| Issue |
A&A
Volume 689, September 2024
|
|
|---|---|---|
| Article Number | A153 | |
| Number of page(s) | 17 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202348485 | |
| Published online | 10 September 2024 | |
LYαNNA: A deep learning field-level inference machine for the Lyman-α forest
1
University Observatory, Faculty of Physics, Ludwig-Maximilians-Universität,
Scheinerstr. 1,
81679
Munich,
Germany
2
Excellence Cluster ORIGINS,
Boltzmannstr. 2,
85748
Garching,
Germany
3
Department of Psychology, Columbia University,
New York,
NY
10027,
USA
Received:
3
November
2023
Accepted:
29
May
2024
The inference of astrophysical and cosmological properties from the Lyman-α forest conventionally relies on summary statistics of the transmission field that carry useful but limited information. We present a deep learning framework for inference from the Lyman-α forest at the field level. This framework consists of a 1D residual convolutional neural network (ResNet) that extracts spectral features and performs regression on thermal parameters of the intergalactic medium that characterize the power-law temperature-density relation. We trained this supervised machinery using a large set of mock absorption spectra from NYX hydrodynamic simulations at z = 2.2 with a range of thermal parameter combinations (labels). We employed Bayesian optimization to find an optimal set of hyperparameters for our network, and then employed a committee of 20 neural networks for increased statistical robustness of the network inference. In addition to the parameter point predictions, our machine also provides a self-consistent estimate of their covariance matrix with which we constructed a pipeline for inferring the posterior distribution of the parameters. We compared the results of our framework with the traditional summary based approach, namely the power spectrum and the probability density function (PDF) of transmission, in terms of the area of the 68% credibility regions as our figure of merit (FoM). In our study of the information content of perfect (noise- and systematics-free) Lyα forest spectral datasets, we find a significant tightening of the posterior constraints – factors of 10.92 and 3.30 in FoM over the power spectrum only and jointly with PDF, respectively – which is the consequence of recovering the relevant parts of information that are not carried by the classical summary statistics.
Key words: methods: numerical / methods: statistical / intergalactic medium / quasars: absorption lines
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1 Introduction
The characteristic arrangement of Lyα absorption lines in the spectra of distant quasars, commonly known as the “Lyα forest” (Lynds 1971), has been shown to be a unique probe of the physics of the Universe at play over a wide window of cosmic history (z ≲ 6). As the continua of emission by the quasars traverse the diffuse intergalactic gas, resonant scattering by the neutral Hydrogen leads to a net absorption of the radiation at the wavelength of the Lyα transition (Gunn & Peterson 1965). In an expanding Universe where spectral redshift z is a proxy of distance, a congregation of absorber clouds in the intergalactic medium (IGM) along a quasar sight line imprints a dense forest of Lyα absorption lines on their spectra. Due to cosmic reionization of Hydrogen being largely complete by z ~ 6 (e.g., McGreer et al. 2015), its neutral fraction xHI within the IGM is extremely minute, yet sufficient to produce this unique feature that enables a continuous trace of the cosmic gas.
The observations of the Lyα forest, through the advent of high-resolution instruments such as Keck/HIRES and VLT/UVES as well as large-scale structure surveys such as the extended Baryon Oscillation Spectroscopic Survey (eBOSS; Dawson et al. 2013) of the Sloan Digital Sky Survey (SDSS; Blanton et al. 2017) and the Dark Energy Spectroscopic Instrument (DESI; DESI Collaboration 2022), have delivered a wealth of information about the nonlinear matter distribution on submegaparsec scales, thermal properties of the intergalactic gas, and large-scale structure. Not only is the Lyα forest an extremely useful tool to study the thermal evolution of the IGM and reionization (as demonstrated, e.g., by Becker et al. 2011; Walther et al. 2019; Boera et al. 2019; Gaikwad et al. 2021), but it has also opened up avenues for constraining fundamental cosmic physics. Chief among those are the baryon acoustic oscillation (BAO) scale and cosmic expansion (e.g., Slosar et al. 2013; Busca et al. 2013; du Mas des Bourboux et al. 2020; Gordon et al. 2023; Cuceu et al. 2023), the nature and properties of dark matter (e.g., Viel et al. 2005, 2013; Iršič et al. 2017; Armengaud et al. 2017; Rogers & Peiris 2021), and in combination with the cosmic microwave background (CMB, e.g., Planck Collaboration VI 2020) also inflation and neutrino masses (e.g., Seljak et al. 2006; Palanque-Delabrouille et al. 2015; Yèche et al. 2017; Palanque-Delabrouille et al. 2020).
The classical way of carrying out parameter inference with the Lyα forest, as for any other cosmic tracer, relies on summary statistics of the underlying field, as they conveniently pick out a small number of relevant features from a much larger number of degrees of freedom of the full data. For the Lyα forest, a number of summary statistics exists that have been accurately measured and effectively used for cosmological and astrophysical parameter inference. These include the line-of-sight (1D) transmission power spectrum (TPS hereinafter; e.g., Croft et al. 1998; Chabanier et al. 2019; Walther et al. 2019; Boera et al. 2019; Ravoux et al. 2023; Karaçaylı et al. 2024), transmission probability density function (TPDF hereinafter; e.g., McDonald et al. 2000; Bolton et al. 2008; Viel et al. 2009; Lee et al. 2015), wavelet statistics (e.g., Meiksin 2000; Theuns & Zaroubi 2000; Zaldarriaga 2002; Lidz et al. 2010; Wolfson et al. 2021), curvature statistics (e.g., Becker et al. 2011; Boera et al. 2014); distributions of absorption line fits (e.g., Schaye et al. 2000; Bolton et al. 2014; Hiss et al. 2019; Telikova et al. 2019; Hu et al. 2022), and combinations thereof (e.g., Garzilli et al. 2012; Gaikwad et al. 2021). While these provide accurate measurements of parameter values, they fail to capture all of the information contained in the transmission field, thereby resulting in a loss of constraining power the full spectral datasets have to offer.
Recently, deep learning approaches have become popular in the context of cosmological simulations and data analysis. Complex and resource-heavy conventional problems in cosmology have started to see fast, efficient, and demonstrably robust solutions in neural network (NN) based algorithms (see, e.g., Moriwaki et al. 2023 for a recent review). Artificial intelligence has opened up a broad avenue for studies of the Lyα forest as well. Cosmological analyses with the Lyα forest generally demand expensive hydrodynamic simulations for an accurate modeling of the small-scale physics of the IGM. Deep learning offers alternative, light-weight solutions to such problems. For instance, Harrington et al. (2022) and Boonkongkird et al. (2023) recently built U-Net based frameworks for directly predicting hydrodynamic quantities of the gas from computationally much less demanding, dark-matter-only simulations. A super-resolution generative model of Lyα-relevant hydrodynamic quantities is presented in Jacobus et al. (2023), based on conditional generative adversarial networks (cGANs). These works greatly accelerate the generation of mock data for Lyα forest analyses. Deep learning is also demonstrated to be a very effective methodology for a variety of tasks involving spectral, 1D datasets. Ďurovčíková et al. (2020) introduced a deep NN to reconstruct high-z quasar spectra containing Lyα damping wings. Melchior et al. (2023) and Liang et al. (2023) describe a framework for generating, analyzing, reconstructing, and detecting outliers from SDSS galaxy spectra consisting of an autoencoder and a normalizing flow architecture. Recent works have shown immense potential of various deep NN methods for the analysis of the Lyα forest. For example, a convolutional neural network (CNN) model to detect and characterize damped Lyα systems (DLAs) in quasar spectra was introduced by Parks et al. (2018). Similarly, Busca & Balland (2018) applied a deep CNN called “QuasarNET” for the identification (classification) and redshift estimation of quasar spectra. Huang et al. (2021) constructed a deep learning framework to recover the Lyα optical depth from noisy and saturated Lyα forest transmission. Later, Wang et al. (2022) applied the same idea to the reconstruction of the line-of-sight temperature of the IGM and detection of temperature discontinuities (e.g., hot bubbles). In neighboring disciplines, deep learning is already identified as a reliable tool for field-level inference. For instance, a set of recent works (Gupta et al. 2018; Fluri et al. 2018; Ribli et al. 2019; Kacprzak & Fluri 2022 among others) has established the superiority of deep learning techniques for cosmological inference directly from weak gravitational lensing maps over the classical two-point statistics of the cosmic density-field proxies.
In this work we present LYαNNA – short for “Lyα Neural Network Analysis” – a deep learning framework for the analysis of the Lyα forest. Here, we have implemented a 1D ResNet (a special type of CNN with skip-connections between different convolutional layers to learn the residual maps; He et al. 2015a) called “SANSA” for inference of model parameters with Lyα forest spectral datasets, harvesting the full information carried by the transmission field. We perform nonlinear regression on the thermal parameters of the IGM directly from the spectra containing the Lyα forest absorption features that are extracted efficiently by our deep model. This architecture was trained in a supervised fashion using a large set of mock spectra from cosmological hydrodynamic simulations with known parameter labels to not only distinguish between two distinct parameter combinations but also pinpoint the exact location of a given spectral set in the parameter space. For better statistical reliability of our results, we employed a committee of 20 neural networks for the inference, combining the outputs via bootstrap aggregation (Breiman 2004). Finally, we built a likelihood model to perform inference on mock datasets via Markov chain Monte Carlo (MCMC) and compared with classical summary statistics, namely a combination of TPS and TPDF, showcasing the improvement we gain by working at the field level.
This paper is structured as follows. Section 2 describes the simulations, the mock Lyα forest spectra we use for training and testing our methodology, and the summary statistics we compare to. In Section 3 we introduce the inference framework of SANSA with details of the architecture and its training. Our results of doing inference with SANSA and a comparison with the traditional summary statistics are presented and discussed in Section 4. We conclude in Section 5 with a précis of our findings and an outlook.
2 Simulations
In this section we introduce the hydrodynamic simulation used throughout this work as well as the post-processing approach we adopt to generate mock Lyα forest spectra.
2.1 Hydrodynamic simulations
We used a NYX cosmological hydrodynamic simulation snapshot generated for Lyα forest analyses (see Walther et al. 2021) to create the mock data used for various purposes in this work. NYX is a relatively novel hydrodynamics code based on the AMREX framework and simulates an ideal gas on an Eulerian mesh interacting with dark matter modeled as Lagrangian particles. While adaptive mesh refinement (AMR) is possible and would allow better treatment of overdense regions, we used a uniform grid here as the Lyα forest only traces mildly overdense gas, rendering AMR techniques inefficient. Gas evolution was followed using a second-order accurate scheme (see Almgren et al. 2013 and Lukić et al. 2015 for more details). In addition to solving the Euler equations and gravity, NYX also models the main physical processes required for an accurate model of the Lyα forest. The chemistry of the gas was modeled following a primordial composition of H and He. Inverse Compton cooling of the CMB was taken into account as well as the updated recombination, collisional ionization, dielectric recombination and cooling rates from Lukić et al. (2015). All cells were assumed to be optically thin to ionizing radiation and a spatially uniform ultraviolet background (UVB) was applied according to the late reionization model of Oñorbe et al. (2017), where heating rates were modified by a fixed factor AUVB affecting the thermal history and thus pressure smoothing of the gas. Here, we used a simulation box at z = 2.2 with 120 Mpc side length and 40963 volumetric cells (“voxels”) and dark matter particles, motivated by recent convergence analyses (Walther et al. 2021 and Chabanier et al. 2023). The cosmological parameters of the box are h = 0.7035, ωm = Ωmh2 = 0.1589, ωb = Ωbh2 = 0.0223, As = 1.4258, ns = 1.0327, AUVB = 0.9036.
