| Issue |
A&A
Volume 697, May 2025
|
|
|---|---|---|
| Article Number | A93 | |
| Number of page(s) | 8 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202453402 | |
| Published online | 08 May 2025 | |
Power spectrum of the CODEX clusters
1
Department of Physics, University of Helsinki, PO Box 64 00014 Helsinki, Finland
2
Helsinki Institute of Physics, University of Helsinki, Gustaf Hällströmin katu 2, Helsinki, Finland
3
Instituto de Astrofísica de Canarias, s/n, E-38205 La Laguna, Tenerife, Spain
4
Departamento de Astrofísica, Universidad de La Laguna, E-38206 La Laguna, Tenerife, Spain
5
INAF-Osservatorio Astronomico di Trieste, Via G. B. Tiepolo 11, 34143 Trieste, Italy
6
INFN, Sezione di Trieste, Via Valerio 2, 34127 Trieste, TS, Italy
7
IFPU, Institute for Fundamental Physics of the Universe, Via Beirut 2, 34151 Trieste, Italy
⋆ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
11
December
2024
Accepted:
19
March
2025
Abstract
Aims. We analyze the clustering of galaxy clusters in a large contiguous sample, the Constrain Dark Energy with X-ray (CODEX) sample. We construct a likelihood for cosmological parameters by comparing the measured clustering signal and a theoretical prediction, and use this to obtain parameter constraints.
Methods. We measured the three multipole moments (monopole, quadrupole, and hexadecapole, ℓ = 0, 2, 4) of the power spectrum of a subset of the CODEX clusters. To fully model cluster clustering, we also determined the expected clustering bias of the sample using estimates for the cluster masses and a mass-to-bias model calibrated using N-body simulations. We estimated the covariance matrix of the measured power spectrum multipoles using a set of simulated dark-matter halo catalogs. Combining all these ingredients, we performed a Markov chain Monte Carlo sampling of cosmological parameters Ωm and σ8 to obtain their posterior.
Results. We found the CODEX clustering signal to be consistent with an earlier X-ray selected cluster sample, the REFLEX II sample. We also found that the measured power spectrum multipoles are compatible with the predicted, bias-scaled linear matter power spectrum when the cosmological parameters determined by the Planck satellite are assumed. Furthermore, we found the marginalized parameter constraints of Ωm = 0.24−0.04+0.06 and σ8 = 1.13−0.24+0.43. The full 2D posterior is consistent, for example, with the Planck cosmology within the 68% confidence region.
Key words: galaxies: clusters: general / cosmology: observations / large-scale structure of Universe
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
The clustering of galaxy clusters is sensitive to the geometry and the growth of structure in the Universe. Because of this, it has been an active field of cosmological research (see e.g., Bahcall 1995; Borgani et al. 1999; Moscardini et al. 2000; Estrada et al. 2009; Sánchez et al. 2005; Allen et al. 2011; Marulli et al. 2018, 2021; Moresco et al. 2021; Garrel et al. 2022; Lesci et al. 2022; Euclid Collaboration: Fumagalli et al. 2024). X-ray selected galaxy clusters, in particular, have been shown to possess great potential as a cosmological probe (see e.g., Guzzo et al. 1999; Schuecker et al. 2003; Schuecker 2005; Pratt et al. 2009; Guzzo et al. 2009; Pillepich et al. 2012; Böhringer et al. 2014; Mantz et al. 2014; Schellenberger & Reiprich 2017; Käfer et al. 2019; Clerc & Finoguenov 2023; Ghirardini et al. 2024). This paper is another contribution to this field of research.
The dataset we analyze in this paper is the Constrain Dark Energy with X-ray (CODEX) galaxy cluster catalog (Finoguenov et al. 2020). This is a large catalog of X-ray sources identified as galaxy clusters by detecting an optical counterpart. The combined X-ray and optical observations allow for an accurate characterization of cluster properties, such as their masses. We give a description of the CODEX catalog and our sample selection in Section 2.
This paper aims to present the measurements of the power spectrum of the CODEX sample and infer cosmological information in the form of constraints on the cosmological parameters. Previous measurements (Schuecker et al. 2001; Hütsi 2010; Balaguera-Antolínez et al. 2011) have characterized the cluster power spectrum as a scaled version of the underlying dark matter power spectrum, and show how the cluster clustering amplitude depends on observed properties such as the X-ray luminosity and richness, which paves the way toward a joint astrophysical and cosmological analysis (Allen et al. 2011; Evrard et al. 2014; Balaguera-Antolínez 2014). In Section 3 we describe the respective methods to measure the cluster power spectrum and to model it. We present our measurements of the CODEX power spectrum and the results of our cosmological analysis in Section 4. Section 5 provides the conclusion of our analysis and results.
This paper is a continuation of the work presented in Lindholm et al. (2021) (L21 hereafter), where the clustering of CODEX clusters was studied using the two-point correlation function. Theoretically, the two-point correlation function is simply the Fourier transform of the power spectrum, so the quantities are equivalent. In practice, however, the two quantities rely on completely different estimators and are thus complementary. In addition to measuring different clustering statistics, this work includes a few improvements to the L21 analysis. The most important ones are a more accurate covariance matrix (Section 3.4) and a proper handling of uncertainty in the cluster mass estimates (Section 4).
2. The CODEX catalog
The CODEX galaxy cluster survey is constructed by applying the red-sequence matched-filter probabilistic percolation (redMaPPer) algorithm (Rykoff et al. 2014) to the Sloan Digital Sky Survey (SDSS, Blanton et al. 2017) photometry inside the 10 000 square degree area of the Baryon Oscillation Spectroscopic Survey (BOSS, Dawson et al. 2013) footprint and identifying faint X-ray sources detected in the ROentgen SATellite (ROSAT) All-Sky Survey (RASS) (Truemper 1993); voges:1999. A detailed description of the survey and the catalog is presented in Finoguenov et al. (2020).
