| Issue |
A&A
Volume 668, December 2022
|
|
|---|---|---|
| Article Number | A21 | |
| Number of page(s) | 21 | |
| Section | Stellar atmospheres | |
| DOI | https://doi.org/10.1051/0004-6361/202243701 | |
| Published online | 01 December 2022 | |
SDSS-IV MaStar: Stellar parameter determination with continuum-supplemented full-spectrum fitting
1
Department of Physics and Astronomy, University of Kentucky,
505 Rose St.,
Lexington, KY
40506-0057, USA
e-mail: dan.lazarz.mail@gmail.com
2
Department of Physics, The Chinese University of Hong Kong,
Shatin, N.T., Hong Kong S.A.R., PR China
e-mail: rbyan@cuhk.edu.hk
3
New York University Abu Dhabi,
Abu Dhabi
PO Box 129188, United Arab Emirates
4
Institute of Cosmology and Gravitation, University of Portsmouth,
Burnaby Road,
Portsmouth
PO1 3FX, UK
5
Department of Astronomy, New Mexico State University,
Box 30001, MSC 4500,
Las Cruces NM
88003, USA
6
Institute of Cosmology & Gravitation, University of Portsmouth,
Dennis Sciama Building,
Portsmouth
PO1 3FX, UK
7
MTA-ELTE Exoplanet Research Group, ELTE Eötvös Loránd University, Gothard Astrophysical Observatory,
9700
Szombathely,
Szent Imre H. st. 112, Hungary
8
MTA-ELTE Lendület “Momentum” Milky Way Research Group, ELTE Eötvös Loránd University, Gothard Astrophysical Observatory,
9700
Szombathely,
Szent Imre H. st. 112, Hungary
9
Center for Astrophysics and Space Astronomy, Department of Astrophysical and Planetary Sciences, University of Colorado,
389 UCB,
Boulder, CO
80309-0389, USA
10
Department of Physics and Astronomy and JINA Center for the Evolution of the Elements (JINA-CEE), University of Notre Dame,
Notre Dame, IN
46556, USA
11
Apache Point Observatory and New Mexico State University,
PO Box 59,
Sunspot, NM
88349, USA
12
Sternberg Astronomical Institute, Moscow State University,
Universitetskij pr. 13,
Moscow, Russia
13
McDonald Observatory, The University of Texas at Austin,
1 University Station,
Austin, TX
78712, USA
14
Centro de Investigación en Astronomía, Universidad Bernardo O’Higgins,
Avenida Viel,
1497
Santiago, Chile
15
Centro de Astronomía (CITEVA), Universidad de Antofagasta,
Avenida Angamos 601,
Antofagasta
1270300, Chile
Received:
3
April
2022
Accepted:
25
July
2022
Aims. We present a stellar parameter catalog built to accompany the MaStar Stellar Library, which is a comprehensive collection of empirical, medium-resolution stellar spectra.
Methods. We constructed this parameter catalog by using a multicomponent χ2 fitting approach to match MaStar spectra to models generated by interpolating the ATLAS9-based BOSZ model spectra. The total χ2 for a given model is defined as the sum of components constructed to characterize narrow-band features of observed spectra (e.g., absorption lines) and the broadband continuum shape separately. Extinction and systematics due to flux calibration were taken into account in the fitting. The χ2 distribution for a given region of model space was sampled using a Markov chain Monte Carlo (MCMC) algorithm, the data from which were then used to extract atmospheric parameter estimates (Teff, log g, [Fe/H], and [α/Fe]), their corresponding uncertainties, and direct extinction measurements.
Results. Two methods were used to extract parameters and uncertainties: one that accepts the MCMC’s prescribed minimum-χ2 result, and one that uses Bayesian inference to compute a likelihood-weighted mean from the χ2 distribution sampled by the MCMC. Results were evaluated for internal consistency using repeat observations where available and by comparing them with external data sets (e.g., APOGEE-2 and Gaia DR2). Our spectral-fitting exercise reveals possible deficiencies in current theoretical model spectra, illustrating the potential power of MaStar spectra for helping to improve the models. This paper represents an update to the parameters that were originally presented with SDSS-IV DR17. The MaStar parameter catalog containing our BestFit results is available on the SDSS-IV DR17 website as part of version 2 of the MaStar stellar parameter value-added catalog.
Key words: stars: abundances / stars: atmospheres / Hertzsprung–Russell and C–M diagrams / methods: data analysis
© D. Lazarz et al. 2022
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe-to-Open model. Subscribe to A&A to support open access publication.
1 Introduction
Libraries of stellar spectra represent an essential component of Stellar-population Synthesis (SPS), alongside stellar isochrone models and an initial mass function (IMF). They can be divided into two broad categories: theoretical and empirical spectral libraries. Theoretical (or synthetic) spectra come with a number of advantages. These include arbitrarily high spectral resolution and more comprehensive stellar parameter space coverage than modern observing techniques allow. However, they suffer from a number of drawbacks as well, including incomplete atomic and molecular line lists due to inadequacies in our present understanding of stellar atmospheric physics. Empirical stellar spectra refer to spectra obtained from observations of actual stars. While they are limited in spectral resolution and parameter space coverage by observation techniques and the availability of desirable targets, they come with the benefit of providing the most accurate possible representation of real-world stellar physics.
Previous empirical stellar libraries have proven invaluable for stellar population research. Examples of such libraries include MILES (Sánchez-Blázquez et al. 2006; Falcón-Barroso et al. 2011), the X-shooter Stellar Library (XSL, Chen et al. 2014; Verro et al. 2022), ELODIE (Soubiran et al. 1998; Prugniel & Soubiran 2001, 2004; Prugniel et al. 2007; Gunn & Stryker 1983), Pickles (Pickles 1985, 1998; Diaz et al. 1989; Silva & Cornell 1992), Lick/IDS (Worthey et al. 1994; Lançon & Wood 2000), STELIB (Le Borgne et al. 2003), INDO-US (Valdes et al. 2004), CaT (Cenarro et al. 2001), HST NGSL (Gregg et al. 2006), the NASA Infrared Telescope Facility (IRTF) Library (Rayner et al. 2009), and the Extended IRTF library (Villaume et al. 2017). However, these libraries have several significant shortcomings, including limited wavelength and parameter coverage. A project on the scale of Mapping Nearby Galaxies at Apache Point Observatory (MaNGA, Bundy et al. 2015; Yan et al. 2016) stands to benefit greatly from a larger library with a wider variety of stellar types of varying parameters. MaNGA is a large survey containing detailed integral field unit (IFU) spectroscopy data for approximately 10 000 galaxies, and it was one of three major projects undertaken as part of the fourth generation of the Sloan Digital Sky Survey (SDSS-IV, Blanton et al. 2017), alongside the extended Baryon Oscillation Spectroscopic Survey (eBOSS, Dawson et al. 2016), and the second generation of the Apache Point Observatory Galactic Evolution Experiment (APOGEE-2, Majewski et al. 2016).
In an effort to address the issues with present stellar libraries, we have constructed the MaNGA stellar library (MaStar, Yan et al. 2019), an empirical stellar library built to accompany MaNGA using the same instrumentation via parallel observing. The final library contains more than 25 000 empirical spectra from nearly 12 000 unique science targets, supplemented by more than 33 500 spectra from more than 12 000 unique standard stellar targets. These spectra are uniform in quality and provide a broad and comprehensive coverage of stellar parameter space. These parameters include effective temperature, surface gravity, iron abundance (as a proxy for overall stellar metallicity), and α abundance, hereafter Teff, log g, [Fe/H], and [α/Fe].
Of the three aforementioned ingredients for SPS (the IMF, stellar isochrones, and stellar spectra), the last two are closely linked as they contain the information needed to understand how individual stellar atmospheres evolve. This information is necessary for reproducing composite spectra of stellar populations. However, in order to make use of isochrone data in conjunction with empirical stellar spectra, it is necessary to have a set of accurate stellar parameters at the correct locations along the stars’ evolutionary tracks. The three atmospheric parameters, Teff, log g, and [Fe/H], are usually sufficient for this task, but additional parameters, such as α abundance, are also useful for recreating abundance patterns observed in nature.
There are several common methods for estimating stellar parameters, including some that involve the use of sophisticated machine learning algorithms, such as The Cannon or The Payne (Ness et al. 2015; Ting et al. 2019). These are data-driven approaches that require a training set of stellar spectra for which the desired parameters are assumed to already be known accurately. While these methods have the advantage of being primarily based on empirical spectral data, they are limited by the availability, quality, and parameter coverage of the training set being used. In other words, the set of estimated stellar parameters obtained is only as good as the input training set, both in accuracy and coverage. As a consequence, such data-driven methods have difficulty assigning parameters to a star that lies outside the region of parameter space spanned by its training set. While this approach is still extremely useful for many applications, it presents a problem when developing parameter sets for newer libraries that aim to obtain broader parameter coverage than previous catalogs, which is one of the primary goals of MaStar. As a result, such machine learning approaches should be treated with caution.
Another category of methods involves matching theoretical templates with predetermined parameters to empirical spectra in order to find the best-fitting model, and hence, the best-fitting stellar parameters. Such model-based methods have the advantage of not being limited by the parameter space coverage or quality of previously obtained empirical spectra, since models can be generated for a wide variety of stars at whatever resolution is desired. However, this approach relies on our previously mentioned incomplete understanding of the stellar atmospheric physics. As a result, precautions must be taken, and the possibility that the models may contain subtle inaccuracies must be considered.
In this paper, we present our set of parameters for the MaStar library and discuss our approach to parameter determination. Our method used a set of theoretical model spectra to perform a minimum-χ2 fitting of the data in order to obtain best-fitting models via interpolation according to several measures. These measures included comparing the data with models according to narrow-band spectral features, such as absorption lines, as well as broadband features that make up the continuum shape. Our method’s use of the information contained in the continuum in addition to the continuum-normalized full-spectrum fitting makes it unique. Various complicating effects were taken into account, such as interstellar extinction, and imperfect flux calibration. The final product is a set of stellar parameters (Teff, log g, [Fe/H], and [α/Fe]) for the complete set of MaStar spectra, ready for use in stellar-population synthesis. Our independently derived extinction estimates, in the form of AV, are also included with the final parameter set.
There have been several other concurrent parameter determination efforts for MaStar underway in recent years. Hill et al. (2021) presents a method that uses a version of the penalized pixel-fitting method (pPXF, Cappellari & Emsellem 2004; Cappellari 2016) for full-spectrum fitting, using a Bayesian approach for parameter estimation with priors based on Gaia photometry (Gaia Collaboration 2018). Imig et al. (2022) presents a data-driven approach that uses a neural network model trained on previously obtained APOGEE-2 parameters for a subset of MaStar targets. Chen et al. (2022, in prep.) will present a Bayesian method using priors based on isochrone data. Chen et al. (2020) also presents an early parameter set for MaStar’s first data release as a part of SDSS DR15.
