| Issue |
A&A
Volume 685, May 2024
|
|
|---|---|---|
| Article Number | A161 | |
| Number of page(s) | 41 | |
| Section | Numerical methods and codes | |
| DOI | https://doi.org/10.1051/0004-6361/202346978 | |
| Published online | 22 May 2024 | |
GalaPy: A highly optimised C++/Python spectral modelling tool for galaxies
I. Library presentation and photometric fitting
1
Scuola Internazionale Superiore di Studi Avanzati (SISSA),
Via Bonomea 265,
34136
Trieste,
Italy
e-mail: This email address is being protected from spambots. You need JavaScript enabled to view it.
2
Institute for Fundamental Physics of the Universe (IFPU),
Via Beirut 2,
34151
Trieste,
Italy
3
INAF – Osservatorio di Astrofisica e Scienza dello Spazio (OAS),
Via Gobetti 93/3,
40127
Bologna,
Italy
4
IRA-INAF,
Via Gobetti 101,
40129
Bologna,
Italy
5
INFN-Sezione di Trieste,
Via Valerio 2,
34127
Trieste,
Italy
6
National Centre for Nuclear Research,
Pasteura 7,
02-093
Warsaw,
Poland
7
Sterrenkundig Observatorium Universiteit Gent,
Krijgslaan 281 S9,
9000
Gent,
Belgium
8
Dip. Fisica e Astronomia ’Augusto Righi’, Univ. Bologna,
Viale Berti Pichat 6/2,
40127,
Bologna,
Italy
9
INAF – Osservatorio Astrofisico di Arcetri,
Largo Enrico Fermi, 5,
50125
Firenze,
FI,
Italy
10
INAF-OATS,
Via Tiepolo 11,
34143
Trieste,
Italy
11
ICSC – Centro Nazionale di Ricerca in High Performance Computing, Big Data e Quantum Computing,
Via Magnanelli 2,
Bologna,
Italy
Received:
23
May
2023
Accepted:
20
February
2024
Abstract
Bolstered by upcoming data from new-generation observational campaigns, we are about to enter a new era in the study of how galaxies form and evolve. The unprecedented quantity of data that will be collected from distances that have only marginally been grasped up to now will require analytical tools designed to target the specific physical peculiarities of the observed sources and handle extremely large datasets. One powerful method to investigate the complex astrophysical processes that govern the properties of galaxies is to model their observed spectral energy distributions (SEDs) at different stages of evolution and times throughout the history of the Universe. To address these challenges, we have developed GalaPy, a new library for modelling and fitting SEDs of galaxies from the X-ray to the radio band, as well as the evolution of their components and dust attenuation and reradiation. On the physical side, GalaPy incorporates both empirical and physically motivated star formation histories (SFHs), state-of-the-art single stellar population synthesis libraries, a two-component dust model for attenuation, an age-dependent energy conservation algorithm to compute dust reradiation, and additional sources of stellar continuum such as synchrotron, nebular and free-free emission, as well as X-ray radiation from low-and high-mass binary stars. On the computational side, GalaPy implements a hybrid approach that combines the high performance of compiled C++ with the user-friendly flexibility of Python. Also, it exploits an object-oriented design via advanced programming techniques. GalaPy is the fastest SED-generation tool of its kind, with a peak performance of almost 1000 SEDs per second. The models are generated on the fly without relying on templates, thus minimising memory consumption. It exploits a fully Bayesian parameter space sampling, which allows for the inference of parameter posteriors and thereby facilitates the study of the correlations between the free parameters and the other physical quantities that can be derived from modelling. The application programming interface (API) and functions of GalaPy are under continuous development, with planned extensions in the near future. In this first work, we introduce the project and showcase the photometric SED fitting tools already available to users. GalaPy is available on the Python Package Index (PyPI) and comes with extensive online documentation and tutorials.
Key words: methods: data analysis / galaxies: evolution / galaxies: high-redshift / galaxies: photometry
© The Authors 2024
 Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Open Access article, published by EDP Sciences, under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
This article is published in open access under the Subscribe to Open model. This email address is being protected from spambots. You need JavaScript enabled to view it. to support open access publication.
1 Introduction
Galaxies are extremely complex astrophysical objects resulting from the processes affecting baryonic matter after its collapse within dark matter halos. Their formation and evolution strongly depend on the interplay of several factors, including their matter reservoir and accretion history, their environment and possible interactions with neighbours and, ultimately, the large scale structure of the Universe and the physics regulating it on cosmo-logical scales. By studying the properties of individual galaxies, such as their luminosity, stellar mass, chemical composition, and star formation history, we can learn how such objects form and evolve over time as well as the cosmological conditions that lead to their assembly.
The broadband spectral energy distribution (SED) of a galaxy describes the distribution of its light across the electromagnetic spectrum, from gamma rays to radio waves, and bears the imprints of the baryonic components and processes determining its evolutionary history. Galaxy SEDs constitute primary tools of extra-galactic astronomy to constrain models of galaxy formation and evolution, which are an essential part for our understanding of the Universe as a whole. The majority of commonly used SED fitting tools (e.g. Da Cunha et al. 2008; Chevallard & Charlot 2016; Carnall et al. 2018; Boquien et al. 2019; Johnson et al. 2021; Vidal-García et al. 2024; Doore et al. 2023) have mainly been developed for studies of low-redshift objects, thus providing the user with empirical fitting recipes that are (mostly) constrained in the local Universe. Even though such tools have been extensively used in constraining the physical properties of galaxies, even at high redshift, they lack a physically motivated interplay between the recipes they use and the actual evolution of the modelled galaxy SED over cosmic time. In several studies, this has required some tweaking and hacking, especially when it comes to the high-redshift Universe (Novak et al. 2017; Jin et al. 2018; Wang et al. 2019; Gruppioni et al. 2020; Pantoni et al. 2021; Talia et al. 2021; Giulietti et al. 2023; Enia et al. 2022; Jin et al. 2022; Castellano et al. 2022; Rodighiero et al. 2022; Finkelstein et al. 2023). Moreover, since the quality and spectral resolution of the SEDs in high-z galaxies are typically much worse than for local objects, a detailed modelling of spectral features can be traded off for a focus on the quantities crucial to derive information about the star formation histories, dust content, and properties of the interstellar medium (see, e.g. Förster Schreiber & Wuyts 2020; Tacconi et al. 2020, for two reviews on high redshift galaxies and the evolution of their content).
On the theoretical side, investigating the SEDs of high-z galaxies can inform us about the evolution of the overall galaxy population across cosmic times. For example, one crucial issue in galaxy evolution concerns the formation of local quiescent galaxies; the issue can (in principle) be resolved by investigating the SEDs of their high-redshift progenitors, which are thought to be dust-enshrouded star-forming objects forming most of their stars at z ≳ 2, during the so-called cosmic noon or further back in time during cosmic dawn, at z ≳ 3 (Shapley 2011; Lapi et al. 2018; Gruppioni et al. 2020; Talia et al. 2021). In addition, more physical (but also time-consuming) radiative transfer SED models (e.g. Silva et al. 1998; Camps & Baes 2020) are not suitable for application to the large observational datasets that are available.
In fact, on the observational side, ongoing and upcoming experiments are (and will continue to be) producing an ever-increasing amount of data from galaxies at high redshifts. For example, ALMA has opened a window up to redshift z ~ 8 in the (sub-)millimetre bands (see e.g. Walter et al. 2012; Simpson et al. 2014, 2017, 2020; Brisbin et al. 2017; González-López et al. 2017; Scoville et al. 2017; Franco et al. 2018; Bischetti et al. 2019; Dudzeviciute et al. 2020; Gruppioni et al. 2020; Pensabene et al. 2020, 2021; Hodge & da Cunha 2020; Smail et al. 2021; Ferrara et al. 2022; Hamed et al. 2023). Meanwhile, JWST is investigating the Universe in the observed near-IR (NIR) bands, both in photometry and spectroscopy, out to the Epoch of Reionization (EoR) and beyond (e.g. Castellano et al. 2022; Naidu et al. 2022; Labbé et al. 2023; Finkelstein et al. 2022; Adams et al. 2023; Atek et al. 2023; Harikane et al. 2023; Yan et al. 2023); these data complement the already available multi-wavelength datasets from large high-z observational campaigns, such as the Great Observatories Origins Survey (GOODS, Giavalisco et al. 2004), Hubble Ultra-Deep Field (HUDF, Beckwith et al. 2006), and COSMOS (Scoville et al. 2007), as well as data from deep and large-area blind surveys in the infrared domain, such as PACS Evolutionary Probe (PEP, Lutz et al. 2011), Herschel Multi-tired Extra-galactic Survey (Her-MES, Oliver et al. 2012), Herschel Astrophysical Terahertz Large Area Survey (H-ATLAS, Eales et al. 2010), and Herschel Extragalactic Legacy Project (HELP, Shirley et al. 2019, 2021). Ongoing experiments, such as the Evolutionary Map of the Universe (EMU, Norris et al. 2021), performed with ASKAP (Johnston et al. 2007, 2008; McConnell et al. 2016; Hotan et al. 2021) and the MeerKAT (Booth & Jonas 2012; Jonas & MeerKAT Team 2016) International GHz Tiered Extragalactic Exploration (MIGHTEE, Jarvis et al. 2016; Taylor & Jarvis 2017), are tackling sensitivities never achieved before at the longest wavelengths of the extra-galactic emission spectrum. These latter experiments are nonetheless only pathfinders for the unprecedented amount of data and scientific information that will be collected by the Square Kilometre Array Observatory (SKAO, Blyth et al. 2015) in the same wavelength range. In a complementary way, the Euclid mission (Amendola et al. 2018) with its visible imager (VIS, Cropper et al. 2016) and near infrared imaging photometer (NIP, Schweitzer et al. 2010), along with the Vera C. Rubin Observatory and its Legacy Survey of Space and Time (LSST, LSST Science Collaboration 2009), as well as the Dark Energy Spectroscopic Instrument (DESI, DESI Collaboration 2016), will probe the visible and infra-red regions of the spectrum on extremely wide areas and high sensitivities.
In this work, we present GalaPy, an extensible application programming interface (API) for modelling broadband galaxy SEDs with a particular focus on high-redshift objects1. It provides an easy-to-use Python user interface while the number-crunching is done with compiled, high-performance, object-oriented C++. The development of this tool is an ongoing project and the software has been designed to envisage modelling extensions and computational upgrades that are already planned and under development.
In the deepest extra-galactic fields, such as COSMOS, the large amount of high-quality, panchromatic data requires not only the derivation of physical parameters, but also their interpretation. One possibility to tackle this point, is to provide informative priors on the model defining parameters, in GalaPy this is guaranteed by the implemented Bayesian framework, which provides an interface to sophisticated statistical analysis, not possible with template-fitting codes. Another possible approach is to directly include physical models (e.g. analytic solutions for galaxy evolution) within the SED modelling and fitting code. This solution seems particularly important in the era of the large programs outlined above (e.g. synergy between JWST, ALMA, Euclid, and LSST) that aim to explore the co-evolution of stars, dust, gas, and metals. Indeed, in spite of its potential importance, many previous SED models have not considered the co-evolution of all these components in a physically consistent manner. To this end, along with more classical empirically motivated models, we have implemented a physically motivated model of star formation history (SFH): the in situ model based on works from Lapi et al. (2018, 2020) and Pantoni et al. (2019). With this model, it is possible to get to an analytical estimate of various physical quantities characterising a galaxy, such as its dust and gas content as well as its metallicity. It is mainly designed to interpret the emission of highly star forming galaxies that end up in local early type galaxies, along all their evolution from the highest to the lowest redshifts, and it also proves effective in modelling local late-type galaxies.
As it is being confirmed by JWST since it started taking data, the high redshift Universe is populated by objects that are intensively star-forming and (crucially) highly obscured. Dust plays a main role in shaping the emission of galaxies, especially in the earliest phases of evolution, but it is not granted that its absorption properties at high redshift can be safely modelled with attenuation laws empirically derived from observations of the low redshift Universe. The approach we implement in GalaPy to model dust is inspired by the one presented in the classical GRASIL code (Silva et al. 1998), with two dust components: one for the age-dependent evolution of molecular clouds around star-forming regions and the other for diffuse dust, distributed on larger scales along the galaxy structure. Differently from GRASIL, we account for the twofold role of dust, which obscures the emission at short wavelengths and re-emits at longer wavelengths, with an age-dependent energy conservation algorithm. This approach, while being physically motivated, keeps the execution time extremely contained with respect to radiative transfer algorithms. With our dust model we can derive non-parametric total attenuation laws, blind to assumptions on the grain physics, and with two components that contribute to the emission blend, thereby shaping the dust emission peak.
In this work we showcase the current status of the project and we demonstrate its power for modelling broadband photometric datasets. The structure of the paper is as follows. In Sect. 2, we describe in detail all the physical models currently delivered with GalaPy. In Sect. 3, we discuss the statistical inference tools used for sampling the parameter space. In Sect. 4, we show the results of the thorough validation tests we performed to verify reliability of the results and demonstrate the potential of our tool. Finally, in Sect. 5, we summarise the key results presented in this manuscript. We note that in Appendix C, we provide a primer on installation and usage of the package. Throughout the work, we adopt the standard, flat ΛCDM cosmology from Planck Collaboration VI (2020) with rounded parameter values: matter density, ΩM ≈ 0.3; baryon density, Ωb ≈ 0.05; Hubble constant H0 = 100 h km s–1 Mpc–1 with h ≈ 0.7. A Chabrier (Chabrier 2003) initial mass function is assumed.
2 Library models
In this section, we introduce the physics modelled by the GalaPy library. All the physical components and processes have been implemented in separate modules, with the requirement of making each component and process self-consistent, meaning that every module (and therefore any physical process) can be imported and used as a stand-alone module of the library.
Conveniently, a master class galapy. Galaxy. GXY wraps-up all of the physical modules described in this section, dealing with the interplay between different parameters and components. The latter allows for computing straightforwardly the overall emission and derived quantities for a given set of parameters, enhancing the general user-friendliness of the workflow. This class is meant to help the user accessing directly all the functionalities of the models already implemented in the library with minimal effort, as well as to ease the correct setting of the parameters that are interdependent among the different modular components. It is nonetheless always possible to customise the workflow by accessing the API, importing functions and classes from the different modules into which the GalaPy library is organised2.
Along the rest of this section we provide a detailed description of all the physics currently implemented in GalaPy. We refer the reader to Appendix B.2 for a complete list of all the possible free parameters that can be selected when fitting observational data. Table B.3 provides a handy conversion between the symbol uniquely identifying a parameter in the library and the mathematical symbol used in this manuscript, along with a short description and a reference to locate the position in text where the parameter is used.
2.1 Star formation history
Implemented in the galapy.StarFormationHistory module, the SFH object allows for the selection of various parametric and non-parametric star-formation history models. GalaPy offers the possibility to use standard empirical models of SFH (Sect. 2.1.1) as well as non-parametric models (Sect. 2.1.2). However, the default SFH model, namely, the in situ model by Lapi et al. (2018; Sect. 2.1.3), has proven particularly successful in predicting the evolution of massive proto-elliptical galaxies and it is also very promising in explaining the fast formation of relatively massive galaxies at z ≳ 10, one of the key regimes probed by modern observational campaigns (e.g. JWST, SKAO). A quick summary of the parameterised SFRs provided by the different models follows:
-
Constant SFR:
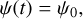 (1)
(1)where ψ0 is a constant floating-point value expressed in units of M⊙ yr–1.
-
Generalised version of the delayed exponential SFR:
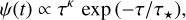 (2)
(2)where τ★ is the characteristic star-formation timescale and κ is a shape parameter for the early evolution; κ = 0 corresponds to a pure exponential, while κ = 1 to the standard delayed exponential.
-
Log-normal SFR:
![Mathematical equation: $\psi (t) \propto {1 \over \tau }{1 \over {\sqrt {2\pi \sigma _ \star ^2} }}\exp \left[ { - {{{{\ln }^2}\left( {\tau /{\tau _ \star }} \right)} \over {2\sigma _ \star ^2}}} \right];$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq3.png) (3)
(3)where τ★ and σ★ control the peak age and width.
-
In situ physically motivated model (Lapi et al. 2018, 2020; Pantoni et al. 2019):
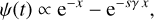 (4)
(4)where x = τ/sτ★ with s ≈ 3 a parameter related to gas condensation, while γ is a parameter including gas dilution, recycling and the strength of stellar feedback (see Lapi et al. 2020, for details), whose value is described in Sect. 2.1.3.
We also allow for the existence of an eventual quenching event that stops the star formation. This is modelled with a heavi-side function, multiplying the SFR of choice, which is 1 before τquench and 0 afterwards. The above rates are plotted for fixed values of the parameters in Fig. 1 where we also show the effect of assuming an abrupt quenching event happening at an age of τ ≈ 109 yr. We note that, in this first version of the library, we only consider the primary episode of star formation, not secondary bursts that will be included in future updates of the package. Nevertheless, pure burst SFHs can be rendered either using the interpolated model or by particular combinations of the free-parameters regulating the shape of the models whose rates are reported above.
In our chemical evolution model, the stellar mass of a galaxy at a given age, τ, is given by the integral
![Mathematical equation: ${M_ \star }(\tau ) = \mathop \smallint \limits_0^\tau {\rm{d}}\tau '\left[ {1 - {\cal R}\left( {\tau - \tau '} \right)} \right]\psi \left( {\tau '} \right)$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq5.png) (5)
(5)
where ℛ is the recycled fraction of gas from stellar evolution. The ℛ(τ) factor is given by (see e.g. Cimatti et al. 2020):
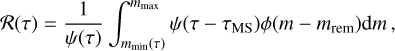 (6)
(6)
where τMS the time spent by a star with mass m in the main sequence, mrem is the mass of its remnant, mmin(τ) satisfies τMS(mmin) = τ and ϕ(m) is the Initial Mass Function (IMF). For example, with respect to a Chabrier IMF (Chabrier 2003), it is well approximated by
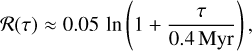 (7)
(7)
with typical values around ℛ ≈ 0.4 ÷ 0.5 after 1 ÷ 10 Gyr (Pantoni et al. 2019; Lapi et al. 2020); in the instantaneous recycling approximation ℛ ≈ 0.45. Even though, at the current state of development, GalaPy implements the aforementioned values only for the case of a Chabrier IMF in the mass range 0.1 ≤ M★ ≤ 100, the library is easily extensible with further models of IMF, including non-standard ones (e.g. Kroupa et al. 2013; Fontanot et al. 2018), that will be added in future releases of the library.
Figure 2 shows the stellar mass growth history corresponding to the models of Fig. 1. As shown in Fig. 2, the overall stellar mass slowly decreases after star formation starts to fade, as a result of the ageing of stellar populations.
 |
Fig. 1 Different models of star formation histories (SFH). Each coloured line shows the star formation rate ψ of a galaxy as a function of its age τ, according to empirical (constant SFR, Eq. (1), green; delayed exponential, Eq. (2) with κ = 1, red; log-normal, Eq. (3), yellow) and physically-motivated (In situ, Eq. (4): blue line) models. The vertical dotted line marks the age τquench of a possible abrupt quenching event; solid lines refer to the SFH of objects undergoing quenching, while dashed lines to the SFH of objects for which no quenching occurs. |
2.1.1 Empirical models
Most of the SED-fitting libraries available in the literature are delivered with empirical models of SFH (see e.g. Da Cunha et al. 2008; Boquien et al. 2019, for two popular SED-fitting libraries). Such models are primarily motivated by the necessity of reproducing the shape of the cosmic star formation history or, either, to provide a numerically tractable function that returns reasonable values of SFR. A notable exception is Prospector (Johnson et al. 2021), which provides a step-wise tunable SFH module. Even though this approach avoids assumptions on uncertain processes, it ends up in a high dimensional parameter space that slows down inference and reduces accuracy on the parameters estimate.
