| Issue |
A&A
Volume 683, March 2024
|
|
|---|---|---|
| Article Number | A145 | |
| Number of page(s) | 23 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202347216 | |
| Published online | 15 March 2024 | |
Detecting the edges of galaxies with deep learning
1
GIR GCME. Departamento de Informática, Universidad de Valladolid,
47011
Valladolid, Spain
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Departamento de Física Teórica, Atómica y Óptica, Universidad de Valladolid,
47011
Valladolid, Spain
3
Instituto de Astrofísica e Ciências do Espaço, Universidade de Lisboa, OAL,
Tapada da Ajuda,
1349-018
Lisbon, Portugal
Received:
16
June
2023
Accepted:
17
November
2023
Abstract
Galaxy edges or truncations are low-surface-brightness (LSB) features located in the galaxy outskirts that delimit the distance up to where the gas density enables efficient star formation. As such, they could be interpreted as a non-arbitrary means to determine the galaxy size and this is also reinforced by the smaller scatter in the galaxy mass-size relation when comparing them with other size proxies. However, there are several problems attached to this novel metric, namely, the access to deep imaging and the need to contrast the surface brightness, color, and mass profiles to derive the edge position. While the first hurdle is already overcome by new ultra-deep galaxy observations, we hereby propose the use of machine learning (ML) algorithms to determine the position of these features for very large datasets. We compare the semantic segmentation by our deep learning (DL) models with the results obtained by humans for HST observations of a sample of 1052 massive (Mstellar > 1010 M⊙) galaxies at z < 1. In addition, the concept of astronomic augmentations is introduced to endow the inputs of the networks with a physical meaning. Our findings suggest that similar performances than humans could be routinely achieved, although in the majority of cases, the best results are obtained by combining (with a pixel-by-pixel democratic vote) the output of several neural networks using ensemble learning. Additionally, we find that using edge-aware loss functions allows for the networks to focus their optimization on the galaxy boundaries and, therefore, to provide estimates that are much more sensitive to the presence of neighboring bodies that may affect the shape of the truncation. The experiments reveal a great similarity between the semantic segmentation performed by the AI compared to the human model. For the best model, an average dice of 0.8969 is achieved, while an average dice of 0.9104 is reached by the best ensemble, where the dice coefficient represents the harmonic mean between the precision and the recall. This methodology will be profusely used in future datasets, such as that of Euclid, to derive scaling relations that are expected to closely follow the galaxy mass assembly. We also offer to the community our DL algorithms in the author's github repository.
Key words: galaxies: evolution / galaxies: fundamental parameters / galaxies: general / galaxies: spiral / galaxies: statistics / galaxies: structure
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Identifying the appropriate method to determine the size of a galaxy is a longstanding problem in astrophysics since galaxies are diffuse objects without sharply defined edges. Many different approaches have been adopted in the last century (see Chamba 2020 for a thorough review). In recent decades, the effective radius (re, the semi-major axis of the ellipse encompassing half of the light from a galaxy) has been the most widely used proxy for the size. The main reasons behind this decision are twofold: on the one hand, its robustness against different values for signal-to-noise ratio (S/N) and exposure time and, on the other hand, its connection with galaxy surface brightness parametric fitting, namely, the Sérsic (1968) functions. However, taking a half-light radius as the proxy for galaxy size is an arbitrary choice and its calculation is tightly connected with the galaxy concentration (see the discussion in the introduction of Trujillo et al. 2020).
The aforementioned Trujillo et al. (2020) suggested R1 (the isomass contour at 1 M⊙ pc−2) as a physically motivated size proxy. Considering the two-phase formation scenario for galaxies (see, e.g., Hilz et al. 2013; Pulsoni et al. 2021), a first period of in situ star formation should be followed by the subsequent accretion of galaxy satellites. Therefore, the cessation of that first stage must be imprinted in the galaxy outskirts, as there is a spatial limit for reaching the gas density threshold enabling star formation (Schaye 2004). The gas density translates into a stellar density, assuming a certain (low) efficiency into converting gas to stars and this is the reason why R1 is connected with a sudden change in the galaxy properties (surface brightness, color, and mass profiles) for Milky Way-like galaxies in the local Universe (Martínez-Lombilla et al. 2019; Díaz-García et al. 2022). However, the 1 M⊙ pc−2 threshold seems to be dependent (at least) on the galaxy stellar mass or (ultimately) on the physical conditions of the star formation episode. To investigate in depth where these features appear, irrespective of their surface mass density value, Chamba et al. (2022) and Buitrago & Trujillo (2024; with the former study focused in the low-z Universe and the latter at intermediate, z < 1, redshifts) detected these sudden drops or changes in the galaxy outer profiles, studying the evolution on their location with stellar mass and redshift. The series of observational tests conducted in these articles, together with the reduction in the scatter in the mass-size relation by a factor of 2–2.5, solidified this metric as a physically motivated means to define galaxy sizes. Very interestingly, these edges could be identified with the previously known galaxy truncations (van der Kruit 1979) and, as such, we utilize these two names interchangeably in the present work.
Galaxy truncations have initially been identified for edge-on galaxy disks whose sizes did not seem to change despite integrating the images for longer exposure times (van der Kruit & Searle 1981a,b). It is to noteworthy that this is not at variance with the fact of galaxies being fuzzy objects, because there are always stars and light beyond this distance due to the existence of a stellar halo or stellar migration. Nevertheless, they had not been considered useful size proxies in the past because of the low surface brightness (LSB) levels where they appear (μ > 26–27 mag/arcsec−2 in 10 × 10 arcsec apertures Martín-Navarro et al. 2012, 2014; Trujillo & Fliri 2016). This situation could be changed with the arrival of future telescope facilities, especially the large-aperture synoptic telescopes that will be able to routinely reach very deep surface brightness levels (μ > 28–30 mag arcsec−2; Euclid Collaboration 2022). This research has been branded the LSB regime of galaxy formation and evolution (Duc et al. 2015; Mihos 2019). However, if we are to extract the maximum information from these incoming images, our endeavor is not only about building the right telescopes and other instruments, but also to develop the next generation software able to deal with the millions and even billions of objects to be studied, while simultaneously achieving high accuracy in our feature extraction.
As this is a pattern-recognition problem, machine learning (ML) is especially suited for tackling these problems in spite of the diversity of galaxy shapes. Deep learning (DL), and specifically convolutional neural networks (CNN), have shown their power in similar big data projects focused on astrophysical and extragalactic studies (Huertas-Company et al. 2015a; Domínguez Sánchez et al. 2018; Hausen & Robertson 2020; Vega-Ferrero et al. 2021, to name a few).
The DL technique that we present here goes beyond the algorithmic segmentation performed by other codes such as Source-Extractor (Bertin & Arnouts 1996) or NoiseChisel (Akhlaghi & Ichikawa 2015; Akhlaghi 2019) because of the fact that several pieces of evidence (1D or 2D surface brightness and color and mass profiles) must be taken into account in order to derive the truncation position. Generative networks like U-Nets (Ronneberger et al. 2015) or variational autoencoders (VAE, Kingma & Welling 2013) are capable of generating pixel level segmentation and separate the background noise from the information of the galaxy. Specific axis and edge detection techniques have been recently proposed (Soria et al. 2020) along with novel DL models such as EfficientNet (Tan & Le 2019), ResNet (He et al. 2016, 2019), DenseNet (Huang et al. 2017), FastFCN (Wu et al. 2019), GatedSCNN (Takikawa et al. 2019) or Mask RCNN (He et al. 2020) to perform this task. Other proposal (González et al. 2018) rely on the use of object detection networks such as YOLO (Redmon et al. 2015) for automated galaxy detection and classification. Other works (Walmsley et al. 2020) have suggested leveraging bayesian DL techniques to investigate morphological features of galaxies. Such an approach provides an avenue to incorporate uncertainty into the process of edge estimation.
In the present work, we take a first step on the characterization of truncations and galaxy edges with ML and with the relatively small (> 1000) albeit meaningful sample from Buitrago & Trujillo (2024), which will be the base for the framework that will be developed for the forthcoming Euclid satellite (Laureijs et al. 2011). Of course, this approach could also be extended for other future enterprises such as the Vera Rubin Observatory's Legacy Survey of Space and Time (LSST, Ivezić et al. 2019) or the ARRAKIHS satellite1 among others. The tools to be created will become open-source in the following repository2 and our aim is that they could be applied to different fits images and galaxy surveys than the ones that we took as a basis for our study.
The paper structure is the following: Sect. 2 summarizes the parent imaging and the adopted methodology in order to infer galaxy edges or truncations, Sect. 3 describes the models we built to analyze our data, Sect. 4 details our results and Sect. 5 reports our conclusions. Hereafter, our assumed cosmology is Ωm = 0.3, ΩΛ= 0.7 and H0 = 70 km s−1 Mpc−1. We used the Chabrier (2003) initial mass function (IMF), unless otherwise stated. Magnitudes are provided in the AB system (Oke & Gunn 1983).
2 Dataset: Astronomic augmentations (AAs)
The parent sample comes from Buitrago & Trujillo (2024), where the reader can find all the details from our galaxy sample and associated data. Here, we summarize its most important characteristics, highlighting the necessary changes to adapt our previous datasets to become the inputs for our ML algorithms.
