| Issue |
A&A
Volume 698, June 2025
|
|
|---|---|---|
| Article Number | A108 | |
| Number of page(s) | 16 | |
| Section | Cosmology (including clusters of galaxies) | |
| DOI | https://doi.org/10.1051/0004-6361/202554189 | |
| Published online | 03 June 2025 | |
Quantifying the detectability of Milky Way satellites with image simulations: Case study with KiDS
1
Ruhr University Bochum, Faculty of Physics and Astronomy, Astronomical Institute (AIRUB), German Centre for Cosmological Lensing, 44780 Bochum, Germany
2
Department of Physics and Astronomy, University of Victoria, Victoria, BC V8P 1A1, Canada
3
INAF – Osservatorio Astronomico di Capodimonte, via Moiariello 16, 80131 Napoli, Italy
4
Leiden Observatory, Leiden University, Einsteinweg 55, 2333 CC Leiden, The Netherlands
5
TU Dortmund University, Department of Physics, 44227 Dortmund, Germany
⋆ Corresponding author: This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
19
February
2025
Accepted:
18
April
2025
Abstract
Ultra-faint dwarf galaxies, which can be detected as resolved satellite systems of the Milky Way, are critical to our understanding of galaxy formation, evolution, and the nature of dark matter, as they are the oldest, smallest, most metal-poor, and most dark matter-dominated stellar systems known thus far. Quantifying the sensitivity of surveys is essential to investigating their capability and limitations in searching for ultra-faint satellites. In this paper, we present the first study of the image-level observational selection function for Kilo-Degree Survey (KiDS) based on the Synthetic UniveRses For Surveys (SURFS) based on KiDS Legacy-like simulations. We generated mock satellites and simulated images that included resolved stellar populations of the mock satellites and the background galaxies, capturing realistic observational effects such as source blending, photometric uncertainties, and star-galaxy separation. We applied the matched-filter method to recover the injected satellites. We derived the observational selection function of the survey in terms of the luminosity, half-light radius, and heliocentric distance of the satellites. Compared to the catalogue-level simulation typically used in previous studies, the image-level simulation provides a more realistic assessment of survey sensitivity, accounting for observational limitations that are neglected in catalogue-level simulations. The image-level simulation shows a detection loss for compact sources with a distance d ≳ 100 kpc. We argue that this is because compact sources are more likely to be identified as single sources, rather than being resolved during the source extraction process.
Key words: Galaxy: halo / galaxies: dwarf / dark matter
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Dwarf galaxies are the most abundant galaxies in the Universe. Among them, dwarf galaxies with absolute magnitudes fainter than MV = −7.7 (corresponding to L ≈ 105 L⊙) are classified as ultra-faint dwarf galaxies (UFDs, see e.g. Simon 2019, for a review). These galaxies are the oldest, smallest, most metal-poor, and most dark matter-dominated stellar systems known, representing the lowest limit of the galaxy luminosity function. They play a significant role in testing and developing fundamental models in astronomy. Due to their high dark matter concentrations, UFDs are important targets for searching for gamma-rays from weakly interacting massive particle (WIMP) dark matter annihilation and decay (e.g. Ackermann et al. 2011; LAT Collaboration 2015; Drlica-Wagner et al. 2015a; Ahnen et al. 2016; Di Mauro & Winkler 2021; Acciari et al. 2023; McDaniel et al. 2024). These galaxies underwent little evolution and have survived to the present day as pristine relics of the early Universe (e.g. Bovill & Ricotti 2009, 2011; Wheeler et al. 2015). The physical properties and star formation processes of UFDs provide critical insights into galaxy formation and evolution (e.g. Mashchenko et al. 2008; Agertz et al. 2020) and motivate studies of the physical conditions during the reionisation stage (e.g. Bullock et al. 2000; Shapiro et al. 2004; Weisz et al. 2014) of the Universe.
Interest in UFDs has increased significantly over the past two decades (e.g. Willman et al. 2005a; Bechtol et al. 2015; Laevens et al. 2015a; Homma et al. 2016; Mau et al. 2020; Smith et al. 2023; Gatto et al. 2024), especially with the emergence of wide-field imaging photometric surveys. However, the detection of these UFDs remains challenging even with modern facilities because of their low surface brightness. Typically, they are too faint to be observed beyond the Local Volume and have only been identified as resolved stellar populations of the Milky Way or nearby galaxies within a few megaparsecs. These satellite galaxies have mostly been detected in wide-field optical imaging surveys through statistical overdensities of individually resolved stars. The number of confirmed Milky Way satellites has grown to approximately 60, with the inclusion of candidate satellites bringing the total to around 100, thanks to the rapid development of wide-field deep photometric surveys. The Sloan Digital Sky Survey (SDSS, York et al. 2000), with its digitised wide-area multi-band optical imaging surveys, has greatly improved the search for Milky Way satellites (Willman et al. 2005a,b; Belokurov et al. 2006, 2007, 2008, 2009, 2010; Grillmair 2006, 2009; Sakamoto & Hasegawa 2006; Zucker et al. 2006a,b; Irwin et al. 2007; Walsh et al. 2007; Kim & Jerjen 2015a). More recently, searches from the Dark Energy Survey (DES, Bechtol et al. 2015; Drlica-Wagner et al. 2015b; Kim & Jerjen 2015b; Koposov et al. 2015; Luque et al. 2016), Pan-STARRS (Laevens et al. 2015a,b), DECam Local Volume Exploration Survey (DELVE, Mau et al. 2020; Cerny et al. 2021, 2023), ATLAS (Torrealba et al. 2016a,b), HSC-SSP (Homma et al. 2016, 2018, 2019, 2024), UNIONS (Smith et al. 2023, 2024), and KiDS (Gatto et al. 2024) have significantly advanced the search for Milky Way satellites.
Despite significant progress in recent years, many faint and distant satellites still remain undiscovered, which is closely tied to the ‘missing satellites problem’ (Klypin et al. 1999; Moore et al. 1999). It is a classical tension wherein the standard ΛCDM model predicts many more dark matter halos around Milky Way mass host halos in dark matter-only simulations than observed galaxies. This tension has been largely alleviated (Sales et al. 2022) by implementing baryonic processes that suppress star formation, including radiation from reionisation (e.g. Bullock et al. 2000; Bovill & Ricotti 2009), ram pressure stripping (e.g. Grcevich & Putman 2009; Spekkens et al. 2014), feedback from supernova explosions (e.g. Stinson et al. 2007; Sawala et al. 2010; Hopkins et al. 2018), and radiation winds from young stars (e.g. Hopkins et al. 2020). More contemporary studies have applied observational selection functions derived from photometric data to high-resolution simulations of the Milky Way environment (e.g. Tollerud et al. 2008; Newton et al. 2018; Nadler et al. 2020) to determine the completeness of the Milky Way satellite population. A separate but related area of interest is determining the lowest mass dark matter halo that is able to harbour a luminous galaxy (e.g. Benitez-Llambay & Frenk 2020), which has also been explored through the combination of dwarf galaxy detection limits and Milky Way-mass simulations (e.g. Jethwa et al. 2018; Nadler et al. 2024). These powerful methods are explicitly dependent on the observational selection function, making an accurate assessment of detectability essential.
A comprehensive analysis of UFDs as satellites of the Milky Way requires a thorough evaluation of survey sensitivity. The observational selection function, which shows the detectability of a satellite galaxy as a function of heliocentric distance, size, and luminosity, is widely used to quantify the capability of a survey to detect Milky Way satellites (e.g. Koposov et al. 2008; Walsh et al. 2008; Drlica-Wagner et al. 2020). These studies estimate the selection function at the catalogue level by injecting mock satellites into a survey stellar catalogue and applying observational uncertainties, such as photometric errors and detection incompleteness in post-processing. This approach provides an effective way to predict the number of satellites that likely exist but remain undetected. However, it does not fully capture the complexities of the imaging and subsequent data reduction, including the effects of point spread functions (PSF), saturated stars, blending, and background noise.
In this study, we present the image-level measurement of the observational selection function of KiDS with multi-band images simulated by SKiLLS (Li et al. 2023). KiDS has observed about 1350 square degrees of the sky and covered nine optical and near-infrared bands in conjunction with infrared data from the VISTA Kilo-degree INfrared Galaxy survey (VIKING, Edge et al. 2013). In its fifth data release (Wright et al. 2024), KiDS reports 5σ limiting magnitudes of 24.79 in the r-band and 24.96 in the g-band, with a median seeing of 0.7″ in the r-band. With good seeing conditions and multi-band coverage, KiDS provides deep and accurate star catalogues, making it a valuable survey for the research of resolved stellar systems in the local volume.
SKiLLS is a suite of multi-band image simulations for weak lensing analysis of KiDS, using customised input galaxy and star mock catalogues, combining cosmological simulations with high-quality imaging observations to achieve realistic galaxy properties, including multi-band photometry, galaxy morphology, and their correlations (Li et al. 2023). We generated close to ∼20 000 resolved mock satellites with a variety of stellar masses, heliocentric distances, sizes, ellipticities, and position angles and embedded them into 100 KiDS-like images. We then applied a matched-filter method (Koposov et al. 2008; Walsh et al. 2008) to search for the simulated satellites. The observational selection function was quantified by cross-matching the detection catalogue with the input satellite catalogue. This selection function can be used to estimate the abundance of Milky Way satellites and assess the confidence of a candidate satellite based on its size, absolute magnitude, and heliocentric distance.