In tools based on empirical star formation laws, the dust mass, Mdust, and the gas (or stellar) metallicity ratio, Zgas = Z★, are typically free parameters, while the gas mass is derived on the basis of a (possibly metallicity-dependent) dust-to-gas mass ratio, D, gauged on observations. A common expression is (e.g. Tacconi et al. 2018):
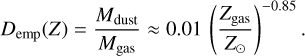 (8)
(8)
In GalaPy, we keep such an approach for backward compatibility and comparison with alternative fitting codes.
 |
Fig. 2 Evolution of the stellar mass M★ of a galaxy as a function of its age τ, for the SFH models shown in Fig. 1. |
2.1.2 Interpolated model
We provide a non-parametric, interpolated, step-wise SFH model with derived components (like dust/gas mass and metal-licity) treated as free parameters, as in the previous empirical models presented. This model is designed for users willing to predict the emission from galaxies for which the stellar mass growth history is available (e.g. obtained from hydro-dynamical simulations or with semi-analytical models) or to test the behaviour of exotic and arbitrarily complex SFH shapes.
In Fig. 3, we show an example of this non parametric model. In the upper panel we plot "observed" samplings of a simulated galaxy’s SFH (blue markers with error bars) and the up-sampled prediction of our interpolated model (dashed grey line). On the lower panel we show the stellar mass growth history resulting from integrating the interpolated SFH along the time coordinate.
2.1.3 In situ model
The In situ SFH delivered as default in GalaPy implements the (mostly analytic) galaxy formation model first presented in Lapi et al. (2018) for ETGs, further developed in Pantoni et al. (2019) and extended to LTGs in Lapi et al. (2020). This model is based on a self-consistent treatment of the black-hole/host-galaxy co-evolution, which captures the fast collapse, with low angular momentum, of the innermost gaseous regions of a galaxy and the resulting stellar feedback. Such a regime is extremely important when interpreting the datasets of galaxies at considerable redshift (i.e. z > 4 and beyond). Furthermore, the model allows for the derivation of age-dependent analytical expressions of the evolution of the gas, metals and dust content in galaxies. Concerning the SFR, the effects of recycling and stellar feedback are encapsulated in the parameter γ that appears in Eq. (4) and is defined as:
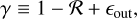 (9)
(9)
in terms of the recycled gas fraction ℛ of Eq. (7) and of the mass loading factor of the outflows from stellar feedback, eout. We gauge ∈out ≈ 3[ψmax/M⊙yr–1]–0.3 according to the hydrody-namic simulations of stellar feedback from Hopkins et al. (2012). Therefore, the parameter γ is completely determined in terms of the free parameter ψmax and, eventually, by the age of the galaxy τ, through Eq. (7).
In the in situ model, the evolution of the gas and dust masses and of the gas and stellar metallicities can be followed analytically as a function of the galactic age and self-consistently with respect to the evolution of the SFR. Specifically, the gas mass is given by
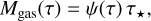 (10)
(10)
while the dust mass,
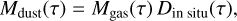 (11)
(11)
is computed in terms of the gas mass and of the dust-to-gas mass ratio Din situ. As discussed in Pantoni et al. (2019) and Lapi et al. (2020), for this latter quantity it is possible to derive an analytical expression, as follows:
![Mathematical equation: $\matrix{ {{D_{{\rm{insitu}}}}(\tau ) \approx {{{s^3}{_{{\rm{acc}}}}{y_{\rm{D}}}{y_{\rm{Z}}}} \over {[s\gamma - 1]\left[ {s\left( {\gamma + {\kappa _{{\rm{SN}}}}} \right) - 1} \right][s(\gamma + \mathop \limits^ ) - 1]}}} \hfill \cr {\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \times \left\{ {1 - {{(s\gamma - 1)x} \over {{{\rm{e}}^{(s\gamma - 1)x}} - 1}}\left[ {1 + {{s\gamma - 1} \over {s\mathop \limits^ }}\left( {1 - {{1 - {{\rm{e}}^{ - s\mathop \limits^ x}}} \over {s\mathop \limits^ x}}} \right)} \right]} \right\};} \hfill \cr } $](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq12.png) (12)
(12)
where
![Mathematical equation: $\mathop \limits^ \equiv {\kappa _{{\rm{SN}}}} + {_{{\rm{acc}}}}s{y_{\rm{D}}}/\left[ {s\left( {\gamma + {\kappa _{{\rm{SN}}}}} \right) - 1} \right].$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq13.png) (13)
(13)
This provides a measure of the efficiency with which dust grains form in terms of the metal coagulation efficiency, ∈acc ≈ 106, onto dust grains, of the dust spallation efficiency κSN ≈ 10 by SN shock-waves, and of the dust production yield yD ≈ 3.8 × 10–4.
On the left panel of Fig. 4, we show the evolution of the gas-mass (blue lines) and of the dust-mass (green lines), for the in situ SFH model with the same parameters as for the blue line of Fig. 1. As made evident from the figure, the effect of assuming an abrupt quenching event is to wash out the diffuse matter reservoir of the interested galaxy, that therefore ends up loosing its primary source of star formation and starts ageing.
These authors also derived the following expressions for the gas and stellar metallicity:
![Mathematical equation: $\{ \matrix{ {{Z_{{\rm{gas}}}}(\tau ) \approx {{s{y_Z}} \over {(s\gamma - 1)}}\left[ {1 - {{(s\gamma - 1)x} \over {{{\rm{e}}^{(s\gamma - 1)x}} - 1}}} \right],} \hfill \cr {{Z_ \star }(\tau ) \approx {{{y_Z}} \over \gamma }\left[ {1 - {{s\gamma } \over {s\gamma - 1}}{{{{\rm{e}}^{ - x}} - {{\rm{e}}^{ - s\gamma x}}[1 + (s\gamma - 1)x]} \over {s\gamma - 1 + {{\rm{e}}^{ - s\gamma x}} - s\gamma {{\rm{e}}^{ - x}}}}} \right],} \hfill \cr } $](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq14.png) (14)
(14)
where again x ≡ τ/sτ★, and yZ ≈ 0.04 is the metal production yield (already including recycling) for a Chabrier IMF. We show the behaviour of the metallicity evolution of the two different components on the right panel of Fig. 4. As the gaseous component is expected to be enriched more readily with respect to stars, Zgas is higher than Z★ consistently along all the evolution history of the galaxy.
Despite being a spatially averaged description of the interplay between the different galaxy components, as well as their evolution, having access to analytical expressions allows us to effectively reduce the volume of the parameter space that has to be sampled for fitting an SED. This not only allows for a faster convergence to an optimal SED, but it also increases the accuracy of our estimates. Furthermore, it is worth highlighting that such a consistent interplay between components, as well as the age-evolution of these derived quantities, are not commonly present in SED-fitting libraries based on energy conservation. In this respect, GalaPy constitutes an innovative and powerful tool for providing non-parametric estimates of the components building up galaxies.
 |
Fig. 3 Interpolated SFH model. Upper panel: SFR at different epochs as measured for a simulated galaxy (blue markers with errors) and our interpolated model (dashed grey line). Lower panel: evolution of the integrated stellar mass at different epochs (solid red line) resulting from the SFH interpolated from data in the upper panel. |
2.2 Stellar emission
Under the assumption of an Universal IMF, the stellar birthrate of a galaxy can be split (Bressan et al. 1994, see their Eqs. (1)– (3)) in the product of a mass dependent function (i.e. the IMF) and of a time dependent function (i.e. the SFR). In this scenario, the intrinsic luminosity of stars in a galaxy at a given age is the result of the evolution of the several simple stellar populations (SSPs) that have formed and have aged within the structure in all of its history. Each of the SSPs yields a luminosity LSSP that is computed by the convolution of an initial mass function (IMF), ϕ(m★), with the luminosity of single stars from stellar evolutionary tracks, Lstar.
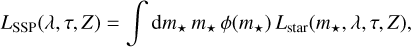 (15)
(15)
where m★ is the mass of a single star, λ is the wavelength, τ is the age and Z is the metallicity of the given SSP.
In GalaPy we use pre-computed SSP libraries in the form of binary files with specific formatting3. In its first release GalaPy is distributed with two main libraries.
The first one is the classic and popular Bruzual & Charlot (2003) in its updated version (v2016). This library provides the continuum luminosity from SSPs for a set of different IMFs, at varying wavelength, age and metallicity. We refer to these set of libraries as BC03. Blue lines in Fig. 5 show SSPs extracted from this set of libraries, for different metal-licities (different line-styles) and for different ages (different panels).
As an alternative we have also produced an additional set of SSPs with the PARSEC code (Bressan et al. 2012; Chen et al. 2014, 2015) for a Chabrier IMF and varying ages and metal-licities, including emission from dusty AGB stars (Bressan et al. 1998). These libraries come in two flavours, the first one with continuum emission only (green lines in Fig. 5) and the second also including nebular emission (red lines in Fig. 5). In the former, besides continuum stellar emission, non-thermal synchrotron emission from core-collapse super-novae is also included in each SSP spectrum (see, e.g. Vega et al. 2008). In the latter, on top of the stellar continuum and non-thermal synchrotron, nebular emission is also included, with both free-free continuum and nebular emission (see, e.g. Mayya et al. 2004), calculated with CLOUDY (Ferland et al. 1998, 2013, 2017). We refer to these set of libraries as PARSEC22.
We highlight that, using the PARSEC22 SSP libraries come with the advantage of reducing the total amount of computations the code has to perform for getting to a final equivalent SED. Namely, using our custom SSP libraries avoids the need to compute the radio stellar emissions that otherwise would require building the synchrotron and nebular free-free contributions described in Sect. 2.4. Furthermore, nebular line emission is currently only available with the PARSEC22 SSP libraries. We refer the reader to Appendix B.1 for further discussion on the differences between the two SSP libraries distributed with GalaPy.
At a given age τ a galaxy that has followed a SFH ψ(τ) will host a composite stellar population (CSP) resulting from all the SSPs formed and evolved up to that moment. The overall unattenuated stellar luminosity of the CSP, 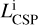 (where the superscript "i" stands for intrinsic), is therefore computed by integrating the contribution of SSPs at different ages and stellar metallicities weighted by the formed stellar mass:
(where the superscript "i" stands for intrinsic), is therefore computed by integrating the contribution of SSPs at different ages and stellar metallicities weighted by the formed stellar mass:
![Mathematical equation: $L_{{\rm{CSP}}}^{\rm{i}}(\lambda ,\tau ) = \mathop \smallint \limits_0^\tau {\rm{d}}{\tau _{{\rm{SSP}}}}{L_{{\rm{SSP}}}}\left[ {\lambda ,{\tau _{{\rm{SSP}}}},{Z_ \star }\left( {\tau - {\tau _{{\rm{SSP}}}}} \right)} \right]\psi \left( {\tau - {\tau _{{\rm{SSP}}}}} \right),$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq17.png) (16)
(16)
where τSSP is the age of the SSP, LSSP is the luminosity of the SSP per unit stellar mass defined in Eq. (15) and Z★(τ – τSSP) is the metallicity of stars at a given instant in the galactic history of metal enrichment. Equation (16) is computed by summing up the light emitted by all the contributing SSPs (as described in Appendix A.1.1 and Eq. (A.1)), the resolution used to compute ψ(τ – τSSP) is fixed at a value dτ = 105 yr. For both the BC03 tables and the PARSEC22 tables, the time domain is sampled on an irregular grid that reaches a maximum accuracy of δτ = 105 yr.
In Fig. 6, we show the unattenuated stellar emission computed with GalaPy and by integrating Eq. (16) up to different galactic ages. We use our PARSEC22 SSP libraries with nebular emission and integrate them along an in situ SFH with parameters set as for the blue line in Fig. 1 with quenching. We note that the younger CSPs (τ = 107 yr in blue and τ = 108 yr in green) also show at the longer wavelengths the radio component resulting from the SN synchrotron and nebular emission. It is also worth mentioning that the UV part of the spectrum in the aforementioned CSPs is somewhat depressed as that fraction of the energy budget is absorbed in nebular regions around massive stars and re-emitted by line-transitions.
As a further open question in galaxy evolution is whether the models of IMF developed from studies on the local Universe are representative of stellar populations in the high redshift Universe, we plan to detach from fixed IMF models. In particular and thanks to its object oriented design, the library is already prepared to work with a parameterised IMF. This would mean to integrate Eq. (15) directly instead of getting it from pre-computed libraries.
 |
Fig. 4 Evolution of various quantities according to the in situ SFH model. Left panel: stellar mass (Eqs. (4)–(5), red), gas mass (Eq. (10), blue) and dust mass (Eq. (11), green). Right panel: gas (blue) and stellar (green) metallicities (Eq. (14)). Linestyles as in Fig. 1. |
 |
Fig. 5 Comparison among the different simple stellar population libraries included in GalaPy: classic BC03 (blue), PARSEC22 without line emission (green), PARSEC22 with line emission (red). Linestyles refer to different metallicity as reported in legend. In all panels the approximate age of the stellar population is reported. In the top two panels we show SSPs from young stellar populations for whom the PARSEC22 models include the contribute of synchrotron (green models) as well as that of nebular emission (red models). |
2.3 The age-dependent, two-component dust model
Despite the dust mass in galaxies is usually a few orders ofmag-nitude less than other components (behaviour that is captured by our In situ SFH model, as it is shown in the left panel of Fig. 4), it plays a fundamental role on the emitted spectrum (Draine & Li 2001, 2007; Draine 2011). Interstellar dust grains contribute to a galaxy’s spectrum by playing a dual role: they absorb and scatter the intrinsic stellar radiation from CSPs, especially in the UV/optical range, while re-radiating the absorbed energy, primarily in the infrared part of the spectrum.
In GalaPy, we implement an age-dependent, two-component dust model. It comprises a typically hotter molecular cloud phase (in the literature, also referred to as ‘birth clouds’) and a colder diffuse medium (in the literature, also dubbed a ‘cirrus’). The fraction of dust that resides in molecular clouds, ƒMC is a free-parameter of the GalaPy model. This parameter anyways assumes typical values around 0.5 and is likely larger in more violently star-forming systems and towards high redshift.
The modelling of the two dust components and of their attenuation and re-radiation has been inspired from previous works, namely from the radiative transfer code GRASIL (Silva et al. 1998), and from popular SED-fitting libraries such as MAG-PHYS (Da Cunha et al. 2008), CIGALE (Boquien et al. 2019) and Prospector (Johnson et al. 2021). Like in the latter libraries, GalaPy bypasses the computational cost of radiative transfer by exploiting an energy conservation scheme; however, GalaPy implements energy conservation in an age-dependent way. This means that the attenuation from dust is age-dependent (like in GRASIL) and this in turn determines, via a self-consistent energy conservation calculated time-step by time-step, age-dependent dust temperatures across the galaxy lifetime. Details of such modelling are provided in the rest of this Section, that we divide into two parts for clarity, separating between the two main effects that result from the presence of a dust component, namely attenuation of UV-optical radiation and re-emission in the IR and (sub)mm bands.
2.3.1 Extinction and attenuation
We assume two different, piece-wise extinction curves for the diffuse dust and molecular cloud components (DD and MC, hereafter). The behaviour of the two extinctions is shown in Fig. 7 normalised to their value computed in the V-band (λV ≈ 5500 Å), AV. This value is parameterised differently for the two components.
For the DD phase we assume an extinction normalisation scaling as
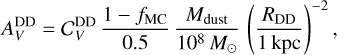 (17)
(17)
here Mdust is the dust mass in the galaxy (that can be age dependent if the in situ SFH model is selected), RDD is the characteristic radius of the diffuse dust component and 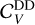 is a normalisation constant of order unity. The extinction law for the diffuse component is prescribed to follow the piece-wise power-law behaviour
is a normalisation constant of order unity. The extinction law for the diffuse component is prescribed to follow the piece-wise power-law behaviour
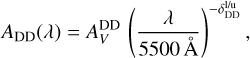 (18)
(18)
with 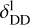 taking on values of around ≈ 0.7 for λ ≲ 100 μm and
taking on values of around ≈ 0.7 for λ ≲ 100 μm and 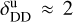 for λ ≳ 100 μm; nonetheless GalaPy allows us to give up on these two reference values by directly fitting the parameters
for λ ≳ 100 μm; nonetheless GalaPy allows us to give up on these two reference values by directly fitting the parameters 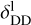 and
and 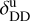 . In Fig. 7, we mark the normalised DD extinction law with reference slopes with a green line.
. In Fig. 7, we mark the normalised DD extinction law with reference slopes with a green line.
The piece-wise behaviour imposed by the relation above results from observations of the different cross section of dust grains settling-in at around ≈100 μm. The flatter power-law dependence has been previously assumed by Charlot & Fall (2000) and Da Cunha et al. (2008) basing on the observed relation between the ratio of far-infrared to UV luminosity and the UV spectral slope for nearby starburst galaxies, while the break to a steeper slope reflects the behaviour of the scattering and absorption cross section of dust grains at longer wavelengths (e.g. Silva et al. 1998; Draine & Li 2001).
On the other hand, for the MC component, we adopt a V-band extinction
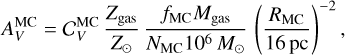 (19)
(19)
which is dependent on the average gas mass of a molecular cloud 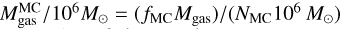 in units of 106 M⊙, on the radius of the cloud RMC, on the total number of MCs in the system and on the gas metallicity Zgas. The latter dependence is reasonable since within molecular clouds the growth of dust grains is expected to mainly occur via sticking/accretion of metals onto core grains produced during stellar evolution. The normalization
in units of 106 M⊙, on the radius of the cloud RMC, on the total number of MCs in the system and on the gas metallicity Zgas. The latter dependence is reasonable since within molecular clouds the growth of dust grains is expected to mainly occur via sticking/accretion of metals onto core grains produced during stellar evolution. The normalization 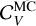 can be of order several tens to hundreds, since the V–band emission in MCs is expected to be completely absorbed. For the MCs we also assume a double power-law extinction curve of
can be of order several tens to hundreds, since the V–band emission in MCs is expected to be completely absorbed. For the MCs we also assume a double power-law extinction curve of
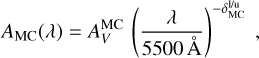 (20)
(20)
with 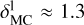 for λ ≲ 100 μm and
for λ ≲ 100 μm and 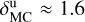 for λ ≳ 100 μm. The former slope corresponds to the middle range of the optical properties of dust grains between the Milky Way, the Large and the Small Magellanic Clouds (see Charlot & Fall 2000; Da Cunha et al. 2008). The slope at long wavelengths, which is slightly shallower than for the diffuse medium, has been advocated to reproduce the sub-mm emission for ULIRGs such as Arp220, where the MC re-radiation dominate over the cirrus’ (see Silva et al. 1998; Lacey et al. 2016). MC extinction with reference slopes is shown in Fig. 7 by a blue piece-wise power law. Once again, the slopes can be free-parameters of the model to be fitted directly.
for λ ≳ 100 μm. The former slope corresponds to the middle range of the optical properties of dust grains between the Milky Way, the Large and the Small Magellanic Clouds (see Charlot & Fall 2000; Da Cunha et al. 2008). The slope at long wavelengths, which is slightly shallower than for the diffuse medium, has been advocated to reproduce the sub-mm emission for ULIRGs such as Arp220, where the MC re-radiation dominate over the cirrus’ (see Silva et al. 1998; Lacey et al. 2016). MC extinction with reference slopes is shown in Fig. 7 by a blue piece-wise power law. Once again, the slopes can be free-parameters of the model to be fitted directly.