In what follows, we refer to several probability distributions that are logarithmically normal. Thus, we define the following quantities: rc ≡ ln(Rc/kpc) (core radius of the X-ray surface brightness), l ≡ ln(LX/ergs/s) (rest-frame X-ray luminosity in the 0.1–2.4 keV band), μ ≡ ln(M200c/M⊙) (total mass measured within the overdensity of 200 with respect to the critical density), λ ≡ ln(SDSS Richness) (defined at the optical peak, with a detailed description provided in Rykoff et al. 2014).
To perform the clustering analysis, we selected the part of the CODEX catalog characterized by a low probability of chance cluster identification. Following previous CODEX studies, we applied the following cut, based on the measurement of SDSS richness,
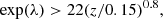 (1)
(1)
where z is the redshift of the cluster. Further discussion of cleaning is presented in Klein et al. (2019). We describe the effect of this cleaning as a PRASS(I|λ, z) term in the modeling. As well as applying a redshift-dependent richness cut, we also excluded all clusters with a richness below 25.
We applied the BOSS stellar mask to remove the areas in which stars affect optical cluster detection. We assume that the optical completeness of the CODEX catalog, above the applied richness cut, is constant across the BOSS area and model it using
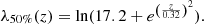 (2)
(2)
This is obtained using the tabulations of Rykoff et al. (2014). We use an error function with the mean of λ50%(z) and a σ = 0.2, which reproduces the 75% and 90% quantiles of the distribution tabulated in Rykoff et al. (2014). The probability of optical detection of a cluster in SDSS data is modeled as
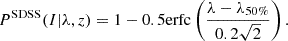 (3)
(3)
The RASS survey coverage is highly inhomogeneous, with the limiting flux varying by an order of magnitude. To properly account for the variations in the cluster distribution caused by this, we generate a random catalog, with a total number of objects six times that of the data catalog. We partition the survey area into 100 zones of equal sensitivity, S, with each consecutive zone having a 12% difference in flux sensitivity. We denote the sky area of these zones as ΔΩS. The probability of cluster detection is computed as
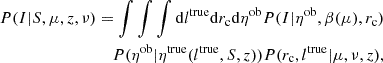 (4)
(4)
where η denotes the X-ray count (superscript “true” stands for predicted, “ob” for detected), 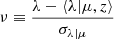 , and all the probability distributions are described in detail in Finoguenov et al. (2020). Equation (4) takes into account how the X-ray shapes (rc, β) of the clusters and the RASS sensitivity affect the selection of the clusters, and it predicts changes in the distribution of X-ray shapes based on the measured covariance of the properties of the cluster (Cavaliere & Fusco-Femiano 1976; Mulroy et al. 2019; Farahi et al. 2019; Käfer et al. 2019). This approach allows us to account for the anticorrelation between X-ray luminosity scatter and optical richness, as well as the anticorrelation between galaxy cluster core radii and their luminosity scatter. Finally, we estimate the expected number of clusters in each redshift bin as
, and all the probability distributions are described in detail in Finoguenov et al. (2020). Equation (4) takes into account how the X-ray shapes (rc, β) of the clusters and the RASS sensitivity affect the selection of the clusters, and it predicts changes in the distribution of X-ray shapes based on the measured covariance of the properties of the cluster (Cavaliere & Fusco-Femiano 1976; Mulroy et al. 2019; Farahi et al. 2019; Käfer et al. 2019). This approach allows us to account for the anticorrelation between X-ray luminosity scatter and optical richness, as well as the anticorrelation between galaxy cluster core radii and their luminosity scatter. Finally, we estimate the expected number of clusters in each redshift bin as
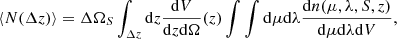 (5)
(5)
where
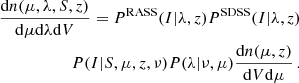 (6)
(6)
The sample selection in terms of richness and the construction of the random catalog described above is the same as in L21. However, our final sample differs from L21 in two ways. First, we selected a subset of the full CODEX footprint to have the sky area fully covered by simulated catalogs. The CODEX catalog consists of two disjoint patches, one of which has slightly larger angular coverage than the mock catalogs available to us (see Section 3.4). We thus selected a subset of the larger patch to be able to cover the whole footprint with one set of mock catalogs. Second, we also used a slightly narrower redshift range, namely z = 0.12 − 0.30 (as opposed to z = 0.1 − 0.5), to be compatible with the simulations. The final cluster sample we used for the power spectrum estimation contains 615 objects and the corresponding random sample is 11 160 objects. The sky footprint of each sample can be seen in Fig. 1 and the corresponding redshift and richness distributions in Fig. 2 (along with those of the simulated mock catalogs). We also show the standard deviation of the mock catalogs as error bars. Clearly, the differences in the distributions are within the estimated variance, so the three types of catalogs (CODEX, random, and mocks) are compatible with being drawn from the same ensemble.
