| Issue |
A&A
Volume 629, September 2019
|
|
|---|---|---|
| Article Number | A34 | |
| Number of page(s) | 14 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/201935223 | |
| Published online | 02 September 2019 | |
Machine learning in APOGEE
Identification of stellar populations through chemical abundances⋆
1
Instituto de Astrofísica de Canarias, 38200 La Laguna, Tenerife, Spain
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Departamento de astrofísica, Universidad de La Laguna, Tenerife, Spain
Received:
6
February
2019
Accepted:
27
June
2019
Abstract
Context. The vast volume of data generated by modern astronomical surveys offers test beds for the application of machine-learning. In these exploratory applications, it is important to evaluate potential existing tools and determine those that are optimal for extracting scientific knowledge from the available observations.
Aims. We explore the possibility of using unsupervised clustering algorithms to separate stellar populations with distinct chemical patterns.
Methods. Star clusters are likely the most chemically homogeneous populations in the Galaxy, and therefore any practical approach to identifying distinct stellar populations should at least be able to separate clusters from each other. We have applied eight clustering algorithms combined with four dimensionality reduction strategies to automatically distinguish stellar clusters using chemical abundances of 13 elements. Our test-bed sample includes 18 stellar clusters with a total of 453 stars.
Results. We have applied statistical tests showing that some pairs of clusters (e.g., NGC 2458–NGC 2420) are indistinguishable from each other when chemical abundances from the Apache Point Galactic Evolution Experiment (APOGEE) are used. However, for most clusters we are able to automatically assign membership with metric scores similar to previous works. The confusion level of the automatically selected clusters is consistent with statistical tests that demonstrate the impossibility of perfectly distinguishing all the clusters from each other. These statistical tests and confusion levels establish a limit for the prospect of blindly identifying stars born in the same cluster based solely on chemical abundances.
Conclusion. We find that some of the algorithms we explored are capable of blindly identify stellar populations with similar ages and chemical distributions in the APOGEE data. Even though we are not able to fully separate the clusters from each other, the main confusion arises from clusters with similar ages. Because some stellar clusters are chemically indistinguishable, our study supports the notion of extending weak chemical tagging that involves families of clusters instead of individual clusters.
Key words: open clusters and associations: general / globular clusters: general / Galaxy: abundances / methods: numerical / methods: statistical / methods: data analysis
The list of stars is only available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/qcat?J/A+A/629/A34
© ESO 2019
1. Introduction
Handling the overwhelming volume of data generated by many existing and forthcoming astronomical instruments is challenging. The future of astronomy depends on the development of efficient algorithms capable of making the best of all available data. Pattern recognition in high dimensional space is a fundamental task needed for the analysis of massive datasets. Spectroscopic surveys such as the Apache Point Galactic Evolution Experiment (APOGEE; Majewski et al. 2017), allow two main approaches to target classification. It is possible to directly use the stellar spectra or to work with the corresponding atmospheric parameters and chemical abundances.
The first approach does not depend on stellar model atmospheres. At present, all the available models have limitations. They are either constrained by the lack of knowledge on the input atomic data (e.g., oscillation strengths) or are limited by the approximations made to accelerate the calculations, such as the assumption of plane-parallel geometry and local thermodynamic equilibrium.
The legacy of the MK classification, named after W. W. Morgan and P. C. Keenan (Morgan et al. 1943) to stellar astrophysics is undeniable. The classification is based on spectral features that are easily identifiable by visual inspection in medium-resolution spectra. This method does not depend on model atmospheres, but has the downside of being heavily supervised, which is inconvenient for the very large datasets.
The search for chemical abundance patterns relies on model atmospheres but enables a finer description of the stellar populations. While the spectral classification is more sensitive to physical parameters of the stars, i.e., effective temperature (Teff) and surface gravity (log g), pattern recognition in chemical abundance space can potentially uncover the star formation history of our Galaxy through the identification of chemical signatures shared by stars with a common origin, commonly referred to as chemical tagging (Freeman & Bland-Hawthorn 2002). We opt for the chemical abundances approach in this work, in order to test the feasibility of chemical tagging.
Significant progress has been made in recent years using both strategies. For example, supervised spectral classification has been adopted in works such as those by Bailer-Jones et al. (1998), Singh et al. (1998), Bailer-Jones (2002), Rodríguez et al. (2004), Giridhar et al. (2006), Manteiga et al. (2009), and Navarro et al. (2012). Unsupervised spectral classification was also explored in works such as Sánchez Almeida et al. (2009, 2010, 2016), Vanderplas & Connolly (2009), Daniel et al. (2011), Morales-Luis et al. (2011), Sánchez Almeida & Allende Prieto (2013), Fernández-Trincado et al. (2017), Matijevič et al. (2017), Price-Jones & Bovy (2017, 2019), Traven et al. (2017), Valentini et al. (2017), Garcia-Dias et al. (2018), and Reis et al. (2018).
The classification of stars based on chemical abundances has been explored by Blanco-Cuaresma et al. (2015) using homogeneous observations for 339 stars in 35 open clusters. Applying machine-learning techniques, Hogg et al. (2016) were able to identify known star clusters and the Sagittarius dwarf galaxy in the APOGEE DR12 dataset. Schiavon et al. (2017) identified a stellar population that was unusually rich in nitrogen in the central part of the Galaxy. Kos et al. (2018) used GALactic Archaeology with HERMES (GALAH) data to spot new members of the Pleiades cluster. The application of machine-learning algorithms to stellar abundances was also employed by da Silva et al. (2012), Ting et al. (2012), Jofré et al. (2017), Anders et al. (2018), Boesso & Rocha-Pinto (2018), and Price-Jones & Bovy (2019).
We here explore the limits of a large battery of unsupervised clustering algorithms in distinguishing single-abundance-pattern stellar populations in the chemical space explored by APOGEE. Star clusters are likely the most chemically homogeneous populations in the Galaxy, thus any practical approach to chemical tagging should at least be able to separate known clusters from each other. Section 2 describes the details of the APOGEE data used in this work. Section 3 presents the star cluster samples. Section 4 discusses the feasibility of the task. Section 5 presents the algorithms we tested, and Sect. 6 describes the results. Finally, Sect. 7 summarizes the work and discusses the viability of applying these algorithms to blindly identifying families of stellar populations in the complete APOGEE dataset. We remark that all conclusions derived from the result presented in this study are restricted to the stellar population and chemical elements we explored. The APOGEE abundances from IR spectra are restricted to the alpha-capture elements and Fe-peak elements. The dimensionality of the APOGEE’s elemental abundance space is expected to be restricted. Including other elements can potentially change the results we found here.
2. Data
APOGEE is spectroscopically observing hundreds of thousands of stars, primarily giants, which emphasizes regions that are obscured by dust: the Galactic plane and the central parts of the Galaxy. With these observations, a chemical map is created (Blanton et al. 2017; Majewski et al. 2017). The project employs two twin spectrograph on 2.5 m telescopes (Gunn et al. 2006) on the Northern (using the Sloan Digital Sky Survey, SDSS telescope at Apache Point Observatory, USA) and Southern (using the DuPont Telescope at Las Campanas, Chile) hemispheres. This work is based on data from SDSS Data Release 14 (Abolfathi et al. 2018), which includes observations of more than 260 000 stars.
