| Issue |
A&A
Volume 685, May 2024
|
|
|---|---|---|
| Article Number | A66 | |
| Number of page(s) | 26 | |
| Section | Catalogs and data | |
| DOI | https://doi.org/10.1051/0004-6361/202348031 | |
| Published online | 07 May 2024 | |
A catalogue of asteroseismically calibrated ages for APOGEE DR17
The predictions of a CatBoost machine learning model based on the [Mg/Ce] chemical clock and other stellar parameters★
1
Instituto de Astrofísica e Ciências do Espaço, Universidade do Porto, CAUP, Rua das Estrelas,
4150-762
Porto,
Portugal
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Departamento de Física e Astronomia, Faculdade de Ciências, Universidade do Porto,
Rua do Campo Alegre,
4169-007
Porto,
Portugal
Received:
20
September
2023
Accepted:
24
December
2023
Abstract
Context. The formation history and evolution of the Milky Way through cosmological time is a complex field of research requiring the sampling of highly accurate stellar ages for all Galaxy components. Such highly reliable ages are starting to become available thanks to the synergy of asteroseismology, spectroscopy, stellar modelling, and machine learning analysis in the era of all-sky astronomical surveys.
Aims. Our goal is to provide an accurate list of ages for the Main Red Star Sample of the APOGEE DR17 catalogue. In order to reach this goal, ages obtained under asteroseismic constraints are used to train a machine learning model.
Methods. As our main objective is to obtain reliable age predictions without the need for asteroseismic parameters, the optimal choice of stellar non-asteroseismic parameters was investigated to obtain the best performances on the test set. The stellar parameters Teff and L, the abundances of [CI/N],[Mg/Ce], and [α/Fe], the U(LSR) velocity, and the vertical height from the Galactic plane ‘Z’ were used to predict ages with a categorical gradient boost decision trees model. The model was trained on two merged samples of the TESS Southern Continuous Viewing Zone and the Second APOKASC catalogue to avoid a data shift and to improve the reliability of the predictions. Finally, the model was tested on an independent data set of the K2 Galactic Archaeology Program.
Results. A model with a median fractional age error of 20.8% is obtained. Its prediction variance between the validation and the training set is 4.77%. For stars older than 3 Gyr, the median fractional error in age ranges from 7% to 23%. For stars with ages ranging from 1 to 3 Gyr, the median fractional error in age ranges from 26% to 28%. For stars younger than 1 Gyr, the median fractional error is 43%. The optimised model applies to 125 445 stars from the Main Red Star Sample of the APOGEE DR17 catalogue. Our analysis of the ages confirms previous findings regarding the flaring of the young Galactic disc towards its outer regions. Additionally, we find an age gradient among the youngest stars within the Galactic plane. Finally, we identify two groups of a few metal-poor ([Fe/H] < −1 dex) young stars (Age < 2 Gyr) with similar peculiar chemical abundances and halo kinematics. These are likely the outcomes of the predicted third and latest episode of gas infall in the solar vicinity (~2.7 Gyr ago).
Conclusions. We make a catalogue of asteroseismically calibrated ages for 125 445 red giants from the APOGEE DR17 catalogue available to the community. The analysis of the associated stellar parameters corroborates the predictions of different literature models.
Key words: asteroseismology / catalogs / Galaxy: abundances / Galaxy: evolution / Galaxy: formation
Catalogue of stellar ages and other stellar parameters (full Table 6) is available at the CDS via anonymous ftp to cdsarc.cds.unistra.fr (130.79.128.5) or via https://cdsarc.cds.unistra.fr/viz-bin/cat/J/A+A/685/A66
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Galactic archaeology is the study of the formation and evolution of the Milky Way (Miglio et al. 2017), with stellar age precision being crucial for progress (Hekker 2018). The isochrone placement method (Soderblom 2010) has yielded precise results (Nissen 2015; Delgado Mena et al. 2019; Casali et al. 2020), although these are limited to the stellar cluster population, turn-off stars, and solar analogues (Morel et al. 2021).
Solar-like red giants are the major target of interest for studying the Galaxy because of their intrinsic brightness, seismic constraints, and observational ubiquity (Hayden et al. 2015; Hekker 2018). Red giants reveal Galactic chemical evolution information, except for certain elements affected by stellar diffusion. These elements are atomic carbon (CI), nitrogen (Masseron & Gilmore 2015; Martig et al. 2016; Ness et al. 2016; Hasselquist et al. 2019), and lithium (Deal et al. 2021), but also include sodium and aluminium for stellar masses above 1.8 M⊙ (Smiljanic et al. 2016).
As red giants are the preferred targets for studying the Galaxy, the APOGEE survey (Majewski et al. 2017) stands out as the most suited mission, having probed the vastest number of them across a large fraction of the celestial sphere in both the Northern and Southern Hemispheres in the infrared H band (1.51 µm–1.70µm). The latest public release (APOGEE DR17; Abdurro’uf et al. 2022) contains data on 657 000 unique stars.
In general, for individual field stars, age precision is limited to about 40% (Lebreton & Montalbán 2009) at any evolutionary stage. Asteroseismic constraints improve the precision to 10–20% (Soderblom 2010; Lebreton et al. 2014; Pinsonneault et al. 2018).
However, there is a limitation to using asteroseismic constraints for dating methods. The majority of stars observed by all-sky spectroscopic surveys do not benefit from asteroseismic data. The disparity between the availability of asteroseismic data and chemical abundance data has motivated the search for age-abundance relations, also known as ‘chemical clocks’ (da Silva et al. 2012; Nissen 2015).
Chemical clock modelling improved dating precision within the solar neighbourhood (Feuillet et al. 2018; Delgado Mena et al. 2019; Sharma et al. 2021, 2022; Moya et al. 2022; Hayden et al. 2022). Nevertheless, applying chemical clocks to vast regions of the Galaxy beyond the solar neighbourhood is inefficient because of the significant scatter in abundance. This was observed, for example, in red clump stars by Casamiquela et al. (2021) beyond 1 kpc from the Sun.
Recent advancements relying on a data-driven approach have enabled the expansion of dating capabilities from the solar neighbourhood to the entire Milky Way Galactic disc. This approach is based on the spectroscopic determination of age for red giants, and relies on a function to model the flux of reference stars at each wavelength.
The Cannon (Ness et al. 2015; Ness 2018) was a pioneering method to implement this data-driven approach using APOGEE DR 12 (Holtzman et al. 2015) stellar spectra from stars sampled from the Second APOKASC asteroseismic catalogue (APOKASC-2; Pinsonneault et al. 2018). Following the release of The Cannon, two other methods based on the same principle were developed. “ASTRO-NN” (Leung & Bovy 2019) relies on a neural network to deal with high-resolution spectra (R ~ 22 500) from APOGEE DR14 (Holtzman et al. 2018). On the other hand, “DD-Payne” (Xiang et al. 2019) uses the same training scheme as “The Cannon” but combines it with a flexible and efficient tool for the simultaneous determination of several stellar parameters with full spectral fitting called “Payne” (Ting et al. 2019). DD-Payne was used to predict stellar parameter values for 6 million stars from ~8 million low-resolution (R ~ 1800) spectra from LAMOST DR5 (Zhao et al. 2012). These three methods have achieved a maximum age precision of 30% because of the inherent limitations in extracting information from the subtle differences in red giant stellar spectra.
In order to avoid the limitations of these data-driven methods, a promising approach was developed by Anders et al. (2023). Instead of relying on stellar spectra, it directly utilises the stellar parameters from the APOGEE-Kepler catalogue (Miglio et al. 2021) as features for training a machine learning model, specifically an XGBoostRegressor (Chen & Guestrin 2016).
The work presented in this article differs from that of Anders et al. (2023) in three major respects. Firstly, the model presented in the present article is trained with a CatBoostRegressor (Prokhorenkova et al. 2018) instead of an XGBoostRegressor. Secondly, a different set of stellar parameters are used to train the model, including the [Mg/Ce] chemical clock. Finally, the training set is not only made of APOGEE red giants from the Kepler (Koch et al. 2010) field but also incorporates red giants observed with the Transiting Exoplanet Survey Satellite (TESS; Ricker et al. 2014) in its Southern Continuous Viewing Zone (TESS SCVZ, hereafter). TESS, a recent asteroseismological mission, overcomes the limitations of the previous missions CoRoT (Alecian et al. 2007), Kepler, and K2 (Rendle et al. 2019), offering advantages for studying the vertical and radial structure of the Milky Way.
The goals of the present work are to compile a catalogue of asteroseismically calibrated ages for stars within the Main Red Sample of the APOGEE DR17 catalogue and to subsequently analyse the distribution of stellar parameters associated with the obtained ages.
The research sample studied here is described in Sect. 2. Section 3 provides basic concepts in machine learning and justifies the choice of the selected model. Section 4 deals with the choice of features for the model. Section 5 details all the various optimisation processes employed to improve the accuracy of the predictive model. In Sect. 6, the optimal performances of the model and the associated results are presented, and in Sect. 7, the results are discussed. The conclusions of this article are outlined in Sect. 8.
2 Sample description
A sequential approach was adopted to achieve the highest accuracy in predicting ages for APOGEE DR17. Initially, one training set was used that is made of stars from the APOKASC-2 catalogue. However, upon observing a decline in model performance when tested on a TESS SCVZ sample, the decision was made to merge the two datasets, creating what is referred to as the MCK-APOKASC sample. The rationale for this combination is discussed in Sect. 5.3. The resulting merged dataset yields more robust predictions in both regions, contributing to an overall improvement in the prediction accuracy of the model.
The selection of APOKASC-2 as the primary dataset was driven by three key factors. Firstly, this catalogue contains the highest number of red giants in the Kepler field, that is, 6676 evolved stars. Secondly, it offers high-quality stellar ages due to asteroseismic parameters obtained using five independent techniques from continuous monitoring by Kepler over a 4-yr period. Notably, the resulting asteroseismic constraints allowed the authors to reach fractional age uncertainties of mainly between 0.6% and 5%, as illustrated in Fig. 1b. However, it is important to note that these uncertainties are of random origin and do not reflect systematic errors in inputs or theoretical age inferences (Pinsonneault et al. 2018). Thirdly, APOKASC-2 provides a dynamically sampled representation of a large portion of the Galactic disc, as depicted in Fig. 1c.
To ensure the highest accuracy in stellar age data, the APOKASC-2 sample was refined. Only stars with evolutionary states determined through the asteroseismology method described in Elsworth et al. (2017) were retained, excluding those identified spectroscopically. The resulting APOKASC-2 sample spans a galactocentric radius exceeding 5 kpc, as calculated using the astropy Python package (Astropy Collaboration 2013, 2018, 2022). The closest stars to the Sun are located just beyond the Local Bubble (Zucker et al. 2022); that is, with a heliocentric spherical radius (RHelio) surpassing 300 pc.
