| Issue |
A&A
Volume 688, August 2024
|
|
|---|---|---|
| Article Number | A166 | |
| Number of page(s) | 7 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202450712 | |
| Published online | 15 August 2024 | |
Optimal bolometer transfer function deconvolution for CMB experiments through maximum likelihood mapmaking
Institute of Theoretical Astrophysics, University of Oslo, Blindern, Oslo, Norway
e-mail: artem.basyrov@astro.uio.no
Received:
14
May
2024
Accepted:
24
June
2024
We revisit the impact of finite time responses of bolometric detectors used for deep observations of the cosmic microwave background (CMB). Until now, bolometer transfer functions have been accounted for through a two-step procedure by first deconvolving an estimate of their Fourier-space representation from the raw time-ordered data (TOD), and then averaging the deconvolved TOD into pixelized maps. However, for many experiments, including the Planck High Frequency Instrument (HFI), it is necessary to apply an additional low-pass filter to avoid an excessive noise boost, which leads to an asymmetric effective beam. In this paper we demonstrate that this effect can be avoided if the transfer function deconvolution and pixelization operations are performed simultaneously through integrated maximum likelihood mapmaking. The resulting algorithm is structurally identical to the artDeco algorithm for beam deconvolution. We illustrate the relevance of this method with simulated Planck HFI 143 GHz data, and find that the resulting effective beam is both more symmetric than with the two-step procedure, resulting in a sky-averaged ellipticity that is 64% lower, and an effective beam full-width-at-half-maximum (FWHM) that is 2.3% smaller. Similar improvements are expected for any other bolometer-based CMB experiments with long time constants.
Key words: instrumentation: detectors / methods: data analysis / methods: numerical / methods: statistical / cosmic background radiation / cosmology: observations
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1. Introduction
During the last three decades, our understanding of the cosmic microwave background (CMB) has been revolutionized by a series of increasingly sensitive instruments (e.g., Bennett et al. 1996; Hinshaw et al. 2013; Planck Collaboration I 2014, 2016, 2020). These advances have been made possible by increased sensitivity, driven by improvements in detector technology both for coherent radiometer and incoherent bolometer detectors.
Bolometric detectors in particular have gone a long way in improving both sensitivity and the frequency range they are able to operate in (e.g., Zhao et al. 2008; Bersanelli et al. 2010; Lamarre et al. 2010; Stevens et al. 2020). One of the main characteristics of a bolometer is a finite time constant that describes its temporal response to a signal change (e.g., Planck Collaboration VII 2014). The main observational signature of a finite bolometer transfer function is an apparent smoothing of the true underlying signal along the scanning path of the instrument. Fortunately, the magnitude of this effect has diminished over time, as the bolometer detector technology has improved and the response rates have become faster. Still, this effect has to be accounted for during mapmaking in order to establish an accurate estimate of the true sky signal.
The traditional approach to account for this effect is simply to deconvolve an estimate of the bolometer transfer function from the time-ordered data (TOD), which results in an unbiased signal. A significant drawback of this method, however, is that it not only affects the sky signal, but also the noise measured by the detector, which originates at a later point in the electronic circuitry and is not affected by the bolometer time constant at all. The noise is therefore effectively amplified on short time-scales. In the original Planck analysis, this problem was solved by applying an extra low-pass regularization filter function that suppresses high-frequency noise (Planck Collaboration VII 2014). While using this filter does solve the noise amplification problem at high temporal frequencies, it also modifies the signal, thereby introducing an extra component to the effective beam.
In this work, we propose an alternative approach that exploits the same ideas as proposed for beam deconvolution by Keihänen & Reinecke (2012). Specifically, rather than explicitly deconvolving the beam transfer function in a pre-processing step prior to mapmaking, we integrate the deconvolution operator directly into the maximum likelihood mapmaking equation, which then is solved using a conjugate gradient method (e.g., Shewchuk 1994). This approach has several advantages. Firstly, it does not require an explicit additional noise regularization kernel, but relies on the scanning strategy itself to regularize the high-frequency noise. This method yields an unbiased estimate of the true sky signal without modifying the effective beam. Secondly, it results in significantly weaker noise correlations at high temporal frequencies. The main drawback of the method is a higher computational expense.
The rest of the paper is organized as follows. We first describe the new method in Sect. 2. We then illustrate the main points with a simple one-dimensional case in Sect. 3 in which all calculations can be performed by using dense linear algebra. Next, we consider the two-dimensional case in Sect. 4, and start by characterizing its performance for a grid of point sources. Finally, we apply the method on the simulated CMB map in Sect. 5 with properties similar to the Planck 143 GHz channel. We discuss the computational cost of the proposed method in Sect. 6, before concluding in Sect. 7.
