| Issue |
A&A
Volume 623, March 2019
|
|
|---|---|---|
| Article Number | A30 | |
| Number of page(s) | 21 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/201834718 | |
| Published online | 27 February 2019 | |
Measuring the local matter density using Gaia DR2
The Oskar Klein Centre for Cosmoparticle Physics, Department of Physics, Stockholm University, AlbaNova, 10691 Stockholm, Sweden
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
26
November
2018
Accepted:
23
January
2019
Abstract
Aims. We determine the total dynamical matter density in the solar neighbourhood using the second Gaia data release (DR2).
Methods. The dynamical matter density distribution is inferred in a framework of a Bayesian hierarchical model, which accounts for position and velocity of all individual stars, as well as the full error covariance matrix of astrometric observables, in a joint fit of the vertical velocity distribution and stellar number density distribution. This was done for eight separate data samples, with different cuts in observed absolute magnitude, each containing about 25 000 stars. The model for the total matter density does not rely on any underlying baryonic model, although we assumed that it is symmetrical, smooth, and monotonically decreasing with distance from the mid-plane.
Results. We infer a density distribution which is strongly peaked in the region close to the Galactic plane (≲60 pc), for all eight stellar samples. Assuming a baryonic model and a dark matter halo of constant density, this corresponds to a surplus surface density of approximately 5–9 M⊙ pc−2. For the Sun’s position and vertical velocity with respect to the Galactic plane, we infer Z⊙ = 4.76 ± 2.27 pc and W⊙ = 7.24 ± 0.19 km s−1.
Conclusions. These results suggest a surplus of matter close to the Galactic plane, possibly explained by an underestimated density of cold gas. We discuss possible systematic effects that could bias our result, for example unmodelled non-equilibrium effects, and how to account for such effects in future extensions of this work.
Key words: Galaxy: kinematics and dynamics / Galaxy: disk / solar neighborhood / astrometry
© ESO 2019
1. Introduction
The distribution of matter in the Galactic disc has implications for the composition, dynamics and formation history of the Milky Way, as well as indirect and direct dark matter detection experiments (Jungman et al. 1996; Purcell et al. 2009; Ruchti et al. 2014). The local matter distribution can be estimated dynamically by measuring the velocity and stellar number density distributions of the Galactic disc; assuming statistical equilibrium, these distributions are interrelated via the gravitational potential. Such measurements have been developed and applied by Kapteyn (1922), Oort (1932), Bahcall (1984a,b), Kuijken & Gilmore (1989a,b,c, 1991), Crézé et al. (1998), Holmberg & Flynn (2000), Bienayme et al. (2006), Garbari et al. (2012), Bovy & Tremaine (2012), Zhang et al. (2013), Widmark & Monari (2018). A history of pre-Gaia dynamical mass measurements of the Galactic disc can be found in a review by Read (2014).
The distribution of matter in the solar neighbourhood is dominated by baryons, which are believed to be constituted by roughly equal densities of stars and gas (Flynn et al. 2006; McKee et al. 2015; Kramer & Randall 2016a). Out of all baryonic components, the density of cold gas (atomic and molecular) is the most uncertain. Precise constraints to the distribution of the total dynamical matter density can help constrain the distribution of baryonic components, supplementing other observations. Dynamical matter density measurements can also constrain or give insights into the particle nature of dark matter. Fan et al. (2013a,b) have proposed what they call “double-disc dark matter”: a dark matter sub-component with dissipative self-interaction, that can cool to form a thin dark disc, embedded inside a galaxy’s stellar disc. The presence of such a thin dark disc in the Milky Way has been constrained in previous studies (Kramer & Randall 2016b; Caputo et al. 2018; Schutz et al. 2018; Buch et al. 2019), where the most stringent upper bound to its local surface density is approximately 7 M⊙ pc−2 for a thin dark disc with a scale height of 30 pc (95% confidence).
With the quality of the second Gaia data release (DR2), released in April 2018 (Gaia Collaboration 2016, 2018b), it is possible to fit more complicated models with greater precision than ever before. The depth and astrometric precision is significantly better than for previous data sets, and Gaia DR2 also includes radial velocity measurements for 7.2 million stars. In this work we utilised the full potential of Gaia DR2, in order to infer the dynamical matter distribution; we considered both position and velocity of all stars (not only those close to the Galactic plane), in a joint fit of the velocity and stellar number density distributions, while accounting for the full error covariance matrix of astrometric observables for each individual star. We did so for eight separate samples of stars within a 200 pc distance limited volume. This improves on previous works in terms of statistical modelling and sample size. Another key difference is that the total matter density inferred in this work does not rely on an underlying model for the baryonic and dark matter density distributions.
This article is structured as follows. In Sect. 2, we outline our model of the solar neighbourhood stellar phase space density, and the distribution of baryonic matter. In Sect. 3, we present the stellar parameters that describe the stellar properties and the Gaia data that constrains these properties, as well as our stellar sample construction and its resulting selection effects. We present our statistical model in Sect. 4, and our results in Sect. 5. Finally, in Sect. 6, we discuss and conclude.
2. Galactic model
In this section we describe our model of the phase-space distribution of stars in the solar neighbourhood. We used a system of Cartesian coordinates, where x = (x, y, z) denotes a position with respect to the Sun, where positive x is in the direction of the Galactic centre, positive y is in the Galaxy’s rotational direction, and positive z is in the direction of the Galactic north pole. The directions parallel and perpendicular to the Galactic plane are also referred to as horizontal and vertical directions. The Cartesian coordinate first order time derivative, ν ≡ (u, v, w) ≡ (ẋ,ẏ,ż), is velocity in the Sun’s rest frame. When writing Z, we refer to height with respect to the Galactic plane. Similarly, when writing W, we refer to the vertical velocity in the Galactic rest frame.
In this work, we are volume limited to 200 pc in distance from the Sun, meaning that we also stay very close to the Galactic plane. Within this small volume, we made the following assumptions: the stellar phase-space density f is invariant under translation in x and y; the gravitational potential is separable in the horizontal and vertical directions, and the vertical energy is an integral of motion (Binney & Tremaine 2008); stars are in steady-state, such that their distribution in space and vertical velocity is completely described by the gravitational potential and their distribution in vertical energy.
Any coupling between the vertical and horizontal velocity distributions are thus neglected; in Jeans theory such couplings are known as the “axial” and “tilt” terms, which are believed to be small this close to the Galactic plane (Büdenbender et al. 2015; Sivertsson et al. 2018). Garbari et al. (2011) has a useful discussion on the validity of these assumptions and test them on simulations. They find that systematic errors become significant at distances of about 500 pc above the galactic plane. Hence, the problem of inferring the gravitational potential is reduced to one dimension and can be formulated in terms of f⊥(W, Z), which is the vertical velocity distribution as a function of height with respect to the Galactic plane. This distribution is discussed in detail below.
Vibrational modes of the Galactic disc are probably not of importance this close to the Galactic plane. Banik et al. (2017) has shown that a breathing mode can affect the inference of the dynamical matter density at kpc heights, but this is at significantly greater distances than what is relevant for this work.
With Gaia DR2, many studies demonstrate phase-space substructure both in the local region and in the larger Galactic structure, with moving groups that exhibit incomplete vertical phase-mixing (Gaia Collaboration 2018c; Monari et al. 2017, 2018; Hunt et al. 2018; Ramos et al. 2018; Soubiran et al. 2018; Antoja et al. 2018; Necib et al. 2018; Bennett & Bovy 2019). It is difficult to quantify the significance and potential bias that arises from the assumption of statistical equilibrium. In Sect. 6, we discuss possible ways to relax them in future extensions of this work.
2.1. Vertical velocity and stellar number density
The population parameters of our model parametrise the vertical velocity distribution and how it changes with height with respect to the Galactic plane, as well as how the stellar number density varies with height. There are four parameters that parametrise the matter density as a function of height above the Galactic plane, ρ{1, 2, 3, 4}; five parameters that describe the distribution of vertical velocity in the plane, c2, c3, and σ{1, 2, 3}; one parameter is the vertical height of Sun with respect to the Galactic plane, Z⊙; one parameter is the vertical velocity of the Sun in the Galactic rest frame, W⊙. The eleven population parameters are listed in Table 1.
Population parameters, object parameters and data of each stellar object, parameters and distributions with implicit dependence on the population parameters, and fixed background distributions of our model.
The gravitational potential Φ(Z) is given by the total dynamical matter density of the Galactic disc, according to the one-dimensional Poisson equation
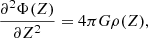 (1)
(1)
which is valid close to the plane. The gravitational potential is defined to be zero and have a zero valued first order derivative in the Galactic plane (Z = 0). The matter density as a function of height is taken as a sum of four matter components with different scale heights, according to
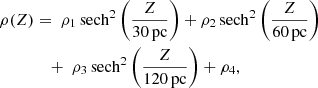 (2)
(2)
where these densities are in units of mass over volume.
