| Issue |
A&A
Volume 692, December 2024
|
|
|---|---|---|
| Article Number | A149 | |
| Number of page(s) | 13 | |
| Section | Galactic structure, stellar clusters and populations | |
| DOI | https://doi.org/10.1051/0004-6361/202450033 | |
| Published online | 09 December 2024 | |
Determining stellar properties of massive stars in NGC346 in the SMC with a Bayesian statistic technique★
1
Institut für Physik und Astronomie, Universität Potsdam,
Karl-Liebknecht-Str. 24/25,
14476
Potsdam,
Germany
2
Department of Physics and Astronomy, University College London,
Gower Street,
London
WC1E 6BT,
UK
3
Zentrum für Astronomie der Universität Heidelberg, Astronomisches Rechen-Institut,
Mönchhofstr. 12–14,
69120
Heidelberg,
Germany
4
AURA for the European Space Agency (ESA), ESA Office, Space Telescope Science Institute,
3700 San Martin Drive,
Baltimore,
MD
21218,
USA
★★ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
19
March
2024
Accepted:
17
October
2024
Abstract
Context. NGC 346 is a young cluster with numerous hot OB stars. It is part of the Small Magellanic Cloud (SMC), and has an average metallicity that is one-seventh of the Milky Way’s. A detailed study of its stellar content provides a unique opportunity to understand the stellar and wind properties of massive stars in low-metallicity environments, and enables us to improve our understanding of star formation and stellar evolution.
Aims. The fundamental stellar parameters defining a star’s spectral appearance are its effective surface temperature, surface gravity, and projected rotational velocity. Unfortunately, these parameters cannot be obtained independently from only H and He spectral features as they are partially degenerate. With this work we aim to overcome this degeneracy by applying a newly developed Bayesian statistic technique that can fit these three parameters simultaneously.
Methods. Multi-epoch optical spectra are used in combination with a Bayesian statistic technique to fit stellar properties based on a publicly available grid of synthetic spectra of stellar atmospheres. The use of all of the multi-epoch observations simultaneously allows the identification of binaries.
Results. The stellar parameters for 34 OB stars within the core of NGC 346 are derived and presented here. By the use of both He I and He II lines, the partial degeneracy between the stellar parameters of effective surface temperature, surface gravity, and projected rotational velocity is overcome. A lower limit to the binary fraction of the sample of stars is found to be at least 46%.
Conclusions. Based on comparisons with analysis conducted on an overlapping sample of stars within NGC 346, the Bayesian statistic technique approach is shown to be a viable method to measure stellar parameters for hot massive stars in low-metallicity environments even when only low-resolution spectra are available.
Key words: stars: atmospheres / stars: massive / galaxies: star clusters: individual: NGC 346
Based on observations made with the NASA/ESA Hubble Space Telescope (HST), obtained from the data archive at the Space Telescope Science Institute. STScI is operated by the Association of Universities for Research in Astronomy, Inc. under NASA contract NAS 5-26555.
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Massive stars have a large impact on the evolution of their environment, a disproportionately great effect given their relative scarcity. They drive ionisation feedback of interstellar material with their high ultraviolet (UV) flux (Hollenbach & Tielens 1999; Matzner 2002). This high UV flux drives strong line-driven winds, depositing this shed wind material in the interstellar medium (Rogers & Pittard 2013). Many of the most massive stars are believed to end their lives as supernova explosions, which influence their environments by rapidly depositing huge amounts of energy and metal-enriched material (Rogers & Pittard 2013). Through these two mechanisms, massive stars are the main drivers of the chemical enrichment of the interstellar medium (Burbidge et al. 1957; Pignatari et al. 2010; Thielemann et al. 2011; Kasen et al. 2017; Kajino et al. 2019).
One critical property that has a significant impact on the evolution of massive stars is metallicity; the chemical abundance of elements heavier than He. As these metals provide the transition lines used for accelerating the stellar wind (Lucy & Solomon 1970; Castor et al. 1975), the abundance of these metals has a significant impact on the proportion of the mass of a massive star lost through winds throughout its evolution (Brott et al. 2011; Georgy et al. 2013; Pauli et al. 2023). Stellar winds can strongly impact a star’s evolutionary pathway and its final stages, and defines the nature of the compact object that will be left behind (Heger et al. 2003). Despite this, the scaling of mass-loss rate with metallicity is poorly defined (Abbott 1982; Vink et al. 2000, 2001). The need to resolve this has resulted in a significant quantity of work to study massive stars in low-metallicity environments (e.g. Bouret et al. 2003; Martayan et al. 2007; Ramírez-Agudelo et al. 2013; Ramachandran et al. 2018, 2019; Dufton et al. 2019; Rickard et al. 2022).
The Small Magellanic Cloud (SMC) is an irregular dwarf galaxy within the Local Group with a metallicity ZSMC = 1/7 Z⊙(Trundle et al. 2007; Hunter et al. 2007). It is close enough to Earth for massive stars within it to be observed and analysed in great detail (distance, D = 61 kpc, distance modulus, DM = 18.9 dex; Hilditch et al. 2005). Due to a metal abundance that is lower than Galactic massive stars, those in the SMC can maintain their mass for longer due to the reduced mass loss through stellar winds. This not only impacts the stellar parameters of temperature, surface gravity, and luminosity, but also affects parameters such as rotational velocity, as less angular momentum is carried away, leading to faster rotating stars (Martayan et al. 2007; Ramírez-Agudelo et al. 2013; Dufton et al. 2013; Ramachandran et al. 2019).
NGC 346 is a stellar cluster within the H II region N 66 that is within the SMC. The OB star population of NGC 346, a young cluster (≳3 Myr, Rickard et al. 2022; Rickard & Pauli 2023) in the SMC, has been a target of particular interest in the study of massive star winds at low metallicity, due to the abundance of mid-O-type stars (Massey et al. 1989; Evans et al. 2006; Dufton et al. 2019; Rickard et al. 2022). Large samples of massive stars from within the Magellanic Clouds have been analysed based on their optical spectra (Ramachandran et al. 2018, 2019; Dufton et al. 2019).
The three stellar parameters, which have the largest impact on an OB star’s spectral appearance are its temperature (T*), surface gravity (log ɡ), and projected rotational velocity (v sin i). Unfortunately, these three stellar parameters are affectbed by partial degeneracy when measured based on H and He spectral lines. This means they cannot be fitted independently as each of these stellar properties has a measurable impact on the depth and width of photospheric H and He spectral lines. The parameters T* and log ɡ affect the depth, and log ɡ and v sin i both impact the line broadening. To overcome this partial degeneracy, the usual method is to measure v sin i independently of the He lines by fitting the line broadening of metal lines. The best-fit T* and log ɡ is then found by comparing observations to a grid of synthetic spectra generated from stellar atmosphere model codes such as the Potsdam Wolf-Rayet code (PoWR, Gräfener et al. 2002; Hamann & Gräfener 2004; Oskinova et al. 2011; Hainich et al. 2014, 2015; Shenar et al. 2015; Sander et al. 2015), CMFGEN (Hillier 1987; Hillier & Miller 1998; Hillier & Lanz 2001; Hillier 2012), and TLUSTY (Hubeny 1988; Hubeny & Lanz 1995; Hubeny et al. 1998; Lanz & Hubeny 2007), among others.
The resultant fit for the stellar parameters for each target in a large sample forms the starting approximation. The next step would then be to carry out a significant manual adjustment to fit a suitable set of model parameters. As a result, studying populations of massive stars represents a significant time investment. Efforts have been made to automate this time consuming process, for example HiLineThere (Rübke et al. 2023), which automates the line selection process, the measurement of v sin i, and the selection of the most appropriate model from a grid of synthetic spectra based on a χ2 technique.
