| Issue |
A&A
Volume 688, August 2024
|
|
|---|---|---|
| Article Number | A165 | |
| Number of page(s) | 15 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/202449938 | |
| Published online | 15 August 2024 | |
A baseline on the relation between chemical patterns and the birth stellar cluster
1
Instituto de Estudios Astrofísicos, Facultad de Ingeniería y Ciencias, Universidad Diego Portales, Av. Ejercito 441, Santiago, Chile
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Inria Chile Research Center, Av. Apoquindo 2827, Piso 12, Las Condes, Santiago, Chile
3
Millenium Nucleus ERIS, Chile
Received:
11
March
2024
Accepted:
22
May
2024
Abstract
Context. The chemical composition of a star’s atmosphere reflects the chemical composition of its birth environment. Therefore, it should be feasible to recognize stars born together that have scattered throughout the galaxy, solely based on their chemistry. This concept, known as “strong chemical tagging”, is a major objective of spectroscopic studies, but it has yet to yield the anticipated results.
Aims. We assess the existence and the robustness of the relation between chemical abundances and the birthplace using known member stars of open clusters.
Methods. We followed a supervised machine learning approach, using chemical abundances obtained from APOGEE DR17, observed open clusters as labels, and different data preprocessing techniques.
Results. We find that open clusters can be recovered with any classifier and on data whose features are not carefully selected. In the sample with no field stars, we obtain an average accuracy of 75.2% and we find that the prediction accuracy mostly depends on the uncertainties of the chemical abundances. When field stars outnumber the cluster members, the performance degrades.
Conclusions. Our results show the difficulty of recovering birth clusters using chemistry alone, even in a supervised scenario. This clearly challenges the feasibility of strong chemical tagging. Nevertheless, including information about ages could potentially enhance the possibility of recovering birth clusters.
Key words: stars: abundances / Galaxy: abundances / open clusters and associations: general
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Most of the star formation in the Milky Way is believed to take place in chemically homogeneous collapsing molecular clouds (Lada & Lada 2003), forming stellar aggregates such as open clusters or unbound associations. These birth aggregates are characterized by having similar chemical compositions, ages, and motions through space (e.g., Soubiran et al. 2018; Randich et al. 2022, and references therein).
However, as most stars are born in a weakly bound association and thus are rapidly dispersed and separated from their siblings due to a gravitational interaction (Krumholz et al. 2019), the motions of the members of these groups quickly lose all the information about the birthplace. The chemical composition of the atmosphere of low- to intermediate-mass stars, on the other hand, remains largely constant throughout their life. This means that, if the cloud is actually chemically homogeneous (Feng & Krumholz 2014; Bland-Hawthorn et al. 2010), it should be possible to use their chemical patterns as a fingerprint of their birth environments and birth stellar associations, even when these are disrupted (Freeman & Bland-Hawthorn 2002). The task of uniquely and confidently assigning individual stars to specific birthplaces is referred to as “strong chemical tagging”.
Some of these birth stellar associations are massive enough to remain gravitationally bound from millions to billions of years, and these are the open clusters we observe today. Observational studies have been a crucial part of testing the feasibility of strong chemical tagging. Surveys such as the Apache Point Observatory Galactic Evolution Experiment (APOGEE, Majewski et al. 2017), the Large Sky Area Multi-Object Fiber Spectroscopic Telescope (LAMOST, Cui et al. 2012), Galactic Archaeology with HERMES (GALAH, De Silva et al. 2015), the Radial Velocity Experiment (RAVE, Steinmetz et al. 2020), and Gaia-ESO (Randich et al. 2022) have aimed to gather data on the chemical composition of stars in these open clusters. These datasets allow us to test if there is a relation between chemical patterns and the birth association, and if this relation can be estimated from observations.
One major challenge of chemical tagging is the complexity of the chemical evolution of the galaxy. While the chemical composition of a star depends on its birthplace, the chemical enrichment history of that birthplace has a further dependency on the chemical evolution of the region in which it formed (Magrini et al. 2023; Vitali et al. 2024). This evolution might be further affected by inhomogeneous mixing of gases, accretion of smaller galaxies, and stellar migration (Bird et al. 2012; Johnson et al. 2021). This means that stars that formed in different regions of the galaxy may have similar chemical compositions (Edvardsson et al. 1993), making it difficult to confidently assign a specific birthplace to an individual star.
The accuracy of the observational data poses another significant challenge for chemical tagging (Blanco-Cuaresma et al. 2015; Bovy 2016). High-resolution spectroscopy is needed to measure the detailed chemical fingerprints of individual stars, but the precision and accuracy of these measurements are still limited (see e.g., Jofré et al. 2019, for a review). This means that the chemical fingerprints of some stars may not be distinct enough to disentangle different birthplaces (Ness et al. 2018; Manea et al. 2023).
Previous attempts at addressing strong chemical tagging have been focused in performing a machine learning clustering analysis on some chemical abundance space to evaluate if observed open clusters are recovered. Overall, they are about applying clustering analysis techniques in order to perform an unsupervised classification, as they make use of known cluster members to evaluate the recovery performance. An unsupervised classification involves grouping (clustering) and distributing stars solely based on their similarity, computed through a distance metric, in some chemical abundances’ space. Then a class, or label, is assigned to each of the groups found. Essentially, these methods aim to identify statistical groups of stars sharing similarities, with an expectation that these would somewhat correspond to actual clusters.
For example, one of the first attempts to perform strong chemical tagging following Blanco-Cuaresma et al. (2015) was presented in Price-Jones et al. (2020), where a sample of more than 180 000 stars belonging to all the Galactic components was used. The reported inability of recovering any of the known open clusters present in their dataset stresses the difficulty of the task. This is especially true when noisy data significantly blur and wash out the chemical patterns we rely on (see e.g., discussions in Bovy 2016).
To address this last limitation, the studies from Casamiquela et al. (2021) and Spina et al. (2022) used precise chemical abundance estimates for member stars in open clusters to group them using the density-based clustering algorithms HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise, Campello et al. 2013) and OPTICS (Ordering Points To Identify the Clustering Structure, Ankerst et al. 1999). Despite using higher-quality data and sophisticated clustering methods, they were not able to recover open clusters with more than 50% completeness and homogeneity. Most of the groups did indeed find statistical groups containing stars belonging to different open clusters. These recent works thus support previous conclusions on the impossibility of strong chemical tagging.
How the various groups found with clustering algorithms are computed depends on the adopted algorithm and other parameters defined beforehand by the user, such as the threshold for similarity (Casamiquela et al. 2021). The real classes are never provided to the clustering algorithm. Furthermore, the clustering very strongly depends on the feature space and the samples provided to the algorithm. This has a larger impact on the result than the specific algorithm being used (e.g., Manea et al. 2023).
In this work, differently from the ones mentioned above, we aim to give a step prior to clustering, which is to classify, so as to evaluate, if a grouping of abundance data of open clusters is possible. We reframed the task as a supervised classification problem, as we made use of the labels of class (the truth labels y) to learn the mapping y = f(x) from the chemical features x to these labels y. Once this function was estimated from some training data, we could use it to reconstruct it or make a prediction on unknown data and thus assess its quality.