 |
Fig. 1. Sky footprint of the subset of the CODEX catalog used for computing the power spectrum. The plot is a zoomed-in view of a Mollweide projection. The orange points show the clusters and the blue points show the random points. |
 |
Fig. 2. One-point statistics of the random catalog and the mock catalogs compared to the corresponding CODEX quantities. The blue bars show the CODEX sample and the empty orange bars show the random sample. The bars that correspond to the random sample have been normalized with the ratio of objects in the CODEX and random samples. The empty black bars show the mean values over all the mock catalogs and the error bars show the standard deviation. Top panel: redshift. Bottom panel: richness. |
3. Cluster power spectrum: measurements and modeling
3.1. Measurements
We performed the measurements of a three-dimensional power spectrum in redshift space, Pℓ(k), using the estimator of Bianchi et al. (2015), which is a generalization of the celebrated Feldman–Kaiser–Peacock (FKP) estimator (Feldman et al. 1994) applied to samples covering a wide area, in which the distant observer approximation is no longer valid. The minimum variance weights provided by the FKP estimator 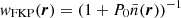 were implemented using a power spectrum amplitude P0 = 1.5 × 105 (h Mpc−1)3 and the mean cluster density
were implemented using a power spectrum amplitude P0 = 1.5 × 105 (h Mpc−1)3 and the mean cluster density 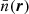 was evaluated at each cluster position. The normalization and (Poisson) shot-noise contribution were estimated from the set of random tracers (see e.g., Balaguera-Antolínez et al. 2011; Beutler et al. 2014, for a detailed implementation of the estimator). The transformation from redshifts to comoving distances was performed under the assumption of a ΛCDM cosmological model with the parameters from Planck Collaboration VI (2020) (Planck 2018 cosmology hereafter). We estimated the CODEX power spectrum multipoles in 35 linearly spaced k bins from 0.1h Mpc−1 to 0.35h Mpc−1. We used the nbodykit1 Python library (Hand et al. 2018) to obtain estimates of the monopole (ℓ = 0), quadrupole (ℓ = 2), and hexadecapole(ℓ = 4). The box used to perform the Fourier transform had sides with a comoving length of (1133 h−1 Mpc, 1151 h−1 Mpc, 651 h−1 Mpc) and the mesh resolution was 128 cells per side.
was evaluated at each cluster position. The normalization and (Poisson) shot-noise contribution were estimated from the set of random tracers (see e.g., Balaguera-Antolínez et al. 2011; Beutler et al. 2014, for a detailed implementation of the estimator). The transformation from redshifts to comoving distances was performed under the assumption of a ΛCDM cosmological model with the parameters from Planck Collaboration VI (2020) (Planck 2018 cosmology hereafter). We estimated the CODEX power spectrum multipoles in 35 linearly spaced k bins from 0.1h Mpc−1 to 0.35h Mpc−1. We used the nbodykit1 Python library (Hand et al. 2018) to obtain estimates of the monopole (ℓ = 0), quadrupole (ℓ = 2), and hexadecapole(ℓ = 4). The box used to perform the Fourier transform had sides with a comoving length of (1133 h−1 Mpc, 1151 h−1 Mpc, 651 h−1 Mpc) and the mesh resolution was 128 cells per side.
3.2. Modeling
All the cosmology-dependent quantities mentioned in the following section were computed using the COLOSSUS2 Python library (Diemer 2018).
We model the cluster power spectrum based on a linear matter power spectrum, which was computed using the transfer function of Eisenstein & Hu (1998) (EH hereafter). Even though we tested more accurate models computed from Boltzmann solvers (see e.g. Lesgourgues 2011), the differences are small compared to the statistical errors of the power spectrum. Therefore, we adopted the EH parameterization, which helps to increase the speed of the likelihood calculations (Section 4). We model the redshift-space cluster power spectrum using the Kaiser approximation (Kaiser 1987), which, for the three explored multipoles, is written as
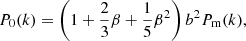 (7)
(7)
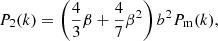 (8)
(8)
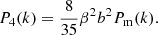 (9)
(9)
Here β ≡ f/b, where f ≡ −dlnD(z)/dln(1 + z) is the growth rate, b is the large-scale (or effective) galaxy cluster bias, and Pm(k) is the isotropic matter power spectrum.
To obtain an estimate of the large-scale galaxy cluster bias, we follow the procedure of L21. First, we estimate the cluster masses using their observed richness and the scaling relation calibrated in Kiiveri et al. (2021) (K21 hereafter). The relation is a power law, parametrized as
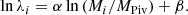 (10)
(10)
Here λi is the richness and Mi the mass of the ith cluster, MPiv = 1014.81 M⊙ is a pivot mass, and α and β are the model parameters to be calibrated. The particular calibration we used employs parameter priors from the South Pole Telescope Polarimeter (SPTpol) Extended Cluster Survey (Bleem et al. 2020). Equation (10) can be inverted to estimate the mass of a cluster with an observed richness of λi. With these mass estimates, we compute a large-scale bias using the model calibrated in Comparat et al. (2017)3 An extensive comparison of various scaling relations and bias models in the context of the CODEX clusters can be found in L21. Finally, we compute a weighted mean over all the clusters in our sample:
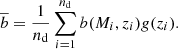 (11)
(11)
In this expression, nd is the number of clusters and b(Mi, zi) is the effective bias that corresponds to a cluster of mass Mi at redshift zi; g(zi)≡D(zi)/D(0), where D(z) is the growth function at redshift z. The growth is included to scale all the biases with respect to the matter power spectrum at z = 0. We use the bias factor of Eq. (11) to describe the cluster power spectrum in Eqs. (7)–(9).
The parameters that define the richness-mass scaling relation have a certain uncertainty, and there is also an intrinsic scatter of true cluster masses around the value predicted by the scaling relation. We take both of these effects into account as additional uncertainty when we fit the cosmological parameters. Details can be found in Section 4.
3.3. Window function
The measurements of the power spectrum using the aforementioned estimators are the response of the convolution between the survey window function (the Fourier transform of the selection function) and the underlying (theoretical) cluster power spectrum (Feldman et al. 1994). In a likelihood analysis, instead of deconvolving the measurements to obtain the underlying power spectrum (and retrieve cosmological information therefrom), it is simpler and numerically more stable to convolve a theoretical model Pℓ′th(k) with the window function. Such a convolution can be transformed into a matrix multiplication of the form
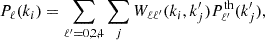 (12)
(12)
where the mixing matrix Wℓℓ′(ki, k′j) is computed using the approach of Beutler et al. (2014). We used 200 linearly spaced k′ bins in the range 0.1 h Mpc−1 − 0.35 h Mpc−1.
