| Issue |
A&A
Volume 687, July 2024
|
|
|---|---|---|
| Article Number | A269 | |
| Number of page(s) | 20 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202346426 | |
| Published online | 23 July 2024 | |
Identifying type II quasars at intermediate redshift with few-shot learning photometric classification
1
Departamento de Física e Astronomia, Faculdade de Ciências, Universidade do Porto,
Rua do Campo Alegre 687,
4169-007
Porto,
Portugal
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Instituto de Astrofísica e Ciências do Espaço, Universidade do Porto, CAUP,
Rua das Estrelas,
4150-762
Porto,
Portugal
3
DTx – Digital Transformation CoLab, Building 1, Azurém Campus, University of Minho,
4800-058
Guimarães,
Portugal
4
Departamento de Física, Faculdade de Ciências, Universidade de Lisboa,
Edifício C8, Campo Grande,
1749-016
Lisboa,
Portugal
5
Instituto de Astrofísica e Ciências do Espaço, Universidade de Lisboa,
OAL, Tapada da Ajuda,
1349-018
Lisboa,
Portugal
Received:
15
March
2023
Accepted:
14
May
2024
Abstract
Context. A sub-population of AGNs where the central engine is obscured are known as type II quasars (QSO2s). These luminous AGNs have a thick and dusty torus that obscures the accretion disc from our line of sight. Thus, their special orientation allows for detailed studies of the AGN-host co-evolution. Increasing the sample size of QSO2 sources in critical redshift ranges is crucial for understanding the interplay of AGN feedback, the AGN-host relationship, and the evolution of active galaxies.
Aims. We aim to identify QSO2 candidates in the ‘redshift desert’ using optical and infrared photometry. At this intermediate redshift range (i.e. 1 ≤ ɀ ≤ 2), most of the prominent optical emission lines in QSO2 sources (e.g. CIVλl549; [OIII]λλ4959, 5008) fall either outside the wavelength range of the SDSS optical spectra or in particularly noisy wavelength ranges, making QSO2 identification challenging. Therefore, we adopted a semi-supervised machine learning approach to select candidates in the SDSS galaxy sample.
Methods. Recent applications of machine learning in astronomy focus on problems involving large data sets, with small data sets often being overlooked. We developed a ‘few-shot’ learning approach for the identification and classification of rare-object classes using limited training data (200 sources). The new AMELIA pipeline uses a transfer-learning based approach with decision trees, distance-based, and deep learning methods to build a classifier capable of identifying rare objects on the basis of an observational training data set.
Results. We validated the performance of AMELIA by addressing the problem of identifying QSO2s at 1 ≤ ɀ ≤ 2 using SDSS and WISE photometry, obtaining an F1-score above 0.8 in a supervised approach. We then used AMELIA to select new QSO2 candidates in the ‘redshift desert’ and examined the nature of the candidates using SDSS spectra, when available. In particular, we identified a sub-population of [NeV]λ3426 emitters at ɀ ~ 1.1, which are highly likely to contain obscured AGNs. We used X-ray and radio crossmatching to validate our classification and investigated the performance of photometric criteria from the literature showing that our candidates have an inherent dusty nature. Finally, we derived physical properties for our QSO2 sample using photoionisation models and verified the AGN classification using an SED fitting.
Conclusions. Our results demonstrate the potential of few-shot learning applied to small data sets of rare objects, in particular QSO2s, and confirms that optical-IR information can be further explored to search for obscured AGNs. We present a new sample of candidates to be further studied and validated using multi-wavelength observations.
Key words: methods: data analysis / methods: statistical / techniques: photometric / techniques: spectroscopic / galaxies: active / quasars: general
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
The study of the Universe around us is extremely dependent on our understanding of galaxies since various key processes, such as star formation, accretion, and feedback are present on galaxy scales (Silk & Rees 1998; Ferrarese & Merritt 2000; Gebhardt et al. 2000; Fabian 2012; Hopkins et al. 2006). Active galactic nuclei (AGNs) – supermassive black holes (SMBHs) powered by gas accretion (Lynden-Bell 1969) – are particularly relevant in this context due to their often significant impact on the properties of their host galaxies (e.g. Ciotti & Ostriker 1997; Kauffmann et al. 2003; Bower et al. 2006; Constantin et al. 2008; Silverman et al. 2008; Pimbblet et al. 2013; Porqueres et al. 2018; Soussana et al. 2020; Torrey et al. 2020; Harrison et al. 2021; Ruffa et al. 2022; Elford et al. 2023).
From the panoply of currently known AGN classes, obscured AGNs – or type II quasars (QSO2s) – are particularly useful for studying AGN hosts. According to the unified AGN model (Antonucci 1993; Urry & Padovani 1995; Ramos Almeida & Ricci 2017), the luminous central engine of QSO2s is hidden from view by what is typically argued to be a fortuitously orientated dusty torus (e.g. Kleinmann et al. 1988). This favourable geometry allows the host galaxy to be studied in greater detail, compared to the case of unobscured quasars (QSO1s), where the active nucleus often outshines the host galaxy. In some obscured AGNs, infrared and sub-millimetre observations have hinted at a different scenario in which the obscuration of the central engine is caused by a two-component dusty structure with equatorial and polar components, with radiation pressure playing an important rule (Hönig 2019; Stalevski et al. 2023, and references therein). Thus, the selection and study of obscured AGNs are essential for understanding the AGN population, the co-evolution of AGNs with their host galaxies, and other open issues, such as the radiative efficiency of SMBHs (Hickox & Alexander 2018).
Since their discovery in significant numbers in the Sloan Digital Sky Survey (SDSS; Zakamska et al. 2004), QSO2s have been studied in various wavelengths and with various observational techniques. They typically have an optical emission line spectrum consisting of narrow lines from low-ionisation species (e.g. [OΠ]λλ3727, 3730) and high-ionisation species (e.g. [OIII]λλ4959, 5008) in addition to recombination lines such as Hα. The luminosities of their narrow forbidden lines are comparable to those found in QSO1s (e.g Reyes et al. 2008). Moreover, IR observations have played a crucial role in the selection of active galaxies, including QSO2s, across different redshifts (e.g. Stern et al. 2005; Martínez-Sansigre et al. 2006; Zakamska et al. 2008). X-ray surveys have also detected this type of source, with LX ≥ 1044 erg s−1 (e.g. Barger et al. 2003; Szokoly et al. 2004; Zakamska et al. 2004; Severgnini et al. 2005, 2006; Ptak et al. 2006; Tajer et al. 2007), revealing a wide range of X-ray luminosities and HI column densities. For example, in Ptak et al. (2006), five of the eight studied QSO2s showed column densities consistent with Compton-thick sources (i.e. NH ≥ 1022 cm−2). Additionally, Compton-thick sources have very faint emission at 0.1–10 keV (restframe) due to absorbed emission by the circumnuclear clouds of gas and dust. Therefore, QSO2s typically have similar relations between X-ray, optical, and IR as an extremely obscured AGN (Tajer et al. 2007).
These sources also showcase a variety of unique features, with frequent tidal features from mergers or interactions (e.g Villar-Martín et al. 2012; Bessiere et al. 2012; Pierce et al. 2023), intense star-formation activity (e.g. Lacy et al. 2007; Zakamska et al. 2008; Hiner et al. 2009), ionised gas outflows (Humphrey et al. 2010; Villar-Martín et al. 2016), and polarised emission with an obscured non-thermal continuum (e.g. Vernet et al. 2001; Zakamska et al. 2005). Thus, multi-wavelength observations remain crucial for the validation of the nature of this type of source (e.g. Stern et al. 2002; Della Ceca et al. 2003; Zakamska et al. 2004; Yang et al. 2016; Matsuoka et al. 2022).
In the 'redshift desert' (i.e. 1 ≤ ɀ ≤ 2), most of the prominent emission lines in QSO2 sources (e.g. CIVλ1549; [OIII]λλ4959,5008) fall either outside the wavelength range of the SDSS optical spectra or in particularly noisy wavelength ranges (Zakamska et al. 2003, 2004; Alexandroff et al. 2013; Ross et al. 2014). This intermediate redshift regime is still only scarcely explored. For example, in ultraluminous infrared galaxies, QSO2s (ULIRG, LIR ≥ 1012 L⊙) have been detected at ɀ < 1 and ɀ ≥ 2 (e.g. Zakamska et al. 2004; Reyes et al. 2008; Rodríguez et al. 2014). Studying QSO2s in this redshift range will provide new insights into the properties of AGNs and their host galaxies near the peak of star-formation rate in the universe. The potential correlation between star-formation rate, merger history, and QSO2 sources makes this type of study essential in order to complete our view of the AGN-galaxy co-evolution (Magorrian et al. 1998; Di Matteo et al. 2008; Greene et al. 2011; Bessiere et al. 2012; Humphrey et al. 2015b; Padovani et al. 2017; Villar Martín et al. 2020, 2021).
Following the constant technological innovation in astronomical surveys, the demand to deal with data in a fast and effective manner is not only relevant but also becoming mandatory. Traditionally, classification and physical property estimation has been done using colour-colour methods (e.g. Haro 1956; Daddi et al. 2004; Richards et al. 2002; Glikman et al. 2008; Stern et al. 2012; Lacy et al. 2004) and spectral fitting codes (template or model-based, e.g. Bolzonella et al. 2000; Ilbert et al. 2006; Gomes & Papaderos 2018). While spectral fitting codes have been shown to be extremely useful and to provide solid results, they become difficult to use with massive data sets due to time and computational constraints. In the last decade, the use of machine learning (Samuel 1959) in astronomy has increased rapidly, allowing new and more complex models to be developed and helping astronomers retrieve physical meaning from observational data (Baron 2019). Machine learning has proved to be particularly efficient at dealing with multidimensional data sets and often gives similar or better results compared to traditional methods (e.g. Odewahn et al. 1993; Collister & Lahav 2004; Baqui et al. 2021; Euclid Collaboration 2023b). The flexibility of this method allows for a wide range of applications, including object classification using photometry data (e.g. Cavuoti et al. 2014; Logan & Fotopoulou 2020; Clarke et al. 2020; Mechbal et al. 2024; Hviding et al. 2024; Pérez-Díaz et al. 2024; Zeraatgari et al. 2024); morphological classification with images (e.g. Huertas-Company et al. 2015; Holincheck et al. 2016; Domínguez Sánchez et al. 2018; Bowles et al. 2021; Walmsley et al. 2022; Bickley et al. 2023); estimation of the redshift of galaxies with tabular and imaging data (e.g. Euclid Collaboration 2020; Razim et al. 2021; Curran et al. 2022; Lin et al. 2022; Henghes et al. 2022; Cunha & Humphrey 2022; Cabayol et al. 2023); and physical property estimation (e.g. Bonjean et al. 2019; Mucesh et al. 2021; Simet et al. 2021; Euclid Collaboration 2023a; Humphrey et al. 2023).
Few-shot learning (Li et al. 2006; Abdo et al. 2013; Wang et al. 2020) is a machine learning method that allows for the construction of models using relatively small data sets. It takes advantage of the size of the data set to reduce computation time and better recognise rare examples or classes. This is achieved by learning the distribution of rare labelled features, contrary to the common case where the main statistical distribution of the features is obtained from a large sample of data. Although this method was first applied to computer vision tasks (e.g. Tian et al. 2020; Qin et al. 2020; Li et al. 2023; Jiang et al. 2023b), it can also be applied to tabular data (e.g. Chen et al. 2019; Khajezade et al. 2021; Hegselmann et al. 2023; Nam et al. 2023; eon Lee & Lee 2024). Domain knowledge (e.g. Shi et al. 2008; Mirchevska et al. 2014; Dash et al. 2022) plays an important role to be able to use this technique, especially in astronomy. Prior knowledge, from previous observations, and the physical correlations in astronomical data allows the machine learning model to learn in an efficient manner (e.g. Gong et al. 2023). By combining both techniques, the identification of rare astronomical sources can potentially be enhanced.
Transfer learning in machine learning involves using models pre-trained with specific data sets, either from simulations or real data, to make predictions in new data sets or in different domains (e.g. Smith et al. 2022; Almeida et al. 2022; Krishnakumar 2022; Villaescusa-Navarro et al. 2022). Instead of training and optimising a completely new model, transfer learning allows learned patterns and mappings from the original training episode to be re-used for similar tasks. This approach is particularly useful when labelled data for the target task is scarce or expensive to obtain (e.g. spectroscopic data). Therefore, transfer learning enables the application of machine learning to new domains or tasks with smaller data sets, which is particularly relevant in astronomy (e.g. Vilalta 2018; Kouw & Loog 2018; Tang et al. 2019).
Traditional single-colour selection methods of obscured AGNs are often unreliable (Hickox & Alexander 2018), prompting the exploration of machine learning techniques for more robust selections. Motivated by the difficulty to identify QSO2 sources at the ‘redshift desert’, we have developed a few-shot machine-learning methodology that correlates optical-infrared photometry by linking faint optical emissions and dust features, which are characteristic of obscured AGNs (e.g. Piconcelli et al. 2015; Assef et al. 2015; Hviding et al. 2018; Yang et al. 2023; Ishikawa et al. 2023). Our pipeline is design to handle smaller training data sets (~200 sources) and to be applied at the ‘redshift desert’ via transfer learning. To test our pipeline, we performed a blind test, using semi-supervised learning to identify QSO2 candidates. The methodology outlined here offers a photometric pre-selection of QSO2 candidates for multi-wavelength follow-up.
This paper is organised as follows. We briefly describe the photometric data used to distinguish QSO2s from galaxies and the pre-processing steps necessary for the machine learning pipeline in Sect. 2. The AMELIA pipeline is described in Sect. 3, and the statistical metrics to evaluate the pipeline are in Sect. 4. A proof-of-concept task and a semi-supervised approach to identify QSO2s are presented in Sect. 5. In Sect. 6, we test our ability to recover QSO2 candidates through spectroscopic analysis, X-ray and radio cross-matching, and comparison with AGN photometric criteria in the literature. Then, in Sect. 7, we derive the physical properties of the QSO2 candidate sample using pho-toionisation models and spectral energy distribution analysis. Finally, in Sect. 8, we discuss the nature of our sample and how it can be placed into the AGN-galaxy co-evolution scheme. Last, we summarise our results in Sect. 9. Throughout this paper, we adopt a flat-universe cosmology with H0 = 70 km s−1 Mpc−1, ΩM = 0.3 and Ωλ = 0.7 (Planck Collaboration VI 2020).
