| Issue |
A&A
Volume 658, February 2022
|
|
|---|---|---|
| Article Number | A125 | |
| Number of page(s) | 18 | |
| Section | Stellar structure and evolution | |
| DOI | https://doi.org/10.1051/0004-6361/202141536 | |
| Published online | 11 February 2022 | |
Bonn Optimized Stellar Tracks (BoOST)
Simulated populations of massive and very massive stars for astrophysical applications⋆
1
Institute of Astronomy, Faculty of Physics, Astronomy and Informatics, Nicolaus Copernicus University, Grudzidzka 5, 87-100 Toruń, Poland
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
I. Physikalisches Institut, Universität zu Köln, Zülpicher-Strasse 77, 50937 Cologne, Germany
3
Center for Astrophysics and Supercomputing, Swinburne University of Technology, Hawthorn, Victoria 3122, Australia
4
OzGrav: The ARC Center of Excellence for Gravitational Wave Discovery, Hawthorn, Australia
5
McWilliams Center for Cosmology, Department of Physics, Carnegie Mellon University, Pittsburgh, PA 15213, USA
6
Astronomical Institute of the Czech Academy of Sciences, Boční II 1401, 141 00 Prague 4, Czech Republic
7
Argelander-Institut für Astronomie der Universität Bonn, Auf dem Hügel 71, 53121 Bonn, Germany
Received:
14
June
2021
Accepted:
7
December
2021
Abstract
Massive and very massive stars can play important roles in stellar populations by ejecting strong stellar winds and exploding in energetic phenomena. It is therefore imperative that their behavior be properly accounted for in synthetic model populations. We present nine grids of stellar evolutionary model sequences, together with finely resolved interpolated sequences and synthetic populations, of stars with 9–500 M⊙ and with metallicities ranging from Galactic metallicity down to 1/250 Z⊙. The stellar models were computed with the Bonn evolutionary code with consistent physical ingredients, and covering core hydrogen- and core helium-burning phases. The interpolation and population synthesis were performed with our newly developed routine SYNSTARS. Eight of the grids represent slowly rotating massive stars with a normal or classical evolutionary path, while one grid represents fast-rotating, chemically homogeneously evolving models. The grids contain data on stellar wind properties such as estimated wind velocity and kinetic energy of the wind, as well as common stellar parameters such as mass, radius, surface temperature, luminosity, mass-loss rate, and surface abundances of 34 isotopes. We also provide estimates of the helium and carbon-oxygen core mass for calculating the mass of stellar remnants. The Bonn Optimized Stellar Tracks (BoOST) project is published as simple tables that include stellar models, interpolated tracks, and synthetic populations. Covering the broadest mass and metallicity range of any published massive star evolutionary model sets to date, BoOST is ideal for further scientific applications such as star formation studies in both low- and high-redshift galaxies.
Key words: stars: massive / stars: evolution / stars: formation / gravitational waves / stars: black holes / methods: numerical
The BoOST data (stellar model grids, interpolated tracks and synthetic populations) are all available online: http://boost.asu.cas.cz.
© D. Szécsi et al. 2022
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
1. Introduction
Stellar evolutionary model sequences provide the basis for several astrophysical investigations. These investigations include the simulation of galaxies close (e.g., Gatto et al. 2017) and far (e.g., Rosdahl et al. 2018), obtaining mass and age of observed stars (e.g., Schneider et al. 2014; Grin et al. 2017; Ramírez-Agudelo et al. 2017), studying the formation of ancient globular clusters (e.g., de Mink et al. 2009a; Szécsi & Wünsch 2019), and predicting the outcome of binary populations in terms of gravitational wave event rates (e.g., Kruckow et al. 2018). Because massive (> 9 M⊙) and very massive (> 100 M⊙) stars can play important roles in stellar populations by ejecting strong stellar winds and exploding in energetic phenomena, it is very important that their behaviour is properly accounted for in synthetic populations (Agrawal et al. 2020). For example if the early Universe is to be studied, very massive stars are key: the first few generations of galaxies at cosmic dawn might have formed them in larger numbers and with higher initial mass than what is typical today.
The Bonn code1 has been used in the past decades to compute stellar evolutionary model sequences with the most recent input physics. Amongst other things, it is especially suited to simulating massive stars due to the large nuclear reaction network and the high spacial resolution it applies. Stellar grids of massive stars with various chemical composition and various rotational properties have been created and analyzed (Yoon et al. 2006, 2012; Brott et al. 2011; Köhler et al. 2015; Szécsi et al. 2015), occasionally including detailed binary models (de Mink et al. 2009a,b; Yoon 2015).
Nonetheless, the models published so far can be further optimized. Consistency in the initial parameter space, as well as a reliable treatment of the late phases of evolution, is necessary in order to make these models applicable within a wide range of astrophysical studies. The Bonn code has been used to create and publish four grids of rotating single-star models. Their initial compositions correspond to the Milky Way (MW; Brott et al. 2011), the Large and Small Magellanic Clouds (LMC and SMC; Brott et al. 2011; Köhler et al. 2015), and the dwarf galaxy I Zwicky 18 (IZw18; Szécsi et al. 2015). In the current project, we extend the mass range of all published Bonn grids up to very massive stars. The metallicity range of the models is also extended down to the lowest metallicities observed in ancient globular clusters.
We publish stellar evolutionary model predictions as well as synthetic populations based on published and unpublished results of the Bonn code in a physically consistent way. That is, the Bonn Optimized Stellar Tracks (BoOST) project provides the following three types of published data:
(a) Grids: Nine grids of stellar models with initial masses of 9−500 M⊙ each. The metallicities of the grids are equally distributed between Galactic2 ([Fe/H] ≲ 0.0) and very low ([Fe/H] =–2.4) metallicities. These grids are in part based on published stellar models (MW, LMC, SMC, IZw18, and IZw18-CHE), while four new grids have been computed for the present work and cover various sub-SMC metallicities. These are typical for dwarf galaxies and the early Universe. The models have been post-processed into equivalent evolutionary phase format.
(b) Tracks: Interpolated sets of tracks3 corresponding to all nine grids, which can serve as the basis of synthetic stellar populations. We publish them as simple tables.
(c) Populations: After weighting the interpolated sets of tracks with a Salpeter initial mass function, the result are synthetic populations of massive and very massive stars for an instantaneous starburst episode at age 0. The total mass of the populations is set to 107 M⊙. The populations are published as tables, up to ∼25 Myr (when the 9 M⊙ stars die).
This is the first time that stellar evoluionary predictions for massive and very massive stars in such a broad metallicity range are published. The models in eight of the grids (a) have been computed with moderate rotation rates leading to normal or classical stellar evolution (i.e., initial rotational velocity of 100 km s−1 uniformly), while one of the grids corresponds to extreme rotation rates leading to chemically homogeneous evolution (CHE; initial rotational velocity of 500 km s−1). In addition to the usual surface properties (mass, temperature, luminosity, mass-loss rate, etc.), detailed information about the chemical composition (yields of 34 isotopes) and kinetic energy of the stellar winds is provided at various metallicities as a function of time. Additionally, estimates for the helium and carbon-oxygen core masses are provided to facilitate predictions for the mass of the remnant.
Moreover, we present the newly developed stellar population synthesis tool SYNSTARS, which performs spline-based interpolation on the precomputed stellar models based on the initial mass of the star. In addition to performing the interpolation, SYNSTARS also creates the time-dependent synthetic populations by weighting the tracks with a Salpeter initial mass function and integrating over the stellar feedback (total mass in the wind, total kinetic energy in the wind, etc.). To facilitate reproducibility, the current version of SYNSTARS is also available along with the model data.
With their broad range in mass and metallicity, the BoOST model populations are suitable for applications in star formation studies, for instance. They can also be used to simulate the formation and evolution of young clusters, dwarf galaxies, and high-redshift galaxies, where the feedback from massive stellar winds play a crucial and metallicity dependent, role.
This paper is organized as follows. In Sect. 2 we present nine grids of stellar models computed with the Bonn code. In Sect. 3.1 we describe how we identified the equivalent evolutionary phases (EEPs), while in Sects. 3.2 and 3.3, we present our new tool SYNSTARS and use it to interpolate between the stellar models and perform population synthesis. In Sect. 4 we discuss the models that did not converge due to numerical instabilities and our novel solution for including their contributions into the populations. In Sect. 5 we explain our method for defining the mass of the final stellar cores, which is a proxy for the mass of the compact object remnant. In Sect. 6 we discuss similarities to previous projects, suggest possible astrophysical applications, and describe future plans. In Sect. 7 we conclude.
2. Grids of stellar models
2.1. Physical ingredients
The BoOST project relies on stellar evolutionary models created with the Bonn code. Some of these models have been published earlier (Brott et al. 2011; Köhler et al. 2015 and Szécsi et al. 2015), but most are newly computed. A description of the input physics implemented in the version of the Bonn code we use here was given by Heger et al. (2000), Heger & Langer (2000), Petrovic et al. (2005), Brott et al. (2011), Yoon et al. (2012), Szécsi et al. (2015) and references therein. To summarize, the models follow the prescription from Vink et al. (2000) for hot wind-driven mass loss of OB stars and Nieuwenhuijzen & de Jager (1990) for cool dust-driven mass loss of supergiants. As for the naked helium star phase – i.e., Wolf–Rayet stars or Transparent Wind UV-Intense (TWUIN) stars; cf. Kubátová et al. 2019 –, they follow the rates from Hamann et al. (1995) reduced by a factor of ten (Yoon & Langer 2005). A metallicity dependence of ∼Z0.86 (Vink et al. 2001) was applied. Convective mixing was included based on the mixing-length theory approach (Böhm-Vitense 1958) with a mixing length parameter αMLT = 1.5. For convective overshooting, step overshooting was employed with a parameter αover = 0.335 as calibrated by Brott et al. (2011) for massive stars in the LMC. Convective boundaries were determined using the Ledoux criterion with a semiconvective mixing parameter of αsc = 1.0. Rotationally induced mixing of chemical elements was treated with an efficiency parameter fc = 0.0228 (Heger et al. 2000; Heger & Langer 2000, calibrated by Brott et al. 2011). Furthermore, transport of angular momentum by magnetic fields due to the Spruit–Taylor dynamo (Spruit 2002; Heger et al. 2005) was included.