As an example, we show three blocks of the estimated window function in Fig. 3. The first one is the quadrupole-quadrupole block (ℓ,ℓ′) = (2, 2), the second one the quadrupole-monopole block (ℓ,ℓ′) = (2, 0), and the third one the quadrupole-hexadecapole block (ℓ,ℓ′) = (2, 4). The amplitude of the (ℓ,ℓ′) = (2, 0) block is similar to the (ℓ,ℓ′) = (2, 2) block, which highlights the anisotropy induced by the survey selection. The full window matrix is shown in the bottom panel of Fig. 5.
 |
Fig. 3. Elements of the matrix window that contribute to the power spectrum quadrupole. Top panel: ℓ = 2, ℓ′ = 2 block. Bottom panel: ℓ = 2, ℓ′ = 0 block in solid lines and the ℓ = 2, ℓ′ = 4 block in dashed lines. Each peak corresponds to a single wave number, ki, at which the power spectrum multipoles are estimated. |
3.4. Mock catalogs
To generate mock catalogs suitable for estimating the covariance matrix of the cluster power spectrum, we used a set of dark matter halo catalogs produced with the PINpointing Orbit Crossing Collapsed HIerarchical Objects (PINOCCHIO4) algorithm (Monaco et al. 2002); munari:2017. These simulations correspond to the flat ΛCDM model, and the values for the cosmological parameters used in the simulation are listed in Table 1. There are no massive neutrinos in the simulation.
Values for the cosmological parameters used in the PINOCCHIO simulations.
We started with a set of 500 light cones that contain ∼6 × 107 dark matter halos. They cover a spherical cap of a radius of 45deg and a redshift range of z = 0.0 − 1.0. They are based on 1h−1Gpc simulation boxes with a 20483 grid. The light cones are constructed with a redshift-dependent lower limit for halo mass. The limit has a maximum of 1013 h−1 M⊙, which is well below the smallest cluster masses in our CODEX sample. We applied the CODEX selection function to the mock catalogs and assigned a cluster richness to each halo based on their masses. Finally, we applied the same redshift and richness cuts that define the CODEX sample to the resulting mock cluster catalog. Figure 2 shows the redshift and richness distributions of the final mock samples, along with the CODEX sample. These demonstrate the compatibility between the mock catalogs and the CODEX catalog.
In Fig. 4 we show all the simulated spectra used for computing the covariance matrix, along with the CODEX spectrum. The figure shows that the CODEX spectrum is compatible with the simulated ensemble up to wave numbers of k ∼ 0.2 h Mpc−1 but has a larger amplitude for higher k. As shown by Munari et al. (2017) (Fig. 9, for example), the ability of the PINOCCHIO code to reproduce power spectra of N-body simulations starts to deteriorate at around these scales. Hence, we limited ourselves to scales k < 0.2 h Mpc−1 in our cosmological parameter estimation. This is because modeling the effects of non-linear growth of the structure that is not fully captured by the PINOCCHIO mock catalogs can lead to biased cosmological constraints (Munari et al. 2017; Euclid Collaboration: Fumagalli et al. 2024) and is outside the scope of this work.
 |
Fig. 4. Power spectrum multipoles used to compute the covariance matrix. Top panel: monopole. Middle panel: Quadrupole. Bottom panel: hexadecapole. Each panel shows all the 500 simulated spectra used to compute the covariance in transparent blue. The orange line is the corresponding CODEX spectrum. |
We compute the covariance matrix as the sample covariance
![Mathematical equation: $$ \begin{aligned} C_{\ell \ell ^{\prime }}(k_i, k_j) = \frac{1}{n_{\rm m} - 1}\sum _{\alpha =1}^{n_{\rm m}} \left[ P^{\alpha }_{\ell }(k_i) - \overline{P}_{\ell }(k_i) \right]\left[P^{\alpha }_{\ell ^{\prime }}(k_j) - \overline{P}_{\ell ^{\prime }}(k_j) \right], \end{aligned} $$](/articles/aa/full_html/2025/05/aa53402-24/aa53402-24-eq18.gif) (13)
(13)
where 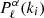 are the power spectrum multipoles computed from each mock,
are the power spectrum multipoles computed from each mock, 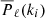 is their mean, and nm is the number of mock catalogs. Figure 5 shows the elements of the covariance matrix Cij normalized by the corresponding diagonal elements:
is their mean, and nm is the number of mock catalogs. Figure 5 shows the elements of the covariance matrix Cij normalized by the corresponding diagonal elements:
 |
Fig. 5. Top panel: covariance matrix of the CODEX power spectrum multipoles, as computed from the PINOCCHIO mocks. The elements are normalized with the diagonal. Bottom panel: full matrix window. Both matrices have the same structure. Starting from the bottom left corner, the diagonal blocks correspond to ℓ = 0, 2, 4 auto-correlation. The off-diagonal blocks show the corresponding cross-correlations. |
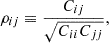 (14)
(14)
where indices i, j are also taken to include the multipole numbers ℓ = 0, 2, 4.