2 Sample and data
2.1 Photometric data
2.1.1 Quasar sample
Our methodology requires a sample from which the defining characteristics of QSO2 may be learnt. For this purpose, we use the 144 sources identified and described by Alexandroff et al. (2013) as ‘class A’ QSO2 candidates, which the authors selected from BOSS in SDSS DR9 (Ahn et al. 2012). Alexandroff et al. (2013) used a selection approach that combined the properties of the emission line and continuum properties: They required a detection of Lyαλl2l6 and CIV λ1550 at 5σ significance or higher, and an emission line full-width half-maximum (FWHM) ≤2000 km s−1. The final sources have narrow emission lines, no associated absorption and weak continuum. The authors discarded narrow-line Seyfert 1 galaxies and broad-absorption-line quasars, since they are Type 1 objects. The selected QSO2 candidates have a redshift between 2 and 4, and a median FWHM of the CIV λl550 emission line equal to 1260 km s−1. (For more details, see Alexandroff et al. 2013.)
2.1.2 Galaxy sample
In addition, we select a sample of sources previously classified as galaxies in the SDSS DR16 catalogue (Ahumada et al. 2020) with spectroscopic redshifts, to be used as a ‘test set’ for models. Our selection criteria are designed to yield galaxies with SDSS magnitudes in a similar range to those of the QSO2 sample above, but without any specific constraints on their colours or morphology. Specifically, our magnitude selection criteria are: (i) 19 ≤ u ≤ 26; (ii) 19 ≤ g ≤ 24; (iii) 19 ≤ r ≤ 24; (iv) 19 ≤ i ≤ 24; (v) 19 ≤ ɀ ≤ 25 (AB magnitudes). An SQL query on CasJobs1 was performed using these criteria. We opted to use the aperture-matched modelMag magnitudes, since they are expected to be more reliable than cModelMag, for example, due to the higher signal-to-noise of the resulting colours (Stoughton et al. 2002). Since we are interested in the ‘redshift desert’, we restrict the galaxy redshift to ɀ >1 and ɀ <2 with ɀ=2 being the maximum value for sources classified as a galaxy in SDSS.
When searching for QSO2 in UV-optical photometric surveys, the primary challenge lies in distinguishing them from non-AGN galaxies, given the optical depth of dust and the faint emission diluted by star formation (e.g. Calzetti et al. 1994; Draine 2003). The uncertainty in the photometric classification boundary, caused by dust and gas obscuration, introduces the possibility of “hidden” QSO2 sources in archival data, which can be untangled by adding infrared information (Kleinmann 1988). Therefore, we include Wide-field Infrared Survey Explorer (WISE; Wright et al. 2010) W1, W2, W3, and W4 (3.4, 4.6, 12, and 22 µm) photometry. These data were obtained by including a cross-match with the AllWISE catalogue in our SQL query. The final galaxy sample is composed of 21, 943 sources.
2.2 Spectroscopic data
We also make use of SDSS BOSS spectra when required for the validation of our machine learning results. We used the SDSS Science Archive Server2 to retrieve FITS spectra. The zWARNING flag is used as a quality filter: Only sources with zWARNING= 0, no problems detected, or 4, MANY_OUTLIERS, are considered.
In the ‘redshift desert’, the [OII]λλ3727, 3730 emission is used to determine the redshift of the source. This makes the redshift determinations more prone to errors. Therefore, we will consider the spectroscopic redshift provided by SDSS with caution (more details are provided in Sect. 6.1). It is also important to mention that the spectroscopic data available is close to the limit that can be achieved with a 2.5 m telescope and faint sources (r magnitude ~21). Faint emission lines becomes more difficult to detect as they may be diluted in the noisy continuum.
3 The AMELIA pipeline
AMELIA3 is an interactive, modular, and adaptive machine learning pipeline capable of performing classification tasks using tabular data from astronomy surveys. It takes advantage of six different classifications algorithms and an ensemble method, generalised stacking (Wolpert 1992), to combine the outputs using soft-vote and meta-learner correction (Zitlau et al. 2016; Cunha & Humphrey 2022; Euclid Collaboration 2023b). The following subsections describe the technical details of AMELIA. In Sect. 3.1, we describe data pre-processing tasks required to extract the most out of the available data. Then, in Sect. 3.2 the machine learning methodology is described. In particular, in Sect. 3.2.1 a brief overview of the inner works of our methodology is described.
3.1 Feature engineering
3.1.1 Feature creation
As the input features for all the models, we used both magnitudes and colours. Due to the diversity of machine learning models, we perform feature scaling (Wan 2019) using classes from Scikit-Learn (Pedregosa et al. 2011). For all algorithms, the RobustScaler was applied, which ensures that potential outliers in the data are kept. All unique permutations of broadband colours were calculated from the following features: modelMag (i.e. u − g, …, i − ɀ); WISE (i.e. W1 − W2, …, W3 − W4); and optical-infrared colours (i.e. u − W1,…, ɀ − W4). When we perform binary classification tasks, a binary (0/1) target feature is created, where 0 indicates a normal galaxy and 1 indicates a QSO2.
3.1.2 Imputation
In astronomy, missing values are commonly due to instrumental limitations (i.e. non-detections) and do not necessarily represent an incomplete data set, as they may carry a relevant physical meaning. For instance, some galaxies have sudden spectral breaks at specific wavelengths that can manifest themselves as “dropouts”, revealing both the source’s nature and the red-shift. Nonetheless, missing values can cause problems on how different algorithms interplay and digest data. A common solution is imputation, where missing values are replaced with an alternative value with statistical or physical meaning.
The effects of imputation have also been extensively studied in Euclid Collaboration (2023b). The authors explored the impact that different imputation techniques, such as the mean, median, minimum and a so-called “magic value” (e.g. −99.9), have in decision-tree and distance based, deep learning and meta-learner ensemble models. The chosen imputation techniques impact the model’s performance and should therefore be selected according to the scientific problem.
For the QSO2 sources from Alexandroff et al. (2013), missing values are present in the WISE photometry for 74 sources, which represents ~51% of the sample (identified using a 2″ cone search). To impute the missing values, we used the KNNImputer, from Scikit-Learn, version 1.2.1, with the following configuration: missing_values=0; n_neigbors=6; and weights=distance. As in the k-nearest neighbours algorithm, this method predicts the missing value by computing the mean value based on the distance between points in the training set and the number of defined neighbours.
3.2 Machine learning
After the feature engineering process, described in Sect. 3.1, the data are divided into training and test set, depending on the final objective (for further details, see Sect. 5). Every time a data set is split, the procedure is performed randomly, never considering the balance between the properties of the features. This allows experiments in the stacking process to be applied and compared with the each base learner. However, this variability can easily be changed and different training-test splits tested.
In Fig. 1, the flow diagram of the AMELIA pipeline is shown. Six different algorithms were used to perform a binary classification, which we call base learners. We combine one distance-based algorithm, four decision tree-based algorithms, and a deep learning-based model (see more details in Sect. 3.2.2).
3.2.1 AMELIA overview
In our pipeline, we explored two distinct approaches: supervised and semi-supervised learning. In the supervised learning approach, we adhered to the conventional procedure, where the data set is divided into training and testing sets, utilising k-fold cross-validation, with the class labels of all sources known.
In contrast, with the semi-supervised learning approach, we adopted a unique strategy where the test set consists exclusively of a single class, that is, galaxy class (see Jiang et al. 2023a, for an application to galaxy morphology classification). Our approach is based on the foundational one-class classification problem (Moya & Hush 1996; Schölkopf et al. 1999), taking advantage of the capabilities of one-class classifiers to discern distinct patterns within a multidimensional space. These classifiers are trained using a set of positive examples (e.g. Tax & Duin 2001; Yu et al. 2002). To augment the generalisation capability of our models, we embraced a semi-supervised one-class approach (e.g Bauman & Bauman 2017; Akcay et al. 2019; Cai et al. 2023), introducing a limited number of contrasting examples during training and applying to a single class test set. Therefore, while the model is trained with two distinct classes, when the model is applied to the one-class test set, the main target is to identify the galaxy class. Due to the contrasting examples, we then consider sources that are not classified as galaxy to be QSO2 candidates.
In our approach, the model is trained with both QSO2 sources and a subset of SDSS galaxies, ensuring a balanced training set, that is, same number of examples for both classes. Subsequently, the model is applied to the one-class test set (i.e. galaxies) to compute the probabilities for the predictive class (i.e. QSO2). Then, a classification threshold is set to refine the predictions. Specifically, this semi-supervised one-class approach identifies sources labelled as galaxies in the SDSS spectroscopic data but exhibiting photometric characteristics consistent with a QSO2. Our proof of concept uses data sets with diverse redshift ranges, detailed in Sect. 2, resulting from specific selection criteria in the chosen data set. Given the absence of a catalogue of spectroscopically confirmed QSO2 in the “redshift desert”, a redshift transfer-learning method is employed by leveraging prior domain knowledge concerning the correlation between optical and infrared photometric properties from QSO2 at ɀ ≥ 2.
3.2.2 Algorithms
AMELIA takes advantage of the predictive capabilities of three decision tree-based algorithms, all falling under the category of gradient-boosting decision tree algorithms. This choice is intentional, as these algorithms demonstrate superior performance and exhibit inherent distinctions in their underlying mechanisms4. The nuances between the three gradient-boosting decision tree algorithms, namely XGBoost (version 1.7.35; Chen & Guestrin 2016), CatBoost (version 1.16; Prokhorenkova et al. 2018), and LightGBM (version 3.3.37; Ke et al. 2017) are described in Cunha & Humphrey (2022) and Euclid Collaboration (2023b).
For completeness and diversity, we incorporate a k-nearest neighbours algorithm, a randomised decision trees algorithm, and a multi-layer Perceptron classifier, MLPClassifier, from Scikit-Learn (version 1.1.38). The inclusion of a diverse set of algorithms is crucial as it enables a wider range of predictions. This diversity will become particularly pertinent later within the context of the generalised stacking approach with meta-learning correction (see Sect. 3.2.4).
In Table 1, the hyper-parameters of the algorithms used as base learners and meta-learners are described. The number of estimators were defined as being the minimum number to obtain reliable metrics, as increasing the estimators can lead to overfitting. This was done using a randomised grid search for XGBoostClassifier and replicated for the remaining algorithms. For the MLPClassifier, we set the initial hidden layer with the same number of layers as the n_estimators. Additional layers were added and a manual optimisation was performed. For the KNeighborsClassifier, we set a range of n_neighbours from 0 to 20, and selected the one that had the best metrics.
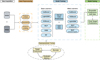 |
Fig. 1 Flow diagram for the AMELIA pipeline. The process begins with the assembly of SDSS and WISE data. As seen in the orange box, feature creation is used to generate optical, optical-IR, and IR colours. The imputation method is applied to the training set and followed by feature scaling due to the use of different algorithms. The blue box shows a description of the model training procedures, but we recount them here as well: Each base learner is first loosely optimised for generalisation. Subsequently, out-of-fold predictions are combined with the average predictions from the base learners, utilising a soft-vote mechanism for the training of the meta-learners. The predictions from the meta-learners are then combined through ensembling, using a soft-vote fusion that results in the final predictions for the test set. |
Description of the algorithms and hyper-parameters used as base learners and meta-learners.
3.2.3 K-fold cross-validation
To assess the performance of each base learner, we employed a data partitioning strategy known as k-fold cross-validation (refer to, for instance, Hastie et al. 2009). In this methodology, the data set is randomly divided into five folds, ensuring the preservation of both the number of sources and the target class distribution. Following this division, the models are trained on the partitioned data set, utilising k-1 folds for training, while the remaining fold is designated for validating the predictions, known as out-of-fold (OOF) predictions. This iterative process repeats through the defined k iterations and an average is calculated on the predictions for the final metric analysis.
K-fold cross-validation proves to be an effective methodology to prevent overfitting, especially in smaller data sets where the conventional training-test-validation split may not be feasible (Lachenbruch & Mickey 1968; Stone 1974; Luntz 1969; Wang & Zou 2021). An additional advantage is to obtain OOF predictions, even for the training set. In this study, the k-fold cross-validation method plays a crucial role in validating the performance of each individual learner before implementing the stacking approach.
3.2.4 Approach to generalised stacking
Our approach to handling the output predictions of the base learners closely follows the generalised stacking methodology presented by Euclid Collaboration (2023b) and Cunha & Humphrey (2022). The primary difference is how the final combination of the predictions is performed. In this study, we opt for a soft vote, that is, average vote, coupled with a meta-learner approach to combine the probabilistic predictions.
Upon receiving predictions from the six base learners for the test set, a new data set is constructed, comprising individual predictions from each base learner. Additionally, a new feature is created by averaging these predictions. To integrate the predictions of the individual learners and the average feature, we employ a combination of five meta-learners: XGBoostClassifier; CatBoostClassifier; LGBMClassifier; MLPClassifier (as described in Table 1); together with an additional MLPClassifier with activation=logistic. The inclusion of the MLPClassifier model with a distinct activation model aims to increase the diversity of predictions by adding an additional deep learning based model.
The final predictions result from an ensemble of the individual outputs of the meta-learners, utilising a soft vote to generate the final classifications. This methodology explores how various algorithms analyse the distribution of predictions and combine them into a robust classifier. Furthermore, the exclusion of the Random Forest and KNN algorithms is attributed to the influence of outliers on the number of outputs, which can impact the soft vote combination. This decision was validated through a supervised approach, as detailed in Sect. 5.1.
In summary, one can interpret our approach as an analogous of the ensemble random forest, where instead of randomly decision-trees, we have individual base models. Then, instead of combining the predictions for each model, we use a meta-learner to analyse the variance between the base learners’ predictions, adding the average predictions as a feature. The main advantage of this method is that the output model will be robust to outliers by studying the variance between predictions and preventing systemic biases underlying particular models. Finally, to avoid selection bias from a single meta-learner, we average the predictions from four meta-learners. With this approach, one can create more robust predictions by leveraging the statistical validation provided by the ensemble models.
