| Issue |
A&A
Volume 618, October 2018
|
|
|---|---|---|
| Article Number | A66 | |
| Number of page(s) | 19 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/201833412 | |
| Published online | 15 October 2018 | |
XZ: Deriving redshifts from X-ray spectra of obscured AGN⋆
1
Pontificia Universidad Católica de Chile, Instituto de Astrofísica, Casilla 306, Santiago 22, Chile
e-mail: cpsimmonds@uc.cl
2
Millenium Institute of Astrophysics, Vicuña, MacKenna 4860, 7820436 Macul, Santiago, Chile
3
Excellence Cluster Universe, Boltzmannstr. 2, 85748
Garching, Germany
4
Max Planck Institut für Extraterrestrische Physik Giessenbachstrasse, 85748 Garching, Germany
5
Institute of Astronomy & Astrophysics, Academia Sinica, Taipei, Taiwan
Received:
11
May
2018
Accepted:
7
July
2018
Context. Redshifts are fundamental for our understanding of extragalactic X-ray sources. Ambiguous counterpart associations, expensive optical spectroscopy, and/or multimission multiwavelength coverage to resolve degeneracies often make estimation difficult in practice.
Aims. We attempt to constrain redshifts of obscured active galactic nuclei (AGN) using only low-resolution X-ray spectra.
Methods. Our method for determining redshifts from the X-ray spectrum (XZ) fits AGN X-ray spectra with a moderately complex spectral model incorporating a corona, a torus obscurer, and a warm mirror. Using the Bayesian X-ray Astronomy (BXA) package, we constrain redshift, column density, photon index, and luminosity simultaneously. The redshift information primarily comes from absorption edges in Compton-thin AGN, and from the Fe Kα fluorescent line in heavily obscured AGN. A new generic background fitting method allows us to extract more information from limited numbers of source counts.
Results. We derive redshift constraints for 74/321 hard-band detected sources in the Chandra deep field South. Comparing with spectroscopic redshifts, we find an outlier fraction of 8%, indicating that our model assumptions are valid. For three Chandra deep fields, we release our XZ redshift estimates.
Conclusions. The independent XZ estimate is easy to apply and effective for a large fraction of obscured AGN in today’s deep surveys without the need for any additional data. Compared to different redshift estimation methods, XZ can resolve degeneracies in photometric redshifts, help detect potential association problems, and confirm uncertain single-line spectroscopic redshifts. With high spectral resolution and a large collecting area, this technique will be highly effective for Athena/WFI observations.
Key words: galaxies: active / X-rays: galaxies / galaxies: distances and redshifts
The XZ redshift estimates are only available at the CDS via anonymous ftp to cdsarc.u-strasbg.fr (130.79.128.5) or via http://cdsarc.u-strasbg.fr/viz-bin/qcat?J/A+A/618/A66
© ESO 2018
1. Introduction
Measuring redshifts for distant active galactic nuclei (AGN) is notoriously difficult, yet crucial for constraining the accretion history of the Universe. Spectroscopic redshifts (hereafter specz values) are desirable but costly, and remain impossible for targets that are faint in the optical and near-infrared bands. Thus, it is common practice to rely on photometric redshifts (hereafter photoz’s), which when given a sufficient number of photometric bands can effectively provide very low-resolution spectra (e.g., Baum 1962; Koo 1985; Pello et al. 1996).
For galaxies, photoz values can be extremely accurate when the spectral energy distributions (SEDs) of various types have distinct sharp features (e.g., Lyman and Balmer breaks, or high equivalent width, EW, emission lines). This is complicated for AGN because the AGN component dilutes or hides the host galaxy features and has a number of high EW lines, leading to multiple degenerate redshift solutions (Salvato et al. 2009), and because the intrinsic variability of these sources makes the photometry gathered over years very uncertain (Simm et al. 2015).
Additionally, AGN selected in one waveband (in this case X-rays) have thus far had to be associated with counterparts to obtain photometry or spectroscopy. However, finding the correct counterpart when the X-ray position uncertainties are large can be ambiguous, especially in deep X-ray observations (see, e.g., Hsu et al. 2014; Salvato et al. 2018). Misassociations can affect both photoz and specz and are difficult to detect.
In this work we demonstrate that for obscured AGN there is sufficient information in the X-ray spectrum to compute a reliable redshift. Although typical redshift uncertainties are usually substantial (σ(z)∼0.2), they remain sufficiently accurate for verifying the association and checking for photoz outliers. The presented technique can be applied already with the low-resolution X-ray imaging spectrometers in current AGN surveys.
We describe in Sect. 2 the redshift information that is present in low-resolution, relatively low-count X-ray spectra. In Sect. 3 we explain our method in detail and quantify the redshift information gain. In Sect. 4 we test the reliability of our method with real survey data and provide redshift catalogues (additional fields in Appendix B). Synergies with ambiguous specz and photoz information are discussed in Sect. 5. Simulations are presented in Sect. 6 where we highlight the number of counts needed for current instruments (Chandra, XMM-Newton, NuSTAR, Swift) and future surveys with eROSITA and Athena.
2. Data
To demonstrate and validate our method, a meaningful test sample of obscured AGN with X-ray spectra and previously obtained specz and photoz information is needed. We primarily use data from the Chandra Deep Field-South (CDF-S; Xue et al. 2011; Rangel et al. 2013), which has extensive spectroscopic and multiwavelength photometric coverage, and thanks to its deep exposure features a large fraction of obscured sources.
The CDF-S survey (464.5 arcmin2) was reduced following the procedure of Laird et al. (2009). Here we work with the 326 hard (2–7 keV) detected X-ray sources in the 4Ms data from Rangel et al. (2013), whose X-ray identification numbers (IDs) we use throughout. Three Ms of additional X-ray data have recently been obtained (Luo et al. 2017). However, 4Ms spectra and associated data products are available from our previous efforts and these are sufficient for our purposes here, where we seek to generically demonstrate the utility of the method. Multiwavelength counterparts were found by Hsu et al. (2014) who also computed photoz data and collated specz values in a large catalogue. Because our goal is to apply an X-ray spectral model suitable for AGN, we discard sources whose photometry is best fitted with a stellar template in Hsu et al. (2014). X-ray spectra and related data products1 were generated with ACIS EXTRACT (Broos et al. 2010) by Brightman et al. (2013). Our final X-ray sample, previously analyzed in Buchner et al. (2015), consists of 321 AGN, 264 of which are obscured (N H ≥ 1022 cm−2). We have optical redshift measurements for the entire sample (100% photoz; 56% specz). For photoz, we use a state-of-the-art photoz technique optimized for AGN (Hsu et al. 2014) and throughout use redshift probability distributions.
To test our technique in wider fields, we later also report results from the All Wavelength Extended Groth strip International Survey (AEGIS-XD; Nandra et al. 2015) and the Cosmological evolution Survey (C-COSMOS; Elvis et al. 2009). The X-ray spectra products were derived as in Brightman et al. (2013), with multiwavelength associations and redshift determinations by (Nandra et al. 2015; AEGIS-XD) and (Salvato et al. 2009; C-COSMOS). These samples were previously analyzed (see Buchner et al. 2015 for more details).
