| Issue |
A&A
Volume 698, June 2025
|
|
|---|---|---|
| Article Number | A153 | |
| Number of page(s) | 18 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202452099 | |
| Published online | 12 June 2025 | |
AAS2RTO: Automated Alert Streams to Real-Time Observations
Preparing for rapid follow-up of transient objects in the era of LSST
1
DARK, Niels Bohr Institute, University of Copenhagen,
Jagtvej 155A,
2200
Copenhagen N,
Denmark
2
INAF, Osservatorio Astronomico di Capodimonte,
Salita Moiariello 16,
80131
Naples,
Italy
3
STFC Hartree Centre, Sci-Tech Daresbury,
Keckwick Lane, Daresbury,
Warrington
WA4 4AD,
UK
4
Astrophysics Research Centre, School of Mathematics and Physics, Queen’s University Belfast,
Belfast
BT7 1NN,
UK
★ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
3
September
2024
Accepted:
18
March
2025
Abstract
Context. The upcoming Vera C. Rubin Legacy Survey of Space and Time (LSST) will discover tens of thousands of astrophysical transients per night, far outpacing available spectroscopic follow-up capabilities. Carefully prioritising candidates for follow-up observations will maximise the scientific return from small telescopes with a single-object spectrograph.
Aims. We introduce AAS2RTO, an astrophysical transient candidate prioritisation tool written in Python. AAS2RTO is flexible in that any number of criteria that consider observed properties of transients can be implemented. The visibility of candidates from a given observing site is also considered. The prioritised list of candidates provided by AAS2RTO is continually updated when new transient data are made available. Therefore, it can be applied to observing campaigns with a wide variety of scientific motivations.
Methods. AAS2RTO uses a greedy algorithm to prioritise candidates. Candidates are represented by a single numerical value, or ‘score’. Scores are computed by constructing simple numerical factors that individually consider the competing facets of a candidate that make it suitable for follow-up observation. AAS2RTO is currently configured to work primarily with photometric data from the Zwicky Transient Facility (ZTF), distributed by certified LSST community brokers.
Results. We provide an example of how AAS2RTO can be used by defining a set of criteria to prioritise observations of type Ia supernovae (SNe Ia) close to peak brightness, in preparation for observations with the spectrograph at the Danish-1.54 m telescope. Using a sample of archival alerts from ZTF, we evaluate the criteria we have designed to estimate the number of SNe Ia that we will be able to observe with a 1.5 m telescope. Finally, we evaluate the performance of our criteria when applied to mock LSST observations of SNe Ia.
Key words: instrumentation: spectrographs / methods: observational / techniques: spectroscopic / surveys
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
The Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST, Ivezić et al. 2019) will monitor the entire southern sky for the next ten years. This next-generation optical photometric survey will produce a unique data set that will enable us to address the most pressing science questions revolving around the formation and evolution of our Universe and the objects within it. LSST’s special telescope and camera design results in a large field of view of 9.6 square degrees (Graham et al. 2020), allowing it to swiftly image large areas of the sky. Every night, about 1000 images will be taken in a selection of six filters (u, g, r, i, z and y) in a pre-defined pattern. This, together with the high depth of each image (e.g. the anticipated 5σ point source r-band depth ≈24.5 mag), makes LSST unique in detecting a large range of astrophysical objects and transient phenomena that are either faint or change in either brightness or position on short timescales. Within 60 seconds of observations, LSST will alert the community of these events, totalling around 10 million alerts every night (Ridgway et al. 2014). Therefore, LSST will enable the exploration of as-yet-unknown regions in the phase space of transient phenomena (Ivezić et al. 2019), extending the volume-time space to about 100 times over ongoing surveys such as the Young Supernova Experiment (Jones et al. 2021; Aleo et al. 2023), the Zwicky Transient Facility (ZTF, Bellm et al. 2019a), the Asteroid Terrestrial-impact Last Alert System (ATLAS, Tonry et al. 2018), BlackGEM (Bloemen et al. 2015), the All-Sky Automated Survey for Supernovae (ASAS-SN, Shappee et al. 2014). Planned complementary photometric and spectroscopic surveys such as La Silla Schmidt Southern Survey (LS4, Nugent et al. 2020; Miller et al. 2025), which is expected to begin operation in 2025, will aid this endeavour.
LSST alerts will be distributed to the astronomical community through dedicated community alert brokers (‘brokers’) that include FINK (Möller et al. 2021), the Automatic Learning for the Rapid Classification of Events broker (ALeRCE, Förster et al. 2021), Lasair (Smith et al. 2019), and the Arizona-NOIRLab Temporal Analysis and Response to Events System (ANTARES, Matheson et al. 2021). All brokers will filter and process the received LSST alerts according to broker-specific criteria. Potential ‘bogus’ (false positive) alerts will be filtered out prior to processing. For alerts considered ‘real’, additional information, such as the predicted classifications of an astrophysical object, can be added to the original LSST alert. Brokers refer to this extra information as ‘annotating’. However, all brokers have different approaches to annotating alerts, and distributing alerts in real-time. Despite this, the capacity to query archival alerts, and entire light curves, is common to all brokers.
With ongoing dedicated photometric transient surveys, such as the Zwicky Transient Facility (ZTF, Bellm et al. 2019b) (with single-epoch 5σ-depth of r = 20.6 mag), it has been possible to either spectroscopically or photometrically follow up on a large fraction of the newly discovered transient candidates. For instance, the ZTF Bright Transient Survey (BTS, Fremling et al. 2020; Perley et al. 2020), has obtained spectra of almost every ZTF candidate with a peak brightness of rpeak ≲ 18.5 mag and has spectroscopically confirmed over 8800 transients within the past six years1.
However, the unprecedented photometric depth and resulting high rate of alerts (e.g. ~1 million supernovae (SNe) per year) from LSST challenges current spectroscopic follow-up capacities. To this end, dedicated new instruments and surveys, such as the Time-Domain Extragalactic Survey (Swann et al. 2019, TiDES) at the 4-meter Multi-Object Spectroscopic Telescope, are currently being developed. The Son of X-Shooter spectrograph (SOXS, Schipani et al. 2018) for the 3.58-m European Southern Observatory (ESO) New Technology Telescope at La Silla will cover a wavelength range 0.35–2.0 micron, with a significant portion of its observing time dedicated to characterising newly-discovered transients.
On the other hand, existing smaller telescopes may be utilised for spectroscopic follow-up observations of specific targets and for specific science cases, aiding the limited spectroscopic resources currently available. To maximise the scientific return from small telescopes, careful prioritisation of LSST-discovered transient candidates will be essential.
Here, we have developed the Automated Alert Streams to Real-Time Observations tool (AAS2RTO). The primary goal is to aid in the prioritisation of LSST discovered transient candidates to optimise spectroscopic follow-up observations with the Danish-1.54 m telescope (DK1.54 m). There are already several existing tools to aid in prioritising observations for a very large variety of scientific goals (e.g. Steele & Carter 1997; Denny 2004; Rana et al. 2017; Dyer et al. 2018, 2020; Fredslund Andersen et al. 2019; Ishida et al. 2019; Sravan et al. 2020; Asquini et al. 2022; Rehemtulla et al. 2024). However, none exactly meet the requirements for using the DK1.54 m as a flexible LSST spectroscopic follow-up resource.
The DK1.54 m is located at the European Southern Observatory (ESO) at La Silla, Chile, which is ~100 km north of the Vera C. Rubin Observatory located at Cerro Pachón. The main instrument at the DK1.54 m is the Danish Faint Object Spectrograph and Camera (DFOSC, Andersen et al. 1995), which can be used for photometry and spectroscopy, covering the same optical to near-infrared wavelength range as LSST. DFOSC has a history of spectroscopic follow-up of a wide variety of transients. For instance, it was used in the study of SN 1998bw and the associated gamma-ray burst GRB980425 (Patat et al. 2000, 2001), and in identifying the optical counterpart of the X-ray pulsar GS 1843+009 (Israel et al. 2001). However, since 2003, the spectrograph has been decommissioned. The DK1.54 m has recently been used solely for photometric observations, for projects such as the Ondrejov Asteroid Photometry Project (e.g. Pravec et al. 2014, 2024) and the Microlensing Network for the Detection of Small Terrestrial Exoplanets (MiNDSTEp, Braga-Ribas et al. 2014; Southworth et al. 2016; Giannini et al. 2017). With the upcoming event of LSST and the need for spectroscopy, efforts are being made to re-commission the spectrograph.
Despite AAS2RTO being primarily intended to be used with the DK1.54 m, the algorithm is flexible, and therefore can be adjusted for any other telescope. Further, it can be adapted to a wide range of scientific goals and observing strategies. This also requires that different data and alert streams from either private or public surveys can easily be incorporated, which AAS2RTO’s modular structure allows. Here, to test the algorithm, we primarily use data and alerts from ZTF as a substitute for future streams from LSST.
The paper is organised as follows. In Sect. 2, we describe the main concept of AAS2RTO, and outline the structure of the prioritisation algorithm. We also outline the key sources of data that are used in this work. Sect. 3 describes the implementation of AAS2RTO for an example science case, which is aimed at obtaining spectra of type Ia supernovae at peak brightness. We use two years of archival data from ZTF to illustrate candidates which would have been highly ranked by AAS2RTO. Finally, in Sect. 4, we compare the prioritisation strategy used by AAS2RTO to a selection of other available schedulers and prioritisation tools. AAS2RTO is written in PYTHON and is publicly available2.
2 Methods
The aim of AAS2RTO is to automatically ingest and process transient data streams, and rank transient candidates according to the scientific interest of a user. This said, AAS2RTO is not a broker, as it compiles alert streams that have already been pre-filtered by brokers. The main functionality of AAS2RTO is to decide which of these pre-filtered alerts have attributes that match best the criteria of a given scientific use-case. Our algorithm neither filters or classifies all transient alerts from a given survey, nor does it redistribute alerts.
AAS2RTO uses a greedy strategy (e.g. Black 2005; Goodrich & Tamassia 2014) for prioritising candidates Such a strategy is also referred to as a ‘dispatch’ or ‘just-in-time’ strategy by other observation management systems. Steele & Carter (1997) summarise this strategy as finding ‘the best observation at a given time based on the current telescope state and [observing] conditions without any attempt to look ahead’. AAS2RTO assesses an unordered set of candidates and computes a single value for each candidate. This value quantifies how ‘interesting’ (favourable for observation) the candidate is according to the user-specified criteria. We refer to this single value as the ‘score’, and it is described in detail in Sect. 2.3. This single score is used to rank candidates, to determine which candidate is best scheduled for the next possible observation.
Figure 1 depicts a schematic view of the key components of AAS2RTO in the context of an automated observing cycle with the DK1.54 m. The primary elements are data acquisition, candidate prioritisation, observing block generation, actual observation, (automated) data reduction, distribution and storage. For observations specifically with the DK1.54 m, we are separately developing reduction pipelines with PypeIt (Prochaska et al. 2020). Data can then be made publicly available (for example, via the TNS).
When LSST begins operation, alerts will be produced and distributed at timescales that can be shorter than the required exposure times for a given candidate (particularly for spectroscopy). To optimise observations, a ranked candidate list needs to be updated on timescales at least shorter than that of spectroscopic observations, but ideally with a similar frequency to that of the alert distribution. AAS2RTO therefore repeatedly performs a ‘prioritisation loop’. This loop is visualised in Fig. 2 and can be understood as follows:
Data acquisition: AAS2RTO receives alerts from broadcasting services (for example, FINK or Lasair) of new detections of candidates. Transient surveys such as LSST or ZTF send ‘raw alerts’ to brokers, which comprise a data packet of a single photometric detection of an astrophysical event that changed in either brightness or position. Along with the photometric information of the detection (aperture magnitudes and 5σ detections limits), an alert packet contains information of the celestial coordinates, a time stamp and small image cutouts (single-epoch, static sky and difference image) of the event. Alerts are aggregated (by on-sky position) into objects or candidates. Brokers then ingest, filter, annotate and redistribute viable alerts (see Sect. 1). AAS2RTO integrates some alert information (i.e. magnitude, time stamp) either into an existing light curve of an already-known candidate, or into photometric data that are queried for new candidates. Any additional candidates which users have specified manually can be included at this stage. This allows for Target of Opportunity (ToO) events to be scored and ranked along with candidates which are received from broadcasting services. To add new ToOs in AAS2RTO, users must write the details in simple ASCII text files which are saved in a pre-defined directory. Finally, for each candidate, other light curves and additional data from non-broadcasting services are queried.
Candidate pre-filtering: we compute a first estimate of the ‘score’ for any previously unknown candidates. This initial pre-filtering uses the components of the score which do not depend on any models, and therefore are not expensive to compute. This is explained more thoroughly with an example in Sect. 3.2. Any new candidates which can already be labelled unsuitable in this step (2) will be removed. For prioritising observations of transients, the age of the transient (measured by the total duration of the light curve, for example) often plays a key role in whether it aligns with the science criteria.
Fit relevant models: theoretical models (e.g. light curve fits for transients) can be useful aids in identifying and prioritising viable candidates. Any theoretical models are fit after the pre-filtering stage so that computation is not spent on candidates which are already known to be unsuitable.
Compute full score: taking all compiled information into account (light curves, theoretical models), the full ‘score’ for each candidate can be computed. At this stage, we also consider observing site-specific criteria. For instance, we calculate if candidates are actually observable from the observing site of interest (i.e. the DK1.54 m at La Silla). As observers may have access to more than one observatory (for parallelising observations of many candidates, for example), we compute the site-specific components of the score for each observing site in a pre-defined list provided by users.
Candidate removal: we remove candidates with a score which labels them as unsuitable because of their observed characteristics. However, candidates are not removed because of site-specific reasons alone. For example, a candidate is not removed for being below the horizon, as it may be observable later, or be currently observable from another observatory.
Compile ranked lists: we compile a list of the remaining candidates, ranked by the score computed in Step (4) using the user-defined science criteria. We produce additional ranked lists for each observing site of interest which exclude candidates that are not visible.
Inform users: AAS2RTO optionally sends messages to users which contain candidate properties and lighcurve figures, and visibility plots for the list of observing sites. These messages only contain candidates which have been updated in the current iteration of the prioritisation loop. These messages are detailed in Appendix A.