4 Statistical metrics
Statistical metrics quantify the ability of a particular model to retrieve the desired information (e.g. Powers 2008). Herein, we describe the statistical metrics used to validate the perform of our machine learning methodology.
Accuracy is the fraction of correct predictions for all classes compared to the to the total number of predictions:
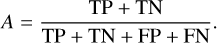 (1)
(1)
Here, TP is the number of true positives, TN is the number of true negatives, FP is the number of false positives, and FN is the number of false negatives for a given class.
Precision, or purity, is the fraction of correct predictions for a given class compared to the overall number of predictions for that class:
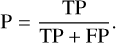 (2)
(2)
Unlike the accuracy metric, precision focus on the positive predictions to asses their quality.
Recall, or completeness, is the fraction of correct predictions for a given class compared to the overall number of positive cases for that class:
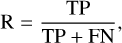 (3)
(3)
where FN is the number of false negatives in each class. The symbiotic relation between precision and recall makes their use valuable to asses the quality of the predictions.
By combining the precision and recall metrics, one can create informative metrics such as the F1-score (e.g. Blair 1979). The F1-score is the harmonic mean of the precision and recall,
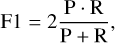 (4)
(4)
where equal weight is given to precision and recall.
Specificity, also called true negative rate, computes the true negative fraction identified by the model:
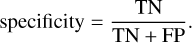 (5)
(5)
High specificity implies that a high fraction of true negatives is recognised.
5 Results from the application of AMELIA
5.1 Proof of concept for QSO2 selection
Before selecting new QSO2 candidates, we first conduct a test to ascertain the performance of our pipeline for selection of QSO2 in a fully labelled data set. By employing a supervised classification on SDSS-WISE photometric data, we assess the reliability of the binary classification. Our primary goal is to establish a control test to explore correlations in optical-infrared photometric data.
For this proof of concept, the data set was constructed using 144 sources randomly selected from our SDSS galaxy sample (see Sect. 2.1.2), and all 144 spectroscopically confirmed sources in our QSO2 sample (see Sect. 2.1.1)9. After combining the data from the two classes, we performed a train test splif using 70% of the total data for training and 30% of the total data for testing.
The AMELIA pipeline was able to successful distinguish between galaxies and the QSO2, validating the application of machine learning for this task. Detailed in Table 2 are the statistical metrics for each individual model, together with the metrics obtained after generalised stacking with a threshold ≥0.5. Individual models exhibited satisfactory performance, with a slight advantage noted for the decision-tree-based models, XGBoost and CatBoost, compared to the rest of the models.
The metrics for the generalised stacking, also seen in Table 2, may not be sufficiently improved to validate the advantage of generalised stacking in this context. Methodological intricacies arise when models yield similar results, causing meta-learners to mimic clustered values for the final predictions, converging around the optimal value. However, this does not diminish the potential of the methodology to identify QSO2 sources, where individual learners achieve an F1-score ≥0.88. As the size of the data set increases, which would be the case when our methodology is applied to future survey data, we anticipate an improvement in performance (as seen in Euclid Collaboration 2023b; Cunha & Humphrey 2022).
Classification evaluation metrics for KNNeigbors, RandomForest, LightGBM, CatBoost, XGBoost, MLP, and generalised stacking with a threshold ≥0.5.
5.2 Selection of new QSO2 candidates
Having shown in Sect. 5.1 that AMELIA is capable of successfully identifying QSO2, we now proceed to apply the pipeline to the task of identifying new QSO2 candidates. In particular, the objective is to select QSO2 that were previously misclassified in SDSS as galaxies, after template fitting. Thus, we now use the AMELIA pipeline in semi-supervised mode (see Sect. 3.2.1), utilising a balanced training set (same number of sources per class), and a classification probability threshold ≥ 0.8. By using this probability threshold instead of the often used ‘default’ value 0.5, we aim to select sources with a higher confidence of being a QSO2 (see Baqui et al. 2021; Alegre et al. 2022; Jiang et al. 2023a, for different study cases with classification threshold tuning and Appendix A for a more detailed analysis).
For this task, the training set contains the 144 spectroscop-ically confirmed QSO2, and a further 144 sources selected randomly from our SDSS galaxy sample, so make up the balanced training set. The testing set was created using the remaining 21 799 sources from the galaxy sample; no spectroscopically confirmed QSO2 were included in this set.
When applying the AMELIA pipeline on the test set, 366 sources were classified as QSO2 with a classification probability of ≥0.8. In the following sections, we will address the reliability of our new QSO2 candidates by analysing photometry and spectra, including multi-wavelength information where available.
6 Testing the recovery of QSO2
In this section, we assess the robustness of our new QSO2 candidate sample by examining available optical photometry and spectra, and X-ray and radio detections. This procedure ensures the reliability of the identified candidates; while not providing a definitive classification of the target sample as QSO2 sources, with multi-wavelength data being essential. Nonetheless, the identification of specific fingerprints indicative of AGN activity significantly enhances our confidence in the efficacy of our selection method.
6.1 Searching for AGN signatures in the spectrum
Of the 366 candidates, only 138 had clean spectra in SDSS DR16 (i.e. without any problematic flag, zwarning=0). Thus, our spectroscopic analysis includes only these 138 candidates.
After downloading the SDSS spectra, we considered the spectroscopic redshifts (described in Sect. 2.2) to search for AGN associated emission lines. We found that the redshift listed in the SDSS database occasionally did not match what we obtained from the observed emission lines (e.g. Wu & Shen 2022, detected 1900 broad-line quasars in SDSS DR16, around 0.002% of their sample, had catastrophically wrong redshifts). In such cases, we adopted our new value of the redshift for the source. An example is provided in Appendix D. When no clear emission lines were detected, we could not validate the provided spectroscopic redshift and therefore assumed the provided redshift value.
Our main objective was to identify [NeV]λ3426, successfully used as an AGN identification criterion (e.g. Schmidt et al. 1998; Gilli et al. 2010; Mignoli et al. 2013; Vergani et al. 2018), and [NeIII]λ3869 emission lines. [NeV]λ3426 is a high ionisation line with a relatively high ionisation potential (IP; Ne4+ IP=97.16 eV) requiring a hard ionising source, such as an accretion disk of an AGN (Haehnelt et al. 2001; e.g. Schmidt et al. 1998; Gilli et al. 2010; Mignoli et al. 2013; Feltre et al. 2016). Alternative, other more “exotic” ionisation sources might be able to produce [NeV]λ3426 such as supernovae, Population III stars, Wolf–Rayet stars, stripped stars in binaries, high-mass X-ray binaries, and hot, low-mass evolved stars (e.g. Flores-Fajardo et al. 2011; Eldridge et al. 2017; Schaerer et al. 2019; Martínez-Paredes et al. 2023).
In our spectroscopic analysis, we fitted each emission line and identified 30 [NeV]λ3426 and 52 [NeIII]λ3869 emitters with S/N ≥ 3σ. In total, we found 65 objects with [NeV]λ3426 or [NeIII]λ3869 emission lines, around 47% of the total number of candidates.
Figure 2 shows the spectrum of three [NeV] emitters from our sample of QSO2 candidates. The final candidates were divided into three groups based on the detected emission lines10: Clear AGN: [NeV]λ3426 detected with S/N ≥ 3σ; Ambiguous AGN: [NeIII]λ3869 detected with S/N ≥ 3σ; Unclear: No [NeV]λ3426 or [NeIII]λ3869 detected.
Figure 3 shows the stacked spectra for the [NeV] and [NeIII] emitters. For stacking the spectra, we used the software specstack11 (Thomas 2019), with a limit of 3σ clipping and rest-frame limit between 1795 and 3838 Å. Due to the low S/N of the spectra only the most prominent emission lines are detected, in particular [NeV]λ3426, [OII]λλ3727, 3730, and [NeIII]λ3869.
Additionally, we compared our methodology with random selection. From the test set, 366 sources were randomly selected. From the selected sources, we investigated 255 sources, with clean spectra, and found that 13 of them had [NeV]λ3426 lines. This corresponds to 5% of the total random sample. As expected, our methodology is much more efficient at selecting QSO2 candidates than a random selection. We argue that our classification pipeline may use specific features, that is, combination of magnitudes and colours with specific weights, within the broadband SED that indicate the presence of an obscured AGN, even in the cases where no clear AGN emission lines could be detected in the SDSS spectrum, most probably due to the low S/N or instrumentation limitations (e.g. Mignoli et al. 2013; Vergani et al. 2018, see references therein). This is mainly due to the optically faint nature of the sample and designed strategy of the SDSS facility. Follow-up spectroscopic both in optical and infrared regimes will allow us to improve this analysis and distinguish QSO2 from star-forming galaxies.
An unsupervised learning analysis was also performed to study the possible variability within the photometric data between [NeV] and [NeIII] emitters and non-[Ne] emitters. We applied the KMeans algorithm with PCA dimensionality reduction on the input features to identify potential clusters and structures within the data. The number of clusters was set to three, representing the three different emitter labels defined previously. We found no clear separation or intrinsic property to distinguish between the sources, implying no significant variance exists between our sub-classes. This results supports the hypothesis that the unclear sources might have similar features as clear and ambiguous AGNs, requiring high spectroscopic resolution.
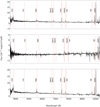 |
Fig. 2 SDSS spectra from BOSS spectrograph for a sample of three QSO2 candidates with a [NeV]λ3426 detection. From top to bottom: SDSS J141542.16+522206.9, SDSS J013056.89-022638.1, and SDSS J141542.16+522206.9. The red vertical lines indicate where the different emission lines should be with respect to the SDSS spectroscopic redshift. |
 |
Fig. 3 Stacked spectra of the [NeV] and [NeIII] emitters from the QSO2 candidate sample. The fluxes for the [NeIII] emitters is offset for a better visualisation. |
6.2 Cross-matching with radio and X-ray catalogues
Given that QSO2 might have faint X-ray emission (e.g. Barger et al. 2003; Ptak et al. 2006; Tajer et al. 2007), the detection of X-ray emission from our sources would corroborate our classification. Additionally, radio emission is present in previously identified QSO2 sources at low redshift (e.g. Villar Martin et al. 2014, 2021), allowing for better characterisation of the sources.
In this section, we examine currently available X-ray and radio data sets to evaluate the detection of our QSO2 candidate sample. Also, we make use of the Millions of Optical-Radio/X-ray Associations (MORX) Catalogue, v212 (Flesch 2024) to cross-match our candidates using the VizieR service.
6.2.1 X-ray cross-identification
The coverage of our sources by deep X-ray observations from XMM-Newton and Chandra is patchy and does not lend itself to statistical studies. However, we highlight that XMM-Newton (Lin et al. 2012) has detected the five QSO2 candidates: SDSS J092106.72+302737.8, SDSS J014104.76-005209.2, SDSS J020711.42+021549.5, SDSS J141542.16+522206.9, and SDSS J011219.62+023732.7. Additionally, SDSS J160852.36+443028.0 has been detected in the XMM-Newton slew survey (Saxton et al. 2008). Chandra (Vagnetti et al. 2016) has detected three QSO2 candidates, two of which also have XMM-Newton detection: SDSS J141542.16+522206.9, SDSS J092106.72+302737.8, and SDSS J014546.90-043318.8. Additionally, SDSS J084126.29+411059.9 is included in the eROSITA Data Release 1 (Merloni et al. 2024).
While these detections confirm the AGN nature for these 10 cases, we can still be missing Compton-thick sources, as previously observed (e.g. Ptak et al. 2006; Carroll et al. 2021, 2023).
6.2.2 Radio cross-identification
We cross-matched our sample with the LOw-Frequency ARray (LOFAR) Two-metre Sky Survey (LoTSS, Shimwell et al. 2022) Data Release 2, and obtained a total of 20 detected sources from our sample. Since we get a higher number of sources, we have performed a statistical analysis for this sub sample.
We took into account the following equation from de Jong et al. (2024) to calculate the total flux density (S ν):
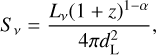 (6)
(6)
where Lν is the source luminosity, dL is the luminosity distance, and (1 + ɀ)1−α considers the K-correction with spectral index α. We could rearrange this equation to estimate Lν, with S ν as the total flux density estimated in the LoTSS catalogue. We used this estimation to determine if the origin of the radio emission is star-formation driven or AGN driven. Following Hardcastle et al. (2016), we used the following criterion to set a confidence level on the origin of radio emission: log10L150mhz ≥ 23.5 (see also Best & Heckman 2012, in particular, Fig. 3 and Table 4 therein). We estimated the following range for the L150MHz: log10L150MHz = 24.32–27.05 W Hz−1. Thus, the measured L150MHZ shows a high probability that radio emission has an AGN origin since it is within the interval mainly populated by detected LOFAR AGNs (Hardcastle et al. 2016, see Fig. 17).
Finally, by cross-matching with Faint Images of the Radio Sky at Twenty-cm (FIRST, Becker et al. 1994) catalogue, we identified five QSO2 candidates: SDSS J083317.63+242113.8, SDSS J020711.42+021549.5, SDSS J115621.12+552723.7, SDSS J000844.13-015212.0, and SDSS J160852.36+443028.0 (also detected with LoTSS and XMM-Newton). From the Rapid ASKAP Continuum Survey (RACS, Hale et al. 2021), three QSO2 candidates are detected: SDSS J020711.42+021549.5 (also detected with FIRST and XMM-Newton), SDSS J084035.02+225159.2, and SDSS J224340.32+255931.8 (also detected in LoTSS). Future studies in the radio and X-ray wavelength, will allow us to better characterise the nature of our candidates.
6.3 Comparison with AGN colour criteria from the literature
Since only 38% of our QSO candidates have clean SDSS spectra, it is interesting to apply colour-colour criteria from the literature to further extend our analysis. Our QSO2 candidate sample was compared with the colour criteria for the selection of AGN sources, including: Stern et al. (2012); Mateos et al. (2012); Mingo et al. (2016); Blecha et al. (2018); Carvajal et al. (2023).