The measurement of v sin i is complicated by additional mechanisms that broaden the profiles of absorption and emission lines within the star’s observed spectrum. Rotation broadening dominates the broadening effects, with rotation velocities being of the order of 10 s or 100 s of km s−1 up to the critical rotation velocity. The additional broadening mechanism have magnitudes typically of the order of a few km s−1 (Aerts et al. 2009). The term adopted for these additional broadening mechanisms is macroturbulence, even though it is likely that it is not large-scale turbulent motion (Simón-Díaz & Herrero 2014). With high-resolution spectra it is possible to measure the rotational broadening separately from the combined broadening effects of both rotation and macroturbulence. This has been done for massive stars in NGC 346, and the difference between the two measurements was found to be ∼11 km s−1 (Dufton et al. 2019). When comparing results between numerous sources, it is important to consider if the measurement of v sin i given excludes macroturbulence or includes macroturbulence, and thus it must be considered a likely small overestimation.
In this work, we present a novel approach to automating the measurement of the stellar parameters of T*, log ɡ, and v sin i of massive stars. This uses the Bayesian statistic technique of Markov chain Monte Carlo (MCMC), while also accounting for the radial velocity (RV) of each object in each observation. The aim is to develop a tool applicable for low-resolution spectra where narrow metal lines are not visible, overcoming the partial degeneracy between these stellar parameters. We employ multi-epoch observations to mitigate the inaccuracies introduced by noise across different observations and to measure the RV movement between epochs and identify binary candidates.
The paper is organised as follows. Section 2 describes the observations before setting out the Bayesian statistic technique in Section 3. The results are described in Section 4, with the discussion of these results following in Section 5. Our conclusions are presented in Section 6. The observation list and full results table are available in Appendix A. Further supporting plots are available on Zenodo1, including the results of individual stars and observations of miscellaneous targets.
2 Observations and data reduction
NGC 346 was observed with the Multi Unit Spectroscopic Explorer (MUSE), an integrated field unit spectrograph (IFU), on the European Southern Observatory (ESO) Very Large Telescope (VLT) between August 11 and 22, 2016 (ESO programme 098.D-0211(A), PI W.-R. Hamann). While previous studies employed this data (Zeidler et al. 2022), for this work we included new extractions of spectra for each target. Ultraviolet (UV) spectra previously presented in Rickard et al. (2022) were also utilised.
2.1 MUSE observations
The MUSE observations were taken in wide-field mode (WFM). This field of view (FOV, 1′) covers the central part of the giant H II region N 66 that is powered by the massive star cluster NGC 346. MUSE has a spectral resolution of R ∼ 2000–4000 and a wavelength range of ∼4800–9300 Å (Bacon et al. 2010). Altogether 11 observing blocks (OBs), consisting of eight science exposures of 315 s each, were obtained. The observing conditions for the individual OBs are listed in Table A.1 in Appendix A, showing how the seeing varied between 1.17″ and 1.92″. The observations were carried out without adaptive optics, which was not yet available in 2016.
NGC 346 has strong nebular emission, including [O III] λ 5007, He I λ 7065, and Hα. The inhomogeneity of the nebula makes it difficult to effectively remove the nebular lines from the stellar spectra. A background subtraction was tested using the subtraction function provided by PAMPELMUSE, but nebular lines were often still present, with under- or over-subtractions affecting these lines. Thus, the effort was abandoned and instead the presence of nebular features were considered when selecting which photospheric lines to fit to. For example, only the wings of Hβ and Hα lines were considered due to nebular H features (see Sect. 3.2 for the full description of the lines selected).
Using the Sabbi et al. (2007) catalogue as the input to the pipeline, a non-flux calibrated spectrum for each target position from each OB was produced, regardless of quality of the output. The signal-to-noise ratio (S/N) for each spectrum is calculated as the mean S/N for a small selection of continuum regions based on the MUSE pipeline, free from nebular contributions. A S/N cutoff is employed, keeping only spectra with S/N > 50. A total of 226 targets are found to have at least one MUSE observation extracted that fulfils this S/N criteria.
Initially, the number of spectra to consider numbered in the thousands. Therefore, for the normalisation, an automated process was employed. This enabled a first attempt at the analysis using the MCMC method described in Section 3. This first pass allowed the characteristics of the process to be considered, including limiting factors such as the requirement for some He II lines to be present in the observations. This allowed the targets where the Bayesian statistic technique would be successfully identified. The number of spectra when limiting the selection to these targets alone was ∼300. These spectra were then normalised again with a visual check and adjustment of the wavelengths of the normalisation points to improve the quality of the data used in the final pass of the Bayesian statistic technique.
The process of normalising a spectrum introduces an error beyond the calculated S/N. The error on the normalised flux of each spectrum is calculated from the standard deviation of four continuum regions absent of lines, each 50 Å wide, centred on 4500 Å, 4805 Å, 5450 Å, and 6485 Å. These regions are selected as broad regions devoid of lines, but located near the lines employed later for fitting. This value is used within the likelihood function of our fitting tool to weight the observations based on the flux error (Sect. 3.3).
2.2 Ultraviolet observations
The brightest objects in the core 1′ of NGC 346 were previously observed in UV with the Hubble Space Telescope (HST; GO 15112, PI L. Oskinova & GO 8629, PI F. Bruhweiler). These observations were presented in Rickard et al. (2022). These spectra are included in this work to allow the measurement of luminosity and extinction. These HST observations are single-source extractions from the long-slit G140L on STIS. The extracted UV spectra cover an approximate range λ 11501700 Å, with some variation depending on the stars’ offset from the centre of the observing slit. The spectra have the resolution λ/Δλ ~ 2400. The extraction of this data is described in more detail in Rickard et al. (2022).
3 Data analysis
Each target within the sample was analysed with a Bayesian statistic technique using the Python package for MCMC methods EMCEE (Foreman-Mackey et al. 2013). In the language of the Bayes theorem, the data (the MUSE observations) are compared to a hypothesis (a synthetic spectrum created from a set of stellar parameters, see Sect. 3.1). In this way, the best-fitting stellar parameters, the ones that create the best-fitting synthetic spectrum, can be identified. This method was designed here to rely entirely on H and He lines within the spectra of the target stars. Due to the low metallicity of our targets and the high temperature, very few metal lines are detectable in the MUSE wavelength range. Even when a metal line is present in the spectrum of some target stars (such as O III λ 5591), it is very weak and not present for the full sample of targets. Thus, for consistency, the method was designed to not require any metal lines.
Each observed spectrum was included independently, each shifted by the RV shift for each epoch. This created an additional free parameter, the RV shift, per epoch.
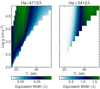 |
Fig. 1 Equivalent widths of He I λ 4713 (left) and He II λ 5412 (right), bilinearly interpolated for the whole PoWR grid range. |
3.1 The hypothesis: Synthetic spectrum generation
The hypothesis is a synthetic normalised spectrum generated based on T* and log ɡ and then convolved to simulate v sin i and convolved to account for the instrument’s observation profile. The interpolated normalised synthetic spectrum is based on a grid of synthetic spectra generated by the PoWR code model, presented in publicly available grids2. The grids of synthetic OB- type star spectra have a step of 1000 K in T* and 0.2 dex in log ɡ. Within the PoWR grid, T* is defined as the temperature at the Rosseland continuum optical depth. As the sample is within the SMC, the ‘SMC OB Vd3’ grid (Pauli et al. in prep.) was utilised. In this grid, the wind mass-loss rates employed in the model calculations use the recipe from Vink et al. (2000, 2001) divided by a factor of three. From previous studies of stars in NGC 346 (Rickard et al. 2022), this grid was selected as the most suitable of the available options as no obvious wind effects are seen in the optical to near-infrared spectra of these massive stars.