Table 1 provides a summary of all the BoOST grids and their initial compositions. The already published and the newly created models were computed with the same version of the code, that is, the same input physics as above were applied consistently. As for the previous publications, Brott et al. (2011) published stellar models with an MW, LMC, and SMC composition between 9−60 M⊙. Köhler et al. (2015) extended the LMC grid with main-sequence models up to 500 M⊙. Szécsi et al. (2015) published models with the much lower IZw18 metallicity (corresponding to 0.1 × ZSMC) in the mass range of 9−300 M⊙, also on the main sequence. All other models, as well as the post-main-sequence phases when needed, were newly computed by us.
Nine BoOST grids published here, and their compositions in various units.
We consistently used the moderate initial rotational rate of 100 km s−1 because this rotational rate is representative of nonrotating or slowly rotating massive stars. Additionally, one of our grids was composed of chemically homogeneous models, which have a very fast initial rotation rate, 500 km s−1.
2.2. Design of the grids
To be able to create synthetic populations out of these models in a consistent way, we extended the parameter space. In particular, we (i) computed new models up to 500 M⊙ in all the grids, (ii) computed new grids for a good metallicity coverage with equal steps, and (iii) either simulated the post-main-sequence evolution or provided a reliable approximation for this phase. Thus we designed eight consistent grids with equal log-metallicity steps from Galactic down to the most metal-poor clusters observed. Additionally, (iv) we provide one grid with chemically homogeneous evolution.
Every grid contains ten stellar models, starting with 9 M⊙. We did not fix any consistent value for the mass steps between the ten models in the grids. Instead, their initial masses were chosen in a way that facilitated the best interpolation between them. For example, we ensured that we properly covered the part of the HR diagram in which the models show blue loops or luminous blue variable-type features. Indeed, because these effects are highly metallicity dependent, the design of the grids was kept flexible in terms of the mass step, so that abrupt changes in the models were followed properly.
(i) New models up to 500 M⊙. We extended the published grids (MW, LMC, SMC, and IZw18) with very massive models (up to around 500 M⊙). For consistency, all these new models also had an initial rotational rate of 100 km s−1, and all their physical ingredients were the same as in the published models. The only two exceptions were the models with 250 and 500 M⊙ at MW metallicity, for which the initial rotational rate was set to 0 km s−1 for convenience. We find that this does not make any practical difference in the evolution: at this mass and metallicity, mass loss is so strong already at the beginning of the main sequence that these stars would spin down very soon in any case.
(ii) New grids for a good metallicity coverage. We present here four new grids (cf. Table 1). Two of them were designed so that the metallicity gap between SMC and IZw18 is filled. The other two belong to metallicities below IZw18, down to 1/250th ZMW. Because these metallicities are typical of star-forming dwarf galaxies, we call these grids dwarfA, dwarfB, dwarfD, and dwarfE (dwarfC is consistent with the IZw18 grid). With these, our models allow studying the formation of even the lowest-metallicity globular clusters (with [Fe/H] ∼ −2.3).
(iii) Late phases of evolution. Most of the models in this work were computed with the Bonn code until core-helium exhaustion. In some cases, however, this was not possible due to numerical reasons. High-metallicity models above ∼40 or 60 M⊙ and lower-metallicity models above ∼100 M⊙ have inflated envelopes, and in this state, the computations become numerically challenging4. It is difficult to ensure that all our models completely include the post-main-sequence phase (i.e., core-helium-burning). Here we offer a new solution that is described in Sect. 4. With this new method, we approximate for the remaining evolution, completing the last phases of our stars.
(iv) Models with chemically homogeneous evolution. We provide one grid of fast-rotating, chemically homogeneously evolving models with [Fe/H] = −1.7 called IZw18-CHE. In this grid, the initial composition of the models is the same as in the IZw18 grid, but the initial rotational velocity is 500 km s−1 (except in the case of the 9 M⊙ model, where it is somewhat lower, 450 km s−1, to avoid reaching critical rotation). The main-sequence phase of these models (up to 300 M⊙) was published and analyzed by Szécsi et al. (2015), and their atmospheres were studied by Kubátová et al. (2019). Here we complete this grid with two new very massive models (388 M⊙ and 575 M⊙) as well as the post-main-sequence phase of all of the models (computed properly for almost all of them, except for the highest mass, where we had to include the remaining phases in an approximate way; cf. Sect. 4).
We only included core hydrogen- and core helium-burning in our published stellar models. This is justified by the fact that core carbon-burning and subsequent burning phases constitute only ≲1% of a massive star’s life, during which no significant contribution to stellar feedback is expected (except for the supernova explosion; cf. Sect. 5). For example, by simulating the core carbon-burning phase of the 26 M⊙ model in our IZw18 grid, we find that this lasts for ∼7300 years, which is a mere 0.12% of the total 6.21 Myr lifetime of the model. The mass that is lost during this time is about 0.02 M⊙, which is an order of magnitude less than what is lost during the whole evolution. Because some of our models experience numerical difficulties in their late phases in any case (we approximate for them in Sect. 4), omitting carbon-burning and beyond from the present version of BoOST is not expected to cause additional discrepancies in our simulated populations from the point of view of stellar feedback and wind properties.
We publish the stellar model grids as simple tables. They include the following quantities as functions of time (cf. also the Readme file attached to the table, as well as Appendix A): the stellar mass, M as a function of time, the effective temperature of the surface, Teff, the bolometric luminosity, Lbol, the stellar radius, R, the mass loss, Ṁ, the logarithm of the surface gravity, log(g), the rotation velocity at the surface at the equator, vsurf, the critical rotation velocity, vcrit, the Eddington factor, Γ, and abundances of 34 isotopes at both the stellar surface and in the center of the star, as listed below. Additionally, the mass of the final He core and CO core are included as a proxy for the mass of the compact object remnant (cf. Sect. 5).
The Bonn code simulates nuclear reaction networks for the following 34 isotopes: 1H, 2H, 3He, 4He, 6Li, 7Li, 7Be, 9Be, 8B, 10B, 11B, 11C, 12C, 13C, 12N, 14N, 15N, 16O, 17O, 18O, 19F, 20Ne, 21Ne, 22Ne, 23Na, 24Mg, 25Mg, 26Mg, 26Al, 27Al, 28Si, 29Si, 30Si, and 56Fe. They are all included in the published tables.
2.3. HR diagrams
Hertzsprung–Russell diagrams of all the BoOST stellar models are shown in Fig. 1. Additionally, Figs. 2–4 present various diagnostic diagrams showing important properties of stellar feedback such as mass-loss rate, wind velocity, and kinetic energy of the winds. As expected, both the zero-age main sequence and the supergiant branch shift to higher effective temperatures when the metallicity is lower due to the lower opacities. Furthermore, there are two features that gradually change from high to low metallicity: very luminous supergiants at high masses, and blue supergiants at lower masses (in the blue loop of the evolutionary models).
 |
Fig. 1. Hertzsprung–Russell diagrams. Initial mass is color-coded (between 9 and ∼500 M⊙); dots mark every 105 yr of evolution along the stellar models. Dashed black lines represent interpolated tracks (up to 500 M⊙); brown crosses mark the phases in which the direct extension method (Sect. 4) has been applied. For details about the models and their postprocessing, see Sects. 2 and 4, respectively, and for details about the interpolated tracks, see Sect. 3. |
 |
Fig. 2. Time evolution of the mass-loss rate. The initial mass is color-coded (between 9 and ∼500 M⊙). The dashed black lines represent interpolated tracks (up to 500 M⊙); cf. Fig. 1.. While here only shown until 10 Myr, the files published in the BoOST project contain data until the end of the lifetimes of the longest-living model in the population (∼30 Myr). |
 |
Fig. 3. Time evolution of the escape velocity; cf. Eq. (1). The initial mass is color-coded (between 9 and ∼500 M⊙). The dashed black lines represent interpolated tracks (up to 500 M⊙); cf. Figs. 1 and 2. While here only shown until 10 Myr, the files published in the BoOST project contain data until the end of the lifetimes of the longest-living model in the population (∼30 Myr). |
 |
Fig. 4. Time evolution of the wind kinetic energy rate. The initial mass is color-coded (between 9 and ∼500 M⊙). The dashed black lines represent interpolated tracks (up to 500 M⊙); cf. Figs. 1–3. While here only shown until 10 Myr, the files published in the BoOST project contain data until the end of the lifetimes of the longest-living model in the population (∼30 Myr). |
The luminous supergiants are the natural result of envelope inflation in these massive stars. As explained by Sanyal et al. (2015), for example, in stellar models close to the Eddington limit (Langer 1997), density and pressure-inversion regions can develop in the outer regions. In the absence of any user intervention (cf. the discussion in Sect. 4.1), the code deals with this by increasing the physical extent of the star, that is, by inflating the envelope and thus producing luminous supergiants (cf. also Sect. 5 of Szécsi et al. 2015 as well as Sanyal et al. 2017). These special supergiants have been shown to possibly contribute to the formation of globular clusters (in two different scenarios, the first presented by Szécsi et al. 2018 and the second in Szécsi & Wünsch 2019). Thus, with the metallicity coverage the BoOST grids provide, the door opens to studying the role of these supergiants in cluster and star formation research and beyond.
