| Issue |
A&A
Volume 679, November 2023
|
|
|---|---|---|
| Article Number | A76 | |
| Number of page(s) | 17 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202347016 | |
| Published online | 09 November 2023 | |
A versatile classification tool for galactic activity using optical and infrared colors
1
Physics Department, and Institute of Theoretical and Computational Physics, University of Crete,
71003
Heraklion, Greece
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Institute of Astrophysics, Foundation for Research and Technology-Hellas,
71110
Heraklion, Greece
3
Astronomical Institute, Academy of Sciences,
Boční II 1401,
14131
Prague, Czech Republic
4
Center for Astrophysics, Harvard & Smithsonian,
60 Garden St.,
Cambridge, MA
02138, USA
Received:
26
May
2023
Accepted:
2
October
2023
Abstract
Context. The overwhelming majority of diagnostic tools for galactic activity are focused mainly on the classes of active galaxies. Passive or dormant galaxies are often excluded from these diagnostics, which usually employ emission-line features (e.g., forbidden emission lines). Thus, most of them focus on specific types of activity or only on one activity class, for example active galactic nucleus (AGN) galaxies
Aims. In this work we used infrared and optical colors to build an all-inclusive galactic activity diagnostic tool that can discriminate between star-forming, AGN, low-ionization nuclear emission-line region, composite, and passive galaxies, and which can be used in local and low-redshift galaxies.
Methods. We used the random forest algorithm to define a new activity diagnostic tool. As the ground truth for the training of the algorithm, we considered galaxies that have been classified based on their optical spectral lines. We explored classification criteria based on infrared colors from the first three WISE bands (bands 1, 2, and 3) supplemented with optical colors from the u, g, and r SDSS bands. From them, we sought the combination with the minimum number of colors that provides optimal results. Furthermore, to mitigate biases related to aperture effects, we introduced a new WISE photometric scheme that combines apertures of different sizes.
Results. Using machine learning methods, we developed a diagnostic tool that accommodates both active and passive galaxies under one unified classification scheme using just three colors. We find that the combination of W1-W2, W2-W3, and g-r colors offers a good performance, while the broad availability of these colors for a large number of galaxies ensures it can be applied to large galaxy samples. The overall accuracy is ~81%, and the achieved completeness for each class is ~81% for star-forming, ~56% for AGN, ~68% for LINER, ~65% for composite, and ~85% for passive galaxies.
Conclusions. Our diagnostic represents a significant improvement over existing infrared diagnostics because it includes all types of active galaxies, as well as passive galaxies, extending their application to the local Universe. The inclusion of the optical colors improves its ability to identify low-luminosity AGN galaxies, which are generally confused with star-forming galaxies, and helps us identify cases of starbursts with extreme mid-infrared colors that mimic obscured AGN galaxies, a well-known problem for most infrared diagnostics.
Key words: galaxies: active / galaxies: star formation / galaxies: starburst / galaxies: Seyfert / infrared: galaxies / methods: statistical
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Galaxies can be classified into different categories based on their activity. Some form new stars (i.e., star-forming galaxies, also referred to as H II galaxies due to their H II-region-like spectra), while others present intense nuclear activity fueled by the supermassive black hole (SMBH) in their active galactic nucleus (AGN). Some galaxies simultaneously exhibit both of these behaviors. They are known as composite galaxies or transition objects (e.g., Ho et al. 1997). In another galactic category, we find galaxies that host old stellar populations, contain small amounts of gas or dust, and do not exhibit any star formation or nuclear activity. These are the passive galaxies. Finally, there are also the low-ionization nuclear emission-line region (LINER) galaxies (Heckman 1980). These galaxies can be separated into two distinct categories: those powered by a SMBH (type 1; Ho et al. 1997) and those for which the source of excitation is UV emission from post-asymptotic-giant-branch stars (Binette et al. 1994; Stasińska et al. 2008; Papaderos et al. 2013).
Before now, the best way to discriminate between these four classes of active galaxies (star-forming, AGN, LINER, and composite) had been via the use of the emission-line ratio diagrams introduced by Baldwin et al. (1981), hereafter BPT diagrams. These are two-dimensional diagrams that separate galaxies into H II regions (star-forming), AGN (Seyfert), LINER, and composite classes using the characteristic emission-line ratio fluxes. The most commonly used version of this diagram is a plot of [O III]λ5007/Hβ against [N II]λ6584/Hα, [S II]λλ6716,6731/Hα, or [O I]λ6300/Hα (Kewley et al. 2001; Kauffmann et al. 2003; Schawinski et al. 2007). The classification of a galaxy depends on its location on the diagram. Although it has been a highly accurate and reliable method for galactic activity classification for many years, it presents some disadvantages. One is that in order to classify a galaxy, one needs to obtain an optical spectrum, which can be challenging for very large samples of galaxies. A second reason is absorption by the interstellar medium, which may obscure the AGN emission. Additionally, some emission lines are weak, hampering the application of these diagnostics to faint objects. In order to overcome these difficulties, new methods for classifying galaxies that use infrared photometry, specifically in the mid-infrared (3–24 μm) part of the spectrum, have emerged. The use of photometry allows the diagnostic to be applied to large samples of galaxies, and the use of infrared data allows the identification of obscured AGNs.
Observations with the Spitzer Space Telescope (Werner et al. 2004) led to the development of the first versatile activity diagnostics in the near- to mid-infrared by Stern et al. (2005) and Donley et al. (2012). Subsequently, the launch of the Wide-field Infrared Survey Explorer (WISE) satellite (Wright et al. 2010) enabled systematic studies of large populations of galaxies by providing sensitive all-sky photometry in the 3–24 μm range; its four bands, W1, W2, W3, and W4, have effective wavelengths of 3.4, 4.6, 12.0, and 22.0 μm, respectively. This led to the development of a new family of diagnostic tools.
One widely used diagnostic for AGN identification based on WISE infrared photometry is the criterion of W1–W2 ≥ 0.8 (Stern et al. 2012). Another diagnostic is based on the W1–W2 color against the W2–W3 color (Mateos et al. 2012).
Even though these two infrared AGN selection methods have had great success in identifying high-redshift galaxies in several surveys (e.g., CANDELS; Koekemoer et al. 2011), they are tailored toward higher-redshift, more luminous, or obscured AGNs. In fact, the diagnostic of Mateos et al. (2012) was built based on an X-ray-selected sample of AGNs. However, the application of such diagnostics to other samples of galaxies shows that they fail to identify a large population of AGNs, especially in the local Universe. In a sample of galaxies taken from the Sloan Digital Sky Survey (SDSS), most of the AGN galaxies are located below the W1–W2 = 0.8 AGN selection line of Stern et al. (2012) or are located outside the AGN wedge of Mateos et al. (2012, see our Sect. 5.4).
In order to overcome this limitation, we have developed a new mid-infrared-optical color activity diagnostic using advanced methods, including machine learning algorithms, to supplement and enhance the performance of the existing diagnostic methods. The main reason we considered these algorithms as the basis of our diagnostic tool is that there is strong mixing between the mid-infrared colors of the different types of galaxies. Sensitive all-sky surveys provide photometric data for millions of galaxies, and machine learning methods allow us to efficiently exploit these rich databases and capture their complexity in multidimensional parameter spaces.
Since in this work we do not use emission lines, we are able to include the class of passive galaxies, which is often excluded in standard diagnostic tools. Therefore, we embarked on the development of a new activity diagnostic based on infrared (WISE) and optical (SDSS) photometry and machine learning methods. More specifically, this new diagnostic utilizes three colors in order to classify galaxies into five different activity classes: star-forming (SF), AGN, LINER, composite, and passive.
The paper is organized as follows. In Sect. 2 we describe the data, introduce the photometry scheme, and describe the methods used for the selection of each galactic activity class. In Sect. 3 we introduce the classification method. In Sect. 4 we present the results of the training of our diagnostic tool and investigate its performance. In Sect. 5 we discuss the achieved results and the limitations of the tool, and we explore the reliability of the classifier. We also compare our results with other widely used infrared classification methods for AGNs. In Sect. 6 we summarize our conclusions.
2 Data accumulation
2.1 The Sloan-Digital Sky Survey
Our main galaxy sample is drawn from the SDSS, a northern sky survey that provides homogeneous and high-quality photometric and spectral data. For the activity classification of the galaxies in our sample (see Sect. 2.3) we used the spectroscopic information provided by the SDSS-MPA-JHU catalog (Kauffmann et al. 2003; Brinchmann et al. 2004; Tremonti et al. 2004). This catalog includes spectroscopic line and redshift measurements for more than one million galaxies within the SDSS footprint. In order to obtain photometric data for these galaxies we crossed-matched the galaxies with reliable measurements (RELIABLE ≠ 0) with the SDSS – DR16 photometric catalog based on their specObjID. The SDSS – DR16 provides measurements for a number of surface brightness profiles and aperture sizes in five filters: u, g, r, i, and z. For our purposes, we opted to use the fiberMag (flux within an appropriate to the SDSS spectrograph 3" aperture) and cModelMag photometry. The cModelMag photometry is based on a radial profile that is a linear combination of the best fit of an exponential and a de Vaucouleurs profile. The fiberMag is a good approximation of the flux in a galaxy's nucleus (especially for the nearby galaxies) and the cModelMag profile gives the total flux of a galaxy in a given band.
2.2 Wide-field Infrared Survey Explorer photometry
The WISE satellite (Wright et al. 2010) mapped almost the entire sky. The WISE All-Sky Release Source Catalog covers 42 195 deg2, or 99.86% of the entire sky in four broad bands in the ~3–25 μm range. Its bands W1, W2, W3, and W4 have effective wavelengths at 3.4, 4.6, 12, and 22 μm respectively. Their angular resolution was 6.1, 6.4, 6.5, and 12 arcseconds, respectively. The WISE survey provides several advantages for the classification of large populations of galaxies: it is more sensitive than previous broadband infrared surveys; it covers the 3–25 μm range, which includes several important diagnostic features, for example the polycyclic aromatic hydrocarbon (PAH) emission features, primarily found in SF galaxies; and the 3–20 μm continuum probes the transition from the stellar continuum to dust emission of a galaxy that hosts an AGN.