Our technique of determining redshifts from the X-ray spectrum (hereafter XZ) relies on fitting physically motivated templates commonly applied in obscured AGN. The intrinsic X-ray photon spectrum of AGN is to first order a power law E−Γ with photon index (typically Γ = 1.9 ± 0.15; Nandra & Pounds 1994). Most AGN additionally feature photo-electric absorption (due to O, Fe, H, and He atoms along the line of sight) as well as Compton scattering (e.g., Rivers et al. 2013; Buchner et al. 2014). Figure 1 illustrates the resulting spectral shapes. Weak soft power law emission is also frequently observed (e.g., Brightman et al. 2014; Buchner et al. 2014), which can be explained by Thomson scattering of the intrinsic power law by a warm mirror which may bypass the obscurer.
 |
Fig. 1. AGN X-ray spectra from the TORUS model of Brightman & Nandra (2011). The intrinsic power law has a photon index of Γ = 1.9. Labeled numbers indicate the obscurer column density NH = 1022−25 cm−2 . At high column densities, the Fe Kα line at 6.4 keV becomes prominent. A unobscured power law component normalized to 1% of the intrinsic power law has been added. |
In unobscured sources, the spectrum is essentially a featureless2 power law, and little to no redshift information can be gained. However, in obscured sources the obscurer imprints absorption edges at characteristic energies. In heavily obscured AGN (NH ≳ 1024 cm−2), the Fe Kα line is prominent (Turner et al. 1998) and can pinpoint the redshift. We find in this work that in mildly obscured AGN, given enough photons, the absorption edge depths and turnover energies can uniquely constrain the redshift, obscurer column density and photon index simultaneously, even using current CCD spectral resolution data.
Figure 2 shows the spectra of two illustrative examples in which the method provides precise and correct redshift estimates. In the heavily obscured case (left panel; R65), the redshift determination relies on identification of the Fe Kα feature is not the source of redshift information. Instead, the location of the absorption edges rule out high-redshift solutions, as can be seen when comparing the two spectral fit curves. Because of the non-smooth instrument response the edges are difficult to identify by eye, and full forward modeling is needed to explore the possible redshifts, column densities, and spectral slopes. Full parameter space exploration with forward modeling also permits going to lower count spectra.
 |
Fig. 2. Two extreme cases in which XZ provides the correct redshift. Left panel: unbinned X-ray source and background region counts for R65, a heavily obscured AGN (log NH ≃ 24.4 cm−2) with a relatively low number of source counts. The counts are plotted in a horizontal line to show their energy in the observed frame. While the background count rate is nearly independent of energy, source counts clearly cluster at 4 keV. Assuming that feature corresponds to the rest-frame 6.4 keV Fe Kα feature, we can compute the corresponding redshift z = 6.4 keV/Eobs−1 to the energy (top axis). We find z = 0.69, which is consistent with the optically derived spectroscopic redshift. Right panel: binned X-ray spectrum of source R4, a mildly obscured AGN with a high number of counts. The green curve is the best fit, yielding log NH ≃ 22.6 cm−2 and Γ ∼ 1.9 and finds the spectroscopic redshift z = 0.31 (see Fig. 3). The black curve shows the fit if the redshift is fixed to z = 2, which does not follow the data points as well. |
Figure 3 shows the redshift, photon index, and column density parameter space of the two examples. For R4 (mildly obscured; gray), the column density (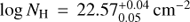 ) and redshift (XZ = 0.31 ± 0.02) of the source are both well constrained. The redshift uncertainty also agrees with specz (0.31). However, a degeneracy between redshift and column density (bottom middle panel) is visible.
) and redshift (XZ = 0.31 ± 0.02) of the source are both well constrained. The redshift uncertainty also agrees with specz (0.31). However, a degeneracy between redshift and column density (bottom middle panel) is visible.
The turnover shape in the model and the limited number of photons detected produces a degeneracy between redshift (decreasing the turnover energy) and column density (increasing the turnover energy). If this degeneracy is not resolved, large uncertainties remain on the redshift. However, given enough photon counts, the detection of absorption edges allows a relatively unique determination of redshift and column density. Furthermore, towards the Compton-thick limit of NH ∼ 1024 cm−2 the model shapes change (see Fig. 1) as the Fe Kα absorption edge becomes stronger. Because of this behavior, very heavily obscured solutions (and associated low redshifts) can be excluded in the degeneracy (see gray “streak” of degeneracy in the lower middle panel of Fig. 3).
 |
Fig. 3. Corner plot showing the parameter space over photon index, column density, and redshift for the heavily obscured AGN R65 (blue) and the mildly obscured AGN R4 (gray), see Fig. 2. Contours indicate 1, 2, and 3σ uncertainties. Any posterior samples outside are plotted as gray dots. Bottom right panel: shows the marginalized redshift probability distribution. In the bottom middle panel a modest degeneracy between column density and redshift is present for R4. |
The two cases illustrate the redshift precision that can be attained. The mildly obscured source has 5690 source counts while the heavily obscured case (R65; blue) has only 128 source counts. Nonetheless, the redshift error for the latter is slightly smaller (XZ = 0.69 ± 0.01), with a unique column density solution (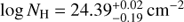 ). We note that the photon counts, source obscuration level, and source redshift all contribute to the redshift uncertainties.
). We note that the photon counts, source obscuration level, and source redshift all contribute to the redshift uncertainties.
3. Methodology
This section outlines our spectral model assumptions and parameter exploration algorithms used, as well as how redshift probability distributions are computed from X-ray spectra.
3.1. Spectral model assumptions
To fit the source we use the torus model from (Brightman & Nandra 2011), which models the circumnuclear material around the X-ray emitting corona and computes the spectrum with photo-electric absorption, Compton scattering, and fluorescent line emission (most importantly Fe Kα). We combine this model with a soft scattering power law with a normalization of up to 10%. We also model the galactic absorption towards the source, such that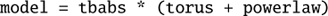
This is the torus+scattering model described in Buchner et al. (2014), which fits the CDF-S field data reasonably well. We also tested replacing the torus model with a simple photo-electric absorber model (wabs) and find comparable but slightly worse results for Compton-thin sources. This indicates that the Fe Kα line is not necessary to determine redshifts in these sources.
Non-informative priors are assumed for all parameters (uniform on log NH = 20−26 and z = 0−7; log-uniform for normalizations), except for the photon index which has an informative Gaussian prior with mean 1.9 and standard deviation 0.15 (e.g., Nandra & Pounds 1994).
Solar abundances are assumed throughout. In obscured AGN, XZ primarily measures the total column density of oxygen and iron, and XZ succeeds only when the column density is high (e.g., NH > 1022). Extremely subsolar oxygen-to-iron abundance ratios could hide edges and lead to poor or invalid redshift estimates. In general, if sources do not adhere to our model assumptions we should see a large outlier fraction in our test sample.
To model the contribution of background spectra, we use a new automatic fitting technique, BStat. Modeling the background carefully by incorporating prior knowledge of background shapes seen in other observations also permits us to work with very few source counts. To create empirical background models with just a few parameters we use a simple machine learning method on archival observations (described in Appendix A). We carry this out for several detectors including those on Chandra, XMM, and NuSTAR. To reduce the number of parameters, we fit the background model to the background spectrum first and freeze its shape parameters. The source parameters and background normalization are then fitted jointly. In low-count sources, our approach extracts more information from the X-ray spectrum because the machine-learned background model exploits instrument-specific prior information.
3.2. Quantifying redshift information
Full exploration of the parameter space is crucial but not trivial. The parameter space of AGN obscuration presents multiple solutions due to the different spectral behavior in the Compton-thin and Compton-thick regimes (see Fig. 1) and due to the spectral turnover degeneracy involving redshift, column density, photon index, and source flux normalization. This presents difficulties for commonly employed minimization algorithms or Markov chain Monte Carlo techniques, and necessitates a global search algorithm (Buchner et al. 2014). We use the analysis software BXA (Buchner et al. 2014), which connects the Monte Carlo nested sampling algorithm MultiNest (Feroz et al. 2009) with the fitting environment CIAO/Sherpa (Fruscione et al. 2006). BXA yields probability distributions on all physical parameters left free in the fit, including the photon index Γ, the line-of-sight column density NH, and most importantly the redshift z. These three parameters are often degenerate and their uncertainties large when the X-ray spectrum has insufficient information. To avoid overconfidence in the best fit, throughout we use the full posterior probability distribution for XZ. As we later show, the combination of XZ redshift probability distributions with those from photoz can be very powerful even in the presence of large uncertainties.