The whole idea of applying this kind of analysis is to shift the question from “is it possible to group stars together in chemical space to recover birth clusters?” to “is it possible to connect chemistry to a stars’ birthplace?” A supervised classification, with its greater accuracy compared to its unsupervised counterpart, sets an upper limit to our capabilities of performing strong chemical tagging with the currently available datasets. Furthermore, finding a supervised learning link might open the door to eventually finding a representation where open clusters can be found unsupervisingly.
In summary, the goal of this work is not to attempt to recover disrupted clusters, but to evaluate the feasibility of this task from an empirical perspective, by trying to answer in a systematic way the following questions:
-
Is there actually a link between chemical abundances and birth open clusters?
-
What are the most important factors of variation in the recovery of open clusters?
-
Which are the most important chemical elements?
-
Is it possible to find a better representation for these chemical abundances in a physics-agnostic way?
The structure of the paper is then as follows. In Sect. 2 the data used are introduced. In Sect. 3 the main methods to achieve our goals are described, followed by the results obtained in Sect. 4. Finally, Sect. 5 concludes this paper and provides a summary of the main results and the perspectives for future work.
2. Data
We made use of the seventeenth data release of the APOGEE survey (Abdurro’uf et al. 2022). The catalog includes data for a total of about 657 000 stars, both in the field and in clusters. The stars are observed with the APOGEE spectrograph, which is an infrared instrument with a resolving power of about 20 000, allowing the determination of radial velocities (RVs; Nidever et al. 2015), atmospheric parameters and abundances of about 20 different chemical species (García Pérez et al. 2016).
To assess whether each single star is a member of an open cluster, we use of membership probabilities from the Open Cluster Chemical Analysis and Mapping (OCCAM) catalog (Donor et al. 2018, 2020; Myers et al. 2022). This is obtained by combining the provided APOGEE RVs and metallicities ([Fe/H]) with proper motion observations (PM) from the Gaia Data Release 3 (Gaia Collaboration 2023) to establish membership probabilities for APOGEE stars in open cluster fields. The DR17 version of this catalog contains a total of 153 open clusters and some of them are flagged as “high quality” based on the appearance of their color-magnitude diagram. We consider members of open clusters all the stars with pPM > 0.6, pRV > 0.6, p[FE/H] > 0.3 or with pPM × pRV > 0.25, pCG > 0.85. Here pPM, pRV, and p[Fe/H] represent the membership probabilities based on proper motion, radial velocity, and metallicity, respectively. pCG indicates the membership probability from Cantat-Gaudin et al. (2018). We also discard clusters with fewer than eight observed members. These thresholds and cuts are arbitrary, involving a trade-off between maintaining an adequate sample size and ensuring quality in membership assessments.
For what concerns the chemical abundances, our input features, we adopt those obtained from AstroNN (Leung & Bovy 2019). This data analysis pipeline provides abundance determinations (along with their uncertainties σ) of all the following elements: C, Ci1, N, O, Na, Mg, Al, Si, P, S, K, Ca, Ti, Ti II, V, Cr, Mn, Fe, Co, and Ni, expressed as the logarithm of the ratio of a star’s element abundance with the hydrogen abundances and compared to that of the Sun (indicated with ⊙):
![Mathematical equation: $$ \begin{aligned} \left[\frac{X}{H}\right] = \log _{10} \left(\frac{N_X}{N_{\rm H}}\right) - \log _{10} \left(\frac{N_X}{N_{\rm H}}\right)_{\odot }, \end{aligned} $$](/articles/aa/full_html/2024/08/aa49938-24/aa49938-24-eq1.gif) (1)
(1)
where NX and NH are the number of element X and hydrogen atoms per unit of volume, respectively. While some of these elements, like carbon and nitrogen, can be modified by stellar evolution (Masseron & Gilmore 2015; Salaris et al. 2015), we remind how our supervised classification approach, contrarily to its unsupervised counterpart, should be able to mitigate this concern by learning to assign appropriate weights to each feature during training. We show deviations from the cluster mean for each element as a function of effective temperature in Fig. A.2, finding that variations in this parameter do not introduce systematic trends within the chemical abundances of cluster members. Notably, carbon and nitrogen abundances do not exhibit significantly larger deviations than other elements. This could be due, in part, to a selection bias favoring unevolved stars within our cluster member sample, where mixing has not yet substantially altered the abundance of these elements.
Our motivation to use this dataset is that it has higher precision compared to the standard data releases of APOGEE because the results are obtained after training a neural network on a sample of well determined abundances from ASPCAP (García Pérez et al. 2016). This further ensures consistency between the membership probabilities and the chemical abundances used in this work, since only precision is improved, not accuracy.
We discarded phosphorous as a feature because of its errors, and stars with [Fe/H] < −0.6 dex and mean chemical abundances uncertainties > 0.6 dex. After all these selections and quality cuts we count m = 775 stars in 27 clusters. In Table 1 we show the resulting number of members per cluster.
Member counts, average metallicity, galactic radius, and age for clusters in our selection.
The distribution of the abundance uncertainties of the different elements is shown in the top panel of Fig. 1, with horizontal lines indicating the median value. In the bottom panel of Fig. 1, we plot the distribution of abundance uncertainties (i.e., the median uncertainty across elements) for each cluster. Members of high-quality clusters show mostly uniform uncertainties, often with a dispersion less than ≈0.05 dex. In contrast, clusters not flagged as high-quality tend to display greater variability, as exemplified by Collinder 69, which has a dispersion around ≈0.12 dex.
 |
Fig. 1. Distributions of uncertainties. Top: distribution of the abundance uncertainties of the different elements for individual stars. Bottom: distribution over cluster members of the median (over chemical abundances) uncertainties. In both panels, each box plot is relative to the group indicated in the x-axis. Each blue box and contains the middle 50% of the data, and the horizontal line within the box denotes the median value. Outliers are indicated as individual points. |
Since our purpose is to classify open clusters using chemistry only, we refer to a vector of chemical abundances as x, and the cluster name as the label y. For now on, we thus consider our data as vectors and labels to study the various classifier methods.
3. Methods
The problem of finding a mapping from chemical abundances to birth stellar cluster is recasted as a classification problem: the question is if it is possible to represent the open cluster label y as a function f of the chemical abundances x, that is,
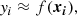 (2)
(2)
where i = 1, …, m runs over samples. In this section we present the main methods employed in this work, which include the performance metrics and the evaluation methods, the classifiers and the choices of the feature space.
3.1. Performance metrics
Four metrics are used to evaluate the cluster classification performance. In the following definitions, α indicates a specific true label (i.e., a specific open cluster), True Positives(α) is the number of samples that are correctly classified with label α, False Positives(α) is the number of samples that are incorrectly classified as positive for label α, False Negatives(α) is the number of instances that are incorrectly classified as negative for label α.
-
The accuracy score is the ratio between the number of correct predictions and the total number of predictions:
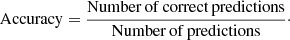 (3)
(3) -
The recall(α) indicates the ratio of clusters members of cluster α correctly assigned to cluster α:
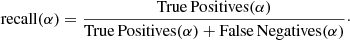 (4)
(4)A high recall(α) indicates it is possible to identify most of (or all) the members of the cluster α in the data, while a low recall(α) means that it is not possible to identify siblings born in cluster α.