The WISE survey offers different photometry profiles and apertures. In this project, we used the w?mag_2 and w?gmag (the question mark corresponds to different band numbers 1, 2, 3, and 4 for W1, W2, W3, and W4, respectively). The w?mag_2 photometry is the calibrated source brightness measured within a circular aperture of 8.25 arcseconds radius centered on the source position for every WISE band and no curve growth correction has been applied. The background sky was measured from an annulus with an inner and outer radius of 50 and 70 arcsec, respectively. The w?gmag photometry is based on elliptical aperture photometry for every WISE band (the question mark corresponds to 1, 2, 3, and 4 for W1, W2, W3, and W4, respectively). The parameters of the elliptical apertures (semimajor axis and position angle) are based on the 2MASS survey (Skrutskie et al. 2006). In addition, the WISE survey provides extended source photometry, which however, is subjected to significant photometric uncertainties due to the low signal-to-noise ratio in the lower-surface brightness regions of the galaxies.
As this project aims to study galaxies in the local Universe, we started our analysis by considering photometry from the w?gmag photometric aperture as these galaxies will appear extended in the WISE apertures. The use of a fixed photometric aperture means some of the galaxy emission for the nearest galaxies will be missed and, most importantly, an increasingly large galactic region will be included for more distant galaxies. Although this may dilute some of the nuclear (AGN) emission, it allows the application of the diagnostic to a wide range of distances, from local galaxies to more distant unresolved ones. We find that ~20% of the galaxies in our sample appear extended in the WISE apertures (ext_flg≠0). This reduces aperture effects and allows the application of the diagnostic even to very local galaxies (z ~ 0).
For more distant objects that are unresolved by WISE, we used the w?mag_2 photometry aperture. The reason for choosing the w?mag_2 over other similar WISE photometry apertures (e.g., w?mag_1) was that the former has an aperture radius similar to that of the PSF. For each of the four individual WISE bands, the w?gmag photometry is kept for all galaxies that have measurements in that aperture, and the w?mag_2 photometry is used for all galaxies that did not have measurements on the w?gmag aperture. The consideration of the integrated photometry eliminates any aperture-related bias resulting from the large distance range of our galaxies, since galaxies that belong to the same activity class but have different distances will now have the same colors. Given the different photometry apertures available in the WISE catalog, in order to overcome this photometric bias, our photometry consists of the extended apertures for the resolved and of the point-like apertures for the unresolved sources. In addition, spiral galaxies tend to have H II regions scattered across the galaxy disk and a bulge region dominated by old stellar populations in the center (e.g., Feltzing & Gilmore 2000; Ortolani et al. 2001). This hybrid photometry scheme is ideal for accounting for the infrared emission of these gas regions and also avoids confusion in the classification process due to aperture effects.
Lang et al. (2016) obtained WISE integrated photometry by using higher-resolution WISE maps together with apertures from the SDSS data, that is, WISE-forced (WF) photometry. This information is only available for the galaxies in the SDSS footprint and therefore not appropriate for an all-sky sample. Nonetheless in Fig. 1 we compare our hybrid photometry with the WF photometry. Since in our diagnostic we considered WISE colors, in that plot, we see the one-to-one comparison of the two WISE colors, W1–W2 and W2–W3, calculated with WF photometry and with our hybrid scheme. This comparison shows that the two methods show good agreement apart from a small systematic offset of ~0.1 mag in the W1–W2 color and ~0.5 mag in the W2–W3 color. We also color-coded the sources based on their ext_flg value. If the source has ext_flg=0 means that its shape is consistent with a point-source profile in the WISE. We see there is no dependence on the measured colors in our hybrid scheme depending on the source extent.
2.3 Activity classes and passive galaxies
For the activity classification of galaxies with emission-line spectra, we used the diagnostic tool defined by Stampoulis et al. (2019). This is an extension of the generally used diagnostics of Baldwin et al. (1981), Kewley et al. (2001), Kauffmann et al. (2003), and Schawinski et al. (2007) that allows the simultaneous use of all available diagnostic line ratios, avoiding contradictory classifications and providing more robust results. This scheme is based on fitting multivariate Gaussian distributions to the four-dimensional emission-line ratio distributions of log10([N II]/Hα), log10([S II]/Hα), log10([O I]/Hα), and log10([O III]/Hβ). For this reason if we project these objects on the two-dimensional BPT diagram, the tails of the distributions of the different activity classes may not be confined within the demarcation lines that separate the different activity classes defined by Kewley et al. (2001), Kauffmann et al. (2003), and Schawinski et al. (2007). The emission-line measurements were obtained from the SDSS JHU-MPA catalog (Kauffmann et al. 2003; Brinchmann etal. 2004; Tremonti et al. 2004). The classes of galaxies considered in that classification scheme were: SF, Seyfert, LINER, and composite. This diagnostic is based on a probabilistic classifier. That means that based on the location of an object in this four-dimensional space, one can also determine the probability that it belongs to each of the classes that the classifier has been designed to discriminate. In our analysis, we used their Soft Data-Driven Analysis (SoDDA) classifier, adopting the class with the highest probability.
So far, most galactic emission-line diagnostic tools do not include the class of passive galaxies. Inactive or passive galaxies are defined as galaxies that do not show any evidence of activity (i.e., SF or AGN) based on the lack of optical emission lines. Since in this work we also considered the class of passive galaxies, we needed to define the corresponding sample. Thus, since we were seeking inactive galaxies, the sample of passive galaxies was selected using the following criteria: emission lines of Hα, Hβ, [O III] λ5007, [O I] λ6300, [N II] λ6584, and [S II] λλ6717,6731 should have had signal-to-noise ratio below 3 and the signal-to-noise ratio of the continuum at the location of each emission line was above 3. This ensures that the lack of emission lines was not the result of the difficulty in measuring them in poor-quality spectra. A confirmation that this method of classifying galaxies as passive is effective, is their location on the color-magnitude diagram (e.g., Bell et al. 2004). Figure 2 shows the g–r color against the absolute r-band photometry (Mr). The galaxies selected spectroscopically as passive are located on the upper part of the diagram in the so-called red sequence region, where early-type galaxies are found.
 |
Fig. 1 Comparison between the forced photometry, WF, and the hybrid photometry scheme introduced in this work. Top: W1–W2 color calculated with the hybrid scheme against the same color but calculated with the WF photometry. Bottom: same but for W2–W3 color. The galaxies have been color-coded according to their extension in the WISE data (ext_flg=0 for point-like sources and ext_flg≠0 for extended sources). The black solid line is the y = x. |
 |
Fig. 2 Color-magnitude diagram of g–r against Mr. On the y-axis is the g–r color against the absolute magnitude in the SDSS r band, Mr. The red points represent the sample of passive galaxies and the gray points the whole sample of galaxies (all classes). |
2.4 Final sample
After defining the criteria for the selection of each galaxy class, we filtered the galaxies that will constitute the final training sample based on the quality of the photometric data and the activity classification.
As our goal here was to train a machine learning algorithm, the filtering had to be done in two stages. The first one ensured that the true labels (i.e., activity classes) are well defined, as a poor true label definition based on insecure classification can lead to an algorithm with significant uncertainty in its predictions. The other stage regarded the features (photometric measurements) that was used for the discrimination between the different galaxy classes by the new activity diagnostic tool.
For the first step, we only selected active galaxies that have S/N above 5 for all optical emission lines that were used for the characterization of the true class of each galaxy (Sect. 2.3), namely, Hα, Hβ, [O III] λ5007, [O I] λ6300, [N II] λ6584, and [S II] λλ6717,6731. As stated earlier, the classification of each galaxy was based on the class with the highest probability in the diagnostic of Stampoulis et al. (2019). As the classifier also provides the probabilities of each galaxy belonging to the other considered classes, we chose galaxies that have been classified with high confidence based on the probability difference of the highest and second highest predicted probability that were assigned by the classifier for each galaxy. Classifications with a large difference between the first and the second-ranking class are considered highly reliable. In this respect, we considered galaxies with a difference in their predicted probabilities of at least 25%.
First, we considered objects with reliable photometric measurements based on the WISE quality flags. To identify and remove these problematic cases, we consulted the AllWISE Source Catalog and Reject Table1, where we found the quality flags for the photometry of a galaxy in the first three WISE bands. We considered as unreliable photometry every detection that, in at least one of the three WISE bands (1, 2, and 3), has been flagged in the above-mentioned catalog as having a measurement error of 9.999, as this indicates that even though a measurement exists it should be considered as highly suspicious. Also, another flag concerning the quality of the photometry is the w?flg=32. Every galaxy with this flag means that its photometry measurement is in the 95% upper limit and should not be considered reliable detection. Other important factors that had to be accounted for in the quality of the photometry measurements are source contamination and confusion. If a source has been flagged in cc_flags with a value of D, P, H, O, d, p, h, or o, it means that the source may be contaminated due to its proximity to an image artifact, and thus we removed any galaxy that has one of these flags in any of the W1, W2, and W3 bands. Concerning the second stage of filtering, we chose active and passive galaxies that have photometric data with S/N > 5 in the two WISE bands, W1 and W2, as well as for the two SDSS filters (g and r). A more relaxed lower limit of S/N = 3 for the W3 WISE band was selected. The reasoning behind these choices is that the W3 WISE band has lower sensitivity than the W1 and W2 bands and a strict S/N selection criterion will result in a significant reduction in the number of galaxies in our sample.
Other important facts that had to be taken into consideration are survey selection and galaxy evolution effects. We found that in our sample the number of AGN and passive galaxies tended to increase sharply with redshift. In order to create a uniform distribution of activity classes of galaxies across the whole red-shift range, we split the sample into four equal redshift bins. Our sample of galaxies spans the redshift range from z = 0.02 to z = 0.08. We limited the lower cutoff of redshift to z = 0.02 as this is compatible with the definition range of the BPT diagrams (i.e., from z ~ 0.02 to z ~ 0.06) and thus avoids strong aperture effects during the training of the algorithm. We proceeded by finding a "reference" redshift bin, which was used as the basis for selecting the number of objects to sample from each class in each redshift bin. We find that the 0.033 < z < 0.047 bin is ideal as a reference bin as it is close to the middle of the redshift range. Based on this bin, we randomly selected the same number of objects for each class individually from the other three redshift bins (namely 0.02 < z < 0.033, 0.047 < z < 0.063, and 0.063 < z < 0.08.)
After the implementation of the two stages of filtering, the redshift balancing, and the removal of unreliable detections in the WISE photometry we obtained the final sample that contains all the eligible galaxies for the training process of our diagnostic tool. In that sample, there are 40 954 galaxies in total, with redshifts between z = 0.02 and z = 0.08. The composition of the training sample per galactic activity class is given in Table 1. We note that although our classifier was trained on a sample with high quality optical spectroscopy classifications, it can be used on any sample of galaxies with available photometry in the WISE and SDSS bands. The only limitation is that the infrared photometry should encompass the extent of the galaxy, and the optical photometry the central 3" of the galaxy (to match the SDSS fiberMag).
