| Issue |
A&A
Volume 660, April 2022
|
|
|---|---|---|
| Article Number | A15 | |
| Number of page(s) | 14 | |
| Section | Stellar structure and evolution | |
| DOI | https://doi.org/10.1051/0004-6361/202141125 | |
| Published online | 01 April 2022 | |
Stellar dating using chemical clocks and Bayesian inference
1
Departament d’Astronomia i Astrofísica, Universitat de València, C. Dr. Moliner 50, 46100 Burjassot, Spain
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Electrical Engineering, Electronics, Automation and Applied Physics Department, E.T.S.I.D.I., Polytechnic University of Madrid (UPM), Madrid 28012, Spain
3
School of Physics and Astronomy, University of Birmingham, Edgbaston, Birmingham B15 2TT, UK
4
Stellar Astrophysics Centre, Department of Physics and Astronomy, Aarhus University, Ny Munkegade 120, 8000 Aarhus C, Denmark
5
Departamento de Inteligencia Artificial, ETSI Informática, UNED, Juan del Rosal, E-16, 28040 Madrid, Spain
6
Instituto de Astrofísica e Ciências do Espaço, Universidade do Porto, CAUP, Rua das Estrelas, 4150-762 Porto, Portugal
7
Departamento de Física e Astronomia, Faculdade de Ciências, Universidade do Porto, Rua do Campo Alegre, 4169-007 Porto, Portugal
8
Harvard-Smithsonian Center for Astrophysics, 60 Garden Street, Cambridge, MA 02138, USA
Received:
19
April
2021
Accepted:
4
January
2022
Abstract
Context. Dating stars is a major challenge with a deep impact on many astrophysical fields. One of the most promising techniques for this is using chemical abundances. Recent space- and ground-based facilities have improved the quantity of stars with accurate observations. This has opened the door for using Bayesian inference tools to maximise the information we can extract from them.
Aims. Our aim is to present accurate and reliable stellar age estimates of FGK stars using chemical abundances and stellar parameters.
Methods. We used one of the most flexible Bayesian inference techniques (hierarchical Bayesian models) to exceed current possibilities in the use of chemical abundances for stellar dating. Our model is a data-driven model. We used a training set that has been presented in the literature with ages estimated with isochrones and accurate stellar abundances and general characteristics. The core of the model is a prescription of certain abundance ratios as linear combinations of stellar properties including age. We gathered four different testing sets to assess the accuracy, precision, and limits of our model. We also trained a model using chemical abundances alone.
Results. We found that our age estimates and those coming from asteroseismology, other accurate sources, and also with ten Gaia benchmark stars agree well. The mean absolute difference of our estimates compared with those used as reference is 0.9 Ga, with a mean difference of 0.01 Ga. When using open clusters, we reached a very good agreement for Hyades, NGC 2632, Ruprecht 147, and IC 4651. We also found outliers that are a reflection of chemical peculiarities and/or stars at the limit of the validity ranges of the training set. The model that only uses chemical abundances shows slightly worse mean absolute difference (1.18 Ga) and mean difference (−0.12 Ga).
Key words: stars: evolution / astrochemistry / methods: data analysis / methods: statistical / stars: fundamental parameters / stars: abundances
© ESO 2022
1. Introduction
Among all the stellar characteristics, age is one of the most difficult variables to measure because it cannot be directly observed. It must be inferred using diverse methods. Soderblom (2010, 2015) presented a summary of most of these techniques and proposed their classification into five groups: fundamental, empirical, semi-empirical, statistical, and modelling.
One of these techniques is the so-called chemical clocks (CCs) method. It exploits the fact of the chemical evolution of the Galaxy. This chemical evolution is a consequence of the dependence of the stellar fusion and thermonuclear reactions operating in stellar interiors (and the atomic elements thereby created) and the stellar evolution depending on the stellar mass, that is, the more massive the star, the faster its evolution (of the order of Ma1 for the most massive ones, with masses higher than 8 M⊙). Low-mass stars (M < 8 M⊙) evolve far more slowly, of the order of even Ga1, and the chemical elements that are created are different in general (Johnson et al. 2020).
We can assume that the current stellar surface abundances of certain elements are those of the original cloud from which the star was born, that is, stars act as fossil relics in terms of chemical composition. This can be verified using stellar structure and evolution models, where only slight surface abundance variations are predicted during stellar evolution (Dotter et al. 2017; Gavel et al. 2021). Therefore, we can use these abundances to estimate the age of the star. This concept has been used in recent years to propose a few chemical abundance ratios for which this evolution is especially clear. The different contribution to the chemical evolution of the Galaxy of supernovae of types II and Ia (SNe II and SNe Ia, respectively) and low-mass asymptotic giant branch stars (AGB) opens the door to the stellar dating using certain surface chemical abundances (Nissen 2016). The work by da Silva et al. (2012) was the first to explore the relation with age of abundance ratios of Y or Sr over Mg, Al, or Zn. More recently, Nissen (2015, 2016) found that ratios of [Y/Mg], [Y/Al], or [Al/Mg] are precise age indicators in the case of solar twin stars. These are the so-called CCs and have been studied in other samples of solar twins (Spina et al. 2016; Tucci Maia et al. 2016), in a larger sample of stars within the AMBRE project (Titarenko et al. 2019; Santos-Peral et al. 2021), and recently in a number of papers (e.g. Casali et al. 2020; Casamiquela et al. 2021; Rebassa-Mansergas et al. 2021; Tautvaišienė et al. 2021; Espinoza-Rojas et al. 2021; Morel et al. 2021). Moreover, the application of these CCs to solar twin stars was cross-checked using stars dated by asteroseismology (Nissen et al. 2017; Jofré et al. 2020). However, Feltzing et al. (2017) and Delgado Mena et al. (2019, DM19) reported that when stars of different metallicities and/or effective temperatures are included, these simple correlations are no longer valid. DM19 defined up to ten CCs presenting different linear expressions for stellar age estimations involving different observables and different numbers of dimensions, and extended the validity range of these ratios beyond solar twins, increasing the utility of these ratios. This dependence of the age – CC relation on stellar metallicity has been confirmed for some CCs and stars in the Galactic disk by Casali et al. (2020). However, these authors and also Magrini et al. (2021) and Katz et al. (2021) cautioned that that the CCs might not be applicable for all the stars in the Galaxy, in particular not for those in the inner disk. That is, there is a dependence of the age versus CC relations on the Galactocentric distance. In particular, Casali et al. (2020) and Magrini et al. (2021) found that the 2D relation between stellar age, a CC, and [Fe/H] does not map all the Galaxy.
On the other hand, CCs such as Li (Llorente de Andrés et al. 2021) or the ratio [C/N] (Casali et al. 2019; Jofré 2021) are known in the literature. These CCs are based on stellar evolution and they are not considered for this work.
Morel et al. (2021) recently extended the use of asteroseismic ages beyond solar twins using the Kepler Legacy data-base to explore these CCs, in particular those presented in DM19. They also confirmed these relations and reported that seismic ages and ages from 3D formulas agree well and that the differences were below typical error levels. Nevertheless, they also reported that CC ages are systematically younger than seismic ages.
Recent studies have explored the use of machine-learning techniques in this context. Sharma et al. (2022), using the GALAH survey, proposed a number of 2D relations where the stellar age is estimated as a function of the stellar metallicity (Fe/H) and the abundance of different elements over iron. Stellar ages for the training set were obtained using evolutionary models. Hayden et al. (2020) used this work to improve age estimates using one of the most efficient tools for stacking. They combined a number of weak estimators such as those coming from each 2D relation to construct a strong estimator using the XGBoost algorithm.
Chemical clocks are useful not only for stellar dating. They can also be used to distinguish Galactic events such as the existence of two episodes of accretion of gas onto the Galactic disk with an episode of star formation in between (Nissen et al. 2020), and to understand the timescale of different nuclear processes in the Galaxy (Jofré et al. 2020) or in nearby galaxies (Skúladóttir et al. 2019).
In this paper, we take advantage of the extraordinary data set presented in DM19 and the power of machine-learning techniques to go a step further. We present the best possible age estimates using CCs and our training set.
In particular, we train a multi-level or hierarchical Bayesian model combining information from different CCs and stellar effective temperature, metallicity, and gravity to estimate ages. There are two main advantages of using this technique in this context. The first advantage is that it naturally combines information from different linear regressions: as such, we do not need to choose one particular CC, and its related regression, over another. If different observations of CCs are available, this technique takes the information provided by all of them into account in the stellar age estimation. The second advantage is the proper and consistent treatment of uncertainties, ensuring reliable age uncertainty estimations.