This paper is structured as follows. In Sect. 2, we introduce the KiDS data and the simulation of KiDS-like multi-band images. Section 3 details the methods of satellite simulation and the satellite search algorithm. We present our results on the observational selection function derived from the KiDS survey in Sect. 4 and present our conclusions in Sect. 5.
2. Simulation set-up
In this work, we simulated the nine-band KiDS-like images by combining mock galaxies and foreground Milky Way stars using a GALSIM package-based MultiBand_ImSim pipeline (Li et al. 2023)1. KiDS (de Jong et al. 2013) is an optical wide-field imaging survey conducted with the OmegaCAM camera on the VLT Survey Telescope (VST, Capaccioli & Schipani 2011) to study weak gravitational lensing and the large-scale structure of the Universe. It covers ∼ 1350 deg2, with its footprint divided into two patches: KiDS-N, along the celestial equator, and KiDS-S, in the southern sky. In conjunction with the VISTA Kilo-degree Infrared Galaxy Survey (VIKING), it provides photometry in nine optical and near-infrared bands: ugriZYJHKs (Kuijken et al. 2019), making it suitable for the photometric redshift estimation and redshift distribution calibration.
We used galaxy and star catalogues as inputs to the pipeline to produce KiDS-like images. The input galaxy catalogue was drawn from SKiLLS, a mock galaxy catalogue that combines cosmological simulations with high-quality imaging observations to achieve realistic galaxy properties, including multi-band photometry, galaxy morphology, and their correlations (Li et al. 2023). The backbone cosmological simulations are the SURFSN-body simulations (Elahi et al. 2018), with galaxy properties generated using the open-source semi-analytic model SHARK (Lagos et al. 2018). The observed galaxy morphology was modelled using a Sérsic profile (Sérsic 1963). The structural parameters involved were derived from high-quality imaging observations obtained with the Advanced Camera for Surveys instrument on the Hubble Space Telescope (Griffith et al. 2012). For details on the learning algorithm and validation, we refer to Li et al. (2023). We used all the galaxies from the input catalogue and placed them randomly within each image, ensuring a sufficient separation between galaxies to avoid overlap or clustering effects. The input star catalogue included satellite member stars with nine-band synthetic magnitudes generated from the PARSEC model (Bressan et al. 2012) and foreground stars derived from the TRILEGAL model (Girardi et al. 2005). Each simulated image covers 108 deg2 (108 tiles), with observational conditions, including nine-band noise and PSF information, selected from the full KiDS-DR4 (Kuijken et al. 2019) dataset of 979 tiles to represent the fiducial settings of the KiDS observations. The tiles were stacked using the SWARP software (Bertin 2010) following the same configurations as in the KiDS pipelines.
For the simulated images, the photometry was measured using the Gaussian Aperture and PSF (GAAP) pipeline (Kuijken et al. 2015). GAAP applies homogenised Gaussian PSFs and elliptical apertures adapted to each galaxy’s shape and size to mimic the KiDS photometric process. It focusses on the high-signal-to-noise-ratio regions of the sources, ensuring consistent and accurate colour measurements across multiple bands; however, this approach might underestimate the total flux, particularly for extended sources.
3. Methods
In this section, we detail the processes of this analysis, including the preparation of the input satellite catalogue, star-galaxy separation, recovery of the mock satellites, and derivation of the observational selection function. We simulated the satellites at both the catalogue-level and image-level, comparing the selection functions of both simulated surveys. The main pipeline processes are shown as a flowchart in Fig. 1.
 |
Fig. 1. Flowchart summarising the pipeline processes. The output star catalogues are obtained through image-level and catalogue-level simulations. We apply the matched-filter method to recover the injected mock satellites for both catalogues. The observational selection function is constructed by mapping the properties of the satellites to their detectability. |
3.1. Satellite simulations
We simulated Milky Way satellite galaxies with various properties including stellar mass, heliocentric distance, size, ellipticity, and position angle. To efficiently map the detectability of the satellite searches, we focussed on a three-dimensional parameter space defined by heliocentric distance, half-light radius, and V-band absolute magnitude. The parameter space is divided into logarithmically spaced grids: 6 bins for heliocentric distances, d; 12 bins for half-light radii, rh; and 24 bins for V-band absolute magnitudes, MV. To optimise the use of computational resources, we generated 5 satellites per grid cell for the first three distance bins and 20 per grid cell for the last three bins. The bright and small satellites were not fully simulated, and only mock satellites with at least 3 detectable member stars were retained, resulting in a total of 19 647 mock satellites, as shown in the satellite counts per grid in Fig. 2. The properties of the satellites were randomly sampled as described in Table 1, to form the mock satellite catalogue.
 |
Fig. 2. Counts of mock satellites generated in the parameter space. To efficiently use resources for image generation, we did not fully generate mock satellites for very bright and compact satellites, or those with large sizes. For mock satellites with half-light radii exceeding the sizes of the tiles for KiDS-like images, their detection is beyond the capabilities of KiDS and has a lower likelihood of being identified. The non-generated regions will be extrapolated in the observational selection function. The heliocentric distance d is given in kpc. |
Properties of the simulated satellites.
To generate a single mock satellite with given properties and location, we sampled the member stars of the mock satellite to match the given stellar mass from an old and metal-poor star population with a total mass of 106 M⊙. The photometry of the stars was simulated using CMD version 3.72 with stellar isochrones from Bressan et al. (2012), assuming a metallicity of Z = 0.0001 and an age of 12 Gyr. The initial masses of the satellite member stars follow a canonical two-part power-law initial mass function (IMF), corrected for unresolved binaries (Kroupa 2001, 2002). Apparent magnitudes were obtained by adding the distance modulus to the given heliocentric distance and we excluded stars with r-band magnitudes fainter than 26.5, which approximately corresponds to the 1σ magnitude limit derived from the 5σ limit r-magnitude of 24.79. The remaining stars, which form the member stars of the mock satellite, were spatially distributed according to a Plummer profile (Plummer 1911), with a specific half-light radius. The satellite was drawn at the given position coordinates with the specified position angle and ellipticity. This analysis assumes a single stellar population, which does not consider potential variations in age and metallicity. Although no significant bias is expected, such variations could affect the brightness and colour distributions of satellite members, introducing a source of systematic uncertainty in the detectability analysis.
We placed the mock satellites on the 108 deg2 images efficiently, aiming to maximise the number of satellites per image while ensuring that there was adequate spacing between them. We randomly sampled the satellites from the catalogue and placed each mock satellite at a minimum spatial separation of 0.25 deg. For larger satellites, we determined the minimum separation according to their tangential projection of the half-light radius. The minimal spatial separation can be described as:
![Mathematical equation: $$ \begin{aligned} \Delta _{\text{separation}} = \max [F (r_{\rm new} + r), 0.25~\mathrm {deg}] , \end{aligned} $$](/articles/aa/full_html/2025/06/aa54189-25/aa54189-25-eq1.gif) (1)
(1)
where rnew represents the projection of the half-light radius of the next satellite to be placed on the canvas, r represents the projected radius of each already placed satellite, both in units of degrees. Then, F represents a scaling factor for the sum of the sizes, ensuring that the minimum distance between satellites exceeded F times the sum of their radii. To optimise the placement of mock satellites during the generation process, F was dynamically adjusted within a range of 2–5, depending on the projected half-light radius of the satellites being placed. Higher values of F were used to ensure wider separations for smaller satellites and the lower values of F were applied to efficiently fit larger satellites into the image and maximise the use of less dense regions. In real observations, the number density of satellites is much lower, making overlaps nearly impossible to detect. This adaptive approach balances between the need to prevent crowding and the efficient use of the image area, ensuring a proper spacing between satellites. Figure 3 shows an example image, with red circles indicating the positions of each generated satellite. Once the spatial coordinates of the satellites were determined, we placed the satellites with the given properties at these positions. We added foreground stars with their nine-band photometry from TRILEGAL (Girardi et al. 2005), using the default model from version 1.6 available on the website3. We generated the star catalogue for a total field area of 10 deg2 and simulated each tile image that covers 1 deg2 by randomly sampling ten percent of the stars in the catalogue.
