| Issue |
A&A
Volume 577, May 2015
|
|
|---|---|---|
| Article Number | A19 | |
| Number of page(s) | 15 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201425460 | |
| Published online | 24 April 2015 | |
Evidence for the inside-out growth of the stellar mass distribution in galaxy clusters since z ~ 1⋆
1
Laboratoire AIM, IRFU/Service d’Astrophysique − CEA/DSM – CNRS – Université
Paris Diderot, Bât. 709, CEA-Saclay,
91191
Gif-sur-Yvette Cedex
France
e-mail:
This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Leiden Observatory, Leiden University,
PO Box 9513, 2300 RA
Leiden, The
Netherlands
3
Kavli Institute for Cosmology, University of
Cambridge, Madingley
Road, Cambridge,
CB3 0HA,
UK
4
Department of Physics and Astronomy, University of
Waterloo, Waterloo,
Ontario, N2L 3G1, Canada
5
School of Physics and Astronomy, University of
Birmingham, Edgbaston, Birmingham, B15
2TT, UK
Received: 4 December 2014
Accepted: 13 February 2015
Abstract
We study the radial number density and stellar mass density distributions of satellite galaxies in a sample of 60 massive clusters at 0.04 <z< 0.26 selected from the Multi-Epoch Nearby Cluster Survey (MENeaCS) and the Canadian Cluster Comparison Project (CCCP). In addition to ~10 000 spectroscopically confirmed member galaxies, we use deep ugri-band imaging to estimate photometric redshifts and stellar masses, and then statistically subtract fore- and background sources using data from the COSMOS survey. We measure the galaxy number density and stellar mass density distributions in logarithmically spaced bins over 2 orders of magnitude in radial distance from the BCGs. For projected distances in the range 0.1 <R/R200< 2.0, we find that the stellar mass distribution is well-described by an NFW profile with a concentration of c = 2.03 ± 0.20. However, at smaller radii we measure a significant excess in the stellar mass in satellite galaxies of about 1011M⊙ per cluster, compared to these NFW profiles. We do obtain good fits to generalised NFW profiles with free inner slopes and to Einasto profiles. To examine how clusters assemble their stellar mass component over cosmic time, we compare this local sample to the GCLASS cluster sample at z ~ 1, which represents the approximate progenitor sample of the low-z clusters. This allows for a direct comparison, which suggests that the central parts (R< 0.4 Mpc) of the stellar mass distributions of satellites in local galaxy clusters are already in place at z ~ 1, and contain sufficient excess material for further BCG growth. Evolving towards z = 0, clusters appear to assemble their stellar mass primarily onto the outskirts, making them grow in an inside-out fashion.
Key words: galaxies: clusters: general / galaxies: evolution / galaxies: photometry
Appendix A is available in electronic form at http://www.aanda.org
© ESO, 2015
1. Introduction
Our concordance cosmological model describes a Universe dominated by dark matter and dark energy, in which structures form hierarchically. Within this Lambda-Cold-Dark-Matter (ΛCDM) framework, N-body simulations provide clear predictions for the structure and evolution of dark matter haloes (e.g. Duffy et al. 2008; Dutton & Macciò 2014), and a confrontation with observations provides an important test of our ΛCDM paradigm. A key open question is how galaxies form in this dark-matter-dominated Universe. The baryonic physics involved may also play a significant role in altering the total mass profiles (e.g. van Daalen et al. 2011; Velliscig et al. 2014) and therefore complicate a direct comparison with predictions from dark matter simulations. However, as hydrodynamical simulations continue to advance (e.g. Schaye et al. 2010; Cen 2014; Genel et al. 2014; Schaye et al. 2015), they provide testable predictions of the distribution of baryonic tracers, such as gas and stars.
An important open question in this context is how well stellar mass traces the underlying dark matter distribution, and if the distribution of galaxies is consistent with what we expect for the sub-haloes in ΛCDM (e.g. Boylan-Kolchin et al. 2011). On the scale of our Milky Way, recent hydrodynamical simulations are able to alleviate the tension between the abundance of sub-haloes in N-body simulations, and the observed distribution of satellites, by incorporating baryonic processes such as supernova feedback (e.g. Geen et al. 2013; Sawala et al. 2013). More massive haloes, such as galaxy clusters, have correspondingly more massive sub-haloes, which is expected to make them more efficient at forming stars, less subjective to feedback processes, and relatively easy to identify through observations.
Measuring the radial number and stellar mass density distribution of satellite galaxies in clusters has been the focus of several studies. These distributions have been observed to be well described by Navarro-Frenk-White (NFW; Navarro et al. 1997) profiles for group-sized haloes and clusters, from the local Universe to z ~ 1 (Carlberg et al. 1997; Lin et al. 2004; Muzzin et al. 2007; Giodini et al. 2009; Budzynski et al. 2012; van der Burg et al. 2014). Each observational study, however, is based on a different data set and analysis and presents results in a different form. Lin et al. (2004) and Budzynski et al. (2012) studied the number density of galaxies, but owing to interactions between galaxies and, in particular, the mass-dependence of the dynamical friction timescale, the number density distribution of galaxies can be different for galaxies with different luminosities or stellar masses. Their results are therefore dependent on the depth of their data set. Giodini et al. (2009) measured the number density distribution of generally lower mass systems from the COSMOS field. Carlberg et al. (1997) and Muzzin et al. (2007) measured the luminosity density distribution in the r-band and K-band, respectively, for clusters from the Canadian Network for Observational Cosmology Survey (CNOC; Yee et al. 1996). The advantage of this measurement is that, provided the measurements extend significantly below the characteristic luminosity L∗, it is almost insensitive to the precise luminosity cut. That is because the total luminosity in each radial bin is dominated by galaxies around L∗. However, especially in the r-band, it is not straightforward to relate the luminosity distribution to a stellar mass distribution due to differences in mass-to-light-ratio between different galaxy types, and because the distributions of these types vary spatially. Inconsistencies between all these studies prevent us from drawing firm conclusions on comparisons between them.
In this paper we present a comprehensive measurement of the radial galaxy number density and stellar mass density from a sample of 60 massive clusters in the local Universe (0.04 <z< 0.26), based on deep ugri-band photometry and verified with ample spectroscopic data. The clusters in this sample are approximate descendants of the Gemini Cluster Astrophysics Spectroscopic Survey (GCLASS) cluster sample (by number density), which is a spectroscopic survey of ten rich clusters at z ~ 1 (see Muzzin et al. 2012). In Appendix A, we provide more details on the GCLASS sample selection, and illustrate that the selected clusters make up an approximately representative sample of the high-mass tail of the underlying halo mass distribution. For the GCLASS clusters, the satellite number density (down to galaxies with stellar mass 1010.2M⊙) and stellar mass density distribution have been measured by van der Burg et al. (2014, hereafter vdB14). By performing the measurements in the present study as consistently as possible with the GCLASS measurement, we study how the stellar mass distribution in massive haloes evolves since z ~ 1.
The structure of this paper is as follows. In Sect. 2 we give an overview of the cluster sample, the available spectroscopic data set and the photometric catalogues based on ugri-band photometry. Section 3 presents the measurement of the radial density profiles, based on a photometric study but compared with the spectroscopic data for robustness tests. The results are presented in Sect. 4, and put into context against low-z literature measurements by a comparison of their best-fitting NFW-profile parameters. In Sect. 5 we study the cluster centres in more detail, examining whether the central excess depends on a cluster property in particular. In Sect. 6 we discuss the observed evolution between z ~ 1 and our local study by comparing their stellar mass density profiles on the same physical scale, and discuss the role of build-up of the BCG and ICL components in this context. We summarise and conclude in Sect. 7.
All magnitudes we quote are in the AB magnitudes system, and we adopt ΛCDM cosmology with Ωm = 0.3, ΩΛ = 0.7 and H0 = 70 km s-1 Mpc-1. For stellar mass estimates we assume the same initial mass function (IMF) as was used in vdB14, namely the one from Chabrier (2003).
2. Data overview and processing
The sample we study consists of 60 massive clusters in the local Universe, drawn from two large X-ray selected surveys: the Multi-Epoch Nearby Cluster Survey (MENeaCS) and the Canadian Cluster Comparison Project (CCCP). For each cluster we acquired deep ugri-band photometry (see Sect. 2.1 for details), to allow for a clean cluster galaxy selection.
A substantial number of spectroscopic redshifts in these cluster fields are available from the literature, specifically from CNOC (Yee et al. 1996), the Sloan Digital Sky Survey Data Release 10 (SDSS DR10; Ahn et al. 2014), and the Hectospec Cluster Survey (HeCS; Rines et al. 2013). We searched the NASA/IPAC Extragalactic Database (NED)1 to obtain additional spectroscopic information for galaxies that have not been targeted by these surveys, see Sifón et al. (2015) for details.
The 60 clusters selected from MENeaCS and CCCP that form the basis of this study, with their dynamical properties.
 |
Fig. 1 Lines: expected growth curves as a function of cosmic time (or redshift) for massive haloes based on the Millennium simulation (Springel et al. 2005), in which we followed these haloes at fixed cumulative comoving number density. Red: the GCLASS cluster sample studied in vdB14. Black triangles: low redshift cluster sample studied here. Purple: the CNOC1 cluster sample studied by Muzzin et al. (2007). The cluster samples are linked by the evolutionary growth curves. |
In addition to the determination of cluster membership these redshifts allow us to estimate dynamical masses (Sifón et al. 2015). In summary, cluster membership and velocity dispersions are determined using the shifting gapper approach (Fadda et al. 1996). To relate the velocity dispersion σv to estimates of R200, the radius at which the mean interior density is 200 times the critical density (ρcrit), and M200, the mass contained within R200, the Evrard et al. (2008) scaling relation is used. We applied the same scaling relation to the GCLASS cluster sample in vdB14 (Sect. 2.1). The 60 clusters used in this study are listed in Table 1.