2. Method
We start by assuming that the data d recorded by a bolometer may be modeled as
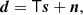
where s is the true sky signal projected from the sky map as s = Pms; P is a pointing matrix of size (npix, ntod) that maps between pixel space and time ordered data; T represents convolution with a bolometer transfer function T = F−1T(ω)F, where F denotes a Fourier transform; and n denotes noise. In this work, we assume that the latter only consists of zero-mean Gaussian noise, and we define its covariance matrix as N ≡ ⟨nnT⟩. However, there are many other sources of instrumental noise in the real data (e.g., Planck Collaboration VII 2016; Ihle et al. 2023) that must be taken into account in a full analysis pipeline.
Our goal now is to derive an accurate estimate of s given some observed data, and we will denote this estimate 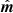 . The traditional approach for doing this adopted by most bolometer-based experiments consists of a two-step procedure; one specific example that is particularly relevant for this paper is Planck HFI (Planck Collaboration VII 2014, 2016). The first step is to explicitly apply the inverse transfer function operator to the raw TOD,
. The traditional approach for doing this adopted by most bolometer-based experiments consists of a two-step procedure; one specific example that is particularly relevant for this paper is Planck HFI (Planck Collaboration VII 2014, 2016). The first step is to explicitly apply the inverse transfer function operator to the raw TOD,
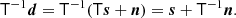
As long as T is non-singular, this results in an unbiased estimate of the signal s. However, it also modifies the noise, n. In particular, due to the shape of the transfer function (as shown in Fig. 1), this inverse operator significantly boosts the noise level at high frequencies in Fourier space. To prevent the introduction of excessive noise, a common solution is to apply an additional low-pass filter function K(ω), such that the total filtered TOD reads
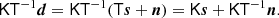
 |
Fig. 1. Amplitudes of the Planck HFI bolometer transfer function T(ω) (green), the low-pass filter K(ω) employed by Planck HFI to keep the high-k modes from blowing up (red), and the former divided by the latter (black), which is the resulting function applied to the data in Planck deconvolution method. The presented functions are in absolute amplitudes. The bolometer transfer function also has a complex component. |
Here we have introduced a filter operator K similar to the transfer function operator T as K = F−1K(ω)F.
The second step in the traditional procedure is to apply a mapmaking algorithm to this deconvolved TOD. Under the assumption of Gaussian noise, the optimal solution for this is given by the normal equations (e.g., Tegmark 1997),
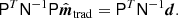
In practice, this optimal mapmaking equation is often replaced with a computationally cheaper solution that does not require inversion of a full dense noise covariance matrix. In many cases N is simply approximated with its diagonal, and in that case the equation may be solved pixel-by-pixel (so-called binning). Another common solution is to apply a destriping algorithm, which accounts for large-scale noise fluctuations. In either case, 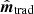 is sub-optimal in two respects: First, if K ≠ I, then
is sub-optimal in two respects: First, if K ≠ I, then 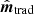 is a biased estimator of s. In practice, this is typically accounted for in higher-level analysis by modifying the effective instrumental beam, which then introduces significant asymmetries that couple to the scanning strategy. Second, the actual noise covariance matrix in the post-deconvolved TOD reads KT−1NT−1K, but these additional terms are not accounted for in the above solution. As such, the noise weighting of
is a biased estimator of s. In practice, this is typically accounted for in higher-level analysis by modifying the effective instrumental beam, which then introduces significant asymmetries that couple to the scanning strategy. Second, the actual noise covariance matrix in the post-deconvolved TOD reads KT−1NT−1K, but these additional terms are not accounted for in the above solution. As such, the noise weighting of 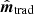 is also sub-optimal.
is also sub-optimal.
Aiming to resolve both these deficiencies, we adopt a simpler approach in this paper, and note that an unbiased and optimal estimate of 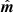 can be obtained directly from the data model in Eq. (1) as follows,
can be obtained directly from the data model in Eq. (1) as follows,
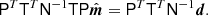
We denote the solution of this equation 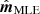 , where MLE is short of maximum likelihood estimate. The equation involves the transpose of T, which may be written as TT = F−1T*(ω)F, where T*(ω) = T*(ω) is the complex conjugate of the transfer function T(ω).
, where MLE is short of maximum likelihood estimate. The equation involves the transpose of T, which may be written as TT = F−1T*(ω)F, where T*(ω) = T*(ω) is the complex conjugate of the transfer function T(ω).