An interpolated synthetic normalised spectrum can be created for any T* and log ɡ within the limits of the PoWR SMC grid by bi-linearly interpolating between the four synthetic spectra flanking the required T* and log ɡ values. Figure 1 shows the equivalent widths (EWs) of two He lines for the full parameter space, interpolated between grid points.
The synthetic spectrum is sliced as per the observed spectra (See Sect. 3.2). Each segment is convolved with a half ellipse with the equivalent width associated with a value of v sin i to simulate the effect of rotation and other broadening mechanisms, such as macroturbulence. The rotational broadening velocity will be of the order of tens or hundreds of km s−1 up to the critical rotation velocity, while the macroturbulent broadening is of the order of 10 km s−1 (Aerts et al. 2009; Dufton et al. 2019). It is therefore important to be aware that the values of v sin i returned from this method will be a slight overestimation of approximately 10 km s−1. This is important to consider when comparing results to other sources.
Finally, the instrument profile is simulated by convolving the synthetic spectral line segment with a Gaussian of FWHM appropriate for the instrument profile for MUSE at the wavelength of that line segment. The MUSE documentation shows the instrument profile changes linearly with wavelength up to λ ~ 7000 Å and non-linearly beyond that (see Figure 18 in the MUSE User Manual3). The adopted FWHM for each line segment is shown in Table 1.
Line segments for fitting.
3.2 Line segment selection
A critical choice for the process of comparing the observations to a synthetic spectrum is the choice of wavelength ranges used for the comparison. The line segments used for fitting are detailed in Table 1. These were carefully selected to include a selection of He I and He II lines, as well as Hβ and Hα lines. The line boundaries were chosen to exclude nebular emission features. To do this, the Hβ line was split into two segments (to exclude nebular Hβ emission) and Hα was split into four segments (including He II λ 6529.5 which overlaps with the blue wing of Hα).
The He II λ4686 line was excluded as it can be seen that on the hotter stars there is some back filling due to stronger stellar winds than included in the model. In addition, some single He I lines such as He I λ 4922 are not well modelled by codes such as PoWR and CMFGEN (Najarro et al. 2006) and were therefore not selected.
3.3 Determining stellar parameters using a Bayesian statistic technique
The Bayesian statistic technique measures the quality of the fit of the data, H and He line segments from up to 11 observations, against the hypothesis, the synthetic spectrum generated based on a set of stellar parameters. In doing so, the process identifies the three best-fitting stellar parameters that generate the synthetic spectrum (T*, log ɡ, and v sin i) and the best-fitting RV for each observation. This means there may be as many as 14 free parameters (when a target has 11 observations with sufficient S/N) or as few as 4 (if there is only one usable observation). The data is measured against the hypothesis by way of a least mean squared likelihood function (Eq. (1)):
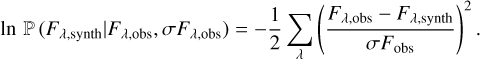 (1)
(1)
A flat prior probabilty is assumed for all the fitted parameters, with T* and log ɡ values limited to the range of the PoWR grid. v sin i is limited to 10 km s−1 < v sin i < 600 km s−1 and the RV of each observation is limited to 90 km s−1 < RV < 240 km s−1, a wide range centred on 165 km s−1, the mean RV value for OB-star members of NGC 346 (Zeidler et al. 2022).
The parameter space is seeded with 250 ‘walkers’ or chains. Each chain starts with a set of initial values for the stellar parameters and for the RV of each observation. This set of initial values is randomly distributed across the space described by the flat prior. The MCMC process tests these parameters against the observations using the likelihood function. The automated chain process then tests another set of parameters, adjusted from the first by a random offset. The new likelihood is calculated and compared to the previous, to evaluate whether the new parameters are a better fit or a worse fit than the previous parameter set. This then informs the next set of parameters to be tried and assessed with the likelihood function, and again compared to the previous likelihood. In this way, these chains ‘walk’ towards the more likely solution, as defined by the likelihood function.
For an MCMC process, the auto-correlation time (τ) is a measure of how many steps a walker will need to take until the initial position has no bearing on the parameters it is testing, when it is said to have ‘forgotten’ its starting position. The value of τ can be calculated during the process of running an analysis within EMCEE. The auto-correlation time is used here to dynamically set the number of iterations needed to be run and to estimate when additional iterations will not improve the final result, meaning the process can be halted and said to have converged. Every 100 iterations, τ is calculated and the result is considered converged if either the sampler has run for >20 ⋅ τ for each fit parameters or τ has changed by less than 1% for each fit parameter over the last 100 iterations compared to the previous 100 iterations. Once complete, the first 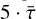 steps are discarded to allow for burn-in, to ensure that there is no impact on the final result from the starting positions, and the sample is thinned by
steps are discarded to allow for burn-in, to ensure that there is no impact on the final result from the starting positions, and the sample is thinned by 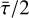 , for reasons of computational speed.
, for reasons of computational speed.
3.4 Convergence checks
As these results are obtained from an automated procedure, the sampler output for each target is closely inspected in the following ways to ensure confidence in the results for each individual target: a corner plot of the three stellar parameters (e.g. Figure 2), a violin plot of the RV parameter sampler (e.g. Figure 3), and a plot showing the observations compared the best-fitting synthetic spectrum. This is created by interpolating from the median T* and log ɡ sampler results and broadened the synthetic spectrum generated by the median v sin i and convolving by the MUSE instrument profile. This is then plotted against the normalised MUSE observations, each shifted by the corresponding median RV (e.g. Figure 4). This inspection can result in a seemingly converged result being rejected even when the τ-convergence criteria has been reached.
A result may be rejected if the corner plot of the three stellar parameters show that the result is on the edge of the grid. This indicates that the degeneracy between the three parameters has not been resolved. An inspection of these cases shows that this occurs when there is insufficient He II line strength. This results in the inability to fit temperature.
 |
Fig. 2 Corner plot showing the PDF of the sampler results of the three stellar parameters for SSN 62. This is an example of a well-converged single-star fit. |
 |
Fig. 3 Violin plot of sampler RV returns for each MUSE observation of SSN 62. This is an example of an SB1 as at least two median RVs have a separation of >10 km s−1 and the RV differences in two epochs is significant with a separation >4σ. |
3.5 Error estimation
Typically from an MCMC process, the statistical upper and lower errors are taken from the quartiles (typically the 16th and 84th) of the sampler results. In this case, the statistical errors of this method would be of the order of 10 K for Teff, less than 0.01 dex [cm s−2] for log ɡ, and only a few km s−1 for v sin i. It is clearly not suitable to consider these minute statistical errors as the errors on the fit of the physical parameters of the targets.
To provide an estimation of the errors on the stellar parameters, we consider the variations in the found best-fit parameters that may occur from fitting individual observations. While the method described in Section 3.3 considers all observations simultaneously to find the model that best fits all observations, weighted by the S/N of each, it is also possible to repeat the process for each observation individually. The result is then a separate sampler return for each observation, and, after discarding the burn-in, the median of the sampler for each stellar parameter can be taken to find the best-fit value from that observation alone. The standard deviation of the set of each stellar parameter provides a stronger estimate of the error, as it shows the variation in the best-fit parameter that may have been found if only considering one observation at a time. This method for each target in estimated errors on the order of 200–1200 K for Teff, 0.05–0.20 dex [cm s−2] for log ɡ and 10–80 km s−1 for v sin i. These error estimation for each target are included in Table A.2.
