| Issue |
A&A
Volume 691, November 2024
|
|
|---|---|---|
| Article Number | A360 | |
| Number of page(s) | 18 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202451429 | |
| Published online | 26 November 2024 | |
Simulating images of radio galaxies with diffusion models
Hamburger Sternwarte, Universität Hamburg, Gojenbergsweg 112, 21029 Hamburg, Germany
⋆ Corresponding author; This email address is being protected from spambots. You need JavaScript enabled to view it.
Received:
9
July
2024
Accepted:
4
October
2024
Abstract
Context. With increasing amounts of data produced by astronomical surveys, automated analysis methods have become crucial. Synthetic data are required for developing and testing such methods. Current classical approaches to simulations often suffer from insufficient detail or inaccurate representation of source type occurrences. Deep generative modeling has emerged as a novel way of synthesizing realistic image data to overcome those deficiencies.
Aims. We implemented a deep generative model trained on observations to generate realistic radio galaxy images with full control over the flux and source morphology.
Methods. We used a diffusion model, trained with continuous time steps to reduce sampling time without quality impairments. The two models were trained on two different datasets, respectively. One set was a selection of images obtained from the second data release of the LOFAR Two-Metre Sky Survey (LoTSS). The model was conditioned on peak flux values to preserve signal intensity information after re-scaling image pixel values. The other, smaller set was obtained from the Very Large Array (VLA) survey of Faint Images of the Radio Sky at Twenty-Centimeters (FIRST). In that set, every image was provided with a morphological class label the corresponding model was conditioned on. Conditioned sampling is realized with classifier-free diffusion guidance. We evaluated the quality of generated images by comparing the distributions of different quantities over the real and generated data, including results from the standard source-finding algorithms. The class conditioning was evaluated by training a classifier and comparing its performance on both real and generated data.
Results. We have been able to generate realistic images of high quality using 25 sampling steps, which is unprecedented in the field of radio astronomy. The generated images are visually indistinguishable from the training data and the distributions of different image metrics were successfully replicated. The classifier is shown to perform equally well for real and generated images, indicating strong sampling control over morphological source properties.
Key words: methods: data analysis / techniques: image processing / surveys / galaxies: general / radio continuum: galaxies
Publisher note: Following the publication of the Corrigendum, the citations for some bibliographic references, inadvertently swapped in the text, where corrected on 16 June 2025.
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Sky surveys have become essential to modern astronomy with respect to improving our understanding of the universe, as they significantly expand the amount of recorded signals available to scientific exploration. Their growing range and sensitivity have brought on an exponential increase in data volumes (Smith & Geach 2023). For instance, LOFAR Two-Metre Sky Survey will gather a total amount of about 50 PB of data (Shimwell et al. 2017), while Square Kilometre Array (SKA) is expected to yield approximately 4.6 EB (Zhang & Zhao 2015). As conventional analysis often relies on human supervision and expert knowledge, many commonly used techniques become intractable for larger amounts of data. This entails an inevitable demand for automated methods to extract useful information at scale and thereby facilitate scientific discoveries. In the case of radio observations, this challenge is manifested in tasks such as source detection, image segmentation, and morphological classifications. Those are frequently obstructed by high levels of background noise and nearby artifacts arising from the imaging process, or complicated by the fact that many sources show multiple non-contiguous islands of emission that are often ambiguous and not easy to associate with each other.
In this context, the use of synthetic data that are applied in several different ways has become particularly valuable. For instance, tools for automatic source extraction are tested on simulated image data (Boyce et al. 2023a), which makes it possible to evaluate the results against properties introduced in the simulation. Furthermore, simulated observations have also been employed in developing deep learning-based methods for automatic calibration (Yatawatta & Avruch 2021) and system health inspection (Mesarcik et al. 2020) of modern radio telescopes. Simulated data are also commonly employed in testing methods for radio image reconstruction, as, for instance, in Garsden et al. (2015). Another use case for synthetic radio images explored by Rustige et al. (2023) is the augmentation of available training data required for deep learning methods such as morphological classification, where data sets are often insufficiently sized or highly imbalanced.
In the absence of an analytical model for radio galaxy formation and evolution, generating synthetic images that are representative of real observations is not a straightforward task. Simulations often rely on the assumption of an ideal background and extended sources are typically modeled with geometrical shapes. For instance, Wilman et al. (2008) simulate flux distributions of extended sources as combinations of point source cores or hot-spots, and elliptical lobes. Similarly, Boyce et al. (2023b) represent extended sources as composites of 2D Gaussian components. These representations are insufficient to capture the morphological complexity of real extended sources. Furthermore, in addition to properties of the signal, an accurate portrayal of astronomical observations also requires detailed knowledge of telescope properties, observation conditions, and data processing. A different approach, as employed in the first SKA Data Challenge (Bonaldi et al. 2021), consists of using real high-resolution images enhanced with random transformations, such as rotations and scaling that provide further variability. While resulting in more accurate representations, this approach lacks diversity in the generated images and can lead to an under-representation of different morphological sub-classes, inherited from the corresponding distribution present in the applied image library.
A promising way to overcome these limitations is through the use of deep generative models. As the field of image synthesis with methods of machine learning has experienced tremendous progress in recent years in the domain of natural images, those techniques have also found their way into the field of radio astronomy. Generative models are deep learning models that learn to represent the underlying probability distribution of the data sets they are trained on. Once that training is completed, they can be used to synthesize new data points that follow the learned distribution. This facilitates the generation of realistic artificial images containing complex structures, without the need for explicit modeling. Imaging properties of the telescope are implicitly learned from the training images. In addition, the possibility of conditioned sampling allows us to control of different image parameters, such as the morphological class of depicted sources, thereby circumventing the potential issue of under-representation.
A particular type of deep generative models that has experienced a recent rise in popularity across different domains is called score-based models or, more commonly, diffusion models (DMs). These models make use of neural networks that at first are trained to remove Gaussian noise, added during the training process, from images. Once trained, this neural network is then employed in an iterative fashion to morph a seed array of pure Gaussian noise into an image that is equivalent to a sample drawn from the distribution underlying the training dataset. In the domain of natural imaging, this class of generative models has emerged as state-of-the-art in terms of sample quality, outperforming other common approaches (Dhariwal & Nichol 2021) such as variational autoencoders (VAEs) or generative adversarial networks (GANs).
While different approaches to generative modeling have already been employed in the context of astronomical imaging (e.g. Bastien et al. 2021), DMs have been explored more recently across a range of contexts. Smith et al. (2022) implemented a DM trained on optical galaxy observations and demonstrated the similarity of generated images to the real data. In addition, they demonstrated the potential use of DMs for image in-painting, using their model to remove simulated satellite trails from images and reliably reconstruct parts of the image. They further show the use of domain transfer, where the model is utilized to make cartoon images look like real observations with similar features, giving an idea of the degree of control that can be exerted over the sampling process of a DM.
Sortino et al. (2024) implemented a latent DM, namely, a DM that acts on the latent space of an autoencoder to generate synthetic images of radio sources. The model is conditioned on segmentation maps and reference images, allowing the user to control the shape of the source and the background properties of the image, which has been shown to work reliably. While this facilitates radio image synthesis with explicit image properties, this approach requires a background reference image together with a corresponding semantic map for every generated sample, which is not easy to obtain at scale.
Zhao et al. (2023) used simulated images of 21 cm temperature mapping to train both a DM and a GAN, conditioned on cosmological parameters that influence the result of the simulation. They quantitatively demonstrated the superiority of DMs over GANs in terms of image quality, as well as the recovery of the properties determined by the conditioning parameters.
Apart from image generation, Wang et al. (2023) and Drozdova et al. (2024) demonstrated the successful use of DMs for the reconstruction of radio interferometric images. Waldmann et al. (2023) used a DM to remove noise and artifacts from optical observations of satellites and space debris. In a recent paper, Reddy et al. (2024) used DMs for implementing a super-resolution model for gravitational lensing data, which allows for both the lensing system and the background source to be understood in more detail. Their studies show that the DM outperforms existing techniques. In this work, we introduce a DM that can generate realistic radio galaxy images over a wide dynamic range. In an approach novel to radio astronomy, we employed a recent framework referred to as continuous-time DMs, which allows for a flexible sampling procedure with a reduced number of steps.
Whenever we mention radio images in this paper, we mean cleaned and deconvolved images, since these are the images that we train on. The generation of synthetic radio data that includes the dirty images (which are the initial images of the sky produced directly by Fourier transforms of the raw data) is done elsewhere (e.g. Geyer et al. 2023). The dirty images obviously depend on the telescope and the parameters of each individual observation, such as the uv-coverage. Hence we also do not deal with the imperfections in the dirty image that are often dominated by sidelobes and other artifacts. This is discussed further in Sect. 7.
