| Issue |
A&A
Volume 575, March 2015
|
|
|---|---|---|
| Article Number | L13 | |
| Number of page(s) | 6 | |
| Section | Letters | |
| DOI | https://doi.org/10.1051/0004-6361/201525762 | |
| Published online | 03 March 2015 | |
Mass-ratio distribution of extremely low-mass white dwarf binaries ⋆
ESO, Alonso de Córdova 3107, Casilla 19001, Santiago Chile
e-mail:
This email address is being protected from spambots. You need JavaScript enabled to view it.
Received: 28 January 2015
Accepted: 15 February 2015
Abstract
Knowing the masses of the components of binary systems is very useful for constraining the possible scenarios that could lead to their existence. While it is sometimes possible to determine the mass of the primary star, it is challenging to obtain good mass estimates of the secondary of a single-line spectroscopic binary. If the sample of such binaries is large enough, however, it is possible to use statistical methods to determine the mass-ratio distribution, and thus, the mass distribution of the secondary. Recently, the mass distribution of companions to extremely low-mass white dwarfs was studied using a sample of binaries from the ELM WD Survey. I reanalyse the same sample with two different methods: in the first one, I assume some functional form for the mass distribution, while in the second, I apply an inversion method. I show that the resulting companion-mass distribution can be as well approximated by either a uniform or a Gaussian distribution. The mass-ratio distribution derived from the inversion method without assuming any a priori functional form shows some additional fine-grain structure, although, given the small sample, it is difficult to claim that this structure is statistically significant. I conclude that it is not yet possible to fully constrain the distribution of the mass of the companions to extremely low-mass white dwarfs, although it appears that the probability to have a neutron star in one of the systems is indeed very low.
Key words: binaries: spectroscopic / methods: statistical / white dwarfs
Appendix A is available in electronic form at http://www.aanda.org
© ESO, 2015
1. Introduction
Extremely low-mass white dwarfs (ELMs) are thought to be the end products of binary star interactions and generally have a companion (e.g., Marsh et al., 1995; Rebassa-Mansergas et al., 2011). Although still far from understood, binary models predict that the companions to these ELMs are white dwarfs because the system has undergone one or two common-envelope phases (Nelemans et al., 2001; van der Sluys et al., 2006; Woods et al., 2012; Toonen et al., 2014). Knowing the distribution of the companion’s mass to these ELMs could provide useful constraints on the various parameters that enter binary star evolution and the common-envelope phase, as well as to predict whether and when they will merge and, more generally, how they will evolve (Dan et al., 2012; Kilic et al., 2012). Thanks to the ELM Survey, which has identified 61 ELMs and provided orbital parameters for 54 of them1 (see Brown et al., 2013, and references therein), it is now possible to begin envisaging conducting a statistical analysis as was done by Andrews et al. (2014). The problem is that ELMs are single-lined spectroscopic binaries and as such, it is not possible to obtain the mass ratio directly (see, e.g., Boffin, 2010, 2012; Curé et al., 2014), but one needs to apply statistical methods to derive the mass-ratio (or companion mass) distribution. Andrews et al. (2014) developed a Bayesian probabilistic model to infer the companion mass distribution for the above-mentioned sample, assuming a functional form – a two-component Gaussian, with one component representing white dwarfs with masses between 0.2 and 1.44 M⊙, and the other neutron stars with masses centred around 1.4 M⊙ and a standard deviation of 0.05 M⊙. Using a Markov chain Monte Carlo algorithm, they found that their best fit is given by a population of white dwarfs centred around 0.74 M⊙ and a standard deviation of 0.24 M⊙, without a neutron star. This is quite an interesting result that also indicates that in contrast to population synthesis models, the majority of companions to ELMs are CO-core WDs, and not another He WD. As such, it is important to examine whether this result holds when using different methods, including when the functional form is not fixed a priori. This is what I present here.
