| Issue |
A&A
Volume 673, May 2023
|
|
|---|---|---|
| Article Number | A123 | |
| Number of page(s) | 27 | |
| Section | Stellar atmospheres | |
| DOI | https://doi.org/10.1051/0004-6361/202346048 | |
| Published online | 17 May 2023 | |
Unveiling the chemical fingerprint of phosphorus-rich stars
I. In the infrared region of APOGEE-2★
1
Instituto de Astrofísica de Canarias, C/Via Láctea s/n,
38205
La Laguna, Tenerife, Spain
e-mail: maren.brauner@iac.es
2
Departamento de Astrofísica, Universidad de La Laguna,
38206
La Laguna, Tenerife, Spain
3
Konkoly Observatory, Research Centre for Astronomy and Earth Sciences, Eötvös Loránd Research Network (ELKH),
1121
Budapest,
Konkoly Thege M. út 15-17,
Hungary
4
CSFK, MTA Centre of Excellence,
Budapest,
Konkoly Thege Miklós út 15–17,
1121,
Hungary
5
E. A. Milne Centre for Astrophysics, University of Hull,
Hull
HU6 7RX,
UK
6
Joint Institute for Nuclear Astrophysics – Center for the Evolution of the Elements, 640 S Shaw Lane,
East Lansing
MI 48824,
USA
7
ELTE Eötvös Loránd University, Institute of Physics,
Budapest
1117,
Pázmány Péter sétány 1/A,
Hungary
8
School of Physics and Astronomy, Monash University,
VIC
3800,
Australia
9
NRC Herzberg Astronomy and Astrophysics Research Centre,
5071 West Saanich Road,
Victoria,
BC V9E 2E7,
Canada
Received:
1
February
2023
Accepted:
21
March
2023
Context The origin of phosphorus, one of the essential elements for life on Earth, is currently unknown. Prevalent models of Galactic chemical evolution (GCE) systematically underestimate the amount of P compared to observations, especially at low metallicities. The recently discovered P-rich ([P/Fe] ≳ 1.2 dex) and metal-poor ([Fe/H] ≃ −1.0 dex) giants further challenge the GCE models, calling current theories on stellar nucleosynthesis into question.
Aims. Since the observed low-mass giants are not expected to produce their high P contents themselves, our primary goal is to find clues on their progenitor or polluter. By increasing the number of known P-rich stars, we aim to narrow down a statistically reliable chemical abundance pattern that defines these peculiar stars. In this way, we place more robust constraints on the nucleosynthetic mechanism that causes the unusually high P abundances. In the long term, identifying the progenitor of the P-rich stars may contribute to the search for the source of P in our Galaxy.
Methods. We performed a detailed chemical abundance analysis based on the high-resolution near-infrared (H band) spectra from the latest data release (DR17) of the APOGEE-2 survey. Employing the BACCHUS code, we measured the abundances of 13 elements in the inspected sample, which is mainly composed of a recent collection of Si-enhanced giants. We also analyzed the orbital motions and compared the abundance results to possible nucleosynthetic formation scenarios, and also to detailed GCE models. These models were produced with the OMEGA+ chemical evolution code, using four different massive star yield sets to investigate different scenarios for massive star evolution.
Results. We enlarged the sample of confirmed P-rich stars from 16 to a group of 78 giants, which represents the largest sample of P-rich stars to date. The sample includes the first detection of a P-rich star in a Galactic globular cluster. Significant enhancements in O, Al, Si, and Ce, as well as systematic correlations among the studied elements, unveil the unique chemical fingerprint of the P-rich stars. In contrast, the high [Mg/Fe] and [(C+N)/Fe] found in some of the P-rich stars with respect to P-normal stars is not confirmed over the full sample because of the current uncertainties. Strikingly, the strong overabundance in the α-element Si is accompanied by normal Ca and S abundances. This is at odds with current stellar nucleosynthesis models of massive stars. Our analysis of the orbital motion showed that the P-rich stars do not belong to a locally specific population in the Galaxy. In addition, we confirm that the majority of the sample stars are not part of binary systems.
Key words: nuclear reactions, nucleosynthesis, abundances / stars: abundances / stars: chemically peculiar / surveys
Full Table 2 is only available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/673/A123
The NuGrid Collaboration, http://www.nugridstars.org
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1 Introduction
Phosphorus (P) is a crucial component in the building blocks of life on Earth (see, e.g., Gulick 1955; Butusov & Jernelov 2013). However, the Galactic origin of this critical element is only sparsely explored. To trace the evolution of P over time, observations of long-lived stars covering a broad range of metallicities are required. The difficulty of obtaining observations like this is that the P I absorption features, located in the near-ultraviolet (NUV) and near-infrared (NIR) J- and H-band spectral regions, are intrinsically weak and consequently hard to detect (e.g., Caffau et al. 2011; Roederer et al. 2014). Some high-resolution observations in the NIR, intended for determining the P content in stellar atmospheres, have been carried out by Caffau et al. (2011) using the single-object spectrographs CRIRES at VLT1 and by Caffau et al. (2016, 2019) using GIANO at the TNG2, spanning a total metallicity range of −1.0 dex < [Fe/H] < 0.3 dex. Complementary observations in the NUV region enabled Roederer et al. (2014) and Jacobson et al. (2014) to derive the P abundances of 13 late-type stars down to [Fe/H] ≈ −3.3 dex. The most recent observation by Nandakumar et al. (2022), who used the NIR spectrograph IGRINS3, provided P measurements of 38 K-type giants in the metallicity range −1.2 dex < [Fe/H] < 0.4 dex. Detailed reviews of the few estimations of P in stars can be found in Roederer et al. (2014); Maas et al. (2019) and Nandakumar et al. (2022).
In stellar nucleosynthesis, the odd-Z element P, which has only one stable isotope (31P), is mostly produced via neutron capture on isotopes of Si during the convective C-burning shell in massive stars (e.g., Woosley et al. 2002; Pignatari et al. 2016). The produced P is ejected into the interstellar medium (ISM) by the following core-collapse supernovae (CCSNe). The nucleosynthesis triggered by the CCSN explosion itself is not expected to contribute significantly to the final P yields (e.g., Woosley & Weaver 1995). In Type la supernovae (SNela), the thermonuclear explosion of a carbon-oxygen white dwarf (WD), the production of P is also irrelevant (Leung & Nomoto 2018). Asymptotic giant branch (AGB) stars are likewise not expected to produce significant amounts of P (Karakas & Lugaro 2016).
By taking into account the nucleosynthetic yields from different stellar sources, Galactic chemical evolution (GCE) models replicate the evolution of elements in the Galaxy as a function of metallicity and time (see Matteucci 2021, and references therein). In particular, the understanding of the chemical evolution of P in the Galaxy has been challenging since the earliest GCE simulations. In general, while the [P/Fe]4 abundance ratio can be roughly reproduced for stars at solar metallicity (Cescutti et al. 2012), it becomes difficult to produce enough P to match observations in metal-poor stars because of the secondary-like production of this element in massive stars (see, e.g., Goswami & Prantzos 2000). Several authors (e.g., Caffau et al. 2011; Roederer et al. 2014; Jacobson et al. 2014; Maas et al. 2019) reported a major discrepancy between models and observations, concluding that GCE models are not able to quantitatively reproduce the behavior of [P/Fe] at subsolar metallicities. In particular, Cescutti et al. (2012) demonstrated that the P yields from Woosley & Weaver (1995) and Kobayashi et al. (2006) have to be multiplied by a factor of approximately 3 to match the observations from Caffau et al. (2011). The recent observation by Nandakumar et al. (2022) confirmed the conclusions made by Cescutti et al. (2012). Nandakumar et al. (2022) showed that the behavior of P is more similar to that of the α-elements produced in CCSNe, such as Mg, Si and S, than to other odd-Z elements. This finding supports the hypothesis from Clayton (2003), who proposed that in contrast to Woosley & Weaver (1995), CCSNe indeed contribute to the P production. More recently, Ritter et al. (2018a) showed that a merger between the convective C shell and the convective O shell in massive stars may boost the production of P in the CCSN progenitor and in the final CCSN ejecta. The following impact on the GCE is uncertain, and it depends, among other things, on the frequency and the nature of the shell mergers. However, Ritter et al. (2018a) showed that they could potentially explain the typical [P/Fe] ratio in stars in the MW and even reach a much larger P enrichment. In summary, the exact production sites of P is still unclear, causing a mismatch between GCE models and observations.
Through the advent of multi-object spectroscopic surveys, such as the Apache Point Observatory Galactic Evolution Experiment (APOGEE; e.g., Majewski et al. 2017), it became possible to perform an abundance census in the infrared on a vast number of stars. The APOGEE-2 data release 14 (DR14; Abolfathi et al. 2018) provided NIR H-band spectra of more than 263 000 stars in the Milky Way and allowed the discovery of 16 metal-poor ([Fe/H] ≃ −1.0 dex) giants with high and unexplained amounts of P ([P/Fe] ≳ 1.2 dex) (Masseron et al. 2020a‚b). The GCE models, which already fail to reproduce the usual Galactic P abundances, are even less capable of accounting for the overabundances of these P-rich stars.
According to Masseron et al. (2020a), the P-rich stars also present high amounts of O, Mg, Al, Si, and Ce. Because they are low-mass giants, it is not expected that the P-rich stars produced the enhanced elements themselves (Masseron et al. 2020a). An extragalactic origin of these stars was also discarded by Masseron et al. (2020a), and therefore, the search for the source of P is now focused on finding the progenitor that polluted the ISM out of which the now observed P-rich stars were born. By comparing their chemical abundance pattern with current theoretical models of stellar nucleosynthesis, Masseron et al. (2020a‚b) were able to rule out a number of possible formation scenarios, among others, novae and super-AGB stars. Masseron et al. (2020a) also discussed the aforementioned contribution of stellar rotation and/or nucleosynthesis in convective-reactive regions in massive stars such as C-0 shell mergers (Ritter et al. 2018a) as possible alternatives to explain the peculiar chemistry of P-rich stars.
In the present work, we built an enlarged sample of P-rich star candidates and performed a line-by-line abundance analysis on this new sample using the Brussels Automatic Code for Characterizing High accuracy Spectra (BACCHUS). The analysis includes 13 elements and is based on the NIR spectra from the latest APOGEE-2 data release (DR17). We found a total of 78 P-rich stars, the highest number of known P-rich stars to date, allowing us to report a statistically reliable chemical fingerprint of these peculiar stars. This new sample can guide us in the search for their progenitor by placing more robust constraints on the nucleosynthetic channel that produced the unusual abundance pattern. Furthermore, we studied the orbital motion of the P-rich stars in the Galaxy and discuss nucleosynthetic scenarios that have not been considered until now or have been suggested recently, such as nonthermal nucleosynthesis. Finally, we present four updated GCE models aiming to improve our understanding of the P production in the Milky Way.
2 Spectral data and sample
2.1 APOGEE-2 survey
We used the spectral data provided by the APOGEE survey (e.g., Majewski et al. 2017) and its extension APOGEE-2 (Blanton et al. 2017), which are both part of the Sloan Digital Sky Survey (SDSS-IV). The latter combines observations from the Northern and Southern hemispheres, using the 2.5 m Sloan Foundation Telescope at the Apache Point Observatory (Gunn et al. 2006) and the 2.5 m Irénée du Pont Telescope at Las Campanas Observatory (Bowen & Vaughan 1973), respectively, alongside the corresponding APOGEE twin spectrographs (Wilson et al. 2019).
The latest data release (DR17; Abdurro’uf et al. 2022) delivered high-resolution (R ≈ 22 500) and spectra with a high signal-to-noise ratio S/N (> 100 /pixel) in the NIR H-band (λ = 1.51 μm−1.70 μm) for more than 650 000 targets in the Galaxy. The reduction procedure of the DR17 data is mostly the same as described in Nidever et al. (2015) and Holtzman et al. (2015), including various updates made in previous data releases (see Abdurro’uf et al. 2022, and references therein).
To automatically obtain stellar parameters and chemical abundances, the APOGEE Stellar Parameters and Chemical Abundance Pipeline (ASPCAP; García Pérez et al. 2016) is used. This tool is based on the optimization code FERRE (Allende Prieto et al. 2006) and MARCS model atmospheres (Gustafsson et al. 2008; Jönsson et al. 2020). In DR17, as an update to previous data releases, ASPCAP employs the synthetic spectra generated by the code Synspec (Hubeny & Lanz 2011). This change was made to enable the use of new NLTE population calculations for the elements Na, Mg, K, and Ca performed by Osorio et al. (2020). Another update was made by adopting an improved line list with respect to DR16 (Smith et al. 2021).
In short, the ASPCAP workflow is as follows: First, the MARCS atmospheres and line lists are combined to generate the grid of synthetic spectra (see, e.g., Zamora et al. 2015) using the Synspec code. The grid is then used to identify the best-matching model compared to the observed spectrum. Finally, stellar parameters and chemical abundances are derived from the best match.
2.2 Sample selection
Masseron et al. (2020a‚b) showed that their 16 P-rich stars are also significantly enriched in Si and Al, suggesting that they might be part of a larger population of Si- or Al-rich stars (e.g., Schiavon et al. 2017; Fernández-Trincado et al. 2019). Silicon displays many strong H-band absorption lines, which are accessible in a wide metallicity range, and therefore, it is one of the most precisely determined elements from APOGEE-2 spectra (Jönsson et al. 2020). Thus, the sample of Galactic Si-rich ([Si/Fe] ≳ +0.5 dex) giants previously identified by Fernández-Trincado et al. (2019, 2020) served as a starting point for us to build a sample of potentially P-rich stars. After dropping a suspected member of a binary system included in the work of Fernández-Trincado et al. (2020; discussed in Sect. 4.1.1), we ended with a group of 53 Si-rich stars that constitute the first subsample of P-stars candidates. To our analysis, we also added the 16 P-rich and metal-poor (−1.26 < [Fe/H] < −0.75) giants reported by Masseron et al. (2020a‚b) for homogeneity and consistency reasons; that is, to update their chemical abundances using the latest APOGEE-2 data release (DR17). Another subsample of 18 stars was obtained by applying the merely arbitrary conditions on the P abundance ratio [P/Fe] > 0.8 and on the overall metallicity [M/H] < −0.6 to the targets included in the Value Added Catalog (VAC) called BACCHUS Analysis of Weak Lines in APOGEE spectra (BAWLAS5; Hayes et al. 2022). This VAC explored weak and blended elemental species, such as Na, P, and S, of approximately 120000 giants with high S/N (>150 px−1) spectra in the APOGEE-2 DR17. The calculation of their chemical abundances was performed by means of the same code as employed in the present work (BACCHUS; Masseron et al. 2016), which is presented in Sect. 3.1. By merging these three subgroups, a total of 87 P-rich star candidates with overall metallicities −1.5 < [M/H] < −0.6 were found to be the input of our chemical abundance analysis.
