| Issue |
A&A
Volume 697, May 2025
|
|
|---|---|---|
| Article Number | A160 | |
| Number of page(s) | 16 | |
| Section | Catalogs and data | |
| DOI | https://doi.org/10.1051/0004-6361/202453247 | |
| Published online | 16 May 2025 | |
Performance of photometric template fitting for ultra-high-redshift galaxies
1
Cosmic Dawn Center (DAWN),
Denmark
2
Niels Bohr Institute, University of Copenhagen,
Jagtvej 128,
2200
Copenhagen N,
Denmark
3
Department of Physics and Astronomy, University of Missouri,
Columbia,
MO,
USA
4
DARK Cosmology Center, University of Copenhagen,
Jagtvej 128,
2200
Copenhagen N,
Denmark
5
California Institute of Technology,
1200 E. California Blvd.,
Pasadena,
CA
91125,
USA
★ Corresponding author.
Received:
1
December
2024
Accepted:
17
March
2025
The James Webb Space Telescope (JWST) has enabled the discovery of a significant population of galaxies at z > 10. Our understanding of the astrophysical properties of these galaxies relies on fitting templates developed using models predicting the differences between these first galaxies and lower-redshift counterparts. In this work, tests are performed on several of these high-redshift template sets in order to determine how successful they are at predicting both photometric redshifts and full spectral energy distributions (SEDs). Our work shows that the best templates for photometric redshift estimation differ from the best templates for predicting the full SED. Overall, some templates perform adequately at photometric redshift estimation, while all are generally poor predictors of the full SED. A few objects in particular are poorly fit by all the template sets tested. We conclude that although photometric redshifts can be reliable when given a high enough observational depth and adequate filters, models are not yet able to produce robust astrophysical properties for these ultra-high-redshift galaxies.
Key words: methods: data analysis / techniques: photometric / techniques: spectroscopic / catalogs / surveys / galaxies: high-redshift
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. Subscribe to A&A to support open access publication.
1 Introduction
Due to the high observational cost, large blind spectroscopic surveys are infeasible at very high redshift. As a result, all recent high-redshift galaxy studies have used either photometric surveys alone or spectroscopic follow-up of photometric targets. Consequently, our knowledge of the first galaxies relies on an ability to successfully identify high-redshift galaxies as well as several of their properties from photometry alone. This is done by fitting a series of spectral energy distribution (SED) models to the observed multi-wavelength photometry and then assuming that the properties of the best-fit model are also those of the galaxy.
However, there is a high computational complexity in fitting properties to photometry due to a combination of many astrophysical parameters and a search space with a large number of local minima that can lie far from the global minimum (Speagle et al. 2016). In practice, solving this problem requires finding a way to significantly reduce the search space. One of the most successful techniques, which is employed by codes such as EAZY (Brammer et al. 2008), is to choose a limited basis of templates and then to find the best-fit linear combination of the templates to the observed photometry.
The main drawback of this method is that success hinges on the set of templates chosen and whether the limited basis spanned by these templates contains a good approximation for the true properties of these galaxies. This is a particularly strong assumption when observing in a new regime since the template basis must be chosen based on extrapolations from existing observations.
Fortunately, follow-up spectroscopy has typically shown that photometric redshifts have generally been a good predictor of spectroscopic redshifts (Hildebrandt et al. 2010). It has thus been assumed that the properties produced by template fitting are similarly good predictors of true galaxy properties, although there is less direct evidence of these properties to use as a basis for comparison.
However, with the Cycle 1 observations from the James Webb Space Telescope (JWST), several candidates for z > 15 galaxies have been reported using photometric template fitting (Donnan et al. 2022; Castellano et al. 2022; Yan et al. 2022), but spectroscopic follow-ups and photometric observations at other wavelengths have shown that these galaxies are much lower-redshift objects (Arrabal Haro et al. 2023; Zavala et al. 2023). Additionally, many z ∼ 10 candidates have indeed been found to lie at high redshift but had spectroscopic redshifts 10% to 20% lower than those fitted photometrically (Fujimoto et al. 2023). These performances can in part be attributed to spectral “dropouts” (e.g., photometric filters returning zero-values), which in effect limits information for higher redshift objects. However, these discrepancies also indicate that revised templates could be crucial to probing these early galaxies.
Several approaches have been taken to revise templates in order to better describe galaxies and their stellar populations at z ∼ 10. Some template sets have been produced based on using astrophysical arguments to choose parameters in stellar population synthesis (SPS) models that should better reflect early galaxies (Steinhardt et al. 2023; Larson et al. 2023; Adams et al. 2022). Alternatively, the approach chosen by Turner (in prep.) restricts SPS models to those with younger stellar populations. Finally, a hybrid approach consists of taking star formation histories from early universe simulations and synthesizing a stellar population by including an age restriction (see Table 1, Brammer et al. 2008).
This variety of meaningful approaches means that astronomers are now forced to choose which template to use. In this work, different template sets and techniques are evaluated in order to determine which is the most robust. Currently, photometric template fits are used in two different ways. In some cases, only the photometric redshift is relevant since high-redshift candidates are then targeted for follow-up spectroscopy in order to better determine their properties. In other cases, physical parameters are inferred directly from photometric template fits and used to draw scientific conclusions without additional observations. As a result, two different tests are conducted, one to determine which template basis is best at redshift estimation and the other to determine which is most successful at recreating spectral features.
In Sect. 2, the various datasets available for photometry and spectroscopy with high-redshift sources (here defined as z > 5) are described along with the template sets used to fit them. The fitting technique is then described in Sect. 3. In Sect. 4, the template sets are evaluated on their ability to both provide photometric redshifts and predict the full SED. Finally, the implications for future surveys are discussed in Sect. 5.
Template sets used.
2 Sample description
Any evaluation of template performance requires a benchmark dataset with robust measurements of properties that template sets can then be asked to predict. This requires spectroscopic observations in addition to the photometry, which will be made available for template fitting. Here, the spectroscopy was drawn from several JWST catalogs, with photometry supplemented by any additional available observations.
The template sets were evaluated based on both redshift prediction and SED feature prediction since a template might excel in one and not the other. This evaluation was thus done with two separate tests and two separate samples.
An SED sample was chosen to determine whether reconstructed SEDs correctly predict observed SEDs. Many of the differences between models lie in the strength of the emission lines, which have been observed to be unexpectedly strong at higher redshifts (Boyett et al. 2024; Trump et al. 2023). Therefore, this test required sufficiently deep spectra to separate the continuum emission from the spectral lines and to measure the continuum shape. This was further complicated by the significant discrepancies in spectral properties from independent spectroscopic catalogs (Mugnai et al. 2024) reporting the same JWST observations. This is likely due to differing assumptions about properties such as slit loss. Therefore, the SED sample was highly restricted to only the objects with clean and simple reduction. The result is a limited but robust test, where negligible future revisions are needed as spectroscopic reductions improve.
A far larger redshift sample was also chosen in order to determine which template sets produced photometric redshifts (zphot) that most closely mirror spectroscopic redshifts (zspec). This spectroscopic sample is more robust since it is only necessary to demonstrate a few emission lines rather than a continuum. In addition, although independent spectroscopic catalogs often report differences in the strength of emission lines, there is a broad agreement on the observed wavelength and thus the redshifts. As a result, the redshift sample is far larger, allowing comprehensive results and subsampling.
2.1 Redshift sample
The redshift sample was used as a benchmark sample to evaluate the accuracy of the photometric redshift. The benchmark sample consists primarily of zspec > 5 objects, which shall henceforth be defined to be high-redshift. However, with practical analysis of high-redshift sources being inseparable to knowing a prior of whether an object is high-redshift in the first place, evaluation of an all-regime sample was also necessary (here cut by zspec > 0.1). Datasets from three surveys were used for this analysis, collecting the following object counts:
114 objects in the high-redshift sample from CEERS: There are 76 637 total objects in The Cosmic Evolution Early Release Science Survey (CEERS; August 30, 2023 – update used; Finkelstein 2023; Bagley et al. 2023; Yang et al. 2021), in a combined dataset with data from the Hubble legacy field (HLF). CEERS employs photometric exposure times between 1.5 ks and 3.1 ks, achieving 5σ per-filter depths between 26.67 magAB and 29.22 magAB (avg. 28.4 magAB), reported with 0.2′ ′ diameter aperture. Photometry includes bands in Near Infrared (NIR) and Mid Infrared (MIR), with additional bands from the HLF, all with varying coverage, as summarized in Figure 1. A combined photometric catalog was provided by the DAWN JWST Archive (DJA)1.