Figure 1 suggests that the cluster sample we study covers the mass regime of the likely descendants from GCLASS in the local Universe. Curves in this figure connect haloes selected from the Millennium simulation (Springel et al. 2005) at fixed cumulative comoving number density, and are thus approximate growth curves. The lines are logarithmically spaced, each successive line changing the density by a factor of 3. We also show that the CNOC1 cluster sample, studied by Muzzin et al. (2007), are close to the approximate evolutionary sequence, and we will also compare our results to theirs in this paper. In Sect. 5.1 of vdB14, the GCLASS sample is sub-divided to show that SpARCS-1613, which is the highest mass system, has a similar stellar mass distribution as the other clusters, and thus does not bias the analysis in a significant way.
2.1. Photometry and catalogues in the ugri-bands
Each of these clusters is covered by deep photometric data taken through the g-, and r-filters using MegaCam mounted on the Canada-France-Hawaii Telescope (CFHT). The data are pre-processed using the Elixir pipeline (Magnier & Cuillandre 2004). For MENeaCS, photometric data in the two bands have been taken for these clusters, with a significant dither pattern, and a cadence of several weeks to allow for the detection of type Ia supernovae in these clusters (Sand et al. 2011). Data for CCCP have been taken consecutively under the best seeing conditions to facilitate weak-lensing measurements (Hoekstra et al. 2012). For some clusters we further retrieved archival MegaCam data in the u-, and i-bands (7 and 2 clusters in the respective bands).
The approach we take to process these data further is described in van der Burg et al. (2013, hereafter vdB13, Appendix A), and leads to deep image stacks to measure accurate and precise colours for the purpose of estimating photometric redshifts and stellar masses. We homogenise the PSF of each exposure before stacking, as opposed to homogenising the stack. The former approach leads to a final deep image with a cleaner PSF, especially given that the MENeaCS data have been taken under varying conditions and with substantial dithers. The spatially dependent convolution kernel has been chosen such that the PSF in the final stack has the shape of a circular Gaussian. By applying a Gaussian weight function for aperture fluxes we then optimise colour measurements in terms of signal-to-noise ratio (see Appendix A in vdB13; Kuijken 2008).
For the clusters that have not been imaged in the u-, and i-bands with the CFHT, we acquired photometry in these bands using the Wide-Field Camera (WFC), mounted on the Isaac Newton Telescope (INT) in La Palma. Given its field-of-view (FoV) of roughly 30 × 30 arcmin, we applied a dithered pointing strategy to be able to study the distribution and properties of galaxies that extend up to the clusters’ R200. Since the angular size of the virial radius depends both on the cluster total mass and its angular diameter distance (through redshift), we varied the number of pointings per cluster. In this way, the area within at least R200 is covered to a stacked depth of at least 3 exposures (400 s each). Near the cluster centres there are more overlapping pointings which further enhance the depth.
After pre-processing the images, we convolve them with a position-dependent kernel to homogenise the PSF to a circular Gaussian, similarly to what is done for the MegaCam data. Relative scaling of the photometric zero point between exposures is determined by considering objects that are imaged on overlapping parts between exposures. After these steps, we achieve a systematic uncertainty on flux measurements smaller than 1% in the two bands.
Because of the excellent image quality and depth in the MegaCam r-band stacks, we use these as our detection images. For galaxies with redshift z ≲ 0.4 the r-band filter probes the rest-frame SED redward of the  break, which makes the observed r-band flux a reasonable proxy for stellar mass. We measure aperture fluxes in the seeing-homogenised images using a Gaussian weight function, which we adjust in size to account for different PSF sizes. To estimate errors on these measurements, we randomly place apertures with the same shape on the seeing-homogenised images and measure the dispersion in the background. Since the flux measurements of our faint sources are background-noise limited, this way we probe the dominant component of the aperture flux error. For the WFC data we compare aperture flux measurements for each source in the individual exposures and (through sigma-clipping) combine this into a flux measurement and error.
break, which makes the observed r-band flux a reasonable proxy for stellar mass. We measure aperture fluxes in the seeing-homogenised images using a Gaussian weight function, which we adjust in size to account for different PSF sizes. To estimate errors on these measurements, we randomly place apertures with the same shape on the seeing-homogenised images and measure the dispersion in the background. Since the flux measurements of our faint sources are background-noise limited, this way we probe the dominant component of the aperture flux error. For the WFC data we compare aperture flux measurements for each source in the individual exposures and (through sigma-clipping) combine this into a flux measurement and error.
To calibrate the flux measurements in the different filters with respect to each other, we exploit the universal properties of the stellar locus (e.g. High et al. 2009, vdB13 Appendix A). The median limiting magnitudes (5σ for point sources measured with a Gaussian weight function, adjusted in size to accommodate the worst seeing conditions) in the ugri-filters are 24.3, 24.8, 24.2 and 23.3, respectively.
We mask stars brighter than V = 15, selected from the Guide Star Catalog II (GSC-II; Lasker et al. 2008), and their diffraction spikes and haloes in the images, which typically cover a few percent of the area. The effective area from which we can measure the properties of satellite galaxies is further reduced around and beyond the virial radius, since the fractional area with four-band photometry is reduced. This is especially true for massive clusters at low-z, given that they have the largest angular size on the sky. In the following, we take account of these reduced effective areas.
3. Analysis
Our primary method to measure the radial stellar mass distribution in the ensemble cluster is based on the deep four-band photometry, and relies on a statistical subtraction of background galaxies. We compare this result to the stellar mass distribution of spectroscopically confirmed members as a robustness test. Both approaches are described below.
3.1. Statistical background subtraction
The first approach is to estimate a photometric redshift for every galaxy in the cluster images, apply a cut in redshift space (z< 0.3) and statistically subtract galaxies in the fore-, and background by applying the same redshift cut to the reference COSMOS field. We use ugri photometric data in both our cluster fields and the COSMOS field to estimate photometric redshifts using the EAZY (Brammer et al. 2008) photometric redshift code. We use an r-band selected catalogue from the COSMOS field which has been constructed in the same way as the K-band selected catalogue of Muzzin et al. (2013b). The field has an effective area of 1.62 deg2, and we only use data in the ugri-filters to provide a fair reference to our cluster sample.
Because our bluest band is the u-band, it is challenging to constrain the location of the -break for galaxies at low (z ≲ 0.15) redshift, since the break is then located in this filter. Like many redshift codes, EAZY applies a flux-, and redshift-based prior, which gives the redshift probability distribution for a galaxy of a given r-band flux P(z,r). This prior has a strong effect in estimating the most probable redshift of a galaxy when the u − g colour loses its constraining power (as is the case for redshifts z ≲ 0.15). In the low redshift regime (z ≲ 0.3), the comoving volume element dVc/ dz/ dΩ is a strong function of redshift (e.g. Hogg 1999), but the luminosity function does not evolve strongly in this redshift range (e.g. Muzzin et al. 2013a). Therefore the prior in this regime is decreasing rapidly towards P(z,r) = 0 with decreasing redshift, independently of the r-band flux. Consequently, according to the prior, it is much more likely to find a galaxy at z = 0.2 compared to e.g. z = 0.1. Once a field is centred on a massive cluster at low redshift, this prior is no longer applicable since the probability of finding a galaxy to be at the cluster redshift is significantly increased. Besides the general redshift and flux-dependence of the prior, one should therefore also include information on e.g. the galaxy’s distance to the cluster centre. This however, is beyond our requirements, since we subtract the field statistically, and the volume (and therefore the number of contaminating galaxies) in the field is small for redshift z< 0.3. A correction on the prior will only affect lower redshifts, and will therefore not change which galaxies survive the redshift cut. For galaxies with a photometric redshift below zEAZY = 0.16 we apply a simple correction of the form photo-z = 0.16·(zEAZY − 0.10) / 0.06 to the EAZY output, which we find to lower the scatter between spectroscopic and photometric redshifts for this photometric setup (ugri-filters). We apply the same correction to the EAZY output on the COSMOS catalogue. A comparison between spec-z’s and photo-z’s is shown in Fig. 2. The axes are truncated at z = 1.0, but we verified that the confusion between Lyman-break and Balmer-break identifications happens only for ~0.3% of the total spectroscopic sample, and has a negligible effect on our analysis.
 |
Fig. 2 Left panel: spectroscopic versus photometric redshifts for the 60 cluster fields in this study. Outliers, objects for which |

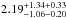
Since the distance modulus is a strong function of redshift in this regime, a small uncertainty in photometric redshift will result in a relatively large uncertainty in luminosity (or stellar mass) of a galaxy. For example, a simple test shows that, for a hypothetical cluster at z = 0.10, a photo-z bias of +0.005 (–0.005) would result in an inferred luminosity bias that is +11% (–10%). For a scatter in the estimated photo-zs of σz = 0.035 (and no bias), we find that the inferred total luminosity in this cluster would be biased high by 19%. Given that the cluster redshift is well-known, we therefore assign the distance modulus of the cluster to every galaxy in the cluster fields. In order to properly subtract contaminating fore- and background galaxies, we also assign this distance modulus to each galaxy in the reference COSMOS field (after applying the redshift cut). We then use the SED-fitting code FAST (Kriek et al. 2009) to estimate the stellar-mass-to-light ratio (M/L) (in the r-band) for each galaxy. For this we again assume the same redshift and distance modulus (corresponding to the cluster) for each galaxy. Then in each of the radial bins (which are scaled by the size R200 of each cluster) we measure the area (in angular size) that is covered with four-band photometry, but is not masked by bright stars, and estimate the expected number of sources in this area (which is also different for each cluster through their angular diameter distance) in the COSMOS field. We estimate the total stellar mass and corresponding error for those sources by performing a series of 10 000 Monte-Carlo realisations of the background, by randomly drawing sources from the COSMOS catalogue. We subtract the estimated field values from the raw number counts to obtain the cluster stellar mass density profile.