In this paper, we discuss our approach to stellar parameter determination in detail in Sect. 2, covering each step of the procedure. In Sect. 3, we evaluate the reliability of the parameters through internal and external comparisons and discuss the implications of our results on the present state of atmospheric models. Finally, in Sect. 4, we discuss our closing thoughts and the potential for future work.
2 Method
2.1 Overview
The method we developed combines the use of traditional continuum-normalized spectral fitting with a more novel form of continuum fitting. The goal of this was to use the information contained within a star’s broadband shape to place constraints on the traditional spectral-fitting procedure, and break degeneracies that arise in certain regions of parameter space. This is particularly helpful for hotter stars, with temperatures above 7000 K. The reasoning behind this is that the continuum itself characterizes certain useful parameter-dependent features (e.g., the Balmer break) in a similar way to photometry. So, in essence, this approach combines the spirit of spectroscopic parameter fitting with that of traditional photometric fitting to arrive at a solution that is consistent with both methods.
The procedure we used to compare a MaStar spectrum with a given model involved a reduced-χ2 calculation, in which a total χ2 was defined as the weighted sum of three components, defined as the following:
High-Frequency Component (
 ): Computed by comparing the continuum-normalized MaStar spectrum and continuum-normalized model spectrum directly.
): Computed by comparing the continuum-normalized MaStar spectrum and continuum-normalized model spectrum directly.Low-Frequency Component (
 ): Computed by comparing the large-wavelength-scale (or “low-frequency”) features of the MaStar spectrum with that of the model spectrum with foreground extinction applied.
): Computed by comparing the large-wavelength-scale (or “low-frequency”) features of the MaStar spectrum with that of the model spectrum with foreground extinction applied.Flux Calibration Component (
 ): Computed by evaluating the polynomial correction needed to account for flux-calibration residuals. This generally amounted to only a small addition to the total χ2.
): Computed by evaluating the polynomial correction needed to account for flux-calibration residuals. This generally amounted to only a small addition to the total χ2.
These three components were combined additively to give  , which was used to quantify a given model’s overall agreement with the data. With
, which was used to quantify a given model’s overall agreement with the data. With  defined, we were free to use whichever minimization algorithm we preferred to find the model that minimized
defined, we were free to use whichever minimization algorithm we preferred to find the model that minimized  , and take that model’s parameters to be correct. In practice, this procedure came with several caveats, which we discuss in later sections. These included the need for strategic weighting of certain components of
, and take that model’s parameters to be correct. In practice, this procedure came with several caveats, which we discuss in later sections. These included the need for strategic weighting of certain components of  , as well as the masking or deweighting of certain spectral features that were believed to be inaccurately represented by the models.
, as well as the masking or deweighting of certain spectral features that were believed to be inaccurately represented by the models.
The χ2 fitting was carried out in four phases:
Phase 1: Initialization. Prepare the model set according to the given MaStar spectrum’s unique instrumental line spread function (LSF), approximate the continua, and generate continuum-normalized spectra for both the data and the models using an identical procedure.
Phase 2: Global Grid Search. Find the best-fitting discrete model grid point from the continuum-normalized spectral fitting to use as an initial parameter estimate for the next phase.
Phase 3: Interpolator Search. Use a Markov chain Monte Carlo (MCMC) algorithm to sample the distribution of
 in the vicinity of the initial estimate.
in the vicinity of the initial estimate.Phase 4: Parameter Extraction. Derive parameter values and corresponding error estimates from the MCMC data.
These phases were performed for each individual MaStar spectrum, and diagnostic data were recorded where appropriate for use in post processing.
Figure 1 contains a flowchart describing these phases in further detail. From this, it is easy to see that the bulk of our method’s nuance was applied within Phase 3. It was here that we considered several important but more subtle factors, such as  scaling and rejection, and when extinction and flux-calibration correction were applied. We discuss these topics in detail below.
scaling and rejection, and when extinction and flux-calibration correction were applied. We discuss these topics in detail below.
 |
Fig. 1 Flowchart detailing our parameter-determination procedure (upper) with an additional chart detailing the subroutine used for all χ2 calculations following the initial global grid search (lower). |
2.2 Data
Data for MaStar was obtained at the Apache Point Observatory in New Mexico, alongside that of the aforementioned main surveys that make up SDSS-IV, using the Sloan 2.5-m telescope (Gunn et al. 2006). APOGEE-2, being a near-infrared H-band stellar survey, conducted observations during bright time. Since APOGEE-2 used its own infrared spectrograph, this presented an opportunity for MaStar to piggyback on APOGEE-2 observations using the unoccupied BOSS spectrograph (Smee et al. 2013) to observe at optical wavelengths simultaneously. This could be done using the MaNGA fiber bundles (Drory et al. 2015) to target stars. This setup allowed us to observe MaStar targets with a wavelength range of 3622–10 354 Å at a resolving power of R ~ 1800. To ensure high signal-to-noise ratios, MaStar targets were selected to be at least as bright as 17.5 in either the g- or the i-band, and fainter than 8.1 in both the g- and i-band, according to preexisting data.
As of its final data release, MaStar contains 25 683 stellar spectra from 11 817 unique science targets with a median signal-to-noise ratio of 110. Each target received one or more observing visits, with a median of two visits and a maximum of 17 visits. Of these targets, 4783 received only one visit. In addition to the science targets, 33 583 spectra from 12 477 unique standard stars (targeted for flux calibration purposes) are also included in the final MaStar data file.
A great deal of effort has been put into optimizing MaNGA and MaStar’s flux calibration and LSF calibration. Flux calibration is considered to be accurate to within 3.9% in g–r, 2.7% in r–i, and 2.2% in i–z when compared to photometry (Yan et al. 2019, Fig. 5), but is expected to vary slightly between spectra. The instrumental LSF, while having been acquired to similar accuracy (Law et al. 2021), does vary as a function of wavelength, and thus must be considered when conducting any comparison between MaStar spectra and high-resolution models.
2.3 Model spectra
The model grid we employed was constructed using the ATLAS9-based model atmosphere database presented in Mészáros et al. (2012) specifically for use with MaNGA and MaStar flux calibration, making it an excellent choice for our parameter-determination efforts. The line lists adopted for these models were the same as those described in Bohlin et al. (2017), though the grid is updated to have finer parameter sampling. The spectra cover a wavelength range of 3000–11 000 Å using vacuum wavelengths, with a resolution R = 10 000. The spectra contain no rotational broadening, and the micro-turbulent velocity is the same as that used in the original model atmospheres, 2 km s−1.
The grid covers most of MaStar’s parameter footprint, ranging 3500–30 000 K in temperature, 0–5.0 in log g, −2.5 to +0.5 in [Fe/H], and −0.25 to +0.5 in [α/Fe]. The grid we chose is moderately dense, with grid points having a spacing of 0.4 dex in log g (with the exception of the two highest bins, 4.8 and 5.0), 0.2 dex in metallicity, and 0.25 dex in α abundance. The temperature grid spacing, however, is nonuniform, giving denser coverage at lower temperatures (100 K spacing below 6000 K), and becoming more sparse at higher temperatures (200 K spacing between 6000 K and 15000 K, and 1000 K spacing above 15 000 K). For computational convenience, we found it necessary to modify the step sizes above 10 000 K and in the log g dimension, making our final grid slightly less dense than the original that was provided to us. One could use a denser grid if desired, though it would be more computationally expensive. The BOSZ model atmospheres are also capable of representing multiple carbon abundances, but keeping [C/M] = 0 was sufficient for our purposes. The layout of our final model grid is described by Table 1 and Fig. 2.
 |
Fig. 2 Atlas9-based BOSZ model grid used for multicomponent χ2-fitting. |
Atmospheric parameters of ATLAS9-based BOSZ model spectra.
2.4 LSF model correction
Our chosen set of model spectra were provided at a much higher resolution than that of the observed MaStar spectra (R ≈ 1800), thus, in order to make an accurate pixel-by-pixel comparison between the observed MaStar spectra and the model spectra, it was necessary to both 1) convolve the model spectra with MaStar’s instrumental broadening kernel to bring them to the correct resolution, and 2) resample the model spectra according to MaStar’s wavelength array. Neglecting this first step would have led to disagreement in line profiles and different degrees of blending of unresolved lines.
Since the LSF varies with wavelength in a way that is unique to each visit, LSF convolution had to be done on a pixel-by-pixel and spectrum-by-spectrum basis. To accomplish this, we constructed a 3D array containing the full set of model spectra convolved with Gaussian kernels with 17 successive σ values. We then interpolated this array using the pixel-by-pixel dispersion provided with each MaStar spectrum in order to obtain a version of the model grid that was smoothed and resampled to a resolution that matches the data. We could then store this array and call it for each new MaStar spectrum to provide a model grid that had been convolved appropriately to match that particular spectrum’s wavelength-dependant LSF.
For each MaStar spectrum, the appropriate LSF-smoothed set of model spectra was generated up front during Phase 1, as represented in the flowchart in Fig. 1. We then used this smoothed model set in subsequent steps to generate new model spectra via interpolation.
2.5 Continuum normalization
Characterizing the large-scale shape of stellar spectra is a necessary step for most traditional spectroscopy-based parameter-determination methods, which typically perform some sort of continuum normalization on observed spectra prior to fitting. The reason for doing this is that imperfect flux calibration can have an impact on the overall spectral shape, and removing the low-frequency spectral features that are susceptible to such problems helps to mitigate this. However, the broadband, low-frequency shape of a spectrum contains information that can be used for constraining atmospheric parameters. One of our goals was to make the best possible use of this information, which many previous efforts have disregarded entirely. Throughout this paper, the term “continuum” is used to refer to the broadband shape of a stellar spectrum, as opposed to high-frequency features such as atomic and molecular lines. This is not necessarily the same as the physical continuum that one would observe in a spectrum with very high resolution.
To capture the broadband shape, we used a simple mean-filter smoothing routine that was weighted by the pixel-by-pixel inverse variance provided with the MaStar spectra. This provided an easy way of smoothing an observed spectrum down to an approximation of its broadband continuum shape, preserving its large-wavelength-scale features. We preferred this method over the use of b-spline or polynomial functions, since it was computationally more efficient than b-spline fits and more accurate than polynomial fits. In addition, since the smoothing was weighted by the pixel-by-pixel uncertainties unique to each observed spectrum, we could perform an identical smoothing on all the model spectra using the same inverse variance vector as the weight function, resulting in an unbiased comparison. This provided an advantage over many other continuum-determination methods.
This inverse variance weighted mean smoothing routine was essentially a boxcar running mean calculation that uses a window size of 300 pixels (260–690 Å, depending on the wavelength regime), represented by RM in Eq. (1):
 (1)
(1)
where  is the mean-smoothed flux, and σ2 is the unique pixel-by-pixel dispersion provided for each MaStar spectrum. An analogous running sum was also performed on the inverse variance associated with each spectrum, giving the appropriate smoothed inverse variance at each pixel, which was needed for the subsequent χ2 fitting.
is the mean-smoothed flux, and σ2 is the unique pixel-by-pixel dispersion provided for each MaStar spectrum. An analogous running sum was also performed on the inverse variance associated with each spectrum, giving the appropriate smoothed inverse variance at each pixel, which was needed for the subsequent χ2 fitting.