During the epoch of reionization the ionizing UV radiation from star-forming galaxies heats up the intergalactic gas as well. Afterward, as the universe expands, the IGM cools down mostly adiabatically with subdominant nonadiabatic contribution, for instance, from inverse Compton scattering off of the CMB and recombination of the ionized medium, as well as heating due to photoionization and gravitational collapse. The bulk of this gas is diffuse (relatively cool with T < 105 K and mildly overdense with ![$\[\log _{10}\left(\rho_{\mathrm{b}} / \bar{\rho}_{\mathrm{b}}\right)<2\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq1.png) ), contained mostly in cosmic voids, sheets, and filaments; see, e.g., Martizzi et al. 2019) and imprints the Lyα forest absorption features on to quasar spectra. The IGM at z ~ 2.2 can be further classified into subdominant phases such as warm-hot intergalactic medium (WHIM; T > 105 K and
), contained mostly in cosmic voids, sheets, and filaments; see, e.g., Martizzi et al. 2019) and imprints the Lyα forest absorption features on to quasar spectra. The IGM at z ~ 2.2 can be further classified into subdominant phases such as warm-hot intergalactic medium (WHIM; T > 105 K and ![$\[\log _{10}\left(\rho_{\mathrm{b}} / \bar{\rho}_{\mathrm{b}}\right)<2\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq2.png) ), condensed halo (T < 105 K and
), condensed halo (T < 105 K and ![$\[\log _{10}\left(\rho_{\mathrm{b}} / \bar{\rho}_{\mathrm{b}}\right)>2\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq3.png) ) and warm halo or circumgalactic medium (WCGM; T > 105 K and
) and warm halo or circumgalactic medium (WCGM; T > 105 K and ![$\[\log _{10}\left(\rho_{\mathrm{b}} / \bar{\rho}_{\mathrm{b}}\right)>2\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq4.png) ). At this redshift, the effects due to the inhomogeneous UVB of the reionization of H and He are considered to be small (e.g., Oñorbe et al. 2019; Upton Sanderbeck & Bird 2020) and we ignore them for this work. The diffuse IGM component in our cosmological simulation exhibits a tight power-law relation in temperature and density (Hui & Gnedin 1997; McQuinn & Upton Sanderbeck 2016) that is classically characterized by
). At this redshift, the effects due to the inhomogeneous UVB of the reionization of H and He are considered to be small (e.g., Oñorbe et al. 2019; Upton Sanderbeck & Bird 2020) and we ignore them for this work. The diffuse IGM component in our cosmological simulation exhibits a tight power-law relation in temperature and density (Hui & Gnedin 1997; McQuinn & Upton Sanderbeck 2016) that is classically characterized by
![$\[T=T_0\left(\frac{\rho_{\mathrm{b}}}{\bar{\rho}_{\mathrm{b}}}\right)^{\gamma-1},\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq5.png) (1)
(1)
where ![$\[\bar{\rho}_{\mathrm{b}}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq6.png) is the mean density of the gas, and T0 (a temperature at the mean gas density) and γ (adiabatic power-law index) are the two free parameters of the model. Indeed, a strong systematic ρb-T relationship is visually apparent in a slice through our simulation box (Figure 1). We performed a linear least-squares fit of the above relation through our simulation in the range
is the mean density of the gas, and T0 (a temperature at the mean gas density) and γ (adiabatic power-law index) are the two free parameters of the model. Indeed, a strong systematic ρb-T relationship is visually apparent in a slice through our simulation box (Figure 1). We performed a linear least-squares fit of the above relation through our simulation in the range ![$\[-0.5<\log _{10}\left(\rho_{\mathrm{b}} / \bar{\rho}_{\mathrm{b}}\right)<0.5\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq7.png) and log10(T/K) < 4. The bestfit (fiducial) values are T0 = 10 104.15 K and γ = 1.58. While a range of works have demonstrated the potential of using different summary statistics of the Lyα forest as probes to measure T0 and γ (see, e.g., Gaikwad et al. 2020), in this work we highlight a first field-level framework for inference of these two thermal parameters of the IGM.
and log10(T/K) < 4. The bestfit (fiducial) values are T0 = 10 104.15 K and γ = 1.58. While a range of works have demonstrated the potential of using different summary statistics of the Lyα forest as probes to measure T0 and γ (see, e.g., Gaikwad et al. 2020), in this work we highlight a first field-level framework for inference of these two thermal parameters of the IGM.
The following strategy was adopted for sampling the parameter space of (T0, γ) to produce labeled data for the supervised training of the inference machine. Both the parameters were varied by a small amount at a time, log T0 → log T0 + log x and γ → γ + y to obtain a new temperature-density relation (TDR). We then rescaled the simulated temperatures at every cell of the simulation by ![$\[T \rightarrow x \cdot\left(\rho_{\mathrm{b}} / \bar{\rho}_{\mathrm{b}}\right)^{y} \cdot T\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq8.png) at fixed densities ρb to appropriately incorporate the scatter off the TDR into our mock data, effectively conserving the underlying T-ρb distribution rather than drawing from a pure power-law. This procedure is illustrated in Figure 2 with the help of the full 2D histograms of temperature and density for two individual parameter rescalings as well as the fiducial case.
at fixed densities ρb to appropriately incorporate the scatter off the TDR into our mock data, effectively conserving the underlying T-ρb distribution rather than drawing from a pure power-law. This procedure is illustrated in Figure 2 with the help of the full 2D histograms of temperature and density for two individual parameter rescalings as well as the fiducial case.
 |
Fig. 1 Slice (29 kpc thick) through our NYX simulation box (120 Mpc side length, with 4096 cells along a side) at z = 2.2 shown here for the gas overdensity (left) and temperature (right). A systematic relationship between both the hydrodynamic fields can be seen. |
2.2 Mock Lyman-α forest
In order to simulate the Lyα forest transmission F = e−τ (τ being the optical depth), we first chose 105 random lines of sight (LOS, a.k.a. skewers) parallel to one of the Cartesian sides (e.g., Z-axis) of the box by picking all consecutive 4096 voxels along that axis while keeping the other two coordinates (X and Y) fixed at a time. The Lyα optical depth at an output pixel in a spectrum was calculated from the information of the density, temperature, and the LOS component of gas peculiar velocity (υpec,‖) at each corresponding voxel along the given skewer. Here, the gas was reasonably assumed to be in ionization equilibrium among the different species of H and He and further that He is almost completely (doubly) ionized at z ~ 2.2 (i.e., xHeIII ≈ 1; Miralda-Escudé et al. 2000; Becker et al. 2015) in order to estimate the neutral H density, nHI for each of those voxels. The Lyα optical depth at a pixel with Hubble velocity υ and gas peculiar velocity υpec,‖ was estimated as
![$\[\tau(\nu)=\frac{\pi e^2 \lambda_{\mathrm{Ly} \alpha} f_{l u}}{m_{\mathrm{e}} c H(z)} \int n_{\mathrm{H~\small{I}}}\left(\nu^{\prime}\right) \phi_{\mathrm{D}}\left(\nu^{\prime} ; \nu+\nu_{\mathrm{pec}, \|}, b\right) \mathrm{d} \nu^{\prime},\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq9.png) (2)
(2)
where the rest-frame λLyα = 1215.67 Å, the Lyα oscillator strength flu = 0.416, and
![$\[\phi_{\mathrm{D}}\left(v ; v_0, b\right) \equiv \frac{1}{b \sqrt{\pi}} \exp \left[-\left(\frac{v-v_0}{b}\right)^2\right]\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq11.png) (3)
(3)
is the Doppler line profile with the temperature-dependent broadening parameter ![$\[b=\sqrt{2 k_{\mathrm{B}} T / m_{\mathrm{H}}}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq12.png) . These τ values were additionally rescaled by a constant factor such that the mean Lyα transmission in our full set of 105 skewers matched its observed value of
. These τ values were additionally rescaled by a constant factor such that the mean Lyα transmission in our full set of 105 skewers matched its observed value of ![$\[\bar{F}_{\text {obs }}=0.86\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq13.png) , compatible with Becker et al. (2013). For our simulation, we performed tests with a simplified, approximate model of lightcone evolution along the LOS (Appendix A) and found negligible impact on the performance of our inference framework. Therefore, we ignored any small lightcone evolution along our skewers and used the snapshot of the simulation for creating mock Lyα forest spectra, assuming a constant TDR for simplicity.
, compatible with Becker et al. (2013). For our simulation, we performed tests with a simplified, approximate model of lightcone evolution along the LOS (Appendix A) and found negligible impact on the performance of our inference framework. Therefore, we ignored any small lightcone evolution along our skewers and used the snapshot of the simulation for creating mock Lyα forest spectra, assuming a constant TDR for simplicity.
To mimic observational limitations and minimize the impact of numerical noise on small scales in the simulations, we restricted the Fourier modes within the spectra to k < k*, k* = 0.18 s km−1. This was effectively achieved by smoothing them with a spectral resolution kernel of Rfwhm ≈ 11000 and additionally rebinning them by 8-pixel averages, matching the Nyquist sampling limit. The final size of a spectrum in our analysis is thus 512 pixels.
When sampling the (T0, γ) space, new mock spectra were produced for each parameter combination with the new (rescaled) temperatures and the original densities and line-of-sight peculiar velocities along the same set of skewers. An example skewer is shown in Figure 3 for three different TDRs. Since the temperature rescaling is a function of ![$\[\rho_{\mathrm{b}} / \bar{\rho}_{\mathrm{b}}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq14.png) through γ, characteristic differences in skewer temperatures and Lyα transmission between cases with varying γ are visible. Changes in T0 result in a homogeneous broadening of the absorption lines, whereas changes in γ (for γ > 1)1, depending on the underlying overdensity being probed, result in larger or smaller broadening (i.e., generally, the shallower lines are broadened less than the deeper ones). We expect our convolutional architecture to be able to pick up such features in order to discriminate between thermal models. In this work, we sampled a grid of 11×11 (T0, γ) combinations as shown in Figure 4 – for each of which we have the same set of 105 physical skewers – for training and testing our deep learning machinery. This grid is oriented in a coordinate system that captures the well-known degeneracy direction in the (T0, γ) space as identified in many TPS analyses (e.g., Walther et al. 2019) and is motivated by the heuristic argument that it is easiest to train a neural network for inference with an underlying parametrization that captures the most characteristic variations in the data. The exact sampling strategy is further described in Appendix B. We used the gray-shaded region in Figure 4 as our prior range of parameters having a uniform prior distribution in all our further analyses.
through γ, characteristic differences in skewer temperatures and Lyα transmission between cases with varying γ are visible. Changes in T0 result in a homogeneous broadening of the absorption lines, whereas changes in γ (for γ > 1)1, depending on the underlying overdensity being probed, result in larger or smaller broadening (i.e., generally, the shallower lines are broadened less than the deeper ones). We expect our convolutional architecture to be able to pick up such features in order to discriminate between thermal models. In this work, we sampled a grid of 11×11 (T0, γ) combinations as shown in Figure 4 – for each of which we have the same set of 105 physical skewers – for training and testing our deep learning machinery. This grid is oriented in a coordinate system that captures the well-known degeneracy direction in the (T0, γ) space as identified in many TPS analyses (e.g., Walther et al. 2019) and is motivated by the heuristic argument that it is easiest to train a neural network for inference with an underlying parametrization that captures the most characteristic variations in the data. The exact sampling strategy is further described in Appendix B. We used the gray-shaded region in Figure 4 as our prior range of parameters having a uniform prior distribution in all our further analyses.
