| Issue |
A&A
Volume 657, January 2022
|
|
|---|---|---|
| Article Number | A126 | |
| Number of page(s) | 15 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202141710 | |
| Published online | 21 January 2022 | |
Disentangling the optical AGN and host-galaxy luminosity with a probabilistic flux variation gradient⋆,⋆⋆
Astroinformatics, Heidelberg Institute for Theoretical Studies, Schloss-Wolfsbrunnenweg 35, 69118 Heidelberg, Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
5
July
2021
Accepted:
21
October
2021
Abstract
Context. We present a novel probabilistic flux variation gradient (PFVG) approach to separate the contributions of active galactic nuclei (AGN) and host galaxies in the context of photometric reverberation mapping (PRM) of AGN.
Aims. We explored the ability of recovering the fractional contribution in a model-independent way using the entire set of light curves obtained through different filters and photometric apertures simultaneously.
Methods. The method is based on the observed “bluer when brighter” phenomenon that is attributed to the superimposition of a two-component structure; the red host galaxy, which is constant in time, and the varying blue AGN. We describe the PFVG mathematical formalism and demonstrate its performance using simulated light curves and available PRM observations.
Results. The new probabilistic approach is able to recover host-galaxy fluxes to within 1% precision as long as the light curves do not show a significant contribution from time delays. This represents a significant improvement with respect to previous applications of the traditional FVG method to PRM data.
Conclusions. The proposed PFVG provides an efficient and accurate way to separate the AGN and host-galaxy luminosities in PRM monitoring data. The method will be especially helpful in the case of large upcoming photometric survey telescopes such as the public optical/near-infrared Legacy Survey of Space and Time (LSST) at the Vera C. Rubin Observatory. Finally, we have made the algorithms freely available as part of our Julia PFVG package.
Key words: galaxies: active / galaxies: nuclei / galaxies: Seyfert / quasars: general
The PFVG code can be downloaded from: https://github.com/HITS-AIN/ProbabilisticFluxVariationGradient.jl/
Instructions and specific examples used in this paper can be found in: https://github.com/HITS-AIN/PFVG_AA2021
© ESO 2022
1. Introduction
Powered by supermassive black holes in their centers, active galactic nuclei (AGN) are considered to be the most energetic sources in the Universe. The involved physical regions are extremely compact and hard to resolve with existing instrumentation. As a result, AGN often appear as a point-like sources compared with their host galaxy, which can have a great variety of morphologies (e.g., Gabor et al. 2009; Villforth et al. 2014), and whose degree of contribution to the total flux varies significantly (e.g., Pierce et al. 2010; Pović et al. 2012; Falomo et al. 2014; Bettoni et al. 2015).
The case of local Seyfert galaxies is particularly challenging. In these galaxies, the starlight contribution can reach up to 50 to ∼80% of the total optical (e.g., Bentz et al. 2009; Sakata et al. 2010; Pozo Nuñez et al. 2012, 2013) and infrared luminosities (e.g., Glass 1998, 2004; Suganuma et al. 2006; Pozo Nuñez et al. 2014, 2015; Koshida et al. 2014). An overestimation of the AGN luminosity due to the contamination of its host galaxy has strong implications on the refinement of scaling relations for single-epoch black hole estimates, such as the relation of the Hβ broad-line region (BLR) size to the 5100 Å monochromatic luminosity (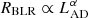 ; Bentz et al. 2013). The
; Bentz et al. 2013). The 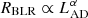 relation offers the possibility of using quasars as standard candles for cosmological distance studies (Oknyanskij 1999; Watson et al. 2011). However, this can only be achieved if the scatter is reduced considerably. The scatter in this relation appears not only because of the noise in time-delay measurements, from which BLR sizes are inferred, but also from erroneous separation of AGN and host galaxy luminosities. This has been demonstrated by Bentz et al. (2013), who obtained an improved slope of
relation offers the possibility of using quasars as standard candles for cosmological distance studies (Oknyanskij 1999; Watson et al. 2011). However, this can only be achieved if the scatter is reduced considerably. The scatter in this relation appears not only because of the noise in time-delay measurements, from which BLR sizes are inferred, but also from erroneous separation of AGN and host galaxy luminosities. This has been demonstrated by Bentz et al. (2013), who obtained an improved slope of 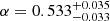 for a sample of 41 reverberation-mapped Seyfert 1 galaxies after correcting for starlight contamination.
for a sample of 41 reverberation-mapped Seyfert 1 galaxies after correcting for starlight contamination.
To date, there are two main methods for isolating nuclear flux: fitting galaxy templates to the observed AGN spectrum (e.g., Mehdipour et al. 2015), and modeling the host galaxy profile using high-resolution images (e.g., Pogge & Martini 2002; Bentz et al. 2009, 2013, using Hubble Space Telescope, HST, imaging). The first method can be directly applied to spectroscopic reverberation mapping (SRM) campaigns, while the second is mostly restricted to local Seyfert galaxies in which the host galaxy is optically resolved, and it depends strongly on the adopted galaxy model. However, neither method is efficient in the case of large monitoring programs, in particular, in the case of large-scale photometric reverberation-mapping (PRM) surveys. This raises a practical concern regarding the processing of the unprecedented amount of data that will be provided by large ground-based photometric surveys (LSST1; Abell 2009, SDSS2-V; Kollmeier et al. 2019), and satellite missions (TESS3; Jenkins et al. 2018, JWST4; Natarajan et al. 2017, Euclid5; Amendola et al. 2018) in the near future.
An alternative approach that does not require the use of high spatial resolution images is the flux variation gradient method (FVG, Winkler et al. 1992; Glass 1997, 1998). The FVG is based on the flux-flux diagrams by Choloniewski (1981), who attributed the observed “bluer when brighter” phenomenon to the superimposition of a two-component structure: the contribution of a red host galaxy that is constant in time, including nonvarying emission lines, and the varying contribution of an AGN with constant blue color.
Recently, given a well-defined range of host-galaxy slopes (e.g., Sakata et al. 2010), the FVG has been successfully employed to separate host and AGN contributions in narrow- and broad-band PRM campaigns (e.g., Pozo Nuñez et al. 2012, 2019; Ramolla et al. 2015; Chelouche et al. 2019), as well as in dust near-infrared RM studies (e.g., Pozo Nuñez et al. 2014, 2015; Vazquez et al. 2015; Ramolla et al. 2018). Moreover, the FVG method can be applied without a prior assumption about the host-galaxy slopes. In this case, the method requires simultaneous observations with at least one photometric band in which the host-galaxy contribution is negligible (e.g., ∼2000 Å), thus providing a lower limit for the host-galaxy flux (Starkey et al. 2017; McHardy et al. 2018; Cackett et al. 2020; Hernández Santisteban et al. 2020). However, the actual FVG application has considerable difficulties and limitations that have not yet been fully addressed and quantified. For instance, it is unclear whether an FVG analysis can give a reliable estimate of the host-galaxy contribution based solely on traditional linear regression analysis. It might equally rather return biased results given the observational errors in the data, different amplitudes, and variability features in the light curves. It is also unclear to which degree FVGs are affected by light curves with time delays obtained from PRM observations. To answer these questions in this paper, we study the reliability of the FVG method under different observational conditions, and introduce a new probabilistic approach that can be efficiently applied to PRM monitoring data.
2. Methods
In the following section, we briefly revisit the FVG method and introduce a new probabilistic reformulation. We note that a review of the FVG method and its application to PRM data can be found in Pozo Nuñez et al. (2012). Here we list the formulae and principle for the sake of comprehensiveness.
