF and BRF, we use the default values of niter, nrepeat, and nsplits. To avoid unnecessary complexity in the calculations, we retain the default values for the current and following analysis. For the tuning process, we select a range of possible values for each hyperparameter and then apply it to the randomized search. This generates random combinations of hyperparameters and selects the combination that yields the best performance based on a chosen metric, which in our case is balanced accuracy. It is worth highlighting the significant difference in the number of trees between both classifiers, where SMOTE + RF has 1500 trees in comparison with BRF, which only has 128. This discrepancy in the number of trees might be attributed to the added complexity and variability introduced to the minority class by the SMOTE oversampling process. As it creates synthetic data, the complexity and variability of the sample increases, requiring SMOTE + RF to utilize a larger ensemble of trees to effectively generalize the data and achieve robust results.
Results of the hyperparameter tuning using RANDOMIZED-SEARCHCV for each model, SMOTE + RF and BRF.
3.3. Evaluation metrics
To measure the performance of both SMOTE + RF and BRF, we used the following metrics considering the use of binary classifiers:
-
Precision: Ratio of the number of correctly predicted positive class to the total number of predicted positive class. Expressed as:
where TP represents true positives (i.e., symmetric galaxies with A1 < 0.1 pre-classified as symmetric by our selected models) and FP represents false positives (i.e., lopsided galaxies with A1 > 0.1 pre-classified as symmetric).
-
TPR: Ratio of the number of correctly predicted positive class to the number of actual positive class. Expressed as:
where FN represents false negatives (i.e., symmetric galaxies with A1 < 0.1 pre-classified as lopsided by our models).
-
F1-score: Harmonic mean of precision and TPR. Expressed as:
-
True negative rate (TNR) or specificity: Ratio of the correctly predicted negative class to the total number of the actual negative class. Expressed as:
where TN represents true negatives (i.e., lopsided galaxies with A1 > 0.1 pre-classified as lopsided by our models).
-
Balanced accuracy: Average of the recall obtained for each class. Expressed as:
-
Geometric mean (G-mean): Square root of TNR and TPR. Expressed as:
-
ROC-AUC: Calculates the area under the Receiver Operating Characteristic (ROC) curve, by using the trapezoidal rule, which approximates the area under the curve as a series of trapezoids. Considering a series of points in the ROC curve, in the form of (x1, yi),(x2, y2),…,(xN, yN), the area under the curve is expressed as:
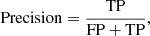
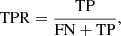
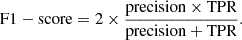
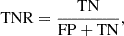
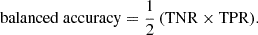
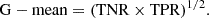
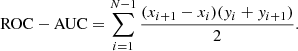
The selected metrics are used to evaluate the results of our classifiers. In particular, precision, TPR, and F1-score are important metrics to evaluate the performance of any type of model. However, these metrics are all sensitive to imbalanced dataset. As a result, they could mislead the algorithm during the training and validation process. To avoid this, we focus the analysis of our classifiers to TNR, balanced accuracy, and G-mean. These metrics are selected following Chen & Breiman (2004) work, which ensure a correct analysis due to the imbalanced nature of our dataset. Lastly, we also consider ROC-AUC for the analysis, as it gives us an important insight on how the model is performing without any effect of the imbalance. Still, we present the values for TPR, precision, and F1-score, as a reference.
4. Results and analysis
In this section we introduce and analyze the results of the RF algorithm trained to pre-classified subsamples of lopsided and symmetric galaxies. The quantification of its accuracy was performed by contrasting against the galaxies A1 values on each pre-classified subsample. We then explored in detail the most common caused behind misclassifications.
4.1. Classification results
As a brief outline of our classification pipeline, we train the classifiers mentioned in Sect. 3.2 with 5542 galaxies, constituting ∼70% of the total sample. This enables the algorithm to obtain important underlying patterns and/or relationships between the galaxies and their features, which are then used for the prediction in the final step. The remaining galaxies are consider for the testing set, which compromises a total of 2377 galaxies, or 30% of the remaining sample. For each galaxy, these decision trees produce a class prediction, either lopsided or symmetric. The class that is predicted in more than half of the decision trees is taken as the final prediction for that galaxy. Due to the imbalanced nature of our dataset, we define lopsided as the negative class and symmetric galaxies as the positive class. Usually, the majority class is better represented and naturally favorable by the algorithm over the minority class. To avoid this problem, we designate the minority class as the positive class, which helps with the interpretability of metrics, such as TPR, precision, and ROC-AUC for rare cases. Since we also obtain a proxy of the probability of a galaxy being in the positive/negative class, we test different thresholds, or cut-offs, to classify the samples and to explore how such a threshold can affect our results. As a default, this threshold is set at 0.5. Galaxies with probabilities equal or greater than 0.5 are labeled as the positive class or, in our case, symmetric galaxies. Galaxies with probabilities lower than this value are labeled as the negative class, in our case being lopsided galaxies. Our analysis showed that differences in the results obtained between the different cut-offs is negligible. Therefore, the following analysis was performed with the default value, 0.5, for SMOTE + RF and BRF. We emphasize that the random forest classifier is designed as a fast pre-selection tool rather than a replacement for a Fourier decomposition, and thus we consider the results given by our models as a “preselection” or “preclassification”.
The results of each model’s performance for the testing set are listed in Table 3. Each value of the metrics is obtained by averaging the result scores of each iteration of a cross-validation with number of iterations niter = 10 and taking into consideration its standard deviation. It is clear that both classifiers provide similar results, with comparable values in most metrics. Based on this, we select as our classifier SMOTE + RF since it results in a better TNR metric. As previously discussed, we are working with an imbalanced data set, with more than 70% of the data belonging to the negative class (lopsided objects). Thus, a high TNR indicates a better performance for the most populated class of our sample.
Metric scores of the selected model, SMOTE + RF, applied to the testing set.