 |
Fig. 3. Input star catalogue for one of the 108 deg2 generated images. Each square block represents a tile in KiDS-like image generation. The red circles indicate the locations of the mock satellites, with the radii representing the smallest separation for each pair of mock satellites with F = 3 in Eq. (1). Each blue point represents a star, with the input star catalogue consisting of satellite member stars and foreground stars. |
For the image-level analysis, we used MultiBand_ImSim to simulate images and mock the observations according to the input star and galaxy catalogues. The output catalogues of stars and galaxies for each image were obtained by applying SEXTRACTOR to extract sources and GAAP to measure photometry. The output stellar catalogues (branch B in the flowchart) were perfectly separated by cross-matching the outputs with the input catalogue from the pipeline. Figure 4 compares the input and output stars and output galaxies in four specific tiles. Two zoom-in subplots further highlight the local environments of two injected mock satellites. The satellite on the left (blue rectangle) contains multiple resolved member stars that are successfully detected. In contrast, the satellite on the right (orange rectangle) exhibits a very limited member star detection. This injected satellite is more compact and lies in a tile with higher background noise, which likely contributes to its stars blending and make it mis-classified as extended sources. As simplifying assumptions, we did not include Galactic extinction or spatial variations in stellar density in our simulations. The simulated region spans RA = [211.5° ,223.5° ], Dec = [ − 4.5° ,4.5° ], corresponding to moderate Galactic latitudes (|b|∼50°). At these Galactic latitudes, foreground extinction is generally low and local stellar density tends to be relatively uniform. Based on the KiDS DR4 catalogue, the mean absorption within the simulation region is 0.152 ± 0.044 mag for g-band and 0.105 ± 0.031 mag for r-band. In our simulation, spatial variations in detection depth have been taken into account, with the standard deviation of limiting magnitudes of 0.195 mag in the g-band and 0.188 mag in the r-band. As a result, we expect extinction contributes a smaller level of variation and, thus, has a subdominant effect on the overall sensitivity. Nonetheless, neglecting these factors may still lead to slight overestimations of sensitivity. Foreground extinction can reduce the brightness of sources, potentially pushing faint objects below the detection threshold, whereas spatial variations in stellar density could increase any source confusion, particularly for faint or diffuse satellites. Therefore, incorporating spatially varying extinction and stellar density into sensitivity modelling would be necessary for analyses requiring higher precision or extending to lower Galactic latitudes, where the extinction and density fluctuations are more significant (Drlica-Wagner et al. 2021).
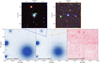 |
Fig. 4. Comparison of the input and detected stars and galaxies for four tiles. The left panel displays the input stars and the middle panel shows the detected stars that are cross-matched with the input catalogue, indicating that only about 60% of the stars survived the image simulation and source extraction process. The right panel illustrates the detected galaxies identified. Two zoom-in panels show the local environments of two injected satellites. The left panel (blue rectangle) shows a satellite with multiple member stars identified, while the right panel (orange rectangle) shows very few of the member stars are detected, likely due to its compactness and the higher background noise in that region. |
For the catalogue-level analysis (branch C), we used the input star catalogue and estimated the photometric uncertainties based on the depth of KiDS-like images for each band. The flux error, Δfi, x, for a point source is described as (Linke et al. 2025):
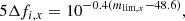 (2)
(2)
where mlim, x refers to the 5σ limiting magnitudes for filter x, taken from Wright et al. (2019). The uncertainty of each band magnitude follows:
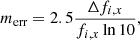 (3)
(3)
where fi, x is the flux for each point source, which can be obtained from the given magnitude. We show a comparison of the uncertainties to those from image-level simulations in Fig. 5.
 |
Fig. 5. Comparison of the magnitude uncertainties for nine-band photometry with respect to GAAP magnitude ranging from 14 to 24. The black lines represent the GAAP photometric measurements from image-level simulation, and the red lines represent the estimations from Eq. (3) for a catalogue-level simulation. |
3.2. Star-galaxy separation
We evaluated the impact of the applied star-galaxy separation method on the observational selection function in KiDS surveys (as represented in branch A of the flowchart shown in Fig. 1). We applied a combination of methods, including photometric (Sect. 3.2.1) and machine learning-based approaches (Sect. 3.2.2), to effectively distinguish between stars and galaxies in the catalogue. The image-level simulations are employed to evaluate the point source detection performance of the combined methods. We used two samples, including 216 tiles with more than 24 million valid sources. We assessed the point source detection performance using the true positive rate (TPR), false positive rate (FPR) and positive predictive value (PPV), with stars considered as positive and galaxies as negative. The TPR, also referred to as sensitivity or recall, represents the completeness of the star-galaxy separation in detecting stars. It is defined as:
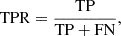 (4)
(4)
where TP denotes true positives (correctly identified stars) and FN denotes false negatives (stars misclassified as galaxies). The FPR, also known as contamination, measures the proportion of galaxies incorrectly classified as stars, and it is given by:
 (5)
(5)
where FP denotes false positives (the galaxies incorrectly classified as stars) and TN denotes true negatives (correctly identified galaxies). The PPV, referred to as purity, indicates the proportion of objects identified as stars that are truly stars, and it can be expressed as follows:
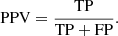 (6)
(6)
For the purpose of detecting faint dwarf galaxies, it is crucial to make the combined classifier able to identify positive sources with high sensitivity, minimise the number of false detections, and maintain high purity. We applied a magnitude cut at MAG_AUTO ≤ 25 to balance completeness and purity in the source catalogue, as objects fainter than this magnitude typically have higher photometric uncertainties in KiDS-like surveys and are more likely to introduce false positives in the classification. An example of the comparison with and without the star-galaxy separator is shown in Fig. 6.
 |
Fig. 6. Left panel: Detected perfect flag stars are identified by cross-matching the detected sources from SEXTRACTOR (branch B) with the input mock satellite catalogue. The red circles represent the locations of the input mock satellites, and the radii of the circles indicate the smallest separation for each pair of mock satellites. Right panel: Remaining stars after applying star-galaxy separation (branch A), with a MAG_AUTO cut at 25. |
3.2.1. Template-fitting with the Bayesian photometric redshift code
The Bayesian photometric redshift (BPZ) code (Benitez 2000) is widely used for estimating photometric redshifts from multi-band data based on Bayesian statistics, which uses a library of spectral energy distribution (SED) templates to fit the observed photometric magnitude. Due to its functionality, template-fitting approaches can also be used as star-galaxy classifiers (Hildebrandt et al. 2012), particularly at faint magnitudes (r ≳ 24). This is where star-galaxy separation becomes increasingly challenging, as compact galaxies begin to outnumber halo stars (Fadely et al. 2012).
In our analysis, stars were assumed to have a fixed redshift of z = 0, using the Pickles (1998) stellar spectral library as their template. For galaxies, the redshift was allowed to vary freely, spanning the range of 0 to 2 with the CWWSB_capak templates. The BPZ code incorporates a spectral energy distribution interpolation of 2 and evaluates redshift steps of dz = 0.05 to calculate the best-fit estimations for each object along with χstar2 and χgalaxy2. The classification is determined by comparing the chi-square values: if a source achieves a smaller χstar2, indicating a better fit with the star template than the galaxy template, we classified the source as more likely to be a star.
By comparing the difference of the chi-square, the test sample achieves a TPR of 0.6161 and an FPR of 0.0671, indicating that the catalogue is sufficiently clean for further analysis. We note that the classification results are based on simulated data, where the spectral templates used for star generation are closely matched to those in the BPZ classifier. In real observations, differences in SEDs, photometric systematics, and variations in galaxy properties may affect the classification performance. Thus, while our method demonstrates the capability of BPZ for star-galaxy separation under idealised conditions, its effectiveness in real KiDS data requires further validation.
3.2.2. Multilayer perceptron classifier
A multilayer perceptron (MLP) classifier is a neural network-based supervised learning algorithm that can be used to train datasets and classify data into different categories. It consists of multiple layers of interconnected nodes that process and transform input data.
We customised an MLP star-galaxy classifier using the SCIKIT-LEARN package4 (Pedregosa et al. 2011) for KiDS-like catalogues. The input features for the classifier were obtained from extracted source catalogues in the image-level simulations. These catalogues were cross-matched with the input catalogues, allowing each source to be labelled as a star or galaxy. Training features include all columns related to magnitude, size, and flux. Due to the varying depth of each image tile, the performance of the classifier with flux- and radius-related columns shows variation across tiles.
In the image simulation, we mimicked the noise levels of KiDS to approximate realistic survey conditions. To simplify the process, we used the same combination of noise levels across all samples. However, within each sample (108 tiles), the noise levels vary between tiles. As a result, specific tiles across all samples share the same background noise and seeing conditions, which could potentially bias the performance of the classifier, making it location dependent.
Therefore, to minimise this effect, we trained two MLP classifiers. Specifically, MLP1 has the columns: {MAG_AUTO, MAGERR_AUTO, MAG_GAAP_0p7_x, MAG_GAAP_1p0_x, MAGERR_GAAP_0p7_x, MAGERR_GAAP_1p0_x, MAG_GAAP_x, MAGERR_GAAP_x}, where the keyword x represents the different bands and the names containing _0p7 and _1p0 represent the photometry where the minimum aperture size considered by GAAP is set to 0.7″ and 1.0″, respectively; while MLP2 uses the columns {MAG_AUTO, MAGERR_AUTO, FLUX_AUTO, FLUXERR_AUTO, FLUX_RADIUS}. Although MLP classifiers show relatively low TPR for star-galaxy separation, the high accuracy and effectiveness in identifying true negatives (galaxies) enabled us to confidently remove false detections from the catalogue.