We demonstrate control over the morphological properties of the samples by training a DM conditioned on morphological class labels. In Sect. 2 we introduce the theory behind DMs. Section 3 describes the gathering and pre-processing of the image data used to train our models. In Sect. 4 we describe the neural network architecture, as well as the training and sampling procedures. Finally, our metrics used to evaluate the model performance are defined in Sect. 5. The results are presented in Sect. 6 and discussed in Sect. 7.
2. Diffusion models
A DM transforms images of pure Gaussian noise into images that look as if they had been drawn from the training data set. Implicitly, this constitutes a mapping between two probability distributions in image space: a normal Gaussian distribution on one hand and a distribution that models the training dataset, on the other. The underlying theory is derived by first considering the opposite direction, a gradual diffusion of a training image into pure noise, referred to as the ‘forward process’ that is trivial to accomplish in practice. With the correct description, this process becomes time-reversible and the desired backward process can be approximated at discretized time steps using a denoising neural network.
The concept was first introduced in Sohl-Dickstein et al. (2015) and further developed in Ho et al. (2020) and subsequent studies. In those works, the model is trained on fixed discrete time steps of the diffusion process, which are also used for sampling. Later, Song et al. (2020) found a framework that unified different approaches to DM training, and Karras et al. (2022) proceeded to show the benefits of training the model with random continuous time values sampled from a distribution. In this work, we implement such a “continuous-time” DM and this section presents the underlying theory.
2.1. Forward process and probability flow ODE
For a vector x ∈ ℝd × d in the space of all images with d × d pixels, the forward process of gradually diffusing an image with Gaussian noise corresponds to a probabilistic trajectory through that space. Song et al. (2020) introduce a modeling of the forward process x(t) as a function of a continuous time variable t ∈ [0, T] expressed by a stochastic differential equation (SDE)
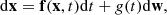 (1)
(1)
where f and g are called the drift and diffusion coefficients, respectively. Those two functions are free parameters that can be chosen to construct a process with desired properties that serve different practical purposes. Also, w is the standard Wiener process, also referred to as Brownian motion, which describes continuous-time independent Gaussian increments of zero mean and unit variance. If x(0) is sampled from an initial distribution p0(x), which in this context is the distribution underlying the training data, then Eq. (1) defines a marginal probability density pt(x) for x(t) at every point in time given by:
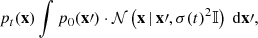 (2)
(2)
where 𝒩(x | x′,σ(t)2𝕀) is the Gaussian normal distribution centered at x′ with a standard deviation of σ(t), the value of which depends on the choices of f and g. In the context of DMs, σ is referred to as the noise level, and the function σ(t) is called the noise schedule. We note that pt(x) is always dependent on the initial distribution p0(x); however, for simplicity we omit this relation in the corresponding expression.
In the same work, the authors also derive an equivalent ordinary differential equation (ODE) for every SDE as expressed in Eq. (1), given by
![Mathematical equation: $$ \begin{aligned} \mathrm{d} \mathbf{x}=\left[\mathbf{f}(\mathbf{x}, t)-\frac{1}{2} { g}(t)^2 \nabla _{\mathbf{x}} \log p_t(\mathbf{x})\right] \mathrm{d} t, \end{aligned} $$](/articles/aa/full_html/2024/11/aa51429-24/aa51429-24-eq3.gif) (3)
(3)
which is named probability flow ODE (PF-ODE). The term ∇xlog pt(x) is referred to as the score function, and can be thought of as a vector field pointing in the direction of increasing probability density of pt(x). Equation (3) is equivalent to Eq. (1) in the sense that the solving trajectories share the same marginal probabilities pt(x) at every point in time. However, the advantage of using the PF-ODE is that the process described therein is not probabilistic but deterministic and, therefore, time-reversible. Consequently, if the score function is known, the process can be described in both directions of time by solving Eq. (3). For a large enough T, the vector x(T) is practically indistinguishable from pure Gaussian noise, in other terms, pT(x)≈𝒩(0, σ(T)2𝕀). Thereby, Eq. (3) defines a deterministic mapping between a Gaussian noise vector xT and an initial image x0 ∼ p0(x). As we will discuss in the following section, it is possible to train a neural network to estimate the score function, and images can then be sampled from p0(x) by starting with random Gaussian noise and numerically solving the PF-ODE.
In the scope of a more general description, Karras et al. (2022) give a different formulation of the PF-ODE. Choosing f ≡ 0 and re-writing g as an expression of σ(t), Eq. (3) becomes
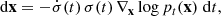 (4)
(4)
enabling us to directly construct the process according to the desired noise schedule, which is chosen to optimize the intended goal, typically high quality of sampled images.
2.2. Reverse process and denoising score matching
Karras et al. (2022) proceed to show that the score function can be expressed through an ideal denoiser function. If D(x; σ) is a function that, for every σ(t) with t ∈ [0, T] separately, minimizes the expected L2 denoising loss over the initial distribution p0(x) expressed as
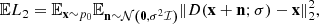 (5)
(5)
then the score function can be written as
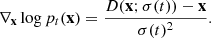 (6)
(6)
This denoiser function can be approximated by a neural network Dθ, trained to minimize Eq. (5) over a dataset of real images. In this way, the network implicitly models a probability distribution for the image data it was trained on. This distribution can then be sampled from by solving the equation obtained substituting Eq. (6) into Eq. (4), which results in
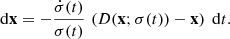 (7)
(7)
In practice, Eq. (7) is solved through discretization, where the denoiser function is evaluated using Dθ. This can in principle be done with any ODE solver, our implementation is described in Sect. 4.3.
2.3. Guided diffusion
In addition to x and σ, the neural network Dθ can be designed as a function of additional parameters c that are passed as input, such as class labels describing the morphological class of the imaged galaxy for every training sample. This technique is referred to as conditioning, since the model then describes conditional probabilities pt(x | c) that depend on the added parameters. In order to achieve high quality for conditional sampling, Ho & Salimans (2022) introduce the concept of classifier-free diffusion guidance, which builds on the idea of classifier guidance described in Dhariwal & Nichol (2021). For classifier-free guidance, the network is simultaneously trained with and without conditioning by randomly dropping out the additional input c during training and replacing it with a null token ∅ that has no effect on the network. Once trained, the denoiser is evaluated as a linear combination 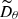 of both the conditioned and unconditioned model. This is expressed by
of both the conditioned and unconditioned model. This is expressed by
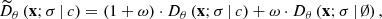 (8)
(8)
where ω is called guidance strength and is a parameter that can be chosen to optimize the desired output. Ho & Salimans (2022) show that the choice of ω presents a trade-off between sample variety for lower values and sample fidelity for higher values.
3. Training data
This work is carried out on two different sets of radio galaxy images. One is an extensive dataset with radio galaxy images gathered from observations made with the LOFAR telescope. The other is the FIRST dataset from Griese et al. (2023), a smaller set with images obtained from observations with the Very Large Array (VLA) telescope that was provided with labels which categorize every image into one of four morphological classes. This section describes how those datasets are assembled, processed and prepared for training.
3.1. LOFAR dataset
The unlabeled LOFAR dataset used to train our LOFAR model is based on the second data release of the LOFAR Two-metre Sky Survey (LoTSS-DR2), a survey covering 27% of the northern sky in a band of 120 − 168 MHz with a central frequency of 144 MHz, details are given in Shimwell et al. (2022). We retrieve the publicly available mosaics of the Stokes I continuum maps as the base to draw images of single sources from, alongside with the corresponding optical cross-match catalog described in Hardcastle et al. (2023) that lists known sources and contains information on different characteristics thereof.
Cut-outs from the maps are taken around all resolved sources listed in the catalog, which is a total of 314 942. The size of the cut-outs is 120″, which at the given resolution of 1.5″/px corresponds to images of 80 × 80 pixels in size. The cut-outs are centered around the coordinates of the optical counterparts of each radio source; however, if such a source is not present in the catalog, they are centered around the corresponding position of the radio source itself. We removed cut-outs that contain NaN or blank image values, referred to as “broken images” in this work.