The first useful way to characterize the redshift constraints is via the mean and standard deviation of the probability distribution. If there is a single peak and the standard deviation is σ(z)< 0.1, we can say that we have constrained the redshift relatively well. However, the situation is less clear when there are multiple redshift solutions and upper or lower redshift bounds.
Thus, we define a redshift uncertainty measure that can deal with multiple redshift solutions. How much redshift information was gained from a measurement can be expressed by how different the posterior is from the (uninformative) prior. If at least some redshift intervals have zero posterior probability (i.e., they are excluded), we have learned something. We use the Kullback–Leibler definition of the information gain (IG):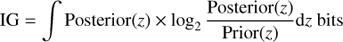
A value of IG = 0 bits means there was no information gained, i.e., the posterior is equal to the prior. A high value of IG means a larger amount of information gained. We define three classes and provide simplifying labels:
-
(A)
IG > 2 bits: Redshift constrained
-
(B)
IG = 1−2 bits: Some redshift information
-
(C)
IG < 1 bit: Little to no redshift information in the X-ray spectrum.
4. Results
We first present some basic statistics about number and types of sources where XZ is able to extract redshift information from the X-ray data alone. Table 1 shows the sample statistics and the relative effectiveness of XZ, photoz, and specz. We find 74 (out of 321) CDF-S sources with constrained redshifts (IG > 2) from the X-ray spectra alone, which corresponds to ∼23 % of the sample. Table 2 shows the properties of all 138 CDF-S sources with IG ≥ 1. The XZ method works not only for heavily obscured sources, but also in mildly obscured ones if the count statistics are good enough.
To build a better understanding of the IG quantity, we compare it to the simpler redshift error σ in Fig. 4. In a large fraction of CDF-S sources the IG has a close correspondence to σ(z): High σ correspond to low IG. As the color-coding in Fig. 4 highlights, high-IG sources tend to be obscured. Our three IG classes are delimited by black vertical lines. Nearly all of the sources found in region A (redshift constrained, IG ≥ 2 bits) have σ ≤ 1. For region B (some redshift information, IG = 1−2 bits), there is large scatter in σ. The highest standard deviations here correspond to sources with multiple redshift solutions. In these cases simple error bars do not faithfully represent the uncertainties. Finally, sources in region C have little or no redshift information in their X-ray spectrum.
We test XZ against specz and photoz measurements in the following subsections. For this, we define three subsamples: The first two are composed of region A sources with constrained redshifts from XZ, which we compare to specz in subsample I (48 AGN; Sect. 4.1), and photoz in subsample II (26 AGN; Sect. 4.2). Sources with some XZ redshift information (region B, 1 ≤ IG < 2 bits) are compared to photoz in subsample III (64 AGN; Sect. 4.3). In all cases the specz and photoz information is taken from the compilation of Hsu et al. (2014).
 |
Fig. 4. Comparison of two redshift uncertainty measures, the information gain (IG; x-axis) and the standard deviation σ(z) (y-axis). Generally, a larger σ(z) implies a smaller IG. However, the IG also captures multiple solutions (examples are shown in subsequent figures) which can inflate the simple σ(z) measure (symbolized by the gray arrow). The color-coding indicates the obscuration (median of uncertainties); darker colors represent higher column densities. Heavily obscured sources typically have only a single solution and are at lower σ. The vertical lines delimit three regions, A (IG ≥ 2 bits, “constrained redshift”), B (1 ≤ IG < 2 bits, “has redshift information”), and C (IG < 1 bit, “no redshift information”). The top and right panels show normalized histograms. |
Sample statistics.
Redshift catalogue of CDF-S sources with IG≥1 bit (excerpt).
4.1. Constrained XZ vs. specz (subsample I)
We first test the reliability of our XZ method against specz measurements.
Figure 5 plots XZ against specz for subsample I. For ∼60 %, the specz resides within the 68% quantile of XZ. In many cases the uncertainties are very small, providing relatively precise redshift measurements. The inset of Fig. 5 shows the deviations between the specz and XZ median. For 75 %, these are within ±0.15(1 + z) with a median absolute deviation of 0.04(1 + z). Thus, for the vast majority of this sample, XZ provides redshifts consistent with specz.
 |
Fig. 5. Comparison of XZ and specz for constrained cases (IG ≥ 2). The filled circles show the median of the XZ probability distribution while the error bars correspond to 1σ-equivalent quantiles and color-coded by the median of the obscuration level. Dashed error bars indicate XZ found multiple solutions. The black solid line shows XZ = specz, while the gray dotted lines show XZ = specz ± 0.15(1 + specz). Points outside this region and where the XZ error bars do not cover the specz value are circled in black. Square symbols show insecure specz values (Luo et al. 2017). The inset shows the relative difference between XZ and specz. |
The ability to correctly recover specz values implies that the specz counterparts are correct and that the XZ model assumption are generally valid. We define outliers as those where the 1− σ XZ error bars do not cover the specz value and the XZ median is outside specz ±0.15(1 + specz). With this criterion, we find seven outliers among the 48 well-constrained sources (R49, R68, R156, R213, R446, R458, and R465). We discuss them in more detail in Sect. 5, where we find that, at least in some cases, the specz has to be corrected.
The dashed error bars in Fig. 5 indicate multiple-peaked redshift solutions. In these cases, error bars oversimplify the redshift probability distribution. To show the full distribution, a violin plot visualization is presented in Fig. 6. There we compare the XZ redshift probability distributions (cyan violin plots) and the specz values (black vertical lines). Multiple solutions can be seen for several sources (e.g., R179, R181, R428).
 |
Fig. 6. XZ probability distributions (cyan violin plots) for subsample I compared to specz values (black vertical lines). Sources are ordered by increasing specz. Insecure specz values are shown as gray crosses. |
4.2. Constrained XZ vs. photoz (subsample II)
Next, we consider sources without specz measurements, and validate XZ against photoz. This generally probes sources that are fainter in the optical/near-infrared wavelengths. The mutual validation of photoz and XZ can confirm redshifts or point out potentially problematic cases.
Figure 7 plots XZ against photoz for subsample II. While the majority of the sources show consistent redshifts (XZ ≈ photoz) within the errors, there are six outliers out of 26 sources (using the same definition as above). This is a higher fraction than in subsample I. In order to analyze these cases in more detail, we show in Fig. 8 the normalized XZ and photoz probability distributions (gray and cyan, respectively). Disagreements are seen, for example in R115, R263, and R471. An interesting case is R227, which has two solutions in XZ, one of which overlaps with the photoz uncertainties. The combination of the constraints implies a redshift just above 2, demonstrating the synergy of the two techniques.
 |
Fig. 8. XZ (cyan) and photoz (gray) probability distributions for subsample II (IG ≥ 2 bits, no specz). XZ and photoz can mutually confirm redshifts and narrow uncertainties (e.g., R56, R116, R227, R444) or select between multiple photoz solutions (e.g., R12, R333). Some cases show disagreements (e.g., R115, R273, R471). For R265 the photoz was taken from Luo et al. (2010). Sources ordered by increasing XZ median values. |
4.3. XZ redshift predictions (subsample III)
Finally, we consider XZ constraints that are weaker, but that can be combined with photoz constraints to distinguish between degenerate or multiple redshift solutions. Figure 9 shows the redshift probability distributions for subsample III (IG = 1−2 bits), as before the gray violin plots represent photoz, while the cyan plots show XZ. In several cases (e.g., R5, R185, R194, R306) X-ray spectral fitting can confirm results found via photometry and distinguish between multiple photoz redshift solutions. In one of the cases, R22, no photoz is presented because this X-ray source has an ambiguous association; for one of these opt/NIR counterparts (Hsu et al. ID 105068) the photoz is highly uncertain, while the other (61367) is constrained to photoz = 2.11 ± 0.06. Unfortunately, the wide XZ error is not able in this case to provide much clarity.
 |
Fig. 9. XZ (cyan violin plots) and photoz (gray violin plots) probability distributions for subsample III (1 bits ≤ IG < 2 bits). |
5. Discussion
We now discuss differences in XZ, photoz, and specz redshift estimates.
