| Issue |
A&A
Volume 693, January 2025
|
|
|---|---|---|
| Article Number | A256 | |
| Number of page(s) | 27 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202451073 | |
| Published online | 23 January 2025 | |
Stellar parameter prediction and spectral simulation using machine learning
A systematic comparison of methods with HARPS observational data★
1
Department of Cybernetics, Czech Technical University in Prague,
Czech Republic
2
European Southern Observatory,
Karl-Schwarzschild-Str. 2,
85748
Garching,
Germany
★★ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
12
June
2024
Accepted:
4
November
2024
Abstract
Aims. We applied machine learning to the entire data history of ESO’s High Accuracy Radial Velocity Planet Searcher (HARPS) instrument. Our primary goal was to recover the physical properties of the observed objects, with a secondary emphasis on simulating spectra. We systematically investigated the impact of various factors on the accuracy and fidelity of the results, including the use of simulated data, the effect of varying amounts of real training data, network architectures, and learning paradigms.
Methods. Our approach integrates supervised and unsupervised learning techniques within autoencoder frameworks. Our methodology leverages an existing simulation model that utilizes a library of existing stellar spectra in which the emerging flux is computed from first principles rooted in physics and a HARPS instrument model to generate simulated spectra comparable to observational data. We trained standard and variational autoencoders on HARPS data to predict spectral parameters and generate spectra. Convolutional and residual architectures were compared, and we decomposed autoencoders in order to assess component impacts.
Results. Our models excel at predicting spectral parameters and compressing real spectra, and they achieved a mean prediction error of ~50 K for effective temperatures, making them relevant for most astrophysical applications. Furthermore, the models predict metallicity ([M/H]) and surface gravity (log g) with an accuracy of ~0.03 dex and ~0.04 dex, respectively, underscoring their broad applicability in astrophysical research. Moreover, the models can generate new spectra that closely mimic actual observations, enriching traditional simulation techniques. Our variational autoencoder-based models achieve short processing times: 779.6 ms on a CPU and 3.97 ms on a GPU. These results demonstrate the benefits of integrating high-quality data with advanced model architectures, as it significantly enhances the scope and accuracy of spectroscopic analysis. With an accuracy comparable to the best classical analysis method but requiring a fraction of the computation time, our methods are particularly suitable for high-throughput observations such as massive spectroscopic surveys and large archival studies.
Key words: methods: data analysis / methods: statistical / techniques: spectroscopic / stars: fundamental parameters / stars: statistics
Based on data obtained from the ESO Science Archive Facility with DOI(s): https://doi.eso.org/10.18727/archive/33
© The Authors 2025
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Deriving reliable source parameters from very large sets of spectra has been rapidly gaining importance as the amount of such data massively increases, for example, through dedicated observational campaigns and/or data piling up in public archives. Perhaps the most notable case is the analysis of spectra from the ESA Gaia mission, as it has provided the largest homogeneously observed stellar spectral sample to date (470 million stars with spectra in Data Release 3; Recio-Blanco et al. 2023).
Manual analyses of such large datasets are “de facto” impossible, and automatic techniques need to take their place. As with any data analysis, it is imperative that the associated uncertainties, random and systematic, as well as the limitations of the methodologies are thoroughly understood and quantified so that the results can be reliably used, including by researchers who have not participated in their generation. Also, the methods need to be computationally efficient in order to cope with the correspondingly large data volumes in terms of the number of individual spectra and their sheer size. This, of course, is in addition to the need to deliver precision and accuracy that are competitive with the best results available in the literature.
In this research, we use machine learning (ML) to interpret spectral data, focusing on key physical and observational parameters as our primary interest. These spectral parameters include temperature, surface gravity, radial velocity, metallicity, airmass, and barycentric Earth radial velocity. Within our ML framework, these spectral parameters are treated as “labels,” and they are the outcomes our model is designed to predict.
We chose the public catalog of observations from the HARPS instrument at the ESO La Silla Observatory for our study. This dataset is accessible through the ESO Science Archive1 and is continually updated as the instrument remains in active operation. As per the nature of the instrument, the targets are stars in the solar neighborhood mostly originally observed with the intention of searching for planets around them. Our study does not focus on this particular aspect but instead on the determination of the physical parameters of the stars. The sample is particularly well suited for this since given the relatively small distance from Earth to the targets, they have been well studied in the literature, and thus there is an extensive set of physical parameters that can be used as labels to train the networks with. Also, the spectra themselves are extremely rich in information. Due to the high spectral resolution and broad wavelength coverage of HARPS, a normal stellar spectrum displays hundreds of features (absorption lines).
Machine learning techniques have experienced a rise in popularity in the past several years, being promising tools for analyzing astronomical spectra (as well as other types of astronomical data). Once trained, the methods can be applied to large datasets, usually in a computationally efficient way. Many trained models exist, but their inner workings are not always clear, so they frequently resemble black boxes. Moreover, distinct techniques are frequently utilized for specific datasets, which complicates the disentanglement of their individual roles and impacts.
Typically, ML algorithms offer a large set of customizable options that must be tuned to get optimal results. This can be a confusing and daunting task. Here, we have pursued a systematic approach by comparing different ML algorithms and setups and applying them to the same dataset. Our goal is to find a set of principles regarding how to navigate through these options and propose a practical methodology that can be applied to other similar investigations. To achieve this goal, we aim to provide objective and reproducible results, tracing the effects of the input assumptions and setup choices on the output by exploring a representative set of techniques and ML parameters. Crucially, these techniques and parameters include the number of labels available for training. Since labels may not always be copiously accessible, they will be, in many cases, the limiting factor to the attainable accuracy.
Our primary objective is to predict stellar parameters, a task we call “label prediction.” Our secondary objective is to generate realistic synthetic spectra, a task we call “ML simulation,” to clearly distinguish from the traditional physics-based simulations based on solving the transfer equations in the stellar atmospheres. We are interested in solving these tasks jointly with models that can harness multiple sources of information: the data itself, in order to circumvent the challenging task of obtaining enough reliable labels for supervised learning; catalog data, to form a semantically meaningful latent space directly; and synthetic data with uniform distributions of spectral parameters, which can serve as an alternative strategy to deal with a lack of labels.
We work under the assumption that label prediction and ML simulation are related tasks. Therefore, a joint model capable of performing both tasks simultaneously could outperform models that specialize in these tasks separately. Lastly, we hypothesize that the model can benefit from the additional information provided by the synthetic data, which can be used to regularize the model and improve its generalization capabilities.
The paper is organized as follows. Section 2 presents the problem and explains in detail the methods used. Section 3 covers the data, its augmentation, our learning approach, and the metrics employed. Section 4 presents the experimental results, while Sect. 5 offers a discussion of these results. Finally, Sect. 6 summarizes the conclusions of the paper and explores possible future research directions.
2 Machine learning methods
This section provides a concise overview of the ML models and methods we employ to achieve our objectives, as well as alternative, state-of-the-art models. We begin by defining fundamental ML terminology and mathematical notation relevant to our experiments. Next, we clarify our objectives by defining the inference tasks for label prediction and ML simulation. Subsequently, we formalize the learning problem associated with these inference tasks. Finally, we introduce specific ML models that we use to address the inference tasks.
2.1 Machine learning preliminaries
In this section we explain the relevant concepts and terminology that are essential to understand the following text. We also investigate the application of ML techniques for label prediction and ML simulations. We specifically examine the use of interpretable unsupervised models and how to combine them with supervision to enhance performance.
We start with classic “supervised learning” (Murphy 2022, p. 1) as a basic framework to extract labels from spectral data. This involves the application of an ML model learned from data annotated by experts, which can then be used to predict parameters for previously unseen data. Supervised learning has seen wide-ranging applications in astronomy, such as galaxy morphology classification (Cavanagh et al. 2021), star-galaxy separation (Muyskens et al. 2022), and transient detection and classification (Mahabal et al. 2017). These works often employ methods such as random forests and neural networks. An overview of supervised learning in astronomy is presented in (Baron 2019).
The estimation of physical parameters from spectra has been done in the literature using supervised learning methods, employing linear regression (Ness et al. 2015), neural networks (Fabbro et al. 2018; Leung & Bovy 2019), or a combination of classic synthetic models of spectra and simple neural networks (Ting et al. 2019). However, typical supervised approach is inherently limited by the amount and quality of annotated data. Data annotation is often tedious and time-consuming, and it is not always possible to obtain reliable labels (Gray & Kaur 2019).
“Unsupervised learning” methods (Murphy 2022, p. 14) are appealing due to their ability to discover inner structures or patterns in data without relying on labels. These learned representations attempt to capture essential data features and can be beneficial in various tasks, such as clustering or reconstruction. Although representations may capture the underlying patterns of the data, there is no guarantee that they align with our human understanding or are easily interpretable in specific contexts, such as spectral parameters (Gray & Kaur 2019; Sedaghat et al. 2021).
Autoencoders (AEs) are a key technique in unsupervised learning that focus on learning a low-dimensional representation of high-dimensional input data (Murphy 2022, p. 675). AEs consist of two parts: an encoder and a decoder. The encoding process involves passing the data through a “bottleneck” a middle part of the network where the data are transformed into a “latent representation.”
To ensure that the latent representation is useful and the network does not learn merely an identity mapping, some form of regularization must be applied to the bottleneck. In this paper, we achieve compression of the input by choosing a bottleneck that is much smaller than the input (bottleneck autoencoder; Murphy 2022, p. 667).
The latent representation is crucial for data reconstruction and analysis, as it encodes essential underlying features for these tasks. The space composed of all possible latent representations is called the “latent space.” The decoding process attempts to reconstruct the input from its latent representation, which is the learning objective of the AEs. AEs determine the optimal latent space without any supervision, and the resulting latent space is optimal vis-à-vis the reconstruction of the input. This process does not require any labeled data at any step. AEs are used for denoising (Murphy 2022, p. 677), dimensionality reduction, and data compression (Murphy 2022, p. 653).
However, the latent space of AEs poses several challenges. One key issue, as mentioned, is the lack of a guarantee to extract meaningful variations in the data (Leeb et al. 2022). This is informally known as interpretability since the meaningfulness of latent space is subjective with respect to the target application. Additionally, the deterministic nature of AEs, where each input corresponds to a single point in the latent space, poses risks of overfitting and limits the model’s generalization capabilities to new, unseen data (Kingma & Welling 2014).
The concept of “disentangled representation” is a possible formalization of interpretability. Disentangled representation refers to the ability of a model to autonomously and distinctly represent the fundamental statistical factors of the data (Locatello et al. 2020). In the context of this paper, statistical factors refer to various independent characteristics of celestial objects, such as their luminosity, temperature, chemical composition, or velocity. A model that learns a disentangled representation can represent each of these astronomical factors independently.
For a model to perform well on new data (beyond interpolation), the decoder must correctly interpret the cause-and-effect relationships of individual factors on the resulting spectrum (Montero et al. 2022). Determining causality from purely observational data is generally an unsolved problem that requires strong assumptions (Peters et al. 2017, pp. 44–62). The process of learning causality can be simplified when we have access to physical simulations, which would allow us to model and test causal relationships more effectively (Peters et al. 2017, pp. 118–120).
Variational autoencoders (VAEs; Kingma & Welling 2014) represent a promising category of models capable of achieving a disentangled latent space. This ability stems from the way VAEs conceptualize and manage the latent space. Unlike traditional AEs, which generate a single latent representation for each input (such as a spectrum), VAEs produce a distribution over the latent space for the same input. We provide more details of the two basic VAEs variants in Appendix C.
Variational autoencoders have some associated training challenges. They require careful tuning of the hyperparameters to ensure the latent space is properly utilized and the model does not collapse to a trivial solution (posterior collapse; Murphy 2023, pp. 796–797). Other well-known issues are blurry reconstructions that are caused by over-regularized latent space (Murphy 2023, pp. 787–788).
Independent studies have employed VAEs for HARPS (Mayor et al. 2003) and SDSS (Abazajian et al. 2009) spectra to self-learn an appropriate representation, thereby attempting to eliminate the need for annotation entirely (Portillo et al. 2020; Sedaghat et al. 2021). Although it was shown to be empirically possible to obtain some spectral parameters (Sedaghat et al. 2021), it is not clear how to obtain all of them or control which ones are obtained.
The large-scale study conducted by Locatello et al. (2020) proves that it is not feasible to achieve unsupervised disentanglement learning without making implicit assumptions that are influenced by ML models, data, and the training approach. These assumptions, commonly referred to as “inductive bias” in the field of ML (Gordon & Desjardins 1995), are challenging to manage due to their implicit nature. Therefore, to successfully acquire disentangled representations in practical situations, it is crucial to obtain access to high quality data, establish suitable distributions that accurately model the underlying structure and complexity of the data, and use labels at least for the model validation (Dittadi et al. 2021).
In light of these challenges with unsupervised learning, “semi-supervised learning,” which combines the advantages of both supervised and unsupervised learning, is a promising approach. It is beneficial when the amount of labeled data are limited or labeling is costly, but the unlabeled data are abundant (Murphy 2022, p. 634). Semi-supervision utilizes all data to overcome the lack of labels. However, semi-supervised learning in astronomy can be challenging due to unbalanced datasets (where classes are unevenly represented, often with a significant imbalance in the number of instances per class), covariate shifts, and a lack of reliably labeled data (Slijepcevic et al. 2022).
Semi-supervised2 AEs incorporate label prediction on top of reconstruction to improve their performance (Le et al. 2018). The same principle can be applied to VAEs (Kingma et al. 2014) to obtain semi-supervised VAEs. There are many variants; for example, Le et al. (2018) uses a pair of decoders – one for input reconstruction and another for label prediction. Alternatively, Kingma et al. (2014) (model M2) employs two encoders: one to provide an unsupervised bottleneck and the other to handle label prediction. The semi-supervised approach allows us to jointly solve the label prediction and ML simulation tasks.
However, not all architectural choices lead to the same outcomes. For instance, the approach of Le et al. (2018) does not use predicted labels for reconstruction, meaning that the reconstruction error is not back-propagated to influence the predictions. In contrast, architectures that incorporate predicted labels during the reconstruction process allow the reconstruction error to inform and refine the label predictions through backpropagation, thus potentially improving prediction accuracy.
Concentrating only on label prediction, we considered simulation-based inference (SBI; Cranmer et al. 2020). SBI utilizes existing simulations to infer parameters without relying on annotated data. SBI methods either examine a grid of parameters (Cranmer et al. 2020) or iteratively improve initial estimates of parameters, such as in Markov chain Monte Carlo (MCMC) methods (Miller et al. 2020). Modern approaches to SBI (Cranmer et al. 2020) employ machine learning techniques, like normalizing flows (NFs; Rezende & Mohamed 2015), for precise density estimation and to increase the speed. However, training NFs or conditional NFs, is challenging due to the high dimensions of HARPS spectra. Another issue is the significant differences between synthetic and observed data.
We prefer VAEs because they offer an efficient and flexible approach to modeling high-dimensional data, such as HARPS spectra, with a simpler and faster alternative to traditional SBI. By leveraging semi-supervised VAEs, we can directly obtain posterior distributions when the variational distribution is flexible enough to match the target distribution, which is ideal for cases with high-dimensional observations, low-dimensional parameter spaces, and unimodal posteriors. Additionally, VAEs have the capability to discover new parameters and integrate both known and unknown factors into simulations, enhancing their accuracy and adaptability. This allows for quick sampling of candidate solutions and significantly reduces computational demands. Moreover, VAEs can serve as a preprocessing step to reduce dimensionality, optimizing computational efficiency for downstream tasks, including those that use NFs for modeling more complex and multi-modal distributions.
We considered other generative models for ML simulation, such as diffusion models (Sohl-Dickstein et al. 2015), NFs (Rezende & Mohamed 2015), and generative adversarial networks (GANs; Goodfellow et al. 2014). These powerful ML models project a vector of Gaussians into the simulations. If desired, these models can condition the output on spectral parameters to provide greater control over the simulations. Their flexibility allows them to adapt to different types of data and applications, providing a robust framework for generating realistic simulations across various domains. However, these models have several limitations that make them less suitable for our specific ML simulation task.
These models intentionally function as black boxes, where the connection between the latent space and the generated simulation is hidden. As a result, we obtain simulations with variations without understanding their origin. This is acceptable in domains where explicit parametrization of the target domain is not possible or practical, such as in natural scenes for computer vision. However, in spectroscopy applications, it is desirable to control ML simulations with known or discovered parameters. Introducing variations into simulations merely to create an illusion of realism, without understanding the underlying processes, is meaningless in our context. Additionally, training these models demands a large amount of computational resources to achieve good results.