Figure 1 summarises the key characteristics of the sample. The age histogram (refer to Fig. 1a) reveals some stars with ages exceeding that of the Universe (13.77 Gyr; Planck Collaboration VI 2020). The guiding radius computed using the Galpy code (Bovy 2015) spans a wider range than current stellar positions (refer to Fig. 1c). Evolutionary states illustrated in the HR diagram (refer to Fig. 1d) clearly identify red clump stars. The velocities were computed using the method outlined in Johnson & Soderblom (1987), incorporating the latest data from Bensby et al. (2003), Reid & Brunthaler (2004) and Bland-Hawthorn & Gerhard (2016). Additionally, Galpy was used to confirm the consistency between the two techniques used to compute velocity. The resulting stellar velocities are illustrated in a Toomre diagram, as presented in Fig. 1e, revealing the identification of 32 kinematically distinct halo stars. The expected blurred metallicity gradient with age (Nissen et al. 2020) is displayed in Fig. 1f, and the chemical dichotomy in the sample is illustrated in Fig. 1g.
In order to decide which α-elements to retain in the computation of the [α/Fe] ratio, several [X/Fe] versus [Fe/H] plots were compared. The goal was to find the sharpest separation between the two α-populations. Eventually, the analysis led to retaining the mean of [Si/Fe] and [Mg/Fe] as the [α/Fe]. No flagged abundances were found in the sample for these two α-elements.
The additional sample is the result of the cross-match between the age-asteroseismic catalogue from (MCK; Mackereth et al. 2021) and APOGEE DR17. This sample is made of 1025 stars and spans a spatial extension of approximately 2 kpc. As in the APOKASC-2 sample, its closest stars to the Sun are located slightly beyond the Local Bubble. Our motivations for its selection were the same as for APOKASC-2; one is the reliability of the ages, as they were derived using stellar modelling with asteroseismic constraints. The ages in the MCK catalogue display a mean fractional uncertainty of close to 22%. Also, its stars reveal that MCK managed to sample a substantial part of the Galactic disc dynamically. The main characteristics of the sample are summarised in Fig. 2.
Overall, the MCK sample displays similar properties to the APOKASC-2 sample, but there are a few differences. The guiding radius spans a narrower range of distances. There are fewer halo stars, which is expected given that the MCK sample is smaller. Finally, the fractional age uncertainty distribution is wider.
As MCK relied on the SkyMapper effective temperatures, we conducted a straightforward ordinary square regression. The aim of this analysis, performed with the built-in Python stats-model package, was to verify the agreement between the two sets of effective temperatures. The results of the regression, available in Appendix B, indicate that the two Teff scales are compatible when considering uncertainties. Consequently, we made the decision to utilise the APOGEE DR17 effective temperature for the MCK sample.
 |
Fig. 1 Ensemble of plots summarising the information on the APOKASC-2 component of the research sample. Panel a: age histogram. A box plot is systematically added to the histograms. Panel b: histogram of the random fractional uncertainties on age. Panel c: histogram comparison of the current galactocentric distances and the guiding radii. Panel d: HR diagram of the sample. Panel e: Toomre diagram of the velocities in the galactocentric referential. Panel f: age vs metallicity. Panel g: [α/Fe] vs [Fe/H] plane. The black point with error bars depicts the mean uncertainty for both parameters. |
 |
Fig. 2 Ensemble of plots summarising the information on the MCK component of the research sample. We refer to Fig. 1 for the description of the panels. |
3 Selection of a machine learning model
3.1 The training scheme
In supervised machine learning, data are divided into a training set used to train the model and a testing set used to assess the model’s performance on unseen data, ensuring an evaluation of its generalisation ability. To attain the best complexity for the model, we carried out three optimisation steps. Initially, emphasis was placed on the selection of a set of features. Subsequently, we fine-tuned the hyperparameters using the Grid-SearchCV method. Finally, we determined the optimal set of random seeds.
The GridSearchCV method, a scikit-learn (Pedregosa et al. 2011) class, was employed to construct a grid of models with all combinations of selected hyperparameters. This process allows the identification of the model with the best hyperparameter values through cross-validation, employing a 10 K-fold of the training set.
Cross-validation involves dividing the training set into multiple subsets known as folds. The model is trained on several folds and is validated on a separate fold (the validation set) not used during training. This process is repeated, and the performance metrics are averaged across folds to provide a more robust assessment of the model’s generalisation performance. The validation set helps tune hyperparameters and prevents overfitting by simulating how the model might perform on the testing set or any unseen data.
The random seed is used to initialise the random number generator used by machine learning algorithms. The random number generator is used in many different ways during the training process; for example, it is used to initialise the weights of the model and to select samples for each batch. The reason for testing different sets of values for the random seed is that even small differences in the sequence of random numbers can have a large impact on the final accuracy of the model.
The optimisation process was initiated by the selection of a set of features for a default grid of hyperparameter values. After computation of the predicted target values, a graphical check was conducted to ensure that the spread in predictions was well reproduced. Subsequently, an assessment for overfitting and underfitting was made using the root mean squared error (RMSE) metric.
If the RMSE on the validation set exceeded that of the training set, it was concluded that the model was overfitting. Overfitting was avoided when the relative difference in RMSE between the training set and the validation set known as the variance of the model was small.
In this study, the variance threshold was set to 5%, an arbitrary but motivated choice, similar to typical p-value thresholds in statistical tests.
Once overfitting was ruled out, a check for underfitting was performed by ensuring that the RMSE on the test set was lower than the baseline RMSE. The baseline RMSE is obtained on the test set and is achieved with a model trained on a single feature, namely the one with the highest feature importance (refer to Sect. 3.3).
3.2 Regression trees in machine learning
The choice was made to employ a machine learning technique based on tree-based models for the research objective, specifically using decision trees for regression. The primary advantage of opting for tree-based models lies in their ability to effectively capture non-linear relationships between features (the parameters of a model) and labels (the variables the model predicts).
However, according to Hastie et al. (2009, we refer to their Table 10.1 for more details), this type of learner confers several comparative advantages over other machine learning methods. These advantages concern their performances in terms of the natural handling of mixed data types, the handling of missing values, the robustness to outliers in the input space, the insensitivity to the monotone transformation of features, the computable scalability, and the ability to deal with irrelevant inputs. Nevertheless, the use of a single tree leads to weak predictive power, which is the reason for the creation of the ensemble learning approach. This approach is designed to train different trees on the same dataset and let each model make its predictions. In the end, a meta-model aggregates predictions of the individual models. The final predictions are therefore more robust and less prone to errors. In the case of boosting-ensemble, when the base learner is a regression tree, the most suited ensemble approach is gradient boosting. In gradient boosting, each tree is trained using the residual errors of its predecessor as labels. The first tree is initially trained on the input dataset (X, y), where X represents the feature values matrix and y is the column vector of label values. The predictions (ŷ1) from the first tree are then used to calculate the residual errors (r1 = y − ŷ1).
Next, the second tree is trained using the feature matrix X and the residual errors (r1) of the first tree as labels. The predicted residuals 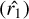 from the second tree are then used to calculate the residuals of residuals, labelled as
from the second tree are then used to calculate the residuals of residuals, labelled as 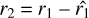 .
.
An important factor in training gradient-boosted trees to enhance performance is shrinkage. In this context, shrinkage involves multiplying each residual error by the learning rate (ϵ). Notably, it is crucial to be aware of the trade-off between the learning rate and the number of trees in the model’s final performances.
This process is iteratively repeated until all N trees in the ensemble are trained. Once all the trees are trained, introducing an unknown instance of data prompts each tree to make predictions, and the final predicted label value (ypred) is determined from Eq. (1):
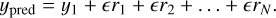 (1)
(1)
Gradient-boosting algorithms, such as XGBoost (Chen & Guestrin 2016) and CatBoost (Prokhorenkova et al. 2018), share common characteristics, including efficient handling of large datasets and support for parallel processing. Notably, they are recognised as state-of-the-art performers. Comparing their performances on the MCK-APOKASC sample using XGBoostRegressor and CatBoostRegressor models reveals better results with CatBoost in terms of the variance between the validation and training sets. Specifically, the variance with CatBoost (see Table 1) is, on average, two times smaller than with XGBoost. Consequently, we decided to continue our analysis with CatBoostRegressor as our machine learning model.
The performance of CatBoost can be attributed to its robust decision-tree algorithm, leveraging Oblivious Trees (Ferov & Modrý 2016) for outlier handling. Its L2 regularisation approach, applied to both leaves and nodes, is more effective at preventing overfitting compared to other algorithms. Additionally, CatBoost benefits from a distinct hyperparameter random_strength, controlling randomness in the tree construction process to prevent overfitting and improve generalisation. For details on the tuned hyperparameters, we refer to Table D.1.
The final optimised results derived from the MCK-APOKASC sample are summarised in Table 1. These results match the case displaying the highest accuracy in predictions among 1000 different random configurations of the three different random seeds. These configurations imply the random splitting of the training-test sets (90%-10%), and the random instantiation of a CatBoostRegressor and the RandomSampler method (refer to Sect. 5.2). The variance is sufficiently small to confidently consider that the model is not overfitting the data set. Also, the baseline test reveals that the model is not underfitting the data set.
3.3 Feature importance metric
The importance of the features in the model predictions was evaluated using the Shapley value technique. A Shapley value quantifies the average impact of a feature on a model output magnitude. This technique satisfies a set of axioms that make it more reliable than other feature-importance calculation techniques (Young 1985).
Tree-based models in scikit-learn have a built-in feature-importance calculation method based on the Gini impurity index. However, Gini impurity-based feature importances may lead to inaccurate results, as a large number of distinct values tend to lead the associated feature to a higher importance score with Gini impurity, even if it might not be as informative as suggested.
In our analysis, we frequently noticed that the rank of the most important features was permuted between the results based on the Gini index and the Shapley values. Therefore, the importance of the features is based on the Shapley values. The Shapley values were computed thanks to the SHAP Python package (Lundberg & Lee 2017). The plot of the Shapley features importance obtained on the MCK-APOKASC test set is displayed in Sect. 6.1 (refer to Fig. 3e).
Summary of the best performances obtained on the MCK-APOKASCK sample.
4 Feature selection
In this section, the rationale for selecting each age-correlated feature is described. The model was trained with a progressively expanding set of features, each known or expected to be age dependent. The addition of each new feature depended on its capacity to improve the capture of age dispersion, depict overall trends, reduce the variance of the model, and improve accuracy in age determination. There is a separate and dedicated section (refer to Sect. 5.4) dealing with an extra feature with no direct correlation to age. Notably, [Fe/H] was not a selected feature in the model for two reasons. First, there is an expected blurring of the age-metallicity relationship for large data sets with wide dispersion in age (Nissen et al. 2020), rendering the correlation between [Fe/H] and age statistically insignificant. Second, there is a negligible Shapley value for [Fe/H] compared to other features when included in the model. Eventually, the impact of [Fe/H] was accounted for through the [α/Fe] ratio, which serves as a proxy for metallicity.
4.1 [Mg/Ce]
The Galactic chemical clock, chosen as the primary feature, showed the best performance in age prediction. To identify this clock, abundance correlations with age were computed using the 20 calibrated abundances from APOGEE DR17. The APOGEE calibrated abundances, denoted as [X/Fe], are obtained by aligning solar-metallicity stars to [X/M]=0. These abundances exclude stars with suspect or known incorrect values based on various criteria set by the APOGEE consortium.