2. Methods
The derivation of the orbital elements for a single-lined spectroscopic binary (period, radial velocity amplitude, and eccentricity) allows obtaining the spectroscopic mass function, f(m), which is a combination of the masses of the two components and the (unknown) inclination of the orbit on the line of sight, i:
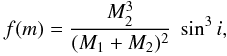 where M1 is the mass of the primary (in this case, the ELM), and M2, the mass of its companion. If M1 is known, as it is the case here, then one can rewrite this as a function of the mass ratio, q = M2/M1:
where M1 is the mass of the primary (in this case, the ELM), and M2, the mass of its companion. If M1 is known, as it is the case here, then one can rewrite this as a function of the mass ratio, q = M2/M1:
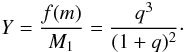 The distribution of the logarithm of f(m) – or Y – can be used to determine the distribution of M2 or q. This was done here using two different methods, in which I always assumed that the inclination i is randomly distributed on the sky, that is, P(i) = sini. I used the sample of Brown et al. (2013, similar to that used by Andrews et al. 2014, which provides a list of 54 systems with known f(m) and M1.
The distribution of the logarithm of f(m) – or Y – can be used to determine the distribution of M2 or q. This was done here using two different methods, in which I always assumed that the inclination i is randomly distributed on the sky, that is, P(i) = sini. I used the sample of Brown et al. (2013, similar to that used by Andrews et al. 2014, which provides a list of 54 systems with known f(m) and M1.
In the first method, I assumed a functional form for the distribution of M2: this is either a Gaussian with mean μ and standard deviation σ, or a uniform distribution, defined between a lower, M2,l, and an upper, M2,u value of the companion mass. I then applied a Kolmogorov-Smirnov statistical test. I assumed a single population of companions, without distinguishing between a neutron star (NS) and a white dwarf companion population, for instance. This is based on the fact that Andrews et al. (2014) found the NS fraction to be very low, as I confirm here as well.
In each case, I ran 10 000 Monte Carlo simulations, where M1 is distributed according to the observed distribution (see Fig. A.1), M2 according to the chosen distribution with one set of parameters, and i is assumed to be randomly distributed on the sky. For each sample of simulations, I calculated the cumulative distribution of log f(m), which I compared with the observed one. To do this, I calculated the largest deviation between the two distributions, D∗ = D54,10 000. Running 10 000 simulations provides very good precision, and there would be no gain in running more, as the estimator D∗ saturates for large numbers2.
This estimator allows determining the probability with which the simulated and the observed distribution are extracted from the same population. Thus, if D∗> 0.2628, the chance is only 0.1% that the two populations are extracted from the same population, and we may most likely ignore such solutions. For D∗> 0.1274 and D∗> 0.0506, these probabilities become 33% and 99.9%, respectively. The first value provides a 1σ estimate of the parameters that are allowed, while the latter number can be used to estimate the 0.1% confidence interval of parameters that provide a very good match to the observed distribution.
In the second method, I took a more direct approach and inverted the distribution of Y to derive the mass-ratio distribution.
3. Results
3.1. Functional form
3.1.1. Gaussian
 |
Fig. 1 Standard deviation, σ, versus the mean mass of the companion, μ, for all simulated samples where the companion mass is distributed according to a Gaussian, and which have D∗ < 0.1274 (in black) and those that have D∗ < 0.0506 (in green). The heavy, red dot shows the location μ = 0.74, σ = 0.24. (A colour version of the figure is available online.) |
As mentioned above, I here assumed that the distribution of the companion mass, Φ(M2), is given by a Gaussian:
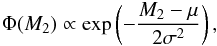 and I determined for a plane 0 <μ < 2,0 <σ < 1 the value of D∗. The relation of D∗ with μ is shown in Fig. A.2, where I also show the lines corresponding to D∗ = 0.0506, 0.1274, and 0.2628. This figure shows that one can find simulations spanning the whole range 0 <μ < 1.22 M⊙ that would lead to D∗ < 0.2628, while the 1σ range covers the values 0.3 <μ < 0.92 M⊙. This indicates that it is difficult to constrain the parameters of such a functional form based on the small observed sample. It is clear, however, that the simulations with μ between 0.7 and 0.8 M⊙ correspond to the lowest values of D∗, with the minimum being around μ = 0.76 M⊙ and σ = 0.27 M⊙, leading to D∗ = 0.027. This value indicates that this simulation and the observed distribution are consistent at a very high level because the null hypothesis that the two populations are drawn from the same population can only be rejected at a level of 1.3 × 10-12%.