The blue loop is known to be sensitive to any change in physical parameters during the evolution. For example, Schootemeijer et al. (2019) presented stellar models with an SMC composition between 9−100 M⊙ using various semiconvective and overshooting parameters. They showed that the presence or absence of blue loops depends on these parameters, as well as on the applied rotational velocity. In short, the phenomenon was found to be tightly linked to internal mixing. They did not study the effect of metallicity, but our models show that this influences blue loops as well. With both semiconvection and overshooting fixed (αsc = 1.0 and αover = 0.335; cf. Sect. 2.1), and with the same initial rotational velocity chosen for all the models (100 km s−1), we find no blue loops at metallicities above that of the SMC (consistent with Schootemeijer et al. 2019), while with decreasing metallicity, the feature becomes increasingly prominent. This may provide a way to improve our models in the future: because blue supergiants are observed in the SMC (Humphreys et al. 1991; Kalari et al. 2018), a next version of the BoOST grids, for example, may be computed with testing a higher semiconvective parameter.
3. Interpolation and population synthesis: Presenting SYNSTARS
We have developed the simple stellar population synthesis code SYNSTARS written in Python with libraries NUMPY (Oliphant 2006) and SCIPY (Virtanen et al. 2020). In addition to the actual population synthesis (to be discussed in Sect. 3.3), SYNSTARS is also able to interpolate between our precomputed stellar models (those presented in Sect. 2). Below we describe how the interpolation of the tracks is implemented (including preprocessing in Sect. 3.1) and what the published tables contain in Sect. 3.2.
3.1. Finding equivalent evolutionary phases
A stellar population consists of stars of varying initial masses. To construct them, we interpolate between the precomputed stellar models from Sect. 2. During the process, it is important to ensure that the resulting set of interpolated tracks shows only gradual changes. However, the evolutionary models of stars vary significantly between non-neighboring masses, especially within the wide mass range covered in this project. For example, a star with 9 M⊙ has a different evolutionary path in the HR diagram from a star with 60 M⊙ or from a star with 500 M⊙. To correctly interpolate the evolutionary sequence of a star using sequences of neighboring masses, it is thus common to determine EEPs (Prather 1976; Bergbusch & Vandenberg 1992, 2001; Pietrinferni et al. 2004) between stellar models. EEPs are identified by using evolutionary features that occur across the range of stellar tracks, such as the amount of hydrogen burned in the core, and they represent different phases during the evolution of a star.
For our models we identified seven EEPs (labeled A to G). Each EEP was further subdivided into an equal number of points, so that each phase of stellar evolution was represented by a fixed number of points (i.e., lines in the data file) to ensure that the nth point in one model has a comparable interpretation in another model. The seven EEPs for different stellar models are shown in Figs. 5–7. The method of identifying these EEPs is explained below.
 |
Fig. 5. Position of EEPs (i.e., fixed points in evolution) during the lifetime of some typical models. Colored lines represent the original output of our computations with the Bonn code, and black lines and crosses mark the filtered version (consistently containing the same number of dots between EEPs). The seven EEPs are labeled A–G; our method of choosing them is explained in the text. |
 |
Fig. 6. Same as Fig. 5 but for a model with prominent blue loop (without a starting point in the red supergiant branch, left) and one with inflated envelope (right). For more details on the latter, which is a core-hydrogen-burning supergiant, we refer to e.g. Sanyal et al. (2015, 2017), Szécsi et al. (2015, 2018), Szécsi & Wünsch (2019). |
 |
Fig. 7. Same as Fig. 5 but for models that show features associated with a luminous blue variable phase before becoming Wolf-Rayet stars. In both cases, we use our newly developed method for a direct extension in the post-main-sequence phase (that is, removing mass layers one by one from the last computed model’s envelope and correcting for the values of the surface properties, as explained in Sect. 4). Red line marks this phase of stellar life. |
The first EEP (A) is the zero-age main sequence (excluding the initial hook phase caused by hydrogen ignition). The second EEP (B) is the local minimum of the mass-loss rate corresponding to the bistability jump, that is, when it occurs during the main sequence. If the local minimum of the mass-loss rate occurs after the main sequence ends, we chose the second EEP simply to be at about three-fourths of the main-sequence lifetime. Assigning our second EEP to the local minimum of the mass-loss rate ensures that the interpolation behaves nicely at quick changes in mass loss, which is an important requirement when these models are to be applied to studying their feedback on star formation.
The third EEP (C) is the tip of the hook at the end of the main sequence. However, for very massive stars, this hook is not visible; in this case, we simply chose a point close to core hydrogen-exhaustion. The fourth EEP (D) is the bottom of the red supergiant branch where the luminosity has a local minimum. If this was not visible, for instane, in the case of an extreme blue loop without a base at the red supergiant branch, a point in the middle of the loop blueward progression was chosen. Some examples are shown in Fig. 6.
The fifth EEP (E) is the middle of the helium-burning phase. It corresponds to the hottest point of the blue loop if there is one, otherwise, YC ∼ 0.5. The sixth EEP (F) is chosen near the end of core helium-burning when the model has a small dip in luminosity. If this was not visible, we chose a point at around YC ∼ 0.1. The seventh EEP (G) is the end of the helium-burning phase where YC = 0.0, and we did not include carbon burning in our models.
For the most massive models at high metallicities, we chose the EEPs to be equally distributed in time during the luminous blue variable phase because these stars have no systematically recognizable surface features except for their extremely strong winds. Some examples are shown in Fig. 7.
The precomputed stellar evolutionary models were filtered so that the published files are in EEP format. To choose the number of points between each EEP, we followed the convention established by Choi et al. (2016). Our EEPs occur at lines 1, 151, 252, 403, 429, 505, and 608 for each stellar track. We did not include the pre-main-sequence phase of stars in our models: all models start their evolution at the zero-age main sequence. Consequently, BoOST models have 200 fewer lines than those in Choi et al. (2016). The simulation of the pre-main-sequence phase for these very massive stars is hardly physical because a clear picture of how they form in reality is still lacking. Thus, following a pre-main-sequence path that imitates the behavior of low-mass stars on the pre-main-sequence is not more realistic than starting out with a homogeneous zero-age main-sequence model and evolving the star from there on, as we did.
3.2. Interpolation with SYNSTARS
The precomputed and EEP-filtered stellar models were read in by SYNSTARS for each model characterized by its initial mass, M0. Several additional quantities were calculated by SYNSTARS, namely, the velocity of the stellar wind, vwind, was determined with the procedure suggested by Lamers & Cassinelli (1999) and Vink et al. (2001) following from the theory of line-driven winds,
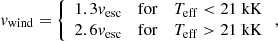 (1)
(1)
where vesc = (2GM/R)(1/2) is the escape velocity from the stellar surface and G is the constant of gravity. Additionally, following Leitherer et al. (1992), for instance, the wind velocity was corrected for the metallicity of the wind material, Z, by multiplying it by a factor (Z/Z⊙)0.13. Furthermore, the wind power was given by 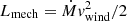 .
.
Interpolated tracks with M0 between the EEP-filtered models were then calculated with SYNSTARS. The interpolation was performed separately for the stellar age, t, and for all the other quantities, using the SCIPY function INTERPOLATEDUNIVARIATESPLINE implementing the spline interpolation method of a given order. The stellar age, t(M0), was interpolated in the log(t)−log(M0) space using splines of the second order by default. This default can be changed by the user; however, we found while testing various choices that the first-order interpolation can lead to unphysical discontinuities in quantities integrated over the stellar population (cf. Cerviño et al. 2001, who documented a similar effect). All the other quantities, Q(M0), were also interpolated in the log(Q)−log(M0) space, but the default order for them is 1, that is, the interpolation is linear, to avoid errors due to overshooting for quantities that change abruptly (e.g., abundances).
The interpolated tracks computed with SYNSTARS are presented in Fig. 1 in the HR-diagram, and in Figs. 2–4 in terms of mass-loss rate, wind velocity, and kinetic energy deposition rate of the wind. As these quantities are typically needed to study stellar feedback in star formation, we especially ensured that they did not include any numerical artifacts.
We used only the initial mass as the basis for the interpolation. In some of the grids we used stellar models with 560 or 575 M⊙ as the highest mass (cf. Sect. 2.2), but still took the upper limit Mtop = 500 M⊙ for the interpolated set of tracks to be consistent.
We tested the validity of our interpolation method by comparing interpolated tracks and their corresponding original models in Fig. 8. The largest difference in terms of surface temperature is 0.47 dex, and in terms of luminosity, the difference is 0.08 dex, meaning that the interpolated tracks match the original models well within the error margins of massive star evolution.
 |
Fig. 8. Validating the interpolation. Colored lines represent the original stellar models (IZw18 grid), dotted black lines represent the interpolated tracks created by removing the corresponding original while performing these test interpolations. See also Sect. 3.2. |
We publish the interpolated (synthetic) tracks as one large data table per grid. These files contain 1856 records between 9 M⊙ and 498.4 M⊙, equally distributed in log(M0), all having 608 lines. (Figures 1–4 only show every 50th interpolated track for clarity.) Thus, the size of this data file is about 800 MB. Tracks are marked by their initial mass values before their record starts (in M⊙ and in cgs units). The following columns are provided (cf. the Readme file next to the published tables): initial mass, time, actual mass, wind velocity, kinetic energy generation rate of the wind, luminosity, radius, effective temperature, mask, type of interpolation, surface rotational velocity, critical rotational velocity, Eddington factor, flag marking whether the phase includes the direct extension method of Sect. 4 or not, helium-core mass, carbon-oxygen core mass, and surface mass fraction of the same 34 isotopes as in the original stellar models.
3.3. Synthetic populations
Synthetic populations of single massive and very massive stars are also computed with SYNSTARS based on the interpolated tracks. The population data we publish here represent massive star clusters with a total mass of 107 M⊙ that were formed as the result of a single, burst-like star formation event in which the initial mass function follows a classical Salpeter distribution (with an upper mass limit of 500 M⊙). The evolution of these populations is presented in the data files with equal time-steps up to ∼25 Myr, that is, when the life of the longer-living star of our models (the star with 9 M⊙) ends. After this, such a cluster will only contain stars below 9 M⊙, the contribution of which to feedback processes can typically be neglected. In addition, the compact object remnants of the dead massive stars are also expected to still be within the cluster (see Sect. 5, and we note that remnant types are not specifically listed in the published tables, only final core masses are).
