| Issue |
A&A
Volume 672, April 2023
|
|
|---|---|---|
| Article Number | A187 | |
| Number of page(s) | 18 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/202244723 | |
| Published online | 20 April 2023 | |
Global survey of star clusters in the Milky Way
VII. Tidal parameters and mass function
1
Zentrum für Astronomie der Universität Heidelberg, Astronomisches Rechen-Institut, Mönchhofstraße 12-14, 69120 Heidelberg, Germany
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Institute of Astronomy of the Russian Acad. Sci., 48 Pyatnitskaya Str., 109017 Moscow, Russia
Received:
9
August
2022
Accepted:
27
January
2023
Abstract
Aims. We built Galactic open star cluster mass functions (CMFs) for different age sub-samples and spatial locations in the wider solar neighbourhood. Here, we present a simple cluster formation and evolution model to reproduce the main features of the CMFs.
Methods. We used an unbiased working sample of 2227 clusters of the Milky Way Star Cluster (MWSC) catalogue, which occupy the heliocentric cylinders with magnitude-dependent completeness radii of 1–5 kpc. The MWSC survey provides an extended set of open star cluster parameters, including tidal radii, distances, and ages. From an analytic three-component Galaxy model, we derived tidal masses of clusters with a typical accuracy of about 70%. Our simple model includes a two-section cluster initial mass function, constant cluster formation rate, supervirial phase after a sudden expulsion of the remaining gas, and cluster mass loss due to stellar evolution and the clusters’ gradual destruction in the Galactic tidal field. The dynamical evolution model is based on previous N-body simulations.
Results. The obtained tidal masses have been added to the MWSC catalogue. A general CMF (GCMF), built for all cluster ages around the Sun, has a bell-like shape and extends over four decades in mass. The high-mass slope found for tidal mass log mt/M⊙ ≥ 2.3 is equal to 1.14 ± 0.07. The CMFs for different age groups show the same high-mass slopes, while the low-mass slope is nearly flat for the youngest sub-sample (clusters younger than 20 Myr) and about −0.7 for the others. The inner and outer sub-samples covering Galactocentric radii R = 4.2–8.1 kpc and 8.9–13.5 kpc, respectively, are consistent with the GCMF, once the exponential decline of the Galactic disc density is taken into account. The model suggests star formation with low efficiency of 15–20%, where only 10% of stars remain bound in a cluster after gas expulsion and subsequent violent relaxation. The cluster formation rate required to reproduce the observed distributions in age and mass is about 0.4 M⊙ pc−2 Gyr−1.
Conclusions. The obtained high-mass slope of the GCMF for the wide neighbourhood of the Sun is similar to slopes determined earlier in nearby galaxies for more luminous clusters with log m/M⊙ > 3.8. The MWSC catalogue supports models with a low star-formation efficiency, where 90% of stars are lost quickly after gas expulsion. The obtained cluster formation rate corresponds to open clusters’ contribution to the stellar content of the thin disc at the level of 30%.
Key words: Galaxy: evolution / open clusters and associations: general / Galaxy: stellar content / galaxies: fundamental parameters / galaxies: photometry / galaxies: star clusters: general
© The Authors 2023
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
The mass of star clusters is one of the basic parameters of these objects that specify their birth and subsequent fate. Determination of the masses for a large cluster sample is a non-trivial task. The obvious summation of masses of individual cluster members suffers from a problem of data loss due to overlapping images of stars in the central, dense regions of clusters, clogging up the counts with the surrounding background and missing the mass below or outside the observation thresholds. There are only a few publications devoted to the cluster mass function (CMF) for our Galaxy (Lada & Lada 2003; Lamers et al. 2005; Piskunov et al. 2008).
Another possible way of obtaining the mass is to use the mass-to-light ratio, which is widely applied for distant extragalactic clusters (Zhang & Fall 1999; Bik et al. 2003; Fall et al. 2005, 2009; Dowell et al. 2008; Larsen 2009; Chandar et al. 2010; Fouesneau et al. 2012). This approach suffers from low sensitivity to the statistics of faint stars, since the luminosity of clusters is dominated by the brightness of several most massive stars, whereas its mass is determined by the abundance of low-mass members.
In large surveys consisting of clusters located at different distances from the Sun, these difficulties are exacerbated by the variable observational limit of the counts, which require unreliable extrapolations. These problems can be overcome by constructing a single scale of observational parameters sensitive to the cluster’s mass. We propose to use the tidal radii of star clusters, which are tightly related to their bound masses. Thanks to extensive cluster member lists becoming available in recent years, the opportunity to use these data for statistical purposes has increased considerably.
Currently, the relevant data on cluster parameters can be queried from three general data sources. The first one is the Catalogue of Open Cluster Data (COCD, Kharchenko et al. 2005a), based on HIPPARCOS/Tycho all-sky catalogues and their reduction ASCC-2.51. Secondly, an extended source of the cluster data for population studies is the Milky Way Star Clusters survey (MWSC, Kharchenko et al. 2012, 2013, referred to as Paper I and Paper II). It has appeared as a result of open cluster studies based on all-sky ground-based catalogues, mainly the Two Micron All Sky Survey2 (2MASS, Skrutskie et al. 2006) and the Catalog of Positions and Proper Motions on the ICRS3 (PPMXL, Röser et al. 2010a). The third catalogue is an extended compilation of Dias et al. (2002), comprising collected literature data. Nowadays, a new cluster parameter list created by community efforts based on the most recent space born observations of the Gaia Telescope has emerged.
The first results from Gaia (Gaia Collaboration 2016) provided a quality leap in astrometric and photometric data. They were followed by a burst of widespread astronomical interest in star cluster studies. Cantat-Gaudin et al. (2018) proposed a method of automatic identification of open clusters and compiled a list of 1229 clusters based on the Tycho-Gaia Astrometric Solution (TGAS) exploration experience verified with Gaia DR2 (Gaia Collaboration 2018) data. It relies on an algorithm of blind search of stellar over-densities in 5D parameter space, including Galactic longitude and latitude (l, b), proper motions along right ascension and declination (μα, μδ), and parallax (ϖ). The method was modified (Cantat-Gaudin et al. 2019) and this approach was gradually applied for extending the list, compiling the membership probability and determining cluster basic parameters (Cantat-Gaudin & Anders 2020; Cantat-Gaudin et al. 2020; Castro-Ginard et al. 2020). In total, the authors were able to detect in Gaia DR2 1867 objects with photometric and high-quality astrometric parameters.
Simultaneously, Liu & Pang (2019) and Sim et al. (2019) published the results of their quests in Gaia DR2. Liu & Pang (2019) used the friend-of-friend (FoF) based cluster-finding method to identify in 5D parameter space 2443 clusters, including 76 that had not been mentioned in the literature before. Almost similar figures received Sim et al. (2019), who identified 2080 clusters known in the literature and 207 unknown candidates using an unsupervised machine-learning method and blind search for |b|< 20°. Ferreira et al. (2021) surveyed 200 fields selected from Gaia DR2 in the direction of the Milky Way centre and detected 34 open cluster candidates. He et al. (2021) used Gaia DR2 at |b|< 20° and ϖ > 0.2 mas and re-identified 2080 already known clusters and also found 74 more new open cluster candidates. He et al. (2022) investigated the Gaia EDR3 (Gaia Collaboration 2021) data from the point of Galactic latitudes higher than |b|> 20° and close to the Sun (ϖ > 0.8 mas) clusters. In this area, they found 886 objects, with 270 that had not been catalogued before, and 46 of the latter reside at relatively high latitudes. Recently Hao et al. (2022) were hunting for star clusters in Gaia EDR3. At Galactic latitudes of |b|≤20 ° , they were able to find 1930 previously known open clusters, 82 known globular clusters, and 704 new open cluster candidates.
Most of the above results were derived with the help of the Density-Based Spatial Clustering of Applications with Noise (DBSCAN, introduced in Ester et al. 1996), one of two clustering algorithms that can operate in the presence of background contamination typical to the star cluster environment. More recently, Hunt & Reffert (2021) compared the effectiveness of three scanning approaches based on the Gaia DR2 catalogue in 100 selected sky areas located along the Milky Way. They found that the second known algorithm Hierarchical DBSCAN (HDBSCAN, Campello et al. 2013) is able to rediscover 82% of real clusters compared to the DBSCAN rate of 50–62%. For the third popular algorithm, the Gaussian mixture model (GMM, Pedregosa et al. 2011), they found a success rate of 33%. As a by-product, they were also able to identify 41 new clusters.
The flow of newly identified clusters is accompanied by newly determined Gaia-based cluster parameters (first astrometric and then photometric ones), Bossini et al. (2019) for Gaia DR2, as well as Castro-Ginard et al. (2021) for Gaia EDR3, which extend the horizons for cluster population studies. For example, Soubiran et al. (2018, 2019) used Gaia DR2-based 6D data for 861 clusters and 5 newly identified cluster pairs to study Galactic disc kinematics. Castro-Ginard et al. (2021) used 264 open clusters younger than 80 Myr and 84 star-forming regions younger than 30 Myr, all residing around the four spiral arms nearest to the Sun to outline the arms, characterise them, and determine their kinematics. Tarricq et al. (2021) studied the kinematics of the open cluster population from data of Gaia DR2 with the primary aim to investigate its kinematics and orbital properties with age. They also investigated the rotation curve of the Galactic disc traced by open clusters. Anders et al. (2021) build an age distribution for 834 Gaia DR2 clusters residing within 2 kpc from the Sun. Their statistics indicate that the present cluster formation rate is 0.55 Myr−1 kpc−2, and only 16% of field stars were formed in bound clusters.
We note that Gaia provides an exceptionally valuable opportunity to study the star cluster outskirts, which had hitherto escaped the community’s attention. However, after reporting the impressive results of studies of nearby clusters (Röser et al. 2019; Röser & Schilbach 2019), interest has strongly risen. Angelo et al. (2020, 2021) used Gaia DR2 to study a number of low-contrast clusters. Based on safe membership, for 65 clusters, they determined the structure and dynamical parameters (King and half-mass radii, ages, and crossing times) with the purpose of estimating the cluster dynamical state. Tarricq et al. (2022) using advanced tools (HDBSCAN, GMM algorithms) for Gaia EDR3 data have established wide-area memberships (within 50 pc) of 467 clusters. For 389 of them, they were able to construct radial profiles, fit to them King profiles (146 quality fits) and determined tidal parameters. For 71 clusters they identified the tidal tails and studied the degree of mass segregation. Zhong et al. (2022) continued to exploit this approach with Gaia EDR3 and studied wide area radial profiles of 256 open clusters within 1–2 kpc from the Sun. As they find, the profiles can be represented as a sum of two distributions: the internal profile, which follows a King model, and the outer one obeying a log-normal law.
As it follows from above, the current status of cluster population characterization with Gaia is unstable and swiftly developing. Despite the high quality and homogeneity of data on individual stars, this cannot be determined for a representative cluster sample nor for high-significance astrophysical parameters, such as the luminosities or masses characterising the cluster population with regard to its formation and evolution. This is why we base this study on the MWSC sample, as it provides the necessary fundamental qualities such as estimated completeness and an extended set of relevant parameters, including almost 100%-coverage with tidal radii. Our ultimate aim is based on independent and uniform estimates of cluster masses drawn in this study from tidal radii. We strive to build a Galactic star cluster mass function, study its temporal and spatial variations, and advance a cluster population model which adequately describes these features.