Fig. 5 shows the confusion matrix (CM) for SMOTE + RF. The x axis indicates the predicted class or label, obtained from the classifier, and the y axis shows the actual class or label, obtained from the A1 parameter. In general, a CM allows us to visually inspect the fractions of correct and incorrect classification we have obtained. In our testing sample, and based on our A1 classification criteria, we count with 1578 true lopsided and a total of 799 true symmetric galaxies. Interestingly, our classifier is able to correctly pre-classify 81% of the lopsided objects and approximately the same amount for their symmetric counterparts. In absolute number, we obtain a total of 1922 correctly pre-classified galaxies, against 455 incorrectly pre-classified objects. It is worth highlighting the very good performance of the SMOTE + RF classifier, which has been purely obtained based on features that are related to our simulated galaxies internal properties. No information about environments has been introduced during the training process.
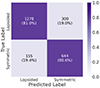 |
Fig. 5. Confusion matrix for the testing set of the best model, SMOTE + RF. The x axis is the predicted class or predicted label, and the y axis is the actual class or actual label. The percentage with respect each type of galaxy set is on parenthesis. |
4.2. Interpretation of the random forest classification
Supervised algorithms, including RF algorithms, suffer from interpretability of the decisions leading to the classification. This is often called the “black box” problem. In RF, it arises due to the high quantity of decision trees added to the ensemble. In this section we interpret and analyze the decisions lead by the model to pre-select the galaxies between lopsided and symmetric by ranking the importance of the features used in the classification process.
We used the PERMUTATION_IMPORTANCE_ attribute from RANDOMFORESTCLASSIFIER. There are various methods of ranking feature importance, but given the continuous nature of our dataset, where no categorical features are used for training or testing, we rely solely on PERMUTATION_IMPORTANCE_. This attribute works by permuting, or shuffling, the values of each feature and calculating the resulting decrease in a specified metric, which by default is accuracy, defined as the fraction or count of the correct predictions. The decrease in the score is then used to rank each feature: the higher the score, the more it affects the model’s performance, thus making the feature important for the model to maintain a higher accuracy. However, since our dataset is imbalanced, using accuracy would not return an accurate representation of the importance of our features. To address this issue, we use balanced-accuracy instead. As discussed in Sect. 3.3, this metric represents the averaged fraction of correct classified galaxies for both the negative and positive class. In this, each class contribute equally to the final score, regardless of its size. Considering that the accuracy metric disproportionately favors the majority class in imbalanced datasets due to its overrepresentation, balanced accuracy is great alternative to avoid inaccurate results.
The results of this procedure are shown in Table 4, where it lists the rank of each feature obtained by PERMUTATION_IMPORTANCE_. Considering that we want to focus on the performance of SMOTE + RF with unseen data, we only calculate the feature importance for the testing set. We obtain each score by averaging the iterations of a cross-validation with niter = 5 and taking into consideration its standard deviation. This analysis clearly shows that both μ* and TP are the highest-ranked parameters, with μ* ranked first and TP ranked second. As a way to better visualize this, Fig. 6 also shows the variation of balanced-accuracy with a box plot. Each box represents the distribution of the score value for each iteration. The dotted line inside each box is the median of the distribution, and each whisker represents the first and last score value. Indeed, we note that μ* is the top-ranked parameter overall, indicating that it is the most important parameter to consider in the classification process made by SMOTE + RF. As we previously mentioned, and as seen in Fig. 4, lopsided and symmetric galaxies are characterized by different μ* distributions. This is in agreement with previous results (Reichard et al. 2008; Zaritsky et al. 2013; Varela-Lavin et al. 2023; Dolfi et al. 2023), where lopsided galaxies tend to show significantly lower a densities in the inner regions (as defined by their R50) with respect to the symmetric counterparts.
 |
Fig. 6. Box plot of each feature from the testing set, ranked by their importance as determined by the feature permutation attribute from SMOTE + RF. Each box represents the range of the different scores obtained from a cross-validation with niter = 5. The inner dashed line represents the median value of each distribution. The whiskers on each box represent the minimum and maximum value of each distribution. |
Feature Importance of each parameter calculated by PERMUTATION_IMPORTANCE_ for SMOTE + RF.
Although not as important as μ*, TP and SFR also play an important role in the classification process in comparison with the rest of the features. This is also in agreement with previous results, where an (anti) correlation between lopsidedness and TP (e.g., Gómez et al. 2016) and a correlation between lopsidedness and SFR (e.g., Conselice et al. 2000) have been reported. In particular, TP represents a proxy of the tidal force exerted by the inner galactic regions on the outer disk material. In other words, it indicates how gravitationally cohesive a galaxy is. The relevance of this parameter is clearly reflected in the separation between the distribution of both types of galaxies, as previously seen in Fig. 4, where lopsided galaxies tend to have lower values of TP than symmetric galaxies. These findings align with the conclusions of Varela-Lavin et al. (2023) and Dolfi et al. (2023), which propose that lopsided perturbations serve as indicators of intrinsic galaxy properties, rather than being predominantly driven by environmental processes. In other words, galaxies with low central stellar densities are weakly gravitationally cohesive and, thus, are more susceptible to lopsided perturbations, independently of a particular perturbing agent. On the other hand, SFR ranking third place is an interesting result, as it is been shown that there is a correlation between A1 and current SFR (Zaritsky & Rix 1997; Rudnick et al. 2000; Reichard et al. 2009). As discussed by Łokas (2022), some internal properties of lopsided and symmetric galaxies can be linked with their current SFR, such as lopsided galaxies having bluer colors, larger gas fractions, and lower metallicity than symmetric galaxies. Moreover, Dolfi et al. (2023) showed that lopsided galaxies tend to be, on average, significantly more star forming than symmetric galaxies at later times. Symmetric galaxies, on the contrary, have an earlier assembly with shorter and more intense star forming bursts. As a result, and considering galaxies with similar stellar masses at the present-day, while symmetric galaxies tend to develop a more pronounced central region at earlier times, lopsided galaxies tend to form a larger fraction of their stellar populations later, typically developing a more extended stellar disk and less dense inner regions. Lastly, Fig. 6 shows the relative importance of the remaining 7 features. It is clear that they have a minimal impact on the classification procedure.