3.6 Luminosity and extinction
Luminosity and extinction are constrained independently from the Bayesian statistic technique by using the UV spectral observations (Rickard et al. 2022), along with HST F225W, F555W, and F814W photometry (Sabbi et al. 2007; Rickard et al. 2022). The PoWR grid model with the closest parameters to the fit found for each target is selected, and the synthetic emergent spectral energy distribution (SED) for that model is compared to the observed HST UV spectra and HST photometry.
The adopted reddening value strongly influences the slope of the UV spectrum for each object, and thus the luminosity and extinction must be found simultaneously. Extinction is applied to the synthetic SED following the same method as in Rickard et al. (2022), which incorporates two elements. The first is a foreground Galactic extinction component, constant for all targets at E(B−V) = 0.06 mag, applied with the extinction law from Seaton (1979). The second is a local extinction specific for each star. This is applied using the extinction law for the SMC from Howarth (1983) with RV = 2.7 (Bouchet et al. 1985). Both luminosity and E(B−V) are adjusted simultaneously until the synthetic SED matches the observations. Where there is disagreement between the best extinction value to match the photometry and the HST UV SED, a preference is given to the best value for the UV SED observations. Where there is no UV spectrum for the target, no luminosity or extinction is given.
3.7 Spectral typing
Given the lack of metal lines in the low-resolution MUSE spectra, a classical spectral classification that uses line ratios of metal lines is not possible. To approximate the spectral type here, we use the approximation for SMC stars reported by Ramachandran et al. (2019). Without any obvious giants, the relation for dwarfs and subdwarfs between O3 and B1 is used (T*[kK] = 56.602.74 × ST, where ST is the spectral type given as a number beginning with O3 = 3 and ending with B1 = 11).
3.8 Binary candidate identification
Single-line spectroscopy binary (SB1) candidates are determined from the parameters for each observation from the return of the MCMC sampler. The median RV from the sampler return is the RV result for each observation with the standard deviation as the error. The criteria to identify targets with significant RV variation to consider SB1 candidates is taken from Dufton et al. (2019) and Sana et al. (2013). From Dufton et al. (2019), we adopt the minimum variation to be considered an SB1 candidate to be at least 10 km s−1 between two median RVs. As the targets all appear to be dwarfs, such a low number is suitable as they do not have strong intrinsic variability. From Sana et al. (2013) we adopt the significance check used, where the RV differences between two epochs are significant if the separation is at least 4σ.
The violin plot (e.g. Fig. 3) of the sampler RV returns for each target is inspected. This is required as some of the observations within this study follow on from one another. The RVs of these sequential observations usually agree with each other, but not always, for example when one of them has a low S/N (see Sect. 2 for the discussion about observing conditions). Some targets show erroneous median RV results between the results for two consecutive observations. If an erroneous median RV has caused a target to be classified as an SB1 candidate, this status is then revoked based on this inspection.
In addition, SB2 and even SB3 candidates can be identified by inspection of the morphology of the absorption lines. Multiple absorption peaks may be observed in one epoch, while others may show the peaks overlapping and contributing towards a combined deeper absorption feature. This will either result in a failed convergence with the number of steps exceeding 20τ, or the process can converge, but with a set of parameters that can be seen to poorly fit the multiple components in the observations.
It is also possible for SB2 candidates to show up in another way. This is exemplified by two particular targets, SSN 13 and SSN 15. These targets have strong He II lines, and in both cases the Bayesian statistic technique finds an RV fit that shifts the observations to closely match these lines. The weak He I lines are then shown to be best fit by a different RV value. This, in combination with the RV shifts evident for both targets, leads us to categorise both targets as SB2 candidates, where the He II lines are the result of a hot primary and the He I lines are due to a cooler secondary. SB2 and SB3 candidates identified through any means are noted separately, and the best-fit parameters are not included in the results.
 |
Fig. 4 Synthetic spectrum created from the median sampler results for SSN 22 (red), with the normalised MUSE observations (blue), each observation shifted by the median RV sampler result for that observation. The red shading above and below the synthetic spectrum indicates the limit of all error bounds combined (as determined in the method described in Section 3.5), also including the largest error for RV of any observations. The shaded wavelength regions are not within the selected line regions detailed in Table 1 and so are not considered in the fitting process. |
4 Results
The stellar parameters results (T*, log ɡ, and v sin i) are from the sampler return of the MCMC process. With the burn-in samples discarded, the median result serves as the best-fit result for these parameters. Table A.2 lists the single-star fit found for 34 stars. These results include the error estimations for each stellar parameter (Sect. 3.5). Histograms of the measured temperature, surface gravity, projected rotational velocity, luminosity, and spectroscopic mass of the targets within the sample are shown in Fig. 5. They show that the majority of the targets have T* > 30 kK, showing the reliance on prominent He spectral lines. The distribution shows far fewer targets with T* > 34 kK. Among the stars in our sample, ten stars meet these criteria and are designated accordingly as SB1.
5 Discussion
5.1 Rejected results for individual stars
Over 200 targets have at least one observation meeting the minimum S/N criteria, yet only 34 have single-star results where the result is accepted (Sect. 4). Whether or not the process produces a result for a target that is accepted based on inspection is not influenced by the number of observations available, with some of the accepted results being for objects with as few as two observations. Even with multiple high S/N observations, a target without He II lines cannot be fit. Without the balance of the He I and He II lines, the temperature becomes less constrained. As the parameters of T*, log ɡ, and v sin i are partially degenerate when fitting using only the H and He diagnostic lines, the lack of information about temperature from the balance of He I and He II lines results in too little information to constrain all three parameters simultaneously. These features of the Bayesian statistic technique give it a selection bias. Lower temperature objects and peculiar objects are necessarily excluded from the final results.
5.2 Comparison to previous works
The population of massive stars in NGC 346 have been catalogued before (Dufton et al. 2019), creating the opportunity to compare the results in this work with other methods for estimating stellar parameters. Sixteen of the 34 stars in the sample of single stars have been previously studied (see Dufton et al. 2019). They find Teff and log ɡ by fitting the FLAMES spectra to synthetic spectra generated from TLUSTY and SYNSPEC model codes (Hubeny 1988; Hubeny & Lanz 1995; Hubeny et al. 1998; Lanz & Hubeny 2007). This code produces publicly available TLUSTY grids of synthetic spectra4. The estimated errors in Dufton et al. (2019) are 1 kK in Teff and 0.2 dex in log ɡ. Figure 6 shows a comparison between the fitted temperature values and Fig. 7 shows a comparison of the log ɡ values.
Figure 6 shows that there is no agreement between the temperature results of the overlapping samples, but that both results agree as to the temperature order of the sample (i.e. hotter stars are identified as hotter objects via both methods). However, there is a difference, especially at higher temperatures: the method based on the PoWR grid of synthetic spectra generally does not find temperatures as high as those found by Dufton et al. (2019) via matching to the TLUSTY grid of synthetic spectra. This difference warrants further investigation.
