| Issue |
A&A
Volume 624, April 2019
|
|
|---|---|---|
| Article Number | A140 | |
| Number of page(s) | 16 | |
| Section | Stellar structure and evolution | |
| DOI | https://doi.org/10.1051/0004-6361/201834095 | |
| Published online | 26 April 2019 | |
Two’s a crowd? Characterising the effect of photometric contamination on the extraction of the global asteroseismic parameter νmax in red-giant binaries
1
Instituut voor Sterrenkunde (IvS), KU Leuven, Celestijnenlaan 200D, 3001 Leuven, Belgium
e-mail: sanjay.sekaran@kuleuven.be
2
Instituto de Astrofísica de Canarias, 38200 La Laguna, Tenerife, Spain
3
Departamento de Astrofísica, Universidad de La Laguna, 38206 La Laguna, Tenerife, Spain
4
Dept. of Astrophysics and Planetary Science, Villanova University, 800 Lancaster Ave, Villanova 19085, USA
Received:
15
August
2018
Accepted:
20
March
2019
Context. Theoretical scaling relations for solar-like oscillators and red giants are widely used to estimate fundamental stellar parameters. The accuracy and precision of these relations have often been questioned in the literature, with studies often utilising binarity for model-independent validation. However, it has not been tested if the photometric effects of binarity introduce a systematic effect on the extraction of the seismic properties of the pulsating component(s).
Aims. In this paper, we present an estimation of the impact of a contaminating photometric signal with a distinct background profile on the global asteroseismic parameter νmax through the analysis of synthetic red-giant binary light curves.
Methods. We generated the pulsational and granulation parameters for single red giants with different masses, radii and effective temperatures from theoretical scaling relations and use them to simulate single red-giant light curves with the characteristics of Kepler long-cadence photometric data. These are subsequently blended together according to their light ratio to generate binary red-giant light curves of various configurations. We then performed a differential analysis to characterise the systematic effects of binarity on the extraction of νmax.
Results. We quantify our methodological uncertainties through the analysis of single red-giant light curves, both in the presence and absence of granulation. This is used as a reference for our subsequent differential binary analysis, where we find that the νmax extraction for red-giant power spectra featuring overlapping power excesses is unreliable if unconstrained priors are used. Outside of this scenario, we obtain results that are nearly identical to single-star case.
Conclusions. We conclude that (i) the photometric effects of binarity on the extraction of νmax are largely negligible as long as the power excesses of the individual components do not overlap, and that (ii) there is minimal advantage to using more than two super-Lorentzian components to model the granulation signal of a binary red-giant.
Key words: asteroseismology / binaries: general / stars: oscillations / stars: individual: Red Giants
© ESO 2019
1. Introduction
The revolution in red-giant asteroseismology began with the advent of the CoRoT space mission (Auvergne et al. 2009), which delivered high-precision and high duty-cycle photometry. These data enabled the first detections of non-radial pulsations in red-giants (e.g. De Ridder et al. 2009; Kallinger et al. 2010) and gave rise to the birth of galactic archaeology (e.g. Miglio et al. 2013). The CoRoT data revolution had paved the way for the Kepler space mission (Borucki et al. 2010), producing data of an unprecedented precision with a four-year nominal duty cycle. These new high-precision data have prompted numerous studies to test and improve asteroseismic scaling relations.
First introduced by Kjeldsen & Bedding (1995), these theoretical relations enable the determination of the masses and radii of stars exhibiting solar-like pulsations in a minimally model-dependent manner. Kjeldsen & Bedding (1995) had originally deduced these relations by calculating the global asteroseismic parameters known as the frequency of maximum oscillation power (νmax) and the large frequency separation (Δν) from the fundamental parameters of a sample of stars with detected solar-like oscillations, including the Sun (used as the reference star).
Scaling relations take the form of a power-law with the effective temperature (Teff), νmax and Δν as inputs. It is most commonly formulated in the following manner, first introduced by Kallinger et al. (2010):
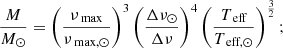
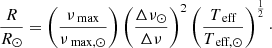
M and R are the stellar mass and radius, and the quantities with the ⊙ subscript refer to the solar reference values.
The large frequency separation (Δν) is the average difference in frequency between modes of the same spherical degree (ℓ) and consecutive radial orders (n). This quantity was first defined theoretically by Tassoul (1980) as a consequence of the asymptotic approximation. The asymptotic large frequency separation (Δνas), which is directly proportional to the mean density (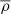 ) of the star, is related to the sound speed (cs) and radius (R) of the star according to the following equation:
) of the star, is related to the sound speed (cs) and radius (R) of the star according to the following equation:
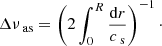
However, the observational large frequency separation (Δνobs) is typically determined from the mean difference between frequencies of the modes (typically radial) of the same ℓ but different n (i.e. Δνobs = < νn, ℓ+1 − νn, ℓ>). This necessarily implies that the observational and asymptotic Δν are not equivalent, although the differences are small for red giants (see Mosser et al. 2013 for a detailed discussion on the observed vs asymptotic Δν).
The frequency of maximum power (νmax) is an observational characterisation of the pulsational envelope of the star and was first used by Brown et al. (1991) to characterise the pulsations of Procyon, referring to it as an “envelope peak”. It it most commonly used to refer to the frequency centre of the Gaussian that is used to approximate the power excess displayed by all solar-like pulsators. Interestingly, there have been a few studies in the literature indicating that a Gaussian may not be the most optimal function to characterise the power excess for certain stars (e.g. Procyon, see Arentoft et al. 2008 for more details). However, the Gaussian still remains the most ubiquitously-used function to characterise the oscillation power excess for solar-like oscillators.
Brown et al. (1991), and later Kjeldsen & Bedding (1995), theorised that νmax was related to the acoustic wave cutoff frequency in an isothermal atmosphere, and therefore scales with the surface gravity (g) and the effective temperature (Teff) according to the following approximation:
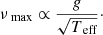
While studies such as Belkacem et al. (2011, 2013) provide a full theoretical formulation for νmax, it has yet to be adopted ubiquitously in the current literature and is therefore mostly regarded as an observational quantity.
The accuracy of these scaling relations has often been tested in the literature, most commonly through ensemble studies (e.g. Chaplin et al. 2011, 2014; Huber et al. 2011; Kallinger et al. 2010, 2014). These studies are complemented by the Tycho-Gaia astrometric solution (TGAS) parallaxes (Salgado et al. 2017), an offshoot of the data products provided by the recently launched Gaia space mission (Gaia Collaboration 2016). These parallaxes enable independent radii measurements that can be confronted to the scaling relation values, as demonstrated in De Ridder et al. (2016) and Huber et al. (2017).
Another method to test and verify scaling relations is through the confrontation of scaling relation-derived masses and radii with those extracted from eclipsing binary dynamics (e.g. Frandsen et al. 2013; Gaulme et al. 2016; Brogaard et al. 2018; Themeßl et al. 2018), or otherwise constrained from spectroscopic binaries (e.g. Beck et al. 2018a). A notable example of the advantages offered by binarity is presented in Bellinger et al. (2017), where the application of binary constraints allowed for the successful execution of inversion techniques in the modelling of 16 Cyg A and B. The common occurrence of binaries with solar-like pulsating components has allowed for the critical evaluation of evolutionary models (Mathur et al. 2013; Appourchaux et al. 2015; Beck et al. 2014, 2018a; White et al. 2017; Li et al. 2018) and tidal theory (Beck et al. 2018b). The far less-common occurrence of eclipsing binaries with a solar-like pulsating red giant, however, requires more attention to detail to fully exploit the potential provided by dynamical mass and radius determinations.
The task of comparing asteroseismic and dynamical parameters is a complex one, with a number of requirements and drawbacks: For example, (i) long time-series of both photometric, and high-resolution, high signal-to-noise spectroscopic observations (implying that said objects must be bright enough to be observed from the ground); (ii) small sample sizes (few objects display eclipses of sufficient depth for analysis); and (iii) complicated multi-step analyses involving binary and asteroseismic modelling (see e.g. Rawls 2016). However, precision and accuracy (∼1% uncertainty; Torres et al. 2010) of the masses and radii derived from eclipse modelling provide highly stringent constraints that scan be used to confront red-giant asteroseismic results, as exemplified by studies such as Gaulme et al. (2013, 2014, 2016), Beck et al. (2014, 2018a), Huber (2015), Brogaard et al. (2016, 2018) and Themeßl et al. (2018).
Of particular concern are the claims of Gaulme et al. (2016), who had found an average overestimation of ∼15%/5% of red-giant mass/radius extracted from scaling relations when confronted with the mass/radius extracted from eclipsing binary dynamics. The departure of observationally-derived red-giant global asteroseismic parameters (νmax and Δν) from theoretical ones is typically attributed to deficiencies in the scaling relations themselves. This phenomenon was most notably discussed in Mosser et al. (2013), who had proposed empirical corrections to account for this discrepancy. Indeed, many attempts to propose corrections to scaling relations have been published (e.g. White et al. 2011; Miglio et al. 2012; Guggenberger et al. 2016, 2017; Sharma et al. 2016; Rodrigues et al. 2017), typically involving new reference values for νmax, ⊙ and Δν⊙, or empirical or model-dependent corrections to the derived νmax and Δν, or both. In fact, the aforementioned studies of Brogaard et al. (2018) and Themeßl et al. (2018) also attempt to reconcile the discrepancy between eclipsing binary-analysis derived and scaling-relation derived parameters through similar corrections. However, there is still no agreement on the exact form of the corrections to the scaling relations.
Most recently, non-linear scaling relations that claim to solve the eclipsing binary-analysis derived and scaling-relation derived parameter discrepancy have been proposed by Kallinger et al. (2018), based on the systems studied by Gaulme et al. (2016). However, this study, as well as the studies proposing scaling-relation corrections, still utilise the global asteroseismic parameter νmax as an input parameter. So far, there have not been any studies that have attempted to quantify, in general for a wide range of stars, the impact (if any exists) that the light contribution of each component in a binary has on the extraction of these parameters.