The vertical velocity distribution in the Galactic mid-plane is described by population parameters c2, c3, and σ{1, 2, 3}, according to
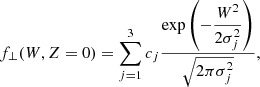 (3)
(3)
where c1 ≡ 1 − c2 − c3, with constraints ∑cj = 1 and cj ≥ 0, ∀j. This function integrates to unity. The index j is only ever used to label the Gaussian mixture of the vertical velocity distribution.
Leaving the plane, the vertical velocity distribution becomes
![Mathematical equation: $$ \begin{aligned} f_\perp (W,Z) = \sum _{j=1}^3 c_j\frac{\exp \left[-\dfrac{W^2+2\Phi (Z)}{2\sigma _j^2}\right]}{\sqrt{2\pi \sigma _j^2}}\cdot \end{aligned} $$](/articles/aa/full_html/2019/03/aa34718-18/aa34718-18-eq11.gif) (4)
(4)
When Z ≠ 0, integrating f⊥(Z, W) over W does not give unity, but is equal to the relative change to the stellar number density,
![Mathematical equation: $$ \begin{aligned} n(Z)=\sum _{j=1}^3 c_j \exp \left[-\frac{\Phi (Z)}{\sigma _j^2}\right]\cdot \end{aligned} $$](/articles/aa/full_html/2019/03/aa34718-18/aa34718-18-eq12.gif) (5)
(5)
2.2. Horizontal velocity distribution
The stellar velocities parallel to the Galactic plane, written u and v in the solar rest frame, are not of primary importance for this study, although necessary to account for if we want to use the velocity information of all stellar objects. For stellar objects that are missing radial velocity measurements, the horizontal‘ velocities must be marginalised over. In order to perform this marginalisation in a computationally efficient way, we made the assumption that the vertical and horizontal velocity distributions are separable, such that
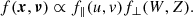 (6)
(6)
This approximation is a simplification and not actually true (even though the gravitational potential is separable in the sample volume); stars with high vertical energies also have a larger velocity dispersion in the horizontal directions, and the vertical energy is also correlated with the mean azimutal velocity (v). Such correlations are not accounted for in our model, but this is expected to have a minor effect. For the range of apparent magnitudes used in this work, at least 80% of stars have radial velocity measurements, meaning that full three-dimensional velocity information is available. For most stellar objects, the velocity uncertainty in any direction is significantly smaller than 1 km s−1. For such objects, the horizontal velocity distribution has a negligible impact; it mainly acts as a prior to the objects that are missing radial velocity measurements. For this reason, the approximation of separability, as expressed in Eq. (6), is not expected to produce a significant bias in our result. We also quantified this bias, by performing a fit where we only consider the velocity information of stars with good radial velocity measurements (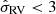 km s−1), and disregard the horizontal velocity distribution completely. This is described in more detail in Sect. 5.
km s−1), and disregard the horizontal velocity distribution completely. This is described in more detail in Sect. 5.
The horizontal velocity distribution is not well described by a separable bivariate Gaussian; instead, we fitted a joint (u, v) distribution with a Gaussian mixture model, written f∥(u, v). This Gaussian mixture model is parametrised by five weights, ak; five two-dimensional mean values, gk = {gu, k, gv, k}; and five 2 × 2 covariance matrices, Gk. The index k is only ever used to label the Gaussian mixture of this velocity distribution. Because f∥(u, v) is formulated in terms of velocities in the Sun’s rest frame, it accounts for the Sun’s velocity parallel to the plane. Having the velocity distribution on a Gaussian form is useful computationally, as the integration over three-dimensional velocity can be done analytically. Details of how the Gaussian mixture model is fitted is found in Appendix A.
The Gaussian mixture model is shown in Fig. 1, in two-dimensional and projected one-dimensional histograms over u and v. The overall structure of the joint velocity distribution is well described by the Gaussian mixture model, although there are some substructures that are not captured, most clearly seen in the projection over v. We expect these smaller inaccuracies to have a negligible effect on our end result, much smaller than other systematic uncertainties.
 |
Fig. 1. Gaussian mixture model and data over u and v velocities. Bottom-left panel: data is plotted as a 2D histogram, overlaid by the 1-sigma ellipses of the five Gaussians of the mixture model. The shading of the ellipses correspond to the weight of the respective Gaussians, where a darker colour correspond to a larger weight. Top and bottom-right panels: fitted model and the data are marginalised to 1D histograms over u and v. |
2.3. Dust
Extinction due to dust is most likely a negligible effect in this analysis. To a distance of at least 100 pc, the solar neighbourhood is almost devoid of dust. Dust reddening is typically E(B − V)≃0.01 at 100 pc distance, and E(B − V)≃0.025 at 200 pc, with some smaller patches of more severe reddening (Capitanio et al. 2017; Green et al. 2018). We use a conversion factor of 3.1 for going from E(B − V) reddening to GaiaG-band extinction (Fitzpatrick 1999; Danielski et al. 2018). Although the extinction factor has some dependence on colour, such effects are negligible compared to other dust uncertainties.
The dust extinction is significantly smaller than the absolute magnitude sample ranges. Despite being having a minor effect, the three-dimensional dust map of Capitanio et al. (2017) was used in this analysis, although uncertainties to the dust distribution were ignored. The resulting G-band extinction is a function of three-dimensional spatial position, and is written Ξ(x).
2.4. The luminosity function F(MG)
The luminosity function describes the number density of stars as a function of absolute magnitude. We fitted this distribution to data and treated it as a fixed background distribution. The data consists of stars with a distance in range 100–200 pc, binned in terms of M̂G (calculated from the observed apparent magnitude, observed position, and dust map). The function F(MG) is a spline on this binned data, as is shown in Fig. 2.
The luminosity function is important for calculating the normalisation factor N̄, which is discussed in Sect. 4.3. It also gives some power of inference, albeit very weak, in terms of the true distance of a star, as brighter stars are less numerous than dimmer stars.
2.5. Baryonic density
In this work, we infer the local dynamical density without relying on any underlying model for the baryonic density. However, a baryonic density model is presented in this section, in order to be able to compare the inferred dynamical density with the expected distribution of matter. The baryonic density model was taken from Schutz et al. (2018), who have compiled a table of baryonic components using results from Flynn et al. (2006), McKee et al. (2015), Kramer & Randall (2016a). A list of the baryonic density components is presented in Table 2.
Mid-plane densities ρt and velocity dispersions σt of baryonic matter components.
Summing the densities of these components (and their uncertainties in quadrature), the total baryonic mid-plane density is equal to 0.0889 ± 0.0071 M⊙ pc−3. The total baryonic density, as a function of height over the Galactic plane, is equal to
![Mathematical equation: $$ \begin{aligned} \rho _{\rm b} = \sum _{t} \rho _{t}\exp \left[ -\frac{\Phi (Z)}{\sigma _{t}^2} \right], \end{aligned} $$](/articles/aa/full_html/2019/03/aa34718-18/aa34718-18-eq15.gif) (7)
(7)
where the index t denotes the respective baryonic components.
The baryonic density distribution is shown in Fig. 3, as a sum total and also split into different components. The molecular gas and cold atomic gas components are the coldest components, hence they have the smallest scale heights, and their respective mid-plane densities are more uncertain than that of any other baryonic component. The bands represent 1-σ error bars, which accounts for uncertainties of both the baryonic component mid-plane densities as well as the baryonic component velocity dispersions. In this model, the gravitational potential is set by a homogeneous dark matter halo density of 0.01 M⊙ pc−3 and the baryonic density itself. If the gravitational well is steeper, due to a higher mid-plane density for example, the baryonic density will fall off quicker with distance from the Galactic plane (referred to as “pinching” by Kramer & Randall 2016a).
 |
Fig. 2. Luminosity function F(MG), describing the number density of stars in the solar neighbourhood, as a function of absolute magnitude in the GaiaG-band. The solid lines are the binned data and the spline function F(MG). The dashed lines correspond to the absolute magnitude bounds by which the four data samples are constructed. The function is not normalised and need not be. |
 |
Fig. 3. Baryonic matter density, as a function of height above the Galactic plane. Five coloured 1-σ bands show the total baryonic density, as well as a division into four separate groups: the “stars and dwarfs” include all types of stars, white dwarfs, and brown dwarfs; the “cold atomic gas” and “molecular gas” correspond directly to their respective single components of Table 2; the “warm and hot gas” correspond to the warm atomic gas and hot ionised gas components. |
There are improvements that can be made to this model. The list of stellar components is not based on Gaia data, but less precise surveys. Furthermore, the vertical velocity distribution of the different stellar populations are parametrised by a single velocity dispersion; it is clear from the Gaia data that the vertical velocity distribution is not well described by a single Gaussian. This is important to account for, especially further from the Galactic plane, in order to correctly model the density of stars as a function of height. In this work, we stay close to the Galactic plane, which is why uncertainties to the molecular and atomic gas densities are more critical.
