| Issue |
A&A
Volume 694, February 2025
|
|
|---|---|---|
| Article Number | A207 | |
| Number of page(s) | 15 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202452028 | |
| Published online | 14 February 2025 | |
Detecting clusters and groups of galaxies populating the local Universe in large optical spectroscopic surveys
1
European Southern Observatory, Karl Schwarzschildstrasse 2, 85748 Garching bei München, Germany
2
Excellence Cluster ORIGINS, Boltzmannstr. 2, D-85748 Garching bei München, Germany
3
Universitäts-Sternwarte, Fakultät für Physik, Ludwig-Maximilians-Universität, Scheinerstr.1, 81679 München, Germany
4
Max-Planck-Institut für Astrophysik, Karl-Schwarzschildstr. 1, 85741 Garching bei München, Germany
5
Department of Physics & Astronomy, McMaster University, 1280 Main Street W, Hamilton, ON L8S 4M1, Canada
6
International Centre for Radio Astronomy Research, University of Western Australia, M468, 35 Stirling Highway, Perth, WA 6009, Australia
7
ARC Centre of Excellence for All Sky Astrophysics in 3 Dimensions (ASTRO 3D), Australia
8
Tartu Observatory, University of Tartu, Observatooriumi 1, Tõravere 61602, Estonia
9
Estonian Academy of Sciences, Kohtu 6, 10130 Tallinn, Estonia
10
Department of Astronomy, School of Physics and Astronomy, Shanghai Jiao Tong University, Shanghai 200240, China
11
Tsung-Dao Lee Institute, Shanghai Jiao Tong University, Shanghai 200240, China
12
Key Laboratory for Particle Astrophysics and Cosmology (MOE) & Shanghai Key Laboratory for Particle Physics and Cosmology, Shanghai Jiao Tong University, Shanghai 200240, China
13
Universität Innsbruck, Institut für Astro- und Teilchenphysik, Technikerstr. 25/8, 6020 Innsbruck, Austria
14
Department of Astronomy and Steward Observatory, University of Arizona, Tucson, AZ 85721, USA
15
Division of Science, National Astronomical Observatory of Japan, 2-21-1 Osawa, Mitaka, Tokyo 181-8588, Japan
16
INAF – Osservatorio Astronomico di Trieste, Via Tiepolo 11, 34143 Trieste, Italy
17
IFPU – Institute for Fundamental Physics of the Universe, Via Beirut 2, I-34014 Trieste, Italy
18
Leibniz-Institut für Astrophysik Potsdam (AIP), An der Sternwarte 16, 14482 Potsdam, Germany
19
Max Planck Institute for Extraterrestrial Physics, Giessenbachstrasse 1, 85748 Garching, Germany
20
Department of Physics, College of Natural and Mathematical Sciences, University of Dodoma, P.O. Box 338 Dodoma, Tanzania
⋆ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
28
August
2024
Accepted:
22
December
2024
Abstract
Context. With the advent of wide-field cosmological surveys, samples of hundreds of thousands of spectroscopically confirmed galaxy groups and clusters are becoming available. While these large datasets offer a valuable tool to trace the baryonic matter distribution, controlling systematics in the identification of host dark-matter halos and estimating their properties remains crucial.
Aims. We intend to evaluate the predictions of retrieving the population of cluster and group of galaxies using three group-detection methods on a simulated dataset replicating the GAMA survey selection. Our goal is to understand the systematics and selection effects of each group finder, which will be instrumental for interpreting the unprecedented volume of spectroscopic data from SDSS, GAMA, DESI, and WAVES, and for leveraging optical catalogues in the (X-ray) eROSITA era to quantify the baryonic mass in galaxy groups.
Methods. We simulated a spectroscopic galaxy survey in the local Universe (down to z < 0.2 and stellar mass completeness M⋆ ≥ 109.8 M⊙) using a lightcone based on the cosmological hydrodynamical simulation Magneticum. We assessed the completeness and contamination levels of the reconstructed halo catalogues and analysed the reconstructed membership. Finally, we evaluated the halo-mass recovery rate of the group finders and explored potential improvements.
Results. All three group finders demonstrate high completeness levels (> 80%) on the galaxy group and cluster scales, confirming that optical selection is suitable for probing dense regions in the Universe. Contamination at the low-mass end (M200 < 1013 M⊙) is caused by interlopers and fragmentation. Galaxy membership is at least 70% accurate above the group-mass scale; however, inaccuracies can lead to systematic biases in halo-mass determination using the velocity dispersion of galaxy members. We recommend using other halo-mass proxies less affected by contamination – such as total stellar luminosity or mass – to recover accurate halo masses. Further analysis of the cumulative luminosity function of the galaxy members has shown remarkable accuracy in the group finders’ predictions of the galaxy population.
Conclusions. These results confirm the reliability and completeness of the spectroscopic catalogues compiled by these state-of-the-art group finders. This paves the way for studies that require large sets of spectroscopically confirmed galaxy groups and clusters or studies of galaxy evolution in different environments.
Key words: methods: numerical / techniques: spectroscopic / galaxies: clusters: general / galaxies: groups: general
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
In the standard cosmological model, galaxies (or visible matter, in general) are bound to deep dark-matter (DM) potentials, a dense environment that favours the cooling and condensation of baryons, in turn forming cosmological structures (Peebles 1980; Mo et al. 2010). Theoretically, DM halos are the primary drivers of gravitational collapse shaping the evolution of the galaxies they host and their surrounding medium. Numerous observational studies, such as the morphology-density relation (e.g. Dressler 1980), the star formation activity or colour-density relations (Gómez et al. 2003), and the central galaxy-halo mass relation (Moster et al. 2010; Behroozi et al. 2013a, 2019), naturally align with the hierarchical paradigm of structure formation.
Galaxy groups, which are the most common galaxy environments (Eke et al. 2005), are often difficult to identify. For instance, our own Milky Way, with its close companion and dwarf satellites, forms what we would classify as a typical loose group. Furthermore, halo-mass estimates are derived from X-ray or spectroscopic observations. Due to the low X-ray emission and limited member counts in galaxy groups, most studies linking galaxy and gas properties to halo mass focus on extreme environments, such as galaxy clusters.
The intragroup medium in low-mass halos emits primarily through Bremsstrahlung radiation or metal line emissions in the X-rays. Still, detecting this gas at temperatures below 1 − 2 keV has been a significant challenge for previous X-ray surveys, which often lacked the sensitivity or coverage needed for these lower mass ranges (Ponman et al. 1996; Mulchaey 2000; Osmond & Ponman 2004; Sun et al. 2009; Lovisari et al. 2015). This has led to a substantial ‘group desert’ in main scaling relations, making it difficult to study galaxies in groups unless they are among the brightest in X-rays. However, the launch of eROSITA aboard SRG in 2019 promised to change this. The first catalogue based on the eROSITA All Sky Survey (eRASS) (Merloni et al. 2024) and future, deeper data releases covering half the sky are expected to fill this ‘group desert’ in X-ray scaling relations. Nonetheless, deeper analyses from the eROSITA Final Equatorial-Depth Survey (eFEDS) suggest that even at its nominal eRASS:8 depth, eROSITA only detects a small fraction of galaxy groups below halo masses of 1014 M⊙ (Popesso et al. 2024a). Synthetic eROSITA data, derived from Magneticum hydrodynamical simulation lightcones, indicate that eROSITA’s selection function is biased against galaxy groups with lower surface brightness profiles and higher core entropy (Marini et al. 2024). Consequently, future X-ray large-scale surveys may continue to provide a skewed view of the relationship between galaxies, gas, and their host halo masses.
In parallel with the efforts of the X-ray community, the last few decades have seen an increasing number of large (optical) spectroscopic redshift surveys and continuous development of group finder algorithms to use in these surveys. These algorithms extract the galaxy clustering information from highly complete samples, rather than gas distribution, to identify DM halos and infer their masses. As a result of these large-scale surveys, numerous group catalogues have been constructed, including those from the CfA redshift survey (e.g. Geller et al. 1987), the Las Campanas Redshift Survey (e.g. Tucker et al. 2000), the 2dFGRS (e.g. Colless et al. 2001; Yang et al. 2005a; Tago et al. 2006), the high-redshift DEEP2 survey (Gerke et al. 2005), the Two Micron All Sky Redshift Survey (2MASS; e.g. Crook et al. 2007; Díaz-Giménez & Zandivarez 2015; Lu et al. 2016; Lim et al. 2017), zCOSMOS (Wang et al. 2020), and most notably the SDSS (Yang et al. 2007; Tempel et al. 2017), and GAMA (Driver et al. 2022; Robotham et al. 2011). Various group catalogues based on SDSS observations have been developed using the friends-of-friends (FOF) algorithm (e.g. Berlind et al. 2006; Merchán & Zandivarez 2005), the C4 algorithm (e.g. Miller et al. 2005), and the halo-based group finder developed by Yang et al. (2005a) (e.g. Weinmann et al. 2006; Yang et al. 2007, 2021; Duarte & Mamon 2015; Rodriguez & Merchán 2020) and Tempel et al. (2016). While the SDSS group catalogues are limited to the local Universe, mainly at z < 0.2, the deeper GAMA survey, which has a magnitude limit two magnitudes deeper than the SDSS in the r band and a spectroscopic completeness level of 95%, provides a galaxy-group sample based on the FOF algorithm of Robotham et al. (2011) up to z ∼ 0.5. The deeper magnitude limit and the extremely high spectroscopic completeness level enable us to capture the most common galaxy pairs, such as our own Milky Way and the Andromeda galaxy, thus, sampling the most common galaxy environment.