This question can then be further generalised: what is the impact of a contaminating photometric signal (whether a background object or companion) with a distinct background profile on the extraction of global asteroseismic parameters? This knowledge will be of particular importance in the context of the recently-launched TESS space mission (Ricker et al. 2015), where the larger pixel sizes imply an increased likelihood of contamination from a background object. In this study, we attempt to answer the aforementioned question for the context of red-giant/red-giant binaries. This synergises with one of the suggestions in Beck et al. (2018a): reformulating scaling relations in terms of mass ratios and light factors in order to exploit the typical outputs of binary analysis. To that end, we simulated the light curves of red-giant/red-giant binaries, with the characteristics of Kepler long-cadence photometric data, and extracted the values of the global asteroseismic parameter νmax from our synthetic light curves, comparing them to the input values calculated from theoretical scaling relations.
Section 2 describes the methodology used in our study. Section 3 details the results of our single red-giant simulations, and Sect. 4 details the results of the binary red-giant simulations. We end by discussing our results and presenting our conclusions in Sect. 5.
2. Methodology
2.1. Red-giant signal components
The signals that constitute a typical red giant (RG) power spectral density (PSD) that is generated from Kepler long-cadence photometric data can be separated into three distinct categories: (i) stellar pulsation, (ii) stellar background, and (iii) noise. The proper extraction of individual pulsational frequencies requires, and is strongly dependent on, the proper fitting and removal of the stellar background and noise.
The noise in the PSD is comprised of a frequency-independent (white) photon-shot noise component and a frequency-dependent (coloured) instrumental noise component, where the instrumental noise is thought to be a result of aperture optimisation during the pointing of Kepler. This can be represented by the following equation:
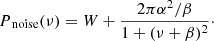
Pnoise(ν) is the PSD of the noise signal, W is the white noise, and 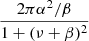 is the coloured instrumental noise represented by a Lorentzian profile, with α and β representing the amplitude and turnover frequency of the instrumental noise. Kallinger et al. (2014) had shown that in practice, the coloured noise component is negligible, and therefore the noise can be assumed to be completely white.
is the coloured instrumental noise represented by a Lorentzian profile, with α and β representing the amplitude and turnover frequency of the instrumental noise. Kallinger et al. (2014) had shown that in practice, the coloured noise component is negligible, and therefore the noise can be assumed to be completely white.
The background signal, however, is not well-understood. The general consensus is that the background consists of frequency-dependent (coloured) components that have been surmised to be the result of granulation occurring at different length- and time-scales. The first attempt to model this background signal was performed by Harvey (1985), who used a super-Lorentzian (or Harvey) profile that differed from a regular Lorentzian in that it had a larger exponent in the denominator. Since then, there have been several attempts to more accurately represent the background. Most notably, Kallinger et al. (2014) tested several background models using Kepler data and concluded that, at the data quality level provided by Kepler for a sufficiently bright target (i.e. brighter than Kp = 12, where Kp is the Kepler magnitude), a background model consisting of two super-Lorentzian profiles of the form
![$$ \begin{aligned} P_{\text{ bg}}(\nu )=\eta ^{2}(\nu )\left[\sum _{i}^{2}\frac{\xi a_{{i}}^{2}/b_{{i}}}{1+(\nu /b_{i})^{4}}\right], \end{aligned} $$](/articles/aa/full_html/2019/04/aa34095-18/aa34095-18-eq8.gif)
best reproduced the data. Pbg(ν) is the PSD of the background signal, and the sum of the two super-Lorentzian profiles 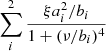 represent granulation occurring at different timescales, each with their respective amplitudes (ai) and turnover frequencies (bi), and the normalisation factor1
represent granulation occurring at different timescales, each with their respective amplitudes (ai) and turnover frequencies (bi), and the normalisation factor1
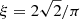 . η2(ν) is the sinc-squared attenuation factor that accounts for the suppression of the amplitude of the oscillations and background occurring close to the Nyquist frequency due to the finite integration time of Kepler (García et al. 2011).
. η2(ν) is the sinc-squared attenuation factor that accounts for the suppression of the amplitude of the oscillations and background occurring close to the Nyquist frequency due to the finite integration time of Kepler (García et al. 2011).
The pulsational signal present in RGs is understood to be a signature of stochastically-excited pulsations, with frequency-dependent driving and damping rates (see Samadi et al. 2015 for a full description). This results in the formation of modes, which are typically described by spherical harmonics, around discrete frequencies dictated by the boundary conditions of stellar structure. The modes that result from this frequency-dependent driving and damping can be modelled as damped harmonic oscillators, which manifest as simple Lorentzian functions in the Fourier domain. Therefore, we can model the PSD of this pulsational signal with a sum of m Lorentzian functions:
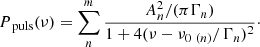
Ppuls(ν) is the PSD of the pulsational signal, and An, Γn, and ν0 (n) are the amplitude, width and central frequency of the nth Lorentzian profile respectively. The pulsational signal appears as a power excess in the PSD of a RG, and as mentioned is approximated by a Gaussian centred at νmax, with an amplitude and width of Apuls and σpuls respectively. The PSD of the Gaussian that represents the pulsational envelope (Penv) can be calculated using the following equation:
![$$ \begin{aligned} P_{\text{ env}}(\nu ) = A_{\text{ puls}}\left[\text{ exp}\left(\frac{-(\nu -\nu _{\text{ max}})^{2}}{2\sigma _{\text{ puls}}^{2}}\right)\right]\cdot \end{aligned} $$](/articles/aa/full_html/2019/04/aa34095-18/aa34095-18-eq12.gif)
The standard practice in the literature is to fit the noise and background together with this Gaussian approximation of the pulsational power excess in order to constrain the morphology (or slope) of the background. The background fit is then removed from the PSD, and the individual peaks extracted by fitting Lorentzians to the residual signal.
2.2. Light curve synthesis
To synthesise the light curve of a RG, we need to simulate both the pulsational signal and the background signal. To simulate the pulsational signal, we first have to compile sets of template modes with known frequencies, amplitudes and mode lifetimes.
To that end, we created a grid of stellar models of RGs using the stellar evolution code MESA (revision 10348; Paxton et al. 2011, 2018). We adopted an exponential diffusive overshooting scheme (Herwig 2000), and a predictive mixing scheme as described in Paxton et al. (2018), with abundances based primarily on the work of Asplund et al. (2009), with more-current values for certain elements taken from Nieva & Przybilla (2012) and Przybilla et al. (2013). The full contents of the inlist used to generate our evolutionary models is specified in Appendix A. The models were made to evolve until the ignition of core-helium burning, resulting in a grid of RG models with masses of 1.0 M⊙–2.0 M⊙ in steps of 0.2 M⊙, and a νmax of approximately 20 μHz–200 μHz in steps of 10 μHz for each mass value. These νmax values were calculated from the M and R outputs of MESA by using the following equations (a result of Eqs. (3) and (4)) as follows:
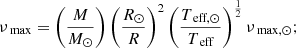
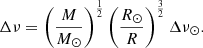
The νmax range was chosen in such a way as to cover a large portion of the red giant branch (RGB) and an upper limit of 200 μHz for νmax was set to ensure that the pulsational power excesses were well within the Nyquist frequency threshold of 284 μHz for Kepler long-cadence data. The ranges of the M, R, Teff and νmax values of our grid are listed in Table 1. This grid of RG models was then used as inputs for the stellar pulsation code GYRE (revision 5.1; Townsend & Teitler 2013), which we used to compute non-rotating pulsational models in the adiabatic framework. These pulsational models comprise the frequencies and normalised mode inertias of the ℓ = 0, 1, 2 and 3 modes for each MESA evolutionary model. The contents of the inlist used to generate our pulsational models are specified in Appendix B.
Ranges of M, R, Teff and νmax of the RG models used for the creation of our synthetic single- and binary-RG light curves.
The corresponding mode amplitudes for each frequency were then generated using the following steps, similar to the methodology detailed in Sect. 4.3 of Kallinger et al. (2014) for the creation of synthetic RG data:
1. Initial amplitude ratios (Aratio) between 0 and 1 were assigned to each frequency (νi) by using a Gaussian centred on νmax with a standard deviation2 of 1.5Δν. This is represented by the following equation:
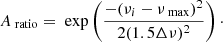
2. These amplitude ratios were then modulated by mode visibilities of 1.00, 1.35, 0.64 and 0.071 for the ℓ = 0, 1, 2 and 3 modes respectively, as reported by Mosser et al. (2012) for RGB stars.
3. The amplitude ratios of the ℓ = 1, 2 and 3 modes were then further modulated by the inverse of the local relative mode inertia3.
4. To obtain realistic pulsational amplitudes, we refer to the characterisation of pulsational amplitudes reported in Corsaro et al. (2013), where different amplitude scaling-relation models were investigated in a Bayesian framework. We calculated the total bolometric pulsational amplitude Apuls, bol from the scaling relation given in Eq. (19) of Corsaro et al. (2013):
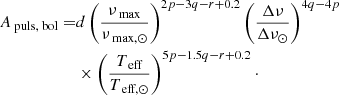
The values for the coefficients and exponents in the equation are as follows: d = e0.45, p = 0.602, q = 1.31, and r = 5.87. These are taken from the long-cadence expectation values of model ℳ4,d of Corsaro et al. (2013), which they found to have the best Bayesian Information Criterion (BIC) value in their analysis.
5. Amplitudes (in ppm) for each frequency can then obtained by taking the product of the modulated amplitude ratios and Apuls, bol.
We generated mode lifetimes for each frequency based on the work of Vrard et al. (2018), who discussed both global (variation with stellar mass and temperature across all stars) and local (variation with frequency within a single star) modewidth variation in their study. Based on their results, we generated the modewidth at νmax for each star by using the following equation:
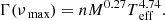
Γ(νmax) is the modewidth at νmax, with the exponents of M and Teff taken from the characterisation of RGB stars by Vrard et al. (2018). n is a multiplicative constant used to ensure that the modewidths occupy a range of 0.05–0.17 μHz, which is well within the distribution of modewidths displayed in Fig. 3 of Vrard et al. (2018).