The window size essentially set an upper limit on the width of features that could remain in the normalized spectra. As such, the width of 300 pixels was chosen in an ad hoc manner in order to smooth out low-frequency features while leaving high-frequency features intact in the final normalized spectra. Future work may be needed to determine whether or not 300 pixels is truly the optimal width for this purpose, and whether the optimal width ought to vary significantly between different spectral types. However, we found this choice to be perfectly acceptable for our purposes. For hotter stars (Teff ≥ 6000 K), this method typically gave a very accurate representation of the continuum. It also remained effective at lower temperatures, where molecular features become prominent, but the smoothed spectra in such regimes became less representative of the true physical continua due to the very wide molecular features. However, this did not impact the ability of the routine to find a reasonable match between the data and the models, since their continua were treated identically.
Figure 3 shows several examples of how the continuum representation behaves for a variety of spectral types. It is also worth noting that higher-frequency spectral features, such as prominent Hydrogen absorption lines, metal lines, and line blanketing could often cause small wiggles in the continuum. This can be seen in some of the intermediate-temperature spectra shown in Fig. 3. Since the data and the models were treated in exactly the same way, these features did not bias the fitting at all.
Once we obtained the continuum, we could then generate a continuum-normalized spectrum by dividing the original spectrum by the continuum. This normalized spectrum could then be used for high-frequency spectral fitting, and the continuum could be used for low-frequency spectral fitting. This continuum calculation and normalization for the data and models were done in Phase 1, as shown in Fig. 1.
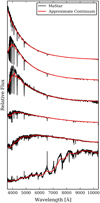 |
Fig. 3 Several examples of observed stellar spectra (black) with their inverse-variance-weighted mean smoothed counterparts (red). The latter was used for continuum normalization and for direct comparison with model continua. Temperatures range from hottest to coolest from top to bottom. |
2.6 Defining the primary components of χ2
The agreement between a given MaStar spectrum and a model spectrum was characterized by 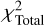 , which we defined as the sum of two main constituents,
, which we defined as the sum of two main constituents,  and
and  . These two components were obtained using simple reduced-χ2 calculations, measuring the agreement between the given spectra on a pixel-by-pixel basis, as shown in Eqs. (2) and (3):
. These two components were obtained using simple reduced-χ2 calculations, measuring the agreement between the given spectra on a pixel-by-pixel basis, as shown in Eqs. (2) and (3):
 (2)
(2)
 (3)
(3)
where N is the number of pixels in the wavelength array, fi and fm,i are the continuum-normalized flux for the data and the model, respectively, and Ci∙ and Cmi are the data and model continuum, respectively.  is the variance at pixel i provided with the data, and
is the variance at pixel i provided with the data, and  is the variance associated with the continuum, obtained via mean-smoothing, as discussed in Sect. 2.5.
is the variance associated with the continuum, obtained via mean-smoothing, as discussed in Sect. 2.5.
Despite the similarity in their construction, the values of  and
and  could differ greatly. It was typical for
could differ greatly. It was typical for  to be significantly greater than
to be significantly greater than  , often exceeding it by an order of magnitude or more. This put
, often exceeding it by an order of magnitude or more. This put  in danger of dominating
in danger of dominating  , often leading to inaccurate estimates. This discrepancy in scale indicated that our formulation for
, often leading to inaccurate estimates. This discrepancy in scale indicated that our formulation for  as described by Eq. (3) does not properly take into account the covariance introduced by the mean-smoothing routine used to obtain Ci. This would typically result in being significantly underestimated. We addressed this by introducing an ad hoc fix in the form of a corrective scaling factor, as shown in Eq. (4):
as described by Eq. (3) does not properly take into account the covariance introduced by the mean-smoothing routine used to obtain Ci. This would typically result in being significantly underestimated. We addressed this by introducing an ad hoc fix in the form of a corrective scaling factor, as shown in Eq. (4):
 (4)
(4)
where  refers to the scaled χ2 measurement associated with the low-frequency component of a particular model’s spectral shape. This prevented the low-frequency fitting from dominating the high-frequency fitting, thus preventing our result from being driven to an incorrect part of parameter space.
refers to the scaled χ2 measurement associated with the low-frequency component of a particular model’s spectral shape. This prevented the low-frequency fitting from dominating the high-frequency fitting, thus preventing our result from being driven to an incorrect part of parameter space.
To obtain a value for  and
and  for use in Eq. (4), we used an optimization function scipy.optimize (Virtanen et al. 2020). This package was only used for calculating the scaling factor, not for finding the best fit with the combined χ2. We chose to use a different algorithm for minimizing
for use in Eq. (4), we used an optimization function scipy.optimize (Virtanen et al. 2020). This package was only used for calculating the scaling factor, not for finding the best fit with the combined χ2. We chose to use a different algorithm for minimizing  , since the scipy.optimize algorithm had a tendency to become trapped in local minima, which would ultimately lead to gridding artifacts in the final distribution.
, since the scipy.optimize algorithm had a tendency to become trapped in local minima, which would ultimately lead to gridding artifacts in the final distribution.
In a number of cases, we found that the mitigating scaling factor alone was not sufficient for addressing the problem of  being dominated by
being dominated by  . This would occur predominantly for the cool main sequence (Teff < 4000 K) and at the tip of the red giant branch (log g < 1). We believe that the cause for this was a mismatch between the data and the models in the molecular features present in cool stars. As a result,
. This would occur predominantly for the cool main sequence (Teff < 4000 K) and at the tip of the red giant branch (log g < 1). We believe that the cause for this was a mismatch between the data and the models in the molecular features present in cool stars. As a result,  could exceed
could exceed  by a factor of 20 or more, leading to a tendency for the algorithm to underestimate log g in cool dwarfs. To mitigate this, we imposed a minimum permissible scaling factor of 1/15. That is, if
by a factor of 20 or more, leading to a tendency for the algorithm to underestimate log g in cool dwarfs. To mitigate this, we imposed a minimum permissible scaling factor of 1/15. That is, if  exceeded
exceeded  by more than a factor of 15, then we chose to disregard all continuum-related components of
by more than a factor of 15, then we chose to disregard all continuum-related components of  entirely, including both
entirely, including both  and
and  . In these cases, the only point where the continuum was still used was in the continuum-normalization step. It is important to note here that this effect was not due to a shortcoming of the fitting technique. Rather, it suggests some overall disagreement between the data and the models in this parameter regime. We discuss this in more detail in Sect. 2.10.
. In these cases, the only point where the continuum was still used was in the continuum-normalization step. It is important to note here that this effect was not due to a shortcoming of the fitting technique. Rather, it suggests some overall disagreement between the data and the models in this parameter regime. We discuss this in more detail in Sect. 2.10.
These χ2 components were computed at several different stages throughout the routine. In the global grid search performed in Phase 2, only 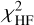 was used, since the goal of this step was only to generate an initial estimate of the stellar parameters to later be used as a starting point for the MCMC. Throughout Phase 3, all χ2 calculations were handled by a subroutine described by the lower section of the flowchart in Fig. 1.
was used, since the goal of this step was only to generate an initial estimate of the stellar parameters to later be used as a starting point for the MCMC. Throughout Phase 3, all χ2 calculations were handled by a subroutine described by the lower section of the flowchart in Fig. 1.
2.7 Extinction fitting
Accounting for the reddening effect of interstellar extinction was critical for our approach, since it can dramatically affect the broadband shape of a spectrum. Hence, when attempting to fit a given MaStar spectrum, we had to consider the possibility that its shape may have been significantly altered by the presence of interstellar dust along the line of sight.
One possible approach to accounting for extinction involves the use of 3D dust maps (such as those presented in Green et al. 2019) to estimate the line-of-sight extinction. This usually gives a reliable extinction estimate, provided the distance and the distribution of dust in the vicinity of the star are sufficiently well known. The number of MaStar targets that satisfy this condition is quite large, thanks to projects such as the Gaia mission (Gaia Collaboration 2018), which can provide accurate distance estimates using parallax measurements, especially for relatively nearby stars (Bailer-Jones et al. 2018). However, this dust map approach becomes less reliable for distant stars and hot stars. Distant stars are problematic because distance estimates become more uncertain as the fractional uncertainties in their parallax measurements become larger. Hot stars are also problematic because they tend to be located within star forming regions, where the extinction level jumps significantly. As a result, a small error in distance could cause a large error in extinction. Given that upper main-sequence stars and giant stars make up an important portion of MaStar’s target set, we chose not to rely on 3D dust map information for extinction fitting.
Rather than trusting literature values for the extinction along a given line of sight, we instead incorporated extinction fitting into the model search by computing the extinction that a given model being tested would need in order to match the data using extinction curves provided in the literature. To illustrate this, consider the usual expression used to compute the extincted flux, FE, given an extinction value, AV:
 (5)
(5)
In principle, there is a proportional constant that depends on the normalization differences between the data and the model, which we represent with Q. The fraction Aλ/AV is provided by the Fitzpatrick extinction curves (Fitzpatrick et al. 2019). By rearranging Eq. (5), we can obtain an expression that is linear in Av:
 (6)
(6)
Substituting FE,λ with the MaStar spectrum for which we wish to obtain an extinction estimate (FMaStar) and Fλ for a given model spectrum that we wish to compare (FModel), and plotting log10(FModel/FMaStar) as a function of  , typically yields a near straight-line curve that can be fit with a linear function having a slope that can be used as an AV estimate, as shown in Fig. 4. This function also has a vertical offset
, typically yields a near straight-line curve that can be fit with a linear function having a slope that can be used as an AV estimate, as shown in Fig. 4. This function also has a vertical offset  , which we can discard. In developing this method, we took special care here to limit the range of the fitting to a wavelength range that was less sensitive to model mismatch, had high signal-to-noise ratios, and was free of potential data issues. For this reason, we only performed the fit over the wavelength range 4775–9500 Å.
, which we can discard. In developing this method, we took special care here to limit the range of the fitting to a wavelength range that was less sensitive to model mismatch, had high signal-to-noise ratios, and was free of potential data issues. For this reason, we only performed the fit over the wavelength range 4775–9500 Å.
It is important to note that this technique faced a disadvantage at low temperatures. For cool dwarf and cool giant stars, any deviation seen in log10(FModel/FMaStar) from a linear function was often dominated by deviations due to significant model mismatches, which occurred frequently for cool stars, since the models provided poor fits to the large molecular bands in cool stellar spectra. Because of this, we recommend that our extinction estimates be used with caution in certain parameter regimes. Such problematic cases can usually be identified by their high error estimates. We discuss this in further detail in Sect. 3.5. We performed our extinction-fitting procedure every time  was calculated throughout Phase 3 of the routine, as described in Fig. 1. It was built into the χ2 subroutine.
was calculated throughout Phase 3 of the routine, as described in Fig. 1. It was built into the χ2 subroutine.
 |
Fig. 4 Extinction fitting using a linear fit of the log10 of the flux ratio of a given data-model pair. The fitting was limited to a wavelength range that was relatively insensitive to model mismatch, had good S/N, and was free of data issues. R = 3.1 was assumed. |
2.8 Flux-calibration systematics
While MaStar’s flux calibration is considered to be very accurate, even slight systematics can have a significant impact on low-frequency spectral features. In practice, this means that, at any given wavelength, an observed spectrum’s continuum shape may be off by as much as 5–15% (Yan et al. 2019, Fig. 6), so we had to adjust our low-frequency fitting accordingly.
