| Issue |
A&A
Volume 633, January 2020
|
|
|---|---|---|
| Article Number | A109 | |
| Number of page(s) | 16 | |
| Section | The Sun | |
| DOI | https://doi.org/10.1051/0004-6361/201936662 | |
| Published online | 20 January 2020 | |
An improved multi-ridge fitting method for ring-diagram helioseismic analysis
1
Max-Planck-Institut für Sonnensystemforschung, Justus-von-Liebig-Weg 3, 37077 Göttingen, Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
JILA & Department of Applied Mathematics, University of Colorado, Boulder, CO 80309-0440, USA
3
Institut für Astrophysik, Georg-August-Universität Göttingen, Friedrich-Hund-Platz 1, 37077 Göttingen, Germany
Received:
10
September
2019
Accepted:
6
November
2019
Abstract
Context. There is a wide discrepancy in current estimates of the strength of convection flows in the solar interior obtained using different helioseismic methods applied to observations from the Helioseismic and Magnetic Imager onboard the Solar Dynamics Observatory. The cause for these disparities is not known.
Aims. As one step in the effort to resolve this discrepancy, we aim to characterize the multi-ridge fitting code for ring-diagram helioseismic analysis that is used to obtain flow estimates from local power spectra of solar oscillations.
Methods. We updated the multi-ridge fitting code developed by Greer et al. (2014, Sol. Phys., 289, 2823) to solve several problems we identified through our inspection of the code. In particular, we changed the (1) merit function to account for the smoothing of the power spectra, (2) model for the power spectrum, and (3) noise estimates. We used Monte Carlo simulations to generate synthetic data and to characterize the noise and bias of the updated code by fitting these synthetic data.
Results. The bias in the output fit parameters, apart from the parameter describing the amplitude of the p-mode resonances in the power spectrum, is below what can be measured from the Monte-Carlo simulations. The amplitude parameters are underestimated; this is a consequence of choosing to fit the logarithm of the averaged power. We defer fixing this problem as it is well understood and not significant for measuring flows in the solar interior. The scatter in the fit parameters from the Monte-Carlo simulations is well-modeled by the formal error estimates from the code.
Conclusions. We document and demonstrate a reliable multi-ridge fitting method for ring-diagram analysis. The differences between the updated fitting results and the original results are less than one order of magnitude and therefore we suspect that the changes will not eliminate the aforementioned orders-of-magnitude discrepancy in the amplitude of convective flows in the solar interior.
Key words: Sun: helioseismology / methods: data analysis
© K. Nagashima et al. 2020
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access funding provided by Max Planck Society.
1. Introduction
Understanding solar interior dynamics is crucial to understanding the mechanisms of the solar dynamo. As one example, convection may play an important role in the formation of magnetic flux tubes, as well as in their rise through the convection zone and their tilts at the solar surface (e.g., Brun & Browning 2017). Helioseismology, which uses observation of oscillations on the solar surface, is an important probe of interior dynamics.
Currently there is a major discrepancy between the time-distance (Hanasoge et al. 2012) and ring-diagram (Greer et al. 2015) estimates of the strength of solar subsurface convection at large spatial scales. The measurements from time-distance helioseismology suggest flows orders-of-magnitude weaker than those seen in convection simulations (e.g., in the anelastic spherical harmonic (ASH) convection simulations by Miesch et al. 2008), while the measurements from ring-diagrams are closer to the expectations from simulations.
Time-distance helioseismology (Duvall et al. 1993; Kosovichev & Duvall 1997) is based on measuring and interpreting the travel times of acoustic and surface-gravity wave packets. These travel times are measured from the temporal cross-covariances between the Doppler observations at pairs of points on the solar surface (see Gizon & Birch 2005, for a review). Ring-diagram analysis (Hill 1988; Antia & Basu 2007) measures the Doppler shift of acoustic and surface-gravity oscillation modes in the local power spectra and uses these Doppler shifts to infer local flows in the solar interior. To compute the local power spectra, the solar surface is divided into a number of spatial tiles. Each tile is tracked at a rate close to the solar rotation rate. The power spectra of the solar oscillations (Doppler observations) are computed for each tile. In the three-dimensional power spectra, roughly concentric rings with high power are present at each frequency and they correspond to the modes of different radial orders. Flow and wave-speed anomalies in the Sun shift and distort the rings and, hence, one can obtain information about the solar interior from the ring parameters. Flow maps from Doppler observations by the Helioseismic and Magnetic Imager (HMI; Schou et al. 2012) onboard the Solar Dynamics Observatory (SDO; Pesnell et al. 2012) are automatically computed by the SDO/HMI ring-diagram pipeline (Bogart et al. 2011a,b) on a daily basis since the SDO launch in 2010.
The HMI ring pipeline codes separately fit each single ridge (single radial order n) in the power in slices at constant horizontal wavenumber or slices in temporal frequency. Greer et al. (2014) developed an alternative approach based on simultaneously fitting multiple ridges (multiple radial orders) at each horizontal wavenumber. Greer et al. (2015) introduced another innovation: they chose a much denser tile layout than other ring-diagram analyses: 16-degree tiles with the separation of 0.25 degree instead of the 7.5 degree spacing (at the equator, the spacing increases at higher latitude to maintain 50% overlap between neighboring tiles) used for 15-degree tiles in the HMI ring pipeline. As described in detail in Appendix A.2, the ATLAS code from Greer et al. (2014, 2015) provides seven parameters for each ridge and five parameters for the background power at each wavenumber k. Greer et al. (2015) applied a three-dimensional flow inversion to these fit results to estimate the three-dimensional flow field in the solar interior. Both the dense packing of tiles and the three-dimensional inversions are unique to ATLAS, however, in this paper we focus only on the fitting component of the code.
As one step toward understanding the causes of the above-mentioned disagreement between the helioseismic measurements of subsurface convection, here we focus on the ring-diagram analysis described by Greer et al. (2015). We revisit the analysis code (Greer et al. 2014; Greer 2015) that was used in that work and identify several issues through a step-by-step examination of the code. In response to these issues, we have developed an updated method and characterize the updated code by applying it to synthetic data generated from Monte-Carlo simulations.
2. Description of the updated code
In this section, we describe our updated ATLAS code. Each of the updates is a response to a problem that we found in our inspection of the original code. In this section we will refer to Appendix A for the details of the original code.
After computing the power spectrum for a particular tile, the processing steps are: (1) remap the power spectrum from Cartesian (kx, ky) to polar (k, θ) coordinates, (2) rebin the power in azimuth θ; the number of grid points in θ is reduced from npix = 256 to npix = 64, (3) fit the logarithm of a Lorentzian model to the logarithm of the smoothed power by least-squares minimization at each k using the Levenberg–Marquardt (Marquardt 1963) technique; the model function has 7nr + 4 parameters at each horizontal wavenumber k, where nr is the number of ridges at the particular value of k, and (4) estimate the covariance matrix of the errors of the fitted parameters by computing the inverse of the Hessian matrix of the cost function. In the following subsections we describe the changes that we introduced to each of these steps.
2.1. Re-binning in azimuth
The computed local power spectra O(kx, ky, ν) and the interpolated spectra in polar coordinates are non-negative by construction. Following the original code, the interpolated spectra have 256 pixels at each k. At k R⊙ ≡ ℓ ∼ 500 (where R⊙ is the solar radius), which corresponds to kpix ≡ k/hk = 21 (where hk = 3.37 × 10−2 Mm−1 is the grid spacing in k) and which we use in most of the Monte-Carlo test calculations shown later, this is about twice of the number of grid points in θ from the full resolution, which has npix ≈ 2πk/hk. For the sake of computational efficiency, it is desirable to reduce the number of points in azimuth. In the updated code, we use a running box-car smoothing of four-pixel width followed by subsampling by a factor of four to reduce to the number of grid points in θ. This procedure ensures that the resulting smoothed power spectrum Os(k, θ, ν) will be positive. We expect that as flows produce θ variations that are dominantly at azimuthal wavenumber one, it should be possible retain only very low resolution in θ; Sect. 4.1 discusses this in more detail. We retain 64 points in θ for the examples shown in this paper.
The original code used a low-pass Fourier filter to smooth the power spectrum in the θ direction. This procedure produces occasional points where the smoothed power is negative.