In Sect. 2, we briefly outline the cluster data set applied in this study. In Sect. 3, we characterise the used tidal radii and in Sect. 4, we describe how they were converted to tidal masses. Section 5 is devoted to the construction of the general cluster mass function (GCMF). We pay special attention to the data completeness, the unbiased sample construction issue, and describe the technique of the GCMF construction and define the basic relevant entities. We investigate the stability of the results against some accompanying effects and compare the results with recent literature data. Section 6 is devoted to the issues of temporal and spatial variations of the CMF, including the cluster initial mass runction (CIMF), and evolutionary changes of the CMF. In Sect. 7, we propose a simple model of the formation and evolution of the Galactic disc cluster population, which can reproduce the GCMF and the main features of the CMFs of different age groups. In Sect. 8, we give our results and conclusions.
2. Data
For this study, we use the results of our all-sky MWSC survey, aimed at a homogeneous, extensive, and multilateral characterisation of Galactic open clusters based on the analysis of their spatial, kinematic, and photometric cluster membership. It has been made possible thanks to accurate and systematic all-sky ground-based photometry and astrometry published at the beginning of the 2000s in the 2MASS (Skrutskie et al. 2006) and PPMXL (Röser et al. 2010a) catalogues. The complete list of Galactic star clusters known at that time was examined and additional effort was undertaken to search for as-yet unidentified objects.
The sky area covered to study a particular cluster is limited only by the properties of the surrounding stellar field and usually is equal to the cluster size taken from the literature, along with an additional ring of 0.3° width if no indication of further area extensions was found in the study. The magnitude depth of MWSC counts is as a rule equal to KS = 15–16 mag. Over 63 million stars in these areas were considered and about 0.2% were identified as the most probable cluster members. It should be noted that the depth exceeds the completeness limit, which depends on the local conditions and varies with cluster area around KS = 13–14 mag.
The selected members were used for the cluster parameter determination. In every cluster, the spatial distribution of cluster members was built. The member density profiles were built for every cluster, and angular structure parameters were determined. These were used as initial conditions to establish a standardised scale of cluster structure parameters via the fit of a three-parameter King model to the observed density profiles. This gave us a unique scale of cluster structure parameters for more than 3000 MW open clusters. The (KS, J − KS), (KS, J − H) CMDs and two-colour (H − KS, J − H), and (QJHKS, J − KS) diagrams were constructed and used for reddening and photometric distance determination (for more details see Paper I). These parameters were used to fit theoretical isochrones to the cluster member CMDs and to determine the cluster age, reddening, and distance modulus. For the age indication, both the turn-off and turn-on (if observed) CMD regions (where the isochrone respectively departs from and joins ZAMS) were used. The integrated near-infrared (NIR) magnitudes and colours of MWSC clusters are also additionally computed.
The results of the MWSC were published in a series of papers and submitted as online catalogues to the CDS archive4. In the above-mentioned work of Paper I, the cluster membership pipeline is described, which is the main instrument of the MWSC. It provides data on individual stars observed in the search area in the form of combined astrometric and photometric cluster membership probabilities and integrated parameters of the derived member ensembles characterising the clusters themselves. For all studied clusters, the MWSC provided an extended list of their parameters: structural ones, including the sizes of cluster core, total cluster extent, cluster proper motions, and, when possible, radial velocities, as well as photometric parameters: reddening, distance modulus, and age. All these data were presented in Paper I for the second quadrant objects and in Paper II, for the rest of the known Galactic clusters. In addition, we have searched for as-yet unidentified clusters (Schmeja et al. 2014; Scholz et al. 2015, hereafter Papers III and IV). In Paper III the new candidates were searched as sky field over-densities for apparent colour-magnitude diagrams (CMD) reproducing patterns typical to older clusters, while in Paper IV the new candidates were searched as enhanced densities in the proper-motion vector-point diagrams (VPD). At last, the integrated near-infrared 2MASS magnitudes and colours of MWSC clusters were also additionally computed (Kharchenko et al. 2016, hereafter, Paper V).
As a result, our final compilation contains 3210 previously known and newly identified star clusters, with 3063 of them classified as open clusters. The MWSC covers a substantial part of the Galactic disc radius (R) from the very centre at R ≃ 2 kpc to the outer regions at R ≃ 20 kpc. An important feature of the MWSC is the uniformity of the parameters obtained during its execution. This homogeneity is ensured by the fact that the entire survey is performed by one person (N.V. Kharchenko) in the framework of uniform methods and approaches. The sample of clusters built in such a way contains an unprecedentedly wide set of various parameters of a spatial, kinematic, photometric, and astrophysical nature, representing a perfect tool for studying the Galactic star cluster population. It was already used to study the open cluster near-infrared luminosity functions (Paper V) and the history of the cluster formation rate (Piskunov et al. 2018, hereafter Paper VI). The next natural step of its application is to study various issues related to the star cluster mass function.
3. Tidal radii
The sizes of the star clusters have a clear physical meaning, they characterise the mass and population of the grouping and its dynamic state. An accurate and homogeneous fixation of the boundaries of open star clusters is a non-trivial task: low star density in the cluster outskirts, an admixture of residual field stars, the expected non-sphericity of the clusters, the possible presence of secondary structures (e.g. tidal tails), variations of observations, and dependence on observation sources – all of these aspects require a certain standard approach for the cluster size definition.
The method we used is based on the well-known empirical King’s model (King 1962), which describes the radial profiles of the surface density of stars observed in globular clusters using curves depending on the parameters, rc, rt, and k. According to King’s definition, rc is the radius of the core, rt is the tidal radius, and k is the normalising factor associated with the central density of the cluster. The logarithm of the radii ratio c = log(rt/rc), called concentration, is also widely used. In addition to globular clusters, this approach was also used to determine the King parameters of several nearby open clusters (see e.g. earlier Raboud & Mermilliod 1998a,b) or recently Angelo et al. (2020, 2021), Tarricq et al. (2022). However, the direct definition of differential density profiles does not work for most open clusters due to the relatively small number of members observed in them and the relatively low density at the cluster’s periphery. This causes a systematic distortion of the outer areas of the clusters, especially important for determining tidal radii. Therefore, to reduce the effect of poor statistics, we used the integral form of the King’s profile for our purposes:
![Mathematical equation: $$ \begin{aligned} \begin{aligned} n(r) = \pi \, r_{\rm c}^{2}k\,&\left\{ \ln [1+(r/r_{\rm c})^{2}]-4\frac{\left[1+(r/r_{\rm c})^{2}\right]^{1/2}-1}{\left[1+(r_{\rm t}/r_{\rm c})^{2}\right]^{1/2}} \right.\\&\left.+\frac{(r/r_{\rm c})^{2}}{1+(r_{\rm t}/r_{\rm c})^{2}}\right\} \,, \end{aligned} \end{aligned} $$](/articles/aa/full_html/2023/04/aa44723-22/aa44723-22-eq1.gif) (1)
(1)
where n(r) is the number of cluster members within a sky area with radius (r). In COCD, we fit integrated profiles of 236 clusters (Piskunov et al. 2007).
To construct the observed cluster profile, we counted cluster members in concentric rings around the centre of the cluster at distances up to 5r2, where r2 is the apparent radius of the cluster’s corona, obtained from MWSC. To standardise the density profiles observed for clusters embedded in different environments, we used the most reliable members of the cluster that provide the exhaustive completeness of the data and help to avoid the respective bias in the working sample. Special attention was given to the cluster membership probability and apparent magnitude limits. Their values were varied in a broad range and optimised by the goodness-of-fit parameter. The sampling parameters were selected individually for each cluster and varied depending on its individual properties: distances, degrees of immersion in the surrounding stellar back- and foreground, uniformity, and heaviness of interstellar extinction. The decisive factor was the completeness and purity of the data, especially in the outer parts of the cluster. Therefore, we took additional measures to take into account the residual background and remove “false” member field stars that satisfy the member selection filters (for example, co-moving field stars on the proper-motion diagram or stars projecting onto the cluster main sequence in the colour-magnitude diagram). To do this, we calculated the level of residual density of field stars, typical for the surrounding stellar field, and subtracted it from the primary empirical profile. The approximation and determination of the parameters were carried out using the MPFIT procedure from the Markwardt et al. (2009) IDL library.
Figure 1 shows the empirical profile approximation for clusters residing at different heliocentric distances: 0.13 kpc for one of the closest to the Sun open cluster Pleiades, 0.89 kpc for a typical to MWSC sample cluster M67, and 2.7 kpc for a remote cluster Berkley 58. It can be seen that the approximation works equally well at different distances and that the profile correction for residual background plays a critical role in the correct determination of tidal radii.
 |
Fig. 1. Fit of King curves to observed density profiles of open clusters residing at different heliocentric distances: small (Pleiades), medium (M67), and large (Berkley 58), shown from left to right. The curves represent the observed distribution of safe cluster members (dots), the one corrected for the residual background (circles with Poisson error bars), and the fitted King profile (solid red curve). Vertical lines indicate core radii (rc, solid) and tidal radii (rt, dashed). Blue lines indicate visual estimates, made earlier in MWSC, red ones are the current values of rc and rt derived from the profile fit. Horizontal bars indicate fit errors. |
Using the described method, we determined the tidal parameters of 3017 open clusters (98% of all MWSC objects classified as open clusters). For the remaining 2%, satisfactory density profiles were not built due to the poor quality of the input data (poor statistics, ragged absorption, near bright star, etc.). The typical (most frequent) determination accuracy is 29 to 33% for the radii. The distribution of these parameters and their accuracy for the clusters studied is shown in Fig. 2. It can be seen that, according to our determination, the typical core radius of open clusters is 1.1 pc, which corresponds to widespread belief about the sizes of open clusters. The actual size of a typical open cluster confined by the gravitational field of the Galaxy (rt) is, by our determination, 8.4 pc, and the typical concentration, c, of disc clusters is 0.91.
 |
Fig. 2. Tidal parameters of MWSC clusters. Distributions of log rc, log rt, and c (top row) and of their relative errors (bottom row). Vertical lines show sample averages. |
Figure 3 compares our determinations of tidal parameters made based on data for 222 common clusters of COCD and MWSC depending on MWSC heliocentric distances. Methods for determining the radii of both samples differ only in details related to the specifics of the data, in particular, with a brighter completeness magnitude in COCD. Despite the difference in observational properties, both surveys show good agreement: the core radii differ by no more than 18% and the tidal radii by 7% on average. At the same time, there are no systematic differences up to the distances of about 3 kpc. Some trend over larger distances appears to be associated with lower reliability of structure data in remote clusters in COCD.
 |
Fig. 3. Relative difference in COCD and MWSC estimates of rc and rt radii as function of MWSC heliocentric distance (d). Red lines show average differences and yellow stripes are respective standard deviations. Statistical parameters were computed with the help of data marked with filled circles, open circles are omitted as 3-σ outliers (24 and 13 for rc and rt, respectively). Vertical bars are fit errors. |
4. Tidal masses
To determine the tidal mass of the cluster (mt), we follow King (1962) and use a condition for the balance of gravitational forces between the Galaxy and the cluster on a circular orbit:
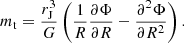 (2)
(2)
Here, rJ is the Jacobi radius (distance from the cluster centre to Lagrange points, L1, or L2, where its self-gravity is equal to the Galaxy field in the corotating frame), Φ is the Milky Way potential, R is the Galactocentric radius, G is the gravitational constant.