 |
Fig. 2 Joint, volume-weighted distribution of the temperature and density of baryons in our simulation at z = 2.2. Center: the fiducial (T0, γ) parameter case (values obtained by fitting a power-law through gas temperatures and densities). Left: the case with rescaled temperatures for a lower γ than the fiducial and the same T0. This can be seen to affect the slope of the TDR by a twisting of the 2D distribution. Right: the case with rescaled temperatures for a higher T0 than the fiducial and the same γ. The entire distribution is shifted along the log10(T/K) axis, keeping the shape the same. (Note that the color-bar label is using shorthand for |
![$\[p\left(\log _{10}\left(\rho_{\mathrm{b}} / \bar{\rho}_{\mathrm{b}}\right), \log _{10}(T / \mathrm{K})\right)\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq10.png)
2.3 Summary statistics
We considered two summary statistics – TPS and TPDF – of the Lyα forest in this work for demonstrating the benefit of field-level inference. The TPS is defined here as the variance of the transmitted “flux contrast” ![$\[\delta_{F} \equiv(F-\bar{F}) / \bar{F}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq15.png) in Fourier space, that is,
in Fourier space, that is, ![$\[P_{F}(k) \sim\left\langle\tilde{\delta}(k)^{*} \cdot \tilde{\delta}(k)\right\rangle\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq16.png) . For a consistent comparison of inference outcomes, we applied the same restriction k < 0.18 s km−1 as in the input to our deep learning machinery (see Section 2.2). To obtain the TPDF, we considered the histogram of the transmitted flux F in the full set of skewers over 50 bins of equal width between 0 and 1. For the likelihood analysis with the TPDF we left the last bin out as it is fully degenerate with the rest due to the normalization of the PDF. The mean TPS and TPDF computed from the 105 skewers for three different TDR parameter combinations are shown in Figure 5 along with the relative differences in both the statistics between pairs of TDR models. The uncertainty range shown as a gray band therein corresponds to a 1σ equivalent of 100 spectra. The TPS follows a power-law increase for small k and exhibits a suppression of power at larger k (smaller physical scales) due to deficiency of structures as well as the thermal broadening of lines. The variations in the thermal parameters that effectively result in the broadening of absorption lines amount to a shift in this turnover scale toward smaller k-modes2. Equivalently, the broader lines have shallower depths (in this low density regime of the curve of growth), which in turn results in a transfer of probability from smaller (F ≲ 0.4) to larger (F ≳ 0.6) transmission. We also computed the joint covariance matrix of the concatenated summary vector of the TPS and TPDF from our full set of mock spectra by the estimator
. For a consistent comparison of inference outcomes, we applied the same restriction k < 0.18 s km−1 as in the input to our deep learning machinery (see Section 2.2). To obtain the TPDF, we considered the histogram of the transmitted flux F in the full set of skewers over 50 bins of equal width between 0 and 1. For the likelihood analysis with the TPDF we left the last bin out as it is fully degenerate with the rest due to the normalization of the PDF. The mean TPS and TPDF computed from the 105 skewers for three different TDR parameter combinations are shown in Figure 5 along with the relative differences in both the statistics between pairs of TDR models. The uncertainty range shown as a gray band therein corresponds to a 1σ equivalent of 100 spectra. The TPS follows a power-law increase for small k and exhibits a suppression of power at larger k (smaller physical scales) due to deficiency of structures as well as the thermal broadening of lines. The variations in the thermal parameters that effectively result in the broadening of absorption lines amount to a shift in this turnover scale toward smaller k-modes2. Equivalently, the broader lines have shallower depths (in this low density regime of the curve of growth), which in turn results in a transfer of probability from smaller (F ≲ 0.4) to larger (F ≳ 0.6) transmission. We also computed the joint covariance matrix of the concatenated summary vector of the TPS and TPDF from our full set of mock spectra by the estimator
![$\[\mathbf{C}_{\mathrm{s}}=\frac{1}{N-1} \sum_{i=1}^N\left(\mathbf{s}_i-\overline{\mathbf{s}}\right)^T\left(\mathbf{s}_i-\overline{\mathbf{s}}\right),\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq17.png) (4)
(4)
where N = 105 and s is a vector of which the first 256 entries are the Fourier modes in the TPS (k < k*) and the later 49 entries are the bins in the TPDF, F ∈ [0, 1). The joint correlation matrix for a thermal model from our sample is shown in Figure 6. Mild correlations among relatively close entries within the TPS or the TPDF can be observed as well as moderate cross-correlations between the two summary statistics.
For inference with these summary statistics, we cubic-spline interpolated both (the TPDF per histogram bin and the TPS per discrete k-mode) as a function of the parameters (T0, γ) to obtain an emulator over our prior range as depicted in Figure 4 where we assumed a flat (uniform) prior in both the parameters. We verified that choosing a different interpolation scheme, such as linear, does not strongly affect the results of the inference.
 |
Fig. 3 Simulated baryon overdensities, temperatures, line-of-sight peculiar velocity, and transmission along an example skewer through our box for three different temperature-density relations – one pair each for fixed T0 and fixed γ – to indicate characteristic variations with respect to the two TDR parameters. The line shifts due to the peculiar velocity component (υpec,‖) can be easily noticed. Since the rescaling of the temperatures depends on the densities, inhomogeneous differences are seen in the skewer temperatures in the cases with varying γ. The absorption lines are broader where the temperatures are higher and the amount of broadening is also a function of densities being probed through γ. |
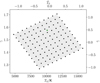 |
Fig. 4 Our sample of thermal models for the various training and test purposes that contains 11×11 (121) distinct (T0, γ) combinations. The fiducial TDR parameter combination is depicted as the green square. The rescaled |
![$\[\left(\tilde{T}_{0}, \tilde{\gamma}\right)\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq18.png)
 |
Fig. 5 Transmission power spectrum (left) and transmitted PDF (right) computed from our set of 105 skewers for three TDR parameter combinations; the same as in Figure 3. The fractional differences between different TDR cases are shown in the corresponding bottom panels with the gray-shaded areas as 1σ uncertainty ranges (bands drawn from discrete k-modes in TPS and discrete histogram bins in TPDF), equivalent of 100 spectra. |
 |
Fig. 6 Correlation matrix of the joint summary vector (the first 256 entries being TPS and the later 49 being TPDF) estimated from our set of 105 mock spectra for the fiducial thermal model. Notice the mild correlations within the individual summaries and the cross-correlations between the two summaries. |
3 Field-level inference machinery
As described in Section 2, we have simulated Lyα forest absorption profiles (spectra) from hydrodynamic simulations having known thermal (T0, γ) parameter values. The aim of our machinery is to learn the characteristic variations in the spectra (i.e., at the field level) with respect to those parameters in order first to distinguish between two adjacent thermal models and ultimately also to provide an uncertainty estimate as well as a point estimate of the parameter values whereby Bayesian inference can be performed. Thus framed, this is a very well-suited problem for application of supervised machine learning. The output of a fully trained deep neural network can be used as a model (emulator) for a newly learned, optimal “summary statistic” of the Lyα transmission field that is fully degenerate with the thermal parameters3, hence carrying most of the relevant information about them that the full field offers. In the following we describe our framework in detail, with a special focus on the neural network architecture and training.
3.1 Overview
The general structure of inference with LYαNNA entails a feed-forward 1D ResNet neural network called “SANSA” that connects an underlying input information vector (transmission field) to an output “summary vector” that can be conveniently mapped to the thermal parameters (T0, γ). Ideally, we expect this summary vector to be a direct actual estimate of the parameters itself, however, due to a limited prior range of thermal models available for training, a systematic (quantifiable) bias was observed in the pure network estimates (see Appendix C). Nonetheless, these estimates can be mapped to the parameters via a tractable linear transformation. For brevity our network encompasses this mapping4 such that its output is a direct estimate of the parameters ![$\[\tilde{\pi}=\left(\tilde{T}_{0}, \tilde{\gamma}\right)\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq19.png) . As an estimate of its own uncertainty of a given prediction, the network also returns a parameter covariance matrix
. As an estimate of its own uncertainty of a given prediction, the network also returns a parameter covariance matrix ![$\[\tilde{\mathbf{C}}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq20.png) . Since our two parameters have dynamic ranges different by orders of magnitude, we linearly rescaled them as
. Since our two parameters have dynamic ranges different by orders of magnitude, we linearly rescaled them as ![$\[T_{0} \rightarrow \tilde{T}_{0}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq21.png) and
and ![$\[\gamma \rightarrow \tilde{\gamma}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq22.png) , to fall in the same range ~ (−1, 1). This bijective mapping ensures numerical stability of the point estimates by the network and is a common practice for deep learning regression schemes. The output covariance matrix (and its inverse) must be positive-definite as a mathematical requirement. This was ensured in our framework in a way similar to Fluri et al. (2019) by a Cholesky decomposition of the form
, to fall in the same range ~ (−1, 1). This bijective mapping ensures numerical stability of the point estimates by the network and is a common practice for deep learning regression schemes. The output covariance matrix (and its inverse) must be positive-definite as a mathematical requirement. This was ensured in our framework in a way similar to Fluri et al. (2019) by a Cholesky decomposition of the form
![$\[\tilde{\mathbf{C}}^{-1}=\mathbf{L} \mathbf{L}^T,\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq23.png) (5)
(5)
where L is a lower triangular matrix. Our network predicts the three independent components of that matrix (log L11, log L22, L12 to further ensure uniqueness5) rather than the covariance matrix directly. The network was optimized following a Gaussian negative log-likelihood loss (hereinafter NL3),
![$\[\mathcal{L}(\tilde{\pi})=\log |\tilde{\mathbf{C}}|+(\tilde{\pi}-\hat{\pi}) \tilde{\mathbf{C}}^{-1}(\tilde{\pi}-\hat{\pi})^T,\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq24.png) (6)
(6)
where ![$\[\hat{\pi}=\left(\hat{T}_{0}, \hat{\gamma}\right)\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq27.png) are the true parameter labels. This can be seen as an extension of the conventional mean squared error,
are the true parameter labels. This can be seen as an extension of the conventional mean squared error, ![$\[\operatorname{MSE}=(\tilde{\pi}-\hat{\pi})(\tilde{\pi}-\hat{\pi})^{T}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq28.png) , in the presence of a network estimated covariance. It can be noted that the covariance matrix does not have any labels and is primarily a way to regularize network predictions under a Gaussian likelihood assumption.
, in the presence of a network estimated covariance. It can be noted that the covariance matrix does not have any labels and is primarily a way to regularize network predictions under a Gaussian likelihood assumption.
 |
Fig. 7 Schematic representation of the architecture of SANSA. It comprises a 1D residual convolutional neural network with four residual blocks in series for extracting crucial features from the spectra of size 512 pixels, followed by a fully connected layer to map the outcome to the parameter point predictions |
![$\[\tilde{\pi}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq25.png)
![$\[\tilde{\mathbf{C}}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq26.png)
3.2 Architecture
We built our architecture using the open-source PYTHON package TENSORFLOW/KERAS (Chollet et al. 2015). The neural network for field-level inference with LYαNNA is called SANSA and consists of a 1D ResNet (He et al. 2015a), a residual convolutional neural network that extracts useful features from spectra and turns them into a “summary” vector which can then be used for inference of model parameters. Figure 7 shows a schematic representation of the architecture of SANSA. The input layer consists of 512 spectral units. This input is passed through four residual blocks in series with varying numbers of input and output units, each block having the same computational structure as illustrated in Figure 8. Each residual block is followed by a batch normalization and an average-pooling layer to down-sample the data vectors consecutively. A ResNet architecture is particularly attractive because of its ease of convergence during training owing to predominantly learning the residual mappings that could conveniently be driven to zero if identity maps are the most optimal in intermediate layers. This is achieved by introducing “skip-connections” in a sequential convolutional architecture that fulfill the role of identity (linear) functions. The residual blocks can more easily adapt to those linear mappings than having to train nonlinear layers to mimic them. A special advantage of the skip-connections is that they do not introduce more parameters than a sequential counterpart. Our neural network has a total of 136 784 trainable parameters that were tuned via back-propagation. We used the TENSORFLOW in-built leaky ReLU (rectified linear unit) function for all the nonlinear activations in the residual blocks with the negative-slope of 0.3. The resultant set of feature tensors is flattened into a single vector of size 128 and mapped to the output vector ![$\[\left(\tilde{T}_{0}, \tilde{\gamma}, \log L_{11}, \log L_{22}, L_{12}\right)\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq29.png) with a fully connected, unbiased linear layer. We regularized the network kernels with a very small L2 weight decay (
with a fully connected, unbiased linear layer. We regularized the network kernels with a very small L2 weight decay (![$\[\mathcal{O}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq30.png) (10−8) in the convolutional layers,
(10−8) in the convolutional layers, ![$\[\mathcal{O}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq31.png) (10−7) in the fully connected layer). We also used a dropout (Srivastava et al. 2014) of 0.09 after each residual block during training for encouraging generalization6.