and I determined for a plane 0 <μ < 2,0 <σ < 1 the value of D∗. The relation of D∗ with μ is shown in Fig. A.2, where I also show the lines corresponding to D∗ = 0.0506, 0.1274, and 0.2628. This figure shows that one can find simulations spanning the whole range 0 <μ < 1.22 M⊙ that would lead to D∗ < 0.2628, while the 1σ range covers the values 0.3 <μ < 0.92 M⊙. This indicates that it is difficult to constrain the parameters of such a functional form based on the small observed sample. It is clear, however, that the simulations with μ between 0.7 and 0.8 M⊙ correspond to the lowest values of D∗, with the minimum being around μ = 0.76 M⊙ and σ = 0.27 M⊙, leading to D∗ = 0.027. This value indicates that this simulation and the observed distribution are consistent at a very high level because the null hypothesis that the two populations are drawn from the same population can only be rejected at a level of 1.3 × 10-12%.
Of course, the standard deviation σ is correlated with μ, and Fig. 1 shows the solutions that lead to D∗ < 0.0506 and D∗ < 0.1274, illustrating the allowed range. For D∗ < 0.1274, I found that the mean value of the companion mass is μm = 0.70 ± 0.12 M⊙, while the mean value of the standard deviation is σm = 0.45 ± 0.22 M⊙. For D∗ < 0.0506, these values become μm = 0.76 ± 0.03 M⊙ and σm = 0.27 ± 0.06 M⊙.
A χ2 analysis that computes the deviation of the computed and observed distribution of log f(m) provides a similar result, with the best fit being given by μ = 0.76 ± 0.02 M⊙ and σ = 0.27 ± 0.02 M⊙ (see Fig. A.4).
 |
Fig. 2 Highest mass of the companion as a function of the lowest mass of the companions for all simulated uniformly distributed samples that have D∗ < 0.1274 (in black) and those that have D∗ < 0.0506 (in green). The two masses are clearly correlated, and I show a linear fit to the green dots as the heavy, solid red line. (A colour version of the figure is available online.) |
3.1.2. Uniform distribution
I repeated the same analysis but using a uniform distribution of the companion mass, between a lowest (M2,l) and a highest value (M2,u), which were assumed to be in the range 0 <M2,l < 0.9 M⊙ and M2,l<M2,u<M2,l + 1.5 M⊙. The results are shown in Figs. A.3 and 2. Again, the range of allowed values is very wide. If this is restricted to D∗ < 0.2628, the whole range of M2,l is allowed, while for M2,u, it is restricted to values between 0.5 and 1.95 M⊙. The range becomes narrower for lower values of D∗, as shown in Fig. 2, which also shows that the acceptable values of M2,l and M2,u are correlated. A linear fit gives
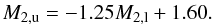 The mean values of M2,l and M2,u are 0.36 ± 0.18 M⊙ and 1.20 ± 0.23 M⊙ for D∗ < 0.1274, and 0.33 ± 0.07 M⊙ and 1.19 ± 0.10 M⊙ for D∗ < 0.0506. The lowest value of D∗ (0.02793) is reached for M2,l = 0.25 M⊙ and M2,u = 1.28 M⊙. This value corresponds to a probability that the two distributions are not extracted from the same population of 4 × 10-10%. Perhaps most importantly, this shows that a uniform distribution of the companion mass fits the data very well and cannot be discarded. With such a functional form, a Gaussian or a uniform distribution cannot be preferred; they do, of course, quite overlap (see Fig. A.5).