We find a few noteworthy cases which we put into two distinct categories: (1) cases in which XZ and photoz agree, but neither agrees with specz, and (2) cases in which photoz and specz agree, but neither agrees with XZ.
5.1. Potential specz issues
Some disagreements with specz may be caused by incorrect spectral line identification, especially when only a single line has been observed. In some such cases, the redshift is nevertheless classified as “secure” in published catalogues.
We identified several cases where XZ = photoz ≠ specz. These include sources with constrained redshifts (R49, R156, R446; from subsample I) and others with more limited redshift information (IG > 1 in R157, R334). For these five sources, we present the (dis)agreements between XZ, photoz, and specz in Fig. 10.
 |
Fig. 10. Normalized redshift probability distributions where XZ (blue solid) and photoz (green dashed) agree but are different than the specz values (orange vertical lines). Black vertical lines in R156 and R334 show updated specz values from Balestra et al. (2010) and Barro et al. (2014), respectively, which agree with the photoz and XZ. Dashed vertical lines show insecure specz values. |
Through a literature search on these sources we found updated specz for two, R156 and R334, in Balestra et al. (2010) and Barro et al. (2014), respectively. We indicate these in Fig. 10 as vertical black lines. These new specz values agree with XZ. This makes us question the reliability of specz for the remainder of this group, in particular for R446. For R446 we do not have an updated specz; however, the redshift reported in Szokoly et al. (2004) relies on only a single spectral line. In Fig. 11 we show the evolution of the observed wavelength of two spectral lines according to redshift. The specz (0.72) was derived from a spectroscopic line assumed to be MgII. However, XZ and photoz indicate z ∼ 1.56. This would be consistent if the line was CIII. Given that the literature search provided updated specz values for two sources, which agree with XZ, we caution that specz can sometimes be incorrect and this can be detected by our method.
 |
Fig. 11. Observed wavelength of MgII and CIII spectroscopic lines as a function of redshift. The horizontal dashed line shows the observed wavelength of a single detected optical spectral line in source R446. The vertical lines indicate the reported specz (orange), photoz (green), and XZ (blue). The dotted vertical lines show the errors of photoz and XZ, respectively. The specz was derived assuming MgII, but agrees with XZ and photoz if we assume CIII instead. |
5.2. Potential association issues
We find four constrained sources where XZ ≠ photoz = specz, namely R68, R213, R458, and R465. For these outliers, Fig. 12 shows the redshift probability distributions, along with their associated specz. The disagreement likely indicates that some assumptions of the XZ method are invalid in these cases. From these we estimate that the outlier fraction is ∼8% of the sample, indicating a high reliability of the XZ method.
 |
Fig. 12. Same as Fig. 10, but for cases where photoz (green dashed) and specz (orange vertical line) agree and are noticeably different than XZ (blue curve). |
For this group, in principle the XZ could be correct if both the specz and photoz are incorrect. This could occur because of incorrect optical counterpart associations. For our sample, this is not very probable because the Chandra positional error with approximately one hundred counts is usually not large enough to allow multiple counterpart associations.
5.3. Potential XZ issues
In six constrained cases XZ disagrees with photoz (from subsample II): R37, R56, R115, R227, R263, and R471 (see Fig. 8). All of these sources fall within the sensitivity range of the method, with either a high count number or a high level of obscuration. It is necessary to investigate these sources further to confirm the correct redshift since one (or both) of the methods fails in these cases. As discussed above, photoz (like specz) can suffer from possible counterpart misassociations, while XZ is far less likely to do so (given the X-ray source density). Both photoz and XZ can yield multiple solutions and sometimes the correct solution is outweighed by an incorrect one, leading to incorrect redshifts.
Figure 13 shows an example of the multiple solution issue, R447. While the photoz = 0.74 ± 0.01 and specz = 0.735 agree, the XZ (nominally 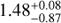 ) has two solutions, with the less probable solution covering the same range as the photoz and specz. Thus, the most probable redshift solution reported by XZ is not necessarily the correct one, which is why it is advisable to combine the results with photoz in order to get more reliable results. In addition, XZ can be affected by AGN variability. This is an open or unclear issue, as variability might either weaken or strengthen features needed for XZ depending on the sense of the variability (i.e., increasing or decreasing NH or intrinsic continuum).
) has two solutions, with the less probable solution covering the same range as the photoz and specz. Thus, the most probable redshift solution reported by XZ is not necessarily the correct one, which is why it is advisable to combine the results with photoz in order to get more reliable results. In addition, XZ can be affected by AGN variability. This is an open or unclear issue, as variability might either weaken or strengthen features needed for XZ depending on the sense of the variability (i.e., increasing or decreasing NH or intrinsic continuum).
Finally, there could be fundamental issues with the XZ approach. XZ is model-based and thus invalid model assumptions could lead to incorrect results. The model could be extended to be more realistic, e.g., by allowing different obscurer metallicities, obscurer geometries, multiple AGN components, and/or soft energy contaminants. However, the low outlier fraction of 8% when validating against specz indicates that the simple adopted model is adequate in general.
 |
Fig. 13. Same as Fig. 10, but for case R447 where XZ (blue) presents multiple solutions, one of which agrees with photoz (green dashed) and specz (orange vertical line). |
XZ is most useful when obscured AGN with moderate count statistics make up a sizable fraction of the sample.Because of the observed increase in the obscured fraction at low luminosities and high redshifts (e.g., Ueda et al. 2003; Hasinger et al. 2005), XZ is most useful in deep surveys like the CDF-S. Consistent with this, we find lower percentages of constrained redshifts when testing our method on data from the COSMOS and AEGIS-XD fields (see Table 1). The detailed results from these two surveys are presented in Appendix B, including redshift catalogues and photoz/specz plots.
6. Sensitivity analysis for different X-ray Instruments
6.1. Simulation setup
To answer how many source photon counts are needed for good redshift constraints, we performed extensive realistic simulations for multiple instruments. We generate source and background spectra and fitted them as with the real observations. The recovery is tested across different redshift (z = 0−5) and column density regimes (NH = 1022−25 cm−2). The simulation parameter grid is listed in Table 3.
For each such scenario (z, NH), several instruments are considered, including Chandra, XMM-Newton, Swift, NuSTAR, eROSITA, and Athena. Importantly, we vary the expected number of source counts to find the relation between number of counts and XZ redshift uncertainty. We also tested different background levels by varying the exposure time, but find that these show small differences (also thanks to the background model fitting), and that NH and the number of counts remain the most important variables. For Chandra, for example, we adopted a relatively long exposure time representative of the CDF-S, which gives the worst case of high background levels. For each instrument, Table 4 shows the counts, the exposure time, and the total number of simulations created and fitted.