To clearly detect (and visualize) possible chemical overabundances, a sample of field stars with similar stellar parameters as the P-star candidates was also selected to constitute a reference group. The detailed selection procedure for this reference group (or background sample) is described in Appendix A. Finally, the reference group of field stars comprises about 5500 stars.
3 Abundance calculations
3.1 BACCHUS code
The elemental abundances of interest were derived by means of the latest version (~v67) of BACCHUS (Masseron et al. 2016). As its basic functionality, BACCHUS computes synthetic spectra for a range of abundances by combining MARCS model atmosphere grids especially built for APOGEE (Gustafsson et al. 2008; Jönsson et al. 2020) with the 1D-LTE turbospectrum radiative transfer code V19.1.3 (Plez 2012), incorporating a spherical radiative transfer and the APOGEE-2 DR17 line list version 20180901t206 (Shetrone et al. 2015; Smith et al. 2021). Molecular line lists were taken from Li et al. (2015) for CO, from Sneden et al. (2014) for CN, and from Brooke et al. (2016) for OH. The generated synthetic spectra were then compared to those observed in each spectral line, allowing the measurement of abundance values on a line-by-line basis.
The input data processed by BACCHUS consist of the APOGEE-2 DR17 spectra downloaded from the SDSS-IV Science Archive Server7 together with the calibrated parameters and abundances derived by the ASPCAP pipeline (García Pérez et al. 2016). In case of duplicate entries in the ASPCAP data table, which are due to multiple observations of the same target in different fields, the entry corresponding to the highest S/N value was used. For ten stars, multiple spectra are available, but only five of them had more than one spectrum without flag (see Appendix A for a description of the flags). We do not expect a significant improvement of the measurement precision by combining them because all of these spectra have an S/N > 150. Missing entries in parameter values of the sample, for example, in Teff or log g, were replaced by the values provided by Fernández-Trincado et al. (2020), which correspond to DR16. This had to be done for five stars. The absence of parameter values in DR17 can be ascribed to warnings in the ASPCAP quality flags. Therefore, we checked the spectra of the five affected stars and found that the warnings did not influence the abundance analysis. Nevertheless, we report the source of the parameters (DR16 or DR17) in our final abundance table.
To obtain the synthetic spectra, the MARCS model atmospheres grid in spherical geometry was interpolated at the calibrated values of Teff, log g, and [M/H] from ASPCAP and the microturbulence velocity (μt) from Masseron et al. (2019), where μt is described as a function of log g. For the synthetic spectra, a Gaussian line profile was adopted to account for the line broadening through instrumental resolution, macroturbulence, and rotation. The corresponding convolution parameter (CONVOL) was determined for each spectrum by means of the Si lines because they are reliable in strength and clearness over the whole [M/H] and Teff range considered in this work.
From the synthetic spectra, the code identifies the continuum points to use for the normalization of the observed spectra. Additionally, a window of relevant pixels for the abundance determination is selected in each line.
In its latest version, BACCHUS includes five different methods that compare the observed spectrum with the synthetic spectra. Each method has its own set of quality flags in the form of integers, indicating whether the fit is of good quality (flag =1) or if a fit is considered problematic (flag ≠ 1). The different methods are more or less beneficial depending on the specific line case (Hayes et al. 2022). For example, two of the five methods (called win and int) are based on individual pixels, exactly at or around the line core, and are therefore suitable for examining heavily blended lines. The problem with using this type of methods is their sensitivity to adverse effects on the level of individual pixels. Instead, the remaining three methods (called eqw, syn, and chi2 or χ2) use multiple pixels of a line, including the wings. As a consequence, these methods are less sensitive to effects occurring in individual pixels, but may be affected by poorly fitted blends at the wings. One of the methods that uses multiple pixels, the χ2-method, minimizes the squared differences between synthetic and observed spectra. The choice of minimizing the squared differences adds weight to the core of the line, making the χ1-method less sensitive to blends at the wings compared to the eqw and syn methods, which apply a rather flat weighting over the line. We therefore chose the χ2-method to be the default method for our measurements because it has the best balance between strengths and weaknesses for our purpose and is therefore the most robust approach, especially in combination with a visual inspection intended to trace poorly fitted blends.
3.2 Line selection and processing
We started the BACCHUS iteration by fitting C, O, and N, aiming to properly subtract the corresponding molecular features because they mainly cause the blends in the lines of other species of interest. We then continued the iteration by determining the abundances of the remaining elements Na, Mg, Al, Si, S, Fe, Ce, Nd, P, and Ca. The wavelengths of the lines used in the fitting procedure are listed in Table B.1. For each element, the BACCHUS code iterated automatically until it reached convergence. To accelerate this procedure, the ASPCAP abundances were used as the initial guess. When no abundance was provided by ASPCAP, the initial guess was fixed to a common abundance value of the sample stars. For self-consistency between the abundances, we carried out a total of three iterations over all the elements.
The next step consisted of an examination of the fits, where we required that none of the methods should be quality flagged for that line to be further processed. A visual inspection of the fitting output was also performed, rejecting suspicious fits that passed the intrinsic quality flagging of BACCHUS. In this procedure, a line was rejected when the abundance values derived by the different methods disagreed significantly or when the abundance of a certain line differed notably from the values obtained in the other lines of the element. We also paid special attention to possible blends, for example, in the case of P, by observing the quality of the fit of the CO line near 15724.00 Å. Since CO features may affect the P I line at 16482.93 Å, a correctly modeled CO line near 15724.00 Å indicates that the P I is deblended from this feature. Furthermore, we visually monitored the potential blend in the P I 15711.62 Å line by a residual telluric feature. Figure 1 displays the spectra of a P-rich star compared to a P-normal star around the aforementioned lines of P I that we used for the abundance determination.
After completing the quality selection, we proceeded with the post-processing of the line-by-line abundance measurements, given for each line in the form of 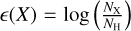 when extracted from the χ2-method. These values were converted into bracket notation4 using the solar zeropoints from Grevesse et al. (2007). In the case of P, the value from Grevesse et al. (2007) (5.36 ± 0.04 dex) is slightly lower than the solar value from Asplund et al. (2021; 5.41 ± 0.03 dex). The final abundance was then obtained by averaging the abundance over all selected lines.
when extracted from the χ2-method. These values were converted into bracket notation4 using the solar zeropoints from Grevesse et al. (2007). In the case of P, the value from Grevesse et al. (2007) (5.36 ± 0.04 dex) is slightly lower than the solar value from Asplund et al. (2021; 5.41 ± 0.03 dex). The final abundance was then obtained by averaging the abundance over all selected lines.
To determine the abundances of the approximately 5500 reference group stars, an automated run of three iterations in the same form as for the sample was performed on a supercomputer. Since a visual inspection is not viable in this approach, the employed line list was updated (see Table B.1), excluding the lines that were repeatedly problematic during the visual inspection of the sample fits. In doing this, we aimed to minimize the contribution of poorly fitted lines to the results (see Appendix C for the validation).
We complemented the results with an estimation of upper limits in cases where no valid measurement was obtained. For the sample stars, we estimated an upper limit by manually generating a set of synthetic spectra and visually choosing the best match for each line. The final upper limit for the element in question was then chosen to be the highest value out of all estimates in the lines. For the reference group, we applied the upper limit relations from Hayes et al. (2022). These linear relations depend on Teff and act as cuts for distinguishing upper limits from real measurements. Unlike Hayes et al. (2022), we applied the relations only on the usually most reliable line of each element to identify the upper limit. Because of the high quality of the APOGEE-2 spectra, the threshold t defined by Hayes et al. (2022) up to which an abundance should be detectable was imposed to be t = 1% for all the elements. In other words, if the average χ2 abundance value was lower than the corresponding relation of the best line with t = 1% (see Table 7 of Hayes et al. 2022), the value was considered an upper limit and was not reported as a measurement.
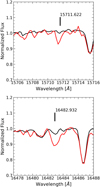 |
Fig. 1 Spectra around the P I lines at 15711.622 Å (top panel) and 16482.932 Å (bottom panel) of a P-rich (red line) and a P-normal (black line) star with similar stellar parameters: 2M18280709-3900094 (P-rich) with Teff = 4574.4 K, log g = 1.77, [M/H] = −0.95 dex, and [P/Fe] = 1.42 dex, and 2M16353092+2651591 (P-normal) with Teff = 4502.0 K, log g = 1.74, [M/H] = −0.92 dex, and [P/Fe] < 0.48 dex. |
3.3 Uncertainty estimation
We explored the influence of errors associated with the most important parameters used in the abundance derivation, that is, the systematic errors σparam,[x/Fe]. The parameters and error intervals we considered, following the analysis of Fernández-Trincado et al. (2020), are Teff ± 100 K, logg ± 0.3 dex and μt ± 0.05 km s−1. For the overall metallicity, we adopted the error [M/H] ± 0.15 dex, corresponding to the highest difference between literature and ASPCAP-derived [M/H] from García Pérez et al. (2016). In addition to these stellar parameters, we also varied the convolution parameter CONVOL. As mentioned before, this parameter accounts for several line-broadening effects and is determined based on the Si lines before iterating over the elements. When CONVOL is determined, BACCHUS provides an estimation of the corresponding error based on the root-mean-square error of the individual Si lines convolution that is used to refine this parameter. We used a typical value of this estimation as error interval, that is, CONVOL ± 1.5. To perform the uncertainty analysis, we selected two typical stars from the sample, 2M16441013-1850478 and 2M18070782-1517393, with the stellar parameters given in Table 1. We fixed their chemical composition to the є(X) values obtained from the final iteration. Thereafter, we changed one of the parameters of interest and derived the є(X) value of each element again, but without updating the chemical composition with these new є(X). In this manner, we achieved an independent error analysis of all the elements. The abundances obtained in the + and − run (e.g., Teff + 100 K and Teff − 100 K, respectively) were then compared to the original abundance values of the stars, and the highest difference was stored in σparam,[x/Fe]. The values obtained in the two runs can be found for each parameter in Table D.1.
Similar to Eq. (1) from Fernández-Trincado et al. (2020), the total uncertainty is given by the sum of the squared σparam,[x/Fe] for each element,
![$\matrix{ {\sigma _{\left[ {{X \mathord{\left/ {\vphantom {X {Fe}}} \right. \kern-\nulldelimiterspace} {Fe}}} \right]}^2\, = \,\sigma _{{T_{ef\,f}},\left[ {{X \mathord{\left/ {\vphantom {X {Fe}}} \right. \kern-\nulldelimiterspace} {Fe}}} \right]}^2\, + \,\sigma _{\log \,g,\left[ {{X \mathord{\left/ {\vphantom {X {Fe}}} \right. \kern-\nulldelimiterspace} {Fe}}} \right]}^2} \hfill \cr {\quad \quad \quad \,\,\,\, + \sigma _{{\mu _t},\left[ {{X \mathord{\left/ {\vphantom {X {Fe}}} \right. \kern-\nulldelimiterspace} {Fe}}} \right]}^2\, + \,\sigma _{\left[ {{M \mathord{\left/ {\vphantom {M H}} \right. \kern-\nulldelimiterspace} H}} \right],\left[ {{X \mathord{\left/ {\vphantom {X {Fe}}} \right. \kern-\nulldelimiterspace} {Fe}}} \right]}^2\, + \,\sigma _{CONVOL,\left[ {{X \mathord{\left/ {\vphantom {X {Fe}}} \right. \kern-\nulldelimiterspace} {Fe}}} \right]}^2.} \hfill \cr } $](/articles/aa/full_html/2023/05/aa46048-23/aa46048-23-eq2.png) (1)
(1)
We found that the largest σparam,[x/Fe] is related to Teff and log g followed by CONVOL, meaning that uncertainties in these parameters have the highest impact on the final abundances. In contrast, deviations in [M/H] and μt do not have a great influence. The final systematic errors ![$\sigma _{\left[ {{\rm{X/Fe}}} \right]}^2$](/articles/aa/full_html/2023/05/aa46048-23/aa46048-23-eq3.png) are also listed in Table D.1.
are also listed in Table D.1.
Another estimation of the uncertainty is provided by the line-to-line random error or standard deviation σstdev,[χ/Fe], calculated for each element simultaneously to the final abundances. When the abundance is based on one spectral line only, the standard deviation was set to be a typical value, that is, the average σstdev‚[x/Fe] of that element over all the sample stars. The average σstdev‚[x/Fe] alongside σ[X/Fe] is given in Table D.2. Both types of errors are on the same order of magnitude for nearly every element. In general, σ[X/Fe] is lower than or equal to 0.20 dex, except for S in 2M18070782-1517393, which reflects the strong temperature dependence of the S lines (see Sect. 4.2.3). The abundances of C, O, and N are also highly dependent on temperature because the measurements of these species are mainly based on molecular lines. This explains the relatively strong deviation toward higher values of σ[X/Fe] compared to σstdev‚[X/Fe].
For clarity, we provide a general error bar in the following figures, corresponding to the typical (average) σstdev‚[X/Fe]. This is listed in Table D.2.
All parameters, abundances, and standard deviations obtained by the approach outlined in Sect. 3 for the entire sample described in Sect. 2.2 are available in electronic form at the CDS. A preview including only the abundance results is given in Table 2.
Parameters of the two stars used for the uncertainty estimation.
4 Sample analysis
4.1 Refining the sample: Outliers and special cases
As described in Sect. 2.2, the sample is composed of three subgroups. Two of them potentially host P-rich stars, and the third is already proved to be P-rich.
The selection of 18 additional stars from the VAC (Hayes et al. 2022) by applying rather arbitrary conditions ([P/Fe] > 0.8 dex and without imposing ASPCAPFLAG = 0) aimed to uncover possible underestimates of their P abundance made in the catalog. Recalculating the abundances of these stars confirmed the results from the VAC in some cases, meaning that not all of the stars contained in this subgroup can be called P rich. Except for this expected reduction, some more stars are not P rich for various reasons. In the following, we point out each case separately and justify the rejection before we present the final chemical signature in Sect. 4.2.