4. Results
Figure 6 shows the power spectrum multipoles measured from the CODEX sample, along with the theoretical predictions from Eqs. (7), (8) and (9). We show predictions for the Planck 2018 cosmology, the best-fit cosmology obtained by fitting all the CODEX power spectrum multipoles, and the best-fit cosmology obtained by fitting the monopole alone to highlight the importance of the higher multipoles in our cosmological analysis (see the following paragraphs for more details). In Fig. 7 we show a comparison of the power spectrum monopole measured from our CODEX sample (same as the solid blue line in the top panel of Fig. 6) and the isotropic power spectrum measured from the REFLEX II sample (Balaguera-Antolínez et al. 2011). In both figures, the error bars are computed as the square root of the diagonal elements of the covariance matrix of Eq. (13). Our measurement of the CODEX power spectrum is in agreement with the Planck 2018 cosmology prediction within the error bars. A qualitative agreement with results from the REFLEX II samples is also seen, with differences likely being due to the redshift range and cluster mass cut used in each sample.
 |
Fig. 6. Multipoles of the CODEX cluster’s power spectrum. The solid lines with error bars show the measurements, and the dashed lines show the corresponding theoretical predictions. The orange lines show the theoretical prediction using the Planck 2018 cosmology, the green lines the prediction using the best-fit cosmology obtained using all the multipoles, and the red lines the prediction using the best-fit cosmology obtained using the monopole alone. Top panel: monopole (ℓ = 0). Second panel: Quadrupole (ℓ = 2) Third panel: hexadecapole (ℓ = 4). Bottom panel: relative difference of the measured and predicted spectra (Planck 2018 cosmology) for monopole and quadrupole. The predicted hexadecapole is close to zero, which makes the relative difference extremely large. The vertical black line shows up to which wavenumbers we include the measurements in our cosmological analysis. |
 |
Fig. 7. Comparison of power spectra from CODEX and REFLEX II samples. The blue line with error bars is the CODEX power spectrum monopole, and the orange line is the REFLEX II isotropic power spectrum. |
The power spectrum measurements described above can be used to obtain constraints on cosmological parameters. To do this, we ran a Markov chain Monte Carlo (MCMC) sampling of the present-day matter density parameter Ωm and the power spectrum amplitude σ8 to obtain their posterior. The other ΛCDM parameters were fixed to the Planck 2018 values. We expect the main uncertainty in our modeling to be associated with the cluster mass estimates. To fully account for this, we also sampled the two richness-to-mass scaling relation parameters α and eβ. We used Gaussian approximations to the posteriors presented in K21 as priors for these parameters. To include the scatter in the richness-to-mass conversion, we generated a Gaussian noise vector with σ = 0.28 (corresponding to the scatter determined in K21) and added this to the logarithmic mass of each cluster at each likelihood evaluation. The sampling was implemented using the emcee5 Python library (Foreman-Mackey et al. 2013).
We combine all the power spectrum multipoles into a single data vector, denoted with 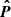 . The same goes for the covariance matrix, denoted with C. These are taken to be independent of the cosmology, even though estimating
. The same goes for the covariance matrix, denoted with C. These are taken to be independent of the cosmology, even though estimating 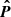 and C requires assuming a cosmology, to transform angles and redshifts into distances. Instead, we include the geometric effects of changing the cosmology in our modeling of the power spectrum multipoles following Gil-Marín et al. (2020). The method consists of two steps:
and C requires assuming a cosmology, to transform angles and redshifts into distances. Instead, we include the geometric effects of changing the cosmology in our modeling of the power spectrum multipoles following Gil-Marín et al. (2020). The method consists of two steps:
-
Transforming the wave vector magnitude and the angle with the line of sight direction according to changes in the Hubble distance DH(z)≡c/H(z) and the angular diameter distance due to differences in cosmology.
-
Renormalizing all the multipoles with a single factor to account for the isotropic volume rescaling caused by the differences in cosmology.
In our case, the reference cosmology is the one used to compute the CODEX power spectra and the covariance matrix (Planck 2018) and the comparison cosmology is the one used at each likelihood evaluation. Both transformations 1 and 2 are redshift-dependent. Here we used the mean redshift of our sample, z = 0.20. We assume the likelihood to be Gaussian in 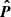 :
:
![Mathematical equation: $$ \begin{aligned} \ln \mathcal{L(\boldsymbol{\Theta }) } = -\frac{1}{2}\left[ \boldsymbol{\hat{P}} -\boldsymbol{P}(\boldsymbol{\Theta })\right]^\mathrm{T} \boldsymbol{C}^{-1} \left[ \boldsymbol{\hat{P}} -\boldsymbol{P}(\boldsymbol{\Theta }) \right] + \mathrm{a\ constant}. \end{aligned} $$](/articles/aa/full_html/2025/05/aa53402-24/aa53402-24-eq25.gif) (15)
(15)
Here vector Θ denotes the sampled parameters and P(Θ) are the predicted power spectrum multipoles. The vector P(Θ) depends on Ωm and σ8 through both the linear matter power spectrum prediction and the mean bias of Eq. (11). The dependence on the scaling parameters α and eβ comes from the masses entering the computation of the mean bias.
We used the estimated power spectrum multipoles over scales of k < 0.2 h Mpc−1. Figure 6 suggests that the Planck 2018 cosmology model and the measurements agree up to the largest k = 0.35 h Mpc−1. We notice that, since our mock measurements exhibit a weaker monopole for k ≳ 0.2 h Mpc−1, the covariance matrix estimate might not be reliable on these scales. However, we did run a cosmological parameter fit including all scales up to k = 0.35 h Mpc−1 to assess their effect on the obtained parameter constraints. This is shown in Fig. 11 and the discussion at the end of this section.
