| Issue |
A&A
Volume 678, October 2023
|
|
|---|---|---|
| Article Number | A169 | |
| Number of page(s) | 10 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202347358 | |
| Published online | 18 October 2023 | |
COSMOGLOBE: Towards end-to-end CMB cosmological parameter estimation without likelihood approximations
1
Institute of Theoretical Astrophysics, University of Oslo, Blindern, Oslo, Norway
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Imperial Centre for Inference and Cosmology, Department of Physics, Imperial College London, Blackett Laboratory, Prince Consort Road, London SW7 2AZ, UK
3
Department of Physics, Indian Institute of Technology (BHU), Varanasi 221005, India
4
Dipartimento di Fisica, Università degli Studi di Milano, Via Celoria, 16, Milano, Italy
5
Instituto de Física, Universidade de São Paulo, 66318, CEP 05315-970, São Paulo, Brazil
6
Department of Physics and Astronomy, University of British Columbia, 6224 Agricultural Road, Vancouver, BC V6T1Z1, Canada
7
David A. Dunlap Department of Astronomy & Astrophysics, University of Toronto, 50 St. George Street, Toronto, ON M5S 3H4, Canada
8
Dunlap Institute for Astronomy & Astrophysics, University of Toronto, 50 St. George Street, Toronto, ON M5S 3H4, Canada
9
Waterloo Centre for Astrophysics, University of Waterloo, Waterloo, ON N2L 3G1, Canada
10
Department of Physics and Astronomy, University of Waterloo, Waterloo, ON N2L 3G1, Canada
11
Indian Institute of Astrophysics, Koramangala II Block, Bangalore 560034, India
Received:
4
July
2023
Accepted:
24
August
2023
Abstract
We implement support for a cosmological parameter estimation algorithm in Commander and quantify its computational efficiency and cost. For a semi-realistic simulation similar to Planck LFI 70 GHz, we find that the computational cost of producing one single sample is about 20 CPU-hours and that the typical Markov chain correlation length is ∼100 samples. The net effective cost per independent sample is ∼2000 CPU-hours, in comparison with all low-level processing costs of 812 CPU-hours for Planck LFI and WMAP in COSMOGLOBE Data Release 1. Thus, although technically possible to run already in its current state, future work should aim to reduce the effective cost per independent sample by one order of magnitude to avoid excessive runtimes, for instance through multi-grid preconditioners and/or derivative-based Markov chain sampling schemes. This work demonstrates the computational feasibility of true Bayesian cosmological parameter estimation with end-to-end error propagation for high-precision CMB experiments without likelihood approximations, but it also highlights the need for additional optimizations before it is ready for full production-level analysis.
Key words: polarization / cosmic background radiation / cosmology: observations
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
High-precision cosmic microwave background (CMB) measurements currently provide the strongest constraints on a wide range of key cosmological parameters (e.g., Planck Collaboration VI 2020). Traditionally, these constraints are derived by first compressing the information contained in the high-dimensional raw time-ordered data into pixelized sky maps and angular power spectra (e.g., Bennett et al. 2013; Planck Collaboration II 2020; Planck Collaboration III 2020). This compressed dataset is typically summarized in terms of a low-dimensional power spectrum-based likelihood from which cosmological parameters are derived through Markov chain Monte Carlo (MCMC) sampling (Lewis & Bridle 2002; Planck Collaboration V 2020).
A key element in this pipeline procedure is the so-called likelihood function, ℒ(Cℓ), where Cℓ denotes the angular CMB power spectrum (e.g., Planck Collaboration V 2020). This function summarizes both the best-fit values of all power spectrum coefficients and their covariances and correlations. The accuracy of the resulting cosmological parameters, both in terms of best-fit values and their uncertainties, corresponds directly to the accuracy of this likelihood function. As such, this function must account for both low-level instrumental effects (such as correlated noise and calibration uncertainties) and high-level data selection and component separation effects. In general, this function is neither factorizable nor Gaussian, and, except for a few well known special cases, it has no analytical exact and closed form. Unsurprisingly, significant efforts have therefore been devoted to establishing computationally efficient and accurate approximations. Perhaps the most well known example of this is a standard multivariate Gaussian distribution in units of the angular power spectrum of the sky signal, Cℓ, with a covariance matrix tuned by end-to-end simulations (e.g., Planck Collaboration V 2020). A second widely used case is that of a low-resolution multivariate Gaussian defined in pixel space with a dense pixel-pixel noise covariance matrix (Hinshaw et al. 2013; Planck Collaboration V 2020). Yet other examples include log-normal or Gaussian-plus-lognormal distributions (e.g., Verde et al. 2003), as well as various hybrid combinations (e.g., Gjerløw et al. 2013).
However, as the signal-to-noise ratios of modern CMB data sets continue to increase, the relative importance of systematic uncertainties grows, and they are often highly nontrivial to describe through low-dimensional and simplified likelihood approximations, both in terms of computational expense and accuracy. These difficulties were anticipated more than two decades ago, and an alternative end-to-end Bayesian approach was proposed independently by Jewell et al. (2004) and Wandelt et al. (2004). The key aspect of this framework is that the analysis is global, meaning all aspects of the data are modeled and fitted simultaneously, as opposed to compartmentalized, which is the more traditional CMB pipeline approach. Technically speaking, this is implemented in the form of an MCMC sampler in a process that is statistically analogous to the very last cosmological parameter estimation step in a traditional pipeline, such as CosmoMC (Lewis & Bridle 2002) or Cobaya (Torrado & Lewis 2021), with the one fundamental difference that all parameters in the entire analysis pipeline are sampled over jointly within the MCMC sampler. Thus, while a standard cosmological parameter code typically handles a few dozen, or perhaps a hundred, free parameters, the global approach handles billions of free parameters. One practical method of dealing with such a large number of parameters of different types is Gibbs sampling, which draws samples from a joint distribution by iterating over all relevant conditional distributions.
In principle, a global approach is preferable, since better results are in general obtained by fitting correlated parameters jointly rather than separately. However, and equally clearly, this approach is also organizationally and technically more complicated to implement in practice, simply because all aspects of the analysis have to be accounted for simultaneously within one framework. One example of this type of approach is Commander3 (Galloway et al. 2023), which is an end-to-end CMB Gibbs sampler developed by the BeyondPlanck Collaboration (2023) to reanalyze the Planck Low Frequency Instrument (LFI) observations. To date, using Gibbs sampling within this framework is the only way to sample over the entire joint distribution of low-level instrumental parameters, component maps, and cosmological parameters. This work was subsequently superseded by the COSMOGLOBE project1, which is a community-wide open science collaboration that ultimately aims to perform the same type of analysis for all available state-of-the-art large-scale radio, microwave, and submillimeter experiments to then use the resulting analysis to derive one global model of the astrophysical sky. The first COSMOGLOBE Data Release (DR1) was made public in March 2023 (Watts et al. 2023), and included the first joint end-to-end analysis of both Planck LFI and the Wilkinson Microwave Anisotropy Probe (WMAP; Bennett et al. 2013), resulting in lower systematic residuals in both experiments.