We use a standard preconditioned conjugate gradient method (CG; Shewchuk 1994) to solve Eq. (5), and we find that a simple diagonal preconditioner of the form
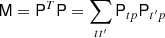
results in a speed-up of almost a factor of 10 compared to no preconditioning. This algorithm is conceptually identical to the artDeco algorithm introduced by Keihänen & Reinecke (2012) for asymmetric beam deconvolution, the main difference being that our T operator is computationally much cheaper than their asymmetric beam operator B.
3. One-dimensional toy model: Intuition
In general, our own primary motivation for this line of work lies in a future reanalysis of the Planck HFI observations. We therefore adopt the HFI 143-5 bolometer transfer function T(ω) and low-pass filter K(ω) as an explicit test case, which is shown in Fig. 1. The goal of this and the following two sections is to compare the performance of the traditional and the optimal methods in various settings for this case. In fact, most of the key algebraic points can be easily demonstrated and visualized through a simple one-dimensional case in which all matrix operations can be solved quickly by brute-force methods
In this first example, we define our true input sky map to consist of an array with 200 one-dimensional pixels. This signal map is then scanned by a simple sinusoidal scanning strategy θ = sin(2πft), where f = 0.2 Hz and the sampling rate is fsamp = 180.3737 Hz, similar to Planck HFI 143 GHz sampling rate. The resulting signal-only TOD has length ntod = 10 000 and is then convolved with the Planck transfer function shown in Fig. 1. Finally, white Gaussian noise is added. We then solve Eqs. (4) and (5) for 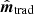 and
and 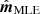 , respectively. Since the number of pixels is only 200, these solutions are very fast even with brute-force matrix inversion.
, respectively. Since the number of pixels is only 200, these solutions are very fast even with brute-force matrix inversion.
We consider two different cases for this 1D model. In the first case, we set s = 0, with the goal of understanding the effects of the different deconvolution methods on the noise properties of the resulting maps. In the second case, we insert a single narrow Gaussian peak in the middle of the map, representing a point source in a typical CMB map, with the goal of understanding the relative impact of the two methods on a sharp signal.
Starting with the noise-only case, we simulate a total of 10 000 independent noise realizations, and use these to build up the post-solution noise covariance matrix explicitly. For each realization, we calculate the power spectrum defined as P(k) = ⟨|f(k)|2⟩, where f(k) is the Fourier transform of 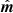 . In the case of
. In the case of 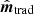 , we have to deconvolve the effective transfer function arising from K to obtain an unbiased estimate. This is found by simulating a large ensemble of random signal-only maps and taking the ensemble average of the ratio between the corresponding output and input spectra. To illustrate the adverse impact of unregularized high-frequency noise on
, we have to deconvolve the effective transfer function arising from K to obtain an unbiased estimate. This is found by simulating a large ensemble of random signal-only maps and taking the ensemble average of the ratio between the corresponding output and input spectra. To illustrate the adverse impact of unregularized high-frequency noise on 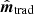 , we also include a case corresponding to K = I for
, we also include a case corresponding to K = I for 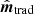 in this demonstration.
in this demonstration.
The results from these calculations are summarized in Fig. 2. For reference, the blue curve shows the power spectrum of a white noise TOD directly binned into a map, without taking into account T; this illustrates the intrinsic noise level that is subsequently boosted by the bolometer transfer function deconvolution in the actual methods. Starting from the top, the green dots show the noise in 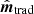 when not applying the regularization kernel K. The y-axis in the plot is broken into linear and logarithmic scaling. The high-frequency noise must be suppressed prior to mapmaking in some way or other to obtain meaningful results. Moving on to the realistic cases corresponding to
when not applying the regularization kernel K. The y-axis in the plot is broken into linear and logarithmic scaling. The high-frequency noise must be suppressed prior to mapmaking in some way or other to obtain meaningful results. Moving on to the realistic cases corresponding to 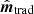 with K and
with K and 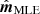 shown in red and black, respectively, we see that the two methods perform similarly in terms of total noise power.
shown in red and black, respectively, we see that the two methods perform similarly in terms of total noise power.
 |
Fig. 2. Comparison of noise power spectra for noise-only 1D simulations for four different analysis configurations, as evaluated by the mean and standard deviation from 10 000 simulations. The y-axis is broken into linear and logarithmic portions. |
However, even though the two methods perform similar in terms of absolute noise power, they still perform quite differently in terms of noise correlations. This is illustrated in Fig. 3, which shows a slice through the empirical correlation matrix evaluated as 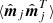 over the simulated ensemble, where j indicates simulation number. We see that the correlation values fall off by almost an order of magnitude lower for
over the simulated ensemble, where j indicates simulation number. We see that the correlation values fall off by almost an order of magnitude lower for 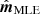 compared to
compared to 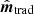 at long distances; the low absolute values for
at long distances; the low absolute values for 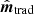 at a few pixels separation is just a ringing artifact from the K filter.