It is important to distinguish and account for the different sources of statistical uncertainties that enter our analysis. In the stacked radial profiles, we bootstrap the galaxies in each bin to estimate a statistical error on each data point. We show these error bars in the plots, after including the Poisson uncertainty of the background galaxy counts. We use these errors when fitting profiles, since they are independent between bins, and hence provide a goodness-of-fit test. However, since galaxy clusters are complex systems which are individually not necessarily described by the same profile, we also provide an uncertainty due to sample-to-sample variance. For example, if we would have studied 60 different clusters drawn from the same parent sample (that is, X-ray selected clusters at similar masses and redshifts as the current sample), the resulting stack would have been different. By performing 100 bootstraps (drawing with replacement) of the cluster sample we show that, when stacking a number of 60 clusters with deep photometric data, this sample-to-sample uncertainty dominates over the former statistical error, especially for bins that contain many galaxies and thus have a small statistical error. To estimate this sample-to-sample uncertainty on the best-fitting parameters that describe the stellar mass distribution of the stacked cluster, we perform the fitting procedure on each of the 100 realisations, and combine the range of different best-fitting parameters into an uncertainty. We do not explicitly account for uncertainties on R200, but we checked that these have an effect on the data points that is comparable in size to the Poisson uncertainty on the galaxies, and is thus negligible compared to the sample-to-sample uncertainty.
In addition to these statistical uncertainties, and the Poisson noise term in the reference field estimated with the Monte-Carlo realisations, cosmic variance (e.g. Somerville et al. 2004) also contributes to the error in the background. Both the field component that is included in the cluster raw number counts, and the reference field sample from COSMOS, which we subtract from the raw counts, contain this type of uncertainty. However, when several tens of independent cluster fields are stacked, the dominant cosmic variance error arises from the COSMOS reference catalogue. Our analysis, in which we assign the same distance modulus to all galaxies with zphot< 0.3 complicates an estimate of this cosmic variance, since the basic recipes by e.g. Trenti & Stiavelli (2008), Moster et al. (2011) cannot be applied. We do however make an empirical estimate based on catalogues from the 4 spatially independent CFHT Legacy Survey Deep fields (Erben et al. 2009; Hildebrandt et al. 2009), which each cover an un-masked area of about 0.8 deg2. After applying the same photometric redshift selection, and masking bright stars, we study the difference between the 4 fields for the following galaxy selections. Assuming a distance modulus corresponding to a redshift of z = 0.15, the differences in number density of galaxies with stellar mass 109<M⋆/M⊙< 1010 is 14% among the 4 fields, while the differences for galaxies with stellar mass M⋆> 1010M⊙ is about 16%. When we sum the r-band fluxes of all galaxies with zphot< 0.3, as a proxy for the total stellar mass, we find differences between the 4 fields of about 23% in the total r-band flux. Although these fields are a factor of ~2 smaller than the COSMOS field, we will use these differences as a conservative estimate of the cosmic variance error. A measurement of the intrinsic scatter in the profiles of individual clusters requires a more sophisticated investigation of the cosmic variance in annuli centred on individual cluster fields, and is beyond the scope of this paper.
We perform a consistency check between the COSMOS field and field galaxies that are probed far away from the cluster centres in the low-z cluster data. Although the COSMOS data are significantly deeper, we find no systematic difference in the galaxy stellar mass function between the field probed around the cluster and reference COSMOS field in the regime we are interested in (stellar masses exceeding M⋆> 109M⊙).
To investigate the spatial distribution of individual galaxy types, we locate the red sequence in the (g − r)-colour versus r-band total magnitude in each of the clusters to distinguish between red and blue galaxies. We find that the slope, and particularly the intersect, of the red sequence vary smoothly with redshift. The dividing line that we use to separate the galaxy types lies just below the red sequence, and is described by (g − r)div = [ 0.475 + 2.459·z ] − [ 0.036 + 0.024·z ] × (rtot − 18.0), where z is the cluster redshift, and rtot is the total r-band apparent magnitude. As expected, the intersect becomes redder with redshift, wheras the slope becomes steeper. Using the location of spectroscopically confirmed cluster members in colour-magnitude space we finetune the intersect and slope on a cluster-by-cluster basis by hand. This leads to small adjustments with a median absolute difference of 0.017 in the intersect, and a median absolute difference of 0.0016 in the slope, compared to the general equation. In the following we refer to red galaxies as galaxies above the dividing line (which thus lie on the red sequence), and blue galaxies as anything bluer than this dividing line. For each of the clusters we again subtract the field statistically for each of the populations by applying the same colour cut to the COSMOS catalogue.
3.2. Comparison with spectroscopic data
In the method described above, we subtract the galaxies in the fore-, and background statistically based only on the photometric data. However, as discussed in Sect. 2, we can use a substantial number of spectroscopic redshifts in the cluster fields from the literature. In this second approach we measure the stellar mass contained in spectroscopically confirmed cluster members to provide a lower limit to the full stellar mass distribution.
Since the spectroscopic data set is obtained after combining several different surveys, the way the spectroscopic targets have been selected is not easily reconstructed. Figure 3 shows the spectroscopic completeness for all galaxies with a photometric redshift z< 0.3 as a function of stellar mass (assuming the same distance modulus as the cluster redshift), and for different radial bins. For stellar masses M⋆> 1011M⊙, the completeness is high (>70%) in each of the radial bins. Since these objects constitute most of the total stellar mass distribution (see vdB14 Fig. 2 for this argument), we can get a fairly complete census of stellar mass by just considering the galaxies for which we have a spectroscopic redshift. We estimate the fraction of the stellar mass that is in spectroscopically confirmed members, for each of the four radial bins. For this we assume a stellar mass distribution following a Schechter (1976) function with characteristic mass M∗ = 1011M⊙, and low-mass slope α = −1.3. These choices are motivated by the low-z bin of the field stellar mass function as measured by Muzzin et al. (2013a). When we multiply this distribution with the completeness curves as shown in Fig. 3, we find a spectroscopic completeness for the total stellar mass in satellite galaxies of 59%, 57%, 52%, and 43% for the four radial bins, respectively.
 |
Fig. 3 Spectroscopic completeness for sources with a photometric redshift z< 0.3 as a function of stellar mass (assuming the same distance modulus as the cluster redshift). The four lines show different radial bins. For targets of a given stellar mass, the spectroscopic completeness is slightly higher for those that are closer to the cluster centres. For each of the radial bins, the completeness is larger than 70% for stellar masses M⋆> 1011M⊙. |
3.3. The presence of the BCG
In order to measure the number density and stellar mass density profiles of the satellites close to the cluster centres, we subtract the primary component of the BCGs’ flux-profiles with GALFIT (Peng et al. 2002) prior to source extraction and satellite photometry. We find that this step has a significant impact on the measured number density of faint satellites (M⋆< 1010M⊙) near the cluster centres, which was also mentioned by Budzynski et al. (2012). In the next section we mask the inner two bins (for which R< 0.02·R200) given that their values change by more than two times their statistical error. We find that the effect on the number density distribution of more massive satellites (M⋆> 1010M⊙) is negligible. The effect is largest in the first logarithmic bin (for which R ≈ 0.015·R200), but even here the results change by less than the size of the statistical error. The effects on the stellar mass density distribution are also smaller than the statistical error. The reason for this is that the stellar mass density distribution is primarily composed of more massive satellites which are relatively unobscured by the BCG. We therefore conclude that, although we remove the BCG profile prior to satellite detection and photometry, doing so has a negligible effect on the measured stellar mass density profile.
4. Results in the context of the NFW profile
In this section we present the galaxy number and stellar mass density distributions of the 60 clusters we study, based on the two independent analyses described in Sect. 3. We discuss these results by considering the NFW (Navarro et al. 1997) fitting function, since that is the parameterisation generally used in previous studies. We can therefore compare the results in this context with measurements in the literature, both at low and high redshift.
4.1. Galaxy number density profile
 |
Fig. 4 Galaxy number density distributions for masses 109<M⋆/M⊙< 1010 (left panel), and M⋆> 1010M⊙ (right panel) for the ensemble cluster at z ~ 0.15. Black points with the best-fitting projected NFW (dashed) and gNFW (solid) functions are our best estimates for the cluster number counts. The inner two points in the left panel are masked due to obscuration from the BCG, which is more severe for low-mass galaxies, and are excluded from the fitting. Purple points indicate the number of spectroscopically confirmed cluster members. |
Ignoring baryonic physics, the galaxy number density distribution in cluster haloes can be compared to the distribution of sub-haloes in N-body simulations as a test of ΛCDM. Due to mergers and interactions between galaxies, and in particular the mass-dependence of the dynamical friction timescale, the number density distribution of galaxies may be different for galaxies with different stellar masses.
Figure 4 shows the projected galaxy number density distribution for galaxies with stellar masses 109<M⋆/M⊙< 1010 (left panel), and M⋆> 1010M⊙ (right panel) in the ensemble cluster. Before stacking the 60 clusters, their radial distances to the BCGs are scaled by R200, but the BCGs themselves are not included in the data points. Error bars reflect bootstrapped errors arising from both the cluster galaxy counts and the field value that is subtracted. The shaded area around the data points shows the systematic effect due to cosmic variance in the background, which we estimated in Sect. 3.1. The number of spectroscopically confirmed cluster members follow a similar distribution but have a different normalisation due to spectroscopic incompleteness.
We fit projected NFW profiles to the data points, and show those corresponding to the minimum χ2 values with the dashed lines in Fig. 4. For the lower-mass galaxies (109<M⋆/M⊙< 1010), we find an overall goodness-of-fit of χ2/ d.o.f. = 1.19, with a concentration of 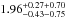 . Both a sample-to-sample variance (first) and systematic (second) error are quoted. For the higher-mass galaxies (M⋆> 1010M⊙), the overall goodness-of-fit is χ2/ d.o.f. = 3.00 with a concentration of
. Both a sample-to-sample variance (first) and systematic (second) error are quoted. For the higher-mass galaxies (M⋆> 1010M⊙), the overall goodness-of-fit is χ2/ d.o.f. = 3.00 with a concentration of 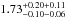 . In both stellar mass bins, we find that the best-fitting NFW function gives a reasonable description of the data for most of the cluster (R ≳ 0.10·R200), but that the centre has an excess in the number of galaxies compared to the NFW profile. In the next section we provide a more detailed investigation of this excess; in this section we continue working with the standard NFW profile in order to compare with previous work.
