| Issue |
A&A
Volume 698, June 2025
|
|
|---|---|---|
| Article Number | A92 | |
| Number of page(s) | 24 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202452651 | |
| Published online | 04 June 2025 | |
Gamma-ray burst redshift estimation using machine learning and the associated web app
1
Astronomical Observatory of Jagiellonian University in Kraków,
Orla 171,
30-244
Kraków,
Poland
2
Jagiellonian University, Doctoral School of Exact and Natural Sciences,
Krakow,
Poland
3
Division of Science, National Astronomical Observatory of Japan,
2-21-1 Osawa, Mitaka,
Tokyo
181-8588,
Japan
4
The Graduate University for Advanced Studies (SOKENDAI), Shonankokusaimura, Hayama, Miura District,
Kanagawa
240-0115,
Japan
5
Space Science Institute,
4765 Walnut St Ste B,
Boulder,
CO
80301,
USA
6
Nevada Center for Astrophysics, University of Nevada,
4505 Maryland Parkway,
Las Vegas,
NV
89154,
USA
7
Bay Environmental Institute,
PO Box 25,
Moffett Field,
CA,
USA
8
National Center for Nuclear Physics (NCBJ),
Warsaw,
Poland
9
Department of Physical Sciences, Indian Institute of Science Education and Research (IISER),
Mohali,
Punjab,
India
10
Department of Physics and Kavli Institute of Particle Astrophysics and Cosmology, Stanford University,
Stanford,
CA
94305,
USA
11
University of Nevada, Las Vegas,
4505 S. Maryland Pkwy,
Las Vegas,
NV
89154,
USA
12
Department of Mathematics, University of Wroclaw,
50-384
Wrocław,
Poland
13
Department of Statistics,
Lund University,
221 00
Lund,
Sweden
14
Center for Computational Astrophysics, National Astronomical Observatory of Japan,
2-21-1 Osawa, Mitaka,
Tokyo
181-8588,
Japan
★★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
17
October
2024
Accepted:
5
April
2025
Abstract
Context. Gamma-ray bursts (GRBs), which have been observed at redshifts as high as 9.4, could serve as valuable probes for investigating the distant Universe. However, using them in this manner necessitates an increase in the number of GRBs with determined redshifts, as currently only 12% of them have known redshifts due to observational biases.
Aims. We aim to address the shortage of GRBs with measured redshifts to enable full realization of their potential as valuable cosmological probes.
Methods. Following our previous approach, in this work we take a further step to overcome this issue by adding 30 more GRBs to our ensemble supervised machine learning training sample, representing an increase of 20%, which will help us obtain more accurate pseudo-redshifts. In addition, we have built a freely accessible and user-friendly web application that infers the redshift of long GRBs (LGRBs) with plateau emission using our machine learning model. The web app is the first of its kind for such a study and will allow the community to obtain pseudo-redshifts by entering the GRB parameters into the app.
Results. Through our machine learning model, we successfully estimated redshifts for 276 LGRBs using X-ray afterglow parameters detected by the Neil Gehrels Swift Observatory and increased the sample of LGRBs with known redshifts by 110%. We also performed Monte Carlo simulations to demonstrate the future applicability of this research.
Conclusions. The results presented in this work will enable the community to increase the sample of GRBs with known pseudoredshifts. This can help address many outstanding issues, such as GRB formation rate, luminosity function, and the true nature of low-luminosity GRBs, and it can enable the application of GRBs as standard candles.
Key words: methods: data analysis / techniques: photometric / distance scale / gamma rays: general
First and second authors share the same contribution.
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Gamma-ray bursts (GRBs) are the brightest and most powerful explosion events after the Big Bang and are observed across a wide range of redshifts, from 0.0085 (Galama et al. 1998) to 8.2 and 9.4 (Tanvir et al. 2009; Cucchiara et al. 2011). This vast range of redshifts (z) makes GRBs ideal probes for studying the early Universe and tracking its evolution to gain insights into the composition, expansion rate, and other key aspects. GRBs, generally detected in γ-rays, X-rays, and occasionally in optical wavelengths, are classified into two types based on their duration, which is characterized by the T90 parameter. The parameter T90 is the time span during which the GRB emits 90% of its total observed fluence in γ-rays. The GRBs with T90 < 2 s are classified as short GRBs (SGRBs), and those with T90 > 2s are classified as long GRBs (LGRBs). The LGRBs are produced by core collapse supernovae (Mazets et al. 1981; Kouveliotou et al. 1993; Paczyński 1998; Woosley & Bloom 2006), while SGRBs are produced by neutron star–neutron star or neutron star-black hole mergers (Narayan et al. 1992; Duncan & Thompson 1992; Usov 1992; Thompson 1994; Nakar 2007; Goldstein et al. 2017a,b; Abbott et al. 2017).
In addition to these two main categories of GRBs, numerous other sub-classes have been identified in the literature. These classes are based only on observational properties such as the T90 duration as well as spectral and light curve (LC) properties, and they include classes such as SGRBs with extended emission (SEE; Norris et al. 2000; Norris & Bonnell 2006; Levan et al. 2007; Norris et al. 2010), where T90 is greater than two seconds but with similar spectral properties to SGRBs, Very Long GRBs (VLGRBs, Levan et al. 2014) and Ultra Long GRBs (ULGRBs, Stratta et al. 2013; Zhang et al. 2014; Gendre et al. 2019), where T90 is greater than 500 or 1000 seconds, respectively. Zhang et al. (2007) unified these various classes based on their GRB progenitors. According to their prescription, Type I GRBs comprise classes that are SGRBs, SEEs, and other GRBs similar to SGRBs and occur due to compact binary mergers (Nakar 2007; Abbott et al. 2017). Type II GRBs comprise LGRBs, VLGRBs, ULGRBs, and other similar classes with core-collapse supernova progenitors (the so-called collapsar events) (Woosley 1993; Woosley et al. 1993). Irrespective of these efforts, an exhaustive classification of GRBs has not yet been found, and this is an active field of research.
Phenomenologically, the GRB LC from across all the classes can be separated into two distinct phases. The prompt emission is the main emission, and it is characterized by a burst of high-energy photons spanning γ-rays to hard X-rays that sometimes extends into optical wavelengths (Vestrand et al. 2005; Beskin et al. 2010; Gorbovskoy et al. 2012; Vestrand et al. 2014). Following the prompt emission, the afterglow is a long-lasting, multiwavelength emission powered by the interaction of the GRB ejecta with the surrounding medium (van Paradijs et al. 1997; Costa et al. 1997; Piro et al. 1998). It is detected across various wavelengths, such as X-rays, optical, and occasionally even radio.
A peculiar trait of GRBs, uncovered by the Neil Gehrels Swift observatory (hereafter Swift, Gehrels et al. (2004)), is the presence of a flat region in the LC, the so-called plateau emission, which is characterized by almost constant flux values (Nousek et al. 2006; Zhang et al. 2006; O’Brien et al. 2006; Sakamoto et al. 2007; Liang et al. 2007b; Dainotti et al. 2008; Zaninoni et al. 2013; Rowlinson et al. 2014). The end of the plateau is considered to be a point in the LC’s afterglow where the luminosity begins to decay with time as a power law. The plateau feature has been found in 42% of X-ray afterglows (Evans et al. 2009; Li et al. 2018). In our recent estimate, the percentage of GRBs with an observable plateaus is 38.5%.
Currently, the primary hurdle in the study of the LGRB population is the lack of a large GRB sample with known redshift. Quick localization and spectral data are required to determine the redshift of GRBs. Notably, Swift allows for this quick detection as well as multi-wavelength follow-up in γ-rays, X-rays, and ultraviolet/optical. Swift has three telescopes: the Burst Alert Telescope (BAT; Burrows et al. 2005), the X-ray Telescope (XRT; Barthelmy et al. 2005), and the Ultraviolet/Optical Telescope (UVOT; Roming et al. 2005). It uses XRT for precise localization, and with UVOT, it obtains spectra and sometimes redshifts. Swift’s rapid localization abilities have contributed significantly to exploring the high-z Universe.
Although Swift triggers many observation programs, only 26% (431) of its 1656 GRBs have known spectroscopic redshifts (as of 20 August 2024). The Fermi Telescope has observed more than 3700 GRBs with its Large Area Telescope (LAT; Ajello et al. 2019) and the Fermi Gamma-ray Burst Monitor (GBM; Meegan et al. 2009). Currently, only 12% of the GRBs detected by Swift and Fermi have spectroscopic redshift (zobs), and approximately 90% of them were observed by Swift. Measuring redshift, especially high- z, is challenging due to limited telescope time and the difficulty of securing time for follow-up observations using large aperture telescopes. Therefore, determining the z of GRBs via alternative methods is crucial.
Correctly determining the GRB luminosity function (LF) is one of the main goals that can be achieved by increasing the number of GRBs with known redshifts. The LF provides the number of GRBs per unit luminosity and is vital for understanding the properties of the GRB population, such as their energy release and emission mechanisms. Another principal objective is determining the cosmic GRB formation rate (GRBFR). The GRBFR measures the frequency of GRBs across cosmic time.
Petrosian et al. (2015); Petrosian & Dainotti (2024) have found a discrepancy at low redshift (0 < z < 1) between the LGRB formation rate and the star formation rate (SFR). This discrepancy, which has been observed by several research groups independently, remains an active area of investigation, and addressing it requires a bigger sample of GRBs with known redshift, thus highlighting the importance of our study.
The correct determination of the GRB rate for both LGRBs and SGRBs is hampered by the broad range of GRB physical features; therefore, a precise distribution of these features and their evolution over cosmic time is necessary. In Dainotti et al. (2024b), we investigated this issue with a sample of 179 GRBs with optical LCs, where we determined the luminosity and formation rate evolutions and the general shape of the LF after correcting for evolution. We observed the average LGRB’s rate at a low-z (z < 1) to be 10.46 Gpc−3 yr−1, which is roughly three times more than Hopkins & Beacom (2006) SFR (3.7 Gpc−3 yr−1). This LGRB rate is an actual rate where the normalization is in physical units, which contrasts with the arbitrary normalization used in most of the current literature.
To address the challenges outlined above, we propose a machine learning (ML)-based approach for estimating the redshift of GRBs. This work is a follow-up of Dainotti et al. (2024c) and Dainotti et al. (2024b), and we utilize a sample that is 20% larger than the sample in Dainotti et al. (2024c) to train our ML models. In addition, we extend the generalization sample by 35%. This sample is the set of GRBs without known redshifts, and we predict the redshift of 276 GRBs using our trained ML model. Furthermore, we release a user-friendly web application that provides pseudo-redshifts for new GRBs built on the ML models described in this paper.
The paper is structured as follows. In Sect. 2, we discuss the advantages of using an ML approach compared to using linear relations for the redshift estimation. In Sect. 3, we describe our data set. In Sect. 4, we describe the functionalities and various modules of our web app as well as details of the ML models being used. We also describe the Monte Carlo (MC) simulation performed to understand the viability of our ML models in relation to future data. Sect. 5 shows the results obtained from our analysis and the usability of the web app. Here, we also present the future applicability of our ML approach. In Sect. 6, we discuss the relevance of our results. Finally, we summarize and conclude in Sect. 7.
2 Advantage of machine learning versus linear relationships
Expanding the GRB sample with redshift provides a significant benefit, notably the possibility of using them as standardized candles, objects with known intrinsic luminosities, or with luminosities that can be derived via established relationships among GRB properties. The adoption of empirical relations between the distance-dependent and intrinsic properties of GRBs enables cosmological studies in unexplored redshift ranges. One of the earliest efforts is the Dainotti Relation (Dainotti et al. 2008, 2011a, 2015, 2017), a roughly inversely proportional relationship between the rest-frame time at the end of the plateau phase (Ta/(1 + z)) and its corresponding X-ray luminosity (La). Later, Dainotti et al. (2013) showed via the use of the Efron and Petrosian method (Efron & Petrosian 1992), this relation is intrinsic and not due to selection biases nor the redshift evolution. The Dainotti Relation has also been observed in radio wavelengths (Dainotti et al. 2020a; Levine et al. 2022). It has also been extended in three dimensions in X-ray, optical (Dainotti et al. 2022b), and γ-rays (Dainotti et al. 2021b), where the peak prompt luminosity (Lpeak) has been added to the twodimensional Dainotti relation (Dainotti et al. 2016, 2017, 2020a).
The Dainotti relationships (both in two and three dimensions) were a subject of cosmological investigations, and have been utilized as valuable tools (Cardone et al. 2009, 2010; Dainotti et al. 2013; Postnikov et al. 2014; Cao et al. 2021, 2022b,a; Dainotti et al. 2023a,b; Bargiacchi et al. 2023; Dainotti et al. 2023c). The Dainotti relations have been shown to provide compatible results for ΩM (the matter density parameter) under the assumption of flat ΛCDM model when used in conjunction with supernovae (SNe) Ia (Dainotti et al. 2023a). This approach also has the advantage of expanding the distance ladder up to z = 5, which is much higher than the most distant SNe Ia observed up to date (z = 2.9) (Pierel et al. 2024). Wang et al. (2022) further extended the Dainotti relation up to z = 5.91. They also standardized the LGRB sample using a method similar to the Phillips Correlation (Phillips 1993). This standardization helped Wang et al. (2022) achieve a lower scatter on the rescaled luminosity, thus highlighting the importance of the plateau phase as a possible standard candle.
Another notable effort in establishing a fundamental GRB relation is the so-called Combo relation (Izzo et al. 2015), joining La, Ta/(1 + z), power-law decay of afterglow, and intrinsic spectral peak energy of prompt (Ep, i). Izzo et al. (2015) demonstrated, with a limited sample of 5 GRBs, a minimization of the dependency on SNe Ia for calibrating GRBs. They use a two-step calibration process for the Combo relation and measured 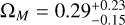 in ΛCDM.
in ΛCDM.
Recently, Yi et al. (2022) analyzed samples of 174 X-ray LCs of GRBs with plateau and 104 GRBs with flares, overlapping by 51 sources. They discovered three tight correlations between plateau energy (Eplat), flare energy (Eflare) and isotropic prompt energy (Eγ,iso). The correlations were between Eplat − Eγ,iso, Eflare − Eγ,iso and (Eplat + Eflare) − Eγ,iso. Eplat − Eγ,iso correlation is similar to the La − Lpeak Dainotti correlation (Dainotti et al. 2011b), thus independently confirming it. Yi et al. (2022) also conclude that X-ray plateaus and flares may originate in the same way but, due to the effects of the surrounding medium, appear as different features in the afterglow LC.
