| Issue |
A&A
Volume 690, October 2024
|
|
|---|---|---|
| Article Number | A311 | |
| Number of page(s) | 22 | |
| Section | Extragalactic astronomy | |
| DOI | https://doi.org/10.1051/0004-6361/202451671 | |
| Published online | 21 October 2024 | |
Validating the clustering predictions of empirical models with the FLAMINGO simulations
1
Donostia International Physics Center, Manuel Lardizabal Ibilbidea, 4, 20018
Donostia, Gipuzkoa, Spain
2
IKERBASQUE, Basque Foundation for Science, 48013
Bilbao, Spain
3
Institut de Física d’Altes Energies, The Barcelona Institute of Science and Technology, Campus UAB, E-08193
Bellaterra, Barcelona, Spain
4
Leiden Observatory, Leiden University, PO Box 9513
2300 RA
Leiden, The Netherlands
5
Lorentz Institute for Theoretical Physics, Leiden University, PO box 9506
2300 RA
Leiden, The Netherlands
Received:
26
July
2024
Accepted:
24
August
2024
Abstract
Context. Mock galaxy catalogues are essential for correctly interpreting current and future generations of galaxy surveys. Despite their significance in galaxy formation and cosmology, little to no work has been done to validate the predictions of these mocks for high-order clustering statistics.
Aims. We compare the predicting power of the latest generation of empirical models used in the creation of mock galaxy catalogues: a 13-parameter halo occupation distribution (HOD) and an extension of the SubHalo Abundance Matching technique (SHAMe).
Methos. We built GalaxyEmu-Planck, an emulator that makes precise predictions for the two-point correlation function, galaxy-galaxy lensing (restricted to distances greater than 1 h−1 Mpc in order to avoid baryonic effects), and other high-order statistics resulting from the evaluation of SHAMe and HOD models.
Results. We evaluated the precision of GalaxyEmu-Planck using two galaxy samples extracted from the FLAMINGO hydrodynamical simulation that mimic the properties of DESI-BGS and BOSS galaxies, finding that the emulator reproduces all the predicted statistics precisely. The HOD shows a comparable performance when fitting galaxy clustering and galaxy-galaxy lensing. In contrast, the SHAMe model shows better predictions for higher-order statistics, especially regarding the galaxy assembly bias level. We also tested the performance of the models after removing some of their extensions, finding that we can withdraw two (out of 13) of the HOD parameters without a significant loss of performance.
Conclusions. The results of this paper validate the current generation of empirical models as a way to reproduce galaxy clustering, galaxy-galaxy lensing, and other high-order statistics. The excellent performance of the SHAMe model with a small number of free parameters suggests that it is a valid method to extract cosmological constraints from galaxy clustering.
Key words: galaxies: formation / galaxies: statistics / large-scale structure of Universe
Corresponding authors; This email address is being protected from spambots. You need JavaScript enabled to view it. ; This email address is being protected from spambots. You need JavaScript enabled to view it. ; This email address is being protected from spambots. You need JavaScript enabled to view it.
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1. Introduction
Understanding the galaxy-halo connection is one of the biggest challenges of modern astrophysics. In the current galaxy formation paradigm, galaxies are born from the baryonic matter trapped in the gravitational potential of dark matter haloes. The evolution of galaxies is linked to the evolution of their host dark matter haloes, as both grow hierarchically. Over the past two decades, several relationships have been found between galaxy and halo properties. We have used these relationships not only to enhance our understanding of galaxy formation physics, but also to construct mock galaxy catalogues.
With a new generation of galaxy surveys (e.g. DESI, EUCLID, LSST, 4MOST, J-PAS, SKA), the need for realistic mock galaxy catalogues is critical to correctly interpret these observations, as well as to extract their cosmological and galaxy formation information. One of the most complex and arguably realistic ways to model galaxies is through hydrodynamic simulations (e.g. Schaye et al. 2015; Vogelsberger et al. 2014; Dubois et al. 2014; Davé et al. 2019; Springel et al. 2018; McCarthy et al. 2018). These simulations track the evolution of dark matter and baryonic matter simultaneously, which requires a considerable amount of computational resources compared to only simulating dark matter. This additional computational cost means that hydrodynamic simulations have a smaller volume or lower resolution compared to dark matter-only simulations. During the last year, two suites of simulations have set a new standard for large-volume hydrodynamic simulations: the MTNG suite of simulations (Pakmor et al. 2023) and the FLAMINGO suite of simulations (Schaye et al. 2023; Kugel et al. 2023). The largest FLAMINGO simulation has a box size of more than 1.9 h−1 Gpc (2.8 Gpc), an unprecedented volume for this type of simulation.
Unfortunately, the number of simulations of these two suites is not enough to fulfil the required number of mocks needed for the upcoming generation of surveys. Other alternatives to model galaxies, such as semi-analytical models (SAM, e.g. Croton et al. 2016; Lagos 2018; Stevens & Lagos 2018; Henriques et al. 2020; Perez et al. 2023) and semi-empirical models (e.g. Moster et al. 2018; Behroozi et al. 2019), offer a valid alternative to following the evolution of galaxies. Because of their lower computational requirements, these models can be run on dark matter-only simulations in a fraction of the time a hydrodynamic simulation takes to run, offering one of the best ways to study galaxy formation and evolution on really large scales. Unfortunately, these models can still be too slow to be run on large cosmological volumes, and they do not always provide enough flexibility in their astrophysical prescriptions, which limits their predictive power.
Another alternative for modelling galaxies is empirical models. These models use fundamental relations from the galaxy-halo connection to populate galaxies in the haloes and subhaloes of dark matter-only simulations. Although empirical models are not entirely capable of tracking the evolution of galaxies, they do possess the adaptability to accurately reproduce the galaxy clustering of different kinds of galaxy samples in a highly precise way (e.g. Guo et al. 2015a; Chaves-Montero et al. 2016). These models can populate large cosmological volumes on a standard laptop or a small computer cluster in minutes if not seconds. Two of the most popular empirical models today are the halo occupation distribution and the subhalo abundance matching technique.
The halo occupation distribution (HOD, Jing et al. 1998; Benson et al. 2000; Peacock & Smith 2000; Berlind et al. 2003; Zheng et al. 2005, 2007; Contreras et al. 2013, 2017; Guo et al. 2015a) characterises the mean number of galaxies that populate a halo as a function of the halo mass. This technique was developed to interpret galaxy clustering (e.g. Zehavi et al. 2011; Guo et al. 2015b) and later expanded into the creation of mock galaxy catalogues (e.g. Grieb et al. 2016). Initially, this method relied on three to five parameters to define its parametric shape (Zehavi et al. 2005; Zheng et al. 2005) and was meant to be used along with the halo model (e.g. Berlind & Weinberg 2002; Berlind et al. 2003). However, it has since evolved to populate dark matter-only simulations and include most of the processes we know affect galaxy clustering, such as assembly bias (Hearin et al. 2016; Xu et al. 2021), velocity bias (Guo et al. 2015a), and satellite segregation (Yuan et al. 2018). One of the primary advantages of the HOD technique is that it typically only requires information from dark matter haloes, not subhaloes or merger trees. These requirements imply that low-resolution simulations can be used to generate HOD mocks, contrary to other mock galaxy algorithms.
Another popular technique to create mock galaxy catalogues is the subhalo abundance matching (SHAM, Vale & Ostriker 2006; Conroy et al. 2006). In its original form, this technique matched the most massive haloes or the haloes with the highest maximum circular velocity (Vmax) to the most massive and brightest galaxies. Later improvements to the SHAM technique used subhaloes instead of haloes by calculating the subhalo’s peak mass or rotational velocity during its evolutionary history. The model had a single free parameter that added scatter between the subhalo and galaxy properties. With these two inclusions, the SHAM can reproduce accurate galaxy clustering predictions in real and redshift space (Chaves-Montero et al. 2016). The reason for this technique’s success is that it uses the positions and velocities of the dark matter simulation’s subhaloes to assign the positions and velocities of satellite galaxies, which is not possible in a standard HOD. This improvement, however, comes at the additional cost of only being able to create SHAM mocks using intermediate or high-resolution simulations.
Empirical models are used to interpret clustering data (e.g. Zehavi et al. 2011; Guo et al. 2015b), characterise different galaxy samples (Contreras et al. 2013; Yuan et al. 2022), create mock galaxy catalogues (e.g. Grieb et al. 2016), examine galaxy assembly bias effects (e.g. Zehavi et al. 2018; Salcedo et al. 2022), and constrain cosmological parameters (e.g. Cacciato et al. 2013; More et al. 2015; Zhai et al. 2019, 2023; Miyatake et al. 2022; Yuan et al. 2022). Aside from their numerous applications, few studies have attempted to compare their accuracy to more complex (and potentially realistic) mock galaxy samples, such as those predicted by hydrodynamic simulations. These simulations provide us with galaxy clustering statistics that are not subject to observational uncertainty and have a defined cosmology, implying that any differences between the predictions of the empirical models will be due to limitations in their implementation.
In this paper, we test the performance of two state-of-the-art empirical models: a 13-parameter HOD (based on the work of Yuan et al. 2022) and a five-parameter extension of the SHAM technique (SHAMe, Contreras et al. 2021a,b). We compare their clustering predictions (the projected correlation function and the multipoles of the correlation function) with those of the FLAMINGO suite of simulations. We also expand this comparison to include higher-order statistics like galaxy-galaxy lensing, count-in-cylinders, the void probability function, and k-nearest neighbours, as well as derivate statistics like the galaxy occupation number and galaxy assembly bias. To facilitate the comparison with FLAMINGO, we build an emulator called GalaxyEmu-Planck, capable of reproducing all these statistics in a fraction of a second for both empirical models. We find that both models perform well in reproducing most of these statistics. These findings will help validate both empirical models while determining their accuracy in each of these statistics.
The outline of this paper is as follows. Section 2 presents FLAMINGO and the dark matter simulations used in this work. The empirical models, the clustering statistics we compute, and GalaxyEmu-Planck are described in Sect. 3. The main results of this paper, the measurement of galaxy clustering, galaxy-galaxy lensing, and the rest of the statistics are presented in Sect. 4. In Sect. 5, we test the importance of the different extensions of both empirical models when reproducing galaxy clustering and galaxy-galaxy lensing. We finish by presenting our conclusions in Sect. 6.
Unless otherwise stated, the standard units in this paper are h−1 M⊙ for masses and h−1 Mpc for distances. All logarithm values are in base 10.
2. Numerical simulations and galaxy samples
In this section, we first describe the FLAMINGO suite of simulations used to test our models (Sect. 2.1) and then the galaxy samples we extract from these simulations (Sect. 2.2). Finally, we describe the dark matter-only simulation we used to build our mocks (Sect. 2.3).
2.1. The FLAMINGO simulations
We used galaxy samples from the FLAMINGO suite of hydrodynamic simulations (Schaye et al. 2023; Kugel et al. 2023; McCarthy et al. 2023; Braspenning et al. 2024; Elbers et al. 2024; Broxterman et al. 2024) to test the performance of our empirical models. This is one of the largest suites of hydrodynamic simulations available today. The simulations were run using the SWIFT code (Schaller et al. 2024), a highly efficient gravity and smoothed particle hydrodynamics (SPH) solver using the SPHENIX SPH implementation (Borrow et al. 2022). The simulation includes most of the astrophysical processes we expect to affect galaxies in the Universe, such as radiative cooling and heating, stellar and AGN feedback, chemical enrichments, and others. In this paper, we mainly used the galaxies from the largest box of FLAMINGO, with a box length of 1906.8 h−1 Mpc (2800 Mpc) and a resolution of 2 × 50403 particles (same number of dark matter and initial gas particles), equivalent to a mass of 3.85 109 h−1 M⊙ and 7.29 108 h−1 M⊙ for the dark matter and the initial gas particles, and 28003 neutrino particles. The cosmology of these simulations is ΩM = 0.306, Ωb = 0.0486, σ8 = 0.807, ns = 0.967, h = 0.681, and Ων = 1.38 10−3, with this last value being the neutrino matter density parameter (Ων ∼ ∑mνc2/(93.14 h2 eV)). The simulation used partially fixed initial conditions, effectively reducing its cosmic variance (Angulo & Pontzen 2016). Unless we specify otherwise, we shall refer to this simulation as ‘FLAMINGO’.
In addition to the largest hydrodynamic simulation, we also used a set of the FLAMINGO simulations run with the same cosmology and resolution but a smaller volume and different astrophysics implementations. These simulations have a box length of 681 h−1 Mpc (1000 Mpc) and 2 × 18003 particles (the same amount of dark matter and initial gas particles) and 10003 neutrino particles (i.e. the same resolution as the larger volume). We used these simulations to test the validity of our main findings for other galaxy formation prescriptions. In addition to a simulation with the same calibration as the biggest hydrodynamic run, which we shall refer to as the ‘fiducial’ model, this sample has two other groups of simulations. The first group comprises six distinct simulations, calibrated similarly to the fiducial model but incorporating a modified observed cluster gas fraction and/or observed stellar mass function in the calibration process. These simulations are ‘fgas + 2σ’, ‘fgas − 2σ’, ‘fgas − 4σ’, ‘fgas−8σ’, ‘M* − σ’ and ‘M* − 1σ fgas − 4σ’. Their names indicate the number of sigmas the observed gas fraction (fgas) and the observed stellar mass function (M*) were shifted during the calibration (Kugel et al. 2023). Instead of using the thermal AGN model in the fiducial method, the remaining simulations employ jet-like AGN feedback (Huško et al. 2024) instead of a thermally driven AGN feedback (Booth & Schaye 2009). These simulations are called ‘Jet’ and ‘Jet fgas − 4σ’, with the last case also including a shift in the observed cluster gas fraction by 4 sigmas (see Table 2 of Schaye et al. 2023 for a list of all these simulations).