Composition of the final sample per galactic activity class.
3 The diagnostic tool
3.1 The random forest algorithm
For the development of our diagnostic we opted to use the random forest algorithm (Louppe 2014), which is based on the concept of decision trees. A decision tree starts with a root node that contains all the training data, then it will use the considered features to progressively create more homogeneous groups of data (nodes). Ideally, at the end of the process, the final nodes (leaves) will only contain data of the same kind (class). The problem with a single decision tree is that, in most cases, the tree tends to adapt too well to the training data, and as a result, its performance is poor when it is applied to new data (overfitting). To avoid overfitting, we can combine many decision trees in parallel to build a random forest. Each decision tree of the random forest is trained on a subsample of the training data. Every such subsample of the full data set that is used for the training of the trees is selected by randomly shuffling the full training set.
During the classification process, each tree takes as input an object and gives as output (or vote) the class that this individual object belongs. Then, this process continues until that object has been through every tree of the ensemble. In the end, the decisions made by every tree of the ensemble for the object under question are summed and the object belongs to the class that collected the most votes. The algorithm also allows us to calculate the probability of that object belonging to each of the classes. This probability is given by the ratio of the number of votes the object received to belong in a particular class to the total number of trees considered in the algorithm.
It is called random because, during the training process of the algorithm, the features used to make the split of the data into the new nodes are selected randomly. The random forest offers several advantages: it is intuitive, probabilistic and it is easily adaptable to many problems. We used the implementation of the random forest algorithm provided by sklearn.ensemble.RandomForestClassifier() from the scikit-learn Python 3 package, version 1.1.2.
3.2 Performance metrics
To evaluate the performance of our diagnostic tool, we adopted standard metrics such as the accuracy, the precision, the recall, and the F1-score. The exact definition of each performance metric we used for the evaluation is presented in Table 2. Evaluating the performance of an algorithm based on the accuracy metric may lead to misleading results, especially in cases with skewed data sets like the one we are dealing with here.
The metrics that we considered as more appropriate are the recall and the precision for each class. Recall is a metric that quantifies completeness (how many objects of each class have been correctly selected) while the precision quantifies contamination (the fraction of correctly selected objects within the population of all selected elements). To properly evaluate performance, we plotted the confusion matrix and calculated the precision and the recall scores per class.
3.3 Feature selection
There are many characteristics that one can use to classify galaxies based on their activity. Our main goal here is to define a diagnostic tool that is capable of discriminating efficiently between the galaxy classes by utilizing observables that can easily be acquired for a large number of galaxies. Considering all the above, in this work, we used only infrared and optical colors that are available from all-sky or wide-area surveys. Initially, we started by considering colors that are the combinations of the three WISE bands and three SDSS filters. More specifically, using combinations of the WISE bands 1, 2, and 3 along with the u, g, and, r SDSS (fiberMag photometry) filters, we calculated the colors: W1–W2, W2–W3, g–r, and u–g. In Fig. 3 we see the distributions of each color we considered as a potential feature, for the different classes, normalized by the total number of objects in each activity class. In our analysis, we also considered including the W3–W4 color as a potential feature. However, due to the low sensitivity of the detector at the 24 μm band, combined with the weak emission from passive galaxies in the mid-infrared, we found that almost none of the passive galaxies has reliable detections in the W4 WISE band. Therefore, this band (and the colors involving it) was not considered further in our study.
These particular features were chosen based on the broadband spectral shape of these five different galaxy classes. Previous diagnostics have demonstrated the diagnostic power of WISE. Star-forming galaxies have H II regions that are rich in dust and gas heated up by hot young stars, producing strong emission in the infrared WISE bands (in particular in W3 due to the PAHs and dust). The AGN-hosting galaxies have a rising red continuum due to dust heated by the power-law UV spectrum while at the same time, this extreme UV radiation environment results in the dissociation of the large molecules, leading to suppressed PAH emission (Alonso-Herrero et al. 2014). However, the two top plots of Fig. 3 show that there is an overlap between the classes in the WISE colors, especially in the case of the W1–W2 color. In the two bottom plots of the same figure, we see that the optical colors help break the degeneracy observed in the mid-infrared colors.
Even though there is astrophysical reasoning behind our initial feature selection, we cannot know a priori which combinations give optimal results and which ones do not provide any improvements in the performance of this multi-class classification problem. In order to determine which combination can yield optimum results with the minimum number of features, we trained the algorithm with different combinations of features and recorded the performance of each training scheme. This method helped us compare the performance of the different models and identify highly informative or redundant features. The total number of models examined was six, and they are presented in Table 3. In Fig. 4 we plot the recall score of each activity class for each model (i.e., feature scheme) presented in Table 3. We started from the simplest case by testing one infrared and one optical color. For the first two simple models from the two available infrared colors, we decided to test only the W2–W3 combined with a different optical color each time as the W2–W3 provides greater dynamic range and discrimination between the different classes compared to the W1–W2. The selection of a feature scheme (model) for this new diagnostic was made using two basic criteria: (1) it had to offer high recall scores for each class, and (2) it used the minimum number of features. We chose to use the recall as a performance metric since it also offers information about completeness.
In our analysis we used the average value of the recall scores calculated with the cross-validation (CV) method. In more detail, we used galaxies from the final sample (see Sect. 2.4) by imposing the additional criterion that all galaxies must have S/N >5 in the u SDSS band. Then, we split those galaxies in k-folds and used the k-1 folds for training and one for the performance evaluation of the model (testing fold). Every time, we replaced the testing fold with one of the training folds and repeated this step until all the k folds were in the position of the testing fold. We kept the k total recall scores and calculated the average. The error bars on the average recall are the standard deviation of the k recall scores. We selected the number of folds to be 10 (k = 10), which is the maximum number of folds that offered a balance between satisfactory number of objects in each fold for the under-represented classes and good statistics for evaluating the performance metrics.
After evaluating each possible model, we conclude that the model that includes all the available colors (Model 6) does not improve the performance when compared to the models that use two infrared and one of the two optical colors (Model 4 and 5). The performance of Model 3 is generally the same as that of Models 4, 5, and 6, but the lack of an optical color results in dramatically lower recall for the SF galaxies. This can be attributed to the fact that SF galaxies have bluer g–r colors, which separate them clearly from the other activity classes (Fig. 3). For the other two models (Models 1 and 2), we notice that the classifier does not have enough information to separate the classes effectively. In particular, we notice that there is a significant performance drop for the AGN and composite galaxy classes. This can probably be explained by the nature of the AGN and composite galaxies. The W2–W3 color records the infrared emission from the circumnuclear dust heated by the SMBH that is found in every AGN galaxy but can also be present in a composite galaxy. Although AGN-heated dust can lead to stronger emission in the W2 band, the majority of the AGN-hosting galaxies have similar W1–W2 colors to SF and of course to composite galaxies. This creates confusion on a classifier that is defined based only on the feature schemes of Models 1 and 2, leading to an extensive mixing between these two classes. Based on these results, we decided to adopt Model 4 as our basic model, which has the following features: two infrared colors (WISE), W1–W2, W2–W3, and one optical color (SDSS), the g–r. In Fig. 4, we see that Model 5 has a similar performance as Model 4. However, Model 5, relies on u-band photometry, which often has lower signal-to-noise measurements than the r band, limiting the applicability of the classifier to larger data samples.
After the optimal combination of features was determined, we proceeded with the optimization of the algorithm. In this process we searched for the values of the algorithm's hyperparameters that offer the best performance in a particular problem. Upon investigation, we find that by tweaking nearly half of the algorithm's hyperparameters the scores do not improve significantly and thus they are left in their default values, as imported from scikit-learn. The hyper-parameters that have a significant impact and hence are worth optimizing are the following: max_depth, max_leaf_nodes, max_samples, min_samples_leaf, min_samples_split, and n_estimators. The exact procedure of the optimization as well as a table (Table A.1) with the best values for each important hyperparameter are presented in Appendix A.1.
Definition of each performance metric used for the evaluation of the performance of our diagnostic tool.
Different combinations of features (colors) that were tested as potential models for the definition of the diagnostic.
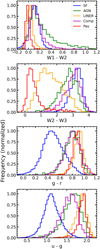 |
Fig. 3 Distributions of colors considered as potential features for the definition of our diagnostic tool. Starting from top to bottom, we see the distributions of colors W1–W2, W2–W3, g–r, and u–g for each galactic activity class. Combinations of these four colors are used as potential feature schemes for defining our diagnostic. Due to the high imbalance of the sample, the number of galaxies is normalized based on the frequency of occurrence in our data sample. Blue histograms correspond to the SF, green to the AGN, yellow to LINER, purple to composite, and red to passive galaxies. |
 |
Fig. 4 Recall scores of the different models (features schemes) considered for our diagnostic tool. The description of the models is presented in Table 3. The error is the standard deviation of the k recall scores (here k = 10), calculated using the CV method. The error on the recall scores for the SF galaxies is too small to be depicted here. Blue points correspond to the SF, yellow to AGN, green to LINER, red to composite, and purple to passive galaxies. |
3.4 Implementation
The standard procedure for this step is to separate the sample of all available data, into three random subsets. One of them contains the majority of the objects (50% of the total or 20 476 galaxies) and it will be used for the training. The data from that subset are used to adapt the algorithm to the individual problem. The rest of the data form the test and the validation set. The validation is used for the calibration of the classifier while the test set is only used for the evaluation of its performance after the training and calibration processes (see Sect. 3.5). For this project, we performed a training-validation-test set with proportions of 50-25-25% or 20476-10239-10239 galaxies, respectively. The split was stratified, which ensures that each subset has the same percentage of objects in each class as the original sample.
The high imbalance in the number of objects between the five classes in the training sample cannot be left unnoticed, since it can lead to biases in the classification in favor of the class that has the higher frequency of appearance. To avoid such an effect, we have two options: one is to reduce the sample in such a way that every individual class has the same number of objects, and the second is to assign weights to each class, that is, to adjust the impact of each object will have during the training of the algorithm. In the implementation of the random forest we used here, these weights are calculated internally by setting the class_weight parameter to "balanced_subsample." We selected the second option, as it makes use of all available data, leading to a more robust classification tool as the training will contain a broader range of examples.