The extension of the Dainotti relations in three dimensions has also been achieved by Xu & Huang (2012), where they add the isotropic γ-ray energy to the two-dimensional relation, naming it the L − T − E correlation. Zhao et al. (2019); Tang et al. (2019) independently confirmed the existence of this correlation for 174 GRBs from Swift. Tang et al. (2019) also improved the best-fit relation to be 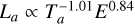 . This work was expanded upon further by Xu et al. (2021) and Deng et al. (2023). Xu et al. (2021) showed the redshift evolution of the L − T − E correlation and introduced a new correlation with the spectral peak energy labeled L − T − Ep correlation. Deng et al. (2023) updated coefficients of the L − T − E correlation of Tang et al. (2019) to
. This work was expanded upon further by Xu et al. (2021) and Deng et al. (2023). Xu et al. (2021) showed the redshift evolution of the L − T − E correlation and introduced a new correlation with the spectral peak energy labeled L − T − Ep correlation. Deng et al. (2023) updated coefficients of the L − T − E correlation of Tang et al. (2019) to  with 210 LGRBs with plateau and also derived pseudo-redshifts for 108 plateau GRBs. However, their pseudo-redshifts are limited by intrinsic scatter and functional form of the L − T − E correlation. Moreover, the precision of their approach is not tested against GRBs with known redshift. In comparison, our ML-based approach tests the performance of our model on events with known redshifts.
with 210 LGRBs with plateau and also derived pseudo-redshifts for 108 plateau GRBs. However, their pseudo-redshifts are limited by intrinsic scatter and functional form of the L − T − E correlation. Moreover, the precision of their approach is not tested against GRBs with known redshift. In comparison, our ML-based approach tests the performance of our model on events with known redshifts.
Previously, there have been several other efforts aiming to enhance the count of GRBs with known redshifts by exploring correlations between distance-independent parameters (such as peak flux and afterglow plateau duration) and distance-dependent GRB characteristics (such as prompt emission and peak luminosity) to estimate pseudo-redshifts for GRBs lacking observed values (Reichart 2001; Atteia 2003, 2005; Yonetoku et al. 2004; Dainotti et al. 2011b). Very few GRBs can reach the small uncertainty (5%) (Guiriec et al. 2016). Specifically, when using a relation between the rest-frame Ta and its luminosity, only 28% of cases have uncertainties Δ z/zobs < 0.90 (Dainotti et al. 2011a). If the redshift is extracted by employing the Amati correlation (Amati et al. 2002) between Epeak (the peak in the vFv spectrum) and the energy emitted isotropically during the prompt emission, the Pearson coefficient (r) of correlation between zobs and predicted redshift (zpred) is 0.67. Amati (2006) provided zpred for 17 GRBs, and these are accurate within a factor of 2.
Another often overlooked issue is the inherent inaccuracies of these pseudo-redshifts, which arise from their non-linear dependence on the luminosity distance (DL).
At low-z since the DL(z) changes rapidly, even with parametric relations, we can infer the redshift, but as soon as DL(z) becomes flat around z = 2, it is difficult to distinguish between the predictions among the highz (>2), because a small variation of DL can still be reflected in a large variation of redshifts. In addition, DL(z) they have such a complex analytical dependence z that their relation cannot be determined analytically but only numerically.
The major problem in the forward-fitting relationships is the dependence on cosmology. Indeed, one of the parameters of this relationship depends on the DL, which itself depends on cosmological parameters. We also would like to stress that it is important to have a method that is not dependent on a given cosmological model; otherwise, we incur the so-called “circularity problem”. Indeed, it would be highly circular to use the pseudo-redshifts derived from the forward fitting method, which assumes a given cosmology to then derive cosmological parameters. Even if the goal of the pseudo-redshift is not to derive the cosmological parameters, we avoid being biased toward a particular or a given cosmological model for the analysis of the LF and density rate evolution here. Although, the error bars for the LF are not negligible, in the procedure of the selection biases detailed in Dainotti et al. (2024b) if the cosmology had been inferred, we would have had a different number of associated sets (described in the appendix of that paper), because of the choice of a different limiting luminosity. Hence, this will also affect the density rate evolution.
Thus, using any of these methods would induce a circularity problem, which must be avoided, especially when we tackle cosmology. In addition, given the functional form of log(DL), as it flattens at z ≳ 3, any small variation of log(DL) can become a large variation in redshift determination. Hence, the difficulty in determining the redshifts accurately with these forward-fitting methods. Furthermore, based on relationships, the forward fitting methods mentioned do not account for the errors on the parameters, thus underestimating the realistic uncertainties on the redshifts. Thus, we have followed a route via ML algorithms to obtain more accurate predictions and overcome these issues.
Similar work has been done by Ukwatta et al. (2016); Aldowma & Razzaque (2024). However, here we use the plateau features, whose correlations have less intrinsic scatter than prompt ones. This can ensure more stable ML results.
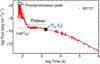 |
Fig. 1 Typical GRB LC. The X-ray LCs are fit with the W07 model, denoted with the darker red line. The end time of the plateau (Ta, Fa) and the prompt emission peak are shown as a black-filled dot and as an empty dot, respectively. |
3 The data sample
Due to the diverse nature of various GRB classes, it is essential to avoid mixing the characteristics of these classes in an ML analysis. In a previous paper (Dainotti et al. 2024c), some members of our research team have pointed out that the removal of some additional classes, especially the SEE, does not significantly affect the prediction. Thus, this study focuses only on LGRBs, the most numerous and homogeneous subset, and all SGRBs were removed from our sample. Our data comprises of LGRBs observed in γ-rays and X-rays by the BAT and XRT telescopes onboard the Swift. They are found in the Third Swift-BAT GRB Catalogue (Lien et al. 2016), and for data from 2016 until 12th December 2023, we use the NASA Swift GRB Search Tool. This sample is an extension of the one presented in Dainotti et al. (2024c), which itself was taken from Dainotti et al. (2020a) and Srinivasaragavan et al. (2020). For training our models, we have removed the GRBs that have photometric redshifts; an example is the famous high- z GRB090429B. Each GRB has ten properties (features). Four features belong to the prompt: the energy fluence over T90 of the prompt emission in units of erg cm−2 (Fluence), T90, the prompt peak photon flux in units of the number of photons cm−2 s−1 (Peak Flux), and from the BAT Telescope, the prompt photon index of the photon energy distribution modeled with a power law (PhotonIndex). Six features belong to the X-ray plateau and afterglow: the time at the end of the plateau emission (Ta), its corresponding flux (Fa), the temporal power-law index after the end of the plateau emission (α), the spectral index of the plateau (β) assuming a power law for the spectral energy distribution, the neutral hydrogen column density along the line of sight (NH), the spectral index obtained as the time-averaged spectral fit from the Swift XRT Photon counting mode data (γ). The plateau emission feature is modeled using the so-called Willingale function (W07, Willingale et al. (2007)).
Some of the parameters such as the Peakflux, Ta, Fa, and T90, are shown the Fig. 1, with Ta, Fa representing the x and y coordinates of the black dot. All of the parameters of the afterglow were obtained in 0.3−10 keV.
The initial data set contains 251 GRBs, including all classes. Compared with Dainotti et al. (2024c), there are an additional 30 GRBs with redshift that are added to the sample, an increase of 13%. From this sample, we remove 13 SGRBs and are left with 238 LGRBs with all the features listed above, as well as our response variable, the log(z + 1)1. The response variable is the variable that we train our ML models to predict. We call this set of 238 GRBs the training set. This training set is 20% larger than the previous training set of Dainotti et al. (2024c). For the generalization set, we use the 221 GRBs of Dainotti et al. (2024c) and add 78 GRBs (an increase of 35%) taken from the Swift website. The additional 78 GRBs of the generalization set were fit with the W07 model to obtain their Ta, Fa, α, and β.
In Fig. 2 we present the scatter matrix plot between the training set from Dainotti et al. (2024c) (cyan) and the 30 new GRBs (orange) added in this analysis for comparing the distribution of the variables. We applied the Kolmogorov–Smirov test (KS test) and the Anderson-Darling test (AD test) for each variable between the two data sets.
All the variables pass the two tests with a p-value >0.05, indicating that they originate from the same parent population, except T90 and γ, which obtain p-values <0.05 for both KS test and AD test, and log(Fa) which obtained a p-value <0.05 for AD test. For further discussion see the Appendix and the Fig. A.1. Here, we are presenting the comparison between the redshift distributions.
In the left panel of Fig. 3, the redshift distribution is illustrated, with the new sample depicted by a dashed line and the old sample by a solid line, both normalized to one. The right panel of Fig. 3 presents the actual distribution with no normalization. The redshift distributions pass the KS test with a p-value of 0.35 and the AD test with p-value of 0.41, as it can be seen from the right panel of Fig. 3. Thus, we cannot reject the hypothesis that the two sets of redshifts originate from the same parent population.
4 Methodology and web app
In this research, we expand the methodology implemented in Dainotti et al. (2024c), and in addition, we make the webapp available to the community via an easy-to-use open-source web app. This web app is designed to let users input GRB parameters and quickly obtain pseudo-redshifts within hours of the GRB trigger. This will allow the community to conduct followup observations of interesting bursts, such as high-z events or low-z low-luminosity GRB (LLGRB) events. This web app is also highly modular, and users are free to train their own custom models using their data.
We here detail in each subsection the various methods implemented in our analysis and the associated functions of the web app.
4.1 MICE
Similar to the sample in Dainotti et al. (2024c), both our training and generalization sets have missing data. Out of the 238 LGRBs composing our training set, 29 GRBs have missing variables: 15 GRBs have missing log(NH) entries, three GRBs have missing log(Peakflux) entries, two GRBs have missing entries in both log(Peakflux) and log(NH) simultaneously, three GRBs have missing entries in α, two GRBs have missing entries in α and log(NH) simultaneously, two GRBs have missing entries in PhotonIndex, one GRB has a missing entry in β only, and one GRB has missing entries in both γ and β simultaneously (see Fig. 4).
In Dainotti et al. (2024c), we removed the GRBs from the generalization set with missing entries. However, in this analysis, we impute them in a similar fashion to the training set. It should be noted that the imputation for the training set and the generalization set are conducted separately so that the training set does not influence the generalization set, thus preventing data bleeding. All 299 GRBs in our generalization set are LGRBs, out of which 11 have missing data entries. Two GRBs have missing entries in γ, two have missing entries in log(NH), two GRBs have missing entries in both γ and log(NH) simultaneously, two GRBs have missing entries in log(Peakflux) and log(T90) and three GRBs have simultaneous missing data in PhotonIndex, log(T90) and log(Peakflux). In addition to the previously noted missing entries, we identify GRBs with log(NH) < 20, α, β, and γ > 3, and a PhotonIndex <0 as outliers, as these values fall toward the extreme ends of their respective feature distributions. Instead of removing these values from the analysis, we consider these as missing data and impute them alongside the previously mentioned missing data.
To minimize data loss and enhance the size of both the training and generalization sets, we utilized the imputation technique known as multivariate imputation by chained equations (MICE; Van Buuren & Groothuis-Oudshoorn 2011; Gibson et al. 2022). MICE leverages the data currently in use to infer the missing data. Here, for the data imputation to be reliable, MICE implicitly assumes that the data are missing at random. This means that the observed data can explain the missing data, and the probability of the data not being observed does not depend on the missing data’s value itself. Furthermore, MICE also assumes that the data have a multivariate distribution and thus considers the relations between features for imputing missing data. Here, we stress that random imputation is appropriate, as the missing values of the variable are mainly due to the good and bad time intervals, orbital gaps, instrumental errors, and satellite follow-up repointing.
The imputed data are sampled from the observed data, and the distribution is kept the same. We did this on purpose so that we would not have differences that could bias the analysis. In this study, we used the predictive mean matching method (PMM), specifically the mida-touch approach (see Little & Rubin (2019) for details). Using PMM ensures that the imputed data are sampled from the observed data. This method fills in a feature’s missing values with its mean and then iteratively refines these values by training a model on the complete data available. Each prediction is assigned a probability based on its proximity to the imputed value for the missing variable. The missing entry is then set by randomly choosing it from the observed values of the respective variable, weighted according to the previously defined probability. This process is carried out iteratively for each feature with missing entries until the values stabilize or a predetermined number of iterations is reached. We perform this iteration 20 times to have a reliable imputation. With the application of MICE, we increase our training sample by 14% and the generalization set by 4%.
We also implemented MICE imputation in the web app so that any user can upload data with missing entries and obtain a complete data set with imputed values. The web app also shows the missing entries in the user’s data, as shown in Fig. 4 when the “Apply MICE” option is selected (see Fig. 8).
 |
Fig. 2 Scatter matrix plot showing the distribution of the features involved, with the diagonal showing the distributions. The 30 GRBs added to the training set are shown as orange dots, while those of the previous sample from Dainotti et al. (2024c) are represented by cyan dots. The numbers in the upper triangle show the correlation between two respective features measured for new GRBs, the previous sample, and the combined sample. |
 |
Fig. 3 Left panel: redshift distribution of the new sample (dashed lines) and the old sample (solid line) normalized to one. Right panel: distribution of the new and the old samples when not normalized. |
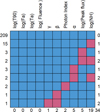 |
Fig. 4 Distribution of missing data in our data set. The figure is divided into rows and columns. The top axis of the columns corresponds to the features in the data set, and the bottom axis corresponds to the total number of missing entries in that specific feature. Thus, for log(NH) there are 19 missing entries, for log(Peakflux) there are five missing entries, and so on. The left axis corresponds to the number of GRBs, and the right axis corresponds to the number of features with missing entries. The blue squares show the complete entries, and the red squares show which features are missing for a given number of GRBs. Thus, the first row indicates that there are 209 GRBs with no missing features, and the second row indicates that there are 15 GRBs with missing entries in only one feature, which is log(NH). The third row indicates that there are three GRBs with missing entries in one feature, which is log(Peakflux), and the fourth row indicates that there are two GRBs with missing entries in two features simultaneously, which are log(Peakflux) and log(NH). |
4.2 Machine learning methods
In the upcoming sections, we outline this study’s machine learning methods and models. We discuss the feature selection methodology, the ML models used and the formula generation methodology.
