| Issue |
A&A
Volume 685, May 2024
|
|
|---|---|---|
| Article Number | A37 | |
| Number of page(s) | 21 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202348965 | |
| Published online | 03 May 2024 | |
Characterizing structure formation through instance segmentation
1
Donostia International Physics Center (DIPC), Paseo Manuel de Lardizabal, 4, 20018 Donostia-San Sebastián, Spain
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Departamento de Física Teórica, Módulo 15, Facultad de Ciencias, Universidad Autónoma de Madrid (UAM), 28049 Madrid, Spain
3
Institute for Astronomy, University of Edinburgh, Royal Observatory, Blackford Hill, Edinburgh EH9 3HJ, UK
4
IKERBASQUE, Basque Foundation for Science, 48013 Bilbao, Spain
5
Department of Computer Science and Artificial Intelligence, University of the Basque Country (UPV/EHU), Donostia-San Sebastián, Spain
Received:
15
December
2023
Accepted:
12
February
2024
Abstract
Dark matter haloes form from small perturbations to the almost homogeneous density field of the early universe. Although it is known how large these initial perturbations must be to form haloes, it is rather poorly understood how to predict which particles will end up belonging to which halo. However, it is this process that determines the Lagrangian shape of proto-haloes and it is therefore essential to understand their mass, spin, and formation history. We present a machine learning framework to learn how the proto-halo regions of different haloes emerge from the initial density field. We developed one neural network to distinguish semantically which particles become part of any halo and a second neural network that groups these particles by halo membership into different instances. This instance segmentation is done through the Weinberger method, in which the network maps particles into a pseudo-space representation where different instances can easily be distinguished through a simple clustering algorithm. Our model reliably predicts the masses and Lagrangian shapes of haloes object by object, as well as other properties such as the halo-mass function. We find that our model extracts information close to optimally by comparing it to the degree of agreement between two N-body simulations with slight differences in their initial conditions. We publish our model open source and suggest that it can be used to inform analytical methods of structure formation by studying the effect of systematic manipulations of the initial conditions.
Key words: cosmology: theory / dark matter
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Dark matter (DM) haloes are the primary structures in the universe within which galaxies form and evolve. Acting as gravitational anchors, they play a pivotal role in connecting theoretical cosmology with empirical observations from galaxy surveys. Given their significance in cosmology, a comprehensive understanding of DM haloes and their behaviour is paramount. Currently, our most detailed insights into their formation and properties come from N-body simulations (see Frenk & White 2012, for a review). These computationally intensive simulations model the interactions of vast numbers of particles, pinpointing the regions of the density field where gravitational collapse leads to the formation of DM haloes (e.g. Angulo & Hahn 2022). Therefore, understanding the formation and behaviour of DM haloes is essential to bridge the gap between theoretical models and observational data.
However, providing quick and accurate predictions (based on the initial conditions of a simulation) remains a challenging task for physically motivated models. An accurate model for halo formation must be able to capture the non-linear growth of density fluctuations. Previous analytical or semi-analytical models for halo formation, such as the top-hat spherical collapse (Gunn & Gott 1972; Gunn 1977; Peebles 1980), the Press–Schechter/excursion set theory (Press & Schechter 1974; Bond et al. 1991; Lacey & Cole 1993), and ellipsoidal collapse approaches (e.g. Sheth et al. 2001; Sheth & Tormen 2002), qualitatively reproduce the behaviour of the halo-mass function and the merging rate of haloes; however, they fail to predict these quantities accurately (e.g. Jiang & van den Bosch 2014). Further, N-body simulations show the formation of “peak-less” haloes that cannot be accounted for by any of these methods (Ludlow & Porciani 2011).
Traditional analytical methods have provided foundational insights into the process of halo formation, but they struggle to capture the full complexity of it. Machine learning (ML) techniques have emerged as a promising alternative, capable of capturing intricate non-linear dynamics inherent to the gravitational collapse of structures. ML algorithms can be trained on N-body simulations to emulate the results of much more expensive calculations. Previous studies have trained ML models to map the initial positions and velocities of particles to their final states (He et al. 2019; Giusarma et al. 2023; Alves de Oliveira et al. 2020; Wu et al. 2021; Jamieson et al. 2022) and to predict the distribution of non-linear density fields (Rodríguez et al. 2018; Perraudin et al. 2019; Schaurecker et al. 2021; Zhang et al. 2024; Schanz et al. 2023).
Further, ML has been used to predict and gain insights into the formation of haloes. Some studies utilized classification methods to anticipate if a particle will become part of a halo (Lucie-Smith et al. 2018; Chacón et al. 2022; Betts et al. 2023), or to predict its final mass category (Lucie-Smith et al. 2019). In Lucie-Smith et al. (2024), a regressor network was trained to predict the final halo mass for the central particle in a given simulation crop. The work by Bernardini et al. (2020) demonstrates how ML-segmentation techniques can be applied to predict halo Lagrangian regions. In Berger & Stein (2019), a semantic segmentation network was trained to predict peak-patch haloes. In Lucie-Smith et al. (2023), a network was trained to predict the mass of haloes when provided with a Lagrangian region centred on the centre of mass of proto-halo patches and it was then used to study assembly bias when exposed to systematic modifications of the initial conditions.
While interesting qualitative insights have been obtained in these studies, it would be desirable to develop a model that accurately predicts halo membership at a particle level, surpassing some of the limitations from previous works. An effective model should predict particles forming realistic N-body halos, improving upon previous models restricted to simpler halo definitions (e.g. Berger & Stein 2019, where peak-patch haloes are targeted). Additionally, an ideal model should be able to predict disconnected Lagrangian halo patches, overcoming the limitations of methods such as the watershed technique used in Bernardini et al. (2020), which can only handle simply connected regions. Furthermore, particles within the same halo should share consistent mass predictions, avoiding having different halo mass estimates for particles belonging to the same halo.
We present a general ML framework to predict the formation of haloes from the initial linear fields. We created a ML model designed to forecast the assignment of individual particles from the initial conditions of an N-body simulation to their respective haloes. To do so we trained two distinct networks, one for conducting semantic segmentation and another for instance segmentation. These two networks together conform what is known as a panoptic-segmentation model. Our model effectively captures the dynamics of halo formation and offers accurate predictions. We provide the models used in this study for public access through our GitHub repository1.
The rest of this paper is organized as follows: In Sect. 2, we define the problem of identifying different Lagrangian halo regions from the initial density field (Sect. 2.1), introduce the panoptic segmentation method (Sect. 2.2), present the loss function employed to perform instance segmentation (Sect. 2.3), describe the simulations used for model training (Sect. 2.4), asses the level of indetermination for the formation of proto-haloes (Sect. 2.5), outline the convolutional neural network (CNN) architecture (Sect. 2.6), and explain our training process (Sect. 2.7). In Sect. 3, we present the outputs of our semantic model (Sect. 3.1) and our instance segmentation approach (Sect. 3.2). We investigate how our model reacts to changes in the initial conditions in Sects. 4.1 and 4.2, and study how the predictions of our model are affected when varying the cosmology Sect. 4.3. We conclude with a summary and final thoughts in Sect. 5.
2. Methodology
We aim to predict the formation of DM haloes provided an initial density field. To comprehensively address this problem, we divide this section into distinct parts. In Sect. 2.1, we explain the problem of predicting halo-collapse and discuss the most general way to phrase it. In Sect. 2.2, we introduce the panoptic segmentation techniques and explain how they can be employed to predict halo formation. We divide Sect. 2.2 into two separate parts: semantic segmentation and instance segmentation. In Sect. 2.3 we describe the loss function employed to perform instance segmentation. In Sect. 2.4, we present the suite of simulations generated to train and test our models. In Sect. 2.5 we assess the level of indetermination of proto-halo formation. In Sect. 2.6 we explain how to build a high-performance model employing convolutional neural networks. Finally, in Sect. 2.7 we present the technical procedure followed to train our models.
2.1. Predicting structure formation
The goal of this work is to develop a ML framework to predict the formation of haloes from the initial conditions of a given universe. Different approaches are possible to define this question in a concrete input/output setting. We want to define the problem in a way that is as general as possible so that our model can be used in many different contexts.
The input of the model will be the linear density field discretized to a three-dimensional grid δijk. A slice through such a linear density field is shown in the top panel of Fig. 1 and represents how our universe looked in early times, for example, z ≳ 100. Beyond the density field, we also provide the linear potential field ϕijk as an input. The information included in the potential is in principle degenerate with the density field if the full universe is specified. However, if only a small region is provided, then the potential contains additional information of e.g. the tidal field sourced by perturbations outside of the region considered.
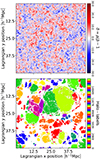 |
Fig. 1. Example of the prediction problem considered in this article. Top panel: Slice of the three-dimensional initial density field of an N-body simulation. Each voxel (represented here as a pixel) corresponds to a particle that can become part of a halo at later times. Bottom panel: Regions in the initial condition space (same slice as the top panel) that are part of different DM haloes at redshift z = 0. Pixels coloured in white do not belong to any halo. Pixels with different colours belong to different haloes. In this work, we present a machine-learning approach to predict the formation of haloes (as in the bottom panel) from the initial condition field (top panel). |
The model shall predict which patches of the initial density field become part of which haloes at later times. Concretely, we want it to group the N3 initial grid cells (corresponding, e.g., to particles in a simulation) into different sets so that each set contains exactly all particles that end up in the same halo at a later time. Additionally, there has to be one special extra set that contains all remaining particles that do not become part of any halo:
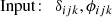 (1)
(1)
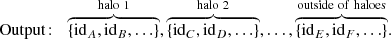 (2)
(2)
In the ML literature, this task is called an instance segmentation problem. It is important to note that it is different from typical classification problems since (A) the number of sets depends on the considered input and (B) the sets have no specific order. In practice, it is useful to define the different sets by assigning different number-labels to them. For example, one possible set of particles belonging to the same halo can be given the label “1”, another set the label “2”, and so forth. These number-labels do not have a quantitative meaning and are permutation invariant, for example, interchanging the label “1” with “2” yields the same sets.
We show such labelling of the initial space in the bottom panel of Fig. 1. In this case, the labels were inferred by the membership to haloes in an N-body simulation that employs the initial conditions depicted in the top panel of Fig. 1 (see Sect. 2.4). Our goal is to train a model to learn this instance segmentation into halo sets by training it on the output from N-body simulations.
We note that other studies have characterized the halo-formation processes through a slightly different prediction problem. For example, Lucie-Smith et al. (2024) trains a neural network to predict the final halo masses directly at the voxel level. While their approach offers insights into halo formation, our method provides a broader perspective: halo masses can be inferred easily through the size of the corresponding sets, but other properties can be inferred as well – for example the Lagrangian shapes of haloes which are important to determine their spin (White 1984). Furthermore, our approach ensures the physical constraint that particles that become part of the same halo are assigned the same halo mass.
2.2. Panoptic segmentation
The proposed problem requires first to segment the particles semantically into two different classes (halo or non-halo) and then to classify the particles inside the halo class into several different instances. The combination of such semantic plus instance segmentation is sometimes referred to as panoptic segmentation. Several strategies have been proposed to solve such panoptic segmentation problems (Kirillov et al. 2016, 2018, 2023; Bai & Urtasun 2016; Arnab & Torr 2017; De Brabandere et al. 2017) and they usually operate in two-steps:
Semantic segmentation. The objective of this task is to predict, for each voxel in our initial conditions (representing a tracer particle in the N-body code), whether it will be part of a DM halo at z = 0. This task is a classification problem, and we will employ the balanced cross-entropy (BaCE) loss (Xie & Tu 2015) to tackle it:
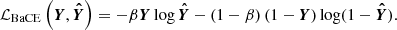 (3)
(3)
Here, Y represents the ground truth data vector, each entry corresponds to a voxel and is equal to 1 if the associated particle ends up being part of a halo; otherwise, its value is 0. 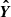 contains the model predictions, with each entry representing the probability that this particle ends up in a halo. The parameter β handles the class imbalance and is calculated as the number of negative samples divided by the total number of samples. We measure β using our training simulations (see Sect. 2.4) and obtain a value of β = 0.58152. After training our network, we need to choose a semantic threshold to generate the final semantic predictions. This threshold is calibrated to ensure that the fraction of predicted particles belonging to haloes is equal to 1 − β, resulting in a value of 0.589 (refer to Appendix C for an in-depth explanation).
contains the model predictions, with each entry representing the probability that this particle ends up in a halo. The parameter β handles the class imbalance and is calculated as the number of negative samples divided by the total number of samples. We measure β using our training simulations (see Sect. 2.4) and obtain a value of β = 0.58152. After training our network, we need to choose a semantic threshold to generate the final semantic predictions. This threshold is calibrated to ensure that the fraction of predicted particles belonging to haloes is equal to 1 − β, resulting in a value of 0.589 (refer to Appendix C for an in-depth explanation).
Instance segmentation. The objective of this task is to recognize individual haloes (instances) by identifying which particles (from those that are predicted to be part of a DM halo) belong to the same object and separating them from others.
Instance segmentation tasks are not conventional classification problems and tackle the problems of having a varying number of instances and a permutational-invariant labelling. To our knowledge, there is no straightforward way to phrase the problem of classifying each voxel into a flexible number of permutable sets through a differentiable loss function. Typical approaches train a model to predict a related differentiable loss and then apply a postprocessing step on top of it. Unfortunately, this leads to the loss function not directly reflecting the true objective.