Given the extinction curves of Eqs. (18) and (20), we compute the attenuated galaxy luminosity (i.e. the transmitted one) as
![Mathematical equation: $\matrix{ {} \hfill & {L_{{\rm{CSP}}}^{\rm{a}}(\lambda ,\tau ) = {{\cal A}_{{\rm{DD}}}}(\lambda ) \times } \hfill \cr {} \hfill & {\quad \int_0^\tau {\rm{d}} {\tau _{{\rm{SSP}}}}{{\cal A}_{{\rm{MC}}}}\left( {\lambda ,{\tau _{{\rm{SSP}}}}} \right){L_{{\rm{SSP}}}}\left[ {\lambda ,{\tau _{{\rm{SSP}}}},{Z_ \star }\left( {\tau - {\tau _{{\rm{SSP}}}}} \right)} \right]\psi \left( {\tau - {\tau _{{\rm{SSP}}}}} \right),} \hfill \cr } $](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq31.png) (21)
(21)
where 𝒜DD(λ) and 𝒜MC(λ,τ) are the extinction factors due to diffuse and MC dust, respectively, and the superscript ‘a’ stands for attenuated. We assume the attenuation suffered by radiation from stars that have already escaped their birth MCs to be independent from stellar age; thus the DD extinction factor is simply expressed as:
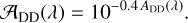 (22)
(22)
where ADD(λ) is given by Eq. (18).
On the other hand, since birth clouds tend to be evaporated as the hosted SSPs evolve, the extinction factor due to dust in MCs is defined to be age dependent
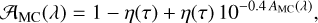 (23)
(23)
where η(τ) defines the fraction of stars with age τ still inside their MC. We define this latter quantity taking up from GRASIL the parametrization
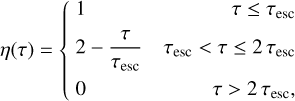 (24)
(24)
with τesc a free-parameter which defines the typical time required by stars to start escaping MCs; after 2τesc all the stars have escaped.
We can take the luminosity-weighted average over stellar ages of the MC extinction law defined in Eq. (23) and re-write Eq. (21) in compact form:
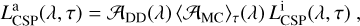 (25)
(25)
where 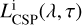 is the intrinsic CSP luminosity of Eq. (16) and
is the intrinsic CSP luminosity of Eq. (16) and
![Mathematical equation: ${\left\langle {{{\cal A}_{{\rm{MC}}}}} \right\rangle _\tau }(\lambda ) = 1 - {\langle \eta \rangle _\tau }(\lambda )\left[ {1 - {{10}^{ - 0.4{A_{{\rm{MC}}}}(\lambda )}}} \right],$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq37.png) (26)
(26)
with
![Mathematical equation: ${\langle \eta \rangle _\tau }(\lambda ) = {{\int_0^\tau {\rm{d}} {\tau _{{\rm{SSP}}}}\eta \left( {{\tau _{{\rm{SSP}}}}} \right){L_{{\rm{SSP}}}}\left[ {\lambda ,{\tau _{{\rm{SSP}}}},{Z_ \star }\left( {\tau - {\tau _{{\rm{SSP}}}}} \right)} \right]\psi \left( {\tau - {\tau _{{\rm{SSP}}}}} \right)} \over {\int_0^\tau {\rm{d}} {\tau _{{\rm{SSP}}}}{L_{{\rm{SSP}}}}\left[ {\lambda ,{\tau _{{\rm{SSP}}}},{Z_ \star }\left( {\tau - {\tau _{{\rm{SSP}}}}} \right)} \right]\psi \left( {\tau - {\tau _{{\rm{SSP}}}}} \right)}}.$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq38.png) (27)
(27)
We show the behaviour of the latter quantity in Fig. 8 for different galactic ages for a fixed value of τesc = 5 × 107 yr. While almost all the radiation is absorbed in the younger objects (blue and green lines) a considerable part of the stellar radiation escapes when the galaxy ages (red and purple lines).
To wrap up, we obtain the wavelength- and age-dependent total galactic attenuation curve, given by
![Mathematical equation: ${A_{{\rm{TOT}}}}(\lambda ,\tau ) = - 2.5{\log _{10}}\left[ {{{\cal A}_{{\rm{DD}}}}(\lambda ){{\left\langle {{{\cal A}_{{\rm{MC}}}}} \right\rangle }_\tau }(\lambda )} \right],$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq39.png) (28)
(28)
shown in Fig. 9 for galaxies with different age, normalised with respect to the global attenuation in the visible band (λV ≈ 5500 Å). The attenuation curves are built assuming the in situ SFH (blue line in Fig. 1) assuming no quenching and a characteristic escape time from MCs of τesc = 5 × 107 yr4. In young galaxies (dot-dashed black line) all the stellar populations will still be embedded by their birth MC, therefore their global attenuation curve traces the intrinsic extinction of MCs (blue solid line in Fig. 7). Instead, older galaxies (dashed and solid black lines) will host populations of different ages which therefore will provide different contributions to the global attenuation, as some of them will still be embedded in their birth cloud while some others will have partially or completely escaped it. This evolution with time is reflected on the bending of the global attenuation curve and on the peaks due to the presence of intense emission lines, the latter being the imprint of the youngest stellar populations.
It is also interesting to compare our age-dependent attenuation curves with those predicted by Calzetti-like models (Calzetti et al. 2000; Salim & Narayanan 2020). In Fig. 9, curves with different colours mark different values of the total-to-selective extinction ratio in the V-band, RV. The shape of Calzetti-like attenuation curves is obtained by empirical considerations on the UV/optical photometry of observed galaxies (Salim & Narayanan 2020). In our dust model we do not rely on tem-plated nor parametric global attenuation curves and we are independent from dust-grain physics models. We, nonetheless, manage to derive shapes similar to those found in the literature by consistently treating the age-evolution and stellar population dependency of the two different dust phases. We derive a model of the global attenuation in a galaxy from data of the transmitted light, by fitting directly the free parameters in from Eqs. (17) to (20) and Eq. (24).
The absorption from the two different components on stellar emission is decomposed in Fig. 10 for a 100 Myr galaxy at the peak of its star formation history and with a characteristic escape time from MCs of τesc = 50 Myr. While the dotted black line marks the intrinsic stellar emission, 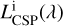 , the dashed black line marks the luminosity escaping from molecular clouds,
, the dashed black line marks the luminosity escaping from molecular clouds, 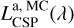 , and the solid black line the obscured stellar emission resulting from Eq. (25),
, and the solid black line the obscured stellar emission resulting from Eq. (25), 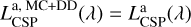 .
.
We stress that, internally, the overall contribution is computed by integrating numerically Eq. (21), therefore directly obtaining the SSP luminosity averaged value of Eq. (28) (shown in Fig. 9) by computing the ratio between the attenuated and intrinsic luminosity: 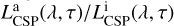 . The direct time integration of SSPs attenuation is a peculiarity of our library and is intended to provide blindness to the specific attenuation model. This choice has been made so that we do not have to rely on parametric total attenuation models; therefore, we are able to loosen the assumptions on the dust physics. We believe that our model will prove relevant, e.g. in studies of primordial galaxies at the highest redshifts, such as those that are currently being probed by JWST (sources at z > 4–6), and, in general, all those cases that lie outside the typical definition range of existing attenuation laws.
. The direct time integration of SSPs attenuation is a peculiarity of our library and is intended to provide blindness to the specific attenuation model. This choice has been made so that we do not have to rely on parametric total attenuation models; therefore, we are able to loosen the assumptions on the dust physics. We believe that our model will prove relevant, e.g. in studies of primordial galaxies at the highest redshifts, such as those that are currently being probed by JWST (sources at z > 4–6), and, in general, all those cases that lie outside the typical definition range of existing attenuation laws.
Finally, at this stage we do not yet include a treatment of the UV-bump at 2200 Å as observed in the total attenuation of some close-by sources (see e.g. Noll et al. 2009; Salim & Narayanan 2020), nor its possible relation with the PAH emission, as claimed by some authors. We note that the object oriented design of the library allows us to easily extend the dust modelling to include further components, that we may take in considerations for further developments.
 |
Fig. 6 Composite stellar populations as a function of the age, on assuming the in situ SFH (blue line of Fig. 1 with quenching at τ = 8 × 108 yr) and different single stellar population libraries (left: BC03; centre: PARSEC22 without nebular emission; right: PARSEC22 with nebular emission). |
 |
Fig. 7 Extinction laws adopted in GalaPy, normalised to the value in the V–band at 5500 Å, for diffuse dust (green) and dust in molecular clouds (blue). The extinction is modelled as a double powerlaw (see Eqs. (18)–(20)) with slope changing at around 100 μm (marked with a dotted line; the default values of the slopes are adopted in the plot (see Sect. 2.3 for details). |
 |
Fig. 8 Average fraction of stellar luminosity (see Eq. (27)) that is absorbed by MCs as a function of wavelength for galaxies of different age (colour-coded as in the legend). |
 |
Fig. 9 Overall attenuation curve at ages of 107 yr (dot-dashed, i.e. 0.5τesc), 5 × 108 yr (dashed, i.e. 10τesc), and 109 yr (solid, i.e. 20τesc), we include age effects and plot the value in units of the attenuation in the visible band (λV ≈ 5500 Å). We note that these values correspond to the blue, green and red lines of Fig. 8. Our attenuation curves are compared with Calzetti-like attenuation curves (dotted) for different values of the total-to-selective extinction ratio RV in the V–band (colour-coded). |
 |
Fig. 10 Impact of absorption from the two component dust models (molecular clouds, MC; diffuse dust, DD) implemented in GalaPy on the intrinsic stellar emission (dotted black line). Luminosity escaping from MCs is marked by a dashed black line, while the final stellar emission escaping MCs and DD is shown by a solid black line. The luminosity re-emitted in the IR bands is highlighted with a solid blue line for MCs and with a solid green line for the DD(+PAH) component. |
2.3.2 Energy conservation and emission
By absorbing stellar radiation, dust heats up. The bolometric intrinsic luminosity coming from the CSP hosted by a galaxy of given age is obtained by integrating Eq. (16) over all the spectrum:
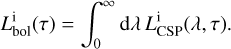 (29)
(29)
In GalaPy, such luminosity is absorbed in two stages for stars still embedded within their birth cloud: first it has to pass through the MC phase, and then the remainder of this radiation has then to cross the DD region. The amount of bolometric luminosity, 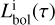 , which is absorbed by dust in MCs is obtained by filtering the integral above with the age-dependent law defined in Eq. (26):
, which is absorbed by dust in MCs is obtained by filtering the integral above with the age-dependent law defined in Eq. (26):
![Mathematical equation: $L_{{\rm{abs}}}^{{\rm{MC}}}(\tau ) = \int_0^\infty {\rm{d}} \lambda \left[ {1 - {{\left\langle {{{\cal A}_{{\rm{MC}}}}} \right\rangle }_\tau }(\lambda )} \right]L_{{\rm{CSP}}}^{\rm{i}}(\lambda ,\tau ).$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq46.png) (30)
(30)
The luminosity that has not been transferred to MCs (i.e.  = {{\left\langle {{{\cal A}_{{\rm{MC}}}}} \right\rangle }_\tau }(\lambda )L_{{\rm{CSP}}}^{\rm{i}}(\lambda ,\tau )} \right)$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq47.png) is then further absorbed by DD:
is then further absorbed by DD:
![Mathematical equation: $L_{{\rm{abs}}}^{{\rm{DD}}}(\tau ) = \int_0^\infty {\rm{d}} \lambda \left[ {1 - {{\cal A}_{{\rm{DD}}}}(\lambda )} \right]{\left\langle {{{\cal A}_{{\rm{MC}}}}} \right\rangle _\tau }(\lambda )L_{{\rm{CSP}}}^{\rm{i}}(\lambda ,\tau ).$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq48.png) (31)
(31)
In the left panel of Fig. 11, we show the age-dependency of the percentage of bolometric luminosity that is absorbed by the two different dust phases in units of the typical escape time from MCs, τesc defined in Eq. (24). When the stars begin to radiate energy but the galaxy is still younger than the characteristic escape time τesc, the amount of luminosity absorbed by MCs grows steadily (blue line), while the radiation absorbed by DD is negligible (green line). At an escape time, the percent of luminosity going to MCs instead starts to decrease, while the relevance of the DD component grows. All in all though, the combined effect of the two phases is to trap more than 90% of the total energy budget. This value decreases only at several tens of escape times, when the SFR decreases (see the in situ SFH model marked by a blue line in Fig. 1 and compare to Fig. 9, commented in Sect. 2.3.1) or, either, after an abrupt quenching event that wipes out most of the ISM.
It has to be noted that, in the earliest stages of evolution (i.e. τ ≈ 10−2τesc) the overall total absorbed fraction of Fig. 11 is of about 0%. This results from the way we compute the evolution of the absorption curves. Namely, in our model this process is strictly dependent on the total budget of absorbing medium that is consistently computed from the evolutionary stage of the stars populating a galaxy. As a consequence, when the galaxy is extremely young (i.e. τ ≲ 106 yr ≡ 0.1 τesc), stars do not have had time yet to pollute the medium with dust and therefore, no absorption is possible.
Energy conservation ensures that (having heated up as a consequence of the luminosity absorbed) the two dust components radiate, in good approximation, as two optically thick grey-bodies. This emission depends on the extinction laws as defined in Eqs. (22) and (23) for the two respective dust phases. We define:
![Mathematical equation: ${L_{{\rm{DD}}}}\left( {\lambda ,\tau \mid {T_{{\rm{DD}}}}} \right) = {{16{\pi ^2}} \over 3}R_{{\rm{DD}}}^2\left[ {1 - {{10}^{ - 0.4{A_{{\rm{DD}}}}(\lambda ,\tau )}}} \right]B\left( {\lambda ,{T_{{\rm{DD}}}}} \right),$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq49.png) (32)
(32)
for the DD phase and
![Mathematical equation: ${L_{{\rm{MC}}}}\left( {\lambda ,\tau \mid {T_{{\rm{MC}}}}} \right) = {{16{\pi ^2}} \over 3}{N_{{\rm{MC}}}}R_{{\rm{MC}}}^2\left[ {1 - {{10}^{ - 0.4{A_{{\rm{MC}}}}(\lambda ,\tau )}}} \right]B\left( {\lambda ,{T_{{\rm{MC}}}}} \right),$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq50.png) (33)
(33)
for the MC phase. Notice that, in the limit of an optically-thin emission, the factor 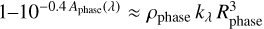 is approximately the optical depth, thus, it can be written in terms of the dust-phase density ρphase and of the opacity kλ. Using ρphase ≈
is approximately the optical depth, thus, it can be written in terms of the dust-phase density ρphase and of the opacity kλ. Using ρphase ≈ 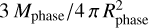 , the emitted luminosity can then be recast in the form Lλ ≈ 4 π Mphase kλ B(λ, Tphase), which frequently occurs in the literature (e.g. Lacey et al. 2016).
, the emitted luminosity can then be recast in the form Lλ ≈ 4 π Mphase kλ B(λ, Tphase), which frequently occurs in the literature (e.g. Lacey et al. 2016).
In both Eqs. (32) and (33), luminosity is given in terms of the black body spectrum:
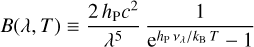 (34)
(34)
where vλ = c/λ is the frequency corresponding to the wavelength λ, c is the speed of light, hP is the Planck constant and kB is the Boltzmann constant.
At any given age, the temperatures TDD and TMC of the diffuse and MC dust component are set by requiring that the total emitted power equals the luminosity absorbed by each of the two phases. Therefore, in GalaPy, the dust temperatures are not free parameters, they are age-dependent outputs obtained by imposing a self-consistent energy conservation.
For the emission coming from MCs we impose:
![Mathematical equation: $\int_0^\infty {\rm{d}} \lambda {L_{{\rm{MC}}}}\left[ {\lambda ,\tau \mid {T_{{\rm{MC}}}}(\tau )} \right] = L_{{\rm{abs}}}^{{\rm{MC}}}(\tau ),$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq54.png) (35)
(35)
where the left hand side is obtained by integrating over the whole spectrum Eq. (33) and the right hand side has been computed with Eq. (30).
We make the assumption that the emission from poly-cyclic aromatic hydrocarbons (PAH) is suppressed in MCs, but we include it in the emission coming from the DD phase (Vega et al. 2008). We define a free parameter 0 ≤ fPAH ≤ 1 regulating the fraction of absorbed power 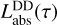 that at some given time is re-radiated by PAH. Therefore, the temperature of the DD grey-body is computed by imposing
that at some given time is re-radiated by PAH. Therefore, the temperature of the DD grey-body is computed by imposing
![Mathematical equation: $\int_0^\infty {\rm{d}} \lambda {L_{{\rm{DD}}}}\left[ {\lambda ,\tau \mid {T_{{\rm{DD}}}}(\tau )} \right] = \left( {1 - {f_{{\rm{PAH}}}}} \right)L_{{\rm{abs}}}^{{\rm{DD}}}(\tau ),$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq56.png) (36)
(36)
where the left hand side is obtained by integrating over the whole spectrum Eq. (32) and the right hand side has been computed with Eq. (31) excluding the fraction of energy that is radiated by PAH.
By solving numerically the two energy conservation equations, Eqs. (35) and (36), we obtain the temperatures of the two media consistently with their evolution with time. In the right panel of Fig. 11 we show the age evolution of the dust phases’ temperature obtained above in units of the characteristic escape time from MCs. Young galaxies display a steady increase in temperature, steeper and some factors larger for the MC component. When the escape time is reached, the temperatures of both MCs and DD begin to decrease. However, while MCs continue to decrease over time, the temperature of DD initially decreases but then begins to increase again. This instant in the evolution of the galaxy is due to the presence of a large number of stars that have escaped their MC and whose energy therefore contributes only to the heating of the DD phase. Depending on the value of the model parameters, the DD medium could also become hotter than MCs, when most of them have been evaporated. It is interesting to notice how in the early stages of evolution, the DD temperature reaches some tens of degrees even though its contribution to absorption in this stage is negligible (cf. left panel of Fig. 11).
We adopt the PAH template LPAH (λ) by Da Cunha et al. (2008) constructed on the behaviour in the photo-dissociation regions of the Milky Way. It includes PAH line emission mainly in mid-IR (MIR), PAH continuum emission in the NIR, and NIR continuum emission due to very small, hot dust grains. All in all, the global emission due to diffuse dust including PAH is given by:
![Mathematical equation: ${L_{{\rm{DD}} + {\rm{PAH}}}}(\lambda ,\tau ) = {L_{{\rm{DD}}}}\left[ {\lambda ,\tau \mid {T_{{\rm{DD}}}}(\tau )} \right] + {f_{{\rm{PAH}}}}L_{{\rm{abs}}}^{{\rm{DD}}}(\tau )L_{{\rm{PAH}}}^{{\rm{norm }}}(\lambda ),$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq57.png) (37)
(37)
where 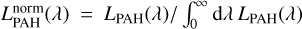 is the normalised PAH spectrum.
is the normalised PAH spectrum.