3.5 Classifier calibration
Every probabilistic classifier provides us with not only the class of the object under investigation but also the probability that this object belongs to each of the classes that the classifier was designed to discriminate. When the classes are very well separated in the feature space these probabilities represent the actual likelihood of finding an object to belong to a certain class given its location in the feature space. However, in classification problems where there is some mixing between the distribution of the features for the considered classes, these probabilities do not necessarily reflect the actual probability of the true class. To correct for this effect in our classification problem, we calibrated our classifier. This way the output of the classifier represents the actual probability of finding an object of a particular class within a given region of the feature space.
In the case of a multi-class classification problem, the process of calibration is performed in a one versus rest fashion, that is, following the same process as in the binary classification for each class individually and splitting the multi-class problem into multiple binary-class problems. The calibration in a binary classification is achieved by applying a regression algorithm (calibrator) that rescales the raw predicted probabilities so that these probabilities match the expected distribution of the actual probabilities. This is based on the frequency of an object of a given class appearing among the sample in the feature space. The subsample that is used for the calibration must contain objects that have not been used during the training of the classifier to avoid any bias.
The data we used for the calibration of our diagnostic was from the validation subset (see Sect. 3.4), a held-out subset of the data that was not a part of the training process. The algorithm we used to perform the calibration is the CalibratedClassifierCV, which is provided by the scikit-learn package. We opted to use the "sigmoid" over the "isotonic regression" method as the latter is prone to overfitting, especially in problems with severely under-presented classes. Due to the fact that SF galaxies are the overwhelming majority of the objects in our sample, a feature that is preserved in the stratified split of the data among the three subsets of data (i.e., training, validation, and test set), the validation set has an excess number of SF galaxies.
This imbalance in the number of objects in each class can lead to biases in the calibration in favor of the class with the higher frequency of appearance. To avoid such effects, only for the validation set, we manually balanced the sample by keeping the same number of objects from each class.
4 Results
4.1 Performance
We started by calculating the overall accuracy of our diagnostic. As before, we used the k-fold CV method. However, here we used a reduced number of folds because, in this case, we had to keep an additional subset of data separate from the final sample, which we later used for the probability calibration of the algorithm. We find that the maximum number of folds we can split our data into while maintaining enough objects to adequately represent the minority classes and still have good statistics is five. The overall accuracy achieved is 81% ± 1%. We acknowledge that the accuracy alone is not enough to describe the performance. Thus, we considered additional performance evaluation metrics, such as the confusion matrix. This is a two-way table in which the lines (y-axis) represent the true labels and the columns (x-axis) are the predicted labels for each data point made by the classifier. Each cell gives the fraction of the objects from a given true-class that is classified in each of the considered classes (columns). Therefore, the confusion matrix is the summary of the results made by the algorithm when evaluated on the test subset on a class-by-class basis. In a perfect classifier, all objects populate only the primary diagonal (y = –x). The confusion matrix provides information not only for the number of correct predictions but also about the objects that were misclassified, by checking what classes the classifier mixes. In Fig. 5 we present the confusion matrix calculated on the test subset of the final data sample defined in Sect. 2.4. Inspecting the confusion matrix we conclude that the overall performance is good, with the higher scores achieved for the classes of the SF and passive galaxies.
Based on these results we could also calculate additional metrics that can give us a more detailed view of the performance per class. In Table 4 we present the values for the metrics defined in Table 2 calculated for each class. In that table we see that the SF and passive galaxies have excellent scores while the rest of the classes (AGN, LINER, and composite) have good to moderate performances.
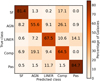 |
Fig. 5 Confusion matrix for the test subset of galaxies. The numbers (and the color-code) in this plot represent the percentage of the classified objects in each class with respect to the total true population in each class. The labels on the x- and y-axis represent the predicted and the true class of a galaxy, respectively. Here "Comp" stands for composite galaxies and "Pas" for passive galaxies. |
4.2 Feature importance
A useful output of the random forest algorithm is the feature importance, which describes the relevance of each feature during the training of the classifier. Therefore, it provides a measure of how much a given feature contributes to the ability of the random forest to discriminate between the different classes. So, a feature that clearly characterizes a class will have high relevance (or importance). Furthermore, it provides insights into the physical parameters that drive the performance of the classifier.
In Fig. 6 we present a bar plot of the feature importance scores. As the feature importance is calculated in each node, we can calculate the average and its standard deviation. From Fig. 6 we see that the chosen feature scheme is well defined, as all features play a similar role in the classification of these five activity classes. Thus, the feature importance helps us better understand the operation of this algorithm.
Performance metrics calculated for each class.
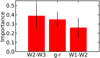 |
Fig. 6 Importance (relevance) of the three features used for the definition of the diagnosis as calculated during the training of the random forest. The W2–W3 color is the most important feature, and all other features are of comparable relevance. |
4.3 Application to the different redshift subsamples
After we trained and optimized the diagnostic tool, we proceeded by applying it to two different subsets of the test set (Sect. 3.5), spanning two different redshift ranges: 0.02 < z < 0.05 and 0.05 < z < 0.08. Since the initial training of the algorithm was performed on the full redshift range of z = 0.02 to z = 0.08, this exercise shows whether the performance of our diagnostic has a redshift dependence. The number of true objects per class in the 0. 02 < z < 0. 05 redshift range is as follows: 3982 SF, 164 AGN, 150 LINER, 216 composite, and 93 passive galaxies. In the redshift range of 0.05 < z < 0.08 the number of objects is as follows: 4978 SF, 165 AGN, 170 LINER, 218 composite, and 103 passive galaxies. In Fig. 7 we present the recall score for each class in these two redshift bins when we apply our diagnostic to each one separately. For reference, we also show the scores of the diagnostic in the overall redshift range (0.02 < z < 0.08). In this figure we see that the diagnostic has similar behavior (similar recall scores) for SF galaxies for the whole redshift range of our sample of galaxies. However, we notice that AGN galaxies have slightly reduced performance in the lower-redshift compared to the higher-redshift bin (~20% lower recall compared to the bin having higher-redshift galaxies). Similar discrepancy is seen in the case of LINER and passive galaxies. The reason for this behavior is discussed in Sect. 5.3.
 |
Fig. 7 Fraction of correctly classified objects to the total true objects for each class, for three redshift ranges. The first redshift range is z = 0.02 to z = 0.05 (galaxies in the HECATE catalog; Kovlakas et al. 2021), indicated by blue disks in the plot, the second redshift bin is z = 0. 05 to z = 0.08, indicated by red squares. The third redshift range includes galaxies from the whole redshift range that the diagnostic was trained on, 0.02 < z < 0.08, which is indicated by black x marks. Here "Comp" stands for composite galaxies and "Pas" passive galaxies. |
5 Discussion
In this work we have defined a new all-inclusive (i.e., including active and passive galaxies) diagnostic tool based on the combination of commonly available mid-infrared and optical colors. In the following sections, we further discuss the behavior and robustness of the diagnostic and we compare it with other commonly used diagnostics.
5.1 Physical interpretation of the results
So far we have seen that our diagnostic achieves very good performance despite the limited information it uses. The use of the optical color of the galactic nucleus seems to have an important role in the efficient classification of galaxies (see Figs. 4 and 6). In Fig. 3 we see that the five activity classes present different behavior in terms of the distribution of the colors considered in our diagnostic.
In particular, in the case of SF and composite galaxies, we see higher values of the W2–W3 color attributed to significant emission from PAHs in the W3 band. On the other hand, passive galaxies are poor in dust and their stellar populations are older, resulting in a declining emission in redder wavelengths. In contrast, AGN galaxies show rising emission in the mid-infrared in all three WISE bands. This can be explained by emission from the dusty torus around the accretion disk. However, in contrast to SF galaxies they have weak PAH emission since these sensitive molecules are destroyed by the strong UV radiation from the accretion disk (e.g., Alonso-Herrero et al. 2014) or their emission is diluted by the AGN continuum (e.g., Genzel 1998).
Composite galaxies have weaker continua in the 3–12 μm range than AGN, but with stronger PAH emission, which however is weaker than that of SF galaxies. They also show strong silicate absorption. This is reflected in their W1–W2 and W2–W3 colors, which are in between those of AGN and SF galaxies. On the other hand, passive galaxies have W1–W2 and W2–W3 colors close to 0.
In the paragraphs above we have analyzed the discriminating power that the mid-infrared colors can have in the activity classification of a galaxy. However, the mid-infrared color diagnostic tools that have been developed so faroften sufferfromdust obscuration effects. A well-known example is that a starburst galaxy can mimic an AGN galaxy (e.g., Hainline et al. 2016). The introduction of an optical color is able to identify these cases and breaks the degeneracy present in the mid-infrared color space. In Fig. 3 we see that the distribution of the SF galaxies have g-r color that is clearly separated from the other activity classes.
Our results (Sect. 4) show that the random forest diagnostic achieves an overall accuracy of 81%. As this score was calculated on an independent sample (galaxies that were not used for its training) it is a good estimation of its general performance. In addition, the low standard deviation of the accuracy indicates that our diagnostic has stable performance.
Now, considering the above-mentioned trend, we can look back at the feature importance (Sect. 4.2) to see why some of the features were more important than others for the training of the algorithm. Observing Fig. 6 we see that the feature with the highest impact is the W2–W3 color. This can be explained by the strong PAH emission of SF galaxies, which dominates the emission in the W3 (centered at 12 μm) band.
5.2 Probability distributions
Besides the classification of each galaxy, the random forest algorithm can also give an estimation of the probability of an object belonging to each of the classes individually. A significant difference between the probability of the first ranking and the probability of the second-ranking class indicates a highly confident classification. The probabilities we examine in this section are the calibrated predicted probabilities (see Sect. 3.5).
In order to evaluate the confidence of the classifications performed for each galaxy, we compared the probability of the highest and the second-highest ranking class. For this reason, in Fig. 8, we show the probability difference between the highest and the second-highest probabilities, Δp, and we plot it against the maximum predicted probability for each of the five classes. Objects appearing in the top right corner of that plot have high probability of belonging to the first-rank class (close to 1) while the probability difference from the second class is also high. These objects have been classified with very high confidence and thus have high reliability. Another test we performed to check the reliability of the predicted probabilities was plotting the "recall" and the "precision" for each class as a function of their predicted probability. The process to calculate these curves is the following: after we took objects that belong to only one class, we split them into bins based on their predicted probability. Then, we calculated the fraction of objects that were correctly predicted to belong to the class under examination to the total predictions made in that bin to belong to that class (i.e., a measure of precision). Also, we calculated the fraction of galaxies in each probability bin that were identified correctly as belonging to a class by the new diagnostic to the total number of objects that truly belong to that class (i.e., a measure of recall). These plots are also shown in Fig. 8. The error bars that are displayed in the above-mentioned fractions (recall and precision are proportional to the square root of the instances found in each bin. So, through error propagation, we find the error for the recall to be 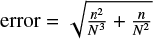 , where n is the true positive and N is the sum of the true positive and false negative examples in each predicted probability bin, while for the precision we used the same equation, but the n is the true positive and N is the sum of the true positive and false positive examples in each predicted probability bin. By inspecting Fig. 8 we see that Δp is high for almost all classes indicating a highly confident classification. Also, we see that as the predicted probability increases the recall and precision increase, indicating the reliability of the classifications as a function of the maximum predicted probability.