Various approaches have been proposed to tackle this problem (Kirillov et al. 2016, 2018, 2023; Bai & Urtasun 2016; Arnab & Torr 2017; De Brabandere et al. 2017). A popular method is the watershed technique (Kirillov et al. 2016; Bai & Urtasun 2016). This method uses a network to predict semantic segmentation and the borders of different instances (Deng et al. 2018) and then applies a watershed algorithm to separate different instances in a post-processing step. However, the watershed approach comes with several limitations:
It cannot handle the identification of disconnected regions belonging to the same instance, a problem known as occlusion.
It is necessary to select appropriate threshold values for the watershed post-processing step to generate the final instance map. These parameters are typically manually chosen to match some particular metric of interest, but might negatively impact the prediction of other properties. For instance, in Bernardini et al. (2020), they apply the watershed technique to predict Lagrangian halo regions identified with the HOP algorithm (Eisenstein & Hut 1998). However, they choose the watershed threshold to reproduce the halo-mass-function, which does not ensure that the Lagrangian halo regions are correctly predicted.
The watershed approach would struggle to identify the borders of Lagrangian halo regions since they are difficult to define. In Fig. 1 it can be appreciated that the borders of halo regions are very irregular. There also exist points in the “interior” of these regions which are “missing” and make it particularly complex to define the border of a halo.
Despite all the challenges presented by the watershed approach, in Sect. A, we apply this method to predict the formation of FoF haloes and discuss how the border-prediction problem can be addressed.
An approach that offers greater flexibility for grouping arbitrarily arranged particles was presented by De Brabandere et al. (2017). We will follow this approach through the remainder of this work. The main idea behind this method, which we will refer to as the “Weinberger approach”3, is to train a model to produce a “pseudo-space representation” for all the elements of our input space (i.e. voxels/particles in the initial conditions). An ideal model would map voxels belonging to the same instance close together in the pseudo-space while separating them from voxels belonging to different instances. Consequently, the pseudo-space distribution would consist of distinct clouds of points, each representing a different instance (see Fig. 2). The postprocessing step required to generate the final instance segmentation in the Weinberger approach is a clustering algorithm which operates on the pseudo-space distributions.
 |
Fig. 2. Example of a two-dimensional pseudo-space employed to separate different instances according to the Weinberger loss. Coloured points represent individual points mapped into the pseudo-space. The centres of the clusters are presented as coloured crosses. Coloured arrows depict the influence of the pull force term, only affecting points outside the δPull range of their corresponding cluster centre. Grey arrows show the influence of the push force that manifests if two cluster centres are closer than the distance 2 ⋅ δPush. |
2.3. Weinberger loss
The Weinberger approach possesses some advantages over other instance segmentation techniques: First of all, the loss function more closely reflects the instance segmentation objective; that is, to classify different instances into a variable number of permutationally invariant sets. Secondly, the approach is more flexible and makes fewer assumptions, for example, it can handle occlusion cases and does not need to assume the existence of well-defined instance borders.
In Fig. 2, we schematically illustrate the effects of the individual components of the Weinberger loss. Each point in this figure represents a pseudo-space embedding of an input voxel. The colours indicate the assigned labels based on the ground truth. Points sharing the same colour belong to the same instance (according to the ground truth), whereas different colours depict separate instances. The “centre of mass” for each cluster is computed and indicated with coloured crosses as “cluster centres”. The Weinberger loss is constituted by three separate terms:
Pull force, Eq. (4):
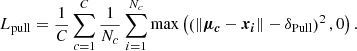 (4)
(4)
Given a certain instance c (where C is the total number of instances), a point i belonging to that set, whose pseudo-space position is xi, will feel an attraction force proportional to the distance to the instance centre  , where Nc is the number of members associated with the instance c. Points closer than δPull (which is a hyperparameter of the Weinberger loss) from the instance centre will not experience any pull force. The pull force is represented in Fig. 2 as coloured arrows pointing towards the instance centres outside the solid-line circles, which symbolize the distance δPull to the instance centres.
, where Nc is the number of members associated with the instance c. Points closer than δPull (which is a hyperparameter of the Weinberger loss) from the instance centre will not experience any pull force. The pull force is represented in Fig. 2 as coloured arrows pointing towards the instance centres outside the solid-line circles, which symbolize the distance δPull to the instance centres.
Push force, Eq. (5):
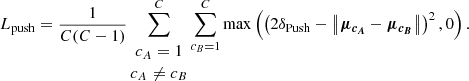 (5)
(5)
Two instances A and B will repel each other if the distance between their instance centres in the pseudo-space, μcA and μcB, is smaller than 2δPush (a hyperparameter of the Weinberger loss). The force they feel is proportional to the distance between them. In Fig. 2 the push force is represented as grey arrows. The dashed circles represent the distance δPush to the instance centres.
Regularization force, Eq. (6):
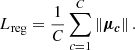 (6)
(6)
To avoid having an arbitrarily big pseudo-space distribution all instance centres will feel an attraction towards the pseudo-space origin.
The overall effect of these forces on the total Weinberger loss is written as
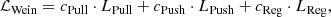 (7)
(7)
where cPull, cPush, and cReg are hyperparameters that regulate the strength of the different components.
Minimizing Eq. (7) ensures that the pseudo-space mapping produces instance clusters separated from each other. A model trained effectively predicts pseudo-space distributions with points corresponding to the same instances being grouped together and distinctly separated from other instances. In an ideal scenario in which the Weinberger loss is zero, all points are closer than δPull to their corresponding cluster centres, and clusters are at least 2δPush apart. However, realistically, the Weinberger loss is not exactly zero, necessitating a robust clustering algorithm for accurate instance map predictions.
In Appendix B we describe the clustering algorithm that we have developed to robustly identify the different instance maps. In our clustering algorithm we first compute the local density for each point in our pseudo-space based on a nearest neighbours calculation. We then identify groups as descending manifolds of density maxima surpassing a specified persistence ratio threshold. Particles are assigned to groups according to proximity and density characteristics. We merge groups selectively, ensuring that the persistence threshold is met. The algorithm relies on three key hyper-parameters for optimal performance: Ndens, Nngb and pthresh. This approach effectively segments the pseudo-space distribution of points, even when perfect separation is not achieved, thus enhancing the reliability of predicted instance maps.
2.4. Dataset of simulations
We generate twenty N-body simulations with different initial conditions to use as training and validation sets for our panoptic segmentation model. Our simulations are carried out using a lean version of L-Gadget3 (see Springel et al. 2008; Angulo et al. 2012, 2021). For each of these simulations, we evolve the DM density field employing NDM = 2563 DM particles in a volume of Vbox = (50 h−1 Mpc)3, resulting in a DM particle-mass of mDM = 6.35 × 108 h−1 M⊙. All our simulations employ the same softening length: ϵ = 5 h−1 kpc, and share the cosmological parameters derived by Planck Collaboration VI (2020), that is, σ8 = 0.8288, ns = 0.9611, h = 0.6777, Ωb = 0.048252, Ωm = 0.307112, and ΩΛ = 0.692888. Our suite of simulations is similar to the one employed in Lucie-Smith et al. (2024).
We use a version of the NgenIC code (Springel 2015) that uses second-order Lagrangian Perturbation Theory (2LPT) to generate the initial conditions at z = 49. We employ a different random seed for each simulation to sample the Gaussian random field that determines the initial density field. We identify haloes at redshift z = 0 in our simulations using a Friends-of-Friends algorithm (Davis et al. 1985), with linking length b = 0.2. In this work, we will only consider haloes formed by 155 particles or more, corresponding to MFoF ⪆ 1011 h−1 M⊙. We use 18 of these simulations to train our model and keep 2 of them to validate our results.
2.5. Assessing the level of indetermination
In addition to the training and test sets, we run a set of simulations to establish a target accuracy for our model. These simulations test to what degree small sub-resolution changes of the initial density field can affect the final Lagrangian halo regions.
Structure formation simulations resolve the initial conditions of a considered universe only to a limited degree and exhibit therefore an inherent degree of uncertainty. (1) The numerical precision of simulations is limited (e.g. to 32 bit floating point numbers) and therefore any results that depend on the initial conditions beyond machine precision are inherently uncertain. For example, Genel et al. (2019) show that changes in the initial displacement of N-body particles at the machine-precision level can lead to differences in the final locations of particles as large as individual haloes. (2) The initial discretization can only resolve the random perturbations of the Gaussian random field down to a minimum length scale of the mean-particle separation. If the resolution of a simulation is increased, then additional modes enter the resolved regime and act as additional random perturbations. Such additional perturbations may induce some random changes in the halo assignment of much larger-scale structures.
A good model should learn all aspects of structure formation that are certain and well resolved at the considered discretization level. However, there is little use in predicting aspects that are under-specified and may change with resolution levels. Therefore, we conduct an experiment to establish a baseline of how accurate our model shall be.
We run two additional N = 2563 simulations with initial conditions generated by MUSIC code (Hahn & Abel 2011). For these simulations we keep all resolved modes fixed (up to the Nyquist frequency of the 2563 grid), but we add to the particles different realisations of perturbations that would be induced by the next higher resolution level. We do this by selecting every 23th particle from two initial condition files with 5123 particles and with different seeds at the highest level (“level 9” in MUSIC). Therefore, the two simulations differ only in the random choice of perturbations that are unresolved at the 2563 level. We refer to these two simulations as the “baseline” simulations.
In Fig. 3 we show a slice of the Lagrangian halo patches at z = 0 through these simulations (left and right panels, respectively). The colour map in this figure represents the masses of the halo that each particle becomes part of, which correspond to the size of the corresponding halo-set. We colour each pixel (which corresponds to a certain particle) according to the mass of the halo that it belongs to. We can appreciate that the outermost regions of the Lagrangian regions are particularly affected while the innermost parts remain unchanged. Notably, in certain instances, significant changes appear due to the merging of haloes in one of the simulations where separate haloes are formed in the other (black-circled regions).
 |
Fig. 3. Slice of the Lagrangian halo regions of the two “baseline” simulations (left and right panels, respectively). These simulations only differ in sub-resolution perturbations to the initial conditions and their level of agreement sets a baseline for the desired accuracy of our models. The colours employed for both panels represent the mass of the halo associated with each particle for the different Lagrangian halo patches. Circled regions highlight Lagrangian patches whose associated mass significantly changes between the two simulations. |
Throughout this article, we will use the degree of correspondence between the baseline simulations as a reference accuracy level. We consider a model close to optimal if the difference between its predictions and the ground truth is similar to the differences observed between the two baseline simulations. A lower accuracy than this would mean that a model has not optimally exploited all the information that is encoded in the initial conditions. A higher accuracy than this level is not desirable, since it is not useful to predict features that depend on unresolved aspects of the simulation and may be changed by increasing the resolution level.
2.6. V-net architecture
V-nets are state-of-the-art models and a product of many advances in the field of ML over the last decades (Fukushima 1980; Lecun et al. 1998; Krizhevsky et al. 2012; Szegedy et al. 2014; Long et al. 2014; Ronneberger et al. 2015; He et al. 2015). They are a particular kind of CNN developed and optimized to efficiently map between volumetric inputs and volumetric outputs. V-nets are formed by two separate modules: the encoder (or contracting path) which learns how to extract large-scale abstract features from the input data; and the decoder (or up-sampling path) that translates the information captured by the encoder to voxel-level predictions (also making use of the information retained in the “skipped connections”). We train V-nets to minimize the loss functions presented in Sects. 2.2 and 2.3. We now explain the technical characteristics of how we have implemented a V-net architecture in TensorFlow (Abadi et al. 2016) (see Fig. 4 for a schematic representation of our network architecture):
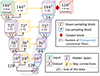 |
Fig. 4. Flowchart of the particular V-Net architecture we have implemented. The network can take as input multiple channels with dimensions of 1443 (top left green cube) and generates predictions for the central voxels with dimensions 1283 (top right red cube). The flowchart illustrates the encoder and decoder paths, along with other distinctive features of the network. Notably, the hidden layers and skip connections are represented by purple and yellow cubes, with their respective dimensions annotated at their centres. The down-sampling and up-sampling blocks are shown as brown and purple trapezoids, in their centres we indicate the number of filters employed for the convolution (or transposed convolution) operations. |
Input: Our network is designed to accept as input 3D crops consisting of 1443 voxels4. For the results presented in Sect. 3, we employ two input channels for the semantic segmentation model, corresponding to the initial density field and the displacement potential, which is defined through Poisson’s equation as
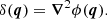 (8)
(8)
For the instance segmentation model, we include three additional input channels corresponding to the Lagrangian positions of particles. This is necessary since the network has to be able to map different haloes with the same density (and potential) structure at different locations in the initial field to different locations in the pseudo space.
Encoder/contractive/down-sampling/down-scaling path: This module consists of consecutive down-scaling blocks that reduce the number of voxels per dimension by half at each level of the network. The purpose of the down-scaling path is to enlarge the network’s field of view, enabling per-voxel predictions that take into account distant regions of the field. Achieving this would be impractical using large convolution kernels, as they would consume excessive memory. Within each down-sampling block, we apply three consecutive convolution operations followed by a Leaky–ReLu activation function. The number of convolution filters in a contractive block doubles with each level of compression to improve the performance of the model. For each level, the latent maps computed before the final convolution (the one used to reduce the data size) are temporarily stored to serve as a skip connection for the up-scaling path. In Fig. 4 we show the dimensions of the latent maps computed at each level of the contractive path; the deepest level of our network has a size of 93 × 128.