To filter out images with a high degree of background noise or artifacts, which cause the source not to be distinctly visible on the image, we define a quantity that serves as a proxy for the signal-to-noise ratio (S/N) of every image and is intended to characterize the source visibility in a quantitative way. This quantity, which we denote as S/Nσ, is calculated in the following way. For a given image x, the median 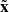 and standard deviation σx of the image are calculated using the sigma_clipped_stats method contained in the astropy package Astropy Collaboration (2022). Next, based on a sigma threshold, the image is segmented into two sections xsrc and xbg, which are considered source and background regions, with the source region defined by
and standard deviation σx of the image are calculated using the sigma_clipped_stats method contained in the astropy package Astropy Collaboration (2022). Next, based on a sigma threshold, the image is segmented into two sections xsrc and xbg, which are considered source and background regions, with the source region defined by
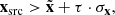 (9)
(9)
where τ is a threshold that is initially set to τ = 5. For images where no source region is found, meaning no pixels of x satisfy Eq. (9), the threshold τ is iteratively reduced by 0.5 until a region can be identified. The background region is then defined by the remaining pixels in x. Finally, the value for S/Nσ is computed as the ratio of average pixel values in both regions, reading
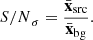 (10)
(10)
Under visual assessment, this quantity empirically shows to provide a good representation of how clearly a source is distinguished from background signals on the respective image. A few examples of this are shown in Fig. 1. We choose a threshold value of S/Nσ = 5 for our dataset, excluding all images that fall below this limit. Subsequently, we filter out images where the source is not well centered, or where the source is cropped by the cutout. This is done by excluding all images whose edge pixels have values exceeding a certain threshold, which we set to 0.8 times the maximum value of that image. Finally, we remove images with incomplete coverage, which are produced for sources that lie close to the edge of the sky area covered by the survey. In the end, this results in a dataset containing 106 787 images of radio sources. A summary of the described selection cuts, with the corresponding numbers of excluded images at every step, is given in Table 1. Some examples of excluded images, and a selection of the images contained in the final selection that composes the LOFAR dataset, are shown in Figs. 2 and 3, respectively.
 |
Fig. 1. Distribution of S/Nσ over the entire set of cut-outs extracted from the LOFAR continuum map. The top panel shows the distribution over a range relevant to the selection cut threshold, while the inset figure in the top right shows the entire distribution. The bottom grid shows random examples out of the different histogram bins, stacked vertically and aligned horizontally with the corresponding bin. |
 |
Fig. 2. Examples of cut-outs excluded from the training set due to bright edge pixels (top) or incomplete coverage (bottom). |
 |
Fig. 3. Random examples of images included in the final LOFAR dataset. |
Numbers of removed and included images at each step of data selection.
Following the data selection, two steps of pre-processing are applied to the retrieved images. First, any negative pixel values of the images are set to 0, since they are considered artifacts that result from the image reconstruction process and are physically unmotivated. Afterwards, every image is individually scaled to a range of [0, 1] by applying the minmax-scaling according to
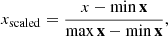 (11)
(11)
where x is any individual pixel of an image x. The scaled images are saved together with the original maximum pixel values for later retrieval and restoration of the original image. The radio images in the dataset show large variations in their maximum flux values, as can be contemplated in the top panel in Fig. 4. This property is desired to be reproduced when sampling from the trained model. However, this information is lost in the pre-processing, since the model is trained only on images that are individually scaled and therefore share the same magnitudes. Since the source flux can influence the image qualitatively even after scaling, e.g. in the value of S/Nσ, we choose to pass the maximum flux value of every image as an additional conditioning parameter during training. To standardize the distribution of those values, we apply a scaling known as Box-Cox power transform Box & Cox (1964), defined as
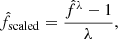 (12)
(12)
 |
Fig. 4. Distributions of maximum flux values |
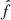

where 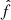 and
and  are the original and scaled maximum flux values, and λ is a parameter that is optimized via maximum likelihood estimation to make the transformed distribution resemble a normal distribution, i.e. zero mean and unit variance. This optimum is found for the LOFAR dataset at λ = −0.23. The transformed distribution is shown in the bottom panel of Fig. 4.
are the original and scaled maximum flux values, and λ is a parameter that is optimized via maximum likelihood estimation to make the transformed distribution resemble a normal distribution, i.e. zero mean and unit variance. This optimum is found for the LOFAR dataset at λ = −0.23. The transformed distribution is shown in the bottom panel of Fig. 4.
3.2. FIRST dataset
A second, smaller dataset with morphological class labels is used to train a class-conditioned model, from hereon referred to as the FIRST model. This dataset was introduced in Griese et al. (2023) and contains 2158 images retrieved from the VLA survey of Faint Images of the Radio Sky at Twenty-Centimeters (FIRST), see Becker et al. (1995). Morphological class labels are collected from different catalogs and summarized into a classification scheme of four different categories. The first two correspond to the traditional classes from the Fanaroff-Riley (FR) scheme introduced in Fanaroff & Riley (1974), with FR-I for extended sources that have their maximum radio emission close to the center, and FR-II for sources with maxima close to their edges. Further, unresolved point sources are classified as Compact, and finally sources for which the angle between the jets differs significantly from 180° are classified as Bent. The numbers of examples for the different classes are given in Table 2, a few examples of the images are shown in Fig. 5. As part of the pre-processing, the authors remove background noise by fixing all pixel values below three times the local RMS noise to that value, and subsequently applying minmax-scaling. For a more detailed description, we refer to Griese et al. (2023).
 |
Fig. 5. Random examples of images from the FIRST dataset, showing one grid for each of the four morphological classes contained in the dataset, as indicated in the corresponding caption. (a) FRI, (b) FRII, (c) Compact, (d) Bent. |
Numbers of images corresponding to the different classes in the FIRST dataset.
The publicly available dataset1 provides the images in PNG format scaled to [0, 255]. Since the images are retrieved already individually scaled, we hence apply no conditioning on the flux values when training the FIRST model. For our training, we crop the images from their original 300 × 300 pixels to 80 × 80 pixels around the image center, and subsequently rescale them to [0, 1] according to Eq. (11). To train the FIRST model, for simplicity, we employ random undersampling to balance the dataset, limiting the number of images in every class to the size of the least populated one. This results in a reduced training set of 1392 images with equal amounts corresponding to the four classes.
4. Model and training
In the following section, we describe technical details of the DM. This includes the neural network architecture, the training procedure and the sampling algorithm.
4.1. Model architecture
The denoiser neural network Dθ takes as input an image with added noise, additionally the corresponding noise level is injected as conditioning information throughout different parts of the network, together with the other optional conditioning information containing peak flux levels, or class labels respectively, for the two trained models. We refer to the entire conditioning information as context.
To implement the network, we employ a U-Net (Ronneberger et al. 2015) architecture, which consists of an encoder and a decoder part with a bottleneck part in-between. The entire network architecture is illustrated in Fig. 7. Its constituents are mainly composed of convolutional neural network (CNN) layers, as well as self-attention layers. During a forward pass, the encoder gradually reduces the resolution of the feature maps while increasing the channel dimensions, the opposite happens in the decoder. In addition, the encoder and decoder are linked through skip connections at equal levels of resolution. All parts of the network are assembled using the same building block, which is illustrated in Fig. 6. Depending on the given function in different parts of the network, i.e. changing the resolution or number of channels, this block has slight variations in its architecture.
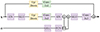 |
Fig. 6. Architecture of the U-Net building block. Optional elements of different variations are colored in agreement with Fig. 7. The first 3 × 3-convolution is always present. However, the included change in channel dimensions is optional. |
 |
Fig. 7. Architecture of the U-Net. Skip connections between encoder and decoder are indicated with dashed lines. |
The standard block contains two successive sequences of group normalization (GN) (Wu & He 2018), Sigmoid Linear Unit (SiLU) activation (Hendrycks & Gimpel 2016) and a CNN layer with a kernel size of 3 × 3. The SiLU activation function is defined by
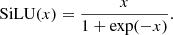 (13)
(13)
All elements are bypassed by an additional skip connection that is added to the output at the end of the block. For every single block in the entire network, the conditioning is applied after the second GN layer. The noise level is embedded using sinusoidal position encoding (Vaswani et al. 2017) followed by a single-layer fully connected network (FCN). For the two different models, class labels are encoded with one-hot vectors and the peak flux values are passed as single neuron activations, respectively. This information is fed through an embedding network that consists of a two-layer FCN with Gaussian error linear unit (GELU) activation. The GELU activation is defined by
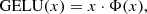 (14)
(14)
where Φ(x) is the standard Gaussian cumulative distribution function. The advantage over the often used ReLU activation function is the smoother transition. The embedding is subsequently added to the noise level embedding. The resulting vector is passed through another embedding network of identical architecture, and finally injected into the block through feature-wise linear modulation (Perez et al. 2018). For some blocks, the first convolution layer changes the number of channels. In that case, a 1 × 1-kernel convolution layer is added to the skip connection to match the dimensions at recombination. For blocks that change the image resolution, down- or upsampling layers are added before the first convolution, as well as to the skip connection. Upsampling is done with the nearest neighbor algorithm, where each pixel is quadrupled. Downsampling is done by splitting the image into four equal parts, then applying 1 × 1-convolution with the four sub-images stacked along the input channel dimension.