, where n is the true positive and N is the sum of the true positive and false negative examples in each predicted probability bin, while for the precision we used the same equation, but the n is the true positive and N is the sum of the true positive and false positive examples in each predicted probability bin. By inspecting Fig. 8 we see that Δp is high for almost all classes indicating a highly confident classification. Also, we see that as the predicted probability increases the recall and precision increase, indicating the reliability of the classifications as a function of the maximum predicted probability.
By inspecting the probabilities for each class individually, we deduce that, especially for the classes of SF and passive galaxies, the combination of high recall and high classification probabilities makes it a highly confident classifier. However, despite the excellent results for these two classes in the case of AGNs, we see moderate performance scores. As shown in Sect. 4, regarding the predictions on the true AGN galaxies (ground truth), there was considerable confusion with the class of composite and LINER galaxies. This is because the AGN galaxies share common properties with the LINER but also with the composite galaxies. For example composite galaxies are the result of AGN activity superimposed on a SF component (Kewley et al. 2001) or a SF component with photoionization by old stellar populations (Cid Fernandes et al. 2010). Similarly, old stellar populations (Stasińska et al. 2008) or AGNs could be the excitation in LINER galaxies (González-Martín et al. 2009). This is reflected in the feature distributions we present in Fig. 3.
Another reason for this is the fact that the spectroscopic classifications that we considered as true (ground truth) are subject to aperture effects. Maragkoudakis et al. (2014) studied the effect of a changing aperture on the classification of an AGN galaxy finding that AGN features change as a function of the physical distance of the region within the spectral aperture and hence as a function of the observed distance. For example, an AGN galaxy observed with an increasing aperture (starting from the core) tends to move toward the H II region in a BPT diagram. Two techniques to mitigate this problem are the definition of diagnostics in a specific redshift range and the star-light subtraction but this behavior is not fully removed. Another source of aperture effects is the difference between the optical spectra and the infrared photometry (WISE) we used for the definition of our diagnostic. This is discussed in detail in the next section.
In an attempt to explore the role of aperture effects for the optical colors, we explored two distinct diagnostic schemes based on the redshift. We created two separate classifiers, each specialized in a specific redshift area. One classifier was trained in the range 0.02 < z < 0.05 and the other is 0.05 < z < 0.08. Also, we tried a unified scheme that contained galaxies across the entire range of the redshift (0.02 < z < 0.08) with the addition of the redshift as an extra discriminating feature to the three originally considered. Both attempts failed to improve the performance.
5.3 Mixing between classes
In Sect. 4, we measured the performance of the diagnostic based on its predictions on the test subset of galaxies. We find that the classifier has excellent performance for the SF and passive galaxies and good performance on the rest of the classes. But, besides its high performance for SF galaxies, we observe that there is a non-negligible fraction (confusion matrix; Fig. 5), of these galaxies that are predicted as composites. Composites galaxies have some common characteristics with SF galaxies so this is a somewhat expected behavior. Further analysis of these misclassified SF galaxies shows that they tend to have redder g–r colors than a typical SF galaxy.
Figure 9 shows the fraction of the correctly identified SF galaxies (i.e., recall) and the true SF (spectroscopic classification) that are predicted as different galaxy classes as a function fiberMag (g–r) color (top panel), which was used for the classification (Sect. 3.3), and the cModelMag (g–r) color, which reflects the overall light of a galaxy. We estimated the errors as described in Sect. 5.2. It is clear that for SF galaxies with bluer g–r colors, the classifier has a recall rate close to 1. On the other hand, as the optical colors of the SF galaxies become redder, their recall drops, and the galaxies are predicted almost exclusively as composites. This result indicates that as these galaxies have gradually older stellar populations their infrared colors resemble these of a composite galaxy. Another interesting fact is that the recall of the SF galaxies is more gradual if we use the integrated photometry to calculate the g–r color, suggesting that SF galaxies with a prominent bulge are more likely to be classified as composite. However, the value of the g–r color at which the fraction of the SF galaxies predicted as SF becomes equal to the fraction of SF galaxies predicted as composites remains almost the same for both photometries (g–r ~ 0.65). This suggests that the classification of a SF galaxy is insensitive to aperture effects as star formation is a galaxy-wide phenomenon and is not concentrated in one area as the H II regions are scattered across the galaxy disk.
To further analyze the performance of the classifier, we needed to understand the underlying activity of each class in more detail. Starting from AGN galaxies, their emission comes from accretion of circumnuclear material onto the SMBH at their cores. The energy source of a LINER galaxy can be either a SMBH or old stellar populations, including post-asymptotic-giant-branch stars (Binette et al. 1994; Stasińska et al. 2008; Papaderos et al. 2013). Composite galaxies may have some starformation activity but can also harbor an accreting SMBH. Lately, it has been suggested that these galaxies may host old stellar populations that can actively contribute to their emissionline spectrum (Stasińska et al. 2008). Finally, a passive galaxy is a system without any star formation or AGN activity, with low to no reservoirs of dust and cold gas, with its main component being the old stellar populations.
The class of passive galaxies is very well characterized by this diagnostic tool. However, the confusion matrix (Fig. 5) shows that some passive galaxies are misclassified by the diagnostic as LINER galaxies. This is consistent with studies claiming that LINER-like activity originates from old stellar populations like a passive galaxy (Byler et al. 2019). For the class of LINER galaxies, we see that most of the misclassified galaxies are predicted as passive (in agreement with the connection between the LINER-like spectra and old stellar populations) followed by the composite, and finally the AGN galaxies. Composite galaxies often have large bulges (Feltzing & Gilmore 2000; Ortolani et al. 2001) and they contain old stellar populations similar to passive galaxies. Therefore, composite galaxies could be excited by old stellar populations as discussed earlier, and their photometric colors can resemble those of passive galaxies (Fig. 3). Finally, LINER activity can sometimes be attributed to an active nucleus (i.e., Ho 1999). In this case, the optical and infrared colors of the galaxy would be consistent with those of AGNs. For the class of composite galaxies, we see that (Fig. 5) the misclassified galaxies are mainly predicted as AGNs, which is an expected result considering all the above-mentioned facts in this section.
During the evaluation of our model, we found that the recall of the AGN galaxies tends to increase with increasing distance (Fig. 7). An explanation of this effect is that due to the aperture effects (as well as volume and sensitivity effects) the AGNs identified at larger distances tend to be more luminous. This is seen in Fig. 10, which shows the histograms of Hα luminosity of the AGN galaxies for two redshift bins, one for the very nearby galaxies (0.02 < z < 0.05) and one for galaxies further away (0.05 < z < 0.08). More luminous AGNs are more likely to dominate the mid-infrared colors of a galaxy. Further supporting evidence is provided by Fig. 11, which shows the fraction of spectroscopically selected AGNs classified in different classes by the classifier as a function of their Ha luminosity. To produce this plot we split the AGNs (regardless of redshift) in our sample into bins of increasing Hα luminosity. Then, we applied our diagnostic and calculated the fraction of objects predicted to belong to each class with respect to the spectroscopic AGN in each bin. We can see that the fraction of the correctly identified (i.e., the recall) AGN increases as their Hα luminosity increases. It is also clear that the diagnostic confuses cases of low-luminosity AGNs (LLAGNs) as composites, which is reasonable if we also consider the aperture effects. Based on this we estimate that AGN galaxies with Hα luminosities below ~5 × 1040 erg s−1 are increasingly misclassified as composite galaxies.
Another interesting fact about the class of AGN galaxies comes from the misclassification instances that our diagnostic tool makes. In Fig. 12 we plot the emission-line ratios of [O III]/Hβ against [N II]/Hα, [S II]/Hα, and [O I]/Hα. The location of spectroscopic AGN classified in different classes on the [O III]/Hβ against [N II]/Hα diagram shows that the AGN galaxies that have been misclassified as SF are located primarily close to the line of maximum starburst defined by Kewley et al. (2001), which is the line that separates AGN and SF galaxies. In addition, in the plot of [O III]/Hβ against [S II]/Hα, we see that AGN galaxies that have been predicted as LINER galaxies are located very close to the separating line of Schawinski et al. (2007) that separates AGN and LINER galaxies and are systematically located in the upper right area of the AGN locus having higher values of [S II]/Hα. Also, we see that AGN galaxies misclassified as LINER galaxies show a similar trend in the plot of [O III]/Hβ against [O I]/Hα as in the [O III]/Hβ against [S II]/Hα. However, we notice that there is significant mixing between the composite and AGN galaxies. The misclassified AGN predicted as composites have no specific trend as they are scattered across the AGN locus of these plots, an effect that can be attributed to the use of the galaxy-wide infrared colors. Nonetheless this is acceptable, especially considering the flexibility provided by using the integrated colors of the galaxies and the excellent performance in the case of the other classes.
 |
Fig. 8 Plots for the reliability analysis of the predicted probabilities of each galaxy activity class. For each class, we plot two diagrams. First, on the left under each class label, we plot the probability difference of the highest and second-highest predicted probability (Δp) against the maximum predicted probability. In every such plot, each black dot represents a galaxy, while the red line is the normalized cumulative histogram with respect to Δp (top x-axis tick marks represent the fraction of the total objects). Second, in the right plot under each class label, we also plot the recall and precision scores as a function of the maximum predicted probability for each activity class. |
 |
Fig. 9 Two plots of the recall of SF galaxies as a function of the g–r (SDSS) color. The blue line shows the fraction of predicted SF galaxies to the total number of true SF galaxies per bin of increasing g–r color. The rest of the lines describe the fraction of SF galaxies that change classification (orange line, AGN; green line, LINER; red line, composite; purple, passive) to the total number of SF galaxies in a particular bin. On the top, we use the g–r color from fiberMag, while on the bottom plot we use the g–r color from the cModelMag photometry. Again, "Comp" stands for composite galaxies and "Pas" for passive galaxies. |
 |
Fig. 10 Histogram of the Hα luminosity for our sample of spectroscopically classified AGN galaxies (considered as the ground truth). We split them into two redshift bins. The first bin is from z = 0.02 to z = 0.05 (HECATE catalog; Kovlakas et al. 2021), plotted with the blue line, and the second is from z = 0.05 to z = 0.08, plotted with the green line. |
 |
Fig. 11 Fraction of the correctly identified AGN galaxies (true positives) to the total true AGN galaxies (i.e., a measure of recall or "completeness") as a function of the AGN Ha luminosity for all spectroscopically selected AGN galaxies in our sample (orange line). All other colored lines represent the fraction of true AGN galaxies that the diagnostic predicted to belong to a class other than AGN (false negatives) to the total true AGN (blue, SF; green, LINER; red, composite; purple, passive). All fractions were calculated after the galaxies were split into bins of increasing Ha luminosity that contain the same number of galaxies. |
5.4 Comparison with other methods
In order to determine if this new diagnostic, which is based on infrared and optical colors, provides any advantage over the already established ones, we compared their performances against the performance of our diagnostic. Taking into account the fact that they are based on different criteria and parent samples, we discuss their advantages and disadvantages.