2.2. Least-squares fitting of the logarithm of power
In the updated code, we use a least-squares fitting to fit the logarithm of the model power to the logarithm of the remapped and smoothed power. Following Greer et al. (2014), the fitting is carried out independently at each horizontal wavenumber k. As the amount of smoothing is increased, the probability distribution function (PDF) of the power, as well as its logarithm, approaches a normal distribution (see Appendix B.4 for more details), and it is therefore appropriate to use a least-squares fit. The logarithm of the smoothed power has the convenient property that the variance of the logarithm of power (σN in Eq. (B.4)) depends only on the details of the remapping and smoothing and does not depend on θ or ν (see Appendix B.2 for details).
In our approach, the cost function at a single k is:
![Mathematical equation: $$ \begin{aligned} -\ln L(\boldsymbol{q}) = \sum _j \left[\ln {O_s(\theta _j, \nu _j)} - \ln {P(\theta _j, \nu _j; \boldsymbol{q})}\right]^2 \ , \end{aligned} $$](/articles/aa/full_html/2020/01/aa36662-19/aa36662-19-eq1.gif) (1)
(1)
where Os(θ, ν) is the observed spectrum at some fixed k after smoothing in θ and P(θ, ν; q) is the model of the spectrum with model parameters q. The summation is taken over all bins j within the fitting range. We note that as the error estimates for lnOs (σN in Eq. (B.4)) are all the same, we set them all to one in writing the cost function. For the sake of readability, throughout the remainder of this paper we do not introduce or carry notation to denote the value of k; the fitting problems at each k are treated as independent and we will not be comparing fit parameters for different values of k. This is an approximation as the interpolation from (kx, ky) space to (k, θ) space does imply error correlation between the fit parameters at different values of k.
In the updated code, we use the Levenberg–Marquardt technique to solve the minimization problem. In particular, we use mpfit.c (Markwardt 2009), one of the codes in the MINPACK-1 least-squares fitting library (Moré 1978; Moré & Wright 1993). The covariance matrix of the errors associated with the fitted parameters are estimated at the last step of the Levenberg-Marquardt procedure. As a practical note, the error estimates obtained by this method must be scaled as we have assumed σ = 1 in Eq. (1); see original PDF, Eq. (B.4). In general, calling the code with an incorrect estimate of σ could cause poor performance of the fitting algorithm. In the current case σ is not far from one (σ ∼ 0.5, see Sect. 3.1) and we do not expect that this is a significant issue here. To implement the σ estimation in the code is a task for the future.
The original ATLAS code used a maximum-likelihood method based on the assumption that the power spectrum in a single bin in (kx, ky, ν) space follows a chi-squared distribution with two degrees of freedom; see Appendix B.1 for the original likelihood function. This method does not account for the impact of smoothing on the PDF of the power spectrum.
2.3. The functional form of the power spectrum
The model function for the power spectrum at a single k in our updated code is
![Mathematical equation: $$ \begin{aligned}&P (\theta , \nu ; \boldsymbol{q}_{\mathrm{BG} }) =\nonumber \\&\sum ^{n_{\mathrm{r} }-1}_{n=0} \frac{q_{1,n} (q_{2,n}/2) F(\theta ;q_{5,n} , q_{6,n}) }{[\nu - q_{0,n} + k (q_{3,n} \cos \theta + q_{4,n} \sin \theta ) /(2\pi )]^2+(q_{2,n}/2)^2} \nonumber \\&+ B(\theta , \nu ; \boldsymbol{q}_{\mathrm{BG} }) \ , \end{aligned} $$](/articles/aa/full_html/2020/01/aa36662-19/aa36662-19-eq2.gif) (2)
(2)
where
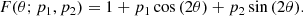 (3)
(3)
The fitting parameters for the peaks (n = 0, …nr − 1, where nr is the number of the ridges) are q0, n = νn is the frequency of the nth peak, q1, n = An is the amplitude, q2, n = Γn is the width, (q3,n, q4,n) = u = (ux,n, uy,n) is the horizontal velocity, q5, n = fc, n and q6, n = fs, n are parameters to handle anisotropy. The background is modeled at each k as
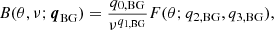 (4)
(4)
where F is again given by Eq. (3) and q0, BG = B0 is the amplitude, q1, BG = b is the power-law index, q2, BG = fc, bg and q3, BG = fs, bg are the parameters to handle the anisotropy. The number of the parameters in total is 7nr + 4 at each k. For reference, Tables C.1–C.3 show the physical meaning of each of the fitting parameters.
We altered the model function Eq. (2) from the original Eq. (A.1) to make the parameterization more stable. The following subsections describe the motivation for these changes.
2.3.1. Parameters of the anisotropy terms
We replaced F′ defined by Eq. (A.2) with F defined by Eq. (3) and used the same form for the anisotropy terms for the background, although the exact form for the background function is subject to other alterations discussed in Sect. 2.3.2.
Our alteration does not change the space of functions that can be fit with F(θ) but it does not suffer from the issue of indeterminate phase for nearly isotropic power spectra. In the original parameterization, the amplitudes of the anisotropic part of the model function (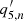 and
and 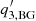 ) are usually much smaller than one. As a consequence, the phase (
) are usually much smaller than one. As a consequence, the phase (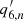 or
or 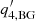 ) does not matter much in the fitting, and, hence, it is unstable. In the particular case of isotropic power spectra with
) does not matter much in the fitting, and, hence, it is unstable. In the particular case of isotropic power spectra with 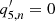 for all n and
for all n and 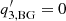 , the phases
, the phases 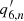 and
and 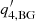 are indeterminate.
are indeterminate.
2.3.2. Parameters of the background model
We also changed the background parameterizations for the sake of stability. The background model (Eq. (A.3)) originally contained five parameters. In this section we explain our motivation for reducing this to the four parameters shown in Eq. (4).
The background model in Eq. (A.3) is based on the model of Harvey (1985):
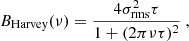 (5)
(5)
where τ is the characteristic timescale of the velocity field in question and σrms is the rms velocity. In this case the index in the original background model (Eq. (A.3)) would be 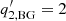 . Appourchaux et al. (2002) suggested a generalization of the Harvey (1985) model, where
. Appourchaux et al. (2002) suggested a generalization of the Harvey (1985) model, where 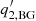 can be the range of 2 to 6.
can be the range of 2 to 6.
In the ATLAS fittings, however, we typically obtain the index 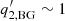 for HMI observations. Also, the roll-off frequency obtained from the fitting of HMI observations,
for HMI observations. Also, the roll-off frequency obtained from the fitting of HMI observations, 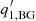 , is quite low (∼1 μHz) and below the frequency resolution for 28.8 h power spectra (9.7 μHz), which is the typical observation length for 15-degree tiles in HMI pipeline and 16-degree tiles in ATLAS.
, is quite low (∼1 μHz) and below the frequency resolution for 28.8 h power spectra (9.7 μHz), which is the typical observation length for 15-degree tiles in HMI pipeline and 16-degree tiles in ATLAS.
This suggests that the background is not related to either the supergranulation (τ ≈ 105 s, or ν ≈ 10 μHz) or granulation time scales (τ ≈ 4 × 102 s, ν ≈ 2.5 mHz), based on Table 1 of Harvey (1985). As these background parameters are not consistent with the original physical model, we might need to reconsider the background model. At this moment, however, this is a task for the future, and we retain this model in the altered form mentioned below.
In the case of 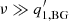 , the original background model, Eq. (A.3), can be simplified:
, the original background model, Eq. (A.3), can be simplified:
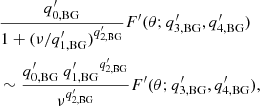 (6)
(6)
we therefore redefine the background model B(θ, ν) with four parameters qi, BG(i = 0, 1, 2, 3) with the altered anisotropy terms in the form of Eq. (4). As the new background model (qi, BG) has only four parameters instead of the original five, the index i has different meanings in the two models.
3. Performance of the updated code
Monte-Carlo simulations are a powerful tool for testing fitting methods. In this section, we use this approach to characterize the performance of the updated fitting code. In Sect. 3.1 we compare the scatter of the fitting results of Monte-Carlo simulations with the noise estimated by the updated code. In Sect. 3.2 we measure the bias of the flow estimates for some simple cases.