2. Training data sample
The data sample we used as the training sample is well described in DM19 and references therein. It consists of 1059 stars observed within the HARPS-GTO planet search program. These stars belong to a volume-limited sample around 70 pc of the Sun with very few stars at greater distances, ensuring that the relations we were going to determine are applicable to all these stars. The final spectra have a resolution of R ∼ 115 000 and high S/N (45% of the spectra have 100 < S/N < 300, 40% of the spectra have S/N > 300, and the mean S/N is 380). Stellar parameters such as Teff, [Fe/H], and log g were derived using a special set of iron lines (see Delgado Mena et al. 2017, for details). The chemical abundances [X/Fe] were determined under local thermodynamic equilibrium (LTE) using the 2014 version of the code MOOG (Sneden 1973) and a grid of Kurucz ATLAS9 atmospheres (Kurucz 1993).
Stellar masses and ages were obtained with the PARAM v1.3 tool using the PARSEC isochrones (Bressan et al. 2012) and a Bayesian estimation method (da Silva et al. 2006) together with the values for Teff and [Fe/H] from Delgado Mena et al. (2017), V magnitudes from the main HIPPARCOS catalogue (Perryman et al. 1997), and parallaxes from the second Data Release (DR2) of Gaia (Gaia Collaboration 2016, 2018; Lindegren et al. 2018), which are available for 1057 out of 1059 stars.
Not all the ages derived for these 1059 stars are reliable using this method. DM19 decided to define reliable age estimates as those with an age uncertainties smaller than 1.5 Ga. In this work, we also filtered out stars with age uncertainties smaller than 0.2 Ga, which we regard as being unrealistic for standard isochrone fitting, which can erroneously bias our final model. These cuts leave 328 out of 1059 stars for use in our studies. We refer to DM19 for details of the main characteristics of this subset. In summary, we worked with 244 thin-disk stars, 14 high-α metal-rich stars, 68 thick-disk stars, and 2 halo stars. These classifications were made following Adibekyan et al. (2011, 2012). These 328 stars also have a wide range in parameters Teff: 5010−6788 K (95% between 5271 and 6416 K), log g: 3.73−4.71 dex (95% between 3.93 and 4.58 dex), and [Fe/H]: −1.15 − 0.55 dex (95% between −0.81 and 0.33 dex). In terms of uncertainties, eTeff has an exponential distribution between 61−107 K (95% between 61 and 79 K), elog g is also distributed exponentially between 0.1−0.22 dex (95% between 0.1 and 0.12 dex), and 95% of the e[Fe/H] has a 95% values lie in the range 0.04−0.05 dex; only a few values lie around 0.06 and 0.07 (maximum Δ[Fe/H] of the sample).
3. Inference technique: hierarchical Bayesian model
We defined a Bayesian hierarchical model that is graphically described in Fig. 1 and in the following paragraphs. Inspired by the multi-dimensional linear relations described in DM19 and given the indication in Dotter et al. (2017) and Gavel et al. (2021) that all of the potential predictive variables may carry a piece of physical information, we followed Gelman et al. (2004) and included all available predictors with priors centred at zero. This is in practice equivalent to a regularisation that will only produce regression coefficient posteriors that are effectively different from zero if the data support them (see Gelman et al. 2004). In the top layer of the model, we have then the true values of the stellar physical parameters (hereafter stellar parameters) effective temperature Teff, iron abundance [Fe/H], (logarithm of the) surface gravity log g, and age t. The true values of the abundance ratios used as CCs are (deterministically) modelled as a linear combination of these four stellar parameters,
![Mathematical equation: $$ \begin{aligned}{}[R_i] = k_{i,0}+k_{i,1}\cdot t+k_{i,2}\cdot T_{\rm eff}+k_{i,3}\cdot \mathrm{[Fe/H]}+k_{i,4}\cdot \log g, \end{aligned} $$](/articles/aa/full_html/2022/04/aa41125-21/aa41125-21-eq1.gif) (1)
(1)
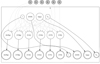 |
Fig. 1. Logical structure of the hierarchical Bayesian model we trained for this study. See text for details. |
where Ri is the ith abundance ratio used as CC and ki, j is the jth constant coefficient of the linear combination. The five coefficients ki, j of each linear combination are also model parameters.
Finally, observables are set at the lowest level of the model and are defined as random variables normally distributed around the true values and with a standard deviation given by the measurement uncertainties described in Sect. 2. This is the most reasonable approximation possible for the distribution of these observables since we do not have their probabilistic distributions but their measurements and standard deviations.
We used the training set described in DM19 in order to infer the posterior distributions of the ki, j coefficients that were subsequently used to predict ages for other stars not in the training set. We refer to the first stage (inferring posterior distributions for the ki, j coefficients) as the training phase and to the second stage (applying the model to infer ages of stars not in the training set) as the prediction stage.
Following DM19, we used five α, odd- and even-Z element abundances (Mg, Ti, Al, Si, and Zn) on the one hand, and two s-process element abundances (Y and Sr) on the other to obtain the CCs. This allows the definition of ten ratios. Because we combined information of all of them, we must note that only six are linearly independent of the rest. We selected the five ratios that involve the Y abundance ([Y/Si], [Y/Mg], [Y/Ti], [Y/Zn], and [Y/Al]) and [Sr/Mg] as CCs because Y is usually easier to obtain than Sr, and its values are also usually more precise. In the following we refer to the vector of CCs thus defined for the ith star as 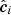 , where the circumflex denotes observed values. The CCs of our training set are affected by two sources of random noise. One source is those physical parameters not accounted for in our model, such as how well the ISM is mixed within the Galaxy or if the material is not well mixed (Adibekyan et al. 2015). We refer to this as the intrinsic scatter. The second source is the measurement uncertainties. In our model we assumed that the intrinsic scatter is much smaller than the measurement uncertainties and cannot be constrained from the observations. Hence, only the latter was included explicitly.
, where the circumflex denotes observed values. The CCs of our training set are affected by two sources of random noise. One source is those physical parameters not accounted for in our model, such as how well the ISM is mixed within the Galaxy or if the material is not well mixed (Adibekyan et al. 2015). We refer to this as the intrinsic scatter. The second source is the measurement uncertainties. In our model we assumed that the intrinsic scatter is much smaller than the measurement uncertainties and cannot be constrained from the observations. Hence, only the latter was included explicitly.
The model then contains 328 × 4 parameters that correspond to the true values of the stellar parameters, plus 6 × 5 parameters that correspond to the linear combination coefficients for each CC. We denote the vector of true values of the stellar parameters of the ith star as θi. As before, we use the circumflex to denote observed values. The likelihood function is then defined as
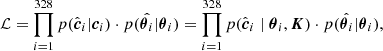 (2)
(2)
where we denote with K the set of six vectors of coefficients ki. The posterior probability distribution of the model parameters is then obtained applying Bayes’ rule,
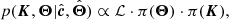 (3)
(3)
where we use the notation π(⋅) instead of p(⋅) to denote prior probability distributions, and we use c and Θ to denote the set of 328 CC values and stellar parameters, respectively.
We defined multivariate normal priors for each of the ki vectors centred at the values of a maximum likelihood linear fit to the data, KML. The covariance matrix ΣK is a modification of the maximum likelihood fit covariance matrix, whereby the original diagonal is scaled (multiplied) by ten to make the prior significantly less informative. Hence,
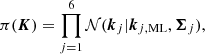 (4)
(4)
where 𝒩(⋅ ∣ μ, Σ) denotes the multi-variate Gaussian probability distribution centred at μ and with covariance matrix Σ, and the subscript ML denotes the maximum likelihood solution.
We used a non-informative multivariate Gaussian prior for Teff, [Fe/H], and t to account for the known correlations existing between the three, and defined an independent prior for the surface gravity, log g. The reason for this election can be found in the appendix. Correlations between CCs and stellar parameters are not taken into account because in our HBM, each CC follows a deterministic relation with the independent variables, not a probabilistic one. The multivariate Gaussian was centred at the mean of the observed values and the covariance matrix was added as an additional model parameter. We decomposed the covariance matrix into a scale and a correlation matrix (see e.g. Gelman & Hill 2007),
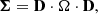 (5)
(5)
where D is a diagonal matrix with a scale for each stellar parameter, and Ω is the correlation matrix. We defined an LKJ prior (Lewandowski et al. 2009) with shape parameter η = 1 for the correlation matrix, representing the equivalent to a uniform distribution on correlations. Finally, we defined a Cauchy prior on the scales centred at 0 and γ = 5. We omit these so-called hyperparameters in Fig. 1 for the sake of clarity. This model is hierarchical in the sense that the prior on the stellar parameters is learnt from the data. Hence, there are two levels in the model: one level for the model parameters (coefficients and true stellar parameters), and one level for the hyperparameters (the covariance matrix of Teff, [Fe/H], and t multivariate normal, having a LKJ prior).