With a signal-to-noise ratio per half a resolution element > 100, the H-band APOGEE spectra, analyzed by the APOGEE Stellar Parameters and Chemical Abundances Pipeline (García Pérez et al. 2016), provide determinations of the chemical abundances for about 20 elements with a precision that ranges from 0.03–0.05 dex for iron, oxygen or magnesium in solar metallicity K-giants to ∼0.2 dex for nitrogen in moderately metal-poor stars (Holtzman et al. 2015; Bertran de Lis et al. 2016; Bovy 2016). Of these elements, we retained those that have been shown to be reliable in previous studies (Holtzman et al. 2015, 2018; Jönsson et al. 2018). The elements used in the clustering applications are Al, C, Ca, Fe, K, Mg, Na, N, Ni, O, P, S, and Si.
APOGEE includes observations of globular clusters and many open clusters targeted for science and calibration purposes (see, e.g., Frinchaboy et al. 2013). Most clusters have a fairly limited extent on the sky and pose a challenge for the 70-arcsec fiber collision radius of APOGEE. Only a limited number of members are therefore typically observed per cluster. Only a few of the clusters targeted by APOGEE have tens of observed stars (e.g., NGC 2420, NGC 6791, the Pleiades, or M 67; see, e.g. Cunha et al. 2015; Linden et al. 2017; Souto et al. 2016, 2018). About 20 clusters include 5–30 stars each, and those are the ones we focus on in this paper. APOGEE provides the abundances determined directly from the fitting of the observations with synthetic spectra based on standard model atmospheres. The optimization of the parameters is based on a χ2 criterion, and it is performed using the FERRE code1 (Allende Prieto et al. 2006). These abundances show mild trends with the stellar effective temperature for star members of open clusters. Even though diffusion in stellar envelopes can systematically alter photospheric abundances in a manner that depends on stellar mass (see, e.g., Dotter et al. 2017; Souto et al. 2018), and therefore on effective temperature, such trends are interpreted mainly as a result of shortcomings in the model atmospheres and radiative transfer calculations that are used to derive the abundances, for example, departures from local thermodynamic equilibrium (LTE) or 3D effects. In an attempt to remove such effects, the trends with effective temperature are modeled with smooth functions, that take all the open clusters into account. This produces internally calibrated abundances that are the default abundances that are published in the data releases.
We are interested in relative abundances of stars with similar atmospheric parameters and not in absolute values, therefore we preferred to use the uncalibrated abundances. These are released together with the calibrated abundances for each data release2. Far more stars have uncalibrated abundances than the calibrated ones because the calibrations span a limited range in parameters space. We did not use dwarfs in this particular study, but dwarf stars have only uncalibrated values, and they make up about 20% of the total APOGEE sample. Most importantly, the smooth functions used to correct the trends with effective temperature may lose some of the precision of the original uncalibrated values for stars with similar parameters. In addition, the calibration process requires placing the abundances for all clusters on the same scale, and therefore adopting a fiducial metallicity for each cluster, which may introduce additional offsets. Some of the elements, such as Na, P and S, present offsets compared with abundance results from spectroscopy in the visible. In this work, however, we explore the relative differences among the clusters that are not affected by these issues. From a practical standpoint, we decided to test our analysis on both calibrated and uncalibrated abundances. We found better3 results with the latter. In Appendix A we present the results for the same analysis as described in Sects. 3–6, but for the results in the appendix we used the calibrated abundances.
3. Sample
We selected clusters in APOGEE DR14 with at least five members. Membership was determined based on radial velocities and on the distribution of chemical abundances. We selected the stars that were compatible with the mean radial velocities and velocity dispersions in Dias et al. (2002) for open clusters and those in Francis & Anderson (2014) for globular clusters. We then applied one iteration of two-σ clipping in all the chemical abundances to guarantee a single composition. Table 1 shows the list of selected clusters. We provide a table with a list of all the stars in the clusters (available at the CDS). Figure 1 shows the distribution of Teff and logg for the whole sample.
Clusters used in this study.
 |
Fig. 1. Distribution of Teff and logg for all the stars used in the unsupervised clustering exercise. For each cluster we used a unique combination of symbol and color, as shown in the plot legend. |
4. Cluster distinguishability according to chemical abundance
In order to determine whether the clusters can be distinguished from each other based on their abundances distributions, we have performed two statistical tests. The 1D Kolmogorov-Smirnov two-sample test (K–S test; Smirnov 1939; Darling 1957) was applied for each pair of clusters and each chemical element, and the Cramer multivariate test (Baringhaus & Franz 2004; Elias et al. 2006; Yeremi et al. 2014) was applied for each pair of clusters and then for all chemical elements at once. In both tests, the outcome is the probability (p-value) that the two samples are drawn from the same distribution (the null hypothesis). If the p-value is lower than 0.01, we can reject the null hypothesis with a confidence level of 99%. That is to say, we can conclude that the two samples are unlikely to be drawn from the same distribution, and the clusters can be considered distinguishable4.
We first applied the tests to subsamples of stars in each individual cluster in order to understand the systematics of the tests. For this, we took the median p-value over 1000 tests performed with random subsamples of each cluster. The subsamples were obtained by dividing the cluster into two groups of nearly equal size. Figure 2 shows the results of applying the K–S test for carbon. We note that Fig. 2 is symmetric with respect to the main diagonal. We exploit this symmetry in Figs. 3 and 4 to facilitate the direct comparison of the outcomes of different tests. The main diagonal presents the median p-value of the 1000 subsamples of each cluster, and the off-diagonal cells give the result for a single run using all stars in each pair of clusters. This figure shows that it is not possible to distinguish many pairs of cluster based on their carbon abundances alone. For instance, M 3 and M 13 have indistinguishable carbon distributions. In some cases, even globular and open clusters have indistinguishable carbon distributions, as is the case for the pair M 67–M 71.
 |
Fig. 2. Logarithm of the p-values of the K–S two-sample test for the carbon distributions of each pair of clusters. The cells are colored in five shades of red, from light to dark in logarithmic scale. Inside each cell, we show the p-value of the test for that particular pair of clusters. Superscripts in the cluster names indicate the number of stars in the cluster. The main diagonal shows the median p-value of 1000 tests resulting from randomly dividing the cluster into two subsamples of nearly equal sizes. Two blue lines separate the objects into globular clusters (lower right) and open clusters (upper left). Dark red represents values greater than 0.01: we cannot reject the null hypothesis for these cases. |
 |
Fig. 3. Logarithm of the p-values of the K–S two-sample test for each pair of clusters. The elements of the main diagonal and above the main diagonal represent the lowest p-value found among all the elements, and while the elements below the main diagonal represent the p-value for carbon. The cells are colored in shades of red as shown in the color bar. Red colors are saturated at 0.01. Superscripts in the cluster names indicate the number of stars in the cluster. At the center of each cell, we show the element for which the p-value is calculated. Two blue lines separate the objects into globular and open clusters. |
 |
Fig. 4. Median log p-values of 100 runs of the Cramer two-sample test for each pair of clusters. The elements below the main diagonal show the median value of 100 runs of the Cramer test, and the elements above the diagonal show the results for the K–S test. The cells are colored in shades of red as shown in the color bar. Inside each cell, we show the p-value of the test for each particular pair of clusters. Superscripts in the cluster names indicate the number of stars in the cluster. Two blue lines separate the objects into globular and open clusters. |
In contrast, performing the K–S test for all pairs of clusters and taking the lowest p-value of all the 13 elements, we show that, except for the pair Berkeley 17-Berkeley 71, all the 23, clusters can be distinguished from each other in at least one element, as shown in Fig. 3. The main diagonal in the figure is calculated as explained above for Fig. 2, but showing only the lowest p-value of all the elements. In Fig. 3 we combine the results for C with those obtained for all elements. All the cells above the diagonal represent the lowest p-value of all elements to that pair of clusters. The cells below the main diagonal represent the results for carbon. In each cell, we identify the element for which the p-value is presented.
