| Issue |
A&A
Volume 576, April 2015
|
|
|---|---|---|
| Article Number | A24 | |
| Number of page(s) | 10 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/201425188 | |
| Published online | 17 March 2015 | |
A new model to predict weak-lensing peak counts
I. Comparison with N-body simulations⋆
Service d’Astrophysique, CEA Saclay,
Orme des Merisiers, Bât 709,
91191
Gif-sur-Yvette,
France
e-mail:
chieh-an.lin@cea.fr
Received: 20 October 2014
Accepted: 20 January 2015
Context. Weak-lensing peak counts have been shown to be a powerful tool for cosmology. They provide non-Gaussian information of large scale structures and are complementary to second-order statistics.
Aims. We propose a new flexible method for predicting weak-lensing peak counts, which can be adapted to realistic scenarios, such as a real source distribution, intrinsic galaxy alignment, mask effects, and photo-z errors from surveys. The new model is also suitable for applying the tomography technique and nonlinear filters.
Methods. A probabilistic approach to modeling peak counts is presented. First, we sample halos from a mass function. Second, we assign them density profiles. Third, we place those halos randomly on the field of view. The creation of these “fast simulations” requires much less computing time than do N-body runs. Then, we perform ray-tracing through these fast simulation boxes and select peaks from weak-lensing maps to predict peak number counts. The computation is achieved by our Camelus algorithm.
Results. We compare our results to N-body simulations to validate our model. We find that our approach is in good agreement with full N-body runs. We show that the lensing signal dominates shape noise and Poisson noise for peaks with S/N between 4 and 6. Also, counts from the same S/N range are sensitive to Ωm and σ8. We show how our model can distinguish between various combinations of those two parameters.
Conclusions. In this paper, we offer a powerful tool for studying weak-lensing peaks. The potential of our forward model is its high flexibility, which makes the using peak counts under realistic survey conditions feasible.
Key words: gravitational lensing: weak / large-scale structure of Universe / methods: statistical
The Camelus source code is released via the website http://www.cosmostat.org/software/camelus/
© ESO, 2015
1. Introduction
Weak gravitational lensing (WL) probes matter structures in the Universe. It contains information from the linear growth of structures to the recent highly nonlinear evolution, going from scales of hundreds of Mpc down to sub-Mpc levels. Until now, most studies have focused on two-point-correlation functions, but the non-Gaussianity of WL cannot be ignored if one aims for a deep understanding of cosmology.
One simple way to extract higher order WL information is peak counting. Peaks are defined as local maxima of the projected mass measurement. They are particularly interesting for at least two reasons. First, peaks are tracers of high-density regions. While other tracers of halo mass such as optical richness, X-ray luminosity or temperature, or the SZ Compton-y parameter depend on scaling relations and often require assumptions about the dynamical state of galaxy clusters such as isothermal equilibrium and relaxedness, lensing does not. It therefore provides us with a direct way to study cosmology with the cluster mass function. Second, the lensing signal is highly non-Gaussian, and two-point-function-only studies deprive one of the information richness beyond second order. For example, Dietrich & Hartlap (2010) show that parameter constraints can be highly improved by joining peak counts and using second-order statistics, and Pires et al. (2012) find that peak counts capture more than the convergence skewness and kurtosis of the non-Gaussian information. Another advantage of WL peaks is information about the halo profile. Mainini & Romano (2014) showed that combining peak information with other cosmological probes provides an interesting way to study the mass-concentration relation.
For studies of the mass function via X-ray or the SZ effect, most works have adapted a reverse-fitting approach. This means that from diverse observables, one first establishes the observed mass function and then fit it with a theoretical model. To extract the mass function, this process needs to reverse the effect of selection functions, to use scaling relations, and to make further assumptions about sample properties. Alternatively, one can proceed with a forward-modeling approach: starting from an analytical mass function, we compute predicted values for observables and compare them to the data to carry out parameter fits (Fig. 1). The corresponding forward application of selection functions is typically much simpler than its reverse. Moreover, instrumental effects can be easily included, and model uncertainties can be marginalized over. Forward modeling requires well-motivated models of physical phenomena, which is challenging in the case of observables derived from baryonic physics, yet Clerc et al. (2012) still provide a forward analysis from X-ray observations. For WL peak counts, however, computing the observable prediction is more straightforward, as long as using some appropriate assumptions.
 |
Fig. 1 Forward- and reverse-modeling diagram for the mass function studies. Two different approaches to establishing links between the theoretical mass function (the upper round rectangle) and the observables (the lower round rectangle) are to compare the observable mass function nobs with the theoretical one (reverse modeling), or to compare “predicted” observable values Xmodel with observations (forward modeling). In this paper, the forward modeling is adopted and we propose a new method to “predict” peak conuts. |
One of the difficulties of predicting WL peak counts is that peaks can come from several mass overdensities at various redshifts due to projection effects (Jain & Van Waerbeke 2000; Hennawi & Spergel 2005; Kratochvil et al. 2010). This makes counting nonadditive even in the linear regime, and the prediction becomes less trivial. To overcome this ambiguous effect, some previous works have used N-body simulations, e.g., Dietrich & Hartlap (2010). They perform peak counts from N-body runs with different paremeter sets to obtain confidence contours for constraints. However, since N-body simulations are very costly in terms of computation time, input parameter sets should be carefully chosen, and an interpolation of results is needed. Thus the resolution in the parameter space is limited, and the Fisher matrix is only available for the fiducial parameters.
Alternatively, there have been several attempts at peak-count modeling. Maturi et al. (2010) propose to study contiguous areas of high-signal regions instead of peaks, and provide a model that predicts the amount of this alternative observable. Meanwhile, Fan et al. (2010, hereafter FSL10 propose a model for convergence peaks by supposing at most one halo exists on each line of sight. Both models are analytical and based on calculation from Gaussian random field theory. A comparison of the FSL10 model with observation has been shown by Shan et al. (2014), using the data from the Canada-France-Hawaii Telescope Stripe 82 Survey.