To analyze the classification made by SMOTE + RF, we plot in Fig. 7 the median of A1 as a function of radius for the four cases defined by the classifier. To generate this figure, the radial extension of each simulated galaxy was normalized by its corresponding R90. We focus on the radial interval (0.5 − 1.4)R90, as it is the considered interval for the Fourier decomposition. The shaded areas represent the 25th and 75th percentiles of the distribution. In the left plot, the fuchsia distribution represents true lopsided galaxies pre-classified by our model as lopsided, 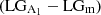 , whereas the purple distribution represent true lopsided galaxies pre-classified by our model as symmetric,
, whereas the purple distribution represent true lopsided galaxies pre-classified by our model as symmetric,  . The right plot is the same as the left one but for symmetric galaxies. Here, the cyan color represent the distribution of true symmetric galaxies pre-classified by our model as symmetric,
. The right plot is the same as the left one but for symmetric galaxies. Here, the cyan color represent the distribution of true symmetric galaxies pre-classified by our model as symmetric, 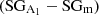 , while in green we show true symmetric galaxies pre-classified by our model as lopsided,
, while in green we show true symmetric galaxies pre-classified by our model as lopsided,  . We note that both incorrectly classified cases,
. We note that both incorrectly classified cases,  and
and  , do not follow the same trend as the correctly classified distributions. In the case of
, do not follow the same trend as the correctly classified distributions. In the case of 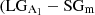 ) on the left plot, from 0.5R90 to 0.9R90 the magnitude of A1 starts increasing at the same rate than the correctly classified sample. However, from 0.9R90 onward, the slope is less steep, meaning that the magnitude of A1 does not increase as much as in
) on the left plot, from 0.5R90 to 0.9R90 the magnitude of A1 starts increasing at the same rate than the correctly classified sample. However, from 0.9R90 onward, the slope is less steep, meaning that the magnitude of A1 does not increase as much as in 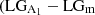 ). In other words, while incorrectly classified galaxies have indeed an outer perturbed region, the strength of the perturbations is typically weaker with respect to correctly classified galaxies. On the right panel we show that the A1 profile of both correctly
). In other words, while incorrectly classified galaxies have indeed an outer perturbed region, the strength of the perturbations is typically weaker with respect to correctly classified galaxies. On the right panel we show that the A1 profile of both correctly 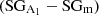 and incorrectly classified galaxies
and incorrectly classified galaxies  remains below the 0.1 threshold chosen to classify lopsided galaxies based on the A1 parameter. Nonetheless, incorrectly classified symmetric galaxies tend to have larger A1 values at all radii and they do cross the threshold at the outermost edge. In the following section we explore in detail the main reasons that drove the SMOTE + RF method to misclassify these galaxies.
remains below the 0.1 threshold chosen to classify lopsided galaxies based on the A1 parameter. Nonetheless, incorrectly classified symmetric galaxies tend to have larger A1 values at all radii and they do cross the threshold at the outermost edge. In the following section we explore in detail the main reasons that drove the SMOTE + RF method to misclassify these galaxies.
 |
Fig. 7. Radial profiles of A1 for our four classification cases, calculated as the median of A1 for each bin with respect to R90. The fuchsia and blue distributions represent the correctly classified lopsided galaxies |
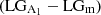
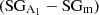


4.3. Interpretation of the misclassified cases
In the previous section we analyzed the results of applying RFs algorithms to the internal parameters of our selected sample of lopsided and symmetric galaxies. In particular, we find that the μ* and TP parameters are the primary features used by the classifier to classify galaxies as either lopsided or symmetric, consistent with previous observational studies. However, there are 455 galaxies in the testing set that are misclassified. In this section, we focus on the misclassified cases,  and
and  , to investigate the underlying reasons behind the misclassification.
, to investigate the underlying reasons behind the misclassification.
To further study the incorrectly classified galaxies, in Fig. 3 we highlight their A1 distributions. Again, the dashed purple distribution represents true lopsided galaxies pre-classified as symmetric galaxies  with a median of ∼0.09. The dashed green distribution represents true symmetric galaxies pre-classified as lopsided galaxies
with a median of ∼0.09. The dashed green distribution represents true symmetric galaxies pre-classified as lopsided galaxies  with a median of ∼0.12. It is clear that all misclassified galaxies are adjacent to the threshold A1 = 0.1 and, thus, represent challenging cases for our classification models. In Fig. 8 we show the distribution of μ*, TP, and Rext for all the four different classification cases, following the same color coding as in Fig. 7. Each dashed line represents the median of the corresponding distribution. The top panels show the results obtained from the correctly pre-classified galaxy samples by our model. Note that the distributions differ significantly in all three parameters. As expected, the largest differences are found in μ*. However, even the Rext distributions differ, with median values of 11 kpc and 14.3 kpc for symmetric and lopsided galaxies, respectively. The bottom panels show the distributions obtained from the incorrectly pre-classified samples. Two important things stand out. First, the distributions of the three inspected parameters show more significant overlap with respect to the correctly classified sample. The medians are, in all cases, closer to the median of the overall sample. This is most clear in the Rext distributions, where both symmetric and lopsided nearly perfectly overlap with each other. Second, and most importantly, we find that galaxies classified as lopsided by our global A1 parameter, but pre-classified as symmetric by our model
with a median of ∼0.12. It is clear that all misclassified galaxies are adjacent to the threshold A1 = 0.1 and, thus, represent challenging cases for our classification models. In Fig. 8 we show the distribution of μ*, TP, and Rext for all the four different classification cases, following the same color coding as in Fig. 7. Each dashed line represents the median of the corresponding distribution. The top panels show the results obtained from the correctly pre-classified galaxy samples by our model. Note that the distributions differ significantly in all three parameters. As expected, the largest differences are found in μ*. However, even the Rext distributions differ, with median values of 11 kpc and 14.3 kpc for symmetric and lopsided galaxies, respectively. The bottom panels show the distributions obtained from the incorrectly pre-classified samples. Two important things stand out. First, the distributions of the three inspected parameters show more significant overlap with respect to the correctly classified sample. The medians are, in all cases, closer to the median of the overall sample. This is most clear in the Rext distributions, where both symmetric and lopsided nearly perfectly overlap with each other. Second, and most importantly, we find that galaxies classified as lopsided by our global A1 parameter, but pre-classified as symmetric by our model  , have values of μ* and TP that are consistent with the distribution of correctly classified symmetric galaxies. In other words, they have relatively large central surface density and TP values. Upon closer inspection of their images, we observe that such galaxies typically display a symmetric overall disk, but a significant asymmetry in their outermost region. An example of such a galaxy is shown in the top right panel of Fig. 9. These localized asymmetries, captured by the global A1 parameter, do not necessarily reflect the overall structure of the disk and can be caused by recent episodes of gas accretion or very recent strong interactions. On the other hand, galaxies classified as symmetric by the global A1 parameter but pre-classified as lopsided by our model
, have values of μ* and TP that are consistent with the distribution of correctly classified symmetric galaxies. In other words, they have relatively large central surface density and TP values. Upon closer inspection of their images, we observe that such galaxies typically display a symmetric overall disk, but a significant asymmetry in their outermost region. An example of such a galaxy is shown in the top right panel of Fig. 9. These localized asymmetries, captured by the global A1 parameter, do not necessarily reflect the overall structure of the disk and can be caused by recent episodes of gas accretion or very recent strong interactions. On the other hand, galaxies classified as symmetric by the global A1 parameter but pre-classified as lopsided by our model  show low μ* and TP values. Such galaxies display internal properties of typical lopsided galaxies, but simply the morphological perturbation has not yet been triggered. The top left panel of Fig. 9 shows an example of such a situation.