A practical example of a GAN application is CYCLE-STARNET (O’Briain et al. 2021), which combines GANs and autoencoders to transform synthetic spectra into realistic ones and vice versa. The method introduces two latent spaces: one shared between synthetic and real data and one specific to real observations. By learning mappings between these spaces, CYCLE-STARNET can enhance the realism of synthetic spectra and facilitate the transformation of observed spectra back into the synthetic domain. The learning process is unsupervised, and the method does not provide label prediction.
In this study, we chose supervised VAEs for the ML simulation task because they facilitate explicit representation of stellar parameters. VAEs can create a structured latent space that combines both known and unknown factors. This allows us to obtain both the simulated spectrum and the parameters that were used. Unlike other generative models, AEs and VAEs directly learn how to project the structured latent space to observations, making this approach deterministic and aligning with practical scientific requirements where we aim to minimize random variances in the output. Furthermore, VAEs are significantly faster to train and can handle larger data dimensions than diffusion models or NFs. Finally, as demonstrated in Rombach et al. (2022), compressing data with AEs is necessary to make diffusion models with high-dimensional data feasible. This demonstrates that scalable compression techniques, such as AEs or VAEs, are still highly relevant for these models.
We enrich the training data with simulated data to create a balanced dataset with reliable labels. We mix these synthetic data with real data to minimize the impact of covariate shifts. We also explore splitting the latent space in a supervised (label-informed) and an unsupervised part, so as to ensure that the model learns the correct labels where possible, while utilizing disentangled methods for its unsupervised parts.
We identified a gap in the literature concerning the semantic correctness of ML simulations, specifically whether individual labels in these simulations behave according to theoretical expectations (causality). In this study, we suggest modifications to existing methods and novel metrics to explore and solve this problem.
2.2 Semi-supervised latent space
Semi-supervised latent space ℬ is a tool for representing input spectra that is influenced by both labels and the spectra themselves. Within the latent representation b ∈ ℬ, “factors” specifically denote the set of independent core characteristics or attributes that have been abstracted from higher-dimensional input spectra s. We further divide the latent representation into two components: “label-informed factors” ![Mathematical equation: $\[\hat{\mathbf{l}}^{\mathrm{LIF}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq1.png) and “unknown factors” u, that is,
and “unknown factors” u, that is, ![Mathematical equation: $\[\mathbf{b}=\left(\hat{\mathbf{l}}^{\mathrm{LIF}}, \mathbf{u}\right)\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq2.png) . The label-informed factors
. The label-informed factors ![Mathematical equation: $\[\hat{\mathbf{l}}^{\mathrm{LIF}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq3.png) are supervised by known spectra parameters l from a catalog, where l undergoes a normalization process to ensure a consistent scale and distribution across the dataset. This ensures that both the label-informed factors and the original labels are consistently scaled, enhancing the ability of our machine learning models to learn and generalize from the data effectively. In this study, the symbol ˆ denotes prediction.
are supervised by known spectra parameters l from a catalog, where l undergoes a normalization process to ensure a consistent scale and distribution across the dataset. This ensures that both the label-informed factors and the original labels are consistently scaled, enhancing the ability of our machine learning models to learn and generalize from the data effectively. In this study, the symbol ˆ denotes prediction.
The normalization procedure adjusts label to follow a standard normal distribution. Specifically, the normalization and scaling of the kth label are defined as
![Mathematical equation: $\[\underline{l}^{k}=\frac{l^{k}-\mu^{k}}{\sigma^{k}} \quad \text{and} \quad l_{\text {scale }}^{k}=\frac{l^{k}}{\sigma^{k}},\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq4.png) (1)
(1)
where μk and σk are the mean and standard deviation of the kth label across the dataset, respectively. The scaling operation enables the addition of unnormalized labels with normalized labels by first scaling the unnormalized labels. In this study, ![Mathematical equation: $\[\mathbf{\underline{l}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq5.png) denotes normalized labels and lscale denotes scaled labels.
denotes normalized labels and lscale denotes scaled labels.
The unsupervised part, unknown factors u, represents undetermined spectral parameters and other statistically relevant features. Working in tandem with the supervised label-informed factors, these unknown factors help create a more comprehensive and informative representation of the latent space. This holistic approach allows us to uncover hidden patterns and relationships within the spectral data, leading to more accurate ML simulation and label prediction as shown in Sect. 4.
We use the term “label-aware” when talking about models that utilize labels during the training process, regardless of whether the approach is fully supervised or semi-supervised. Later, we assess the impact of the labels by comparing label-aware and unsupervised models.
2.3 Inference tasks
In ML, an inference task refers to a specific problem that we aim to solve. This includes stating the assumed deployment condition, in other words, what data the model will receive and what output it should produce. Specifying and formalizing the inference tasks is crucial for designing the ML models and selecting appropriate loss functions for learning the models.
We assume there is a dataset in the form ![Mathematical equation: $\[\left\{\mathbf{s}_{i}, \mathbf{l}_{i}, \mathbf{u}_{i}\right\}_{i=1}^{D}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq6.png) . Here, D is the number of samples in the dataset,
. Here, D is the number of samples in the dataset, ![Mathematical equation: $\[\mathbf{s}_{i} \in \mathbb{R}^{N}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq7.png) represents an observed spectrum, N is the number of pixels in a spectrum,
represents an observed spectrum, N is the number of pixels in a spectrum, ![Mathematical equation: $\[\mathbf{l}_{i} \in \mathbb{R}^{K}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq8.png) denotes the associated labels, where each label corresponds to a known spectral parameter such as temperature or airmass, K denotes the number of labels,
denotes the associated labels, where each label corresponds to a known spectral parameter such as temperature or airmass, K denotes the number of labels, ![Mathematical equation: $\[\mathbf{u}_{i} \in \mathbb{R}^{L}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq9.png) denotes unknown factors, where each factor corresponds to an undetermined spectra parameter, and L is the number of assumed unknown factors. The wavelength vector is constant across all samples, and therefore, the spectrum si is represented just by the flux vector.
denotes unknown factors, where each factor corresponds to an undetermined spectra parameter, and L is the number of assumed unknown factors. The wavelength vector is constant across all samples, and therefore, the spectrum si is represented just by the flux vector.
In this work, the spectra are standardized by dividing each spectrum by its median value, equivalent to the approach in Sedaghat et al. (2021). This process is formally defined as
![Mathematical equation: $\[\mathbf{s} \leftarrow \frac{\mathbf{s}}{\operatorname{median}(\mathbf{s})},\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq10.png) (2)
(2)
where median(s) computes the median flux value across all pixels in the spectrum. This step is fundamental for our ML models, ensuring that the spectral data are prepared consistently for all samples. In this study, we always use the standardized spectra.
The true generative process M is unknown and complex, involving both known and unknown factors. We formalize this as a generative process M : (l, u) → s, which maps known and undetermined parameters to the observed spectrum. Traditional simulations omit u and only map l to s.
Our prime inference task aims to reverse the generative process M and make label prediction ![Mathematical equation: $\[\hat{\mathbf{l}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq11.png) . Our secondary inference task aims to model the generative process M, including the unknown factors. We call our secondary task ML simulation, to better distinguish it from the traditional simulations approach using the applicable physical laws. We seek M such that if they obtain latent representation b = (
. Our secondary inference task aims to model the generative process M, including the unknown factors. We call our secondary task ML simulation, to better distinguish it from the traditional simulations approach using the applicable physical laws. We seek M such that if they obtain latent representation b = (![Mathematical equation: $\[\underline{\mathbf{l}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq12.png) , u) for a particular spectrum s, intervening on a factor in b should result in changes to
, u) for a particular spectrum s, intervening on a factor in b should result in changes to ![Mathematical equation: $\[\hat{\mathbf{s}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq13.png) according to the semantics of that factor. For example, modifying a factor associated with radial velocity should produce a Doppler shift in the stellar lines and no other effect.
according to the semantics of that factor. For example, modifying a factor associated with radial velocity should produce a Doppler shift in the stellar lines and no other effect.
2.4 Learning problem statement
Once the inference tasks have been defined, we can formalize the learning problem. Learning is the process of obtaining a model that solves the defined inference tasks. This involves selecting appropriate ML models, defining a loss function that penalizes discrepancies between the model outputs and the actual observations, and partitioning the data to facilitate training, validation, and testing of the model. An ML model is completely described by its parameters and hyperparameters. For neural networks, ML hyperparameters – such as architecture, learning rate, batch size, and optimization methods – externally characterize the model and are either not directly related to the loss function or we want to keep them constant during training. ML parameters, which include the weights and biases within the model, determine the neural network’s output and directly influence the loss function.
During training, the ML parameters are fitted to the training data using backpropagation (Murphy 2022, p. 434), which computes the gradient of the loss function with respect to the ML parameters. This gradient is then used for non-linear optimization. Since ML hyperparameters do not contribute to the loss function gradient, we have to experiment with different combinations of ML hyperparameters to optimize the model’s performance. During “model selection,” we train a model for each combination of ML hyperparameters and validate each model by evaluating the loss function (or some other metric) on the validation data. We select the model with the best performance among all other models. Optionally, during testing, we evaluate the selected model on the testing data to obtain an unbiased estimate of the model’s expected performance.
We aim to train ML models that approximate M and M−1 using the dataset ![Mathematical equation: $\[\left\{\mathbf{s}_{i}, \mathbf{l}_{i}, \mathbf{u}_{i}\right\}_{i=1}^{D}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq14.png) . We have chosen the encoderdecoder architecture Bengio et al. (2013) as the suitable ML model. Encoders map high-dimensional input (spectra) to low-dimensional output (labels), effectively approximating M−1. Decoders, conversely, map low-dimensional input (labels) back to high-dimensional output (spectra), serving as a suitable approximation of M.
. We have chosen the encoderdecoder architecture Bengio et al. (2013) as the suitable ML model. Encoders map high-dimensional input (spectra) to low-dimensional output (labels), effectively approximating M−1. Decoders, conversely, map low-dimensional input (labels) back to high-dimensional output (spectra), serving as a suitable approximation of M.
We train the encoder model either in isolation using a supervised approach, or in conjunction with the decoder using a semi-supervised or unsupervised approach. Semi-supervised learning enables us to leverage labeled and unlabeled data, potentially enhancing performance. Moreover, the secondary inference objective of the ML simulation cannot be optimally achieved through supervised learning alone, since, by definition, we cannot supervise unknown factors u.
All of our models minimize the loss functions that represent the disparity between the model output and the actual observations. Next, we briefly discuss progressively more complex models for the inference tasks and the corresponding learning loss functions.
2.5 Machine learning models
Here, we present the ML models that target our inference tasks as described in Sect. 2.3. We begin with encoders and decoders as they are the foundational elements of the subsequent models. Beyond serving as foundational elements, an individual decoder can be used for ML simulation tasks, whereas an individual encoder is useful for label prediction. Building upon these, we develop both semi-supervised and unsupervised AEs. This section concludes with a description of semi-supervised VAEs and their derived methods. All AE-based methods are capable of jointly addressing label prediction and ML simulation tasks. The source code, including model implementations, data preprocessing, and training scripts, can be accessed online3.
2.5.1 Encoders
Encoders are part of AEs and the basic model that can provide label prediction. We employ convolutional neural networks (CNNs) that stack layers of convolutions along with differentiable non-linear activation functions to process an input spectrum. The CNN output is processed by a single fully connected layer to learn the encoding ![Mathematical equation: $\[q_{\phi}^{c}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq15.png) from spectrum s to latent representation b. The CNN architecture is based on the encoder proposed in Sedaghat et al. (2021), and a detailed description is given in Table B.1. We can achieve label prediction by ignoring u(u = 0).
from spectrum s to latent representation b. The CNN architecture is based on the encoder proposed in Sedaghat et al. (2021), and a detailed description is given in Table B.1. We can achieve label prediction by ignoring u(u = 0).
We defined the loss function for label prediction using encoders as the mean absolute label difference:
![Mathematical equation: $\[L_{\text {lab }}(\phi)=\mathbb{E}_{(\mathbf{s}, \mathbf{l}) \sim p_{\mathcal{D}}}\left[\frac{1}{K} \sum_{k=1}^{K}\left|\underline{l}^{k}-q_{\phi}^{c, k}(\mathbf{s})\right|\right],\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq16.png) (3)
(3)
where ![Mathematical equation: $\[\mathbb{E}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq17.png) is expected value, lk is the kth label (ground truth),
is expected value, lk is the kth label (ground truth), ![Mathematical equation: $\[q_{\phi}^{c, k}(\mathbf{s})\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq18.png) is the predicted value for kth label,
is the predicted value for kth label, ![Mathematical equation: $\[p_{\mathcal{D}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq19.png) is the distribution of the spectra s and associated catalog values l, and K is the number of labels for each spectrum. For instance, in the case of HARPS observational spectra, the distribution is empirical, based on the actual data samples we have. We sample from this distribution by randomly selecting a spectrum.
is the distribution of the spectra s and associated catalog values l, and K is the number of labels for each spectrum. For instance, in the case of HARPS observational spectra, the distribution is empirical, based on the actual data samples we have. We sample from this distribution by randomly selecting a spectrum.
The effectiveness of training encoder in isolation depends on the availability of learning data with sufficient variability in all factors. However, in our data set, only 1498 unique spectra are fully annotated (as described in Sect. 3). Most samples have incomplete annotations, and many spectra lack annotations altogether. Furthermore, corrupted, incorrect, or mislabeled data can negatively impact the supervised learning process.
Therefore, we investigate the incorporation of unsupervised methods to improve the accuracy of label prediction. A key ingredient in learning directly from spectra is the ability to reverse the encoding process through the use of decoders.
2.5.2 Decoders
Decoders are part of AEs and the basic model that provides ML simulation. In our decoder architecture pθ, we have used residual network (ResNet; He et al. 2016), as shown in Table B.3, or CNN, as illustrated in Table B.2 In either case, our objective is to learn the ML parameters θ. The loss function for the ML simulation is the mean reconstruction error:
![Mathematical equation: $\[L_{\mathrm{sim}}(\theta)=\mathbb{E}_{\left(\mathbf{(\mathbf{s, l })} \sim p_{\mathcal{D}}\right.}\left[\frac{1}{N} \sum_{j}^{N}\left|s^{j}-p_{\theta}^{j}(\underline{\mathbf{l}})\right|\right],\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq20.png) (4)
(4)
where sj represents the flux at pixel j of spectrum ![Mathematical equation: $\[\mathbf{s}, ~p_{\theta}^{j}(\underline{\mathbf{l}})\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq21.png) is the predicted flux at pixel j for labels l and N is the total number of pixels in the spectrum.
is the predicted flux at pixel j for labels l and N is the total number of pixels in the spectrum.
A potential downside of CNN architectures is that each layer processes only the output of its preceding layer. While ResNet mitigates this by incorporating short-range skip connections across two layers, this strategy may still be suboptimal. As data pass through deeper layers, the input labels or bottleneck representations may become diluted, leading to a loss of important information. To address this, we considered alternative architectures, including skip-VAEs (Dieng et al. 2019), DenseNet (Huang et al. 2017), and FiLM layers (Perez et al. 2018), which can allow labels to influence any layer. Nevertheless, in this work, we have focused on CNN and ResNet architectures, deferring exploration of these alternatives to future research.
2.5.3 Autoencoders and downstream learning
Autoencoders are a type of machine learning architecture that enables unsupervised learning directly from data. An AE is constructed by connecting an encoder to a decoder. It does not require labels because it feeds the encoder’s output directly into the decoder to achieve reconstruction. AEs are trained to minimize the reconstruction loss between the input and the reconstructed output.
Reconstruction loss is a measure of fidelity, quantifying how closely the reconstructed output matches the input. It also reflects the efficiency of the bottleneck, ensuring that it retains essential features for reconstruction. The reconstruction loss is again defined as the mean absolute difference across all pixels:
![Mathematical equation: $\[L_{\mathrm{rec}}(\theta, \phi)=\mathbb{E}_{\mathbf{s} \sim p_{\mathcal{D}}}\left[\frac{1}{N} \sum_{j}^{N}\left|s^{j}-p_{\theta}^{j}\left(q_{\phi}^{c}(\mathbf{s})\right)\right|\right].\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq22.png) (5)
(5)
Here, ![Mathematical equation: $\[p_{\theta}^{j}(q_{\phi}^{c}(\mathbf{s}))\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq23.png) is the AE’s prediction for the same pixel. Optimizing this loss over (θ, ϕ), the AE is trained to effectively capture the salient features of the spectral data necessary for reconstruction. The resulting latent representation might be practical for new tasks, such as label prediction, since it is much easier to process small latent representation instead of the full spectrum.
is the AE’s prediction for the same pixel. Optimizing this loss over (θ, ϕ), the AE is trained to effectively capture the salient features of the spectral data necessary for reconstruction. The resulting latent representation might be practical for new tasks, such as label prediction, since it is much easier to process small latent representation instead of the full spectrum.
