| Issue |
A&A
Volume 625, May 2019
|
|
|---|---|---|
| Article Number | A66 | |
| Number of page(s) | 32 | |
| Section | Catalogs and data | |
| DOI | https://doi.org/10.1051/0004-6361/201832860 | |
| Published online | 14 May 2019 | |
Consistent dust and gas models for protoplanetary disks
IV. A panchromatic view of protoplanetary disks⋆
1
Department of Astrophysics, University of Vienna, Türkenschanzstrasse 17, 1180 Vienna, Austria
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
SUPA School of Physics & Astronomy, University of St. Andrews, North Haugh, KY16 9SS St. Andrews, UK
3
Centre for Exoplanet Science, University of St. Andrews, St. Andrews, UK
4
Instituut voor Sterrenkunde, K.U. Leuven, Celestijnenlaan 200D, 3001 Leuven, Belgium
5
Univ. Grenoble Alpes, CNRS, IPAG, 38000 Grenoble, France
6
Kapteyn Astronomical Institute, University of Groningen, Postbus 800, 9700 AV Groningen, The Netherlands
7
Astrophysics Research Centre, School of Mathematics and Physics, Queen’s University Belfast, University Road, Belfast BT7 1NN, UK
8
IRAP, Université de Toulouse, CNRS, UPS, Toulouse, France
9
Astronomical institute Anton Pannekoek, University of Amsterdam, Science Park 904, 1098 XH Amsterdam, The Netherlands
10
School of Physics and Astronomy, Cardiff University, 4 The Parade, Cardiff CF24 3AA, UK
11
Institute of Astronomy, University of Cambridge, Madingley Road, Cambridge CB3 0HA, UK
12
SRON Netherlands Institute for Space Research, Sorbonnelaan 2, 3584 CA Utrecht, The Netherlands
13
UMI-FCA, CNRS/INSU France (UMI 3386), and Departamento de Astronomica, Universidad de Chile, Santiago, Chile
14
Monash Centre for Astrophysics (MoCA) and School of Physics and Astronomy, Monash University, Clayton, VIC 3800, Australia
15
Max-Planck-Institut für extraterrestrische Physik, Giessenbachstrasse 1, 85748 Garching, Germany
Received:
20
February
2018
Accepted:
22
February
2019
Abstract
Context. Consistent modeling of protoplanetary disks requires the simultaneous solution of both continuum and line radiative transfer, heating and cooling balance between dust and gas and, of course, chemistry. Such models depend on panchromatic observations that can provide a complete description of the physical and chemical properties and energy balance of protoplanetary systems. Along these lines, we present a homogeneous, panchromatic collection of data on a sample of 85 T Tauri and Herbig Ae objects for which data cover a range from X-rays to centimeter wavelengths. Datasets consist of photometric measurements, spectra, along with results from the data analysis such as line fluxes from atomic and molecular transitions. Additional properties resulting from modeling of the sources such as disk mass and shape parameters, dust size, and polycyclic aromatic hydrocarbon (PAH) properties are also provided for completeness.
Aim. The purpose of this data collection is to provide a solid base that can enable consistent modeling of the properties of protoplanetary disks. To this end, we performed an unbiased collection of publicly available data that were combined to homogeneous datasets adopting consistent criteria. Targets were selected based on both their properties and the availability of data.
Methods. Data from more than 50 different telescopes and facilities were retrieved and combined in homogeneous datasets directly from public data archives or after being extracted from more than 100 published articles. X-ray data for a subset of 56 sources represent an exception as they were reduced from scratch and are presented here for the first time.
Results. Compiled datasets, along with a subset of continuum and emission-line models are stored in a dedicated database and distributed through a publicly accessible online system. All datasets contain metadata descriptors that allow us to track them back to their original resources. The graphical user interface of the online system allows the user to visually inspect individual objects but also compare between datasets and models. It also offers to the user the possibility to download any of the stored data and metadata for further processing.
Key words: stars: formation / circumstellar matter / stars: variables: T Tauri / Herbig Ae/Be / accretion / accretion disks / astronomical databases: miscellaneous
A copy of the X-ray data is only available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/qcat?J/A+A/625/A66
© ESO 2019
1. Introduction
Knowledge is advanced with the systematic analysis and interpretation of data. This statement is especially valid in fields such as contemporary astrophysics, amongst others, where observational data play a fundamental role in describing objects and phenomena on different cosmic scales. Data alone is however not sufficient; it is the accurate description of data, the evaluation of the data quality (collectively coined as metadata), and the integration of data into large datasets that can provide a solid basis for understanding the mechanisms involved in diverse physical phenomena. Such datasets can then be analyzed consistently and systematically through meta-analysis to confirm existing and reveal new trends and global patterns.
The study of star and planet formation, in particular, is a field that requires extensive wavelength coverage for an appropriate characterization of sources. Such coverage can only be obtained by combining data from different facilities and instruments, which, however come with very different qualities (e.g., angular and spectral resolution, sensitivity and spatial or spectral coverage). The importance of the study of protoplanetary disks is today even more pronounced when seen from the perspective of planet formation and habitability. Protoplanetary disks are indeed the places where the complex process of planet formation takes place, described by presently two competing theories. The core accretion theory (Laughlin et al. 2004; Ida & Lin 2005), initially developed to explain our Solar System architecture, posits collisional growth of submicron sized dust grains up to km-sized planetesimals on timescales of 105 − 107 years, and further growth to Earth-sized planets by gravitational interactions. Once protoplanetary cores of ten Earth-masses have formed, the surrounding gas is gravitationally captured to form gas giant planets. Alternatively, gravitational instabilities in disks may directly form planets on much shorter timescales (few thousand years), but require fairly high densities and short cooling timescales at large distances from the star (Boss 2009; Rice & Armitage 2009). The field is going through major developments following recent advances in instrumentation (e.g., ALMA, VLT/SPHERE Ansdell et al. 2016; Garufi et al. 2017, respectively) but also due to more complex and sophisticated numerical codes. This input challenges our understanding of disk evolution, so it becomes increasingly important to evaluate it and interpret the data in terms of physical disk properties such as disk mass and geometry, dust size properties and chemical concentrations.
Observations of protoplanetary disks are challenging to interpret since physical densities in the disks span more than ten orders of magnitude, ranging from about 1015 particles per cm3 in the midplane close to the star to typical molecular cloud densities of 104 particles per cm3 in the distant upper disk regions. At the same time, temperatures range from several 1000 K in the inner disk to only 10–20 K at distances of several 100 au. The central star provides high energy UV and X-ray photons which are scattered into the disk where they drive various non-equilibrium processes. The exact structure of the disks is not known, but it strongly affects the excitation of atoms and molecules and therefore their spectral appearance in form of emission lines. The morphology of the inner disk regions, for example, is expected to have a direct impact on the appearance of the outer disk. An inclined inner disk geometry or a puffed up morphology will cast shadows in the outer disk regions, while gaps may allow the direct illumination of the inner rim of the outer disk. Such complex disk topologies can be understood only through multiwavelength studies. Emission at short wavelengths (X-ray, UV, optical) links to the high-energy processes like mass accretion, stellar activity, and jet acceleration close to the star. Intermediate wavelengths (near to mid-IR) trace the nature and distribution of dust and gas in the inner disk, while observations at longer wavelengths provide information about the total mass and chemistry of the gas and dust in the most extended parts of the disk. A better understanding of these multiwavelength observations requires consistent models that are capable of treating all important physical and chemical processes in detail, simultaneously, in the entire disk.
In this paper we present a coherent, panchromatic observational datasets for 85 protoplanetary disks and their host stars, and derive the physical parameters and properties for a subset of 27 disks. The present collection was created as one of the two main pillars (the other being consistent thermochemical modeling) of the “DiscAnalysis” (DIANA)1 project, aiming to perform a homogeneous and consistent modeling of their gas and dust properties with the use of sophisticated codes such as ProDiMo (Woitke et al. 2009, 2016; Kamp et al. 2010, 2017; Thi et al. 2011), MCFOST (Pinte et al. 2006, 2009) and MCMax (Min et al. 2009). In the context of the DiscAnalysis project, data assemblies for each individual source along with modeling results for both continuum and line emission are now publicly distributed through the “DiscAnalysis Object Database” (DIOD)2. The basic functionalities of the end-user interface of DIOD is presented in Appendix A.
2. The data
The majority of the sample sources consists of Class II and III, T Tauri and Herbig Ae systems. Selected targets cover an age spread between ∼1 and 10 million years and spectral types ranging from B9 to M3. Sources were selected based on availability and overlap of good quality data across the electromagnetic spectrum. We avoided known multiple objects where disk properties are known to be modified by the gravitational interaction of the companion and that at different wavelengths and angular resolutions may appear as single objects. We also avoided highly variable objects and in most cases edge-on disk geometry, as in such configurations the stellar properties are not well constrained and often remain unknown. In terms of sample demographics, the sample consists of 13 Herbig Ae, 7 transition disks, 58 T Tauri systems along with 7 embedded (Class I) sources or systems in an edge-on configuration (Table C.1).