3. Stellar parameters, data and selection
In our model, each stellar object has seven degrees of freedom: three-dimensional position, x; three-dimensional velocity, ν; and absolute magnitude in the GaiaG-band, MG. The properties of the ith stellar object are encapsulated in ψi, where i ranges from one to N, where N is the total number of stellar objects in a sample. We use the term “stellar object” rather than “star”, as some of them are unresolved multiple stellar systems.
The Gaia observables, written with hats, that constrain the stellar parameters are: apparent magnitude, m̂G; Galactic longitude and latitude, l̂ and b̂; observed parallax, 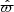 ; observed proper motions in the latitudinal and longitudinal directions,
; observed proper motions in the latitudinal and longitudinal directions, 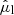 and
and 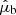 ; and observed radial velocity,
; and observed radial velocity, 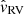 . The radial velocity is available only for a subset of stars in Gaia. The data of a stellar object is written di, where i ranges from one to N, just like for the stellar parameters.
. The radial velocity is available only for a subset of stars in Gaia. The data of a stellar object is written di, where i ranges from one to N, just like for the stellar parameters.
The observational uncertainties on apparent magnitude and angular coordinates are small and can be neglected. The former has uncertainties of around 1 mmag, with possible systematic errors up to 10 mmag (Gaia Collaboration 2018a).
There are systematic errors to the astrometric measurements of the Gaia DR2 catalogue. According to Luri et al. (2018), such systematic errors are smaller than 0.1 mas for parallax measurements and 0.1 mas yr−1 for proper motion measurements. In addition to a global parallax zero-point shift of −0.03 mas, which we corrected for, there are spatially correlated systematic errors as large as 0.04 mas for parallax and 0.07 mas yr−1 for proper motion, on angular scales as large as roughly 20°. Because we are distance limited to 200 pc, parallax errors of order 0.1 mas correspond to relative errors in distance of at most a few percent. Systematic proper motion errors as large as 0.1 mas yr−1 correspond to velocity errors ≲0.1 km s−1. The radial velocity measurements of Gaia have been compared with several ground-based catalogues, as detailed in Katz et al. (2019); the difference in radial velocity median values with respect to these catalogues is of the order 0.1 km s−1. Even assuming a worst case scenario of very large systematic errors, such errors are not large enough to significantly bias the result of this work.
The uncertainties of the proper motions and parallax measurements are encoded in an error covariance matrix
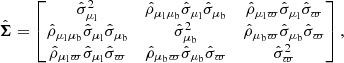 (8)
(8)
where 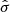 is an uncertainty, and
is an uncertainty, and 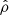 is a correlation coefficient. The uncertainty on the radial velocity is written
is a correlation coefficient. The uncertainty on the radial velocity is written 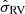 , which is uncorrelated with other observables.
, which is uncorrelated with other observables.
The likelihood of observing the data di, given a stellar object with stellar parameters ψi, is interpreted as being proportional to
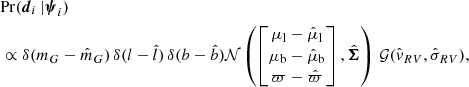 (9)
(9)
where δ(…) is the Dirac delta function, 𝒩(…) is the multivariate Gaussian distribution, and 𝒢(…) is the one-dimensional Gaussian distribution. Quantities without hats correspond to the observable’s true value, as given by the stellar parameters; for example, the parallax ϖ is given by the inverse of the true distance. The last factor of this expression is dropped when no radial velocity measurement is available. The multivariate Gaussian distribution is defined by
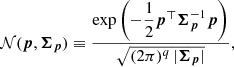 (10)
(10)
where p is a column vector of length q, and Σp is a q × q matrix with determinant |Σp|. The one-dimensional Gaussian distribution is defined by
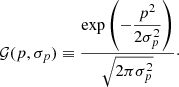 (11)
(11)
In the rest of this article, the hats on m̂G, l̂, and b̂ are dropped, to signify that their uncertainties were neglected. The stellar parameters and the data are listed in Table 1.
3.1. Sample construction
In terms of constructing data samples, the general approach of this work was to make a minimal amount of cuts, directly on Gaia observables, in order not to invoke any uncontrolled biases. Rather than cleaning the data of objects with large observational uncertainties, we carefully accounted for the effects of the overall uncertainty distribution.
We constructed eight separate stellar samples from Gaia DR2, by making cuts in observed distance and observed absolute magnitude, according to
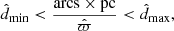 (12)
(12)
and
![Mathematical equation: $$ \begin{aligned} {\hat{M}}_{G,\mathrm{min}} < m_G-5\Bigg [\log _{10}\Bigg (\frac{\mathrm{arcs}}{\hat{\varpi }}\Bigg )-1\Bigg ]-\Xi ({\hat{\boldsymbol{x}}}) < \hat{M}_{G,\mathrm{max}}, \end{aligned} $$](/articles/aa/full_html/2019/03/aa34718-18/aa34718-18-eq28.gif) (13)
(13)
where it is implicit that the observed position 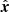 is given by l, b and
is given by l, b and 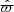 . The limits in distance are d̂min = 100 pc and d̂max = 200 pc for all samples.
. The limits in distance are d̂min = 100 pc and d̂max = 200 pc for all samples.
The dynamical assumptions made in Sect. 2 are expected to hold only close to the Galactic plane, which is why we set a limit of 200 pc in distance. Furthermore, dust extinction becomes more severe and more uncertain with greater distances (see Sect. 2.3). We set a lower distance bound of 100 pc, such that the sample volume is the shape of a shell. The main reason for this is that the completeness is lower and more poorly modelled for bright objects. There can also be a number count bias due to multiple stellar systems. Treating unresolved binaries as single stellar objects is not in itself a problem, but a binary system of a certain orbital separation will be resolved only if it is sufficiently close. For this reason, not considering the volume within 100 pc distance reduces the number count bias that can arise from having a sample volume that spans a wide range of distances.
The limits in absolute magnitude for the respective samples are listed in Table 3. Given these data cuts, the stellar objects will have an apparent magnitude in range 8–15. The ranges in absolute magnitude are chosen such that each sample has a roughly equal number of stellar objects. The range of absolute magnitude (3.0–6.3) corresponds to stars that are mainly of F and G classification.
List of stellar samples.
3.2. Selection function
The selection function consists of the two parts: the data cuts of the sample construction and the completeness function. The completeness of Gaia DR2, written C(l, b, mG), is a function of angular position and apparent magnitude. It was calculated from a cross-match with the 2MASS catalogue, made by Rybizki et. al1. This selection function is very coarse in apparent G-band magnitude range, split in bins of 8–12 and 12–15 mag, where the latter has marginally better completeness. An error in the Gaia completeness function could affect the result, probably in the sense of a bias that is shared between samples of similar brightness. However, the all-sky completeness is evaluated to around 99%, which has a negligible effect. The selection function acts solely on the data, according to
![Mathematical equation: $$ \begin{aligned} S({\boldsymbol{d}}_i)&= C(l,b,m_G) \times \Theta \left( \frac{\mathrm{arcs \times pc}}{\hat{\varpi }} > \hat{d}_{\rm min} \right)\, \Theta \left( \frac{\mathrm{arcs \times pc}}{\hat{\varpi }} < \hat{d}_{\rm max} \right)\nonumber \\&\quad \times \Theta \left\{ m_G-5\Bigg [\log _{10}\Bigg (\frac{\mathrm{arcs}}{\hat{\varpi }}\Bigg )-1\Bigg ]-\Xi ({\hat{\boldsymbol{x}}}) > \hat{M}_{G,\mathrm{min}} \right\} \nonumber \\&\quad \times \Theta \left\{ m_G-5\Bigg [\log _{10}\Bigg (\frac{\mathrm{arcs}}{\hat{\varpi }}\Bigg )-1\Bigg ]-\Xi ({\hat{\boldsymbol{x}}}) < \hat{M}_{G,\mathrm{max}} \right\} , \end{aligned} $$](/articles/aa/full_html/2019/03/aa34718-18/aa34718-18-eq32.gif) (14)
(14)
where Θ(…) is the Heaviside step function.
3.3. Parallax uncertainties
In order to calculate the expected number of stellar objects that are included in the sample (N̄, discussed at length in Sect. 4.3), it is necessary to model the distribution of observational uncertainties that affect selection. The one observational quantity with significant uncertainties that affects selection is the parallax.
The distribution of parallax uncertainties was modelled as a function of apparent magnitude in the GaiaG-band and Galactic latitude b, and is written 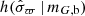 . Using only a cut in distance with an upper limit of 200 pc, the Gaia DR2 catalogue is split into bins of apparent magnitude of width 0.5 mag, and ten bins in Galactic latitude that divide the sky in regions of equal area. There is no need to also divide the data into bins in Galactic longitude, as this will be integrated out when calculating the N̄.