(10−7) in the fully connected layer). We also used a dropout (Srivastava et al. 2014) of 0.09 after each residual block during training for encouraging generalization6.
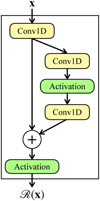 |
Fig. 8 Residual block in SANSA. An input vector x is first passed through a convolutional layer and a copy of the output tensor is made which consecutively goes through a pair of convolutional layers introducing nonlinearity, all the while preserving the shape of the output tensor. The outcome is then algebraically added to the earlier copy (i.e., a parallel, identity function) and the sum is passed through a nonlinear activation to obtain the final outcome of the block. The latter two convolutional layers thus learn a residual nonlinear mapping. (Note that a zero-padding is applied during all convolutions in order to preserve the feature shape in the subsequent layers through the network.) |
3.3 Training
All convolutional kernels in SANSA were initialized following the approach of Glorot & Bengio (2010) and the weights in the final linear layer were initialized similarly to He et al. (2015b). After a preliminary convergence test with respect to training dataset size, we chose a training set consisting of 10000 distinct spectra from each thermal model in our sample. We also had a separate validation set for monitoring overfitting viz. 2/5 the size of the training set with an equivalent distribution of spectra among thermal models. The network was trained by minimizing the NL3 loss function in Eq. (6). Additionally, three other metrics were monitored during the training: ![$\[\log |\tilde{\mathbf{C}}|, \chi^{2}=\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq32.png)
![$\[(\tilde{\pi}-\hat{\pi}) \tilde{\mathbf{C}}^{-1}(\tilde{\pi}-\hat{\pi})^{T}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq33.png) , and the MSE. We notice that the loss function is simply the sum of the first two metrics.
, and the MSE. We notice that the loss function is simply the sum of the first two metrics.
The training was performed by repeatedly cycling through the designated training dataset in randomly chosen batches of a fixed size. Each cycle through the data was deemed an “epoch”, and each back-propagation action on a batch was termed a “step of training”. Since the spectra follow periodic boundary conditions, a cyclic permutation of pixels (“rolling”) is mathematically allowed and leads to no alteration of underlying physical characteristics (e.g., thermal parameters T0, γ). This is also true for reverting the order of the pixels (“flipping”). These are some of the modifications that augment the existing training set and we expect our network to be robust against. Therefore, at every epoch we applied a uniformly randomly sampled amount (in number of pixels) of rolling and a flipping with 50% probability to each of the training spectra, on the fly. We note that the validation set was not augmented on the fly because we would like to compare the generalization of the network predictions at different epochs for the same set of input spectra.
We expect the χ2 metric to optimally take the value ~ Npar because of the underlying Gaussian assumption (in our case Npar = 2). The improvement of the network during training is then in large parts due to a decrement in ![$\[\log |\tilde{\mathbf{C}}|\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq34.png) which indicates that the network becomes less uncertain of its estimates as the training progresses. The state of a network is said to be improving if the value of NL3 decreases and the network χ2 remains close to 2 for data unseen during back-propagation, the validation set. Therefore, we deemed the best state of the network to be occuring at the epoch during training at which the validation NL3 was minimal while the validation |χ2 − 2| < ϵ, for a small ϵ = 0.057. We used the Adam optimizer (Kingma & Ba 2014) with a learning-rate of 5.8 × 10−4. The Adam moment parameters had the values β1 = 0.97 and β2 = 0.999. We performed a Bayesian hyperparameter tuning for fixing the values of kernel weight decays, the dropout rate, the learning rate, and the optimizer moment β1 parameter. We refer the reader to Appendix D for a further description of our strategy for choosing optimal hyperparameters for our network architecture and training. We present the progress of the network’s training quantified by the four metrics mentioned above in Appendix E.
which indicates that the network becomes less uncertain of its estimates as the training progresses. The state of a network is said to be improving if the value of NL3 decreases and the network χ2 remains close to 2 for data unseen during back-propagation, the validation set. Therefore, we deemed the best state of the network to be occuring at the epoch during training at which the validation NL3 was minimal while the validation |χ2 − 2| < ϵ, for a small ϵ = 0.057. We used the Adam optimizer (Kingma & Ba 2014) with a learning-rate of 5.8 × 10−4. The Adam moment parameters had the values β1 = 0.97 and β2 = 0.999. We performed a Bayesian hyperparameter tuning for fixing the values of kernel weight decays, the dropout rate, the learning rate, and the optimizer moment β1 parameter. We refer the reader to Appendix D for a further description of our strategy for choosing optimal hyperparameters for our network architecture and training. We present the progress of the network’s training quantified by the four metrics mentioned above in Appendix E.
3.4 Ensemble learning
The initialization of our network weights (kernels) as well as the training over batches and epochs is a stochastic process. This introduces a bias in the network predictions that can be traded for variance in a set of randomly initialized and trained networks. Essentially, if the errors in different networks’ predictions are uncorrelated, then combining the predictions of multiple such networks helps in improving the accuracy of the predictions. It has been shown that a “committee” of neural networks could outperform even the best-performing member network (Dietterich 2000). This falls under the umbrella of “ensemble learning”.
Once we found an optimal set of hyperparameter values for SANSA, we trained 20 neural networks with the exact same architecture and the learning hyperparameters but initializing the network weights with different pseudo-random seeds and training with differently shuffled and augmented batches of the dataset. The output predictions by all the member networks of this committee of NSANSA = 20 neural networks were then combined in the form of a weighted averaging of the individual predictions to obtain the final outcome (this is commonly known as bootstrap aggregating or “bagging”; see, e.g., Breiman 2004). For a given input spectrum x, let Si(x) denote the output point predictions by the ith network in our committee. Then the combined prediction of the committee is
![$\[\mathcal{S}(x) \propto \frac{1}{N_{\mathrm{S\small{ANSA}}}} \sum_i \frac{1}{\left|\tilde{\mathbf{C}}_i(x)\right|} \mathcal{\mathbf{S}}_i(x),\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq35.png) (7)
(7)
where ![$\[\tilde{\mathbf{C}}_{i}(x)\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq36.png) is the output estimate of the covariance matrix by the ith network for the input spectrum x. This combination puts more weight on less uncertain network predictions and thus is optimally informed by the individual network uncertainties. Even with such a small number of cognate members, we observed slight improvements with respect to the best-performing member as discussed in Appendix F. All the output point predictions by SANSA considered in the following part of the text are implicitly assumed to be that of the committee and not of an individual network unless specified otherwise.
is the output estimate of the covariance matrix by the ith network for the input spectrum x. This combination puts more weight on less uncertain network predictions and thus is optimally informed by the individual network uncertainties. Even with such a small number of cognate members, we observed slight improvements with respect to the best-performing member as discussed in Appendix F. All the output point predictions by SANSA considered in the following part of the text are implicitly assumed to be that of the committee and not of an individual network unless specified otherwise.
3.5 Inference
We performed Bayesian inference of the model parameters with SANSA as well as the traditional summary statistics introduced in Section 2.3. In all the cases, we assumed a Gaussian likelihood and a uniform prior over the range shown in Figure 4. For inference with SANSA we created an emulator for a likelihood analysis in the following way. A test set of spectra8 for a given truth ![$\[\left(\hat{T}_{0}, \hat{\gamma}\right)\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq37.png) were fed into SANSA and a corresponding set of parameter point estimates (
were fed into SANSA and a corresponding set of parameter point estimates (![$\[\tilde{T}_{0}, \tilde{\gamma}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq38.png) ) were obtained. Owing to our optimization strategy (described in Section 3.3) these network predictions have an inherent scatter that is consistent with a network covariance estimate
) were obtained. Owing to our optimization strategy (described in Section 3.3) these network predictions have an inherent scatter that is consistent with a network covariance estimate ![$\[\tilde{\mathbf{C}}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq39.png) . A mean point prediction
. A mean point prediction ![$\[\bar{\pi}=\left(\bar{T}_{0}, \bar{\gamma}\right)\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq40.png) and a covariance matrix were estimated from the scatter of the point estimates. This was performed for each of our 121 thermal models in the test sample. We then cubic-spline interpolated the mean network point prediction and the scatter covariance9 over our prior range of thermal parameters π to obtain a model (emulator) [μ(π), ∑(π)]. The advantage of creating such a model for the likelihood is two-fold: (i) we can perform Bayesian inference with a different choice of prior (e.g., Gaussian) within the gray-shaded area of Figure 4, and (ii) the inference results of our machinery could, in principle, be combined with other probes of interest to further constrain our knowledge of the thermal state of the IGM. This emulator was then used to perform an MCMC analysis for getting posterior constraints with a likelihood function,
and a covariance matrix were estimated from the scatter of the point estimates. This was performed for each of our 121 thermal models in the test sample. We then cubic-spline interpolated the mean network point prediction and the scatter covariance9 over our prior range of thermal parameters π to obtain a model (emulator) [μ(π), ∑(π)]. The advantage of creating such a model for the likelihood is two-fold: (i) we can perform Bayesian inference with a different choice of prior (e.g., Gaussian) within the gray-shaded area of Figure 4, and (ii) the inference results of our machinery could, in principle, be combined with other probes of interest to further constrain our knowledge of the thermal state of the IGM. This emulator was then used to perform an MCMC analysis for getting posterior constraints with a likelihood function,
![$\[\begin{aligned}& \log L_N(\pi) \\& \quad \sim-\frac{1}{2}\left[\log \left|\mathbf{\Sigma}_N(\pi)\right|-\left(\bar{\pi}_N-\mu(\pi)\right) \mathbf{\Sigma}_N^{-1}(\pi)\left(\bar{\pi}_N-\mu(\pi)\right)^T\right],\end{aligned}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq41.png) (8)
(8)
where ![$\[\bar{\pi}_{N}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq42.png) is the mean network point prediction for a given set of N test spectra and ∑N(π) = ∑(π)/N quantifies the uncertainty in the mean point estimate for the given dataset size10. We show this model in Figure 9. The model for the mean parameter values, μ(π), consists of rather smoothly varying functions approximating μ1,2(π1, π2) = π1,2, conforming to our expectation.
is the mean network point prediction for a given set of N test spectra and ∑N(π) = ∑(π)/N quantifies the uncertainty in the mean point estimate for the given dataset size10. We show this model in Figure 9. The model for the mean parameter values, μ(π), consists of rather smoothly varying functions approximating μ1,2(π1, π2) = π1,2, conforming to our expectation.