Three main conclusions can be drawn from Fig. 3: (1) the probability stemming from the K–S test is extremely low for many of the pairs; it is lower than 10−5 in many cases. The clusters can therefore be distinguished in at least one element. p-values higher than 10−3 are found for several pairs, for example, M 13–M 71 and NGC 7789–NGC 2682, and therefore we expect that it will be harder to separate these pairs by any unsupervised clustering algorithm than it would be for pairs with p-values lower than 10−5. (2) All clusters present high median p-values when compared with themselves. This fact underlines the cohesion of the clusters and demonstrates the consistency of the test. (3) A few elements are particularly important for distinguishing the clusters from each other.
Table 2 contains the times that each element is best for distinguishing a unique pair of clusters. Five elements are sufficient to separate 80% of the pairs. Calcium never appears to be the best element to distinguish a pair of clusters. In addition, the most useful elements for distinguishing pairs of globular clusters are not those that are most useful for separating pairs of open clusters, or pairs composed of a globular and an open cluster. We see that Na and C are particularly well suited to separate globular clusters from each other, and N, Na, and C are excellent in separating pairs of globular and open clusters. Fe might be expected to be very effective in distinguishing globular and open clusters from each other, but this element often presents higher p-values in the K–S test when pairs of distributions are compared that containing open and globular clusters than the p-value we found for other elements. Pairs of open clusters are best distinguished using C, N, and Na.
The results of the Cramer test are presented in Fig. 4. The main diagonal is also the median value of 1000 runs of the test over random subsamples of the clusters, as described for the K–S test. The Cramer test has a stochastic nature, and thus some variation is expected. In order to avoid picking an atypical outcome, the values presented in the cells below the main diagonal are the median value of 100 runs of the Cramer test. The cells above the main diagonal represent the lowest p-values of the K–S test.
Figure 4 shows that we cannot reject the null hypothesis for ten pairs of clusters: Berkeley 71-King 7, IC 166-King 7, NGC 1245-King 7, King 5-King 7, Berkeley 66-King 7, Berkeley 17-King 7, King 5-Berkeley 71, Berkeley 66-Berkeley 71, Berkeley 17-Berkeley 66 and M 15–M 92. In these ten pairs, only six have p-values higher than 10−3 in the K–S test. This discrepancy between the tests is expected, because the problem of comparing multidimensional samples is not trivially reduced to 1D pieces as we attempt to do in the exercise with the K–S test. However, we present the analysis with the K–S test because it is intuitive and provides insight on which chemical elements better distinguish the clusters from each other.
We note that passing the tests does not guarantee that the samples can be separed. The tests only evaluate whether two clusters can be drawn from the very same distribution. For example, two samples generated from two Gaussian distributions with the same center and different widths would be distinguishable by these tests but would not be fully separable by a clustering algorithm.
These tests are valuable for establishing the potentials and limitations of the unsupervised algorithms. From the Cramer test we conclude that we should not expect any algorithm to completely separate Berkeley 71 from King 7, IC 166 from King 7, NGC 1245 from King 7, King 5 from King 7, Berkeley 66 from King 7, Berkeley 17 from King 7, King 5 from Berkeley 71, Berkeley 66 from Berkeley 71, Berkeley 17 from Berkeley 66, and M 15 from M 92.
5. Clustering algorithms
We have applied eight different clustering algorithms for the classification of stellar clusters in chemical abundances space ([Al/M], [C/M], [Ca/M], [Fe/H], [K/M], [Mg/M], [N/M], [Na/M], [Ni/M], [O/M], [P/M], [S/M], and [Si/M]5) to determine how well they perform in separating known clusters. The algorithms are an affinity propagation (Frey & Dueck 2007), agglomerative clustering (Fränti et al. 2006), DBSCAN (Daszykowski & Walczak 2010), K-means (Macqueen 1967), mini-batch K-means (Bouveyron et al. 2007), spectral clustering (Ng et al. 2002), Gaussian mixing models (Bouveyron et al. 2007), and Bayesian Gaussian mixing models (Neal 1992; Lartillot & Philippe 2004). These are all the nonhierarchical clustering algorithms available in the scikit-learn library (Thirion et al. 2016). The complete description of these methods is beyond the scope of this paper; we refer to Jain et al. (1999) who provide a review of these algorithms and to the scikit-learn website, which contains the documentation for the library used in this work6.
To evaluate the algorithm that is best suited for this task, we compared the algorithms through three different metrics (merit functions): homogeneity score, accuracy score, and v-measure score. When unsupervised clustering algorithms are run, the labels generated for the clusters can vary from one run to another. Even when the same objects are grouped together in both runs, their labels can differ. The v-measure score and homogeneity score are transparent to permutations of the labels, but the accuracy score needs all the clusters to be cross-matched. In this case, we matched each group of stars found by the unsupervised tool to the star cluster with the highest number of member stars inside the group, as was done in Sánchez Almeida & Allende Prieto (2013) and Garcia-Dias et al. (2018). However, in this work when the number of clusters in the real dataset did not match the number of clusters in the predicted model, or when the objects in one group did not match any of the available clusters, we assigned the group to the cluster with the highest number of coincident objects, even when the cluster had previously been assigned to another group.
The accuracy score measures the number of coincidences between the real classification and the label assigned by for the clustering algorithm. It is a value from zero to one that represents the fraction of stars that are classified into the right cluster. The homogeneity score measures at which level the predicted clusters contain only data points that are members of one real cluster. The score value varies from zero to one, where 1 means that the clusters are perfectly homogeneous. The v-measure score is the harmonic mean between completeness and homogeneity. Rosenberg & Hirschberg (2007) present a rigorous description of these merit functions.
For each of these algorithms, we performed an extensive optimization of their hyperparameters searching for the highest homogeneity score. The list of hyperparameters we tuned for each clustering method is shown in Table 3, together with their best-fit values. The description of each of these parameters is given in the articles cited and also in the documentation of scikit-learn. The hyperparameters presented in Table 3 are labeled exactly as in the documentation of scikit-learn.
Hyperparameters we explored for each algorithm.