Spectroscopy (Haro et al. 2023) is obtained in parallel using both the micro-shutter assembly (MSA) and wide field slitless spectroscopy (WFSS), providing many robust zspec measurements. A total of 466 objects have zspec>0.1 and were thus included in the all-range redshift sample, and 114 of these have zspec > 5 placing them in the high-redshift sample. The survey, generally having relatively shorter exposures (see Figure 1) but broad wavelength coverage, yields a large and relatively shallow wide-field survey of high-redshift objects.
30 objects in the high-redshift sample from UNCOVER: There are 61648 objects in the Ultradeep NIRSpec and NIRCam ObserVations before the Epoch of Reionization (UNCOVER) catalog (downloaded 2024 March 6; Bezanson et al. 2024; Weaver et al. 2023; Furtak et al. 2023; Fujimoto et al. 2023; Wang et al. 2023) in a combined dataset from the Hubble Frontier Field (HFF; Lotz et al. 2017), and other programs not utilized here. NIRCam measurements have exposures ranging from 9.4 ks to 21.6 ks (average ∼ 15 ks), yielding per-filter 5σ depths of ∼29.5 magAB with variable aperture (0.16′′-0.32′′). Bands were included from NIRCam with additional bands from the HFF, all summarized in Figure 1. The photometric catalog was provided by DJA. Crucially, the survey predominantly covers lensed regions, with expected magnifications between mild values of ∼1.2 and very high values of ∼10 (Bezanson et al. 2024). This yields effective depths up to ∼32 magAB, albeit highly variable within the field.
Spectroscopy in the UNCOVER field includes both prior HST coverage and JWST’s MSA and WFSS observations. This provides robust redshift measurements of 447 objects (zspec > 0.1), and 30 with zspec > 5 (values were collected from the DJA archive).
99 objects in the high-redshift sample from JADES: The JADES catalog contains 94 000 objects in a combined catalog including JWST Advanced Deep Extragalactic Survey (JADES; Bunker et al. 2024; Eisenstein et al. 2023b; Hainline et al. 2024; Rieke et al. 2023; Eisenstein et al. 2023a; D’Eugenio et al. 2025), JWST Extragalactic Medium-band Survey (JEMS; Williams et al. 2023) and the Hubble Legacy Field (HLF) with parts of the Hubble Ultra Deep Field (HUDF; downloaded on 2024 March 6). JADES has mixed exposure times between 8.7 ks and 77.6 ks, achieving 10 σ depths of ∼ 29.7 magAB with 0.2′′ aperture diameter with NIR bands. The adjacent JEMS survey has exposure times of ∼ 23.6 ks, achieving 5σ depth of 23.6 ks with 0.3′′ aperture diameter in MIR bands. The HLF adds additional coverage in optical bands. A summary of band coverage is provided in Figure 1.
Spectroscopy is measured through follow-up observations using JWST’s MSA and from the HST, achieving reliable redshifts for 446 objects with zspec > 0.1 (predominantly from the DJA archive; Brammer 2023c; Heintz et al. 2024). 99 objects have zspec > 5 and were thus included in the high-redshift sample.
JADES includes variable coverage across the survey rather than a fixed number of available bands (e.g., there are 74 objects with 20 bands available). In brief, JADES is a prototypical example of a large “conventional” (non-lensed) JWST survey with deep measurements in NIR bands and additional shallow measurements in MIR bands. Furthermore, the inclusion of MSA metadata allowed the use of several spectra in the SED sample, as described below.
In total, from these three surveys, 143 objects were included in the high-redshift sample, and 1359 objects in the all-regime sample. In the all-regime sample, 466 objects were included from CEERS, 447 from UNCOVER, and 446 from JADES.
 |
Fig. 1 Filters covered in the surveys used and the reported observational depth of individual filters. Solid lines (“—”) indicate JWST NIRCam filters, dashed lines (“- -”) indicate filters from the HST, and dotted lines (“…”) indicate filters from the JWST MIRI instrument. Apertures were set variably according to the Rayleigh criterion formula and thus range from 0.035′′ to 0.81′′. The depth data presented was derived from reported values by survey authors (Weaver et al. 2023; D’Eugenio et al. 2025; Rieke et al. 2023; Hainline et al. 2024; Guo et al. 2013; Bagley et al. 2023; Yang et al. 2023). Some surveys employ in-house processes to the Hubble data and thus report adjusted depths. |
2.2 SED subsample
The high-redshift SED subsample required spectroscopy sufficiently deep and resolved to be able to measure the continuum emission in addition to spectral lines. Specifically, the SED subsample was restricted to spectra from the high-redshift sample with a continuum average signal-to-noise ratio (S/N) ≥ 5, and R > 1000 (where R is the spectral resolution, defined as 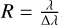 , with Δλ being the smallest distinguishable wavelength at a given wavelength).
, with Δλ being the smallest distinguishable wavelength at a given wavelength).
In addition, due to significant discrepancies between the reduced versions of the same spectra from different catalogs, further restrictions were applied to the SED subsample to minimize these effects (see Fig. 2). These discrepancies are likely due to complicated distortions from neighboring objects, slit misalignment effects, assumptions about the shape of the source, and differing techniques employed to mitigate those differences. To decrease contamination from neighboring sources, only slit spectroscopy was used (specifically MSA). Additionally, objects were constrained to not have neighboring emission within the slit length of ∼0.46′′ (thus angular distance added to the Point Spread Function (PSF) Full Width at Half Maximum (FWHM) radius must be ≥0.46′′). To further simplify the data reduction of a given object, a selection was performed toward “centered” objects, where the majority of the object’s flux must be enclosed in the slit. This minimized the influence of potentially dissimilar methods for accounting for slit-diffraction effects. In practice, this limited the dataset to a subset of JADES where both dimensions of slit-offset were available in the metadata. Finally, sources were limited to only point-like sources (FWHM ≤ 0.15′′).
In summary, the additional cuts made to the SED subsample with the high-redshift sources were as follows:
Combined-grating average S/N ≥ 5 in the rest frame 1000 Å to 5000 Å with R = 1000: this signal strength requirement was necessary in order to meaningfully compare the distribution between the continuum and the line flux from the best-fit and observed SEDs. Eddington bias was introduced as a consequence and should be considered when evaluating the results.
R ≥ 1000: the sample was limited to objects with highly resolved SED measurements to ensure resolved spectral features for the comparison. If available, additional measurements with R < 1000 of the same object (for instance, a measurement using the JWST PRISM disperser) were combined to observations with R>1000, upon the condition that a majority of the SED had spectroscopic coverage with R > 1000.
Only MSA spectroscopy with RFWHM/2 within the slit opening: This ensured the majority of the object flux was within the slit, safeguarding against anomalies in the compensation of slit-edge effects. It also put an upper bound on object radius, effectively limiting sources to point-like sources. This decouples spectra quality from any assumptions of object shape or size in the reduction, while biasing toward lower observed object sizes. This yields a heavy bias toward both object type and distance.
No other object with its RFWHM F444W emission within 0.46′′ of target object (0.46′′ being the length of the microshutters): This was done to prevent other objects from contaminating observations within the same slit. This cut eliminates known cases of two objects located within one slit, but at the same time it removes any mergers or doubly cataloged galaxies.
As with any cuts, these choices introduced biases into the sample, some of which may be significant. This included an Eddington bias with the continuum S/N limit, and a bias toward higher redshift or smaller objects with the point-like source requirement. Perhaps the strongest bias was that the selection was biased against objects such as disk-like galaxies, with higher angular momentum, mass, or both, since these typically have a larger source diameter (Romanowsky & Fall 2012). However, these quality cuts were deemed necessary in order to produce a robust sample.