Vrard et al. (2018) also investigated local modewidth variation for the radial modes of RGs as per the work of Appourchaux et al. (2014) for subgiants and Lund et al. (2017) for dwarfs. While they found a general increase in modewidth with frequency, they did not find the modewidth “dip” around νmax (although they did find evidence of a reduction in the rate of increase around νmax). Although their results suffer from large uncertainties, we note a general exponential morphology of the variation of modewidths with frequency. As such, we chose to adopt an exponential scaling of local modewidth with frequency as follows:
![$$ \begin{aligned} \Gamma (\nu ) = \Gamma (\nu _{\text{ max}}) \left[\text{ exp}\left(\frac{z(\nu -\nu _{\text{ max}})}{\nu _{\text{ max}}}\right)\right]\cdot \end{aligned} $$](/articles/aa/full_html/2019/04/aa34095-18/aa34095-18-eq18.gif)
Γ(ν) is the modewidth at frequency ν, and z = 3.0 is a constant designed to keep the modewidth increase with frequency within the ranges reported by Vrard et al. (2018).
The frequencies, amplitudes and modewidths (see Fig. 1 for an example of a pulsation spectrum) are then fed to a first-order auto-regressive function to generate a synthetic time-series, following the methodology laid out in De Ridder et al. (2006). This procedure transforms the “perfect” comb of our input pulsation spectrum into a more-realistic representation of a RG pulsation spectrum (cf. Fig. D.1). The time sampling of this function was setup in such a way as to produce a time-series with the same time-stamps as a full four-year Kepler long cadence light curve with no gaps.
 |
Fig. 1. Example of a synthetic RG pulsation spectrum for a star with νmax ∼ 100 μHz, used as an input to generates synthetic pulsational time-series for the RG light curves. The ℓ = 0, 1, 2, and 3 modes are represented by Lorentzians and colour-coded as displayed in the legend. The presence of multiplets, particularly around the ℓ = 1 modes, correspond to mixed modes with the same p-mode radial order but different g-mode radial order. |
To simulate the granulation signal for our light curves, we first generated super-Lorentzian profiles as per Eq. (6). The granulation amplitudes (ai) and turnover frequencies (bi) were calculated from the scaling relations and coefficients listed in Table 2 of Kallinger et al. (2014), using the M values from MESA and our calculated νmax values:
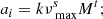
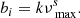
The coefficients k, s, and t for a1, 2 and b1, 2 are listed in Table 2. As the granulation signals of observational PSDs are often very noisy, we added a fixed amount of Gaussian noise to each granulation profile to make them more realistic.
Coefficients k, s, and t for the granulation amplitudes (a1, 2) and turnover frequencies (b1, 2).
To mimic the procedure that we had performed for the pulsation spectrum, we chose to generate synthetic time-series for our granulation spectra. While it is possible to transform a simple Harvey profile into a time-series using an auto-regressive function, there is currently no analogue that can transform our granulation profiles into a time-series. We therefore performed inverse Fourier transforms (iFTs) of our granulation PSDs in order to generate them. Similar to the pulsational time-series, the iFTs are calculated in such a way that the resulting time-series has the same time-stamps as a full Kepler long-cadence light curve.
We chose to include a luminosity-dependent white noise component as per the work of Pande et al. (2018), who characterised the variation of white noise with magnitude for approximately 2100 stars from short-cadence Kepler data. They reported an almost-linear variation of the logarithm of white noise with magnitude. We adapted this result and chose to scale the logarithm of white noise with the logarithm of luminosity as per the following equation:
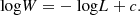
L is the luminosity of star, which is one of the outputs of MESA, and c is a constant designed to ensure that the range of white noise amplitudes are within that of the stars in the 8–12 Kepler magnitude range as reported by Pande et al. (2018). This is within the range in which a two super-Lorentzian-component model can accurately describe the granulation signal of a Kepler RG, as detailed in Kallinger et al. (2014). The implicit assumption being made here is that these stars are all at the same distance, which we adopt in order to investigate the effect of white noise on the extraction of νmax. Similar to the granulation signal, iFTs were performed in order to produce white noise time-series.
The three time-series are then added to produce the final synthetic light curve for a single RG of mass M, radius R and effective temperature Teff.
2.3. Synthetic PSD fitting
We fit the synthetic PSDs, generated by taking the Fourier transforms of our synthetic light curves, as per what is done in the literature (see Sect. 2.1). This fitting function, essentially a sum of the pulsational, granulation, and noise model functions, takes the following form:
![$$ \begin{aligned} P_\text{ model}(\nu )=&W+A_{\text{ puls}}\left[\text{ exp}\left(\frac{-(\nu -\nu _{\text{ max}})^{2}}{2\sigma _{\text{ puls}}^{2}}\right)\right]\nonumber \\&+\sum _{i}^{2}\frac{(2\sqrt{2}/\pi )\tau _{\text{ gran,} \text{ i}}A_{\text{ gran,} \text{ i}}^{2}}{1+(\nu \tau _{\text{ gran,} \text{ i}})^{4}}\cdot \end{aligned} $$](/articles/aa/full_html/2019/04/aa34095-18/aa34095-18-eq22.gif)
The terms in the function echo those in Eqs. (5), (6) and (8): Pmodel(ν) is the PSD of the model; W is the white noise; ![$ A_{\text{ puls}}\left[\text{ exp}\left(\frac{-(\nu-\nu_{\text{ max}})^{2}}{2\sigma_{\text{ puls}}^{2}}\right)\right] $](/articles/aa/full_html/2019/04/aa34095-18/aa34095-18-eq23.gif) represents the Gaussian power excess, with the amplitude, width and central frequency represented by Apuls, σpuls and νmax respectively; and
represents the Gaussian power excess, with the amplitude, width and central frequency represented by Apuls, σpuls and νmax respectively; and 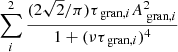 are the two super-Lorentzian components representing the granulation signal, with the amplitude and characteristic timescale of the ith super-Lorentzian represented by Agran, i and τgran, i respectively.
are the two super-Lorentzian components representing the granulation signal, with the amplitude and characteristic timescale of the ith super-Lorentzian represented by Agran, i and τgran, i respectively.
We perform our fit in a Bayesian framework using the Markov chain Monte Carlo (MCMC) routine emcee (Foreman-Mackey et al. 2013). emcee makes use of an ensemble sampler with numerous Markov chains to efficiently sample the posterior probability distribution as described by Bayes’ theorem:

P(Hi|I) is known as the prior probability, which is the probability of the hypothesis Hi with knowledge of prior information I, but in the absence of the data D. P(Hi|D, I) is known as the posterior probability, which is the probability of the hypothesis with knowledge of both I and D. The quantities P(D|Hi, I) and P(D|I) are the likelihood of Hi and the global likelihood of all hypotheses respectively.
For numerical simplicity, we evaluate Bayes’ theorem in log-space, where our log-likelihood function (ℒ) is

Pinput(ν) is the PSD of the input light curve that has been smoothed by a Gaussian filter. We use a smoothed PSD to mitigate the impact of noise in the background profile on the fit. We adopt a convergence criterion based on the integrated autocorrelation time (τautocorr) as per Goodman & Weare (2010). We compute τautocorr for every 100 iterations and consider the MCMC routine to have achieved convergence if τautocorr changes by less than 1% between two successive computations.
After our MCMC routines have achieved convergence, we extract our fit parameters and determine νmax, fit from the marginalised posterior distributions, comparing them with our input νmax, scaling from scaling relations. An example fit of the PSD of one of our synthetic light curves is shown in Fig. 2.
 |
Fig. 2. Example of a single-RG PSD fit. The grey line is the unsmoothed PSD, the black line is the smoothed PSD, the red line represents the overall fit, the dashed green line represents the Gaussian used to fit the pulsational power excess, the blue dotted line represents the white noise, and the blue dashed lines represent the super-Lorentzians used to fit the granulation signal. |
2.4. Red-giant binary simulation setup
To create the light curve of a RG/RG binary, it was necessary to deal with the pulsations and granulation, and white noise separately. We first generated the white noise signal of the binary light curve according to Eq. (5) by using the total luminosity of the individual components as the input. We then scaled the pulsational and granulation signals of the individual components by their individual light contribution and added them together with the white noise according to the following equation:
![$$ \begin{aligned} F_{\text{ binary}}&=\frac{1}{L_{\text{ A}}+L_{\text{ B}}}\bigg [L_{\text{ A}}\left(F_{\text{ puls,} \text{ A}}+F_{\text{ gran,} \text{ A}}\right)\nonumber \\&\quad +L_{\text{ B}}\left(F_{\text{ puls,} \text{ B}}+F_{\text{ gran,} \text{ B}}\right)\bigg ]+W. \end{aligned} $$](/articles/aa/full_html/2019/04/aa34095-18/aa34095-18-eq27.gif)
Fbinary is the flux of the binary light curve, and LA, Fpuls, A, Fgran, A, LB, Fpuls, B, and Fgran, B are the luminosities, and the pulsational and granulation fluxes of each binary component (A and B) respectively. Implicit in this methodology is that all orbital and tidal effects are ignored4.
We created two sets of light curves with each set containing a specific pulsational configuration: (i) one pulsating component (e.g. Gaulme et al. 2014; Beck et al. 2014), and (ii) two pulsating components (e.g. Rawls et al. 2016; Beck et al. 2018a). For each set of binary light curves, we tested the impact of different granulation models by performing fits with (i) two super-Lorentzians (as in the single-RG case), and with (ii) four super-Lorentzians (two super-Lorentzians for each component), to model the granulation signal of each binary light curve.