The haloes and substructures of the simulations are identified using the VELOCIRAPTOR subhalo finder algorithm (Elahi et al. 2019). This approach first identifies the haloes using a 3D friend-of-friend algorithm (FOF) with a linking length of l = 0.2 of the mean interparticle separation (Davis et al. 1985). Substructures are then identified within haloes by performing an iterative 6D FOF search in phase space and including all particle types except neutrinos. Finally, galaxy properties are computed using the Spherical Overdensity and Aperture Processor (SOAP), a tool developed for the FLAMINGO project. This paper uses the galaxy properties computed by SOAP in apertures of 50 kpc, excluding other substructures and unbound particles.
2.2. Target galaxy samples
Using the galaxies of FLAMINGO, we built two different samples that resemble the selection function of two galaxy surveys. The first selection is an incomplete red sample that resembles the BOSS-LOWZ galaxies (Dawson et al. 2013). We selected the galaxies of FLAMINGO following the selection procedure described in Chaves-Montero et al. (2023). This approach selects the most massive LRGs based on the galaxies’ colour and magnitude. This sample is built at z = 0.4 and has a number density of approximately 3.16 10−4 h3 Mpc−3. We refer to this selection as the BOSS-like sample.
The second galaxy sample is complete in Mr with a number density of 10−3 h3 Mpc−3 also at z = 0.4. This number density is similar to the one we expect from the DESI-BGS (Hahn et al. 2023) galaxies at z = 0.4. While the mean redshift (number density) of the DESI-LRG is expected to be lower (higher), this sample allowed us to have a more straightforward comparison with the BOSS-like galaxies while using a number density allowed by the resolution of FLAMINGO. We call this the DESI BGS-like sample.
We used both samples with the main FLAMINGO simulation, while we only used the DESI BGS-like galaxies when using the suite of simulations with different astrophysical prescriptions. We facilitate the comparison between samples with different colour distributions. We would like to emphasise that this paper does not aim to make precise observational samples but rather to show the performance of the empirical models when reproducing galaxies obtained using different selection functions.
Fig. 1 shows the stellar mass function of the DESI BGS-like and BOSS-like samples of the FLAMINGO simulation. As wasexpected, the galaxies from DESI BGS-like are complete until a specific stellar mass value, and then their abundance decreases (due to the scatter in the stellar mass-Mr relation), while the BOSS-like sample is incomplete for all stellar masses.
 |
Fig. 1. Stellar mass function of the FLAMINGO simulation at z = 0.4. The solid black line represents all the galaxies from the simulation, while the blue and red lines represent the galaxies from the DESI BGS-like and BOSS-like samples. As is explained in Sect. 2.2, the DESI BGS-like sample is complete in Mr with a number density of 10−3h3 Mpc−3, while the BOSS-like sample is incomplete and red with a number density of 10−3.5h3 Mpc−3. |
2.3. The Planck-1Gpc simulation
In this paper, we run our empirical models on a pair of gravity-only simulations with a ‘Planck cosmology’1. The pair of simulations were run with opposite initial Fourier phases, using the procedure of Angulo & Pontzen (2016), which suppresses cosmic variance by up to 50 times when compared to a simulation with random phases for the same volume. The simulations have a volume of (1024 h−1 Mpc)3, a resolution of 30723 particles, and were carried out using an updated version of L-Gadget3 (Angulo et al. 2012), a lean version of GADGET (Springel et al. 2005) used to run the Millennium XXL simulation (Angulo et al. 2012) and the Bacco Simulations (Angulo et al. 2021). This implementation enables on-the-fly identification of haloes and subhaloes using a friend-of-friend algorithm and uses an extended version of SUBFIND (Springel et al. 2001) that better identifies substructures by considering their past history (see Sect. 2.1.1 of Angulo et al. 2021 for more details). In addition, this version of SUBFIND provides properties that are non-local in time, such as the maximum circular velocity (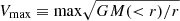 ) attained by a subhalo during its evolution, Vpeak. The code is also capable of identifying orphan substructures – satellite structures with known progenitors that the simulation cannot resolve but that are expected to exist in the halo – by tracing the most bound particle of all subhalos after these cannot be identified. Using a different halo finder algorithm between the hydrodynamic and this dark matter-only simulation could produce small differences in the galaxy clustering measurements. Nevertheless, we expect most of these differences to be absorbed when running the empirical models on the dark matter-only simulations. We discuss some of the impacts of the different halo-finder algorithms in Sect. 4.2.
) attained by a subhalo during its evolution, Vpeak. The code is also capable of identifying orphan substructures – satellite structures with known progenitors that the simulation cannot resolve but that are expected to exist in the halo – by tracing the most bound particle of all subhalos after these cannot be identified. Using a different halo finder algorithm between the hydrodynamic and this dark matter-only simulation could produce small differences in the galaxy clustering measurements. Nevertheless, we expect most of these differences to be absorbed when running the empirical models on the dark matter-only simulations. We discuss some of the impacts of the different halo-finder algorithms in Sect. 4.2.
3. Galaxy models
In this section, we first describe the empirical models we use to create the mocks: the SHAMe model (Sect. 3.1) and the HOD model (Sect. 3.2). The description of the clustering statistics we measure from FLAMINGO and the empirical models are presented in Sect. 3.3. We describe the process of fitting the data of FLAMINGO in Sect. 3.4. We finalise by presenting GalaxyEmu-Planck in Sect. 3.5.
3.1. SHAMe
The Sub-Halo Abundance Matching extended model (SHAMe) developed by Contreras et al. (2021a,b) is an extension of the standard SHAM approach (Vale & Ostriker 2006; Conroy et al. 2006; Reddick et al. 2013; Contreras et al. 2015; Guo et al. 2016; Chaves-Montero et al. 2016; Lehmann et al. 2017; Dragomir et al. 2018; Hadzhiyska et al. 2021; Favole et al. 2022) that includes a more sophisticated treatment of the satellite galaxies as well as a flexible level of galaxy assembly bias.
As in the standard SHAM approach, we began by matching a subhalo property (in this case, Vpeak) to the expected luminosity function. We included a log-normal noise element in the matching process to reproduce the expected scatter between Vpeak and the luminosity of galaxies. For galaxy samples selected according to a number density (instead of a cut in luminosity), this scatter only fulfils the purpose of assigning a physical unit to the value of the scatter of the SHAMe model; the choice of luminosity function has no significant effect on galaxy clustering statistics (Contreras et al. 2021b).
The number of satellite galaxies is set by a free parameter that removes substructures that have been satellites for long periods of time. This process intends to reproduce the disappearance of satellite galaxies into the intra-cluster medium before they can merge with their central galaxy. The number of orphan satellite galaxies is controlled by a free parameter that is compared with the ratio of the time since accretion and the dynamical friction timescale (based in Eq. (7.26) of Binney & Tremaine 1987). If this ratio exceeds our threshold, we assume that the orphan merged with its central galaxy.
The final step in the SHAMe implementation involves incorporating additional galaxy assembly bias (Croton et al. 2007), which is the impact of the evolutionary history of their host haloes on galaxy clustering. This effect is introduced using two free parameters (one for centrals and one for satellites), which modulate the luminosity of the galaxies based on their large-scale bias. To define this bias, we used the individual bias-per-object of the galaxies (Paranjape et al. 2018), corresponding to the cross-correlation between a given point in space and the dark matter density field. We computed this property by measuring the power spectrum around each object on scales between 0.08 < k/ h Mpc−1 < 2.
The positions and velocities of the galaxies in SHAMe are equal to the positions and velocities of their assigned subhaloes. The velocity of the subhaloes is computed as the average of the inner 10% of the particles. We describe all the SHAMe parameters in the top part of Table 1. For a more detailed description of this model, we refer the reader to Contreras et al. (2021b, 2023b).
Description of the SHAMe and HOD parameters.
3.2. Halo occupation distribution
The HOD describes the average number of galaxies that populate haloes as a function of halo mass, ⟨N(Mh)⟩. This relation can be parametrised independently for centrals (⟨Ncen(Mh)⟩) and satellites (⟨Nsat(Mh)⟩), where its parametric form is motivated by the occupation distribution of semi-analytical models and hydrodynamic simulations (Zheng et al. 2005).
In this paper, we use the base model of Zheng et al. (2005), along with the model extensions presented in Yuan et al. (2022). These extensions include the relocation of satellite galaxies to the inner or outer part of the halo (satellite segregation, one free parameter), the modulation of the velocities of galaxies (velocity bias, two free parameters), galaxy assembly bias via environment (two free parameters) and concentration (also known as occupancy variation, two free parameters); and incompleteness due to the selection of galaxies (one free parameter).
We describe all the HOD parameters in the bottom part of Table 1. A more detailed description of these extensions is present in Appendix A (see also Yuan et al. 2022). While this HOD model is based on the work of Yuan et al. (2022), there are two differences with their implementation. The first is that we assumed that the mean number of galaxies is equal to the sum of the mean number of centrals and satellites, ⟨Ntot⟩=⟨Ncen⟩+⟨Nsat⟩, while Yuan et al. (2022) used ⟨Ntot⟩=⟨Ncen⟩(1 + ⟨Nsat⟩). The later approach aims to suppress the occupation of satellite galaxies in haloes without a central. Still, it has recently been shown that it is expected to find haloes with satellites and no centrals (Jiménez et al. 2019; Chaves-Montero et al. 2023). Nonetheless, we do not expect significant differences in the performance of this model due to this different implementation.
The second difference is the environmental property used to add assembly bias, which is, in our case, the individual bias per object described in the previous section (different from the local overdensity used by Yuan et al.). During this study, we found that different environmental properties significantly impact the quality of the clustering prediction, especially for the galaxy-galaxy lensing signal. The individual bias-per-object computed on the scales we mentioned before was the property that gave the best performance. In future work, we shall compare the performance of different environmental properties and their impact on galaxy assembly bias (Contreras et al., in prep.).
3.3. Clustering statistics
This section describes the clustering statistics we measure from the FLAMINGO simulations and the empirical models. These statistics are the projected correlation function (wp), the multipoles of the correlation function (ξℓ), the galaxy-galaxy lensing (ΔΣ), the k-nearest neighbour cumulative distribution function, the counts-in-cylinder, and the void probability function. We average each statistic over three lines of sight to reduce the uncertainty in our calculations. All calculations include redshift space distortion effects. In addition, we compute two derivate statistics normally inferred from galaxy clustering: galaxy assembly bias and halo occupation number.
3.3.1. Projected correlation function
The projected correlation function is obtained by integrating the 2-point correlation function, ξ(rπ, rp), over the line-of-sight,
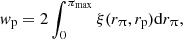 (1)
(1)
with πmax = 30 h−1 Mpc the maximum depth used in this work. The computations were done using the public code corrfunc (Sinha 2016; Sinha & Garrison 2017).
3.3.2. Multipoles of the correlation function
To measure the multipoles of the correlation function, we first measure the 2-point correlation function in bins of s and μ, where s2 = rp2 + rπ2 and μ is the cosine of the angle between s and the line-of-sight. We compute this statistic once again with corrfunc. The multipoles of the correlation functions are then defined as follows:
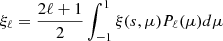 (2)
(2)
where Pℓ is the ℓ-th order Legendre polynomial. In this paper, we only use the monopole (ξℓ = 0) and quadrupole (ξℓ = 2) since higher orders are noisier and do not provide significant additional information.
3.3.3. Galaxy-galaxy lensing
A foreground mass distribution induces a shear signal on background sources that varies with the lens-source pair’s separation. The signal stacked from a sufficient number of lenses is proportional to the excess surface density
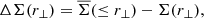 (3)
(3)
where Σ is the azimuthally averaged surface mass density and 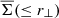 is the mean surface density within the projected radius r⊥. We estimate the azimuthally averaged surface mass density using
is the mean surface density within the projected radius r⊥. We estimate the azimuthally averaged surface mass density using
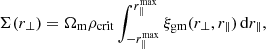 (4)
(4)
where r∥ and r⊥ refer to the projected distance along and perpendicular to the line-of-sight from the lens galaxy, r∥max is the integration boundary, ξgm is the galaxy-matter three-dimensional cross-correlation, Ωm and ρcrit are the matter and critical density of the Universe, respectively, and the mean surface mass density within a radius r⊥ is
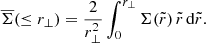 (5)
(5)
We measure ξgm using corrfunc, with 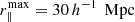 , and a subsampled version of the matter density field diluted by a factor of ≈3000 for the mocks and 100 for FLAMINGO (we checked lower dilute factors, finding almost identical results).
, and a subsampled version of the matter density field diluted by a factor of ≈3000 for the mocks and 100 for FLAMINGO (we checked lower dilute factors, finding almost identical results).