JADES is the only survey with the required metadata to perform these cuts easily available. The survey measures its spectra with the JWST parallel (MSA). It consists of two deep pointings of 192 ks exposure, 14 “medium-depth” pointings of ∼43 ks, and a shallow set of 15 with ∼14 ks exposure times. The observations of each object include a coarse prism observation with R ∼ 30−300, three medium dispersion R ≈ 1000 gratings, and one R ≈ 2700 grating, giving a combined overlapping coverage over 0.6−5.3 μm.
These quality restrictions yielded six objects for use, summarized in Figure 3. Given the small sample size, it is likely that the SED sample is not fully representative of the high-redshift galaxy population. However, the sample is still sufficient to draw conclusions of ill-fit sources.
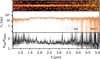 |
Fig. 2 Example of reduction discrepancy between MAST and DJA reductions of JADES ID = 4413 (MAST NIRSpec ID). The object was selected arbitrarily as an example with typical rather than maximal reduction discrepancy. A stacked combination of available dispersers is shown (middle plot), along with the raw 2D Prism slit measurements (logarithmic color-scale, Fv, top plot). The ratio Fv, DJA/Fv,MAST is also color-dependent (bottom plot). The SEDs are sampled at R = 1000. Noteworthy discrepancies include the overall uncertainty difference, and a blue tendency in the DJA reduction as compared to MAST. Furthermore, feature differences around the 1-2 μm and 3-4 μm ranges are present. The reductions used here were collected from: D’Eugenio et al. (2025); Brammer (2023a). |
 |
Fig. 3 Objects in the SED subsample. Selected by the criteria above from JADES Data Release 2. Cutouts are selected from the DJA archive and are produced with the GRIZLI utility (Brammer 2023b). Redshifts, catalog NIRCam ID, and coordinates are noted. F150W, F277W, and F444W was used to make an RGB cutout with equal weighing. The MSA shutter placement is overlaid in orange, with primary source slits marked in magenta. |
2.3 Template sets
The templates included were chosen as a representative set of high-redshift templates in current use. Each of these templates have in their development somewhat started with lower redshift templates, but made modifying choices designed for high-redshift application. Three broad approaches has been taken in choosing which modifications were needed for the high-redshift regime: (1) changes driven by empirical differences between low-redshift and high-redshift SEDs; (2) changes motivated by pen-and-paper theory, predicting the ways that high-redshift galaxies are predicted to be distinct; and (3) changes driven by simulations modeling the ways that high-redshift galaxies are predicted to be distinct.
Perhaps the most straightforward approach is to modify previous templates based on empirical differences between high-redshift galaxies and those at lower redshift. This can both take the form of empirically motivated adjustment, or direct empirical changes. For example, z ≳ 8 galaxies have significantly stronger emission lines than previously predicted (Boyett et al. 2024; Trump et al. 2023). Thus, templates can be modified by re-scaling emission line strengths in order to better match observations, such as in the A22 template (see our Table 1 and Adams et al. 2022). Other similar approaches include BlSFH and L23 (Brammer et al. 2008; Larson et al. 2023), motivated by favoring bluer spectra than predecessors; and CaSFH and T22 (Brammer et al. 2008; Turner in prep.) based on wider varieties of synthetic stellar populations with varying properties. A significant disadvantage of a purely empirical approach is that the templates are not necessarily produced by underlying astrophysical models, making it more difficult to infer astrophysical parameters from the best-fit spectrum. Thus, a model-driven approach would be preferred if it can reproduce observed SEDs equivalently well.
An alternate approach is to use theoretical predictions about the properties of the first galaxies to modify astrophysical parameters, then to use stellar population synthesis codes to turn those parameters into template sets. For example, because the cosmic microwave background temperature at z > 7 exceeds temperatures in galactic star-forming regions, the IMF is expected to be bottom-lighter than previously assumed (Jermyn et al. 2018; Sneppen et al. 2022; Steinhardt et al. 2023). Similarly, an unconstrained fit often produces stellar populations or other features of the SED that must be older than the presumed age of the universe under the standard ΛCDM cosmological paradigm (Steinhardt et al. 2024). Thus, limited template sets have been constructed that are constrained to remain consistent with ΛCDM (BlSFH, CaSFH, S23; Brammer et al. 2008; Steinhardt et al. 2023). T22 has taken a similar approach, adjusting population synthesis parameters to better represent high-redshift populations, with a “bursty” SFH and generally younger stellar populations (Turner 2024 priv. comm.).
Another approach is to derive spectra from the properties of the first galaxies from numerical simulations. Here, template sets are intended to be representative of the properties of a wide array of simulated galaxies, while avoiding the inclusion of properties that are uncharacteristic of simulated results. This approach has been taken by (Larson et al. 2023), with the goal of producing bluer templates to better match observations at high-redshift. These bluer spectra are added to a previous template “tweak_fsps_QSF_v12_v3” (TwSPS; Brammer et al. 2008). TwSPS was also added as a control sample since L23 is an extension to this template set.
Finally, a template originally developed for lower redshift, “eazy_v1.3” (Brammer et al. 2008), was included as a control sample. No modifications have been made to tune this template set to the properties of high-redshift galaxies. Thus, it is expected that if the differences are significant, this lower redshift template set should perform relatively poorly.
Determining which of these approaches are the most successful at reconstructing observed SEDs, is also a tracer for gauging the current state of template fitting and the underlying physical models. If the empirical approaches are better, it would suggest that the current models of the first galaxies are still insufficient at inferring meaningful astrophysical parameters. In this case, only redshifts and properties that can be calculated from the redshift alone, such as luminosity functions, would be meaningful. However, if the theoretical approach is more successful, it would indicate that the major differences between the first galaxies and subsequent evolution are now well understood. Similarly, if simulation-driven approaches are successful, it would indicate that the constrained set of astrophysics included is adequate for the high-redshift regime.
3 Methodology and metrics
As described in Sect. 2, two tests were performed, one of redshift accuracy for the 243-object high-redshift sample and 1359-object all-range sample, and another of full SED reconstruction for the 6-object SED sample. All template fits were done with EAZY, as it provides a platform to exhaustively explore the entire template fit search space up to a few minor nonlinear fit improvements (G. Brammer, private communication).
By default, EAZY uses a luminosity prior function when assessing highest likelihood redshifts. It should be noted that some results might be sensitive the choice of prior (see Brammer et al. 2008 for the specific prior distribution). Here, the default recommended EAZY settings were chosen since those were likely to be the settings most commonly used, and a proper investigation of alternative priors was left to future work.
3.1 Redshift performance
The redshift test followed the methodology outlined in Hildebrandt et al. (2010), in order to use established metrics for testing photometric redshift performance. All comparisons are expressed in terms of the fractional difference between the photometric and spectroscopic redshifts,
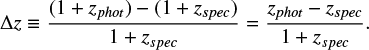 (1)
(1)
Template sets were then compared on three initial criteria, each potentially most important under different circumstances. For the purposes of producing a sample suitable for follow-up spectroscopy, the most important metric is the catastrophic error fraction 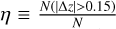 . However, often if photometric redshifts are to be used directly, the scatter σnmad ≡ σ(Δ z) or bias Δbias ≡
. However, often if photometric redshifts are to be used directly, the scatter σnmad ≡ σ(Δ z) or bias Δbias ≡ 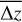 might be more important.
might be more important.
One may naturally expect the set of metrics {Δbias, σnmad, η} to be well correlated, in that a very poor fitting procedure is likely to produce photometric redshifts that perform poorly in all three metrics. Similarly, if a model better describes the underlying astrophysics, it would naturally perform better in all three. However, it is also possible to over-tune a model to a limited dataset such as early JWST observations. In such cases, there will instead be a trade-off between bias and variance (von Luxburg & Schoelkopf 2008; Geman et al. 1992). As models become more complex and use additional parameters to match a training set, the bias decreases. Since additional tuning may not describe the data better, the model will typically produce a higher variance when fit to a new sample. Specific science results might depend almost solely on the bias or variance alone, but for more purposes, a balance of low bias and low variance is optimal.