show low μ* and TP values. Such galaxies display internal properties of typical lopsided galaxies, but simply the morphological perturbation has not yet been triggered. The top left panel of Fig. 9 shows an example of such a situation.
 |
Fig. 8. Normalized distribution of μ*(left), TP(middle), and Rext(right), considering the correct (upper) and incorrect (bottom) classification made by SMOTE + RF. Each distribution has been normalized by their corresponding number of galaxies of each subsample. Their respective number of galaxies is in parenthesis. The fuchsia and blue distributions represent the correctly classified lopsided galaxies |
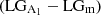
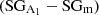


 |
Fig. 9. Top panels: V-band face-on projected surface brightness distribution of a (left) symmetric galaxy pre-classified as lopsided |


To further explore the two examples of misclassified galaxies, in the second and third row of Fig. 9 we show their radial A1 and density profiles, respectively. The cyan regions in the second row highlight the radial interval (0.5–1.4)R90, considered to measure A1. It is worth noting that both galaxies were selected by considering extreme values of μ* and TP while having similar stellar mass. For  , the galaxy shows consistently low A1(R), even up to the disk outermost regions. Interestingly, its inner stellar density is notably lower than expected for a symmetric galaxy. Even its μ*, highlighted with a red star, falls below the mean of the overall sample (dashed magenta line). On the other hand, for
, the galaxy shows consistently low A1(R), even up to the disk outermost regions. Interestingly, its inner stellar density is notably lower than expected for a symmetric galaxy. Even its μ*, highlighted with a red star, falls below the mean of the overall sample (dashed magenta line). On the other hand, for  , while A1(R) shows values consistent with 0 within most of the considered radial range, it shows a very strong rise in the disk outskirts. We note that this galaxy has a denser inner stellar region, highlighted by its large μ* value which significantly surpass the median of the overall distribution.
, while A1(R) shows values consistent with 0 within most of the considered radial range, it shows a very strong rise in the disk outskirts. We note that this galaxy has a denser inner stellar region, highlighted by its large μ* value which significantly surpass the median of the overall distribution.
To understand these unexpected behavior, we explore on the two lower rows the time evolution of the lopsided parameter and the orbital histories. Interestingly, we find that the  galaxy (right panels) became a satellite of a larger host approximately 1.5 Gyr ago. Previous to the pericentric passage, this galaxy showed A1 values below the threshold. After the close interaction, the A1 value rapidly grows as a result of the tidal perturbation of its outer disk. Indeed, we find that this galaxy has internal properties consistent with the symmetric sample, but the strong recent interaction forced an outer tidal disruption, captured by the A1 parameter. In the case of
galaxy (right panels) became a satellite of a larger host approximately 1.5 Gyr ago. Previous to the pericentric passage, this galaxy showed A1 values below the threshold. After the close interaction, the A1 value rapidly grows as a result of the tidal perturbation of its outer disk. Indeed, we find that this galaxy has internal properties consistent with the symmetric sample, but the strong recent interaction forced an outer tidal disruption, captured by the A1 parameter. In the case of  (left panels), the time evolution of A1 shows that, over most of its evolution, this galaxy was indeed strongly lopsided. The initial perturbations was likely induced by significant interaction with a massive satellite galaxy (∼1:10) 6.5 Gyr ago (first pericentric passage). After this point, the galaxy suffered no other interaction with satellite of mass ratios < 1:100. Thus, the lopsided perturbation gradually relaxed, reaching a present-day A1 value below the considered threshold. Even though its internal structure make this galaxy susceptible to lopsided perturbations, the lack of significant external perturbation during its late evolution resulted on a symmetric configuration at the present-day.
(left panels), the time evolution of A1 shows that, over most of its evolution, this galaxy was indeed strongly lopsided. The initial perturbations was likely induced by significant interaction with a massive satellite galaxy (∼1:10) 6.5 Gyr ago (first pericentric passage). After this point, the galaxy suffered no other interaction with satellite of mass ratios < 1:100. Thus, the lopsided perturbation gradually relaxed, reaching a present-day A1 value below the considered threshold. Even though its internal structure make this galaxy susceptible to lopsided perturbations, the lack of significant external perturbation during its late evolution resulted on a symmetric configuration at the present-day.