There are many other methods of Bayesian inference that can be used to estimate cosmological parameters from CMB maps. For example, Anderes et al. (2015) show how to efficiently sample the joint-posterior of the CMB lensing potential and sky map using Hamiltonian Monte Carlo techniques, and Carron (2019) created a framework to measure the tensor-to-scalar ratio using an approximate, analytic marginalization of lensed CMB maps. The marginal unbiased score expansion method has also been shown to be a powerful algorithm for high-dimensional CMB analyses (Millea & Seljak 2022).
The numerical challenges involved in implementing cosmological parameter estimation without likelihood approximations in Gibbs sampling were originally explored and partially resolved by Jewell et al. (2009) and Racine et al. (2016). A similar approach was taken by Millea et al. (2020), who derived a re-parameterization of the unlensed sky map and the lensing potential to improve the runtime of Gibbs sampling, similar to the method of Racine et al. (2016). This framework was later enhanced in Millea et al. (2021) to included several systematic parameters and was applied to SPTpol data.
In principle, each of the aforementioned methods could be used as the CMB map-to-parameter sampling step within a larger time-ordered-data-to-parameter end-to-end Gibbs sampler. The goal of this work is to focus on the algorithm of Racine et al. (2016) and implement it in Commander3. We will apply it to simulations with realistic noise and sky coverages, validate the implementation and evaluate its performance. Until now, the highest-level output from Commander3 has been the angular CMB power spectrum. With the code development that led to this paper, it is now technically able to also directly output cosmological parameters.
The rest of the paper is organized as follows. In Sect. 2 we provide a brief review of both the COSMOGLOBE Gibbs sampler method in general and the specific cosmological parameter sampler described by Racine et al. (2016). In Sect. 3 we validate our implementation by comparing it to two special cases, namely (i) Cobaya coupled to a uniform and (ii) full-sky case and a special-purpose Python sampler for a case with uniform noise but a constant latitude Galactic mask. We also characterize the computational costs of the new sampling step for various data configurations. Finally, we summarize and conclude in Sect. 4.
2. Algorithms
We start by briefly reviewing the Bayesian framework for global end-to-end analysis as described by the BeyondPlanck Collaboration (2023) and Watts et al. (2023) and the cosmological parameter estimation algorithm proposed by Racine et al. (2016), and discuss how these can be combined in Commander3 (Galloway et al. 2023).
2.1. Bayesian end-to-end CMB analysis
The main algorithmic goal of the COSMOGLOBE framework is to derive a numerical representation of the full posterior distribution P(ω ∣ d), where ω is the set of all free parameters and d represents all available data. In this notation, ω simultaneously accounts for instrumental, astrophysical, and cosmological parameters, which are typically explicitly defined by writing down a signal model, for instance taking the form
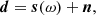 (1)
(1)
where d is the data vector; s(ω) represents some general data model with free parameters ω; and n is instrumental noise. In practice, one typically assumes that the noise is Gaussian distributed with a covariance matrix N, and the likelihood can therefore be written as
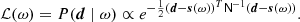 (2)
(2)
The full posterior distribution reads P(ω ∣ d)∝ℒ(ω)P(ω), where P(ω) represents some set of user-defined priors.
As a concrete example, COSMOGLOBE Data Release 1 (Watts et al. 2023) adopted the following data model for the time-ordered data to describe Planck LFI and WMAP,
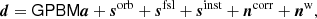 (3)
(3)
where G is a time-dependent gain factor; P is a pointing matrix; B denotes instrumental beam convolution; M is a mixing matrix that describes the amplitude of a given sky component at a given frequency; a describes the amplitude of each component at each point in the sky; sorb is the orbital CMB dipole; sfsl is a far sidelobe contribution; sinst is an instrument-specific correction term; ncorr denotes correlated noise; and nw denotes white noise. This expression directly connects important instrumental effects (e.g., gains, beams, and correlated noise) with the astrophysical sky (e.g., M and a), and provides a well-defined model for the data at the lowest level; this approach is what enables global modeling.
For our purposes, the most important sky signal component is the CMB anisotropy field, aCMB. The covariance of this component reads 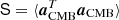 . Under the assumption of a statistically isotropic universe, this matrix is diagonal in harmonic space,
. Under the assumption of a statistically isotropic universe, this matrix is diagonal in harmonic space, 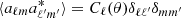 , where
, where 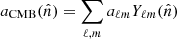 is the usual spherical harmonics expansion and Cℓ is called the angular power spectrum. This power spectrum depends directly on a small set of cosmological parameters, θ, and for most universe models can be computed efficiently by Boltzmann solvers such as CAMB (Lewis et al. 2000) or CLASS (Lesgourgues 2011).
is the usual spherical harmonics expansion and Cℓ is called the angular power spectrum. This power spectrum depends directly on a small set of cosmological parameters, θ, and for most universe models can be computed efficiently by Boltzmann solvers such as CAMB (Lewis et al. 2000) or CLASS (Lesgourgues 2011).
With this notation, the goal is now to compute P(ω ∣ d), where ω = {G, ncorr, M, a, θ, …}. Unfortunately, directly evaluating or sampling from this distribution is unfeasible. In practice, we therefore resort to MCMC sampling in general, and Gibbs sampling in particular, which is a well-established method for sampling from a complicated multivariate distribution by iterating over all conditional distributions. For the data model described in Eq. (3), this process can be described schematically in the form of a Gibbs chain,
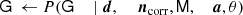 (4)
(4)
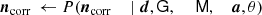 (5)
(5)
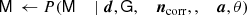 (6)
(6)
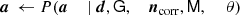 (7)
(7)
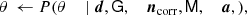 (8)
(8)
where ← indicates replacing the parameter on the left-hand side with a random sample from the distribution on the right-hand side.
As described by the BeyondPlanck Collaboration (2023) and Watts et al. (2023), this process has been implemented in Commander3 by BEYONDPLANCK and COSMOGLOBE. However, in the code described there, the last step only supports a power spectrum estimation (i.e., θ = Cℓ). In this work, we did not sample any instrumental or foreground parameters, and we assumed a foreground-cleaned map of the CMB as a starting point. Rather, the goal of the paper is to replace the last step, Eq. (8), with actual cosmological parameter estimation of a CMB map, in which θ takes on the usual form of the dark matter density Ωc, the Hubble constant H0, the spectral index of scalar perturbations ns, etc.