Some of this difference will come down to the choice of line selection used by Dufton et al. (2019) to find the best-fitting TLUSTY synthetic spectrum, such as the use of He I λ 4922 and He II λ 4686. These lines are not included for the method used in this work, due to the reasons detailed in Sect. 3.2. Further differences can be explained by the difference between the PoWR models used to generate the PoWR grid of the synthetic spectra and the TLUSTY and SYNSPEC model codes used for the TLUSTY grid of the synthetic spectra.
As an example, Figure 8 shows the Hα, Hβ, He I, and He II line segments from a synthetic spectrum taken from the TLUSTY grid for T* = 40kK and log ɡ = 4.0, convolved with a rotation profile equivalent to v sin i = 150 km s−1. This is shown in comparison to the same line segments from the PoWR grid synthetic spectrum for the same stellar parameters. It can be seen immediately that the PoWR synthetic spectrum shows stronger He II lines. This means that when using this PoWR grid, a star of this temperature will be fitted to a synthetic spectrum generated with a lower temperature PoWR model than if using a grid of synthetic spectra generated with the TLUSTY and SYNSPEC model codes.
A detailed investigation into the differences between the PoWR model code and the TLUSTY model code is beyond the scope of this work, but a brief set of reasons why the two codes may result in such a difference in the resultant synthetic spectra may include the following: the difference in metal abundances adopted, the difference between the selected mass loss recipe used, the difference in the treatment of line blanketing, the differences in implementation of microtubulence as an additional broadening mechanism, and the luminosity selected for each model. With such differences in the set-up of the models, it is not surprising that the overlapping sample shows different stellar parameter results between the two samples. By way of reassurance, the line comparison figure for each target is included on Zenodo, and an example is shown in Fig. 4. These show how the observations are each well fit by a synthetic spectrum based on the grid of spectra generated by the PoWR model code.
The MUSE observations included in this work were also employed in the analysis presented in Rickard et al. (2022). This previous work focused on the wind parameters of massive stars in the central core of NGC 346 using PoWR models. This required PoWR models to be run to determine the wind parameters. These models use the input of stellar parameters determined from optical spectra. For the majority of the brightest objects within the sample, previous studies such as Bouret et al. (2003) and Dufton et al. (2019) provided the stellar parameters of T*, log ɡ and v sin i. For the remainder, where no previous analysis existed, a mean MUSE spectrum was generated from each target, with each epoch shifted by a suitable RV found through a shift-and-add process. For these, v sin i was measured using the IACOB-BROAD tool from He lines. The best-fitting synthetic spectrum from the grid generated from PoWR models was then selected using a χ2 test, with changes to T* and log ɡ applied to the custom PoWR models only in the small number of cases where it was clearly needed.
Despite the difference in method, the results found in this work are very similar to those results presented in Rickard et al. (2022). For the eight objects where Rickard et al. (2022) uses the MUSE spectra to determine stellar parameters, the average difference between the results presented there and those found here with the Bayesian statistic technique is 0.7kK for T* and 0.1 dex for log ɡ, well within the steps in the PoWR grid of 1kK for and 0.2 dex This suggests that the difference between these results and those found by Dufton et al. (2019) are due to the underlying differences in the model codes and the model setup choices and not are not the result of the Bayesian statistic technique.
Figure 7 shows the derived log ɡ in this work compared to that found in Dufton et al. (2019). There is much greater scatter for this parameter and a less clear trend, due to the difficulty in measuring log ɡ from the wings of the Balmer lines via both methods. In addition, T* and log ɡ are partially degenerate and measured simultaneously. If the two methods do not find the same T*, they will not agree in their measurement of log ɡ. Regardless, there is agreement for both of the overlapping objects, with both methods agreeing on which targets show indications of lower log ɡ and which show indications of higher log ɡ.
In Dufton et al. (2019) v sin i is measured using Mg and Si lines with a goodness of fit (GF) method and a Fourier transform (FT) method (IACOB-BROAD, Simón-Díaz & Herrero 2014). These lines are outside the MUSE wavelength range. Figure 9 shows the overlapping samples and the comparison between the GF results from Dufton et al. (2019) and to the fitted v sin i in this work. By comparing the GF method results from Dufton et al. (2019) we are, for both cases, considering a method that not only includes rotation, but also macroturbulence. From the difference between the GF and FT results presented in Dufton et al. (2019) of ≈11km s−1, we can judge that the overestimation of our v sin i value due to the inclusion of all broadening affects at once in to one parameter to be of a similar scale of ≈11 km s−1.
It can be seen in Figure 9 that overall the agreement trend for v sin i in the overlapping sample is very good. However this is a false impression generated by the four objects with rotation ≳250 km s−1. It is clear that both methods correctly identify objects with indications of high broadening velocity in their spectra. In the overlapping sample with rotational broadening velocity ≲200 km s−1 there is more disagreement.
While Zeidler et al. (2022) used the same MUSE observations to derive RVs of 103 stars within the core of NGC 346 for the purpose of understanding the internal kinematics, and this sample would provide a useful verification of the technique used for measuring RV, no overlap exists between the 103 stars reported and this sample because for most of the stars in their sample, Zeidler et al. (2022) use metal lines such as Mg I and Ca II, which are not present in the spectra of the hot stars fitted in this work, or they use very strong He I lines, which would be less prominent in these hot stars with strong He II.
 |
Fig. 5 Distribution of the stellar parameters of the sample shown as stacked histograms of the sample. Blue: single stars, no evidence of multiplicity found. Cyan: SB1s based on RVs. |
 |
Fig. 6 Comparison of fitted temperature found via the Bayesian statistic technique used in this work to that found by Dufton et al. (2019) fitting to TLUSTY grid models. The stars shown are limited to those in the overlap between the two samples. The black dashed line shows a gradient of one, where the two methods would have complete agreement. The orange dashed line shows the best-fit line between T* of the two samples. |
 |
Fig. 7 Comparison of surface gravity found via the Bayesian statistic technique used in this work to that found by Dufton et al. (2019) fitting to TLUSTY grid models. The stars shown are limited to those in the overlap between the two samples. The dashed lines are coloured as in Fig. 6. |
 |
Fig. 8 Synthetic spectral lines created from PoWR (red dashed line) and TLUSTY (black solid line) grid models. Each synthetic spectrum is for a model with the same temperature (T* = 40 kK) and surface gravity (log ɡ = 4.0). Each synthetic spectra has been convolved with a rotation profile for v sin i = 150 km s−1. |
 |
Fig. 9 Comparison of the projected rotational velocity as found from the Bayesian statistic technique used in this work on H and He lines along with that found by Dufton et al. (2019) using the goodness of fit method to Mg and Si. Stars shown are limited to those in the overlap between the two samples. The dashed line colours are the same as in Fig. 6. |
5.3 Binary candidates and binary fraction
The requirements for a target to be considered SB1 are stringent (Sect. 3.8), yet this method finds additional SB1s with respect to those found by Dufton et al. (2019). A total of nine SB1 candidates are identified here from the RV shifts from 11 days of MUSE observations.
The selection criteria for Dufton et al. (2019) was for there to be an RV shift of >10 km s−1 between two epochs. They identify two SB1 candidates that are not found to be SB1s based on these MUSE observations. These are SSN 33 and SSN 34. A review of the violin plot for SSN 33 shows that the variation does not meet the >10 km s−1 requirement. For SSN 34, the RV distribution shown in the violin plot does exceed the >10 km s−1 requirement, and shows a clear trend over the 11 days of the observations, but the 4σ significance test is not satisfied.