. In both stellar mass bins, we find that the best-fitting NFW function gives a reasonable description of the data for most of the cluster (R ≳ 0.10·R200), but that the centre has an excess in the number of galaxies compared to the NFW profile. In the next section we provide a more detailed investigation of this excess; in this section we continue working with the standard NFW profile in order to compare with previous work.
The number density and luminosity density profiles of group and cluster sized haloes in the literature have generally been measured on smaller samples, and do not focus on the smallest radial scales around the BCGs. On the scales these studies have focussed on, NFW profiles have been shown to be an adequate fit to the data over the whole radial range. We therefore compare the concentration parameters fitted by the NFW profile with the values presented in the literature.
Lin et al. (2004) studied the average number density profile of a sample of 93 clusters at 0.01 <z< 0.09 with 2MASS K-band data. They were able to measure down to a magnitude limit (Vega) of Ks,lim = 13.5, which corresponds to M⋆ ≈ 1010M⊙ at z = 0.05 (Bell & de Jong 2001). Although they studied clusters with a lower mass range than we probe, they found a number density concentration of 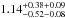 , which is comparable to the value that we find for the high mass galaxies (M⋆> 1010M⊙).
, which is comparable to the value that we find for the high mass galaxies (M⋆> 1010M⊙).
Budzynski et al. (2012) measured the radial distribution of satellite galaxies in groups and clusters in the range 0.15 <z< 0.40 from the SDSS DR7. For the satellite galaxies they applied a magnitude limit of Mr = −20.5. This corresponds to about M⋆ = 1010.5M⊙ for galaxies with a high M/L. The best-fitting concentration parameter of c ~ 2.6 they found is also consistent with our measurement for the high-mass sample. They found that the concentration of the satellite distribution decreases slightly as their brightness increases, but note that they compared satellites in a higher luminosity range with respect to our study.
vdB14 measured the number density distribution of the GCLASS cluster ensemble at z ~ 1 down to a stellar mass of M⋆ = 1010.2M⊙. They measured an NFW concentration parameter of 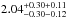 , which is significantly higher than the value we find for the low-z sample, indicating that there is a substantial evolution with redshift. A comparison between the number density distribution and the stellar mass density distribution presented in vdB14 suggests that the more massive galaxies are situated closer towards the cluster centres than lower mass galaxies, which is qualitatively consistent with the trend we find here.
, which is significantly higher than the value we find for the low-z sample, indicating that there is a substantial evolution with redshift. A comparison between the number density distribution and the stellar mass density distribution presented in vdB14 suggests that the more massive galaxies are situated closer towards the cluster centres than lower mass galaxies, which is qualitatively consistent with the trend we find here.
4.2. Stellar mass density profile
 |
Fig. 5 Stellar mass density distribution of the ensemble cluster at z ~ 0.15. Black points: cluster stellar mass distribution, with best-fitting projected NFW (dashed) and gNFW (solid) functions. Purple points: stellar mass distribution in spectroscopically confirmed cluster members. Dotted line: total stellar mass density profile on the images (background subtracted, with the 68% confidence region around these values shown by the thinner dotted lines), including the BCG and part of the ICL component. |
Whereas the number density distribution of galaxies depends sensitively on the stellar mass range considered (or the depth of the data set), the stellar mass density distribution is less sensitive to this, because it is primarily set by the distribution of galaxies around the characteristic mass (M∗). Figure 5 shows the radial stellar mass density distribution of satellite galaxies in the ensemble cluster. Radial distances are normalised by the clusters’ R200. Black data points give the background-subtracted cluster stellar mass distribution, with errors estimated by bootstrapping the galaxies in the stack. Ignoring systematic uncertainties such as the shape of the IMF, stellar mass errors of individual galaxies are negligible compared to this bootstrap error. We do, however, show a systematic uncertainty of 23% in the background due to cosmic variance by the shaded region around the data points. The spectroscopic completeness in terms of total stellar mass is about 50%, and does not significantly depend on radial distance (cf. Fig. 3).
As for the number density profiles, we fit a projected NFW profile to the black data points, minimizing the χ2 value. Again we find that the best-fitting NFW function gives a reasonable description (dashed curve in the figure) of the data for most of the cluster (R ≳ 0.10·R200), but that the central parts show a significant excess of stellar mass in satellites near the centre compared to this function. To provide a consistent comparison with previous studies, we consider the best-fitting NFW concentration parameter, 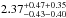 , here and present a more detailed investigation of the central excess in the next section. As before, sample-to-sample variance (first) and systematic errors (from cosmic variance in the background, second) are quoted. We again limit a comparison with literature studies to the NFW concentration parameters, since the NFW profile has been used as an adequate description of previous measurements.
, here and present a more detailed investigation of the central excess in the next section. As before, sample-to-sample variance (first) and systematic errors (from cosmic variance in the background, second) are quoted. We again limit a comparison with literature studies to the NFW concentration parameters, since the NFW profile has been used as an adequate description of previous measurements.
Muzzin et al. (2007) measure the K-band luminosity profiles for a stack of 15 CNOC1 (Yee et al. 1996) clusters in the redshift range 0.2 <z< 0.5. In this redshift range, the luminosity in the K-band is expected to be a good proxy for stellar mass. They find a concentration of the luminosity density of c = 4.28 ± 0.70. These clusters are only slightly more massive than the progenitors of the sample we study (see Fig. 1).
At higher redshift (z ~ 1), vdB14 present the stellar mass density distribution of the GCLASS cluster sample, and find that an NFW profile with a high concentration of 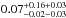 fits the data. These systems are likely to grow into the low-z clusters studied in this paper.
fits the data. These systems are likely to grow into the low-z clusters studied in this paper.
Together, these studies span an interval of about 8 Gyr of cosmic time, and comparisons among these results indicate that the stellar mass distribution in clusters evolves significantly. This trend is visualised by the four data points in Fig. 6, which represent the studies discussed above. The black points represent the present study, divided over two redshift bins (see Sect. 5.1).
4.2.1. Discussion
Although satellite galaxies are expected to mark the location of dark matter sub-haloes, a comparison with theoretical predictions has limitations. Most studies are based on large N-body simulations (Springel et al. 2005), and dark matter haloes falling into larger haloes experience tidal forces leading to the stripping of their constituent particles (Ghigna et al. 2000; Binney & Tremaine 2008), also see Natarajan et al. (2002), Gillis et al. (2013) for observational studies. As a sub-halo falls into the main halo, it will continuously lose mass through the process of tidal stripping, and it may eventually fall below the mass resolution of the simulation. The sub-halo is then no longer identified as such, its mass is deposited on the central galaxy or dispersed between the galaxies, and its orbit is no longer defined. For this reason, the radial distribution of sub-haloes is less concentrated than the dark matter in N-body simulations (Nagai & Kravtsov 2005). While the sub-haloes in these dissipationless simulations are eventually destroyed, the galaxies that have formed inside of them are expected to be more resistive to tidal forces. The observed distribution of satellite galaxies may therefore be more similar to the distribution of dark matter in N-body simulations.
In Fig. 6, the evolution of the NFW concentration parameter in N-body simulations is shown (Duffy et al. 2008), for relaxed haloes with masses similar to the massive galaxy clusters studied here. The grey area indicates the intrinsic scatter around the solid line. For the full sample of haloes (including non-relaxed), the average concentration is slightly lower, but the intrinsic scatter is slightly larger. But note that these results are based on a WMAP5 cosmology, and e.g. Macciò et al. (2008) have shown that the shapes of dark matter halo profiles depend sensitively on the cosmological parameters. Indeed, Dutton & Macciò (2014) base their study on a Planck cosmology, which is characterised by a larger Ωm and σ8, and find that the haloes are more concentrated by about 30% in our mass and redshift regime. The concentration shown in Fig. 6 might therefore be 30% higher, but the evolution in the concentration parameters is qualitatively independent of the cosmology.
Therefore, the evolution of the simulated dark matter distribution is significantly different than the observed evolution of the stellar mass distribution. Note again that, at low redshift we find that the NFW profile does not give a proper representation of the data at the inner parts of the cluster. In the next section we focus on the excess of stellar mass in more detail, and expand the discussion in Sect. 6.
Parameters describing the best-fitting NFW (where α is fixed to 1) and gNFW (where α is a free parameter) profiles to the radial density distributions.
 |
Fig. 6 Black points: stellar mass density concentration for the clusters used in this study, split in two redshift bins. Purple: K-band luminosity density concentration in CNOC1 from Muzzin et al. (2007). Red: stellar mass density concentration in GCLASS from vdB14. The horizontal bars indicate the redshift range for each sample. Black lines: the NFW concentration in the sample of relaxed haloes from Duffy et al. (2008) as a function of redshift. Dotted and dashed: haloes of a given mass as a function of redshift. Solid: NFW concentration of a halo that is evolving in mass, with scatter given by the shaded region. |
5. A closer investigation of the cluster cores
In the previous section we discussed the number density and stellar mass density profiles of the ensemble cluster, and found that these are well-described by NFW profiles, except for the inner regions (R ≲ 0.10·R200). The central parts show a significant and substantial excess, both in galaxy numbers and their stellar mass density distribution. Per cluster this excess within the inner regions is on average ~1 galaxy with 109<M⋆/M⊙< 1010, and ~2 galaxies with M⋆> 1010M⊙, and a total stellar mass excess in satellite galaxies of ~1011M⊙ per cluster, compared to the NFW profiles.
The purple points in Figs. 4 and 5 show the numbers of spectroscopically confirmed member galaxies. Although these data points are off-set with respect to the full photometric measurement as a result of spec-z incompleteness, they are consistent with the central excess of galaxy numbers and stellar mass density compared to the standard NFW profile.
To study the central parts of our cluster-sized haloes further, we revisit the fits to the number density and stellar mass density distributions by allowing the inner slope of the density profiles to vary. We hence fit so-called generalised NFW (gNFW) profiles (e.g. Zhao 1996; Wyithe et al. 2001) to the data points. These profiles are described by 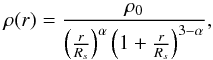 (1)where the concentration is defined, as in the case of the standard NFW profile, to be
(1)where the concentration is defined, as in the case of the standard NFW profile, to be 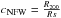 . For α = 1, the inner slope equals –1, corresponding to the standard NFW profile. We project the generalised NFW profile numerically along the line-of-sight.