The images for our study come from the CANDELS fields (the best trade-off between area and depth for HST observations), namely, the CANDELS survey (Grogin et al. 2011; Koekemoer et al. 2011) for GOODS-N, UDS, EGS and COSMOS, HLF (Illingworth et al. 2016) for GOODS-S, while for HUDF we used the dataset in Beckwith et al. (2006) for the optical and ABYSS (Borlaff et al. 2019) in the near-infrared (NIR) bands. We took the galaxy IDs, photometric masses, and spectroscopic redshifts (only those flagged as the ones with top quality) for all galaxies from the CANDELS public catalogs3 (Santini et al. 2015; Stefanon et al. 2017; Nayyeri et al. 2017; Barro et al. 2019), whereas to increase our sample, we also took galaxies with spectroscopic redshifts from other sources (van der Wel et al. 2016, 2021; Straatman et al. 2018; Lilly et al. 2009; Damjanov et al. 2019). Then, we selected galaxies with Mstellar > 1010 M⊙ and zspec < 1.1 (in order to maximize the S/N of our targets). As we are looking for features regarding the limits of gas density enabling star formation, truncations should be more easily visible in disk galaxies (Martín-Navarro et al. 2012) and, as such, we only selected this type of galaxies according the criteria in Huertas-Company et al. (2015a). In this publication, these galaxies are later subdivided as pure disks (DISK), disks with central spheroids (DISKSPH), and irregular disks (DISKIRR). We use these subclasses in the present work. Lastly, any galaxy displaying an observational artifact was also removed from our final sample. In summary, our initial mass-selected sample of 3460 galaxies was reduced to 1052 galaxies after applying all the aforementioned selection criteria with integrated apparent magnitudes of 17.5 < HAB < 22.5.
The observed images for the galaxies in our sample were cut with a fixed stamp size of 12 × 12 arcsec, ergo 400 × 400 pixels for the optical ACS images, for the F606W (V) and F814W (I) filters, while 200 × 200 pixels for the near-infrared WFC3 images, for the F125W (J) and F160W (H) filters; however, these latter ones were later resampled to the near-infrared resolution to match the same pixel scale. A representative sky background value was subtracted from each image (details in Buitrago & Trujillo 2024). From these postage stamps we derived g, r, i, and z Sloan Digital Sky Survey (SDSS)-restframe equivalent images in the same manner as the profiles in Buitrago et al. (2017) or Buitrago & Trujillo (2024), but this time on a pixel-by-pixel basis. Basically, we interpolated linearly between contiguous observed bands converted to surface brightness using the formula:
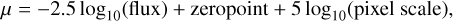
while taking as a reference the mean wavelength of each filter4. These SDSS-restframe images were also corrected by galaxy inclination according to the model in Trujillo et al. (2020), along with the extinction from our galaxy5 and cosmological dimming. To avoid numerical errors, in the case of negative pixel values in the images to be interpolated, we substituted their values with the noise level of each image. This limiting magnitude was calculated utilizing 104 1 × 1 arcsec2 boxes to match the characteristic spatial scales of the galaxy in our sample, and then deriving the 3σ clipped standard deviations of those.
We obtained color images (g-i, g-r, g-z, i-z, r-i, r-z) from these SDSS-restframe equivalent images by subtracting one from another. Overly high (>5) or low values (<−1) were trimmed out setting not-a-number (NaN) values instead. Finally, these SDSS-restframe images and their color images were combined pixel-by-pixel using the recipes in Roediger & Courteau (2015) for retrieving mass images. We note that by using these methods, we obtained 24 mass images (one per combination of base filter and color) and thus our final mass image is the median of all of them in units of M⊙ pc−2. Again, pixels displaying too high (>105) or too low (<10−3) values were discarded.
Summarizing, our final inputs to our neural networks are all the previously enumerated 200 × 200 pixel images, namely, the HST observations, the SDSS-restframe equivalent images, and the color and mass images. Our labels are also 200 × 200 pixel images set to 1 for all the pixels belonging to the central galaxy and 0 otherwise. Any neighbor overlapping the galaxy has also been set to 0 after a thorough masking. The borders between the central galaxy and the rest of the pixels are our galaxy edges or truncations (see Fig. 1). They are defined as ellipses whose semi-major axis is the truncation position or edge radius found in Buitrago & Trujillo (2024), with the axis ratio and position angle being representative of those found for the galaxy outer parts in the H-band. Mind this is approximate labelling, i.e. the truncation might be found at slightly different radial distances azimuthally or they might be erased in certain parts due to previous galaxy merging. These aspects will be expanded in future publications (Raji et al., in prep.; Fernández et al., in prep.). Finally, it is to note that our sample (both galaxies and their associated truncation values) differs somewhat from the one in Buitrago & Trujillo (2024) in terms of the number of objects (four more in our analysis) and truncation values (96 reassessed different values, with a median variation of 1.25 kpc). These changes are not important for our objectives, since our purpose is to create a neural network that is able to reproduce the decisions of human astronomers based on certain data and inputs; thus, it is to be expected (and this is indicated by the preliminary results) that with the new data, the DL models will also be able to adapt with a high level of precision.
The process of labeling galaxy edges in LSB areas is a complex task that requires time for an experienced researcher to analyze all the input data. For these reasons, we did not have access to a large number of galaxies available for our study. It is well known that one of the main problems derived from the scarcity of data is overfitting in the training phase. That is why the application of data augmentation techniques is very relevant to achieve the best possible learning., namely, performing slight modifications of the input images to be fed into the networks. In this work, we have used some of the most standard ones, such as random 90-degree-multiple rotations (0°, 90°, 180°, or 270°), flipping the images (horizontally, vertically, or not at all) and adding Gaussian noise (standard deviations of 0.01, 0.05, or 0.1).
Nevertheless, we wanted to increase the number of augmentations with the goal of not only gaining access to more examples for learning features, but also to change how the network learns as well. We combined the information that researchers use when detecting truncations and we utilized this data in the training phase, thus providing extra sets of physically meaningful inputs to the networks. The use of multiple combinations of all the available data maximizes the variability of the information used in the training phase, always referring to the same physical reality, which greatly improves the robustness of the training. We enumerate these new augmentations here, that we call "astronomic" augmentations (given their origin), with the corresponding names to each one of their types: (1) visual: creating RGB images by using all possible range of observational bands sorted by wavelength. Consequently, the different possibilities are UH, VIJ, VIH, and VJH; (2) color: creating all possible color images: g-i, g-r, g-z, i-z, r-i, and r-z; (3) sloan: creating b/w and color images with the SDSS-restframe equivalent images: g, r, i, z, gri, giz, riz, grz; (4) and mass: creating the mass per pixel images, as detailed in Sect. 2.
 |
Fig. 1 Image-mask-truncation equivalence. Left: image created combining the V, I, and H bands. Center: associated segmentation mask, where the only active pixels are those belonging to the main galaxy. Right: determination of the truncation from the perimeter of the segmentation mask. Note: the jagged profile is due to the superposition of a neighboring galaxy. |
3 Models and training
To detect the galaxy edges, we used a DL-based semantic segmentation approach. Semantic segmentation is aimed at classifying all the pixels in an input, grouping together those pixels that share the same characteristics or belong to the same type of object. The aim of the DL methodology developed in this work is to determine and isolate the bodies of the central galaxies from the noise and other secondary galaxies. Therefore, each of the different algorithms attempts to classify the pixels of the images into two categories, main galaxy, and the rest of the pixels (where this latter category includes both background noise and secondary galaxies) as seen in Fig. 1. Using the masks generated by the semantic segmentation model, the radius of the associated truncations can be easily determined. Hence, it is crucial that the forthcoming DL models exhibit a good performance in the pixels situated near to the galaxy edges. The current section presents the architecture configurations of our models along with the training specifications.
 |
Fig. 2 Example of the architecture designed for experiments with mass-type AAs. The architecture consists of two stages. In the first stage, grouped convolutions process each image in isolation and then a U-Net with a pre-trained encoder uses all the information from the different AAs to infer the truncations. |
3.1 Architectural configurations
There are several CNN architectures that have been proposed over the years to solve the problem of semantic segmentation. The best known examples are U-Nets (Ronneberger et al. 2015), nested U-Nets (Zhou et al. 2018), or the DeepLab (Chen et al. 2018) family of architectures. In this work, we decided to use the U-Nets as the base scheme from which to derive the models for estimating galactic truncations. This type of network is able to achieve reasonable quality segmentation with a relatively small training sample size, which is a very relevant restriction in this work. They are composed of two symmetrical stages. The first one, the contraction stage, is carried out by an encoder and tries to extract the most relevant features from the inputs (down-sampling). The second one, the expansion stage, is performed by a decoder and reconstructs the segmentation mask using the previously obtained features. In order to avoid a vanishing gradient problem (due to the concatenation of many layers) and to enhance the retrieval of spatial information (that may be lost during downsampling) skip connections are utilized. These links allow the cross flow of information between the symmetrical layers of the encoder and decoder.