To account for the different cosmologies, we apply a correction factor equal to the ratio of the ΔΣ for SHAMe mocks on scaled simulations (Angulo & White 2010; Contreras et al. 2020) with the cosmologies from FLAMINGO and Planck. The parameters used to build the mocks were obtained by fitting simultaneously wp, ξℓ = 0, ξℓ = 2 and ΔΣ from the DESI BGS-like and BOSS-like samples. The correction changes the amplitude of the lensing signal by ≈2%, which did not end up affecting our results in a significant way. We did not correct the rest of the statistics since the impact for these changes in cosmologies are much lower.
3.3.4. k-nearest neighbour
The k-Nearest Neighbour Cumulative Distribution Function (kNN-CDF, Banerjee & Abel 2021) measures the cumulative distribution function of distances of the galaxies to a set of volume-filling Poisson distributed random points to the k-nearest data points (P(Nk)). We computed this statistic for k = 1, 2, 3, 4 and 5 but limited them to showing only k = 2 and 5 to facilitate the comparison between the different samples. The number of random points we used equals ten times the number of galaxies for each sample. The computations were done using the KDTree function from scipy (Virtanen et al. 2020).
3.3.5. Counts-in-cylinder
The counts-in-cylinder (CIC, P(rCIC)) statistic measures the probability of having ‘N’ galaxies inside a cylinder centred in each galaxy with a radius, ‘eCIC’, and a half-depth of rπ, 1/2. We characterise this probability by showing the probability of having fewer than ‘N’ for a fixed radius (i.e. 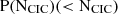 ). We measure this statistic for different radii (rCIC = 1, 2, 4, 7 and 10 h−1 Mpc). For simplicity, we only show the results for rCIC = 1, and 10 h−1 Mpc. The counts-in-cylinder were computed using HALOTOOLS (Hearin et al. 2017).
). We measure this statistic for different radii (rCIC = 1, 2, 4, 7 and 10 h−1 Mpc). For simplicity, we only show the results for rCIC = 1, and 10 h−1 Mpc. The counts-in-cylinder were computed using HALOTOOLS (Hearin et al. 2017).
3.3.6. Void probability function
The void probability function (VPF, P0) measures the probability of finding a void (i.e. no objects from a galaxy sample) of radius ‘r’ at any point in the simulation. We compute P0(r) from a set of volume-filling Poisson distributed random points. The number of random points equals five times the number of galaxies in each sample. We again compute P0(r) using HALOTOOLS. This statistic contains the same information as the kNN-CDF with k = 1.
3.3.7. Galaxy assembly bias
Unlike previous statistics, galaxy assembly bias cannot be measured directly from the spatial distribution of galaxies. This is why it is difficult to get definite proof of the existence of this bias in the real universe. To estimate the amount of galaxy assembly bias from a mock or a simulation, we used the ‘shuffling technique’ developed by Croton et al. (2007). The method consists of creating a version of a mock without assembly bias and measuring the difference in their 2-point correlation function. These mocks without assembly bias are produced by shuffling the galaxy positions among haloes of the same mass, erasing any dependence of the galaxy population with any halo property besides halo mass (see Contreras et al. 2019, 2021c for more details about the creation of the shuffle mock). The level of assembly bias is then quantified as
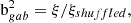 (6)
(6)
with ξ the correlation function of the original galaxy sample, ξshuffled the correlation function of the shuffled sample and bgab the level of assembly bias. We compute ξshuffled as the average of two independent shuffle runs to reduce the noise of this measurement. To ease the comparison with the literature, we refer to galaxy assembly bias as the ratio of the correlation functions ξ/ξshuffled and not the square root of this ratio. The correlation function was computed with CORRFUNC.
3.3.8. Halo occupation number
The halo occupation number measures the average number of galaxies that populate haloes as a function of halo mass, ⟨N(Mh)⟩. This statistic is usually called halo occupation distribution, but we shall avoid referring to it as that to avoid confusing it with the HOD mocks. We computed ⟨N(Mh)⟩ by measuring the ratio between the number of galaxies and the number of haloes in bins of 0.1 dex in halo mass.
We correct the halo masses of the halo occupation number of FLAMINGO to account for the effects of the different cosmologies between the simulations and the impact of baryons on the halo mass function. We do this using a similar approach as Contreras et al. (2015), which consists of matching the cumulative halo mass function by creating a displacement vector as a function of the halo mass (Δlog(Mh)). We do this to facilitate the comparison between samples with different halo mass functions.
3.4. Fitting data
We use two techniques to determine the best-fitting parameters for our empirical models. When we only want to find the mock parameters that best match the target sample, we use the Particle Swarm Optimisation (PSO) algorithm. To predict the likelihood of a range of parameters being a good representation of a target sample, we use the Markov Chain Monte Carlo (MCMC) algorithm.
The PSO tracks a group (or swarm) of particles in the parameter space in which we want to evaluate our model. After assigning each particle a random velocity, they will feel an attraction (or acceleration) to two different points in the parameter space: the point where each individual particle has the smallest difference with the target sample and the point where the swarm of particles has the smallest difference with the target sample. We calculate the likeness of the samples by computing their χ2. The algorithm stops when the velocities of all particles become small, and the best-fitting value does not change significantly for at least 100 steps. In this paper, we use the public code PSOBACCO2 (see Aricò et al. 2021a).
An MCMC is used to generate a probability distribution from our parameter space. We use this distribution to evaluate the parameter space of the empirical models that successfully reproduced the statistics of FLAMINGO. The empirical models’ performance is evaluated by computing the χ2 between the samples. This paper employs the Affine Invariant Markov Chain Monte Carlo Ensemble sampler emcee (Foreman-Mackey et al. 2013) public code3. For the SHAMe (HOD) model, we ran 1000 (2000) chains of 10 000 (20 000) steps each, which included a 1000-step burn-in phase. This combination of chains and steps is ideal for emulator-based MCMC, which is extremely efficient when computing a large number of points at the same time.
We used MCMC to predict extended clustering statistics (kNN-CDF, CIC, VPF, halo occupation number, and galaxy assembly bias) when fitting galaxy clustering and galaxy-galaxy lensing, as is explained in Sect. 4. Following Contreras et al. (2023a,b), we extract a random set of points from the MCMC chains after burn-in (1000 points) and compute the extended statistics for all points. The median, 16th, and 84th per cent of the distribution for each statistic will represent their expected distribution when fitting galaxy clustering and galaxy-galaxy lensing.
The PSO and MCMC depend on estimating the χ2 between the clustering predictions of our empirical models and FLAMINGO. We calculate χ2 as
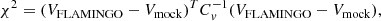 (7)
(7)
where VFLAMINGO and Vmock are vectors that combine all the statistics we want to fit (for example, the projected correlation function and the galaxy-galaxy lensing) from the FLAMINGO simulation and the empirical models. The covariance matrix (Cv) is computed using 103 jackknife subsamples (73 for the FLAMINGO suite of simulations with different astrophysics). Each volume is equal to the total volume minus a cubic subvolume equal to 1/103 (or 1/73) of the entire volume (Zehavi et al. 2002; Norberg et al. 2008). The covariance matrix is then computed as:
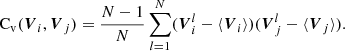 (8)
(8)
To compensate for the larger volume of FLAMINGO compared to the Planck-1Gpc simulations, we scaled the error by the square root of the ratio between the simulation volumes. We did not perform this for the smaller boxes of FLAMINGO because they are smaller than our dark matter-only pair of simulations. Following Contreras et al. (2023a), we add a 5% signal in the diagonal of the covariance matrices to account for various model and observational systematics; for example, emulator errors, shotnoise, and differences in the cosmologies of the simulations. We replace the 5% error on the quadrupole of the correlation function by adding 1.3/r2, which is similar to the errors of BOSS for a similar selection sample as in our sample. The range of scales we computed the covariance matrix is 100 h−1 kpc to 100 h−1 Mpc for the projected correlation function, monopole and quadrupole (up to 70 h−1 Mpc for the FLAMINGO simulations with different astrophysical implementations) and between 1 h−1 Mpc to 30 h−1 Mpc for the galaxy-galaxy lensing. We remind the reader that the goal of this paper is not to obtain the exact errors of a specific survey but rather to provide a fair comparison of the performance of two state-of-the-art galaxy population models when reproducing different galaxy populations. While the results differed slightly, our conclusions remained unchanged when we changed the covariance matrix definition or the range of scales used to fit our data.
3.5. GalaxyEmu-Planck
One of the primary advantages of empirical models is their computational efficiency. An empirical model takes only a few minutes to run, whereas a standard hydrodynamic simulation takes millions of CPU hours. Reading a dark matter simulation, creating a mock and computing all the statistics mentioned in the previous section takes less than 10 minutes (on an 8-threaded CPU task). While efficient, this time is significant when performing multiple fits or Monte Carlo analyses. This is why we developed a suite of emulators capable of performing all of the aforementioned statistics: projected correlation function, multipoles of the correlation function, galaxy-galaxy lensing, k-nearest neighbours cumulative distribution function, counts-in-cylinder, void provability function, galaxy assembly bias, and halo occupation number.
We call this suite emulator GalaxyEmu-Planckit was built using ≈30 000 SHAMe and HOD mocks between z = 0 and z = 0.8, computing all our statistics for seven number densities between 0.0001 h3 Mpc−3 and 0.00316 h3 Mpc−3 (equally separated in logarithmic space, which includes the two number densities used in this work, 0.000316 and 0.001 h3 Mpc−3). We compute each statistic by averaging the results from two mocks with different random seeds (which effectively reduces the shotnoise from our mocks to less than 0.5%) and from both Planck-1Gpc simulations (paired phases), which significantly reduces the cosmic variance of our statistics (see Sect. 2.3 for more details). We compute the 2D correlation functions ξ(rπ, rp) and ξgm(r⊥, r∥) (from Eqs. (1) and (4)) up to 100 h−1 Mpc and 240 h−1 Mpc, even though we end up integrating up to πmax = 30 h−1 Mpc. These additional ranges, combined with the wider range of redshifts and number densities, will allow this emulator to be compared to observational samples such as KiDS, DESI, EUCLID, and so on.
One of the aims of this paper is to show the performance of empirical models for different samples of galaxies. This is why we chose two galaxy samples with different selection functions (DESI BGS-like and BOSS-like galaxies) and why we tested our results on the FLAMINGO simulations with different astrophysical prescriptions. To ensure that our emulator covers these and any other selection samples, we used a broad range of SHAMe and HOD parameters. For SHAMe we based our constraints on Contreras et al. (2023a), where we tested this model against extreme physical modifications of the L-Galaxies semi-analytical model (e.g. Henriques et al. 2020). For the HOD, we used a range of parameters from Yuan et al. (2022) and extended some parameters when it was necessary to fit all the astrophysical variations of FLAMINGO easily.
To reduce the number of free parameters in the HOD, we fixed the target number density (nden) to the one we want to measure. This constraint allowed one degree of freedom to be removed from the mock. We fix all the parameters that impact the number density (e.g. σlogM, M1, Mcut and α) except Mmin and find the value that produces a number density of the HOD equal to our target number density. This number density is equal to the integral of the HOD times the halo mass function, ϕ(Mh):
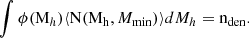 (9)
(9)
We use the Newton–Raphson root-finding algorithm to find the value of Mmin. We check the precision of this minimisation even when using galaxy assembly bias and occupancy variation parameters, finding excellent agreement with the target number density.
To use a single range of parameters for all HOD mocks and to avoid a non-physical combination of parameters, we vary M1/Mmin, which is normally used to characterise the HODs (Zheng et al. 2005; Zehavi et al. 2005; Contreras et al. 2017), and 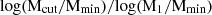 , which is not expected to be lower than zero (i.e. Mcut > Mmin) and cannot be above one (i.e. Mcut < M1). This parameterisation enabled all parameter combinations to be valid for any number density. Although this parametrisation reduces the number of free parameters in the HOD model to 12, we shall still refer to it as a 13-parameter HOD for clarity.
, which is not expected to be lower than zero (i.e. Mcut > Mmin) and cannot be above one (i.e. Mcut < M1). This parameterisation enabled all parameter combinations to be valid for any number density. Although this parametrisation reduces the number of free parameters in the HOD model to 12, we shall still refer to it as a 13-parameter HOD for clarity.
For the SHAMe model we normalised the value of βlum (βlum*) by dividing the value for the lookback time when the mock is created (≈13.8 Gyr). A value of zero indicates that the model has no satellites at the current time, while a value of one indicates that all non-orphan galaxies in the simulation are used. The assembly bias parameters are expressed as the sum (fk,cen+sat) and difference (fk,cen-sat) of the parameters to facilitate the training.
