| Issue |
A&A
Volume 651, July 2021
|
|
|---|---|---|
| Article Number | A108 | |
| Number of page(s) | 17 | |
| Section | Catalogs and data | |
| DOI | https://doi.org/10.1051/0004-6361/202040219 | |
| Published online | 27 July 2021 | |
Active galactic nuclei catalog from the AKARI NEP-Wide field⋆
1
National Centre for Nuclear Research, Pasteura 7, 093 Warsaw, Poland
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Astronomical Observatory of the Jagiellonian University, ul.Orla 171, 244 Krakow, Poland
3
Aix Marseille Univ. CNRS, CNES, LAM, Marseille, France
4
Institute of Astronomy, National Tsing Hua University, 101, Section 2. Kuang-Fu Road, Hsinchu 30013, Taiwan
5
Department of physics and astronomy, UCLA, 475 Portola Plaza, Los Angeles, CA 90095-1547, USA
6
Tokyo University of Science, 1-3, Kagurazaka, Shinjuku, Tokyo 8601, Japan
7
Department of Earth Science Education, Kyungpook National University, Daegu 41566, Korea
8
RAL Space, Rutherford Appleton Laboratory, Chilton, Didcot, Oxfordshire OX11 0QX, UK
9
School of Physical Sciences, The Open University, Milton Keynes MK7 6AA, UK
10
Oxford Astrophysics, University of Oxford, Keble Rd, Oxford OX1 3RH, UK
11
Astronomy Program, Department of Physics and Astronomy, Seoul National University, 1 Gwanak-ro, Gwanak-gu, Seoul 08826, Korea
12
Department of Astronomy, Kyoto University, Kitashirakawa-Oiwake-cho, Sakyo-ku, Kyoto 8502, Japan
13
Academia Sinica Institute of Astronomy and Astrophysics, 11F of Astronomy-Mathematics Building, AS/NTU, No.1, Section 4, Roosevelt Road, Taipei 10617, Taiwan
14
Research Center for Space and Cosmic Evolution, Ehime University, 2-5 Bunkyo-cho, Matsuyama, Ehime 8577, Japan
15
Korea Astronomy and Space Science Institute (KASI), 776 Daedeok-daero, Yuseong-gu, Daejeon 34055, Korea
Received:
23
December
2020
Accepted:
13
April
2021
Abstract
Context. The north ecliptic pole (NEP) field provides a unique set of panchromatic data that are well suited for active galactic nuclei (AGN) studies. The selection of AGN candidates is often based on mid-infrared (MIR) measurements. Such methods, despite their effectiveness, strongly reduce the breadth of resulting catalogs due to the MIR detection condition. Modern machine learning techniques can solve this problem by finding similar selection criteria using only optical and near-infrared (NIR) data.
Aims. The aim of this study is to create a reliable AGN candidates catalog from the NEP field using a combination of optical SUBARU/HSC and NIR AKARI/IRC data and, consequently, to develop an efficient alternative for the MIR-based AKARI/IRC selection technique.
Methods. We tested set of supervised machine learning algorithms for the purposes of carrying out an efficient process for AGN selection. The best models were compiled into a majority voting scheme, which used the most popular classification results to produce the final AGN catalog. An additional analysis of the catalog properties was performed as a spectral energy distribution fitting via the CIGALE software.
Results. The obtained catalog of 465 AGN candidates (out of 33 119 objects) is characterized by 73% purity and 64% completeness. This new classification demonstrates a suitable consistency with the MIR-based selection. Moreover, 76% of the obtained catalog can be found solely using the new method due to the lack of MIR detection for most of the new AGN candidates. The training data, codes, and final catalog are available via the github repository. The final catalog of AGN candidates is also available via the CDS service.
Conclusions. The new selection methods presented in this paper are proven to be a better alternative for the MIR color AGN selection. Machine learning techniques not only show similar effectiveness, but also involve less demanding optical and NIR observations, substantially increasing the extent of available data samples.
Key words: infrared: galaxies / galaxies: active / catalogs / techniques: photometric / methods: data analysis
Final catalog of AGN candidates is also available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/cat/J/A+A/651/A108
Note to the reader: the co-author's name Małek has been corrected on 05 August 2021.
© ESO 2021
1. Introduction
Active galactic nuclei (AGN) are identified through the centers of galaxies occupied by supermassive back holes (SMBH) in the violent accretion phase of their surrounding matter. Despite the known relation between the activity of central supermassive black holes and the general evolution of galaxies, in particular star formation processes, our understanding of this co-evolutionary behavior is still incomplete (Netzer 2015; Padovani et al. 2017).
An AGN definition can be assigned to a broad class of objects, starting from quasars, the most luminous objects in the universe, to spiral galaxies characterized by a high nuclear luminosity (Seyfert galaxies), or radio galaxies. These types display different observational properties in both optical and non-optical domains. This diversity does not necessarily correspond to differences in the physical properties of objects and can be explained in terms of the AGN unified model (Antonucci 1993; Netzer 2015). In the unified model, an AGN is described as an axisymmetric layered structure. It is formed by a central engine surrounded by the sub-pc accretion disc of infalling matter. At the range of ≃1 pc, the broad line region (BLR) of high density, there is dust-free gas located here. Outside a BLR lies a dusty torus, the geometry of which determines the ionization cone shape. The cone itself is a place of lower density ionized gas – a narrow line region (NLR). In its basic form, the unified AGN model, described by Antonucci (1993), attempts to characterize different AGN types as a combination of two parameters: the torus inclination to the line of sight and the source luminosity.
Two main AGN types are referred to as type-I and type-II. Type-I AGN are characterized by the presence of broad permitted and semi-forbidden emission lines. Objects of this type with low to intermediate luminosity also show the presence of strong narrow emission lines. The appearance of a type-I is explained in terms of a geometrical phenomena – an AGN, with the ionization cone facing towards the observer, shows emission from the BLR as well as from the NLR (Antonucci 1993; Stern & Laor 2012). If the observer is not able to observe the BLR directly, then the AGN is defined as type-II. It is characterized by narrow emission lines showing photoionization features (Merloni et al. 2014). In this case, the observer is facing a side of the AGN’s dusty torus, so the emission from the BLR might be absorbed and reemitted at longer wavelengths in the infrared. Nonetheless, broad emission lines can still be observed via spectropolarimetrical techniques (Marinucci et al. 2012; Tran 2003). This two-type classification is further complicated by the existence of so called “true type-II”, with no detectable broad lines, and without strong dust coverage (Panessa & Bassani 2002; Shi et al. 2010). Moreover, some works (e.g., Assef et al. 2015) suggest an under-representation of type-II objects in a modern catalogs, causing a lack of realistic perspectives of the coexistence of both types.
Another big question on AGN physics is based on recently discovered changing look (CL) AGNs (e.g., LaMassa et al. 2015; Sheng et al. 2017; Stern et al. 2018; Charlton et al. 2019). This type of objects can exhibit transitions between AGN types by the emergence or disappearance of broad emission lines. As a generally accepted hypothesis about the mechanism of CL AGN activity that is based on instabilities in the accretion disc cannot be explained in terms of a unified model and requires further research (Lawrence 2018; Dodd et al. 2021).
1.1. AGN photometric selection.
In order to better understand the physics hidden behind the AGN appearance, we need to gather a large amount of observational data in different spectral ranges. The AGN classification is commonly done via “diagnostic diagrams” describing emission and absorption line ratios (e.g., Baldwin et al. 1981; Kauffmann et al. 2003; Kewley et al. 2006). Such classification requires time consuming spectroscopic measurements, which should be preceded by a careful target selection.
A general characteristic of many AGN types is the form of a power-law shaped spectral energy distribution (SED) that allows us to effectively construct such preselection as a photometric classification task (Alonso-Herrero et al. 2006). A power-law SED shape of an AGN, caused mainly by a central engine activity, shows the emission growth with the wavelength from the ultraviolet (UV) to infrared (IR) wavelength ranges (Elvis et al. 1994; Alonso-Herrero et al. 2006). Despite this common property, AGN catalogs selected with photometry-only data obtained from various wavelength ranges can be biased and contaminated by other sources.
Optical broadband selection is sensitive to broad emission lines. In the rest frame, optical photometry gives a standard set of colors providing an easy method of AGN separation. However, due to varying redshift, the same AGN emission lines can be detected in different passbands, often giving stellar-like colors. This results in low completeness or high contamination in the redshift ranges between 2.6 and 3.5 (Richards et al. 2002). Examples of an optical selection can be a quasar (also known as a quasi-stellar object, QSO) target selection from the SDSS (York et al. 2000) spectroscopic observations, where the combination of morphological properties and color selection methods have been used to separate QSOs from stars (Richards et al. 2004, 2009). The biggest issue with the optical-only selection is a very low completeness of type-II AGN, caused by colors, which might be easily classified as stellar-like or type-I-like due to the conjunction of host and scattered AGN emission (Zakamska et al. 2003, 2019).
A wavelength range that is free from the mentioned bias is the X-ray range. The hard X-ray emission, taking place in the accretion disk region (and also in the region of jets) can penetrate the dust and gas, providing an opportunity to detect even very obscured objects and complement the underrepresented type-II AGN class (e.g., Malizia et al. 2012). The main selection effect present in X-ray AGN catalogs comes from a higher absorption of lower energy X-ray photons, which may interfere with the identification of heavily obscured AGN (Padovani et al. 2017). Nevertheless, weak X-ray emission from a host galaxy as well as easily recognizable emission from a central engine makes X-ray surveys an efficient tool for AGN selection (e.g., Lehmer et al. 2012; Luo et al. 2017).
Another way to select AGN is to look for the infrared emission of a dusty torus, which comes from a reprocessed emission of accretion disk and, due to power-law behavior, dominates AGN SED in the near-infrared (NIR, 1–3 μm) and mid-infrared (MIR, 3–50 μm). The NIR AGN selection (e.g., Francis et al. 2004; Kouzuma & Yamaoka 2010), while being highly prone to contamination (see below), gives essential information about red AGN and red QSO in particular (Glikman et al. 2007, 2012, 2013; Banerji et al. 2012). What is more efficient and more common is MIR AGN selection (e.g., de Grijp et al. 1987; Stern et al. 2005, 2012; Oyabu et al. 2011). It enables to fully take advantage of the power-law SED to detect both type-I and II AGN that are characterized by hot dust MIR emission. Despite its effectiveness, MIR AGN selection is not free of biases and contamination sources and these aspects should be carefully studied (for further discussion see Padovani et al. 2017).