The mean values of M2,l and M2,u are 0.36 ± 0.18 M⊙ and 1.20 ± 0.23 M⊙ for D∗ < 0.1274, and 0.33 ± 0.07 M⊙ and 1.19 ± 0.10 M⊙ for D∗ < 0.0506. The lowest value of D∗ (0.02793) is reached for M2,l = 0.25 M⊙ and M2,u = 1.28 M⊙. This value corresponds to a probability that the two distributions are not extracted from the same population of 4 × 10-10%. Perhaps most importantly, this shows that a uniform distribution of the companion mass fits the data very well and cannot be discarded. With such a functional form, a Gaussian or a uniform distribution cannot be preferred; they do, of course, quite overlap (see Fig. A.5).
 |
Fig. 3 Comparison between the observed distribution of the logarithm of the spectroscopic mass function (solid black line) and the best fits for the uniformly distributed (red dotted line connected by heavy dots) and Gaussian-distributed (green dashed line connected by open squares) companion masses. For the former, I used M2,l = 0.25 M⊙ and M2,u = 1.28 M⊙, while for the latter, I used μ = 0.76 M⊙ and σ = 0.27 M⊙. The top panel shows the fraction of systems, while the bottom panel is the cumulative fraction of systems. It is clear that both samples are good fits, given the intrinsic errors of the observed distribution. (A colour version of the figure is available online.) |
This is further illustrated in Fig. 3, which shows the distribution of log f(m) for the observed sample as well as for the two best fits of the functional form, a Gaussian, and a uniform distribution. It is clear that both simulated distributions are good fits to the observed distribution, while it is very hard to distinguish the results from the two different functional forms.
3.1.3. Inversion method
Using a functional form for the mass distribution allows a better control of the systematics of a method, but at the cost of risking missing some interesting deviations. This is for example the case in the paper by Andrews et al. (2014) in their test 4, where they compare the distribution they obtain for a sample of post-common envelope systems to that obtained from spectroscopy. Although they clearly reproduce the bulk distribution, they miss the tail and other details of the distribution (see their Fig. 3). Moreover, Andrews et al. (2014) also pointed out that for the sample of ELMs, their result “could indicate that the true WD distribution may not be exactly Gaussian” – and indeed the previous section has shown that a uniform distribution also provides a good fit to the observations. It is therefore useful to consider exploring methods that do not require the a priori input of a functional form. This is the case of the Richardson-Lucy (R-L) inversion method, as used by Boffin et al. (1993); Boffin (2010, 2012), and Curé et al. (2014).
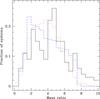 |
Fig. 4 Distribution of the mass ratios as determined by the Richardson-Lucy algorithm (solid black line) and as obtained for the best fits with a Gaussian (red dotted line) and a uniform (blue dashed line) distribution of companions. (A colour version of the figure is available online.) |
I refer to these papers and references therein for a full discussion of the method, and in particular to Cerf & Boffin (1994) for a more formal presentation. Here, I just mention that the Richardson-Lucy method relies on the Bayes theorem on conditional probabilities and solves the Fredholm integral equation that links Y with q by an iterative scheme. It is important to note that we do not directly have the distribution of the companion mass, but only of the mass ratio. This is, however, a very important parameter for binary evolution models, and given that the mass of the primary is very peaked at 0.17 M⊙, the distribution of the mass ratio can give an idea of the distribution of the companion mass. The outcome of this method is shown in Fig. 4, where I also compare it with the distribution derived from the best fits of the functional form method. For the latter, I derived the mass-ratio distribution by using the functional form for the companion mass and the primary mass distribution as determined by Brown et al. (2013).
All three methods provide a rather similar mass-ratio distribution, with some small differences. The outcome of the R-L method gives a broad Gaussian distribution, but with two more pronounced peaks, around q ~ 2−2.5 and around q ~ 4−5. This may indicate that a simple functional form may be missing on some small structure in the data, although a much larger sample is needed to be able to confirm these (Boffin, 2012). A K-S test indicates that the hypothesis that the functional forms and the outcome of the R-L method are drawn from the same population can be rejected at the level of 92% – a rather high number, but perhaps not convincing enough. Indeed, given the small sample, this is at most a two-sigma result. However, it shows that the true mass-ratio distribution (and companion mass distribution) may have a more complicated structure than any simple functional form we can think of. Only with much larger samples will be able to know this.