However, these models encounter difficulties for additional complications and subtleties. On one hand both models require Gaussian noise and linear filters, otherwise the Gaussian random field theory becomes invalid. As a result, nonlinear, optimized reconstruction methods of the projected overdensity are automatically excluded. On the other hand realistic scenarios, such as mask effects and intrinsic ellipticity alignment, introduce asymmetric changes into the peak counts. The impact of these additional effects are unpredictable in purely analytical models. This encourages us to propose a new model for WL peak counts.
In this paper, we adopt a probabilistic approach to forecasting peak counts. This can be handled by our Camelus algorithm (Counts of Amplified Mass Elevations from Lensing with Ultrafast Simulation). Unlike N-body simulations which are very time-consuming, we create “fast simulations” by sampling halos from the mass function. The only requirement is a cosmology with a known mass function and halo mass profiles. To validate this method and to justify various hypotheses that our model makes, we compare results from our fast simulations to those from N-body runs. This approach is similar to the sGL model of Kainulainen & Marra (2009, 2011a,b), where they show that the stochastic process provides a quick and accurate way to recover the lensing signal distribution.
The outline of this paper is as follows. In Sect. 2, we recall some of the WL formalism and theoretical support for our model. In Sect. 3, a full description of our model is given. In Sect. 4, we give the details concerning the N-body and the ray-tracing simulations. Finally, the results are presented in Sect. 5, before we summarize and conclude in Sect. 6.
2. Theoretical basics
In this section, we define the formalism necessary for our analysis. To model the convergence field lensed by halos, we need to specify their profile, projected mass, and distribution in mass and redshift, which is the mass function.
2.1. Weak-lensing convergence
Observationally, galaxy shape distortions can be displayed at linear order in the form of the lensing distortion matrix 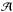 . For an angular position θ,
. For an angular position θ,  is given by
is given by 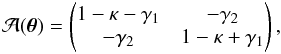 (1)which defines two WL observables: convergence κ and shear γ. The latter is a complex number given by γ = γ1 + iγ2. This linearization of the light distortion can be calculated explicitly in general relativity. Accordingly, the matrix elements are linked to second derivatives of the Newtonian gravitational potential φ by
(1)which defines two WL observables: convergence κ and shear γ. The latter is a complex number given by γ = γ1 + iγ2. This linearization of the light distortion can be calculated explicitly in general relativity. Accordingly, the matrix elements are linked to second derivatives of the Newtonian gravitational potential φ by 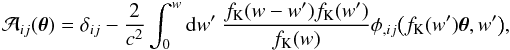 (2)where fK is the comoving transverse distance and δij the Kronecker delta. In particular, an explicit expression of κ is given as follows (see, e.g., Schneider et al. 1998),
(2)where fK is the comoving transverse distance and δij the Kronecker delta. In particular, an explicit expression of κ is given as follows (see, e.g., Schneider et al. 1998), 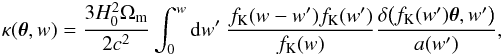 (3)where H0 is the Hubble parameter, Ωm the matter density, c the speed of light, a(w′) represents the scale factor at the epoch to which the comoving distance from now is w′, and δ is the matter density contrast.
(3)where H0 is the Hubble parameter, Ωm the matter density, c the speed of light, a(w′) represents the scale factor at the epoch to which the comoving distance from now is w′, and δ is the matter density contrast.
2.2. Halo density profile and its projected mass
Consider now a dark matter (DM) halo with a Navarro-Frenk-White (NFW) density profile (Navarro et al. 1996, 1997), given by  (4)where ρs and rs are the characteristic mass density and the scale radius of the halo, respectively, and α is the inner slope parameter. The concentration parameter cNFW is defined as the ratio of the virial radius to the scale radius, cNFW = rvir/rs. We assume the following expression (proposed by Takada & Jain 2002):
(4)where ρs and rs are the characteristic mass density and the scale radius of the halo, respectively, and α is the inner slope parameter. The concentration parameter cNFW is defined as the ratio of the virial radius to the scale radius, cNFW = rvir/rs. We assume the following expression (proposed by Takada & Jain 2002): 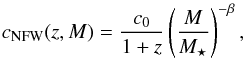 (5)where M is the halo mass and M⋆ the pivot mass such that δc(z = 0) = σ(M⋆), with δc the threshold overdensity for the spherical collapse model, and σ2(M) is the variance of the density contrast fluctuation smoothed with a top-hat sphere with radius R such that
(5)where M is the halo mass and M⋆ the pivot mass such that δc(z = 0) = σ(M⋆), with δc the threshold overdensity for the spherical collapse model, and σ2(M) is the variance of the density contrast fluctuation smoothed with a top-hat sphere with radius R such that  .
.
In this paper, we take c0 = 8, α = 1, and β = 0.13. The value of α corresponds to the classical NFW profile. The value of β is provided by Bullock et al. (2001), and c0 corresponds to the best-fit value, using rvir, rs, z, M derived from the N-body simulations that we use and fixing β. For δc, we use the fitting formula of Weinberg & Kamionkowski (2003) with  (6)and
(6)and  (7)Lensing by an NFW halo is characterized by its projected mass. More precisely, defining the scale angle θs = rs/Dℓ as the ratio of the scale radius to the angular diameter distance Dℓ between lens and observer, we get (following Bartelmann 1996; Takada & Jain 2003)1,2
(7)Lensing by an NFW halo is characterized by its projected mass. More precisely, defining the scale angle θs = rs/Dℓ as the ratio of the scale radius to the angular diameter distance Dℓ between lens and observer, we get (following Bartelmann 1996; Takada & Jain 2003)1,2 (8)with
(8)with 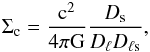 (9)where the quantities Ds and Dℓs are the angular diameter distances between source and observer, and lens and source, respectively, and
(9)where the quantities Ds and Dℓs are the angular diameter distances between source and observer, and lens and source, respectively, and
![\begin{eqnarray} \label{for:WL_3} G(x) =\left\{ \begin{array}{l} \hspace{-0.5em}\displaystyle -\frac{1}{1-x^2}\frac{{\sqrt{\cNFW^2-x^2}}}{\cNFW+1} + \frac{1}{(1-x^2)^{3/2}} \arcosh\left[ \frac{x^2+\cNFW}{{x(\cNFW+1)}} \right]\\[3ex] \hfill \text{if}\quad x<1; \notag\\ \displaystyle\frac{{\sqrt{\cNFW^2-1}}}{\cNFW+1} \cdot \frac{\cNFW+2}{3(\cNFW+1)} \hfill \text{if}\quad x=1;\\[3ex] \displaystyle\frac{1}{x^2-1}\frac{{\sqrt{\cNFW^2-x^2}}}{\cNFW+1} - \frac{1}{(x^2-1)^{3/2}}\arccos\left[ \frac{x^2+\cNFW}{{x(\cNFW+1)}} \right]\\[3ex] \hfill \text{if}\quad 1<x\leq\cNFW;\\[1ex] \displaystyle 0 \hfill \text{if}\quad x > \cNFW. \end{array}\right.\\ \end{eqnarray}](/articles/aa/full_html/2015/04/aa25188-14/aa25188-14-eq54.png) (10)We have truncated the projected mass distribution at θ = cNFWθs. Equation (8) is used and computed for the ray-tracing simulations with NFW halos.