In addition to the U-Net block, some parts of the network contain multi-head self-attention layers. We implement the efficient self-attention mechanism introduced in Shen et al. (2021), preceded by a single GN layer. For an attention head with c channels and an input feature map with n pixels, three tensors Q, K and V of dimensions n × c are obtained through a 3 × 3-CNN layer applied on the input. The attention tensor A is then computed as
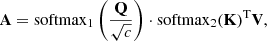 (15)
(15)
with the softmaxd function on a tensor, T, defined as
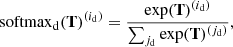 (16)
(16)
where d indicates one specific dimension of the tensor, T(id) is the ith sub-tensor along that dimension, and the exponential function operates on the individual tensor components. This entire self-attention mechanism is carried out with multiple separate instances in parallel, which are called attention heads. The resulting attention tensors are subsequently concatenated and brought back to the input shape through another 3 × 3-CNN layer, followed by layer normalization (Lei Ba et al. 2016), and finally added to the input via a skip connection.
Our implementation of the U-Net uses three levels of resolution, with each level containing two, respectively three resolution-preserving U-Net blocks for the encoder and decoder. Resampling blocks are added at the end of each resolution level, with exception of the lower-most in the encoder and upper-most in the decoder. The bottleneck part consists of two standard blocks with an attention layer in-between. On the lower two resolution levels, self-attention layers are added after all resolution-preserving blocks. The U-net is completed by skip connections at equal levels of resolution between blocks of the encoder and decoder, giving it the characteristic shape it is named after. The network is encompassed by two 3 × 3-convolutions at the beginning and end. Further technical details about different architectural choices are given in Table 3.
Details of the implemented U-Net architecture.
To model the denoiser function, we employ a scaling to the network as described in Karras et al. (2022), where the authors derive the following expressions from first principles to reduce variations in signal and gradient magnitudes. Let Fθ denote the neural network, then the parameterized denoiser function Dθ(x; σ) as introduced in Sect. 2 is defined as
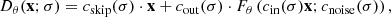 (17)
(17)
where the different constants are given by
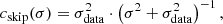 (18)
(18)
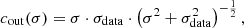 (19)
(19)
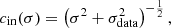 (20)
(20)
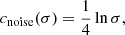 (21)
(21)
with σdata = 0.5 fixed.
4.2. Training
An overview of all hyperparameters used for the different training runs is given in Table 4. As introduced in Karras et al. (2022), noise levels σ are sampled from a log-normal distribution referred to as ptrain, such that lnσ ∼ 𝒩(PMean,PStd), where we find the parameter values given in Table 4 to provide the best results. Following the same paper, we weigh the L2 loss with cout(σ)−2 (see Eq. (19)) to keep a balanced loss magnitude across different noise levels. This results in a loss function ℒ defined by
![Mathematical equation: $$ \begin{aligned} {\mathcal{L} }(\theta ) = {\mathbb{E} }_{{\mathbf{x}} \sim p_{\mathrm{data}}} {\mathbb{E} }_{\sigma \sim p_{\rm train}} {\mathbb{E} }_{{\mathbf{n}} \sim {\mathcal{N} }\left(\boldsymbol{0}, \sigma ^2 {\mathcal{I} }\right)} \left[c_{\rm out}(\sigma )^{-2} \Vert D_\theta (\mathbf{x}+\mathbf{n} ; \sigma )-\mathbf{x}\Vert _2^2\right], \end{aligned} $$](/articles/aa/full_html/2024/11/aa51429-24/aa51429-24-eq28.gif) (22)
(22)
Hyperparameters used during training.
which is used to optimize the model weights.
We train both models with the Adam optimizer (Kingma & Ba 2014). For the LOFAR model, weights are stabilized by keeping an exponential moving average (EMA) of their values. During training, images are rescaled to [ − 1, 1] using Eq. (11), with a subsequent rescaling step to obtain the desired interval boundaries. The model is trained with mixed precision, meaning forward pass and backpropagation are calculated with half-precision weights, but weight updates are done in full precision. In this context, we employ loss scaling to prevent underflow for small gradient values. For both the LOFAR and the FIRST model, the respective datasets are split into training and validation sets of 90% and 10% size, respectively. The latter is used to monitor the validation loss at regular intervals to ensure that the model is not overfitting the training data. To prevent this from happening, we applied dropout layers after each U-Net block. With the described architecture, the model was run with a total of about 3.1 × 108 trainable parameters. We employed a classical data augmentation by applying random horizontal and vertical flips, followed by a random rotation of multiples of 90°. The training was performed using distributed data parallel training on two NVIDIA A100 GPUs and completed in approximately 19 hour for the LOFAR dataset and 4 hour for the FIRST dataset.
4.3. Sampling
In order to map a sample of pure Gaussian noise onto a realistic image, as described in Sect. 2, we solve Eq. (7) numerically through discretization, using the neural network to evaluate the denoiser function. Our choices for the ODE solver, noise schedule σ(t), and discretization time steps are taken from Karras et al. (2022). We use the Heun’s second-order method (Ascher & Petzold 1998) as ODE solver, with the noise schedule defined as
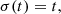 (23)
(23)
by which the noise level σ and time parameter t become interchangeable. Thus, Eq. (7) simplifies to:
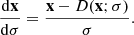 (24)
(24)
The solution to Eq. (24) can be understood as a trajectory through image space whose tangent vector points in the direction of the denoiser output for the respective image and noise level. In order to solve the equation numerically, we iteratively evaluate the right-hand side expression at previously selected discrete time steps, i.e. noise levels. Starting from pure Gaussian noise, we proceed to take small steps in the direction of the resulting vector to approximate the solution trajectory. The number of time steps N presents a trade-off between sampling time and quality. For our purposes, we find N = 25 time steps to be optimal. The noise levels {σi} for i ∈ {0, …, N} selected for the ODE solver are defined by
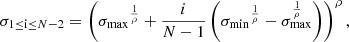 (25)
(25)
with σ0 = σmax, σN − 1 = σmin and σN = 0. The values given to the free parameters are σmax = 80, σmin = 2 × 10−3 and ρ = 7. The detailed procedure used for sampling is described in algorithm 1. Conditioned sampling is realized by using the linear combination 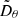 as described in Sect. 2.3, where the guidance strength ω varies for different parts of this work. After sampling, pixel values are clamped to [ − 1, 1], and rescaled to [0, 1] for further analysis.
as described in Sect. 2.3, where the guidance strength ω varies for different parts of this work. After sampling, pixel values are clamped to [ − 1, 1], and rescaled to [0, 1] for further analysis.
For a fixed model, the wall-clock inference time is generally bound by the capacities of the underlying hardware. Since the denoiser network is called at every time step during the sampling process, its total duration grows linearly with the number of time steps, N. The inference time further depends on the model size and the choice of the solver. For instance, note that due to the 2nd order correction in algorithm 1, the model is run twice for every sampling step. On a single Nvidia A100 GPU, with our choice of N = 25, it takes 3 min 17 s to sample a batch of 1000 images.
1: procedure HEUNSAMPLER(Dθ(x;σ), {σi}i∈{0,...,N})
▹ Seed image from pure Gaussian noise:
2: sample x0 ∼ 𝒩( 0;σ20𝕀)
3: for i = 0, ..., N − 1 do ▹ Discretization steps
4: 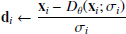 ▹ Evaluate ODE at σi
▹ Evaluate ODE at σi
5: xi+1 ← xi + (σi+1 − σi)di ▹ Euler step
▹ Apply 2nd order correction if not σi = 0:
6: if i + 1 ≠ N then
▹ Evaluate ODE at σi+1.
7: 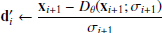
▹ Trapezoidal rule:
8: 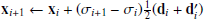 (di + d′i)
(di + d′i)
9: end if
10: end for
11: return xN ▹ Final image
12: end procedure
5. Evaluation metrics
When assessing the quality of generated images resulting from our training, two separate aspects are to be considered: In general, the images should resemble the training dataset in terms of signal intensity and source morphology. In addition, the different types of conditioning information used during model training should be accurately represented in the samples, indicating that the corresponding image properties can be controlled through those parameters. In this section we describe different metrics used to monitor both of these aspects.
