| Issue |
A&A
Volume 619, November 2018
|
|
|---|---|---|
| Article Number | A6 | |
| Number of page(s) | 20 | |
| Section | Stellar structure and evolution | |
| DOI | https://doi.org/10.1051/0004-6361/201732525 | |
| Published online | 30 October 2018 | |
Estimating activity cycles with probabilistic methods
II. The Mount Wilson Ca H&K data
1 ReSoLVE Centre of Excellence, Department of Computer Science, Aalto University, PO Box 15400 , 00076 Aalto, Finland
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2 Max-Planck-Institut für Sonnensystemforschung, Justus-von-Liebig-Weg 3, 37077 Göttingen, Germany
3 Tartu Observatory, 61602 Tõravere, Estonia
4 Department of Computer Science, Aalto University, PO Box 15400, 00076 Aalto, Finland
Received:
21
December
2017
Accepted:
1
July
2018
Abstract
Context. Debate over the existence of branches in the stellar activity-rotation diagrams continues. Application of modern time series analysis tools to study the mean cycle periods in chromospheric activity index is lacking.
Aims. We develop such models, based on Gaussian processes (GPs), for one-dimensional time series and apply it to the extended Mount Wilson Ca H&K sample. Our main aim is to study how the previously commonly used assumption of strict harmonicity of the stellar cycles as well as handling of the linear trends affect the results.
Methods. We introduce three methods of different complexity, starting with Bayesian harmonic regression model, followed by GP regression models with periodic and quasi-periodic covariance functions. We also incorporate a linear trend as one of the components. We construct rotation to magnetic cycle period ratio-activity (RCRA) diagrams and apply a Gaussian mixture model to learn the optimal number of clusters explaining the data.
Results. We confirm the existence of two populations in the RCRA diagram; this finding is robust with all three methods used. We find only one significant trend in the inactive population, namely that the cycle periods get shorter with increasing rotation, leading to a positive slope in the RCRA diagram. This is in contrast with earlier studies, that postulate the existence of trends of different types in both of the populations. Our data is consistent with only two activity branches (inactive, transitional) instead of three (inactive, active, transitional) such that the active branch merges together with the transitional one. The retrieved stellar cycles are uniformly distributed over the RHK′ activity index, indicating that the operation of stellar large-scale dynamos carries smoothly over the Vaughan-Preston gap. At around the solar activity index, however, indications of a disruption in the cyclic dynamo action are seen.
Conclusions. Our study shows that stellar cycle estimates from time series the length of which is short in comparison to the searched cycle itself depend significantly on the model applied. Such model-dependent aspects include the improper treatment of linear trends, while the assumption of strict harmonicity can result in the appearance of double cyclicities that seem more likely to be explained by the quasi-periodicity of the cycles. In the case of quasi-periodic GP models, which we regard the most physically motivated ones, only 15 stars were found with statistically significant cycles against red noise model. The periodicities found have to, therefore, be regarded as suggestive.
Key words: stars: activity / methods: statistical
© ESO 2018
1. Introduction
Stellarcycles need to be studied to understand how stellar dynamos, including the solar one, operate. It is clear that latitudinal and radial shear play important roles in the operation of the solar dynamo, (see e.g. the discussion in Böhm-Vitense 2007), but recent numerical work of fully three-dimensional compressible magnetoconvection in the regime of the solar (Warnecke et al. 2018) and stellar (Warnecke 2018) dynamos has confirmed the existence of various important turbulent effects that cannot be neglected. These include the inductive effects arising from helical turbulence, known as the α-effect, and turbulent diffusion, known as the β-effect, that were reported to be active throughout the convection zone. In particular, net advection of magnetic fields by turbulence, contributing to the effective meridional flow, was found to be significant for the solar-like dynamo solutions (Warnecke 2018), indicating that turbulence has many effects some of which have been neglected especially in the solar dynamo investigations so far. Therefore, even the workings of the solar dynamo remain enigmatic.
From the dynamo modelling point-of-view, however, it is crucial to know how the observed properties of the dynamo depend on the basic system parameters (such as rotation). This provides stronger constraints for dynamo models than the requirement of reproducing solely the solar dynamo solution, which can be obtained by a wide variety of parameter combinations and with very different dynamo models (compare e.g. Käpylä et al. 2006; Guerrero & de Gouveia Dal Pino 2008).
One recent observational finding with far-reaching implications for dynamos was obtained by Wright & Drake (2016). They studied the X-ray luminosity of slowly rotating, fully convective main-sequence stars, and compared the activity level with a sample containing solar-like main-sequence stars. The former class of stars cannot possess layers of strong shear in the transition region between the radiation and convection zones, called tachocline. The latter class, to which the Sun belongs, will most likely exhibit such layers, verified by helioseismology for the Sun. Both classes were concluded to exhibit very similar levels of magnetic activity, and its dependence on rotation is also nearly identical. Together with the recent modelling results discussed above, highlighting the importance of turbulent processes, these findings cast doubt on the role of the tachoclinic shear layers alone being decisive for stellar dynamos.
Crucial sources of information to determine stellar cycles are long-term datasets monitoring the magnetic activity level and its variability in stars. To detect a solar-like cycle, however, such monitoring should be performed over decades, narrowing down the number of useful datasets to a very few. Such datasets are available in photometry, for example the Tennessee State University T3 photometry since 1987 (Henry et al. 1995), the Vienna photometry since 1991 (Strassmeier et al. 1997), and the ASAS photometry since 1996 (Pojmanski 1997), as well as in chromospheric line emission. Of the latter, the Mount Wilson (MW) chromospheric Ca H&K sample has been one of the main datasets to study stellar activity cycles for decades, attracting attention up to the present day (see e.g. Noyes et al. 1984; Baliunas et al. 1995; Brandenburg et al. 1998, 2017; Saar & Brandenburg 1999; Böhm-Vitense 2007; Oláh et al. 2016; Metcalfe et al. 2016; Boro Saikia et al. 2018).
A basis for many of these studies, concentrating on the dependence of stellar cycles on the stellar parameters, is the magnetic period determination undertaken in Baliunas et al. (1995; hereafter Cyc95) using the Lomb-Scargle (LS) method. While the aim in Cyc95 was to detect periods stable over the whole dataset length, Oláh et al. (2016) used short-term Fourier transform to detect locally active periods. Many studies have attempted to find dependencies of the cycle length or the ratio of cycle length to rotation period as function of some stellar activity measure; in this study we concentrate on the latter type of dependency, which we label as Rotation period-to-Cycle length Ratio-Activity (RCRA). By using these quantities one aims at removing the dependence of the cycle length on the poorly known convective turnover time τ, as originally pointed out by Tuominen et al. (1988). Many studies, however, bring back this dependence by considering the Rossby (or Coriolis) number instead of an independent activity measure (e.g. Saar & Brandenburg 1999). As the activity indices themselves are correlated with rotation, some studies rely on even simpler statistics by plotting cycle length vs. the rotation period (e.g. Böhm-Vitense 2007); we have also studied these diagrams and denote them with Cycle length-Rotation period (CR) diagrams.
Brandenburg et al. (1998) were the first to report on the existence of two different linear branches with positive slopes in RCRA diagram, dividing the stars into two groups depending on their activity index, based on the Cyc95 period analysis. A third branch of super-active stars with a negative slope was identified by Saar & Brandenburg (1999), by combining the cycle length estimates from the MW sample with estimates from photometric and other studies. They had to resort to diagrams with Rossby numbers on the abscissa due to the non-existence of chromospheric activity indices for the super-active stars. Böhm-Vitense (2007) found positive linear scalings in the CR diagram of the Cyc95 data, and observed that the Sun is a peculiar case lying in between the branches. Similarly, Metcalfe & van Saders (2017) studied data from various sources, including MW and Kepler targets and showed two different linear relationships in a CR diagram. By analysing the extended MW sample using a generalized Lomb-Scargle method (GLS), Boro Saikia et al. (2018) no longer find the Sun being an outlier, and claim that the active branch is caused by a selection effect arising from the upper and lower limit of cycle lengths.
These positive “detections” of branches are accompanied with many “non-detections” even when the same data is used (compare e.g. the results of Baliunas et al. 1996; Brandenburg et al. 1998). Most often the negative detections, however, come from different datasets. The other sources that have long enough time extents are photometric time series. If long enough, usually results consistent with the MW sample are obtained (see e.g. Lehtinen et al. 2016). However, in Distefano et al. (2017), where a photometric sample of 49 nearby main-sequence (MS) stars from the ASAS campaign with the extent of roughly ten years were analysed, no correlation between cycle length and rotation period was found. This has been explained by the hypothesis that these stars are mostly belonging to the transitional region between the active and superactive branches. Neither was in the study of Kepler stars by Reinhold et al. (2017) detected any functional dependence between these quantities. This was in turn explained by the hypothesis that on the active and superactive branches the stars show less signatures in their photosphere thus not detected using Kepler data.
The aim of this study is to re-analyse the recently released extended MW dataset with different kinds of probabilistic period search methods of increasing complexity. We investigate the reliability of the earlier determinations with a strictly harmonic model, and the overall limitations related to retrieving cycle lengths from datasets the extent of which is in the same order of magnitude as the desired cycles. We start the cycle search with a bayesian generalised Lomb-Scargle periodogram with trend1 (BGLST) introduced in Olspert et al. (2018; Paper I). Then we explain the necessity of including the trend component directly into the model as opposed to detrending the data beforehand or leaving the data undetrended. Next we apply more complex, periodic and quasi-periodic Gaussian process (GP) models to the data, construct the RCRA and CR diagrams for the subset of stars with known rotational period, and as the last step, we apply the Gaussian mixture model (GMM) to it. We show that two activity clusters describe the data better than one or three.
In the next section we shortly describe the MW dataset and how we pre-processed it before starting the analysis. After that we will discuss the points which led us to the simplest model, that is, the harmonic model with trend. Subsequently we briefly discuss the issue of rotational period removal from the data and then turn to the description of the regression models. In the end we discuss the significance of the results to the theory.
2. Data and pre-processing
In the current study we analyse the dataset of one of the chromospheric activity proxies known as MW Observatory S-index2. Its definition can be found for example in Egeland et al. (2017). The MW dataset being recently made publicly available contains time series of more than 2300 objects including the Sun, 137 of which were monitored for more than ten years, and are therefore suitable to be used in this study. The time span of the observations is ranging for most of the stars from years 1966 to 1995 while for 35 of the stars up to the year 2001.
For some stars, however, the full range of observations was unsuitable for use. Namely, a closer look at the raw data revealed some possibly erroneous measurements, including full observing seasons potentially biased and other abrupt systematic changes in the data. To eliminate these problems we preprocessed the time series of 13 stars by omitting the corresponding measurements. From all the time series we further omitted all data points residing farther than 4σ distance from the sample mean. In the case of the Sun we used a hybrid dataset combined from the MW S-index dataset and the Sacramento Peak Ca K observations transformed into the same scale as the MW S-index. We used the scaling SSac = 2.61KSac − 0.0647 for the Sacramento Peak data, which we determined as a linear fit onto coeval solar observations from MW and Sacramento Peak.
To make the computations feasible for GP models, we further downsampled the datasets to keep only one data point per every ten days from the original dataset. We tested that this had negligible effect on the results, which is expected as we are estimating cycle periods starting from 2 yr and up. For the harmonic model, however, no downsampling was used.
3. Finding the lengths of the activity cycles
In the current work we use the so called effective methods to estimate the cycle lengths. Such methods do not solve for any physical model directly, but describe the behaviour of the system with functions that depend on a certain set of parameters, that in turn have a relation to the physical quantities, such as rotation period or activity cycle length of a star.
First thing to notice is that the time series of stellar activity proxies cannot be assumed to be strictly periodic. The most clear evidence of deviation from pure periodicity can be seen for instance in the 11 yr cycle of the Sun. This is commonly interpreted as the solar dynamo behaving in a similar manner as a nonlinear oscillator in a quasi-periodic regime. This can be verified when solving for the dynamics together with the dynamo equation, when the frequency and amplitude become correlated (Waldmeier rule), and also the rise and fall times of the cycle are different (for one of the earliest examples, see Yoshimura 1978). The stellar dynamos have no reason to be any less nonlinear – on the contrary, the nonlinearities can be expected to be stronger in more active stars. From this perspective, for modelling the datasets, it would be preferable to use quasi-periodic models over the periodic ones, however the stellar activity datasets currently available span maximally several decades, limiting the count of observed cycles to very low numbers. It opens the question whether fitting the more complex GP models is feasible to the given data or should one restrict to a harmonic model. We will discuss the related issues in Sect. 3.3 and get some empirical evidence of usefulness of the quasi-periodic GP model in Sect. 3.4.