Due to their morphology, U-Nets allow for different types of convolutional neural networks to be used as encoders. In this work, three families of CNNs are tested: ResNet (He et al. 2016), EfficientNet (Tan & Le 2019) and DenseNet (Huang et al. 2017). These families correspond to well-known models that have obtained state-of-the-art results in a wide range of computer vision tasks. Specifically, from the ResNet family, we used the 18-hidden layers and the 50-hidden layers models. From the EfficientNet family, variants B1, B2, and B6 have been used. Lastly, from the DenseNet family, the DenseNet-161 and DenseNet-201 architectures have been used as encoders. These choices reflect the requirement to include encoders of different sizes, considering the size as the number of training parameters of the model. All the encoders have been initialized with pretrained weights from the ImageNet dataset (Deng et al. 2009). The use of pretrained deep neural networks usually improves the performance and generalization capacity. The main reason is that they use previously acquired knowledge related to high and low-level features (edges, textures) that are useful for many computer vision tasks, such as the identification of galaxy truncations.
AAs are represented as different images generated for each galaxy, as explained in the Sect. 2. The simplest solution to combine the AAs in the training phase is to concatenate the generated images in some dimension of the input tensors. However, in this work, we decide to exploit the concept of grouped convolutions as a way to solve the problem. Grouped convolutions were primarily introduced in Krizhevsky et al. (2017), as part of the well-known AlexNet architecture, with the main objective of reducing memory needs during training. However, further studies showed that grouped convolutions have a clear advantage in improving the representation of the training data than classical convolutions, as for instance in Xie et al. (2017). Therefore, in this work, grouped convolutions on the different inputs are used to extract independently the most relevant spatial information from each image and, subsequently, a second network (U-Net with pre-trained encoder) is used to estimate the galactic truncations from all this information (Fig. 2).
3.2 Hyperparameters and training specifications
In order to estimate the true error rate of the DL methods, we split the original dataset into two subsets, training and test, using the hold-out technique. The number of observations making up the training set is 952, while the number of instances reserved for the test set is 100. Furthermore, the training set is divided into two subsets, training and validation, based on a proportion of 80 and 20%, respectively. The validation set is used at the end of each epoch to assess learning and make decisions about training hyperparameters for the next epoch.
We train our DL models using a weighted categorical cross-entropy (CCE) loss function. Weights are necessary in order to counterbalance the strong imbalance of categories present in the images. Otherwise, there is a high risk that models only predict the noise category for each pixel, due to the high dominance of these pixels with respect to the ones representing the central galaxy. Weights for the loss function have been estimated empirically. Their values are ωn = 0.075, for the class representing noise, and ωg = 0.925, for the class representing the main galaxy. This way, hits and misses in pixels belonging to galaxies are weighted more heavily than in pixels belonging to noise. The batch size was set to 32, learning rate was fixed to 10−3, and the maximum number of training epochs is 1000. The Adam optimizer, from Kingma & Ba (2014), was used to update the networks' weights.
In order to mitigate the possible overfitting, which commonly occurs in the domain of deep convolutional neural networks, three regularization techniques were used: data augmentation, early stopping, and ridge penalty. For data augmentation each training image, before being introduced into the network, is randomly rotated 0°, 90°, 180°, or 270° and, once this transformation is applied, the image is randomly kept without further changes, mirrored around the abscissa axis or mirrored with respect to the ordinate axis. Thus, there are 11 possible combinations that induce images different from the original one, making it much more difficult for the network to memorize the training examples. After this process, random noise from a normal distribution is added to each training example. The noise added to each image comes from a normal distribution with μ = 0 and σ chosen randomly (0.01, 0.05, or 0.1) for each electromagnetic band of each image.
The second regularization technique is the selection of the model that maximizes the performance over the validation set, which is very similar in interpretation to early stopping. Finally, ridge regularization, also known as l2 or the Tikhonov regularization, is used. This technique, originally presented in Hoerl & Kennard (1970) for a linear regression problem, imposes a penalty on the estimated model coefficients. This way, when applied to a DL optimization problem, a penalty is added to the loss function. Equation (1) shows the application of the technique, where J(y, hθ(x)) represents the traditional loss function between the labels (y) and the model outputs (hθ (x)) and 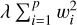 represents the penalty (sum of the squared model weights driven by a λ penalty factor). The effect of applying this technique is to reduce proportionally the value of all the model's weights, without reducing them to zero. The result is that the flexibility of the relationship between the model predictions and the target variable is reduced, acting as a powerful technique for avoiding overfitting.
represents the penalty (sum of the squared model weights driven by a λ penalty factor). The effect of applying this technique is to reduce proportionally the value of all the model's weights, without reducing them to zero. The result is that the flexibility of the relationship between the model predictions and the target variable is reduced, acting as a powerful technique for avoiding overfitting.
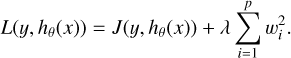 (1)
(1)
For the performance evaluation of the model we used three metrics: precision, recall, and Sørensen-dice or dice coefficient (Eq. (2)), also known as ℱ1 score in some contexts. We did not use a pixel-level hit rate because it is not sensitive to the cost of misclassification. The dice coefficient takes into account the cost of misclassification and adapts to the imbalance present in the images. It represents the harmonic mean between the precision, which measures the influence of false positives, and the recall, which measures the influence of false negatives. A perfect precision could be achieved by correctly predicting a single pixel as a galaxy, predicting all other pixels as noise. A perfect recall could be achieved by predicting all pixels in the image as a galaxy. Therefore, it is necessary to perform a weighting of both metrics. The harmonic mean, being more demanding and pessimistic than its arithmetic and geometric counterparts, guarantees that it accurately reflects the quality of the results obtained by our DL models.
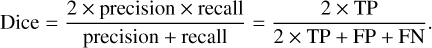 (2)
(2)
Results for the base experiment.
4 Segmentation results
This section shows the results obtained with the different DL models trained according to the specifications described in the Sect. 3. All the results shown in this section have been obtained on the test set of galaxies. This set consists of 100 randomly chosen galaxies representative of the whole dataset and which have not been used during the training phase. First of all, the different encoders without AAs are evaluated in order to check the feasibility of our proposal. Next, the impact of the AAs is evaluated and a complete analysis of the best performing model is carried out. Finally, the results of a complete ensemble analysis are shown.
4.1 Base experiment
The base experiment uses the seven models and the training specifications described in Sects. 3.1 and 3.2 without applying AAs, that is, the training is done with the images of galaxies formed by the H, J, and I bands. Table 1 shows dice, precision, and recall for each of the seven encoders embedded in the U-Net's backbone. The general trend reveals that recall is higher than precision for all experiments. This behavior indicates that networks tend to give slightly optimistic estimates of galaxy size, placing the truncations further away from the center of the galaxy than they actually are. The high value for recall shows that the vast majority of the image regions belonging to the galaxies of interest are correctly inferred, however, the slightly lower value of precision shows that there are areas outside the galaxy that have been incorrectly labeled. The dice index shows reasonably good segmentation qualities (>0.88 for all encoders), oscillating narrowly between the different schemes. The worst value is reached by the Efficient-B2 encoder, and the best one is reached by DenseNet-161.
Results with AAs over the test sample.
 |
Fig. 3 Learning curves showing the loss evolution over train and validation datasets of some DL configurations using the base scheme (a) and different AAs (b, c, d, e). |
4.2 Other experiments: Effects of AAs
In this section, we analyze the variability induced in the learning process by the introduction of the different AAs which are classified into four groups: (1) the visual group is made up of RGB files created with the four possible combinations of filters V, I, J, and H, always assigning the bluer channels to shorter wavelength bands (IJH, VIJ, VIH, and VJH). In other words, the visual group is formed by the base experiment plus the images formed by the VIJ, VIH and VJH combinations; (2) the color group is composed of the visual group to which six images are added, each one created by each of the six possible colors (g-i, g-r, g-z, i-z, r-i, and r-z); (3) the sloan group is formed by the visual group plus eight images formed both by the combination of the SDSS filters ordered by wavelength (gri, giz, riz, and grz) and by each of the filters individually (g, r, i, and z); (4) finally, the mass group is formed by the visual group together with the mass image.
Table 2, analogous to Table 1, shows results over the test set in terms of dice, precision, and recall indicators per encoder embedded in the U-Net's backbone and AA (visual, mass, color, and sloan). All average values of the dice coefficient are higher than in the base experiment case, showing that the introduction of the AAs leads to an improvement in the performance of the DL models. The average recall takes lower values with AAs compared with the base experiment. However, having obtained higher mean dice values means that the precision values have to rise considerably. This behavior could suggest that the estimates of the truncations with AAs are somewhat more conservative, placing them closer to the centre of the galaxy than in the case of the base experiment. In other words, AAs cause a substantial decrease in the number of image regions misdetected as galaxy, maintaining a very good proportion of pixels correctly categorized as a galaxy, leading to a marked improvement in the overall quality of the inferences.
According to the results shown in Table 2, mass (visual+mass) displays the best results, visual ranks second, while color and sloan have the worst results. Given that both color and sloan include visual augmentations, it may be assumed that these two sets of images do not improve the accurate prediction of truncations by DL models. In any case, the performance offered by all configurations, regardless of the inputs or architectures used, is remarkably uniform. None of the experiments obtained notably worse results than the rest. All configurations produce quality results, which are product of a stable training. This is illustrated in Fig. 3, which shows the evolution of the loss over the epochs on the training and validation datasets. Five combinations of DL models and AAs representative of the general behavior have been selected. It can be seen that the learning patterns are consistent and do not show large oscillations. Moreover, there is no obvious overfitting, which is evidence of a good convergence towards optimal models. This provides evidence of stable training processes and, therefore, quality of results across all AAs and architectures.