In order to allow for this possible deviation from a star’s true spectral shape for each data-model pair of spectra, we evaluated the extent to which the flux calibration would have to be off in order to account for any disagreement. This could be characterized by the ratio between the data and model continua of each spectrum, CMaStar/CBOSZ, as a function of wavelength. In this representation of the flux-calibration residuals, a ratio that is equal to 1 at every wavelength would correspond to a perfect broadband fit, and no inaccuracy in flux calibration would be suggested. However, in a realistic case, we would expect that this ratio could deviate between ~0.85 and ~1.15 at either end of the wavelength range, while still corresponding to an acceptable fit. For each pair of data and model spectra, we fitted a fifth-order polynomial to the continuum ratio to approximate the flux-calibration residual vector. The model spectrum was then divided by this fifth-order polynomial to make it conform to the data, in effect removing the flux calibration residuals present in the fit, and allowing for a much more fair comparison between the data and model continua.
The obvious danger involved with this procedure was the possibility that we could be forcing poorly fitting models to fit the data. For this reason, we chose to impose some limitation on what level of disagreement we considered to be explainable by flux-calibration systematics. For example, if a data-model pair had a continuum ratio that extended much higher than 1.15 or much lower than 0.85, we needed to have a way of ruling out that model as a reasonable choice. To do this, we characterized the extremeness of the fifth-order polynomial correction with its own component of  , which we refer to as
, which we refer to as  . This component has the form:
. This component has the form:
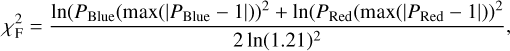 (7)
(7)
where PBlue and PRed are the fifth-order polynomial correction being applied to the model, evaluated for λ < 6980 Å and λ > 6980 Å, respectively. Each section is evaluated at its point of maximum absolute deviation from 1 at the blue and red ends of the wavelength range. This would typically amount to a very small correction to  near the minimum of the distribution, but was used to ensure that models that would require an unreasonable flux-calibration correction were deprioritized. This flux-calibration correction procedure was performed every time
near the minimum of the distribution, but was used to ensure that models that would require an unreasonable flux-calibration correction were deprioritized. This flux-calibration correction procedure was performed every time  was calculated in Phase 3, as described in Fig. 1. It was built into the χ2 subroutine that is described in the lower part of the figure.
was calculated in Phase 3, as described in Fig. 1. It was built into the χ2 subroutine that is described in the lower part of the figure.
 |
Fig. 5 Example of a cool dwarf spectrum with prominent TiO bands below 7800 Å, which our model set struggled to represent accurately. The raw spectrum, along with its corresponding BestFit model, is displayed in the top panel. The continuum-normalized spectrum and model are displayed in the middle panel. The absolute residuals from this fit are shown in the bottom panel, and show significantly better agreement in the 7800–9900 Å range. |
 |
Fig. 6 Comparison between MaStar’s parameter distribution before (left) and after (right) introducing wavelength weighting to give higher priority to redder wavelengths. Deprioritizing fitting spectral features below 7800 Å led to better performance at lower temperatures. |
2.9 Markov chain Monte Carlo (MCMC) algorithm
With all of the components of  defined, the next task was to search the 4D parameter space for the model that gives the minimum
defined, the next task was to search the 4D parameter space for the model that gives the minimum  . Our approach to this used a simple MCMC algorithm to sample the
. Our approach to this used a simple MCMC algorithm to sample the  distribution. The MCMC algorithm is a well known tool for sampling multidimensional parameter spaces, and has the advantage of being easy to understand and operate.
distribution. The MCMC algorithm is a well known tool for sampling multidimensional parameter spaces, and has the advantage of being easy to understand and operate.
The MCMC algorithm essentially amounts to a random walk, in which a starting point is chosen, and each new step is proposed by drawing randomly from a given distribution and accepted with a χ2-dependent probability. We chose our walker’s starting point to be the location of the model grid point that provided the minimum  , which was obtained during the global grid search step in Phase 2 of the procedure. This ensured that the starting point for the walker was usually not far from the true χ2 minimum that we wished to sample. Each subsequent proposed step was selected from a 4D Gaussian distribution with dimensional standard deviations initially determined by the model grid spacing. The proposed step was accepted into the step chain with a probability given by
, which was obtained during the global grid search step in Phase 2 of the procedure. This ensured that the starting point for the walker was usually not far from the true χ2 minimum that we wished to sample. Each subsequent proposed step was selected from a 4D Gaussian distribution with dimensional standard deviations initially determined by the model grid spacing. The proposed step was accepted into the step chain with a probability given by  or 1 (whichever was smaller). This made the walker naturally tend toward better-fitting models without being limited to stay within local minima. We continuously adjusted the walker’s step size to maintain an acceptance rate close to 0.234, which is considered to be optimal for n-dimensional MCMC algorithms (Gelman et al. 1997).
or 1 (whichever was smaller). This made the walker naturally tend toward better-fitting models without being limited to stay within local minima. We continuously adjusted the walker’s step size to maintain an acceptance rate close to 0.234, which is considered to be optimal for n-dimensional MCMC algorithms (Gelman et al. 1997).
The walker was typically required to take several hundred initial steps to ensure that it had successfully located and begun sampling the vicinity of the absolute minimum. This initial series of steps (often called the burn-in period) had to be discarded before the step chain could be treated as a proper sampling of the χ2 distribution. For our purposes, a chain of 2000 accepted steps following the burn-in period was considered to be a sufficient sample, at which point the algorithm would terminate. To improve efficiency, we also allowed the MCMC to stop early if it had found enough data points close to the absolute minimum of the distribution. If the step chain accumulated 1000 accepted steps with χ2 values no greater than that of the running minimum χ2 +1, we permitted the MCMC to stop before the chain reached 2000 accepted steps. Prioritizing this subset of points near the minimum of the distribution also proved helpful in extracting parameter and error estimates at a later point, as discussed in Sect. 2.11. We specified a third condition to stop the MCMC if it had been compiling a single chain for more than 20 min. The MCMC occasionally had difficulty finding a well-defined minimum in the χ2 distribution, and the problem could usually be traced back to some artifact in the data. This was extremely rare, and is only known to have affected two of the 59 266 spectra. Any such problematic cases were flagged appropriately in the final parameter set. For several illustrative examples of the MCMC’s behavior and convergence on a set of minimum-χ2 parameters, we refer the reader to Appendix A. The MCMC was run in Phase 3. At each step, it called the χ2 subroutine to compute  for the newly generated model spectrum.
for the newly generated model spectrum.
2.10 Wavelength regime weighting
Through inspection of the fitting performance, we found that the BOSZ model grid faced difficulties fitting intermediate-scale spectral features for cool stars with Teff < 4000 K (e.g., TiO molecular bands). The scale of these features was problematic, since it was large enough to affect the broadband χ2 fitting as well as the narrow-band component. The former was partially addressed by the continuum rejection described in Sect. 2.6, in which  and
and  were excluded from
were excluded from  when certain conditions were met. However, the direct impact on
when certain conditions were met. However, the direct impact on  proved to be sufficiently strong as to still affect final parameter estimations for cool stars. A simple solution to this problem would be to mask the most problematic features and exclude them from the
proved to be sufficiently strong as to still affect final parameter estimations for cool stars. A simple solution to this problem would be to mask the most problematic features and exclude them from the  fitting entirely. However, this would run a major risk of discarding useful data in regions of parameter space where molecular bands are not a problem.
fitting entirely. However, this would run a major risk of discarding useful data in regions of parameter space where molecular bands are not a problem.
The approach we took was to de-weight pixels below 7800Å universally, forcing them to have a smaller contribution to  than those at the red end of the spectra by a factor of C, as shown in Eq. (8). This can be viewed as a further decomposition of
than those at the red end of the spectra by a factor of C, as shown in Eq. (8). This can be viewed as a further decomposition of 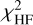 into blue and red parts:
into blue and red parts:
 (8)
(8)
This was an ad hoc approach that we chose to take based on trial and error, allowing the final distribution and its agreement with external calibration sets to determine which value of C we adopted. Based on a series of tests, we found C = 0.1 to produce satisfactory results in low-temperature regimes, such as the cool main sequence and the tip of the red giant branch. Our reason for choosing 7800 Å as the wavelength cutoff for this weighting scheme is the presence of large molecular bands that are common in cool dwarfs below this limit. An example case exhibiting some of these features is shown in Fig. 5.
The effect this had on the parameter distribution in the cool main sequence and the red giant branch can be seen in Fig. 6, which compares results obtained with and without the wavelength weighting. For the cool main sequence, log g underestimation was greatly reduced by the introduction of the weighting. Other changes include the split in the upper red giant branch near Teff = 4500 K being filled in, and the line of metal-rich giants continuing to the tip of the red giant branch, as opposed to stopping abruptly at log g ~ 1.8. Further effects from this are discussed in Sect. 3.3. This weighting procedure was incorporated in every  calculation throughout the entirety of the parameter-determination process.
calculation throughout the entirety of the parameter-determination process.
2.11 Extracting parameters and uncertainties
For each MaStar spectrum that was processed by our parameter pipeline, two separate methods were used to extract the desired atmospheric parameters, Teff, log g, [Fe/H], and [α/Fe], from the data collected by the MCMC. The simpler method involved adopting the parameters associated with the best-fitting model encountered by the MCMC (that is, the one with the minimum  ), and computing errors based on the sample contained in the step chain. We refer to these parameters as the “BestFit” parameters. For an alternative method, we used the MCMC step chain to compute a set of likelihood-weighted mean parameters. Since this method closely resembles the standard Bayesian approach to parameter and error estimation using a set of synthetic spectra, we refer to these results as our “Bayesian” parameters. Since the latter approach was based on an ensemble of model fits, rather than a single minimum-χ2 model, it is important to note that the final parameter estimate would depend more strongly on the shape of the distribution sampled by the MCMC. This is important to remember for irregular cases, in which the MCMC sampled a section of parameter space that contained two or more local minima. The possibility of the MCMC step chain repeatedly running into a model grid boundary, yielding an artificially truncated sample, was also likely to bias the sample resulting in an unreliable estimate. Because of this, Bayesian parameters positioned near the grid boundaries should be treated with caution.