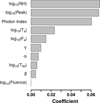 |
Fig. 5 LASSO coefficients for all ten predictors. The top seven were selected for further analysis. |
4.2.1 LASSO feature selection
The least absolute shrinkage and selection operator (LASSO) is a method for selecting the best features for a given response variable. This method employs shrinkage for linear regression by constraining the ℓ1 norm (the sum of the magnitudes of all vectors in the given space) of the solution vector (in this case, log(z + 1)) to be less than or equal to a positive value called the tuning parameter (λ). This penalization enables the model to choose a subset of features and eliminate the remaining by assigning a zero coefficient (Tibshirani 1996). In this work, we apply the LASSO selection feature using the GLMNET function (Hastie et al. 2017; Tibshirani et al. 2012; Dainotti et al. 2021a). Then, we select the features’ coefficients corresponding to the largest value of λ, with errors less than one standard deviation (Friedman et al. 2010). The top seven features, log(NH), log(Peakflux), PhotonIndex, log(Ta), log(Fa), γ, and α, (see Fig. 5) are picked for further analysis.
4.2.2 The machine learning models used
The ML models in general require a large amount of data to train. Here, even though we have the largest sample of LGRBs with plateau and redshift, this is still at least an order of magnitude less than the amount of data required to reliably train more complex ML models, such as neural networks. Thus, we tested multiple different ML models to find the best set of models that can give accurate redshift predictions with the data set currently available. The three chosen models performed the best during our analysis. Furthermore, to test whether the performance of these models is maintained as the data set increases, we have performed a MC simulation as well (see Sect. 4.7). Thus, based on our analysis we are confident that these chosen models are best suited for the data at hand.
Generalized additive model (GAM; Hastie & Tibshirani 1990) is a semi-parametric method in which the response variable is connected to the predictors via the sum of either a parametric or non-parametric function or a combination of both. GAM provides the option for fitting smooth spline functions to the data that can enable non-linear fits. We explore the performance of GAM with and without the application of smoothing functions.
Generalized linear model (GLM; Nelder & Wedderburn 1972) is an extension of the linear model that uses an iteratively weighted least squares method for the estimation of maximum likelihood to fit the relation between the response variable and the predictors. GLM allows for non-linear distributions of the response variable through a link function. In our analysis, we use the default Gaussian link function.
Random forest (RF) is a tree-based ML method that generates multiple independent regression trees (Breiman 2001; Miller et al. 2015; Dainotti et al. 2021a). The final results are an average of these regression trees. RF has three hyperparameters: depth, number of trials, and number of trees. Hyperparameters are function parameters that determine a function’s properties and dictate how well they fit a given set of data. In our analysis, we use the default implementation of RF from the Caret package (Kuhn & Max 2008).
4.2.3 Formula generation
Following the methodology established by Dainotti et al. (2024c), we aim to select the best formulas for GAM and GLM that can give us the most accurate predictions.
After performing LASSO-based feature selection to determine the set of the most predictive variables, we apply a method we call the formula generator. This method creates formulas based on combinations of these seven predictors and their squared terms. The sets of best formulas for GAM and GLM are determined independently. The process is described below. One of the formulas that perform best with GLM is shown in Eq. (1) for demonstration purposes. The full list of formulas used in this analysis can be found on the web app and the text files provided in the associated GitHub repository.
To determine the best formulas for our data set, we divided the set of GRBs with zobs into a training set and a test set with an 80:20 split. A total of 16 510 formulas were created from combinations of the seven variables chosen by LASSO (see Sect. 4.2.1). Each formula was tested by performing a ten-fold cross-validation (10fCV) with the training set 100 times. The 10fCV is an ML method for assessing the performance of a model. It splits a given training set into ten parts (folds). The model is trained on nine folds and predicts on the tenth fold. This step is repeated until the model has predicted for all ten folds, and then the results are assimilated, providing a measure of the model’s performance. We thus obtained a cross-validated Pearson correlation coefficient (r) and root mean square error (RMSE) values for each formula. Based on these scores, we select a subset of formulas that have achieved r above 99.9% quantile and RMSE score below 2% quantile (see red points in the left panel of Fig. 6). The exact cutoff for r is 0.565, and for RMSE is 1.167. This subset of formulas is used for obtaining predictions on the test set, which we had initially created (see right panel of Fig. 6). Finally, we selected the best formulas based on this test set’s performance. Specifically, we picked three formulas that achieve the highest r, lowest median absolute deviation (MAD), and lowest RMSE:
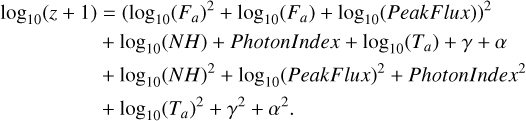 (1)
(1)
However, during our analysis, we discovered that the formulas determined via the above-mentioned methodology are sensitive to the particular training set selected. Thus, minimizing this strong dependence on the training set and selecting formulas that generalize to the full set of GRBs is important. To accomplish this, we follow the steps mentioned above; however, we randomized the GRBs used in the training and test sets while maintaining the 80: 20 split ratio. We created 100 pairs of training and test sets and performed the subsequent steps for each pair. Furthermore, all the above-mentioned steps were repeated independently for GAM and GLM.
At the end of the computation, we counted which formulas were the best on the 100 different test sets and selected those that appeared the maximum number of times. With this extension to the methodology, the formulas picked in this manner are generalized to the full GRB data set rather than a particular instance of training-test set combination. Following this, we pick six formulas for GAM and four formulas for GLM.
In addition to testing the 16 510 formulas with GAM and GLM, we also tested exclusively 148 formulas with GAM that have smoothing terms. We note here that even though these 148 formulas with smoothing were included in the 16 510 formula set, they were not chosen during the analysis. However, it is essential to test these because in our previous work (Dainotti et al. 2024c), smoothing formulas worked better, as they can capture the non-linear relations between features. Thus, we decided to test them separately. These 148 formulas include smoothing terms applied to features individually and in pairs. The methodology described above was applied to these 148 formulas, and we obtained two formulas that work best with our data set. These were included in our final ensemble.
We also tested formulas where three and four features were applied to the smooth function together. However, this did not improve our ML performance, and thus, we did not go forward with that set of formulas.
On the web app, we enable users to obtain the best formulas for their given data set. However, the full methodology mentioned above has not been implemented due to computational limitations. Performing 10 fCV on 100 randomized training test sets for thousands of formulas requires extensive computational time. We leveraged the supercomputing cluster at the Center for Computational Astrophysics at NAOJ, Tokyo, Japan and the PLGrid facility at Cyfronet, Krakow, Poland for our analysis and results. This, however, is beyond the scope of a web application at this stage. The formulas provided by the web app are determined on a single randomized training test set, similar to Dainotti et al. (2024c). Furthermore, the formulas are generated using only the variables, not their squared terms. However, formulas with smoothing terms are included within this.
The web app, however, allows for the customization of correlation and RMSE thresholds to determine the formulas that meet the user’s criteria. However, as this work demonstrated, it is advisable to select a higher percentile for correlation and a lower percentile for RMSE. The idea behind the chosen percentile is that we would need to keep the number of selected formulas small to prevent over-fitting. The web app determines GAM formulas by default. However, the user can choose GLM by selecting the ‘Use GLM’ option. The interface for the web app is presented in the upper panel of Fig. 7 and the final formulas are presented in a tabular format, as presented in the bottom panel of Fig. 7.
Our approach of using analytic expressions is similar to the symbolic regression approach of Cranmer (2023). However, the key difference here is that we are not using exponential powers or trigonometric functions of our features. Given our smaller data sample, we focus on additive expressions. However, investigating a symbolic regression could provide an interesting avenue of research. For now, it is beyond the scope of this paper.
 |
Fig. 6 Left panel: plot showing the RMSE and correlation scores for 16 510 formulas. The red points show the formulas selected for analysis on the test set. These formulas achieve correlation and RMSE scores above the cutoffs mentioned at the top of the figure. Right panel: performance of the selected subset of formulas on the test set. Each plus symbol here represents one formula selected from the left panel (red points). The red vertical and horizontal lines point to the formula that obtained the lowest RMSE and highest correlation on the test set. |
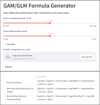 |
Fig. 7 Image of the GAM and GLM Formula Generator page of the web app. This module allows users to access the best formula for predicting redshift based on the training set provided and its predictors. The user can also manually set the cutoff for the correlation and RMSE in order to select the formula. |
4.3 Outlier removal
Before performing any ML training, we need to remove outliers, as these can affect the model performance. We use the M-estimator technique to remove outliers (Huber 1996, 1964). This is a robust regression method where the outliers are determined based on a robust loss function. Unlike ordinary least squares regression, which is sensitive to outliers, M-estimator assigns lower weights to extreme observations, making the results more robust. For the outlier removal, we selected the formula (Eq. (1)), which obtained the highest counts for GLM. Using this formula, the M-estimator fits the 238 GRBs and assigns weights ranging from 0 to 1. GRBs that obtained weights less than 0.65 were eliminated. This specific weight of 0.65 was selected because it removes 5% of the data set as outliers. Thus, we were left with 226 GRBs, which were split again into training and test sets containing 180 and 46 GRBs, respectively. This training set of 180 GRBs is 20% larger than the training set used in Dainotti et al. (2024c).
For the generalization set, we remove GRBs that lie outside the training set’s parameter space. This minimizes the ML model’s chance of extrapolating results, which may lead to inaccurate redshift predictions. Thus, using our trained model, we predict the redshifts of this trimmed generalization sample of 276 GRBs.
4.4 The SuperLearner
SuperLearner is an ensemble method that combines multiple ML models and leverages these models to obtain the best prediction. SuperLearner assigns to each model a weight based on its performance (larger weight for better performance), and the sum of all weights is one, as indicated in the following formula:
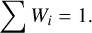 (2)
(2)
Here, Wi is the weight for the ith model. The performance of the constituent models is determined via the 10fCV method, which is built into SuperLearner. The advantage of the SuperLearner is that its prediction is a weighted average of the predictions of its constituent models, with better-performing models obtaining larger weights. However, different ML models have their own individual implicit assumptions and priors, which can impact the redshift estimation. Here, we use the SuperLearner weights to select models whose implicit priors best work with our data set. Models that obtain higher weights are included in the final nested 100 times 10fCV procedure, which provides the results presented in this paper. Furthermore, we are combining parametric (GLM), semi-parametric (GAM) and non-parametric (RF) into the final SuperLearner model, highlighting the benefits of an ensemble approach. A linear model such as GLM enables higher performance for linear relations in the data, while GAM and RF enable a better fit for non-linear relations. Thus, the models share features along with their individual features, enabling a performative ensemble ML model.
In our web app, we allow users to provide their data and obtain results of the SuperLearner through the metrics of our analysis: the Pearson correlation plots, both in linear and log scale, between zobs and zpred, the bias, defined as < zpred − −zobs>, the normalized median absolute deviation (NMAD), and the RMSE. Additionally, the SuperLearner module of the web app also supports features such as M-estimator, MICE, the removal of catastrophic outliers, model integration such as GAM, GLM, etc., and parallel processing. This enables users to tune the functionality to their liking. The user interface of the Superlearner module in the web app is presented in Fig. 8.
The results presented here use a SuperLearner model that incorporates six GAM formulas, two smooth GAM formulas, four GLM formulas, and RF (see Sects. 4.2.2 and 4.2.3 for details).
 |
Fig. 8 Image of the SuperLearner page of the web app. Shown are the data upload panel and options to choose model and data parameters. |
4.5 Balance sampling
We aim to investigate how a more balanced sample of sources will affect the performance of our ML model. A balanced sample is a data set in which the response variable’s distribution is close to uniform. Such a distribution helps train the model over the full range of potential values for the response variable, thus helping it generalize to future samples. In this analysis, we deal with an unbalanced sample where the number of GRBs at z > 2.5 (80) is fewer than the number of GRBs at z < 2.5 (158). This phenomenon can be attributed to the Malmquist bias effect, which causes us to only detect the brightest astrophysical sources at high-z due to detector thresholds. This effect prevents us from seeing a large population of dim sources at high-z. If we had a perfect satellite with extremely high sensitivity, we could populate the distribution at high-z. There are several methods to balance the sample: up-sampling, down-sampling, and balance sampling. For up-sampling, the original data remains unchanged, and duplicate samples of the minority class are added. In downsampling, data are randomly selected to ensure that all classes are equally represented, matching the frequency of the minority class.
For up-sampling, multiple methods exist. We applied the Synthetic Minority Over-sampling Technique (SMOTE, Chawla et al. 2011; Dal Pozzolo et al. 2013). As the name implies, SMOTE creates synthetic copies of the minority class, thereby increasing its sample count. This is achieved by generating new data points within the feature space of the minority class dictated by the real nearest-neighbor data points. This prevents overfitting, which can happen when minority class samples are duplicated. It also eliminates the need to remove samples from the majority class, which may lead to information loss and reduced accuracy.
The redshift distribution of the upsampled data are shown in Fig. 9. This balanced sample also undergoes the same data treatment process as mentioned in Sect. 4.3.
Since this is an important part of the inference of the redshifts, we have also made this part available through the web app, see Fig. 8. The user can tick the ‘Apply Upsampling’ button to obtain results with an augmented and balanced sample.
 |
Fig. 9 Redshift distribution obtained with the upsampling (solid lines) and the original redshift distribution (dashed lines). |
4.6 Bias correction
Bias correction is a technique that is used to correct biases in an ML model’s prediction.
Bias is defined as the difference between the observed and predicted response variables. ML models trained on an imbalanced training set are more biased toward the range containing more examples. In our sample of GRBs, the models tend to predict more toward lower redshift ranges as there are more GRBs in that range (see Sect. 4.5). Balanced sampling can mitigate this issue to an extent. However, we applied the optimal transport bias correction technique (Ferradans et al. 2013) to address this issue more directly. Some of us have already used it in Dainotti et al. (2024c,b); Narendra et al. (2022).