Contaminants. One of the most informative parts of AGN emission is located in range of 3–5 μm, where the AGN stand out from the rest of the sources as typically redder objects. There are two main types of contaminants. Both share similar colors and should be taken into account during selection. Near the galactic plane, the main contamination comes from brown dwarfs (BD) and young stellar objects (YSO, Koenig et al. 2012). In particular, YSO, as a much more numerous class, can strongly reduce an AGN catalog purity. At high galactic latitudes, AGN can be easily confused with star forming galaxies (SFG) because AGN-like MIR colors can be produced both by polycyclic aromatic hydrocarbons (PAH) molecules emission as well as the 1.6 μm stellar bump. At low-z, the stellar bump is a serious contamination source in NIR-selected AGN catalogs, at the same time high-z SFG occupy AGN color space in the MIR, forcing to set a completeness-purity trade-off (Donley et al. 2010; Assef et al. 2013).
Biases. Bias present in MIR-selected AGN catalogs comes from three main sources: redshift dependence, dust luminosity, and black hole scaling relations. Sensitivity of short MIR wavelengths to hot dust emission decreases with increasing redshift due to both K-correction and Hα emission line contamination. The latter results in a strong bias against AGN at redshifts z = [4, 5] (e.g., Assef et al. 2013). Redshift-based biases present in IR and optical AGN selections can be partially bypassed by combined optical-IR methods (Richards et al. 2015; Banerji et al. 2015). However, some AGN might also be missed in IR selection due to low dust content or to low hot dust emission relative to emission from the host galaxy (see e.g., Roseboom et al. 2013). The last source of bias comes from the correlation of SMBH mass with luminosity of spheroidal component detected for low-redshift AGN (Marconi & Hunt 2003). This dependency relates the ratio the of AGN luminosity to host luminosity measured at a particular wavelength (Lλ, AGN/Lλ, host) to L/LEdd, where LEdd refers to Eddington luminosity. Since the MIR AGN selection is sensitive only to the high-value tail of the L/LEdd distribution, AGN with significant disk or irregular components need to show high L/LEdd value to be selected in the MIR (Hickox et al. 2009). As a consequence, lower-mass galaxies, which often have a strong non-bulge component, are underrepresented in MIR AGN catalogs (Magorrian et al. 1998).
All selection methods discussed above primarily use color cuts and magnitude limits to define the parameter space occupied by AGN candidates and do not fully utilize advantages offered in operating in a high dimensional space. Modern approaches to data analysis often use automated machine learning (ML) techniques, which allow not only for the discovery of more sophisticated dependencies in a high dimensional space, but also to efficiently process big data volumes present in modern day surveys. An ML-based AGN selection is mostly done in a supervised manner, where the algorithm first learns how to select a specific class of objects on the data set with known classes (we refer to this process as training). After the learning stage, a trained algorithm can classify objects with unknown class (or label) during the generalization stage. Supervised learning allows for the precisely control of the process of selection at the expense of effectiveness, which depends on a training sample quality. Supervised learning has successfully been applied to AGN selection in broad a spectral range, for instance, in X-ray surveys (McGlynn et al. 2004), optical data (Claeskens et al. 2006; Nakoneczny et al. 2019), and IR or combined optical-IR data (Zhang & Zhao 2004; Małek et al. 2013; Nakoneczny et al. 2021).
1.2. North ecliptic pole field.
A satisfactory picture of complex AGN properties requires the provision of information over a broad spectral range, as described above. Hence, the most suitable for AGN studies are fields with broad panchromatic coverage. A region at the north ecliptic pole (NEP; α = 18h00m00s, δ = 66° 33′88″) is well suited for this task since it provides broad range of information: from X-ray observations taken by ROSAT and Chandra space missions (Henry et al. 2006; Krumpe et al. 2015), UV (GALEX satellite, Burgarella et al. 2019), and from optical measurements taken by Canada France Hawaii Telescope (CFHT) and, recently, by the SUBARU Hyper-Suprime Camera (HSC) instrument (Hwang et al. 2007; Huang et al. 2020; Ho et al. 2021), NIR observations performed by the CFHT/Wircam and FLAMINGOS instruments (Oi et al. 2014; Jeon et al. 2014), IR covered by the space missions AKARI, Spitzer Space Telescope, WISE and Herschel (Kim et al. 2012; Jarrett et al. 2011; Nayyeri et al. 2018; Pearson et al. 2017), up to sub-mm (SCUBA-2, Geach et al. 2017; Shim et al. 2020) and radio (WSRT, GMRT) wavelengths (White et al. 2010, 2017). The high galactic latitude of the NEP field ensures little galactic dust and star pollution, creating a good conditions for deep, extragalactic observations.
The NEP panchromatic data have been extensively used to test or develop several AGN selection techniques, such as SED fitting classification (Huang et al. 2017; Oi et al. 2020; Wang et al. 2020; Yang et al. 2020), traditional color selection (Jarrett et al. 2011; Fadda & Rodighiero 2014), combinations of both (Barrufet et al. 2020), machine learning selection (Poliszczuk et al. 2019; Chen et al. 2020), or radio-based selection (Karouzos & Im 2012; Barrufet de Soto et al. 2017).
1.3. Outline.
This work aims to create a new, reliable AGN catalog from NEP data based on a combination of optical data from SUBARU/HSC and NIR data gathered by AKARI satellite. The AKARI satellite mission (Murakami et al. 2007) carried out observations in near-(NIR) mid-(MIR) and far-infrared (FIR). In particular it observed the NEP field with NIR and MIR passbands in two surveys (Matsuhara et al. 2006): AKARI NEP-Wide (Lee et al. 2009; Kim et al. 2012), and AKARI NEP-Deep (Wada et al. 2008), creating unique IR catalogs in terms of both, photometric coverage and depth. Data gathered by the AKARI telescope in conjunction with new observations of the NEP field provided by the SUBARU/HSC instrument (Oi et al. 2020; Kim et al. 2021) establish the cutting edge environment for AGN selection as well as setting the broad picture of its optical-IR relation. This data set can be also viewed as a test ground for upcoming synergies of the future photometric surveys, such as Vera C. Rubin Observatory (Ivezić et al. 2019) and Euclid (Laureijs et al. 2010).
A ML approach to combined NIR and MIR AGN selection in AKARI NEP-Deep data described in Poliszczuk et al. (2019) serves as an introductory study for the present paper in terms of feature importance, extrapolation risk estimation and application of fuzzy logic to classification algorithms. The new method overcomes previously encountered difficulties related to small generalization volume and extrapolation risk and shows that it is possible to recover properties of AGN MIR selection using only optical and NIR data. Such improvement significantly increases the catalog volume and makes the presented method suitable for modern AGN studies. The final AGN catalog, training sample, Python codes and training results can be found on authors github1. The AGN catalog can be also accessed via CDS database and Virtual Observatory tools2.
This present work is organized as follows. In Sect. 2, we describe the data used for training and generalization stages of ML. In Sect. 3, we walk through the applied ML pipeline. In Sect. 4, we describe the classification evaluation results, the AGN catalog we obtained, and a comparison with other AGN selection methods. Section 5 summarizes properties of the obtained catalog as well as the effectiveness of the applied methods. The appendix contains information about software used in the present work and additional data describing the performance evaluation.
2. Data
2.1. AKARI NEP-Wide data
The AKARI NEP-Wide survey covers a circular area of 5.4 deg2 centered at the North Ecliptic Pole (NEP). It provides photometric observations in the NIR and MIR passbands, taken by the Infra-red Camera instrument (IRC, Onaka et al. 2007). The IRC was equipped with nine filters: three NIR filters centered at 2 μm (N2; with coverage range 1.9–2.8 μm), 3 μm (N3; 2.7–3.8 μm), 4 μm (N4; 3.6–5.3 μm) and six MIR filters centered at 7 μm (S7; 3.6–5.3 μm), 9 μm (S9W; 6.7–11.6 μm), 11 μm (S11; 8.5–13.1 μm), 15 μm (L15; 12.6–18.4 μm), 18 μm (L18W; 13.9–25.6 μ), and 24 μm (L24; 20.3–26.5 μm). The “W” letter next to filters centered at 9 μm and 18 μm refers to wide coverage of wavelengths relevant to the neighboring filters (e.g., S9W covers the wavelength range of S7 and S11 filters).
The IRC continuous wavelength coverage, as well as choice of filter placement and profile gives important insights into the stellar and AGN activity (for further discussion see Matsuhara et al. 2006). The N2 and N3 filters can trace the stellar mass of galaxies at different redshifts as well as help to identify star-forming galaxies (SFG) due to the location of the 1.6 μm stellar bump. Moreover, the NIR filters are sensitive to the 3.3 μm PAH feature of local starburst galaxies and carbon dust absorption feature located at 3.4 μm, which characterizes low-z obscured AGN. The N4 passband is the most crucial from the perspective of AGN identification, since it covers 3–5 μm range, where the power-law properties of an AGN SED are the most prominent. The 9–20 μm range covered by MIR passbands gives the possibility to trace dust emission from AGN and LIRG/ULIRG due to presence of several silicate dust features with particularly strong 9.8 μm absorption features. On the other hand, PAH emission features centered around 7.7 μm fall into the range of the S7 band, allowing identification of starburst galaxies (Kim et al. 2019).
2.2. Optical photometry and training sample
SUBARU/HSC (Miyazaki et al. 2012) optical observations of the NEP field (Goto et al. 2017) allows for the detection of optical counterparts for even the faintest of AKARI sources. Previous optical follow-ups of the AKARI NEP field performed by CFHT/MegaCam (Hwang et al. 2007) and Maidanak/SNUCam (Jeon et al. 2010) instruments were unable to detect sufficient fraction of IR sources due to the depth limit. New HSC data processed by Oi et al. (2020) and matched with AKARI data by Kim et al. (2021) gives measurements in g, r, i, z, Y passbands 1.7−2.5 mag deeper than previous surveys.