2.1. Flux variation gradient
The purpose of the FVG is to separate the AGN and host-galaxy contributions given the observed total flux and a ratio of colors characterizing the host galaxy in question. The observed total fluxes yi(t) are the sum of a host-galaxy flux that is constant in time, gi(t) = gi, and the variable AGN flux vi(t),
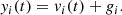 (1)
(1)
Two assumptions underpin the FVG method. The first assumption is that the AGN fluxes vi(t) form a line that goes through the origin. The second assumption, supported by observations, is that total fluxes yi(t) obtained through different photometric bands i ∈ {1, …, F}, where F is the total number of filters, follow a linear relation. The AGN optical spectral shape does not change, that is, the ratio 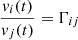 is a constant, known as the flux variation gradient, as described by Winkler et al. (1992). Hence, we can write the assumption of a linear relation as
is a constant, known as the flux variation gradient, as described by Winkler et al. (1992). Hence, we can write the assumption of a linear relation as
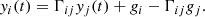 (2)
(2)
Figure 1 sketches the FVG method. The right side shows observations in two different filters. By pairing flux values of observations that occur at the same time, we form points (yi(t),yj(t)) in the flux-flux plot that fall on the dashed line, as dictated by Eq. (2). Each of the instantiated points (yi(t),yj(t)) in the flux-flux plot can be understood as a vector that results from adding the unobserved AGN vector (vi(t),vj(t)) (not plotted in Fig. 1) to the unobserved galaxy vector gij = (gi, gj) (brown vector in Fig. 1), as implied by Eq. (1). If we knew the galaxy vector gij, we could clearly subtract it from the observed (yi(t),yj(t)) and obtain the desired AGN activity (vi(t),vj(t)). The unobserved vector gij defines a line gij ⋅ x, with x ∈ ℝ, that intersects the dashed line in Fig. 1 at point x0 ∈ R2, which stands for the (not necessarily observed) minimum AGN activity at filters i and j. Hence, if we can find x0, then we know gij. The FVG method suggests the following: if we knew a vector u with the same direction as gij, this would define the line u ⋅ x, which is just a reparameterization of the line gij ⋅ x. Hence, the intersection of the line u ⋅ x with the dashed line would also occur at x0, which would give us gij. In a nutshell, FVG proposes that if we know the ratio of colors characterizing the host galaxy in question, then we can find the point x0 and separate the AGN and host galaxy luminosities.
 |
Fig. 1. Sketch of FVG. Observations in filters i and j measured at three different time instances (right). By pairing flux values of co-occurring observations, we form points in the flux-flux plot that fall on a line (dashed). Vector gij (in brown) corresponds to the unobserved host-galaxy and defines a line gij ⋅ x that intersects the dashed line at x0, the point of (unobserved) minimum AGN activity. The FVG method consists of finding the intersection of u ⋅ x and the dashed line; u (in green) is a vector that has the same direction (i.e., same colors) as gij and therefore also intersects the dashed line at x0. |
In practical implementations of the FVG, the lines describing the total fluxes are identified using linear regression analysis. As pointed out in Pozo Nuñez et al. (2012), the choice of the regression method is not trivial as the methods will fare differently depending on how well separated the dependent and independent variables are and depending on the intrinsic dispersion of data around the best fit and others factors (e.g., Isobe et al. 1990; Winkler et al. 1992). The regression algorithms are based on the formulae provided by Isobe et al. (1990). The authors recommend a symmetric treatment of the variables using the ordinary least-squares (OLS) bisector method. A mean host-galaxy estimate is obtained from a random uniform distribution of possible host-galaxy values enclosed by the area that is formed by the intersection between a well-defined range of host-galaxy colors6 and the AGN slopes derived from the bisector analysis.
2.2. Issues with previous FVG implementations
Aggregating filters. As illustrated in Fig. 1, the FVG works on a flux-flux plot, defined by a pair of filters, and finds an intersection point x0 ∈ R2. This is repeated for each pair of filters, and the resulting intersection points are then aggregated in some fashion or considered independently. In previous applications of the FVG, aggregation of the intersection points per filter pair has been done by averaging estimates (e.g., Pozo Nuñez et al. 2012; Ramolla et al. 2015; Chelouche et al. 2019). Here we avoid this heuristic aggregation by considering all filters simultaneously to infer x0. Hence, instead of working in a flux-flux space that contains information about two filters only, we work in the F-dimensional space of all filters (i.e., each filter has an axis) populated by tuples (y1(t),…,yF(t)), and infer an intersection point x0 ∈ RF.
Data uncertainty. The linear regression algorithms that were used in the past, such as the OLS bisector, assumed that the intrinsic dispersion of the data is larger than individual error measurements, hence the intersection point between the AGN and galaxy slopes, that is, the host galaxy, depends solely on the error range of the bisector fit. In this work, we account for the presence of noise in the data by explicitly taking error measurements into account in our model formulation (see Sect. 2.3).
Uncertainty in the galaxy estimation. Previous FVG implementations provided point estimates for the intersection points and hence the galaxy contribution. By formulating a probabilistic version of FVG in this work, we are able to produce not just a point estimate for the intersection point, but rather a density of possible intersection points (see Sect. 2.3.2). This density expresses our inability to pinpoint a unique intersection point due to the presence of noise (i.e., uncertainty) in the observed data, and acknowledges that a range of solutions are in fact plausible.
2.3. Proposed probabilistic FVG
In this section we put forward a probabilistic reformulation of FVG based on probabilistic principal component analysis (PPCA; Tipping & Bishop 1999), which we call PFVG. In a first step, our method identifies the line formed by the total fluxes, and in a second step, it seeks the intersection of the unobserved galaxy line with the identified line.
We modeled the observed flux yi(t) in each filter i ∈ {1, …, F} at time t as a noisy observation from a latent signal f(t)7, common to all filters, scaled and shifted by filter-dependent parameters ai and bi,
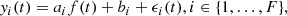 (3)
(3)
where ϵi(t) is observational noise assumed to be drawn from a Gaussian distribution, ϵi(t)∼𝒩(0, σ2(t)). This incorporates the FVG assumption that a flux observation in a filter at time t is linearly related to the observations in all other filters at time t. Assuming observations co-occur, that is, they are observed at the same time instance, we form vectors y(t) = (y1(t),y2(t),…,yF(t)) ∈ ℝF for each observed t. Similarly, we also form σ2(t) = (σ1(t),σ2(t),…,σF(t)).
2.3.1. Line identification
The co-occurring, noisy observed total fluxes in Eq. (3) gives rise to the joint likelihood8,
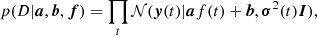 (4)
(4)
where a = (a1, …, aF),b = (b, …, bF), and D stands for all observed measurements, that is, all available data. The proposed model seeks to find the line that goes through the observed total fluxes. It is essentially identical to PPCA in the special case where only one principal component is sought. Because we are not interested in the latent signal values f(t), we treat them as nuisance variables: following PPCA, we impose on them a Gaussian prior 𝒩(f|0, I) = ∏t𝒩(f(t)|0, 1) and integrate them out,
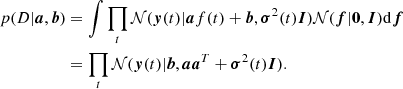 (5)
(5)
Maximizing p(D|a, b) in Eq. (5) with respect to line parameters a and b gives us point estimates for these parameters. However, we wish to obtain a posterior density for these parameters because we are interested in the uncertainty of our estimates. Following Bayesian principal component analysis (Bishop 1999a,b), we treat a and b as random variables and impose priors 𝒩(a|0, ναI) and 𝒩(b|0, νbI)9. We now seek to obtain the posterior density p(a, b|D)∝p(D|a, b)p(a)p(b).
Unfortunately, the posterior density p(a, b|D) cannot be calculated analytically. Instead, we seek a Gaussian approximating posterior 𝒩(a, b|μ, Σ) that is as close as possible to the exact posterior p(a, b|D) (Bishop 1999b). An appropriate notion of closeness is given by the Kullback-Leibler divergence between the two densities, DKL(𝒩(a, b|μ, Σ)||p(a, b|D)). By minimizing this divergence with respect to the free parameters μ and Σ, we obtain the optimal (i.e., closest) Gaussian approximation to p(a, b|D).