), and computing errors based on the sample contained in the step chain. We refer to these parameters as the “BestFit” parameters. For an alternative method, we used the MCMC step chain to compute a set of likelihood-weighted mean parameters. Since this method closely resembles the standard Bayesian approach to parameter and error estimation using a set of synthetic spectra, we refer to these results as our “Bayesian” parameters. Since the latter approach was based on an ensemble of model fits, rather than a single minimum-χ2 model, it is important to note that the final parameter estimate would depend more strongly on the shape of the distribution sampled by the MCMC. This is important to remember for irregular cases, in which the MCMC sampled a section of parameter space that contained two or more local minima. The possibility of the MCMC step chain repeatedly running into a model grid boundary, yielding an artificially truncated sample, was also likely to bias the sample resulting in an unreliable estimate. Because of this, Bayesian parameters positioned near the grid boundaries should be treated with caution.
Both approaches to parameter extraction make use of the mathematical likelihood, which could be calculated directly from the  distribution:
distribution:
 (9)
(9)
where Li represents the likelihood of a single model i being the correct representation of the MaStar spectrum in question. This acted as a statistical weight when computing the weighted mean of the distribution in each parameter dimension. As such, models that yielded high  contributed very little to the final result, and the opposite was true for models that yielded low
contributed very little to the final result, and the opposite was true for models that yielded low  . The likelihood was used to construct the first, second, and third order moments to be used in subsequent calculations:
. The likelihood was used to construct the first, second, and third order moments to be used in subsequent calculations:
 (10)
(10)
where, above, we use the symbol x to represent whichever of the four desired parameters is being evaluated.
As described previously, the BestFit parameters were extracted by adopting the parameters associated with the lowest 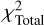 encountered by the MCMC step chain:
encountered by the MCMC step chain:
![$\matrix{{\,\,\,\,\,\,\,\,{{\left( {{{\rm{T}}_{{\rm{eff}}}}} \right)}_{{\rm{BestFit}}}}} \hfill & = \hfill & {{T_{{\rm{eff}}}}\left| {_{\min \left( {\chi _{{\rm{Total}}}^2} \right)}} \right.} \hfill \cr {\,\,\,\,\,{{\left( {\log \,{\rm{g}}} \right)}_{{\rm{BestFit}}}}} \hfill & = \hfill & {log\,\,g\left| {_{\min \left( {\chi _{{\rm{Total}}}^2} \right)}} \right.} \hfill \cr {\left( {{{\left[ {{\rm{Fe/H}}} \right]}_{{\rm{BestFit}}}}} \right)} \hfill & = \hfill & {\left[ {Fe/H} \right]\left| {_{\min \left( {\chi _{{\rm{Total}}}^2} \right)}} \right.} \hfill \cr {{{\left( {\left[ {\alpha {\rm{/Fe}}} \right]} \right)}_{{\rm{BestFit}}}}} \hfill & = \hfill & {\left[ {\alpha /Fe} \right]\left| {_{\min \left( {\chi _{{\rm{Total}}}^2} \right)}} \right..} \hfill \cr}$](/articles/aa/full_html/2022/12/aa43701-22/aa43701-22-eq73.png) (11)
(11)
Errors associated with the BestFit parameters were then calculated using the moments given in Eq. (10):
 (12)
(12)
The Bayesian parameter and error estimates were also calculated using the moments given in Eq. (10):
 (13)
(13)
Limiting the set of points we use in the preceding calculations to those with  helped to ensure that the results were not artificially influenced by outlying entries in the MCMC step chain, or in instances in which the step chain ran into the grid boundary, resulting in an asymmetric sample. The first and fourth cases discussed in Appendix A are examples in which this latter scenario was of concern. All of the MCMC parameter and error calculations were performed in Phase 4 of the procedure.
helped to ensure that the results were not artificially influenced by outlying entries in the MCMC step chain, or in instances in which the step chain ran into the grid boundary, resulting in an asymmetric sample. The first and fourth cases discussed in Appendix A are examples in which this latter scenario was of concern. All of the MCMC parameter and error calculations were performed in Phase 4 of the procedure.
3 Results
3.1 Parameter distribution and uncertainty estimates
Figures 7–9 show the final 4D distributions of the BestFit and Bayesian parameters (excluding those for standard stellar targets) prior to imposing any quality control cuts. While the two distributions bear an overall resemblance, there are several distinctions.
Looking first at the BestFit parameters, the log g versus Teff distribution (analogous to a traditional Hertzsprung-Russell Diagram or Color-Magnitude Diagram) shows most of the features one would expect in MaStar’s footprint: a distinct upper and lower main sequence, a red giant branch, and a horizontal branch. Several obvious artifacts are present. For example, our grid’s lower temperature limit and upper surface gravity limit had an impact on the shape of the cool main sequence. This forced it to take an artificial downward turn in log g (upward on the plot) at very low temperatures. As discussed below, this problem would be much worse without our decision to exclude the continuum-based components of  from the final fit in certain cases. Based on comparison with APOGEE parameters, we believe that some of these stars ought to extend to lower temperatures and higher surface gravity than are permitted by our model grid. This may be addressed in the future by supplementing our model set with cooler spectra, and perhaps allowing some limited extrapolation beyond the boundaries. The tip of the red giant branch was also affected by the model grid’s limitations, producing the feature extending to log g ~ 2.9 near Teff = 3500 K. We believe that most of these targets belong at either slightly lower temperature, or slightly lower surface gravity than our model grid is able to accommodate.
from the final fit in certain cases. Based on comparison with APOGEE parameters, we believe that some of these stars ought to extend to lower temperatures and higher surface gravity than are permitted by our model grid. This may be addressed in the future by supplementing our model set with cooler spectra, and perhaps allowing some limited extrapolation beyond the boundaries. The tip of the red giant branch was also affected by the model grid’s limitations, producing the feature extending to log g ~ 2.9 near Teff = 3500 K. We believe that most of these targets belong at either slightly lower temperature, or slightly lower surface gravity than our model grid is able to accommodate.
One other notable feature is the gap in the upper main sequence at approximately 9250 K. Based on external verification using Gaia color data, it is extremely unlikely that this feature is due to any target selection effect on the part of MaStar. As we discuss in Sect. 3.6, we believe that this is most likely due to inaccuracies in the BOSZ model spectra.
The subsequent [Fe/H] versus Teff and [α/Fe] versus [Fe/H] distributions (the latter shown in Fig. 9) also look reasonable. The α abundance distribution displays the expected bimodality described thoroughly in previous works relating to the “chemical cartography” of the Milky Way’s disk, such as Hayden et al. (2015).
Looking next at the Bayesian parameter distributions, shown in Fig. 8, many of the features described previously are still present, including the 9250 K gap and cool main sequence turn, though the former appears less prominent. The reason for this is likely the aforementioned “minimum-splitting” effect that the Bayesian methodology was susceptible to. This refers to cases in which the final parameter estimate fell between two comparable local minima in the χ2 distribution. In such cases, specifically for the 9250 K gap, the fact that some points migrated inward to populate the gap is incidental, and does not necessarily indicate that a model generated at those parameters using our model grid would actually fit the data better. Also worth noting in this distribution, is the presence of far fewer cases of the parameters falling directly on the grid edge. This is an artificial effect due to cases in which the MCMC step chain ran into the grid boundary. We refer to this phenomenon as “edge-clipping”. Since the Bayesian result was obtained from a weighted average of points surrounding the minimum of the distribution, this would often cause the final Bayesian parameter to be artificially pulled away from the grid boundary by the asymmetric distribution. Due to these problems with the Bayesian approach, we chose to adopt the BestFit results as our final parameters to recommend for external use. Figure 10 shows the uncertainty distributions for the BestFit and Bayesian parameter estimates with median uncertainties included for the BestFit parameter set.
 |
Fig. 7 Distribution of MPL-11 BestFit parameters (standard stars excluded). |
 |
Fig. 8 Distribution of MPL-11 Bayesian parameters (standard stars excluded). |
 |
Fig. 9 Distribution of MPL-11 BestFit (left) and Bayesian (right) parameters (Standard Stars excluded). |
 |
Fig. 10 Histograms showing error distributions for BestFit and Bayesian parameter estimates for Teff, log g, [Fe/H], and [α/Fe] (σT, σG, σF, and σα respectively). Standard targets have been excluded. |
3.2 Internal consistency of error estimates
Since many of MaStar’s targets have multiple observations associated with them, it was relatively simple to evaluate the internal consistency of our error estimates. This allowed us to discern whether or not the uncertainties associated with the BestFit and Bayesian parameter sets were overestimated or underestimated, based on their consistency across multiple observations. Our preferred metric for evaluating this was the pairwise difference between the parameter estimates obtained from different observations, scaled by the quadratic sum of the errors associated with those estimates. We refer to this quantity as  .
.
 (14)
(14)
 was calculated for each unique pair of distinct MaStar spectra, i and j, that were associated with the same target. Targets with only one visit were excluded in this analysis.
was calculated for each unique pair of distinct MaStar spectra, i and j, that were associated with the same target. Targets with only one visit were excluded in this analysis.
Figure 11 shows a set of histograms representing the distribution of  for the BestFit and Bayesian parameters, with a Gaussian fit shown for each distribution in red. Cases in which the BestFit parameters were determined to fall on the edge of the model grid were excluded from both parameter sets to avoid giving an artificially inflated measure of their consistency. According to Eq. (14), a standard deviation of 1 in the Gaussian fits for all of these distributions would indicate perfect consistency between the error estimates produced by our MCMC algorithm and the scatter between repeated observations. Likewise, a standard deviation of less than 1 would imply that our MCMC-based errors are overestimated by a factor of 1/σFit. Therefore, according to this metric, the errors provided by the MCMC for both of our sets of parameters were overestimated by an approximate factor of 2.5.
for the BestFit and Bayesian parameters, with a Gaussian fit shown for each distribution in red. Cases in which the BestFit parameters were determined to fall on the edge of the model grid were excluded from both parameter sets to avoid giving an artificially inflated measure of their consistency. According to Eq. (14), a standard deviation of 1 in the Gaussian fits for all of these distributions would indicate perfect consistency between the error estimates produced by our MCMC algorithm and the scatter between repeated observations. Likewise, a standard deviation of less than 1 would imply that our MCMC-based errors are overestimated by a factor of 1/σFit. Therefore, according to this metric, the errors provided by the MCMC for both of our sets of parameters were overestimated by an approximate factor of 2.5.
 |
Fig. 11 Histograms showing the distribution of |



3.3 External comparison
For comparison of our parameter estimates with external data sets, the APOGEE-2 catalog is the most appropriate choice. Since APOGEE-2 is a stellar survey covering near-infrared wavelengths, they use an entirely different approach to parameter determination in their ASPCAP pipeline (García Pérez et al. 2016). This makes it a good source for independent verification for some of our most critical targets. Additionally, since APOGEE has a much higher spectral resolution than MaStar, with R ~ 22 500, we consider its parameters to be very accurate. It should be noted, however, that APOGEE primarily targeted low-temperature stars on the cool main sequence and red giant branch. This means that we have to rely on other forms of verification for hotter regions of parameter space, such as the hot main sequence and the horizontal branch.