Optical and IR photometry gathered by SUBARU/HSC and AKARI/IRC was used to perform AGN selection on the data set. Additionally, we need class labels for a training sample in order to adjust ML algorithms to a specific classification task. The majority of labels for a training sample were taken from spectroscopic follow-up (Shim et al. 2013) performed by MMT/HECTOSPEC (Fabricant et al. 2005) and WYIN/HYDRA (Barden et al. 1993) spectrographs. The choice of training sample is crucial in ML classification methods since it has direct impact on the algorithm performance and generalization possibilities. Hence, both target selection criteria as well as the process of class assignment in the labeled data must be well understood. Primary targets for spectroscopic observations were defined as objects bright in MIR passbands (S11 < 18.5 mag and L15 < 17.9 mag) with an additional limit in the Maidanak R band (16 < R < 21−22.5 mag depending on a spectrograph) in order to select objects suitable for spectroscopic observations. A secondary targets group was made of specific classes of candidates described in terms of optical, NIR and MIR color cuts. AGN candidates from the secondary target group were selected using a color-cut method developed by Lee et al. (2007), which uses power-law SED properties of AGN manifested in red NIR and MIR colors: N2 − N4 < 0 and S7 − S11 < 0. This method was originally used on the S11 < 18.5 mag limited sample. The catalog, presented in Shim et al. (2013), was augmented by additional spectroscopic measurements taken by Keck/DEIMOS (Faber et al. 2003), GTC/OSIRIS (Cepa et al. 2000) and SUBARU/FMOS (Kimura et al. 2010) instruments by AKARI NEP Team as well as X-ray measurements from the Chandra (Weisskopf et al. 2000; Krumpe et al. 2015) telescope. This way the AGN training sample was constructed mainly from targets fulfilling the Lee et al. (2007) AGN candidate conditions or X-ray active sources. Sources detected by Chandra with an X-ray luminosity of log LX > 41.5 erg s−1 (0.5–7 keV) will be referred to as XAGN. Optically detected objects with at least one emission line with Full Width at Half Maximum (FWHM) larger than 1000 km s−1 are referred to as AGN1.
Table 1 shows the number of objects measured in particular HSC and IRC passbands. The decrease in the data volume for the passbands corresponding to the longer wavelengths is caused by decreasing sensitivity in the MIR range as well as the gradual disappearance of Galactic stars in the MIR bands. In order to preserve larger data volume only optical and NIR data were used for the AGN selection in the present work. It resulted in 1547 objects in the training set consisting of 1348 galaxies and 199 AGN (163 AGN1 and 36 XAGN) and 45 841 in the generalization set (additional limitations applied to the generalization set are described in Sect. 3.5). Table 2 shows general statistical properties of the training sample.
Number of objects detected in particular SUBARU/HSC and AKARI/IRC passbands.
Statistical properties of the training sample.
Figure 6a presents a N2 − N4 vs N4 color-magnitude (CM) plot for training data. This particular CM dependency is often used for AKARI/IRC data presentation (e.g., Lee et al. 2007, 2009) and is present in classification analysis in Sect. 4. The N2 − N4 color, being sensitive to power-law propreties of the short MIR AGN SED, brings out the main characteristics of the sselection task described in the present paper. We can see that the main locus of type-I AGN is placed in the red part of N2 − N4 color as it is imposed by the selection creteria of the Lee et al. (2007) method. One can also observe the increase of galaxy redshift with N2 − N4 reddening, making high-z SFG the main contaminant source in the type-I AGN area. The XAGN objects are scattered around whole training sample area, reaching even very low N2 − N4 values. The stellar locus, not represented in this work, is placed in the left lower corner of the plot.
2.3. Panchromatic NEP catalog
In the present work, the properties of both training data set and the obtained catalog were investigated a posteriori via a SED fitting analysis. In order to obtain a robust estimation of the SED, we need a broad wavelength photometric coverage of the studied object. For this purpose, part of the Kim et al. (2021) panchromatic catalog covering optical to sub-mm wavelength range was used. In order to obtain more precise fitting results and to ensure the correct matching of objects from different surveys, several limitations were made in the further analysis: the WISE W4 data were excluded, g, r, i, z, and Y measurements were taken only from SUBARU/HSC instrument and the J passband data were taken from CFHT/Wircam instead of FLAMINGOS, despite the smaller field observed by the first instrument.
3. Methodology
3.1. Feature selection
The usual astronomical parameters frequently prove not to be optimal for a specific ML task. To obtain a more suitable data representation, we can use feature engineering techniques for data transformation. In the present paper, the Kolomogorov-Smirnov two sample test (Massey 1951) was used. By calculating the biggest difference in cumulative distribution functions of two samples (referred to as the KS-statistic), we can test whether samples come from the same distribution. In a case of binary classification problem, this method can be used for feature selection by calculating the KS-statistic value for class samples represented by different features. Features that are expected to obtain the highest KS-statistic value will show the biggest difference in class distributions, hence, they will be the most suitable for a specific classification problem. The KS two-sample test gives information about separate features, without estimating their importance in interaction with a particular feature subset.
Another important issue that should be addressed during feature selection is the number of selected features. This number cannot be too high due to two (often connected) possible risks: first, it might introduce redundant features, that carry information already present in a feature set, second, the curse of dimensionality (Bishop 2006) might cause substantial sparsity of the data in a high-dimensional space, resulting in a poor performance. In the present work, the limit imposed on the number of selected features was based on the assumption that adding a filter to the feature set would not introduce redundant information. Thus, the optimal feature set should contain information from most of the available filters, but the number of features should not be significantly larger than the number of available filters.
3.2. Classification algorithms
In the present paper, several types of supervised classification algorithms were tested. The imbalanced nature of the training data set can have a major impact on the classifier performance and thus has to be taken into account at several stages of the ML pipeline construction. It is considered a good practice to test several types of classification algorithms in a classical setup and in a setup that is suitable for imbalanced data (Fernández et al. 2018). This is done not only to find the best algorithm for a particular data set and classification task, but also to control how the growing model complexity will improve performance on the labeled data set. This issue can be analyzed in terms of bias-variance dependency of the model. One bias within the model is the strength of assumptions it is making about a decision boundary. In general, linear models have a larger bias than nonlinear ones. If a bias is too great, the model will not be able to properly adapt to the training data. Such a model is referred to as underfitted. On the other hand, a model can learn specific training data too precisely, including the statistical noise of the sample. This situation is called overfitting. An overfitted model will have high variance, that is, it will be very sensitive to changes in a training data. In an ideal situation, we should strive for an optimal bias-variance trade-off, where a model can be effectively fitted to a training data set without learning its random fluctuations.
Before applying real world algorithms, one has to settle on some lowest boundaries for a classifier performance comparison. For this purpose, a so called dummy classifier was constructed. It classifies objects according to the class fraction in the training data. Next, a linear model with the form of the logistic regression algorithm (Berkson 1944) was tested. It relates a linear combination of the input variables (features) to the logarithm of the odds for the positive value target variable. In this way, it can directly model the probability of a particular target value for a given input.
Often the separation of the classes in the input feature space is very hard or even impossible. The main goal of the support vector machine (SVM) algorithm developed by Cortes & Vapnik (1995) is to map data into the high dimensional space, where the separating hyperplane can be constructed. An output of the SVM classifier relies on the position of objects with respect to such a hyperplane; This distance also serves as a basis for indirect probability estimation. In the SVM formulation, the mapping from an input to a high-dimensional space is substituted by a kernel function which is set to be a radial basis function (RBF) in this work.
Another family of popular classification algorithms are based on decision tree structures (Breiman et al. 1984). Single tree classifiers can perform very well on the training data, but due to the high variance of the model, it often tends to overfit the data. An effective way to reduce the variance of the model is to introduce randomization into the training or construction of the classifier and then collect such different models into an ensemble. A final prediction is made by averaging the outputs of a particular classifiers. The random forest (Breiman 2001) algorithm incorporates two forms of randomness into the training. First, it trains each decision tree model on a different data set drawn with replacement from the training data. Second, the best split in each node is found using a random subset of features. In this case, the number of features is controlled by a parameter that can be tuned. An additional level of randomness is used in the extremely randomized tree (Geurts & Ernst 2006), where node splitting is done not by the most discriminative threshold, but by setting a threshold at random for each candidate feature separately and taking the best threshold as the splitting rule.
Besides averaging the output of particular classifiers, as it was described in the previous paragraph, it is possible to build classifiers in a sequential form, where the model is trying to correct the output of its predecessor. This way of constructing ensembles is called boosting. In recent years, the most popular and effective implementation of boosting tree ensembles is an XGBoost (Chen & Guestrin 2016) algorithm, which shows leading results in many ML competitions.
In the case of an imbalanced data, a classifier often tends to minimize the area of feature space assigned to the smaller class prediction. As a consequence, one would obtain a catalog of smaller class candidates characterized by a high level of purity and low completeness. In order to minimize this tendency, one can introduce the class balance, where the importance of smaller-class objects is increased in training proportionally to the class fraction in the labeled data. All previously mentioned classifiers (except the dummy classifier) were tested in both class-balanced and non-balanced versions.
In most cases, the default values of the model hyperparameters are not optimal for a specific ML task. This issue was addressed in the present work by tuning hyperparameters via a randomized grid search. It samples a prearranged hyperparameter grid a certain number of times, giving a set of hyperparameter combinations used in a training. The effectiveness comparison of these combinations was done via performance evaluation described in Sect. 3.4. While logistic regression, SVM and XGBoost classifiers were tuned using the above method, random forest, and extremely randomized trees algorithms were excluded due to their insensitivity to the tuning process (Probst et al. 2019).
Finally, with the predictions from different models described above, we can combine their outputs into a voting schemes. In the present work, two types of voters were used, namely hard voter classifier, where the majority predicted class was used as a final result, and the stacked classifier, where the logistic regression was trained on the probability estimations from different models as features.
3.3. Fuzzy logic
One can further tune the weights of the labeled data to improve the training process by applying instance-weighting often referred to as “fuzzy logic”. In this case, each object in a training set has its own importance according to some chosen properties. This instance weight is referred to as “fuzzy membership”. Specific applications of instance-weighting to logistic regression, SVM, and tree-based algorithms are discussed in Hosmer et al. (2013), Lin & Wang (2002), Ting (2002), respectively.