In total, 9 out of the initial group of 87 stars were excluded, leading to a final sample of 78 stars. This is still the largest number of P-rich giants to date. It is necessary here to clarify that we did not systematically search for P-rich stars in the APOGEE-2 DR17 with more than 650000 targets, as was done previously in DR14 (263 000 targets; Abolfathi et al. 2018) to find the first set of P-rich stars (Masseron et al. 2020a). This means that our final number of 78 P-rich stars has to be regarded as a lower limit because we expect more undiscovered P-rich stars to be present in DR17.
Stars that show outstanding properties compared to the reference group become visible in various planes of the abundance versus abundance diagrams. In the following, we use the [Al/Fe]-[Mg/Fe] plane to spot outliers that might be related with GCs. Additionally, we examine the [P/Fe]-[Si/Fe] plane with the aim to define a limit on the P abundance that indicates whether a star can be considered as P rich. When outliers were detected, we analyzed their properties and decided whether they should be included in the P-rich sample or be eliminated from the current study. The detected outliers and finally excluded stars are listed in Table 3 alongside their abundance values.
The [Al/Fe]-[Mg/Fe] plane is shown in Fig. 2. Two stars of the sample can be found in the Mg depleted region of Fig. 2, 2M22375002-1654304 and 2M14513934-0602148 (green stars). For the first star, the abundance values from Table 3 are in accordance with the results from Fernández-Trincado et al. (2020), showing a chemical pattern consistent with a second-generation GC star or escapee. The low upper limit of the [P/Fe] value of 2M22375002-1654304 caused us to drop this star from the P-rich sample. The chemistry of the second star, 2M 14513934-0602148, is also compatible with that of a GC star or escapee. Like for 2M22375002-1654304, it was only possible to give an upper limit instead of an actual value for the P abundance of 2M 14513934-0602148. This star was therefore also removed.
Another discovery from the [Al/Fe]-[Mg/Fe] plane is related to the background sample. Several stars of the background sample in Fig. 2 (violet crosses) show characteristics of GC stars, but passed the cross matching of the two GC catalogs (see Appendix A), meaning that these stars are currently not included in these catalogs or are GC escapees. Two of these outliers, 2M12155306+1431114 and 2M17350460-2856477 (dark violet crosses), present high values of [O/Fe] and [N/Fe], indicating that they are not GC escapees. It is possible that they belong to a set of N-rich stars in the inner Galaxy (Schiavon et al. 2017), although they do not have the same stellar parameters as the N-rich stars. The nature of these outliers still has to be investigated in a different context. In the following, we have eliminated them from the background sample.
The second plane, [P/Fe]-[Si/Fe] (Fig. 3), was used to search for a cut in the P abundance that defines P-rich stars. In Fig. 3, no background sample is plotted because of the bias toward high metallicity in the VAC stars and the low reliability of the automated [P/Fe] determination (see Appendix C). The plot reveals that five stars, 2M04371861-5916494, 2M06330984-6104151, 2M06394177-6757357, 2M 16485945-2647326, and 2M 17073023-2717147 (orange star symbols), have relatively low values of P and Si, combined with upper limits or uncertain measurements of P. Furthermore, they do not show similarities with the group regarding the O, Mg, Al, and Ce abundances, as we discuss in the following. Three of these stars, 2M06330984-6104151, 2M06394177-6757357, and 2M 16485945-2647326, belong to the subgroup of 18 stars that was filtered out of the VAC. In this case, the P abundances were most likely overestimated by the VAC, and we decided to exclude these stars from the P-rich sample. Finally, given the cut [P/Fe] < 0.8 dex arising from Fig. 3, stars with [P/Fe] < 0.8 dex are not counted to our P-rich sample. This is a slightly lower value than the empirical cut [P/Fe] < 1.0 dex used by Masseron et al. (2020a).
The last candidate eliminated from the sample is 2M15170852+4033475 (blue star). This star presents suspiciously high upper limits in N, O, Na, Ce, and Nd, resulting from the poor quality of the spectrum, which also complicates a proper measurement of the P abundance. We therefore decided to reject this star.
As mentioned at the beginning of this section, nine stars were eliminated of the P-rich star candidates group. In summary, we excluded stars with [P/Fe] < 0.8 dex, GC characteristics (Mg depleted and Al enhanced) and no constraining (i.e., too high) upper limits. The remaining sample of 78 stars represents a fraction of approximately 0.24% out of all APOGEE-2 DR17 giants with similar stellar parameters (Teff, log g, and [M/H]). We emphasize again that this percentage has to be regarded as a lower limit.
Final abundance ratios of the studied sample (87 stars).
Abundance table of outliers, peculiar cases, and finally excluded stars.
 |
Fig. 2 Abundances in the [Al/Fe]-[Mg/Fe] plane, showing the background stars (gray color-coded density map) and the full P-rich candidates sample (black circles) described in Sect. 2.2. Empty black circles represent upper limits in [P/Fe]. Outliers identified in this or the plane shown in Fig. 3 are highlighted with orange, green, and blue stars. The red star corresponds to the P-rich GC (M4) member 2M16231729-2624578. Violet crosses indicate outliers in the background sample with GC characteristics, two of which (dark violet crosses; 2M12155306+1431114, 2M 17350460-2856477) have a high [O/Fe] abundance ratio. As defined in Sect. 3.3, the error bar represents the typical standard deviation of the elements listed in Table D.2. |
 |
Fig. 3 Abundances in the [Si/Fe] vs. [P/Fe] plane. The symbols are the same as in Fig. 2. The error bar represents the typical standard deviation of the elements listed in Table D.2. No background stars are displayed because the reliability of the P abundances obtained by the automatic calculation is limited (see Appendix C for further justifications). |
4.1.1 Double-lined spectroscopic binary 2M17171752-2148372
As pointed out in Sect. 2.2, while discovering the Si-rich stars, Fernández-Trincado et al. (2020) also analyzed a binary member with ID 2M17171752-2148372. In DR17, this star is flagged, indicating that 2M17171752-2148372 might be a double-lined spectroscopic binary (SB2)8. The identification of SBs indicated by the flag is based on the work of Kounkel et al. (2021). A visual inspection of the spectrum confirms that 2M 17171752-2148372 is part of a binary system.
The abundance values corresponding to 2M 17171752-2148372 are listed in the penultimate line of Table 3. The strikingly high upper limit of P is caused by the fact that the second P I line (16482.93 Å) is close to the CCD edge, and therefore, the measurement quality is poor. When only the first P I line (15724.00 Å) is considered, the abundance value would be [P/Fe] = 1.18 dex, manifesting an enhancement in P. This finding, if confirmed, is interesting because it suggests that the P-rich star progenitor may also affect a binary system, for example, by polluting the material from which one or more components were born. Nevertheless, we decided to exclude this star from the current study because of the spectral quality and because the stellar parameters might be suspect, for example, due to contamination of the spectrum through the companion. We aim to revisit the special case of 2M 17171752-2148372 in future works.
4.1.2 Other possible binary stars
We identified other possible binary stars in the sample by searching for a radial velocity (RV) scatter higher than 1 km s−1 (or higher than ten times the median of the individual visit RV errors)9. Applying this criterion, we found four stars in the sample that are likely binaries: 2M 18043255-4819138, 2M 19193412-2931210, 2M 17033361-2254246, and 2M 13303961+2719096 with 13.14 km s−1, 2.42 km s−1, 1.76 km s−1, and 1.22 km s−1, respectively.
We recall that although the RV scatter of the remaining 74 stars is lower than 1 km s−1, they might also be binaries. Because the RV scatter is derived from the RV measurements obtained in various visits, a significant scatter can only be detected when the visits are sufficiently separated in time. To evaluate the reliability of the low RV scatter results, we analyzed the RV measurements on the visit level. We applied the recommended quality cuts9 and found that 72 stars have at least one visit that is not flagged. We then extracted the number of valid visits (Nvisits) and the corresponding modified Julian date (MJD) to calculate the maximum time lag ΔTmax between the visits. Out of the 72 stars, 13 have been visited only once, meaning that the RV scatter is set to be zero and no conclusion on binarity can be drawn in these cases. In Fig. 4 we display the RV scatter versus the maximum time lag ΔTmax, color-coded by the number of visits. The accumulation of points at ΔTmax = 1 day corresponds to stars that have been visited on consecutive days, which means that the reliability of the RV scatter for these stars can be regarded as low. Imposing the conservative condition that at least 1000 days should have passed between the visits in order to trust the low RV scatter value, we find that the RV of 7 stars did not vary over a long period of time, meaning that a close binary scenario can be discarded in these cases. For the less conservative case and when the criterion is applied that 100 days should have passed between the visits, 30 stars are likely non-binaries. Although few binary stars are present in the sample, the previous considerations show that the majority of the sample stars is not part of close binary systems. Instead, if they were part of widely separated binary systems, we would not expect significant interaction to take place between the components. We therefore conclude that the P-richness cannot be attributed to a binary mass-transfer scenario.
 |
Fig. 4 RV scatter vs. maximum time lag ∆Tmax between visits that are color-coded by the number of visits. Stars with fewer than two visits have been excluded. |
4.1.3 Globular cluster member 2M 16231729-2624578
By cross-matching the GC catalog based on Harris (1996; see Appendix A) and inspecting the information provided by the ASPCAP flag that indicates possible GC members, we are able to report the first detection of a P-rich star in a GC, namely M4. The chemical abundances of this star with ID 2M16231729-2624578 are presented in the last line of Table 3. In Figs. 2 and 3, we highlight 2M 16231729-2624578 with a red star. We know from Yong et al. (2008) that M4 is a peculiar GC, rich in slow-neutron capture (s-process) elements (Ce, Ba, and Pb) with a mean [Ce/Fe] abundance ratio of 0.46 ± 0.07 dex (Contursi et al. 2023). The Ce abundance of 2M 16231729-2624578 is compatible with this mean.
In addition to the slight enhancement in Ce and the C-N anti-correlation typical for GCs, this star also presents an enrichment in P, with [P/Fe] = (1.00 ± 0.14) dex10, O and Al, and moderate enhancements in Si and Mg (see Table 3) compared to the P-rich group. Although its [Al/Fe] is higher than 0.3 dex, the limit used by Mészáros et al. (2020) to separate first- (unenriched) and second-generation (enriched) GC stars, there is no depletion in O and Mg. This abundance pattern suggests that 2M 16231729-2624578 presumably belongs to the first generation and may have been polluted by the P-rich star progenitor, implying that the pollution or the progenitor timescale is short compared to the typical evolution timescale of GCs. A second-generation status for this star is probably less likely because it would produce a different chemical pattern, in particular, much higher Al and Si than observed.
The presence of a P-rich star in a GC enhanced in s-process elements could give rise to the speculation that the P-rich star progenitor must be an AGB star, the stellar site where the 5-process mainly takes place. However, this hypothesis has already been ruled out by Masseron et al. (2020b) based on discrepancies in the light element abundance pattern. Our finding that 2M 16231729-2624578 belongs to M4, however, supports the assumption from Masseron et al. (2020b) that the P-rich star progenitor has undergone a neutron-capture process similar to the s-process. Overall, we can state that regardless of what the progenitor of the P-rich stars turns out to be, it must have been present in M4 as well.
4.2 Chemical signature of the final sample
4.2.1 Phosphorus
The behavior of the P abundance in our final sample of 78 P-rich stars compared to literature values is shown in Fig. 5. The top panel, an updated version of Fig. 1 from Masseron et al. (2020a), shows the abundance ratio [P/Fe] versus metallicity [Fe/H] of the enlarged sample, covering a slightly wider [Fe/H] range than the 16 P-rich stars from Masseron et al. (2020a‚b). At this point, we again refer to Fig. 1, which illustrated the spectral difference between a P-rich and a P-normal star with similar stellar parameters.
Although some stars near [Fe/H] = −0.8 dex fall below the empirical line drawn by Masseron et al. (2020a) at [P/Fe] = 1.00 dex, we count them to the P-rich sample because they do not fulfill the exclusion criteria defined in Sect. 4.1, and their overall chemical signature, which is discussed in the following subsections, fits the characteristic group of P-rich stars. Nevertheless, this updated version also shows a clear separation between the sample and the reference group. The plot [P/Fe] versus Teff in the bottom panel of Fig. 5 demonstrates that there is no trend of [P/Fe] with Teff, suggesting that the P lines are unaffected by NLTE effects.
In Fig. 6 we plot the abundance ratios [X/Fe] of the remaining elements considered in this work versus [Fe/H]. Figure E.1 shows the same abundance ratios [X/Fe] versus Teff. As in the bottom panel of Fig. 5, the [X/Fe] versus Teff in Fig. E.1 rules out possible trends with Teff. In Fig. 6 we identify other enriched elements in our P-rich sample: the α-elements O and Si, the odd-Z element Al, and the heavy neutron-capture element Ce. In the cases of Mg and Nd, overabundances are present in some stars. We also plotted [(C+N)/Fe] versus [Fe/H] (Fig. 7) to explore a possible enhancement in C+N, which is discussed in the next section. For the following, more detailed discussion of certain elements, a zoom into the corresponding [X/Fe] versus [Fe/H] panel of Fig. 6 is provided in Figs. 8 (for Si) and F.1–F.5 (for O, Mg, Al, Ce, and Nd, respectively) alongside a [X/Fe] versus [P/Fe] plot to illustrate their correlated relation with P. A summary of the identified enhancements is given in Fig. 9, where we compare the median chemical abundances of the P-rich stars with those of the background sample. In the case of P, we compare the P-rich sample to the median abundance of the literature values shown in Fig. 5.
 |
Fig. 5 Abundance ratio [P/Fe] vs. metallicity [Fe/H] (top panel) and vs. effective temperature Teff (bottom panel) of the final sample of 78 P-rich stars (black dots). Downward triangles indicate upper limits in [P/Fe]. Literature values are shown with open black squares (Jacobson et al. 2014), crosses (Maas et al. 2017, 2019), diamonds (Masseron et al. 2020a), and plus signs (Caffau et al. 2011, 2019). Typical errors are indicated in the top left corner. |
4.2.2 Carbon and nitrogen
The amounts of C and N observed in the P-rich stars may arise from a superposition of different origins. In general, C is made during He-burning in CCSNe and AGB stars (Hawkins et al. 2016; Kobayashi et al. 2020). Nitrogen is produced by the CN(O)-cycle in H-burning conditions in nearly all types of stars, including low-mass red giant branch stars such as the P-rich stars. We note a slight enhancement of N in Fig. 6, which can be caused by intrinsic production or pollution from the progenitor. Because the CN-cycle consumes C and produces N, their respective amounts may change over the evolutionary phases, but the sum of C+N remains constant in the P-rich stars (see, e.g., Masseron & Gilmore 2015; Hawkins et al. 2015). Thus, it is reasonable to plot the [(C+N)/Fe] abundance ratio versus [Fe/H] in order to explore whether C is produced in the P-rich star progenitors. Figure 7 reveals that the majority of the sample stars is not enhanced in C+N compared to the background stars. Masseron et al. (2020b) already indicated this lack of an enhancement. This observation is also supported by Fig. 9, which does not allow us to state an enhancement of C+N within the current error intervals. The right panel of Fig. 7 also shows that C+N and P are not clearly correlated, and we therefore conclude that the C production is not a direct attribute of the P-rich star progenitors.