Most of the criteria are based on a combination of MIR colours, and the results are summarised in Fig. 4. Three groups were used in this analysis: (a) [NeV] emitters (or clear AGN; see Sect. 6.1), (b) candidates with clean spectra, and (c) all QSO2 candidates.
For group (a), the results are as follows: seven sources (23%) met all criteria, 15 sources (50%) met at least three criteria, 11 sources (~37%) did not meet any criteria. On group (b): 22 sources (~16%) met all criteria, 65 sources (~47%) met at least three criteria, and 56 sources (41%) did not met any criteria. Finally, for group (c): 49 sources (~13%) met all criteria, 126 sources (~35%) met at least three criteria, and 179 sources (~49%) did not meet any criteria.
Additionally, we performed the same analysis using the colour selection criteria proposed by Hickox et al. (2017), where a combination of a simple MIR colour (W1 − W2 ≥ 0.7; Vega) and an optical-infrared colour [(u-W3[AB])≥ 1.4(W1-W2[Vega])+3.2], is used to select obscured quasars. For group (a), three candidates (~10%) met this criterion. In group (b), 12 candidates (~9%) satisfied the criterion. Finally, in group (c), 30 candidates (~8%) met the criteria.
Colour criteria serve as an effective but conservative preselection tools, which fall short in capturing all relationships across the SED. Relying on two or three highly correlated features only partially taps into the available data potential. For example, the detection percentage of [NeV] emitters surpasses the number obtain using the condition where at least three colour criteria are required. While computationally efficient, these methods tend to have conservative classification boundaries, missing potentially interesting objects, that generally lay close to the boundary conditions. This result aligns with Vergani et al. (2018), where a sample of [NeV] emitters was selected, and traditional AGN selection techniques showed low efficiency in their selection.
 |
Fig. 4 Bar plot illustrating the performance of the colour criteria in selecting AGN for the QSO2 candidates, as described in the studies by Stern et al. (2012); Mateos et al. (2012); Mingo et al. (2016); Blecha et al. (2018); Carvajal et al. (2023). Each bar represents a specific subset: (a) [NeV] emitters (30 sources), (b) sources with clean spectra (138 sources), and (c) all candidate sources (365 sources). |
7 Physical property estimation
Additional efforts can be made to analyse and derive physical properties for our QSO2 candidate sample, using both spectro-scopic and photometric SDSS data. In this section, we explore the use of photoionisation models and SED fitting to further characterise our sample.
7.1 Physical properties derived from [Nelll]
Considering that our sample has an active black hole, we can estimate relevant physical properties, such as the black hole mass. Assuming the source is radiating at the Eddington limit, the black hole mass can then be estimated using the following equation:
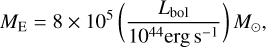 (7)
(7)
where Lbol is the bolometric luminosity. A common approach to estimate Lbol is to use the [OIII]λ5007 emission line as a proxy (e.g. Kong & Ho 2018, see also references therein).
However, our new QSO2 candidates with spectra lie in the so-called redshift desert, a redshift range in which the bright optical and UV lines are outside or near the noisy edges and do not allow for reliable analysis. In the absence of the bright high-ionisation line [OIII]λ5007, we will instead take advantage of the detected [NeIII]λ3869 emission line. We used the MAPPINGS 1e (Binette 1985; Ferruit et al. 1997; Binette et al. 2012) photoionisation model from Morais et al. (2021) to compute the [OIII]λ5007/[NeIII]λ3869 ratio, and then estimate the [OIII]λ5007 luminosity from the observed [NeIII]λ3869 flux.
The photoionisation model has parameters that are expected to be in the correct range for luminous QSO2s since the Alexandroff et al. (2013) sample was used. The photoionisation model parameters from Morais et al. (2021), which are also used in this work, are the following:
ionisation parameter13 = 0.01
spectral index of the ionising continuum14: α = −1.5
high energy cut-off for the ionising continuum of 5 × 104eV
metallicity15: Z = Z⊙
hydrogen density16: nH = 100 cm−2.
We obtained an [OIII] λ5007/[NeIII] λ3869 flux ratio equal to 11.9. The flux-luminosity relation to estimate the [OIII]λ5007 luminosity can thus be defined as
![Mathematical equation: ${L_{[{\rm{OIII}}]}} = 11.9{F_{[{\rm{NeIII}}]}}4\pi D_L^2,$](/articles/aa/full_html/2024/07/aa46426-23/aa46426-23-eq8.png) (8)
(8)
where DL is the luminosity distance and F[NeIII] is the [NeIII]λ3869 flux.
Next, we estimate the bolometric luminosity, Lbol, using [OIII]λ5007. This conversion has been extensively performed in the literature (e.g. Heckman et al. 2004; Lamastra et al. 2009; Singh et al. 2011). Here, we estimate Lbol using the relation given by Pennell et al. (2017):
![Mathematical equation: $\log \left( {{L_{{\rm{bol }}}}} \right) = (0.5617 \pm 0.0978)\log \left( {{L_{[OIII]}}} \right) + (22.186 \pm 4.164).$](/articles/aa/full_html/2024/07/aa46426-23/aa46426-23-eq9.png) (9)
(9)
Another important physical property of AGNs is the mass accretion rate, which can be calculated using
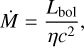 (10)
(10)
where η is the accretion efficiency, Lbol is the bolometric luminosity, and c is the speed of light. We considered an accretion efficiency of η = 0.1 (Trakhtenbrot et al. 2017).
A summary of the results of the characterisation of the QSO2 candidates is shown in Table 3 (see Appendix G for the full table). For Lbol, typical values for AGN sources range between 1042 and 1046 erg s−1 (Hönig & Beckert 2007). Additionally, the bolometric luminosities are similar to the ones estimated for the QSO2 sample with 1046.3–1046.8 erg s−1 (Alexandroff et al. 2013). The AGN black hole mass range is roughly between 107 and 108 M⊙ (Laor 2000). Finally, following the criterion in Zakamska et al. (2003) for the selection of QSO2, LOIII/L⊙ > 3 × 108 L⊙, we obtained 47 sources that fulfil the criterion. The remaining five sources have LOIII/L⊙ between 1.72–2.37 × 108 L⊙. Thus, the overall physical properties derived for the QSO2 candidates are consistent with being a luminous AGN.
Summary of the characterisation of the QSO2 candidates.
7.2 SED fitting with CIGALE
Due to the low S/N or the lack of an SDSS spectrum, conducting a comprehensive spectroscopic analysis for the entire sample was not possible. Thus, for our entire sample of QSO2 candidates we additionally performed an SED fitting analysis using Code Investigating GALaxy Emission(CIGALE; Burgarella et al. 2005; Noll et al. 2009; Boquien et al. 2019; Yang et al. 2022, version 2022.1). CIGALE performs the SED fit in a self-consistent framework considering the energy balance between UV/optical absorption and IR emission. From the best-fit model, various parameters can be estimated, including parameters related to the AGN or stellar components of the SED. The models used here are described in Yang et al. (2020) and the parameters are presented in Appendix F.
To estimate the contribution of the AGN to the SED, we used the SKIRTOR model, which conceptualises the torus as comprised of dusty clumps (Stalevski et al. 2012, 2016). This model considers that 97% of the mass fraction within the AGN is in the form of high-density clumps, with the remaining 3% evenly distributed, while incorporating an anisotropic disk emission.
For our study, the AGN fraction, fracAGN, is among the most interesting parameters, as it allows one to understand whether an obscured AGN is likely to be present, validating our AGN classification. The fracAGN is defined as the AGN contribution to the total IR dust luminosity:
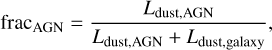 (11)
(11)
where Ldust,AGN and Ldustıgalaxy are the AGN and galactic dust luminosity, integrated over all wavelengths. We allowed fracAGN to vary between zero (no AGN) to 0.99 (AGN dominated).
Figure 5 displays the distribution of fracAGN obtained using CIGALE. A significant number of QSO2 candidates require high fracAGN values, implying that dust re-emission due to a high ion-isation source is necessary to explain the observed enhancement in the IR part of the SED. Therefore, including an AGN component to account for the optical-NIR-MIR SED with enhanced dust emission is mandatory to analyse these sources.
A more thorough analysis of the SED fitting results, including a comparison with existing literature, lies beyond the scope of this paper and will be presented in an upcoming publication (Cunha et al., in prep.).
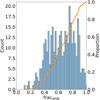 |
Fig. 5 Histogram (blue) and empirical cumulative distribution function (orange) for the AGN fraction, fracAGN, derived using CIGALE using the SKIRTOR model. |
8 Placing the QSO2 candidates into the galaxy evolution history
Currently, mergers and interactions between galaxies are believed to play crucial roles in the evolutionary history of galaxies and AGNs (e.g. Sanders et al. 1988; Hopkins et al. 2008; Treister et al. 2012; Villar-Martín et al. 2012; Goulding et al. 2018). While there is no consensus on the impact of the merger process on the physical properties of obscured AGNs (e.g. Mechtley et al. 2016; Marian et al. 2019), morphological studies have demonstrated its potential as a driving mechanism (e.g. Treister et al. 2012; Urbano-Mayorgas et al. 2019; Zhao et al. 2019; Marian et al. 2020), in particular for QSO2 (e.g. Greene et al. 2009; Villar-Martín et al. 2011; Bessiere et al. 2012; Wylezalek et al. 2016; Araujo et al. 2023; Pierce et al. 2023).
When two galaxies merge, the first by-product is thought to be a dusty star-forming galaxy which evolves into a dusty AGN. During this transitional phase, the galaxy is heavily obscured by dust, also known as a dust-obscured galaxy (DOG; Dey et al. 2008; Fiore et al. 2008; Bussmann et al. 2009; Desai et al. 2009; Bussmann et al. 2011; Yutani et al. 2022). Therefore, DOGs are believed to be a transition phase from a gas-rich major merger to an optically thin quasar in a gas-rich major merger scenario (Dey et al. 2008). Due to the dusty environment, DOGs have a very red optical-MIR colour with i − [W4]AB ≥ 7.0 where the i-band and W4 band are in AB magnitude (Toba et al. 2015, 2017, 2018). Applying this criterion to our new QSO2 candidates, we find that 208 (~57%) of them met the DOG selection criterion. We note that 127 (~88%) of the spectroscopically confirmed QSO2 used for model training (see Sect. 2.1.1) also meet the criterion. This result allowed us to confirm that dust related features are also seen in our candidate sample, validating the presence of high amount of dust, excepted in obscured AGNs.
Extremely red quasars (ERQs; e.g. Ross et al. 2015; Hamann et al. 2017; Villar Martin et al. 2020) are of significant relevance in this context. ERQs represent a distinct transition phase population that exhibits both AGN and star-forming activity. Ross et al. (2015) identified ERQs using SDSS and WISE photometry, which included various AGN types, including obscured and unobscured QSO, starburst-dominated quasars, and quasars with broad absorption lines. Finally, Hamann et al. (2017) refined the selection criteria based on broadband photometry and emission line measurements: i − [W3]AB ≥ 4.6. Interestingly, 38 (~10%) of our new QSO2 candidates meet these criteria (and also meet the DOG criterion). Similarly to the previous analysis, this analysis allowed us to better understand the reliability of this selection, always keeping in mind the different nature of these type of sources from QSO2s.
In summary, we find that most of our QSO candidates are consistent with being dust-obscured host galaxies, as also supported by the results in Sect. 7.2. As such, we argue that the sources are likely to be a transitional evolutionary stage, similar to the findings of Ishikawa et al. (2023) (see discusion in Sect. 4 therein). High-resolution imaging will be crucial to asses this question.
It is tantalising to speculate further on the nature of our QSO2 candidates. The fact that many do not show optical emission lines in their spectra, despite showing infrared colours consistent with the presence of an AGN, might be due to the AGN being so heavily obscured by dust that the ionising UV continuum from the accretion disk is fully absorbed in the nucleus, and does not escape to produce a classical narrow line region. This scenario would represent a relatively early stage in the life of the AGN.
Furthermore, the dearth of emission lines could mean that our sample contains some analogues of the ‘line-dark’ radio galaxies studied by Humphrey et al. (2015a, 2016), where no significant UV continuum or lines were detected (see also Willott et al. 2001). In a detailed case-study of one such source, Humphrey et al. (2015a) concluded that the host galaxy is in an advanced stage of being cleansed of its cold ISM by feedback driven by the AGN, thus representing a relatively late stage in the life of the AGN. One particular source, SDSS J121805.63+583904.6, falls within the definition of a ‘line-dark’ radio galaxy (see Appendix E). High spatial resolution radio and optical imaging as well as deep optical and IR spectroscopy will be crucial to clarifying the nature and evolutionary stage of our QSO2 candidates.
9 Conclusions
We have presented AMELIA, an application of the few-shot machine-transfer-learning based method to identify QSO2s using optical and infrared photometric data. AMELIA uses a generalised stacking ensemble technique, which acts as an intelligent system of optimisation and model selection, to improve classification performance. We validated the performance of AMELIA for the selection of QSO2s by performing a binary classification of spectroscopically confirmed QSO2s and ‘normal' galaxies, with an F1-Score ≥0.8 for QSO2 selection.
We applied the AMELIA pipeline to the problem of identifying QSO2s that were previously misclassified as (non-active) galaxies by the SDSS classification pipeline. We selected 366 new QSO2 candidates, using a class probability of ≥0.8.
From the 138 candidates that have reliable spectra, we obtained a mean redshift of ɀ ~ 1.1. Of these sources, 30 were detected in [NeV]λ3426 and thus can be considered ‘spectroscopically confirmed’ QSO2s. For an additional 35 candidates, the [NeIII]λ3869 line was instead detected, making them ‘likely’ QSO2s. In total, 65 of our QSO2 candidates show [NeV]λ3426 or [NeIII]λ3869, so ~47% of the candidates have reliable spectra.
We cross-matched our candidates with X-ray and radio catalogues and found that ten candidates have X-ray detection and 24 candidates have radio detection. We derived the radio luminosity of these sources and concluded that they show L150MHz, which is consistent with an AGN source.