For an explicit representation of the Galactic potential, we use a Plummer-Kuzmin three-component model (Miyamoto & Nagai 1975):
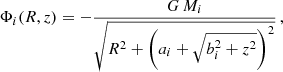 (3)
(3)
where z is the distance from the Galactic plane, i = b, d, h are indices of the components bulge, disc, and halo respectively, and Mi are the masses of these components. Model parameters Mi, ai, and bi were optimised to represent the Galactic rotation curve adopting R⊙ = 8.5 kpc for the Galactocentric distance of the Sun (Kharchenko et al. 2009). These are shown in Table 1.
Parameters of Galactic potential components.
At the distance (R) from the Galactic centre, the angular velocity (Ω) and the epicyclic frequency (κ) can be expressed as follows:
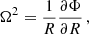 (4)
(4)
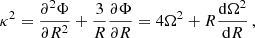 (5)
(5)
and Eq. (2) is written as:
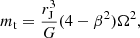 (6)
(6)
where Ω and β ≡ κ/Ω depend on R.
To apply Eq. (6), in practice, it is necessary to know its main components in advance. For example, the Jacobi radius rJ could be scaled via the tidal radius computed from the fit of King profiles to the observed radial distributions of cluster member counts. In turn, the parameters β and Ω can be taken from the Galactic potential model.
The relation between Jacobi and tidal radii for realistic clusters in the framework of the adopted Galactic potential model was studied using N-body calculations by Ernst et al. (2010). They show that the ratio, rt/rJ, depends on cluster coordinates in the sky and, to a lower degree, on their age. For Galactic latitudes, |b|< 30°, where the bulk of open clusters reside, this ratio varies between 1.00 and 1.20 with the most frequent value of 1.06. A maximum of about 1.4 is reached near the Galactic poles. Although the derived bias is well within the typical random error of the rt determination (see Fig. 2), it leads to a perceptible change in cluster masses. The respective ratio of tidal and Jacobi masses varies for different latitudes and ages between 1.0 and 2.0, having a broad asymmetric maximum at about 1.2 (see Fig. 8 in Ernst et al. 2010). Having in mind these figures, we adopt hereafter as zero-order approximation a hypothesis on the equality of tidal and Jacobi radii.
Figure 4 shows the distribution of clusters with respect to their Galactocentric distance (R). The dependencies of the derived tidal masses and radii of clusters on R are given in the top and middle panels, respectively. It can be seen that the constructed relations have several characteristic details. Despite the large extent of massive clusters, the observed clusters occupy only part of the MWSC sample space. Both relations have clearly defined boundaries of R, reducing its width with decreasing rt or mt, respectively. This behaviour indicates the magnitude limit of the sample (which is the case for the MWSC survey) and the implicit dependence of the considered parameters on the cluster brightness, which is the basic factor affecting cluster visibility.
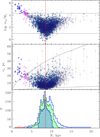 |
Fig. 4. Radial distributions of tidal masses (top panel), radii (middle panel), and cluster counts (bottom panel). Filled and open circles in the upper two panels show clusters inside and outside the magnitude-dependent completeness limits described in Sect. 5.1, respectively. Bars are errors in the determination of the tidal parameters. Crosses are central (R ≤ 3 kpc) clusters before (blue) and after (magenta) the artificial decrease of 0.6 mag in their distance moduli is applied. Solid lines are theoretical relations for cases of a constant mass of mt = 2 × 104 M⊙ (upper line) and mt = 10 M⊙ (lower line). The red vertical line shows the Galactocentric radius of the Sun. Histograms in the bottom panel show raw counts for all clusters (background), ones within the single completeness limit (foreground), and those within magnitude-dependent completeness limits (in between). The red histogram shows the central clusters. |
Solid lines in the top and middle panels of Fig. 4 show the upper and lower bounds of the samples. As can be seen, the lower boundary of the observed tidal masses is about or somewhat less than 10 M⊙, then, as the upper limit is mt = 2 × 104 M⊙ and practically does not depend on R. An exception is the innermost clusters (see below). The distribution of the tidal radii of clusters is skewed along R: the distribution boundaries drawn on the middle panel are calculated by Eq. (6) for cases of constant mass 10 M⊙ and 2 × 104 M⊙. As follows from the middle panel, relatively extended clusters should be observed in the outer areas of the disc and more compact ones in the centre.
Filled circles show the sub-sample of clusters inside the magnitude-dependent completeness limit (derived in Sect. 5.1), which is free from selection effects. Clusters outside it may also be useful for studying the properties of their population. As follows from the top panel of Fig. 4, the completeness limits are mass-dependent. For massive clusters with log mt/M⊙ = 4, the variation in R reaches 10 kpc, while for low-mass clusters with log mt/M⊙ = 1 it is as low as 2 kpc. Thus, our sample is biased and must be corrected to study the population characteristics (for example, the mass function).
The upper mass limit is broken by 21 clusters located in the very centre of the Milky Way (R ≤ 3 kpc), having about the same size as external clusters. Their resultant masses are much larger (by 1.5 orders of magnitude) than the total upper mass limit noted above. Of the two possibilities that explain this peculiarity: the real difference between the central clusters and the whole population, or the effect of systematic error we prefer the second one. We consider it quite likely that the distances to some clusters observed in the direction of the centre of the Milky Way are overestimated in the MWSC. This may be due to the ragged structure of dense dust clouds in this region of the sky: 15 of 21 ‘central’ clusters reside at |b|< 6°, and five more at |b| = 6 − 15°. Additionally, these clusters are located near the observed MWSC magnitude limit. Therefore, only branches of red giants that are very unreliable distance indicators are available for observation. To estimate the effect of distance, we artificially reduced the modulus of the distance of these clusters by Δ(KS − MKS) = 0.6 mag. The result is shown in both diagrams in Fig. 4 with crosses. As can be seen in this case, the central clusters occupy a natural position on the radial diagrams typical to the rest of the clusters. The bottom panel of Fig. 4 provides the cluster counts as a function of the Galactocentric radius for the different samples.
5. Cluster mass function
The raw cluster mass distribution of 3017 MWSC clusters with mt determinations is shown in Fig. 5 as a background histogram. One can see that it is dominated by small/medium-mass clusters with log mt/M⊙ = 1.7–2.7. After taking into account the data completeness effect it is used as a basis for the mass function construction.
 |
Fig. 5. Raw distributions of MWSC clusters with tidal mass (top panel) and with its relative error (bottom panel). Different histograms in the top panel correspond to different cluster samples. The total sample is shown in the background with a solid cyan histogram, the clusters selected within the single completeness circle are shown with a histogram hatched with blue (foreground) and those within their magnitude-dependent completeness limits are shown with a back-hatched green histogram (in between). The red-colour massive end of the distribution is built of ‘central’ (R ≤ 3 kpc) clusters. |
5.1. Data completeness
As cluster counts show, the MWSC can be classified as a magnitude-limited sample (for details, see Paper V). The surface density profile for such a sample can be represented schematically by a flat inner area, where the data incompleteness is negligible and by a long outer tail of gradually decreasing density, which is biased by the survey incompleteness at faint magnitudes. The incompleteness can be quantified in a statistical sense as a measure of the decrease of the observed surface density compared to the averaged local density (see e.g. Morales et al. 2013). We note that as a measure of the distance we use a Galactic plane projection, dxy, of solar-centric distance, d. The radius of the flat area, 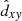 , is then called the completeness limit of the survey. Once established, the bias-free statistic is gathered within the completeness limit.
, is then called the completeness limit of the survey. Once established, the bias-free statistic is gathered within the completeness limit.
This method (which we call hereafter the ‘single’ completeness limit approach) is attractive due to its simplicity and is commonly used, but it is inherently biased for objects which are absolutely fainter or brighter than the clusters typical for the given sample. For example, when applying the single-limit approach to faint objects, which can be observed near the Sun only, one underestimates their density when one divides their counts by the completeness area defined by the common completeness limit. In contrast, since the typical distance to bright objects may exceed the completeness limit, one can lose them from the statistics. Therefore, to avoid important biases which might affect the low- and/or high-mass extrema of the distribution, we decided to abandon the single-limit approach. Instead, we apply a strategy used previously for the cluster luminosity function (Paper V) and age distribution construction (Paper VI), which collects star clusters of different absolute magnitudes from proportionally extended completeness areas. We refer to this method as a ‘magnitude-dependent’ completeness limit approach.
This procedure became feasible since in Paper V we determined integrated NIR magnitudes for all MWSC clusters and built magnitude-dependent completeness limits. For the absolute integrated magnitude I(MKS) in the KS passband, this relation can be written for the total cluster sample as:
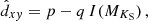 (7)
(7)
with p = 0.36 kpc and q = 0.54 kpc mag−1 (see Sect. 6.3 for more details). To derive the relation coefficients at the distance scale extrema more precisely, we repeated the procedure described in Paper V, using a more disturbance-resistant (sliding window average) approach. As in Paper V, the completeness distances cover a large range up to about 5 kpc and the MWSC is generally complete within 1.8 kpc from the Sun (except for the faintest clusters). About half of all MWSC open clusters are inside this single completeness limit.
In Fig. 5 (top panel), we compare the distributions of tidal masses of all clusters (except ‘central’ ones) with known mt (2996 objects, cyan histogram), and of the complete samples represented by hatched histograms (blue for the single completeness limit with 1328 clusters, and green for the magnitude-dependent completeness limit with 2227 clusters). One can see that the distributions coincide at the low-mass end (log mt/M⊙ ≤ 1.5). At higher masses, the magnitude-dependent completeness limits exceed 1.8 kpc resulting in a larger number of clusters.
The difference between the ‘complete’ samples can be understood with the help of Fig. 6, where we compare both these approaches in the completeness treatment in the ‘dxy versus log mt/M⊙’ diagram. We can see that the single completeness limit approach cuts almost all potentially useful masses higher than log mt/M⊙ ≈ 2.7, leaving only an insignificant number of objects for the massive end of the mass function. In the alternative case, we can extend the size of the completeness area more than by a factor of two: the upper limit of the completeness zone reaches for the intrinsically brightest clusters dxy = 5 kpc. Hereafter, we use the magnitude-dependent completeness limits to have better statistics at the high-mass end (general sample).
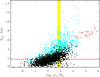 |
Fig. 6. Distribution of cluster distances with mass. The clusters located inside and outside the magnitude-dependent completeness limits computed in Eq. (7) are shown with black and light blue dots, respectively. The single completeness limit for the MWSC sample is given by the horizontal red line. A vertical yellow stripe is given for illustration and indicates an arbitrary log mt-box with clusters of the two kinds falling in it. Red crosses show ‘central’ (R ≤ 3 kpc) clusters excluded from further consideration. |
The red-coloured histogram in the top panel of Fig. 5 shows the innermost clusters discussed in Sect. 4. Following this discussion, we consider the derived masses of these clusters to be unrealistic, exclude them from further discussion, and assume that the massive end of the Galactic star cluster mass function extends to about log mt/M⊙ = 4.4 only. At small masses, the raw mass distribution ends at log mt/M⊙ ≈ 0. Since according to the bottom panel of Fig. 5, the distribution of relative errors in the determination of tidal masses sharply peaks at about δmt ≈ 70%, corresponding to ε(log mt/M⊙)≈0.3, we can assume that the real low-mass end of the masses of star clusters is close to log mt/M⊙ = 1, and the lower masses form the error tail at this limit.
