| Issue |
A&A
Volume 566, June 2014
|
|
|---|---|---|
| Article Number | A58 | |
| Number of page(s) | 24 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/201322183 | |
| Published online | 11 June 2014 | |
Online material
Appendix A: Data reduction
Appendix A.1: Scattered light subtraction
Besides the traces of the individual science fibres and the bias level, we found an additional light component in each of our exposures, scattered all over the CCD. The origin of this straylight component is unknown. It may be light scattered in the spectrograph or result from problems with the CCD controller (Husemann et al. 2013). However, it varies in strength and can reach intensities comparable to the science signal. Therefore we had to develop a method to subtract it. Using the trace mask, i.e. the position of each fibre in cross-dispersion direction as a function of wavelength, we first masked out all pixels around the traces. The remaining pixels should then contain only the scattered light. For each column of the CCD, we modelled the scattered light along the cross-dispersion direction by fitting a low order polynomial to the unmasked pixels. To obtain a smooth representation of the scattered light also as a function of wavelength, the sequence of one-dimensional fits was finally smoothed with a Gaussian kernel. This procedure has meanwhile also been implemented into p3d (Sandin et al. 2012).
In Fig. A.1 we show the drastic improvement in data quality that we achieved when we accounted for scattered light. The difference image shows that the scattered light was not just a spatially flat component in the reduced datacubes, but strongly influenced the relative amount of light that was extracted for individual fibres. Remember that our analysis relies on determining the PSF in an observation from the datacube and using this information to deblend stellar spectra. Any artefact in the data that changes the relative intensities of spaxels would have a severe influence on the determination of the PSF because the intensities of the individual spaxels are no more governed by the shape of the PSF. Therefore, it is no surprise that the scattered
light strongly biases the spectra that are extracted for the individual stars. This can be verified from the two spectra that are shown in the rightmost panel of Fig. A.1 that were extracted for the same star, before and after the scattered light subtraction.
 |
Fig. A.1
Effect of scattered light in our PMAS data. For a reduced data cube of our central PMAS pointing in M3 the first three panels show, from left to right, a white light image with the scattered light still included, a white light image with the scattered light subtracted, and the difference in flux between the two. All images are displayed on the same intensity scale indicated by the colour bar on the right-hand side of the plot. The rightmost panel compares the spectra extracted for the star marked by a white cross in the PMAS data before and after the scattered light subtraction. |
| Open with DEXTER | |
Appendix A.2: Flat fielding
In order to obtain correct relative spaxel intensities, a high quality fibre-to-fibre flat fielding of the data is essential. A problem of PMAS is that calibration data obtained during the night cannot be used to correct for the different efficiencies of the individual fibres because the calibration lamps do not illuminate the lens array homogeneously. Therefore one has to rely on twilight flats. However, PMAS is mounted on the Cassegrain focus of the telescope, thereby it is strongly affected by flexure. As a consequence, the twilight flats cannot be used to correct the data for the fringing of the CCD because the fringing pattern is time-dependent.
We applied the following flat fielding procedure: starting from the reduced twilight flat, we divided each fibre signal by the mean of all fibres and fitted the resulting curves with Chebyshev polynomials of order around 10. Each science datacube was then flat fielded using the polynomial fits. This step corrects for the different (wavelength-dependent) transmissivities of the fibres, but it does not correct for the fringing. The fringing pattern was removed using the night-time calibration data: each spectrum in the continuum flat, originally used to trace the spectra across the CCD, was also fitted with a Chebyshev polynomial and afterwards divided by the fit. As a result, we obtained a normalized spectrum for each fibre that still included the fringes. Division of the science data by these spectra finally removed the fringes.