The Spearman coefficient (ρ) was used for correlation calculations because it does not require the assumption of a linear relationship. Stars with masses of greater than 1.8 M⊙ were excluded for [Na/Fe] and [Al/Fe] (refer to Sect. 1). The APOGEE DR17 did not provide [S/Fe] abundances for the stars in the training sample because of the unreliability of the associated spectra. Titanium (Ti) was excluded from the study due to persistent discrepancies between the APOGEE DR16 [Ti/Fe]–[Fe/H] trend and the optical trend as identified and discussed in Jönsson et al. (2020), which continue to be observed in APOGEE DR17. [CI/Fe] and [N/Fe] were not considered as Galactic chemical clocks, as they track stellar evolution rather than chemical Galactic evolution (Hasselquist et al. 2019).
The Spearman coefficients are detailed in Table 2, calculated using the scipy.stats package (Jones et al. 2001). Chromium ([Cr/Fe]) showed no statistical evidence of correlation with age and was excluded. [X/Ce] abundances, particularly [O/Ce] and [Mg/Ce], displayed the strongest correlation with age (refer to Fig. A.1). These robust correlations align with the findings of Casali et al. (2020) and Casamiquela et al. (2021), who demonstrate that combinations of α and s-process elements make the most effective chemical clocks.
[Mg/Ce] was chosen as the Galactic chemical clock rather than [O/Ce] because it displays the smallest intrinsic dispersion (σ[Mg/Ce] = 0.22) in the data. Extensive studies on the non-local thermodynamic equilibrium (NLTE) effects of magnesium in the H-band (Osorio et al. 2020; Abdurro’uf et al. 2022), on its reliability in chemical enrichment studies (Gonzalez et al. 2011; Kobayashi et al. 2020), and on the recommendation of its use as a reference element (Weinberg et al. 2019, 2022) further justify the choice of magnesium over oxygen to obtain the chemical clock with the most reliable performance.
Spearman correlation coefficients with their p-values for the relations involving [X/Fe] vs. age.
4.2 [α/Fe]
The second selected feature was the α-dichotomy ratio used to isolate the Galactic disc in two distinct chemical populations (Adibekyan et al. 2012). When using regression trees, as long as [α/Fe] is a parameter of the model, there is no need to separate the analysis into the α-rich and α-poor components of the Galactic disc, as done in Delgado Mena et al. (2019). Moreover, limiting the training set to the α-poor disc diminishes model performance due to fewer training data.
[α/Fe] has proved to be efficient in separating each of the Galactic components in the [α/Fe] versus [Fe/H] diagram (Spitoni et al. 2016; Rojas-Arriagada et al. 2017; Hawkins & Wyse 2018). This chemical tagging property is exploitable by regression trees as they can identify distinct hidden trends in the data, matching regions with different chemical-enrichment histories.
Stellar age modelling codes, specifically BeSPP (Serenelli et al. 2013) and PARAM (Rodrigues et al. 2017), employed for calculating ages in APOKASC-2 and MCK, respectively, do not take into account the stellar Galactic population membership (bulge, disc, halo). Consequently, this information is not incorporated into the final CatBoost model. In other words, the model assigns similar age confidence to bulge or halo stars if their parameters match the training set, regardless of population.
The final age catalogue (refer to Sect. 6.3) reveals that 2% of the stars are in the halo, with the rest in the disc. Probabilities of the Galactic population membership of each star were calculated using the method described in Bensby et al. (2003, 2005), updated with priors from Anguiano et al. (2020).
4.3 [CI/N]
The third feature selected was the carbon-to-nitrogen ratio. It is important to know that the APOGEE catalogue comprises two types of carbon abundance: [C/Fe], derived from carbon molecule lines, and [CI/Fe], computed from neutral carbon lines. To emphasise the use of atomic carbon abundance, the carbon-to-nitrogen ratio is depicted as [CI/N].
Studies on [CI/N] as an age indicator in red giants have confirmed the correlation with age, albeit with some dispersion (Hasselquist et al. (2019) and references therein). According to Karakas (2010), given the mass range (0.64 < M(M⊙) < 3.48) of the MCK-APOKASC sample, stars likely underwent only the first dredge-up, as their mass remains below the critical threshold of 5 M⊙. This suggests a significant role for [CI/N] in indicating the evolutionary state within MCK-APOKASC, particularly impacting the surface composition of low- to intermediate-mass stars (0.8 < M(M⊙) < 8) (Karakas 2010).
The scatter in the [CI/N] versus age relationship arises from various factors, including mixing processes, nucleosynthesis, and chemical evolution. In the model, the influence of chemical evolution was included by incorporating the Galactic chemical clock [Mg/Ce] as well as the [α/Fe] ratio. While [CI/N] is valuable for age predictions in red giants, it alone has limitations in providing accurate ages for individual stars (Salaris & Cassisi 2005). Additional factors, such as metallicity and effective temperature, influence stellar evolution and must be considered for reliable age estimates. Therefore, for robust age estimates, it is essential to combine the [CI/N] ratio with other stellar parameters.
4.4 Teff, Z, and L
The remaining features selected were the effective temperature, the vertical distance from the disc, and the luminosity. Given that the total evolutionary lifetime of a star on the main sequence scales with its mass (Serenelli et al. 2017), incorporating features related to stellar mass significantly improves model performance. This improvement is particularly evident in better fitting age dispersion. As the effective temperature is linked to stellar mass through asteroseismic scaling relations for red giants (Gaulme et al. 2016), it was selected as a relevant feature. The vertical distance from the Galactic disc (Z) is crucial for model accuracy, considering the known vertical gradient in the stellar-mass distribution across the Galactic disc (Miglio et al. 2012; Casagrande et al. 2015; Hon et al. 2021). Z ranked among the most impactful features, leading to an improvement in accuracy (refer to Fig. 3e).
To address the generation of fractional residuals in age exceeding values of 100%, luminosity (L) was chosen over log(g). Log(g) results in outliers reaching up to 150%, while L successfully mitigates this issue. Including both L and log(g) does not improve accuracy but increases the variance of the model, likely because of the lower Shapley feature importance of log(g) compared to luminosity (SHAP = 0.053 vs. SHAP = 0.063).
As luminosities are not provided in the second APOKASC catalogue, we computed them using the same method as in Mackereth et al. (2021) for consistency reasons. This method relies on bolometric corrections and the use of a 3D dust map library. The bolometric corrections in the Ks band were computed using the bolometric-corrections code(Casagrande & VandenBerg 2014, 2018a,b), with a preference for the Ks band given its lower sensitivity to extinction.
As bolometric corrections depend on reliable distances, stars with negative parallaxes were removed, and a fractional parallax uncertainty criterion (ƒpu = σp/p, where σp is uncertainty on parallax and p is parallax) was applied to filter out stars with ƒpu > 0.2 (Bailer-Jones et al. 2021). After applying these filters, 6466 APOKASC-2 stars remain. Finally, the reddening (E(B − V)) was computed using the MWDust code (Bovy et al. 2016a) and the 3D dust map library from Green et al. (2019).
4.5 Summary of features
The first feature configuration set obtained is ([CI/N],[Mg/Ce], [α/Fe], Teff, L, Z).
Except for Z, which shows no significant Spearman correlation with age (ρ = −0.05, p = 4.7 × 10−6), all features exhibit visible correlations with age (refer to Fig. 4). However, it is important to note that the correlation with age for [α/Fe] is significant only for the α-poor component, aligning with the findings of Delgado Mena et al. (2019). Additionally, Teff exhibits noticeable scatter, increasing as the temperature diminishes towards 4000 K.
5 Model optimisation
5.1 Rescaling the age distribution
Regression trees, which are designed to minimise mean squared error (MSE), may exhibit bias in the presence of skewed target variables, such as age (refer to Fig. 4). Higher values disproportionately influence the optimisation process, leading to unbalanced splits in a tree’s nodes and potential isolation of data tails (Hastie et al. 2009, refer to their section 10.7).
To address this, log-transforming the data reduces the impact of high values, improving accuracy for the majority. Tests with age as the target variable demonstrate a 33% mean error in residuals and a fractional residual maximum outlier of 359%. Logarithmic transformation reduces these values to 28% and 281%, respectively, improving prediction accuracy. It is important to note here that residuals were computed by converting ages back to the linear scale.
Ages older than the age of the Universe were not included in the model training (13.77 < age (Gyr) < 20). There are several reasons for this decision. Firstly, the model has been observed to predict such ages to a noticeable extent. This is expected because these ages were included as inputs for the model. Secondly, these ages are known to be mainly due to unconstrained systematic errors in the stellar modelling (Pinsonneault et al. 2018). Thirdly, setting these ages arbitrarily to the age of the Universe would result in the generation of fabricated data with age-stellar parameter inconsistencies. This last point underscores a fundamental limitation of machine learning models in general; namely their lack of built-in methods to explicitly incorporate uncertainties in the input parameters. Models assume that the input data are accurate and the training data are representative of the underlying distribution. Therefore, to mitigate the generation of potential machine learning artefacts, the machine learning model was eventually applied solely to APOGEE stars with a fractional luminosity uncertainty inferior to 30% (refer to Sect. 6.3).
 |
Fig. 3 Ensemble of plots summarising the final performances on the MCK-APOKASC training-test sample. Panel a: evolution of the median of the absolute value for the fractional error on age per bin. Panel b: comparison of the ages of reference and those predicted by the model. The black line is the identity function ∣ΔA/A∣is the absolute fractional error on age. The black error bars represent the means of the errors in age. Panel c: evolution of the standard deviation of the fractional error on age per bin. The vertical-horizontal bar depicts the mean value for the whole age range. Panel d: histogram of the absolute fractional error on age. Panel e: bar plot of the feature importance for all the retained features. Panel f: Plot of the learning curves. |
5.2 Oversampling imbalanced data
A noticeable data imbalance exists between ages older and younger than 10 Gyr, where ‘imbalance’ in machine learning refers to a skewed or unequal distribution of data classes. This imbalance was suspected to contribute to increased mean fractional residuals at the oldest ages. To address this issue, the ‘oversampling’ technique was applied using the Imbalance-Learn package (Lemaître et al. 2017). Random oversampling was chosen as it involves duplicating existing data without the need to synthesise any. Importantly, oversampling was applied only to the training set. The approach sets a threshold at 10 Gyr, classifying data beyond this age as the minority class and everything below as the majority class. While experimenting with different thresholds, the one at 10 Gyr yields the best age accuracy performances. Overall, this oversampling significantly improved accuracy performances.
 |
Fig. 4 Corner plot of the retained stellar features, with a significant correlation with age, in the full training sample (MCK-APOKASCK). The diagonal depicts the histogram associated with each feature and the triangular bulk displays the correlation trends between each feature. Each plot displays the associated Spearman correlation coefficient (ρ) with the p-value of the test. |
5.3 identification of a data shift
As mentioned in Sect. 2, the model optimisation followed a sequential process. Initially, the model was trained exclusively on the APOKASC-2 sample. Subsequently, its predictive performance was assessed on the MCK sample to validate its generalisation capabilities. The relevance of the MCK sample lies in the distinct derivation of its asteroseismic constraints and ages compared to the second APOKASC catalogue. Specifically, the asteroseismic parameters in the MCK sample were derived from TESS light curves. The optimised model, trained on the APOKASC-2 sample, led to several key outcomes:
The maximum fractional error in predicting age is 131%, indicating instances where the model predictions deviate significantly.