-
The precision(α) indicates the fraction of cluster members assigned to cluster α with respect to the total number of predictions in cluster α:
 (5)
(5)Within everything that has been predicted as a member of cluster α, precision counts the percentage that is correct. A high precision(α) indicates that although we failed to identify all members of the cluster, the ones are identified as members of α are very likely to be correct. Precision is also sometimes referred to as purity.
-
The F1 score is an harmonic mean of precision and recall:
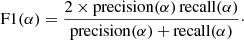 (6)
(6)
The overall recall, precision and F1 score for the multi-label classification problem are computed as the weighted average over all labels α, where the weight of each label is proportional to its occurrence in the data. Weighted recall is equal to accuracy. All these metrics will also be presented in percentage values.
3.2. Model evaluation
When using a supervised machine learning model, it is important to assess its generalization capabilities, that is, its ability to perform well on unseen data. The most common risk is overfitting, where the model simply memorizes the input-output mapping from the provided data, which also includes noise and irrelevant features. This leads to poor model performance on new data, as an overfitted model would represent the underlying relationships between features and the target variable.
Given the very small dataset in hand, we use a repeated k-fold cross-validation to get a more robust assessment of the classification performance (Hastie et al. 2009). In k-fold cross-validation, the dataset is divided in k subsets (folds) and the model is trained on k − 1 of these subsets and evaluated on the remaining one. This process is repeated until every subset is used for the evaluation. The performance of the model is then an average across these iterations. A repeated k-fold cross-validation, as the name suggests, is just a k-fold cross-validation repeated more than once. In this work, we opt for k = 3 to balance between assessing the model’s performance effectively and mitigating the variance of performance across folds.
3.3. Classifiers
Five different classifiers with different learning philosophies have been tested. We provide here a brief descriptions of the algorithms:
-
Nearest Neighbors classifier. A k-neighbor classifier (Cover & Hart 1967) implements learning based on the nearest k neighbors of each sample: every sample is assigned to the class that has the most representatives within the nearest neighbors of the point. Rather than learning a function between inputs and outputs, this approach is more closely related to clustering algorithms.
-
Random Forest classifier. The Random Forest classifier (Ho 1995; Breiman 2001) is a type of ensemble algorithm, in which the relationships between the features and the target variable are learned fitting multiple decision trees, each trained on a different random subsample of the data and columns. The output of the random forest is the class selected by most trees. It is robust to overfitting, can handle nonlinearly separable data, missing data, and noisy data.
-
XGBoost classifier. The XGBoost classifier (Chen & Guestrin 2016) is also a type of ensemble algorithm, but unlike Random Forest, which trains each tree independently, XGBoost iteratively improves upon the previous models by optimizing the cumulative prediction error. This iterative process allows XGBoost to build subsequent trees to correct the errors of preceding ones.
-
Support Vector Machine (SVM) classifier. The SVM classifier (Cortes & Vapnik 1995) works by finding the boundary (also called the decision boundary) that best separates the data into different classes. This boundary is defined by a line (in two-dimensional data) or a hyperplane (in higher-dimensional data) that maximizes the margin between the closest data points of different classes. The SVM classifier is able to handle nonlinearly separable data by transforming the data into a higher-dimensional space where a linear boundary can be found. In this work we both use a linear SVM and a radial basis function (RBF) SVM.
-
Multi-Layer Perceptron classifier. The Multi-Layer Perceptron (MLP, Hastie et al. 2009) classifier is a kind of feedforward artificial neural network. The MLP classifier has the ability to learn complex, nonlinear relationships between the input features and the output class.
Hyperparameter tuning was conducted for each classifier to optimize performance on our dataset2.
The performance of these models will be compared to two other classifiers: the dummy classifier and the random classifier. The dummy classifier is a model that makes predictions based on simple, predetermined rules, such as always predicting the most common class in the dataset. The random classifier is a model that randomly assigns class labels to data points without considering their features. These comparisons will help to assess if modeling the birth cluster with chemistry performs significantly better than chance.
3.4. The feature space
Regardless of the data or the model, an improperly constructed feature space will have a negative impact on the performance of the model used. The most common and natural choice is to just use as many features as possible: a first-level approach is to use all the features provided in the dataset (in this case 19 chemical abundances).
This can be a suboptimal choice because of some common difficulties arising when attempting classification in an unnecessarily high-dimensional space. These problems are well known as the “curse of dimensionality” (Bellman 1958), as also discussed in the chemical tagging framework in Spina et al. (2022) and Jackson et al. (2021).
The curse of dimensionality happens because the number of samples required to accurately model the relationship between features and target variables increases exponentially with the number of dimensions. In these higher-dimensional spaces, distance measures become less meaningful and thus identifying patterns more complicated. Furthermore, increasing the number of dimensions often introduces features that do not add much value to our model. When this is the case, the model may start to interpret noise or irrelevant data as significant, leading it to learn from them. This, in turn, results in a reduction in performance of the classifier.
These challenges are very relevant when it comes to using stellar chemical abundances, as they are estimated with limited precision and accuracy, and it is now believed that no more than seven to ten elements actually matter (Ting & Weinberg 2022). Chemical abundances are often tightly and linearly correlated, other than being noisy (e.g., Ness et al. 2018, 2022). Therefore, the space composed by the 19 chemical elements from our catalog very likely contains redundant features.
Another possible limiting factor is that the chemical abundances provided in the catalog are defined using the total hydrogen content (Eq. (1)). This representation, even if commonly adopted, is just a convention. There is no evidence showing that it is the best representation for identifying co-natal stars. Indeed, using wide binaries – which are also expected to be co-natal and chemically homogeneous such as open clusters (Hawkins 2020; Espinoza-Rojas et al. 2021) showed that stars were more similar to each other in the so-called chemical clock abundance ratios discussed in Jofré (2021) than in abundance ratios with respect to Fe.
Overall, both the choice of the elemental abundance space and the choice of its representation are fundamental decisions that have to be taken. That is why in this work, more than focusing on applying and evaluating what is the best classification model, we focus on the abundance space, by taking a dimensionality reduction approach.
Dimensionality reduction is the process of reducing the dimensionality of the feature space by obtaining a subset of the original features, for instance by judiciously picking a subset of the original features based on their usefulness for prediction, or by combining them to extract new ones. This can be achieved by leveraging statistical or machine learning approaches to project raw features into desired, nonredundant features, with the goal of enhancing the relationship between features and target variables.
This better “perspective” on the data may thus result in improved accuracy. To achieve this, several approaches can be taken, among which we consider: removing the most uncertain features; removing low mutual-information score features; applying a principal component analysis; clustering correlated features together; and combining representation learning with classification via multitask learning. These approaches are explained with more detail below.
3.4.1. Removing noisy features
Given the small size of our dataset, during the training the model might be giving too much importance to very noisy features, thus delivering lower generalization capabilities. We can then run our tests in a dataset where the most uncertain feature (Cobalt, Fig. 1, top panel) is removed.
3.4.2. Removing uninformative features
Another simple way to define a space with a smaller number of dimensions is to identify which elements are the most meaningful to predict the class. To do so, we estimate for each element the Mutual Information score (Witten et al. 2011) between every chemical abundance and the target label as
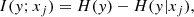 (7)
(7)
where I(y; xj) is the mutual information for xj and y, H(y) is the entropy for y and H(y|xj) is the conditional entropy for y given xj. This quantity measures the average amount of information about a random variable (y) that another feature (xj) carries. This score is also influenced by the intra-class entropy of each element, which in turn is influenced by the uncertainty the element is estimated with. High uncertainty means higher entropy, and higher entropy means lower Mutual Information score, regardless of the importance that feature might have to link stars to their open cluster.