There is a significant variation between the different catalogs for the same JWST photometry. Therefore, in estimating uncertainties, it was assumed that a significant source of error might be attributed to unspecified systematics within the encompassing JWST photometry pipeline. Estimated errors were assigned to each photometric band and propagated using bootstrapping within the attained errors for each band. Errors were conservatively set to a 2% baseline, to both account for the <1% reported calibration and potential reduction systematics. F277W, F430M, F460M, and F470M, being filters with reported greater systematics, were cautiously assigned 6%, 4%, 4%, 8%, respectively given reported pipeline issues (STScI 2024). These errors are propagated through the fitting procedure to attain distributions of redshift metrics. Average values are reported with 3σ deviations. Combined with the conservative bounds, this ensures that the reported metrics are robust toward even major future systematics mitigation. ≥250 resamples were produced until convergence of the metrics (specifically ∼250, ∼250, ∼350 for UNCOVER, CEERS, JADES respectively).
JADES z > 5 photometric redshift performance metrics.
3.2 SED performance
The SED performance was tested by how well the photometrically reconstructed SEDs from templates reproduced the measured SEDs. In the reconstruction, EAZY might have found incorrect redshifts to be more favorable for reconstructing the SED. To standardize the test, the reconstructed SEDs were specifically chosen to be the best matches at zspec. Here, 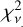 was compared against the observed SED across templates to give a quantitative measure of template performance.
was compared against the observed SED across templates to give a quantitative measure of template performance.
The differences between the observed and reconstructed SEDs comes from two primary sources: (1) spectral features that are unrepresented in template sets; and (2) a lack of information available from the photometric bands with sufficient S/N, as opposed to a higher-resolution spectrum. To determine which was more significant, a secondary fit was produced with information from spectroscopic observations calibrated to photometry, where again the best fit at zspec was obtained. This enabled a more controlled analysis of whether a template represents an object well, as opposed to the photometry-based fit, where other effects such as lacking information, degeneracies or strong covariances can affect the fit.
4 Template performance
Using the samples described in Sect. 2 and methods described in Sect. 3, all eight template sets (Table 1) are evaluated based on their predictive performance in the redshift and SED samples. The results are as follows.
4.1 Redshift analysis
Overall, most of the template sets designed for high-redshift galaxies are broadly successful at using photometry to predict spectroscopic redshifts. Here, they are compared using three datasets with varying survey designs: UNCOVER, with the deepest observations (due to its lensed field) but with fewer bands; JADES, which is not as deep as UNCOVER but has wider photometric coverage; and CEERS, a wide-band but relatively shallow survey, making it the best probe for galaxies near detection thresholds. For all three, the redshift subsample only consists of galaxies with spectroscopic z > 5 since the S23 template sets preferentially do not include templates that would be valid for older (lower redshift) galaxies (subsequently reducing the number of fit parameters at higher redshift).
Previous evaluations have typically focused on the catastrophic error rate, 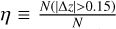 (Hildebrandt et al. 2010). A template set that minimizes the catastrophic error rate is then considered the most useful. However, the template sets considered here have two potential failure modes. A catastrophic error in redshift is what might be termed a silent error since there is no indication given that the photometric redshift is wrong. In addition, several template sets considered here have noisy error modes, in which they are unable to return any photometric redshift because there is no good fit. A noisy error is certainly preferable to a silent error since additional information allows for the selection of a high-purity sample. However, this also leads to a sample with lower completeness, and if the noisy errors are predominantly due to a specific SED shape (which arguably likely is true), quite possibly a biased sample as well. Thus, here two metrics are used, ηf, the catastrophic error fraction in the sample that returns a photometric redshift, and ηc, which includes both silent and noisy errors and is given as a fraction of the complete sample. This distinction is greatest in the two control samples, Ev3 and TwSPS, as they were not designed for high-redshift fitting and thus are unable to return fits for 1−10% of the high-redshift objects (Tables 2, 3, 4).
(Hildebrandt et al. 2010). A template set that minimizes the catastrophic error rate is then considered the most useful. However, the template sets considered here have two potential failure modes. A catastrophic error in redshift is what might be termed a silent error since there is no indication given that the photometric redshift is wrong. In addition, several template sets considered here have noisy error modes, in which they are unable to return any photometric redshift because there is no good fit. A noisy error is certainly preferable to a silent error since additional information allows for the selection of a high-purity sample. However, this also leads to a sample with lower completeness, and if the noisy errors are predominantly due to a specific SED shape (which arguably likely is true), quite possibly a biased sample as well. Thus, here two metrics are used, ηf, the catastrophic error fraction in the sample that returns a photometric redshift, and ηc, which includes both silent and noisy errors and is given as a fraction of the complete sample. This distinction is greatest in the two control samples, Ev3 and TwSPS, as they were not designed for high-redshift fitting and thus are unable to return fits for 1−10% of the high-redshift objects (Tables 2, 3, 4).
For UNCOVER (Fig. 4), the S23 (ηf = 5.0%), and L23 (5.5%) template sets produce the highest-purity redshifts (Table 3). Furthermore, S23 is shown to have the smallest σ and Δ as compared to other template sets. With a complete sample, S23 is thus best for characterizing redshifts in a UNCOVER-like sample. Most of the other template sets with small silent error fractions are unable to return photometric redshifts for 1–3% of the full sample.
For most template sets, the difficulty in constraining photometric redshifts comes from insufficient wavelength coverage rather than from insufficient depth. As a result, with the additional filters available in JADES (Fig. 4), most template sets now return fits for 99% or more of the available sample (Tables 2, 5). Still, the effectively reduced depth means that most template set performs worse than for UNCOVER. L23 (ηf = 8.8%), BlSFH (9.2%), and T22 (9.7%) have significantly lower catastrophic error rates and are thus preferred (Table 2). However, S23 (with ηf = 9.8%) has the smallest RMS error while maintaining high purity. On the entire sample, L23 again has the smallest ηc = 9.1%, although S23 (ηc = 9.9%) still has the smallest RMS error with a less significant difference in η, and therefore may be preferred.
Finally, CEERS is toughest to fit, as every template set has a catastrophic error rate over 22% (Tables 4, 7). Despite the decreased depth, fit return rates are relatively high ∼99% (Table 4). However, all RMS redshift errors are ≥22%. S23 produces the best performance by every metric, returning a fit for every object with ηf ≈ ηc = 22.4%. T22, with ηf = 24.1% and ηc = 25.3%, is the next best choice for a high-purity and completeness sample. Still, no template performs satisfactory for the full CEERS sample. The results for all three datasets are summarized in Table 8.
Given the relatively poor fits, it is worth examining differentiating factors in the CEERS survey. Examining the band coverage (Fig. 1), the inclusion of the MIRI bands stands out. This suggests that the inclusion of MIRI-bands has little to no effect on redshift constraint at this depth. When comparing to JADES, CEERS have many fewer measured bands in the NIR spectrum. Lastly, CEERS has for the most part marginally or significantly lower depths than both UNCOVER and JADES. In summary, significant factors that improve JADES and UNCOVER’s redshift estimation as compared to CEERS, include their higher depth in optical and NIR ranges, and higher high-depth filter-count.
UNCOVER z > 5 photometric redshift performance metrics.
CEERS z > 5 photometric redshift performance metrics.
4.2 Asymmetry in catastrophic redshift errors
Catastrophic redshift errors comes in two types: lower redshift objects scattering to higher redshift and higher redshift objects scattering to lower redshift. Since a common cause of catastrophic errors is an inability to distinguish between Lyman and Balmer breaks (Hovis-Afflerbach et al. 2021; Pirzkal et al. 2013), or low-redshift strong line emitters mimicking high-redshift breaks in photometric data (Atek et al. 2011; Pénin et al. 2015), these errors commonly result in objects being included in or excluded from high-redshift samples. Thus, for a purely photometric study, scattering an object up, would result in the overestimation of the luminosity and mass functions at high redshifts, and similarly an object mistakenly excluded results in the underestimation of such functions. For studies with planned follow-up spectroscopy, false high-redshift targets result in wasted observing time, whereas objects scattered to low redshifts result in incomplete and likely biased samples. Depending upon the specific study, either type of error could be more important to avoid.