3.1. Error estimates
We use the approach of Gizon & Birch (2004) to generate realizations of the wavefield. The assumption of this approach is that the real and imaginary parts of the wavefield at each point (kx, ky, ν) are independent Gaussian random variables. In more detail, the method is as follows: (1) create a Lorentzian model (Eq. (2)) for the limit spectrum using a set of input parameters, (2) pick two standard normally distributed random numbers at each grid point (kx, ky, ν) and take sum of the squared numbers divided by two to make a chi-square distribution with two degrees of freedom, and (3) multiply the limit spectrum by these random numbers to obtain one realization of the power spectrum.
After each realization of the power spectrum is generated in (kx, ky, ν) space, it is then remapped and rebinned in the same manner as the local power spectra computed from the observations. To obtain the parameters for the input model power spectrum in the first step above, we used the average over Carrington rotation 2211 of the power spectra for the disc center tile from the SDO/HMI pipeline (these average power spectra were obtained using the Data Record Management System (DRMS) specification hmi.rdvavgpspec_fd15[2211][0][0]). We then used the updated code to fit these average power spectra. The parameters resulting from these fits at ℓ = 328, 492, and 984 (kpix = 14, 21, and 42, respectively) are shown in Tables C.1–C.3, respectively. We later use these parameters to generate Monte-Carlo synthetic data.
Figure 1 shows a few slices of the input limit spectrum, namely, Eq. (2) evaluated for the parameters q listed in Tables C.1–C.3. The original observed power spectrum is also shown. Figure 1 shows that the model power spectrum is reasonable compared to the observables, although the details of the peak shapes and the background slopes are not always reproduced by the model and there is still room for improvement with regard to the model function.
 |
Fig. 1. Slices through the input limit spectrum (black) and observational spectrum averaged over one Carrington rotation (gray), which was used to obtain the input parameters, at θ = 0 and a few different values of k. Vertical dashed lines indicate the fitting ranges and the models are plotted only within these ranges. Lower limits for all k are fixed at 0.4 mHz, while the upper limits depend on the initial guess for each k, and they are the highest peak frequencies plus the widths of the peak. For the cases of ℓ = 328 and 492 (kpix = 14 and 21, respectively), the peaks with the radial order, n, from 0 to 7 are used in the fitting, while for the case of ℓ = 984 (kpix = 42), 0 ≤ n ≤ 3. |
We created 500 realizations of the power spectrum using the above procedure. The fitting code occasionally produces outliers and for these computations, we removed them. Specifically, we removed outliers iteratively: in each iteration we computed the standard deviation of the samples between the tenth and 90th percentile and we discarded points at more than five times the standard deviation away from the mean. We repeated this procedure until no further points were removed. After this outlier removal, the number of valid samples are 489 (ℓ = 328, kpix = 14), 500 (ℓ = 492, kpix = 21), and 496 (ℓ = 984, kpix = 42) out of 500 samples.
Figure 2 shows the average and scatter of the output peak parameters associated with the n = 0…5 ridges for ℓ = 492 (kpix = 21) from fitting 500 Monte-Carlo realizations of the power spectrum. Table 1 shows the average and scatter of the output background parameters from the same set of fitting results. From Fig. 2 and Table 1, we see that most of the averages of the parameters estimated by the fitting are within the expected scatter in the mean (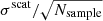 , where Nsample is the number of Monte-Carlo realizations, hence Nsample = 500 here). The amplitude is an exception; it is always smaller than the input. This is the result of taking the logarithm of the smoothed power; see Appendix D for details. Also, from Fig. 2 and Table 1, we see that the error estimated by the updated code σcode is consistent with the scatter of the samples σscat. This shows that the error estimates produced by the updated code are reasonable.
, where Nsample is the number of Monte-Carlo realizations, hence Nsample = 500 here). The amplitude is an exception; it is always smaller than the input. This is the result of taking the logarithm of the smoothed power; see Appendix D for details. Also, from Fig. 2 and Table 1, we see that the error estimated by the updated code σcode is consistent with the scatter of the samples σscat. This shows that the error estimates produced by the updated code are reasonable.
 |
Fig. 2. Fitting parameters and their errors for the case ℓ = 492 (kpix = 21). Each panel has three parts. In the upper part of each panel, squares indicate the input parameters, |
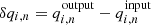
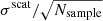
Background parameters in the input model for the Monte Carlo simulation and the fitting results at ℓ = 492 (kpix = 21).
We carried out the analogous Monte-Carlo simulations for the cases of twice larger k and two-thirds k. Although the number of peaks to be fitted is not the same in these cases as the number of prominent peaks is smaller for larger k, the behavior of the fitting results and their error estimates are similar to those in the case shown in Fig. 2 and Table 1.
3.2. Bias of the flow estimates and correlations between the fitting parameters
To measure the bias of the flow estimates and the correlations between the fitting parameters, we make models with a simple flow: isotropic models, except for a specific flow ux for the n = 3 ridge.
The parameters for the model are identical to those from Sect. 3.1, except for the parameters related to the azimuthal angle θ; namely, the peak parameters q3, n, q4, n, q5, n, and q6, n (for all n) and the background parameters q2, b and q3, b are all set to zero. The flow ux, n (q3, n) is non-zero for a single n, n = 3. The limit spectrum is constructed with Eq. (2) and these input parameters, and the realizations of the power spectrum are generated in the same way as those in Sect. 3.1.
In this subsection we compare results from the updated code with results from the original code and also a modified version of the original code. While the original code fits a Lorentzian model to the square root of the power, the modified original code fits a Lorentzian model to the power itself. Although the original and modified original codes assumes the five-parameter background model (Eq. (A.3)), here we created the limit spectrum using the four-parameter background model (Eq. (4)), which we use in our updated code. As described in Sect. 2.3.2, under the current conditions, our updated four-parameter background model can approximate well the original five-parameter background model and the original and the modified original codes are applicable, although we need to keep in mind that the meaning of the background parameters in the results from different codes are different. Comparable tests using input parameters obtained by the original code give similar correlation coefficients maps.
3.2.1. Bias of the flow estimate
Figure 3 shows the fitting results for ux, n = 3 at ℓ = 492 (kpix = 21) in the form of normalized histograms of 500 Monte–Carlo simulations. The input models have q3, n = ux, n = 0, 80, …400 m s−1 for the n = 3 ridge. Before plotting, we removed outliers from the output fit parameters. We removed outliers as described in Sect. 3.1. After the outlier removal procedure, the sample numbers for each methods are 394–466 depending on the value of ux, n = 3 (79–93%, modified original), 436–488 (87–98%, original), and 499–500 (100%, updated). The updated code provides almost no outliers, while there are some outliers in the fitting results by the modified original and original codes. The number of outliers depends on ux, n, although there is no clear trend with ux, n; for example, we cannot say that the stronger flow produces more outliers. We did not further investigate the details of the outliers in the fitting results by the original and modified original codes.
 |
Fig. 3. Fitting results of ux, n = 3 at ℓ = 492 (kpix = 21) in the form of normalized histograms by the original code which fit the model to the square root of power (black), the modified original code which fit the power (blue), and the updated code (red). Horizontal lines indicate the average of 500 Monte–Carlo realizations given by the three codes (in the same colors as the histograms, dash-dotted black, dashed blue, and solid red). The short vertical lines on the horizontal lines indicates the error estimated by the codes (thin lines with short horizontal bars) and the standard deviations of the 500 fitting results (thick lines) in the same color as the histograms centered at the means (horizontal lines) by the three codes. We note that the fitting results with overly large deviation are omitted. See text for details. |
Figure 3 shows that the original fitting code underestimates the input flow by about 3%. This trend is consistent with what was reported by Greer et al. (2014). The modified original and updated codes produce less-biased flow estimates. Figure 3 also compares the errors estimated by the code and the scatter in the Monte Carlo simulation. The errors from the updated code are consistent with the scatter of the Monte-Carlo results, while the original code overestimates the errors.
3.2.2. Correlations between the fitting parameters
Figure 4 shows the correlation coefficients between the fitting parameters of 500 Monte Carlo samples. For this computation, outliers were removed as described in Sect. 3.1. The original and modified original codes both produce stronger correlations in some of the output parameters than the updated code. In particular, for the original code, these parameters show the strongest correlations: the amplitude An (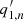 ) and the width Γn′ (
) and the width Γn′ (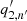 ) at peaks |n − n′| ≤ 1, the roll-off frequency νbg (
) at peaks |n − n′| ≤ 1, the roll-off frequency νbg (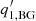 ) and the index b (
) and the index b (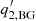 ) of the background, and the index b (
) of the background, and the index b (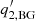 ) of the background and An (
) of the background and An (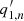 ) or Γn (
) or Γn (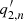 ) of higher-n peaks.