A widely used infrared diagnostic is the W1–W2 ≥ 0.8 criterion (Stern et al. 2012; Assef et al. 2013), where a demarcation line based on two WISE bands (band 1 and 2) separates AGN galaxies from the rest of the galaxies. Other similar diagnostic tools have been introduced by Jarrett et al. (2011), Mateos et al. (2012), and Coziol et al. (2014). The first two are two-dimensional diagnostics defined based on the W1–W2 against the W2–W3, while the third was based on a plot of W3–W4 against W2–W3 colors. In the case of the Mateos et al. (2012) diagnostic tool, which was focused on high-luminosity AGNs, the authors define an AGN selection wedge on the upper right corner of the plot defined by the equations: (W1–W2) = 0.315*(W2–W3) +0.796, (W1–W2) = 0.315*(W2–W3) −0.222, and (W1–W2) = −3.172*(W2–W3) +7.624. To test the applicability of this diagnostic to the wider population of (non-X-ray selected) AGN galaxies, in Fig. 13 we plot the W1–W2 against the W2–W3 colors of the galaxies in our full sample (Sect. 2.4) color-coded according to their spectroscopic classification (left) and the classification based on our diagnostic (right). The galaxies presented in Fig. 13 originate from the SDSS sample in the redshift range of z = 0.02 to z = 0.08. We see that a significant number of AGN galaxies are located outside of the AGN locus of Mateos et al. (2012) and below the demarcation line of Stern et al. (2012). This behavior holds even with the diagnostic of Jarrett et al. (2011), since all three diagnostics (Jarrett et al. 2011; Mateos et al. 2012; Assef et al. 2013) are based on luminous AGN samples for their definition. Furthermore, we observe that there are SF galaxies that the two methods of AGN identification (Mateos et al. 2012; Assef et al. 2013) classify wrongly as AGN galaxies, which we discuss further in Sect. 5.5.
For the AGN galaxies, we included one more mid-infrared diagnostic and performed a quantitative comparison between our diagnostic tool and the rest widely used infrared diagnostic tools that were mentioned earlier. The other diagnostic we included in our comparison was defined by Coziol et al. (2014). This particular diagnostic focuses on spectroscopically selected LLAGNs. The selection criteria of this diagnostic consist of a two-dimensional plot of W3–W4 against W2–W3 that is separated into four parts with two crossing lines; (W3–W4) = 1.6 * (W2–W3) + 3.2 and (W3–W4) = −2.0 * (W2–W3) + 8.0.
To obtain a quantitative comparison between our diagnostic and the four aforementioned tools, we used the test sample (Sect. 4.1) and chose only the AGN galaxies (329 in total), which will be considered as the ground truth for the comparison. We focused on AGN galaxies since these tools are tailored for the classification of AGN galaxies in which our diagnostic shows weaker performance. Then we applied our new diagnostic and the diagnostic tools of Mateos et al. (2012), Assef et al. (2018), Coziol et al. (2014), and Jarrett et al. (2011) to that sample of optically selected AGN galaxies. Since the other diagnostics offer only AGN or non-AGN classification, we adapted our results accordingly. Any galaxy that receives a classification by our diagnostic other than AGN (SF, LINER, composite, or passive) is characterized as non-AGN. In Table 5 we present the results of this comparison between the classifications made by our diagnostic and the other diagnostic methods. We see that despite our moderate scores for the class of AGN galaxies, our diagnostic tool identifies more AGN galaxies than any other method tested here.
While the existing diagnostics are very effective in identifying reliable samples of AGNs (albeit with some contamination by extreme starburst; see the next section), they are biased toward the more obscured and more luminous AGNs, missing the bulk of their populations. In Fig. 14 we plot the W1–W2 against the W2–W3 for all the spectroscopically classified AGNs in our sample color-coded with their Hα luminosity. In that figure we see that only the more luminous AGNs will be selected by the diagnostics of Jarrett et al. (2011), Mateos et al. (2012), and Stern et al. (2012). Instead, our diagnostic also provides samples of LLAGNs, with the unavoidable mixing with composite and LINER galaxies. Furthermore, since they are driven by the classification of one activity class they are not efficient in identifying reliable samples of SF galaxies (which have strong contamination by LLAGNs) or other types of galaxies (composite, passive, and LINER).
 |
Fig. 12 Diagrams of [O III] λ5007/Hβ against [N II] λ6584/Hα (left), [S II] λλ6716,6731/Hα (middle), and [O I] λ6300/Hα (right), showing the location of an optically selected sample of AGN galaxies from our test sample (Sect. 4.1). The points are color-coded depending on their classification based on our diagnostic: AGN in green, SF in red, LINER in blue, and composite in yellow. We see that, since these are two-dimensional projections of the four-dimensional space used for the optical line-ratio classification, some AGN galaxies may fall outside the AGN demarcation line. The solid black curve is the extreme starburst line defined by Kewley et al. (2001). The straight black line is the separating line between AGN and LINER galaxies as defined by Schawinski et al. (2007). The dashed black curve is the Kauffmann et al. (2003) line separating SF from composite galaxies. |
 |
Fig. 13 Color-color plots of W1–W2 against W2–W3 for our sample of galaxies. Left: galaxies based on their spectroscopic classification (true class). Right: same but for galaxies whose class labels were assigned by the new diagnostic tool. The solid black line is the locus of AGN galaxies as defined by Mateos et al. (2012), while the dashed black line is the demarcation line between an AGN and a non-AGN galaxy as defined by Stern et al. (2012). The dashed blue lines define the AGN galaxy selection box as defined by Jarrett et al. (2011). SF galaxies are shown in blue, LINER in yellow, passive in red, composite in purple, and AGN in green. Labels in the legend are the same as in Fig. 9. We see that there is a significant population of spectroscopic AGN galaxies located below the existing infrared diagnostics, which are correctly identified with our diagnostic. There is also a population of extreme SF galaxies located in the AGN locus of the existing AGN diagnostics that are also correctly classified by our diagnostic. |
Comparison of the classification results between our diagnostic and other widely used mid-infrared diagnostics.
5.5 Star-forming galaxies with extremely red mid-infrared colors
By inspecting Fig. 13 (left panel) more closely, we see that there is a significant number of spectroscopically classified SF galaxies with mid-infrared colors of W1–W2 ≥ 0.8 (Stern et al. 2012). Normally these galaxies would have been classified as AGN galaxies by most mid-infrared selection methods (Jarrett et al. 2011; Mateos et al. 2012; Assef et al. 2013). In contrast to these AGN selection methods, our diagnostic tool is able to separate these cases as we can see that it manages to retrieve ~82% of the spectroscopically classified SF galaxies that are located above the Stern et al. (2012) line. This means that our diagnostic has the ability to correctly identify a case where a starburst galaxy looks like an AGN (e.g., Hainline et al. 2016). This ability is the result of the use of optical colors, which is a tell-tale signature of extreme starburst galaxies.
By further investigating the optical spectra and SDSS images of these peculiar SF galaxies (W1–W2 ≥ 0.8) we find that their majority have spectra that are indicative of an H II region appearing as blue compact spherical objects in the SDSS images. There is also a population with redder SDSS colors, indicating the presence of dust. These SF galaxies appear to have W2–W3 colors that are systematically redder than the AGNs. An interesting fact is that the "dusty" SF galaxies are mainly located in the area of W2–W3 ≲ 3.5, while above that value almost all SF galaxies seem to be blue and compact.
Additional evidence for a population of SF galaxies contaminating the mid-infrared AGN diagnostics is provided by the Hainline et al. (2016). The focus of this work is the properties of a spectroscopically selected sample of dwarf galaxies including AGN and SF galaxies. They find that a significant fraction of the optically selected AGN galaxies is not selected as AGNs by the mid-infrared diagnostics of Jarrett et al. (2011) and Stern et al. (2012). They also find that in these two AGN diagnostics, there is a significant contamination in the mid-infrared selected samples of AGNs, a result that is supported by our analysis.
These galaxies with AGN-like mid-infrared colors are consistent with the "blueberry" galaxies, which are characterized by compact sizes, extreme blue colors, and H II region-like spectra (Yang et al. 2017). Also, these galaxies tend to be metal-poor with extreme mid-infrared colors (Hainline et al. 2016). In our analysis, we find that galaxies with extreme mid-infrared colors (W2–W3 ≳ 3.5) that are spectroscopically identified as SF have g–r color <0 (median approximately −0.35). In fact, this is the main differentiating factor between the AGNs with extreme mid-infrared colors and the blueberry galaxies for our diagnostic. Star-forming galaxies above the W1–W2 = 0.8 and with W2–W3 ≲ 3.5 seem to have optical g–r colors redder than the ones with W2–W3 ≳ 3.5 (median -0.2).