5.2. Construction of the mass function
We define the cluster mass distribution φ(m) as a surface density of objects in the unit interval of mass m:
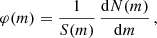 (8)
(8)
where dN(m) is the number of clusters with masses between m and m + dm residing within the completeness area S(m). It is related to the more convenient logarithmic mass distribution:
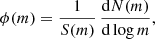 (9)
(9)
via
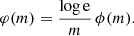 (10)
(10)
Since both distributions are frequently mentioned in the literature, we hereafter for more certainty call φ(m) the mass spectrum and ϕ(m) the mass function.
If one adopts a single completeness limit 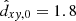 kpc, valid for clusters of all masses (horizontal line in Fig. 6), then
kpc, valid for clusters of all masses (horizontal line in Fig. 6), then 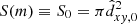 , and Eq. (9) re-written in the discrete form simply reflects the distribution of cluster numbers ΔkN within the completeness area (i.e. below the horizontal line):
, and Eq. (9) re-written in the discrete form simply reflects the distribution of cluster numbers ΔkN within the completeness area (i.e. below the horizontal line):
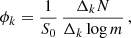 (11)
(11)
where the mass step (Δklog m) can be a variable.
In the case of the magnitude-dependent completeness limit, the cluster density will be computed as a sum of partial densities 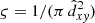 of clusters located within their proper completeness limits given by Eq. (7), that is those with
of clusters located within their proper completeness limits given by Eq. (7), that is those with 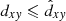 (black dots in Fig. 6):
(black dots in Fig. 6):
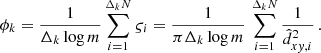 (12)
(12)
Here, we sum over the ΔkN black dots within the mass interval of Δklog m. We note that in the case of the constant completeness limit 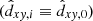 , Eq. (12) is naturally reduced to Eq. (11).
, Eq. (12) is naturally reduced to Eq. (11).
The resulting distribution, computed with the help of Eqs. (11) and (12) with ΔkN ≥ 7 and Δklog m ≥ 0.05, is shown in Fig. 7. In total, it consists of 2227 clusters residing within the completeness area, which is the wide solar neighbourhood shown with black dots in Fig. 6. Since it contains clusters of various ages, we call it the general CMF (GCMF). The distribution extends over more than four decades in mass (between log mt/M⊙ = 0.2 and 4.4). The mass distribution has a bell-like shape and resembles cluster mass functions observed in the Milky Way and in other galaxies (as discussed in more detail in Sect. 5.3). The difference is in the position of the apparent maximum: in external galaxies, it depends on the distance to the galaxy, which implies that it is related rather to incompleteness beyond the observation limit. In contrast, in the GCMF built within the completeness zone, the position of the maximum manifests the details of cluster formation, evolution, and death.
 |
Fig. 7. GCMF computed with magnitude-dependent completeness limits in Eq. (12), (light-blue filled histogram). Vertical bars show errors mainly due to uncertainty in mass. Top panel shows the low- and high-mass power-law fits (solid red lines) and the smoothed histogram data (green line). The middle panel presents different approaches to the mass function construction: single completeness limit with |
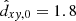
The low-mass and high-mass branches of CMFs usually exhibit power-law shapes and characterised by the slope (x). We quantify them by linear fits as follows:
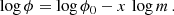 (13)
(13)
For the determination of fit parameters, we use the standard IDL routine LINFIT. Uncertainties in the mass of the clusters dominate errors in the input data, which were estimated using Monte Carlo simulations. We calculate the reduced goodness-of-fit statistic 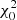 along with the P-value that gives the probability that the computed fit would have a value of
along with the P-value that gives the probability that the computed fit would have a value of 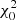 or larger. If P is greater than 0.1, the linear model parameters are ‘believable’. The mass intervals are selected to maximise the P-values.
or larger. If P is greater than 0.1, the linear model parameters are ‘believable’. The mass intervals are selected to maximise the P-values.
The fit for the high-mass end is drawn in the range log mt/M⊙ = 2.3 − 4.3 (top panel of Fig. 7). The parameters of the fit are zero point log ϕ0 = 4.53 ± 0.21 and slope x = 1.14 ± 0.07. Substitution of Eq. (10) for Eq. (13) shows that the mass spectrum also follows a linear relation with a slope α = x + 1 = 2.14 ± 0.07. For the low-mass end, we find a rising slope with x = −0.61 ± 0.13 (see also Table 3 in Sect. 6).
The tolerance of the mass function to some systematic effects is illustrated in the middle panel of Fig. 7. It shows a function obtained with the assumption of a single completeness limit and a function built using tidal masses determined for parameters of the tidal field at the solar position (referred to as local tidal masses) for comparison. We can see that both effects have a small impact on the final mass function. The distribution of the local tidal masses perfectly fits the GCMF (most log m-bins only differ within the statistical uncertainty due to binning effect). This can be explained by the fact that the dependence of the tidal parameters, Ω and β, (cf. Eq. (6)) on the Galactocentric radius cancels out in the lowest order within the completeness area. Despite the considerable difference in the number of objects collected from different areas (1328 versus 2227), the disagreement between the GCMF and the single completeness limit mass function is on the order of the statistical uncertainty, although it seems to be systematic at the limits of the mass scale. We also note that the single completeness limit approach is unable to provide a reliable mass function at the high-mass end (log mt/M⊙ > 3.4).
5.3. Comparison with prior results
In the Milky Way, the first attempt to build the luminosity function of the Galactic clusters from the literature data was undertaken by van den Bergh & Lafontaine (1984). It was based on a sample of 142 clusters that, according to the authors, is to two-thirds complete within 400 pc.
A higher completeness degree within 650 pc was achieved later with our HIPPARCOS-based survey COCD (Kharchenko et al. 2005a). Lamers et al. (2005) used a sub-sample of 114 COCD clusters within 600 pc from the Sun. For a cluster mass estimation, they integrated a Salpeter (1955) stellar initial mass function (IMF) from the brightest end of the cluster Main Sequence down to an arbitrary common mass limit of 0.15 M⊙. The IMF was properly normalised for every cluster based on the COCD data on the number of observed cluster 2σ-members. They built the number distribution within 600 pc from the Sun and found that at the low mass end it is limited to 100 M⊙.
The full COCD survey including the extension by Kharchenko et al. (2005b) was used to build cluster mass and luminosity functions by Piskunov et al. (2008). The cluster masses were estimated from tidal radii determined from King profiles. The cluster distribution over apparent integrated magnitudes shows that the cluster sample is complete down to the apparent integrated magnitude V = 8 mag, with 440 clusters above this completeness limit. This, on average, corresponds to a completeness area in the solar neighbourhood with an effective radius of about 1 kpc. The masses of the Galactic clusters span a range from a few solar masses to log mt/M⊙ ≈ 5.5.
Among extragalactic results, the following two could be used for our comparison purposes. Larsen (2009), in his study of the massive end of cluster mass functions in spiral galaxies, also built a mass function of star clusters in the Large Magellanic Cloud. He used literature data on UBV photometry of 504 clusters and applied simple stellar population (SSP) models for the mass and age determination for clusters with ages log t/yr < 9. The estimated completeness limit of the photometry is V ≈ 13 mag, which corresponds to a limiting mass of log m/M⊙ ≈ 4.
Fouesneau et al. (2012) studied the age and mass distributions of 1242 star clusters in the central and north-eastern part of the galaxy M83, a nearby analogue of the Milky Way. The observed basis was provided by the Hubble Space Telescope (HST) aperture UBVIHα photometry corrected for foreground Galactic extinction. The cluster parameters were determined with the help of stochastic SSP models. The mass function was constructed for masses log m/M⊙ > 3. The mass spectrum at log m/M⊙ > 3.5 (which is close to the survey completeness limit at V ≈ 23 mag) was fitted by a power law with a slope α = 2.15 ± 0.14.
The comparison of the above distributions with the GCMF is shown in Fig. 7 (bottom panel). To convert the Lamers et al. (2005) counts into surface densities, we divided their data by the area of the circle with a radius of 0.6 kpc. Lamers et al. (2005) data fit the GCMF at log mt/M⊙ = 3.0–3.5. At lower masses, their distribution shows increasing deficiency compared to our GCMF due to incompleteness. At higher masses there is a cut-off bias in the Lamers et al. (2005) sample due to low-number statistics. For the full COCD sample, the derived CMF agrees reasonably well with the GCMF over the total range of masses (Piskunov et al. 2008). The observed scatter is significantly larger due to the smaller sample size. The counts of Larsen (2009) and Fouesneau et al. (2012) were adjusted vertically to be comparable to the GCMF. One can see that the slopes of both samples at log mt/M⊙ > 3.5 are consistent with the GCMF. Our general conclusion is that the agreement between the GCMF and the literature on the MW and some nearby galaxies is satisfactory.
6. Temporal and spatial variations of the CMF
The GCMF that we describe is a product of several processes: the formation of clusters, their dynamic evolution associated with mass loss and disintegration, as well as the evolution of the Galactic disc as a whole by, for instance, changes in the rate of star formation with time. As a result, we observe as the GCMF a certain integral including all these processes. In this section, we study the age dependence of the CMF over the entire period of cluster existence.
6.1. Age group definition
Considering the mass functions of clusters of different age groups, we noticed that although they may share a resemblance with the GCMF, they nevertheless slowly change their morphology with age, an attribute that appears to be associated with the evolution of clusters. Since these variations are insignificant and it is unclear a priori how they may be formalised, we first scanned a complete sample of clusters over the entire interval of available ages, log t/yr = 6.4–9.6, using the sliding window method with a carriage width of Δ log t/yr = 0.4 and a step of δlog t/yr = 0.1. For every sub-sample falling into the window, we built the respective mass function. We limit ourselves by this lower limit of the ages since: (i) it is about the original young limit of Padova isochrones available for log t/yr ≥ 6.6; and (ii) we isolate in this way the embedded phase of cluster evolution assumed to last for 3 Myr (Parmentier & Pfalzner 2013). As the analysis has shown, the constructed family of mass functions can be divided into several groups based on the CMF features in the region of moderate and small masses. It turns out that this classification correlates well with the age of the clusters. In Fig. 8, we show the obtained mass function groups. Curves belonging to our classification to the same age group have the same colour.
 |
Fig. 8. Comparison of selected CMF age groups built as described in the text. The groups are marked with different colours and are artificially shifted vertically to reduce the overlap. From bottom up, we show the initial-age (violet), young (blue), medium-age (green), and old (orange) cluster groups. The uppermost dark curve is the GCMF (including all ages) constructed in Sect. 5.2. The groups and their age limits are presented in Table 2. |
We attribute the youngest group (designated with I, which stands for ‘initial-age’ clusters) to clusters with a long and almost flat low-mass segment (log mt/M⊙ ≲ 2.7). In the other age groups, this section is no longer flat, but has a noticeable maximum, with the position being shifted with age toward larger masses. According to the position of the maximum, we distinguish a young group (Y, representing ‘young’ clusters) with a maximum at log mt, max/M⊙ ≃ 1.7, a medium group (M, for ‘medium-age’ clusters) with log mt, max/M⊙ ≃ 1.8, and an old group (O, for ‘old’ clusters) with log mt, max/M⊙ ≃ 2.1. The dependence of the position of the CMF maximum on time leads to the appearance of a broad maximum at the integral function, which is the GCMF. Table 2 gives the number of clusters in each group, the age limits including mean age and standard deviation, and the mass range covered. The youngest 48 clusters with log t/yr < 6.4 are excluded from the age groups.