The total dust bolometric luminosity is given by the all-spectrum integral
![Mathematical equation: ${L_{{\rm{dust }}}}(\tau ) = \int_0^\infty {\rm{d}} \lambda \left[ {{L_{{\rm{MC}}}}(\lambda ,\tau ) + {L_{{\rm{DD}} + {\rm{PAH}}}}(\lambda ,\tau )} \right] = \int_0^\infty {\rm{d}} \lambda {L_{{\rm{dust }}}}(\lambda ,\tau ).$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq59.png) (38)
(38)
We note that other definitions exploited in the literature involve this integral over the wavelength range 8–1000 μm (dubbed FIR for far infrared luminosity) or 3–1100 μm (dubbed TIR for total infrared luminosity).
The emission from the two different dust components, including PAH, is shown in Fig. 10. The blue solid line marks the grey-body emission from molecular clouds, as computed from Eq. (33), while the green solid line shows the overall diffuse dust emission, Eq. (37), from both the grey-body of Eq. (32) and PAH.
 |
Fig. 11 Behaviour of the two different dust components (molecular clouds, MC; diffuse dust, DD) as a function of galactic age in units of the characteristic escape time from molecular clouds τesc. We assume an in situ SFH as the blue line in Fig. 1 and set the characteristic escape time to 5 × 107 yr. Left panel: percentage of the intrinsic stellar luminosity absorbed by MC (blue), DD (green), and by both components (black). Right panel: temperature of the dust component computed from the age-dependent energy-conservation scheme implemented in GalaPy. The vertical dotted line marks the age, τquench = 8.8 × 108 yr, of a possible abrupt quenching event; solid lines refer to the evolution with quenching, dashed lines to that with no quenching. |
2.4 Additional sources of stellar continuum
The two different SSP libraries delivered with GalaPy provide different recipes for the stellar emission. As already explained in Sect. 2.2, while PARSEC22 libraries have been computed either with supernova synchrotron included and with supernova synchrotron and nebular emission included, the BC03 libraries do not include either of these contributes. To homogenise (and extend to higher energies) the spectral emission due to the stellar component among the different possible SSP library choice, we provide additional (optional) modules for modelling radiative processes that impact mostly on the rest-frame X-ray and radio bands. Thanks to these, we are able to extend the spectral coverage of the library to the overall range 1 Å ≤ λ ≤ 1010 Å, independently of the SSP library of choice.
Including these components is optional, as the photometric system of the dataset under study might not cover such an extended range of wavelengths. To have nebular free-free emission (Sect. 2.4.1) and stellar synchrotron (Sect. 2.4.2) when building models with the helper class galapy.Galaxy.GXY, the user has to require for radio-support (as these components mostly impact on the radio bands). We note that both nebular free-free and SN-synchrotron might be already present in the SSPs if, as discussed in Sect. 2.2, one of the PARSEC22 libraries is chosen. In this case requiring for radio-support would be redundant and the system will ignore it5. Vice-versa, X-ray binaries (Sect. 2.4.3) are considered by requiring for X-ray support, which will also include high energy emission from an eventual AGN as in Sect. 2.5, if required. We underline that, the choice of SSP library should be driven by the dataset studied. In particular, when working with young objects, the attenuation due to line absorption and re-emission has a non-negligible effect also on photometric observations. In such cases is therefore preferable to work with the PARSEC22 library including line-emission.
Figure 12 shows the impact of the additional stellar continuum processes, with respect to the continuum coming from stellar atmospheres and dust. In the rest of this section, we describe how these components are modelled in GalaPy.
2.4.1 Nebular free-free
The nebular free-free (NFF) emission is originated in HII regions associated with short-lived ionising massive stars (stars with age ≲ 107 yr in simple stellar evolution models). For the intrinsic NFF luminosity (blue solid line in Fig. 12), we use the expression (see, e.g. Bressan et al. 2002; Murphy et al. 2012; Mancuso et al. 2017)
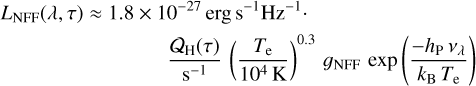 (39)
(39)
in terms of the Gaunt factor (see Draine 2011)
![Mathematical equation: ${g_{{\rm{NFF}}}} = \ln \left\{ {\exp \left[ {5.96 - {{\sqrt 3 } \over \pi }\ln \left( {{Z_i}{{{v_\lambda }} \over {G{\rm{Hz}}}}{{\left( {{{{T_{\rm{e}}}} \over {{{10}^4}{\rm{K}}}}} \right)}^{ - 1.5}}} \right)} \right] + \exp (1)} \right\}$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq61.png) (40)
(40)
and of the Boltzmann correction exp(−hP vλ/kB Te) due to the thermal nature of the process. The latter induces a suppression in the high energy part of the spectrum, due to the decreasing number of high energy photons. In the frequency range satisfying 0.14 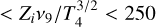 and vp < v < kT/h, where vp is the plasma frequency, the free-free emission spectrum is almost flat. Such frequencies correspond to the microwave and radio part of the NFF spectrum where it can be shown that the emission slowly declines with increasing frequency as ~ v−0.12 (Vega et al. 2008; Draine 2011; Mancuso et al. 2017).
and vp < v < kT/h, where vp is the plasma frequency, the free-free emission spectrum is almost flat. Such frequencies correspond to the microwave and radio part of the NFF spectrum where it can be shown that the emission slowly declines with increasing frequency as ~ v−0.12 (Vega et al. 2008; Draine 2011; Mancuso et al. 2017).
In Eq. (40), it is often assumed Zi = 1, corresponding to a pure hydrogen plasma. Te refers to the electron temperature in HII regions, whose dependence on gas metallicity, Zgas, can be expressed as (Vega et al. 2008)
![Mathematical equation: $\log {T_{\rm{e}}} \approx 3.89 - 0.4802\log \left( {{Z_{{\rm{gas}}}}/0.02} \right) - 0.0205{\left[ {\log \left( {{Z_{{\rm{gas}}}}/0.02} \right)} \right]^2}.$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq63.png) (41)
(41)
The intrinsic photo-ionisation rate can be computed from the intrinsic stellar luminosity of Eq. (16) by the integral
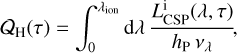 (42)
(42)
with λion ≈ 912 Å being the wavelength corresponding to the H ionisation potential.
In Fig. 12, we also show the attenuation induced by dust in the optical-IR part of the NFF spectrum (solid green line), which is computed as
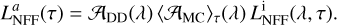 (43)
(43)
where 𝒜DD(λ) and 〈𝒜MC〉τ(λ) are given by Eqs. (22) and (23), respectively. When the SSP chosen is not one among the PAR-SEC22 libraries with nebular emission included (see Sect. 2.2 and Appendix B.1), this additional source of stellar emission is added a-posteriori to the overall spectrum and, therefore, it is not taken into account automatically in the energy balance described in Sect. 2.3.2. Given that the amount of energy transferred to dust by this process is negligible (i.e. less than 1% in most of the cases), this choice has not a relevant impact for the majority of sources. Nevertheless, for particularly young ages, when the contribution from short lived massive stars is dominant and the energy transferred to nebular emission both in terms of continuum and line emission has a relevant impact also in terms of photometric observations, we recommend using the PARSEC22 SSP libraries with nebular emission included (i.e. parsec22.ntl family). This not only guarantees to account for the presence of emission lines but also guarantees that the nebular emission is accounted for in the energy balance algorithm.
 |
Fig. 12 Additional stellar components contributing to the overall continuum emission in GalaPy: intrinsic (blue) and attenuated (green) free-free emission from nebular regions, synchrotron emission from SN (red), X-ray emission from high-mass and low-mass binary stars (yellow). For reference, the luminosity from attenuated stellar continuum and dust re-radiation, i.e. the sum of the solid lines in Fig. 11, is also reported (dashed black). |
2.4.2 Synchrotron from supernovae
The synchrotron (non-thermal) emission is likely originated from relativistic electrons accelerated into the shocked interstellar medium, following core-collapse SN explosions. A possible minor contribution from SN remnants is also possible.
When not running with the PARSEC22 SSP libraries, we use the equivalent expression (Bressan et al. 2002; Mancuso et al. 2017)
![Mathematical equation: $\matrix{ {} \hfill & {{L_{{\rm{syn}}}}(\lambda ,\tau ) \approx {{10}^{30}}{\rm{erg}}{{\rm{s}}^{ - 1}}{\rm{H}}{{\rm{z}}^{ - 1}}{{{{\cal R}_{{\rm{CCSN}}}}(\tau )} \over {{\rm{y}}{{\rm{r}}^{ - 1}}}}{{\left( {{{{v_\lambda }} \over {G{\rm{Hz}}}}} \right)}^{ - {\alpha _{{\rm{syn}}}}}}} \hfill \cr {} \hfill & { & \cdot {{\left[ {1 + {{\left( {{v \over {20G{\rm{Hz}}}}} \right)}^{0.5}}} \right]}^{ - 1}}F\left[ {{\tau _{{\rm{syn}}}}\left( {{v_\lambda }} \right)} \right],} \hfill \cr } $](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq66.png) (44)
(44)
where ℛCCSN is the core-collapse SN rate, αsyn ≈ 0.75 is the spectral index, the term in square brackets takes into account spectral-ageing effects, and the function F(x) = (1 − e−x)/x incorporates synchrotron self-absorption in terms of the optical depth 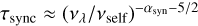 that is thought to become relevant at frequencies v ≲ vself ≈ 200 MHz.
that is thought to become relevant at frequencies v ≲ vself ≈ 200 MHz.
The age-evolution of the CCSN rate per unit solar mass of formed stars has been computed from the SSPs and can be rendered in terms of the simple relation:
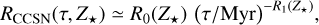 (45)
(45)
where R0 and R1 are fitting functions dependent on stellar metallicity (some values are tabulated in Table B.2).
The overall rate entering the expression of the synchrotron luminosity is then
![Mathematical equation: ${{\cal R}_{{\rm{CCSN}}}}(\tau ) = \int_0^\tau {\rm{d}} {\tau _{{\rm{SSP}}}}R\left[ {\tau - {\tau _{{\rm{SSP}}}},{Z_ \star }\left( {\tau - {\tau _{{\rm{SSP}}}}} \right)} \right]\psi \left( {\tau - {\tau _{{\rm{SSP}}}}} \right),$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq69.png) (46)
(46)
where, as in Sect. 2.2, τSSP is the time passed since some given SSP has formed, Z✶(τ) is the metallicity of stars at given galactic age and ψ(τ) the SFR.
Equation (44) with its normalisation is obtained by requiring that the quantity
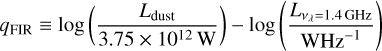 (47)
(47)
takes on values close to the observed qFIR ≈ 2.35–2.7 at an age of about 108 yr.
To take into account the lower efficiency in producing synchrotron radiation at small SFRs, we correct the above equation as
![Mathematical equation: $L_{{\rm{syn}}}^{{\rm{corr}}}(\lambda ,\tau ) = {{{L_{{\rm{syn}}}}(\lambda ,\tau )} \over {1 + {{\left[ {L_{{\rm{syn}}}^0/{L_{{\rm{syn}}}}(\lambda ,\tau )} \right]}^\zeta }}},$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq71.png) (48)
(48)
with ζ ≈ 2 and 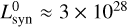 erg s−1 Hz−1. The corrected synchrotron emission
erg s−1 Hz−1. The corrected synchrotron emission 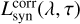 is marked by a red solid line in Fig. 12. We stress that attenuation on the synchrotron emission has been applied but turns out to be irrelevant since the corresponding spectrum is strongly suppressed by self-absorption for wavelengths λ ≲ 1 mm.
is marked by a red solid line in Fig. 12. We stress that attenuation on the synchrotron emission has been applied but turns out to be irrelevant since the corresponding spectrum is strongly suppressed by self-absorption for wavelengths λ ≲ 1 mm.
2.4.3 X-ray binaries
The X-ray emission associated with star formation comes mainly from high and low mass X-ray binaries. For their total output, we use the prescriptions by Fragos et al. (2013) based on stellar population synthesis simulation for a Chabrier IMF. Specifically, the contribution to the emission in the 2–10 keV band from high-mass X-ray binaries can be described via the polynomial expression
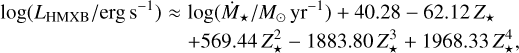 (49)
(49)
while that from low-mass X-ray binaries reads
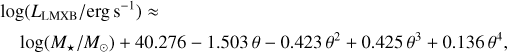 (50)
(50)
where θ ≡ log(τ/Gyr).
We distribute both emissions according to a power-law with an exponential cutoff
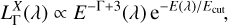 (51)
(51)
with E(λ) = hP vλ = hP c/λ the energy of a photon with wavelength λ. The photon index is set to Γ ≈ 1.6 for LMXB and to Γ ≈ 2.0 for HMXB (see Fabbiano 2006); the high-energy cutoff is fixed at Ecut ≈ 100 keV, while at the other end the spectrum is extended up to λ ≈ 50 Å.
The resulting total emission from X-ray binaries,
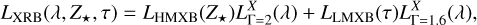 (52)
(52)
is marked by a solid yellow line in Fig. 12.
2.5 Active galactic nucleus
The panchromatic emission from galaxies modelled by GalaPy can be enriched by the inclusion of templated spectral models of the emission due to a luminous nuclear component. Even though GalaPy is currently intended for the study of galaxies which are not dominated by an active galactic nucleus (i.e. not AGN-dominated), accounting for this component can be important when trying to refine the inference of the hosting galaxy properties from its overall emission, provided that the AGN properties are known.
We adopted the AGN templates 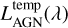 by Fritz et al. (2006, F06 hereafter), which have been computed via a radiative transfer model and take into account three components: the accretion disk around the central supermassive black hole, the scattered emission by a surrounding dusty torus, and the thermal dust emission associated with the heated dust.
by Fritz et al. (2006, F06 hereafter), which have been computed via a radiative transfer model and take into account three components: the accretion disk around the central supermassive black hole, the scattered emission by a surrounding dusty torus, and the thermal dust emission associated with the heated dust.
The overall shape of the template depends on six discrete tunable parameters: the ratio 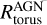 of the maximum to minimum radii of the dusty torus, the optical depth
of the maximum to minimum radii of the dusty torus, the optical depth 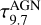 at 9.7 μm, the dust density distribution rβ e−γ|cos θ| in terms of two parameters, β and γ, the covering angle, Θ, of the torus, and the viewing angle
at 9.7 μm, the dust density distribution rβ e−γ|cos θ| in terms of two parameters, β and γ, the covering angle, Θ, of the torus, and the viewing angle 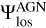 between the AGN axis and the line of sight. The template library we are using, by the variation of these six parameters, counts 24000 spectra among which the user can choose. We further vary the overall contribution of the AGN spectrum over the total galactic emission by an additional parameter, fAGN, defined as the contribution of the AGN to the IR emission from interstellar dust.
between the AGN axis and the line of sight. The template library we are using, by the variation of these six parameters, counts 24000 spectra among which the user can choose. We further vary the overall contribution of the AGN spectrum over the total galactic emission by an additional parameter, fAGN, defined as the contribution of the AGN to the IR emission from interstellar dust.
Specifically, the fraction fAGN regulates the fractional intensity of the normalised AGN SED at any given galactic age:
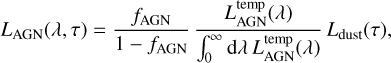 (53)
(53)
where Ldust(τ) is the bolometric dust luminosity at given galactic age as defined in Eq. (38). This modelling choice is valid for objects where the AGN emission in the IR band is sub-dominant with respect to the inter-stellar dust emission. For this reason and to guarantee that Eq. (53) is not diverging, GalaPy forces fAGN < 1.
We also model the intrinsic X-ray emission coming from the inner parts of the accretion disk. This contribution is added on top of the optical/MIR template and is modelled by adopting the same shape of Eq. (51), with photon index Γ ≈ 1.8 and high-energy cutoff Ecut ≈ 300 keV. The normalisation in the 2–10 keV band is based on the hard X-ray bolometric correction by Duras et al. (2020):
![Mathematical equation: ${{L_{{\rm{AGN}}}^{{\rm{bol}}}} \over {L_{{\rm{AGN}}}^X}} \approx 10.96{\left[ {1 + {{\log \left( {L_{{\rm{AGN}}}^{{\rm{bol}}}/{L_ \odot }} \right)} \over {11.93}}} \right]^{17.79}}.$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq83.png) (54)
(54)
We first compute 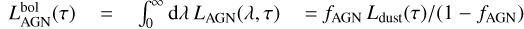 from Eq. (53) and then use Eq. (54) to obtain the spectrum normalisation
from Eq. (53) and then use Eq. (54) to obtain the spectrum normalisation 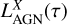 in the hard X-ray band 2–10 keV.
in the hard X-ray band 2–10 keV.
F06 templates are excellent for modelling AGNs for which the geometry is well known and/or when the AGN contribution is dominant over the spectrum. Nonetheless, due to their high number of dimensions, they prove to add a level of complexity to the model that would require extremely large datasets to produce significant parameters posteriors if used for fitting. Furthermore, our current implementation of the X-Ray emission from AGN does not account for the torus attenuation nor for that due to galactic dust and, therefore, should also be included carefully. The purpose of the current implementation of the AGN module in GalaPy is to add a already known AGN emission to the overall spectrum, when needed. We plan to extend GalaPy with a self-consistent parameterised modelling of the AGN accounting for BH-galaxy co-evolution and clumpy torus emission in the nearest future. This extension will be intended for continuous exploration of the parameter space within the Bayesian framework of the library.
2.6 Build a galaxy model
The overall rest-frame SED is obtained by summing all the contributions from the components building up the galaxy model of choice. The default minimal set-up provides a total emission given by
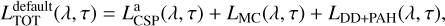 (55)
(55)
where the different terms are computed via the relevant equations provided in the previous sections. Including all the optional components to the galaxy model will produce an SED given by
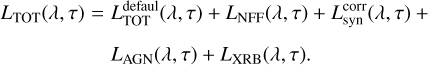 (56)
(56)
We provide a convenient class GXY that can be instantiated by importing it from the galapy.Galaxy module. This class manages the interplay between all the components and provides access to all the free-parameters tuning. It can both be used for building mock SED observations and for modelling emission. A summary of all the tunable parameters available through this interface is reported in Appendix B.2 and in Table B.3.
2.6.1 Cosmology and redshifting
When dealing with the emission from galaxies, choosing a cosmological model plays a primary role in deriving the flux received by an observer at a given distance from the source, along with a secondary role in imposing an upper limit to the age the modelled galaxy can have. Given these considerations, we implemented a Cosmology class with limited functionalities but significant flexibility. It is built by passing two grids used for interpolation: a redshift-luminosity distance grid and a redshift-cosmic age grid. Along with the possibility to provide directly grids computed with external libraries (such as with e.g. astropy, The Astropy Collaboration 2013), we provide several ready-to-use popular parameterisations in our database that can be chosen easily by passing the relevant string (e.g. ‘Planck2018’ for rounded Planck Collaboration VI 2020 parameters6).
For a galaxy at redshift z, we compute the observed SED in terms of flux density Sv(λO) in mJy at the observation wavelength λO = λR(1 + z) by redshifting the rest-frame SED, converting it from energy to flux via the cosmological luminosity distance DL(z)
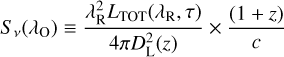 (57)
(57)
expressed as a function of the rest frame wavelength, λR and where LTOT(λR, τ) is given by Eq. (56).
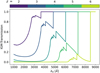 |
Fig. 13 Overall IGM transmission functions predicted by Inoue et al. (2014) for different values of redshift (colour-coded). |
2.6.2 Intergalactic medium
The main contribution to the damping of ultra-violet photons due to the absorption from the intergalactic medium (IGM) is ascribed to hydrogen, with a minor contribution from heavier elements. To model this effect we exploit the fitting functions from Inoue et al. (2014), provided in terms of piece-wise equations for the Lyman-series (LS) and Lyman-continuum (LC) absorption from Damped Lyman-α systems (DLA) and from the Lyman-α Forest (LAF). The authors approximated model provides a fair trade-off between accuracy and performance.