5.1. Scalers
When high-dimensional data are used to perform clustering, it is essential to ensure all the dimensions are properly scaled. Many standard algorithms are availiable in the literature to achieve this kind of normalization. In this work, we have tested all the clustering algorithms with two different scaler algorithms (scikit-learn package; Thirion et al. 2016) that are known as the standard scaler and the robust scaler. The standard scaler sets the mean value of all dimensions to zero and scales the variance of all dimensions to one. The robust scaler sets the median to zero and scales the data according to the range between the first and the third quantile, making it robust to outliers.
When the two types of scaler were tested with the clustering algorithms, we found the highest homogeneity scores using the standard scaler for the affinity propagation, DBSCAN, and K-means algorithms. For the other five algorithms, the highest homogeneity score was found using the robust scaler.
5.2. Dimensionality reduction
Dimensionality reduction is important not only to reduce computational cost but also to eliminate redundancy. Redundant dimensions can hamper the finding of clusters by the dilution of Euclidean distances when dimensions grow. This phenomenon is known as the curse of dimensionality, and it is discussed, for example, in Zimek et al. (2012). We ran each clustering algorithm after dimensionality reduction with a principal component analysis (PCA; Wold et al. 1987), a linear discriminant analysis (LDA; Fisher 1936), a independent component analysis (ICA; Hyvärinen & Oja 2000), a t-distributed stochastic neighbor embedding (t-SNE; Maaten & Hinton 2008), and also without dimensionality reduction.
For all clustering algorithms tested here, we found the highest homogeneity scores when the clustering algorithms were associated with the LDA dimensionality reduction algorithm. We varied the number of dimensions from 2 to 12 for all the dimensionality reduction tools. The number of dimensions that maximizes the homogeneity score differs among the algorithms. For the DBSCAN and spectral clustering, the highest homogeneity scores are found by projecting the data into two components. For agglomerative clustering and K-means, the best-suitable number of dimensions is 4. Five dimensions give the highest homogeneity score for the Gaussian mixture models and the mini-batch K-means. For affinity propagation, the best number of components is 6, and for the Bayesian Gaussian mixture models the best value is 7. In machine-learning it is common practice to use the components that conserve a certain variance threshold, such as using the components that retain 90% of the original variance in the dataset. This analysis shows that this approach to determine the best number of components can favor some clustering algorithms over others, because the best number of components depends on the clustering method.
6. Results of the clustering algorithms
We tested the eight clustering algorithms listed in Sect. 5 by varying their hyperparameters and combining them with four different dimensionality (Sect. 5.2) reductions tools and two different scaling methods (Sect. 5.1). Figure 5 shows the best scores achieved for each of the clustering algorithms when the number of clusters is 23, that is, the number of real stellar clusters in this sample. The algorithms are ordered by their best homogeneity score.
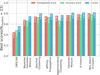 |
Fig. 5. Best result for each of the algorithms tested in this work represented by bars. Different colors are used to distinguish among the metrics, as shown in the legend. In groups of three bars, the leftmost bar represents the homogeneity score, the bar in the middle represents the accuracy score, and the rightmost bar represents the v-measure score. |
These results were obtained through working with the APOGEE uncalibrated elemental abundances, [Al/M], [C/M], [Ca/M], [Fe/H], [K/M], [Mg/M], [N/M], [Na/M], [Ni/M], [O/M], [P/M], [S/M], and [Si/M], for 453 stars in 23 clusters. Figure 6 shows the confusion matrix of the clustering result with the highest homogeneity score, which was obtained with the mini-batch K-means. The confusion matrix compares the actual labels with the predicted labels. Each cell shows the ratio of the objects belonging to the class indicated in the vertical axis classified as belonging to the class in the horizontal axis. The main diagonal presents the true positives, namely when an object is classified in the cluster it belongs to, while the off-diagonal elements represent confusion between clusters (an object from one cluster is classified as belonging to another cluster). Of the six pairs that appear as indistinguishable in Fig. 4, four of them present a degree of confusion higher than 20% in Fig. 6. The pairs M 3–M 13, M 67–NGC 6819, and NGC 188–NGC 6819, on the other hand, are slightly mixed in the classification but are not pointed out as problematic by the Cramer test. Because the test does not guarantee separability, these cases are to be expected.
 |
Fig. 6. Confusion matrix for our the best classification. The cells are color-coded according to the fraction of stars that are correctly classified as cluster members. The vertical axis corresponds to the real clusters, and the horizontal axis represents the clusters obtained with the mini-batch K-means. The main diagonal shows well-classified objects, and the cells out of the diagonal represent misclassifications. |
Figure 7 shows the variation in homogeneity score with the number of dimensions for all different dimensionality reduction algorithms, and for the two different scalers. The highest homogeneity score is found using LDA as dimensionality reduction. Moreover, LDA is almost unaffected by the choice of the scaler. The best result is found when we used LDA with nine dimensions: the homogeneity score is 0.807. When no dimensionality reduction tools were used, we obtain the results shown in Table 4. In this case, the highest homogeneity score is found for the Gaussian mixture model, 0.737, which is lower than we obtain using LDA but higher than we observe for the other dimensionality reduction tools.
 |
Fig. 7. Best homogeneity score. This varies for each of the dimensionality reduction models with the variation of the number of components. The labels at the top of each panel indicate the dimensionality reduction algorithm. Different colors are used for each clustering algorithm. Solid lines present the results obtained when we applied the robust scaler, and dotted lines show the results for the standard scaler. |
Highest scores found using clustering without dimensionality reduction.
The LDA is a supervised dimensionality reduction algorithm that uses knowledge of the classes to create a linear projection of the data that maximizes the separation among the classes. The projection could be determined using a few known clusters and might then be applied to any number of stars. When the search for stellar populations is made blindly, we could use the known star populations to determine the projection and apply this to the whole sample.
For comparison with Blanco-Cuaresma et al. (2015), we present in Fig. 8 the best scores without constraining the number of clusters to 23. Blanco-Cuaresma et al. (2015) found the best result with the Mitschang algorithm7 (Mitschang et al. 2013), with a homogeneity score of 0.86 and a v-measure score of 0.75. Our highest homogeneity score is 0.853, found using DBSCAN, with a v-measure score of 0.861. The quality of the data used by Blanco-Cuaresma et al. (2015) is arguably better than ours, in the sense that the spectral resolution of their spectra is higher than in APOGEE, and the authors used chemical abundances for 17 elements, while we used 13. In addition, we did not use the same clusters as they did, which can bias the comparison. However, assuming that the overall distribution of chemical abundances of both samples are comparable, our results show that APOGEE data are capable of yielding results at a similar level as those obtained by Blanco-Cuaresma et al. (2015) from optical spectroscopy.
 |
Fig. 8. Best result for each of the algorithms we tested without constraining the number of clusters, represented by bars. Different colors are used to distinguish among the metrics, as shown in the legend. In groups of three bars, the leftmost bar represents the homogeneity score, the bar in the middle represents the accuracy score, and the rightmost bar represents the v-measure score. The actual values are given in each bar. |
7. Conclusions
We have explored the application of unsupervised clustering on the APOGEE survey to chemically separate star clusters from each other. We statistically tested the feasibility of the task and concluded that it cannot be accomplished perfectly because of the intrinsic overlap of the clusters in chemical space. Eight different clustering algorithms were combined with four dimensionality reduction techniques and two scaling approaches. We have shown that the highest homogeneity score obtained from the clustering process is consistent with the expectations from the Cramer test.