The parameter space we used for SHAMe model are:
![Mathematical equation: $$ \begin{aligned} \sigma _{\rm lum}&\in [0, 1.8],\\ \log (t_{\rm merger})&\in [-1.5, 1.2],\\ f_{\rm k,cen+sat}&\in [-0.5, 0.5],\\ f_{\rm k,cen-sat}&\in [-0.5, 0.5],\\ \beta _{\rm lum}^*&\in [0,1]. \end{aligned} $$](/articles/aa/full_html/2024/10/aa51671-24/aa51671-24-eq15.gif)
The parameters used for the HOD model are:
![Mathematical equation: $$ \begin{aligned} \sigma _{\rm logM}&\in [0, 1.5],\\ \log (\mathrm{M}_{\rm 1}/\mathrm{M}_{\rm min})&\in [0, 2],\\ \frac{\log (\mathrm{M}_{\rm cut}/\mathrm{M}_{\rm min})}{\log (\mathrm{M}_{\rm 1}/\mathrm{M}_{\rm min})}&\in [0,1],\\ \alpha&\in [0.5,1.4],\\ f_{\rm ic}&\in [0.2,1],\\ \alpha _c&\in [0,0.7],\\ \alpha _s&\in [0.5,1.5],\\ \mathrm{GAB}_{\mathrm{cen}}&\in [-0.5,0.5],\\ \mathrm{GAB}_{\mathrm{sat}}&\in [-0.5,0.5],\\ \mathrm{OV}_{\mathrm{cen}}&\in [-0.5,0.5],\\ \mathrm{OV}_{\mathrm{sat}}&\in [-0.5,0.5],\\ \mathrm{s}_{\mathrm{segr.}}&\in [-0.7,0.7]. \end{aligned} $$](/articles/aa/full_html/2024/10/aa51671-24/aa51671-24-eq16.gif)
Similar to Angulo et al. (2021), Aricò et al. (2021a,b), Pellejero Ibañez et al. (2023), Zennaro et al. (2023), Contreras et al. (2023a,b), we used a feed-forward neural network to build our emulators. The architecture is made up of three fully connected hidden layers, each with 200 neurons, and a Rectified Linear Unit activation function for the multipoles of the correlation function and the galaxy-galaxy lensing signal. The remaining statistics are calculated using two fully connected layers. Each statistic has a separate network. We explored alternative configurations and obtained comparable results.
The neural networks were trained with the Keras interface of the Tensorflow library (Abadi et al. 2016). We used the Adam optimisation algorithm with a 0.001 learning rate and a mean-absolute error loss function. Our dataset is divided into distinct groups for training and validation. A single Nvidia Quadro RTX 8000 GPU card took around 30 minutes per number density/statistic to process the training set, which contains 90% of the data. On an 11-year-old Intel i7-3820, evaluating one emulator takes ≈6 milliseconds, whereas evaluating batches of 1 000 000 samples takes ≈22 seconds.
Following Contreras et al. (2023b), we directly trained the projected correlation function, monopole, quadrupole, hexadecapole (not used in this work), and galaxy-galaxy lensing. This means that we do not compress this information (such as polynomial fit coefficients) in order to simplify neural network training.
The new statistics included in this work can be easily represented by a functional form, which allows us to represent them with a set of coefficients that we trained to produce our neural network. We described the various parameterisations done to all these statistics in Appendix C. We evaluated the performance of GalaxyEmu-Planck for these statistics and found excellent agreement across all redshifts and number densities.
4. Reproducing the clustering statistics of the FLAMINGO simulation
With GalaxyEmu-Planck, we can predict any clustering statistics mentioned in the previous sections in milliseconds. We are now focussing on quantifying how well GalaxyEmu-Planck can reproduce the statistics from FLAMINGO. We used two different fits for each galaxy sample and empirical model: (i) the projected correlation function and galaxy-galaxy lensing (statistics we can obtain from a photometric survey), which will be represented as dotted lines in most of the plots unless specified otherwise; (ii) the projected correlation function, the monopole and quadrupole of the correlation function and galaxy-galaxy lensing (statistics we can obtain from a spectroscopic survey). These results will be shown in solid lines unless specified otherwise.
We used fits to the galaxy clustering and galaxy-galaxy lensing to predict values for the rest of the statistics. We do this to (a) reduce the number of fits performed, making the results easier to interpret, and (b) because, for the rest of the statistics, there is a limited amount of observational data or covariance matrices to compare to. Furthermore, the galaxy assembly bias, and halo occupation number cannot be directly measured through observation; they must be inferred. The predicted values for these statistics are derived from the best fit using MCMCs as is described in Sect. 3.4.
In Sect. 4.1, we show the prediction of our mock models for the statistics we fit, and in Sect. 4.2, we show the constraints for the rest of the parameters.
From now on, all the mock predictions will come directly from GalaxyEmu-Planck since the differences with predictions of the mocks are much lower than the errors we used to fit the data.
4.1. Fitting galaxy clustering and galaxy-galaxy lensing
The projected correlation function, monopole, quadrupole, and galaxy-galaxy lensing of the FLAMINGO simulation and the best fitting SHAMe and HOD models are shown in Figs. 2 and 3. We fit galaxy clustering for all scales between 100 h−1 kpc and 100 h−1 Mpc, i.e. a three-orders of magnitude window. We use 100 h−1 kpc since it is usually the lower scale used in observational clustering measurements, and both models reproduce the FLAMINGO suite of simulations well on these scales. We set the 100 h−1 Mpc limit to avoid the BAO scales, which we shall explore in a follow-up work. We fit galaxy-galaxy lensing from scales above 1 h−1 Mpc to avoid the impact of baryonic effects, which are not modelled by any of our mocks (see Appendix B for more details). We therefore expect some differences in the galaxy-galaxy lensing at these scales, since we do not fit them and because they are affected by physical processes not accounted for by the empirical models. Each figure shows the results from two galaxy samples, the DESI BGS-like galaxies in blue and the BOSS-like galaxies in red. Along the y axis we have displaced the predictions for the BOSS-like galaxies to improve the clarity of the plot. The largest panels show the value for each statistic, while the bottom panels show the differences between the mock predictions and the FLAMINGO data normalised by the square root of the diagonal of the covariance matrix used for the fits (which we shall refer to from now on as the data error).
 |
Fig. 2. Galaxy clustering (wp, top left panel; ξℓ = 0, top right panel; ξℓ = 2, lower left panel) and galaxy-galaxy lensing (ΔΣ, lower right panel) for the FLAMINGO simulation (symbols) and the SHAMe model (lines). The results for the BOSS-like sample, shown in red, are displaced along the y axis for clarity. The different line styles represent the statistics used to fit FLAMINGO. The solid line corresponds to the best-fitting model when fitting to the projected correlation function, the monopole and quadrupole of the correlation function, and the galaxy-galaxy lensing. The dotted line corresponds to the best-fitting model when fitting only to the projected correlation function and the galaxy-galaxy lensing. The bottom subpanels show the difference between the empirical model and FLAMINGO, normalised by the error in each point. The fits are performed for all scales shown for the galaxy clustering statistics and for scales above 1 h−1 Mpc for galaxy-galaxy lensing (denoted by a vertical line in the bottom right panel) to avoid baryonic effects. |
We find excellent agreement across all statistics, galaxy samples, and empirical models. The HOD model performs slightly better than the SHAMe model but with differences within the statistical error bars. We find only a minor improvement when fitting the projected correlation function and galaxy-galaxy lensing (dotted line) but at the expense of a significant discrepancy in the multipole predictions, particularly for the HOD model.
One of the most exciting results is the simultaneous fit of galaxy clustering and galaxy-galaxy lensing for the HOD model. Until recently, most attempts to reproduce galaxy clustering and galaxy-galaxy lensing from the BOSS galaxy survey were unsuccessful, with a constant gap in the galaxy-galaxy lensing measurements compared to the observed ones at small scales (an effect known as the lensing-is-low problem, Leauthaud et al. 2017). While there were explanations for this effect linked to a problem with the fiducial cosmology (suggesting a lower value of the 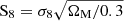 cosmological parameter), Chaves-Montero et al. (2023) found that the most probable origin of this problem were the assumptions made by some mocks models (such as the lack of galaxy assembly bias, the functional form of the HOD, the way satellite galaxies distribute within the halo among others). In this study, the authors used a simple HOD model to analyse a BOSS-like galaxy sample extracted from a hydrodynamic simulation, finding a lensing-is-low signal with similar amplitude and scale-dependence as the one found when using the same HOD model to analyse BOSS galaxies. As we will show in Sect. 5, simple HOD models are incapable of simultaneously reproducing galaxy clustering and galaxy-galaxy lensing, for FLAMINGO galaxies, yielding a lensing-is-low signal with similar properties as the one found when analysing observational data. Recently, a more complex HOD model was able to fit these two statistics simultaneously (Paviot et al. 2024). The SHAMe model also proves to be capable of simultaneously fitting these two statistics (Contreras et al. 2023b).
cosmological parameter), Chaves-Montero et al. (2023) found that the most probable origin of this problem were the assumptions made by some mocks models (such as the lack of galaxy assembly bias, the functional form of the HOD, the way satellite galaxies distribute within the halo among others). In this study, the authors used a simple HOD model to analyse a BOSS-like galaxy sample extracted from a hydrodynamic simulation, finding a lensing-is-low signal with similar amplitude and scale-dependence as the one found when using the same HOD model to analyse BOSS galaxies. As we will show in Sect. 5, simple HOD models are incapable of simultaneously reproducing galaxy clustering and galaxy-galaxy lensing, for FLAMINGO galaxies, yielding a lensing-is-low signal with similar properties as the one found when analysing observational data. Recently, a more complex HOD model was able to fit these two statistics simultaneously (Paviot et al. 2024). The SHAMe model also proves to be capable of simultaneously fitting these two statistics (Contreras et al. 2023b).
In addition to the main FLAMINGO simulation, we fit all the different astrophysical implementations mentioned in Sect. 2.1. Because of the smaller volume of these simulations, we limited the clustering measurements to scales up to ≈70 h−1 Mpc, which is approximately ≈10% of the simulation box size. We only looked at the DESI BGS-like sample, since it has a higher number density and does not rely on colours to select the galaxies.
We show the galaxy clustering and galaxy-galaxy lensing measurements for the FLAMINGO suite of simulations along with the best fitting SHAMe and HOD model in Figures 4 and 5. The empirical models shown in the figures are those that better reproduce the projected correlation function, the multipoles of the correlation functions and the galaxy-galaxy lensing (the solid lines in Figs. 2 and 3). The top panels show the statistics for all models; the middle panels show the difference between the FLAMINGO variations and the mocks, normalised by the error; and the bottom panel displays the relative difference between the FLAMINGO variations and the fiducial run, normalised by the error (black line).
 |
Fig. 4. Galaxy clustering (wp, top left panel; ξℓ = 0, top right panel; ξℓ = 2, lower left panel) and galaxy-galaxy lensing (ΔΣ, lower right panel) for the FLAMINGO suite of simulations with different astrophysical implementations (symbols) and the SHAMe model (lines). The different colours represent the various astrophysical implementations, as labelled. All samples are displaced along the y axis for clarity. Only the results from the DESI BGS-like sample are shown in the plot. The middle subpanel shows the difference between the empirical model and FLAMINGO, normalised by the error. The bottom subpanel shows the difference between theFLAMINGO model variations and the fiducial FLAMINGO model. The fits are performed for all scales shown for the galaxy clustering statistics and for scales above 1 h−1 Mpc for galaxy-galaxy lensing. |
The empirical models reproduce clustering statistics equally well for all the astrophysical variations of FLAMINGO, regardless of whether they target an extreme astrophysical variation. Only small differences between the fits can be found for the SHAMe model in the quadrupole at scales of log(r/h−1 Mpc)≈0.5. This agreement is especially impressive for galaxy-galaxy lensing. We anticipated that due to differences in the baryonic implementations (particularly for the most extreme models), some models could end up being difficult to fit.
These results demonstrate the accuracy of the current generation of empirical models and how GalaxyEmu-Planck can reproduce galaxy clustering and galaxy-galaxy lensing for most target galaxy samples.
4.2. Predicting higher-order statistics
In this section, we show the results for to the rest of the statistics. As was mentioned in Sect. 3.4, we predict these statistics by taking 1000 random points from the MCMC chains used to fit the galaxy clustering and galaxy-galaxy lensing and then evaluate them using GalaxyEmu-Planck. The predictions for the kNN-CDF, counts-in-cylinder and void probability function are shown in Fig. 6 for the SHAMe model and in Fig. 7 for the HOD model. For the kNN-CDF, we only show k = 2 and 5 and for the counts-in-cylinder only r = 1 and 10 h−1 Mpc. The lines represent the median of the 1000 random points, while the shaded region represents the 16th and 84th percentile of the distribution (only shown for the solid line, i.e. the fit for wp, ξℓ = 0, ξℓ = 2 and ΔΣ). These statistics, along with the galaxy clustering and galaxy-galaxy lensing measurements of the previous section, can be directly measured from observations. This means these properties provide an opportunity to improve the constraints from empirical models when used to predict cosmology or other properties from a target galaxy sample.
 |
Fig. 6. k-nearest neighbour cumulative distribution functions (kNN-CDF, left panel), count-in-cylinder (CIC, middle panel), and void probability function (VPF, right panel) of the FLAMINGO simulation (symbols) and the SHAMe model (lines). The results for BOSS-like, shown in red, are displaced along the y axis to facilitate the comparison. The different line styles represent the statistics used to fit FLAMINGO as labelled. The lines represent the median of 1000 MCMC points when fitting the projected correlation function and the galaxy-galaxy lensing (dotted lines), as well as the projected correlation function, multipoles of the correlation function, and galaxy-galaxy lensing (solid lines). It is worth noting that none of the statistics shown in this figure were used in the empirical model fitting process. The shaded region corresponds to the 16th and 84th percentile of the distribution (only shown for the solid line). Only the predictions for Nk = 2 and 5 are shown for the kNN-CDF. Similarly, the CIC only shows the predictions for rCIC = 1 and 10 h−1 Mpc. The bottom panels show the ratio between the empirical models and FLAMINGO. |
Overall, the predictions for both empirical models show very good agreement with the ones from FLAMINGO. Most of the differences in the bottom panels (the ratio between the mocks and FLAMINGO) occur when both curves reach small values, and the ratio diverges (notice that the BOSS-like sample is displaced along the y axis for clarity). The ability to predict multiple statistics simultaneously demonstrates the robustness of the current generation of empirical models. These results also highlight the amount of information contained in galaxy clustering and galaxy-galaxy lensing and the advantages of having a model capable of simultaneously reproducing all these statistics.