In this technique, first, the observed and predicted values of the response variable are sorted in ascending order. Next, a linear model is fit between them and the predicted values are corrected by multiplying the slope (A) and adding the intercept (B) of the linear fit. Furthermore, bias correction is performed separately in three redshift ranges: 0 < z < 2, 2 < z < 3.5, and 3.5 < z < 8.4. These particular ranges were selected as they produced the best results for our particular ML model and data set. The bias correction equation is as follows:

where ZC is the corrected log(z + 1) prediction, ZP is the SuperLearner prediction. The assumption we are making here is that the log(zpred + 1) follows the same distribution as log(zspec + 1).
4.7 Monte Carlo analysis
With the MC simulations, we aim to explore the reason for the changes in our results compared to Dainotti et al. (2024c). The MC simulations also help us assess the degree of uncertainties in the prediction once the sample size is increased. In the procedure detailed in Dainotti et al. (2024c), we applied MICE to impute the missing data and then ran Superlearner on the imputed data. Therefore, in this work also we perform MC simulations on the imputed data to keep the comparison more straightforward.
We perform simulations on the 7 predictors which are selected by LASSO, see Fig. 5. We simulate three sample sizes: 14, 28, and 42. This reflects, on average, how many GRBs with redshift and plateau will be added to the Swift catalog in one, two, and three years, respectively. This average was calculated based on the training set currently being used. Each sample size was generated 200 times with unique instances and combined with the training set of observed GRBs. For sampling, we used the SMOTE method (see Sect. 4.5), as this enables multivariate sampling of the data. Multivariate sampling is important as it maintains the correlations between the seven parameters involved, such as between log (Ta) and log(Fa) and log(Peakflux) (Dainotti et al. 2008). We simulated the samples so that the distributions of the variables resemble the current ones, and thus we retained only the samples that pass the KS test. Each simulated sample was tested with 10fCV using the ensemble SuperLearner model. The results from this analysis are presented in Sect. 5.4.
4.8 Model comparison with web app
The web app’s Model comparison module is designed to allow users to investigate their data using more ML models than those used in this work. This is important because the best model for predicting redshift may vary depending on the data being used. Figure 10 shows the Model Comparison module’s interface on the web app. This process is initiated by importing data files provided by the user. Moreover, this module also offers functionalities such as MICE for data imputation and allows users to specify the number of loops for 10fCV (see Sect. 4.2.3). The web app lists predefined models for use, as shown in Fig. 10. Users can tailor their selections based on specific requirements and commence the analysis by clicking on the submit button. The application then constructs an ensemble SuperLearner model based on the selected parameters and models. The application generates a correlation plot depicting the zpred vs zspec distribution and metrics showing the performance of the selected models over the provided data set. This visualization aids users in understanding the relative strengths and weaknesses of the models under consideration.
 |
Fig. 10 Various options and parameters available to a user of the web app when using the Model Comparison functionality. |
4.9 Relative importance of variables
The Relative Importance module of the web app evaluates the relative significance of the variables used for predicting the redshift. The process is initiated by importing data files the user provides. The ML model used for this module is the best model determined from our analysis in this publication (see Sect. 4.2.2). The relative importance of the predictors is decided based on this model’s performance. Users can also use the pretrained models from the web app’s Model Comparison or Superlearner modules to obtain relative importance values for their data.
The interface of the web app for this module is presented in the upper panel of Fig. 11.
4.10 Data visualization with the web app
The Data Visualization module of the web app (see Fig. 12) provides the user with an option to visualize their training set or generalization set via the scatter matrix plot (as shown in Fig. 2) and missing data (as shown in Fig. 4). The scatter matrix plot offers a comprehensive view of the uploaded data along with histograms and correlation coefficients between pairs of features. This visualization tool facilitates a deeper understanding of the data set’s relationships and distributions, aiding users in making informed decisions and gaining valuable insights. This module’s plot of missing data helps users determine which features in the provided data set have missing entries.
5 Results
Our Results section is split into four subsections. First, we present the results demonstrating the effectiveness of our ML model. Here, we also show the results obtained using balanced sampling. Second, using the trained model, we present the redshift predictions obtained on the generalization set. Third, we present the results from our MC analysis. Finally, we provide an overview of the performance of the web app’s redshift estimator module.
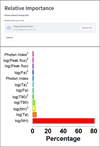 |
Fig. 11 Upper panel: user interface of the Relative Influence module of the web app. Lower panel: relative importance bar plot for the predictors used in this analysis. |
 |
Fig. 12 Interface for the data visualization module of the web app. |
5.1 Performance of the machine learning model
The results shown here are obtained after performing 10fCV 100 times on 180 GRBs using the SuperLearner model. The correlation plot between zobs and zpred obtained from SuperLearner is shown in the upper left panel of Fig. 13. We achieve an r=0.646, RMSE =1.011, bias =0.14 and NMAD =1.34. We apply the optimal transport bias correction (see Sect. 4.6) to these results to obtain the plot shown in the upper right panel of Fig. 13. Here, we obtain r=0.89, RMSE = 0.62, bias = 0.0047, and NMAD = 0.86. Sect. 6 discusses how these results compare with those presented in Dainotti et al. (2024c) and its implications.
We also present the results for our ML model when using a balanced sample. The plots are presented in the bottom left and right panels of Fig. 13. The bottom left panel shows the correlation plot obtained from the SuperLearner model, similar to the upper left panel without balanced sampling. We achieve r = 0.668, RMSE = 1.005, bias = 0.13, and NMAD = 1.56. The results then undergo the same bias correction step, and they are shown in the bottom right panel of Fig. 13. Here we obtain an r= 0.902, RMSE= 0.59, bias= 0.003, and NMAD= 0.76. The discussion about these results compared to those without balanced sampling is presented in Sect. 6.
Ukwatta et al. (2016) obtained r =0.57 using RF. We have the four features common with their analysis, namely T90, PhotonIndex, log(Fluence), and log(NH). Our correlation value is 13.3% higher for the SuperLearner results and 56% higher for the bias-corrected results. Our balanced sample results are 17.1% higher, and the bias-corrected results are 58% higher. We can attribute this improvement to our use of a more robust methodology and the plateau features. We also obtained similar results in Dainotti et al. (2024c).
Aldowma & Razzaque (2024) use DeepNeural networks and RF with Fermi-GBM and Konus-Wind observed GRBs for estimating pseudo-redshifts. They achieved the highest r2 of 0.86 on their test set, which is equal to r=0.92. Compared to our bias-corrected results, they achieved an improvement of 4%. However, in their analysis, it is unclear whether they discard duplicated GRBs between the Konus-Wind and Fermi-GBM catalogs. Furthermore, they seem to have trained the model on a single training-test split. These two effects can make the ML model overfit their data, leading to a higher correlation score.
Racz (2023) used RF and extreme gradient boosting with GRBs taken directly from the Swift catalog. Similar to our analysis, they use log(z + 1) as their response variable and obtain a r = 0.76 in the log(z + 1). However, other metrics such as RMSE, bias, and NMAD are not quoted. Furthermore, they do not quote the metrics in the linear scale. Thus, comparing our results in the log(z + 1) scale, we find that our r is lower by 20% and higher by 19% for the non-bias-corrected and bias-corrected results, respectively.
 |
Fig. 13 Results obtained from performing 10fCV 100 times using the SuperLearner model. The bottom and upper panels present results with and without balanced sampling, respectively. The upper-left panel shows the results obtained from the SuperLearner model. The upper-right panel shows the corresponding bias-corrected results. The bottom-left panel shows the result obtained from the SuperLearner model when using a balanced sample. The bottom-right panel shows the corresponding bias-corrected results. |
5.2 Relative importance results
The relative importance of the seven features is presented in the lower panel of Fig. 11. Similar to Dainotti et al. (2024c,b), we observe that the highest influence on the redshift prediction is assigned to log(NH). The log(NH) is obtained from the Swift catalog and is determined by spectral fitting with a fixed galactic absorption with the HEASoft software2. Thus, the log(NH) value we use here is the column density between the burst and the Milky Way.
The dependence of log(NH) on the redshift is expected; however, this relation is non-trivial. The value of log(NH) is impacted by the density and metallicity of the intervening medium, and thus, we discuss some of the factors that can affect this complex correlation (Arumaningtyas et al. 2024).
The first factor is the absorption of the GRB’s emission by the intergalactic medium between our galaxy and the GRB’s host galaxy. Evidence for this was found by Rahin & Behar (2019), who attributed the evolution of log(NH) with redshift to the accumulation of the ionized and diffuse gas in the intergalactic medium.
The second factor is the interstellar medium (ISM) density inside the host galaxy. Generally, high-z galaxies have larger star-forming regions, and this corresponds to the presence of more neutral hydrogen in the ISM. This causes more absorption of the GRB’s emission than inside low-z galaxies, thus affecting the log(NH) − z relation.
The third factor is the evolution of the metallicity of the progenitor’s ejecta. Heintz et al. (2023) found that the effective metallicity derived from the GRB spectra does evolve with redshift, and thus, it might have some impact on the log(NH) − z relation. We expect the progenitors of GRBs at high-z to have lower metallicity than their low-z counterparts. This can lead to the complex evolution of absorption of the GRB’s emission and thus significantly affect the log(NH) − z relation.
Finally, the metallicity of the host galaxy’s ISM has a limited impact on the log(NH) − z relation. This is evident from the findings of Cucchiara et al. (2015); Graham et al. (2023) where they observed that high-z GRBs occur in low metallicity regions. Furthermore, Bolmer et al. (2018) found that GRB host galaxies at z > 4 have less dust and extinction value (Av < 0.5 mag) than low-z sources. This leads to the conclusion that the evolution of metallicity cannot be explained by higher dust content at z > 4.
5.3 Estimating new redshifts in the generalization sample
As stated in Sect. 3, we have increased the generalization sample by 35%, from 221 GRBs (Dainotti et al. 2024c) to 276 GRBs. The histogram and scatter matrix plots comparing the training and generalization sets’ features are shown in Figs. 14 and 15, respectively. We compared the distribution of each parameter between the generalization set and the training set via the KS test, and the p-values are stated at the top of each parameter distribution.
Compared to the training set, all distributions, except the one of log(NH), have a p-value greater than 0.05. This means that the features are sampled from the same parent distribution. This indicates that the training set’s distribution of log(NH) differs from that of the generalization set and is not representative of the parent population.
In Fig. 16, we compare the distributions of predicted redshift and the redshift of the training set. The training set’s redshift distribution is presented in red histograms, and the generalization set’s redshift distributions are presented in white and green histograms, with and without bias correction, respectively. Performing the KS test between the redshift distributions of the training set and the generalization set gives p-values lower than the threshold of 0.05. Specifically, we obtain p-values of 2.5 × 10−7 and 0.0002 for the non-bias-corrected and biascorrected redshift distributions, respectively. This discrepancy can be attributed to the different log(NH) distributions of the generalization and training sets. However, we can observe that the bias correction step does bring the redshift distribution closer to the training set distribution. Thus, this is an essential step in the redshift prediction.
It should also be noted that GRBs with and without zobs might differ in their physical origin and chances of observations. Thus, they can have different intrinsic redshift distributions. The low-luminosity sources have a lower chance of having their redshift measured due to the difficulty of obtaining the redshift from the afterglow spectral features, the trouble of observing the host galaxy, or the fact that the host galaxy is not in the database and is not pointed by any observing facilities. Moreover, we observe a statistically smaller log(NH) in the generalization set. This corresponds to less absorption via the intergalactic medium, thus making the absorption-based redshift measurements harder. Those two effects could explain the difference in redshift distributions between the training and generalization sets. We discuss the physical origins of each variable in Dainotti et al. (2025). However, we can adopt certain strategies to help us constrain the differences. The first strategy one could adopt would be to ensure that the parameter spaces of the generalization set and training set are same, which is what we do here in this paper. Indeed, to prevent biases in the pseudo-redshifts, we trim the generalization set before predicting its redshift so that our ML model will predict only those GRBs whose parameter space falls within our training set. This will ensure that any outlier GRBs in the generalization set that are more likely to have a different physical origin can be minimized. Another strategy would be better classify GRBs, regardless of whether they have z or not. Indeed, some of us have already attempted to address this Bhardwaj et al. (2023), where we attempted to classify GRBs based on their properties using unsupervised ML. Efforts in this direction can help ensure that a homogeneity is maintained between the training set of an ML model and the generalization set used. Next, we have already investigated how the performance of our ML model changes when more GRBs are added to the generalization set, making sure that our model is predictive enough to handle the additional data and continue to perform at the expected level. We explore this in the next section.
We show a box plot distribution of the predicted redshifts in the lower panel of Fig. 5.3. The red and gray box plots show the bias-corrected and non-bias-corrected distributions. The x-axis shows the names of the generalization set GRBs, and the y-axis shows the redshift values. We note that because of the image’s scale, not all the GRB names are present along the axis. Our work here has enabled us to increase the Swift sample with pseudo-redshifts by 110%.
 |
Fig. 14 Histograms showing the distribution of the seven features of the generalization set against the training set. The KS test p-value scores are shown in the title of each figure. The dashed lines and solid lines represent the generalization and training sets, respectively. |
5.4 Monte Carlo simulation results
To understand if the result of an MC simulation is due to one realization only, we have then repeated the simulations with 200 different samples to de-randomize the process. The MC simulation results shown in Fig. 17 combine 200 instances of 14, 28, and 42 samples. Following the 10fCV analysis of each sample, we plot the r, RMSE, bias, and NMAD distributions for each sample size in columns 1, 2, and 3 for the samples of 14, 28, and 42, respectively. The red vertical line in the r and RMSE distributions shows the mean of the distribution.
The 14-sample case: The top image shows the r distribution. Here, we see the mean value of the distribution is 1.5% higher at r=0.656 than the r value of our SuperLearner results (see the upper left plot of Fig. 13). In fact, 80% of the simulated samples attained a r greater than our SuperLearner result of r=0.646. The mean value of RMSE is 3% lower at RMSE=0.978 than our SuperLearner result.
The 28-sample case: The mean values of the r and RMSE distributions are 2.3% higher at r=0.661 and 3.7% lower at RMSE=0.961, respectively, than our SuperLearner results. Here, 94% of the simulated samples attained a r greater than our SuperLearner result.
The 42-sample case: Here, we see that the mean values of the r and RMSE distributions are 3.4% higher at r=0.668 and 4.4% lower at RMSE=0.956, respectively, than our SuperLearner results. Also, 97.5% of the simulated samples attained a r greater than our SuperLearner result.