(10)We have truncated the projected mass distribution at θ = cNFWθs. Equation (8) is used and computed for the ray-tracing simulations with NFW halos.
2.3. Halo mass function
The halo mass function n(z,<M) indicates the halo number density with mass less than M at redshift z3, often characterized by a function f(σ,z) as 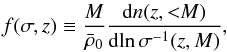 (11)where
(11)where 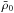 is the current matter density, and σ(z,M) is defined as σ(M) multiplied by the growth factor D(z). In this study, we adopt the model proposed by Jenkins et al. (2001) in which a fit for f is given as
is the current matter density, and σ(z,M) is defined as σ(M) multiplied by the growth factor D(z). In this study, we adopt the model proposed by Jenkins et al. (2001) in which a fit for f is given as ![\begin{eqnarray} f(\sigma) = 0.315 \exp\left[ -\left|\ln\sigma\inv + 0.61\right|^{3.8} \right]. \end{eqnarray}](/articles/aa/full_html/2015/04/aa25188-14/aa25188-14-eq64.png) (12)
(12)
3. A new model for WL peak counts
3.1. Probabilistic approach: fast simulations
Our model is based on the idea that we can replace N-body simulations with an alternative random process, such that the relevant observables are preserved, but the computation time is drastically reduced. We call this alternative process “fast simulations”, which are produced by the following steps:
-
1.
generate halo masses by sampling from a mass function;
-
2.
assign density profiles to the halos;
-
3.
place the halos randomly on the field of view;
-
4.
perform ray-tracing simulation.
One can notice that we have made two major hypotheses. First, we assume that diffuse, unbound matter, for example cosmological filaments, does not significantly contribute to peak counts. Second, we suppose that the spatial correlation of halos has a minor influence, since this correlation is broken down in fast simulations. Previous work has shown that correlated structures influence number and height of peaks by only a few percentage points (Marian et al. 2010). Furthermore, assuming a stochastical distribution of halos can lead to accurate predictions of the convergence probability distirbution function (Kainulainen & Marra 2009). One may also notice that halos can overlap in 3D space, and indeed we do not exclude this possibility. We test and validate these hypotheses in Sect. 5, and discuss possible improvements to our model in Sect. 6
Although we have chosen NFW profiles for the density of DM halos, using any halo profile model for which the projected mass is known is of course possible, such as triaxial halos or profiles offered by baryonic feedback (Yang et al. 2013). In addition, our prediction model is completely independent of the method by which peaks are extracted from the WL data. The same analysis can be applied to data (or N-body simulations + ray-tracing) and to fast simulations. Moreover, survey characteristics, such as masks, photometric redshift errors, PSF residuals, and other systematics, can be incorporated and forward-propagated as model uncertainties. Furthermore, the halo sampling technique is much faster than a full N-body run. For instance, it only takes a dozen seconds on a single-CPU desktop computer to generate a box that is large enough for our use (see specifications in Sect. 4.2).
This is a probabilistic approach to forecast peak counts, and we compare the convergence peaks obtained with those from full N-body runs in order to validate our forward model. This is described in Sect. 5.1.
3.2. Peak selection
In this paper, we focus on convergence peaks. We have followed a classical analysis used in former studies (e.g., Hamana et al. 2004; Wang et al. 2009; Fan et al. 2010; Yang et al. 2011) to extract peaks.
First, we should highlight that κ and κproj (respectively given by Eqs. (3)and (8)) do not follow the same definition. Actually, Eq. (8) can be recovered by replacing δ with 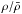 in Eq. (3). This means that κproj does not take lensing by underdense regions into account and is shifted by a constant value, which corresponds to the mass-sheet degenerency. To obtain a model that is consistant with a zero-mean convergence field, we subtract the mean value of κproj from our convergence maps, so that
in Eq. (3). This means that κproj does not take lensing by underdense regions into account and is shifted by a constant value, which corresponds to the mass-sheet degenerency. To obtain a model that is consistant with a zero-mean convergence field, we subtract the mean value of κproj from our convergence maps, so that 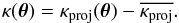 (13)We use this approximation throughout this study when ray-tracing is done with projected mass.
(13)We use this approximation throughout this study when ray-tracing is done with projected mass.
 |
Fig. 2 Comparison between an analytical mass function (blue line), halo mass histograms for N-body runs (green points), and sample histograms for realizing of the fast simulation (red crosses). The plots are drawn at 4 different redshift planes, and for each the thickness is dz = 0.1. |
Consider now a reconstructed convergence field κn(θ) in the absence of intrinsic ellipticity alignment. The presence of galaxy shape noise leads to the true lensing field κ(θ) being contaminated by a linear additive noise field n(θ), such that  (14)In general, κ is dominated by n, and one way to suppress the noise is to apply a smoothing:
(14)In general, κ is dominated by n, and one way to suppress the noise is to apply a smoothing: 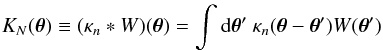 (15)where W(θ) is a window function, chosen to be Gaussian in this study as
(15)where W(θ) is a window function, chosen to be Gaussian in this study as 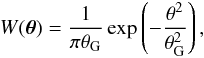 (16)which is specified by the smoothing scale θG. We denote KN(θ), K(θ), and N(θ) as corresponding smoothed fields to Eq. (14), such that
(16)which is specified by the smoothing scale θG. We denote KN(θ), K(θ), and N(θ) as corresponding smoothed fields to Eq. (14), such that 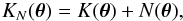 (17)and set θG = 1 arcmin in the following.