Simulations were created in Sherpa using the fake_pha command. We used the same spectral model for simulation as in the fitting. To simulate background spectra, we let fake_pha resample a representative bkg file for each instrument. For upcoming missions Athena and eROSITA we simulated a background following the information provided by the respective mission websites3.
Simulation parameter grid.
Simulation setup for tested instruments.
6.2. Redshift recovery
The recovery of input redshifts is presented in Fig. 14. The XZ uncertainties are presented for various instruments and redshifts. Here, a total source count number was chosen for each instrument representing the approximate threshold where the XZ method starts to be useful. Figure 14 demonstrates the accuracy and precision of XZ. The correct retrieval of the redshift (y-axis) at each input redshift (x-axis) is expected because the model used to simulate data is the same as the fitted model. While optimistic, Fig. 14 demonstrates that the parameter space is reliably explored. It also shows that when the X-ray spectrum contains no redshift information, the XZ uncertainties increase dramatically, but the results are not incorrect. For instance, at z > 1 any discriminatory information from the Fe Kα line is redshifted out of the NuSTAR observing window, and the uncertainties increase drastically.
 |
Fig. 14. Recovery of redshifts by the XZ method. Output XZ redshift probability distributions are shown as violin plots for each input z (x-axis). In all cases NH = 1024 cm−2 is shown. The panels correspond to different instruments, with a total number of source counts chosen at the approximate threshold where the XZ method starts to work optimally. |
6.3. Minimal counts for XZ constraints
We now investigate the minimum number of counts needed to obtain redshift information (IG ≥ 1). Figure 15 shows redshift uncertainty (darker: larger errors, white: tightly constrained) as a function of total source counts (y-axis), input source redshift (x-axis), instrument (rows), and column density (columns). The thick black contour line shows IG = 1 bit, i.e., above it (higher counts), some redshift information can be extracted by XZ from the X-ray data alone. Considering Chandra for instance, we find that the sensitivity of the XZ method depends on both the count number and the neutral hydrogen column density value along the line of sight. In general, the best results are obtained with heavily obscured column densities. The required count number varies from instrument to instrument, from 50 to 500 minimal counts. Compared to Chandra the number of counts required is higher with eROSITA and Swift (both are less sensitive at >4 keV). In NuSTAR, only Compton-thick AGN are usable because the Fe Kα line is the primary source of information.
 |
Fig. 15. Sensitivity heat maps for each instrument. Redshift uncertainty (colors) are plotted against source redshift (x-axis) and total source counts (y-axis). Above the thick contour lines, IG > 1 bit, i.e., the number of counts is sufficient to provide some redshift information. From left to right panels, the columns show log NH = 22, 23, 24, and 25 cm−2. XMM total source counts refer to total counts across PN/MOS1+2. |
The required number of counts imply minimal exposure times and luminosities for the different instruments. For Chandra, for example, we assume a relatively long exposure time (see Table 4), which gives the worst case of high background levels. We tested different exposure times, but find that these show small differences (also thanks to the background model fitting), and that NH and number of counts remain the most important variables. To compare the efficiency of the XZ technique for each instrument, we assume 100ks exposures and determine the luminosity limit that can be probed. Figure 16 shows this limit as a function redshift for each instrument. The panels correspond to different column densities NH = 1023−25 cm−2. At higher luminosities, Swift and eROSITA are found to be similarly sensitive. However, the eROSITA all-sky survey (eRASS) will only reach exposures of several ks (Merloni et al. 2012), thus its luminosity limit will be substantially higher. At these fluxes, only a few AGN are expected across the full sky (Kolodzig et al. 2013), and have likely already been identified, for example in the WISE all-sky survey (Wright et al. 2010).
 |
Fig. 16. 2–10 keV luminosity (observed-frame, absorbed) vs. redshift plot that shows the sensitivity limit of the XZ method for NH = 1023 (top panel), 1024 (middle panel) and 1025 (bottom panel) cm−2. In order to compare the response of XZ for different instruments, we normalize the luminosity values to 100 ks. Both current and future missions are shown; XZ is particularly sensitive to the upcoming mission Athena. |
We have also considered applying the XZ method to gamma-ray bursts, which frequently show Compton-thin obscuration up to NH = 1023 cm−2 (e.g., Buchner et al. 2017). Swift (Gehrels et al. 2004) detects gamma-ray bursts and observes X-ray spectra with XRT. Obtaining redshift constraints is crucial in order to probe massive star formation in the early Universe. Today, this requires timely follow-up and favorable observing conditions. XZ could improve this process by augmenting photometric redshifts. We tested XZ on a large sample of X-ray afterglow spectra from the Swift archive (described in Buchner et al. 2017). However, the emission in these sources is generally too short to accumulate the necessary counts for XZ to provide constraints with Swift/XRT. For some ultra-long gamma-ray bursts the counts are sufficient, but these sources present unusual spectral features that are poorly understood and likely arise from spectral variability (Piro et al. 2014; Evans et al. 2014). In any case, these sources are a small subpopulation of all gamma-ray bursts. An observatory with higher collecting area is required to obtain XZ constraints for gamma-ray bursts.
The best performance is seen with the next-generation Athena mission (Nandra et al. 2013), which will feature a mirror with large effective area (2m2), wide energy coverage (0.3–12 keV) and good resolution (< 150 eV) even for the Wide-field Imager (WFI; Meidinger et al. 2017). With this mission, surveys as deep as the CDF-S 4Ms can be performed twenty times faster (Rau et al. 2016), and cover larger areas (∼100 deg2), allowing a deep and complete census of the AGN population at high redshift. Previously, Castelló-Mor et al. (2011) developed a redshift extraction technique based on finding the Fe Kα line in Fourier-transformed spectra. In 100ks exposures, this succeeds in unobscured AGN with luminosities of 1044erg s−1 at z = 1. In Fig. 16 we estimate that XZ can measure redshift of obscured AGN, which constitute the bulk of the population in deep observations, down to luminosities as low as 1041erg s−1. This indicates that for a substantial fraction of sources detected in such a survey, expensive follow-up may be unnecessary, as redshift information can be extracted directly from Athena/WFI X-ray spectra.
7. Conclusions
Deep X-ray fields probe accretion in the early Universe, and are dominated by obscured AGN. The deep observations require time-consuming follow-up campaigns to obtain reliable redshift estimates. In this regime we demonstrated that for a sizable fraction of sources, the X-ray spectrum contains substantial redshift information in the absorption edges and, if Compton-thick, the Fe Kα fluorescent line. Through simulations, we characterized in detail the obscuration level and number of counts required to find constrained and reliable solutions. However, failure to meet such conditions does not lead to incorrect results, only to large uncertainties.
Sidestepping association problems, our XZ method is promising for estimating redshifts or confirming/reinforcing photoz and specz estimates. The XZ estimate is easy to apply and does not require additional data. In addition to direct redshift estimates in some high-count sources, it can discriminate between multiple photoz solutions in a large fraction of obscured AGN in today’s deep surveys. We demonstrate that disagreements of the independent XZ estimate with photoz/specz estimates can help to flag problematic measurements, for example due to incorrectly identified spectroscopic lines, to contaminated photometric data due to blending or variability, or to ambiguous counterparts. With high spectral resolution and a large collecting area, this technique will be highly effective for Athena+/WFI observations.
The equivalent width of the Fe Kα line is below 100 eV (Turner et al. 1998), which is below the typical spectral resolution of most X-ray CCDs operating today.