3.2.3. Combining strategy
The combined classifier was constructed considering the performance of both classifiers. Since the classifiers are based on different properties of the stars, the overlap of the candidates from each method increases the confidence in star identification. The BPZ template fitting method is effective for initial screening, providing a star sample with a low FPR. However, the clean sample generated by BPZ alone does not sufficiently increase the TPR when integrated with the MLP classifiers, which maintain a remarkably low FPR and are suitable for refinement of the selection without having to introduce additional false positives (misclassified galaxies). Therefore, we extended the BPZ classified star sample by including sources with χstar2 − χgalaxy2 < 0.5, thereby forming a broader pool of stars. For MLP classifiers, to ensure robust classification across varying conditions for all tiles, we primarily relied on MLP1 (p1 > 0.4), which uses features such as magnitude and photometric errors that are less sensitive to local variations. However, MLP1 alone does not maximise completeness. Therefore, we included high-confidence results from MLP2, applying a stricter threshold (p2 > 0.8) to minimise contamination while improving completeness. The union of sources from MLP1 and MLP2 was then intersected with the BPZ template fitting results to create the final set of classified sources.
We evaluated the performance of the combined star-galaxy classifier as a function of magnitude, as shown in Fig. 7. The classifier shows high performance in the brighter region, with a gradual decrease in TPR and PPV as the magnitude increases, while the FPR remains low across the entire magnitude range. This indicates that the classified source catalogue remains clean even in the faint region. The classifier achieves a TPR of 83.13%, an FPR of 4.06%, and a PPV of 82.65% for MAG_AUTO ≤25 on the test sample. In Fig. 6, we provide an example of the star catalogue with (right) and without (left) applying the star-galaxy separation in the 2.5° ×2.5° region, where the red circles show the locations of the input mock satellites. From the figure, we observe that the star-galaxy separator functions as expected, without introducing observable contamination, although there is some loss in classifying stars in dense regions.
 |
Fig. 7. True positive rate, false positive rate, and positive predictive value for star-galaxy separation with MAG_AUTO in the range of [16, 25] for star-galaxy catalogues for all image samples. |
3.3. Search algorithm and observational selection function
We recovered the injected resolved satellites by identifying overdensities of old and metal-poor stars based on their distinct positions in the colour-magnitude diagram (CMD). We adopted a spatially matched-filter method (Koposov et al. 2008; Walsh et al. 2008) which has been widely applied and proven to be efficient for detecting low-luminosity Milky Way satellites (e.g. Koposov et al. 2015; Kim & Jerjen 2015a,b; Homma et al. 2016; Smith et al. 2023; Gatto et al. 2024).
We selected stars based on their locus in the CMD of g and g − r, matching an isochrone with an age of τ = 12 Gyr and a metallicity of Z = 0.0001, obtained from PARSEC (Bressan et al. 2012). The isochrone was shifted corresponding to logarithmically spaced heliocentric distances d in the range [10, 1000] kpc, divided into ten steps. The criteria for the colour difference between each star and the given isochrone is defined as:
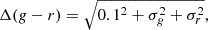 (7)
(7)
where Δ(g − r) is the colour difference for each given star and the isochrone at the same magnitude, and σg, r are the photometric uncertainties of the g and r bands. Figure 8 illustrates a representative CMD of a generated mock satellite, including both the mock satellite’s member stars and Milky Way foreground stars, located at a heliocentric distance of 98.95 kpc.
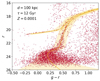 |
Fig. 8. CMD of an example mock satellite galaxy located at a distance of 98.95 kpc, with a half-light radius of 69.45 pc and an absolute magnitude MV = −6.38 (Chain B). The red points represent point sources selected from the central region of the mock satellite up to 2 times the satellite’s rh. These point sources consist of both the mock satellite’s member stars and the Milky Way foreground stars. The yellow region corresponds to the selection criteria derived from Eq. (7) to isolate the member stars of the satellite. Stars falling within this region are considered as member stars of the mock satellite. |
We projected the position of the stars that met the colour-magnitude criteria onto tangential planes and binned them spatially to create stellar number density maps. The projection bin sizes were 0.5′×0.5′ and 0.25′×0.25′, specified for different projected sizes of the mock satellites injected. The filtered stellar density maps were smoothed with 2D top-hat kernels to estimate the local stellar background, noted as ρloc. The standard deviation of the local stellar background, σloc, was calculated as the square root of the variance of the smoothed map:
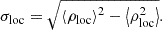 (8)
(8)
We also convolved the filtered stellar density maps with 2D Gaussian kernels of different sizes to obtain the smoothed density maps, ρsm, according to the projected sizes of the mock satellites. For stellar density maps, the projection sizes were set to 0.5′×0.5′ and 2D top-hat kernels were chosen from {15′,20′,30′}, and the Gaussian kernel sizes were chosen from {1.2′,2.4′,4.8′}. For projection sizes with 0.25′×0.25′, we adopted 5′ and 0.5′ for the local stellar backgrounds, ρloc, and smoothed density maps, ρsm, respectively. The significance map was then obtained as the ratio of the statistical overdensities to the local stellar background as:
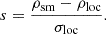 (9)
(9)
We calculated the significance map for a logarithmic range of distances, producing ten maps for each distance by applying various combinations of bin sizes and smoothing kernels. To validate the algorithm, we assessed the capability to identify the known stellar systems within the KiDS footprint and we have successfully recovered satellites such as Sculptor, Fornax, Leo IV, and Leo V.
We cross-matched the candidate catalogue spatially with the mock satellite catalogue, considering only candidates with a significance greater than the threshold s ≥ 1.5. The threshold was chosen to balance the detection of satellite candidates while minimising contamination from noise. We found that lowering the threshold led to a significant increase in false detections, with a substantial number of noise fluctuations being misidentified as candidates. We required the centroids of the candidates to be within a radius Δr = max(0.75′,rh/Fm), where rh is the projected half-light radius of the mock satellite in arcminutes. Also, Fm = 5, indicating that the minimal separation for the cross-match with these satellites is within one fifth of the projected radius.
Following the work from Drlica-Wagner et al. (2020), we presented the observational selection function with heliocentric distance, d, absolute V-band magnitude, MV, and physical half-light radius, rh. These parameters were divided into grids with 6 logarithmically spaced d bins from 10 to 1000 kpc, 24 linearly spaced MV bins in the range [−10, 2], and 12 logarithmically spaced rh bins in the range [0, 1000] pc. The detectabilities of a total of 19 647 mock satellites were mapped onto the grid map for both image-level and catalogue-level analyses.
 |
Fig. 9. Detection efficiency of searches for satellites for KiDS-like catalogue-level simulation (chain C). The detectability ranges from 0% (dark blue) to 100% (bright yellow) as a function of the V-band absolute magnitude, physical half-light radius, and heliocentric distance. The 50% detectability limits fitted by polynomials (n = 3) are shown in yellow dashed lines. The detectability limits of image-level simulations are plotted in red dashed lines. The satellites found within KiDS footprint are overplotted in the detection efficiency map. |
 |
Fig. 10. Same as Fig. 9, except for image-level simulation (chain B). The detectability ranges from 0% (dark blue) to 100% (bright yellow) similar as shown in Fig. 9. The 50% detectability limits fitted by polynomials (n = 3) are shown in red dashed lines. The detectability limits of catalogue-level simulations are plotted in yellow dashed lines. The satellites found within KiDS footprint are overplotted in the detection efficiency map. |
4. Results
By applying the matched-filter method and cross-matching the candidates with the injected mock satellite catalogue, we generated an output catalogue of satellites, with detections marked as 1 and non-detections marked as 0. The outputs are then binned according to their physical properties and the observational selection function is presented using logarithmically spaced heliocentric distance bins (d), absolute magnitude (MV), and azimuthally averaged projected physical half-light radius (rh). The counts of the mock satellites generated in the parameter space are shown in Fig. 2. We applied 2D grid interpolation to fill in the blank grids where no mock satellites had been generated.
To fit the 50% detection probability limit, we first smoothed the detection efficiency map with a Gaussian kernel. The smoothed detectabilities of three different scenarios (corresponding to chains B, C, and A) are shown in Figs. 9–11. We then plotted the 50% limit Pdet(MV, rh) = 0.5 for each distance bin, and the limits were fitted with polynomials (n = 3) as:
 |
Fig. 11. Same as Fig. 9, except with the star-galaxy separator applied in the image-level (chain A). The detectability ranges from 0% (dark blue) to 100% (bright yellow) similar as shown in Fig. 9. The 50% detectability limits fitted by polynomials (n = 3) are shown in bright blue dashed lines. The detectability limits of image-level and catalogue-level simulations are plotted in red and yellow dashed lines. The satellites found within in KiDS footprint are overplotted in the detection efficiency map. |
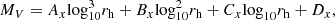 (10)
(10)
where rh is the half-light radius in each distance bin in units of pc and MV is in units of mag. The distance-dependent parameters Ax, Bx, Cx, Dx were fitted for each distance bin and summarised in Table 2; the x represents the type of simulation; ‘im’ refers to chain B in Fig. 1 using perfect stars, ‘sg’ corresponds to chain A applying star-galaxy separation, and ‘cat’ represents the catalogue-level simulations. We overplotted the Pdet, 50 for both the image- (red) and catalogue-level (yellow) cases as dashed lines.
Parameters for a 50% detectability limit.