(17)and set θG = 1 arcmin in the following.
If intrinsic ellipticities are uncorrelated between source galaxies, N(θ) can be described as a Gaussian random field (Bardeen et al. 1986; Bond & Efstathiou 1987) for which the variance is related to the number of galaxies contained in the filter. This is given by Van Waerbeke (2000) as 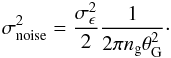 (18)Here, ng is the source galaxy number density, and
(18)Here, ng is the source galaxy number density, and 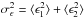 is the variance of the intrinsic ellipticity distribution. We then define the lensing signal-to-noise ratio (S/N) as
is the variance of the intrinsic ellipticity distribution. We then define the lensing signal-to-noise ratio (S/N) as 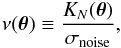 (19)and the peaks are extracted from the ν field, defined as pixels that have a S/N value higher than their eight neighbors. This implies that peak analyses require S/N values on a well-defined grid (e.g., HEALPix grid). Furthermore, we suppose that source galaxies are uniformly distributed in this study, so σnoise is a constant. However, this does not have to be true in general.
(19)and the peaks are extracted from the ν field, defined as pixels that have a S/N value higher than their eight neighbors. This implies that peak analyses require S/N values on a well-defined grid (e.g., HEALPix grid). Furthermore, we suppose that source galaxies are uniformly distributed in this study, so σnoise is a constant. However, this does not have to be true in general.
In summary, convergence peaks are selected by the following steps:
-
1.
compute the projected mass κproj(θ) by ray-tracing;
-
2.
subtract the mean to obtain κ(θ);
-
3.
add the noise to obtain κn(θ);
-
4.
smooth the field and acquire KN(θ);
-
5.
determine the S/N ν(θ); and
-
6.
select local maxima and compute the density npeak(ν).
Only positive peaks are selected, and the analysis is based on the abundance histograms from peak counts. From fast simulation, through ray-tracing, to peak selection, the calculation is carried out by our Camelus algorithm.
4. Simulations
4.1. N-body simulations
As provided by A. Evrard, the N-body simulations “Aardvark” have been used in this study. They were generated by LGadget-2, a DM-only version of Gadget-2 (Springel 2005). The Aardvark parameters had been chosen to represent a WMAP-like ΛCDM cosmology, with Ωm = 0.23, ΩΛ = 0.77, Ωb = 0.047, σ8 = 0.83, h = 0.73, ns = 1.0, and w0 = −1.0.
The DM halos in Aardvark were identified using the Rockstar friends-of-friends code (Behroozi et al. 2013). The field of view is 859 deg2. This corresponds to a HEALPix patch with nside = 2 (for HEALPix, see Górski et al. 2005).
4.2. Fast simulations
As described in Sect. 3.1, our model requires a mass function as input. We chose the model of Jenkins et al. (2001, see Sect. 2.3 to sample halos. This is done in ten redshift bins from z = 0 to 1. We set the sample mass range to the interval 1012 and 1017M⊙/h. For each halo, the NFW parameters were set to be (c0,α,β) = (8.0,1.0,0.13). We suggest seeing Sect. 2.2 for their definitions.
Figure 2 shows an example of our halo samples, compared to the original mass function, and mass histograms established from the Aardvark simulations. Although halos with high mass can be 103–105 times less populated than low-mass halos, our sampling is still in a perfect agreement with the original mass function. One may notice a shift and a tilt in the Aardvark halo mass function for low and high redshifts, however, in these regimes, the lensing efficiency is low because of the distance weight term DℓDℓs/Ds, so this mismatch is not very large.
4.3. Ray-tracing simulations
For the Aardvark simulations, ray-tracing was performed with CALCLENS (Becker 2013). Galaxies were generated using ADDGALS (by M. Busha and R. Wechsler4). Ray-tracing information is available only on a subset of 53.7 deg2 (a HEALPix patch with nside = 8), which is 16 times smaller than the halo field. In this study, only galaxies at redshift between 0.9 and 1.1 were chosen for drawing the convergence map. It led to an irregular map, and in order to clearly define eight neighbors to identify peaks, we used a 2D-linear interpolation to obtain κ values on a grid. This was done after carrying out a projection to Cartesian coordinates.
For computational purposes, in order not to handle too many galaxies at a time, we split the field into four “ray-tracing patches”, the size of which is 13.4 deg2 each (corresponding to nside = 16). We then project the coordinates with regard to the center of each patch using the Gnomonic projection. The size lengths of the ray-tracing patches are between 3.5 and 6.2 deg, so small enough to retain a good approximation.
 |
Fig. 3 Patch of a map projected with regard to its center, taken from a realization of fast simulations. The left, middle, and right panels give the fields κ1 / 3, |
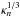
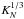
For the fast simulations and the two intermediate cases that we study in Sect. 5.1, source galaxies have a fixed redshift zs = 1.0. They are regularly distributed on a HEALPix grid and placed at the center of pixels. Each ray-tracing pixel is a HEALPix patch with nside = 16 384, for which the characteristic size is θpix ≈ 0.215 arcmin. Thus, the galaxy number density is 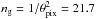 arcmin-2. Ray-tracing for fast simulations is carried out after splitting and projection to Cartesian coordinates. There are 64 ray-tracing patches in a halo field, and each patch contains 1024 × 1024 pixels. The convergence was computed using Eqs. (8)–(10). As a remark, no mask was applied in this study.
arcmin-2. Ray-tracing for fast simulations is carried out after splitting and projection to Cartesian coordinates. There are 64 ray-tracing patches in a halo field, and each patch contains 1024 × 1024 pixels. The convergence was computed using Eqs. (8)–(10). As a remark, no mask was applied in this study.