3. Single red-giant simulations and results
To ensure the self-consistency of our methodology and to establish a baseline for comparison with our subsequent binary results, we first simulated the light curves and fit the PSDs of the 114 single RGs that we created using our methodology. We investigated the effect of the granulation on the extraction of νmax by performing one iteration of fits with only the pulsational signal (e.g. Fig. D.1), and another with both the pulsational and granulation signals (e.g. Fig. D.2) included in the light curves of the RGs. This is demonstrated in Fig. 3, showcasing the percentage difference between the fit (νmax, fit) and the scaling relation (νmax, scaling) input values. The mean percentage difference and the 1σ scatter of the νmax, fit − νmax, scaling values, and the mean precision of the extraction of νmax, fit are detailed in Table 3.
 |
Fig. 3. Comparison of the νmax values extracted from our synthetic single-RG PSDs. We tested synthetic light curves containing only a pulsational signal (triangles), and both a pulsational and a granulation signal (circles). The vertical axis corresponds to the scaling relation (νmax, scaling) input values of the light curves, and the horizontal axis corresponds to the percentage difference between the fit (νmax, fit) and the scaling relation (νmax, scaling) values. The vertical dashed line represents the zero-point of the difference between νmax, fit and νmax, scaling. The dash-dotted lines represent the 1σ level about the mean scatter of the datapoints corresponding to the pulsational signal (red), and both the pulsational and granulation signals (green). The horizontal dotted lines connect the datapoints corresponding to the same RG model. The error bars correspond to the 68% Bayesian credible intervals of the marginalised posterior distributions of the fit parameters. The symbols are colour-coded according the logarithm of the white noise (log W) included in the light curves and PSDs. |
Mean percentage difference, 1σ scatter, and precision of the νmax values extracted from our single-RG PSDs.
It can be seen that in general, for the iterations both with and without the inclusion of granulation in the PSDs, there is a systematic underestimation of the νmax, fit compared to the νmax, scaling values. This was the opposite of the expected result, which was a systematic overestimation due to an excess of power in the frequency domain above νmax, scaling as the modewidths increase with increasing frequency.
However, there is an additional source of asymmetry in the input pulsational spectra: uneven distribution of modes and mode amplitudes. For example, in the input pulsation spectrum displayed in Fig. 1 (which correponds to a νmax, scaling ∼ 100 μHz), there is a larger number of strong peaks in the frequency domain below νmax, scaling than above it, particularly from the ℓ = 1 mixed-mode multiplets. This distribution is a result of the mode inertia distribution (e.g. Fig. C.1) for the frequencies output by GYRE, which directly affects the amplitudes of the modes that were used in the input. This result indicates that the input pulsational spectra generally have more power in the frequency domain below νmax, scaling than above it, and is the source of our systematic uncertainty. To confirm that this is indeed the reason for the obtained systematic effect, we performed a test by artificially symmetrising our pulsational inputs with respect to νmax, scaling and repeating the same fitting procedure. We found that the systematic offset between the νmax, fit and νmax, scaling was no longer present, confirming our suspicion that its origins was indeed in the uneven distribution of modes and amplitudes.
Another result from these simulations is the difference in the νmax, fit values extracted from PSDs with and without granulation. The νmax, fit values for the iteration with granulation are slightly more underestimated on average compared to the νmax, scaling values, seemingly exacerbating the asymmetry in the power excesses. In addition, the scatter of the νmax, fit is greater, and the extraction of the νmax, fit values is less precise for the iteration with granulation. These phenomena can be explained by the stochastic nature of the granulation signal and the degenerate nature of the background fit, where a smooth function (the two super-Lorentzians) are being fit to a rather noisy background. The effect of the inclusion and the fitting of the granulation seems to be rather unpredictable as the degree of underestimation of νmax, fit is decreased in some cases when comparing the results with and without granulation.
It can also be seen in Fig. 3 that the precision of the extraction seems to decrease as the νmax, scaling values decrease, and that this decrease seems to be correlated with a decrease in the amount of white noise. However, this is simply due to the fact that we represented our results in terms of percentages: the absolute errors for the different stars within a single iteration (i.e. whether with or without granulation) were very similar and similarly uncorrelated with the amount of white noise in the PSDs.
In addition, there seems to be a marked increase in the percentage difference and scatter of the νmax, fit values, for the iterations with and without granulation, as the νmax, scaling values decrease below ∼100 μHz. While asymmetrical mode distributions and our representation of the errors in percentages are partially to blame, there seems to be a trend in the scatter below ∼100 μHz that requires additional explanation. We posit that this result is a consequence of the large changes in the gradient of the granulation morphology (i.e. the “flattening” of the background slope) below ∼50 μHz (see e.g. Fig. D.2). Due to the fact that the pulsational power excesses lie partially on top of this “flattened” portion of the granulation morphology, the extraction of νmax, fit between the two iterations shows greater deviance.
Overall, we observe systematic errors of the order of 1% in νmax, 3% in M and 1% in R, with an intrinsic scatter of the order of 0.5% in νmax, 1.5% in M and 0.5% in R. For all three parameters, the combined errors are smaller or of the order of the typical uncertainties of 4%/2% in mass/radius reported for the scaling relations in literature (e.g. Pérez Hernández et al. 2016; Kallinger et al. 2018).
The systematic errors and intrinsic scatter of the masses and radii follow from the scaling relations (Eqs. (1) and (2)) as expected, with ΔM = 3 ⋅ |d(log νmax)| and ΔR = |d(log νmax)|. As such, in this and in the subsequent sections, we only present the mean percentage difference, 1σ scatter, and the mean precision of the νmax values extracted from our PSDs, as those of the masses and radii can effectively be calculated from the νmax results.
4. Red-giant binary simulations and results
We used a subset of the light curves generated using the methodology laid out in Sect. 2.2 for the creation of our binary grid, ensuring that the subset was relatively representative of the entire grid in terms of M, R, Teff and νmax. This was done in order to keep the binary grid, which comprises combinations of each star with every other star, relatively manageable in size. The subset comprises 30 stars, and their M, R, and Teff distributions are displayed in Fig. 4.
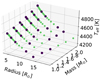 |
Fig. 4. M, R, and Teff values of the individual components (highlighted in dark blue) used to create our binary grid. |
We therefore generated a total of two sets of 435 (i.e. 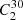 ) binary light curves, with one set consisting of binaries with only one pulsating component, and the other consisting of binaries with both components pulsating. These were fit using different granulation model configurations (two and four super-Lorentzians), and we perform a differential analysis by comparing the νmax values extracted from our binary-RG PSDs (νmax, binary) with the maximum likelihood estimates of the νmax values extracted from our single-RG PSDs (νmax, single).
) binary light curves, with one set consisting of binaries with only one pulsating component, and the other consisting of binaries with both components pulsating. These were fit using different granulation model configurations (two and four super-Lorentzians), and we perform a differential analysis by comparing the νmax values extracted from our binary-RG PSDs (νmax, binary) with the maximum likelihood estimates of the νmax values extracted from our single-RG PSDs (νmax, single).
4.1. Results of RG binaries with two pulsating components
Figures 5 and 6 show the νmax extraction results for a two super-Lorentzian granulation model and a four super-Lorentzian granulation model respectively, where both components (Star A and Star B) in the RG binary are pulsating. The mean percentage difference and the 1σ scatter of the νmax, binary − νmax, single values, and the mean precision of the νmax, binary extraction are detailed in Table 4.
 |
Fig. 5. Comparison of the νmax values of each component (Star A, left panel; and Star B, right panel) extracted from our synthetic RG-binary light curves where both components are pulsating, using a two super-Lorentzian granulation model. The vertical axis corresponds to the difference between the single-RG reference values for Star A (νmax, single (Star A)) and Star B (νmax, single (Star B)). The horizontal axis corresponds to the difference between the binary (νmax, binary) and the single-RG (νmax, single) reference values. The vertical dashed line represents the zero-point of the difference between νmax, binary and νmax, single. The dash-dotted green lines represent the interpolated 1 − σ level about the mean scatter of the datapoints grouped into 10 μHz bins along the vertical axis. The horizontal dashed line represents the zero-point of νmax, single (Star A) − νmax, single (Star B). The error bars correspond to the 68% Bayesian credible intervals of the marginalised posterior distributions of the binary fit parameters. The symbols are colour-coded according the percentage light contribution of each component to the binary light curve. |
 |
Fig. 6. Comparison of the νmax values of each component (Star A, left panel; and Star B, right panel) extracted from our synthetic RG-binary light curves where both components are pulsating, using a four super-Lorentzian granulation model. The axes, symbols, error bars and colour-coding is the same as in Fig. 5. |
Mean percentage difference, 1σ scatter, and precision of the νmax, binary values extracted from our RG-binary PSDs, using either two or four super-Lorentzians to fit the granulation signal.
The most obvious feature in Figs. 5 and 6 is the large scatter in the central region of the plot, which is where the νmax values for Star A (νmax, single (Star A)) and Star B (νmax, single (Star B)) are very similar. This scatter is a result of fitting the binary star PSDs where the power excesses of each component overlap (e.g. Fig. D.3). This necessarily results in degeneracies during the fitting process that are difficult to alleviate without tight constraints on the prior distributions (we use relatively unconstrained priors). In addition, approximately 20% of the RG/RG binaries with overlapping power excesses displayed non-Gaussian posterior distributions of νmax values. This results in the asymmetric, and often large, error bars for the datapoints in the region around the zero-point value of νmax, single (Star A) − νmax, single (Star B).
We also observe a marked increase in the scatter of νmax, binary − νmax, single as the light contribution increases (see zoomed insets in Fig. 5). This is once again a consequence of representing our results in percentages, and is also observed in the single-RG case (see Sect. 3): The component with the higher light contribution tends to have the lower νmax (as νmax is inversely proportional to L), and therefore similar absolute νmax, binary − νmax, single values are larger in terms of percentage at lower νmax, single values.