Nevertheless, concerns persist regarding potential contamination in optically selected group samples and uncertainties in their halo-mass measurements. Indeed, while different selection effects might be attributed to different group samples due to the varying depth and selection functions of the spectroscopic galaxy samples on which they are based, large discrepancies might also arise from different approaches to measuring group halo mass (see Wojtak et al. 2018). Some algorithms use velocity-dispersion-based halo-mass estimates (e.g. the GAMA catalogue and the SDSS sample of Tempel et al. 2017), which heavily depend on the galaxies used to estimate the velocity distribution. Others, such as the algorithms by Yang et al. (2005b) and Tinker (2021), rely on different calibrations of the total luminosity or stellar mass-halo mass correlation.
While each of these group finders has been tested on dedicated simulations to compare input and output consistency and estimate uncertainties, a direct comparison of different algorithms based on the same spectroscopic survey is still missing. In the current work, we aim to benchmark the predictions of three optical group detection algorithms (Robotham et al. 2011; Yang et al. 2005a; Tempel et al. 2017) on the same synthetic dataset that mimics the GAMA selection. These group finders have been (or will be) extensively used on SDSS (Yang et al. 2007; Tempel et al. 2014, 2017), GAMA (Driver et al. 2022), DESI (DESI Collaboration 2016), DEVILS (Davies et al. 2018), and WAVES (Driver et al. 2016) data, providing us with an unprecedented volume of spectroscopic data. Naturally, their efficiency can only be calibrated and tested in controlled experiments, when the properties of the associated DM halos are known, for example in mock observations created with hydrodynamical simulations. The goal is to understand the systematics and selection effects for each of the optical group finders and assess their reliability in their predictions (Popesso et al. 2024b). In the eROSITA era (Merloni et al. 2012), the combination of these optical catalogues will help us shed light on the baryonic mass in groups, which remains an ongoing topic of debate today (see, for example, Oppenheimer et al. 2021). Recently, optical selection has been used to stack eROSITA data on SDSS (Zhang et al. 2024) and GAMA (Popesso et al. 2024a,c) galaxy groups that open the doors to probe the X-ray-undetected sources. For this particular experiment, we focused on the performance of the three algorithms in a GAMA-like survey in the local Universe at z < 0.2. However, in the future, we will test the algorithms on a WAVES-like survey at high redshift to check the reliability of the group finders in the more distant Universe.
The paper is structured as follows. In Sect. 2, we present the simulation set and the optical lightcone extracted. Sect. 3 describes the optical halo finders’ run to detect the galaxy groups and clusters. Sect. 4 illustrates the outcome of the detection procedure evaluating completeness, contamination, and halo-mass proxies. Sect. 5 focuses on the optical selection effects and their implications in extragalactic surveys. Finally, Sect. 6 concludes our study, providing a summary of our findings.
2. Simulations
2.1. The Magneticum simulation
The Magneticum Pathfinder simulation1 is an extensive series of cosmological hydrodynamical simulations performed using the TreePM/SPH code P-GADGET3. The latter is an improved version of the publicly available GADGET-2 code (Springel 2005), which also introduces several key advances, such as a higher order kernel function, time-dependent artificial viscosity, and artificial conduction schemes (Dolag et al. 2005; Beck et al. 2016).
Subgrid models account for the unresolved baryonic physics, including radiative cooling (Wiersma et al. 2009), a time-evolving UV background (Haardt & Madau 2001), star formation, stellar feedback (i.e. galactic winds; Springel & Hernquist 2003), and chemical enrichment due to stellar evolution (Tornatore et al. 2007), explicitly tracking multiple elements (i.e. H, He, C, N, O, Ne, Mg, Si, S, Ca, Fe). They also incorporate models for supermassive black-holes (SMBHs) and feedback from active galactic nuclei (AGNs), based on the frameworks developed in Springel (2005), Di Matteo et al. (2005), Fabjan et al. (2010), Hirschmann et al. (2014).
The specific simulation run referenced in this work, known as Box2/hr, tracks the evolution of 2 × 15843 particles in a large cosmological volume with dimensions of (352 h−1 cMpc)3. The particle masses are set at mDM = 6.9 × 108 h−1 M⊙ for DM and mgas = 1.4 × 108 h−1 M⊙ for gas particles. The softening lengths are ϵ = 3.75 h−1 kpc for DM, gas, and black-hole particles, whereas stars have ϵ = 2 h−1 kpc at z = 0.
Post-processing uses a FOF algorithm followed by SubFind (Springel et al. 2001; Dolag et al. 2009) to identify halos and substructures (i.e. galaxies). Additional details on SubFind are provided in Sect. 2.2.
The cosmological parameters used in the simulations follow the WMAP7 values (Komatsu 2010): ΩM = 0.272, Ωb = 0.0168, ns = 0.963, σ8 = 0.809, and H0 = 100 h kms−1 Mpc−1, with h = 0.704.
2.2. Designing the lightcone
The lightcone is extracted from the parent cosmological Box2/hr described above. Its geometrical design is extensively outlined in Marini et al. (2024), where a complementary X-ray catalogue is produced. Here, we provide only the essential information and the differences related to mocking the optical counterpart.
Clusters, groups, and member galaxies are all identified by the halo finder SubFind (Springel et al. 2001; Dolag et al. 2009) in the parent box. SubFind is a refined step in the structure identification procedure after the FOF run (with linking length b = 0.16 times the mean inter-particle distance in the simulation). The algorithm descends along the density gradient given by the particles to find the local maxima and minima of the gravitational potential. Each three-dimensional volume encompassed by local minima is a potential substructure (or subhalo) candidate. In addition, SubFind implements an unbinding procedure, to include only particles that are gravitationally bound to each substructure. This step eliminates particles whose internal energy is positive (unbound particles): if more than a certain minimum number of particles (50) survives the unbinding, the substructure is identified as a genuine subhalo. Therefore, every future reference to clusters and groups in the paper will correspond to the identified FOFs (including the central and satellite galaxies); the member galaxies are the sole bound substructures within. The centre of each halo is identified with the minimum gravitational potential occurring among the member particles, other than a complete set of observables (e.g. stellar mass, halo mass, star formation) computed by integrating the properties of the constituent particles. The lightcone is constructed by extracting random sub-cubes from five different simulation snapshots and arranging them in a geometrical configuration of our choosing, progressing from the most recent snapshot to the most distant. This method can result in abrupt cuts in structures or the absence of galaxies within a cluster or group. However, we verify that these effects do not significantly impact the results. The percentage of lost galaxies is minimal and does not influence the conclusions of the study.
We used the SubFind galaxy and group catalogue as a base to construct the mock galaxy catalogue limited to the local Universe (up to z < 0.2), which covers an area of 30 × 30 deg2. The galaxy mock catalogue stores the observer-frame absolute magnitudes in the SDSS filters (u, g, r, i, z), the observed redshifts, the stellar mass, and the projected position on the sky (i.e. RA, Dec) for each galaxy. Stellar magnitudes (more details in Saro et al. 2006) are calculated assuming a single stellar population model for each star particle (with its initial mass, metallicity, and redshift of formation), an initial mass function (Chabrier 2003), and stellar evolution tracks (Girardi et al. 2000). The absolute rest-frame magnitude completeness is at r = −21. To accurately account for observational uncertainties and incorporate the K correction, the rest-frame magnitudes given by Magneticum have been fitted through a standard SED fitting technique with CIGALE (Yang et al. 2022 and references therein). The best-fit template is then shifted to the observed frame at the galaxy’s redshift, and the magnitudes in the desired filters are recalculated from this. This approach inherently includes the K correction. Furthermore, the observed redshift and stellar masses have errors sampled from a Gaussian distribution with σ = 45 km s−1 and 0.2 dex M⊙, respectively. Additionally, we set 5% of the galaxies to undergo catastrophic failure in the spectroscopic survey (i.e. Δv > 500 km s−1). This design is intended to replicate the spectroscopic completeness of GAMA, thereby providing a benchmark for our pipelines. However, fully mimicking the GAMA catalogue would require applying a magnitude cut, as in a magnitude-limited survey (Driver et al. 2022), which would result in a sample with significant stellar-mass incompleteness for Magneticum. By adopting our approach, we ensure that less than 10% of halos fall below the GAMA magnitude limit, bringing us very close to accurately mimicking the GAMA selection.
The resulting distribution of galaxies in the redshift space of LC30 is illustrated in Fig. 1. Structures such as filaments and voids are present at all redshifts, indicating a variety of environments in which galaxy groups and clusters reside. Magneticum has provided reliable predictions for its simulated galaxy population (e.g. Teklu et al. 2015, 2017, 2023; Remus et al. 2017; Schulze et al. 2017, 2018, 2020; Popesso et al. 2024d; Vladutescu-Zopp et al. 2024) and on the scale of galaxy clusters and groups (see Angelinelli et al. 2022, 2023; Ragagnin et al. 2022; Marini et al. 2024). We limited the galaxy sample to a stellar mass of ≥109.8 M⊙ to ensure completeness for Magneticum’s stellar-mass resolution. However, compared to observational data, the chosen cosmological box Box2/hr shows a significant tension at the massive end of the galaxy stellar-mass function (GSMF). In Fig. 2, we illustrate this comparison between the GSMF from LC30 (with Poisson uncertainty) and Bernardi et al. (2013). Galaxies with log(M⋆/M⊙) > 11.5 are primarily the central galaxies of the simulated galaxy clusters and groups, leading our simulations to predict more massive brightest cluster galaxies (BCGs) and brightest group galaxies (BGGs) compared to observed ones (see also discussion in Ragone-Figueroa et al. 2018).
 |
Fig. 1. Distribution of galaxies in LC30. A stellar mass cut ≥109.8 M⊙ is applied to the galaxy sample. The survey is depicted in the redshift space down to redshift z < 0.2. |
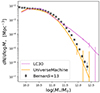 |
Fig. 2. GSMF of the lightcone from Magneticum and UniverseMachine within z < 0.2. The mock catalogues are compared to the results from the SerExp model in Bernardi et al. (2013). |
The tension between observed and simulated stellar masses at these scales has been addressed in many works (e.g. Pillepich et al. 2018; Bassini et al. 2020). Part of the tension is necessarily linked to how different simulations and observations estimate the stellar mass. Frequently, the observed stellar luminosity in a given central aperture is converted with a mass-to-light ratio and extrapolated to larger radii (e.g. Kluge et al. 2020). A less diffuse and more expensive method requires near-infrared luminosity since the K band is a good measure of its underlying stellar mass regardless of how that mass assembled itself (Kauffmann & Charlot 1998). Simulations tend to replicate these results (e.g. by measuring the mass of the star particles within a given central aperture), alleviating such tensions (see Kravtsov et al. 2018, for example); however, an important role is played by the AGN feedback implementation (Ragone-Figueroa et al. 2013) and the uncertainty on the intracluster light contribution (e.g. Gonzalez et al. 2007; Montes 2022).