To complement the spectroscopic analysis, we also performed an SED fitting using the CIGALE code. We found that all the QSO2 candidates require an AGN component to account for their SED, corroborating their AGN classification and dusty nature. In fact, more than half of our QSO2 candidates (208) meet the DOG selection criterion, and a significant number (38) also meet the ERQ criterion.
The physical properties of the AGNs were also derived by extrapolation from the [NeIII] λ3869 flux. We obtained the following median values: LOIII = 2.9 × 1042 erg s−1; Lbol = 1.1 × 1046 erg s−1; Ṁ = 2.4 M⊙ yr−1; and MBH = 8.8 × 107 M⊙.
To further characterise our QSO2 candidate sample and confirm our classification, more observations are necessary, which would also allow for more reliable estimation of the host galaxy and AGN properties (e.g. star-formation status, stellar mass, outflow activity status). Multi-wavelength observations (e.g. X-ray, IR, sub-millimetre, and radio) along with high-resolution imaging will play a pivotal role in obtaining a better understanding of the nature of our candidates. Finally, we remark that despite the substantial observational challenges involved with the study of sources in the ‘redshift desert’, QSO2s in this redshift regime provide a crucial bridge between obscured quasar activity at ‘cosmic noon’ (ɀ ~ 2) and in the low-redshift Universe (ɀ < 1), potentially allowing us to gain insights into the evolution of AGN and galaxy co-evolution across cosmic time.
Acknowledgements
P.A.C.C. thanks Daniel Vaz, Catarina Marques, Christina Thörne and José Fernández for the very useful comments and suggestions. P.A.C.C. also acknowledges financial support by Fundação para a Ciência e Tecnologia (FCT) through the grant 2022.11477.BD, and through the research grants UIDB/04434/2020, UIDP/04434/2020 and EXPL/FIS-AST/1085/2021. A.H. acknowledges supported by Fundação para a Ciência e Tecnologia (FCT) through grants UID/FIS/04434/2019, UIDB/04434/2020, UIDP/04434/2020 and PTDC/FIS-AST/29245/2017, and an FCT-CAPES Transnational Cooperation Project. SGM acknowledges support from Fundação para a Cência e Tecnolo-gia (FCT) through the Fellowships PD/BD/135228/2017 (PhD:SPACE Doctoral Network PD/00040/2012), POCH/FSE (EC) and COVID/BD/152181/2021. SGM was also supported by Fundação para a Ciência e Tecnologia (FCT) through the research grants UIDB/04434/2020 and UIDP/04434/2020, and an FCT-CAPES Transnational Cooperation Project “Parceria Estratégica em Astrofisica Portugal-Brasil”. R.C. acknowledges support from the Fundação para a Ciência e a Tec-nologia (FCT) through the Fellowship PD/BD/150455/2019 (PhD:SPACE Doctoral Network PD/00040/2012) and POCH/FSE (EC) and through research grants PTDC/FIS-AST/29245/2017, EXPL/FIS-AST/1085/2021, UIDB/04434/2020, and UIDP/04434/2020. J.B. acknowledges financial support from the Fundação para a Ciência e a Tecnologia (FCT) through national funds PTDC/FIS-AST/4862/2020 and work contract 2020.03379.CEECIND. A.P.A. acknowledges support from the Fundação para a Ciência e a Tecnologia (FCT) through the work Contract No. 2020.03946.CEECIND. AH acknowledges support from NVIDIA through an NVIDIA Academic Hardware Grant Award. This publication makes use of data products from the Wide-field Infrared Survey Explorer, which is a joint project of the University of California, Los Angeles, and the Jet Propulsion Laboratory/California Institute of Technology, funded by the National Aeronautics and Space Administration. Funding for the Sloan Digital Sky Survey IV has been provided by the Alfred P. Sloan Foundation, the US Department of Energy Office of Science, and the Participating Institutions. SDSS-IV acknowledges support and resources from the Center for High Performance Computing at the University of Utah. The SDSS website is www.sdss.org. SDSS-IV is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS Collaboration including the Brazilian Participation Group, the Carnegie Institution for Science, Carnegie Mellon University, Center for Astrophysics I Harvard & Smithsonian, the Chilean Participation Group, the French Participation Group, Instituto de Astrofísica de Canarias, The Johns Hopkins University, Kavli Institute for the Physics and Mathematics of the Universe (IPMU) / University of Tokyo, the Korean Participation Group, Lawrence Berkeley National Laboratory, Leibniz Institut für Astrophysik Potsdam (AIP), Max-Planck-Institut für Astronomie (MPIA Heidelberg), Max-Planck-Institut für Astrophysik (MPA Garching), Max-Planck-Institut für Extraterrestrische Physik (MPE), National Astronomical Observatories of China, New Mexico State University, New York University, University of Notre Dame, Observatário Nacional/MCTI, The Ohio State University, Pennsylvania State University, Shanghai Astronomical Observatory, United Kingdom Participation Group, Universidad Nacional Autónoma de México, University of Arizona, University of Colorado Boulder, University of Oxford, University of Portsmouth, University of Utah, University of Virginia, University of Washington, University of Wisconsin, Vanderbilt University, and Yale University. LOFAR is the Low Frequency Array designed and constructed by ASTRON. It has observing, data processing, and data storage facilities in several countries, which are owned by various parties (each with their own funding sources), and which are collectively operated by the ILT foundation under a joint scientific policy. The ILT resources have benefited from the following recent major funding sources: CNRS-INSU, Observatoire de Paris and Université d'Orléans, France; BMBF, MIWF-NRW, MPG, Germany; Science Foundation Ireland (SFI), Department of Business, Enterprise and Innovation (DBEI), Ireland; NWO, The Netherlands; The Science and Technology Facilities Council, UK; Ministry of Science and Higher Education, Poland; The Istituto Nazionale di Astrofisica (INAF), Italy. This research made use of the Dutch national e-infrastructure with support of the SURF Cooperative (e-infra 180169) and the LOFAR e-infra group. The Jülich LOFAR Long Term Archive and the German LOFAR network are both coordinated and operated by the Jülich Supercomputing Centre (JSC), and computing resources on the supercomputer JUWELS at JSC were provided by the Gauss Centre for Supercomputing e.V. (grant CHTB00) through the John von Neumann Institute for Computing (NIC). This research made use of the University of Hertfordshire high-performance computing facility and the LOFAR-UK computing facility located at the University of Hertfordshire and supported by STFC [ST/P000096/1], and of the Italian LOFAR IT computing infrastructure supported and operated by INAF, and by the Physics Department of Turin university (under an agreement with Consorzio Interuniversitario per la Fisica Spaziale) at the C3S Supercomput-ing Centre, Italy. This research has made use of the VizieR catalogue access tool, CDS, Strasbourg, France (Ochsenbein 1996). The original description of the VizieR service was published in Ochsenbein et al. (2000). In preparation for this work, we used the following codes for Python: Numpy (Harris et al. 2020), Scipy (Virtanen et al. 2020), Astropy (Astropy Collaboration 2013, 2018, 2022), Scikit-Learn (Pedregosa et al. 2011), Pandas (Wes McKinney 2010), XGBoost (Chen & Guestrin 2016), CatBoost (Prokhorenkova et al. 2018), LightGBM (Ke et al. 2017), specstack (Thomas 2019), matplotlib (Hunter 2007), seaborn (Waskom 2021). Data availability. All data used within this work are publicly available in the SDSS archive. The code is publicly available on GitHub (https://github.com/pedro-acunha/AMELIA). The complete candidates data set are available from the corresponding author upon reasonable request.
Appendix A The impact of the training data distribution
 |
Fig. A.1 Visual representation of the three different training scenarios. From left to right: Balanced training set, unbalanced training set, and equal ratio training set. The yellow colour represents the QSO2 sources, and the blue colour indicates SDSS galaxies. |
Percentage of False Positives and False Negatives for the different strategies of train-test splits and threshold values.
We explored two distinct methods for the training-test split and assessed their implications within the semi-supervised one-class approach. We established three different training scenarios for the training set, as illustrated in Fig. A.1 for visual reference:
balanced training set: The balanced training set comprises 100 QSO2 sources and 100 galaxy sources. The QSO2 data is distributed in a 7 : 3 ratio, with 70% allocated to the training set and 30% to the test set. Conversely, the galaxy data follows a 10 : 90 ratio, where 10% is included in the training set, and 90% is reserved for the testing set.
unbalanced training set: In the unbalanced training set, there are 100 QSO2 sources and 500 galaxy sources. The QSO2 data maintains a 7 : 3 ratio, while the galaxy data adopts a 1:1 ratio, signifying an equal 50% distribution between the training and testing sets.
equal ratio training set: The equal ratio training set ensures the equality of class ratios across both training and testing sets, maintaining a constant 7:3 distribution for both QSO2 and galaxy classes.
To explore the implications of various configurations in one-class semi-supervised tasks, as detailed in Sect. 5.2, our investigation focusses on the evaluation of two key metrics. Specifically, we concentrate on evaluating the total number of false positives (FP) for the galaxy class (sources labelled as ‘galaxy’ but classified as QSO2) as well as the false negatives (FN) for the QSO2 class (sources labelled as ‘QSO2’ but classified as galaxy). Table A.1 displays the analysis of four distinct training data distributions utilising the XGBoost algorithm.
The balanced training set exhibits a lower FN percentage, indicating greater efficiency in identifying QSO2 sources. These results hold significant value as they aid in selecting the most suitable training distribution for a given task. For instance, the equal ratio training set can be used for selecting galaxies, while the balanced training set demonstrates more promising results for selecting QSO2 sources. This result is not surprising, as it is well-established in the machine learning community (e.g. Lemaître et al. 2017, and references herein).
The primary goal of our machine learning pipeline is to identify QSO2 sources within a data set that includes known and unknown classification labels. In the context of dealing with misclassified data in binary classification, false positive (FP) is the most relevant metric for analysis. As the volume of test data increases, the number of FPs also increases. Therefore, we opted for the balanced training set with a threshold ≥ 0.8, as it achieves a balance between FPs and false negatives (FNs), as seen in Table A.l. In Fig. A.2, we show the distribution of the average classification probability from our meta-learners. Since this is a semi-supervised approach, it is not possible to conduct any threshold optimisation analysis, as the ground-truth is not known. Choosing a lower threshold, between 0.5 and 0.8, would substantially increase the number of targets to validate. Our choice, threshold ≥ 0.8, enables us to mitigate the bias of our model by balancing the number of misclassifications, due to the increase of the classification threshold, while reducing the number of potential candidates for further validation.
 |
Fig. A.2 Histogram with the average probability predictions from the generalised stacking method with meta-learner correction. The black dashed line shows the ‘default value’, 0.5, and the yellow dashed line shows the chosen classification threshold in this study, 0.8. |
Appendix B Feature importance analysis
One of the primary advantages of employing a decision-tree-based algorithm lies in its capability to identify crucial features. These models can quantify the utility of individual features (or observables) in selecting QSO2 sources.
Top five features with the highest feature importance for theRandomForest, XGBoost, CatBoost, and LightGBM models.
We provide a quick analysis of the feature importance provided by RandomForest, LightGBM, CatBoost, and XGBoost models. The majority of the methodologies use different techniques to compute the feature importances. While their examination can inform about the relevant features, their interpretation should be taken with a grain of salt. In the RandomForest algorithm, the feature importance is impurity-based, meaning that it is calculated based on the mean and standard deviation of the impurity measurement from top to bottom of the tree. LightGBM can compute feature importance based on split and gain. In this work, we used the split method which is based on the number of times the feature is used within the model to compute the final prediction. For the CatBoost algorithm, we used the PredictionValuesChange method, which computes the average change in the predicted values if the feature value changes. Finally, for XGBoost the weight importance was used, which computes the number of times a feature appears in a tree, similar to the method used in LightGBM.
The top five features with the highest importance of the features are summarised in Table B, ordered by decreasing importance. Some features, such as u-g, g, and W4, appear as some of the most important features in different models. Even though some features appear as less important, it does not mean they do not make a difference in the final classification. We inferred that it is the balance between optical-infrared information that allows the machine learning models to distinguish between the two classes successfully. Some studies explore the relationship between feature importance and final predictions in more depth (e.g. Ansari et al. 2022; He et al. 2022). We did not perform such an analysis due to the limited size of our training set.
In Euclid Collaboration (2023b), the authors conducted A/B tests (randomised experiments where one or more feature is removed and the performance model re-evaluated) to understand the impact of features in the classification models, while doing cross-validation and randomly changing random seeds. They have shown that removing multiple features (e.g. broad-band colours, magnitudes) impacts negatively the F1-scores metrics when classifying quiescent galaxies, in the context of Euclid. We performed similar A/B tests for the selection of QSO2 and found that removing features independently of their importance in individual learners has a negative impact.
Appendix C Performance prediction functions to estimate statistical metrics
Since we do not have access to ground-truth labels for our test set, it is interesting to quantify the performance of the model based on the model output. In Humphrey et al. (2022), the authors used a Confidence-Based Performance Estimation (CBPE)17 method from the NANNYML18 package to predict the impact of population shifts in unlabelled data for the selection of quasars using decision-tree ensemble models.
Therein, performance prediction functions allow the estimation of the following metrics for our semi-supervised approach: F1-score, precision, accuracy, recall and specificity. For the performance prediction metrics, we obtain A= 0.90, P= 0.92, R= 0.26, F1-Score= 0.40 and specificity of 0.997. Low recall can be explained with the high-threshold setup.