A strong asymmetry exists due to relative population sizes, as there are far more galaxies at z ∼ 3−5 than z > 10 which are at the detection limit. For example, if 5% of each population were misclassified, this would result in a high-redshift selection that would be 95% complete; yet, it would also be dominated by low-redshift interlopers due to their relative abundances. An extreme version of this effect occurred in very early JWST studies, in which several z ≳ 15 candidates were selected from photometry, yet none of them was found to lie at these extreme redshifts in follow-up observations (Yan et al. 2022; Castellano et al. 2022; Bunker et al. 2024). Several fitting techniques place a Bayesian prior on the redshift distribution in an attempt to mitigate this effect (including a luminosity prior in EAZY). However, an incorrect prior will produce a biased sample, and an accurate prior is typically only possible at redshifts where complete statistical samples already exist.
JADES z > 0.1 photometric redshift performance metrics.
UNCOVER z > 0.1 photometric redshift performance metrics.
 |
Fig. 4 JADES, CEERS, and UNCOVER template set redshift performance mosaics. The template sets are set against each other in order to compare their accuracy, completeness, and bias in the high-redshift domain (zspec > 5) through η, σnmad, Δbias, and e. Color coding is based on the relative 1 − s + ηf value, with the color scale centered on the median. Points are colored from blue to red after its color index (U − V) in the rest frame. The point markers designate filter coverage, with “×” marking objects lacking four of the five NIRCam filters otherwise in the catalog, “∘” marking objects with next to full NIRCam filter coverage, and “•” marking full NIRCam coverage, along with additional MIRI filters. |
4.2.1 Redshift overestimation
The most common class of high-redshift interlopers are seen in CEERS at zspec ∼4−5, where a Balmer break in dusty starforming galaxies can be mistaken for a Lyman break, leading to a significantly overestimated zphot. Several of these easily mistakable objects have previously been reported (Zavala et al. 2023), where deep millimeter-wave observations have been used to adjust redshifts of CEERS observations. However, the lack of similar interlopers in the JADES and UNCOVER suggests that the additional observational depths and filters in these surveys is the key to avoiding this type of catastrophic error. Specifically, higher depth in the 0.5 μm to 20 μm bands (∼0.09 μm to 0.36 μm in rest-frame) is a noteworthy survey differentiator (especially in JADES). Additionally, the unique addition of Hubble F435W and NIRCam F090W among UNCOVER and JADES (see Fig. 1) could have significantly assisted in breaking the Lyman and Balmer break degeneracy.
Additional catastrophic redshift overestimates are common at zspec < 5 for all catalogs (Fig. 4, Tables 5, 6, 7). Although there is no singular nor common cause that would produce zphot ≫ zspec. However, for these objects as well, it is likely that additional observing time or different observing strategies would mitigate such catastrophic redshift overestimations the need for spectroscopy.
For JADES, these catastrophic overestimates only occur in objects without full filter coverage. This illustrates the importance of broad SED coverage to avoid confusion between the emission lines and spectral breaks. CEERS, with similar filter coverage at lower depths, contains overestimates even for objects with full coverage. Thus, it is a combination of depth and coverage that ensures low catastrophic redshift overestimation rates. Specifically, one can conclude that the JADES&JEMS > 20 filters with depth ≳ 29 should be sufficient to produce a high-purity photometric sample of high-redshift galaxies.
UNCOVER has a distinct lack of similar catastrophic redshift overestimations for all zspec > 1 despite offering a lower number of filters as compared to JADES. With the main other relative difference between the two surveys being effective depth, it suggests that the additional depth also provides sufficient constraint to hinder catastrophic redshift overestimation. The additional effective depth of a lensed field is thus an effective solution to benefit purity in high-redshift selection.
CEERS z > 0.1 photometric redshift performance metrics.
Most successful templates for photometric redshift in different scenarios.
4.2.2 Catastrophic redshift underestimation
The same confusion between Balmer and Lyman breaks also causes high-redshift galaxies to be fit at zphot ≪ zspec. The problem is exacerbated because the highest-redshift objects in any survey, regardless of depth, always lie near the detection threshold, producing low signal-to-noise ratios. Further, for the highest-redshift objects, fewer bands are available with non-zero detections due to the longer observed wavelength of the Lyman break.
Technically, this would be avoided by using template sets that do not contain galaxies with older stellar populations or high extinction since any discernible break would only be fit as a Lyman break by such templates. Thus, by construction, there are fewer catastrophic redshift underestimates produced especially by the S23 template set. However, the same lack of templates with Balmer breaks would result in an overwhelming population of catastrophic redshift overestimates if used without a prior high or redshift assessment. Using S23 as an example, it is clear to see that these young-population templates only are valid for use after a prior demarcation of whether objects are high redshift or not.
Overall, the best procedure for determining photometric redshifts of high-redshift galaxies should therefore be to combine two template sets. First, L23 should be run to produce an initial selection of high-redshift candidates. Of the template sets that include older stellar populations and lower redshift models, it has the fewest catastrophic redshift underestimates. Therefore, it produces the most complete sample of high-redshift candidates. Subsequently, S23 should be run on that restricted sample.
4.3 SED analysis
The templates are also evaluated on their ability to reproduce the full observed SED using the six objects from the SED sample (Fig. 3). Although this is a small sample, the test itself is critical because in order for the properties derived using models to be reliable, these models must satisfactorily reproduce the full SED. If uncertainties are properly calibrated and independent, this would result in a 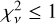 , with respect to either the spectra or the photometry.
, with respect to either the spectra or the photometry.
For photometry, this is indeed what results from template fitting. For five of the six objects in the SED sample, the best-fit reconstructed SEDs have 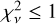 compared against the photometry. This demonstrates that the photometric information has been entirely exhausted. The test presented here determines whether these reconstructions are good approximations to the true SED or whether the additional information from spectroscopy is necessary to produce a meaningful fit.
compared against the photometry. This demonstrates that the photometric information has been entirely exhausted. The test presented here determines whether these reconstructions are good approximations to the true SED or whether the additional information from spectroscopy is necessary to produce a meaningful fit.
The overall performance is summarized in Table 9. Although several templates have comparable performance, L23 and T22 produces the closest match to the observed spectroscopy. The S23 template, which was the most successful at producing complete samples of high-redshift galaxies from photometry, is unable to successfully describe any of the six full spectroscopic SEDs. BISFH has similar behavior, if slightly less extreme.
S23 is unique in its treatment of the high-redshift IMF but does not produce a consistent set of corresponding changes to nebular emission. Nebular emission has been observed to be significantly stronger than anticipated at high redshift (Carnall et al. 2023), so a failure to model the nebular emission properly leads to an inability to match the full SED. However, the salient features used to produce photometric redshifts instead rely on the stellar population and its age, which is improved in the astrophysical model used by S23. An ideal template set would therefore combine the improved models for both the stellar population and nebular emission in a consistent manner.
For most models, the reduced 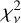 between observed spectroscopy and the SED reconstructed from photometry alone is similar to the best-fit
between observed spectroscopy and the SED reconstructed from photometry alone is similar to the best-fit 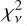 given the full spectrum. Thus, photometry alone is generally sufficient to produce the best-fit reconstruction with a template. Further, EAZY is able to successfully find the right solution within a set of templates, even if that template set does not always produce a good description of the true SED.
given the full spectrum. Thus, photometry alone is generally sufficient to produce the best-fit reconstruction with a template. Further, EAZY is able to successfully find the right solution within a set of templates, even if that template set does not always produce a good description of the true SED.
If this remains true as models improve, it would produce a surprising and optimistic conclusion. For more local galaxies, it has been well established that multi-wavelength observations are necessary to robustly determine the best reconstructed SEDs (Hayward & Smith 2014; Schreiber et al. 2004; Smith & Hayward 2015). As a result, broad wavelength coverage is required to constrain stellar masses, star formation rates, and other physical parameters. However, at high-redshift there is a more limited set of bands with non-zero detections. If these fewer bands are sufficient to robustly determine astrophysical parameters, then purely photometric surveys with JWST will be sufficient to produce mass functions and related studies.