) of higher-n peaks.
 |
Fig. 4. Correlation coefficients between the parameters (500 Monte-Carlo realizations) for the isotropic model (ux, n = 0 for all n) and for the isotropic model except with ux = 400 m s−1 for the n = 3 peak (on the next page) at ℓ = 492 (kpix = 21). Each box indicates the parameters for n-th peak (n = 0, 1, …5), qi, n (i = 0, …6, from left to right and from bottom to top in each box) and the background parameters (BG). As we defined in Sect. 2q0, n = νn is the frequency of the n-th peak, q1, n = An is the amplitude, q2, n = Γn is the width, q4,n) = u = (ux,n, uy,n) is the horizontal velocity, q5, n = fc, n and q6, n = fs, n are parameters to handle anisotropy. Background parameters are q0, BG = B0 is the amplitude, q1, BG = b is the power-law index, q2, BG = fc, bg and q3, BG = fs, bg are the parameters to handle the anisotropy of the background. Color scale is shown by the color bar on the right side. We note that the last columns and rows (i = 4) of BG on the top panels are empty because the number of the background parameters in the model in the updated code is four, instead of five. |
 |
Fig. 4. continued. |
The modified original code and the updated code did not show such strong biases, except for the width and amplitude of each peak, along with the background index and some weaker peaks (smaller and larger n). In terms of correlations between the parameters, the updated code shows an overall improvement in comparison with the original, but the correlation coefficients between ux and uy on the same peaks or on the peaks next to each other are ∼0.1 at most for any ux and any fitting results by all three codes shown in Fig. 4.
3.3. Summary of the Monte-Carlo test
The Monte-Carlo tests show that the updated code is able to reasonably recover the parameters, apart from the amplitude, that are used to generate the input power spectra. Other than the amplitudes, we were not able to measure a statistically meaningful bias in the fit results using 500 Monte-Carlo simulations. The underestimation of the amplitude is the result of taking the logarithm of the rebinned power. Appendix D discusses this issue in detail. Since current ring-diagram flow inversions are carried out using the mode shifts, (q3, n, q4, n) = (ux, n, uy, n), and the other fitting parameters including mode amplitudes are not used, we believe underestimated amplitudes will not substantially impact on further analysis.
4. Discussion
4.1. Further rebinning in azimuth
We explored the idea of rebinning the data further in θ. If we rebin further, the PDF of the resulting power spectrum is closer to Gaussian. Additional rebinning has the additional benefit of reducing the underestimation of the amplitude. Another benefit is that if we can reduce the number of pixels involved in the fit without a significant decrease of the fitting quality, it will reduce calculation costs.
Figure 5 shows the fitting results corresponding to the four-time further rebinning. Specifically, we rebin the 64-pixel azimuth grid into 16 pixels. In this case, valid sample numbers for the three codes are 351–429 (70–86%, modified original), 406–487 (81–97%, original), and 500 (100%, updated). While the updated code had no outliers, the numbers of outliers in the results by the original and modified original codes increase compared to the case without further rebinning (see Sect. 3.2). This also confirms the stability of the updated code.
 |
Fig. 5. Fitting results of ux, n = 3 at ℓ = 492 (kpix = 21), similar to Fig. 3, but for the further rebinned data. In this case, the number of azimuthal pixels, npix is reduced to 16, instead of the original 64. Legends and colors are similar to those of Fig. 3. Scale factors for the error estimates by the updated code are adjusted accordingly. |
This figure tells us that our updated code is better than the original for this further rebinned case as well, in terms of a more reasonable error estimate and a smaller bias. Moreover, using our updated code, we can rebin further up to 16 pixels at this k (kpix = 21) without a significant increase in the noise or the underestimate of the parameters or outliers in comparison with the original 64-pixel case. In the further rebinned case, the correlations between parameters show a trend that is essentially similar to that of Fig. 4. The only exception is in the fitting results obtained by the modified original code; they show less correlation even in the case of ux, n = 3 = 400 m s−1 in the further rebinned case.
In the original code, there is no scaling factor related to the bin number and the error estimate by the code is needed to be scaled properly. For these 64-pixel and 16-pixel cases, the scatters are not significantly changed and it is the case as well for the error estimated with the proper scaling. For these plots, again we note that we need a sufficient number of pixels for a good fitting; in this case 8 or 4 bins were too small, because the functional form of the model has terms that vary as cos θ and sin θ but also as cos2θ and sin2θ as parameters.
4.2. Future work
The modifications described in this work are mainly corrections of problems in the original code. The exception to this is the change of the algorithm from the maximum likelihood method based on the chi-square distribution function to the one based on the normal distribution function, namely the least-squares method, and the fitting not to the square-root of power but to the logarithm of the power. There are several potential improvements of the analysis. While implementing such further alterations are beyond the scope of this paper, we will briefly discuss some potential future improvements.
One of the open issues is the remapping and rebinning. Currently the power is remapped from Cartesian to polar coordinates and then smoothed in the azimuthal direction. However, it is possible to do the analysis in the original Cartesian system as it is done in the HMI pipeline fitsc module (Bogart et al. 2011a), which fits in slices at constant temporal frequency. The fitting approach shown here would only need to be slightly modified to be carried out in a region with 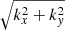 near k. We expect that the main issue would be extending the model to allow for small variations in k. As most parameters are presumably smooth in k, we speculate the fitting small range in the k rather than single k would help the stability of the fits.
near k. We expect that the main issue would be extending the model to allow for small variations in k. As most parameters are presumably smooth in k, we speculate the fitting small range in the k rather than single k would help the stability of the fits.
In the current code, we approximate the PDF of the remapped and smoothed power spectrum as a normal distribution function. But how we rebin, including the topic mentioned in Sect. 4.1, is still open. In the method shown here, we do not rebin the model function but use the model function calculated on the same grid as the rebinned data. This is an approximation in the limit where the rebinning does not significantly change the shape of the limit spectrum and we expect that it will cause a bias in the case of extreme rebinning. Figures 3 and 5 show that the bias in the fitting results of the updated code is less than about 5 m s−1 in the range of |ux| ≤ 400 m s−1 even in the further rebinned case (Fig. 5).
The choice of the model function (currently Eq. (2)) is also an open issue. As shown in Fig. 1, the current model function does not reproduce the detailed structure of the observed power spectrum. For example, the current model function does not take into account the asymmetry of the ridge shape in terms of frequency. Currently, we use the power spectrum of the tile at the disc center only but that is the simplest case and when we investigate the deep convection, we cannot avoid using the tiles on various locations on the disc. In such a case, in order to construct a model function, we need to take into account further effects, such as the effect of the center-to-limb variations (Zhao et al. 2012), the line-of-sight effect on shape of the power, or the effect of the Postel projection. Also, the effects of differential rotation on eigenfunctions are to be accounted for in future.
5. Conclusions
We identified several problems in the multi-ridge fitting code ATLAS (Greer et al. 2014) and we updated the code in response. We confirmed that flow-estimate biases and error overestimates exist in the fitting results by the original code. The biases that we found are insufficient to resolve the discrepancy presented in Hanasoge et al. (2016).
The updated code is based on a consistent model and an appropriate likelihood function. Monte Carlo tests show the fitting results and their error estimates by the updated code are reasonable and confirm the improvement of the fitting.
The work shown here is limited to the fitting part of the ring-diagram analysis codes. The next step in the ring-diagram analysis is flow inversion using the mode-shift parameters (q3, n and q4, n in Eq. (2)). Unlike the HMI ring-diagram pipeline in which the inversion is done at each tile, Greer et al. (2015) used a 3-D inversion using multiple tiles. This unique step should be the focus of examination in future works.
This library code minimizes the sum of square of given function, and ℬi in Eq. (A.5) is given in the original ATLAS code.
Acknowledgments
We thank Rick Bogart for useful discussions. The German Data Center for SDO (GDC-SDO), funded by the German Aerospace Center (DLR), provided the IT infrastructure to process the data. The HMI data used are courtesy of NASA/SDO and the HMI science teams. BWH acknowledges NASA support through grants 80NSSC17K0008, 80NSSC18K1125, and 80NSSC19K0267. We acknowledge partial support from ERC Synergy grant WHOLE SUN 810218.