In practice, we used Stan (Carpenter et al. 2017) and the NUTS version of the Hamiltonian Monte Carlo (HMC) sampler in order to obtain samples of the posterior distribution defined in Eq. (3). A more detailed analysis of the model and the reasons for the different choices we made can be found in the appendix.
The same model as described in Fig. 1 can be used to predict the ages of stars not in the training phase. In this case, we are interested in the posterior probability density of the age given a set of observations of the remaining physical parameters and CCs. In the prediction, we did not aim to infer the distribution of the linear combination coefficients and instead used the distribution obtained in the training stage. We also used the posterior distribution of the covariance matrix Σ for the prior of the stellar parameters θ. Let θ′ be the set of true stellar parameters excluding the age (i.e. Teff, log g, and [Fe/H]) and 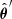 the vector of observed values. The posterior distribution of the age can be obtained from the full posterior by marginalising out the uninteresting parameters (θ′ and the coefficients K),
the vector of observed values. The posterior distribution of the age can be obtained from the full posterior by marginalising out the uninteresting parameters (θ′ and the coefficients K),
![Mathematical equation: $$ \begin{aligned} p(t\mid \hat{\boldsymbol{c}},\hat{\boldsymbol{\theta }}^\prime ) = \int p(t, \boldsymbol{\theta }^\prime , \boldsymbol{K} \mid \hat{\boldsymbol{c}},\hat{\boldsymbol{\theta }}^\prime )\cdot \mathrm{d} T_{\rm eff}\cdot \mathrm{d} \log g\cdot \mathrm{d} \mathrm{[Fe/H]}\cdot \mathrm{d} \boldsymbol{K}, \end{aligned} $$](/articles/aa/full_html/2022/04/aa41125-21/aa41125-21-eq8.gif) (6)
(6)
and using Bayes’ rule,
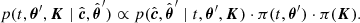 (7)
(7)
We approximated the integral in Eq. (6) with a sum of terms evaluated at the posterior samples of K and Σ obtained during the training stage. As stated above, we used the posterior draws for K as the prior π(K) in the prediction stage and the posterior samples of Σ to define the prior for θ = (t, θ′), and we use these samples to evaluate the likelihood term 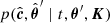 . In Eq. (7) the marginalisation over
. In Eq. (7) the marginalisation over 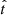 is implicit. Finally, for reasons that will be clearly understood in Sect. 5.6, for each star we performed ten age estimates. The final result we used is the mean value of these ten realisations.
is implicit. Finally, for reasons that will be clearly understood in Sect. 5.6, for each star we performed ten age estimates. The final result we used is the mean value of these ten realisations.
Our inferences are slightly dependent on priors. They are multivariate normal priors centred at the values of a maximum likelihood linear fit to the data, that is, they are dependent on our training set. Therefore, any prediction obtained with our model is not reliable for stars that are not represented in our training set, such as M stars, giants, and sub-giants.
4. Testing samples
To test the HBM constructed with the training sample described in Sect. 2, we gathered four complementary testing samples comprised of stars not belonging to the training set, as described below.
Twenty-three stars with ‘reliable’ ages, twenty of them dated using asteroseismology, two belonging to the cluster M 67, and the Sun. The main characteristics of these stars are shown in Table 1. Here we can see the effective temperature, surface gravity, [Fe/H], age, and the relative abundances of Mg, Al, Si, Zn, Ti, Sr, and Y with respect to iron, and their respective uncertainties. Not all the chemical abundances are known for all the stars, which makes our test more realistic. To treat the Sun as a standard field star from this testing sample, its uncertainties were deliberately inflated to be similar to those of the remaining stars. These data were obtained as follows:
Physical characteristics of the first set of testing stars 23 stars with ‘reliable’ ages.
The general characteristics of the Sun were taken from Prša et al. (2016). For the abundances, we analysed the Sun as a star using a Vesta spectrum and the line-list presented in Sousa et al. (2007, 2008). This line-list was created by calibrating the log g of lines to obtain an adopted reference solar Fe abundance of 7.47 dex as measured in the solar ATLAS spectrum. Because we used the Vesta spectra from HARPS as Sun, the iron is slightly different, as is [Fe/H] = −0.02 using this line-list. Nevertheless, since we used the differences between these abundances, this zero-point is irrelevant. That is, for the Sun, all the CCs are equal to zero. The uncertainties we used are quite conservative and are representative of the typical uncertainties for this stellar type.
The characteristics of the two stars in the open cluster M 67 come from Liu et al. (2016). These stars are two solar twins in an open cluster with an age similar to that of the Sun. The age of the cluster was taken from Yadav et al. (2008).
The characteristics of the eight KIC stars and 16 Cyg A and B were obtained from Nissen et al. (2017) and Morel et al. (2021). Ages for all stars come from asteroseismology, and their abundances were obtained in a special campaign for Kepler legacy stars with the HARPS-N2 spectrograph at the TNG3 in Nissen et al. (2017) and with the échelle fibre-fed SOPHIE spectrograph installed at the 1.93 m telescope of the Observatoire de Haute Provence (OHP, France) in the case of Morel et al. (2021). Because Nissen et al. (2017) did not report any uncertainty for log g, we imposed a standard and conservative uncertainty of 0.05 dex. Ages in the case of Nissen et al. (2017) were taken from Silva Aguirre et al. (2017), where six different stellar structure and evolution codes and fitting algorithms were used. They re-analysed a few stars using ASTFIT (Christensen-Dalsgaard 2008a,b) and BASTA (Silva Aguirre et al. 2015). On the other hand, Morel et al. (2021) used two different studies for stellar dating, again Silva Aguirre et al. (2017) on the one hand, and Creevey et al. (2017), where the AMP algorithm (Metcalfe et al. 2009) was used, on the other hand. They finally used the main of these two estimates because no clear differences were found in general. For more details about the age determination performed in these works and the treatment of the discrepancies, we refer to these papers.
Seventy-nine stars from Spina et al. (2018). They analysed high-resolution HARPS spectra with a high signal-to-noise ratio of 79 solar twin stars in order to study the formation and evolution of the Galactic disk through the chemical composition of these stars. They provided atmospheric parameters, ages, and chemical abundances of 12 neutron-capture elements (Sr, Y, Zr, Ba, La, Ce, Pr, Nd, Sm, Eu, Gd, and Dy). The remaining chemical abundances were presented in Bedell et al. (2018). In this case, stellar ages were obtained by fitting evolutionary models (isochrones) to classic stellar parameters using the q2 code, as shown in Ramírez et al. (2014a,b).
Ten Gaia benchmarks stars. We selected Gaia benchmark stars with Teff, log g, and [Fe/H] within the range of values covered by our training sample. This means a total of ten stars. The stellar parameters were taken from the Gaia benchmark papers Heiter et al. (2015) and Jofré et al. (2014). The chemical abundances were derived in this work by applying the same methodology as in our previous works (Delgado Mena et al. 2017; Adibekyan et al. 2012) to very high quality ESPRESSO spectra obtained by Adibekyan et al. (2020) and using the stellar parameters mentioned above. Ages were obtained from Sahlholdt et al. (2019). In that work, the authors determined ages by balancing all the previous determinations in the literature and different estimations of their own from different isochrones. Therefore, every individual determination is a heterogeneous inference from many different techniques (isochrone fitting, gyrochronology, activity, and/or asteroseismology), and the techniques used are different from one star to the next. The main physical characteristics of these stars can be found in Table 2.
Physical characteristics of the Gaia benchmark testing stars.