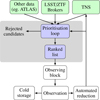 |
Fig. 1 Sketch of the logic behind automated observations using AAS2RTO and the Danish-1.54 m. Green boxes indicate data compiled by AAS2RTO. White boxes are out of the scope of AAS2RTO. The steps made by AAS2RTO in the grey box are detailed in Fig. 2. |
 |
Fig. 2 Prioritisation loop of AAS2RTO. First, data is compiled (step (1); Sect. 2.1) from broadcasting services (e.g. ZTF/LSST brokers) and non-broadcasting services (e.g. ATLAS/TNS). A pre-filtering step (step (2)) identifies new candidates which can immediately be removed without detailed modelling or visibility considerations. Theoretical models (e.g. light curve fits) are fit to new candidates (step (3)), or candidates which have received new data/alerts in the data compilation step. The full score is computed for each candidate (step (5); Sect. 2.3), considering the light curve, and models fit in the previous step, and observing site conditions. Finally, list of candidates are produced, in order of descending score (step (6); Sect. 2.4). |
2.1 Data sources
The transient survey that is closest to the upcoming LSST survey in terms of footprint, cadence, and alert distribution is currently ZTF. Therefore, we chose ZTF as our baseline survey to develop and test AAS2RTO. ZTF monitors the entire northern sky visible from Palomar, California (USA), approximately every two nights in two photometric broadband filters: ZTF g- and r-band, covering a wavelength range of 3676–5613 Å and 5497–7394 Å, respectively.
The ZTF camera provides an extremely wide 47 deg2 field of view, and reaches median 5σ limiting magnitudes of 20.8 mag and 20.6 mag in g- and r-band respectively (in 30 sec exposures). In its first 2.5 years of operation, it discovered >3000 type Ia supernovae, of which 934 have spectra (Dhawan et al. 2022). As of 2024, ZTF has spectroscopically confirmed nearly 9000 transients3. Bellm (2016) developed the survey speed metric ![Mathematical equation: $\[\dot{V}_{-19}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq1.png) (measured in Mpc3 s−1), which measures the comoving volume in which an object of absolute magnitude −19 (characteristic of supernovae type Ia) can be detected per exposure time. By this metric, and by the simpler étendue (AΩ, light-collecting area times field of view, m2 deg2), ZTF is the fastest existing transient survey to date. ZTF has
(measured in Mpc3 s−1), which measures the comoving volume in which an object of absolute magnitude −19 (characteristic of supernovae type Ia) can be detected per exposure time. By this metric, and by the simpler étendue (AΩ, light-collecting area times field of view, m2 deg2), ZTF is the fastest existing transient survey to date. ZTF has ![Mathematical equation: $\[\dot{V}_{-19}=2.5 \times 10^{4} ~\mathrm{Mpc}^{3} \mathrm{~s}^{-1}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq2.png) and AΩ = 53.1m2 deg2.
and AΩ = 53.1m2 deg2.
To compare, LSST will have ![Mathematical equation: $\[\dot{V}_{-19}=3.7 \times 10^{5} ~\mathrm{Mpc}^{3} \mathrm{~s}^{-1}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq3.png) and AΩ = 319.5 m2 deg2. LSST will be the fastest transient survey by an order of magnitude, when it begins operation. Since all LSST alerts will be distributed by brokers which are currently distributing ZTF alerts (see Sect. 1), we can confidently use these brokers for testing and developing AAS2RTO. The specific brokers used by AAS2RTO are discussed in more detail in Sect. 2.2.
and AΩ = 319.5 m2 deg2. LSST will be the fastest transient survey by an order of magnitude, when it begins operation. Since all LSST alerts will be distributed by brokers which are currently distributing ZTF alerts (see Sect. 1), we can confidently use these brokers for testing and developing AAS2RTO. The specific brokers used by AAS2RTO are discussed in more detail in Sect. 2.2.
The Asteroid Terrestrial-impact Last Alert System (ATLAS, Tonry et al. 2018) is an astronomical survey which scans the whole sky every two nights. ATLAS was proposed as a system to detect potentially hazardous near-Earth asteroids, and has discovered 976 such objects since beginning operation in 2015 (as of the end of 20234). Originally operating with two 0.5 m independent units at Haleakalā Observatory and Mauna Loa Observatory in Hawai’i, USA, two more units have since been added at Sutherland Observatory, South Africa, and El Sauce Observatory, Chile. The survey is conducted in two broad photometric bands: ATLAS-o (‘orange’, 420–650 nm) and ATLAS-c (‘cyan’, 560–820 nm). A single ATLAS unit has an étendue AΩ = 11.8 m2 deg2.
As a high-cadence survey, ATLAS is an extremely useful resource for a wide variety of scientific interests in addition to its asteroid detection purpose. For example, it is a proven resource for variable star discovery and classification having discovered >400 000 candidates in the first ATLAS variable star catalogue (Heinze et al. 2018). Furthermore, as of the end of 2023, it was the instrument of discovery for over 3700 spectroscopically confirmed SNe Ia5. In particular, the high cadence of ATLAS data enabled the discovery of the unprecedented ‘early flux excess’ seen in the 02es-like Type-Ia supernova 2022ywc (Srivastav et al. 2023).
The Transient Name Server6 (Gal-Yam 2021) is a database of known transient objects, continuously updated with discoveries from many transient surveys. For each transient, the TNS database provides various information such as the coordinates, name of the discovery team and instrument, and the time, brightness, and photometric band of the discovery. For transients which have been observed spectroscopically, the classification spectra and details, such as the astrophysical type and redshift, z, are made available. For instance, there are more than 11 000 type Ia supernovae with spectroscopically measured redshifts as of the end of 2023.
2.2 Data collection and community brokers
We are listening for ZTF alerts from the FINK broker7 (Möller et al. 2021). FINK annotates alerts with predicted classifications of physical type, using machine learning methods. ZTF alerts are then broadcast with Apache Kafka in ‘streams’ according to this predicted class. There are streams of alerts for transients classified as candidate supernovae (Möller & de Boissière 2020; Leoni et al. 2022), microlensing events, kilonovae (Biswas et al. 2023), active galactic nuclei (Russeil et al. 2022), and others. This allows us (and any other FINK user) to only receive alerts which are relevant to our scientific interests. FINK flags ZTF alerts as ‘bad quality’ if they do not meet certain internal thresholds. For instance, an alert is flagged if any of the three image cutouts contains known bad pixels, or the aperture and PSF photometry measurements disagree by more than 0.1 mag. Such bad quality alerts are not distributed with Kafka, but the detections are made available through queries for candidate light curves. We still use these data when fitting light curves (see Sect. 3.1), however.
In a similar vein, the ALeRCE broker8 also annotates alerts using machine learning-based classifications, based on both the light curve and image cutouts (‘stamps’). The ALeRCE ‘light curve classifier’ (Sánchez-Sáez et al. 2021) has a two-level classification approach. Firstly, the ‘top-level’ classifies candidate sources into periodic, stochastic and transient classes. Subsequently, the ‘bottom-level’ further resolves each of these broad classifications into sub-classes (e.g. the transient class is further split into SN Ia, SN Ibc, SNII and super-luminous SN). On the other hand, the ALeRCE ‘stamp classifier’ (Carrasco-Davis et al. 2021) has five classes: AGN, SNe, Variable Star, asteroid and ‘bogus’ (false detections). It uses three stamp types associated with an alert, which are the science image (the single-epoch image of source in its environment or host galaxy), reference image (a deep image of the static sky), and difference image (science minus reference, the source without its environment). The stamp classifier has the advantage of being able to classify candidates after only a single alert, whereas the light curve classifier provides more detailed classification with its two-level approach.
We query alerts from ALeRCE by specifying a class from a particular ALeRCE classifier, a classification threshold, and a time interval (e.g. all alerts in the last 24 hr classified as SNe candidates by the stamp classifier, with a minimum 80% confidence). At present, we query for ‘SN’-classified alerts from the stamp classifier, and ‘SNIa’-classified alerts from the transient top-level light curve classifier.
The Lasair broker9 (Smith et al. 2019) annotates ZTF alerts using the Sherlock Sky Context software (Smith et al. 2020; Young 2023, Young et al. in prep). Sherlock crossmatches alerts with existing deep sky catalogues (by sky position) to identify potential host galaxies for transients, known variable stars and AGN, and close bright galactic stars (angular separation). Lasair enables us to filter alerts by defining quality cuts on the light curves of candidates and Sherlock annotations on the Lasair webpages. For example, it could be required that light curves have a minimum number of detections and minimum peak brightness, or a specific Sherlock classification, or minimum separation from bright galactic stars. Alerts that pass these quality cuts are redistributed with Apache Kafka.
ATLAS provides access to forced photometry through an API10 (Shingles et al. 2021). Forced photometry queries are made by providing a pair of RA and Dec coordinates, and a start and end date (in MJD). Queries for ATLAS forced photometry return a light curve, which is produced by measuring PSF fluxes and magnitudes at the requested coordinates in all difference images available in the requested MJD interval. However, ATLAS takes four images (30 sec exposures) of the same field in a 90 minute interval, instead of a single image with a long exposure. This strategy enables measurements of the proper motion of near-earth and solar system objects, but, the observed flux of extragalactic transients will not change detectably within these 90 minute intervals (within ATLAS flux uncertainties). Therefore, we choose to compute the uncertainty-weighted mean of the four forced PSF flux measurements from each 90 minute interval, and convert this mean PSF flux into a magnitude. Each of the four ATLAS images has an associated 5σ detection limit, which quantifies the minimum measured flux for which we can consider a detection to be reliable. We compute the mean 5σ flux of these four detection limits, and convert it to a magnitude. The computed mean PSF magnitude is a ‘valid’ detection if it is brighter than the mean 5σ detection limit. Otherwise, it is flagged as an upper limit (non-detection).
As the ATLAS server can only process a limited number of forced photometry queries per day, we limit the number of queries queued at any given time. ATLAS photometry is only requested for candidates that have already had a valid score computed (see Sect. 2.3). Additionally, we request forced photometry for candidates in descending order of their last computed score. In this way, the ATLAS photometry queries that are submitted first are for the candidates that are already highly ranked.
The TNS also provides access to data through an API. We query for all spectroscopically confirmed transients in the last 30 days and crossmatch the results with the set of all AAS2RTO candidates. For example, TNS queries could be used to aid an observing campaign that has the aim of observing currently-unclassified transients. Candidates that have a TNS match could be demoted or rejected.
2.3 Scores and scoring functions
The ‘score’, and the ‘scoring function’ that produces the score, are at the heart of AAS2RTO’s use as a candidate prioritisation tool. The primary intent of introducing a scoring function is to balance competing attributes of all available candidates that make a candidate favourable to be observed. Each of these attributes are considered independently to produce a numerical ‘factor’, xi, for each attribute. The final score, S, used for ranking is then computed as the product of all of the factors, and a ‘base score’, Sbase,
![Mathematical equation: $\[S=S_{\text {base}} ~\Pi x_i.\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq4.png) (1)
(1)
This single score produced for each candidate allows a set of candidates to be ranked, with the candidate with the highest score being ranked first, and so on. The base score, Sbase, is a value that is fixed for each candidate, and is by default the same for each candidate (e.g. Sbase = 1). We provide an example of constructing factors for an example science case in Sect. 3.2.
The scoring function also serves as the means of deferring observations of currently unsuitable candidates to later times (‘excluding’ candidates), or permanently removing candidates from consideration (‘rejecting’ candidates). If any of the factors xi indicate that a candidate is irrelevant or unsuitable, the computed score reflects this. AAS2RTO will reject candidates that have a non-finite score, and exclude candidates that have a negative score. Importantly, this means that care must be taken in designing factors xi to be positive and finite. An odd number of factors that are negative will produce a negative score, unintentionally excluding candidates. Factors that are non-finite can also multiply together to give a non-finite score, causing a candidate to be unintentionally rejected.
Factors xi can be designed to weight attributes that are more important to a certain science case. For instance, if the goal is to observe bright supernovae, but with a preference towards those that are blue in colour, then two factors, xflux and xcolour, can be constructed to range between 1 < xflux < 100 and 1 < xcolour < 10 (for the range of observed candidate fluxes and colours). This way, the final score will be more sensitive to changes in brightness than colour.
Modifying the base score is useful if candidates are known ahead of time to be of particular interest. For example, if there is a new, high-priority candidate that a user wishes to add to the set of existing candidates, it can be added with a larger base score than the default value. In the example above with 1 < xflux < 100 and 1 < xcolour < 10 and a default value of Sbase = 1, the maximum value of the score is S = 1000. Therefore, a high-priority candidate added with Sbase = 1000 is guaranteed to be the highest-ranked. This is useful for manually including ToOs. Candidates added as described above will naturally appear on top of the ranked list. Therefore, the remaining observations can continue to be scheduled in the prioritised order that AAS2RTO produces (see Sect. 2.4).
We stress that these scores are used only for ranking candidates, and they do not have a physical interpretation. It is not the actual value of the score of any given candidate that is important, but its value relative to another candidate.
2.4 Ranked lists and scheduling
The ultimate aim of AAS2RTO is to aid in real-time prioritisation candidates for rapid follow-up observations. As is described in Sect. 2.3, the score of each candidate considers any observed quantity that makes it ‘interesting’. After computing a score for each candidate, a simple observing schedule can be written by listing the candidates in order of decreasing score.
The visibility of candidates from a given observing site will also have an impact on the priority with which they are observed. In some cases, candidates may not be at all visible from an observing site. Scoring functions can take into account observing sites, and therefore, factors xi can be constructed to account for visibility. This is demonstrated explicitly in Sect. 3.2.
Observing campaigns are often carried out using more than one telescope or observatory (for example, to divide candidates amongst several sites). Therefore, AAS2RTO is capable of considering many observatories of interest to a user, individually. This means that a ranked list is produced for each observatory, which accounts for candidate visibility (current altitude). Candidates that are not visible from a particular observing site are excluded from the ranked list for that observatory. The ranked list for a particular observatory can then be used as an observing schedule specific to that site. Furthermore, the ranked list is updated every iteration of the prioritisation loop (see Fig. 2). However, we note that the ranked lists produced with AAS2RTO for a given observatory are not a ‘joint’ schedule, and therefore will not provide a globally optimised observing schedule for a telescope network. This type of schedule could be produced using integer linear programming (ILP), similar to the solution demonstrated in Solar et al. (2016) for the Atacama Large Millimeter/submillimeter Array (ALMA) observatory.