The current version of SYNSTARS is attached to the published data. Thus if needed, the user can feed the precomputed stellar grids to it and create their own interpolated tracks or their own synthetic populations. For example, the interpolated tracks and populations computed here have an upper mass of 500 M⊙, but the user may need populations with an upper mass limit that is lower than this. Thus they can create their own synthetic population with 150 or 250 M⊙ as an upper mass, for example, and even change the index of the mass function and the total mass of the stellar cluster. (For the highest mass achievable with SYNSTARS, see the precomputed models with the highest mass in the grids, Sect. 2.2.) A typical run of SYNSTARS creating thousands of tracks takes a few minutes on a normal workstation.
Alternatively, the user may wish to use their own population synthesis tool. This is also a possibility because one of the outputs of SYNSTARS is the set of interpolated stellar tracks, and their resolution (bin size) can be defined simply as a command line input. These interpolated tracks can then be fed into any population synthesis code, thus providing great flexibility for the user.
In the synthetic population data files created by SYNSTARS (not the same as the interpolated track data tables), the following quantities are given as a function of time (also see the Readme file attached to the tables): mass lost from stars in the form of fast stellar wind (i.e., faster than 100 km s−1), mass lost from stars in the form of slow stellar wind (i.e., slower than 100 km s−1), kinetic energy in the fast winds, integrated bolometric luminosity, integrated UV flux (including corrections for optically thick stellar winds, following the method presented in Szécsi 2016, cf., Chapt. 4.5.1), time-integrated values of Ṁ and Ė, that is, the total mass and mechanical energy produced (in the form of winds and their power) by the all stars up to a given time, as well as the mass fraction of all 34 isotopes in the wind (i.e., integrated over the population).
3.4. Red supergiant luminosity histogram
To test our stellar populations against observations, we created a luminosity histogram as in Neugent et al. (2020). Our results are shown in Fig. 9 for an MW composition, to be compared with two sets of super-solar M31 observations (Neugent et al. 2020; Massey et al. 2021). Following the method presented in Neugent et al. (2020, see their Fig. 11c), we normalized the number of red supergiant stars in our theoretical sample to 1000. We defined red supergiants as log Teff < 3.7 (Neugent 2021, priv. comm.).
 |
Fig. 9. Luminosity histogram of our BoOST models with an MW composition (yellow). The original is taken from Neugent et al. (2020), including M31 observations (black) and theoretical predictions from the Geneva (green) and BPASS stellar models (red and blue) for solar metallicity. An even larger and more recent dataset of M31 observations from Massey et al. (2021) is overplotted (violet). Our MW population follows the observed luminosity histograms as closely as the Geneva and BPASS stellar models. See Sect. 3.4 for further details. |
As Fig. 9 attests, our models reproduce the observations of red supergiant luminosities as closely as other published sets of stellar models. Because we worked only with massive stars, our stellar models have a lower mass limit at 9 M⊙, meaning that our data do not contain any assymptotic giant branch stars. Therefore our theoretical histogram does not reach below L ∼ 4.2.
4. Numerically problematic late phases of stellar evolution
4.1. Role of the Eddington limit
The maximum luminosity that can be transported by radiation while maintaining hydrostatic equilibrium is called the Eddington luminosity (Eddington 1926). However, in the envelopes of massive stars, where the density is low, changes in the elemental opacities can cause the local radiative luminosity to exceed this Eddington luminosity (Langer 1997; Sanyal et al. 2015). To maintain hydrostatic equilibrium, density and pressure inversions develop in such envelopes. In the absence of efficient convection (which is also typical for the low-density envelopes of massive stars, Grassitelli et al. 2016), this can lead to numerical difficulties in 1D stellar evolution codes (Paxton et al. 2013), meaning in practice that the time-steps become exceedingly small, preventing further computation of the model. While less massive and less metal-rich stars are only affected by this issue in their late evolutionary phases, more massive and high-metallicity stars (at ≳40 M⊙ for solar composition) can exceed the Eddington limit inside their envelopes already during the core hydrogen-burning phase (Gräfener et al. 2012; Sanyal et al. 2015).
Stellar evolution codes employ pragmatic solutions to avoid or overcome the above-mentioned numerical difficulties (Agrawal et al. 2021b). For example, in the PARSEC stellar models, an artificial limit is set for the temperature gradient (see Sect. 2.4 of Chen et al. 2015, as well as Alongi et al. 1993), which ensures that the density gradient never becomes negative and thus inefficient convection is prevented. Additionally, a mass-loss enhancement following (Vink et al. 2011) is applied whenever the total luminosity of the star approaches the Eddington luminosity. On the other hand, in the MIST stellar models (Choi et al. 2016) computed with the MESA code (Paxton et al. 2013), density inversions are suppressed through the MLT++ formalism: the actual temperature gradient is artificially reduced to make it closer to the adiabatic temperature gradient whenever the radiative luminosity exceeds the Eddington luminosity above a predefined threshold. Radiative pressure at the surface of the star is also enhanced. This approach again increases the convective efficiency, helping the stars to overcome density inversions. Yet another pragmatic solution is employed in the GENEVA models (see Sect. 2.3 of Ekström et al. 2012): the mixing length is set to be comparable with the density scale height, which helps avoid density inversions (Nishida & Schindler 1967; Maeder 1987), while the mass-loss rates are increased by a factor of three whenever the local luminosity in any of the layers of the envelope is higher than five times the local Eddington luminosity.
Most of the stellar models in this work are not effected by the above-mentioned numerical difficulties, and are thus computed with the Bonn code without interruption until their core helium is exhausted. However, the very massive high-metallicity models do develop density inversion regions due to their proximity to the Eddington limit. Instead of artificially avoiding or surpassing these density inversions, we employed another solution.
4.2. Another solution: Inflated envelopes and the direct extension method
If the density and pressure inversions are not avoided in some pragmatic way (as above), the envelope grows (or inflates, Gräfener et al. 2012; Sanyal et al. 2015, 2017), and the star may become a core hydrogen-burning cool supergiant (cf. Sect. 5 of Szécsi et al. 2015). These cool supergiants might explain globular cluster formation (Szécsi et al. 2018; Szécsi & Wünsch 2019). Because we wish our models to be applicable in this field of research, and because for these masses, the available observational constraints cannot exclude the existence of stars with such inflated envelopes, we continue the approach of the previously published Bonn models, and let the envelope of all our stars inflate as well. This makes our BoOST models special amongst other stellar evolutionary models, but it comes at a cost.
In some models (those with very high mass and high metallicity), the time-steps become exceedingly small and the computation is halted before the end of core helium-burning is reached. These models need to be further treated in postprocessing (we call this the direct extension method, see below), to make them ready to still serve as a proxy for the chemical yields and radiation of the remaining lifetimes. In terms of stellar populations, the missing phases comprise less than 3% of the stellar lifetimes because the Eddington-limit proximity only influences the most massive models, which live shorter lives. Moreover, the lower the metallicity, the less relevant this effect: for example, in our lowest metallicity grid called dwarfE, all the models, even the inflated ones, are properly computed until the end. In Fig. 1, crosses mark the models that were postprocessed with the direct extension method, and the tables in Appendix B.2 provide some quantitative summary. Eight of the 90 models have evolved past the end of the main sequence, but stopped short of completing core helium-burning, and 27 of the models stopped at the end of the main sequence. These are therefore the models for which we developed the method below. The remaining 58 models are complete.
4.3. The method
A 1D stellar evolutionary model sequence consists of consecutive stellar models (structure models, or profiles) belonging to a certain age. One such structure model consists of about 1500 grid points (layers) between the core and the surface. For every layer, physical variables such as local temperature and density are computed in the code, including the chemical composition of the layer. When the computation was halted due to the above-mentioned numerical difficulties, we postprocessed the data by removing mass from the surface layer by layer from the last computed structure model. This approach allows us to predict the composition of the material ejected by the stellar winds even during the phases for which the code did not converge.
We continued to remove layers until the projected lifetime of the star ended. The projected lifetime was estimated as follows. If the model had already burned away at least 2% of helium when the simulation stopped, the remaining lifetime was calculated by linearly extrapolating the central helium abundance as a function of time until it reached zero. If the model had not burned that much helium, but stopped before this (e.g., at the terminal-age main sequence), the remaining lifetime was simply defined as 10% of the main-sequence lifetime. In five cases (cf. Table B.2) was the terminal-age main sequence not reached: here first we established the projected main-sequence lifetime by quadratically extrapolating the central helium mass fraction as a function of time, and then again assumed that the post-main sequence lasts for 10% as long as the main sequence. We ensured that the whole process, including the quadratic extrapolation, provided a good estimation for the projected lifetimes by testing it on existing models. For stars that lose much mass, however, the process may only provide a lower limit because the lifetime of stars is inversely proportional to the actual mass.
Mass-loss rates. During the direct extension phase, the same mass-loss rate prescriptions were applied as in the stellar evolution code. Namely, Nieuwenhuijzen & de Jager (1990) rates were applied for supergiants with Teff < 22 500 and Xsurf > 0.45, and Hamann et al. (1995) scaled by ten (which is consistent with Nugis & Lamers 2000 and is representative of Wolf–Rayet stars) otherwise. In both cases, a metallicity dependence of ∼Z0.86 was included, following Vink et al. (2001).