The Kolmogorov–Smirnov test allowed us to identify the chemical elements that are the most sensitive for the identification of stellar populations. Seven elements are sufficient to distinguish 90% of the pairs of clusters. Table 2 shows that the best set of elements depends on the type of cluster. For example, some elements are more relevant for separation globular clusters from each other (Fe and K), while other elements are more suitable for distinguishing open from globular clusters (C, Al, and Na). This information is highly relevant when the decision needs to be made whether to allocate computational and observational resources to improve the precision of abundance measurements or to expand the number of elemental species to be measured. We stress that this information is restricted to the set of elements explored here ([Al/M], [C/M], [Ca/M], [Fe/H], [K/M], [Mg/M], [N/M], [Na/M], [Ni/M], [O/M], [P/M], [S/M], and [Si/M]) and the stellar populations we studied.
The Cramer test suggests that there are six pairs of indistinguishable clusters in our sample, M 2–M 5, M 2–M 13, M 15–M 92, NGC 2158–NGC 2420, NGC 2158–Pleiades, and NGC 2420–Pleiades. This does not mean the other pairs are fully separable, because different but overlapping distributions can be distinguishable and not separable. On the other hand, it does not mean the that indistinguishable cluster pairs are intrinsically identical; it only guarantees that the particular samples of stars and chemical elements that we have studied are indistinguishable. It is possible that the same stars measured with higher precision, the use a different set of elements, or the availability of larger samples of stars in the analysis, could lead to a different conclusion.
We have tried to separate the cluster members using unsupervised classification algorithms. These reached a maximum homogeneity score of 0.85, where the confusion is primarily associated with pairs that were marked as indistinguishable by the Cramer test. The best result was found using mini-batch K-means, but K-means and Gaussian mixture models give a very similar performance. Gaussian mixture models offer a more elegant solution, providing not only the classification of the stars, but also the probability of belonging to other groups. Moreover, the mixture of Gaussian functions can generate decision boundaries that can adapt better to the intrinsic form of the clusters, while K-means like algorithms assume hyperspherical boundaries, when Euclidean metric is applied. However, in larger samples where the computational cost can be a constraint, mini-batch K-means would be preferable.
In summary, we have tested the limits of the distinguishability of the stellar clusters with APOGEE data and explored the performance of various clustering algorithm to reach these limits. In this sense, we have shown that the chemical identification of stellar populations is limited by the available data. We have slightly improved the results of the classification compared with previous attempts. With the chemical information provided by APOGEE, it is not possible to completely distinguish all the stellar clusters from each other. Even though we are not able to completely separate the clusters from each other, the primary sources of confusion are clusters with similar ages, as is the case for the three globular clusters M 2, M 3 and M 13, and the pair of open clusters NGC 2158 and NGC 2420. On the other hand, old metal-poor globular clusters were much easier to distinguish, as could be naturally expected because their chemical patterns are distinct Therefore, strong chemical tagging might yield better results on these populations.
In a recent study, Ness et al. (2018) demonstrated the existence of stars with almost identical chemical composition, but with a different galactic origin, which adds to the limitations presented in this work. However, our results indicate that if chemical tagging is not possible to the level of star clusters, the existing clustering algorithms can blindly identify stellar populations with similar ages and chemical distributions in APOGEE data (but not the exact clusters).
Traditionally, the chemical distributions of stellar populations are either used to distinguish large-scale Galactic components, such as the thin and thick disk, or to identify populations at the star cluster level. The results found in this paper add to what has been found by Blanco-Cuaresma et al. (2015) and Ness et al. (2018) in demonstrating the difficulties for blind searches to identify star clusters from their chemical abundances.
There is a possibility of improving the spectroscopic data or including radial velocities or proper motions in the cluster identification, which would proceed the process to a chemical and kinematic tagging as in Chen et al. 2018. Alternatively, chemical tagging might be thought of as an intermediate level between the Galactic components and the stellar clusters. If we identify many stars that are chemically very similar to those in a cluster, we expect them to share a similar chemical evolution history with the cluster, even if the two sets are spatially unrelated.
FERRE is available from github.com/callendeprieto/ferre
See the data model and specifically the description of the FELEM array in http://www.sdss.org/dr14/irspec/abundances/
Clusters were more clearly distinguished from each other.
We used the SciPy software library version 1.1.0 to perform the K–S tests.
The bracket notation for two given elements X and Y, [X/Y] is defined as
![Mathematical equation: $$ \begin{aligned}[\mathrm{X} /\mathrm{Y} ]= \log _{10}{\left({\frac{N_{\mathrm{X} }}{N_{\mathrm{Y} }}}\right)_{\mathrm{star} }}-\log _{10}{\left({\frac{N_{\mathrm{X} }}{N_{\mathrm{Y} }}}\right)_{\odot }}, \end{aligned} $$](/articles/aa/full_html/2019/09/aa35223-19/aa35223-19-eq3.gif) (1)
(1)
where NX and NY are the number of X and Y nuclei per unit volume, respectively.
The Mitschang algorithm is not publicly available, therefore we were unable to test it against our sample.
Acknowledgments
We acknowledge financial support through grants AYA2014-56359-P, AYA2017-86389-P, and AYA2016-79724-C4-2-P (MINECO/FEDER). The research that led to this article was partially funded by the Brazilian National Research Council (CNPq) through scholarship of the CSF program. CAP is thankful to the Spanish Government for funding for his research through grant AYA2014-56359-P. Funding for SDSS-III has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, and the US Department of Energy Office of Science. The SDSS-III website is http://www.sdss3.org/. SDSS-III is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS-III Collaboration including the University of Arizona, the Brazilian Participation Group, Brookhaven National Laboratory, Carnegie Mellon University, University of Florida, the French Participation Group, the German Participation Group, Harvard University, the Instituto de Astrofisica de Canarias, the Michigan State/Notre Dame/JINA Participation Group, Johns Hopkins University, Lawrence Berkeley National Laboratory, Max Planck Institute for Astrophysics, Max Planck Institute for Extraterrestrial Physics, New Mexico State University, New York University, Ohio State University, Pennsylvania State University, University of Portsmouth, Princeton University, the Spanish Participation Group, University of Tokyo, University of Utah, Vanderbilt University, University of Virginia, University of Washington, and Yale University.