Secondary tasks that utilize compressed representations from an AE are called downstream tasks. The typical deployment scenario occurs when we have abundant high-dimensional unlabeled data, of which only a small subset is labeled, and we aim to predict the labels. The workflow consists of two steps: first, learning an AE using the unlabeled data. This allows us to map high-dimensional data to a lower-dimensional space. Second, we use the low-dimensional representations (such as spectra) from the labeled subset to learn label prediction. There is no guarantee that an AE will learn a latent space useful for the target downstream task. This is influenced by the choice of the AE’s architecture, optimization techniques, and the properties of the data and labels. Therefore, the downstream task, which is usually the main objective, can serve as a criterion for model selection.
Our downstream tasks are label prediction and ML simulation. We chose linear regression for label prediction for two reasons. First, we are interested in AEs that provide a meaningful, disentangled latent space that can be straightforwardly translated into labels. A more complex model might recover labels from an entangled latent space, which has no clear connection to the labels. Second, since our second inference task is ML simulation, we need to map the labels back to the latent representation, which is then mapped to a spectrum. Complex models with multiple layers and non-linearities would be challenging to invert.
We used the following linear regression to map latent representation b to labels l:
![Mathematical equation: $\[\hat{\mathbf{l}}=\sum_{k=1}^{B} w^{k} \mathbf{b}^{k}+w^{k},\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq24.png) (6)
(6)
where w are weights defining the linear regression, ![Mathematical equation: $\[\hat{\mathbf{l}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq25.png) are predicted labels, and B is the size of the bottleneck. The model was trained using ordinary least squares linear regression.
are predicted labels, and B is the size of the bottleneck. The model was trained using ordinary least squares linear regression.
The downstream learning represents a two-step approach that links unsupervised preprocessing and supervised learning for label prediction or ML simulation. Next, we investigate the semi-supervised methodology where we use a single training phase that combines spectra and labels.
2.5.4 Semi-supervised autoencoder
We can trivially add supervision to the unsupervised AE, thus obtaining semi-supervised AE. Similarly to the supervision in Sect. 2.5.1, we use the known labels l to supervise the label-informed factors ![Mathematical equation: $\[\hat{\mathbf{l}}^{\mathrm{LIF}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq26.png) . Hence, we have label-informed factors that are influenced by both unsupervised and supervised objectives. In addition, we allow the unknown factors u to learn statistically meaningful information not provided by the known labels l. We achieve this by expanding the loss function in Eq. (5) while preserving the architecture of unsupervised AEs.
. Hence, we have label-informed factors that are influenced by both unsupervised and supervised objectives. In addition, we allow the unknown factors u to learn statistically meaningful information not provided by the known labels l. We achieve this by expanding the loss function in Eq. (5) while preserving the architecture of unsupervised AEs.
The integration of unsupervised and supervised learning objectives is captured by the following loss function, which combines the reconstruction loss Lrec from Eq. (5) for unsupervised learning with the label loss Llab from Eq. (3) from supervised learning:
![Mathematical equation: $\[L_{\mathrm{AE}}(\theta, \phi)=L_{\mathrm{rec}}(\theta, \phi)+\lambda_{\text {lab}} L_{\text {lab}}(\phi),\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq27.png) (7)
(7)
where λlab is a hyperparameter that allows balancing between reconstruction and label loss.
By design, the supervised portion ![Mathematical equation: $\[\hat{\mathbf{l}}^{\mathrm{LIF}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq28.png) of the latent representation b is meaningful and disentangled. However, the unsupervised portion u faces the same problems as latent representation in AEs: a lack of interpretability and entanglement. As a result, unsupervised nodes can become entangled with supervised nodes in the bottleneck. This is especially problematic for ML simulations, as the unsupervised nodes can interfere with the role of the supervised nodes during the simulation.
of the latent representation b is meaningful and disentangled. However, the unsupervised portion u faces the same problems as latent representation in AEs: a lack of interpretability and entanglement. As a result, unsupervised nodes can become entangled with supervised nodes in the bottleneck. This is especially problematic for ML simulations, as the unsupervised nodes can interfere with the role of the supervised nodes during the simulation.
As a solution, we investigated methods to regularize the bottleneck to achieve disentanglement of the unsupervised nodes. By imposing suitable constraints on the bottleneck, the model can maintain the integrity of the supervised nodes while ensuring that the unsupervised nodes capture information not contained in the known labels. Additionally, disentangling the unsupervised nodes allows them to be integrated into the ML simulation because we can easily sample from independent unsupervised nodes.
2.5.5 Semi-supervised variational autoencoder
Variational autoencoders are suitable for learning disentangled latent representations. The VAE is a probabilistic variant of AEs adept at learning disentangled latent representations. The key difference between VAEs and AEs lies in treating the latent representation as a distribution over the latent space, versus a single latent representation. We employ the β-VAE, a modification of the classic VAE. This adaptation introduces a ML hyperparameter ![Mathematical equation: $\[\lambda_{\mathbb{K L}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq29.png) that enables a flexible balance between reconstruction quality and the penalization of the latent representation distribution, thus facilitating a more controlled disentanglement of features.
that enables a flexible balance between reconstruction quality and the penalization of the latent representation distribution, thus facilitating a more controlled disentanglement of features.
The loss function of the β-VAE is
![Mathematical equation: $\[L_{\beta-\mathrm{VAE}(\mathrm{U})}\left(\theta, \phi, \lambda_{\mathbb{K L}}\right)=L_{\mathrm{rec}}(\theta, \phi)-\lambda_{\mathbb{K L}} \mathbb{E}_{\mathbf{s} \sim p_{\mathcal{D}}}\left[D_{\mathbb{K L}}\left(q_{\phi}^{p}(\mathbf{b} \mid \mathbf{s}) \| p_{b}(\mathbf{b})\right)\right],\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq30.png) (8)
(8)
where ![Mathematical equation: $\[p_{\mathcal{D}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq31.png) is a data distribution,
is a data distribution, ![Mathematical equation: $\[q_{\phi}^{p}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq32.png) is a probabilistic encoder that maps spectra s to a distribution over latent space
is a probabilistic encoder that maps spectra s to a distribution over latent space ![Mathematical equation: $\[\mathbf{b} \sim q_{\phi}^{p}(\cdot \mid \mathbf{s}), p_{b}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq33.png) is the spherical normal distribution that represents the implicitly disentangled prior over the latent space,
is the spherical normal distribution that represents the implicitly disentangled prior over the latent space, ![Mathematical equation: $\[\lambda_{\mathbb{K L}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq34.png) is the weight placed on the Kullback-Leibler (KL) term (called β in Higgins et al. 2017), and
is the weight placed on the Kullback-Leibler (KL) term (called β in Higgins et al. 2017), and ![Mathematical equation: $\[D_{\mathbb{K L}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq35.png) is the KL divergence described in Eq. (C.2). The equation reflects how the β-VAE’s objective function, derived from the original VAE, balances reconstruction accuracy and the latent space’s regularization. Further insights into the original β-VAE objective and its relation to our implementation can be found in Appendix C.1.
is the KL divergence described in Eq. (C.2). The equation reflects how the β-VAE’s objective function, derived from the original VAE, balances reconstruction accuracy and the latent space’s regularization. Further insights into the original β-VAE objective and its relation to our implementation can be found in Appendix C.1.
To achieve supervision, we added the label loss to the objective in Eq. (8):
![Mathematical equation: $\[\begin{align*}L_{\beta-\mathrm{VAE}}(\theta, \phi, \lambda_{\mathbb{KL}})= & L_{\beta-\mathrm{VAE}~(\mathrm{U})}(\theta, \phi, \lambda_{\mathbb{KL}})\\& +\lambda_{\mathrm{lab}} \mathbb{E}_{(\mathbf{s}, \mathbf{l}) \sim p_{\mathcal{D}}}\left[\frac{1}{K} \sum_{k=1}^{K}\left|l_{-k}-b_{k}(\mathbf{s})\right|\right],\end{align*}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq36.png) (9)
(9)
where ![Mathematical equation: $\[\mathbf{b}(\mathbf{s}) \sim q_{\phi}^{p}(\cdot \mid \mathbf{s})\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq37.png) denotes a vector sampled from
denotes a vector sampled from ![Mathematical equation: $\[q_{\phi}^{p}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq38.png) given the input s, and bk(s) represents the k-th element of that vector. This sampling strategy incorporates the stochastic nature of
given the input s, and bk(s) represents the k-th element of that vector. This sampling strategy incorporates the stochastic nature of ![Mathematical equation: $\[q_{\phi}^{p}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq39.png) into the supervised learning framework.
into the supervised learning framework.
An inherent challenge associated with the β-VAE framework is posterior collapse, where the latent representation fails to capture meaningful information from the input (Murphy 2023, pp. 796–797). This results in underutilization of nodes, effectively reducing the size of the bottleneck.
To address the problem of posterior collapse in β-VAEs, we adopt a mutual information-based method known as the Informational Maximizing Variational Autoencoder (InfoVAE; Zhao et al. 2019). This approach balances the disentanglement and informativeness of the latent representation. The corresponding loss function for unsupervised InfoVAE (U) is defined as
![Mathematical equation: $\[\begin{align*}L_{\mathrm{InfoVAE}(\mathrm{U})}(\theta, \phi & \left., \lambda_{\mathrm{MI}}, \lambda_{\mathrm{MMD}}\right)=L_{\mathrm{rec}}(\theta, \phi)\\& -\left(1-\lambda_{\mathrm{MI}}\right) \mathbb{E}_{\mathbf{s} \sim p_{\mathcal{D}}} D_{\mathbb{KL}}\left(q_{\phi}^{p}(\mathbf{b} \mid \mathbf{s}) \| p_{b}(\mathbf{b})\right)\\& -\left(\lambda_{\mathrm{MI}}+\lambda_{\mathrm{MMD}}-1\right) D_{\mathbb{KL}}\left(q_{\phi}^{p}(\mathbf{b}) \| p_{b}(\mathbf{b})\right),\end{align*}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq40.png) (10)
(10)
where a higher λMI means s and b have higher mutual information, and higher λMMD brings ![Mathematical equation: $\[q_{\phi}^{p}(\mathbf{b})\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq41.png) closer to the priors pb(b).
closer to the priors pb(b).
The term 1 − λMI serves a purpose similar to ![Mathematical equation: $\[\lambda_{\mathbb{KL}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq42.png) in the original β-VAE model. The primary distinction between β-VAE (U) and InfoVAE (U) lies in the term
in the original β-VAE model. The primary distinction between β-VAE (U) and InfoVAE (U) lies in the term ![Mathematical equation: $\[D_{\mathbb{K L}}\left(q_{\phi}^{p}(\mathbf{b}) {\mid} p_{b}(\mathbf{b})\right)\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq43.png) and the addition of extra ML hyperparameter. InfoVAE (U) allows us to balance disentanglement, reconstruction, and informativeness. For a more in-depth understanding and computational specifics of the InfoVAE loss function, please refer to Appendix C.2.
and the addition of extra ML hyperparameter. InfoVAE (U) allows us to balance disentanglement, reconstruction, and informativeness. For a more in-depth understanding and computational specifics of the InfoVAE loss function, please refer to Appendix C.2.
By adding the label loss, we obtain the loss function for supervised InfoVAE:
![Mathematical equation: $\[\begin{align*}L_{\mathrm{InfoVAE}}\left(\theta, \phi, \lambda_{\mathrm{MI}}, \lambda_{\mathrm{MMD}}\right)= & L_{\mathrm{InfoVAE}~(\mathrm{U})}\left(\theta, \phi, \lambda_{\mathrm{MI}}, \lambda_{\mathrm{MMD}}\right)\\& +\lambda_{\mathrm{lab}} \mathbb{E}_{(\mathbf{s,l}) \sim p_{\mathcal{D}}}\left[\frac{1}{K} \sum_{k=1}^{K}\left|\underline{l}_{k}-b_{k}(\mathbf{s})\right|\right].\end{align*}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq44.png) (11)
(11)
This final formulation, InfoVAE, integrates the strengths of InfoVAE with supervised learning elements. The complete visualization is shown in Fig. B.1.
3 Application of machine learning to spectra
In this section we describe the results of applying the methods introduced in Sect. 2 to the HARPS spectra described below in Sect. 3.1. We used a simulated dataset to cover various combinations of spectral parameters. These simulations are obtained from synthetic spectral energy distributions (SEDs) computed from the Kurucz (Kurucz 2005) stellar atmosphere models, processed through the instrument’s Exposure Time Calculator (ETC; Boffin et al. 2020). The ETC simulates atmospheric effects and those of the measurement apparatus, including the telescope and the HARPS instrument itself. To further increase the variability of the data, we propose transformation strategies to generate new data on the fly from the simulated data. This approach, known as data augmentation in ML terminology, is typically used to improve training by effectively increasing the quantity of data. These datasets aim to encompass a comprehensive range of astrophysical scenarios.
Next, we describe our approach to train and optimize the models. Then, we present the metrics used to evaluate the quality of label prediction. We evaluate the quality of ML simulation using three metrics, each targeting different properties. We use the standard reconstruction error to investigate the faithfulness of the reconstruction. Our two generative metrics are designed to measure how well an ML model grasps the cause-and-effect relationship between the spectral parameters and the output spectrum. Finally, we discuss our approach to model selection.
3.1 Data
In this section we describe both the use of real spectra from the HARPS instrument and our methodology for generating simulated spectra to enrich our dataset. This dual approach broadens our capabilities for both training and evaluating our models. The summary of the datasets we are using is in Table 1.
The selected dataset is comprised of HARPS observations ranging from October 24, 2003, to March 12, 2020 (the instrument is still in active operation, so more observations are being added regularly). Through the ESO Science Archive, we have access to 267361 fully reduced 1-dimensional (1D) HARPS spectra, consisting of flux as a function of wavelength. The processing that went from raw data to products is described in the online documentation4. About 2% of the raw science files failed processing into 1D spectra and are therefore not included in our analysis. Each spectrum has a spectral resolving power of R = λ/Δλ ≃ 115 000, and covers a spectral range from 380 to 690 nm, with a 3 nm gap in the middle.
Our machine learning experiments necessitate verified labels, which we consider the “ground truth.” We have two sources for the physical parameters used as labels: (1) the TESS Input Catalog (TIC, Stassun & et al. 2019), as already used by Sedaghat et al. (2021), serves as the source of our labels for the real data; and (2) the set of spectral parameters used to generate the ETC dataset. ETC labels are the most reliable with absolute control and consistency.
The TESS Input Catalog (and HARPS dataset) exhibits bias that is shown in Fig. 1, where each point represents a single observation. The data in this figure has already been filtered to remove underrepresented labels, as described below. The top histogram shows the distribution of the effective temperature, while the right histogram shows the distribution of the surface gravity. The color of the points represents metallicity, with black points indicating missing metallicity data. The figure shows that the main sequence is well represented, while other regions are underrepresented.
Therefore, we have filtered out spectra with labels that are significantly underrepresented in the catalog. Specifically, we have removed spectra with temperatures below 3000 K and above 11 000 K, metallicities below −1.2 dex and above 0.4 dex, and surface gravities below 3.5 dex and above 5 dex. This filtering was a practical necessity for model training since these ranges contain less than 2% of the samples, making it difficult to achieve reliable training, validation, and testing. This limits the model’s ability to generalize to these edge cases. We intend to address these limitation in future work through proper uncertainty quantification methods that would allow the model to express reduced confidence when making predictions near or beyond these boundaries.
We prepared the simulated data in two stages. First, we generated the intrinsic Spectral Energy Distribution emerging from the stars (“SED dataset”) by employing the ATLAS9 software (Kurucz 2005), facilitated by the use of Autokur (Mucciarelli 2019) to generate a dense grid that samples the stellar parameter space covered by the real data. This is driven by the following stellar parameters: effective temperature, surface gravity, and the chemical composition of the star. We fixed the microturbulent velocity at 2 km s−1, because this number is rarely available in catalogs for an individual spectrum.
To generate stellar parameters for our SED dataset, we sampled from uniform distributions with the following ranges: effective temperature from 3000 K to 11 000 K, surface gravity from 3.5 dex to 5.0 dex, and metallicity from −1.2 dex to 0.4. This approach ensures that our simulated data cover the same parameter space as the filtered HARPS dataset, allowing for direct comparisons while also providing more uniform coverage of underrepresented regions.