at a few pixels separation is just a ringing artifact from the K filter.
 |
Fig. 3. Absolute value of a middle row map covariance matrix slice, |
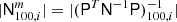
Next, we consider the signal case with a Gaussian point source in the middle of the 1D map. We repeat the same procedure as outlined in the previous section for both techniques. However, since we are now interested in the effect on the signal, and the mapmaking equations are linear, we now omit the noise in the actual simulated TOD. The resulting products therefore correspond directly to ensemble-averaged quantities, and require no Monte Carlo simulation. The outputs from these calculations are summarized in Fig. 4. The top panel shows the input model as a solid black curve, and the reconstructed estimates are shown as dashed orange (for 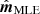 ) and dashed green (for
) and dashed green (for 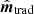 ) curves. The bottom panel shows the difference between output and input signals. The input signal is normalized to unity at the peak, so that the bottom panel can be interpreted as a fractional error. The MLE solution results in an unbiased estimate of the input signal, and any uncertainties in this solution are given by numerical round-off errors. In contrast, the traditional method results in residuals at the 10% level at the peak, with significant ringing extending to large distances.
) curves. The bottom panel shows the difference between output and input signals. The input signal is normalized to unity at the peak, so that the bottom panel can be interpreted as a fractional error. The MLE solution results in an unbiased estimate of the input signal, and any uncertainties in this solution are given by numerical round-off errors. In contrast, the traditional method results in residuals at the 10% level at the peak, with significant ringing extending to large distances.
 |
Fig. 4. Comparison of reconstructed 1D point source signals for |
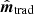
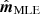
4. Two-dimensional toy model: Impact on effective beam
In this section we apply the methods outlined in Sect. 2 to a two-dimensional case, with the goal of comparing the performance of the traditional and the MLE methods in terms of their impact on the effective beam. In this case, we construct an input sky signal that is mostly empty, except for one or more bright point sources depending on the test in question. In the first case we study a single point source located at the Ecliptic South Pole, and the input map is defined by setting the closest pixel to 100 in arbitrary units. The map is then smoothed with a symmetric Gaussian beam with the full width at half maximum (FWHM) set to 7.2 arcmin, similar to the 143 GHz Planck HFI effective beam (Planck Collaboration VII 2014).
Using this map, the sky signal TOD is created using the Planck 143-5 pointing matrix as s = Pmsky. For the purposes of this experiment, which is designed to build intuition regarding the effect of a bolometer transfer function on a point source, we only use the first three months of the HFI survey. The measured TOD d is created through Eq. (1) by applying the bolometer transfer function and adding white noise. The white noise level is set to σwn = 0.3125 in arbitrary units, which corresponds to a signal-to-noise ratio of 320 at the peak of the point source. This value is chosen to represent the typical signal-to-noise ratio of planet observations reported by Planck Collaboration VII (2014). The maps for both the input sky signal s and the corresponding naively binned sky map 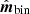 are shown in Fig. 5. In the first case, the point source appears azimuthally symmetric, while in the second case it is significantly deformed. Because the satellite scanning moved from right to left in this figure, the transfer function effectively drags the signal along the scanning path.
are shown in Fig. 5. In the first case, the point source appears azimuthally symmetric, while in the second case it is significantly deformed. Because the satellite scanning moved from right to left in this figure, the transfer function effectively drags the signal along the scanning path.
 |
Fig. 5. Simulated point source signal s on the left panel and detector measured signal d = Ts + n on the right panel. The effect of the transfer function T can be observed in the smearing of the point source signal along the scanning path, resulting in a deformed beam. |
We now apply both the traditional and the MLE methods to these simulated data, each producing a map of the true sky signal. The results from these calculations are shown in Fig. 6 in terms of the difference between the reconstructed and the true input maps. Starting with the traditional method, we observe at least two noticeable residuals related to the transfer function. First, since the traditional method includes a regularization kernel K, the algorithm is unable to reconstruct the true input sky signal, and a quadrupolar residual aligned with the scanning path is present in the residual map. For an isotropic and random field, such as the CMB, the average effect of this can be accounted for by modifying the effective azimuthally symmetric beam response function bℓ, as for instance is done in the Planck analysis, but this method is clearly unable to reconstruct an optimal image of the true sky. In contrast, the integrated MLE solution shows no signs of scan-aligned effects, and the residual is consistent with white noise. Secondly, far away from the point source, the traditional method smooths the white noise more than the MLE method. Both of these effects correspond directly to what was found for the one-dimensional toy model in the previous section.