References
- Abolfathi, B., Aguado, D. S., Aguilar, G., et al. 2018, ApJS, 235, 42 [NASA ADS] [CrossRef] [Google Scholar]
- Allende Prieto, C., Beers, T. C., Wilhelm, R., et al. 2006, ApJ, 636, 804 [NASA ADS] [CrossRef] [Google Scholar]
- Anders, F., Chiappini, C., Santiago, B. X., et al. 2018, A&A, 619, A125 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bailer-Jones, C. A. L. 2002, in Automated Data Analysis in Astronomy, eds. R. Gupta, H. P. Singh, & C. A. L. Bailer-Jones (London: Narosa Pub. House), 99 [Google Scholar]
- Bailer-Jones, C. A. L., Irwin, M., & Von Hippel, T. 1998, MNRAS, 298, 361 [NASA ADS] [CrossRef] [Google Scholar]
- Baringhaus, L., & Franz, C. 2004, J. Multivar. Anal., 88, 190 [CrossRef] [Google Scholar]
- Bertran de Lis, S., Allende Prieto, C., Majewski, S. R., et al. 2016, A&A, 590, A74 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blanco-Cuaresma, S., Soubiran, C., Heiter, U., et al. 2015, A&A, 577, A47 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blanton, M. R., Bershady, M. A., Abolfathi, B., et al. 2017, AJ, 154, 28 [NASA ADS] [CrossRef] [Google Scholar]
- Boesso, R., & Rocha-Pinto, H. J. 2018, MNRAS, 474, 4010 [NASA ADS] [CrossRef] [Google Scholar]
- Bouveyron, C., Girard, S., & Schmid, C. 2007, Comput. Stat. Data Anal., 52, 502 [CrossRef] [MathSciNet] [Google Scholar]
- Bovy, J. 2016, ApJ, 817, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, B., D’Onghia, E., Pardy, S. A., et al. 2018, ApJ, 860, 70 [NASA ADS] [CrossRef] [Google Scholar]
- Cunha, K., Smith, V. V., Johnson, J. A., et al. 2015, ApJ, 798, L41 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Daniel, S. F., Connolly, A., Schneider, J., Vanderplas, J., & Xiong, L. 2011, AJ, 142, 203 [NASA ADS] [CrossRef] [Google Scholar]
- Darling, D. A. 1957, Ann. Math. Stat., 28, 823 [Google Scholar]
- da Silva, R., Porto de Mello, G. F., Milone, A. C., et al. 2012, A&A, 542, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Daszykowski, M., & Walczak, B. 2010, Compr. Chemom., 2, 635 [Google Scholar]
- Dias, W. S., Alessi, B. S., Moitinho, A., & Lépine, J. R. D. 2002, A&A, 389, 871 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dotter, A., Conroy, C., Cargile, P., & Asplund, M. 2017, ApJ, 840, 99 [NASA ADS] [CrossRef] [Google Scholar]
- Elias, F., Alfaro, E. J., & Cabrera-Caño, J. 2006, AJ, 132, 1052 [NASA ADS] [CrossRef] [Google Scholar]
- Fernández-Trincado, J. G., Zamora, O., García-Hernández, D. A., et al. 2017, ApJ, 846, L2 [NASA ADS] [CrossRef] [Google Scholar]
- Fisher, R. A. 1936, Ann. Eugen., 7, 179 [Google Scholar]
- Forbes, D. A., & Bridges, T. 2010, MNRAS, 404, 1203 [NASA ADS] [Google Scholar]
- Francis, C., & Anderson, E. 2014, MNRAS, 441, 1105 [NASA ADS] [CrossRef] [Google Scholar]
- Fränti, P., Virmajoki, O., & Hautamäki, V. 2006, IEEE Trans. Pattern Anal. Mach. Intell., 28, 1875 [CrossRef] [Google Scholar]
- Freeman, K., & Bland-Hawthorn, J. 2002, ARA&A, 40, 487 [NASA ADS] [CrossRef] [Google Scholar]
- Frey, B. J., & Dueck, D. 2007, Science, 315, 972 [Google Scholar]
- Frinchaboy, P. M., Thompson, B., Jackson, K. M., et al. 2013, ApJ, 777, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Garcia-Dias, R., Allende Prieto, C., Sánchez Almeida, J., & Ordovás-Pascual, I. 2018, A&A, 612, A98 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- García Pérez, A. E., Allende Prieto, C., Holtzman, J. A., et al. 2016, AJ, 151, 144 [NASA ADS] [CrossRef] [Google Scholar]
- Giridhar, S., Muneer, S., & Goswami, A. 2006, Mem. Soc. Astron. It., 77, 1130 [NASA ADS] [Google Scholar]
- Gunn, J. E., Siegmund, W. A., Mannery, E. J., et al. 2006, AJ, 131, 2332 [NASA ADS] [CrossRef] [Google Scholar]
- Hogg, D. W., Casey, A. R., Ness, M., et al. 2016, ApJ, 833, 262 [NASA ADS] [CrossRef] [Google Scholar]
- Holtzman, J. A., Shetrone, M., Johnson, J. A., et al. 2015, AJ, 150, 148 [NASA ADS] [CrossRef] [Google Scholar]
- Holtzman, J. A., Hasselquist, S., Shetrone, M., et al. 2018, AJ, 156, 125 [NASA ADS] [CrossRef] [Google Scholar]
- Hyvärinen, A., & Oja, E. 2000, Neural Netw., 13, 411 [CrossRef] [PubMed] [Google Scholar]
- Jain, A. K., Murty, M. N., & Flynn, P. J. 1999, ACM Comput. Surv., 31, 264 [CrossRef] [Google Scholar]
- Jofré, P., Das, P., Bertranpetit, J., & Foley, R. 2017, MNRAS, 467, 1140 [NASA ADS] [CrossRef] [Google Scholar]
- Jönsson, H., Allende Prieto, C., Holtzman, J. A., et al. 2018, AJ, 156, 126 [NASA ADS] [CrossRef] [Google Scholar]
- Kos, J., Bland-Hawthorn, J., Freeman, K., et al. 2018, MNRAS, 473, 4612 [NASA ADS] [CrossRef] [Google Scholar]
- Lartillot, N., & Philippe, H. 2004, Mol. Biol. Evol., 21, 1095 [CrossRef] [Google Scholar]
- Linden, S. T., Pryal, M., Hayes, C. R., et al. 2017, ApJ, 842, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Maaten, L. V. D., & Hinton, G. 2008, J. Mach. Learn. Res., 9, 2579 [NASA ADS] [Google Scholar]
- Macqueen, J. 1967, Proc. Fifth Berkeley Symp. Math. Stat. Probab., 281, 1 [Google Scholar]
- Majewski, S. R., Schiavon, R. P., Frinchaboy, P. M., et al. 2017, AJ, 154, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Manteiga, M., Carricajo, I., Rodríguez, A., Dafonte, C., & Arcay, B. 2009, AJ, 137, 3245 [NASA ADS] [CrossRef] [Google Scholar]
- Marín-Franch, A., Aparicio, A., Piotto, G., et al. 2009, ApJ, 694, 1498 [NASA ADS] [CrossRef] [Google Scholar]
- Matijevič, G., Chiappini, C., Grebel, E. K., et al. 2017, A&A, 603, A19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mitschang, A. W., De Silva, G., Sharma, S., & Zucker, D. B. 2013, MNRAS, 428, 2321 [NASA ADS] [CrossRef] [Google Scholar]