However, at present the most successful models still yield fits with a median 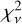 ∼ 2−5, suggesting that even the best current models still are unable to accurately describe the full SED. For object 113585 (NIRCam ID, MAST), the mismatch is particularly strong, with no model producing
∼ 2−5, suggesting that even the best current models still are unable to accurately describe the full SED. For object 113585 (NIRCam ID, MAST), the mismatch is particularly strong, with no model producing 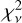 ≲ 50. This appears to be part of a class of extremely blue object that have features not represented in any of the template sets. The L23 reconstruction is a good match for the rest-frame UV emission (Fig. 5). However, this is with the strong exceptions of the Lyman break, and the strong Ly α λ 121.6 (= (1035 ± 60) × 10−19 erg cm−2 s−1) and [CIV] λ 154.9(=(386 ± 30) × 10−19 erg cm−2 s−1) lines (Bunker et al. 2024). In the redder end, emission lines are seen to be stronger in the residuals without consistent over or under estimations between the two fits. The continuum emission is overestimated in the red end, with the effect stronger among the other templates (see Appendix B), making the object bluer than expected by templates.
≲ 50. This appears to be part of a class of extremely blue object that have features not represented in any of the template sets. The L23 reconstruction is a good match for the rest-frame UV emission (Fig. 5). However, this is with the strong exceptions of the Lyman break, and the strong Ly α λ 121.6 (= (1035 ± 60) × 10−19 erg cm−2 s−1) and [CIV] λ 154.9(=(386 ± 30) × 10−19 erg cm−2 s−1) lines (Bunker et al. 2024). In the redder end, emission lines are seen to be stronger in the residuals without consistent over or under estimations between the two fits. The continuum emission is overestimated in the red end, with the effect stronger among the other templates (see Appendix B), making the object bluer than expected by templates.
An example of a strong difference between template sets is 110996 (Trussler et al. 2025), which is fit well by T22 and L23 but poorly by several other template sets (As seen in Figures 7, 6, 8). 110996 has very weak emission lines, a possibility which is only part of the T22 template set. As a result, this object is best fit by T22. All other templates (including to a small degree L23), were forced to fit strong emission lines, leading to incorrect stellar populations and ages.
In summary, a majority of high-redshift galaxies are currently poorly described by every template set evaluated. The size of the discrepancy between observation and model varies, both between template sets and depending upon the shape of the SED. The best template set, L23 and T22, only have 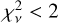 for two of the six objects. Furthermore, the templates with the best performance in determining photometric redshifts did not fit any of the six SEDs successfully. Significant improvements will be needed before template fitting, can be used to derive reliable astrophysical properties. However, for the better fit cases,
for two of the six objects. Furthermore, the templates with the best performance in determining photometric redshifts did not fit any of the six SEDs successfully. Significant improvements will be needed before template fitting, can be used to derive reliable astrophysical properties. However, for the better fit cases, 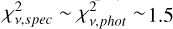 , implying that improved models would enable extracting successful SEDs from purely photometric surveys even at high redshift.
, implying that improved models would enable extracting successful SEDs from purely photometric surveys even at high redshift.
Fit residuals for the SED sample on both photometric and spectroscopic data.
 |
Fig. 5 Best-fit L23 reconstruction for NIRCam-ID = 113585, with zspec = 5.9 and zphot = 5.9. In this fit, z is constrained to zspec. The template is fit both to photometry (in blue) and a concatenated photometric and spectroscopic dataset (orange). JADES 113585 appears to be poorly represented in template sets optimized for high-redshift galaxies, likely due to emission lines and Lyman break physics. |
 |
Fig. 6 Best-fit BlSFH reconstruction for NIRCam-ID = 110996, with zspec = 7.3 and zphot = 7.7. In this fit, z is constrained to zspec. The template is fit to both to photometry (in blue) and a concatenated photometry and spectroscopy dataset (orange). The template produces significantly stronger emission lines than in the observed SED of JADES 110996 since there are no BlSFH templates with minimal emission lines. |
 |
Fig. 7 Best-fit template with L23 on object NIRCam-ID = 110996, with zspec = 7.3 and zphot = 7.7. In this fit, z is constrained to zspec. The template is fit to both photometry (in blue) and a concatenated photometry and spectroscopy dataset (orange). ID denotes the JADES catalog photometric ID, and |
5 Discussion
In summary, if template sets are selected correctly and used on deep datasets, they can fit adequate models for typical high-redshift galaxies. Within the redshift sample, most templates can be trusted to only rarely produce catastrophic redshift errors since the cause of bad fits can often be attributed to poor filter coverage, depth, or both (see Figure 4). Of the templates considered, the S23 template has roughly the best performance when constrained to the high-redshift set (η ∼ 10); however, it must be paired with a prior selection screen, Tables 2, 3, 4. The L23 template is generally the set that performs best in creating such a prior. It performs with a lower, but not great, η ∼ 10%. If a prior is not possible, L23 also has the best rough estimation performance of the templates considered.
The template sets L23 and T22 best represent the full SED for the six high-redshift objects tested, albeit for a small sample that likely does not represent the full range of high-redshift galaxies. Even within the limited sample, it is clear that some classes of objects are not well represented by the current templates. This includes both largely featureless objects, which indicate a class of even lower metallicity objects than has been expected in these templates, and a set of extremely blue objects. Thus, some revision in the astrophysical models producing these templates appears to be required.
High-redshift templates are primarily developed using one of several approaches to choose parameters for SPS models. These can include simulations, astrophysical arguments from first principles, or even empirical constraints. In catalogs with fewer observational constraints (depth, coverage), the most successful redshift predictions come predominantly from templates adopting simple astrophysical models to generate their templates. This includes mainly S23, which is produced primarily from first principles. The more detailed models arising from either more complex astrophysical constraints or numerical simulations produce less reliable photometric redshifts. Thus, one might be tempted to conclude that the additional complexity introduced by these models is a poor description of the true astrophysics of the earliest galaxies.
However, improved observations produce a different picture. In the UNCOVER and CEERS high-redshift samples, S23 and T22 outperform other templates in redshift estimation in many metrics (especially ηf) (Tables 3, 4). In JADES, however, with the increased depth and coverage, S23 no longer produces the fewest catastrophic outliers (Table 2). A closer examination of the objects with incorrect redshifts reveals that with the increased depth in the NIR bands, these simple models are not the best performing models. As measurements improve, it is the more sophisticated models that start to produce the best redshifts.
This can be seen even more strongly when comparing reconstructed SEDs with JWST spectroscopy. The more sophisticated models such as L23 and T22 strongly outperform S23. Some of this might be due to specific missing features, such as damped Lyα, which is not present in any S23 template. However, more generally, this indicates that the simpler models cannot reproduce the full complexity of high-redshift SEDs. This simplicity also avoids complex degeneracies and is thus well suited for photometric redshift estimation from limited information. Still, the fits are poor predictors of the full SED and thus should not be used to estimate other astrophysical properties, such as stellar masses.
The best performance in predicting the full SED comes from models that are empirically motivated to match observations. Thus, both the simpler first principles arguments and more complex simulations appear to still be incomplete descriptions of the earliest galaxies. A natural path toward improvement then comes from modeling galaxies that are poorly represented by templates generated using these techniques.
Perhaps the most intriguing objects are those such as 113585, which is poorly fitted by every template set considered here. Even empirical models fail to fit the extremely blue spectra of 113585, suggesting that it has properties that are uncommon in previous samples at only slightly lower redshifts. One might expect that rather than merely being an individual object, 113585 could be typical of larger classes of z > 10 galaxies. An additional feature of the object is the strong flux from otherwise minor emission lines, with the [HeI]λ587.5 line in object 113585 being the most pronounced (=(25.6 ± 1.5) × 10−19 erg cm−2 s−1.; Bunker et al. 2024) emission, which is not prominent in any of the template sets.