The overall median fractional age error is 21%, decreasing as the stellar age increases, except for a specific range between 11 and 13.77 Gyr.
The standard deviation of the fractional error in a given age bin (σ) varies between σ=10 and σ=25, showing moderate fluctuations in model accuracy across different age ranges.
However, when the model trained on the APOKASC-2 sample is tested on the MCK sample, notable changes in its characteristics are observed:
Numerous fractional age errors increase significantly, reaching values close to 600%.
The median of the fractional age error distribution shows a global increase, reaching 25%. The most substantial increments occur for age intervals of 0 < Age(Gyr) < 1 and 1 < Age(Gyr) < 3, with corresponding values of 80% and 40%, respectively.
The standard deviation associated with the fractional age error exhibits a continuously increasing trend from the youngest to the oldest age bins, ranging from σ=5 to σ=100.
Consequently, these findings indicate that the model, trained solely on the APOKASC-2 sample, exhibits a serious deterioration in its prediction accuracy when applied to the MCK sample. Kolmogorov-Smirnov (KS) tests indicate the possible presence of a data shift between the two data sets (refer to Table 3). These tests were conducted by considering variables related to stellar dynamics as well as chemical ratios. The test results indicate that all variables tested, except W(LSR), exhibit a significant difference in the origin of their distribution.
The most pronounced differences are observed in U(LSR) and the guiding radius. The difference in [α/Fe] is not surprising, as previous research by Queiroz et al. (2020) and Hayden et al. (2015) demonstrated its distribution shapeshift, with APOGEE DR16 and APOGEE DR12 data, respectively, at different distances from the Galactic centre and heights above the Galactic plane.
KS test results between APOKASC-2 and MCK samples, sorted by the test statistic.
5.4 Additional feature
To address the deterioration of the performance of our model, the APOKASC-2 sample was merged with the MCK sample, and an additional feature was added to the model. This approach effectively resolves the issue. Indeed, it results in improved reliability, robustness, and accuracy of the model predictions for both APOKASC-2 and MCK data.
The most pronounced difference between the two samples is the sign shift in radial velocity U(LSR). In the merged sample, stars below the Galactic plane mostly display negative speeds and stars above the Galactic plane mostly display positive speeds. The associated mean and standard deviations in U(LSR) are (µ = −19.5, σ = 42.5) for the MCK sample and (µ = +47.5, σ = 51.3) for the APOKASC-2 sample.
This asymmetry in U(LSR) in the region (8 < R (kpc) < 9, −1 < Z (kpc) < 1) is expected from the robust measurements of the three-dimensional velocity moments presented in the detailed Galactic disc kinematics study with LAMOST K giants in Ding et al. (2021, refer to their Fig. 6). Symmetries and asymmetries in the (U, Z) and (W, Z) planes are considered indicators of breathing and bending velocity motions in the Milky Way (Ding et al. 2021) but also in other disc galaxies (Kumar et al. 2022).
Ding et al. (2021) showed that the local asymmetry discussed earlier does not have a consistent shape and extent throughout the entire Galactic disc. In fact, it does not exist in some regions of the Galactic disc. Therefore, the U(LSR) feature was added to the model in order for it to be able to generalise its predictions across the disc.
Finally, although U(LSR) shows no significant Spearman correlation with age (ρ = 0.059, p = 8.99 × 10−7), incorporating U(LSR) further improves the performance of the model by reducing the fractional error, particularly for the youngest and oldest age groups.
5.5 Unreliable [Ce/Fe] abundances
The research by Casali et al. (2023) using APOGEE DR17-TESS-Kepler-K2 data suggests that combining cerium with α-elements is a promising proxy for understanding star formation. However, it also suggests that uncertainties, especially in [Ce/Fe], are likely underestimated. A comparative study by Contursi et al. (2023) with Gaia DR3 (Gaia Collaboration 2016, 2023), Forsberg’s catalogue (Forsberg et al. 2019), GALAH DR3 (Buder et al. 2021), and APOGEE DR17 reveals improved agreement by rejecting low [Ce/Fe] values.
Based on these studies, criteria were implemented: excluding [Ce/Fe] with uncertainties greater than 0.2 dex, removing flagged abundances, and establishing a threshold at [Ce/Fe] = −0.46 dex based on the median minus 1.5 times the interquartile range (M − 1.5 • IQR). The unreliable values of [Ce/Fe] account for 2.6% of the dataset.
No threshold was applied to the highest values of cerium (0.5 < [Ce/Fe] (dex) < 1.4) for two reasons. Firstly, they are expected from the study of Contursi et al. (2023), as these values have been observed in Baryum stars, which are known to have higher levels of barium, cerium, zirconium, ytterbium, and lanthanum (de Castro et al. 2016; Jorissen et al. 2019). Secondly, excluding these values from the training sample leads to a model with poorer accuracy performances. Rejecting unreliable cerium abundances improves the performance of the model, particularly reducing standard deviation in fractional age error in the range 11–13.77 Gyr.
6 Results
6.1 Final performances on the test set
As a result of the full optimisation, the performance of the model reveals an overall decline in the median fractional error on age per age bin up to 11 Gyr (refer to Fig. 3a). The median fractional error is approximately 20% in the age range (3 < Age (Gyr) < 8), while it is around 10% in the range (8 < Age (Gyr) < 10). For the range (10 < Age (Gyr) < 11), the median fractional error decreases further to approximately 7%. Furthermore, the oldest stars exhibit a median fractional error of 23%.
Regarding the youngest stars, the age range (1 < Age (Gyr) < 3) corresponds to a fractional error of approximately 27%, while the range (0 < Age (Gyr) < 1) exhibits a fractional error of approximately 43%. Despite their higher fractional error, the predictions for these very young cases are considered as accurate as the older cases due to their lower age values.
There is a consistent decline in the standard deviation of the fractional error per age bin (refer to Fig. 3c). This indicates that the predictions become increasingly robust as one deals with increasing age values. Among all the stars analysed, there are only two instances where the fractional errors slightly surpass 100%, as depicted in Fig. 3d. In Fig. 3b, the blue points represent cases with an absolute fractional age error of lower than the third quartile of the distribution. Conversely, the red points lie outside the range of the box plot of Fig. 3d and are consequently categorised as statistical outliers. It is important to bear in mind that the fractional error for a given age serves as a measure of the proportion by which the predicted age should be adjusted (either increased or decreased) to align with the reference age.
An increased amount of data generally improves model performance until a ceiling is reached; this threshold is determined by the quality of available information. Learning curves, comparing training and validation performance, help identify this ceiling. In this study, using RMSE as the scoring metric, the small gap observed between the learning curves depicts a relative difference of 4.77%, also known as the variance of the model (Fig. 3f). This suggests high performance on the MCK-APOKASC sample. Consequently, the CatBoostRegressor model exhibits sufficient quality for a reliable application to the APOGEE Main Red Star Sample (refer to Sect. 6.3).
 |
Fig. 5 Ensemble of plots summarising the performance of the model on the K2-GALAH sample. Panel a: plot of the scatter between the predicted ages and reference ages. The black line serves to visualise the residuals. Panel b: histogram of the absolute residuals between the predicted ages and the reference ages in absolute value. |
6.2 Performance on an independent set
Given the inclusion of the MCK sample in the training set to address the data shift (refer to Sect. 5.3), we performed an extra evaluation to gauge the model’s capability to generalise to new, independent data testing on a stellar age sample from Zinn et al. (2022, K2-GALAH, hereafter). This catalogue is made of red giants enriched with asteroseismic parameters derived from various sources, including anterior K2 Galactic Archaeology Program data (Stello et al. 2017; Zinn et al. 2019) and APOGEE DR16 (Jönsson et al. 2020) spectroscopic data for calibration. Their ages were computed using asteroseismic masses, GALAH DR3 temperatures (Buder et al. 2021), and stellar modelling with the code BSTEP (Sharma et al. 2018). GALAH data were used for age-abundance analysis.
To ensure a fair evaluation of the model on the K2-GALAH catalogue, only stars with fractional age uncertainties of lower than or equal to 30% were sampled. Also, stars with fractional luminosity uncertainties of greater than 30% were excluded. Consequently, the K2-GALAH testing sample comprises 371 stars (refer to Fig. C.1).
Figure 5 displays residual distribution plots for the K2-GALAH test set. Lower and upper thresholds of absolute fractional residuals correspond to the third quartile and the upper edge in the box plot of Fig. 5b. Error bars represent mean errors in ages for each age bin, except the last one, where bars represent mean errors for stars with predicted ages of between 6 and 13 Gyr.
Given the smaller size of the K2-GALAH test set (371 stars vs. 653 stars in MCK-APOKASC), the Wilcoxon-Mann-Whitney (WMW) test was chosen over the KS test. The reason behind this choice is that the KS test is recognised as being potentially unreliable when sample sizes are significantly different, as it relies upon the comparison of the empirical cumulative distribution function of the two samples. The WMW test yielded the following test statistic and p-value: (ρ = 68820.5, p = 1.000). Therefore, insufficient evidence exists to conclude differences in the distribution of fractional age errors between the two samples. Consequently, contrary to results in Sect. 5.3, no significant difference in model performance is observed when applied to independent data. This consistency can be explained by the training data effectively capturing key stellar parameters of the distribution in the reference Main Red Star sample from APOGEE DR17 (for more details, refer to Sect. 7).
6.3 The age map
The APOGEE Main Red Star Sample (MRS) comprises 372 000 stars randomly selected from the Two Micron All Sky Survey (2MASS) photometric catalogue (Skrutskie et al. 2006). The MRS was designed to select red giants based on colour-magnitude criteria made to provide a clear set of rules for a robust selection function reconstruction.
To ensure the relevance of the MRS in Galactic archaeology, kinematic data are crucial. Obtaining such information involves a sequential process: first, cross-referencing the MRS with the Gaia DR3 catalogue, followed by excluding stars with negative parallax or fractional parallax error of greater than 20%, as described in Sect. 4.4. The refined sample, named MRS-Gaia, contains 283 196 stars, ensuring reliable astrometric information for deriving kinematic parameters.
Given the potential contamination from undesired targets due to colour–magnitude criteria, we inspected the MRS log(g) histogram (refer to Fig. G.6). The analysis reveals a bimodal distribution, indicating contamination with main sequence stars, which make up 42%.
To handle this issue, the stars with log(g) values surpassing 3.7 dex are excluded. This threshold is selected because it marks the shift from the declining trend of the initial component to the rising trend of the second component. Considering that a log(g) of around 3.5 dex is the theoretical upper boundary for red giants, the selection of the 3.7 dex threshold matches the usual 0.1 dex uncertainty associated with log(g) determination using spectroscopic methods. As a result of this refinement, the MRS-Gaia sample size is subsequently reduced to 176 516 stars.