In the final step, we used the ETC (Boffin et al. 2020) to create a simulated dataset that more closely resembles the real HARPS dataset by including in the SEDs generated above the effects of the observing process, such as the imprints of the telescope, the instrument, and the Earth’s atmosphere. The spectral parameters are the magnitude, atmospheric water vapor, airmass, fractional lunar illumination, seeing, and exposure time. When referring to the ETC data in the text, we implicitly mean the combination of SED and ETC data. Full technical details are provided in Appendix A. In total, we generated 44 000 simulated HARPS spectra.
We utilize ETC data for pre-training, regularization, and transfer learning. We can generate an almost arbitrary combination of spectral parameters in the desired quantity. Although having more data is generally beneficial, combining data from multiple sources can be challenging and does not guarantee positive outcomes. Therefore, we investigate the impact of mixing ETC and HARPS data on model performance through several experiments, specifically examining the effect of adding simulated data to the real one.
The labels are further categorized as “intrinsic” (temperature, metallicity, and surface gravity) and “extrinsic” (radial velocity, airmass, and barycentric Earth radial velocity-BERV). The overview of labels availability for HARPS is presented in Table 2.
Each model can use either the observational HARPS dataset, the ETC dataset, or a mixture of both. We split the HARPS dataset into 90% data for training, 5% data for validation, and 5% for testing. Furthermore, some of our experiments utilized only 1% of the available labels for the real HARPS dataset. This is done to test and quantify how the accuracy and fidelity of the label prediction depend on the availability of input labels, which may be scarce in real-life scenarios.
For the ETC dataset, we generated separate datasets for training (42 000 samples), validation (1000 samples), and testing (1000 samples). The labels were sampled independently, each chosen randomly from a uniform distribution.
To assess the generative properties of models, we construct a generative ETC dataset. In this context, a generative dataset is one specifically designed to understand how isolated changes in certain labels affect the behavior and output of ML models. The dataset is organized into subsets, with each subset dedicated to exploring the variations of a single specific label.
The assembly process includes several steps. First, we generate a set of c core samples. Each core sample acts as a baseline configuration where all labels are set to uniformly sampled random values. Next, for each core sample, we systematically alter one of f labels and create v variations. In these variations, only the target label is altered from its baseline value in the core sample, while the other labels remain unchanged.
As a result of this process, the final dataset contains c · f · v samples, representing an exploration of how changes in each label affect the generative properties of the models. This dataset provides the basis for a detailed evaluation of the individual impact of each label.
Datasets used.
 |
Fig. 1 Distribution of effective temperature, surface gravity, and metallicity in the HARPS dataset. |
HARPS label availability.
3.2 Data augmentation
As detailed in Appendix A, our data collection method allows for the generation of synthetic spectra with arbitrary radial velocities without further reliance on the ETC tool. This allows us to randomly alter radial velocities during training with minimal impact on performance, a technique known as “data augmentation” in ML. Our augmentation reduces the likelihood of memorization, since no single spectrum is repeated with the same radial velocity. Therefore, the augmentation encourages the model to disentangle the radial velocity more effectively. For this study, we uniformly sample radial velocities between −100 and 100 km/s. However, this method does have drawbacks, including slower I/O and increased memory demands per individual spectrum.
Our second strategy for augmentation focuses on annotation. We know that ETC spectra can be fully described by l, and u is relevant only for real spectra. We complied with this by allowing ETC spectra to utilize u, but penalize its usage to encourage the model to prefer representations that do not rely on u for ETC data. This penalization is implemented through a supervised loss, where we supervise u to be equal to the zero vector.
As a consequence, the ML model uses u only for real data. This might help with disentanglement as any attempt by the ML model to entangle unsupervised nodes with supervised will be penalized for ETC data. Furthermore, this strategy calibrates u as zero is connected to simulation data, while values different from zero inform about deviations from the simulated data.
Both strategies target the simulated data. The first strategy is specific to radial velocity and increases the variability of the simulated data without impacting the real data, that is, we could achieve the same effect by simply sampling more simulated data. The second strategy involves weak supervision of the unsupervised nodes u for simulated data during training. Consequently, the treatment of the real data is affected as well. Therefore, the second strategy is more general.
3.3 Model training and optimization
In this section we describe the process of implementing and training the various models. The models we focus on include stand-alone encoders, stand-alone decoders, AEs, β-VAEs, and infoVAEs, as detailed in Sect. 2. All models that include an encoder use the CNN encoder as specified in Table B.1. The decoding process is implemented by a CNN, detailed in Table B.2, or a ResNet decoder as outlined in Table B.3. All models were implemented and trained using the PyTorch Lightning framework (Falcon & The PyTorch Lightning team 2019).
We aim to select the highest possible value for the learning rate, as it speeds up the training. However, a learning rate that is too high results in spectral parameter divergence during training due to the vanishing or exploding gradient (Murphy 2022, p. 443). We set the learning rate to 10−4 for models that use CNN in encoder or decoder configurations. A higher learning rate of 10−3 is acceptable for models exclusively based on ResNet due to their enhanced stability. Thus, we can learn ResNet models significantly faster.
The training phase utilizes an Adam optimizer (Kingma & Ba 2015), a stochastic gradient descent variant, to efficiently manage backpropagation (Murphy 2022, p. 434) and update of ML parameters. Informally, the Adam optimizer can be seen to be adaptively modifying the learning rate based on the optimization process of the ML parameters. This optimizer includes a pair of ML hyperparameters, set to (β1, β2) = (0.9, 0.999). These ML hyperparameters help balance the influence of recent and past gradients. For more details on the Adam optimizer, see Kingma & Ba (2015). The Adam optimizer is a common and often default choice. Since we did not encounter any problems, exploring further alternatives was not worthwhile.
The standard practice in ML training is to monitor a metric that is evaluated on the validation dataset and stop training once the metric starts increasing; this practice is called “early stopping.” We initially chose the label prediction error as our stopping metric due to its relevance and quick evaluation. However, despite many days of training, we never observed the label prediction error increase; instead, it oscillated randomly while continuing to converge, resembling the double descent phenomenon for training epochs (Nakkiran et al. 2021). This unpredictable oscillation made setting an early stopping rule difficult.
As a result, we decided to train each model for a fixed 1000 epochs, where a single epoch is a complete pass through the dataset. An epoch is composed of numerous mini-batches, with the batch size indicating the number of spectra processed in each mini-batch. Given the extensive scale of our models and data, we opted for relatively small batch size, setting it to 32 spectra per batch. For additional details on optimizers and general machine learning concepts, readers may refer to Goodfellow et al. (2016); Murphy (2022).
3.4 Label prediction error
Our primary objective is focused on label prediction. We aim to produce results that closely match the labels provided by the catalog, for which we need to assess how successful our ML models are. The most straightforward approach is plotting the distribution of the errors. For visualization of error distributions, we use kernel density estimation (KDE) with bandwidth set according to Scott’s rule (Scott 1992), as shown in Fig. 2. This visualization is useful for qualitative analysis but does not provide a single numerical value that summarizes the model’s performance for the label prediction.
We achieved this by using the mean absolute error (MAE) between the predicted and the unnormalized ground truth labels:
![Mathematical equation: $\[\operatorname{MAE}(\{\mathbf{s}_{i}, \mathbf{l}_{i}, \hat{\mathbf{l}}_{i}\}_{i=1}^{D}, k)=\frac{1}{D} \sum_{i=1}^{D}\left|\mathbf{l}_{i}^{k}-\hat{\mathbf{l}}_{i}^{k}\right|.\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq45.png) (12)
(12)
The set ![Mathematical equation: $\[\left\{\mathbf{s}_{i}, \mathbf{l}_{i}\right\}_{i=1}^{D}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq46.png) denotes the testing dataset, where D is its size. The set
denotes the testing dataset, where D is its size. The set ![Mathematical equation: $\[\{\hat{\mathbf{l}}_i\}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq47.png) corresponds to the labels predicted by a ML model. The index k specifies the element of the label vector for which the MAE is computed. For the purpose of error analysis, we consider
corresponds to the labels predicted by a ML model. The index k specifies the element of the label vector for which the MAE is computed. For the purpose of error analysis, we consider ![Mathematical equation: $\[\hat{\mathbf{I}}^{\mathrm{LIF}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq48.png) as the autoencoder’s predictions for labels
as the autoencoder’s predictions for labels ![Mathematical equation: $\[(\hat{\mathbf{\underline{l}}}_{i}=\hat{\mathbf{l}}_{i}^{\mathrm{LIF}})\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq49.png) . The MAE provides a single number summarizing the overall performance of a model for a given label with index k. However, since different labels have different units, it is not possible to compare the MAE values across different labels.
. The MAE provides a single number summarizing the overall performance of a model for a given label with index k. However, since different labels have different units, it is not possible to compare the MAE values across different labels.
To compare the performance across different labels, we use the normalized MAE (NMAE). Compared to MAE, we preceded the computation with a normalization step:
![Mathematical equation: $\[\operatorname{NMAE}(\{\mathbf{s}_{i}, \mathbf{l}_{i}, \hat{\mathbf{l}}_{i}\}_{i=1}^{D}, k)=\frac{1}{D} \sum_{i=1}^{D} \frac{|\mathbf{l}_{i}^{k}-\hat{\mathbf{l}}_{i}^{k}|}{\sigma_{k}},\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq50.png) (13)
(13)
where σk is the standard deviation of the ground truth labels for the k-th label. This modification enables us to compare performance across different labels, and we utilize it to analyze groups of labels.
3.5 Reconstruction error
Reconstruction error is instrumental in evaluating the model’s ability to compress data while preserving key features. Additionally, this metric helps determine the effectiveness of our models in the ML simulation task.
Measuring reconstruction quality across the entire spectrum, including both the continuum and the spectral lines, presents a challenge due to the relative rarity of line pixels compared to continuum pixels. This difference can lead to misidentifying spectral lines as outliers.
An ideal metric would accurately capture deviations in both the continuum and spectral lines while being robust to outliers. However, our experiments with traditional data reconstruction metrics reveal a trade-off: either we fail to fit the continuum adequately (while capturing lines and outliers) or we overfit the continuum and miss both outliers and lines. Therefore, we chose MAE′ as the balanced metric:
![Mathematical equation: $\[\operatorname{MAE}^{\prime}(\{\mathbf{s}_{i}, \hat{\mathbf{s}}_{i}\}_{i=1}^{D})=\frac{1}{D N} \sum_{i=1}^{D} \sum_{j=1}^{N}\left|\mathbf{s}_{i}^{j}-\hat{\mathbf{s}}_{i}^{j}\right|,\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq51.png) (14)
(14)
where N is the number of pixels in the spectrum, ![Mathematical equation: $\[\mathbf{s}_{i}^{j}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq52.png) is the j-th pixel of the i-th spectrum, and
is the j-th pixel of the i-th spectrum, and ![Mathematical equation: $\[\hat{\mathbf{s}}_{i}^{j}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq53.png) is the corresponding prediction. It is well known that the absolute difference metric in MAE′ is robust to outliers (Murphy 2022, p. 399). We experimentally observed that it balances being too robust (insensitive to lines) and not robust enough (sensitive to artifacts).
is the corresponding prediction. It is well known that the absolute difference metric in MAE′ is robust to outliers (Murphy 2022, p. 399). We experimentally observed that it balances being too robust (insensitive to lines) and not robust enough (sensitive to artifacts).
3.6 Generative metrics
Generative metrics are an integral part of the evaluation process for models in ML simulation tasks. The true generative process involves cause-and-effect relationships between the spectral parameters and the resulting spectrum. However, the learned ML model is not required to replicate these relationships. It might introduce dependencies between supervised and unsupervised nodes, favor unsupervised nodes for reconstruction, or even ignore supervised nodes. For example, an ML model could learn to link effective temperature with some of its unsupervised nodes. Simply adjusting the supervised node that directly represents effective temperature will not be enough for correct simulation. This is because the model has spread the influence of effective temperature across multiple nodes, complicating how changes in temperature affect the predicted spectrum.
The mapping of labels to spectra and the measurement of reconstruction error cannot identify any of these issues. Therefore, we need metrics that specifically evaluate the model’s ability to simulate spectra based on interventions in individual labels, thus accurately measuring the cause-and-effect relationships between isolated spectral parameters and the resulting spectrum.
Our chosen approach is inspired by the latent space traversal (Chen et al. 2016), which is a recognized method for qualitative evaluation of generative properties. In latent space traversal, we manually modify the latent representation and observe the effects on the output spectrum. For example, we can alter the node responsible for the radial velocity and observe a Doppler shift in the output spectrum, provided the node captures the essence of radial velocity. This approach provides insight into the connection between labels and spectra. However, the challenge lies in quantifying this intuition.
Quantification of latent space traversal can be achieved by automatically intervening in the spectral parameters and measuring the reconstruction error against the true generative process, denoted as M. To facilitate this, we introduce a do operator to represent interventions on specific spectral parameters:
![Mathematical equation: $\[\mathbf{b}_{i}^{\prime}=\operatorname{do}\left(\mathbf{b}_{i}, \Delta l_{\text {scaled}}^{k}, k\right),\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq54.png) (15)
(15)
where bi denotes the latent representation of the i-th spectrum by some encoder q, k refers to the index of the node that is associated with the intervened spectral parameter, and ![Mathematical equation: $\[\Delta l_{\text {scaled }}^{k}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq55.png) is the intervention value for the spectral parameter (scaled using Eq. (1)). The operation do(bi,
is the intervention value for the spectral parameter (scaled using Eq. (1)). The operation do(bi, ![Mathematical equation: $\[\Delta l_{\text {scaled }}^{k}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq56.png) , k) modifies the k-th element of bi by adding the value
, k) modifies the k-th element of bi by adding the value ![Mathematical equation: $\[\Delta l_{\text {scaled }}^{k}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq57.png) , resulting in the altered latent representation
, resulting in the altered latent representation ![Mathematical equation: $\[\mathbf{b}_{i}^{\prime}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq58.png) .
.
Our first generative metric is specific to radial velocity since we can model M by the operator shift(s, v) that applies a Doppler shift to the spectrum s based on the radial velocity v. This approach is valid for real data if we carefully select a range of wavelengths that are minimally affected by telluric lines, which are not affected by shift in a star’s radial velocity. We defined the radial velocity intervention score (RVIS) metric as the reconstruction error between Doppler shifting a spectrum s and using the node associated with radial velocity to shift the same spectrum s:
![Mathematical equation: $\[\text{RVIS} =\mathbb{E}_{i, \Delta v \in V, \lambda \in \Lambda}\left[\left|p \circ \operatorname{do}\left(\mathbf{b}_{i}, \Delta v_{\text {scaled }}, k_{v}\right)(\lambda)-\operatorname{shift}\left(\hat{\mathbf{s}}_{i}, \Delta v\right)(\lambda)\right|\right],\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq59.png) (16)
(16)
where i is the index of the spectrum in the dataset, Δv is the radial velocity intervention, V ∈ [−40, 40] km s−1 is a uniformly sampled set of considered shifts, λ is a wavelength, Λ ∈ [6050, 6250] Å is a narrow wavelength range that is minimally affected by the telluric lines, kv is the index of the node associated with radial velocity, p is any decoder capable of projecting the vector b onto a spectrum s, the operator ∘ represents the composition of functions, and ![Mathematical equation: $\[\hat{\mathbf{s}}_{i}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq60.png) represents the output without any intervention (Δv = 0). This metric is evaluated on the HARPS test dataset.
represents the output without any intervention (Δv = 0). This metric is evaluated on the HARPS test dataset.
For the other labels, we have to utilize the simulation data and the known associated M. Specifically, we use ETC simulations to evaluate the generative properties of ML models for temperature, metallicity, and surface gravity. The generative metric is called the general intervention score (GIS) and is defined as follows:
![Mathematical equation: $\[\begin{aligned}\operatorname{GIS}(k)= & \mathbb{E}_{i, \Delta l^k, \lambda}\left[{\mid} p \circ \operatorname{do}\left(\mathbf{b}_i, \Delta l_{\text {scaled }}^k, k\right)(\lambda)\right. \\& \left.-p \circ q \circ M \circ \operatorname{do}\left(\mathbf{l}, \Delta l^k, k\right)(\lambda) {\mid}\right].\end{aligned}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq61.png) (17)
(17)
The first term in Eq. (17) gives us reconstruction of a spectrum, when constraining modification to the target node-label pair. The second term gives us reconstruction, when the ML model is unconstrained. Hence, the score indicates how the average reconstruction error suffer when cause-and-effect relationship is enforced during decoding. If q is a classic encoder, we simply send the output to the decoder p. Alternatively, if q is a probabilistic encoder, we first randomly sample the latent representation from it.