As an alternative to the GP methods we mention yet another effective method developed for cycle search, namely the D2 phase dispersion statistic (Pelt 1983). When used with variable coherence length this method is suitable for time series with slowly changing period or modulated phase and amplitude. We have previously applied this method to estimate the rotational period of the young solar analogue LQ Hya (Olspert et al. 2015) and magnetic activity cycles in multidimensional magnetohydrodynamic simulation data (Olspert et al. 2016). We did not consider using the given method here though, as the D2 statistic in the given formulation would not allow us to incorporate a trend. We will, however, want to avoid detrending the data beforehand due to the possible issues discussed below.
Different past studies have handled the MW dataset slightly differently. In Cyc95 the cycle lengths were calculated using the LS periodogram (Lomb 1976; Scargle 1982) with detrending in case of need, while in Oláh et al. (2016) time-frequency analysis methods were used to extract locally persistent periods from the data. In the latter study only the stars with long and continuous observations (no gaps in the seasons) from the MW sample were used. The selection criteria remain fully unclear though, as the majority of these stars have well determined cycle periods from Cyc95. The methods in these two studies contrast significantly as Cyc95 is primarily dedicated to analysing stationary, but Oláh et al. (2016) to nonstationary time series, that is, finding globally persistent vs. local periods respectively.
Our aim is to focus on an approach similar to Cyc95 and we start the analysis with the method as simple as possible. Most obvious choice for that would be a harmonic model similar to GLS periodogram (Zechmeister & Kürster 2009), as was used in the study of Boro Saikia et al. (2018). However, closer look at the MW data reveals apparent trends in case of many stars in the sample. This opens up the question whether we should remove the linear trend before the period search or leave the data undetrended. In Paper I we address this question more thoroughly and give empirical evidence that similarly to why the GLS method is preferred over the approach consisting of first centring the data and then applying the LS method, it is advantageous to directly include linear trend component into the regression model rather than doing detrending followed by application of any period search method. The opposite also holds – leaving the data undetrended before doing the period search is generally less beneficial, compared to the model including the trend component.
Returning to the discussion of the MW dataset, it is hard to say if the apparent trends are real, caused for example by instrumental effects, or are they actually manifestations of very long cycles or even both. While the last explanation may seem more likely as the trends vary from dataset to dataset, answering this question fully is difficult and, in fact, is not strictly necessary. Instead we find a workaround to this problem by using the BGLST method. This way by optimizing the parameters we assume that the best estimate for the trend will be automatically inferred from the data. Before moving to the regression models used in cycle detection we add a couple of remarks about removing the rotational signal from the data.
3.1. Removing the rotational signal
The estimation of the rotational period being a complicated task enough is not part of the current study and we leave the details of it for an upcoming paper. Here we just mention that the estimates were obtained by fitting the periodic GP to individual observing seasons and refining these estimates using the Continuous Period Search (CPS) method (Lehtinen et al. 2011). This procedure gave us robust error estimates for the rotation periods and allowed us to assess their reliability. We only accepted period estimates from those stars where the CPS produced reliable fits that agreed with the GP periods. For a handful of objects, the rotation periods were refined w.r.t. previous studies, and for a few stars with no previous period detections, rotation periods were obtained. For the current study these refinements are of minor importance, and therefore not discussed here any further.
Before the activity cycle search, we removed the rotational signal from the data using the following procedure: We first removed the slow trends from the data by fitting a GP with squared-exponential kernel with a time-scale3 of 1 yr. Then we calculated GLS periodograms and performed spectral cleaning in the narrow band of frequencies around the known rotational period using 99% significance level (more about cleaning in the next section). Finally we added back the slow trend model. The calculations showed that the reduction of variance in most cases was only couple of per cents, but in the best case as high as 39% for the stars HD 68290 and HD 32008.
3.2. BGLST model
As the simplest case we decided to use the BGLST method (for more detailed discussion see Paper I), which is defined as the following regression model:
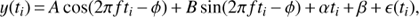 (1)
(1)
where 𝓎(ti) and ϵ(ti) are the observation and noise at time ti, f = 1/P is the frequency of the cycle, A, B, α, β are the parameters to be optimized but φ is set to a frequency dependent value such that the orthogonality of the cos and sin functions on a nonuniform set of ti is guaranteed (see Mortier et al. 2015). We assume that the noise is Gaussian and independent between any two time moments, but we do not assume the constancy of variances. For parameter inference we use the Bayesian model, where the marginal posterior probability for frequency f is given by
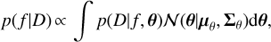 (2)
(2)
where p(D| f, θ) is the likelihood of the data, θ = [A, B, α, β]⊤ and 𝓝(θ|μθ, Σθ) is their Gaussian independent prior distribution. For the frequency f we use a uniform prior. The likelihood is given by
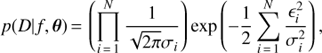 (3)
(3)
where N is the number of data points, ϵi = ϵ(ti) and 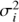 is the noise variance at ti.
is the noise variance at ti.
The derivation of a closed formula for the spectrum Eq. (2), the selection of priors for θ, the error and significance estimation of the optimal period are discussed in more detail in Paper I. Here we only make some comments about particular approaches used in the current study. We followed the spectral cleaning procedure similar to Roberts et al. (1987) until no more significant peaks were found and we claim significant all the peaks which satisfy the following quite strong criteria:
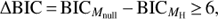 (4)
(4)
where Mnull is the linear model without harmonic MH is the BGLST model, 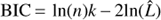 is the Bayesian Information Criterion (BIC), n is the number of data points, k the number of model parameters and
is the Bayesian Information Criterion (BIC), n is the number of data points, k the number of model parameters and 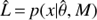 is the likelihood of data for model M using the parameter values that maximize the likelihood.
is the likelihood of data for model M using the parameter values that maximize the likelihood.
Due to the nonuniformity in the average sampling frequency in the data (in most cases the subset of data spanning until the year 1980 is much more sparse compared to the later subset), the values of BIC were not calculated for the original data, but instead for the seasonal means. This way we reject the models whose harmonic parts fit well only those regions of the data, which are more densely populated (moreover we avoid finding only locally stable periods).
When all the harmonics are extracted, we calculate once more the spectra separately for each of them and assume them to represent true probability distributions. One can then fit the Gaussian to the spectral line to estimate the error of the frequency (Bretthorst 1988, Chapter 2.4). This technique is known as Laplace approximation. However, we take the simpler path and calculate the proxy for the error estimate as ![Mathematical equation: $$\sigma _f^2 = \mathbb{E} [{(f - {f_{{\rm{opt}}}})^2}] = \int {{{(f - {f_{{\rm{opt}}}})}^2}} p(f|D,{M_{\rm{H}}}){\rm{d}}f$$](/articles/aa/full_html/2018/11/aa32525-17/aa32525-17-eq9.gif) , where fopt is the optimal frequency found for the harmonic4. This is just an estimate of the variance assuming that the mean coincides with the optimal frequency.
, where fopt is the optimal frequency found for the harmonic4. This is just an estimate of the variance assuming that the mean coincides with the optimal frequency.
In our analysis we did not assume constant noise variance, but took the seasonal variances (after removal of the rotational signal) as the estimate for the noise variances of data points belonging to the corresponding seasons. What favoured us using this kind of a noise model was the evidence of highly variable scatter of data in different observing seasons. More precisely if 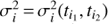 is the empirical variance of the ith observing season starting at ti1 and ending at ti2 then the noise variance
is the empirical variance of the ith observing season starting at ti1 and ending at ti2 then the noise variance 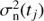 of a data point at time tj satisfying
of a data point at time tj satisfying 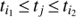 is set to
is set to 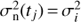 . For the seasons which had less than ten data points we used the variance of the full sample. The given approach still leads to a slight overestimation of the noise variance as seasonal segments also contain some part of the long term variations, but we consider this fact negligible to the results.
. For the seasons which had less than ten data points we used the variance of the full sample. The given approach still leads to a slight overestimation of the noise variance as seasonal segments also contain some part of the long term variations, but we consider this fact negligible to the results.
In Fig. 1 we show the difference between the period estimates for the star HD 37394 using the BGLST model introduced above and models with harmonic component only (GLS), with and without de-trending. More examples with synthetic data can be found in Paper I. It is important to note that the linear trend fitted directly to the data significantly differs from the trend component estimated from the BGLST method and it is clear that all three period estimates slightly differ. For the reasons explained in Paper I, we assume, that the estimate from the BGLST method is the most reliable of the three.
 |
Fig. 1. Comparison of the results for the star HD 37394 using BGLST model and GLS models with and without detrending. Panel a: data (black crosses), BGLST model (red continuous curve), GLS model fitted to detrended data with trend added back (blue dashed curve), GLS model fitted to the original data (green dash-dotted curve), trend component of the BGLST model (red line) and empirical trend (blue dashed line). Panel b: spectra of the models with the same colours. Vertical lines mark the locations of the corresponding maxima. |
3.3. GP models
We now turn from fully harmonic models to more complex ones, carried by the idea that due to nonlinearities magnetic cycles of active stars may neither be fully harmonic nor even periodic. One way of effectively describing any kind of time series is to use a GP model with a suitable covariance function.
A GP is a collection of random variables which have a joint Gaussian distribution and it is fully specified by its mean m(x) and covariance k(x, x′) functions (Rasmussen & Williams 2006). GP is written as
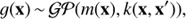 (5)
(5)
where
![Mathematical equation: $$\matrix{ {m\left( x \right)} & = & \mathbb{E} {\left[ {g\left( x \right)} \right]),} \cr {k\left( {x,x'} \right)} & = & \mathbb{E} {\left[ {\left( {g\left( x \right) - m\left( x \right)} \right)\left( {g\left( {x'} \right) - m\left( {x'} \right)} \right)} \right].} \cr } $$](/articles/aa/full_html/2018/11/aa32525-17/aa32525-17-eq15.gif) (6)
(6)
In our case the input vector x is one dimensional time t and the value of S-index 𝓎i at time ti corresponds to the noisy observation of the function value ℊ(ti), that is, 𝓎i = ℊ(xi) + ϵ(ti). We also take the mean function to be constant, that is, m(t) = μ. If we denote the vector of observations as y = [𝓎1, 𝓎2, …, 𝓎N]⊤, then
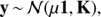 (7)
(7)
where 1 ∈ ℝN is the vector of all ones and K ∈ ℝN × N is the covariance matrix, whose elements are 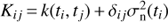 . Here δij is the Kronecker delta and
. Here δij is the Kronecker delta and 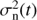 is the noise variance.
is the noise variance.
In the context of stellar rotation period estimation and variable star light curve fitting, GPs have recently been used more extensively (see e.g. Wang et al. 2012; McAllister et al. 2017; Grunblatt et al. 2015; Angus et al. 2018; Littlefair et al. 2017).
Now we turn to the question of selecting the covariance function k(t, t′). The next logical step from fully harmonic models towards more complex ones is to drop the assumption of strict harmonicity but to allow other types of waveforms. In this case the GP model would be periodic with 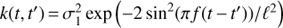 , where
, where 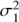 , ℓ and f = 1/P are the variance, time-scale and frequency. However, due to the reasons discussed in Sect. 3 we further add to the model the linear trend component. The full covariance function is then given by
, ℓ and f = 1/P are the variance, time-scale and frequency. However, due to the reasons discussed in Sect. 3 we further add to the model the linear trend component. The full covariance function is then given by
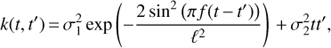 (8)
(8)
where 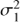 , ℓ and f = 1/P are the variance, time-scale and frequency of the periodic component,
, ℓ and f = 1/P are the variance, time-scale and frequency of the periodic component, 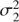 is the variance of the trend component. The time-scale ℓ in the equation defines how much the form of the signal can deviate from the sine wave. The longer ℓ the more harmonic the process is and vice versa.
is the variance of the trend component. The time-scale ℓ in the equation defines how much the form of the signal can deviate from the sine wave. The longer ℓ the more harmonic the process is and vice versa.