Decoder/up-sampling/up-scaling path: This path operates opposite to the contractive path; each up-scaling block doubles the number of voxels per dimension, ultimately recovering an image with the same dimensions as the original input (see Fig. 4). The up-sampling path facilitates the extraction of smaller-scale features that influence the final per-voxel predictions. Within an up-sampling block, the final convolution is substituted with a transposed convolution operation, that allows doubling the output size per dimension.
Output: The final module of our network takes as input the latent maps with dimensions 1443 × 16. The functionality of this module varies depending on the task at hand. For semantic segmentation, a single convolution operation is performed, resulting in a latent map of 1443 × 1. This map is subsequently cropped to 1283 × 1, and finally, a sigmoid activation function is applied. In the case of instance segmentation, we have decided to work in a three-dimensional pseudo-space, hence, we employ a convolution with three filters to obtain 1443 × 3 maps, which are cropped afterwards to 1283 × 3. In both cases, the final cropping operation is implemented to enhance model performance by focusing on the central region of the image.
2.7. Training
We train our segmentation networks using a single Nvidia Quadro RTX 8000 GPU card. As mentioned in Sect. 2.4, we employ 18 simulations for training, dividing the training process into separate stages for the semantic and instance models.
To ensure robust training and enhance the diversity of training examples without needing to run more computationally expensive simulations, we apply the following data augmentation operations each time we extract a training sample from our simulation suite:
-
Select one of the training simulation boxes at random.
-
Select a random voxel as the centre of the input and output regions.
-
Extract the input (1443) and target (1283) fields of interest by cropping the regions around the central point, considering the periodic boundary conditions of the simulations.
-
Randomly transpose the order of the three input grid dimensions qx, qy, qz.
-
Randomly chose to flip the axes of the input fields.
To train our semantic and instance segmentation networks we minimize the respective loss functions – Eq. (3) and Eq. (7) – employing the Adam optimizer implemented in TensorFlow (Abadi et al. 2016). We train our models for over 80 epochs, each epoch performs mini-batch gradient descent using 100 batches, and each batch is formed by 2 draws from the training simulations. We deliberately choose a small batch size to avoid memory issues and ensure the network’s capability to handle large input and output images (1443 and 1283, respectively). Selecting a small batch size induces more instability during training; we mitigate this issue by using the clip normalization operation defined in TensorFlow during the backpropagation step.
The hyper-parameter β in the Balanced Cross-Entropy Eq. (3) is determined by computing the ratio of negative samples to the total number of samples in the training data. The value of β measured in different training simulations lies in the interval [0.575,0.5892]. There exists a slight predominance of voxels/particles that do not collapse into DM haloes with mass MFoF ⪆ 1011 h−1 M⊙ at z = 0 considering the Planck Collaboration VI (2020) cosmology. We fix the hyper-parameter β in Eq. (3) to the mean value β = 0.5815.
Regarding the hyper-parameters in the Weinberger loss Eq. (7), we adopt the values presented in De Brabandere et al. (2017), as we have observed that varying these parameters does not significantly affect our final results. The specific hyper-parameter values are the following: cPull = 1, δPull = 0.5, cPush = 1, δPush = 1.5, and cReg = 0.001. We have conducted a hyper-parameter optimization for the clustering algorithm described in Appendix B and found the following values: Ndens = 20, Nngb = 15 and pthresh = 4.2 (see Table 1).
Hyper-parameters employed in our instance segmentation pipeline.
Our semantic and instance models are designed to predict regions comprising 1283 particles due to technical limitations regarding GPU memory. To overcome this limitation and enable the prediction of larger simulation volumes, we have developed an algorithm that seamlessly integrates sub-volume crops. For our semantic model, we serially concatenate sub-volume predictions to cover the full simulation box. For our instance network, we propose the method described in Appendix D. In summary, this method works as follows: we generate two overlapping lattices. Both lattices cover the entire simulation box, but the second one is shifted with respect to the first one (its sub-volume centres lay in the nodes of the first one). The overlapping regions between the lattices are employed to determine whether instances from different crops should merge or not. We have verified that this procedure is robust by checking that the final predictions are not sensitive to the particular lattice choice.
We train our semantic and instance networks separately. The semantic predictions are not employed at any stage during the training process of the instance model. To compute the instance loss, Eq. (7) is evaluated using the true instance maps and the pseudo-space positions. The semantic predictions are only employed once both models have been trained. We use the semantic predictions to mask out pseudo-space particles not belonging to haloes. Then, the clustering algorithm described in Appendix B is applied to identify clusters of particles in the pseudo-space (which yields the final proto-halo regions).
3. Model evaluation
In this section, we test the performance of our models for semantic segmentation (Sect. 3.1) and instance segmentation (Sect. 3.2). We use the two simulations reserved for validation to generate the results presented in this section.
3.1. Semantic results
In Fig. 5, we compare the predictions of the semantic segmentation network with the halo segmentation found in the validation simulation. The leftmost panel illustrates a slice of the ground truth. Voxels/particles of the initial conditions belonging to a DM halo at z = 0 are shown in red; blue voxels represent particles not belonging to a DM halo at z = 0.
 |
Fig. 5. Slice through the predictions of our semantic segmentation network applied to a validation simulation. Left panel: Ground truth representation showing in red the voxels/particles belonging to a DM halo at z = 0 and in blue those particles that do not belong to a DM halo. Central panel: Probabilistic predictions of the semantic network with colour-coded probabilities for halo membership. Right panel: Pixel-level error map indicating true positive (green), true negative (blue), false negative (black), and false positive (red) regions resulting after applying a semantic threshold of 0.589 to our predicted map. The network effectively captures complex halo boundaries and exhibits high validation accuracy (acc = 0.86) and F1-score (F1 = 0.83). |
The central panel of Fig. 5 displays the probabilistic predictions from our semantic model for the same slice. The colour map indicates the probability assigned to each pixel for belonging or not to a DM halo. Voxels with a white colour have a 50% predicted probability of belonging to a halo. The neural network tends to smooth out features, assigning uncertain probabilities to regions near halo borders, while consistently assigning high probabilities to inner regions and low probabilities to external regions. In the ground truth it is possible to observe that some interior particles within proto-haloes are predicted to belong to the background. We refer to these as “missing voxels”. One of the consequences of the smoothing effect of our network is to ignore these missing voxels, predicting a homogeneous probability of collapse in the interior regions of proto-haloes. The missing voxels in the Lagrangian structure seem to be a feature very sensitive to the initial conditions impossible to capture accurately at a voxel level. This is supported by the fact that the missing voxels also change significantly in the baseline simulations (see Fig. 3).
The rightmost panel of Fig. 5 shows the pixel-level error map for the same slice. We select a semantic threshold value equal to 0.589 to generate these results. We choose this value for the semantic threshold so that the total predicted number of particles that belong to a halo matches the number of collapsed voxels in the validation simulations. In Appendix C we further analyse the sensitivity of our semantic results to the value chosen for the semantic threshold. We use different colours to represent the corresponding classes of the confusion matrix: Green corresponds to true positive (TP) cases, blue to true negatives (TN), black to false negatives (FN), and red to false positives (FP).
Some regions are particularly challenging to predict for the network, likely due to their sensitivity to changes in the initial conditions. For example, in the rightmost panel of Fig. 5, it is easy to appreciate many FN regions that appear as black string-like structures surrounding TP collapsed regions. These FN cases likely correspond to particles infalling into the halo at z = 0, identified as part of the FoF group despite not having completed the first pericentric passage. Capturing this behaviour might be particularly challenging for the network since the exact shape of these “first-infall” regions is more sensitive to small changes in the initial condition and can also be influenced by distant regions of the proto-haloes that do not completely fit within the field of view of our network (which can occur for very massive proto-halos). Also, we can appreciate FP regions that appear between the FN string-like regions and the TPs corresponding to the central Lagrangian regions of haloes. Additionally, the boundaries of the largest haloes may be especially difficult to predict for the network, since they only fit partially into the field of view.
The results presented in Fig. 5 suggest, upon visual inspection, that our model accurately captures many of the complex dynamics that determine halo collapse. To rigorously assess the performance of our model we need to quantify the results obtained from our semantic network and compare them with the differences between the baseline simulations, as discussed in Sect. 2.
In Table 2 we present the values of some relevant metrics that we can employ to evaluate the performance of our semantic network (we have considered the semantic threshold of 0.589). In particular, we study the behaviour of five different metrics: True Positive Rate TPR = TP/(TP + FN), True Negative Rate TNR = TN/(TN + FP), Positive Predictive Value PPV = TP/(TP + FP), Accuracy ACC and the F1-score (which is a more representative score than the accuracy when considering unbalanced datasets), see Eq. (9):
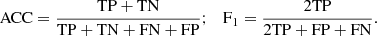 (9)
(9)
Performance metrics of our semantic segmentation model, along with the EXSHALOS results, compared against the optimal target accuracy estimated from the baseline simulations.
Table 2 also contains the scores measured using the baseline simulations. Our model returns values for all the metrics very close to the optimal target from the baseline simulations. This demonstrates the reliability of our model in predicting the well-specified aspects of halo collapse. See Appendix C for a more detailed discussion about the performance of our semantic model and the relation between the selected semantic threshold with the results contained in Table 2.
In addition to the optimal case, we compare our semantic model with the explicit implementation of the excursion set theory from EXSHALOS (Voivodic et al. 2019). The EXSHALOS code grows spheres around the density peaks in the Lagrangian density field until the average density inside crosses a specified barrier for the first time. The barrier shape is motivated by the ellipsoidal collapse (Sheth et al. 2001; de Simone et al. 2011) with three free parameters that were fitted to reproduce the mean mass function of our simulations. In Table 2 we include the semantic metrics measured with the EXSHALOS results. While EXSHALOS can describe halo formation to some degree, there exist some aspects that go beyond the spherical excursion set paradigm which are better captured by our semantic model. A more detailed analysis of the results obtained with EXSHALOS is presented in Appendix E.
In Fig. 6 we compare the values of the predicted TPR as a function of ground truth halo mass (TPRPred, solid green line), with the TPR values measured from the baseline simulations (TPRbase, solid black line). It is possible to perform this comparison for the TPR because, in the ground truth data, we retain information about the mass of the FoF haloes associated with each DM particle. Therefore, we can compute the fraction of TP cases in different ground-truth-mass-bins by selecting the voxels according to the mass associated with them in the ground truth.
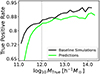 |
Fig. 6. True positive rate expressed as a function of the halo mass associated with the ground truth voxels. We present the results measured from the model predictions (solid bright green line) in comparison to the optimal target accuracy from the baseline simulations (solid black line). The vertical dotted line at 1012 h−1 M⊙ marks the point where model predictions start to differ from the baseline results. |
In Fig. 6, the values for TPRbase increase with halo mass, indicating that particles that end up in lower-mass haloes are more sensitive to small-scale changes in the initial conditions, consequently, harder to predict accurately. Our network’s predictions follow a similar trend, albeit with some discrepancies. The model seems to under-predict the number of particles that end up in haloes with masses lower than MTrue ⪅ 1012 h−1 M⊙ (dotted vertical black line in Fig. 6). This indicates that our model tends to under-predict the number of pixels that are identified as TPs in the lower mass end. For haloes whose mass is greater than 1012 h−1 M⊙, our model returns accurate predictions to a good degree over a broad range, extending more than two orders of magnitude in halo mass.
In this subsection, we have demonstrated that our semantic model extracts most of the predictable aspects of halo formation by comparing our results with the baseline simulations (which only differ in unresolved aspects of the initial conditions). We now employ the predictions of our semantic network to generate the final results using our instance segmentation model.
3.2. Instance results
We provide some examples of our instance predictions in Fig. 7. The left column displays the ground truth masses of halo Lagrangian regions extracted from the simulation results (analogous to Fig. 3); the right column shows the predictions obtained from our segmentation pipeline. The way in which we compute halo masses from the instance predictions is by counting the number of particles/voxels that have been assigned to the same label and multiplying that by the particle mass of our simulations, mDM = 6.35 × 108 h−1 M⊙.
 |
Fig. 7. Examples of the instance segmentation results obtained with our model. Left column: Ground truth masses obtained using N-body simulations. Right column: Predicted masses obtained using our instance segmentation pipeline. The model can predict the Lagrangian patches of haloes, although some small differences – e.g. regarding the connectivity of haloes – exist. |
The shapes of the halo contours are well-captured thanks in part to the semantic predictions. The instance segmentation pipeline successfully distinguishes the different haloes that have formed, and in most cases, correctly separates neighbouring haloes. This is not a trivial task since the size of halo Lagrangian regions varies across several orders of magnitude. Therefore, the instance segmentation pipeline must correctly separate wildly different particle groupings in the pseudo-space. Figure 7 shows that our instance segmentation pipeline correctly identifies different Lagrangian halo regions for the majority of cases. However, we note that differences arise on the one hand for very small haloes that are close to the resolution limit and on the other hand for very large haloes that are larger than the field of view of the network.