Yang et al. (2017) provide a catalog of 41 objects with a spectroscopically selected sample of blueberry galaxies that appear to be compact and blue in the SDSS gri (blue-green-red) images. After cross-matching these galaxies with the HECATE catalog (Kovlakas et al. 2021), a value-added catalog for the local Universe (distances up to 200 Mpc), and applying quality cuts to photometry (as described in Sect. 2.4), we applied our diagnostic. Seven out of 41 objects satisfied our quality criteria. All seven of them were classified correctly by the diagnostic as being SF, while four out of seven of them are above the AGN demarcation line of Stern et al. (2012). Also, we find that the Jarrett et al. (2011) wedge classifies as AGNs two out of seven objects, while Mateos et al. (2012) classifies three out of seven as AGNs. Of course, these results must be taken with caution as the number of objects is limited.
 |
Fig. 14 W1–W2 color against W2–W3 color for the spectroscopically classified AGN galaxies in our sample, color-coded by Hα luminosity. The solid black line is the locus of AGN galaxies as defined by Mateos et al. (2012), while the dashed black line is the demarcation line between an AGN and a non-AGN galaxy as defined by Stern et al. (2012). The dashed blue lines define the AGN selection box as defined by Jarrett et al. (2011). |
6 Conclusions
In this work we have combined mid-infrared and optical photometry to define a new galactic activity diagnostic that includes all activity classes under one unified scheme while offering improved performance. Our results are summarized as follows:
We have created a new machine learning activity diagnostic tool for galaxy classification that can discriminate between five different classes of galaxies. This is the first machine-learning-based tool for galaxy classification that includes not only active but also passive galaxies. The code, with application instructions, is available via the GitHub repository2.
This diagnostic extends the existing infrared diagnostics to additional types of activity, is more sensitive to LLAGNs, and can be used for local galaxies (z ~ 0) up to z ~ 0.08.
The addition of the optical color, g–r, to the two infrared WISE colors that were used in previous works means our tool can go beyond the bimodal classification (AGN or non-AGN) of most diagnostic methods, allowing their extension to four different activity classes as well as passive galaxies.
There is some mixing between the classification of some objects, but this is observed mainly in classes that share common properties (e.g., composite and AGN galaxies). Although this results in reduced performance scores for the class of AGN galaxies, the performance we achieve is still superior to that achieved by previous works. However, the addition of extra features (e.g., UV colors) may help improve the performance, though it will limit its applicability to objects with photometry from the UV to infrared wavelengths.
By including optical information (the g–r color), our diagnostic is able to distinguish a starburst galaxy with extreme mid-infrared colors (e.g., blueberries) from an obscured AGN galaxy that would have been classified as a true AGN based on traditional infrared diagnostic methods.
There are several directions that can be taken to improve the performance of the diagnostic, especially for classifying AGN galaxies and reducing the mixing between the AGN and composite galaxies. These include: adding features that are characteristic of AGN activity (e.g., UV colors), luminosity, or even spectral information, but this would be at the cost of reducing the applicability of the diagnostic to a larger sample of data.
Acknowledgements
We thank the anonymous referee for their constructive comments and suggestions that helped to improve this work and the clarity of this manuscript. We thank Paolo Bonfini for very useful disscusions on machine-learning methods that helped to improve the performance of the classifier. We also thank Sotiria Fotopoulou for discussions on the classification of the AGN. C.D. and E.K. acknowledge support from the Public Investments Program through a Matching Funds grant to the IA-FORTH. The research leading to these results has received funding from the European Research Council under the European Union's Seventh Framework Programme (FP/2007-2013)/ERC Grant Agreement n. 617001, and the European Union's Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie RISE action, Grant Agreement n. 873089 (ASTROSTAT-II). K.K. is supported by the project "Support of the international collaboration in astronomy (Asu mobility)" with the number: CZ 02.2.69/0.0/0.0/18_053/0016972. Funding for SDSS-III has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, and the U.S. Department of Energy Office of Science. The SDSS-III web site is http://www.sdss3.org/. SDSS-III is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS-III Collaboration including the University of Arizona, the Brazilian Participation Group, Brookhaven National Laboratory, Carnegie Mellon University, University of Florida, the French Participation Group, the German Participation Group, Harvard University, the Instituto de Astrofisica de Canarias, the Michigan State/Notre Dame/JINA Participation Group, Johns Hopkins University, Lawrence Berkeley National Laboratory, Max Planck Institute for Astrophysics, Max Planck Institute for Extraterrestrial Physics, New Mexico State University, New York University, Ohio State University, Pennsylvania State University, University of Portsmouth, Princeton University, the Spanish Participation Group, University of Tokyo, University of Utah, Vanderbilt University, University of Virginia, University of Washington, and Yale University.
Appendix A Optimization of significant hyperparameters
The process of optimizing this activity diagnostic is performed with the use of the GridSearchCV algorithm, which is provided by the scikit-learn Python 3 package, version 1.1.2. The determination of the optimal values of each hyperparameter is usually done by training the algorithm several times with different choices of the hyperparameter values each time, typically by means of a grid search. The performance of the algorithm is evaluated at each point of the grid, and the optimal set of parameters that maximizes the performance is chosen. Since only some of the available hyperparameters have significant impact on the performance of our diagnostic, it is inefficient to perform a grid search including all of them. We find that only the following seven hyperparameters are important:
n_estimators : The number of decision trees.
max_depth : The maximum depth of a decision tree.
min_samples_split : The minimum required number of samples to split a node.
min_samples_leaf : The minimum number of samples in a leaf node.
max_leaf_nodes : The maximum allowable number of terminal nodes in a tree.
max_samples : The number of samples from the training set to build each tree.
criterion : The function to measure the quality of a split.
However, since a broad grid search in a seven-dimensional space can still be computationally intensive, we first narrowed the range of these parameters by calculating its performance for different values of each hyperparameter separately. To do this, we calculated the validation curves that show different performance metrics as a function of each hyperparameter value (see Fig. A.1). More specifically, each validation curve has the performance score of a metric (e.g., accuracy) on the y-axis and a range of the possible values of one hyperparameter (e.g., n_estimators) on the x-axis while keeping all the other hyperparameters constant. The performance reported on each plot is the performance on the testing fold calculated with the CV method, which is performed by splitting the data into k folds and using k-1 folds for its training and one for testing its performance. The algorithm is trained k times in total for each combination of hyperparameters by cycling the folds so that all k folds have been in the position of the testing fold once. The reported performance score is the average of these k scores.
By inspecting Fig. A.1 we see that the ranges of values for the best hyperparameters are found in the areas where the scores start to converge to the best achievable score (curves start to converge parallel to the x-axis). When this happens it means that overfitting starts to occur. This way we significantly reduced the ranges of the hyperparameters that we have to test to find the optimal ones. Afterward, from these validation curves we determined the sensitivity of the algorithm to the different hyperparameters, we find the ranges of the parameters that significantly affect its performance in order to perform a grid search around these ranges. The range for each hyperparameter was found by inspecting the behavior of the accuracy score.
The next step is to use these best value ranges for each hyperparameter extracted by the plots as input to the grid search algorithm. Then, that algorithm will make combinations of the hyperparameters from the best value ranges and it will fit each derived model in order to find which model has the best performance scores. In Table A.1 we present the hyperparameters that have been considered for optimization along with their search ranges and their best values.
 |
Fig. A.1 Validation curves for the determination of the best hyperparameter ranges for reducing the possible values of each hyperparameter. The CV scores refer to accuracy as a function of each hyperparameter. The red line is the average accuracy calculated using the k-fold CV method (k = 5), while the shaded gray area is the standard deviation (1σ) of the k-scores for each value of the hyperparameter under examination. |
After we obtained the set of the best hyperparameters, we could test the stability of the algorithm when it is trained and tested on all possible subsets for the training and the test data. One such performance stability test is to perform k-fold CV and observe the change in the accuracy score. A stable algorithm should have a low standard deviation on its accuracy, which means that the performance of the algorithm does not significantly fluctuate between its subsequent application to similar data, although small fluctuations are unavoidable as a result of the stochastic nature of the algorithm. Even though the sample is fairly large, for some minority classes there are not much data. For that reason, the number of folds chosen here is 5 (each fold consists of 8190 objects), as even though we have a significant number of objects, some classes will be underrepresented with a choice of a higher number of folds. The overall accuracy score of the model when calculated with the k-fold CV method is 81%±1%. This suggests that the fluctuations of the performance scores are low, suggesting a stable algorithm.
Important hyperparameters that were optimized for the adaption random forest algorithm in our sample of galaxies.