In this study, we evaluate the GIS using the generative ETC dataset described in Sect. 3.1, wherein a single label changes while the remaining ones stay constant. Hence, we can automatize traversing individual labels.
 |
Fig. 2 Kernel density estimation plots illustrating the distribution of absolute error differences. The KDE bandwidth is determined by Scott’s rule and is clipped between the first and 99th percentiles. The models are supervised encoders (real and mixed data), supervised AE (bottleneck = 9), supervised infoVAE (bottleneck=32), and VAE (bottleneck = 128) (Sedaghat et al. 2021). |
3.7 Model selection
Model selection in machine learning refers to the process of evaluating a specific metric on a validation dataset for a set of model candidates and selecting the best model based on the chosen metric. The candidates may include various settings of ML hyperparameters, such as modifications to the model’s architecture or training process, as well as different types of models. The metric used is often the same loss function that is utilized during training. In our case, we would like metrics that can relate our models back to our inference tasks described in Sect. 2.3, specifically, label prediction and ML simulation. This is quite straightforward for label prediction, where we simply use the supervised term introduced in Eq. (3).
Model selection for ML simulation is far more challenging since the reconstruction error is not suitable for model selection. The critical ML hyperparameter for an AE is the bottleneck size; however, we cannot use the reconstruction error as a metric because it generally decreases as the bottleneck size increases. Constants λ𝒦ℒ in β-VAE, and λMI and λMMD in infoVAE loss functions also serve as regularization of the bottleneck, similar to using different bottleneck sizes in AEs. Therefore, we minimize reconstruction error by setting all constants to zero, which results in a collapse of the advanced models into the AE model. Without a suitable metric, the model selection process requires careful manual analysis of each model candidate (Sedaghat et al. 2021). This process is computationally expensive and time-consuming, especially when the dataset is large, the model is complex, and there is a need to compare many candidates.
Therefore, we chose the RVIS metric in Eq. (16) as the model selection metric because it provides a direct interpretation and exhibits a convex curve with respect to ML hyperparameters, allowing for the selection of an optimum without a computationally costly grid search. We expect similar behavior for the GIS metric in Eq. (17), but we have not investigated this, as we cannot evaluate it on real data.
Figure 3 presents our experimentation with various sizes of u for AEs. The size of l is fixed to seven. All models were trained on a mixture of real and ETC data. In the graph, each point represents a single experiment; the x-axis shows the total size of the bottleneck, while the y-axis shows the RVIS metric from Eq. (16), evaluated using a testing real dataset. The red curve illustrates results from experiments in which we supervise u = 0 for ETC data, as described in Sect. 3.2. Conversely, the blue curve represents results from experiments conducted without this specific augmentation.
We interpret the results in Fig. 3 as follows: A bottleneck size of nine appears to be optimal. For the bottleneck with just seven or eight nodes, the node responsible for radial velocity is pushed to contain additional information, which leads to the worsening of the RVIS performance. When the bottleneck is larger, the dispersion of radial velocity information between multiple nodes also results in an increase in RVIS.
While the overall trends are not altered by the augmentation (u = 0), the red curve is noticeably flatter. Hence, the suggested augmentation alleviates the RVIS sensitivity to the size of the bottleneck. As a result, it allows us to slightly increase the bottleneck size without significant penalization. As shown in Fig. 3, increasing the bottleneck size to 10 minimally impacts RVIS.
We set the hyperparameter λlab, which balances reconstruction loss and label loss, to 1 based on initial experiments showing that label prediction performance is relatively insensitive to its value. Results for other values of λlab and their impact on reconstruction and label prediction are presented in Appendix D.
In order to configure the ML hyperparameters for the supervised β-VAE models, we proceeded in the following way. First, we set the bottleneck to a fixed size of 32 nodes, of which seven were supervised and the remaining 25 were not. We searched for a ![Mathematical equation: $\[\lambda_{\mathbb{K L}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq62.png) that minimizes the RVIS metric, eventually selecting
that minimizes the RVIS metric, eventually selecting ![Mathematical equation: $\[\lambda_{\mathbb{K L}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq63.png) = 0.00001. The same value of
= 0.00001. The same value of ![Mathematical equation: $\[\lambda_{\mathbb{K L}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq64.png) was used for the β-VAE (U) model, in which all nodes are unsupervised.
was used for the β-VAE (U) model, in which all nodes are unsupervised.
For the supervised infoVAE model, we initially set λMI to 1 − ![Mathematical equation: $\[\lambda_{\mathbb{K L}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq65.png) and λMMD to 1 − λMI, essentially using the β-VAE model, given that the third term in Eq. (10) is nullified by these ML hyperparameter settings. The bottleneck configuration was identical to that of the supervised β-VAE model. Subsequently, we increased λMMD until the RVIS metric was minimized, establishing that λMMD should be set to 100. The same values of
and λMMD to 1 − λMI, essentially using the β-VAE model, given that the third term in Eq. (10) is nullified by these ML hyperparameter settings. The bottleneck configuration was identical to that of the supervised β-VAE model. Subsequently, we increased λMMD until the RVIS metric was minimized, establishing that λMMD should be set to 100. The same values of ![Mathematical equation: $\[\lambda_{\mathbb{MI}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq66.png) and
and ![Mathematical equation: $\[\lambda_{\mathbb{MMD}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq67.png) were applied to the unsupervised infoVAE (U) model.
were applied to the unsupervised infoVAE (U) model.
 |
Fig. 3 Relation between bottleneck size and RVIS. The vector l size is fixed to seven. In addition, vector u, which represents the unsupervised portion of the latent representation, varies in size from zero to 13. |
4 Results
In this section, we present the results of our experiments. We investigate our two main objectives: label prediction and ML simulation, as detailed in Sect. 2.3. The evaluation of label prediction is straightforward, as we have access to the catalog that we consider the source of ground truth. We focus on the performance under varying conditions to better understand the contribution of individual components.
The summary of results for label prediction is in Table 3. The summary table contains a selection showcasing the most significant results with practical implications. It also includes references to other tables that present additional nuances.
Conversely, the evaluation of ML simulation remains challenging due to the semi-supervised nature of the training. The full extent of the challenges associated with ML simulation evaluation is explained in Sect. 4.2. Here, we focus on establishing an appropriate evaluation approach for ML simulations.
In the remaining sections, we relate the results to applications in spectroscopy. Therefore, we occasionally refrain from using the ML term labels that were defined in Sect. 1. Instead, we specify that we discuss stellar, spectral, or physical parameters.
Summary comparison of supervised, semi-supervised, and unsupervised models in this work for label prediction.
4.1 Label prediction
An important application of our ML models is to predict physical parameters of the stars from the data. For that purpose, we tested various models to predict labels: stand-alone encoders from Sect. 2.5.1, AEs from Sect. 2.5.3 and Sect. 2.5.4, and VAEs from Sect. 2.5.5. Models were trained for 1000 epochs using Adam Optimizer with a learning rate of 10−4. Both AEs and VAEs used a decoder pretrained on ETC data.
We evaluated all models on the HARPS test dataset described above, categorizing label errors into intrinsic to the star (temperature, metallicity, and surface gravity) and extrinsic (radial velocity, BERV, and airmass) groups. Individual label errors were calculated using Mean Absolute Error (MAE, Eq. (12)), and overall errors (“All”) for each label group were determined using Normalized Mean Absolute Error (NMAE, Eq. (13)).
Table 4 presents various prediction errors across different models, including those for temperature and metallicity. The unsupervised model β-VAE (U*) from Sedaghat et al. (2021), which relies on a posteriori training for label prediction, produced a temperature error of 978.0 ± 13.0 K and a metallicity error of 0.1578 ± 0.0027 dex, using essentially the same data employed in this work. In contrast, the supervised model CNN (mix) achieved a temperature error of only 50.21 ± 0.82 K and a metallicity error of 0.02118 ± 0.00064 dex, demonstrating improvements by nearly a factor of 20 and 7.5, respectively, over the unsupervised model. These findings underscore that label-aware (supervised or semi-supervised) representation learning is crucial for accurate label prediction, achieving significant improvements on par with the best traditional methods (e.g., Miller et al. 2020).
Each physical parameter achieves the best prediction with a different model in Table 4, which could be a consequence of degeneracy, where different combinations of physical parameters lead to similar spectra. This suspicion is partially supported by MAE distributions in Fig. 2. Most prominently, infoVAE (mix) appears multimodal for temperature (where it also achieves the best performance with an MAE of 43.68 ± 0.73 K). The metallicity error distributions also show multimodality, especially for AE (mix) and CNN (mix) (the best model with an MAE of 0.02118 ± 0.00064 dex). Radial velocity and airmass do not demonstrate similar behavior. Further experimentation is necessary to support the degeneracy claim, as alternative explanations exist for the observed multimodalities, such as clusters in the data.
The residual plots in Fig. 4 illustrate the relationship between the true and predicted labels as a function of the true label for selected models from Table 4: CNN (mix), AE (real), AE (mix), and infoVAE (mix). The x-axis shows the ground truth values, while the y-axis displays the residuals (predicted minus true values). The plots show that model performance decreases in sparsely populated regions. In particular, we observe a decline in performance for high temperatures (above 10000 K) and low surface gravity (below 3.8 dex). These observations are consistent with the bias observed in Fig. 1. Additionally, there is no significant difference between the various models in terms of residuals. Since these parameters are also challenging for classical methods, the reliability of the catalog values is questionable, further complicating the analysis.
Table 4 indicates that the CNN (ETC) outperforms the β-VAE (U*), specifically in the cases of temperature, radial velocity, and metallicity. We suspect that this superiority is due to the critical roles of temperature (a prime factor influencing the continuum) and radial velocity (which shifts every pixel in the spectrum) in achieving accurate reconstruction. However, the CNN (ETC) model performs significantly worse than all the other label-aware models, as shown in Tables 4 and 5. This observation suggests that models trained solely on simulated data may be inadequately equipped to handle the variations encountered in real-world data.
Table 5 examines how reducing the quantity of the label and considering different datasets and model types affect the mean absolute label error. The “legend descriptor” column specifies the model type (CNN or AE), the percentage of catalog labels utilized in training (100% or 1%), and the dataset employed (real or mixed).
The results from employing the full dataset of real labels are detailed in Table 5. The CNN 100% (real) model achieves an intrinsic error of 0.1837 ± 0.0022, while the CNN 100% (mix) model slightly improves with an intrinsic error of 0.1793 ± 0.0022. Conversely, the extrinsic error increases in the mixed model, with the CNN 100% (real) model at 0.07591 ± 0.00098 compared to 0.0815 ± 0.001 for the CNN 100% (mix) model. Semi-supervision yields mixed results; temperature labels improve, but radial velocity labels exhibit a negative trend.
These findings indicate that potential benefits from mixed data or semi-supervision are small and inconclusive if we have a large dataset with labels. The efficacy of semi-supervision varies depending on the category of the label being predicted, suggesting that while mixed data approaches do not degrade network performance, their advantages are inconsistent across all label types and error metrics. This implies that semi-supervised learning or simulated data are unnecessary for label prediction if we have sufficient data.
Table 5 shows that the model CNN 1% (mix) achieves a temperature prediction error of 108.6 ± 5.6 when trained with just 1% of available labels. In comparison, the model trained exclusively on real data has a higher error of 154.4 ± 5. This pattern is consistent across different model types and label groups, as evidenced by the CNN 1% (mix) model’s intrinsic error of 0.2984 ± 0.0051, which is superior to the CNN 1% (real) model’s error of 0.3954 ± 0.0061. Moreover, even with only 1% of the available labels, effective temperature reconstruction remains accurate enough for various astrophysical applications. These findings expose the role of simulated data in boosting label prediction accuracy in scenarios with limited real data, while maintaining equivalent efficacy in cases where real data are abundant.
Table 5 also compares supervised CNN 1% (mix) and semi-supervised AE 1% (mix). The most striking difference is the prediction of BERV, which is 0.787 ± 0.011 for CNN 1% (mix) and 0.3719 ± 0.0062 for AE 1% (mix). However, there is also a significant improvement for temperatures (108.6 ± 5.6 vs. 75.2 ± 2.8), metallicity (0.04468 ± 0.00081 vs. 0.02934 ± 0.00081), radial velocity (3.91 ± 0.14 vs. 3.53 ± 0.15), and overall intrinsic labels (0.2984 ± 0.0051 vs. 0.2578 ± 0.0037). The only reason why CNN 1% (mix) performs better on overall extrinsic labels is that airmass dominates this metric due to the normalization. Our results suggest that semi-supervision is another source of improvement when real data are scarce and we have access to simulated data.
Table 6 investigates the ability of our unsupervised models, trained with the unsupervised bottleneck, to predict labels for all models as a downstream task. In this experiment, we used the models β-VAE and infoVAE, as well as real and mixed datasets.
As already demonstrated in Table 4, the unsupervised model β-VAE (U*) exhibits significantly higher errors than their semi-supervised or supervised counterparts (except the CNN encoder trained exclusively on ETC data). Table 6 shows consistent performance across all the unsupervised models and datasets we tested. Additionally, adding ETC data to the training set (mixed data) seems to worsen the performance of the unsupervised models. This is in contrast to the semi-supervised models, where the mixed data improves the performance.
Overview of learning paradigms and architectures and their corresponding MAE for various labels.
4.2 Machine learning simulation of spectra
Our secondary goal is to create model spectra for given sets of physical parameters, as described in Sect. 2.3. This task can be approached using the isolated decoder or one of our semi-supervised models. As the semi-supervised models can accommodate unsupervised information, the resulting simulations can reflect unknown statistical factors. This difference is the main advantage over the isolated decoder or the traditional approach (ETC; Boffin et al. 2020). However, this advantage also complicates the evaluation, as it requires consideration of unknown statistical factors that by definition cannot be annotated.
We have already encountered these challenges, as shown in Fig. 3, where the number of unsupervised nodes is critical. Too few unsupervised nodes u can compromise the precision of the label-informed nodes as they attempt to encode extra information unrelated to the actual labels. In contrast, the excessively large size of u allows the model to reconstruct spectra from unsupervised nodes, without even utilizing label-informed nodes, thus breaking the connection between label-informed nodes and the output spectrum. Thus, with real-world data, our ML models must balance high fidelity reconstruction (achieved with a large unsupervised bottleneck, as measured by the reconstruction error from Sect. 3.5) against preserving cause-and-effect relationships in ML simulation (achieved with a small or constrained bottleneck, as measured by generative metrics from Sect. 3.6). To navigate these inherent challenges of the ML simulation, we split the evaluation into three parts, each revealing a particular property.
First, we train stand-alone decoders (CNN and ResNet) for ML simulation using the loss function from Eq. (4) and the ETC data. Then, we evaluate the reconstruction error for these decoders. Because the ETC data are optimally represented by l, we teach a decoder to map l to s. This allows us to analyze the behavior of the decoders without having to deal with unsupervised nodes or imprecise real data. We determine the decoder with the smallest reconstruction error and use it in all our models, that is, we use real training data to train an AE model, and mixed training data to train AE and infoVAE model.
Second, we compute reconstruction errors for AEs, infoVAE, and reference model (Sedaghat et al. 2021) on the real testing dataset. This approach avoids the problem of unknown factors, as the encoders extract this information from the input spectrum. By comparing the input and output spectrum, we can assess the implicit quality of the learned representation. This provides a global comparison between individual models.
Third, we examine the generative properties of AEs and infoVAE on the generative ETC dataset discussed in Sect. 3.1. The generative properties measure how well the ML models emulate the cause-and-effect relationships and conclude our evaluation of ML simulation.
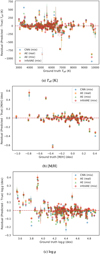 |
Fig. 4 Residual plots for effective temperature (Teff), metallicity ([M/H]), and surface gravity (log g) predictions across different models. |
4.2.1 Decoders and exposure time calculator data
We start by evaluating the reconstruction error of individual decoders on the ETC dataset. We utilize the ETC dataset because the unsupervised part of the bottleneck prevents us from evaluating this simplified ML simulation task on real data. Table 7 and Fig. 5 present the results of our ML simulation experiments comparing CNN and ResNet decoders. Both decoders were trained for 1000 epochs using the Adam optimizer. CNN (Table B.2) used a learning rate of 0.0001, while ResNet (Table B.3) used a learning rate of 0.001.
Table 7 shows that the CNN decoder has a significantly higher reconstruction error 0.0139 ± 0.0026 compared to the ResNet decoder 0.0064 ± 0.0011. We measure the error using MAE′, as defined in Eq. (14). Although both decoders demonstrate proficiency in reconstructing continua, the CNN decoder frequently overestimates, underestimates, or misses the absorption lines. This limitation is evident in Fig. 5, where, as a representative example, we show a narrow spectral region to highlight the individual characteristics of the spectra. The figure illustrates a CNN decoder overestimating or underestimating almost all the lines and missing two lines around 4800 Å and another around 4801 Å. In contrast, the ResNet decoder reconstructs the spectra with much greater accuracy.