When applying a CatBoostRegressor, the reliability of the model is generally higher when used on data with values similar to those in the initial training set. Therefore, the MRS-Ga/a sample is restricted to values seen during the training phase, except for the variable ‘Z’, which captures the vertical age gradient of the Galactic disc. Without the need for restrictions on Z, the model has effectively captured the Z trend with age previously found in Ness (2018) and Anders et al. (2023), as demonstrated in Appendix F.
Table 4 illustrates each range of values for which a restriction in the application of the model was necessary. Given that CatBoost assumes the accuracy of input data and the representativeness of training data for the underlying distribution, age calculations were confined to stars with a luminosity uncertainty of lower than 30% to mitigate the potential introduction of machine-learning artefacts. Additionally, stars displaying flagged abundances in the features [CI/N], [Mg/Ce], and [α/Fe] were excluded from the age-determination process. Moreover, in accordance with the observations detailed in Sect. 5.5, only stars meeting the criteria of [Ce/Fe] surpassing −0.46 dex and having errors below 0.2 dex were considered for age determination.
Ultimately, out of the 176 516 stars in the MRS-Gaia sample, 125 445 stars were selected for age determination. In summary, 51 071 could not be dated mainly because of their unreliable abundances and luminosities. Additionally, but to a lesser extent, this is also due to their parameter values not being encountered during the training phase. The age map associated with these data is displayed in Fig. 6.
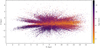 |
Fig. 6 APOGEE age map for the sample of red giants computed with CatBoost. |
Range of values used for age computation within the MRS-Gaia sample.
7 Discussion
7.1 Completeness of the training set
In Sect. 6.2, we demonstrate that the CatBoost model trained on MCK-APOKASC is able to make predictions that extend effectively to stars with reliable ages in the K2 Galactic program, without a decrease in performance. Nevertheless, to assess the potential limitation of the model when predicting stellar ages in wider and future surveys, it is crucial to discuss whether the APOGEE stars in the training set fairly sample the underlying distribution of targets in the MRS-Gaia sample. Moreover, as MRS-Gaia is a refinement of the MRS sample, it is also crucial to discuss whether MRS accurately reflects the broader population of red giants in the Galaxy.
Given the disparity in the size of the MCK-APOKASC and MRS-Gaia samples, the non-normally distributed nature of the samples, and the fact they are not independent of each other, the application of semi-parametric (KS-test), non-parametric (MWM test), or parametric statistical tests to compare them is precluded. In situations where statistical tests cannot be employed, a conventional strategy involves employing box plots to scrutinise the distributional properties and draw comparisons between the two datasets.
These tests were conducted for the main stellar parameters ([Fe/H], Teff, and log(𝑔)), the chemical dichotomy feature [α/Fe], and the guiding radius; this latter is a proxy for the stellar birth radius. In Appendix G, the comparison of the box plots indicates that the medians of the two distributions are nearly identical, or that they differ by an amount smaller than the typical uncertainty associated with each respective feature. As an example, the temperature difference is less than 100 K and the differences in log(𝑔) and abundance are less than 0.1 dex.
As anticipated, the interquartile ranges (IQRs) are smaller for almost all the tested features in the MCK-APOKASC sample, except for [Fe/H], which displays an IQR that is almost identical to that of the MRS-Gaia sample. Notably, the upper fences of each box plot consistently encompass the IQR of the larger MRS-Gaia sample. Consequently, one can confidently conclude that the training sample fairly underlines the MRS-Gaia sample.
In order to determine whether or not the Main Red Star sample effectively represents the population of red giants in the Galactic disc, we conducted a review of the APOGEE literature. Within the APOGEE framework, the accurate computation of selection biases is feasible for samples chosen in a genuinely random manner. This is due to the fact that only under such conditions can the sample selection function be reconstructed (Bovy et al. 2016b). The stars satisfying this criterion are referred to as the Main Red Star sample. Notably for previous APOGEE data releases, Nandakumar et al. (2017) showed that there is a negligible selection function effect on the metallicity distribution function (MDF) and the vertical metallicity gradients for APOGEE, RAVE (Steinmetz et al. 2006), and LAMOST (Zhao et al. 2012) using two stellar population synthesis models. This outcome suggests that it is feasible to combine data from different surveys when studying the MDF in common fields.
The selection function and completeness of the APOGEE DR17 Main Red Star sample are discussed in an article in preparation by members of the SDSS-IV collaboration (Imig et al. in prep). Consequently, one cannot currently address the potential limitations of the Main Red Star sample in fairly underlying the population of red giants in the Galactic disc.
Nevertheless, the APOGEE documentation online has already provided an analysis of previous selection functions relying on the Python code apogee, which are described in Bovy (2016) and in full detail in the associated documentation online1. These analyses revealed that APOGEE has covered an increasingly large portion of the sky, with a far higher selection fraction in many fields of the Main Red Star sample between DR12 and DR16. Notably, it is already known from APOGEE documentation that the number of stars passed from 357 167 in DR16 to 372458 in DR17. Finally, APOGEE has probed the vastest number of red giants for a great fraction of the sky in both the Northern and Southern Hemisphere (Abdurro’uf et al. 2022).
7.2 Comparison with other age maps
In the pioneering work of Ness (2018), age labels were provided for 73 180 red giant stars. The associated mean fractional error on age was reported to be 40%. The age map obtained with the CatBoost model is presented similarly to Fig. 14 in Ness (2018). Hereafter, we refer to this age map as the Ness map.
Similarly, Anders et al. (2023) contributed a catalogue of 178 825 red giants from APOGEE DR17. Their training sample consists of stars exclusively from the Kepler field (3060 stars) with ages sourced from Miglio et al. (2021). Achieving a median statistical uncertainty of 17% with an XGBoostRegressor, Anders et al. (2023) conducted validation plots that reproduced expected trends in chemistry, position, and kinematics with age. However, evaluating potential overfitting and underfitting, or assessing the bias and the variance of the model, is challenging due to the absence of learning curves in their study.
As discussed in Sect. 3, using the APOKASC-MCK training dataset for a CatBoostRegressor model results in more stable predictions (i.e. lower variance of the model) compared to training with an XGBoostRegressor model. Additionally, it is important to highlight that the dataset used in this study offers relevant advantages over the datasets used in the studies by Ness (2018) and Anders et al. (2023). For example, it includes more stars from the Kepler field (APOKASC-2 and APOGEE-Kepler) and also incorporates stars from the MCK catalogue. The inclusion of MCK stars is crucial, as explained in Sect. 5.3, because relying solely on data from the APOKASC catalogue for training leads to a significant drop in model performance when applied to stars from the MCK catalogue.
The enhancement in machine learning model performance is inherently linked to the amount of available data. This improvement can be attributed to several factors: a larger dataset provides more examples for learning, reducing the risk of overfitting. It better represents the diversity of cases, mitigating potential bias and allowing for the use of more complex models without over-fitting concerns. Additionally, a more extensive dataset reduces variance, resulting in more stable predictions while minimising statistical uncertainty. Consequently, the model can adjust its parameters more robustly and reliably.
Comparing the age map presented in this article (refer to Fig. 6) with those of Ness and Anders reveals several differences.
The map presented here spans a more comprehensive age range than the Ness map but a similar age range to the Anders map.
The stars in our map reach a greater vertical extension (−6 < Z (kpc) < 7) than in the maps of Ness and Anders, but a smaller extension along the Sun-Galactic centre axis (1.2 < X (kpc) < 14.7).
Our age map fills the gap of data found in the Ness map in the region (Z < −3 kpc, 0 < X (kpc) < 6) and that in the region (Z ≈ −2 kpc, 4 < X (kpc) < 6) for the map of Anders.
However, some similarities are also apparent.
Our map shows the flaring of the young Galactic disc (Age < 6 Gyr), as already outlined in the maps of Ness and Anders (refer to Fig. 6).
The youngest stars (Age ≤ 2 Gyr) are mostly found close to the Galactic plane (Z = 0 kpc) (refer to Fig. 7), as also revealed by the Ness and Anders maps.
The expected gap of data within the Galactic plane towards the bright Galactic centre for X < 6 kpc is also seen in all three maps. This gap prevents us from gaining insight into the age distribution close to the Galactic plane for this inner part of the Galaxy.
7.3 Unprecedented features in APOGEE age maps
The analysis of the APOGEE age map reveals new features not previously seen in other maps. The level of age resolution contributes to revealing the theoretically expected age gradient among the youngest stars within the Galactic plane (refer to Fig. 7). In order to unveil this gradient, the youngest stars were divided into two groups. The first group is made of stars younger than one billion years and the second contains stars of between one billion and two billion years old. As an example, while both groups share approximately the same median vertical height above the Galactic plane (m ≈ 0.30 kpc), the IQR of the youngest group (IQR ≈ 0.17) is significantly lower than that of the older group (IQR ≈ 0.47). This matches the findings of Mackereth et al. (2019) and the simulation results from Martig et al. (2014), where in periods of no gas accretion, new stars are born within the Galactic plane and are later kinematically heated. The kinematical heating is thought to be mainly due to disc growth with a combination of spiral arms and bars coupled with overdensities in the disc and vertical bending waves (Martig et al. 2014; Aumer et al. 2016).
Additionally, our results reveal that the newborn stars (Age < 1 Gyr) in the solar neighbourhood (7.5 < X (kpc) < 8.5) are clustered along a plane shifted approximately 300 pc from the Galactic plane. In contrast, beyond the solar neighbourhood, these stars are more scattered and there is a non-negligible number of them closer to the Galactic plane. Also, one notices a few newborn stars on the south side of the Galactic plane. In the solar neighbourhood, the resulting distribution of these newborn stars is expected from the analysis of the Local Bubble. The Local Bubble is a known zone of low gas density in which Zucker et al. (2022) found that the expansion of its surface has driven the star formation near the Sun. These authors found that almost all star-forming complexes within a 200 pc radius from the Sun are situated along the surface boundary of the Local Bubble and have experienced an outward expansion mainly orthogonal to the surface.
Two young metal-poor groups of stars were identified by analysing their stellar parameters. They have an age estimate of younger than 2 Gyr, matching the sparsely populated tail of the Main Red Star sample metallicity distribution ([Fe/H] ≲ −1 dex) (refer to Fig. G.1). These stars cluster in two distinct groups of abundance and stand out at a significance level exceeding 5σ from the mean [Fe/H] in the [α/Fe] versus [Fe/H] plane (refer to Fig. 8). Interestingly, they display orbital eccentricities of greater than 0.79. Such high values, for associated low [Fe/H], are known indicators of stars with halo kinematics (Reddy et al. 2006). We confirmed this possibility using the probabilistic kinematic stellar component technique described in Bensby et al. (2003, 2005). The results, summarised in Appendix E, namely in Tables E.1 and E.3, reveal that every star within these groups exhibits a probability of belonging to the halo of greater than 97%.
Subsequently, the dynamics of these groups was examined with the distribution of vertical angular momentum in relation to age, denoted as Lz (refer to Fig. 9). This distribution unveils bulk Lz values, from which these stars emerge as notable outliers.