4.4. Adding noise
Shape noise n(θ) is added to each pixel after we obtain κ(θ) from N-body runs or fast simulations. It is modeled as a Gaussian random field with a top-hat filter with a size that corresponds to the pixel area Apix. The variance of this is given by Van Waerbeke (2000) as 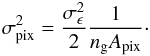 (20)We choose σϵ = 0.4 which corresponds to a CFHTLenS-like survey, and ngApix is chosen to be 1 so that each pixel represents one galaxy. This leads to σpix ≈ 0.283. We can also estimate σnoise with Eq. (18) and obtain σnoise ≈ 0.024. This shows that a real map is in general dominated by the noise (Fig. 3). Even for a peak at ν = 5, the lensing signal is only on the order of κ = 0.12, less than half of the pixel noise amplitude.
(20)We choose σϵ = 0.4 which corresponds to a CFHTLenS-like survey, and ngApix is chosen to be 1 so that each pixel represents one galaxy. This leads to σpix ≈ 0.283. We can also estimate σnoise with Eq. (18) and obtain σnoise ≈ 0.024. This shows that a real map is in general dominated by the noise (Fig. 3). Even for a peak at ν = 5, the lensing signal is only on the order of κ = 0.12, less than half of the pixel noise amplitude.
5. Results
5.1. Validation of our model: comparison to N-body runs
To validate our model, we compare it to the N-body simulations. We compute peak abundance histograms from both simulations, together with two intermediate steps. This results in four cases in total:
-
Case 1:
full N-body runs;
-
Case 2:
replacing N-body halos with NFW profiles with the same masses;
-
Case 3:
randomizing angular positions of halos from Case 2;
-
Case 4:
fast simulations, corresponding to our model.
These cases form a progressive transition from full N-body runs toward our model. More precisely, Case 2 tests the hypothesis corresponding to the second step of our model (see Sect. 3.1); i.e., diffuse, unbound matter contributes little to peak counts. Case 3 additionally tests the assumption made in the third step. (Halo clustering plays a minor role.) Finally, Case 4 completes our model with the missing first step. As a result, the halo population and their redshifts are identical to N-body runs in Cases 2 and 3.
 |
Fig. 4 Comparison of the peak abundance from different cases. Upper panel: blue solid line: full N-body runs (Case 1); green circles: replacement of halos by NFW profiles (Case 2); red squares: replacement of halos by NFW profiles and randomization of halo angular positions (Case 3); cyan diamonds: fast simulations, corresponding to our model (Case 4); magenta dashed line: peaks from noise-only maps. Lower panel: we draw the upper and lower limits of error bars shifted with regard to the N-body values. This refers to the standard deviation over 4 maps (green dash-dotted line for Case 2) or 16 maps (red dashed line for Case 3, cyan solid line for Case 4). The field of view is 53.7 deg2. |
Figure 4 shows the peak abundance histograms for all four cases. In this section, the field of view is 53.7 deg2, since we are limited by the available information of ray-tracing for the N-body runs. For Cases 1 and 2, we compute the average in each histogram bin for eight noise maps. For Cases 3 and 4, this is done with eight realizations (of randomization and of fast simulations, respectively) and eight noise maps, thus 64 maps in total. The error bars therefore refer to the combination of the statistical fluctuation due to the random process and the shape noise uncertainty.
For low peaks with ν ≤ 3.75, we observe that npeak(ν) remains almost unchanged between the different cases. This is not suprising because in this regime, npeak(ν) is mainly contributed by noise. This argument is supported by the noise-only peak histogram. The lower panel of Fig. 4 shows that there exist some systematic overcounts in this regime on the order of 10%. The cause of this bias is ambiguous. One possibility might be the use of NFW profiles for ray-tracing simulations. It might also come from the subtraction of the mean κ value from the maps. We leave this to future studies. Another observation in this regime is that by adding the signal to the noise field, the number of peaks with ν ≤ 2.75 decreases. This proves that the effect of noise is not additive for peak counts.
In the regime of ν ≥ 3.75, we observe that replacement by NFW profiles enhances the peak counts, while position randomization introduces an opposite effect of a similar order of magnitude. The enhancement from Case 2 may be explained by the halo triaxiality. A spherical profile such as the NFW model may lead to an overestimation of the projected mass at the center of halos if the major axis is not aligned with the line of sight, and this would probably be the case for most of the N-body halos. It could also be an effect of the M − c relation: we might overestimate cNFW for large M.
Comparing Cases 2 and 3, we discover that position randomization decreases peak counts by 10% to 50%. Apparently, decorrelating angular positions breaks down the two-halo term, so that halos overlap less on the field of view and decreases high-peak counts. Yang et al. (2011) shows that high peaks with ν ≥ 4.8 are mainly contributed by one single halo, and about 12% of total high-peak counts are contributed by multiple halos. This number agrees with the undercount from our hypothesis of randomization. Combining this step with the former one, we confirm that considering lensing contribution from spatially decorrelated clusters is a good approximation for peak counts.
The impact of the mass function is shown by comparing Case 3 to Case 4. Peak counts are more numerous in our forward model based on the mass function of Jenkins et al. (2001). This excess compensates for the deficit from randomization. However, as shown by Fig. 2, the real mass function in N-body runs is coherent to the analytical model that we use, except for the low-mass deficit tails from N-body runs. To test the impact from this, we ran fast simulations with different lower limit for the halo sampling, and we discover that peak counts do not depend on the lower sampling limit Mmin when Mmin remains lower than 1013M⊙/h. This proves that the deficit tails are not the cause of the peak count enhancement. Without this explanation, we may have to test with another N-body simulation set to understand the origin of this effect.
 |
Fig. 5 Similar plot to Fig. 4, but in a larger field. Cases 2–4 are carried out for 859 deg2. Case 1 should only be taken as an indication, since its size of field is the same as in Fig. 4, and therefore 16 times smaller than cases 2–4. The fluctuation from high ν bins is much reduced compared to Fig. 4. |
Figure 5 shows a similar study of Cases 2–4 for a larger field of 859 deg2. One can recover the same effects: compensation of effects deriving from NFW profiles and randomization. Therefore, the difference between our model and N-body simulations is at the same order of magnitude of the one between the analytical and the N-body mass functions. We would like to point out that the Poisson fluctuation has been largely suppressed. A quick calculation shows that, for a given peak density n and a survey area A, the ratio of the Poisson noise to peak density is 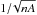 . The error bars for high peaks in both Fig. 4 and Fig. 5 stay within 50% of the values given by this formula. As a result, we argue that to reduce the Poisson fluctuation at the level of 10%, a survey of more than 150 deg2 is preferable using WL peaks with ν ≲ 5.25 and 800 deg2 using peaks with ν ≲ 6.25.