Acknowledgments
We thank the referee for helpful comments that have improved this paper. We thank Laurent Douchy for creating Docker container images. We also thank Alex Markowitz and Claudio Ricci for providing example background spectra for XRTE, Suzaku, and Swift/XRT. We acknowledge support from the CONICYT-Chile grants Basal-CATA PFB-06/2007 (JB, FEB), FONDECYT Regular 1141218 (FEB), FONDECYT Postdoctorados 3160439 (JB), EMBIGGEN Anillo ACT1101 (FEB), and the Ministry of Economy, Development, and Tourism’s Millennium Science Initiative through grant IC120009, awarded to The Millennium Institute of Astrophysics, MAS (JB, FEB). This research was supported by the DFG cluster of excellence Origin and Structure of the Universe.
References
- Akaike, H. 1974, IEEE Trans. Autom. Control, 19, 716 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Balestra, I., Mainieri, V., Popesso, P., et al. 2010, A&A, 512, A12 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Barro, G., Trump, J. R., Koo, D. C., et al. 2014, ApJ, 795, 145 [NASA ADS] [CrossRef] [Google Scholar]
- Baum, W. A. 1962, in Problems of Extra-Galactic Research, ed. G. C. McVittie, IAU Symp., 15, 390 [NASA ADS] [Google Scholar]
- Brightman, M., & Nandra, K. 2011, MNRAS, 413, 1206 [CrossRef] [Google Scholar]
- Brightman, M., Silverman, J. D., Mainieri, V., et al. 2013, MNRAS, 433, 2485 [NASA ADS] [CrossRef] [Google Scholar]
- Brightman, M., Nandra, K., Salvato, M., et al. 2014, MNRAS, 443, 1999 [NASA ADS] [CrossRef] [Google Scholar]
- Broos, P. S., Townsley, L. K., Feigelson, E. D., et al. 2010, ApJ, 714, 1582 [NASA ADS] [CrossRef] [Google Scholar]
- Buchner, J., Georgakakis, A., Nandra, K., et al. 2014, A&A, 564, A125 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Buchner, J., Georgakakis, A., Nandra, K., et al. 2015, ApJ, 802, 89 [NASA ADS] [CrossRef] [Google Scholar]
- Buchner, J., Schulze, S., & Bauer, F. E. 2017, MNRAS, 464, 4545 [NASA ADS] [CrossRef] [Google Scholar]
- Castelló-Mor, N., Barcons, X., & Ballo, L. 2011, Adv. Space Res., 48, 1304 [NASA ADS] [CrossRef] [Google Scholar]
- Civano, F., Elvis, M., Brusa, M., et al. 2012, ApJS, 201, 30 [NASA ADS] [CrossRef] [Google Scholar]
- Elvis, M., Civano, F., Vignali, C., et al. 2009, ApJS, 184, 158 [NASA ADS] [CrossRef] [Google Scholar]
- Evans, P. A., Willingale, R., Osborne, J. P., et al. 2014, MNRAS, 444, 250 [NASA ADS] [CrossRef] [Google Scholar]
- Feroz, F., Hobson, M. P., & Bridges, M. 2009, MNRAS, 398, 1601 [NASA ADS] [CrossRef] [Google Scholar]
- Fruscione, A., McDowell, J. C., Allen, G. E., et al. 2006, in SPIE Conf. Ser., 6270, 62701V [Google Scholar]
- Gehrels, N. 2004, in Gamma-Ray Bursts: 30 Years of Discovery, eds. E. Fenimore, & M. Galassi, AIP Conf. Ser., 727, 637 [NASA ADS] [CrossRef] [Google Scholar]
- Hasinger, G., Miyaji, T., & Schmidt, M. 2005, A&A, 441, 417 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hsu, L.-T., Salvato, M., Nandra, K., et al. 2014, ApJ, 796, 60 [NASA ADS] [CrossRef] [Google Scholar]
- Kolodzig, A., Gilfanov, M., Sunyaev, R., Sazonov, S., & Brusa, M. 2013, A&A, 558, A89 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Koo, D. C. 1985, AJ, 90, 418 [NASA ADS] [CrossRef] [Google Scholar]
- Laird, E. S., Nandra, K., Georgakakis, A., et al. 2009, ApJS, 180, 102 [NASA ADS] [CrossRef] [Google Scholar]
- Luo, B., Brandt, W. N., Xue, Y. Q., et al. 2010, ApJS, 187, 560 [NASA ADS] [CrossRef] [Google Scholar]
- Luo, B., Brandt, W. N., Xue, Y. Q., et al. 2017, ApJS, 228, 2 [Google Scholar]
- Meidinger, N., Barbera, M., Emberger, V., et al. 2017, SPIE Conf. Ser., 10397, 103970V [Google Scholar]
- Merloni, A., Predehl, P., Becker, W., et al. 2012, ArXiv e-prints [arXiv:1209.3114] [Google Scholar]
- Nandra, K., Barret, D., Barcons, X., et al. 2013, ArXiv e-prints [arXiv:1306.2307] [Google Scholar]
- Nandra, K., Laird, E. S., Aird, J. A., et al. 2015, ApJS, 220, 10 [NASA ADS] [CrossRef] [Google Scholar]
- Nandra, K., & Pounds, K. A. 1994, MNRAS, 268, 405 [NASA ADS] [CrossRef] [Google Scholar]
- Pello, R., Miralles, J. M., Le Borgne, J.-F., et al. 1996, A&A, 314, 73 [NASA ADS] [Google Scholar]
- Piro, L., Troja, E., Gendre, B., et al. 2014, ApJ, 790, L15 [NASA ADS] [CrossRef] [Google Scholar]
- Ptak, A., & Griffiths, R. 2003, in Astronomical Data Analysis Software and Systems XII, eds. H. E. Payne,R. I. Jedrzejewski, & R. N. Hook, ASP Conf. Ser., 295, 465 [NASA ADS] [Google Scholar]
- Rangel, C., Nandra, K., Laird, E. S., & Orange, P. 2013, MNRAS, 428, 3089 [NASA ADS] [CrossRef] [Google Scholar]
- Rau, A., Nandra, K., Aird, J., et al. 2016, in Proc. SPIE, 9905, 99052B [Google Scholar]
- Ricci, C., Trakhtenbrot, B., Koss, M. J., et al. 2017, ApJS, 233, 17 [NASA ADS] [CrossRef] [Google Scholar]
- Rivers, E., Markowitz, A., & Rothschild, R. 2013, ApJ, 772, 114 [NASA ADS] [CrossRef] [Google Scholar]
- Salvato, M., Hasinger, G., Ilbert, O., et al. 2009, ApJ, 690, 1250 [CrossRef] [Google Scholar]
- Salvato, M., Buchner, J., Budavári, T., et al. 2018, MNRAS, 473, 4937 [NASA ADS] [CrossRef] [Google Scholar]
- Simm, T., Saglia, R., Salvato, M., et al. 2015, A&A, 584, A106 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Szokoly, G. P., Bergeron, J., Hasinger, G., et al. 2004, ApJS, 155, 271 [NASA ADS] [CrossRef] [Google Scholar]
- Turner, T. J., George, I. M., Nandra, K., & Mushotzky, R. F. 1998, ApJ, 493, 91 [NASA ADS] [CrossRef] [Google Scholar]
- Ueda, Y., Akiyama, M., Ohta, K., & Miyaji, T. 2003, ApJ, 598, 886 [NASA ADS] [CrossRef] [Google Scholar]
- Willis, J. P., Pacaud, F., Valtchanov, I., et al. 2005, MNRAS, 363, 675 [NASA ADS] [CrossRef] [Google Scholar]
- Wright, E. L., Eisenhardt, P. R. M., Mainzer, A. K., et al. 2010, AJ, 140, 1868 [NASA ADS] [CrossRef] [Google Scholar]
- Xue, Y. Q., Luo, B., Brandt, W. N., et al. 2011, ApJS, 195, 10 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Automatic background fitting
This section describes a new technique, BStat, for characterizing spectra of background regions. With principal component analysis (PCA) this technique learns the typical background shape and variations from a large sample. The technique is applied for each telescope and detector separately and forms a general solution to empirical background modeling.