For the catalogue-level simulations shown in Fig. 9, we find that the shapes of our Pdet, 50 limits are similar to the satellite detectability limits from Drlica-Wagner et al. (2020) and Koposov et al. (2008), indicating that our results are consistent with established findings. The differences between the limits are acceptable because the exact shape of the limits depends on the specific survey and searching algorithm used. Additionally, our results are based on pure simulation data and we employ different distance bins and parameter spaces.
For the image-level simulations shown in Fig. 10, the detectability of the satellites is lower for the given MV and rh in each distance bin compared to the catalogue-level case. This difference becomes larger as the distance increases. The most noticeable difference in the limits of Pdet, 50 is shown in the lower panel of the detection efficiency maps, where compact satellites are less likely to be detected in the image-level simulation. The turning points of the Pdet, 50 limits occur at about log10rh = {0.5, 1, 1.25} in the last three distance bins, corresponding to a projected half-light radius rh, proj of around 0.09 arcmin.
The loss of compact satellites is probably caused by several effects. We tested insufficient minimum separation during satellite generation as a potential cause by regenerating some of the compact satellites with larger separations, as detailed in Appendix B. However, the issue of missing compact sources persists. Since this issue only appears in the image-level simulation, the insufficient separation of the satellite is less likely to be the main source of the difference. A potential reason for the loss of compact satellites is that these satellites are so small that they are detected as single sources rather than collections of stars by SEXTRACTOR. For example, the input satellite (left panel in Fig. 4) with a small size at location (RA,Dec) = (212.51,−2.91) deg is not found in the detected perfect star catalogue (middle panel, in blue rectangle), while larger satellites (e.g. in orange rectangle) can still be detected. Thus, compact satellites with 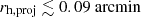 at heliocentric distances d ≳ 100 kpc in KiDS-like images have a low probability of being detected using methods based on resolved stars, as these satellites remain unresolved in the detection.
at heliocentric distances d ≳ 100 kpc in KiDS-like images have a low probability of being detected using methods based on resolved stars, as these satellites remain unresolved in the detection.
We overplotted the Sextans II discovered with KiDS DR4 (Gatto et al. 2024) and independently with HSC-SSP (Homma et al. 2024) onto the detection efficiency map for both the image-level and the catalogue-level cases. With a 2D interpolation, the detectability is 48.70% for the image-level simulation and 71.37% for the catalogue-level simulation. The detection of Sextans II with KiDS is reliable as it does not exceed the sensitivity limit of the KiDS-like simulation survey. Other satellites that can be found in the KiDS footprint are also plotted on both maps, with their detectability data summarised in Table 3.
Detectability of simulated objects resembling known satellites within the KiDS footprint.
We also present the smoothed detectability of image-level simulations using the customised star-galaxy separation (chain A) detailed in Sect. 3.2. As shown in Fig. 11, the limits of Pdet, 50 are fitted with polynomials (n = 3) and plotted as bright blue dashed lines on the detection efficiency maps. From the figure, the shapes of the Pdet, 50 limits for the star-galaxy separated scenario are similar to those from the image-level simulation with perfect stars, but are shifted toward the lower left. This shift highlights the significant impact of the star-galaxy separation process on the selection function, where the incompleteness of the star-galaxy classification leads to a loss of faint and extended satellites. The resulting reduction in source significance causes these stellar systems to fall below the detection threshold, making them undetectable with the matched-filter search algorithm. This effect is particularly relevant for real dwarf galaxy searches, where star-galaxy separation is a crucial but challenging step. The observational selection function derived in this study is more restrictive than that from injections at the catalogue-level only, suggesting a more realistic detection capability when accounting for star-galaxy classification effects. Although our star-galaxy separation is only based on simulated data, it highlights the potential application for further refinement and customisation of the star-galaxy separator in future observational studies. It emphasises the importance of incorporating realistic observational effects when assessing survey sensitivity and suggests that improved star-galaxy separation techniques can enhance the detectability of faint satellites.
In addition, since different noise levels and seeing conditions are applied to different tiles, the performance of the star-galaxy separator varies across tiles. The detection efficiency for image-level simulations, with or without the applied star-galaxy separator, reflect an averaged effect on all tiles. In the figure, the detection rate of Sextans II drops to 10.85% for the star-galaxy separated image-level simulation case, indicating that it is unlikely to be detected under these conditions. However, this value should be considered as a reference only, as Sextans II is located at (RA, Dec) = (156.44, −0.64) deg within the tile KIDS_156.0_-0.5. This tile benefits from good seeing conditions, with a full width at half maximum (FWHM) of 0.57 arcsec and a limiting magnitude of 25.02 in the r-band. These conditions are expected to contribute to improving source extraction and star-galaxy separation, potentially enhancing the detectability of Sextans II compared to regions with poorer observational conditions.
5. Conclusions and discussions
This study aims to evaluate the sensitivity of KiDS in searching for ultra-faint satellites of the Milky Way, using the first image-level simulation conducted with MultiBand_ImSim in SKiLLS. To achieve this, we generated 19 647 satellites arranged in 100 KiDS-like images with various stellar masses, half-light radii, heliocentric distances, ellipticities, and position angles, for each image size of 108 deg2. We established the star catalogue by combining randomly placed foreground stars and satellite member stars sampled from a Z = 0.0001 and τ = 12 Gyr star pool for each image. For the image-level simulations, we generated the images with the input star and galaxy catalogue and applied SEXTRACTOR and GAAP to extract sources and measure their nine-band photometry. For the catalogue-level simulations, the uncertainty of the star photometry was estimated for each star from the input star catalogue. Furthermore, we trained a star-galaxy separation method using a combination of a multilayer perceptron and BPZ model fitting. The matched-filter method was applied to recover the injected mock satellites in both image- and catalogue-level simulations, with the image-level simulation including cases with both perfect star detection and star-galaxy separation applied.
We quantified the smoothed observational selection functions for both KiDS-like simulations in terms of V-band absolute magnitude, MV, half-light radius, rh, and the heliocentric distance, d, providing selection functions with 50% detectability limit through analytical fitting with third-order polynomials. Compared with the catalogue-level cases, the image-level cases report a loss of compact sources in the recovery of the satellites; the probable reason is that the compact satellites are more likely to be identified as the single sources during the source extraction process. The results from the catalogue-level selection function qualitatively match the results from Drlica-Wagner et al. (2020), where the catalogue-level dwarf galaxy detection efficiency was assessed for DES and Pan-STARRS. The critical differences between the two studies are the loss of compact satellites and an overall lower detection efficiency as a function of magnitude in the image-level selection function at distances greater than 100 kpc and a substantial loss in detection efficiency across the board when factoring in star-galaxy separation. The consequence is that our results imply that our current knowledge of the completeness of the Milky Way satellite population is less optimistic than previously thought, as inferred through our method applied to KiDS.
The differences derived from image-level injections provide valuable insights into the ‘missing satellites problem’ and the completeness of the Milky Way satellite census. If the most compact and faint satellites, especially beyond 100 kpc, are systematically missed due to observational selection effects, the apparent dearth of low-mass halos might partially reflect detection limitations rather than a fundamental absence. However, it is important to note that our analysis is based on satellite detection using the matched-filter method, which is optimised for identifying resolved stellar systems. Bright and compact sources may still be detectable through alternative methods. A more comprehensive approach incorporating improved detection techniques and deeper observations will be necessary to fully assess the impact of these selection effects.
Our results also point to possible ways to improve the detectability of ultra-faint satellites in future surveys. The suppression of compact satellite recoveries in image-level simulations suggests that some of these stellar systems might be classified as single sources in the SEXTRACTOR pipeline. Adjusting source extraction settings may be helpful in improving the recovery rate of these small mock satellites. Additionally, non-stellar overdensity-based methods, such as machine-learning approaches trained on simulated small and faint dwarf galaxies (e.g. Jones et al. 2023), may provide a more effective means of detecting those sources that are not easily recovered through matched-filter searches. An additional caveat is that all detection efficiency assessments must choose a significance threshold where a mock satellite is deemed to have been detected. However, in all data mining projects that have successfully discovered dwarf galaxies in deep photometric surveys, follow-up imaging and spectroscopy have been necessary to confirm the reality of the faintest candidates, often with a high rate of success. This likely means that all currently derived detection limits are inherently conservative as a function of absolute magnitude. While the fully simulated images presented in this study offer a controlled and internally consistent framework for evaluating detection efficiency, they may not fully capture certain observational systematics appear in real survey images, such as PSF variation, image background inhomogeneities, and Galactic extinction. Recent studies (e.g. Mutlu-Pakdil et al. 2021; Carlin et al. 2024) adopted synthetic satellite injection into real survey images to empirically evaluate completeness under such effects. These injection-based methods are especially powerful in characterising detection sensitivity within existing observational data, allowing for a detailed assessment of survey completeness around specific galaxies or targeted regions. In contrast, our simulation framework is particularly suited to rapidly and flexibly evaluating detection efficiency for ongoing and planned wide-field surveys. Together, these complementary approaches underscore the importance of carefully balancing observational realism with the capability for systematic exploration when assessing the completeness of satellite surveys.