3 Example science case: Selecting SNe la at peak brightness
As an example of AAS2RTO, we prioritise type Ia supernovae (SNe Ia) that are at their peak brightness, with the aim of taking spectra at this peak. While there are many classes of astronomical transients that we could prioritise, SNe Ia are among the most frequent and brightest events and thus, ideally suited. About three quarters of SN-like transients detected in a magnitude-limited survey are SNe Ia. This has been the case in, for example, ZTF BTS (Fremling et al. 2020) and the All-Sky Automated Survey for SN (ASAS-SN; Holoien et al. 2019). The peak absolute magnitude of SNe Ia is M ~ −19 mag compared with M ~ −17 mag for core collapse supernovae (Perley et al. 2020). Due to these attributes, choosing to observe SNe Ia at peak brightness maximises the number of observable transients for a fixed magnitude limit, such as is the case here for the DK1.54 m telescope. We caution that such a sample will be biased towards the brightest events observed at the magnitude limit of a given telescope such as the DK1.54 m telescope. However, in this work we do not go into detail of possible selection criteria and biases as their relevance depends on the final science use case. The most strict criterion for observations is a faint limit of i < 18.5 mag. Although this science case is motivated by the capabilities of the DK1.54 m and its proximity to Rubin, the factors we describe here can be applied to any facility (or applied with minor modifications).
3.1 Light curve fitting
The data sources described in Sect. 2.1 provide candidate light curves. However, for optimised observations at a given point in a transient’s evolution we need to be able to predict this point of evolution. This can be done by fitting the available data that so far have been ingested with either simple fitting functions or physically motivated light curve models. Here, for our test science case of predicting the time of peak brightness of an SN Ia light curve, we implement two options. However, AAS2RTO is not limited to the models we describe in this Section.
We use the Spectral Adaptive Lightcurve Template (SALT, Guy et al. 2005, 2007) within the SNCOSMO framework (Barbary et al. 2016) to model the light curves of candidates. SALT is an empirical model for describing the evolution of SNe Ia as a function of time. Specifically, we use the SALT2 revision of the SALT models presented in Taylor et al. (2021).
The spectral flux density, F (p, λ) of a source computed with the SALT2 model is given by
![Mathematical equation: $\[F(p, \lambda)=x_0\left[M_0(p, \lambda)+x_1 M_1(p, \lambda)\right] \times 10^{-0.4 C L(\lambda) c}.\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq5.png) (2)
(2)
The model has component templates M0 (p, λ), M1 (p, λ) and CL (λ), where p is phase (defined for SALT as the time since the peak brightness in the B-band, Guy et al. 2005), λ is wavelength, and x0, x1 and c are free parameters. The three components M0, M1 and CL have been computed from a sample of 420 SNe Ia, of which 83 have at least one spectrum. They represent the global model of SNe Ia light curves as a function of time and wavelength. Guy et al. (2007) state that SALT would be equivalent to a principal component analysis if it were not modulated by the colour law CL (λ). M0 (p, λ) and M1 (p, λ) are time-dependent model components. M0 and M1 respectively encode the mean spectral energy distribution of SNe Ia, and variation from this mean.
The free parameters amplitude x0, stretch x1 and colour c are determined for a particular supernovae light curve, using a least squares fitting process or Monte Carlo methods. The amplitude parameter x0 is related to mB, the apparent B-band peak magnitude, as mB = −2.5 log10 (x0) + 10.5 (Kenworthy et al. 2021). The zero-phase parameter, t0 is defined as the time of the peak brightness in the B-band (p = 0, in days, often given as a Modified Julian Date). This parameter, along with the redshift, z, of the source are also allowed to vary. We use the dustmaps from Schlegel et al. (1998) to compute the Milky Way dust extinction. We do not attempt to fit SALT models to light curves until there are at least five detections.
As described earlier, we crossmatch all candidates with the recent TNS database entries. If a candidate has a match from the TNS database with a spectroscopic redshift, we fix the redshift of the SALT model to this value.
An alternative would be to use a functional form, such as the one suggested in Bazin et al. (2011) for modelling the flux Fk (t):
![Mathematical equation: $\[F^k(t)=A^k \frac{\exp \left[-\left(t-t_0^k\right) / \tau_{\text {fall }}^k\right]}{1+\exp \left[-\left(t-t_0^k\right) / \tau_{\text {rise }}^k\right]}+q^k,\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq6.png) (3)
(3)
where index k is the photometric band (e.g. ZTF g or r) that the best-fitting parameters A, t0, τfall, τrise and q are estimated for each band k. A is the amplitude, τfall and τrise are characteristic fall and rise timescales (respectively), and q is a constant offset. As derived in Bazin et al. (2011), for each photometric band k, t0 is related to the time of maximum tmax as
![Mathematical equation: $\[t_{\max }^k=t_0^k+\tau_{\text {rise }}^k ~\ln~ \left(\tau_{\text {fall }}^k / \tau_{\text {rise }}^k-1\right),\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq7.png) (4)
(4)
meaning that τfall > τrise is required for a Bazin light curve model to have a maximum value.
By default, there are no relationships encoded between free parameters as a function of index k (photometric band), meaning that the parameters for each photometric band are independent. This is a disadvantage compared with the SALT models, as SALT uses all available detections to find a single set of best-fitting parameters.
As the SALT M0 and M1 templates are derived from SNe Ia observations, they are not strictly appropriate for modelling other types of SNe. Nevertheless, we use the SALT templates to fit the light curves of all of our candidates, and use them to estimate the time of peak brightness because we will not know in advance the spectral type of the candidate. Although it is a more general light curve model, the Bazin form is less useful for estimating a peak time for a supernovae that is still rising (increasing in brightness), as the τfall parameter requires appropriate priors. As the SALT models are based on templates of SNe Ia light curves (which rise and fall), they have a peak ‘built in’.
AAS2RTO is not limited to SALT or Bazin models, however, and is flexible enough to be adapted to other models that users may prefer.
3.2 Designing a scoring function
Here, we describe factors that are used to promote candidate SNe Ia that are close to peak brightness.
3.2.1 Candidate properties
The strictest criterion for selecting candidates for the DK1.54 m telescope is the limiting magnitude of i > 18.5 mag. Aside from this practical limitation, the example science case does not depend on the observed SNe Ia magnitude, so we promote candidates that are brighter simply because they can be observed with a shorter integration time for a desired signal-to-noise ratio. We therefore define the factor
![Mathematical equation: $\[x_{\mathrm{mag}}=10^{0.5 \times(18.5-m)},\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq8.png) (5)
(5)
where m is the latest ZTF detection (in mag), in either the ZTF g- or r-band. This prescription means that a candidate with m = 16.5 mag will have xmag = 10. Candidates with m > 18.5 mag are flagged so that their final score will be negative, so they are excluded from ranked lists. These candidates are not rejected outright, as they could be rising and have m < 18.5 mag in the future.
To increase the probability that a candidate is real, we also require there to be at least four detections in the light curve (from both g- or r-bands). Candidates with fewer than this are excluded from ranked lists, meaning that very young candidates are likely to be excluded. This could be avoided by reducing the minimum number of detections, and using some other criteria to ensure ‘real’ candidates. For instance, by requiring all detections to meet a prescribed minimum broker classification threshold. However, as young candidates are not the focus of this example, we do not make this adjustment.
To promote candidates that are near peak brightness, we constructed a factor based on a normal distribution with centred at the latest estimate of the SALT zero-phase parameter t0 (described in Sect. 3.1), with width σ,
![Mathematical equation: $\[x_{\text {peak }}=A \times \exp \left[-\frac{\left(t_{\mathrm{obs}}-t_0\right)^2}{2 \sigma^2}\right].\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq9.png) (6)
(6)
Here, tobs is the time of the next observation. We choose the width of the distribution σ = 1 day. This can be adjusted depending on how critical it is to select candidates at their peak brightness. For instance, if spectra within two days of the peak are acceptable, the width of the function could be adjusted to σ = 2 days. We set the amplitude parameter A = 30, so that the factor xpeak has a maximum value of 30 (when tobs = t0). This choice of maximum value gives more weight to candidates that are close to the peak than the maximum expected values of xmag ~ 10. We also set a minimum value of xpeak = 10−2, which occurs around when |tobs − t0|> 4. If the SALT model fitting fails, we set xpeak = 1.0.
As it is based on a function that is symmetric about t0, the factor xpeak alone gives equal priority to a candidate two days before t0 and a candidate two days after t0. It is better to promote candidates before peak brightness rather than after (i.e. still increasing in brightness) − it is still possible to observe these candidates at their peak brightness. We define factors, ![Mathematical equation: $\[x_{\text {rise}}^{k}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq10.png) (for each photometric band k in the light curve), which are the fraction of detections in a light curve that are brighter than the previous one. That is,
(for each photometric band k in the light curve), which are the fraction of detections in a light curve that are brighter than the previous one. That is,
![Mathematical equation: $\[x_{\mathrm{rise}}^k=\sum_{i=1}^{N^k-1}\left[m_{i+1}^k<m_i^k\right] /\left(N^k-1\right),\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq11.png) (7)
(7)
where index k is the photometric band (ZTF g or r, ATLAS o or c), and ![Mathematical equation: $\[m_{i}^{k}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq12.png) is the magnitude of the i th detection in band k (in mag). Nk are the number of detections in band k. Iverson bracket notation evaluates to 1, if the logical statement enclosed is true, and 0 otherwise. Here, this means
is the magnitude of the i th detection in band k (in mag). Nk are the number of detections in band k. Iverson bracket notation evaluates to 1, if the logical statement enclosed is true, and 0 otherwise. Here, this means ![Mathematical equation: $\[\left[m_{i+1}^{k}<m_{i}^{k}\right]=1\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq13.png) if
if ![Mathematical equation: $\[m_{i+1}^{k}<m_{i}^{k}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq14.png) is true, and 0 otherwise. The denominator in Eq. (7) is Nk − 1 as this is the number of consecutive pairs from Nk detections. This factor can vary between 0 and 1, and we choose to reject candidates if all
is true, and 0 otherwise. The denominator in Eq. (7) is Nk − 1 as this is the number of consecutive pairs from Nk detections. This factor can vary between 0 and 1, and we choose to reject candidates if all ![Mathematical equation: $\[x_{\text {rise }}^{k}<0.4\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq15.png) and Nk > 2. If Nk ≤ 3, we choose
and Nk > 2. If Nk ≤ 3, we choose ![Mathematical equation: $\[x_{\text {rise }}^{k}=1.0\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq16.png) . Candidates are therefore only rejected due to
. Candidates are therefore only rejected due to ![Mathematical equation: $\[x_{\text {rise}}^{k}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq17.png) if there are at least four detections in each band. In this way we avoid rejecting candidates with a pair of detections, which happen to appear to be declining in brightness only due to one poor photometric detection.
if there are at least four detections in each band. In this way we avoid rejecting candidates with a pair of detections, which happen to appear to be declining in brightness only due to one poor photometric detection.
We also consider the time since the first observation, T (in days), again with the motivation of disfavouring candidates that are past the peak brightness. We define
![Mathematical equation: $\[x_{\mathrm{span}}= \begin{cases}1 & T<20 \text { days; } \\ L\left(T ; r, x_{\mathrm{m}}\right) & \text { otherwise, }\end{cases}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq18.png) (8)
(8)
with logistic function, L, as:
![Mathematical equation: $\[L\left(x ; r, x_{\mathrm{m}}\right)=\frac{1}{1+\exp \left(-r\left(x-x_{\mathrm{m}}\right)\right)}.\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq19.png) (9)
(9)
The logistic function L varies smoothly from 0 to 1 around the midpoint parameter, xm. The steepness of the logistic is set by the parameter r, with larger values of r producing steeper increase. Negative values of r mean that L instead starts at 1 for x < xm and decreases to 0. We choose xm = 25 days and r = −1 days−1, which means that the function decreases from 0.99 to 0.01 between 20 and 30 days, and 0.9 to 0.1 between 23 and 27 days. Finally, we reject candidates with T > 30 days. We have designed this factor to decrease after 20 days because the rise time of SNe Ia is around 19 days in the rest-frame (e.g. Riess et al. 1999; Firth et al. 2015).
As mentioned above, the factors xrise and xspan serve to promote supernovae that have not yet passed peak brightness, although in a less direct way than comparison with the best estimate of the time of the peak. This is useful in cases where SALT model fitting fails for a candidate.
We then compute the score for each candidate SNe Ia following Eq. (1),
![Mathematical equation: $\[S_{\text {Ia }}=S_{\text {base }} x_{\text {mag }} x_{\text {peak }} x_{\text {rise }} x_{\text {span}},\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq20.png) (10)
(10)
and we choose the base score Sbase = 1.
In Sect. 2, in step (2) of the numerical description, we describe using the score for an initial check, which does not depend on any of the factors dependent on any model. Here, those are the three factors xmag, xrise and xspan. Candidates that are rejected because of any of these factors should not have SALT models fit.
3.2.2 Candidate visibility
So far all of the factors we have described consider only the observed properties of a candidate. We also consider the visibility of candidates from a given observatory. A simple prescription uses the current airmass, X, or altitude, a, of the candidate
![Mathematical equation: $\[x_{\mathrm{alt}}=\frac{1}{X} \sim \sin ~(a),\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq21.png) (11)
(11)
using the simple secant approximation X ~ sec (90° − a), where a is the altitude of the candidate above the horizon in degrees. This is a good approximation for a ≳ 5° (Young & Irvine 1967; Kasten & Young 1989). This definition of xalt means 0 < xalt < 1. We choose to exclude candidates with a < 30° (where airmass X > 2).