Nevertheless, beyond the fact that some AAs induce better or worse results, the variability and singularities they introduce in the training process can be used a posteriori to build a democratic system that takes advantage of the majorities. It would therefore be interesting to demonstrate statistically that the different AAs influence the learning process (and, thus, the performance) of the different U-Nets. In order to demonstrate this assertion, we carried out a Friedman two-way analysis of variance by ranks non-parametric test, as used in Sheskin (2000). To this end, we transformed the dice results obtained over the test set in Table 2 into a rank-order format for each model, as can be seen in Table 3, having n = 7 experiments and k = 5 experimental conditions in which every experiment is assessed.
![Mathematical equation: $\chi _r^2 = {{12} \over {nk\left( {k + 1} \right)}}\left[ {\sum\limits_{j = 1}^k {{{\left( {\sum\limits_{j = 1}^n {{R_{i,j}}} } \right)}^2}} } \right] - 3n\left( {k + 1} \right) = 11.4286.$](/articles/aa/full_html/2024/03/aa47216-23/aa47216-23-eq6.png) (3)
(3)
The null hypothesis represents the absence of a significant difference between any of the k = 5 population medians. To reject the null hypothesis the computed value 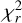 (see Eq. (3)) must be equal to or greater than the tabled critical chi-square value at the prespecified level of significance, 5% in this work, with k − 1 degrees of freedom (d.o.f.). For d.o.f. = 4, the reported critical 5% chi-square value is 9.4877. Since the computed value
(see Eq. (3)) must be equal to or greater than the tabled critical chi-square value at the prespecified level of significance, 5% in this work, with k − 1 degrees of freedom (d.o.f.). For d.o.f. = 4, the reported critical 5% chi-square value is 9.4877. Since the computed value 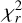 is greater than the chi-square value, the alternative hypothesis is supported at the prespecified level, showing that training with different AAs influence the U-Nets performance for at least two of the five experimental conditions.
is greater than the chi-square value, the alternative hypothesis is supported at the prespecified level, showing that training with different AAs influence the U-Nets performance for at least two of the five experimental conditions.
To find out which of the AAs are significantly different from each other, it is necessary to conduct comparisons contrasting specific AAs between them. For this purpose, several sources (Daniel 1990; Siegel & Castellan 1988) describe a comparison procedure based on the application of the Bonferroni-Dunn method. Using Eq. (4), we can compute the minimum required difference (designated as CDF) between the sums of the ranks of any two AAs at the prespecified level of significance (5% in this work):
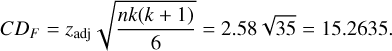 (4)
(4)
When comparisons are not planned beforehand, the zadj value of Eq. (4) can be established by dividing the maximum tolerated familywise Type I error by the total number of comparisons conducted (see Sheskin 2000). In this case, the error is 5% and the total number of comparisons to be performed is 10, giving the quotient of both 0.005 (directional hypothesis). In the table of the normal distribution, the z value that corresponds to that quotient is 2.58. Therefore, the significant comparisons are those whose ranks differences are equal to or greater than the value computed in Eq. (4). The significant comparisons found are highlighted in green in Table 4. Thus, we can state that there is a significant difference between the results of the U-Nets when using base and mass AAs and when using sloan and mass AAs. Once it can be concluded that learning processes differ due to the introduction of the AAs, we can take advantage of this variability to develop the concept of democratic ensemble learning in Sect. 4.5.
Notes. Green rows show the significantly different AAs.
Rank-ordered results for AAs.
4.3 Best model performance
This section shows the results obtained by the best performing model, that is, the one using a DenseNet-201 neural network as encoder and trained with visual astronomical augmentations. We isolated the performance of the model in terms of different characteristics into which the test sample can be grouped. Specifically, these characteristics are the galaxy morphology (DISK, DISKIRR, and DISKSPH), the exposure field (EGS, GOODSN, COSMOS, UDS, and GOODSS), the redshift and the size. Figure 4 shows the results in terms of dice, precision and recall estimators. Figure 5 shows the precision-recall (P-R) curves. We did not use ROC curves due to the imbalance of our data. Each P-R curve includes both the point where the 0.5 threshold is located (the one used to give a binary classification between galaxy and noise) and the point where the optimal dice index is reached. The results show that the morphological type for which the worst performance is obtained is DISKSPH, as expected given of the fuzzier nature of these objects (Fig. 4a). Ultimately, the DISK and DISKIRR morphologies perform best. Differences between precision and recall are much more marked for the DISKIRR morphology than for the DISK. This indicates that the estimated truncations are much more balanced in the latter case, leading to a higher number of false positives for DISKIRR galaxies. In any case, the results obtained on DISKIRR galaxies are highly valuable. The reason is that this morphology is characterized by the presence of asymmetric features (Huertas-Company et al. 2015b), which makes the precise estimation of its edges more challenging than for DISK-type galaxies. Although the dice index for the 0.5 threshold is higher for the DISKIRR morphology, the quality over the whole spectrum of thresholds is higher for inferences of DISK galaxies, as can be seen in Fig. 5a. For all morphologies, all thresholds that induce an optimal dice index are greater than 0.5. This may indicate that the model is overconfident, and it is necessary for the network to have a high certainty that a pixel belongs to the galaxy class.
Assessing the metrics by field of exposure (Fig. 4b), the performance is very similar for all of them except for the GOODSS field where we retrieve the worst values. The images in this field are, on average, the deepest (i.e., with the least noise) that we are analyzing. Therefore, our network better discerns the central galaxy from any other neighbor, and so our network becomes more conservative in detecting pixels belonging to the central body. This leads to a smaller recall, which, in turn, produces a reduction in the dice index. Looking at the P-R curves (Fig. 5b), it has been observed that the threshold inducing an optimal dice coefficient is higher than 0.5 for EGS, GOODSN, COSMOS, and UDS. However, in the case of GOODSS, this threshold is below the threshold used for binary classification. This result suggests that while the model exhibits a high level of confidence, with respect to the first fields it is cautious when categorizing pixels as galaxies in the GOODSS field. This may be another reason that explains the worse behavior of the model on the GOODSS field than on the rest of the fields.
There is no marked variation in the quality of the estimated truncations for the different redshift values (Fig. 4c). The dice index does not decrease uniformly as galaxies become more distant, which is reasonable considering the high quality of the whole data sample for all redshifts. Nevertheless, it can be seen that the trends in precision and recall are opposite. While the former increases along with the redshift, the latter gradually decreases. This means that as galaxies become more distant, the DL model infers masks with fewer false positives and more false negatives, namely, the truncations are tighter, but some areas that are actually galaxies are not detected as such. To explain this, it should be noted that the higher the redshift, the higher the effect of the cosmological dimming decreasing the contrast between galaxy and background noise pixels, thereby making the 2D galaxy surface brightness profiles appear fainter. Consequently, the number of false positive pixels is progressively smaller and thus increasing the precision. The P-R curves and their inner area also reflect the same results for the different redshift levels (Fig. 5c). Similar to what was observed for the different morphologies, all thresholds inducing an optimal dice index are greater than 0.5, suggesting some overconfidence.
Finally, when the results are analyzed by galaxy size, it can be found that the performance varies considerably (Fig. 4d).
The pattern seems to indicate that, on average, the dice index improves with increasing galaxy size. Furthermore, while the recall evolution appears to be slightly more stable, the main improvement lies in the precision. One of the possible reasons may be that as a galaxy gets larger, it is easier for the DL model not to make false positive errors, which leads to an increase in the precision. For very large galaxies (Q5) the results worsen. This may be because in such galaxies, the amount of noise that appears in the stamp is very small, with most of the image occupied by the galaxy and the galaxy-noise transition. As a result, it is more difficult for the model to locate the truncation and the performance worsens. The information provided by the P-R curves aligns with this pattern, as galaxies of larger sizes consistently yield to better results when using different thresholds (Fig. 5d). Again, all thresholds inducing an optimal dice index are greater than 0.5, reflecting the ease of the model to be very confident in its predictions about the galaxy class.
Figure 6 shows the most and least accurate inferences by galaxy morphology. From the first row to the last one, it can be appreciated the images, the superimposed real and predicted masks, the residuals and the superimposed real and predicted truncations. For the masks, true positives, false positives and false negatives are represented by yellowish, reddish, and greenish tones, respectively. The information provided by the residuals is richer. Reddish tones represent those areas where the real mask is 0, greenish tones represent those areas where the real mask is 1 and black tones indicate residuals very close to 0, that is, there are almost identical behaviors seen between the predictions and labels. Analyzing the best cases (Fig. 6a) it can be seen that for the three types of morphologies, the predictions reveal a high degree of similarity with respect to the ground truths (dice >0.94). Regarding the masks, reddish and greenish tones are barely visible, leading to very high values of both precision and recall. Concerning the residuals, it can be seen that the largest ones (less dark colors) appear in the boundary regions of the galaxies, that is, the zones close to the truncation. This event reflects that the model has more doubts about the category of these pixels, which is a desirable behavior. For the worst cases (Fig. 6b), the neural network infers the shape of the truncation remarkably well. However, the penalty suffered in the dice index is caused by an optimistic estimation of the limits. This can be easily seen by analyzing both the overlap of the masks and the residuals. For the former, reddish tones predominate around the yellowish areas, causing an increase in the number of false positives and penalizing the precision. For the latter, residuals in bright red clearly indicate an overconfidence of the model about the presence of galaxy, estimating much larger truncations than those reflected in the masks.