It is particularly surprising that the extremely blue 113585 is not fit well by L23, which had an explicit goal of fitting extremely blue objects when developing the template set. Although one possible explanation is missing astrophysics, another possible explanation could still lie in the data reduction. JWST catalogs produced using different reduction pipelines still exhibit significant differences in the resulting spectroscopy after more than two years since first light (see Fig. 2). Currently, the standard approach still relies on calibrating spectroscopy to photometric observations rather than on an absolute calibration2. Errors in data reduction could also be responsible for the mismatch between observation and theory. If so, any template set empirically tuned to match spectroscopic observations would essentially be overfit to incorrect reductions and would need to be regenerated every time an improvement is made to the reduction pipeline.
It is also possible that templates lack other astrophysics that are significant at higher redshifts. For instance, active galactic nuclei (AGN) type sources might be surprisingly frequent at early times (Scholtz et al. 2025), but because they were not expected to be common, they have generally not been included in high-redshift template sets. As such, it would be worthwhile to examine the redshift and SED fit improvement from inclusions of template spectra that include an AGN or quasar component.
Finally, it is worth noting that because no template set is representative of the full SED for even a majority of high-redshift galaxies, there is no single optimal choice. Rather, the best choice depends on the use case, survey plan, and survey depth. The best basis for producing photometric redshifts from lower-depth photometry is only suitable as the second step in a two-step procedure. Here, a prior screening of whether an object can be classified as high-redshift or not is needed. For multi-wavelength surveys with many bands and high depth, a different basis becomes optimal. And yet, a different basis is best for fitting the full SED, although no basis can fit the majority of the galaxies tested. Thus, significant improvements in both modeling and data reduction will be needed before template fitting can produce robust results with well-constrained astrophysical properties for high-redshift sources. Perhaps additional observations would be beneficial to uncover the astrophysics of objects that cannot currently be fit. Until then, only redshift and luminosity appear to be reliable properties (however, only when specific observational criteria of depth and coverage are imposed), so the primary result of high-redshift surveys are luminosity functions. The SEDs and astrophysical parameters, on the other hand, require further development in the reliability of the spectral pipeline and of our understanding of high-redshift objects to achieve a complete fit of even the current sample.
 |
Fig. 8 Best-fit template with S23 on object NIRCam-ID = 110996, with zspec = 7.3 and zphot = 7.8. In this fit, z is constrained to zspec. The template is fit to both photometry (in blue) and a concatenated photometry and spectroscopy dataset (orange). ID denotes the JADES catalog photometric ID, and |
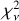
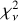
Acknowledgements
The authors would like to thank Charlie Lind-Thomsen, Gabriel Brammer, Gustav Lindstad, Harley Katz, Jack Turner, Nathan Adams, Martin Rey, Ryan Endsley, and Stephen Wilkins for helpful comments, and Vadim Rusakov for code contributions. Some of the data products presented herein were retrieved from the Dawn JWST Archive (DJA). DJA is an initiative of the Cosmic Dawn Center (DAWN), which is funded by the Danish National Research Foundation under grant DNRF140. The Cosmic Dawn Center (DAWN) is funded by the Danish National Research Foundation under grant no. 140. C.S. was supported by research grants (VIL16599, VIL54489) from VILLUM FONDEN.
Appendix A Best SED fits
 |
Fig. A.1 Best-fitting template fit for every object in the SED sample. |
Appendix B Object 113585 fits with additional templates
 |
Fig. B.1 Best fits for object 113585 with various templates. |
References
- Adams, N. J., Conselice, C. J., Ferreira, L., et al. 2022, MNRAS, 518, 4755 [NASA ADS] [CrossRef] [Google Scholar]
- Arrabal Haro, P., Dickinson, M., Finkelstein, S. L., et al. 2023, Nature, 622, 707 [NASA ADS] [CrossRef] [Google Scholar]
- Atek, H., Siana, B., Scarlata, C., et al. 2011, ApJ, 743, 121 [NASA ADS] [CrossRef] [Google Scholar]
- Bagley, M. B., Finkelstein, S. L., Koekemoer, A. M., et al. 2023, ApJ, 946, L12 [NASA ADS] [CrossRef] [Google Scholar]
- Bezanson, R., Labbe, I., Whitaker, K. E., et al. 2024, ApJ, 974, 92 [NASA ADS] [CrossRef] [Google Scholar]
- Boyett, K., Bunker, A. J., Curtis-Lake, E., et al. 2024, MNRAS, 535, 1796 [NASA ADS] [CrossRef] [Google Scholar]
- Brammer, G., 2023a, The Dawn Jwst Archive, https://dawn-cph.github.io/dja/index.html [Google Scholar]
- Brammer, G., 2023b, https://doi.org/10.5281/zenodo.8370018 [Google Scholar]
- Brammer, G., 2023c, https://doi.org/10.5281/zenodo.8319596 [Google Scholar]
- Brammer, G. B., van Dokkum, P. G., & Coppi, P., 2008, ApJ, 686, 1503 [Google Scholar]
- Bunker, A. J., Cameron, A. J., Curtis-Lake, E., et al. 2024, A&A, 690, A288 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Carnall, A. C., McLure, R. J., Dunlop, J. S., et al. 2023, Nature, 619, 716 [NASA ADS] [CrossRef] [Google Scholar]
- Castellano, M., Fontana, A., Treu, T., et al. 2022, ApJ, 938, L15 [NASA ADS] [CrossRef] [Google Scholar]
- D’Eugenio, F., Cameron, A. J., Scholtz, J., et al. 2025, ApJS, 277, 4 [Google Scholar]
- Donnan, C. T., McLeod, D. J., Dunlop, J. S., et al. 2022, MNRAS, 518, 6011 [NASA ADS] [CrossRef] [Google Scholar]
- Eisenstein, D. J., Johnson, B. D., Robertson, B., et al. 2023a, arXiv e-prints [arXiv:2310.12340] [Google Scholar]
- Eisenstein, D. J., Willott, C., Alberts, S., et al. 2023b, arXiv e-prints [arXiv:2306.02465] [Google Scholar]
- Finkelstein, Bagley, Y. 2023, Data from The Cosmic Evolution Early Release Science Survey (CEERS), https://dx.doi.org/10.17909/z7p0-8481 [Google Scholar]
- Fujimoto, S., Haro, P. A., Dickinson, M., et al. 2023, ApJ, 949, L25 [NASA ADS] [CrossRef] [Google Scholar]
- Furtak, L. J., Zitrin, A., Weaver, J. R., et al. 2023, MNRAS, 523, 4568 [NASA ADS] [CrossRef] [Google Scholar]
- Geman, S., Bienenstock, E., & Doursat, R., 1992, Neural Computat., 4, 1 [Google Scholar]
- Guo, Y., Ferguson, H. C., Giavalisco, M., et al. 2013, ApJS, 207, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Hainline, K. N., Johnson, B. D., Robertson, B., et al. 2024, ApJ, 964, 71 [CrossRef] [Google Scholar]
- Haro, P. A., Dickinson, M., Finkelstein, S. L., et al. 2023, ApJ, 951, L22 [NASA ADS] [CrossRef] [Google Scholar]
- Hayward, C. C., & Smith, D. J. B., 2014, MNRAS, 446, 1512 [Google Scholar]
- Heintz, K. E., Watson, D., Brammer, G., et al. 2024, Science, 384, 890 [NASA ADS] [CrossRef] [Google Scholar]
- Hildebrandt, H., Arnouts, S., Capak, P., et al. 2010, A&A, 523, A31 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hovis-Afflerbach, B., Steinhardt, C. L., Masters, D., & Salvato, M., 2021, ApJ, 908, 148 [NASA ADS] [CrossRef] [Google Scholar]