2.2. Joint sampling of CMB sky signal and cosmological parameters
Cosmological parameter estimation through end-to-end CMB Gibbs sampling has been discussed in the literature for almost two decades, starting with Jewell et al. (2004) and Wandelt et al. (2004). However, as pointed out by Eriksen et al. (2004), a major difficulty regarding this method is a very long correlation length in the low signal-to-noise regime, i.e., at high multipoles. Intuitively, the origin of this problem lies in the fundamental Gibbs sampling algorithm itself, namely that it only allows for parameter variations parallel or orthogonal to the coordinate axes of each parameter in question, and not diagonal moves. For highly degenerate distributions, this makes it very expensive to move from one tail of the distribution to the other. A solution to this problem was proposed by Jewell et al. (2009), who introduced a joint CMB sky signal and Cℓ move. This idea was further refined by Racine et al. (2016), who noted that faster convergence could be obtained by only rescaling the low signal-to-noise multipoles. In the following, we give a brief summary of these ideas, both standard Gibbs sampling in Sect. 2.2.1 and joint sampling in Sect. 2.2.2.
2.2.1. Standard CMB Gibbs sampling
Starting with the standard Gibbs sampling algorithm (Jewell et al. 2004; Wandelt et al. 2004), we first note that as far as cosmological parameter estimation with CMB data is concerned, only the CMB map, aCMB (which we for brevity denote a in the rest of this section), is directly relevant. All other parameters in Eq. (3) only serve to produce the cleanest possible estimate of a and to propagate the corresponding uncertainties. From now on, we therefore consider a greatly simplified data model of the form,
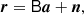 (9)
(9)
where r now represents a foreground-cleaned CMB map (or residual) obtained by subtracting all other nuisance terms from the raw data, and our goal is to estimate cosmological parameters from this map. Under the assumption that the CMB is a Gaussian random field, this could in principle be done simply by mapping out the exact marginal posterior distribution by brute force,
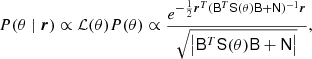 (10)
(10)
where BTS(θ)B is the beam-convolved CMB signal covariance matrix and N is the corresponding noise covariance matrix, and we have assumed uniform priors, P(θ) = 1. This, however, becomes intractable for modern CMB experiments as the computational expense scales as 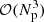 , where Np is the number of pixels, and nowadays typical CMB maps include millions of pixels.
, where Np is the number of pixels, and nowadays typical CMB maps include millions of pixels.
In the special (and unrealistic) case of uniform noise and no Galactic mask, this likelihood can be simplified in harmonic space, in which it does become computationally tractable. Let us define the observed angular CMB power spectrum (including beam convolution and noise) to be 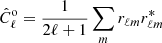 and the corresponding white noise spectrum to be defined by Nℓmℓ′m′ = Nℓδℓℓ′δmm′. In that case, the likelihood in Eq. (10) for temperature-only observations simplifies to
and the corresponding white noise spectrum to be defined by Nℓmℓ′m′ = Nℓδℓℓ′δmm′. In that case, the likelihood in Eq. (10) for temperature-only observations simplifies to
![Mathematical equation: $$ \begin{aligned} \ln P(\theta \mid {\boldsymbol{r}}) = \sum _{\ell } -\frac{2\ell +1}{2} \left[\frac{\hat{C}^{\mathrm{o} }_{\ell }}{b_\ell ^2 C_{\ell }(\theta ) + N_\ell }-\ln \left(\frac{\hat{C}^{\mathrm{o} }_{\ell }}{b_\ell ^2 C_{\ell }(\theta ) + N_\ell } \right) \right], \end{aligned} $$](/articles/aa/full_html/2023/10/aa47358-23/aa47358-23-eq16.gif) (11)
(11)
where bℓ is the beam response function and we have removed constant terms; a similar expression for polarization is available in, for example, Larson et al. (2007) and Hamimeche & Lewis (2008). This expression is used later to validate the production code.
While it is difficult to evaluate Eq. (10) directly, it is in fact possible to sample from it using Gibbs sampling (Jewell et al. 2004; Wandelt et al. 2004). First, we note that the joint posterior distribution P(θ, a ∣ r) can be written as
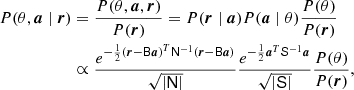 (12)
(12)
and drawing samples from this distribution can be achieved through Gibbs sampling,
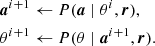 (13)
(13)
With these joint samples in hand, a numerical representation of P(θ ∣ r) can be obtained simply by marginalizing over a, which is equivalent to simply making histograms of the θ samples.
For this algorithm to work, we need to be able to sample from each of the two conditional distributions in Eqs. (13) and (14). Starting with the cosmological parameter distribution in Eq. (14), we note that P(θ ∣ ai + 1, r) = P(θ ∣ ai + 1), which is equivalent to the distribution in Eq. (11) with no beam and noise. This can be coupled to a standard Boltzmann solver and Metropolis-Hastings sampler, similar to CAMB and CosmoMC. We return to this step in the next section.
Next, for the amplitude distribution in Eq. (13), one can show by “completing the square” of a in Eq. (12) that
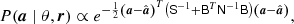 (14)
(14)
where we have defined the so-called mean field map,
![Mathematical equation: $$ \begin{aligned} \hat{{\boldsymbol{a}}} \equiv \left[\mathsf S ^{-1} + \mathsf B ^T \mathsf N ^{-1}\mathsf B \right]^{-1} \mathsf B ^T \mathsf N ^{-1} {\boldsymbol{r}}. \end{aligned} $$](/articles/aa/full_html/2023/10/aa47358-23/aa47358-23-eq20.gif) (15)
(15)
This is a multivariate Gaussian distribution with mean 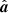 and a covariance matrix [S−1+BTN−1B]−1 that can be sampled from solving the following equation using conjugate gradients (Shewchuk 1994; Seljebotn et al. 2019),
and a covariance matrix [S−1+BTN−1B]−1 that can be sampled from solving the following equation using conjugate gradients (Shewchuk 1994; Seljebotn et al. 2019),
![Mathematical equation: $$ \begin{aligned} \left[\mathsf S ^{-1} + \mathsf B ^T \mathsf N ^{-1}\mathsf B \right]{\boldsymbol{a}} = \mathsf B ^T \mathsf N ^{-1} {\boldsymbol{r}} + \mathsf S ^{-\frac{1}{2}}{\boldsymbol{w}}_0 +\mathsf B ^T \mathsf N ^{-\frac{1}{2}}{\boldsymbol{w}}_1, \end{aligned} $$](/articles/aa/full_html/2023/10/aa47358-23/aa47358-23-eq22.gif) (16)
(16)
where w0 and w1 are randomly drawn Gaussian maps with unit variance and zero mean. The resulting sample is typically referred to as a “constrained realization”.