References
- Anderson, E. R., Duvall, Jr., T. L., & Jefferies, S. M. 1990, ApJ, 364, 699 [NASA ADS] [CrossRef] [Google Scholar]
- Antia, H. M., & Basu, S. 2007, Astron. Nachr., 328, 257 [NASA ADS] [CrossRef] [Google Scholar]
- Appourchaux, T., Andersen, B., & Sekii, T. 2002, in From Solar Min to Max: Half a Solar Cycle with SOHO, ed. A. Wilson, ESA SP, 508, 47 [NASA ADS] [Google Scholar]
- Bogart, R. S., Baldner, C., Basu, S., Haber, D. A., & Rabello-Soares, M. C. 2011a, GONG-SoHO 24: A New Era of Seismology of the Sun and Solar-Like Stars, 271, 012008 [Google Scholar]
- Bogart, R. S., Baldner, C., Basu, S., Haber, D. A., & Rabello-Soares, M. C. 2011b, GONG-SoHO 24: A New Era of Seismology of the Sun and Solar-Like Stars, 271, 012009 [Google Scholar]
- Brun, A. S., & Browning, M. K. 2017, Liv. Rev. Sol. Phys., 14, 4 [Google Scholar]
- Duvall, Jr., T. L., & Harvey, J. W. 1986, in NATO Advanced Science Institutes (ASI) Series C, ed. D. O. Gough, 169, 105 [Google Scholar]
- Duvall, Jr., T. L., Jefferies, S. M., Harvey, J. W., & Pomerantz, M. A. 1993, Nature, 362, 430 [NASA ADS] [CrossRef] [Google Scholar]
- Gizon, L., & Birch, A. C. 2004, ApJ, 614, 472 [NASA ADS] [CrossRef] [Google Scholar]
- Gizon, L., & Birch, A. C. 2005, Liv. Rev. Sol. Phys., 2, 6 [Google Scholar]
- Greer, B. J. 2015, Ph.D. thesis, University of Colorado at Boulder [Google Scholar]
- Greer, B. J., Hindman, B. W., Featherstone, N. A., & Toomre, J. 2015, ApJ, 803, L17 [NASA ADS] [CrossRef] [Google Scholar]
- Greer, B. J., Hindman, B. W., & Toomre, J. 2014, Sol. Phys., 289, 2823 [NASA ADS] [CrossRef] [Google Scholar]
- Hanasoge, S., Gizon, L., & Sreenivasan, K. R. 2016, Annu. Rev. Fluid Mech., 48, 191 [Google Scholar]
- Hanasoge, S. M., Duvall, T. L., & Sreenivasan, K. R. 2012, Proc. Nat. Acad. Sci., 109, 11928 [NASA ADS] [CrossRef] [Google Scholar]
- Harvey, J. 1985, in Future Missions in Solar, Heliospheric & Space Plasma Physics, eds. E. Rolfe, & B. Battrick, ESA SP, 235, 199 [NASA ADS] [Google Scholar]
- Hill, F. 1988, ApJ, 333, 996 [NASA ADS] [CrossRef] [Google Scholar]
- Kosovichev, A. G., & Duvall, Jr., T. L. 1997, in SCORe’96 : Solar Convection and Oscillations and their Relationship, eds. F. P. Pijpers, J. Christensen-Dalsgaard, & C. S. Rosenthal (Dordrecht: Springer Science Business Media), Astrophys. Space Sci. Libr., 225, 241 [NASA ADS] [CrossRef] [Google Scholar]
- Markwardt, C. B. 2009, in Astronomical Data Analysis Software and Systems XVIII, eds. D. A. Bohlender, D. Durand, & P. Dowler, ASP Conf. Ser., 411, 251 [NASA ADS] [Google Scholar]
- Marquardt, D. 1963, J. Soc. Ind. Appl. Math., 11, 431 [Google Scholar]
- Miesch, M. S., Brun, A. S., DeRosa, M. L., & Toomre, J. 2008, ApJ, 673, 557 [NASA ADS] [CrossRef] [Google Scholar]
- Moré, J. J. 1978, in Numerical Analysis, ed. G. A. Watson (Berlin, Heidelberg: Springer), 105 [Google Scholar]
- Moré, J., & Wright, S. 1993, Optimization Software Guide (Society for Industrial and Applied Mathematics) [Google Scholar]
- Pesnell, W. D., Thompson, B. J., & Chamberlin, P. C. 2012, Sol. Phys., 275, 3 [NASA ADS] [CrossRef] [Google Scholar]
- Schou, J., Scherrer, P. H., Bush, R. I., et al. 2012, Sol. Phys., 275, 229 [Google Scholar]
- Woodard, M. F. 1984, Ph.D. thesis, University of California, San Diego [Google Scholar]
- Zhao, J., Nagashima, K., Bogart, R. S., Kosovichev, A. G., & Duvall, Jr., T. L. 2012, ApJ, 749, L5 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Original ATLAS code
A.1. Fitting method of the original ATLAS code
In the original ATLAS code (Greer et al. 2014, 2015), the processing steps after computing the power spectrum for each tracked tile are as follows:
-
at each frequency ν, remap the log of the square root of the power spectrum
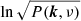 from the Cartesian (kx, ky) to polar (k, θ) coordinates,
from the Cartesian (kx, ky) to polar (k, θ) coordinates, -
compute
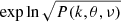 and carry out Fourier interpolation using a box-car low-pass filter to smooth in the azimuthal (θ) direction. The number of the grid points in azimuth θ is reduced from npix = 256 to npix = 64,
and carry out Fourier interpolation using a box-car low-pass filter to smooth in the azimuthal (θ) direction. The number of the grid points in azimuth θ is reduced from npix = 256 to npix = 64, -
fit a Lorentzian model (see Appendix A.2) to the smoothed square-root power at each k. The fitting is done based on the maximum likelihood method assuming that the PDF of the power is the chi-square distribution with two degrees of freedom (see more details in Appendix B.1), and
-
estimate error of the fitting parameters separately from the fitting using the Fisher information matrix based on the final fitting results.
A.2. Model for the power spectrum in the original ATLAS code
In the original ATLAS code (Greer et al. 2014, 2015), the power at each k is modeled with the sum of Lorentzians with seven parameters (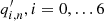 ) for each ridge n = 0, …nr − 1, where nr is the number of ridges, and a background model with five parameters (
) for each ridge n = 0, …nr − 1, where nr is the number of ridges, and a background model with five parameters (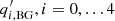 ) at each k. The total number of fit parameters at each k is 7nr + 5.
) at each k. The total number of fit parameters at each k is 7nr + 5.
The model power spectrum, at a single k, is:
![Mathematical equation: $$ \begin{aligned}&P^{\prime }(\theta ,\nu ; \boldsymbol{q}^\prime _\mathrm{BG} ) = \nonumber \\&\sum ^{n_{\mathrm{r} }-1}_{n=0} \frac{q^\prime _{1,n} (q^\prime _{2,n}/2) F^\prime (\theta ;q^\prime _{5,n}, q^\prime _{6,n})}{[\nu - q^\prime _{0,n} + k (q^\prime _{3,n} \cos \theta + q^\prime _{4,n} \sin \theta ) /(2\pi )]^2+(q^\prime _{2,n}/2)^2} \nonumber \\&+ \ B^\prime (\theta ,\nu ; \boldsymbol{q}^\prime _\mathrm{BG} ) , \end{aligned} $$](/articles/aa/full_html/2020/01/aa36662-19/aa36662-19-eq37.gif) (A.1)
(A.1)
where
![Mathematical equation: $$ \begin{aligned} F^\prime (\theta ; p_0, p_1 )= 1 +p_0\cos [2(\theta -p_1)] , \end{aligned} $$](/articles/aa/full_html/2020/01/aa36662-19/aa36662-19-eq38.gif) (A.2)
(A.2)
and 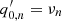 is the frequency of the nth peak,
is the frequency of the nth peak, 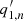 = An is the amplitude,
= An is the amplitude, 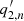 = Γn is the width,
= Γn is the width, 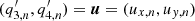 is the horizontal velocity,
is the horizontal velocity, 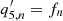 and
and 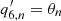 are anisotropy terms in Eqs. (5) and (6) in Greer et al. (2014). The background is modeled at each k as
are anisotropy terms in Eqs. (5) and (6) in Greer et al. (2014). The background is modeled at each k as
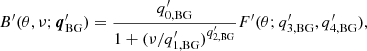 (A.3)
(A.3)
where 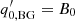 is an amplitude,
is an amplitude, 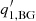 = νbg is a roll-off frequency,
= νbg is a roll-off frequency, 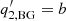 is the power-law index,
is the power-law index, 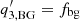 is the amplitude of the anisotropy term, and
is the amplitude of the anisotropy term, and 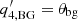 is the phase of the anisotropy term in Eq. (7) in Greer et al. (2014).
is the phase of the anisotropy term in Eq. (7) in Greer et al. (2014).