In Fig. 8, we present a comparison between the ground truth halo masses and the predicted masses associated with the particles/voxels in our validation set. To generate these results we apply the following procedure: We select all the ground truth voxels/particles that end up in FoF haloes and study the predictions associated with them. We can associate a predicted mass for all the voxels that belong to a DM halo. In these cases, we can compare the predicted mass values (MPred) with the ground truth masses (MTrue) at a voxel level. This comparison is shown in the main panel of Fig. 8 as black violin plots (“violins” henceforth). The mass range covered by the black violins goes from MTrue = 1011 h−1 M⊙, corresponding to the minimum mass of haloes (155 particles), to MTrue ≈ 1014.7 h−1 M⊙, which is the mass of the most massive halo identified in the validation simulations. The number of high-mass haloes is smaller than small-mass ones and therefore the higher-mass end of the violin plot exhibits more noise. We can appreciate that the median predictions (black dots) correctly reproduce the expected behaviour (ground truth) for several orders of magnitude.
 |
Fig. 8. “Violin plot”, visualizing the distribution of predicted halo masses (at a voxel level) for different ground-truth mass bins. The black violin plots show the results obtained with our instance segmentation model. Green violin plots show the agreement between the two baseline simulations – representing an optimal target accuracy. The blue violin plots in the main panel show the results presented in Lucie-Smith et al. (2024). The solid black line in the top panel shows the false negative rate, FNR, as a function of the ground truth halo mass. The dashed black line represents the fraction of predicted collapsed pixels that are not actually collapsed as a function of predicted halo mass (false discovery rate, FDR). The green lines on the top panel correspond to the analogous results obtained from the baseline simulations. The model predicts haloes accurately object-by-object for masses M ≳ 1012 h−1 M⊙. |
The voxels identified as part of a halo in the ground truth, but not in the predicted map, are false negative (FN) cases. For these occurrences, we can study the dependence of the false negative rate (FNR) as a function of the ground truth halo mass (solid black line on the top panel of Fig. 8; analogous to Fig. 6). We can also study the reciprocal case in which a voxel is predicted to be part of a halo (hence, it has an associated MPred) but the ground truth voxel is not collapsed. These cases correspond to false positives (FP) but to make a comparison as a function of mass we can only express it in terms of the predicted mass. Therefore, we show as a dashed black line in the top panel of Fig. 8 the false discovery rate,
![Mathematical equation: $$ \begin{aligned} \mathrm{FDR} = \frac{\left[\mathrm{FP} |M_{\rm Pred}\right]}{\left[\mathrm{TP} |M_{\rm Pred}\right] + \left[\mathrm{FP} |M_{\rm Pred}\right]}\cdot \end{aligned} $$](/articles/aa/full_html/2024/05/aa48965-23/aa48965-23-eq12.gif) (10)
(10)
We compare our results with those obtained from the baseline simulations. In the main panel of Fig. 8 we present the corresponding violin plots from the baseline simulations with green lines. The range that the green violins span is smaller than the black violins since the most massive halo identified in the baseline simulations has a mass of MTrue ≈ 1014.4 h−1 M⊙. In the top panel, the solid and dashed green lines represent the FPR and FDR, respectively. As expected, the FPR and FDR coincide in the case of the baseline simulations. The top panel results demonstrate that our predictions are comparable to those of the baseline simulations (as pointed out in Fig. 6) over most of the considered mass range. However, they get progressively worse for masses below MTrue ⪅ 1012 h−1 M⊙ (vertical dotted black line), deviating from the baseline trend. This indicates that our model struggles to capture the correct behaviour of lower-mass haloes but it produces accurate predictions for higher-mass ones. When comparing the violin plot distributions of our model with the baseline simulations we appreciate that we obtain similar (but slightly broader) contours. Being able to achieve a similar scatter as in the baseline simulations indicates that our model can capture the well-resolved aspects of halo formation. We want to emphasize that precise predictions for halo masses are not directly enforced through the training loss, but are a side product, consequence of precisely reproducing halo Lagrangian patches. The scatter broadens for smaller halo mass and the network loses accuracy in these cases, sometimes associating smaller haloes close to a big Lagrangian patch to its closest more massive neighbour.
In the main panel of Fig. 8, we include the violin plot lines presented in Lucie-Smith et al. (2024) (blue violin lines). In this study, a neural network was trained to minimize the difference between predicted and true halo-masses at the particle level using as inputs the initial density field or the potential. The focus of Lucie-Smith et al. (2024) is to examine how different features of the initial conditions influence mass predictions within a framework that mirrors analytical models.
The comparison between our methodology and Lucie-Smith et al. (2024) in Fig. 8 highlights the differing outcomes that arise from the unique objectives and constraints each model employs. While both models ultimately predict halo masses, we suggest that our approach benefits from the rigid operator that groups particles together and assigns them the same halo mass. Therefore, analytical approaches towards predicting the formation of structures may benefit from knowing about the fate of neighbouring particles. Since in excursion set formalisms, this is only possible to a limited degree, this increases the motivation for considering alternative approaches, like the one proposed by Musso & Sheth (2023).
In Appendix E, we include a comparison of our instance model with the predictions of EXSHALOS (Voivodic et al. 2019). In Fig. E.1, we show a map-level comparison between the Lagrangian shapes of friends-of-friends proto-haloes and EXSHALOS predictions. The shapes of proto-haloes predicted by the EXSHALOS implementation are limited to sphere-like volumes, which affects its flexibility and, consequently, its accuracy (see Table 2). While EXSHALOS correctly replicates the halo mass function of friends-of-friends haloes, it struggles to reproduce particle-level mass predictions, as shown in the violin plot in Fig. E.2.
In Fig. 9 we present the halo-mass-function (HMF) computed using the validation simulations (solid black line). The dashed black line shows the predicted HMF computed using the results of our instance segmentation pipeline. We can appreciate that our predictions reproduce the N-body results over a range that spans more than two orders of magnitude. Our results improve upon the prediction mass range for the HMF of previous similar approaches (Berger & Stein 2019; Bernardini et al. 2020). This is despite the fact that Bernardini et al. (2020) select their hyper-parameters to reproduce the HMF; while in Berger & Stein (2019) they reproduce the HMF corresponding to Peak Patch haloes (Stein et al. 2019), instead of the HMF associated with FoF haloes. In Fig. 9 we also include a solid blue line representing the theoretical HMF predictions using the model by Ondaro-Mallea et al. (2022). We compare this result with the HMF associated with the haloes predicted by our model using the density and potential fields of a realization with 10243 particles and a volume of Vbox = (200 h−1Mpc)3. Both lines show a good agreement in the 1012 − 1015 h−1 M⊙ range.
 |
Fig. 9. Halo-mass function (HMF) computed using our N-body simulations reserved for validation (solid black line). The dashed black line represents the predicted HMF using the Lagrangian halo regions obtained with our instance segmentation pipeline. The solid blue line shows the HMF prediction from Ondaro-Mallea et al. (2022). The dashed blue line corresponds to the HMF obtained after evaluating our model in a simulation with 10243 particles and Vbox = (200 h−1Mpc)3. |
We conclude that our semantic plus instance segmentation pipeline correctly reproduces the Lagrangian halo shapes of FoF haloes spanning a mass range between 1012 h−1 M⊙ and 1014.7 h−1 M⊙. We have tested the accuracy of our results employing different metrics (presented in several tables and figures). Inferred quantities from our predicted Lagrangian halo regions, such as the predicted halo masses, correctly reproduce the trends computed using N-body simulations and improve upon the results presented in previous studies.
4. Experiments
In this section, we test how our network reacts to systematic modifications to the input density field and potential and how well it generalizes to scenarios that lie beyond the trained domain. Therefore, we analyse the response to large-scale density perturbations, to large-scale tidal fields and to changes in the variance of the density field.
4.1. Response to large-scale densities
We study the response of the haloes to a large-scale over-density such as typically considered in separate universe simulations (Wagner et al. 2015; Lazeyras et al. 2016; Li et al. 2014). We add a constant δϵ to the input density field δ(q) so that the new density field δ*(q) is given by
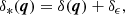 (11)
(11)
and to maintain consistency with Poisson’s equation, see Eq. (8), we add a quadratic term to the potential:
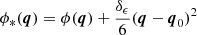 (12)
(12)
where q0 is an arbitrary (and irrelevant) reference point (Stücker et al. 2021a), which we choose to be in the centre of our considered domain. Note that we break the periodic boundary conditions here, so it is difficult to do this operation for the whole box, but instead we consider it only for a smaller region to avoid boundary effects.
We show how haloes respond to this modification in Fig. 10. The middle panel shows the predicted masses associated with the particles/voxels (in a similar way to Fig. 7) for the reference field, δϵ = 0. The upper and lower panels show the results of including a constant term to the initial over-density field of δϵ = −0.5 and δϵ = 0.5, respectively.
 |
Fig. 10. Response of proto-haloes to large-scale over-densities. The three panels show over-densities of δϵ = −0.5, 0 and 0.5, respectively. A larger large-scale density tends to increase the Lagrangian volume of haloes and leads to additional mergers in some cases. |
Increases in the background density lead to more mass collapsing onto haloes, thus generally increasing the Lagrangian volume of haloes. Furthermore, it leads in many cases to previously individual haloes merging into one bigger structure. This is qualitatively consistent with what is observed in separate universe simulations (e.g. Dai et al. 2015; Wagner et al. 2015; Barreira et al. 2019; Jamieson & Loverde 2019; Terasawa et al. 2022; Artigas et al. 2022).
To evaluate quantitatively whether the model has learned the correct response to large-scale density perturbations, we test whether it recovers the same halo bias that has been measured in previous studies (Desjacques et al. 2018, for a review). In separate universe experiments, the linear bias parameter can be inferred as the derivative of the halo mass function with respect to the large-scale density:
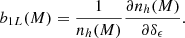 (13)
(13)
Therefore, Lazeyras et al. (2016) used the halo mass function measured in separate universe simulations with different large-scale densities δϵ to measure the bias parameters through a finite differences approach. While our qualitative experiment from Fig. 11 follows this in spirit, it is difficult to do the same measurement here, since the addition of the quadratic potential term in Eq. (12) breaks the periodic boundary conditions and makes it difficult to measure the mass function reliably over a large domain. Therefore, we instead adopt an approach to infer the bias from the unperturbed δϵ = 0 case. Paranjape et al. (2013) shows that the Lagrangian bias parameter can be measured by considering the (smoothed) linear over-density at the Lagrangian location of biased tracers δi:
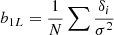 (14)
(14)
 |
Fig. 11. Linear Lagrangian bias parameter b1L for the haloes, measured for different boxsizes L and comparing simulation and model. The model agrees well with the simulation at the L = 50 h−1 Mpc scale, but both are inconsistent with the true large-scale bias relation from Lazeyras et al. (2016) due to effects from the limited size of the simulation volume. Evaluation on larger boxes moves the prediction closer to the known relation, but some deviation is maintained. |
where the sum goes over N different tracers (e.g. all haloes in a given mass bin) and where σ2 = ⟨δ2⟩ is the variance of the (smoothed) linear density field. Since this measurement should give meaningful results only on reasonably large scales, we smooth the Lagrangian density field with a Gaussian kernel with width σr = 6 h−1 Mpc. We measure the smoothed linear density δi at the Lagrangian centre of mass of each halo patch and then we measure the bias by evaluating Eq. (14) in different mass bins.
We show the resulting b1L as a function of mass in Fig. 11. The blue solid and dashed lines show the bias parameters measured in an L = 50 h−1 Mpc box for the simulated versus predicted halo patches respectively. These two seem consistent, showing that the model has correctly learned the bias relation that is captured inside of the training set. However, this (L = 50 h−1 Mpc) relation is not consistent with the well-measured relation from larger scale simulations, indicated as a black solid line adopted from Lazeyras et al. (2016). This is because very massive haloes M ≫ 1014 h−1 M⊙ do not form in simulations of such a small volume, but they are important to get the correct bias of smaller mass haloes, since wherever a large halo forms, no smaller halo can form. Our network has never seen such large scales, so it is questionable whether it has any chance of capturing the large-scale bias correctly. However, it might be that what it has learned in the small-scale simulation transfers to larger scales. To test this, we evaluate the network on two larger boxes, L = 100 h−1 Mpc and L = 200 h−1 Mpc, shown as orange and green lines in Fig. 11. These cases match the true bias relation better, but still show some significant deviation e.g. at M ∼ 1014 h−1 M⊙. Therefore, we conclude that the network generalizes only moderately well to larger scales and halo masses. Improved performance could possibly be achieved by extending the training set to larger simulations and by increasing the field of view of the network.