Figure 12 shows a direct comparison between APOGEE-2 stellar parameters and the MaStar parameters generated using the approach described in this work. The agreement in temperature is generally quite good, with slight systematics across the temperature range crossing the one-to-one line near 5000 K. Above ~8000 K, temperature measurements show less agreement for some hot stars.
Comparison in log g shows good agreement at high surface gravity with a slight positive offset, and a slightly larger offset at surface gravities below log g = 2.5. A clump of stars with significant scatter is visible near the center of the distribution, at log g = 2.5 according to APOGEE. This is related to our decision to de-weight wavelengths below 7800 Å, which limited the influence of certain spectral features that are useful for constraining log g for hot stars. This was a calculated trade-off made in favor of obtaining better performance for the cool main sequence, and the improvement we saw from this is partially demonstrated in Fig. 6. Figure 13 further demonstrates this improvement by showing that the artificial feature present at the high-log g end was eliminated by the wavelength weighting entirely. Performance was also improved for warmer stars with log g > 3.0, where the offset was slightly reduced.
Our agreement with APOGEE in [Fe/H] is also generally good, though some nonlinear systematics may be present. This mostly affects parameters near the middle of our metallicity range. Referring back to Fig. 13, we see that our [Fe/H] estimates also benefited substantially after implementing wavelength weighting, especially for cool stars. Metallicity scatter may have increased slightly for hotter stars, but the effect of this is mild.
According to the far-right panel of Fig. 12, our agreement with APOGEE in α abundance is also reasonable. This is especially clear when considering the relatively narrow range in this parameter dimension. The APOGEE parameters have more distinct high and low α abundance populations, whereas our distribution shows some overlap between the two. This may suggest that our routine had some difficulty constraining [α/Fe], leading to greater scatter. This is not surprising for hot stars, since spectral features sensitive to [α/Fe] disappear at higher temperatures. This explains why we see the most scatter in stars around and above 5000 K. The fifth case discussed in Appendix A demonstrates this effect. This is also the most likely explanation for some of the artifacts visible in Fig. 9. In the right panel, showing our [α/Fe] estimates computed using the Bayesian approach, many of our hottest stars appear to have accumulated around [α/Fe]= 0.1. The absence of this artifact in the BestFit estimates indicates that the MCMC step chains for these stars tended to be spread out over a wide range in [α/Fe].
Another helpful set of comparison data is provided with Gaia DR2 (Gaia Collaboration 2018). Gaia provides accurate parallax and photometric measurements in the G, GBP, and GRP bands. Combining the photometry with the Gaia-based distance estimates from Bailer-Jones et al. (2018), and the Bayestar19 3D dust map produced by Green et al. (2019), one can derive the extinction-corrected absolute G-band magnitude and GBP − GRP color (Yan et al. in prep.). This allowed us to construct a color-magnitude diagram (CMD) analogous to our log g versus Teff diagram, shown in Fig. 14. It is important to note that the Gaia CMD is not a perfect one-to-one analog to the log g versus Teff diagram as magnitude and color are not always good proxies for surface gravity and temperature. Given this, the CMD serves primarily as a guide for the broader regions of parameter space, rather than a data source for direct one-to-one comparison similar to APOGEE.
The CMDs shown in Fig. 14 are color-coded by each of our four atmospheric parameters. The top-left panel shows that our temperature estimates are consistent with Gaia’s GBP − GRP measurements, given the rough correlation between the two. This relationship becomes degenerate, however, where GBP − GRP ≲ 0. This is where the upper main sequence and the horizontal branch overlap in the CMD, as opposed to the log g versus Teff diagram, in which they differ in log g. Some extreme-horizontal branch stars and white dwarfs are also present in the CMD as well, showing up at higher Mg than the body of the main sequence.
The top-right panel in Fig. 14 is color-coded by log g. This also shows consistency with Gaia color and magnitude measurements over the entire parameter space, except for the tip of the red giant branch. Here, a small group of targets have been assigned higher log g values than the Gaia data would suggest. This is due to a combination of factors that we have already discussed. The fact that our model set cuts off abruptly at log g = 0 forces some red giant branch tip stars to be matched with higher surface gravity models. This is a good example of how the Gaia data can be used to identify such cases.
The bottom-left panel of Fig. 14 is color-coded by [Fe/H]. The most interesting thing to note here is the metallicity gradients visible in the mid giant branch and cool main sequence. This is expected, and suggests good consistency between our [Fe/H] measurements and the Gaia color data throughout most of parameter space. The hotter region (bluer on the CMD) appears to display more scatter, but this is partially due to the aforementioned overlapping between the upper main sequence and the horizontal branch.
The bottom-right panel of Fig. 14 is color-coded by [α/Fe]. Similar to the previous panel color-coded by overall metallicity, abundance gradients are visible here in the mid giant branch and the cool main sequence. The red giant branch tip also shows an anomalously high α abundance, similar to what we saw in the panel color-coded by log g. This is simply another manifestation of the same mismatch effect due to model limitations that we described previously.
 |
Fig. 12 Direct comparison between APOGEE DR17 ASPCAP parameters and MaStar parameters. |
 |
Fig. 13 Direct comparison with APOGEE DR17 ASPCAP parameters shown with and without wavelength weighting implemented for log g (left) and [Fe/H] (right). |
 |
Fig. 14 Gaia color-magnitude diagrams color-coded by BestFit parameter estimates. The temperature panel (top left) has had its color-coding scaled to make the temperature gradient among cooler stars more visible. |
3.4 Quality control
In the final release of this parameter set, we have included several quality control flags, which fall into two categories.
Low-temperature artifact: points that were placed between the cool main sequence and the upper red giant branch at temperatures near the lower limit of the model grid. These were selected by taking spectra with Teff < 3540 K and 0.5 < log g < 4.0.
[α/Fe] edge cases: points that were assigned [α/Fe] values lying at the very top or bottom of the model grid’s range. This indicates our routine’s failure to constrain α abundance in these cases. These were selected by taking spectra with [α/Fe] < −0.22 or [α/Fe] > +0.47.
The final parameter space distributions after implementing these flags are shown in Fig. 15. The important distinction between these categories is that, for Category 1, all stellar parameters have been flagged, and their use is not generally recommended. Category 2, on the other hand, has been addressed by a flag applied to the [α/Fe] parameters only. That is, despite our considering the α abundance values to be invalid in these cases, we consider the remaining atmospheric parameters to still be trustworthy.
The data points that make up Category 1 are easily visible in Fig. 7, in both the spur extending upward in log g from the red giant branch tip and downward in log g from the cool main sequence. Our decision to recommend omitting these data points is largely based on the fact that real stars generally do not exist in that part of parameter space. That is to say we believe these features to be part of the same artifact, which is related to model inaccuracy at low Teff. Omitting these points also removes the near-vertical linear structures in the upper-right corner of the left panel of Fig. 9, further implying the artificial nature of these features.
The data points in Category 2 are visible in Fig. 9, at the top and bottom of the left panel. These are cases in which the MCMC had excessive difficulty constraining [α/Fe].
 |
Fig. 15 Distribution of MPL-11 BestFit parameters with flagged entries omitted. |
3.5 Accuracy of extinction estimates
As we discussed in Sect. 2.7, we believe our extinction measurements to be at least as reliable for warm and hot stars (Teff ≳ 5000 K) as those calculated from the most up-to-date 3D dust map data using the Bailer-Jones distance estimates from Gaia. A direct comparison between our AV estimates and reddening estimates given by 3D dust map data is shown in Fig. 16. It is important to note that the 3D-dust-map-based reddening is given by the arbitrary reddening coefficient E (as opposed to E(B − V), for example). This comparison shows a strong linear correlation for a large percentage of targets. Performing a linear fit on this distribution gives a slope of 3.37, though this is partially affected by outliers. For a number of stars that the 3D dust map suggests have near-zero AV, our approach suggests much higher extinction. We can better understand this disagreement by looking at both the temperature and standard AV error associated with these targets.
Figure 17 shows our AV uncertainty estimates as a function of AV, color-coded by temperature. Here, it is clear that the error estimates for many cool stars show a strong positive correlation with AV itself. These problematic AV estimates result from molecular bands interfering with the linear fitting described in Sect. 2.7. These points can be easily excluded by rejecting entries for which the formal AV error exceeds 0.005 mag.
In addition, it should be noted that in a number of cases, our method yielded a negative slope in the linear fit described in Fig. 4. This corresponds to a negative AV, which is nonphysical. However, we found that, for the majority of such cases, the degree to which AV was found to be negative is consistent with the expected uncertainty in flux calibration. This issue affects approximately 8000 spectra, whose negative AV estimates have an root-mean-square deviation from 0 of σ = 0.138 mag. To eliminate outlying cases, we flagged the spectra for which AV < −3σ from the final set. This left approximately 7000 spectra for which AV was permitted to be slightly negative.
Figure 18 shows the same direct comparison between our AV estimates and those from the 3D dust map data after applying the 0.005 mag error cut and removing the flagged negative AV values. This yields a much more uniform agreement at low extinction than we saw before. Performing a new linear fit on this distribution gives the following empirical relationship between AV and the reddening coefficient, EDustMap:
 (15)
(15)
This relationship is consistent with the one derived by Green et al. between E(g − r) and the independently derived AV estimates that they used for testing.
The uncertainties in AV included with our parameter set were given by the standard error on the linear fit described in Sect. 2.7. Due to flux-calibration systematics, we believe these uncertainties to be significantly underestimated. To get a better estimate of typical uncertainties in AV, we can use repeated observations to calculate a median absolute deviation (MAD) in AV associated with each target. The MAD can then be normalized to have the same metric as σ by dividing by 0.6745 (Beers et al. 1990), giving a quantity that is more representative of the true uncertainty. Doing this suggests that stars with Teff ≳ 5000 K have a typical true uncertainty in AV of 0.049 mag. To evaluate how this compares with uncertainties associated with 3D Dust Map estimates, we analyzed the residuals of our AV versus EDustMap comparison.
This gave a median scatter of σResid = 0.205. We expect the relative contributions to this scatter from both the MaStar data and the 3D Dust Map data to contribute in the form of a quadratic sum, such that:
 (16)
(16)
Taking  and solving this equation gives
and solving this equation gives  . This estimate of the typical uncertainty on EDustMap is roughly consistent with the systematic error floor of 0.08 that Green et al. placed on the uncertainty in E(g − r) (Green et al. 2019, Fig. 16). With the slope of 3.31, the uncertainty from the 3D dust map measurements contributes 0.20 mag to the vertical scatter in Fig. 18, which is much larger than the contribution by the uncertainty of our MaStar-based extinction estimates. Thus, we conclude that our AV estimates are superior in precision.