This effect might bias our analysis if group finders are systematically led to identify the central galaxy due to the massive end of the GSMF distribution. We assess this effect in Appendix A by performing the same analysis on a lightcone that has the same volume but is produced with UniverseMachine (Behroozi et al. 2019, 2023). We created a mock galaxy catalogue to run one of the group finders to test the hypothesis on the assumed GSMF in Magneticum. This is possible since the UniverseMachine mock catalogue derives from empirical models of galaxy formation, specifically calibrated to the most recent observational data and thus tuned to reproduce observables such as the GSMF. Our investigation shows that the findings in Magneticum are robust and are not biased by the central galaxy modelling.
3. Group finders
Here, we briefly present the three group finders we used for this experiment. Groups are identified with a geometrical criterion derived by a FOF in all three methods; however, parameter tuning and halo-mass estimation vary from one another. Although reconstructing halo masses is a crucial step in the parameter exploration, connecting a given true observable with halo mass is not trivial and many efforts have been put into improving and understanding systematics there (e.g. Saro et al. 2013; Old et al. 2014, 2018; Wojtak et al. 2018; Vázquez-Mata et al. 2020). In this paper, we attempt to address all crucial points in such estimates, progressing into a deeper discussion of different halo-mass proxies in Sect. 4.3.
3.1. Tempel et al. (2017)
The group finder described in Tempel et al. (2017) (T17, hereafter) was used to determine the group catalogue in the SDSS data release 12. Here, we list the main steps of the algorithm.
-
The galaxy catalogue is run through a FOF algorithm in redshift space. Due to its nature, the linking lengths are required to be different in the transversal and radial (i.e. along the line of sight) directions. The transversal linking length depends only on the redshift and is calibrated using the mean separation of galaxies in the plane of the sky as described in Tempel et al. (2014). Radial linking length is taken to be ten times the transversal linking length.
-
Next, the algorithm runs a group membership refinement to filter nearby field galaxies or filaments from incorrect group assignments, according to Tempel et al. (2016). The first step involves multimodality analysis to separate multiple components within groups into distinct systems. This is achieved through a model-based clustering analysis using the mclust package in the statistical computing environment R. In this analysis, one coordinate axis is fixed with the line of sight, while the other two are allowed free orientation in the sky plane. This clustering analysis is applied to groups with at least seven galaxies. For each potential number of subgroups (ranging from one to ten), mclust determines the most probable locations, sizes, and shapes of these subgroups. The Bayesian information criterion is used to select the number of subgroups, and each galaxy is assigned to a group based on the highest probability calculated by mclust.
-
The second step in membership refinement involves estimating the group’s radius R200, assuming an NFW profile. A galaxy is excluded from a group if its distance in the sky plane from the group centre exceeds the virial radius, or if its velocity relative to the group centre exceeds the escape velocity at its projected distance from the group centre. This exclusion process is carried out iteratively and usually converges after a few iterations. The refinement process is only applied to groups with at least five members.
-
Finally, the group detection and membership refinement procedures are reiterated for all excluded members to determine if they form separate groups. This step is crucial for detecting small groups that may have been missed during the initial multi-modality analysis.
The derivation of the group masses is only estimated for groups with three or more members. The group finder uses the virial relation M200 ∝ σ2R200, which connects the mass M2002 to the member’s velocity dispersion σ and extension R200. The group extent in the sky and velocity dispersion are not clearly defined for galaxy pairs. However, the estimated group mass is also largely uncertain for other poor groups. By iteratively estimating the velocity dispersion and extension, one can determine the group’s mass.
3.2. Yang et al. (2005)
The group finder described in Yang et al. (2005a) (Y05, hereafter) has been successfully applied to numerous galaxy samples with both spectroscopic and photometric redshifts (e.g. Yang et al. 2005b, 2007, 2021). Its strengths lie in its iterative nature and adaptive filter modelled after the general properties of DM halos. Here, we outline the procedure, while the interested reader can find a more detailed description in Yang et al. (2005a, 2007, 2021).
-
The group finder starts by assuming that all galaxies are tentative groups. Then, abundance matching between the total group luminosity and the halo mass is used to obtain the mass-to-light ratios iteratively.
-
To reduce the influence of the survey magnitude limit on the halo-mass estimation, different redshift bins are used to divide galaxy samples, and their mass-to-light ratios are determined individually. By interpolating in both redshift and group luminosity, the halo mass for each group is derived. Based on the halo mass, the size and velocity dispersion of the underlying DM halo are computed.
-
Based on the DM halo properties, the group finder assigns galaxies assuming that the phase-space distribution of galaxy members follows the DM particles, where the luminosity-weighted centre is used to trace the group centre. Therefore, the number density contrast of galaxies in redshift space around the group centre at redshift zgroup can be written as
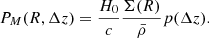 (1)
(1)Here, Δz = z − zgroup, c is the speed of light,
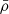 is the average density of the Universe, and Σ(R) is the projected surface density of a spherical NFW halo. The function p(Δz)dΔz describes the redshift distribution of galaxies, which are assumed to be Gaussian.
is the average density of the Universe, and Σ(R) is the projected surface density of a spherical NFW halo. The function p(Δz)dΔz describes the redshift distribution of galaxies, which are assumed to be Gaussian. -
Galaxies with PM ≥ B, where B = 10 is the background level, are assumed to be the member galaxies of this group. If a galaxy fulfils this criterion for more than one group, it is only assigned to the group with the highest PM. If all members of two groups can be assigned to one group according to the above criterion, the two groups are merged into a single group.
-
Once all the galaxies are assigned to groups, the group centres are recomputed and iterated to step 2 until group memberships are stable.
Within the above framework, Yang et al. (2021) extended this algorithm so that it can simultaneously deal with galaxies with either spectroscopic or photometric redshifts. The halo masses estimated via this procedure are calculated within the virial definition described in Bryan & Norman (1998), which uses an overdensity equal to Δ = 180. Therefore, we estimate a correction factor to translate M180 into M200, assuming a model for the concentration (Diemer 2018).
3.3. Robotham et al. (2011)
The group finder outlined in Robotham et al. (2011) (R11, hereafter) processed the galaxies in the GAMA survey to extract a galaxy-group catalogue. The algorithm also relies on a (single-step) FOF procedure to identify groups, with the base choice of radial and projected maximum linking lengths (two free parameters) being scaled on a per-galaxy basis as a function of both local-density contrast (five free parameters) and galaxy brightness (one free parameter).
The free parameters were calibrated against a set of simulated lightcones that reproduced the observed GAMA luminosity function, with only groups with five or more members used to determine the appropriate combination of parameters: five or more members are required for a meaningful estimate of the dynamical velocity dispersion and 50th percentile radius Rad50. In this work, we used the same values adopted for the latest version of the GAMA galaxy group catalogue, except for the parameter controlling the link scaling with galaxy brightness, which we set to zero (i.e. no scaling)3.
The halo properties – such as mass, total luminosity, centre, and velocity dispersion – are estimated from the galaxy members. The centre is iteratively computed within the brightest galaxies in the group (i.e. IterCen in the catalogue). The velocity dispersion is derived with the gapper estimator, (Beers et al. 1990) which underweights the outliers. The halo radius considered is Rad50 containing 50% of the galaxies in the group. These two quantities are used to estimate the halo mass from a dynamical argument, since, in the first order for a virialised system, we expect its dynamical mass to scale as M ∝ σ2R. Robotham et al. (2011) determined the proportionality constant using a semi-empirical estimation from the mock catalogue used to calibrate the fitting parameters, as a function of richness and redshift. The total luminosity needs to account for the missing faint galaxies in the groups; thus, the group finder measures the r band luminosity contained within the survey’s limit and then integrates the global galaxy luminosity function to a nominal faint limit used to correct for the missing flux.
Interestingly, the authors find the group dynamical masses more intrinsically stable (require smaller corrections) as a function of redshift, whilst group luminosities are more stable as a function of multiplicity. Furthermore, the scatter in extrapolated group luminosity is much smaller than seen for dynamical masses (Robotham et al. 2011). Similarly, Vázquez-Mata et al. (2020) found that using the luminosity estimator as a halo-mass proxy returns a better correlation with the true halo mass than the dynamical estimator. We further investigate this issue in Sect. 4.3.
4. Detecting optical groups and clusters
Each group finder is tested on LC30 to assess its reliability in recovering the underlying halo population in a blind study. We provide the spectroscopic catalogue containing the five bands’ magnitudes, the stellar mass, the observed redshift, and the position in the sky as derived in Sect. 2.2.
In Table 1, we report the group numbers from Magneticum and the FOF catalogues, before and after the matching (see next section). The FOF catalogues are based on different definitions of FOF groups: Y05 includes isolated galaxies, whereas R11 and T17 yield groups with a minimum of two members. To ensure equality, we applied a richness cut of ≥2 galaxies in the FOF catalogue before the matching.