Based on the above-mentioned results, we can say that for the majority of simulated samples, there is an improvement in the results across all metrics. This result is very promising because it indicates that our ML model generalizes to the GRB sample well and should give improved results for at least three years.
5.5 Future of multi-wavelength redshift estimates via machine learning
The following subsection draws upon the results from Sects. 5.4 and 5.3 for estimates on the number of GRB redshifts that can be predicted using ML analysis for future X-ray and optical observations of afterglows. These estimates are based on the estimates presented in Dainotti et al. (2023a), which in turn rely on the existing X-ray and optical samples determined by Dainotti et al. (2024c) and Dainotti et al. (2024b), provided up to May 2025.
For the X-ray afterglow, we currently have 255 GRBs possessing plateaus and measured zobs, observed from 03/2005 to 12/2023. We have 299 events with X-ray plateaus but without redshifts, observed from 01/2005 to 02/2024. Both sets of GRBs are taken from the Swift/XRT catalogs. Based on these data, ∼13.6 GRBs with X-ray plateaus and zobs, and ∼15.7 GRBs with X-ray plateaus and unknown redshifts are expected annually. For GRBs with zobs and X-ray plateau, 24 additional GRBs are expected from 12/2023 until 09/2025. For GRBs with X-ray plateaus and without zobs, 25 additional GRBs are also expected from 02/2024 until 09/2025. This sample with unknown redshift will be the generalization set. So, the number of GRBs with zpred from ML analysis will be greater than 324.
For the optical afterglow, we have gathered 536 LCs through the 416 ground-based Telescopes, the HST, the Swift/UVOT satellites, the GCN, and private communications. These 536 GRBs, observed from 05/1997 to 10/2023, have zobs and optical afterglow. Out of these 536 GRBs, 180 (34%) GRBs have optical plateau observations. As of this writing, according to the Greiner webpage3, the total number of GRBs with optical afterglow is 932, and 622 have secure redshifts. Thus, 310 GRBs (932 – 622) do not have redshift but have an optical afterglow. Assuming the same fraction of plateau observations in the optical afterglow, our current generalization set would be 34% of 310, which is 104 GRBs. If we extrapolate to 09/2025, we expect to have 112 GRBs with an optical plateau and no measured redshifts. Similarly, we expect to have 193 GRBs by 09/2025, which have an optical plateau and zobs. Thus, we expect more than 112 GRBs with zpred from ML analysis. Thus, the new zpred will be more than 436 (324+112), where 324 and 112 are GRBs with X-ray and optical plateaus, respectively. With this increase of 92% in the redshift sample, we will enhance the accuracy of the LF and density rate evolution estimates, and thus it will help address the discrepancy between the GRBFR and SFR evolution. The above numbers are also reflected in the Table 1. This analysis can be extended for future reference, and it serves as our foundation to compute how many GRBs we will approximately have in the next one, two, and three years from now.
Present and future numbers of GRB observations.
Dainotti et al. (2022a) also calculated the number of GRB observations required to achieve similar precision on ΩM for the flat Λ CDM model as obtained in studies by Conley et al. (2011); Betoule et al. (2014); Scolnic et al. (2018) (for SNe Ia).
According to Table 9 of Dainotti et al. (2022a), to reach the precision of Conley et al. (2011), the lowest number of X-ray platinum sample GRBs with redshift needed, with half error bars on plateau parameters, is 354. To achieve this number, we assume that by using an updated LC reconstruction (LCR) technique, an improvement of the methodology from Dainotti et al. (2023b), which is in preparation, we will have the same number of GRBs with half error bars (denoted by n=2) as with full error bars (denoted by n=1). Currently, we have 105 GRBs that belong to the platinum sample with zobs. Assuming the same fraction of platinum GRBs exists in the generalization set, we should have another 125 GRBs from the generalization set used in this work. Combining these two, we estimate that we currently have 230 platinum sample GRBs with pseudo-redshifts. Further, considering the observations we will obtain from SVOM (Godet et al. (2014) and SVOM webpage4) and the application of ML and LCR, we can expect to reach the precision of Conley et al. (2011) by 2029 (see PLATtrim20 column of Table 2). Thus, this ML effort reduces the number of years required to reach the precision of Conley et al. (2011) by 26 years. Similarly, to reach the precision of Betoule et al. (2014), we need the observational capabilities of THESEUS. According to our estimates in Table 2, again, using LCR and ML to boost the numbers and GRBs with half error, we should be able to reach the precision of Betoule et al. (2014) by 2041 at least.
Similarly, let us consider the optical estimates from Table 9 of Dainotti et al. (2022a). We should be able to reach the precision of Conley et al. (2011) with the current data we have if we assume that we will have an equal number of half error GRBs as we have full error GRBs, achieved by using updated LCR methodology. If we, however, trim the sample in the closest 25 to the 3D fundamental plane (OPTtrim25 column of Table 3), we would have reached the precision of Conley et al. (2011) even in 2005, 6 years earlier than the one reached by the SNe Ia. We note that the numbers mentioned along the fourth row of Table 3 are estimated based on GRBs observed from January 2005. This is done to avoid negative numbers, as some of the estimates are reached well before 2024. The corresponding year estimates are obtained based on the rate of observation using Swift and other ground-based optical observatories. Furthermore, if we take into account the rate of observation of SVOM and the fraction of optical GRBs with the plateau we currently have, then we can reach the precision of Conley et al. (2011) by 2028 (only 4 years from now), with the current error bars. However, to reach the precision of Betoule et al. (2014), we need to consider the observation of THESEUS as well. Considering THESEUS’s rate of observation to be 700 GRBs per year (Dainotti et al. 2022a; Amati et al. 2018), we again consider the same fraction of optical plateau GRBs as we currently have. With this, we can reach the precision of Betoule et al. (2014) by 2039, 7 years after the launch of THESEUS (the current expected launch is 2032, if the mission is approved). However, to reach the same precision as Scolnic et al. (2018), we would need to wait at least until 2041 and use both ML and LCR and half error bars.
However, we can say that these estimates are rather conservative since new optical telescopes and facilities will be operating in the future, and we can rely on the efforts of some of us to continue building the largest optical GRB catalog to date (Dainotti et al. 2024a). Indeed, one of the outcomes of gathering multiple data points from several sources has the advantage of allowing an increase of data points, in general, in the LCs and, in particular, in the plateau region when it occurs. Thus, we assumed that once the optical GRB sample is updated, our estimates will be larger in terms of the total number of optical plateaus, and therefore the number of years needed to reach SNe Ia precision will be less. In addition, regarding the X-ray sample, some of us are currently working on choosing a subsample, not driven by phenomenological reasons but driven by the magnetar model (Zhang & Mészáros 2001; Rowlinson et al. 2014; Yi et al. 2017). In such a case, we can have a smaller scatter of the plane as shown for the 2D Dainotti relation between the X-ray luminosity at the end of the plateau and its rest-frame duration (Dainotti et al. 2008, 2011b, 2013, 2017; Wang et al. 2022), and we can reach again the precision of the SNe Ia sooner, using the X-ray sample.
 |
Fig. 15 Scatter matrix plot of the generalization and training sets. The generalization set is presented with orange dots, and the training set is presented with cyan dots. The diagonal shows the histogram distribution for the generalization set, while the upper triangle shows the Pearson correlation values for respective pairs of parameters. |
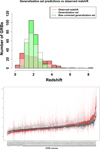 |
Fig. 16 Upper panel: redshift distribution of the generalization and training sets. The training set is shown with red histograms, while the generalization set with and without bias correction is shown in white and green histograms, respectively. Lower panel: box plot distribution of the generalization set redshift predictions, sorted from lowest to highest redshift. The bias-corrected and non-bias-corrected distributions are shown in red and gray box plots, respectively. The dots show the outlier predictions obtained. |
Forecast on the future precision of X-ray GRB cosmology.
 |
Fig. 17 Results of our MC analysis. All the plots shown are combined results of 200 simulated samples. The first column of histograms shows the distribution of properties for the 14 sample cases. The second and third columns of histograms present the distribution of properties for 28 and 42 sample cases, respectively. The first row shows the correlation distribution, and the red line shows the mean. The second row shows the RMSE distribution. The third and fourth rows show the bias and NMAD distributions, respectively. |
5.6 Applicability to future missions
It is important to note that all the methodologies spelled out here can be applied not only to GRBs observed by Swift, but also to any GRB for which we can observe the plateau emission. Thus, we envision this method can be applied to GRBs observed by Space-based multi-band astronomical Variable Objects Monitor (SVOM, Wei et al. (2016)), the Transient High-Energy Sky and Early Universe Surveyor (THESEUS) mission (Amati et al. 2018), and the Einstein Probe mission (Yuan et al. 2015). Surely, with the new data from other satellites, one needs to be cautious about how the variables’ parameter spaces will change compared to the space of the Swift variables and how much this will impact the prediction. Properly leveraging the power of these new satellites will require a re-training of the ML models. However, the base methodology described here and in our previous works (Dainotti et al. 2024c,b) should still produce reliable results.
The SVOM mission, in particular, is very promising indeed, as one of their key aims is to quickly identify and observe the afterglow of GRBs at both X-ray and visible wavelength. The SVOM mission was launched in June 2024. The methodology described here requires the GRB to have a plateau emission. Thus, SVOM’s ability to quickly slew to a GRB’s location will enable quick follow-up of afterglow emission. This will lead to more observations of the plateau, especially at X-ray wavelengths, and make the GRBs observed by SVOM compatible with our methodology, albeit with careful consideration of their parameter spaces.
Forecast on the future precision of optical GRB cosmology.
According to Cordier et al. (2018), the planned mission duration for SVOM is 3 years. Based on estimates by Godet et al. (2014), 200 GRBs are expected to be observed by SVOM over its 3-year lifetime. However, considering that satellites such as Swift, Chandra, INTEGRAL, and Hubble have lasted well beyond their originally intended lifetime, we can safely assume that SVOM will continue to work beyond its 3-year lifetime. Thus, based on estimates from Dainotti et al. (2022a), we take 15 years (up to 2039) as the estimated lifetime for SVOM. After this, the observational duties would be taken up by the THESEUS mission. Following these assumptions, we estimate that SVOM will make around 1005 GRB observations over its extended lifetime. Out of these 1005 GRBs, we expect 825 GRBs to be detected in X-ray. This is derived from the fraction of GRBs detected in X-ray by Swift. Next, based on the data presented here, we can estimate that around 38% (318 GRBs) of these GRBs will exhibit the plateau feature. Furthermore, of these 318 GRBs with plateau, we expect 46% (147) to have spectroscopic redshift measurements. Again, this estimate is based on current Swift data. If we train an ML model on these 147 GRBs, we should be able to predict the redshift of the 171 GRBs (318 – 147). This will effectively increase the number of GRBs from SVOM that can have pseudo-redshifts by 117%. We note that we have not considered the degradation of the SVOM’s orbit over time. However, these estimates are a lower limit on SVOM’s actual observation rates, as we expect it to be more efficient. THESEUS is expected to identify around 20 events at z > 6 in 3.5 years of nominal operation; hence, it will provide a much larger sample of high redshift GRBs than achieved so far (Tanvir et al. 2021). High-z Gundam mission might be comparable to THESEUS (five events per year, Yonetoku & Hiz-Gundam Collaboration (2023)). SVOM is already operational and equipped with the 4 – 150 keV wide-field trigger camera and is sensitive to a wide variety of GRBs, including those at high redshifts. It is expected to detect around 80–100 GRBs per year.
5.7 Redshift inference with the web app
Our web app has various functionalities, but its main focus is inferring the redshift of GRBs without zobs. Users have the flexibility to upload a file containing the predictors discussed in this work (see Sect. 4.2.1) or manually enter the parameters of a single GRB for redshift estimation. This interface is presented in Fig. 18. This module of the web app also allows the user to obtain MICE imputations if their data contains missing values. To do so, they select the ‘Apply MICE’ button. After providing the data, the web app initiates the back-end ML codes, the results and performance of which have been presented in this work. Upon successful execution, the user is presented with individual redshift values for each GRB in a tabular manner, which can also be downloaded as a text file. This table displays the GRB IDs along with zpred and its associated uncertainties. Furthermore, if a user already has their custom model, trained from modules such as Model Comparision and SuperLearner, then they can use that model for predictions. For this, they need to select the “Do you have modeled data?” option. However, the users can use the model trained on our data without necessarily providing their own training set. Finally, comprehensive documentation is available on the web app in the ‘Documentation’ module to help users navigate.
 |
Fig. 18 Redshift estimator, the homepage of the app, depicted with the options of choosing MICE, uploading a file, entering parameters manually, and using custom models. |
6 Discussion
The findings from Dainotti et al. (2024b) demonstrate the promise of using machine learning for redshift estimation, particularly in overcoming the limited number of GRBs with precise redshift measurements. In this work, we have expanded both the methodology and the sample sizes for the training and generalization data sets. Providing redshift predictions for the generalization set will help future population studies address the GRBFR and SFR discrepancy and other relevant issues. In the future, the zpred values obtained here can also be utilized to explore the characteristics of the central engine in GRB events, focusing on GRBFR, LF, and the structure of LCs. We can also use GRB LCs obtained from reconstruction, which some of us did in Dainotti et al. (2023b). We demonstrated the effectiveness of this reconstruction technique in reducing the errors on plateau parameters by an average of 30%-40%.
Another point we wish to highlight here is that even though we have the largest sample of LGRBs with plateau and redshift, this is still at least an order of magnitude less than the data required to reliably train more complex ML models, such as neural networks. Indeed, without including the plateau, Swift XRT observed 1420 GRBs up to December 2024, which is too small to train complex ML models properly. In some of our previous works, using Active Galactic Nuclei data (Dainotti et al. 2021a; Narendra et al. 2022; Gibson et al. 2022), we have shown that SuperLearner picks different, more complex models (e.g., XGBoost, EARTH) for the larger sample size. Similarly, we tested multiple ML models to find the best set of models that can give accurate redshift predictions with the current data set. The three chosen models performed the best during our analysis. Given the size of our data set, parametric and semi-parametric functions such as GLM and GAM perform better. This fact is further highlighted in the Appendix in Fig. B.1, where the weight assigned by SuperLearner to the model EARTH is lower than the weights assigned to the GAM, GLM, and RF models. This is in contrast with the results presented in Narendra et al. (2022) where Earth was one of the best models. Furthermore, to test whether the performance of these models is maintained as the data set increases, we have also performed a MC simulation (see Sect. 5.4). From those simulations we can say that our models will be reliable for up to three years, after which we will require them to be retrained with different models and training data. Thus, based on our analysis, these chosen models are best suited for the data at hand.