In each group, stars show vertical angular momentum close to the group mean <Lz>. Both group means deviate from the bulk mean by more than 3σ, indicating the emergence of two distinct kinematic groups. This notable difference in kinematical properties is likely attributed to the distinct gravitational potentials experienced by the stars in these widely separated regions (approximately 6 kpc apart). Indeed the first group is situated in the range (6.04 < X (kpc) < 6.34, −0.33 < Y (kpc) < −0.28, 0.53 < Z (kpc) < 0.62), while the second one occupies the range (7.24 < X (kpc) < 7.42, −6.89 < Y (kpc) < −5.61, 0.88 < Z (kpc) < 1.07).
The existence of these young metal-poor stars is consistent with recent evidence pointing to a metal-poor gas infall, as reported by Spitoni et al. (2023). This gas infall event is estimated to have taken place around 2.7 Gyr ago.
We performed several tests to ensure the robust age derivation of these young metal-poor stars and to eliminate the possibility of machine learning artefacts. As these young red giants are absent from the comprehensive asteroseismic parameter catalogue of Hon et al. (2021), and corresponding light curves are unavailable in the TASOC database (Handberg et al. 2021; Lund et al. 2021), their ages could not be reliably calculated using state-of-the-art stellar modelling codes. However, one advantage of having Gaia luminosities is that the use of stellar tracks for mass determination is no longer required. Therefore, derivations of the stellar mass for red giants can be independent of the systematic errors originating from the effective temperature scale and the stellar tracks.
Consequently, the procedure to determine the stellar mass implies the use of the Stefan-Boltzmann and surface gravity equations, leading to an algebraic formula (refer to Eq. (2)) where L is the luminosity, 𝑔 is the surface gravity, σ is the Stefan-Boltzmann constant, G is the universal gravitational constant, and T is the effective temperature. This equation makes mass determination only dependent on the quality of the data, but not on stellar models.
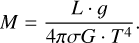 (2)
(2)
The associated uncertainties were propagated linearly. As the uncertainties on Teff and [Fe/H] are known to be underestimated from the ASPCAP abundance fitting procedure (García Pérez et al. 2016), it was decided to set them to 100 K and 0.1 dex. This enabled us to obtain more reliable uncertainties on the computed stellar masses (refer to Table E.2). Subsequently, we directly compared the masses and associated [Fe/H] to the comprehensive grid of BaSTI (Hidalgo et al. 2018; Pietrinferni et al. 2021) stellar tracks in order to derive the ages, using the publicly available online BaSTI stellar track table maker2. Only one star per group has displayed a sufficiently high median mass estimate and a sufficiently low mass uncertainty to provide a robust young age estimate from the stellar tracks (refer to Table 5).
The fact that these stars have clustered chemical and kinematical values provides confidence in the observation that they share similar age values below 2.7 Gyr. However, definitive confirmation of the age for the entire two groups will necessitate acquiring lower and more robust uncertainties in Teff and [Fe/H] with the future public release of the APOGEE SDSS V survey (Almeida et al. 2023) or acquiring their global asteroseismic parameters from dedicated surveys with TESS or the upcoming PLATO mission (Rauer et al. 2014).
The above tests provide evidence that at least two of these stars were recently made from the most recent metal-poor gas infall, as described in Spitoni et al. (2023). As the classical twoinfall model cannot predict this type of young low-metallicity population, the discovery of these stars advocates for the three-infall chemical evolution model described in Spitoni et al. (2023).
 |
Fig. 7 Youngest stars in the (X, Z) plane within the APOGEE map. |
 |
Fig. 8 [±/Fe] against [Fe/H] for the stars younger than 2 Gyr. |
 |
Fig. 9 Vertical angular momentum against the stellar age for the stars younger than 2 Gyr. |
Stellar parameters of the two most massive young metal-poor stars.
Partial content of the age catalogue.
8 Conclusion
We developed a machine learning model to provide a list of asteroseismically calibrated ages for the APOGEE DR17 catalogue, working with a sample of 6539 stars. One component of this sample comes from the TESS SCVZ catalogue (Mackereth et al. 2021) cross-matched with the APOGEE DR17 catalogue. The other component comes from the second APOKASC catalogue (Pinsonneault et al. 2018) updated with data from APOGEE DR17.
We introduce the main concepts underlying the construction and evaluation of a machine learning model. We justify the use of a CatBoostRegressor model by listing the advantages of tree-based models. In order to build the model, a feature-selection phase was first undertaken. We justify the selection of each feature. We then explain the several strategies used to optimise the performance of the model. We describe how we address the issue of the age-skewed target distribution by rescaling it with a logarithmic transformation. The imbalance in the data is managed by applying the random oversampling technique, which increases the representation of the minority class (ages older than 10 Gyr).
We identified a data shift between the APOKASC-2 and MCK samples. To address this shift, the two datasets were combined. We discuss the unreliable nature of the lowest values of the [Ce/Fe] abundances and constrain the criteria to mitigate their impact. By removing the unreliable [Ce/Fe], the performance of the model is improved, particularly in terms of standard deviation per age bin, which leads to a higher robustness in the resulting predictions.
The fully optimised model demonstrates performance characterised by a decreasing trend in the median fractional error and in the standard deviation per age bin as the age increases. The median fractional error reaches its lowest point at approximately 7% for ages between 10 and 11 Gyr, and its highest point at 43% for stars younger than 1 Gyr. The overall median fractional error reaches 20.8%.
Moreover, we tested the integrity of the CatBoostRegressor performances on an independent data set of the K2 Galactic Archaeology Program. This test shows that there is no significant decay in the performances of the model, indicating that the model is generalisable.
The model yields an age map made of 125,445 red giants from the Main Red Star Sample within the APOGEE DR17 catalogue. The associated age catalogue is available at the CDS and Table 6 depicts some of its columns.
The age map reveals features confirming the flaring of the disc young stars (Age < 6 Gyr) towards the Galaxy’s outer regions, as previously found in Ness (2018) and Anders et al. (2023). Furthermore, features not previously found in Ness (2018) and Anders et al. (2023) are revealed. Notably, our map shows two groups of young metal-poor stars. Their chemical abundance and kinematical parameters appear to be clustered. In each group, the most massive star can be robustly dated using the BaSTI stellar tracks (Hidalgo et al. 2018; Pietrinferni et al. 2021) confirming an age of below 2.7 Gyr. This provides evidence supporting the most recent metal-poor gas infall proposed by Spitoni et al. (2023) and therefore advocates for their three-infall chemical evolution model.
In the future, the performance of the CatBoost model is expected to improve with the release of larger datasets from the APOGEE consortium. Indeed the cross-match of APOGEE DR17 with the MCK catalogue leads to only 1025 stars among the 5574 stars benefiting from the most reliable asteroseismic data within the TESS-SCVZ. The first public release of SDSS V is expected to fill this gap. Moreover, the forthcoming PLATO mission is anticipated to make a substantial contribution to the augmentation of both the quantity and quality of data available for Galactic archaeology (Miglio et al. 2017). Indeed, it will bring higher precision in asteroseismic data associated with a 20 times larger field of view than the Kepler mission (2132 deg2 vs 105 deg2) in two long-pointing surveys of 2 yr each. Therefore, the portion of ages derived with stellar modelling codes will need to scale this increase in available data to benefit the machine learning training samples. Consequently, there are substantial grounds to anticipate an enhancement in the performance of machine learning models, which will play a crucial role in leading the field of Galactic archaeology to new discoveries.
Acknowledgements
I acknowledge the Fundação para Ciênça e Technologia for its financial support through the grant PD/BD/150426/2019. I would like to express my gratitude to the referee for her remarks and advice. Moreover, I thank Aldo Serenelli for his advice regarding the robust dating of the young metal-poor stars and the age errors in the Second APOKASC catalogue. I thank Tiago Campante for his advice regarding the choice of the training age-asteroseismic catalogues. I thank Vardan Adibekyan for his advice regarding the kinematics and chemical analysis. I thank Andrew Humphrey for his advice regarding the optimisation of the machine learning performances. I thank Elisa Delgado Meña for her advice regarding the Cerium abundance and the Barium stars. I thank Andreas Neitzel for his advice regarding the choice of the 3D dust maps and the criteria to refine the quality of the parallaxes. Finally, I thank them all for the general advice they gave me on the paper as a whole.
Appendix A Spearman coefficients matrix
 |
Fig. A.1 Map of the Spearman correlation coefficients for the [X/Ce] abundances. |
Appendix B Comparison between two scales of temperature
The graphical representation of the ordinary least square regression between APOGEE DR17 and SkyMapper effective temperature values for the MCK component of the training sample is displayed in Figure B.1. Regression quality parameters obtained for the fit can be found in Table B.1. The p-value of the F-statistic test reveals the linear relation is statistically significant. The regression slope and the R2 are approximately close to one, and therefore one can state the two sets of temperatures form a coherent ensemble.
 |
Fig. B.1 Regression plot between effective temperatures provided by APOGEE DR17 and SkyMapper on the MCK component of the training sample. |
Summary of some of the statsmodel Python parameters provided for an ordinary least square regression.
Appendix C The data sets
 |
Fig. C.1 Visual representation of the spatial location of the APOKASC-2 and MCK components of the training-test sample, plus the K2-GALAH sample. The X-axis represents the distance from the Galactic centre. |
Appendix D Hyperparameters of CatBoost
List of the hyperparameters tuned for the grid optimisation of the data. The ones not mentioned kept their default values.
Appendix E The young metal-poor stars
In this section, the probability threshold for a star to belong to a stellar kinematic component is 70%. It is taken from Adibekyan et al. (2012). The probabilities were computed using the probabilistic method described in Bensby et al. (2003, 2005).
Kinematic properties pertaining to the first group of young metal-poor stars. From left to right the parameters are the Gaia DR3 identifier, the three velocity components in the local standard of rest, the orbital eccentricity, the probability of belonging to a given kinematic population, and the designation of the kinematic population to which the star is affiliated.
Stellar parameters for the first group of young metal-poor stars. The errors on log(𝑔) originate from the predictions of the neural network reported in APOGEE DR17. The ages are derived from the CatBoostRegressor model. The errors on age are computed based on the median fractional error obtained with the model for ages between one and two billion years, i.e. 26%.