. For α = 1, the inner slope equals –1, corresponding to the standard NFW profile. We project the generalised NFW profile numerically along the line-of-sight.
For the number density profiles we find that, for galaxies with 109<M⋆/M⊙< 1010, a profile with 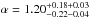 and
and 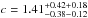 gives a good description of the data (χ2/ d.o.f. = 1.04). For the more massive galaxies (M⋆> 1010M⊙), the best-fitting parameters are
gives a good description of the data (χ2/ d.o.f. = 1.04). For the more massive galaxies (M⋆> 1010M⊙), the best-fitting parameters are 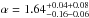 and
and 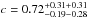 , with goodness-of-fit χ2/ d.o.f. = 1.19. Again, both a sample-to-sample variance (first) and systematic (due to cosmic variance in the background, second) error are quoted. The significantly steeper inner slope we find for the high mass sample compared to the lower mass sample indicates that the more massive galaxies are more strongly concentrated in the cluster ensemble. The effect of dynamical friction, which is more efficient for massive galaxies, can be the cause of this mass segregation.
, with goodness-of-fit χ2/ d.o.f. = 1.19. Again, both a sample-to-sample variance (first) and systematic (due to cosmic variance in the background, second) error are quoted. The significantly steeper inner slope we find for the high mass sample compared to the lower mass sample indicates that the more massive galaxies are more strongly concentrated in the cluster ensemble. The effect of dynamical friction, which is more efficient for massive galaxies, can be the cause of this mass segregation.
For the stellar mass density we also find a better fit over-all, with χ2/ d.o.f. = 1.24 instead of 2.51. The best-fitting profile is given by 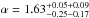 and
and 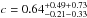 . The shape of the stellar mass density profile closely agrees with the number density profile for the massive galaxies, which is expected since these dominate in total stellar mass over the less massive galaxies. In Figs. 4 and 5, the gNFW profiles are shown by the solid lines.
. The shape of the stellar mass density profile closely agrees with the number density profile for the massive galaxies, which is expected since these dominate in total stellar mass over the less massive galaxies. In Figs. 4 and 5, the gNFW profiles are shown by the solid lines.
For reference we also consider Einasto (1965) profiles, which are described by ![Mathematical equation: \begin{equation} \rho(r)= \rho_{0}\,\exp \left( -\frac{2}{\alpha} \left[ \left(\frac{r}{R_{s}}\right)^{\alpha} -1 \right]\right), \end{equation}](/articles/aa/full_html/2015/05/aa25460-14/aa25460-14-eq348.png) (2)and have been found to provide good fits to the dark matter density distribution of massive haloes in N-body simulations (e.g. Dutton & Macciò 2014; Klypin et al. 2014). We project these profiles numerically along the line-of-sight, and find that they give a similarly good representation of the data as the gNFW profile. Parameters α and c (≡
(2)and have been found to provide good fits to the dark matter density distribution of massive haloes in N-body simulations (e.g. Dutton & Macciò 2014; Klypin et al. 2014). We project these profiles numerically along the line-of-sight, and find that they give a similarly good representation of the data as the gNFW profile. Parameters α and c (≡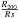 , as before), and reduced χ2 values are presented in Table 3.
, as before), and reduced χ2 values are presented in Table 3.
A significant part of the total stellar mass distribution is the stellar mass contained in the BCG and ICL. Although a full accounting of the ICL component is beyond the scope of the current paper, we assess their contribution by measuring the distribution of the stellar mass including the BCG. To measure this total, we directly sum all measured flux around the BCG locations of the original r-band images (i.e. without first removing the BCGs’ main profiles with GALFIT). To estimate the stellar mass distribution, we multiply this with the stellar-mass-to-light ratio (M/L) of the BCG under the assumption that there is no M/L-gradient. We mask the locations of bright stars, sum the flux in annuli that are logarithmically spaced, and statistically subtract the field by considering a large annulus far away from the cluster centres. The background-subtracted central stellar mass density profile is shown as a thick dotted line in Fig. 5, with thinner dotted lines marking the 68% uncertainty region as estimated from cluster-bootstrapping. At a projected radius of R ~ 0.02·R200, the contribution of stellar mass in satellites is roughly similar to that of the BCG component. As a good consistency check we note that the dotted line, which by definition also includes stellar mass in satellites, and the black data points have consistent values in the outermost region where they overlap (at R ~ 0.08·R200). By construction, part of the ICL is also included in this total profile. However, because of the way the background is subtracted from our images, the larger scale component of the ICL is not taken into account. A more sophisticated data reduction is required to measure this component down to sufficiently low surface brightnesses (e.g. Ferrarese et al. 2012), and we leave this to a future study.
Excess of stellar mass in satellites in each of the subsamples, with respect to the overall best-fitting NFW profile.
5.1. Dependence on cluster physical properties
Given our sample of 60 clusters over a range of redshifts and halo masses, we investigate if the excess of stellar mass in satellite galaxies is related to any specific cluster (or BCG) property. The properties we consider are cluster redshift and cluster halo mass (see Table 1), BCG stellar mass (based on estimated M/L and integrated r-band luminosity with GALFIT), and cluster richness2. If we split the sample on the medians of these properties, we measure for each subset a significant central excess in the stellar mass distribution with respect to the best-fitting NFW profile, see Table 4. This excess is ~1011M⊙ per cluster, comprising about 30% of the stellar mass contained in the NFW profile for R< 0.10·R200.
A thermodynamical property that is measured for 37 of the clusters in our sample is the central entropy (K0, presented in Bildfell 2013; Mahdavi et al. 2013), which is defined as the deprojected entropy profile evaluated at a radius of 20 kpc from the cluster centre. This observable is related to the dynamical state of the cluster (Pratt et al. 2010), and correlates (by definition) with the inner slope of the gas density distribution. We therefore investigate if the inner part of the stellar mass distribution also depends on this property. Mahdavi et al. (2013) found a hint of bimodality in the distribution of the central entropy, on either side of K0 = 70 keV cm2. Following that work, we split our sample between galaxies with central entropies smaller (13 clusters) and higher (24 clusters) than this value. Again, the stellar mass excess is significant in both subsamples (Table 4).
In each subsample, the gNFW profile provides a better fit to the data than a standard NFW profile. Note that the gNFW profile parameters α and c are degenerate, but none of the splits results in a best-fitting profile that is significantly (>2σ) different from the over-all stack (Table 2). Note that the splits themselves are not independent of each other, due to relations between, for example, richness and halo mass (e.g. Andreon & Hurn 2010), and a slight covariance between mass and redshift in this sample (Fig. 1). Although the stellar mass excess with respect to the NFW profile is thus significant in each subsample, we cannot draw firm conclusions regarding the dependence of the stellar mass profile shape on cluster properties with the current data set.
 |
Fig. 7 Left panel: red points: average stellar mass density profile of GCLASS, in physical units. Black points: stellar mass density profile at low-z, at the same physical scale. The orange region marks the part of the z ~ 1 profile that is in excess of the z ~ 0.15 profile, and comprises a stellar mass of about 7 × 1011M⊙. Black dotted: stellar mass at z ~ 0.15, including BCG+ICL. Dashed purple and solid blue: stellar mass in blue galaxies at z ~ 1 and z ~ 0.15, respectively. Right panel: dark matter profiles from N-body simulations, using the average profile parameters from Duffy et al. (2008) and Dutton & Macciò (2014), but with the profiles plotted on the same physical scale. Shown are profiles at redshifts of z = 1.00 (red) and z = 0.15 (black), with masses of M200 = 3 × 1014M⊙ and M200 = 9 × 1014M⊙, respectively. |
6. Discussion: the evolving stellar mass distribution
In this study we found that the NFW profile provides a good description of the stellar mass density distribution of satellites in clusters in the local (0.04 <z< 0.26) Universe, but only at radii R ≳ 0.10 R200. Following studies on the evolution of the dark matter profiles in N-body simulations (e.g. Duffy et al. 2008; Dutton & Macciò 2014), we discussed the evolution of the stellar mass distribution by considering an evolution in the NFW concentration parameter in Sect. 4.2.1. However, since Sect. 5 shows that there is a significant excess in the stellar mass density distribution of satellite galaxies compared to this NFW profile, a simple comparison of these parameters does not cover the full story.
Furthermore, note that the concentration parameters we are comparing are defined with respect to the clusters’ R200. Since the critical density ρcrit, with respect to which these radii are defined, evolves, the measured concentrations will change, even if the physical profile remains constant over time (pseudo-evolution, e.g. Diemer et al. 2013). Together with the expected halo mass growth of a factor of ~3 between z = 1 and z = 0 (Wechsler et al. 2002; Springel et al. 2005), R200 correspond to a physical size of ~1 Mpc for the GCLASS clusters, and R200 ~ 2 Mpc for the low-z sample.
Because of these complications, we make a direct, and more intuitive, comparison in Fig. 7 (left panel) by studying the cluster stellar mass density profiles on the same physical scale. This way we are not affected by pseudo-evolution, are not dependent on a chosen parameterisation of the density profiles, and study directly how the profiles of these clusters evolve since z ~ 1. We can make this comparison without re-scaling because the GCLASS clusters are the approximate progenitors of the clusters studied in this work. However, to make a fair comparison we only integrate the stellar mass contained in satellite galaxies down to stellar masses of M⋆> 1010M⊙ at z ~ 0.15, since that represents the approximate stellar mass depth of GCLASS.