- Morales-Luis, A. B., Sánchez Almeida, J., Aguerri, J. A. L., & Muñoz-Tuñón, C. 2011, ApJ, 743, 77 [NASA ADS] [CrossRef] [Google Scholar]
- Morgan, W. W., Keenan, P. C., & Kellman, E. 1943, An Atlas of Stellar Spectra, with an Outline of Spectral Classification (Chicago: The University of Chicago Press) [Google Scholar]
- Navarro, S. G., Corradi, R. L. M., & Mampaso, A. 2012, A&A, 538, A76 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Neal, R. M. 1992, in Bayesian Mixture Modeling, eds. C. R. Smith, G. J. Erickson, & P. O. Neudorfer (Dordrecht: Springer, Netherlands), 197 [Google Scholar]
- Ness, M., Rix, H.-W., Hogg, D. W., et al. 2018, ApJ, 853, 198 [NASA ADS] [CrossRef] [Google Scholar]
- Ng, A. Y., Jordan, M. I., & Weiss, Y. 2002, Adv. Neural Inf. Process. Syst., 14, 849 [Google Scholar]
- Paust, N. E. Q., Chaboyer, B., & Sarajedini, A. 2007, AJ, 133, 2787 [NASA ADS] [CrossRef] [Google Scholar]
- Price-Jones, N., & Bovy, J. 2017, MNRAS, 475, 1410 [NASA ADS] [CrossRef] [Google Scholar]
- Price-Jones, N., & Bovy, J. 2019, MNRAS, 487, 871 [NASA ADS] [CrossRef] [Google Scholar]
- Reis, I., Poznanski, D., Baron, D., Zasowski, G., & Shahaf, S. 2018, MNRAS, 476, 2117 [NASA ADS] [CrossRef] [Google Scholar]
- Rodríguez, A., Arcay, B., Dafonte, C., Manteiga, M., & Carricajo, I. 2004, Expert Syst. Appl., 27, 237 [CrossRef] [Google Scholar]
- Rosenberg, A., & Hirschberg, J. 2007, V-Measure: A Conditional Entropy-based External Cluster Evaluation Measure, 410 [Google Scholar]
- Sánchez Almeida, J., & Allende Prieto, C. 2013, ApJ, 763, 50 [NASA ADS] [CrossRef] [Google Scholar]
- Sánchez Almeida, J., Aguerri, J. A. L., Muñoz-Tuñón, C., & Vazdekis, A. 2009, ApJ, 698, 1497 [NASA ADS] [CrossRef] [Google Scholar]
- Sánchez Almeida, J., Aguerri, J. A. L., Muñoz-Tuñón, C., & de Vicente, A. 2010, ApJ, 714, 487 [NASA ADS] [CrossRef] [Google Scholar]
- Sánchez Almeida, J., Pérez-Montero, E., Morales-Luis, A. B., et al. 2016, ApJ, 819, 110 [NASA ADS] [CrossRef] [Google Scholar]
- Schiavon, R. P., Zamora, O., Carrera, R., et al. 2017, MNRAS, 465, 501 [NASA ADS] [CrossRef] [Google Scholar]
- Singh, H. P., Gulati, R. K., & Gupta, R. 1998, MNRAS, 295, 312 [NASA ADS] [CrossRef] [Google Scholar]
- Smirnov, N. V. 1939, Bull. Math. Univ. Moscou, 2, 3 [Google Scholar]
- Souto, D., Cunha, K., Smith, V., et al. 2016, ApJ, 830, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Souto, D., Cunha, K., Smith, V. V., et al. 2018, ApJ, 857, 14 [NASA ADS] [CrossRef] [Google Scholar]
- Thirion, B., Duschenay, E., Michel, V., et al. 2016, scikitlearn, http://mloss.org/software/view/240/ [Google Scholar]
- Ting, Y. S., Freeman, K. C., Kobayashi, C., De Silva, G. M., & Bland-Hawthorn, J. 2012, MNRAS, 421, 1231 [NASA ADS] [CrossRef] [Google Scholar]
- Traven, G., Matijevič, G., Zwitter, T., et al. 2017, ApJS, 228, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Valentini, M., Chiappini, C., Davies, G. R., et al. 2017, A&A, 600, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vanderplas, J., & Connolly, A. 2009, AJ, 138, 1365 [NASA ADS] [CrossRef] [Google Scholar]
- Wold, S., Esbensen, K., & Geladi, P. 1987, Tutorial in Chemometrics and Intelligent Laboratory Systems Elsevier Science Publishers B.V., 2, 37 [Google Scholar]
- Yeremi, M., Flynn, M., Offner, S., Loeppky, J., & Rosolowsky, E. 2014, ApJ, 783, 93 [NASA ADS] [CrossRef] [Google Scholar]
- Zimek, A., Schubert, E., & Kriegel, H.-P. 2012, Stat. Anal. Data Mining, 5, 363 [CrossRef] [Google Scholar]
Appendix A: Main results with calibrated abundances
In order to enrich the description of the analysis while preserving a comprehensive flow of ideas in the article, we reserved the presentation of the results for the calibrated sample in this appendix. Here we reproduce the main relevant results we presented in the analysis of the article to demonstrate that the choice for uncalibrated abundances only quantitatively affects the results. The conclusions presented in the main section of the article remain the same. Here the initial sample was the same as the uncalibrated sample, and all steps were applied in exactly the same manner. We therefore refer to the main sections for more details in the analysis.
Although we have started with the same dataset for the calibrated analysis, the cleaning process was more severe in this case: fewer star per cluster were kept after the sigma clipping. Because we established a minimum threshold of five stars per clusters, here the analysis is based on fewer clusters. In Fig. A.1 the clusters King 7, M 107, M 15 and M 92 were excluded from the analysis with calibrated abundances. We also excluded the abundances for Al and Na because we lack of measurements for 11% and 18% of the stars in the sample, respectively.
In Figs. A.1–A.3 we show the results of the K–S test and the Cramer test for all clusters in the calibrated sample. The degree of confusion among the clusters is even more severe than in the uncalibrated abundances. The indistinguishability of more pairs of clusters results in a poorer performance of the algorithms in separating the clusters, as shown in Figs. A.4 and A.5.
This small section supports the focus on the uncalibrated for the rest of the analysis. The same conclusions as presented for the uncalibrated sample apply to the calibrated sample. However, working with uncalibrated data is a more conservative approach in our hypothesis of cluster indistinguishability because this characteristic is more even more obvious in the calibrated data and is probably aggravated by the calibration.