. Using only a cut in distance with an upper limit of 200 pc, the Gaia DR2 catalogue is split into bins of apparent magnitude of width 0.5 mag, and ten bins in Galactic latitude that divide the sky in regions of equal area. There is no need to also divide the data into bins in Galactic longitude, as this will be integrated out when calculating the N̄.
The median parallax uncertainty in these bins is about 0.05 mag, but there is a tail of higher uncertainties; the 95th percentile of these bins vary between 0.2–0.7 mag. This tail is especially pronounced for dimmer stars close to the Galactic plane, presumably due to stellar crowding.
4. Statistical model
In this section we present the statistical model and sampling technique by which we inferred the population parameters, which was implemented in a framework of a Bayesian hierarchical model (BHM). A BHM is statistical model that works on several levels, where lower levels inherit their probability distributions from higher levels. In this case there are two levels: the top-level population parameters Ψ that describe the overall population of stars, and the bottom-layer of stellar parameters ψi that describe the properties of individual stellar objects. The stellar parameters are connected to the data di.
From Bayes’ theorem, the posterior on the population parameters, with stellar parameters marginalised, is proportional to
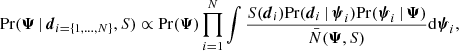 (15)
(15)
where Pr(Ψ) is the prior over the population parameters, S(di) is the selection function, Pr(di | ψi) is the likelihood of the data given the stellar parameters, Pr(ψi | Ψ) is the probability of the stellar parameters given the population model with fixed population parameters, and N̄(Ψ,S) is the normalisation to the nominator of the integrand. These terms are discussed in detail below.
The posterior over the population parameters is written with a proportionality sign. The quantity of interest is the ratio of posterior values between points in population parameter space. Therefore any constant factor that does not depend on the population parameters can be dropped.
4.1. Prior
The population parameter prior that we used in this work is uniform in the volume of parameter space that fulfil the following conditions:
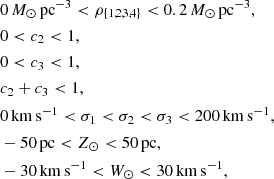 (16)
(16)
and is otherwise zero valued. The velocity dispersions σj are required to be in ascending order for reasons of multiplicity, which would otherwise cause sampling difficulties.
4.2. Integration over stellar parameters
When evaluating the posterior, as expressed in Eq. (15), the most demanding part computationally is the integral over the stellar parameters,
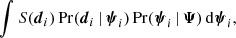 (17)
(17)
which is done N times, where N is the number of stellar objects in the sample. For a given stellar object, the data is fixed, meaning that the selection factor S(di) is a constant that can be dropped. Because uncertainties on l, b, and mG are neglected, the integral is reduced from seven to four dimensions, where these degrees of freedom are parametrised by distance and velocity in three dimensions.
The integral can in part be computed analytically, as the velocity distribution is a sum of multivariate Gaussians and uncertainties in velocity are described by a Gaussian covariance matrix. For this reason, it is only necessary to numerically compute the one-dimensional integration over distance.
Dropping the index i on the right-hand side for shorthand, the integral can be written
![Mathematical equation: $$ \begin{aligned}&\int \mathrm{Pr}({\boldsymbol{d}}_i \, | \, {\boldsymbol{\psi }}_{i})\, \mathrm{Pr}({\boldsymbol{\psi }}_{i} \, | \, {\boldsymbol{\Psi }})\, \mathrm{d}{\boldsymbol{\psi }}_{i} \nonumber \\&\quad \quad \propto \int \Bigg [ \int \mathrm{Pr}({\boldsymbol{d}} \, |\, {\boldsymbol{\nu }},\varpi )\,\mathrm{Pr}({\boldsymbol{\nu }}\, |\, {\boldsymbol{\Psi }},\varpi ) \, n(z) \,\mathrm{d}^3{\boldsymbol{\nu }} \Bigg ]\nonumber \\&\quad \quad \times \, {\mathcal{G} }(\varpi -\hat{\varpi },\hat{\sigma }_\varpi )\, F(M_G)\, d^2\, \mathrm{d} d, \end{aligned} $$](/articles/aa/full_html/2019/03/aa34718-18/aa34718-18-eq37.gif) (18)
(18)
where the integral over velocity, within the large brackets, has an analytic form. It is implicit that the true parallax value ϖ is given by the inverse of the distance d, and that the absolute magnitude MG is set by the distance d, apparent magnitude mG, and dust extinction Ξ(x). In principle, also the function n(z) can be moved outside the inner integral, but not doing so makes the end result somewhat more elegant.
We express the likelihood of the data Pr(d | ν, ϖ) in terms of velocities vl, vb, and vRV, which are the velocities in longitudinal, latitudinal and radial directions. The integral over velocities is performed under a fixed true parallax value ϖ (or fixed distance, equivalently). Quantities which are conditional on a fixed parallax are marked with a tilde. The conditional likelihood mean value for velocity in the latitudinal direction is equal to
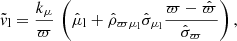 (19)
(19)
where kμ = 4.74057 yr × km s−1 is a unit conversion constant. The equivalent expression holds for ṽb. We define a vector of conditional mean values for the velocity likelihood, which is
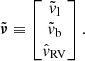 (20)
(20)
The conditional error covariance matrix for velocities in the latitudinal and longitudinal directions is
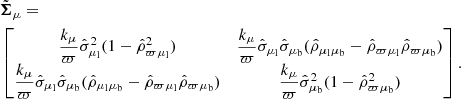 (21)
(21)
The full conditional error covariance matrix for velocity is
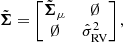 (22)
(22)
where ∅ are zero valued sub-matrices of shapes 1 × 2 and 2 × 1.
The velocity distribution Pr(ν | Ψ, ϖ) is described by a Gaussian mixture, according to
![Mathematical equation: $$ \begin{aligned} \mathrm{Pr}({\boldsymbol{\nu }}\, |\, {\boldsymbol{\Psi }},\varpi )\, n(z) = \sum _{k=1}^5 \, \sum _{j=1}^3\, a_k \, c_j \, \exp \left[-\frac{\Phi (Z)}{\sigma _j^2}\right] \, {\mathcal{N} }({\boldsymbol{\nu }}-{\boldsymbol{\nu }}_{k},{\boldsymbol{\Sigma }}_{jk}), \end{aligned} $$](/articles/aa/full_html/2019/03/aa34718-18/aa34718-18-eq42.gif) (23)
(23)
where
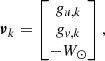 (24)
(24)
and
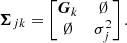 (25)
(25)
Because the likelihood of the data is also on a multivariate Gaussian form, the integral over velocity in Eq. (18) becomes an analytic sum over the multivariate Gaussians of the velocity distribution. It is equal to
![Mathematical equation: $$ \begin{aligned}&\int \mathrm{Pr}({\boldsymbol{d}} \, |\, {\boldsymbol{\nu }},\varpi )\, \mathrm{Pr}({\boldsymbol{\nu }}\, |\, {\boldsymbol{\Psi }},\varpi ) \, n(z) \, \mathrm{d}^3{\boldsymbol{\nu }} \nonumber \\&\quad \quad = \sum _{k=1}^5 \, \sum _{j=1}^3\, a_k \, c_j \, \exp \left[-\frac{\Phi (Z)}{\sigma _j^2}\right] {\mathcal{N} }\big ({\boldsymbol{R}}\tilde{\boldsymbol{\nu }}-{\boldsymbol{\nu }}_{k},{\boldsymbol{R}}\tilde{\boldsymbol{\Sigma }}{\boldsymbol{R}}^{-1}+{\boldsymbol{\Sigma }}_{jk}\big ), \end{aligned} $$](/articles/aa/full_html/2019/03/aa34718-18/aa34718-18-eq45.gif) (26)
(26)
where
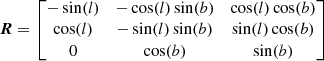 (27)
(27)
is the rotational matrix going from longitudinal-latitudinal-radial velocities to u-v-w velocities.
In the case that an object is missing a radial velocity observation, the three-dimensional velocity distribution is projected to the plane perpendicular to the line-of-sight. The integral over velocity becomes
![Mathematical equation: $$ \begin{aligned}&\int \mathrm{Pr}({\boldsymbol{d}} \, |\, {\boldsymbol{\nu }},\varpi )\, \mathrm{Pr}({\boldsymbol{\nu }}\, |\, {\boldsymbol{\Psi }},\varpi ) \, n(z) \, \mathrm{d}^3{\boldsymbol{\nu }} \nonumber \\&\quad \quad = \sum _{k=1}^5 \, \sum _{j=1}^3\, a_k \, c_j \, \exp \left[-\frac{\Phi (Z)}{\sigma _j^2}\right] {\mathcal{N} }\Big ( \big \langle \tilde{\boldsymbol{\nu }}-{\boldsymbol{R}}^{-1}{\boldsymbol{\nu }}_{k} \big \rangle , \big \langle \tilde{\boldsymbol{\Sigma }}+{\boldsymbol{R}}^{-1}{\boldsymbol{\Sigma }}_{jk}{\boldsymbol{R}} \big \rangle \Big ), \end{aligned} $$](/articles/aa/full_html/2019/03/aa34718-18/aa34718-18-eq47.gif) (28)
(28)
where ⟨…⟩ denotes this projection; for example, ![Mathematical equation: $ \big\langle \tilde{\boldsymbol{\nu}} \big \rangle = [\tilde{\mathit{v}}_{\mathrm{l}},\tilde{\mathit{v}}_{\mathrm{b}}] $](/articles/aa/full_html/2019/03/aa34718-18/aa34718-18-eq48.gif) and
and 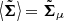 .