Parameters of cluster age groups.
6.2. CMFs at different age groups
The CMFs for different age groups are built in the same way as the GCMF described in Sect. 5. The resulting CMFs (shown in Fig. 9) can be characterised by power laws at the low- and high-mass ends. These segments are connected by a weakly pronounced maximum with varying positions and widths in the different age groups. The maxima of the distributions tend to have higher masses with age in groups Y, M, and O. The power-law fits were done as for the GCMF (Sect. 5.2). Table 3 contains the mass intervals in which the fits are performed (Col. 3), the derived fit parameters and their errors (Cols. 4 and 5), and the fit quality parameters, 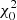 and P. The last two lines related to the GCMF (Sect. 5.2) are given for comparison.
and P. The last two lines related to the GCMF (Sect. 5.2) are given for comparison.
 |
Fig. 9. Mass functions of star clusters of four age groups (group identification and age limits are shown in the panels). The CMFs are given by green histograms, while the background shows the GCMF. The straight lines represent the linear fit of the CMFs with power laws. The mass intervals used for the fit determinations are shown by solid red lines. |
The slopes of the high-mass sections (subscript 1) are found near x = 1.15 and they are almost independent of age, except for the youngest group (I), for which the slope is slightly shallower. The slope of the low-mass end also does not depend on age for groups Y, M, and O and is close to x = −0.7. For group I, the CMF is remarkably flat up to log mt/M⊙ ≈ 2.3.
In our earlier work based on COCD (Piskunov et al. 2008) it was found that the CMF for the youngest clusters (log t/yr ≤ 6.9) takes the form of a two-section distribution with a quasi-flat slope of x = −0.18 ± 0.14 at the low-mass end (log mt/M⊙= 1.7–3.4) and with a slope of x = 0.66 ± 0.14 at the high-mass end (log mt/M⊙ = 3.4 − 4.9). The latter steepens with age up to x = 1.17.
Bik et al. (2003) constructed mass functions from several hundred clusters observed in the region of the inner arms of the galaxy M51. According to the data of broadband photometry UBVRIHα and narrow-band indices OIII over an area of ∼3 × 3 kpc, they constructed a mass distribution of 354 objects younger than log t/yr = 7.0 in the mass range log m/M⊙ = 2.3–5. The masses are determined from the data on SSP models for UBVR photometry with completeness for log m/M⊙ ≳ 3. The resulting slope of the mass spectrum for 149 objects from this mass interval is α = 2.16, which corresponds to x = 1.16.
Dowell et al. (2008) constructed the mass spectrum of young clusters (log t/yr < 7.3) from the SDSS survey in 13 nearby irregulars and 3 spiral galaxies. Cluster parameters (including absolute magnitudes, interstellar extinction, age, and mass) were determined from the colour charts of the ugriz system. A total of 321 and 358 clusters were used in irregular and spiral galaxies. The mass range covers log m/M⊙ ∼ 4.2–6.6 and the slopes (α) are equal to 1.88 ± 0.09 and 1.75 ± 0.06, respectively.
Fall et al. (2005, 2009) implemented a simple model of the formation and evolution of star cluster population to the observations of the HST in the Antenna galaxies (NGC 4038 and NGC 4039). Observations cover the main body of both galaxies. Cluster parameters such as age or absorption were determined from UBVIHα photometry, using Bruzual & Charlot (2003) SSP models with Salpeter IMF and mass from m/LV ratio. To reduce star contamination with bright stars the sample was cut (objects fainter than LV/L⊙ < 3 × 105 are removed), which limits cluster masses to log m/M⊙ > 5.3, with about 2300 clusters. The mass and luminosity functions were constructed for age intervals log t/yr = 6–7 and 7–8. It was found that for the mass interval log m/M⊙ = 4.5–7, the slope is α = 2.14 ± 0.03 and 2.03 ± 0.07, respectively.
Chandar et al. (2010) studied the two-dimensional (2D) mass and age function of star clusters in the Large and Small Magellanic Clouds. They constructed mass distributions of clusters in different age ranges. To do this, they used Hunter et al. (2003) integrated UBVR photometry (854 clusters in an area of 11 kpc2 in the LMC and 239 clusters in an area of 8.3 kpc2 in the SMC). Masses are determined using the m/LV ratio and ages are determined from SSPs of Bruzual & Charlot (2003) with a Salpeter IMF. Due to the proximity of the Magellanic Clouds, the work extends the range of masses and ages of clusters compared to those from the Antennae galaxies previously studied by the authors. It was found that the obtained distributions are close to similar distributions in the aforementioned galaxies, representing another more massive class of stellar systems. As Chandar et al. (2010) established for log t/yr ≤ 9, the slope (α) of the constructed mass functions is practically independent of age and is equal to 1.8 ± 0.2 in both LMC and SMC.
Larsen (2009) constructed the CMF of star clusters in several spiral galaxies and considered the possibility of representing them as a distribution within the framework of the Schechter approximation (Schechter 1976). Using selected spiral galaxies and SSP models, the CMF was constructed for young (log t/yr < 8.3) clusters in rich (NGC 5236, NGC 6946 having more than 100 objects per galaxy) and poor (more than 40 objects per galaxy, cf. Table 1 therein) spirals. Observations span over log m/M⊙ = 4.0–6.0, the masses are determined with the help of SSP models and photometric data, the count completeness is expected at log m/M⊙ > 5. For these masses, the data are compatible with a slope α = 2.0 and Schechter cut-off of mS = 2.1 × 105 M⊙. The comparison given above shows that the new data supports our previous findings on the CMFs slopes for different age groups in the Milky Way and are similar to the high-mass end slopes found for extragalactic systems.
6.3. CMFs at different Galactocentric radii
In the sections above, we assume that there is independence of the completeness limit with regard to the direction of observations and, thus, the uniformity of the clusters’ distribution in the Galactic plane as well. In this sub-section, we address this assumption in more detail.
Since CMFs depend on the disc surface density, we would expect larger and lower values for the inner and outer sub-samples, respectively, compared to the GCMF. The difference should be more pronounced at the high-mass end resulting in a bias in the shape of the CMFs because massive clusters are seen reliably at larger distances. In the following, we evaluate the impact of a radially decreasing cluster surface density on the CMF by selecting an inner (R⊙ − R > 0.35 kpc) and outer (R − R⊙ > 0.35 kpc) sub-samples of clusters. We excluded the region |R − R⊙|≤0.35 kpc hosting 450 clusters to increase the contrast between the inner and the outer sub-samples.
Paper V has shown that the parameters (p, q) for the completeness limit (Eq. (7)) depend on the direction in the Galaxy. Here, we determine these parameters separately for the inner and outer sub-samples. Following the procedure given in Sect. 4.2 of Paper V, we recalculated the parameters (p, q) given therein by applying additional smoothing with the sliding window method (as done for the total set of clusters in Sect. 5). The new parameters and the radial ranges for the general, inner, and outer sub-samples are given in Table 4. They describe a somewhat stronger dependence of the completeness limit on the integrated magnitude I(MKS), compared to the one obtained in Paper V. Using the newly derived parameters (p, q), we redefined the completeness subsets for the inner and outer sub-samples. The number of clusters (Nobj) in the respective magnitude-limited completeness ranges are given in Table 4. We note that the inner and outer sub-samples do not coincide with the clusters in the corresponding Galactocentric ranges of the general sample due to the different completeness limits. A comparison of the respective CMFs (red circles and green triangles) with the GCMF constructed in Sect. 5.2 is presented in Fig. 10. As expected, the vertical offsets are more pronounced at the high-mass end.
 |
Fig. 10. CMFs of star clusters for two ranges of Galactocentric radii, as presented in Table 4: red dots are for the inner sub-sample and green triangles are for the outer sub-sample. The vertical bars are statistical errors characterising a bin population and the horizontal bars indicate the bin widths. The bold blue line is the smoothed GCMF derived in Sect. 5.2 and the yellow background highlight represents its statistical errors. Thin red and green solid and dotted lines represent GCMFs of the inner and outer sub-samples after applying the bias due to the exponential decline of the Galactic disc surface density with a scale length of 3.8 and 6 kpc, respectively. |
To calculate the impact of a Galactic cluster surface density profile, we adopted a universal shape of the GCMF and applied an average individual radial offset of each mass bin. Solid red and green lines in Fig. 10 represent the resulting CMFs of the inner and outer sub-samples, respectively, assuming a radial scale length equal to 3.8 kpc (as found for the young disc population by Amôres et al. 2017). The dotted red and green lines are calculated for a radial scale length of 6 kpc. We can see that the observed CMFs of star clusters of the inner and outer sub-samples (red circles and green triangles) agree well with a universal shape of the GCMF distorted by the radial gradient of the cluster surface density.
In summary, the full cluster sample with magnitude-dependent completeness limits and the corresponding GCMF is representative of the open cluster population in the wider solar neighbourhood, despite the statistical impact of a radial decrease of the Galactic cluster surface density.
7. Cluster formation and evolution model
In Sect. 6.2, we discuss and quantify the CMFs of different age groups (see also Fig. 9). In this section, we present a simple model of cluster formation and its subsequent evolution that reasonably reproduces the obtained mass functions. At this stage, parameters for the model were found by hand, without using any best-fitting algorithm.
For CMFs at different ages, we need the CIMF, the cluster formation rate (CFR), and the cluster bound-mass function m(M, t), depending on the initial mass (M) and age (t). In the subsections below, we derive the surface density of clusters from the data and describe our model in detail. All parameters adopted for the model are compiled in Table 5.
Parameters of cluster formation and evolution model.
7.1. Surface density of clusters
The number surface density of clusters as a function of current mass (m) and age (t) is given by:
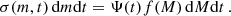 (14)
(14)
Here, Ψ(t) is the CFR as a function of age and f(M) is the CIMF. To convert the initial mass bins to bins of the current mass, we need to know the bound-mass function m(M, t). From Eq. (14), we obtain:
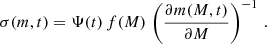 (15)
(15)
Here, it is assumed that the partial derivative is positive and does not vanish (see also discussion in Sect. 7.4). Then one can invert the bound-mass function in favour of the initial mass M = M(m, t) for fixed age (t). However, if m(M, t) is a non-monotonic function of M, then there is no one-to-one correspondence between initial and current masses. Some values of the current mass (m) can be obtained for several initial masses, Mk(m, t). Eq. (15) can then be modified as follows:
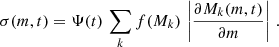 (16)
(16)
The cluster mass spectrum φ(m) is obtained for a given age range t0 < t < t1 by integrating the cluster surface density over age:
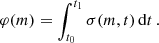 (17)
(17)
Lastly, the total number surface density for this age range is given by:
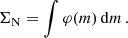 (18)
(18)
7.2. Cluster formation rate
We are interested in the number surface density of clusters in the solar neighbourhood. Therefore, the unit of the cluster formation rate Ψ(t) in the Galactic plane is the number of clusters per square kpc and Myr. Since the CFR is strongly degenerate with the cluster mass loss function, it is sufficient for our simple model to use a constant CFR, given by:
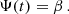 (19)
(19)
The value of β is adapted to reproduce the total number density of observed clusters in the mass range of log m/M⊙ = 0 − 4.5 and the age range of log t/yr = 6.5 − 10.