At the suggestion of the referee, I have also examined the mass-ratio distribution derived with the R-L method when limiting to the least massive primary stars, that is, the 33 systems with masses lower than 0.2 M⊙. The resulting distribution is shown in Fig. A.6. It shows a single-peaked distribution centred around q ~ 4−5, that is (given that we now examine systems with a primary mass M1 = 0.17 M⊙), M2 = 0.68−0.85 M⊙. In the figure, the corresponding mass-ratio distributions for the functional forms were computed with a single value of the primary mass. The outcome of the R-L method apparently agrees better with the Gaussian distribution, but given that we have now an even smaller sample, the data should not be overinterpreted because the three distributions are again compatible within 2σ. This peak may correspond to the similar peak seen in the mass-ratio distribution seen for the entire sample, while the fact that there is a possible second peak in Fig. 4 at a lower mass ratio is most probably linked to the more massive primaries.
The very small excess of high mass ratios seen in Figs. 4 and A.6 should not be given too much importance: firstly, it is a well-known effect of the R-L method to smooth the distribution, the effect becoming weaker depending on the number of iterations (Cerf & Boffin, 1994), and secondly, their value is compatible with zero, given the size of the sample.
4. Discussion and conclusions
The results of Andrews et al. (2014) in the study of ELM WDs are very important, therefore I have reanalysed the same sample of spectroscopic binaries they used with two different techniques. In the first one, I assumed functional forms and applied a K-S statistics. The obtained results were confirmed by a χ2 statistical test. The parameters for the Gaussian functional form are very similar to those found using a different method by Andrews et al. (2014), but I showed that a uniform distribution of the companion mass can provide as good a fit to the observed data and that the range of
parameters allowed is rather large, making it hard to provide a definitive answer as to the real distribution. If the uniform distribution illustrated in Fig. A.5 is more representative of the companion mass distribution, then more double He WD binary systems may be expected, such as the eclipsing double white dwarf binary CSS 41177 (Bours et al., 2014): the uniform distribution shown in this figure leads to a 24% probability (this is the fraction of systems that have a secondary mass lower than 0.5 M⊙), compared to 16% for the Gaussian fit shown in the same figure or as derived by Andrews et al. (2014). If I take into account all the possible values at the 1σ level (i.e. those with D∗ < 0.1274), I also derive a 26% probability for both my Gaussian and uniform distributions.
In addition, I applied an inversion method to derive the mass-ratio distribution, without the need to assume any functional form. The results are compatible with those derived from the functional form, although they seem to indicate some additional fine-grained structures.
An important question that Andrews et al. (2014) addressed is the possibility to have a neutron star as a companion to the ELM WD. Andrews et al. (2014) found that the probability of this is very low. This is also confirmed by my results. For example, the uniform distribution of companion masses indicates that the range allowed for D∗ < 0.0506 ends at 1.4 M⊙. If this is relaxed to D∗ < 0.1274, however, the highest companion mass can be up to 1.7 M⊙, but all in all, the probability to have one system with such a high mass (>1.44 M⊙) is very low: for the uniform distribution, the 1σ probability is zero, while for the Gaussian distribution it is 6.5%.