2.3.2. Intersection
The Gaussian approximating posterior 𝒩(a, b|μ, Σ) presents not just a single solution for the parameters of the line formed by the total fluxes, but rather a density of possible parameter solutions and hence a density of possible lines. Our goal here is to work out the density of intersection x0 between a given candidate line u ⋅ x for the unobserved galaxy and the density of lines implied by 𝒩(a, b|μ, Σ).
While the term intersection has a clear meaning for two lines that live in a Euclidean space, we still need to clarify what we mean by it in our setting. We consider a point x0 to be an intersection if it simultaneously satisfies two conditions, namely: (1) it is close to the line u ⋅ x, and (2) it is close to a line a ⋅ t + b, which enjoys high density according to 𝒩(a, b|μ, Σ). Allowing momentarily for some noise tolerance ς and 𝜚, we express the joint satisfaction of these two conditions as the product 𝒩(x0|u ⋅ x, ς2)⋅𝒩(x0|a ⋅ t + b, 𝜚2) where each term stands for conditions (1) and (2), respectively. Noise ς and 𝜚 control how close x0 must be to the two lines in order to be considered an intersection. Hence, we view the two terms as soft constraints that need to be satisfied. By driving ς to 0, the first constraint becomes a hard constraint that states that x0 must be on the line u ⋅ x. Roughly speaking, the product now becomes limς → 0𝒩(x0|u ⋅ x, ς2I)𝒩(x0|a ⋅ t + b, 𝜚2I) = 𝒩(u ⋅ x|a ⋅ t + b, 𝜚2I).
Hence, given a, b, and t, the conditional support for u ⋅ x being an intersection point, or equivalently, the conditional support for coordinate10x addressing an intersection point is p(x|a, b, t) = 𝒩(u ⋅ x|a ⋅ t + b, 𝜚2I). Assuming the improper prior11p(t)∝1, the unconditional support for x is
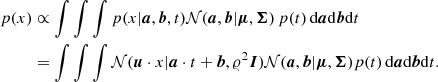 (6)
(6)
Specifying the following partitions of mean and covariance,
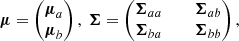 (7)
(7)
as well as 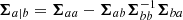 , integration over a and b yields
, integration over a and b yields
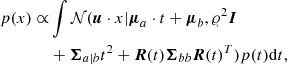 (8)
(8)
where we have defined 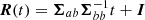 . Again, by driving noise 𝜚 to 0, we finally arrive at the support for x given by the density of lines implied by 𝒩(a, b|μ, Σ) in the absence of noise (i.e., ς = 𝜚 = 0)12:
. Again, by driving noise 𝜚 to 0, we finally arrive at the support for x given by the density of lines implied by 𝒩(a, b|μ, Σ) in the absence of noise (i.e., ς = 𝜚 = 0)12:
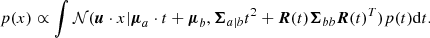 (9)
(9)
Unfortunately, we cannot calculate the integral in Eq. (9) analytically. To make progress, we proceed in two steps: first, we approximate the integrand with the Gaussian approximation 𝒩(x, t|m, S) by minimizing the Kullback-Leibler divergence between them. Second, we calculate the Gaussian marginal 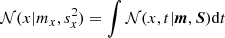 , which is the approximate support for coordinate x.
, which is the approximate support for coordinate x.
Hence, the density that describes the distribution of the ith coordinate of the sought intersection ux is the Gaussian 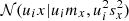 . We note, however, that the Gaussian density allows negative values for coordinate x. To avoid this, we work with the reparameterization
. We note, however, that the Gaussian density allows negative values for coordinate x. To avoid this, we work with the reparameterization 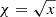 , that is, we infer an approximate Gaussian marginal posterior
, that is, we infer an approximate Gaussian marginal posterior 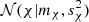 for χ instead of x. Consequently, because χ has a Gaussian distribution, coordinate x has a noncentral chi-squared distribution that supports only positive values (Johnson et al. 1995).
for χ instead of x. Consequently, because χ has a Gaussian distribution, coordinate x has a noncentral chi-squared distribution that supports only positive values (Johnson et al. 1995).
Finally, because of the complex probability density of the noncentral chi-squared distribution, we define the density of the ith coordinate of the sought intersection ux implicitly as
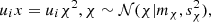 (10)
(10)
3. Simulations
In this section we explore the ability of the FVG, along with our probabilistic reformulation, to recover the host-galaxy contribution under different simulated scenarios. We consider the observational characteristics of PRM campaigns such as time sampling, signal-to-noise ratio (S/N), and the occurrence of time delays in the observed light curves. In particular, we focus on the next future public optical or near-infrared Legacy Survey of Space and Time (LSST), which will monitor about ten million quasars in six broad-band filters (ugrizy) during ten years of operation.
Our simulation method follows that of Pozo Nuñez et al. (2019). First, we modeled the driving AGN continuum light curves as a random walk process with a power spectral density P(ν)∝ν−2 (Kelly et al. 2009; Caplar et al. 2017). The total emission L(AGN)ν from the AGN was then calculated by integrating the Planck function of a black body,
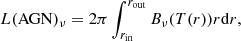 (11)
(11)
where Bν is characterized by the radial temperature profile of an optically thick geometrically thin accretion disk, T(r)∝r−3/4. The effects of varying the disk luminosity as a function of orientation are negligible for the purpose of this work. Consequently, we assume in Eq. (11) a face-on (i = 0°) configuration. We then mixed the AGN accretion disk emission with the host-galaxy contribution measured from the UV/optical galaxy templates obtained by Kinney et al. (1996) for different morphology types. Finally, the total observed fluxes were calculated by convolving each model component with the transmission curves of the LSST broad-band filters. In Fig. A.1 we show an example of the random walk simulated light curves, AGN accretion disk, and host-galaxy spectrum for an arbitrary local Seyfert galaxy from our mock catalog.
3.1. Effects of time sampling, S/N, and AGN activity
The light curves of AGN have a stochastic nature, and it is very likely to encounter cases in which either a low or a high level of activity is observed. Combined with the fact that astronomical observations are frequently affected by weather conditions, technical issues, and seasonal gaps, this poses significant challenges to the FVG method. In Fig. 2 we present an example that illustrates the impact of the above issues on the traditional FVG analysis. The time sampling, Δt, during the LSST monitoring is expected to be between 2 and 5 days. Thus, the light curves were randomly sampled with an average sampling of Δt = 3 days. In this example, we adopted an S/N = 30, which corresponds to the highest expected photometric noise, in particular, for the u band (at ∼3% noise level). The left panel shows the light curves depicting two distinct states of AGN activity. A low state characterized by small variability amplitudes, with fluxes undergoing a steep decrease of about 40% before reaching a minimum at day 65. Afterward, the flux starts to increase by about the same amplitude (40%) until a maximum is reached at 100 days. This represents the beginning of the higher state of AGN activity. At this point, the luminosity has already increased by a magnitude of about 1.5 in all filters. During this state, the AGN exhibit a period of stronger variability with light curve features characterized by single outbursts with ∼10% variability amplitudes, as seen in the range between 140−180 days. These variability events, regulated by both low and high states of AGN activity, are crucial for the performance of the FVG method. On the one hand, identifying a line requires that we know any two points. However, because the points are noisy, not every pair of points leads to a reliable identification of the line. If we had the ability of measuring both the highest activity flux and the lowest activity flux, we would obtain the two most distant points in the multidimensional flux space. This particular pair of points would lead to a reliable identification of the line we are looking for. This can be understood intuitively; perturbing one of these two points by noise would only perturb the line slightly. In other words, the more of the dynamic flux range we observe, the more reliably we can estimate the line. In contrast, if we only measure two fluxes of average activity, this would give us two points in the multidimensional flux space that are very close together. This pair of points would lead to a nonrobust identification of the sought line; perturbing one of these points by noise would perturb the line significantly. In other words, the less of the dynamic flux range we observe, the less robustly we can estimate the line. To quantify the impact of the observed dynamic range in flux, we applied the FVG method on low and high states of AGN activity. These states are shown in the FVG diagram in the right panel of Fig. 2.