Our results shown in Table 4 indicate that there is no appreciable systematic offset in our νmax, binary values when compared to our νmax, single values. The small residual systematic offsets that remain are certainly well below the 1σ scatter reported in the single-RG case (cf. Table 3). However, the 1σ scatter of the νmax, binary values is much higher, and the mean precision is much lower than in the single-star case. It must be noted that these results represent the global properties of the entire grid, and are therefore largely biased by the datapoints corresponding to overlapping power excesses, where a large 1σ scatter and low precision are expected. For the cases where the power excesses are well separated (e.g. Fig. D.4), we clearly see a much smaller scatter that is quantitatively comparable to the single star case discussed in the Sect. 3.
Another interesting observation is that there is little difference in the overall results of the two and four super-Lorentzian component fits. This can be attributed once again to the degenerate nature of the background fit: adding additional super-Lorentzians does not seem to improve the quality of the fit. This is in agreement with the conclusions of Kallinger et al. (2014) and is demonstrated in Fig. 7, which shows the input super-Lorentzians for one of our synthetic PSDs compared with those derived from the maximum-likelihood values for the two and four super-Lorentzian component granulation models. The background fit is so degenerate that (i) two super-Lorentzians can still adequately model the background (verifying the approach of Beck et al. 2018a), and (ii) the input parameters are not recovered using the four super-Lorentzian model.
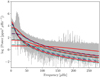 |
Fig. 7. Comparison of the input granulation signal with those from the maximum-likelihood values of the two and four super-Lorentzian granulation model fits, for one of our binary-RG PSDs where both components are pulsating. The super-Lorentzians used as inputs are represented by the solid red curves, with the two and four super-Lorentzians fits represented by the dark blue and blue-green dash-dotted lines respectively. |
Overall, we observe an intrinsic scatter of the order of 2% in νmax, corresponding to a scatter of 6% in M and 6% in R. We once again stress that the larger scatter in νmax is a direct consequence of the additional fitting degeneracy under the condition of the overlapping power excesses of the two pulsating components: Our uncertainties are otherwise comparable to the single-RG case and do not exceed the typical uncertainties for the scaling relations reported in the literature (cf. Sect. 3).
4.2. Results of RG binaries with one pulsating component
Figure 8 shows the νmax extraction results for the two and four super-Lorentzian component granulation models, where only one of the two components (Star A) in the RG binary is pulsating (e.g. Fig. D.5). The mean percentage difference and the 1σ scatter of the νmax, binary − νmax, single values, and the mean precision of the νmax, binary extraction are also detailed in the last column of Table 4.
 |
Fig. 8. Comparison of the νmax values for a two super-Lorentzian (left panel) and a four super-Lorentzian (right panel) granulation model, extracted from our synthetic RG-binary light curves where only one component (Star A) is pulsating. The axes, symbols, error bars and colour-coding is the same as in Fig. 5. |
Once again, our results show that there is no appreciable systematic offset in our νmax, binary values when compared to our νmax, single values. In fact, the results that we had obtained were very similar to that of the single-RG case: The 1σ scatter and precision of the νmax extraction is almost identical to that of the single-RG case (detailed in Table 3), with perhaps a slight decrease in mean precision (0.3% vs. 0.2%). We do not observe the large 1σ scatter that was observed in the double-pulsator case, as was expected due to the absence of a second power excess that would add significant degeneracy in the overlapping case. We do, however, observe the increase in the scatter of νmax, binary − νmax, single as the light contribution increases (see zoomed insets in Fig. 8) as per the double-pulsator case, which is, as mentioned, due to the representation of our results in percentages.
Similar to our binary-RG results, we once again observe very small differences between the different granulation model configurations: a consequence of the degeneracy of the background fit. This is demonstrated in Fig. 9, which shows the input super-Lorentzians for one of our single-pulsator synthetic PSDs compared with those derived from the maximum-likelihood values for the two and four super-Lorentzian component granulation models. Once again, we observe that the background fit is so degenerate that (i) two super-Lorentzians can still adequately model the background, and (ii) the input parameters are not recovered using the four super-Lorentzian model. This is in line with the conclusions of Kallinger et al. (2014) that there is a limit to the number of granulation components that can be uniquely modelled for a sufficiently-bright (Kp < 12) RG.
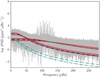 |
Fig. 9. Comparison of the input granulation signal with those from the maximum-likelihood values of the two and four super-Lorentzian granulation model fits, for one of our binary-RG PSDs where only one component is pulsating. The super-Lorentzians used as inputs are represented by the solid red curves, with the two and four super-Lorentzian fits represented by the dark blue and blue-green dash-dotted lines respectively. |
Overall, we observe an intrinsic scatter of the order of 0.5% in νmax, corresponding to a scatter of 1.5% in M and 0.5% in R, which is compatible with the single-RG case. It should be noted that the uncertainties typically reported for the scaling relations are larger than, or of the order of, the combined errors reported here.
4.3. Comparison between the different granulation model configurations
We performed a comparison of the two different granulation model configurations by taking the absolute difference of νmax, binary values extracted from the fits using each type of granulation model, for light curves with two pulsating components and a single pulsating component. The left and middle panels of Fig. 10 show the difference in νmax, binary for the RG-binary light curves where both components (Star A and Star B) are pulsating, and the right panel shows the difference in νmax, binary for the RG-binary light curves where only one component (Star A) is pulsating. All of these results are detailed in the bottom row of Table 4, where we show the mean percentage difference and the 1σ scatter of the |νmax, binary (2SL) − νmax, binary (4SL)| values.
 |
Fig. 10. Difference in the νmax values extracted from the fits using a two super-Lorentzian and a four super-Lorentzian granulation model. Left and middle panels: difference in νmax, fit for the RG-binary light curves where both components (Star A and Star B) are pulsating. Right panel: difference in νmax, fit for the RG-binary light curves where only one component (Star A) is pulsating. The axes, symbols, error bars and colour-coding is the same as in Fig. 5, except that the horizontal axis corresponds to the absolute percentage difference between the νmax, fit values for the two super-Lorentzian (2SL) and four super-Lorentzian (4SL) cases. |
Once again, the greatest percentage difference between the νmax, fit values extracted from fits using the two and four super-Lorentzian granulation models is in the region around the zero-point value of νmax, single (Star A) − νmax, single (Star B). As mentioned, the νmax extraction from PSDs with overlapping power excesses is generally unreliable, and the different granulation models function as an additional confounding factor in these cases. It can also be seen that the differences between the different granulation model configurations increases as with increasing light contribution, which is once again a consequence of expressing our results in percentages.
In general, it can be seen that the difference between the νmax values for the two and four super-Lorentzian granulation model configurations are small outside of the case of overlapping power excesses, with differences and scatter of the order of 0.5% in νmax, corresponding to 1.5% in M and 0.5% in R.
5. Discussion and conclusions
This paper details the results of our study, where we attempted to estimate the impact of a contaminating photometric signal with a distinct background profile on the extraction of the global asteroseismic parameter νmax. We developed a robust methodology for the simulation of the light curves of first-ascent RGB single- and binary stars, incorporating frequency-dependent modewidths and luminosity-dependent white noise.
We simulated the light curves of single RGs, and RG/RG binaries with (i) one pulsating component and (ii) two pulsating components and extracted the νmax values of the pulsating component. We also tested two different granulation model configurations for our RG binaries: (i) a two super-Lorentzian and (ii) a four super-Lorentzian granulation profile and computed the differences between the binary-RG and single-RG reference νmax values using each type of granulation model configuration. A summary of these results is presented below:
Single RGs
-
Systematics: We find a systematic underestimation of 1% in νmax, 2.5% in M and 1% in R. This is caused by asymmetric mode distribution in the power excesses (see Fig. 1), resulting in differences between the νmax values derived from the fit and from scaling relations.
-
Granulation: We confirm the randomising effect of the granulation signal, slightly increasing the degree of systematic underestimation, the intrinsic scatter, and the precision of extraction. We also find that the νmax values extracted from our single-RG PSDs with and without granulation often did not showcase agreement within the formal errors.
-
White Noise: We find that white noise has a negligible effect on the extraction of νmax for stars with Kp < 12, as noted by Kallinger et al. (2014).
Binary RGs
-
Systematics: We find negligible systematic differences between the binary-RG and single-RG νmax values, confirming that the systematic offset observed in the single-RG case is a methodological issue.
-
Two pulsating components: We find that the νmax extraction for PSDs featuring overlapping power excesses was highly unreliable, as was expected due to the use of unconstrained Gaussians to fit the power excesses. Outside of this scenario, we find that our results are very similar to the single-RG case.
-
One pulsating component: We find that our results are very similar to the single-RG case, showing that the light contribution of the individual components has minimal effect on the νmax extraction for cases where the light contribution of the component is above ∼10%.
-
Granulation model configurations: We find minimal difference in the results when using either two or four super-Lorentzian components to represent the granulation signal. This is due to the degeneracy of the granulation fits such that both model configurations are able to represent it equally well.
Our results indicate that binarity has a strong effect on the extraction of νmax in configurations where both components are pulsating and their power excesses overlap in the frequency domain. These particular binary configurations need a special treatment when using binarity for testing and validating scaling relations (e.g. such as using methodology proposed by Beck et al. 2018a). Outside of the abovementioned scenario, irrespective of individual light contributions of the two stars, the extraction of νmax is not affected by binarity and is only subject to systematic uncertainties due to the adopted methodology.
Our findings indicate that a systematic offset of observationally-derived parameters from scaling-relation derived parameters might be a result of the discrepancy between the observed νmax, which we found to be highly sensitive to mode distribution in the power excess, and the theoretical νmax. Our results also indicate that the ∼15%/5% overestimation of seismic versus dynamical mass/radius reported by Gaulme et al. (2016) is unrelated to the effect of photometric contamination due to binarity and hence requires alternative explanations. We also find that while granulation does function as a randomisation element, resulting in discrepancies in the extraction of νmax, the differences in νmax extraction between different methods (as reported in Hekker et al. 2011) are significantly larger than the granulation discrepancy. In addition, the minimal difference in our binary results when using either two or four super-Lorentzian components to represent the granulation indicates that the current physical interpretation of the granulation terms is suspect. Additional investigation of the physics of granulation and its observational signature would be required before the degeneracy in the granulation fit can be lifted.