4.2.3 α-elements
Figures 6, 8, 9, E.1‚ and F.1 show that the α-elements O and Si are clearly enhanced in the P-rich stars, confirming the results from Masseron et al. (2020a‚b). The right panel of Fig. 8 illustrates the correlation between Si and P. This correlation implies that it is possible to detect P-rich stars through the measurement of Si lines, which is convenient because they are much more accessible in the NIR than P lines. The enhancements in O and Si are accompanied by a small enhancement of Mg in only some of the stars. Compared to the background stars, a clear overall Mg-rich signature for the P-rich stars is not observable within the current errors (Fig. 9). Nevertheless, Fig. F.2 allows us to report a correlation between Mg and P. Figure 2 shows that Mg is also correlated with Al. This interconnection leads us to the conclusion that although not clearly enhanced, the behavior of the Mg abundance is coupled with the P-richness, confirming the results from Masseron et al. (2020a). The large star-to-star abundance scatter in Fig. 9 can be explained by the broader P abundance range considered in this work, which naturally leads to a broader Mg abundance range due to the correlation.
Similar to Masseron et al. (2020a‚b), we find that S and Ca are not enhanced, which is unexpected because these α-elements should be correlated with Si (Thielemann et al. 1996). However, it is necessary here to clarify that in the case of S, the background stars in Figs. 6, 9 and E.1 are taken from the VAC (Hayes et al. 2022) because S was added to the group of studied elements after the supercomputer run. Furthermore, the results from the VAC were obtained with a careful line selection and are therefore more suitable for the comparison than an automated calculation. Because the S lines in cool metal-poor stars are affected by blends and temperature dependences (see Hayes et al. 2022), it is difficult to determine a reliable abundance of S, even with a visual inspection as we did for the sample. Hence, the results for S have to be treated with caution.
In contrast, there was no difficulty in measuring the Ca abundance based on the five lines that are present. In general, the Ca lines are clear and strong, leading to more robust abundance results. We therefore state that the normal Ca abundance shown in Fig. 6 is reliable and that it belongs to the characteristic fingerprint of P-rich stars (Fig. 9). We conclude that the process that causes the enhancements of Si does not produce higher S and Ca abundances.
 |
Fig. 6 Abundance ratios [X/Fe] vs. metallicity [Fe/H], displaying one element X in each panel. Gray downward triangles indicate upper limits. The background sample was selected and the corresponding abundances were calculated following the procedure described in Sects. 2.2 and 3.2, respectively. In the case of S, the background stars and their corresponding abundances have been extracted from the VAC from Hayes et al. (2022). The color-coding reflects the number density of the stars. For clarity, error bars are suppressed. The errors adopted for each element are given in the title of each panel and correspond to the average standard deviation listed in Table D.2. The error of the metallicity [Fe/H] is ±0.08. |
4.2.4 Sodium and aluminum
In the spectral range covered by APOGEE-2, the odd-Z element Na exhibits two lines that are both affected by CO blends (Hayes et al. 2022). We found that the Na abundance could only be measured for a small number of stars. In these cases, the measurements are mostly based on one of the two available lines. For the majority of the sample stars, only upper limits could be provided. Although the measurements for Na given in Figs. 6 and E.1 have to be handled with caution because of the blends, we can conclude from the figures that Na is not enriched in our P-rich stars.
Unlike Na, the other odd-Z element Al is easily measurable because three of the four spectral lines are strong and provide consistent abundance values. Thus, the results presented in Figs. 6, E.1 and F.3 only consist of real measurements, showing that the detected enrichment and correlation is reliable. It is known that in the NIR H band, the strong Al lines are affected by NLTE effects and that the abundance results obtained in this spectral region differ from the results obtained in the optical (Masseron et al. 2020a). To account for NLTE effects, it is possible to implement coefficients that correct for departures from LTE (see, e.g., Amarsi et al. 2020). As a result, the absolute abundance scale can be improved. In this work, we did not use coefficients like this because we used a differential approach to identify enhancements under the assumption that the background stars are affected by NLTE effects in the same way.
 |
Fig. 7 Detailed representation of the [(C+N)/Fe] abundance ratio. Left panel: abundance ratio [(C+N)/Fe] vs. metallicity [Fe/H]. Stars with upper limits in C or N have not been considered. Right panel: [(C+N)/Fe] vs. [P/Fe]. Solid circles correspond to real measurements in P, and empty circles denote upper limits in P. In both panels, the error of [(C+N)/Fe] was defined as the quadratic sum of the standard deviation of the C and N measurements. |
 |
Fig. 8 Detailed representation of the [Si/Fe] abundance ratio. Left panel: zoom into the [Si/Fe] vs. [Fe/H] plot of Fig. 6. Right panel: [Si/Fe] vs. [P/Fe]. Solid circles correspond to real measurements in both Si and in P, and empty circles denote upper limits in P. |
4.2.5 Cerium and neodymium
The first heavy neutron-capture element that we considered is Ce. The measurement of Ce is robust, and its enhancement in the P-rich stars is visible in Figs. 6, E.1 and F.4. Regarding future investigations, the Ce abundance is of great interest, for example, to explore the relation between P-rich stars and the peculiar GC M4 mentioned in Sect. 4.1.3.
Measuring the second heavy neutron-capture element Nd is, similar to Na, a complex issue. The three lines available in the APOGEE-2 DR17 spectral range are in general weak and blended, leading to a small number of real measurements in Figs. 6, E.1, and F.5. Instead, there is a high number of upper limits. In the low-metallicity region, there is a lack of reference stars, making it difficult to evaluate a possible enrichment of Nd in the P-rich stars. A correlation with P cannot be observed in Fig. F.5 because only a few real measurements are available. Figure E.1 also reveals the limitation of the Nd measurement with temperature. At higher Teff, it is not possible to detect low amounts of Nd, resulting in a biased selection. Although the comparison of the median values in Fig. 9 suggests a slight enhancement of Nd, we are not able to declare with certainty that P-rich stars are also enhanced in Nd. However, the Nd abundances obtained from optical spectra in the two P-stars from Masseron et al. (2020b) are consistent with our results.
In summary, a comparison of Fig. 9 with Fig. 4 from Masseron et al. (2020a) shows that the chemical signature revealed in this work, although containing fewer elements, but a larger number of stars, supports the results reported by Masseron et al. (2020a). In addition to P, we confirm the enhancements in O, Mg (for part of the stars), Al, Si, and Ce. Instead, the possible enhancement of Nd remains unclear, and we do not report a relation between the C+N and P abundances.
Additionally, we have robust evidence for rather normal abundances of S and Ca. The hypothesis made by Masseron et al. (2020a) that P-rich stars are part of a larger family of Si- and Al-rich stars is also confirmed by our results. In this context, we highlight the clear correlations between P and the enhanced species, as illustrated in Figs. F.1–F.4, which naturally leads to a correlation among these species, for example, between Si and Al. We also recall that there is also a correlation between Mg and P, even though Mg is not enhanced in the entire sample.
A last general aspect about the chemical fingerprint of the P-rich stars is related to their metallicity. Although our [Fe/H] range of the P-rich stars is slightly broader (−1.36 dex < [Fe/H] < −0.58 dex) than the rather narrow range from Masseron et al. (2020a), we confirm for now that P-rich stars can only be found at low metallicities, meaning that during this work, we did not detect any P-rich star with [M/H] > −0.6 dex. We found that the VAC (Hayes et al. 2022) contains 37 stars with [M/H] > −0.6 dex and [P/Fe] > 0.8 dex, but a reanalysis of a random sample of 6 of these stars showed that they are not P rich. Extrapolating this result, we tentatively conclude that the low metallicity is indeed characteristic of P-rich stars and not a bias of the searching algorithm used in Masseron et al. (2020a).
 |
Fig. 9 Chemical abundance pattern of our sample of P-rich stars. Dark red stars correspond to the median chemical abundance of the P-rich sample, and gray dots show the median chemical abundance of the background sample. Stars with upper limits were excluded from the median. The red and gray error bars denote the corresponding average line-to-line abundance scatter (typical standard deviation) from Table D.2, which reflects the quality of the measurements. We also provide the star-to-star abundance scatter of the sample as dotted error bars to reflect the spread of abundances. In the case of P, the gray dot indicates the median abundance of the literature values shown in Fig. 5, and the gray error bar shows the mean error of the literature values. |
5 Search for the P-rich star progenitor
We begin this section by presenting some detailed GCE models for the Milky Way. We then revisit the possibility of an extragalactic origin of the P-rich stars by performing an orbital analysis. To conclude the discussion, we compare the outcome of potential nucleosynthetic scenarios with the chemical composition of the P-rich stars, including a new theory that was proposed recently.
5.1 Galactic chemical evolution of P with theoretical models
More recent calculations have provided new insights into possible additional sources of P in the Galaxy that might be related to the formation of P-rich stars. The impact of fast-rotating massive stars for the GCE of P was studied by Kobayashi et al. (2011) and more recently by Prantzos et al. (2018). Both studies showed a marginal effect of rotation on the production of P in the Galaxy. Ritter et al. (2018a) instead studied the impact of C-0 shell mergers on the element production in massive stars and on chemical evolution of odd intermediate-mass elements. Their preliminary results show that these events might even boost the production of P in CCSN ejecta by up to an order of magnitude, and if 10-50% of CCSNe were affected by C-O shell mergers, the GCE evolution of [P/Fe] and its observed dispersion might be reproduced. However, C-O shell mergers are convective-reactive events that require multidimensional hydrodynamics simulations (e.g., Andrassy et al. 2020; Yadav et al. 2020). While calculations by Ritter et al. (2018a) provide valuable insights into the possible nucleosynthesis in C-O shell mergers, they are mostly qualitative, without further guidance from stellar hydrodynamics simulations to implement in the next generations of one-dimensional massive star models and CCSN yields for GCE (e.g., Ritter et al. 2018a; Cristini et al. 2019; Andrassy et al. 2020; Schatz et al. 2022). In order to place P-rich and P-normal stars in the same astrophysical context and discuss them, we present four GCE models for the Milky Way in this section.
The GCE simulations were made using the Python code OMEGA+11 (Côté et al. 2018). This is a two-zone model comprised of a central, star-forming, cold gas reservoir modeled using the code OMEGA12 (Côté et al. 2017), surrounded by a non-star-forming, hot gas reservoir considered as the circumgalactic medium (CGM).
At each time step, we followed the evolution of the CGM and the internal star-forming region. The evolution of the mass of the gas in the CGM (MCGM) follows
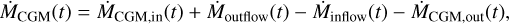 (2)
(2)
where ṀCGM‚in is the inflow rate from the external intergalactic medium into the CGM, Ṁoutflow is the mass removed from the central galaxy and added to the CGM via outflow, Ṁinflow is the gas that flows into the galaxy from the CGM, and ṀCGM‚out is the outflow rate of gas from the CGM into the intergalactic medium. The evolution of the galactic gas mass is then defined as (Tinsley 1980; Pagel 1997; Matteucci 2012)
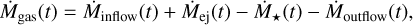 (3)
(3)
where Ṁinflow is the mass added by galactic inflows from the CGM, Ṁej is the mass added by stellar ejecta, Ṁ✶. is the mass locked away by star formation, and Ṁoutflow is the mass lost by outflows into the CGM. Gas infalls into the galaxy from the CGM using a dual-infall model based on Chiappini et al. (1997). This prescription for gas infall combines two exponential gas inflow events and is described as
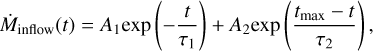 (4)
(4)
where A1, A2, τı, τ2, and tmax are free parameters that are presented in Table 4.
The star formation rate is defined as
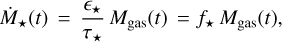 (5)
(5)
where є⋆ and τ⋆ are the dimensionless star formation efficiency (sfe) and star formation timescale, respectively. The outflow rate is proportional to the star formation rate and is defined as
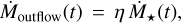 (6)
(6)
where η, the mass-loading factor, is a free parameter and controls the strength of the outflows. The values for f⋆ and η are found in Table 4. To follow the chemical evolution, we calculated the mass of the gas added by stellar ejecta at each time step. To do this, simple stellar populations (SSPs) were generated at each time step by the code stellar yields for galactic modeling applications (SYGMA; Ritter et al. 2018b). An SSP is a population of stars with the same age and chemical composition, with the number of stars of each mass given by the initial mass function (IMF) of Kroupa (2001).