Lastly, we trained this best performance model with the final masks in Buitrago & Trujillo (2024) as explained toward the end of Sect. 2. The numbers are very similar to those already quoted in the paper: the mean dice is 0.8933, the mean precision is 0.8685, and the mean recall is 0.9411. We also conducted this experiment with other architectures and AAs. The outcome of all these tests is that there is not a substantial change by using or not these new labels, reassuring us of the stability of our results.
 |
Fig. 4 Metrics over the test set by galaxy morphology (a), field of view (b), redshift (c), and size (d) for our best performing model. The first plot a shows mean dice, precision, and recall for DISKIRR, DISKSPH, DISK, and all morphologies. The second plot b displays the same metrics for all our galaxy fields, namely EGS, GOODSN, COSMOS, UDS, and GOODSS. The third and fourth plots shows the same metrics for the five redshift bins and the five size quintiles the galaxy sample is split into. |
 |
Fig. 5 Precision-recall curves, along with the area under the curves (AUC), over the test set by galaxy morphology (a), galaxy field (b), redshift (c), and size (d). The categories for each plot are the same as in Fig. 4. The dot symbol represents the location of the threshold 0.5 (the one used for binary classification). The star symbol shows the optimal threshold that maximizes the dice index. |
 |
Fig. 6 Greatest (a) and least (b) accurate inferences by morphology for the best-performing model on the test dataset. First row shows the images of the galaxies. Second row displays the overlap of the predicted and real masks, where yellow, red and green zones represent true positives, false positives, and false negatives, respectively. The third row shows the residuals, where reddish and greenish tones represent negative and positive residuals, and the value (from light to dark) indicates their magnitude (from higher to lower). The last row shows the predicted and real truncations superimposed on the images. |
4.4 Prioritizing boundary proximity: A close look at edge-aware loss functions
The DL models presented so far have been optimized using a loss function that equally weights all pixels belonging to the same class (ωg = 0.925 for galaxy class and ωn = 0.075 for noise class). Thus, a pixel located at the center of the galaxy will have the same importance as a pixel placed just inside the truncation. Similarly, a noise pixel that is far away from the central body will be worth the same as a noise pixel just outside the truncation. This situation might potentially induce the network to minimize the loss by focusing its attention on those areas that are easy to learn, so that precise behavior is not necessary in the most doubtful areas to categorize (those close to the truncations). In order to overcome this situation, in this section we explore the performance of some loss functions that aim to ensure that DL models give more importance to those regions that are close to the boundaries of the galaxies.
We propose to use a variant of the CCE loss, where the weighting is performed per pixel rather than per class. Two different formulas are suggested for assigning the weight of each pixel. The first one (Pixel-CCE1 from now on) is in Eq. (5), where d((i, j), c) represents the Euclidean distance from the pixel (i, j) to the point c, while C represents the set of all pixels that make up the truncation contour and α acts as a weighting factor. This factor marks the weight intensity in the neighboring areas of the truncation compared to the more distant zones, as can be seen in (Fig. 7). Weights belonging to the internal and external parts of the truncation are scaled independently.
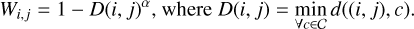 (5)
(5)
The second one (Pixel-CCE2 hereafter) is in Eq. (6). The terms d((i, j), c) and C have the same meaning as in the previous equation, while δ acts as an offset. That offset determines how broad the truncation-surrounding area that is highly weighted is (Fig. 7).
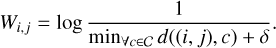 (6)
(6)
In order to assess the performance of the presented loss functions, we used the configuration that yielded the best-performing model (DenseNet-201 encoder with visual AAs). We trained the model using different configurations for both pixel CCE approaches. In the first case, we launched six experiments, varying the values of the hyperparameter α. In the second case, we ran nine experiments, using different values for the hyperparameter δ. The results obtained on the test set can be seen in Table 5. In the case of pixel-CCE1, none of the six configurations obtained a better dice index than the obtained using class-CCE. For pixel-CCE2, two of the nine configurations were able to improve the results. In both cases, and for all configurations tested, no clear pattern is observed indicating that these functions are a better alternative to class-CCE. When the pixel-CCE1 α hyperparameter increases, the results seem to worsen markedly. This suggests that excessive weighting of the zones adjacent to the truncation, in relation to the rest of the parts, leads to a decrease in performance. On the other side, when the pixel-CCE2 δ hyperparameter is varied, the results do not appear to follow a linear trend. The only two configurations that lead to better results than class-CCE are achieved with δ = 0.9 and δ = 1.7. However, the intermediate values between these deltas show an oscillating and irregular behavior.
Although the average performance of both losses does not seem to improve the behavior of class-CCL, sometimes their use may be worthwhile. In Fig. 8, we illustrate a significant example of the difference between the different loss functions. We chose two representative galaxies from the test dataset in which differences between the approaches can be seen. It can be observed the probability maps obtained by class-CCE and by all the tested pixel-CCE1 and pixel-CCE2 variants. In the first case (Fig. 8a), we can notice the presence of a foreign body on the right side of the galaxy. In the respective mask, it can be seen the impact this object has on the truncation. The class-CCE configuration reflects some doubt about whether that zone should be categorized as a main galaxy or as noise (yellowish tones). However, several pixel-CCE1 (α = 1 , 2, 3 , 4) and pixel-CCE2 (δ = 0.5, 0.7, 1.1, 1.3, 1.5, 1.9) configurations reflect more clearly the notion that this zone is not a central galaxy and it corresponds to noise (blue-greenish and bluish colors). Furthermore, although it does not appear to affect the truncation since it is more distant, the galaxy also has a neighboring object on its left side. The class-CCE configuration interprets this object as an obvious area of noise (very dark blue tone), which does not impact the shape of the truncation. However, certain configurations (primarily pixel-CCE1 with α = 2, and to a lesser extent pixel-CCE1 with α = 3,5 and pixel-CCE2 with δ = 0.7, 0.9, 1.7) seem to be more sensitive to this object, reflecting lower probabilities of belonging to the central galaxy and thus affecting the shape of the truncation. This behavior leads to a decrease in performance, in terms of the dice coefficient, which is due to the absence of this object in the mask and this may prove more interesting and reliable when estimating truncations in images with numerous clustered bodies. In the second case (Fig. 8b), the galaxy also has a neighboring object, this time in the upper-left part. This object affects its boundaries and, consequently, the shape of its truncation. Once again, the probability map provided by Class-CCE is uniform in that area and is not affected by the presence of the object. However, several configurations of the edge-aware alternatives (primarily pixel-CCE1 with α = 2, 3, 4, 5, 6 and pixel-CCE2 with δ = 0.5) detect the presence of this object. Consequently, they give much lower probabilities of galaxy membership (greenish tones) to the pixels in that area. In a general sense (for both galaxies), it can be observed that for the majority of configurations, edge-aware alternatives produce probability maps that are less pronounced. This can be verified by observing fewer sharp transitions between intense reddish areas and dark blue areas. More uncertainty may be beneficial in situations where a range of predictions needs to be considered, ranging from scenarios where high confidence in the pixels being galaxies is required (resulting in smaller truncations) to scenarios where greater flexibility in dealing with model false positives is allowed (resulting in more lenient truncations).
 |
Fig. 7 IJH image with its associated mask (left) and different weight matrices using the pixel-CCE1 (center) and pixel-CCE2 (right) losses. |
Results over the test set using the edge-aware loss functions and the encoder DenseNet-201 with visual AAs.
 |
Fig. 8 Probability maps obtained by class-CCE, pixel-CCE1 and pixel-CCE2 losses for two galaxies (a, b) of the test set. Dark red tones show confidence values close to 1 (high probability of galaxy), while dark blue tones reflect values close to 0 (high probability of noise). |
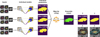 |
Fig. 9 Designed ensemble architecture. Predictions from the individual models are combined using a majority vote criterion to provide a final output. |
 |
Fig. 10 Metrics summarizing the behavior of the ensembles. The left plot a shows the sorted dice index values for all built ensembles. The right plot b displays, for each AA, the average dice index of all assemblies in which that AA participates at least one time. |
4.5 Approaching human expert behavior via democratic ensemble learning
In this section, the use of ensemble learning is proposed in order to improve the quality of the segmentation performed by DL models. Ensemble learning combines more than one base algorithm to obtain, through an aggregation mechanism, a unitary prediction. Intuitively, decision-making improves when diverse opinions are contrasted. Thus, the algorithms to be combined need to be diverse, that is, they need to make errors on different instances. The experimental grid, in which different AAs are combined with different encoders, results in the derivation of highly diverse models. Therefore, the 35 segmentation networks that have been presented throughout the work are used as the base algorithms. To keep the computation within reasonable limits, it was decided to combine the base models in groups of three. This gives rise to 6545 unique ensembles, which are combined by the democratic criterion of the majority vote (mode), as can be seen in Fig. 9 We note that this way of aggregating predictions forces to take an odd number of base models to form the ensemble.