Contrary to the previous section, the predictions of SHAMe show better agreement than the predictions of the HOD model. In this case, we find some systematic differences between both samples (with the DESI BGS-like sample showing larger differences in the kNN-CDF and counts-in-cylinder, and the BOSS-like sample for the void probability function). We also notice that the constraints for this technique are broader for the HOD. We test using real mocks instead of GalaxyEmu-Planck, finding the same discrepancies. The additional flexibility of the HOD model may cause these differences. The larger number of free parameters of the HOD (2–3 times more than the SHAMe model) improves the fit, as demonstrated in the previous section. Still, these fits may attempt to reproduce any minor feature of the target sample, sometimes forcing a parameter to reach unrealistic values to improve the fit.
This becomes more evident in the top panel of Fig. 8, where we show the predicted level of galaxy assembly bias of the models. For this statistic, the HOD model does not properly constrain the level of galaxy assembly bias of FLAMINGO. For these cases, we believe the HOD model requires a larger amount of assembly bias to fit the clustering of FLAMINGO, to compensate for any limitation of the model, which results in a larger discrepancy with the statistics we do not use to fit. The SHAMe model is able to correctly constrain galaxy assembly bias within one sigma for the DESI BGS-like sample and two sigmas for the BOSS-like sample, consistent with previous studies (Contreras et al. 2023a,b). The galaxy assembly bias predictions for the FLAMINGO variations exhibit a similar level of accuracy as for the largest FLAMINGO simulation (see Appendix D for more details).
 |
Fig. 8. (Top) Galaxy assembly bias of the FLAMINGO simulation (dots points) and the empirical models when fitting to the galaxy clustering and galaxy-galaxy lensing predicted by FLAMINGO. From top to bottom, we show the SHAMe predictions for the DESI BGS-like galaxies, the SHAMe predictions for the BOSS-like galaxies, the HOD predictions for the DESI BGS-like galaxies, and the HOD predictions for the BOSS-like galaxies. The shaded region around the solid line represents the 1-σ prediction region for the empirical models, as is explained in Sect. 3.4. (Bottom) Similar to the top panel, but for the halo occupation number. |
The last statistic we measure is the halo occupation number (bottom panel of Fig. 8). In this case, we almost perfectly reproduce the satellite occupation (massive end of the plot) but struggle to constrain the central occupation for all samples within the shaded region. It is possible that there are some discrepancies in the classification of ‘centrals’ and ‘satellite’ galaxies between the simulations due to the different resolutions and baryonic implementation. The different halo finder algorithms can also affect the central/satellite classification with VELOCIRAPTOR, allowing satellites to be more massive than centrals on some occasions. It is also well documented that the sharpness (width) of the transition from zero to one central per halo is not strongly constrained by galaxy clustering (Zehavi et al. 2011); nevertheless, we were surprised that this difference did not manifest itself in any of the additional clustering statistics we measure in this work. This suggests that both models still have room for improvement. The halo occupation number predictions for the FLAMINGO variations exhibit a similar level of accuracy as for the largest FLAMINGO simulation (see Appendix D for more details).
All in all, while there are some discrepancies between the models and FLAMINGO, they all performed very well. Even the poorest performance, which is arguably the galaxy assembly bias for the HOD, is still, in our opinion, an excellent prediction. Up till now, most constraints to galaxy assembly bias (most of them using HODs) have only limited themselves to predicting if the assembly bias level is consistent with zero. To our knowledge, this is the only proper validation of the HOD predictions of assembly bias using a galaxy formation model where we can measure this signal’s amplitude.
5. Testing the performance of simplified empirical models
In the previous section, we showed the performance of the SHAMe and the HOD models when reproducing galaxy clustering and galaxy-galaxy lensing, as well as their predictions for other high-order statistics. The excellent agreement we achieved for both models was partly due to the different extensions we added over the most basic version of these models, the basic SHAM and the five-parameter HOD described in Sects. 3.1 and 3.2.
We show the predictions for the SHAMe simplified models in Fig. 9. We again only show the predictions when fitting all the statistics simultaneously, but show the value of the χ2 for both fittings (all the statistics and only using the projected correlation function and galaxy-galaxy lensing) in the top panel of Fig. 10. For this empirical model, we notice a significant improvement in performance when including the galaxy assembly bias parameters. We find that having only one assembly bias parameter is not enough to achieve a good performance.
 |
Fig. 9. Galaxy clustering (wp, top left panel; ξℓ = 0, top right panel; ξℓ = 2, lower left panel) and galaxy-galaxy lensing (ΔΣ, lower right panel) for the FLAMINGO simulation (symbols), the fiducial SHAMe model (black lines) and two different variations of the SHAMe model (colour lines). The bottom subpanels show the difference between the empirical models and FLAMINGO, normalised by the error. |
 |
Fig. 10. (Top) χ2 of the fits of the SHAMe model for the DESI BGS-like and BOSS-like samples (left and right panels, respectively) when reproducing simultaneously: the projected correlation function and the galaxy-galaxy lensing signal (wp + ΔΣ, blue bars) and the projected correlation function, the monopole and quadrupole of the correlation function and the galaxy-galaxy lensing signal (wp ξℓ = 0,2 + ΔΣ, orange bars). The bottom bar shows the χ2 for the primary model, and the following bars represent two simplifications of the models by removing either one or both of the galaxy assembly bias parameters. (Bottom) Similar to the upper panel but for the HOD model. |
The statistic that exhibited the most substantial enhancement upon the incorporation of the assembly bias parameter was galaxy-galaxy lensing. The lack of additional assembly bias produces an excess of signal on small scales compared to the target one, which goes in the same direction as the lensing-is-low signal. This finding aligns with the results presented in Contreras et al. (2023b), where we show that assembly bias was key to simultaneously reproducing galaxy clustering and galaxy-galaxy lensing from the galaxies of BOSS. These findings are also consistent with those of Leauthaud et al. (2017), who found that the lensing-is-low problem is also present in a basic SHAM model.
For the HOD, we used nine additional models, including the full model a basic five-parameter HOD, the basic HOD plus incompleteness (six free parameters), the basic HOD plus velocity bias (seven free parameters), the full 13-parameters HOD without incompleteness (12 free parameters), velocity bias (11 free parameters), galaxy assembly bias (11 free parameters), occupancy variation (11 free parameters), galaxy assembly bias and occupancy variation (nine free parameters), and satellite segregation (12 free parameters). We show the predictions of these models in Fig. 11 and the χ2 in the bottom panel of Fig. 10.
For this empirical model, we find that all extensions are necessary, except for the occupancy variation with concentration. We see no significant improvement for any sample or combination of the fitting statistics when we include this extension. This is consistent with the results from Xu et al. (2021), who show that the galaxy assembly bias of galaxy formation models is not well modelled by concentration alone, and Yuan et al. (2022) who show that this extension was not useful to reproduce galaxy clustering. We originally believed this extension could help to reproduce galaxy-galaxy lensing, but we find this is also not the case. Because of this, we shall consider omitting this extension from the next version of GalaxyEmu-Planck.
For the rest of the HOD extensions, satellite segregation was the least important parameter we included, but it still provides an improvement when fitting ξℓ = 0 and ξℓ = 2. Velocity bias appears to be the next least important extension. This extension is expected to be more relevant in samples with a higher number density; that is a larger satellite fraction. We indeed tested fitting only wp, ξℓ = 0, and ξℓ = 2 in the DESI BGS-like sample, finding that velocity bias is fundamental for having a good fit (not shown here). Incompleteness is not necessary for the DESI BGS-like sample, which is expected since this sample is complete. Leaving out this extension for the BOSS-like sample reduces the fit quality significantly. Finally, we found that assembly bias is the most important extension of the HOD model. We see that incompleteness and galaxy assembly bias have a significant impact when attempting to reproduce galaxy-galaxy lensing. Their absence produces an increase in signal for the galaxy-galaxy lensing at small scales, consistent with the lensing-is-low problem. We also notice that more complex galaxy samples, such as the one of BOSS, will present a more significant deviation in their galaxy-galaxy lensing measurement than the one of a complete sample, such as for our DESI BGS-like sample. These results are in agreement with Chaves-Montero et al. (2023), where we predict that these limitations of the basic HOD approach are partially responsible for the model not being able to reproduce galaxy clustering and galaxy-galaxy lensing simultaneously.
6. Summary
In this paper, we investigate the performance of two state-of-the-art galaxy population models, a 13-parameter HOD and the SHAMe model, in reproducing the galaxy clustering (in redshift space), galaxy-galaxy lensing, and five other clustering statistics from the FLAMINGO hydrodynamic simulation. In all cases, the agreement between FLAMINGO and our mocks is excellent. Here, we summarise our most important findings.
-
We built GalaxyEmu-Planck, an emulator capable of reproducing the projected correlation function, the monopole, quadrupole and hexadecapole of the correlation function, the galaxy-galaxy lensing, the k-nearest neighbour cumulative distribution function, the counts-in-cylinder, the void probability function, the galaxy assembly bias and the halo occupation number. This emulator can predict these statistics for SHAMe and HOD mocks, for redshifts between 0 and 0.8 and number densities between 0.0001 h3 Mpc−3 and 0.00316 h3 Mpc−3.
-
We reproduced galaxy clustering in redshift space (wp, ξℓ = 0, and ξℓ = 2) and galaxy-galaxy lensing (ΔΣ) for two different galaxy samples from the largest hydrodynamic run of the FLAMINGO suite of simulations. The samples have a distinct selection function: a DESI BGS-like sample with a number density of 0.001 h3 Mpc−3 complete in the r-band, and the incomplete red BOSS-like sample with a number density of 0.00316 h3 Mpc−3 (Fig. 1). The SHAMe and HOD models perform well for both target samples (Figures 2 and 3). The galaxy-galaxy lensing was only fit to scales above 1 h−1 Mpc to avoid scales impacted by baryonic effects.
-
We also tested the performance of the two empirical models on the FLAMINGO suite of simulations with different astrophysical implementations. While the clustering measurements were different between the simulations, the models were able to fit them equally well for all cases (Figures 4 and 5).
-
We tested the ability of the empirical models to reproduce the other statistics predicted by FLAMINGO when fitting only to the galaxy clustering and galaxy-galaxy lensing predictions, finding excellent agreement for most cases. In this case, the results look slightly better for the SHAMe model. The differences between the models and FLAMINGO are largest for the low-end part of the halo occupation number (which is usually poorly constrained by galaxy clustering) and for the galaxy assembly bias in the case of the HOD model (Figures 6, 7 and 8).
-
The empirical models used in this study include several extensions beyond their more conventional implementations. We explore the effects of these extensions when reproducing galaxy clustering and galaxy-galaxy lensing. We find that, for both models, incorporating galaxy assembly bias is critical for accurately reproducing galaxy clustering and galaxy-galaxy lensing. Using one galaxy assembly bias parameter instead of two yields comparable performance for the SHAMe model. For the HOD model, we found that all extensions were useful to better reproduce galaxy clustering and galaxy-galaxy lensing, except for the occupancy variation with concentration (Figures 9 and 11).
-
An excess of the galaxy-galaxy lensing signal by empirical models on BOSS has been reported when using basic empirical models. The extensions to the empirical models are very effective at reducing the amplitude of the galaxy-galaxy lensing signal on small scales. This effect is especially noticeable in the BOSS-like sample with the HOD model. The additional assembly bias for both empirical models and the incompleteness for the HOD model were found to be the most effective extensions for decreasing the difference with the target lensing signal.
The empirical models we used in this work used dark matter-only simulations, which lack of the complexity of a hydrodynamic simulation as FLAMINGO. These mocks are fast, taking only a fraction of the time required to run a hydrodynamic simulation or a semi-analytical model, and are entirely based on our understanding of the galaxy-halo connection. The excellent performance achieved by both empirical models validates them as suitable methods for reproducing any of the statistics measured in this study. We tested these models for samples with very different and distinct selection functions, and we also tested our main results in a suite of hydrodynamic simulations with various astrophysical implementations, demonstrating that our results are robust to uncertainties in the simulation predictions.