For the purposes of the next section, it is useful to decompose the full constrained realization into two separate components, namely the mean field map defined by Eq. (16) and the fluctuation map,
![Mathematical equation: $$ \begin{aligned} \hat{{\boldsymbol{f}}} \equiv \left[\mathsf S ^{-1} + \mathsf B ^T \mathsf N ^{-1}\mathsf B \right]^{-1} \left(\mathsf S ^{-\frac{1}{2}}{\boldsymbol{w}}_0 +\mathsf B ^T \mathsf N ^{-\frac{1}{2}}{\boldsymbol{w}}_1 \right) \end{aligned} $$](/articles/aa/full_html/2023/10/aa47358-23/aa47358-23-eq23.gif) (17)
(17)
such that 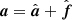 . For a data configuration with uniform noise and full-sky temperature data, these equations can be solved exactly in spherical harmonics space, fully analogously to Eq. (11),
. For a data configuration with uniform noise and full-sky temperature data, these equations can be solved exactly in spherical harmonics space, fully analogously to Eq. (11),
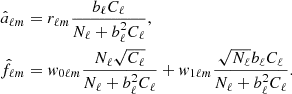 (18)
(18)
As summarized in Appendix A, we can find a closed-form expression for 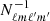 for a constant latitude mask with isotropic noise which greatly simplifies solving Eq. (17), and we have made a Python script that performs these calculations in order to validate the main Commander3 code discussed below.
for a constant latitude mask with isotropic noise which greatly simplifies solving Eq. (17), and we have made a Python script that performs these calculations in order to validate the main Commander3 code discussed below.
To build intuition, these maps are illustrated for one random sample with semi-realistic instrument characteristics in Fig. 1. The top panel shows the mean field map (or “Wiener filter map”); this map summarizes all significant information in r, and each mode is weighted according to its own specific signal-to-noise ratio taking into account both instrumental noise and masking. As a result, all small scales in the Galactic plane are suppressed, and only the largest scales are retained, which are constrained by the high-latitude observations in conjunction with the assumptions of both Gaussianity and statistical isotropy. The second panel shows the fluctuation map, which essentially serves to replace the lost power in 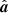 with a completely random fluctuation. The sum of the two terms, shown in the bottom panel, represents one possible full-sky realization that is consistent with both the data and the assumed cosmological parameters, θ. If we were to produce a second such constrained realization, it would look almost identical at high Galactic latitudes, where the data are highly constraining, while the Galactic plane would exhibit different structures on small and intermediate scales.
with a completely random fluctuation. The sum of the two terms, shown in the bottom panel, represents one possible full-sky realization that is consistent with both the data and the assumed cosmological parameters, θ. If we were to produce a second such constrained realization, it would look almost identical at high Galactic latitudes, where the data are highly constraining, while the Galactic plane would exhibit different structures on small and intermediate scales.
 |
Fig. 1. Example of a constrained CMB sky map realization produced during traditional Gibbs sampling. From top to bottom, the three panels show the mean field map ( |
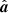
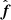
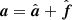
A corresponding comparison of angular power spectra is shown in Fig. 2. The relative signal-to-noise ratio of each multipole moment can be seen as the ratio between the intermediate and dark-colored lines. In temperature, this value is higher than unity up to ℓ ≲ 700, while for EE polarization it is less than unity everywhere except at the very lowest multipoles. A closely related way to interpret this figure is that the intermediate curve shows the total information content of the data. Thus, for the BB spectrum there is no visually relevant information present at all, and the full constrained realization is entirely defined by the fluctuation map, which is given by the assumed cosmological model, θ. This explains why the standard Gibbs sampler works well in the high signal-to-noise regime but poorly in the low signal-to-noise limit: When we have high instrumental noise, N → ∞, then we have no information about aℓm from the data rℓm, and the total sky sample only becomes a realization of the assumed variance, Cℓ (i.e., 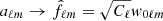 ). However, since we have no information of the mean field map
). However, since we have no information of the mean field map 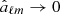 , we also do not know Cℓ. Hence, we get a strong degeneracy between the Cℓ and aℓm. Gibbs sampling is well known to perform poorly for strongly correlated parameters, as one cannot move diagonally through the parameter space from one end of the joint posterior distribution to the other.
, we also do not know Cℓ. Hence, we get a strong degeneracy between the Cℓ and aℓm. Gibbs sampling is well known to perform poorly for strongly correlated parameters, as one cannot move diagonally through the parameter space from one end of the joint posterior distribution to the other.
 |
Fig. 2. Angular power spectra for each of the constrained realization maps shown in Fig. 1. The ΛCDM cosmological model corresponding to θ is shown as a dashed black line, while the colored curves show (from dark to light) spectra for the fluctuation map, the mean field map, and the full constrained realization. Note that in the fully noise-dominated cases, such as the entire B-mode power spectrum and all high multipoles, the fluctuation term |
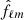
2.2.2. Joint sky signal and cosmological parameter sampling
As the Gibbs sampler struggles with long correlation lengths, a joint sampler was proposed by Jewell et al. (2009) and Racine et al. (2016) that was designed to establish an efficient sampling algorithm for the degeneracy between a and θ in the low signal-to-noise regime. Mathematically, this algorithm is a standard Metropolis-Hastings sampler with a Gaussian transition rule for θ,
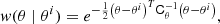 (19)
(19)
where Cθ is a user-specified (and pre-tuned) proposal covariance matrix made from a previous chain using a suboptimal, diagonal proposal matrix. This is followed by a deterministic rescaling of the fluctuation map in the signal amplitude map,
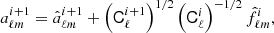 (20)
(20)
where we have defined the covariance matrix
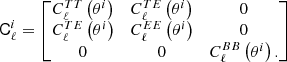 (21)
(21)
Here, we have set the parity-odd power spectra to zero as predicted by Λ cold dark matter (CDM), 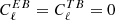 . Therefore, we defined the rescaled fluctuation map,
. Therefore, we defined the rescaled fluctuation map,
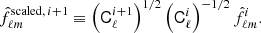 (22)
(22)
As shown by Racine et al. (2016), the acceptance rate for this joint move is
![Mathematical equation: $$ \begin{aligned} A = \mathrm{min} \left[1, \frac{\pi (\theta ^{i+1})}{\pi (\theta ^i)} \frac{P(\theta ^{i+1})}{P(\theta ^i)} \right], \end{aligned} $$](/articles/aa/full_html/2023/10/aa47358-23/aa47358-23-eq39.gif) (23)
(23)
where P(θ) is the prior on θ and
![Mathematical equation: $$ \begin{aligned} \nonumber \pi (\theta ^{i}) = \mathrm{exp} \bigg [&-\frac{1}{2} \left({\boldsymbol{r}}-\mathsf B \hat{{\boldsymbol{a}}}^i\right)^T \mathsf N ^{-1}\left({\boldsymbol{r}}-\mathsf B \hat{{\boldsymbol{a}}}^i\right)\\&-\frac{1}{2}{\boldsymbol{a}}^{i,T} \mathsf S ^{i, -1}\hat{{\boldsymbol{a}}}^i -\frac{1}{2} \hat{{\boldsymbol{f}}}^{i, T}\mathsf B ^T\mathsf N ^{-1} \mathsf B \hat{{\boldsymbol{f}}}^i\bigg ], \end{aligned} $$](/articles/aa/full_html/2023/10/aa47358-23/aa47358-23-eq40.gif) (24)
(24)
where we for brevity have omitted the θi dependence of 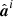 ,
, 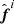 and Si.
and Si.