We can include yields from low- and intermediate-mass stars, massive stars, SNIa, and neutron star mergers. Other additional sources can be added manually by the user. Ejecta from SSPs is instantaneously and uniformly mixed into the gas reservoir at each time step. To calculate the mass of the gas added to the galaxy by stellar ejecta, the contribution of every stellar population formed by time t is summed so that
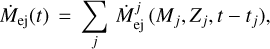 (7)
(7)
where 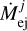 is the mass ejected by the jth stellar population, Mj is the initial mass of the population, Zj is the initial metallicity of the population, and t − tj is the age of the jth population at time t. The stellar yield sets used by each of these models are summarized in Table 5. In summary, all models use the FRUITY asymptotic giant branch (AGB) yields from Cristallo et al. (2015) and the SNIa yields of Iwamoto et al. (1999). Model CLC uses the rapidly rotating, massive star yields of Limongi & Chieffi (2018), where low-metallicity stars rotate faster than high-metallicity stars according to the mixed rotational velocity prescription of Prantzos et al. (2018). CRit(del) uses the massive star yields of Ritter et al. (2018c) with C-O shell mergers and the delayed explosion prescription, while CRit(rap) uses the same yields, but with the rapid explosion prescription. Finally, CNom uses the massive star yields of Nomoto et al. (2013).
is the mass ejected by the jth stellar population, Mj is the initial mass of the population, Zj is the initial metallicity of the population, and t − tj is the age of the jth population at time t. The stellar yield sets used by each of these models are summarized in Table 5. In summary, all models use the FRUITY asymptotic giant branch (AGB) yields from Cristallo et al. (2015) and the SNIa yields of Iwamoto et al. (1999). Model CLC uses the rapidly rotating, massive star yields of Limongi & Chieffi (2018), where low-metallicity stars rotate faster than high-metallicity stars according to the mixed rotational velocity prescription of Prantzos et al. (2018). CRit(del) uses the massive star yields of Ritter et al. (2018c) with C-O shell mergers and the delayed explosion prescription, while CRit(rap) uses the same yields, but with the rapid explosion prescription. Finally, CNom uses the massive star yields of Nomoto et al. (2013).
In Fig. 10, the results of the GCE simulations are shown compared to the observations of P-normal stars (Hinkel et al. 2014) and of P-rich stars. In the top panel, the abundance trend of [P/Fe] confirms what we discussed before for P-normal stars. While the solar [P/Fe] is reproduced from GCE models, theoretical predictions underproduce the [P/Fe] at metallicities lower than solar, consistently with previous results in the literature. In GCE calculations, most of the P is made in CCSN models by local neutron captures starting from Si isotopes, both before the CCSN explosion in the convective C shell and in explosive C-burning (Woosley & Weaver 1995; Woosley et al. 2002; Pignatari et al. 2016). Therefore, P is made in different parts of the ejecta compared to Fe, which instead is the main product of explosive Si burning. In these conditions, CCSN yields are the dominant source of uncertainties for GCE simulations (e.g., Romano et al. 2010; Mollá et al. 2015; Mishenina et al. 2017; Matteucci 2021). While the production of CCSN yields for GCE calculations are delivered by one-dimensional stellar models, several uncertainties still affect the last evolutionary stages of massive star progenitors (see, e.g., Ritter et al. 2018a) and multidimensional simulations of CCSN explosions (Burrows & Vartanyan 2021, and references therein). Concerning our analysis in this work, although the P-enrichment in P-rich stars is not a GCE product but most likely is a signature of local stellar nucleosynthesis, we can compare these stars with GCE results for qualitative purposes. As shown already by Masseron et al. (2020a), the [P/Fe] predicted by GCE is about a factor of ten lower than P-rich stars.
In the middle panel of Fig. 10, we show the evolution of the [Mg/O] ratio with metallicity. As we have discussed in the previous sections, in P-rich stars, both [O/Fe] and [Mg/Fe] may be enhanced with respect to solar. However, the [Mg/O] ratio in P-rich stars is rather consistent with other Milky Way stars considering both errors and lower limits. In particular, [Mg/O] is well reproduced by GCE simulations. The bulk of Mg and O in the Galaxy is made by massive stars (e.g., Woosley et al. 2002). O is mostly made in He-burning conditions in the stellar progenitor by the 12C(α,γ)160 reaction. Mg is made as 24Mg during hydrostatic shell C-burning evolving on the previous He-core ashes, via the α-capture sequence 16O(α,γ)20Ne(α,γ)24Mg and directly from the C-fusion products 20Ne and 23Na (e.g., Chieffi et al. 1998; Rauscher et al. 2002; Pignatari et al. 2016; Sukhbold et al. 2016; Curtis et al. 2019). They are both ejected together in the O-rich stellar layers, with only minor modification by CCSN nucleosynthesis (Thielemann et al. 1996). Because massive stars are the only relevant galactic source for Mg and O, their relative GCE ratio is therefore simply given by the relative ratios from the CCSN stellar yield sets used for the calculations. The GCE models in Fig. 10 show a [Mg/O] variation of about 0.2 dex at solar metallicities, which reflects the variation in the CCSN yields we adopted (see Table 5). This dispersion tends to increase with decreasing [Fe/H], in particular, for model CLC. This is due to the enhanced production of O in the external layers in massive star models induced by rotation (e.g., Limongi & Chieffi 2018), which are used in model CLC. In summary, while both Mg and O may be enhanced in P-rich stars, their relative ratio is overall consistent with the theoretical ratios from typical CCSN yields used for GCE calculations, and it is consistent with ratios obtained in shell C-burning stellar layers.
In the bottom panel, we finally show the evolution of the [Si/S] ratio with [Fe/H]. Even though different CCSN yield sets are used, the GCE models show a solar [Si/S], with a variation smaller than 0.1 dex between them. Si and S in the Galaxy are mostly made by CCSNe, with a relevant contribution from SNIa (e.g., Kobayashi et al. 2020). For all the CCSNe models we considered, Si and S are produced in the same CCSN layers and are ejected together, mostly as a direct product of explosive O-burning (e.g., Pignatari et al. 2016). Therefore, GCE models typically carry the same [Si/S] ratios as are generated in these layers from the CCSN yields. Instead, a significant fraction of P-rich stars tend to show a [Si/S] higher than solar due to the Si-enrichment. This decoupling in the nucleosynthesis signature of Si and S observed in P-rich stars is indeed puzzling and difficult to match with typical stellar models. Si and S are also produced in the same parts of the ejecta in SNIa, showing a similar relative production for different progenitor masses (e.g., Iwamoto et al. 1999; Gronow et al. 2020; Nomoto & Leung 2018). We note that P-normal stars at metallicities [Fe/H] ≳−0.5 seem to show a significant [Si/S] variation, between −0.5 dex and super-solar [Si/S] up to about 0.5 dex. Therefore, we cannot exclude that a small number of P-normal stars has anomalous [Si/S] ratios.
To summarize, P-rich stars represent a really interesting challenge for nuclear astrophysics. For instance, they might be the main fingerprints of a new P stellar nucleosynthesis component that is still missing in GCE calculations. Since the production of P is disentangled from the production of Fe, it is in principle simple to find stellar sources with high [P/Fe] abundance ratios. However, in this section, we discussed the anomalous [Si/S] ratio as an example, which provides strong constraints for defining the correct astrophysics scenario that explains these stars. We defer the detailed analysis of the observed elemental ratios in comparison with theoretical stellar simulations to a future paper. We showed that the observed enhancement in both O and Mg, combined in a rather normal [Mg/O] ratio, is a strong indication that massive stars might be the source of the nucleosynthesis anomalies carried by P-rich stars. However, the details of the astrophysics context still need to be defined.
Parameter values of the model.
 |
Fig. 10 Predicted evolution curves. Top panel: [P/Fe] as a function of [Fe/H] in the Galactic disk is shown for four GCE simulations using OMEGA+: the models are CLC (blue line), CRit(del) (red line), CRit(rap) (green line) and CNom (yellow line). For comparison, our new sample of P-rich stars with errors is shown (brown points) together with data from Hinkel et al. (2014) as representative of P-normal stars (black contours). Middle panel: Same as the top panel, but for the [Mg/O] ratio. Bottom panel: Same as the top panel, but for the [Si/S] ratio. For each panel, upper limits in the P-rich sample are represented by downward triangles and lower limits by upward triangles. The black contours allow us to map the distribution density of the stellar abundances. |
Combinations of yields used for the chemical evolution modeling.
5.2 Orbital analysis
Taking advantage of the new sample size, we analyzed the dynamics of the P-rich stars using the astroNN13 VAC described in Abdurro’uf et al. (2022), and references therein. Included in this VAC, among other properties, are the stellar orbits in the Milky Way, determined by applying the deep learning code astroNN to the APOGEE-2 DR17 data. More precisely, the orbital parameters of the VAC were calculated by the fast method from Mackereth & Bovy (2018) using the gravitational potential MWPotential2014 (Bovy 2015).
A cross-match between the astroNN VAC and our sample enabled us to extract the orbital parameters and plot them in three dynamical planes shown in Fig. 11: total energy versus angular momentum Lz, eccentricity versus Lz, and maximum height above the midplane Zmax versus eccentricity. The P-rich stars are plotted against a sample of S/N > 70 background stars that are color-coded according to the Galactic components. To separate the background sample into thin- and thick-disk stars, we used the chemical information contained in the [α/Fe]-[Fe/H] plots presented in Fig. 1 of Hawkins et al. (2015) and Fig. 4 of Masseron & Gilmore (2015). We dropped stars from the intersection region. To separate the canonical halo from the accreted population, we estimated and adopted the cuts made in Fig. 4 of Hayes et al. (2018). For clarity, we used the average error of the parameters over the P-rich sample as a typical error bar in Fig. 11. Regarding the overall uncertainty, Abdurro’uf et al. (2022) stated that the orbital parameters have a precision between 4% and 8%.
From the distribution of the P-rich stars in the orbital plots, we conclude that most of the P-rich stars belong to the thick disk and the inner Galactic halo, without any particular motion. This means that the P-rich stars cannot be assigned exclusively to any dynamical subgroup from either an in situ or an accreted origin. However, some P-rich stars are located in regions of accreted material in the planes shown in Fig. 11. Our rather rough comparison with the background sample does not allow us to completely discard the possibility that some of the P-rich stars might be the result of a merger event. In a recent work, Dodd et al. (2023) identified numerous subgroups of stars in the Milky Way based on similarities in their dynamical and chemical properties and interpreted them as remnants of past merger events. For future works, it might be of interest to determine whether some of the P-rich stars belong to the subgroups reported by Dodd et al. (2023).
In search of the progenitor, the source of the P-richness, this dynamical diagnostics shows us that the mechanism that causes the overabundance of P is not bound to a specific location or population. Although some P-rich stars might have been accreted from external galaxies, which is in agreement with the low-metallicity range, the P-richness cannot be attributed to ex situ formation alone.
5.3 Nucleosynthetic scenarios
With a reliable chemical fingerprint of the P-rich stars, we are able to compare it with other chemical signatures. As the main objective of this work is to find clues on the P-rich star progenitor, we compared our results with nucleosynthetic scenarios that might have caused the strong P pollution of the ISM, out of which the observed low-mass P-rich stars were born. As mentioned in Sect. 1, Masseron et al. (2020a) already discarded a number of possible P-rich star progenitors, including super-AGB stars and novae, through a comparison with their nucleosynthetic theoretical predictions. They tentatively suggested that investigating possible combinations of specific effects, such as rotation (e.g., Prantzos et al. 2018) and/or nucleosynthesis in convective-reactive regions (e.g., Ritter et al. 2018a) in massive stars, might represent a promising way to explain the peculiar chemical pattern of the P-rich stars. In the following subsections, we continue the discussion from Masseron et al. (2020a‚b) and focus on three nucleosynthetic scenarios that have not been considered until now or have been suggested recently.
5.3.1 Sub-Chandrasekhar supernovae la
It is known that the final yields derived from SNe are bound to numerous parameters, such as the initial mass and the metallicity. A striking example for the strong dependence on the initial conditions are SNela, the thermonuclear explosion of carbon-oxygen white dwarfs (WDs; Sanders et al. 2021; Bravo et al. 2022, and references therein). The properties of these SN explosions depend on the mass of the WD at the time of explosion, which can fall into one of the following two categories: (i) the mass is close to the Chandrasekhar-limit (M ≈ 1.4 M⊙) (Ch-m WD), or (ii) the mass is below this limit (M ≲ 1.4 M⊙) (subCh-m WD). Sanders et al. (2021) explored the abundance signature of SNela by fitting the chemical evolution models from Weinberg et al. (2017) to the Gaia-Enceladus chemical space. They speculated that subCh-m WD channels constitute a significant fraction of SNela in metal-poor systems. This speculation was motivated by their prediction of a subsolar production of Mn and Ni ([Mn/Fe] ≈ −0.15 dex and [Ni/Fe] ≈ −0.3 dex) in these objects. Although P has not been measured in relation with subCh SNe so far, we used the information from Sanders et al. (2021) to find indications of a possible contribution to the P-rich stars because, as we have shown in the previous section, some P-rich stars might have been part of or may have formed from material of accreted dwarf galaxies where subCh SNe occur. The metallicity of these systems also matches the metallicity range of the P-rich stars. Thus, we compared the predicted Mn and Ni abundances from Sanders et al. (2021) with the corresponding abundances of the P-rich stars, using the abundances provided by ASPCAP (García Pérez et al. 2016; Abdurro’uf et al. 2022). In the case of Mn, the P-rich stars reproduce the predicted yield with a mean [Mn/Fe] of −0.15 ± 0.03 dex. In contrast to Mn, the mean Ni abundance of the P-rich stars is slightly supersolar (0.07 ± 0.03 dex) and therefore does not match the result from Sanders et al. (2021). We note that the Mn and Ni abundances were determined via an automatic pipeline and thus have to be handled carefully. However, we tentatively conclude that subCh SNe are not the primary polluter.
 |
Fig. 11 P-rich stars (black dots) plotted against a background sample in three different dynamical planes: total energy vs. angular momentum Lz (top panel), eccentricity vs. Lz (middle panel), and maximum height above the midplane Zmax vs. eccentricity (bottom panel). To separate the background sample into thin-disk, thick-disk, canonical halo, and accreted halo stars, we used the results from Hawkins et al. (2015), Masseron & Gilmore (2015), and Hayes et al. (2018) (see main text for more details). For clarity, we give a typical error bar for the P-rich stars corresponding to the average error of their parameters. |
5.3.2 Pair-instability supernovae
Pair-instability SNe (PISNe) are the thermonuclear explosion of very massive stars (M > 100 M⊙) induced by oxygen burning after a gravitational collapse caused by the generation of electron-positron pairs (see, e.g., Kozyreva et al. 2014, and references therein). PISNe of very massive metal-poor stars are suggested to be relevant in the local Universe (Kozyreva et al. 2014), even though an observational proof for this type of SN event is still lacking (Takahashi et al. 2018). One requirement for a PISN to occur is the formation of a high-mass CO core. In metal-rich environments, the formation of this core is hindered by the high mass-loss rates caused by stellar winds (Georgy et al. 2017; Takahashi et al. 2018). The P-rich stars considered in this work are found in a narrow low-metallicity range, which means that massive stars causing PISNe are a possible progenitor. Another aspect indicating a massive progenitor is the identification of a GC P-rich star, which most likely belongs to the first generation. This discovery, if confirmed, would indicate that the progenitor has evolved on a shorter timescale than the GC, meaning that only a massive progenitor can be considered. In addition, a significant fraction of the P-rich stars are most likely not part of close binary systems due to their low RV scatter. Because PISNe do not leave any remnant (i.e., a possible binary companion of the P-rich stars), it could be speculated that these very massive stars exploding as a PISN are potential candidates for the P-rich star progenitor.