5.1. Image quality
In order to compare a set of generated images to the training dataset, we calculate the distributions of different single-image quantities and compare the resulting histograms for the two datasets. This is done for the mean value and standard deviation of the scaled images. In addition, we compare the distributions of pixel values for both datasets, i.e. here one data point corresponds to a single pixel rather than an entire image.
To further compare quantities that are more descriptive of the source properties, we run the Python Blob Detector and Source Finder (PyBDSF) (Mohan & Rafferty 2015) on both datasets to obtain a corresponding flux model image for every sample. This allows us to characterize the sources in an automated way and analyze their properties separately from the background. The settings used for PyBDSF are fixed for all images, with the values given in Table 5. A few examples of training images and the corresponding source model are shown in Fig. 8. As a result of the PyBDSF analysis, we obtain a value of integrated source model flux for every image, which again is used to compare the distributions between datasets. Finally, as an indicator of the source extension, we calculate the minimum area A50% that contains 50% of the integrated model flux, given in pixels. Under visual inspection, this quantity correlates well with the perceived extension of the source, as demonstrated in Fig. 9. We note that this is not equivalent to its actual physical size. For instance, a single source with two bright, small and widely separated hot-spots has a large physical extension; however, the A50% area will be small, since only the constrained regions of high signal intensity will be covered. Therefore, this quantity should be regarded as a property of the image, rather than the source itself.
 |
Fig. 8. Examples of images from the LOFAR dataset (top), with their corresponding reconstructed flux model images generated with PyBDSF (bottom). |
 |
Fig. 9. Examples of images from the LOFAR dataset (top) and flux model (bottom), with increasing values of A50% from left to right. The bottom figures indicate the calculated area with white contours, the corresponding A50% values are shown below. |
Settings used for the PyBDSF analysis.
5.2. Flux conditioning
For the LOFAR model, as described in Sect. 3, we condition the model on the standardized peak flux  to preserve flux information that is otherwise lost through the rescaling of pixel values. Typically, images with lower peak flux show more prominent background noise, since the source is not as bright in comparison. We quantify this property by calculating the residual with respect to the PyBDSF source model. Since this model ideally only describes the source and not the background, the difference should be representative of the background seen in the image. To further reduce the influence of residuals caused by the limited accuracy of flux modeling, we consider only the positive residual values. This positive flux residual Δ+ is then given by
to preserve flux information that is otherwise lost through the rescaling of pixel values. Typically, images with lower peak flux show more prominent background noise, since the source is not as bright in comparison. We quantify this property by calculating the residual with respect to the PyBDSF source model. Since this model ideally only describes the source and not the background, the difference should be representative of the background seen in the image. To further reduce the influence of residuals caused by the limited accuracy of flux modeling, we consider only the positive residual values. This positive flux residual Δ+ is then given by
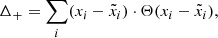 (26)
(26)
where i runs over all image pixels xi and model image pixels 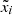 , and Θ is the Heaviside step function. A few examples are shown in Fig. 10, showcasing the relationship between
, and Θ is the Heaviside step function. A few examples are shown in Fig. 10, showcasing the relationship between  and Δ+. To evaluate whether the conditioning information is learned correctly, we quantitatively compare the relation between the two properties for the training images and generated samples.
and Δ+. To evaluate whether the conditioning information is learned correctly, we quantitatively compare the relation between the two properties for the training images and generated samples.
 |
Fig. 10. Examples of positive residuals for different values of |


5.3. Class conditioning
Finally, in order to evaluate how well the morphological information contained in the class labels is learned by the FIRST model, we train a classifier on the FIRST dataset and compare its performance between the training data and the class-conditioned samples.
The classifier is composed of a CNN-based encoder part and a subsequent FCN-head that maps the encoder output onto one of the four classes. The encoder is implemented using the resnet-18 architecture (He et al. 2016), a residual CNN that takes an image as input and outputs a vector of 512 dimensions. The head consists of two fully connected layers with 256 hidden units and a four-dimensional output vector representing the classification logits for the four classes. We use batch norm after the encoder and apply dropout after the encoder and after the linear layers of the head, for which we make no use of non-linearities.
We train the model for 200 epochs with the cross-entropy loss on the predicted class labels, using the Adam optimizer (Kingma & Ba 2014) with a learning rate scheduler (LRS) that reduces the learning rate by a given factor when learning stagnates after a given number of epochs, called patience. All training hyperparameters are given in Table 6. During training, we apply a set of random augmentations consisting of random blurring, addition of random Gaussian noise, random cropping, random rotations and random vertical flips. The blurring is done with a 3 × 3 Gaussian kernel, where the standard deviation is sampled uniformly between 0.1 and 1. Similarly, the added noise has a standard deviation uniformly sampeled between 1 × 10−4 and 0.1. The size of the crop is chosen uniformly between 0.9 and 1 times the original image size, and the crop is subsequently resampled to the original image size. The rotations are performed with an arbitrary random angle, where resulting gaps in the image are filled with pixels of value −1. For the classifier training, the entire dataset of 2158 images is separated into a training (1758 images), test, and validation (200 images each) set, which approximately corresponds to proportions of 0.9, 0.1 and 0.1. We employ loss weighting as balancing strategy, meaning for every image the training loss is weighted with the reciprocal proportion of the corresponding class in the dataset.
Hyperparameters used for the classifier training.
With the trained classifier, we compare its performance on the test split and on the generated data set. For this, we evaluate the overall classification accuracy and calculate the confusion matrices to obtain a detailed overview of the accuracy for the individual classes.
6. Results
6.1. Image quality
To evaluate the LOFAR model, we sample a set of 50 000 images after training. This requires setting the conditioning parameter  as a sampling input to every image. To resemble the properties of the training dataset in this regard, we model the distribution of
as a sampling input to every image. To resemble the properties of the training dataset in this regard, we model the distribution of  shown in the bottom plot of Fig. 4 and sample the conditioning parameters from this model distribution. This is done by first choosing one of 100 histogram bins with probability proportional to the bin counts, and then uniformly sampling a value within the bin boundaries. To produce images conditioned on those values, we set the guidance strength to ω = 0.1.
shown in the bottom plot of Fig. 4 and sample the conditioning parameters from this model distribution. This is done by first choosing one of 100 histogram bins with probability proportional to the bin counts, and then uniformly sampling a value within the bin boundaries. To produce images conditioned on those values, we set the guidance strength to ω = 0.1.
A selection of images generated with the LOFAR model is shown in Fig. 11. A first visual comparison between Figs. 3 and 11 shows that the samples are not distinguishable by eye from the training images. This is confirmed by further visual comparison of subsets larger than the image grids provided in this work. To illustrate the similarity between the generated samples and training data, we select a few generated samples and identify the five most similar images from the training dataset for each. This is shown in Appendix A. We proceed to assess the sample quality in a more quantitative manner.
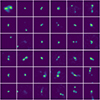 |
Fig. 11. Random examples of images generated with the trained LOFAR model. |
The distributions described in Sect. 5.1 are shown in Figs. 12–16, calculated over both the LOFAR dataset and the generated images. Error margins correspond to the 1σ frequentist confidence intervals2.
 |
Fig. 12. Pixel intensity distribution for the LOFAR dataset and LOFAR model-generated images. |
 |
Fig. 13. Image mean value distribution for the LOFAR dataset and LOFAR model-generated images. |
 |
Fig. 14. Image standard deviation distribution for the LOFAR dataset and LOFAR model-generated images. |
 |
Fig. 15. BDSF model flux distribution for the LOFAR dataset and LOFAR model generated-images. |
 |
Fig. 16. BDSF 50%-Area A50% distribution for the LOFAR dataset and LOFAR model-generated images. |
The pixel value distribution shown in Fig. 12 is very well replicated by the sampled images. Only the sharp dip at the right end of the distribution, close to pixel values of 1, appears more blunt in the sample distribution. We note that the outlier at the highest-value bin in the training distribution is an artifact of scaling the pixel values to [0, 1], i.e. every single image has exactly one pixel of value 1. This is not explicitly implemented in the model training, hence the steepness of this feature is not expected to be replicated by the sampling process that is inherently noisy. The peak is only replicated by clamping the pixel values to a maximum of 1 after the sampling procedure. The same explanation holds for the lowest-value bin, for which pixels are slightly underrepresented in the generated images. Apart from the described details, the pixel value distribution is matched to a high degree.