Our results indicate that the presence of systematic errors in the extraction of νmax are a consequence of the fitting methodology. We find that while these uncertainties are smaller than or of the order of typical uncertainties reported for the scaling relations in the literature, they still worth considering when interpreting results in the context of observed discrepancies between scaling relations-based masses/radii and those inferred from binary dynamics. We can therefore conclude that photometric contamination, besides decreasing the signal-to-noise ratios of the individual components in the binary PSD, would have a negligible effect on the extraction of the global asteroseismic parameter νmax from TESS data.
See Kallinger et al. (2014) for a detailed explanation and mathematical background for the inclusion of a normalisation factor in the super-Lorentzian profiles.
We use a standard deviation of 1.5Δν, resulting in a full-width at half-maximum (FWHM) of 3.5Δν, which is well within the FWHM ranges for RGs reported by Mosser et al. (2010).
The normalised mode inertias exhibit local minima in intervals of Δν, but display a global decreasing trend that can span more than one order of magnitude (e.g. Fig. C.1). This results in modes with high amplitudes clustered around Δν, which mirrors observational oscillation patterns. See Dupret et al. (2009) for a full description.
The observational signature and efficiency of dynamical and equilibrium tides in RG-binaries are discussed in Beck et al. (2018b).
Acknowledgments
The authors would like to thank the anonymous referee for the constructive criticism that had radically transformed the manuscript into the form seen here. The research leading to these results has received funding from the Fonds Wetenschappelijk Onderzoek – Vlaanderen (FWO) under the grant agreement G0H5416N (ERC Opvangproject), and from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement no. 670519: MAMSIE). PGB acknowledges the support of the MINECO under the program “Juan de la Cierva incorporacion” (IJCI-2015-26034). The authors would also like to thank Prof. C. Aerts and the MAMSIE team for useful discussions.
References
- Appourchaux, T., Antia, H. M., Benomar, O., et al. 2014, A&A, 566, A20 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Appourchaux, T., Antia, H. M., Ball, W., et al. 2015, A&A, 582, A25 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Arentoft, T., Kjeldsen, H., Bedding, T. R., et al. 2008, ApJ, 687, 1180 [NASA ADS] [CrossRef] [Google Scholar]
- Asplund, M., Grevesse, N., Sauval, A. J., & Scott, P. 2009, ARA&A, 47, 481 [NASA ADS] [CrossRef] [Google Scholar]
- Auvergne, M., Bodin, P., Boisnard, L., et al. 2009, A&A, 506, 411 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Beck, P. G., Hambleton, K., Vos, J., et al. 2014, A&A, 564, A36 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Beck, P. G., Kallinger, T., Pavlovski, K., et al. 2018a, A&A, 612, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Beck, P. G., Mathis, S., Gallet, F., et al. 2018b, MNRAS, 479, L123 [NASA ADS] [CrossRef] [Google Scholar]
- Belkacem, K., Goupil, M. J., Dupret, M. A., et al. 2011, A&A, 530, A142 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Belkacem, K., Samadi, R., Mosser, B., Goupil, M. J., & Ludwig, H. G. 2013, in Progress in Physics of the Sun and Stars: A New Era in Helio- and Asteroseismology, eds. H. Shibahashi, & A. E. Lynas-Gray, ASP Conf. Ser., 479, 61 [NASA ADS] [Google Scholar]
- Bellinger, E. P., Basu, S., Hekker, S., & Ball, W. H. 2017, ApJ, 851, 80 [NASA ADS] [CrossRef] [Google Scholar]
- Borucki, W. J., Koch, D., Basri, G., et al. 2010, Science, 327, 977 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Brogaard, K., Jessen-Hansen, J., Handberg, R., et al. 2016, Astron. Nachr., 337, 793 [NASA ADS] [CrossRef] [Google Scholar]
- Brogaard, K., Hansen, C. J., Miglio, A., et al. 2018, MNRAS, 476, 3729 [NASA ADS] [CrossRef] [Google Scholar]
- Brown, T. M., Gilliland, R. L., Noyes, R. W., & Ramsey, L. W. 1991, ApJ, 368, 599 [NASA ADS] [CrossRef] [Google Scholar]
- Chaplin, W. J., Kjeldsen, H., Christensen-Dalsgaard, J., et al. 2011, Science, 332, 213 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Chaplin, W. J., Basu, S., Huber, D., et al. 2014, ApJS, 210, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Corsaro, E., Fröhlich, H.-E., Bonanno, A., et al. 2013, MNRAS, 430, 2313 [NASA ADS] [CrossRef] [Google Scholar]
- De Ridder, J., Arentoft, T., & Kjeldsen, H. 2006, MNRAS, 365, 595 [NASA ADS] [CrossRef] [Google Scholar]
- De Ridder, J., Barban, C., Baudin, F., et al. 2009, Nature, 459, 398 [Google Scholar]
- De Ridder, J., Molenberghs, G., Eyer, L., & Aerts, C. 2016, A&A, 595, L3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dupret, M.-A., Belkacem, K., Samadi, R., et al. 2009, A&A, 506, 57 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [CrossRef] [Google Scholar]
- Frandsen, S., Lehmann, H., Hekker, S., et al. 2013, A&A, 556, A138 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- García, R. A., Hekker, S., Stello, D., et al. 2011, MNRAS, 414, L6 [NASA ADS] [CrossRef] [Google Scholar]
- Gaulme, P., McKeever, J., Rawls, M. L., et al. 2013, ApJ, 767, 82 [NASA ADS] [CrossRef] [Google Scholar]
- Gaulme, P., Jackiewicz, J., Appourchaux, T., & Mosser, B. 2014, ApJ, 785, 5 [NASA ADS] [CrossRef] [Google Scholar]
- Gaulme, P., McKeever, J., Jackiewicz, J., et al. 2016, ApJ, 832, 121 [NASA ADS] [CrossRef] [Google Scholar]
- Goodman, J., & Weare, J. 2010, Appl. Math. Comput. Sci., 5, 65 [Google Scholar]
- Guggenberger, E., Hekker, S., Basu, S., & Bellinger, E. 2016, MNRAS, 460, 4277 [NASA ADS] [CrossRef] [Google Scholar]
- Guggenberger, E., Hekker, S., Angelou, G. C., Basu, S., & Bellinger, E. P. 2017, MNRAS, 470, 2069 [NASA ADS] [CrossRef] [Google Scholar]
- Harvey, J. 1985, in Future Missions in Solar, Heliospheric& Space Plasma Physics, eds. E. Rolfe, & B. Battrick, ESA SP, 235, 3 [NASA ADS] [Google Scholar]
- Hekker, S., Elsworth, Y., De Ridder, J., et al. 2011, A&A, 525, A131 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Herwig, F. 2000, A&A, 360, 952 [NASA ADS] [Google Scholar]
- Huber, D. 2015, in Giants of Eclipse: The zeta Aurigae Stars and Other Binary Systems, Astrophysics and Space Science Library, 408, 169 [NASA ADS] [CrossRef] [Google Scholar]
- Huber, D., Bedding, T. R., Stello, D., et al. 2011, ApJ, 743, 143 [NASA ADS] [CrossRef] [Google Scholar]
- Huber, D., Zinn, J., Bojsen-Hansen, M., et al. 2017, ApJ, 844, 102 [NASA ADS] [CrossRef] [Google Scholar]
- Kallinger, T., Weiss, W. W., Barban, C., et al. 2010, A&A, 509, A77 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kallinger, T., De Ridder, J., Hekker, S., et al. 2014, A&A, 570, A41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kallinger, T., Beck, P. G., Stello, D., & Garcia, R. A. 2018, A&A, 616, A104 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kjeldsen, H., & Bedding, T. R. 1995, A&A, 293, 87 [NASA ADS] [Google Scholar]
- Li, Y., Bedding, T. R., Li, T., et al. 2018, MNRAS, 476, 470 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lund, M. N., Silva Aguirre, V., Davies, G. R., et al. 2017, ApJ, 835, 172 [CrossRef] [Google Scholar]
- Mathur, S., Bruntt, H., Catala, C., et al. 2013, A&A, 549, A12 [CrossRef] [EDP Sciences] [Google Scholar]
- Miglio, A., Brogaard, K., Stello, D., et al. 2012, MNRAS, 419, 2077 [NASA ADS] [CrossRef] [Google Scholar]
- Miglio, A., Chiappini, C., Morel, T., et al. 2013, MNRAS, 429, 423 [NASA ADS] [CrossRef] [Google Scholar]
- Mosser, B., Belkacem, K., Goupil, M.-J., et al. 2010, A&A, 517, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mosser, B., Goupil, M. J., & Belkacem, K. 2012, VizieR Online Data Catalog: III/54 [Google Scholar]
- Mosser, B., Michel, E., Belkacem, K., et al. 2013, A&A, 550, A126 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nieva, M.-F., & Przybilla, N. 2012, A&A, 539, A143 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pande, D., Bedding, T. R., Huber, D., & Kjeldsen, H. 2018, MNRAS, 480, 467 [NASA ADS] [CrossRef] [Google Scholar]
- Paxton, B., Bildsten, L., Dotter, A., et al. 2011, ApJS, 192, 3 [Google Scholar]
- Paxton, B., Schwab, J., Bauer, E. B., et al. 2018, ApJS, 234, 34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pérez Hernández, F., García, R. A., Corsaro, E., Triana, S. A., & De Ridder, J. 2016, A&A, 591, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Przybilla, N., Nieva, M. F., Irrgang, A., & Butler, K. 2013, in EAS Publ. Ser., eds. G. Alecian, Y. Lebreton, O. Richard, & G. Vauclair, 63, 13 [Google Scholar]
- Rawls, M. L. 2016, PhD Thesis, New Mexico State University [Google Scholar]
- Rawls, M. L., Gaulme, P., McKeever, J., et al. 2016, ApJ, 818, 108 [NASA ADS] [CrossRef] [Google Scholar]
- Ricker, G. R., Winn, J. N., Vanderspek, R., et al. 2015, Instrum. Syst., 1, 014003 [Google Scholar]
- Rodrigues, T. S., Bossini, D., Miglio, A., et al. 2017, MNRAS, 467, 1433 [NASA ADS] [Google Scholar]
- Salgado, J., González-Núñez, J., Gutiérrez-Sánchez, R., et al. 2017, Astron. Comput., 21, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Samadi, R., Belkacem, K., & Sonoi, T. 2015, EAS Publ. Ser., 73, 111 [CrossRef] [Google Scholar]
- Sharma, S., Stello, D., Bland-Hawthorn, J., Huber, D., & Bedding, T. R. 2016, ApJ, 822, 15 [NASA ADS] [CrossRef] [Google Scholar]
- Tassoul, M. 1980, ApJS, 43, 469 [NASA ADS] [CrossRef] [Google Scholar]
- Themeßl, N., Hekker, S., Southworth, J., et al. 2018, MNRAS, 478, 4669 [NASA ADS] [CrossRef] [Google Scholar]
- Torres, G., Andersen, J., & Giménez, A. 2010, A&ARv, 18, 67 [Google Scholar]
- Townsend, R. H. D., & Teitler, S. A. 2013, MNRAS, 435, 3406 [NASA ADS] [CrossRef] [Google Scholar]
- Vrard, M., Kallinger, T., Mosser, B., et al. 2018, A&A, 616, A94 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- White, T. R., Bedding, T. R., Stello, D., et al. 2011, ApJ, 743, 161 [NASA ADS] [CrossRef] [Google Scholar]
- White, T. R., Benomar, O., Silva Aguirre, V., et al. 2017, A&A, 601, A82 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
Appendix A: MESA inlist file
The running and output of the MESA stellar evolutionary code is configured by an inlist file. While the code does have a default configuration, any parameters that the user wishes to alter must be specified in the inlist file. The contents of the inlist file for creating our RG models are shown below:
&star_job
show_log_description_at_start = .false.