.
It might seem superfluous to integrate over the velocity for stellar objects that are missing radial velocity measurements and are situated in the direction of the Galactic north or south pole, as they do not directly constrain the vertical velocity distribution. However, the proper motion is still informative about the distance of such a stellar object, since their velocity parallel to the plane must be consistent with f∥. This is especially informative when the parallax uncertainty is large.
4.3. Normalisation
The normalisation N̄(Ψ, S) is in the denominator of the integrand of Eq. (15). It normalises the nominator of the integrand, and depends on the population parameters Ψ and the selection function S. It is equal to
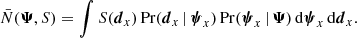 (29)
(29)
The index x on ψx and dx signifies that this is not an integral over an object in the sample, but an integral over a hypothetical object’s generated stellar parameters and data, as drawn from the population model.
The selection function, described in Sect. 3.2, is only dependent on position and magnitude, where uncertainty on angles l and b are small enough to be neglected. Therefore, the integral in the normalisation factor reduces to
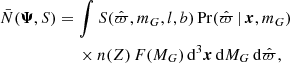 (30)
(30)
where the only degree of freedom that remains in terms of the data is the observed parallax. It is implicit that the apparent magnitude is given by the true position and true absolute magnitude, according to
![Mathematical equation: $$ \begin{aligned} m_G=M_G+5\Bigg [\log _{10}\Bigg (\frac{\mathrm{arcs}}{\varpi }\Bigg )-1\Bigg ]+\Xi ({\boldsymbol{x}}). \end{aligned} $$](/articles/aa/full_html/2019/03/aa34718-18/aa34718-18-eq52.gif) (31)
(31)
The only component of Eq. (30) that remains to be explained is 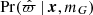 , which is the probability of observing a certain parallax, given a stellar object’s true position and true absolute magnitude. It is given by an integral over parallax uncertainties,
, which is the probability of observing a certain parallax, given a stellar object’s true position and true absolute magnitude. It is given by an integral over parallax uncertainties,
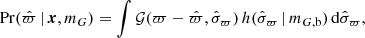 (32)
(32)
where 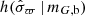 is the density of parallax uncertainties as described in Sect. 3.3.
is the density of parallax uncertainties as described in Sect. 3.3.
Despite the above simplifications, this integral is still high-dimensional and expensive to compute. However, it is possible to catalogue a vector of effective area Aeff, reducing this integral to only one dimension. The normalisation factor can be written on the form
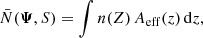 (33)
(33)
where n(Z) is the number density function of Eq. (5), and Z = z + Z⊙. The effective area is given by
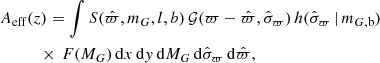 (34)
(34)
where the true parallax ϖ has an implicit dependence on the coordinates x = {x, y, z}. The effective area does not depend on the population parameters, but only on fixed background distributions. The effective area is plotted in the control plots of Appendix D.
5. Results
In order to explore the posterior distribution of the population parameters, as defined in Eq. (15), we sampled this function using a Metropolis-Hastings Markov chain Monte-Carlo (MCMC) algorithm (Gelman et al. 2013). After a thorough burn-in phase, where the maximum mode was located and the step length is calibrated, the MCMC was run for 10 000 steps. The MCMC chain was then thinned by a factor of 10. The code that was used to generate the results presented in this article is open source and available online2.
5.1. Mock data
In order to test the method and its constraining power, the statistical method was applied to four mock data samples. The construction of mock data samples and the statistical results are explained in detail in Appendix C. For all mock data samples, the matter distribution of the generated data was recovered in the 90% highest posterior density region, with statistical uncertainties similar to those of the real data samples.
5.2. Gaia data
For the eight Gaia data samples, S1–S8, the population parameter inference was performed for three separate cases. In the first case, we used the velocity information of all stellar objects. In the second case, we used the velocity information only of stellar objects with a good radial velocity measurement (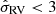 km s−1, amounting to 75–85% of the respective sample’s total number of stellar objects), with no dependence of the horizontal velocity distribution f∥. For the third case, we used the velocity information of stellar objects with |b|≤5°, and therefore close to the mid-plane. For stellar objects where the velocity information was neglected, only their position was integrated over.
km s−1, amounting to 75–85% of the respective sample’s total number of stellar objects), with no dependence of the horizontal velocity distribution f∥. For the third case, we used the velocity information of stellar objects with |b|≤5°, and therefore close to the mid-plane. For stellar objects where the velocity information was neglected, only their position was integrated over.
Comparing the results of these three cases functions as a test of possible systematic errors to the model, which could manifest as an inconsistency between them. The second case does not depend on the horizontal velocity distribution, providing a test of the approximation that f∥ and f⊥ are separable. The latter case is similar to the method used by Widmark & Monari (2018), Schutz et al. (2018), Buch et al. (2019), and is therefore useful for comparing results with these previous studies.
The inferred density of samples S1–S8 are shown in Fig. 4, for the three cases described above. The respective bands correspond to the 16th and 84th percentiles of the inferred density at different heights Z. In this figure, the eight samples’ posterior densities are summed together; hence, the width of the bands include statistical variance within samples as well as variance between samples. Also shown is a baryonic model, as described in Sect. 2.5. The density at heights |Z|≳60 pc is consistent with the baryonic model and a dark matter halo density of 0.01 M⊙ pc−3 (although not strong enough to constrain it). Closer to the mid-plane, the inferred matter density is significantly higher than that of the baryonic model, with a surplus that is roughly in the range 0.05–0.15 M⊙ pc−3. The case with full velocity information agrees well with the case where we consider the velocity information only of stellar objects with good radial velocity measurements, although the inferred densities are marginally higher. The case with only mid-plane velocities differs somewhat, preferring a lower mid-plane matter density for most samples. The inferred matter density is also shown in more detailed figures in Appendix B.
 |
Fig. 4. Inferred total matter density of data samples S1–S8, as a function of height with respect to the Galactic plane. The matter density is plotted for three different cases: when using the velocity information of all stellar objects, when using the velocity information of stellar objects with good radial velocity measurements only, and when using the velocity information of stellar objects in the mid-plane only. Also shown is the 1-σ band of the baryonic model (see Sect. 2.5). |
In Fig. 5, we show the surplus of the inferred matter density distribution within 60 pc from the Galactic disc, for the three cases described above. The surplus is with respect to a background model, consisting of a homogeneous dark matter halo with a density of 0.01 M⊙ pc−3 and a distribution of baryons, following the model described Sect. 2.5 and using the mean values of Table 2. The uncertainty of the matter density of the baryonic model is 0.0071 M⊙ pc−3 in the mid-plane. Assuming that the dark matter halo uncertainty is sub-dominant, this amounts to an uncertainty of about 0.85 M⊙ pc−2 to the surface density within |Z| < 60 pc.
 |
Fig. 5. Surplus surface density of matter within |Z| < 60 pc, when comparing the inferred dynamical matter density with a model consisting of baryons and a dark matter halo. Upper panel: posterior for the case when the velocity information of all stellar objects are considered, middle panel: case when only the velocity information of stellar objects with good radial velocity measurements are considered, lower panel: case when only mid-plane velocities are considered. |
For the first case where the velocity information of all stellar objects are accounted for (upper panel), samples S1–S5 agree very well, centred on about 5 M⊙ pc−2. Samples S6–S8, which are the least luminous, are outliers in the sense that they all infer higher mid-plane matter densities, possibly indicating some kind of systematic bias. The results of the second case, which has no dependence on the horizontal velocity distribution, shows a similar result. Comparing with the first case, the posterior medians are marginally higher and the posterior widths are inflated by up to 20%. This indicates that the approximation of separability of f∥ and f⊥ does not give rise to any significant bias. For the third case where only mid-plane velocities are accounted for (lower panel), samples S6–S8 are not strong outliers, although they infer slightly higher values than most other samples. Compared to other two cases, the posterior widths are larger and the inferred surplus density is slightly lower for most samples.
