| Issue |
A&A
Volume 699, July 2025
|
|
|---|---|---|
| Article Number | A63 | |
| Number of page(s) | 18 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202452299 | |
| Published online | 02 July 2025 | |
Probabilistic Zeeman-Doppler imaging of stellar magnetic fields
I. Analysis of τ Scorpii in the weak-field limit
1
Department of Information Technology, Uppsala University,
Box 337, 75105
Uppsala,
Sweden
2
Department of Physics and Astronomy, Uppsala University,
Box 516, 75120
Uppsala,
Sweden
3
Department of Computer and Information Science, Linköping University,
58183
Linköping,
Sweden
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
18
September
2024
Accepted:
1
May
2025
Abstract
Context. Zeeman-Doppler imaging (ZDI) is used to study the surface magnetic field topology of stars, based on high-resolution spectropolarimetric time series observations. Multiple ZDI inversions have been conducted for the early B-type star τ Sco, which has been found to exhibit a weak but complex non-dipolar surface magnetic field.
Aims. The classical ZDI framework suffers from a significant limitation in that it provides little to no reliable uncertainty quantification for the reconstructed magnetic field maps, with essentially all published results being confined to point estimates. To fill this gap, we propose a Bayesian framework for probabilistic ZDI. Here, the proposed framework is demonstrated on τ Sco in the weak-field limit. Methods. We propose three distinct statistical models, and use archival ESPaDOnS high-resolution Stokes V observations to carry out the probabilistic magnetic inversion in closed form. The surface magnetic field is parameterised by a high-dimensional sphericalharmonic expansion.
Results. We provide mean magnetic field distributions along with the corresponding surface uncertainty maps for τ Sco. By comparing three different prior distributions over the latent variables in the spherical-harmonic decomposition, our results showcase the ZDI sensitivity to various hyperparameters. The mean magnetic field maps are qualitatively similar to previously published point estimates, but analysis of the magnetic energy distribution indicates high uncertainty and higher energy content at low angular degrees l.
Conclusions. Our results effectively demonstrate that, for stars in the weak-field regime, reliable uncertainty quantification of recovered magnetic field maps can be obtained in closed form with natural assumptions on the statistical model. Future work will explore extending this framework beyond the weak-field approximation and incorporating prior uncertainty over multiple stellar parameters in more complex magnetic inversion problems.
Key words: Key words. / methods: numerical / methods: statistical / techniques: polarimetric / stars: activity / stars: magnetic field / stars: individual: τ Sco
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Magnetic fields are understood to play a significant role in the formation and evolution of stars. For example, magnetic interlocking of young stars with their accretion discs and winds is the main mechanism behind stellar rotational braking (Shu et al. 1994; Bouvier et al. 2014), and is therefore a key component of the early stellar evolution. At all stellar ages, a multitude of time-dependent surface phenomena and processes – spots, flares, and chromospheric emission – is believed to be driven by magnetic fields (Reiners 2012). Extension of the surface field into the circumstellar environment – the stellar magnetosphere – shapes stellar winds, thereby governing the stellar angular momentum evolution (Weber & Davis 1967; Matt & Pudritz 2008; Vidotto et al. 2009), and strongly impacts the interaction of stars and nearby planets (Lanza 2018; Strugarek 2016; Vidotto 2020).
Two basic types of magnetic fields are known to exist in stars (e.g. Donati & Landstreet 2009). On the one hand, all cool, low-mass stars, including the Sun and similar objects, continuously generate magnetic fields in their interiors through the so-called dynamo process. The resulting fields emerge at stellar surfaces in the form of evolving structures with moderate average strengths (10–100 G) and spatial scales ranging from a tiny fraction of the stellar surface (small-scale fields) all the way to the scales comparable to stellar radii (large-scale or global fields). On the other hand, the majority of hot, intermediate-mass and massive stars are not immediately recognised as magnetic. Only about 10% or less, depending on the stellar mass, of these objects possess detectable magnetic fields (Grunhut et al. 2017; Sikora et al. 2019). Characteristics of these fields are drastically different from those in cool stars. Magnetic fields of hot stars are topologically simple and strong (∼kG), lack significant small-scale components, and are constant on the observable time scales.
Irrespective of the type of stellar magnetic field, information about its strength and surface geometry represents a critical stellar parameter highly sought after by theoretical and observational studies alike. Direct detection of stellar magnetic fields typically relies on the Zeeman effect in spectral lines (e.g. Landi Degl’Innocenti & Landolfi 2004). In the presence of a field, atomic energy levels split into magnetic sub-levels. This produces the corresponding splitting of spectral lines. Additionally, lines become polarised, with the direction of polarisation dependent on the field vector orientation and the amplitude of the polarisation signal linked to the field strength. This Zeemaninduced polarisation is particularly useful for detecting and characterising stellar magnetic fields.
Polarisation observations of stars are typically carried out using a combination of a high-resolution spectrograph and a circular polarimeter (e.g. Donati et al. 1997). Such instrumentation can measure the total intensity spectrum (Stokes I parameter) together with the circular polarisation spectrum (Stokes V parameter). The latter is sensitive to the line of sight component of the magnetic field. A complementary measurement of linear polarisation spectra (Stokes Q and U parameters), which provide information on the transverse field component, is also possible, but rarely accomplished due to a factor of 10 weaker linear polarisation signals (Wade et al. 2000; Kochukhov et al. 2011; Rosén et al. 2015).
Quantitative interpretation of the observed polarisation spectra of stars other than the Sun faces a significant challenge due to the unresolved nature of these observations. Polarisation signatures recorded by a distant observer represent an average of Stokes V profiles originating from different locations on the visible stellar hemisphere, which makes it impossible to infer the magnetic field geometry from a single observation. Considerably more information is contained in a time sequence of polarisation observations of rotating magnetic stars. First, the rotational Doppler shift redistributes signals from different parts of the stellar surface within a spectral line profile, allowing one to relate the position in the line profile to the longitude on the stellar surface. Effectively, this makes a single line profile observation equivalent to a one-dimensional projection of the stellar surface map (Vogt et al. 1987). Second, the spectral line profile changes due to stellar rotation as different parts of the stellar surface come in and out of view. Combining these two effects in the inversion technique known as Doppler imaging (DI) offers the possibility to reconstruct two-dimensional maps of the surfaces of unresolved distant stars by fitting a set of spectral line profiles recorded at different stellar rotation phases (e.g. Kochukhov 2016a).
Doppler imaging was initially applied to map spots on different kinds of rapidly rotating stars with inhomogeneous surfaces using intensity spectra (Khokhlova et al. 1986; Vogt et al. 1999). The same inversion principles were subsequently extended to the problem of reconstructing the magnetic geometry of both cool stars with complex fields (Brown et al. 1991; Donati 1999) and hot stars with simple field topologies (Piskunov & Kochukhov 2002; Kochukhov et al. 2002). These early Zeeman-Doppler imaging (ZDI) studies approximated magnetic field distributions as a set of three independent images corresponding to the three magnetic field vector components, and employed either maximum entropy or Tikhonov regularisation to ensure convergence to a stable and unique solution. The majority of more recent ZDI applications use the spherical-harmonic decomposition to describe the stellar surface magnetic field (Donati et al. 2006b; Kochukhov et al. 2014; Folsom et al. 2018). This approach ensures that the reconstructed magnetic field is solenoidal and provides a convenient framework to characterise poloidal versus toroidal as well as axisymmetric versus non-axisymmetric magnetic field components as a function of the spatial scale (angular degree l). In this case, spherical-harmonic coefficients, rather than the field vector component values at particular coordinates on the stellar surface, represent the free parameters of the inversion problem. Unless the stellar field is restricted to a very simple configuration (e.g. a pure dipole with only l = 1 harmonics), regularisation is still required for stable recovery, due to the ill-posedness of the inverse problem.
Regardless of the specific implementation of ZDI, existing magnetic inversion methods suffer from one major shortcoming: it is difficult or outright impossible to provide realistic uncertainties of the derived magnetic field maps. Essentially all published mapping results represent point estimates, without an attempt to explore the full range of solutions compatible with observations. Due to the high dimensionality of the spectropolarimetric inversion problem and the complexity and computational intensity of the synthetic forward model, obtaining a probabilistic solution is challenging. Occasionally, uncertainties are assessed empirically by comparing magnetic field distributions computed from independent line profile observations (Kochukhov et al. 2019, 2022). Some ZDI studies also considered formal uncertainties obtained from the diagonal of a Hessian matrix (Piskunov & Kochukhov 2002). The former approach is, however, feasible only for strongly magnetic stars, and the latter yields biased uncertainties since parameter correlations are not considered. Additionally, several important stellar parameters (including rotational period, projected rotational velocity and inclination of the rotational axis) enter ZDI calculations. Each of these parameters is known to a limited precision, but their uncertainties are rarely propagated to magnetic maps (Petit et al. 2008). All these problems make it difficult to judge the reliability of published ZDI results, hindering their interpretation and wide utilisation.
In this paper, we address the problem of deriving realistic ZDI uncertainties by presenting a fully Bayesian framework for probabilistic ZDI. Previously, similar methods have only been applied to determine properties of stellar magnetic fields from circular spectropolarimetric observations under an oblique dipole model assumption (Petit & Wade 2012), which is a restrictive assumption not suitable for many magnetic stars. Here, we present a general framework for probabilistic ZDI, using a probabilistic model based on a general spherical-harmonic field parameterisation. Compared to the dipolar modelling approach, our probabilistic ZDI framework applies to arbitrarily complex magnetic field geometries. To present the proposed framework, we start with the comparatively simple problem of probabilistic ZDI reconstruction for a target star with fixed nuisance parameters and a weak magnetic field, which ensures a linear relation between the free parameters describing the magnetic map and the modelled polarisation signal. More specifically, we apply the Bayesian framework for uncertainty quantification of the surface magnetic field of the star τ Sco (HD149438, HR6165). In a future paper, we will extend our approach to stars exhibiting stronger magnetic fields, corresponding to a non-linear line profile response, and incorporate a Bayesian treatment of input stellar parameters.