The distributions of image mean and standard deviation in Figs. 13 and 14 show high compatibility between real and generated data in lower pixel value ranges, whereas the counts in the upper ranges shift towards lower values for the generated images with increasing relative deviations. This indicates a subtle bias of the model towards images of lower pixel activity. The generated images also show fewer occurrences for very small mean values, which is likely a direct consequence of the underrepresented small pixel values seen in Fig. 12.
The deviation towards higher values is also observed in the distribution of model flux in Fig. 15 and A50% in Fig. 16, both quantities obtained from the pyBDSF analysis. Altogether, those observations indicate that the model produces slightly fewer images with large source extensions as compared to the training data set. Apart from that, the shapes of the distributions are generally very well reproduced, indicating that the properties of the generated images are realistic and representative of the training dataset.
6.2. Flux conditioning
Next, we investigate how well the information contained in the peak flux conditioning is learned by the model. As discussed in Sect. 5.2, we expect a negative correlation between the positive flux model residual Δ+ and the scaled peak flux,  . Figure 17 shows this relation as a scatter plot for the LOFAR data set and the set of generated images, where each data point corresponds to one image. The expected negative correlation is confirmed for the training data set, and proves to be well replicated by the generated images, meaning the encoded information is successfully learned during training. This happens especially well for the lower end of the distribution of
. Figure 17 shows this relation as a scatter plot for the LOFAR data set and the set of generated images, where each data point corresponds to one image. The expected negative correlation is confirmed for the training data set, and proves to be well replicated by the generated images, meaning the encoded information is successfully learned during training. This happens especially well for the lower end of the distribution of  , where both scatter plots are almost identical. At higher levels, there seems to be a cut-off at around Δ+ ∼ 5, below which the population of generated images becomes sparser. With higher levels of
, where both scatter plots are almost identical. At higher levels, there seems to be a cut-off at around Δ+ ∼ 5, below which the population of generated images becomes sparser. With higher levels of  , the background signals in the training images become increasingly weak, and possibly the information becomes too nuanced to be efficiently learned during training. Also, this effect might be related to the difficulties of the model in replicating pixel values that are very close to 0. Furthermore, the training data shows more outliers towards higher values of Δ+ over the entire range. This is explained by instances of sources with extended, diffuse emission, which the pyBDSF model struggles to accurately represent as part of the source. The lack of those in the generated images can be attributed to the under-representation of extended sources established in Sect. 6.1. Nonetheless, this result clearly indicates that the conditioning mechanism for the peak flux value works as intended.
, the background signals in the training images become increasingly weak, and possibly the information becomes too nuanced to be efficiently learned during training. Also, this effect might be related to the difficulties of the model in replicating pixel values that are very close to 0. Furthermore, the training data shows more outliers towards higher values of Δ+ over the entire range. This is explained by instances of sources with extended, diffuse emission, which the pyBDSF model struggles to accurately represent as part of the source. The lack of those in the generated images can be attributed to the under-representation of extended sources established in Sect. 6.1. Nonetheless, this result clearly indicates that the conditioning mechanism for the peak flux value works as intended.
 |
Fig. 17. Scatter plot showing the negative correlation between the positive flux model residual Δ+ and the scaled peak flux, |

6.3. Class conditioning
We proceed to evaluate the class-conditioning mechanism of the FIRST model. For this, we sample a set of 2000 images for each of the four morphological classes using the trained model, experimenting with different values of guidance strength ω. We obtain the best results with ω = 0.75. Figure 18 shows a random selection of those images, which again under visual inspection provide an accurate representation of the training dataset.
 |
Fig. 18. Random examples of images generated with the FIRST model, showing one grid for each of the four morphological classes contained in the dataset, as indicated in the corresponding caption. |
The classifier trained on the FIRST dataset achieves an accuracy of 81.5% over the test split, the corresponding confusion matrix is shown in the top panel of Fig. 19. The classifier performs quite well over all classes. It shows most difficulties to distinguish between classes FRI and Bent in both ways, and also a significant proportion of FRIIs is mislabeled as FRIs. The rest of the sources is classified with high accuracy. Remarkably, the total accuracy is slightly improved over the set of generated images, reaching a value of 83.4%. While the bidirectional confusions between FRIs and Bent-tail sources are still present, the mislabeling of FRIs for FRIIs disappears. Further experiments reveal that the accuracy does decrease for samples generated with lower values of guidance strength, results are shown in Table 7. This relation is expected, since at lower ω the sample fidelity is reduced in exchange for higher variability, effectively resulting in more overlap between the conditioned distributions in image space for the different classes.
 |
Fig. 19. Confusion matrices of the classifier trained on the FIRST dataset, for the test split (top) and the generated images (bottom). |
Classifier accuracy for sets of images sampled with different values of guidance strength, ω.
7. Discussion
In this work, we have shown the use of DMs for synthetic generation of high-quality, realistic images of radio galaxies. Our model is capable of generating images whose properties resemble real images of radio galaxies. This is shown by the accurate replication of metric distributions that characterize different properties of the imaged sources and confirmed through visual comparison. In addition, the model is able to learn and accurately reproduce detailed morphological characteristics, which is demonstrated by the stable classifier accuracy over the class-conditioned samples. Furthermore, our results on, both, peak-flux and class conditioning show that a DM can be trained with different kinds of additional parameters that relate to any characteristic of the image, such as properties of the background or morphological features, and reliably recreate those relations at the sampling stage. This allows for precise control over the properties of simulated images, which can be tailored depending on the scientific use case for the synthetic data.
The ability to realistically reproduce fine-grained morphological properties of radio sources in a targeted, controlled way is critical for the generation of synthetic large-survey sky maps, where current methods of generation either employ simplified source models of composite 2D Gaussians that are limited in their amount of detail or use classically augmented real observations, which can lead to imbalances and lack of diversity. As we show in our work, the use of a DM can mitigate both problems, leading to significant improvements in the quality of simulated data. In addition, with our peak flux conditioning mechanism, this can be accurately done over a large dynamic range, which is relevant for simulating large-scale maps.
Our methodology represents a step forward with respect to previous work regarding DMs in radio astronomy. We replace the framework of “discrete-time” DMs and move on to training a “continuous-time” DM by following the methods proposed in Karras et al. (2024). This allows us to reduce the number of denoising steps to 25 during sampling, which constitutes an improvement of at least one order of magnitude in comparison to previous work with DMs, which employ between 250 (Drozdova et al. 2024) and 1000 (Sortino et al. 2024) steps. Even though the sampling algorithm used here employs two model passes per sampling step, this still constitutes a significant reduction of the neural network evaluations required for image generation, which directly translates into a reduction of computing needs, while still achieving high quality results. Nonetheless, as is the case with DMs in general, the sampling time elevated through significant computational requirements constitutes the principal limitation to the use of our model. Further improvements in this regard might be made through a detailed exploration of different architectural choices. The possibility to reduce the number of model parameters while maintaining sample quality would facilitate a further decrease in both training and sampling time. Especially the latter would make the use of the model more accessible to the scientific community, reducing the extent of required computational resources. This could be approached in a simple way by experimenting with different parameters of the network employed in this work or, more profoundly, by implementing architectural improvements to the U-Net proposed in Kingma & Ba (2014) intended to optimize training and model efficiency. Another interesting approach is the idea of consistency models (Song et al. 2023), which are trained to solve the PF-ODE in a single inference step. These can be trained stand-alone or through knowledge distillation from an already trained DM, where our model can be employed. A different, complementary improvement would be the use of latent diffusion (Rombach et al. 2022), which could potentially reduce the computational cost, while allowing for a sampling of larger images. Sortino et al. (2024) demonstrated promising results in this regard.