This experiment has some limitations. For example, the reconstruction loss does not take into account the causal impact of the labels. This can lead to a situation where the model learns to ignore labels that have minimal impact on the output spectrum. Nevertheless, this experiment is a prerequisite for a good simulation model and validates the decoder choice.
4.2.2 Autoencoders and reconstruction results
The reconstruction error between the input and output spectra is a useful metric for both AEs and VAEs, as it can compensate for the lack of ground truth in unsupervised settings. The results themselves demonstrate the efficiency of compression achieved by AEs or VAEs. Figure 6 shows the distribution of reconstruction error (MAE′ from Eq. (14)) for our two semi-supervised models (AE, infoVAE) and the β-VAE (U*) model from Sedaghat et al. (2021). The reconstruction error is evaluated using the real testing dataset. The supervised models are excluded from this comparison as they do not produce reconstructions.
Overall, the error distributions are similar for AE (real), AE (mix), and infoVAE (mix). The β-VAE with CNN decoder (Sedaghat et al. 2021) has the poorest performance. We hypothesize that AE (real) outperforms AE (mix) because the ResNet model is underfitting; thus, the added complexity from a mixed dataset results in poorer performance. To validate this hypothesis, we would need to evaluate models more complex than ResNet, as listed in Table B.3. We defer this evaluation to a future study.
The difference in spectra reconstruction between models is affected by the choice of the decoder, as already shown in Sect. 4.2.1. While larger bottleneck size also helps with reconstruction (Sedaghat et al. 2021), it does so at the cost of generative properties (Sect. 3.7).
This experiment shares all the problems of the previous experiment. To make matters worse, we cannot distinguish between the problematic encoder and decoder. For example, the encoder may not learn meaningful representation, but the decoder can still reconstruct the spectra. Conversely, even if the encoder learns meaningful representation, the decoder can still fail to reconstruct the spectra. Similarly to the previous experiment, a good reconstruction error by itself does not translate to a good simulation model but is a necessary prerequisite.
Effects of reduced label quantity and mixed datasets on mean absolute errors for various labels.
4.2.3 Generative results
Generative metrics from Sect. 3.6 are essential to evaluate the cause-and-effect connection between an individual spectral parameter and the output spectrum of our ML models. These metrics directly target the shortcomings of the previous two experiments. We examined the generative properties using both RVIS, as defined in Eq. (16), and GIS, as outlined in Eq. (17). We use boxplots to visualize the distribution of RVIS and GIS across various models. A summary of our findings is presented in Table 8.
Both generative metrics are based on reconstruction error, making it difficult to distinguish between continuum shift and incorrect line prediction. Consequently, the metrics are mostly indicative. The generative metrics can be interpreted as an additional reconstruction error, which is caused by constraining the ML models by the cause-and-effect relationship.
We investigated the RVIS for AE (real), AE (mix), and infoVAE (mix). Additionally, the unsupervised model from Sedaghat et al. (2021) is incorporated due to its capability, with proper calibration, to generate interventions over radial velocities for real data within telluric-free wavelength ranges. The results in Fig. 7 and Table 8 show an average error close to 0.02 for semi-supervised models. This is significantly better than the unsupervised model with a value of 0.063.
Even a minor discrepancy in radial velocity can lead to substantial reconstruction errors, as the entire spectrum is impacted. Therefore, the relatively small RVIS observed for the semi-supervised model demonstrates it correctly captures radial velocity effects.
We investigated the GIS for AE (real), AE (mix), and infoVAE (mix). The unsupervised model from Sedaghat et al. (2021) was left out because it lacks the capability to generate new samples with predefined stellar parameters. The focus of our investigation comprises labels such as temperature, metallicity, and gravity.
The GIS results in Fig. 8 demonstrate excellent temperature modeling, with even the AE (real) model achieving an average error below 0.008. The difference between the AE (real) and other models is even more pronounced for metallicity and surface gravity. The results show that the reconstruction error due to physical parameters intervention is very small for all examined physical parameters. This indicates that the investigated models can emulate the effects of the selected physical parameters.
We train the AE (real) model exclusively on real data; therefore, its poorer performance could be attributed to an unfamiliar testing dataset. Alternatively, simulated data may have improved the generative outcomes of AE (mix) and InfoVAE (mix). Given the similar performance for RVIS that is tested on the HARPS dataset, we suspect that the former scenario is likely. More experimentation is required to determine the impact of simulated data on the generative properties.
The generative results suggest that once the ML hyperparameters are optimized, the distinction between AE and VAE becomes less significant. Employing the label-aware paradigm remains crucial to enhance generative properties. Moreover, these properties represent a valuable criterion for model selection, as described in Sect. 3.7.
We presented three different experiments to evaluate a model’s suitability for the ML simulation task. First, we demonstrated a method for selecting the optimal decoder for reconstruction and identified the suitable ResNet decoder. Second, we illustrated how to choose a model that can achieve high reconstruction fidelity for complete autoencoders, selecting the CNN-ResNet combination as a result. Third, we introduced a novel approach to identify ML models that capture the cause-effect relationships between individual spectral parameters and the resulting spectrum, concluding that properly setting the ML hyperparameters causes the compared models to behave similarly.
Utilizing outputs from unsupervised models for label prediction.
Comparison of CNN and ResNet decoders for ETC data.
Generative results.
 |
Fig. 5 Comparison of reconstruction capabilities between CNN and ResNet models using the ETC dataset. The elevated error rate for the CNN model, as shown in Table 7, is attributed to missing absorption lines. |
 |
Fig. 6 Kernel density plot for mean absolute error for reconstructions is shown. The KDE’s bandwidth was set according to Scott’s rule. The supervised infoVAE (CNN-ResNet) exhibits the lowest error, although its performance closely resembles that of AEs (CNN-ResNet). The unsupervised β-VAE (CNN-CNN), cited from Sedaghat et al. (2021), shows the highest error, which can be attributed to its less complex decoder. |
 |
Fig. 7 Radial velocity intervention score comparison between models boxplot. We do not include the supervised encoder because they do not provide reconstructions. The unsupervised model (Sedaghat et al. 2021) is included since we can generate intervention over radial velocities for real data when concentrating on a wavelength range without tellurics. |
4.3 Comparison of computational resources for different models
Here, we describe how the time and memory requirements were evaluated. We begin by discussing the setups of the time and memory experiment. We are interested in the time and memory requirements of our ML models, additionally we analyzed the time requirements of the ETC simulator and the computation of intrinsic stellar SEDs with ATLAS9. All experiments were restricted to use a single core of an AMD RyzenTM 9 3900X, equipped with 64 GB of RAM. For experiments that required GPU, we used a single NVIDIA GeForce RTX 3090, which features 24 GB of GDDR6X VRAM.
We evaluated the time requirements of our ML models by processing a single batch of 32 spectra and measuring the time per spectrum for CPU usage. For GPU assessments, several such batches were processed. The data used in this experiment were not loaded from disk, but were instead randomly generated on the RAM.
Memory requirements are measured by counting the number of ML parameters in each model. This method provides a straightforward way to compare the memory demands of different models. Such an assessment is valuable for evaluating the scalability of our models and determining their feasibility for deployment on various devices and datasets of different sizes. The batch size, when processing large input data, significantly impacts practical memory requirements during inference. Additionally, memory demands can vary substantially between the training and inference phases. This variation is due to the need to store intermediate results during backpropagation.
Our time measurements showed that ATLAS 9 takes 89 s on average to generate a single spectrum using a single core. Similarly, we measured ETC performance, and the processing time was 27 s. However, this time includes the time required to download the spectrum from the remote server. As such, the ETC time measurements are not reliable. Given that the ETC could be computed in principle extremely fast, we decided to exclude it from the timing comparison. Instead, we consider the ATLAS9 time requirement as the baseline, as it is a prerequisite for ETC.
Table 9 presents the timing results and computational complexities for a range of machine learning models in inference mode, that is, processing new data using trained models. Specifically, the table includes all autoencoders, encoders, and simulation models.
The time requirements for ML models, as shown in Table 9, reveal that even the slowest model takes only 795 ms on a single CPU core while generating the intrinsic stellar SED with ATLAS9 requires 89 s. Since this is a prerequisite for the ETC models, 89 s represents the minimum time needed to generate a spectrum. ML models can operate over a hundred times faster than ATLAS9 on identical CPUs. Furthermore, ML models can be easily run on GPUs. For instance, the CNN-CNN model from Sedaghat et al. (2021) takes just 0.386 ms on a GPU, while the infoVAE CNN-ResNet model takes 3.970 ms.
The ResNet model demonstrates a low reconstruction error in Table 7 and efficient processing time in Table 9, making it an appropriate option for significantly accelerating the computation of ETC (or SED). On the other hand, the CNN model is even faster, with a reconstruction error that may be deemed acceptable for numerous applications.
In practice, the time requirements extend beyond just the runtime of the ML model due to I/O constraints. Considering that each memory-optimized HARPS spectrum is approximately 1.2 MB, and we are loading batches of 32 spectra simultaneously, this translates to a data load of 38.4 MB per batch. When SSDs offer read speeds ranging from 200 MB/s to 5500 MB/s, the loading time for one batch can vary between 0.007 and 0.192 seconds. By contrast, conventional hard drives, which typically have read speeds ranging from 100 MB/s to 150 MB/s, would require approximately 0.256 to 0.384 seconds to complete the identical task. These I/O times, especially when using slower hard drives, can become a dominating factor in the overall time efficiency of the system, often surpassing the runtime of the machine learning models themselves. Additionally, loading large batches introduces overhead, potentially exacerbating the impact of I/O times on the total computation time.
The memory requirements for the ML models are presented in Table 9. In particular, the CNN-CNN model requires 7 million ML parameters, similar in scale to the CNN-ResNet, which has 14 million ML parameters. An examination of CNN (simulation) and CNN (mix), the components of CNN-CNN, reveals that most ML parameter requirements stem from the larger bottleneck.
Our ML models are highly memory efficient. For instance, 14 million ML parameters would roughly translate to 40 HARPS spectra. Therefore, even hardware with modest memory and processing capabilities can efficiently infer labels or construct new spectra. This presents a clear advantage over traditional approaches.
 |
Fig. 8 Boxplots showing GISs for our semi-supervised models. |
Comparative analysis of time and memory across models.
5 Discussion
In this study, we systematically explored the influence of various techniques on label prediction and ML simulation for high-resolution spectra. Our investigation spanned different learning paradigms, including supervised, unsupervised, and semi-supervised, as well as various architectures such as autoencoders and their variational counterparts. Additionally, we delved into experimenting with decoder architectures and rigorously tuned ML hyperparameters to discover the most optimal variant while introducing novel metrics to evaluate ML simulations.
The research examines HARPS spectra, real and simulated. The proposed architecture can be easily adapted to process 1D spectra of any length, making it suitable for handling data of similar types.
The results presented in Table 3 demonstrate that label-aware learning is the most significant factor in determining the accuracy of the label prediction. The differences within label-aware models appear to be more nuanced, and no single model emerged as the clear best. Therefore, in applications where label prediction is the sole objective and a sufficient number of labels are available, it is sufficient to employ the supervised CNN model. This approach minimizes computational and memory overhead while delivering excellent results.
Semi-supervised learning proved significant when we used as little as 1% of the labels that we had available for real data, as shown in Table 5. This can be useful when drawing conclusions from a limited amount of labeled data. Stellar effective temperature, radial velocity, and BERV predictions benefit significantly from the inclusion of simulated data and semi-supervised techniques. Most strikingly, temperature prediction improves twofold when comparing CNN 0.01 (real) with AE 0.01 (mix) in Table 5. This suggests that labels with a strong impact on reconstruction benefit most from semi-supervision. The strong connection between labels and spectra is further illustrated in Fig. D.1, where the label error demonstrates relative insensitivity to the label loss weight, suggesting that the network effectively recovers information from the spectra itself.
Label prediction performance remained similar across various unsupervised models, as summarized in Table 6. As anticipated, our supervised CNN model outperformed its unsupervised counterparts, reaffirming the value of supervision. Our linear regression approach (downstream task from Sect. 2.5.3) empirically highlights the inherent challenges of disentangled learning with unsupervised training.
Our findings show that ResNet decoders achieve lower reconstruction errors compared to the state-of-the-art CNNs, as reported by Sedaghat et al. (2021). This is consistent across both simulated (Table 7) and real datasets (Fig. 6) when using bottlenecks of comparable sizes. Qualitatively, ResNets significantly outperform CNNs in reconstructing absorption lines for both real and simulated data (Fig. 5). This is a critical distinction, as absorption lines carry most of the relevant spectroscopic information.
As summarized in Table 8, the GIS metric for temperature, metallicity, and surface gravity shows minimal reconstruction error due to intervention, with the highest error being at most 0.0078. The RVIS is comparatively higher, approximately 0.02, for semi-supervised models. However, the impact of radial velocity mismatch on the reconstruction error is significantly higher than any other label.
The results for generative properties in Figs. 8 and 7 showed a marginal difference between AEs and VAEs. However, VAEs benefit from a probabilistic framework that allows for easier manipulation of the latent space. Specifically, by assigning desired values to supervised nodes and sampling unsupervised nodes from the VAE’s prior distribution, VAEs can generate spectra that not only mirror known labels l but also incorporate a degree of randomness to account for unknown factors u, effectively sampling from f(u|l) = f(u) = 𝒩(0, I), where f denotes the probability distribution function. The process critically depends on disentanglement, which separates unsupervised nodes both from each other and from supervised nodes, ensuring that the generative model can accurately reflect the underlying data structure. Conversely, in AEs, the entanglement between nodes often becomes arbitrary, complicating the separation between supervised and unsupervised nodes. This entanglement renders the conditional probability f(u|l) effectively unknown, limiting the AE’s capacity to generate novel observations by directly manipulating the latent space.
The RVIS metric emerged as an instrumental tool for tuning ML hyperparameters of all our semi-supervised models. The RVIS experiment for semi-supervised AEs determined that the optimal size of the bottleneck is nine, as shown in Fig. 3. Specifically, with seven supervised nodes, it suffices to add just two unsupervised nodes to optimize RVIS. Expanding the bottleneck beyond nine elements to improve reconstruction comes at the cost of cause-and-effect relationship between supervised nodes and the output spectrum. The ML model gradually loses the connection between the node representing the radial velocity and the true radial velocity.
We successfully tuned the VAE-based models using RVIS. We fixed the size of the bottleneck and focused on tuning ML hyperparameters ![Mathematical equation: $\[\lambda_{\mathbb{K L}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq68.png) from Eq. (9) and λMI and λMMD from Eq. (11). Typical tuning of these ML hyperparameters requires manual investigation of properties of each model, such as reconstruction error, mutual information, posterior collapse (unused nodes), and correlation between nodes (Sedaghat et al. 2021; Portillo et al. 2020). This manual investigation is necessary because we cannot a priori determine the optimal criteria. The RVIS metric greatly simplified the process of tuning ML hyperparameters, as it provides a concrete and meaningful optimization objective. We leave the analysis of the GIS metric as a model selection metric to future work, since it does not permit the use of real data for evaluation.
from Eq. (9) and λMI and λMMD from Eq. (11). Typical tuning of these ML hyperparameters requires manual investigation of properties of each model, such as reconstruction error, mutual information, posterior collapse (unused nodes), and correlation between nodes (Sedaghat et al. 2021; Portillo et al. 2020). This manual investigation is necessary because we cannot a priori determine the optimal criteria. The RVIS metric greatly simplified the process of tuning ML hyperparameters, as it provides a concrete and meaningful optimization objective. We leave the analysis of the GIS metric as a model selection metric to future work, since it does not permit the use of real data for evaluation.
In this study, our models have demonstrated a significant advantage over standard approaches with respect to processing speed. Our fast simulation models, in particular, have shown potential (Table 7) to accelerate the generation of ETC data, a benefit that is especially valuable for high-resolution spectra. Although we observed a trade-off between reconstruction accuracy and processing time in machine learning models, our ResNet model, while slower, offers superior accuracy compared to the CNN model. Given that our application does not require real-time solutions, the ResNet model is recommended where resources allow in order to leverage accuracy over speed.
6 Summary and conclusions
Our study successfully developed robust joint models that exhibit generative capabilities for both actual and simulated data. These models are versatile tools well-suited for tasks including label prediction, real spectra encoding, anomaly detection, and the generation of highly realistic spectra that accurately reflect real-world scenarios.
In essence, our research underscores that while high-quality data and labels are essential for joint models with generative properties, the specific choice between AE and VAE remains noncritical. Simulated data are a valuable resource, especially when real data are limited. Such data ensure that the accuracy of label predictions is maintained thanks to their abundant availability. Semi-supervised learning shows improvement in label prediction when access to labeled data is limited.