In previous works on the SVM-based AGN selection (Poliszczuk et al. 2019), authors used the measurement uncertainty based weighting system (referred to as “error fuzzy weights”), where precisely measured objects were treated as more important than the noisy ones during training. It allowed the authors to reduce the impact of the noise and increase the reliability of the output catalog. In the present paper, besides the error weights, distance-based weights inspired by Lin & Wang (2002) were also used. In this case, the Euclidean distance in the feature space was translated to the importance weight of the object. This way objects typical for a particular class were treated as more important, while the influence of the outliers was reduced. In both cases, fuzzy memberships si, normalized to the range [0, 1], were calculated using the same scheme:
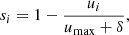 (1)
(1)
where the ui is a measurement uncertainty of the object or its Euclidean distance from its class center and umax is a maximal uncertainty or distance for a specific class. The δ parameter is a small value used to avoid division by zero. Since only the relative difference between instance weights has an impact on the training process, the delta parameter is added only for a purpose of the numerical safety. In this work δ = 10−4. Histograms of both, error- and distance-based fuzzy memberships calculated for galaxy and AGN training samples used for the creation of final catalog (first iteration, see Sect. 4) are shown in Fig. 2. Error-based weights were calculated with respect to measurement uncertainties of optical and NIR passbands. Distance-based weights were calculated with respect to class center in the high-dimensional space of selected features.
 |
Fig. 1. Scheme of the machine learning pipeline described in the present work. Upper part of the scheme shows the general outline, lower part of the scheme, shown in the violet rectangle, refers to the training of the models. |
 |
Fig. 2. Fuzzy memberships calculated for the training data from first iteration (see Sect. 4.3). Panel a: error-based fuzzy membership. Error-based weights were calculated with respect to optical and NIR passbands measurement uncertainties, giving higher priority to objects with better measurements within AGN or galaxy sample. Panel b: distance-based fuzzy membership. Distance-based weights were calculated with respect to the class center calculated in a feature space, reducing impact of outliers on classification result. |
3.4. Evaluation
The quality of classifier performance and obtained AGN catalog can be measured in two ways. The first approach is based on a comparison with results given by other methods and this type of evaluation is described in the next sections. The second approach is based on estimating the generalization performance by evaluation metrics calculation for the classification performed on the labeled data. In order to get a reliable evaluation one has to test the classifier on data that was not used in the training, since training scores, being prone to overfitting, might show inflated results. To address this issue, training-test splitting of the labeled data was done: the classifier was trained on a training part of the data and evaluated on a test one. This process was repeated many times by shuffling the data before each training-test split. Such an approach allows us to obtain a meaningful evaluation with a measurement uncertainty.
Imbalanced data learning introduces additional challenges in the performance evaluation process. Simple metrics such as accuracy cannot be treated as reliable performance measures any longer due to their tendency to return high values even for poor performances on a smaller class (Fernández et al. 2018). The purpose of the present work is to produce a reliable catalog of AGN characterized by high purity and completeness, hence these should be the main metrics of a classifier performance evaluation. If we refer to the AGN class as “positive” and galaxies class as “negative”, the purity of the AGN catalog will be known through a precision metric value:
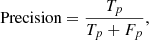 (2)
(2)
which is a fraction of properly classified AGNs (true positives Tp) to all AGN candidates (true positives and false positives Fp). On the other hand, the completeness of the AGN catalog, referred to as recall, is a fraction of properly selected AGNs to all AGNs (true positives and false negatives) in the classified data and can be written as:
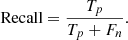 (3)
(3)
In order to maximize both these measures during learning and to effectively compare performance of different classifiers one can use several compound metrics. The first is the F1 score, which is a harmonic mean of precision and recall:
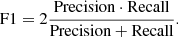 (4)
(4)
If we can obtain a probability estimation for a particular object belonging to one of two classes, the precision-recall curve can be constructed. It is done by calculating the precision and recall scores for different decision thresholds. Beside analyzing the shape of the PR-curve, we can evaluate the effectiveness of the classifier by calculating area under the PR-curve (PR-AUC).
The final metric used in this paper is the balanced accuracy (bACC), which normalizes true positive and true negative predictions by the number of positive and negative samples, respectively. If we create a metric called the true negative rate (TNR), which is the same as precision but made for a negative class, we can express bACC as:
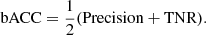 (5)
(5)
3.5. Generalization sample limit
The supervised classification result can only be as good as the provided labeled sample. This assumption can be also expressed in a different way, namely: a classifier can give reliable results only in areas of feature space occupied by the training data. In other words, we have to be very careful with extrapolation during the generalization phase since we cannot control performance in the unknown regions of the feature space. The application of simple magnitude cuts to limit the generalization data to the labeled data ranges is not enough since a high-dimensional manifold created by generalization set in feature space might still preserve some regions requiring extrapolation.
In the present work, we used a simple conservative approach in the form of a minimum covariance determinant estimator algorithm (MCD, Rousseeuw & Driessen 1999). It allows us to fit an n-dimensional ellipsoid to the training data and limit generalization data to its range. The MCD algorithm has a free parameter α called the contamination rate, which defines the number of outliers present in a training sample and controls how conservative the limiting process will be.
In order to find adequate α value, the Mahalanobis distance histograms were used. The Mahalanobis distance dM is defined as:
 (6)
(6)
where x is an object location, μ is the mean and Σ is the covariance matrix. Making a dM histogram one can look for the smallest dM value, corresponding to the histogram discontinuity. This range might be used to select an optimal α value.
3.6. SED fitting
Considering the tight link between the galaxy SED shape and the presence of an AGN, a SED fitting was performed for the training sample and objects selected during generalization step. The broad band multiwavelength SED fitting tool, The Code Investigating GALaxy Emission3 (CIGALE, Boquien et al. 2019) was used to estimate the possible presence of an AGN and main physical parameters of the sample.
The CIGALE software was incorporated into the analysis, as it is a physically motivated state-of-the-art python code for SED fitting of the extragalactic sources, and moreover, it was already used and tested for the AKARI-NEP galaxies (i.e., Buat et al. 2015; Solarz et al. 2015; Toba et al. 2020; Barrufet et al. 2020) and AGN (see Sects. 1). This code employs both galaxy and AGN models and allows one to fit both components in a flexible way. CIGALE simultaneously fits the AGN and galaxy spectrum from far-UV to far-IR4 and returns the estimate of the main galaxy properties such as stellar mass, dust luminosity, star formation rate, and the relative contribution of the dusty torus of the AGN to the total IR luminosity, that is, the AGN fraction. For each estimated parameter, CIGALE uses a probability distribution function (PDF) analysis, and the final physical parameters are built based on the likelihood-weighted mean of the PDF. Each parameter is associated with an error calculated also from the PDF’s likelihood-weighted standard deviation. A more detailed description of the code itself can be found in Burgarella et al. (2005), Noll et al. (2009), and Boquien et al. (2019).
To briefly summarize, CIGALE is designed to model a galaxy SED by conserving the energy balance between the dust-absorbed stellar emission and its re-emission in the IR. The same strategy is also used for the AGN emission absorbed and re-emitted by the dusty torus. Many authors already presented the mechanism of the SED fitting with CIGALE including Fritz et al. (2006) AGN module (i.e., Buat et al. 2015; Ciesla et al. 2015; Małek et al. 2018; Wang et al. 2020; Toba et al. 2020), which assumes a central engine surrounded by a smooth dusty torus. In the present work SED fitting is performed using more advanced AGN module, SKIRTOR (Stalevski et al. 2012, 2016). SKIRTOR was implemented to the v2020.0 version of CIGALE and tested by Yang et al. (2020) based on the already known AGNs from the COSMOS and the AKARI NEP field. This AGN module adopts a clumpy two-phase dusty torus which can be manifested as an obstruction of the UV/optical emission from the disk.
The SED fitting was based on a delayed star formation history with a possible additional burst, the Bruzual & Charlot (2003) single stellar population, and the Charlot & Fall (2000) attenuation law. The same set of modules was used, for instance, for infrared detected galaxies from the Herschel Extragalactic Legacy Project, as described in Małek et al. (2018).
The dust emissison was calculated using the Dale et al. (2014) templates. These templates are based on the sample of nearby star-forming galaxies originally presented in Dale & Helou (2002) with an improved modelling of emission from Polycyclic Aromatic Hydrocarbons (PAH). The Dale et al. (2014) model uses only one free parameter, which is the α power law slope in the dust mass (Mdust) and radiation field intensity (U) relation: dMdust ∝ U−αdU. It simplifies the SED fitting procedure reducing the number of parameters difficult to constrain without far infrared measurements. This module also allows one to use an optional AGN component. In the present work, a dedicated AGN module was used instead.
In the case of the AKARI-NEP SED fitting, the SKIRTOR AGN model was used. The adopted parameters used for the SED fitting are presented in Table 3. The SEDs were fitted to objects with respect to spectroscopic redshift (training sample) and photometric redshift (training sample and output catalog of AGN candidates). The photometric redshift were taken from Ho et al. (2021), where it was estimated on the panchromatic NEP data using the LePHARE5 software (Arnouts et al. 1999; Ilbert et al. 2006; Arnouts & Ilbert 2011).
Modules and core input parameters used in the SED fitting with CIGALE.
In particular, estimations of two parameters were investigated during analysis of ML output: AGN fraction (fracAGN), which is the AGN contribution to LIR in 8−1000 μm range and AGN viewing angle (θ), where θ = 30° defines type-I and θ = 70° corresponds to type-II.
3.7. Machine learning pipeline
The ML pipeline for AGN selection, shown in Fig. 1, is constructed as follows. The feature selection based on the KS-statistic was performed on the labeled data, giving the final form of a training sample. The training data, in the form of flux measurements present on the selected features, was then used to determine limits of the final generalization sample.
During the training stage, the models described in Sect. 3.2 were tested in several settings: non-balanced and class-balanced models were applied in classical and instance-weighted (in the form of error-based and distance-based fuzzy memberships) setups. First, the hyperparameter tuning was performed. Logistic regression, SVM and XGBoost models were tuned using a randomized grid searches consisting of 1000 different hyperparameters combinations. In order to search for the optimal combination, the F1 metric was maximized during the grid search. The value of the F1 metric was estimated using 100 shuffled train-test splits. An analogous split was used to calculate other evaluation metrics and their uncertainties. Finally, the selected hyperparameter combination was used to make predictions on the training data using a five-fold cross-validation.
After the training, the best model was used to select the AGN candidates from the generalization sample. In order to better understand the outcome of the generalization, as well as to track possible model bias uncaptured by the previous analysis, additional SED fitting tests were carried out on the output catalog, as well as the training set.
4. Results
4.1. Feature selection
In order to select features that are suitable for AGN extraction, the KS-statistic was calculated on the AGN and galaxy training samples using HSC g, r, i, z, Y and IRC N2, N3, N4 bands and all possible colors. Part of the KS-statistic values for best features are shown in Fig. 3a. The optimal feature set was defined as a set where all available filters were used and the KS-statistic value was not substantially lower for less important features. This way eight features with the highest KS-statistic values were selected as a final data representation. The selected features demonstrate an evident importance of the NIR colors as compared to VIS-based measurements.
 |
Fig. 3. Features selected using KS-statistic value. Panel a: first (main) iteration. Panel b: second iteration experiment. For the first (main) iteration the KS-statistic was calculated on AGN and galaxy training samples using the HSC g, r, i, z, Y and IRC N2, N3, N4 bands along with all possible colors. The optimal feature set was defined as a set where all available filters were used and the KS-statistic value was not substantially lower for less important features. For the second iteration experiment, additional MIR features in form of S7, S9, S11, L15, and L18 bands and all possible colors were used. In order to minimize the risk of data sparsity, the selection of optimal feature set was restricted to features with the highest KS-statistic value. Only the most important features are shown. |
4.2. Generalization sample limit
The process of limiting the generalization sample to the training sample range was performed in a space constructed from the flux measurements in passbands used for the feature selection. The passband measurements were used instead of selected features in order to simplify the impact of selection effects on the generalization sample. To find the generalization sample limit, two different ellipsoids were first fitted to the AGN and galaxy classes from the training data. Objects from the unlabeled data set, which belong to at least one of these ellipsoids, were selected to build a final generalization sample. The split into two separate ellipsoids was dictated by the structure of the MCD algorithm and the imbalance of the class sizes in the training data. The single ellipsoid fitted to the whole training set would treat objects from the smaller AGN class placed outside the main part of the galaxy distribution as outliers and thus reject the most important part of the feature space that allows AGN classification.