In the Fig. 10a, it can be seen how 64.75% of the constructed ensembles exceed the highest dice index obtained with any of the individual models (namely DenseNet-201 trained with visual AAs). These data show the effectiveness of the ensemble learning approach to approximate human behavior in finding the galaxy truncations. In fact, the approach can be linked to the creation of a committee of expert astronomers in which the opinion of the majority prevails. The best configuration found is made up of the models EfficinetNet-B6, ResNet-18, and DenseNet-161, all of them trained with mass-type AAs, reaching a dice index of 0.9104, a precision of 0.9016, and a recall of 0.9353. On the other hand, Fig. 10b shows that the AA that induces, on average, ensembles with a higher dice index is mass. The visual, color, and sloan type AAs (in that order) are placed later. At the end, we have the ensembles consisting of at least one base model. In order to quantify the improvement caused by the participation of each AA in the ensemble, we order the results from lowest to highest (base < sloan < color < visual < mass) and compute the improvement ratio caused by each AA. This way, the sloan improvement over base is 1.1 per ten thousand, the color improvement over sloan is 3.3 per ten thousand, the visual improvement over color is 2.2 per ten thousand, and the mass improvement over visual is 1.8 per thousand. The improvement induced by the mass-type AA is one order of magnitude greater than any of the other improvements, which indicates that this type of AA is clearly the one that induces the best performance. These results are coherent with those shown in the Sects. 4.1 and 4.2.
Analogously to the best individual model, Fig. 11 shows the dice, precision, and recall estimators by galaxy morphology, field of view, redshift, and size for the best ensemble configuration. In order to simplify comparisons with the best individual model, its results have also been plotted in Fig. 11 with dashed more-transparent lines. Analyzing the morphology, in terms of the dice index, DISK performs the best, followed by DISKSPH and DISKIRR, respectively. It is worthwhile to analyze the oscillation of precision and recall for the different morphologies. In the case of DISK and DISKSPH, the recall is higher than the precision, however, for DISKIRR the opposite happens. The inferred masks for DISKIRR type galaxies show far fewer false positives than for the other morphologies, while the inferred masks for DISK and DISKSPH type galaxies show fewer false negatives. Comparing the results with those of the best single model, the main change occurs over DISKIRR galaxies. While the individual model had a high recall and a lower precision, the ensemble model greatly increases the recall and decreases the precision. This means that the truncations offered by the ensemble for these types of galaxies are much more optimistic than those offered by the individual alternative. For DISKSPH and DISK type galaxies, the ensemble improves the results proportionally, improving both precision and recall. Regarding the field of view, UDS achieves the best results, as already found for the best individual model in Sect. 4.3. Similarly, the worst performance is also obtained for the GOODSS type galaxies. GOODSN, COSMOS, and EGS are in the mid-range, with a dice index that goes from best to worst, respectively. While for the GOODSN, COSMOS, and GOODSS fields, the recall is much higher than the precision, for the EGS and UDS fields, the predictions are much more balanced in terms of false positives and negatives. Performance, as in the case of the best single model, shows signs of invariance to redshift. Again, the precision seems to increase as the galaxies become more distant, while the recall decreases. In terms of size, the conclusions are similar to the case of the best individual model. The best results are achieved for medium-size galaxies (in the third and fourth quintiles). For the smallest and largest galaxies, lower quality inferences are obtained.
In order to explore the performance of ensemble learning when combining more than three models, we have selected some relevant cases. The results can be seen in Table 6. First, we built the ensembles consisting of all the models that have been trained with the same astronomic augmentation (Table 6a). Thus, for each AA, the results of the seven encoders were combined. The results are consistent with those obtained in Tables 1 and 2. The best ensemble is the one that uses all seven encoders trained with mass-type AAs. The worst results were still obtained when no AA is used (base case). Between them, ranked from best to worst, we have: visual, color, and sloan AAs. Nevertheless, all five ensembles improve the results of the best individual model, showing the ability of this technique to enhance and complement the results of models that make diverse errors. We have also calculated the ensemble consisting of all available individual models (35). Although the result is excellent, achieving a dice of 0.9054 and surpassing the best individual model, it does not overcome the best ensemble formed by three models (dice of 0.9104). In order to explore more possibilities, we also constructed the ensembles formed by all the models using the same encoder (Table 6a). Thus, for each encoder, the five versions that have been trained using different AAs are combined. All ensembles, except the one formed by the EfficientNetB2 encoder, outperform the best single model. The best results are obtained by DenseNet encoder ensembles (DenseNet201 and DenseNet161), followed by the ResNet ones (ResNet18 and ResNet50) and, finally, by the EfficientNet ones (EfficientNetB1, EfficientNetB6, and EfficientNetB2).
Appendix A shows the truncations predicted by the best combination of ensemble learning for the 100 galaxies in the test set.
 |
Fig. 11 Metrics over the test set by galaxy morphology (a), field of view (b), redshift (c), and size (d) for the best ensemble configuration. The categories for each plot are the same as in Fig. 4. Dashed (more transparent) lines show the results for the best individual model. |
Metrics over the test set obtained by the ensembles, grouping the individual models by AA (a) and by encoder (b).
5 Conclusions
Galaxies are thought to be diffuse objects without clear borders and, as a result, their nature impedes measurements of physically motivated galaxy sizes. However, LSB observations have shown that galaxy outskirts display sudden drops in their mass density profiles, which also display a counterpart in their surface brightness profiles. These features, which trace a perimeter much closer to our intuitive idea of the end of a galaxy, are linked with the radial location of the gas density threshold enabling star formation and actually produce size-related scaling relations with a much smaller scatter (Trujillo et al. 2020). Chamba et al. (2022) and Buitrago & Trujillo (2024) also identified them with the galaxy truncations detected from the seminal works by Piet van der Kruit (van der Kruit 1979). Current ultra-deep observations and next-generation synoptic telescopes will reveal these features for millions of galaxies. Because of the numerous pieces of evidence needed to derive the positions of these edges, and considering the inherent pattern-recognition nature of this problem, using DL (in general) and CNNs (in particular) appears to be the only way forward to address these measurements for the swarm of data to come in the near future.
Based on the detections of these edges or truncations for a sample of 1052 massive (Mstellar > 1010 M⊙) disk galaxies at zspec < 1.1 in the CANDELS fields (Buitrago & Trujillo 2024), we built a series of U-Nets that make use of convolutional neural networks as encoders. Our final objective is both to construct an algorithm able to detect efficiently these LSB features as well as understanding the best inputs to achieve our aims. This last point has to do with the fact that our neural networks do not only analyze the HST parent sample images, but they are also feed with ancillary data, namely, SDSS-restframe equivalent images, as well as color and mass images (see Sect. 2). In this way, we are providing the same information as the one given to humans when inferring the positions of these edges or truncations. We called these transformations of the original images "astronomic augmentations", as they are similar to standard machine learning augmentations, but they are based on our astronomical knowledge. All average values of the dice coefficient improve in comparison with those of the base experiment when making use of such "astronomic augmentations".
The several experiments that we carried out, namely, visual (HST RGB images), sloan (visual + SDSS bands and SDSS RGB images), color (visual + SDSS colors), and mass (visual + mass images), display an inherent variability in their outcome metrics for the various U-Net architectures we utilize (see Sect. 4 and Tables 1 and 2). This ensures that our neural networks learn in a different manner based on different inputs (see Sect. 3.1). Among all the AAs, the best results are recurrently obtained when using the mass-type ones, which actually makes physical sense as it is the channel that directly refers to the drop in the galaxies' stellar mass density profiles. Even though we highlight the best model performance (see Sect. 4.3), which we obtained for the encoder DenseNet-201 trained with visual AAs (dice: 0.8969, precision: 0.8863, recall: 0.9274; see Table 2), we want to emphasize that the best results are retrieved for ensembles where different neural networks democratically vote the best solution in a pixel-by-pixel mode (see Fig. 10). Using this method, 64.75% of the ensembles improve the highest dice value in comparison with our best individual model.
This best ensemble is the combination of EfficientNet-B6, ResNet-18, and DenseNet-161, all of them (very remarkably, as it is similar to what human astronomers need) trained with mass AAs. The metrics in this case are dice: 0.9104, precision: 0.9016, and recall: 0.9353. Finally, we also performed a series of tests checking our results versus morphological disk type, depth (i.e., galaxy field), redshift, and size, in order to ensure their robustness (see Sect. 4.3).
Galaxy edges or truncations will permit us to obtain physically motivated galaxy sizes for images fulfilling the adequate depth and data reduction requirements. Our study shows that ML is able to reach a similar performance to that of humans and it will be mandatory to apply this technique for the billions of galaxies and tens of thousands of square degrees to be imaged in the future. In addition, the extraction of these features could be beneficial to other studies of galaxy morphology, as they will help identify any excess of light in the galaxy outer parts, thus indicating the presence of stellar haloes or minor merging. In summary, analyses with state-of-the-art tools as the one we are presenting here, will pave the way for solidifying galaxy edges or truncations as a viable physically motivated proxy for galaxy sizes.