Most of the data presented here were retrieved from public archives but were also collected from more than 100 published articles. In a few cases, unpublished datasets were collected through private communications. An exception to the above is the X-ray data that were reduced for the purposes of this project and are presented in this paper for the first time. Datasets consist of photometric data points along with spectra, where available. Together, they provide a complete description of the spectral energy distribution (SED). Such data were assembled from more than 150 individual filters and spectral chunks observed with ∼50 different telescopes and facilities. Information on the gas content of disks is provided in the form of measured fluxes per transition for different atoms and molecules, and when available, as complete spectral line profiles.
A basic data quality check was performed using the following scheme: for data assembled from large surveys we propagated the original data quality flags; however, in cases that more datasets exist at the same or adjacent wavelengths, flags were modified to reflect inconsistencies and systematic (e.g., calibration) errors. In all cases links to the relevant papers are maintained so that the end-user can efficiently trace back the original data resources. An example showing different qualities of assembled data are given in the SED plots in Fig. 1, while the complete collection of SEDs for all sources is provided as online material in Fig. C.1.
 |
Fig. 1. Example of “raw” collected data represented as SED diagrams for three sources (top row). Data for AB Aur (left panel) delineate well the stellar and disk emission and show little scatter. The same is true for MWC 480 (mid panel), the Akari data points however show some deviation when compared to the Spitzer/IRS spectra. For a weaker source like LkCa 15 (right panel), the scatter is significant due to certain, not well pointed observations, and therefore the SED is not well defined. SED plots for all sources are given as online data in Fig. C.1. Lower row presents the actual modeled data for the three sources, after being hand-selected for consistency. |
In the following sections we provide a detailed account of the major facilities or other resources used to assemble our data sample. An overview of the assembled photometric and spectroscopic datasets per wavelength regime along with information on the number of line fluxes and high resolution imaging information for each individual source is provided in Table C.1.
2.1. X-rays
While X-rays do not provide direct information about the disk, they can represent an important part of the total stellar radiation field which is directly affects the physical and chemical structure of the disk. We mined the XMM-Newton3 (Jansen et al. 2001) and Chandra4 (Weisskopf et al. 2000) mission-archives for X-ray observations of our target-list and obtained data for 56 sources (Table 1). X-ray data was extracted by using the SAS software (version 12.0.1) for the XMM-Newton data and the CIAO software (version 4.6.1) for the Chandra data. The CALDB calibration data used for the spectral extraction of the Chandra data were taken from version 4.6.2., while the XMM-Newton calibration data is put on a rolling release and thus has no version number. In order to get the source spectra, we selected a circular extraction region around the center of the emission, while the background area contained a large source-free area on the same CCD. The extraction tools (EVSELECT for XMM and SPECEXTRACT for Chandra) delivered the source and background spectra as well as the redistribution matrix and the ancillary response files.
List of X-ray observations.
The spectra were modeled by using the package XSPEC (Arnaud 1996), assuming a plasma model (VAPEC – an emission spectrum for collisionally ionized diffuse plasma, based on the ATOMDB code [v.2.0.2]) combined with an absorption column model (WABS) based on the cross-sections from Morrison & McCammon (1983). The element abundance values in the VAPEC models were set to typical values for premain sequence stars, as chosen by the XEST project (see also Table 2, Güdel et al. 2007), unless otherwise noted in Table 2. Either a one component (1T), a two component (2T) or a three component (3T) emission model is fitted to the data. Highly absorbed sources or scarce data allow only for 1T fits. In some cases sources show such a high absorption that it is impossible to fix the higher temperature due to low constraints on the slope of the harder (meaning more energetic >1 keV) part of the spectrum. In both these cases the higher temperature was fixed to 10 keV. The fit delivers the absorption column density toward the source NH, the plasma emission temperature TX for each component. Finally, the unabsorbed spectrum is calculated after setting the absorption column density parameter to zero, and the flux is derived by integrating over the energy range from 0.3 to 10 keV. Hardness is defined by 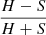 , with H and S denoting the hard part (1–10 keV) and the soft part (0.3–1 keV) of the spectrum respectively. Thus the hardness factor delivers a value between 1 and −1, showing a hard spectrum in the case of ∼1 and a soft spectrum in the case of ∼ − 1. Results from the fitting process are given in Table 3.
, with H and S denoting the hard part (1–10 keV) and the soft part (0.3–1 keV) of the spectrum respectively. Thus the hardness factor delivers a value between 1 and −1, showing a hard spectrum in the case of ∼1 and a soft spectrum in the case of ∼ − 1. Results from the fitting process are given in Table 3.
Standard XEST abundances and deviations for particular sources used in the VAPEC models.
Results from the X-ray reduction.
2.2. Ultraviolet
Ultraviolet data were collected from different resources. Spectra were obtained from the archives of the International Ultraviolet Explorer (IUE)5, the Far Ultraviolet Spectroscopic Explorer (FUSE)6 and the Hubble Space Telescope (HST)7. Hubble data originate from three instruments, namely the Space Telescope Imaging Spectrograph (STIS), the Cosmic Origins Spectrograph (COS) and the Advanced Camera for Surveys (ACS).
All instrument data is integrated over a number of wavelength bins and then combined with weights as 1/σ2, where sigma is the given instrument error after integration. An iterative procedure is carried out where the number of retrieved spectral points is lowered step-by-step, until statistically relevant data is obtained (Fk > 3 * σk), as described in detail in Appendix B. The idea for this procedure is from Valenti et al. (2000, 2003), but we have modified it to include data from multiple instruments, and we have added the idea to lower number of bins until statistically significant data is obtained. Below we summarize the main characteristics of each data type used and its applicability in our data collection.
-
IUE’s short and long wavelength spectroscopic cameras provided low resolution (R ≈ 400) spectra covering the 1150–1980 Å and 1850–3350 Å windows, respectively. Often, a large number of data files exists per source in the archive8, however we have typically used the first ∼20 with the longest integration times for each source. IUE averaged spectra as treated in Valenti et al. (2000, 2003) were collected for comparisons but not used, as we combine IUE data along with spectra from other instruments.
-
The Far Ultraviolet Spectroscopic Explorer (FUSE) covers the important 900–1190 Å band in high resolution (R ≈ 20 000). The FUSE data may be affected by a number of emission lines due to the residual Earth atmosphere, also known as “airglow”. At first, FUSE data on faint disk sources may appear quite noisy, however combining and processing as described in Appendix B can lead to high quality data in the very important region around 1000 Å.
-
The HST Cosmic Origins Spectrograph (COS) and Space Telescope Imaging Spectrograph (STIS) cover wavelengths 1150–3600 Å and for our purposes the range 1150–3200 Å in very different resolutions up to R ≳ 10 000. High resolution data come in chunks that rarely cover large wavelength ranges, so they need to be combined. Combined HST datasets including lower resolution ACS data, are provided in Yang et al. (2012)9.
The original datasets are therefore inhomogeneous, as they originate from different instruments with different resolutions, integration times and sensitivities. Moreover, some sources were targeted multiple times with a number of different instruments (see also Table 4). Intrinsic variation in the UV spectra as a result of changing accretion rates is expected, it is however beyond the scope of this study. As a first step, exceedingly noisy spectra were discarded after visual inspection. We note that IUE data shortward of the Ly α (λ ≈ 1215 Å) show abnormally high fluxes when compared to HST/COS spectra and were consequently not used. IUE data longward of about 3100 Å can become exceedingly noisy and were also disregarded. We also note that while UV data of high quality exist for sources with spectral type ranging from A to M, data for the K and M-type stars either are sparse or do not exist.
Number of archival UV data files collected.
An example of a co-added UV spectrum is presented in Fig. 2 for HD 163296, while more plots for all other sources are provided as online material in Fig. C.2.
For the cases that UV spectra were not available, we have collected photometric data points from a number of space facilities, namely:
-
The Ultraviolet Sky Survey Telescope (UVSST) onboard the TD1 satellite (Humphries et al. 1976), provides photometry down to 10th mag in four UV 4 bands at 1565 Å, 1965 Å, 2365 Å and 2740 Å.
-
The ultraviolet photometer of the Astronomical Netherlands Satellite (ANS) having five bands at 1500 Å, 1800 Å, 2500 Å and 3300 Å (Wesselius et al. 1982).
-
The Galaxy Evolution Explorer (GALEX) mission provided wide band photometry in two windows; the FUV channel between 1350 and 1750 Å and the NUV channel between 1750 and 2800 Å (Morrissey et al. 2007).
2.3. Visual
Visual data are considered the photometric data in all major photometric systems that can traditionally be observed from ground based facilities. Visual data have been collected using customized query scripts that scan and automatically retrieve data from online data archives. Such resources include:
-
The Amateur Sky Survey (TASS) of the Northern Sky, measured Mark IV magnitudes which are then converted to Johnson-Cousins V- and I-magnitudes (Richmond 2007).
-
General Catalog of Photometric Data II (GCPD), was queried for standard photometric systems (Mermilliod et al. 1997).
-
Sloan Digital Sky Survey Photometric Catalog, release 8 (Adelman-McCarthy 2011) and release 6 (Adelman-McCarthy et al. 2008).