In Fig. 2 we show in blue the mutual information scores between every chemical abundance and open cluster label and in red the ones obtained by perturbing the abundances with their provided uncertainty. We observe that chemical elements with lower uncertainty exhibit higher scores, with carbon being the most informative feature, and vanadium the least.
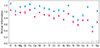 |
Fig. 2. Mutual information (Eq. (2)) between every chemical abundance (x-axis) and the target variable y. The results shown are averaged across different random subsets of the dataset, and the error bars indicate the standard deviation. In blue we indicate the mean chemical abundances and in red the abundances perturbed with their provided uncertainty. The gray vertical bands indicate the median error of every feature. |
3.4.3. Feature selection through correlation clustering
As mentioned in Sect. 3.4, many chemical abundances show strong correlations. The main problem caused by the presence of highly correlated features is the addition of sources of noise, without adding any new information. To tackle this problem, we performed a hierarchical clustering on the Spearman rank-order correlations, and keeping a single feature from each cluster.
In Fig. 3 we show a dendrogram representing the arrangement of the elements that have been clustered based on their Spearman order correlation. Here, each tip represents a chemical element, and the length of the branches represents the correlation distance between features. Elements that are more similar to each other are joined together under shorter branches, while those that are less similar are joined under longer branches.
 |
Fig. 3. Hierarchical clustering on the Spearman rank-order correlations. The value of the y-axis is 1− the Spearman correlation coefficient. For example, the correlation coefficient between Ti and Cr is ≈0.93. Features with a correlation > 0.9 are grouped together, as indicated by the branch colors. |
As expected, the correlations follow the nucleosynthetic origins of the elements (Kobayashi et al. 2020). For example, Mn and Fe, both iron-peak elements, exhibit the strongest correlation. Similarly, elements such as O, Al, Si, and C/Ci, as well as α elements display significant collinearity. Interestingly, the feature least correlated with all the others, V, is also the feature that carries the least information about y (Fig. 2).
3.4.4. Principal component analysis
The most popular dimensionality reduction technique is the Principal Component Analysis (PCA, Pearson 1901), which has been extensively discussed in the context of chemical tagging (e.g., Ting et al. 2012; Blanco-Cuaresma et al. 2015). PCA consists in linearly rotating the data (with d features) into a new coordinate system where most of the variation in the data can be described with d′< d dimensions (principal components). Additionally, a beneficial byproduct of this process is the expected reduction in noise.
Although finding the direction of greatest variation in a dataset may seem like a good approach, it does not always result in greater separation of groups in the transformed space and improved results. In fact, it may have the opposite effect and blur the distinctions between classes (e.g., Zheng & Rakovski 2021). In Fig. 4 we show the variance explained by each principal component with blue bars, and the cumulative explained variance in red. This demonstrates that more than 85% of the variation in our dataset can be captured by only one component, and that only ten of them contain more than 99% of the total variance.
 |
Fig. 4. Individual and cumulative explained variance by principal components. The blue bars represent the percentage of variance explained by each individual principal component, while the red line indicates the cumulative explained variance. This plot demonstrates that 85.5% the total variance in the dataset is captured by only one component, and that only ten components are required in order to capture more than 99% of the total variance. |
3.4.5. Multitask learning
Multitask learning (Thrun 1995; Caruana 1997; Crawshaw 2020) is a machine learning technique that uses a single model to perform multiple related tasks. It aims to improve the performance of related tasks by consolidating information from them in a single representation. This leads to several advantages, including improved data efficiency, faster model convergence and reduced model overfitting. It is also known as joint learning, learning to learn, and learning with auxiliary tasks.
In our case, the goal is to learn both the representation and the classification tasks simultaneously. Rather than training independent models for each of these tasks, we allow a single model to learn to complete them at once. In this process, the model uses all the available data information to learn representations of the data that are useful for linking chemical abundances to birth clusters.
The motivation behind using multitask learning is to identify the optimal lower dimensional representation of the input features, by leveraging the knowledge of abundance uncertainties and incorporating field stars data from APOGEE to enhance and generalize the representation learning process.
Several multi-task models were thus tried and tested on the same dataset. The most representative one is shown in Fig. 5. It is composed by a one layer encoder, followed by a decoder of the same size. To the latent space we append a single fully connected layer with softmax activation function, acting as a classifier. In this way, we regularize the latent space by forcing the encoder to represent classes in a linearly separable way. This simple classification module will also ease the training process, likely reduce overfitting, and possibly improve interpretability.
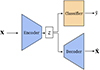 |
Fig. 5. Representation learning architecture used in this work. The feature extraction task is assigned to the autoencoder (constituted by encoder and decoder) to learn cleaner data and more efficient features, while the classifier classifies and regularizes this new representation. |
One can think of it as a multi-layer perceptron classifier, but the reconstruction auxiliary task explicitly forces the network to learn an encoder that produces a representation that is informative enough to be able to reconstruct the original data.
To optimize this model, we define the loss function
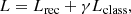 (8)
(8)
where Lclass is the classification loss defined as the sparse categorical cross entropy
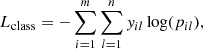 (9)
(9)
where yil is the true label of the sample i and pil is the predicted probability for it belonging to the lth class.
As our data contain noise, mostly caused by observational Gaussian noise in the spectra and uncertainties in the abundances estimations pipelines, we train the autoencoder by optimizing a weighted version of the mean squared error
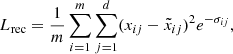 (10)
(10)
where xij and 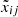 are the data and the reconstructed j-th abundance of star i, respectively, and σij its reported uncertainty. The goal is to learn clean data from noisy data to promote the robustness of the algorithm in the classification task.
are the data and the reconstructed j-th abundance of star i, respectively, and σij its reported uncertainty. The goal is to learn clean data from noisy data to promote the robustness of the algorithm in the classification task.
4. Results
In Table 2 we report the classification performance, obtained using different classifiers and the feature space defined by all the 19 chemical features provided in the catalog.
Classification performance.
The highest metrics achieved among the classifiers, although being significantly better than random chance, are still around 70%. This performance may be considered low in the context of the classification task at hand. What we also note here is how the performance obtained does not change significantly with the classifier used. It is then possible to conclude that the bottleneck in the performance is not how we chose to model the data, but the data itself. We also note that the top-performing models in this study, as indicated by highest metrics and lowest dispersion, are the two support vector machines, the less complex and fewer parametric models (after the nearest neighbor classifier) tested.
Given the similar behavior shown by all the classifiers tested, we retrained an RBF SVM classifier, always with a repeated three-fold cross validation, and for every iteration we computed the recall and precision for every cluster. The results reported afterward refer to the average of these quantities. We use them as an example to understand our results further.