We note that recent interactions cannot explain all the misclassified cases. Indeed, only 76 of the 300 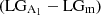 cases are satellite galaxies of a more massive host. Eight (8) additional galaxies have suffered significant interactions (> 1:20) as centrals during the last 3 Gyr. Thus, important interaction can be attributed to this misclassified class in only 28% of the cases. Nonetheless, as previously discussed, other mechanisms such as gas accretion, instability in a counter-rotating disk and torques from an off-centered dark matter halo could be at play in the remaining cases (Jog & Combes 2009). Among these mechanisms, asymmetric gas accretion has been proposed as a common driver of lopsidedness. As shown by Bournaud et al. (2005), interactions and mergers can trigger strong lopsidedness in some cases, but they do not account for all the observed statistical properties, such as a correlation between lopsidedness and the Hubble Type, or a correlation between m = 1 and m = 2 asymmetries, among others. In a follow-up study, we shall focus on the misclassified cases to further the origin of lopsidedness in galaxies with internal properties common to symmetric disks.
cases are satellite galaxies of a more massive host. Eight (8) additional galaxies have suffered significant interactions (> 1:20) as centrals during the last 3 Gyr. Thus, important interaction can be attributed to this misclassified class in only 28% of the cases. Nonetheless, as previously discussed, other mechanisms such as gas accretion, instability in a counter-rotating disk and torques from an off-centered dark matter halo could be at play in the remaining cases (Jog & Combes 2009). Among these mechanisms, asymmetric gas accretion has been proposed as a common driver of lopsidedness. As shown by Bournaud et al. (2005), interactions and mergers can trigger strong lopsidedness in some cases, but they do not account for all the observed statistical properties, such as a correlation between lopsidedness and the Hubble Type, or a correlation between m = 1 and m = 2 asymmetries, among others. In a follow-up study, we shall focus on the misclassified cases to further the origin of lopsidedness in galaxies with internal properties common to symmetric disks.
4.4. Classification with observable parameters
Several of the parameters considered in this work require additional modeling to be estimated. Thus, they cannot be directly obtained from observation based on, for example, photometric data. For example, the calculation of μ* involves the application of additional stellar population models. Indeed, Reichard et al. (2008) calculated the stellar surface mass density following Kauffmann et al. (2003) definition, which considers the stellar mass and the Petrosian half-light radius in the z-band. Their stellar massed were estimated using a method that combines spectral diagnostics of star formation histories with photometric data. Additionally, the tidal parameter, TP, requires an estimation of the total mass enclosed within R50, which involves dynamical modeling of the galaxy.
Despite the importance of these parameters in the classification process, in this section we explore wether it is still possible to obtain a reliable pre-classification of lopsided and symmetric galaxies using parameters that are more readily obtainable from photometric data. We follow the same pipeline mentioned earlier, but we train and test the SMOTE + RF classifier with a subset of features that could be estimated from multiband photometric surveys, such as S-Plus (Mendes de Oliveira et al. 2019) and J-PAS (Benitez et al. 2014). In particular, we replace the parameter M50 by the galaxies r-band luminosity within R50, L50, thus avoiding the need of stellar population models. In addition to L50, we consider as features R50, Rext, c/a, and SFR. The later can be obtained from narrow band photometry around the Hα line through the Kennicut relation (Kennicutt 1998). We keep the same hyperparameters listed in Table 2, along with the same training and testing sets.
The results are presented in Table 5, where it lists the metrics obtained from the testing set. Interestingly, we find very good results, with a performance of the SMOTE + RF algorithm that is only very mildly affected by the limited number of features considered. Indeed, most scores are not significantly affected. Compared to our previous results we find a negligible decrease of 0.4% for balanced accuracy and no change for TNR. Additionally, ROC-AUC has a score of ∼80.9%, which reflects on how well the model is able to differentiate between both classes. As expected, substituting M50 by L50 did not introduced a significant drop in the performance. To further characterize our pre-classification, the left panel of Fig. 10 shows the resulting CM. Note that we obtain a total of 1927 correctly pre-classified galaxies and only 535 incorrectly pre-classified cases, which represent a 15% increase from the previous model. Compared to our previous results, this model improves in the identification of actual lopsided galaxies, but performs slightly worse in pre-classifying actual symmetric galaxies as symmetric. The feature importance ranking is shown on the right panel of Fig. 10, generated with the FEATURE_IMPORTANCE attribute. We find that the most important parameters are now L50, R50 and SFR. As before, c/a provides no significant information for the RF classifier.
Metric scores of the SMOTE + RF model on the testing set, using only observational parameters.
 |
Fig. 10. Left: Confusion matrix of the testing set using SMOTE + RF with only observational parameters. The x axis is the predicted class or predicted label, and the y axis is the actual class or actual label. The percentage with respect each class is on parenthesis. Right: Box plot of each observational feature from the testing set, ranked by their importance as determined by the feature permutation attribute from SMOTE + RF. Each box represents the range of the different scores obtained from a cross-validation with niter = 5. The inner dashed line represents the median value of each distribution. The whiskers on each box represent the minimum and maximum value of each distribution. |
Our results show that using readily available observational parameters offers a simpler and reliable approach to pre-classify lopsidedness in large observational samples of galaxies, without the need of parameters that required additional modeling to be estimated, such as μ* and TP. This approach could be particularly valuable in large-scale surveys such as the ones that will soon be provided by LSST (Ivezić et al. 2019).
5. Conclusions and discussion
In this work we selected a large sample of disk-like galaxies from the IllustrisTNG simulation to develop an algorithm capable of automatically pre-classifying galaxies between lopsided and symmetric. Our main goal was to explore whether this classification can be accurately performed using only internal galactic parameters, thus neglecting information about their present-day environment.
To achieve this we employed the random forest algorithm, a machine learning approach that involves a supervised training process. To label our data as lopsided and symmetric galaxies we employed a Fourier decomposition of the galaxies’ stellar density distribution over the radial interval R50 − 1.4R90. We computed a radially average power of the m = 1 mode, A1, within this range. Galaxies with A1 > 0.1 were classified as lopsided, and the remaining as symmetric. Our sample resulted in a total of 5273 lopsided and 2646 symmetric galaxies. To avoid problems in the classification process due to the imbalanced an nature of the dataset, we employed two variations of the RF algorithm: i) we used SMOTE to oversample symmetric galaxies in the training set, thus evening both classes, and ii) we used the BRF algorithm, which balances both classes on each tree by only bootstrapping the minority class while undersampling the majority. Based on the considered metrics, we selected SMOTE + RF as the best model. The classification resulted in a total of 1922 correctly pre-classified galaxies and 455 incorrectly pre-classified galaxies. This translates in a balanced accuracy of accurate classification rate of ≈80% for both classes. To interpret and understand the different decisions leading the RF to the classification, we used a method of quantifying “features importance”. In particular we utilized an algorithm that randomly permutes the features’ values and calculates the decrease in a certain metric; which in our case we choose balanced-accuracy. We found that, to distinguish between both classes, the three most important parameters for the model are μ*, TP, and SFR. The excellent results obtained by our classifier, trained with features that do not account for the galaxies environment, strongly supports the hypothesis that lopsidedness is mainly a tracer of galaxies internal structures.