We note that the acceptance rate uses the scaled fluctuation term,  , for sample i + 1 instead of the calculated fluctuation term in Eq. (17). Hence, we only need to calculate
, for sample i + 1 instead of the calculated fluctuation term in Eq. (17). Hence, we only need to calculate 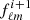 from this equation if the sample is accepted. This allows us to save roughly half the computational time of discarded samples as compared to accepted samples.
from this equation if the sample is accepted. This allows us to save roughly half the computational time of discarded samples as compared to accepted samples.
The full algorithm can now be summarized in terms of the following steps:
-
We start with an initial guess of the cosmological parameters, θ0. From that, we calculate S0 with CAMB; the mean field map,
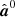 from Eq. (16); and the fluctuation map,
from Eq. (16); and the fluctuation map, 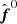 , from Eq. (18).
, from Eq. (18). -
We then draw a new cosmological parameter sample from w(θ ∣ θi), and reevaluate Si + 1,
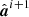 , and the scaled fluctuation term
, and the scaled fluctuation term 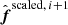 .
. -
We calculate the acceptance term of Eq. (25), and accept or reject according to the regular Metropolis-Hasting rule.
-
If the sample is accepted, then we calculate
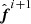 . In the next iteration this term becomes
. In the next iteration this term becomes 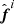 , which will appear in the acceptance probability and the equation for
, which will appear in the acceptance probability and the equation for 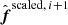 .
. -
Iterate 2–4.
The intuition behind this joint move is illustrated in Fig. 3. The top panel shows the standard Gibbs sampling algorithm, in which only parameter moves parallel to the axes are allowed. This works well in the high signal-to-noise regime (left column), where the joint distribution is close to symmetric. In the low signal-to-noise regime, however, the distribution is strongly tilted, because of the tight coupling between 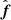 and θ discussed at the end of Sect. 2.2.1, and many orthogonal moves are required in order to move from one tail of the distribution to the other. On the other hand, with the joint algorithm, in the bottom panel, steps are non-orthogonal, with a slope defined exactly by the local signal-to-noise ratio of the mode in question. The net result is a much faster exploration of the full distribution.
and θ discussed at the end of Sect. 2.2.1, and many orthogonal moves are required in order to move from one tail of the distribution to the other. On the other hand, with the joint algorithm, in the bottom panel, steps are non-orthogonal, with a slope defined exactly by the local signal-to-noise ratio of the mode in question. The net result is a much faster exploration of the full distribution.
 |
Fig. 3. Schematic comparison of the standard Gibbs sampler (top panels) and the joint sampler of Racine et al. (2016), bottom panels. The left and right columns show high and low signal-to-noise regimes, respectively. The Gibbs sampler performs poorly in the low signal-to-noise regime as it requires a large number of samples to explore the posterior distribution. The joint sampler in the lower panels performs well in both regimes as it allows the next sample to move diagonally in the {a, θ} parameter space. |
3. Results
The main goal of this paper is to implement the joint sampling algorithm into Commander3 and characterize its performance both in terms of accuracy and computational cost on simulated data. All Commander code used in the following is available as Open Source software in a GitHub repository2. For the current paper, we focused on a standard six-parameter ΛCDM model and chose θ = (Ωbh2, ΩCDMh2, H0, τ, As, ns) as our base parameters, where Ωb and ΩCDM are the current density of baryonic and CDM; H0 is the Hubble parameter (and h is the normalized Hubble constant, 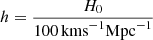 ); τ is the optical depth at reionization; and As and ns are the amplitude and tilt of the scalar primordial power spectrum. We used CAMB3 (Lewis et al. 2000) to evaluate all ΛCDM power spectra, Cℓ(θ).
); τ is the optical depth at reionization; and As and ns are the amplitude and tilt of the scalar primordial power spectrum. We used CAMB3 (Lewis et al. 2000) to evaluate all ΛCDM power spectra, Cℓ(θ).
In the following we consider three different simulations, corresponding to increasing levels of complexity and realism. A natural early target for this algorithm is a reanalysis of COSMOGLOBE DR1; hence, all three cases are similar to the Planck LFI channels. We use the Planck data release 4 70 GHz beam transfer functions (Planck Collaboration Int. LVII 2020), and for the two first cases, the noise level is isotropic with a value matching twice the mean of the full-sky 70 GHz rms map, while for the third case is given by one realization of the actual non-isotropic BEYONDPLANCK 70 GHz noise rms distribution.
The second difference between the three cases is their sky coverage. The first case considers full-sky data, for which the analytical posterior distribution solution is readily available through Eq. (11). The second case implements a constant-latitude Galactic mask for which an analytical expression is also available, albeit more complicated than for the full sky (see Appendix A for details). The third case uses a realistic Galactic and point-source mask, for which no analytical expression is available.
To validate the main Commander3 results, we developed a special-purpose Python program4 that implements the same joint sampling algorithm described above for the two first cases, and this serves essentially as a basic bug-check with respect to the Fortran implementation. In addition, we also implemented a uniform, full-sky likelihood module for Cobaya (Torrado & Lewis 2021), an industry-standard cosmological parameter Metropolis sampler, and this serves as an end-to-end check on the entire code, including integration with CAMB.