An alternative factor considers how visible a candidate will be for the remainder of the night. We first define the quantity Avis by considering the integral of a candidate’s altitude as a function of time, a (t),
![Mathematical equation: $\[A_{\mathrm{vis}}=\int_{t_{\mathrm{obs}}}^{t_{\mathrm{SR}}}\left(a(t)-a_{\mathrm{min}}\right) \mathrm{d} t,\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq22.png) (12)
(12)
where tobs is the time of the next observation (when the score will be evaluated) and tSR is the time of the following sunrise (i.e. the end of the night’s observations). If the current time is during the daytime, we set tobs = tSS, the time of the upcoming sunset (so tSS ≤ tobs < tSR). Altitude amin is the minimum acceptable altitude that a candidate can be observed at.
The factor xvis is then
![Mathematical equation: $\[x_{\mathrm{vis}}=\left(\frac{A_{\mathrm{vis}}}{\left(a_{\mathrm{ref}}-a_{\mathrm{min}}\right)\left(t_{\mathrm{SR}}-t_{\mathrm{obs}}\right)}\right)^{-1},\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq23.png) (13)
(13)
with reference altitude aref used for normalisation (in the numerator). A smaller Avis gives larger xvis, so that candidates that are going to set below the horizon sooner are promoted. The numerator is the rectangle enclosed between tobs, tSR, amin and aref. We choose aref = 90°. This normalisation ensures that the value of xvis does not change dramatically through the night due to decreasing observing time remaining. Even for a(t) constant (such as Polaris), Avis approaches zero as tobs approaches tSR. Normalisation also makes xvis a dimensionless quantity.
The motivation for factor xvis is illustrated in Fig. 3, which shows a hypothetical scenario where there are three candidates to be observed (T1, T2, and T3). If the goal is to maximise the number of candidates that are observed, candidate T3 should be observed first (as it will set soonest), followed by T1, and finally T2. Using the simpler approach of xalt, Eq. (11), the candidates with the current highest altitude would have been observed first. Here, T2 would have been observed first, followed by T1 - after which time T3 would no longer observable.
One issue with the factor xvis is that it does not have an upper bound for candidates that are very close to setting below amin. This is undesirable if all the other factors for a candidate have been carefully constructed to be well behaved to reflect the scientific aims of a user. This could be avoided by modifying the definition to ‘suppress’ extreme values with min (xvis, A) function (where A is the maximum allowed), for example. There is more discussion of the behaviour of xvis in Appendix B.
For the DK1.54 m observatory, we compute for each candidate
![Mathematical equation: $\[S_{\mathrm{DK} 154}=S_{\mathrm{Ia}} ~x_{\mathrm{vis}},\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq24.png) (14)
(14)
where xvis is computed considering the candidate altitude from La Silla observatory.
For the example score we have presented here, we have not implemented a factor to account for the telescope slew time (from one candidate to the next). Ideally, telescope slew time should be minimised, so we would construct a factor to promote candidates that are near the current telescope pointing. This would require information about the current pointing of the telescope under consideration (for instance, the DK1.54 m). Accessing this information will require specific implementations for each telescope. For similar reasons, we have not yet included factors to account for observing conditions, such as wind speed (the DK1.54 m has strict wind speed limits for safe operation). Further, we have not yet implemented a factor to consider moon separation or moon phase.
We stress that the absolute value of a candidates’ score is unimportant, as it is only used in comparison with other candidates.
 |
Fig. 3 Altitude of three hypothetical candidates (T1, T2, T3) from La Silla on the spring equinox. The current time tobs is indicated, and tSS and tSR are the sunset and sunrise time respectively. The shaded grey regions are day and twilight (the Sun’s altitude a > −18°, when astronomical observations are not possible). The shaded region under each altitude curve between tobs and tSR is Avis, computed in Eq. (12). The reference altitude aref for normalisation is also indicated. |
3.3 Testing with archival ZTF data
We selected all ZTF light curves between 1 October 2020 and 30 October 2022 that have any detection tagged by FINK as ‘SN candidate’ or ‘Early SN Ia candidate’. There are 314265 alerts in the ZTF g- and r-bands, comprising 120212 unique candidates. We used this data to illustrate how AAS2RTO might operate with real data from ZTF for the scientific objective outlined above.
We fitted SALT2 models to all of the light curves with eight or more detections, which have a ZTF g-band detection brighter than g < 19 mag. We used SNCOSMO’s least squares fitting method. There are 6714 such light curves in the sample. To ensure that the best-fitting SALT models are self-consistent, we required that there are at least four detections after the best-fitting t0, and further that at least one of these detections is a minimum of five days after t0. Similarly we required that there are at least three detections before the zero-phase parameter, t0. We also removed light curves that are longer than 120 days and those which have a gap in the light curve longer than 20 days. This cut quickly removes variable or stochastic sources that have been misclassified as SNe, although it may remove ‘real’ SNe which have long light curves. Finally, we required that the best-fitting SALT model has a reduced χ2 of ![Mathematical equation: $\[\chi_{v}^{2}<5.0\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq25.png) (
(![Mathematical equation: $\[\chi_{v}^{2}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq26.png) is χ2 per degree of freedom). After these quality cuts, there are 2205 candidates remaining. The distribution of the best-fitting SALT2 stretch x1 and colour c parameters of the remaining 2205 light curves are shown in Fig. 4 (solid black, labelled as FINK ‘SNe’). For comparison, we also show the distributions of the x1 and c parameters from Taylor et al. (2021), who use the Dark Energy Survey SNe sample, the distributions from Nielsen et al. (2016) using the Joint Lightcurve Analysis sample of SN Ia, and the distributions from Brout et al. (2022) using the Pantheon+ sample11. Our distributions of both stretch x1 and colour c parameters have heavier tails than the literature distributions, but are still in good agreement.
is χ2 per degree of freedom). After these quality cuts, there are 2205 candidates remaining. The distribution of the best-fitting SALT2 stretch x1 and colour c parameters of the remaining 2205 light curves are shown in Fig. 4 (solid black, labelled as FINK ‘SNe’). For comparison, we also show the distributions of the x1 and c parameters from Taylor et al. (2021), who use the Dark Energy Survey SNe sample, the distributions from Nielsen et al. (2016) using the Joint Lightcurve Analysis sample of SN Ia, and the distributions from Brout et al. (2022) using the Pantheon+ sample11. Our distributions of both stretch x1 and colour c parameters have heavier tails than the literature distributions, but are still in good agreement.
We crossmatched all 2205 candidates with the TNS database of spectroscopically confirmed SNe (within 5 arcsec) that were listed in TNS between 1 October 2020 and 30 October 2022 (the same dates as the FINK alert sample). Of the 5191 spectroscopically confirmed TNS SNe, there are 1515 matches with our sample (68% of our sample has been spectroscopically confirmed as SNe). Out of the 3781 SNe Ia in the full TNS dataset, there are 1383 that match with our sample. By contrast, there are only 132 matches with spectroscopically confirmed SNe that are not type Ia, out of 1410 non-Ias listed in the full TNS dataset (1016 of which are type II SNe). The x1 and c parameter distributions of the spectroscopically confirmed TNS subset of SNe Ia are also shown in Fig. 4 (labelled as FINK/TNS SNe Ia). These statistics are summarised in Fig. 5. The distributions of SALT x1 and c for the TNS-confirmed subset of SNe Ia are in good agreement with the full sample of 2205 SNe (solid grey in Fig. 4). This indicates that the FINK sample we select and the quality cuts we impose are useful for selecting SNe Ia.
 |
Fig. 4 Distribution of SALT2 stretch parameter x1 (left panel) and colour parameter c (right panel) for all light curves with eight or more detections, for the sample of 2205 light curves that meet our criteria (black), and for the subset of 1383 that are spectroscopically confirmed SNe Ia in TNS (grey). Distributions of x1 (left panel) and c are also shown from Taylor et al. (2021) using the Dark Energy Survey (DES) supernovae sample (blue line; taken from their Fig. 9), from Nielsen et al. (2016) using the Joint Lightcurve Analysis (JLA) sample (green; taken from their Fig. 1), and from Scolnic et al. (2022) using the Pantheon+ sample (orange). |
 |
Fig. 5 Sample of SNe Ia selected from FINK (central circle, red), and the overlap with the TNS spectroscopically confirmed sample of SNe Ia (left circle, green), and SNe non-Ia (right circle, blue). |
3.3.1 Timing of type la supernovae peak brightness
Here, we investigate how well we are able to estimate the zero-phase parameter, t0, as a supernova light curve evolves. We note that the estimates of the zero-phase parameter, t0, for a still-evolving light curve are not intended to be precise or final measurements, and are not used for any cosmological or astrophysical analyses. Rather, they are a useful tool to aid in prioritisation, and we aim here (in Sect. 3.3.1) to quantify how useful they are.
Figure 6 shows how the estimate of t0 converges through the duration of a light curve. We used the sample of 2205 SNe Ia that meet the quality cuts we describe above. For each candidate, we used the SALT2 templates described in Sect. 3.1 to model the full available light curve to recover the best-fitting parameters, and label the best-fitting zero-phase parameter as ![Mathematical equation: $\[t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq27.png) . We then fitted a SALT2 model to the first N detections in the light curve and recover the same parameters, and repeated this for each of the N detections in the light curve. That is, if there are 20 detections in a light curve, there will be 20 sets of parameters – using all 20 detections, the first 19 detections, the first 18 detections, and so on.
. We then fitted a SALT2 model to the first N detections in the light curve and recover the same parameters, and repeated this for each of the N detections in the light curve. That is, if there are 20 detections in a light curve, there will be 20 sets of parameters – using all 20 detections, the first 19 detections, the first 18 detections, and so on.
For each value of t0 (estimated with increasing number of detections), we computed the difference from the best estimate, ![Mathematical equation: $\[t_{0}-t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq33.png) . These difference values are plotted as a function of
. These difference values are plotted as a function of ![Mathematical equation: $\[t-t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq34.png) (that is, light curve phase, the time since
(that is, light curve phase, the time since ![Mathematical equation: $\[t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq35.png) ). In principle, a single candidate could appear N − 1 times in Fig. 6, once for each estimate of t0, excluding the final estimate (as the difference here is by definition zero). We do not use estimates of t0 that use only the first one, two, three or four detections, as we do not attempt to fit SALT models until there are at least five detections. This is the number of free parameters for a SALT light curve fit.
). In principle, a single candidate could appear N − 1 times in Fig. 6, once for each estimate of t0, excluding the final estimate (as the difference here is by definition zero). We do not use estimates of t0 that use only the first one, two, three or four detections, as we do not attempt to fit SALT models until there are at least five detections. This is the number of free parameters for a SALT light curve fit.
We choose to show this convergence as a function of phase rather than number of detections, as the sampling of light curves is different for each object (that is, the time between detections in each light curve is not the same). Additionally, this is how we will use the SALT models in practice, where we compute the factor xpeak (Eq. (6)) as a function of time, not number of detections.
The median difference from the final estimate of the peak is shown as the solid black line in Fig. 6. The shaded grey region is contains the central 65% of the difference measurements.
At time ![Mathematical equation: $\[t=t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq36.png) , the median difference
, the median difference ![Mathematical equation: $\[t_{0}-t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq37.png) is less than one day. We also note that at
is less than one day. We also note that at ![Mathematical equation: $\[t=t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq38.png) , there is a spread in the difference values,
, there is a spread in the difference values, ![Mathematical equation: $\[t_{0}-t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq39.png) . The central 68% of these difference are within −2.1 to +1.3 days. We interpret this as a representative uncertainty on the SALT t0 estimate at
. The central 68% of these difference are within −2.1 to +1.3 days. We interpret this as a representative uncertainty on the SALT t0 estimate at ![Mathematical equation: $\[t=t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq40.png) (for any candidate with peak magnitude brighter than 19 mag). We expect that the asymmetry is due to the fact that the peak is more easily constrained when the light curve has begun to ‘turn over’.
(for any candidate with peak magnitude brighter than 19 mag). We expect that the asymmetry is due to the fact that the peak is more easily constrained when the light curve has begun to ‘turn over’.
Möller et al. (2021) show that on average, FINK’s first classification of type Ia SNe is six days before peak brightness using ZTF data. At ![Mathematical equation: $\[t-t_{0}^{*}=-6.0\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq41.png) , SALT fits underestimate t0 by around two days on average. That is, six days before the ‘true’ peak, the best available SALT fit estimates that the peak will be in only four days. However, we expect that the first correct classification from FINK will occur at an earlier phase with LSST data, given LSST’s increased depth.
, SALT fits underestimate t0 by around two days on average. That is, six days before the ‘true’ peak, the best available SALT fit estimates that the peak will be in only four days. However, we expect that the first correct classification from FINK will occur at an earlier phase with LSST data, given LSST’s increased depth.
Figure 7 shows the same statistic as Fig. 6, but with candidates separated by their brightest detection in ZTF-g, in three magnitude bins. The behaviour is similar for all three bins. For the supernovae in the brightest magnitude bin, the 68% confidence interval is narrower (from −1.5 to +1 days), but noisier around the time of the peak when compared with the fainter magnitude bins. The confidence interval and median difference as a function of time for the faintest subset (the lower panel of Fig. 7) is very similar to that of the whole subset, simply because there are far more candidates in this subset.
 |
Fig. 6 Convergence SALT2 zero-phase parameter t0 to the final ‘best’ estimate, |
![Mathematical equation: $\[t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq28.png)
![Mathematical equation: $\[t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq29.png)
![Mathematical equation: $\[t_{0}=t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq30.png)
![Mathematical equation: $\[t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq31.png)
![Mathematical equation: $\[t_{0}-t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq32.png)
 |
Fig. 7 Convergence of the SALT zero-phase parameter t0, as a function of SN phase, separating candidates by their maximum model g measurement. Large, dark grey points are the |
![Mathematical equation: $\[t_{0}-t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq42.png)
![Mathematical equation: $\[t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq43.png)
![Mathematical equation: $\[t_{0}-t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq44.png)
![Mathematical equation: $\[t-t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq45.png)
 |
Fig. 8 Upper panel: median (black line) of the normalised distributions of all SNe Ia scores per night, log10 (SIa). The shaded grey region shows the central 68% of the distributions. Lower panel: normalised distribution of scores of candidates within one day of |
![Mathematical equation: $\[t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq46.png)
![Mathematical equation: $\[\left|t-t_{0}^{*}\right|<1\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq47.png)
3.3.2 Candidate rates
We simulated how AAS2RTO would perform on the ZTF archival data we describe above, by processing alerts in chronological order and calculating the score that would have been available on that day (24 hour period). In this test, we used the full set of alerts that we have scraped from FINK instead of the smaller, high-quality sample of 2205 SNe light curves, as this is how AAS2RTO will operate in real-time. That is, we will not know in advance (at a point part way through the evolution of any given SN candidate) whether the final light curve will meet the quality cuts.