Another generalization towards nonharmonic models would be to assume that the process is only locally harmonic, or in other words the covariance function has the form of a harmonic with some damping term. One of the options for such a model would be to use a GP with covariance function given by
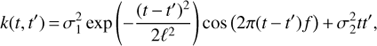 (9)
(9)
where 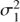 , ℓ and f = 1/P are the variance, time-scale and frequency of the quasi-periodic component and the meanings of the other hyperparameters are the same as in Eq. (8). The first term in the equation is a truncated case of a more general quasi-periodic covariance function5. This particular simplification was made for the reason to avoid giving too much freedom to the model by reducing the number of parameters by one. The time-scale ℓ in the equation defines how coherent the process is. Again, the longer ℓ the more harmonic the process is and vice versa. The main difference between the two GP models is that the first one describes a strictly periodic process, but possibly having a non-sinusoidal shape, while the second one describes a locally harmonic process. However, in the latter case, if ℓ is shorter than f the process is dominated by red (locally correlated) noise having no strict period at all.
, ℓ and f = 1/P are the variance, time-scale and frequency of the quasi-periodic component and the meanings of the other hyperparameters are the same as in Eq. (8). The first term in the equation is a truncated case of a more general quasi-periodic covariance function5. This particular simplification was made for the reason to avoid giving too much freedom to the model by reducing the number of parameters by one. The time-scale ℓ in the equation defines how coherent the process is. Again, the longer ℓ the more harmonic the process is and vice versa. The main difference between the two GP models is that the first one describes a strictly periodic process, but possibly having a non-sinusoidal shape, while the second one describes a locally harmonic process. However, in the latter case, if ℓ is shorter than f the process is dominated by red (locally correlated) noise having no strict period at all.
Next thing we need to do is to select suitable prior distributions for the hyperparameters σ1, σ2, f, ℓ. This can generally be a difficult task, especially when there is only a small number of data points available. Typical of period search problems is that the likelihood of the data as function of f (but not only) tends to be highly multimodal so that the hyperparameter optimization task becomes extremely difficult. To overcome this problem and reduce the computational complexity, different approximations were proposed in Wang et al. (2012). An alternative possibility, which we will use here, is to narrow down the hyperparameter search space by considering informative priors. In Angus et al. (2018) the authors set the GP prior as a multimodal distribution with candidate periods chosen by calculating the autocorrelation function of the light curve. In our case, however the spectra in the regions of interest are relatively smooth, because we are looking for the very long cycle periods. Thus, it suffices to assign significant probability mass to the region of frequency from 0 to 0.5 yr−1 (see Eq. (10)).
Yet another difficulty with applying the quasi-periodic model comes from the fact that the lengths of the datasets compared to the cycle periods are relatively short. Our tests showed that the model tends to prefer solutions with small ℓ where the squared-exponential factor in the first term of Eq. (9) dominates over the harmonic factor. On the contrary, we would be interested in finding only solutions where the harmonic factor is dominating as we are assuming the cyclic nature of the time series after all. Therefore, we used total variance of the data instead of seasonal variances as the noise variance in the model and set a prior for ℓ satisfying 1/ ℓ ∼ Half Normal (0, f /3). These two measures regularise the model towards smoother solutions with longer length scales. After the optimal hyperparameters ℓopt and Popt are found we further reject all the models where ℓopt < Popt. In the case of periodic GP model we imposed a less restrictive prior on ℓ, namely 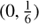 . This selection was made to suppress time-scales that are much shorter than 2 yr (3σ of the Gaussian being set equal to 0.5 yr−1).
. This selection was made to suppress time-scales that are much shorter than 2 yr (3σ of the Gaussian being set equal to 0.5 yr−1).
The priors for the remaining hyperparameters are
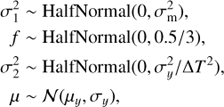 (10)
(10)
where 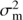 is the variance of the seasonal means,
is the variance of the seasonal means, 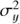 is the total variance of the data, ΔT is the time span of the observations,
is the total variance of the data, ΔT is the time span of the observations, 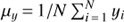 . The selection of priors for f and ℓ was discussed above, but for the other hyperparameters we selected the given informative priors to concentrate the probability density at the places where it intuitively makes the most sense. For strictly positive parameters we used the positive half of the Gaussians. The distribution of the signal variance
. The selection of priors for f and ℓ was discussed above, but for the other hyperparameters we selected the given informative priors to concentrate the probability density at the places where it intuitively makes the most sense. For strictly positive parameters we used the positive half of the Gaussians. The distribution of the signal variance 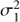 was scaled with the variance of the seasonal means
was scaled with the variance of the seasonal means 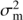 as we assume the cyclic signal to be visible primarily in the inter-seasonal variation. The prior for the trend variance
as we assume the cyclic signal to be visible primarily in the inter-seasonal variation. The prior for the trend variance 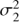 we scaled according to the rough empirical estimate of the slope the data. For the mean μ we set the expected value to the empirical mean of the S-index values and its variance equal to the empirical variance of the data.
we scaled according to the rough empirical estimate of the slope the data. For the mean μ we set the expected value to the empirical mean of the S-index values and its variance equal to the empirical variance of the data.
For modelling and parameter inference we used the statistical library Stan6. Due to limited computational resources we drew a relatively low number of 12 800 samples from the joint posterior distribution of the parameters, from which first 6400 were disregarded. Tracking the number of effective samples returned by the library we concluded that this was, however, sufficient for our purposes. The error estimate for the period we calculated as the standard deviation of the Gaussian fit to the mode of the empirical posterior distribution obtained from sampling. We ran the sampler several times to minimize the possibility that the hyperparameter estimates would correspond to the local instead of the global optimum. This can happen as for multimodal distributions it is not guaranteed that the sampler explores the neighbourhood of all the modes.
To estimate the significance of the cycles periods retrieved by the GP models one should use red noise models, such as the GP with squared exponential covariance function as a null hypothesis. Then one can show whether the given harmonic, periodic or quasi-periodic model truly holds or the data is drawn by pure chance from the red noise process. However, due to the high observational noise level, the extreme shortness and potential multicyclic nature of the data, this kind of model selection leads to very low number of detected cycles. Therefore we must conclude that one cannot reliably prove that the repeating patterns in the data truly correspond to cyclic behaviour no matter which type of waveform (harmonic, periodic, quasi-periodic) is assumed. This also holds for the solar dataset, manifesting that data of similar quality spanning over equally long time span w.r.t. the cycle count also yields insignificant cycle detection, while over longer time spans the cyclicity of its behaviour is well established. As stars, in analogy to the Sun, are highly chaotic nonlinear oscillators, we expect that the same is true for them, that is, the significance of the cyclicity over correlated noise can be established only with extended datasets.
As such extended datasets are not available, we estimate the significance of the retrieved cycles from the GP models using a similar approach that is commonly accepted in harmonic period estimation. We take a GP model with a bilinear kernel given by the last term in Eq. (9) using leave one out crossvalidation (LOO-CV) on seasonal chunks. However, in the quasiperiodic case we do report whether the cycle is significant also w.r.t. to the red noise model. LOO-CV was chosen as the Bayes factor (and therefore also BIC) is not recommended for nonparametric models due to being sensitive to prior definitions (Vehtari & Ojanen 2012, Chapter 5.6).
Measure of nonharmonicity. For the quasiperiodic GP model the period is not anymore constant. To quantify the measure of nonharmonicity of the cycle we calculated the so called period spread, which we will denote by σP. This quantity reflects how much the period can on average deviate from the mean value, given that the time-scale ℓ is known exactly. In frequency domain this quantity is defined as the square root of 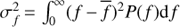 , where
, where 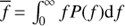 and P( f ) is the normalised power spectrum of the process (see e.g. Cohen 1995). As according to Wiener–Khinchin theorem the power spectrum of the stationary process is the Fourier transform of its covariance function, for our model σf is inversely proportional to ℓ.
and P( f ) is the normalised power spectrum of the process (see e.g. Cohen 1995). As according to Wiener–Khinchin theorem the power spectrum of the stationary process is the Fourier transform of its covariance function, for our model σf is inversely proportional to ℓ.
3.4. Tests with quasi-periodic GP
From now on we use shorthand H for harmonic, P for periodic GP and QP for quasi-periodic GP models. To check the performance of the proposed QP model we first made some experiments with synthetic data. For that reason we drew realizations from the GP with cosine covariance function with squared-exponential damping term added with a linear trend as given by Eq. (9). We varied the S/N ratio in the range from 0.25 to 4, cycle period from 2 yr up to the 2/3 of the duration of the dataset and time-scale ℓ from half of the cycle period up to four cycle periods. We used a sampling similar to the sampling of the real data. For each dataset we first estimated the cycle period using the harmonic model, then we downsampled the data in a way as described in Sect. 2 and fitted QP model.
The first observation we made from the experiments was that ℓ could not be very reliably estimated, especially when the true value was longer than the total duration of the dataset. For shorter time-scales at least the order of magnitude of the estimate was adequate. It turned out, however, that this was sufficient for the QP model to yield more precise period estimates compared to the ones from H model.
As a diagnostic we choose the relative error of the frequency estimate Δ= | fest − ftrue|/ ftrue, where fest is the estimated cycle frequency and ftrue is the true cycle frequency. For each value of ℓ less than a chosen limit we calculated the relative errors for both QP and H estimates ΔGP and ΔH and their corresponding mean values over the set of experiments denoted by 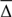 .
.
From Fig. 2a we see that, on average, the estimate from QP is more accurate than the one from H, but this difference decreases towards the longer time-scales. This is easy to understand, as the signals with longer time-scales are more harmonic. Similarly from Fig. 2b we see that the fraction of experiments where the period estimates from QP were more accurate than the estimates from H is larger than 50% for time-scales in the range from 0.5 to 5. In Fig. 2c we show the average relative errors of period separately for QP (red continuous curve) and H (blue dashed curve) models. Again we see that the QP outperforms H, while the difference is more pronounced for short time-scales than for very long ones. The reason why relative errors are large even for the longer values of ℓ (always above 10%) could be explained by the biased estimates in the experiments with low S/N ratio and/or bad sampling.
 |
Fig. 2. Diagnostics of the experiments comparing QP and H models. Panel a: ratio of average relative errors, panel b: fraction of experiments where GP outperformed harmonic model, panel c: relative errors of QP (red continuous curve) and H (blue dashed curve) models. |
From the experiments we conclude that in the case of not strictly harmonic processes and regardless of the datasets being extremely short, one can use QP model to obtain more accurate period estimate compared to the estimates from the fully harmonic model. This is regardless of the fact that for the QP model downsampled datasets were used. This observation motivated us to actually use the QP model on real data. We did not repeat the tests with the periodic covariance function, believing that the results differ less compared to the harmonic model, especially when the true process is quasi-periodic.
We note that in these experiments, both the form of the true covariance function and the one used in the QP model coincided. In practice, however, the form of the true covariance function is usually unknown and can only be guessed based on some physical arguments. Drawn from the arguments given in the beginning of Sect. 3, we have a strong belief that a more natural choice for modelling time series of stellar activity would be with quasi-periodic covariance function rather than with harmonic or periodic ones. Which exact form of the quasi-periodic covariance function to use depends, however, on the situation. In our case, as we briefly commented above, we decided to keep the covariance function as simple as possible, building it up from the widely used squared-exponential damping and cosine terms. We did not consider other forms of the damping term, but one of the well known alternatives would be given by exp(−|t − t′|/ℓ). It has the desirable property of the computational cost of fitting the model scaling linearly with the number of data points (Foreman-Mackey et al. 2017). We did not consider using this approach, however, because we needed to incorporate the linear trend into the model as an additional component.
In the experiments with synthetic data we knew the true cycle frequencies which allowed us to calculate the actual errors. In Sect. 4 we give error estimates for the real datasets, which are calculated as the standard deviations of the highest modes of the posterior distributions. One could expect these quantities to give information on the possible values of the true errors, however, due to additional uncertainties (e.g. whether the process can be assumed to be Gaussian and the form of the covariance function is correct) in practice the errors are most likely underestimated.