HR diagram and radius. If mass layers are removed from a stellar model, this is expected to change the stellar structure and thus influence surface temperature and luminosity, and hence not only the radius of the star, but also the total ionizing radiation, which is important for stellar feedback predictions. We accounted for this by causing these quantities to transition towards the so-called helium zero-age main sequence (helium ZAMS, cf. Appendix B.1) in the HR diagram. To achieve smoothness, we took the surface temperature and the surface luminosity to be log-linear functions of the surface helium mass fraction. The stellar radius was calculated from these according to the Stefan-Boltzmann law. When a layer was removed, the helium mass fraction of the next layer was used as a weight to find the new surface temperature and luminosity values between the old ones and those of the helium ZAMS given the new total mass of the star. In this way, the stellar models in the HR diagram converged smoothly and directly towards the helium ZAMS while losing mass from the surface layers. Examples are shown in Fig. 7 and Fig. 10.
 |
Fig. 10. Example of the results of the direct extension method (Sect. 4). The complete evolution of five stellar models (see the key legend) is plotted. The direct extension phase (typically lasting for 9% of the lifetime of these particular models) is marked with red in four of them (MW, LMC, SMC, and dwarfD); the fifth model (dwarfE) was properly computed without interruption, and is shown here as reference. During the direct extension phase, the models converge to their corresponding helium ZAMS position while loosing mass from their surface layers (cf. Sect. 4.3). Helium ZAMS positions in the HR diagram are shown for MW, LMC, and SMC compositions. The details of constructing these lines are given in Appendix B.1. Numbering indicates stellar masses (in M⊙). |
4.4. Caveats
Numerical difficulties in stellar modeling are a known issue (Aarseth et al. 2008); we have summarized some of the solutions offered by modelers in Sect. 4.1. The common feature of all these solutions is that they are pragmatic: technical maneuvers usually need to be employed for models to evolve without interruption. In the absence of a homogeneous sample of massive stars observed through various metallicities and various evolutionary phases, based on which 1D stellar evolutionary models could be constrained, none of the solutions can be established as preferable over the others. Our solution, in which the inflated envelope develops and the remaining life is continued by carefully postprocessing the models when numerical issues are encountered, is just one possible way to solve the common issue in stellar evolution modeling pragmatically. The inflated-envelope phase has special astrophysical applications (Moriya & Langer 2015; Szécsi et al. 2015, 2018; Szécsi & Wünsch 2019) that make our BoOST models especially useful in globular cluster research, for example.
While our direct extension method is quite robust and provides an acceptable approximation for the late phases of very massive stars, there necessarily are some caveats. Removing layers from the last computed structure model involves the assumption that no more mixing occurs during the remaining lifetime. This may not be true. The evolution of stars near the Eddington limit is unclear, and the projected lifetimes ignore remaining changes in the model until the end of helium burning. As no nuclear reactions are simulated for this phase, the central quantities in our output files are simply kept the same as in the last simulated structure model. We add a flag to all our published tables to indicate when this is the case. All these caveats should be kept in mind when using BoOST populations.
Helium stars are expected to evolve away from the helium ZAMS during their nuclear burning lifetime. In the absence of properly computed helium star evolutionary models in a sufficiently wide mass range (as explained in Appendix B.1), we approximate the post-main-sequence position of our helium stars simply by the helium ZAMS position. This is still within the error bars of massive star physics. In other words, the fact that the mass-loss rates of these stars so unconstrained, for example, introduces a larger uncertainty in any grid of stellar models than our simple treatment of the direct extension towards the helium ZAMS.
We emphasize that the direct extension method did not need to be applied for most of the published data (in terms of stellar lifetimes, > 97% of the published data are properly computed with the code; also cf. Fig. 1, where crosses indicate when the method is applied). Even at high metallicities, only the latest phases of the tracks are influenced; and at low metallicies, we hardly had to apply it at all, as shown by the tables in Appendix B.2. The reason for this is that envelope inflation starts at higher masses when the metallicity is low (Sanyal et al. 2017). In our lowest-metallicity grid with 1/250 ZMW, even the highest-mass star of 560 M⊙ is computed with the Bonn code without any numerical issues until the end of core-helium exhaustion, making the grid called dwarfE perfectly complete; and for applications in which the upper mass in the population is chosen to be 150 M⊙, the IZw18 grid can be used without problem as well because up to this mass, it is not influenced by the DEM treatment.
5. Final-fate predictions
5.1. Final core-mass estimates
The core mass of a pre-supernova star before the collapse (defined either as the helium-rich or the carbon-oxygen-rich central region) is often used as an estimated upper limit for the mass of the compact remnant (Belczynski et al. 2002, 2008; Fryer et al. 2012). While our modeling stops before carbon burning begins, we provide a proxy for these pre-supernova core-mass values based on the status of the model at the end of core-helium burning. Our models develop a carbon- and oxygen-rich core in this phase already because helium mainly burns into carbon and oxygen. We define the He core mass to be the mass coordinate where the mass fraction of everything but helium drops below 12%, and the CO core mass where the mass fraction of everything but carbon and oxygen drops below 12%.
During the remaining evolution, the inner regions of the core would undergo nuclear processing, and the core mass would change somewhat: for a naked helium star because mass is lost in the hot wind, and for a hydrogen-rich star because shell helium-burning replenishes the core with more carbon and oxygen. However, because core carbon-burning and the subsequent burning phases last for about 1% of the life of a massive star, these changes are expected to be minor enough for an order-of-magnitude estimate. For example, Chieffi & Limongi (2013) reported that in their Solar metallicity models (computed with the FRANEC code, see their Table 1), stars in the mass range of 13−40 M⊙ change their CO core mass during the post-helium-burning phases by merely 1−4% in terms of the initial mass; and stars in the mass range of 60−120 M⊙ do so typically by 3−8%. (The situation is further complicated by the technical difficulty of defining core masses throughout the life of a star; we refer to Sect. 3.3 of Kruckow et al. 2018 for further discussions and references.) We therefore suggest that the pre-carbon-burning core mass values we provide for our models can serve as an order-of-magnitude estimate for the pre-supernova values.
In the case of the models for which the direct extension method was applied (Sect. 4), the definitions above do not always hold because the core composition may not yet have reached the required amount of carbon and oxygen. Therefore, we define the CO core mass for these models as 0.8 times the He core mass. We chose this value because we found that the CO cores of models that are not treated with the direct extension method are about 0.7–0.8 times as massive as their corresponding He cores.
5.2. Assigning supernova types to stellar models
Associating supernova types with stellar models is a complex task, hence simplifying assumptions are often made. In star formation studies, for example, when the feedback from supernova explosions is included, it is commonly assumed that all massive stars explode as core-collapse supernovae (e.g., Gatto et al. 2017). Moreover, the kinetic energy of the explosion is sometimes simply taken uniformly to be 1051 erg. We suggest caution with this approach, especially when our very massive BoOST models are applied, for the following reasons.
In the case of very massive CO cores, stellar models are known to undergo pair-creation related instability during their oxygen-burning phases (Burbidge et al. 1957; Langer 1991; Heger et al. 2003; Langer et al. 2007; Kozyreva et al. 2014). This is in fact what would occur in our very massive models as well if their simulations were continued after the helium burning. Thus, simply associating such a stellar model with a core-collapse supernova explosion is inaccurate. Instead, very massive models are expected to undergo one of the following final fates (relying on the work of Heger & Woosley 2002; Woosley et al. 2007 and Chatzopoulos & Wheeler 2012).
For core masses higher than 130 M⊙, the star will directly collapse into a black hole without a supernova explosion.
For core masses between 65–130 M⊙, the model will explode as a pair-instability supernova. This will completely disrupt the whole star, leaving no remnant. The brightness of such a supernova depends strongly on the amount of nickel that is synthesized (Herzig et al. 1990; Dessart et al. 2013), but according to the analysis of Kasen et al. (2011), some of these supernovae should be observable out to large distances. The total explosive energy in such a stellar model is about 1051–1052 erg.
For core masses between 40–65 M⊙, the model will undergo pair instability but should not explode in a pair-instability supernova explosion. Such a model may be associated with large pulsations leading to mass ejection and flashes of emitted light, which is called a pulsational pair-instability supernova (Woosley et al. 2007; Sukhbold et al. 2016; Stevenson et al. 2019). However, these models will continue their evolution until an iron core forms, and will then explode as a core-collapse supernova.
For core masses below 40 M⊙, iron core collapse is expected, which may lead to a regular core-collapse supernova.
Since research on core-collapse supernovae, pair-instability supernovae, and pulsational pair-instability supernovae is currently ongoing, we suggest that the user investigate the related literature for further developments before assigning supernova types to our models. No core-collapse type supernova explosions should be assigned to models with cores above 130 M⊙ in any case: these certainly do not explode, as explained above. We also suggest to refrain from assigning remnant masses to models with cores between 65–130 M⊙: these do explode, but leave no remnant.
The situation for our chemically homogeneously evolving grid IZw18-CHE may become even more complicated due to the fast rotation of these models. Models with core masses of ∼12–30 M⊙ may be progenitors of long-duration gamma-ray bursts in either the collapsar or the magnetar scenario, as explained in Szécsi (2017); also cf. Chapter 4.7 of Szécsi (2016). For the pair-instability processes in them, we refer to Aguilera-Dena et al. (2018).
6. Discussion
6.1. Comparison to other synthetic populations based on the Bonn code
The four Bonn grids that existed before the BoOST project (MW, LMC, SMC, and IZw18) have already been applied in population synthesis codes. Examples include Bonnsai (Schneider et al. 2014, in which the ages of observed massive stars can be established) and ComBinE (Kruckow et al. 2018, in which predictions of gravitational wave event rates are made). While the basic method of creating a synthetic population out of a stellar grid is the same in these two projects and in ours, the details tend to depend on many things. For one, the mass range of the models depends on the actual scientific question: Bonnsai and ComBinE worked with stars only up to 100 M⊙. We intend the BoOST models for astrophysical applications such as star formation studies in clusters and galaxies in which the contribution from very massive stars may be important, therefore we extended the grids to 500 M⊙. In order to study the early universe (e.g., high-redshift galaxies and the origin of globular clusters), a good metallicity coverage including sub-IZw18 metallicities is achieved here.