In order to find a proper contamination parameter α value, which defines the size of the ellipsoid, we pursued the discontinuities in the dM histograms (shown in Fig. 4). In the case of the AGN sample, the strong decrease in the number of objects occurs in the range of dM ≃ 43, that corresponds to αAGN = 0.065. In the case of the galaxy sample, a more conservative approach was used due to the higher dM dispersion. The dM = 80 value was selected, what corresponds to αGAL = 0.05. By applying this method, the initial generalization sample size was reduced from 45 841 to 33 119 objects.
 |
Fig. 4. Mahalanobis distance histograms for AGN and galaxy training samples. Panel a: AGN sample. Panel b: galaxy sample. Dashed red lines correspond to a particular contamination parameter value of the MCD algorithm used to limit generalization data set to the training sample range. |
4.3. Performance evaluation and creation of the final catalog
Each type of classification algorithm was trained and tested according to the method described in Sect. 3.7. Detailed values of the performance evaluation can be found in Table B.1. Visual comparison of performance evaluation is presented in Fig. 5a. In these figures one can observe a general tendency for class-balanced classifiers: an increase of recall due to the higher importance of positive class objects during training process, followed by a higher contamination of the positive candidates catalog, translates into a lower precision. Over the course of the performance comparison of non-balanced and class-balanced classifiers, several models were rejected. These were: non-balanced logistic regression due to its low recall value, class-balanced logistic regression due to its low precision and non-balanced SVM due it its low PR AUC value. The remaining classifiers showed acceptable trade-offs between precision and recall. Each one of them was used in three different instance-weight setups: uncertainty-based fuzzy membership, distance-based fuzzy membership, and no instance weight. Performance comparison of these three types of models in terms of F1 metric (which was the main metric optimized during the grid search) is presented in Fig. 5b. It shows not only a major impact of instance weighting on classification performance but also the opposite tendencies of error and distance weighting with respect to the non-weighted models. One can distinguish two groups of classifiers showing similar behavior: class-balanced SVM and XGBoost in all three instance-weight types preserve high recall at the expense of precision, while the rest of the classifiers exhibit the opposite tendency (see Appendix B.1). In order to benefit from both of these tendencies, all remaining classifiers were used for the construction of two types of voters: hard voter and stacked classifier. Their performance is also shown in Fig. 5a. Due to the lack of probability estimation in the case of hard voter, the PR AUC measurement is missing.
 |
Fig. 5. Performance evaluation of different classification models. Panel a: evaluation metric values for different classification algorithms. Only models with no instance-weighting are presented. Panel b: F1 value for different instance-weighting strategies for selected types of classification algorithms. Panel c: evaluation metric values for second iteration experiment. Panel d: legend. |
A small amount of training data causes difficulties in the performance evaluation and relatively low values of both precision and recall, shifting the focus to a classifier that can provide more certain information (higher precision) about a smaller number (lower recall) of the positive class candidates. In the present work, the best results were shown by the non-balanced fuzzy distance XGBoost classifier in the form of the most optimal precision-recall trade off (manifested also in a high F1 score). The hard voting classifier showed almost identical metric values except for a slightly lower precision (and lack of the PR AUC measurement), which is still situated within the uncertainty of XGBoost precision measurement. Since the hard voting classifier allows one to additionally reduce the variance of the final model, it was selected as the final classification scheme characterized by 0.73 precision and 0.64 recall. The generalization performed on the unlabeled data set provided a catalog of 465 AGN candidates (1.4% of the generalization sample).
The AGN candidates CM plot of N4 vs N2 − N4 is shown in Fig. 6b. The output catalog recreates general properties of a preselected AGN target sample from Shim et al. (2013): it has a high number of proper detections around the AGN class center recovering most of type-I AGN with the main contamination source (FP) in form of high-z SFG. Another characteristic property is the impossibility of efficient class separation in the galaxies-dominated region showing mainly false negative (FN) results in the N2 − N4 < 0 area. During the analysis of training objects classification presented in CM and color-color plots, we should keep in mind that predicted labels were assigned during the five-fold CV process and might exhibit an underestimated performance (compared to the generalization) in some feature space regions due to an absence of essential objects in the training sample.
 |
Fig. 6. NIR and MIR properties of the training set and classification results. Panel a: properties of the training data. Color of galaxies correspond to spectroscopic redshift value. Panel b: first iteration training and final AGN catalog properties. Right part of the figure shows density histogram for components of the labeled set with corresponding color. Panel c: second iteration experiment. Modified training sample is shown as well as two parts of generalization: “rejected” objects, which occupy the red N2 − N4 color range and new objects below this range. These candidates were not included in final catalog. Right part of the figure shows density histogram for components of the labeled set with corresponding color. Panel d: color-color plot used for Lee et al. 2007 AGN selection. Its selection criteria demarcate the upper right square, marked by the black lines. Training objects and AGN candidates selected during the first and the second iteration from the present work, are shown in form of different markers. Predictions for the labeled data shown in Figs. 6b–d are compound classifications of the test data from five-fold cross-validation. |
4.4. Second iteration experiment
Lack of detections in the blue part of N2 − N4 distribution shows that information contained in optical and NIR passbands is not sufficient to select AGN in that region. Classifiers tend to define most of the blue AGN objects as galaxy representatives. In order to address this issue, a supplementary classification experiment with additional information from MIR passbands (S7, S9W, L15, L18W) was performed. The main classification described in the previous section will be referred to as the first iteration, while the supplementary experiment will be called the second iteration. In the second iteration, the training AGN class was formed from false negative cases of the first iteration, while the galaxy class remained the same, so the training sample consisted of the 744 objects in total, with 39 AGNs. In order to create an experiment that would be easily comparable to the first iteration, the second iteration generalization sample was selected as a subset of the first iteration generalization sample. It was done by applying an additional requirement of MIR detection in previously mentioned filters. Such a sample contained 2207 objects.
Feature selection, also based on KS-statistic, enabled to choose ten features that are well suited for this specific task. Since some of the filters were present only in features with a low KS-statistic value, the assumption that all of the filters should be utilized was omitted. In order to minimize the risk of data sparsity, the selection of optimal feature set was restricted to features with the highest KS-statistic value. The best features are shown in Fig. 3b. It is worthwhile noting that features with the highest KS-statistic value typically consist of MIR measurements.
Performance evaluation is presented in detail in Table B.2. It is also partially shown in Fig. 5c. This time only class-balanced SVM, class-balanced logistic regression and class-balanced XGBoost were used for the hard voter creation. The stacked classifier was not used in this case due to the high risk of overfitting caused by the small amount of data. In the second iteration, the highest precision was the main priority due to its very low value. The best results of a precision-recall trade off were shown by class-balanced fuzzy distance XGBoost of 0.25 ± 0.11 and 0.37 ± 0.16 respectively. This model was selected as the final classifier for the second iteration AGN selection. Generalization performed by the second iteration classifier gives 354 AGN candidates. They are presented on CM plot alongside classified labeled samples in Fig. 6c. Some of them (AGN candidates are presented in form of light blue and pink squares) occupy the N2 − N4 region avoided during the first iteration. This new behavior is caused by three factors: additional information obtained from MIR measurements allowing to work in new feature regions, modified AGN distribution in the training sample forces a change of classification boundaries and a lower precision that gives higher contamination of the final catalog. Since the second iteration was supposed to be a supplement for the main, first iteration, only objects with N2 − N4 < 0 carry meaningful information supplementary to the main catalog. This cut limits an additional AGN catalog from 354 to 198 objects (9% of the generalization sample). Due to a very high level of contamination and low completeness, the classification performed in the second iteration is treated only as a test ground to determine limits of both the training sample and the information content of HSC and IRC data. The second iteration generalization is not included in the final AGN candidate catalog. Statistical properties of the final catalog obtained during the first iteration are presented in Table 4.
Statistical properties of the final catalog of AGN candidates.
4.5. Comparison with the color-cut method
Since the training sample used in the present work is mainly based on NIR+MIR target preselection as described in Lee et al. (2007), it is crucial to investigate how ML-based selection performs with respect to this color-cut method. In the original NIR+MIR method, AGN selection was performed on a S11 < 18.5 mag limited sample in order to increase completeness of the output catalog. A comparison of the two methods presented in this paper was performed without this condition, since the S11 limit is impossible to apply in optical+NIR combined space. Figure 6d shows a N2 − N4 vs S7 − S11 color-color plot. The color-cut method reflects the power-law properties of the AGN SED that should cause red MIR colors. The upper right square (N2 − N4 > 0, S7 − S11 > 0) used to select AGN in the Lee et al. (2007) method is also a location of the majority of AGN candidates (yellow points). Objects selected during the second iteration are located in between the AGN and galaxy classes giving an indication that part of these objects might be low activity AGN. It is also worth notice that a large fraction XAGN are located far outside AGN class center escaping both selection methods.
Table 5 shows the performance comparison between the color-cut method and the classification scheme formulated in the present work. Hard voter data shows higher precision and balanced accuracy values, but lower F1 and recall. Such values are consistent with precision-recall trade-off established during model selection, when precision was recognized as a more important metric. Both the color-color plot and the metric values show good consistency between the two methods. However, in order to perform such comparison, both the training sample and output catalog were limited to objects detected in S7 and S11 passbands. The training sample was reduced from 1547 to 815 objects and the final catalog from 465 to 113 objects. Despite similar metric values, the color-cut method was able to detect only 24% of objects selected in the present work.
Performance comparison of final selected classifier with color-cut method described in Lee et al. (2007).