In the near future, the Legacy Survey of Space and Time at the Vera C. Rubin Observatory (Ivezić et al. 2019) will provide groundbreaking photometric depth over much of the extra-galactic sky. In addition, the Euclid Wide Survey from the Euclid mission (Laureijs et al. 2011; Euclid Collaboration: Scaramella et al. 2022) will provide the space-based image quality necessary to separate stars and galaxies at extremely faint magnitudes. In tandem, these data sets are expected to enable a huge advance in the detection of extraordinarily faint stellar systems by reducing source blending and improving star-galaxy classification issues that plague current ground-based observations, coupled with the increase in photometric depth. Future analyses should be aimed at integrating image-level effects into survey completeness assessments to ensure a more accurate census of Milky Way satellites and to refine the constraints on dark matter properties derived from their observed population. While this study focuses on UFDs, ultra-diffuse galaxies (UDGs) remain largely absent from our analysis. Their presence and detectability are important issues that ought to be investigated by future surveys.
Acknowledgments
We gratefully acknowledge the anonymous referee for their valuable comments that helped us to improve the manuscript. Special thanks are extended to our colleagues at GCCL for their support and constructive discussions during the preparation of this work. S.Z. acknowledges the support from the Deutsche Forschungsgemeinschaft (DFG) SFB1491. H. Hildebrandt is supported by a DFG Heisenberg grant (Hi 1495/5-1), the DFG Collaborative Research Center SFB1491, an ERC Consolidator Grant (No. 770935), and the DLR project 50QE2305. ZY acknowledges support from the Max Planck Society and the Alexander von Humboldt Foundation in the framework of the Max Planck-Humboldt Research Award endowed by the Federal Ministry of Education and Research (Germany). M.G. acknowledges the INAF AstroFIt grant 1.05.11. SSL acknowledges funding from the programme “Netzwerke 2021”, an initiative of the Ministry of Culture and Science of the State of Northrhine Westphalia and support from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program with Grant agreement No. 101053992. D.E. acknowledges the support from DFG Sonderforschungsbereich 1491 Project F5 and BMBF ErUM-Pro.
References
- Acciari, V. A., Agudo, I., Aniello, T., et al. 2023, A&A, 670, A145 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ackermann, M., Ajello, M., Albert, A., et al. 2011, PRL, 107, 241302 [Google Scholar]
- Agertz, O., Pontzen, A., Read, J. I., et al. 2020, MNRAS, 491, 1656 [Google Scholar]
- Ahnen, M. L., Ansoldi, S., Antonelli, L., et al. 2016, arXiv e-prints [arXiv:1601.06590] [Google Scholar]
- Bechtol, K., Drlica-Wagner, A., Balbinot, E., et al. 2015, ApJ, 807, 50 [NASA ADS] [CrossRef] [Google Scholar]
- Belokurov, V., Zucker, D. B., Evans, N. W., et al. 2006, ApJ, 647, L111 [NASA ADS] [CrossRef] [Google Scholar]
- Belokurov, V., Zucker, D. B., Evans, N., et al. 2007, ApJ, 654, 897 [Google Scholar]
- Belokurov, V., Walker, M., Evans, N., et al. 2008, ApJ, 686, L83 [NASA ADS] [CrossRef] [Google Scholar]
- Belokurov, V., Walker, M., Evans, N., et al. 2009, MNRAS, 397, 1748 [CrossRef] [Google Scholar]
- Belokurov, V., Walker, M., Evans, N., et al. 2010, ApJ, 712, L103 [NASA ADS] [CrossRef] [Google Scholar]
- Benitez, N. 2000, ApJ, 536, 571 [CrossRef] [Google Scholar]
- Benitez-Llambay, A., & Frenk, C. 2020, MNRAS, 498, 4887 [CrossRef] [Google Scholar]
- Bertin, E. 2010, SWarp: Resampling and Co-adding FITS ImagesTogether, Astrophysics Source Code Library [record ascl:1010.068] [Google Scholar]
- Bovill, M. S., & Ricotti, M. 2009, ApJ, 693, 1859 [NASA ADS] [CrossRef] [Google Scholar]
- Bovill, M. S., & Ricotti, M. 2011, ApJ, 741, 17 [NASA ADS] [CrossRef] [Google Scholar]
- Bressan, A., Marigo, P., Girardi, L., et al. 2012, MNRAS, 427, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Bullock, J. S., Kravtsov, A. V., & Weinberg, D. H. 2000, ApJ, 539, 517 [CrossRef] [Google Scholar]
- Capaccioli, M., & Schipani, P. 2011, The Messenger, 146, 27 [NASA ADS] [Google Scholar]
- Carlin, J. L., Sand, D. J., Mutlu-Pakdil, B., et al. 2024, ApJ, 977, 112 [Google Scholar]
- Cerny, W., Pace, A., Drlica-Wagner, A., et al. 2021, ApJ, 910, 18 [CrossRef] [Google Scholar]
- Cerny, W., Martínez-Vázquez, C., Drlica-Wagner, A., et al. 2023, ApJ, 953, 1 [NASA ADS] [CrossRef] [Google Scholar]
- de Jong, J. T. A., Verdoes Kleijn, G. A., Kuijken, K. H., & Valentijn, E. A. 2013, Exp. Astron., 35, 25 [Google Scholar]
- Di Mauro, M., & Winkler, M. W. 2021, PRD, 103, 123005 [Google Scholar]
- Drlica-Wagner, A., Albert, A., Bechtol, K., et al. 2015a, ApJ, 809, L4 [Google Scholar]
- Drlica-Wagner, A., Bechtol, K., Rykoff, E., et al. 2015b, ApJ, 813, 109 [Google Scholar]
- Drlica-Wagner, A., Bechtol, K., Mau, S., et al. 2020, ApJ, 893, 47 [CrossRef] [Google Scholar]
- Drlica-Wagner, A., Carlin, J. L., Nidever, D. L., et al. 2021, ApJS, 256, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Edge, A., Sutherland, W., Kuijken, K., et al. 2013, The Messenger, 154, 32 [NASA ADS] [Google Scholar]
- Elahi, P. J., Welker, C., Power, C., et al. 2018, MNRAS, 475, 5338 [NASA ADS] [CrossRef] [Google Scholar]
- Euclid Collaboration (Scaramella, R., et al.) 2022, A&A, 662, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fadely, R., Hogg, D. W., & Willman, B. 2012, ApJ, 760, 15 [CrossRef] [Google Scholar]
- Gatto, M., Bellazzini, M., Tortora, C., et al. 2024, A&A, 681, L13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Girardi, L., Groenewegen, M., Hatziminaoglou, E., & da Costa, L. 2005, A&A, 436, 895 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Grcevich, J., & Putman, M. E. 2009, ApJ, 696, 385 [NASA ADS] [CrossRef] [Google Scholar]
- Griffith, R. L., Cooper, M. C., Newman, J. A., et al. 2012, ApJS, 200, 9 [NASA ADS] [CrossRef] [Google Scholar]
- Grillmair, C. J. 2006, ApJ, 645, L37 [Google Scholar]
- Grillmair, C. J. 2009, ApJ, 693, 1118 [NASA ADS] [CrossRef] [Google Scholar]
- Hildebrandt, H., Erben, T., Kuijken, K., et al. 2012, MNRAS, 421, 2355 [Google Scholar]
- Homma, D., Chiba, M., Okamoto, S., et al. 2016, ApJ, 832, 21 [NASA ADS] [CrossRef] [Google Scholar]
- Homma, D., Chiba, M., Okamoto, S., et al. 2018, PASJ, 70, S18 [NASA ADS] [CrossRef] [Google Scholar]
- Homma, D., Chiba, M., Komiyama, Y., et al. 2019, PASJ, 71, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Homma, D., Chiba, M., Komiyama, Y., et al. 2024, PASJ, psae044 [Google Scholar]
- Hopkins, P. F., Wetzel, A., Kereš, D., et al. 2018, MNRAS, 477, 1578 [NASA ADS] [CrossRef] [Google Scholar]
- Hopkins, P. F., Grudić, M. Y., Wetzel, A., et al. 2020, MNRAS, 491, 3702 [CrossRef] [Google Scholar]
- Irwin, M., Belokurov, V., Evans, N., et al. 2007, ApJ, 656, L13 [NASA ADS] [CrossRef] [Google Scholar]
- Ivezić, Ž., Kahn, S. M., Tyson, J. A., et al. 2019, ApJ, 873, 111 [Google Scholar]
- Jethwa, P., Erkal, D., & Belokurov, V. 2018, MNRAS, 473, 2060 [NASA ADS] [CrossRef] [Google Scholar]
- Jones, M. G., Mutlu-Pakdil, B., Sand, D. J., et al. 2023, ApJ, 957, L5 [Google Scholar]
- Kim, D., & Jerjen, H. 2015a, ApJ, 799, 73 [Google Scholar]
- Kim, D., & Jerjen, H. 2015b, ApJ, 808, L39 [NASA ADS] [CrossRef] [Google Scholar]
- Klypin, A., Kravtsov, A. V., Valenzuela, O., & Prada, F. 1999, ApJ, 522, 82 [Google Scholar]