One hundred and three stars in open clusters. Casamiquela et al. (2020) studied the physical characteristics and abundances of 93 stars belonging to Hyades, Praesepe (NGC 2632), and Ruprecht 147, with ages of about 0.8 Ga for Hyades, in the range [0.7, 0.83] Ga for NGC 2632, and in the range [2, 2.5] Ga for Ruprecht 147, according to Table 1 of Casamiquela et al. (2020). The spectra were collected from many different instruments such as UVES at VLT4, FEROS at MPG5, HARPS, HARPS-N, FIES at NOT6, ESPaDOnS at CFHT7, NARVAL at TBL8, and ELODIE at OHP. For the abundances, they used stars as reference that were similar in terms of their Teff and [Fe/H] to those of the Hyades cluster. In addition, we included stars from Blanco-Cuaresma & Fraix-Burnet (2018). They studied a total of 207 stars belonging to 34 open clusters with NARVAL, with 300−1100 nm and an average resolution of 80 000; with HARPS, with 378−691 nm and a gap between chips that affects the region from 530 to 533 nm and a resolution of 115 000; and with UVES, with 476−683 nm and a small gap between 580 and 582 nm and a minimum resolution of 47 000. Unfortunately, the vast majority of stars observed from these clusters were giant stars, and only 93 from Casamiquela et al. (2020) and 10 in the cluster IC 4651 from Blanco-Cuaresma & Fraix-Burnet (2018) can be analysed using our model mainly because of the log g range that is covered by our training sample. We also discarded clusters in which the number of remaining stars after filtering was statistically not significant. The ages of the clusters were taken from Dias et al. (2021).
For all these stars, except those from Casamiquela et al. (2020), the different authors performed a differential analysis with respect to the Sun to obtain abundances. Therefore, the [X/H] values are all in the same scale. Casamiquela et al. (2020) used two approaches. First, they derived abundances with respect to the Sun in the same way as the other works, and these are the [X/H] values they provide. Later, however, they performed a differential analysis with respect to reference stars in the Hyades.
With these four testing samples, we analysed the performance of our HBM in estimating stellar ages. The first three testing sets (i.e., the 23 stars with ‘reliable’ ages, 79 stars from Spina et al. (2018), and 10 Gaia benchmarks stars) tested the performance of our model on individual stars (separated in terms of the techniques used for estimating their ages and their astrophysical interest). The testing sample using stellar clusters was used to assess the statistical performance of our model, that is, how it estimate ages for a large set of stars with the same age, but very different stellar parameters.
Therefore, we gathered 215 stars for the testing sample covering many different situations in terms of input quality and age determination. To show how well this testing sample represents the training sample, Fig. 2 shows density distributions for Teff, log g, [Fe/H], and age from the testing and training samples. This figure clearly shows that the testing sample properly covers the range of Teff defined by the training sample. There is only a lack of stars with high temperatures, but this range is poorly described by the training sample. On the other hand, for log g, there is a bias in the testing sample to large log g. Nevertheless, almost all the log g space is tested. The situation is similar for the ages, where almost the entire range is covered by the testing sample, but with a clear overtesting of young ages, mainly because of the number of young cluster in our sample. The least covered variable is metallicity. The range covered by our training sample is far larger than that covered by the testing sample. The testing sample has a lack of low-metallicity stars. This bias must be corrected for in the future to offer a more consistent testing of the model, but it currently is a hard task to find testing stars in this context because stars with accurate abundances of the elements we need for this study and accurate ages are lacking. This last requirement is the most limiting one in general. This also limits the total number of testing stars we can use.
 |
Fig. 2. Histograms for Teff, log g, [Fe/H], and age of the testing (red) and training samples (blue). |
5. Results and discussion
In this section, we test the performance of the model described in Sect. 3 that we obtained using the training set described in Sect. 2. These tests were made to compare the estimated ages in the literature for the testing stars described in Sect. 4 and the ages predicted by our model. Each subsection is devoted to each of the four testing sets presented in Sect. 4. We also add a subsection presenting the combination of the results obtained for the three first testing sets (field stars). This is done to show the performance of our model for all the individual stars together, and to verify the consistency of our model compared with other dating methods in the literature. We finally analyse the outliers we found to understand their origin.
5.1. Results for the 23 stars with ‘reliable’ ages
In Fig. 3 we show the comparison between the test ages that were obtained via asteroseismology, cluster membership, and so on with the ages predicted by the HBM. For the ages obtained in this work, uncertainties always represent the 1σ dispersion. We evaluated the absolute differences, in the sense test minus estimated ages. We did not evaluate relative differences because uncertainties are not in general related to the age of the star. Therefore, the same uncertainty at two different ages may produce very different relative differences. For the complete set, we find a mean absolute difference (MAD) of 0.86 Ga. The mean difference (MD, a measure of the bias) is 0.19 Ga, that is, CCs slightly underestimate the age compared with asteroseismology, but this underestimation is within uncertainties. This agrees with the results of Morel et al. (2021), who found an MAD of 0.7 Ga with a bias towards younger ages estimated via CCs. A possible source for this bias is the fact that ages for the training sample were obtained using isochrones, as described in DM19, and with this test, we are evaluating the differences between asteroseismology and those isochrones plus CC predictors.
 |
Fig. 3. Age predictions for the 23 stars with ‘reliable’ ages (test ages) using our HBM. The black line represents the one-to-one relation to guide the eye. |
In addition, this figure shows some interesting features. The ages of the Sun and the two stars in M 67 (blue and green dots in Fig. 3) are predicted very well. Asteroseismic ages are also predicted with an MAD of 1 Ga. In general, for almost all the 23 stars, the ranges of test and predicted uncertainty overlap.
We identify three outliers with differences larger than 2 Ga and underctainties that do not overlap: KIC 3656476, KIC 6603624, and KIC 8006161. These cases are discussed in Sect. 5.6.
5.2. Results for the 79 stars from Spina et al. (2018)
In Fig. 4 we show the comparison between the ages estimated in Spina et al. (2018) with the ages predicted by our HBM. The figure shows that the ages estimated by our model are similar to those provided by the authors using other isochrones. Nevertheless, we find a clear trend in this comparison that can be attributed to the different techniques used in Spina et al. (2018) and DM19 to estimate ages from isochrones or to the different methods used by these authors to estimate abundances. Distinguishing these two options is beyond the scope of this work. On the other hand, we find a clear outlier. The star HIP 64150 is also identified by Spina et al. (2018) as a chemically anomalous star. These authors explained that this star belongs to a binary system in which the primary is orbited by a white dwarf. Therefore, its atmospheric abundances may be enhanced by pollution from an AGB companion (Spina et al. 2018). Again, we evaluated the absolute differences without the outlier, finding an MAD of 0.93 Ga. and an MD of 0.38 Ga. That is, the bias is almost negligible within the errors, as for the previous testing set.
 |
Fig. 4. Age predictions for the 79 stars from Spina et al. (2018) (test ages) using our HBM. The black line represents the one-to-one relation to guide the eye. |
5.3. Gaia benchmark stars
In the case of the Gaia benchmark stars, Sahlholdt et al. (2019) and references therein made a comprehensive study of estimates coming from many stellar dating techniques, such as asteroseismology, gyrochronology, stellar activity, and isochrone fitting, to name the most frequently used methods, and many sources in the literature, finally giving an age summary of all these estimates. Therefore, we can place our estimates in this context for a better understanding of our results compared with other techniques in the literature.
In Fig. 5 we show the comparison between the ages estimated in Sahlholdt et al. (2019) with the ages predicted by our HBM. Here we find that for seven of the stars, the ages overlap (taking the uncertainties into account). There are three outliers (τ Cet, α Cen B, and ϵ Eri). These cases are analysed in Sect. 5.6.
 |
Fig. 5. Age predictions for ten Gaia benchmark stars (test ages are taken from Sahlholdt et al. 2019) using our HBM. The black line represents the one-to-one relation to guide the eye. |
Ignoring these three outliers, the remaining set has an MAD of 0.86 Ga and an MD of 0.22 Ga. That is, the bias is much lower than the uncertainty, and the MAD is of the order of or lower than 1 Ga, as was the case for the previous tests discussed above.
5.4. All the field stars together
Finally, if we consolidate all the field stars studied in Sects. 5.1–5.3 in a single plot, we obtain Fig. 6. In addition to the already noted outliers, the results are quite stable, despite the fact that the age estimation techniques used for this testing sample are very heterogeneous. The trend found in the comparison with Spina et al. (2018) is somewhat mitigated in the global dispersion, even when it is the subsample with the largest population. That is, it is not possible to distinguish the original dating technique in Fig. 6. This shows that this heterogeneity in estimation techniques for the testing stars has a negligible impact on the final results. Removing the Gaia benchmark outliers and the Spina et al. (2018) single outlier, that is, those that can be clearly identified by comparison with another methods, we obtain an MAD of 0.93 Ga, and an MD of 0.35 Ga in this joint case. These values can be regarded as the performance of our HBM for estimating ages of field stars taking our testing sample into account.