Groups in Magneticum and FOF catalogues.
4.1. Matching with the input catalogue
We evaluate the completeness and contamination of the FOF catalogue by matching it with the input-halo catalogue. In the following, we refer to quantities with the following subscripts:
-
DET: referencing the subsample of true detections
-
HALOS: for all the Magneticum groups and clusters
-
SPUR_1: for the spurious sources (i.e. unmatched detections)
-
FOF: for all the group finders’ detections.
The matching procedure is as follows.
-
For all the candidate groups in the FOF catalogue (i.e. groups with a minimum of two galaxies and thus no isolated galaxies), we search for a halo counterpart in LC30. We do not apply any richness cut to the Magneticum catalogue; therefore isolated galaxies are included in the matching since a FOF group could be mistakenly associated with them. We emphasise that this matching would lead to significantly incorrect halo masses; hence, we treat them as incorrect associations in the contaminants. If a detection is within a maximum offset of R200 from the centre, we match it. It is unlikely that the peak stellar emission will be farther away than the virial radius. Additionally, we assess that the estimated redshift is within 3 × 10−3 of the input redshift of the candidate group. This is comparable to the velocity dispersion of a massive cluster. Thus, it is unlikely that groups identified at greater redshift distances are associated with the given halo.
-
If more than one halo falls within the cylindrical volume, we check whether there is one whose mass dominates (i.e. at least six times the second most massive group). If this is the case, we match it; otherwise, we list the primary in the matched catalogue (i.e. the most massive detection), adding the flag FRAG_1. Many of the later ‘undetected’ halos will be among these secondary detections (with the flag FRAG_2) and are lost.
-
In the end, we check whether, according to these criteria, any halo in the input catalogue has been matched more than once to a FOF detection, and, if so, we define the matching as fragmented.
Using this matching procedure, we classify the detected groups into three categories: primary, secondary, and tertiary detections. These are categorised as follows.
-
Primary detections: These are either the unique matches or the most massive halos within the detection’s R200 radius. When fragmentation occurs, the detection with the highest mass is labelled as the primary fragment (FRAG_1).
-
Secondary detections: These are fragments of a larger halo split into smaller detections and are labelled as FRAG_2.
-
Tertiary detections: These are clearly incorrect matches. For example, we often find two (or more) members of FOF groups associated with isolated Magneticum galaxies. This incorrect matching would lead to very biased halo masses. We flag these matches as SPUR_2.
Halos that remain undetected fall into two categories:
-
Halos obscured by a more massive detection within their R200.
-
Halos without any corresponding FOF detection.
These undetected halos are compiled into a single undetected halo catalogue. This categorisation allows us to evaluate the completeness and contamination of our group catalogue by comparing it against the input-halo catalogue.
4.2. Completeness and contamination
Here, we discuss the performance of the group finders in detecting groups and clusters of galaxies in our mock observation. We cross-match the detections with Magneticum’s halo catalogue; nevertheless, we only comment the detections corresponding to halos with a mass of M200 ≥ 1012.5 M⊙ (i.e. due to the halo completeness limit of our simulation) and a minimum of two members in the Magneticum catalogue. Therefore, we define completeness as the ratio between the number of detected halos over the total (per input halo-mass bin), namely
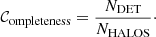 (2)
(2)
It is important to note that this definition does not consider the consistency of galaxy membership in the matching process. Therefore, we redefine completeness as the ratio of detected halos (whose corresponding match includes at least 50% of the member galaxies) to the total. This is referred to as DET + MEMB.
Similarly, we define contamination as the fraction of spurious detections in the FOF catalogue per bin of FOF halo-mass proxy:
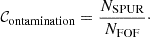 (3)
(3)
Spurious sources can be SPUR_1 (i.e. unmatched FOF groups), SPUR_2 (i.e. incorrect matching), and FRAG_2 (i.e. fragments of larger halos). Often in the literature (e.g. in Yang et al. 2005b) we speak of purity (as opposed to contamination), which is simply defined as 𝒫 = 1 − 𝒞ontamination.
Completeness and contamination are complementary in describing the detection process: completeness defines the accuracy of recovering the input catalogue, whereas contamination clarifies to what extent the FOF catalogue is susceptible to false detections. The optimal case would be completeness equal to one and contamination zero; however, there might be cases where both completeness and contamination are high (e.g. a group finder detects almost all halos at the cost of detecting extra false halos) or low (equivalently, a group finder cannot find any halo, but it does not overpredict halos when there are none). A good group finder should overlook false detections due to improper member classification caused by projection effects or the splitting of large groups and clusters. On the other hand, contamination is derived as a function of the recovered halo mass using the estimates from our best halo-mass proxy (see Sect. 4.3).
Fig. 3 reports our results. In the left panel, we illustrate the completeness of all the primary detections as a function of the true halo mass. For masses above 1013 M⊙, the completeness (solid lines) is at least 80% in all group finders. Alternatively, if completeness is determined solely by the identified halos that have at least 50% of their member galaxies in common with their match (i.e. most of the members overlap), we observe that for masses exceeding 1013 M⊙, the completeness (represented by the dashed lines) is approximately 70%. Galaxy membership is an important step in the group finder; it is also responsible for correctly estimating halo properties – such as halo mass – as discussed in Sect. 4.3, for example. The scatter is mass-dependently increasing for larger masses, which is due to the limited number of halos with M200 > 1014 M⊙. This seems to be especially true for Y05.
 |
Fig. 3. Completeness (left panel) and contamination (right panel) as function of halo mass. The shaded bands mark the 95th binomial confidence interval. The solid lines report the definitions in Eqs. (2)–(3) whereas the dashed lines report stricter ones provided in the main text. We note that the y-axis is different in the two panels. |
In the right panel, we plot the contamination (solid lines) defined in Eq. (3) as a function of the halo mass of the FOF catalogue. This ranges below 10% for all group finders in the regime > 1013 M⊙. These false detections correspond to groups of a few galaxies, aligned in projection, but not necessarily belonging to a DM halo. Furthermore, a fraction of true detections is fragmented and fragmentation can lead to systematic biases in halo properties. If we include FRAG_2 as a contributing spurious source in the definition of contamination (dashed lines), the increase is negligible. In the high-mass end, contamination is mostly due to SPUR_2 sources, namely FOF groups that have been associated with Magneticum halos whose mass is 1 dex larger than the true match. These are examples of incorrect matching, and a true match is beyond the virial radius used to match. Contamination is higher at the low- and high-mass end, especially for T17, reaching an optimal range in the group’s mass regime.
In Fig. 4, we investigate which primary detections are mostly fragmented. In the left panel, we illustrate the halo-mass distribution for the three group finders. Not surprisingly, most of the fragmented sources are the largest ones. From a more quantitative point of view, the average number of fragments as a function of halo mass is a monotonically increasing distribution for all group finders, reaching four to six fragments at the highest masses. Fragmentation will be almost redshift-independent for the group finders. Since fragmentation occurs in all samples and no direct method can shed light on its nature in a FOF catalogue, we advise taking care when considering low-mass FOF groups within the projected R200 of a large group.
 |
Fig. 4. Statistical distribution of fragmentation as function of halo mass (left) and redshift (right panel). The shaded bands mark the 95th binomial confidence interval. This represents the fraction of systems that have one or more fragments in the FOF catalogue. The colours follow the same legend used in Fig. 3. |
In conclusion, we argue that optical group finders best recover the underlying halo population in the mass range 1013 − 1014 M⊙. The most consistent finder seems to be R11, which has high completeness and low contamination for masses larger than 1013 M⊙. However, for scenarios where minimising fragmentation is critical, Y05 may be a better choice across a broader range of halo masses, though potentially at the cost of completeness.
4.3. Halo-mass proxies
A non-trivial task all group finders are required to perform is to recover a reliable halo mass associated with a group of galaxies.
R11 and T17 exploit the virial theorem to connect the velocity dispersion of the member galaxies with M200. Using the velocity dispersion as a proxy might lead to inaccurate results for poor groups since a robust velocity dispersion can only be attained with a minimum number of members. In this regard, Y05 argued that a more reliable estimate can be provided by modelling the mass-to-light ratio from the total luminosity of the member galaxies: such a method seems to be only mildly dependent on the assumed mass-to-light ratio.
Therefore, we compare the scatter of the distribution when using the halo masses included in the FOF catalogue and, when possible, attempt to improve such estimates with other assumptions. Here, we list the different methods used to reconstruct the halo mass.
-
STELLAR MASS OF THE BCG. Locating the BCG of a galaxy cluster or group is a relatively easy task since it is the brightest (often most massive) galaxy in a virialised system. Its properties are tightly connected to the host DM halo properties, given their co-evolution is predicted to be present since at least z ≤ 2 (Ragone-Figueroa et al. 2018). Therefore, correctly identifying the central galaxy can help us infer several host-halo properties with reasonable uncertainty. The intrinsic scatter in the M⋆, BCG − M200 relation has been extensively studied (e.g. Behroozi et al. 2010; Moster et al. 2013; Kravtsov et al. 2018). From this, one can conclude that if the algorithms are accurate enough in recovering at least the central galaxy in a group, we can estimate a roughly consistent host halo mass. Fig. 5 reassures us that the consistency of each group finder in recovering the BCG is high, once the matching is done. We report, with the shaded band, the 95th binomial confidence interval for each sample. The latter is defined as ±1.96(f(1 − f)/N)1/2. Above 1013 M⊙ all algorithms recover at least 90% of all central galaxies, although T17 has a sharp decline at the massive end. In the simulation, the BCG is the most massive galaxy in a halo, generally sitting at the bottom of the gravitational potential. However, the group finders identified the BCG based on its luminosity, with it being the brightest galaxy in the group. These two definitions coincide in most cases; however, incorrect galaxy membership and/or equally bright galaxies in a halo might affect the recovery process. We observe that the recovery rate is high in the group regime for all finders overall, decreasing at the low-mass end (< 1013 M⊙, halos formed by one or two galaxies) or the very high-mass end (> 1014 M⊙ where most fragmentation happens).