Even though our classifier demonstrated a very good performance, we find that ≈20% of the galaxies were misclassified. To study the misclassified cases, we first explore the distribution of the main parameters used by the RF. First, we find that the A1 value of the misclassified cases lies very close to the threshold used to label galaxies as lopsided or symmetric. As a result, these cases are typically associated with “borderline classifications” by A1. Interestingly, we find that the distribution of the most important parameters, such as μ* and Tp are in good agreement with the class they have been associated with by the RF algorithm. In other words, galaxies classified by A1 as lopsided, but pre-classified as symmetric by the RF, have large μ* and Tp values. Conversely, galaxies classified by A1 as symmetric but pre-classified as lopsided by the RF, have low μ* and Tp values.
To further explore why galaxies with large central surface density and strongly cohesive present perturbed outer disk region, we selected a representative case. We find that the selected galaxy became a satellite of a more massive host ≈1.7 Gyr ago. Previous to the crossing of the host virial radius, the galaxy had a symmetric configuration. However, shortly after its first pericentric passage, its outer regions become perturbed due to the strong tidal interaction. Such a strong and recent interaction induced a temporary lopsided perturbation on this galaxy. We find that 28% of this misclassified class are either satellites of a more massive host, or have had a very recent strong tidal interactions with a massive companion (> 1:20). For the other misclassified cases, other mechanism, such as asymmetric gas accretion, must be considered to explain the classifications. We shall further explore this in a follow-up analysis. In the case of galaxies with low μ* and TP that are misclassified as symmetric by the RF algorithm, we find that, typically, they have not experienced recent significant interactions with massive companions. Thus, even though the are susceptible to develop a lopsided perturbation, no external interaction have trigger its onset.
Several parameters considered in this work as features require additional modeling to be estimated. Considering the advent of several surveys such as S-PLUS (Mendes de Oliveira et al. 2019), J-PAS (Benitez et al. 2014), and the LSST (Ivezić et al. 2019), we explored whether the performance of our classifier significantly drops when considering features that can be readily obtained from multiband photometric surveys. In particular, we replaced stellar mass estimates with their corresponding luminosity in the r-band, and dropped parameters such as Tp that involve dynamical modeling to estimate the total galaxy mass within R50. Interestingly, we find the performance of our modeling is very mildly affected, with recovery rates of ≈78%. These results are very promising, as our algorithm could allow us to rapidly preselect samples of lopsided galaxies from large surveys, allowing us to explore, through other methods such as Fourier decomposition, whether lopsidedness in present-day disk galaxies is connected to their specific evolutionary histories, which shaped their distinct internal properties (Dolfi et al. 2023).
Acknowledgments
We thank the anonymous referee again for the valuable comments and suggestions, which have help us improve the final presentation of this manuscript. V.F. and F.A.G. acknowledge support from ANID FONDECYT Regular 1211370 and 1251493. V.F., F.A.G., and A.D. acknowledge support from the ANID Basal Project FB210003, and the HORIZON-MSCA-2021-SE-01 Research and innovation programme under the Marie Sklodowska-Curie grant agreement number 101086388. M.J.A. acknowledge support from the ANID FONDECYT Iniciación 11251912. This article is based on the research for the master’s thesis to obtain the title of MSc. in Astronomy at the University of La Serena. V.F. acknowledges the partial financial support of DIDULS through the project PTE2353855. V.F. also thanks Cristian Vega Martinez for his support on an early version of this project.
References
- Aguirre, C., Pichara, K., & Becker, I. 2019, MNRAS, 482, 5078 [CrossRef] [Google Scholar]
- Appleby, S., Davé, R., Sorini, D., Lovell, C. C., & Lo, K. 2023, MNRAS, 525, 1167 [NASA ADS] [CrossRef] [Google Scholar]
- Aumer, M., White, S. D. M., Naab, T., & Scannapieco, C. 2013, MNRAS, 434, 3142 [Google Scholar]
- Baldwin, J. E., Lynden-Bell, D., & Sancisi, R. 1980, MNRAS, 193, 313 [NASA ADS] [CrossRef] [Google Scholar]
- Ball, N. M., Loveday, J., Fukugita, M., et al. 2004, MNRAS, 348, 1038 [Google Scholar]
- Baron, D., & Poznanski, D. 2017, MNRAS, 465, 4530 [NASA ADS] [CrossRef] [Google Scholar]
- Benitez, N., Dupke, R., Moles, M., et al. 2014, ArXiv e-prints [arXiv:1403.5237] [Google Scholar]
- Bournaud, F., Combes, F., Jog, C. J., & Puerari, I. 2005, A&A, 438, 507 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bowyer, K. W., Chawla, N. V., Hall, L. O., & Kegelmeyer, W. P. 2011, arXiv e-prints [arXiv:1106.1813] [Google Scholar]
- Breiman, L. 1996, Mach. Learn., 24, 123 [Google Scholar]
- Breiman, L. 2001, Mach. Learn., 45, 5 [Google Scholar]
- Carliles, S., Budavári, T., Heinis, S., Priebe, C., & Szalay, A. S. 2010, ApJ, 712, 511 [NASA ADS] [CrossRef] [Google Scholar]