3.1. Accuracy validation
The first main goal of this paper is to demonstrate that the new Commander3 implementation of the Racine et al. (2016) algorithm performs as expected with respect to accuracy. Thus, we start our discussion by considering the uniform and full-sky case discussed above. For each of the three available codes – Commander3, Python, and Cobaya – we produced 50 000 samples; we show the full posterior distributions in Fig. 4. The agreement between all three codes is excellent, and the overall variations are within ∼0.1σ.
 |
Fig. 4. Comparison of cosmological parameter posterior distributions derived with Commander3 (blue), Python (red), and Cobaya (gray) for a simulation with uniform noise and full-sky coverage. They are made from a single chain per code, and the true input cosmological parameter values are indicated by vertical and horizontal dashed lines. |
Second, Fig. 5 shows a similar comparison between the Commander3 and Python implementation. The sky mask is in this case defined by |b|< 5.7° where b is the Galactic latitude, removing 10% of the sky. We also find good agreement in this case between the two implementations, and the true input values (marked by vertical dashed lines) all fall well within the full posterior distributions. However, we do note that the introduction of a sky mask significantly increases the overall run time of the algorithm, since one now has to solve for the mean field map repeatedly at each step with conjugate gradients, rather than with brute force matrix inversions. In total, we only produce ∼11 000 and 17 000 samples for each of the two codes for this exercise, at a total cost of 𝒪(105) CPU-hours.
 |
Fig. 5. Comparison of marginal cosmological parameter posterior distributions derived with Commander3 and Python for a simulation with uniform noise and a 10% constant latitude mask. The total number of independent samples produced by the two codes is 𝒪(102), which accounts for the Markov chain correlation length of the algorithm; the Monte Carlo uncertainty due to a finite number of samples is therefore significant. |
Finally, in Fig. 6 we show trace plots for each cosmological parameter for the realistic configuration as produced with Commander3, noting that none of the other codes are technically able to produce similar estimates. In this case, the computational cost is even higher, and we only produce a total of 1600 samples. Still, by comparing these traces with the true input values (marked as dashed horizontal lines), we do see that the resulting samples agree well with the expected mean values. The uncertainties are also as expected since they are smaller and on the order of the noisier 10% constant latitude and isotropic noise case in Fig. 5.
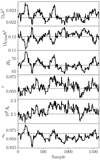 |
Fig. 6. Trace plot of the cosmological parameters for a semi-realistic case based on the Planck LFI 70 GHz noise level and a realistic Galactic mask. The dashed horizontal lines show the true input values. |
3.2. Markov chain correlation length and computational costs
The second main goal of this paper is to quantify the computational costs involved in this algorithm and identify potential bottlenecks that could be optimized in future work. The effective cost per independent Markov chain sample can be written as the product of the raw sampling cost per sample and the overall Markov chain correlation length. The latter can be quantified in terms of the autocorrelation function,
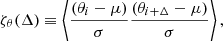 (25)
(25)
where μ and σ are the posterior mean and standard deviation computed from the Markov chain for θ. We define the overall correlation length to be the first value of Δ for which ζ < 0.1. This function is plotted for both Cobaya and Commander3 in Fig. 7; for the latter, dashed lines show full-sky results and dot-dashed lines show results for a 10% mask. Overall, we see that the Commander3 correlation length is 50–60 for the full-sky case, increasing to 50–100 for the masked case. For comparison, Cobaya typically has a correlation length of about 10.
 |
Fig. 7. Markov chain autocorrelation functions for Cobaya (solid lines) and Commander3 for a set of typical cosmological parameters. Dashed and dot-dashed lines show Commander3 results for the full-sky case and the 10 % mask case, respectively. The horizontal dashed gray line indicates an autocorrelation of 0.1, which we use to define the overall correlation length. |
The basic computational cost per sample for Commander3 is plotted as black points in Fig. 8. Here we see that the overall cost increases rapidly with decreasing sky coverage, starting at 0.2 CPU-hours for a full-sky sample to about 4 CPU-hours for a 20% constant latitude mask and uniform noise. As the isotropic noise cases have twice the noise of the mean of the 70 GHz rms map, the higher signal-to-noise causes an increase in runtime, and for the realistic LFI 70 GHz scanning pattern and 15% mask, the cost is 20 CPU-hours/sample. Taking into account that the overall correlation length is ∼100, the effective cost is therefore about 2000 CPU-hours per independent sample; the gray dots in Fig. 8 indicates this total cost for each configuration.
 |
Fig. 8. CPU-hours per accepted sample. The black dots are the costs per sample, while the gray dots are the costs per effective sample, i.e., normalized by the correlation length of the chain. This is compared to the 812 CPU-hours to generate one single end-to-end sample of DR1 COSMOGLOBEPlanck LFI and WMAP channels, in red. |
To interpret the implications of these costs, it is useful to compare with the overall cost of the full end-to-end processing pipeline within which this algorithm is designed to operate. The most relevant comparison point is therefore the cost of the COSMOGLOBE DR1 processing, which is 812 CPU-hours for the combination of Planck LFI and WMAP, marked as a red dot in Fig. 8. In its current state, we find that the new cosmological parameter step alone is thus about 2.5 times more expensive than the full end-to-end processing.
4. Summary and discussion
This work had two main goals. The first goal was simply to implement the cosmological parameter sampling algorithm proposed by Racine et al. (2016) into the state-of-the-art Commander3 CMB Gibbs sampler and demonstrate that this new step works in a production environment. A head-to-head comparison with both Cobaya and a stand-alone Python implementation demonstrates the fidelity of the method. We therefore conclude that this goal has been met, and as such this work finally adds true “end-to-end” processing abilities to Commander3.
The second goal was to measure the computational performance of the method, assess whether it is already suitable for large-scale production, and identify potential bottlenecks that should be resolved in future work. In this case, we find that the overall cost per independent Gibbs sample for a data set similar to COSMOGLOBE DR1 is about 2000 CPU-hours, which is more than a factor of two higher than the total cost of all other steps in the end-to-end algorithm, including low-level calibration, map-making, and component separation. Therefore, although the code is technically operational at the current time, we also conclude that it is still too expensive to be useful in a full-scale production environment.
At the same time, this analysis has also revealed the underlying origin of these high expenses, which can be divided into two parts. First, the overall cost per sample is dominated by the expense for solving for the mean field (Eq. (16)) and fluctuation maps (Eq. (18)) using conjugate gradients. In this respect, we note that the current implementation uses a standard diagonal preconditioner to solve these equations, as described by Eriksen et al. (2004). However, after more than two decades of development, far more efficient preconditioners have been explored and described in the literature, including multi-resolution or multi-grid methods (e.g., Seljebotn et al. 2014, 2019). Implementing one of them can potentially reduce the basic cost per sample by one or two orders of magnitude. The second issue is a long correlation length. We note that the current algorithm is based on a very basic random-walk Metropolis sampler, which generally performs poorly for highly correlated parameters; in the cases considered here, the correlation between the amplitude of scalar perturbations, As, and the optical depth of reionization, τ, is a typical example of such a correlation. This suggests that the correlation length can be greatly reduced in several ways, for instance either by adding new data sets (such as weak gravitational lensing constraints) or by implementing a more sophisticated sampling algorithm that uses derivative information, such as a Hamiltonian sampler. Overall, we consider it very likely that future work will be able to reduce the total cost by one or two orders of magnitude, as needed for production, and we hope that the current results can provide inspiration and motivation for experts in the field to join the effort.