BoOST populations also differ from earlier population synthesis studies in that the models and the interpolated tracks are optimized for smoothness and consistency. For example, in Bonnsai, only the main-sequence phases of the massive single-star models were included, while for star formation studies, the main-sequence phase and the post-main-sequence phase should be included (i.e., the role of massive supergiants and pure helium stars may be relevant).
6.2. Future updates
We foresee possible future updates of BoOST models as follows. The first possible update concerns stellar rotation. In the present work we uniformly set all rotational velocities to a 100 km s−1 initial value; however, massive stars rotate with various rotational rates that can to some extent change the predictions in terms of chemical yields, radiation, final core mass, etc. While the 100 km s−1 value we use here is typical for massive stars (as observed in the MW and the Magellanic Clouds, cf., e.g., Hunter et al. 2008; Dufton et al. 2013; Ramírez-Agudelo et al. 2013, 2017), a possible future update of BoOST may be carried out by including stellar models with various rotational velocities.
Similarly, the initial composition of the BoOST grids could be refined. While the current version of the grids covers a broad range in metallicities from Galactic down to 1/250 lower, we provide only eight metallicity values. This constitutes quite a discrete binning. One possible future endeavor is to simulate grids with a much better resolution in metallicity than this, for instance, by either computing stellar models with metallicities in between or performing interpolation between the grids published here.
The same is true for the post-helium-burning phases of our models: while they were omitted in the present version for consistency (and for not being relevant for stellar feedback related applications), a possible update may include these phases.
We certainly plan to provide in an updated version of BoOST the chemical yields retained in the stellar envelope (to be released by a stripping of the envelope due to binary interaction). This would allow combining binary population synthesis studies with star formation studies in a powerful way.
Finally, we encourage future studies in the direction of solving the convergence issues in the inflated envelope near the Eddington limit in a reliable and physically consistent way in the Bonn code and in other stellar evolution codes such as MESA (cf. Agrawal et al. 2021a). While our method of direct extension for the phases in which the models are numerically unstable is quite robust and produces an acceptable result, it is of course not free of caveats (as discussed in Sect. 4.4). Therefore, when stellar evolutionary models become available in which these inflated phases are reliably computed, we will update our interpolated tracks and synthetic populations accordingly.
7. Conclusions
The BoOST project covers the mass-metallicity parameter space with an unprecedented resolution for the first time. We presented nine grids of massive stars between Galactic and 1/250 lower metallicities, including interpolated tracks and synthetic populations. They are available under this link as simple tables. The stellar models were computed with the Bonn evolutionary code and were post-processed with methods optimized for massive and very massive stars. Interpolated tracks and synthetic populations were created by our newly developed stellar population synthesis code SYNSTARS. Eight of the grids represent slowly rotating massive stars with normal or classical evolution, while one grid represents fast-rotating, chemically homogeneously evolving models. In addition to the common stellar parameters such as mass, radius, surface temperature, luminosity, and mass-loss rate, we present stellar wind properties such as the estimated wind velocity and kinetic energy of the wind. Additionally, we provide chemical yields of 34 isotopes, and the mass of the core at the end of the stellar lifetimes.
The BoOST models (grids, tracks, and populations) are thus suitable for further scientific applications, for example, in simulations of star formation in various environments. Future updates are planned in terms of adding models with various rotational rates, and with various initial compositions (i.e., a better resolution in metallicity). Post-helium-burning phases will also be added in future work, as will chemical yields retained in the envelope.
In the future we plan to apply the BoOST grids to study the formation and early evolution of globular clusters and young massive clusters in a metallicity-dependent way (following Wünsch et al. 2017; Szécsi & Wünsch 2019). Beyond this, however, BoOST models open the door for testing the effect of stellar metallicity in many astrophysical contexts in a simple and straightforward way. By optimizing the models for an easy application by the user, our BoOST project harvests the full scientific potential of the Bonn stellar evolutionary code and will contribute to a new era of studying massive stars and their roles in various fields of astrophysics.
Also known as the Binary Evolutionary Code.
By Galactic metallicity, we mean the metallicity of MW stars as defined and applied to stellar models by Brott et al. (2011), cf. their Tables 1 and 2: ZMW = 0.0088. This is somewhat lower than the solar metallicity, which is Z⊙ ∼ 0.012. See Brott et al. (2011) for a discussion of this definition.
We use the term ‘stellar model’ to mean a detailed evolutionary model sequence computed in a stellar evolution code from first principles. In turn, we use the term ‘track’ to mean synthetically created (here: interpolated) evolutionary models. Similarly, we consistently use the term ‘grid’ to mean a grid of stellar models, and the term ‘set’ to mean a set of interpolated tracks.
The massive and very massive LMC and IZw18 models in Köhler et al. (2015) and Szécsi et al. (2015) were only computed and published up to the end of the main sequence mainly for this same reason.
Acknowledgments
This research was funded in part by the National Science Center (NCN), Poland under grant number OPUS 2021/41/B/ST9/00757. For the purpose of Open Access, the author has applied a CC-BY public copyright license to any Author Accepted Manuscript (AAM) version arising from this submission. D.Sz. was supported by the Alexander von Humboldt Foundation. P.A. acknowledges the support from the Australian Research Council Centre of Excellence for Gravitational Wave Discovery (OzGrav), through project number CE170100004. R.W. acknowledges the support from project 19-15008S of the Czech Science Foundation and institutional project RVO:67985815. The authors thank I. Brott, V. Brugaletta, M. Kruckow, I. Mandel, K. Neugent, D. Sanyal, F. Schneider, H. Stinshoff, A. Vigna-Gomez, S. Walch-Gassner and the anonymous referees for valuable discussions and kind advice.
References
- Aarseth, S. J., Tout, C. A., & Mardling, R. A. 2008, The Cambridge N-Body Lectures, 760 (Netherlands: Springer) [CrossRef] [Google Scholar]
- Agrawal, P., Hurley, J., Stevenson, S., Szécsi, D., & Flynn, C. 2020, MNRAS, 497, 4549 [NASA ADS] [CrossRef] [Google Scholar]
- Agrawal, P., Stevenson, S., Szécsi, D., & Hurley, J. 2021a, MNRAS, submitted [arXiv:2112.02801] [Google Scholar]
- Agrawal, P., Szécsi, D., Stevenson, S., & Hurley, J. 2021b, MNRAS, submitted [arXiv:2112.02800] [Google Scholar]
- Aguilera-Dena, D. R., Langer, N., Moriya, T. J., & Schootemeijer, A. 2018, ApJ, 858, 115 [NASA ADS] [CrossRef] [Google Scholar]
- Alongi, M., Bertelli, G., Bressan, A., et al. 1993, A&AS, 97, 851 [NASA ADS] [Google Scholar]
- Belczynski, K., Kalogera, V., & Bulik, T. 2002, ApJ, 572, 407 [NASA ADS] [CrossRef] [Google Scholar]
- Belczynski, K., Kalogera, V., Rasio, F. A., et al. 2008, ApJS, 174, 223 [Google Scholar]
- Bergbusch, P. A., & Vandenberg, D. A. 1992, ApJS, 81, 163 [NASA ADS] [CrossRef] [Google Scholar]
- Bergbusch, P. A., & Vandenberg, D. A. 2001, ApJ, 556, 322 [CrossRef] [Google Scholar]
- Böhm-Vitense, E. 1958, Z. Astrophys., 46, 108 [Google Scholar]
- Brott, I., de Mink, S. E., Cantiello, M., et al. 2011, A&A, 530, A115 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Burbidge, E. M., Burbidge, G. R., Fowler, W. A., & Hoyle, F. 1957, Rev. Mod. Phys., 29, 547 [NASA ADS] [CrossRef] [Google Scholar]
- Cerviño, M., Gómez-Flechoso, M. A., Castander, F. J., et al. 2001, A&A, 376, 422 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chatzopoulos, E., & Wheeler, J. C. 2012, ApJ, 748, 42 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, Y., Bressan, A., Girardi, L., et al. 2015, MNRAS, 452, 1068 [Google Scholar]
- Chieffi, A., & Limongi, M. 2013, ApJ, 764, 21 [Google Scholar]
- Choi, J., Dotter, A., Conroy, C., et al. 2016, ApJ, 823, 102 [Google Scholar]