A.3. Problems in the original ATLAS code
First, the Lorentzian model for the power in the original code was fit to the square root of the observed power. This is inconsistent with what is stated in Greer et al. (2014, 2015) and it is also an inconsistency between the model and the observable. Therefore, we made them consistent in the updated code (see Sect. 2.2).
Second, the cost function to be minimized in the original code was not a good approximation. The cost function to be minimized in the maximum likelihood method based on the chi-square-distribution with two degrees of freedom as PDF is
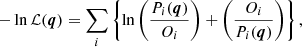 (A.4)
(A.4)
where Oi is the observed spectrum and Pi is the model, as given in Sect. A.2. The sum is taken over all grid points (θi, νi) in the fitting range.
Instead, the original code minimizes
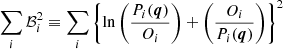 (A.5)
(A.5)
using the mpfit.c code1. This is conceptually inconsistent with the description in Greer (2015), although the likelihood function itself is not explicitly stated there. While it can be shown that the results of minimizing of the exact cost function (Eq. (B.3)) and the wrong one (Eq. (A.5)) are identical in the limit of linear perturbations, there is no reasonable computational or physical reason to take the extra square in the calculations. Moreover, it is not useful for the error estimates. Therefore, we decided to correct this issue; Sect. 2.2 describes our changes.
Third, in the original ATLAS code, error estimates are obtained by an independent calculation of the Fischer information using the final fitting results and using the chi-square distribution with two degrees of freedom as the likelihood function. It is not consistent to compute the error estimates with a likelihood function that is different than what was used in the fitting itself. In Sect. 2.2, we also describe a consistent approach to the computation of error estimates in our updated code.
Fourth, several parameters are unstable. Therefore, we have changed the parameterizations as we discussed in Sects. 2.3.1 and 2.3.2.
Appendix B: Probability distribution function (PDF) and maximum likelihood method based on the PDF
B.1. PDF of the raw power spectrum
Woodard (1984) demonstrated that the PDF of a single observed power spectrum divided by the expectation value of the spectrum is the chi-square distribution with two degrees of freedom. On this basis, Duvall & Harvey (1986) and Anderson et al. (1990) introduced the probability density at a given grid point in the Fourier space (kx, ky, ν)i
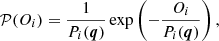 (B.1)
(B.1)
where Oi is the observed spectrum, Pi is the model for the limit spectrum, and q is the model parameters. The joint probability density for the experimental outcome at horizontal independent wavevectors and frequencies is given by
![Mathematical equation: $$ \begin{aligned} \mathcal{L} =\prod _i \mathcal{P} (O_i)= \exp \left[ -\sum _i \left(\ln P_i (\boldsymbol{q}) +\frac{O_i}{P_i(\boldsymbol{q}) } \right) \right]. \end{aligned} $$](/articles/aa/full_html/2020/01/aa36662-19/aa36662-19-eq54.gif) (B.2)
(B.2)
This is the likelihood function, and the model parameters which maximize this ℒ are the targets in the maximum likelihood method. In practice −lnℒ is minimized to use standard minimization procedures. To make the computation simpler, lnOi is subtracted from −lnℒ. The minimization of −lnℒ − lnOi in terms of q is identical to that of −lnℒ, because Oi is not a function of the model parameter q. In conclusion,
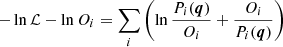 (B.3)
(B.3)
is minimized.
B.2. PDF of logarithm of averaged power
The PDF of a well-averaged power spectrum is also a chi-square distribution but with many more than the two degrees of freedom of the original and given the central limit theorem, it can be approximated by a normal distribution. To carry out the least-squares fitting based on the normal distribution function and estimate errors of the fitting results, we need the variance of the normal distribution function. We therefore take advantage of the fact that the logarithm of the averaged spectrum obeys a normal distribution function with a constant variance. In Appendix B.3, we show that if we have a spectrum obtained by averaging over N spectra, each normally distributed with the same expectation value M, the logarithm of averaged spectra, y, obeys the normal distribution function 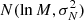 :
:
![Mathematical equation: $$ \begin{aligned} f(y) = \frac{1}{\sqrt{2\pi }\sigma _N} \exp {\left[-\frac{1}{2} \left(\frac{y-\ln M}{\sigma _N}\right)^2\right]}\ , \end{aligned} $$](/articles/aa/full_html/2020/01/aa36662-19/aa36662-19-eq57.gif) (B.4)
(B.4)
where 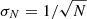 , therefore, σN is a constant over y. We note that the function f(y) is linearized around the mean to derive Eq. (B.4); see Appendix B.3 for details.
, therefore, σN is a constant over y. We note that the function f(y) is linearized around the mean to derive Eq. (B.4); see Appendix B.3 for details.
In the present case, we fit one k at a time. To do this, the spectra are, at each frequency, linearly interpolated in kx and ky to a circle with radius kpix, where kpix is k in units of bins, and smoothed to npix azimuths. On this basis, the question is if we can still use a least-squares fit with a diagonal covariance and a single σN and, if so, which value of σN (or equivalently N) in Eq. (B.4) should be used. In particular, it needs to be considered that more than 2πkpix are used for the interpolation and that the averaged values will be correlated.
In the limit of averaging over the entire circle, namely npix = 1, and in the case with kpix ≫ 1, it might be reasonable to assume that N = 2πkpixα, with α accounting for the fact that the averaging is essentially over an annulus around kpix. Indeed, a Monte-Carlo test shows that α ≈ 1.5 gives a very good estimate of the error on the average, which will be shown in Fig. B.1 later in this subsection.
 |
Fig. B.1. Standard deviation of the logarithm of chi-square distributed white noise rebinned on the annulus with the radius of kpix pixels, σscat, is plotted against the square-root of the pixel number on the annulus after rebinning, |
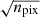
For npix ≫ 1 the variances, as well as the off-diagonal elements of the covariance matrix of the interpolated datapoints will, in general, depend on azimuth. Assuming that the fitted function may be linearized in the fitted parameters, a linear fit implies that the fitted parameters are given by a linear combination of the observed values. Assuming that the functions are smooth (as in the present case where they are low-order harmonic functions), the coefficients in the linear combination are also smooth. From this it follows that if the variations in the properties of the covariance matrix average on the scale of the variations in the fitted functions, then the same scaling factor may be used and that
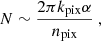 (B.5)
(B.5)
which a Monte-Carlo test again confirms.
To validate the arguments above, a simple Monte-Carlo test is carried out to measure the scatter (standard deviation, σscat) of the logarithm of averaged white noise. White-noise fields with the chi-square distribution with two degree of freedom in a three-dimensional Cartesian Fourier space (kx, ky, ν) = (384, 384, 1152) [pix] are remapped at several annuli with specific radii kpix in the same way as the data in the updated analysis code. At first, there are 256 pixels on each annulus after remapping, we then rebin them into npix = 4, 8, 16, 32, 64, and 128 pixels. The standard deviation of the logarithm of the rebinned white noise, σscat, are computed and plotted against the square root of the number of datapoints after rebin on the annuli, npix = 14, 21, and 42 in Fig. B.1. As we mentioned above, in the case of npix ≪ 2πkpix, σscat ≃ σα(α = 1.5), where 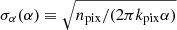 . In the case of npix ≳ 2πkpix the deviation of σscat from σα is not negligible, and σscat approaches a constant 2/3; this constant can be derived from the bi-linear interpolations of chi-square distributed random variables in two dimensions. Also we note that we have not included the apodization effect in the data to create the noise field in this test calculation. Without apodization σscat might be overestimated; in any case, this does not affect the parameter estimates but only the error estimates.