Finally, before concluding this paper, we note that a key application of the Bayesian end-to-end analysis framework as pioneered by BEYONDPLANCK and COSMOGLOBE is the analysis of next-generation CMB B-mode experiments, for instance LiteBIRD. In this case, it is worth noting that the polarization-based signal-to-noise ratio of the tensor-to-scalar ratio, r, is much lower than Planck and WMAP’s temperature signal-to-noise ratio to the ΛCDM parameters, and both the conjugate gradient cost and Markov chain correlation length are likely to be much shorter than for the case considered in this paper. As such, it is conceivable that the current method already performs adequately for LiteBIRD, and this will be explored5 in future work.
Publicly available at https://github.com/LilleJohs/COLOCOLA
Acknowledgments
The current work has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement numbers 819478 (ERC; COSMOGLOBE) and 772253 (ERC; BITS2COSMOLOGY). In addition, the collaboration acknowledges support from RCN (Norway; grant no. 274990). Moreover, Simone Paradiso aknowledges support from the Government of Canada’s New Frontiers in Research Fund, through grant NFRFE-2021-00595. We acknowledge the use of the Legacy Archive for Microwave Background Data Analysis (LAMBDA), part of the High Energy Astrophysics Science Archive Center (HEASARC). HEASARC/LAMBDA is a service of the Astrophysics Science Division at the NASA Goddard Space Flight Center. Some of the results in this paper have been derived using the healpy and HEALPix packages (Górski et al. 2005; Zonca et al. 2019).
References
- Anderes, E., Wandelt, B., & Lavaux, G. 2015, ApJ, 808, 152 [NASA ADS] [CrossRef] [Google Scholar]
- Bennett, C. L., Larson, D., Weiland, J. L., et al. 2013, ApJS, 208, 20 [Google Scholar]
- BeyondPlanck Collaboration 2023, A&A, 675, A1 [Google Scholar]
- Carron, J. 2019, Phys. Rev. D, 99, 043518 [NASA ADS] [CrossRef] [Google Scholar]
- Eriksen, H. K., O’Dwyer, I. J., Jewell, J. B., et al. 2004, ApJS, 155, 227 [Google Scholar]
- Galloway, M., Andersen, K. J., & Aurlien, R. 2023, A&A, 675, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gjerløw, E., Mikkelsen, K., Eriksen, H. K., et al. 2013, ApJ, 777, 150 [CrossRef] [Google Scholar]
- Górski, K. M., Hivon, E., Banday, A. J., et al. 2005, ApJ, 622, 759 [Google Scholar]
- Hamimeche, S., & Lewis, A. 2008, Phys. Rev. D, 77, 103013 [NASA ADS] [CrossRef] [Google Scholar]
- Hinshaw, G., Larson, D., Komatsu, E., et al. 2013, ApJS, 208, 19 [Google Scholar]
- Jewell, J., Levin, S., & Anderson, C. H. 2004, ApJ, 609, 1 [Google Scholar]
- Jewell, J. B., Eriksen, H. K., Wandelt, B. D., et al. 2009, ApJ, 697, 258 [NASA ADS] [CrossRef] [Google Scholar]
- Larson, D. L., Eriksen, H. K., Wandelt, B. D., et al. 2007, ApJ, 656, 653 [Google Scholar]
- Lesgourgues, J. 2011, ArXiv e-prints [arXiv:1104.2932] [Google Scholar]
- Lewis, A., & Bridle, S. 2002, Phys. Rev. D, 66, 103511 [Google Scholar]
- Lewis, A., Challinor, A., & Lasenby, A. 2000, ApJ, 538, 473 [Google Scholar]
- Millea, M., & Seljak, U. 2022, Phys. Rev. D, 105, 103531 [NASA ADS] [CrossRef] [Google Scholar]
- Millea, M., Anderes, E., & Wandelt, B. D. 2020, Phys. Rev. D, 102, 123542 [NASA ADS] [CrossRef] [Google Scholar]
- Millea, M., Daley, C. M., Chou, T-L., et al. 2021, ApJ, 922, 259 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration II. 2020, A&A, 641, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration III. 2020, A&A, 641, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration V. 2020, A&A, 641, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration Int. LVII. 2020, A&A, 643, A42 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Racine, B., Jewell, J. B., Eriksen, H. K., & Wehus, I. K. 2016, ApJ, 820, 31 [NASA ADS] [CrossRef] [Google Scholar]
- Seljebotn, D. S., Mardal, K.-A., Jewell, J. B., Eriksen, H. K., & Bull, P. 2014, ApJS, 210, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Seljebotn, D. S., Bærland, T., Eriksen, H. K., Mardal, K. A., & Wehus, I. K. 2019, A&A, 627, A98 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shewchuk, J. R. 1994, An Introduction to the Conjugate Gradient Method Without the Agonizing Pain, Edition 1 1/4, http://www.cs.cmu.edu/~quake-papers/painless-conjugate-gradient.pdf [Google Scholar]
- Torrado, J., & Lewis, A. 2021, JCAP, 05, 057 [Google Scholar]
- Verde, L., Peiris, H. V., Spergel, D. N., et al. 2003, ApJS, 148, 195 [NASA ADS] [CrossRef] [Google Scholar]
- Wandelt, B. D., Larson, D. L., & Lakshminarayanan, A. 2004, Phys. Rev. D, 70, 083511 [Google Scholar]
- Watts, D. J., Basyrov, A., Eskilt, J. R., et al. 2023, A&A, in press, https://doi.org/10.1051/0004-6361/202346414 [Google Scholar]
- Wieczorek, M. A., & Meschede, M. 2018, Geochem. Geophys. Geosyst., 19, 2574 [Google Scholar]
- Zonca, A., Singer, L., Lenz, D., et al. 2019, J. Open Source Softw., 4, 1298 [Google Scholar]
Appendix A: Analytic expression for a constant latitude mask
The goal of this appendix is to show how we can calculate 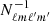 analytically for a constant latitude mask and uniform noise. This expression makes the map-making equation, in Eq. (17), computationally faster to solve as we derive our expression to be
analytically for a constant latitude mask and uniform noise. This expression makes the map-making equation, in Eq. (17), computationally faster to solve as we derive our expression to be 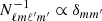 . These results are generally known, but we re-derive them here for completeness.
. These results are generally known, but we re-derive them here for completeness.
For uniform instrumental noise with no mask, the pixel covariance matrix is Npp′ = σ2δpp′ where σ is the white noise uncertainty per pixel. Including the constant latitude mask, the inverse of the noise covariance matrix can be written in pixel space as
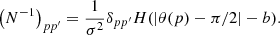
Here, H is the Heaviside function, meaning that we mask every pixel p where |θ(p)−π/2|< b for some latitude b in radians. For a masked pixel, we have (N−1)pp = 0, meaning that the noise at that pixel is infinite, Npp = ∞.