4 Results and discussion
In this section, we show the results of doing mock inference with our machinery as described in Section 3 and compare them with a summary-based approach (see Section 2.3 for more details on the summaries used). We investigated a few different test scenarios for establishing robustness of our inference pipeline. For each test case, we quantify our results in two chief metrics:
(i) precision, in terms of the area of posterior contours as a figure of merit (FoM),
![$\[\text { FoM } \sim 1 / \sqrt{|\mathbf{C}|};\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq43.png) (9)
(9)
and (ii) accuracy, in terms of a reduced χ2,
![$\[\delta \chi_{\mathrm{r}}^2 \equiv\left\langle\mathbf{\Delta {C}}^{-1} \mathbf\Delta^T\right\rangle / N_{\mathrm{par}}-1;\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq44.png) (10)
(10)
where ![$\[\boldsymbol{\Delta}_{i}=\left(\pi_{i}-\hat{\pi}\right)\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq45.png) is a point in the posterior MCMC sample, C is a covariance matrix of π estimated from the posterior sample and the average ⟨⟩ is taken over the entire sample. We note that in the two parameter case, the area of the posterior contours is proportional to
is a point in the posterior MCMC sample, C is a covariance matrix of π estimated from the posterior sample and the average ⟨⟩ is taken over the entire sample. We note that in the two parameter case, the area of the posterior contours is proportional to ![$\[\sqrt{|\mathbf{C}|}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq46.png) . We expect that the FoM improves when including more information (about the parameters of interest) in the underlying summary statistic from the transmission field, since the constraints get tighter (contours smaller) as a consequence. A smaller value of
. We expect that the FoM improves when including more information (about the parameters of interest) in the underlying summary statistic from the transmission field, since the constraints get tighter (contours smaller) as a consequence. A smaller value of ![$\[\delta \chi_{\mathrm{r}}^{2}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq47.png) implies a more accurate recovery of the true parameters.
implies a more accurate recovery of the true parameters.
First, we considerd a test set of spectra that are distinct from those used in training and validation to evaluate the performance of our inference pipeline for previously unseen data (we recall that the likelihood model for SANSA was built using the validation set). This set consisted of 4000 spectra for the underlying true (fiducial) thermal model, ![$\[\hat{T}_{0}=10104.15 \mathrm{~K}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq48.png) and
and ![$\[\hat{\gamma}=1.58\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq49.png) (we note that this model is off the training grid, as shown in Figure 4, affording us a test of the machinery’s performance off-grid). To distinguish this set with the other test sets in the following, we call it the “original” set hereinafter. In Figure 10, we show the output scatter of point estimates by SANSA for the original test set, with contours of 68 and 95% probability. For comparison, we also plot the posterior contours (obtained by SANSA following the strategy outlined in Section 3.1), inflated to emulate the uncertainty equivalent of one input spectrum. A very good agreement is observed between both the cases, suggesting that a cubic-spline interpolation of the scatter covariance is a sufficiently good emulator for a likelihood analysis as discussed in Section 3.5. We performed inference with three further previously unseen sets of 4000 random spectra with the fiducial TDR to establish the statistical sanity of our pipeline. We show the posterior contours obtained for those in Figure 11 and the metric values in Table 1.
(we note that this model is off the training grid, as shown in Figure 4, affording us a test of the machinery’s performance off-grid). To distinguish this set with the other test sets in the following, we call it the “original” set hereinafter. In Figure 10, we show the output scatter of point estimates by SANSA for the original test set, with contours of 68 and 95% probability. For comparison, we also plot the posterior contours (obtained by SANSA following the strategy outlined in Section 3.1), inflated to emulate the uncertainty equivalent of one input spectrum. A very good agreement is observed between both the cases, suggesting that a cubic-spline interpolation of the scatter covariance is a sufficiently good emulator for a likelihood analysis as discussed in Section 3.5. We performed inference with three further previously unseen sets of 4000 random spectra with the fiducial TDR to establish the statistical sanity of our pipeline. We show the posterior contours obtained for those in Figure 11 and the metric values in Table 1.
Skewers can be picked along any of the three axes of the simulation box (see Section 2.2), each leading to a different realization of the Lyα transmission, mimicking cosmic variance. We expect our pipeline to be robust to the choice of axis along which the input skewers are extracted. We chose three different test sets of skewers along another axis (“Y”) of our box that have the same underlying thermal parameters (fiducial). We estimated the posterior constraints for all three (Y1,2,3) datasets with SANSA and we show them in Figure 12, along with the “original” (skewers extracted along the Z-axis of the simulation box). The corresponding metric values are listed in Table 2. We observe a statistically consistent posterior distribution in each of the three Y-extracted test cases with the original case, indicating that SANSA is agnostic to the choice of LOS direction, even though it was trained only with one of the three possibilities.
Moreover, we tested our inference machinery with numerically modified (augmented) spectra, as discussed in Section 3.3. In one case, we applied a cyclic permutation of the pixels (rolling) by a random amount (between 1 and 512 pixels) to each spectrum of our original test set. We denote this by “rolled”. In a second, we flipped an arbitrary 50% of the original test set of spectra, denoted by “flipped”. We generated another set of spectra with a random mix of both of the above operations applied to the original set; this is labeled “mixed”. We present the posterior constraints for all of these cases in Figure 13 and list the metric values in Table 3. The posterior constraints in all the augmented test scenarios agree very well with each other and with the original test case, establishing robustness of the inference against such degeneracies.
Finally, we compared the inference outcome of SANSA with the traditional summary statistics (TPS and TPDF) based procedure. We present the posterior constraints on ![$\[(\pi-\hat{\pi}) / \hat{\pi}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq55.png) obtained by a MCMC analysis of TPS only, TPS and TPDF jointly, and SANSA for the fiducial thermal model in Figure 14. Evidently, the joint constraints of the two summary statistics are tighter than the TPS-only case as there is more information of the thermal parameter in the former. However, by far the field-level constraints by SANSA are tighter than both the traditional summary statistics cases, namely, a factor of 10.92 compared to the TPS-only case and a factor of 3.30 compared to the joint constraints in our FoM. Indeed, the TPS is only a two-point statistic of the transmission field that has a highly non-Gaussian one-point PDF itself. Combining TPS and TPDF provides some more leverage, however, it still fails to account for some relevant parts of the information for inference. As illustrated by Figure 14, SANSA provides a remedy to the lost information by trying to optimally extract all the features of relevance at the field level.
obtained by a MCMC analysis of TPS only, TPS and TPDF jointly, and SANSA for the fiducial thermal model in Figure 14. Evidently, the joint constraints of the two summary statistics are tighter than the TPS-only case as there is more information of the thermal parameter in the former. However, by far the field-level constraints by SANSA are tighter than both the traditional summary statistics cases, namely, a factor of 10.92 compared to the TPS-only case and a factor of 3.30 compared to the joint constraints in our FoM. Indeed, the TPS is only a two-point statistic of the transmission field that has a highly non-Gaussian one-point PDF itself. Combining TPS and TPDF provides some more leverage, however, it still fails to account for some relevant parts of the information for inference. As illustrated by Figure 14, SANSA provides a remedy to the lost information by trying to optimally extract all the features of relevance at the field level.
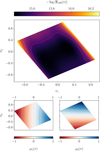 |
Fig. 9 Likelihood model of inference with SANSA over our prior range for the rescaled π parameters. The top panel shows a measure of the covariance model ∑(π) and the bottom panels the model for the two rescaled parameters, |
![$\[\mu_{1} \equiv \tilde{T}_{0}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq50.png)
![$\[\mu_{2} \equiv \tilde{\gamma}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq51.png)
 |
Fig. 10 Scatter of point predictions for the original test set of spectra from our fiducial TDR model shown here with the 68 and 95% contours (green). The contours of the posterior distribution (purple) obtained by SANSA with the procedure outlined in Section 3.1, inflated to match the information equivalent to one spectrum, follow the scatter contours very closely. SANSA also recovers the true parameters (dashed) with a very good accuracy, as indicated by the mean of the point prediction scatter (green cross) as well as that of the posterior (purple cross). |
 |
Fig. 11 Comparison of posterior contours obtained for four different sets of 4000 spectra, where #1 is the “original” (for information equivalent to 100 spectra). |
Comparison metric values for SANSA with four distinct sets of test spectra (for information equivalent to 100 spectra).
 |
Fig. 12 Comparison of posterior contours obtained for three different sets of 4,000 spectra computed along another axis (“Y”) of the simulation box (for information equivalent to 100 spectra). “Z” corresponds to the “original.” |
Comparison metric values for SANSA with spectra along different axes of the simulation (for information equivalent to 100 spectra).
 |
Fig. 13 Comparison of posterior contours for differently augmented test spectra. In the “rolled” case, a uniform random amount (between 1 and 512 pixels) of cyclic permutation of the pixels is applied to each spectrum in the original test set. An arbitrary 50% of spectra from the original test set are flipped (mirrored) in the “flipped” case. A random mix of both is applied in the “mixed” case. All of the contours carry information equivalent to 100 skewers. A mean (expectation) value of all the posterior distributions is also shown with a cross of the corresponding color. The posterior contours for all the cases agree extremely well with the original test case. |
Comparison metric values in data-augmentation scenarios for SANSA (for information equivalent to 100 spectra).
5 Conclusion
We built a convolutional neural network called SANSA for inference of the thermal parameters (T0, γ) of the IGM with the Lyα forest at the field level. We trained this using a large set of mock spectra extracted from the NYXydrodynamic simulations. For estimating posterior constraints, we created a reasonably robust pipeline that relies on the point predictions of the parameters and the uncertainty estimates by our neural network and that can in principle be easily combined with multiple other probes of the thermal state of the IGM. A comparison of our results with those of traditional summary statistics (TPS and TPDF in particular) revealed an improvement of posterior constraints in area of the credible regions by a factor 10.92 with respect to TPS-only and 3.30 with respect to a joint analysis of TPS and TPDF. We established statistical robustness of our pipeline by performing tests with a few different sets of input spectra.
However, our neural network that is trained with noiseless mock spectra for inference fails for spectra with even very small noise (as small as having a continuum-to-noise ratio of 500 per 6 km/s). Indeed, our framework must be adapted for use with noisy spectra by retraining SANSA with datasets containing artificially added noise that varies on the fly during training (to prevent learning from the noise).
Furthermore, in this work we have assumed a fixed underlying cosmology for generating the various datasets used for training and inference. However, the Lyα forest carries information about the cosmological parameters that may be correlated with the thermal properties, and as a consequence, our machinery would exhibit a bias if the cosmology of the training data were not equal to that of the test case. A generalized pipeline would thus require marginalization over the cosmological parameters. Our proof-of-concept analysis, however, opens up an avenue for constraining cosmological parameters at the field level as well.
Baryonic feedback from AGN and supernovae (and similarly, inhomogeneous reionization) affects the phase-space distribution of the IGM and is thus expected to influence the performance of our neural machinery. Nonetheless, we anticipate this impact to be marginal since the network is more sensitive to the power-law regime of the diffuse gas which still holds to a large degree.
As described in Section 2.2, we used snapshots of the skewers to train our pipeline instead of accounting for a lightcone evolution of the IGM properties along the LOS pixel-by-pixel. We performed a test of this framework with an approximate model of such evolution; see Appendix A. For the length of our skewers, we expect the actual lightcone evolution of the gas properties to be marginal and as such unproblematic for network inference.
Nevertheless, in the spirit of creating a robust pipeline for highly realistic spectral datasets, a plethora of physical and observational systematic effects (such as limited spectral resolution, sky lines, metal absorption lines, continuum fitting uncertainty, damped Lyα systems on the observational side; and lightcone effects, baryon feedback, cosmological correlations on the modeling side) must also be incorporated in the training data. This warrants a further careful investigation into training supervised deep learning inference algorithms with a variety of accurately modeled systematics added to our mock Lyα forest datasets and we plan to carry it out in future works.
 |
Fig. 14 Posterior contours obtained by SANSA for the underlying fiducial thermal model. The posterior contours from the two traditional summary statistics are shown for comparison: (i) TPS only and (ii) joint constraints of TPS and TPDF where the cross-correlations of the summaries are accounted for by a joint covariance matrix. In terms of the size of the contours, the SANSA constraints are tighter than the TPS-only ones by a factor 10.92 and the joint constraints by 3.30, corroborating the claim that SANSA recovers relevant information for inference that is not carried by the TPS and/or the TPDF. All the cases carry information equivalent to 100 spectra. |
Data availability
The data and/or code pertaining to the analyses carried out in this paper shall be made available upon reasonable request to the corresponding author.