. The error bars for high peaks in both Fig. 4 and Fig. 5 stay within 50% of the values given by this formula. As a result, we argue that to reduce the Poisson fluctuation at the level of 10%, a survey of more than 150 deg2 is preferable using WL peaks with ν ≲ 5.25 and 800 deg2 using peaks with ν ≲ 6.25.
5.2. Comparison to an analytical model
In Fig. 6, we draw peak histograms obtained from the analytical model of FSL10 and from our model. The computation for the FSL10 model is done with the same halo profiles and parameters, and the same mass function. For our model, we use our large-field result as mentioned in the previous section. Both models are computed with the same parameter set as the Aardvark N-body simulation inputs. We observe that the FSL10 model is also in good agreement with N-body runs. The prediction from the FSL10 model is more consistent with N-body values for high-peak counts, whereas our model performs better in the low-peak regime. In general, the deviation of both models for ν ≤ 5.25 stays under 25%.
5.3. Sensitivity tests on cosmological parameters
Finally in this section, we show how our model depends on cosmological parameters. Weak lensing is particularly sensitive to Ωm and σ8, hence we carry out nine series of fast simulations for which (Ωm,σ8) is chosen from 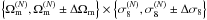 , where
, where 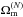 and
and 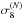 are input from our N-body runs. The values of ΔΩm and Δσ8 are chosen to be 0.03 and 0.05, respectively, and the remaining parameters are identical to the N-body simulations. Each scenario is the average over 16 combinations of four fast simulation realizations and four noise maps.
are input from our N-body runs. The values of ΔΩm and Δσ8 are chosen to be 0.03 and 0.05, respectively, and the remaining parameters are identical to the N-body simulations. Each scenario is the average over 16 combinations of four fast simulation realizations and four noise maps.
Figure 7 shows four plots that correspond to four variation directions on the Ωm-σ8 parameter plane, with regard to 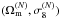 . Both upper panels show the variation of only one parameter. They reveal that our model performs a neat, progressive difference of peak abundance in every bin, ranging from ν = 4 to 6. We notice that the differences between cyan diamonds (higher value of Ωm or σ8) and red squares (N-body value) are always narrower than those between green circles (lower value of Ωm or σ8) and red squares. This is triggered by the banana-shape constraint on the Ωm-σ8 plane, from which a horizontal or a vertical cut will result in an asymmetric confidence level for a single parameter.
. Both upper panels show the variation of only one parameter. They reveal that our model performs a neat, progressive difference of peak abundance in every bin, ranging from ν = 4 to 6. We notice that the differences between cyan diamonds (higher value of Ωm or σ8) and red squares (N-body value) are always narrower than those between green circles (lower value of Ωm or σ8) and red squares. This is triggered by the banana-shape constraint on the Ωm-σ8 plane, from which a horizontal or a vertical cut will result in an asymmetric confidence level for a single parameter.
The two lower panels are variations in the diagonal and anti-diagonal directions. Like what we expect, the diagonal variation is the most efficient discriminant of Ωm-σ8. In contrast, peak counts for different parameter sets completely merge together in the lower right-hand panel, since the anti-diagonal direction corresponds roughly to the degenerency lines. Furthermore, all error bars (for 3.75 ≤ ν ≤ 6.25) remain smaller than 5%, which shows the robustness of our model. We recall that blue solid lines correspond to a small 53.7 deg2 field, such that the Poisson noise might bias high peak counts, as explained in Sect. 5.1. At the end of the day, the performance of our model at distinguishing different cosmological models has been confirmed.
 |
Fig. 6 Comparison of the FSL model (orange triangles) to our model (cyan diamonds). The full N-body peak histogram is shown as a blue line. Lower panel: we draw the difference between the FSL model and N-body data within an orange dashed line. The cyan-colored zone represents the error bars for our model. The field of view for fast simulations is 859 deg2. The N-body data is only indicative. |
Figure 7 also shows that systematic biases of our model could lead to parameter biases. A simple interpolation for the bin ν = 5 shows that N-body peak counts correspond to a cosmology with Ωm ≈ 0.212 if the knowledge of σ8 is perfect. The bias is then ΔΩm ≈ 0.018. Similarly, the bias on σ8 is Δσ8 ≈ 0.030 if Ωm is known. The origin of the biases of our model is complex. We discuss a list of possible improvements that reduce potential systematics in the following section.
6. Summary and perspectives
WL peaks probe cosmological structures in a straightforward way, since they are directly induced by total-mass gravitational effects, and they especially probe the high-mass part of the mass function. Unlike other tracers, WL peaks provide a forward-fitting approach to study the mass function and cosmology. This makes WL peaks a very competitive candidate for improving our knowledge about structure formation.
In this paper, we presented a new model that predicts weak-lensing peak counts. We generated fast simulations by sampling halos from analytical expressions. By assuming that halos in these simulations are randomly distributed on the sky, we count peaks from ray-tracing maps obtained from these simulations to predict number counts. In this model, we have supposed that unbound matter contributes little to the lensing and that halo clustering has little impact on peak counts.
 |
Fig. 7 Sensitivity tests on (Ωm,σ8). The four plots indicate different variation directions in the Ωm-σ8 plane. The upper left, upper right, lower left, and lower right panels: variation in Ωm, σ8, diagonal, and anti-diagonal direction, respectively. Blue solid lines represent full N-body runs, while red squares are always our model with N-body input. The field of view is 859 deg2. The N-body data is only indicative. |
We validated our approach by comparing number counts with N-body results. In particular, we focused on peaks with ν ≈ 4–6, since lower ν are dominated by shape noise, and higher ν are dominated by the Poisson fluctuation. We showed how the three steps corresponding to the main assumptions of our model influence convergence peak abundance. First, NFW profiles tend to shift some medium peaks to higher values, in spite of the lack of unbound objects. Second, the number of peaks decreases when halo positions are randomized. Last, the difference between the N-body mass function and the analytical one is observable in produced peak counts. In summary, our model is in good agreement with results from full N-body runs.