Appendix F Extra Age map plots
One of the means to assess the quality of the model is to check for the expected general symmetry of ages in relation to the vertical distance from the Galactic star formation plane. Figure F.1 illustrates that the three chosen age groups exhibit a clear overlap. Since this study and previous ones (Ness 2018; Anders et al. 2023) highlight that the flaring of the young Galactic disc is most noticeable for stars under 6 billion years old, this age was chosen as the threshold for the second group. Specifically, the three groups share a similar median (m ~ 0.25 kpc). Progressing from the youngest to the oldest group, the skewness values are s=0.46, s=0.81, and s=0.15, indicating negligible skewness (|s| < 1). Notably, the skewness for all ages is s=0.18.
 |
Fig. F.1 Plot of histograms regarding the Z feature across three age groups from the age map. |
Appendix G Extra statistical plots
 |
Fig. G.1 Box plots of the [Fe/H] distributions for the MCK-APOKASC and MRS-Gaia samples. |
 |
Fig. G.2 Box plots of the Teff distributions for the MCK-APOKASC and MRS-Gaia samples. |
 |
Fig. G.3 Box plots of the log(𝑔) distributions for the MCK-APOKASC and MRS-Gaia samples. |
 |
Fig. G.4 Box plots of the [α/Fe] distributions for the MCK-APOKASC and MRS-Gaia samples. |
 |
Fig. G.5 Box plots of the guiding radius distributions for the MCK-APOKASC and MRS-Gaia samples. |
 |
Fig. G.6 Histogram of log(𝑔) for the MRS-Gaia sample without the cut on log(𝑔). |
References
- Abdurro’uf, Accetta, K., Aerts, C., et al. 2022, ApJS, 259, 35 [NASA ADS] [CrossRef] [Google Scholar]
- Adibekyan, V. Z., Sousa, S. G., Santos, N. C., et al. 2012, A&A, 545, A32 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Alecian, G., Michel, E., Auvergne, M., et al. 2007, in JENAM-2007, “Our Non-Stable Universe”, 12 [Google Scholar]
- Almeida, A., Anderson, S. F., Argudo-Fernández, M., et al. 2023, ApJS, 267, 44 [NASA ADS] [CrossRef] [Google Scholar]
- Anders, F., Gispert, P., Ratcliffe, B., et al. 2023, A&A, 678, A158 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Anguiano, B., Majewski, S. R., Hayes, C. R., et al. 2020, AJ, 160, 43 [NASA ADS] [CrossRef] [Google Scholar]
- Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2018, AJ, 156, 123 [Google Scholar]
- Astropy Collaboration (Price-Whelan, A. M., et al.) 2022, ApJ, 935, 167 [NASA ADS] [CrossRef] [Google Scholar]
- Aumer, M., Binney, J., & Schönrich, R. 2016, MNRAS, 462, 1697 [NASA ADS] [CrossRef] [Google Scholar]
- Bailer-Jones, C. A. L., Rybizki, J., Fouesneau, M., Demleitner, M., & Andrae, R. 2021, AJ, 161, 147 [Google Scholar]
- Bensby, T., Feltzing, S., & Lundström, I. 2003, A&A, 410, 527 [CrossRef] [EDP Sciences] [Google Scholar]
- Bensby, T., Feltzing, S., Lundström, I., & Ilyin, I. 2005, A&A, 433, 185 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bland-Hawthorn, J., & Gerhard, O. 2016, ARA&A, 54, 529 [Google Scholar]
- Bovy, J. 2015, ApJS, 216, 29 [NASA ADS] [CrossRef] [Google Scholar]
- Bovy, J. 2016, ApJ, 817, 49 [NASA ADS] [CrossRef] [Google Scholar]
- Bovy, J., Rix, H.-W., Green, G. M., Schlafly, E. F., & Finkbeiner, D. P. 2016a, ApJ, 818, 130 [Google Scholar]
- Bovy, J., Rix, H.-W., Schlafly, E. F., et al. 2016b, ApJ, 823, 30 [NASA ADS] [CrossRef] [Google Scholar]
- Buder, S., Sharma, S., Kos, J., et al. 2021, MNRAS, 506, 150 [NASA ADS] [CrossRef] [Google Scholar]
- Casagrande, L., & VandenBerg, D. A. 2014, MNRAS, 444, 392 [Google Scholar]
- Casagrande, L., & VandenBerg, D. A. 2018a, MNRAS, 479, L102 [NASA ADS] [CrossRef] [Google Scholar]
- Casagrande, L., & VandenBerg, D. A. 2018b, MNRAS, 475, 5023 [Google Scholar]
- Casagrande, L., Silva Aguirre, V., Schlesinger, K. J., et al. 2015, MNRAS, 455, 987 [Google Scholar]
- Casali, G., Spina, L., Magrini, L., et al. 2020, A&A, 639, A127 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casali, G., Grisoni, V., Miglio, A., et al. 2023, A&A, 677, A60 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casamiquela, L., Soubiran, C., Jofré, P., et al. 2021, A&A, 652, A25 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Chen, T., & Guestrin, C. 2016, in 22nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 785 [Google Scholar]
- Contursi, G., de Laverny, P., Recio-Blanco, A., et al. 2023, A&A, 670, A106 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- da Silva, R., Porto de Mello, G. F., Milone, A. C., et al. 2012, A&A, 542, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Deal, M., Richard, O., & Vauclair, S. 2021, A&A, 646, A160 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- de Castro, D. B., Pereira, C. B., Roig, F., et al. 2016, MNRAS, 459, 4299 [NASA ADS] [CrossRef] [Google Scholar]
- Delgado Mena, E., Moya, A., Adibekyan, V., et al. 2019, A&A, 624, A78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ding, P.-J., Xue, X.-X., Yang, C., et al. 2021, AJ, 162, 112 [Google Scholar]
- Elsworth, Y., Hekker, S., Basu, S., & Davies, G. R. 2017, MNRAS, 466, 3344 [NASA ADS] [CrossRef] [Google Scholar]
- Ferov, M., & Modrý, M. 2016, arXiv e-prints [arXiv:1609.05610] [Google Scholar]
- Feuillet, D. K., Bovy, J., Holtzman, J., et al. 2018, MNRAS, 477, 2326 [NASA ADS] [CrossRef] [Google Scholar]
- Forsberg, R., Jönsson, H., Ryde, N., & Matteucci, F. 2019, A&A, 631, A113 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Prusti, T., et al.) 2016, A&A, 595, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Gaia Collaboration (Vallenari, A., et al.) 2023, A&A, 674, A1 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- García Pérez, A. E., Allende Prieto, C., Holtzman, J. A., et al. 2016, AJ, 151, 144 [Google Scholar]
- Gaulme, P., McKeever, J., Jackiewicz, J., et al. 2016, ApJ, 832, 121 [NASA ADS] [CrossRef] [Google Scholar]
- Gonzalez, O. A., Rejkuba, M., Zoccali, M., et al. 2011, A&A, 530, A54 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Green, G. M., Schlafly, E., Zucker, C., Speagle, J. S., & Finkbeiner, D. 2019, ApJ, 887, 93 [NASA ADS] [CrossRef] [Google Scholar]
- Handberg, R., Lund, M. N., White, T. R., et al. 2021, AJ, 162, 170 [NASA ADS] [CrossRef] [Google Scholar]
- Hasselquist, S., Holtzman, J. A., Shetrone, M., et al. 2019, ApJ, 871, 181 [NASA ADS] [CrossRef] [Google Scholar]
- Hastie, T., Tibshirani, R., & Friedman, J. 2009, Ensemble Learning (New York, NY: Springer New York), 605 [Google Scholar]
- Hawkins, K., & Wyse, R. F. G. 2018, MNRAS, 481, 1028 [NASA ADS] [CrossRef] [Google Scholar]
- Hayden, M. R., Bovy, J., Holtzman, J. A., et al. 2015, ApJ, 808, 132 [Google Scholar]
- Hayden, M. R., Sharma, S., Bland-Hawthorn, J., et al. 2022, MNRAS, 517, 5325 [NASA ADS] [CrossRef] [Google Scholar]
- Hekker, S. 2018, Asteroseismology of Red Giants and Galactic Archaeology, 49 (Springer), 95 [NASA ADS] [Google Scholar]
- Hidalgo, S. L., Pietrinferni, A., Cassisi, S., et al. 2018, ApJ, 856, 125 [Google Scholar]
- Holtzman, J. A., Shetrone, M., Johnson, J. A., et al. 2015, AJ, 150, 148 [Google Scholar]
- Holtzman, J. A., Hasselquist, S., Shetrone, M., et al. 2018, AJ, 156, 125 [Google Scholar]
- Hon, M., Huber, D., Kuszlewicz, J. S., et al. 2021, ApJ, 919, 131 [NASA ADS] [CrossRef] [Google Scholar]
- Johnson, D. R. H., & Soderblom, D. R. 1987, AJ, 93, 864 [Google Scholar]
- Jones, E., Oliphant, T., Peterson, P., et al. 2001, SciPy: Open source scientific tools for Python, http://www.scipy.org [Google Scholar]
- Jönsson, H., Holtzman, J. A., Allende Prieto, C., et al. 2020, AJ, 160, 120 [Google Scholar]
- Jorissen, A., Boffin, H. M. J., Karinkuzhi, D., et al. 2019, A&A, 626, A127 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Karakas, A. I. 2010, Astrophys. Space Sci. Proc., 16, 107 [NASA ADS] [CrossRef] [Google Scholar]
- Kobayashi, C., Karakas, A. I., & Lugaro, M. 2020, ApJ, 900, 179 [Google Scholar]
- Koch, D. G., Borucki, W. J., Basri, G., et al. 2010, ApJ, 713, L79 [Google Scholar]
- Kumar, A., Ghosh, S., Kataria, S. K., Das, M., & Debattista, V. P. 2022, MNRAS, 516, 1114 [NASA ADS] [CrossRef] [Google Scholar]
- Lebreton, Y., & Montalbán, J. 2009, in The Ages of Stars, 258, eds. E. E. Mamajek, D. R. Soderblom, & R. F. G. Wyse, 419 [NASA ADS] [Google Scholar]
- Lebreton, Y., Goupil, M. J., & Montalbán, J. 2014, in EAS Pub. Ser., 65, eds. Y. Lebreton, D. Valls-Gabaud, & C. Charbonnel, 177 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Lemaître, G., Nogueira, F., & Aridas, C. K. 2017, J. Mach. Learn. Res., 18, 1 [Google Scholar]
- Leung, H. W., & Bovy, J. 2019, MNRAS, 483, 3255 [NASA ADS] [Google Scholar]
- Lund, M. N., Handberg, R., Buzasi, D. L., et al. 2021, ApJS, 257, 53 [NASA ADS] [CrossRef] [Google Scholar]
- Lundberg, S. M., & Lee, S.-I. 2017, in Advances in Neural Information Processing Systems, 30, eds. I. Guyon, U. V. Luxburg, S. Bengio, et al. (Curran Associates, Inc.), 4765 [Google Scholar]
- Mackereth, J. T., Bovy, J., Leung, H. W., et al. 2019, MNRAS, 489, 176 [Google Scholar]
- Mackereth, J. T., Miglio, A., Elsworth, Y., et al. 2021, MNRAS, 502, 1947 [NASA ADS] [CrossRef] [Google Scholar]
- Majewski, S. R., Schiavon, R. P., Frinchaboy, P. M., et al. 2017, AJ, 154, 94 [NASA ADS] [CrossRef] [Google Scholar]
- Martig, M., Minchev, I., & Flynn, C. 2014, MNRAS, 443, 2452 [Google Scholar]
- Martig, M., Fouesneau, M., Rix, H.-W., et al. 2016, MNRAS, 456, 3655 [NASA ADS] [CrossRef] [Google Scholar]
- Masseron, T., & Gilmore, G. 2015, MNRAS, 453, 1855 [CrossRef] [Google Scholar]
- Miglio, A., Chiappini, C., Morel, T., et al. 2012, MNRAS, 429, 423 [Google Scholar]
- Miglio, A., Chiappini, C., Mosser, B., et al. 2017, Astron. Nachr., 338, 644 [Google Scholar]