 |
Fig. 2. Flux variation gradient applied to set of light curves from our LSST mock catalog. Left panel: light curves with an average time sampling of Δt = 3 days, S/N = 30, and total time span of T = 200 days. Low and high levels of AGN activity are marked with blue and magenta circles, respectively. Right panel: FVG analysis for the u and g bands only. Other bands are given in Fig. A.2. The dotted orange and black lines cover the upper and lower standard deviations of the OLS bisector fit (solid lines) for the combined (black) and higher (orange) AGN state of activity. The color of the Sa galaxy we used in the simulations is shown as a dotted red line. |
In a first test, we simulated the aforementioned situation where we observe a large part of the dynamic flux range. Therefore we considered the combined AGN states (hereafter denoted as CS) and performed an OLS bisector linear regression analysis. The bisector method yields a linear gradient of Γug = 1.04 ± 0.02, which is consistent with ΓUB ∼ 1 derived from observations of Seyfert 1 galaxies (e.g., Winkler et al. 1992; Sakata et al. 2010). The intersection point (red circle in Fig. 2) between the AGN and galaxy slopes gives a host-galaxy flux of 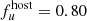 mJy and
mJy and 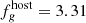 mJy. Here the true host-galaxy vector, gal0 = (0.89, 3.70)13, obtained from the scaled Sa-type template (Fig. A.1), is recovered at 10 and 10.5% precision for u and g bands, respectively.
mJy. Here the true host-galaxy vector, gal0 = (0.89, 3.70)13, obtained from the scaled Sa-type template (Fig. A.1), is recovered at 10 and 10.5% precision for u and g bands, respectively.
In a second test, we considered only the higher state of AGN activity (hereafter denoted as HS). In this case, we simulated the situation in which we observe a smaller part of the dynamic flux range. The bisector method yields a linear gradient of Γug = 1.13 ± 0.13 (orange line). The AGN slope is notably steeper, and with a larger uncertainty, hence leading to a different intersection point (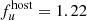 mJy and
mJy and 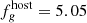 mJy; red diamond), and overestimating the true host galaxy by about ∼40% in both u and g bands.
mJy; red diamond), and overestimating the true host galaxy by about ∼40% in both u and g bands.
To study the performance of the FVG under different observational conditions, we repeated the same analysis for simulated light curves with various S/Ns (10, 30, 60, 100, 150, and 200) and time sampling chosen in the interval [Δtmin, Δtmax] = [0.1, 10] spaced by 0.01 days. We denote by gal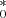 the estimated host-galaxy vector14. The recovered distributions of host-galaxy fluxes, gal
the estimated host-galaxy vector14. The recovered distributions of host-galaxy fluxes, gal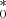 , are shown in Fig. 3. We find that the performance of the FVG when applied to the HS is strongly dependent on the quality of the light curves; in particular, the FVG appears more sensitive to the presence of noise rather than to time sampling. In the case of S/N < 100, the HS (black histograms) exhibits a broad and asymmetric distribution around the central values, with a systematic bias (up to about 50%) toward small gal
, are shown in Fig. 3. We find that the performance of the FVG when applied to the HS is strongly dependent on the quality of the light curves; in particular, the FVG appears more sensitive to the presence of noise rather than to time sampling. In the case of S/N < 100, the HS (black histograms) exhibits a broad and asymmetric distribution around the central values, with a systematic bias (up to about 50%) toward small gal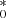 . For higher-quality data (i.e., S/N ≥ 100), the distributions are more symmetric and unbiased with
. For higher-quality data (i.e., S/N ≥ 100), the distributions are more symmetric and unbiased with 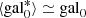 , but they are still substantially broader around the mean value. In contrast to the HS, the FVG performance on the CS (colored histograms) becomes less sensitive to the S/N, leading to improved galaxy statistics with a relatively unbiased and narrower distributions of gal
, but they are still substantially broader around the mean value. In contrast to the HS, the FVG performance on the CS (colored histograms) becomes less sensitive to the S/N, leading to improved galaxy statistics with a relatively unbiased and narrower distributions of gal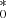 . An exception is seen for the lower quality data (i.e., S/N ≤ 30), where a bias (up to about 30%) toward lower values is still present. For the case of S/N ≥ 100, the CS distributions becomes narrower and the true galaxy is recovered with a precision of 10%. Based on these simulations, the recovered precision is consistent with the precision obtained from PRM observational campaigns. We return to this issue in Sect. 4.
. An exception is seen for the lower quality data (i.e., S/N ≤ 30), where a bias (up to about 30%) toward lower values is still present. For the case of S/N ≥ 100, the CS distributions becomes narrower and the true galaxy is recovered with a precision of 10%. Based on these simulations, the recovered precision is consistent with the precision obtained from PRM observational campaigns. We return to this issue in Sect. 4.
 |
Fig. 3. Recovered FVG host-galaxy fluxes (gal |
3.2. Comparison with the proposed PFVG method
We have carried out the PFVG analysis using the same simulated light curves as for the traditional FVG in the previous section. The results are summarized in Fig. 4. The PFVG performance on the CS appears to be considerably superior to the traditional FVG, especially for the case of the worst quality data (case a in Fig. 4; S/N = 10, Δt = 10 days); it exhibits a very narrow distribution around the central value, with the true galaxy underestimated by only 15% compared to the HS. In this particular case, the HS deviates from the true galaxy by about twice the value. The PFVG performance substantially improves already at S/N = 100 (panels b and d) where the HS exhibits a more symmetric distribution with the true galaxy within the 1σ sigma range. Notably, the CS distributions are significantly narrower and the true galaxy is recovered with an exceptional precision of 0.5%. We attribute the good performance of the PFVG to the fact that it accounts for the data measurement errors σi(t) in its formulation (see Eq. (4)). As a consequence, we see that as S/N decreases, the performance of PFVG deteriorates in a graceful manner rather than abruptly. A comparison between the recovered FVG and PFVG galaxy fluxes is shown in Fig. 5. The PFVG results are summarized in Table A.1.
 |
Fig. 4. Recovered PFVG distributions (see Eq. (10)) of host-galaxy fluxes obtained for the HS (transparent colored histogram) and CS (solid colored histogram). Distributions obtained for poorly sampled light curves, with low and high S/N, are shown in panels a and b, respectively. Distributions obtained for well-sampled light curves, with low and high S/N, are shown in panels c and d, respectively. The vertical dotted line marks the true galaxy value used in the simulations (gal0). The 68% confidence range used to estimate the 1σ uncertainty around the median is shown as transparent black boxes. (a) S/N = 10, Δt = 10 days. (b) S/N = 100, Δt = 10 days. (c) S/N = 10, Δt = 1 days. (d) S/N = 100, Δt = 1 days. |
 |
Fig. 5. Precision on the recovered galaxy fluxes obtained from the FVG (upper panels) and PFVG (lower panels) distributions for the CS and HS of AGN activity. The red line shows the Sa-type host-galaxy (observer’s frame) spectrum. The galaxy fluxes (in mJy) at each filter are plotted as filled black stars. The lines indicate the range of galaxy values that is recovered within the 68% confidence interval, and they are given for an S/N = 10 (purple), 100 (cyan), and 200 (yellow). |
3.3. PRM light curves with time delays
Time delays, τc(λ), between different UV/Optical continuum bands are a prediction of the AD thermal reprocessing scenario (τc ∝ λ4/3; Collier et al. 1998; Frank et al. 2002; Cackett et al. 2007). The delays are interpreted in terms of the light travel time across different regions of the AD, and have been detected for a few sources over the past years. The reported measurements are found to be overestimated by factor of ∼3 than the expected for an optically thick geometrically thin AD (see Pozo Nuñez et al. 2019 and references therein). This overestimation has been attributed mainly to contamination of broad emission lines into the bandpasses, including additional diffuse continuum from the BLR (Chelouche et al. 2019; Korista & Goad 2019). Regardless of their magnitude, there is growing evidence that supports their existence in most, if not all, AGN. Whether their production mechanism is exclusively due to AD continuum contribution is a matter of current debate.