Although PISNe seem to be promising candidates for the P-rich star progenitor based on the arguments above, comparing the abundance pattern of the PISNe with the P-rich stars causes us to doubt this scenario. Stellar evolution simulations performed by Kozyreva et al. (2014) and Takahashi et al. (2018) revealed that PISN exhibit a deficiency of odd-Z elements compared to even-Z elements, meaning that the production of P is reduced compared to, for example, Mg, Si, and S. This so-called odd-even effect is not observed in our sample. According to Kozyreva et al. (2014), the odd-even effect is weakened with increasing metallicity due to a stronger contribution of CCSNe. Regarding the observed high amounts of P and Al in our sample, weakening the odd-even effect would not be enough to match the abundance patter, making it less plausible that PISNe are the progenitor of the P-rich stars.
5.3.3 Nonthermal nucleosynthesis
Since the discovery of the P-rich stars, a new theory beyond standard nucleosynthesis models emerged, aiming to account for the unusual P abundances. Goriely (2022) explored the irradiation by stellar energetic particles (SEPs) as a nonthermal nucleosynthesis process and found that, globally, the relative abundance pattern of the P-rich stars is reproduced to a great extent. Four different spallation events have been considered by Goriely (2022), consisting of either α-particles only or α-particles in combination with protons as SEPs, and either CNO in solar ratio or pure C as target material. The results show that particles with energies of a few MeV are able to produce significant amounts of P. However, there are some main discrepancies between the P-rich stars abundance pattern and the results from Goriely (2022). In particular, the [Ba/La] ratio as well as the Al and Si abundances are strongly underpredicted by the considered spallation models. In the case of Al and Si, Goriely (2022) proposed possible corrections that can be applied to improve the agreement, such as modifying the target material or adding an extra SEP component. Nevertheless, there are only two P-rich stars with measurements of Ba and La (Masseron et al. 2020b), and therefore, it would be useful to increase this number to have more reliable evidence that this discrepancy indeed exists. Goriely (2022) also stated that in addition to P, a significant amount of F and Cl is produced in this type of process. However, thus far, we lack observational data for these elements. Furthermore, several questions about the nature of these processes are left unanswered by Goriely (2022) and will require further studies. The source and the acceleration mechanism of the SEPs, as well as quantitative declarations about the SEPs and the target material that needs to be affected by the SEPs to reproduce the abundances, are not reported. The definition of the site where these spallation processes occur is still lacking. In particular, Goriely (2022) left open whether the atmosphere of the P-rich stars has been polluted by the outcomes of the spallation processes or if it was directly irradiated by the SEPs. Moreover, the output produced by a superposition of different events and the use of distinct target materials is still unexplored.
6 Summary and conclusions
We presented a follow-up study of P-rich stars that began with the discovery of 16 giants exhibiting unusually high abundances of P, as well as enhancements in O, Al, Si, and Ce (Masseron et al. 2020a). Because these P-rich stars are low-mass giants, it is most likely that a progenitor caused the observed abundance pattern by polluting the gas out of which the stars were born. To draw statistically reliable conclusions on the progenitor of these chemically peculiar stars, we carried out a chemical abundance analysis on an enlarged sample, mainly consisting of a collection of Si-rich giants (Fernández-Trincado et al. 2019, 2020) that were suspected to be P-rich as well. The final group of 78 giants represents the largest sample of confirmed P-rich stars to date. Using the NIR (H-band) observations from DR17 of the APOGEE-2 survey and the BACCHUS code, we determined the abundances of 13 elements in the stars of the new sample. Finally, we compared our abundance results with detailed GCE models, each using a different prescription for the massive star yields, performed an orbital diagnostic, and discussed possible progenitor candidates.
Our main results, interpretations and recommendations for future investigations are summarized in the following bullet points:
The chemical abundance analysis of our enlarged sample revealed the unique fingerprint of the P-rich stars, supporting the abundance pattern that was previously found by Masseron et al. (2020a), with high abundances of O, Al, Si, P, and Ce. Consequently, the hypothesis made by Masseron et al. (2020a) that P-rich stars are part of a larger family of Si- and Al-rich stars is confirmed. We also validated that S and Ca are not enriched, which is at odds with current stellar nucleosynthesis models of massive stars because Si is enhanced instead. The low-metallicity range in which the P-rich stars from Masseron et al. (2020a) are located is also tentatively confirmed because no P-rich stars with [M/H] > −0.6 dex have been detected during this work.
In addition, we identified several correlations among the enriched elements as well as between Mg and P, converting Mg to a characteristic component of the P-rich stars abundance pattern even though it is not enhanced in the entire sample. In contrast, no correlation between the C+N abundances was detected, although some stars show a C+N enhancement.
We highlight the correlation between P and Si, which is particularly useful for the search of P-rich stars in large data sets. For example, the performance of machine-learning (ML) techniques could be improved if the algorithm is trained on the more accessible Si lines instead of on P lines. As there was no systematic search for P-rich stars in DR17, it would be interesting to perform this search with improved ML algorithms, bearing in mind that P is correlated with other elements.
Nandakumar et al. (2022) also discovered two P-rich stars that are enriched in Ce, but not in other elements, however, as reported by Masseron et al. (2020a‚b). It still has to be determined whether these two stars and their origin can be related to the P-rich stars from Masseron et al. (2020a‚b) or if they constitute a new class of P-rich stars. Furthermore, the automated supercomputer calculation of the background sample uncovered 139 stars with [P/Fe] > 0.8 dex. Although we did not rate the results for P as reliable enough to be used for comparison, it might be reasonable to revisit these stars in order to validate the high abundances and expand the P-rich sample.
From the analysis of the RV scatter, we conclude that the P-rich stars are not exclusively binaries. Although four stars have been found to be likely binaries due to their high RV scatter, the majority of the sample stars shows a low RV scatter. Depending on the time-lag cut between individual visits, the low RV scatter is reliable for a significant fraction, allowing us to conclude that the sample is not composed of close binaries alone, but also of field stars. Hence, the peculiar abundance pattern cannot be assigned to close binary interaction.
We made four GCE models of the MW disk using different stellar yields. We confirm that P-rich stars are not reproduced. In addition to the high [P/Fe], the P-rich stars also show an anomalous high [Si/S] ratio with respect to P-normal stars and GCE simulations, which is difficult to reproduce by standard nucleosynthesis in supernovae.
The orbital analysis implies that the P-rich stars cannot be assigned to one specific population alone. Instead, they can be found in accreted streams as well in the in situ population of the Milky Way. This indicates a universal process that leads to the unusual abundance pattern and that is not locally bound.
By comparison of the abundance pattern with possible progenitor candidates, we discard the scenario of sub-Chandrasekhar SNeIa. We considered this type of SNeIa because they share the same metallicity range as the P-rich stars and are thought to be significant contributors to metal-poor dwarf galaxies, out of which some P-rich stars might have been accreted. Because the Mn and Ni abundances of the P-rich stars do not match the predicted yields from subCh SNela, we ruled out subCh SNela as possible progenitor, however.
The assignment of one P-rich star to the GC M4 motivated us to study the possibility of a massive progenitor that ends its life through a pair-instability SNe. We suggest that the P-rich star in M4 belongs to the first-generation GC stars, indicating that the corresponding progenitor has evolved faster than the GC itself. This in turn indicates a massive origin. Predictions show that the odd-even effect is typical for PISNe, but this effect is not observed in the P-rich stars, leading us to discard PISNe as a possible progenitor.
As a next observational step, we recommend the expansion of the chemical space to explore heavier elements, for example, s-process elements such as Ba and Pb. Observations in the optical range that supplement the APOGEE-2 data, such as those from Masseron et al. (2020b), have to be carried out on a larger set of P-rich targets. In particular, further observations of the P-rich star that is part of M4 would be of interest in either the optical or another NIR band, to confirm the results found with the APOGEE-2 data.
A possible alternative to standard nucleosynthesis was presented recently by Goriely (2022), who studied nonthermal nucleosynthesis in the form of spallation processes that are able to produce a pattern consistent with the P-rich stars to a great extent. There are still some discrepancies, for example, in the [Ba/La] ratio, but [Ba/La] measurements are lacking for an extended sample of P-rich stars. Other indicators could be the F and Cl abundances, which are predicted to be high in P-rich stars if spallation is the mechanism that causes the high P abundances. Unfortunately, F and Cl cannot be measured with the available spectral data. Thus, we emphasize the need for observations to explore the viability of this theory. Furthermore, this process would also need to be tested quantitatively within a GCE context, in particular, if it might affect the ISM at least locally and the abundance of the rare P-rich stars.
Following from the conclusions listed above, the next step on the search for the P-rich star progenitor should consist of the exploration of more (heavy) elements to constrain the astrophysical origin. This may be achieved through observations in spectral ranges other than the NIR.
Acknowledgements
The authors are grateful for the positive feedback from the anonymous referee that helped to improve this paper. M.B. acknowledges financial support from the European Union and the State Agency of Investigation of the Spanish Ministry of Science and Innovation (MICINN) under the grant PRE-2020-095531 of the Severo Ochoa Program for the Training of Pre-Doc Researchers (FPI-SO). M.B. and T.M. acknowledge support from the ACIISI, Consejería de Eeonomía, Conoeimiento y Empleo del Gobierno de Canarias and the European Regional Development Fund (ERDF) under grant with reference PROID2021010128. T.M. also acknowledges financial support from the Spanish Ministry of Science and Innovation (MICINN) through the Spanish State Research Agency, under the Severo Ochoa Program 2020-2023 (CEX2019-000920-S). This research made use of computing time available on the high-performance computing systems at the Instituto de Astrofísica de Canarias. The authors thankfully acknowledge the technical expertise and assistance provided by the Spanish Supercomputing Network (Red Española de Supereomputacion), as well as the computer resources used: the La Palma Supercomputer, located at the Instituto de Astrofísica de Canarias. K.A.W. acknowledges the support of the European Union’s Horizon 2020 research and innovation programme (ChETEC-INFRA - Project no. 101008324) and ongoing access to viper, the University of Hull’s High Performance Computing Facility. M.P. and M.L. thank the “Lendulet-2014” Program of the Hungarian Academy of Sciences (Hungary) and the ERC Consolidator Grant (Hungary) funding scheme (Project RADIOSTAR, G.A. no. 724560). The data processing of this work relies on the Pandas (Reback et al. 2022), NumPy (Harris et al. 2020), Astropy (Astropy Collaboration 2013, 2018, 2022) and Matplotlib (Hunter 2007) Python libraries. This work has made use of Sloan Digital Sky Survey IV (SDSS-IV) data. Funding for the Sloan Digital Sky Survey IV has been provided by the Alfred P. Sloan Foundation, the US Department of Energy Office of Science, and the Participating Institutions. SDSS-IV acknowledges support and resources from the Center for High Performance Computing at the University of Utah. The SDSS website is www.sdss4.org. SDSS-IV is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS Collaboration including the Brazilian Participation Group, the Carnegie Institution for Science, Carnegie Mellon University, Center for Astrophysics/Harvard & Smithsonian, the Chilean Participation Group, the French Participation Group, Instituto de Astrofísica de Canarias, The Johns Hopkins University, Kavli Institute for the Physics and Mathematics of the Universe (IPMU) / University of Tokyo, the Korean Participation Group, Lawrence Berkeley National Laboratory, Leibniz Institut für Astrophysik Potsdam (AIP), Max-Planck-Institut für Astronomie (MPIA Heidelberg), Max-Planck-Institut für Astrophysik (MPA Garching), Max-Planck-Institut für Extraterrestrische Physik (MPE), National Astronomical Observatories of China, New Mexico State University, New York University, University of Notre Dame, Observatário Nacional/MCTI, The Ohio State University, Pennsylvania State University, Shanghai Astronomical Observatory, United Kingdom Participation Group, Universidad Nacional Autónoma de Mexico, University of Arizona, University of Colorado Boulder, University of Oxford, University of Portsmouth, University of Utah, University of Virginia, University of Washington, University of Wisconsin, Vanderbilt University, and Yale University.
Appendix A Selection of the background sample
To define the background sample, we applied the following criteria to the full APOGEE-2 DR17 data contained in the ASPCAP table14:
4000 K < Teff < 5000 K
log g < 3.5
RV scatter < 1 km s−1
−1.5 dex < [M/H] < −0.6dex
56 px−1 ≲ SNR ≲ 640 px−1
ASPCAPFLAG = 0; STARFLAG = 0; ANDFLAG = 0.
These conditions mainly serve to filter out reference stars with similar stellar parameters as the P-star candidates, but also to reject possible binary members15 by restricting the radial velocity (RV) scatter (criterion 3). We also rejected targets with flagged entries (criterion 6). These quality flags are given in the form of bitmasks, which may indicate several issues in the ASPCAP results. In short, ASPCAPFLAG takes into account any potential problem with the derived stellar parameters, while STARFLAG indicates issues in the spectra, for example, a high number of bad pixels (Holtzman et al. 2015). The ANDFLAG bitmask has the same meaning as STARFLAG, indicating whether all the spectra used for the final combination present the same issue (Holtzman et al. 2018). In addition, both ASPCAPFLAG and STARFLAG may also identify possible spectroscopic binaries (Abdurro’uf et al. 2022).