Acknowledgements
We thank all the members of the chair of Astrophysics, Cosmology and Artificial Intelligence (ACAI) at LMU Munich for their continued support and very interesting discussions. We acknowledge the Faculty of Physics of LMU Munich for making computational resources available for this work. We acknowledge PRACE for awarding us access to Joliot-Curie at GENCI@CEA, France via proposal 2019204900. We also acknowledge support from the Excellence Cluster ORIGINS which is funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy – EXC-2094 – 390783311. P.N. thanks the German Academic Exchange Service (DAAD) for providing a scholarship to carry out this research.
Appendix A An approximate lightcone model
Due to unavailability of lightcone simulations, our skewers come entirely from a single cosmic epoch (snapshot) and do not capture any evolution of underlying hydrodynamic fields along the LOS. Consequently the spectra carry this modeling uncertainty. However, we implemented an approximate model of lightcone evolution for testing our machinery, by interpolating certain physical quantities among close-by snapshots (in z). For four snapshots at z ~ 2.0, 2.2, 2.4, and 2.6, we estimated the true underlying TDR parameters (see Figure A.1) and then linearly interpolated them to obtain T0(z) and γ(z). The redshift span of our skewers is Δz ~ 0.1. Assuming the centers of our skewers at z ~ 2.2, we rescaled all the skewer temperatures according to the interpolated lightcone TDR for nonlightcone ![$\[\rho_{\mathrm{b}} / \bar{\rho}_{\mathrm{b}}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq56.png) (with the same procedure for sampling in the parameter space described in Section 2.1).
(with the same procedure for sampling in the parameter space described in Section 2.1).
 |
Fig. A.1 TDR parameters at four different redshifts; a generally smooth, linear variation can be seen in both T0 and γ. |
Additionally, we incorporated the overall evolution of the mean Lyα transmission through rescaling τ at the pixel level as follows. We first estimated ![$\[\tau_{\text {eff }}(z)=-\log \bar{F}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq57.png) along our skewers from Becker et al. (2013) and then rescaled all the nonlightcone optical depth values as τ0(z) → τ1c(z) = τeff(z)/τeff(z = 2.2) · τ0(z) to eventually obtain mock Lyα transmission spectra. Figure A.2 shows the fractional variation in the TDR parameters and the Lyα transmission across our skewers according to this approximate lightcone model. A maximum of ≲ 1.5% deviation in T0 and ≲ 0.4% in γ can be seen. In
along our skewers from Becker et al. (2013) and then rescaled all the nonlightcone optical depth values as τ0(z) → τ1c(z) = τeff(z)/τeff(z = 2.2) · τ0(z) to eventually obtain mock Lyα transmission spectra. Figure A.2 shows the fractional variation in the TDR parameters and the Lyα transmission across our skewers according to this approximate lightcone model. A maximum of ≲ 1.5% deviation in T0 and ≲ 0.4% in γ can be seen. In ![$\[\bar{F}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq58.png) , there is a maximum of ≲ 2.6% variation across the redshift span of the skewers. We followed the above procedure for generating 4,000 lightcone spectra with the same 4,000 physical skewers as the “original” test case (Section 4).
, there is a maximum of ≲ 2.6% variation across the redshift span of the skewers. We followed the above procedure for generating 4,000 lightcone spectra with the same 4,000 physical skewers as the “original” test case (Section 4).
 |
Fig. A.2 Percentage variations in the TDR parameters and the Lyα transmission in our approximate lightcone model for the redshift span of our skewers. |
With these 4,000 lightcone spectra, we performed inference with SANSA; see the posterior constraints in Figure A.3. We expect SANSA to be able to recover a “mean” TDR along the skewers, that is, the thermal parameters at the centers of the skewers, ![$\[\hat{T}_{0}=10104.15 \mathrm{~K}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq59.png) and
and ![$\[\hat{\gamma}=1.58\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq60.png) (the fiducial values). The metrics for the lightcone and the original test cases are compared in Table A.1.
(the fiducial values). The metrics for the lightcone and the original test cases are compared in Table A.1.
 |
Fig. A.3 Comparison of posterior contours between the original (snapshot) and approximate lightcone model test cases. Both carry information equivalent to 100 skewers. A mean (expectation) value of the posterior distributions are also shown with crosses of the corresponding colors. In both the cases, statistically inter-consistent posterior distributions are obtained, recovering the fiducial TDR of the snapshot. |
Comparison metric values for the original (snapshot) and approximate lightcone test cases for SANSA (for information equivalent to 100 spectra).
Appendix B Orthogonal basis of the parameters
Heuristically, the training of the network is most efficient when our training sample captures the most characteristic variations in the data with respect to the two parameters of interest, T0 and γ. Indeed, as found by many previous analyses (e.g., Walther et al. 2019), there appears to be an axis of degeneracy in the said parameter space given by the orientation of the elongated posterior contours. This presented us with an alternative parametrization of the space accessible via an orthogonalization of a parameter covariance matrix. By doing a mock likelihood analysis with a linear interpolation emulator of the TPS on a preexisting grid of thermal models, we first obtained a (rescaled) parameter covariance matrix C and then diagonalized that such that Λ = VTCV is a 2 × 2 diagonal matrix (V symmetric). An “orthogonal” representation of the parameters was then found by a change of basis,
![$\[\mathbf{A}^T=\mathbf{V} \pi^T,\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq62.png) (B.1)
(B.1)
where A = (α,β) and π = (T0, γ). In the above definition, β represents the degeneracy direction in the π parameters and α corresponds to the axis of the most characteristic deviation. Thence, we sampled the parameter space for training with an 11×11 regular grid in the orthogonal parameter space.
Appendix C Biases due to a limited prior range
After a cursory network training we observed that when the true labels fall close to the edges of our prior range set by the training sample as shown in Figure 4, the mean network predictions are biased toward the center of that space. We also found that in the central region of our prior space, all the network predictions are roughly Gaussian distributed but closer to the edges of that prior they are more skewed, that is, the mode of the distribution is closer to the ground truth than the median. To regularize this, we sampled an extended, sparser grid of thermal models along the degeneracy direction β (in which SANSA provides weaker constraints), to augment our training dataset as shown in Figure C.1. After retraining SANSA on this extended grid, we observed that a (quantifiable) bias still exists (Figure C.2) but the predictions have mostly Gaussianized. The mean point predictions for each of the thermal models on the original grid along a given orthogonal parameter axis fall on approximately a straight line, and hence we can perform a linear transformation of all the raw network predictions such that they satisfy our expectation, ![$\[\tilde{\pi}=\hat{\pi}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq63.png) . This tractable transformation can be represented as follows. In the orthogonal parameters,
. This tractable transformation can be represented as follows. In the orthogonal parameters,
![$\[\tilde{\mathbf{A}}_{\mathrm{f}}^T=\mathbf{M} \tilde{\mathbf{A}}_{\mathrm{i}}^T+\mathbf{c}^T,\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq64.png) (C.1)
(C.1)
where ![$\[\tilde{\mathbf{A}}=(\tilde{\alpha}, \tilde{\beta})\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq65.png) is a point prediction vector in the orthogonal basis, M is a diagonal matrix and the subscripts “i” and “f” denote the original and transformed states of the vector, respectively. This linear transformation is also shown for each parameter α and β independently in Figure C.2. We note that since the change of basis is also a linear operation, the overall transformation in π parameters is linear and preserves the Gaussianity of the point predictions. Following Eq. (B.1), the transformation applied to the actual parameters
is a point prediction vector in the orthogonal basis, M is a diagonal matrix and the subscripts “i” and “f” denote the original and transformed states of the vector, respectively. This linear transformation is also shown for each parameter α and β independently in Figure C.2. We note that since the change of basis is also a linear operation, the overall transformation in π parameters is linear and preserves the Gaussianity of the point predictions. Following Eq. (B.1), the transformation applied to the actual parameters ![$\[\tilde{\pi}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq66.png) looks like
looks like
![$\[\tilde{\pi}_{\mathrm{f}}^T=\mathbf{W} \tilde{\pi}_{\mathrm{i}}^T+\mathbf{d}^T,\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq67.png) (C.2)
(C.2)
where W = V−1MV and d = cV−1 due to the symmetric V. All the network covariance estimates ![$\[\tilde{\mathbf{C}}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq68.png) can also be linearly mapped with a matrix operation
can also be linearly mapped with a matrix operation ![$\[\tilde{\mathbf{C}} \rightarrow \mathbf{W} \tilde{\mathbf{C}} \mathbf{W}^{T}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq69.png) . We used our validation set to fit the linear transformation parameters, W and d, for each trained neural network in the committee individually (the two parameter combinations (true labels) closest to the prior boundaries in each orthogonal parameter were not considered for this fitting). The full neural network SANSA presented in this paper has this tractable linear transformation incorporated as a final, unbiased layer.
. We used our validation set to fit the linear transformation parameters, W and d, for each trained neural network in the committee individually (the two parameter combinations (true labels) closest to the prior boundaries in each orthogonal parameter were not considered for this fitting). The full neural network SANSA presented in this paper has this tractable linear transformation incorporated as a final, unbiased layer.
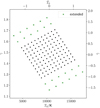 |
Fig. C.1 Extended grid of thermal models for regularizing the point predictions of SANSA. The extension is sparser than the actual training grid as it is only used for rectifying the skewed network predictions for models on the original grid by implicitly allowing a larger prior volume during training. No further test (or network validation) is performed for the models on the extended grid. |
 |
Fig. C.2 Mean point predictions on the validation set from a network trained on an extended grid as shown in Figure C.1 and a straight line fit of each independent orthogonal parameter (averaged over the other). The mean predictions after applying the linear transformation can be seen to follow the expected y = x behavior. |
Appendix D Hyperparameter optimization
As in every deep learning implementation, our algorithm is defined by a large set of hyperparameters that must be tuned in order to arrive at the best possible location on the bias-variance trade-off. Our hyperparameters include the dropout rate, the amplitude of the kernel regularization (l2), number of residual blocks, number of filters and kernel size in each residual block, weight initialization, amount of downsampling per pooling layer, size of the batches of training data, learning rate, Adam β1 parameter, etc. Two strategies were adopted to explore this vast hyperparameter space. Hyperparameters having a finite number of discrete possible values (e.g., architecture in the residual parts) were manually tuned with informed heuristic choices of values to try. The rest of the hyperparameters having continuous spectra; namely kernel regularization, dropout, learning rate, and Adam β1; were tuned with a Bayesian optimization algorithm – based on tree-structured Parzen estimators – for an informed search of the space and an economical use of the resources. This was performed using the predefined routines of the python package OPTUNA (Akiba et al. 2019).