In order to quantify any potential biases that might be introduced by PRM light curves with time delays, we generated mock light curves of the continuum based on the AD thermal reprocessing scenario, as outlined in Pozo Nuñez et al. (2019). In brief, the observed AD UV or optical continuum emission, Fc(λ, t), is the result of the convolution of the X-ray driving light curve, Fx(t), with a response function Ψ(τ|λ)∝∂Bν(λ, T(t − τ))/∂Lx(t − τ), so that Fc(λ, t) = Fx(t)*Ψ(τ|λ), where τ ∝ (r2 + h2)1/2 is the time-delay function for a face-on Keplerian ring or disk structure. The disk is irradiated by an X-ray corona located at a distance h above the plane (Sergeev et al. 2005) and has a temperature profile, T(r) ∝ (MBHṀ)1/4r−3/4, given by the standard Shakura & Sunyaev (1973) theory.
We generated the AD mock light curves for three objects with black hole masses MBH = 107, 108, and 109 M⊙ and accretion rates Ṁ = 0.12, 0.22, and 2.2 M⊙ yr−1, respectively. We assumed that the objects are accreting at 10% Eddington. We used the same random seed as in Fig. 2 to create the driving X-ray light curve. The driver was then convolved with transfer functions obtained for each black hole mass and accretion rate. We note that the choice of these model parameters is only for illustrative purposes, allowing the time delay to be long enough to quantify possible biases while neglecting the effects of redshift and galaxy contribution dependence.
Figure 6 shows an example of the simulated AD light curves observed in the u and y bands. These two bands display the largest difference between them in terms of time delay, as measured by the centroid of the transfer functions. The original light curves have an ideal time sampling of Δt = 0.1 days and a time span of 190 days. We added the galaxy contribution, observational noise, and resampled the light curves in the same way as performed in Sect. 3.1. The FVG and PFVG were applied on the resampled and noisy light curves. The recovered distributions of the host galaxy, gal , as a function of τ for different bands are shown in Fig. 7. The results are shown for a fixed time sampling of Δt = 3 days and for an S/N = 30 and 100. The analysis includes both CS and HS cases of AGN activity. We find that the traditional FVG is more sensitive to the presence of time delays in the light curves; in the CS case, it shows a clear bias toward higher galaxy values by up to ∼20% as the time delay increases and the S/N decreases (open squares). A more stable behavior is seen for S/N = 100 (open circles), where the galaxy is underestimated by only ∼5% of the true value. The opposite behavior is seen for the HS case, in which the galaxy is biased toward lower values as the S/N decreases. In this case, the galaxy is underestimated by about 50% for an S/N = 30 and overestimated by up to ∼15% for an S/N = 100.
, as a function of τ for different bands are shown in Fig. 7. The results are shown for a fixed time sampling of Δt = 3 days and for an S/N = 30 and 100. The analysis includes both CS and HS cases of AGN activity. We find that the traditional FVG is more sensitive to the presence of time delays in the light curves; in the CS case, it shows a clear bias toward higher galaxy values by up to ∼20% as the time delay increases and the S/N decreases (open squares). A more stable behavior is seen for S/N = 100 (open circles), where the galaxy is underestimated by only ∼5% of the true value. The opposite behavior is seen for the HS case, in which the galaxy is biased toward lower values as the S/N decreases. In this case, the galaxy is underestimated by about 50% for an S/N = 30 and overestimated by up to ∼15% for an S/N = 100.
 |
Fig. 6. AD mock light curves with time delays. For illustration, only the u (blue) and y (black) light curves are shown. The former have the longer delay. The centroid of the transfer function obtained for the y band with respect to the u band is labeled inside each panel. |
The bottom panel of Fig. 7 shows that the proposed PFVG method is less sensitive to time delays in the light curves, and it clearly outperforms the FVG in CS and HS cases of AGN activity. It shows considerably less biased results and a more stable behavior per filter. The CS case is most notable, where the host galaxy is recovered within a precision of ∼1 and 5% for S/Ns of 100 and 30, respectively. In the HS case, the magnitude of the bias increases up to ∼10% of the true value.
 |
Fig. 7. Distributions of host-galaxy fluxes (gal |
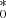
4. Data applications
In this section we apply the PFVG method to AGN data obtained by PRM campaigns, for which host-galaxy estimates have been obtained with the traditional FVG method. We select three sources: Mrk 509, Mrk 279, and 3C 120. The Mrk objects were monitored as part of a narrow-band PRM campaign dedicated to the RM of the accretion disk in AGN (Pozo Nuñez et al. 2017; Chelouche et al. 2019). The object 3C 120 was observed as part of a simultaneous broadband PRM monitoring of the BLR and the dust torus in AGN (Ramolla et al. 2018). In the following cases, the candidate host-galaxy vector (denoted by u in Sect. 2.3.2) is given by Sakata et al. (2010) unless stated otherwise. All data are publicly available and can be retrieved directly from the respective journals.
4.1. Mrk 509
Mrk 509 is a nearby (z = 0.0344; Huchra et al. 1993) and bright (V = 13 mag) Seyfert 1 galaxy known for its strong variability and characteristic outflows (Kaastra et al. 2011). Through modeling high-resolution Hubble Space Telescope (HST) images, Bentz et al. (2009) found a host-galaxy profile consistent with a bulge morphology type. These results are in agreement with the host-galaxy fluxes derived by the traditional FVG analysis presented in Pozo Nuñez et al. (2019) (PN+2019). Here we analyze the photometric light curves obtained in two different epochs (2016 and 2017) using the narrow bands with central wavelengths at 4300 ± 50, 5700 ± 50, 6200 ± 60, and 7000 ± 60 Å. The quality of the light curves obtained during both epochs is similar, with an average sampling of 1 day and an S/N ∼ 150 for each photometric band. Figure 8 shows the PFVG results along with the FVG obtained by PN+2019. As in PN+2019, we adopted the host-galaxy color given by Sakata et al. (2010). The recovered PFVG distributions are shown in Fig. A.4. Overall, the results obtained for 2016 and 2017 are consistent, as expected, given the high quality of the light curves. The PFVG is able to recover the galaxy fluxes with a precision of 10% compared to a precision of 20% obtained by the traditional FVG method. These new results lead to a better match with the bulge galaxy template, as can be seen in the fit residuals at the bottom panel of Fig. 8. Deviations from the assumptions of the linear relation between the fluxes (Eq. (2)) due to the accretion disk time delays observed in Mrk 509 (PN+2019) are negligible (< 1%).