4.1. Why are some clusters not recovered? Looking into the confusion
In Fig. 6 we report the average (over folds) confusion matrix. The diagonal entries represent the percentage of correctly classified samples (i.e., the classifier’s recall per cluster), while off-diagonal entries indicate misclassifications.
 |
Fig. 6. Average over folds’ confusion matrix for clusters’ members’ classification. Each row of the matrix represents the percentage of samples in an actual cluster, while each column represents the percentage of samples predicted in a cluster. Thus, the normalization of the matrix is such that the sum over columns is 100. Cells with missing annotation contain zero samples. For example, considering the second to last row (Trumpler 20): on average, 90% of members are correctly classified as such, while 10% as members of NGC 6819. Rows and columns in shades of gray indicate clusters not flagged as high-quality. |
Generally, we can observe some clusters, such as NGC 6705 and NGC 6791, are always recovered (almost 100% recall, very high precision), while others, for Collinder 69, for example, are never recovered (very low recall). We further observe that most of the largest confusions are between ASCC 16, ASCC 19, BH 56, Collinder 69, and IC 348 (see, for example, Fig. 6, first row). These clusters are all flagged as not high-quality clusters in the OCCAM catalog. Finally, we find that some members belonging, for example, to Kharchenko 1 or NGC 752, are assigned to NGC 2682, the class with most members in our dataset (see Table 1). The non-recovery of certain clusters can be easily attributed to their inherently distinct and nonunique chemical patterns. This would clearly make it impossible to definitively link specific chemical signatures to particular birth clusters, regardless of the methods and quality of data in hand. Our objective is to explore alternative factors contributing to this confusion and determine if resolving these issues can facilitate the establishment of this link.
We identify four main factors within the dataset in use: the quality of the clusters, the imbalance between classes, the uncertainties associated with abundances, and the biased importance attributed to certain features. These factors are discussed further below.
Quality of clusters. We first evaluated how the cluster quality flag provided in the OCCAM catalog affects the quality of classification. This flag is based on a visual assessment that evaluates whether stars that pass the combined radial velocity, proper motion and metallicity criteria also lie in a sensible position in the observed cluster color-magnitude diagram (CMD), considering their spectroscopically determined log g. Clusters with poorly populated main sequences, or significant contamination from field stars are flagged as “potentially unreliable”. For more details, readers can refer to Donor et al. (2020).
From Fig. 6 we see how none of the clusters flagged as “potentially unreliable” is decently recovered, as can also be seen from Fig. A.3. Considering only high-quality clusters, the performance for all the classifiers improve. In particular, for an RBF SVM the accuracy, precision and F1 score are, respectively, 75.2 ± 2.3, 75.5 ± 2.3, and 75.7 ± 2.3.
We thus decided to remove these clusters from the following analyses, as their assigned members are not very likely to be actual birth siblings. We further note that the stars belonging to the clusters flagged as potentially unreliable are predominantly cool dwarfs and pre-main sequence stars. This poses further uncertainties in their parameters and abundances. As a result, clusters with poor quality have larger uncertainties and abundance spread (see Fig. 1). The spectral analysis of cool dwarfs and pre-main sequence stars was not optimized for ASPCAP thus atmospheric parameters and abundances are more uncertain for such stars (see extensive discussions in Jönsson et al. 2020). Since the training set used for AstroNN, which is the catalog we use in this work, is based on ASPCAP catalogs, we expect these labels to be more uncertain. We remark however that the scope of this paper is to assess how with state-of-the-art data analysis methods can we retrieve open clusters as provided in public catalogs.
Imbalanced dataset. Imbalanced classification (Krawczyk 2016) refers to a scenario where the distribution of classes in the target variable is unequal, that is, when the number of samples in one or more classes (minority classes) is significantly lower than other classes (majority classes). This imbalance can result in models that have poor predictive performance for the open clusters with fewer members in the training dataset. We display the trend of average recall in blue and precision in red for each class in relation to their size in the left panel of Fig. 7. We can see how there is no notable difference in performance between small and large classes, hence rejecting the size of the class as a source of uncertainty in the results.
 |
Fig. 7. Average over folds’ recall (blue) and precision (red) as a function of (left) the size of the cluster and (right) average over cluster members of chemical abundances’ uncertainties. Each point represents a high-quality flagged open cluster, with error bars indicating the standard deviation across folds. Clearly, the uncertainty decreases when the cluster size increases due to sampling effects. |
Abundances uncertainties. Generally speaking, when there is strong noise, the performance of machine learning methods decrease. In the right panel of Fig. 7 we show in blue the recall and in red the precision as function of the average abundance error. We can see a clear negative trend of both these metrics. The Spearman correlation coefficient for the average abundance uncertainty for both the recall and precision is ≈ − 0.78 with a low p-value (see Table 3). This shows that the uncertainty in the measurements have a significant impact in the recovery of clusters.
Spearman correlation coefficient ρ between data properties and performance.
Biased feature importance. Especially given the small size of our dataset, during the training the model might be giving too much importance to noisy and/or irrelevant features, thus delivering lower generalization capabilities. We test this source of discrepancy by applying the feature selection and extraction methods described in Sect. 3.4. The results are reported and discussed in the next sections.
4.2. Changing the chemical representation
Motivated by the performance trends as function of the chemical abundances uncertainties (see right panel of Fig. 7), we run the same analysis as before, but with the different representations of the input features described in Sect. 3.4. By reducing the number of input features, we hope to decrease the noise in the data and thus improve the performance, or at least obtain the same results as given by using all the chemical abundances provided.
For this analysis, we maintained the same hyperparameters that were previously optimized for the full feature set, to establish a consistent baseline for the comparison of performance across the various representations. By doing so, we aim to isolate the impact of chemical representation on model efficacy.
In Table 4 we report the classification performance from a RBF SVM classifier, using only high-quality clusters and different input feature spaces. The values are sorted in increasing accuracy.
Classification performance obtained with different input feature spaces.
From the table, we find that removing the feature with the lowest mutual information score (vanadium), led to a slight improvement in the performance of the classifier. This finding underscores the risk of overfitting in our simple models. The feature space defined through this process yields the best average performance in this work. We further find that removing the most noisy feature (cobalt) and the two with the lowest information score (vanadium and titanium II), we also obtain an improvement in the performance.
It is worth to comment that the use of PCA as a feature reduction technique, even if applied on a dataset without nuisance features like V, results in a poorer performance compared to the baseline. As anticipated in Sect. 3.4, while PCA efficiently condenses feature space by capturing maximum variance, it may not necessarily preserve the discriminative information for our task of distinguishing between open clusters.
4.3. On the memberships selection criteria
The reliability of the assigned membership probabilities is another crucial factor that could limit performance. To assess the robustness of our findings to variations in membership probability selection, we replicated the main analyses considering as members of open clusters all the stars with pRV > 0.6, pHunt > 0.9. pHunt indicates probabilities from Hunt & Reffert (2023), computed for sources in Gaia DR3 (Gaia Collaboration 2023) down to magnitude G ∼ 20 using the HDBSCAN clustering algorithm.
Results remain qualitatively consistent, exhibiting a comparable range of accuracy and precision scores (the best model being an SVM classifier, with accuracy and precision of 70.8% and 72.9%, respectively). The most influential factors for successful cluster recovery continue to be the precision of chemical abundances and the quality of clusters (see Sect. 4.1). Also, the behavior with different feature spaces remained consistent. We therefore argue that despite potential slight quantitative differences arising from different membership probability choices, the core results presented in the previous sections remains unaltered.