Appendix D QSO2 candidate with wrong spec-z estimation: SDSS J013056.89-022638.1
In our QSO2 candidate sample, we noticed that the spectrum for the source SDSS J013056.89-022638.1 showed emission lines that did not match the estimated SDSS spectroscopic red-shift. In particular, [OII]λλ3727, 3730 and [OIII]λλ4959, 5008 were misidentified. By computing the redshift using the [OIII]λλ4959, 5008 doublet, we obtain a spectroscopic red-shift z≈ 0.960, quite different from z≈ 1.633 (computed with idlspec2d). In Fig.D.1, the top plot shows where the emission lines would be placed with z≈ 1.633, and the middle plot shows the wavelength for the emission lines with the estimated redshift z≈ 0.960. One can easily identify the following emission lines: MgIIλ2799, [NeV]λλ3347, 3426, [OII]λλ3727, 3730, [NeIII]λ3869, HeIλ3889, and [OIII]λλ4959, 5008 doublets.
 |
Fig. D.1 Spectrum of SDSSJ013154.44 + 224437.9 from the BOSS spectrograph. In the top plot, the red vertical lines indicate the emission lines for z≈ 1.633, computed by idlspec2d from SDSS. In the middle plot, the red vertical lines indicate the emission lines for z≈ 0.960, computed by the authors. In the bottom plot, the spectrum without any smoothing is shown. |
Appendix E Notes on individual object: SDSS J121805.63+583904.6
Previously identified in the Millions of Optical Radio/X-ray Associations (MORX) v2 catalogue Flesch (2024), this faint optical source (u: 22.594; g: 23.394; r: 22.368; i: 20.782; z: 19.634) exhibit double radio lobes in the image mosaics from LoTSS DR2. The SDSS spectrum shows no emission lines, being an unclear source, assuming our spectroscopic classification (see Sect. 6.1). Also, this source is consistent with a featureless spectrum, making it a good candidate for a ‘line-dark’ radio galaxy (Humphrey et al. 2015a, 2016). Even though, it is not possible to confirm the redshift, from the lack of strong AGN emission lines one can extrapolate that this source could be within the ‘redshift desert’.
 |
Fig. E.1 Optical and radio imaging and spectrum for the SDSS J121805.63+583904.6. From left to right, top to bottom: (a) grz cutout image from SDSS with 1′ size; (b) LoTSS DR2 cutout image with 1′ size; (c) SDSS optical spectrum from BOSS spectrograph, assuming z= 1.122 . |
Appendix F CIGALE SED fitting parameters
Summary of the CIGALE SED fitting parameters used in this work.
Appendix G Estimation of physical properties
Physical properties derived for the [NeIII] emitters using Morais et al. (2021) photoionisation models.
References
- Abdo, N., Kretzschmar, H., Spinello, L., & Stachniss, C. 2013, in 2013 IEEE International Conference on Robotics and Automation, 1268 [CrossRef] [Google Scholar]
- Ahn, C. P., Alexandroff, R., Allende Prieto, C., et al. 2012, ApJS, 203, 21 [Google Scholar]
- Ahumada, R., Prieto, C. A., Almeida, A., et al. 2020, ApJS, 249, 3 [Google Scholar]
- Akcay, S., Atapour-Abarghouei, A., & Breckon, T. P. 2019, in Computer Vision-ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, December 2–6, 2018, Revised Selected Papers, Part III 14 (Springer), 622 [CrossRef] [Google Scholar]
- Alegre, L., Sabater, J., Best, P., et al. 2022, MNRAS, 516, 4716 [NASA ADS] [CrossRef] [Google Scholar]
- Alexandroff, R., Strauss, M. A., Greene, J. E., et al. 2013, MNRAS, 435, 3306 [NASA ADS] [CrossRef] [Google Scholar]
- Almeida, I., Duarte, R., & Nemmen, R. 2022, MNRAS, 509, 5657 [Google Scholar]
- Anghel, A., Papandreou, N., Parnell, T., De Palma, A., & Pozidis, H. 2018, arXiv e-prints [arXiv: 1809.04559] [Google Scholar]
- Ansari, Z., Gall, C., Wesson, R., & Krause, O. 2022, A&A, 666, A176 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Antonucci, R. 1993, ARA&A, 31, 473 [Google Scholar]
- Araujo, B. L. C., Storchi-Bergmann, T., Rembold, S. B., Kaipper, A. L. P., & Dall’Agnol de Oliveira, B. 2023, MNRAS, 522, 5165 [NASA ADS] [CrossRef] [Google Scholar]
- Assef, R. J., Eisenhardt, P. R. M., Stern, D., et al. 2015, ApJ, 804, 27 [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2022, ApJ, 935, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Baqui, P. O., Marra, V., Casarini, L., et al. 2021, A&A, 645, A87 [EDP Sciences] [Google Scholar]
- Barger, A. J., Cowie, L. L., Capak, P., et al. 2003, AJ, 126, 632 [NASA ADS] [CrossRef] [Google Scholar]
- Baron, D. 2019, arXiv e-prints [arXiv: 1904.07248] [Google Scholar]
- Bauman, E., & Bauman, K. 2017, arXiv e-prints [arXiv: 1705.00797] [Google Scholar]
- Becker, R. H., White, R. L., & Helfand, D. J. 1994, in Astronomical Society of the Pacific Conference Series, 61, Astronomical Data Analysis Software and Systems III, eds. D. R. Crabtree, R. J. Hanisch, & J. Barnes, 165 [Google Scholar]
- Bessiere, P. S., Tadhunter, C. N., Ramos Almeida, C., & Villar Martin, M. 2012, MNRAS, 426, 276 [NASA ADS] [CrossRef] [Google Scholar]
- Best, P. N., & Heckman, T. M. 2012, MNRAS, 421, 1569 [NASA ADS] [CrossRef] [Google Scholar]
- Bickley, R. W., Ellison, S. L., Patton, D. R., & Wilkinson, S. 2023, MNRAS, 519, 6149 [CrossRef] [Google Scholar]
- Binette, L. 1985, A&A, 143, 334 [NASA ADS] [Google Scholar]
- Binette, L., Matadamas, R., Hägele, G. F., et al. 2012, A&A, 547, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blair, D. C. 1979, J. Am. Soc. Inform. Sci., 30, 374 [CrossRef] [Google Scholar]
- Blecha, L., Snyder, G. F., Satyapal, S., & Ellison, S. L. 2018, MNRAS, 478, 3056 [Google Scholar]
- Bolzonella, M., Miralles, J. M., & Pelló, R. 2000, A&A, 363, 476 [NASA ADS] [Google Scholar]
- Bonjean, V., Aghanim, N., Salomé, P., et al. 2019, A&A, 622, A137 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Boquien, M., Burgarella, D., Roehlly, Y., et al. 2019, A&A, 622, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bower, R. G., Benson, A. J., Malbon, R., et al. 2006, MNRAS, 370, 645 [Google Scholar]
- Bowles, M., Scaife, A. M. M., Porter, F., Tang, H., & Bastien, D. J. 2021, MNRAS, 501, 4579 [CrossRef] [Google Scholar]
- Burgarella, D., Buat, V., & Iglesias-Páramo, J. 2005, MNRAS, 360, 1413 [NASA ADS] [CrossRef] [Google Scholar]
- Bussmann, R. S., Dey, A., Borys, C., et al. 2009, ApJ, 705, 184 [NASA ADS] [CrossRef] [Google Scholar]
- Bussmann, R. S., Dey, A., Lotz, J., et al. 2011, ApJ, 733, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Cabayol, L., Eriksen, M., Carretero, J., et al. 2023, A&A, 671, A153 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cai, Y., Chen, H., Yang, X., Zhou, Y., & Cheng, K.-T. 2023, Med. Image Anal., 86, 102794 [CrossRef] [Google Scholar]
- Calzetti, D., Kinney, A. L., & Storchi-Bergmann, T. 1994, ApJ, 429, 582 [Google Scholar]
- Carroll, C. M., Hickox, R. C., Masini, A., et al. 2021, ApJ, 908, 185 [NASA ADS] [CrossRef] [Google Scholar]
- Carroll, C. M., Ananna, T. T., Hickox, R. C., et al. 2023, ApJ, 950, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Carvajal, R., Matute, I., Afonso, J., et al. 2023, A&A, 679, A101 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cavuoti, S., Brescia, M., D’Abrusco, R., Longo, G., & Paolillo, M. 2014, MNRAS, 437, 968 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, T., & Guestrin, C. 2016, in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 785 [Google Scholar]
- Chen, Z., Eavani, H., Chen, W., Liu, Y., & Wang, W. Y. 2019, arXiv e-prints [arXiv:1904.09521] [Google Scholar]
- Ciotti, L., & Ostriker, J. P. 1997, ApJ, 487, L105 [NASA ADS] [CrossRef] [Google Scholar]
- Clarke, A. O., Scaife, A. M. M., Greenhalgh, R., & Griguta, V. 2020, A&A, 639, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Collister, A. A., & Lahav, O. 2004, PASP, 116, 345 [NASA ADS] [CrossRef] [Google Scholar]
- Constantin, A., Hoyle, F., & Vogeley, M. S. 2008, ApJ, 673, 715 [NASA ADS] [CrossRef] [Google Scholar]
- Cunha, P. A. C., & Humphrey, A. 2022, A&A, 666, A87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Curran, S. J., Moss, J. P., & Perrott, Y. C. 2022, MNRAS, 514, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Daddi, E., Cimatti, A., Renzini, A., et al. 2004, ApJ, 617, 746 [NASA ADS] [CrossRef] [Google Scholar]
- Dash, T., Chitlangia, S., Ahuja, A., & Srinivasan, A. 2022, Sci. Rep., 12, 1040 [NASA ADS] [CrossRef] [Google Scholar]
- de Jong, J. M. G. H. J., Röttgering, H. J. A., Kondapally, R., et al. 2024, A&A, 683, A23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Della Ceca, R., Braito, V., Beckmann, V., et al. 2003, A&A, 406, 555 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Desai, V., Soifer, B. T., Dey, A., et al. 2009, ApJ, 700, 1190 [NASA ADS] [CrossRef] [Google Scholar]
- Dey, A., Soifer, B. T., Desai, V., et al. 2008, ApJ, 677, 943 [NASA ADS] [CrossRef] [Google Scholar]
- Di Matteo, T., Colberg, J., Springel, V., Hernquist, L., & Sijacki, D. 2008, ApJ, 676, 33 [NASA ADS] [CrossRef] [Google Scholar]
- Domínguez Sánchez, H., Huertas-Company, M., Bernardi, M., Tuccillo, D., & Fischer, J. L. 2018, MNRAS, 476, 3661 [Google Scholar]
- Draine, B. T. 2003, ApJ, 598, 1017 [NASA ADS] [CrossRef] [Google Scholar]
- Eldridge, J. J., Stanway, E. R., Xiao, L., et al. 2017, PASA, 34, e058 [Google Scholar]
- Elford, J. S., Davis, T. A., Ruffa, I., et al. 2023, arXiv e-prints [arXiv:2311.17848] [Google Scholar]
- Euclid Collaboration (Desprez, G., et al.) 2020, A&A, 644, A31 [EDP Sciences] [Google Scholar]
- Euclid Collaboration (Bisigello, L., et al.) 2023a, MNRAS, 520, 3529 [NASA ADS] [CrossRef] [Google Scholar]
- Euclid Collaboration (Humphrey, A., et al.) 2023b, A&A, 671, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fabian, A. C. 2012, ARA&A, 50, 455 [Google Scholar]
- Feltre, A., Charlot, S., & Gutkin, J. 2016, MNRAS, 456, 3354 [Google Scholar]
- Ferrarese, L., & Merritt, D. 2000, ApJ, 539, L9 [Google Scholar]
- Ferruit, P., Binette, L., Sutherland, R. S., & Pecontal, E. 1997, A&A, 322, 73 [NASA ADS] [Google Scholar]
- Fiore, F., Grazian, A., Santini, P., et al. 2008, ApJ, 672, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Flesch, E. W. 2024, Open J. Astrophys., 7, 6 [NASA ADS] [CrossRef] [Google Scholar]
- Flores-Fajardo, N., Morisset, C., Stasinska, G., & Binette, L. 2011, MNRAS, 415, 2182 [NASA ADS] [CrossRef] [Google Scholar]
- Gebhardt, K., Bender, R., Bower, G., et al. 2000, ApJ, 539, L13 [Google Scholar]
- Gilli, R., Vignali, C., Mignoli, M., et al. 2010, A&A, 519, A92 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Glikman, E., Eigenbrod, A., Djorgovski, S. G., et al. 2008, AJ, 136, 954 [NASA ADS] [CrossRef] [Google Scholar]
- Gomes, J. M., & Papaderos, P. 2018, A&A, 618, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gong, Y., Yue, Y., Ji, W., & Zhou, G. 2023, Sci. Rep., 13, 1427 [NASA ADS] [CrossRef] [Google Scholar]
- Goulding, A. D., Greene, J. E., Bezanson, R., et al. 2018, PASJ, 70, S37 [NASA ADS] [CrossRef] [Google Scholar]
- Greene, J. E., Zakamska, N. L., Liu, X., Barth, A. J., & Ho, L. C. 2009, ApJ, 702, 441 [NASA ADS] [CrossRef] [Google Scholar]
- Greene, J. E., Zakamska, N. L., Ho, L. C., & Barth, A. J. 2011, ApJ, 732, 9 [NASA ADS] [CrossRef] [Google Scholar]
- Grevesse, N., Asplund, M., Sauval, A. J., & Scott, P. 2010, Ap&SS, 328, 179 [Google Scholar]
- Haehnelt, M. G., Madau, P., Kudritzki, R., & Haardt, F. 2001, ApJ, 549, L151 [NASA ADS] [CrossRef] [Google Scholar]
- Hale, C. L., McConnell, D., Thomson, A. J. M., et al. 2021, PASA, 38, e058 [NASA ADS] [CrossRef] [Google Scholar]
- Hamann, F., Zakamska, N. L., Ross, N., et al. 2017, MNRAS, 464, 3431 [Google Scholar]
- Hardcastle, M. J., Gürkan, G., van Weeren, R. J., et al. 2016, MNRAS, 462, 1910 [Google Scholar]
- Haro, G. 1956, Bol. Observ. Tonantzintla Tacubaya, 2, 8 [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Harrison, C. M., Molyneux, S. J., Scholtz, J., & Jarvis, M. E. 2021, in Galaxy Evolution and Feedback across Different Environments, 359, eds. T. Storchi Bergmann, W. Forman, R. Overzier, & R. Riffel, 203 [NASA ADS] [Google Scholar]