 |
Fig. 8. Application of the PFVG method to the object Mrk 509 for epochs 2016 (left) and 2017 (right). The black dots correspond to the median of the recovered distributions of host galaxy fluxes (see Fig. A.4). The error bars show the formal 1σ uncertainty around the median. The results obtained by the FVG are shown with open blue squares. The redshifted bulge galaxy template of Kinney et al. (1996) is fitted to both PFVG (red) and FVG (blue) host-galaxy fluxes. The fit residuals, as obtained for the PFVG and FVG, are shown in the bottom panels. A small wavelength shift between the PFVG and FVG was introduced for clarity. |
4.2. Mrk 279
Mrk 279 is a nearby (z = 0.031) low-luminosity (V = 15 mag) Seyfert 1 galaxy. The FVG analysis by Chelouche et al. (2019) revealed an S0/Sa host-galaxy morphology, in agreement with the results obtained through modeling high-resolution HST images (Pogge & Martini 2002). The PFVG is able to recover the galaxy fluxes with an exceptional precision of 1% compared to the precision of 30% obtained by the traditional FVG method (Fig. 9). As shown in Fig. A.4, the average S/N of the light curves is ∼90. This is considerably lower than the average S/N ∼ 150 obtained for Mrk 509, but consistent with the fact that Mrk 279 is about 50% less luminous. Just as we remarked in the simulations in Sect. 3.2, we attribute the superior performance of the PFVG to the fact that it explicitly accounts for errors in the measurements.
 |
Fig. 9. Same as Fig. 8, but for Mrk 279 and a redshifted Sa galaxy template of Kinney et al. (1996) (red and blue lines). |
4.3. 3C 120
3C 120 is a nearby Fanaroff-Riley class I radio galaxy at redshift z = 0.033 (Walker et al. 1987). It has often been the target of several RM campaigns due to its strong variability, with amplitudes of up to ∼2 mag on timescales of a few years (Sakata et al. 2010; Pozo Nuñez et al. 2012; Grier et al. 2012). More recently, Ramolla et al. (2018) (R+2018) carried out a PRM campaign in order to study the BLR and the dust torus. R+2018 used the Johnson B and V broadbands to estimate the AGN continuum emission and the R and I broadbands to estimate the fraction of the continuum underneath the Hα emission line. The FVG analysis by R+2018 was performed using the BVI bands. The host-galaxy contribution in the R band was not recovered by the FVG due to the contamination of the Hα emission line, which is about 14% of the total flux. Moreover, deviations from the linear relation between the fluxes (Eq. (2)) were noted because the R band contains the delayed Hα emission, which does not correlate with the continuum variations traced by the other bands. To overcome these issues, R+2018 fit the spectral energy distribution (SED) with a redshifted S0 (Bentz et al. 2009) galaxy template and recovered an R-band galaxy flux of 5.90 ± 0.30 mJy.
Following R+2018, we adopted a host-galaxy color given by an S0 template (Kinney et al. 1996). The results are shown in Fig. 10. Notably, the recovered R-band galaxy flux 5.24 ± 0.32 mJy is in full agreement with the SED value reported by R+2018. Previous knowledge of the true color of the host galaxy provides an important advantage for the proposed PFVG method, hence the R-band galaxy flux can be directly recovered from the observed light curves. This is possible because the PFVG estimates a density of likely host-galaxy vectors along the assumed host-galaxy line. In this particular case, the method is therefore similar to searching for the best fit in a traditional SED analysis, but with the advantage of using the full information from the observed light curves.
 |
Fig. 10. Same as Fig. 8, but for 3C 120, and a redshifted S0 galaxy template of Kinney et al. (1996) (red and blue lines). |
Overall, our results for 3C 120 are consistent with those derived from the FVG method, except for the B band, where the PFVG flux is about 1.5 lower than the reported FVG value 1.69 ± 0.28 by R+2018. The PFVG shows a very narrow distribution of fluxes (see Fig. A.5) with a median value of 1.15 and a 1σ uncertainty of 6% compared to 16% obtained by the traditional FVG. The median of the PFVG distribution, however, agrees better with the S0 host-galaxy spectrum shown in Fig. 10. The better performance of the PFVG is expected because the B band corresponds to the light curve with the lowest S/N = 46. As shown in the simulations in Sect. 3.1, if the noise level differs considerably from band to band, then the PFVG method will outperform the FVG, as it weights data items according to their noise measurement.
5. Summary and conclusions
We have presented a novel probabilistic flux variation gradient approach to separate the AGN and host-galaxy contributions in the context of photometric reverberation mapping of AGN. We studied its performance using simulated light curves of varying quality, in particular, focusing on the observational characteristics of the next LSST survey. We have demonstrated that by explicitly accounting for error measurements in the light curves, the new probabilistic approach outperforms the traditional FVG in all simulated observational scenarios explored in this work. This leads to recovered galaxy fluxes with a precision lower than 1% for light curves with a moderate S/N. This represents a significant improvement compared to the 20% precision obtained by the traditional FVG.
Unlike the traditional FVG, PFVG does not identify just a single line that goes through the given total fluxes, but rather a density of possible lines. This makes it more robust to the presence of noise and informs us about the uncertainty in our estimates.
Both FVG and PVFG assume that the total flux observations form a line in the space of all filters (see Sect. 2). Both assume that the only reason that observations may deviate from this line is due to noise. In reality, however, total flux observations may additionally deviate from this line due to time delays that originate in the AGN accretion disk or BLR, for instance. This can lead to galaxy measurements that are biased by less than 5% in the case of objects with low to intermediate black hole masses. The biases can reach up to 10% in the case of the highest black hole masses (∼6-day time delay). In view of the overall measurements errors of typically more than 10% introduced by the absolute calibration of the photometric data, any bias in the PFVG galaxy estimation appears to be negligible.
We emphasize that the PFVG we presented is not a method for estimating the delay, but a method for separating the host galaxy contribution. Introducing a correction for the time delays requires a different model for the PFVG method, which is beyond the scope of this manuscript. When long delays are suspected, special methods that are based on a cross-correlation analysis or measurement of randomness of the data, for example (e.g., interpolated cross-correlation function Gaskell & Peterson 1987, discrete correlation function Edelson & Krolik 1988, von Neumann estimator Chelouche et al. 2017) could be used to correct for the delay and restore the linear relation between the fluxes on which the PFVG relies.
The application of the PFVG to PRM data sets yielded host-galaxy fluxes that agree better with the host-galaxy morphology types obtained through modeling high-resolution images. As a consequence, the method enables reliable estimates of the pure AGN luminosity, which is necessary to probe theoretical models of the AGN accretion disk, BLR, and dust-torus structure. This is especially important considering the large amount of data that will be provided by future large photometric survey telescopes such as the LSST.
In future endeavors, we would like to address certain assumptions made in the formulation of the proposed PVFG: we currently assume that observational noise is Gaussian distributed, but other choices may be more appropriate, especially in the presence of outliers. Moreover, we assume that no observations are missing and that observations in different filters co-occur (i.e., they are observed at the same time instance) so that we can form vectors of them. This limitation prevents the PFVG from combining observations from different surveys because each survey typically has its own observational characteristics (e.g., monitoring schedules, cadence).
Finally, an implementation of our method is publicly available through as a Julia package15.
Legacy Survey of Space and Time. https://www.lsst.org/
Sloan Digital Sky Survey. https://www.sdss.org/future/
Transiting Exoplanet Survey Satellite. https://tess.mit.edu/
James Webb Space Telescope. https://www.jwst.nasa.gov/
European Space Agency mission. https://sci.esa.int/web/euclid
PRM studies typically consider the host-galaxy slopes given by Sakata et al. (2010) obtained for 11 Seyfert 1 galaxies.
In the context of this work, the latent signal f(t) correspond to the driving AGN continuum light curves modeled as a random walk in Sect. 3.
I stands for the identity matrix. Its dimensions are implicitly defined by its context, e.g., in Eq. (4), it is of dimensions F × F.
In all numerical experiments, we use να = νβ = 10−4.
Coordinate x addresses a unique point on the line u ⋅ x.
Our method does not rely on this particular choice of prior.
In practice, we set them to a low value, e.g., ς = 𝜚 = 10−10 for numerical stability.