-
DENIS J–K photometry (Kimeswenger et al. 2004).
-
USNO-B1 All Sky Catalog (Monet et al. 2003).
-
VizieR Online Data Catalog: Homogeneous Means in the UBV System (Mermilliod 2006).
-
The Geneva-Copenhagen survey of the solar neighbourhood. III. Improved distances, ages, and kinematics (Holmberg et al. 2009).
-
Catalog of stars measured in the Geneva Observatory photometric system (Rufener 1988).
-
VizieR Online Data Catalog: Catalog of Stellar Photometry in Johnson’s 11-color system (Ducati 2002).
-
All-sky compiled catalog of 2.5 million stars, comprising data from HIPPARCOS, Tycho, PPM and CMC11 catalogs (Kharchenko 2001).
-
UBVRIJKLMNH photoelectric photometric catalog (Morel & Magnenat 1978).
-
Uvby β photoelectric photometric catalog (Hauck & Mermilliod 1998).
-
Uvby β photometry of 1017 stars earlier than G0 in the Centaurus-Crux-Musca-Chamaeleon direction (Corradi & Franco 1995).
-
Tycho-2 bright source catalog (Høg et al. 2000).
-
The HIPPARCOS and Tycho catalogs (ESA 1997).
-
SDSS g, r, i, z filters calculated from HIPPARCOS and Tycho data (Ofek 2008).
-
Catalog of photoelectric photometry in the Vilnius system (Straizys et al. 1989).
-
HIPPARCOS catalog photometric filters (Perryman et al. 1997)
The offset positions for different sets of observations along with proper motion vectors were visually inspected and subsequently selected or deselected by hand. In order to maintain homogeneity in our datasets, fluxes and corresponding errors were converted from original units to Jy. Data from different catalogs were cross-correlated and checked against and flags were applied according to their quality. If no flux errors were given in the original catalogs, a nominal 10% error was assumed, which sometimes was increased to 30% for particularly unreliable passbands.
There are some noticeable trends among the collected visual datasets. The SDSS data, for example, are of high quality but the survey was designed to be deep, so that background sources are sometimes confused with our intended targets. Such cases are easily identifiable and corrected. Photometric data from DENIS/VLTI are often saturated for rather bright sources, and in such cases data are flagged as unreliable. Data from the USNO-B1 survey suffer from rather high uncertainties, estimated between 30 and 50%, and the photometric filters of the survey are not well defined (Monet et al. 2003).
2.4. Near-infrared
For the purposes of the present data collection, near-infrared lies between 0.8 (i.e., the Johnson I band) and ∼2.2 μm (KS band). In addition to the references from the Visual wavelengths that also apply here in some cases (the DENIS/ VLTI datasets, for example), near infrared data were additionally collected from the following resources:
-
Two Micron All Sky Survey (2MASS) (Cutri et al. 2012, 2003).
-
The Cosmic Background Explorer (COBE) Diffuse Infrared Background Experiment (DIRBE) Point Source Catalog (Smith et al. 2004).
-
J, H, and Ks for sources in Chameleon were retrieved from Carpenter et al. (2002).
2.5. Mid- and far-infrared
Mid- and far-infrared refers here to photometric and spectroscopic data data between 5 and 200 μm, observed mainly with space facilities. Data collection in this wavelength range consists of already reduced and previously published data, and quite often different reductions of the same dataset exist. The wavelength range is of particular importance for the proper modeling of the dust content in disks. Therefore special care has been taken in order to evaluate the different datasets and reductions, in order to provide high quality data of silicate features, especially the most intense one centered at ∼10 μm.
The mid- and far-infrared data were collected from the following resources:
-
The Faint Source Catalog (Moshir 1990) of the Infrared Astronomical Satellite (IRAS; Helou & Walker 1988)
-
Spitzer spectra from “Dust Evolution in Protoplanetary Disks Around Herbig Ae/Be Stars” (Juhász et al. 2010)
-
Spitzer data from the Cores 2 Disks (c2d) Survey (Evans et al. 2003; Wahhaj et al. 2010).
-
Smoothed ISO spectra for a sample of Herbig Ae/Be systems (Meeus et al. 2001).
-
Spectra from the “Spitzer Infrared Spectrograph Survey of T-Tauri Stars in Taurus” (Furlan et al. 2011).
-
Spitzer IRAC data from “Galactic Legacy Infrared Midplane Survey Extraordinaire (GLIMPSE)” (Spitzer Science 2009).
-
Spitzer IRAC and MIPS, data from “The Disk Population of the Taurus Star-Forming Region” (Luhman et al. 2010).
-
Spitzer IRAC data from “Taurus Spitzer Survey: New Candidate Taurus Members Selected Using Sensitive Mid-Infrared Photometry” (Rebull et al. 2010).
-
Spitzer spectrophotometric data from “The Formation and Evolution of Planetary Systems: Placing Our Solar System in Context with Spitzer”, (Meyer et al. 2006).
-
Data from the “The Cornell Atlas of Spitzer/IRS Sources (CASSIS10)” (Lebouteiller et al. 2011).
-
Data from the Spitzer Map of the Taurus Molecular Clouds (Rebull et al. 2011).
-
AKARI/IRC mid-infrared all-sky survey (Murakami et al. 2007; Ishihara et al. 2010).
-
Spitzer/IRS data from the “The Different Evolution of Gas and Dust in Disks around Sun-Like and Cool Stars” project (Pascucci et al. 2009).
-
Midcourse Space Experiment (MSX) Infrared Point Source Catalog11 (Egan et al. 2003).
-
Wide-field Infrared Survey Explorer (WISE12) catalog (Cutri 2012).
-
Herschel/PACS spectra for sources in the Upper Scorpius star-forming region (Mathews et al. 2013).
-
Herschel/PACS spectra from the “Gas in Protoplanetary Systems Survey” (GASPS) (Meeus et al. 2012; Dent et al. 2013).
-
Herschel/PACS spectra from the “Dust, Ice and Gas in Time Survey” (DIGIT; Green et al. 2016; Fedele et al. 2013; Meeus et al. 2012, 2013; Cieza et al. 2013).
-
Herschel/SPIRE spectra sample of Herbig Ae/Be systems from van der Wiel et al. (2014).
2.6. Submillimeter and millimeter wavelength data (continuum)
Continuum data in the (sub)-millimeter come from a large number of facilities, including both single-dish telescopes and interferometers, and were mainly compiled from published articles. In the following we give a complete description of these resources per wavelength band.
-
350 μm: Andrews & Williams (2007), Mannings & Emerson (1994), Carpenter et al. (2005), Mannings (1994), Dent et al. (1998)
-
450–850 μm: the SCUBA Legacy Catalogs Di Francesco et al. (2008) and from individual papers Sandell et al. (2011), Andrews & Williams (2007), Mannings & Emerson (1994), Mannings (1994), Dent et al. (1998), Beckwith & Sargent (1991), Nilsson et al. (2009).
-
1.0–2.0 mm: Beckwith & Sargent (1991), Mannings (1994), Dent et al. (1998), Henning et al. (1993, 1994), Nuernberger et al. (1997), Guilloteau et al. (2011), Schaefer et al. (2009), Mannings & Emerson (1994), Carpenter et al. (2005), Andre & Montmerle (1994), Osterloh & Beckwith (1995), Mannings (1994), Motte et al. (1998), Lommen et al. (2007).
-
2.0–5.0 mm: Mannings & Emerson (1994), Kitamura et al. (2002), Schaefer et al. (2009), Dutrey et al. (1996), Guilloteau et al. (2011), Carpenter et al. (2005), Ubach et al. (2012), Ricci et al. (2010).
-
7 mm: Ubach et al. (2012), Lommen et al. (2007), Rodmann et al. (2006).
Data were also hand-picked from papers focusing on the study of individual sources. Examples of such resources include:
-
mm and cm observations of PDS 66 from Cortes et al. (2009)
-
7 mm observations of DO Tau from Koerner et al. (1995)
-
CARMA observations of RY Tau and DG Tau at wavelengths of 1.3 mm and 2.8 mm from Isella et al. (2010)
-
mm and cm ATCA observations of WW Chamaeleontis, RU Lupi, and CS Chamaeleontis from Lommen et al. (2009)
-
850 and 450 micron observations of the TWA 7 debris disk from Matthews et al. (2007)
-
Millimeter Continuum Image of the disk around the Haro 6-5B from Yokogawa et al. (2001)
-
Multiwavelength observations of the HV Tau C disk from Duchêne et al. (2010).
2.7. Gas lines
Fluxes for gas lines along with spectral line profiles have been retrieved from a limited number of gas-line surveys of protoplanetary disks. More lines were handpicked for individual sources and from articles focusing on the modeling of gas lines with thermochemical codes (e.g., Carmona et al. 2014; Woitke et al. 2019).