 |
Fig. 6. Residual comparison between the traditional deconvolution method and MLE based deconvolution method. The left panel shows the residual between the signal deconvolved using the inverse of the transfer function operator T−1 in combination with filter K(ω) and the original point source signal s (left panel in Fig. 5). The right panel shows the residual between the signal deconvolved by solving Eq. (5) and the original point source signal. |
The magnitude of this effect depends on the detailed scanning path of the instrument, and hence changes with the position on the sky. We now aim to quantify the effective beam deformation produced by the bolometer transfer function for both methods in terms of the effective beam FWHM and ellipticity over the full sky. For these purposes a statistically meaningful number of point sources is required. Therefore, we create a map with 12 288 point sources, each located at the center of a HEALPix Nside = 32 map. The analysis itself is performed with Nside = 2048, corresponding to a pixel size of 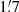 . Then we apply exactly the same process as earlier in this section in terms of transfer function operator T, white noise, and map-making methods.
. Then we apply exactly the same process as earlier in this section in terms of transfer function operator T, white noise, and map-making methods.
For each point source and both methods, we measure the effective FWHM and ellipticity by fitting a two-dimensional Gaussian following the steps similar to Fosalba et al. (2002). We define the ellipticity parameter ε = σlong/σshort as the ratio between the long and short axes of the ellipse. An azimuthally symmetric object corresponds to ε = 1, while ε > 1 corresponds to a deformed beam. In terms of polar coordinates (ρ, ϕ), the actual function fitted to each two-dimensional object is
![$$ \begin{aligned} z(\rho , \phi ) = A \cdot \exp \left[- \frac{\rho ^{2}}{2\sigma _{\mathrm{short} }^{2}} \left(1 - \chi \cdot \cos (\phi - \alpha )^{2}\right) \right], \end{aligned} $$](/articles/aa/full_html/2024/08/aa50712-24/aa50712-24-eq33.gif)
where σshort is the width of the short axis of the ellipse, χ ≡ 1 − 1/ε2, and α is the rotation angle to align coordinate axes with the ellipse axes. The effective FWHM is defined as 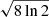 times the average between the long and short axes widths, where long axis width can be found from the relation for ellipticity σlong = ε ⋅ σshort.
times the average between the long and short axes widths, where long axis width can be found from the relation for ellipticity σlong = ε ⋅ σshort.
The function defined in Eq. (7) assumes that the coordinate center is located at the peak, and this is not necessarily true after beam convolution. We therefore run an additional fit for the center pixel coordinates from the Nside = 32 map to the center coordinates of these beams on the Nside = 2048 map. We can assume local space around a given beam to be Euclidean. Then Eq. (7) follows from a regular two-dimensional normal distribution in Cartesian coordinates after the polar coordinate transformation. In order to align the axes of the ellipse with the smearing effect produced by the deconvolution, a rotational angle α is introduced into the fitting function.
In Fig. 7 we show the distribution of ε over the full sky for both mapmaking methods, and we notice that the traditional method results in a noticeably higher ellipticity across the sky compared to the MLE method proposed in this paper, and it has a much stronger imprint of the Planck scanning strategy. In contrast, the distribution seen for the MLE method is defined primarily by the underlying HEALPix grid, which is unavoidable given the choice of pixelization.
 |
Fig. 7. Distribution of ellipticity ε = σlong/σshort over the sky. The ellipticity was measured as a parameter in a Gaussian fit in Eq. (7). The upper panel shows the ellipticity of the beams deconvolved using traditional method, and the lower panel – deconvolved with MLE method. |
Figure 8 shows the same information in terms of histograms of ε − 1. The corresponding means and standard deviations for the two distributions are εtrad − 1 = 0.025 ± 0.014 and εMLE − 1 = 0.009 ± 0.010. The mean ellipticity of the MLE method is thus 65% smaller than for the traditional method. The values found for the traditional method are close to those reported by Planck Collaboration VII (2014) for the 143 GHz channel.
 |
Fig. 8. Distribution of effective ellipticities, ε − 1, for the traditional (orange histogram) and MLE mapmaking (blue histogram) algorithms. |
Performing a similar comparison for the effective FWHM, we find that the MLE method results in a 2.3% lower value than the traditional method. The net impact of this difference in terms of effective beam transfer functions, bℓ, is shown in Fig. 9, where
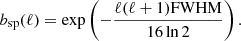
 |
Fig. 9. Spherical beam function for the two deconvolution methods. These functions are calculated based on the average FWHM for each method. The blue line shows the spherical beam function for the maximum likelihood deconvolution method, while the orange line shows Planck method. |
At ℓ = 2500, the ratio between these two functions is 1.14, while at ℓ = 4000 it is 1.38.