For each night with a non-zero number of alerts, we found the distribution of the log of scores SIa (the SNe Ia score without considering candidate visibility; Eq. (10)). The median of these distributions is shown in Fig. 8, along with the central 68% range. The shape of this median distribution is mainly influenced by the factors xmag and xpeak. The peak at log10 (SIa) ~ −2 is due to the minimum allowed value of xpeak = 10−2, when candidates are very far from the apparent peak. On average, a large fraction of candidates have a score below the base score of Sbase = 1 (that is, they have log10 (SIa) < 0). These are candidates that are penalised due to being faint, far from the estimated model peak, declining, or old. The candidates with log10 (SIa) > 0.0 will have been promoted for the opposite reasons.
Figure 8 also shows distributions of log10 (SIa) for any candidate within one day of the final peak estimate ![Mathematical equation: $\[t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq48.png) , separated by magnitude (lower panel). These distributions contain all SIa values from the duration of the simulated flow of alerts, as we are unable to present the median distribution per night due to the small number of candidates on average per night that meet these criteria (see Fig. 9 below). On the whole, these distributions of SIa for the candidates we aim to select behave as designed. The candidates in the brightest subset within one day of the peak have higher values of SIa on average. There are a few candidates within one day of
, separated by magnitude (lower panel). These distributions contain all SIa values from the duration of the simulated flow of alerts, as we are unable to present the median distribution per night due to the small number of candidates on average per night that meet these criteria (see Fig. 9 below). On the whole, these distributions of SIa for the candidates we aim to select behave as designed. The candidates in the brightest subset within one day of the peak have higher values of SIa on average. There are a few candidates within one day of ![Mathematical equation: $\[t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq49.png) that have very low values of SIa, likely where the best SALT fit available at
that have very low values of SIa, likely where the best SALT fit available at ![Mathematical equation: $\[t \sim t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq50.png) is poor. Although Fig. 7 shows that on average the best available estimate of t0 is accurate at
is poor. Although Fig. 7 shows that on average the best available estimate of t0 is accurate at ![Mathematical equation: $\[t=t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq51.png) , there is still some scatter. We expect that the smaller peak at log10 (SIa) ~ 0 for the faintest subset is due to candidates which have insufficient detections before the peak for a SALT fit at MJD =
, there is still some scatter. We expect that the smaller peak at log10 (SIa) ~ 0 for the faintest subset is due to candidates which have insufficient detections before the peak for a SALT fit at MJD = ![Mathematical equation: $\[t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq52.png) , and so are assigned the default value of xpeak = 1.0.
, and so are assigned the default value of xpeak = 1.0.
On days with a non-zero number of alerts, we counted the number of supernovae within half, one and two days of the best available value of t0, and plot the frequency distribution in Fig. 9, for candidates that have magnitude m < 18.5 mag. That is, we counted the number of candidates with |t − t0| < 1 day. We only include days when ZTF alerts were broadcast (for example, we do not include the large gap between December 2021 and February 2022 when there were no ZTF alerts broadcast by FINK).
From Fig. 9, we expect an average of ![Mathematical equation: $\[\bar{N}=4.4 \pm 0.1\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq56.png) SNe which are within one day of peak brightness, and
SNe which are within one day of peak brightness, and ![Mathematical equation: $\[\bar{N}=8.7 \pm 0.1\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq57.png) SNe within two days of peak brightness. We chose to report the number of candidates N per day using the current value of t0 (not the final value,
SNe within two days of peak brightness. We chose to report the number of candidates N per day using the current value of t0 (not the final value, ![Mathematical equation: $\[t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq58.png) ), as this is the information that AAS2RTO will have when it operates in real-time. For this same reason, we have not excluded candidates which have later been spectroscopically classified as non-Ia supernovae.
), as this is the information that AAS2RTO will have when it operates in real-time. For this same reason, we have not excluded candidates which have later been spectroscopically classified as non-Ia supernovae.
We present the values of ![Mathematical equation: $\[\bar{N}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq59.png) only to demonstrate the number of potential candidates for an observing campaign aided by AAS2RTO, and do not intend that they should be read as a measurement of the cosmological rate of Type Ia supernovae. However, it is still useful to compare the mean number of SNe Ia candidates we could expect from ZTF to the number that could be expected based on estimates of SNe Ia rates. To compute a simple estimate of the expected number of supernovae in the ZTF footprint, we assumed a characteristic absolute magnitude of an SN Ia as ℳB = −19.3 mag, motivated by the peak of the SNe Ia luminosity function (e.g. Perley et al. 2020; Desai et al. 2024). For simplicity, we assumed the same B-band apparent magnitude as the i-band limit, Blim = 18.5. Combining these two values results in a distance modulus limit of μ = 37.8 mag, corresponding to z = 0.08. Using Palomar Transient Factory data, Frohmaier et al. (2019) compute the volumetric rate of SNe Ia (rV, the number of SNe Ia per co-moving volume, per year), and obtain
only to demonstrate the number of potential candidates for an observing campaign aided by AAS2RTO, and do not intend that they should be read as a measurement of the cosmological rate of Type Ia supernovae. However, it is still useful to compare the mean number of SNe Ia candidates we could expect from ZTF to the number that could be expected based on estimates of SNe Ia rates. To compute a simple estimate of the expected number of supernovae in the ZTF footprint, we assumed a characteristic absolute magnitude of an SN Ia as ℳB = −19.3 mag, motivated by the peak of the SNe Ia luminosity function (e.g. Perley et al. 2020; Desai et al. 2024). For simplicity, we assumed the same B-band apparent magnitude as the i-band limit, Blim = 18.5. Combining these two values results in a distance modulus limit of μ = 37.8 mag, corresponding to z = 0.08. Using Palomar Transient Factory data, Frohmaier et al. (2019) compute the volumetric rate of SNe Ia (rV, the number of SNe Ia per co-moving volume, per year), and obtain ![Mathematical equation: $\[r_{\mathrm{V}}=2.43 \pm 0.29 \times 10^{-5} ~\mathrm{SNe} ~\mathrm{Mpc}^{-3} ~\mathrm{yr}^{-1} \mathrm{~h}_{70}^{3}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq60.png) (statistical uncertainty) at redshift z < 0.08. Perley et al. (2020) estimate that the effective area of the ZTF public survey which has been observed with at least three day cadence is 14 400 deg2. From the rate rV quoted above, we should expect ~1750 supernovae per year in this ZTF footprint at z < 0.08, or approximately 3.72 ± 0.44 per 24 hours.
(statistical uncertainty) at redshift z < 0.08. Perley et al. (2020) estimate that the effective area of the ZTF public survey which has been observed with at least three day cadence is 14 400 deg2. From the rate rV quoted above, we should expect ~1750 supernovae per year in this ZTF footprint at z < 0.08, or approximately 3.72 ± 0.44 per 24 hours.
The value which we can most fairly compare with rV is the number of candidates within ±0.5 days of the peak (an interval of 24 hours), ![Mathematical equation: $\[\bar{N}=2.08 \pm 0.07\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq61.png) . This is a factor of two smaller than the expected 3.72 ± 0.44 supernovae per 24 hours estimated with the measured SNe Ia rate, rV. We attribute this to missed SNe, and poorly sampled light curves that do not meet the quality cuts when computing the score SIa, and so are excluded from our ranked lists. We expect that the completeness of the FINK classifier only plays a small role. Möller & de Boissière (2020) show the FINK Ia-vs-non-Ia classifier is capable of correctly classifying 86% of SNe at two days before the SN Ia peak.
. This is a factor of two smaller than the expected 3.72 ± 0.44 supernovae per 24 hours estimated with the measured SNe Ia rate, rV. We attribute this to missed SNe, and poorly sampled light curves that do not meet the quality cuts when computing the score SIa, and so are excluded from our ranked lists. We expect that the completeness of the FINK classifier only plays a small role. Möller & de Boissière (2020) show the FINK Ia-vs-non-Ia classifier is capable of correctly classifying 86% of SNe at two days before the SN Ia peak.
Finally, we consider the number of candidates which are ranked highly and are also in our sample of high-quality SNe light curves (summarised in Table 1). We counted the number of SNe from this sample which occur at least once in the top three or top five ranked candidates output from AAS2RTO. For instance, 38 out of the 49 in the brightest subset of high-quality SNe light curves (16 < g < 17 mag) appear in the top five ranked candidates at least once, or 81%. This compares with 53% in the second brightest subset, and only 19% in the faintest subset. We expect that this is primarily driven by the factor xmag, which promotes brighter candidates. However, we also note that the fraction of light curves with peak 16 < g < 17 mag that are included in the high-quality ZTF sample is larger than the fraction of light curves 17 mag < g < 18 mag included, and similarly for the 18 mag < g < 18.5 mag subset. That is, there is a larger fraction of faint candidates which are included in ranked lists, but do not meet the stricter criteria we use for evaluating the use of SALT light curves to estimate the time of peak brightness. In Table 1, the faintest subset is shallower than in Fig. 7 (18 < g < 18.5 mag instead of 18 < g < 19 mag), as candidates with g > 18.5 mag are automatically excluded from ranked lists.
 |
Fig. 9 Frequency of number of candidates per day (24 hour period) within half a day, one day and two days of the current predicted peak (in black, red and blue respectively). These measurements are made only for days where ZTF alerts were delivered. The mean number of candidates per day for each selection is denoted by the dashed vertical line. There are a mean of |
![Mathematical equation: $\[\bar{N}=2.08 \pm 0.07\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq53.png)
![Mathematical equation: $\[\bar{N}=4.2 \pm 0.1\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq54.png)
![Mathematical equation: $\[\bar{N}=8.3 \pm 0.2\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq55.png)
Percentage of candidates from the high-quality sample of 2205 ZTF light curves which appear at least once in the top N candidates of a ranked list.
3.4 Simulating LSST SNe la observations
To investigate how useful our scoring function will be for prioritising SNe Ia candidates discovered by LSST, we used the LSST Operations Simulator tool12 (OpSim, Delgado et al. 2014) to build a simple simulation of SNe Ia observations. We used OpSim’s baseline simulation (version 3.3), a realistic ten-year simulation of LSST visits providing an observation schedule with celestial coordinates, time stamp, filter, and 5σ depth for each visit. The baseline simulation also includes a realistic number of nights where no observations are taken, based on the expected observing conditions at Cerro Pachón.
In 100 redshift shells spaced logarithmically from 0 < z < 0.4, we computed the expected number of SNe Ia per volume using the volumetric rate, rV, from Dilday et al. (2008),
![Mathematical equation: $\[r_V=2.6 \times 10^5~(1+z)^{1.5} ~\mathrm{SNe} ~\mathrm{Mpc}^{-3} ~\mathrm{yr}^{-1},\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq62.png) (15)
(15)
using the midpoint redshift z of the shell. For each shell, we drew the number of simulated SNe from a Poisson distribution with a mean rV (z) × V (z) × L, where V (z) is the comoving volume of the redshift shell and L is the length of the survey measured in years. We chose L = 5 yr + 30 days. We assigned a random zero-phase parameter t0 to each supernovae, distributed uniformly from 30 days before the first simulated LSST visit, to the length of the survey L. The extra 30 days ensures that there are SNe that are declining in brightness at the time of the first simulated visit. Simulated SNe in each redshift shell were assigned a redshift, z, distributed uniformly across the shell, and a random pair of coordinates distributed uniformly on the celestial sphere. We assigned SALT parameters x1 and c following the distributions from Taylor et al. (2021) using the DES survey (see Fig. 4).
To determine the SALT amplitude parameter, x0, we have considered the Tripp relation (Tripp 1998),
![Mathematical equation: $\[\mu(z)=m_B-\mathcal{M}_B+\alpha x_1-\beta c,\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq63.png) (16)
(16)
where μ (z) is distance modulus, ℳB is the absolute B-band magnitude of SNe Ia, mB is the apparent B-band magnitude, and α and β are the parameters that represent the slopes of the stretch-luminosity and colour-luminosity relations. We used α = 0.148 and β = 3.1 as reported in Brout et al. (2022) using the Pantheon+ sample (their Table 2). Simulated SNe Ia are assigned an absolute magnitude ℳB using a normal distribution centred at mean ![Mathematical equation: $\[\overline{\mathcal{M}}_{B}=-19.3 ~\mathrm{mag}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq64.png) , with width σ = 0.15 mag. Using the Planck cosmological parameters (Planck Collaboration VI 2020) to compute μ (z), we have rearranged Eq. (16) to find the apparent magnitude mB. For the SALT templates in the SNCOSMO framework, the amplitude x0 is related to apparent peak magnitude as mB = −2.5 log10 (x0) + 10.5.
, with width σ = 0.15 mag. Using the Planck cosmological parameters (Planck Collaboration VI 2020) to compute μ (z), we have rearranged Eq. (16) to find the apparent magnitude mB. For the SALT templates in the SNCOSMO framework, the amplitude x0 is related to apparent peak magnitude as mB = −2.5 log10 (x0) + 10.5.
For each simulated LSST visit provided by OpSim, we ‘measured’ the flux of simulated SNe Ia (using SNCOSMO’s implementation of the SALT models) at the observation time stamp in the appropriate filter, for each SN Ia in the field of view of 9.4 deg2. We calculated the true apparent magnitude from the SALT model flux, and use the S/N estimate to obtain an uncertainty estimate (on both flux and magnitude). We then obtained ‘observed’ apparent magnitudes by sampling a single value from a Gaussian centred at the true apparent magnitude, with a width equal to the magnitude uncertainty estimate.