-
CO J = 1-0, 2-1 transitions from Schaefer et al. (2009)
-
The Herschel/DIGIT and GASPS line surveys ([OI], [CII], H2O, OH, CH+ and CO transitions), (Fedele et al. 2013; Meeus et al. 2012, 2013; Mathews et al. 2010, 2013; Dent et al. 2013)
-
Herschel SPIRE lines (van der Wiel et al. 2014)
-
Spitzer lines (Pontoppidan et al. 2010; Salyk et al. 2011; Boogert et al. 2008; Öberg et al. 2008; Pontoppidan et al. 2008; Bottinelli et al. 2010).
Space-born data was complemented by data or line measurements from ground-based high-spectral resolution near- and mid-IR surveys:
-
CO ro-vibrational data from the ESO-VLT/CRIRES large program “The planet-forming zones of disks around solar-mass stars” (PI. van Dishoeck)13 (Pontoppidan et al. 2011; Brown et al. 2013; Banzatti et al. 2017).
-
CO ro-vibrational line-measurements from Najita et al. (2003), Blake & Boogert (2004), Carmona et al. (2014)
-
Near- and mid-IR H2 emission in Herbig Ae/Be stars (Carmona et al. 2011, 2008; Bitner et al. 2008; Martin-Zaïdi et al. 2010)
-
Millimeter and submillimeter line surveys (Dutrey et al. 1996; Öberg et al. 2010, 2011; Guilloteau et al. 2012; Fuente et al. 2010; Bergin et al. 2013; Cleeves et al. 2015).
3. Auxiliary data and model results.
As a starting point for modeling efforts, we have collected descriptive parameters of the central protostar from more than sixty refereed articles. A detailed account of these records is given in Table C.2, along with corresponding references. Stellar parameters along with the interstellar extinction are used as starting points for dust radiative transfer and thermochemical models.
Along with the observational data collection, we employ the same database infrastructure to also provide results from models that were run on a subset of sources. These results include accurate SED fits to 27 sources along with consistent 18 dust and gas models using the DiscAnalysis standards as described in Woitke et al. (2019).
Modeling is divided into three major phases. The first phase involves fitting of stellar and extinction properties, using the UV to near-IR data. Xray-derived extinction data was partly used, but only to see which range of extinction data it supports, in the case of multiple, degenerate extinction estimations. The second phase involves modeling of the SED alone using MCFOST, while the third phase involves the DIANA-standard fitting, using either a combination of MCFOST with ProDiMo, MCMax with ProDiMo, or just ProDiMo alone. We mention that all codes employed have been benchmarked for consistency (Woitke et al. 2016).
During the first modeling phase, additional photometric data are searched for, and initial values for e.g., Teff, extinction, distance and luminosity values are looked up in previous spectral analysis papers. The fitting is then made by varying Teff, Lstar and AV by a genetic algorithm (evolutionary strategy) until a good fit with all selected photometric and (for Herbig Ae) soft UV data is obtained. The fit uses standard PHOENIX photospheric model spectra (which have no additional hot components). Mstar and log(g) are found by using stellar evolutionary tracks from Siess et al. (2000). In some cases it is necessary to connect the photospheric model with the UV observations by a power-law. In other cases (mostly for Herbig Ae stars) there is a good overlap. Other groups proceed in a different way here, using early-type template spectra from selected sources, which have veiled photospheric emission already built-in. During the first phase Mstar, Lstar, Teff, log(g), AV, spectral type, distance and age are estimated as a result of the modeling process. However, initial values for a subset of these parameters can be collected from the rich literature which then are used as a starting point for the modeling (e.g., see Table C.2).
The second phase involves a collection of additional photometric points, extending from the near IR to millimeter wavelengths, including far-IR lines from Herschel and ISO. If polycyclic aromatic hydrocarbon (PAH) features are apparent in the Spitzer/IRS spectra, we include the PAH fitting (amount and average charge of PAHs) consistently in the SED fitting. As a result from the fitting process, the dust mass, disk size and shape, the dust settling and the dust-grain size parameters are constrained and if applicable, the amount and charge of PAHs. The result for 27 SED-fitted sources are included in the database and examples are presented in Fig. 3.
 |
Fig. 2. Ultraviolet spectrum of HD163296, consisting of a series of individual observations from HST, FUSE and IUE. Black line represents the co-added spectrum of all observations as described in Appendix B. |
 |
Fig. 3. Examples of results from the SED-fits included in the database. The red line is the assumed photospheric + UV spectrum of the star. The black dots are the fluxes computed by MCFOST, at all wavelength points where we could find observations. The other colored dots and lines and observational data as indicated in the embedded legends. |
In the third phase, line fluxes, line profiles, with resolved images from ALMA and NICMOS or visibility data from PIONIER and MIDI are included. The modeler decides which data to trust and which not (for example because the data is contaminated by backgroud or foreground cloud emission), assigns fitting weight to each observation, then follows the most appropriate fitting strategy, e.g., genetic fitting algorithm or by-hand-fitting. Fitting in phases two and three starts assuming a single-zone disk without gaps. If this fails, then a two-zone disk model is employed with a possible gap between the two zones. During the third phase, all phase 2 data refitted, where in particular the radial extension, tapering parameters and shadow-casting from the inner to the outer zones can now be fitted using line observations, while the gas to dust ratio is constrained.
The methods are detailed in Woitke et al. (2016, 2019), and the results are listed in Table 5 for 27 sources. The second step of the modeling is to determine the disk shape, dust and PAH properties by means of highly automated SED-fits. The result for 27 SED-fitted sources are included in the DIOD database and examples are presented in Fig. 3.
Stellar parameters, and UV and X-ray irradiation properties, for 27 protoplanetary disks.
4. Summary
In this paper we presented a large sample of Class II and III, T Tauri and Herbig Ae systems with spectral types ranging from B9 to M3 which cover ages between 1 and 10 Myr. The sample of 85 sources in expected to include another 30–40 sources in the near future, rendering this one of the largest and most complete collections of its kind. The collection was assembled combining data from more than 50 observational facilities and 100 published articles in a transparent manner, so that each dataset can be back-traced to each original resources. In addition, 27 of the sources in the collection have their SEDs consistently modeled with dust radiative transfer models (MCFOST, MCMAX and ProDiMo)14, and a subset of 18 that have both dust and gas consistently modeled with ProDiMo15. The user interface and the supporting DIOD database provide the user with the flexibility to compare different characteristics among the sample sources and models, but also directly download data for further use. We believe that this collection with its future extensions will provide a reference point, facilitating observational and modeling studies of protoplanetary disks.
An EU FP7-SPACE 2011 funded project, http://www.diana-project.com/.
ESO-program 179.C-0151 http://www.stsci.edu/~pontoppi/
All SED input files and output models available at: http://www-star.st-and.ac.uk/~pw31/DIANA/SEDfit/
Gas line input files and output models available at: http://www-star.st-and.ac.uk/~pw31/DIANA/DIANAstandard/
Acknowledgments
The research leading to these results has received funding from the European Union Seventh Framework Programme FP7-2011 under grant agreement no 284405. OD acknowledges support from the Austrian Research Promotion Agency (FFG) under the framework of the Austrian Space Applications Program (ASAP) projects JetPro* and PROTEUS (FFG-854025, FFG-866005).