 |
Fig. A.1. Same as Fig. 2 for the calibrated abundances. Logarithm of the p-values of the K–S two-sample test for the carbon distributions of each pair of clusters. The cells are colored in five shades of red, from light to dark in logarithmic scale. Inside each cell, we show the p-value of the test for that particular pair of clusters. Superscripts in cluster names indicate the number of stars in the cluster. The main diagonal shows the median p-value of 1000 tests resulting from randomly dividing the cluster into two subsamples of nearly equal sizes. Two blue lines separate the objects into globular clusters (lower right) and open clusters (upper left). Dark red represents values greater than 0.01: we cannot reject the null hypothesis for these cases. |
 |
Fig. A.2. Same as Fig. 3 for the calibrated abundances. Logarithm of the p-values of the K–S two-sample test for each pair of clusters. The elements of the main diagonal and above the main diagonal represent the lowest p-value found among all the elements, while the elements below the main diagonal represent the p-value for carbon. The cells are colored in shades of red as shown in the color bar. Red colors are saturated at 0.01. Superscripts in the cluster names indicate the number of stars in the cluster. At the center of each cell, we show the element for which the p-value is calculated. Two blue lines separate the objects into globular and open clusters. |
 |
Fig. A.3. Same as Fig. 4 for the calibrated abundances. Median log p-values of 100 runs of the Cramer two-sample test for each pair of clusters. The elements below the main diagonal show the median value of 100 runs of the Cramer test, and the elements above the diagonal show the results for the K–S test. The cells are colored in shades of red as shown in the color bar. Inside each cell, we show the p-value of the test for each particular pair of clusters. Superscripts in the cluster names indicate the number of stars in the cluster. Two blue lines separate the objects into globular and open clusters. |
 |
Fig. A.4. Same as Fig. 6 for the calibrated abundances. The confusion matrix for our the best classification. The cells are color-coded according to the fraction of stars that is correctly classified as cluster members. The vertical axis corresponds to the real clusters, and the horizontal axis represents the clusters obtained with the mini-batch K-means. The main diagonal shows well-classified objects, and the cells out of the diagonal represent misclassifications. |
 |
Fig. A.5. Same as Fig. 8 for the calibrated abundances. The bars represent the best result for each of the algorithms we tested in this work without constraining the number of clusters. Different colors are used to distinguish the metrics, as shown in the legend. In groups of three bars, the leftmost represents homogeneity score, the bar in the middle represents the accuracy score, and the rightmost bar represents the v-measure score. The actual values are given in each bar. |
All Tables
All Figures
|
Fig. 1. Distribution of Teff and logg for all the stars used in the unsupervised clustering exercise. For each cluster we used a unique combination of symbol and color, as shown in the plot legend. |
| In the text | |
|
Fig. 2. Logarithm of the p-values of the K–S two-sample test for the carbon distributions of each pair of clusters. The cells are colored in five shades of red, from light to dark in logarithmic scale. Inside each cell, we show the p-value of the test for that particular pair of clusters. Superscripts in the cluster names indicate the number of stars in the cluster. The main diagonal shows the median p-value of 1000 tests resulting from randomly dividing the cluster into two subsamples of nearly equal sizes. Two blue lines separate the objects into globular clusters (lower right) and open clusters (upper left). Dark red represents values greater than 0.01: we cannot reject the null hypothesis for these cases. |
| In the text | |
|
Fig. 3. Logarithm of the p-values of the K–S two-sample test for each pair of clusters. The elements of the main diagonal and above the main diagonal represent the lowest p-value found among all the elements, and while the elements below the main diagonal represent the p-value for carbon. The cells are colored in shades of red as shown in the color bar. Red colors are saturated at 0.01. Superscripts in the cluster names indicate the number of stars in the cluster. At the center of each cell, we show the element for which the p-value is calculated. Two blue lines separate the objects into globular and open clusters. |
| In the text | |
|
Fig. 4. Median log p-values of 100 runs of the Cramer two-sample test for each pair of clusters. The elements below the main diagonal show the median value of 100 runs of the Cramer test, and the elements above the diagonal show the results for the K–S test. The cells are colored in shades of red as shown in the color bar. Inside each cell, we show the p-value of the test for each particular pair of clusters. Superscripts in the cluster names indicate the number of stars in the cluster. Two blue lines separate the objects into globular and open clusters. |
| In the text | |
|
Fig. 5. Best result for each of the algorithms tested in this work represented by bars. Different colors are used to distinguish among the metrics, as shown in the legend. In groups of three bars, the leftmost bar represents the homogeneity score, the bar in the middle represents the accuracy score, and the rightmost bar represents the v-measure score. |
| In the text | |
|
Fig. 6. Confusion matrix for our the best classification. The cells are color-coded according to the fraction of stars that are correctly classified as cluster members. The vertical axis corresponds to the real clusters, and the horizontal axis represents the clusters obtained with the mini-batch K-means. The main diagonal shows well-classified objects, and the cells out of the diagonal represent misclassifications. |
| In the text | |
|
Fig. 7. Best homogeneity score. This varies for each of the dimensionality reduction models with the variation of the number of components. The labels at the top of each panel indicate the dimensionality reduction algorithm. Different colors are used for each clustering algorithm. Solid lines present the results obtained when we applied the robust scaler, and dotted lines show the results for the standard scaler. |
| In the text | |
|
Fig. 8. Best result for each of the algorithms we tested without constraining the number of clusters, represented by bars. Different colors are used to distinguish among the metrics, as shown in the legend. In groups of three bars, the leftmost bar represents the homogeneity score, the bar in the middle represents the accuracy score, and the rightmost bar represents the v-measure score. The actual values are given in each bar. |
| In the text | |
|
Fig. A.1. Same as Fig. 2 for the calibrated abundances. Logarithm of the p-values of the K–S two-sample test for the carbon distributions of each pair of clusters. The cells are colored in five shades of red, from light to dark in logarithmic scale. Inside each cell, we show the p-value of the test for that particular pair of clusters. Superscripts in cluster names indicate the number of stars in the cluster. The main diagonal shows the median p-value of 1000 tests resulting from randomly dividing the cluster into two subsamples of nearly equal sizes. Two blue lines separate the objects into globular clusters (lower right) and open clusters (upper left). Dark red represents values greater than 0.01: we cannot reject the null hypothesis for these cases. |
| In the text | |
|
Fig. A.2. Same as Fig. 3 for the calibrated abundances. Logarithm of the p-values of the K–S two-sample test for each pair of clusters. The elements of the main diagonal and above the main diagonal represent the lowest p-value found among all the elements, while the elements below the main diagonal represent the p-value for carbon. The cells are colored in shades of red as shown in the color bar. Red colors are saturated at 0.01. Superscripts in the cluster names indicate the number of stars in the cluster. At the center of each cell, we show the element for which the p-value is calculated. Two blue lines separate the objects into globular and open clusters. |
| In the text | |
|
Fig. A.3. Same as Fig. 4 for the calibrated abundances. Median log p-values of 100 runs of the Cramer two-sample test for each pair of clusters. The elements below the main diagonal show the median value of 100 runs of the Cramer test, and the elements above the diagonal show the results for the K–S test. The cells are colored in shades of red as shown in the color bar. Inside each cell, we show the p-value of the test for each particular pair of clusters. Superscripts in the cluster names indicate the number of stars in the cluster. Two blue lines separate the objects into globular and open clusters. |
| In the text | |
|
Fig. A.4. Same as Fig. 6 for the calibrated abundances. The confusion matrix for our the best classification. The cells are color-coded according to the fraction of stars that is correctly classified as cluster members. The vertical axis corresponds to the real clusters, and the horizontal axis represents the clusters obtained with the mini-batch K-means. The main diagonal shows well-classified objects, and the cells out of the diagonal represent misclassifications. |
| In the text | |
|
Fig. A.5. Same as Fig. 8 for the calibrated abundances. The bars represent the best result for each of the algorithms we tested in this work without constraining the number of clusters. Different colors are used to distinguish the metrics, as shown in the legend. In groups of three bars, the leftmost represents homogeneity score, the bar in the middle represents the accuracy score, and the rightmost bar represents the v-measure score. The actual values are given in each bar. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.