4.4. Adding random field stars
It is important to include field stars in the evaluation of chemical tagging because they provide a representative sample of the overall population of stars in the Milky Way, and it is the ultimate dataset for which chemical tagging aims to be applied (Freeman & Bland-Hawthorn 2002). This allows us to validate if we can still identify birth siblings in a training set highly contaminated by stars in the general field, providing a critical benchmark for evaluating the feasibility of strong chemical tagging. To do so, we repeated the analysis presented in Sect. 3, with only high-quality clusters with at least 12 members, all the 19 chemical abundances and an RBF SVM classifier with a training set with varying number of field stars categorized as “Field”, whose chemical abundances are always retrieved from the AstroNN catalog for APOGEE DR17. These field stars are sampled randomly from this catalog and are required to have a metallicity between −0.6 and 0.3, a range similar to that of our open clusters (see Table 1).
We trained the classifier in a balanced way, that is, the weight assigned to each sample is adjusted to be inversely proportional to the frequency of its respective class3. This assigns equal importance to all classes present in the dataset.
We report in Fig. 8 the recall and precision computed only for cluster members (i.e., not field stars) as a function of the ratio between the number of field stars and number of cluster members in the train set. We observe a decrease in recall as the ratio of field stars to cluster members increased in the training set. This shows how the contamination introduced by field stars, makes the task much more complex, even in the supervised scenario. On the other hand, the precision increases as the number of field stars increases: if the model predicts that a star belongs to an open cluster, the probability of this prediction being correct is high when precision is high. Essentially, a higher number of stars are classified as field stars.
 |
Fig. 8. Recall (blue) and precision (red) as a function of the ratio between the number of field stars and number of cluster members in the train set. The corresponding linear fits are also shown. |
To further demonstrate how the inclusion of random field stars affects the classification, we find that for one of the best-recovered open clusters, NGC 6791, the recall goes from 98.4% (see Fig. 6, seventh to last row) to ≈82% when the field stars are ten times the members in the training set, as 18% of its members are classified as field stars.
It is worth considering the possibility that some of the field stars added in the dataset might indeed be siblings to the open clusters members which left the cluster in the past. Open clusters evaporate and populate the field with their members (Krumholz et al. 2019). We did not perform an evaluation to know which of the field stars could have been indeed members of the open clusters.
5. Summary and discussion
In this study, we have attempted a supervised approach to determine if chemical abundances alone can provide enough information to allow us to identify co-natal stars that have dispersed in the Milky Way, and thus enable the reconstruction of the star formation history of the galaxy. To do so, we considered chemical abundances of a sample of open cluster stars that we know to be co-natal. Our work was motivated by the recent findings that have shown that such stellar groups are hard to recover via chemistry alone in all spectroscopic surveys (e.g., Mitschang et al. 2014; Ness et al. 2018; Price-Jones et al. 2020; Casamiquela et al. 2021). Given that current methods to analyze ongoing large spectroscopic surveys are still not able to estimate both accurate and precise chemical abundances for a large sample of cluster members, recovering open cluster members from clustering chemistry alone remains a hard task. This raises questions about the feasibility of strong chemical tagging, at least in this era. To answer that question, we should first evaluate if a discriminative relationship between chemical abundances and birth stellar associations is there.
The goal of this paper was thus to assess the existence of this relationship using supervised learning and, if found, to identify a better representation space for chemical abundances to recover the birth associations of known open cluster members in APOGEE DR17. This approach is meant to provide a baseline for evaluating the relationship between chemical patterns and birth stellar cluster, and thus setting an upper limit in our hopes to perform strong chemical tagging. We summarize our main analyses below.
-
We applied several supervised machine learning techniques (specifically nearest neighbors, random forest, XGBoost, support vector machines, and multi-layer perceptrons) for the classification of open clusters based on all 19 chemical abundances provided in AstroNN (excluding phosphorous), finding these features carry a certain amount of information about the cluster membership of stars. In particular, considering only high-quality clusters, we obtain an accuracy, a precision, and an F1 score of 75.2 ± 2.3, 75.5 ± 2.3, and 75.7 ± 2.3, respectively. These percentages, although significantly better than the dummy and the random classifier, do not significantly change by using the different machine learning techniques, making us conclude that the main influence on the relationship has to do with the features and not the model employed.
-
This finding is further supported by the evident correlation between performance and the average abundance error we found. We did not find a correlation between the performance and cluster size, but found that for low-quality clusters the results were more uncertain. This underscores the importance of data quality and feature engineering.
-
We applied various feature selection and engineering techniques, finding that feature space can be improved, even in a supervised scenario. For instance, the simple removal of a less informative feature vanadium led to enhanced model performance. We found that the best performance is obtained by removing V from the input chemical features, reaching a 76.4% accuracy, 76.7% precision under the RBF SVM classifier.
-
We determined the precision and recall for open clusters while adding a different number of field stars to the dataset, obtaining a decline in recall as the number of field stars increased. This indicates the high difficulty in identifying birth siblings within this contaminated scenario.
With these results, we address the specific questions posed in Sect. 1 as motivation of this work.
Is there actually a link between chemical abundances and birth open clusters? While there is a discernible link between chemical abundances and birth open clusters, this relationship is not strong enough to reliably recover disrupted clusters using chemical abundances alone. Even under a supervised approach, we found that we are not able to recover open clusters with a satisfying performance: we are not able to fully identify which stars belong to which cluster using chemistry alone, even using 19 chemical species obtained from high-resolution spectra. This is further emphasized with the inclusion of field stars. While certain clusters, such as NGC 6791, are consistently identified, their distinctive chemical compositions amidst the field stars categorize their identification more as an anomaly detection task (Chandola et al. 2009) rather than a conventional classification.
What are the most important factors of variation in the recovery of open clusters? Our findings clearly indicate that the precision of chemical abundances, coupled with the robustness of cluster membership determinations, are the most influential factors in the successful recovery of open clusters.
Which are the most important chemical elements? Is it possible to find a better representation for these chemical abundances in a physics-agnostic way? While we did not find elements significantly more important than others, we found that the inclusion of elements such as V and TiII was detrimental. This highlights the nontrivial nature of finding the best feature space for this kind of problem, but it also stresses the potential for optimizing feature sets to improve results. The impact of feature selection and engineering is particularly pronounced in clustering analysis, where the choice and quality of features are critical due to the need for meaningful distance metrics.
Overall, given the superior capabilities of classification compared to clustering analysis – namely its higher accuracy, precision, and ability to handle complex data patterns – and recognizing that strong chemical tagging aims to recover disrupted clusters without explicit labels, these findings collectively challenge the feasibility of strong chemical tagging with the current measurements of chemical abundances. Using a supervised machine learning approach introduces certain limitations when compared to the more common clustering methods applied for chemical tagging. While unsupervised methods identify groups in the data without being influenced by predefined labels, supervised models rely on labeled data to train, making them heavily dependent on the quantity of ground truth labels. In this study, the limited number of stars available for supervised learning analysis, particularly in certain clusters, introduces some statistical uncertainties and limits to what extent our findings can be generalized. The availability of a larger sample of stars representing various birth clusters could potentially alleviate this issue.
The choice of a catalog or of the selection criteria may also lead to potential biases that can impact the reliability of the analysis. Findings derived from a specific survey, such as APOGEE DR17, might not directly translate to other surveys characterized by distinct instrumentation, data quality, or target and feature selection strategies. Consequently, the findings may carry survey-specific characteristics. To mitigate this, future research could involve applying the same approach to other surveys, for broader validation and comparability of results (see recent discussion of Manea et al. 2023 about doppelgängers in different surveys).