Fig. 5. Percentage of BCG correctly identified for each detected halo in the input catalogue. The shaded band marks the dispersion given by the 95th binomial confidence interval.
-
STELLAR MASS OF MEMBER GALAXIES. Another optical halo-mass proxy often used in the literature is the total stellar mass, often estimated by applying a light-to-mass conversion to the galaxy candidate members of a cluster or group (e.g. Andreon et al. 2022). Although robust, this method might suffer from incorrect galaxy member assignments due to projection effects. We extract from Magneticum the scaling relation between total stellar mass and M200 and calibrate the halo-mass proxy.
-
STELLAR LUMINOSITY OF MEMBER GALAXIES. Similarly to the stellar mass, the optical luminosity can be a good tracer of the stellar content of galaxy groups and clusters to derive the host halo mass. In observations, such a scaling relation is particularly useful given that the optical luminosity is directly observable. We use the best-fit relation for the SDSS r band listed in the Appendix Table of Popesso et al. (2007) with a scatter ∼0.20 dex.
Each scaling relation carries an intrinsic scatter σ(log M200|Y), which is the scatter in recovering the logarithmic halo mass at a given proxy Y, generally as a function of the halo mass. Table 2 illustrates the result for the sample of groups in LC30.
Scatter in the halo-mass proxies.
Fig. 6 illustrates the scatter around the 1:1 relation (dashed black line) between the input halo mass and the matched halo mass estimated using different methods (reported at the top of each panel) and for each group finder (going from top to bottom R11, T17, and Y05). Considering that the group finders by R11 and T17 use the velocity dispersion of member galaxies to estimate the halo mass, we mark the data points with richness below five in grey in their leftmost panels. These estimates cannot be considered reliable with this mass proxy. Using the other methods gives us the advantage of keeping these halos since the other mass proxies are less affected.
 |
Fig. 6. Comparison of estimated halo mass in the FOF catalogues as function of true input mass from Magneticum. Each row represents the results from the different group finders: R11, T17, and Y05 from top to bottom. Each panel reports a different halo-mass proxy. The algorithm developed by R11 and T17 estimates the halo mass based on the members’ velocity dispersion; thus we show the distribution of points based on their richness (i.e. at least four members are the coloured points) in their panels. Points are the primary detections. Y05 uses the total stellar luminosity to probe the halo mass; therefore, there is no richness limit. We note that in Y05 the first panel and last thus display the same data. For each distribution, we include a bottom rectangular panel with the scatter (mean and standard deviation) in bins of the true Magneticum’s halo mass. In the text at the top, we report the total mean scatter (in dex). The dashed black line marks the 1:1 relation. |
Each panel reports the relative scatter (mean and standard deviation) of the primary detections as a function of the Magneticum’s true halo masses in the lower section, whereas the number enclosed within the parentheses in the text above reports the mean scatter (in dex). Both metrics show that the stellar luminosity is the mass proxy with the smallest scatter, followed by the total stellar mass.
We can derive two important results from the outcome of this experiment. Firstly, the stellar luminosity of the brightest member galaxies in a cluster or group scales fairly well with the host halo mass. This mass proxy is the best for our catalogue, closely followed by the total stellar mass. Secondly, using either one of these two proxies allows us to keep halos with multiplicity lower than five.
4.4. Consistency of galaxy membership
Another way to quantify the accuracy of the group finders is to investigate the consistency rate in recovering the underlying galaxy member population. In other words, after matching the halo catalogues, we cross-match their galaxy population and assess the impact of interlopers in the catalogue. Interlopers are the main contaminant in optical surveys – affecting the purity of the galaxy members – and they might cause significant damage when assessing the halo mass. Methods to recover the halo mass based on the purity of the galaxy-member sample (e.g. velocity dispersion) will tend to under- or overestimate the mass based on an incorrect assignment.
Given our best mass proxy, we wish to know how significant the latent scatter is in the recovered mass versus input mass as a function of galaxy membership. In other words, provided that FOF detection is matched to a true halo in Magneticum – following the method in Sect. 4.1 – we can find out how comparable their two galaxy member populations are. We define ℱgal as
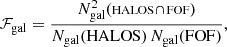 (4)
(4)
where 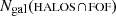 is the number of true galaxy members, and
is the number of true galaxy members, and 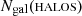 and
and 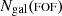 refer to the number of members in the Magneticum and FOF catalogues, respectively. This quantity will be one if all the galaxy members are recovered in the matched catalogue and it will decrease otherwise. In Fig. 7 we show the halo-mass distribution estimated via the scaling relation with the stellar luminosity for all group finders, and we colour-code the data according to ℱgal. Overall, smaller ℱgal corresponds to an equivalently smaller deviation from the 1:1 relation. Low-mass halos (< 1013 M⊙) generally have a high consistency level, since only a few galaxies form them; however, the scatter in the mass in this range is quite large. On the groups and cluster scale, ℱgal decreases, not necessarily hindering the capability of recovering the true halo mass. We find that correctly assigning the most massive satellites (i.e. contributing mostly to the stellar luminosity and mass budget) to the halo is far more important.
refer to the number of members in the Magneticum and FOF catalogues, respectively. This quantity will be one if all the galaxy members are recovered in the matched catalogue and it will decrease otherwise. In Fig. 7 we show the halo-mass distribution estimated via the scaling relation with the stellar luminosity for all group finders, and we colour-code the data according to ℱgal. Overall, smaller ℱgal corresponds to an equivalently smaller deviation from the 1:1 relation. Low-mass halos (< 1013 M⊙) generally have a high consistency level, since only a few galaxies form them; however, the scatter in the mass in this range is quite large. On the groups and cluster scale, ℱgal decreases, not necessarily hindering the capability of recovering the true halo mass. We find that correctly assigning the most massive satellites (i.e. contributing mostly to the stellar luminosity and mass budget) to the halo is far more important.
 |
Fig. 7. Scatter plot of luminosity-based mass (best proxy) and true mass colour-coded for the accuracy of the membership ℱgal for the three group finders. We define ℱgal in Eq. (4). |
Given that the total stellar luminosity is the most accurate halo-mass proxy, we might ask how comparable the member galaxy luminosity functions are: this is a good diagnostic of the distribution of galaxy properties within their DM halos between input and the FOF datasets. To address the issue, we study the conditional luminosity function (CLF, hereafter; Yang et al. 2003; van den Bosch et al. 2003), which describes the average number of galaxies with luminosity within L and L + dL that reside in a halo of mass M200. This formalism allows us to simultaneously address galaxies’ clustering and abundance properties as a function of their luminosity.
We report the results in Fig. 8, expressing the CLF in terms of the rest-frame magnitude in the SDSS r-band ℳr. The bright end of the CLF extends to very low values of ℳr, which is consistent with a broad GSMF (as discussed in Fig. 2) and no dust attenuation in the stellar luminosity. Such a CLF is not comparable with observational data; however, it provides us with insights into the recovery rate of the group finders, since we only need them to be self-consistent with the simulations. Furthermore, it is useful to disentangle the role played by the central galaxies (central panel) and the satellites (right panel) in the total CLF (left panel), since by definition the central galaxy is the brightest galaxy in each DM halo. We split the groups into five halo-mass bins and report the median halo mass in the legend. The solid lines represent the results from the Magneticum halo catalogue, whereas the dotted lines mark the different FOF catalogues, according to the various symbols. We check that including FRAG_2 has a negligible effect on the plots, and only at the low-luminosity end, and therefore we do not include them in the count.
 |
Fig. 8. CLF of all member galaxies (left panel), only central galaxies (central panel), and only satellites (right panel) as function of halo mass. The halo masses are split into five equally spaced logarithmic bins, whose median is reported in the legend. The samples of each group finder are marked with symbols whose legend is listed in the central panel, and the solid lines represent the input distribution from the SubFind halo catalogue. |
We do not observe any significant difference between the input and FOF distributions, except in the highest mass bin, where we see that Y05 tends to overestimate the intermediate luminous satellite population (i.e. in the magnitude range between −24 and −26) as opposed to the other CLFs. This result agrees with the decrease in the completeness at high masses seen in Fig. 3 when accounting for the galaxy membership. Furthermore, splitting the sample between the central and satellite galaxies allows us to disentangle the two peaks in the total CLF in most mass bins. Overall, the group finders provide a reliable distribution of the galaxy properties, which are self-consistent within the simulation. This result demonstrates that the group finders can also offer reliable catalogues of galaxies within different environments.
5. Discussion: Halo-mass distribution
Having discussed the completeness and contamination of each optical catalogue and deriving the best halo-mass proxy, we can now investigate how representative the recovered group and cluster catalogues are of the underlying (true) halo population in LC30.
To further expand the discussion, we include the recovered halo-mass distribution extracted in Marini et al. (2024) from the same simulated lightcone. Marini et al. (2024) created a full mock X-ray observation of the extended ROentgen Survey with an Imaging Telescope Array (eROSITA) in LC30. The real survey will scan the entire X-ray sky both in the soft band (i.e. 0.2 − 2.0 keV) and hard one (i.e. 2.0 − 10 keV), allowing us to probe galaxy clusters and groups at these wavelengths in an unprecedented volume. The mock observation is performed with an exposure time similar to that of the four-year eROSITA All-Sky Survey (eRASS:4). The authors self-consistently modelled the X-ray photons of the hot gas, AGNs, and XRB using PHOX (Biffi et al. 2012, 2013, 2018; Vladutescu-Zopp et al. 2023), which are post-processed by SIXTE (Dauser et al. 2019), the official end-to-end eROSITA simulator, to account for the telescope’s technical features and scanning strategy. Following the spectral decomposition of the eFEDS background emission in Liu et al. (2022), foreground and background components are added. Extended and point-source detections are derived by running the eROSITA Science Analysis Software System (eSASS) on the event files. Each extended detection is cross-matched to the input halo catalogue in a similar manner to what is described in Sect. 4.1. From the X-ray catalogue, the authors derived the expected completeness and contamination of the sample, and the luminosity function and discuss the intrinsic systematics included in such observation.