- Jermyn, A. S., Steinhardt, C. L., & Tout, C. A., 2018, MNRAS, 480, 4265 [Google Scholar]
- Larson, R. L., Hutchison, T. A., Bagley, M., et al. 2023, ApJ, 958, 141 [NASA ADS] [CrossRef] [Google Scholar]
- Lotz, J. M., Koekemoer, A., Coe, D., et al. 2017, ApJ, 837, 97 [Google Scholar]
- Mugnai, L. V., Swain, M. R., Estrela, R., & Roudier, G. M., 2024, MNRAS, 531, 35 [Google Scholar]
- Pénin, A., Cuby, J.-G., et al., Clément, B., 2015, A&A, 577, A74 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pirzkal, N., Rothberg, B., Ryan, R., et al. 2013, ApJ, 775, 11 [Google Scholar]
- Rieke, M. J., Robertson, B., Tacchella, S., et al. 2023, ApJS, 269, 16 [NASA ADS] [CrossRef] [Google Scholar]
- Romanowsky, A. J., & Fall, S. M., 2012, ApJS, 203, 17 [Google Scholar]
- Scholtz, J., Maiolino, R., D’Eugenio, F., et al. 2025, arXiv e-prints [arXiv:2311.18731] [Google Scholar]
- Schreiber, N. M. F., van Dokkum, P. G., Franx, M., et al. 2004, ApJ, 616, 40 [CrossRef] [Google Scholar]
- Smith, D. J. B., & Hayward, C. C., 2015, MNRAS, 453, 1597 [NASA ADS] [CrossRef] [Google Scholar]
- Sneppen, A., Steinhardt, C. L., Hensley, H., et al. 2022, ApJ, 931, 57 [NASA ADS] [CrossRef] [Google Scholar]
- Speagle, J. S., Capak, P. L., Eisenstein, D. J., Masters, D. C., & Steinhardt, C. L., 2016, MNRAS, 461, 3432 [NASA ADS] [CrossRef] [Google Scholar]
- Steinhardt, C. L., Kokorev, V., Rusakov, V., Garcia, E., & Sneppen, A., 2023, ApJ, 951, L40 [NASA ADS] [CrossRef] [Google Scholar]
- Steinhardt, C. L., Sneppen, A., Clausen, T., et al. 2024, ApJ, 967, 172 [NASA ADS] [CrossRef] [Google Scholar]
- STScI 2024, NIRCam Imaging Calibration Status, https://jwst-docs.stsci.edu/jwst-calibration-status/nircam-calibration-status/nircam-imaging-calibration-status#gsc.tab=0 [Google Scholar]
- Trump, J. R., Haro, P. A., Simons, R. C., et al. 2023, ApJ, 945, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Trussler, J. A. A., Conselice, C. J., Adams, N., et al. 2025, MNRAS, 537, 3662 [Google Scholar]
- von Luxburg, U., & Schoelkopf, B., 2008, arXiv e-prints [arXiv:0810.4752] [Google Scholar]
- Vujeva, L., Steinhardt, C. L., Jespersen, C. K., et al. 2024, ApJ, 974, 23 [NASA ADS] [CrossRef] [Google Scholar]
- Wang, B., Leja, J., Labbé, I., et al. 2023, ApJS, 270, 12 [Google Scholar]
- Weaver, J. R., Cutler, S. E., Pan, R., et al. 2023, ApJS, 270, 7 [Google Scholar]
- Williams, C. C., Tacchella, S., Maseda, M. V., et al. 2023, ApJS, 268, 64 [NASA ADS] [CrossRef] [Google Scholar]
- Yan, H., Ma, Z., Ling, C., Cheng, C., & Huang, J.-S. 2022, ApJ, 942, L9 [Google Scholar]
- Yang, G., Papovich, C., Bagley, M. B., et al. 2021, ApJ, 908, 144 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, G., Papovich, C., Bagley, M. B., et al. 2023, ApJ, 956, L12 [NASA ADS] [CrossRef] [Google Scholar]
- Zavala, J. A., Buat, V., Casey, C. M., et al. 2023, ApJ, 943, L9 [NASA ADS] [CrossRef] [Google Scholar]
Such as the DAWN JWST archive; https://dawn-cph.github.io/dja/
All Tables
All Figures
|
Fig. 1 Filters covered in the surveys used and the reported observational depth of individual filters. Solid lines (“—”) indicate JWST NIRCam filters, dashed lines (“- -”) indicate filters from the HST, and dotted lines (“…”) indicate filters from the JWST MIRI instrument. Apertures were set variably according to the Rayleigh criterion formula and thus range from 0.035′′ to 0.81′′. The depth data presented was derived from reported values by survey authors (Weaver et al. 2023; D’Eugenio et al. 2025; Rieke et al. 2023; Hainline et al. 2024; Guo et al. 2013; Bagley et al. 2023; Yang et al. 2023). Some surveys employ in-house processes to the Hubble data and thus report adjusted depths. |
| In the text | |
|
Fig. 2 Example of reduction discrepancy between MAST and DJA reductions of JADES ID = 4413 (MAST NIRSpec ID). The object was selected arbitrarily as an example with typical rather than maximal reduction discrepancy. A stacked combination of available dispersers is shown (middle plot), along with the raw 2D Prism slit measurements (logarithmic color-scale, Fv, top plot). The ratio Fv, DJA/Fv,MAST is also color-dependent (bottom plot). The SEDs are sampled at R = 1000. Noteworthy discrepancies include the overall uncertainty difference, and a blue tendency in the DJA reduction as compared to MAST. Furthermore, feature differences around the 1-2 μm and 3-4 μm ranges are present. The reductions used here were collected from: D’Eugenio et al. (2025); Brammer (2023a). |
| In the text | |
|
Fig. 3 Objects in the SED subsample. Selected by the criteria above from JADES Data Release 2. Cutouts are selected from the DJA archive and are produced with the GRIZLI utility (Brammer 2023b). Redshifts, catalog NIRCam ID, and coordinates are noted. F150W, F277W, and F444W was used to make an RGB cutout with equal weighing. The MSA shutter placement is overlaid in orange, with primary source slits marked in magenta. |
| In the text | |
|
Fig. 4 JADES, CEERS, and UNCOVER template set redshift performance mosaics. The template sets are set against each other in order to compare their accuracy, completeness, and bias in the high-redshift domain (zspec > 5) through η, σnmad, Δbias, and e. Color coding is based on the relative 1 − s + ηf value, with the color scale centered on the median. Points are colored from blue to red after its color index (U − V) in the rest frame. The point markers designate filter coverage, with “×” marking objects lacking four of the five NIRCam filters otherwise in the catalog, “∘” marking objects with next to full NIRCam filter coverage, and “•” marking full NIRCam coverage, along with additional MIRI filters. |
| In the text | |
|
Fig. 5 Best-fit L23 reconstruction for NIRCam-ID = 113585, with zspec = 5.9 and zphot = 5.9. In this fit, z is constrained to zspec. The template is fit both to photometry (in blue) and a concatenated photometric and spectroscopic dataset (orange). JADES 113585 appears to be poorly represented in template sets optimized for high-redshift galaxies, likely due to emission lines and Lyman break physics. |
| In the text | |
|
Fig. 6 Best-fit BlSFH reconstruction for NIRCam-ID = 110996, with zspec = 7.3 and zphot = 7.7. In this fit, z is constrained to zspec. The template is fit to both to photometry (in blue) and a concatenated photometry and spectroscopy dataset (orange). The template produces significantly stronger emission lines than in the observed SED of JADES 110996 since there are no BlSFH templates with minimal emission lines. |
| In the text | |
|
Fig. 7 Best-fit template with L23 on object NIRCam-ID = 110996, with zspec = 7.3 and zphot = 7.7. In this fit, z is constrained to zspec. The template is fit to both photometry (in blue) and a concatenated photometry and spectroscopy dataset (orange). ID denotes the JADES catalog photometric ID, and |
| In the text | |
|
Fig. 8 Best-fit template with S23 on object NIRCam-ID = 110996, with zspec = 7.3 and zphot = 7.8. In this fit, z is constrained to zspec. The template is fit to both photometry (in blue) and a concatenated photometry and spectroscopy dataset (orange). ID denotes the JADES catalog photometric ID, and |
| In the text | |
|
Fig. A.1 Best-fitting template fit for every object in the SED sample. |
| In the text | |
|
Fig. B.1 Best fits for object 113585 with various templates. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.