- Koposov, S., Belokurov, V., Evans, N., et al. 2008, ApJ, 686, 279 [NASA ADS] [CrossRef] [Google Scholar]
- Koposov, S. E., Belokurov, V., Torrealba, G., & Evans, N. W. 2015, ApJ, 805, 130 [NASA ADS] [CrossRef] [Google Scholar]
- Kroupa, P. 2001, MNRAS, 322, 231 [NASA ADS] [CrossRef] [Google Scholar]
- Kroupa, P. 2002, Science, 295, 82 [Google Scholar]
- Kuijken, K., Heymans, C., Hildebrandt, H., et al. 2015, MNRAS, 454, 3500 [Google Scholar]
- Kuijken, K., Heymans, C., Dvornik, A., et al. 2019, A&A, 625, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Laevens, B. P., Martin, N. F., Bernard, E. J., et al. 2015a, ApJ, 813, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Laevens, B. P., Martin, N. F., Ibata, R. A., et al. 2015b, ApJ, 802, L18 [NASA ADS] [CrossRef] [Google Scholar]
- Lagos, C. d. P., Tobar, R. J., Robotham, A. S. G., et al. 2018, MNRAS, 481, 3573 [CrossRef] [Google Scholar]
- LAT Collaboration 2015, arXiv e-prints [arXiv:1503.02641] [Google Scholar]
- Laureijs, R., Amiaux, J., Arduini, S., et al. 2011, arXiv e-prints [arXiv:1110.3193] [Google Scholar]
- Li, S.-S., Kuijken, K., Hoekstra, H., et al. 2023, A&A, 670, A100 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Linke, L., Unruh, S., Wittje, A., et al. 2025, A&A, 693, A210 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Luque, E., Queiroz, A., Santiago, B., et al. 2016, MNRAS, 458, 603 [NASA ADS] [CrossRef] [Google Scholar]
- Mashchenko, S., Wadsley, J., & Couchman, H. 2008, Science, 319, 174 [NASA ADS] [CrossRef] [Google Scholar]
- Mau, S., Cerny, W., Pace, A., et al. 2020, ApJ, 890, 136 [NASA ADS] [CrossRef] [Google Scholar]
- McDaniel, A., Ajello, M., Karwin, C. M., et al. 2024, PRD, 109, 063024 [Google Scholar]
- Moore, B., Ghigna, S., Governato, F., et al. 1999, ApJ, 524, L19 [Google Scholar]
- Mutlu-Pakdil, B., Sand, D. J., Crnojević, D., et al. 2021, ApJ, 918, 88 [CrossRef] [Google Scholar]
- Nadler, E. O., Wechsler, R. H., Bechtol, K., et al. 2020, ApJ, 893, 48 [NASA ADS] [CrossRef] [Google Scholar]
- Nadler, E. O., Gluscevic, V., Driskell, T., et al. 2024, ApJ, 967, 61 [Google Scholar]
- Newton, O., Cautun, M., Jenkins, A., Frenk, C. S., & Helly, J. C. 2018, MNRAS, 479, 2853 [CrossRef] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Pickles, A. 1998, PASP, 110, 863 [NASA ADS] [CrossRef] [Google Scholar]
- Plummer, H. C. 1911, MNRAS, 71, 460 [Google Scholar]
- Sakamoto, T., & Hasegawa, T. 2006, ApJ, 653, L29 [Google Scholar]
- Sales, L. V., Wetzel, A., & Fattahi, A. 2022, Nat. Astron., 6, 897 [NASA ADS] [CrossRef] [Google Scholar]
- Sawala, T., Scannapieco, C., Maio, U., & White, S. 2010, MNRAS, 402, 1599 [Google Scholar]
- Sérsic, J. L. 1963, Boletin de la Asociacion Argentina de Astronomia La Plata Argentina, 6, 41 [Google Scholar]
- Shapiro, P. R., Iliev, I. T., & Raga, A. C. 2004, MNRAS, 348, 753 [NASA ADS] [CrossRef] [Google Scholar]
- Simon, J. D. 2019, ARA&A, 57, 375 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, S. E., Jensen, J., Roediger, J., et al. 2023, AJ, 166, 76 [CrossRef] [Google Scholar]
- Smith, S. E., Cerny, W., Hayes, C. R., et al. 2024, ApJ, 961, 92 [Google Scholar]
- Spekkens, K., Urbancic, N., Mason, B. S., Willman, B., & Aguirre, J. E. 2014, ApJ, 795, L5 [NASA ADS] [CrossRef] [Google Scholar]
- Stinson, G. S., Dalcanton, J. J., Quinn, T., Kaufmann, T., & Wadsley, J. 2007, ApJ, 667, 170 [NASA ADS] [CrossRef] [Google Scholar]
- Tollerud, E. J., Bullock, J. S., Strigari, L. E., & Willman, B. 2008, ApJ, 688, 277 [NASA ADS] [CrossRef] [Google Scholar]
- Torrealba, G., Koposov, S., Belokurov, V., & Irwin, M. 2016a, MNRAS, 459, 2370 [NASA ADS] [CrossRef] [Google Scholar]
- Torrealba, G., Koposov, S., Belokurov, V., et al. 2016b, MNRAS, 463, 712 [NASA ADS] [CrossRef] [Google Scholar]
- Walsh, S., Jerjen, H., & Willman, B. 2007, ApJ, 662, L83 [Google Scholar]
- Walsh, S., Willman, B., & Jerjen, H. 2008, AJ, 137, 450 [Google Scholar]
- Weisz, D. R., Dolphin, A. E., Skillman, E. D., et al. 2014, ApJ, 789, 147 [Google Scholar]
- Wheeler, C., Onorbe, J., Bullock, J. S., et al. 2015, MNRAS, 453, 1305 [NASA ADS] [CrossRef] [Google Scholar]
- Willman, B., Blanton, M. R., West, A. A., et al. 2005a, AJ, 129, 2692 [NASA ADS] [CrossRef] [Google Scholar]
- Willman, B., Dalcanton, J. J., Martinez-Delgado, D., et al. 2005b, ApJ, 626, L85 [Google Scholar]
- Wright, A. H., Hildebrandt, H., Kuijken, K., et al. 2019, A&A, 632, A34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Wright, A. H., Kuijken, K., Hildebrandt, H., et al. 2024, A&A, 686, A170 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- York, D. G., Adelman, J., Anderson, J. E., Jr, et al. 2000, AJ, 120, 1579 [Google Scholar]
- Zucker, D. B., Belokurov, V., Evans, N. W., et al. 2006a, ApJ, 650, L41 [Google Scholar]
- Zucker, D. B., Belokurov, V., Evans, N. W., et al. 2006b, ApJ, 643, L103 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Detectability and interpolation
We detail the process of interpolation and smoothing of the satellites detectability in this appendix. We show Fig. A.1 as an example case of the catalogue-level simulation with a distance range of [21.5, 46.4] kpc. We did not fully generate satellites across the entire parameter space because it would be inefficient for computing resources to simulate many extended satellites in projection size. As shown in subplot B, a total of 1 497 satellites are generated. For the lower left region, we assume that all satellites generated will be detected, while for the upper region we generate fewer satellites. The colour of each scatter indicates the distance of each mock satellite. We suggest that future results can be further refined by generating more mock satellites around the 50% detectability limit.
The detection catalogue was cross-matched with the input and we binned them according to the absolute magnitude MV and the half-light radius rh, with the original detection efficiency map shown in subplot A. We assume that the detectability of a satellite with parameters corresponding to the top-right grid point of the map results in no detection, namely, 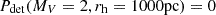 ; whereas satellites with parameters in the lower-left grid point can always be detected, namely,
; whereas satellites with parameters in the lower-left grid point can always be detected, namely, 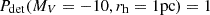 . We then applied 2D grid interpolation to fill the blanks, as shown in subplot C. The unsmoothed detection efficiency maps for both image-level and catalogue-level simulations are shown in Figs. A.3 and A.2 for reference, while Fig. A.4 shows the results of image-level simulation with the star-galaxy separator applied. The Gaussian kernel with σ = 1 is used on the grid map to produce the smoothed detection efficiency map, as shown in subplot D. The 50% detectability limit Pdet, 50 is overplotted on the map.
. We then applied 2D grid interpolation to fill the blanks, as shown in subplot C. The unsmoothed detection efficiency maps for both image-level and catalogue-level simulations are shown in Figs. A.3 and A.2 for reference, while Fig. A.4 shows the results of image-level simulation with the star-galaxy separator applied. The Gaussian kernel with σ = 1 is used on the grid map to produce the smoothed detection efficiency map, as shown in subplot D. The 50% detectability limit Pdet, 50 is overplotted on the map.