Appendix B: Checking the completeness of the ACS data
To cross-check the photometry we searched for data obtained with WFPC2. While probably being less accurate compared to ACS, WFPC2 data do not suffer as strongly from bleeding artefacts. For M13, we used the available photometry from Piotto et al. (2002). Unfortunately, neither M3 nor M92 were observed during this campaign. For those two clusters, however, we obtained raw V- and I-band photometry from the HST archive and analysed them using dolphot (Dolphin 2000). The available photometry for M13 covers the B- and V-bands, but our spectra are in the near infrared and I-band magnitudes were used in the source selection process for the deblending. To get I-band magnitudes for the M13 stars, we used the isochrones of Marigo et al. (2008), available for a wide range of magnitudes in the HST photometric system. We compared the magnitudes in B and V for every star in the HST photometry to those in the isochrone and then assigned it the I-band magnitude of the best match in the isochrone.
As expected, the ACS catalogue is quite complete at the magnitude levels that we are most interested in. However, we find that occasionally giant stars are missing. The reason for this becomes clear in Fig. B.1, where we illustrate the result of our cross checking procedure for M3. The image shown in Fig. B.1 is a combination of all data used to create the ACS catalogue. If bright stars were located directly on the bleeding artefacts caused by even brighter ones, they might have been missed. To avoid this, a single short exposure was taken as part of the ACS survey for every cluster observed. However, ACS has a gap of some arcseconds width in between the two chips and no short exposure data exist in that area. The stars we additionally detect using the second catalogue lie preferentially in the same area and are highlighted in the colour−magnitude diagrams in Fig. B.2. We note that some of the added stars are offset from the cluster population, especially for M92. We verified that those are not spurious detections. However, their measurements might have been affected by the presence of nearby stars that are significantly brighter.
 |
Fig. B.1
Illustration of incompleteness in the ACS input catalogue, using the central region of M3. Green crosses indicate sources included in the ACS catalogue, sources marked by red circles were added after a comparison with archival WFPC2 photometry. For clarity, only stars with I-band magnitudes brighter than 17 are highlighted. The cluster centre is located directly on the central bright star. |
| Open with DEXTER | |
 |
Fig. B.2
Colour−magnitude diagrams of M3 (left), M13 (centre), and M92 (right). The photometry obtained in the ACS survey of Galactic globular clusters is shown as a blue density plot. Red crosses mark the individual stars we added based on the analysis of archival HST WFPC2 data. |
| Open with DEXTER | |
Appendix C: Processing of literature data
 |
Fig. C.1
Comparison of the different literature datasets in M3 (top), M13 (centre), and M92 (bottom). The different panels show the offsets in the measured radial velocities between the various studies and the reference study for stars present in both samples. The probability that the scatter of the individual offsets is consistent with the provided uncertainties is given in the upper right corner of each panel. The abbreviations used to denote the individual studies are given in Table 4. |
| Open with DEXTER | |
For each star in each catalogue listed in Table 4, we determined the weighted mean velocity and its uncertainty from the available data. This combination process also offers a convenient way to detect stars with variable radial velocities. For the scatter of the individual measurements to be consistent with the uncertainties, their χ2 value should be comparable to the number of degrees of freedom Ndof, i.e., the number of measurements minus one. For any combination of χ2 and Ndof, the probability of consistency can be calculated from the probability density function of the χ2 distribution. We identified as “RV variable” all stars with probabilities less than 1% and absolute offsets ≥2 km s-1.
Any meaningful combination of the velocities relies on the assumption that the individual studies yield consistent results. We checked that this is the case by defining a reference dataset for each cluster and identifying the subset of stars that was also observed by one or more of the other studies. For this subset, which contained ≳20 stars for any given combination of two studies, we computed the differences in the measured radial velocities. In the case of consistent results, the differences should scatter around zero. If the mean of the distribution deviates from zero, this indicates different assumed systemic cluster velocities, a minor inconsistency that can be easily corrected for. We show the results of this comparison in Fig. C.1. In most of the cases, the measured offsets were small (≲1 km s-1) and no systematic trends were observed. A notable exception are the data of Soderberg et al. (1999) in M92. As already mentioned by Drukier et al. (2007), the velocities measured are biased towards the cluster mean, a trend likely caused by the presence of interstellar absorption lines in the spectra. We observed the same trend with respect to both comparison catalogues and therefore decided to omit this dataset. However, neither in M13 nor in M3 did we observe a similar trend, likely because the spectra covered a different wavelength range. Therefore, we kept the data of Soderberg et al. for those two clusters.