In Appendix D and Figs. D.1–D.8, we show comparisons between model and binned data, and the residual between the two, for data samples S1–S8. It is clear that there is substructure in phase-space that our model does not account for (also seen in Fig. 1). There is no signature of asymmetry to the stellar number density across the Galactic plane (although statistics are low for |z|≳150 pc), but there are signs of spatial substructure in all samples (left panels), where the residuals are as high as roughly three standard deviations at most. More severe are the substructures seen in the velocity distributions (right panels), where the highest residual is roughly four and a half standard deviations.
The inferred height and vertical velocity of the Sun with respect to the Galactic plane (Z⊙ and W⊙) are presented in Table 4 (for the case when all velocity information is accounted for). The marginalised posteriors over these parameters agree well with a Gaussian distribution, which is why they are presented in terms of their mean values and standard deviation. For the inferred height of the Sun above the Galactic plane, the most severe tension is almost two standard deviations between samples S2 and S8. For the inferred vertical velocity of the Sun, the different samples are in reasonable agreement with the exception of S8; between S3 and S8 there is a tension of four standard deviations. This is suggestive of a systematic error in how the velocity distribution is modelled. These discrepancies between samples are not, in and of themselves, indicative of systematic errors in other parameters; the uncertainties are very small, and there are no strong correlations between Z⊙, W⊙ and other population parameters. For the values where all samples are considered in unison, the posteriors of the respective samples are added together (not multiplied); this is very conservative, in the sense that the uncertainties are inflated, also accounting for systematic discrepancies between samples.
Inferred height Z⊙ and vertical velocity W⊙ of the Sun, with respect to the Galactic plane, for data samples S1–S5.
While uncertainties of the dust map were not accounted for in this work, dust extinction probably has a negligible effect, as argued in Sect. 2.3. We performed inference while completely ignoring dust effects, and found similar results as presented above.
6. Discussion
In all eight stellar samples analysed in this work, we infer a surplus of matter confined to the Galactic plane (|Z|≲60 pc), to high statistical significance. Comparing this with the expected density distribution of a baryonic model and a dark matter halo density of approximately 0.01 M⊙ pc−3, this surplus corresponds to an excess surface density of approximately 5–9 M⊙ pc−2.
These results are in mild tension with Schutz et al. (2018) and Buch et al. (2019), who report 95% constraints of around 7 M⊙ pc−2 to a surplus matter density with a scale height of 30 pc. There are a number of differences between these two studies and our analysis. They only use the velocity information of stars close to the Galactic plane, and have fewer and smaller stellar samples. In the latter study, bases on Gaia DR2, the limit comes from a sample of 4544 A type stars, out of which 310 constrain the velocity distribution.
There are some discrepancies between the results of the respective samples. While samples S1–S5 agree very well, samples S6–S8 are outliers with higher mid-plane matter densities. This is indicative of a smaller systematic error (not large enough to invalidate the inferred mid-plane surplus), likely correlated with stellar luminosity. As argued in Sect. 3, this is unlikely to be due to systematic errors in the data (astrometric systematics are small, and the completeness function would have to be incorrect by at least a few percent in order to explain this discrepancy). Potentially, the discrepancy is due to substructures in phase-space, which could be correlated with stellar type, luminosity and age, in the sense that different stellar populations are affected differently by non-stationary effects.
The inferred surplus matter density in the Galactic mid-plane could be explained by an underestimated density of baryons. The scale height of the matter surplus corresponds well with that of molecular gas, which is the coldest baryon component. It would be necessary to add a mid-plane density of at least 0.05 M⊙ pc−3 to the cold gas components in the baryonic model, thereby doubling the matter density of cold gas. In the baryonic model, the statistical uncertainty of the combined cold atomic and molecular mid-plane densities amount to 0.0064 M⊙ pc−3. In studies to determine the local density of gas, there is some variation comparable to the statistical error of the baryonic model used in this work (see for example Table 1 in Kramer & Randall 2016a). The local density of cold gas would have to be severely misunderstood in order to account for the inferred surplus. As mentioned in Sect. 1, an alternative and more exotic explanation for the surplus matter density could be double-disc dark matter, formed from a dark matter sub-component with strong dissipative self-interaction (Fan et al. 2013a,b).
The results for the vertical velocity of the Sun with respect to the Galactic plane is in accordance with most previous studies, for example Schönrich et al. (2010), Widmark & Monari (2018). The results for the height of the Sun with respect to the Galactic plane (4.76 ± 2.27 pc) agree well with Buch et al. (2019), but is in tension with for example Jurić et al. (2008), Yao et al. (2017), Widmark & Monari (2018), Bennett & Bovy (2019), who report higher values of 25 ± 5 pc, 13.4 ± 4.4 pc, 15.3 ± 2.2 pc, and 20.8 ± 0.3 pc, respectively. Bennett & Bovy (2019) demonstrate that the distribution of stars is not symmetric across the Galactic plane, and exhibit wave-like patterns in both number density and vertical velocity, especially at greater distances from the plane (>200 pc). For this reason, measurements of the Sun’s position with respect to the mid-plane can differ depending on how the mid-plane is defined, and what distance cuts are made in the analysis. Jurić et al. (2008), Yao et al. (2017), Bennett & Bovy (2019) all extend to kpc distances and fit symmetric stellar number density distributions, which could explain why they all infer higher values.
As discussed in the beginning of Sect. 2, there are phase-space structures observed with Gaia that our model does not account for. In a first step to relax the assumptions of a well-mixed, symmetric, separable and decoupled vertical velocity distribution, we plan to extend this work by instead fitting a Gaussian mixture model to the full three-dimensional velocity distribution. Effective sampling of such a model would constitute a significant computational challenge, due to its high dimensionality. It should be feasible by implementing such a model in a computational framework capable of auto-differentiation and using Hamiltonian Monte-Carlo sampling.
This work adds to the increasingly complex picture of Galactic dynamics that is emerging with Gaia DR2, calling for more sophisticated methods and models. With future data releases, increasingly accurate and robust dynamical determinations of the distribution of matter in the Galactic disc is expected.
Acknowledgments
I would like to thank Hiranya Peiris, Daniel Mortlock, Boris Leistedt, Jens Jasche, Sofia Sivertsson, and Giacomo Monari for helpful discussions. I would also like to thank the anonymous referee for contributing to this article. This work has made use of data from the European Space Agency (ESA) mission Gaia (https://www.cosmos.esa.int/gaia), processed by the Gaia Data Processing and Analysis Consortium (DPAC, https://www.cosmos.esa.int/web/gaia/dpac/consortium). Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement.