5.5. Stars in different open clusters
Dating using CCs is based on statistics. The idea is to analyse many stars and find a number of correlations between CCs, stellar parameters, and stellar age. One of the best ways of testing the statistical nature of the technique is to have many stars with many different physical parameters but the same age. Then the intrinsic dispersion of the method becomes visible.
In this section we propose using open clusters for this test. DM19 showed that the training sample has a clear dispersion and also outliers. Therefore, we can expect a similar statistical behaviour when stellar ages are estimated based on this training sample.
For this study, we used the data of Casamiquela et al. (2020), who analysed the open clusters Hyades, NGC 2632, and Ruprecht 147. They obtained Teff, log g, [Fe/H], and the abundances of [Mg/Fe], [Al/Fe], [Ti/Fe], [Si/Fe], and [Y/Fe] for groups of stars in each cluster. In total, 58 stars belong to the Hyades, 18 belong to NGC 2632, and 17 belong to Ruprecht 147. The galactocentric radii of these three clusters are larger than 7 kpc (Wu et al. 2009; McMillan 2013), out of the inner disk, where Casali et al. (2020) found that these CCs do not work correctly. We also added ten stars from the cluster IC 4651 studied by Blanco-Cuaresma & Fraix-Burnet (2018). The galactocentric radius of this cluster is also larger than 7 kpc. For each cluster we identified the outliers, if any. In the case of Hyades, we found four outliers, one for Ruprecht 147, and none for IC 4651 and NGC 2632. The quantity of outliers is related to the population of stars belonging to each cluster in the testing set. These five outliers were removed for the following analysis and are studied separately in Sect. 5.6.
In Fig. 7 we provide boxplots of the distribution of estimated ages obtained for four clusters. Each boxplot is represented by a rectangle bounding the first and third quartiles of the distribution. The thick black line represents the median. The thin vertical lines bound the maximum and minimum values of the distribution and empty circles represent the outliers. In addition, we included blue points showing the mean of each distribution, and a brown point for the assumed age of the cluster. Our model estimates a mean age for NGC 2632 and Hyades that is slightly older than the assumed age, with a difference between the estimated mean age and the age from the literature of 0.36 Ga and 0.9 Ga for Hyades and NGC 2632, respectively. In the case of Ruprecht 147, the mean value of our estimated ages is 0.04 Ga younger than the assumed age of this cluster. IC 4651 presents a mean age 0.14 Ga older than the accepted age for the cluster. The MADs for these clusters are 0.712, 1.35, 1.02, and 0.95 Ga for Hyades, IC 4651, NGC 2632, and Ruprecht 147, respectively.
 |
Fig. 7. Boxplots of the estimated age distribution for the clusters under study using our HBM. The red dots represent the literature ages of the clusters, and the blue dots show the mean ages we obtained. |
This means that although there is a bias larger than expected for the younger clusters, especially for NGC 2631, most of the stars in general present age estimates using CCs with accuracies of about 1 Ga, confirming the results for field stars with well-known ages. This is a statement regarding a statistical behaviour, however. There are individual outliers in some of these clusters with estimates even higher than 5 Ga for a few stars. A summary of the results of all these testing sets (Sects. 5.1–5.3 and 5.5) can be found in Table 3.
Summary of the general results obtained with our HBM in comparison to the test ages for all the testing sets. MD accounts for the mean differences, SD for the standard deviation of these differences, and MAD for the mean absolute differences.
5.6. Outlier analysis
In Fig. 8 we show a histogram with all the differences between the ages estimated using our HBM and the test ages from the literature. This histogram shows eight stars whose inaccuracies clearly exceed those of the main group around Error = 0, all higher than 4 Ga in absolute value. These eight stars are those identified in Sects. 5.2 and 5.5, and α Cen B and τ Cet from the Gaia benchmark sample. In addition, we identified four additional stars to be studied in this section: three stars from Sect. 5.1 that are not outliers when all the testing stars are considered, but they are outliers when only these 23 stars are considered, and the special case of ϵ Eri. Thus we identified 12 outliers from a total of 215 stars, that is, 5.6% of the complete testing sample. All these stars were removed from the previous analysis and are studied in detail in this section.
 |
Fig. 8. Histogram of the differences between the ages estimated by our model and the ‘test’ ages for the 215 stars of out testing set. |
The outlier found in the set of Spina et al. (2018), as we commented before, was also found and studied by these authors. They concluded that the chemical peculiarities of this star deserve a dedicated analysis that it is beyond the scope of this work. We refer to Spina et al. (2018) for the details of this case. The most interesting point here is that we found more cases like this in terms of chemical peculiarities in the other samples we studied.
5.6.1. α Cen B
This is one of our most worrying outliers. Sahlholdt et al. (2019) estimated an age of 5.5 ± 1.5 Ga, and our HBM estimates an age of 0.11 − 0.02 + 2.1 Ga. Our estimate seems unreasonable, but considering the different estimates shown in Sahlholdt et al. (2019), this star is quite pathological. It is part of a triple system and should have a similar age as α Cen A, but the literature disagrees about this. The asteroseismic estimate of Lundkvist et al. (2014) points to a very young star, like our results; gyrochronology in general points to a star older than α Cen A, and all the estimates range between 1 and 9 Ga. Our estimated uncertainties overlap with the youngest estimates for this star. Nevertheless, there may be a reason for our low estimate. With a Teff in the lower 2.5% range of our training sample, a log g in the top 2.5%, and [Sr/Mg] pointing to a very young star, the results are not as reliable as the remaining cases that are properly covered by the training sample.
5.6.2. τ Cet
This is one of our outliers with clearer chemical peculiarities or an incorrect dating in the literature. The estimates for τ Cet in the literature cover a wide range (0−14 Ga), with large uncertainties. Therefore, Sahlholdt et al. (2019) listed an age of 7 ± 4, that is, in the middle of the range of estimates in the literature. However, their own analysis points to a very old star. Our estimate is 14 + 0 − 1.2 Ga, supporting the analysis of Sahlholdt et al. (2019). Its CCs are all compatible with an age older than 10 Ga, with some lying at the top limit of the training sample (the older stars), for example, [Y/Ti], [Y/Al], and [Y/Si]. All this is shown in Fig. 9, where the position of the red dots is clearly different from those corresponding to its age in the literature compared to the training sample. They point to an older star. We repeat that this is an indication of chemical peculiarities for this star or an incorrect dating in the literature.
 |
Fig. 9. Position of the CCs of τ Cet in the CCs vs. age diagrams. Red dots are the CCs of this star. Black dots are the CCs of the training sample. The black cross represents the mean 1σ uncertainty of the training sample. |
5.6.3. Other stars with chemical peculiarities
Therefore, we can use CCs in combination with other stellar dating methods to identify potentially very interesting cases with chemical peculiarities. Another example of chemical peculiarities is the only outlier found in Ruprecht 147. In Fig. 10 we highlight (with a red symbol) the values of the CCs of this star. Its chemical peculiarities clearly differ from the general trend of the remaining stars in this cluster. The values of the CCs for this outlier point to an older star compared to the rest of its companions. Our model only reflects this fact. Distinguishing the origin of these peculiarities is beyond the scope of this work, but two possible explanations for the outliers found in clusters may be the real chemical peculiarities of these stars, or stars that do not really belong to the cluster. The remaining outliers in clusters, in addition to KIC 3656476 and KIC 6603624, have a similar behaviour.
 |
Fig. 10. CCs of the stars belonging the open cluster Ruprecht 147. The red points represent the outlier found in Fig. 8 for this open cluster. The x-axis represents the star ID of our sample. The red point corresponds to the star Gaia DR2 4087853875535923200. |
5.6.4. Special cases of KIC 8006161 and ϵ Eri
In these two cases we found a intrinsic variability in the age estimate of our HBM when we reran it. The reason is related to the combination of two factors: a relatively low number of sampling points (3000, see the appendix), and inconsistent input variables or variables that are not correctly covered by our training sample. These inconsistencies are illustrated using ϵ Eri as an example. Sahlholdt et al. (2019) estimated an age of 0.65 ± 0.25 Ga, and our HBM estimates an age of 4.1 − 2 + 2.1 Ga. In this case, gyrochronology and chromochronology provide very stable estimates between 0 and 1 Ga. On the other hand, isochrone fitting provides highly variable results, with ages up to 14 Ga. In a recent work, Petit et al. (2021) studied this star using data from SPIRou, NARVAL, and TESS, confirming its young age by the presence of a debris disk.