The comparison between X-ray and optical catalogues allows one to examine different selection effects on a group and cluster scale. With this approach in mind, in Fig. 9 we present the complete halo-mass distribution in LC30 (dashed black line) from the optical surveys (i.e. Y05, R11, and T17) and the X-ray catalogue. Marini et al. (2024) thoroughly discuss the selection effects in the X-ray sample related to the amount of X-ray-emitting hot gas in the halos. Such a bias leads to a higher likelihood detection of gas-rich and low-entropy systems within a fixed halo-mass bin. These represent the vast majority for M200 > 1014 M⊙ and diminish for smaller masses. This effect is evident in our catalogues and causes a drastic decrease in detected halos for M200 < 1014 M⊙. On the other hand, the optical catalogues (using the halo mass derived from the stellar luminosity, and thus allowing us to include objects with low multiplicity) tend to be more complete for lower masses. Overall, the T17 catalogue provides the most accurate halo-mass distribution.
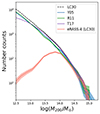 |
Fig. 9. Number-count distribution of halo masses in input catalogue (black dashed line) and the other samples. We report the Poissonian uncertainty with the shaded area. |
We argue that the higher number of statistics offered by the optical selection allow one to study halos at the galaxy group scales with far fewer biases than in X-ray selection. In this context, stacking X-ray observations on optically selected halos will allow the mapping of the distribution of baryonic mass on smaller scales and potentially infer the average properties of the hot gas in galaxy groups. A number of studies have exploited this in the group’s regime and, without the aim of being complete, we name a few here: Crossett et al. (2022), Ota et al. (2023), Popesso et al. (2024a).
6. Summary
The results presented in this study are based on predictions from the Magneticum Pathfinder, a suite of cosmological hydrodynamical simulations. The parent Box2/hr simulation serves to extract a mock spectroscopic catalogue of optical galaxy groups and clusters down to z < 0.2, complete for stellar masses ≥ 109.8 M⊙. Galaxies in the lightcone LC30 (with a field of view of 30 × 30 deg2) are simulated with observed magnitudes in the SDSS bandpass (i.e. u, v, g, r, and i) and an additional K correction. The corresponding group catalogues are constructed using three widely employed group finders (i.e. Robotham et al. 2011; Yang et al. 2005a; Tempel et al. 2017) on the mock galaxy catalogues. We compare the results in terms of completeness, contamination, and recovery of the halo mass.
Our main findings are summarised as follows:
-
The optical catalogues show that at least 80% of the halos with M200 > 1013 M⊙ are recovered (Fig. 3) when membership is not taken into account. Above M200 > 1013 M⊙, the FOF catalogue is ∼70% accurate in assigning the galaxy members to their respective groups, as shown in Fig. 3.
-
Contamination at the low-mass end (i.e. M200 < 1013 M⊙) is due to projection effects and fragmentation, since many FOF groups correspond to FRAG_2 of massive halos in all group finders. Primary fragments (i.e. FRAG_1) have no redshift dependence, albeit there is a significant halo-mass dependence (see Fig. 4).
-
Fragmentation and incorrect galaxy membership might systematically bias the halo-mass estimates by the group finders. This is crucial for group finders that use the velocity dispersion of the galaxy members as a mass proxy via dynamical modelling. Fig. 6 analyses the total stellar mass, central galaxy stellar mass, and r band luminosity to determine the best halo-mass proxy. Stellar luminosity shows the smallest scatter for all three group finders (0.24–0.40 dex), followed by the total stellar mass (0.37–0.49 dex).
-
The recovery rate of the BCG in all groups is also very high (refer to Fig. 5), allowing the calibration of halo masses on the BCG stellar mass with a small scatter.
-
Using stellar luminosity (or total stellar mass) as a halo-mass proxy allows us to estimate halo masses with sufficient accuracy, even when not all member galaxies are correctly associated. This holds if at least some of the most luminous (or most massive) member galaxies are included, which is a common scenario for all group finders.
-
The true and recovered CLFs for centrals and satellites (see Fig. 8) are broadly consistent at all masses, allowing us to further confirm that these group finders are also robust for studies of galaxies as a function of the environment.
-
The halo-mass distribution in Fig. 9 highlights the selection effect in X-ray surveys of galaxy groups. While optical group finders may require tuning for halo-mass calibration, they are powerful tools for discovering and detecting galaxy groups, even in the local Universe.
Our study highlights the suitability of optical (spectroscopic) surveys for detecting galaxy clusters and groups in the local Universe. Interlopers and fragmentation, primarily affecting high-mass halos, can impact our ability to use galaxy members to probe halo masses. However, different mass proxies can mitigate this negative impact and yield complete halo catalogues. Ultimately, the error budget for determining accurate halo masses should account for all possible systematics that cannot be further improved through simulation tuning. A clear understanding of both selection effects in optical data and irreducible systematics in group finders is essential for highly complete, optically selected samples of galaxy groups.
We define MΔ as the mass encompassed by a mean overdensity equal to Δ times the critical density of the universe ρc(z).
The value adopted in GAMA increases the linking lengths for bright galaxies. With the over-prediction on the number of massive (bright) galaxies in LC30 (shown in Figure 2), the group finder merged multiple haloes, leading to a significant over-estimation of the high-mass end of the HMF.
Acknowledgments
The authors thank the referee for the valuable suggestions to the paper. This project has received funding from the European Research Council (ERC) under the European Union’s Horizon Europe research and innovation programme ERC CoG (Grant agreement No. 101045437). KD acknowledges support by the COMPLEX project from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program grant agreement ERC-2019-AdG 882679. The calculations for the Magneticum simulations were carried out at the Leibniz Supercomputer Center (LRZ) under the project pr83li. ET acknowledges funding from the HTM (grant TK202), ETaG (grant PRG1006) and the EU Horizon Europe (EXCOSM, grant No. 101159513). XY acknowledges the support from the National Key R&D Program of China (2023YFA1607800, 2023YFA1607804). NM acknowledges funding by the European Union through a Marie Skłodowska-Curie Action Postdoctoral Fellowship (Grant Agreement: 101061448, project: MEMORY). However, the views and opinions expressed are those of the author alone and do not necessarily reflect those of the European Union or the Research Executive Agency. Neither the European Union nor the granting authority can be held responsible for them. MB acknowledges the support of McMaster University through the William and Caroline Herschel Fellowship.