In order to measure fluxes for all six LSST ugrizy bands, we must use SALT3 models (Kenworthy et al. 2021) instead of SALT2. This is because SALT2 is trained on data 2000–9200 Å, and is therefore unable to measure the flux in the LSST z- and y-bands (8030–9385 Å and 9084–10945 Å respectively). However, Kenworthy et al. (2021) show (using a Kolmogorov-Smirnov test) that the joint distributions of x1 and c for SALT2 and SALT3 models are statistically indistinguishable.
In Fig. 10, we show the time to peak convergence plot using these simulated light curves (shown for ZTF in Fig. 6). We refitted the first N simulated detections in the light curve, and computed the difference between the latest estimate of the zero-phase parameter, t0, and the true value ![Mathematical equation: $\[t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq67.png) (which was input to the simulated SNe). We applied the same quality cuts as for the ZTF data (described in Sect. 3.3). However, given LSST’s significantly increased depth compared with ZTF, we use a limiting magnitude of mB < 21.0 mag. Figure 10 shows that the estimates of t0 with increasing phase converge to the true value earlier than that of the real ZTF data, with a smaller spread.
(which was input to the simulated SNe). We applied the same quality cuts as for the ZTF data (described in Sect. 3.3). However, given LSST’s significantly increased depth compared with ZTF, we use a limiting magnitude of mB < 21.0 mag. Figure 10 shows that the estimates of t0 with increasing phase converge to the true value earlier than that of the real ZTF data, with a smaller spread.
Finally, Fig. 11 shows the number of simulated LSST candidates per night which are within half, one and two days of the true (simulation input) value of t0 with a peak g < 18.5 mag. Here, we used the number of candidates within, for example, one day of the true value of the zero-phase parameter, ![Mathematical equation: $\[t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq68.png) . The main reason for this is that the accuracy of the time to peak estimates presented in Fig. 10 will likely be different when using ‘real’ LSST data (see below for more discussion of assumptions made in this section). That is, although the number of input SNe is realistic, the final LSST observation cadence is not fixed, and will therefore have some impact on Fig. 10. As with the similar statistic from ZTF, we only compute the number of nights in the simulation where OpSim provides simulated observations. We find that we select 2.05 ± 0.04 within 0.5 days of the true peak, 4.12 ± 0.06 within one day of the true peak, and 8.2 ± 0.1 within two days of the true peak.
. The main reason for this is that the accuracy of the time to peak estimates presented in Fig. 10 will likely be different when using ‘real’ LSST data (see below for more discussion of assumptions made in this section). That is, although the number of input SNe is realistic, the final LSST observation cadence is not fixed, and will therefore have some impact on Fig. 10. As with the similar statistic from ZTF, we only compute the number of nights in the simulation where OpSim provides simulated observations. We find that we select 2.05 ± 0.04 within 0.5 days of the true peak, 4.12 ± 0.06 within one day of the true peak, and 8.2 ± 0.1 within two days of the true peak.
The results in this section are based on an very simple and idealised ‘toy model’ of LSST supernovae observations, with the impact of our assumptions described here. First, we do not include other types of SNe in our simulation, whose light curves are poorly explained by SALT models. Therefore, there is no ‘contamination’ by non-Ia SNe types.
We compute the uncertainties on measured fluxes and magnitudes using OpSim’s point source signal-to-noise ratio (S/N) estimation tool. This tool estimates the S/N using only the observed magnitude of a point source and 5σ depth. However, this S/N is for a single-epoch science image. In reality, SNe fluxes are measured with from difference images (the single-epoch image minus a deep coadd image), so that the flux contribution from the host galaxy has been removed. As we do not consider host galaxies in our simulated SNe Ia sample, we do not make this subtraction step, so our SNe flux uncertainties will be underestimates. Additionally, this means that we do not account for the possibility that the earliest stages of an SN Ia light curve are masked by their host galaxy (i.e. are non-detections).
When simulating the alerts from LSST, we assume that every photometric detection is a ‘valid’ alert, and would be correctly classified as a supernovae. These last two assumptions will have very little impact on our results, because the broker classifiers have a high classification accuracy by the time SNe Ia are at peak brightness. For a score designed to promote very young supernovae, this assumption may have more of an impact, as the LSST broker classifiers do not have as high a recall (true positive rate) at early light curve phase.
 |
Fig. 10 Convergence of estimate of time to peak, |
![Mathematical equation: $\[t_{0}-t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq65.png)
![Mathematical equation: $\[t_{0}^{*}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq66.png)
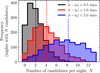 |
Fig. 11 Number of expected candidates within half a day, one day and two days of the peak from simulated LSST observations. There are a mean of 2.05 ± 0.04 within 0.5 days of the true peak, 4.12 ± 0.06 within one day of the peak, and 8.2 ± 0.1 within two days of the peak (indicated by dashed vertical lines). |
4 AAS2RTO’s place amongst schedulers
4.1 Greedy strategy
The concept of greedy algorithms for telescope scheduling that we have implemented for AAS2RTO is not a new one. An advantage of greedy schedulers is that they are extremely flexible, and can respond rapidly to new data or conditions. The original scheduler at the 2 m robotic Liverpool Telescope at La Palma is described as a ‘dispatch’ scheduler (Steele & Carter 1997). It uses an ‘efficiency’ function (written in Perl), which considers altitude, site conditions and a prescribed values of scientific priority, which our factors and scoring function is similar to. The scientific priority values are provided for each observation target when it is submitted by Telescope Allocation Groups. The scientific priorities are normalised so that the overall priority of the set of observations for each Telescope Allocation Group is equal. AAS2RTO differs in that a candidate’s priority value (score) can vary with time, as fixed priority values are less useful for transient objects which evolve on short timescales. Further, as AAS2RTO is primarily designed to prioritise targets according to a single scientific goal (that is, not for a facility with competing observing programmes from many groups), we do not carry out the priority normalisation step of Steele & Carter (1997).
More recently, the ‘Conductor’ scheduler (Fredslund Andersen et al. 2019) for the Stellar Observations Network Group13 (SONG, Grundahl et al. 2008) first makes a broad prioritisation of their ‘targets’ with a pre-determined list of categories. These categories have a priority which decreases with how critical the timing of the next observation is. The first category contains targets that must be observed at a specific time, followed by targets which require many observations at regular intervals, and then targets that require few observations which can be taken at any time. Targets in each of these categories are then ranked according to priorities calculated similarly to our own factors. They consider the required time interval between observations and the time since the last observation, and pre-assigned scientific priorities by a Time Allocation Committee. Targets in the first category are observed until this list is exhausted, then observing continues with the highest ranked in the second category. As AAS2RTO is designed for prioritisation of candidates based on alerts distributed in real-time, we have decided against using a semi-automated pre-categorisation strategy like SONG.
AAS2RTO is also similar in approach to the scheduler for the Gravitational-wave Optical Transient Observer (GOTO, Dyer et al. 2018, 2020). The aim of GOTO is to cover the large ‘probability regions’ for finding optical counterparts of gravitational wave signals and Gamma Ray Bursts (GRBs) with imaging ‘tiles’ (telescope pointings). This aim is very different to the example AAS2RTO case we present in Sect. 3. Nevertheless, there are similarities in prioritisation strategy. The GOTO scheduler begins with a predefined ‘starting rank’ for a candidate, which our ‘base score’, Sbase, can be compared with. The starting rank for each tile covering a probability regions is based on the astrophysical type (gravitational wave event from black hole and/or neutron star merger, or a GRB), and detection instrument. The rank is then modified by considering the time since a tile was last observed, the fraction of probability it contains, and the airmass of the tile at its current altitude. Each of these is considered independently, as with our factors, xi.
The primary purpose of the SOXS instrument is to conduct spectroscopic follow-up observations of astrophysical transients in the UV-visible and near-infrared. The SOXS scheduler scrapes data from ZTF, ATLAS and other surveys in a similar manner to AAS2RTO to ingest new candidates and update the existing candidate pool. In contrast to AAS2RTO, the SOXS scheduler (Asquini et al. 2022, 2024) is not designed to schedule observations for a single science case, meaning that assigning scientific priorities to candidates is not as straightforward. These priorities are therefore assigned and updated by a SOXS scientific committee on a daily basis. The SOXS scheduler then takes the assigned priorities, and proposes an observing schedule that maximises the number of candidates observed with high scientific priority, while also respecting any observing constraints (visibility, moon separation). The scientific committee still has a ‘veto’ power on the proposed schedule, and modifies it to account for any additional targets of opportunity. We expect that for the first few months of operation of LSST (at least), we will use the output ranked lists from AAS2RTO in a similar manner to SOXS, using them initially as a ‘proposed schedule’. This will allow us to make any necessary adjustments to the scoring function, or data ingestion steps (e.g. due to any unforeseen differences between ZTF and LSST alerts), before the DK1.54 m is operated in a more and more autonomous manner.
Machine learning (ML) techniques have also been successfully used for optimising allocation of spectroscopic followup resources. The Recommendation System for Spectroscopic follow-up (RESSPECT, Ishida et al. 2019; Kennamer et al. 2020) uses active learning (AL) to improve the photometric classification of astronomical transients. Similar to other ML techniques, AL models are trained on a dataset of instances of known classification (‘labelled’), and then deployed on a much larger dataset of instances to predict the currently unknown classification (‘unlabelled’). In an astronomy context, this means training on a spectroscopically classified set of transients (the labelled dataset), and predicting classifications for transients with only photometric data (the larger unlabelled dataset). The novel aspect of AL systems is that they iteratively propose an optimal number of the unlabelled instances (photometrically classified transients) that should be labelled for the greatest improvement in classification accuracy. In other words, to ask ‘which (small number of) unclassified transients are worth allocating spectroscopic resources for an improved classifier overall?’ AL strategies take advantage of the fact that astronomical datasets are continually updated, and that existing spectroscopic datasets (for cosmological analysis, for instance) may not be representative of the overall population of astronomical transients. On a simulated survey, Ishida et al. (2019) demonstrate that spectroscopic targets chosen by their AL model achieve higher purity classifiers, with fewer days of survey operation, than a selection that tries to replicate the initial spectroscopic dataset.
Rehemtulla et al. (2024) introduce BTSbot, a new tool which automates identifying new bright candidates for the ZTF BTS spectroscopic follow-up survey. BTSbot uses a convolutional neural network trained on the images from ZTF alerts, along with features extracted from ZTF light curves to provide a ‘bright transient score’ for individual ZTF alerts. BTSbot performs with comparable purity to human ‘scanners’ who manually select and trigger spectroscopic observations. At present, AAS2RTO does not use any deep learning modules (although many alert streams from brokers are filtered using deep learning). Further, as transient classification is not the main goal of the example science case we have provided (Sect. 3), we have not implemented an AL system similar to RESSPECT. However, it would be useful to produce individual factors using machine learning. For instance, a factor could be designed around a deep learning model that predicts the time of a candidate SN Ia peak brightness, and reserve fitting expensive SALT model fitting for the most promising candidates.
Very large projects with a variety of scientific goals often prefer not to use a greedy strategy as they do not provide a ‘globally’ optimum schedule. For instance, ZTF (Bellm et al. 2019a) describe their aim of maximising transient discovery rate, and the need to balance the total number of exposures taken, the cosmological volume probed, and cadence. Similarly, LSST’s Deep-Fast-Wide survey has many scientific aims, and will need to balance transient discovery as well as overall depth and homogeneity over the whole survey footprint. As a counterexample, however, the Science Planning and Scheduling System for the Hubble Space Telescope used a greedy search algorithm successfully during the first seven years of operation (Samson 1998).
The Target and Observation Manager Toolkit (TOMToolkit, Street et al. 2018) has a different aim to the tools mentioned above in that it is a general-purpose toolkit. It can be used to build whole observation management systems from scratch, or used as a library of useful tools. We aim in future to use some of the functionality of TOMToolkit to improve AAS2RTO. In particular, we will use the alert and data management modules. Currently, AAS2RTO stores photometric data from ZTF/LSST brokers and ATLAS and transient listings from TNS very simply using ASCII files. Although this is not the most efficient approach, it is easiest to implement. This works well for the narrow science case we have described in Sect. 3, but could become unwieldy for broader science cases in which there are more candidates. Further, AAS2RTO is currently controlled only with command-line interface. The TOMToolkit allows for Graphical User Interfaces (GUIs) to be easily implemented, which would make AAS2RTO more user-friendly.
Finally, we compare AAS2RTO with schedulers which use a (mixed) integer linear programming solution (MILP/ILP). MILP and ILP solutions have been shown to provide globally optimal solutions for extremely complex scheduling problems. For instance, Solar et al. (2016) demonstrate how a MILP solution can provide an optimal observing schedule for an entire six-month ALMA observing season, while still maintaining the flexibility to adapt in the short-term. Like other schedulers for observatories with many competing observing programmes (often containing several targets), fixed scientific priorities for each programme are assigned by science committees. Solar et al.’s ALMA scheduler uses a commercial MILP solver (IBM-ILOG-CPLEX) to maximise the total ‘scientific throughput’ of the observatory (the sum of the scientific priorities of programmes observed) in the long-term, while also minimising telescope idle time in the short-term and preferring completed programmes. Similarly, Lampoudi et al. (2015) use an ILP solution to schedule the Las Cumbres Observatory Global Telescope (LCOGT) network, with a very large number of telescopes of different sizes and capabilities. Requests for observations with LCOGT are made on a twice-yearly basis, with the additional complication that requests can ask for any subset of the available telescope resources. Lampoudi et al.’s scheduler maximises the sum of scientific priorities of observed targets, and is shown to provide a close-to-optimal solution when the network is over-subscribed (that is, more observing time is requested than is available). The LCOGT scheduler uses the commercial Gurobi ILP solver. The ZTF scheduler described above (Bellm et al. 2019a) also uses the Gurobi ILP solver. As AAS2RTO is designed for observing candidates which are known only within days of observation (SNe Ia with a rise time of ~19 days), and not for competing proposals which are submitted before an observing season, the simple greedy scheduler allows for sufficient flexibility in the short-term.