Although the agreement between the spatial distribution of our mocks and that of FLAMINGO is excellent, we observe that both models still have room for improvement. Fig. 10 shows that the SHAMe model performed less well than the HOD model, particularly when fitting the multipoles of the correlation function. This means that better modelling of galaxies’ velocity or adding a velocity bias parameter may be able to improve these results even further. On the other hand, the additional flexibility of the HOD may create models with some unphysical characteristics, such as a larger amount of assembly bias. We believe the additional assembly bias found in the HOD mocks may have caused performance issues when reproducing the kNN-CDF, counts-in-cylinder, and the void probability function. These discrepancies can potentially be reduced by incorporating them into the fitting process, which could eventually improve the constraints on galaxy assembly bias. The predictions of these simplified models on galaxy-galaxy lensing confirm the finding of Chaves-Montero et al. (2023) that part, if not all, of the origin of the lensing-is-low problem is caused by limitations in the galaxy modelling.
The findings in this paper provide proof of the accuracy of both empirical models. We intend to expand the reach of GalaxyEmu-Planck through scaled simulations (Angulo & White 2010), following the procedure of Contreras et al. (2023a). In this approach, we can change not only the mock describing the galaxy-halo connection but also the cosmological parameters. This method will allow us to derive cosmological constraints (as well as assembly bias constraints) from galaxy clustering measurements. The validations provided by this work will allow us to test the additional cosmological constraints from the kNN-CDF, counts-in-cylinder, and void probability function. This work also validates the models’ clustering predictions on scales spanning three orders of magnitude, which we anticipate will provide additional cosmological information. We are especially enthusiastic regarding the potential of the SHAMe model. When combined with the scaling technique, its performance across all galaxy samples and statistics with only five free parameters could result in tighter cosmological constraints.
We want to emphasise that the conclusions of this work are only valid for the specific mock empirical models used here. We cannot guarantee that other SHAM and HOD model extensions will perform similarly well. In particular, we find that the performance of the models strongly depends on the environmental property used to mimic the assembly bias signal. We tested a more basic environmental property on both models before, finding that, while the SHAMe approach produced similar results, the HOD model was not able to simultaneously reproduce the galaxy clustering and galaxy-galaxy lensing predictions, finding a lensing-is-low like effect for the BOSS-like sample. We highly encourage the performance of basic tests on any empirical model before using them on an observational sample. This basic test includes checking its performance with a complex galaxy population model, such as a semi-analytical model or hydrodynamic simulations.
ΩM = 0.3089, Ωb = 0.0486, σ8 = 0.8159, ns = 0.9667 and h = 0.6774.
Acknowledgments
We thank Tom Abel and Eduardo Rozo for useful comments and suggestions. SC acknowledges the support of the ‘Juan de la Cierva Incorporacíon’ fellowship (IJC2020-045705-I). REA and SC acknowledge support under the grant number PID2021-128338NB-I00 from the Spanish Ministry of Science and support from the European Research Executive Agency HORIZON-MSCA-2021-SE-01 Research and Innovation programme under the Marie Skłodowska-Curie grant agreement number 101086388 (LACEGAL). REA and JCM acknowledge support from the ERC-StG number 716151 (BACCO). REA from the Project of Excellence Prometeo/2020/085 from the Conselleria d’Innovació, Universitats, Ciència i Societat Digital de la Generalitat Valenciana and JCM from the European Union’s Horizon Europe research and innovation programme (COSMO-LYA, grant agreement 101044612). IFAE is partially funded by the CERCA program of the Generalitat de Catalunya. RK from the research programme Athena 184.034.002 from the Dutch Research Council (NWO). The authors also acknowledge the computer resources at MareNostrum and the technical support provided by Barcelona Supercomputing Center (RES-AECT-2019-2-0012 and RES-AECT-2020-3-0014) Technical and human support provided by DIPC Supercomputing Center is gratefully acknowledged. This work used the DiRAC@Durham facility managed by the Institute for Computational Cosmology on behalf of the STFC DiRAC HPC Facility (www.dirac.ac.uk). The equipment was funded by BEIS capital funding via STFC capital grants ST/K00042X/1, ST/P002293/1, ST/R002371/1 and ST/S002502/1, Durham University and STFC operations grant ST/R000832/1. DiRAC is part of the National e-Infrastructure.
References
- Abadi, M., Agarwal, A., Barham, P., et al. 2016, arXiv e-prints [arXiv:1603.04467] [Google Scholar]
- Angulo, R. E., & Pontzen, A. 2016, MNRAS, 462, L1 [NASA ADS] [CrossRef] [Google Scholar]
- Angulo, R. E., & White, S. D. M. 2010, MNRAS, 405, 143 [NASA ADS] [Google Scholar]
- Angulo, R. E., Springel, V., White, S. D. M., et al. 2012, MNRAS, 426, 2046 [NASA ADS] [CrossRef] [Google Scholar]
- Angulo, R. E., Zennaro, M., Contreras, S., et al. 2021, MNRAS, 507, 5869 [NASA ADS] [CrossRef] [Google Scholar]
- Aricò, G., Angulo, R. E., Hernández-Monteagudo, C., Contreras, S., & Zennaro, M. 2021a, MNRAS, 503, 3596 [Google Scholar]
- Aricò, G., Angulo, R. E., Contreras, S., et al. 2021b, MNRAS, 506, 4070 [CrossRef] [Google Scholar]
- Banerjee, A., & Abel, T. 2021, MNRAS, 500, 5479 [Google Scholar]
- Behroozi, P., Wechsler, R. H., Hearin, A. P., & Conroy, C. 2019, MNRAS, 488, 3143 [NASA ADS] [CrossRef] [Google Scholar]
- Benson, A. J., Cole, S., Frenk, C. S., Baugh, C. M., & Lacey, C. G. 2000, MNRAS, 311, 793 [NASA ADS] [CrossRef] [Google Scholar]
- Berlind, A. A., & Weinberg, D. H. 2002, ApJ, 575, 587 [Google Scholar]
- Berlind, A. A., Weinberg, D. H., Benson, A. J., et al. 2003, ApJ, 593, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Binney, J., & Tremaine, S. 1987, Galactic Dynamics (Princeton, NJ: Princeton University Press), 747 [Google Scholar]
- Booth, C. M., & Schaye, J. 2009, MNRAS, 398, 53 [Google Scholar]
- Borrow, J., Schaller, M., Bower, R. G., & Schaye, J. 2022, MNRAS, 511, 2367 [NASA ADS] [CrossRef] [Google Scholar]
- Braspenning, J., Schaye, J., Schaller, M., et al. 2024, MNRAS, 533, 2656 [NASA ADS] [CrossRef] [Google Scholar]
- Broxterman, J. C., Schaller, M., Schaye, J., et al. 2024, MNRAS, 529, 2309 [NASA ADS] [CrossRef] [Google Scholar]
- Cacciato, M., van den Bosch, F. C., More, S., Mo, H., & Yang, X. 2013, MNRAS, 430, 767 [Google Scholar]
- Chaves-Montero, J., Angulo, R. E., Schaye, J., et al. 2016, MNRAS, 460, 3100 [NASA ADS] [CrossRef] [Google Scholar]
- Chaves-Montero, J., Angulo, R. E., & Contreras, S. 2023, MNRAS, 521, 937 [Google Scholar]
- Conroy, C., Wechsler, R. H., & Kravtsov, A. V. 2006, ApJ, 647, 201 [Google Scholar]
- Contreras, S., Baugh, C. M., Norberg, P., & Padilla, N. 2013, MNRAS, 432, 2717 [Google Scholar]
- Contreras, S., Baugh, C. M., Norberg, P., & Padilla, N. 2015, MNRAS, 452, 1861 [CrossRef] [Google Scholar]
- Contreras, S., Zehavi, I., Baugh, C. M., Padilla, N., & Norberg, P. 2017, MNRAS, 465, 2833 [NASA ADS] [CrossRef] [Google Scholar]
- Contreras, S., Zehavi, I., Padilla, N., et al. 2019, MNRAS, 484, 1133 [NASA ADS] [CrossRef] [Google Scholar]
- Contreras, S., Angulo, R. E., Zennaro, M., Aricò, G., & Pellejero-Ibañez, M. 2020, MNRAS, 499, 4905 [Google Scholar]
- Contreras, S., Angulo, R. E., & Zennaro, M. 2021a, MNRAS, 504, 5205 [CrossRef] [Google Scholar]
- Contreras, S., Angulo, R. E., & Zennaro, M. 2021b, MNRAS, 508, 175 [NASA ADS] [CrossRef] [Google Scholar]
- Contreras, S., Chaves-Montero, J., Zennaro, M., & Angulo, R. E. 2021c, MNRAS, 507, 3412 [NASA ADS] [CrossRef] [Google Scholar]
- Contreras, S., Angulo, R. E., Springel, V., et al. 2023a, MNRAS, 524, 2489 [NASA ADS] [CrossRef] [Google Scholar]
- Contreras, S., Chaves-Montero, J., & Angulo, R. E. 2023b, MNRAS, 525, 3149 [NASA ADS] [CrossRef] [Google Scholar]
- Croton, D. J., Gao, L., & White, S. D. M. 2007, MNRAS, 374, 1303 [Google Scholar]
- Croton, D. J., Stevens, A. R. H., Tonini, C., et al. 2016, ApJS, 222, 22 [Google Scholar]
- Davé, R., Anglés-Alcázar, D., Narayanan, D., et al. 2019, MNRAS, 486, 2827 [Google Scholar]
- Davis, M., Efstathiou, G., Frenk, C. S., & White, S. D. M. 1985, ApJ, 292, 371 [Google Scholar]
- Dawson, K. S., Schlegel, D. J., Ahn, C. P., et al. 2013, AJ, 145, 10 [Google Scholar]
- Dragomir, R., Rodríguez-Puebla, A., Primack, J. R., & Lee, C. T. 2018, MNRAS, 476, 741 [NASA ADS] [CrossRef] [Google Scholar]
- Dubois, Y., Pichon, C., Welker, C., et al. 2014, MNRAS, 444, 1453 [Google Scholar]
- Elahi, P. J., Cañas, R., Poulton, R. J. J., et al. 2019, PASA, 36, e021 [NASA ADS] [CrossRef] [Google Scholar]
- Elbers, W., Frenk, C. S., Jenkins, A., et al. 2024, MNRAS, submitted [arXiv:2403.12967] [Google Scholar]
- Favole, G., Montero-Dorta, A. D., Artale, M. C., et al. 2022, MNRAS, 509, 1614 [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Grieb, J. N., Sánchez, A. G., Salazar-Albornoz, S., & Dalla Vecchia, C. 2016, MNRAS, 457, 1577 [NASA ADS] [CrossRef] [Google Scholar]
- Guo, H., Zheng, Z., Zehavi, I., et al. 2015a, MNRAS, 446, 578 [NASA ADS] [CrossRef] [Google Scholar]
- Guo, H., Zheng, Z., Zehavi, I., et al. 2015b, MNRAS, 453, 4368 [Google Scholar]
- Guo, H., Zheng, Z., Behroozi, P. S., et al. 2016, MNRAS, 459, 3040 [NASA ADS] [CrossRef] [Google Scholar]
- Hadzhiyska, B., Bose, S., Eisenstein, D., & Hernquist, L. 2021, MNRAS, 501, 1603 [Google Scholar]
- Hahn, C., Wilson, M. J., Ruiz-Macias, O., et al. 2023, AJ, 165, 253 [CrossRef] [Google Scholar]
- Hearin, A. P., Zentner, A. R., van den Bosch, F. C., Campbell, D., & Tollerud, E. 2016, MNRAS, 460, 2552 [NASA ADS] [CrossRef] [Google Scholar]
- Hearin, A. P., Campbell, D., Tollerud, E., et al. 2017, AJ, 154, 190 [Google Scholar]
- Henriques, B. M. B., Yates, R. M., Fu, J., et al. 2020, MNRAS, 491, 5795 [NASA ADS] [CrossRef] [Google Scholar]
- Huško, F., Lacey, C. G., Schaye, J., Nobels, F. S. J., & Schaller, M. 2024, MNRAS, 527, 5988 [Google Scholar]
- Jiménez, E., Contreras, S., Padilla, N., et al. 2019, MNRAS, 490, 3532 [CrossRef] [Google Scholar]
- Jing, Y. P., Mo, H. J., & Börner, G. 1998, ApJ, 494, 1 [NASA ADS] [CrossRef] [Google Scholar]
- Kugel, R., Schaye, J., Schaller, M., et al. 2023, MNRAS, 526, 6103 [NASA ADS] [CrossRef] [Google Scholar]
- Lagos, C. D. P., Tobar, R. J., Robotham, A. S. G., et al. 2018, MNRAS, 481, 3573 [CrossRef] [Google Scholar]
- Leauthaud, A., Saito, S., Hilbert, S., et al. 2017, MNRAS, 467, 3024 [Google Scholar]
- Lehmann, B. V., Mao, Y.-Y., Becker, M. R., Skillman, S. W., & Wechsler, R. H. 2017, ApJ, 834, 37 [NASA ADS] [CrossRef] [Google Scholar]
- McCarthy, I. G., Bird, S., Schaye, J., et al. 2018, MNRAS, 476, 2999 [NASA ADS] [CrossRef] [Google Scholar]
- McCarthy, I. G., Salcido, J., Schaye, J., et al. 2023, MNRAS, 526, 5494 [NASA ADS] [CrossRef] [Google Scholar]
- McCullagh, N., Norberg, P., Cole, S., et al. 2017, arXiv e-prints [arXiv:1705.01988] [Google Scholar]
- Miyatake, H., Sugiyama, S., Takada, M., et al. 2022, Phys. Rev. D, 106, 083520 [NASA ADS] [CrossRef] [Google Scholar]
- More, S., Miyatake, H., Mandelbaum, R., et al. 2015, ApJ, 806, 2 [CrossRef] [Google Scholar]
- Moster, B. P., Naab, T., & White, S. D. M. 2018, MNRAS, 477, 1822 [Google Scholar]
- Norberg, P., Frenk, C. S., & Cole, S. 2008, MNRAS, 383, 646 [NASA ADS] [CrossRef] [Google Scholar]