- Cenarro, A. J., Moles, M., Cristóbal-Hornillos, D., et al. 2019, A&A, 622, A176 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chen, C., & Breiman, L. 2004, University of California, Berkeley [Google Scholar]
- Conselice, C. J. 2014, ARA&A, 52, 291 [CrossRef] [Google Scholar]
- Conselice, C. J., Bershady, M. A., & Jangren, A. 2000, ApJ, 529, 886 [NASA ADS] [CrossRef] [Google Scholar]
- Cover, T., & Hart, P. 1967, IEEE Trans. Inf. Theory, 13, 21 [CrossRef] [Google Scholar]
- Dieleman, S., Willett, K. W., & Dambre, J. 2015, MNRAS, 450, 1441 [NASA ADS] [CrossRef] [Google Scholar]
- Dolfi, A., Gómez, F. A., Monachesi, A., et al. 2023, MNRAS, 526, 567 [NASA ADS] [CrossRef] [Google Scholar]
- Erwin, P. 2019, MNRAS, 489, 3553 [NASA ADS] [CrossRef] [Google Scholar]
- Farias, H., Ortiz, D., Damke, G., Jaque Arancibia, M., & Solar, M. 2020, Astron. Comput., 33, 100420 [NASA ADS] [CrossRef] [Google Scholar]
- Friedman, J. H. 2001, Ann. Stat., 29, 1189 [Google Scholar]
- Gao, D., Zhang, Y.-X., & Zhao, Y.-H. 2009, Res. Astron. Astrophys., 9, 220 [Google Scholar]
- Genel, S., Vogelsberger, M., Springel, V., et al. 2014, MNRAS, 445, 175 [Google Scholar]
- Giles, D., & Walkowicz, L. 2019, MNRAS, 484, 834 [Google Scholar]
- Gómez, F. A., White, S. D. M., Marinacci, F., et al. 2016, MNRAS, 456, 2779 [Google Scholar]
- Guha, S., Rastogi, R., & Shim, K. 2000, Inf. Syst., 25, 345 [Google Scholar]
- Guzmán-Ortega, A., Rodriguez-Gomez, V., Snyder, G. F., Chamberlain, K., & Hernquist, L. 2023, MNRAS, 519, 4920 [CrossRef] [Google Scholar]
- Hocking, A., Geach, J. E., Sun, Y., & Davey, N. 2018, MNRAS, 473, 1108 [CrossRef] [Google Scholar]
- Huertas-Company, M., Gravet, R., Cabrera-Vives, G., et al. 2015, ApJS, 221, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Jog, C. J. 1997, ApJ, 488, 642 [NASA ADS] [CrossRef] [Google Scholar]
- Jog, C. J. 1999, ApJ, 522, 661 [CrossRef] [Google Scholar]
- Jog, C. J. 2000, ApJ, 542, 216 [Google Scholar]
- Jog, C. J. 2002, A&A, 391, 471 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jog, C. J., & Combes, F. 2009, Phys. Rep., 471, 75 [NASA ADS] [CrossRef] [Google Scholar]
- Jolliffe, I. T. 2002, Principal Component Analysis, 2nd edn. (Springer) [Google Scholar]
- Joshi, G. D., Pillepich, A., Nelson, D., et al. 2020, MNRAS, 496, 2673 [Google Scholar]
- Kauffmann, G., Heckman, T. M., White, S. D. M., et al. 2003, MNRAS, 341, 33 [Google Scholar]
- Kennicutt, R. C., Jr. 1998, ARA&A, 36, 189 [Google Scholar]
- Kollmeier, J., Anderson, S. F., Blanc, G. A., et al. 2019, BAAS, 51, 274 [NASA ADS] [Google Scholar]
- Lagos, C. d. P., Theuns, T., Stevens, A. R. H., et al. 2017, MNRAS, 464, 3850 [Google Scholar]
- Lee, J., & Shin, M.-S. 2021, AJ, 162, 297 [NASA ADS] [CrossRef] [Google Scholar]
- Lloyd, S. 1982, IEEE Trans. Inf. Theory, 28, 129 [Google Scholar]
- Łokas, E. L. 2022, A&A, 662, A53 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mendes de Oliveira, C., Ribeiro, T., Schoenell, W., et al. 2019, MNRAS, 489, 241 [NASA ADS] [CrossRef] [Google Scholar]
- Monsalves, N., Jaque Arancibia, M., Bayo, A., et al. 2024, A&A, 691, A106 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mucesh, S., Hartley, W. G., Palmese, A., et al. 2021, MNRAS, 502, 2770 [NASA ADS] [CrossRef] [Google Scholar]
- Nelson, D., Pillepich, A., Genel, S., et al. 2015, Astron. Comput., 13, 12 [Google Scholar]
- Nelson, D., Pillepich, A., Springel, V., et al. 2018, MNRAS, 475, 624 [Google Scholar]
- Nelson, D., Pillepich, A., Springel, V., et al. 2019a, MNRAS, 490, 3234 [Google Scholar]
- Nelson, D., Springel, V., Pillepich, A., et al. 2019b, Comput. Astrophys. Cosmol., 6, 2 [Google Scholar]
- Noordermeer, E., Sparke, L. S., & Levine, S. E. 2001, MNRAS, 328, 1064 [NASA ADS] [CrossRef] [Google Scholar]
- O’Shea, K., & Nash, R. 2015, ArXiv e-prints [arXiv:1511.08458] [Google Scholar]
- Phookun, B., Vogel, S. N., & Mundy, L. G. 1993, ApJ, 418, 113 [NASA ADS] [CrossRef] [Google Scholar]
- Pillepich, A., Springel, V., Nelson, D., et al. 2018, MNRAS, 473, 4077 [Google Scholar]
- Pillepich, A., Nelson, D., Springel, V., et al. 2019, MNRAS, 490, 3196 [Google Scholar]
- Planck Collaboration XIII. 2016, A&A, 594, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Reichard, T. A., Heckman, T. M., Rudnick, G., Brinchmann, J., & Kauffmann, G. 2008, ApJ, 677, 186 [Google Scholar]
- Reichard, T. A., Heckman, T. M., Rudnick, G., et al. 2009, ApJ, 691, 1005 [NASA ADS] [CrossRef] [Google Scholar]
- Richter, O., & Sacisi, R. 1994, A&A, 290, L9 [Google Scholar]
- Rudnick, G., & Rix, H.-W. 1998, AJ, 116, 1163 [NASA ADS] [CrossRef] [Google Scholar]
- Rudnick, G., Rix, H.-W., & Kennicutt, R. C., Jr. 2000, ApJ, 538, 569 [NASA ADS] [CrossRef] [Google Scholar]
- Rumelhart, D. E., & McClelland, J. L. 1987, Learning Internal Representations by Error Propagation (MIT Press), 318 [Google Scholar]
- Sánchez-Sáez, P., Reyes, I., Valenzuela, C., et al. 2021, AJ, 161, 141 [CrossRef] [Google Scholar]
- Sarkar, J., Bhatia, K., Saha, S., Safonova, M., & Sarkar, S. 2022, MNRAS, 510, 6022 [CrossRef] [Google Scholar]
- Sellwood, J. A. 2013, in Planets, Stars and Stellar Systems. Volume 5: Galactic Structure and Stellar Populations, eds. T. D. Oswalt, & G. Gilmore, 5, 923 [Google Scholar]