load_saved_model = .false.
create_pre_main_sequence_model = .true.
kappa_file_prefix = 'OP_a09_p13'
kappa_lowT_prefix = 'lowT_fa05_a09p'
kappa_CO_prefix = 'a09_p13_co'
initial_zfracs = 8
change_net = .true.
new_net_name =
'pp_cno_extras_o18_ne22_extraiso.net'
change_initial_net = .true.
pgstar_flag = .false.
pause_before_terminate = .false.
save_photo_when_terminate = .false.
save_model_when_terminate = .false.
write_profile_when_terminate = .false.
save_pulse_data_when_terminate = .false.
new_rotation_flag = .false.
change_rotation_flag = .false.
change_initial_rotation_flag = .false.
new_omega = 0
set_omega = .false.
set_initial_omega = .false.
/ !end of star_job namelist
&controls
star_history_name =
initial_mass =
mixing_length_alpha = 1.8
overshoot_f_above_burn_h_core = 0.02
overshoot_f_above_burn_he_core = 0.02
min_D_mix = 1.0
initial_y = 0.2485
initial_z = 0.018
varcontrol_target = 1d-4
log_directory =
terminal_interval = 200
photo_interval = 1000000
photo_directory = './photos'
write_profiles_flag = .false.
history_interval = 1
write_pulse_data_with_profile = .true.
pulse_data_format = 'GYRE'
add_atmosphere_to_pulse_data = .true.
add_center_point_to_pulse_data = .true.
keep_surface_point_for_pulse_data = .true.
add_double_points_to_pulse_data = .true.
interpolate_rho_for_pulse_data = .true.
threshold_grad_mu_for_double_point = 5d0
alpha_bdy_core_overshooting = 5
he_core_boundary_h1_fraction = 1d-2
hot_wind_scheme = 'Vink'
Vink_scaling_factor = 0.3d0
hot_wind_full_on_T = 1d4
xa_central_lower_limit_species(1) = 'he4'
xa_central_lower_limit(1) = 1d-3
remove_small_D_limit = 1d-6
use_Ledoux_criterion = .true.
num_cells_for_smooth_gradL_composition_
term = 0
alpha_semiconvection = 0d0
semiconvection_option =
'Langer_85 mixing; gradT = gradr'
thermohaline_coeff = 0d0
alt_scale_height_flag = .true.
MLT_option = 'Cox'
mlt_gradT_fraction = -1
okay_to_reduce_gradT_excess = .false.
set_min_D_mix = .true.
D_mix_ov_limit = 5d-2
max_brunt_B_for_overshoot = 0
limit_overshoot_Hp_using_size_of_convection_
zone = .true.
overshoot_alpha = -1
predictive_mix(1) = .true.
predictive_zone_type(1) = 'burn_H'
predictive_zone_loc(1) = 'core'
predictive_bdy_loc(1) = 'any'
predictive_mix(2) = .true.
predictive_zone_type(2) = 'burn_He'
predictive_zone_loc(2) = 'core'
predictive_bdy_loc(2) = 'any'
predictive_mix(3) = .true.
predictive_zone_type(3) = 'nonburn'
predictive_zone_loc(3) = 'shell'
predictive_bdy_loc(3) = 'any'
predictive_mix(4) = .true.
predictive_zone_type(4) = 'burn_H'
predictive_zone_loc(4) = 'shell'
predictive_bdy_loc(4) = 'any'
conv_bdy_mix_softening_f0 = 0.002
conv_bdy_mix_softening_f = 0.001
conv_bdy_mix_softening_min_D_mix = 1d-1
overshoot_f0_above_burn_h_core = 0.001
overshoot_f0_above_burn_h_shell = 0.001
overshoot_f_above_burn_h_shell = 0.005
overshoot_f0_below_burn_h_shell = 0.001
overshoot_f_below_burn_h_shell = 0.005
overshoot_f0_above_burn_he_core = 0.001
overshoot_f0_above_nonburn_shell = 0.001
overshoot_f_above_nonburn_shell = 0.001
overshoot_f0_below_nonburn_shell = 0.005
overshoot_f_below_nonburn_shell = 0.005
smooth_convective_bdy = .false.
do_element_diffusion = .false.
which_atm_option = 'simple_photosphere'
cubic_interpolation_in_X = .false.
cubic_interpolation_in_Z = .false.
num_cells_for_smooth_brunt_B = 0
interpolate_rho_for_pulsation_info = .true.
max_allowed_nz = 40000
mesh_delta_coeff = 0.4
mesh_adjust_use_quadratic = .true.
mesh_adjust_get_T_from_E = .true.
P_function_weight = 40
T_function1_weight = 110
T_function2_weight = 0
T_function2_param = 2d4
gradT_function_weight = 0
xtra_coef_os_above_burn_h = 0.1d0
xtra_dist_os_above_burn_h = 2d0
mesh_dlogX_dlogP_extra = 0.15
mesh_dlogX_dlogP_full_on = 1d-6
mesh_dlogX_dlogP_full_off = 1d-12
mesh_logX_species(1) = 'he4'
xtra_coef_czb_full_on = 1.0d0
xtra_coef_czb_full_off = 1.0d0
xtra_coef_a_l_hb_czb = 0.5d0
xtra_dist_a_l_hb_czb = 1d0
xtra_coef_b_l_hb_czb = 0.5d0
xtra_dist_b_l_hb_czb = 1d0
xtra_coef_a_l_hb_czb = 0.5d0
xtra_dist_a_l_hb_czb = 1d0
xtra_coef_b_l_hb_czb = 0.5d0
xtra_dist_b_l_hb_czb = 1d0
! non-burning zone
xtra_coef_a_l_nb_czb = 0.5d0
xtra_dist_a_l_nb_czb = 1d0
xtra_coef_b_l_nb_czb = 0.5d0
xtra_dist_b_l_nb_czb = 1d0
xtra_coef_a_l_nb_czb = 0.5d0
xtra_dist_a_l_nb_czb = 1d0
xtra_coef_b_l_nb_czb = 0.5d0
xtra_dist_b_l_nb_czb = 1d0
! He burning zone
xtra_coef_a_l_heb_czb = 0.5d0
xtra_dist_a_l_heb_czb = 1d0
xtra_coef_b_l_heb_czb = 0.5d0
xtra_dist_b_l_heb_czb = 1d0
xtra_coef_a_l_heb_czb = 0.5d0
xtra_dist_a_l_heb_czb = 1d0
xtra_coef_b_l_heb_czb = 0.5d0
xtra_dist_b_l_heb_czb = 1d0
xtra_coef_os_full_on = 1.0d0
xtra_coef_os_full_off = 1.0d0
xtra_coef_os_above_burn_h = 0.5d0
xtra_dist_os_above_burn_h = 0.5d0
xtra_coef_os_below_burn_h = 0.5d0
xtra_dist_os_below_burn_h = 0.5d0
xtra_coef_os_above_nonburn = 0.5d0
xtra_dist_os_above_nonburn = 0.5d0
xtra_coef_os_below_nonburn = 0.5d0
xtra_dist_os_below_nonburn = 0.5d0
xtra_coef_os_above_burn_he = 0.5d0
xtra_dist_os_above_burn_he = 0.5d0
xtra_coef_os_below_burn_he = 0.5d0
xtra_dist_os_below_burn_he = 0.5d0
/ ! end of controls namelist
Appendix B: GYRE inlist file
Similar to MESA stellar evolutionary code, the running and output of the GYRE stellar pulsation code is configured by an inlist file. The code will output the pulsational parameters of the modes specified in the input file for a specific input model. The contents of the inlist file for computing the pulsational frequencies and parameters for our input RG models are shown below:
&constants
/
&model
model_type = 'EVOL'
file =
file_format = 'MESA'
/
&mode
l = 0
m = 0
tag = 'l0m0' ! Tag for namelist matching
/
&mode
l = 1
m = 0
tag = 'l1m0' ! Tag for namelist matching
/
&mode
l = 2
m = 0
tag = 'l2m0' ! Tag for namelist matching
/
&mode
l = 3
m = 0
tag = 'l3m0'
/
&osc
inner_bound = 'REGULAR'
outer_bound = 'JCD'
variables_set = 'JCD'
inertia_norm = 'BOTH'
rotation_method = 'NULL'
/
&num
diff_scheme = 'MAGNUS_GL4'
n_iter_max = 50
/
&scan
grid_type = 'LINEAR'
grid_frame = 'INERTIAL'
freq_min =
freq_max =
freq_min_units = 'UHZ'
freq_max_units = 'UHZ'
freq_frame = 'INERTIAL'
n_freq = 400
/
&grid
alpha_osc = 10
alpha_exp = 5
n_inner = 5
alpha_thm = 0
alpha_str = 0
&ad_output
summary_file = 'Mini0100_profiles/
Mini0100_at_nu_max_0020.profile.freqs'
freq_units = 'UHZ'
summary_file_format = 'TXT'
summary_item_list = 'l,m,n_p,n_g,n_pg,freq,
E_norm'
/
&nad_output
Appendix C: The variation of the normalised mode inertia with frequency
 |
Fig. C.1. Variation of the normalised mode inertia values for each frequency output by GYRE for a star with νmax ∼ 100 μHz. The ℓ = 1, 2 and 3 modes are colour-coded as displayed the legend. It should be noted that the local minima in mode inertia in intervals of Δν, and the general decreasing trend of mode inertia with frequency. |
Appendix D: Power spectrum fit examples
This section contains examples of the fits obtained for our synthetic single- and binary-RG PSDs.