Online material
Appendix A: Additional figures
 |
Fig. A.1 Distribution of primary mass in the sample of Brown et al. (2013). The sample contains many objects with primary mass equal to 0.17 M⊙. |
 |
Fig. A.2 Maximum deviation between the observed sample with N = 54 and a synthetic sample containing N′ = 10 000 objects, with the companion mass being distributed as a Gaussian with a mean mass as given by the abscissa. The blue dotted line is drawn at D∗ = 0.2628: all simulations with a higher value of the estimator can be rejected at the 99.9% level as being drawn from the same population as the observed distribution. The magenta dashed line is drawn at D∗ = 0.1274 and provide a 1σ estimate of the allowed parameter range, while the red solid line is drawn at D∗ = 0.0506. |
 |
Fig. A.3 Top: maximum deviation as a function of the highest mass of the companion if the latter is uniformly distributed between a lowest and highest mass. Bottom: the same, but as a function of the lowest mass. The lines are drawn at the same value of D∗ as in Fig. A.2. |
 |
Fig. A.4 Reduced χ2 map in the mean companion mass vs. standard deviation for an assumed Gaussian functional form of the companion mass distribution – contours are shown at levels of 1, 1.5, 2, and 2.5. The red dot shows the position of the best fit of Andrews et al. (2014). The χ2 map confirms the result that was obtained with the K-S statistics. |
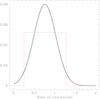 |
Fig. A.5 Comparison between the two best functional forms that lead to the lowest values of D∗: a Gaussian distribution with μ = 0.76 M⊙ and σ = 0.27 M⊙ (solid black line) and a uniform distribution with M2,l = 0.25 M⊙ and M2,u = 1.28 M⊙ (dotted red line). |
 |
Fig. A.6 Distribution of the mass ratios as determined by the Richardson-Lucy algorithm (solid black line) for all systems with a primary mass below 0.2 M⊙, and as obtained for the best fits with a Gaussian (red dotted line) and a uniform (blue dashed line) distribution of companions. |
Andrews et al. (2014) used the 55 systems of Gianninas et al. (2014), which are essentially based on the list of 54 systems from Brown et al. (2013). Here I used these 54 latter systems because they come from a homogeneous sample.
This is because 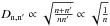 for n′ ≫ n and n ≫ 1.
for n′ ≫ n and n ≫ 1.
Acknowledgments
I would like to thank the referee, J.J. Andrews, for a careful reading of the manuscript and for providing suggestions to improve the paper.
References
- Andrews, J. J., Price-Whelan, A. M., & Agüeros, M. A. 2014, ApJ, 797, L32 [NASA ADS] [CrossRef] [Google Scholar]
- Boffin, H. M. J. 2010, A&A, 524, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Boffin, H. M. J. 2012, in Orbital Couples: Pas de Deux in the Solar System and the Milky Way, Proc. of the Workshop, Observatoire de Paris, 41 [Google Scholar]
- Boffin, H. M. J., Cerf, N., & Paulus, G., 1993, A&A, 271, 125 [NASA ADS] [Google Scholar]
- Bours, M. C. P., Marsh, T. R., Parsons, S. G., et al. 2014, MNRAS, 438, 3399 [NASA ADS] [CrossRef] [Google Scholar]
- Brown, W. R., Kilic, M., Allen de Prieto, C., Gianninas, A., & Kenyon, S. J. 2013, ApJ, 769, 66 [NASA ADS] [CrossRef] [Google Scholar]
- Cerf, N., & Boffin, H. M. J. 1994, Inverse Problems, 10, 533 [Google Scholar]
- Curé, M., Rial, D. F., Christen, A., Cassetti, J., & Boffin, H. M. J. 2014, A&A, 573, A86 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dan, M., Rosswog, S., Guillochon, J., & Ramirez-Ruiz, E. 2012, MNRAS, 422, 2417 [NASA ADS] [CrossRef] [Google Scholar]
- Gianninas, A., Dufour, P., Kilic, M., et al. 2014, ApJ, 794, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Kilic, M., Brown, W. R., Allen de Prieto, C., et al. 2012, ApJ, 751, 141 [NASA ADS] [CrossRef] [Google Scholar]
- Marsh, T. R., Dhillon, V. S., & Duck, S. R. 1995, MNRAS, 275, 828 [NASA ADS] [CrossRef] [Google Scholar]
- Nelemans, G., Yungelson, L. R., Portegies Zwart, S. F., & Verbunt, F. 2001, A&A, 365, 491 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rebassa-Mansergas, A., Nebot Gómez-Morán, A., Schreiber, M. R., Girven, J., & Gänsicke, B. T. 2011, MNRAS, 413, 1121 [NASA ADS] [CrossRef] [Google Scholar]