 |
Fig. A.1. Chandra/ACIS background PCA components. The average spectrum plus the selected principle component is plotted in arbitrary units. All CCDs have been combined as they show broadly similar background shapes. |
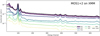 |
Fig. A.2. XMM/MOS background PCA components. MOS1 and MOS2 have been combined as they show similar background shapes. |
 |
Fig. A.3. XMM/PN background PCA components. |
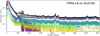 |
Fig. A.4. NuSTAR background PCA components. The FPMA and FPMB detectors have been combined as they show similar background shapes. |
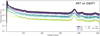 |
Fig. A.5. Swift/XRT background PCA components. WT and PC mode observations have been combined as they show similar background shapes. |
To obtain training data, we download background spectra for Chandra ACIS and XMM-Newton PN&MOS from the Xassist website4 (Ptak & Griffiths 2003). We extracted NuSTAR point source spectra with corresponding backgrounds at the locations of the Chandra hard-band detected sources in the COSMOS, CDF-S, and AEGIS-XD surveys handled in this paper using the standard NuSTAR pipeline. Most of these sources are undetected. We further obtained Swift XRT background spectra5 (Buchner et al. 2017) and the Swift/BAT survey (Ricci et al. 2017). This yielded a sample of 1895 (Chandra/ACIS), 575 (NuSTAR), 414 (Swift/XRT), 1859 (XMM/PN), and 1982 (XMM/MOS) background spectra.
Principal component analysis (PCA) identifies the eigenvectors (in this case, background components) as primary axes of variance (background diversity). We stacked the background spectra so that each background spectrum has at least 10 000 total counts. This avoids non-Gaussianity in the Poisson counts. On this sample we apply PCA and extract the mean and the 20 most important features (background spectra vectors). Figures A.1 (Chandra), A.2 and A.3 (XMM MOS & PN), A.5 (Swift/XRT), and A.4 (NuSTAR) illustrate some examples of these components.
We then use in Sherpa these components to fit the background. Our fitting procedure starts by having all component normalizations free and performing a normal simplex fit to the background spectrum. Then, the least important component is disabled (normalization set to zero) and another fit is done. This is repeated until only the mean background component remains. For each of these fits we note the Akaike Information criterion (AIC; in this case the C statistic plus twice the number of fit parameters; Akaike 1974; Buchner et al. 2014), and choose the fit with the highest AIC. For fit robustness against local minima, we try to increase the number of components again from there until the AIC does not increase further. Choosing the fit with the highest AIC selects only the K most important components where the background spectrum has enough information to justify activating these components, while the remainder of the spectrum is aligned with the typical (based on the training sample) background spectrum for this detector. Using the AIC thus avoids over-fitting.
Throughout the study we work with background counts without convolving through the response as some background components originate on the detectors and this is an empirical model. Working in linear space (on the counts) would be ideal because some background components are additive. However, this can lead to negative backgrounds when we fit. Instead, we transform into logarithmic space with log(counts + 1). This has the benefit that all possible combinations of background spectral features are positive counts because in linear space the (positive) spectral components are multiplied together. However, a drawback is that Gaussian lines of varying strength can not be characterized well. We address this by adding Gaussian lines on top when needed (i.e., as long as justified by an increase in the AIC). Overall this fitting procedure works robustly and captures the background spectrum well.
When fitting a science target we add the background model to the source model. We scale the background contribution proportionally to the source and background region sizes. In the source fitting we keep the background shape fixed. However, we allow the background normalization to vary freely and simultaneously fit the source and background spectra. Freezing the background normalization as well sometimes leads to overly small uncertainties, in particular when few background counts have been detected.
Our technique decreases the fit uncertainties compared to WStat, the xspec default behavior. WStat does per-bin estimates of the background, i.e., does not assume any continuity between spectral bins. Additionally, zero or low-count count bins produce biases (e.g., Willis et al. 2005) and require rebinning. In contrast, our technique always works with continous background spectral models across bins, and can handle even zero-count bins. Both in our approach and when using custom-built background models, source fit uncertainties are smaller than in WStat because prior knowledge about typical background shapes is exploited. Our machine learning approach, however, does this without requiring the user to hand-craft a model. Our automatic background fitting technique is released as part of BXA (Buchner et al. 2014).
Appendix B: COSMOS and AEGIS-XD results
Similar to Table 2 for CDF-S sources, we present XZ constraints catalogues for the COSMOS and AEGIS fields in Tables B.1 and B.2, respectively. The data products used are described in Brightman et al. (2013) and Buchner et al. (2015).
Figures B.1 and B.5 present the performance of COSMOS and AEGIS samples, respectively, where XZ constrained the redshifts. AEGIS, a relatively deep yet wide field has the largest number of constrained redshifts across the three fields.
Similar to the CDF-S results, we plot the XZ constraints in three subsamples divided by information gain. Subsample I contains sources with specz and XZ-constrained redshifts (Figs. B.2 and B.6). Subsample II contains sources without specz and compares XZ-constrained redshifts to photoz (Figs. B.3 and B.7). Subsample III contains sources without specz and compares XZ with some redshift information to photoz (Figs. B.4, B.8, and B.9).
Properties of COSMOS Sources with IG ≥ 1 bit.
Properties of AEGIS-XD Sources with IG ≥ 1 bit.