5. CMB simulation
Finally, we consider a semi-realistic CMB-plus-noise case. In this case, the sky signal s is generated as a Gaussian random realization based on a best-fit ΛCDM temperature power spectrum computed with CAMB (Lewis et al. 2000; Howlett et al. 2012) and adopting best-fit parameters from Planck Collaboration V (2020). The simulated TOD is then generated by observing this map with the full-mission Planck 143-5 scanning path, and applying the corresponding bolometer transfer function T. Finally, we add white noise with σ = 200 μK per sample. This value corresponds to coadding all 143 GHz bolometers into one, such that our final simulation has similar sensitivity as the true 143 GHz frequency map, but the data volume of only a single detector. To allow for the calculation of cross-power spectra, we split the data into two halves, and process each half independently.
We now apply the same three map-making methods to this TOD simulation as shown in Fig. 2 for the one-dimensional case, namely the traditional method (with and without a regularization kernel) and the new MLE method. The results from this calculation are summarized in Fig. 10 in terms of cross-angular power spectra Dℓ = Cℓℓ(ℓ+1)/2π.
 |
Fig. 10. Upper panel: power spectra Dℓ of the deconvolved CMB maps. The original signal was simulated based on the ΛCDM spectrum shown with the black solid line. The blue line shows the power spectrum obtained from the maximum likelihood based deconvolution. The orange line shows the power spectrum of the map obtained from the traditional deconvolution process KT−1d. The grey line shows the power spectrum of the map obtained from the unfiltered (K = I) traditional deconvolution process T−1d. All spectra are calculated as cross power spectra using two noise realisations |
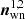
The traditional method without a low-pass filter K (gray) produces results that are extremely noisy even after taking the cross-power spectrum, mirroring the 1D case shown in Fig. 2. Secondly, we see that both the traditional and MLE methods reproduce the original ΛCDM power spectrum at low multipoles, ℓ ≲ 100. However, at higher multipoles the traditional method is noticeably lower. This deviation is caused by the additional K smoothing operator, which has not been deconvolved in this plot.
In order to correct for this bias, one has to include the effect of K into the effective beam profile, as for instance done by Planck Collaboration VII (2014). To measure the total beam profile, we simply calculate the square root of the ratio between output and input power spectra. The results are shown in Fig. 11. Here we see that the MLE method produces an effective beam profile that is very close to unity for almost all multipoles. The small deviations seen at higher ℓ are due to instrumental and numerical noise. On the other hand, the traditional method results in a ratio that monotonically increases with ℓ.
 |
Fig. 11. Effective beam function introduced by the deconvolution method. This function is found as the square of a ratio between the simulated ΛCDM power spectrum and the power spectrum calculated for the respective deconvolution method. The maximum likelihood based method produces a beam function equal to one, as shown by the blue line. The traditional deconvolution method results in the beam function increasing with the multipole moment ℓ and is illustrated with the orange line. |
6. Computational expense
The code used in this this paper was written in Python, and relies on utilities provided by the scipy (Virtanen et al. 2020) and numpy (Harris et al. 2020) libraries. The majority of the runtime is spent on fast Fourier transforms (FFT), which are performed with a compiled C++ code under the hood. However, the emphasis in this paper has been the fundamental algebraic solution, and not code optimization, and the runtimes quoted in the following can very likely be improved by a significant factor in a future production implementation.
Overall, the total cost for the MLE solution is given by the product of the cost for a single CG iteration and the total number of CG iterations. The number of CG iterations depends in turn on the noise level of the data, and the runtimes below are given for the full-sky and full-mission Planck HFI 143 GHz case. For a noise level of σ = 200 μK, the algorithm requires 29 iterations to converge using the preconditioner from Eq. (6), with a convergence criterion defined by a relative error of δnew/δ0 = 10−10. Each iteration costs 32.9 CPU-hrs, out of which 19.2 CPU-hrs are used on parallel FFT calculations and application of the transfer function T(ω) within the TTN−1T operator. In order to parallelise and speed up the Fourier transformations efficiently, the TODs are divided into overlapping segments of length 219, similar to Planck Collaboration VI (2014). The run required a total of 563 CPU-hrs, or 14.9 wall-hours when parallelized over 64 cores. We note here, that only a part of that time is spent in parallel regime, while the other part is not parallelized. Ultimately, this algorithm is intended to be integrated in the end-to-end CMB Gibbs sampler Commander (Galloway et al. 2023). For comparison, the cost for a full Gibbs sample for all three Planck LFI channels was 169 CPU-hrs (BeyondPlanck Collaboration I 2023; Galloway et al. 2023; Basyrov et al. 2023). Assuming no further optimizations, full analysis of all Planck HFI channels with this algorithm will increase the total runtime by more than an order of magnitude. Full optimization will happen in the future Fortran implementation, and for now we simply conclude that this algorithm is indeed feasible, even though it is computationally expensive.