- Orsi, Á. A., & Angulo, R. E. 2018, MNRAS, 475, 2530 [NASA ADS] [CrossRef] [Google Scholar]
- Pakmor, R., Springel, V., Coles, J. P., et al. 2023, MNRAS, 524, 2539 [NASA ADS] [CrossRef] [Google Scholar]
- Paranjape, A., Hahn, O., & Sheth, R. K. 2018, MNRAS, 476, 3631 [NASA ADS] [CrossRef] [Google Scholar]
- Paviot, R., Rocher, A., Codis, S., et al. 2024, arXiv e-prints [arXiv:2402.07715] [Google Scholar]
- Peacock, J. A., & Smith, R. E. 2000, MNRAS, 318, 1144 [Google Scholar]
- Pellejero Ibañez, M., Angulo, R. E., Zennaro, M., et al. 2023, MNRAS, 520, 3725 [Google Scholar]
- Perez, L. A., Genel, S., Villaescusa-Navarro, F., et al. 2023, ApJ, 954, 11 [NASA ADS] [CrossRef] [Google Scholar]
- Reddick, R. M., Wechsler, R. H., Tinker, J. L., & Behroozi, P. S. 2013, ApJ, 771, 30 [Google Scholar]
- Salcedo, A. N., Zu, Y., Zhang, Y., et al. 2022, Sci. China: Phys. Mech. Astron., 65, 109811 [NASA ADS] [CrossRef] [Google Scholar]
- Schaller, M., Borrow, J., Draper, P. W., et al. 2024, MNRAS, 530, 2378 [NASA ADS] [CrossRef] [Google Scholar]
- Schaye, J., Crain, R. A., Bower, R. G., et al. 2015, MNRAS, 446, 521 [Google Scholar]
- Schaye, J., Kugel, R., Schaller, M., et al. 2023, MNRAS, 526, 4978 [NASA ADS] [CrossRef] [Google Scholar]
- Sinha, M. 2016, https://doi.org/10.5281/zenodo.55161 [Google Scholar]
- Sinha, M., & Garrison, L. 2017, Astrophysics Source Code Library [record ascl:1703.003] [Google Scholar]
- Springel, V., White, S. D. M., Tormen, G., & Kauffmann, G. 2001, MNRAS, 328, 726 [Google Scholar]
- Springel, V., White, S. D. M., Jenkins, A., et al. 2005, Nature, 435, 629 [Google Scholar]
- Springel, V., Pakmor, R., Pillepich, A., et al. 2018, MNRAS, 475, 676 [Google Scholar]
- Stevens, A. R. H., Lagos, C. D. P., Obreschkow, D., & Sinha, M., 2018, MNRAS, 481, 5543 [NASA ADS] [CrossRef] [Google Scholar]
- Vale, A., & Ostriker, J. P. 2006, MNRAS, 371, 1173 [NASA ADS] [CrossRef] [Google Scholar]
- van Daalen, M. P., Schaye, J., McCarthy, I. G., Booth, C. M., & Dalla Vecchia, C. 2014, MNRAS, 440, 2997 [NASA ADS] [CrossRef] [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nat. Methods, 17, 261 [Google Scholar]
- Vogelsberger, M., Genel, S., Springel, V., et al. 2014, MNRAS, 444, 1518 [Google Scholar]
- Xu, X., Zehavi, I., & Contreras, S. 2021, MNRAS, 502, 3242 [NASA ADS] [CrossRef] [Google Scholar]
- Yuan, S., Eisenstein, D. J., & Garrison, L. H. 2018, MNRAS, 478, 2019 [NASA ADS] [CrossRef] [Google Scholar]
- Yuan, S., Garrison, L. H., Hadzhiyska, B., Bose, S., & Eisenstein, D. J. 2022, MNRAS, 510, 3301 [NASA ADS] [CrossRef] [Google Scholar]
- Zehavi, I., Blanton, M. R., Frieman, J. A., et al. 2002, ApJ, 571, 172 [NASA ADS] [CrossRef] [Google Scholar]
- Zehavi, I., Zheng, Z., Weinberg, D. H., et al. 2005, ApJ, 630, 1 [Google Scholar]
- Zehavi, I., Zheng, Z., Weinberg, D. H., et al. 2011, ApJ, 736, 59 [NASA ADS] [CrossRef] [Google Scholar]
- Zehavi, I., Contreras, S., Padilla, N., et al. 2018, ApJ, 853, 84 [NASA ADS] [CrossRef] [Google Scholar]
- Zennaro, M., Angulo, R. E., Pellejero-Ibáñez, M., et al. 2023, MNRAS, 524, 2407 [Google Scholar]
- Zhai, Z., Tinker, J. L., Becker, M. R., et al. 2019, ApJ, 874, 95 [CrossRef] [Google Scholar]
- Zhai, Z., Tinker, J. L., Banerjee, A., et al. 2023, ApJ, 948, 99 [NASA ADS] [CrossRef] [Google Scholar]
- Zheng, Z., Berlind, A. A., Weinberg, D. H., et al. 2005, ApJ, 633, 791 [NASA ADS] [CrossRef] [Google Scholar]
- Zheng, Z., Coil, A. L., & Zehavi, I. 2007, ApJ, 667, 760 [Google Scholar]
Appendix A: HOD extensions
This section gives a detailed description of the HOD model used in this work. As was mentioned in Sect. 3.2, we used the parametric form of Zheng et al. (2005) and the HOD-extensions listed in Yuan et al. (2022), plus some extra modifications we specify in the main text. Following Zheng et al., we decompose the halo occupation into the contribution of centrals (Ncen) and satellite galaxies (Nsat). We defined the average halo occupation as a function of halo mass (⟨N(Mh)⟩) as the sum of the average central occupation and the average satellite occupation:
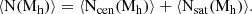 (A.1)
(A.1)
The central occupation is described as
![Mathematical equation: $$ \begin{aligned} \langle N_{\rm cen}(M_{\rm h})\rangle = \frac{1}{2}\left[ 1 + \mathrm{erf} \left( \frac{\log M_{\rm h} - \log M_{\rm min}}{\sigma _{\log M}} \right) \right], \end{aligned} $$](/articles/aa/full_html/2024/10/aa51671-24/aa51671-24-eq19.gif) (A.2)
(A.2)
with erf(x) is the error function,
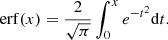 (A.3)
(A.3)
The parameter Mmin is the halo mass where half of the haloes are occupied by a central galaxy (i.e. ⟨Ncen(Mmin)⟩ = 0.5) and σlogM characterise the sharpness (width) of the transition from zero to one central per halo and is linked to the scatter between the galaxy properties (e.g. luminosity, stellar mass, etc) to the host halo mass. The satellite occupation is described as
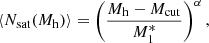 (A.4)
(A.4)
with Mh > Mcut, representing a power-law shape with a smooth cutoff at low halo masses; M1 − Mcut ≡ M1* is the mass where there is on average one satellite galaxy per halo (⟨Nsat(M1)⟩ = 1) and α is the slope between the ⟨Nsat⟩−Mh relation, and it has a value of ≈1.
By going through all the haloes of a dark matter simulation and populating these haloes with an average of ⟨Ncen(Mh)⟩ centrals and ⟨Nsat(Mh)⟩ satellites, a mock galaxy catalogue can be built in a matter of minutes, if not seconds. The probability of putting a central and satellite galaxy follows a nearest-integer distribution and a Poissonian distribution, respectively. Although some deviations from a Poissonian distribution have been detected in recent works, their impact on galaxy clustering is not expected to be significant (Jiménez et al. 2019) but could modify galaxy-galaxy lensing on sub-megaparsec scales (Chaves-Montero et al. 2023). These scales, however, were not used during the fitting process of the galaxy-galaxy lensing in this paper. In its most basic form, central galaxies are placed in the centre of the potential of the dark matter haloes, whether the satellite galaxies are either assigned to the position of a random particle of their host halo or distributed following an NFW profile.
We now list the extensions we implement over the basic HOD model.
A.1. Satellite segregation
Selection effects significantly impact the distribution of satellite galaxies within haloes. Redder galaxies tend to follow the density profile of haloes, while blue galaxies tend to accumulate in their outskirts (Orsi & Angulo 2018). Other physical processes, such as baryonic effects, will also impact the satellite distribution (e.g. van Daalen et al. 2014).
We assign the position and velocities of satellite galaxies using the dark matter particles of the halo. To select the particles for each galaxy, we follow Yuan et al. (2022). In this approach, particles are first ranked by their distance to their halo centre. The ranking of each particle, ri, will be 0 for the particle closest to the halo centre and Np −1 for the farthest particle (for a halo with Np particles). The probability of a particle ‘i’ hosting a galaxy is then described as:
![Mathematical equation: $$ \begin{aligned} p_{i} = \frac{\mathrm{N}_{\rm sat}}{\mathrm{N}_{\rm p}} \left[1+ {\mathrm{s}_{\rm segr.}}\left(1-\frac{2 r_i}{\mathrm{N}_{\mathrm{p}} - 1}\right)\right] \end{aligned} $$](/articles/aa/full_html/2024/10/aa51671-24/aa51671-24-eq22.gif) (A.5)
(A.5)
with Nsat the number of satellite galaxies of a halo and ssegr. a free parameter that can have a value within the range -1 to 1, with ‘-1’ meaning that all galaxies are close to the halo centre, zero meaning the particles will be randomly chosen, and ‘1’ that all galaxies will be in the outskirts of the haloes.
A.2. Velocity bias
In addition to the positions, galaxy velocities are also not expected to be identical to the velocities of dark matter particles or the velocity of their host dark matter halo. Following Guo et al. (2015b,a), we apply a correction to the velocities of centrals and satellite galaxies. For central galaxies, where the velocity is assumed to be equal to the velocity of the dark matter halo (vh), we add a Gaussian scatter equal to the linear velocity dispersion (i.e. σvel) of the halo modulated by a free parameter, αc:
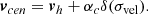 (A.6)
(A.6)
For the satellite galaxies, we modulate the relative velocity of the assigned dark matter particle to its host dark matter halo (vdm.part.) by the free parameter αs:
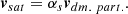 (A.7)
(A.7)
While these modifications will not change the positions of galaxies and will have a low to null impact on the projected correlation function (when integrated over a long range along the line of sight) or galaxy-galaxy lensing, they will impact other statistics more susceptible to redshift space distortion effects, such as the multipoles of the correlation function.
A.3. Galaxy assembly bias and occupancy variation
Unlike a SHAM-like model, the basic HOD does not include galaxy assembly bias or occupancy variation since the occupation number depends only on halo mass. We add additional dependences on concentration and environment following Xu et al. (2021). This approach consists of having variable values of Mmin and M1 as a function of secondary halo properties. As with the SHAMe model, we use the individual bias-per-object (Paranjape et al. 2018) to characterise the large-scale environment and add an additional bias to the sample that will behave as galaxy assembly bias. We also add an additional dependence on concentration, mainly for historical reasons, since this was the most common way to add assembly bias until a few years ago (Hearin et al. 2016), but later works have shown it does not add a significant amount. Since the dependence on concentration impacts the internal distribution of the satellite galaxies (by preferentially choosing more/less concentrated haloes) rather than assembly bias, we refer to this effect as occupancy variation.
The modified values of M1 and Mmin, called M1mod and Mminmod, are then computed using the ranking of the individual bias-per-object (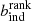 ) and the halo concentration (crank) of haloes of similar mass (bins of 0.1 dex in halo mass). The resulting values for these parameters are:
) and the halo concentration (crank) of haloes of similar mass (bins of 0.1 dex in halo mass). The resulting values for these parameters are:
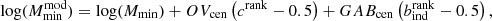 (A.8)
(A.8)
 (A.9)
(A.9)
with OVcen and OVsat the occupational variation-free parameters for the central and satellite galaxies (called Acent and Asat in Yuan et al. 2022) and GABcen and GABsat the occupational variation free parameters for the central and satellite galaxies (called Bcent and Bsast in Yuan et al. 2022).
A.4. Incompleteness
The last extension we include in our HOD model is incompleteness. Due to several observational limitations, the target galaxy samples may not be complete, meaning that a fraction of the galaxies expected from a given selection will not become part of the final sample. To account for this limitation, we randomly remove a fraction of all galaxies (fic) in bins of halo mass:
 (A.10)
(A.10)
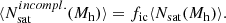 (A.11)
(A.11)
Since we assumed that the mean number of galaxies is equal to the sum of the mean number of centrals and satellites (⟨Ntot⟩=⟨Ncen⟩+⟨Nsat⟩) we need to apply this parameter on the centrals and satellites separately. This is different from other approaches, such as the one of Yuan et al. (2022), which assumed (⟨Ntot⟩=⟨Ncen⟩(1 + ⟨Nsat⟩) and therefore only need to apply this factor to the central galaxies.