6.1 LGRBs versus SGRBs
Contemporaneously, this research can also shed light on the distinction between various GRB classes. As mentioned previously, LGRBs and SGRBs are characterized by different properties. Thus, one has to classify GRBs as accurately as possible in order to conduct high-precision population studies. Traditionally, the division between collapsar and merger type (non-collapsar) origin has been discussed mainly in terms of the T90 distribution for the BATSE observed events. Collapsar events are characterized by T90 ≥2 s, while non-collapsar events by T90 < 2 s. An updated division based on T90 observed by Swift has been discussed in Bromberg et al. (2013), where the T90 cut has been set to 0.8. With the advent of gravitational waves (GW) observed with the case of GRB 170817 and the consequent observation of the kilonovae, it was discussed that the merger of neutron stars was the smoking gun event to distinguish between collapsar and non-collapsar and should be accompanied by the GW and the kilonova presence. However, it has also been discussed extensively how the case of GW 170817 was peculiar and an unusually low luminosity event. Moreover, there have been two GRB cases that have properties of LGRBs in terms of T90 > 2 s, but there was evidence of an associated kilonovae (KN): these are the instances of GRB 211211A and GRB 230307A. The latter case has a larger value for the luminosity of the KN=1042 erg s−1.
6.2 Issue of LLGRBs
This leads us to another pertinent question about the true nature and origin of LLGRBs. Research by Coward (2005); Liang et al. (2007a); Bernardini et al. (2007); Virgili et al. (2009); Patel et al. (2023) suggests that LLGRBs represent a distinct class of phenomena. Due to their low luminosities, these events are typically observed at low redshifts, such as GRB 060218 at z = 0.033 (Mirabal et al. 2006) and GRB 980425 at z = 0.0085 (Tinney et al. 1998). Coward (2005) simulated the local density rate of LLGRBs to be 220 Gpc−3 yr−1, based on the under-luminous GRB 980425. Under the assumption that the luminosity of GRB 980425 was typical of such a population of LLGRBs, the authors claim the luminosity cutoff between LLGRBs and high-luminosity GRBs (HLGRBs) to be 2 × 10−53 erg s−1. However, based on GRB 980425 and GRB 060218 Liang et al. (2007a) defined LLGRBs as GRBs with luminosity < 10−49 erg s−1. The authors found the LLGRB event rate to be 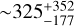 Gpc−3 yr−1 while that of HLGRBs to be
Gpc−3 yr−1 while that of HLGRBs to be 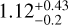 Gpc−3 yr−1. They also showed that the LFs of LLGRBs and HLGRBs are different and cannot be represented by a single function. Chapman et al. (2007) also investigated the local density rate of LLGRBs based on GRB 980425 and GRB 060218 and found a result of 700 ± 360 Gpc−3 yr−1 within a distance of 155 Mpc. Virgili et al. (2009) provided further evidence that LLGRBs are a distinct class of GRBs from HLGRBs. They demonstrated that a simple power-law LF is insufficient and that a smooth broken power-law fit is necessary to obtain a good prediction for the distribution of a combined sample of LLGRBs and HLGRBs. Using MC simulation and the LF, they derive an event rate of ∼100−400 Gpc−3 yr−1 for LLGRBs and ∼1 Gpc−3 yr−1 for HLGRBs. However, they conclude that the sample is too small and more data are needed to draw stronger conclusions. Dainotti et al. (2024b) obtained a GRB event rate of 8.47–9 Gpc−3 yr−1 between 1.9 < z < 2.3 using zobs. This matches the HLGRB rate found by Dong et al. (2023); Liang et al. (2007a); Virgili et al. (2009). Lan et al. (2021) utilized 5 LLGRBs out of a collection of 1111 LGRBs obtained from Swift to demonstrate that a triple power-law LF provides a superior fit for the data, again indicating the existence of LLGRBs as a separate component. Recently, Dong et al. (2023) demonstrated that the event rate of HLGRB closely follows the SFR, while that of LLGRB shows an excess at low-z(z < 1). Combining the sample leads to the observed low-z excess and mismatch between the GRBFR and SFR. These previous works strongly suggest that LLGRBs are a distinct class of GRBs with the potential to solve the GRB-SFR discrepancy. However, to draw more definitive conclusions, a larger sample of GRBs with redshift is needed.
Gpc−3 yr−1. They also showed that the LFs of LLGRBs and HLGRBs are different and cannot be represented by a single function. Chapman et al. (2007) also investigated the local density rate of LLGRBs based on GRB 980425 and GRB 060218 and found a result of 700 ± 360 Gpc−3 yr−1 within a distance of 155 Mpc. Virgili et al. (2009) provided further evidence that LLGRBs are a distinct class of GRBs from HLGRBs. They demonstrated that a simple power-law LF is insufficient and that a smooth broken power-law fit is necessary to obtain a good prediction for the distribution of a combined sample of LLGRBs and HLGRBs. Using MC simulation and the LF, they derive an event rate of ∼100−400 Gpc−3 yr−1 for LLGRBs and ∼1 Gpc−3 yr−1 for HLGRBs. However, they conclude that the sample is too small and more data are needed to draw stronger conclusions. Dainotti et al. (2024b) obtained a GRB event rate of 8.47–9 Gpc−3 yr−1 between 1.9 < z < 2.3 using zobs. This matches the HLGRB rate found by Dong et al. (2023); Liang et al. (2007a); Virgili et al. (2009). Lan et al. (2021) utilized 5 LLGRBs out of a collection of 1111 LGRBs obtained from Swift to demonstrate that a triple power-law LF provides a superior fit for the data, again indicating the existence of LLGRBs as a separate component. Recently, Dong et al. (2023) demonstrated that the event rate of HLGRB closely follows the SFR, while that of LLGRB shows an excess at low-z(z < 1). Combining the sample leads to the observed low-z excess and mismatch between the GRBFR and SFR. These previous works strongly suggest that LLGRBs are a distinct class of GRBs with the potential to solve the GRB-SFR discrepancy. However, to draw more definitive conclusions, a larger sample of GRBs with redshift is needed.
6.3 Discrepancy with star formation rate
This discrepancy with the SFR could also be due to the effects of collimated emission within narrow jets not being taken into account in the current analysis.
Indeed, we need such collimated emission to achieve the observed high luminosity. Unlike most parametric forward fitting methods, which assume both no luminosity evolution and that the GRBFR should be the same as SFR, the approach of Dainotti et al. (2024b) offers the advantage of deriving the formation rate evolution non-parametrically directly from the data. Thus, we can safely bypass the assumption about the GRB rate following the SFR. This result is also shown for LGRBs by the Konus-WIND team (Tsvetkova et al. 2017) and the other 5 teams independently (Petrosian et al. 2015; Yu et al. 2015; Pescalli et al. 2016; Lloyd-Ronning et al. 2019; Yonetoku et al. 2004), using the same statistical methods adopted by Dainotti et al. (2021c). Regarding SGRBs, including those with extended emission, Dainotti et al. (2021c) found that SGRB rates also do not follow the SFR at low-z, even when adding a delay for SGRBs to account for the older age of the progenitors.
6.4 Impact of our research
Our research here can help address the above-mentioned issues. First, employing 276 GRBs with zpred will allow the community to distinguish between GRB rate and SFR and what the GRB progenitors are, specifically regarding LLGRBs. Furthermore, the web app will enable the whole community to quickly obtain zpred and this will enhance the above-mentioned advantages. The web app’s versatility will help it stay updated when new GRBs with zobs are obtained, leading to more accurate predictions.
Finally, our MC simulations and analysis of SVOM’s upcoming data paint a very promising future for GRB cosmology. Our analysis, combined with comprehensive progenitor studies (Dainotti et al. 2020b; Wang et al. 2022), will provide a set of sources that can be used as reliable cosmological tools. The high-z GRBs that THESEUS will explore (expected launch 2032, Amati et al. (2021)) are crucial probes for investigating the SFR at the epoch of reionization and investigate the number of Population 3 stars.
7 Summary and conclusion
In this study, we have built upon the methodology established by Dainotti et al. (2024b) and Dainotti et al. (2024c). We used a 20% larger training set and more robust formula estimation to predict the redshifts of 276 GRBs. In addition, we performed an extensive MC simulation to evaluate how our ML model will perform in the upcoming years. For the benefit of the community, we have produced a publicly available and free-to-use web app designed to provide pseudo-redshifts for any GRB with plateau emission, along with other additional functionalities. From this reasearch, we draw the following conclusions:
The ML results obtained in this analysis, presented in Sect. 5.1, have a similar accuracy with those presented in Dainotti et al. (2024c) but are slightly lower. Specifically, we have a 10% decrease in r, from 0.719 to 0.644, and a 9.8% increase in RMSE, from 0.91 to 1. These changes in the metrics can be attributed to two reasons. First, the new sample of GRBs added to the training set has a higher percentage of GRBs at a larger redshift, as compared to the training set in Dainotti et al. (2024c) (see Sect. 3). This can lead to the ML model having to adjust to the new data with a larger intrinsic scatter, thus leading to a decrease in the performance metrics. The second reason is the change in the methodology for formula estimation. In Dainotti et al. (2024c), the formulas estimated for GAM and GLM were determined using a single training-test split instance. Here, we expanded the methodology and generalized the formulas. Generalizing the formula here means it can better capture the underlying relations among GRB properties for a larger population of GRBs rather than just a small, limited sample of the training set. However, this generalization leads to poorer performance on a singular training-test split, as the variability of the underlying relation is higher in a smaller sample. Nonetheless, the formulas generalize well to additional synthetic GRB samples with a more uniform redshift distribution, which is evident from the improved balanced sampling result across all the metrics (lower-right and -left panels of Fig. 13). This promising result indicates that our ML model has effectively generalized to the entire GRB sample, and the MC simulations further emphasize this point;
In Section 5.2, we demonstrated that log(NH) exerts the greatest influence on redshift predictions. This finding is consistent with the results reported in Dainotti et al. (2024c) and Dainotti et al. (2024b). A similar result was also discovered independently by Racz (2023), who found that the performance of their ML model was reduced when they removed log(NH) from their list of predictors. We also find that log(Ta) is the second most important predictor of redshift, similar to Dainotti et al. (2024c). However, we note that Dainotti et al. (2024b) found that log(Fa) is the second most predictive feature. Given the correlation of log(Ta) and log(Fa), these results demonstrate that plateau features are important when predicting the redshift of GRBs;
In Sect. 5.3, we predicted the redshift of 276 GRBs using our trained model. Both the bias-corrected and non-bias-corrected predictions are freely available to the community through this publication. However, we still have a discrepancy between the predicted redshift distributions and the redshift distribution of the training set. Dainotti et al. (2024c) questioned the extent the variation between the redshift distributions of GRBs with and without zobs are inherently different and whether the variation might be attributed to the limited size of the training set. In this analysis, we have increased the training set with 30 additional GRBs. However, we still need to investigate the origin of the different distributions. A KS test comparing the log(NH) distributions for the training and the generalization sets still presents us with the conclusion that they are derived from different parent populations. Given the fact that log(NH) is the most important predictor, this could explain the discrepancy in the redshift distributions;
The MC simulations of future data in Sect. 5.4 present us with promising results. Based on those estimates, we conclude that our ML model is robust enough to last for at least three more years before major retraining is needed. The histogram distributions for r, RMSE, and MAD show that our ML model performs better when more sources are added to the training set. It is important to note that this condition holds only if the additional data incorporated into the training set in the future comes from the same parent population as the existing sample;
The methodology described here can be accessed via the associated web app. The app enables users to obtain redshift predictions based on the ML model presented here for their GRBs. It also enables users to choose from a set of predefined models that, in our experience, work well with GRB samples and to subsequently train the models with their data. Then, they can obtain redshift predictions from the customized model built using the web app. The web app is designed to provide results similar to those presented in this work for any custom data the user may input;
In Sect. 5.6, we presented calculations on how many GRB’s pseudo-redshifts we will be able to obtain in the future using SVOM data and possibly THESEUS. The numbers mentioned there are based on current estimates from publications of SVOM and Swift’s observational statistics. These numbers will need to be updated as more GRBs by SVOM are detected. Regardless, the numbers paint a promising picture of the future applicability of such ML techniques. In fact, this work has already enabled us to increase the Swift GRB sample with redshift by roughly 110%.
Data availability
The web app is available for free on the following Github page: https://github.com/gammarayapp/GRB-Web-App
Acknowledgements
The authors thank Omar Elsherif for his contributions to building the basic structure of the web app, upon which the whole functionality is based. We gratefully acknowledge Polish high-performance computing infrastructure PLGrid (HPC Center: ACK Cyfronet AGH) for providing computer facilities and support within computational grant no. PLG/2024/017205. We acknowledge Biagio de Simone and Christopher Cook for helping with the MC computations. We acknowledge funding from Swift GI Cycle XIX, grant number 22-SWIFT22-0032. Numerical computations were in part carried out on Small Parallel Computers at the Center for Computational Astrophysics, National Astronomical Observatory of Japan.