In Fig. 11 we compare the values of the input variables of this star with those of our training sample. In this case, [Fe/H] and [Y/Al] mildly indicate an older star. When these ratios are dismissed, our estimate is reduced in 1 Ga, overlapping the estimate of Sahlholdt et al. (2019). We must take into account, however, that the Teff of this star is in the lower 2.5% of our training sample, making our result not as reliable as for the remaining cases that are properly covered by the sample. This lack of reliability is confirmed with the variability we found when we ran the HBM several times on this star. Therefore, as we described in Sect. 3, we ran this HBM ten times on each star. The final result we used for the comparisons is the mean age from these ten estimations. The reason for this procedure is located in the behaviour of this star and KIC 8006161. If we calculate the standard deviation of these ten realisations for ϵ Eri, we obtain an SD of 1.46, and for KIC 8006161, the SD is 0.76. These are very high values.
 |
Fig. 11. Input variables of ϵ Eri. The red points represent the values for this star. The black points show the corresponding values of our training sample. The black cross represents the mean 1σ uncertainty of the training sample. |
As we mentioned, the combination of input values pointing to different ages and, in some cases, with values poorly covered by our training sample, with only 3000 sampling points generates this variability due to the stochastic nature of the estimation algorithm. If we increase the number of sample points to 30 000, for example, we find that the mean age estimate remains unaltered (from 3.16 Ga to 2.95 Ga in the case of ϵ Eri, e.g.), but the SD of the ten realisations decreases from 1.47 to 0.65. Nevertheless, we decided to keep this low number of sampling points for the inference because the final age estimate is not affected, but this dispersion offers a quality test for our estimates.
This is shown in Fig. 12, where we show the accuracy of our predictions (or the differences between the HBM estimations and the test ages) versus the standard deviation of these ten realisations. The precision, or 1σ uncertainty range, is shown in colour. The vast majority of the stars present a low SD and reasonable accuracy. On the other hand, we identify two ranges of extreme values:
 |
Fig. 12. Accuracy of our predictions (observed – estimated age) vs. the standard deviation of the ten realisations. The 1σ uncertainty (precision) is shown in colour. |
– Those with low SD and poor accuracy. These stars belong to the outliers described at the begining of this section. The inputs are consistent, and the age differences are only due to physical reasons.
– Those with high SD (about five stars). Here the SD is a signal of an inconsistency in the input variables, a poor coverage from the training sample, or both. This high SD shows that the age estimate provided by the HBM is not reliable and must be taken with caution.
In both cases, a poor precision can be indicative of inputs with large uncertainties, and the result must also be taken with caution. In general, a high SD is also followed by a precision worst than 3 Ga.
6. HBM using only CCs
In general, in the literature CCs are used alone or in combination of the stellar metallicty for stellar dating. In the model we presented, we added information from Teff and log g for reasons already exposed, but the question is how these results compare with using only CCs and [Fe/H]. To answer it, we trained an HBM only using CCs and [Fe/H]. In this section we present the comparison, using our testing field stars, between the results obtained with this simplified model.
In Fig. 13 we show the equivalent to Fig. 6, but this model used only CCs and [Fe/H]. The result, as expected, is very similar to the result obtained using all the input variables, but with a larger dispersion and some new outliers. This is confirmed in Table 4. Compared to Table 3, the bias (MD) in general increases and the MAD does as well, although this increase is not significant in some subsets. This means that this simplified model can be used for a first estimate, avoiding some of the inconsistencies we have found for peculiar stars, but for the best possible accurate age estimate, it is better to use all the input variables.
 |
Fig. 13. Age predictions for the stars studied in Sects. 5.1–5.3 using our HBM with only CCs and [Fe/H]. |
7. Conclusions
The use of stellar chemical abundances for stellar dating using certain abundance ratios (the chemical clocks, CCs) has been improved in recent years with the definition of more than ten CCs, and the extension of the use of CCs beyond solar twins. We took advantage of the exceptional database presented in DM19 to go one step further in the use of CCs for stellar dating. We trained a hierarchical Bayesian model to combine the information coming from different CCs and other physical observables such as Teff, log g, or [Fe/H] to provide robust stellar age estimates with good precision.
To test our model, we gathered a number of different testing sets. We used stars with ages estimated by asteroseismology, Gaia benchmark stars, stars from other studies in the context of CCs, and four stellar clusters. We found that our estimates using CCs and an HBM are similar to the reference ages for almost all the tested stars. Compared with all the testing samples, our estimates present an MAD of about 0.91 Ga, with a really short MD of 0.008 Ga, which reflects the error compensations. A most reliable MD was obtained by studying the individual testing subsamples, where MD ranges between −0.4 and 0.4 Ga.
Nevertheless, we must take some important aspects related to this technique into account. It is based on the statistical properties of a large amount of stars. Therefore, its predictions for individual stars must always be taken with caution because we are not safe from outliers related to chemical peculiarities or stellar parameters, or observed CCs that are poorly covered by our training sample. Nevertheless, our test shows that the estimates we provide are generally very good age indicators. If this technique is used in combination with any other age estimator, outliers can be identified, and then very interesting cases can be discovered from the point of view of a chemical abundance. In addition, we verified that our model is sometimes not as accurate for cool stars (below 5200 K) as it is for Sun-like stars. For these cool stars, abundance determinations are not completely reliable in our training sample. In general, we suggest that our method is used to predict ages only for stars with stellar characteristics within the 95% ranges of the properties of the training sample, as shown in Sect. 2, in order to avoid boundary effects and hence inaccuracies in estimating stellar ages with our model.
We have also presented a simplified version of the HBM using only [Fe/H] and CCs. This model provides reasonable and useful age estimates, but with lower accuracies and precisions than the estimates obtained with the complete model.
One of the main benefits of this dating technique is that it is almost independent of the stellar structure and evolution. It depends mainly on the chemical evolution of certain parts of the Galaxy, where the training sample is located, and the chemical abundances of the original cloud from which the stars formed. Finally, we note that while the ages of the training sample we used were obtained using isochrone fitting, it seems that this has a small impact on the final results.
High Accuracy Radial velocity Planet Searcher – North.
Telescopio Nazionale Galileo Galilei.
UV-visual echelle spectrograph, Very Large Telescope.
Fiberfed Extended Range Optical Spectrograph, Max Planck Gesellschaft.
FIbre-fed Echelle Spectrograph, Nordic Optical Telescope.
Echelle SpectroPolarimetric Device for the Observation of Stars, Canada France Hawaii Telescope.
Telescope Bernard Lyot.
Acknowledgments
The authors want to thank an anonymous referee for his/her very interesting and constructive comments. The paper was clearly improved thanks to them. We also want to thank editor M. Salaris for his understanding during the refereeing procedure. A.M. acknowledges funding support from the European Union’s Horizon 2020 research and innovation program under the Marie Sklodowska-Curie grant agreement No. 749962 (project THOT), from Grant PID2019-107061GB-C65 funded by MCIN/AEI/10.13039/501100011033, and from Generalitat Valenciana in the frame of the GenT Project CIDEGENT/2020/036. V.A. and E.D.M. were supported by FCT – Fundação para a Ciência e Tecnologia (FCT) through national funds and by FEDER through COMPETE2020 – Programa Operacional Competitividade e Internacionalização by these grants: UID/FIS/04434/2019; UIDB/04434/2020; UIDP/04434/2020; PTDC/FIS-AST/32113/2017 and POCI-01-0145-FEDER-032113; PTDC/FIS-AST/28953/2017 and POCI-01-0145-FEDER-028953. V.A. and E.D.M. also acknowledge the support from FCT through Investigador FCT contracts nr. IF/00650/2015/CP1273/CT0001 and IF/00849/2015/CP1273/CT0003, and POPH/FSE (EC) by FEDER funding through the program “Programa Operacional de Factores de Competitividade – COMPETE”.