 |
Fig. B.1. Plot of best-fit XZ values vs. photoz from Salvato et al. (2009). |
 |
Fig. B.2. XZ (cyan violin plots) and specz (black vertical lines) probability distributions for subsample I (IG ≥ 2 bits). |
 |
Fig. B.3. XZ (cyan violin plots) and photoz (gray violin plots) probability distributions for subsample II (IG ≥ 2 bits). |
 |
Fig. B.4. XZ (cyan violin plots) and photoz (gray violin plots) probability distributions for subsample III (IG ≥ 2 bits). |
 |
Fig. B.5. Plot of best-fit XZ values vs. photoz from Nandra et al. (2015). |
 |
Fig. B.6. XZ (cyan violin plots) and specz (black vertical lines) probability distributions for subsample I (IG ≥ 2 bits). |
 |
Fig. B.7. XZ (cyan violin plots) and photoz (gray violin plots) probability distributions for subsample II (IG ≥ 2 bits). |
 |
Fig. B.8. XZ (cyan violin plots) and photoz (gray violin plots) probability distributions for subsample III (IG ≥ 2 bits). |
All Tables
All Figures
|
Fig. 1. AGN X-ray spectra from the TORUS model of Brightman & Nandra (2011). The intrinsic power law has a photon index of Γ = 1.9. Labeled numbers indicate the obscurer column density NH = 1022−25 cm−2 . At high column densities, the Fe Kα line at 6.4 keV becomes prominent. A unobscured power law component normalized to 1% of the intrinsic power law has been added. |
| In the text | |
|
Fig. 2. Two extreme cases in which XZ provides the correct redshift. Left panel: unbinned X-ray source and background region counts for R65, a heavily obscured AGN (log NH ≃ 24.4 cm−2) with a relatively low number of source counts. The counts are plotted in a horizontal line to show their energy in the observed frame. While the background count rate is nearly independent of energy, source counts clearly cluster at 4 keV. Assuming that feature corresponds to the rest-frame 6.4 keV Fe Kα feature, we can compute the corresponding redshift z = 6.4 keV/Eobs−1 to the energy (top axis). We find z = 0.69, which is consistent with the optically derived spectroscopic redshift. Right panel: binned X-ray spectrum of source R4, a mildly obscured AGN with a high number of counts. The green curve is the best fit, yielding log NH ≃ 22.6 cm−2 and Γ ∼ 1.9 and finds the spectroscopic redshift z = 0.31 (see Fig. 3). The black curve shows the fit if the redshift is fixed to z = 2, which does not follow the data points as well. |
| In the text | |
|
Fig. 3. Corner plot showing the parameter space over photon index, column density, and redshift for the heavily obscured AGN R65 (blue) and the mildly obscured AGN R4 (gray), see Fig. 2. Contours indicate 1, 2, and 3σ uncertainties. Any posterior samples outside are plotted as gray dots. Bottom right panel: shows the marginalized redshift probability distribution. In the bottom middle panel a modest degeneracy between column density and redshift is present for R4. |
| In the text | |
|
Fig. 4. Comparison of two redshift uncertainty measures, the information gain (IG; x-axis) and the standard deviation σ(z) (y-axis). Generally, a larger σ(z) implies a smaller IG. However, the IG also captures multiple solutions (examples are shown in subsequent figures) which can inflate the simple σ(z) measure (symbolized by the gray arrow). The color-coding indicates the obscuration (median of uncertainties); darker colors represent higher column densities. Heavily obscured sources typically have only a single solution and are at lower σ. The vertical lines delimit three regions, A (IG ≥ 2 bits, “constrained redshift”), B (1 ≤ IG < 2 bits, “has redshift information”), and C (IG < 1 bit, “no redshift information”). The top and right panels show normalized histograms. |
| In the text | |
|
Fig. 5. Comparison of XZ and specz for constrained cases (IG ≥ 2). The filled circles show the median of the XZ probability distribution while the error bars correspond to 1σ-equivalent quantiles and color-coded by the median of the obscuration level. Dashed error bars indicate XZ found multiple solutions. The black solid line shows XZ = specz, while the gray dotted lines show XZ = specz ± 0.15(1 + specz). Points outside this region and where the XZ error bars do not cover the specz value are circled in black. Square symbols show insecure specz values (Luo et al. 2017). The inset shows the relative difference between XZ and specz. |
| In the text | |
|
Fig. 6. XZ probability distributions (cyan violin plots) for subsample I compared to specz values (black vertical lines). Sources are ordered by increasing specz. Insecure specz values are shown as gray crosses. |
| In the text | |
 |
Fig. 7. As in Fig. 5, but comparing XZ to photoz (subsample II). |
| In the text | |
|
Fig. 8. XZ (cyan) and photoz (gray) probability distributions for subsample II (IG ≥ 2 bits, no specz). XZ and photoz can mutually confirm redshifts and narrow uncertainties (e.g., R56, R116, R227, R444) or select between multiple photoz solutions (e.g., R12, R333). Some cases show disagreements (e.g., R115, R273, R471). For R265 the photoz was taken from Luo et al. (2010). Sources ordered by increasing XZ median values. |
| In the text | |
|
Fig. 9. XZ (cyan violin plots) and photoz (gray violin plots) probability distributions for subsample III (1 bits ≤ IG < 2 bits). |
| In the text | |
|
Fig. 10. Normalized redshift probability distributions where XZ (blue solid) and photoz (green dashed) agree but are different than the specz values (orange vertical lines). Black vertical lines in R156 and R334 show updated specz values from Balestra et al. (2010) and Barro et al. (2014), respectively, which agree with the photoz and XZ. Dashed vertical lines show insecure specz values. |
| In the text | |
|
Fig. 11. Observed wavelength of MgII and CIII spectroscopic lines as a function of redshift. The horizontal dashed line shows the observed wavelength of a single detected optical spectral line in source R446. The vertical lines indicate the reported specz (orange), photoz (green), and XZ (blue). The dotted vertical lines show the errors of photoz and XZ, respectively. The specz was derived assuming MgII, but agrees with XZ and photoz if we assume CIII instead. |
| In the text | |
|
Fig. 12. Same as Fig. 10, but for cases where photoz (green dashed) and specz (orange vertical line) agree and are noticeably different than XZ (blue curve). |
| In the text | |
|
Fig. 13. Same as Fig. 10, but for case R447 where XZ (blue) presents multiple solutions, one of which agrees with photoz (green dashed) and specz (orange vertical line). |
| In the text | |
|
Fig. 14. Recovery of redshifts by the XZ method. Output XZ redshift probability distributions are shown as violin plots for each input z (x-axis). In all cases NH = 1024 cm−2 is shown. The panels correspond to different instruments, with a total number of source counts chosen at the approximate threshold where the XZ method starts to work optimally. |
| In the text | |
|
Fig. 15. Sensitivity heat maps for each instrument. Redshift uncertainty (colors) are plotted against source redshift (x-axis) and total source counts (y-axis). Above the thick contour lines, IG > 1 bit, i.e., the number of counts is sufficient to provide some redshift information. From left to right panels, the columns show log NH = 22, 23, 24, and 25 cm−2. XMM total source counts refer to total counts across PN/MOS1+2. |
| In the text | |
|
Fig. 16. 2–10 keV luminosity (observed-frame, absorbed) vs. redshift plot that shows the sensitivity limit of the XZ method for NH = 1023 (top panel), 1024 (middle panel) and 1025 (bottom panel) cm−2. In order to compare the response of XZ for different instruments, we normalize the luminosity values to 100 ks. Both current and future missions are shown; XZ is particularly sensitive to the upcoming mission Athena. |
| In the text | |
|
Fig. A.1. Chandra/ACIS background PCA components. The average spectrum plus the selected principle component is plotted in arbitrary units. All CCDs have been combined as they show broadly similar background shapes. |
| In the text | |
|
Fig. A.2. XMM/MOS background PCA components. MOS1 and MOS2 have been combined as they show similar background shapes. |
| In the text | |
|
Fig. A.3. XMM/PN background PCA components. |
| In the text | |
|
Fig. A.4. NuSTAR background PCA components. The FPMA and FPMB detectors have been combined as they show similar background shapes. |
| In the text | |
|
Fig. A.5. Swift/XRT background PCA components. WT and PC mode observations have been combined as they show similar background shapes. |
| In the text | |
|
Fig. B.1. Plot of best-fit XZ values vs. photoz from Salvato et al. (2009). |
| In the text | |
|
Fig. B.2. XZ (cyan violin plots) and specz (black vertical lines) probability distributions for subsample I (IG ≥ 2 bits). |
| In the text | |
|
Fig. B.3. XZ (cyan violin plots) and photoz (gray violin plots) probability distributions for subsample II (IG ≥ 2 bits). |
| In the text | |
|
Fig. B.4. XZ (cyan violin plots) and photoz (gray violin plots) probability distributions for subsample III (IG ≥ 2 bits). |
| In the text | |
|
Fig. B.5. Plot of best-fit XZ values vs. photoz from Nandra et al. (2015). |
| In the text | |
|
Fig. B.6. XZ (cyan violin plots) and specz (black vertical lines) probability distributions for subsample I (IG ≥ 2 bits). |
| In the text | |
|
Fig. B.7. XZ (cyan violin plots) and photoz (gray violin plots) probability distributions for subsample II (IG ≥ 2 bits). |
| In the text | |
|
Fig. B.8. XZ (cyan violin plots) and photoz (gray violin plots) probability distributions for subsample III (IG ≥ 2 bits). |
| In the text | |
 |
Fig. B.9. Figure B.8 cont. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.