4. Results
When analysing the real datasets we rejected all the cycle lengths (regardless of the significance level) below two years or longer than 2/3 of the total time span of the dataset. The reason for the lower limit comes from the arguments related to the seasonal sampling patterns in the data as well as from the need to avoid falling into the domain of rotational periods of the stars. The longest known rotational period in our dataset is around 163 days, but for some of the stars the estimate is missing. Setting the lower limit prohibits us from finding for example the 120 days cycle of τ Boo reported by (Mittag et al. 2017; Jeffers et al. 2018; clearly distinct from its Prot = 3.07 days rotation period), but it is a necessary constraint for performing a uniform cycle search for all the stars in our sample. The upper limit was fixed for the sake of not making too light conclusions on the existence of long cycles. Obviously by using the given period search range we also fail to detect very long cycles. However, as even in the best cases we see only a couple of full cycles, all the given estimates, especially those with lower significance level, should be taken with some caution. Only future observations can make the estimates of these cycles more accurate.
4.1. Summary of the cycles
In summary, we find 61 stars with cycles (hereafter class C), the cycle periods, with their error estimates and significances for all the three methods used here being gathered into Table 1. In addition, we find 26 stars with trends (hereafter class T), that may represent cycles longer than can be reliably detected from the current data. The sample contains 49 noncyclic stars (hereafter class NC) that do not show any trend either. Stars in classes T and NC are not listed in any table, but they are included in the plots in Fig. 3.
Stars with cycles agreeing with either harmonic or GP models.
 |
Fig. 3. Panel a: ratio of total variance to average seasonal variance vs. log |
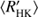
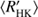
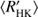
A measure of total variability of the stars is shown in Fig. 3a. We define total variability as the ratio of total variance σ2 and average seasonal variance 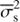 . The idea of this plot is to indicate how much irregular inter-seasonal variability occurs in the stars; constant noise level would be manifested by this quantity being close to one. The less active stars belonging to class NC all cluster close to the value of one, or slightly above, and only weak scatter is observed. The more active stars of class NC exhibit larger values (between 1 and 2) of total variability (even up to 3), and show much larger scatter. A linear fit to all stars in class NC (shown with a dashed line) clearly demonstrates this behaviour. We interpret this as the active stars having significantly increased tendency to show irregular variability, that cannot be detected nor characterised with the available statistical toolboxes from the given data.
. The idea of this plot is to indicate how much irregular inter-seasonal variability occurs in the stars; constant noise level would be manifested by this quantity being close to one. The less active stars belonging to class NC all cluster close to the value of one, or slightly above, and only weak scatter is observed. The more active stars of class NC exhibit larger values (between 1 and 2) of total variability (even up to 3), and show much larger scatter. A linear fit to all stars in class NC (shown with a dashed line) clearly demonstrates this behaviour. We interpret this as the active stars having significantly increased tendency to show irregular variability, that cannot be detected nor characterised with the available statistical toolboxes from the given data.
In the light of dynamo theory, the less systematic behaviour of the active stars could simply be interpreted as their dynamos operating in a more supercritical regime, assuming that the field generators are increasing in magnitude as function of rotation, therefore showing a tendency for more complex solutions, as proposed by Durney et al. (1981). Class C stars do not show any clear trends in Fig. 3a, but the overall scatter of points is higher than for NC stars indicating the fact that strong inter-seasonal variations are always explained by cyclic, not irregular behaviour. The largest variability is seen for the C stars that are located in the mid-range of 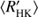 , where the overall density of stars is significantly decreased (see next paragraph).
, where the overall density of stars is significantly decreased (see next paragraph).
We also plot the histograms of all the stars, and separately for classes C and T, over log 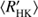 in Fig. 3b. We clearly see that the distribution of all the stars in this sample is bimodal, there being a clear minimum around the activity index value −4.8. This “gap”, which is not totally void of stars, divides them into two populations, a distribution with active and inactive stars. The minimum seen corresponds to the Vaughan–Preston gap (VPG), that is the decreased abundance of stars in a certain range of the chromospheric activity index (Vaughan & Preston 1980). The Sun with log
in Fig. 3b. We clearly see that the distribution of all the stars in this sample is bimodal, there being a clear minimum around the activity index value −4.8. This “gap”, which is not totally void of stars, divides them into two populations, a distribution with active and inactive stars. The minimum seen corresponds to the Vaughan–Preston gap (VPG), that is the decreased abundance of stars in a certain range of the chromospheric activity index (Vaughan & Preston 1980). The Sun with log 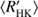 ≈−4.911 is located nearby the region of the minimum (or gap). We note that in the larger catalogue of nearly 4500 chromospherically active stars, compiled by Boro Saikia et al. (2018), the VPG is, however, much less pronounced.
≈−4.911 is located nearby the region of the minimum (or gap). We note that in the larger catalogue of nearly 4500 chromospherically active stars, compiled by Boro Saikia et al. (2018), the VPG is, however, much less pronounced.
Comparing the relatively low probability to find either C or T stars among the inactive stars with the distribution of all the stars, we can conclude that NC stars form the major part of the inactive population. Class C shows an opposite trend: there is an increased probability to find a cyclic star close to the gap in the active population than elsewhere. However, as stated before, more prominent cycles seem to appear near the “gap”. Also, the active population shows more stars with a trend, indicative of the presence of many undetectable long cycles in this population. In that sense, the cycles discussed later on for this population might not be truly indicative of these stars, but their cycles need even longer time spans to be detected properly.
4.2. Comparison with Cyc95
Next we turn into more detailed comparison of the cycle length estimates found in the current study to those of Cyc95. We note here that the stars excluded from Table 1 have no cycles detected from neither of the studies and the datasets, for which we have ten additional observing seasons compared to Cyc95, are highlighted using boldface font in the first columns of this table. For the rest of the datasets we have only four additional seasons.
The first observation we make is that the cycle estimates for the stars, which Cyc95 classified having “excellent” cycle grades, agree reasonably well between both studies. Small discrepancy can be found only for the star HD 152391 where there were two cycles detected in our study, but neither of them matches the single estimate from Cyc95. Here we note, however, that the difference can be explained by the fact that for the given star ten years longer dataset was available to us.
For stars with “good” grades, we find many more discrepancies between the results. The extreme case is HD 115404, for which no cycle was detected at all from our study. Here again our dataset was ten years longer compared to the older study. Another significant discrepancy takes place for HD 3651, where the cycle period from H is longer (however, the QP estimate is shorter). In Cyc95 the trend was removed beforehand, while in our case it is fit to the data simultaneously with the harmonic component.
Next we proceed to the comparison of stars with “fair” grade. For them we see agreement in only one occasion, namely for HD 165341A do the estimates coincide. Mostly there is neither a cycle detected from our methods or the estimated cycle lengths are differing. The reason for the former is that we used a rather strong significance level and rejected all weak estimates. There is one exception here, namely HD 18256, in which case H did not detect the cycle, but the estimates from P and QP match well with the estimate from Cyc95.
Lastly, for none of the “poor” cycles except for HD 37394 did we find a cycle using H, but even in this case the estimated cycle lengths are differing. Interestingly, QP in this case detected very close value to the one from Cyc95, however, in most of the other cases the GP estimates strongly differ from Cyc95 as well.
The number of double harmonics found from both of the studies is different. There are total of nine stars reported in Cyc95 with double harmonicity, but excluding the stars with poor cycle estimates, this number reduces to 5, which matches the number of double harmonics found in our study. However, none of the stars with double periodicities match, indicating that the treatment of the trends and the inclusion of new data have altered the picture of double periodicities very significantly. Therefore, these earlier detections appear unreliable. The most striking disagreement is found for HD 149661. In the previous study there were two good cycles found, but no significant cycles from H at all in the current study, where we had ten years longer dataset available. There is an estimate found from P, but this is not agreeing with neither of the estimates from Cyc95. Furthermore there is a star HD 155886 with double cyclicity detected in the present study with no clear cycle from Cyc95, although there was a remark made on the presence of significant variability in the data.
Another difference between the studies is that the frequencies of double harmonics found in Cyc95 form irrational ratios, while in our study they tend to form ratios of integer multiples. For six of the stars our harmonic model detected two separate periods, and in the case of three of them (HD 155886, HD 201091 and HD 76151), the two cycle periods were integer multiples of each other within given uncertainty limits. For the former star the ratio is roughly two and for the latter two ones roughly 3, whereas for the star HD 201091 the higher harmonic is the more prominent one. We argue that the periods whose ratios form integer numbers cannot be considered as different magnetic cycles, but as the harmonics of the same cycle. Usually these harmonics appear as the weaker overtones of the harmonic with the basic frequency, however, due to sub-harmonic bifurcation this needs not always be the case.
For two of the stars for which we detected irrational cycle fractions using the harmonic model, the period estimates are quite close to each other. Due to the poor spectral resolution, especially for HD 29317 because of very poor sampling, we cannot state if there are actually two approximately harmonic cycles or one less coherent one. At least the cycle estimate from QP being between the two estimates from H for HD 152391 seems to confirm the latter case
Finally, there is a number of stars with short time series which have not been analysed by Cyc95, but for which we report significant cycles at least from two analysis methods. These stars include HD 10072, HD 27022, HD 29317, HD 60522, HD 68290, HD 82635 and HD 146233.
To summarise this subsection, the biggest differences between the studies originate from two causes. Firstly, the linear trend components retrieved by our models significantly differ from zero, from the trends obtained directly from linear regression. The fact that the trends differ also from star to star indicates that they are most likely not due to systematic instrumental trend. This is the major reason for the different cycle length estimates obtained in the case of good, fair, and poor cycle grades of Cyc95. Secondly, the extended lengths of the datasets available to us enabled improving of some cycle length estimates.
4.3. Differences between the models
Next we summarise the differences between H, P and QP models. The primary observation we make is the fact that QP detected slightly more cycles as the other methods. We note that the model selection methods differ between the H and GP methods; hence the corresponding significance levels shown in Table 1 are not directly comparable. However, as the numbers for the strong cycles are roughly speaking equal, we chose the same cut-off level for the GP models as for H. We therefore find the most likely explanation to the higher number of cycles from QP to be the increased flexibility of the model because of the squared-exponential damping term in the covariance function.
We omit detailed investigation of differences between the models per each individual star, but highlight some of the interesting cases. First, there are plenty of stars for which P did detect cycle, but H did not and vice versa. The reason for the former can be explained by the additional freedom in P to model nonharmonic phase behaviour in comparison to H. The reason for the latter is that in some cases P detected double, triple or quadruple period compared to H. However, some of these periods were too long and were rejected, see for example the case presented in Fig. A.3. Our second general observation is that, when both P and H have detected a cycle, they mostly agree well. One exception to this is HD 103095, where P detected three times longer cycle compared to H. The reasons here are the same as just explained. In this particular case the result is obviously physically meaningless as one would not expect the phase behaviour of the signal to contain many extrema. Therefore the true cycle period is most likely around the shorter one obtained by H.
When comparing the results of QP to the other methods we see more dramatic differences. There are several cases where QP detected significantly different cycle period than H or P. The example of HD 114710, presented in Fig. A.2, illustrates one such case. Taking into account the fact that quasi-periodic phenomena occur very naturally in highly nonlinear systems, and also relying on the results with synthetic data we would expect the QP estimate to be closer to the true cycle length compared to H and P.
There are several stars for which QP did not detect a cycle while one of the other methods did. Mostly this is the case when only P detected the cycle and is therefore explained by the nonharmonic phase behaviour of the signal, which the regularised QP model was not able to detect.
We note that 15 of the cycles detected using the QP model became significant w.r.t. the red noise model. This is not directly an indication that these cycles are more reliable, as obviously even some of the visually strongest cycles do not fall into that category. However, it might be an indication that on top of the cyclic behaviour there is less irregular behaviour for these stars.
In the penultimate column of Table 1 we give the measure of nonharmonicity σP of the cycle for the QP models. This quantity is totally unrelated to the error estimate of the cycle period. Closer look reveals that the values of σP are rather small due to relatively large time-scale estimates of the models. Interestingly there are couple of stars for which σP is practically zero, meaning that the cycle is almost harmonic, however, the H model has not detected the cycle. This is obviously due to the difference in the model selection algorithm. The largest value of σP (also when compared to the cycle period) is seen for HD 224930. While this can potentially be an example of rather nonharmonic cycle, the cycle period estimate is also extremely long, thus the conclusion cannot be strong.
As a validation we should pay attention to the results obtained for the Sun. We see that the cycle estimates in this case agree quite well with the commonly accepted value 11 yr, which is established from the longer datasets. The estimate from QP seems to be slightly lower, but still within reasonable bounds from the expected value given the error estimate. For the comparison of the fits see Fig. A.1.