Our target, τ Sco, is a bright, massive star with spectral type B0.2V. This star is located in the ∼10 Myr-old (Feiden 2016) Upper Sco stellar association. This star exhibits unusual characteristics, such as a slow rotation, a younger age than the surrounding stellar population, and a nitrogen excess (e.g. Przybilla et al. 2010; Nieva & Przybilla 2014), which distinguishes it from the other massive stars in Upper Sco. Even more remarkably, Donati et al. (2006b) demonstrated through spectropolarimetric observations and ZDI modelling the presence of a relatively weak (≤600 G) and unusually complex magnetic field at the surface of that star. Unlike the majority of hot, magnetic stars, which possess roughly dipolar (i.e. sphericalharmonic modes with l = 1) field geometries (Shultz et al. 2018), τ Sco was found to exhibit a surface magnetic structure containing significant power in the harmonic modes of up to l = 5, with the largest contribution coming from l ∈ [3,4].
These unusual chemical, rotational, and magnetic characteristics of τ Sco spurred a series of studies to explain this star as a product of a stellar merger (Nieva & Przybilla 2014; Schneider et al. 2016; Keszthelyi et al. 2021). In particular, Schneider et al. (2019) presented 3D magnetohydrodynamical simulations tailored to τ Sco that demonstrated generation of a powerful magnetic field during a stellar merger event. This field decays quickly after the merger, settling into the stable non-axisymmetric configuration observed today (Schneider et al. 2020; Braithwaite 2008). So far, τ Sco remains the only well-established magnetic star that is likely a merger product. Therefore, it plays the role of a key benchmark object for investigations into both binarity and magnetism of massive stars. At the same time, a follow-up ZDI analysis of τ Sco by Kochukhov & Wade (2016), using an extended observational dataset, suggested that the outcome of magnetic inversions based on circular polarisation spectra strongly depends on the assumptions of the magnetic field parameterisation. This non-uniqueness problem may arise in various applications of ZDI (e.g. Donati & Brown 1997; Kochukhov et al. 2002), but is particularly significant for τ Sco due to its field complexity and small amount of rotational Doppler broadening. Consequently, Kochukhov & Wade (2016) obtained vastly different magnetic field geometries and strengths with equally good fits to available observations of τ Sco by using different, but equally plausible, harmonic parameterisations. These issues, and the significance of τ Sco for wider massive-star research, position this star as a particularly interesting target for probabilistic ZDI.
This paper is organised in the following way: in Sect. 2, the spectropolarimetric observations of τ Sco used for probabilistic spectropolarimetric inversion are introduced. Sect. 3 presents a detailed description of the proposed Bayesian framework for probabilistic ZDI. We propose several probabilistic models, some of which aim to incorporate uncertainties in design parameters corresponding to hyperparameters in the regularisation function often used in conventional ZDI. Then, in Sect. 4, we present summary statistics of the magnetic field map distributions obtained using our framework for probabilistic ZDI. Finally, in Sect. 5, we discuss and summarise the results and conclusions.
2 Observational data and stellar parameters
We use the same observations of τ Sco as analysed by Kochukhov & Wade (2016). The spectropolarimetric data available for this star comprises 49 circular polarisation observations collected in 2004–2009 with the ESPaDOnS instrument (Donati et al. 2006a) at the 3.6 m Canada–France–Hawaii telescope. The spectra, publicly available in the PolarBase archive1 (Petit et al. 2014), were processed with the least-squares deconvolution (LSD, Kochukhov et al. 2010) method, yielding high-quality mean Stokes I and V profiles.
We refer the readers to Kochukhov & Wade (2016) for further details on the data reduction and pre-processing. Following that study, as well as the earlier work by Donati et al. (2006b), we adopted a rotational period of Prot = 41.033 d, a projected rotational velocity of ve sin i = 6 kms−1 and an inclination angle of i = 70◦ for the ZDI analysis, without accounting for possible errors in these parameters.
The observational data used in our work includes uncertainties for each velocity bin in the Stokes I and V parameter profiles. For data with high signal-to-noise ratio, as considered here, the errors are uncorrelated and follow a Gaussian distribution. For a detailed discussion of how these errors are derived by the data reduction pipelines from raw spectropolarimetric exposures and then propagated through the derivation of LSD profiles, we refer the readers to Donati et al. (1997) and Kochukhov et al. (2010).
3 Methods
3.1 Magnetic field map parameterisation
There are multiple ways of parameterising the magnetic field distribution across the surface of a target star. Earlier ZDI inversions have adopted direct parameterisation techniques (e.g. Brown et al. 1991; Kochukhov et al. 2002), in which each magnetic field vector component map is represented by the nodes of a discrete surface grid, and fitted to the data independently. Since then, alternative parameterisations of the surface magnetic field, employing spherical-harmonic expansions, have often been preferred (e.g. Donati et al. 2006b; Kochukhov et al. 2014). In contrast to the direct approach, this magnetic field parameterisation allows us to impose restrictions on the magnetic geometry to follow Maxwell’s equations. Specifically, excluding the l = 0 harmonic component ensures no net signed magnetic flux through the closed stellar surface. There are several other appealing properties of the spherical-harmonic field parameterisation, see e.g. the discussion by Kochukhov & Wade (2016).
In this work, we use the spherical-harmonic representation of the surface magnetic field defined as follows:
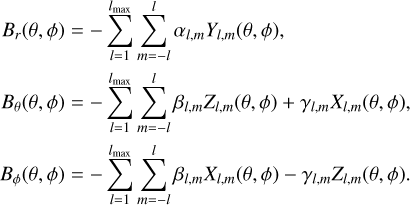 (1)
(1)
Here, Br(θ,ϕ), Bθ(θ,ϕ), and Bϕ(θ,ϕ) denote the surface magnetic field components in the radial, meridional, and azimuthal direction, respectively, with θ and ϕ corresponding to the surface colatitude and longitude. The spherical-harmonic functions and their derivatives for each angular degree l and azimuthal order m are denoted by Yl,m(θ,ϕ),Zl,m(θ,ϕ) and Xl,m(θ,ϕ). Finally, the amplitudes of the spherical-harmonic modes, αl,m, βl,m and γl,m, delineate characteristics of the poloidal and toroidal magnetic field components. Together, these coefficients represent the free parameters in the spectropolarimetric inversion problem. See Kochukhov et al. (2014) for a more detailed description of the field parameterisation and relevant notations. One difference compared to Kochukhov et al. (2014) is that the constant Cl,m, defined by their Eq. (7), was modified2 here to ensure that equal values of the harmonic coefficients yield equal total magnetic energy, independent of l and m.
3.2 Forward line profile model
In this study, we restrict our attention to stars for which the weak-field assumption (Landi Degl’Innocenti & Landolfi 2004) is a good approximation for the forward Stokes I and V profile model. This approach is typically valid for sub-kG fields studied with spectral lines at optical wavelengths and is applicable to a large group of stars, including solar-like stars, the majority of low-mass stars, and a few weak-field hot stars such as τ Sco.
In practice, we follow Petit & Wade (2012) in representing the local Stokes I profile using a Gaussian function. Its strength (d = 0.115), position (radial velocity shift v0 = −0.48 kms−1), and width (FWHM=14.3 kms−1 corresponding to σ = 6.1 kms−1) were adjusted to fit the observed LSD Stokes I spectrum. The adopted Gaussian line width includes the effect of intrinsic stellar line broadening as well as the smearing by the instrumental profile of ESPaDOnS (R ≈ 68000).
The local Stokes V profile is derived from the velocity derivative of the Gaussian function
![Mathematical equation: $$\eqalign{V\left( \upsilon \right) = - 1.4 \times {10^{ - 3}}\lambda o{g_{eff}}{B_{||}}{{\partial I} \over {\partial \upsilon }} \cr = 1.4 \times {10^{ - 3}}\lambda o{g_{eff}}{B_{||}}{{d\left( {\upsilon - {\upsilon _0}} \right)} \over {{\sigma ^2}}}\exp \left[ { - {{{{\left( {\upsilon - {\upsilon _0}} \right)}^2}} \over {2{\sigma ^2}}}} \right]. \cr} $$](/articles/aa/full_html/2025/07/aa52299-24/aa52299-24-eq2.png) (2)
(2)
Here, the central wavelength adopted for the LSD profile is λ0 = 500 nm and the effective Landé factor is geff = 1.2 (see Kochukhov & Wade 2016). The quantity B∥ denotes the line of sight (longitudinal) component of the magnetic field (in kG) at the θ,ϕ location on the stellar surface, as seen by the observer at the rotational phase t, defined over the interval [0,1). This magnetic field projection can be calculated with
![Mathematical equation: $$\eqalign{{B_{||}} = [\cos \theta \cos i + \sin \theta i\cos \left( {\phi + 2\pi t} \right)]{B_r} \cr - [\sin \theta \cos i - \cos \theta \sin i\cos \left( {\phi + 2\pi t} \right)]{B_\theta } \cr - \sin i\sin \left( {\phi + 2\pi t} \right){B_\phi }. \cr} $$](/articles/aa/full_html/2025/07/aa52299-24/aa52299-24-eq3.png) (3)
(3)
To obtain the disc-integrated Stokes I and V profiles, we divided the stellar surface into ≈104 elements, pre-calculated the areas S of these elements, and evaluated the magnetic field using Eq. (1). Then, for each rotational phase, t, we determined the cosine µ of the angle between the observer’s line of sight and the surface normal (the limb angle) using
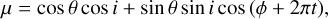 (4)
(4)
and located visible surface elements with the condition µ > 0. Eq. (3) was then applied to determine B∥ for visible surface elements. Following this, the local Stokes I and V spectra were calculated as described above. This calculation was carried out on the velocity grid of observations, vobs, Doppler-shifted according to the local component of the projected rotational velocity, ve sin i,
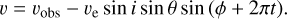 (5)
(5)
Finally, we added together all profiles from the visible stellar hemisphere using the product of the projected surface area and a linear continuum limb-darkening function with the coefficient u = 0.3 as an integration weight W
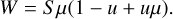 (6)
(6)
Due to the weak-field assumption expressed by Eq. (2), this sequence of operations represents a linear transformation from a set of the spherical harmonic coefficients, α, β and γ, to the phase-dependent disc-integrated Stokes V profiles. We take advantage of this linearity of the problem in this paper. At the same time, we anticipate a generalisation to the strong-field situation in future studies by replacing Eq. (2) with another relation, not limited to weak fields.
While we used the observed Stokes I LSD profiles to adjust the Gaussian function parameters and determine a radial velocity offset, the magnetic field does not impact Stokes I in the weak-field limit. Consequently, the classical and probabilistic ZDI analyses presented in this paper consider only the Stokes V observations.