In Fig. 8 we show the 2D posterior distributions for Ωm and σ8 in the case where ℓ = 0, ℓ = 0, 2, and ℓ = 0, 2, 4 are included in the data vector. For the monopole alone, we found the distribution to be bimodal, with one peak at around canonical values of σ8 ∼ 1 and another one with significantly larger values of σ8 ≳ 3. Adding the quadrupole removes the latter peak due to the large amplitude of the model P2(k) in this region (see Fig. 6), which is inconsistent with the measurement. This effect is also shown in Fig. 9, in which we show the posterior distribution for Ωm and σ8 when we only use the quadrupole. In this case, the peak at σ8 ≳ 3 is excluded with high significance. Including the hexadecapole has a significantly smaller effect, but still decreases the area of the 68% and 95% confidence regions by 13% and 6%, respectively.
 |
Fig. 8. Posterior distribution for the two cosmological parameters Ωm and σ8 in the case where varying sets of power spectrum multipoles are included in the sampling. The filled blue contours correspond to ℓ = 0 only, the red contours correspond to ℓ = 0, 2, and the black contours to ℓ = 0, 2, 4. The contours correspond to the 68% and 95% confidence regions. |
 |
Fig. 9. Posterior distribution for the two cosmological parameters Ωm and σ8 in the case where only the power spectrum quadrupole is included in the sampling. The contours correspond to the 68% and 95% confidence regions. |
Figure 10 shows the posterior distributions for the two cosmological parameters Ωm and σ8, along with the two scaling relation parameters, α and eβ, when we include all the three multipoles in the sampling. The plot was made using the corner6 Python library (Foreman-Mackey 2016). From these, we obtained parameter constraints of 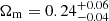 and
and 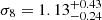 , which correspond to the 16%, 50%, and 84% quantiles of the marginalized posterior distributions. These can be compared, for example, to the Planck 2018 results, Ωm = 0.315 ± 0.007 and σ8 = 0.811 ± 0.006. Our marginalized constraints would suggest a larger than 1σ difference compared to the Planck 2018 results, but in Fig. 10 the Planck 2018 value is indeed contained within the 68% confidence region in the (σ8, Ωm) plane. Regarding the richness–mass scaling relation, we obtained marginalized constraints of α = 0.98 ± 0.09 and
, which correspond to the 16%, 50%, and 84% quantiles of the marginalized posterior distributions. These can be compared, for example, to the Planck 2018 results, Ωm = 0.315 ± 0.007 and σ8 = 0.811 ± 0.006. Our marginalized constraints would suggest a larger than 1σ difference compared to the Planck 2018 results, but in Fig. 10 the Planck 2018 value is indeed contained within the 68% confidence region in the (σ8, Ωm) plane. Regarding the richness–mass scaling relation, we obtained marginalized constraints of α = 0.98 ± 0.09 and 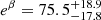 . So, in essence, we reproduced the results of K21: α = 0.98 ± 0.09 and
. So, in essence, we reproduced the results of K21: α = 0.98 ± 0.09 and 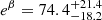 .
.
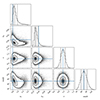 |
Fig. 10. Posterior distribution for the two cosmological parameters Ωm and σ8, and the two scaling relation parameters α and eβ. The 2D contours show the 68% and 95% confidence levels and the dashed lines in the 1D histograms show the 16%, 50%, and 84% quantiles. The blue lines show the Planck 2018 values for Ωm and σ8 and the K21 mean values for α and eβ. |
Figure 11 shows the effect of including wavenumbers up to 0.35 h Mpc−1 in obtaining the posterior distribution for Ωm and σ8. The results are statistically consistent with the k < 0.2 h Mpc−1 case. Going to smaller scales shrinks the 68% and 95% confidence regions by 36% and 39%, respectively. Clearly, the additional data points at 0.2 h Mpc−1 < k < 0.35 h Mpc−1 increase the constraining power of the power spectrum measurement. However, due to potential problems with the covariance matrix estimate in this region (as demonstrated by Fig. 4), we consider k < 0.2 h Mpc−1 our conservative baseline case.
 |
Fig. 11. Posterior distribution for the two cosmological parameters, Ωm and σ8, in the case of varying which wavenumbers are included in the sampling. The filled blue contours correspond to the case of k < 0.2 h Mpc−1 and the red contours to the case of k < 0.35 h Mpc−1. |
5. Conclusions
We presented power spectrum measurements for a subset of CODEX galaxy clusters and used these measurements to constrain cosmological parameters. This is a continuation of the work in L21, in which the cluster two-point correlation function was implemented. We have made some improvements to the L21 analysis methods, most notably regarding the covariance matrix estimation and the handling of the mass estimate uncertainties.
We found that the measured power spectrum multipoles are compatible with theoretical predictions that combine the linear matter power spectrum, the Kaiser approximation for redshift space distortions, and a large-scale bias estimated from the observed cluster richnesses. We constructed a likelihood function using the measured and predicted multipole signal and used this to generate constraints on the cosmological parameters Ωm and σ8, which led to 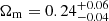 and
and 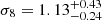 . These suggest slightly larger than 1σ deviations from Planck 2018 cosmology, for example. However, taking the degeneracy of these parameters into account shows that the 68% confidence region of our posterior distribution does indeed contain the Planck 2018 cosmology.
. These suggest slightly larger than 1σ deviations from Planck 2018 cosmology, for example. However, taking the degeneracy of these parameters into account shows that the 68% confidence region of our posterior distribution does indeed contain the Planck 2018 cosmology.
We see a few possible extensions as future work prospects. The full CODEX catalog consists of two disjoint patches. In this work, we included only one of them to be able to cover the sky region with mock catalogs. To expand our sample, we would need to use a set of mock catalogs that span larger cosmological volumes to cover the full CODEX footprint, or to cover the excluded patch with another set of mock catalog realizations drawn from the same ensemble as the ones used in this work. The latter option could cause an under-representation of large-scale correlations between the two patches, the importance of which should be verified. Another improvement would be to include the halo mass function in our MCMC sampling. Also, improving the modeling of the mock measurements would allow us to use the measured spectra up to larger wavenumbers in the cosmological analysis and most likely significantly tighten the obtained parameter constraints.
Note that this assigns the average bias to each halo, which is already averaged from the full sample, (see e.g., Balaguera-Antolínez et al. 2024).