The optical depth is then given by the sum of the various contributions:
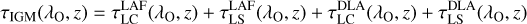 (58)
(58)
where the different terms are computed from Eqs. (20), (21) and (25)–(29) of Inoue et al. (2014).
As a result, the observed flux of Eq. (57) is multiplied by a transmission term given by 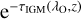 . In Fig. 13, we show this transmission for different values of redshift above z = 2.
. In Fig. 13, we show this transmission for different values of redshift above z = 2.
2.6.3 Photometry and spectroscopy
GalaPy is capable of generating synthetic spectra from extra-galactic sources at the native resolution of the input SSP library used. To compute fluxes in the observational band-pass filters, we use the transmission function Ti(λ) in units of photons7 associated with each instrumental filter, i. We obtain the band-averaged flux as:
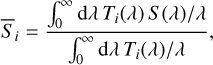 (59)
(59)
where the flux S (λ) is computed through Eq. (57). Band emission can be associated with a typical, ‘pivot’ wavelength of the filter:
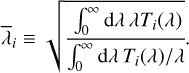 (60)
(60)
In our database, a set of band-pass transmissions from popular experiments is made available (e.g. JWST, SDSS, HST, Spitzer, Herschel, ALMA, VLA), but users can also load their custom transmissions by providing a wavelength-transmission grid over which the system should interpolate the function T(λ).
A utility class PhotoGXY can be instantiated by importing the galapy.Galaxy module. Objects of PhotoGXY type allow the user to provide a photometric system to simulate and model observations on a set of band-pass transmissions of choice.
At current stage of development, the library does allow for fitting both photometric and spectroscopic datasets. Nonetheless, this requires us to modify the default likelihood from the python API (tutorials are available in the documentation). Automatised sampling of the parameter space with spectroscopic datasets will be the subject of a focussed forthcoming work in the GalaPy series.
3 Parameters inference and analysis
In GalaPy, we use Monte Carlo techniques in a Bayesian framework in order to sample the posterior probability distributions in the parameter space defining our galaxy models. A sampling sub-module is accessible from the Python API which provides an interface to two popular pure-Python libraries for parameter-space sampling, emcee (Foreman-Mackey et al. 2013) and dynesty (Speagle 2020). The two libraries offered by GalaPy provide distinct techniques and philosophies for addressing the challenge of multi-dimensional sampling.
We describe here our current implementation and default set-up of the hyper-parameters8, highlighting though that the sampling module of GalaPy will be extended in future developments of the library. For the latest functionalities of the library, users should always refer to the on-line documentation. Furthermore, all the discussion below only refers to the out-of-the-box functionalities, accessed through the entry-points described in Appendix C, that can always be extensively customised by accessing the GalaPy Python API.
3.1 Statistical set-up: Likelihood, noise, and priors
In GalaPy, parameter space is sampled with the intent of maximising the log-likelihood
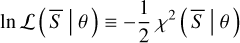 (61)
(61)
where 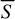 are the observed band-averaged fluxes. Observations are compared against simulated fluxes obtained by means of Eq. (59) with a galaxy model sampled from some position θ in parameter space.
are the observed band-averaged fluxes. Observations are compared against simulated fluxes obtained by means of Eq. (59) with a galaxy model sampled from some position θ in parameter space.
When observing a source with a given instrument, the signal to noise ratio (S/N) might be small due to instrumental or environmental noise of different origins. It is not rare that the measurement in some band is not considered a detection, due to the low value of S/N. Even though it should be kept in mind that also small values of the S/N are measurements with an associated error, and should therefore be treated as such, we allow for a different treatment of data-points and upper limits.
The χ2 statistics appearing in Eq. (61) can be expanded as
![Mathematical equation: ${\chi ^2}(\bar S\mid \theta ) \equiv \sum\limits_{i = 0}^{{N_{{\rm{det }}}}} {{{\left( {{{{{\bar S}_i} - {{\bar S}_i}(\theta )} \over {{\sigma _i}}}} \right)}^2}} + \sum\limits_{j = 0}^{{N_{{\rm{up - ims }}}}} f \left[ {{{\bar S}_j},{{\bar S}_j}(\theta ),{\sigma _j}} \right]$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq95.png) (62)
(62)
where the first sum is a simple χ2 among all the Ndet bands where the measurement has been classified as a detection. The second sum instead runs on the Nup-lims functions f accounting for the probability that the upper-limit in band j is drawn from a given model θ.
We provide three different possible treatments for upper limits:
χ2 (default): non-detections are treated exactly as detections with a large error;
naive: a simple step-wise function setting the log-likelihood to -∞ (i.e. zero probability) when the model predicts a flux larger than observed and to 0 (i.e. probability equal to one) when the predicted flux is lower than the limit
![Mathematical equation: $f\left[ {{{\bar S}_j},{{\bar S}_j}(\theta ),{\sigma _j}} \right] = \left\{ {\matrix{ { - \infty } \hfill & {{{\bar S}_j}(\theta ) > {{\bar S}_j}} \hfill \cr 0 \hfill & {{\rm{ otherwise }};} \hfill \cr } } \right.$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq96.png) (63)
(63)-
Sawicki (2012): the author proposes a modification of the χ2 that consists of the integral of the probability of some observation up to the given proposed model. If the errors on data are Gaussian, this integral provides the following analytical expression for the corresponding log-likelihood:
![Mathematical equation: $f\left[ {{{\bar S}_j},{{\bar S}_j}(\theta ),{\sigma _j}} \right] = - 2\ln \left\{ {\sqrt {{\pi \over 2}} {\sigma _j}\left[ {1 + {\mathop{\rm erf}\nolimits} \left( {{{{{\bar S}_j} - {{\bar S}_j}(\theta )} \over {\sqrt 2 {\sigma _j}}}} \right)} \right]} \right\}.$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq97.png) (64)
(64)Even though it can be argued that using the expression above is the most formally correct way of accounting for upper limits when errors are Gaussian, the combination of logarithm and error function is particularly risky in computational terms. Specifically, it tends to hit the numerical limit of floating point numbers representation accuracy really fast, leading to undefined behaviour. These problems, even though negligible in most of the occurrences, might lead to difficulties in the convergence of the posteriors for particularly complex posterior shapes.
As already mentioned though, in a Bayesian framework based on direct parameter-space sampling, even in the case of low S/N there is no real reason for using a different statistical treatment with respect to detections9. The large relative error already contains the information necessary to inform the χ2 about the lack of flux in the specific band. We therefore set as default behaviour for upper-limits the usage of a standard χ2. We strongly recommend to provide the actual measured flux, independently from its S/N, to the sampling algorithm. When such measurement is not available, a safe choice would be to set the flux measurement to the same value of the absolute error.
At the current state, GalaPy is thought for the study of individual galaxies and not for the study of the correlation between the parameters in a large sample of objects, therefore, a sophisticated treatment of noise and systematic uncertainties is not necessary (e.g. Kelly et al. 2012; Galliano 2018). Nevertheless, in preparation for future extensions of the library and for completeness, we have implemented a simplistic naive treatment of calibration errors and/or unknown systematic errors that might be present in the modelled datasets. To this purpose, we allow for the presence of a nuisance parameter, fsys, that modifies the measured uncertainties as
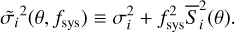 (65)
(65)
This modified error depends on the model parameters θ through the predicted SED band flux 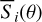 and on the nuisance parameter fsys as well as from the original measured error σi. By adding a positive value to the observed variance we are making the assumption it had been underestimated by a relative factor fsys.
and on the nuisance parameter fsys as well as from the original measured error σi. By adding a positive value to the observed variance we are making the assumption it had been underestimated by a relative factor fsys.
We are not accounting for eventual correlations between observational bands thus our Gaussian log-likelihood is simply modified by an additional term accounting for the dependence of the variance on the model parameters. For the case of detections Eq. (61) becomes
![Mathematical equation: $\matrix{ {\ln {\cal L}\left( {\bar S\mid \theta ,{f_{{\rm{sys }}}}} \right) \equiv } \hfill \cr {\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, - {1 \over 2}\sum\limits_i {\left\{ {{{{{\left[ {{{\bar S}_i} - {{\bar S}_i}(\theta )} \right]}^2}} \over {{{\tilde \sigma }_i}^2\left( {\theta ,{f_{{\rm{sys }}}}} \right)}} + \ln \left[ {2\pi \tilde \sigma _i^2\left( {\theta ,{f_{{\rm{sys }}}}} \right)} \right]} \right\}} ;} \hfill \cr } $](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq100.png) (66)
(66)
we note that a similar modification is applied to the case of upper limits.
This simple noise model adds only one parameter to the multi-dimensional space that has to be sampled, therefore it does not particularly burden the sampling procedure. We have tested on multiple problem set-ups that fsys is completely uncorrelated to the other free parameters: the only net effect on the final posterior is to make the constraints less tight, as it would be expected if errors in the observed dataset were larger. Nonetheless, we have also observed that the addition of this systematic error in some cases help in breaking the degeneracy between parameters, especially in the case of multi-modal posteriors such as when we are estimating photometric redshifts.
In closing this section, we highlight that the default behaviour of GalaPy currently only accounts for uniform unin-formative priors, whose limits are set by the user. This choice is motivated by the argument that each galaxy should be considered as an independent object for which a-priori knowledge of the parameters can be hardly argued.
Accessing the GalaPy Python API, the aforementioned behaviours can be easily modified. Furthermore, more sophisticated statistical tools, such as non-Gaussian errors and non-uniform priors, are planned for future extensions of the library. We are already working at the implementation of a hierarchical Bayesian sampling scheme that, along with a more sophisticated treatment of the systematic errors, is intended for the application of GalaPy on large samples of galaxies, foreseeing upcoming data from future surveys.
3.2 Samplers
The statistical framework of GalaPy comes with a Sampler object that provides a common interface for the parameter-space samplers we rely on, namely, emcee (Foreman-Mackey et al. 2013) and dynesty (Speagle 2020; Koposov et al. 2023). These two libraries provide different and complementary approaches to Monte Carlo sampling of a multi-dimensional space. We maintain both tools in order to provide a flexible machinery that can be adapted to different problems.
emcee, provides an implementation of the Markov-chain Monte Carlo (MCMC) technique. Specifically, it implements an ensemble sampler with affine invariance (Goodman & Weare 2010) that, by instantiating many test particles (walkers) in the parameter space, builds first order Markov sequences of proposals that are tested against the likelihood. The dynamics of this system of particles is regulated by the requirement that, at each new step, a better estimate of the parameters is drawn.
-
dynesty implements Dynamic Nested Sampling (Higson et al. 2019), a generalised version of nested sampling (Skilling 2004, 2006) where the number of test particles (here live points) is dynamically increased in regions of the posterior where a higher accuracy is required. The parameter space is modelled as a nested set of iso-likelihood regions that are sampled until the overall evidence reaches a stopping criterion set by the user. In our default hyper-parameters set-up we provide an 80%/20% posterior/evidence split and we model the posterior space with multiple ellipsoids (Feroz et al. 2009), as we expect to have multiple peaks and correlations when sampling high dimensional parameter spaces. We use the default stopping function
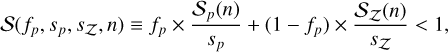
where fp is the fractional importance we place on posterior estimation (20%, as mentioned above), 𝒮p is the posterior stopping function, 𝒮𝒵 is the evidence stopping function, sp is the posterior “error threshold”, s𝒵 is the evidence error threshold, and n is the total number of Monte Carlo realisations, used to generate the posterior/evidence stopping values.
When sampling high-dimensional large volumes the degeneracy between parameters can easily generate a complex posterior topology, such as multiple peaks on some parameters or nonlinear correlations. Our suggestion for an optimal usage of GalaPy is to rely on dynamic nested sampling in this case. As an empirical rule of thumb, we can recommend to rely on nested sampling when the number of free parameters is larger than 5 and when it is not necessary to include extremely complex priors (as this, even though feasible, is not trivial).
On the other hand, MCMC provides a more straightforward interface to the inclusion of sophisticated priors and proves to be efficient and to possibly converge faster when working on smaller and well-behaved volumes, i.e. when multiple peaks and complex correlations among parameters are not to be expected.
GalaPy comes with a default set-up for the hyper-parameters determining the behaviour of the two currently available samplers. The chosen values should work, and have been tested, on several common possible problems. For both the nested sampler and the MCMC sampler, a drawback of this default set-up is that it might not be the fastest to converge, nonetheless convergence should be guaranteed. We stress that it is not possible to provide a general set-up of the aforementioned hyper-parameters. Experienced users can access and modify the default values to better suit the specific needs of the problem at study.
As already mentioned, we plan to include additional samplers in future extensions of the library.
3.3 Results
We provide a Results class that collects all the information acquired during the sampling run and computes derived quantities for easy access and analysis. This includes all the full-SEDs computed for each position in the parameter space, all the derived quantities (masses, metallicities and temperatures) as well as all the coordinates in the parameter space and all the GalaPy objects built during the run.
Results objects tend to be particularly heavy in terms of both volatile and non-volatile memory. The typical size primarily depends on the number of samples that were needed to obtain a converged posterior and, secondarily, on the number of free-parameters and the other characteristics of the sampling run. Given the large amount of memory that could be necessary for computation and storage, we offer the possibility to store the results of a sampling run without computing the associated Results object, leaving this process for when the results have to be analysed.
The output formats available in GalaPy are:
pickle: the standard Python serialisation protocol. Results object are computed at the end of a sampling run then serialised and stored in non-volatile memory. The typical size of the output file can reach up to ~ 1 GB.
hdf5: the Hierarchical Data Format (Folk et al. 2011), a widespread method for storing heterogeneous data. When using this format storage in non-volatile memory is possible in two flavours:
light: store only samples coordinates, likelihood values and weights along with minimal additional information to re-build the models used in the sampling (typical size 10 MB);
heavy: along with the information available also with the light option, all the additional derived quantities computed when building the Results object are stored (typical size up to ~1 GB).
Once stored, results can be accessed and analysed by users in any moment. We note that, when choosing the HDF5 format in either its heavy or light version, results can be accessed even without having to instantiate a Results object and can be loaded in memory as simple dictionaries or accessed as regular HDF5 files. The drawback of choosing lightweight storage is an additional overhead when instantiating the Results object for the analysis.
By instantiating or de-serialising the Results class several functions for statistical analysis, TEX table formatting and plotting are made available. This should guarantee quick access to data and user-friendliness. All the plots and tables provided in the following Sect. 4 have been produced using these tools.
3.4 Analysis
We distinguish among two broad categories of quantities that are stored and/or that can be computed after a sampling run:
free parameters, are all the parameters that define the behaviour of the emission model chosen. These parameters define the size of the parameter-space that is sampled by the Monte Carlo algorithm of choice. Parameters of this kind can be e.g. the age of the galaxy, its redshift, the indexes of the extinction power-law in Eqs. (18) and (20). A complete list of all the possible free-parameters is provided in Table B.3.
derived parameters, are all those parameters that do not directly define an additional dimension in the parameter-space inspected by the sampler but can be computed by choosing a given position in the parameter space.
GalaPy provides several different tools for analysing the results of a sampling run. These tools are primarily accessible as functions of the Results class described in Sect. 3.3 and by importing the sub-package galapy.analysis. The latter contains two modules: plot and funcs, which respectively provide interfaces for plotting and generating formatted tables of different statistics measured both on the free-parameters, θ, and on the derived parameters, δ.
For each sampled position in the free-parameters space we have an associated value of the log-likelihood, ln ℒ(θi), and a weight, wi. Furthermore, we pre-compute at the end of the run several derived quantities automatically such as, the full SED in the whole wavelength grid (as it is defined by the SSP library of choice), temperatures of the two ISM components, masses of the different components (stars, dust and gas), metallicities, star formation rate.
In Bayesian inference we want to get to an estimate of the free-parameters posteriors, P(θ|D), given a dataset, D, a model of the data depending on the free-parameters, θ, and some priors, P(θ). From the sampled posterior one can derive an estimate of the true value of each parameter, free 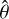 or derived
or derived 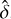 , using an estimator (such as e.g. the weighted mean of samples). Monte Carlo techniques allow to derive a sample of positions in the parameter space from which we can get to an approximate estimate of the posterior. It is therefore possible to weight each position in the parameters space by the likelihood and compute weighted summary statistics and estimators.
, using an estimator (such as e.g. the weighted mean of samples). Monte Carlo techniques allow to derive a sample of positions in the parameter space from which we can get to an approximate estimate of the posterior. It is therefore possible to weight each position in the parameters space by the likelihood and compute weighted summary statistics and estimators.
The two samplers currently available in GalaPy provide different philosophies to approximate the posterior. The Monte Carlo Markov chain (MCMC) method implemented in emcee generates samples proportional to the posterior, so that
 (67)
(67)
On the other hand, the Dynamic Nested Sampling algorithm used in dynesty, generates samples in nested (possibly disjoint) “shells” of increasing likelihood. The associated estimate of the posterior is then obtained by combining the set of samples with weights defined as
![Mathematical equation: ${w_i} \equiv {1 \over 2}\left[ {{\cal L}\left( {{\theta _{i - 1}}} \right) + {\cal L}\left( {{\theta _i}} \right)} \right] \times \left[ {{X_{i - 1}} - {X_i}} \right]$](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq105.png) (68)
(68)
where ℒ(θi) is the likelihood of the i-th sample and Xi is its associated volume of the prior10 where the likelihood ℒ(θi) ≥ λ is above some threshold λ.
When a sampling run converges, as already mentioned, we provide users with all the samples, their associated log-likelihoods and weights, along with derived-parameter values in all these positions. In this way users can choose to use their custom estimators to get to an estimate of the true values of these parameters. Conveniently though, we also provide functions for computing some useful estimators, accessible either from the galapy.analysis sub-package or the Results class.
Along with the weighted average and standard deviation, percentiles and best-fitting value (i.e. the position in the parameter space among all those sampled where the log-likelihood has assumed its maximum value) we also give the possibility to compute credible intervals around a given position of the parameter space. All of these quantities are weighted with values from Eqs. (67) and (68).
In particular, we define the central credible interval for a marginalised parameter θ as that region of the parameter space enclosed in an interval [θlow, θupp] defined around the best-fitting (i.e. maximum likelihood) value of the parameter, θbest. The limits of this interval are defined by
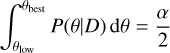 (69)
(69)
for the lower bound, and
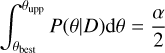 (70)
(70)
for the upper bound. A value of, for instance, α = 0.68 gives the 68% credible interval.
For highly asymmetric or multi-modal marginalised posteriors, one of the two half-integrals in Eqs. (69) and (70) might not encompass enough samples to embed the requested probability value. In these cases only upper/lower limits on the parameter value can be retrieved and the equations become
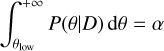 (71)
(71)
for lower limits and
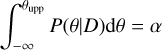 (72)
(72)
for upper limits.
4 Validation
In this section, we present a sanity check for GalaPy. We both verify that all the components of the library are behaving as expected as well as validate the scientific return of the physical models proposed. Even though we limit our presentation here to the aspects involving the science that can be performed with our tool, we provide some preliminary discussion on the computational side and on software performances in Appendix A. A thorough discussion on performances and a comparison with other codes goes beyond the scope of this manuscript and is left for a future work.