- de Mink, S. E., Pols, O. R., Langer, N., & Izzard, R. G. 2009a, A&A, 507, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de Mink, S. E., Cantiello, M., Langer, N., et al. 2009b, A&A, 497, 243 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dessart, L., Waldman, R., Livne, E., Hillier, D. J., & Blondin, S. 2013, MNRAS, 428, 3227 [NASA ADS] [CrossRef] [Google Scholar]
- Dufton, P. L., Langer, N., Dunstall, P. R., et al. 2013, A&A, 550, A109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Eddington, A. S. 1926, The Internal Constitution of the Stars [Google Scholar]
- Ekström, S., Georgy, C., Eggenberger, P., et al. 2012, A&A, 537, A146 [Google Scholar]
- Fryer, C. L., Belczynski, K., Wiktorowicz, G., et al. 2012, ApJ, 749, 91 [Google Scholar]
- Gatto, A., Walch, S., Naab, T., et al. 2017, MNRAS, 466, 1903 [NASA ADS] [CrossRef] [Google Scholar]
- Gräfener, G., Owocki, S. P., & Vink, J. S. 2012, A&A, 538, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Grassitelli, L., Fossati, L., Langer, N., et al. 2016, A&A, 593, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Grin, N. J., Ramírez-Agudelo, O. H., de Koter, A., et al. 2017, A&A, 600, A82 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hamann, W.-R., Koesterke, L., & Wessolowski, U. 1995, A&A, 299, 151 [NASA ADS] [Google Scholar]
- Heger, A., & Langer, N. 2000, ApJ, 544, 1016 [CrossRef] [Google Scholar]
- Heger, A., & Woosley, S. E. 2002, ApJ, 567, 532 [Google Scholar]
- Heger, A., Langer, N., & Woosley, S. E. 2000, ApJ, 528, 368 [NASA ADS] [CrossRef] [Google Scholar]
- Heger, A., Fryer, C. L., Woosley, S. E., Langer, N., & Hartmann, D. H. 2003, ApJ, 591, 288 [CrossRef] [Google Scholar]
- Heger, A., Woosley, S. E., & Spruit, H. C. 2005, ApJ, 626, 350 [Google Scholar]
- Herzig, K., El Eid, M. F., Fricke, K. J., & Langer, N. 1990, A&A, 233, 462 [NASA ADS] [Google Scholar]
- Humphreys, R. M., Kudritzki, R. P., & Groth, H. G. 1991, A&A, 245, 593 [NASA ADS] [Google Scholar]
- Hunter, I., Lennon, D. J., Dufton, P. L., et al. 2008, A&A, 479, 541 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kalari, V. M., Carraro, G., Evans, C. J., & Rubio, M. 2018, ApJ, 857, 132 [CrossRef] [Google Scholar]
- Kasen, D., Woosley, S. E., & Heger, A. 2011, ApJ, 734, 102 [NASA ADS] [CrossRef] [Google Scholar]
- Kippenhahn, R., & Weigert, A. 1990, Stellar Structure and Evolution (Springer) [Google Scholar]
- Köhler, K., Langer, N., de Koter, A., et al. 2015, A&A, 573, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kozyreva, A., Blinnikov, S., Langer, N., & Yoon, S.-C. 2014, A&A, 565, A70 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kruckow, M. U., Tauris, T. M., Langer, N., Kramer, M., & Izzard, R. G. 2018, MNRAS, 481, 1908 [CrossRef] [Google Scholar]
- Kubátová, B., Szécsi, D., Sander, A. A. C., et al. 2019, A&A, 623, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lamers, H., & Cassinelli, J. 1999, Introduction to Stellar Winds (Cambridge University Press) [CrossRef] [Google Scholar]
- Langer, N. 1991, A&A, 252, 669 [NASA ADS] [Google Scholar]
- Langer, N. 1997, in Luminous Blue Variables: Massive Stars in Transition, eds. A. Nota, & H. Lamers, ASP Conf. Ser., 120, 83 [Google Scholar]
- Langer, N., Norman, C. A., de Koter, A., et al. 2007, A&A, 475, L19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Leitherer, C., Robert, C., & Drissen, L. 1992, ApJ, 401, 596 [Google Scholar]
- Maeder, A. 1987, A&A, 178, 159 [NASA ADS] [Google Scholar]
- Massey, P., Neugent, K. F., Dorn-Wallenstein, T. Z., et al. 2021, ApJ, 922, 177 [NASA ADS] [CrossRef] [Google Scholar]
- Moriya, T. J., & Langer, N. 2015, A&A, 573, A18 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Neugent, K. F., Massey, P., Georgy, C., et al. 2020, ApJ, 889, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Nieuwenhuijzen, H., & de Jager, C. 1990, A&A, 231, 134 [NASA ADS] [Google Scholar]
- Nishida, M., & Schindler, A. M. 1967, PASJ, 19, 606 [NASA ADS] [Google Scholar]
- Nugis, T., & Lamers, H. 2000, A&A, 360, 227 [Google Scholar]
- Oliphant, T. 2006, Guide to NumPy (USA: Trelgol Publishing) [Google Scholar]
- Paxton, B., Cantiello, M., Arras, P., et al. 2013, ApJS, 208, 4 [Google Scholar]
- Petrovic, J., Langer, N., Yoon, S.-C., & Heger, A. 2005, A&A, 435, 247 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pietrinferni, A., Cassisi, S., Salaris, M., & Castelli, F. 2004, ApJ, 612, 168 [Google Scholar]
- Prather, M. J. 1976, Ph.D. Thesis, Yale University, New Haven, CT, USA [Google Scholar]
- Ramírez-Agudelo, O. H., Simón-Díaz, S., Sana, H., et al. 2013, A&A, 560, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ramírez-Agudelo, O. H., Sana, H., de Koter, A., et al. 2017, A&A, 600, A81 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rosdahl, J., Katz, H., Blaizot, J., et al. 2018, MNRAS, 479, 994 [NASA ADS] [Google Scholar]
- Sanyal, D., Grassitelli, L., Langer, N., & Bestenlehner, J. M. 2015, A&A, 580, A20 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sanyal, D., Langer, N., Szécsi, D., Yoon, S. C., & Grassitelli, L. 2017, A&A, 597, A71 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schneider, F. R. N., Langer, N., de Koter, A., et al. 2014, A&A, 570, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schootemeijer, A., Langer, N., Grin, N. J., & Wang, C. 2019, A&A, 625, A132 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Spruit, H. 2002, A&A, 381, 923 [CrossRef] [EDP Sciences] [Google Scholar]
- Stevenson, S., Sampson, M., Powell, J., et al. 2019, ApJ, 882, 121 [Google Scholar]
- Sukhbold, T., Ertl, T., Woosley, S. E., Brown, J. M., & Janka, H.-T. 2016, ApJ, 821, 38 [Google Scholar]
- Szécsi, D. 2016, Ph.D. Thesis Mathematisch-Naturwissenschaftlichen Fakultät der Universität Bonn, Germany [Google Scholar]
- Szécsi, D. 2017, Proceedings of Science, PoS(MULTIF2017)065, 2017 [Google Scholar]
- Szécsi, D., & Wünsch, R. 2019, ApJ, 871, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Szécsi, D., Langer, N., Yoon, S.-C., et al. 2015, A&A, 581, A15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Szécsi, D., Mackey, J., & Langer, N. 2018, A&A, 612, A55 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vink, J., de Koter, A., & Lamers, H. 2000, A&A, 362, 295 [NASA ADS] [Google Scholar]
- Vink, J., de Koter, A., & Lamers, H. 2001, A&A, 369, 574 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vink, J., Muijres, L. E., Anthonisse, B., et al. 2011, A&A, 531, A132 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Woosley, S. E., Blinnikov, S., & Heger, A. 2007, Nature, 450, 390 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Wünsch, R., Palouš, J., Tenorio-Tagle, G., & Ehlerová, S. 2017, ApJ, 835, 60 [CrossRef] [Google Scholar]
- Yoon, S.-C. 2015, PASA, 32, 15 [NASA ADS] [CrossRef] [Google Scholar]
- Yoon, S.-C., & Langer, N. 2005, A&A, 443, 643 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Yoon, S.-C., Langer, N., & Norman, C. 2006, A&A, 460, 199 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Yoon, S.-C., Dierks, A., & Langer, N. 2012, A&A, 542, A113 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
Appendix A: Columns in the BoOST data files
BoOST data files are available under this link. The authors welcome feedback from the community, in particular, if there are physical quantities that a next version of our BoOST stellar models and populations should provide in order to serve the community’s scientific goals better. Our aim is to provide a flexible model set that can be used in several astrophysical applications.
The current version (v1.3) of BoOST tables contain the columns described below.
A.1. Stellar models
All data files contain 608 lines. The nth line in one model data file has a comparable evolutionary interpretation in another model data file. Columns are
- 1.
Time [yr]
- 2.
Actual mass [M⊙]
- 3.
Surface temperature [K]
- 4.
Surface luminosity [log L⊙]
- 5.
Radius [R⊙]
- 6.
Mass-loss rate [log M⊙ yr−1]
- 7.
Surface gravity [log cm s−2]
- 8.
Surface rotational velocity [km s−1]
- 9.
Critical velocity (assuming an Eddington factor for pure electron scattering) [km s−1]
- 10.
Eddington Γe factor calculated for pure electron scattering
- 11.
Flag marking whether the phase is simulated [0] or approximated with the direct extension method [1] (cf. Sect. 4)
- 12.
– 24. Surface abundances of elements (by summing the abundance of all corresponding isotopes): ϵ(H), ϵ(He), ϵ(Li), ϵ(Be), ϵ(B), ϵ(C), ϵ(N), ϵ(O), ϵ(F), ϵ(Ne), ϵ(Na), ϵ(Mg), ϵ(Al), where ϵ(X) = NX/NH+12, and NX is the number fraction of element X
- 25.
Helium-core mass [M⊙]
- 26.
Carbon-oxygen core mass [M⊙]
- 27.
– 60. Surface mass fraction of isotopes: 1H, 2H, 3He, 4He, 6Li, 7Li, 7Be, 9Be, 8B, 10B, 11B, 11C, 12C, 13C, 12N, 14N, 15N, 16O, 17O, 18O, 19F, 20Ne, 21Ne, 22Ne, 23Na, 24Mg, 25Mg, 26Mg, 26Al, 27Al, 28Si, 29Si, 30Si, and 56Fe.
- 61.
– 94. Core mass fraction of isotopes: 1H, 2H, 3He, 4He, 6Li, 7Li, 7Be, 9Be, 8B, 10B, 11B, 11C, 12C, 13C, 12N, 14N, 15N, 16O, 17O, 18O, 19F, 20Ne, 21Ne, 22Ne, 23Na, 24Mg, 25Mg, 26Mg, 26Al, 27Al, 28Si, 29Si, 30Si, and 56Fe.