3.3 Standard ZDI
We define the vector z=(αl,m,βl,m,γl,m), where m ∈ {−l, −l + 1,...,l − 1,l} for each l ∈ {1,2,...,lmax}, as a collection of the amplitudes of the spherical-harmonic modes, αl,m,βl,m, and γl,m. In practice, we truncated the expansion by lmax = 10, corresponding to 360 free parameters in the resulting magnetic field parameterisation. In a nutshell, standard ZDI amounts to solving the weighted least-squares (LS) problem
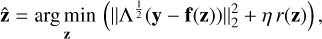 (7)
(7)
with respect to the spherical-harmonic coefficients z. In the above formulation, f(z) denotes the forward mapping function (corresponding to the computations described in Sect. 3.2) between z and the observed Stokes V spectra denoted y. Moreover, Λ denotes the inverse covariance matrix of the measurement noise (i.e. the precision matrix). Another important component is the regulariser
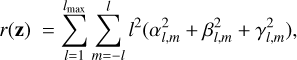 (8)
(8)
with regularisation strength η. The regulariser ensures that, despite the ill-posedness of the Stokes V-only ZDI inversion (Piskunov & Kochukhov 2002), a unique solution exists, that avoids the introduction of higher-order modes unless the added flexibility is motivated by the data. The regularisation structure presented in Eq. (8), where the regularisation objective is to minimize the l2-weighted magnetic energies of the sphericalharmonic coefficients, is commonly used in some ZDI studies (e.g. Hussain et al. 2000; Kochukhov et al. 2014; Kochukhov 2016b) while others adopt the l-weight for this regularisation (Morin et al. 2008, 2010).
The first part of the optimisation objective in Eq. (7) is hereon referred to as the weighted LS objective, and the second part is referred to as the regularisation objective. Since η determines the trade-off between these two optimisation objectives, the choice of η has a significant impact on the properties of the solution. Larger η may result in information loss by favouring the generation of smoother magnetic field maps. On the other hand, small η may introduce spurious high-order modes, resulting in magnetic field maps containing unjustified surface details. To choose the regularisation parameter, we can follow the empirical approach of choosing η such that the quotient between the weighted LS objective value and the regularisation objective value at the optimum is between 2 and 4. To briefly summarise the underlying motivation, this region defines a breaking point after which the fit quality improves slowly as the regularisation strength decreases. This approach to choosing the regularisation parameter is discussed in more detail by Kochukhov (2017).
This classical ZDI framework views the model parameters, z, as fixed quantities to infer. To express uncertainty about the resulting point estimates, ẑ, of these quantities, the distribution of possible datasets can be considered. However, data collection in the context of ZDI is very costly and stellar magnetic fields often evolve between different observing runs, rendering this approach impractical. Moreover, due to the ill-posedness of the problem, formal error bars on ẑ become strongly dependent on the regularisation strength, η. For these reasons, and due to computational limitations of previous ZDI approaches, such error bars have generally not been presented in previous ZDI studies. In the following section, we describe a procedure for quantifying uncertainty in the parameters z according to the Bayesian viewpoint.
3.4 Probabilistic ZDI
In this section, we propose several statistical models to extend the standard ZDI framework, discussed in Sect. 3.3, into a fully Bayesian setting. The Bayesian setting (e.g. Gelman et al. 2020) provides a framework for updating prior beliefs about the uncertainty in the spherical-harmonic coefficients, represented as a probability distribution over z, as new data becomes available. To this end, we treat the spherical-harmonic coefficients z as latent random variables. Given a set of spectropolarimetric observations y, the resulting posterior distribution, p(z|y), captures our informed state of knowledge about the parameters z conditioned on y. Conveniently, this framework brings inherent regularisation into the inversion process; an especially attractive property in light of the ill-posedness of the problem at hand. We begin by constructing a probabilistic model and describing how to calculate the posterior distribution in the context of probabilistic ZDI. At the end of the section, we dive deeper into the choice of prior distribution, aiming to capture uncertainty propagated through its hyperparameters.
3.4.1 Model formulation
To model the likelihood, the observational noise is assumed to be Gaussian with diagonal covariance (see Sect. 2), such that p(y|z) = 𝒩(y;f(z),Λ−1)3. Then, given a prior distribution p(z), the posterior distribution p(z|y) can be obtained following Bayes’ theorem, according to
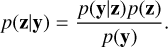 (9)
(9)
Given p(z|y), the posterior magnetic field distribution can then be obtained by applying the transformation in Eq. (1). In general, exact determination of the posterior distribution according to Eq. (9) is challenging since the marginal likelihood p(y) is often intractable. When the posterior distribution has been inferred, the predictive distribution over the modelled Stokes V profiles y∗ can be obtained by marginalisation:
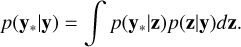 (10)
(10)
We model the prior distribution by a Gaussian distribution, p(z) = 𝒩(z;0,Ω−1), where Ω−1 is a diagonal covariance matrix. Despite the Gaussian likelihood and Gaussian prior distribution, Eq. (9) is in general intractable if the forward mapping function f(z) is non-linear.
In the initial analysis, we use the parameters Ωi,i = ηli2 in the marginal prior distribution for each spherical-harmonic coefficient zi. While it is difficult to construct a fully physics-informed prior distribution over the spherical-harmonic coefficients, this choice of prior distribution captures our prior belief that spherical-harmonic coefficients of high degree l are less prevalent in the solution. In addition, the prior variance adds implicit regularisation to the solution, and with the proposed likelihood model and prior distribution, the resulting maximum a posteriori probability (MAP) estimate, ẑMAP = argmaxz log p(z|y), can be shown to solve the regularised weighted LS problem arising in the standard ZDI formulation given by Eq. (7). In that sense, the proposed probabilistic model allows us to generalise the regularisation structure often used in standard ZDI inversion (see Eq. (8)), with the hyperparameter η in the prior distribution corresponding to the regularisation strength in the standard ZDI formulation. This means that, if the mean of the full posterior distribution coincides with the MAP estimate, the Bayesian formulation results in an uncertainty quantification centred around the point estimate obtained from standard ZDI.
3.4.2 Posterior inference
In the weak-field regime, adopted in this paper, the forward model can be approximated by a function linear in the parameters z such that f(z) = Az, where A is the transformation matrix. This linearity follows from the set of equations presented in Sect. 3.2. In this case, the Gaussian prior in our probabilistic model is conjugate to the likelihood, and a closed-form expression for the posterior distribution exists (e.g. Murphy 2022; Bishop 2007; Sjölund et al. 2018). In fact, following the derivation in Murphy (2022, Sect. 3.3.2), it can be shown that the posterior distribution is also a Gaussian p(z|y)= 𝒩(z;µ,Σ) with Σ−1 =Ω+ATΛA and µ = ΣATΛy. Since p(z|y) is Gaussian and, according to Eq. (1), the magnetic field B is a linear function of the sphericalharmonic coefficients z, the posterior magnetic field distribution is also Gaussian. This distribution can be expressed in closed form according to the linear transformation theorem for the multivariate Gaussian distribution: if z ∼ p(z|y) = 𝒩(z;µ,Σ), then 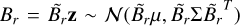 ,
, 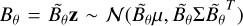 and
and 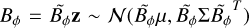 . Here,
. Here, 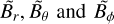 are defined according to the linear transformations in Eq. (1).
are defined according to the linear transformations in Eq. (1).
In this setting, the predictive distribution, see Eq. (10), is also available in closed form. We use y∗ to denote the vector representing the modelled LSD Stokes V profiles, whereas y continues to denote the specific observations used to fit the probabilistic model. The corresponding transformation matrix used to make predictions is then denoted by A∗. This transformation matrix can be different from the transformation matrix A used to fit the model, for example if we wish to increase the discretisation of the predicted Stokes V profiles compared to the observations y. Given the transformation matrix A∗, the predictive distribution over y∗ is then given by p(y∗|y) = 𝒩(y∗;µ∗,Σ∗), where µ∗ = A∗µ and Σ∗ =A∗Σ(A∗)T +Λ∗−1. Here, Λ∗−1 is a diagonal matrix containing the estimated observational noise corresponding to y∗. This result follows from Eq. (2.115) in Bishop (2007).
3.4.3 Prior hyperparameter selection
In the statistical model described in the previous subsections, a specific set of hyperparameters Ωi,i is assumed to parameterise the variance in the prior distribution. In our initial analysis, we used the hyperparameters Ωi,i = ηli2 with η = 100. Here, η was determined according to the empirical approach described in Sect. 3.3, motivated by the connection to the regularisation strength in the standard ZDI formulation. However, there is no consensus regarding the choice of regularisation in existing ZDI literature. Other authors favour a regularisation function that, in the probabilistic model formulation, corresponds to the hyperparameters Ωi,i = ηli (without the square) in the prior variance (Morin et al. 2008). Previous studies also adopt different approaches to choosing the hyperparameter η or use an entirely different form of regularisation altogether (Folsom et al. 2018). Even using a single approach, like the empirical approach described in Sect. 3.3, there is an inherent uncertainty in the choice of η. Since the proposed framework for probabilistic ZDI quantifies uncertainty within the chosen model class, the uncertainty estimate can become more reliable by broadening the class of models under consideration. This can be achieved by modifying the prior distribution. In Sects. 3.4.4–3.4.6, we describe three ways of selecting hyperparameters in the prior distribution; either as a point estimate or by incorporating prior uncertainty over these parameters.
3.4.4 Empirical Bayes
One method for determining hyperparameters in the prior distribution of a probabilistic model is called empirical Bayes, or evidence maximisation (e.g. Bishop 2007). With this approach, a point estimate 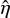 of the hyperparameter η is determined by maximising the marginal likelihood p(y|η) = ∫p(y|z)p(z|η)dz, i.e.
of the hyperparameter η is determined by maximising the marginal likelihood p(y|η) = ∫p(y|z)p(z|η)dz, i.e.
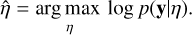 (11)
(11)
To make the dependence on the hyperparameter η explicit here, p(z|η) denotes the prior distribution over the model parameters z, parameterised by η. The marginal likelihood quantifies how well the model using the hyperparameter η, with latent variables z governed by the prior distribution p(z|η), explains the observed data y. The empirical Bayes hyperparameter estimate can then be viewed as a maximum likelihood estimate given a likelihood function defined over a specified model space, from which the random variables z have been marginalised out. In relation to the fully Bayesian approach to hyperparameter optimisation, we can view the empirical Bayes approach as an approximation of the posterior distribution p(η|y) by a point function at its mode. This point estimate is equivalent to the point estimate obtained assuming an improper prior distribution according
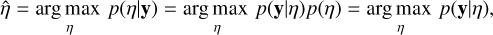 (12)
(12)
where, in the last step, we let p(η) = 1. As we can see, the point estimates in Eqs. (11) and (12) are identical.