Acknowledgements
We acknowledge the referee for the insightful comments and feedback on the paper. We have used extensively the following software packages: TOPCAT (Taylor 2005), ALADIN (Bonnarel et al. 2000), SEGMENTATION MODELS (Iakubovskii 2019), MATPLOTLIB (Hunter 2007) and PYTORCH (Paszke et al. 2019). J.F. and F.B. acknowledge the support from the grant PID2020-116188GA-I00 by the Spanish Ministry of Science and Innovation, while F.B. also acknowledges PID2019-107427GB-C32. This work has made use of the Rainbow Cosmological Surveys Database, which is operated by the Centro de Astrobiología (CAB/INTA), partnered with the University of California Observatories at Santa Cruz (UCO/Lick,UCSC). Based on zCOSMOS observations carried out using the Very Large Telescope at the ESO Paranal Observatory under Programme ID: LP175.A0839. We also thank Jesús Vega-Ferrero, Ignacio Trujillo, Nushkia Chamba and Helena Dominguez-Sánchez for their advice.
Appendix A Test set inferences
Here, we present the inferences for all the galaxies in the test set (one row per galaxy) using the best ensemble configuration. The first column shows the RGB color image created from the concatenation of the I, J and H bands. The second one represents the overlap between the label and the output of the neural networks (true positives in yellow, true negatives in dark blue, false positives in red, and false negatives in green). The third column depicts the RGB image with the human-created (cyan) and the model-created (coral) truncations superimposed. The fourth column shows the output of the ensemble in a probabilistic way. Thus, the pixels represented in dark blue indicate that the three models that make up the ensemble have categorized them as noise. The violet pixels indicate that while two of the models have categorized them as noise, one has categorized them as a galaxy. Pixels represented in dark green indicate that while one model has categorized them as noise, two have categorized them as galaxies. Finally, the pixels represented in light green show total agreement for the categorization as a galaxy. Therefore, we note that the mask predicted by the ensemble corresponds with the area colored in light green plus the area colored in dark green.
 |
Fig. A.1 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 1 to 4 in the test set. |
 |
Fig. A.2 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 5 to 8 in the test set. |
 |
Fig. A.3 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 9 to 12 in the test set. |
 |
Fig. A.4 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 13 to 16 in the test set. |
 |
Fig. A.5 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 17 to 20 in the test set. |
 |
Fig. A.6 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 21 to 24 in the test set. |
 |
Fig. A.7 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 25 to 28 in the test set. |
 |
Fig. A.8 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 29 to 32 in the test set. |
 |
Fig. A.9 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 33 to 36 in the test set. |
 |
Fig. A.10 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 37 to 40 in the test set. |
 |
Fig. A.11 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 41 to 44 in the test set. |
 |
Fig. A.12 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 45 to 48 in the test set. |
 |
Fig. A.13 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 49 to 52 in the test set. |
 |
Fig. A.14 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 53 to 56 in the test set. |
 |
Fig. A.15 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 57 to 60 in the test set. |
 |
Fig. A.16 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 61 to 64 in the test set. |
 |
Fig. A.17 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 65 to 68 in the test set. |
 |
Fig. A.18 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 69 to 72 in the test set. |
 |
Fig. A.19 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 73 to 76 in the test set. |
 |
Fig. A.20 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 77 to 80 in the test set. |
 |
Fig. A.21 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 81 to 84 in the test set. |
 |
Fig. A.22 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 85 to 88 in the test set. |
 |
Fig. A.23 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 89 to 92 in the test set. |
 |
Fig. A.24 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 93 to 96 in the test set. |
 |
Fig. A.25 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 97 to 100 in the test set. |
References
- Akhlaghi, M. 2019, arXiv e-prints [arXiv:1989.11238] [Google Scholar]
- Akhlaghi, M., & Ichikawa, T. 2015, ApJS, 220, 1 [Google Scholar]
- Barro, G., Pérez-González, P. G., Cava, A., et al. 2019, ApJS, 243, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Beckwith, S. V. W., Stiavelli, M., Koekemoer, A. M., et al. 2006, AJ, 132, 1729 [Google Scholar]
- Bertin, E., & Arnouts, S. 1996, A & AS, 117, 393 [NASA ADS] [Google Scholar]
- Bonnarel, F., Fernique, P., Bienaymé, O., et al. 2000, A & AS, 143, 33 [NASA ADS] [Google Scholar]
- Borlaff, A., Trujillo, I., Román, J., et al. 2019, A & A, 621, A133 [Google Scholar]
- Buitrago, F., & Trujillo, I. 2024, A & A, 682, A110 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Buitrago, F., Trujillo, I., Curtis-Lake, E., et al. 2017, MNRAS, 466, 4888 [NASA ADS] [Google Scholar]
- Chabrier, G. 2003, PASP, 115, 763 [Google Scholar]
- Chamba, N. 2020, Res. Notes Am. Astron. Soc., 4, 117 [NASA ADS] [Google Scholar]
- Chamba, N., Trujillo, I., & Knapen, J. H. 2022, A & A, 667, A87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chen, L. C., Papandreou, G., Kokkinos, I., Murphy, K., & Yuille, A. L. 2018, EEE Trans. Pattern Anal. Mach. Intell., 40, 834 [CrossRef] [Google Scholar]
- Damjanov, I., Zahid, H. J., Geller, M. J., et al. 2019, ApJ, 872, 91 [NASA ADS] [CrossRef] [Google Scholar]
- Daniel, W. 1990, Applied Nonparametric Statistics, Duxbury Advanced Series in Statistics and Decision Sciences (Boston: PWS-KENT Pub.) [Google Scholar]
- Deng, J., Dong, W., Socher, R., et al. 2009, in IEEE conference on computer vision and pattern recognition, 248 [Google Scholar]
- Díaz-García, S., Comerón, S., Courteau, S., et al. 2022, A & A, 667, A109 [CrossRef] [EDP Sciences] [Google Scholar]
- Domínguez Sánchez, H., Huertas-Company, M., Bernardi, M., Tuccillo, D., & Fischer, J. L. 2018, MNRAS, 476, 3661 [Google Scholar]
- Duc, P.-A., Cuillandre, J.-C., Karabal, E., et al. 2015, MNRAS, 446, 120 [Google Scholar]
- Euclid Collaboration (Borlaff, A. S. P., et al.), 2022, A & A, 657, A92 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- González, R. E., Muñoz, R. P., & Hernández, C. A. 2018, Astron. Comput., 25, 103 [CrossRef] [Google Scholar]
- Grogin, N. A., Kocevski, D. D., Faber, S. M., et al. 2011, ApJS, 197, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Hausen, R., & Robertson, B. E. 2020, ApJS, 248, 20 [CrossRef] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2016, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770 [Google Scholar]
- He, T., Zhang, Z., Zhang, H., et al. 2019, IEEE/CVF Conf. Computer Vision Pattern Recognition, 2019, 558 [Google Scholar]
- He, K., Gkioxari, G., Dollár, P., & Girshick, R. 2020, IEEE Trans. Pattern Anal. Mach. Intell., 42, 386 [CrossRef] [Google Scholar]
- Hilz, M., Naab, T., & Ostriker, J. P. 2013, MNRAS, 429, 2924 [NASA ADS] [CrossRef] [Google Scholar]
- Hoerl, A. E., & Kennard, R. W. 1970, Technometrics, 12, 69 [CrossRef] [Google Scholar]
- Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. 2017, in IEEE Conference on Computer Vision and Pattern Recognition (CPVR), 2261 [Google Scholar]
- Huertas-Company, M., Gravet, R., Cabrera-Vives, G., et al. 2015a, ApJS, 221, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Huertas-Company, M., Pérez-González, P. G., Mei, S., et al. 2015b, ApJ, 809, 95 [NASA ADS] [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Iakubovskii, P. 2019, https://github.com/qubvel/segmentation_models.pytorch [Google Scholar]
- Illingworth, G., Magee, D., Bouwens, R., et al. 2016, arXiv e-prints [arXiv:1686.88841] [Google Scholar]
- Ivezic, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Kingma, D. P., & Ba, J. 2014, arXiv e-prints [arXiv:1412.6988] [Google Scholar]
- Kingma, D. P., & Welling, M. 2013, arXiv e-prints [arXiv: 1312.6114] [Google Scholar]
- Koekemoer, A. M., Faber, S. M., Ferguson, H. C., et al. 2011, ApJS, 197, 36 [NASA ADS] [CrossRef] [Google Scholar]
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. 2017, Commun. ACM, 60, 84 [CrossRef] [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, arXiv e-prints [arXiv:1118.3193] [Google Scholar]
- Lilly, S. J., Le Brun, V., Maier, C., et al. 2009, ApJS, 184, 218 [Google Scholar]
- Martín-Navarro, I., Bakos, J., Trujillo, I., et al. 2012, MNRAS, 427, 1102 [Google Scholar]
- Martín-Navarro, I., Trujillo, I., Knapen, J. H., Bakos, J., & Fliri, J. 2014, MNRAS, 441, 2809 [CrossRef] [Google Scholar]
- Martínez-Lombilla, C., Trujillo, I., & Knapen, J. H. 2019, MNRAS, 483, 664 [CrossRef] [Google Scholar]
- Mihos, J. C. 2019, arXiv e-prints [arXiv: 1989.89456] [Google Scholar]
- Nayyeri, H., Hemmati, S., Mobasher, B., et al. 2017, ApJS, 228, 7 [NASA ADS] [CrossRef] [Google Scholar]
- Oke, J. B., & Gunn, J. E. 1983, ApJ, 266, 713 [NASA ADS] [CrossRef] [Google Scholar]
- Paszke, A., Gross, S., Massa, F., et al. 2019, in Advances in Neural Information Processing Systems 32 (USA: Curran Associates, Inc.), 8024 [Google Scholar]
- Pulsoni, C., Gerhard, O., Arnaboldi, M., et al. 2021, A & A, 647, A95 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. 2015, arXiv e-prints [arXiv:1586.82648] [Google Scholar]