For a fixed distance, fits to the 50% detectability limit for catalogue-level simulations can be described as an analytical approximation in the form of inverse proportional functions described in Drlica-Wagner et al. (2020) or in terms of the limiting absolute magnitude, as in Koposov et al. (2008). However, for the image-level case, these forms are insufficient to describe the peaks of the limits that appear at 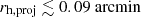 for the heliocentric distance d > 100 kpc. Therefore, we fit the Pdet, 50 limits for both cases with a third-order polynomial, and we plot the fitting limit of this case as a yellow dashed line in subplot D.
for the heliocentric distance d > 100 kpc. Therefore, we fit the Pdet, 50 limits for both cases with a third-order polynomial, and we plot the fitting limit of this case as a yellow dashed line in subplot D.
 |
Fig. A.1. Example of the detectability interpolation and smoothing for the catalogue-level simulation in the second distance bin with d in the range of [21.5, 46.4] kpc. Detection of satellites within this distance range is binned as a function of MV and rh as shown in subplot A. A total of 1497 mock satellites are plotted as scatters in the MV − rh map in subplot B. The 2D interpolation is applied to generate the full detection efficiency map, as shown in subplot C. We apply a Gaussian kernel to smooth the map, with the 50% detectability limit plotted in red in subplot D, and the fitted limit plotted in yellow. |
 |
Fig. A.2. Detection efficiency of satellites searches without smoothing for KiDS-like catalogue-level simulations similar as shown in Fig. 9. The 50% detectability limits fitted with polynomials (n = 3) are shown in yellow dashed lines. The detectability limits from the image-level simulations are plotted in red dashed lines. |
 |
Fig. A.3. Detection efficiency of satellites searches without smoothing for KiDS-like image-level simulation similar as shown in Fig. 10. The 50% detectability limits fitted with polynomials (n = 3) are shown in red dashed lines. The detectability limits from the catalogue-level simulations are plotted in yellow dashed lines. |
 |
Fig. A.4. Detection efficiency of satellite searches without smoothing for KiDS-like image-level simulations, with star-galaxy separation applied similarly to Fig. 11. The 50% detectability limits, fitted with polynomials (n = 3), are shown as bright blue dashed lines. The detectability limits from the image-level and the catalogue-level simulations are plotted as red and yellow dashed lines. |
Appendix B: Compact sources
In image-level simulations, we find that at distance d > 100 kpc, bright and compact satellites are not fully identified as expected. We also notice that during the image simulation, there are some compact satellites placed close to bright and extended satellites.
To verify whether the proximity of compact satellites to large and bright satellites during image generation can explain the detection loss, we regenerate all the compact satellites that were not detected and had projected half-light radii 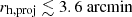 , placing them with separations described as:
, placing them with separations described as:
![Mathematical equation: $$ \begin{aligned} \Delta _{\text{separation}} = \max [F (r_{\rm new} + r), 0.5 \mathrm ~deg] , \end{aligned} $$](/articles/aa/full_html/2025/06/aa54189-25/aa54189-25-eq16.gif) (B.1)
(B.1)
similar to the definition in Eq. (1), rnew represents the projection of the half-light radius of the next satellite to be placed on the canvas, r represents the projected radius of each satellite already placed, and they are both in units of degrees. F is the factor for the sum of the projected radii and is selected here as 10. The minimum separation is set to 0.5deg for these small satellites.
After image simulation and detection of the injected satellites, the detectability of compact sources with larger separation is obtained as shown in Fig. B.1. This figure focuses on satellites at distances d > 100 kpc, and the detection for compact satellites is still not complete, suggesting that this issue does not arise from the positioning of small satellites.
 |
Fig. B.1. Detection efficiency for searches on compact satellites with d > 100 kpc in image-level simulations. The figure shows that the loss of detection for compact satellites still persists. |
All Tables
Detectability of simulated objects resembling known satellites within the KiDS footprint.
All Figures
|
Fig. 1. Flowchart summarising the pipeline processes. The output star catalogues are obtained through image-level and catalogue-level simulations. We apply the matched-filter method to recover the injected mock satellites for both catalogues. The observational selection function is constructed by mapping the properties of the satellites to their detectability. |
| In the text | |
|
Fig. 2. Counts of mock satellites generated in the parameter space. To efficiently use resources for image generation, we did not fully generate mock satellites for very bright and compact satellites, or those with large sizes. For mock satellites with half-light radii exceeding the sizes of the tiles for KiDS-like images, their detection is beyond the capabilities of KiDS and has a lower likelihood of being identified. The non-generated regions will be extrapolated in the observational selection function. The heliocentric distance d is given in kpc. |
| In the text | |
|
Fig. 3. Input star catalogue for one of the 108 deg2 generated images. Each square block represents a tile in KiDS-like image generation. The red circles indicate the locations of the mock satellites, with the radii representing the smallest separation for each pair of mock satellites with F = 3 in Eq. (1). Each blue point represents a star, with the input star catalogue consisting of satellite member stars and foreground stars. |
| In the text | |
|
Fig. 4. Comparison of the input and detected stars and galaxies for four tiles. The left panel displays the input stars and the middle panel shows the detected stars that are cross-matched with the input catalogue, indicating that only about 60% of the stars survived the image simulation and source extraction process. The right panel illustrates the detected galaxies identified. Two zoom-in panels show the local environments of two injected satellites. The left panel (blue rectangle) shows a satellite with multiple member stars identified, while the right panel (orange rectangle) shows very few of the member stars are detected, likely due to its compactness and the higher background noise in that region. |
| In the text | |
|
Fig. 5. Comparison of the magnitude uncertainties for nine-band photometry with respect to GAAP magnitude ranging from 14 to 24. The black lines represent the GAAP photometric measurements from image-level simulation, and the red lines represent the estimations from Eq. (3) for a catalogue-level simulation. |
| In the text | |
|
Fig. 6. Left panel: Detected perfect flag stars are identified by cross-matching the detected sources from SEXTRACTOR (branch B) with the input mock satellite catalogue. The red circles represent the locations of the input mock satellites, and the radii of the circles indicate the smallest separation for each pair of mock satellites. Right panel: Remaining stars after applying star-galaxy separation (branch A), with a MAG_AUTO cut at 25. |
| In the text | |
|
Fig. 7. True positive rate, false positive rate, and positive predictive value for star-galaxy separation with MAG_AUTO in the range of [16, 25] for star-galaxy catalogues for all image samples. |
| In the text | |
|
Fig. 8. CMD of an example mock satellite galaxy located at a distance of 98.95 kpc, with a half-light radius of 69.45 pc and an absolute magnitude MV = −6.38 (Chain B). The red points represent point sources selected from the central region of the mock satellite up to 2 times the satellite’s rh. These point sources consist of both the mock satellite’s member stars and the Milky Way foreground stars. The yellow region corresponds to the selection criteria derived from Eq. (7) to isolate the member stars of the satellite. Stars falling within this region are considered as member stars of the mock satellite. |
| In the text | |
|
Fig. 9. Detection efficiency of searches for satellites for KiDS-like catalogue-level simulation (chain C). The detectability ranges from 0% (dark blue) to 100% (bright yellow) as a function of the V-band absolute magnitude, physical half-light radius, and heliocentric distance. The 50% detectability limits fitted by polynomials (n = 3) are shown in yellow dashed lines. The detectability limits of image-level simulations are plotted in red dashed lines. The satellites found within KiDS footprint are overplotted in the detection efficiency map. |
| In the text | |
|
Fig. 10. Same as Fig. 9, except for image-level simulation (chain B). The detectability ranges from 0% (dark blue) to 100% (bright yellow) similar as shown in Fig. 9. The 50% detectability limits fitted by polynomials (n = 3) are shown in red dashed lines. The detectability limits of catalogue-level simulations are plotted in yellow dashed lines. The satellites found within KiDS footprint are overplotted in the detection efficiency map. |
| In the text | |
|
Fig. 11. Same as Fig. 9, except with the star-galaxy separator applied in the image-level (chain A). The detectability ranges from 0% (dark blue) to 100% (bright yellow) similar as shown in Fig. 9. The 50% detectability limits fitted by polynomials (n = 3) are shown in bright blue dashed lines. The detectability limits of image-level and catalogue-level simulations are plotted in red and yellow dashed lines. The satellites found within in KiDS footprint are overplotted in the detection efficiency map. |
| In the text | |
|
Fig. A.1. Example of the detectability interpolation and smoothing for the catalogue-level simulation in the second distance bin with d in the range of [21.5, 46.4] kpc. Detection of satellites within this distance range is binned as a function of MV and rh as shown in subplot A. A total of 1497 mock satellites are plotted as scatters in the MV − rh map in subplot B. The 2D interpolation is applied to generate the full detection efficiency map, as shown in subplot C. We apply a Gaussian kernel to smooth the map, with the 50% detectability limit plotted in red in subplot D, and the fitted limit plotted in yellow. |
| In the text | |
|
Fig. A.2. Detection efficiency of satellites searches without smoothing for KiDS-like catalogue-level simulations similar as shown in Fig. 9. The 50% detectability limits fitted with polynomials (n = 3) are shown in yellow dashed lines. The detectability limits from the image-level simulations are plotted in red dashed lines. |
| In the text | |
|
Fig. A.3. Detection efficiency of satellites searches without smoothing for KiDS-like image-level simulation similar as shown in Fig. 10. The 50% detectability limits fitted with polynomials (n = 3) are shown in red dashed lines. The detectability limits from the catalogue-level simulations are plotted in yellow dashed lines. |
| In the text | |
|
Fig. A.4. Detection efficiency of satellite searches without smoothing for KiDS-like image-level simulations, with star-galaxy separation applied similarly to Fig. 11. The 50% detectability limits, fitted with polynomials (n = 3), are shown as bright blue dashed lines. The detectability limits from the image-level and the catalogue-level simulations are plotted as red and yellow dashed lines. |
| In the text | |
|
Fig. B.1. Detection efficiency for searches on compact satellites with d > 100 kpc in image-level simulations. The figure shows that the loss of detection for compact satellites still persists. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.