 |
Fig. D.1. Example of a single-RG PSD fit where light curve contains only the pulsational signal of the RG. The grey line is the unsmoothed PSD, the black line is the smoothed PSD, the red line represents the overall fit, the dashed green line represents the Gaussian used to fit the pulsational power excess, and the blue dotted line represents the white noise. |
 |
Fig. D.2. Example of a single-RG PSD fit where the light curve contains both the pulsational and granulation signals of the RG. The grey, black, red, green and blue lines represent the same signals as in Fig. D.1, with the addition of blue dash-dotted lines to represent the super-Lorentzians. |
 |
Fig. D.3. Example of a RG-binary PSD fit where both components, with very similar νmax values, are pulsating. Here we use four super-Lorentzians to fit the granulation signal in the PSD. The grey, black, red, green and blue lines (both dashed and dotted) represent the same signals as in Fig. D.2. |
 |
Fig. D.4. Example of a RG-binary PSD fit where both components, with very different νmax values, are pulsating. Here we use four super-Lorentzians to fit the granulation signal in the PSD. The grey, black, red, green and blue lines (both dashed and dotted) represent the same signals as in Fig. D.2. |
 |
Fig. D.5. Example of a RG-binary PSD fit where only one component is pulsating. Here we use four super-Lorentzians to fit the granulation signal in the PSD. The grey, black, red, green and blue lines (both dashed and dotted) represent the same signals as in Fig. D.2. |
All Tables
Ranges of M, R, Teff and νmax of the RG models used for the creation of our synthetic single- and binary-RG light curves.
Coefficients k, s, and t for the granulation amplitudes (a1, 2) and turnover frequencies (b1, 2).
Mean percentage difference, 1σ scatter, and precision of the νmax values extracted from our single-RG PSDs.
Mean percentage difference, 1σ scatter, and precision of the νmax, binary values extracted from our RG-binary PSDs, using either two or four super-Lorentzians to fit the granulation signal.
All Figures
|
Fig. 1. Example of a synthetic RG pulsation spectrum for a star with νmax ∼ 100 μHz, used as an input to generates synthetic pulsational time-series for the RG light curves. The ℓ = 0, 1, 2, and 3 modes are represented by Lorentzians and colour-coded as displayed in the legend. The presence of multiplets, particularly around the ℓ = 1 modes, correspond to mixed modes with the same p-mode radial order but different g-mode radial order. |
| In the text | |
|
Fig. 2. Example of a single-RG PSD fit. The grey line is the unsmoothed PSD, the black line is the smoothed PSD, the red line represents the overall fit, the dashed green line represents the Gaussian used to fit the pulsational power excess, the blue dotted line represents the white noise, and the blue dashed lines represent the super-Lorentzians used to fit the granulation signal. |
| In the text | |
|
Fig. 3. Comparison of the νmax values extracted from our synthetic single-RG PSDs. We tested synthetic light curves containing only a pulsational signal (triangles), and both a pulsational and a granulation signal (circles). The vertical axis corresponds to the scaling relation (νmax, scaling) input values of the light curves, and the horizontal axis corresponds to the percentage difference between the fit (νmax, fit) and the scaling relation (νmax, scaling) values. The vertical dashed line represents the zero-point of the difference between νmax, fit and νmax, scaling. The dash-dotted lines represent the 1σ level about the mean scatter of the datapoints corresponding to the pulsational signal (red), and both the pulsational and granulation signals (green). The horizontal dotted lines connect the datapoints corresponding to the same RG model. The error bars correspond to the 68% Bayesian credible intervals of the marginalised posterior distributions of the fit parameters. The symbols are colour-coded according the logarithm of the white noise (log W) included in the light curves and PSDs. |
| In the text | |
|
Fig. 4. M, R, and Teff values of the individual components (highlighted in dark blue) used to create our binary grid. |
| In the text | |
|
Fig. 5. Comparison of the νmax values of each component (Star A, left panel; and Star B, right panel) extracted from our synthetic RG-binary light curves where both components are pulsating, using a two super-Lorentzian granulation model. The vertical axis corresponds to the difference between the single-RG reference values for Star A (νmax, single (Star A)) and Star B (νmax, single (Star B)). The horizontal axis corresponds to the difference between the binary (νmax, binary) and the single-RG (νmax, single) reference values. The vertical dashed line represents the zero-point of the difference between νmax, binary and νmax, single. The dash-dotted green lines represent the interpolated 1 − σ level about the mean scatter of the datapoints grouped into 10 μHz bins along the vertical axis. The horizontal dashed line represents the zero-point of νmax, single (Star A) − νmax, single (Star B). The error bars correspond to the 68% Bayesian credible intervals of the marginalised posterior distributions of the binary fit parameters. The symbols are colour-coded according the percentage light contribution of each component to the binary light curve. |
| In the text | |
|
Fig. 6. Comparison of the νmax values of each component (Star A, left panel; and Star B, right panel) extracted from our synthetic RG-binary light curves where both components are pulsating, using a four super-Lorentzian granulation model. The axes, symbols, error bars and colour-coding is the same as in Fig. 5. |
| In the text | |
|
Fig. 7. Comparison of the input granulation signal with those from the maximum-likelihood values of the two and four super-Lorentzian granulation model fits, for one of our binary-RG PSDs where both components are pulsating. The super-Lorentzians used as inputs are represented by the solid red curves, with the two and four super-Lorentzians fits represented by the dark blue and blue-green dash-dotted lines respectively. |
| In the text | |
|
Fig. 8. Comparison of the νmax values for a two super-Lorentzian (left panel) and a four super-Lorentzian (right panel) granulation model, extracted from our synthetic RG-binary light curves where only one component (Star A) is pulsating. The axes, symbols, error bars and colour-coding is the same as in Fig. 5. |
| In the text | |
|
Fig. 9. Comparison of the input granulation signal with those from the maximum-likelihood values of the two and four super-Lorentzian granulation model fits, for one of our binary-RG PSDs where only one component is pulsating. The super-Lorentzians used as inputs are represented by the solid red curves, with the two and four super-Lorentzian fits represented by the dark blue and blue-green dash-dotted lines respectively. |
| In the text | |
|
Fig. 10. Difference in the νmax values extracted from the fits using a two super-Lorentzian and a four super-Lorentzian granulation model. Left and middle panels: difference in νmax, fit for the RG-binary light curves where both components (Star A and Star B) are pulsating. Right panel: difference in νmax, fit for the RG-binary light curves where only one component (Star A) is pulsating. The axes, symbols, error bars and colour-coding is the same as in Fig. 5, except that the horizontal axis corresponds to the absolute percentage difference between the νmax, fit values for the two super-Lorentzian (2SL) and four super-Lorentzian (4SL) cases. |
| In the text | |
|
Fig. C.1. Variation of the normalised mode inertia values for each frequency output by GYRE for a star with νmax ∼ 100 μHz. The ℓ = 1, 2 and 3 modes are colour-coded as displayed the legend. It should be noted that the local minima in mode inertia in intervals of Δν, and the general decreasing trend of mode inertia with frequency. |
| In the text | |
|
Fig. D.1. Example of a single-RG PSD fit where light curve contains only the pulsational signal of the RG. The grey line is the unsmoothed PSD, the black line is the smoothed PSD, the red line represents the overall fit, the dashed green line represents the Gaussian used to fit the pulsational power excess, and the blue dotted line represents the white noise. |
| In the text | |
|
Fig. D.2. Example of a single-RG PSD fit where the light curve contains both the pulsational and granulation signals of the RG. The grey, black, red, green and blue lines represent the same signals as in Fig. D.1, with the addition of blue dash-dotted lines to represent the super-Lorentzians. |
| In the text | |
|
Fig. D.3. Example of a RG-binary PSD fit where both components, with very similar νmax values, are pulsating. Here we use four super-Lorentzians to fit the granulation signal in the PSD. The grey, black, red, green and blue lines (both dashed and dotted) represent the same signals as in Fig. D.2. |
| In the text | |
|
Fig. D.4. Example of a RG-binary PSD fit where both components, with very different νmax values, are pulsating. Here we use four super-Lorentzians to fit the granulation signal in the PSD. The grey, black, red, green and blue lines (both dashed and dotted) represent the same signals as in Fig. D.2. |
| In the text | |
|
Fig. D.5. Example of a RG-binary PSD fit where only one component is pulsating. Here we use four super-Lorentzians to fit the granulation signal in the PSD. The grey, black, red, green and blue lines (both dashed and dotted) represent the same signals as in Fig. D.2. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.