We can determine the hyperparameter η given the probabilistic model described in Sect. 3.4.1 by solving the maximisation problem in Eq. (11). Given the conjugacy between the likelihood and our choice of prior, a closed-form expression for the marginal likelihood exists in this case, namely p(y|η)= 𝒩(y; 0,Λ−1 + AΩ−1(η)AT). This result is derived using Eq. (2.115) in Bishop (2007).
Using a prior distribution with parameters Ωi,i = ηli2 in the statistical model described in Sect. 3.4.1, the empirical Bayes estimate, 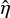 , is in the order of 10−3, yielding a quotient exceeding a magnitude of 15 between the weighted LS objective value and the regularisation objective value. Fig. 1 shows the log evidence as a function of η near the maximum. In other words, the resulting quotient is far outside the interval [2,4] at the mean of the posterior distribution p(z|y). The resulting magnetic field strength becomes too large, violating the weak-field assumption on the magnetic field used to model the likelihood. Thus, estimating
, is in the order of 10−3, yielding a quotient exceeding a magnitude of 15 between the weighted LS objective value and the regularisation objective value. Fig. 1 shows the log evidence as a function of η near the maximum. In other words, the resulting quotient is far outside the interval [2,4] at the mean of the posterior distribution p(z|y). The resulting magnetic field strength becomes too large, violating the weak-field assumption on the magnetic field used to model the likelihood. Thus, estimating 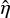 using empirical Bayes gives a magnetic field with properties inconsistent with the underlying physical assumptions even at the mean of the posterior distribution, suggesting that the marginal likelihood, and by extension empirical Bayes, is not useful in this particular context. We conclude that maximum likelihood estimation of this hyperparameter is ill-posed in this case, and we observe that the marginal likelihood is sensitive to small variations in η. Analysing the well-posedness of maximum likelihood estimation in the regression setting is non-trivial (see, e.g., Karvonen & Oates 2024, for a deeper exposition). Consequently, maximum likelihood estimates in such settings may not reliably respect underlying assumptions.
using empirical Bayes gives a magnetic field with properties inconsistent with the underlying physical assumptions even at the mean of the posterior distribution, suggesting that the marginal likelihood, and by extension empirical Bayes, is not useful in this particular context. We conclude that maximum likelihood estimation of this hyperparameter is ill-posed in this case, and we observe that the marginal likelihood is sensitive to small variations in η. Analysing the well-posedness of maximum likelihood estimation in the regression setting is non-trivial (see, e.g., Karvonen & Oates 2024, for a deeper exposition). Consequently, maximum likelihood estimates in such settings may not reliably respect underlying assumptions.
 |
Fig. 1 Unnormalised log evidence as a function of η on a region close to η = 0. The log evidence is maximised for η ≈ 0.002. As η grows outside of the displayed region, the log evidence continues to decrease. |
3.4.5 Hierarchical model
In a fully Bayesian setting, we treat hyperparameters in the prior distribution p(z) as latent random variables in an extended probabilistic model. Let us consider the case in which we treat the prior hyperparameter η, corresponding to the regularisation strength in the standard ZDI framework, as a random variable. Prior knowledge of the distribution over η can then be incorporated into the joint prior distribution, p(z,η). The posterior distribution p(z,η|y) is then
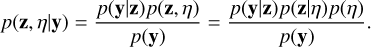 (13)
(13)
Here, p(η) is referred to as the hyperprior distribution. Treating hyperparameters of the prior distribution as random variables results in a so-called hierarchical probabilistic model. The sought posterior distribution is then given by marginalising over η according to
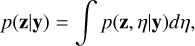 (14)
(14)
which is equivalent to assuming the prior distribution
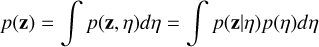 (15)
(15)
in Eq. (9). Defining a suitable prior distribution p(η) can be challenging, and this distribution will also be defined in terms of its own set of hyperparameters that need to be chosen. We can extend the probabilistic model with another hierarchical layer by treating the hyperparameters in the hyperprior distribution as random variables, but the hyperparameters in the final hierarchical layer eventually need to be fixed. The limiting distribution, however, often becomes invariant to the specific form of the hyperprior distributions, and the specific hyperparameters in the hyperprior distributions therefore become less and less important as the number of hierarchical layers grows, as long as the distributions are sufficiently broad (see, e.g. Roberts & Rosenthal 2001).
We restrict our attention to the one-layer hierarchical model in Eq. (13), and begin by modelling the hyperprior distribution p(η). Its exact form is a modelling choice, and one possible approach is to let the hyperprior distribution be informed by the empirical approach to selecting η described in Sect. 3.3. Recall that this approach suggests that a reasonable point estimate of η can be obtained in the range within which the quotient between the weighted LS objective value and the regularisation objective value is between 2 and 4 using standard ZDI. For τ Sco, this region is illustrated in Fig. 2. The figure shows the two components of the objective function in Eq. (7), i.e. the weighted LS objective and the regularisation objective, evaluated at the solution of the optimisation problem for a range of η−values. Specifically, for each η, we solve the optimisation problem given in Eq. (7), and plot the resulting weighted LS (data fidelity) terms 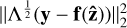 and regularisation terms ηr(ẑ) at the solutions ẑ as a function of η. The region over η where the regularisation term is between 2 and 4 times smaller than the LS objective is shaded in purple, and corresponds to η ∈ [16,421]. As can be seen, the improvement in fit quality (reflected by a decreasing weighted LS objective value) begins to slow down in the vicinity of this region, as η decreases from the right in the plot. Moreover, the difference in magnitude between the weighted LS objective value and the regularisation term increases. Informed by this approach to hyperparameter selection in standard ZDI, we can model p(η) as a distribution with non-zero probability on the interval η ∈ [16,421].
and regularisation terms ηr(ẑ) at the solutions ẑ as a function of η. The region over η where the regularisation term is between 2 and 4 times smaller than the LS objective is shaded in purple, and corresponds to η ∈ [16,421]. As can be seen, the improvement in fit quality (reflected by a decreasing weighted LS objective value) begins to slow down in the vicinity of this region, as η decreases from the right in the plot. Moreover, the difference in magnitude between the weighted LS objective value and the regularisation term increases. Informed by this approach to hyperparameter selection in standard ZDI, we can model p(η) as a distribution with non-zero probability on the interval η ∈ [16,421].
However, exactly inferring the posterior distribution as defined in Eq. (13) is generally intractable, as it is rare to have conjugacy in a hierarchical model even with a single hyperprior distribution. Thus, adopting a hierarchical modelling approach to incorporating uncertainty over the hyperparameters in our prior distribution requires approximate solution methods, such as Markov chain Monte Carlo (MCMC) methods (see, e.g. Meyn & Tweedie 2009; Cotter et al. 2013). While MCMC methods can provide statistically exact sample approximations of the posterior distribution, the computational demand can be prohibitive, especially in high-dimensional settings such as those arising from high-order spherical-harmonic magnetic field parameterisations. This challenge is further compounded when the forward model is even mildly computationally intensive (Brooks et al. 2011). Since we are operating in the weak-field regime in our analysis of τ Sco, under which our probabilistic model formulation conveniently allows for a closed-form expression of the posterior distribution in Eq. (9), we are interested in finding an alternative probabilistic model incorporating uncertainty in the hyperparameter η, allowing for a closed-form expression of the posterior distribution in Eq. (14). This can be achieved by approximating the continuous hyperprior distribution over η by a discrete distribution, obtained by evenly discretising the interval of non-zero hyperprior probability, i.e. η ∈ [16,421], in C components, and assigning each component a prior probability, or weight, ωc. This is equivalent to modelling p(z) as a mixture prior to incorporate our prior belief about η directly into the prior distribution, in place of explicitly extending the model with a hyperprior distribution p(η). A detailed account of this approach is provided in the following section.
 |
Fig. 2 Trade-off between the least-squares fit and the regularisation objective as a function of η. The region where η ∈ [16, 421] is shaded in purple. |
3.4.6 Mixture priors
In this section, we extend the probabilistic model in two ways compared to the initial model described in Sect. 3.4.1, both of which adjusts the prior distribution to incorporate prior uncertainty over hyperparameters in the prior variance using mixture priors. A mixture prior can be constructed according to
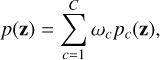 (16)
(16)
where C is the number of mixture components and pc(z) denotes the c−th prior component. In this formulation, each prior component is a properly normalised probability density function and 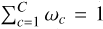 , such that the mixture prior p(z) is also properly normalised. With this notation, the posterior distribution can be expressed as
, such that the mixture prior p(z) is also properly normalised. With this notation, the posterior distribution can be expressed as
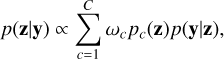 (17)
(17)
where p(y|z) is the likelihood. Now, we define the marginal likelihood for each component c according to pc(y) =∫pc(z)p(y|z)dz. We can then rewrite Eq. (17) according to
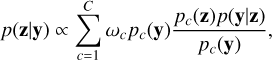 (18)
(18)
where pc(z)p(y|z)/pc(y) is the posterior distribution obtained using the prior distribution component pc(z). Thus, using a mixture prior in the form of Eq. (16), the posterior distribution is a mixture of the posterior distributions obtained from each component in the mixture prior distribution. The unnormalised weights in the posterior mixture are given by ωcpc(y) for each component c, where ωc are the weights of the components in the mixture prior distribution. Properly normalised, the mixture posterior distribution becomes
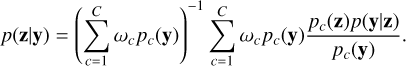 (19)
(19)
The connection between this model and the hierarchical model with a prior defined according to Eq. (15) is now clear. The mixture prior can be viewed as a discretisation of the integral arising when marginalising out η, with the mixture weights ωc forming a discrete hyperprior distribution p(η). Equal weights for each prior component then corresponds to a discrete uniform hyperprior distribution over η. We can also view each mixture component as a separate model, and interpret the prior weights as an expression of our prior belief in each model. With this view, our approach to incorporating uncertainty of prior hyperparameters into the probabilistic model is equivalent to Bayesian model averaging (see, e.g Hoeting et al. 1999).