Appendix A Distribution of training sets
Here, we are presenting the histogram distributions of the training set from Dainotti et al. (2024c) and the training set used in this work. The Fig. A.1 shows the previous sample with solid lines and the new sample with dashed lines. Each feature has the KS test and AD test statistics mentioned at the top of the histogram. As mentioned in Sect. 3, T90, and γ obtain p-values <0.05 in both AD test and KS test, while log(Fa) obtains p-value <0.05 only in AD test. The case can be explained by looking at the distribution, where we see a heavy-tailed distribution for the newer data set (dashed lines). Since the AD test is more sensitive to heavy-tailed distributions, we obtain a p-value of <0.05.
 |
Fig. A.1 Distribution comparing the current training set with the previous training set from Dainotti et al. (2024c). At the top of each distribution, the KS test and AD test comparison results are shown. |
Appendix B Weight distribution by SuperLearner
The weights assigned by SuperLearner to its constituent models vary depending on the data set it is being used. Fig. B.1 shows the weight assigned to EARTH is lower than those of RF, GAM, and GLM models. However, in Narendra et al. (2022), EARTH was the highest-weighted model. Thus, we can say that our final ensemble model is well-suited for the size of our data sample.
 |
Fig. B.1 Weights assigned by SuperLearner to an ensemble of GAM, GLM, RF, and EARTH models. |
References
- Abbott, B. P., Abbott, R., Abbott, T. D., et al. 2017, ApJ, 848, L12 [Google Scholar]
- Ajello, M., Arimoto, M., Axelsson, M., et al. 2019, ApJ, 878, 52 [NASA ADS] [CrossRef] [Google Scholar]
- Aldowma, T., & Razzaque, S., 2024, MNRAS, 529, 2676 [Google Scholar]
- Amati, L., 2006, MNRAS, 372, 233 [Google Scholar]
- Amati, L., Frontera, F., Tavani, M., et al. 2002, A&A, 390, 81 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Amati, L., O’Brien, P., Götz, D., et al. 2018, AdSpR, 62, 191 [Google Scholar]
- Amati, L., O’Brien, P. T., Götz, D., et al. 2021, Exp. Astron., 52, 183 [NASA ADS] [CrossRef] [Google Scholar]
- Arumaningtyas, E. P., Al Rasyid, H., Dainotti, M. G., & Yonetoku, D., 2024, Galaxies, 12 [Google Scholar]
- Atteia, J.-L., 2003, A&A, 407, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Atteia, J.-L., 2005, Il Nuovo Cimento C, 28, 647 [Google Scholar]
- Bargiacchi, G., Dainotti, M. G., & Capozziello, S., 2023, MNRAS, 525, 3104 [NASA ADS] [CrossRef] [Google Scholar]
- Barthelmy, S. D., Barbier, L. M., Cummings, J. R., et al. 2005, Space Sci. Rev., 120, 143 [Google Scholar]
- Bernardini, M. G., Bianco, C. L., Caito, L., et al. 2007, A&A, 474, L13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Beskin, G., Karpov, S., Bondar, S., et al. 2010, ApJ, 719, L10 [NASA ADS] [CrossRef] [Google Scholar]
- Betoule, M., Kessler, R., Guy, J., et al. 2014, A&A, 568, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bhardwaj, S., Dainotti, M. G., Venkatesh, S., et al. 2023, MNRAS, 525, 5204 [Google Scholar]
- Bolmer, J., Greiner, J., Krühler, T., et al. 2018, A&A, 609, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Breiman, L., 2001, Mach. Learn., 45, 5 [Google Scholar]
- Bromberg, O., Nakar, E., Piran, T., & Sari, R., 2013, ApJ, 764, 179 [NASA ADS] [CrossRef] [Google Scholar]
- Burrows, D. N., Hill, J. E., Nousek, J. A., et al. 2005, Space Sci. Rev., 120, 165 [Google Scholar]
- Cao, S., Khadka, N., & Ratra, B., 2021, MNRAS, 510, 2928 [Google Scholar]
- Cao, S., Dainotti, M., & Ratra, B., 2022a, MNRAS, 516, 1386 [NASA ADS] [CrossRef] [Google Scholar]
- Cao, S., Dainotti, M., & Ratra, B., 2022b, MNRAS, 512, 439 [NASA ADS] [CrossRef] [Google Scholar]
- Cardone, V. F., Capozziello, S., & Dainotti, M. G., 2009, MNRAS, 400, 775 [NASA ADS] [CrossRef] [Google Scholar]
- Cardone, V. F., Dainotti, M. G., Capozziello, S., & Willingale, R., 2010, MNRAS, 408, 1181 [NASA ADS] [CrossRef] [Google Scholar]
- Chapman, R., Tanvir, N. R., Priddey, R. S., & Levan, A. J., 2007, MNRAS, 382, L21 [Google Scholar]
- Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P., 2011, arXiv e-prints [arXiv:1106.1813] [Google Scholar]
- Conley, A., Guy, J., Sullivan, M., et al. 2011, ApJS, 192, 1 [Google Scholar]
- Cordier, B., Götz, D., Motch, C., & SVOM Collaboration 2018, Mem. Soc. Astron. Italiana, 89, 266 [Google Scholar]
- Costa, E., Frontera, F., Heise, J., et al. 1997, Nature, 387, 783 [NASA ADS] [CrossRef] [Google Scholar]
- Coward, D. M., 2005, MNRAS, 360, L77 [Google Scholar]
- Cranmer, M., 2023, arXiv e-prints [arXiv:2305.01582] [Google Scholar]
- Cucchiara, A., Levan, A. J., Fox, D. B., et al. 2011, ApJ, 736, 7 [Google Scholar]
- Cucchiara, A., Fumagalli, M., Rafelski, M., et al. 2015, ApJ, 804, 51 [NASA ADS] [CrossRef] [Google Scholar]
- Dainotti, M. G., Cardone, V. F., & Capozziello, S., 2008, MNRAS, 391, L79 [NASA ADS] [CrossRef] [Google Scholar]
- Dainotti, M. G., Fabrizio Cardone, V., Capozziello, S., Ostrowski, M., & Willingale, R. 2011a, ApJ, 730, 135 [NASA ADS] [CrossRef] [Google Scholar]
- Dainotti, M. G., Ostrowski, M., & Willingale, R., 2011b, MNRAS, 418, 2202 [NASA ADS] [CrossRef] [Google Scholar]
- Dainotti, M. G., Petrosian, V., Singal, J., & Ostrowski, M., 2013, ApJ, 774, 157 [NASA ADS] [CrossRef] [Google Scholar]
- Dainotti, M. G., Del Vecchio, R., Shigehiro, N., & Capozziello, S., 2015, ApJ, 800, 31 [Google Scholar]
- Dainotti, M. G., Postnikov, S., Hernandez, X., & Ostrowski, M., 2016, ApJ, 825, L20 [NASA ADS] [CrossRef] [Google Scholar]
- Dainotti, M. G., Hernandez, X., Postnikov, S., et al. 2017, ApJ, 848, 88 [NASA ADS] [CrossRef] [Google Scholar]
- Dainotti, M. G., Livermore, S., Kann, D. A., et al. 2020a, ApJ, 905, L26 [NASA ADS] [CrossRef] [Google Scholar]
- Dainotti, M. G., Lenart, A. Ł., Sarracino, G., et al. 2020b, ApJ, 904, 97 [NASA ADS] [CrossRef] [Google Scholar]
- Dainotti, M. G., Bogdan, M., Narendra, A., et al. 2021a, ApJ, 920, 118 [NASA ADS] [CrossRef] [Google Scholar]
- Dainotti, M. G., Omodei, N., Srinivasaragavan, G. P., et al. 2021b, ApJS, 255, 13 [Google Scholar]
- Dainotti, M. G., Petrosian, V., & Bowden, L. 2021c, ApJ, 914, L40 [NASA ADS] [CrossRef] [Google Scholar]
- Dainotti, M. G., Nielson, V., Sarracino, G., et al. 2022a, MNRAS, 514, 1828 [CrossRef] [Google Scholar]
- Dainotti, M. G., Bargiacchi, G., Łukasz Lenart, Ł., et al. 2022b, ApJ, 931, 106 [NASA ADS] [CrossRef] [Google Scholar]
- Dainotti, M. G., Lenart, A. Ł, Chraya, A., et al. 2023a, MNRAS, 518, 2201 [Google Scholar]
- Dainotti, M. G., Sharma, R., Narendra, A., et al. 2023b, ApJS, 267, 42 [Google Scholar]
- Dainotti, M. G., Bargiacchi, G., Bogdan, M., Capozziello, S., & Nagataki, S., 2023c, arXiv e-prints [arXiv:2303.06974] [Google Scholar]
- Dainotti, M. G., De Simone, B., Mohideen Malik, R. F., et al. 2024a, MNRAS, 533, 4023 [NASA ADS] [CrossRef] [Google Scholar]
- Dainotti, M. G., Narendra, A., Pollo, A., et al. 2024b, ApJ, 967, L30 [Google Scholar]
- Dainotti, M. G., Taira, E., Wang, E., et al. 2024c, ApJS, 271, 22 [Google Scholar]
- Dainotti, M. G., Bhardwaj, S., Bissaldi, E., et al. 2025, ApJ, 978, 51 [Google Scholar]
- Dal Pozzolo, A., Caelen, O., Waterschoot, S., & Bontempi, G., 2013, in Intelligent Data Engineering and Automated Learning – IDEAL 2013, eds. H. Yin, K. Tang, Y. Gao, F. Klawonn, M. Lee, T. Weise, B. Li, & X. Yao (Berlin, Heidelberg: Springer Berlin Heidelberg), 24 [Google Scholar]
- Deng, C., Huang, Y.-F., & Xu, F., 2023, ApJ, 943, 126 [NASA ADS] [CrossRef] [Google Scholar]
- Dong, X. F., Zhang, Z. B., Li, Q. M., Huang, Y. F., & Bian, K., 2023, ApJ, 958, 37 [Google Scholar]
- Duncan, R. C., & Thompson, C., 1992, ApJ, 392, L9 [Google Scholar]
- Efron, B., & Petrosian, V., 1992, ApJ, 399, 345 [NASA ADS] [CrossRef] [Google Scholar]
- Evans, P. A., Beardmore, A. P., Page, K. L., et al. 2009, MNRAS, 397, 1177 [Google Scholar]
- Ferradans, S., Papadakis, N., Rabin, J., Peyré, G., & Aujol, J.-F., 2013, in Scale Space and Variational Methods in Computer Vision, eds. A. Kuijper, K. Bredies, T. Pock, & H. Bischof (Berlin, Heidelberg: Springer Berlin Heidelberg), 428 [Google Scholar]
- Friedman, J., Hastie, T., & Tibshirani, R., 2010, J. Stat. Softw, 33, 1 [Google Scholar]
- Galama, T. J., Vreeswijk, P. M., van Paradijs, J., et al. 1998, Nature, 395, 670 [Google Scholar]
- Gehrels, N., Chincarini, G., Giommi, P., et al. 2004, ApJ, 611, 1005 [Google Scholar]
- Gendre, B., Joyce, Q. T., Orange, N. B., et al. 2019, MNRAS, 486, 2471 [Google Scholar]
- Gibson, S. J., Narendra, A., Dainotti, M. G., et al. 2022, FASS, 9 [Google Scholar]
- Godet, O., Nasser, G., Atteia, J.-., et al. 2014, in Space Telescopes and Instrumentation 2014: Ultraviolet to Gamma Ray, eds. T. Takahashi, J.-W. A. den Herder, & M. Bautz (SPIE) [Google Scholar]
- Goldstein, A., Veres, P., Burns, E., et al. 2017a, ApJ, 846, L5 [Google Scholar]
- Goldstein, A., Veres, P., Burns, E., et al. 2017b, ApJ, 848, L14 [CrossRef] [Google Scholar]
- Gorbovskoy, E. S., Lipunova, G. V., Lipunov, V. M., et al. 2012, MNRAS, 421, 1874 [NASA ADS] [CrossRef] [Google Scholar]
- Graham, J. F., Schady, P., & Fruchter, A. S., 2023, ApJ, 954, 13 [Google Scholar]
- Guiriec, S., Gonzalez, M. M., Sacahui, J. R., et al. 2016, ApJ, 819, 79 [Google Scholar]
- Hastie, T., & Tibshirani, R., 1990, Monographs on Statistics & Applied Probability (Chapman and Hall/CRC), 1 [Google Scholar]
- Hastie, T., Tibshirani, R., & Tibshirani, R. J., 2017, arXiv e-prints [arXiv:1707.08692] [Google Scholar]
- Heintz, K. E., De Cia, A., Thöne, C. C., et al. 2023, A&A, 679, A91 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hopkins, A. M., & Beacom, J. F., 2006, ApJ, 651, 142 [NASA ADS] [CrossRef] [Google Scholar]
- Huber, P. J., 1964, Ann. Math. Stat., 35, 73 [CrossRef] [Google Scholar]
- Huber, P. J., 1996, Robust Statistical Procedures (SIAM) [CrossRef] [Google Scholar]
- Izzo, L., Muccino, M., Zaninoni, E., Amati, L., & Della Valle, M., 2015, A&A, 582, A115 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kouveliotou, C., Meegan, C. A., Fishman, G. J., et al. 1993, ApJ, 413, L101 [NASA ADS] [CrossRef] [Google Scholar]
- Kuhn, & Max. 2008, J. Stat. Softw, 28, 1 [Google Scholar]
- Lan, G.-X., Wei, J.-J., Zeng, H.-D., Li, Y., & Wu, X.-F. 2021, MNRAS, 508, 52 [CrossRef] [Google Scholar]
- Levan, A. J., Jakobsson, P., Hurkett, C., et al. 2007, MNRAS, 378, 1439 [CrossRef] [Google Scholar]
- Levan, A. J., Tanvir, N. R., Starling, R. L. C., et al. 2014, ApJ, 781, 13 [Google Scholar]
- Levine, D., Dainotti, M., Zvonarek, K. J., et al. 2022, ApJ, 925, 15 [NASA ADS] [CrossRef] [Google Scholar]
- Li, L., Wu, X.-F., Lei, W.-H., et al. 2018, ApJS, 236, 26 [NASA ADS] [CrossRef] [Google Scholar]
- Liang, E., Zhang, B., Virgili, F., & Dai, Z. G. 2007a, ApJ, 662, 1111 [NASA ADS] [CrossRef] [Google Scholar]
- Liang, E.-W., Zhang, B.-B., & Zhang, B. 2007b, ApJ, 670, 565 [Google Scholar]
- Lien, A., Sakamoto, T., Barthelmy, S. D., et al. 2016, ApJ, 829, 7 [Google Scholar]
- Little, R. J., & Rubin, D. B., 2019, Statistical Analysis with Missing Data, 793 (John Wiley & Sons) [Google Scholar]
- Lloyd-Ronning, N. M., Aykutalp, A., & Johnson, J. L., 2019, MNRAS, 488, 5823 [NASA ADS] [CrossRef] [Google Scholar]
- Mazets, E. P., Golenetskii, S. V., Ilinskii, V. N., et al. 1981, Ap&SS, 80, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Meegan, C., Lichti, G., Bhat, P. N., et al. 2009, ApJ, 702, 791 [Google Scholar]
- Miller, A. A., Bloom, J. S., Richards, J. W., et al. 2015, ApJ, 798, 122 [NASA ADS] [CrossRef] [Google Scholar]
- Mirabal, N., Halpern, J. P., An, D., Thorstensen, J. R., & Terndrup, D. M., 2006, ApJ, 643, L99 [NASA ADS] [CrossRef] [Google Scholar]
- Nakar, E., 2007, Phys. Rep., 442, 166 [NASA ADS] [CrossRef] [Google Scholar]
- Narayan, R., Paczynski, B., & Piran, T., 1992, ApJ, 395, L83 [NASA ADS] [CrossRef] [Google Scholar]
- Narendra, A., Gibson, S. J., Dainotti, M. G., et al. 2022, ApJS, 259, 55 [NASA ADS] [CrossRef] [Google Scholar]
- Nelder, J. A., & Wedderburn, R. W., 1972, J. R. Stat. Soc. Ser. A, 135, 370 [Google Scholar]
- Norris, J. P., & Bonnell, J. T., 2006, ApJ, 643, 266 [NASA ADS] [CrossRef] [Google Scholar]
- Norris, J. P., Marani, G. F., & Bonnell, J. T., 2000, ApJ, 534, 248 [NASA ADS] [CrossRef] [Google Scholar]