7. Conclusions
In this work we have proposed a new method for accounting for the finite bolometer transfer function in modern bolometer-based CMB experiments. This method integrates the bolometer transfer function directly into the classical maximum-likelihood mapmaking equation, which then is solved with a conjugate gradient method. This method is the optimal solution to the full deconvolution problem, and provides an unbiased signal estimate with proper noise weighting and correlations.
We have compared this method to the traditional two-step procedure used by most bolometer-based experiments to date, in which an estimate of the transfer function is deconvolved from the TOD prior to mapmaking. For slow detectors with a long bolometer time constant compared to the sampling rate, the deconvolution procedure boosts the white noise at high temporal frequencies, and this is usually regularized explicitly by an explicit and additional smoothing kernel. We have shown that the resulting map estimate contains both significant scan-aligned residuals and larger noise correlations than the optimal method discussed in this paper. Calculating the effective ellipticity and FWHM of the beams resulting from the two deconvolution methods, we find that the ellipticity is 64% lower for a Planck 143 GHz-based simulation with the MLE method than for the traditional method, and the FWHM is 2.3% smaller. Another notable advantage of the optimal method is that it does not require an additional power spectrum level deconvolution kernel (because K = I in this case), which should result in significantly lower beam estimation uncertainties when integrated into a full pipeline.
Based on these findings, we conclude that the new method is algebraically preferable over the traditional method. At the same time, the computational cost is also correspondingly higher, with a total runtime of many hundreds of CPU-hours for a typical Planck HFI case. However, this cost will likely be decreased significantly both through better code optimization and algebraic improvements, for instance by implementing a better CG preconditioner. This is left for future work. In addition, the current implementation already results in runtimes that are fully feasible for modern computers. We anticipate that this method will allow for better data extraction both in reanalyses of the previous CMB experiments, such as Planck HFI, and the analysis of the upcoming ones, such as Simons Observatory, LiteBIRD, and CMB-S4.
Acknowledgments
The current work has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement numbers 819478 (ERC; COSMOGLOBE), 772253 (ERC; BITS2COSMOLOGY), and 101007633 (Marie Skłodowska-Curie, CMB-INFLATE). In addition, the collaboration acknowledges support from RCN (Norway; grant no. 274990). Some of the results in this paper have been derived using the healpy and HEALPix (http://healpix.sf.net) packages (Górski et al. 2005; Zonca et al. 2019).
References
- Basyrov, A., Suur-Uski, A.-S., Colombo, L. P. L., et al. 2023, A&A, 675, A10 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bennett, C. L., Banday, A. J., Gorski, K. M., et al. 1996, ApJ, 464, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Bersanelli, M., Mandolesi, N., Butler, R. C., et al. 2010, A&A, 520, A4 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- BeyondPlanck Collaboration I. 2023, A&A, 675, A1 [Google Scholar]
- Fosalba, P., Doré, O., & Bouchet, F. R. 2002, Phys. Rev. D, 65, 063003 [NASA ADS] [CrossRef] [Google Scholar]
- Galloway, M., Andersen, K. J., Aurlien, R., et al. 2023, A&A, 675, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Górski, K. M., Hivon, E., Banday, A. J., et al. 2005, ApJ, 622, 759 [Google Scholar]
- Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Hinshaw, G., Larson, D., Komatsu, E., et al. 2013, ApJS, 208, 19 [Google Scholar]
- Howlett, C., Lewis, A., Hall, A., & Challinor, A. 2012, JCAP, 1204, 027 [Google Scholar]
- Ihle, H. T., Bersanelli, M., Franceschet, C., et al. 2023, A&A, 675, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Keihänen, E., & Reinecke, M. 2012, A&A, 548, A110 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lamarre, J., Puget, J., Ade, P. A. R., et al. 2010, A&A, 520, A9 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lewis, A., Challinor, A., & Lasenby, A. 2000, ApJ, 538, 473 [Google Scholar]
- Planck Collaboration I. 2014, A&A, 571, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration VI. 2014, A&A, 571, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration VII. 2014, A&A, 571, A7 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration I. 2016, A&A, 594, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration VII. 2016, A&A, 594, A7 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration I. 2020, A&A, 641, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration V. 2020, A&A, 641, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