References
- Antoja, T., Helmi, A., Romero-Gómez, M., et al. 2018, Nature, 561, 360 [NASA ADS] [CrossRef] [Google Scholar]
- Bahcall, J. N. 1984a, ApJ, 276, 169 [NASA ADS] [CrossRef] [Google Scholar]
- Bahcall, J. N. 1984b, ApJ, 287, 926 [NASA ADS] [CrossRef] [Google Scholar]
- Banik, N., Widrow, L. M., & Dodelson, S. 2017, MNRAS, 464, 3775 [NASA ADS] [CrossRef] [Google Scholar]
- Bennett, M., & Bovy, J. 2019, MNRAS, 482, 1417 [NASA ADS] [CrossRef] [Google Scholar]
- Bienayme, O., Soubiran, C., Mishenina, T. V., Kovtyukh, V. V., & Siebert, A. 2006, A&A, 446, 933 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Binney, J., & Tremaine, S. 2008, Galactic Dynamics: Second Edition (Princeton University Press) [Google Scholar]
- Bovy, J., & Tremaine, S. 2012, ApJ, 756, 89 [Google Scholar]
- Buch, J., Leung, J. S. C., & Fan, J. 2019, MNRAS, 482, 1417 [NASA ADS] [CrossRef] [Google Scholar]
- Büdenbender, A., van de Ven, G., & Watkins, L. L. 2015, MNRAS, 452, 956 [NASA ADS] [CrossRef] [Google Scholar]
- Capitanio, L., Lallement, R., Vergely, J. L., Elyajouri, M., & Monreal-Ibero, A. 2017, A&A, 606, A65 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Caputo, A., Zavala, J., & Blas, D. 2018, Phys. Dark Univ., 19, 1 [CrossRef] [Google Scholar]
- Crézé, M., Chereul, E., Bienayme, O., & Pichon, C. 1998, A&A, 329, 920 [NASA ADS] [Google Scholar]
- Danielski, C., Babusiaux, C., Ruiz-Dern, L., Sartoretti, P., & Arenou, F. 2018, A&A, 614, A19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fan, J., Katz, A., Randall, L., & Reece, M. 2013a, Phys. Rev. Lett., 110, 211302 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Fan, J., Katz, A., Randall, L., & Reece, M. 2013b, Phys. Dark Univ., 2, 139 [CrossRef] [Google Scholar]
- Fitzpatrick, E. L. 1999, PASP, 111, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Flynn, C., Holmberg, J., Portinari, L., Fuchs, B., & Jahreiss, H. 2006, MNRAS, 372, 1149 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Babusiaux, C., et al.) 2018a, A&A, 616, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2018b, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Katz, D., et al.) 2018c, A&A, 616, A11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garbari, S., Read, J. I., & Lake, G. 2011, MNRAS, 416, 2318 [NASA ADS] [CrossRef] [Google Scholar]
- Garbari, S., Liu, C., Read, J. I., & Lake, G. 2012, MNRAS, 425, 1445 [NASA ADS] [CrossRef] [Google Scholar]
- Gelman, A., Carlin, J., Stern, H., et al. 2013, Bayesian Data Analysis: Third Edition (CRC Press) [Google Scholar]
- Green, G. M., Schlafly, E. F., Finkbeiner, D., et al. 2018, MNRAS, 478, 651 [NASA ADS] [CrossRef] [Google Scholar]
- Holmberg, J., & Flynn, C. 2000, MNRAS, 313, 209 [NASA ADS] [CrossRef] [Google Scholar]
- Hunt, J. A. S., Bovy, J., Pérez-Villegas, A., et al. 2018, MNRAS, 474, 95 [NASA ADS] [CrossRef] [Google Scholar]
- Jungman, G., Kamionkowski, M., & Griest, K. 1996, Phys. Rep., 267, 195 [NASA ADS] [CrossRef] [Google Scholar]
- Juri´c, M., Ivezi´c, Ž., Brooks, A., et al. 2008, ApJ, 673, 864 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Kapteyn, J. C. 1922, ApJ, 55, 302 [NASA ADS] [CrossRef] [Google Scholar]
- Katz, D., Sartoretti, P., Cropper, M., et al. 2019, A&A, 622, A205 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kramer, E. D., & Randall, L. 2016a, ApJ, 829, 126 [NASA ADS] [CrossRef] [Google Scholar]
- Kramer, E. D., & Randall, L. 2016b, ApJ, 824, 116 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K., & Gilmore, G. 1991, ApJ, 367, L9 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K., & Gilmore, G. 1989a, MNRAS, 239, 571 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K., & Gilmore, G. 1989b, MNRAS, 239, 605 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K., & Gilmore, G. 1989c, MNRAS, 239, 651 [NASA ADS] [Google Scholar]
- Luri, X., Brown, A. G. A., Sarro, L. M., et al. 2018, A&A, 616, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- McKee, C. F., Parravano, A., & Hollenbach, D. J. 2015, ApJ, 814, 13 [NASA ADS] [CrossRef] [Google Scholar]
- Monari, G., Kawata, D., Hunt, J. A. S., & Famaey, B. 2017, MNRAS, 466, L113 [NASA ADS] [CrossRef] [Google Scholar]
- Monari, G., Famaey, B., Minchev, I., et al. 2018, Res. Notes Am. Astron. Soc., 2, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Necib, L., Lisanti, M., & Belokurov, V. 2018, ArXiv e-prints [arXiv:1807.02519] [Google Scholar]
- Oort, J. H. 1932, Bull. Astron. Inst. Neth., 6, 249 [NASA ADS] [Google Scholar]
- Purcell, C. W., Bullock, J. S., & Kaplinghat, M. 2009, ApJ, 703, 2275 [NASA ADS] [CrossRef] [Google Scholar]
- Ramos, P., Antoja, T., & Figueras, F. 2018, A&A, 619, A72 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Read, J. I. 2014, J. Phys. G Nucl. Phys., 41, 063101 [NASA ADS] [CrossRef] [Google Scholar]
- Ruchti, G. R., Read, J. I., Feltzing, S., Pipino, A., & Bensby, T. 2014, MNRAS, 444, 515 [Google Scholar]
- Schönrich, R., Binney, J., & Dehnen, W. 2010, MNRAS, 403, 1829 [NASA ADS] [CrossRef] [Google Scholar]
- Schutz, K., Lin, T., Safdi, B. R., & Wu, C.-L. 2018, Phys. Rev. Lett., 121, 081101 [NASA ADS] [CrossRef] [Google Scholar]
- Sivertsson, S., Silverwood, H., Read, J. I., Bertone, G., & Steger, P. 2018, MNRAS, 478, 1677 [Google Scholar]
- Soubiran, C., Cantat-Gaudin, T., Romero-Gómez, M., et al. 2018, A&A, 619, A155 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Widmark, A., & Monari, G. 2018, MNRAS, 482, 262 [Google Scholar]
- Yao, J. M., Manchester, R. N., & Wang, N. 2017, MNRAS, 468, 3289 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, L., Rix, H.-W., van de Ven, G., et al. 2013, ApJ, 772, 108 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Gaussian mixture model of the horizontal velocity distribution
The distribution of velocities parallel to the plane, f∥(u, v), was fitted using a Gaussian mixture model consisting of five Gaussians. It was fitted to Gaia DR2 with the following data cuts: an observed distance in range 100–200 pc; an observed absolute magnitude in range 3.0–6.3; an available radial velocity value; a parallax uncertainty smaller than 0.1 mas. These cuts give a total of 165 593 stellar objects.
The fit was performed using SCIKIT-LEARN. The numerical values of the five Gaussians of the mixture are presented in Table A.1.
Gaussians mixture model component values of f∥(u, v): weights ak, mean values gk, and covariance matrices Gk, where k = {1, 2, 3, 4, 5}.
Appendix B: Posterior densities
The inferred matter density of samples S1–S8 is shown in Fig. B.1, for the case when all velocity information is used, in Fig. B.2, where only where only the velocity information of stellar objects with radial velocity measurements are used (no dependence on the horizontal velocity distribution), and in Fig. B.3, where only the velocity information of the mid-plane stellar objects are used. These posterior probability distributions are not presented in terms of the population parameters ρ{1, 2, 3, 4}, but in terms of the inferred matter density at Z = {0, 50, 120} pc (which is a linear combination of ρ{1, 2, 3, 4}). In order to facilitate an easy comparison, all the axis ranges are the same for these three plots, for each respective panel.
 |
Fig. B.1. Inferred total dynamical matter density of data samples S1–S8 at heights 0, 50, and 120 pc above the Galactic plane, for the case where the velocity information of all stellar objects is accounted for. The panels on the diagonal show one-dimensional projections of the posterior probability density of the eight samples, as well as the 1-σ band of the baryonic model in light grey. The other three panels show two-dimensional projections of the posteriors, represented as 90% highest posterior density regions. Axis are shared between panels, apart from the vertical axis of the one-dimensional projections. The legend applies to all panels. |
 |
Fig. B.2. Inferred total dynamical matter density of data samples S1–S8 at heights 0, 50, and 120 pc above the Galactic plane, for the case where the velocity information of only the stellar objects with good radial velocity information is accounted for. The panels on the diagonal show one-dimensional projections of the posterior probability density of the eight samples, as well as the 1-σ band of the baryonic model in light grey. The other three panels show two-dimensional projections of the posteriors, represented as 90% highest posterior density regions. Axis are shared between panels, apart from the vertical axis of the one-dimensional projections. The legend applies to all panels. |
 |
Fig. B.3. Inferred total dynamical matter density of data samples S1–S8 at heights 0, 50, and 120 pc above the Galactic plane, for the case where the velocity information of only the mid-plane stellar objects is accounted for. The panels on the diagonal show one-dimensional projections of the posterior probability density of the eight samples, as well as the 1-σ band of the baryonic model in light grey. The other three panels show two-dimensional projections of the posteriors, represented as 90% highest posterior density regions. Axis are shared between panels, apart from the vertical axis of the one-dimensional projections. The legend applies to all panels. |
In all three figures, the density close to the mid-plane, at Z = 0 pc, is somewhat anti-correlated with the densities at Z = 50 pc and Z = 120 pc. In Figs. B.1 and B.2, there is tension between samples for the projection over posterior projection over ρ(Z = 0 pc) and ρ(Z = 50 pc); the 90% highest posterior density region of sample S5 is barely or not at all overlapping with those of S6, S7, and S8. The statistical uncertainty is larger for Fig. B.3, and the posterior densities of the different samples overlap without apparent outlier groups.
Appendix C: Mock data
Four mock data samples named M1–M4 were generated using the following population parameter values:
 (C.1)
(C.1)
The background distributions used to generate them were the same as those used for the inference on actual data. The sample cuts were the same as the real data samples S2–S5, listed in Table 3.
The mock samples were constructed by rejection sampling, by generating objects from the true underlying model, assigning uncertainties and errors to those stellar objects, and including them in the sample if they meet the selection criteria. We took care to generate objects also outside the region defined by the selection cuts, to allow for stellar objects to scatter into the sample via observational errors.