This purely observational comparison suggests that, although the total stellar mass content of these clusters grows substantially since z ~ 1, the stellar mass density in the cluster cores (R ≲ 0.4 Mpc) is already present at z = 1. Moreover, there seems to be an excess of stellar mass in this regime at z ~ 1 compared to z ~ 0.15. Note, however, that in this comparison of the stellar mass in satellite galaxies, we do not take account of the ICL component, and excluded the BCGs from the story. The build-up of stellar mass in these components may explain the observed evolution. Massive galaxies close to the BCG are expected to merge with the central galaxy on a relatively short time-scale, and play a dominant role in the build-up of stellar mass in the BCG (e.g. Burke & Collins 2013; Lidman et al. 2013). The stellar mass contained between the two curves in Fig. 7 (left panel, orange region), is on average ~7 × 1011M⊙ per cluster. Given that the BCGs in the GCLASS clusters have typical stellar masses of M⋆,BCG ≃ 3 × 1011M⊙ (vdB14, Table 2), and that the median stellar mass contained in the BCGs in the sample studied here is M⋆ ≃ 9 × 1011M⊙, it is an interesting coincidence that this excess of stellar mass in satellites at z ~ 1 roughly equals the difference in BCG stellar mass between the two samples. The development of an ICL component may also contribute to an evolution in the observed stellar mass density profile. The dotted line in Fig. 7 (left panel) was already shown in Fig. 5, and is consistent with the picture that stellar mass reassembles itself in the direction of the central galaxy, becoming part of the BCGs’ extended light profiles.
A sufficient amount of stellar mass that is required for BCG growth thus seems to already be present in the centres of the clusters at z ~ 1, although it is still part of the satellite galaxy population. However, while these satellites seem to drive most of the BCG mass growth, it is interesting why they do not get replenished with new infalling satellites. In the more massive haloes at low-z, the process of dynamical friction, which is supposed to effectively reduce the orbital energy of massive infalling satellites, seems to work less efficiently. This might be related to the observational result that the massive end of the stellar mass function hardly evolves over cosmic time (e.g. Muzzin et al. 2013a), whereas the haloes we study grow in mass by a factor ~3. Compared to z> 1, the time that it takes for a massive galaxy to lose enough orbital energy to arrive at the centre is longer in the local Universe.
On the other hand, substantial growth of the stellar mass content in the cluster outskirts (R ≳ 1.0 Mpc) is required to match the low-z descendants of the GCLASS systems. Under the assumption that galaxies populate sub-haloes and that these systems are accreted onto the clusters since z = 1, it is expected that dark-matter haloes also accrete matter onto the outskirts. This effect is indeed observed in N-body simulations, if these simulations are compared on the same physical scale, see Fig. 7 (right panel). Recently, Dutton & Macciò (2014) and particularly Klypin et al. (2014) have shown that Einasto profiles provide a better description of the dark matter density distribution of massive haloes in N-body simulations. As a comparison, we therefore compare the results of Duffy et al. (2008), which are based on a WMAP5 cosmology and an NFW parameterisation, with those from Dutton & Macciò (2014), which are based on a Planck cosmology and an Einasto parameterisation. Both are normalised to have the same M200. In both cases, the profiles of these simulated haloes grow at all radii, although their growth is smaller in the centre. The evolution between the observed stellar mass distribution and the dark matter in N-body simulations is thus significantly different (cf. Fig. 6), independent of the used parameterisation.
The observations strongly suggest a scenario in which the stellar mass component grows in an inside-out fashion, indicating that the presence of baryons plays an important role in this assembly process. The observed evolution of the stellar mass distribution is thus a stringent test for existing and future hydrodynamical simulations (e.g. Schaye et al. 2010, 2015; Cen 2014; Vogelsberger et al. 2014; Genel et al. 2014), as it is of importance both in a cosmological context and in our quest to understand the formation and evolution of galaxies in our Universe.
6.1. Radial distribution of different galaxy types
Since blue galaxies are thought of as a dynamically younger component of the galaxy cluster population than red galaxies, a distinction between galaxy types can yield further insight in the way clusters accrete their satellite population. We make a distinction between red and blue galaxies using as simple criterion the cluster red sequence in the (g − r)-colour. Since the colour of the red sequence is redshift-dependent, we identify the red-sequence population in each of the individual clusters, and stack the resulting stellar mass distributions in Fig. 8. The best-fitting gNFW profile to each of the galaxy types is plotted.
Figure 8 shows that galaxies on the red sequence completely dominate the stellar mass distribution in the cluster centres, and are dominant over bluer galaxies (in terms of stellar mass density) up to at least R200. Bluer galaxies are still significantly over-dense compared to the field over the entire radial range that is shown (the field values are subtracted), but note the shallow inner slope of the gNFW profile that describes the blue galaxies (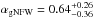 ).
).
In Fig. 7 (left panel), we show the blue galaxy population of this sample, and also the blue galaxy population in the GCLASS clusters (vdB14, their Fig. 7). This shows that there is a dramatic evolution in the relative radial distribution of blue galaxies compared to the overall galaxy population. The blue fraction of cluster galaxies is lower overall at low-z compared to high-z, but the difference is most prominently visible near the cluster cores. In the highly-simplified picture that blue galaxies fall in, and quench by some environmental process with a delay of several Gyr (e.g. Wetzel et al. 2013; Muzzin et al. 2014), we can use their locations in the cluster to study where the stellar mass is most recently accreted. Even after more than a dynamical time-scale, which is typically 1 Gyr, the blue galaxies are mostly on the outskirts of the clusters (note that we are studying the projected surface mass density here). Although the physics involved in the quenching of galaxies require a more detailed modelling, this simplified picture supports a scenario in which clusters assemble their stellar mass distribution in an inside-out fashion. We leave a more detailed discussion on the relative distributions of blue and red-sequence galaxies to a future paper, in which we measure and discuss the stellar mass functions for each of these populations.
 |
Fig. 8 Black: stellar mass density profile of Fig. 5, separated between red-sequence (red) and bluer (blue) galaxies. The best-fitting gNFW profiles to the red and blue sub-samples are also shown here. |
7. Summary and conclusions
In this paper we perform a detailed study of the radial galaxy number density and stellar mass density distribution of satellites in a sample of 60 massive clusters in the local Universe (0.04 <z< 0.26). The cluster sample we study is close in halo mass to the likely descendant population of the z ~ 1 GCLASS cluster sample (vdB14), for which a stellar mass concentration of 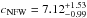 was estimated. The main conclusions of this study at low-z, and the comparison with GCLASS, can be summarised as follows.
was estimated. The main conclusions of this study at low-z, and the comparison with GCLASS, can be summarised as follows.
-
The number density and stellar mass density distribution of satellites in this sample are well-described by an NFW profile in the radial range R ≳ 0.10 R200. The estimated NFW concentration parameters are roughly consistent with literature measurements with which we can compare.
-
At smaller radii, there is a significant and substantial excess in the amount of stellar mass in satellites of about ~1011M⊙ per cluster, compared to the standard NFW profile. The central parts (R ≲ 0.10 R200) of both the number density and stellar mass density distributions are thus significantly steeper than NFW, but generalised NFW profiles with steep inner slopes, and Einasto profiles fit these distributions well. We do not find a significant correlation between the central excess and cluster properties such as redshift, cluster mass, BCG stellar mass, galaxy richness, and cluster central entropy.
-
A naive comparison between the NFW concentration parameter at z = 1 from GCLASS, and the measurement at z ~ 0.15 suggest a dramatic evolution over cosmic time. This observed evolution in the stellar mass concentration is significantly different from what is found for the dark matter distribution in N-body simulations.
-
For a more intuitive and direct comparison, we study the stellar mass density distributions between the two epochs on the same physical scale, showing that the stellar mass density in satellites in the cluster cores (R< 0.4 Mpc) is already in place at z = 1; There is a sufficient amount of stellar mass present for the BCGs to grow by a factor of 3.
-
Although the centre of the stellar mass distribution seems to be in place by z = 1, substantial growth onto the cluster outskirts is required for the two samples to connect. This inside-out growth picture is quantitatively different from the behaviour of dark matter in N-body simulations, illustrating the importance of baryonic effects in understanding the accretion of smaller haloes by galaxy clusters.
Online material
Appendix A: Selection effects in GCLASS
 |
Fig. A.1 Black solid line: Tinker et al. (2008) cumulative mass function at z = 1 for WMAP7 cosmology. Black dotted lines: Tinker et al. (2008) cumulative mass functions at z = 0.86 and z = 1.34, which are the redshift limits within which the GCLASS clusters are selected. Red dashed line: cumulative mass function of the ten GCLASS clusters, normalised by the total volume of SpARCS. |
Given the significant evolution that is observed between the GCLASS sample and the low-z descendant sample, we have to consider the possibility that this inferred evolution is caused by the way these samples are selected. Since it is impossible to select a cluster sample based on halo mass, different selection methods (X-ray, SZ-, or galaxy selections) potentially result in a biased sample of clusters.
The GCLASS sample consists of ten clusters drawn from the 42 degree Spitzer Adaptation of the Red-sequence Cluster Survey (SpARCS; Muzzin et al. 2009; Wilson et al. 2009; Demarco et al. 2010). Clusters in SpARCS were detected using the red-sequence detection method developed by Gladders & Yee (2000), and expanded on in Muzzin et al. (2008). In summary, this detection method was applied to the optical+InfraRed data in SpARCS, so that the z′ − 3.6 μm colour was used to detect clusters at redshifts z> 0.8 after convolving the galaxy number density maps with an exponential kernel (see Gladders & Yee 2000, Eq. (3)). Richnesses were measured in fixed apertures with a radius of 500 kpc, after which the richest systems were considered for follow-up photometry and spectroscopy. Muzzin et al. (2012) describe how this GCLASS follow-up sample was drawn from the richest systems after optimising the redshift baseline and ensuring a spread in RA for observational convenience. The fixed aperture of 500 kpc makes the richness selection independent on concentration. However, in principle it is possible that richness and concentration are correlated quantities, such that a richness selection indirectly biases our sample towards high/low concentrations.
The statistics in the GCLASS sample are insufficient to study a possible trend between richness and concentration at z ~ 1, but we proceed to test a potential bias in the selection of GCLASS by comparing the dynamical masses of the GCLASS sample to the Tinker et al. (2008) cumulative halo mass function based on a WMAP7 cosmology, which we show in Fig. A.1.