7.3. Cluster initial mass function
In principle, the CIMF should be consistent with the observed present-day cluster mass function for the youngest clusters. The observations, however, may be strongly biased for several reasons. Clusters up to an age of a few Myr could still be embedded in their parent molecular cloud and may even still form stars. Furthermore, infant mortality and the very fast evolution in the violent relaxation phase (see next subsection) influence the cluster mass function heavily.
Nevertheless, the two power-law segments shown in the top left panel of Fig. 9 for the initial-age group suggest that we may use a broken-power-law CIMF. Thus, we assume a two-slope broken power law with a smooth transition and an additional exponential Schechter-like cut-off for the largest masses required by the lack of clusters with masses above 50 000 M⊙:
![Mathematical equation: $$ \begin{aligned} f(M) = \frac{{\mathrm{d}} N}{{\mathrm{d}} M} = k_0 \left( \displaystyle \frac{M}{M_\star } \right)^{-(x_1+1)} \left[ 1+\left(\displaystyle \frac{M}{M_\star }\right)^s \right]^{\textstyle \frac{x_1-x_2}{s}} \exp \left(-\frac{M}{m_{\rm S}}\right) \,. \end{aligned} $$](/articles/aa/full_html/2023/04/aa44723-22/aa44723-22-eq32.gif) (20)
(20)
Here, x1 and x2 are low- and high-mass power-law indices, M⋆ and s determine the position and sharpness of the transition, and mS is the characteristic mass for the Schechter cut-off. The normalisation constant, k0, normalises the CIMF, f(M), to unity for the chosen lower cluster mass limit mlower = 2M⊙.
7.4. Cluster bound-mass function
Three processes affect the bound mass of the cluster: the mass loss during violent relaxation, the relatively slow destruction of the cluster in the Galactic tidal field, and the stellar evolution of stars within the cluster. The first two effects reduce the number of stars, whereas the third reduces the masses of stars, not their number. Stellar evolution depends on the initial mass function within the cluster and the metallicity. According to Lamers et al. (2010, Table B2), the normalised stellar mass μ(t) as a function of age can be approximated by the third-order polynomial
![Mathematical equation: $$ \begin{aligned} \mu (t) = \sum _{i=0}^3 p_i\,\Bigr [\log (t/\mathrm{Myr} )\Bigr ]^i. \end{aligned} $$](/articles/aa/full_html/2023/04/aa44723-22/aa44723-22-eq33.gif) (21)
(21)
In our model, we assume a metallicity of Z = 0.008 for the coefficients pi (see Table 5). The time scales of the dynamical processes mentioned above are clearly separated. Here, we used the N-body simulations by Shukirgaliyev et al. (2017, 2018) as an orientation. The initial conditions of these models were based on a centrally peaked star formation efficiency by adopting 5% star formation efficiency per free-fall time. Starting with a Plummer model (Plummer 1911) for the star cluster, the gas profile before instantaneous gas removal was determined and the cluster was initialised in dynamical equilibrium including the gas potential. Instantaneous gas expulsion leads to a supervirial cluster, which quickly expands and loses a large fraction of stars. This phase is called ‘violent relaxation’ and takes 10–20 Myr. Above a threshold of 13% for the global star formation efficiency, a core of stars re-collapses and forms a bound cluster in dynamical equilibrium. The fraction of stars that remain in the cluster depends strongly on the global star formation efficiency, but not on the initial mass and weakly on the Roche volume filling factor. In our model, the decrease in the number star fraction due to violent relaxation is governed by the function:
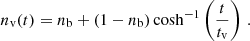 (22)
(22)
Here nb is the bound fraction after violent relaxation and tv determines the timescale of this phase. The adopted values nb = 0.1 and tv = 5 Myr represent (roughly) the violent relaxation phase with a low global star formation efficiency of 15–20%.
The rate of change of the bound-star-number fraction due to cluster dissolution is given in our model in the following form:
![Mathematical equation: $$ \begin{aligned} \frac{{\mathrm{d}} n_{\rm D}}{{\mathrm{d}} t} = -c \left( \frac{M}{M_{\rm br}} \right)^{(a_1-1)}\left[ 1 + \left( \frac{M}{M_{\rm br}} \right)^{a_2} \right] n_{\rm D}^{a_1}\,. \end{aligned} $$](/articles/aa/full_html/2023/04/aa44723-22/aa44723-22-eq35.gif) (23)
(23)
with the boundary condition nD(t = 0) = 1. Here, the rate is proportional to the power a1 of the current value of nD and the constant, c, determines the global rate of long-term decrease of this fraction.
By construction, the rate is proportional to Ma1 − 1 or Ma1 + a2 − 1 for initial masses below or above Mbr, respectively. Having different lifetime scaling for low-number and high-number clusters allows the model to reproduce the observed range of cluster ages without creating an overabundance of very old high-number clusters.
The solution of Eq. (23) can written in a compact form:
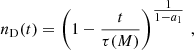 (24)
(24)
![Mathematical equation: $$ \begin{aligned} \tau (M)&= \left\{ c(1-a_1) \left( \frac{M}{M_{\rm br}} \right)^{(a_1-1)}\left[ 1 + \left(\displaystyle \frac{M}{M_{\rm br}} \right)^{a_2}\right]\right\} ^{-1} \,. \end{aligned} $$](/articles/aa/full_html/2023/04/aa44723-22/aa44723-22-eq37.gif) (25)
(25)
For a1 < 1, we have τ(M) giving the lifetime of the clusters.
Next, we combine all three contributions to the cluster bound mass as a function of initial mass (M) and age (t):
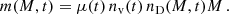 (26)
(26)
The bound-mass fractions (m(M, t)/M) for some values of initial mass are shown in Fig. 11. For clusters with an initial mass of log M/M⊙ > 2, fast mass loss by violent relaxation is clearly separated from the long-term mass loss by stellar evolution and cluster dissolution in the tidal field. Low-mass clusters do not survive the violent relaxation phase.
 |
Fig. 11. Evolution of the modelled mass fraction for clusters of different initial masses. The mass loss just from stellar evolution, μ(t), is shown in addition for comparison. The horizontal dashed line marks the bound fraction, nb, after violent relaxation and the vertical dashed line marks the violent relaxation timescale, tv. |
In Sect. 7.1, we assumed that the partial derivative (∂m/∂M) in Eq. (15) is positive for all M and t. We check the constraints under which Eq. (26) fulfils this condition. With nD given by Eqs. (24) and (25), the logarithmic derivative can be written in the form:
![Mathematical equation: $$ \begin{aligned} \frac{{\partial } \log m}{{\partial } \log M} =\frac{M}{m} \frac{{\partial } m}{{\partial } M} = \frac{\tau }{\tau -t} \left\{ 1 - \frac{a_2}{1-a_1} \frac{t}{\tau } \left[ \frac{M^{a_2}}{M^{a_2} + M^{a_2}_{\rm br}} \right] \right\} \,. \end{aligned} $$](/articles/aa/full_html/2023/04/aa44723-22/aa44723-22-eq39.gif) (27)
(27)
Since for a1 < 1, the age (t) is always smaller than τ(M) and the expression in square brackets can reach unity, the positiveness of the right-hand side of Eq. (27) requires:
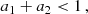 (28)
(28)
which is fulfilled in our model.
7.5. Comparison of the model and data
A comparison between the modelled and observed GCMF and CMFs of the different age groups is shown in Fig. 12. The corresponding total cluster number surface densities (ΣN) are presented in Table 6 (with Eq. (18) using the mass range of log m/M⊙ = 0 − 4.5). The GCMF is very well reproduced by the model over the full mass range, except for the lowest and highest mass bins. The corresponding surface density of clusters is reproduced by construction.
 |
Fig. 12. Comparison of modelled (solid red curves) and observed mass distributions for the same age groups as shown in Fig. 9 (green foreground histograms). The background histogram shows the GCMF constructed in Sect. 5. The hollow red curve is the modelled GCMF. Other designations are the same as in Fig. 9. |
An inspection of the CMFs of the different age groups provides more information about the quality of the model. We find that the agreement among the observed and modelled CMFs across all age groups is good. There remain some minor systematic deviations of the model compared to the data in shape and normalisation of the CMFs. There is a deficit of very low mass clusters in the I-group (top-left panel of Fig. 12), an overabundance of low-mass clusters in the Y-group (top-right panel of Fig. 12), and a shift of the CMF to higher masses in the O-group (bottom-right panel of Fig. 12). The model predicts a more peaked distribution of low-mass clusters at 50 Myr, leading to an excess of clusters in the Y-group and a deficit in the I- and M-group (Table 6).
Our resulting cluster lifetime (see Eq. (25) and Fig. 13) follows a broken power law, which is steeper at the low-mass end and shallower at the high-mass end. For high-mass clusters, M > 1000 M⊙, our lifetimes till complete dissolution are larger than the dissolution time in Shukirgaliyev et al. (2018). We note that they use the cluster mass after violent relaxation (corresponding to nbM in this work) and define the dissolution time as the time when the cluster mass falls below 100 M⊙. The low-mass regime is not covered in their investigation. Figure 13 also shows the cluster lifetimes from Ernst et al. (2015), which we used in Paper VI. In this work, the lifetime falls between the line for underfilling clusters (red line) and that based on the data of Lamers & Gieles (2006) for 100 M⊙-cluster remnants (solid light blue line).
 |
Fig. 13. Lifetime-mass relation (Eq. (25)) of the present model (black) compared to data of Lamers & Gieles (2006) for 100 M⊙-cluster remnant (light blue) and the parametrisation covering the results based on N-body calculations of Ernst et al. (2015) used in Paper VI. The red line corresponds to underfilling clusters, the green dashed line represents Roche volume filling models, and the blue dotted line is for overfilling models. |
The mean mass of the CIMF in the mass range log M/M⊙ ≥ 0.3 is 505 M⊙. Combined with the adopted CFR, we find a formation rate in mass of 409 M⊙ kpc−2 Myr−1. A comparison with the present-day thin disc star formation rate of Sysoliatina & Just (2021) leads to a fraction of 30% of field stars formed in clusters including the 90 percent of stars that were lost during the violent relaxation phase. This value is somewhat smaller but still consistent, due to the large uncertainties, with a fraction of up to 40% found in Piskunov et al. (2008) and Röser et al. (2010b).