We begin by using a mixture prior to capture our prior uncertainty over the hyperparameter η in the prior variance term. The contribution of each component c to the prior distribution is modelled as a Gaussian according to pc(z) = 𝒩(0,Ω−c1), where Ω−c1 is a diagonal covariance matrix. We use the parameter Ωci,i = ηcli2 in the marginal prior distribution for each sphericalharmonic coefficient zi, but now the prior variance depends on c. Specifically, we used a mixture prior with C = 1000 components, with the parameters ηc ∈ [η1,ηC] evenly distributed on the interval [16,421], according to the earlier motivation.
It remains to determine the weights, ωc ∈ [ω1,ωC]. According to Eq. (19), the weights in the mixture posterior distribution are scaled by the corresponding marginal likelihoods pc(y) compared to the weights in the mixture prior. The component-wise marginal likelihood is heavily dependent on η, and varies significantly in magnitude depending on the value of ηc. In fact, using equal prior weights ωc for all components c ∈ [1,1000] results in negligible weights for all components in the mixture posterior, except the component c = 1. This prior component uses η1, the lowest possible value of η within our prior interval of non-zero probability. In light of this reflection, we note that the use of a mixture prior with equal weights in this case gives a result that is approximately equivalent to selecting η using empirical Bayes as discussed in Sect. 3.4.4, with an additional requirement constraining η to the region [16,421] when solving the optimisation problem in Eq. (11). Thus, the choice of using uniform weights may not provide a sufficiently informative uncertainty quantification. Here, we choose a slightly different way of selecting the weights, where we instead incorporate a prior belief that, within the given interval of non-zero prior probability, the prior probability of choosing a model with a larger value of η is higher, reflecting our prior belief of to what extent parameters drawn from each prior component increases the risk of overfitting in the predictive model. To model this prior distribution, the unnormalised weights in the mixture prior were set to the inverse of the corresponding marginal likelihood:
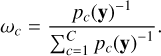 (20)
(20)
We are also interested in incorporating prior uncertainty over the exponent of the angular degree l in the prior variance term. To do this, we used a mixture prior with two components. These components, p1(z) and p2(z), are both Gaussian, with a specific set of hyperparameters. Specifically, p1(z) = 𝒩(0,Ω−11) and p2(z) = 𝒩(0,Ω−21). Each covariance matrix, Ω−11 and Ω−21, is diagonal with parameters Ω1i,i = η1li and Ω2i,i = η2li2, respectively. We fixed the prior variance of each component using η1 = 275.47 and η2 = 100.00, respectively. These values were chosen using the empirical approach discussed previously, based on independent fits using two separate models with priors adopting each set of hyperparameters, respectively. They provide comparable fits to the data in terms of mean deviation from observed values at the mean of the component-wise posterior distributions. We used the weights ω1 = ω2 = 0.5 in the mixture prior.
 |
Fig. 3 Comparison between the mean LSD Stokes V profiles (red) of the predictive distribution and the observed LSD Stokes V profiles (black), for a subset of the rotational phases. The profiles are offset vertically according to the rotational phase, as indicated in blue. The marginal predictive uncertainty is shaded in light grey and depicts three standard deviations. The corresponding posterior predictive uncertainty is shaded in light blue, and the blue bars represent the corresponding observational uncertainties. |
4 Results
In this section, we present the magnetic field distributions and corresponding uncertainty quantifications obtained using a) fixed prior hyperparameters chosen based on the empirical approach commonly used in standard ZDI, and b) the two probabilistic models extended by a mixture prior, as described in the previous section. For code and additional implementation details, we refer the reader to Appendix A.
4.1 Fixed hyperparameters
This section presents the posterior magnetic field distribution obtained using the statistical model described in Sect. 3.4.1 with fixed prior hyperparameters. Specifically, η was determined according to Sect. 3.3. We used the prior parameters Ωi,i = ηli2 with η = 100. At the mean of the posterior distribution, this value of η yields a quotient of 2.9 between the optimised weighted LS objective value and the regularisation objective value, evaluated according to the objective function in Eq. (7). A comparison between the observed and modelled LSD Stokes V profiles is illustrated in Fig. 3, which shows the best fit at the mean of the predictive distribution, along with the predictive uncertainty in terms of the marginal standard deviation of the predictive distribution. These quantities were derived from the predictive distribution given by Eq. (10), with closed form expressions for the mean vector and covariance matrix as detailed in Sect. 3.4.2. Note that the predictive uncertainty arises from two sources: the posterior uncertainty in the latent variables and the observational noise. As expected, the contribution from the posterior predictive uncertainty is generally larger towards the centre of the Stokes V profile at each rotational phase. See Appendix B for the corresponding results for all rotational phases. The mean marginal standard deviation, derived from the predictive distribution, is 4.98·10−5 and the fit quality, in terms of mean deviation between the best fit and the observed Stokes V profiles at the mean of the predictive distribution, is 9.17 · 10−5. These results account for all rotational phases.
The maps of the mean and standard deviation of the posterior magnetic field distribution are displayed in Fig. 4. As evident from these images, the surface distribution of the ZDI uncertainties exhibits a distinct latitudinal pattern, reflecting the different sensitivity of the disc-integrated Stokes V profiles to the three components of the magnetic field vector. Specifically, the radial and azimuthal fields are determined most precisely around the sub-observer latitude whereas the meridional field has the least error at the visible rotational pole. At the same time, the precision of the azimuthal field drops off towards the visible pole less sharply than for the radial field. The lack of longitudinal variation of the standard deviation maps is due to a dense rotational phase sampling of the particular observational data set analysed in our paper. In other situations, for example when large phase gaps exist in the data, we would expect our method to yield a noticeable longitudinal variation of uncertainties corresponding to this uneven phase coverage.
In terms of the average standard deviation, we find values in the 0.056–0.067 kG range. This corresponds to 10.4–14.0% of the peak (95 percentile) values of the respective mean magnetic maps. If we instead consider maximum errors (95 percentile for the visible part of the surface), we obtain 0.065–0.074 kG corresponding to 12.9–15.7% of the magnetic field amplitudes. These two fractional error estimates illustrate the average (most representative) and maximum (conservative) errors of the ZDI inversion for τ Sco with fixed hyperparameters.
 |
Fig. 4 Rectangular maps of the reconstructed magnetic field and the corresponding uncertainty quantification. The left column shows the mean of the posterior magnetic field distribution across the stellar surface, in terms of the radial (top), meridional (middle) and azimuthal (bottom) magnetic field components. The field strength is given in kG. The grey transparent rectangle indicates the part of the stellar surface that is obscured from view. The right column shows the corresponding standard deviation maps. The results were obtained using a statistical model with hyperparameters Ωi,i = ηli2 and η = 100 in the marginal prior distribution for each spherical-harmonic coefficient zi. Note that the contour plots in this paper consistently use the same number of levels between the minimum and maximum values in all figures. |
 |
Fig. 5 Comparison of predicted (mean) LSD Stokes V profiles from independent inversions using η = 16 (blue) and η = 421 (red) for a subset of the rotational phases. The mean deviations between the means of the predictive distributions and the observed Stokes V profiles (black) is 7.87 · 10−5 and 1.05 · 10−4, respectively, across all rotational phases. |
4.2 Mixture priors
We analyse the resulting posterior magnetic field distributions obtained using two different mixture priors, capturing prior uncertainty over the exponent of the angular degree l, and η, respectively, in the parameterisation of the prior variance. First, we present the posterior magnetic field distribution using a mixture prior with 1000 components capturing the prior uncertainty over η. According to Sect. 3.4.6, each prior component pc(z) = 𝒩(0,Ω−c1) has η-dependent parameters Ωci,i = ηcli2, with parameters ηc evenly distributed on the interval [16,421]. To illustrate the impact of η on the predicted LSD Stokes V profiles, the computed means based on independent inversions using η=16 and η=421, respectively, are presented in Fig. 5. Using the prior weights given in Eq. (20), we obtain equal posterior weights for all components in the mixture posterior distribution according to Eq. (19). The final inversion results in a mean deviation of 9.6 · 10−5 between the mean of the predictive distribution and the observed LSD Stokes V profiles, similar in magnitude to the fixed hyperparameter case. The mean marginal standard deviation derived from the predictive distribution has increased slightly, reaching 5.16 · 10−5. Appendix B shows a comparison between the observed LSD Stokes V profiles and the prediction at the mean of the predictive distribution, together with the predictive uncertainty.
The mean and standard deviation of the posterior magnetic field distribution is calculated as that of the mixture distribution obtained by calculating the posterior magnetic field distribution corresponding to each component in the mixture posterior distribution given in Eq. (19). Fig. 6 shows the mean of the resulting mixture posterior magnetic field distribution across the stellar surface, together with the corresponding standard deviation maps. Four samples from the resulting distribution are displayed in Fig. 7. It can be noted that with C = 1000 components, the obtained mean magnetic field maps and corresponding uncertainty maps do not change significantly when the number of components increases. Thus, the obtained results closely correspond to using the corresponding continuous hyperprior p(η) in a hierarchical model.
As one can see in Fig. 6, the surface pattern of the standard deviation changes drastically compared to the results presented in the previous section. Instead of the smooth latitudinal variation seen in Fig. 4, we find a highly structured standard deviation map, with the largest scatter roughly corresponding to the strongest (by absolute value) features in the mean magnetic maps. This is to be expected since decreasing η generally leads to an increase in the contrast of each map, with sharper details and more prominent small-scale features. Quantifying the standard deviation distribution, we derive the average values 0.063–0.088 kG and maximum values 0.087–0.139 kG. This corresponds to 15.9–18.0% and 22.2–28.8.0% of the 95 percentile mean magnetic map amplitudes, respectively – significantly larger than in the fixed-η case.
Next, we present the magnetic field distribution corresponding to the two-component mixture prior. Recall that p1(z)= 𝒩(0,Ω−11) and p2(z)= 𝒩(0,Ω−21), with parameters Ω1i,i = η1li and Ω2i,i = η2li2. With the specific choice of hyperparameters defined in Sect. 3.4.6, and prior weights ω1 = ω2 = 0.5, the marginal likelihoods coincide, i.e. p1(y) = p2(y). Consequently, the normalised weights in the resulting mixture posterior become 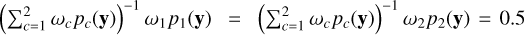 . The mean deviation between the mean of the resulting predictive distribution and the observed LSD Stokes V profiles is 9.09 · 10−5. In this case, the mean marginal standard deviation of the predictive distribution corresponding to the computed LSD Stokes V profiles is 5.00 · 10−5. See Appendix B for a comparison between the observed LSD Stokes V profiles and the prediction at the mean of the predictive distribution. Fig. 8 shows the mean of the posterior magnetic field distribution across the stellar surface, together with the corresponding standard deviation maps. Four samples from the resulting distribution are displayed in Fig. 9.