We test our model on both mock and real observations of star-forming and quiescent objects. Star-forming objects are complex structures that can host several, if not all, of the different components implemented in GalaPy, making them an excellent test-bench for investigating the interplay between the modules building up our library. We first test the constraining capabilities of our machinery by building a set of mock observations of simulated galaxies with different physical properties and perform the regression with GalaPy (Sect. 4.1). In Sect. 4.2, we use the In situ SFH model (Sect. 2.1.3) along with our dust model (Sect. 2.3.1) on a set of real sources, in order to validate the reliability of these models on estimating the astro-physical properties of sources.
Number of generated sources for the different combinations of SFH models.
4.1 Validation on mock sources
In order to verify and prove the efficacy of GalaPy, we first tested it against mock observations generated with the library itself.
As anticipated, we generated a set of mock observations of galaxies simulated using the GalaPy modelling framework. We generated different mock sources by randomly sampling a flat prior space for different models of SFH. For each of these sources we used the parsec22.nt SSP library (see Sect. 2.2; in Appendix B.1 we compare the BC03 libraries with the PAR-SEC22 libraries and show that the results obtained are consistent independently on the choice of SSP library).
In particular, for the sake of investigating the library reliability on a broad parameter space volume, we generated both actively star-forming and passively evolving galaxies. Table 1 summarises the number of mock sources generated for this test. In particular, for each SFH model we generated two sets of objects: 20 sources for which a spectroscopic estimate of red-shift exists, and 20 sources for which redshift has to be estimated photo-metrically (i.e. zphot is a free-parameter of the model). Furthermore, for the in situ and delayed exponential SFH models, we both generated sources that have still an active star-formation and sources that are passively evolving. On the other hand, for the Constant SFH model, we only selected actively star forming objects, as this particular model is intended for objects that are undergoing a secular evolution of their stellar content (e.g. late-type galaxies). We therefore run our test on a total of 200 mock sources, 100 of which are assumed to not have a spectroscopic determination of redshift.
In practical terms, actively star-forming sources are generated by setting the τquench parameter to an arbitrarily large value, consistent with infinite11. On the other hand, for passively evolving objects, we sampled a random value for the quenching time, τquench and imposed that the age should be sampled from an interval of values that is upper-limited by the sampled value of τquench. Each mock source has been generated by sampling uniformly a position in the parameter space defined by the priors summarised in Table 2. The overall SED of actively star-forming galaxies therefore consists of the dust-attenuated emission from stars including nebular thermal emission and non-thermal synchrotron as well as thermal emission coming from the two different components of our dust model. On the other hand, the SED of passively evolving mock sources is given by the un-attenuated stellar emission, possibly including some left-over nebular thermal emission and non-thermal synchrotron, if quenching had been particularly recent. The latter would anyways be extremely sub-dominant and un-investigated given the photometric system shown in Fig. 14.
In order to build a mock photometric observation, we need to assume a photometric system. This is graphically shown in Figs. 15 and 14, where, as a function of wavelength, we show the transmission corresponding to the 24 band-pass filters we used for actively star-forming mock galaxies and the 12 used for passively evolving mock sources, respectively. We selected filters from different well known experiments, covering a wide range of wavelengths. While for passive objects we select filters from the UV/optical bands to the near-infrared, using transmissions from SDSS, 2MASSm and Spitzer, for active objects we extend the spectral coverage up to the sub-mm/mm bands adding also filters from Herschel and ALMA.
To add errors to our mock observation we first associated to each different transmitted flux of each single mock source an error that has been randomly chosen to be between 10% and 50% of the flux. With this value set for all the fluxes, we then generated a random realisation of the mock measurement by extracting it from a Gaussian distribution with mean equal to the real value of the transmitted flux and standard deviation equal to the random error.
The free-parameters chosen for the sampling runs are the same free parameters we varied in generating the mock sources (Table 2). We allowed for nine free parameters, including the age and SFH and ISM defining parameters, in actively star-forming galaxies. For passively evolving sources we instead varied four free parameters, including age of the galaxy, age of quenching, and SFH defining parameters. In both cases, for 100 out of the 200 sources, redshift has been set as an additional free-parameter. Consistently, we modelled each source with the same SFH model and SSP library used for generating it.
For the sampling of the free-parameters of our models, we assumed a set of uninformative uniform priors whose limits correspond to those listed in Table 2, namely, the same intervals defining the parameter space volume sampled by the mock sources. For each source, we ran a dynamic nested sampling using dynesty with default GalaPy sampling hyper-parameters and stopping criterion12.
Sampling runs take (on average) approximately 15 min per source to converge on eight physical cores of an Intel i9-10885H CPU @ 2.40 GHz with x86_64 architecture. The time required for convergence strongly depends on the total number of samples extracted. When running with dynamic sampling, this number is not known in advance (more details in Speagle 2020). Our runs typically converge with a total number of valid samples between 10 to 20 thousands, each with a different weight. This does not reflect the actual number of likelihood calls for (given an average efficiency between 1% to 5% for these kinds of problems) a range spanning 5 ÷ 10 × 105.
4.1.1 Results for the whole sample
In Fig. 16, we show the distribution of the reduced χ2 values for the best-fitting set of parameters obtained by means of the dynamic nested sampling runs detailed above. With a dashed green line we mark the distribution of the 100 sources for which we assumed a value of the spectroscopic redshift was available, while the solid blue histogram marks the distribution of the 100 sources for which redshift was a free-parameter. As a term of comparison, we show as a dotted vertical gray line the value corresponding to the expectanion value χ2 = 1. From the histograms, we can appreciate how, for almost all the sources, 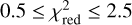 .
.
In Fig. 17, we show the values for a collection of relevant free and derived parameters obtained by computing the weighted median of the samples with errors given by the 16th and 84th percentiles, namely, the limits of a credible interval embedding a 68% probability. Different symbols and colours mark different combinations of SFH model and active/passive evolution, as detailed in the caption. Results are given in terms of the ratio between the measured and real value of the parameter. The top three panel show quantities available for all sources, actively star-forming and passively evolving (i.e. age of the galaxy, redshift and stellar mass), while the lower three panels show quantities that are defined only for the actively star-forming objects (i.e. dust mass, gas mass and current star formation rate). We highlight that, even though Fig. 17 collects only posterior values obtained for the 100 sources without spectroscopic redshift, equivalently consistent results have been found for the other set of sources.
The ratios in Fig. 17 show that the true value of each parameter is within the 68% credible interval for ≳ 90% of the mock observations, with this percentage increasing considerably if accounting for a 95% credible interval. In particular, photometric redshift, stellar mass and star formation rate show an exquisite agreement with the expected value.
It is also interesting to focus on the Mdust and Mgas parameters. As already discussed in Sect. 2.1, the method used to estimate these quantities in the In situ SFH model is different with respect to other empirical models. In particular, while for empirical models of SFH Mdust and Mgas are free-parameters, the in situ model predicts their value analytically, based on the SFH. It is therefore relevant that the estimates obtained by the In situ model (blue circles in Fig. 17) show a smaller error and a better agreement with the real value, with respect to the larger error-bars and scatter shown by the delayed exponential (green triangles) and constant (red squares) models.
We can conclude that the machinery we have built successfully retrieves the correct representation of data. We highlight that the collection of sources used for testing has been selected randomly from a considerably large parameter-space volume without any prescription for the mock observation to be representative of any real source population. Nonetheless the agreement of the results is almost perfect in all the dimensions, demonstrating how the tool is not limited to specific populations of objects and does not require a high level of fine tuning to get to a significant result. This is reflected on the small scatter of the marginalised posteriors of the parameters (as shown in Fig. 17).
 |
Fig. 14 Same as Fig. 15 for the mock observation of the passively evolving simulated galaxies of Sect. 4.1. |
 |
Fig. 15 Photometric system used to generate the mock observation for the actively star-forming simulated galaxies of Sect. 4.1. The lower x-axis shows the keyword name of the band-pass transmission while the upper x-axis shows the corresponding wavelength in angstroms. Transmissions are expressed in terms of photons and the dashed lines mark the position of the pivot wavelength for each band-pass filter. We note that this is just a possible set-up specific to the case of the mock galaxy of Sect. 4.1. It represents only a sub-set of the band-pass transmissions available in the GalaPy database. |
 |
Fig. 16 Distribution of the reduced χ2 for the best-fitting parameters of the two sets of sources (with and without spectroscopic redshift in dashed green and solid blue, respectively), as obtained by sampling the free-parameter space with dynesty. |
4.1.2 Demonstration on a mock source of available tools
Before moving to the analysis of real sources, we select one out of the 200 mock observations generated in the previous section and we show more in detail the results inferred by the analysis of the posteriors on both the free and derived parameters. In particular, as it will be subject to a stress test on real sources on the following section, we pick one of the actively star-forming galaxies generated by sampling the priors defined for an in situ model of SFH (Table 2).
In Fig. 18, we compare the original mock observation (blue empty round markers with error-bars) with the model favoured by the free-parameters posterior distribution. The black solid line marks the best-fit model that results in a reduced 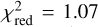 , also reported in the lower panel. With shades of grey we show the 1- and 2-σ confidence regions around the mean SED (in solid grey). Coloured solid lines show instead the contributions to the best-fitting SED, coming from the different components building up our galaxy model. It is worth to highlight the different contributions of molecular clouds and diffuse dust to the peak of dust emission, that naturally blend into the final SED to represent a wider distribution of emission in the MIR-FIR.
, also reported in the lower panel. With shades of grey we show the 1- and 2-σ confidence regions around the mean SED (in solid grey). Coloured solid lines show instead the contributions to the best-fitting SED, coming from the different components building up our galaxy model. It is worth to highlight the different contributions of molecular clouds and diffuse dust to the peak of dust emission, that naturally blend into the final SED to represent a wider distribution of emission in the MIR-FIR.
In the lower panel of Fig. 18, we show the standardised residuals between the best-fitting model and the observed fluxes. These values are defined as
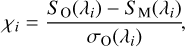 (73)
(73)
where SO(λi) and σO(λi) are, respectively, the flux and error on of the datapoint at pivot wavelength λi and SM(λi) is the corresponding modelled flux. We can see how the best-fit model correctly intercepts the mock-observation while being within 1-σ from the mean of the samples. This agreement is reflected on the marginalised posterior probability of the free-parameters.
Figure 19 shows the triangle plot for a sub-set of the free-parameters posteriors marginalised to 1D and 2D. These marginal posterior probabilities are given as histograms on the diagonal and as grey contours, for the 1D and 2D cases, respectively. We do not show all the parameters to avoid burdening the discussion, so we limit the demonstration to the overall galaxy parameters (i.e. age and redshift), the normalisation of SFH parameter (i.e. ψmax), and to the fraction of total emitted diffuse-dust energy contributed by PAH (i.e. .fPAH). Specifically, the black dashed lines intercept the weighted median value of the samples, darker and lighter grey contours mark the 68% and 95% credible regions (note that, on top of each 1-dimensional marginalised posterior the median value for each parameter with the corresponding 68% credible interval is also reported). As a term of comparison we also show, with orange solid lines, the fiducial value of each parameter. All these fiducial values fall within the 68% credible interval. It is worth to highlight the goodness of our fit for the photometric redshift estimate, as it an extremely sought after quantity and the algorithm was able to correctly infer it with an error of ~5%.
We can use the results obtained with the sampling algorithm to build probability densities also for the derived parameters, as it is shown in Fig. 20. We have selected four interesting derived parameters, namely the star formation rate, SFR, stellar mass, M★ and temperatures of the molecular, TMC, and diffuse dust, TDD, components. The probability densities in 2-dimensional and 1-dimensional space are then built by computing the derived parameter’s values in each position of the free-parameters space, as defined by the galaxy emission model used to represent the mock dataset. Once again, we over-plot with orange solid lines the fiducial value of each parameter which, in all the cases, falls within the region encompassing 68% of the total probability. It is interesting to observe, on the 1D marginalised probabilities of the two temperatures, how in both cases there is a secondary peak that is symmetric in the two components. This is not a surprise as the two dust components compete in contributing both to the absorption at short wavelengths and to the re-emission at longer wavelengths. The modelling we have implemented it’s nevertheless successful in distinguishing between the two, therefore favouring one of the two solution over the other.
 |
Fig. 17 Results for some of the free and derived parameters obtained by fitting with GalaPy the mock observation set generated without spectroscopic redshift detection (see Sect. 4.1). The results are presented in terms of the ratio between the median value of the weighted samples collected by running the dynesty sampler. Errors are given in terms of the 16th and 84th percentiles, defining a 68% credible interval around the median, as detailed in Sect. 3.4. Blue circles, green upward triangles and red squares are actively star-forming sources modelled with an in situ, delayed exponential and constant SFH model, respectively. Violet crosses and yellow downward triangles are instead passively evolving sources modelled with an in situ and delayed exponential SFH model, respectively. |
 |
Fig. 18 Results of the parameters sampling for one of the mock observation of Sect. 4.1. Upper panel: best-fit SED (black solid line) and components (coloured lines) compared to the mock observation data (empty blue markers); 1-σ and 2-σ confidence around the mean of the samples is also shown with grey shaded areas. Lower panel: residuals with respect to the best-fit sample (black); mean and 1-/2-σ confidence regions are also shown with a grey solid line and shaded areas, respectively. |
 |
Fig. 19 Corner plot of the parameter posteriors obtained for the mock galaxy selected in Sect. 4.1.2, illustrating the one- and two-dimensional marginalised posteriors for a subset of the parameter space dimensions (for clarity and visualisation reasons). The shaded grey regions highlight (68%, 95%) confidence from darker to lighter, corresponding to (1-σ, 2-σ). The dashed black lines mark the position of the weighted median value of parameters while the values above the diagonal panels show the median and 68% percentile around the median (roughly corresponding to 1-σ confidence in a Gaussian approximation). As a term of comparison, we also show mark, with orange solid lines, the real value of each parameter. |
4.2 Test on real sources
To validate the scientific throughput of the new models introduced in GalaPy, we compared their predictions with those performed with other SED-fitting codes and with different models for the SFH and for the dust-model. To this end, we selected a small set of sources with interesting properties from several different works. Most of the objects inspected in this section are either high-redshift dusty star-forming galaxies or their supposed descendants at low redshift, namely, quiescent galaxies.
We underline that a validation of other models of SFH has already been performed on mock sources in the previous section. Furthermore, as a thorough analysis of the sources would go beyond the scope of this validation section, we limit the discussion to a simple comparison of the results obtained fitting the SEDs with GalaPy with those obtained with other techniques, as they appear in the literature.
 |
Fig. 21 Results for the four dusty star forming galaxies of Sect. 4.2.1 Upper panels: GalaPy fits to the photometric data of four galaxies selected from the Pantoni et al. (2021) sample (blue markers with error-bars). Best-fitting model (black solid line), different components (colour-coded as in legend), and 1- and 2-σ confidence levels (grey shaded regions) around the mean of the samples are also shown. Lower panels: Standardised residuals with respect to the best-fitting galaxy models, and 1-/2-σ confidence intervals around the mean of the samples (grey shaded regions) are shown; the reduced χ2 of the fit is reported in each sub-panel. |
4.2.1 Dusty star-forming galaxies from Pantoni et al. (2021)
In the work from Pantoni et al. (2021, P21 hereafter), a set of 11 sources selected from 3 millimetre catalogues (ALMA data from Dunlop et al. 2017, reprocessed within the ARI-L project, Massardi et al. 2021; LABOCA, Yun et al. 2012; AzTEC, Targett et al. 2013) in the GOOD-S field and complemented with fluxes from several other bands available in the field. The selected sources are objects at the peak of cosmic star formation history, strongly attenuated by dust, with redshift spanning between 1.5 < z ≲ 2.5. The dataset comes with the advantage of having spectroscopic redshifts and a pan-chromatic coverage spanning from visible to radio bands.
In P21 SEDs have been fitted using the CIGALE code (Boquien et al. 2019), assuming a delayed exponential SFH and the BC03 SSP library. To account for the excess in NIR/MIR, the authors also included a power-law component that should ideally model the combination of diffuse dust, PAH and AGN. For our analysis, we instead used our in situ SFH model and the PARSEC22 SSPsm including lines from nebular regions. Our two-components dust-model automatically accounts for the NIR/MIR excess.
We selected four sources among the 11 available that are not classified as AGNs in the NIR and MIR regions of the spectrum. All the sources have at least 15 observations spanning from optical to radio. We fit the photometries letting ten model parameters vary, including age, SFH and dust properties.
The best-fitting SEDs obtained are shown as black solid lines in Fig. 21 along with the several components contributing to emission (coloured solid lines) and 1-/2-σ confidence around the mean. Band fluxes for each source are marked with empty blue circles. In UDF10, the flux measured with VLA in the radio band is not a detection but was classified as an upper limit, we mark it with a downward arrow in the upper part of the panel. In the lower part of each panel we also plot the standardised residuals with respect to the best-fitting model and the reduced χ2 value. We mark the location of the corresponding radio upper limit of UDF10 with a cross in the residuals plot.
We report the main best-fitting values of free and derived parameters obtained for the 4 galaxies in Tables 3 and 4. We also include the values for the same set of parameters obtained in the original P21 work as a term of comparison. Given that we implement models that are significantly different from the models used in P21, the values obtained with GalaPy do not match exactly those obtained in the original work. Nonetheless, the inferred properties (e.g. the dust and gas masses as reported in Table 4) are in good agreement with the ones obtained in the original work. It as to be further noted that, in the original work these quantities, along with the gas metallicity, were not derived directly from SED-fitting but using post-processing and ALMA-bands emission line analysis.
Focussing on the temperatures of the two dust components, we can first of all notice that, as expected, in most of the cases the MC component is the one having the highest temperature. On the other hand, it is interesting to notice how UDF10 shows a higher temperature in the DD component, while it is significantly older than the other three objects (i.e. age of ~ 109.5 yr). If we compare it to the right panel of Fig. 11, this result suggests that the object could be older than its characteristic escape time from molecular clouds and therefore be in a late stage of evolution. We infer that galaxy is significantly older than its characteristic escape time from molecular clouds, whose predicted value is 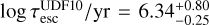 , suggesting that it might be in a late stage of evolution. If we trust the In situ evolution scenario for the formation of ETG galaxies, about to approach a quiescent phase of evolution. From both the plots in Fig. 21 and the values reported in Tables 3 and 4, it is clear that the assumption of a two-component dust model ensures that the dust peak is better modelled with respect to the case of a single component. In particular, the possibility of having two peaks along with PAH emission, allows the overall MIR/FIR model to have more freedom to adapt to the dataset. This is evident from the flex appearing at λ ≈ 107 Å in UDF3 and from the broadening of the peak in UDF10, both effects due to the blending of the two grey-bodies. We can identify a common trend for all the 4 galaxies in the sample as in the single-component estimate of the temperature from the original work, the resulting measurement is systematically over-estimated with respect to the higher temperature dust component in the two-component model used in this work.
, suggesting that it might be in a late stage of evolution. If we trust the In situ evolution scenario for the formation of ETG galaxies, about to approach a quiescent phase of evolution. From both the plots in Fig. 21 and the values reported in Tables 3 and 4, it is clear that the assumption of a two-component dust model ensures that the dust peak is better modelled with respect to the case of a single component. In particular, the possibility of having two peaks along with PAH emission, allows the overall MIR/FIR model to have more freedom to adapt to the dataset. This is evident from the flex appearing at λ ≈ 107 Å in UDF3 and from the broadening of the peak in UDF10, both effects due to the blending of the two grey-bodies. We can identify a common trend for all the 4 galaxies in the sample as in the single-component estimate of the temperature from the original work, the resulting measurement is systematically over-estimated with respect to the higher temperature dust component in the two-component model used in this work.