. This estimate of the typical uncertainty on EDustMap is roughly consistent with the systematic error floor of 0.08 that Green et al. placed on the uncertainty in E(g − r) (Green et al. 2019, Fig. 16). With the slope of 3.31, the uncertainty from the 3D dust map measurements contributes 0.20 mag to the vertical scatter in Fig. 18, which is much larger than the contribution by the uncertainty of our MaStar-based extinction estimates. Thus, we conclude that our AV estimates are superior in precision.
 |
Fig. 16 Distribution of MaStar AV estimates compared with reddening measurements prior to quality cuts. Reddening estimates were made using recent 3D dust maps combined with Bailer-Jones distance estimates, and are given as the arbitrary reddening coefficient E. The corresponding linear fit is shown in red. |
 |
Fig. 17 AV errors plotted as a function of AV estimates, color-coded by Teff. |
 |
Fig. 18 Distribution of MaStar AV estimates compared with reddening measurements based on 3D dust maps following quality cuts. Spectra with AV,error > 0.005 have been excluded from this distribution. The new corresponding linear fit is shown in red. |
3.6 Inaccuracies in the model spectra
One promising application of large stellar libraries similar to MaStar lies with the large-scale comparison between empirical spectral data with present cutting-edge models. While our parameter-measurement efforts have placed the most emphasis on the cases in which the model fitting performs as desired, cases in which it has performed in unexpected ways can be just as informative. For example, the previously mentioned gap in the hot main sequence at approximately 9250 K raises interesting questions about the BOSz models and their representation of certain spectral features in this parameter regime. For stars near this temperature, the most obvious spectral features are the Balmer series of absorption lines. We suspect that the cause of this gap is that the equivalent widths of Balmer lines reach their maximum around this temperature. If the model spectra do not have the same maximum equivalent width (EW), it would result in a bias in temperature measurements. To further test this statement we plotted EW as a function of color.
We measured the synthetic colors for both the data and models using the response curves made available by the Gaia team with Gaia DR2. We then plotted the colors of the observed spectra against the equivalent widths of the first four Balmer absorption lines measured in them and their corresponding best-fit models. This is shown in the four panels on the right side of Fig. 19. The line profile mismatch is relatively mild in the case of Hα. For the three subsequent Balmer lines, however, the disagreement is much stronger. This is even better illustrated if we look at the behavior of the equivalent widths in the models as is shown in the four panels on the left side of Fig. 19, represented by solid lines corresponding to the log g bins of the model grid. For Hβ and Hγ, the models corresponding to the highest log g bins (4.4–5.0) extend far above the equivalent widths given by the data, except for a few outliers. This implies that, in order for the models with the correct Teff and log g to be selected, the MaStar spectra would have had to have much larger Hβ and Hγ equivalent widths. To resolve this disagreement, the algorithm tended to select Teff to be either hotter or cooler by 200–300 K, leading to a gap in the final distribution. An example of typical behavior of the MCMC around the gap is shown in the sixth case discussed in Appendix A, in which two local minima in the MCMC sample appear to be present on either side of the gap.
Several specific examples of this equivalent width discrepancy are shown in Fig. 20. Here, we have compared Hγ lines from three MaStar spectra with models generated in two different ways. The first set of models (shown in red) correspond to the BestFit parameters given by our routine. The alternate models (shown in magenta) correspond to entries in the MCMC step chains that agree closely with temperatures estimated based on Gaia data using a color-temperature relationship described in Mucciarelli & Bellazzini (2020). These are meant to give a reasonable estimate of where in parameter space these stars ought to lie. What we see from this is that the alternate models provide a considerably worse match to the Hγ line profile present in the data, whereas the BestFit models provide a near-perfect match.
The implication of these findings is that the Balmer series equivalent widths in the models disagree with those present in the data. This suggests some fundamental inaccuracy in the BOSZ models for these particular features. This problem could have been caused by the spectral synthesis code used for the BOSZ models, SYNTHE, handling radiation damping incorrectly for the Balmer lines (Szabolcs Mészáros, private communication). This problem could be addressed in the future by employing a newer spectral synthesis program when constructing the next generation of the models. This is an excellent example of the way stellar libraries similar to MaStar can be used to improve current theoretical spectra.
 |
Fig. 19 The relationship between the equivalent width (EW) of the first four Balmer lines and Gaia GBP − GRP color for both the original model grid (left, represented by solid curves) and the interpolated BestFit models corresponding to each MaStar spectrum (right, represented by points color-coded by log g). The EW-color distribution of the set of MaStar spectra, with extinction effects removed, is shown in the background of each panel in gray. |
 |
Fig. 20 Several examples showing the performance of our narrow-band fitting of Hγ for the BestFit parameter solution (shown in red) compared with the Hγ line profile of an alternate model generated using a temperature computed based on Gaia GBP − GRP color (shown in magenta). Both sets of model spectra are compared with the original MaStar spectrum shown in black. The relative position in parameter space of each model is shown in the three panels on the right. |
4 Conclusions
In this paper, we present a stellar parameter determination method and applied it to the spectra from the MaStar library. The method has been shown to have several key characteristics and advantages. It was based purely on theoretical models without the need for priors based on external data, such as isochrones or color measurements. It combined the use of continuum-normalized full-spectrum fitting with continuum fitting, thus taking advantage of both small-scale and large-scale features. Comparison with external data from APOGEE and Gaia have shown that the method performed well over a very wide range of stellar parameter space. Stellar population models based on MaStar’s first data release have been presented in Maraston et al. (2020), and these models will soon be updated using the parameters presented in this work.
While our procedure’s overall performance in all four parameter dimensions was good, several artifacts still show up in the final parameter distribution. Modifying our fitting routine ( scaling, continuum rejection, and scaling the per-pixel χ2 contribution by wavelength), have helped to alleviate some of these artifacts, but have not been able to get rid of them completely. Our method’s dependence on theoretical spectra alone helped to trace the origins of these effects back to inaccuracies in the models. While the ATLAS9-based BOSZ models have proven very accurate in most regions of parameter space, the data suggest there are at least two regions with considerable room for improvement: the warm main sequence at temperatures around 9250 K, and at very low temperatures, both at low surface gravity on the tip of the red giant branch, and at high surface gravity on the cool main sequence. We have shown that the 9250 K gap is due to the BOSZ models having too high of an equivalent width for the Balmer lines when they reach their peaks around this temperature. This could mean there are also systematic biases in the Teff derived based on BOSZ models above and below this temperature. The MaStar spectra could be very useful for correcting the atomic and molecular line lists to improve the accuracy of the model spectra. The MaStar parameter catalog containing our BestFit results is available on the SDSS-IV DR17 website as part of version 2 of the MaStar stellar parameter value-added catalog1.
scaling, continuum rejection, and scaling the per-pixel χ2 contribution by wavelength), have helped to alleviate some of these artifacts, but have not been able to get rid of them completely. Our method’s dependence on theoretical spectra alone helped to trace the origins of these effects back to inaccuracies in the models. While the ATLAS9-based BOSZ models have proven very accurate in most regions of parameter space, the data suggest there are at least two regions with considerable room for improvement: the warm main sequence at temperatures around 9250 K, and at very low temperatures, both at low surface gravity on the tip of the red giant branch, and at high surface gravity on the cool main sequence. We have shown that the 9250 K gap is due to the BOSZ models having too high of an equivalent width for the Balmer lines when they reach their peaks around this temperature. This could mean there are also systematic biases in the Teff derived based on BOSZ models above and below this temperature. The MaStar spectra could be very useful for correcting the atomic and molecular line lists to improve the accuracy of the model spectra. The MaStar parameter catalog containing our BestFit results is available on the SDSS-IV DR17 website as part of version 2 of the MaStar stellar parameter value-added catalog1.
Acknowledgements
D.L., R.Y., and R.W. would like to acknowledge support by the NSF grant AST-1715898. R.Y. would like to acknowledge support by the Hong Kong Global STEM Scholar scheme, by the Hong Kong Jockey Club through the JC STEM Lab of Astronomical Instrumentation program, by the Direct Grant of CUHK Faculty of Science, and by the Research Grant Council of the Hong Kong Special Administrative Region, China (Projects No. 14302522). T.C.B. acknowledges partial support for this work from grant PHY 14-30152; Physics Frontier Center/JINA Center for the Evolution of the Elements (JINA-CEE), awarded by the US National Science Foundation. Funding for the Sloan Digital Sky Survey IV has been provided by the Alfred P. Sloan Foundation, the US Department of Energy Office of Science, and the Participating Institutions. S.D.S.S. acknowledges support and resources from the Center for High-Performance Computing at the University of Utah. The SDSS web site is www.sdss.org. SDSS is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS Collaboration including the Brazilian Participation Group, the Carnegie Institution for Science, Carnegie Mellon University, Center for Astrophysics | Harvard & Smithsonian (CfA), the Chilean Participation Group, the French Participation Group, Instituto de Astrofísica de Canarias, The Johns Hopkins University, Kavli Institute for the Physics and Mathematics of the Universe (IPMU) / University of Tokyo, the Korean Participation Group, Lawrence Berkeley National Laboratory, Leibniz Institut für Astrophysik Potsdam (AIP), Max-Planck-Institut für Astronomie (MPIA Heidelberg), Max-Planck-Institut für Astrophysik (MPA Garching), Max-Planck-Institut für Extraterrestrische Physik (MPE), National Astronomical Observatories of China, New Mexico State University, New York University, University of Notre Dame, Observatório Nacional / MCTI, The Ohio State University, Pennsylvania State University, Shanghai Astronomical Observatory, United Kingdom Participation Group, Universidad Nacional Autónoma de México, University of Arizona, University of Colorado Boulder, University of Oxford, University of Portsmouth, University of Utah, University of Virginia, University of Washington, University of Wisconsin, Vanderbilt University, and Yale University.
Appendix A MCMC behavior
Figure A.1 shows several examples of MCMC step chains selected to illustrate the MCMC’s performance in various regions of parameter space. Each row displays the step chain compiled for a given MaStar spectrum plotted in 4D parameter space using two panels. From top to bottom, the examples shown are a lower-mid RGB star, a warm MS star, a metal-poor giant star, a cool dwarf, a very hot MS star, and a moderately hot MS star falling near the 9,250 K MS gap that is discussed in section 3.6. The first three examples all exhibit excellent constraint in all four parameter dimensions. The fourth case (the cool M-dwarf), falling very close to the edge of the model grid in both Teff and log g, exhibits the edge-clipping effect discussed in section 3.1, despite the exclusion of the higher-χ2 entries in the step chain. The fifth case (the very hot MS star) appears well constrained in Teff-log g space, but [Fe/H] and [α/Fe] are essentially unconstrained. This is due to fact that spectral features lose their dependencies on metal abundances at higher temperatures. In the final case, we show an example of a star whose MCMC step chain contains two distinguishable local minima lying on either side of the 9, 250 K gap, although one was clearly preferred by the algorithm. Similar to the previous case, [Fe/H] and [α/Fe] are completely unconstrained in this regime.