References
- Adelman-McCarthy, J. K., Agüeros, M. A., Allam, S. S., et al. 2008, ApJS, 175, 297 [NASA ADS] [CrossRef] [Google Scholar]
- Adelman-McCarthy, J. K. 2011, VizieR Online Data Catalog: II/306 [Google Scholar]
- Alecian, E., Wade, G. A., Catala, C., et al. 2013, MNRAS, 429, 1001 [NASA ADS] [CrossRef] [Google Scholar]
- Ammons, S. M., Robinson, S. E., Strader, J., et al. 2006, ApJ, 638, 1004 [NASA ADS] [CrossRef] [Google Scholar]
- Andre, P., & Montmerle, T. 1994, ApJ, 420, 837 [NASA ADS] [CrossRef] [Google Scholar]
- Andrews, S. M., & Williams, J. P. 2007, ApJ, 671, 1800 [CrossRef] [Google Scholar]
- Andrews, S. M., Czekala, I., Wilner, D. J., et al. 2010, ApJ, 710, 462 [NASA ADS] [CrossRef] [Google Scholar]
- Ansdell, M., Williams, J. P., van der Marel, N., et al. 2016, ApJ, 828, 46 [Google Scholar]
- Antonellini, S., Kamp, I., Riviere-Marichalar, P., et al. 2015, A&A, 582, A105 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Arnaud, K. A. 1996, in Astronomical Data Analysis Software and Systems V, eds. G. H. Jacoby, & J. Barnes, ASP Conf. Ser., 101, 17 [NASA ADS] [Google Scholar]
- Banzatti, A., Pontoppidan, K. M., Salyk, C., et al. 2017, ApJ, 834, 152 [NASA ADS] [CrossRef] [Google Scholar]
- Beckwith, S. V. W., & Sargent, A. I. 1991, ApJ, 381, 250 [NASA ADS] [CrossRef] [Google Scholar]
- Bergin, E. A., Cleeves, L. I., Gorti, U., et al. 2013, Nature, 493, 644 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Bertout, C., Siess, L., & Cabrit, S. 2007, A&A, 473, L21 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Biller, B., Lacour, S., Juhász, A., et al. 2012, ApJ, 753, L38 [NASA ADS] [CrossRef] [Google Scholar]
- Bitner, M. A., Richter, M. J., Lacy, J. H., et al. 2008, ApJ, 688, 1326 [NASA ADS] [CrossRef] [Google Scholar]
- Blake, G. A., & Boogert, A. C. A. 2004, ApJ, 606, L73 [NASA ADS] [CrossRef] [Google Scholar]
- Boogert, A. C. A., Pontoppidan, K. M., Knez, C., et al. 2008, ApJ, 678, 985 [NASA ADS] [CrossRef] [Google Scholar]
- Boss, A. P. 2009, ApJ, 694, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Bottinelli, S., Boogert, A. C. A., Bouwman, J., et al. 2010, ApJ, 718, 1100 [NASA ADS] [CrossRef] [Google Scholar]
- Brown, J. M., Pontoppidan, K. M., van Dishoeck, E. F., et al. 2013, ApJ, 770, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Cabrit, S., Edwards, S., Strom, S. E., & Strom, K. M. 1990, ApJ, 354, 687 [NASA ADS] [CrossRef] [Google Scholar]
- Calvet, N., Muzerolle, J., Briceño, C., et al. 2004, AJ, 128, 1294 [NASA ADS] [CrossRef] [Google Scholar]
- Carmona, A., van den Ancker, M. E., Henning, T., et al. 2007, A&A, 476, 853 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carmona, A., van den Ancker, M. E., Henning, T., et al. 2008, A&A, 477, 839 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carmona, A., van der Plas, G., van den Ancker, M. E., et al. 2011, A&A, 533, A39 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carmona, A., Pinte, C., Thi, W. F., et al. 2014, A&A, 567, A51 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carpenter, J. M., Hillenbrand, L. A., Skrutskie, M. F., & Meyer, M. R. 2002, AJ, 124, 1001 [NASA ADS] [CrossRef] [Google Scholar]
- Carpenter, J. M., Wolf, S., Schreyer, K., Launhardt, R., & Henning, T. 2005, AJ, 129, 1049 [Google Scholar]
- Chapillon, E., Guilloteau, S., Dutrey, A., Piétu, V., et al. 2008, A&A, 488, 565 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chen, H., Myers, P. C., Ladd, E. F., & Wood, D. O. S. 1995, ApJ, 445, 377 [NASA ADS] [CrossRef] [Google Scholar]
- Cieza, L. A., Olofsson, J., Harvey, P. M., et al. 2013, ApJ, 762, 100 [NASA ADS] [CrossRef] [Google Scholar]
- Cleeves, L. I., Bergin, E. A., Qi, C., Adams, F. C., & Öberg, K. I. 2015, ApJ, 799, 204 [NASA ADS] [CrossRef] [Google Scholar]
- Cohen, M., Emerson, J. P., & Beichman, C. A. 1989, ApJ, 339, 455 [NASA ADS] [CrossRef] [Google Scholar]
- Corradi, W. J. B., & Franco, G. A. P. 1995, A&AS, 112, 95 [NASA ADS] [Google Scholar]
- Cortes, S. R., Meyer, M. R., Carpenter, J. M., et al. 2009, ApJ, 697, 1305 [NASA ADS] [CrossRef] [Google Scholar]
- Cutri, R. M. 2012, VizieR Online Data Catalog: II/311 [Google Scholar]
- Cutri, R. M., Skrutskie, M. F., van Dyk, S., et al. 2012, VizieR Online Data Catalog: II/281 [Google Scholar]
- Cutri, R. M., Skrutskie, M. F., van Dyk, S., et al. 2003, VizieR Online Data Catalog: II/246 [Google Scholar]
- Dent, W. R. F., Matthews, H. E., & Ward-Thompson, D. 1998, MNRAS, 301, 1049 [NASA ADS] [CrossRef] [Google Scholar]
- Dent, W. R. F., Thi, W. F., Kamp, I., et al. 2013, PASP, 125, 477 [NASA ADS] [CrossRef] [Google Scholar]
- Di Francesco, J., Johnstone, D., Kirk, H., MacKenzie, T., Ledwosinska, E., et al. 2008, ApJS, 175, 277 [NASA ADS] [CrossRef] [Google Scholar]
- Donati, J.-F., Gregory, S. G., Montmerle, T., et al. 2011, MNRAS, 417, 1747 [NASA ADS] [CrossRef] [Google Scholar]
- Drabek-Maunder, E., Mohanty, S., Greaves, J., et al. 2016, ApJ, 833, 260 [NASA ADS] [CrossRef] [Google Scholar]
- Ducati, J. R. 2002, VizieR Online Data Catalog: II/237 [Google Scholar]
- Duchêne, G., McCabe, C., Pinte, C., et al. 2010, ApJ, 712, 112 [NASA ADS] [CrossRef] [Google Scholar]
- Dutrey, A., Guilloteau, S., Duvert, G., et al. 1996, A&A, 309, 493 [NASA ADS] [Google Scholar]
- Egan, M. P., Price, S. D., Kraemer, K. E., et al. 2003, VizieR Online Data Catalog: V/114 [Google Scholar]
- ESA 1997, in The HIPPARCOS and Tycho catalogues. Astrometric and Photometric Star Catalogues Derived from the ESA HIPPARCOS Space Astrometry Mission, ESA SP, 1200 [Google Scholar]
- Espaillat, C., Calvet, N., D’Alessio, P., et al. 2007, ApJ, 670, L135 [NASA ADS] [CrossRef] [Google Scholar]
- Evans, II., N. J., Allen, L. E., Blake, G. A., et al. 2003, PASP, 115, 965 [NASA ADS] [CrossRef] [Google Scholar]
- Fedele, D., Bruderer, S., van Dishoeck, E. F., et al. 2013, A&A, 559, A77 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Frasca, A., Biazzo, K., Lanzafame, A. C., et al. 2015, A&A, 575, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fuente, A., Cernicharo, J., Agúndez, M., et al. 2010, A&A, 524, A19 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Furlan, E., Luhman, K. L., Espaillat, C., et al. 2011, ApJS, 195, 3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Garufi, A., Benisty, M., Stolker, T., et al. 2017, The Messenger, 169, 32 [NASA ADS] [Google Scholar]
- Green, J. D., Yang, Y. L., & Evans, II., N. J. 2016, AJ, 151, 75 [NASA ADS] [CrossRef] [Google Scholar]
- Grosso, N., Alves, J., Wood, K., et al. 2003, ApJ, 586, 296 [NASA ADS] [CrossRef] [Google Scholar]
- Güdel, M., Briggs, K. R., Arzner, K., et al. 2007, A&A, 468, 353 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Güdel, M., Lahuis, F., Briggs, K. R., et al. 2010, A&A, 519, A113 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Guilloteau, S., Dutrey, A., Piétu, V., & Boehler, Y. 2011, A&A, 529, A105 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Guilloteau, S., Dutrey, A., Wakelam, V., et al. 2012, A&A, 548, A70 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gullbring, E., Hartmann, L., Briceño, C., & Calvet, N. 1998, ApJ, 492, 323 [NASA ADS] [CrossRef] [Google Scholar]
- Hauck, B., & Mermilliod, M. 1998, A&AS, 129, 431 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Helou, G., & Walker, D. W. 1988, Infrared Astronomical Satellite (IRAS) Catalogs and Atlases. Volume 7: The Small Scale Structure Catalog, 7 [Google Scholar]
- Henning, T., Pfau, W., Zinnecker, H., & Prusti, T. 1993, A&A, 276, 129 [NASA ADS] [Google Scholar]
- Henning, T., Launhardt, R., Steinacker, J., & Thamm, E. 1994, in The Nature and Evolutionary Status of Herbig Ae/Be Stars, eds. P. S. The, M. R. Perez, & E. P. J. van den Heuvel, ASP Conf. Ser., 62, 171 [NASA ADS] [Google Scholar]
- Herczeg, G. J., & Hillenbrand, L. A. 2014, ApJ, 786, 97 [NASA ADS] [CrossRef] [Google Scholar]
- Herczeg, G. J., Cruz, K. L., & Hillenbrand, L. A. 2009, ApJ, 696, 1589 [Google Scholar]
- Hillenbrand, L. A., & White, R. J. 2004, ApJ, 604, 741 [NASA ADS] [CrossRef] [Google Scholar]
- Høg, E., Fabricius, C., Makarov, V. V., et al. 2000, A&A, 355, L27 [Google Scholar]
- Holmberg, J., Nordström, B., & Andersen, J. 2009, A&A, 501, 941 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Howard, C. D., Sandell, G., Vacca, W. D., et al. 2013, ApJ, 776, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Hughes, J., Hartigan, P., Krautter, J., & Kelemen, J. 1994, AJ, 108, 1071 [NASA ADS] [CrossRef] [Google Scholar]