- Miglio, A., Chiappini, C., Mackereth, J. T., et al. 2021, A&A, 645, A85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Morel, T., Creevey, O. L., Montalbán, J., Miglio, A., & Willett, E. 2021, A&A, 646, A78 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Moya, A., Sarro, L. M., Delgado-Mena, E., et al. 2022, A&A, 660, A15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nandakumar, G., Schultheis, M., Hayden, M., et al. 2017, A&A, 606, A97 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Ness, M. 2018, PASA, 35, e003 [NASA ADS] [CrossRef] [Google Scholar]
- Ness, M., Hogg, D. W., Rix, H.-W., Ho, A. Y. Q., & Zasowski, G. 2015, ApJ, 808, 16 [NASA ADS] [CrossRef] [Google Scholar]
- Ness, M., Hogg, D. W., Rix, H. W., et al. 2016, ApJ, 823, 114 [NASA ADS] [CrossRef] [Google Scholar]
- Nissen, P. E. 2015, A&A, 579, A52 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Nissen, P. E., Christensen-Dalsgaard, J., Mosumgaard, J. R., et al. 2020, A&A, 640, A81 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Osorio, Y., Allende Prieto, C., Hubeny, I., Mészáros, S., & Shetrone, M. 2020, A&A, 637, A80 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, J. Mach. Learn. Res., 12, 2825 [Google Scholar]
- Pietrinferni, A., Hidalgo, S., Cassisi, S., et al. 2021, ApJ, 908, 102 [NASA ADS] [CrossRef] [Google Scholar]
- Pinsonneault, M. H., Elsworth, Y. P., Tayar, J., et al. 2018, ApJS, 239, 32 [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Prokhorenkova, L., Gusev, G., Vorobev, A., Dorogush, A. V., & Gulin, A. 2018, in Proceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS'18 (Red Hook, NY, USA: Curran Associates Inc.), 6639 [Google Scholar]
- Queiroz, A. B. A., Anders, F., Chiappini, C., et al. 2020, A&A, 638, A76 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rauer, H., Catala, C., Aerts, C., et al. 2014, Exp. Astron., 38, 249 [Google Scholar]
- Reddy, B. E., Lambert, D. L., & Allende Prieto, C. 2006, MNRAS, 367, 1329 [Google Scholar]
- Reid, M. J., & Brunthaler, A. 2004, ApJ, 616, 872 [Google Scholar]
- Rendle, B. M., Miglio, A., Chiappini, C., et al. 2019, MNRAS, 490, 4465 [NASA ADS] [CrossRef] [Google Scholar]
- Ricker, G. R., Winn, J. N., Vanderspek, R., et al. 2014, SPIE Conf. Ser., 9143, 914320 [Google Scholar]
- Rodrigues, T. S., Bossini, D., Miglio, A., et al. 2017, MNRAS, 467, 1433 [NASA ADS] [Google Scholar]
- Rojas-Arriagada, A., Recio-Blanco, A., de Laverny, P., et al. 2017, A&A, 601, A140 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Salaris, M., & Cassisi, S. 2005, Evolution of Stars and Stellar Populations (Wiley-VCH) [Google Scholar]
- Serenelli, A. M., Bergemann, M., Ruchti, G., & Casagrande, L. 2013, MNRAS, 429, 3645 [NASA ADS] [CrossRef] [Google Scholar]
- Serenelli, A., Johnson, J., Huber, D., et al. 2017, ApJS, 233, 23 [Google Scholar]
- Sharma, S., Stello, D., Buder, S., et al. 2018, MNRAS, 473, 2004 [NASA ADS] [CrossRef] [Google Scholar]
- Sharma, S., Hayden, M. R., Bland-Hawthorn, J., et al. 2021, MNRAS, 510, 734 [NASA ADS] [CrossRef] [Google Scholar]
- Sharma, S., Hayden, M. R., Bland-Hawthorn, J., et al. 2022, MNRAS, 510, 734 [Google Scholar]
- Skrutskie, M. F., Cutri, R. M., Stiening, R., et al. 2006, AJ, 131, 1163 [NASA ADS] [CrossRef] [Google Scholar]
- Smiljanic, R., Romano, D., Bragaglia, A., et al. 2016, A&A, 589, A115 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Soderblom, D. R. 2010, ARA&A, 48, 581 [Google Scholar]
- Spitoni, E., Vincenzo, F., Matteucci, F., & Romano, D. 2016, MNRAS, 458, 2541 [Google Scholar]
- Spitoni, E., Recio-Blanco, A., de Laverny, P., et al. 2023, A&A, 670, A109 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Steinmetz, M., Zwitter, T., Siebert, A., et al. 2006, AJ, 132, 1645 [Google Scholar]
- Stello, D., Zinn, J., Elsworth, Y., et al. 2017, ApJ, 835, 83 [NASA ADS] [CrossRef] [Google Scholar]
- Ting, Y.-S., Conroy, C., Rix, H.-W., & Cargile, P. 2019, ApJ, 879, 69 [Google Scholar]
- Weinberg, D. H., Holtzman, J. A., Hasselquist, S., et al. 2019, ApJ, 874, 102 [NASA ADS] [CrossRef] [Google Scholar]
- Weinberg, D. H., Holtzman, J. A., Johnson, J. A., et al. 2022, ApJS, 260, 32 [NASA ADS] [CrossRef] [Google Scholar]
- Xiang, M., Ting, Y.-S., Rix, H.-W., et al. 2019, ApJS, 245, 34 [Google Scholar]
- Young, H. P. 1985, Int. J. Game Theory, 14, 65 [Google Scholar]
- Zhao, G., Zhao, Y.-H., Chu, Y.-Q., Jing, Y.-P., & Deng, L.-C. 2012, Res. Astron. Astrophys., 12, 723 [NASA ADS] [CrossRef] [Google Scholar]
- Zinn, J. C., Pinsonneault, M. H., Huber, D., et al. 2019, ApJ, 885, 166 [Google Scholar]
- Zinn, J. C., Stello, D., Elsworth, Y., et al. 2022, ApJ, 926, 191 [NASA ADS] [CrossRef] [Google Scholar]
- Zucker, C., Goodman, A. A., Alves, J., et al. 2022, Nature, 601, 334 [NASA ADS] [CrossRef] [Google Scholar]
All Tables
Spearman correlation coefficients with their p-values for the relations involving [X/Fe] vs. age.
Summary of some of the statsmodel Python parameters provided for an ordinary least square regression.
List of the hyperparameters tuned for the grid optimisation of the data. The ones not mentioned kept their default values.
Kinematic properties pertaining to the first group of young metal-poor stars. From left to right the parameters are the Gaia DR3 identifier, the three velocity components in the local standard of rest, the orbital eccentricity, the probability of belonging to a given kinematic population, and the designation of the kinematic population to which the star is affiliated.
Stellar parameters for the first group of young metal-poor stars. The errors on log(𝑔) originate from the predictions of the neural network reported in APOGEE DR17. The ages are derived from the CatBoostRegressor model. The errors on age are computed based on the median fractional error obtained with the model for ages between one and two billion years, i.e. 26%.
All Figures
|
Fig. 1 Ensemble of plots summarising the information on the APOKASC-2 component of the research sample. Panel a: age histogram. A box plot is systematically added to the histograms. Panel b: histogram of the random fractional uncertainties on age. Panel c: histogram comparison of the current galactocentric distances and the guiding radii. Panel d: HR diagram of the sample. Panel e: Toomre diagram of the velocities in the galactocentric referential. Panel f: age vs metallicity. Panel g: [α/Fe] vs [Fe/H] plane. The black point with error bars depicts the mean uncertainty for both parameters. |
| In the text | |
|
Fig. 2 Ensemble of plots summarising the information on the MCK component of the research sample. We refer to Fig. 1 for the description of the panels. |
| In the text | |
|
Fig. 3 Ensemble of plots summarising the final performances on the MCK-APOKASC training-test sample. Panel a: evolution of the median of the absolute value for the fractional error on age per bin. Panel b: comparison of the ages of reference and those predicted by the model. The black line is the identity function ∣ΔA/A∣is the absolute fractional error on age. The black error bars represent the means of the errors in age. Panel c: evolution of the standard deviation of the fractional error on age per bin. The vertical-horizontal bar depicts the mean value for the whole age range. Panel d: histogram of the absolute fractional error on age. Panel e: bar plot of the feature importance for all the retained features. Panel f: Plot of the learning curves. |
| In the text | |
|
Fig. 4 Corner plot of the retained stellar features, with a significant correlation with age, in the full training sample (MCK-APOKASCK). The diagonal depicts the histogram associated with each feature and the triangular bulk displays the correlation trends between each feature. Each plot displays the associated Spearman correlation coefficient (ρ) with the p-value of the test. |
| In the text | |
|
Fig. 5 Ensemble of plots summarising the performance of the model on the K2-GALAH sample. Panel a: plot of the scatter between the predicted ages and reference ages. The black line serves to visualise the residuals. Panel b: histogram of the absolute residuals between the predicted ages and the reference ages in absolute value. |
| In the text | |
|
Fig. 6 APOGEE age map for the sample of red giants computed with CatBoost. |
| In the text | |
|
Fig. 7 Youngest stars in the (X, Z) plane within the APOGEE map. |
| In the text | |
|
Fig. 8 [±/Fe] against [Fe/H] for the stars younger than 2 Gyr. |
| In the text | |
|
Fig. 9 Vertical angular momentum against the stellar age for the stars younger than 2 Gyr. |
| In the text | |
|
Fig. A.1 Map of the Spearman correlation coefficients for the [X/Ce] abundances. |
| In the text | |
|
Fig. B.1 Regression plot between effective temperatures provided by APOGEE DR17 and SkyMapper on the MCK component of the training sample. |
| In the text | |
|
Fig. C.1 Visual representation of the spatial location of the APOKASC-2 and MCK components of the training-test sample, plus the K2-GALAH sample. The X-axis represents the distance from the Galactic centre. |
| In the text | |
|
Fig. F.1 Plot of histograms regarding the Z feature across three age groups from the age map. |
| In the text | |
|
Fig. G.1 Box plots of the [Fe/H] distributions for the MCK-APOKASC and MRS-Gaia samples. |
| In the text | |
|
Fig. G.2 Box plots of the Teff distributions for the MCK-APOKASC and MRS-Gaia samples. |
| In the text | |
|
Fig. G.3 Box plots of the log(𝑔) distributions for the MCK-APOKASC and MRS-Gaia samples. |
| In the text | |
|
Fig. G.4 Box plots of the [α/Fe] distributions for the MCK-APOKASC and MRS-Gaia samples. |
| In the text | |
|
Fig. G.5 Box plots of the guiding radius distributions for the MCK-APOKASC and MRS-Gaia samples. |
| In the text | |
|
Fig. G.6 Histogram of log(𝑔) for the MRS-Gaia sample without the cut on log(𝑔). |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.