After checking the measured velocities for their reliability, we used the comparison shown in Fig. C.1 to further check whether the uncertainties provided in the different studies are reliable. In that case, the scatter of the individual offsets should again be consistent with the measurement errors, i.e., the χ2 value should be of the order of the number of degrees of freedom, in this case the number of stellar pairs minus one. Radial velocity variables will bias this comparison. Therefore we iteratively cleaned the comparison samples from such stars. For each combination plotted in Fig. C.1 the probability that the scatter is consistent with the uncertainties is provided. The probabilities are sometimes quite small, indicating that the uncertainties may be underestimated. In such cases we applied a constant correction factor to the uncertainties that yielded a χ2 equal to the number of degrees of freedom. In doing so, we started from the data of Drukier et al. (2007) in M92 as it contains by far the largest sample of stars and uncertainties were determined very carefully. We then determined the correction factors successively for all other studies. The factors that we obtained were small (~1.2−1.5).
In the final step, we combined the results of the individual samples and again flagged all stars that showed evidence for RV variations, using the same criteria as before. This yielded the final set of stellar velocities that we used in our subsequent analysis.
Appendix D: Comparing data to models
When a model prediction of (vsys, σlos) is
available as a function of radius, as we obtain from our Jeans models, it is possible to
investigate the agreement between the model and the kinematical data without binning the
latter. To do so, the likelihood of each model given the data is computed under the
assumption that each measurement is drawn from the probability distribution
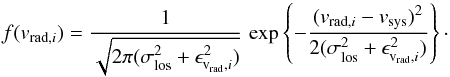 (D.1)Recall that
vrad,i is the
measured velocity of star i (i ∈ [1,N ]) and ϵvrad,i
its uncertainty. The likelihood ℒ of the model parameters is the product of the individual
probabilities. Following Gerssen et al. (2002),
we calculate the quantity λ
≡ −2lnℒ and obtain
(D.1)Recall that
vrad,i is the
measured velocity of star i (i ∈ [1,N ]) and ϵvrad,i
its uncertainty. The likelihood ℒ of the model parameters is the product of the individual
probabilities. Following Gerssen et al. (2002),
we calculate the quantity λ
≡ −2lnℒ and obtain 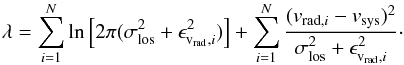 (D.2)
(D.2)
It can be shown that λ follows a χ2
distribution with N degrees of freedom around the expectation value,
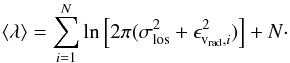 (D.3)Whether or not
a model is statistically acceptable can thus be verified using the well known
characteristics of the
(D.3)Whether or not
a model is statistically acceptable can thus be verified using the well known
characteristics of the 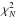 -distribution.
-distribution.
Furthermore, likelihood ratio tests can be applied to discriminate between individual
models in a statistical manner. We assume that the likelihood of models has been
calculated on an m-dimensional grid and that the model that
maximizes the likelihood has λmin. If the range of models is
restricted to an 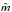 -dimensional
subspace, the quantity λ −
λmin will be ≥0 for each model in
.
A well-known theorem from statistical theory (Wilks
1938) states that for large sample sizes N, the difference
λ −
λmin is distributed according to a
χ2-distribution with
-dimensional
subspace, the quantity λ −
λmin will be ≥0 for each model in
.
A well-known theorem from statistical theory (Wilks
1938) states that for large sample sizes N, the difference
λ −
λmin is distributed according to a
χ2-distribution with
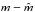 degrees of freedom. Therefore, confidence intervals can also be obtained using
χ2 statistics. This approach was also
followed, e.g., by Merritt & Saha (1993)
or Gerssen et al. (2002).
degrees of freedom. Therefore, confidence intervals can also be obtained using
χ2 statistics. This approach was also
followed, e.g., by Merritt & Saha (1993)
or Gerssen et al. (2002).
© ESO, 2014
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.