4.6. SED fitting analysis
Figure 7a shows a comparison between spectroscopic and photometric redshifts used for the SED fitting analysis. For this analysis the training sample was used. XAGNs, whose redshifts have not been measured, were excluded from further analysis. Good agreements characterize both AGN and galaxy classes up to redshift 1.5. The higher redshift range, occupied almost exclusively by AGN, shows strong bias towards zphot underestimation. Figure 7b shows a viewing angle dependency on AGN fraction calculated using spectroscopic redshifts. Several observations crucial for catalog analysis can be made.
 |
Fig. 7. Visualization of parameters used during SED analysis on the training data. XAGN were excluded from this analysis due to a lack of spectroscopic redshift. Panel a: comparison between spectroscopic redshift and photometric redshift estimation (Ho et al. 2021) for training galaxy and AGN samples. The dotted lines refer to zphot = zspec ± 0.15(1 + zspec) cone. The η describes the fraction of outliers defined as objects outside the cone. σ is the normalised median absolute deviation 1.48 × median(|Δz|/(1 + z). Lower plot shows the mean residuals with standard deviations. Only z < 3 objects are shown. Panel b: dependence of an AGN viewing angle (θ) on AGN fraction (fracAGN) for AGN and galaxy training samples. Both parameters were estimated by SED fitting using spectroscopic redshifts. θ = 30° corresponds to pure type-I AGN and θ = 70° to pure type-II with intermediate types in between. Color intensity corresponds to the spectroscopic redshift value. Dotted line shows fracAGN = 0.2 – value which defines AGNSED. |
As was already observed in Ciesla et al. (2015), constraining the AGN contribution to the total infrared luminosity is challenging for objects with a small fracAGN value. In order to perform a reliable analysis, only objects with fracAGN > 0.2 were used. A similar fracAGN limit was applied in Ciesla et al. (2015), Małek et al. (2018). These objects will be referred to as SED-identified AGN (AGNSED).
The SED-based AGN type identification is done based on AGN properties in UV, MIR, and FIR. The type-I AGN is showing strong emission in UV and MIR. The type-II AGN, devoid of strong UV emission, is characterized by large FIR to MIR emission ratio (Ciesla et al. 2015). Due to the small number of objects with detections in FIR, distinction between the two types might be disturbed. Moreover, as it was pointed out in Mountrichas et al. (2021), the lack of X-ray measurements creates a tendency towards type-I assignment. The majority of AGNSED in the AGN training sample were identified as type-I AGN. The galaxy sample shows the opposite tendency towards type-II representation, which might be even higher due to the present bias caused by lack of X-ray measurements. Since the fracAGN definition is based on IR properties of the SED, this plot is a strong indication of the presence of a different, narrow line AGN class in the NEP data. Most of galaxies from training sample classified as type-I AGN showed strong AGN UV and MIR contribution. These might be AGN characterized by a low signal to noise ratio (S/N) or weak emission lines in the optical range.
More precise information is presented in Table 6 that shows the properties of AGNSED objects within the training sample and the final AGN catalog. It shows an approximately 50% discrepancy between spectroscopic and SED AGN identification within the AGN training sample in all redshift ranges. The difference between the two methods is even higher considering ∼13% of AGNSED are detected in galaxy sample. Completeness and purity loss in the low-z range after application of photometric redshifts manifests itself in a decrease of type-I-dominated AGNSED. Photometric redshift systematics above z = 1.5 results in a substantial completeness loss. The catalog of AGN candidates shows intermediate properties between AGN and galaxy training samples at low photometric redshift. In the high redshift range the training AGN sample and AGN candidates have similar SED AGN contribution and a smaller number of type-I SED AGN in the case of the final catalog.
SED fitting results calculated for training samples and obtained AGN candidates catalog in two photometric redshift zphot ranges (below and above zphot = 1.5).
The SED-fitting analysis in the present work is not very extensive due to several reasons. Firstly, as it was already pointed out, AGNs selected according to their emission line properties are, at least partially, a different class of objects than galaxies with high AGN fraction recognized through the SED fitting (only 50% of spectroscopically-defined AGNs have also high AGN fraction fitted). This behavior is not caused by the low quality of the SED-fitting for AGN from the training set as the distributions of χ2 for spectroscopic AGNs and other objects with fracAGN > 0.2 are very similar. The final ML-based classifier was trained to reproduce the MIR-based selection, which, in turn, was constructed to reflect the structure of the spectroscopically selected AGN training sample, which consists mostly of type I AGNs. Thus, studying the properties of spectroscopic-type AGN class misclassifications through SED-defined AGN class could easily lead to a false conclusion. Second, the data in both training sample and the final AGN catalog are highly inhomogeneous in terms of photometric coverage. Because of this, their SEDs cannot be analyzed as a whole in a statistically consistent manner. To avoid this problem, we would have to clean the catalog, which would result in a strong decrease in the data volume. Such an in-depth study of SEDs was presented in Wang et al. (2020). However, due to the different constraints on the data properties, the sample analyzed in Wang et al. (2020) has only a few objects in common with both the training data and the resulting catalog discussed in the present paper. This discrepancy makes further comparison almost impossible.
Future works may include more extensive AGN classification based on training sets making use of SED templates or both SED templates and spectral features, which should allow not only for the identification of AGN candidates, but also for making classifiers sensitive to chosen types of AGNs. In the present work, the main limitation is the spectroscopy based training sample, making the classifier predominantly sensitive to type I AGNs.
5. Summary
In the present work, several important results were achieved. From the perspective of the main aim of the project, it was possible to successfully reproduce the Lee et al. (2007) NIR+MIR AGN classification only with optical and NIR data. Both methods showed consistent results in NIR+MIR space, but only 24% of objects in the final AGN candidate catalog was detected in MIR. Hence, the new method shows substantial improvement in the NEP AGN detection by preserving the effectiveness of the method in a much larger volume of available data. To obtain satisfying results, a large number of different model types were tested. It has shown that voting schemes, built on an ensemble of models, might improve classification results even when a small amount of training data are available. Additional tests of instance weighting showed that physically or geometrically motivated weights have a major impact on the classification performance; thus, further research in this field should be carried out.
The second iteration experiment pushed classification towards galactic locus, typically occupied by a large XAGN fraction. The result was a drastic increase of catalog contamination. Efficient AGN selection in this region is impossible with training data constructed from currently available spectroscopic and X-ray detections. A SED fitting analysis of training data showed a large amount of AGN which are not identified with spectroscopic observations. A SED fitting analysis of the output catalog of AGN candidates shows intermediate properties between the AGN and galaxy training samples in terms of the fracAGN and θ. This might be caused both by contamination from high-z SFG or presence of AGN types that are not identified by SED fitting. There is a significant difference between SED-identified and spectroscopically identified AGNs – both selection methods trace different AGN classes. Thus, it is impossible to directly compare the performance of ML-based (trained on spectroscopical class labels) and SED-fitting based methods. This result shows also a possible way to overcome difficulties with AGN selection outside the AGN class center: Training sample augmentation with template-based objects might provide a classifier with crucial information about problematic regions of the feature space and extend the selection to other types of AGN.
The special version of CIGALE, called X-CIGALE, allows to fit SEDs from the X-ray to far-IR, Yang et al. (2020).
Acknowledgments
Authors are very thankful to the referee for the comments and corrections provided to the manuscript. They allowed us to create much more understandable and transparent paper. This research was conducted under the agreement on scientific cooperation between the Polish Academy of Sciences and the Ministry of Science and Technology in Taipei and supported by the Polish National Science Centre grant UMO-2018/30/M/ST9/00757 and by Polish Ministry of Science and Higher Education grant DIR/WK/2018/12. K.M. is supported by the Polish National Science Centre grant UMO-2018/30/E/ST9/00082. A.D. is supported by the Polish National Science Centre grant UMO-2015/17/D/ST9/02121. W.J.P. is supported by the Polish National Science Centre grant UMO-2020/37/B/ST9/00466. T.G. acknowledges the support by the Ministry of Science and Technology of Taiwan through grant108-2628-M-007-004-MY3. H.S.H. was supported by the New Faculty Startup Fund from Seoul National University.