- Roediger, J. C., & Courteau, S. 2015, MNRAS, 452, 3209 [NASA ADS] [CrossRef] [Google Scholar]
- Ronneberger, O., Fischer, P., & Brox, T. 2015, Lect. Notes Comput. Sci., including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics (Berlin: Springer), 9351 [Google Scholar]
- Santini, P., Ferguson, H. C., Fontana, A., et al. 2015, ApJ, 801, 97 [Google Scholar]
- Schaye, J. 2004, ApJ, 609, 667 [NASA ADS] [CrossRef] [Google Scholar]
- Sérsic, J. L. 1968, Atlas de Galaxias Australes (Cordoba, Argentina: Observatorio Astronomico) [Google Scholar]
- Sheskin, D. J. 2000, Handbook of Parametric and Nonparametric Statistical Procedures, 2nd edn. (London: CHAPMAN & HALL/CRC) [Google Scholar]
- Siegel, S., & Castellan, N. 1988, Nonparametric Statistics for the Behavioral Sciences, McGraw-Hill international editions statistics series (USA: McGraw-Hill) [Google Scholar]
- Soria, X., Riba, E., & Sappa, A. 2020, in 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), 1912 [CrossRef] [Google Scholar]
- Stefanon, M., Yan, H., Mobasher, B., et al. 2017, ApJS, 229, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Straatman, C. M. S., van der Wel, A., Bezanson, R., et al. 2018, ApJS, 239, 27 [NASA ADS] [CrossRef] [Google Scholar]
- Takikawa, T., Acuna, D., Jampani, V., & Fidler, S. 2019, in IEEE/CVF International Conference on Computer Vision (ICCV), 5228 [Google Scholar]
- Tan, M., & Le, Q. V. 2019, in 36th International Conference on Machine Learning, ICML 2019 [Google Scholar]
- Taylor, M. B. 2005, ASP Conf. Ser., 347, 29 [Google Scholar]
- Trujillo, I., & Fliri, J. 2016, ApJ, 823, 123 [Google Scholar]
- Trujillo, I., Chamba, N., & Knapen, J. H. 2020, MNRAS, 493, 87 [NASA ADS] [CrossRef] [Google Scholar]
- van der Kruit, P. C. 1979, A & AS, 38, 15 [NASA ADS] [Google Scholar]
- van der Kruit, P. C., & Searle, L. 1981a, A & A, 95, 105 [Google Scholar]
- van der Kruit, P. C., & Searle, L. 1981b, A & A, 95, 116 [Google Scholar]
- van der Wel, A., Noeske, K., Bezanson, R., et al. 2016, ApJS, 223, 29 [Google Scholar]
- van der Wel, A., Bezanson, R., D'Eugenio, F., et al. 2021, ApJS, 256, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Vega-Ferrero, J., Domínguez Sánchez, H., Bernardi, M., et al. 2021, MNRAS, 506, 1927 [NASA ADS] [CrossRef] [Google Scholar]
- Walmsley, M., Smith, L., Lintott, C., et al. 2020, MNRAS, 491, 1554 [Google Scholar]
- Wu, H., Zhang, J., Huang, K., Liang, K., & Yu, Y. 2019, arXiv e-prints [arXiv:1983.11816] [Google Scholar]
- Xie, S., Girshick, R., Dollár, P., Tu, Z., & He, K. 2017, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 5987 [Google Scholar]
- Zhou, Z., Siddiquee, M. M. R., Tajbakhsh, N., & Liang, J. 2018, Lect. Notes Comput. Sci., including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics (Berlin: Springer), 11045 [Google Scholar]
Values taken from https://ned.ipac.caltech.edu/extinction_calculator
All Tables
Results over the test set using the edge-aware loss functions and the encoder DenseNet-201 with visual AAs.
Metrics over the test set obtained by the ensembles, grouping the individual models by AA (a) and by encoder (b).
All Figures
|
Fig. 1 Image-mask-truncation equivalence. Left: image created combining the V, I, and H bands. Center: associated segmentation mask, where the only active pixels are those belonging to the main galaxy. Right: determination of the truncation from the perimeter of the segmentation mask. Note: the jagged profile is due to the superposition of a neighboring galaxy. |
| In the text | |
|
Fig. 2 Example of the architecture designed for experiments with mass-type AAs. The architecture consists of two stages. In the first stage, grouped convolutions process each image in isolation and then a U-Net with a pre-trained encoder uses all the information from the different AAs to infer the truncations. |
| In the text | |
|
Fig. 3 Learning curves showing the loss evolution over train and validation datasets of some DL configurations using the base scheme (a) and different AAs (b, c, d, e). |
| In the text | |
|
Fig. 4 Metrics over the test set by galaxy morphology (a), field of view (b), redshift (c), and size (d) for our best performing model. The first plot a shows mean dice, precision, and recall for DISKIRR, DISKSPH, DISK, and all morphologies. The second plot b displays the same metrics for all our galaxy fields, namely EGS, GOODSN, COSMOS, UDS, and GOODSS. The third and fourth plots shows the same metrics for the five redshift bins and the five size quintiles the galaxy sample is split into. |
| In the text | |
|
Fig. 5 Precision-recall curves, along with the area under the curves (AUC), over the test set by galaxy morphology (a), galaxy field (b), redshift (c), and size (d). The categories for each plot are the same as in Fig. 4. The dot symbol represents the location of the threshold 0.5 (the one used for binary classification). The star symbol shows the optimal threshold that maximizes the dice index. |
| In the text | |
|
Fig. 6 Greatest (a) and least (b) accurate inferences by morphology for the best-performing model on the test dataset. First row shows the images of the galaxies. Second row displays the overlap of the predicted and real masks, where yellow, red and green zones represent true positives, false positives, and false negatives, respectively. The third row shows the residuals, where reddish and greenish tones represent negative and positive residuals, and the value (from light to dark) indicates their magnitude (from higher to lower). The last row shows the predicted and real truncations superimposed on the images. |
| In the text | |
|
Fig. 7 IJH image with its associated mask (left) and different weight matrices using the pixel-CCE1 (center) and pixel-CCE2 (right) losses. |
| In the text | |
|
Fig. 8 Probability maps obtained by class-CCE, pixel-CCE1 and pixel-CCE2 losses for two galaxies (a, b) of the test set. Dark red tones show confidence values close to 1 (high probability of galaxy), while dark blue tones reflect values close to 0 (high probability of noise). |
| In the text | |
|
Fig. 9 Designed ensemble architecture. Predictions from the individual models are combined using a majority vote criterion to provide a final output. |
| In the text | |
|
Fig. 10 Metrics summarizing the behavior of the ensembles. The left plot a shows the sorted dice index values for all built ensembles. The right plot b displays, for each AA, the average dice index of all assemblies in which that AA participates at least one time. |
| In the text | |
|
Fig. 11 Metrics over the test set by galaxy morphology (a), field of view (b), redshift (c), and size (d) for the best ensemble configuration. The categories for each plot are the same as in Fig. 4. Dashed (more transparent) lines show the results for the best individual model. |
| In the text | |
|
Fig. A.1 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 1 to 4 in the test set. |
| In the text | |
|
Fig. A.2 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 5 to 8 in the test set. |
| In the text | |
|
Fig. A.3 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 9 to 12 in the test set. |
| In the text | |
|
Fig. A.4 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 13 to 16 in the test set. |
| In the text | |
|
Fig. A.5 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 17 to 20 in the test set. |
| In the text | |
|
Fig. A.6 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 21 to 24 in the test set. |
| In the text | |
|
Fig. A.7 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 25 to 28 in the test set. |
| In the text | |
|
Fig. A.8 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 29 to 32 in the test set. |
| In the text | |
|
Fig. A.9 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 33 to 36 in the test set. |
| In the text | |
|
Fig. A.10 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 37 to 40 in the test set. |
| In the text | |
|
Fig. A.11 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 41 to 44 in the test set. |
| In the text | |
|
Fig. A.12 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 45 to 48 in the test set. |
| In the text | |
|
Fig. A.13 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 49 to 52 in the test set. |
| In the text | |
|
Fig. A.14 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 53 to 56 in the test set. |
| In the text | |
|
Fig. A.15 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 57 to 60 in the test set. |
| In the text | |
|
Fig. A.16 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 61 to 64 in the test set. |
| In the text | |
|
Fig. A.17 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 65 to 68 in the test set. |
| In the text | |
|
Fig. A.18 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 69 to 72 in the test set. |
| In the text | |
|
Fig. A.19 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 73 to 76 in the test set. |
| In the text | |
|
Fig. A.20 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 77 to 80 in the test set. |
| In the text | |
|
Fig. A.21 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 81 to 84 in the test set. |
| In the text | |
|
Fig. A.22 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 85 to 88 in the test set. |
| In the text | |
|
Fig. A.23 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 89 to 92 in the test set. |
| In the text | |
|
Fig. A.24 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 93 to 96 in the test set. |
| In the text | |
|
Fig. A.25 RGB images (first column), superimposed predicted and real masks (second column), superimposed predicted and real truncations (third column), and probabilistic ensemble outputs for galaxies 97 to 100 in the test set. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.