The fact that the performance of our classification is reduced when field stars are included in our dataset challenges the feasibility of chemical tagging even more. Considering that the main purpose of strong chemical tagging is to reconstruct dissolved clusters from the field, and thus identify the building blocks of the galaxy, a promising research direction would involve incorporating supplementary features beyond chemistry, such as kinematical or age information. This augmentation might enhance the identification performance of birth stellar clusters, presenting an opportunity for advancing research in this field.
Ci represents the abundance of atomic carbon only, while C represents the overall carbon abundance, which includes both atomic and molecular carbon.
A hyperparameter is a parameter whose value is used to control the learning process. Consequently, it cannot be learned from the data; instead, it must be set by the user, who evaluates the machine’s performance while varying its value.
The weight assigned to members of class α is Nsamples/(Nclasses × Nα), where Nsamples is the total length of the training set, Nclasses is the number of classes and Nα the number of sample belonging to class α.
Acknowledgments
TS acknowledges support from INRA Chile and Millennium Nucleus ERIS NCN2021_017, Centros ANID Iniciativa Milenio. PJ acknowledges partial financial support of FONDECYT Regular Grant Number 1231057. TS expresses his gratitude to Payel Das for initial guidance and support.
References
- Abdurro’uf, Accetta, K., Aerts, C., et al. 2022, ApJS, 259, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Ankerst, M., Breunig, M. M., Kriegel, H.-P., & Sander, J. 1999, Proceedings of the 1999 ACM SIGMOD International Conference on Management of Data, SIGMOD’99 (New York: Association for Computing Machinery) [Google Scholar]
- Bellman, R. 1958, Inf. Control, 1, 228 [CrossRef] [Google Scholar]
- Bird, J. C., Kazantzidis, S., & Weinberg, D. H. 2012, MNRAS, 420, 913 [NASA ADS] [CrossRef] [Google Scholar]
- Blanco-Cuaresma, S., Soubiran, C., Heiter, U., et al. 2015, A&A, 577, A47 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bland-Hawthorn, J., Krumholz, M. R., & Freeman, K. 2010, ApJ, 713, 166 [CrossRef] [Google Scholar]
- Bovy, J. 2016, ApJ, 817, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Breiman, L. 2001, Mach. Learn., 45, 5 [Google Scholar]
- Bressan, A., Marigo, P., Girardi, L., et al. 2012, MNRAS, 427, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Campello, R. J. G. B., Moulavi, D., & Sander, J. 2013, Advances in Knowledge Discovery and Data Mining (Berlin, Heidelberg: Springer-Verlag), 160 [Google Scholar]
- Cantat-Gaudin, T., Jordi, C., Vallenari, A., et al. 2018, A&A, 618, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Caruana, R. 1997, Mach. Learn., 28, 41 [CrossRef] [Google Scholar]
- Casamiquela, L., Castro-Ginard, A., Anders, F., & Soubiran, C. 2021, A&A, 654, A151 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chandola, V., Banerjee, A., & Kumar, V. 2009, ACM Comput. Surv., 41, 1 [CrossRef] [Google Scholar]
- Chen, T., & Guestrin, C. 2016, arXiv e-prints [arXiv:1603.02754] [Google Scholar]
- Cortes, C., & Vapnik, V. 1995, Mach. Learn., 20, 273 [Google Scholar]
- Cover, T., & Hart, P. 1967, IEEE Trans. Inf. Theory, 13, 21 [CrossRef] [Google Scholar]
- Crawshaw, M. 2020, arXiv e-prints [arXiv:2009.09796] [Google Scholar]
- Cui, X.-Q., Zhao, Y.-H., Chu, Y.-Q., et al. 2012, RAA, 12, 1197 [NASA ADS] [Google Scholar]
- De Silva, G. M., Freeman, K. C., Bland-Hawthorn, J., et al. 2015, MNRAS, 449, 2604 [NASA ADS] [CrossRef] [Google Scholar]
- Dias, W. S., Monteiro, H., Moitinho, A., et al. 2021, MNRAS, 504, 356 [NASA ADS] [CrossRef] [Google Scholar]
- Donor, J., Frinchaboy, P. M., Cunha, K., et al. 2018, AJ, 156, 142 [NASA ADS] [CrossRef] [Google Scholar]
- Donor, J., Frinchaboy, P. M., Cunha, K., et al. 2020, AJ, 159, 199 [NASA ADS] [CrossRef] [Google Scholar]
- Edvardsson, B., Andersen, J., Gustafsson, B., et al. 1993, A&A, 275, 101 [NASA ADS] [Google Scholar]
- Espinoza-Rojas, F., Chanamé, J., Jofré, P., & Casamiquela, L. 2021, ApJ, 920, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Feng, Y., & Krumholz, M. R. 2014, Nature, 513, 523 [NASA ADS] [CrossRef] [Google Scholar]
- Freeman, K., & Bland-Hawthorn, J. 2002, ARA&A, 40, 487 [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2018, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- García Pérez, A. E., Allende Prieto, C., Holtzman, J. A., et al. 2016, AJ, 151, 144 [Google Scholar]
- Hastie, T., Tibshirani, R., & Friedman, J. 2009, The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Springer Series in Statistics (Springer) [Google Scholar]
- Hawkins, K. 2020, Am. Astron. Soc. Meet. Abstr., 235, 214.07 [NASA ADS] [Google Scholar]
- Ho, T. K. 1995, Proceedings of 3rd International Conference on Document Analysis and Recognition (IEEE), 278 [Google Scholar]
- Hunt, E. L., & Reffert, S. 2023, A&A, 673, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jackson, H., Jofré, P., Yaxley, K., et al. 2021, MNRAS, 502, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Jofré, P. 2021, ApJ, 920, 23 [CrossRef] [Google Scholar]
- Jofré, P., Heiter, U., & Soubiran, C. 2019, ARA&A, 57, 571 [Google Scholar]
- Johnson, J. W., Weinberg, D. H., Vincenzo, F., et al. 2021, MNRAS, 508, 4484 [NASA ADS] [CrossRef] [Google Scholar]
- Jönsson, H., Holtzman, J. A., Allende Prieto, C., et al. 2020, AJ, 160, 120 [Google Scholar]
- Kobayashi, C., Karakas, A. I., & Lugaro, M. 2020, ApJ, 900, 179 [Google Scholar]
- Krawczyk, B. 2016, Progr. Artif. Intell., 5, 221 [CrossRef] [Google Scholar]
- Krumholz, M. R., McKee, C. F., & Bland-Hawthorn, J. 2019, ARA&A, 57, 227 [NASA ADS] [CrossRef] [Google Scholar]
- Lada, C. J., & Lada, E. A. 2003, ARA&A, 41, 57 [Google Scholar]
- Leung, H. W., & Bovy, J. 2019, MNRAS, 483, 3255 [NASA ADS] [Google Scholar]
- Magrini, L., Viscasillas Vázquez, C., Spina, L., et al. 2023, A&A, 669, A119 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Majewski, S. R., Schiavon, R. P., Frinchaboy, P. M., et al. 2017, AJ, 154, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Manea, C., Hawkins, K., Ness, M. K., et al. 2023, AAS J., submitted [arXiv:2310.15257] [Google Scholar]
- Masseron, T., & Gilmore, G. 2015, MNRAS, 453, 1855 [CrossRef] [Google Scholar]
- Mitschang, A. W., De Silva, G., Zucker, D. B., et al. 2014, MNRAS, 438, 2753 [NASA ADS] [CrossRef] [Google Scholar]
- Myers, N., Donor, J., Spoo, T., et al. 2022, AJ, 164, 85 [NASA ADS] [CrossRef] [Google Scholar]
- Ness, M., Rix, H. W., Hogg, D. W., et al. 2018, ApJ, 853, 198 [NASA ADS] [CrossRef] [Google Scholar]
- Ness, M. K., Wheeler, A. J., McKinnon, K., et al. 2022, ApJ, 926, 144 [NASA ADS] [CrossRef] [Google Scholar]
- Netopil, M., Paunzen, E., Heiter, U., & Soubiran, C. 2016, A&A, 585, A150 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nidever, D. L., Holtzman, J. A., Allende Prieto, C., et al. 2015, AJ, 150, 173 [NASA ADS] [CrossRef] [Google Scholar]