In addition, the ability to sample from a DM with control over the morphological class is novel in the field of radio astronomical imaging. While the RADiff model introduced in Sortino et al. (2024) offers control over the source shape through conditioning on segmentation masks, this does not influence the distribution of signal intensity over the emitting regions, which is the main property relevant for the Fanaroff-Riley classification scheme. At this point, we achieve high sample fidelity with respect to classifier accuracy using a guidance strength of ω = 7.5, higher than the typical values of ω ≈ 0.1 − 0.2 used for natural image sampling (Ho & Salimans 2022). This confirms the expected relation that a higher value of ω leads to a higher sample fidelity. Consequently, it raises the question to what extent the model is limited in the mode coverage of the different classes, and how the sample variety is affected by this. Some insight could be gained by implementing metrics typically used in the field of natural image generation; for instance, Fréchnet inception distance (FID) or inception score (IS), which compare real and generated datasets based on different quantities derived from network activations of a pre-trained image classifier that for this use should be specific to radio astronomical images. In the case of FID, such an approach is used in Sortino et al. (2024). Although a precise quantitative assessment of the meaning and reliability of such results is challenging, the potential understandings can prove useful for the further development of class-conditioned sampling. We leave this exercise for future endeavors. Overall, we also expect both the class-conditioned DM and the classifier used for evaluation to largely benefit from a larger dataset of labeled sources, which in our case is two orders of magnitude smaller than the unlabeled LOFAR dataset. A minor improvement can potentially be made here with a different balancing strategy for the DM training by employing loss weighting instead of undersampling, as done for the classifier training.
Another limitation of our method is derived from the fact that it is trained on radio images that have been observed, cleaned and deconvolved with a limited variety of telescope configurations and a fixed processing pipeline. Hence, the models capacity of simulating realistic thermal or systematic noise, associated with said properties in the training data, is accordingly constrained in its variability. This also applies to the clean beam of the telescope, which varies across observations. Inversely, some of the low surface brightness features in the DM simulated radio images are caused by clean artifacts which the DM emulates from the training data.
Furthermore, our work presents a scheme for selection of image data derived from the LoTSS-DR2 that is versatile for adaptation to individual purposes, making it universally applicable for extracting training datasets suitable for different machine learning applications. The introduced S/Nσ presents a heuristic that allows for a selection of images where the source morphologies are visible with different degrees of clarity; thus, a variation in the selection cut threshold allows us to achieve a trade-off between completeness and purity. This can also be leveraged to tailor the DM to a specific need; namely, setting a lower threshold to entirely represent properties of the telescope and imaging process, versus a higher threshold to focus on source morphologies as in our work. The parameter can also be used as conditioning information for free post-training control of the generated images with respect to this property. This can in fact be done with any other parameter available in the source catalog, which is seamlessly integrated in the pre-processing pipeline. Alternative ways of quantifying source visibility might include the use of image segmentation models and improved estimates of noise and artifacts and could potentially lead to more precise selection cuts and result in larger datasets of useful images. Our data selection procedure can be expanded to extract cut-outs of larger size, thereby including more extended or badly centered sources that would otherwise not fit on the cut-out and be excluded due to activated edge pixels. Cut-outs larger than the actual images would also facilitate the use of random rotations at arbitrary angles as a method of classical data augmentation, removing the need to fill up gaps in the rotated image with artificial pixel values, which is undesirable for the training of generative models. The missing pixels would instead be completed with the true image data available in the larger cut-outs.
Our DM can be applied to different use cases in radio astronomy. Rustige et al. (2023) investigated the use of GAN-generated images for augmenting a dataset used to train a classifier. In their work, although it does fulfill various benchmarks of sample quality and fidelity, the generated images still show minor differences from the training data noticeable by eye. While simple classifiers experience a benefit from the data augmentation, this is not observed for more complex architectures. With the increased quality of the samples produced from our work, it is worth exploring whether those results can be improved and to what extent different machine learning models can generally benefit from data augmentation with generated images.
Furthermore, sets of single generated source images can be assembled to produce synthetic large-scale survey maps. For this, an artificial radio sky can be populated by sampling from well-known distributions of sky sources, such as the two-point correlation function of radio galaxies observed in the National Radio Astronomy Observatory (NRAO) VLA Sky Survey, as described in Chen & Schwarz (2016). The maps can then be realized by extracting sources from generated images and adding them on a background map that can either be real, generated from an analytical model, or, in a more extensive approach, may be sampled from a generative model trained on source-free regions only. This approach would require us to train the DM on a set of images free of noise and major artifacts to exclusively simulate the source emission. Such a dataset can be obtained through threshold-based masking of high-S/N images, reliably isolating the source signal. Careful consideration should however be given to potential effects caused by selection biases. Noise induced through the measurement and analysis procedure could then be added to the synthetic map through a subsequent step, using such software as the LOFAR simulation tool3 (Edler et al. 2021), which simulates the measurement result for a given sky model and observation configuration.
The design and training of our DM can be extended to serve further purposes. While we are currently working with a single image channel, this is not a necessary constraint, since, by construction, our model supports an arbitrary number of channels. With the use of corresponding training data, this can be leveraged to produce consistent images in different bands typical for radio observations or even to experiment with simultaneous generation of images in entirely different energy domains. Another potential use case is doing super-resolution of radio images similar to the work of Reddy et al. (2024), which might prove useful for classification tasks where different source morphologies become hard to distinguish at the limit of resolution. Overall, this work provides an important step forward in the ability to synthesize realistic radio galaxy image data in a precise and controlled way.
Data availability
The code implemented in this work is available at https://github.com/tmartinezML/LOFAR-Diffusion
Calculated using astropy’s stats.poisson_conf_interval (Astropy Collaboration 2022).
Acknowledgments
We thank the anonymous referee for a very constructive report. MB and TVM acknowledge support by the Deutsche Forschungsgemeinschaft under Germany’s Excellence Strategy – EXC 2121 Quantum Universe – 390833306 and via the KISS consortium (05D23GU4) funded by the German Federal Ministry of Education and Research BMBF in the ErUM-Data action plan.
References
- Ascher, U. M., & Petzold, L. R. 1998, Computer Methods for Ordinary Differential Equations and Differential-algebraic Equations [CrossRef] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2022, ApJ, 935, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Bastien, D. J., Scaife, A. M. M., Tang, H., Bowles, M., & Porter, F. 2021, MNRAS, 503, 3351 [NASA ADS] [CrossRef] [Google Scholar]
- Becker, R. H., White, R. L., & Helfand, D. J. 1995, ApJ, 450, 559 [Google Scholar]
- Bonaldi, A., An, T., Brüggen, M., et al. 2021, MNRAS, 500, 3821 [Google Scholar]
- Box, G. E. P., & Cox, D. R. 1964, J. Royal Stat. Soc. Ser. B (Methodological), 26, 211 [Google Scholar]
- Boyce, M. M., Hopkins, A. M., Riggi, S., et al. 2023a, PASA, 40, e028 [NASA ADS] [CrossRef] [Google Scholar]
- Boyce, M. M., Hopkins, A. M., Riggi, S., et al. 2023b, PASA, 40, e027 [NASA ADS] [CrossRef] [Google Scholar]
- Chen, S., & Schwarz, D. J. 2016, A&A, 591, A135 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Dhariwal, P., & Nichol, A. 2021, Adv. Neural Inf. Process. Syst., 34, 8780 [Google Scholar]
- Drozdova, M., Kinakh, V., Bait, O., et al. 2024, A&A, 683, A105 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Edler, H. W., de Gasperin, F., & Rafferty, D. 2021, A&A, 652, A37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fanaroff, B. L., & Riley, J. M. 1974, MNRAS, 167, 31P [Google Scholar]