8. Summary and conclusions
This paper reports the results of the second part of our study on the history of the formation and evolution of Galactic star clusters based on the MWSC catalogue. In the first part, published in Paper VI, we constructed the global cluster age distribution. We compared the observations with the outcome of a model of the star cluster population of the MW disc. This model included a power law for the lifetime-mass relation, an exponentially declining CFR, and a broken-power-law CIMF. For three different lifetime-mass relations, we found similar good fits for the cluster age distribution but with very different pairs of CFR and CIMF. This degeneracy could not be resolved without additional information about cluster masses.
In the current paper, we determine the tidal masses of the star clusters and derive the CMFs for different age groups to resolve the ambiguity between CFR, CIMF, and cluster mass evolution. We start with the same sample of MWSC star clusters as in Paper VI. It includes 3063 open clusters with homogeneous determinations of spatial-kinematic and astrophysical parameters based on combined kinematic and photometric cluster membership criteria. For 98% of the clusters, the structural King parameters (including tidal radii with a typical accuracy of 30%) are determined. For the most massive clusters, the tidal radius varies from 15 pc near the MW centre to more than 50 pc in the periphery. The sample occupies an extended disc area between Galactocentric radii of 2–20 kpc. As our analysis has shown, the sample is complete for the brightest clusters inside the heliocentric cylinder with a radius of up to 5 kpc. Due to the nature of the MWSC, which is close to a magnitude-limited survey, the radius of completeness depends on the brightness of the clusters and for the faintest objects, it is as small as about 1 kpc. In total, inside the magnitude-dependent completeness limits, there are 2227 MWSC clusters of different ages and brightness.
Equating the tidal radius to the Jacobi radius, we derive a tidal mass (mt) from the balance between Milky Way’s tidal field and cluster’s gravity. The typical accuracy of its determination is 70%. The tidal masses span over log mt/M⊙ = 0.2 − 4.4. The upper limit of this range remains constant throughout all Galactocentric distances covered by the MWSC, except for a dozen of the most massive clusters in the Galactic centre (Fig. 4). The latter were excluded from the analysis: we believe that they suffer from an underestimation of interstellar extinction due to the patched cloud-dominated structure of a dust layer in the Galactic centre.
Using the tidal masses of all clusters within their magnitude-dependent completeness limits, we first built the classic GCMF. It has a bell-like shape and has a power-law dependence for log mt/M⊙ > 2.3, as has been observed for clusters in other galaxies. However, the origin of the apparent maximum is different. In external galaxies, its position depends on the distance to the galaxy, which likely points to data incompleteness below the observation limit. The position of the GCMF maximum obtained here is a consequence of the mass distribution of newly formed clusters and their subsequent evolution. Uncertainties in tidal radii propagated to tidal masses dominate the errors in the GCMF values. The linear best fit of the high-mass slope in the mass range log mt/M⊙ = 2.3–4.4 turned out to be x = 1.14 ± 0.07. This result agrees with previous Milky Way studies based on our COCD results (Lamers et al. 2005; Piskunov et al. 2008).
Then, we analysed variations of the CMF with age and location. To approach the age variation, we divided the general sample into four age sub-samples, built the corresponding CMFs, and determined their individual parameters. We find that similar to the GCMF and independent of the age range, they consist of two qualitatively different segments. In the low-mass range, log mt/M⊙ ≲ 2.0, the CMFs grow with mass. In the high-mass end, log mt/M⊙ ≳ 2.0, they decrease with mass. The slopes do not change significantly with age, except for the low-mass slope of the initial-age (I) sub-sample; in this case, we obtained a nearly flat distribution at log mt/M⊙ ≲ 2.3. The I-sub-sample contains clusters of age between 2.5–20 Myr. On this timescale, violent relaxation is the dominant mechanism of mass function evolution.
To study the dependence of the CMF on spacial location, we compare the CMFs for sub-samples of inner and outer clusters observed in Galactocentric zones with R = 4.2–8.1 kpc and 8.9–13.5 kpc. Applying our standard procedure, we find that the shapes of CMFs are consistent in general with the GCMF centred at the position of the Sun, but there are small systematic vertical shifts relative to the GCMF. The inner CMF shows an overabundance, meantime the outer CMF is underabundant compared to the GCMF. The differences are larger for higher cluster masses, which cover a larger Galactocentric radius range. This variation of the cluster number density with Galactocentric radius is consistent with the surface density profile of the Galactic disc exponentially decreasing. Since other inhomogeneities such as spiral arms may also bias the observed CMF, a more detailed analysis of the cluster distribution is necessary for deriving the radial scale length, which is beyond the scope of this paper.
In Paper VI, we provided a simple analytic model of cluster formation and evolution to reproduce the global age distribution. In the current paper, using the extended data set including the CMFs in four age groups, we can separate the effects of the CIMF and the cluster mass evolution by using the bound mass (mt) instead of the lifetime as a function of the initial mass. The CMFs in the different age groups depend on the CIMF, the CFR, and the cluster bound-mass function. We argue that the differences in the CMFs of the two young populations (I-group at 2.5–20 Myr and Y-group at 20–200 Myr) can be understood by accounting for a strongly enhanced mass loss in the first 20 Myr of cluster evolution. This agrees well with the cluster formation and evolution models of Shukirgaliyev et al. (2017, 2018) based on a concentrated star formation efficiency. Our result supports the models with low global star formation efficiency of approximately 16%, where 90% of the stars are lost in the violent relaxation phase due to the supervirial state after gas expulsion.
Considering an analysis of the four age groups division, it is impossible to derive details of the CFR because of the strong degeneracy with the cluster mass loss. For instance, a time-dependent CFR leads to vertical shifts of the model lines in Fig. 12 without changing its profiles. As is seen from the figure, this can improve the CMF fit of the youngest I-group only. Here, an additional recent cluster formation event adding about 15% young clusters would result in a better fit of the CMF. An appropriate star formation event was recently found in A-type field stars in the solar neighbourhood (Sysoliatina & Just 2021). We also tested the effect of an exponentially declining CFR according to Aumer & Binney (2009) with a decay timescale of 8.5 Gyr. With a slight adaption of the mass loss parameters, a similarly good fit of the CMFs was found, which is an indication of the degeneracy between the CFR and the cluster mass loss.
Our mean CMF corresponds to a cluster formation density of about 0.4 M⊙ pc−2 Gyr−1, including the mass loss during the violent relaxation phase. This gives a cluster contribution of 30% to the stellar content of the thin disc (Sysoliatina & Just 2021), which is lower than the estimate derived by Piskunov et al. (2008) and Röser et al. (2010b). In addition, clusters that dissolve completely after gas removal, a phenomenon that is sometimes referred to as ‘infant mortality’, are not included in this fraction.
In future work, we will investigate the full 2D cluster distribution σ(m, t) as a function of current mass and age, including a large parameter study and more detailed fits of the cluster mass evolution.
Acknowledgments
We thank the anonymous referee for his detailed comments, which helped to improve the paper. This study was partly supported by the Russian Foundation of Basic Research grant 20-52-12009. We would like to acknowledge the previous work with our colleagues N.V. Kharchenko, P. Berczik and M. Ishchenko, who participated in the discussions at the beginning of this work. We acknowledge the use of the Simbad database, the VizieR Catalogue Service and other services operated at the CDS, France and the WEBDA facility operated at the Department of Theoretical Physics and Astrophysics of the Masaryk University.
References
- Amôres, E. B., Robin, A. C., & Reylé, C. 2017, A&A, 602, A67 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Anders, F., Cantat-Gaudin, T., Quadrino-Lodoso, I., et al. 2021, A&A, 645, L2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Angelo, M. S., Santos, J. F. C., & Corradi, W. J. B. 2020, MNRAS, 493, 3473 [CrossRef] [Google Scholar]
- Angelo, M. S., Corradi, W. J. B., Santos, Jr., J. F. C., Maia, F. F. S., & Ferreira, F. A. 2021, MNRAS, 500, 4338 [Google Scholar]
- Aumer, M., & Binney, J. J. 2009, MNRAS, 397, 1286 [NASA ADS] [CrossRef] [Google Scholar]
- Bik, A., Lamers, H. J. G. L. M., Bastian, N., Panagia, N., & Romaniello, M. 2003, A&A, 397, 473 [CrossRef] [EDP Sciences] [Google Scholar]
- Bossini, D., Vallenari, A., Bragaglia, A., et al. 2019, A&A, 623, A108 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bruzual, G., & Charlot, S. 2003, MNRAS, 344, 1000 [NASA ADS] [CrossRef] [Google Scholar]
- Campello, R. J. G. B., Moulavi, D., & Sander, J. 2013, in Advances in Knowledge Discovery and Data Mining, eds. J. Pei, V. S. Tseng, L. Cao, H. Motoda, & G. Xu (Berlin, Heidelberg: Springer), 160 [Google Scholar]
- Cantat-Gaudin, T., & Anders, F. 2020, A&A, 633, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cantat-Gaudin, T., Jordi, C., Vallenari, A., et al. 2018, A&A, 618, A93 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cantat-Gaudin, T., Krone-Martins, A., Sedaghat, N., et al. 2019, A&A, 624, A126 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cantat-Gaudin, T., Anders, F., Castro-Ginard, A., et al. 2020, A&A, 640, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Castro-Ginard, A., Jordi, C., Luri, X., et al. 2020, A&A, 635, A45 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Castro-Ginard, A., McMillan, P. J., Luri, X., et al. 2021, A&A, 652, A162 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chandar, R., Fall, S. M., & Whitmore, B. C. 2010, ApJ, 711, 1263 [Google Scholar]
- Dias, W. S., Alessi, B. S., Moitinho, A., & Lépine, J. R. D. 2002, A&A, 389, 871 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dowell, J. D., Buckalew, B. A., & Tan, J. C. 2008, AJ, 135, 823 [NASA ADS] [CrossRef] [Google Scholar]
- Ernst, A., Just, A., Berczik, P., & Petrov, M. I. 2010, A&A, 524, A62 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ernst, A., Berczik, P., Just, A., & Noel, T. 2015, Astron. Nachr., 336, 577 [NASA ADS] [CrossRef] [Google Scholar]
- Ester, M., Kriegel, H.-P., Sander, J., & Xu, X. 1996, A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise [Google Scholar]
- Fall, S. M., Chandar, R., & Whitmore, B. C. 2005, ApJ, 631, L133 [NASA ADS] [CrossRef] [Google Scholar]
- Fall, S. M., Chandar, R., & Whitmore, B. C. 2009, ApJ, 704, 453 [NASA ADS] [CrossRef] [Google Scholar]
- Ferreira, F. A., Corradi, W. J. B., Maia, F. F. S., Angelo, M. S., & Santos, Jr., J. F. C. 2021, MNRAS, 502, L90 [NASA ADS] [CrossRef] [Google Scholar]