Acknowledgments
The authors wish to acknowledge CSC – IT Center for Science, Finland, for computational resources. It is a pleasure to thank Isabella Baccarelli, Fabio Pitari, and Caterina Caravita for their support with the CINECA environment. The halo mocks were run on the Leonardo-DCGP supercomputer as part of the Leonardo Early Access Program (LEAP).
References
- Allen, S. W., Evrard, A. E., & Mantz, A. B. 2011, ARA&A, 49, 409 [Google Scholar]
- Bahcall, N. A. 1995, in Large Scale Structure in the Universe, eds. J. P. Mücket, S. Gottloeber, & V. Müller [Google Scholar]
- Balaguera-Antolínez, A. 2014, A&A, 563, A141 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Balaguera-Antolínez, A., Sánchez, A. G., Böhringer, H., et al. 2011, MNRAS, 413, 386 [NASA ADS] [CrossRef] [Google Scholar]
- Balaguera-Antolínez, A., Montero-Dorta, A. D., & Favole, G. 2024, A&A, 685, A61 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Beutler, F., Saito, S., Seo, H.-J., et al. 2014, MNRAS, 443, 1065 [NASA ADS] [CrossRef] [Google Scholar]
- Bianchi, D., Gil-Marín, H., Ruggeri, R., & Percival, W. J. 2015, MNRAS, 453, L11 [NASA ADS] [CrossRef] [Google Scholar]
- Blanton, M. R., Bershady, M. A., Abolfathi, B., et al. 2017, AJ, 154, 28 [Google Scholar]
- Bleem, L. E., Bocquet, S., Stalder, B., et al. 2020, ApJS, 247, 25 [Google Scholar]
- Böhringer, H., Chon, G., & Collins, C. A. 2014, A&A, 570, A31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Borgani, S., Plionis, M., & Kolokotronis, V. 1999, MNRAS, 305, 866 [NASA ADS] [CrossRef] [Google Scholar]
- Cavaliere, A., & Fusco-Femiano, R. 1976, A&A, 49, 137 [NASA ADS] [Google Scholar]
- Clerc, N., & Finoguenov, A. 2023, Handbook of X-ray and Gamma-ray Astrophysics, 123 [Google Scholar]
- Comparat, J., Prada, F., Yepes, G., & Klypin, A. 2017, MNRAS, 469, 4157 [NASA ADS] [CrossRef] [Google Scholar]
- Dawson, K. S., Schlegel, D. J., Ahn, C. P., et al. 2013, AJ, 145, 10 [Google Scholar]
- Diemer, B. 2018, ApJS, 239, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Eisenstein, D. J., & Hu, W. 1998, ApJ, 496, 605 [Google Scholar]
- Estrada, J., Sefusatti, E., & Frieman, J. A. 2009, ApJ, 692, 265 [NASA ADS] [CrossRef] [Google Scholar]
- Euclid Collaboration (Fumagalli, A., et al.) 2024, A&A, 683, A253 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Evrard, A. E., Arnault, P., Huterer, D., & Farahi, A. 2014, MNRAS, 441, 3562 [CrossRef] [Google Scholar]
- Farahi, A., Mulroy, S. L., Evrard, A. E., et al. 2019, Nature Communications, 10, 2504 [Google Scholar]
- Feldman, H. A., Kaiser, N., & Peacock, J. A. 1994, ApJ, 426, 23 [Google Scholar]
- Finoguenov, A., Rykoff, E., Clerc, N., et al. 2020, A&A, 638, A114 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Foreman-Mackey, D. 2016, The Journal of Open Source Software, 1, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Garrel, C., Pierre, M., Valageas, P., et al. 2022, A&A, 663, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ghirardini, V., Bulbul, E., Artis, E., et al. 2024, A&A, 689, A298 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gil-Marín, H., Bautista, J. E., Paviot, R., et al. 2020, MNRAS, 498, 2492 [Google Scholar]
- Guzzo, L., Böhringer, H., Schuecker, P., et al. 1999, The Messenger, 95, 27 [NASA ADS] [Google Scholar]
- Guzzo, L., Schuecker, P., Böhringer, H., et al. 2009, A&A, 499, 357 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hand, N., Feng, Y., Beutler, F., et al. 2018, AJ, 156, 160 [Google Scholar]
- Hütsi, G. 2010, MNRAS, 401, 2477 [CrossRef] [Google Scholar]
- Käfer, F., Finoguenov, A., Eckert, D., et al. 2019, A&A, 628, A43 [Google Scholar]
- Kaiser, N. 1987, MNRAS, 227, 1 [Google Scholar]
- Kiiveri, K., Gruen, D., Finoguenov, A., et al. 2021, MNRAS, 502, 1494 [NASA ADS] [CrossRef] [Google Scholar]
- Klein, M., Grandis, S., Mohr, J. J., et al. 2019, MNRAS, 488, 739 [Google Scholar]
- Lesci, G. F., Nanni, L., Marulli, F., et al. 2022, A&A, 665, A100 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lesgourgues, J. 2011, ArXiv e-prints [arXiv:1104.2932] [Google Scholar]
- Lindholm, V., Finoguenov, A., Comparat, J., et al. 2021, A&A, 646, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mantz, A. B., Allen, S. W., Morris, R. G., et al. 2014, MNRAS, 440, 2077 [NASA ADS] [CrossRef] [Google Scholar]
- Marulli, F., Veropalumbo, A., Sereno, M., et al. 2018, A&A, 620, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Marulli, F., Veropalumbo, A., García-Farieta, J. E., et al. 2021, The Astrophysical Journal, 920, 13 [Google Scholar]
- Monaco, P., Theuns, T., & Taffoni, G. 2002, MNRAS, 331, 587 [Google Scholar]
- Moresco, M., Veropalumbo, A., Marulli, F., Moscardini, L., & Cimatti, A. 2021, The Astrophysical Journal, 919, 144 [Google Scholar]
- Moscardini, L., Matarrese, S., Lucchin, F., & Rosati, P. 2000, MNRAS, 316, 283 [CrossRef] [Google Scholar]
- Mulroy, S. L., Farahi, A., Evrard, A. E., et al. 2019, MNRAS, 484, 60 [NASA ADS] [CrossRef] [Google Scholar]
- Munari, E., Monaco, P., Sefusatti, E., et al. 2017, MNRAS, 465, 4658 [Google Scholar]