-
Shewchuk, J. R. 1994, An Introduction to the Conjugate GradientMethod Without the Agonizing Pain, Edition
 , http://www.cs.cmu.edu/~quake-papers/painless-conjugate-gradient.pdf
[Google Scholar]
, http://www.cs.cmu.edu/~quake-papers/painless-conjugate-gradient.pdf
[Google Scholar]
- Stevens, J. R., Cothard, N. F., Vavagiakis, E. M., et al. 2020, J. Low Temp. Phys., 199, 672 [CrossRef] [Google Scholar]
- Tegmark, M. 1997, ApJ, 480, L87 [NASA ADS] [CrossRef] [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Zhao, Y., Allen, C., Amiri, M., et al. 2008, in Millimeter and Submillimeter Detectors and Instrumentation for Astronomy IV, eds. W. D. Duncan, W. S. Holland, S. Withington, & J. Zmuidzinas, SPIE Conf. Ser., 7020, 70200O [NASA ADS] [CrossRef] [Google Scholar]
- Zonca, A., Singer, L. P., Lenz, D., et al. 2019, J. Open Source Software, 4, 1298 [NASA ADS] [CrossRef] [Google Scholar]
All Figures
|
Fig. 1. Amplitudes of the Planck HFI bolometer transfer function T(ω) (green), the low-pass filter K(ω) employed by Planck HFI to keep the high-k modes from blowing up (red), and the former divided by the latter (black), which is the resulting function applied to the data in Planck deconvolution method. The presented functions are in absolute amplitudes. The bolometer transfer function also has a complex component. |
| In the text | |
|
Fig. 2. Comparison of noise power spectra for noise-only 1D simulations for four different analysis configurations, as evaluated by the mean and standard deviation from 10 000 simulations. The y-axis is broken into linear and logarithmic portions. |
| In the text | |
|
Fig. 3. Absolute value of a middle row map covariance matrix slice, |
| In the text | |
|
Fig. 4. Comparison of reconstructed 1D point source signals for |
| In the text | |
|
Fig. 5. Simulated point source signal s on the left panel and detector measured signal d = Ts + n on the right panel. The effect of the transfer function T can be observed in the smearing of the point source signal along the scanning path, resulting in a deformed beam. |
| In the text | |
|
Fig. 6. Residual comparison between the traditional deconvolution method and MLE based deconvolution method. The left panel shows the residual between the signal deconvolved using the inverse of the transfer function operator T−1 in combination with filter K(ω) and the original point source signal s (left panel in Fig. 5). The right panel shows the residual between the signal deconvolved by solving Eq. (5) and the original point source signal. |
| In the text | |
|
Fig. 7. Distribution of ellipticity ε = σlong/σshort over the sky. The ellipticity was measured as a parameter in a Gaussian fit in Eq. (7). The upper panel shows the ellipticity of the beams deconvolved using traditional method, and the lower panel – deconvolved with MLE method. |
| In the text | |
|
Fig. 8. Distribution of effective ellipticities, ε − 1, for the traditional (orange histogram) and MLE mapmaking (blue histogram) algorithms. |
| In the text | |
|
Fig. 9. Spherical beam function for the two deconvolution methods. These functions are calculated based on the average FWHM for each method. The blue line shows the spherical beam function for the maximum likelihood deconvolution method, while the orange line shows Planck method. |
| In the text | |
|
Fig. 10. Upper panel: power spectra Dℓ of the deconvolved CMB maps. The original signal was simulated based on the ΛCDM spectrum shown with the black solid line. The blue line shows the power spectrum obtained from the maximum likelihood based deconvolution. The orange line shows the power spectrum of the map obtained from the traditional deconvolution process KT−1d. The grey line shows the power spectrum of the map obtained from the unfiltered (K = I) traditional deconvolution process T−1d. All spectra are calculated as cross power spectra using two noise realisations |
| In the text | |
|
Fig. 11. Effective beam function introduced by the deconvolution method. This function is found as the square of a ratio between the simulated ΛCDM power spectrum and the power spectrum calculated for the respective deconvolution method. The maximum likelihood based method produces a beam function equal to one, as shown by the blue line. The traditional deconvolution method results in the beam function increasing with the multipole moment ℓ and is illustrated with the orange line. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.