Appendix B: Baryonic effects
The effect of baryons on the density profile of haloes impacts galaxy-galaxy lensing, especially at smaller scales. To determine which distances are safe to use in dark matter-only simulations, we estimate the amplitude of the galaxy-galaxy lensing signal with and without baryonic effects. We estimate the lensing signal without baryonic effects by doing a cross-match of the galaxies in the two galaxy samples of FLAMINGO with the subhaloes of the dark-matter-only version of this hydrodynamic simulation. This N-body simulation has the same cosmology, output redshift, and initial conditions as the original FLAMINGO, which allowed us to find the equivalent haloes without the impact of baryonic physics. We look at the corresponding best match bi-directionally, meaning looking at the corresponding pair from one sample to the next and the other way around. We only admit pairs that have a single match and that are consistent regardless of the direction of the matching process. We find a clean match for 95.6% of the galaxies of the DESI BGS-like sample and 98.5% for the BOSS-like sample. The galaxy-galaxy lensing for the matched samples of FLAMINGO and the subhaloes of the dark matter-only simulation (DMO) are shown in Fig. A.1. We find that a cut of 1 h−1 Mpc ensures that for all the points the impact of the baryonic effect is less than half the size of our error bars.
 |
Fig. A.1. Galaxy-galaxy lensing signal for the galaxies of FLAMINGO (symbols) and for their matched subhaloes in a dark matter-only simulation (lines). The dashed vertical line indicates the lower limit where we fit the lensing signal with the empirical models. |
Appendix C: Compressing the high-order statistics
In this section, we describe the parametrisations done to the high-order statistics to simplify their training in our emulator described in Sect. 3.5. We characterise most properties using a cumulative skew-normal distribution:
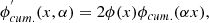 (C.1)
(C.1)
where ϕ is a normal function, ϕcum. the cumulative function of a normal distribution and α the parameter that controls how skewed the distribution is. We also tried other more sophisticated fits, including adding kurtosis to the distribution, but we did not find any significant improvements. The way we represent each of these statistics is as follows:
k-nearest neighbour
To describe the kNN-CDF, we used a cumulative skew normal distribution modulated by an additional free parameter:
![Mathematical equation: $$ \begin{aligned} \mathrm{P(N_{kNN},r)} = \delta \left[1-\phi ^{^{\prime }}_{\rm cum.}\left(\dfrac{\mathrm{r}-\beta }{\gamma },\alpha \right)\right] \end{aligned} $$](/articles/aa/full_html/2024/10/aa51671-24/aa51671-24-eq31.gif) (C.2)
(C.2)
with α, β, γ, & δ free parameters of the model. To better capture the cross-correlation for different NkNN, we train the emulators using the fitting parameters for all k’s. We fit 20 parameters per galaxy sample, similar to the number of bins trained on the projected correlation function or in the multipoles of the correlation function.
Counts-in-cylinders
To describe the counts-in-cylinder, we again use a cumulative skew normal distribution (without any modulation):
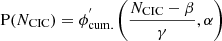 (C.3)
(C.3)
with α, β, & γ free parameters. As with the kNN-CDF, we simultaneously trained the counts-in-cylinders for all the radii we trained (for a total of 15 free parameters per galaxy sample).
Void Probability Function
To represent the void probability function, we use the differential version of the skew-normal distribution (ϕ′), forcing a value of one for a radius equal to zero. We characterise this distribution as
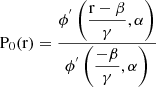 (C.4)
(C.4)
with α, β & γ free parameters of the model.
Galaxy assembly bias
The galaxy assembly bias (ξ/ξshuffled) is described as a smooth transition from one (since by construction, the internal distribution of galaxies is preserved during the shuffling, see Sect. 3.3 for more details) to a value equal to the square root of the additional bias signal. Since we mostly care about the amplitude of this ratio at large distances, we fit the galaxy assembly bias signal in a way that we can extract that value directly from the parameters. We therefore characterise this signal as
![Mathematical equation: $$ \begin{aligned} {\xi (r)/\xi _{\rm shuffled}(r)} = 0.5\left(b^{1/2}_{\rm gab}-1\right)\left[\mathrm{erf}\left(\dfrac{r-\alpha }{\beta }\right) + 1\right]+1 \end{aligned} $$](/articles/aa/full_html/2024/10/aa51671-24/aa51671-24-eq34.gif) (C.5)
(C.5)
with erf(x) the error function described in Appendix A, α & β free parameters of the model, and  a free parameter equal to the square root of the additional bias of the sample.
a free parameter equal to the square root of the additional bias of the sample.
Halo occupation number
To describe the halo occupation number, we used the standard parametrisation of satellite galaxies (equ. A.4) and an extension of equ. A.2 for central galaxies, plus the inclusion of the incompleteness parameter fic. We extend over the standard parametrisation of centrals since the SHAMe mocks were not perfectly represented by the current parametrisation (something that has already been observed for semi-analytical models McCullagh et al. 2017 and hydrodynamic simulations Chaves-Montero et al. 2023). We, therefore, replace the error function that describes the transition from zero to one galaxy per halo with a cumulative skew-normal distribution,
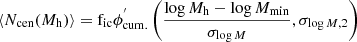 (C.6)
(C.6)
with fic, Mmin, σlog M and σlog M, 2 free parameters (the last one being the level of skewness). While we obtained better fits with this parametrisation, we warn the reader about using it to populate mocks when constraining galaxy clustering. The constraining power on the transition from zero to one galaxy per halo is poor (Zehavi et al. 2011) since it has a really low impact on the bias of the sample, and therefore, we do not think this additional complication will benefit constraint better the occupation number from an observational sample.
Appendix D: Additional predictions for the FLAMINGO physical variations
Different from the rest of the clustering statistics we looked at in this paper, the halo occupation number and the galaxy assembly bias provide a more physical view of the empirical models. In this section, we look into the predictions for these two statistics when fitting only to the galaxy clustering (projected correlation function and multipoles of the correlation function) and galaxy-galaxy lensing for the FLAMINGO physical variations. We show these predictions in Fig. D.1 for the SHAMe model and in Fig. D.2 for the HOD model. In the case of the halo occupation number, both empirical models recover this statistic reasonably well, especially for the satellite occupation. These results are consistent with our constraints to the largest FLAMINGO simulation. For the galaxy assembly bias, the constraints in the SHAMe model are more accurate than for the HOD model, where the value is overestimated in all cases but with an overall good performance in both cases.
For the galaxy assembly bias predictions, we notice its amplitude depends on the physical model of the simulation. This result is consistent with Contreras et al. (2021c), where we found that this amplitude does not depend on cosmology but rather the galaxy formation physics of the model. The good performance of SHAMe, even when fitting models with really low galaxy assembly bias (such as the ‘Jet’ physical model), suggests that it can be successfully used to constrain galaxy assembly bias from the galaxy clustering of the real Universe.
 |
Fig. D.1. Similar to Fig. 8, but for the FLAMINGO suite of simulations with different astrophysical implementations and the SHAMe model. |
 |
Fig. D.2. Similar to Fig. 8, but for the FLAMINGO suite of simulations with different astrophysical implementations and the HOD model. |
All Tables
All Figures
|
Fig. 1. Stellar mass function of the FLAMINGO simulation at z = 0.4. The solid black line represents all the galaxies from the simulation, while the blue and red lines represent the galaxies from the DESI BGS-like and BOSS-like samples. As is explained in Sect. 2.2, the DESI BGS-like sample is complete in Mr with a number density of 10−3h3 Mpc−3, while the BOSS-like sample is incomplete and red with a number density of 10−3.5h3 Mpc−3. |
| In the text | |
|
Fig. 2. Galaxy clustering (wp, top left panel; ξℓ = 0, top right panel; ξℓ = 2, lower left panel) and galaxy-galaxy lensing (ΔΣ, lower right panel) for the FLAMINGO simulation (symbols) and the SHAMe model (lines). The results for the BOSS-like sample, shown in red, are displaced along the y axis for clarity. The different line styles represent the statistics used to fit FLAMINGO. The solid line corresponds to the best-fitting model when fitting to the projected correlation function, the monopole and quadrupole of the correlation function, and the galaxy-galaxy lensing. The dotted line corresponds to the best-fitting model when fitting only to the projected correlation function and the galaxy-galaxy lensing. The bottom subpanels show the difference between the empirical model and FLAMINGO, normalised by the error in each point. The fits are performed for all scales shown for the galaxy clustering statistics and for scales above 1 h−1 Mpc for galaxy-galaxy lensing (denoted by a vertical line in the bottom right panel) to avoid baryonic effects. |
| In the text | |
 |
Fig. 3. Similar to Fig. 2, but for the HOD model. |
| In the text | |
|
Fig. 4. Galaxy clustering (wp, top left panel; ξℓ = 0, top right panel; ξℓ = 2, lower left panel) and galaxy-galaxy lensing (ΔΣ, lower right panel) for the FLAMINGO suite of simulations with different astrophysical implementations (symbols) and the SHAMe model (lines). The different colours represent the various astrophysical implementations, as labelled. All samples are displaced along the y axis for clarity. Only the results from the DESI BGS-like sample are shown in the plot. The middle subpanel shows the difference between the empirical model and FLAMINGO, normalised by the error. The bottom subpanel shows the difference between theFLAMINGO model variations and the fiducial FLAMINGO model. The fits are performed for all scales shown for the galaxy clustering statistics and for scales above 1 h−1 Mpc for galaxy-galaxy lensing. |
| In the text | |
 |
Fig. 5. Similar to Fig. 4, but for the HOD model. |
| In the text | |
|
Fig. 6. k-nearest neighbour cumulative distribution functions (kNN-CDF, left panel), count-in-cylinder (CIC, middle panel), and void probability function (VPF, right panel) of the FLAMINGO simulation (symbols) and the SHAMe model (lines). The results for BOSS-like, shown in red, are displaced along the y axis to facilitate the comparison. The different line styles represent the statistics used to fit FLAMINGO as labelled. The lines represent the median of 1000 MCMC points when fitting the projected correlation function and the galaxy-galaxy lensing (dotted lines), as well as the projected correlation function, multipoles of the correlation function, and galaxy-galaxy lensing (solid lines). It is worth noting that none of the statistics shown in this figure were used in the empirical model fitting process. The shaded region corresponds to the 16th and 84th percentile of the distribution (only shown for the solid line). Only the predictions for Nk = 2 and 5 are shown for the kNN-CDF. Similarly, the CIC only shows the predictions for rCIC = 1 and 10 h−1 Mpc. The bottom panels show the ratio between the empirical models and FLAMINGO. |
| In the text | |
 |
Fig. 7. Similar to Fig. 6, but for the HOD model. |
| In the text | |
|
Fig. 8. (Top) Galaxy assembly bias of the FLAMINGO simulation (dots points) and the empirical models when fitting to the galaxy clustering and galaxy-galaxy lensing predicted by FLAMINGO. From top to bottom, we show the SHAMe predictions for the DESI BGS-like galaxies, the SHAMe predictions for the BOSS-like galaxies, the HOD predictions for the DESI BGS-like galaxies, and the HOD predictions for the BOSS-like galaxies. The shaded region around the solid line represents the 1-σ prediction region for the empirical models, as is explained in Sect. 3.4. (Bottom) Similar to the top panel, but for the halo occupation number. |
| In the text | |
|
Fig. 9. Galaxy clustering (wp, top left panel; ξℓ = 0, top right panel; ξℓ = 2, lower left panel) and galaxy-galaxy lensing (ΔΣ, lower right panel) for the FLAMINGO simulation (symbols), the fiducial SHAMe model (black lines) and two different variations of the SHAMe model (colour lines). The bottom subpanels show the difference between the empirical models and FLAMINGO, normalised by the error. |
| In the text | |
|
Fig. 10. (Top) χ2 of the fits of the SHAMe model for the DESI BGS-like and BOSS-like samples (left and right panels, respectively) when reproducing simultaneously: the projected correlation function and the galaxy-galaxy lensing signal (wp + ΔΣ, blue bars) and the projected correlation function, the monopole and quadrupole of the correlation function and the galaxy-galaxy lensing signal (wp ξℓ = 0,2 + ΔΣ, orange bars). The bottom bar shows the χ2 for the primary model, and the following bars represent two simplifications of the models by removing either one or both of the galaxy assembly bias parameters. (Bottom) Similar to the upper panel but for the HOD model. |
| In the text | |
 |
Fig. 11. Similar to Fig. 9, but for the HOD model. |
| In the text | |
|
Fig. A.1. Galaxy-galaxy lensing signal for the galaxies of FLAMINGO (symbols) and for their matched subhaloes in a dark matter-only simulation (lines). The dashed vertical line indicates the lower limit where we fit the lensing signal with the empirical models. |
| In the text | |
|
Fig. D.1. Similar to Fig. 8, but for the FLAMINGO suite of simulations with different astrophysical implementations and the SHAMe model. |
| In the text | |
|
Fig. D.2. Similar to Fig. 8, but for the FLAMINGO suite of simulations with different astrophysical implementations and the HOD model. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.