. In the case of npix ≳ 2πkpix the deviation of σscat from σα is not negligible, and σscat approaches a constant 2/3; this constant can be derived from the bi-linear interpolations of chi-square distributed random variables in two dimensions. Also we note that we have not included the apodization effect in the data to create the noise field in this test calculation. Without apodization σscat might be overestimated; in any case, this does not affect the parameter estimates but only the error estimates.
In our updated code, σN is set to 1 (see the cost function Eq. (1)), as we mentioned in Sect. 2.2, and after the fitting is done the error provided by the code is scaled by σα. Although calling the minimization code with an incorrect error estimate can lead to worse convergence, the difference in this case should be negligible. Implementing σα in the code is a task for the future.
B.3. Derivation of PDF of the logarithm of averaged power
In this section we briefly summarize how to derive the PDF of the logarithm of the power.
Suppose x is the average of N spectra whose averages are M. If N is large enough, then the PDF of this spectrum is the normal distribution
![Mathematical equation: $$ \begin{aligned} f_x(x) = \frac{1}{\sqrt{2\pi }\sigma } \exp {\left[-\frac{1}{2} \left(\frac{x-M}{\sigma }\right)^2\right]} \end{aligned} $$](/articles/aa/full_html/2020/01/aa36662-19/aa36662-19-eq62.gif) (B.6)
(B.6)
and 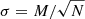 . Here we define
. Here we define
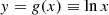 (B.7)
(B.7)
and when x is close to M,
![Mathematical equation: $$ \begin{aligned} y =\ln \left[M\left(1+\frac{x-M}{M}\right)\right] \simeq \ln M + \frac{x-M}{M}\cdot \end{aligned} $$](/articles/aa/full_html/2020/01/aa36662-19/aa36662-19-eq65.gif) (B.8)
(B.8)
Therefore, the inverse function of g is given by
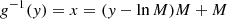 (B.9)
(B.9)
and
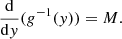 (B.10)
(B.10)
Hence, the PDF of y = lnx is given by
![Mathematical equation: $$ \begin{aligned} f_y(y)&= \left|\frac{\mathrm{d} }{\mathrm{d} y} (g^{-1} (y))\right|f_x(g^{-1}(y)) \nonumber \\&= \frac{1}{\sqrt{2\pi }\sigma _y } \exp {\left[-\frac{1}{2} \left(\frac{y-\ln M}{\sigma _y}\right)^2\right]}, \end{aligned} $$](/articles/aa/full_html/2020/01/aa36662-19/aa36662-19-eq68.gif) (B.11)
(B.11)
where 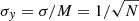 . Therefore, the logarithm of the averaged power has a constant error, which is independent of the original σ and depends only on the number of the averaged spectra, N. For comparison, approximated PDF and the distribution functions of the Monte-Carlo samples are given in Appendix B.4.
. Therefore, the logarithm of the averaged power has a constant error, which is independent of the original σ and depends only on the number of the averaged spectra, N. For comparison, approximated PDF and the distribution functions of the Monte-Carlo samples are given in Appendix B.4.
B.4. Comparison of the distribution functions with Gaussian and chi-square distribution functions
In this subsection we show that Gaussian function is a good approximation for the distribution functions of the logarithm of the synthesized power. We also discuss the degrees of freedom of the chi-square distribution functions of the unwrapped and smoothed power here.
Figure B.2 shows the distribution function of the power and the logarithm of the power at kpix = 21 (ℓ = 492) from the Monte Carlo simulations. The Gaussian function centered at zero whose width is the standard deviation of the samples are overplotted in the figure. These plots show that the Gaussian function is a good approximation for the distribution function of the logarithm of the unwrapped and smoothed power near the mean value, though the tails of the distribution function are longer than those of the Gaussian.
 |
Fig. B.2. Normalized frequency distribution functions of the normalized synthetic power at kpix = 21 (ℓ = 492, black solid lines): top panels are for the subsampled power and the second panels are the unwrapped power without further smoothing, while the lower panels are for the rebinned powers. Left panels: (P − ⟨P⟩)/⟨P⟩, and right panels: lnP − ln⟨P⟩, where ⟨⟩ indicates the expectation value (model). The input model of the power is isotropized (qi, n = 0 for 3 ≤ i ≤ 6 for all n and qi, b = 0 for i = 2, 3) but otherwise it is the same as the model with the parameters given in Table C.2. For this plot, we use 50 realizations for the top two rows and 500 realizations for the rebinned data (lower three rows). The black dashed lines on the lower four panels are the Gaussian function centered at zero whose width is the standard deviation of the samples (shown on the panels). This validates our approximation of the distribution function of the logarithm of the power by the Gaussian function. The thick red dashed curves on the left panels are the chi-square distribution function of various degrees of freedom. The degree of freedom (d.o.f.) for each distribution is determined from the standard deviation of each set of normalized power. See the text for details. |
In the left panels of Fig. B.2, the distribution function of the power is also compared with the chi-square distribution functions with various degrees of freedom: the chi-square distribution functions shown here are
 (B.12)
(B.12)
where X = (P − ⟨P⟩)/⟨P⟩, ⟨⟩ indicates the expectation value, and d is the number of degrees of freedom (d.o.f.). Since in this case ⟨X⟩ = 0 and the variance of X is 2/d, we determine d.o.f. from the variance and show the corresponding chi-square distribution function in the figure. As the original synthesized power is created from the model and the two-d.o.f. chi-square distributed random numbers, subsampled power is purely two d.o.f. The unwrapped power has a four-d.o.f. chi-square distribution; this indicates that unwrapped power is effectively the subsampled power rebinned over two pixels. Because in this case the radius of annulus is kpix = 21 and hence roughly 2πkpix independent pixels are on the annulus, the unwrapped power with 256 pixels on the annulus is roughly twice oversampled. Therefore, the d.o.f. of the power unwrapped and rebinned over two pixels in azimuth (npix = 128, third panel) is five. This is almost unchanged from the original (second panel, d.o.f. = 4). This is also the case when we further rebin the data over four pixels (fourth panel); d.o.f is only eight and this is smaller than 16, which we might have expected for the four-pixel rebinned four-d.o.f. distributed independent variables (i.e., unwrapped power). But we should also note here that 12 is the d.o.f. which we expect on the basis of the effective rebinning numbers we discussed in Appendix B.2 (Eq. (B.5)), N ∼ 3, where α = 1.5. It is also larger than the dof of the distribution function (8); this is partly because the approximation (Eq. (B.5)) is not sufficiently good for npix = 64 case as was shown in Fig. B.1. When we see the further rebinned case with npix = 16, namely the unwrapped power averaged over 16 pixels (the lower-most panel), the d.o.f. is 25 and close to what we expect from Eq. (B.5), N ∼ 6: in this case the d.o.f. is 6 × 4 = 24. For this case the approximation by Eq. (B.5) with α = 1.5 is good according to Fig. B.1. This closeness of the distribution function of the remapped and smoothed power to the chi-square distribution with some degrees of freedom suggest that one might expect improvement to the fitting method by using the maximum likelihood method based on the chi-square distribution with specific degrees of freedom.
Appendix C: Input parameters for smaller and larger wavenumbers
The parameters at several ℓ obtained from the fitting of the observed spectra averaged over one Carrington rotation 2211 for the disc center tile from SDO/HMI pipeline are shown in Tables C.1 (ℓ = 328), C.2 (ℓ = 492), and C.3 (ℓ = 984). These average power spectra were obtained from DRMS specification hmi.rdvavgpspec_fd15[2211][0][0] and the fitting was done using the updated code. These parameters are used as input parameters to generate Monte-Carlo synthetic data in Sect. 3.
Input parameter set at ℓ = 328 (kpix = 14) obtained from the fitting the average power spectrum over one Carrington rotation to the model by the updated code.
Input parameters at ℓ = 492 (kpix = 21) similar to Table C.1.
Input parameter set at ℓ = 984 (kpix = 42), similar to Table C.1.
Appendix D: Underestimated amplitude – Logarithm of average and average of logarithm
Figure 2 shows that the amplitudes (q1, n for all n and q0, b in Eq. (2)) measured by the updated code are underestimated. This is the result of taking the logarithm of the rebinned power and the effect can be reproduced in the following simple test.