As a last remark we note that for two of the stars (HD 29317 and HD 60522) the harmonic model detected a significant period, but in these cases, due to poor sampling, the highest peaks in the spectra were extremely wide and flat. We have listed these values with question marks in the table and omitted them from the clustering analysis. For the former of the objects, QP cycle estimate is significantly higher than that from H while P detected roughly two times longer cycle, which was rejected due to our selection criteria. For the latter of the objects, however, the results from GPs match well with the estimate from H.
4.4. Activity diagram
Next we use the obtained cycle estimates Pcyc, rotational periods Prot and average chromospheric activity indices 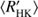 to plot the RCRA diagrams (Brandenburg et al. 1998; Saar & Brandenburg 1999, for a more detailed interpretation see Sect. 5). In Fig. 4 we plot three different diagrams separately for the different methods used to estimate the cycle lengths; panels a, b, and c correspond to the results from H, P and QP respectively. In panel d we present a comparison of results from H with the results from Cyc95. The points in these diagrams, rather independent of the method used, form two distinct clouds, where the inactive stars locate at somewhat higher rotation to cycle period values than the active ones; hence a “gap” in between the clouds, not related to VPG discussed before.
to plot the RCRA diagrams (Brandenburg et al. 1998; Saar & Brandenburg 1999, for a more detailed interpretation see Sect. 5). In Fig. 4 we plot three different diagrams separately for the different methods used to estimate the cycle lengths; panels a, b, and c correspond to the results from H, P and QP respectively. In panel d we present a comparison of results from H with the results from Cyc95. The points in these diagrams, rather independent of the method used, form two distinct clouds, where the inactive stars locate at somewhat higher rotation to cycle period values than the active ones; hence a “gap” in between the clouds, not related to VPG discussed before.
 |
Fig. 4. RCRA diagram for cycles obtained from H (panel a), P (panel b), QP (panel c) models and the comparison of the results of H to Cyc95 (panel d). The colour intensities of the symbols indicate the significance of the cycles and the error bars show the 2σ uncertainties. For better visualization too short error bars have been omitted. The vertical dotted lines connect the cycles found for the same star, while the bigger symbol size denotes the primary cycle. The Sun is shown with the conventional symbol. The red crosses (blue pluses) represents the stars belonging to the inactive (active) clusters respectively. The black diamonds correspond to the giant stars. The ellipses represent the 2σ regions of the Gaussians obtained from GMM model. The small circles correspond to the results from Cyc95. |
Using the points in the activity diagrams as input we further performed clustering analysis using GMM with expectation maximization algorithm (Barber 2012, Chapter 20.3). For simplicity we assumed the points to have no measurement errors and all being equally likely (i.e. we neglected the uncertainty and significance information). We optimized over the number of clusters, cluster centres and covariances, and selected the model with the lowest value of BIC. We tried models with number of clusters from two to five and in all three cases the best model turned out to be the one with two components. The ellipses in Fig. 4 correspond to 2σ regions of the Gaussians, blue ones to the active cluster and red ones to the inactive cluster. With this model, every star is assigned a probability of belonging to either one of the clusters. We have coded the points accordingly to blue pluses (red crosses) if the probability of belonging to the active cluster is greater (smaller) than belonging to the inactive cluster. Giant stars have not been taken into account in the clustering.
It is evident that, in the case of all three methods, the cluster centres agree rather well with each other. The Gaussian distributions obtained, however, are rather different for all the methods, H and QP models being more similar to each other, while P shows somewhat distinct behaviour. The main difference between the results from P and other models is the much wider scatter of points on vertical axis. We also see that both P and QP have some cycles detected for stars with log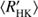 > −4.4, while H has not.
> −4.4, while H has not.
As noted before, in all three cases the locations of the cluster centres coincide quite well, however, their covariances differ much more significantly. The values of the slopes with 2σ errors per cluster and each cycle length estimation method have been collected to Table 2. For the inactive branch we see that a positive correlation between log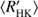 and log Prot/Pcyc is apparent with all methods, but the uncertainties are relatively large. The shapes of the active branch ellipses are much wider, indicative of larger scatter, while all three methods yield negative correlations. However, the correlations in the case of H and P are very weak with large uncertainties. Therefore, we cannot confirm the existence of clear positive linear correlations for both the clusters, in contrast to previous investigations (e.g. Brandenburg et al. 1998; Saar & Brandenburg 1999). The inactive branch slope, however, is consistent with the earlier studies.
and log Prot/Pcyc is apparent with all methods, but the uncertainties are relatively large. The shapes of the active branch ellipses are much wider, indicative of larger scatter, while all three methods yield negative correlations. However, the correlations in the case of H and P are very weak with large uncertainties. Therefore, we cannot confirm the existence of clear positive linear correlations for both the clusters, in contrast to previous investigations (e.g. Brandenburg et al. 1998; Saar & Brandenburg 1999). The inactive branch slope, however, is consistent with the earlier studies.
Slopes of the regression lines in activity branches.
Moreover, Boro Saikia et al. (2018) recently claimed that the negative slope on the active branch is an unphysical selection effect arising from the lower and upper limits of the cycle search interval together with plotting quantities that depend on rotation on each axis. In their plots, they used the inverse Rossby number in the x-axis, computed from the 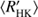 using the rather poorly known convective turnover time empirically determined by Noyes et al. (1984). Our analysis in Fig. 3 clearly indicates that a selection effect due to the upper bound in the cycle search interval for the active population, showing an increased probability for the occurrence of trends, is present. In reality, therefore, the cycles in the active population could be even longer, therefore causing even smaller values of cycle to rotation period relation the higher
using the rather poorly known convective turnover time empirically determined by Noyes et al. (1984). Our analysis in Fig. 3 clearly indicates that a selection effect due to the upper bound in the cycle search interval for the active population, showing an increased probability for the occurrence of trends, is present. In reality, therefore, the cycles in the active population could be even longer, therefore causing even smaller values of cycle to rotation period relation the higher 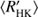 the star would have. In this case, the real slope would be even more negative, and the active population even more distinct from the inactive one.
the star would have. In this case, the real slope would be even more negative, and the active population even more distinct from the inactive one.
In Fig. 4d we have plotted the results from our H model in comparison to Cyc95. The colour and symbol coding is identical to that in the other panels of that figure, except that the small black circles correspond to the results from Cyc95 and their colour intensities reflect the grade of the cycle estimates. The points with poor cycle estimates have been excluded from the plot. Evidently, the inactive branch estimates agree very well with each other, and the GP methods employed in this study do not significantly destroy this agreement. Therefore, the collective behaviour of the inactive stars appears to be robustly captured with the MW sample independent of the method used. For the active stars, however, there are much larger differences in between the methods, and it is very difficult to characterise any collective behaviour in the RCRA diagram, except that their magnetic cycle over rotation period ratio appears robustly distinct from the inactive population. We also see that some of the stars with double cycles from Cyc95 split up between active and inactive populations (see also Brandenburg et al. 2017), while this does not happen at all based on our results. This naturally relates to our other conclusions of double cycles themselves being rare (see our discussion in Sect. 4.2).
In Brandenburg et al. (2017) the dependence between Prot/Pcyc and metallicity [Fe/H] as well as relative convection zone depth d/R was investigated by first calculating the residuals Δi of the data points in the activity diagram to the linear trend in each branch i (i indicating the active or inactive branch), to remove the dependency on 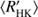 before correlating with the other quantities. Although the significance of the linear trends based on the results in the current study is rather low, we repeated this procedure, as the inactive star trend persists in our results. We used our H model results, but did not find any apparent dependencies with respect to metallicity nor to the convection zone depth, except that the inactive population showed considerably smaller residues with less scatter around the mean than the active population.
before correlating with the other quantities. Although the significance of the linear trends based on the results in the current study is rather low, we repeated this procedure, as the inactive star trend persists in our results. We used our H model results, but did not find any apparent dependencies with respect to metallicity nor to the convection zone depth, except that the inactive population showed considerably smaller residues with less scatter around the mean than the active population.
In Fig. 5 we plot the corresponding CR diagrams for the different methods, with panels a, b, and c corresponding to the results from H, P and QP, respectively. The colours of the data points reflect the cluster labels according to Fig. 4. Based on the Cyc95 data, previously (see e.g. Böhm-Vitense 2007) linear trends were detected in such diagrams for both populations, and the Sun was quite clearly located in between these trends as a solitude object (see e.g. Böhm-Vitense 2007). The inactive population stars exhibit positive linear Prot − Pcyc correlation, that is, the faster the rotation, the shorter the cycle, with all methods used, but the scatter around this trend is far more pronounced as seen in Cyc95 data by Böhm-Vitense (2007). The Sun, however, is no longer far off from the common trend, and is no longer a solitude object. The cycle lengths of the active stars show no trend in this diagram with H and QP methods, while a hint of a linear trend similar to that claimed by Böhm-Vitense (2007) can be seen with method P.
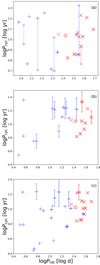 |
Fig. 5. CR diagram for cycles obtained from H (panel a), P (panel b) and QP (panel c) models. The colour and symbol coding is identical to the one in Fig. 4 |
4.5. Giant stars
The MW sample contains 54 giant stars for which more than ten years of data is available, and which are thus included in our analysis. For 17 of them we detected cycles with at least one of our methods. Therefore, the presence of cycles within the giants is less likely (31% show cycles) than in the MS stars (56% show cycles). This is not surprising, as the rotation periods of these stars are generally much longer, and therefore one would assume that the magnetic activity level would be reduced due to a less efficient dynamo, or perhaps a large-scale dynamo would not be excited at all, in which case no cycles would be detected. Remarkably, we detect fairly significant magnetic cycles for four giant stars that have rotation periods exceeding 100 days (HD 10072, HD 29317 and HD 68290) and even 200 days (HD 124897), all with chromospheric activity indices matching with the MS stars.
Based on Fig. 4 we can see that roughly half of the cyclic giant stars fall on the upper part of the RCRA diagram, that is, clearly above both of the inactive and active population clusters, indicative of relatively short magnetic cycles in them. This could, however, be an observational bias due to the even more limited extent of the dataset with respect to the rotation periods. For example, the star HD 68290 has a rotation period of 158 days, which means that only a cycle length longer than 40 yr would place the star on any of the activity clusters on the diagram. Indeed, some of the giant stars with shorter rotation periods, although somewhat depending on the analysis method, fall into the inactive and active populations. It is nevertheless interesting to note that the MS stars seem to have an upper limit of the rotation to cycle period ratio values at around −1.8, although higher values could technically have been observed from our sample, while at the same time there are giant stars that have cycles similar to those of the MS stars.
5. Discussion in the light of theory and numerical models
5.1. On the Vaughan-Preston gap
There are many dynamo-related explanations postulated to lead to the VPG. Some involve arguments of the dynamo mode changing its topological complexity as function of rotation, due to the changing supercriticality of the dynamo solution, from simple to complex ones causing a drastically different chromospheric response (e.g. Durney et al. 1981). Others postulate that even the location of the dynamo might change from a near-surface one for the active stars to one operating near the bottom of the convection zone for the inactive ones (Böhm-Vitense 2007). Metcalfe et al. (2016) proposed that the operation of dynamos could be disrupted due to dramatic changes in the differential rotation, the rotation law changing from solar-like to antisolar one. Also enhanced magnetic braking, leading to a decreased probability to detect stars around certain 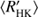 values, has been proposed (e.g. Noyes et al. 1984). If such drastic changes would actually occur, one would expect to see abrupt changes in the quantities describing the large-scale dynamo at around log
values, has been proposed (e.g. Noyes et al. 1984). If such drastic changes would actually occur, one would expect to see abrupt changes in the quantities describing the large-scale dynamo at around log 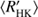 −4.8 corresponding to the VPG.
−4.8 corresponding to the VPG.
Both the RCRA and CR diagrams reveal changes in the cycle length behaviour at around log 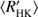 = −4.8, and the re-estimation of the cycle lengths compared to Cyc95 makes this distinction even clearer: in the activity diagrams presented in this study hardly no overlap of cycle lengths w.r.t.