We also tested the dependence of our model on Ωm and σ8. For a 859 deg2 sky area, the Poisson fluctuation is reduced to a reasonable level for peaks with ν ≲ 6. It turns out that different scenarios are discernable for ν ≳ 4, with a degerency direction corresponding roughly to the anti-diagonal in the plane Ωm-σ8. Tests on a large set of different parameters are feasible with our model thanks to the short computation time.
Our probabilistic model has other potential advantages. Repeated simulations for the same cosmological parameters generate the distribution of observables. This allows us to compare observations with our model without the need to define a likelihood function or to assume any Gaussian distribution. For example, model discrimination can be carried out using the false discovery rate method (FDR, Benjamini & Hochberg 1995, an application can be found in Pires et al. 2009), approximate Bayesian computation (ABC, see for example Cameron & Pettitt 2012; Weyant et al. 2013), or other statistical techniques. Another powerful advantage of our model is its flexibility. Additional effects such as intrinsic ellipticity alignment, alternative methods such as nonlinear filters, and realistic survey settings, such as mask effects, magnification bias (Liu et al. 2014), shape measurement errors (Bard et al. 2013), and photo-z errors, can all be modeled in this peak-counting framework. The forward-modeling approach allows for a straightforward inclusion and marginalization of model uncertainties and systematics.
Several improvements to our model are possible. Using perturbation theory, we may take halo clustering into account in fast simulations. This can be done by some fast algorithms, such as PTHalos (Scoccimarro & Sheth 2002), Pinocchio (Monaco et al. 2002; see also Heisenberg et al. 2011), and remapping LPT (Leclercq et al. 2013). In addition, we can go beyond the idealized setting considered in this work by including a realistic source distribution, intrinsic alignment, mask effects, etc. We also expect that nonlinear filters and tomography studies may bring some more refined results for cosmology from peak counting. Finally, peak counts can be supplemented with additional WL observables, such as magnification and flexion.
The Camelus algorithm is implemented in C language. It requires the Nicaea library for cosmological computations. The Camelus source code is released via the website5.
The convention of Takada & Jain (2003) is different from ours. Their dA is actually fK in our notation, and they also express the virial radius rvir in comoving coordinates.
Acknowledgments
This study is supported by Région d’Île-de-France under grant DIM-ACAV and the French national program for cosmology and galaxies (PNCG). The authors acknowledge the anonymous referee for useful comments and suggestions. We would like to thank August Evrard for providing N-body simulations. We also thank Zuhui Fan, Xiangkun Liu, and Chuzhong Pan for giving constructive comments on the preprint. Chieh-An Lin is very grateful for inspiring discussions with François Lanusse, Yohan Dubois, and Michael Vespe.
References
- Bard, D., Kratochvil, J. M., Chang, C., et al. 2013, ApJ, 774, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Bardeen, J. M., Bond, J. R., Kaiser, N., & Szalay, A. S. 1986, ApJ, 304, 15 [NASA ADS] [CrossRef] [Google Scholar]
- Bartelmann, M. 1996, A&A, 313, 697 [NASA ADS] [Google Scholar]
- Becker, M. R. 2013, MNRAS, 435, 115 [NASA ADS] [CrossRef] [Google Scholar]
- Behroozi, P. S., Wechsler, R. H., & Wu, H.-Y. 2013, ApJ, 762, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Benjamini, Y., & Hochberg, Y. 1995, J. Roy. Stat. Soc., Ser. B, 57, 289 [Google Scholar]
- Bond, J. R., & Efstathiou, G. 1987, MNRAS, 226, 655 [NASA ADS] [Google Scholar]
- Bullock, J. S., Kolatt, T. S., Sigad, Y., et al. 2001, MNRAS, 321, 559 [Google Scholar]
- Cameron, E., & Pettitt, A. N. 2012, MNRAS, 425, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Clerc, N., Pierre, M., Pacaud, F., & Sadibekova, T. 2012, MNRAS, 423, 3545 [NASA ADS] [CrossRef] [Google Scholar]
- Dietrich, J. P., & Hartlap, J. 2010, MNRAS, 402, 1049 [NASA ADS] [CrossRef] [Google Scholar]
- Fan, Z., Shan, H., & Liu, J. 2010, ApJ, 719, 1408 [NASA ADS] [CrossRef] [Google Scholar]
- Górski, K. M., Hivon, E., Banday, A. J., et al. 2005, ApJ, 622, 759 [NASA ADS] [CrossRef] [Google Scholar]
- Hamana, T., Takada, M., & Yoshida, N. 2004, MNRAS, 350, 893 [NASA ADS] [CrossRef] [Google Scholar]
- Heisenberg, L., Schäfer, B. M., & Bartelmann, M. 2011, MNRAS, 416, 3057 [NASA ADS] [CrossRef] [Google Scholar]
- Hennawi, J. F., & Spergel, D. N. 2005, ApJ, 624, 59 [NASA ADS] [CrossRef] [Google Scholar]
- Jain, B., & Van Waerbeke, L. 2000, ApJ, 530, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Jenkins, A., Frenk, C. S., White, S. D. M., et al. 2001, MNRAS, 321, 372 [NASA ADS] [CrossRef] [MathSciNet] [Google Scholar]
- Kainulainen, K., & Marra, V. 2009, Phys. Rev. D, 80, 123020 [NASA ADS] [CrossRef] [Google Scholar]
- Kainulainen, K., & Marra, V. 2011a, Phys. Rev. D, 83, 023009 [NASA ADS] [CrossRef] [Google Scholar]
- Kainulainen, K., & Marra, V. 2011b, Phys. Rev. D, 84, 063004 [NASA ADS] [CrossRef] [Google Scholar]
- Kratochvil, J. M., Haiman, Z., & May, M. 2010, Phys. Rev. D, 81, 043519 [NASA ADS] [CrossRef] [Google Scholar]