- Humphries, C. M., Jamar, C., Malaise, D., & Wroe, H. 1976, A&A, 49, 389 [NASA ADS] [Google Scholar]
- Ida, S., & Lin, D. N. C. 2005, ApJ, 626, 1045 [NASA ADS] [CrossRef] [Google Scholar]
- Ingleby, L., Calvet, N., Hernández, J., et al. 2011, AJ, 141, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Ingleby, L., Calvet, N., Herczeg, G., et al. 2013, ApJ, 767, 112 [NASA ADS] [CrossRef] [Google Scholar]
- Isella, A., Carpenter, J. M., & Sargent, A. I. 2010, ApJ, 714, 1746 [NASA ADS] [CrossRef] [Google Scholar]
- Ishihara, D., Onaka, T., Kataza, H., et al. 2010, A&A, 514, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Jansen, F., Lumb, D., Altieri, B., et al. 2001, A&A, 365, L1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Johns-Krull, C. M., Valenti, J. A., & Linsky, J. L. 2000, ApJ, 539, 815 [NASA ADS] [CrossRef] [Google Scholar]
- Juhász, A., Bouwman, J., Henning, T., et al. 2010, ApJ, 721, 431 [NASA ADS] [CrossRef] [Google Scholar]
- Kamp, I., Tilling, I., Woitke, P., Thi, W.-F., & Hogerheijde, M. 2010, A&A, 510, A18 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kamp, I., Thi, W.-F., Woitke, P., et al. 2017, A&A, 607, A41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kharchenko, N. V. 2001, Kinematika i Fizika Nebesnykh Tel, 17, 409 [NASA ADS] [Google Scholar]
- Kimeswenger, S., Lederle, C., Richichi, A., et al. 2004, A&A, 413, 1037 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kitamura, Y., Momose, M., Yokogawa, S., et al. 2002, ApJ, 581, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Koerner, D. W., Chandler, C. J., & Sargent, A. I. 1995, ApJ, 452, L69 [NASA ADS] [CrossRef] [Google Scholar]
- Kraus, A. L., & Hillenbrand, L. A. 2009, ApJ, 704, 531 [Google Scholar]
- Kraus, A. L., Ireland, M. J., Martinache, F., & Hillenbrand, L. A. 2011, ApJ, 731, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Kraus, A. L., Ireland, M. J., Hillenbrand, L. A., & Martinache, F. 2012, ApJ, 745, 19 [NASA ADS] [CrossRef] [Google Scholar]
- Lahuis, F., van Dishoeck, E. F., Blake, G. A., et al. 2007, ApJ, 665, 492 [NASA ADS] [CrossRef] [Google Scholar]
- Laughlin, G., Bodenheimer, P., & Adams, F. C. 2004, ApJ, 612, L73 [NASA ADS] [CrossRef] [Google Scholar]
- Lebouteiller, V., Barry, D. J., Spoon, H. W. W., et al. 2011, ApJS, 196, 8 [NASA ADS] [CrossRef] [Google Scholar]
- Lebreton, J., Augereau, J.-C., Thi, W.-F., et al. 2012, A&A, 539, A17 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lommen, D., Wright, C. M., Maddison, S. T., et al. 2007, A&A, 462, 211 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lommen, D., Maddison, S. T., Wright, C. M., et al. 2009, A&A, 495, 869 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Luhman, K. L. 2007, ApJS, 173, 104 [Google Scholar]
- Luhman, K. L., Allen, P. R., Espaillat, C., Hartmann, L., & Calvet, N. 2010, ApJS, 186, 111 [NASA ADS] [CrossRef] [Google Scholar]
- Manara, C. F., Testi, L., Natta, A., et al. 2014, A&A, 568, A18 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mannings, V. 1994, MNRAS, 271, 587 [NASA ADS] [Google Scholar]
- Mannings, V., & Emerson, J. P. 1994, MNRAS, 267, 361 [NASA ADS] [Google Scholar]
- Manset, N., Bastien, P., Ménard, F., et al. 2009, A&A, 499, 137 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Martin-Zaïdi, C., Augereau, J.-C., Ménard, F., et al. 2010, A&A, 516, A110 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mathews, G. S., Dent, W. R. F., Williams, J. P., et al. 2010, A&A, 518, L127 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mathews, G. S., Williams, J. P., & Ménard, F. 2012, ApJ, 753, 59 [NASA ADS] [CrossRef] [Google Scholar]
- Mathews, G. S., Pinte, C., Duchêne, G., Williams, J. P., & Ménard, F. 2013, A&A, 558, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Matthews, B. C., Kalas, P. G., & Wyatt, M. C. 2007, ApJ, 663, 1103 [NASA ADS] [CrossRef] [Google Scholar]
- McJunkin, M., France, K., Schneider, P. C., et al. 2014, ApJ, 780, 150 [NASA ADS] [CrossRef] [Google Scholar]
- Meeus, G., Waters, L. B. F. M., Bouwman, J., et al. 2001, A&A, 365, 476 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meeus, G., Montesinos, B., Mendigutía, I., et al. 2012, A&A, 544, A78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meeus, G., Salyk, C., Bruderer, S., et al. 2013, A&A, 559, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mendigutía, I., Mora, A., Montesinos, B., et al. 2012, A&A, 543, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mendigutía, I., Fairlamb, J., Montesinos, B., et al. 2014, ApJ, 790, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Mermilliod, J. C. 2006, VizieR Online Data Catalog: II/168 [Google Scholar]
- Mermilliod, J.-C., Mermilliod, M., & Hauck, B. 1997, A&AS, 124, 349 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Meyer, M. R., Hillenbrand, L. A., Backman, D., et al. 2006, PASP, 118, 1690 [NASA ADS] [CrossRef] [Google Scholar]
- Min, M., Dullemond, C. P., Dominik, C., de Koter, A., & Hovenier, J. W. 2009, A&A, 497, 155 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Monet, D. G., Levine, S. E., Canzian, B., et al. 2003, AJ, 125, 984 [NASA ADS] [CrossRef] [Google Scholar]
- Montesinos, B., Eiroa, C., Mora, A., & Merín, B. 2009, A&A, 495, 901 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Morel, M., & Magnenat, P. 1978, A&AS, 34, 477 [NASA ADS] [Google Scholar]
- Morrison, R., & McCammon, D. 1983, ApJ, 270, 119 [NASA ADS] [CrossRef] [Google Scholar]
- Morrissey, P., Conrow, T., Barlow, T. A., et al. 2007, ApJS, 173, 682 [NASA ADS] [CrossRef] [Google Scholar]
- Moshir, M. 1990, IRAS Faint Source Catalogue, version 2.0 (1990) [Google Scholar]
- Motte, F., Andre, P., & Neri, R. 1998, A&A, 336, 150 [NASA ADS] [Google Scholar]
- Murakami, H., Baba, H., Barthel, P., et al. 2007, PASJ, 59, 369 [Google Scholar]
- Najita, J., Carr, J. S., & Mathieu, R. D. 2003, ApJ, 589, 931 [NASA ADS] [CrossRef] [Google Scholar]
- Nilsson, R., Liseau, R., Brandeker, A., et al. 2009, A&A, 508, 1057 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nuernberger, D., Chini, R., & Zinnecker, H. 1997, A&A, 324, 1036 [NASA ADS] [Google Scholar]
- Öberg, K. I., Boogert, A. C. A., Pontoppidan, K. M., et al. 2008, ApJ, 678, 1032 [NASA ADS] [CrossRef] [Google Scholar]
- Öberg, K. I., Qi, C., Fogel, J. K. J., et al. 2010, ApJ, 720, 480 [NASA ADS] [CrossRef] [Google Scholar]
- Öberg, K. I., Qi, C., Fogel, J. K. J., et al. 2011, ApJ, 734, 98 [NASA ADS] [CrossRef] [Google Scholar]
- Ofek, E. O. 2008, PASP, 120, 1128 [NASA ADS] [CrossRef] [Google Scholar]
- Osterloh, M., & Beckwith, S. V. W. 1995, ApJ, 439, 288 [NASA ADS] [CrossRef] [Google Scholar]
- Palla, F., & Stahler, S. W. 2002, ApJ, 581, 1194 [NASA ADS] [CrossRef] [Google Scholar]
- Pascucci, I., Apai, D., Luhman, K., et al. 2009, ApJ, 696, 143 [NASA ADS] [CrossRef] [Google Scholar]
- Perryman, M. A. C., Lindegren, L., Kovalevsky, J., et al. 1997, A&A, 323, L49 [NASA ADS] [Google Scholar]
- Pickles, A., & Depagne, É. 2010, PASP, 122, 1437 [NASA ADS] [CrossRef] [Google Scholar]
- Pinte, C., Harries, T. J., Min, M., et al. 2009, A&A, 498, 967 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pinte, C., Ménard, F., Duchêne, G., & Bastien, P. 2006, A&A, 459, 797 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pontoppidan, K. M., Boogert, A. C. A., Fraser, H. J., et al. 2008, ApJ, 678, 1005 [NASA ADS] [CrossRef] [Google Scholar]
- Pontoppidan, K. M., Salyk, C., Blake, G. A., et al. 2010, ApJ, 720, 887 [NASA ADS] [CrossRef] [Google Scholar]
- Pontoppidan, K. M., van Dishoeck, E., Blake, G. A., et al. 2011, The Messenger, 143, 32 [NASA ADS] [Google Scholar]
- Rebull, L. M., Padgett, D. L., McCabe, C.-E., et al. 2010, ApJS, 186, 259 [NASA ADS] [CrossRef] [Google Scholar]
- Rebull, L. M., Koenig, X. P., Padgett, D. L., et al. 2011, VizieR On-line Data Catalog: J/ApJS/196/4 [Google Scholar]
- Ricci, L., Testi, L., Natta, A., et al. 2010, A&A, 512, A15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rice, W. K. M., & Armitage, P. J. 2009, MNRAS, 396, 2228 [NASA ADS] [CrossRef] [Google Scholar]
- Richmond, M. W. 2007, PASP, 119, 1083 [NASA ADS] [CrossRef] [Google Scholar]
- Roberge, A., Kamp, I., Montesinos, B., et al. 2013, ApJ, 771, 69 [NASA ADS] [CrossRef] [Google Scholar]
- Rodmann, J., Henning, T., Chandler, C. J., Mundy, L. G., & Wilner, D. J. 2006, A&A, 446, 211 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rufener, F. 1988, Catalogue of Stars Measured in the Geneva Observatory Photometric System, 4, 1988 [NASA ADS] [Google Scholar]