References
- Adibekyan, V. Z., Santos, N. C., Sousa, S. G., et al. 2011, A&A, 535, L11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Adibekyan, V. Z., Sousa, S. G., Santos, N. C., et al. 2012, A&A, 545, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Adibekyan, V., Figueira, P., Santos, N. C., et al. 2015, A&A, 583, A94 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Adibekyan, V., Sousa, S. G., Santos, N. C., et al. 2020, A&A, 642, A182 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bedell, M., Bean, J. L., Meléndez, J., et al. 2018, ApJ, 865, 68 [Google Scholar]
- Blanco-Cuaresma, S., & Fraix-Burnet, D. 2018, A&A, 618, A65 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bressan, A., Marigo, P., Girardi, L., et al. 2012, MNRAS, 427, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Carpenter, B., Gelman, A., Hoffman, M., et al. 2017, J. Stat. Softw., 76, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Casamiquela, L., Tarricq, Y., Soubiran, C., et al. 2020, A&A, 635, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casamiquela, L., Soubiran, C., Jofré, P., et al. 2021, A&A, 652, A25 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casali, G., Magrini, L., Tognelli, E., et al. 2019, A&A, 629, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casali, G., Spina, L., Magrini, L., et al. 2020, A&A, 639, A127 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Christensen-Dalsgaard, J. 2008a, Ap&SS, 316, 13 [Google Scholar]
- Christensen-Dalsgaard, J. 2008b, Ap&SS, 316, 113 [Google Scholar]
- Creevey, O. L., Metcalfe, T. S., Schultheis, M., et al. 2017, A&A, 601, A67 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Delgado Mena, E., Tsantaki, M., Adibekyan, V. Z., et al. 2017, A&A, 606, A94 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Delgado Mena, E., Moya, A., Adibekyan, V., et al. 2019, A&A, 624, A78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dias, W. S., Monteiro, H., Moitinho, A., et al. 2021, MNRAS, 504, 356 [NASA ADS] [CrossRef] [Google Scholar]
- Dotter, A., Conroy, C., Cargile, P., et al. 2017, ApJ, 840, 99 [NASA ADS] [CrossRef] [Google Scholar]
- Espinoza-Rojas, F., Chanamé, J., Jofré, P., et al. 2021, ApJ, 920, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Feltzing, S., Howes, L. M., McMillan, P. J., et al. 2017, MNRAS, 465, L109 [NASA ADS] [CrossRef] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2018, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gavel, A., Gruyters, P., Heiter, U., et al. 2021, A&A, 652, A75 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gelman, A., & Hill, J. 2007, Data Analysis using Regression and Multilevel/Hierarchical Models, Analytical Methods for Social Research (Cambridge: Cambridge University Press) [Google Scholar]
- Gelman, A., Carlin, J. B., Stern, H. S., & Rubin, D. B. 2004, Bayesian Data Analysis, 2nd edn. (Chapman and Hall/CRC) [Google Scholar]
- Hayden, M. R., Sharma, S., Bland-Hawthorn, J., et al. 2020, MNRAS, submitted [arXiv:2011.13745] [Google Scholar]
- Heiter, U., Jofré, P., Gustafsson, B., et al. 2015, A&A, 582, A49 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Johnson, J. A., Fields, B. D., & Thompson, T. A. 2020, Phil. Trans. R. Soc. London Ser. A, 378, 20190301 [Google Scholar]
- Jofré, P. 2021, ApJ, 920, 23 [CrossRef] [Google Scholar]
- Jofré, P., Heiter, U., Soubiran, C., et al. 2014, A&A, 564, A133 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jofré, P., Jackson, H., & Tucci Maia, M. 2020, A&A, 633, L9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Katz, D., Gómez, A., Haywood, M., et al. 2021, A&A, 655, A111 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kurucz, R. 1993, ATLAS9 Stellar Atmosphere Programs and 2 km/s Grid (Cambridge: Smithsonian Astrophysical Observatory) [Google Scholar]
- Lewandowski, D., Kurowicka, D., & Joe, H. 2009, J. Multivar. Anal., 100, 1989 [CrossRef] [Google Scholar]
- Lindegren, L., Hernández, J., Bombrun, A., et al. 2018, A&A, 616, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Liu, F., Asplund, M., Yong, D., et al. 2016, MNRAS, 463, 696 [NASA ADS] [CrossRef] [Google Scholar]
- Llorente de Andrés, F., Chavero, C., de la Reza, R., et al. 2021, A&A, 654, A137 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lundkvist, M., Kjeldsen, H., & Silva Aguirre, V. 2014, A&A, 566, A82 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Magrini, L., Vescovi, D., Casali, G., et al. 2021, A&A, 646, L2 [EDP Sciences] [Google Scholar]
- McMillan, P. J. 2013, MNRAS, 430, 3276 [NASA ADS] [CrossRef] [Google Scholar]
- Metcalfe, T. S., Creevey, O. L., & Christensen-Dalsgaard, J. 2009, ApJ, 699, 373 [Google Scholar]
- Morel, T., Creevey, O. L., Montalbán, J., et al. 2021, A&A, 646, A78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nissen, P. E. 2015, A&A, 579, A52 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nissen, P. E. 2016, A&A, 593, A65 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nissen, P. E., Silva Aguirre, V., Christensen-Dalsgaard, J., et al. 2017, A&A, 608, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nissen, P. E., Christensen-Dalsgaard, J., Mosumgaard, J. R., et al. 2020, A&A, 640, A81 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Perryman, M. A. C., Lindegren, L., Kovalevsky, J., et al. 1997, A&A, 500, 501 [NASA ADS] [Google Scholar]
- Petit, P., Folsom, C. P., Donati, J.-F., et al. 2021, A&A, 648, A55 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Prša, A., Harmanec, P., Torres, G., et al. 2016, AJ, 152, 41 [Google Scholar]
- Ramírez, I., Meléndez, J., Bean, J., et al. 2014a, A&A, 572, A48 [Google Scholar]
- Ramírez, I., Meléndez, J., & Asplund, M. 2014b, A&A, 561, A7 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rebassa-Mansergas, A., Maldonado, J., Raddi, R., et al. 2021, MNRAS, 505, 3165 [NASA ADS] [CrossRef] [Google Scholar]
- Sahlholdt, C. L., Feltzing, S., Lindegren, L., et al. 2019, MNRAS, 482, 895 [NASA ADS] [CrossRef] [Google Scholar]
- Sharma, S., Hayden, M. R., Bland-Hawthorn, J., et al. 2022, MNRAS, 510, 734 [Google Scholar]
- Santos-Peral, P., Recio-Blanco, A., Kordopatis, G., et al. 2021, A&A, 653, A85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- da Silva, L., Girardi, L., Pasquini, L., et al. 2006, A&A, 458, 609 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- da Silva, R., Porto de Mello, G. F., Milone, A. C., et al. 2012, A&A, 542, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Silva Aguirre, V., Davies, G. R., Basu, S., et al. 2015, MNRAS, 452, 2127 [Google Scholar]
- Silva Aguirre, V., Lund, M. N., Antia, H. M., et al. 2017, ApJ, 835, 173 [Google Scholar]
- Skúladóttir, Á., Hansen, C. J., Salvadori, S., et al. 2019, A&A, 631, A171 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sneden, C. A. 1973, PhD Thesis, The University of Texas at Austin [Google Scholar]
- Soderblom, D. R. 2010, ARA&A, 48, 581 [Google Scholar]
- Soderblom, D. 2015, Nature, 517, 557 [NASA ADS] [CrossRef] [Google Scholar]
- Sousa, S. G., Santos, N. C., Israelian, G., et al. 2007, A&A, 469, 783 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sousa, S. G., Santos, N. C., Mayor, M., et al. 2008, A&A, 487, 373 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Spina, L., Meléndez, J., Karakas, A. I., et al. 2016, A&A, 593, A125 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Spina, L., Meléndez, J., Karakas, A. I., et al. 2018, MNRAS, 474, 2580 [NASA ADS] [Google Scholar]
- Tautvaišienė, G., Viscasillas Vázquez, C., Mikolaitis, Š., et al. 2021, A&A, 649, A126 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Titarenko, A., Recio-Blanco, A., de Laverny, P., et al. 2019, A&A, 622, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tucci Maia, M., Ramírez, I., Meléndez, J., et al. 2016, A&A, 590, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wu, Z.-Y., Zhou, X., Ma, J., et al. 2009, MNRAS, 399, 2146 [NASA ADS] [CrossRef] [Google Scholar]
- Yadav, R. K. S., Bedin, L. R., Piotto, G., et al. 2008, A&A, 484, 609 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
Appendix A: HBM analysis
In this appendix we show all the tests we performed to ensure the consistency of the HBM we used in this study. The main characteristics of the final selected model can be found in Table A.1. The number of samples, burn-in iterations, and independent chains is considered sufficient to ensure convergence and representativity of the chains. The multivariate Gaussian priors are highly non-informative.