As illustrated in Tables 4 and 5, over a large fraction of the ML hyperparameter space the label-aware models provide an accuracy that is comparable to the most accurate “traditional” methods (Miller et al. 2020), making them competitive and attractive tools for quantitative spectroscopy. In particular, this very good accuracy combined with the extremely fast execution times for inferring stellar parameters (see Table 9; fractions of a second vs. minutes per spectra for most traditional methods) make the methods presented here an almost inescapable choice for high-throughput observations, such as the massive spectroscopic surveys that will be coming online in the near future (DESI-2, MSE, 4MOST, WEAVE, WSU), including if the science case requires near real-time follow up.
Our research has several limitations. First, we rely on the HARPS dataset as the primary evaluation tool, which limits the general applicability of our conclusions. Second, we use normal distributions as priors in VAEs. This introduces imprecision when handling known labels with different distributions and restricts the ability to discover labels within the unsupervised bottleneck that might also have non-normal distributions. Furthermore, the inherent degeneracy of stellar spectra, where different combinations of temperature, metallicity, and surface gravity can produce similar-looking results, makes unimodal distributions ill suited for representing this complexity.
Additionally, while the VAE models for label prediction include both a mean vector and a standard deviation, we did not investigate the potential of the standard deviation as an uncertainty estimate, given its use for sampling and the KL penalty during training. Instead, we opted to treat the output as point estimates derived from the mean vector, as this approach provided clearer interpretations of the predicted labels and avoided conflicts between the goals of uncertainty estimation, sampling, and regularization.
This research opens the door to several promising followup projects, including conducting a comprehensive analysis of the unsupervised elements u and extending our approach to diverse datasets, which can provide a broader understanding of our results. Although we have explored the encoder architectures, we believe that there is more to uncover in this domain. Future research can leverage our trained models to quickly simulate realistic samples, thereby enhancing the training of new models. Moreover, we could focus on the probabilistic nature of VAEs, which by default provide likelihoods for their outputs and support non-Gaussian priors that could aid in discovering new labels. We anticipate addressing some of these topics in a future paper.
Acknowledgements
The first author (V. C.) extends thanks to the European Southern Observatory (ESO) for providing resources and support during his internship. V. C. and R. S. acknowledge support by the OP VVV MEYS-funded project CZ.02.1.01/0.0/0.0/16_019/0000765, “Research Center for Informatics” and the Czech Technical University internal grant SGS24/096/OHK3/2T/13. We are grateful to the anonymous referee for carefully reading the manuscript and providing useful suggestions to improve it. We are also grateful to the Ministry of Education, Youth, and Sports of the Czech Republic for supporting the first author’s internship at ESO.
Appendix A Exposure time calculator dataset
Here, we describe how we used the ETC to simulate the HARPS instrument. We began with with N SED spectra from ATLAS9. For each spectrum, we sampled ETC settings (airmass, brightness, H 20, . . .) and fixed radial velocity to 0. For each pair of SED and ETC settings, we performed the following:
Process ETC settings and SED. Split the output into overlapping orders, where each order contains:
target SED
![Mathematical equation: $\[\hat{S}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq69.png)
target signal S
sky signal B
atmospheric transmission a
blazing b
dispersion d [nm/px] (JSON output is actually [m/px])
readout noise RON e−/bin
number of detector integrations NDIT
dark current DARK
detector integration time DIT
number of spatial pixels Nspat
number of spectral pixels Nspec
Define Nexp ≡ NDIT and Texp ≡ DIT · NDIT.
Denote h = bd. (We removed h to gain overlapping orders.)
Denote n = NspatNspecNexp(Texp · dark + RON2).
Denote the concatenation of even orders with subindex A.
Denote the concatenation of odd orders with subindex B.
Compute the total throughput as
![Mathematical equation: $\[T_{A}=S_{A} / \hat{S}_{A}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq70.png) and TB =
and TB = ![Mathematical equation: $\[T_{B}= S_{B} / \hat{S}_{B}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq71.png) .
.Save
![Mathematical equation: $\[\hat{S}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq72.png) , BA, BB, TA, TB, hA, hB, nA, nB. For a single instrument, nA,B is fixed, and
, BA, BB, TA, TB, hA, hB, nA, nB. For a single instrument, nA,B is fixed, and ![Mathematical equation: $\[\hat{S}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq73.png) is considered a continuous signal without the even or odd splitting. Therefore, we have a sevenfold increase in memory.
is considered a continuous signal without the even or odd splitting. Therefore, we have a sevenfold increase in memory.
Then, at runtime (given the precomputed variables from item 8 and an arbitrary radial velocity v) we perform the following steps to get the simulated flux.
Load
![Mathematical equation: $\[\hat{S}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq74.png) , BA, BB, TA, TB, hA, hB, nA, nB.
, BA, BB, TA, TB, hA, hB, nA, nB.Compute shifted SED as
![Mathematical equation: $\[\hat{S}_{v}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq75.png) .
.Compute
![Mathematical equation: $\[S_{A}=T_{A} \hat{S}_{v}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq76.png) and
and ![Mathematical equation: $\[S_{B}=T_{B} \hat{S}_{v}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq77.png) .
.Define the output signal S as
![Mathematical equation: $\[S= \begin{cases}\left(\frac{S_A}{h_A}+\frac{S_B}{h_B}\right) \frac{1}{2}, & \text { iff A and B overlaps } \\ \frac{S_*}{h_*}, & \text { otherwise }\end{cases}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq78.png) (A.1)
(A.1)Define the variance σ2 as
![Mathematical equation: $\[\sigma^2= \begin{cases}\left(\frac{S_A+B_A+n_A}{h_A^2}+\frac{S_B+B_B+n_B}{h_B^2}\right) \frac{1}{2^2}, & \text { iff A and B overlaps } \\ \frac{S_*+B_*+n_*}{h_*^2}, & \text { otherwise }\end{cases}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq79.png) (A.2)
(A.2)Sample the final output (per pixel) from 𝒩(S, σ).
Encoder layers based on 1D convolution from Sedaghat et al. (2021).
Appendix B Architectures
The architectures of the CNNs and ResNets used in this study are detailed below. This section is intended to aid a reimplementation of our work.
Convolutional neural networks encoder architecture: As outlined in Sedaghat et al. (2021) and depicted in Tab. B.1, each encoder layer consists of a 1D convolution with a dilation of 1 and a Leaky Rectified Linear Unit (Leaky ReLU) activation function with a negative slope of 0.1. The hidden units for each layer are defined by its “chanels_in” and “chanels_out” parameters, with the convolutional kernel’s size and stride varying per layer. For instance, layer 4 has chanels_in = 16 and chanels_out = 32.
Decoder architecture: The decoder in Tab. B.2 employs ConvTranspose1D layers combined with LeakyReLU activation functions (0.1 slope). Similar to the encoder, each layer’s configuration is defined by its chanels_in and chanels_out, along with the convolutional kernel’s size and stride.
PreActTransResNetBlock: This block in Fig. B.2 accepts input “In,” which is the output of the preceding block, and outputs “Out,” which feeds to the next block or is the final output. We use the following components: instance normalization (IN), activation (A), ConvTranspose1D (C), and upsampling (Ups). The block is defined by the “C” configuration, which is the basic building block of the CNN encoder. “C1” has parameters “in_chanels” = chanels_in, “out_chanels” = chanels_in, “kernel_size” = 3, “stride” = 2, “dilation” = 1, while “C2” has in_chanels = chanels_in, out_chanels = chanels_out, kernel_size = 3, stride = 1, dilation = 1. These blocks allow for a modular building of the entire ResNet decoder.
The residual network decoder architecture: Each block of the ResNet decoder in Tab. B.3 is a PreActTransResNetBlock from Fig. B.2. For instance, layer 4 has chanels_out = 256 and chanels_in = 512. This architecture ensures efficient and effective feature translation from encoded to decoded representations.
These architectures are pivotal in our model’s ability to accurately process and reconstruct complex data structures.
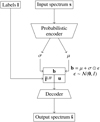 |
Fig. B.1 Illustration of a semi-supervised VAE architecture. Labels l provide bottleneck supervision (injection). Input spectrum s is encoded by probabilistic q into an isotropic Gaussian 𝒩(μ, σ). Latent representation is obtained from this distribution using the reparameterization trick from Kingma & Welling (2014), where ⊙ denotes the element-wise product. We apply the probabilistic decoder p to the latent representation to obtain output spectrum |
![Mathematical equation: $\[\hat{\mathbf{s}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq80.png)
Decoder architecture from Sedaghat et al. (2021).
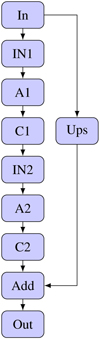 |
Fig. B.2 Diagram of the PreActTransResNetBlock, illustrating the flow from “In” (input) through various components — “IN” (instance normalization), “A” (activation), “C” (transpose convolution), “Ups” (upsampling), “Add” (addition) — to “Out” (output). |
Architecture of the decoder ResNet.
Appendix C Variational autoencoder details
Here, we are going to describe essential concepts of VAEs, which are important to fully understand our text. We start with introducing the original VAEs (Kingma & Welling 2014) and connecting it to our approach. Then, we describe the InfoVAE (Zhao et al. 2019) and how we use it in our work.
C.1 Variational autoencoders
Variational autoencoders are a powerful class of generative models that facilitate the learning of latent representations of input data. Their significance lies in their ability to handle complex data distributions by combining neural networks and probabilistic graphical models.
The core challenge that VAEs address is the intractability of direct likelihood maximization in complex data distributions. Traditional methods of computing likelihoods are often computationally expensive and impractical for high-dimensional data. VAEs circumvent this problem by introducing the concept of the Evidence Lower Bound (ELBO), as proposed in the seminal work on VAEs (Kingma & Welling 2014).
The Evidence Lower Bound is the objective for VAEs, serving as an attainable lower bound to the intractable log-likelihood of the observed data
![Mathematical equation: $\[\mathcal{L}(\theta, \phi, \mathbf{s})=-\mathbb{E}_{\mathbf{b} \sim q_{\phi}(\mathbf{b} \mid \mathbf{s})}\left[\log p_{\theta}(\mathbf{s} \mid \mathbf{b})\right]+D_{\mathbb{K} \mathbb{L}}\left(q_{\phi}(\mathbf{b} \mid \mathbf{s}) \| p(\mathbf{b})\right),\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq81.png) (C.1)
(C.1)
where θ and ϕ represent the parameters of the decoder and encoder networks, respectively. The term s denotes the input data, and b is the latent variable. The ELBO decomposes into two components.
The first term in Eq. (C.1), the reconstruction loss, is the expected negative log-likelihood of the observed data, given the latent representation. This term encourages the model to accurately reconstruct the input data from its latent representation.
The second term in ELBO is the KL divergence between the approximate posterior qϕ(b | s) and the prior distribution p(b). This divergence measures the difference between the two probability distributions, quantifying the amount of information lost when using qϕ to approximate p(b). It is defined as
![Mathematical equation: $\[D_{\mathbb{KL}}(q(\mathbf{b}) \| p(\mathbf{b}))=\mathbb{E}_{\mathbf{b} \sim q(\mathbf{b})}\left[\log \frac{q(\mathbf{b})}{p(\mathbf{b})}\right].\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq82.png) (C.2)
(C.2)
While the standard VAE, as described earlier, focuses on a balanced reconstruction of input data and latent space regularization, the β-VAE (Higgins et al. 2017) introduces a more nuanced control over this balance. By incorporating the hyperparameter β that scales KL divergence, the β-VAE allows for a deliberate emphasis on either aspect, depending on the specific requirements of the task at hand. This flexibility is particularly useful in scenarios where disentangling the latent features is more critical than achieving high-fidelity reconstruction, offering a tailored approach to complex data representation challenges.
It can be shown that the reconstruction loss from Eq. (5) is equivalent to the first term ![Mathematical equation: $\[\mathbb{E}_{\mathbf{b} \sim q(\mathbf{b})}\left[\log~ p_{\theta}(\mathbf{s} \mid \mathbf{b})\right]\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq83.png) in Eq. (C.1), provided certain assumptions are met. The first term is estimated using the Monte Carlo approach, often with the sample size one (Kingma & Welling 2014). Hence
in Eq. (C.1), provided certain assumptions are met. The first term is estimated using the Monte Carlo approach, often with the sample size one (Kingma & Welling 2014). Hence ![Mathematical equation: $\[\mathbb{E}_{\mathbf{b} \sim q(\mathbf{b})}\left[\log~ p_{\theta}(\mathbf{s} \mid \mathbf{b})\right]\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq84.png) is simplified to log
is simplified to log ![Mathematical equation: $\[\log~ p_{\theta}(\mathbf{s} \mid \hat{\mathbf{b}})\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq85.png) , where
, where ![Mathematical equation: $\[\hat{\mathbf{b}} \sim q(\mathbf{b})\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq86.png) . Assuming pθ is a Laplacian distribution, the log-likelihood term
. Assuming pθ is a Laplacian distribution, the log-likelihood term ![Mathematical equation: $\[\log~ p_{\theta}(\mathbf{s} \mid \hat{\mathbf{b}})\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq87.png) simplifies to
simplifies to ![Mathematical equation: $\[-\frac{|\mathbf{s}-\mu(\hat{\mathbf{b}})|}{\mathbf{s}^{\prime}}-\log~ \left(2 \mathbf{s}^{\prime}\right)\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq88.png) , where
, where ![Mathematical equation: $\[\mu(\hat{\mathbf{b}})\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq89.png) represents the mean vector and s′ the scale vector (we note that this s′ is distinct from the spectral data s). If we fix s′ to a vector of ones, this expression reduces to a standard L1 norm, since the division by s′ becomes trivial and the – log(2s′) term becomes a constant. Alternatively, setting s′ to any constant value leads to a scaled L1 norm.
represents the mean vector and s′ the scale vector (we note that this s′ is distinct from the spectral data s). If we fix s′ to a vector of ones, this expression reduces to a standard L1 norm, since the division by s′ becomes trivial and the – log(2s′) term becomes a constant. Alternatively, setting s′ to any constant value leads to a scaled L1 norm.
We note that if we treat the Laplace scale s′ as a hyperparameter, the original VAE is equivalent to β-VAE, where λβ = s′. This can be valuable as modifications to the ELBO can cause it to lose its probabilistic interpretation as a strict evidence lower bound. This point of view opens up probabilistic interpretation even for the β-VAE objective.
C.2 InfoVAE
InfoVAE is one of many modifications of VAEs. Similar to β-VAE, it allows us to control the balance between reconstruction and regularization. Unlike β-VAE, it can achieve greater regularization without risking underutilization of the bottleneck.
This phenomenon, typically known as posterior collapse, is a common problem in VAEs and its derivatives. It occurs when the KL term dominates ELBO, causing the posterior distribution ![Mathematical equation: $\[q_{\phi}^{p}(\mathbf{b} \mid \mathbf{s})\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq90.png) to collapse to the prior distribution pb(b) (Murphy 2023, pp. 796–797).
to collapse to the prior distribution pb(b) (Murphy 2023, pp. 796–797).
InfoVAE solves this problem by introducing an additional term that encourages the latent space to be informative with respect to the input spectrum. The semantic meaning of this VAE modification is shown through the following equation:
![Mathematical equation: $\[\begin{align*}& L_{\text {infoVAE }}(\theta, \phi)=-\lambda_{\mathbb{KL}} D_{\mathbb{KL}}(q_{\phi}^{p}(\mathbf{b}) \| p_{b}(\mathbf{b}))\\& \quad-\mathbb{E}_{\mathbf{b} \sim q_{\phi}^{p}(\mathbf{b})}[D_{\mathbb{KL}}(q_{\phi}^{p}(\mathbf{s} \mid \mathbf{b}) \| p_{\theta}(\mathbf{s} \mid \mathbf{b}))]+\lambda_{\mathrm{MI}} I_{q_{\phi}^{p}(\mathbf{s}, \mathbf{b})}(\mathbf{s}, \mathbf{b}),\end{align*}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq91.png) (C.3)
(C.3)
where ![Mathematical equation: $\[I_{q_{\phi}^{p}(\mathbf{s}, \mathbf{b})}(\mathbf{s}, \mathbf{b})\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq92.png) is the mutual information between s and b,
is the mutual information between s and b, ![Mathematical equation: $\[\lambda_{\mathbb{KL}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq93.png) represents the weight of the KL term (in a form that prevents posterior collapse), and λMI represents the weight assigned to the mutual information term. Notice that
represents the weight of the KL term (in a form that prevents posterior collapse), and λMI represents the weight assigned to the mutual information term. Notice that ![Mathematical equation: $\[q_{\phi}^{p}(\mathbf{b})\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq94.png) in the first term
in the first term ![Mathematical equation: $\[\mathbb{K} \mathbb{L}(q_{\phi}^{p}(\mathbf{b}) \| p_{b}(\mathbf{b}))\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq95.png) is no longer conditioned on the input spectrum s. The first term brings us closer to the goal of having
is no longer conditioned on the input spectrum s. The first term brings us closer to the goal of having ![Mathematical equation: $\[q_{\phi}^{p}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq96.png) match the priors pb, but requires a difficult computation of the marginal distribution
match the priors pb, but requires a difficult computation of the marginal distribution ![Mathematical equation: $\[q_{\phi}^{p}(\mathbf{b})=\int q_{\phi}^{p}(\mathbf{b}, \mathbf{s}) \mathrm{d} \mathbf{s}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq97.png) .