4.2. Response to large-scale tidal fields
In a second experiment, we want to study the response of haloes to purely anisotropic changes of the initial conditions, by adding a large-scale tidal field. We, therefore, aim to emulate a modification similar to the ones considered in anisotropic separate universe simulations (Schmidt et al. 2018; Stücker et al. 2021b; Masaki et al. 2020; Akitsu et al. 2021). We modify the input potential through the term
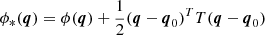 (15)
(15)
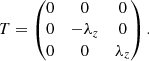 (16)
(16)
Since we are considering a trace-free tidal tensor, we do not need to include any modifications to the initial density field. The results of introducing the tidal field are presented Fig. 12. In the upper panel in which we have imposed a value of λz = −0.5, the regions of typical proto-haloes are slightly reduced in the z-direction and extended in the y-direction. Further, in some cases haloes merge additionally in the y-direction while separating in the z-direction. In the bottom panel with λz = 0.5 we observe the opposite behaviour, with proto-halo shapes elongated in the z-direction and reduced in the y-direction. These observations are consistent with the naive expectation: A positive λz means a contracting tidal field in the z-direction, which facilitates infall in this direction, whereas a negative λz delays the infall. Therefore, proto-haloes appear extended in the direction where the tidal field has a contracting effect. This should not be confused with the response of the halo shapes in Eulerian space which has the opposite behaviour – reducing the halo’s extent in the direction where the tidal field is contracting (Stücker et al. 2021b). Therefore, a large-scale tidal field effects that the direction from which more material falls in, is the direction where the final halo is less extended.
 |
Fig. 12. Response of proto-halo regions towards a large-scale tidal field. The different panels show the cases with λz = −0.5, 0 and 0.5 – corresponding to a stretching tidal field, no tidal field and a compressing tidal field in the vertical direction respectively. A negative (stretching) tidal field delays infall and shrinks the proto-halo patches in the corresponding direction, whereas a positive (compressing) tidal field facilitates infall and extends the proto-halo patches. |
However, by comparing Figs. 10 and 12, we note that the effect of modifying the eigenvalues of the tidal tensor (while keeping the trace fixed) is much less significant than modifying its trace δ by a similar amount. Modifying δ leads to strong differences in the abundance and the masses of haloes whereas the modifications to the tidal field strongly affect the shapes, but has a much smaller effect on typical masses – if at all.
Our investigation into the role of anisotropic features in the initial conditions complements the findings of Lucie-Smith et al. (2024). They find that anisotropic features of the initial conditions do not significantly enhance halo mass predictions when compared to predictions based on spherical averages. Therefore, they conclude that including anisotropic features would not significantly improve the mass predictions that can be obtained within excursion set frameworks. This observation is consistent with masses not changing significantly when applying a large-scale tidal field. However, we find that anisotropic features are in general important for the formation of structures since they affect which particles become part of which halo.
Finally, we note that the response of the Lagrangian shape of haloes is particularly interesting in the context of tidal torque theory (White 1984). To predict the angular momentum of haloes, tidal torque theory requires knowledge of both the tidal tensor and the Lagrangian inertia tensor of haloes. Further, it has been argued that the misalignment of tidal field and Lagrangian inertia tensor is a key factor for predicting galaxy properties (Moon & Lee 2023). Our experiments show that modifications of the tidal tensor itself also trigger modifications of the Lagrangian shape. Precisely understanding this relation would be relevant to correctly predict halo spins from the initial conditions. Note that such responses are inherently absent in most density-based structure formation models (e.g. Press & Schechter 1974; Bond et al. 1991; Sheth & Tormen 2002), but could possibly be accounted for by recently proposed approaches based on the Lagrangian potential (Musso & Sheth 2021, 2023).
4.3. Response to changes in the variance of the density field
We now study whether our model can generalize to scenarios different from the training set by investigating how it responds to variations in σ8, deviating 30% from the original Planck Collaboration VI (2020) cosmology. We aim to discern if the network, trained on a singular variance setting, has gained enough insight into halo formation to anticipate outcomes considering different values for the variance of the initial density field. These modifications only affect the initial conditions which are fully visible to the network, so it could be possible that the network correctly extrapolates to these scenarios.
In Fig. 13 we show how the HMF reacts to changes in σ8 in comparison to the measured mass functions from Ondaro-Mallea et al. (2022) (solid lines) as a benchmark. Our predictions for the HMF (dashed lines) are generated by taking the average results of 10 different boxes, each one spanning L = 50 h−1 Mpc, with σ8 values set to 0.5802 (blue lines), 0.8288 (black lines), and 1.077 (red lines). The model’s predictions reveal a discrepancy with the anticipated HMF behaviour beneath the threshold of ∼1012.7 h−1 M⊙ for both σ8 ≈ 0.5802, and σ8 ≈ 1.077. This discrepancy is attributed to the model’s training on datasets characterized by the specific σ8 from Planck Collaboration VI (2020). The model’s ability to extrapolate to different variances remains limited. At higher masses, however, the network’s predictions correspond more closely with the expected HMF. This partial alignment suggests that the network possesses some degree of generalization capability. Nonetheless, for reliable application across varying cosmologies, incorporating these scenarios into the training set is essential.
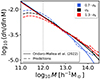 |
Fig. 13. Comparison of HMF predictions with variations in the cosmological parameter σ8. Solid lines represent HMF predictions from Ondaro-Mallea et al. (2022). Dashed lines indicate our model’s predictions. Blue and red curves correspond to scenarios with σ8 = 0.5802 and σ8 = 1.077, respectively. Black lines show the results for σ8 = 0.8288 (our reference cosmology). |
5. Discussion and conclusions
We present a novel approach to understand and predict halo formation from the initial conditions employed in N-body simulations. Benchmark tests indicate that our model can predict Lagrangian FoF halo regions for simulations efficiently, taking around 7 minutes in a GPU for a simulation with 2563 particles in a volume of 50 h−1 Mpc. For those interested in leveraging or further enhancing our work, we have made our codes publicly available5.
Our model consists of a semantic network that reliably recognizes regions in Lagrangian space where haloes form, and an instance segmentation network, which identifies individual haloes from the semantic output. Our predictions accurately reproduce simulation results and outperform traditional analytical, semi-analytical techniques, and prior ML methods.
The foundation for our instance segmentation model is the Weinberger approach, first introduced by De Brabandere et al. (2017). This technique has let us develop a more general framework for identifying Lagrangian halo patches than previous attempts. Employing the Weinberger loss approach, we have bypassed some limitations of other instance segmentation methods, such as the watershed technique employed by Bernardini et al. (2020). With our approach, we have managed to predict the complicated Lagrangian shapes of haloes that are formed in N-body simulations. This is notably more difficult than the predictions of spherical peak-patch haloes that were considered by Berger & Stein (2019).
Additionally, we quantified how much halo formation is affected by the scales that are not resolved in the initial conditions, to establish an optimal performance limit of ML methods. We inferred this limit by comparing two simulations that only differ in their initial conditions’ realization on scales beyond the resolution level. We found an agreement between our model predictions and reference simulations similar to the agreement between the two ‘baseline” simulations. This shows that our model extracts information encoded in the initial conditions close to optimal. We suggest that such reference experiments may also be used as a baseline in other ML studies to establish whether information is extracted optimally.
Upon evaluating our semantic model, we measured an accuracy of 0.864 and an F1 score of 0.838. Compared to the baseline simulations, which have an accuracy of 0.903 and an F1 score of 0.884, our model results stand remarkably close, demonstrating its capability to predict halo regions nearly matching N-body simulations’ natural variability.
We also assessed our instance segmentation network using various metrics. As depicted in Fig. 8, our model closely aligns with the baseline across a broad mass range, outperforming previous methods such as Lucie-Smith et al. (2024). We speculate that our approach benefits from the physical constraint that different particles that belong to the same halo are assigned the same halo mass. Moreover, the HMF predictions in Fig. 9 closely match the true ground truth values across three orders of magnitude. The visual representations in Fig. 7 reinforce our model’s precision, faithfully replicating Lagrangian halo patch positions and shapes.
Through experiments, we have tested how the network reacts to systematic modifications of the initial conditions. We find that the network correctly captures the response to density perturbations at the finite boxsize provided in the training set. However, it struggles to generalize to larger boxsizes and to cosmologies with different amplitudes for the density field σ8. This can easily be improved by increasing the diversity of the training set.
Further, we have found that our network utilizes information from the potential field that is not encoded in the density field of any finite region. Modifications to a large-scale tidal field are consistent with the same linear density field, but they do affect the potential landscape. Our network predicts that such tidal fields affect the Lagrangian shape of haloes in an anisotropic manner which is consistent with the intuitive expectation of how a tidal field accelerates and decelerates the infall anisotropically.
We have demonstrated the robustness of our model in its current applications and we believe it could find potential utility in several other scenarios such as crafting emulated merger trees, aiding separate-universe style experiments (e.g. Lazeyras et al. 2016; Stücker et al. 2021b), and informing the development of analytical methods for halo formation (e.g. Musso & Sheth 2021, 2023). Other works such as MUSCLE-UPS (Tosone et al. 2021) can also benefit from our semantic predictions alone by informing their algorithm about which particles will collapse into haloes.
Additionally, our model can be used to help understand the development of spin and intrinsic alignments in haloes and galaxies by establishing how tidal fields modify the Lagrangian shapes of haloes. This is a vital ingredient to predict the spin of haloes through tidal torque theory (White 1984). Also, we can employ our model to predict changes in the Lagrangian regions of halos in combination with the “splice” technique presented by Cadiou et al. (2021). We believe this approach can provide new insights regarding how modifications in the environment of haloes at initial conditions can affect their final properties. We encourage experts in these fields to use our open-source code as a basis for tackling and exploring these and other related problems.
The models we have presented in this paper can be easily extended to characterize other properties of halos. One possible extension of the model would be to include an additional spatial dimension to our instance network’s output to predict final halo concentrations. In this extension of our model, each particle would have associated a concentration prediction whose average (over all particle members of the same halo) would be trained to minimize the mean square error with respect to the true halo concentration.
The findings presented in this work are promising but there exist some aspects of our models that would benefit from further investigation. For instance, extending our methodology to understand other halo properties beyond mass would be a logical next step. It would also be interesting to test our model’s performance under a wider variety of simulation conditions, including variations in cosmology and redshift. An additional avenue of exploration might involve delving into capturing intricate structural details, specifically the gap features in the predicted Lagrangian halo regions. Generative adversarial networks (GANs) are tools that have demonstrated potential in reproducing data patterns in the context of cosmological simulations (e.g. Rodríguez et al. 2018; Villaescusa-Navarro et al. 2021; Schaurecker et al. 2021; Robles et al. 2022; Nguyen et al. 2023; Zhang et al. 2024). Hence, employing a GAN-like approach might help recreate these gap features, further improving our model’s ability to mimic the structures of haloes found in N-body simulations.
In conclusion, this study showcases the potential of ML for facilitating the study of halo formation processes in the context of cosmological N-body simulations. We provide a fast model that exploits the available information close to optimally. We hope our approach serves as a useful tool for researchers working with N-body simulations, opening avenues for future advancements.
The value of β depends on many properties such as the cosmological parameters chosen for the simulations, the redshift, or the mass resolution. We would need to retrain our network and recompute the value of β to obtain reliable predictions in different scenarios.
The loss function employed by De Brabandere et al. (2017) to perform instance segmentation is inspired by a loss function originally proposed by Weinberger & Saul (2009) in the context of contrastive learning as a triplet-loss function.
Ideally, we would prefer to accept as input 2563 voxels (corresponding to the full simulation box). However, our GPU resources, though powerful (specifically, an NVIDIA QUADRO RTX 8000 with 48 GB of memory), are insufficient to accommodate such an input size while maintaining a reasonably complex network architecture.
using the NETWORKX library (Hagberg et al. 2008)
Acknowledgments
D.L.C., J.S., M.P.I. and R.E.A. acknowledge the support of the ERC-StG number 716151 (BACCO) and of project PID2021-128338NB-I00 from the Spanish Ministry of Science. D.L.C. further thanks Lurdes Ondaro-Mallea for helping to run the baseline simulations, Rodrigo Voivodic for generating the EXSHALOS catalogues, and Luisa Lucie-Smith, Drew Jamieson, Francisco Maion, Matteo Zennaro, and Daniel Muñoz-Segovia for their helpful discussions and comments. This work used the following software: PYTHON, MATPLOTLIB (Hunter 2007), TensorFlow (Abadi et al. 2016), and NUMPY (van der Walt et al. 2011).