Appendix E Training progress
We show the learning curves for SANSA in Figure E.1 containing the four network metrics – MSE, ![$\[\chi^{2}, \log |\tilde{\mathbf{C}}|\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq70.png) , and the NL3 loss – for the best-performing network in our committee. Following our expectation, the values of the loss, MSE, and
, and the NL3 loss – for the best-performing network in our committee. Following our expectation, the values of the loss, MSE, and ![$\[\log |\tilde{\mathbf{C}}|\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq71.png) decreased for the training set and also for the validation set (albeit somewhat stochastically) over the initial epochs and eventually the validation loss stopped improving. On the other hand, χ2 for training converged to ~ 2 and that for validation fluctuated on the higher side, occasionally coming close to 2, with a slow overall gain over the epochs. We restored the network to its state at an epoch j* at which the loss value was minimal while |χ2 − 2| < 0.05 for the validation set. This helped us make sure that the network predictions are generalized enough and regularized under the Gaussian likelihood cost function. For this network j* = 531. The same qualitative behavior was observed for all the networks in our committee.
decreased for the training set and also for the validation set (albeit somewhat stochastically) over the initial epochs and eventually the validation loss stopped improving. On the other hand, χ2 for training converged to ~ 2 and that for validation fluctuated on the higher side, occasionally coming close to 2, with a slow overall gain over the epochs. We restored the network to its state at an epoch j* at which the loss value was minimal while |χ2 − 2| < 0.05 for the validation set. This helped us make sure that the network predictions are generalized enough and regularized under the Gaussian likelihood cost function. For this network j* = 531. The same qualitative behavior was observed for all the networks in our committee.
 |
Fig. E.1 Learning curves of the best-performing network in the committee of SANSA. This network is trained for > 600 epochs. The best state of the network that can be possibly achieved is determined by the minimal value of NL3 while |χ2 − 2| < 0.05 for the validation set and that occurs at epoch j* = 531 during training. |
Appendix F Single network versus committee
As mentioned in Section 3.4, combining outputs of multiple similar neural networks is shown to improve the eventual outcome. Motivated by this, we employed a committee of 20 networks with the same architecture but having different initial weights, and training with different random batches and augmentation on the fly. In practice, the likelihood model of inference described in Section 3.5 can be built for each individual network in the committee in the same way as for the committee itself since the procedure relies purely on the predictions of the network(s) from the validation set. Hence, it was possible to compare the posterior constraints of an individual network with that of the committee. We present a comparison of the committee with the best-performing member network (defined as the one leading to the posterior constraints with the highest FoM of all the individual networks) in Figure F.1 and Table F.1 for our “original” test set of spectra from the fiducial thermal model. The constraints by the committee are ~ 4% tighter than the best-performing network in FoM and they are slightly more accurate as well. Even though NSANSA = 20 is statistically a small number of sample members in a committee, the aggregate results of the ensemble are still a little better than the best-performing network, conforming to the popular findings.
Comparison metric values of the committee and its best-performing member for our original test case for SANSA (for information equivalent to 1,000 spectra).
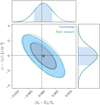 |
Fig. F.1 Comparison of the posterior contours obtained by the committee with those by the best-performing network in the committee for the fiducial thermal model, with information equivalent to 1,000 spectra. The committee constraints are slightly more accurate and ~4% tighter than those of the best member network. |
References
- Akiba, T., Sano, S., Yanase, T., Ohta, T., & Koyama, M. 2019, in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (USA: ACM) [Google Scholar]
- Almgren, A. S., Bell, J. B., Lijewski, M. J., Lukić, Z., & Van Andel, E. 2013, ApJ, 765, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Armengaud, E., Palanque-Delabrouille, N., Yèche, C., Marsh, D. J. E., & Baur, J. 2017, MNRAS, 471, 4606 [NASA ADS] [CrossRef] [Google Scholar]
- Becker, G. D., Bolton, J. S., Haehnelt, M. G., & Sargent, W. L. W. 2011, MNRAS, 410, 1096 [NASA ADS] [CrossRef] [Google Scholar]
- Becker, G. D., Hewett, P. C., Worseck, G., & Prochaska, J. X. 2013, MNRAS, 430, 2067 [Google Scholar]
- Becker, G. D., Bolton, J. S., Madau, P., et al. 2015, MNRAS, 447, 3402 [Google Scholar]
- Blanton, M. R., Bershady, M. A., Abolfathi, B., et al. 2017, AJ, 154, 28 [Google Scholar]
- Boera, E., Murphy, M. T., Becker, G. D., & Bolton, J. S. 2014, MNRAS, 441, 1916 [CrossRef] [Google Scholar]
- Boera, E., Becker, G. D., Bolton, J. S., & Nasir, F. 2019, ApJ, 872, 101 [NASA ADS] [CrossRef] [Google Scholar]
- Bolton, J. S., Viel, M., Kim, T. S., Haehnelt, M. G., & Carswell, R. F. 2008, MNRAS, 386, 1131 [NASA ADS] [CrossRef] [Google Scholar]
- Bolton, J. S., Becker, G. D., Haehnelt, M. G., & Viel, M. 2014, MNRAS, 438, 2499 [NASA ADS] [CrossRef] [Google Scholar]
- Boonkongkird, C., Lavaux, G., Peirani, S., et al. 2023, A&A, submitted [arXiv:2303.17939] [Google Scholar]
- Breiman, L. 2004, Mach. Learn., 24, 123 [Google Scholar]
- Busca, N., & Balland, C. 2018, MNRAS, submitted [arXiv:1808.09955] [Google Scholar]
- Busca, N. G., Delubac, T., Rich, J., et al. 2013, A&A, 552, A96 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chabanier, S., Palanque-Delabrouille, N., Yèche, C., et al. 2019, JCAP, 2019, 017 [Google Scholar]
- Chabanier, S., Emberson, J. D., Lukić, Z., et al. 2023, MNRAS, 518, 3754 [Google Scholar]
- Chollet, F., et al. 2015, Keras, https://keras.io [Google Scholar]
- Croft, R. A. C., Weinberg, D. H., Katz, N., & Hernquist, L. 1998, ApJ, 495, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Cuceu, A., Font-Ribera, A., Nadathur, S., Joachimi, B., & Martini, P. 2023, Phys. Rev. Lett., 130, 191003 [NASA ADS] [CrossRef] [Google Scholar]
- Dawson, K. S., Schlegel, D. J., Ahn, C. P., et al. 2013, AJ, 145, 10 [Google Scholar]
- DESI Collaboration (Abareshi, B., et al.) 2022, AJ, 164, 207 [NASA ADS] [CrossRef] [Google Scholar]
- Dietterich, T. G. 2000, in Multiple Classifier Systems (Berlin, Heidelberg: Springer Berlin Heidelberg), 1 [Google Scholar]
- du Mas des Bourboux, H., Rich, J., Font-Ribera, A., et al. 2020, ApJ, 901, 153 [CrossRef] [Google Scholar]
- Ďurovčíková, D., Katz, H., Bosman, S. E. I., et al. 2020, MNRAS, 493, 4256 [CrossRef] [Google Scholar]
- Fluri, J., Kacprzak, T., Refregier, A., et al. 2018, Phys. Rev. D, 98, 123518 [NASA ADS] [CrossRef] [Google Scholar]
- Fluri, J., Kacprzak, T., Lucchi, A., et al. 2019, Phys. Rev. D, 100, 063514 [Google Scholar]
- Gaikwad, P., Rauch, M., Haehnelt, M. G., et al. 2020, MNRAS, 494, 5091 [Google Scholar]
- Gaikwad, P., Srianand, R., Haehnelt, M. G., & Choudhury, T. R. 2021, MNRAS, 506, 4389 [NASA ADS] [CrossRef] [Google Scholar]
- Garzilli, A., Bolton, J. S., Kim, T. S., Leach, S., & Viel, M. 2012, MNRAS, 424, 1723 [CrossRef] [Google Scholar]
- Glorot, X., & Bengio, Y. 2010, in Proceedings of Machine Learning Research, Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, eds. Y. W. Teh & M. Titterington (Chia Laguna Resort, Sardinia, Italy: PMLR), 9, 249 [Google Scholar]
- Gordon, C., Cuceu, A., Chaves-Montero, J., et al. 2023, J. Cosmology Astropart. Phys., 2023, 045 [Google Scholar]
- Gunn, J. E., & Peterson, B. A. 1965, ApJ, 142, 1633 [Google Scholar]
- Gupta, A., Zorrilla Matilla, J. M., Hsu, D., & Haiman, Z. 2018, Phys. Rev. D, 97, 103515 [NASA ADS] [CrossRef] [Google Scholar]
- Harrington, P., Mustafa, M., Dornfest, M., Horowitz, B., & Lukić, Z. 2022, ApJ, 929, 160 [NASA ADS] [CrossRef] [Google Scholar]
- He, K., Zhang, X., Ren, S., &Sun, J. 2015a, arXiv e-prints [arXiv:1512.03385] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2015b, arXiv e-prints [arXiv:1502.01852] [Google Scholar]
- Hiss, H., Walther, M., Oñorbe, J., & Hennawi, J. F. 2019, ApJ, 876, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Hu, T., Khaire, V., Hennawi, J. F., et al. 2022, MNRAS, 515, 2188 [NASA ADS] [CrossRef] [Google Scholar]
- Huang, L., Croft, R. A. C., & Arora, H. 2021, MNRAS, 506, 5212 [NASA ADS] [CrossRef] [Google Scholar]
- Hui, L., & Gnedin, N. Y. 1997, MNRAS, 292, 27 [Google Scholar]
- Iršič, V., Viel, M., Haehnelt, M. G., Bolton, J. S., & Becker, G. D. 2017, Phys. Rev. Lett., 119, 031302 [CrossRef] [Google Scholar]
- Jacobus, C., Harrington, P., & Lukić, Z. 2023, ApJ, 958, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Kacprzak, T., & Fluri, J. 2022, Phys. Rev. X, 12, 031029 [NASA ADS] [Google Scholar]
- Karaçaylı, N. G., Martini, P., Guy, J., et al. 2024, MNRAS, 528, 3941 [CrossRef] [Google Scholar]
- Kingma, D. P., & Ba, J. 2014, arXiv e-prints [arXiv:1412.6980] [Google Scholar]
- Lee, K.-G., Hennawi, J. F., Spergel, D. N., et al. 2015, ApJ, 799, 196 [NASA ADS] [CrossRef] [Google Scholar]
- Liang, Y., Melchior, P., Lu, S., Goulding, A., & Ward, C. 2023, AJ, 166, 75 [NASA ADS] [CrossRef] [Google Scholar]
- Lidz, A., Faucher-Giguère, C.-A., Dall’Aglio, A., et al. 2010, ApJ, 718, 199 [NASA ADS] [CrossRef] [Google Scholar]
- Lukić, Z., Stark, C. W., Nugent, P., et al. 2015, MNRAS, 446, 3697 [CrossRef] [Google Scholar]
- Lynds, R. 1971, ApJ, 164, L73 [NASA ADS] [CrossRef] [Google Scholar]
- Martizzi, D., Vogelsberger, M., Artale, M. C., et al. 2019, MNRAS, 486, 3766 [Google Scholar]
- McDonald, P., Miralda-Escudé, J., Rauch, M., et al. 2000, ApJ, 543, 1 [NASA ADS] [CrossRef] [Google Scholar]
- McGreer, I. D., Mesinger, A., & D’Odorico, V. 2015, MNRAS, 447, 499 [NASA ADS] [CrossRef] [Google Scholar]
- McQuinn, M., & Upton Sanderbeck, P. R. 2016, MNRAS, 456, 47 [NASA ADS] [CrossRef] [Google Scholar]
- Meiksin, A. 2000, MNRAS, 314, 566 [CrossRef] [Google Scholar]
- Melchior, P., Liang, Y., Hahn, C., & Goulding, A. 2023, AJ, 166, 74 [NASA ADS] [CrossRef] [Google Scholar]
- Miralda-Escudé, J., Haehnelt, M., & Rees, M. J. 2000, ApJ, 530, 1 [CrossRef] [Google Scholar]
- Moriwaki, K., Nishimichi, T., & Yoshida, N. 2023, Rep. Prog. Phys., 86, 076901 [NASA ADS] [CrossRef] [Google Scholar]
- Oñorbe, J., Hennawi, J. F., Lukić, Z., & Walther, M. 2017, ApJ, 847, 63 [CrossRef] [Google Scholar]
- Oñorbe, J., Davies, F. B., Lukić, et al. 2019, MNRAS, 486, 4075 [CrossRef] [Google Scholar]
- Palanque-Delabrouille, N., Yèche, C., Baur, J., et al. 2015, J. Cosmology Astropart. Phys., 2015, 011 [Google Scholar]
- Palanque-Delabrouille, N., Yèche, C., Schöneberg, N., et al. 2020, J. Cosmology Astropart. Phys., 2020, 038 [Google Scholar]
- Parks, D., Prochaska, J. X., Dong, S., & Cai, Z. 2018, MNRAS, 476, 1151 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ravoux, C., Abdul Karim, M. L., Armengaud, E., et al. 2023, MNRAS, 526, 5118 [NASA ADS] [CrossRef] [Google Scholar]
- Ribli, D., Pataki, B. Á., Zorrilla Matilla, J. M., et al. 2019, MNRAS, 490, 1843 [CrossRef] [Google Scholar]
- Rogers, K. K., & Peiris, H. V. 2021, Phys. Rev. Lett., 126, 071302 [NASA ADS] [CrossRef] [Google Scholar]
- Schaye, J., Theuns, T., Rauch, M., Efstathiou, G., & Sargent, W. L. W. 2000, MNRAS, 318, 817 [NASA ADS] [CrossRef] [Google Scholar]
- Seljak, U., Slosar, A., & McDonald, P. 2006, J. Cosmology Astropart. Phys., 2006, 014 [Google Scholar]
- Slosar, A., Iršič, V., Kirkby, D., et al. 2013, J. Cosmology Astropart. Phys., 2013, 026 [Google Scholar]
- Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. 2014, J. Mach. Learn. Res., 15, 1929 [Google Scholar]
- Telikova, K. N., Shternin, P. S., & Balashev, S. A. 2019, ApJ, 887, 205 [NASA ADS] [CrossRef] [Google Scholar]
- Theuns, T., & Zaroubi, S. 2000, MNRAS, 317, 989 [NASA ADS] [CrossRef] [Google Scholar]
- Upton Sanderbeck, P., & Bird, S. 2020, MNRAS, 496, 4372 [NASA ADS] [CrossRef] [Google Scholar]
- Viel, M., Lesgourgues, J., Haehnelt, M. G., Matarrese, S., & Riotto, A. 2005, Phys. Rev. D, 71, 063534 [NASA ADS] [CrossRef] [Google Scholar]
- Viel, M., Bolton, J. S., & Haehnelt, M. G. 2009, MNRAS, 399, L39 [NASA ADS] [CrossRef] [Google Scholar]
- Viel, M., Becker, G. D., Bolton, J. S., & Haehnelt, M. G. 2013, Phys. Rev. D, 88, 043502 [NASA ADS] [CrossRef] [Google Scholar]
- Walther, M., Oñorbe, J., Hennawi, J. F., & Lukić, Z. 2019, ApJ, 872, 13 [NASA ADS] [CrossRef] [Google Scholar]
- Walther, M., Armengaud, E., Ravoux, C., et al. 2021, JCAP, 2021, 059 [Google Scholar]
- Wang, R., Croft, R. A. C., & Shaw, P. 2022, MNRAS, 515, 1568 [Google Scholar]
- Wolfson, M., Hennawi, J. F., Davies, F. B., et al. 2021, MNRAS, 508, 5493 [NASA ADS] [CrossRef] [Google Scholar]
- Yèche, C., Palanque-Delabrouille, N., Baur, J., & du Mas des Bourboux, H. 2017, JCAP, 2017, 047 [CrossRef] [Google Scholar]
- Zaldarriaga, M. 2002, ApJ, 564, 153 [NASA ADS] [CrossRef] [Google Scholar]
γ = 1 would mean the diffuse IGM is roughly isothermal and γ < 1 would lead to an “inverted TDR,” where underdensities are hotter than overdensities as proposed by Bolton et al. (2008), for instance.