4.2 Candidate visibility considerations
One criticism of greedy algorithms in the telescope schedulers is that they do not sufficiently account for the visibility of candidates, and risk missing maximal scientific output by missing candidates which will quickly set below the horizon. Rana et al. (2017) raise this issue in the context of covering the large (≳100 deg2) probability regions for gravitational wave event follow-up. They demonstrate that greedy schedulers can lead to less than optimal coverage compared with their best-performing algorithm due to parts of the probability region setting before observation. Rana et al. (2017) point out, however, that complicated observing schedules can give worse performance than greedy algorithms in case of unreliable instrumentation or weather. Steele & Carter (1997) state this last argument as their reason for implementing a ‘dispatch’ scheduler for the Liverpool Telescope at La Palma, where the observing conditions can change rapidly and frequently.
We partially address concerns about target visibility using the visibility factor in Eq. (13) (Sect. 3.2.2). Our approach is similar to that taken by the ACP scheduler (ACPS, Denny 2004, 2006). ACPS uses an efficiency function modified from Steele & Carter (1997), with an additional term which accounts for the visibility of targets. APCS’s ‘highest altitude’ term is designed to prefer targets at their transit altitude, and accounts for the fact that some rising targets will never reach transit altitude. Additionally, ACPS allows for repeat observations of the same target at a specified time interval. ACPS therefore considers the centroid altitude of the repeat observations at their specified time interval. Given the motivation of rapid response spectroscopic follow-up of primarily newly discovered transients or specifically time-targeted observations with AAS2RTO (which are the main focus in this work), we do not include automated repeating observations of the same target at this point, but can consider this in future upgrades of AAS2RTO. Further, our visibility factor is a similar approach to the SONG’s Conductor scheduler, which gives preference to setting targets over rising targets by using fixed weights.
In future developments to AAS2RTO, we hope to address this issue further by extending the concept of the score to the entire night. Considering combinations of observations throughout the night would allow the for a selection of observations that maximise the score for the entire night, but would result in a more rigid schedule. This option would enable additional use cases for AAS2RTO, but would not provide the flexibility of the existing greedy implementation, which is useful for real-time rapid response observations.
5 Conclusions
We have discussed the implementation and greedy strategy of our new candidate prioritisation tool, AAS2RTO. It will be used to prioritise transient candidates from LSST, in order to use the DK1.54 m telescope at La Silla, Chile, as a spectroscopic followup facility for transient alerts from LSST.
The greedy strategy used by AAS2RTO is described generically, along with the individual factors which constitute the final score. The factors for each candidate can be weighted to preferentially promote candidates with specific properties. As an example science case of AAS2RTO, we have described in detail the factors we use to prioritise candidate SNe Ia that are at peak brightness. In short, these factors promote candidates that are bright, not much older than the typical SNe Ia rise time, and not declining in brightness. The final factor we have described considers the remaining visibility of the candidate during an observing night, and prioritises candidates that will soon set below a permitted minimum altitude.
Using archival ZTF data, we have simulated how AAS2RTO could perform in real-time. We show that using SALT models, we are able to estimate the average epoch when peak brightness occurs with a precision of ![Mathematical equation: $\[\pm_{2.1}^{1.3}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq69.png) days. We estimate that we would have around
days. We estimate that we would have around ![Mathematical equation: $\[\bar{N}=2.08 \pm 0.07\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq70.png) SNe per night within 0.5 days of the peak, for a facility with the same magnitude limitations as the DK1.54 m (r > 18.5 mag). This is around a factor of two lower than the actual number of supernovae we expect in the ZTF footprint, and we attribute this difference to the quality cuts we require for candidates. We have performed a similar experiment with simulated LSST alerts, and found that we can expect 2.05 ± 0.04 candidates from LSST within 0.5 days of the true peak. Finally, we have compared the greedy strategy of AAS2RTO with a selection of other available tools for observing. Although many existing tools also use a greedy strategy for scheduling observations, none exactly match the example science case we have outlined here, or the flexibility of AAS2RTO.
SNe per night within 0.5 days of the peak, for a facility with the same magnitude limitations as the DK1.54 m (r > 18.5 mag). This is around a factor of two lower than the actual number of supernovae we expect in the ZTF footprint, and we attribute this difference to the quality cuts we require for candidates. We have performed a similar experiment with simulated LSST alerts, and found that we can expect 2.05 ± 0.04 candidates from LSST within 0.5 days of the true peak. Finally, we have compared the greedy strategy of AAS2RTO with a selection of other available tools for observing. Although many existing tools also use a greedy strategy for scheduling observations, none exactly match the example science case we have outlined here, or the flexibility of AAS2RTO.
Acknowledgements
We are grateful to Gautham Narayan, Rachel A. Street and Markus Hundertmark for constructive feedback and helpful discussions. This work is supported by a Villum Young Investigator grant (project number 25501), a Villum Experiment grant (VIL69896) and research grants (VIL16599 and VIL54489) from VILLUM FONDEN. This work was made possible through the Preparing for Astrophysics with LSST Program, supported by the HeisingSimons Foundation and managed by Las Cumbres Observatory (proposal ID KSI-24, through grant 2021–2975). The recommissioning of DFOSC spectroscopic capabilities on the DK1.54 m telescope has been supported by the Villum Experiment grant Cosmic Beacons (project number 36225). In addition to tools described in the main text, this work made use of PYTHON (Van Rossum & Drake 2009), and the follow PYTHON packages: ASTROPLAN (Morris et al. 2018), ASTROPY (Astropy Collaboration 2022), DUSTMAPS (Green 2018), MATPLOTLIB (Hunter 2007), NUMPY (Harris et al. 2020), PANDAS (McKinney 2010), SCIPY (Virtanen et al. 2020), and SNCOSMO (Barbary et al. 2016).
Appendix A Messaging examples
AAS2RTO is capable of sending messages about candidates to users through ‘bots’. This is currently implemented with the team communication platform Slack (via the slack_sdk API14), and the instant messaging service Telegram (via the python-telegram-bot API15). Figure A.1 and Fig. A.2 show examples of the Slack and Telegram messages sent from AAS2RTO, respectively.
The messaging functionality is supplementary to the main aim of providing a ranked list of candidates for observation. This functionality is optional, as science cases or scoring functions which produce many candidates may produce an excessive number of messages.
 |
Fig. A.1 Messages sent using a Slack ‘bot’. They contain light curve figures produced by AAS2RTO alongside some summary information about the candidate. |
 |
Fig. A.2 Example screenshot of messages sent using a Telegram ‘bot’. In this example, altitude charts are also sent for a number of observatories in addition to the light curve and summary information about the candidate. |
Appendix B Behaviour of visibility factor
The visibility factor xvis (defined in Eq. 13) does not have a maximum value due to the definition of Avis (Eq. 12). Rather, it is unbounded, with very large values when a candidates’ altitude approaches amin. This behaviour is undesirable if all the other factors for a candidate have been carefully constructed to be well-behaved in order to reflect the scientific aims of a user. Here, we propose a slightly modified ![Mathematical equation: $\[\hat{x_{\mathrm{vis}}}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq71.png) .
.
A simple solution is to define a maximum acceptable value, A, and choose the minimum value.
![Mathematical equation: $\[\hat{x_{\mathrm{vis}}}=\min \left(x_{\mathrm{vis}}, A\right).\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq72.png) (B.1)
(B.1)
An alternative proposal is to suppress the large values of xvis,
![Mathematical equation: $\[\hat{x_{\mathrm{vis}}}=\frac{x_{\mathrm{vis}}}{\left[1+\left(\frac{x_{\mathrm{vis}}}{A}\right)^p\right]^{1 / p}}.\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq73.png) (B.2)
(B.2)
 |
Fig. B.1 The saturation function of Eq. B.2, for combinations of the parameters A and p, which set the maximum value, and the range of linear behaviour, respectively. The dashed black line is a one-to-one |
![Mathematical equation: $\[\hat{x_{\text {vis }}}=x_{\text {vis}}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq74.png)
where A is the maximum acceptable value of xvis, and p is a constant p > 1. This is linear for small input values of xvis, but smoothly ‘saturates’ to A for large xvis. The denominator of this ‘saturation’ function is the Lp-norm of the point (1, xvis/A). For xvis/A ≪ 1, ![Mathematical equation: $\[\hat{x_{\mathrm{vis}}}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq75.png) approaches zero, and the derivative is one (i.e. xvis =
approaches zero, and the derivative is one (i.e. xvis = ![Mathematical equation: $\[\hat{x_{\mathrm{vis}}}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq76.png) ). For xvis/A ≫ 1,
). For xvis/A ≫ 1, ![Mathematical equation: $\[\hat{x_{\mathrm{vis}}}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq77.png) approaches A. For increasing p, the function output is approximately linear a larger ranges of input xvis. As p approaches infinity, the suggestion in Eq. B.1 is recovered. The behaviour of Eq. B.2 is shown in Fig. B.1.
approaches A. For increasing p, the function output is approximately linear a larger ranges of input xvis. As p approaches infinity, the suggestion in Eq. B.1 is recovered. The behaviour of Eq. B.2 is shown in Fig. B.1.
The difference between the xvis definition from the main body of the paper (Eq. 13), and the modified version in Eq. B.2 is shown in Fig. B.2, choosing parameters A = 10 and p = 10, aref = 90°, and amin = 30°. The visibility factor is shown for the same three hypothetical candidates in Fig. 3, an additional candidate which sets close to sunrise (tSR) and a candidate which rises during the night and is still at high altitude at sunrise. At small values of xvis, there is little difference between xvis and ![Mathematical equation: $\[\hat{x_{\text {vis}}}\]$](/articles/aa/full_html/2025/06/aa52099-24/aa52099-24-eq78.png) . For instance, for the candidate T 5 in Fig. B.2, the difference is not visible at any time.
. For instance, for the candidate T 5 in Fig. B.2, the difference is not visible at any time.
For observing time tobs < tSS (during the day, grey shaded regions in Fig. B.2), the visibility factor xvis is constant due to the limits of integration in Eq. 12.
 |
Fig. B.2 The visibility of several hypothetical candidates during a night is shown in the upper panel. The lower panel demonstrates how the visibility factor xvis for each of these candidates changes as a function of time. The xvis definition from the main body of the paper (dashed line) has no upper limit as candidates set below amin. The modified version (Eq. B.2, solid line) ‘saturates’ to a maximum value. For this example, we have chosen A = 10 and p = 10, and aref = 90°. The white region is when the Sun is below altitude a < −18° (astronomical night). Open circles mark when the time the candidate sets below the minimum acceptable altitude, amin, or the sun rises above a = −18° (whichever is earlier). |
References
- Aleo, P. D., Malanchev, K., Sharief, S., et al. 2023, ApJS, 266, 9 [NASA ADS] [CrossRef] [Google Scholar]
- Andersen, J., Andersen, M. I., Klougart, J., et al. 1995, The Messenger, 79, 12 [NASA ADS] [Google Scholar]
- Asquini, L., Landoni, M., Young, D., et al. 2022, Proc. SPIE, 12189, 121890A [Google Scholar]
- Asquini, L., Landoni, M., Young, D., et al. 2024, arXiv e-prints [arXiv:2407.17262] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2022, ApJ, 935, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Barbary, K., Barclay, T., Biswas, R., et al. 2016, Astrophysics Source Code Library [record ascl:1611.017] [Google Scholar]
- Bazin, G., Ruhlmann-Kleider, V., Palanque-Delabrouille, N., et al. 2011, A&A, 534, A43 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bellm, E. C. 2016, PASP, 128, 084501 [Google Scholar]
- Bellm, E. C., Kulkarni, S. R., Barlow, T., et al. 2019a, PASP, 131, 068003 [Google Scholar]
- Bellm, E. C., Kulkarni, S. R., Graham, M. J., et al. 2019b, PASP, 131, 018002 [Google Scholar]
- Biswas, B., Ishida, E. E. O., Peloton, J., et al. 2023, A&A, 677, A77 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Black, P. E. 2005, Dictionary of Algorithms and Data Structures [NIST online], https://xlinux.nist.gov/dads/HTML/greedyalgo.html [Google Scholar]
- Bloemen, S., Groot, P., Nelemans, G., & Klein-Wolt, M. 2015, ASP Conf. Ser., 496, 254 [NASA ADS] [Google Scholar]
- Braga-Ribas, F., Sicardy, B., Ortiz, J. L., et al. 2014, Nature, 508, 72 [NASA ADS] [CrossRef] [Google Scholar]
- Brout, D., Scolnic, D., Popovic, B., et al. 2022, ApJ, 938, 110 [NASA ADS] [CrossRef] [Google Scholar]