We denote the true galaxy vector by gal0, which is represented by the FVG intersection point of the noiseless and ideally sampled light curve (Δt = 0.01 days), as shown in Fig. A.2. The photometric bands implied by gal0 are made clear by the context.
As in the definition of gal0, the implied photometric bands are made clear by the context.
Acknowledgments
The authors gratefully acknowledge the generous and invaluable support of the Klaus Tschira Foundation. This research has made use of the NASA/IPAC Extragalactic Database (NED) which is operated by the Jet Propulsion Laboratory, California Institute of Technology, under contract with the National Aeronautics and Space Administration. This research has made use of the SIMBAD database, operated at CDS, Strasbourg, France. We thank the anonymous referee for his comments and careful review of the manuscript.
References
- Amendola, L., Appleby, S., Avgoustidis, A., et al. 2018, Liv. Rev. Rel., 21, 2 [Google Scholar]
- Bentz, M. C., Peterson, B. M., Netzer, H., et al. 2009, ApJ, 697, 160 [CrossRef] [Google Scholar]
- Bentz, M. C., Denney, K. D., Grier, C. J., et al. 2013, ApJ, 767, 149 [Google Scholar]
- Bettoni, D., Falomo, R., Kotilainen, J. K., et al. 2015, MNRAS, 454, 4103 [NASA ADS] [CrossRef] [Google Scholar]
- Bishop, C. M. 1999a, in Advances in Neural Information Processing Systems 11, eds. M. J. Kearns, S. A. Solla, & D. A. Cohn (Cambridge: MIT Press), 382 [Google Scholar]
- Bishop, C. M. 1999b, Proceedings Ninth International Conference on Artificial Neural Networks, ICANN’99 (IEEE), 1, 509 [CrossRef] [Google Scholar]
- Cackett, E. M., Horne, K., & Winkler, H. 2007, MNRAS, 380, 669 [Google Scholar]
- Cackett, E. M., Gelbord, J., Li, Y.-R., et al. 2020, ApJ, 896, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Caplar, N., Lilly, S. J., & Trakhtenbrot, B. 2017, ApJ, 834, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Chelouche, D., Pozo-Nuñez, F., & Zucker, S. 2017, ApJ, 844, 146 [CrossRef] [Google Scholar]
- Chelouche, D., Pozo-Nuñez, F., & Kaspi, S. 2019, Nat. Astron., 3, 251 [NASA ADS] [CrossRef] [Google Scholar]
- Choloniewski, J. 1981, Acta Astron., 31, 293 [NASA ADS] [Google Scholar]
- Collier, S. J., Horne, K., Kaspi, S., et al. 1998, ApJ, 500, 162 [Google Scholar]
- Edelson, R. A., & Krolik, J. H. 1988, ApJ, 333, 646 [Google Scholar]
- Falomo, R., Bettoni, D., Karhunen, K., et al. 2014, MNRAS, 440, 476 [NASA ADS] [CrossRef] [Google Scholar]
- Frank, J., King, A., & Raine, D. J. 2002, Accretion Power in Astrophysics (Cambridge: Cambridge University Press) [Google Scholar]
- Gaskell, C. M., & Peterson, B. M. 1987, ApJS, 65, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Gabor, J. M., Impey, C. D., Jahnke, K., et al. 2009, ApJ, 691, 705 [NASA ADS] [CrossRef] [Google Scholar]
- Glass, I. S. 1997, MNRAS, 292, L50 [NASA ADS] [Google Scholar]
- Glass, I. S. 1998, MNRAS, 297, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Glass, I. S. 2004, MNRAS, 350, 1049 [CrossRef] [Google Scholar]
- Grier, C. J., Peterson, B. M., Pogge, R. W., et al. 2012, ApJ, 755, 60 [NASA ADS] [CrossRef] [Google Scholar]
- Hernández Santisteban, J. V., Edelson, R., Horne, K., et al. 2020, MNRAS, 498, 5399 [CrossRef] [Google Scholar]
- Huchra, J., Latham, D. W., da Costa, L. N., Pellegrini, P. S., & Willmer, C. N. A. 1993, AJ, 105, 1637 [NASA ADS] [CrossRef] [Google Scholar]
- Isobe, T., Feigelson, E. D., Akritas, M. G., et al. 1990, ApJ, 364, 104 [NASA ADS] [CrossRef] [Google Scholar]
- Johnson, N. L., Kotz, S., & Balakrishnan, N. 1995, Continuous Univariate Distributions (New York: John Wiley), 2 [Google Scholar]
- Jenkins, J. M., Tenenbaum, P., Caldwell, D. A., et al. 2018, Res. Notes Am. Astron. Soc., 2, 47 [NASA ADS] [Google Scholar]
- Kaastra, J. S., Petrucci, P.-O., Cappi, M., et al. 2011, A&A, 534, A36 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kelly, B. C., Bechtold, J., & Siemiginowska, A. 2009, ApJ, 698, 895 [Google Scholar]
- Kinney, A. L., Calzetti, D., Bohlin, R. C., et al. 1996, ApJ, 467, 38 [NASA ADS] [CrossRef] [Google Scholar]
- Kollmeier, J., Anderson, S. F., Blanc, G. A., et al. 2019, BAAS, 51, 274 [NASA ADS] [Google Scholar]
- Korista, K. T., & Goad, M. R. 2019, MNRAS, 489, 5284 [CrossRef] [Google Scholar]
- Koshida, S., Minezaki, T., Yoshii, Y., et al. 2014, ApJ, 788, 159 [Google Scholar]
- LSST Science Collaboration (Abell, P. A., et al.) 2009, ArXiv e-prints [arXiv:0912.0201] [Google Scholar]
- McHardy, I. M., Connolly, S. D., Horne, K., et al. 2018, MNRAS, 480, 2881 [NASA ADS] [CrossRef] [Google Scholar]
- Mehdipour, M., Kaastra, J. S., Kriss, G. A., et al. 2015, A&A, 575, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Natarajan, P., Pacucci, F., Ferrara, A., et al. 2017, ApJ, 838, 117 [NASA ADS] [CrossRef] [Google Scholar]
- Oknyanskij, V. L. 1999, Odessa Astron. Publ., 12, 99 [Google Scholar]
- Pierce, C. M., Lotz, J. M., Primack, J. R., et al. 2010, MNRAS, 405, 718 [NASA ADS] [Google Scholar]
- Pogge, R. W., & Martini, P. 2002, ApJ, 569, 624 [CrossRef] [Google Scholar]
- Pović, M., Sánchez-Portal, M., Pérez García, A. M., et al. 2012, A&A, 541, A118 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pozo Nuñez, F., Ramolla, M., Westhues, C., et al. 2012, A&A, 545, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pozo Nuñez, F., Westhues, C., Ramolla, M., et al. 2013, A&A, 552, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pozo Nuñez, F., Haas, M., Chini, R., et al. 2014, A&A, 561, L8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pozo Nuñez, F., Ramolla, M., Westhues, C., et al. 2015, A&A, 576, A73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pozo Nuñez, F., Chelouche, D., Kaspi, S., & Niv, S. 2017, PASP, 129, 094101 [CrossRef] [Google Scholar]
- Pozo Nuñez, F., Gianniotis, N., Blex, J., et al. 2019, MNRAS, 490, 3936 [Google Scholar]
- Ramolla, M., Pozo Nuñez, F., Westhues, C., et al. 2015, A&A, 581, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ramolla, M., Haas, M., Westhues, C., et al. 2018, A&A, 620, A137 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sakata, Y., Minezaki, T., Yoshii, Y., et al. 2010, ApJ, 711, 461 [NASA ADS] [CrossRef] [Google Scholar]
- Sergeev, S. G., Doroshenko, V. T., Golubinskiy, Y. V., Merkulova, N. I., & Sergeeva, E. A. 2005, ApJ, 622, 129 [NASA ADS] [CrossRef] [Google Scholar]
- Shakura, N. I., & Sunyaev, R. A. 1973, A&A, 24, 337 [NASA ADS] [Google Scholar]
- Starkey, D., Horne, K., Fausnaugh, M. M., et al. 2017, ApJ, 835, 65 [NASA ADS] [CrossRef] [Google Scholar]
- Suganuma, M., Yoshii, Y., Kobayashi, Y., et al. 2006, ApJ, 639, 46 [NASA ADS] [CrossRef] [Google Scholar]
- Tipping, M. E., & Bishop, C. M. 1999, J. R. Stat. Soc.: Ser. B (Stat. Methodol.), 61, 611 [Google Scholar]
- Vazquez, B., Galianni, P., Richmond, M., et al. 2015, ApJ, 801, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Villforth, C., Hamann, F., Rosario, D. J., et al. 2014, MNRAS, 439, 3342 [NASA ADS] [CrossRef] [Google Scholar]
- Walker, R. C., Benson, J. M., & Unwin, S. C. 1987, ApJ, 316, 546 [NASA ADS] [CrossRef] [Google Scholar]
- Watson, D., Denney, K. D., Vestergaard, M., et al. 2011, ApJ, 740, L49 [CrossRef] [Google Scholar]
- Winkler, H., Glass, I. S., van Wyk, F., et al. 1992, MNRAS, 257, 659 [NASA ADS] [Google Scholar]
Appendix A: Additional tables and figures
 |
Fig. A.1. Example of a simulated UV/Optical AGN spectrum (solid blue line, left) along with a Sa-type host-galaxy template (solid red line). The transmission curves of the LSST broadband filters are shown with solid black lines (ugrizy; from left to right). In this particular case, the host galaxy contributes about 50% of the total flux at 5100 Å (rest frame). Flux-calibrated light curves resulting from the convolution between each LSST broadband filter with the AGN and galaxy components (right). |
PFVG results.