Defining the spherical harmonics functions 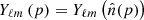 and
and 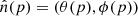 are the spherical coordinates at pixel p, which we can transform into spherical harmonics space,
are the spherical coordinates at pixel p, which we can transform into spherical harmonics space,
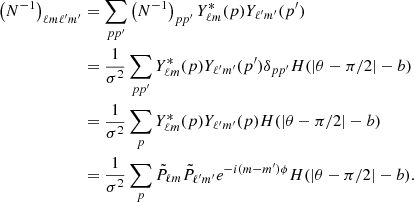 (A.1)
(A.1)
Here, we have defined 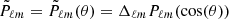 , where
, where 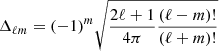 and Pℓm(cos(θ)) are the associated Legendre polynomials. Thus, we write the spherical harmonics functions as
and Pℓm(cos(θ)) are the associated Legendre polynomials. Thus, we write the spherical harmonics functions as 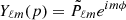 .
.
We now switch from discrete pixels to continuous space, meaning that we change the sum to an integration where we account for the number of pixels, Npix, per area element,
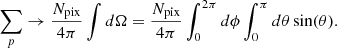 (A.2)
(A.2)
This gives us
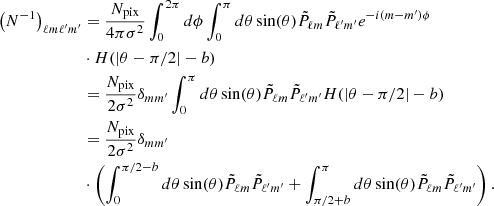 (A.3)
(A.3)
Writing x = cos(θ), we know that the associated Legendre polynomials Pℓm(x) are either symmetric or antisymmetric in x → −x. Pℓm(x) is symmetric in x → −x when ℓ + m = even and antisymmetric when ℓ + m = odd. Since m = m′, we note that the two integrals in the last line of Eq. (A.3) cancel each other if ℓ + ℓ′= odd. We, therefore, only get nonzero elements when ℓ + ℓ′= even, for which the two integrals are equal. Hence, for ℓ + ℓ′= even, we get
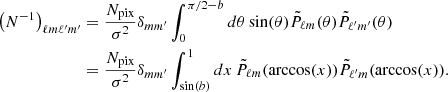 (A.4)
(A.4)
In the full-sky case, b = 0, we find 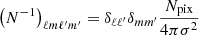 which is equivalent to a diagonal noise power spectrum
which is equivalent to a diagonal noise power spectrum 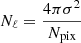 .
.
The integral in Eq. (A.4) can be solved numerically by gridding x, and 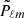 can be calculated in Python using the library pyshtools (Wieczorek & Meschede 2018). The azimuthally symmetric Galactic mask used for this work has a sky coverage of fsky = 0.90, giving sin(b) = 0.1. Therefore, we require many fewer grid points for x if we use the following identity for ℓ + ℓ′= even,
can be calculated in Python using the library pyshtools (Wieczorek & Meschede 2018). The azimuthally symmetric Galactic mask used for this work has a sky coverage of fsky = 0.90, giving sin(b) = 0.1. Therefore, we require many fewer grid points for x if we use the following identity for ℓ + ℓ′= even,
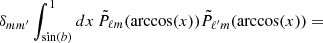 (A.5)
(A.5)
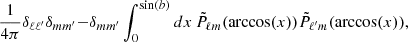 (A.6)
(A.6)
which comes from the orthonormality condition for spherical harmonics. We now only need to grid x in the interval 0 ≤ x ≤ sin(b) = 0.1, as opposed to the interval 0.1 ≤ x ≤ 1.
Since 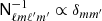 , we get simplified matrix expressions. Imagine multiplying the matrix
, we get simplified matrix expressions. Imagine multiplying the matrix  by the vector b = bℓm:
by the vector b = bℓm:
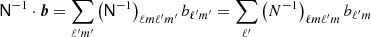 (A.7)
(A.7)
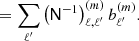 (A.8)
(A.8)
To solve the map-making equation, Eq. (17), we get a matrix equation for each 0 ≤ m ≤ ℓmax. This gives us ℓmax + 1 number of matrix equations where the dimensions of the matrices are maximally (ℓmax + 1)×(ℓmax + 1). This is numerically much quicker to invert rather than inverting the full matrix [S−1+BTN−1B] once.
All Figures
|
Fig. 1. Example of a constrained CMB sky map realization produced during traditional Gibbs sampling. From top to bottom, the three panels show the mean field map ( |
| In the text | |
|
Fig. 2. Angular power spectra for each of the constrained realization maps shown in Fig. 1. The ΛCDM cosmological model corresponding to θ is shown as a dashed black line, while the colored curves show (from dark to light) spectra for the fluctuation map, the mean field map, and the full constrained realization. Note that in the fully noise-dominated cases, such as the entire B-mode power spectrum and all high multipoles, the fluctuation term |
| In the text | |
|
Fig. 3. Schematic comparison of the standard Gibbs sampler (top panels) and the joint sampler of Racine et al. (2016), bottom panels. The left and right columns show high and low signal-to-noise regimes, respectively. The Gibbs sampler performs poorly in the low signal-to-noise regime as it requires a large number of samples to explore the posterior distribution. The joint sampler in the lower panels performs well in both regimes as it allows the next sample to move diagonally in the {a, θ} parameter space. |
| In the text | |
|
Fig. 4. Comparison of cosmological parameter posterior distributions derived with Commander3 (blue), Python (red), and Cobaya (gray) for a simulation with uniform noise and full-sky coverage. They are made from a single chain per code, and the true input cosmological parameter values are indicated by vertical and horizontal dashed lines. |
| In the text | |
|
Fig. 5. Comparison of marginal cosmological parameter posterior distributions derived with Commander3 and Python for a simulation with uniform noise and a 10% constant latitude mask. The total number of independent samples produced by the two codes is 𝒪(102), which accounts for the Markov chain correlation length of the algorithm; the Monte Carlo uncertainty due to a finite number of samples is therefore significant. |
| In the text | |
|
Fig. 6. Trace plot of the cosmological parameters for a semi-realistic case based on the Planck LFI 70 GHz noise level and a realistic Galactic mask. The dashed horizontal lines show the true input values. |
| In the text | |
|
Fig. 7. Markov chain autocorrelation functions for Cobaya (solid lines) and Commander3 for a set of typical cosmological parameters. Dashed and dot-dashed lines show Commander3 results for the full-sky case and the 10 % mask case, respectively. The horizontal dashed gray line indicates an autocorrelation of 0.1, which we use to define the overall correlation length. |
| In the text | |
|
Fig. 8. CPU-hours per accepted sample. The black dots are the costs per sample, while the gray dots are the costs per effective sample, i.e., normalized by the correlation length of the chain. This is compared to the 812 CPU-hours to generate one single end-to-end sample of DR1 COSMOGLOBEPlanck LFI and WMAP channels, in red. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.