References
- Abadi, M., Agarwal, A., Barham, P., et al. 2016, ArXiv e-prints [arXiv:1603.04467] [Google Scholar]
- Akitsu, K., Li, Y., & Okumura, T. 2021, JCAP, 2021, 041 [CrossRef] [Google Scholar]
- Alves de Oliveira, R., Li, Y., Villaescusa-Navarro, F., Ho, S., & Spergel, D. N. 2020, ArXiv e-prints [arXiv:2012.00240] [Google Scholar]
- Andrés-San Roman, J. A., Gordillo-Vázquez, C., Franco-Barranco, D., et al. 2023, Cell Rep. Methods, 3, 100597 [CrossRef] [Google Scholar]
- Angulo, R. E., & Hahn, O. 2022, Liv. Rev. Comput. Astrophys., 8, 1 [CrossRef] [Google Scholar]
- Angulo, R. E., Springel, V., White, S. D. M., et al. 2012, MNRAS, 426, 2046 [NASA ADS] [CrossRef] [Google Scholar]
- Angulo, R. E., Zennaro, M., Contreras, S., et al. 2021, MNRAS, 507, 5869 [NASA ADS] [CrossRef] [Google Scholar]
- Arnab, A., & Torr, P. H. S. 2017, ArXiv e-prints [arXiv:1704.02386] [Google Scholar]
- Artigas, D., Grain, J., & Vennin, V. 2022, JCAP, 2022, 001 [CrossRef] [Google Scholar]
- Bai, M., & Urtasun, R. 2016, ArXiv e-prints [arXiv:1611.08303] [Google Scholar]
- Barreira, A., Nelson, D., Pillepich, A., et al. 2019, MNRAS, 488, 2079 [NASA ADS] [CrossRef] [Google Scholar]
- Berger, P., & Stein, G. 2019, MNRAS, 482, 2861 [NASA ADS] [CrossRef] [Google Scholar]
- Bernardini, M., Mayer, L., Reed, D., & Feldmann, R. 2020, MNRAS, 496, 5116 [NASA ADS] [CrossRef] [Google Scholar]
- Betts, J. C., van de Bruck, C., Arnold, C., & Li, B. 2023, MNRAS, 526, 4148 [NASA ADS] [CrossRef] [Google Scholar]
- Bond, J. R., Cole, S., Efstathiou, G., & Kaiser, N. 1991, ApJ, 379, 440 [NASA ADS] [CrossRef] [Google Scholar]
- Cadiou, C., Pontzen, A., Peiris, H. V., & Lucie-Smith, L. 2021, MNRAS, 508, 1189 [NASA ADS] [CrossRef] [Google Scholar]
- Chacón, J., Vázquez, J. A., & Almaraz, E. 2022, Astron. Comput., 38, 100527 [CrossRef] [Google Scholar]
- Dai, L., Pajer, E., & Schmidt, F. 2015, JCAP, 2015, 059 [CrossRef] [Google Scholar]
- Davis, M., Efstathiou, G., Frenk, C. S., & White, S. D. M. 1985, ApJ, 292, 371 [Google Scholar]
- De Brabandere, B., Neven, D., & Van Gool, L. 2017, ArXiv e-prints [arXiv:1708.02551] [Google Scholar]
- Deng, R., Shen, C., Liu, S., Wang, H., & Liu, X. 2018, ArXiv e-prints [arXiv:1807.10097] [Google Scholar]
- de Simone, A., Maggiore, M., & Riotto, A. 2011, MNRAS, 418, 2403 [CrossRef] [Google Scholar]
- Desjacques, V., Jeong, D., & Schmidt, F. 2018, Phys. Rep., 733, 1 [Google Scholar]
- Eisenstein, D. J., & Hut, P. 1998, ApJ, 498, 137 [NASA ADS] [CrossRef] [Google Scholar]
- Franco-Barranco, D., Muñoz-Barrutia, A., & Arganda-Carreras, I. 2022, Neuroinformatics, 20, 437 [CrossRef] [Google Scholar]
- Franco-Barranco, D., Andrés-San Román, J. A., & Gómez-Gálvez, P., et al. 2023, IEEE 20th International Symposium on Biomedical Imaging (ISBI), 1 [Google Scholar]
- Frenk, C. S., & White, S. D. M. 2012, Ann. Phys., 524, 507 [NASA ADS] [CrossRef] [Google Scholar]
- Fukushima, K. 1980, Biol. Cybern., 36, 193 [CrossRef] [PubMed] [Google Scholar]
- Genel, S., Bryan, G. L., Springel, V., et al. 2019, ApJ, 871, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Giusarma, E., Reyes, M., Villaescusa-Navarro, F., et al. 2023, ApJ, 950, 70 [NASA ADS] [CrossRef] [Google Scholar]
- Gunn, J. E. 1977, ApJ, 218, 592 [NASA ADS] [CrossRef] [Google Scholar]
- Gunn, J. E., & Gott, J. R., III 1972, ApJ, 176, 1 [Google Scholar]
- Hagberg, A., Swart, P., & S Chult, D. 2008, Exploring Network Structure, Dynamics, and Function Using NetworkX, Tech. rep. (Los Alamos, NM (United States): Los Alamos National Lab. (LANL)) [Google Scholar]
- Hahn, O., & Abel, T. 2011, MNRAS, 415, 2101 [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2015, ArXiv e-prints [arXiv:1512.03385] [Google Scholar]
- He, S., Li, Y., Feng, Y., et al. 2019, Proc. Natl. Acad. Sci., 116, 13825 [NASA ADS] [CrossRef] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Jamieson, D., & Loverde, M. 2019, Phys. Rev. D, 100, 123528 [Google Scholar]
- Jamieson, D., Li, Y., He, S., et al. 2022, ArXiv e-prints [arXiv:2206.04573] [Google Scholar]
- Jiang, F., & van den Bosch, F. C. 2014, MNRAS, 440, 193 [CrossRef] [Google Scholar]
- Kirillov, A., Levinkov, E., Andres, B., Savchynskyy, B., & Rother, C. 2016, ArXiv e-prints [arXiv:1611.08272] [Google Scholar]
- Kirillov, A., He, K., Girshick, R., Rother, C., & Dollár, P. 2018, ArXiv e-prints [arXiv:1801.00868] [Google Scholar]
- Kirillov, A., Mintun, E., Ravi, N., et al. 2023, ArXiv e-prints [arXiv:2304.02643] [Google Scholar]
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. 2012, in Advances in Neural Information Processing Systems, eds. F. Pereira, C. Burges, L. Bottou, & K. Weinberger (Curran Associates, Inc.), 25 [Google Scholar]
- Lacey, C., & Cole, S. 1993, MNRAS, 262, 627 [NASA ADS] [CrossRef] [Google Scholar]
- Lazeyras, T., Wagner, C., Baldauf, T., & Schmidt, F. 2016, JCAP, 2016, 018 [CrossRef] [Google Scholar]
- Lecun, Y., Bottou, L., Bengio, Y., & Haffner, P. 1998, Proc. IEEE, 86, 2278 [Google Scholar]
- Li, Y., Hu, W., & Takada, M. 2014, Phys. Rev. D, 89, 083519 [NASA ADS] [CrossRef] [Google Scholar]
- Lin, Z., Wei, D., Petkova, M. D., et al. 2021, Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part I 24 (Springer), 164 [Google Scholar]
- Long, J., Shelhamer, E., & Darrell, T. 2014, ArXiv e-prints [arXiv:1411.4038] [Google Scholar]
- Lucie-Smith, L., Peiris, H. V., Pontzen, A., & Lochner, M. 2018, MNRAS, 479, 3405 [NASA ADS] [CrossRef] [Google Scholar]
- Lucie-Smith, L., Peiris, H. V., & Pontzen, A. 2019, MNRAS, 490, 331 [NASA ADS] [CrossRef] [Google Scholar]
- Lucie-Smith, L., Barreira, A., & Schmidt, F. 2023, MNRAS, 524, 1746 [NASA ADS] [CrossRef] [Google Scholar]
- Lucie-Smith, L., Peiris, H. V., Pontzen, A., Nord, B., & Thiyagalingam, J. 2024, Phys. Rev. D, 109, 063524 [CrossRef] [Google Scholar]
- Ludlow, A. D., & Porciani, C. 2011, MNRAS, 413, 1961 [CrossRef] [Google Scholar]
- Masaki, S., Nishimichi, T., & Takada, M. 2020, MNRAS, 496, 483 [NASA ADS] [CrossRef] [Google Scholar]
- Meyer, F. 1994, Signal Process., 38, 113 [NASA ADS] [CrossRef] [Google Scholar]
- Moon, J.-S., & Lee, J. 2023, ArXiv e-prints [arXiv:2311.03632] [Google Scholar]
- Musso, M., & Sheth, R. K. 2021, MNRAS, 508, 3634 [NASA ADS] [CrossRef] [Google Scholar]
- Musso, M., & Sheth, R. K. 2023, MNRAS, 523, L4 [NASA ADS] [CrossRef] [Google Scholar]
- Nguyen, T., Modi, C., Yung, L. Y. A., & Somerville, R. S. 2023, MNRAS, submitted [arXiv:2308.05145] [Google Scholar]
- Ondaro-Mallea, L., Angulo, R. E., Zennaro, M., Contreras, S., & Aricò, G. 2022, MNRAS, 509, 6077 [Google Scholar]
- Otsu, N. 1979, IEEE Trans. Syst. Man. Cybern., 9, 62 [CrossRef] [Google Scholar]
- Paranjape, A., Sefusatti, E., Chan, K. C., et al. 2013, MNRAS, 436, 449 [CrossRef] [Google Scholar]
- Peebles, P. J. E. 1980, The Large-Scale Structure of the Universe (Princeton University Press) [Google Scholar]
- Perraudin, N., Srivastava, A., Lucchi, A., et al. 2019, Comput. Astrophys. Cosmol., 6, 5 [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Press, W. H., & Schechter, P. 1974, ApJ, 187, 425 [Google Scholar]
- Robles, S., Gómez, J. S., Ramírez Rivera, A., Padilla, N. D., & Dujovne, D. 2022, MNRAS, 514, 3692 [NASA ADS] [CrossRef] [Google Scholar]
- Rodríguez, A. C., Kacprzak, T., Lucchi, A., et al. 2018, Comput. Astrophys. Cosmol., 5, 4 [Google Scholar]
- Ronneberger, O., Fischer, P., & Brox, T. 2015, ArXiv e-prints [arXiv:1505.04597] [Google Scholar]
- Schanz, A., List, F., & Hahn, O. 2023, ArXiv e-prints [arXiv:2310.06929] [Google Scholar]
- Schaurecker, D., Li, Y., Tinker, J., Ho, S., & Refregier, A. 2021, ArXiv e-prints [arXiv:2111.06393] [Google Scholar]
- Schmidt, A. S., White, S. D. M., Schmidt, F., & Stücker, J. 2018, MNRAS, 479, 162 [NASA ADS] [CrossRef] [Google Scholar]
- Sheth, R. K., & Tormen, G. 2002, MNRAS, 329, 61 [Google Scholar]
- Sheth, R. K., Mo, H. J., & Tormen, G. 2001, MNRAS, 323, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Sousbie, T. 2011, MNRAS, 414, 350 [NASA ADS] [CrossRef] [Google Scholar]
- Springel, V. 2015, Astrophysics Source Code Library [record ascl:1502.003] [Google Scholar]
- Springel, V., White, S. D. M., Tormen, G., & Kauffmann, G. 2001, MNRAS, 328, 726 [Google Scholar]
- Springel, V., Wang, J., Vogelsberger, M., et al. 2008, MNRAS, 391, 1685 [Google Scholar]
- Stein, G., Alvarez, M. A., & Bond, J. R. 2019, MNRAS, 483, 2236 [NASA ADS] [CrossRef] [Google Scholar]
- Stücker, J., Angulo, R. E., & Busch, P. 2021a, MNRAS, 508, 5196 [CrossRef] [Google Scholar]
- Stücker, J., Schmidt, A. S., White, S. D. M., Schmidt, F., & Hahn, O. 2021b, MNRAS, 503, 1473 [CrossRef] [Google Scholar]
- Szegedy, C., Liu, W., Jia, Y., et al. 2014, ArXiv e-prints [arXiv:1409.4842] [Google Scholar]
- Terasawa, R., Takahashi, R., Nishimichi, T., & Takada, M. 2022, Phys. Rev. D, 106, 083504 [NASA ADS] [CrossRef] [Google Scholar]
- Tierny, J., Favelier, G., Levine, J. A., Gueunet, C., & Michaux, M. 2018, IEEE Trans. Vis. Comput. Graph. 24, 832 [CrossRef] [Google Scholar]
- Tosone, F., Neyrinck, M. C., Granett, B. R., Guzzo, L., & Vittorio, N. 2021, MNRAS, 505, 2999 [NASA ADS] [CrossRef] [Google Scholar]
- van der Walt, S., Colbert, S. C., & Varoquaux, G. 2011, Comput. Sci. Eng., 13, 22 [Google Scholar]
- Villaescusa-Navarro, F., Anglés-Alcázar, D., Genel, S., et al. 2021, ApJ, 915, 71 [NASA ADS] [CrossRef] [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Voivodic, R., Lima, M., & Abramo, L. R. 2019, ArXiv e-prints [arXiv:1906.06630] [Google Scholar]
- Wagner, C., Schmidt, F., Chiang, C. T., & Komatsu, E. 2015, MNRAS, 448, L11 [CrossRef] [Google Scholar]
- Wei, D., Lin, Z., Franco-Barranco, D., et al. 2020, International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) (Springer), 66 [Google Scholar]
- Weinberger, K. Q., & Saul, L. 2009, J. Mach. Learn. Res., 10, 207 [Google Scholar]
- White, S. D. M. 1984, ApJ, 286, 38 [NASA ADS] [CrossRef] [Google Scholar]
- Wu, Z., Zhang, Z., Pan, S., et al. 2021, ApJ, 913, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Xie, S., & Tu, Z. 2015, ArXiv e-prints [arXiv:1504.06375] [Google Scholar]
- Zhang, X., Lachance, P., Ni, Y., et al. 2024, MNRAS, 528, 281 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Watershed segmentation
In this appendix, we present an alternative approach to instance segmentation, based on the watershed approach. Originally we tried this technique to address the instance segmentation problem, but we finally decided to use the Weinberger approach presented in the main paper because of its theoretical advantages. These are that the loss function closer reflects the objective, that it is possible to predict disconnected regions, and that it is not necessary to define borders. However, during our exploration, we have gained some insights of how to make watershed-based instance segmentation techniques work for friends-of-friends proto-haloes. We will explain these here for the benefit of future studies.
Our watershed approach makes use of a U-Net-based architecture Ronneberger et al. (2015), specifically a 3D Residual U-Net based on previous work Franco-Barranco et al. (2022). The model’s input consisting of 128 × 128 × 128 × 2 voxels for (x, y, z, channels) axes. The two input channels correspond to the initial density field and the potential.