With GalaPy, we can also easily derive the characteristic attenuation curves of the modelled galaxies (as detailed in Sect. 2.3.1). The average attenuation curve for the 4 galaxies is shown in Fig. 22 with solid black lines. We also plot for reference Calzetti-like (Calzetti et al. 2000) attenuation at varying value of the RV parameter. For wavelengths bluer than λV ~ 5500 Å, our attenuation is consistent with RV ~ 4 for UDF10, UDF11 and AzTEC.GS21, while it is RV ≳ 10 for UDF3. For wavelengths redder than λV all the galaxies have an attenuation that could be represented with 4 < RV < 6 Calzetti-shapes.
 |
Fig. 22 Average attenuation curves (black solid line) predicted by GalaPy in the best-fitting models for the 4 galaxies of P21, normalised to the average value of attenuation in the V–band (≈ 5500 Å). For reference, we also show Calzetti-like empirical attenuation curves for different values of the Rv parameter (colour-coded). |
4.2.2 Local late-type galaxies from Casasola et al. (2020)
We extend the validation of our library to a small sub-sample of 4 local (z < 0.01) late-type galaxies from Casasola et al. (2020), extracted from the DustPedia database13 (see also De Vis et al. 2019). The archive provides access to multi-wavelength imagery and photometry for 875 nearby galaxies as well as physical parameters for each galaxy (Davies et al. 2017; Clark et al. 2018) derived by means of the CIGALE code.
To further probe the reliability of GalaPy’s results, we selected four galaxies that are not undergoing major interactions, do not show any nuclear activity in the X-ray, and are not classified as starburst. We once again selected our in situ model of SFH and the SSPs from the PARSEC22 library. We performed several exploration runs of the sampler on the four galaxies, and consequently decided for a model set-up completely equivalent to the one used for the sources of Sect. 4.2.1 for consistency and as the overall results were not differing substantially. Nonetheless, this is not intended to constitute a thorough analysis but just a sanity-check of GalaPy’s validity. In terms of modelling set-up, we also allowed for an eventual systematic error parameterised as described in Sect. 3.1, marginalising the results over the nuisance parameter, fsys.
The best-fitting model and 1-/2-σ confidence regions around the mean of the samples is compared against the multi-band photometry of the sources in Fig. 23 where, as usual, we also show the different contribution to the overall emission and the standardised residuals with respect to the best-fitting model and associated reduced χ2. By inspecting the residuals in Fig. 23 we can see that the estimated best-fit model correctly intercepts the data-points even though, the extremely small errors on the optical flux measurements tend to make the nuisance systematic error parameter converge around values fsys ≲ 0.1.
A comparison of the derived astrophysical properties of the galaxies in the sample are provided in Tables 3 and 4. In particular, we show, for each source the median values with associated 68% credible interval, measured from the weighted posteriors, and the best fitting value (between parenthesis below each row of values). As expected, given the different shape of the delayed truncated SFH model used in the original work (Bianchi et al. 2018), the values for the SFR are in slight disagreement14. While the dust temperatures (Table 3) do agree within the error-bars, quantities that are more strictly related to the SFH model chosen (i.e. the age and SFR in Table 3, and the dust and gas masses in Table 4) deviate by more than 2-σ. On the other hand, for the stellar masses (also shown in Table 4) the agreement between the results is restored, even though this quantity also depends on the SFH and galaxy age. This last observation motivates us to advocate that GalaPy has found a different solution for the most probable properties of the objects.
A special mention must be made for NGC4254, where we measure the largest discrepancy with literature. In particular, while dust temperatures are still in agreement with the literature result, we measure values consistently higher by a factor ≈ 5 ÷ 10 for the other examined quantities. In Hunt et al. (2019) the authors analyse a sample of objects, including NGC4254, with different SED fitting codes (i.e. MAGPHYS, CIGALE and GRASIL). With a photometric system similar to the one used here, the authors find values slightly larger to the ones reported here in the Literature columns of Tables 3 and 4. Nonetheless, these are still in disagreement with our estimates for the same parameters. We still checked that the SFR ≈ 20 M⊙/yr we find is still allowed by the upper limits imposed with empirical relations (Lapi et al. 2011) connecting the object’s flux in different bands with the SFR, with which we find SFRNGC4254 ≲ 50 M⊙ yr−1.
Finally, we also tried to run the analysis assuming a constant SFH model. The main differences worth to report are higher values for both the SFR and age, as a result of a SFH that, by construction, is more diluted in time. Nevertheless, the constant model is statistically disfavoured with respect to the In situ model as, with a larger number of parameters, produces values of the likelihood that are consistently lower for each of the four sources.
 |
Fig. 23 Same as Fig. 21 for the Dustpedia sample of Sect. 4.2.2. |
4.2.3 Lensed NIR-dark galaxy with upper limits from Giulietti et al. (2023)
As a further test-bench for GalaPy, we run the photometric analysis on a lensed, NIR-dark galaxy studied in Giulietti et al. (2023). HATLASJ113526.2-01460 (J1135 hereafter) was selected by Negrello et al. (2016) as a candidate lensed galaxy at redshift z ~ 3.1 (Harris et al. 2012) in the 12th Gama field of the Herschel-ATLAS survey, and then confirmed as a lensed NIR-dark galaxy by Giulietti et al. (2023).
The interest in testing GalaPy on this object resides on the large number of photometric points that are flagged as upper limits. As already mentioned in Sect. 3, the method of choice for treating upper limits in GalaPy is to consider them as regular points entering the same χ2 likelihood used for detections. We assigned, to each of these points marked as non-detections, a flux equal to zero and an error equal to the noise value measured in the broadband photometry. We selected the same hyper-parameters chosen for sources in Sect. 4.2.1: parsec22.ntl SSPs and the In situ SFH model, with ten free parameters.
We show the fitting results in Fig. 24, upper limits are marked as circles with arrows, while detections are round markers with error bars. In the lower panel, we show the standardised residuals and the χ2 associated with the best-fitting model. As we associated a flux value of zero to non-detections, we mark their corresponding positions with downward arrows at the 1-σ value measured for noise in the upper panel and as crosses in the lower panel.
Besides the solid value of the reduced χ1 statistics, we can notice from the grey 2-σ confidence contour in the upper panel how the NIR-MIR region of the spectrum is just the upper limits, as a result of having just observed upper limits in that part. This is of course expected, as one of the free parameters of the model (i.e. the fraction of diffuse dust emission that is in PAH, fPAH) is completely and only determined by measurements in the NIR to MIR.
We conclude this section by highlighting the excellent agreement (Tables 3 and 4) between the parameter values derived with GalaPy, with respect to the values obtained in Giulietti et al. (2023), where the analysis has been performed with different, but compatible, methods (i.e. by analysing the line emission properties of the source in the ALMA bands). In particular, all the quantities do agree within the 1-σ credible interval to the measurements obtained in Giulietti et al. (2023), even though we find both a median and a best-fitting value for the SFR smaller than what found originally by the authors. We manage to also obtain a more precise measure the age of the object and for the stellar mass, consistent with the upper limit imposed in the original work (i.e. 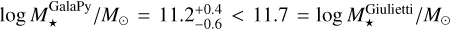 ).
).
Even though not shown in the present manuscript, we have tested the reliability of our treatment of upper limits by both modifying the values used to mark non-detections and by using the other methods presented in Sect. 3.1 to include them in the likelihood. Concerning the former test, we have assumed both fluxes equal to the noise measurement and equal to three times this measurement (what is usually referred to as 1- and 3-σ upper limits). We observe that the result tends to be biased towards higher values for the predicted fluxes in the regions where we only have non-detections (i.e. optical and NIR/MIR). On the other hand, both running with the Sawicki method and with the naive method for the treatment of upper-limits guarantee convergence of the results but, besides requiring more samples (and therefore more time) to converge, the result tends to be statistically less solid, with values of the χ2 statistics consistently higher. It is worth to mention that these considerations are not valid as a general test of the different possible approaches and serve solely has motivation for our final choice. Users of the library should tune their choices on the specific problem at hand.
 |
Fig. 24 Same as Fig. 21 for the J1135 lensed galaxy of Sect. 4.2.3. |
 |
Fig. 25 Same as Fig. 21 for the median of Sect. 4.2.4. |
4.2.4 Stacked NIR-dark radio selected galaxy with no spectroscopic redshift from Behiri et al. (2023)
We validate the library on a case that, to some extent, represents a more extreme case of dust obscured photometry with non-detections. In Behiri et al. (2023), the authors study a radio-selected sample from the VLA-COSMOS 3 GHz Large Project (Smolcic et al. 2017) catalogue, based on a survey covering 1.6 deg1 in the COSMOS field. Thanks to the extremely small value of its limiting flux density (11.6 µJy beam−1 at 5.5 σ), the survey has delivered one of the deepest samples ever obtained. Therefore, this dataset proves an ideal laboratory for estimating the contribution of galaxies at 𝓏 > 3 to the cosmic SFRD.
In their work, the authors produce an ensemble analysis of the average sample properties, by performing SED fitting on the median photometric properties of the sample. The median SED (shown as round blue markers and downward arrows in Fig. 25), is obtained by stacking the individual sources maps for all the bands where a source is detected, and applying survival analysis (Isobe & Feigelson 1986) on all the bands where the presence of eventual upper limits has to be taken into account. This procedure results in 16 bands flagged as detections (empty blue markers with error bar) and 7 bands flagged as upper limits (downward arrows), on an overall wavelength range spanning from ~5 × 103 Å to 1 × 109 Å. The redshift of this artificial median source is unknown, but is expected to be representative of the median redshift of the sample15. The resulting photometry is then fitted using the MAGPHYS+PHOTO-Z code (Da Cunha et al. 2008; Battisti et al. 2019), obtaining the results reported on the right half of Tables 3 and 4.
In running our fit with GalaPy, we select the usual set-up with In situ SFH and PARSEC22 SSPs including nebular lines, free-free and synchrotron and we let 12 physical parameters vary, including redshift, and an additional systematic error parameter to account for eventual errors that might arise from the stacking procedure. The best-fitting SED with 1- and 2-σ confidence regions around the mean of the samples are pictured in Fig. 25 with a black solid line and shaded grey regions, respectively. The best-fit SED is decomposed into its different contributions, reported as coloured solid lines as listed in the legend. The reduced value of the 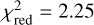 is reported, along with the standardised residuals with respect to the best-fit model, in the lower panel of Fig. 25.
is reported, along with the standardised residuals with respect to the best-fit model, in the lower panel of Fig. 25.
We observe a large uncertainty in the thermal dust emission peak, which is a symptom of the large number of upper-limits in the corresponding part of the observed spectrum. This level of uncertainty is reflected on the large uncertainty for the estimated temperatures of the two media, reported in Table 3 which, compared to the value obtained with MAGPHYS, have fairly small values. The largest difference between our results with those presented in the original work are though in the parameters mostly depending on the CSP, as this part is the most well sampled by the dataset at hand. In particular, we measure an age that is less than two times smaller than the one obtained with MAG-PHYS, even though the two estimates are in agreement within the 68% credible interval. The combined effect of this small value of the age and our weighted median photometric redshift estimate of 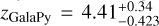 , determine the extremely large value obtained for the SFR (i.e. > 1400 M⊙ yr−1, see Table 3). Given the combination of age and redshift, this value has to be large to explain the 10 mJy flux measurement at the IR peak. As a term of comparison, the photometric redshift estimate obtained with MAGPHYS is
, determine the extremely large value obtained for the SFR (i.e. > 1400 M⊙ yr−1, see Table 3). Given the combination of age and redshift, this value has to be large to explain the 10 mJy flux measurement at the IR peak. As a term of comparison, the photometric redshift estimate obtained with MAGPHYS is 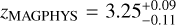 . Both values are consistent with the photometric redshift distribution of the sample from which the median fluxes have been obtained. Note though that, even though the median value of this redshift distribution would be more consistent with the MAGPHYS estimate on the median fluxes, also the photometric redshift estimate of the individual sources in the original work have been obtained using MAGPHYS. It would be interesting to apply our library on the whole sample but this, obviously, goes beyond the scope of this work.
. Both values are consistent with the photometric redshift distribution of the sample from which the median fluxes have been obtained. Note though that, even though the median value of this redshift distribution would be more consistent with the MAGPHYS estimate on the median fluxes, also the photometric redshift estimate of the individual sources in the original work have been obtained using MAGPHYS. It would be interesting to apply our library on the whole sample but this, obviously, goes beyond the scope of this work.
Concerning the component masses instead, we are consistent with the values obtained by the authors of the original work. Both the total mass in dust and the total stellar mass are consistent within the 68% credible interval, even though the best-fitting values are different by some factors.
In closing this section, we stress that even though obtained from stacking the fluxes of different sources, this semi-mock observation should embed the characteristics of the NIR-dark radio-selected population of galaxies at high redshift, from which it has been built. Nonetheless note that, as already mentioned, a thorough comparison of the properties of the median fluxes with the median properties obtained from studying singular objects would require obtaining such individual properties with the same SED-fitting tool, which goes way beyond the objectives of this validation section.
 |
Fig. 26 Same as Fig. 21 for the quiescent sample of Sect. 4.2.5. |
4.2.5 Quiescent galaxies from Donevski et al. (2023)
To provide a consistency check that the in situ model delivered with GalaPy correctly describes the SFH of ETG progenitors and their evolution towards becoming quiescent, we ultimately validated our SED fitting tool on three quiescent galaxies extracted from the parent sample of spectroscopically selected massive quiescent galaxies in the COSMOS field, presented in Donevski et al. (2023). Here we fit the deep optical-to-NIR fluxes of representative sources at different redshifts, spanning in the range from 𝓏 = 0.1 to 𝓏 = 0.6. Testing on quiescent objects is a good test to check on the behaviour of the In situ model when the object is evolved, as this model has been derived to describe the progenitors of early type galaxies in all their evolution towards becoming quiescent.
Along with the in situ model of SFH, we once again select the PARSEC22 SSP libraries and allow for four free parameters: galaxy age, two free parameters of the SFH model, and an age corresponding to an eventual abrupt quenching, to simulate some violent feedback event cleaning up the galaxy from all its diffuse medium.
The best-fitting SEDs are shown in Fig. 26 as well as 1- and 2-σ confidence regions around the mean. In the lower panels, we show the standardised residuals with respect to the best-fitting model and associated reduced χ2
By inspecting the residuals in Fig. 26 we can see that the estimated best-fit model is correctly representing the dataset with 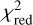 values between 1.3 and 1.6, although the extremely small errors on the optical flux measurements tend to make the nuisance systematic error parameter converge around values fsys ≲ 0.1. Also the results for the derived parameters are extremely consistent with those found in the literature both in terms of age (Table 3) and stellar mass content (Table 4). In the original work, the authors used a truncated delayed SFH which, in case after truncation the star formation drops to zero, has a functional form which can be easily emulated by our quenched In situ shape, as also anticipated in Sect. 4.2.2.
values between 1.3 and 1.6, although the extremely small errors on the optical flux measurements tend to make the nuisance systematic error parameter converge around values fsys ≲ 0.1. Also the results for the derived parameters are extremely consistent with those found in the literature both in terms of age (Table 3) and stellar mass content (Table 4). In the original work, the authors used a truncated delayed SFH which, in case after truncation the star formation drops to zero, has a functional form which can be easily emulated by our quenched In situ shape, as also anticipated in Sect. 4.2.2.
 |
Fig. 27 Relative difference of photometric redshift estimated with GalaPy against the real spectroscopic values for the four dusty star-forming galaxies of the Pantoni et al. (2021) sample (green squares), the three quiescent galaxies of the Donevski et al. (2023) sample (blue circles), and the lensed galaxy with upper limits from (Giulietti et al. 2023, red triangle). Markers with error bars trace the median and 68% credible interval of the samples. |
4.2.6 Photometric redshift
We performed a final validation test on our machinery by inferring an estimate for the photometric redshift of real sources. We selected the sources from Sects. 4.2.1, 4.2.5, and 4.2.3, for which a measurement of the spectroscopic redshift is available. We then sampled again the parameter space by letting the redshift parameter vary along with the other free parameters.
In Fig. 27, we compare the photometric redshift prediction to the real value measured spectroscopically, in terms of the relative redshift difference between estimated (𝓏phot) and fiducial value (𝓏spec). We use coloured markers with error bars for the median value and 68% credible interval of the samples. The dashed grey line marks the real spectroscopic value.
For all the sources, the median values show at most a 2-σ difference with respect to the spectroscopic measurement (i.e. the fiducial value is within the 95% credible interval). Apart from the low redshift sources and most of the P21 sources, the photometric prediction of the J1135 redshift from Giulietti et al. (2023) is extremely close to the expected value (order of percent relative difference). This is a remarkable result, considering the large number of fluxes for which only upper limits are available, especially in the UV/optical part of the spectrum. The reason for this agreement lays on the interplay between the thorough sampling of the dust peak and the precision modelling allowed by our two-component, age-dependent dust model.
These results confirm the reliability of photometric redshift estimates obtained with GalaPy on real sources, as had already been demonstrated on mock sources. This is an asset that will prove powerful for future observational campaingns targeting distant sources (e.g. JWST). In the next future, we also plan to further test the photometric redshift determination capabilities of GalaPy against large datasets up to the highest redshifts currently available, for instance, A3COSMOS (Liu et al. 2019a,b; Fudamoto et al. 2020) and COSMOS-Web (Casey et al. 2023).
5 Summary
We present GalaPy, a highly optimised, open-source, hybrid library for parameterised fitting of the spectral energy distributions (SEDs) of galaxies. The tool currently focuses on photometric SED fitting from galaxies, but future versions will extend its functionalities to include spectroscopic fitting at variable resolutions and AGN modelling. The API is readily available through terminal entry-points or by importing modules from the galapy package. The full documentation, including examples and API usage manual, is available on ReadTheDocs and the code is available on GitHub.
In Sect. 2, we provide a detailed description of the physical models implemented in GalaPy, with a particular focus on the in situ star formation histories and the two-component age-dependent dust model. The former provides a model for the evolution of the extended structure components of a galaxy that depends on both the infall of material in the DM halo and on the evolution of the nuclear regions, driven by the central black hole (Lapi et al. 2018, 2020; Pantoni et al. 2019). The latter, provides a physically motivated model of the time evolution of dust, with overall attenuation directly derived by the contribution of each single simple stellar population hosted in the galaxy. Additionally, GalaPy uses an age-dependent, energy-conservation scheme to derive the evolution of dust temperatures in an analytic way.
In Sect. 3, we describe the statistical tools used to obtain parameter posteriors. The parameter space sampling is based on Bayesian inference methods and we provide interfaces to two samplers, emcee and dynesty. In Sect. 4, we demonstrate the efficacy of GalaPy by testing it on various cases, including dusty star-forming galaxies at high redshift, local late-type, and early-type galaxies, along with aNIR-dark, lensed high-redshift galaxy with mostly upper limits. We have demonstrated that GalaPy can be used to study the main physical characteristics of galaxies, such as their star formation histories, matter content, and physical parameters.
Future extensions of GalaPy include spectroscopic fitting and Hamiltonian parameter space sampling, as well as a hierarchical Bayesian scheme for modelling datasets from large catalogues with correlated systematic errors (see e.g. Kelly et al. 2012; Galliano 2018). Additionally, a consistent modelling of the AGN within the BH-galaxy co-evolution In situ scenario will be introduced soon. Finally, we plan to accelerate posterior inference using active learning techniques.