= −4.8, and the re-estimation of the cycle lengths compared to Cyc95 makes this distinction even clearer: in the activity diagrams presented in this study hardly no overlap of cycle lengths w.r.t. 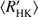 or rotation period occurs in between the active and inactive populations, while some overlap was reported in earlier studies (e.g. Brandenburg et al. 1998; Saar & Brandenburg 1999; Böhm-Vitense 2007), mainly in terms of primary and secondary cycles, if detected, falling on different branches. Intriguingly, however, the histogram of the C class of stars does not show the prominent bimodal distribution of the whole MW sample as seen from Fig. 3b. This indicates that the tendency for cyclic behaviour, a sign of a large-scale dynamo in action, is not similarly reduced as the total distribution of stars in the VPG. The distribution of the relative variance of C stars is similar, that is, unaffected by the VPG. Hence, the data is inconsistent with a disruption of large-scale dynamo action in the VPG, but possibly consistent with a smooth dynamo mode change affecting the cycle lengths but not the overall efficiency of the large-scale dynamo. Moreover, the existence and even slight overabundance of C stars in the VPG is clearly against any scenario that relies on enhanced temporal evolution due to efficient braking by ordered magnetic fields.
or rotation period occurs in between the active and inactive populations, while some overlap was reported in earlier studies (e.g. Brandenburg et al. 1998; Saar & Brandenburg 1999; Böhm-Vitense 2007), mainly in terms of primary and secondary cycles, if detected, falling on different branches. Intriguingly, however, the histogram of the C class of stars does not show the prominent bimodal distribution of the whole MW sample as seen from Fig. 3b. This indicates that the tendency for cyclic behaviour, a sign of a large-scale dynamo in action, is not similarly reduced as the total distribution of stars in the VPG. The distribution of the relative variance of C stars is similar, that is, unaffected by the VPG. Hence, the data is inconsistent with a disruption of large-scale dynamo action in the VPG, but possibly consistent with a smooth dynamo mode change affecting the cycle lengths but not the overall efficiency of the large-scale dynamo. Moreover, the existence and even slight overabundance of C stars in the VPG is clearly against any scenario that relies on enhanced temporal evolution due to efficient braking by ordered magnetic fields.
Interestingly, within the inactive population, we observe an abrupt change in the C star variances at about the solar activity index log 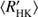 ≈−4.9. This could be an indication of an abrupt change in the operation of the large-scale dynamo. A prominent candidate for such a transition is the change from solar to anti-solar rotation profiles. Both numerical models (e.g. Brun et al. 2017; Viviani et al. 2018) and also a recent study where observations were interpreted with the help of numerical models (Brandenburg & Giampapa 2018) support such a transition near the solar parameter values.
≈−4.9. This could be an indication of an abrupt change in the operation of the large-scale dynamo. A prominent candidate for such a transition is the change from solar to anti-solar rotation profiles. Both numerical models (e.g. Brun et al. 2017; Viviani et al. 2018) and also a recent study where observations were interpreted with the help of numerical models (Brandenburg & Giampapa 2018) support such a transition near the solar parameter values.
5.2. Cycle lengths in different populations
Böhm-Vitense (2007), in an attempt to explain the linear trends seen in the CR diagrams of Cyc95 cycles, proposed that the dynamo type would abruptly change in between the two populations, from an interface dynamo working near the surface (for active stars) to one working at the bottom of their convection zones with deeper mixing (for inactive stars). Hence, one would also expect a dependence of the cycle lengths and properties on the convection zone depth. Brandenburg et al. (2017) tried to find such a dependence, essentially using the Cyc95 cycles, without success. Neither do we after our re-analysis. Therefore, the different cycle lengths are unlikely to reflect such a drastic change in the operation of the dynamo.
In the light of more recent results, it is likely that a different type of dynamo transition occurs in between these two populations. The change from nonaxisymmetric to axisymmetric dynamo modes is a potential candidate to occur close to the transition between the branches, but the current observational data from photometry suggests that the transition points do not exactly match, the nonaxi- to axisymmetric point being located at higher chromospheric activity indices, compare the location of the two vertical lines in Fig. 6. Numerical models place this transition to lower values of the activity index, but relating the models with the observables is still quite difficult, as the models are very likely too laminar.
 |
Fig. 6. Comparison of the results of quasi-periodic GP model and different other observational and modelling studies. Green stars are taken from the analysis of long-term photometry of solar-type stars (Lehtinen et al. 2016), where intensity reflects the cycle grade. Grey squares are from the wedge study of turbulent magnetoconvetion by Warnecke (2018), while grey triangles are from a corresponding study of Viviani et al. (2018), where the wedge assumption was relaxed in the azimuthal direction, allowing for nonaxisymmetric solutions. Larger triangles indicate high-resolution runs. In the bottom of the figure we have shown the ranges of the inactive, active and transitional branches using arrows. The vertical dash-dotted lines mark the points where axi- to nonaxisymmetrical transition occurs accordingly to models and observations. The dashed black curve represents a blend of two linear fits to the inactive and active plus transitional branch. The remaining colour and symbol codings are identical to the one in Fig. 4. Here we have used the magnetic to kinetic energy ratio obtained in the models as a proxy for calculating the |
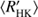
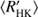
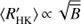
On the other hand, the absolute differential rotation, significant for the dynamo action, remains constant or is at best weakly varying as function of rotation (see the summary of observational results in Lehtinen et al. 2016). The role of turbulent effects, in contrast, is theoretically expected to grow as function of rotation, at least in the regime of slow rotation. This implies a change from αΩ dynamos into the regime where both contributions are equally important (α2Ω). Those global magnetoconvection models that show transition to nonaxisymmetric magnetic field configurations also show that the differential rotation becomes strongly quenched at rapid rotation (Viviani et al. 2018), which might even imply that the dynamos in the very active stars could be of α2 type.
From this it follows that it is not completely safe to assume that the results obtained for the well-studied axisymmetric solar-type αΩ dynamos would directly apply to the stellar populations studied here. A similar wealth of studies of nonaxisymmetric α2Ω or α2 dynamos, unfortunately, does not exist. This relates to the difficulty to obtain oscillatory α2 solutions, even though they have been shown to exist (see Brandenburg 2017, and the references therein). Some useful, albeit simple, studies have been undertaken, however. Cole et al. (2016) studied the cycle frequency in α2Ω dynamos with varying amounts of differential rotation in one-dimensional kinematic dynamo models in spherical geometry. They found out that the general behaviour of such dynamos is similar to their αΩ counterparts in that the cycle period is a decreasing function of increasing amount of differential rotation. With strong shear, the cycle period relation directly following from the dispersion relation for αΩ dynamos, Eq. (11), was followed, but when the strength of differential rotation was decreased, they observed rather a nonmonotonous behaviour with a regime, where the cycle period was strongly increasing when ΔΩ was decreased only a little. When ΔΩ was decreased even further, another power law was established with considerably longer cycle lengths. The nonmonotonous behaviour was linked with a change in the dynamo solution topology, that is, antisymmetric (with respect to the equator) solar-like solutions changed into symmetric ones. A similar, but less pronounced jump in cycle periods from short to long ones was observed close to the transition from axi- to nonaxisymmetric dynamos by Viviani et al. (2018). Studying these types of dynamos further is, therefore, one potential track to understand the cycle length distributions in the two populations.
5.3. Rotation period to cycle length ratio
In the data analysis section we concluded that the physically most plausible model is the quasi-periodic one, best suitable for modelling highly supercritical nonlinear oscillators, such as the Sun. Hence, we plot the results from our QP models together with some previous ones from observations (Lehtinen et al. 2016), and also from models (Warnecke 2018; Viviani et al. 2018) in an RCRA diagram in Fig. 6. Especially the observational points support the interpretation of there being only two branches (inactive and transitional) instead of three (inactive, active and transitional). The inactive branch has a positive slope, while the active branch appears to merge with the transitional branch, which together exhibit a steep negative slope. The main scatter in this plot is due to the points taken from global magnetoconvection models.
Also in the CR diagrams we see only one clear trend, that is the decreasing magnetic cycle length as function of rotation rate for the inactive population. Already this single trend constrains the dynamo solutions, as the two prevailing dynamo paradigms give clearly opposite predictions for it: flux-transport dynamos, accepted as the standard model for a solar dynamo, predict a dependence such that the cycle length grows with rotation, that would manifest as a negative slope in CR-diagrams (opposite to what is observed; e.g. Jouve et al. 2010). The standard αΩ dynamo model based on helical turbulence and differential rotation acting together throughout the convection zone would give a cycle period
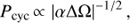 (11)
(11)
where α and ΔΩ describe the strengths of the inductive effects arising from turbulence and radial differential rotation, respectively (Stix 1976). This formula predicts Prot/Pcyc to grow with Prot as the turbulent effects are expected to grow in the regime of slow rotation proportional to Ω (e.g. Krause & Rädler 1980). So, the trend predicted by the turbulent dynamo is of correct sign, but it appears to be far too steep to be easily explained.
This can be seen by comparing the expected scalings in a RCRA diagram from a kinematic αΩ dynamo, that predicts the rotation period to cycle length ratio to scale as
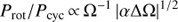 (12)
(12)
If we make the following ansatz for the dependencies for the relevant effects, α =Ωa; ΔΩ = Ωb, we obtain the following relation from Eq. (12):
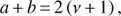 (13)
(13)
with the slope deductible from observations, ν. This immediately demonstrates the evident: values of ν would need to become negative to bring the scaling of α to acceptable limits (a maximally 1), with values of b agreeing with observations and theoretical arguments (0 … 1). This study, using the acceptable limits of b stated above with the ν values from the QP method, gives values of (a ≈ 3.3 … 4.3), far too high to be realistic, agreeing with previous studies.
These trends were explained by Brandenburg et al. (1998) by assuming that the dynamo coefficients are increasing functions of the magnetic field, based on the known dependence of 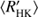 on the magnetic field. This appears as unlikely behaviour for the convection-driven α-effect (see e.g. Karak et al. 2014). More likely scenarios include an α-effect being driven by some other instabilities, such as MRI (e.g. Masada 2011), buoyancy instability (e.g. Chatterjee et al. 2011), or the shear-current effect feeding from the small-scale magnetic field (see e.g. Squire & Bhattacharjee 2016, and references therein). Such effects, however, are only beginning to be considered in stellar dynamos, even though the obvious need, as neither of the prevailing dynamo paradigms offer an explanation to the inactive branch scaling.
on the magnetic field. This appears as unlikely behaviour for the convection-driven α-effect (see e.g. Karak et al. 2014). More likely scenarios include an α-effect being driven by some other instabilities, such as MRI (e.g. Masada 2011), buoyancy instability (e.g. Chatterjee et al. 2011), or the shear-current effect feeding from the small-scale magnetic field (see e.g. Squire & Bhattacharjee 2016, and references therein). Such effects, however, are only beginning to be considered in stellar dynamos, even though the obvious need, as neither of the prevailing dynamo paradigms offer an explanation to the inactive branch scaling.
Nowadays an abundance of global magnetoconvection models are available, that allow for the direct modelling of the stellar dynamo mechanism, and recently studies, where different rotation rates have been considered, have emerged (Strugarek et al. 2017; Warnecke 2018; Viviani et al. 2018). Those models that produce mostly axisymmetric dynamo solutions either by the design of the model itself (e.g. Warnecke 2018, see also rectangular points plotted in Fig. 6) or self-consistently (Strugarek et al. 2017) tend to agree best with the negative slope for the active branch or with the even steeper slope obtained for even more active stars (the transitional branch, e.g. Lehtinen et al. 2016), while no clear inactive population emerges. Remarkably, many of the properties of the obtained dynamo solutions can be explained with the simple αΩ cycle period scaling, Eq. (12), when the turbulent transport coefficients are directly measured from the models (see e.g. Warnecke et al. 2014, 2018; Warnecke 2018). The models of Viviani et al. (2018) allow for and also excite nonaxisymmetric solutions (see the triangular points in Fig. 6). In this case, two distinct populations emerge, but neither of them are in very good agreement with observations: the inactive branch does not well coincide with the observed one, although shows hints of positive slope, while the transitional and superactive branches seem to have merged into one single population with a much shallower negative slope than observed. Although this seems as a very promising approach, it has to be borne in mind that these global magnetoconvection models are unrealistic also in the sense that they produce dynamos that behave very much solar-like, but the cause for this behaviour is not the same as in the Sun (Warnecke et al. 2014). In contrast, the required change of sign of the α with respect to Ω effect to obtain equatorward migration results from a region of negative shear present in the models, but such regions are not observed in the Sun.