References
- Andreon, S., Trinchieri, G., & Moretti, A. 2022, MNRAS, 511, 4991 [NASA ADS] [CrossRef] [Google Scholar]
- Angelinelli, M., Ettori, S., Dolag, K., Vazza, F., & Ragagnin, A. 2022, A&A, 663, L6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Angelinelli, M., Ettori, S., Dolag, K., Vazza, F., & Ragagnin, A. 2023, A&A, 675, A188 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bassini, L., Rasia, E., Borgani, S., et al. 2020, A&A, 642, A37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Beck, A. M., Murante, G., Arth, A., et al. 2016, MNRAS, 455, 2110 [Google Scholar]
- Beers, T. C., Flynn, K., & Gebhardt, K. 1990, AJ, 100, 32 [Google Scholar]
- Behroozi, P. S., Conroy, C., & Wechsler, R. H. 2010, ApJ, 717, 379 [Google Scholar]
- Behroozi, P. S., Wechsler, R. H., & Conroy, C. 2013a, ApJ, 770, 57 [NASA ADS] [CrossRef] [Google Scholar]
- Behroozi, P. S., Wechsler, R. H., & Wu, H.-Y. 2013b, ApJ, 762, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Behroozi, P., Wechsler, R. H., Hearin, A. P., & Conroy, C. 2019, MNRAS, 488, 3143 [NASA ADS] [CrossRef] [Google Scholar]
- Behroozi, P., Wechsler, R. H., Hearin, A. P., & Conroy, C. 2023, Astrophysics Source Code Library [ascl:2302.011] [Google Scholar]
- Berlind, A. A., Frieman, J., Weinberg, D. H., et al. 2006, ApJ, 167, 1 [NASA ADS] [Google Scholar]
- Bernardi, M., Meert, A., Sheth, R. K., et al. 2013, MNRAS, 436, 697 [Google Scholar]
- Biffi, V., Dolag, K., Böhringer, H., & Lemson, G. 2012, MNRAS, 420, 3545 [NASA ADS] [Google Scholar]
- Biffi, V., Dolag, K., & Böhringer, H. 2013, MNRAS, 428, 1395 [Google Scholar]
- Biffi, V., Dolag, K., & Merloni, A. 2018, MNRAS, 481, 2213 [Google Scholar]
- Bryan, G. L., & Norman, M. L. 1998, ApJ, 495, 80 [NASA ADS] [CrossRef] [Google Scholar]
- Chabrier, G. 2003, PASP, 115, 763 [Google Scholar]
- Colless, M., Dalton, G. B., Maddox, S. J., et al. 2001, MNRAS, 328, 1039 [NASA ADS] [CrossRef] [Google Scholar]
- Crook, A. C., Huchra, J. P., Martimbeau, N., et al. 2007, ApJ, 655, 790 [Google Scholar]
- Crossett, J. P., McGee, S. L., Ponman, T. J., et al. 2022, A&A, 663, A2 [Google Scholar]
- Dauser, T., Falkner, S., Lorenz, M., et al. 2019, A&A, 630, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Davies, L. J. M., Robotham, A. S. G., Driver, S. P., et al. 2018, MNRAS, 480, 768 [NASA ADS] [CrossRef] [Google Scholar]
- DESI Collaboration (Aghamousa, A., et al.) 2016, arXiv e-prints [arXiv:1611.00036] [Google Scholar]
- Di Matteo, T., Springel, V., & Hernquist, L. 2005, Nature, 433, 604 [NASA ADS] [CrossRef] [Google Scholar]
- Díaz-Giménez, E., & Zandivarez, A. 2015, A&A, 578, A61 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Diemer, B. 2018, ApJ, 239, 35 [NASA ADS] [Google Scholar]
- Dolag, K., Vazza, F., Brunetti, G., & Tormen, G. 2005, MNRAS, 364, 753 [NASA ADS] [CrossRef] [Google Scholar]
- Dolag, K., Borgani, S., Murante, G., & Springel, V. 2009, MNRAS, 399, 497 [Google Scholar]
- Dressler, A. 1980, ApJ, 236, 351 [Google Scholar]
- Driver, S. P., Davies, L. J., Meyer, M., et al. 2016, Astrophys. Space Sci. Proc., 42, 205 [NASA ADS] [CrossRef] [Google Scholar]
- Driver, S. P., Bellstedt, S., Robotham, A. S. G., et al. 2022, MNRAS, 513, 439 [NASA ADS] [CrossRef] [Google Scholar]
- Duarte, M., & Mamon, G. A. 2015, MNRAS, 453, 3848 [Google Scholar]
- Eke, V. R., Baugh, C. M., Cole, S., et al. 2005, MNRAS, 362, 1233 [NASA ADS] [CrossRef] [Google Scholar]
- Fabjan, D., Borgani, S., Tornatore, L., et al. 2010, MNRAS, 401, 1670 [Google Scholar]
- Geller, M. J., Huchra, J. P., & de Lapparent, V. 1987, IAU Symp., 124, 301 [NASA ADS] [Google Scholar]
- Gerke, B. F., Newman, J. A., Davis, M., et al. 2005, ApJ, 625, 6 [NASA ADS] [CrossRef] [Google Scholar]
- Girardi, L., Bressan, A., Bertelli, G., & Chiosi, C. 2000, A&A, 141, 371 [NASA ADS] [Google Scholar]
- Gómez, P. L., Nichol, R. C., Miller, C. J., et al. 2003, ApJ, 584, 210 [Google Scholar]
- Gonzalez, A. H., Zaritsky, D., & Zabludoff, A. I. 2007, ApJ, 666, 147 [Google Scholar]
- Haardt, F., & Madau, P. 2001, arXiv e-prints [arXiv:astro-ph/0106018] [Google Scholar]
- Hirschmann, M., Dolag, K., Saro, A., et al. 2014, MNRAS, 442, 2304 [Google Scholar]
- Kauffmann, G., & Charlot, S. 1998, MNRAS, 297, L23 [NASA ADS] [CrossRef] [Google Scholar]
- Kluge, M., Neureiter, B., Riffeser, A., et al. 2020, ApJ, 247, 43 [NASA ADS] [Google Scholar]
- Klypin, A., Yepes, G., Gottlöber, S., et al. 2016, MNRAS, 457, 4340 [CrossRef] [Google Scholar]
- Komatsu, E. 2010, Class. Quant. Grav., 27, 124010 [CrossRef] [Google Scholar]
- Kravtsov, A. V., Vikhlinin, A. A., Meshcheryakov, A. V., et al. 2018, Astron. Lett., 44, 8 [CrossRef] [Google Scholar]
- Lim, S. H., Mo, H. J., Lu, Y., Wang, H., & Yang, X. 2017, MNRAS, 470, 2982 [NASA ADS] [CrossRef] [Google Scholar]
- Liu, T., Buchner, J., Nandra, K., et al. 2022, A&A, 661, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lovisari, L., Reiprich, T. H., & Schellenberger, G. 2015, A&A, 573, A118 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lu, Y., Yang, X., Shi, F., et al. 2016, ApJ, 832, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Marini, I., Popesso, P., Lamer, G., et al. 2024, A&A, 689, A7 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Merchán, M. E., & Zandivarez, A. 2005, ApJ, 630, 759 [CrossRef] [Google Scholar]
- Merloni, A., Predehl, P., Becker, W., et al. 2012, arXiv e-prints [arXiv:1209.3114] [Google Scholar]
- Merloni, A., Lamer, G., Liu, T., et al. 2024, A&A, 682, A34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Miller, C. J., Nichol, R. C., Reichart, D., et al. 2005, AJ, 130, 968 [Google Scholar]
- Mo, H., van den Bosch, F. C., & White, S. 2010, Galaxy Formation and Evolution (Cambridge, UK: Cambridge University Press) [Google Scholar]
- Montes, M. 2022, Nat. Astron., 6, 308 [NASA ADS] [CrossRef] [Google Scholar]
- Moster, B. P., Somerville, R. S., Maulbetsch, C., et al. 2010, ApJ, 710, 903 [Google Scholar]
- Moster, B. P., Naab, T., & White, S. D. M. 2013, MNRAS, 428, 3121 [Google Scholar]
- Mulchaey, J. S. 2000, ARA&A, 38, 289 [NASA ADS] [CrossRef] [Google Scholar]
- Old, L., Skibba, R. A., Pearce, F. R., et al. 2014, MNRAS, 441, 1513 [Google Scholar]
- Old, L., Wojtak, R., Pearce, F. R., et al. 2018, MNRAS, 475, 853 [Google Scholar]
- Oppenheimer, B. D., Babul, A., Bahé, Y., Butsky, I. S., & McCarthy, I. G. 2021, Universe, 7, 209 [NASA ADS] [CrossRef] [Google Scholar]
- Osmond, J. P. F., & Ponman, T. J. 2004, MNRAS, 350, 1511 [NASA ADS] [CrossRef] [Google Scholar]
- Ota, N., Nguyen-Dang, N. T., Mitsuishi, I., et al. 2023, A&A, 669, A110 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Peebles, P. J. E. 1980, Large-Scale Structure of the Universe (Princeton: Princeton University Press) [Google Scholar]
- Pillepich, A., Nelson, D., Hernquist, L., et al. 2018, MNRAS, 475, 648 [Google Scholar]
- Ponman, T. J., Bourner, P. D. J., Ebeling, H., & Böhringer, H. 1996, MNRAS, 283, 690 [NASA ADS] [CrossRef] [Google Scholar]
- Popesso, P., Biviano, A., Böhringer, H., & Romaniello, M. 2007, A&A, 464, 451 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Popesso, P., Biviano, A., Bulbul, E., et al. 2024a, MNRAS, 527, 895 [Google Scholar]
- Popesso, P., Marini, I., Dolag, K., et al. 2024b, A&A, submitted [arXiv:2411.16546] [Google Scholar]
- Popesso, P., Marini, I., Lamer, G., et al. 2024c, A&A, submitted [arXiv:2411.17120] [Google Scholar]
- Popesso, P., Biviano, A., Marini, I., et al. 2024d, A&A, submitted [arXiv:2411.16555] [Google Scholar]
- Ragagnin, A., Andreon, S., & Puddu, E. 2022, A&A, 666, A22 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ragone-Figueroa, C., Granato, G. L., Murante, G., et al. 2013, MNRAS, 436, 1750 [NASA ADS] [CrossRef] [Google Scholar]
- Ragone-Figueroa, C., Granato, G. L., Ferraro, M. E., et al. 2018, MNRAS, 479, 1125 [NASA ADS] [Google Scholar]
- Remus, R.-S., Dolag, K., & Hoffmann, T. 2017, Galaxies, 5, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Robotham, A. S. G., Norberg, P., Driver, S. P., et al. 2011, MNRAS, 416, 2640 [NASA ADS] [CrossRef] [Google Scholar]
- Rodriguez, F., & Merchán, M. 2020, A&A, 636, A61 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Saro, A., Borgani, S., Tornatore, L., et al. 2006, MNRAS, 373, 397 [NASA ADS] [CrossRef] [Google Scholar]
- Saro, A., Mohr, J. J., Bazin, G., & Dolag, K. 2013, ApJ, 772, 47 [NASA ADS] [CrossRef] [Google Scholar]
- Schulze, F., Remus, R.-S., & Dolag, K. 2017, Galaxies, 5, 41 [Google Scholar]
- Schulze, F., Remus, R.-S., Dolag, K., et al. 2018, MNRAS, 480, 4636 [Google Scholar]
- Schulze, F., Remus, R.-S., Dolag, K., et al. 2020, MNRAS, 493, 3778 [Google Scholar]
- Springel, V. 2005, MNRAS, 364, 1105 [Google Scholar]
- Springel, V., & Hernquist, L. 2003, MNRAS, 339, 289 [Google Scholar]
- Springel, V., White, S. D. M., Tormen, G., et al. 2001, MNRAS, 328, 726 [NASA ADS] [CrossRef] [Google Scholar]
- Sun, M., Voit, G. M., Donahue, M., et al. 2009, ApJ, 693, 1142 [NASA ADS] [CrossRef] [Google Scholar]
- Tago, E., Einasto, J., Saar, E., et al. 2006, Astron. Nachr., 327, 365 [NASA ADS] [CrossRef] [Google Scholar]
- Teklu, A. F., Remus, R.-S., Dolag, K., et al. 2015, ApJ, 812, 29 [Google Scholar]
- Teklu, A. F., Remus, R.-S., Dolag, K., & Burkert, A. 2017, MNRAS, 472, 4769 [NASA ADS] [CrossRef] [Google Scholar]
- Teklu, A., Kudritzki, R.-P., Dolag, K., Remus, R.-S., & Kimmig, L. 2023, ApJ, 954, 182 [NASA ADS] [CrossRef] [Google Scholar]
- Tempel, E., Tamm, A., Gramann, M., et al. 2014, A&A, 566, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tempel, E., Kipper, R., Tamm, A., et al. 2016, A&A, 588, A14 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tempel, E., Tuvikene, T., Kipper, R., & Libeskind, N. I. 2017, A&A, 602, A100 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Tinker, J. L. 2021, ApJ, 923, 154 [NASA ADS] [CrossRef] [Google Scholar]