- Toonen, S., Claeys, J. S. W., Mennekens, N., & Ruiter, A. J. 2014, A&A, 562, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- van der Sluys, M. V., Verbunt, F., & Pols, O. R. 2006, A&A, 460, 209 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Woods, T. E., Ivanova, N., van der Sluys, M. V., & Chaichenets, S. 2012, ApJ, 744, 12 [NASA ADS] [CrossRef] [Google Scholar]
All Figures
|
Fig. 1 Standard deviation, σ, versus the mean mass of the companion, μ, for all simulated samples where the companion mass is distributed according to a Gaussian, and which have D∗ < 0.1274 (in black) and those that have D∗ < 0.0506 (in green). The heavy, red dot shows the location μ = 0.74, σ = 0.24. (A colour version of the figure is available online.) |
| In the text | |
|
Fig. 2 Highest mass of the companion as a function of the lowest mass of the companions for all simulated uniformly distributed samples that have D∗ < 0.1274 (in black) and those that have D∗ < 0.0506 (in green). The two masses are clearly correlated, and I show a linear fit to the green dots as the heavy, solid red line. (A colour version of the figure is available online.) |
| In the text | |
|
Fig. 3 Comparison between the observed distribution of the logarithm of the spectroscopic mass function (solid black line) and the best fits for the uniformly distributed (red dotted line connected by heavy dots) and Gaussian-distributed (green dashed line connected by open squares) companion masses. For the former, I used M2,l = 0.25 M⊙ and M2,u = 1.28 M⊙, while for the latter, I used μ = 0.76 M⊙ and σ = 0.27 M⊙. The top panel shows the fraction of systems, while the bottom panel is the cumulative fraction of systems. It is clear that both samples are good fits, given the intrinsic errors of the observed distribution. (A colour version of the figure is available online.) |
| In the text | |
|
Fig. 4 Distribution of the mass ratios as determined by the Richardson-Lucy algorithm (solid black line) and as obtained for the best fits with a Gaussian (red dotted line) and a uniform (blue dashed line) distribution of companions. (A colour version of the figure is available online.) |
| In the text | |
|
Fig. A.1 Distribution of primary mass in the sample of Brown et al. (2013). The sample contains many objects with primary mass equal to 0.17 M⊙. |
| In the text | |
|
Fig. A.2 Maximum deviation between the observed sample with N = 54 and a synthetic sample containing N′ = 10 000 objects, with the companion mass being distributed as a Gaussian with a mean mass as given by the abscissa. The blue dotted line is drawn at D∗ = 0.2628: all simulations with a higher value of the estimator can be rejected at the 99.9% level as being drawn from the same population as the observed distribution. The magenta dashed line is drawn at D∗ = 0.1274 and provide a 1σ estimate of the allowed parameter range, while the red solid line is drawn at D∗ = 0.0506. |
| In the text | |
|
Fig. A.3 Top: maximum deviation as a function of the highest mass of the companion if the latter is uniformly distributed between a lowest and highest mass. Bottom: the same, but as a function of the lowest mass. The lines are drawn at the same value of D∗ as in Fig. A.2. |
| In the text | |
|
Fig. A.4 Reduced χ2 map in the mean companion mass vs. standard deviation for an assumed Gaussian functional form of the companion mass distribution – contours are shown at levels of 1, 1.5, 2, and 2.5. The red dot shows the position of the best fit of Andrews et al. (2014). The χ2 map confirms the result that was obtained with the K-S statistics. |
| In the text | |
|
Fig. A.5 Comparison between the two best functional forms that lead to the lowest values of D∗: a Gaussian distribution with μ = 0.76 M⊙ and σ = 0.27 M⊙ (solid black line) and a uniform distribution with M2,l = 0.25 M⊙ and M2,u = 1.28 M⊙ (dotted red line). |
| In the text | |
|
Fig. A.6 Distribution of the mass ratios as determined by the Richardson-Lucy algorithm (solid black line) for all systems with a primary mass below 0.2 M⊙, and as obtained for the best fits with a Gaussian (red dotted line) and a uniform (blue dashed line) distribution of companions. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.