. The mean deviation between the mean of the resulting predictive distribution and the observed LSD Stokes V profiles is 9.09 · 10−5. In this case, the mean marginal standard deviation of the predictive distribution corresponding to the computed LSD Stokes V profiles is 5.00 · 10−5. See Appendix B for a comparison between the observed LSD Stokes V profiles and the prediction at the mean of the predictive distribution. Fig. 8 shows the mean of the posterior magnetic field distribution across the stellar surface, together with the corresponding standard deviation maps. Four samples from the resulting distribution are displayed in Fig. 9.
In this case, the standard deviation maps retain some of the small-scale structures highlighted in the discussion of Fig. 6, but these structures are no longer closely associated with the strongest features in the magnetic maps. The representative amplitude of the standard deviation is comparable to the previous test: 0.072–0.098 kG on average and 0.082–0.137 kG if one considers the 95 percentiles, i.e. 15.3–19.5% and 19.7–27.4% of the magnetic map amplitudes, respectively.
 |
Fig. 6 Same as Fig. 4 but for results obtained using a statistical model with a mixture prior consisting of 1000 η-dependent components pc(z). |
4.3 Magnetic energy spectrum
Using our spherical-harmonic field parameterisation, it is straightforward to assess the strength of the axisymmetric versus non-axisymmetric field, as well as the strength of the poloidal versus toroidal field components. Specifically, the γl,m coefficients specify the strength of the toroidal field component, whereas the αl,m and βl,m coefficients specify the vertical and horizontal components of the poloidal field, respectively. Given the posterior distribution obtained from each independent choice of prior distribution, we analysed the numerical distribution of the magnetic field energy contributions over different harmonic modes (l-modes). These distributions, together with a comparison of the distributions of the magnetic energy of the poloidal and toroidal field components over the harmonic modes, are illustrated in Figs. 10–12. Fig. 10 shows the distributions corresponding to the fixed hyperparameter case, with Ωi,i = ηli2 and η = 100. These magnetic energies correspond to the posterior magnetic field distribution in Fig. 4. As we can see, the total magnetic energy is spread over modes l ∈ [1,5], with a clear peak at l = 1. Considering the poloidal and toroidal field components separately, we note a significant peak in the poloidal field component at l = 1, followed by a smaller peak at l = 4. In contrast, the peak of the toroidal field component ranges over l ∈ [1,2], whereafter the contribution decreases with l. Fig. 11 shows the distribution of magnetic energy over the harmonic modes corresponding to the posterior magnetic field distribution presented in Fig. 6, obtained from a mixture prior with with 1000 η-dependent components pc(z). Finally, Fig. 12 shows the corresponding results for the posterior magnetic field distribution given in Fig. 8, obtained from a mixture prior with components p1(z) and p2(z).
The magnetic energy distributions over harmonic modes illustrated in Figs. 11–12 are qualitatively similar to the distributions in the fixed hyperparameter case illustrated in Fig. 10. Considering the comparatively large scatter in the resulting magnetic energy based on statistical models with mixture priors, our results indicate high uncertainty in the relative magnetic energies recovered in the ZDI analysis of τ Sco.
In addition to analysing the magnetic energy distribution for poloidal versus toroidal field components, we divided the spherical-harmonic modes into two other groups: those with |m| < l/2 and those with |m| ≥ l/2 (Fares et al. 2009). A statistical summary of the magnetic energy distributions in terms of a) the total contribution from the poloidal field component across all harmonic modes, and b) the isolated contribution from the|m| < l/2 field component, is presented in Table 1 for each of the three cases.
Notes. Quantiles of the posterior distribution of the fraction of the total magnetic energy for a) the poloidal field components across harmonic modes and b) the |m| < l/2 field component. Case 1 refers to the fixed hyperparameter case, Case 2 refers to the distribution obtained from a mixture prior with 1000 η-dependent components pc(z), and Case 3 refers to the distribution obtained from a mixture prior with components p1(z) and p2(z).
While the magnetic energy, as discussed here, is more interpretable and comparable between studies, we have included additional visualisations of the posterior distribution over z for completeness. We refer the reader to Appendix C for an overview of these results.
 |
Fig. 7 Four samples of surface magnetic field vector maps drawn from the posterior distribution. The distribution was obtained through posterior inference using a statistical model with a mixture prior consisting of 1000 η-dependent components pc(z). From the left, the samples were drawn from components of the mixture posterior distribution with parameters η ≈ 34,η ≈ 123,η ≈ 62 and η ≈ 258, respectively. |
 |
Fig. 8 Same as Fig. 4 but for results obtained using a statistical model with a mixture prior consisting of the two components p1(z) and p2(z). |
Quantiles of the posterior magnetic energy fractions.
5 Conclusions and discussion
In this study, we have presented magnetic field distributions and corresponding uncertainty maps resulting from a probabilistic ZDI analysis of the early B-type star τ Sco. We considered three distinct prior distributions over the latent variables in the spherical-harmonic field parameterisation. When the hyperparameters in the proposed prior distribution were chosen using the empirical Bayes approach, our investigation showed that the amplitude in the posterior magnetic field distribution violated the weak-field approximation motivating our choice of forward mapping function, f(z). We concluded that maximum likelihood estimation of the hyperparameter η is ill-posed in this case. The uncertainty maps obtained with empirically fixed hyperparameters exhibited a smooth latitudinal variation across the stellar surface. By introducing mixture priors, we accounted for prior uncertainty over two hyperparameters in the original prior distribution, capturing the sensitivity of the magnetic field distribution to the specific choice of prior and, by extension, to the hyperparameters used in the classical ZDI framework. A mixture prior over η increased the structure in the uncertainty maps and raised the overall uncertainty level, particularly around the features in the mean magnetic map with the strongest amplitudes. A similar uncertainty level was observed when introducing a mixture prior over the exponent on the angular degree l. Although small-scale structures remained, the correlation with the strongest magnetic features in the mean magnetic field distribution was less prominent.
We also analysed the magnetic energy spectrum, with emphasis on the posterior magnetic energy distribution across l−modes. Compared to previous ZDI inversions targeting τ Sco, a star assumed to exhibit a complex, non-dipolar surface magnetic field, the fact that the magnetic energy contribution is dominated by l = 1 is unexpected. This result alone would indicate a predominantly dipolar field geometry, in line with the majority of hot, magnetic stars, but in contrast to previous studies of τ Sco. We investigated this issue by an in-depth comparison between our results and the magnetic field map obtained by Kochukhov & Wade (2016) with the same harmonic parameterisation (“model 2” in that paper). It turns out that the overall morphology of the surface distributions of the three vector magnetic components is qualitatively similar in the two studies. However, their relative strengths differ. Here we recover about 20–30% less relative energy in the radial and azimuthal components, which are dominated by higher l modes. Conversely, our meridional field contributes more than twice the relative energy to the total field compared to the results by Kochukhov & Wade (2016). This meridional field component features a simpler, dipolar-like geometry (see Fig. 4). Consequently, the contribution of the l = 1 harmonics is significantly higher in our results. This modification of the outcome of the ZDI analysis is sufficient to noticeably alter the resulting harmonic energy spectrum. While Kochukhov & Wade (2016) found the poloidal field energy to be spread over l ∈ [1,4] and observed a peak in the toroidal field contribution at l ∈ [2,3], we recover a stronger toroidal component peaking at l = 1 with a less important poloidal field peaking at both l = 1 and l = 4.
Since there are differences in modelling choices between the ZDI reconstructions, we do not expect to exactly reproduce the results at the mean of the posterior magnetic field distribution in this case. In general, it is worth remarking that the uncertainty quantification obtained from the proposed framework for probabilistic ZDI is conditioned on our choice of probabilistic model, i.e. p(y|z) and p(z), and the information content in the observations y. As noted in Sect. 1, earlier studies of the surface magnetic field of τ Sco have compared the field geometries obtained using different spherical-harmonic magnetic field parameterisations, ultimately concluding that the topological details in the surface magnetic field, as well as the average magnetic field strengths, vary significantly depending on the parameterisation (Kochukhov & Wade 2016). Since the Bayesian framework naturally extends to Bayesian model selection and Bayesian model averaging, an interesting avenue for future work is to perform probabilistic ZDI analyses of τ Sco using competing field parameterisations to model the likelihood.
While this study focused on ZDI inversion in the weak-field limit, another important direction for future research is to investigate the feasibility of employing probabilistic ZDI to generate reliable uncertainty maps when the line-profile response cannot be modelled under this assumption. Addressing this challenge requires advanced computational techniques, such as MCMC methods or variational Bayes (Blei et al. 2017), since the posterior distribution p(z|y) cannot be expressed in closed form for non-linear response profiles under standard model assumptions. Additionally, the proposed framework for probabilistic ZDI can be expanded by extending the hierarchy in the statistical model (see Sect. 3.4.5) to account for prior uncertainty in stellar parameters beyond the spherical-harmonic coefficients. Such an extension would enable quantification of uncertainty in the surface magnetic field of more complex ZDI targets, including stars in eclipsing binary systems and equator-on hosts of transiting exoplanets, where degeneracy in the latent variables within the spherical-harmonic formulation is likely to occur. Both of these avenues will be pursued in future work.