- Pearson, K. 1901, London Edinb. Dublin Philos. Mag. J. Sci., 2, 559 [CrossRef] [Google Scholar]
- Price-Jones, N., Bovy, J., Webb, J. J., et al. 2020, MNRAS, 496, 5101 [NASA ADS] [CrossRef] [Google Scholar]
- Randich, S., Gilmore, G., Magrini, L., et al. 2022, A&A, 666, A121 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Salaris, M., Pietrinferni, A., Piersimoni, A. M., & Cassisi, S. 2015, A&A, 583, A87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Soubiran, C., Cantat-Gaudin, T., Romero-Gómez, M., et al. 2018, A&A, 619, A155 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Spina, L., Magrini, L., Sacco, G. G., et al. 2022, A&A, 668, A16 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Steinmetz, M., Matijevič, G., Enke, H., et al. 2020, AJ, 160, 82 [NASA ADS] [CrossRef] [Google Scholar]
- Thrun, S. 1995, Proceedings of the 8th International Conference on Neural Information Processing Systems, NIPS’95 (Cambridge: MIT Press) [Google Scholar]
- Ting, Y.-S., & Weinberg, D. H. 2022, ApJ, 927, 209 [NASA ADS] [CrossRef] [Google Scholar]
- Ting, Y. S., Freeman, K. C., Kobayashi, C., De Silva, G. M., & Bland-Hawthorn, J. 2012, MNRAS, 421, 1231 [NASA ADS] [CrossRef] [Google Scholar]
- Vitali, S., Slumstrup, D., Jofré, P., et al. 2024, A&A, 687, A164 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Witten, I. H., Frank, E., & Hall, M. A. 2011, Data Mining: Practical Machine Learning Tools and Techniques, 3rd edn. (San Francisco: Morgan Kaufmann Publishers Inc.) [Google Scholar]
- Zheng, J., & Rakovski, C. 2021, Data Sci. J., 20, 26 [CrossRef] [Google Scholar]
Appendix A: Additional figures
 |
Fig. A.1. Kiel diagrams for open clusters members used in this work, color-coded by pRV × pPM, with lighter colors indicating higher probabilities. We also overlay the relative PARSEC isochrones (Bressan et al. 2012). Gray stars in the background represent the whole sample. (*) clusters flagged not as high-quality. |
 |
Fig. A.2. Deviations from cluster mean abundance as a function of effective temperature for all the considered chemical elements. Each subplot displays a single element, as indicated in the top right corner of every panel, with deviations calculated relative to the mean abundance within each individual cluster. |
 |
Fig. A.3. Distribution of recall (blue) and precision (red) for every high-quality cluster. We normalize each histogram to obtain an area equal to unity. (*) clusters not flagged as high-quality. |
All Tables
Member counts, average metallicity, galactic radius, and age for clusters in our selection.
All Figures
|
Fig. 1. Distributions of uncertainties. Top: distribution of the abundance uncertainties of the different elements for individual stars. Bottom: distribution over cluster members of the median (over chemical abundances) uncertainties. In both panels, each box plot is relative to the group indicated in the x-axis. Each blue box and contains the middle 50% of the data, and the horizontal line within the box denotes the median value. Outliers are indicated as individual points. |
| In the text | |
|
Fig. 2. Mutual information (Eq. (2)) between every chemical abundance (x-axis) and the target variable y. The results shown are averaged across different random subsets of the dataset, and the error bars indicate the standard deviation. In blue we indicate the mean chemical abundances and in red the abundances perturbed with their provided uncertainty. The gray vertical bands indicate the median error of every feature. |
| In the text | |
|
Fig. 3. Hierarchical clustering on the Spearman rank-order correlations. The value of the y-axis is 1− the Spearman correlation coefficient. For example, the correlation coefficient between Ti and Cr is ≈0.93. Features with a correlation > 0.9 are grouped together, as indicated by the branch colors. |
| In the text | |
|
Fig. 4. Individual and cumulative explained variance by principal components. The blue bars represent the percentage of variance explained by each individual principal component, while the red line indicates the cumulative explained variance. This plot demonstrates that 85.5% the total variance in the dataset is captured by only one component, and that only ten components are required in order to capture more than 99% of the total variance. |
| In the text | |
|
Fig. 5. Representation learning architecture used in this work. The feature extraction task is assigned to the autoencoder (constituted by encoder and decoder) to learn cleaner data and more efficient features, while the classifier classifies and regularizes this new representation. |
| In the text | |
|
Fig. 6. Average over folds’ confusion matrix for clusters’ members’ classification. Each row of the matrix represents the percentage of samples in an actual cluster, while each column represents the percentage of samples predicted in a cluster. Thus, the normalization of the matrix is such that the sum over columns is 100. Cells with missing annotation contain zero samples. For example, considering the second to last row (Trumpler 20): on average, 90% of members are correctly classified as such, while 10% as members of NGC 6819. Rows and columns in shades of gray indicate clusters not flagged as high-quality. |
| In the text | |
|
Fig. 7. Average over folds’ recall (blue) and precision (red) as a function of (left) the size of the cluster and (right) average over cluster members of chemical abundances’ uncertainties. Each point represents a high-quality flagged open cluster, with error bars indicating the standard deviation across folds. Clearly, the uncertainty decreases when the cluster size increases due to sampling effects. |
| In the text | |
|
Fig. 8. Recall (blue) and precision (red) as a function of the ratio between the number of field stars and number of cluster members in the train set. The corresponding linear fits are also shown. |
| In the text | |
|
Fig. A.1. Kiel diagrams for open clusters members used in this work, color-coded by pRV × pPM, with lighter colors indicating higher probabilities. We also overlay the relative PARSEC isochrones (Bressan et al. 2012). Gray stars in the background represent the whole sample. (*) clusters flagged not as high-quality. |
| In the text | |
|
Fig. A.2. Deviations from cluster mean abundance as a function of effective temperature for all the considered chemical elements. Each subplot displays a single element, as indicated in the top right corner of every panel, with deviations calculated relative to the mean abundance within each individual cluster. |
| In the text | |
|
Fig. A.3. Distribution of recall (blue) and precision (red) for every high-quality cluster. We normalize each histogram to obtain an area equal to unity. (*) clusters not flagged as high-quality. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.