![$\[\bar{F}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq73.png)
![$\[\bar{F}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq74.png)
![$\[\tilde{C}_{i i}^{-1}=\left(\pm L_{i i}\right)^{2}\]$](/articles/aa/full_html/2024/09/aa48485-23/aa48485-23-eq75.png)
We note that this value of the dropout rate p is consistent with the Keras convention, that is, the fraction of input layer units to drop, unlike the original definition by Srivastava et al. (2014) where p is the probability of the output of a given layer unit being propagated further in the network.
We note that this was the same set of spectra as that used for the validation of generalization during network training (see Section 3.3).
All Tables
Comparison metric values for SANSA with four distinct sets of test spectra (for information equivalent to 100 spectra).
Comparison metric values for SANSA with spectra along different axes of the simulation (for information equivalent to 100 spectra).
Comparison metric values in data-augmentation scenarios for SANSA (for information equivalent to 100 spectra).
Comparison metric values for the original (snapshot) and approximate lightcone test cases for SANSA (for information equivalent to 100 spectra).
Comparison metric values of the committee and its best-performing member for our original test case for SANSA (for information equivalent to 1,000 spectra).
All Figures
|
Fig. 1 Slice (29 kpc thick) through our NYX simulation box (120 Mpc side length, with 4096 cells along a side) at z = 2.2 shown here for the gas overdensity (left) and temperature (right). A systematic relationship between both the hydrodynamic fields can be seen. |
| In the text | |
|
Fig. 2 Joint, volume-weighted distribution of the temperature and density of baryons in our simulation at z = 2.2. Center: the fiducial (T0, γ) parameter case (values obtained by fitting a power-law through gas temperatures and densities). Left: the case with rescaled temperatures for a lower γ than the fiducial and the same T0. This can be seen to affect the slope of the TDR by a twisting of the 2D distribution. Right: the case with rescaled temperatures for a higher T0 than the fiducial and the same γ. The entire distribution is shifted along the log10(T/K) axis, keeping the shape the same. (Note that the color-bar label is using shorthand for |
| In the text | |
|
Fig. 3 Simulated baryon overdensities, temperatures, line-of-sight peculiar velocity, and transmission along an example skewer through our box for three different temperature-density relations – one pair each for fixed T0 and fixed γ – to indicate characteristic variations with respect to the two TDR parameters. The line shifts due to the peculiar velocity component (υpec,‖) can be easily noticed. Since the rescaling of the temperatures depends on the densities, inhomogeneous differences are seen in the skewer temperatures in the cases with varying γ. The absorption lines are broader where the temperatures are higher and the amount of broadening is also a function of densities being probed through γ. |
| In the text | |
|
Fig. 4 Our sample of thermal models for the various training and test purposes that contains 11×11 (121) distinct (T0, γ) combinations. The fiducial TDR parameter combination is depicted as the green square. The rescaled |
| In the text | |
|
Fig. 5 Transmission power spectrum (left) and transmitted PDF (right) computed from our set of 105 skewers for three TDR parameter combinations; the same as in Figure 3. The fractional differences between different TDR cases are shown in the corresponding bottom panels with the gray-shaded areas as 1σ uncertainty ranges (bands drawn from discrete k-modes in TPS and discrete histogram bins in TPDF), equivalent of 100 spectra. |
| In the text | |
|
Fig. 6 Correlation matrix of the joint summary vector (the first 256 entries being TPS and the later 49 being TPDF) estimated from our set of 105 mock spectra for the fiducial thermal model. Notice the mild correlations within the individual summaries and the cross-correlations between the two summaries. |
| In the text | |
|
Fig. 7 Schematic representation of the architecture of SANSA. It comprises a 1D residual convolutional neural network with four residual blocks in series for extracting crucial features from the spectra of size 512 pixels, followed by a fully connected layer to map the outcome to the parameter point predictions |
| In the text | |
|
Fig. 8 Residual block in SANSA. An input vector x is first passed through a convolutional layer and a copy of the output tensor is made which consecutively goes through a pair of convolutional layers introducing nonlinearity, all the while preserving the shape of the output tensor. The outcome is then algebraically added to the earlier copy (i.e., a parallel, identity function) and the sum is passed through a nonlinear activation to obtain the final outcome of the block. The latter two convolutional layers thus learn a residual nonlinear mapping. (Note that a zero-padding is applied during all convolutions in order to preserve the feature shape in the subsequent layers through the network.) |
| In the text | |
|
Fig. 9 Likelihood model of inference with SANSA over our prior range for the rescaled π parameters. The top panel shows a measure of the covariance model ∑(π) and the bottom panels the model for the two rescaled parameters, |
| In the text | |
|
Fig. 10 Scatter of point predictions for the original test set of spectra from our fiducial TDR model shown here with the 68 and 95% contours (green). The contours of the posterior distribution (purple) obtained by SANSA with the procedure outlined in Section 3.1, inflated to match the information equivalent to one spectrum, follow the scatter contours very closely. SANSA also recovers the true parameters (dashed) with a very good accuracy, as indicated by the mean of the point prediction scatter (green cross) as well as that of the posterior (purple cross). |
| In the text | |
|
Fig. 11 Comparison of posterior contours obtained for four different sets of 4000 spectra, where #1 is the “original” (for information equivalent to 100 spectra). |
| In the text | |
|
Fig. 12 Comparison of posterior contours obtained for three different sets of 4,000 spectra computed along another axis (“Y”) of the simulation box (for information equivalent to 100 spectra). “Z” corresponds to the “original.” |
| In the text | |
|
Fig. 13 Comparison of posterior contours for differently augmented test spectra. In the “rolled” case, a uniform random amount (between 1 and 512 pixels) of cyclic permutation of the pixels is applied to each spectrum in the original test set. An arbitrary 50% of spectra from the original test set are flipped (mirrored) in the “flipped” case. A random mix of both is applied in the “mixed” case. All of the contours carry information equivalent to 100 skewers. A mean (expectation) value of all the posterior distributions is also shown with a cross of the corresponding color. The posterior contours for all the cases agree extremely well with the original test case. |
| In the text | |
|
Fig. 14 Posterior contours obtained by SANSA for the underlying fiducial thermal model. The posterior contours from the two traditional summary statistics are shown for comparison: (i) TPS only and (ii) joint constraints of TPS and TPDF where the cross-correlations of the summaries are accounted for by a joint covariance matrix. In terms of the size of the contours, the SANSA constraints are tighter than the TPS-only ones by a factor 10.92 and the joint constraints by 3.30, corroborating the claim that SANSA recovers relevant information for inference that is not carried by the TPS and/or the TPDF. All the cases carry information equivalent to 100 spectra. |
| In the text | |
|
Fig. A.1 TDR parameters at four different redshifts; a generally smooth, linear variation can be seen in both T0 and γ. |
| In the text | |
|
Fig. A.2 Percentage variations in the TDR parameters and the Lyα transmission in our approximate lightcone model for the redshift span of our skewers. |
| In the text | |
|
Fig. A.3 Comparison of posterior contours between the original (snapshot) and approximate lightcone model test cases. Both carry information equivalent to 100 skewers. A mean (expectation) value of the posterior distributions are also shown with crosses of the corresponding colors. In both the cases, statistically inter-consistent posterior distributions are obtained, recovering the fiducial TDR of the snapshot. |
| In the text | |
|
Fig. C.1 Extended grid of thermal models for regularizing the point predictions of SANSA. The extension is sparser than the actual training grid as it is only used for rectifying the skewed network predictions for models on the original grid by implicitly allowing a larger prior volume during training. No further test (or network validation) is performed for the models on the extended grid. |
| In the text | |
|
Fig. C.2 Mean point predictions on the validation set from a network trained on an extended grid as shown in Figure C.1 and a straight line fit of each independent orthogonal parameter (averaged over the other). The mean predictions after applying the linear transformation can be seen to follow the expected y = x behavior. |
| In the text | |
|
Fig. E.1 Learning curves of the best-performing network in the committee of SANSA. This network is trained for > 600 epochs. The best state of the network that can be possibly achieved is determined by the minimal value of NL3 while |χ2 − 2| < 0.05 for the validation set and that occurs at epoch j* = 531 during training. |
| In the text | |
|
Fig. F.1 Comparison of the posterior contours obtained by the committee with those by the best-performing network in the committee for the fiducial thermal model, with information equivalent to 1,000 spectra. The committee constraints are slightly more accurate and ~4% tighter than those of the best member network. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.