Main characteristics of the HBM model.
The posterior distribution for the different coefficients can be found in Fig. A.1 for the case of the relation of one of the CCs, in this case, [Y/Mg]. In this figure, Var 1 to Var 5 represent the coefficients k1 to k5 of Eq. 1. This figure shows that there are no clear correlations between these posteriors, except for the coefficient accompanying the age with that accompanying [Fe/H] and slightly for that accompanying Teff. In any case, the inclusion of these quantities in the correlation matrix ensures the consistency of the model. Another conclusion is that the presence of log g in this matrix is not imperative because no clear correlations are found.
 |
Fig. A.1. Posterior distribution of the coefficients of Eq. 1 in the case of the CC [Y/Mg]. Var 1 to Var 5 correspond to k1 to k5 in this equation. |
The convergence of the MCMC chains can be verified using the 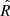 parameter (Gelman et al. 2004). The closer
parameter (Gelman et al. 2004). The closer 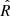 is to one, the better the convergence of the model. This parameter is measured for every variable of the model, that is, the 30 ki, j coefficients, the correlation matrix, the variables standard deviations, and the true values of the variables, adding more than 1000 variables. The mean value of
is to one, the better the convergence of the model. This parameter is measured for every variable of the model, that is, the 30 ki, j coefficients, the correlation matrix, the variables standard deviations, and the true values of the variables, adding more than 1000 variables. The mean value of 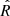 for all these variables is 0.9999, with a standard deviation of 0.0003. In conclusion, the general convergence of the chains is ensured.
for all these variables is 0.9999, with a standard deviation of 0.0003. In conclusion, the general convergence of the chains is ensured.
We also analysed the number of effective sampling points (neff) for each variable. ki, j coefficients are those with the lower neff values, but in any case neff > 4000. Because our model has 30000 sample points, we used only one point of ten to estimate the stellar age, ensuring the statistical consistency of the estimation and speeding up its computation.
In Table A.2 we list the impact on the final general results of using all the 30000 sampling points. This table must be compared with Table 3, where we used one point of ten, but ten realisations. The differences in the final results are negligible, of the second or third significant figure, confirming our choice for the selected model.
Statistical results in the case of using all sampling points for the age estimates, to be compared with Table 3.
A final consistency check is related to the inclusion or exclusion of log g in the correlation matrix. In Table A.3 we show the Spearman coefficient to understand the correlations between the different independent variables of Eq. 1. log g is the variable with the weakest correlations with the other variables. This can also been confirmed with the posterior distribution of Var 5 (the k5 coefficient campaigning log g) in Fig A.1.
Spearman coefficient for the correlation between the different independent variables of Eq. 1.
Therefore, we expect a weak or even negligible impact on the final model and its estimates of including log g in the correlation matrix. In any case, we performed the test, and in Table A.4, we list the final general results when log g is included in the correlation matrix, to be compared with Table 3, where log g is not included. This comparison shows some interesting results. The tests made using field stars show similar results regardless of whether log g is included. In particular, MD with log g in the correlation matrix is slightly lower. When we compared stars in clusters (Blanco and Casamiquela sets), we were surprised, however. In these cases, including log g in the matrix significantly worsens the results. This is illustrated in Fig. A.2, where we show the boxplot of the results obtained with both options for log g (inside the correlation matrix in blue and outside this matrix in red). Brown points represent the accepted age of each cluster. In all cases, including log g provides the worst estimates.
 |
Fig. A.2. Boxplot of the age estimates obtained for all the stars in clusters performed with log g in the correlation matrix (blue) and out of the correlation matrix (red). Brown points represent the accepted age of each cluster. |
Statistical results in the case of including log g in the correlation matrix for the age estimates, to be compared with Table 3.
We can explain this behaviour by recalling that to construct these models, we assumed that correlations between independent variables were Gaussian. Priors were assumed to be multivariable Gaussians. Therefore, if for any reason they were not multivariable, these priors would not be properly supported by the training data. This will have a major impact when these variables are included in the correlation matrix. To identify whether this is the case, we studied the correlations of the independent variables of Eq. 1, as we did for Table A.3, but using the Pearson coefficient. This coefficient is based on the assumption of Gaussian correlations, whereas the Spearman coefficient is not. Any significant difference between these two coefficients is an indicator of a non-Gaussian correlation. Comparing Tables A.3 and A.5, we find that the differences are lower than 30% in general. Only the case of the correlation between age and log g presents a difference of 128%. This points to this correlation as the responsible of the differences found when including or excluding log g in the correlation matrix. This inconsistency is not highly critical for field stars, where ages and log g are mixed and the low correlation between them has a low impact. In the case of stars in clusters, however, when age is the same for all the members, this inconsistency is enhanced because the Gaussian model inferred from the model is far from the real distribution. As a conclusion, we can say that not including log g in this matrix does not solve the problem of the inconsistency of the non-Gaussian correlations, but simplifies the model assuming log g is not correlated to the remaining independent variables (which is a reasonable approximation). This is better than inferring an incorrect correlation. We therefore decided to use the model with log g out of the correlation matrix.
Pearson coefficient for the correlation between the different independent variables of Eq. 1.
All Tables
Physical characteristics of the first set of testing stars 23 stars with ‘reliable’ ages.
Summary of the general results obtained with our HBM in comparison to the test ages for all the testing sets. MD accounts for the mean differences, SD for the standard deviation of these differences, and MAD for the mean absolute differences.
Statistical results in the case of using all sampling points for the age estimates, to be compared with Table 3.
Spearman coefficient for the correlation between the different independent variables of Eq. 1.
Statistical results in the case of including log g in the correlation matrix for the age estimates, to be compared with Table 3.
Pearson coefficient for the correlation between the different independent variables of Eq. 1.
All Figures
|
Fig. 1. Logical structure of the hierarchical Bayesian model we trained for this study. See text for details. |
| In the text | |
|
Fig. 2. Histograms for Teff, log g, [Fe/H], and age of the testing (red) and training samples (blue). |
| In the text | |
|
Fig. 3. Age predictions for the 23 stars with ‘reliable’ ages (test ages) using our HBM. The black line represents the one-to-one relation to guide the eye. |
| In the text | |
|
Fig. 4. Age predictions for the 79 stars from Spina et al. (2018) (test ages) using our HBM. The black line represents the one-to-one relation to guide the eye. |
| In the text | |
|
Fig. 5. Age predictions for ten Gaia benchmark stars (test ages are taken from Sahlholdt et al. 2019) using our HBM. The black line represents the one-to-one relation to guide the eye. |
| In the text | |
 |
Fig. 6. Age predictions for the stars studied in Sects. 5.1–5.3 using our HBM. |
| In the text | |
|
Fig. 7. Boxplots of the estimated age distribution for the clusters under study using our HBM. The red dots represent the literature ages of the clusters, and the blue dots show the mean ages we obtained. |
| In the text | |
|
Fig. 8. Histogram of the differences between the ages estimated by our model and the ‘test’ ages for the 215 stars of out testing set. |
| In the text | |
|
Fig. 9. Position of the CCs of τ Cet in the CCs vs. age diagrams. Red dots are the CCs of this star. Black dots are the CCs of the training sample. The black cross represents the mean 1σ uncertainty of the training sample. |
| In the text | |
|
Fig. 10. CCs of the stars belonging the open cluster Ruprecht 147. The red points represent the outlier found in Fig. 8 for this open cluster. The x-axis represents the star ID of our sample. The red point corresponds to the star Gaia DR2 4087853875535923200. |
| In the text | |
|
Fig. 11. Input variables of ϵ Eri. The red points represent the values for this star. The black points show the corresponding values of our training sample. The black cross represents the mean 1σ uncertainty of the training sample. |
| In the text | |
|
Fig. 12. Accuracy of our predictions (observed – estimated age) vs. the standard deviation of the ten realisations. The 1σ uncertainty (precision) is shown in colour. |
| In the text | |
|
Fig. 13. Age predictions for the stars studied in Sects. 5.1–5.3 using our HBM with only CCs and [Fe/H]. |
| In the text | |
|
Fig. A.1. Posterior distribution of the coefficients of Eq. 1 in the case of the CC [Y/Mg]. Var 1 to Var 5 correspond to k1 to k5 in this equation. |
| In the text | |
|
Fig. A.2. Boxplot of the age estimates obtained for all the stars in clusters performed with log g in the correlation matrix (blue) and out of the correlation matrix (red). Brown points represent the accepted age of each cluster. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.