- Sacco, G. G., Flaccomio, E., Pascucci, I., et al. 2012, ApJ, 747, 142 [NASA ADS] [CrossRef] [Google Scholar]
- Salyk, C., Pontoppidan, K. M., Blake, G. A., Najita, J. R., & Carr, J. S. 2011, ApJ, 731, 130 [NASA ADS] [CrossRef] [Google Scholar]
- Salyk, C., Herczeg, G. J., Brown, J. M., et al. 2013, ApJ, 769, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Sandell, G., Weintraub, D. A., & Hamidouche, M. 2011, ApJ, 727, 26 [NASA ADS] [CrossRef] [Google Scholar]
- Sartori, M. J., Lépine, J. R. D., & Dias, W. S. 2003, A&A, 404, 913 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Schaefer, G. H., Dutrey, A., Guilloteau, S., Simon, M., & White, R. J. 2009, ApJ, 701, 698 [NASA ADS] [CrossRef] [Google Scholar]
- Schindhelm, E., France, K., Herczeg, G. J., et al. 2012, ApJ, 756, L23 [NASA ADS] [CrossRef] [Google Scholar]
- Siess, L., Dufour, E., & Forestini, M. 2000, A&A, 358, 593 [Google Scholar]
- Skiff, B. A. 2014, VizieR Online Data Catalog: B/mk [Google Scholar]
- Smith, B. J., Price, S. D., & Baker, R. I. 2004, ApJS, 154, 673 [NASA ADS] [CrossRef] [Google Scholar]
- Spitzer Science 2009, VizieR Online Data Catalog: II/293 [Google Scholar]
- Stark, C. C., Schneider, G., Weinberger, A. J., et al. 2014, ApJ, 789, 58 [NASA ADS] [CrossRef] [Google Scholar]
- Straizys, V., Kazlauskas, A., Jodinskiene, E., & Bartkevicius, A. 1989, Bulletin d’Information du Centre de Données Stellaires, 37, 179 [NASA ADS] [Google Scholar]
- Testi, L., Natta, A., Shepherd, D. S., & Wilner, D. J. 2003, A&A, 403, 323 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Thi, W.-F., Woitke, P., & Kamp, I. 2011, MNRAS, 412, 711 [NASA ADS] [Google Scholar]
- Torres, C. A. O., Quast, G. R., da Silva, L., et al. 2006, A&A, 460, 695 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Trotta, F., Testi, L., Natta, A., Isella, A., & Ricci, L. 2013, A&A, 558, A64 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ubach, C., Maddison, S. T., Wright, C. M., et al. 2012, MNRAS, 425, 3137 [NASA ADS] [CrossRef] [Google Scholar]
- Valenti, J. A., Johns-Krull, C. M., & Linsky, J. L. 2000, ApJS, 129, 399 [NASA ADS] [CrossRef] [Google Scholar]
- Valenti, J. A., Fallon, A. A., & Johns-Krull, C. M. 2003, ApJS, 147, 305 [NASA ADS] [CrossRef] [Google Scholar]
- van der Wiel, M. H. D., Naylor, D. A., Kamp, I., et al. 2014, MNRAS, 444, 3911 [NASA ADS] [CrossRef] [Google Scholar]
- Verhoeff, A. P., Min, M., Pantin, E., et al. 2011, A&A, 528, A91 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wahhaj, Z., Cieza, L., Koerner, D. W., et al. 2010, ApJ, 724, 835 [NASA ADS] [CrossRef] [Google Scholar]
- Weisskopf, M. C., Tananbaum, H. D., Van Speybroeck, L. P., O’Dell, S. L., et al. 2000, in X-Ray Optics, Instruments, and Missions III, eds. J. E. Truemper, & B. Aschenbach, SPIE Conf. Ser., 4012, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Wesselius, P. R., van Duinen, R. J., de Jonge, A. R. W., et al. 1982, A&AS, 49, 427 [NASA ADS] [Google Scholar]
- White, R. J., & Hillenbrand, L. A. 2004, ApJ, 616, 998 [NASA ADS] [CrossRef] [Google Scholar]
- Woitke, P., Kamp, I., Antonellini, S., et al. 2019, PASP, 131, 1000 [Google Scholar]
- Woitke, P., Kamp, I., & Thi, W.-F. 2009, A&A, 501, 383 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Woitke, P., Min, M., Pinte, C., et al. 2016, A&A, 586, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Yang, H., Herczeg, G. J., Linsky, J. L., et al. 2012, ApJ, 744, 121 [NASA ADS] [CrossRef] [Google Scholar]
- Yokogawa, S., Kitamura, Y., Momose, M., et al. 2001, ApJ, 552, L59 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, K., Isella, A., Carpenter, J. M., & Blake, G. A. 2014, ApJ, 791, 42 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: The DiscAnalysis Object Database (DIOD)
The multiwavelength datasets available through the DIANA Object Database repository are processed end-products, as opposed to raw data, that can be directly compared to models. Deriving meaningful physical quantities from raw astrophysical data is a complex process that requires good knowledge of the instrumentation involved, together with adequate experience and advanced programing skills. Therefore the dissemination of processed end-products has a greater impact to the community as they can be directly used for analysis and interpretation. As an example we mention the SDSS survey that has been up to now the most prolific project in terms of scientific outcome when compared to cost. We therefore anticipate that along with the advancements and increasing interest in the field, our database will become a point of reference for the study of protoplanetary disks.
A.1. The end-user interface
The database functionalities for the end-user are limited to searching, inspecting and downloading datasets and models for either single or multiple sources.
When the Download window is selected in the welcome page, the user is redirected to the data search and retrieval interface. As in most pages of the interface, a short description of the available functions are displayed on the top part. At this stage the user is provided with two options: either search for a source by name, or select sources from a list that is returned when the List all objects button is selected (Fig. A.1). In the list window, presented in Fig. A.2 the user can search the database for alternative source names as provided by online name resolvers. In addition, selection of a source name brings into the foreground a pop-up window, which provides detailed information on the source as retrieved by the SIMBAD, NED and VizieR and CDS name servers (Fig. A.3).
 |
Fig. A.1. The data search and download window, without any sources selected. The user can either search for a source by its name, or get a list of all available sources when selecting the List all sources button. |
 |
Fig. A.2. List of available sources that can be selected for further investigation and download by marking the checkbox on the right of the source name. On the top the user can search the source list with alternative names, as provided by source name resolvers. Direct selection of a source name presents information retrieved by three online name resolver services (see Fig. A.3). |
 |
Fig. A.3. When selecting a source, a pop-up window presents its details as retrieved from SIMBAD, NED and VizieR and CDS name resolvers. |
Once one or more sources are selected, they appear on the right panel of the search and retrieval window (Fig. A.6), under the Selected Objects section. At the same section, sources can be removed by selecting the “X” symbol next to each source name. Below the Select function pane, two lists appear providing the possibility to select first the Data Type (e.g., photometric points, spectra, line fluxes, line shapes, etc). For each data type, the Dataset box is populated with available options (instruments, bands, etc). Information on all selected datasets is listed below under the pane bearing the same title. Here, the user can find information on the original source where the data is retrieved from and an active link to the original publication (if available). In addition, the user is informed on the data quality by relevant flags and comments on the data. Comments are truncated to save space, but the full comments are displayed once the user “hoovers over” the mouse pointer.
A.2. Data preview and retrieval
Selected datasets can be previewed and compared on the plotting window. Once desired datasets or models are selected for one or more sources they are plotted using a color-encoded scheme that allows to distinguish the data origin into individual sources, datasets and instruments. For a “mouse-over” action a pop-up window displays the provenance of the specific data point (see Fig. A.5). When the full screen plotting mode is selected, then a complete list on the provenance of all data points is provided on the left-hand side of the plot. Selected data can be prepared for direct download when the user selects the Prepare files button. If no selections under the Data Type and Dataset(s) boxes have been made, then the full dataset for the selected source is prepared. After the Prepare files button has been pressed, a Download button appears under the Selected Objects pane, and when pressed it provides the user with the selected data.