A.2. Interpolated tracks
The table contains 1856 tracks, and all tracks contain 608 lines. Thus, this data file has about 1.1 M lines (file size: ∼ 800 MB). Tracks are marked by their initial mass values before their record starts (in M⊙ and in cgs units). The following columns are provided:
Initial mass [cgs units]
Time [cgs units]
Actual mass [cgs units]
Mass-loss rate [cgs units]
Wind velocity [cgs units]
Kinetic energy generation rate of the wind [cgs units]
Luminosity [cgs units]
Stellar radius [cgs units]
Surface temperature [K]
Mask [integer]
Type of interpolation [integer]
Surface rotational velocity [km s−1]
Critical rotational velocity [km s−1]
Eddington factor (see column 10. in Sect. A.1 above)
Flag marking whether the phase includes the direct extension method [1] or not [0] (cf. Sect. 4)
Helium-core mass [M⊙]
Carbon-oxygen core mass [M⊙]
– 50. Surface mass fraction of isotopes: 1H, 2H, 3He, 4He, 6Li, 7Li, 7Be, 9Be, 8B, 10B, 11B, 11C, 12C, 13C, 12N, 14N, 15N, 16O, 17O, 18O, 19F, 20Ne, 21Ne, 22Ne, 23Na, 24Mg, 25Mg, 26Mg, 26Al, 27Al, 28Si, 29Si, 30Si, and 56Fe.
A.3. Synthetic populations
These files contain 608 lines (inherited from the stellar models, see above) plus 50 extra lines to ensure the interpolated quantities behave well. The following columns are provided:
Time [cgs units]
Mass lost from all massive stars in the form of stellar wind [cgs units]
Mass lost from all massive stars in the form of dynamical ejection [cgs units] (set to zero for all BoOST models in this paper)
Kinetic energy in the winds [cgs units]
Integrated bolometric luminosity of the population [cgs units]
Integrated UV flux [cgs units]
Total mass released in stellar winds (accumulated) [cgs units]
Total mechanical energy produced in the stellar winds [cgs units]
– 56. Mass fraction of isotopes in the winds: 1H, 2H, 3He, 4He, 6Li, 7Li, 7Be, 9Be, 8B, 10B, 11B, 11C, 12C, 13C, 12N, 14N, 15N, 16O, 17O, 18O, 19F, 20Ne, 21Ne, 22Ne, 23Na, 24Mg, 25Mg, 26Mg, 26Al, 27Al, 28Si, 29Si, and 30Si.
Appendix B: Technical details of the direct extension method
B.1. Establishing the helium zero-age main sequence
To be able to apply the direct extension method (Sect. 4), we need to establish the point toward which the stellar models converge in terms of surface temperature and luminosity (and thus radius) when they lose mass in their late evolution. This point is the helium ZAMS, that is, the position in the HR diagram at which homogeneous, thermally adjusted helium stars are predicted to be by simulations.
The position of the helium ZAMS is well known for massive stars, but it is less well known for very massive stars. Model grids were computed with the Bonn code only for MW and SMC metallicity up to masses of 25 and 109 M⊙, respectively. They are presented in Fig. 19 of Köhler et al. (2015). In this figure, the 35 M⊙ point of the MW helium ZAMS was obtained by linearly extrapolating the data above 25 M⊙ (D. Sanyal 2019, private communication). No helium ZAMS data for the LMC (and for sub-SMC metallicities) are available.
Some of our very massive models in the MW grid retain as much as 44 M⊙ when the simulation stops and those in the SMC grid as much as 170 M⊙. Additionally, we have models with LMC and sub-SMC metallicities. This means that even if we rely on the helium-ZAMS data in Fig. 19 of Köhler et al. (2015), we still have to supplement it to cover our parameter space.
The helium-ZAMS models from Fig. 19 of Köhler et al. (2015) themselves are unpublished but have kindly been provided by D. Sanyal (2019, private communication). We extrapolated the MW and SMC data in terms of M, logT , and log(L/L
, and log(L/L ) up to 500 M⊙. We also interpolated between these two data sets using log(Z) as the interpolation parameter to obtain data for the LMC. The results are shown in Fig. 10.
) up to 500 M⊙. We also interpolated between these two data sets using log(Z) as the interpolation parameter to obtain data for the LMC. The results are shown in Fig. 10.
When supplementing the MW and SMC data, we applied linear extrapolation and also reduced all quantities by a factor of 3. We chose this number for the following reasons. First, the helium-ZAMS models are initial models with a homogeneous composition, while our models would in reality become helium-ZAMS stars with a relaxed composition (i.e., nuclear burning would be ongoing inside). The surface temperature of such relaxed models is typically somewhat higher, while the surface luminosity is somewhat lower than those of unrelaxed models. Second, extrapolating linearly above 100 M⊙ using the original data leads to highly unphysical results. For example, a 200 M⊙ helium-star in the LMC grid would have a surface temperature of ∼3300 K with an extrapolation like this. This is hardly physically possible because massive stars (including very massive stars) are not expected to have a surface temperature lower than ∼4000 K (cf. the Hayashi line, Kippenhahn & Weigert 1990). Third and most conclusively, the helium-ZAMS lines we would obtain by a simple linear extrapolation of the original data lie at higher surface temperatures than the lines in the last computed stages of some of our most massive stellar models. During the late phases of evolution, our models should evolve to higher and not lower surface temperatures when they lose mass (and thereby uncover helium-rich layers). For all these reasons and after testing several values, we decided that including a reduction of a factor of 3 in our linearly extrapolation of the helium-ZAMS lines in the HR diagram gives the most physically consistent result. Examples are presented in Fig. 10.
B.2. Fraction of the data that includes the direct extension method
Tables B.1 provide the percentage of the lifetime influenced by the treatment of direct extension method (DEM) and the central helium mass fraction Ycen of the last computed structure model (cf. Sect. 4). An asterisk denotes if the value is reached during the main sequence (as opposed to the post-main-sequence, which is the most common case). The corresponding lines of the published data files are flagged with [1] in the relevant column (Column 11, cf. Sect. A).
Fraction of the data that includes the direct extension method, cf. Sects. 4 and B.2
All Tables
Fraction of the data that includes the direct extension method, cf. Sects. 4 and B.2
All Figures
|
Fig. 1. Hertzsprung–Russell diagrams. Initial mass is color-coded (between 9 and ∼500 M⊙); dots mark every 105 yr of evolution along the stellar models. Dashed black lines represent interpolated tracks (up to 500 M⊙); brown crosses mark the phases in which the direct extension method (Sect. 4) has been applied. For details about the models and their postprocessing, see Sects. 2 and 4, respectively, and for details about the interpolated tracks, see Sect. 3. |
| In the text | |
|
Fig. 2. Time evolution of the mass-loss rate. The initial mass is color-coded (between 9 and ∼500 M⊙). The dashed black lines represent interpolated tracks (up to 500 M⊙); cf. Fig. 1.. While here only shown until 10 Myr, the files published in the BoOST project contain data until the end of the lifetimes of the longest-living model in the population (∼30 Myr). |
| In the text | |
|
Fig. 3. Time evolution of the escape velocity; cf. Eq. (1). The initial mass is color-coded (between 9 and ∼500 M⊙). The dashed black lines represent interpolated tracks (up to 500 M⊙); cf. Figs. 1 and 2. While here only shown until 10 Myr, the files published in the BoOST project contain data until the end of the lifetimes of the longest-living model in the population (∼30 Myr). |
| In the text | |
|
Fig. 4. Time evolution of the wind kinetic energy rate. The initial mass is color-coded (between 9 and ∼500 M⊙). The dashed black lines represent interpolated tracks (up to 500 M⊙); cf. Figs. 1–3. While here only shown until 10 Myr, the files published in the BoOST project contain data until the end of the lifetimes of the longest-living model in the population (∼30 Myr). |
| In the text | |
|
Fig. 5. Position of EEPs (i.e., fixed points in evolution) during the lifetime of some typical models. Colored lines represent the original output of our computations with the Bonn code, and black lines and crosses mark the filtered version (consistently containing the same number of dots between EEPs). The seven EEPs are labeled A–G; our method of choosing them is explained in the text. |
| In the text | |
|
Fig. 6. Same as Fig. 5 but for a model with prominent blue loop (without a starting point in the red supergiant branch, left) and one with inflated envelope (right). For more details on the latter, which is a core-hydrogen-burning supergiant, we refer to e.g. Sanyal et al. (2015, 2017), Szécsi et al. (2015, 2018), Szécsi & Wünsch (2019). |
| In the text | |
|
Fig. 7. Same as Fig. 5 but for models that show features associated with a luminous blue variable phase before becoming Wolf-Rayet stars. In both cases, we use our newly developed method for a direct extension in the post-main-sequence phase (that is, removing mass layers one by one from the last computed model’s envelope and correcting for the values of the surface properties, as explained in Sect. 4). Red line marks this phase of stellar life. |
| In the text | |
|
Fig. 8. Validating the interpolation. Colored lines represent the original stellar models (IZw18 grid), dotted black lines represent the interpolated tracks created by removing the corresponding original while performing these test interpolations. See also Sect. 3.2. |
| In the text | |
|
Fig. 9. Luminosity histogram of our BoOST models with an MW composition (yellow). The original is taken from Neugent et al. (2020), including M31 observations (black) and theoretical predictions from the Geneva (green) and BPASS stellar models (red and blue) for solar metallicity. An even larger and more recent dataset of M31 observations from Massey et al. (2021) is overplotted (violet). Our MW population follows the observed luminosity histograms as closely as the Geneva and BPASS stellar models. See Sect. 3.4 for further details. |
| In the text | |
|
Fig. 10. Example of the results of the direct extension method (Sect. 4). The complete evolution of five stellar models (see the key legend) is plotted. The direct extension phase (typically lasting for 9% of the lifetime of these particular models) is marked with red in four of them (MW, LMC, SMC, and dwarfD); the fifth model (dwarfE) was properly computed without interruption, and is shown here as reference. During the direct extension phase, the models converge to their corresponding helium ZAMS position while loosing mass from their surface layers (cf. Sect. 4.3). Helium ZAMS positions in the HR diagram are shown for MW, LMC, and SMC compositions. The details of constructing these lines are given in Appendix B.1. Numbering indicates stellar masses (in M⊙). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.