- Tornatore, L., Borgani, S., Dolag, K., & Matteucci, F. 2007, MNRAS, 382, 1050 [Google Scholar]
- Tucker, D. L., Oemler, A., Jr., Hashimoto, Y., et al. 2000, ApJ, 130, 237 [NASA ADS] [Google Scholar]
- van den Bosch, F. C., Mo, H. J., & Yang, X. 2003, MNRAS, 345, 923 [NASA ADS] [CrossRef] [Google Scholar]
- Vázquez-Mata, J. A., Loveday, J., Riggs, S. D., et al. 2020, MNRAS, 499, 631 [Google Scholar]
- Vladutescu-Zopp, S., Biffi, V., & Dolag, K. 2023, A&A, 669, A34 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vladutescu-Zopp, S., Biffi, V., & Dolag, K. 2024, arXiv e-prints [arXiv:2406.02686] [Google Scholar]
- Wang, K., Mo, H. J., Li, C., Meng, J., & Chen, Y. 2020, MNRAS, 499, 89 [CrossRef] [Google Scholar]
- Weinmann, S. M., van den Bosch, F. C., Yang, X., et al. 2006, MNRAS, 372, 1161 [CrossRef] [Google Scholar]
- Wiersma, R. P. C., Schaye, J., & Smith, B. D. 2009, MNRAS, 393, 99 [NASA ADS] [CrossRef] [Google Scholar]
- Wojtak, R., Old, L., Mamon, G. A., et al. 2018, MNRAS, 481, 324 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, X., Mo, H. J., & van den Bosch, F. C. 2003, MNRAS, 339, 1057 [Google Scholar]
- Yang, X., Mo, H. J., van den Bosch, F. C., et al. 2005a, MNRAS, 356, 1293 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, X., Mo, H. J., van den Bosch, F. C., et al. 2005b, MNRAS, 362, 711 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, X., Mo, H. J., van den Bosch, F. C., et al. 2007, ApJ, 671, 153 [Google Scholar]
- Yang, X., Xu, H., He, M., et al. 2021, ApJ, 909, 143 [NASA ADS] [CrossRef] [Google Scholar]
- Yang, G., Boquien, M., Brandt, W. N., et al. 2022, ApJ, 927, 192 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, Y., Comparat, J., Ponti, G., et al. 2024, A&A, 690, A268 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
Appendix A: Testing the GSMF with UniverseMachine
Some concerns may be raised regarding the limitations of these tests being based on a single simulation. For example, the shape of the GSMF in Fig. 2 – particularly the presence of very massive central galaxies within their host halo mass – might influence the mass proxy derived from the central galaxy.
Here, we benchmark our predictions by re-running the detection and matching procedure outlined in Sect. 3 in a lightcone generated with UniverseMachine (Behroozi et al. 2019). The geometrical configuration is the same (i.e. 30 × 30 deg2 down to z < 0.2 and complete down to M⋆ ≥ 109.8 M⊙), however, the parent simulation Bolshoi-Planck (Klypin et al. 2016) is a DM-only cosmological box 250 h−1 Mpc on a side with 20483 particles which uniquely integrates empirical data to create a detailed and comprehensive representation of galaxy population. The subhalos are identified using ROCKSTAR (Behroozi et al. 2013b)
UniverseMachine models individual galaxies’ star formation rates (SFRs) within their DM halos, by parametrising the maximum circular velocity at peak historic halo mass, the assembly history, and redshift. Parameters describing the SFR and the fraction of quenched galaxies based on these variables are constrained using a variety of observations spanning a wide redshift range (up to z < 10). These observations include galaxy abundances, the cosmic SFR, the fraction of quenched galaxies as a function of galaxy observables, and the auto- and cross-correlation of star-forming and quenched galaxies. As a result, the UniverseMachine produces numerous predictions, including the stellar-to-halo mass relation as a function of redshift, the star formation histories of galaxies, their correlation functions, and statistics on infall and quenching for satellites (Behroozi et al. 2023).
A mock galaxy catalogue generated with this method is constrained by galaxies’ observed stellar mass functions, SFRs (specific and cosmic), quenched fractions, UV luminosity functions, UV-stellar mass relations, IRXUVrelations, auto- and cross-correlation functions (including quenched and star-forming subsamples), and quenching dependence on environment. Although this simulation lacks modelling of the optical emission, the group finders can rely on the 3D spatial properties and masses of galaxies to reconstruct the halo catalogue. Therefore, we test our second-best halo-mass proxy (i.e. the stellar mass of the member galaxies) against the group finder results and discuss the catalogue’s completeness and contamination.
Fig. A.1 illustrates the recovery of the halo mass when using the velocity dispersion (left panel) or the stellar mass of the member galaxies (right panel) for the halo catalogue derived with R11. We use the same legend as in Fig. 6 to provide an easy comparison between the two. The scatter is larger (i.e. 0.71) than when using the group finder with Magneticum (0.35), nevertheless when using the stellar mass as a mass proxy, it becomes comparable. We argue that the systematically higher stellar mass function observed in Magneticum does not imply a better recovery of the halo mass when using the stellar mass as a proxy.
Fig. A.2 displays the completeness and contamination levels found for the halo catalogue (in the DET case, see the main text in Sect. 4.2). Completeness and contamination confirm our previous results for galaxy groups and clusters.
 |
Fig. A.1. Scatter plot of halo-mass distribution when using the group finder’s method in R11 (i.e. the member galaxies’ velocity dispersion; left panel) and the stellar mass (right panel). The legend is the same as in Fig. 6. |
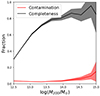 |
Fig. A.2. Completeness and contamination for the input halo mass from the UniverseMachine mock catalogue run with R11. The completeness and contamination are calculated using only the halo matching, with no restriction on the membership (i.e. DET). The shaded bands mark the dispersion given by the Poissonian error. |
All Tables
All Figures
|
Fig. 1. Distribution of galaxies in LC30. A stellar mass cut ≥109.8 M⊙ is applied to the galaxy sample. The survey is depicted in the redshift space down to redshift z < 0.2. |
| In the text | |
|
Fig. 2. GSMF of the lightcone from Magneticum and UniverseMachine within z < 0.2. The mock catalogues are compared to the results from the SerExp model in Bernardi et al. (2013). |
| In the text | |
|
Fig. 3. Completeness (left panel) and contamination (right panel) as function of halo mass. The shaded bands mark the 95th binomial confidence interval. The solid lines report the definitions in Eqs. (2)–(3) whereas the dashed lines report stricter ones provided in the main text. We note that the y-axis is different in the two panels. |
| In the text | |
|
Fig. 4. Statistical distribution of fragmentation as function of halo mass (left) and redshift (right panel). The shaded bands mark the 95th binomial confidence interval. This represents the fraction of systems that have one or more fragments in the FOF catalogue. The colours follow the same legend used in Fig. 3. |
| In the text | |
|
Fig. 5. Percentage of BCG correctly identified for each detected halo in the input catalogue. The shaded band marks the dispersion given by the 95th binomial confidence interval. |
| In the text | |
|
Fig. 6. Comparison of estimated halo mass in the FOF catalogues as function of true input mass from Magneticum. Each row represents the results from the different group finders: R11, T17, and Y05 from top to bottom. Each panel reports a different halo-mass proxy. The algorithm developed by R11 and T17 estimates the halo mass based on the members’ velocity dispersion; thus we show the distribution of points based on their richness (i.e. at least four members are the coloured points) in their panels. Points are the primary detections. Y05 uses the total stellar luminosity to probe the halo mass; therefore, there is no richness limit. We note that in Y05 the first panel and last thus display the same data. For each distribution, we include a bottom rectangular panel with the scatter (mean and standard deviation) in bins of the true Magneticum’s halo mass. In the text at the top, we report the total mean scatter (in dex). The dashed black line marks the 1:1 relation. |
| In the text | |
|
Fig. 7. Scatter plot of luminosity-based mass (best proxy) and true mass colour-coded for the accuracy of the membership ℱgal for the three group finders. We define ℱgal in Eq. (4). |
| In the text | |
|
Fig. 8. CLF of all member galaxies (left panel), only central galaxies (central panel), and only satellites (right panel) as function of halo mass. The halo masses are split into five equally spaced logarithmic bins, whose median is reported in the legend. The samples of each group finder are marked with symbols whose legend is listed in the central panel, and the solid lines represent the input distribution from the SubFind halo catalogue. |
| In the text | |
|
Fig. 9. Number-count distribution of halo masses in input catalogue (black dashed line) and the other samples. We report the Poissonian uncertainty with the shaded area. |
| In the text | |
|
Fig. A.1. Scatter plot of halo-mass distribution when using the group finder’s method in R11 (i.e. the member galaxies’ velocity dispersion; left panel) and the stellar mass (right panel). The legend is the same as in Fig. 6. |
| In the text | |
|
Fig. A.2. Completeness and contamination for the input halo mass from the UniverseMachine mock catalogue run with R11. The completeness and contamination are calculated using only the halo matching, with no restriction on the membership (i.e. DET). The shaded bands mark the dispersion given by the Poissonian error. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.