- Pillepich, A., Porciani, C., & Reiprich, T. H. 2012, MNRAS, 422, 44 [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pratt, G. W., Croston, J. H., Arnaud, M., & Böhringer, H. 2009, A&A, 498, 361 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rykoff, E. S., Rozo, E., Busha, M. T., et al. 2014, ApJ, 785, 104 [Google Scholar]
- Sánchez, A. G., Lambas, D. G., Boehringer, H., et al. 2005, Monthly Notices of the Royal Astronomical Society, 362, 1225 [Google Scholar]
- Schellenberger, G., & Reiprich, T. H. 2017, MNRAS, 469, 3738 [CrossRef] [Google Scholar]
- Schuecker, P. 2005, Reviews in Modern Astronomy, 18, 76 [Google Scholar]
- Schuecker, P., Böhringer, H., Guzzo, L., et al. 2001, A&A, 368, 86 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schuecker, P., Böhringer, H., Collins, C. A., & Guzzo, L. 2003, A&A, 398, 867 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Truemper, J. 1993, Science, 260, 1769 [Google Scholar]
- Voges, W., Aschenbach, B., Boller, T., et al. 1999, A&A, 349, 389 [NASA ADS] [Google Scholar]
All Tables
All Figures
|
Fig. 1. Sky footprint of the subset of the CODEX catalog used for computing the power spectrum. The plot is a zoomed-in view of a Mollweide projection. The orange points show the clusters and the blue points show the random points. |
| In the text | |
|
Fig. 2. One-point statistics of the random catalog and the mock catalogs compared to the corresponding CODEX quantities. The blue bars show the CODEX sample and the empty orange bars show the random sample. The bars that correspond to the random sample have been normalized with the ratio of objects in the CODEX and random samples. The empty black bars show the mean values over all the mock catalogs and the error bars show the standard deviation. Top panel: redshift. Bottom panel: richness. |
| In the text | |
|
Fig. 3. Elements of the matrix window that contribute to the power spectrum quadrupole. Top panel: ℓ = 2, ℓ′ = 2 block. Bottom panel: ℓ = 2, ℓ′ = 0 block in solid lines and the ℓ = 2, ℓ′ = 4 block in dashed lines. Each peak corresponds to a single wave number, ki, at which the power spectrum multipoles are estimated. |
| In the text | |
|
Fig. 4. Power spectrum multipoles used to compute the covariance matrix. Top panel: monopole. Middle panel: Quadrupole. Bottom panel: hexadecapole. Each panel shows all the 500 simulated spectra used to compute the covariance in transparent blue. The orange line is the corresponding CODEX spectrum. |
| In the text | |
|
Fig. 5. Top panel: covariance matrix of the CODEX power spectrum multipoles, as computed from the PINOCCHIO mocks. The elements are normalized with the diagonal. Bottom panel: full matrix window. Both matrices have the same structure. Starting from the bottom left corner, the diagonal blocks correspond to ℓ = 0, 2, 4 auto-correlation. The off-diagonal blocks show the corresponding cross-correlations. |
| In the text | |
|
Fig. 6. Multipoles of the CODEX cluster’s power spectrum. The solid lines with error bars show the measurements, and the dashed lines show the corresponding theoretical predictions. The orange lines show the theoretical prediction using the Planck 2018 cosmology, the green lines the prediction using the best-fit cosmology obtained using all the multipoles, and the red lines the prediction using the best-fit cosmology obtained using the monopole alone. Top panel: monopole (ℓ = 0). Second panel: Quadrupole (ℓ = 2) Third panel: hexadecapole (ℓ = 4). Bottom panel: relative difference of the measured and predicted spectra (Planck 2018 cosmology) for monopole and quadrupole. The predicted hexadecapole is close to zero, which makes the relative difference extremely large. The vertical black line shows up to which wavenumbers we include the measurements in our cosmological analysis. |
| In the text | |
|
Fig. 7. Comparison of power spectra from CODEX and REFLEX II samples. The blue line with error bars is the CODEX power spectrum monopole, and the orange line is the REFLEX II isotropic power spectrum. |
| In the text | |
|
Fig. 8. Posterior distribution for the two cosmological parameters Ωm and σ8 in the case where varying sets of power spectrum multipoles are included in the sampling. The filled blue contours correspond to ℓ = 0 only, the red contours correspond to ℓ = 0, 2, and the black contours to ℓ = 0, 2, 4. The contours correspond to the 68% and 95% confidence regions. |
| In the text | |
|
Fig. 9. Posterior distribution for the two cosmological parameters Ωm and σ8 in the case where only the power spectrum quadrupole is included in the sampling. The contours correspond to the 68% and 95% confidence regions. |
| In the text | |
|
Fig. 10. Posterior distribution for the two cosmological parameters Ωm and σ8, and the two scaling relation parameters α and eβ. The 2D contours show the 68% and 95% confidence levels and the dashed lines in the 1D histograms show the 16%, 50%, and 84% quantiles. The blue lines show the Planck 2018 values for Ωm and σ8 and the K21 mean values for α and eβ. |
| In the text | |
|
Fig. 11. Posterior distribution for the two cosmological parameters, Ωm and σ8, in the case of varying which wavenumbers are included in the sampling. The filled blue contours correspond to the case of k < 0.2 h Mpc−1 and the red contours to the case of k < 0.35 h Mpc−1. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.