- Norris, J. P., Gehrels, N., & Scargle, J. D., 2010, ApJ, 717, 411 [NASA ADS] [CrossRef] [Google Scholar]
- Nousek, J. A., Kouveliotou, C., Grupe, D., et al. 2006, ApJ, 642, 389 [Google Scholar]
- O’Brien, P. T., Willingale, R., Osborne, J., et al. 2006, ApJ, 647, 1213 [NASA ADS] [CrossRef] [Google Scholar]
- Paczyński, B., 1998, ApJ, 494, L45 [Google Scholar]
- Patel, M., Gompertz, B. P., O’Brien, P. T., et al. 2023, MNRAS, 523, 4923 [NASA ADS] [CrossRef] [Google Scholar]
- Pescalli, A., Ghirlanda, G., Salvaterra, R., et al. 2016, A&A, 587, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Petrosian, V., & Dainotti, M. G., 2024, ApJ, 963, L12 [Google Scholar]
- Petrosian, V., Kitanidis, E., & Kocevski, D., 2015, ApJ, 806, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Phillips, M. M., 1993, ApJ, 413, L105 [Google Scholar]
- Pierel, J. D. R., Engesser, M., Coulter, D. A., et al. 2024, ApJ, 971, L32 [Google Scholar]
- Piro, L., Amati, L., Antonelli, L. A., et al. 1998, A&A, 331, L41 [NASA ADS] [Google Scholar]
- Postnikov, S., Dainotti, M. G., Hernandez, X., & Capozziello, S., 2014, ApJ, 783, 126 [NASA ADS] [CrossRef] [Google Scholar]
- Racz, I. I., 2023, CoSka, 53, 100 [Google Scholar]
- Rahin, R., & Behar, E., 2019, ApJ, 885, 47 [NASA ADS] [CrossRef] [Google Scholar]
- Reichart, D. E., 2001, ApJ, 554, 643 [Google Scholar]
- Roming, P. W. A., Kennedy, T. E., Mason, K. O., et al. 2005, Space Sci. Rev., 120, 95 [Google Scholar]
- Rowlinson, A., Gompertz, B. P., Dainotti, M., et al. 2014, MNRAS, 443, 1779 [Google Scholar]
- Sakamoto, T., Hill, J. E., Yamazaki, R., et al. 2007, ApJ, 669, 1115 [NASA ADS] [CrossRef] [Google Scholar]
- Scolnic, D. M., Jones, D. O., Rest, A., et al. 2018, ApJ, 859, 101 [NASA ADS] [CrossRef] [Google Scholar]
- Srinivasaragavan, G. P., Dainotti, M. G., Fraija, N., et al. 2020, ApJ, 903, 18 [Google Scholar]
- Stratta, G., Gendre, B., Atteia, J. L., et al. 2013, ApJ, 779, 66 [NASA ADS] [CrossRef] [Google Scholar]
- Tang, C.-H., Huang, Y.-F., Geng, J.-J., & Zhang, Z.-B., 2019, ApJS, 245, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Tanvir, N. R., Fox, D. B., & Levan, A. J., 2009, Nature, 461, 1254 [Google Scholar]
- Tanvir, N. R., Le Floc’h, E., Christensen, L., et al. 2021, Exp. Astron., 52, 219 [NASA ADS] [CrossRef] [Google Scholar]
- Thompson, C., 1994, MNRAS, 270, 480 [NASA ADS] [CrossRef] [Google Scholar]
- Tibshirani, R., 1996, J. R. Stat. Soc. Ser. B Methodol., 58, 267 [Google Scholar]
- Tibshirani, R., Bien, J., Friedman, J., et al. 2012, J. R. Stat. Soc. Ser. B Methodol, 74, 245 [Google Scholar]
- Tinney, C., Stathakis, R., Cannon, R., et al. 1998, IAU Circ., 6896, 3 [Google Scholar]
- Tsvetkova, A., Frederiks, D., Golenetskii, S., et al. 2017, ApJ, 850, 161 [NASA ADS] [CrossRef] [Google Scholar]
- Ukwatta, T. N., Woźniak, P. R., & Gehrels, N., 2016, MNRAS, 458, 3821 [Google Scholar]
- Usov, V. V., 1992, Nature, 357, 472 [NASA ADS] [CrossRef] [Google Scholar]
- Van Buuren, S., & Groothuis-Oudshoorn, K., 2011, J. Stat. Softw, 45, 1 [Google Scholar]
- van Paradijs, J., Groot, P. J., Galama, T., et al. 1997, Nature, 386, 686 [NASA ADS] [CrossRef] [Google Scholar]
- Vestrand, W. T., Wozniak, P. R., Wren, J. A., et al. 2005, Nature, 435, 178 [NASA ADS] [CrossRef] [Google Scholar]
- Vestrand, W. T., Wren, J. A., Panaitescu, A., et al. 2014, Science, 343, 38 [NASA ADS] [CrossRef] [Google Scholar]
- Virgili, F. J., Liang, E.-W., & Zhang, B., 2009, MNRAS, 392, 91 [Google Scholar]
- Wang, F. Y., Hu, J. P., Zhang, G. Q., & Dai, Z. G., 2022, ApJ, 924, 97 [NASA ADS] [CrossRef] [Google Scholar]
- Wei, J., Cordier, B., Antier, S., et al. 2016, arXiv e-prints [arXiv:1610.06892] [Google Scholar]
- Willingale, R., O’Brien, P. T., Osborne, J. P., et al. 2007, ApJ, 662, 1093 [NASA ADS] [CrossRef] [Google Scholar]
- Woosley, S. E., 1993, ApJ, 405, 273 [Google Scholar]
- Woosley, S. E., & Bloom, J. S., 2006, ARA&A, 44, 507 [Google Scholar]
- Woosley, S. E., Langer, N., & Weaver, T. A., 1993, ApJ, 411, 823 [NASA ADS] [CrossRef] [Google Scholar]
- Xu, M., & Huang, Y. F., 2012, A&A, 538, A134 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Xu, F., Tang, C.-H., et al., Geng, J.-J., 2021, ApJ, 920, 135 [NASA ADS] [CrossRef] [Google Scholar]
- Yi, S.-X., Lei, W.-H., Zhang, B., et al. 2017, JHEAP, 13, 1 [Google Scholar]
- Yi, S.-X., Du, M., & Liu, T. 2022, ApJ, 924, 69 [NASA ADS] [CrossRef] [Google Scholar]
- Yonetoku, D., & Hiz-Gundam Collaboration 2023, in AAS/High Energy Astrophysics Division, 20, 103.18 [Google Scholar]
- Yonetoku, D., Murakami, T., Nakamura, T., et al. 2004, ApJ, 609, 935 [Google Scholar]
- Yu, H., Wang, F. Y., Dai, Z. G., & Cheng, K. S., 2015, ApJS, 218, 13 [Google Scholar]
- Yuan, W., Zhang, C., Feng, H., et al. 2015, PoS, SWIFT 10, 006 [Google Scholar]
- Zaninoni, E., Bernardini, M. G., Margutti, R., Oates, S., & Chincarini, G., 2013, A&A, 557, A12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Zhang, B., & Mészáros, P., 2001, ApJ, 552, L35 [CrossRef] [Google Scholar]
- Zhang, B., Fan, Y. Z., Dyks, J., et al. 2006, ApJ, 642, 354 [Google Scholar]
- Zhang, B., Zhang, B.-B., Liang, E.-W., et al. 2007, ApJ, 655, L25 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, B.-B., Zhang, B., Murase, K., Connaughton, V., & Briggs, M. S., 2014, ApJ, 787, 66 [NASA ADS] [CrossRef] [Google Scholar]
- Zhao, L., Zhang, B., Gao, H., et al. 2019, ApJ, 883, 97 [CrossRef] [Google Scholar]
We note that all the logarithms in this work are in base 10.
All Tables
All Figures
|
Fig. 1 Typical GRB LC. The X-ray LCs are fit with the W07 model, denoted with the darker red line. The end time of the plateau (Ta, Fa) and the prompt emission peak are shown as a black-filled dot and as an empty dot, respectively. |
| In the text | |
|
Fig. 2 Scatter matrix plot showing the distribution of the features involved, with the diagonal showing the distributions. The 30 GRBs added to the training set are shown as orange dots, while those of the previous sample from Dainotti et al. (2024c) are represented by cyan dots. The numbers in the upper triangle show the correlation between two respective features measured for new GRBs, the previous sample, and the combined sample. |
| In the text | |
|
Fig. 3 Left panel: redshift distribution of the new sample (dashed lines) and the old sample (solid line) normalized to one. Right panel: distribution of the new and the old samples when not normalized. |
| In the text | |
|
Fig. 4 Distribution of missing data in our data set. The figure is divided into rows and columns. The top axis of the columns corresponds to the features in the data set, and the bottom axis corresponds to the total number of missing entries in that specific feature. Thus, for log(NH) there are 19 missing entries, for log(Peakflux) there are five missing entries, and so on. The left axis corresponds to the number of GRBs, and the right axis corresponds to the number of features with missing entries. The blue squares show the complete entries, and the red squares show which features are missing for a given number of GRBs. Thus, the first row indicates that there are 209 GRBs with no missing features, and the second row indicates that there are 15 GRBs with missing entries in only one feature, which is log(NH). The third row indicates that there are three GRBs with missing entries in one feature, which is log(Peakflux), and the fourth row indicates that there are two GRBs with missing entries in two features simultaneously, which are log(Peakflux) and log(NH). |
| In the text | |
|
Fig. 5 LASSO coefficients for all ten predictors. The top seven were selected for further analysis. |
| In the text | |
|
Fig. 6 Left panel: plot showing the RMSE and correlation scores for 16 510 formulas. The red points show the formulas selected for analysis on the test set. These formulas achieve correlation and RMSE scores above the cutoffs mentioned at the top of the figure. Right panel: performance of the selected subset of formulas on the test set. Each plus symbol here represents one formula selected from the left panel (red points). The red vertical and horizontal lines point to the formula that obtained the lowest RMSE and highest correlation on the test set. |
| In the text | |
|
Fig. 7 Image of the GAM and GLM Formula Generator page of the web app. This module allows users to access the best formula for predicting redshift based on the training set provided and its predictors. The user can also manually set the cutoff for the correlation and RMSE in order to select the formula. |
| In the text | |
|
Fig. 8 Image of the SuperLearner page of the web app. Shown are the data upload panel and options to choose model and data parameters. |
| In the text | |
|
Fig. 9 Redshift distribution obtained with the upsampling (solid lines) and the original redshift distribution (dashed lines). |
| In the text | |
|
Fig. 10 Various options and parameters available to a user of the web app when using the Model Comparison functionality. |
| In the text | |
|
Fig. 11 Upper panel: user interface of the Relative Influence module of the web app. Lower panel: relative importance bar plot for the predictors used in this analysis. |
| In the text | |
|
Fig. 12 Interface for the data visualization module of the web app. |
| In the text | |
|
Fig. 13 Results obtained from performing 10fCV 100 times using the SuperLearner model. The bottom and upper panels present results with and without balanced sampling, respectively. The upper-left panel shows the results obtained from the SuperLearner model. The upper-right panel shows the corresponding bias-corrected results. The bottom-left panel shows the result obtained from the SuperLearner model when using a balanced sample. The bottom-right panel shows the corresponding bias-corrected results. |
| In the text | |
|
Fig. 14 Histograms showing the distribution of the seven features of the generalization set against the training set. The KS test p-value scores are shown in the title of each figure. The dashed lines and solid lines represent the generalization and training sets, respectively. |
| In the text | |
|
Fig. 15 Scatter matrix plot of the generalization and training sets. The generalization set is presented with orange dots, and the training set is presented with cyan dots. The diagonal shows the histogram distribution for the generalization set, while the upper triangle shows the Pearson correlation values for respective pairs of parameters. |
| In the text | |
|
Fig. 16 Upper panel: redshift distribution of the generalization and training sets. The training set is shown with red histograms, while the generalization set with and without bias correction is shown in white and green histograms, respectively. Lower panel: box plot distribution of the generalization set redshift predictions, sorted from lowest to highest redshift. The bias-corrected and non-bias-corrected distributions are shown in red and gray box plots, respectively. The dots show the outlier predictions obtained. |
| In the text | |
|
Fig. 17 Results of our MC analysis. All the plots shown are combined results of 200 simulated samples. The first column of histograms shows the distribution of properties for the 14 sample cases. The second and third columns of histograms present the distribution of properties for 28 and 42 sample cases, respectively. The first row shows the correlation distribution, and the red line shows the mean. The second row shows the RMSE distribution. The third and fourth rows show the bias and NMAD distributions, respectively. |
| In the text | |
|
Fig. 18 Redshift estimator, the homepage of the app, depicted with the options of choosing MICE, uploading a file, entering parameters manually, and using custom models. |
| In the text | |
|
Fig. A.1 Distribution comparing the current training set with the previous training set from Dainotti et al. (2024c). At the top of each distribution, the KS test and AD test comparison results are shown. |
| In the text | |
|
Fig. B.1 Weights assigned by SuperLearner to an ensemble of GAM, GLM, RF, and EARTH models. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.