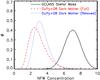 |
Fig. A.2 Black solid line: GCLASS ensemble average stellar mass concentration with a Gaussian probability distribution around c = 7.12. Also shown are the log-normal concentration distribution for clusters with the same mass and redshift as the GCLASS sample for the relaxed haloes in Duffy et al. (2008) (blue dotted line), and their full sample (red dashed line). |
Given the effective area of 41.9 square degrees we estimate the effective volume of the SpARCS survey (from which GCLASS was selected) in the redshift slice 0.86 <z< 1.34 and normalise the cumulative number density of the GCLASS clusters over this volume. At the high-mass end of the distribution we expect Poisson scatter, and there is scatter in the mass-richness relation to be considered. The ten GCLASS systems are therefore not necessarily the most massive ones. Based on this comparison, we estimate that in GCLASS we probe around 10% of the clusters in the SpARCS volume around the median mass of the GCLASS sample (M200 ≃ 1014.3M⊙).
We consider the possibility that the clusters probed by GCLASS are the 10% with the highest concentrations in the simulation. Figure A.2 shows the GCLASS ensemble average stellar mass concentration with a Gaussian probability distribution around c = 7.12. The Duffy et al. (2008) log-normal concentration distribution for cluster-sized haloes in N-body simulations are also shown, both for their relaxed and full sample (haloes were categorised based on the distance between the most bound particle and the centre of mass in the simulation). The relaxed sample has a slightly higher concentration of c = 3.30 compared to c = 2.84 for the full sample, but has a smaller scatter (σ(log10c) = 0.11 dex versus 0.15 dex for the full sample). Where the Duffy et al. (2008) distributions overlap with the GCLASS probability distribution, these two distributions are similar.
We perform a simple test in which we randomly sample 100 concentrations from the Duffy et al. (2008) relations. We do this for 1000 different realisations and each time average the ten most concentrated ones. In only 3% of the realisations we do find a larger average than the measured concentration from GCLASS (), taking account also of the error on this measured concentration. Therefore, even under the most conservative assumption that a richness selection is completely biased towards the most concentrated galaxy clusters, there is only a 3% probability that we measure an average concentration for GCLASS of . Moreover, as we argued in vdB14, the measured concentration of c ≃ 7.12 is a lower limit if we include uncertainties arising from offsets between the BCGs and the “true” cluster centres. Given these arguments, it is unlikely that both the observed evolution since z ~ 1, and the difference between the predictions from N-body simulations and observations at this redshift, are only an effect of the way the GCLASS sample is selected.
Defined here as the number of background-subtracted cluster galaxies with M⋆> 1010M⊙ within a projected radius of 1 Mpc from the BCG.
Acknowledgments
We thank Rob Crain, Gabriel Pratt, Monique Arnaud, and Hervé Aussel for valuable discussions during the course of this project. This work is based on observations made with the Isaac Newton Telescope through program IDs I10AN006, I10AP005, I10BN003, I10BP005, I11AN009, I11AP013. We thank Malin Velander, Emma Grocutt, Lars Koens and Catherine Heymans for help in acquiring the data. The Isaac Newton Telescope is operated on the island of La Palma by the Isaac Newton Group in the Spanish Observatorio del Roque de los Muchachos of the Instituto de Astrofísica de Canarias. Based on observations obtained with MegaPrime/MegaCam, a joint project of CFHT and CEA/DAPNIA, at the Canada-France-Hawaii Telescope (CFHT) which is operated by the National Research Council (NRC) of Canada, the Institut National des Sciences de l’Univers of the Centre National de la Recherche Scientifique of France, and the University of Hawaii. The research leading to these results has received funding from the European Research Council under the European Union’s Seventh Framework Programme (FP7/2007-2013) / ERC grant agreement N° 340519. R.v.d.B. and H.H. acknowledge support from the Netherlands Organisation for Scientific Research grant number 639.042.814. C.S. acknowledges support from the European Research Council under FP7 grant number 279396. M.L.B. acknowledges support from an NSERC Discovery Grant, and NOVA and NWO grants that supported his sabbatical leave at the Sterrewacht at Leiden University.
References
- Ahn, C. P., Alexandroff, R., Allen de Prieto, C., et al. 2014, ApJS, 211, 17 [NASA ADS] [CrossRef] [Google Scholar]
- Andreon, S., & Hurn, M. A. 2010, MNRAS, 404, 1922 [NASA ADS] [Google Scholar]
- Bell, E. F., & de Jong, R. S. 2001, ApJ, 550, 212 [NASA ADS] [CrossRef] [Google Scholar]
- Bildfell, C. J. 2013, Ph.D. Thesis, University of Victoria, Canada [Google Scholar]
- Binney, J., & Tremaine, S. 2008, Galactic Dynamics, 2nd edn. (Princeton University Press) [Google Scholar]
- Boylan-Kolchin, M., Bullock, J. S., & Kaplinghat, M. 2011, MNRAS, 415, L40 [CrossRef] [Google Scholar]
- Brammer, G. B., van Dokkum, P. G., & Coppi, P. 2008, ApJ, 686, 1503 [NASA ADS] [CrossRef] [Google Scholar]
- Budzynski, J. M., Koposov, S. E., McCarthy, I. G., McGee, S. L., & Belokurov, V. 2012, MNRAS, 423, 104 [NASA ADS] [CrossRef] [Google Scholar]
- Burke, C., & Collins, C. A. 2013, MNRAS, 434, 2856 [NASA ADS] [CrossRef] [Google Scholar]
- Carlberg, R. G., Yee, H. K. C., & Ellingson, E. 1997, ApJ, 478, 462 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cen, R. 2014, ApJ, 781, 38 [NASA ADS] [CrossRef] [Google Scholar]
- Chabrier, G. 2003, PASP, 115, 763 [NASA ADS] [CrossRef] [Google Scholar]
- Demarco, R., Wilson, G., Muzzin, A., et al. 2010, ApJ, 711, 1185 [NASA ADS] [CrossRef] [Google Scholar]
- Diemer, B., More, S., & Kravtsov, A. V. 2013, ApJ, 766, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Duffy, A. R., Schaye, J., Kay, S. T., & Dal la Vecchia, C. 2008, MNRAS, 390, L64 [NASA ADS] [CrossRef] [Google Scholar]
- Dutton, A. A., & Macciò, A. V. 2014, MNRAS, 441, 3359 [NASA ADS] [CrossRef] [Google Scholar]
- Einasto, J. 1965, Trudy Astrofizicheskogo Instituta Alma-Ata, 5, 87 [NASA ADS] [Google Scholar]
- Erben, T., Hildebrandt, H., Lerchster, M., et al. 2009, A&A, 493, 1197 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Evrard, A. E., Bialek, J., Busha, M., et al. 2008, ApJ, 672, 122 [NASA ADS] [CrossRef] [Google Scholar]
- Fadda, D., Girardi, M., Giuricin, G., Mardirossian, F., & Mezzetti, M. 1996, ApJ, 473, 670 [NASA ADS] [CrossRef] [Google Scholar]
- Ferrarese, L., Côté, P., Cuillandre, J.-C., et al. 2012, ApJS, 200, 4 [NASA ADS] [CrossRef] [Google Scholar]
- Geen, S., Slyz, A., & Devriendt, J. 2013, MNRAS, 429, 633 [NASA ADS] [CrossRef] [Google Scholar]
- Genel, S., Vogelsberger, M., Springel, V., et al. 2014, MNRAS, 445, 175 [Google Scholar]
- Ghigna, S., Moore, B., Governato, F., et al. 2000, ApJ, 544, 616 [NASA ADS] [CrossRef] [Google Scholar]
- Gillis, B. R., Hudson, M. J., Erben, T., et al. 2013, MNRAS, 431, 1439 [NASA ADS] [CrossRef] [Google Scholar]
- Giodini, S., Pierini, D., Finoguenov, A., et al. 2009, ApJ, 703, 982 [NASA ADS] [CrossRef] [Google Scholar]
- Gladders, M. D., & Yee, H. K. C. 2000, AJ, 120, 2148 [NASA ADS] [CrossRef] [Google Scholar]
- High, F. W., Stubbs, C. W., Rest, A., Stalder, B., & Challis, P. 2009, AJ, 138, 110 [NASA ADS] [CrossRef] [Google Scholar]
- Hildebrandt, H., Pielorz, J., Erben, T., et al. 2009, A&A, 498, 725 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hoekstra, H., Mahdavi, A., Babul, A., & Bildfell, C. 2012, MNRAS, 427, 1298 [NASA ADS] [CrossRef] [Google Scholar]
- Hogg, D. W. 1999, [arXiv:astro-ph/9905116] [Google Scholar]
- Klypin, A., Yepes, G., Gottlober, S., Prada, F., & Hess, S. 2014, MNRAS, submitted [arXiv:1411.4001] [Google Scholar]
- Kriek, M., van Dokkum, P. G., Labbé, I., et al. 2009, ApJ, 700, 221 [NASA ADS] [CrossRef] [Google Scholar]
- Kuijken, K. 2008, A&A, 482, 1053 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lasker, B. M., Lattanzi, M. G., McLean, B. J., et al. 2008, AJ, 136, 735 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Lidman, C., Iacobuta, G., Bauer, A. E., et al. 2013, MNRAS, 433, 825 [NASA ADS] [CrossRef] [Google Scholar]
- Lin, Y.-T., Mohr, J. J., & Stanford, S. A. 2004, ApJ, 610, 745 [NASA ADS] [CrossRef] [Google Scholar]
- Macciò, A. V., Dutton, A. A., & van den Bosch, F. C. 2008, MNRAS, 391, 1940 [NASA ADS] [CrossRef] [Google Scholar]
- Magnier, E. A., & Cuillandre, J.-C. 2004, PASP, 116, 449 [NASA ADS] [CrossRef] [Google Scholar]
- Mahdavi, A., Hoekstra, H., Babul, A., et al. 2013, ApJ, 767, 116 [NASA ADS] [CrossRef] [Google Scholar]