References
- Alonso-Herrero, A., Pérez-González, P. G., Alexander, D. M., et al. 2006, ApJ, 640, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Antonucci, R. 1993, ARA&A, 31, 473 [Google Scholar]
- Arnouts, S., Cristiani, S., Moscardini, L., et al. 1999, MNRAS, 310, 540 [NASA ADS] [CrossRef] [Google Scholar]
- Arnouts, S., & Ilbert, O. 2011, LePHARE: Photometric Analysis for Redshift Estimate [Google Scholar]
- Assef, R. J., Stern, D., Kochanek, C. S., et al. 2013, ApJ, 772, 26 [Google Scholar]
- Assef, R. J., Eisenhardt, P. R. M., Stern, D., et al. 2015, ApJ, 804, 27 [NASA ADS] [CrossRef] [Google Scholar]
- Baldwin, J. A., Phillips, M. M., & Terlevich, R. 1981, PASP, 93, 5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Banerji, M., McMahon, R. G., Hewett, P. C., et al. 2012, MNRAS, 427, 2275 [NASA ADS] [CrossRef] [Google Scholar]
- Banerji, M., Jouvel, S., Lin, H., et al. 2015, MNRAS, 446, 2523 [NASA ADS] [CrossRef] [Google Scholar]
- Barden, S. C., Armandroff, T., Massey, P., et al. 1993, ASPCS, 37, 185 [Google Scholar]
- Barrufet de Soto, L., White, G. J., Pearson, C., et al. 2017, Publ. Korean Astron. Soc., 32, 271 [Google Scholar]
- Barrufet, L., Pearson, C., Serjeant, S., et al. 2020, A&A, 641, A129 [CrossRef] [EDP Sciences] [Google Scholar]
- Berkson, J. 1944, J. Am. Stat. Assoc., 39, 357 [Google Scholar]
- Bishop, C. M. 2006, Pattern Recognition and Machine Learning Information Science and Statistics (Berlin, Heidelberg: Springer-Verlag) [Google Scholar]
- Boquien, M., Burgarella, D., Roehlly, Y., et al. 2019, A&A, 622, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Breiman, L. 2001, Mach. Learn., 45, 32 [Google Scholar]
- Breiman, L., Friedman, J., Olshen, R., & Stone, C. J. 1984, Classification and Regression Trees (Wadsworth) [Google Scholar]
- Bruzual, G., & Charlot, S. 2003, MNRAS, 344, 1000 [NASA ADS] [CrossRef] [Google Scholar]
- Buat, V., Oi, N., Heinis, S., et al. 2015, A&A, 577, A141 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Burgarella, D., Buat, V., & Iglesias-Páramo, J. 2005, MNRAS, 360, 1413 [Google Scholar]
- Burgarella, D., Mazyed, F., Oi, N., et al. 2019, PASJ, 71, 12 [CrossRef] [Google Scholar]
- Cepa, J., Aguiar, M., Escalera, V. G., et al. 2000, SPIE Conf. Ser., 4008, 623 [Google Scholar]
- Chabrier, G. 2003, PASP, 115, 763 [Google Scholar]
- Charlot, S., & Fall, S. M. 2000, ApJ, 539, 718 [Google Scholar]
- Charlton, P. J. L., Ruan, J. J., Haggard, D., et al. 2019, ApJ, 876, 75 [CrossRef] [Google Scholar]
- Chen, B. H., Goto, T., Kim, S. J., et al. 2020, MNRAS, staa3865 [Google Scholar]
- Chen, T., & Guestrin, C. 2016, in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD’16 (New York, NY, USA: Association for Computing Machinery), 785 [CrossRef] [Google Scholar]
- Ciesla, L., Charmandaris, V., Georgakakis, A., et al. 2015, A&A, 576, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Claeskens, J. F., Smette, A., Vandenbulcke, L., & Surdej, J. 2006, MNRAS, 367, 879 [NASA ADS] [CrossRef] [Google Scholar]
- Cortes, C., & Vapnik, V. 1995, Mach. Learn., 20, 273 [Google Scholar]
- Dale, D. A., & Helou, G. 2002, ApJ, 576, 159 [NASA ADS] [CrossRef] [Google Scholar]
- Dale, D. A., Helou, G., Magdis, G. E., et al. 2014, ApJ, 784, 83 [NASA ADS] [CrossRef] [Google Scholar]
- de Grijp, M. H. K., Lub, J., & Miley, G. K. 1987, A&AS, 70, 95 [NASA ADS] [Google Scholar]
- Dodd, S. A., Law-Smith, J. A. P., Auchettl, K., Ramirez-Ruiz, E., & Foley, R. J. 2021, ApJ, 907, L21 [CrossRef] [Google Scholar]
- Donley, J. L., Rieke, G. H., Alexander, D. M., Egami, E., & Pérez-González, P. G. 2010, ApJ, 719, 1393 [NASA ADS] [CrossRef] [Google Scholar]
- Elvis, M., Wilkes, B. J., McDowell, J. C., et al. 1994, ApJS, 95, 1 [Google Scholar]
- Faber, S. M., Phillips, A. C., Kibrick, R. I., et al. 2003, SPIE Conf. Ser., 4841, 1657 [Google Scholar]
- Fabricant, D., Fata, R., Roll, J., et al. 2005, PASP, 117, 1411 [NASA ADS] [CrossRef] [Google Scholar]
- Fadda, D., & Rodighiero, G. 2014, MNRAS, 444, L95 [CrossRef] [Google Scholar]
- Fernández, A., García, S., Galar, M., et al. 2018, Learning from Imbalanced Data Sets (Springer) [CrossRef] [Google Scholar]
- Francis, P. J., Nelson, B. O., & Cutri, R. M. 2004, AJ, 127, 646 [NASA ADS] [CrossRef] [Google Scholar]
- Fritz, J., Franceschini, A., & Hatziminaoglou, E. 2006, MNRAS, 366, 767 [Google Scholar]
- Geach, J. E., Dunlop, J. S., Halpern, M., et al. 2017, MNRAS, 465, 1789 [Google Scholar]
- Geurts, P., Ernst, D., & Wehenkel, L. 2006, Mach. Learn., 63, 42 [CrossRef] [Google Scholar]
- Glikman, E., Helfand, D. J., White, R. L., et al. 2007, ApJ, 667, 673 [NASA ADS] [CrossRef] [Google Scholar]
- Glikman, E., Urrutia, T., Lacy, M., et al. 2012, ApJ, 757, 51 [NASA ADS] [CrossRef] [Google Scholar]
- Glikman, E., Urrutia, T., Lacy, M., et al. 2013, ApJ, 778, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Goto, T., Toba, Y., Utsumi, Y., et al. 2017, Publ. Korean Astron. Soc., 32, 225 [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [CrossRef] [PubMed] [Google Scholar]
- Henry, J. P., Mullis, C. R., Voges, W., et al. 2006, ApJS, 162, 304 [NASA ADS] [CrossRef] [Google Scholar]
- Hickox, R. C., Jones, C., Forman, W. R., et al. 2009, ApJ, 696, 891 [Google Scholar]
- Ho, S. C.-C., Goto, T., Oi, N., et al. 2021, MNRAS, 502, 140 [CrossRef] [Google Scholar]
- Hosmer, D., Lemeshow, S., & Sturdivant, R. 2013, Applied Logistic Regression, 3rd edn. (Wiley) [CrossRef] [Google Scholar]
- Huang, T.-C., Goto, T., Hashimoto, T., Oi, N., & Matsuhara, H. 2017, MNRAS, 471, 4239 [CrossRef] [Google Scholar]
- Huang, T.-C., Matsuhara, H., Goto, T., et al. 2020, MNRAS, 498, 609 [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Hwang, N., Lee, M. G., Lee, H. M., et al. 2007, ApJS, 172, 583 [NASA ADS] [CrossRef] [Google Scholar]
- Ilbert, O., Arnouts, S., McCracken, H. J., et al. 2006, A&A, 457, 841 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Jarrett, T. H., Cohen, M., Masci, F., et al. 2011, ApJ, 735, 112 [Google Scholar]
- Jeon, Y., Im, M., Ibrahimov, M., et al. 2010, ApJS, 190, 166 [NASA ADS] [CrossRef] [Google Scholar]
- Jeon, Y., Im, M., Kang, E., Lee, H. M., & Matsuhara, H. 2014, ApJS, 214, 20 [NASA ADS] [CrossRef] [Google Scholar]
- Karouzos, M., & Im, M. AKARI-NEP Team 2012, Publ. Korean Astron. Soc., 27, 287 [Google Scholar]
- Kauffmann, G., Heckman, T. M., Tremonti, C., et al. 2003, MNRAS, 346, 1055 [Google Scholar]
- Kewley, L. J., Groves, B., Kauffmann, G., & Heckman, T. 2006, MNRAS, 372, 961 [NASA ADS] [CrossRef] [Google Scholar]
- Kim, S. J., Lee, H. M., Matsuhara, H., et al. 2012, A&A, 548, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kim, S. J., Jeong, W.-S., Goto, T., et al. 2019, PASJ, 71, 11 [CrossRef] [Google Scholar]
- Kim, S. J., Oi, N., Goto, T., et al. 2021, MNRAS, 500, 4078 [CrossRef] [Google Scholar]
- Kimura, M., Maihara, T., Iwamuro, F., et al. 2010, PASJ, 62, 1135 [NASA ADS] [Google Scholar]
- Koenig, X. P., Leisawitz, D. T., Benford, D. J., et al. 2012, ApJ, 744, 130 [NASA ADS] [CrossRef] [Google Scholar]
- Kouzuma, S., & Yamaoka, H. 2010, MNRAS, 405, 2062 [NASA ADS] [Google Scholar]
- Krumpe, M., Miyaji, T., Brunner, H., et al. 2015, MNRAS, 446, 911 [NASA ADS] [CrossRef] [Google Scholar]
- LaMassa, S. M., Cales, S., Moran, E. C., et al. 2015, ApJ, 800, 144 [NASA ADS] [CrossRef] [Google Scholar]
- Laureijs, R. J., Duvet, L., Escudero Sanz, I., et al. 2010, SPIE Conf. Ser., 7731, 77311H [Google Scholar]
- Lawrence, A. 2018, Nat. Astron., 2, 102 [NASA ADS] [CrossRef] [Google Scholar]
- Lee, H. M., Im, M., Wada, T., et al. 2007, PASJ, 59, S529 [NASA ADS] [Google Scholar]
- Lee, H. M., Kim, S. J., Im, M., et al. 2009, PASJ, 61, 375 [NASA ADS] [Google Scholar]
- Lehmer, B. D., Xue, Y. Q., Brandt, W. N., et al. 2012, ApJ, 752, 46 [NASA ADS] [CrossRef] [Google Scholar]
- Lin, C.-F., & Wang, S.-D. 2002, IEEE Trans. Neural Networks, 13, 464 [CrossRef] [Google Scholar]
- Luo, B., Brandt, W. N., Xue, Y. Q., et al. 2017, ApJS, 228, 2 [Google Scholar]
- Magorrian, J., Tremaine, S., Richstone, D., et al. 1998, AJ, 115, 2285 [Google Scholar]
- Małek, K., Solarz, A., Pollo, A., et al. 2013, A&A, 557, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Małek, K., Buat, V., Roehlly, Y., et al. 2018, A&A, 620, A50 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Malizia, A., Bassani, L., Bazzano, A., et al. 2012, MNRAS, 426, 1750 [NASA ADS] [CrossRef] [Google Scholar]
- Marconi, A., & Hunt, L. K. 2003, ApJ, 589, L21 [Google Scholar]
- Marinucci, A., Bianchi, S., Nicastro, F., Matt, G., & Goulding, A. D. 2012, ApJ, 748, 130 [NASA ADS] [CrossRef] [Google Scholar]
- Massey, F. J. 1951, J. Am. Stat. Assoc., 46, 68 [CrossRef] [Google Scholar]
- Matsuhara, H., Wada, T., Matsuura, S., et al. 2006, PASJ, 58, 673 [NASA ADS] [Google Scholar]
- McGlynn, T. A., Suchkov, A. A., Winter, E. L., et al. 2004, ApJ, 616, 1284 [CrossRef] [Google Scholar]
- McKinney, W. 2010, in Proceedings of the 9th Python in Science Conference, eds. S. van der Walt, & J. Millman, 56 [Google Scholar]
- Merloni, A., Bongiorno, A., Brusa, M., et al. 2014, MNRAS, 437, 3550 [NASA ADS] [CrossRef] [Google Scholar]
- Miyazaki, S., Komiyama, Y., Nakaya, H., et al. 2012, Proc. SPIE, 8446, 327 [Google Scholar]
- Mountrichas, G., Buat, V., Yang, G., et al. 2021, A&A, 646, A29 [EDP Sciences] [Google Scholar]
- Murakami, H., Baba, H., Barthel, P., et al. 2007, PASJ, 59, S369 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Nakoneczny, S., Bilicki, M., Solarz, A., et al. 2019, A&A, 624, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nakoneczny, S. J., Bilicki, M., Pollo, A., et al. 2021, A&A, 649, A81 [CrossRef] [EDP Sciences] [Google Scholar]
- Nayyeri, H., Ghotbi, N., Cooray, A., et al. 2018, ApJS, 234, 38 [CrossRef] [Google Scholar]
- Netzer, H. 2015, ARA&A, 53, 365 [Google Scholar]
- Noll, S., Burgarella, D., Giovannoli, E., et al. 2009, A&A, 507, 1793 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Oi, N., Goto, T., Matsuhara, H., et al. 2020, MNRAS, 500, 5024 [CrossRef] [Google Scholar]