The uncertainties on the parallax measurements were drawn from the background distribution 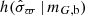 . The uncertainties on proper motions were drawn from corresponding distributions, given by data samples S2–S5. In the Gaia data, the astrometric uncertainties are strongly correlated. We assumed maximum correlation for the mock data, such that the parallax uncertainty and the proper motion uncertainties of a stellar object were drawn from the same percentile in their respective distributions. We took the correlations between astrometric observables to be drawn at random these Gaussian distributions: 𝒢(0, 0.22) for
. The uncertainties on proper motions were drawn from corresponding distributions, given by data samples S2–S5. In the Gaia data, the astrometric uncertainties are strongly correlated. We assumed maximum correlation for the mock data, such that the parallax uncertainty and the proper motion uncertainties of a stellar object were drawn from the same percentile in their respective distributions. We took the correlations between astrometric observables to be drawn at random these Gaussian distributions: 𝒢(0, 0.22) for 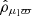 and
and 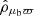 , and
, and 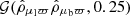 for
for 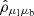 , which mimics the behaviour of correlations in the actual data.
, which mimics the behaviour of correlations in the actual data.
The results of the inference on mock data is presented in Fig. C.1, in plots similar to those of Appendix B. Similarly to the case of the Gaia data samples S1–S8, the density close to the mid-plane is anti-correlated with the density far from the Galactic plane.
 |
Fig. C.1. Inferred total dynamical matter density of mock data samples M1-M4, at heights 0, 50, and 120 pc above the Galactic plane. The panels on the diagonal show one-dimensional projections of the posterior probability density of the eight samples. The other three panels show two-dimensional projections of the posteriors, represented as 90% highest posterior density regions. The dashed lines indicate the matter densities of the model used to generate the data. Axis are shared between panels, apart from the vertical axis of the one-dimensional projections. The legend applies to all panels. |
Appendix D: Control plots
In Figs. D.1–D.8, we show comparisons between model and data for samples S1–S8. The adopted model in these figures is given by the median values of population parameters in the inferred posterior density.
 |
Fig. D.1. Control plot for sample S1, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
 |
Fig. D.2. Control plot for sample S2, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
 |
Fig. D.3. Control plot for sample S3, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
 |
Fig. D.4. Control plot for sample S4, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
 |
Fig. D.5. Control plot for sample S5, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
 |
Fig. D.6. Control plot for sample S6, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
 |
Fig. D.7. Control plot for sample S7, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
 |
Fig. D.8. Control plot for sample S8, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
In the left panel of these figures, we show the stellar object number count in bins of height with respect to the Sun (z), which is equal to the stellar number density times the effective area. The effective area is the number count that would be observed if the stellar number density was uniform, owing its shape to the sample shell volume. In the figure, the effective area is normalised to be equal to the model curve in z = 0 pc. The data of this panel is a histogram over the full data sample, where the height is given by the angle b and observed parallax 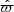 , thus neglecting observational errors.
, thus neglecting observational errors.
In the right panel of these figures, we show the stellar object number count in bins of vertical velocity with respect to the Sun (w). This is for stellar objects that fulfil the following criteria: |Ẑ| = |ẑ + Z⊙| < 10 pc; 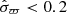 mas; either an available radial velocity measurement, or |b| < 5°. For stellar objects that have a radial velocity measurement, the velocity of that object is taken to be
mas; either an available radial velocity measurement, or |b| < 5°. For stellar objects that have a radial velocity measurement, the velocity of that object is taken to be
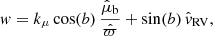 (D.1)
(D.1)
where kμ is the same unit conversion constant that is used in Eq. (19). For stars without radial velocity, but |b| < 5°, the velocity is instead
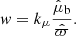 (D.2)
(D.2)
As such, the vertical velocity is only shown for a subset of stellar objects with small uncertainties, close to the Galactic plane. In the full statistical model, the velocity information of all stars is considered. The residuals, calculated for each separate bin, is defined as
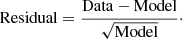 (D.3)
(D.3)
All Tables
Population parameters, object parameters and data of each stellar object, parameters and distributions with implicit dependence on the population parameters, and fixed background distributions of our model.
Mid-plane densities ρt and velocity dispersions σt of baryonic matter components.
Inferred height Z⊙ and vertical velocity W⊙ of the Sun, with respect to the Galactic plane, for data samples S1–S5.
Gaussians mixture model component values of f∥(u, v): weights ak, mean values gk, and covariance matrices Gk, where k = {1, 2, 3, 4, 5}.
All Figures
|
Fig. 1. Gaussian mixture model and data over u and v velocities. Bottom-left panel: data is plotted as a 2D histogram, overlaid by the 1-sigma ellipses of the five Gaussians of the mixture model. The shading of the ellipses correspond to the weight of the respective Gaussians, where a darker colour correspond to a larger weight. Top and bottom-right panels: fitted model and the data are marginalised to 1D histograms over u and v. |
| In the text | |
|
Fig. 2. Luminosity function F(MG), describing the number density of stars in the solar neighbourhood, as a function of absolute magnitude in the GaiaG-band. The solid lines are the binned data and the spline function F(MG). The dashed lines correspond to the absolute magnitude bounds by which the four data samples are constructed. The function is not normalised and need not be. |
| In the text | |
|
Fig. 3. Baryonic matter density, as a function of height above the Galactic plane. Five coloured 1-σ bands show the total baryonic density, as well as a division into four separate groups: the “stars and dwarfs” include all types of stars, white dwarfs, and brown dwarfs; the “cold atomic gas” and “molecular gas” correspond directly to their respective single components of Table 2; the “warm and hot gas” correspond to the warm atomic gas and hot ionised gas components. |
| In the text | |
|
Fig. 4. Inferred total matter density of data samples S1–S8, as a function of height with respect to the Galactic plane. The matter density is plotted for three different cases: when using the velocity information of all stellar objects, when using the velocity information of stellar objects with good radial velocity measurements only, and when using the velocity information of stellar objects in the mid-plane only. Also shown is the 1-σ band of the baryonic model (see Sect. 2.5). |
| In the text | |
|
Fig. 5. Surplus surface density of matter within |Z| < 60 pc, when comparing the inferred dynamical matter density with a model consisting of baryons and a dark matter halo. Upper panel: posterior for the case when the velocity information of all stellar objects are considered, middle panel: case when only the velocity information of stellar objects with good radial velocity measurements are considered, lower panel: case when only mid-plane velocities are considered. |
| In the text | |
|
Fig. B.1. Inferred total dynamical matter density of data samples S1–S8 at heights 0, 50, and 120 pc above the Galactic plane, for the case where the velocity information of all stellar objects is accounted for. The panels on the diagonal show one-dimensional projections of the posterior probability density of the eight samples, as well as the 1-σ band of the baryonic model in light grey. The other three panels show two-dimensional projections of the posteriors, represented as 90% highest posterior density regions. Axis are shared between panels, apart from the vertical axis of the one-dimensional projections. The legend applies to all panels. |
| In the text | |
|
Fig. B.2. Inferred total dynamical matter density of data samples S1–S8 at heights 0, 50, and 120 pc above the Galactic plane, for the case where the velocity information of only the stellar objects with good radial velocity information is accounted for. The panels on the diagonal show one-dimensional projections of the posterior probability density of the eight samples, as well as the 1-σ band of the baryonic model in light grey. The other three panels show two-dimensional projections of the posteriors, represented as 90% highest posterior density regions. Axis are shared between panels, apart from the vertical axis of the one-dimensional projections. The legend applies to all panels. |
| In the text | |
|
Fig. B.3. Inferred total dynamical matter density of data samples S1–S8 at heights 0, 50, and 120 pc above the Galactic plane, for the case where the velocity information of only the mid-plane stellar objects is accounted for. The panels on the diagonal show one-dimensional projections of the posterior probability density of the eight samples, as well as the 1-σ band of the baryonic model in light grey. The other three panels show two-dimensional projections of the posteriors, represented as 90% highest posterior density regions. Axis are shared between panels, apart from the vertical axis of the one-dimensional projections. The legend applies to all panels. |
| In the text | |
|
Fig. C.1. Inferred total dynamical matter density of mock data samples M1-M4, at heights 0, 50, and 120 pc above the Galactic plane. The panels on the diagonal show one-dimensional projections of the posterior probability density of the eight samples. The other three panels show two-dimensional projections of the posteriors, represented as 90% highest posterior density regions. The dashed lines indicate the matter densities of the model used to generate the data. Axis are shared between panels, apart from the vertical axis of the one-dimensional projections. The legend applies to all panels. |
| In the text | |
|
Fig. D.1. Control plot for sample S1, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
| In the text | |
|
Fig. D.2. Control plot for sample S2, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
| In the text | |
|
Fig. D.3. Control plot for sample S3, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
| In the text | |
|
Fig. D.4. Control plot for sample S4, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
| In the text | |
|
Fig. D.5. Control plot for sample S5, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
| In the text | |
|
Fig. D.6. Control plot for sample S6, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
| In the text | |
|
Fig. D.7. Control plot for sample S7, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
| In the text | |
|
Fig. D.8. Control plot for sample S8, comparing the inferred model with the data. Left panel: stellar number count as a function of height with respect to the Sun. Right panel: vertical velocity distribution for stars close to the Galactic plane. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.