The model is trained to predict two output channels: binary foreground segmentation masks and instance contours masks. Following the prediction, the two outputs are thresholded (automatically using Otsu’s method Otsu (1979)) and combined. Next, a connected components operation is applied to generate distinct, non-touching halo instance seeds. Subsequently, a marker-controlled watershed algorithm Meyer (1994) is applied, using three key components: 1) the inverted foreground probabilities as the input image (representing the topography to be flooded), 2) the generated instance seeds as the marker image (defining starting points for the flooding process), and 3) a binarized version of the foreground probabilities as the mask image (constraining the extent of object expansion). To binarize the latter, we employed a threshold value of 0.372, which was determined through the application of the identical methodology outlined in Appendix C. The collective implementation of these components facilitates the creation of individual halo instances (see Fig. A.1 for a visual representation). This strategy has been extensively employed within the medical field with remarkable success Wei et al. (2020), Lin et al. (2021), Andrés-San Roman et al. (2023).
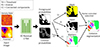 |
Fig. A.1. Processing pipelines of our watershed segmentation approach. The input 3D image contains two channels: the density field and the potential. The model predicts foreground and contour probabilities that are fused to create three inputs for a marker-controlled watershed to produce individual instances. |
In order to facilitate the generation of the two channels used to train the network, several transformations were applied to the labels. For each halo instance, small particles along the edges were removed, central holes were filled, and the labels were dilated by one pixel. This process results in instances with smoother boundaries, thereby aiding the network in training (see Fig. A.2).
 |
Fig. A.2. Data preparation process of our watershed segmentation approach. From left to right: the original halo instances for the considered prediction problem, subsequent modifications involving the removal of small holes and spurious pixels and contour smoothing, and the presentation of both the foreground and contour masks utilized for model training. Pixels coloured in white do not belong to any halo. Pixels with the same colour belong to the same halo and different colours indicate different haloes. |
The result of this method is depicted in Fig. A.3. The code is open source and readily available in BiaPy Franco-Barranco et al. (2023).
 |
Fig. A.3. Results of our watershed segmentation approach presented in an analogous way to results from Fig. 7. |
Appendix B: Clustering algorithm
In this appendix, we describe the clustering algorithm that we have developed. This algorithm calculates instance predictions from the pseudo-space representations that are output by our instance segmentation network.
As described in Sect. 2.2, the output of our instance network consists of a set of points that populate an abstract space (referred to as pseudo-space). Our instance network has been trained to minimize the Weinberger loss function 7, hence, we expect that the predicted mapping of points in the pseudo-space causes that points corresponding to the same instances to be close to each other, and separated to points that correspond to different instances. In the ideal case where ℒWein = 0, all points belonging to the same instance would be no farther apart from each other than a distance 2 ⋅ δPull, and the points corresponding to separate instances would be, as close as a distance 2 ⋅ δPush − δPull close to each other. However, we cannot expect that our network always separates perfectly the different instances. For example, if some Lagrangian voxel has a 60% chance to belong to halo A and a 40% chance to belong to halo B, then the optimal location in pseudo space (that statistically minimizes the loss) may be somewhere in between the centre of halo A and B in pseudo space and not inside the δPull radius of neither. Therefore, we employ a clustering algorithm that can segment the pseudo-space distribution of points also when ℒWein is not exactly zero.
For this, we first estimate the local pseudo-space density ρi for each point i. For this we compute the distance rk, i to the kth-nearest neighbour of the point and assign
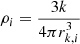 (B.1)
(B.1)
where k = Ndens is a hyper-parameter of the clustering algorithm. We accelerate this step with the CKD-TREE from the SCIPY package in PYTHON (Virtanen et al. 2020).
Then we determine groups as the descending manifold of the maxima that exceed a persistence ratio threshold ρmax/ρsad ≥ pthresh between maximum and saddle-point. The descending manifold corresponds to the set of particles from whose location following the local density gradient would end up in the same maximum (e.g. Sousbie 2011; Tierny et al. 2018). For this, we use a slightly modified version of the density segmentation algorithm used in SUBFIND (Springel et al. 2001):
We consider the particles from highest to lowest density. For each particle we consider from the Nngb nearest particles the subset of particles that have a higher density than ρi (this set may be empty). Among these we select the set Bi of the (up to) two closest particles. This set can have zero, one or two particles.
-
If the set Bi is empty, then there is a density maximum ρmax = ρi and we start growing a new subgroup around it.
-
If the set Bi contains a single particle or two particles that are of the same group, the particle i is attached to the corresponding group.
-
If Bi contains two particles of different groups, then i is potentially a saddle-point. We check whether the group with the lower density maximum ρmax has a sufficient persistence ρmax/ρi ≤ pthresh. If not, then we merge the two groups (and keep the denser maximum). Otherwise, we keep both groups and we assign the particle to the group of the denser particle in Bi. (This step corresponds to following the local discrete density gradient.)
Note that unlike the SUBFIND algorithm, we merge groups not at every saddle-point, but only if they are below a persistence threshold. Therefore, sufficiently persistent groups are grown beyond their saddle point and ultimately correspond to the descending manifold of their maximum.
The clustering algorithm has three hyper-parameters Ndens, Nngb and pthresh. We have done a hyper-parameter optimization over these and found that Ndens = 20, Nngb = 15 (quite close to the default parameters in the SUBFIND algorithm, 20 and 10 respectively) and pthresh = 4.2 give the best results, though our results are not very sensitive to moderate deviations from this. We can understand the quantitative value of the persistence ratio threshold by considering that the relative variance of our density estimate is
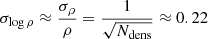 (B.2)
(B.2)
so that at a fixed background density having a density contrast of pthresh = 4.2 due to Poisson noise corresponds to a
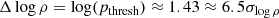 (B.3)
(B.3)
outlier. Therefore, the persistence ratio threshold pthresh ensures that it is very unlikely that our algorithm mistakes a spurious overdensity in the pseudo space for a group.
Appendix C: Semantic threshold
In the bottom panel of Fig. C.1 we present how the predicted fraction of voxels that are members of a halo (that is 1 − β) evolves as we change the semantic threshold (black solid line). As it can be expected when the semantic threshold is close to zero, the majority of voxels are identified as members of haloes, and the contrary occurs when the semantic threshold approximates one. The horizontal dashed-dotted line corresponds to the ground truth value of 1 − β = 0.418, measured in the validation simulations. The semantic threshold value that we have selected is 0.589 (black dotted vertical line). This value corresponds to the intersection between the black solid line and the dashed-dotted line; it ensures that the total fraction of voxels that are members of haloes is correctly reproduced. Choosing this criterion to determine the semantic threshold also ensures more robust instance predictions since the number of FP cases is reduced, hence eliminating potentially uncertain pseudo-space particles that would complicate the clustering procedure.
 |
Fig. C.1. Evaluation of different metrics as a function of the semantic threshold. Top panel: Evolution of different metrics (TPR - green, TNR - blue, PPV - purple, F1-score - yellow & ACC - orange) measured employing the predictions of the semantic model as a function of the semantic threshold selected (solid lines); we also show the values measured for the corresponding metrics studying the differences between the baseline simulations (horizontal dashed lines). Bottom panel: Fraction of voxels predicted to be collapsed (equivalent to 1 − β) as a function of the semantic threshold employed (solid black line); the horizontal black dashed line corresponds to the fraction of particles that end up in DM haloes measured in the validation simulations. In both panels, the vertical black dotted line shows the semantic threshold we employ; this threshold has been selected to match the fraction of collapsed voxels. |
In the top panel of Fig. C.1 we show the evolution of several metrics as a function of the semantic threshold value. These metrics allow us to asses the quality of our semantic predictions by comparing our results with values obtained using the baseline simulations. We study the behaviour of five different metrics: True Positive Rate TPR, True Negative Rate TNR, Positive Predictive Value PPV, Accuracy ACC and the F1-score.
In the top panel of Fig. C.1 we also present the values obtained for the different metrics using the baseline simulations (horizontal dashed lines). We have obtained these results considering one of the baseline simulations as predicted maps and the other simulation as the ground truth. The values measured for the different metrics in the baseline simulations give us an expected ideal performance that we would like to reproduce with our model.
If we focus on the performance curves for the accuracy and the F1-score (orange and yellow lines respectively) we can appreciate that they always remain under the baseline limit. The curve for the F1-score peaks around the value for the semantic threshold of 0.5, which is a behaviour we expected since we considered the balanced cross-entropy loss to train our semantic model. The value for the F1-score at its maximum is F1(0.5) = 0.842, which is very similar to the value at the point in which we have fixed the semantic threshold, F1(0.589) = 0.838. The F1-score obtained is only about 5% away from the optimal value obtained from the baseline simulations 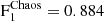 . The accuracy reaches its maximum value around the semantic threshold of 0.58, where ACC(0.58) = 0.864; the value for the model accuracy is even closer to the baseline limit ACCChaos = 0.903.
. The accuracy reaches its maximum value around the semantic threshold of 0.58, where ACC(0.58) = 0.864; the value for the model accuracy is even closer to the baseline limit ACCChaos = 0.903.
Appendix D: Generate full-box predictions from crops
In this appendix, we address the challenge of generating full-box predictions employing our instance segmentation model.
While our network architecture captures intricate features within simulation sub-volumes, the challenge arises when we aim to apply it to arbitrarily large input domains. Unlike some other ML approaches that rely on networks that are translational invariant, our model incorporates the Lagrangian positions of particles as input channels, making it dependent on the relative Lagrangian position. This design choice ensures that similar regions of the initial density field are mapped to distinct locations in the pseudo-space, allowing us to distinguish between separate structures, even if they are locally identical. However, this feature also presents a challenge when creating full-box predictions. Combining independent crop predictions straightforwardly may lead to inconsistencies due to the network’s inherent non-translational invariance. To tackle this issue, we have developed a methodology for predicting sub-volumes independently and then merging these predictions to generate accurate full-box instance segmentation results.
To reduce the boundary effects that may result from such a method we employ the following strategy.
-
We evaluate the instance network centred several times, centred on locations ⃗qijk that are arranged on a grid
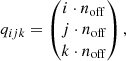 (D.1)
(D.1)where we choose an offset of noff = 64 voxels and (i, j, k) run so far that the whole periodic volume is covered – e.g. from 0 to 4 each for a 2563 simulation box. The network’s input in each case corresponds to the 1443 voxels (periodically) centred on ⃗qijk and the instance segmentation output will predict labels for the 1283 central voxels.
-
From each prediction we only use the predicted labels of the central
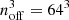 voxels, since we expect these to be relatively robust to field-of-view effects. We combine these from all the predictions to a global grid that has the same dimensions as the input domain. In this step we add offsets to the labels so that the labels that originate from each predicted domain are unique in the global grid (this process will become relevant in step 4 where we define a graph used to link instances).
voxels, since we expect these to be relatively robust to field-of-view effects. We combine these from all the predictions to a global grid that has the same dimensions as the input domain. In this step we add offsets to the labels so that the labels that originate from each predicted domain are unique in the global grid (this process will become relevant in step 4 where we define a graph used to link instances). -
We repeat steps 1-2, but with an additional offset of (noff/2, noff/2, noff/2)T. We additionally offset the labels in this second grid so that no label appears in both grids.
-
We use the two lattices and the intersections between instances to identify which labels should correspond to the same object. We do this by creating a graph6 where each instance label is a node. Initially the graph has no edges, but we subsequently add edges if two labels should be identified (i.e. correspond to the same halo). Each connected component of the graph will then correspond to a single final label. To define the edges of the graph, we consider each quadrant Q of size (noff/2)3 individually, since such quadrants are the maximal volumes over which two labels can intersect. We define the intersection IQ(l1, l2) of two labels l1 and l2 as the number of voxels that both carry label l1 in grid one and label l2 in grid two. We define as the union UQ(l1, l2) the number of voxels inside of quadrant Q that carry l1 in grid 1 or l2 in grid 2 (or both). We then add an edge between l1 and l2 into the graph if for any quadrant Q it is
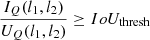 (D.2)
(D.2)where we set IoUthresh = 0.5.
-
We summarize each connected component in the graph into a new label. After this operation for most voxels the new label in grid 1 and in grid 2 agree and we can choose that label as our final label. However, for a small fraction of voxels the labels still disagree, because the corresponding instances had too little overlap to be identified with each other. In this case, we assign to the corresponding voxel the label that contains the larger number of voxels in total.
We illustrate the different steps of this procedure in Fig. D.1. The top panel, labelled ’Lattice1’, shows the individual instances predicted in the first lattice arrangement. Each colour represents a distinct label assigned to a group of voxels within the 643 central region of the sub-volumes. The middle panel, ’Lattice2’, displays the second set of predictions using a shifted lattice by half the offset in each dimension. Here again, different colours represent unique instance labels. The bottom panel, ’Combined’, presents the final merged full-box prediction. It is generated by synthesizing the labels from ’Lattice1’ and ’Lattice2’ using the graph-based method to connect overlapping instances. The resulting image shows larger, coherent structures, indicative of the correct performance of combining both lattices.
 |
Fig. D.1. Process of merging predictions from two overlapping lattice structures to produce a full-box instance segmentation map. ’Lattice1’ (top) and ’Lattice2’ (middle) represent predictions from initial and shifted lattice grids, respectively, with unique colour-coded labels for instances. Black dashed lines indicate the lattice employed in each case, while thin dashed grey lines correspond to the lattice employed in the reciprocal scenario. ’Combined’ (bottom) depicts the final synthesized full-box map, where instances have been merged based on their overlap, demonstrating the effectiveness of the methodology in generating contiguous and comprehensive halo segmentations from smaller, predicted sub-volumes. |
Regarding the semantic segmentation network, we can merge the predictions corresponding to different crops independently since, in this case, we are truly working with a translation-invariant network. We employ the central 643 voxels (analogous to ’Lattice1’) of separate predictions and merge them together to generate the final full-box predictions of the semantic segmentation network.