Similar to the case of binary systems mentioned above, giant stars in Galactic globular clusters (GCs) are also well known to display chemical abundance anomalies, especially the so-called second-generation stars. They neither represent the standard chemical composition of field stars nor the average Galactic chemical enrichment (see, e.g., Mészáros et al. 2020, and references therein). Thus, we aimed to exclude members of Galactic GCs from our reference group by cross-matching the reference stars with the GC stars contained in Table 2 of Mészáros et al. (2020). In addition, we cross-matched with another GC catalog that has been created by selecting stars in APOGEE-2 DR17 within the tidal radius of GCs in the Harris (1996, 2010 edition) GC catalog, which are selected as GC members according to an iterative sigma clipping on RVs and Gaia EDR3 proper motions (Gaia Collaboration et al. 2021).
Appendix B Line list
Spectral lines alongside the corresponding excitation potential and log(gf) used for the abundance determination of each elemental species considered in this work.
Appendix C Background star abundance validation
 |
Fig. C.1 Difference in the abundance ratio Δ[X/Fe] between manual and automated calculation vs. metallicity [Fe/H] for all the elements studied in this work, except for S, because this element was added to our analysis after the calculation with the supercomputer was concluded. The average difference (red line) can be extrapolated to the background sample to validate the performance of the automatic calculation. |
To probe the quality of the supercomputer calculation of the abundances corresponding to the background stars, we added the initial 87 sample stars to the automated run described in Sect. 3.2. We then compared their abundances obtained from the automatic run and the manual inspection. As mentioned before, the manual sanity check of the lines was used to refine the line list used for the automatic run (see B.1) in order to minimize the impact of poorly fitted lines.
To illustrate the performance of the automatic abundance calculation, we plot the difference in the abundance ratio Δ[X/Fe] between manual and automated calculation versus metallicity [Fe/H] for all the elements studied in this work (Fig. C.1), except for S, because this element was included after the calculation with the supercomputer was concluded. The average difference (red line) can be extrapolated to the background sample, giving an impression of the uncertainty related to the automatic calculation mode. Ideally, the average difference should be close to zero, as is the case for mostly all the elements. Nevertheless, because the focus of this work lies on P and its two intrinsically weak lines included in the APOGEE-2 wavelength range, we compared the P abundances of the sample with literature values instead of the background sample, because extracting reliable P abundances require a careful (manual) inspection. In this context, we also point out that the stars contained in the BAWLAS VAC (Hayes et al. 2022) present a metallicity bias, meaning that the number of stars with [P/Fe] values decreases with metallicity. As a result, only a few stars present [P/Fe] values in the metallicity range in which the sample is located. Therefore, the VAC is likewise not suitable for constituting a reference group, which supports our choice of using literature values for comparison.
Appendix D Uncertainty tables
Details of the systematic error calculation.
Typical standard deviation σstdev,[x/Fe] and total systematic σ[X/Fe] error associated with each element.
Appendix E Abundance ratios [X/Fe] versus effective temperature Teff
 |
Fig. E.1 Abundance ratios [X/Fe] vs. effective temperature ‚ displaying one element X in each panel. Gray downward triangles indicate upper limits. The background sample was selected and the corresponding abundances were calculated following the procedure described in Sects. 2.2 and 3.2. In the case of S, the background stars have been selected out of the VAC from Hayes et al. (2022). The color-coding reflects the number density of the stars. For clarity, error bars are suppressed. The errors adopted for each element are given in the title of each panel and correspond to the average standard deviation listed in Table D.2. Here we assume that the error of the effective temperature is the average ASPCAP Teff error over the 78 sample stars (±14.32 K). |
Appendix F Zoom into [X/Fe] versus [Fe/H] and correlations
 |
Fig. F.1 Detailed representation of the [O/Fe] abundance ratio. Left panel: Zoom into the [O/Fe] vs. [Fe/H] plot of Fig. 6 with upper limits (solid triangles). Right panel: [O/Fe] vs. [P/Fe] to illustrate the correlation between P and O. Solid circles correspond to real measurements in both O and in P, empty circles to upper limits in P, solid triangles to upper limits in O, and empty triangles denote upper limits in O and P. Error bars are defined to reflect the typical standard deviation given in Table D.2 |
References
- Abdurro’uf, Accetta, K., Aerts, C., et al. 2022, ApJS, 259, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Abolfathi, B., Aguado, D. S., Aguilar, G., et al. 2018, ApJS, 235, 42 [NASA ADS] [CrossRef] [Google Scholar]
- Allende Prieto, C., Beers, T. C., Wilhelm, R., et al. 2006, ApJ, 636, 804 [NASA ADS] [CrossRef] [Google Scholar]
- Amarsi, A. M., Grevesse, N., Grumer, J., et al. 2020, A&A, 636, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Andrassy, R., Herwig, F., Woodward, P., & Ritter, C. 2020, MNRAS, 491, 972 [NASA ADS] [CrossRef] [Google Scholar]
- Asplund, M., Amarsi, A. M., & Grevesse, N. 2021, A&A, 653, A141 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Robitaille, T.P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A.M., et al.) 2018, AJ, 156, 123 [NASA ADS] [CrossRef] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A.M., et al.) 2022, APJ, 935, 167 [CrossRef] [Google Scholar]
- Blanton, M. R., Bershady, M. A., Abolfathi, B., et al. 2017, AJ, 154, 28 [Google Scholar]
- Bovy, J. 2015, ApJS, 216, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Bowen, I. S., & Vaughan, A. H.J., 1973, Appl. Opt., 12, 1430 [NASA ADS] [CrossRef] [Google Scholar]
- Bravo, E., Piersanti, L., Blondin, S., et al. 2022, MNRAS, 517, L31 [CrossRef] [Google Scholar]
- Brooke, J. S. A., Bernath, P. F., Western, C. M., et al. 2016, J. Quant. Spec. Radiat. Transf., 168, 142 [NASA ADS] [CrossRef] [Google Scholar]
- Burrows, A., & Vartanyan, D. 2021, Nature, 589, 29 [CrossRef] [PubMed] [Google Scholar]
- Butusov, M., & Jernelov, A. 2013, Phosphorus. An Element that could have been called Lucifer (New York, NY: Springer), 9 [Google Scholar]
- Caffau, E., Bonifacio, P., Faraggiana, R., & Steffen, M. 2011, A&A, 532, A98 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Caffau, E., Andrievsky, S., Korotin, S., et al. 2016, A&A, 585, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Caffau, E., Bonifacio, P., Oliva, E., et al. 2019, A&A, 622, A68 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cescutti, G., Matteucci, F., Caffau, E., & François, P. 2012, A&A, 540, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chiappini, C., Matteucci, F., & Gratton, R. 1997, ApJ, 477, 765 [Google Scholar]
- Chieffi, A., Limongi, M., & Straniero, O. 1998, ApJ, 502, 737 [NASA ADS] [CrossRef] [Google Scholar]
- Clayton, D. 2003, Handbook of Isotopes in the Cosmos (Cambridge University Press) [Google Scholar]
- Contursi, G., de Laverny, P., Recio-Blanco, A., et al. 2023, A&A, 670, A106 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Côté, B., O’Shea, B.W., Ritter, C., Herwig, F., & Venn, K.A. 2017, ApJ, 835, 128 [CrossRef] [Google Scholar]
- Côté, B., Silvia, D. W., O’Shea, B.W., Smith, B., & Wise, J.H. 2018, ApJ, 859, 67 [CrossRef] [Google Scholar]
- Côté, B., Lugaro, M., Reifarth, R., et al. 2019, ApJ, 878, 156 [CrossRef] [Google Scholar]
- Cristallo, S., Straniero, O., Piersanti, L., & Gobrecht, D. 2015, ApJS, 219, 40 [Google Scholar]
- Cristini, A., Hirschi, R., Meakin, C., et al. 2019, MNRAS, 484, 4645 [NASA ADS] [CrossRef] [Google Scholar]
- Curtis, S., Ebinger, K., Fröhlich, C., et al. 2019, ApJ, 870, 2 [Google Scholar]
- Dodd, E., Callingham, T. M., Helmi, A., et al. 2023, A&A, 670, L2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fernández-Trincado, J. G., Beers, T. C., Placco, V. M., et al. 2019, ApJ, 886, L8 [Google Scholar]
- Fernández-Trincado, J. G., Beers, T. C., & Minniti, D. 2020, A&A, 644, A83 [Google Scholar]
- Gaia Collaboration (Brown, A.G.A., et al.) 2021, A&A, 649, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- García Pérez, A. E., Allende Prieto, C., Holtzman, J. A., et al. 2016, AJ, 151, 144 [Google Scholar]
- Georgy, C., Meynet, G., Ekström, S., et al. 2017, A&A, 599, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Goriely, S. 2022, A&A, 658, A197 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Goswami, A., & Prantzos, N. 2000, A&A, 359, 191 [NASA ADS] [Google Scholar]
- Grevesse, N., Asplund, M., & Sauval, A. J. 2007, Space Sci. Rev., 130, 105 [Google Scholar]
- Gronow, S., Collins, C., Ohlmann, S. T., et al. 2020, A&A, 635, A169 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gulick, A. 1955, Am. Scientist, 43, 479 [Google Scholar]
- Gunn, J. E., Siegmund, W. A., Mannery, E. J., et al. 2006, AJ, 131, 2332 [NASA ADS] [CrossRef] [Google Scholar]
- Gustafsson, B., Edvardsson, B., Eriksson, K., et al. 2008, A&A, 486, 951 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Harris, W. E. 1996, AJ, 112, 1487 [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S.J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Hawkins, K., Jofré, P., Masseron, T., & Gilmore, G. 2015, MNRAS, 453, 758 [NASA ADS] [CrossRef] [Google Scholar]
- Hawkins, K., Masseron, T., Jofré, P., et al. 2016, A&A, 594, A43 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hayes, C. R., Majewski, S. R., Shetrone, M., et al. 2018, ApJ, 852, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Hayes, C. R., Masseron, T., Sobeck, J., et al. 2022, ApJS, 262, 34 [NASA ADS] [CrossRef] [Google Scholar]
- Hinkel, N. R., Timmes, F. X., Young, P. A., Pagano, M. D., & Turnbull, M. C. 2014, AJ, 148, 54 [NASA ADS] [CrossRef] [Google Scholar]
- Holtzman, J. A., Shetrone, M., Johnson, J. A., et al. 2015, AJ, 150, 148 [Google Scholar]
- Holtzman, J. A., Hasselquist, S., Shetrone, M., et al. 2018, AJ, 156, 125 [Google Scholar]
- Hubeny, I., & Lanz, T. 2011, Astrophysics Source Code Library [record ascl:1109.022] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Iwamoto, K., Brachwitz, F., Nomoto, K., et al. 1999, ApJS, 125, 439 [NASA ADS] [CrossRef] [Google Scholar]
- Jacobson, H. R., Thanathibodee, T., Frebel, A., et al. 2014, ApJ, 796, L24 [NASA ADS] [CrossRef] [Google Scholar]
- Jönsson, H., Holtzman, J. A., Allende Prieto, C., et al. 2020, AJ, 160, 120 [Google Scholar]
- Jorissen, A., Van Eck, S., Van Winckel, H., et al. 2016, A&A, 586, A158 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Karakas, A. I., & Lugaro, M. 2016, ApJ, 825, 26 [NASA ADS] [CrossRef] [Google Scholar]
- Kobayashi, C., Umeda, H., Nomoto, K., Tominaga, N., & Ohkubo, T. 2006, ApJ, 653, 1145 [NASA ADS] [CrossRef] [Google Scholar]
- Kobayashi, C., Karakas, A. I., & Umeda, H. 2011, MNRAS, 414, 3231 [Google Scholar]
- Kobayashi, C., Karakas, A. I., & Lugaro, M. 2020, ApJ, 900, 179 [Google Scholar]
- Kounkel, M., Covey, K. R., Stassun, K. G., et al. 2021, AJ, 162, 184 [NASA ADS] [CrossRef] [Google Scholar]
- Kozyreva, A., Yoon, S. C., & Langer, N. 2014, A&A, 566, A146 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kroupa, P. 2001, MNRAS, 322, 231 [NASA ADS] [CrossRef] [Google Scholar]
- Leung, S.-C., & Nomoto, K. 2018, ApJ, 861, 143 [Google Scholar]
- Li, G., Gordon, I. E., Rothman, L. S., et al. 2015, ApJS, 216, 15 [NASA ADS] [CrossRef] [Google Scholar]
- Limongi, M., & Chieffi, A. 2018, ApJS, 237, 13 [NASA ADS] [CrossRef] [Google Scholar]
- Maas, Z. G., Pilachowski, C. A., & Cescutti, G. 2017, ApJ, 841, 108 [NASA ADS] [CrossRef] [Google Scholar]
- Maas, Z. G., Cescutti, G., & Pilachowski, C. A. 2019, AJ, 158, 219 [NASA ADS] [CrossRef] [Google Scholar]
- Mackereth, J. T., & Bovy, J. 2018, PASP, 130, 114501 [Google Scholar]
- Majewski, S. R., Schiavon, R. P., Frinchaboy, P. M., et al. 2017, AJ, 154, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Masseron, T., & Gilmore, G. 2015, MNRAS, 453, 1855 [CrossRef] [Google Scholar]
- Masseron, T., Merle, T., & Hawkins, K. 2016, Astrophysics Source Code Library [record ascl:1605.004] [Google Scholar]
- Masseron, T., García-Hernández, D. A., Mészáros, S., et al. 2019, A&A, 622, A191 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Masseron, T., García-Hernández, D. A., Santoveña, R., et al. 2020a, Nat. Commun., 11, 3759 [NASA ADS] [CrossRef] [Google Scholar]
- Masseron, T., García-Hernández, D. A., Zamora, O., & Manchado, A. 2020b, ApJ, 904, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Matteucci, F. 2012, Chemical Evolution of the GALAXY (Springer) [CrossRef] [Google Scholar]
- Matteucci, F. 2021, A&AR, 29, 5 [NASA ADS] [CrossRef] [Google Scholar]
- Mészáros, S., Masseron, T., García-Hernández, D. A., et al. 2020, MNRAS, 492, 1641 [Google Scholar]
- Mishenina, T., Pignatari, M., Côté, B., et al. 2017, MNRAS, 469, 4378 [NASA ADS] [CrossRef] [Google Scholar]