- Springel, V. 2010, MNRAS, 401, 791 [Google Scholar]
- van Eymeren, J., Jütte, E., Jog, C. J., Stein, Y., & Dettmar, R. J. 2011, A&A, 530, A30 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Varela-Lavin, S., Gómez, F. A., Tissera, P. B., et al. 2023, MNRAS, 523, 5853 [NASA ADS] [CrossRef] [Google Scholar]
- Vogelsberger, M., Genel, S., Springel, V., et al. 2014, Nature, 509, 177 [Google Scholar]
- Walker, I. R., Mihos, J. C., & Hernquist, L. 1996, ApJ, 460, 121 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, K., Guo, P., & Luo, A. L. 2017, MNRAS, 465, 4311 [Google Scholar]
- Weinberg, M. D. 1994, ApJ, 421, 481 [NASA ADS] [CrossRef] [Google Scholar]
- Zaritsky, D., & Rix, H.-W. 1997, ApJ, 477, 118 [Google Scholar]
- Zaritsky, D., Salo, H., Laurikainen, E., et al. 2013, ApJ, 772, 135 [Google Scholar]
- Zhang, Y., Ma, H., Peng, N., Zhao, Y., & Wu, X.-b. 2013, AJ, 146, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Zheng, H., & Zhang, Y. 2008, Adv. Space Res., 41, 1960 [Google Scholar]
All Tables
List of the internal parameters of the 7919 disk-like galaxies obtained from TNG50-1.
Results of the hyperparameter tuning using RANDOMIZED-SEARCHCV for each model, SMOTE + RF and BRF.
Feature Importance of each parameter calculated by PERMUTATION_IMPORTANCE_ for SMOTE + RF.
Metric scores of the SMOTE + RF model on the testing set, using only observational parameters.
All Figures
 |
Fig. 1. Heatmap of the Pearson Coefficient Correlation of the features listed in Table 1. |
| In the text | |
|
Fig. 2. V-band face-on projected surface brightness distribution of a symmetric (left) and lopsided (right) galaxy, considered as examples of the classification made by A1. Their respective A1 value, ID (as in TNG50-1), and redshift snapshot are plotted on the upper side. On the lower left, the box size considered for each galaxy is also plotted. For both images, the dashed cyan line represents the radius R50 and the solid cyan line represents the radius 1.4R90, which are the limits of the radial interval used in the Fourier decomposition. |
| In the text | |
|
Fig. 3. A1 distribution of our total sample. A1 is defined as the averaged strength of the m = 1 mode of the Fourier decomposition for each stellar particle within the radial range R50 − 1.4R90. The black line represents the threshold used to distinguish between lopsided (orange) and symmetric galaxies (blue). The dashed distributions represent the incorrect classifications of the galaxies made by SMOTE + RF for testing set, as we discuss later in Sect. 4. The dashed purple distribution represents the actual symmetric galaxies classified by the model as lopsided galaxies |
| In the text | |
|
Fig. 4. Distribution of parameters selected to characterize our galaxy sample. These parameters are used as features by the random forest classifier. The orange and blue distributions represent lopsided and symmetric galaxies, respectively. The dashed colored lines represent their respective median. |
| In the text | |
|
Fig. 5. Confusion matrix for the testing set of the best model, SMOTE + RF. The x axis is the predicted class or predicted label, and the y axis is the actual class or actual label. The percentage with respect each type of galaxy set is on parenthesis. |
| In the text | |
|
Fig. 6. Box plot of each feature from the testing set, ranked by their importance as determined by the feature permutation attribute from SMOTE + RF. Each box represents the range of the different scores obtained from a cross-validation with niter = 5. The inner dashed line represents the median value of each distribution. The whiskers on each box represent the minimum and maximum value of each distribution. |
| In the text | |
|
Fig. 7. Radial profiles of A1 for our four classification cases, calculated as the median of A1 for each bin with respect to R90. The fuchsia and blue distributions represent the correctly classified lopsided galaxies |
| In the text | |
|
Fig. 8. Normalized distribution of μ*(left), TP(middle), and Rext(right), considering the correct (upper) and incorrect (bottom) classification made by SMOTE + RF. Each distribution has been normalized by their corresponding number of galaxies of each subsample. Their respective number of galaxies is in parenthesis. The fuchsia and blue distributions represent the correctly classified lopsided galaxies |
| In the text | |
|
Fig. 9. Top panels: V-band face-on projected surface brightness distribution of a (left) symmetric galaxy pre-classified as lopsided |
| In the text | |
|
Fig. 10. Left: Confusion matrix of the testing set using SMOTE + RF with only observational parameters. The x axis is the predicted class or predicted label, and the y axis is the actual class or actual label. The percentage with respect each class is on parenthesis. Right: Box plot of each observational feature from the testing set, ranked by their importance as determined by the feature permutation attribute from SMOTE + RF. Each box represents the range of the different scores obtained from a cross-validation with niter = 5. The inner dashed line represents the median value of each distribution. The whiskers on each box represent the minimum and maximum value of each distribution. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.