.
We have two degrees of freedom in the objective Eq. (C.3). We can adjust ![Mathematical equation: $\[\lambda_{\mathbb{KL}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq98.png) to balance the disentanglement requirement directly, while λMI determines to what degree the latent space is informative with respect to the input spectra, thus preventing posterior collapse.
to balance the disentanglement requirement directly, while λMI determines to what degree the latent space is informative with respect to the input spectra, thus preventing posterior collapse.
The main text contains a more computationally friendly loss function in Eq. (10). This loss function is equivalent to that in Eq. (C.3) up to a constant (see the appendix in Zhao et al. 2019 for a full derivation). This form allows us to use the KL term from Eq. (9), and we do not have to compute the mutual information term explicitly.
The loss function Eq. (10) generalizes the loss function of both VAE and β-VAE. Notice that we can achieve VAE by setting λMI = 0 and λMMD = 1. This implies that VAE can be considered a specific instance of InfoVAE where the mutual information between the latent space and input spectra is not explicitly optimized. Further notice that we can achieve equivalency with β-VAE by setting ![Mathematical equation: $\[\lambda_{\mathrm{MI}}=1-\lambda_{\mathbb{KL}}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq99.png) and λMMD = 1 − λMI.
and λMMD = 1 − λMI.
The computation of ![Mathematical equation: $\[D_{\mathbb{KL}}\left(q_{\phi}^{p}(\mathbf{b}) \| p(\mathbf{b})\right)\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq100.png) is the only remaining problem in Eq. (10). The work Zhao et al. (2019) proposes using Maximum-Mean Discrepancy (MMD) to approximate the KL divergence.
is the only remaining problem in Eq. (10). The work Zhao et al. (2019) proposes using Maximum-Mean Discrepancy (MMD) to approximate the KL divergence.
The Maximum-Mean Discrepancy is a statistical technique in machine learning and statistics that measures the dissimilarity between two probability distributions (Gretton et al. 2012). It is particularly useful when we cannot compare the distributions directly or when they are not known explicitly. MMD compares the means of samples drawn from the two distributions when mapped to a higher-dimensional feature space, typically using a kernel function (kernel trick). The basic idea is that if the means are close in the feature space, then the distributions are likely to be similar. A full theoretical explanation is provided in Gretton et al. (2012). We can compute the MMD that approximates the term ![Mathematical equation: $\[D_{\mathbb{KL}}\left(q_{\phi}^{p}(\mathbf{b}) \| p(\mathbf{b})\right)\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq101.png) in Eq. (10) as follows
in Eq. (10) as follows
![Mathematical equation: $\[\begin{aligned}D_{\mathrm{MMD}}\left(p_b, q_\phi^p\right) & =\mathbb{E}_{\mathbf{b} \sim p_b(\mathbf{b})} \mathbb{E}_{\mathbf{b}^{\prime} \sim p_b\left(\mathbf{b}^{\prime}\right)}\left[k\left(\mathbf{b}, \mathbf{b}^{\prime}\right)\right] \\& -2 \mathbb{E}_{\mathbf{b} \sim p_b(\mathbf{b})} \mathbb{E}_{\mathbf{b}^{\prime} \sim q_\phi^p\left(\mathbf{b}^{\prime} \mid \mathbf{s}\right)}\left[k\left(\mathbf{b}, \mathbf{b}^{\prime}\right)\right] \\& +\mathbb{E}_{\mathbf{b} \sim q_\phi^p(\mathbf{b} \mid \mathbf{s})} \mathbb{E}_{\mathbf{b}^{\prime} \sim q_\phi^p\left(\mathbf{b}^{\prime} \mid \mathbf{s}\right)}\left[k\left(\mathbf{b}, \mathbf{b}^{\prime}\right)\right],\end{aligned}\]$](/articles/aa/full_html/2025/01/aa51073-24/aa51073-24-eq102.png) (C.4)
(C.4)
where k(b, b′) is an arbitrary positive definite kernel function, such as a Gaussian kernel.
Appendix D Analysis of λlab hyperparameter
We investigated the impact of the hyperparameter λlab from Eq. (7), which balances the reconstruction loss and label loss for AEs. We experimented with values ranging from 0.01 to 100 and observed the effects on both reconstruction loss and label loss, as shown in Fig. D.1. All models were trained on a mixture of real and ETC data. In the graph, the x-axis represents the values of λlab, while the y-axis on the left shows the normalized label prediction error, and the y-axis on the right shows the reconstruction error. The blue curve in Fig. D.1 displays errors for intrinsic labels (temperature, gravity, and metallicity), the red curve shows errors for extrinsic labels (radial velocity, barycentric Earth radial velocity, and airmass), and the black curve represents the reconstruction error.
The range of errors for both reconstruction and label loss is relatively small, indicating insensitivity to this parameter. Label loss is especially insensitive to changes within the interval [0.1, 20]. Therefore, for simplicity, we set this hyperparameter to 1 in all our experiments.
 |
Fig. D.1 Impact of hyperparameter λlab from Eq. (7) on label error and reconstruction error. The left x-axis corresponds to the intrinsic and extrinsic curves, while the right x-axis corresponds to the reconstruction curve. |
Appendix E Terminology
Notation.
Terminology
References
- Abazajian, K. N., et al. 2009, ApJS, 182, 543 [NASA ADS] [CrossRef] [Google Scholar]
- Baron, D. 2019, arXiv e-prints [arXiv:1904.07248] [Google Scholar]
- Bengio, Y., Courville, A., & Vincent, P. 2013, IEEE Trans. Pattern Anal. Mach. Intell., 35, 1798 [CrossRef] [Google Scholar]
- Boffin, H. M. J., Vinther, J., Lundin, L. K., & Bazin, G. 2020, SPIE, 11449, 114491B [NASA ADS] [Google Scholar]
- Cavanagh, M. K., Bekki, K., & Groves, B. A. 2021, MNRAS, 506, 659 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, X., Duan, Y., Houthooft, R., et al. 2016, in NIPS’ 16 (Red Hook, NY, USA: Curran Associates Inc.), 2180 [Google Scholar]
- Cranmer, K., Brehmer, J., & Louppe, G. 2020, PNAS, 117, 30055 [NASA ADS] [CrossRef] [Google Scholar]
- Dieng, A. B., Kim, Y., Rush, A. M., & Blei, D. M. 2019, in AISTATS, PMLR, 2397 [Google Scholar]
- Dittadi, A., Träuble, F., Locatello, F., et al. 2021, in ICLR, [openreview: 8VXvj1QNRl1] [Google Scholar]
- Fabbro, S., Venn, K., O’Briain, T., et al. 2018, MNRAS, 475, 2978 [CrossRef] [Google Scholar]
- Falcon, W., & The PyTorch Lightning team 2019, PyTorch Lightning [Google Scholar]
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., et al. 2014, in NIPS’ 14, 27, eds. Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, & K. Weinberger, (Curran Associates, Inc.), 2672 [Google Scholar]
- Goodfellow, I., Bengio, Y., & Courville, A. 2016, Deep Learning (MIT Press) [Google Scholar]
- Gordon, D. F., & Desjardins, M. 1995, Mach. Learn., 20, 5 [Google Scholar]
- Gray, D. F., & Kaur, T. 2019, ApJ, 882, 148 [NASA ADS] [CrossRef] [Google Scholar]
- Gretton, A., Borgwardt, K. M., Rasch, M. J., Schölkopf, B., & Smola, A. 2012, J. Mach. Learn. Res., 13, 723 [Google Scholar]
- Gullikson, K., Dodson-Robinson, S., & Kraus, A. 2014, AJ, 148, 53 [NASA ADS] [CrossRef] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2016, in CVPR, 770 [Google Scholar]
- Higgins, I., Matthey, L., Pal, A., et al. 2017, in ICLR [openreview:Sy2fzU9gl] [Google Scholar]
- Holm, S. 1979, Scand. J. Stat., 6, 65 [Google Scholar]
- Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. 2017, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 4700 [Google Scholar]
- Kingma, D. P., & Welling, M. 2014, in ICLR, Banff, Canada [arXiv:1312.6114] [Google Scholar]
- Kingma, D. P., & Ba, J. 2015, in ICLR [arXiv:1412.6980] [Google Scholar]
- Kingma, D. P., Rezende, D. J., Mohamed, S., & Welling, M. 2014, in NIPS’ 14 (Cambridge, MA,: MIT Press), 3581 [Google Scholar]
- Kurucz, R. L. 2005, Mem. Soc. Astron. Ital. Suppl., 8, 14 [Google Scholar]
- Le, L., Patterson, A., & White, M. 2018, in NIPS’ 18 (Red Hook, NY, USA: Curran Associates Inc.), 107 [Google Scholar]
- Leeb, F., Bauer, S., Besserve, M., & Schölkopf, B. 2022, in NIPS’ 22 (Red Hook, NY, USA: Curran Associates Inc.) [Google Scholar]
- Leung, H. W., & Bovy, J. 2019, MNRAS, 483, 3255 [NASA ADS] [Google Scholar]
- Locatello, F., Bauer, S., Lucic, M., et al. 2020, JMLR, 21, 1 [Google Scholar]
- Mahabal, A., Sheth, K., Gieseke, F., et al. 2017, CoRR, [arXiv:1709.06257] [Google Scholar]
- Mann, H. B., & Whitney, D. R. 1947, Ann. Math. Stat., 18, 50 [Google Scholar]
- Mayor, M., Pepe, F., Queloz, D., et al. 2003, The Messenger, 114, 20 [NASA ADS] [Google Scholar]
- Miller, N. J., Maxted, P. F. L., & Smalley, B. 2020, MNRAS, 497, 2899 [Google Scholar]
- Montero, M., Bowers, J., Ponte Costa, R., Ludwig, C., & Malhotra, G. 2022, in NIPS’ 22, 35, eds. S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, & A. Oh (Curran Associates, Inc.), 10136 [Google Scholar]
- Mucciarelli, A. 2019, Autokur, Unpublished/in proceeding [Google Scholar]
- Murphy, K. P. 2022, Probabilistic Machine Learning: An Introduction (MIT Press) [Google Scholar]
- Murphy, K. P. 2023, Probabilistic Machine Learning: Advanced Topics (MIT Press) [Google Scholar]
- Muyskens, A. L., Goumiri, I. R., Priest, B. W., et al. 2022, AJ, 163, 148 [NASA ADS] [CrossRef] [Google Scholar]
- Nakkiran, P., Kaplun, G., Bansal, Y., et al. 2021, J. Stat. Mech.: Theory Exp., 2021, 124003 [Google Scholar]
- Ness, M., Hogg, D. W., Rix, H.-W., Ho, A. Y. Q., & Zasowski, G. 2015, ApJ, 808, 16 [NASA ADS] [CrossRef] [Google Scholar]
- O’Briain, T., Ting, Y.-S., Fabbro, S., et al. 2021, ApJ, 906, 130 [CrossRef] [Google Scholar]
- Perez, E., Strub, F., de Vries, H., Dumoulin, V., & Courville, A. 2018, in AAAI’ 18/IAAI’ 18/EAAI’ 18 (AAAI Press) [Google Scholar]
- Peters, J., Janzing, D., & Schlökopf, B. 2017, Elements of Causal Inference: Foundations and Learning Algorithms (The MIT Press) [Google Scholar]
- Portillo, S. K. N., Parejko, J. K., Vergara, J. R., & Connolly, A. J. 2020, AJ, 160, 45 [Google Scholar]
- Recio-Blanco, A., Kordopatis, G., de Laverny, P., et al. 2023, A&A, 674, A38 [CrossRef] [EDP Sciences] [Google Scholar]
- Rezende, D., & Mohamed, S. 2015, in ICML, PMLR, 1530 [Google Scholar]
- Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. 2022, in CVPR, 10684 [Google Scholar]
- Scott, D. W. 1992, Multivariate Density Estimation: Theory, Practice, and Visualization (John Wiley & Sons) [Google Scholar]
- Sedaghat, N., Romaniello, M., Carrick, J. E., & Pineau, F.-X. 2021, MNRAS, 501, 6026 [NASA ADS] [CrossRef] [Google Scholar]
- Slijepcevic, I. V., Scaife, A. M. M., Walmsley, M., et al. 2022, MNRAS, 514, 2599 [NASA ADS] [CrossRef] [Google Scholar]
- Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., & Ganguli, S. 2015, in ICLR, PMLR, 2256 [Google Scholar]
- Stassun, K. G., et al. 2019, AJ, 158, 138 [NASA ADS] [CrossRef] [Google Scholar]
- Ting, Y.-S., Conroy, C., Rix, H.-W., & Cargile, P. 2019, ApJ, 879, 69 [Google Scholar]
- Zhao, S., Song, J., & Ermon, S. 2019, in AAAI’ 19/IAAI’ 19/EAAI’ 19 (AAAI Press) [Google Scholar]
The term “supervised AEs” may also be encountered, where the unsupervised nature is implicitly part of AEs.
All Tables
Summary comparison of supervised, semi-supervised, and unsupervised models in this work for label prediction.
Overview of learning paradigms and architectures and their corresponding MAE for various labels.
Effects of reduced label quantity and mixed datasets on mean absolute errors for various labels.
All Figures
|
Fig. 1 Distribution of effective temperature, surface gravity, and metallicity in the HARPS dataset. |
| In the text | |
|
Fig. 2 Kernel density estimation plots illustrating the distribution of absolute error differences. The KDE bandwidth is determined by Scott’s rule and is clipped between the first and 99th percentiles. The models are supervised encoders (real and mixed data), supervised AE (bottleneck = 9), supervised infoVAE (bottleneck=32), and VAE (bottleneck = 128) (Sedaghat et al. 2021). |
| In the text | |
|
Fig. 3 Relation between bottleneck size and RVIS. The vector l size is fixed to seven. In addition, vector u, which represents the unsupervised portion of the latent representation, varies in size from zero to 13. |
| In the text | |
|
Fig. 4 Residual plots for effective temperature (Teff), metallicity ([M/H]), and surface gravity (log g) predictions across different models. |
| In the text | |
|
Fig. 5 Comparison of reconstruction capabilities between CNN and ResNet models using the ETC dataset. The elevated error rate for the CNN model, as shown in Table 7, is attributed to missing absorption lines. |
| In the text | |
|
Fig. 6 Kernel density plot for mean absolute error for reconstructions is shown. The KDE’s bandwidth was set according to Scott’s rule. The supervised infoVAE (CNN-ResNet) exhibits the lowest error, although its performance closely resembles that of AEs (CNN-ResNet). The unsupervised β-VAE (CNN-CNN), cited from Sedaghat et al. (2021), shows the highest error, which can be attributed to its less complex decoder. |
| In the text | |
|
Fig. 7 Radial velocity intervention score comparison between models boxplot. We do not include the supervised encoder because they do not provide reconstructions. The unsupervised model (Sedaghat et al. 2021) is included since we can generate intervention over radial velocities for real data when concentrating on a wavelength range without tellurics. |
| In the text | |
|
Fig. 8 Boxplots showing GISs for our semi-supervised models. |
| In the text | |
|
Fig. B.1 Illustration of a semi-supervised VAE architecture. Labels l provide bottleneck supervision (injection). Input spectrum s is encoded by probabilistic q into an isotropic Gaussian 𝒩(μ, σ). Latent representation is obtained from this distribution using the reparameterization trick from Kingma & Welling (2014), where ⊙ denotes the element-wise product. We apply the probabilistic decoder p to the latent representation to obtain output spectrum |
| In the text | |
|
Fig. B.2 Diagram of the PreActTransResNetBlock, illustrating the flow from “In” (input) through various components — “IN” (instance normalization), “A” (activation), “C” (transpose convolution), “Ups” (upsampling), “Add” (addition) — to “Out” (output). |
| In the text | |
|
Fig. D.1 Impact of hyperparameter λlab from Eq. (7) on label error and reconstruction error. The left x-axis corresponds to the intrinsic and extrinsic curves, while the right x-axis corresponds to the reconstruction curve. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.