Last we note that there would also be a dependence on the square root of the length scale in Eq. (11), which was neglected here and previously, as it appears natural to assume a typical length scale of the dynamo would be of the order of the depth of the convection zone, and this parameter would not change as function of rotation within a given spectral type. The very recent results obtained from turbulent convection modelling, however, have revealed the emergence of sub-adiabatic (formally convectively stable) layers within what is normally considered the convection zone (see e.g. Käpylä et al. 2017, and references therein), possibly changing the location and extent of the dynamo-active layer, which could also depend critically on the rotation rate. Even a weak dependence of the length scales on rotation (such that the relevant length scale grows with rotation) could render the classical dynamo compatible with the observations. One such scenario arises as follows: given a critical Rossby (or Coriolis) number at which the dynamo turns on, the depth of the dynamo-active part of the convection zone increases with decreasing (increasing) Ro (Co) inversely (directly) proportional to the rotation rate. If such convectively stable layers existed in reality, they could act as a storage of magnetic flux, playing at least partly a similar role than tachoclines are supposed to do for solar dynamos. Such layers have been recently detected in global convection models (Karak et al. 2018; Käpylä et al. 2018), and the dynamo solutions were indeed found to be sensitive to the changes in the convection zone structure (Käpylä et al. 2018). Also, such layers might critically contribute to reversing the sign of helicity of the flow, a frequently observed phenomenon in convection models with an overshoot layer (see e.g. Käpylä et al. 2004), that could help in getting the remaining details correct in the turbulent magnetoconvection models (Duarte et al. 2016). Such a helicity inversion has already been reported to occur in the global magnetoconvection models (Käpylä et al. 2018), but its effect appeared rather subtle in these models.
6. Conclusions
In this paper we have presented a re-analysis of the MW chromospheric activity sample starting with a harmonic model with a trend, and refining the model towards a more realistic situation where we allow for quasi-periodic cycles, that highly nonlinear systems often produce. We have identified several potential sources for erroneous detections of periods in the case where the dataset length is of the same order of magnitude as the cycles that are searched, and in addition the sampling is uneven containing large gaps. These include the improper treatment of linear trends and possibly too simple assumptions of the noise variance model. Assumption of strict harmonicity can result in the appearance of double cyclicities that seem more likely to be a result of the quasi-periodicity of the cycles. Consequently, we conclude that only rare cases of reliable double cycle detections can be made based on the MW sample.
We observe an increased tendency of the active population to show trends that are unlikely to be instrumental artefacts. This is indicative of the presence of longer than detectable cycles in them. What is detectable from the MW sample could be subdominant secondary shorter cycles, while the longer basic ones could remain undetected. In conclusion, the MW sample cannot be regarded to well represent this population’s magnetic cycles.
We observe pronounced cycles also in stars that have 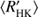 activity indices belonging to the so called VPG. The distribution of all stars, however, shows a clear gap. This suggests that the gap is not related to the operation of the large-scale stellar dynamo. At around solar
activity indices belonging to the so called VPG. The distribution of all stars, however, shows a clear gap. This suggests that the gap is not related to the operation of the large-scale stellar dynamo. At around solar 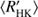 values and slightly below, however, we see a clear drop in year-to-year variance of the cyclic stars, indicating a disruption of cyclic dynamos there. Such a disruption could be caused by the transition of solar-like differential rotation profiles into anti-solar ones, at present indicated by many numerical models. It remains, however, rather unclear how exactly should these models be scaled back to the real stars to allow for direct comparisons.
values and slightly below, however, we see a clear drop in year-to-year variance of the cyclic stars, indicating a disruption of cyclic dynamos there. Such a disruption could be caused by the transition of solar-like differential rotation profiles into anti-solar ones, at present indicated by many numerical models. It remains, however, rather unclear how exactly should these models be scaled back to the real stars to allow for direct comparisons.
We confirm the earlier claims of the existence of two clearly distinct active and inactive populations in the MW sample, based on a clustering analysis performed with GMM. We also confirm the claim of the inactive stars to show a clear linear trend with a positive slope in the RCRA diagram, while discard the claims of the active stars showing a similar trend (see e.g. Brandenburg et al. 1998; Saar & Brandenburg 1999). The data is consistent with the active population representing the less active tail of the transitional branch stars, analysed from other datasets for example by Lehtinen et al. (2016); Distefano et al. (2017).
One interesting question that remains unanswered in this study due to the high observational noise and insufficient length of the datasets is how coherent the found cycles are. One could think that the coherency of the cycle would be dependent on how developed the dynamo of the given star is. Even though we reported the measures of nonharmonicity σP, they are only of theoretical interest because of the high uncertainties in timescale estimates. Nevertheless, we showed with the tests on synthetic data, that the quasi-periodic model can be used to improve the cycle period estimates compared to the values obtained from the fully harmonic model.
In the current study we downsampled the data to make the computations of the GP models feasible. Another possibility to efficiently model the time series would be to use state space models. It has been shown that GPs with periodic and quasi-periodic covariance functions can be reformulated in state space models which reduces the computational complexity to linear in number of time steps (Solin & Särkkä 2014). The link in the opposite direction between different state space models and GP covariance functions, including the quasi-periodic one is discussed in Grigorievskiy & Karhunen (2016). To reduce the computational cost, instead of downsampling the data, one can also use sparse GP models. In these approaches the subset of the inputs and model parameters are simultaneously optimized to obtain a good approximation to the full GP model (Titsias 2009). Applying the aforementioned methods to astronomical datasets we consider as interesting topics for the future studies.
We will interchangeably refer to it as a harmonic model, to emphasize its distinction from periodic and quasi-periodic models.
In GP literature this parameter is generally called length-scale, but in the context of time series we find the term time-scale to be more natural.
To get the proper posterior p( f |D, MH) we need to normalize the value obtained from Eq. (2) by an integral over sufficiently long range of frequencies.
This is usually written as the product of squared-exponential and periodic covariance functions k(t, t′) = 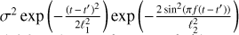 , where the second exponential function can be expanded into an infinite series of cosines.
, where the second exponential function can be expanded into an infinite series of cosines.
Acknowledgments
This work has been supported by the Academy of Finland Centre of Excellence ReSoLVE (NO, MJK, JP), Finnish Cultural Foundation grant no. 00170789 (NO) and Estonian Research Council (Grant IUT40-1; JP). We thank Aki Vehtari for useful discussion and comments on GP related questions. MJK and JL gratefully acknowledge discussions with Petri Käpylä, Andreas Lagg, and Jörn Warnecke on the theoretical interpretation of the observational data. We also thank Katalin Olah for sharing insight into some questions related to MW dataset, as well as Matthias Rheinhardt and Axel Brandenburg for comments on the manuscript. The HK_Project_v1995_NSO data derive from the Mount Wilson Observatory HK Project, which was supported by both public and private funds through the Carnegie Observatories, the Mount Wilson Institute, and the Harvard-Smithsonian Center for Astrophysics starting in 1966 and continuing for over 36 yr. These data are the result of the dedicated work of O. Wilson, A. Vaughan, G. Preston, D. Duncan, S. Baliunas, and many others.
References
- Angus, R., Morton, T., Aigrain, S., Foreman-Mackey, D., & Rajpaul, V. 2018, MNRAS, 474, 2094 [NASA ADS] [CrossRef] [Google Scholar]
- Baliunas, S. L., Donahue, R. A., Soon, W. H., et al. 1995, ApJ, 438, 269 [NASA ADS] [CrossRef] [Google Scholar]
- Baliunas, S. L., Nesme-Ribes, E., Sokoloff, D., & Soon, W. H. 1996, ApJ, 460, 848 [NASA ADS] [CrossRef] [Google Scholar]
- Barber, D. 2012, Bayesian Reasoning and Machine Learning (Cambridge University Press) [Google Scholar]
- Böhm-Vitense, E. 2007, ApJ, 657, 486 [NASA ADS] [CrossRef] [Google Scholar]
- Boro Saikia, S., Marvin, C. J., Jeffers, S. V., et al. 2018, A&A, 616, A108 [Google Scholar]
- Brandenburg, A. 2017, A&A, 598, A117 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Brandenburg, A., & Giampapa, M. S. 2018, ApJ, 855, L22 [NASA ADS] [CrossRef] [Google Scholar]
- Brandenburg, A., Saar, S. H., & Turpin, C. R. 1998, ApJ, 498, L51 [NASA ADS] [CrossRef] [Google Scholar]
- Brandenburg, A., Mathur, S., & Metcalfe, T. S. 2017, ApJ, 845, 79 [NASA ADS] [CrossRef] [Google Scholar]
- Bretthorst, L. G. 1988, Bayesian Spectrum Analysis and Parameter Estimation, 48 (New-York: Springer) [CrossRef] [Google Scholar]
- Brun, A. S., Strugarek, A., Varela, J., et al. 2017, ApJ, 836, 192 [NASA ADS] [CrossRef] [Google Scholar]
- Chatterjee, P., Mitra, D., Rheinhardt, M., & Brandenburg, A. 2011, A&A, 534, A46 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Cohen, L. 1995, Time-Frequency Analysis, Electrical Engineering Signal Processing (Upper Saddle River, NJ: Prentice Hall PTR) [Google Scholar]
- Cole, E., Brandenburg, A., Käpylä, P. J., & Käpylä, M. J. 2016, A&A, 593, A134 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Distefano, E., Lanzafame, A. C., Lanza, A., Messina, S., & Spada, F. 2017, A&A, 606, A58 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Duarte, L. D. V., Wicht, J., Browning, M. K., & Gastine, T. 2016, MNRAS, 456, 1708 [NASA ADS] [CrossRef] [Google Scholar]
- Durney, B. R., Mihalas, D., & Robinson, R. D. 1981, PASP, 93, 537 [NASA ADS] [CrossRef] [Google Scholar]
- Egeland, R., Soon, W., Baliunas, S., et al. 2017, ApJ, 835, 25 [NASA ADS] [CrossRef] [Google Scholar]
- Foreman-Mackey, D., Agol, E., Angus, R., & Ambikasaran, S. 2017, AJ, 154, 220 [NASA ADS] [CrossRef] [Google Scholar]
- Grigorievskiy, A., & Karhunen, J. 2016, in 2016 International Joint Conference on Neural Networks (IJCNN), 3354 [CrossRef] [Google Scholar]
- Grunblatt, S. K., Howard, A. W., & Haywood, R. D. 2015, ApJ, 808, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Guerrero, G. & de Gouveia Dal Pino, E. M. 2008, A&A, 485, 267 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Henry, G. W., Fekel, F. C., & Hall, D. S. 1995, AJ, 110, 2926 [NASA ADS] [CrossRef] [Google Scholar]
- Jeffers, S. V., Mengel, M., Moutou, C., et al. 2018, MNRAS, 479, 5266 [NASA ADS] [CrossRef] [Google Scholar]
- Jouve, L., Brown, B. P., & Brun, A. S. 2010, A&A, 509, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Käpylä, P. J., Korpi, M. J., & Tuominen, I. 2004, A&A, 422, 793 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Käpylä, P. J., Korpi, M. J., & Tuominen, I. 2006, Astron. Nachr., 327, 884 [NASA ADS] [CrossRef] [Google Scholar]
- Käpylä, P. J., Rheinhardt, M., Brandenburg, A., et al. 2017, ApJ, 845, L23 [NASA ADS] [CrossRef] [Google Scholar]
- Käpylä, P. J., Viviani, M., Käpylä, M. J., & Brandenburg, A. 2018, GAFD, submitted [arXiv:1803.05898] [Google Scholar]
- Karak, B. B., Rheinhardt, M., Brandenburg, A., Käpylä, P. J., & Käpylä, M. J. 2014, ApJ, 795, 16 [NASA ADS] [CrossRef] [Google Scholar]