References
- Alonso-Herrero, A., Ramos Almeida, C., Esquej, P., et al. 2014, MNRAS, 443, 2766 [NASA ADS] [CrossRef] [Google Scholar]
- Assef, R. J., Stern, D., Kochanek, C. S., et al. 2013, ApJ, 772, 26 [Google Scholar]
- Assef, R. J., Stern, D., Noirot, G., et al. 2018, ApJS, 234, 23 [Google Scholar]
- Baldwin, J. A., Phillips, M. M., & Terlevich, R. 1981, PASP, 93, 5 [Google Scholar]
- Bell, E. F., Wolf, C., Meisenheimer, K., et al. 2004, ApJ, 608, 752 [NASA ADS] [CrossRef] [Google Scholar]
- Binette, L., Magris, C. G., Stasińska, G., & Bruzual, A. G. 1994, A & A, 292, 13 [NASA ADS] [Google Scholar]
- Brinchmann, J., Charlot, S., White, S. D. M., et al. 2004, MNRAS, 351, 1151 [Google Scholar]
- Byler, N., Dalcanton, J. J., Conroy, C., et al. 2019, AJ, 158, 2 [Google Scholar]
- Cid Fernandes, R., Stasińska, G., Schlickmann, M. S., et al. 2010, MNRAS, 403, 1036 [Google Scholar]
- Coziol, R., Torres-Papaqui, J. P., Plauchu-Frayn, I., et al. 2014, Rev. Mex. A & A, 50, 255 [NASA ADS] [Google Scholar]
- Donley, J. L., Koekemoer, A. M., Brusa, M., et al. 2012, ApJ, 748, 142 [Google Scholar]
- Feltzing, S., & Gilmore, G. 2000, A & A, 355, 949 [Google Scholar]
- Genzel, R. 1998, Nature, 391, 17 [NASA ADS] [CrossRef] [Google Scholar]
- González-Martín, O., Masegosa, J., Márquez, I., Guainazzi, M., & Jiménez-Bailón, E. 2009, A & A, 506, 1107 [CrossRef] [EDP Sciences] [Google Scholar]
- Hainline, K. N., Reines, A. E., Greene, J. E., & Stern, D. 2016, ApJ, 832, 119 [CrossRef] [Google Scholar]
- Heckman, T. M. 1980, A & A, 87, 152 [Google Scholar]
- Ho, L. C. 1999, Adv. Space Res., 23, 813 [NASA ADS] [CrossRef] [Google Scholar]
- Ho, L. C., Filippenko, A. V., & Sargent, W. L. W. 1997, ApJ, 487, 568 [NASA ADS] [CrossRef] [Google Scholar]
- Jarrett, T. H., Cohen, M., Masci, F., et al. 2011, ApJ, 735, 112 [Google Scholar]
- Kauffmann, G., Heckman, T. M., Tremonti, C., et al. 2003, MNRAS, 346, 1055 [Google Scholar]
- Kewley, L. J., Dopita, M. A., Sutherland, R. S., Heisler, C. A., & Trevena, J. 2001, ApJ, 556, 121 [Google Scholar]
- Koekemoer, A. M., Donley, J., Grogin, N., et al. 2011, AAS Meeting Abstracts, 218, 328.03 [NASA ADS] [Google Scholar]
- Kovlakas, K., Zezas, A., Andrews, J. J., et al. 2021, MNRAS, 506, 1896 [NASA ADS] [CrossRef] [Google Scholar]
- Lang, D., Hogg, D. W., & Schlegel, D. J. 2016, AJ, 151, 36 [Google Scholar]
- Louppe, G. 2014, ArXiv e-prints [arXiv:1487.7582] [Google Scholar]
- Maragkoudakis, A., Zezas, A., Ashby, M. L. N., & Willner, S. P. 2014, MNRAS, 441, 2296 [NASA ADS] [CrossRef] [Google Scholar]
- Mateos, S., Alonso-Herrero, A., Carrera, F. J., et al. 2012, MNRAS, 426, 3271 [Google Scholar]
- Ortolani, S., Barbuy, B., Bica, E., et al. 2001, A & A, 376, 878 [CrossRef] [EDP Sciences] [Google Scholar]
- Papaderos, P., Gomes, J. M., Vílchez, J. M., et al. 2013, A & A, 555, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schawinski, K., Thomas, D., Sarzi, M., et al. 2007, MNRAS, 382, 1415 [Google Scholar]
- Skrutskie, M. F., Cutri, R. M., Stiening, R., et al. 2006, AJ, 131, 1163 [NASA ADS] [CrossRef] [Google Scholar]
- Stampoulis, V., van Dyk, D. A., Kashyap, V. L., & Zezas, A. 2019, MNRAS, 485, 1085 [NASA ADS] [CrossRef] [Google Scholar]
- Stasińska, G., Vale Asari, N., Cid Fernandes, R., et al. 2008, MNRAS, 391, L29 [NASA ADS] [Google Scholar]
- Stern, D., Eisenhardt, P., Gorjian, V., et al. 2005, ApJ, 631, 163 [Google Scholar]
- Stern, D., Assef, R. J., Benford, D. J., et al. 2012, ApJ, 753, 30 [Google Scholar]
- Tremonti, C. A., Heckman, T. M., Kauffmann, G., et al. 2004, ApJ, 613, 898 [Google Scholar]
- Werner, M. W., Roellig, T. L., Low, F. J., et al. 2004, ApJS, 154, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Wright, E. L., Eisenhardt, P. R. M., Mainzer, A. K., et al. 2010, AJ, 140, 1868 [Google Scholar]
- Yang, H., Malhotra, S., Rhoads, J. E., & Wang, J. 2017, ApJ, 847, 38 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
Definition of each performance metric used for the evaluation of the performance of our diagnostic tool.
Different combinations of features (colors) that were tested as potential models for the definition of the diagnostic.
Comparison of the classification results between our diagnostic and other widely used mid-infrared diagnostics.
Important hyperparameters that were optimized for the adaption random forest algorithm in our sample of galaxies.
All Figures
|
Fig. 1 Comparison between the forced photometry, WF, and the hybrid photometry scheme introduced in this work. Top: W1–W2 color calculated with the hybrid scheme against the same color but calculated with the WF photometry. Bottom: same but for W2–W3 color. The galaxies have been color-coded according to their extension in the WISE data (ext_flg=0 for point-like sources and ext_flg≠0 for extended sources). The black solid line is the y = x. |
| In the text | |
|
Fig. 2 Color-magnitude diagram of g–r against Mr. On the y-axis is the g–r color against the absolute magnitude in the SDSS r band, Mr. The red points represent the sample of passive galaxies and the gray points the whole sample of galaxies (all classes). |
| In the text | |
|
Fig. 3 Distributions of colors considered as potential features for the definition of our diagnostic tool. Starting from top to bottom, we see the distributions of colors W1–W2, W2–W3, g–r, and u–g for each galactic activity class. Combinations of these four colors are used as potential feature schemes for defining our diagnostic. Due to the high imbalance of the sample, the number of galaxies is normalized based on the frequency of occurrence in our data sample. Blue histograms correspond to the SF, green to the AGN, yellow to LINER, purple to composite, and red to passive galaxies. |
| In the text | |
|
Fig. 4 Recall scores of the different models (features schemes) considered for our diagnostic tool. The description of the models is presented in Table 3. The error is the standard deviation of the k recall scores (here k = 10), calculated using the CV method. The error on the recall scores for the SF galaxies is too small to be depicted here. Blue points correspond to the SF, yellow to AGN, green to LINER, red to composite, and purple to passive galaxies. |
| In the text | |
|
Fig. 5 Confusion matrix for the test subset of galaxies. The numbers (and the color-code) in this plot represent the percentage of the classified objects in each class with respect to the total true population in each class. The labels on the x- and y-axis represent the predicted and the true class of a galaxy, respectively. Here "Comp" stands for composite galaxies and "Pas" for passive galaxies. |
| In the text | |
|
Fig. 6 Importance (relevance) of the three features used for the definition of the diagnosis as calculated during the training of the random forest. The W2–W3 color is the most important feature, and all other features are of comparable relevance. |
| In the text | |
|
Fig. 7 Fraction of correctly classified objects to the total true objects for each class, for three redshift ranges. The first redshift range is z = 0.02 to z = 0.05 (galaxies in the HECATE catalog; Kovlakas et al. 2021), indicated by blue disks in the plot, the second redshift bin is z = 0. 05 to z = 0.08, indicated by red squares. The third redshift range includes galaxies from the whole redshift range that the diagnostic was trained on, 0.02 < z < 0.08, which is indicated by black x marks. Here "Comp" stands for composite galaxies and "Pas" passive galaxies. |
| In the text | |
|
Fig. 8 Plots for the reliability analysis of the predicted probabilities of each galaxy activity class. For each class, we plot two diagrams. First, on the left under each class label, we plot the probability difference of the highest and second-highest predicted probability (Δp) against the maximum predicted probability. In every such plot, each black dot represents a galaxy, while the red line is the normalized cumulative histogram with respect to Δp (top x-axis tick marks represent the fraction of the total objects). Second, in the right plot under each class label, we also plot the recall and precision scores as a function of the maximum predicted probability for each activity class. |
| In the text | |
|
Fig. 9 Two plots of the recall of SF galaxies as a function of the g–r (SDSS) color. The blue line shows the fraction of predicted SF galaxies to the total number of true SF galaxies per bin of increasing g–r color. The rest of the lines describe the fraction of SF galaxies that change classification (orange line, AGN; green line, LINER; red line, composite; purple, passive) to the total number of SF galaxies in a particular bin. On the top, we use the g–r color from fiberMag, while on the bottom plot we use the g–r color from the cModelMag photometry. Again, "Comp" stands for composite galaxies and "Pas" for passive galaxies. |
| In the text | |
|
Fig. 10 Histogram of the Hα luminosity for our sample of spectroscopically classified AGN galaxies (considered as the ground truth). We split them into two redshift bins. The first bin is from z = 0.02 to z = 0.05 (HECATE catalog; Kovlakas et al. 2021), plotted with the blue line, and the second is from z = 0.05 to z = 0.08, plotted with the green line. |
| In the text | |
|
Fig. 11 Fraction of the correctly identified AGN galaxies (true positives) to the total true AGN galaxies (i.e., a measure of recall or "completeness") as a function of the AGN Ha luminosity for all spectroscopically selected AGN galaxies in our sample (orange line). All other colored lines represent the fraction of true AGN galaxies that the diagnostic predicted to belong to a class other than AGN (false negatives) to the total true AGN (blue, SF; green, LINER; red, composite; purple, passive). All fractions were calculated after the galaxies were split into bins of increasing Ha luminosity that contain the same number of galaxies. |
| In the text | |
|
Fig. 12 Diagrams of [O III] λ5007/Hβ against [N II] λ6584/Hα (left), [S II] λλ6716,6731/Hα (middle), and [O I] λ6300/Hα (right), showing the location of an optically selected sample of AGN galaxies from our test sample (Sect. 4.1). The points are color-coded depending on their classification based on our diagnostic: AGN in green, SF in red, LINER in blue, and composite in yellow. We see that, since these are two-dimensional projections of the four-dimensional space used for the optical line-ratio classification, some AGN galaxies may fall outside the AGN demarcation line. The solid black curve is the extreme starburst line defined by Kewley et al. (2001). The straight black line is the separating line between AGN and LINER galaxies as defined by Schawinski et al. (2007). The dashed black curve is the Kauffmann et al. (2003) line separating SF from composite galaxies. |
| In the text | |
|
Fig. 13 Color-color plots of W1–W2 against W2–W3 for our sample of galaxies. Left: galaxies based on their spectroscopic classification (true class). Right: same but for galaxies whose class labels were assigned by the new diagnostic tool. The solid black line is the locus of AGN galaxies as defined by Mateos et al. (2012), while the dashed black line is the demarcation line between an AGN and a non-AGN galaxy as defined by Stern et al. (2012). The dashed blue lines define the AGN galaxy selection box as defined by Jarrett et al. (2011). SF galaxies are shown in blue, LINER in yellow, passive in red, composite in purple, and AGN in green. Labels in the legend are the same as in Fig. 9. We see that there is a significant population of spectroscopic AGN galaxies located below the existing infrared diagnostics, which are correctly identified with our diagnostic. There is also a population of extreme SF galaxies located in the AGN locus of the existing AGN diagnostics that are also correctly classified by our diagnostic. |
| In the text | |
|
Fig. 14 W1–W2 color against W2–W3 color for the spectroscopically classified AGN galaxies in our sample, color-coded by Hα luminosity. The solid black line is the locus of AGN galaxies as defined by Mateos et al. (2012), while the dashed black line is the demarcation line between an AGN and a non-AGN galaxy as defined by Stern et al. (2012). The dashed blue lines define the AGN selection box as defined by Jarrett et al. (2011). |
| In the text | |
|
Fig. A.1 Validation curves for the determination of the best hyperparameter ranges for reducing the possible values of each hyperparameter. The CV scores refer to accuracy as a function of each hyperparameter. The red line is the average accuracy calculated using the k-fold CV method (k = 5), while the shaded gray area is the standard deviation (1σ) of the k-scores for each value of the hyperparameter under examination. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.