To summarise our study, we have proposed a Bayesian framework for probabilistic ZDI allowing for formal uncertainty quantification of the obtained stellar magnetic field maps, given a single set of spectropolarimetric observations. Coupling the magnetic field distributions with interpretable uncertainty maps makes it possible to reason about the uncertainty in the obtained magnetic field distributions in a meaningful way. This is something that has not previously been possible, as classical ZDI has generally been restricted to point estimates. We have demonstrated that, for stars exhibiting relatively weak surface magnetic fields such that the weak-field approximation can be used to model the line-profile response, a closed-form solution for the posterior distribution over the spherical-harmonic coefficients exists under specific model assumptions. Our choice of probabilistic model is convenient in the sense that it makes it easy to quickly conduct Bayesian analyses of the surface magnetic fields of a large group of stars, despite the high-dimensional sphericalharmonic magnetic field parameterisation. Since we obtain an uncertainty quantification centred around the point estimate obtained using standard ZDI, our probabilistic ZDI formulation essentially provides uncertainty quantification as a byproduct compared to standard ZDI, without loss of information.
 |
Fig. 9 Same as Fig. 7 but the four samples were drawn from the posterior magnetic field distribution obtained through posterior inference using a statistical model with a mixture prior consisting of the two components p1(z) and p2(z). From the left, the first and third column represent samples drawn from the first component of the mixture posterior, and the second and fourth column represent samples drawn from the second component. |
 |
Fig. 10 Violin plots illustrating the distribution of magnetic energy over different harmonic modes. In these plots the widths of the coloured regions represent the smoothed probability density of the fraction of the total magnetic energy, numerically obtained by sampling from the posterior distribution p(z|y) corresponding to the results illustrated in Fig. 4. Horizontal lines mark the 0.05-, 0.50- and 0.95-quantiles of the distribution at each mode, respectively. The left panel compares the energy of the toroidal contribution (blue) and the poloidal components (red) as a function of angular degree, l, with values normalised by the total energy, i.e., (Et, Ep)/Etot. The right panel shows the total magnetic energy of the poloidal and toroidal field components as a function of angular degree, l, also normalised by the total energy, i.e. (Ep +Et)/Etot. |
 |
Fig. 11 Same as Fig. 10 but for the results obtained from the posterior distribution p(z|y) corresponding to the magnetic field in Fig. 6. |
 |
Fig. 12 Same as Fig. 10 but for the results obtained from the posterior distribution p(z|y) corresponding to the magnetic field in Fig. 8. |
Acknowledgements
This work was supported by the Wallenberg AI, Autonomous Systems and Software Program (WASP) funded by the Knut and Alice Wallenberg Foundation. Computations were enabled by the Berzelius resource provided by the Knut and Alice Wallenberg Foundation at the National Supercomputer Centre. O.K. acknowledges support by the Swedish Research Council (grant agreements nos. 2019-03548 and 2023-03667), the Swedish National Space Agency, and a sabbatical fellowship from AI4Research at Uppsala University.
Appendix A Implementation details
Our probabilistic ZDI framework is implemented in Python, utilizing NumPy for general numerical computations and JAX for efficient linear algebra and automatic differentiation. In particular, JAX’s automatic differentiation functionality is employed to compute the design matrix A in the forward model, a key component in the Bayesian formulation. For further implementation details, see our probabilistic ZDI code made available on GitHub4.
Appendix B Predictive distribution
In Fig. 3, we showed a comparison between the observed LSD Stokes V profiles and the reconstruction at the mean of the predictive distribution for a subset of the rotational phases, together with the posterior and predictive uncertainties. Fig. B.1 shows the corresponding results for all rotational phases.
 |
Fig. B.1 Same as Fig. 3 but for all rotational phases. Recall that the observed profiles are depicted in black, and the reconstruction at the mean is depicted in red. The shaded light grey area shows the marginal predictive uncertainty, whereas the shaded light blue area shows the corresponding posterior predictive uncertainty. |
Fig. B.2 and Fig. B.3 show the corresponding results obtained from statistical models using the two different mixture priors explored in this paper (referred to as Case 2 and Case 3). We observe that the posterior predictive uncertainty is significantly larger using the mixture prior with 1000 η−dependent components (Case 2).
 |
Fig. B.2 Same as Fig. B.1 but for results obtained using a statistical model with a) a mixture prior consisting of 1000 η-dependent components pc(z). and b) a mixture prior consisting of the two components p1(z) and p2(z). |
 |
Fig. B.3 Same as Fig. 3 but for results obtained using a statistical model with a) a mixture prior consisting of 1000 η-dependent components pc(z).and b) a mixture prior consisting of the two components p1(z) and p2(z). |
Appendix C Results for spherical harmonic coefficients
In the main paper, we focus on the posterior magnetic field distribution and the magnetic energy distributions as a function of l. The posterior distribution over the spherical harmonic coefficients z is also readily available but more difficult to interpret. In addition, the values of the coefficients are generally not comparable between studies due to different formulations in terms of e.g. real and imaginary representations of spherical harmonic expansions and different normalisation approaches. For completeness, we present the covariance matrices and triangular plots for the three posterior distributions p(z|y) presented in this paper. These results can be found in Fig. C.1, Fig. C.2 and Fig. C.3, corresponding to Case 1, Case 2 and Case 3, respectively. The uncertainties over the coefficients are dominated by the trend with l. The apparent trends with m (e.g. a higher uncertainty for the odd-m toroidal modes for l = 1 but a lower uncertainty for the same modes for l = 2) reflect the amplitude of recovered harmonic coefficients and disappear when one considers uncertainties normalised by the absolute value of the coefficients.
 |
Fig. C.1 Graphical representation of the spherical harmonic coefficients and their covariances. This plot corresponds to the magnetic field reconstruction results in Fig. 4. a) Covariance matrix with the three groups of spherical harmonic coefficients, α, β, γ, stored sequentially in the order of increasing l and m numbers. Dashed lines highlight parts of the covariance matrix corresponding to each group of harmonic coefficients. b) Mean value of the spherical harmonic coefficients. c) Standard deviation of the spherical harmonic coefficients. |
 |
Fig. C.2 Same as Fig. C.1 but for the spherical harmonic coefficients corresponding to the magnetic field reconstruction in Fig. 6. |
 |
Fig. C.3 Same as Fig. C.1 but for the spherical harmonic coefficients corresponding to the magnetic field reconstruction in Fig. 8. |
References
- Bishop, C. M. 2007, Pattern Recognition and Machine Learning (Information Science and Statistics), 1st edn. (Springer) [Google Scholar]
- Blei, D. M., Kucukelbir, A., & McAuliffe, J. D. 2017, J. Am. Statist. Assoc., 112, 859 [Google Scholar]
- Bouvier, J., Matt, S. P., Mohanty, S., et al. 2014, In Protostars and Planets VI, eds. H. Beuther, R. S. Klessen, C. P. Dullemond, & T. Henning, 433 [Google Scholar]
- Braithwaite, J. 2008, MNRAS, 386, 1947 [Google Scholar]
- Brooks, S., Gelman, A., Jones, G., & Meng, X.-L. 2011, Handbook of Markov Chain Monte Carlo (CRC press) [CrossRef] [Google Scholar]
- Brown, S. F., Donati, J.-F., Rees, D. E., & Semel, M. 1991, A&A, 250, 463 [NASA ADS] [Google Scholar]
- Cotter, S., Roberts, G., Stuart, A., & White, D. 2013, Statist. Sci., 28, 424 [Google Scholar]
- Donati, J.-F. 1999, MNRAS, 302, 457 [NASA ADS] [CrossRef] [Google Scholar]
- Donati, J.-F., & Brown, S. F.. 1997, A&A, 326, 1135 [Google Scholar]
- Donati, J.-F., & Landstreet, J. D. 2009, ARA&A, 47, 333 [NASA ADS] [CrossRef] [Google Scholar]
- Donati, J. F., Semel, M., Carter, B. D., Rees, D. E., & Collier Cameron, A. 1997, MNRAS, 291, 658 [Google Scholar]
- Donati, J., Catala, C., Landstreet, J. D., Petit, P. 2006a, in Astronomical Society of the Pacific Conference Series, 358, eds. R. Casini, & B. W. Lites, 362 [Google Scholar]
- Donati, J. F., Howarth, I. D., Jardine, M. M., et al. 2006b, MNRAS, 370, 629 [Google Scholar]
- Fares, R., Donati, J. F., Moutou, C., et al. 2009, MNRAS, 398, 1383 [NASA ADS] [CrossRef] [Google Scholar]
- Feiden, G. A. 2016, A&A, 593, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Folsom, C. P., Bouvier, J., Petit, P., et al. 2018, MNRAS, 474, 4956 [NASA ADS] [CrossRef] [Google Scholar]
- Gelman, A., Carlin, J., Stern, H., et al. 2020, Bayesian Data Analysis, http://www.stat.columbia.edu/~gelman/book/ [Google Scholar]
- Grunhut, J. H., Wade, G. A., Neiner, C., et al. 2017, MNRAS, 465, 2432 [NASA ADS] [CrossRef] [Google Scholar]
- Hoeting, J. A., Madigan, D., Raftery, A. E., & Volinsky, C. T. 1999, Statist. Sci., 14, 382 [Google Scholar]
- Hussain, G. A. J., Donati, J.-F., Collier Cameron, A., & Barnes, J. R. 2000, MNRAS, 318, 961 [NASA ADS] [CrossRef] [Google Scholar]
- Karvonen, T., & Oates, C. J. 2024, J. Mach. Learn. Res., 24 [Google Scholar]
- Keszthelyi, Z., Meynet, G., Martins, F., & de Koter, A. & David-Uraz, A. 2021, MNRAS, 504, 2474 [NASA ADS] [CrossRef] [Google Scholar]
- Khokhlova, V. L., Rice, J. B., & Wehlau, W. H. 1986, ApJ, 307, 768 [Google Scholar]
- Kochukhov, O. 2016a, in Lecture Notes in Physics, 914, eds. J.-P. Rozelot, & C. Neiner, 177 [Google Scholar]
- Kochukhov, O. 2016b, in Cartography of the Sun and the Stars, eds. J.-P. Rozelot, & C. Neiner (Springer International Publishing), 177 [Google Scholar]