- Leclercq, F., Jasche, J., Gil-Marín, H., & Wandelt, B. 2013, J. Cosmol. Astropart., 11, 48 [Google Scholar]
- Liu, J., Haiman, Z., Hui, L., Kratochvil, J. M., & May, M. 2014, Phys. Rev. D, 89, 023515 [NASA ADS] [CrossRef] [Google Scholar]
- Mainini, R., & Romano, A. 2014, J. Cosmol. Astropart., 8, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Marian, L., Smith, R. E., & Bernstein, G. M. 2010, ApJ, 709, 286 [NASA ADS] [CrossRef] [Google Scholar]
- Maturi, M., Angrick, C., Pace, F., & Bartelmann, M. 2010, A&A, 519, A23 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Monaco, P., Theuns, T., & Taffoni, G. 2002, MNRAS, 331, 587 [NASA ADS] [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1996, ApJ, 462, 563 [NASA ADS] [CrossRef] [Google Scholar]
- Navarro, J. F., Frenk, C. S., & White, S. D. M. 1997, ApJ, 490, 493 [NASA ADS] [CrossRef] [Google Scholar]
- Pires, S., Starck, J.-L., Amara, A., Réfrégier, A., & Teyssier, R. 2009, A&A, 505, 969 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pires, S., Leonard, A., & Starck, J.-L. 2012, MNRAS, 423, 983 [NASA ADS] [CrossRef] [Google Scholar]
- Schneider, P., Van Waerbeke, L., Jain, B., & Kruse, G. 1998, MNRAS, 296, 873 [NASA ADS] [CrossRef] [Google Scholar]
- Scoccimarro, R., & Sheth, R. K. 2002, MNRAS, 329, 629 [NASA ADS] [CrossRef] [Google Scholar]
- Shan, H. Y., Kneib, J.-P., Comparat, J., et al. 2014, MNRAS, 442, 2534 [NASA ADS] [CrossRef] [Google Scholar]
- Springel, V. 2005, MNRAS, 364, 1105 [NASA ADS] [CrossRef] [Google Scholar]
- Takada, M., & Jain, B. 2002, MNRAS, 337, 875 [NASA ADS] [CrossRef] [Google Scholar]
- Takada, M., & Jain, B. 2003, MNRAS, 340, 580 [NASA ADS] [CrossRef] [Google Scholar]
- Van Waerbeke, L. 2000, MNRAS, 313, 524 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, S., Haiman, Z., & May, M. 2009, ApJ, 691, 547 [NASA ADS] [CrossRef] [Google Scholar]
- Weinberg, N. N., & Kamionkowski, M. 2003, MNRAS, 341, 251 [NASA ADS] [CrossRef] [Google Scholar]
- Weyant, A., Schafer, C., & Wood-Vasey, W. M. 2013, ApJ, 764, 116 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, X., Kratochvil, J. M., Wang, S., et al. 2011, Phys. Rev. D, 84, 043529 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, X., Kratochvil, J. M., Huffenberger, K., Haiman, Z., & May, M. 2013, Phys. Rev. D, 87, 023511 [NASA ADS] [CrossRef] [Google Scholar]
All Figures
|
Fig. 1 Forward- and reverse-modeling diagram for the mass function studies. Two different approaches to establishing links between the theoretical mass function (the upper round rectangle) and the observables (the lower round rectangle) are to compare the observable mass function nobs with the theoretical one (reverse modeling), or to compare “predicted” observable values Xmodel with observations (forward modeling). In this paper, the forward modeling is adopted and we propose a new method to “predict” peak conuts. |
| In the text | |
|
Fig. 2 Comparison between an analytical mass function (blue line), halo mass histograms for N-body runs (green points), and sample histograms for realizing of the fast simulation (red crosses). The plots are drawn at 4 different redshift planes, and for each the thickness is dz = 0.1. |
| In the text | |
|
Fig. 3 Patch of a map projected with regard to its center, taken from a realization of fast simulations. The left, middle, and right panels give the fields κ1 / 3, |
| In the text | |
|
Fig. 4 Comparison of the peak abundance from different cases. Upper panel: blue solid line: full N-body runs (Case 1); green circles: replacement of halos by NFW profiles (Case 2); red squares: replacement of halos by NFW profiles and randomization of halo angular positions (Case 3); cyan diamonds: fast simulations, corresponding to our model (Case 4); magenta dashed line: peaks from noise-only maps. Lower panel: we draw the upper and lower limits of error bars shifted with regard to the N-body values. This refers to the standard deviation over 4 maps (green dash-dotted line for Case 2) or 16 maps (red dashed line for Case 3, cyan solid line for Case 4). The field of view is 53.7 deg2. |
| In the text | |
|
Fig. 5 Similar plot to Fig. 4, but in a larger field. Cases 2–4 are carried out for 859 deg2. Case 1 should only be taken as an indication, since its size of field is the same as in Fig. 4, and therefore 16 times smaller than cases 2–4. The fluctuation from high ν bins is much reduced compared to Fig. 4. |
| In the text | |
|
Fig. 6 Comparison of the FSL model (orange triangles) to our model (cyan diamonds). The full N-body peak histogram is shown as a blue line. Lower panel: we draw the difference between the FSL model and N-body data within an orange dashed line. The cyan-colored zone represents the error bars for our model. The field of view for fast simulations is 859 deg2. The N-body data is only indicative. |
| In the text | |
|
Fig. 7 Sensitivity tests on (Ωm,σ8). The four plots indicate different variation directions in the Ωm-σ8 plane. The upper left, upper right, lower left, and lower right panels: variation in Ωm, σ8, diagonal, and anti-diagonal direction, respectively. Blue solid lines represent full N-body runs, while red squares are always our model with N-body input. The field of view is 859 deg2. The N-body data is only indicative. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.