- Garsden, H., Girard, J. N., Starck, J. L., et al. 2015, A&A, 575, A90 [CrossRef] [EDP Sciences] [Google Scholar]
- Geyer, F., Schmidt, K., Kummer, J., et al. 2023, A&A, 677, A167 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Griese, F., Kummer, J., Connor, P. L., Brüggen, M., & Rustige, L. 2023, Data in Brief, 47, 108974 [NASA ADS] [CrossRef] [Google Scholar]
- Hardcastle, M. J., Horton, M. A., Williams, W. L., et al. 2023, A&A, 678, A151 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- He, K., Zhang, X., Ren, S., & Sun, J. 2016, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770 [Google Scholar]
- Hendrycks, D., & Gimpel, K. 2016, ArXiv e-prints [arXiv:1606.08415] [Google Scholar]
- Ho, J., & Salimans, T. 2022, ArXiv e-prints [arXiv:2207.12598] [Google Scholar]
- Ho, J., Jain, A., & Abbeel, P. 2020, Adv. Neural Inf. Process. Syst., 33, 6840 [Google Scholar]
- Karras, T., Aittala, M., Aila, T., & Laine, S. 2022, Adv. Neural Inf. Process. Syst., 35, 26565 [Google Scholar]
- Karras, T., Aittala, M., Lehtinen, J., et al. 2024, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 24174 [Google Scholar]
- Kingma, D. P., & Ba, J. 2014, ArXiv e-prints [arXiv:1412.6980] [Google Scholar]
- Lei Ba, J., Kiros, J. R., & Hinton, G. E. 2016, ArXiv e-prints [arXiv:1607.06450] [Google Scholar]
- Mesarcik, M., Boonstra, A.-J., Meijer, C., et al. 2020, MNRAS, 496, 1517 [CrossRef] [Google Scholar]
- Mohan, N., & Rafferty, D. 2015, Astrophysics Source Code Library [record ascl:1502.007] [Google Scholar]
- Pearson, K. 1901, Lond. Edin. Dublin Phil. Mag. J. Sci., 2, 559 [Google Scholar]
- Perez, E., Strub, F., De Vries, H., Dumoulin, V., & Courville, A. 2018, in Proceedings of the AAAI Conference on Artificial Intelligence, 32 [Google Scholar]
- Reddy, P., Toomey, M. W., Parul, H., & Gleyzer, S. 2024, Mach. Learn. Sci. Technol., 5, 035076 [Google Scholar]
- Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. 2022, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10684 [Google Scholar]
- Ronneberger, O., Fischer, P., & Brox, T. 2015, in Medical Image Computing and Computer-assisted Intervention-MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18 (Springer), 234 [Google Scholar]
- Rustige, L., Kummer, J., Griese, F., et al. 2023, RAS Tech. Instrum., 2, 264 [NASA ADS] [CrossRef] [Google Scholar]
- Shen, Z., Zhang, M., Zhao, H., Yi, S., & Li, H. 2021, in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 3531 [Google Scholar]
- Shimwell, T. W., Röttgering, H. J. A., Best, P. N., et al. 2017, A&A, 598, A104 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Shimwell, T. W., Hardcastle, M. J., Tasse, C., et al. 2022, A&A, 659, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Smith, M. J., & Geach, J. E. 2023, Royal Soc. Open Sci., 10, 221454 [NASA ADS] [CrossRef] [Google Scholar]
- Smith, M. J., Geach, J. E., Jackson, R. A., et al. 2022, MNRAS, 511, 1808 [CrossRef] [Google Scholar]
- Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., & Ganguli, S. 2015, in International Conference on Machine Learning, PMLR, 2256 [Google Scholar]
- Song, Y., Sohl-Dickstein, J., Kingma, D. P., et al. 2020, ArXiv e-prints [arXiv:2011.13456] [Google Scholar]
- Song, Y., Dhariwal, P., Chen, M., & Sutskever, I. 2023, ArXiv e-prints [arXiv:2303.01469] [Google Scholar]
- Sortino, R., Cecconello, T., DeMarco, A., et al. 2024, IEEE Transactions on Artificial Intelligence [Google Scholar]
- Vaswani, A., Shazeer, N., Parmar, N., et al. 2017, Advances in Neural Information Processing Systems [Google Scholar]
- Waldmann, I., Rocchetto, M., & Debczynski, M. 2023, in Proceedings of the Advanced Maui Optical and Space Surveillance (AMOS) Technologies Conference, ed. S. Ryan, 196 [Google Scholar]
- Wang, Z., Bovik, A. C., Sheikh, H. R., & Simoncelli, E. P. 2004, IEEE Trans. Image Process., 13, 600 [Google Scholar]
- Wang, R., Chen, Z., Luo, Q., & Wang, F. 2023, in ECAI, 2499 [Google Scholar]
- Wilman, R. J., Miller, L., Jarvis, M. J., et al. 2008, MNRAS, 388, 1335 [NASA ADS] [Google Scholar]
- Wu, Y., & He, K. 2018, in Proceedings of the European Conference on Computer Vision (ECCV), 3 [Google Scholar]
- Yatawatta, S., & Avruch, I. M. 2021, MNRAS, 505, 2141 [NASA ADS] [CrossRef] [Google Scholar]
- Zhang, Y., & Zhao, Y. 2015, Data Sci. J., 14, 11 [NASA ADS] [CrossRef] [Google Scholar]
- Zhao, X., Ting, Y.-S., Diao, K., & Mao, Y. 2023, MNRAS, 526, 1699 [NASA ADS] [CrossRef] [Google Scholar]
Appendix A: Samples with the highest similarity training images
To illustrate the similarity between the generated samples and training data, we select a few generated samples and show the five most similar images from the training dataset for each. For this, all generated samples and training images are first aligned along their principal component, for which we consider pixels that exceed a threshold τPCA. This threshold is empirically set to
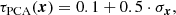 (A.1)
(A.1)
for any given image x, where σx is the standard deviation of the image, determined in the same way as for the S/Nσ (see Sect. 3.1). We subsequently run a principal component analysis (PCA) (Pearson 1901) using the selected pixels, and rotate the images such that the resulting principal component is aligned horizontally.
Image similarity is quantified with the structural similarity index measure (SSIM) (Wang et al. 2004), which for two images x, y is calculated as
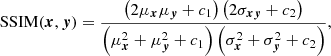 (A.2)
(A.2)
where μi and σi are the pixel mean and variance of image i, and σxy is the covariance between the two images. The constants c1 and c2 are introduced to stabilize the division for small denominators and have values c1 = 1 × 10−4 and c2 = 9 × 10−4. The examples with highest-similarity matches are shown in Figs. A.1 and A.2.
 |
Fig. A.1. Sampled images (left panel) and five most similar images from the training dataset (right panel) as a first example. |
 |
Fig. A.2. Sampled images (left panel) and five most similar images from the training dataset (right panel) as a second example. |
All Tables
Classifier accuracy for sets of images sampled with different values of guidance strength, ω.
All Figures
|
Fig. 1. Distribution of S/Nσ over the entire set of cut-outs extracted from the LOFAR continuum map. The top panel shows the distribution over a range relevant to the selection cut threshold, while the inset figure in the top right shows the entire distribution. The bottom grid shows random examples out of the different histogram bins, stacked vertically and aligned horizontally with the corresponding bin. |
| In the text | |
|
Fig. 2. Examples of cut-outs excluded from the training set due to bright edge pixels (top) or incomplete coverage (bottom). |
| In the text | |
|
Fig. 3. Random examples of images included in the final LOFAR dataset. |
| In the text | |
|
Fig. 4. Distributions of maximum flux values |
| In the text | |
|
Fig. 5. Random examples of images from the FIRST dataset, showing one grid for each of the four morphological classes contained in the dataset, as indicated in the corresponding caption. (a) FRI, (b) FRII, (c) Compact, (d) Bent. |
| In the text | |
|
Fig. 6. Architecture of the U-Net building block. Optional elements of different variations are colored in agreement with Fig. 7. The first 3 × 3-convolution is always present. However, the included change in channel dimensions is optional. |
| In the text | |
|
Fig. 7. Architecture of the U-Net. Skip connections between encoder and decoder are indicated with dashed lines. |
| In the text | |
|
Fig. 8. Examples of images from the LOFAR dataset (top), with their corresponding reconstructed flux model images generated with PyBDSF (bottom). |
| In the text | |
|
Fig. 9. Examples of images from the LOFAR dataset (top) and flux model (bottom), with increasing values of A50% from left to right. The bottom figures indicate the calculated area with white contours, the corresponding A50% values are shown below. |
| In the text | |
|
Fig. 10. Examples of positive residuals for different values of |
| In the text | |
|
Fig. 11. Random examples of images generated with the trained LOFAR model. |
| In the text | |
|
Fig. 12. Pixel intensity distribution for the LOFAR dataset and LOFAR model-generated images. |
| In the text | |
|
Fig. 13. Image mean value distribution for the LOFAR dataset and LOFAR model-generated images. |
| In the text | |
|
Fig. 14. Image standard deviation distribution for the LOFAR dataset and LOFAR model-generated images. |
| In the text | |
|
Fig. 15. BDSF model flux distribution for the LOFAR dataset and LOFAR model generated-images. |
| In the text | |
|
Fig. 16. BDSF 50%-Area A50% distribution for the LOFAR dataset and LOFAR model-generated images. |
| In the text | |
|
Fig. 17. Scatter plot showing the negative correlation between the positive flux model residual Δ+ and the scaled peak flux, |
| In the text | |
|
Fig. 18. Random examples of images generated with the FIRST model, showing one grid for each of the four morphological classes contained in the dataset, as indicated in the corresponding caption. |
| In the text | |
|
Fig. 19. Confusion matrices of the classifier trained on the FIRST dataset, for the test split (top) and the generated images (bottom). |
| In the text | |
|
Fig. A.1. Sampled images (left panel) and five most similar images from the training dataset (right panel) as a first example. |
| In the text | |
|
Fig. A.2. Sampled images (left panel) and five most similar images from the training dataset (right panel) as a second example. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.