Appendix E: Comparison with ExSHalos
In this appendix, we explore how the results obtained with the EXSHALOS code (Voivodic et al. 2019) compare against our semantic and instance predictions.
As mentioned in Sect. 3.1, EXSHALOS is an explicit implementation of the excursion set theory that identifies haloes in Lagrangian space by growing spheres around density peaks until the average density inside crosses a specified barrier for the first time. The barrier shape is motivated by the ellipsoidal collapse (Sheth et al. 2001; de Simone et al. 2011) and we have fitted the three free parameters in the model to reproduce the mean halo mass function of our simulations.
In Fig. E.1 we show a map-level comparison between the Lagrangian proto-haloes identified in one of our validation simulations with the friends-of-friends algorithm (left panel), and the EXSHALOS detected employing the code presented in Voivodic et al. (2019) (central panel). The EXSHALOS regions in Lagrangian space are spherical by construction (see the middle panel of Fig. E.1). The physical approach of the EXSHALOS algorithm enables to identify, with a reasonable degree of accuracy, the location of proto-haloes in Lagrangian space, and their mass. However, the built-in assumption that proto-haloes are spherical gives only a crude approximation to the actual proto-halo shapes. In Table 2 we quantify the differences between EXSHALOS and friends-of-friends employing several semantic metrics.
 |
Fig. E.1. Slices through the Lagrangian field of friends-of-friends proto-haloes, and the corresponding predictions using the EXSHALOS algorithm. Left panel: Ground truth masses obtained using N-body simulations (friends-of-friends proto-haloes). Central panel: Predicted masses obtained using the EXSHALOS algorithm. Right panel (analogous to left panel of Fig. 5): Semantic pixel-level error map between EXSHALOS and friends-of-friends haloes indicating true positive (green), true negative (blue), false negative (black), and false positive (red) regions. |
In Fig. E.2 we present a violin plot analogous to Fig. 8. This plot shows a comparison between the ground truth halo masses (friends-off-friends) and the predicted masses from our model associated with the particles/voxels in our validation set (black violin lines in the main panel). We also include the comparison between the masses of EXSHALOS and of friends-off-friends haloes (purple violin lines). We have generated the violin lines of EXSHALOS employing all our simulations (both training and validation) to achieve better statistics. Our model predictions are capable of achieving greater mass accuracy than EXSHALOS throughout all mass bins considered here.
 |
Fig. E.2. Violin plot, visualizing the distribution of predicted halo masses (at a voxel level) for different ground-truth mass bins. The black violin plots show the results obtained with our instance segmentation model. Green violin plots show the agreement between the two baseline simulations – representing an optimal target accuracy. The purple violin plots in the main panel correspond to the comparison with the EXSHALOS predictions. The solid black line in the top panel shows the false negative rate, FNR, as a function of the ground truth halo mass. The dashed black line represents the fraction of predicted collapsed pixels that are not collapsed as a function of predicted halo mass (false discovery rate, FDR). The green and purple lines on the top panel correspond to the analogous results obtained from the baseline simulations and EXSHALOS respectively. |
In the upper panel of Fig. E.2, we show the false negative rate as solid lines against the ground truth halo mass, and the false discovery rate as dashed lines against the predicted mass. This plot is analogous to the top plot in Fig. 8 (See Sect. 3.2 for details). We additionally include solid and dashed purple lines corresponding to the EXSHALOS case. It’s clear that EXSHALOS predicts higher FNR and FDR values compared to the baseline case and our model predictions, indicating more semantically misclassified particles.
All Tables
Performance metrics of our semantic segmentation model, along with the EXSHALOS results, compared against the optimal target accuracy estimated from the baseline simulations.
All Figures
|
Fig. 1. Example of the prediction problem considered in this article. Top panel: Slice of the three-dimensional initial density field of an N-body simulation. Each voxel (represented here as a pixel) corresponds to a particle that can become part of a halo at later times. Bottom panel: Regions in the initial condition space (same slice as the top panel) that are part of different DM haloes at redshift z = 0. Pixels coloured in white do not belong to any halo. Pixels with different colours belong to different haloes. In this work, we present a machine-learning approach to predict the formation of haloes (as in the bottom panel) from the initial condition field (top panel). |
| In the text | |
|
Fig. 2. Example of a two-dimensional pseudo-space employed to separate different instances according to the Weinberger loss. Coloured points represent individual points mapped into the pseudo-space. The centres of the clusters are presented as coloured crosses. Coloured arrows depict the influence of the pull force term, only affecting points outside the δPull range of their corresponding cluster centre. Grey arrows show the influence of the push force that manifests if two cluster centres are closer than the distance 2 ⋅ δPush. |
| In the text | |
|
Fig. 3. Slice of the Lagrangian halo regions of the two “baseline” simulations (left and right panels, respectively). These simulations only differ in sub-resolution perturbations to the initial conditions and their level of agreement sets a baseline for the desired accuracy of our models. The colours employed for both panels represent the mass of the halo associated with each particle for the different Lagrangian halo patches. Circled regions highlight Lagrangian patches whose associated mass significantly changes between the two simulations. |
| In the text | |
|
Fig. 4. Flowchart of the particular V-Net architecture we have implemented. The network can take as input multiple channels with dimensions of 1443 (top left green cube) and generates predictions for the central voxels with dimensions 1283 (top right red cube). The flowchart illustrates the encoder and decoder paths, along with other distinctive features of the network. Notably, the hidden layers and skip connections are represented by purple and yellow cubes, with their respective dimensions annotated at their centres. The down-sampling and up-sampling blocks are shown as brown and purple trapezoids, in their centres we indicate the number of filters employed for the convolution (or transposed convolution) operations. |
| In the text | |
|
Fig. 5. Slice through the predictions of our semantic segmentation network applied to a validation simulation. Left panel: Ground truth representation showing in red the voxels/particles belonging to a DM halo at z = 0 and in blue those particles that do not belong to a DM halo. Central panel: Probabilistic predictions of the semantic network with colour-coded probabilities for halo membership. Right panel: Pixel-level error map indicating true positive (green), true negative (blue), false negative (black), and false positive (red) regions resulting after applying a semantic threshold of 0.589 to our predicted map. The network effectively captures complex halo boundaries and exhibits high validation accuracy (acc = 0.86) and F1-score (F1 = 0.83). |
| In the text | |
|
Fig. 6. True positive rate expressed as a function of the halo mass associated with the ground truth voxels. We present the results measured from the model predictions (solid bright green line) in comparison to the optimal target accuracy from the baseline simulations (solid black line). The vertical dotted line at 1012 h−1 M⊙ marks the point where model predictions start to differ from the baseline results. |
| In the text | |
|
Fig. 7. Examples of the instance segmentation results obtained with our model. Left column: Ground truth masses obtained using N-body simulations. Right column: Predicted masses obtained using our instance segmentation pipeline. The model can predict the Lagrangian patches of haloes, although some small differences – e.g. regarding the connectivity of haloes – exist. |
| In the text | |
|
Fig. 8. “Violin plot”, visualizing the distribution of predicted halo masses (at a voxel level) for different ground-truth mass bins. The black violin plots show the results obtained with our instance segmentation model. Green violin plots show the agreement between the two baseline simulations – representing an optimal target accuracy. The blue violin plots in the main panel show the results presented in Lucie-Smith et al. (2024). The solid black line in the top panel shows the false negative rate, FNR, as a function of the ground truth halo mass. The dashed black line represents the fraction of predicted collapsed pixels that are not actually collapsed as a function of predicted halo mass (false discovery rate, FDR). The green lines on the top panel correspond to the analogous results obtained from the baseline simulations. The model predicts haloes accurately object-by-object for masses M ≳ 1012 h−1 M⊙. |
| In the text | |
|
Fig. 9. Halo-mass function (HMF) computed using our N-body simulations reserved for validation (solid black line). The dashed black line represents the predicted HMF using the Lagrangian halo regions obtained with our instance segmentation pipeline. The solid blue line shows the HMF prediction from Ondaro-Mallea et al. (2022). The dashed blue line corresponds to the HMF obtained after evaluating our model in a simulation with 10243 particles and Vbox = (200 h−1Mpc)3. |
| In the text | |
|
Fig. 10. Response of proto-haloes to large-scale over-densities. The three panels show over-densities of δϵ = −0.5, 0 and 0.5, respectively. A larger large-scale density tends to increase the Lagrangian volume of haloes and leads to additional mergers in some cases. |
| In the text | |
|
Fig. 11. Linear Lagrangian bias parameter b1L for the haloes, measured for different boxsizes L and comparing simulation and model. The model agrees well with the simulation at the L = 50 h−1 Mpc scale, but both are inconsistent with the true large-scale bias relation from Lazeyras et al. (2016) due to effects from the limited size of the simulation volume. Evaluation on larger boxes moves the prediction closer to the known relation, but some deviation is maintained. |
| In the text | |
|
Fig. 12. Response of proto-halo regions towards a large-scale tidal field. The different panels show the cases with λz = −0.5, 0 and 0.5 – corresponding to a stretching tidal field, no tidal field and a compressing tidal field in the vertical direction respectively. A negative (stretching) tidal field delays infall and shrinks the proto-halo patches in the corresponding direction, whereas a positive (compressing) tidal field facilitates infall and extends the proto-halo patches. |
| In the text | |
|
Fig. 13. Comparison of HMF predictions with variations in the cosmological parameter σ8. Solid lines represent HMF predictions from Ondaro-Mallea et al. (2022). Dashed lines indicate our model’s predictions. Blue and red curves correspond to scenarios with σ8 = 0.5802 and σ8 = 1.077, respectively. Black lines show the results for σ8 = 0.8288 (our reference cosmology). |
| In the text | |
|
Fig. A.1. Processing pipelines of our watershed segmentation approach. The input 3D image contains two channels: the density field and the potential. The model predicts foreground and contour probabilities that are fused to create three inputs for a marker-controlled watershed to produce individual instances. |
| In the text | |
|
Fig. A.2. Data preparation process of our watershed segmentation approach. From left to right: the original halo instances for the considered prediction problem, subsequent modifications involving the removal of small holes and spurious pixels and contour smoothing, and the presentation of both the foreground and contour masks utilized for model training. Pixels coloured in white do not belong to any halo. Pixels with the same colour belong to the same halo and different colours indicate different haloes. |
| In the text | |
|
Fig. A.3. Results of our watershed segmentation approach presented in an analogous way to results from Fig. 7. |
| In the text | |
|
Fig. C.1. Evaluation of different metrics as a function of the semantic threshold. Top panel: Evolution of different metrics (TPR - green, TNR - blue, PPV - purple, F1-score - yellow & ACC - orange) measured employing the predictions of the semantic model as a function of the semantic threshold selected (solid lines); we also show the values measured for the corresponding metrics studying the differences between the baseline simulations (horizontal dashed lines). Bottom panel: Fraction of voxels predicted to be collapsed (equivalent to 1 − β) as a function of the semantic threshold employed (solid black line); the horizontal black dashed line corresponds to the fraction of particles that end up in DM haloes measured in the validation simulations. In both panels, the vertical black dotted line shows the semantic threshold we employ; this threshold has been selected to match the fraction of collapsed voxels. |
| In the text | |
|
Fig. D.1. Process of merging predictions from two overlapping lattice structures to produce a full-box instance segmentation map. ’Lattice1’ (top) and ’Lattice2’ (middle) represent predictions from initial and shifted lattice grids, respectively, with unique colour-coded labels for instances. Black dashed lines indicate the lattice employed in each case, while thin dashed grey lines correspond to the lattice employed in the reciprocal scenario. ’Combined’ (bottom) depicts the final synthesized full-box map, where instances have been merged based on their overlap, demonstrating the effectiveness of the methodology in generating contiguous and comprehensive halo segmentations from smaller, predicted sub-volumes. |
| In the text | |
|
Fig. E.1. Slices through the Lagrangian field of friends-of-friends proto-haloes, and the corresponding predictions using the EXSHALOS algorithm. Left panel: Ground truth masses obtained using N-body simulations (friends-of-friends proto-haloes). Central panel: Predicted masses obtained using the EXSHALOS algorithm. Right panel (analogous to left panel of Fig. 5): Semantic pixel-level error map between EXSHALOS and friends-of-friends haloes indicating true positive (green), true negative (blue), false negative (black), and false positive (red) regions. |
| In the text | |
|
Fig. E.2. Violin plot, visualizing the distribution of predicted halo masses (at a voxel level) for different ground-truth mass bins. The black violin plots show the results obtained with our instance segmentation model. Green violin plots show the agreement between the two baseline simulations – representing an optimal target accuracy. The purple violin plots in the main panel correspond to the comparison with the EXSHALOS predictions. The solid black line in the top panel shows the false negative rate, FNR, as a function of the ground truth halo mass. The dashed black line represents the fraction of predicted collapsed pixels that are not collapsed as a function of predicted halo mass (false discovery rate, FDR). The green and purple lines on the top panel correspond to the analogous results obtained from the baseline simulations and EXSHALOS respectively. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.