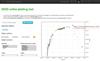 |
Fig. A.4. The basic plotting and overview functionality of DIOD; when desired datasets are selected, they can be plotting through a number of preselected display modes. Color encoding of the data points in the plot corresponds to different datasets or objects. When the mouse pointer is over a specific data point, a popup window displays relevant information on its provenance. |
 |
Fig. A.5. Full screen plotting window, displaying on the left-hand-side a complete list on the provenance of all data points. |
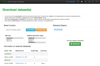 |
Fig. A.6. When a single source is selected, the user can examine all available data by selecting first the Data Type and then the desired Dataset. At the bottom of the screen a detailed description of the selected dataset(s) appears, providing active links to the original work where the data is retrieved, along with quality flags and additional comments. |
The option to inspect and select parts of the available data is only provided when a single object is selected. For multiple objects, the user can only retrieve the full datasets, which are provided as a compressed file.
Appendix B: UV data co-adding and post-processing
Here we provide a detailed account of the process followed to co-add the UV data from different instruments and observing runs. The process is divided in three basic steps, as follows:
Step 1. We first define wavelength-bins as
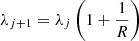 (B.1)
(B.1)
starting with j = 0 (where λ0 = 950 Å if FUSE data is available, otherwise λ0 = 1150 Å). Resolution R ≈ 200 is an adjustable parameter. Index j is then increased until j = J where λJ > 3350 Å is achieved, forming J wavelength bins.
Step 2. Each observational data set d is used to (partly) fill these wavelength bins by integration as
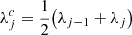 (B.2)
(B.2)
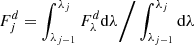 (B.3)
(B.3)
where c is the center wavelength of the bin j. However, even one data set d may come in several, partly overlapping chunks (echelle spectra) and some points may be flagged and hence need to be discarded. To deal with all these special cases, every valid original data point 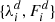 is assigned a spectral width as
is assigned a spectral width as
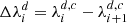 (B.4)
(B.4)
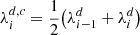 (B.5)
(B.5)
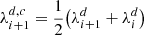 (B.6)
(B.6)
This width 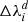 , or precisely speaking the overlap of
, or precisely speaking the overlap of 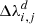 with the interval [λj − 1, λj], is used to numerically calculate the integrals in Eq. (B.2), replacing them by simple sums as
with the interval [λj − 1, λj], is used to numerically calculate the integrals in Eq. (B.2), replacing them by simple sums as
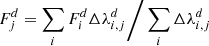 (B.7)
(B.7)
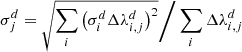 (B.8)
(B.8)
Step 2 results in a number of spectra 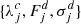 on the same low-resolution wavelength grid for every object. However, usually only a (small) subset of the spectral bins p are populated by a single observational data set.
on the same low-resolution wavelength grid for every object. However, usually only a (small) subset of the spectral bins p are populated by a single observational data set.
Step 3. All available spectra sets d are co-added, using the inverse square of the bin uncertainty as summation weight
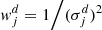 (B.9)
(B.9)
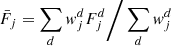 (B.10)
(B.10)
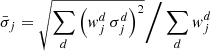 (B.11)
(B.11)
where the uncertainties 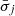 follow from Gauss’ error propagation law applied to Eq. (B.10), i.e.,
follow from Gauss’ error propagation law applied to Eq. (B.10), i.e., 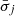 is the error of the mean value
is the error of the mean value
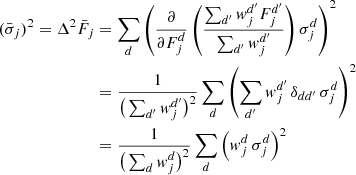 (B.12)
(B.12)
This procedure results in one set of co-added and resolution-decreased spectral data points 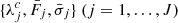 for each object.
for each object.
Step 4. After steps 1 and 2, the data can still be very noisy, negative or otherwise statistically irrelevant, and it would be an error to use such data for disk irradiation. The idea in the following is to join neighboring λ-bins, until statistically relevant data results:
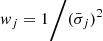 (B.13)
(B.13)
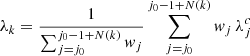 (B.14)
(B.14)
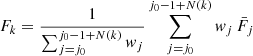 (B.15)
(B.15)
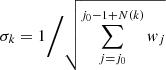 (B.16)
(B.16)
We start at j0 = 1. The number of joined bins N(k) is increased from 1 to any number, until
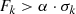 (B.17)
(B.17)
is achieved, where α ≈ 3 is an adjustable parameter. Once N(k) is found, the new data point {λk, Fk, σk} is added, j0 is incremented by N(k), and k is incremented by one. This procedure gives co-added, further resolution-decreased, but statistically relevant ⟨UV⟩-spectrum {λk, Fk, σk} (k = 1, …, K).
Appendix C: Additional tables and figures
 |
Fig. C.1. continued. |
 |
Fig. C.1. continued. |
 |
Fig. C.1. continued. |
 |
Fig. C.1. continued. |
 |
Fig. C.1. continued. |
 |
Fig. C.1. continued. |
 |
Fig. C.2. Plots of UV averaged spectra for all sources with available UV observations (see also Fig. 2 and Appendix B). |
 |
Fig. C.2. continued. |
 |
Fig. C.2. continued. |
 |
Fig. C.2. continued. |
 |
Fig. C.2. continued. |
Overview of photometric and spectroscopic data collected per source and wavelength regime.
Stellar parameters.
All Tables
Standard XEST abundances and deviations for particular sources used in the VAPEC models.
Stellar parameters, and UV and X-ray irradiation properties, for 27 protoplanetary disks.
Overview of photometric and spectroscopic data collected per source and wavelength regime.
All Figures
|
Fig. 1. Example of “raw” collected data represented as SED diagrams for three sources (top row). Data for AB Aur (left panel) delineate well the stellar and disk emission and show little scatter. The same is true for MWC 480 (mid panel), the Akari data points however show some deviation when compared to the Spitzer/IRS spectra. For a weaker source like LkCa 15 (right panel), the scatter is significant due to certain, not well pointed observations, and therefore the SED is not well defined. SED plots for all sources are given as online data in Fig. C.1. Lower row presents the actual modeled data for the three sources, after being hand-selected for consistency. |
| In the text | |
|
Fig. 2. Ultraviolet spectrum of HD163296, consisting of a series of individual observations from HST, FUSE and IUE. Black line represents the co-added spectrum of all observations as described in Appendix B. |
| In the text | |
|
Fig. 3. Examples of results from the SED-fits included in the database. The red line is the assumed photospheric + UV spectrum of the star. The black dots are the fluxes computed by MCFOST, at all wavelength points where we could find observations. The other colored dots and lines and observational data as indicated in the embedded legends. |
| In the text | |
|
Fig. A.1. The data search and download window, without any sources selected. The user can either search for a source by its name, or get a list of all available sources when selecting the List all sources button. |
| In the text | |
|
Fig. A.2. List of available sources that can be selected for further investigation and download by marking the checkbox on the right of the source name. On the top the user can search the source list with alternative names, as provided by source name resolvers. Direct selection of a source name presents information retrieved by three online name resolver services (see Fig. A.3). |
| In the text | |
|
Fig. A.3. When selecting a source, a pop-up window presents its details as retrieved from SIMBAD, NED and VizieR and CDS name resolvers. |
| In the text | |
|
Fig. A.4. The basic plotting and overview functionality of DIOD; when desired datasets are selected, they can be plotting through a number of preselected display modes. Color encoding of the data points in the plot corresponds to different datasets or objects. When the mouse pointer is over a specific data point, a popup window displays relevant information on its provenance. |
| In the text | |
|
Fig. A.5. Full screen plotting window, displaying on the left-hand-side a complete list on the provenance of all data points. |
| In the text | |
|
Fig. A.6. When a single source is selected, the user can examine all available data by selecting first the Data Type and then the desired Dataset. At the bottom of the screen a detailed description of the selected dataset(s) appears, providing active links to the original work where the data is retrieved, along with quality flags and additional comments. |
| In the text | |
 |
Fig. C.1. SED diagrams for all sources reported in Table C.1. |
| In the text | |
|
Fig. C.1. continued. |
| In the text | |
|
Fig. C.1. continued. |
| In the text | |
|
Fig. C.1. continued. |
| In the text | |
|
Fig. C.1. continued. |
| In the text | |
|
Fig. C.1. continued. |
| In the text | |
|
Fig. C.1. continued. |
| In the text | |
|
Fig. C.2. Plots of UV averaged spectra for all sources with available UV observations (see also Fig. 2 and Appendix B). |
| In the text | |
|
Fig. C.2. continued. |
| In the text | |
|
Fig. C.2. continued. |
| In the text | |
|
Fig. C.2. continued. |
| In the text | |
|
Fig. C.2. continued. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.