The targets of SSN 13 and SSN 15 are considered SB2 candidates, due to the difference in the RV shift required to fit the observed He I lines compared to the RV shift required to fit the observed He II lines. Dufton et al. (2019) categorise SSN 13 as an SB1 candidate, while SSN 15 matches the criteria used in this work to qualify as an SB1, adding to the evidence of binarity for these targets. An additional target (SSN 47) identified as an SB1 candidate by Dufton et al. (2019) has been considered here as an SB2 candidate, due to clear double-line features in observations from a number of epochs.
We replicate the SB2 candidate classification from Dufton et al. (2019) for SSN 39 and see the SB2 features already documented in the observations of SSN 7 (Rickard & Pauli 2023). In addition, we categorise SSN 17, SSN 58, SSN 80, and SSN 89 as SB2 candidates. We believe we can see three distinct line features in the observations of SSN 11, making it an SB3 candidate. A complete list of targets considered but not fit due to binary features within the target’s spectrum indicating more than one component, or due to spectral emission features, are listed in Table 2. The best-fit result for SSN 13 and SSN 15 is presented in the additional information available on Zenodo5 and show the best-fit model, demonstrating how the He I and He II lines require differing RV shifts. The observations of the remaining objects in Table 2 are included in this additional information.
There are a total of 34 stars for which we have presented a single-star result. This includes both apparent single stars and SB1s. We do not report the undoubtedly erroneous fit results for SB2 and SB3 candidates and emission stars. With these stars included, the true total number of objects reviewed in this work is 46. If we accept all the SB1 classifications from Dufton et al. (2019) and consider them in combination with the classifications from this work, we find 11 SB1 candidates, 9 SB2 candidates, and 1 SB3 candidate, resulting in a lower limit of the binary fraction of 21/46 = 46%. It is worth noting that our method based on the MCMC is only suitable for objects displaying He II lines in their spectra, and therefore the derived binary fraction probes only the hottest stars in the central core of NGC 346.
Binary candidates or emission stars.
5.4 Rotation
When measuring the projected rotational broadening of a massive star from a single transition line, the lower limit of the rotational velocity that can be measured is limited to the instrument resolution. For this work multiple lines are considered at once, and it is best compared to studies matching the whole spectrum simultaneously to a convolved synthetic spectrum (e.g. Kamann et al. 2018). By measuring the model of a rotational broadening effect against multiple lines at once, the limited effect of instrumental broadening is eliminated as the shape of the line profile will be measured multiple times, meaning the sampling by the bins along the wavelength dispersal direction of the sensor is improved.
Massive stars in low-metallicity environments typically have higher rotational velocities compared to their Galactic counterparts because their weaker stellar winds remove less mass and angular momentum (e.g. Ramachandran et al. 2019). Figure 10 shows the probability distribution of rotational velocities in our sample stars in comparison to other SMC, LMC, and Galactic samples. As in previous studies, the sample presented in this work shows the peak in the projected rotational velocity distribution at higher velocities than for the LMC samples, which in turn peaks at higher velocities than the Galactic samples. This supports the argument that lower metallicity massive stars spin down more slowly than their higher metallicity equivalents, due to their lower stellar wings and a smaller resultant loss of angular momentum. However, caution must be taken when comparing different samples. For example, the OB star sample presented by Ramachandran et al. (2019) includes later-type stars which are not included in our sample, due to the lack of strong He II lines. In addition, the v sin i values found in this work include additional broadening mechanisms such as macroturbulence, and there is a slight overestimation of ∼10 km s−1
Despite this, it is interesting to note that the location of the peak of the probability distribution of rotation rate in our sample is very similar to that found in previous studies of SMC objects, such as OB stars in the SMC Wing (Ramachandran et al. 2019) and in the NGC 330 cluster (Martayan et al. 2007). This can be explained by the lack of a correlation between stellar temperature and the projected rotation rate, meaning that the absence of cooler B stars in our sample does not affect the projected rotational velocity distribution.
 |
Fig. 10 Projected rotational velocity probability distribution compared to numerous other SMC, LMC, and Milky Way samples. Blue lines: SMC samples–Blue solid line: this work (including macroturbulence, and thus a slight overestimation of ∼10km s−1). Blue dotted line: Ramachandran et al. (2019). Blue dashed line: Martayan et al. (2007). Red lines: LMC samples–Red solid line: Ramachandran et al. (2018). Red dotted line: Dufton et al. (2013) and Ramírez-Agudelo et al. (2013). Green lines: Galactic samples–Green solid line: Simón-Díaz & Herrero (2014). Green dashed line: Bragança et al. (2012). Green dotted line: Dufton et al. (2006). |
5.5 Estimating the age of the NGC 346 star cluster
One method to estimate the age of a stellar cluster is to compare the Hertzsprung–Russell diagram (HRD) position and main sequence turnoff to sets of model isochrones with the modelled ages. The best-fit values of luminosity and temperature are plotted on a HRD in Fig. 11. This only includes the stars with available HST UV observations, which we used to derive luminosities (Sect. 3.6). The HRD positions of our sample stars are compared to isochrones with an initial rotation of 200 km s−1 (i.e. matching the projected rotational velocity found in our sample stars). As can be seen in Fig. 11, the positions of hot OB stars in our sample are consistent with a minimum age of at least 3 Myr.
This is higher than the previous age estimates of 1–2.6 Myr (Dufton et al. 2019) and 1–2 Myr (Walborn et al. 2000). The reason for this discrepancy is that the previous works relied on the HRD position of the hotter stars, such as SSN 7 and SSN 9. Care should be taken when using these stars for the age estimates. The very bright star SSN 9 is a giant with high nitrogen content (Walborn et al. 2000; Bouret et al. 2013; Rickard et al. 2022). The other bright star, SSN 7, is a SB2 with two high-mass components that have already exchanged mass (Rickard & Pauli 2023). The evolutionary age of the SSN 7 system is 4.2 Myr (Rickard & Pauli 2023). Therefore, treating it as a single star and using its location on the HRD for comparison with isochrones for cluster age estimates is misleading. The HRD position of the OB stars in the sample of stars we consider in this work provide further support for the estimated minimum age of OB stars in the core of NGC 346 as ≳3 Myr (Rickard et al. 2022; Rickard & Pauli 2023).
 |
Fig. 11 HRD of OB stars in the core of NGC 346. Red markers: SB1s candidates. Black markers: apparent single stars. Dotted lines: isochrones with Z = 0.002 and initial rotation velocity of 200 km s−1 (Georgy et al. 2013). |
6 Summary and conclusions
This work derives the fundamental stellar parameters, T*, log g, and v sin i for a sample of 34 OB-type stars located in the core of the NGC 346 cluster in the SMC. Multi-epoch spectra were obtained with the MUSE IFU spectrograph. The spectroscopic analysis presented in this paper is based on a Bayesian statistic technique. This method is independent of a measurement of projected rotational velocity made through other means and breaks the degeneracy between these three parameters when only considering H and He spectral features. The results are compared to a subsample of 18 stars where these parameters were found using standard methods.
We conclude that the Bayesian statistic technique is an effective method for deriving the most likely stellar parameters of hot OB-type stars using optical spectroscopy and pre-calculated grids of model synthetic spectra. We note that this method for determining temperature, surface gravity, and projected rotational velocity does not require metal lines, and thus can be used for studies of metal-poor massive stars. In order to break the partial degeneracy between the three stellar parameters, clear He II lines are required, which means that this method can only be applied to hotter stars (i.e. mainly O stars).