- Hastie, T., Tibshirani, R., & Friedman, J. 2009, Model Assessment and Selection (New York: Springer), 219 [Google Scholar]
- He, X.-J., Luo, A. L., & Chen, Y.-Q. 2022, MNRAS, 512, 1710 [NASA ADS] [CrossRef] [Google Scholar]
- Heckman, T. M., Kauffmann, G., Brinchmann, J., et al. 2004, ApJ, 613, 109 [Google Scholar]
- Hegselmann, S., Buendia, A., Lang, H., et al. 2023, in International Conference on Artificial Intelligence and Statistics, PMLR, 5549 [Google Scholar]
- Henghes, B., Thiyagalingam, J., Pettitt, C., Hey, T., & Lahav, O. 2022, MNRAS, 512, 1696 [NASA ADS] [CrossRef] [Google Scholar]
- Hickox, R. C., & Alexander, D. M. 2018, ARA&A, 56, 625 [Google Scholar]
- Hickox, R. C., Myers, A. D., Greene, J. E., et al. 2017, ApJ, 849, 53 [NASA ADS] [CrossRef] [Google Scholar]
- Hiner, K. D., Canalizo, G., Lacy, M., et al. 2009, ApJ, 706, 508 [NASA ADS] [CrossRef] [Google Scholar]
- Holincheck, A. J., Wallin, J. F., Borne, K., et al. 2016, MNRAS, 459, 720 [NASA ADS] [CrossRef] [Google Scholar]
- Hönig, S. F. 2019, ApJ, 884, 171 [Google Scholar]
- Hönig, S. F., & Beckert, T. 2007, MNRAS, 000, 1 [Google Scholar]
- Hopkins, P. F., Hernquist, L., Cox, T. J., et al. 2006, ApJS, 163, 1 [Google Scholar]
- Hopkins, P. F., Hernquist, L., Cox, T. J., & Kereš, D. 2008, ApJS, 175, 356 [Google Scholar]
- Huertas-Company, M., Gravet, R., Cabrera-Vives, G., et al. 2015, ApJS, 221, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Humphrey, A., Villar-Martín, M., Sanchez, S. F., et al. 2010, MNRAS, 408, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Humphrey, A., Roche, N., Gomes, J. M., et al. 2015a, MNRAS, 447, 3322 [NASA ADS] [CrossRef] [Google Scholar]
- Humphrey, A., Villar-Martín, M., Ramos Almeida, C., et al. 2015b, MNRAS, 454, 4452 [Google Scholar]
- Humphrey, A., Villar-Martín, M., & Lagos, P. 2016, A&A, 585, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Humphrey, A., Kuberski, W., Bialek, J., et al. 2022, MNRAS, 517, L116 [NASA ADS] [CrossRef] [Google Scholar]
- Humphrey, A., Cunha, P. A. C., Paulino-Afonso, A., et al. 2023, MNRAS, 520, 305 [NASA ADS] [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Hviding, R. E., Hickox, R. C., Hainline, K. N., et al. 2018, MNRAS, 474, 1955 [CrossRef] [Google Scholar]
- Hviding, R. E., Hainline, K. N., Goulding, A. D., & Greene, J. E. 2024, AJ, 167, 169 [NASA ADS] [CrossRef] [Google Scholar]
- Ilbert, O., Arnouts, S., McCracken, H. J., et al. 2006, A&A, 457, 841 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ishikawa, Y., Wang, B., Zakamska, N. L., et al. 2023, MNRAS, 522, 350 [NASA ADS] [CrossRef] [Google Scholar]
- Jiang, J., Zhang, J., Li, X., Li, H., & Du, P. 2023a, Res. Astron. Astrophys., 23, 115019 [CrossRef] [Google Scholar]
- Jiang, L., Zhang, Y., & Shi, Y. 2023b, SPIE Conf. Ser., 12718, 127180I [Google Scholar]
- Kauffmann, G., Heckman, T. M., Tremonti, C., et al. 2003, MNRAS, 346, 1055 [Google Scholar]
- Ke, G., Meng, Q., Finley, T., et al. 2017, in Advances in Neural Information Processing Systems, eds. I. Guyon, U. Von Luxburg, S. Bengio, et al. (Curran Associates, Inc.) [Google Scholar]
- Khajezade, M., Ramezankhani, M., Fard, F. H., Shehata, M. S., & Milani, A. 2021, in 2021 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), 1 [Google Scholar]
- Kleinmann, S. G. 1988, BAAS, 20, 1067 [NASA ADS] [Google Scholar]
- Kleinmann, S. G., Hamilton, D., Keel, W. C., et al. 1988, ApJ, 328, 161 [NASA ADS] [CrossRef] [Google Scholar]
- Kong, M., & Ho, L. C. 2018, ApJ, 859, 116 [NASA ADS] [CrossRef] [Google Scholar]
- Kouw, W. M., & Loog, M. 2018, arXiv e-prints [arXiv:1812.11806] [Google Scholar]
- Krishnakumar, H. 2022, in American Astronomical Society Meeting Abstracts, 54, 241.27 [Google Scholar]
- Lachenbruch, P. A., & Mickey, M. R. 1968, Technometrics, 10, 1 [CrossRef] [Google Scholar]
- Lacy, M., Storrie-Lombardi, L. J., Sajina, A., et al. 2004, ApJS, 154, 166 [Google Scholar]
- Lacy, M., Ridgway, S., Petric, A., et al. 2007, in American Astronomical Society Meeting Abstracts, 210, 02.15 [Google Scholar]
- Lamastra, A., Bianchi, S., Matt, G., et al. 2009, A&A, 504, 73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Laor, A. 2000, ApJ, 543, L111 [NASA ADS] [CrossRef] [Google Scholar]
- Lee, S.-E., & Lee, S.-C. 2024, arXiv e-prints [arXiv:2307.02491] [Google Scholar]
- Lemaître, G., Nogueira, F., & Aridas, C. K. 2017, J. Mach. Learn. Res., 18, 1 [Google Scholar]
- Li, F.-F., Fergus, R., & Perona, P. 2006, IEEE Trans. Pattern Anal. Mach. Intell., 28, 594 [CrossRef] [Google Scholar]
- Li, W., Wang, Z., Yang, X., et al. 2023, IEEE Trans. Pattern Anal. Mach. Intell., 45, 14938 [CrossRef] [Google Scholar]
- Lin, D., Webb, N. A., & Barret, D. 2012, ApJ, 756, 27 [NASA ADS] [CrossRef] [Google Scholar]
- Lin, Q., Fouchez, D., Pasquet, J., et al. 2022, A&A, 662, A36 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Logan, C. H. A., & Fotopoulou, S. 2020, A&A, 633, A154 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Luntz, A., & Brailovsky, V. 1969, Technicheskaya Kibernetica, 3 [Google Scholar]
- Lynden-Bell, D. 1969, Nature, 223, 690 [NASA ADS] [CrossRef] [Google Scholar]
- Magorrian, J., Tremaine, S., Richstone, D., et al. 1998, AJ, 115, 2285 [Google Scholar]
- Marian, V., Jahnke, K., Mechtley, M., et al. 2019, ApJ, 882, 141 [CrossRef] [Google Scholar]
- Marian, V., Jahnke, K., Andika, I., et al. 2020, ApJ, 904, 79 [NASA ADS] [CrossRef] [Google Scholar]
- Martínez-Paredes, M., Bruzual, G., Morisset, C., et al. 2023, MNRAS, 525, 2916 [CrossRef] [Google Scholar]
- Martínez-Sansigre, A., Rawlings, S., Lacy, M., et al. 2006, MNRAS, 370, 1479 [CrossRef] [Google Scholar]
- Mateos, S., Alonso-Herrero, A., Carrera, F. J., et al. 2012, MNRAS, 426, 3271 [Google Scholar]
- Matsuoka, Y., Iwasawa, K., Onoue, M., et al. 2022, ApJS, 259, 18 [NASA ADS] [CrossRef] [Google Scholar]
- McCarthy, P. J., Spinrad, H., van Breugel, W., et al. 1990, ApJ, 365, 487 [NASA ADS] [CrossRef] [Google Scholar]
- Mechbal, S., Ackermann, M., & Kowalski, M. 2024, A&A, 685, A107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mechtley, M., Jahnke, K., Windhorst, R. A., et al. 2016, ApJ, 830, 156 [NASA ADS] [CrossRef] [Google Scholar]
- Merloni, A., Lamer, G., Liu, T., et al. 2024, A&A, 682, A34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mignoli, M., Vignali, C., Gilli, R., et al. 2013, A&A, 556, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mingo, B., Watson, M. G., Rosen, S. R., et al. 2016, MNRAS, 462, 2631 [NASA ADS] [CrossRef] [Google Scholar]
- Mirchevska, V., Luštrek, M., & Gams, M. 2014, Expert Syst., 31, 163 [CrossRef] [Google Scholar]
- Morais, S. G., Humphrey, A., Villar Martín, M., Binette, L., & Silva, M. 2021, MNRAS, 506, 1389 [CrossRef] [Google Scholar]
- Moya, M. M., & Hush, D. R. 1996, Neural Networks, 9, 463 [CrossRef] [Google Scholar]
- Mucesh, S., Hartley, W. G., Palmese, A., et al. 2021, MNRAS, 502, 2770 [NASA ADS] [CrossRef] [Google Scholar]
- Nam, J., Tack, J., Lee, K., Lee, H., & Shin, J. 2023, in The Eleventh International Conference on Learning Representations, STUNT: Few-shot Tabular Learning with Self-generated Tasks from Unlabeled Tables [Google Scholar]
- Noll, S., Burgarella, D., Giovannoli, E., et al. 2009, A&A, 507, 1793 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ochsenbein, F. 1996, The VizieR database of astronomical catalogues [Google Scholar]
- Ochsenbein, F., Bauer, P., & Marcout, J. 2000, A&AS, 143, 23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Odewahn, S. C., Humphreys, R. M., Aldering, G., & Thurmes, P. 1993, PASP, 105, 1354 [NASA ADS] [CrossRef] [Google Scholar]
- Padovani, P., Alexander, D. M., Assef, R. J., et al. 2017, A&A Rev., 25, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Pennell, A., Runnoe, J. C., & Brotherton, M. S. 2017, MNRAS, 468, 1433 [NASA ADS] [CrossRef] [Google Scholar]
- Pérez-Díaz, V. S., Martínez-Galarza, J. R., Caicedo, A., & D’Abrusco, R. 2024, MNRAS, 528, 4852 [CrossRef] [Google Scholar]
- Piconcelli, E., Vignali, C., Bianchi, S., et al. 2015, A&A, 574, L9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pierce, J. C. S., Tadhunter, C., Ramos Almeida, C., et al. 2023, MNRAS, 522, 1736 [NASA ADS] [CrossRef] [Google Scholar]
- Pimbblet, K. A., Shabala, S. S., Haines, C. P., Fraser-McKelvie, A., & Floyd, D. J. E. 2013, MNRAS, 429, 1827 [NASA ADS] [CrossRef] [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Porqueres, N., Jasche, J., Enßlin, T. A., & Lavaux, G. 2018, A&A, 612, A31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Powers, D. 2008, Mach. Learn. Technol., 2 [Google Scholar]
- Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V., & Gulin, A. 2018, Adv. Neural Inform. Process. Syst., 31 [Google Scholar]
- Ptak, A., Zakamska, N. L., Strauss, M. A., et al. 2006, ApJ, 637, 147 [NASA ADS] [CrossRef] [Google Scholar]
- Qin, T., Li, W., Shi, Y., & Gao, Y. 2020, arXiv e-prints [arXiv:200.05805] [Google Scholar]
- Ramos Almeida, C., & Ricci, C. 2017, Nat. Astron., 1, 679 [Google Scholar]
- Razim, O., Cavuoti, S., Brescia, M., et al. 2021, MNRAS, 507, 5034 [NASA ADS] [CrossRef] [Google Scholar]
- Reyes, R., Zakamska, N. L., Strauss, M. A., et al. 2008, AJ, 136, 2373 [Google Scholar]
- Richards, G. T., Fan, X., Newberg, H. J., et al. 2002, AJ, 123, 2945 [NASA ADS] [CrossRef] [Google Scholar]
- Rodríguez, M. I., Villar-Martín, M., Emonts, B., et al. 2014, A&A, 565, A19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ross, N., Strauss, M. A., Greene, J. E., et al. 2014, in American Astronomical Society Meeting Abstracts, 223, 115.04 [Google Scholar]
- Ross, N. P., Hamann, F., Zakamska, N. L., et al. 2015, MNRAS, 453, 3932 [Google Scholar]
- Ruffa, I., Prandoni, I., Davis, T. A., et al. 2022, MNRAS, 510, 4485 [NASA ADS] [CrossRef] [Google Scholar]
- Samuel, A. L. 1959, IBM J. Res. Dev., 3, 210 [CrossRef] [Google Scholar]
- Sanders, D. B., Soifer, B. T., Elias, J. H., Neugebauer, G., & Matthews, K. 1988, ApJ, 328, L35 [NASA ADS] [CrossRef] [Google Scholar]
- Saxton, R. D., Read, A. M., Esquej, P., et al. 2008, A&A, 480, 611 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schaerer, D., Fragos, T., & Izotov, Y. I. 2019, A&A, 622, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schmidt, M., Hasinger, G., Gunn, J., et al. 1998, A&A, 329, 495 [NASA ADS] [Google Scholar]
- Schölkopf, B., Williamson, R. C., Smola, A., Shawe-Taylor, J., & Platt, J. 1999, in Advances in Neural Information Processing Systems, 12, eds. S. Solla, T. Leen, & K. Müller (MIT Press) [Google Scholar]
- Severgnini, P., Della Ceca, R., Braito, V., et al. 2005, A&A, 431, 87 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Severgnini, P., Caccianiga, A., Braito, V., et al. 2006, A&A, 451, 859 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shi, X., Fan, W., & Ren, J. 2008, in Machine Learning and Knowledge Discovery in Databases, eds. W. Daelemans, B. Goethals, & K. Morik (Berlin, Heidelberg: Springer), 342 [CrossRef] [Google Scholar]
- Shimwell, T. W., Hardcastle, M. J., Tasse, C., et al. 2022, A&A, 659, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shwartz-Ziv, R., & Armon, A. 2021, in 8th ICML Workshop on Automated Machine Learning (AutoML) [Google Scholar]
- Silk, J., & Rees, M. J. 1998, A&A, 331, L1 [NASA ADS] [Google Scholar]
- Silverman, J. D., Mainieri, V., Lehmer, B. D., et al. 2008, ApJ, 675, 1025 [NASA ADS] [CrossRef] [Google Scholar]
- Simet, M., Chartab, N., Lu, Y., & Mobasher, B. 2021, ApJ, 908, 47 [NASA ADS] [CrossRef] [Google Scholar]
- Singh, V., Shastri, P., & Risaliti, G. 2011, A&A, 533, A128 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Smith, M. J., Geach, J. E., Jackson, R. A., et al. 2022, MNRAS, 511, 1808 [CrossRef] [Google Scholar]