- Mollá, M., Cavichia, O., Gavilán, M., & Gibson, B. K. 2015, MNRAS, 451, 3693 [CrossRef] [Google Scholar]
- Nandakumar, G., Ryde, N., Montelius, M., et al. 2022, A&A, 668, A88 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nidever, D. L., Holtzman, J. A., Allende Prieto, C., et al. 2015, AJ, 150, 173 [NASA ADS] [CrossRef] [Google Scholar]
- Nomoto, K., & Leung, S.-C. 2018, Space Sci. Rev., 214, 67 [NASA ADS] [CrossRef] [Google Scholar]
- Nomoto, K., Kobayashi, C., & Tominaga, N. 2013, ARA&A, 51, 457 [CrossRef] [Google Scholar]
- Osorio, Y., Allende Prieto, C., Hubeny, I., Mészáros, S., & Shetrone, M. 2020, A&A, 637, A80 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pagel, B. E. J. 1997, Nucleosynthesis and Chemical Evolution of the Galaxies (Cambridge University Press) [Google Scholar]
- Pignatari, M., Herwig, F., Hirschi, R., et al. 2016, ApJS, 225, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Plez, B. 2012, Astrophysics Source Code Library [record ascl:1205.004] [Google Scholar]
- Prantzos, N., Abia, C., Limongi, M., Chieffi, A., & Cristallo, S. 2018, MNRAS, 476, 3432 [Google Scholar]
- Rauscher, T., Heger, A., Hoffman, R. D., & Woosley, S. E. 2002, ApJ, 576, 323 [Google Scholar]
- Reback, J., Jbrockmendel, McKinney, W., et al. 2022, https://doi.org/10.5281/zenodo.5893288 [Google Scholar]
- Ritter, C., Andrassy, R., Côté, B., et al. 2018a, MNRAS, 474, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Ritter, C., Côté, B., Herwig, F., Navarro, J. F., & Fryer, C. L. 2018b, ApJS, 237, 42 [NASA ADS] [CrossRef] [Google Scholar]
- Ritter, C., Herwig, F., Jones, S., et al. 2018c, MNRAS, 480, 538 [NASA ADS] [CrossRef] [Google Scholar]
- Roederer, I. U., Jacobson, H. R., Thanathibodee, T., Frebel, A., & Toller, E. 2014, ApJ, 797, 69 [NASA ADS] [CrossRef] [Google Scholar]
- Romano, D., Karakas, A. I., Tosi, M., & Matteucci, F. 2010, A&A, 522, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sanders, J. L., Belokurov, V., & Man, K. T. F. 2021, MNRAS, 506, 4321 [NASA ADS] [CrossRef] [Google Scholar]
- Schatz, H., Becerril Reyes, A. D., Best, A., et al. 2022, J. Phys. G, 49, 110502 [CrossRef] [Google Scholar]
- Schiavon, R. P., Zamora, O., Carrera, R., et al. 2017, MNRAS, 465, 501 [Google Scholar]
- Shetrone, M., Bizyaev, D., Lawler, J. E., et al. 2015, ApJS, 221, 24 [Google Scholar]
- Smith, V. V., Bizyaev, D., Cunha, K., et al. 2021, AJ, 161, 254 [NASA ADS] [CrossRef] [Google Scholar]
- Sneden, C., Lucatello, S., Ram, R. S., Brooke, J. S. A., & Bernath, P. 2014, ApJS, 214, 26 [Google Scholar]
- Sukhbold, T., Ertl, T., Woosley, S. E., Brown, J. M., & Janka, H. T. 2016, ApJ, 821, 38 [NASA ADS] [CrossRef] [Google Scholar]
- Takahashi, K., Yoshida, T., & Umeda, H. 2018, ApJ, 857, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Thielemann, F.-K., Nomoto, K., & Hashimoto, M.-A. 1996, ApJ, 460, 408 [NASA ADS] [CrossRef] [Google Scholar]
- Tinsley, B. M. 1980, Fundam. Cosmic Phys., 5, 287 [NASA ADS] [Google Scholar]
- Weinberg, D. H., Andrews, B. H., & Freudenburg, J. 2017, ApJ, 837, 183 [NASA ADS] [CrossRef] [Google Scholar]
- Wilson, J. C., Hearty, F. R., Skrutskie, M. F., et al. 2019, PASP, 131, 055001 [NASA ADS] [CrossRef] [Google Scholar]
- Woosley, S. E., & Weaver, T. A. 1995, ApJS, 101, 181 [Google Scholar]
- Woosley, S. E., Heger, A., & Weaver, T. A. 2002, Rev. Mod. Phys., 74, 1015 [NASA ADS] [CrossRef] [Google Scholar]
- Yadav, N., Müller, B., Janka, H. T., Melson, T., & Heger, A. 2020, ApJ, 890, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Yong, D., Karakas, A. I., Lambert, D. L., Chieffi, A., & Limongi, M. 2008, ApJ, 689, 1031 [NASA ADS] [CrossRef] [Google Scholar]
- Zamora, O., García-Hernández, D. A., Allende Prieto, C., et al. 2015, AJ, 149, 181 [CrossRef] [Google Scholar]
![$\left[ {{X \over {{\rm{Fe}}}}} \right] = \log {\left( {{{{N_{\rm{X}}}} \over {{N_{\rm{H}}}}}} \right)_*} - \log {\left( {{{{N_{\rm{X}}}} \over {{N_{\rm{H}}}}}} \right)_ \odot } - \left[ {{{{\rm{Fe}}} \over {\rm{H}}}} \right]$](/articles/aa/full_html/2023/05/aa46048-23/aa46048-23-eq11.png)
![$\left[ {{{{\rm{Fe}}} \over {\rm{H}}}} \right] = \log {\left( {{{{N_{{\rm{Fe}}}}} \over {{N_{\rm{H}}}}}} \right)_*} - \log {\left( {{{{N_{{\rm{Fe}}}}} \over {{N_{\rm{H}}}}}} \right)_ \odot }$](/articles/aa/full_html/2023/05/aa46048-23/aa46048-23-eq12.png)
In this work, an earlier version of the VAC was used. The final version is available at https://www.sdss.org/dr17/data_access/value-added-catalogs/
See paragraph “Spectroscopic Binary Identification” on https://www.sdss.org/dr17/irspec/radialvelocities/
Here the error is the root sum squared of the P standard deviation in this particular star (0.04 dex) and the systematic P error averaged over the two stars given in Table D.2 (0.13 dex).
OMEGA+ is available online as part of the JINAPyCEE package https://github.com/becot85/JINAPyCEE
OMEGA is available online as part of the NuPyCEE package https://github.com/NuGrid/NUPYCEE
The VAC can be found at https://github.com/henrysky/astroNN
We note that binary systems are known to show abundance anomalies (e.g., Jorissen et al. 2016, and references therein) that are not representative of standard field stars and the global chemical enrichment of the Galaxy.
All Tables
Spectral lines alongside the corresponding excitation potential and log(gf) used for the abundance determination of each elemental species considered in this work.
Typical standard deviation σstdev,[x/Fe] and total systematic σ[X/Fe] error associated with each element.
All Figures
|
Fig. 1 Spectra around the P I lines at 15711.622 Å (top panel) and 16482.932 Å (bottom panel) of a P-rich (red line) and a P-normal (black line) star with similar stellar parameters: 2M18280709-3900094 (P-rich) with Teff = 4574.4 K, log g = 1.77, [M/H] = −0.95 dex, and [P/Fe] = 1.42 dex, and 2M16353092+2651591 (P-normal) with Teff = 4502.0 K, log g = 1.74, [M/H] = −0.92 dex, and [P/Fe] < 0.48 dex. |
| In the text | |
|
Fig. 2 Abundances in the [Al/Fe]-[Mg/Fe] plane, showing the background stars (gray color-coded density map) and the full P-rich candidates sample (black circles) described in Sect. 2.2. Empty black circles represent upper limits in [P/Fe]. Outliers identified in this or the plane shown in Fig. 3 are highlighted with orange, green, and blue stars. The red star corresponds to the P-rich GC (M4) member 2M16231729-2624578. Violet crosses indicate outliers in the background sample with GC characteristics, two of which (dark violet crosses; 2M12155306+1431114, 2M 17350460-2856477) have a high [O/Fe] abundance ratio. As defined in Sect. 3.3, the error bar represents the typical standard deviation of the elements listed in Table D.2. |
| In the text | |
|
Fig. 3 Abundances in the [Si/Fe] vs. [P/Fe] plane. The symbols are the same as in Fig. 2. The error bar represents the typical standard deviation of the elements listed in Table D.2. No background stars are displayed because the reliability of the P abundances obtained by the automatic calculation is limited (see Appendix C for further justifications). |
| In the text | |
|
Fig. 4 RV scatter vs. maximum time lag ∆Tmax between visits that are color-coded by the number of visits. Stars with fewer than two visits have been excluded. |
| In the text | |
|
Fig. 5 Abundance ratio [P/Fe] vs. metallicity [Fe/H] (top panel) and vs. effective temperature Teff (bottom panel) of the final sample of 78 P-rich stars (black dots). Downward triangles indicate upper limits in [P/Fe]. Literature values are shown with open black squares (Jacobson et al. 2014), crosses (Maas et al. 2017, 2019), diamonds (Masseron et al. 2020a), and plus signs (Caffau et al. 2011, 2019). Typical errors are indicated in the top left corner. |
| In the text | |
|
Fig. 6 Abundance ratios [X/Fe] vs. metallicity [Fe/H], displaying one element X in each panel. Gray downward triangles indicate upper limits. The background sample was selected and the corresponding abundances were calculated following the procedure described in Sects. 2.2 and 3.2, respectively. In the case of S, the background stars and their corresponding abundances have been extracted from the VAC from Hayes et al. (2022). The color-coding reflects the number density of the stars. For clarity, error bars are suppressed. The errors adopted for each element are given in the title of each panel and correspond to the average standard deviation listed in Table D.2. The error of the metallicity [Fe/H] is ±0.08. |
| In the text | |
|
Fig. 7 Detailed representation of the [(C+N)/Fe] abundance ratio. Left panel: abundance ratio [(C+N)/Fe] vs. metallicity [Fe/H]. Stars with upper limits in C or N have not been considered. Right panel: [(C+N)/Fe] vs. [P/Fe]. Solid circles correspond to real measurements in P, and empty circles denote upper limits in P. In both panels, the error of [(C+N)/Fe] was defined as the quadratic sum of the standard deviation of the C and N measurements. |
| In the text | |
|
Fig. 8 Detailed representation of the [Si/Fe] abundance ratio. Left panel: zoom into the [Si/Fe] vs. [Fe/H] plot of Fig. 6. Right panel: [Si/Fe] vs. [P/Fe]. Solid circles correspond to real measurements in both Si and in P, and empty circles denote upper limits in P. |
| In the text | |
|
Fig. 9 Chemical abundance pattern of our sample of P-rich stars. Dark red stars correspond to the median chemical abundance of the P-rich sample, and gray dots show the median chemical abundance of the background sample. Stars with upper limits were excluded from the median. The red and gray error bars denote the corresponding average line-to-line abundance scatter (typical standard deviation) from Table D.2, which reflects the quality of the measurements. We also provide the star-to-star abundance scatter of the sample as dotted error bars to reflect the spread of abundances. In the case of P, the gray dot indicates the median abundance of the literature values shown in Fig. 5, and the gray error bar shows the mean error of the literature values. |
| In the text | |
|
Fig. 10 Predicted evolution curves. Top panel: [P/Fe] as a function of [Fe/H] in the Galactic disk is shown for four GCE simulations using OMEGA+: the models are CLC (blue line), CRit(del) (red line), CRit(rap) (green line) and CNom (yellow line). For comparison, our new sample of P-rich stars with errors is shown (brown points) together with data from Hinkel et al. (2014) as representative of P-normal stars (black contours). Middle panel: Same as the top panel, but for the [Mg/O] ratio. Bottom panel: Same as the top panel, but for the [Si/S] ratio. For each panel, upper limits in the P-rich sample are represented by downward triangles and lower limits by upward triangles. The black contours allow us to map the distribution density of the stellar abundances. |
| In the text | |
|
Fig. 11 P-rich stars (black dots) plotted against a background sample in three different dynamical planes: total energy vs. angular momentum Lz (top panel), eccentricity vs. Lz (middle panel), and maximum height above the midplane Zmax vs. eccentricity (bottom panel). To separate the background sample into thin-disk, thick-disk, canonical halo, and accreted halo stars, we used the results from Hawkins et al. (2015), Masseron & Gilmore (2015), and Hayes et al. (2018) (see main text for more details). For clarity, we give a typical error bar for the P-rich stars corresponding to the average error of their parameters. |
| In the text | |
|
Fig. C.1 Difference in the abundance ratio Δ[X/Fe] between manual and automated calculation vs. metallicity [Fe/H] for all the elements studied in this work, except for S, because this element was added to our analysis after the calculation with the supercomputer was concluded. The average difference (red line) can be extrapolated to the background sample to validate the performance of the automatic calculation. |
| In the text | |
|
Fig. E.1 Abundance ratios [X/Fe] vs. effective temperature ‚ displaying one element X in each panel. Gray downward triangles indicate upper limits. The background sample was selected and the corresponding abundances were calculated following the procedure described in Sects. 2.2 and 3.2. In the case of S, the background stars have been selected out of the VAC from Hayes et al. (2022). The color-coding reflects the number density of the stars. For clarity, error bars are suppressed. The errors adopted for each element are given in the title of each panel and correspond to the average standard deviation listed in Table D.2. Here we assume that the error of the effective temperature is the average ASPCAP Teff error over the 78 sample stars (±14.32 K). |
| In the text | |
|
Fig. F.1 Detailed representation of the [O/Fe] abundance ratio. Left panel: Zoom into the [O/Fe] vs. [Fe/H] plot of Fig. 6 with upper limits (solid triangles). Right panel: [O/Fe] vs. [P/Fe] to illustrate the correlation between P and O. Solid circles correspond to real measurements in both O and in P, empty circles to upper limits in P, solid triangles to upper limits in O, and empty triangles denote upper limits in O and P. Error bars are defined to reflect the typical standard deviation given in Table D.2 |
| In the text | |
 |
Fig. F.2 Same as Fig. F.1 for Mg. |
| In the text | |
 |
Fig. F.3 Same as Fig. F.1 for A1. |
| In the text | |
 |
Fig. F.4 Same as Fig. F.1 for Ce. |
| In the text | |
 |
Fig. F.5 Same as Fig. F.1 for Nd. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.