To see why this is the case, we define xi (i = 0, 1, …n − 1) as a series of random variables whose distribution function is the chi-square distribution with two degrees of freedom. The expectation values and the variance of x are ⟨x⟩ = 2 and 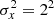 , respectively, and yj(j = 0, 1, …n/a − 1) is smoothed xi over each a-pixel range:
, respectively, and yj(j = 0, 1, …n/a − 1) is smoothed xi over each a-pixel range:
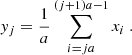 (D.1)
(D.1)
In this case ⟨y⟩=⟨x⟩ = 2, and ln⟨y⟩=ln(2), but ⟨ln(y)⟩ ≤ ln⟨y⟩. The more the array is rebinned (the larger a becomes), the less the scatter of y becomes: ⟨ln(y)⟩ approaches ln⟨y⟩.
This trend is alleviated if the spectra are more strongly averaged. Figure D.1 shows a simple test calculation to illustrate how the average of logarithm is reduced from the logarithm of the average; the ratio of ⟨ln(y)⟩ to ln⟨y⟩ is plotted against the pixel number ratio of the rebinned data to the original. In this simple test calculation, we make 500 realizations of sets of xi (i = 0, 1, …n − 1, where n = 256), calculate y with a = 1, 2, 4, 8, …256, and compute how much smaller the expectation value of the logarithm of y than the logarithm of the expectation value is. The linear regression of the data points are also shown in the plot. For comparison the amplitude fitting results shown in Fig. D.2 are replotted here with squares. This explains how the logarithm of amplitude is reduced. In the case of no rebinning (X = nrebin/noriginal = 1) or only 2-pixel rebin (X = 1/2) the fitting results are deviated significantly from this simple test calculation, but this comes as no surprise because in these cases, the assumption of the well-averaged power as data is not appropriate.
 |
Fig. D.1. exp⟨ln(y)⟩/⟨y⟩, where y is the a-element average of chi-square distributed random variables, as a function of the pixel number ratio of the rebinned data to the original (asterisks). The average ratio of the amplitude fitting results to the input shown in Fig. D.2 is depicted by squares. The dashed line and the equation on the panel are the linear regression of the data points. |
Figure D.2 shows the dependence of the amplitude measurements on the amount of rebinning. The input model is identical to the one used in the calculation in Sect. 3.1. The default rebinning is from 256 pixels to 64 pixels and in this case, the output amplitude is about 88% of the input amplitude but with further rebinning to 16 pixels, it increases up to 96%.
 |
Fig. D.2. Dependence of the peak amplitude parameters at ℓ = 492 (kpix = 21) measured by the updated code on the rebinning strength. Left panel: input (black dotted lines with squares) and measurements with three different rebinning with error bars (scatter of 500 realizations): no rebinning (256 pixels on the azimuthal grid, blue), original rebinning (64 pixels, green), and extra rebinning (16 pixels, red). Right panel: ratio of the amplitude to the input. The numbers are the grid number and the average ratio of six peaks. The input parameters are identical to those in Fig. 2. |
All Tables
Background parameters in the input model for the Monte Carlo simulation and the fitting results at ℓ = 492 (kpix = 21).
Input parameter set at ℓ = 328 (kpix = 14) obtained from the fitting the average power spectrum over one Carrington rotation to the model by the updated code.
All Figures
|
Fig. 1. Slices through the input limit spectrum (black) and observational spectrum averaged over one Carrington rotation (gray), which was used to obtain the input parameters, at θ = 0 and a few different values of k. Vertical dashed lines indicate the fitting ranges and the models are plotted only within these ranges. Lower limits for all k are fixed at 0.4 mHz, while the upper limits depend on the initial guess for each k, and they are the highest peak frequencies plus the widths of the peak. For the cases of ℓ = 328 and 492 (kpix = 14 and 21, respectively), the peaks with the radial order, n, from 0 to 7 are used in the fitting, while for the case of ℓ = 984 (kpix = 42), 0 ≤ n ≤ 3. |
| In the text | |
|
Fig. 2. Fitting parameters and their errors for the case ℓ = 492 (kpix = 21). Each panel has three parts. In the upper part of each panel, squares indicate the input parameters, |
| In the text | |
|
Fig. 3. Fitting results of ux, n = 3 at ℓ = 492 (kpix = 21) in the form of normalized histograms by the original code which fit the model to the square root of power (black), the modified original code which fit the power (blue), and the updated code (red). Horizontal lines indicate the average of 500 Monte–Carlo realizations given by the three codes (in the same colors as the histograms, dash-dotted black, dashed blue, and solid red). The short vertical lines on the horizontal lines indicates the error estimated by the codes (thin lines with short horizontal bars) and the standard deviations of the 500 fitting results (thick lines) in the same color as the histograms centered at the means (horizontal lines) by the three codes. We note that the fitting results with overly large deviation are omitted. See text for details. |
| In the text | |
|
Fig. 4. Correlation coefficients between the parameters (500 Monte-Carlo realizations) for the isotropic model (ux, n = 0 for all n) and for the isotropic model except with ux = 400 m s−1 for the n = 3 peak (on the next page) at ℓ = 492 (kpix = 21). Each box indicates the parameters for n-th peak (n = 0, 1, …5), qi, n (i = 0, …6, from left to right and from bottom to top in each box) and the background parameters (BG). As we defined in Sect. 2q0, n = νn is the frequency of the n-th peak, q1, n = An is the amplitude, q2, n = Γn is the width, q4,n) = u = (ux,n, uy,n) is the horizontal velocity, q5, n = fc, n and q6, n = fs, n are parameters to handle anisotropy. Background parameters are q0, BG = B0 is the amplitude, q1, BG = b is the power-law index, q2, BG = fc, bg and q3, BG = fs, bg are the parameters to handle the anisotropy of the background. Color scale is shown by the color bar on the right side. We note that the last columns and rows (i = 4) of BG on the top panels are empty because the number of the background parameters in the model in the updated code is four, instead of five. |
| In the text | |
|
Fig. 4. continued. |
| In the text | |
|
Fig. 5. Fitting results of ux, n = 3 at ℓ = 492 (kpix = 21), similar to Fig. 3, but for the further rebinned data. In this case, the number of azimuthal pixels, npix is reduced to 16, instead of the original 64. Legends and colors are similar to those of Fig. 3. Scale factors for the error estimates by the updated code are adjusted accordingly. |
| In the text | |
|
Fig. B.1. Standard deviation of the logarithm of chi-square distributed white noise rebinned on the annulus with the radius of kpix pixels, σscat, is plotted against the square-root of the pixel number on the annulus after rebinning, |
| In the text | |
|
Fig. B.2. Normalized frequency distribution functions of the normalized synthetic power at kpix = 21 (ℓ = 492, black solid lines): top panels are for the subsampled power and the second panels are the unwrapped power without further smoothing, while the lower panels are for the rebinned powers. Left panels: (P − ⟨P⟩)/⟨P⟩, and right panels: lnP − ln⟨P⟩, where ⟨⟩ indicates the expectation value (model). The input model of the power is isotropized (qi, n = 0 for 3 ≤ i ≤ 6 for all n and qi, b = 0 for i = 2, 3) but otherwise it is the same as the model with the parameters given in Table C.2. For this plot, we use 50 realizations for the top two rows and 500 realizations for the rebinned data (lower three rows). The black dashed lines on the lower four panels are the Gaussian function centered at zero whose width is the standard deviation of the samples (shown on the panels). This validates our approximation of the distribution function of the logarithm of the power by the Gaussian function. The thick red dashed curves on the left panels are the chi-square distribution function of various degrees of freedom. The degree of freedom (d.o.f.) for each distribution is determined from the standard deviation of each set of normalized power. See the text for details. |
| In the text | |
|
Fig. D.1. exp⟨ln(y)⟩/⟨y⟩, where y is the a-element average of chi-square distributed random variables, as a function of the pixel number ratio of the rebinned data to the original (asterisks). The average ratio of the amplitude fitting results to the input shown in Fig. D.2 is depicted by squares. The dashed line and the equation on the panel are the linear regression of the data points. |
| In the text | |
|
Fig. D.2. Dependence of the peak amplitude parameters at ℓ = 492 (kpix = 21) measured by the updated code on the rebinning strength. Left panel: input (black dotted lines with squares) and measurements with three different rebinning with error bars (scatter of 500 realizations): no rebinning (256 pixels on the azimuthal grid, blue), original rebinning (64 pixels, green), and extra rebinning (16 pixels, red). Right panel: ratio of the amplitude to the input. The numbers are the grid number and the average ratio of six peaks. The input parameters are identical to those in Fig. 2. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.