- Kochukhov, O. 2017, A&A, 597, A58 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kochukhov, O., & Wade, G. A. 2016, A&A, 586, A30 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kochukhov, O., Piskunov, N., Ilyin, I., Ilyina, S., & Tuominen, I. 2002, A&A, 389, 420 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kochukhov, O., Makaganiuk, V., & Piskunov, N. 2010, A&A, 524, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kochukhov, O., Makaganiuk, V., Piskunov, N., et al. 2011, ApJ, 732, L19 [Google Scholar]
- Kochukhov, O., Lüftinger, T., Neiner, C., & Alecian, E. MiMeS Collaboration 2014, A&A, 565, A83 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kochukhov, O., Shultz, M., & Neiner, C. 2019, A&A, 621, A47 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kochukhov, O., Papakonstantinou, N., & Neiner, C. 2022, MNRAS, 510, 5821 [NASA ADS] [CrossRef] [Google Scholar]
- Landi Degl’Innocenti, E., & Landolfi, M., 2004, Astrophysics and Space Science Library, 307, Polarization in Spectral Lines (Kluwer Academic Publishers) [Google Scholar]
- Lanza, A. F. 2018, In Handbook of Exoplanets, eds. H. J. Deeg, & J. A. Belmonte, 17 [Google Scholar]
- Matt, S., & Pudritz, R. E. 2008, ApJ, 678, 1109 [NASA ADS] [CrossRef] [Google Scholar]
- Meyn, S., & Tweedie, R. L. 2009, Markov Chains and Stochastic Stability, 2nd edn. (USA: Cambridge University Press) [CrossRef] [Google Scholar]
- Morin, J., Donati, J. F., & Petit, P., et al. 2008, MNRAS, 390, 567 [NASA ADS] [CrossRef] [Google Scholar]
- Morin, J., Donati, J. F., & Petit, P., et al. 2010, MNRAS, 407, 2269 [Google Scholar]
- Murphy, K. P. 2022, Probabilistic Machine Learning: An introduction (MIT Press) [Google Scholar]
- Nieva, M.-F., & Przybilla, N. 2014, A&A, 566, A7 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Petit, V., & Wade, G. A. 2012, MNRAS, 420, 773 [NASA ADS] [CrossRef] [Google Scholar]
- Petit, P., Dintrans, B., Solanki, S. K., et al. 2008, MNRAS, 388, 80 [NASA ADS] [CrossRef] [Google Scholar]
- Petit, P., Louge, T., & Théado, S., et al. 2014, PASP, 126, 469 [NASA ADS] [CrossRef] [Google Scholar]
- Piskunov, N., & Kochukhov, O. 2002, A&A, 381, 736 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Przybilla, N., Firnstein, M., Nieva, M. F., Meynet, G., & Maeder, A. 2010, A&A, 517, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Reiners, A. 2012, Liv. Rev. Sol. Phys., 9, 1 [Google Scholar]
- Roberts, G. O., & Rosenthal, J. S. 2001, Bernoulli, 7, 453 [Google Scholar]
- Rosén, L., Kochukhov, O., & Wade, G. A. 2015, ApJ, 805, 169 [Google Scholar]
- Schneider, F. R. N., Podsiadlowski, P., Langer, N., Castro, N. & Fossati, L. 2016, MNRAS, 457, 2355 [Google Scholar]
- Schneider, F. R. N., Ohlmann, S. T., Podsiadlowski, P., et al. 2019, Nature, 574, 211 [Google Scholar]
- Schneider, F. R. N., Ohlmann, S. T., Podsiadlowski, P., et al. 2020, MNRAS, 495, 2796 [NASA ADS] [CrossRef] [Google Scholar]
- Shu, F., Najita, J., Ostriker, E., et al. 1994, ApJ, 429, 781 [Google Scholar]
- Shultz, M. E., Wade, G. A., Rivinius, T., et al. 2018, MNRAS, 475, 5144 [NASA ADS] [Google Scholar]
- Sikora, J., Wade, G. A., Power, J. & Neiner, C. 2019, MNRAS, 483, 2300 [NASA ADS] [CrossRef] [Google Scholar]
- Sjölund, J., Eklund, A., & Özarslan, E., et al. 2018, NeuroImage, 175, 272 [Google Scholar]
- Strugarek, A. 2016, ApJ, 833, 140 [NASA ADS] [CrossRef] [Google Scholar]
- Vidotto, A. A. 2020, in IAU Symposium, 354, Solar and Stellar Magnetic Fields: Origins and Manifestations, eds. A. Kosovichev, S. Strassmeier, & M. Jardine, 259 [Google Scholar]
- Vidotto, A. A., Opher, M., Jatenco-Pereira, V., & Gombosi, T. I. 2009, ApJ, 699, 441 [Google Scholar]
- Vogt, S. S., Penrod, G. D., & Hatzes, A. P. 1987, ApJ, 321, 496 [Google Scholar]
- Vogt, S. S., Hatzes, A. P., Misch, A. A., & Kürster, M. 1999, ApJS, 121, 547 [Google Scholar]
- Wade, G. A., Donati, J. F., Landstreet, J. D., & Shorlin, S. L. S. 2000, MNRAS, 313, 823 [NASA ADS] [CrossRef] [Google Scholar]
- Weber, E. J., & DavisLeverett, J. 1967, ApJ, 148, 217 [NASA ADS] [CrossRef] [Google Scholar]
This was accomplished by multiplying Cl,m by 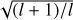 for m = 0 and by
for m = 0 and by 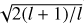 for m ≠ 0
for m ≠ 0
The notation p(x) = 𝒩(x; μ, Σ) represents a Gaussian distribution over the random variable x, with mean vector μ and covariance matrix Σ.
All Tables
All Figures
|
Fig. 1 Unnormalised log evidence as a function of η on a region close to η = 0. The log evidence is maximised for η ≈ 0.002. As η grows outside of the displayed region, the log evidence continues to decrease. |
| In the text | |
|
Fig. 2 Trade-off between the least-squares fit and the regularisation objective as a function of η. The region where η ∈ [16, 421] is shaded in purple. |
| In the text | |
|
Fig. 3 Comparison between the mean LSD Stokes V profiles (red) of the predictive distribution and the observed LSD Stokes V profiles (black), for a subset of the rotational phases. The profiles are offset vertically according to the rotational phase, as indicated in blue. The marginal predictive uncertainty is shaded in light grey and depicts three standard deviations. The corresponding posterior predictive uncertainty is shaded in light blue, and the blue bars represent the corresponding observational uncertainties. |
| In the text | |
|
Fig. 4 Rectangular maps of the reconstructed magnetic field and the corresponding uncertainty quantification. The left column shows the mean of the posterior magnetic field distribution across the stellar surface, in terms of the radial (top), meridional (middle) and azimuthal (bottom) magnetic field components. The field strength is given in kG. The grey transparent rectangle indicates the part of the stellar surface that is obscured from view. The right column shows the corresponding standard deviation maps. The results were obtained using a statistical model with hyperparameters Ωi,i = ηli2 and η = 100 in the marginal prior distribution for each spherical-harmonic coefficient zi. Note that the contour plots in this paper consistently use the same number of levels between the minimum and maximum values in all figures. |
| In the text | |
|
Fig. 5 Comparison of predicted (mean) LSD Stokes V profiles from independent inversions using η = 16 (blue) and η = 421 (red) for a subset of the rotational phases. The mean deviations between the means of the predictive distributions and the observed Stokes V profiles (black) is 7.87 · 10−5 and 1.05 · 10−4, respectively, across all rotational phases. |
| In the text | |
|
Fig. 6 Same as Fig. 4 but for results obtained using a statistical model with a mixture prior consisting of 1000 η-dependent components pc(z). |
| In the text | |
|
Fig. 7 Four samples of surface magnetic field vector maps drawn from the posterior distribution. The distribution was obtained through posterior inference using a statistical model with a mixture prior consisting of 1000 η-dependent components pc(z). From the left, the samples were drawn from components of the mixture posterior distribution with parameters η ≈ 34,η ≈ 123,η ≈ 62 and η ≈ 258, respectively. |
| In the text | |
|
Fig. 8 Same as Fig. 4 but for results obtained using a statistical model with a mixture prior consisting of the two components p1(z) and p2(z). |
| In the text | |
|
Fig. 9 Same as Fig. 7 but the four samples were drawn from the posterior magnetic field distribution obtained through posterior inference using a statistical model with a mixture prior consisting of the two components p1(z) and p2(z). From the left, the first and third column represent samples drawn from the first component of the mixture posterior, and the second and fourth column represent samples drawn from the second component. |
| In the text | |
|
Fig. 10 Violin plots illustrating the distribution of magnetic energy over different harmonic modes. In these plots the widths of the coloured regions represent the smoothed probability density of the fraction of the total magnetic energy, numerically obtained by sampling from the posterior distribution p(z|y) corresponding to the results illustrated in Fig. 4. Horizontal lines mark the 0.05-, 0.50- and 0.95-quantiles of the distribution at each mode, respectively. The left panel compares the energy of the toroidal contribution (blue) and the poloidal components (red) as a function of angular degree, l, with values normalised by the total energy, i.e., (Et, Ep)/Etot. The right panel shows the total magnetic energy of the poloidal and toroidal field components as a function of angular degree, l, also normalised by the total energy, i.e. (Ep +Et)/Etot. |
| In the text | |
|
Fig. 11 Same as Fig. 10 but for the results obtained from the posterior distribution p(z|y) corresponding to the magnetic field in Fig. 6. |
| In the text | |
|
Fig. 12 Same as Fig. 10 but for the results obtained from the posterior distribution p(z|y) corresponding to the magnetic field in Fig. 8. |
| In the text | |
|
Fig. B.1 Same as Fig. 3 but for all rotational phases. Recall that the observed profiles are depicted in black, and the reconstruction at the mean is depicted in red. The shaded light grey area shows the marginal predictive uncertainty, whereas the shaded light blue area shows the corresponding posterior predictive uncertainty. |
| In the text | |
|
Fig. B.2 Same as Fig. B.1 but for results obtained using a statistical model with a) a mixture prior consisting of 1000 η-dependent components pc(z). and b) a mixture prior consisting of the two components p1(z) and p2(z). |
| In the text | |
|
Fig. B.3 Same as Fig. 3 but for results obtained using a statistical model with a) a mixture prior consisting of 1000 η-dependent components pc(z).and b) a mixture prior consisting of the two components p1(z) and p2(z). |
| In the text | |
|
Fig. C.1 Graphical representation of the spherical harmonic coefficients and their covariances. This plot corresponds to the magnetic field reconstruction results in Fig. 4. a) Covariance matrix with the three groups of spherical harmonic coefficients, α, β, γ, stored sequentially in the order of increasing l and m numbers. Dashed lines highlight parts of the covariance matrix corresponding to each group of harmonic coefficients. b) Mean value of the spherical harmonic coefficients. c) Standard deviation of the spherical harmonic coefficients. |
| In the text | |
|
Fig. C.2 Same as Fig. C.1 but for the spherical harmonic coefficients corresponding to the magnetic field reconstruction in Fig. 6. |
| In the text | |
|
Fig. C.3 Same as Fig. C.1 but for the spherical harmonic coefficients corresponding to the magnetic field reconstruction in Fig. 8. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.