In a subsample of stars in the overlap between this work and the sample of OB stars analysed by Dufton et al. (2019), there is agreement as to relative temperature through the course of the samples, but there is disagreement regarding the best-fit values for T*, which consequently affects the best-fit value for log ɡ and v sin i. However, this difference is due to the difference between the model code used to generate the grid of synthetic spectra employed in this work (PoWR) and the model code used to generate the grid of synthetic spectra employed by Dufton et al. (2019) (TLUSTY and SYNSPEC).
The peak in the probability distribution of the projected rotational velocity is at a higher velocity than that of the Galactic and LMC OB populations, in support of other findings that SMC stars have higher rotation. The peak is at a projected rotational velocity similar to that found for other clusters of SMC stars.
Combining multiple epochs allows the detection of binaries. Combining this method with the binary results from other work we obtain a minimum binary fraction of the hot OB stars from the core of NGC 346 of >46%.
The use of synthetic SEDs for each target compared to available HST UV spectra and photometry allowed the fitting of stellar luminosity. The resultant HRD position of each target supports the previously identified minimum age of the OB population of the core of NGC 346 to be ≳3 Myr.
Data availability
The discussion and results from each target included in this work and the observations of the SB2 and SB3 candidates and emission stars can be accessed on the Zenodo repository (https://doi.org/10.5281/zenodo.13991997).
Acknowledgements
We thank the anonymous referee for their constructive comments. DP acknowledges financial support by the Deutsches Zentrum für Luft und Raumfahrt (DLR) grant FKZ 50 OR 2005. This publication has benefited from a discussion at a team meeting sponsored by the International Space Science Institute at Bern, Switzerland. L. M. O. acknowledges support from the Verbundforschung grant 50 OR 1809. Some/all of the data presented in this paper were obtained from the Mikulski Archive for Space Telescopes (MAST). STScI is operated by the Association of Universities for Research in Astronomy, Inc., under NASA contract NAS5-26555. Support for MAST for non-HST data is provided by the NASA Office of Space Science via grant NNX09AF08G and by other grants and contracts. AACS and VR acknowledge support by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) in the form of an Emmy Noether Research Group – Project-ID 445674056 (SA4064/1- 1, PI Sander). ECS acknowledges financial support by the Federal Ministry for Economic Affairs and Climate Action (BMWK) via the German Aerospace Center (Deutsches Zentrum für Luft- und Raumfahrt, DLR) grant 50 OR 2306 (PI: Ramachandran/Sander). AACS, VR, and ECS further acknowledge support from the Federal Ministry of Education and Research (BMBF) and the Baden-Württemberg Ministry of Science as part of the Excellence Strategy of the German Federal and State Governments. This research has made use of the VizieR catalogue access tool, Strasbourg, France. The original description of the VizieR service was published in A&AS 143, 23. Part of work was facilitated by the International Space Science Institute (ISSI) in Bern, through ISSI International Team project 512 (Multiwavelength View on Massive Stars in the Era of Multimessenger Astronomy, PI Oskinova).
Appendix A Additional tables
The full list of MUSE observations, including observing conditions, is included in Table A.1. The full results for each target is included in Table A.2.
Observation diary of the individual MUSE observation blocks.
MCMC results of sample of stars within NGC 346.
References
- Abbott, D. C. 1982, ApJ, 259, 282 [Google Scholar]
- Aerts, C., Puls, J., Godart, M., & Dupret, M. A. 2009, Commun. Asteroseismol., 158, 66 [NASA ADS] [Google Scholar]
- Bacon, R., Accardo, M., Adjali, L., et al. 2010, SPIE Conf. Ser., 7735, 773508 [Google Scholar]
- Bouchet, P., Lequeux, J., Maurice, E., Prevot, L., & Prevot-Burnichon, M. L. 1985, A&A, 149, 330 [NASA ADS] [Google Scholar]
- Bouret, J. C., Lanz, T., Hillier, D. J., et al. 2003, AJ, 595, 1182 [NASA ADS] [CrossRef] [Google Scholar]
- Bouret, J. C., Lanz, T., Martins, F., et al. 2013, A&A, 555, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bragança, G. A., Daflon, S., Cunha, K., et al. 2012, AJ, 144, 130 [CrossRef] [Google Scholar]
- Brott, I., de Mink, S. E., Cantiello, M., et al. 2011, A&A, 530, A115 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Burbidge, E. M., Burbidge, G. R., Fowler, W. A., & Hoyle, F. 1957, Rev. Mod. Phys., 29, 547 [NASA ADS] [CrossRef] [Google Scholar]
- Castor, J. I., Abbott, D. C., & Klein, R. I. 1975, AJ, 195, 157 [NASA ADS] [CrossRef] [Google Scholar]
- Dufton, P. L., Smartt, S. J., Lee, J. K., et al. 2006, A&A, 457, 265 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dufton, P. L., Langer, N., Dunstall, P. R., et al. 2013, A&A, 550, A109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dufton, P. L., Evans, C. J., Hunter, I., Lennon, D. J., & Schneider, F. R. N. 2019, A&A, 626, A50 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Evans, C. J., Lennon, D. J., Smartt, S. J., & Trundle, C. 2006, A&A, 456, 623 [CrossRef] [EDP Sciences] [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Georgy, C., Ekström, S., Eggenberger, P., et al. 2013, A&A, 558, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gräfener, G., Koesterke, L., & Hamann, W.-R. 2002, A&A, 387, 244 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hainich, R., Rühling, U., Todt, H., et al. 2014, A&A, 565, A27 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hainich, R., Pasemann, D., Todt, H., et al. 2015, A&A, 581, A21 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hamann, W. R., & Gräfener, G. 2004, A&A, 427, 697 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Heger, A., Fryer, C. L., Woosley, S. E., Langer, N., & Hartmann, D. H. 2003, ApJ, 591, 288 [CrossRef] [Google Scholar]
- Hilditch, R. W., Howarth, I. D., & Harries, T. J. 2005, MNRAS, 357, 304 [NASA ADS] [CrossRef] [Google Scholar]
- Hillier, D. J. 1987, ApJS, 63, 947 [NASA ADS] [CrossRef] [Google Scholar]
- Hillier, D. J. 2012, in From Interacting Binaries to Exoplanets: Essential Modeling Tools, 282, eds. M. T. Richards, & I. Hubeny, 229 [NASA ADS] [Google Scholar]
- Hillier, D. J., & Lanz, T. 2001, in Astronomical Society of the Pacific Conference Series, 247, Spectroscopic Challenges of Photoionized Plasmas, eds. G. Ferland & D. W. Savin, 343 [NASA ADS] [Google Scholar]
- Hillier, D. J., & Miller, D. L. 1998, AJ, 496, 407 [NASA ADS] [CrossRef] [Google Scholar]
- Hollenbach, D. J., & Tielens, A. G. G. M. 1999, Rev. Mod. Phys., 71, 173 [Google Scholar]
- Howarth, I. D. 1983, MNRAS, 203, 301 [NASA ADS] [CrossRef] [Google Scholar]
- Hubeny, I. 1988, Comput. Phys. Commun., 52, 103 [Google Scholar]
- Hubeny, I., & Lanz, T. 1995, ApJ, 439, 875 [Google Scholar]
- Hubeny, I., Heap, S. R., & Lanz, T. 1998, in Astronomical Society of the Pacific Conference Series, 131, Properties of Hot Luminous Stars, ed. I. Howarth, 108 [NASA ADS] [Google Scholar]