- Fouesneau, M., Lançon, A., Chandar, R., & Whitmore, B. C. 2012, ApJ, 750, 60 [NASA ADS] [CrossRef] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2018, A&A, 616, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Brown, A. G. A., et al.) 2021, A&A, 649, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hao, C. J., Xu, Y., Wu, Z. Y., et al. 2022, A&A, 660, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- He, Z.-H., Xu, Y., Hao, C.-J., Wu, Z.-Y., & Li, J.-J. 2021, Res. Astron. Astrophys., 21, 093 [Google Scholar]
- He, Z., Wang, K., Luo, Y., et al. 2022, ApJS, 262, 7 [NASA ADS] [CrossRef] [Google Scholar]
- Hunt, E. L., & Reffert, S. 2021, A&A, 646, A104 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hunter, D. A., Elmegreen, B. G., Dupuy, T. J., & Mortonson, M. 2003, AJ, 126, 1836 [NASA ADS] [CrossRef] [Google Scholar]
- Kharchenko, N. V., Piskunov, A. E., Röser, S., Schilbach, E., & Scholz, R.-D. 2005a, A&A, 438, 1163 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kharchenko, N. V., Piskunov, A. E., Röser, S., Schilbach, E., & Scholz, R.-D. 2005b, A&A, 440, 403 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kharchenko, N. V., Berczik, P., Petrov, M. I., et al. 2009, A&A, 495, 807 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kharchenko, N. V., Piskunov, A. E., Schilbach, E., Röser, S., & Scholz, R.-D. 2012, A&A, 543, A156, (Paper I) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kharchenko, N. V., Piskunov, A. E., Schilbach, E., Röser, S., & Scholz, R.-D. 2013, A&A, 558, A53, (Paper II) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kharchenko, N. V., Piskunov, A. E., Schilbach, E., Röser, S., & Scholz, R.-D. 2016, A&A, 585, A101, (Paper V) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- King, I. 1962, AJ, 67, 471 [Google Scholar]
- Lada, C. J., & Lada, E. A. 2003, ARA&A, 41, 57 [Google Scholar]
- Lamers, H. J. G. L. M., & Gieles, M. 2006, A&A, 455, L17 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lamers, H. J. G. L. M., Gieles, M., Bastian, N., et al. 2005, A&A, 441, 117 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lamers, H. J. G. L. M., Baumgardt, H., & Gieles, M. 2010, MNRAS, 409, 305 [CrossRef] [Google Scholar]
- Larsen, S. S. 2009, A&A, 494, 539 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Liu, L., & Pang, X. 2019, ApJS, 245, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Markwardt, C. B. 2009, ASP Conf. Ser., 411, 251 [Google Scholar]
- Miyamoto, M., & Nagai, R. 1975, PASJ, 27, 533 [NASA ADS] [Google Scholar]
- Morales, E. F. E., Wyrowski, F., Schuller, F., & Menten, K. M. 2013, A&A, 560, A76 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Parmentier, G., & Pfalzner, S. 2013, A&A, 549, A132 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Piskunov, A. E., Schilbach, E., Kharchenko, N. V., Röser, S., & Scholz, R.-D. 2007, A&A, 468, 151 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Piskunov, A. E., Kharchenko, N. V., Schilbach, E., et al. 2008, A&A, 487, 557 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Piskunov, A. E., Just, A., Kharchenko, N. V., et al. 2018, A&A, 614, A22, (Paper VI) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Plummer, H. C. 1911, MNRAS, 71, 460 [Google Scholar]
- Raboud, D., & Mermilliod, J. C. 1998a, A&A, 329, 101 [NASA ADS] [Google Scholar]
- Raboud, D., & Mermilliod, J. C. 1998b, A&A, 333, 897 [NASA ADS] [Google Scholar]
- Röser, S., & Schilbach, E. 2019, A&A, 627, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Röser, S., Demleitner, M., & Schilbach, E. 2010a, AJ, 139, 2440 [NASA ADS] [CrossRef] [Google Scholar]
- Röser, S., Kharchenko, N. V., Piskunov, A. E., et al. 2010b, Astron. Nachr., 331, 519 [CrossRef] [Google Scholar]
- Röser, S., Schilbach, E., & Goldman, B. 2019, A&A, 621, L2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Salpeter, E. E. 1955, ApJ, 121, 161 [Google Scholar]
- Schechter, P. 1976, ApJ, 203, 297 [Google Scholar]
- Schmeja, S., Kharchenko, N. V., Piskunov, A. E., et al. 2014, A&A, 568, A51 [CrossRef] [EDP Sciences] [Google Scholar]
- Scholz, R. D., Kharchenko, N. V., Piskunov, A. E., Roeser, S., & Schilbach, E. 2015, A&A, 581, A39, (Paper IV) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shukirgaliyev, B., Parmentier, G., Berczik, P., & Just, A. 2017, A&A, 605, A119 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shukirgaliyev, B., Parmentier, G., Just, A., & Berczik, P. 2018, ApJ, 863, 171 [Google Scholar]
- Sim, G., Lee, S. H., Ann, H. B., & Kim, S. 2019, J. Korean Astron. Soc., 52, 145 [NASA ADS] [Google Scholar]
- Skrutskie, M. F., Cutri, R. M., Stiening, R., et al. 2006, AJ, 131, 1163 [NASA ADS] [CrossRef] [Google Scholar]
- Soubiran, C., Cantat-Gaudin, T., Romero-Gómez, M., et al. 2018, A&A, 619, A155 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Soubiran, C., Cantat-Gaudin, T., Romero-Gómez, M., et al. 2019, A&A, 623, C2 [EDP Sciences] [Google Scholar]
- Sysoliatina, K., & Just, A. 2021, A&A, 647, A39 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tarricq, Y., Soubiran, C., Casamiquela, L., et al. 2021, A&A, 647, A19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tarricq, Y., Soubiran, C., Casamiquela, L., et al. 2022, A&A, 659, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- van den Bergh, S., & Lafontaine, A. 1984, AJ, 89, 1822 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, Q., & Fall, S. M. 1999, ApJ, 527, L81 [CrossRef] [Google Scholar]
- Zhong, J., Chen, L., Jiang, Y., Qin, S., & Hou, J. 2022, AJ, 164, 54 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
All Figures
|
Fig. 1. Fit of King curves to observed density profiles of open clusters residing at different heliocentric distances: small (Pleiades), medium (M67), and large (Berkley 58), shown from left to right. The curves represent the observed distribution of safe cluster members (dots), the one corrected for the residual background (circles with Poisson error bars), and the fitted King profile (solid red curve). Vertical lines indicate core radii (rc, solid) and tidal radii (rt, dashed). Blue lines indicate visual estimates, made earlier in MWSC, red ones are the current values of rc and rt derived from the profile fit. Horizontal bars indicate fit errors. |
| In the text | |
|
Fig. 2. Tidal parameters of MWSC clusters. Distributions of log rc, log rt, and c (top row) and of their relative errors (bottom row). Vertical lines show sample averages. |
| In the text | |
|
Fig. 3. Relative difference in COCD and MWSC estimates of rc and rt radii as function of MWSC heliocentric distance (d). Red lines show average differences and yellow stripes are respective standard deviations. Statistical parameters were computed with the help of data marked with filled circles, open circles are omitted as 3-σ outliers (24 and 13 for rc and rt, respectively). Vertical bars are fit errors. |
| In the text | |
|
Fig. 4. Radial distributions of tidal masses (top panel), radii (middle panel), and cluster counts (bottom panel). Filled and open circles in the upper two panels show clusters inside and outside the magnitude-dependent completeness limits described in Sect. 5.1, respectively. Bars are errors in the determination of the tidal parameters. Crosses are central (R ≤ 3 kpc) clusters before (blue) and after (magenta) the artificial decrease of 0.6 mag in their distance moduli is applied. Solid lines are theoretical relations for cases of a constant mass of mt = 2 × 104 M⊙ (upper line) and mt = 10 M⊙ (lower line). The red vertical line shows the Galactocentric radius of the Sun. Histograms in the bottom panel show raw counts for all clusters (background), ones within the single completeness limit (foreground), and those within magnitude-dependent completeness limits (in between). The red histogram shows the central clusters. |
| In the text | |
|
Fig. 5. Raw distributions of MWSC clusters with tidal mass (top panel) and with its relative error (bottom panel). Different histograms in the top panel correspond to different cluster samples. The total sample is shown in the background with a solid cyan histogram, the clusters selected within the single completeness circle are shown with a histogram hatched with blue (foreground) and those within their magnitude-dependent completeness limits are shown with a back-hatched green histogram (in between). The red-colour massive end of the distribution is built of ‘central’ (R ≤ 3 kpc) clusters. |
| In the text | |
|
Fig. 6. Distribution of cluster distances with mass. The clusters located inside and outside the magnitude-dependent completeness limits computed in Eq. (7) are shown with black and light blue dots, respectively. The single completeness limit for the MWSC sample is given by the horizontal red line. A vertical yellow stripe is given for illustration and indicates an arbitrary log mt-box with clusters of the two kinds falling in it. Red crosses show ‘central’ (R ≤ 3 kpc) clusters excluded from further consideration. |
| In the text | |
|
Fig. 7. GCMF computed with magnitude-dependent completeness limits in Eq. (12), (light-blue filled histogram). Vertical bars show errors mainly due to uncertainty in mass. Top panel shows the low- and high-mass power-law fits (solid red lines) and the smoothed histogram data (green line). The middle panel presents different approaches to the mass function construction: single completeness limit with |
| In the text | |
|
Fig. 8. Comparison of selected CMF age groups built as described in the text. The groups are marked with different colours and are artificially shifted vertically to reduce the overlap. From bottom up, we show the initial-age (violet), young (blue), medium-age (green), and old (orange) cluster groups. The uppermost dark curve is the GCMF (including all ages) constructed in Sect. 5.2. The groups and their age limits are presented in Table 2. |
| In the text | |
|
Fig. 9. Mass functions of star clusters of four age groups (group identification and age limits are shown in the panels). The CMFs are given by green histograms, while the background shows the GCMF. The straight lines represent the linear fit of the CMFs with power laws. The mass intervals used for the fit determinations are shown by solid red lines. |
| In the text | |
|
Fig. 10. CMFs of star clusters for two ranges of Galactocentric radii, as presented in Table 4: red dots are for the inner sub-sample and green triangles are for the outer sub-sample. The vertical bars are statistical errors characterising a bin population and the horizontal bars indicate the bin widths. The bold blue line is the smoothed GCMF derived in Sect. 5.2 and the yellow background highlight represents its statistical errors. Thin red and green solid and dotted lines represent GCMFs of the inner and outer sub-samples after applying the bias due to the exponential decline of the Galactic disc surface density with a scale length of 3.8 and 6 kpc, respectively. |
| In the text | |
|
Fig. 11. Evolution of the modelled mass fraction for clusters of different initial masses. The mass loss just from stellar evolution, μ(t), is shown in addition for comparison. The horizontal dashed line marks the bound fraction, nb, after violent relaxation and the vertical dashed line marks the violent relaxation timescale, tv. |
| In the text | |
|
Fig. 12. Comparison of modelled (solid red curves) and observed mass distributions for the same age groups as shown in Fig. 9 (green foreground histograms). The background histogram shows the GCMF constructed in Sect. 5. The hollow red curve is the modelled GCMF. Other designations are the same as in Fig. 9. |
| In the text | |
|
Fig. 13. Lifetime-mass relation (Eq. (25)) of the present model (black) compared to data of Lamers & Gieles (2006) for 100 M⊙-cluster remnant (light blue) and the parametrisation covering the results based on N-body calculations of Ernst et al. (2015) used in Paper VI. The red line corresponds to underfilling clusters, the green dashed line represents Roche volume filling models, and the blue dotted line is for overfilling models. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.