- Moster, B. P., Somerville, R. S., Newman, J. A., & Rix, H.-W. 2011, ApJ, 731, 113 [Google Scholar]
- Muzzin, A., Yee, H. K. C., Hall, P. B., Ellingson, E., & Lin, H. 2007, ApJ, 659, 1106 [NASA ADS] [CrossRef] [Google Scholar]
- Muzzin, A., Wilson, G., Lacy, M., Yee, H. K. C., & Stanford, S. A. 2008, ApJ, 686, 966 [NASA ADS] [CrossRef] [Google Scholar]
- Muzzin, A., Wilson, G., Yee, H. K. C., et al. 2009, ApJ, 698, 1934 [NASA ADS] [CrossRef] [Google Scholar]
- Muzzin, A., Wilson, G., Yee, H. K. C., et al. 2012, ApJ, 746, 188 [NASA ADS] [CrossRef] [Google Scholar]
- Muzzin, A., Marchesini, D., Stefanon, M., et al. 2013a, ApJ, 777, 18 [NASA ADS] [CrossRef] [Google Scholar]
- Muzzin, A., Marchesini, D., Stefanon, M., et al. 2013b, ApJS, 206, 8 [Google Scholar]
- Muzzin, A., van der Burg, R. F. J., McGee, S. L., et al. 2014, ApJ, 796, 65 [NASA ADS] [CrossRef] [Google Scholar]
- Nagai, D., & Kravtsov, A. V. 2005, ApJ, 618, 557 [NASA ADS] [CrossRef] [Google Scholar]
- Natarajan, P., Kneib, J.-P., & Smail, I. 2002, ApJ, 580, L11 [NASA ADS] [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [NASA ADS] [CrossRef] [Google Scholar]
- Peng, C. Y., Ho, L. C., Impey, C. D., & Rix, H.-W. 2002, AJ, 124, 266 [NASA ADS] [CrossRef] [Google Scholar]
- Pratt, G. W., Arnaud, M., Piffaretti, R., et al. 2010, A&A, 511, A85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rines, K., Geller, M. J., Diaferio, A., & Kurtz, M. J. 2013, ApJ, 767, 15 [NASA ADS] [CrossRef] [Google Scholar]
- Sand, D. J., Graham, M. L., Bildfell, C., et al. 2011, ApJ, 729, 142 [NASA ADS] [CrossRef] [Google Scholar]
- Sawala, T., Frenk, C. S., Crain, R. A., et al. 2013, MNRAS, 431, 1366 [NASA ADS] [CrossRef] [Google Scholar]
- Schaye, J., Dal la Vecchia, C., Booth, C. M., et al. 2010, MNRAS, 402, 1536 [Google Scholar]
- Schaye, J., Crain, R. A., Bower, R. G., et al. 2015, MNRAS, 446, 521 [Google Scholar]
- Schechter, P. 1976, ApJ, 203, 297 [Google Scholar]
- Sifón, C., Hoekstra, H., Cacciato, M., et al. 2015, A&A, 575, A48 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Somerville, R. S., Lee, K., Ferguson, H. C., et al. 2004, ApJ, 600, L171 [NASA ADS] [CrossRef] [Google Scholar]
- Springel, V., White, S. D. M., Jenkins, A., et al. 2005, Nature, 435, 629 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Tinker, J., Kravtsov, A. V., Klypin, A., et al. 2008, ApJ, 688, 709 [NASA ADS] [CrossRef] [Google Scholar]
- Trenti, M., & Stiavelli, M. 2008, ApJ, 676, 767 [Google Scholar]
- van Daalen, M. P., Schaye, J., Booth, C. M., & Dal la Vecchia, C. 2011, MNRAS, 415, 3649 [NASA ADS] [CrossRef] [Google Scholar]
- van der Burg, R. F. J., Muzzin, A., Hoekstra, H., et al. 2013, A&A, 557, A15 (vdB13) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- van der Burg, R. F. J., Muzzin, A., Hoekstra, H., et al. 2014, A&A, 561, A79 (vdB14) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Velliscig, M., van Daalen, M. P., Schaye, J., et al. 2014, MNRAS, 442, 2641 [NASA ADS] [CrossRef] [Google Scholar]
- Vogelsberger, M., Genel, S., Springel, V., et al. 2014, Nature, 509, 177 [NASA ADS] [CrossRef] [Google Scholar]
- Wechsler, R. H., Bullock, J. S., Primack, J. R., Kravtsov, A. V., & Dekel, A. 2002, ApJ, 568, 52 [NASA ADS] [CrossRef] [Google Scholar]
- Wetzel, A. R., Tinker, J. L., Conroy, C., & van den Bosch, F. C. 2013, MNRAS, 432, 336 [NASA ADS] [CrossRef] [Google Scholar]
- Wilson, G., Muzzin, A., Yee, H. K. C., et al. 2009, ApJ, 698, 1943 [NASA ADS] [CrossRef] [Google Scholar]
- Wyithe, J. S. B., Turner, E. L., & Spergel, D. N. 2001, ApJ, 555, 504 [NASA ADS] [CrossRef] [Google Scholar]
- Yee, H. K. C., Ellingson, E., & Carlberg, R. G. 1996, ApJS, 102, 269 [NASA ADS] [CrossRef] [Google Scholar]
- Zhao, H. 1996, MNRAS, 278, 488 [Google Scholar]
All Tables
The 60 clusters selected from MENeaCS and CCCP that form the basis of this study, with their dynamical properties.
Parameters describing the best-fitting NFW (where α is fixed to 1) and gNFW (where α is a free parameter) profiles to the radial density distributions.
Excess of stellar mass in satellites in each of the subsamples, with respect to the overall best-fitting NFW profile.
All Figures
|
Fig. 1 Lines: expected growth curves as a function of cosmic time (or redshift) for massive haloes based on the Millennium simulation (Springel et al. 2005), in which we followed these haloes at fixed cumulative comoving number density. Red: the GCLASS cluster sample studied in vdB14. Black triangles: low redshift cluster sample studied here. Purple: the CNOC1 cluster sample studied by Muzzin et al. (2007). The cluster samples are linked by the evolutionary growth curves. |
| In the text | |
|
Fig. 2 Left panel: spectroscopic versus photometric redshifts for the 60 cluster fields in this study. Outliers, objects for which |
| In the text | |
|
Fig. 3 Spectroscopic completeness for sources with a photometric redshift z< 0.3 as a function of stellar mass (assuming the same distance modulus as the cluster redshift). The four lines show different radial bins. For targets of a given stellar mass, the spectroscopic completeness is slightly higher for those that are closer to the cluster centres. For each of the radial bins, the completeness is larger than 70% for stellar masses M⋆> 1011M⊙. |
| In the text | |
|
Fig. 4 Galaxy number density distributions for masses 109<M⋆/M⊙< 1010 (left panel), and M⋆> 1010M⊙ (right panel) for the ensemble cluster at z ~ 0.15. Black points with the best-fitting projected NFW (dashed) and gNFW (solid) functions are our best estimates for the cluster number counts. The inner two points in the left panel are masked due to obscuration from the BCG, which is more severe for low-mass galaxies, and are excluded from the fitting. Purple points indicate the number of spectroscopically confirmed cluster members. |
| In the text | |
|
Fig. 5 Stellar mass density distribution of the ensemble cluster at z ~ 0.15. Black points: cluster stellar mass distribution, with best-fitting projected NFW (dashed) and gNFW (solid) functions. Purple points: stellar mass distribution in spectroscopically confirmed cluster members. Dotted line: total stellar mass density profile on the images (background subtracted, with the 68% confidence region around these values shown by the thinner dotted lines), including the BCG and part of the ICL component. |
| In the text | |
|
Fig. 6 Black points: stellar mass density concentration for the clusters used in this study, split in two redshift bins. Purple: K-band luminosity density concentration in CNOC1 from Muzzin et al. (2007). Red: stellar mass density concentration in GCLASS from vdB14. The horizontal bars indicate the redshift range for each sample. Black lines: the NFW concentration in the sample of relaxed haloes from Duffy et al. (2008) as a function of redshift. Dotted and dashed: haloes of a given mass as a function of redshift. Solid: NFW concentration of a halo that is evolving in mass, with scatter given by the shaded region. |
| In the text | |
|
Fig. 7 Left panel: red points: average stellar mass density profile of GCLASS, in physical units. Black points: stellar mass density profile at low-z, at the same physical scale. The orange region marks the part of the z ~ 1 profile that is in excess of the z ~ 0.15 profile, and comprises a stellar mass of about 7 × 1011M⊙. Black dotted: stellar mass at z ~ 0.15, including BCG+ICL. Dashed purple and solid blue: stellar mass in blue galaxies at z ~ 1 and z ~ 0.15, respectively. Right panel: dark matter profiles from N-body simulations, using the average profile parameters from Duffy et al. (2008) and Dutton & Macciò (2014), but with the profiles plotted on the same physical scale. Shown are profiles at redshifts of z = 1.00 (red) and z = 0.15 (black), with masses of M200 = 3 × 1014M⊙ and M200 = 9 × 1014M⊙, respectively. |
| In the text | |
|
Fig. 8 Black: stellar mass density profile of Fig. 5, separated between red-sequence (red) and bluer (blue) galaxies. The best-fitting gNFW profiles to the red and blue sub-samples are also shown here. |
| In the text | |
|
Fig. A.1 Black solid line: Tinker et al. (2008) cumulative mass function at z = 1 for WMAP7 cosmology. Black dotted lines: Tinker et al. (2008) cumulative mass functions at z = 0.86 and z = 1.34, which are the redshift limits within which the GCLASS clusters are selected. Red dashed line: cumulative mass function of the ten GCLASS clusters, normalised by the total volume of SpARCS. |
| In the text | |
|
Fig. A.2 Black solid line: GCLASS ensemble average stellar mass concentration with a Gaussian probability distribution around c = 7.12. Also shown are the log-normal concentration distribution for clusters with the same mass and redshift as the GCLASS sample for the relaxed haloes in Duffy et al. (2008) (blue dotted line), and their full sample (red dashed line). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.