- Carrasco-Davis, R., Reyes, E., Valenzuela, C., et al. 2021, AJ, 162, 231 [NASA ADS] [CrossRef] [Google Scholar]
- Delgado, F., Saha, A., Chandrasekharan, S., et al. 2014, Proc. SPIE, 9150, 915015 [Google Scholar]
- Denny, R. B. 2004, Soc. Astron. Sci. Ann. Symp., 23, 35 [Google Scholar]
- Denny, R. B. 2006, Dispatch Scheduling of Automated Telescopes [revised], http://scheduler.dc3.com/Scheduler2006.pdf [Google Scholar]
- Desai, D. D., Kochanek, C. S., Shappee, B. J., et al. 2024, MNRAS, 530, 5016 [NASA ADS] [CrossRef] [Google Scholar]
- Dhawan, S., Goobar, A., Smith, M., et al. 2022, MNRAS, 510, 2228 [NASA ADS] [CrossRef] [Google Scholar]
- Dilday, B., Kessler, R., Frieman, J. A., et al. 2008, ApJ, 682, 262 [Google Scholar]
- Dyer, M. J., Dhillon, V. S., Littlefair, S., et al. 2018, in Proc. SPIE, 10704, 107040C [Google Scholar]
- Dyer, M. J., Dhillon, V. S., Littlefair, S., et al. 2020, Proc. SPIE, 11452, 114521Q [Google Scholar]
- Firth, R. E., Sullivan, M., Gal-Yam, A., et al. 2015, MNRAS, 446, 3895 [NASA ADS] [CrossRef] [Google Scholar]
- Förster, F., Cabrera-Vives, G., Castillo-Navarrete, E., et al. 2021, AJ, 161, 242 [CrossRef] [Google Scholar]
- Fredslund Andersen, M., Handberg, R., Weiss, E., et al. 2019, PASP, 131, 045003 [Google Scholar]
- Fremling, C., Miller, A. A., Sharma, Y., et al. 2020, ApJ, 895, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Frohmaier, C., Sullivan, M., Nugent, P. E., et al. 2019, MNRAS, 486, 2308 [CrossRef] [Google Scholar]
- Gal-Yam, A. 2021, AAS Meeting Abstracts, 53, 423.05 [Google Scholar]
- Giannini, E., Schmidt, R. W., Wambsganss, J., et al. 2017, A&A, 597, A49 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Goodrich, M., & Tamassia, R. 2014, Algorithm Design and Applications (Hoboken: Wiley) [Google Scholar]
- Graham, M. L., Bellm, E., Guy, L., Dubois-Felsmann, G., & the Data Management System Science Team 2020, LSST Alerts: Key Numbers, DMTN-102, http://ls.st/dmtn-102 [Google Scholar]
- Green, G. 2018, J. Open Source Softw., 3, 695 [NASA ADS] [CrossRef] [Google Scholar]
- Grundahl, F., Arentoft, T., Christensen-Dalsgaard, J., et al. 2008, J. Phys. Conf. Ser., 118, 012041 [Google Scholar]
- Guy, J., Astier, P., Nobili, S., Regnault, N., & Pain, R. 2005, A&A, 443, 781 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Guy, J., Astier, P., Baumont, S., et al. 2007, A&A, 466, 11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Heinze, A. N., Tonry, J. L., Denneau, L., et al. 2018, AJ, 156, 241 [Google Scholar]
- Holoien, T. W. S., Brown, J. S., Vallely, P. J., et al. 2019, MNRAS, 484, 1899 [NASA ADS] [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Ishida, E. E. O., Beck, R., González-Gaitán, S., et al. 2019, MNRAS, 483, 2 [Google Scholar]
- Israel, G. L., Negueruela, I., Campana, S., et al. 2001, A&A, 371, 1018 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Jones, D. O., Foley, R. J., Narayan, G., et al. 2021, ApJ, 908, 143 [NASA ADS] [CrossRef] [Google Scholar]
- Kasten, F., & Young, A. T. 1989, Appl. Opt., 28, 4735 [CrossRef] [Google Scholar]
- Kennamer, N., Ishida, E. E. O., González-Gaitán, S., et al. 2020, IEEE Symp. Ser. Comput. Intell., 3115 [Google Scholar]
- Kenworthy, W. D., Jones, D. O., Dai, M., et al. 2021, ApJ, 923, 265 [NASA ADS] [CrossRef] [Google Scholar]
- Lampoudi, S., Saunders, E., & Eastman, J. 2015, arXiv e-prints [arXiv:1503.07170] [Google Scholar]
- Leoni, M., Ishida, E. E. O., Peloton, J., & Möller, A. 2022, A&A, 663, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Matheson, T., Stubens, C., Wolf, N., et al. 2021, AJ, 161, 107 [NASA ADS] [CrossRef] [Google Scholar]
- McKinney, W. 2010, in Proceedings of the 9th Python in Science Conference, eds. Stéfan van der Walt, & Jarrod Millman, 56 [CrossRef] [Google Scholar]
- Miller, A. A., Abrams, N. S., Aldering, G., et al. 2025, arXiv e-prints [arXiv:2503.14579] [Google Scholar]
- Möller, A., & de Boissière, T. 2020, MNRAS, 491, 4277 [CrossRef] [Google Scholar]
- Möller, A., Peloton, J., Ishida, E. E. O., et al. 2021, MNRAS, 501, 3272 [CrossRef] [Google Scholar]
- Morris, B. M., Tollerud, E., Sipőcz, B., et al. 2018, AJ, 155, 128 [Google Scholar]
- Nielsen, J. T., Guffanti, A., & Sarkar, S. 2016, Sci. Rep., 6, 35596 [Google Scholar]
- Nugent, P., Aldering, G., Diehl, T., et al. 2020, in Snowmass2021 – Letter of Interest, Snowmass2021 [Google Scholar]
- Patat, F., Augusteijn, T., Böhnhardt, H., et al. 2000, Mem. Soc. Astron. Italiana, 71, 307 [Google Scholar]
- Patat, F., Cappellaro, E., Danziger, J., et al. 2001, ApJ, 555, 900 [Google Scholar]
- Perley, D. A., Fremling, C., Sollerman, J., et al. 2020, ApJ, 904, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pravec, P., Scheirich, P., Ďurech, J., et al. 2014, Icarus, 233, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Pravec, P., Meyer, A. J., Scheirich, P., et al. 2024, Icarus, 418, 116138 [Google Scholar]
- Prochaska, J., Hennawi, J., Westfall, K., et al. 2020, J. Open Source Softw., 5, 2308 [NASA ADS] [CrossRef] [Google Scholar]
- Rana, J., Singhal, A., Gadre, B., Bhalerao, V., & Bose, S. 2017, ApJ, 838, 108 [Google Scholar]
- Rehemtulla, N., Miller, A. A., Jegou Du Laz, T., et al. 2024, ApJ, 972, 7 [Google Scholar]
- Ridgway, S. T., Matheson, T., Mighell, K. J., Olsen, K. A., & Howell, S. B. 2014, ApJ, 796, 53 [Google Scholar]
- Riess, A. G., Filippenko, A. V., Li, W., et al. 1999, AJ, 118, 2675 [NASA ADS] [CrossRef] [Google Scholar]
- Russeil, E., Ishida, E. E. O., Le Montagner, R., Peloton, J., & Moller, A. 2022, arXiv e-prints [arXiv:2211.10987] [Google Scholar]
- Samson, R. J. 1998, Proc. SPIE, 3349, 282 [Google Scholar]
- Sánchez-Sáez, P., Reyes, I., Valenzuela, C., et al. 2021, AJ, 161, 141 [CrossRef] [Google Scholar]
- Schipani, P., Campana, S., Claudi, R., et al. 2018, Proc. SPIE, 10702, 107020F [Google Scholar]
- Schlegel, D. J., Finkbeiner, D. P., & Davis, M. 1998, ApJ, 500, 525 [Google Scholar]
- Scolnic, D., Brout, D., Carr, A., et al. 2022, ApJ, 938, 113 [NASA ADS] [CrossRef] [Google Scholar]
- Shappee, B. J., Prieto, J. L., Grupe, D., et al. 2014, ApJ, 788, 48 [Google Scholar]
- Shingles, L., Smith, K. W., Young, D. R., et al. 2021, Transient Name Server AstroNote, 7, 1 [NASA ADS] [Google Scholar]
- Smith, K. W., Williams, R. D., Young, D. R., et al. 2019, Res. Notes Am. Astron. Soc., 3, 26 [Google Scholar]
- Smith, K. W., Smartt, S. J., Young, D. R., et al. 2020, PASP, 132, 085002 [Google Scholar]
- Solar, M., Michelon, P., Avarias, J., & Garces, M. 2016, Astron. Comput., 15, 90 [Google Scholar]
- Southworth, J., Tregloan-Reed, J., Andersen, M. I., et al. 2016, MNRAS, 457, 4205 [NASA ADS] [CrossRef] [Google Scholar]
- Sravan, N., Milisavljevic, D., Reynolds, J. M., Lentner, G., & Linvill, M. 2020, ApJ, 893, 127 [Google Scholar]
- Srivastav, S., Moore, T., Nicholl, M., et al. 2023, ApJ, 956, L34 [Google Scholar]
- Steele, I. A., & Carter, D. 1997, Proc. SPIE, 3112, 222 [Google Scholar]
- Street, R. A., Bowman, M., Saunders, E. S., & Boroson, T. 2018, Proc. SPIE, 10707, 1070711 [Google Scholar]
- Swann, E., Sullivan, M., Carrick, J., et al. 2019, The Messenger, 175, 58 [NASA ADS] [Google Scholar]
- Taylor, G., Lidman, C., Tucker, B. E., et al. 2021, MNRAS, 504, 4111 [NASA ADS] [CrossRef] [Google Scholar]
- Tonry, J. L., Denneau, L., Heinze, A. N., et al. 2018, PASP, 130, 064505 [Google Scholar]
- Tripp, R. 1998, A&A, 331, 815 [NASA ADS] [Google Scholar]
- Van Rossum, G., & Drake, F. 2009, Python 3 Reference Manual, Documentation for Python (California: CreateSpace Independent Publishing Platform) [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Young, D. R. 2023, Catalogue cross-matching and Sherlock, Zenodo, https://doi.org/10.5281/zenodo.8335195 [Google Scholar]
- Young, A. T., & Irvine, W. M. 1967, AJ, 72, 945 [Google Scholar]
AAS2RTO: https://github.com/aidansedgewick/aas2rto. Configuration and technical details of user-supplied components are available in the README section of the project repository.
CNEOS discovery statistics: https://cneos.jpl.nasa.gov/stats/site_all.html
Classified SNe listed in the Transient Name Server database to 31-12-2023.
FINK API: https://fink-portal.org/api
ALeRCE broker https://alerce.online/
Lasair broker https://lasair-ztf.lsst.ac.uk/
ATLAS forced photometry API: https://fallingstar-data.com/forcedphot/
Also ‘Stellar Oscillations Network Group’.
Slack API: https://slack.dev/python-slack-sdk/
Telegram API: https://python-telegram-bot.org/ (using synchronous version 13.12)
All Tables
Percentage of candidates from the high-quality sample of 2205 ZTF light curves which appear at least once in the top N candidates of a ranked list.
All Figures
|
Fig. 1 Sketch of the logic behind automated observations using AAS2RTO and the Danish-1.54 m. Green boxes indicate data compiled by AAS2RTO. White boxes are out of the scope of AAS2RTO. The steps made by AAS2RTO in the grey box are detailed in Fig. 2. |
| In the text | |
|
Fig. 2 Prioritisation loop of AAS2RTO. First, data is compiled (step (1); Sect. 2.1) from broadcasting services (e.g. ZTF/LSST brokers) and non-broadcasting services (e.g. ATLAS/TNS). A pre-filtering step (step (2)) identifies new candidates which can immediately be removed without detailed modelling or visibility considerations. Theoretical models (e.g. light curve fits) are fit to new candidates (step (3)), or candidates which have received new data/alerts in the data compilation step. The full score is computed for each candidate (step (5); Sect. 2.3), considering the light curve, and models fit in the previous step, and observing site conditions. Finally, list of candidates are produced, in order of descending score (step (6); Sect. 2.4). |
| In the text | |
|
Fig. 3 Altitude of three hypothetical candidates (T1, T2, T3) from La Silla on the spring equinox. The current time tobs is indicated, and tSS and tSR are the sunset and sunrise time respectively. The shaded grey regions are day and twilight (the Sun’s altitude a > −18°, when astronomical observations are not possible). The shaded region under each altitude curve between tobs and tSR is Avis, computed in Eq. (12). The reference altitude aref for normalisation is also indicated. |
| In the text | |
|
Fig. 4 Distribution of SALT2 stretch parameter x1 (left panel) and colour parameter c (right panel) for all light curves with eight or more detections, for the sample of 2205 light curves that meet our criteria (black), and for the subset of 1383 that are spectroscopically confirmed SNe Ia in TNS (grey). Distributions of x1 (left panel) and c are also shown from Taylor et al. (2021) using the Dark Energy Survey (DES) supernovae sample (blue line; taken from their Fig. 9), from Nielsen et al. (2016) using the Joint Lightcurve Analysis (JLA) sample (green; taken from their Fig. 1), and from Scolnic et al. (2022) using the Pantheon+ sample (orange). |
| In the text | |
|
Fig. 5 Sample of SNe Ia selected from FINK (central circle, red), and the overlap with the TNS spectroscopically confirmed sample of SNe Ia (left circle, green), and SNe non-Ia (right circle, blue). |
| In the text | |
|
Fig. 6 Convergence SALT2 zero-phase parameter t0 to the final ‘best’ estimate, |
| In the text | |
|
Fig. 7 Convergence of the SALT zero-phase parameter t0, as a function of SN phase, separating candidates by their maximum model g measurement. Large, dark grey points are the |
| In the text | |
|
Fig. 8 Upper panel: median (black line) of the normalised distributions of all SNe Ia scores per night, log10 (SIa). The shaded grey region shows the central 68% of the distributions. Lower panel: normalised distribution of scores of candidates within one day of |
| In the text | |
|
Fig. 9 Frequency of number of candidates per day (24 hour period) within half a day, one day and two days of the current predicted peak (in black, red and blue respectively). These measurements are made only for days where ZTF alerts were delivered. The mean number of candidates per day for each selection is denoted by the dashed vertical line. There are a mean of |
| In the text | |
|
Fig. 10 Convergence of estimate of time to peak, |
| In the text | |
|
Fig. 11 Number of expected candidates within half a day, one day and two days of the peak from simulated LSST observations. There are a mean of 2.05 ± 0.04 within 0.5 days of the true peak, 4.12 ± 0.06 within one day of the peak, and 8.2 ± 0.1 within two days of the peak (indicated by dashed vertical lines). |
| In the text | |
|
Fig. A.1 Messages sent using a Slack ‘bot’. They contain light curve figures produced by AAS2RTO alongside some summary information about the candidate. |
| In the text | |
|
Fig. A.2 Example screenshot of messages sent using a Telegram ‘bot’. In this example, altitude charts are also sent for a number of observatories in addition to the light curve and summary information about the candidate. |
| In the text | |
|
Fig. B.1 The saturation function of Eq. B.2, for combinations of the parameters A and p, which set the maximum value, and the range of linear behaviour, respectively. The dashed black line is a one-to-one |
| In the text | |
|
Fig. B.2 The visibility of several hypothetical candidates during a night is shown in the upper panel. The lower panel demonstrates how the visibility factor xvis for each of these candidates changes as a function of time. The xvis definition from the main body of the paper (dashed line) has no upper limit as candidates set below amin. The modified version (Eq. B.2, solid line) ‘saturates’ to a maximum value. For this example, we have chosen A = 10 and p = 10, and aref = 90°. The white region is when the Sun is below altitude a < −18° (astronomical night). Open circles mark when the time the candidate sets below the minimum acceptable altitude, amin, or the sun rises above a = −18° (whichever is earlier). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.