- Karak, B. B., Miesch, M., & Bekki, Y. 2018, Phys. Fluids, 30, 046602 [NASA ADS] [CrossRef] [Google Scholar]
- Krause, F., & Rädler, K.-H. 1980, Mean-Field Magnetohydrodynamics and Dynamo Theory (Oxford: Pergamon Press) [Google Scholar]
- Lehtinen, J., Jetsu, L., Hackman, T., Kajatkari, P., & Henry, G. W. 2011, A&A, 527, A136 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lehtinen, J., Jetsu, L., Hackman, T., Kajatkari, P., & Henry, G. W. 2016, A&A, 588, A38 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Littlefair, S. P., Burningham, B., & Helling, C. 2017, MNRAS, 466, 4250 [NASA ADS] [Google Scholar]
- Lomb, N. R. 1976, Astrophys. Space Sci., 39, 447 [Google Scholar]
- Masada, Y. 2011, MNRAS, 411, L26 [NASA ADS] [CrossRef] [Google Scholar]
- McAllister, M. J., Littlefair, S. P., Dhillon, V. S., et al. 2017, MNRAS, 464, 1353 [NASA ADS] [CrossRef] [Google Scholar]
- Metcalfe, T. S., & van Saders, J. 2017, Sol. Phys., 292, 126 [NASA ADS] [CrossRef] [Google Scholar]
- Metcalfe, T. S., Egeland, R., & van Saders, J. 2016, ApJ, 826, L2 [Google Scholar]
- Mittag, M., Robrade, J., Schmitt, J. H. M. M., et al. 2017, A&A, 600, A119 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mortier, A., Faria, J. P., Correia, C. M., Santerne, A., & Santos, N. C. 2015, A&A, 573, A101 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Noyes, R. W., Hartmann, L. W., Baliunas, S. L., Duncan, D. K., & Vaughan, A. H. 1984, ApJ, 279, 763 [NASA ADS] [CrossRef] [Google Scholar]
- Oláh, K., Kővári, Z., Petrovay, K., et al. 2016, A&A, 590, A133 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Olspert, N., Käpylä, M. J., Pelt, J., et al. 2015, A&A, 577, A120 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Olspert, N., Käpylä, M. J., & Pelt, J. 2016, in Proc. of 2016 IEEE International Conference on Big Data, Washington, DC, USA [Google Scholar]
- Olspert, N., Pelt, J., Käpylä, M. J., & Lehtinen, J. 2018, A&A, 615, A111 (Paper I) [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pelt, J. 1983, in Statistical Methods in Astronomy, ed. E. J. Rolfe, ESA SP, 201 [Google Scholar]
- Pojmanski, G. 1997, Acta Astron., 47, 467 [NASA ADS] [Google Scholar]
- Rasmussen, C. E., & Williams, C. K. I. 2006, Gaussian Processes for Machine Learning (Cambridge, MA: The MIT Press) [Google Scholar]
- Reinhold, T., Cameron, R. H., & Gizon, L. 2017, A&A, 603, A52 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Roberts, D. H., Lehar, J., & Dreher, J. W. 1987, AJ, 93, 968 [NASA ADS] [CrossRef] [Google Scholar]
- Saar, S. H., & Brandenburg, A. 1999, ApJ, 524, 295 [NASA ADS] [CrossRef] [Google Scholar]
- Scargle, J. D. 1982, ApJ, 263, 835 [NASA ADS] [CrossRef] [Google Scholar]
- Solin, A., & Särkkä, S. 2014, in Artificial Intelligence and Statistics, 904 [Google Scholar]
- Squire, J., & Bhattacharjee, A. 2016, J. Plasma Phys., 82, 535820201 [CrossRef] [Google Scholar]
- Stix, M. 1976, A&A, 47, 243 [NASA ADS] [Google Scholar]
- Strassmeier, K. G., Bartus, J., Cutispoto, G., & Rodono, M. 1997, A&AS, 125, 11 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Strugarek, A., Beaudoin, P., Charbonneau, P., Brun, A. S., & do Nascimento, J.-D. 2017, Science, 357, 185 [NASA ADS] [CrossRef] [Google Scholar]
- Titsias, M. K. 2009, in International Conference on Artificial Intelligence and Statistics, 567 [Google Scholar]
- Tuominen, I., Rüdiger, G., & Brandenburg, A. 1988, in Activity in Cool Star Envelopes, eds. O. Havnes, J. E. Solheim, B. R. Pettersen, & J. H. M. M. Schmitt, Astrophys. Space Sci. Lib., 143, 13 [NASA ADS] [CrossRef] [Google Scholar]
- Vaughan, A. H., & Preston, G. W. 1980, PASP, 92, 385 [NASA ADS] [CrossRef] [Google Scholar]
- Vehtari, A., & Ojanen, J. 2012, Statist. Surv., 6, 142 [Google Scholar]
- Viviani, M., Warnecke, J., Käpylä, M. J., et al. 2018, A&A, 616, A160 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wang, Y., Khardon, R., & Protopapas, P. 2012, ApJ, 756, 67 [NASA ADS] [CrossRef] [Google Scholar]
- Warnecke, J. 2018, A&A, 616, A72 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Warnecke, J., Käpylä, P. J., Käpylä, M. J., & Brandenburg, A. 2014, ApJ, 796, L12 [NASA ADS] [CrossRef] [Google Scholar]
- Warnecke, J., Rheinhardt, M., Käpylä, P. J., Käpylä, M. J., & Brandenburg, A. 2018, A&A, 609, A51 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wright, N. J., & Drake, J. J. 2016, Nature, 535, 526 [NASA ADS] [CrossRef] [PubMed] [Google Scholar]
- Yoshimura, H. 1978, ApJ, 220, 692 [NASA ADS] [CrossRef] [Google Scholar]
- Zechmeister, M., & Kürster, M. 2009, A&A, 496, 577 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
Appendix A: Comparison of harmonic, periodic GP and quasi-periodic GP models
In this section we illustrate the differences between the fits of H, P and QP models using some of the datasets as examples. The regression curves for the Bayesian models are calculated as the means of the posterior predictive distribution p(ℊ(t∗)|t∗, 𝓓) = ∫Θ p(ℊ(t∗)|t∗, θ, 𝓓)p(θ|𝓓)dθ, where ℊ(t∗) is the function value at test time moment t∗, 𝓓 is the observed data, θ are the parameters and Θ is the domain of θ. In particular for the GP models the posterior predictive is a Gaussian with mean 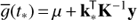 and variance
and variance 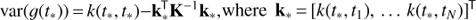 , where k∗ = [k(t∗, t1), … k(t∗, tN)]⊤ and the remaining symbols were defined in Sect. 3.3.
, where k∗ = [k(t∗, t1), … k(t∗, tN)]⊤ and the remaining symbols were defined in Sect. 3.3.
We start with the results for the Sun which are depicted in Fig. A.1. On the top panel we have plotted the mean curve of the H model. It is evident that single harmonic is not realistic model for the data, as it clearly goes out of phase with the data at different cycles. The evidence of the trend in the solution is relatively strong. In the middle panel there is shown a fit from P model. In this case the quality of the fit is somewhat better due to more complex form of the periodic, however we see the similar tendency of the mean curve being slightly out of phase during all but the middle cycle. The linear trend is also evident. On the bottom panel the results from QP model show much better overall fit to the data. As the time-scale of the model is only 1.5 times longer than the cycle period, we see quite heavy modulation of the cycle amplitude. The presence of the trend is also apparent in the model.
 |
Fig. A.1. Comparison of the fits of H (panel a), P (panel b) and QP (panel c) models for the Sun. Black crosses are data and red lines the predictive mean curves. The shaded areas around the means of the GPs correspond to 2σ intervals of the predictive distributions. |
The next example is the star HD 114710, which we selected because of a significant difference in the period estimate for the QP compared to the other models. The fitted curves can be seen in Fig. A.2. From the H model we see that there is a period around 16 yr. In Cyc95 there was detected also a secondary harmonic cycle, which in our analysis, however turned out to be insignificant. From the P fit we see that the dataset is still explained by one periodic, which now has the phase behaviour containing two maxima. So the potential secondary harmonic cycle is enclosed in the behaviour of a single periodic. QP fit on the other hand detected the shorter cycle period around 14 yr. The time-scale of this model is approximately seven times longer than the cycle period.
 |
Fig. A.2. Comparison of the fits of H (panel a), P (panel b) and QP (panel c) models for HD 114710. The meaning of the panels and symbols is the same as in Fig. A.1. |
As a last example we want to show why the P model turned out to be quite impractical in some of the cases, because preferring longer periods with less harmonic phase behaviour over shorter and more harmonic periods. For instance for the star HD 201091 there is obviously a clear cycle present in the data around 7–8 yr. However, the optimal fit from the P corresponds to a very long period around 29 yr, which is almost the length of the dataset, thus being neglected from the results. Neither is this complex phase behaviour physically meaningful. To avoid such fits we could have used more restrictive priors on ℓ, but we decided not to do it to allow finding better fits than those obtained already by using H model. The comparison of the fits for this star are shown in Fig. A.3. On panel a we show both of the cycles detected by the harmonic model plotted on top of the original data and the residuals correspondingly. The time-scale of the QP model in this case is approximately 14 times longer than the cycle period.
 |
Fig. A.3. Comparison of the fits of H (panel a), P (panel b) and QP (panel c) models for HD 201091. The meaning of the panels and symbols is the same as in Fig. A.1. |
All Tables
All Figures
|
Fig. 1. Comparison of the results for the star HD 37394 using BGLST model and GLS models with and without detrending. Panel a: data (black crosses), BGLST model (red continuous curve), GLS model fitted to detrended data with trend added back (blue dashed curve), GLS model fitted to the original data (green dash-dotted curve), trend component of the BGLST model (red line) and empirical trend (blue dashed line). Panel b: spectra of the models with the same colours. Vertical lines mark the locations of the corresponding maxima. |
| In the text | |
|
Fig. 2. Diagnostics of the experiments comparing QP and H models. Panel a: ratio of average relative errors, panel b: fraction of experiments where GP outperformed harmonic model, panel c: relative errors of QP (red continuous curve) and H (blue dashed curve) models. |
| In the text | |
|
Fig. 3. Panel a: ratio of total variance to average seasonal variance vs. log |
| In the text | |
|
Fig. 4. RCRA diagram for cycles obtained from H (panel a), P (panel b), QP (panel c) models and the comparison of the results of H to Cyc95 (panel d). The colour intensities of the symbols indicate the significance of the cycles and the error bars show the 2σ uncertainties. For better visualization too short error bars have been omitted. The vertical dotted lines connect the cycles found for the same star, while the bigger symbol size denotes the primary cycle. The Sun is shown with the conventional symbol. The red crosses (blue pluses) represents the stars belonging to the inactive (active) clusters respectively. The black diamonds correspond to the giant stars. The ellipses represent the 2σ regions of the Gaussians obtained from GMM model. The small circles correspond to the results from Cyc95. |
| In the text | |
|
Fig. 5. CR diagram for cycles obtained from H (panel a), P (panel b) and QP (panel c) models. The colour and symbol coding is identical to the one in Fig. 4 |
| In the text | |
|
Fig. 6. Comparison of the results of quasi-periodic GP model and different other observational and modelling studies. Green stars are taken from the analysis of long-term photometry of solar-type stars (Lehtinen et al. 2016), where intensity reflects the cycle grade. Grey squares are from the wedge study of turbulent magnetoconvetion by Warnecke (2018), while grey triangles are from a corresponding study of Viviani et al. (2018), where the wedge assumption was relaxed in the azimuthal direction, allowing for nonaxisymmetric solutions. Larger triangles indicate high-resolution runs. In the bottom of the figure we have shown the ranges of the inactive, active and transitional branches using arrows. The vertical dash-dotted lines mark the points where axi- to nonaxisymmetrical transition occurs accordingly to models and observations. The dashed black curve represents a blend of two linear fits to the inactive and active plus transitional branch. The remaining colour and symbol codings are identical to the one in Fig. 4. Here we have used the magnetic to kinetic energy ratio obtained in the models as a proxy for calculating the |
| In the text | |
|
Fig. A.1. Comparison of the fits of H (panel a), P (panel b) and QP (panel c) models for the Sun. Black crosses are data and red lines the predictive mean curves. The shaded areas around the means of the GPs correspond to 2σ intervals of the predictive distributions. |
| In the text | |
|
Fig. A.2. Comparison of the fits of H (panel a), P (panel b) and QP (panel c) models for HD 114710. The meaning of the panels and symbols is the same as in Fig. A.1. |
| In the text | |
|
Fig. A.3. Comparison of the fits of H (panel a), P (panel b) and QP (panel c) models for HD 201091. The meaning of the panels and symbols is the same as in Fig. A.1. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.