- Oi, N., Matsuhara, H., Murata, K., et al. 2014, A&A, 566, A60 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Onaka, T., Matsuhara, H., Wada, T., et al. 2007, PASJ, 59, S401 [Google Scholar]
- Oyabu, S., Ishihara, D., Malkan, M., et al. 2011, A&A, 529, A122 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Padovani, P., Alexander, D. M., Assef, R. J., et al. 2017, A&ARv., 25, 2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pandas Development team, 2020, pandas-dev/pandas: Pandas [Google Scholar]
- Panessa, F., & Bassani, L. 2002, A&A, 394, 435 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pearson, C., Cheale, R., Serjeant, S., et al. 2017, Publ. Korean Astron. Soc., 32, 219 [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Poliszczuk, A., Solarz, A., Pollo, A., et al. 2019, PASJ, 71, 65 [CrossRef] [Google Scholar]
- Probst, P., Wright, M. N., & Boulesteix, A.-L. 2019, WIREs Data Mining and Knowledge Discovery, 9, e1301 [CrossRef] [Google Scholar]
- Richards, G. T., Fan, X., Newberg, H. J., et al. 2002, AJ, 123, 2945 [NASA ADS] [CrossRef] [Google Scholar]
- Richards, G. T., Myers, A. D., Gray, A. G., et al. 2009, ApJS, 180, 67 [NASA ADS] [CrossRef] [Google Scholar]
- Richards, G. T., Myers, A. D., Peters, C. M., et al. 2015, ApJS, 219, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Richards, G. T., Nichol, R. C., Gray, A. G., et al. 2004, ApJS, 155, 257 [NASA ADS] [CrossRef] [Google Scholar]
- Roseboom, I. G., Lawrence, A., Elvis, M., et al. 2013, MNRAS, 429, 1494 [NASA ADS] [CrossRef] [Google Scholar]
- Rousseeuw, P. J., & Driessen, K. V. 1999, Technometrics, 41, 212 [CrossRef] [Google Scholar]
- Sheng, Z., Wang, T., Jiang, N., et al. 2017, ApJ, 846, L7 [NASA ADS] [CrossRef] [Google Scholar]
- Shi, Y., Rieke, G. H., Smith, P., et al. 2010, ApJ, 714, 115 [NASA ADS] [CrossRef] [Google Scholar]
- Shim, H., Im, M., Ko, J., et al. 2013, ApJS, 207, 37 [NASA ADS] [CrossRef] [Google Scholar]
- Shim, H., Kim, Y., Lee, D., et al. 2020, MNRAS, 498, 5065 [CrossRef] [Google Scholar]
- Solarz, A., Pollo, A., Takeuchi, T. T., et al. 2015, A&A, 582, A58 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Stalevski, M., Fritz, J., Baes, M., Nakos, T., & Popović, L. Č. 2012, MNRAS, 420, 2756 [NASA ADS] [CrossRef] [Google Scholar]
- Stalevski, M., Ricci, C., Ueda, Y., et al. 2016, MNRAS, 458, 2288 [NASA ADS] [CrossRef] [Google Scholar]
- Stern, D., Eisenhardt, P., Gorjian, V., et al. 2005, ApJ, 631, 163 [NASA ADS] [CrossRef] [Google Scholar]
- Stern, D., Assef, R. J., Benford, D. J., et al. 2012, ApJ, 753, 30 [NASA ADS] [CrossRef] [Google Scholar]
- Stern, D., McKernan, B., Graham, M. J., et al. 2018, ApJ, 864, 27 [Google Scholar]
- Stern, J., & Laor, A. 2012, MNRAS, 423, 600 [NASA ADS] [CrossRef] [Google Scholar]
- Toba, Y., Goto, T., Oi, N., et al. 2020, ApJ, 899, 35 [Google Scholar]
- Tran, H. D. 2003, ApJ, 583, 632 [Google Scholar]
- Ting, K. M. 2002, IEEE Trans Knowledge Data Eng., 14, 659 [CrossRef] [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Wada, T., Matsuhara, H., Oyabu, S., et al. 2008, PASJ, 60, S517 [CrossRef] [Google Scholar]
- Wang, T.-W., Goto, T., Kim, S. J., et al. 2020, MNRAS, 499, 4068 [CrossRef] [Google Scholar]
- Waskom, M., & The Seaborn Development Team 2020, mwaskom/seaborn [Google Scholar]
- Weisskopf, M. C., Tananbaum, H. D., Speybroeck, L. P. V., & O’Dell, S. L. 2000, Proc. SPIE, 4012, 2 [NASA ADS] [CrossRef] [Google Scholar]
- White, G. J., Pearson, C., Braun, R., et al. 2010, A&A, 517, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- White, G. J., Barrufet de Soto, L., Pearson, C., et al. 2017, Publ. Korean Astron. Soc., 32, 231 [Google Scholar]
- Yang, G., Boquien, M., Buat, V., et al. 2020, MNRAS, 491, 740 [NASA ADS] [CrossRef] [Google Scholar]
- York, D. G., Adelman, J., Anderson, Jr., J. E., et al. 2000, AJ, 120, 1579 [CrossRef] [Google Scholar]
- Zakamska, N. L., Strauss, M. A., Krolik, J. H., et al. 2003, AJ, 126, 2125 [NASA ADS] [CrossRef] [Google Scholar]
- Zakamska, N. L., Sun, A.-L., Strauss, M. A., et al. 2019, MNRAS, 489, 497 [Google Scholar]
- Zhang, Y., & Zhao, Y. 2004, A&A, 422, 1113 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
Appendix A: Software
For the ML pipeline construction and performance analysis SciPy (Virtanen et al. 2020), NumPy (Harris et al. 2020), Pandas (McKinney et al. 2010; Pandas Development team 2020), Scikit-learn (Pedregosa et al. 2011), and XGBoost (Chen & Guestrin 2016) python packages were used. Results visualization was done with Matplotlib (Hunter 2007) and Seaborn (Waskom & The Seaborn Development Team 2020) packages. SED fitting was performed via CIGALE (Boquien et al. 2019) software.
Appendix B: Metric values
This appendix presents details of the performance evaluation. Metric values presented in the Table B.1 refer to the main training (first iteration). The best classifier from this set was used for the creation of the final AGN candidates catalog. Table B.2 shows results from the second iteration experiment.
Metrics for the main training (first iteration).
Metrics for the second iteration experiment.
All Tables
Performance comparison of final selected classifier with color-cut method described in Lee et al. (2007).
SED fitting results calculated for training samples and obtained AGN candidates catalog in two photometric redshift zphot ranges (below and above zphot = 1.5).
All Figures
|
Fig. 1. Scheme of the machine learning pipeline described in the present work. Upper part of the scheme shows the general outline, lower part of the scheme, shown in the violet rectangle, refers to the training of the models. |
| In the text | |
|
Fig. 2. Fuzzy memberships calculated for the training data from first iteration (see Sect. 4.3). Panel a: error-based fuzzy membership. Error-based weights were calculated with respect to optical and NIR passbands measurement uncertainties, giving higher priority to objects with better measurements within AGN or galaxy sample. Panel b: distance-based fuzzy membership. Distance-based weights were calculated with respect to the class center calculated in a feature space, reducing impact of outliers on classification result. |
| In the text | |
|
Fig. 3. Features selected using KS-statistic value. Panel a: first (main) iteration. Panel b: second iteration experiment. For the first (main) iteration the KS-statistic was calculated on AGN and galaxy training samples using the HSC g, r, i, z, Y and IRC N2, N3, N4 bands along with all possible colors. The optimal feature set was defined as a set where all available filters were used and the KS-statistic value was not substantially lower for less important features. For the second iteration experiment, additional MIR features in form of S7, S9, S11, L15, and L18 bands and all possible colors were used. In order to minimize the risk of data sparsity, the selection of optimal feature set was restricted to features with the highest KS-statistic value. Only the most important features are shown. |
| In the text | |
|
Fig. 4. Mahalanobis distance histograms for AGN and galaxy training samples. Panel a: AGN sample. Panel b: galaxy sample. Dashed red lines correspond to a particular contamination parameter value of the MCD algorithm used to limit generalization data set to the training sample range. |
| In the text | |
|
Fig. 5. Performance evaluation of different classification models. Panel a: evaluation metric values for different classification algorithms. Only models with no instance-weighting are presented. Panel b: F1 value for different instance-weighting strategies for selected types of classification algorithms. Panel c: evaluation metric values for second iteration experiment. Panel d: legend. |
| In the text | |
|
Fig. 6. NIR and MIR properties of the training set and classification results. Panel a: properties of the training data. Color of galaxies correspond to spectroscopic redshift value. Panel b: first iteration training and final AGN catalog properties. Right part of the figure shows density histogram for components of the labeled set with corresponding color. Panel c: second iteration experiment. Modified training sample is shown as well as two parts of generalization: “rejected” objects, which occupy the red N2 − N4 color range and new objects below this range. These candidates were not included in final catalog. Right part of the figure shows density histogram for components of the labeled set with corresponding color. Panel d: color-color plot used for Lee et al. 2007 AGN selection. Its selection criteria demarcate the upper right square, marked by the black lines. Training objects and AGN candidates selected during the first and the second iteration from the present work, are shown in form of different markers. Predictions for the labeled data shown in Figs. 6b–d are compound classifications of the test data from five-fold cross-validation. |
| In the text | |
|
Fig. 7. Visualization of parameters used during SED analysis on the training data. XAGN were excluded from this analysis due to a lack of spectroscopic redshift. Panel a: comparison between spectroscopic redshift and photometric redshift estimation (Ho et al. 2021) for training galaxy and AGN samples. The dotted lines refer to zphot = zspec ± 0.15(1 + zspec) cone. The η describes the fraction of outliers defined as objects outside the cone. σ is the normalised median absolute deviation 1.48 × median(|Δz|/(1 + z). Lower plot shows the mean residuals with standard deviations. Only z < 3 objects are shown. Panel b: dependence of an AGN viewing angle (θ) on AGN fraction (fracAGN) for AGN and galaxy training samples. Both parameters were estimated by SED fitting using spectroscopic redshifts. θ = 30° corresponds to pure type-I AGN and θ = 70° to pure type-II with intermediate types in between. Color intensity corresponds to the spectroscopic redshift value. Dotted line shows fracAGN = 0.2 – value which defines AGNSED. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.