- Hunter, I., Dufton, P. L., Smartt, S. J., et al. 2007, A&A, 466, 277 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Kajino, T., Aoki, W., Balantekin, A. B., et al. 2019, Progr. Part. Nucl. Phys., 107, 109 [NASA ADS] [CrossRef] [Google Scholar]
- Kamann, S., Husser, T. O., Dreizler, S., et al. 2018, MNRAS, 473, 5591 [NASA ADS] [CrossRef] [Google Scholar]
- Kasen, D., Metzger, B., Barnes, J., Quataert, E., & Ramirez-Ruiz, E. 2017, Nature, 551, 80 [Google Scholar]
- Lanz, T., & Hubeny, I. 2007, ApJS, 169, 83 [CrossRef] [Google Scholar]
- Lucy, L. B., & Solomon, P. M. 1970, AJ, 159, 879 [NASA ADS] [Google Scholar]
- Martayan, C., Frémat, Y., Hubert, A. M., et al. 2007, A&A, 462, 683 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Massey, P., Parker, J. W., & Garmany, C. D. 1989, AJ, 98, 1305 [Google Scholar]
- Matzner, C. D. 2002, ApJ, 566, 302 [NASA ADS] [CrossRef] [Google Scholar]
- Najarro, F., Hillier, D. J., Puls, J., Lanz, T., & Martins, F. 2006, A&A, 456, 659 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Oskinova, L. M., Todt, H., Ignace, R., et al. 2011, MNRAS, 416, 1456 [NASA ADS] [CrossRef] [Google Scholar]
- Pauli, D., Oskinova, L. M., Hamann, W. R., et al. 2023, A&A, 673, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pignatari, M., Gallino, R., Heil, M., et al. 2010, ApJ, 710, 1557 [Google Scholar]
- Ramachandran, V., Hamann, W.-R., Hainich, R., et al. 2018, A&A, 615, A40 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ramachandran, V., Hamann, W.-R., Oskinova, L. M., et al. 2019, A&A, 625, A104 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ramírez-Agudelo, O. H., Simón-Díaz, S., Sana, H., et al. 2013, A&A, 560, A29 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rickard, M. J., & Pauli, D. 2023, A&A, 674, A56 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rickard, M. J., Hainich, R., Hamann, W. R., et al. 2022, A&A, 666, A189 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rogers, H., & Pittard, J. M. 2013, MNRAS, 431, 1337 [CrossRef] [Google Scholar]
- Rübke, K., Marco, A., Negueruela, I., et al. 2023, in Highlights on Spanish Astrophysics XI, eds. M. Manteiga, L. Bellot, P. Benavidez, A. de Lorenzo-Cáceres, M. A. Fuente, M. J. Martínez, M. Vázquez Acosta, & C. Dafonte, 306 [Google Scholar]
- Sabbi, E., Sirianni, M., Nota, A., et al. 2007, AJ, 133, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Sana, H., de Koter, A., de Mink, S. E., et al. 2013, A&A, 550, A107 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Sander, A., Shenar, T., Hainich, R., et al. 2015, A&A, 577, A13 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Seaton, M. J. 1979, MNRAS, 187, 73 [Google Scholar]
- Shenar, T., Oskinova, L., Hamann, W.-R., et al. 2015, ApJ, 809, 135 [NASA ADS] [CrossRef] [Google Scholar]
- Simón-Díaz, S., & Herrero, A. 2014, A&A, 562, A135 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Thielemann, F. K., Arcones, A., Käppeli, R., et al. 2011, Progr. Part. Nucl. Phys., 66, 346 [NASA ADS] [CrossRef] [Google Scholar]
- Trundle, C., Dufton, P. L., Hunter, I., et al. 2007, A&A, 471, 625 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vink, J. S., de Koter, A., & Lamers, H. J. G. L. M. 2000, A&A, 362, 295 [NASA ADS] [Google Scholar]
- Vink, J. S., de Koter, A., & Lamers, H. J. G. L. M. 2001, A&A, 369, 574 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Walborn, N. R., Lennon, D. J., Heap, S. R., et al. 2000, PASP, 112, 1243 [Google Scholar]
- Zeidler, P., Sabbi, E., & Nota, A. 2022, ApJ, 936, 136 [CrossRef] [Google Scholar]
All Tables
All Figures
|
Fig. 1 Equivalent widths of He I λ 4713 (left) and He II λ 5412 (right), bilinearly interpolated for the whole PoWR grid range. |
| In the text | |
|
Fig. 2 Corner plot showing the PDF of the sampler results of the three stellar parameters for SSN 62. This is an example of a well-converged single-star fit. |
| In the text | |
|
Fig. 3 Violin plot of sampler RV returns for each MUSE observation of SSN 62. This is an example of an SB1 as at least two median RVs have a separation of >10 km s−1 and the RV differences in two epochs is significant with a separation >4σ. |
| In the text | |
|
Fig. 4 Synthetic spectrum created from the median sampler results for SSN 22 (red), with the normalised MUSE observations (blue), each observation shifted by the median RV sampler result for that observation. The red shading above and below the synthetic spectrum indicates the limit of all error bounds combined (as determined in the method described in Section 3.5), also including the largest error for RV of any observations. The shaded wavelength regions are not within the selected line regions detailed in Table 1 and so are not considered in the fitting process. |
| In the text | |
|
Fig. 5 Distribution of the stellar parameters of the sample shown as stacked histograms of the sample. Blue: single stars, no evidence of multiplicity found. Cyan: SB1s based on RVs. |
| In the text | |
|
Fig. 6 Comparison of fitted temperature found via the Bayesian statistic technique used in this work to that found by Dufton et al. (2019) fitting to TLUSTY grid models. The stars shown are limited to those in the overlap between the two samples. The black dashed line shows a gradient of one, where the two methods would have complete agreement. The orange dashed line shows the best-fit line between T* of the two samples. |
| In the text | |
|
Fig. 7 Comparison of surface gravity found via the Bayesian statistic technique used in this work to that found by Dufton et al. (2019) fitting to TLUSTY grid models. The stars shown are limited to those in the overlap between the two samples. The dashed lines are coloured as in Fig. 6. |
| In the text | |
|
Fig. 8 Synthetic spectral lines created from PoWR (red dashed line) and TLUSTY (black solid line) grid models. Each synthetic spectrum is for a model with the same temperature (T* = 40 kK) and surface gravity (log ɡ = 4.0). Each synthetic spectra has been convolved with a rotation profile for v sin i = 150 km s−1. |
| In the text | |
|
Fig. 9 Comparison of the projected rotational velocity as found from the Bayesian statistic technique used in this work on H and He lines along with that found by Dufton et al. (2019) using the goodness of fit method to Mg and Si. Stars shown are limited to those in the overlap between the two samples. The dashed line colours are the same as in Fig. 6. |
| In the text | |
|
Fig. 10 Projected rotational velocity probability distribution compared to numerous other SMC, LMC, and Milky Way samples. Blue lines: SMC samples–Blue solid line: this work (including macroturbulence, and thus a slight overestimation of ∼10km s−1). Blue dotted line: Ramachandran et al. (2019). Blue dashed line: Martayan et al. (2007). Red lines: LMC samples–Red solid line: Ramachandran et al. (2018). Red dotted line: Dufton et al. (2013) and Ramírez-Agudelo et al. (2013). Green lines: Galactic samples–Green solid line: Simón-Díaz & Herrero (2014). Green dashed line: Bragança et al. (2012). Green dotted line: Dufton et al. (2006). |
| In the text | |
|
Fig. 11 HRD of OB stars in the core of NGC 346. Red markers: SB1s candidates. Black markers: apparent single stars. Dotted lines: isochrones with Z = 0.002 and initial rotation velocity of 200 km s−1 (Georgy et al. 2013). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.