- Soussana, A., Chisari, N. E., Codis, S., et al. 2020, MNRAS, 492, 4268 [CrossRef] [Google Scholar]
- Stalevski, M., Fritz, J., Baes, M., & Popovic, L. C. 2012, in Torus Workshop, 2012, eds. R. Mason, A. Alonso-Herrero, & C. Packham, 170 [Google Scholar]
- Stalevski, M., Ricci, C., Ueda, Y., et al. 2016, MNRAS, 458, 2288 [Google Scholar]
- Stalevski, M., González-Gaitán, S., Savic, Ð., et al. 2023, MNRAS, 519, 3237 [NASA ADS] [CrossRef] [Google Scholar]
- Stern, D., Moran, E. C., Coil, A. L., et al. 2002, ApJ, 568, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Stern, D., Eisenhardt, P., Gorjian, V., et al. 2005, ApJ, 631, 163 [Google Scholar]
- Stern, D., Assef, R. J., Benford, D. J., et al. 2012, ApJ, 753, 30 [Google Scholar]
- Stone, M. 1974, J. Roy. Stat. Soc. Ser. B (Methodol.), 36, 111 [CrossRef] [Google Scholar]
- Stoughton, C., Lupton, R. H., Bernardi, M., et al. 2002, AJ, 123, 485 [Google Scholar]
- Szokoly, G. P., Bergeron, J., Hasinger, G., et al. 2004, ApJS, 155, 271 [NASA ADS] [CrossRef] [Google Scholar]
- Tajer, M., Polletta, M., Chiappetti, L., et al. 2007, A&A, 467, 73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tang, H., Scaife, A. M. M., & Leahy, J. P. 2019, MNRAS, 488, 3358 [Google Scholar]
- Tax, D. M., & Duin, R. P. 2001, J. Mach. Learn. Res., 2, 155 [Google Scholar]
- Thomas, R. 2019, Astrophysics Source Code Library [record ascl:1904.018] [Google Scholar]
- Tian, P., Wu, Z., Qi, L., et al. 2020, Proc. AAAI Conf. Artif. Intell., 34, 12087 [Google Scholar]
- Toba, Y., Nagao, T., Strauss, M. A., et al. 2015, PASJ, 67, 86 [Google Scholar]
- Toba, Y., Bae, H.-J., Nagao, T., et al. 2017, ApJ, 850, 140 [NASA ADS] [CrossRef] [Google Scholar]
- Toba, Y., Ueda, J., Lim, C.-F., et al. 2018, ApJ, 857, 31 [NASA ADS] [CrossRef] [Google Scholar]
- Torrey, P., Hopkins, P. F., Faucher-Giguère, C.-A., et al. 2020, MNRAS, 497, 5292 [NASA ADS] [CrossRef] [Google Scholar]
- Trakhtenbrot, B., Volonteri, M., & Natarajan, P. 2017, ApJ, 836, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Treister, E., Schawinski, K., Urry, C. M., & Simmons, B. D. 2012, ApJ, 758, L39 [NASA ADS] [CrossRef] [Google Scholar]
- Urbano-Mayorgas, J. J., Villar Martín, M., Buitrago, F., et al. 2019, MNRAS, 483, 1829 [Google Scholar]
- Urry, C. M., & Padovani, P. 1995, PASP, 107, 803 [NASA ADS] [CrossRef] [Google Scholar]
- Vagnetti, F., Middei, R., Antonucci, M., Paolillo, M., & Serafinelli, R. 2016, A&A, 593, A55 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vergani, D., Garilli, B., Polletta, M., et al. 2018, A&A, 620, A193 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vernet, J., Fosbury, R. A. E., Villar-Martín, M., et al. 2001, A&A, 366, 7 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vilalta, R. 2018, J. Phys. Conf. Ser., 1085, 052014 [NASA ADS] [CrossRef] [Google Scholar]
- Villaescusa-Navarro, F., Ding, J., Genel, S., et al. 2022, ApJ, 929, 132 [NASA ADS] [CrossRef] [Google Scholar]
- Villar-Martín, M., Fosbury, R. A. E., Binette, L., Tadhunter, C. N., & Rocca-Volmerange, B. 1999, A&A, 351, 47 [NASA ADS] [Google Scholar]
- Villar-Martín, M., Tadhunter, C., Humphrey, A., et al. 2011, MNRAS, 416, 262 [NASA ADS] [Google Scholar]
- Villar-Martín, M., Cabrera Lavers, A., Bessiere, P., et al. 2012, MNRAS, 423, 80 [CrossRef] [Google Scholar]
- Villar Martín, M., Emonts, B., Humphrey, A., Cabrera Lavers, A., & Binette, L. 2014, MNRAS, 440, 3202 [CrossRef] [Google Scholar]
- Villar-Martín, M., Arribas, S., Emonts, B., et al. 2016, MNRAS, 460, 130 [Google Scholar]
- Villar Martín, M., Perna, M., Humphrey, A., et al. 2020, A&A, 634, A116 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Villar Martín, M., Emonts, B. H. C., Cabrera Lavers, A., et al. 2021, A&A, 650, A84 [CrossRef] [EDP Sciences] [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Walmsley, M., Scaife, A. M. M., Lintott, C., et al. 2022, MNRAS, 513, 1581 [NASA ADS] [CrossRef] [Google Scholar]
- Wan, X. 2019, J. Phys. Conf. Ser., 1213, 032021 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, B., & Zou, H. 2021, Stat, 10, e413 [CrossRef] [Google Scholar]
- Wang, Y., Yao, Q., Kwok, J. T., & Ni, L. M. 2020, ACM Comput. Surv. (CSUR), 53, 1 [Google Scholar]
- Waskom, M. L. 2021, J. Open Source Softw., 6, 3021 [CrossRef] [Google Scholar]
- Wes McKinney 2010, in Proceedings of the 9th Python in Science Conference, eds. Stéfan van der Walt, & Jarrod Millman, 56 [CrossRef] [Google Scholar]
- Willott, C. J., Rawlings, S., & Blundell, K. M. 2001, MNRAS, 324, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Wolpert, D. H. 1992, Neural Netw., 5, 241 [CrossRef] [Google Scholar]
- Wright, E. L., Eisenhardt, P. R. M., Mainzer, A. K., et al. 2010, AJ, 140, 1868 [Google Scholar]
- Wu, Q., & Shen, Y. 2022, ApJS, 263, 42 [NASA ADS] [CrossRef] [Google Scholar]
- Wylezalek, D., Zakamska, N. L., Liu, G., & Obied, G. 2016, MNRAS, 457, 745 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, G., Brandt, W. N., Luo, B., et al. 2016, ApJ, 831, 145 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, G., Boquien, M., Buat, V., et al. 2020, MNRAS, 491, 740 [Google Scholar]
- Yang, G., Boquien, M., Brandt, W. N., et al. 2022, ApJ, 927, 192 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, G., Caputi, K. I., Papovich, C., et al. 2023, ApJ, 950, L5 [NASA ADS] [CrossRef] [Google Scholar]
- Yu, H., Han, J., & Chang, K. C.-C. 2002, in Proceedings of the Eighth acm SIGKDD International Conference on Knowledge Discovery and Data Mining, 239 [CrossRef] [Google Scholar]
- Yutani, N., Toba, Y., Baba, S., & Wada, K. 2022, ApJ, 936, 118 [NASA ADS] [CrossRef] [Google Scholar]
- Zakamska, N. L., Strauss, M. A., Krolik, J. H., et al. 2003, AJ, 126, 2125 [NASA ADS] [CrossRef] [Google Scholar]
- Zakamska, N. L., Strauss, M. A., Heckman, T. M., Ivezić, Ž., & Krolik, J. H. 2004, AJ, 128, 1002 [NASA ADS] [CrossRef] [Google Scholar]
- Zakamska, N. L., Schmidt, G. D., Smith, P. S., et al. 2005, AJ, 129, 1212 [NASA ADS] [CrossRef] [Google Scholar]
- Zakamska, N. L., Gómez, L., Strauss, M. A., & Krolik, J. H. 2008, AJ, 136, 1607 [NASA ADS] [CrossRef] [Google Scholar]
- Zeraatgari, F. Z., Hafezianzadeh, F., Zhang, Y., et al. 2024, MNRAS, 527, 4677 [Google Scholar]
- Zhao, D., Ho, L. C., Zhao, Y., Shangguan, J., & Kim, M. 2019, ApJ, 877, 52 [NASA ADS] [CrossRef] [Google Scholar]
- Zitlau, R., Hoyle, B., Paech, K., et al. 2016, MNRAS, 460, 3152 [NASA ADS] [CrossRef] [Google Scholar]
A benchmark study between the three algorithms was performed by Anghel et al. (2018). Additionally, an interesting analysis of why tree ensemble models can outperform deep learning models with tabular data can be seen in Shwartz-Ziv & Armon (2021).
An examination of how the class distribution of the training data impacts the overall performance of the models is presented in Appendix A.
Throughout this paper, the sources with the emission lines will be name as follows: [NeV] emitters for [NeV]λ3426 emitters; and [NeIII] emitters for [NeIII]λ3869 emitters.
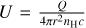 , where Q is the luminosity of ionising photons emitted by the ionising source assuming it is isotropic, r is the distance between the cloud and the ionising source, and nH is the hydrogen density of the cloud.
, where Q is the luminosity of ionising photons emitted by the ionising source assuming it is isotropic, r is the distance between the cloud and the ionising source, and nH is the hydrogen density of the cloud.
We assume a power-law spectrum of ionising radiation, Sv ∝ ν+α.
The gas metallicity is expressed with respect to the solar abundance set of Grevesse et al. (2010).
Column density of neutral hydrogen, following the results from McCarthy et al. (1990); Villar-Martín et al. (1999).
All Tables
Description of the algorithms and hyper-parameters used as base learners and meta-learners.
Classification evaluation metrics for KNNeigbors, RandomForest, LightGBM, CatBoost, XGBoost, MLP, and generalised stacking with a threshold ≥0.5.
Percentage of False Positives and False Negatives for the different strategies of train-test splits and threshold values.
Top five features with the highest feature importance for theRandomForest, XGBoost, CatBoost, and LightGBM models.
Physical properties derived for the [NeIII] emitters using Morais et al. (2021) photoionisation models.
All Figures
|
Fig. 1 Flow diagram for the AMELIA pipeline. The process begins with the assembly of SDSS and WISE data. As seen in the orange box, feature creation is used to generate optical, optical-IR, and IR colours. The imputation method is applied to the training set and followed by feature scaling due to the use of different algorithms. The blue box shows a description of the model training procedures, but we recount them here as well: Each base learner is first loosely optimised for generalisation. Subsequently, out-of-fold predictions are combined with the average predictions from the base learners, utilising a soft-vote mechanism for the training of the meta-learners. The predictions from the meta-learners are then combined through ensembling, using a soft-vote fusion that results in the final predictions for the test set. |
| In the text | |
|
Fig. 2 SDSS spectra from BOSS spectrograph for a sample of three QSO2 candidates with a [NeV]λ3426 detection. From top to bottom: SDSS J141542.16+522206.9, SDSS J013056.89-022638.1, and SDSS J141542.16+522206.9. The red vertical lines indicate where the different emission lines should be with respect to the SDSS spectroscopic redshift. |
| In the text | |
|
Fig. 3 Stacked spectra of the [NeV] and [NeIII] emitters from the QSO2 candidate sample. The fluxes for the [NeIII] emitters is offset for a better visualisation. |
| In the text | |
|
Fig. 4 Bar plot illustrating the performance of the colour criteria in selecting AGN for the QSO2 candidates, as described in the studies by Stern et al. (2012); Mateos et al. (2012); Mingo et al. (2016); Blecha et al. (2018); Carvajal et al. (2023). Each bar represents a specific subset: (a) [NeV] emitters (30 sources), (b) sources with clean spectra (138 sources), and (c) all candidate sources (365 sources). |
| In the text | |
|
Fig. 5 Histogram (blue) and empirical cumulative distribution function (orange) for the AGN fraction, fracAGN, derived using CIGALE using the SKIRTOR model. |
| In the text | |
|
Fig. A.1 Visual representation of the three different training scenarios. From left to right: Balanced training set, unbalanced training set, and equal ratio training set. The yellow colour represents the QSO2 sources, and the blue colour indicates SDSS galaxies. |
| In the text | |
|
Fig. A.2 Histogram with the average probability predictions from the generalised stacking method with meta-learner correction. The black dashed line shows the ‘default value’, 0.5, and the yellow dashed line shows the chosen classification threshold in this study, 0.8. |
| In the text | |
|
Fig. D.1 Spectrum of SDSSJ013154.44 + 224437.9 from the BOSS spectrograph. In the top plot, the red vertical lines indicate the emission lines for z≈ 1.633, computed by idlspec2d from SDSS. In the middle plot, the red vertical lines indicate the emission lines for z≈ 0.960, computed by the authors. In the bottom plot, the spectrum without any smoothing is shown. |
| In the text | |
|
Fig. E.1 Optical and radio imaging and spectrum for the SDSS J121805.63+583904.6. From left to right, top to bottom: (a) grz cutout image from SDSS with 1′ size; (b) LoTSS DR2 cutout image with 1′ size; (c) SDSS optical spectrum from BOSS spectrograph, assuming z= 1.122 . |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.