 |
Fig. A.2. FVG for the LSST-simulated light curves from our mock catalog. Panel (a) shows the FVG results obtained for the ideal noiseless light curve with a time sampling of 0.1 days. Panels (b), (c), and (d) show the FVG results for light curves of varying quality. |
 |
Fig. A.3. Recovered FVG (top) and PFVG (bottom) distributions of host-galaxy fluxes (gal |

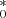
 |
Fig. A.4. Recovered PFVG distributions of host-galaxy fluxes for objects Mrk 509 (top panels) and Mr k279 (bottom panels). The vertical dotted line marks the galaxy flux obtained by the FVG method. The dark shaded area marks the 68% confidence range we used to estimate the 1σ uncertainty around the median of the distribution. |
All Tables
All Figures
|
Fig. 1. Sketch of FVG. Observations in filters i and j measured at three different time instances (right). By pairing flux values of co-occurring observations, we form points in the flux-flux plot that fall on a line (dashed). Vector gij (in brown) corresponds to the unobserved host-galaxy and defines a line gij ⋅ x that intersects the dashed line at x0, the point of (unobserved) minimum AGN activity. The FVG method consists of finding the intersection of u ⋅ x and the dashed line; u (in green) is a vector that has the same direction (i.e., same colors) as gij and therefore also intersects the dashed line at x0. |
| In the text | |
|
Fig. 2. Flux variation gradient applied to set of light curves from our LSST mock catalog. Left panel: light curves with an average time sampling of Δt = 3 days, S/N = 30, and total time span of T = 200 days. Low and high levels of AGN activity are marked with blue and magenta circles, respectively. Right panel: FVG analysis for the u and g bands only. Other bands are given in Fig. A.2. The dotted orange and black lines cover the upper and lower standard deviations of the OLS bisector fit (solid lines) for the combined (black) and higher (orange) AGN state of activity. The color of the Sa galaxy we used in the simulations is shown as a dotted red line. |
| In the text | |
|
Fig. 3. Recovered FVG host-galaxy fluxes (gal |
| In the text | |
|
Fig. 4. Recovered PFVG distributions (see Eq. (10)) of host-galaxy fluxes obtained for the HS (transparent colored histogram) and CS (solid colored histogram). Distributions obtained for poorly sampled light curves, with low and high S/N, are shown in panels a and b, respectively. Distributions obtained for well-sampled light curves, with low and high S/N, are shown in panels c and d, respectively. The vertical dotted line marks the true galaxy value used in the simulations (gal0). The 68% confidence range used to estimate the 1σ uncertainty around the median is shown as transparent black boxes. (a) S/N = 10, Δt = 10 days. (b) S/N = 100, Δt = 10 days. (c) S/N = 10, Δt = 1 days. (d) S/N = 100, Δt = 1 days. |
| In the text | |
|
Fig. 5. Precision on the recovered galaxy fluxes obtained from the FVG (upper panels) and PFVG (lower panels) distributions for the CS and HS of AGN activity. The red line shows the Sa-type host-galaxy (observer’s frame) spectrum. The galaxy fluxes (in mJy) at each filter are plotted as filled black stars. The lines indicate the range of galaxy values that is recovered within the 68% confidence interval, and they are given for an S/N = 10 (purple), 100 (cyan), and 200 (yellow). |
| In the text | |
|
Fig. 6. AD mock light curves with time delays. For illustration, only the u (blue) and y (black) light curves are shown. The former have the longer delay. The centroid of the transfer function obtained for the y band with respect to the u band is labeled inside each panel. |
| In the text | |
|
Fig. 7. Distributions of host-galaxy fluxes (gal |
| In the text | |
|
Fig. 8. Application of the PFVG method to the object Mrk 509 for epochs 2016 (left) and 2017 (right). The black dots correspond to the median of the recovered distributions of host galaxy fluxes (see Fig. A.4). The error bars show the formal 1σ uncertainty around the median. The results obtained by the FVG are shown with open blue squares. The redshifted bulge galaxy template of Kinney et al. (1996) is fitted to both PFVG (red) and FVG (blue) host-galaxy fluxes. The fit residuals, as obtained for the PFVG and FVG, are shown in the bottom panels. A small wavelength shift between the PFVG and FVG was introduced for clarity. |
| In the text | |
|
Fig. 9. Same as Fig. 8, but for Mrk 279 and a redshifted Sa galaxy template of Kinney et al. (1996) (red and blue lines). |
| In the text | |
|
Fig. 10. Same as Fig. 8, but for 3C 120, and a redshifted S0 galaxy template of Kinney et al. (1996) (red and blue lines). |
| In the text | |
|
Fig. A.1. Example of a simulated UV/Optical AGN spectrum (solid blue line, left) along with a Sa-type host-galaxy template (solid red line). The transmission curves of the LSST broadband filters are shown with solid black lines (ugrizy; from left to right). In this particular case, the host galaxy contributes about 50% of the total flux at 5100 Å (rest frame). Flux-calibrated light curves resulting from the convolution between each LSST broadband filter with the AGN and galaxy components (right). |
| In the text | |
|
Fig. A.2. FVG for the LSST-simulated light curves from our mock catalog. Panel (a) shows the FVG results obtained for the ideal noiseless light curve with a time sampling of 0.1 days. Panels (b), (c), and (d) show the FVG results for light curves of varying quality. |
| In the text | |
|
Fig. A.3. Recovered FVG (top) and PFVG (bottom) distributions of host-galaxy fluxes (gal |
| In the text | |
|
Fig. A.4. Recovered PFVG distributions of host-galaxy fluxes for objects Mrk 509 (top panels) and Mr k279 (bottom panels). The vertical dotted line marks the galaxy flux obtained by the FVG method. The dark shaded area marks the 68% confidence range we used to estimate the 1σ uncertainty around the median of the distribution. |
| In the text | |
 |
Fig. A.5. Same as Figure A.4, but for 3C 120. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.