 |
Fig. A.1 Several examples of MCMC step chain convergence in 4D parameter space. The portions of the MCMC step chains used for parameter and error calculations are color-coded by |
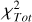


References
- Bailer-Jones, C. A. L., Rybizki, J., Fouesneau, M., Mantelet, G., & Andrae, R. 2018, AJ, 156, 58 [Google Scholar]
- Beers, T. C., Flynn, K., & Gebhardt, K. 1990, AJ, 100, 32 [Google Scholar]
- Blanton, M. R., Bershady, M. A., Abolfathi, B., et al. 2017, AJ, 154, 28 [Google Scholar]
- Bohlin, R. C., Mészáros, S., Fleming, S. W., et al. 2017, AJ, 153, 234 [Google Scholar]
- Bundy, K., Bershady, M. A., Law, D. R., et al. 2015, ApJ, 798, 7 [Google Scholar]
- Cappellari, M. 2016, MNRAS, 466, 798 [Google Scholar]
- Cappellari, M., & Emsellem, E. 2004, PASP, 116, 138 [Google Scholar]
- Cenarro, A. J., Cardiel, N., Gorgas, J., et al. 2001, MNRAS, 326, 959 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, Y.-P., Trager, S. C., Peletier, R. F., et al. 2014, A&A, 565, A117 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chen, Y.-P., Yan, R., Maraston, C., et al. 2020, ApJ, 899, 62 [Google Scholar]
- Dawson, K. S., Kneib, J.-P., Percival, W. J., et al. 2016, AJ, 151, 44 [Google Scholar]
- Diaz, A. I., Terlevich, E., & Terlevich, R. 1989, MNRAS, 239, 325 [NASA ADS] [CrossRef] [Google Scholar]
- Drory, N., MacDonald, N., Bershady, M. A., et al. 2015, AJ, 149, 77 [CrossRef] [Google Scholar]
- Falcón-Barroso, J., Sánchez-Blázquez, P., Vazdekis, A., et al. 2011, A&A, 532, A95 [Google Scholar]
- Fitzpatrick, E. L., Massa, D., Gordon, K. D., Bohlin, R., & Clayton, G. C. 2019, ApJ, 886, 108 [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2018, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- García Pérez, A. E., Prieto, C. A., Holtzman, J. A., et al. 2016, AJ, 151, 144 [Google Scholar]
- Gelman, A., Gilks, W. R., & Roberts, G. O. 1997, Ann. Appl. Prob., 7, 110 [CrossRef] [Google Scholar]
- Green, G. M., Schlafly, E., Zucker, C., Speagle, J. S., & Finkbeiner, D. 2019, ApJ, 887, 93 [NASA ADS] [CrossRef] [Google Scholar]
- Gregg, M. D., Silva, D., Rayner, J., et al. 2006, in The 2005 HST Calibration Workshop: Hubble After the Transition to Two-Gyro Mode, eds. A. M. Koekemoer, P. Goudfrooij, & L. L. Dressel, 209 [Google Scholar] [Google Scholar]
- Gunn, J. E., & Stryker, L. L. 1983, ApJS, 52, 121 [NASA ADS] [CrossRef] [Google Scholar]
- Gunn, J. E., Siegmund, W. A., Mannery, E. J., et al. 2006, AJ, 131, 2332 [NASA ADS] [CrossRef] [Google Scholar]
- Hayden, M. R., Bovy, J., Holtzman, J. A., et al. 2015, ApJ, 808, 132 [Google Scholar]
- Hill, L., Thomas, D., Maraston, C., et al. 2021, MNRAS, 509, 4308 [NASA ADS] [CrossRef] [Google Scholar]
- Imig, J., Holtzman, J. A., Yan, R., et al. 2022, AJ, 163, 56 [NASA ADS] [CrossRef] [Google Scholar]
- Lançon, A., & Wood, P. R. 2000, A&AS, 146, 217 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Law, D. R., Westfall, K. B., Bershady, M. A., et al. 2021, AJ, 161, 52 [NASA ADS] [CrossRef] [Google Scholar]
- Le Borgne, J. F., Bruzual, G., Pelló, R., et al. 2003, A&A, 402, 433 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Majewski, S. R., APOGEE Team, & APOGEE-2 Team. 2016, AN, 337, 863 [NASA ADS] [Google Scholar]
- Maraston, C., Hill, L., Thomas, D., et al. 2020, MNRAS, 496, 2962 [Google Scholar]
- Mészáros, S., Allende Prieto, C., Edvardsson, B., et al. 2012, AJ, 144, 120 [Google Scholar]
- Mucciarelli, A., & Bellazzini, M. 2020, arXiv e-prints [arXiv:2004.06140] [Google Scholar]
- Ess, M., Hogg, D. W., Rix, H.-W., Ho, A. Y. Q., & Zasowski, G. 2015, ApJ, 808, 16 [NASA ADS] [CrossRef] [Google Scholar]
- Pickles, A. J. 1985, ApJS, 59, 33 [NASA ADS] [CrossRef] [Google Scholar]
- Pickles, A. J. 1998, PASP, 110, 863 [NASA ADS] [CrossRef] [Google Scholar]
- Prugniel, P., & Soubiran, C. 2001, A&A, 369, 1048 [CrossRef] [EDP Sciences] [Google Scholar]
- Prugniel, P., & Soubiran, C. 2004, arXiv e-prints [astro-ph/0409214] [Google Scholar]
- Prugniel, P., Soubiran, C., Koleva, M., & Le Borgne, D. 2007, VizieR Online Data Catalog: III/251 [Google Scholar]
- Rayner, J. T., Cushing, M. C., & Vacca, W. D. 2009, ApJS, 185, 289 [Google Scholar]
- Sánchez-Blázquez, P., Peletier, R. F., Jiménez-Vicente, J., et al. 2006, MNRAS, 371, 703 [Google Scholar]
- Silva, D. R., & Cornell, M. E. 1992, ApJS, 81, 865 [NASA ADS] [CrossRef] [Google Scholar]
- Smee, S. A., Gunn, J. E., Uomoto, A., et al. 2013, AJ, 146, 32 [Google Scholar]
- Soubiran, C., Katz, D., & Cayrel, R. 1998, A&AS, 133, 221 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ting, Y.-S., Conroy, C., Rix, H.-W., & Cargile, P. 2019, ApJ, 879, 69 [Google Scholar]
- Valdes, F., Gupta, R., Rose, J. A., Singh, H. P., & Bell, D. J. 2004, ApJS, 152, 251 [Google Scholar]
- Verro, K., Trager, S. C., Peletier, R. F., et al. 2022, A&A, 660, A34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Villaume, A., Conroy, C., Johnson, B., et al. 2017, ApJS, 230, 23 [NASA ADS] [CrossRef] [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Worthey, G., Faber, S. M., Gonzalez, J. J., & Burstein, D. 1994, ApJS, 94, 687 [Google Scholar]
- Yan, R., Bundy, K., Law, D. R., et al. 2016, AJ, 152, 197 [Google Scholar]
- Yan, R., Chen, Y., Lazarz, D., et al. 2019, ApJ, 883, 175 [Google Scholar]
All Tables
All Figures
|
Fig. 1 Flowchart detailing our parameter-determination procedure (upper) with an additional chart detailing the subroutine used for all χ2 calculations following the initial global grid search (lower). |
| In the text | |
|
Fig. 2 Atlas9-based BOSZ model grid used for multicomponent χ2-fitting. |
| In the text | |
|
Fig. 3 Several examples of observed stellar spectra (black) with their inverse-variance-weighted mean smoothed counterparts (red). The latter was used for continuum normalization and for direct comparison with model continua. Temperatures range from hottest to coolest from top to bottom. |
| In the text | |
|
Fig. 4 Extinction fitting using a linear fit of the log10 of the flux ratio of a given data-model pair. The fitting was limited to a wavelength range that was relatively insensitive to model mismatch, had good S/N, and was free of data issues. R = 3.1 was assumed. |
| In the text | |
|
Fig. 5 Example of a cool dwarf spectrum with prominent TiO bands below 7800 Å, which our model set struggled to represent accurately. The raw spectrum, along with its corresponding BestFit model, is displayed in the top panel. The continuum-normalized spectrum and model are displayed in the middle panel. The absolute residuals from this fit are shown in the bottom panel, and show significantly better agreement in the 7800–9900 Å range. |
| In the text | |
|
Fig. 6 Comparison between MaStar’s parameter distribution before (left) and after (right) introducing wavelength weighting to give higher priority to redder wavelengths. Deprioritizing fitting spectral features below 7800 Å led to better performance at lower temperatures. |
| In the text | |
|
Fig. 7 Distribution of MPL-11 BestFit parameters (standard stars excluded). |
| In the text | |
|
Fig. 8 Distribution of MPL-11 Bayesian parameters (standard stars excluded). |
| In the text | |
|
Fig. 9 Distribution of MPL-11 BestFit (left) and Bayesian (right) parameters (Standard Stars excluded). |
| In the text | |
|
Fig. 10 Histograms showing error distributions for BestFit and Bayesian parameter estimates for Teff, log g, [Fe/H], and [α/Fe] (σT, σG, σF, and σα respectively). Standard targets have been excluded. |
| In the text | |
|
Fig. 11 Histograms showing the distribution of |
| In the text | |
|
Fig. 12 Direct comparison between APOGEE DR17 ASPCAP parameters and MaStar parameters. |
| In the text | |
|
Fig. 13 Direct comparison with APOGEE DR17 ASPCAP parameters shown with and without wavelength weighting implemented for log g (left) and [Fe/H] (right). |
| In the text | |
|
Fig. 14 Gaia color-magnitude diagrams color-coded by BestFit parameter estimates. The temperature panel (top left) has had its color-coding scaled to make the temperature gradient among cooler stars more visible. |
| In the text | |
|
Fig. 15 Distribution of MPL-11 BestFit parameters with flagged entries omitted. |
| In the text | |
|
Fig. 16 Distribution of MaStar AV estimates compared with reddening measurements prior to quality cuts. Reddening estimates were made using recent 3D dust maps combined with Bailer-Jones distance estimates, and are given as the arbitrary reddening coefficient E. The corresponding linear fit is shown in red. |
| In the text | |
|
Fig. 17 AV errors plotted as a function of AV estimates, color-coded by Teff. |
| In the text | |
|
Fig. 18 Distribution of MaStar AV estimates compared with reddening measurements based on 3D dust maps following quality cuts. Spectra with AV,error > 0.005 have been excluded from this distribution. The new corresponding linear fit is shown in red. |
| In the text | |
|
Fig. 19 The relationship between the equivalent width (EW) of the first four Balmer lines and Gaia GBP − GRP color for both the original model grid (left, represented by solid curves) and the interpolated BestFit models corresponding to each MaStar spectrum (right, represented by points color-coded by log g). The EW-color distribution of the set of MaStar spectra, with extinction effects removed, is shown in the background of each panel in gray. |
| In the text | |
|
Fig. 20 Several examples showing the performance of our narrow-band fitting of Hγ for the BestFit parameter solution (shown in red) compared with the Hγ line profile of an alternate model generated using a temperature computed based on Gaia GBP − GRP color (shown in magenta). Both sets of model spectra are compared with the original MaStar spectrum shown in black. The relative position in parameter space of each model is shown in the three panels on the right. |
| In the text | |
|
Fig. A.1 Several examples of MCMC step chain convergence in 4D parameter space. The portions of the MCMC step chains used for parameter and error calculations are color-coded by |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.