In conclusion, GalaPy is a timely and valuable tool for the astrophysical community that offers a powerful, self-consistent framework for modelling the SED of galaxies, based on physically-motivated models and a Bayesian statistical approach (in Appendix C.3, we provide recommendations on how to properly acknowledge usage of the library). The physical models implemented in GalaPy, together with the optimisations made to the fitting algorithms, enable the tool to provide robust and accurate parameter estimates for a wide range of astrophysical applications. The main characterising features of GalaPy are
self-consistent modelling of the SFH and derived physical properties that not only reduces the size of the parameter space, but it also allows for a straightforward derivation of the physical properties characterising the galaxy and is specifically designed to follow the evolution of high redshift progenitors up to their quiescence, leading to the formation of local early type galaxies;
two component time-dependent energy-conserving treatment of dust attenuation and re-radiation that allows for both a physical treatment of the process without assuming unknown physics of the dust-grain and for a computationally-efficient balancing of energy;
high resolution integration of stellar populations for the study of primordial galaxies that does not burden the computation, thanks to a memory-efficient caching of the SSP grid (thoroughly treated in Appendix A.1.1);
easily extensible database of cosmological models, SSP libraries, and photometric band-pass filters;
user-friendly API and extensive documentation, allowing for high level of customisation;
state-of-the-art hybrid C++/Python implementation, reaching high performances with minimal memory consumption;
Bayesian framework for the inference of posteriors in the parameter space.
As current and upcoming observational campaigns (e.g. JWST, LSST, SKAO) continue to generate ever-increasing amounts of data, the capabilities of GalaPy will become increasingly important for understanding the physical properties of galaxies, especially in the high-redshift Universe, and their evolution over cosmic time.
Acknowledgements
The authors are grateful to the anonymous referee for the detailed and thorough comments that contributed to improve substantially the present work. The authors are grateful to Nicoletta Krachmalnicoff for the extensive and patient discussion on statistical inference and for her useful suggestions that improved the readability of the software-related sections of this work. The authors also thank Stephan Charlot for stimulating discussion and for his support to the project. This paper is supported by: “Data Science methods for MultiMessenger Astrophysics & Multi-Survey Cosmology” funded by the Italian Ministry of University and Research, Programmazione triennale 2021/2023 (DM n.2503 dd. 9 December 2019), Programma Congiunto Scuole; EU H2020-MSCA-ITN-2019 no. 860744 BiD4BESt: Big Data applications for black hole Evolution STudies; Italian Research Center on High Performance Computing Big Data and Quantum Computing (ICSC), project funded by European Union – NextGenerationEU – and National Recovery and Resilience Plan (NRRP) – Mission 4 Component 2 within the activities of Spoke 3 (Astrophysics and Cosmos Observations); PRIN MUR 2022 project no. 20224JR28W “Charting unexplored avenues in Dark Matter”; INAF Large Grant 2022 funding scheme with the project “MeerKAT and LOFAR Team up: a Unique Radio Window on Galaxy/AGN co-Evolution; INAF GO-GTO Normal 2023 funding scheme with the project “Serendipitous H-ATLAS-fields Observations of Radio Extragalactic Sources (SHORES)”. DD acknowledges support from the National Science Center (NCN) grant SONATA (UMO-2020/39/D/ST9/00720). This work made use of the C++ (Stroustrup 2013) and Python (Van Rossum et al. 2007) programming languages, and of the following software: Astropy (The Astropy Collaboration 2013), NumPy (Harris et al. 2020), SciPy (Virtanen et al. 2020), Matplotlib (Hunter 2007), Emcee (Foreman-Mackey et al. 2013), dynesty (Speagle 2020), GetDist (Lewis 2019), pybind11 (Jakob et al. 2017), HDF5 (Folk et al. 2011), h5py (Collette et al. 2021).
Appendix A Code design
In this section we provide insights on the design choices made both for optimising the performances of the library and with the intent of keeping the structure modular and user friendly. The bulk of the library resides in the computation of the parame-terised models described in Sect. 2. Given that the main (but not only) purpose of GalaPy is to provide a lightning fast tool for parameter inference, these functions have been implemented to reach high performances on a single core. We reach this requirement by exploiting different advanced programming techniques, from register proximity, minimisation of operations and interpolation tactics. A description of the chosen strategies is provided in Sects. A.1 and A.2 showcases briefly the main modules and subpackages building up the library, while in Sect. A.3 we show some loose performance measurements of the main functionalities deployed in GalaPy. All the performance measurements presented in this Section have been obtained by running on a Intel i9-10885H CPU @ 2.40GHz personal computer with a x86_64 architecture. The cache available to CPUs is of average size for modern machines, it has 8 private instances of L1 with 32 KB of memory per instance, 8 private instances of L2 with 256 KB per instance and 1 shared instance of L3 with 2 MB of memory.
Appendix A.1 Implementation strategy
GalaPy has a hybrid implementation which allows us to exploit both the performance efficiency of a compiled language (C++) as well as the flexibility of an interpreted language (Python). The Bushido of GalaPy software development can be summarised in the brief points below:
compiled Object-Oriented C++ crunches all the modelling framework, constituted of complex mathematical relations that burden the computation. The physical components described in Sect. 2 are implemented as independent classes, all of which share a common interface for parameter setting and computation of the eventual emission as a function of wavelength, age and metallicity. At construction time, all the quantities that do not depend on the free parameters of the given component are computed in advance and cached, therefore minimising the amount of operations the machine has to perform. Modelling though is still extremely light on the RAM, as the volatile memory occupied by this cached information does not go beyond a few tens of MB, mostly depending on the size of the SSP library chosen. This choice represents a compromise between the acceleration provided by SED grid interpolation and the flexibility of on-the-fly model computation. All of these objects can be serialised (i.e. converted in a sequential string of bits), allowing them to be picklable, therefore completely Python-compliant. Besides from physical models, the compiled sector of the library also implements a set of data-structures and algorithms for speeding up operations (in Appendix A.1.2 we describe the linear interpolation scheme we use in some parts of the library). Finally, the compiled sector also manages loading the SSP libraries used to compute stellar emission, this is done to favour CPU cache management as described in Appendix A.1.1. The only C++ library used is the STL, therefore minimising the problems that might arise in the installation of the package on different systems.
Python deals with the interplay between all the components and modules, internal and external, that build up the library. It also provides the user-interface and an extensive documentation. Lastly, the terminal commands allowing for quick-access parameterised SED-fitting that come out-of-the-box with library installation (e.g. the galapy-fit command mentioned in Sect. C) are implemented as Python entry-points. By importing the galapy package and subpackages the GalaPy API is exposed, allowing for complete customisation of the algorithms as well as providing the tools for astrophysical modelling and analysis of the sampling results.
pybind11 is a library to generate Python bindings of compiled C++ code. We bind compiled classes and expose our optimised C++ implementation to the Python interface providing access to our functions to users. All the functions that can be applied to arrays of values are vectorised, providing a straightforward integration with the most common python packages for scientific computing (e.g. NumPy and SciPy) and therefore allow for array programming. We have chosen this strategy because, compared to a CPython wrapping layer, it delivers bindings with negligible latency while providing a more intuitive interface.
The primary purpose of GalaPy is to derive the parameters that can be inferred from the spectral properties of galaxies. Our code aims at delivering a high performance serial implementation of parametric SEDs, so that parallelism is not necessary in model generation (some performance testing is shown in Appendix A.3). In this way, the only bottleneck of the work-flow is parameter-space sampling.
Both emcee and dynesty allow for passing a pool of workers to the functions running the sampling. In GalaPy we generate pools exploiting the multiprocessing package of the Python standard library. Because of the structural limits of Python (i.e. the existence of a Global Interpreter Lock that guarantees parallel threads are not modifying concurrently the reference count in the Python interpreter), allocating a pool of parallel workers, with the intent of speeding-up CPU-bound workflows, requires us to generate a copy of the environment. Copying the whole environment though, results in the necessity of generating deep copies of all the variables that can be referenced in a given scope. This not only means a larger memory usage, but it also reduces the effectiveness of shared memory parallelism, as passing around chunks of memory slows down severely the computation.
In the entry-point provided for fitting SEDs (i.e. galapy-fit) the default behaviour tries to reach a compromise between memory usage and parallelism. The variables that require the larger memory budget (e.g. the SSP libraries and the parametric models) are made global, therefore accessible for all the workers in the pool. In the meantime, we spawn as many workers as possible to squeeze all the computing power from the architecture.
In future extensions of the library we will investigate more in parallelism and speed-up of the sampling. We are also considering to implement our own specialised sampler and to test compiled sampling interfaces, that could possibly provide more control on the memory management as well as on the parallel exploitation of CPUs.
Appendix A.1.1 Ordering of the SSP tables and computation of the intrinsic stellar luminosity
A frequently overlooked aspect in scientific software development is the process behind RAM usage and, specifically, the way chunks of data loaded in the volatile memory reach the CPU for usage. To simplify, sequential data is cached on a hierarchy of memory slots with given size. The hierarchy ladder is set by the physical proximity of the memory slots to the CPU performing the computation, the closer the higher. CPUs can access directly only the highest levels of this hierarchy, called registers, which can host a small number of bytes (typically, the amount corresponding to a few floating point numbers).
Registers tend to remain full-filled all the time, meaning that if the CPU needs a number from memory which is not already in one of the registers, this must firstly be emptied and then filled with the number required together with all the numbers which are close to it in memory, until complete occupation. This process takes also place for the lower levels in the hierarchy ladder, namely, caches. Tipically, modern computers own three levels of cache, L1 (tens of kBs) and L2 (hundreads of kBs) are private to each CPU in the processor, while L3 (tens of MBs) is shared between all the CPUs. Since the process of moving cached data from lower to higher levels of cache, up to the registers, is time-consuming, it is desirable that data used in logically sequential operations are also stored sequentially in memory.
This is the reason behind our custom format for storage of SSP libraries, as the operation in GalaPy that makes the most massive usage of cached data is integration of SSPs to generate CSPs (Sect. 2.2). Computing Eq. (16) requires us to perform, for each wavelength, an integral in time and an interpolation in metallicity. This can be easily approximated with a linear integration in time and a linear interpolation in metallicity. The approximated and implemented version of Eq. (16) is:
![Mathematical equation: $\matrix{ {{L_{{\rm{CSP}}}}\left( {{\lambda _i},{\tau _{{\rm{GXY}}}}} \right) = \mathop \sum \limits_{ \vee j > 0\mid {\tau _j} \mathbin{\lower.3ex\hbox{\buildrel<\over {\smash{\scriptstyle\sim}\vphantom{_x}}}} {\tau _{{\rm{GXY}}}}} {{{\tau _j} - {\tau _{j - 1}}} \over 2} \times } \hfill \cr {\,\,\,\, \times \{ \psi \left( {{\tau _j}} \right)P_{{L_{{\rm{SSP}}}}}^{(1)}\left[ {{\lambda _i},{\tau _j},{Z_ \star }\left( {{\tau _{{\rm{GXY}}}} - {\tau _j}} \right)} \right] + } \hfill \cr {\quad + \psi \left( {{\tau _{j - 1}}} \right)P_{{L_{{\rm{SSP}}}}}^{(1)}\left[ {{\lambda _i},{\tau _{j - 1}},{Z_ \star }\left( {{\tau _{{\rm{GXY}}}} - {\tau _{j - 1}}} \right)} \right]\} ,} \hfill \cr } $](/articles/aa/full_html/2024/05/aa46978-23/aa46978-23-eq244.png) (A.1)
(A.1)
where λi is the wavelength, τGXY is the age of the galaxy, τj is the indexed SSP age, ψ(τ) is the SFR at given time and 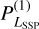 is the first order polynomial interpolating linearly the SSP emission between its two tabulated metallicities Zk ≤ Z⋆ (τGXY − τj) ≤ Zk+l.
is the first order polynomial interpolating linearly the SSP emission between its two tabulated metallicities Zk ≤ Z⋆ (τGXY − τj) ≤ Zk+l.
As made evident from Eq. (A.1), for each wavelength we first perform an interpolation between 2 metallicities, then sum along the time dimension. Even though it might seem that the most logical dimension to keep closest in memory is metallicity, by inspecting Fig. A.1, we can easily see this is not true. In each panel, along the x-axis, we vary the value of one of the model parameters that affect the integration of Eq. (A.1) while, along the y-axis, we show the integration time in milliseconds for the whole λ-grid. Boxes on the lower right show the fixed value of the two non-varying parameters. Each different colour marks the performance of a different ordering of the 3-dimensional matrix storing the SSP library, as encoded in the Figure’s legend, where the shaded regions show fluctuations over ten runs and the solid line marks the mean execution time. It is clear that the most efficient ordering is [Z λ τ] (in purple). The reason for this is found in the slow variation of the Z-dimension as a function of galaxy age, which means that the metallicity of SSPs in the highest cache levels is updated rarely.
SSP tables are objects counting some millions of double precision floating point numbers and their transposition can easily slow down the code. For this reason having the SSPs directly stored with the [Z λ τ] ordering allows to accelerate the process of building objects that depend on them (i.e. the class galapy.CompositeStellarPopulation.CSP provides the most direct user interface to these functionalities). Nonetheless, we provide functions in GalaPy for converting eventual user-defined SSP tables into the format described above, to foster extensibility and customisation.
Appendix A.1.2 Interpolation technique
Interpolation is used for many different purposes in GalaPy: from the computation of SSP emission between the tabulated values of metallicity to the addition of templated emission on the wavelength grid. While for some of these cases the values over which to interpolate change with the variation of the model free parameters, for the majority of the occurrences, the interpolation grid is fixed for all the parameter-space sampling16. We have developed an interpolator object exploiting this condition to speed up the computation.
The interface is optimised for computing interpolated values on 1-dimensional grids with un-evenly spaced values. This is achieved with a high level of specialisation for the functionalities, making therefore the software tool not flexible but extremely efficient when used for all the problem sizes coming up in GalaPy. This results in a smaller efficiency when building the object itself but, since this operation will be done only once for each galaxy object built, we can safely give up on it.
The interpolator object is based on an interval binary search tree (IBST) without overlapping. This data structure provides access to nodes that perform analytic linear interpolation, integration and derivation on a single interval of the grid with log N time scaling, where N is the size of the grid. The find function of the IBST implemented in the core C++ sector of GalaPy is an order of magnitude faster than its C++ STL equivalent (i.e. std::map::find). The interface to the interpolator available from GalaPy’s Python API is up to two orders of magnitude faster than NumPy’s linear interpolation module (i.e. scipy.interpolate.interpld class with kind=’linear’ which is equivalent to the NumPy function numpy.interp) on problem sizes comparable to those of interest for our library. It has to be stressed that interpolator objects from GalaPy are not universally more efficient than equivalent functions and classes from external, wide spread and powerful packages such as SciPy and NumPy. We reach better performances only when the resolution of the interpolation grid (order of 103 points) and the number of interpolated points (order of < 102) is comparable to those arising from the computation of GalaPy models. Our implementation comes with the additional advantage of being available on both the C++ and the Python sectors as well as providing a uniformed interface for interpolation, numerical integration and numerical derivation.
Appendix A.2 Python API structure
A complete description of the classes and functions implemented in the GalaPy package is available in the on-line documentation, in the section Python API. We hereby provide just a short description of the package structure and of the functionalities provided by each module/sub-package.
GalaPy contains modules in the top-level package and on sub-packages as well, divided as follows
galapy
|-- galapy.analysis
|-- galapy.configuration
|-- galapy.internal
|-- galapy.io
‘-- galapy.sampling
 |
Fig. A.1 Dependency of SSP integration performances on the 3-dimensional matrix ordering. Different colours mark different orderings, as reported in the legend. Each panel shows how the integration time changes as a function of one of the three model parameters on which Eq. (A.1) depends. |
The content of each sub-package provides different functionalities:
galapy: the root package contains all the modules providing access to the models described in Sect. 2. Specifically:
galapy.StarFormationHistory: contains the class SFH that can be used to build either empirical, In situ or the interpolated SFH models of Sect. 2.1.
galapy.CompositeStellarPopulation: contains functions for listing and loading SSP libraries and the CSP class, used to build composite stellar populations (Sect. 2.2).
galapy.InterStellarMedium: provides access to the dust-model described in Sect. 2.3. It defines several objects: a base ismPhase class, from which two derived classes inherit, MC and DD, modelling the attenuation and emission due to the two separate dust components; additionally, a ISM type is defined, wrapping the other two components and combining their contributions.
galapy.NebularFreeFree, galapy.Synchrotron and galapy.XRayBinaries: these modules implement (optional) the additional sources of stellar continuum described in Sect. 2.4. They respectively define the classes NFF, SNSYN, and XRB.
galapy.ActiveGalacticNucleus: provides an interface for loading the Fritz et al. (2006) templates and consistently adding on top of them an eventual X-Ray contribution, as described in Sect. 2.5. These functionalities are accessed through the class AGN, defined in this module.
galapy.Cosmology and galapy.InterGalacticMedium, define respectively the classes CSM and IGM, whose implementation provide access to the models of Sect. 2.6.1 and Sect. 2.6.2, respectively.
-
galapy.Galaxy and galapy.Handlers define utility classes and methods designed to ease modelling through the Python API. In particular, the former defines the class GXY which wraps up the models implemented in the other modules, their interplay and parameter settings, optimising the performances through a minimisation of the number of operations. By instantiating one of this objects, i.e.
from galapy.Galaxy import GXY gxy = GXY( age = 1.e9, redshift = 1.0)
users can easily modify the value of the free-parameters (e.g. gxy.set_parameters(age = 1.e10), see Table B.3 for a list of all the tunable parameters), get the emission or flux (e.g. flux = gxy.SED()), or compute derived parameters (e.g. Mstar = gxy.sfh.Mstar( 1.e8), for the stellar mass at an age of τ = 108 yr). We note that all these functionalities are obtained by a combination of tools implemented in the modules listed above. The latter, galapy.Handlers module, is designed for managing the free-parameters when sampling.
galapy.PhotometricSystem: implements the class PMS that can be used to manage band-pass transmission filters, both loaded from the database or user-defined.
galapy.sampling: contains sub-modules used for sampling the parameter space, i.e. the two sub-modules Sampler and Results which unify the interface to the different sampling algorithms implemented in the library along with their results (note in particular, the Results class described in Sect. 3.3), the Observation module which collects observational datasets and the Statistics sub-module, defining statistical functions such as likelihoods and estimators.
galapy.analysis: provides the two sub-modules funcs and plot, both defining functions that facilitate the analysis of sampling results. While the former mainly produces tables with the estimates of several statistics (most of the tables in Sect. 4 have been produced with these functions), the latter produces plots of fitted SEDs, residuals and posteriors (most of the figures in Sect. 4 have been produced with these functions).
galapy.io: used to load and store object types defined in the package.
galapy.configuration and galapy.internal: are mainly for internal usage, even though some classes and functions of galapy.internal might be useful in some parts of the analysis. An example are the interpolator objects described in Appendix A.1.2.
 |
Fig. A.2 Likelihoods generated per second with GalaPy as a function of the wavelength grid resolution. The dashed line marks the average over 1000 measurements and the shaded region highlights the 1-σ confidence intervals. |
Appendix A.3 Insights on performances and scaling
A solid comparison of performances against other libraries would require a thorough analysis that goes beyond the scope of this presentation work. We just mention that the computation of a single model (including parameters setting, computation of the flux and band-averaging) requires ~ 10 milliseconds, depending on the resolution of the wavelength grid over which the flux is computed.
In our Bayesian framework, the time required for convergence of the free-parameters inference algorithms strongly depends on the likelihood estimation time (defined as the time necessary to set a new position in the parameter-space, compute the corresponding flux model, extract the band-averaged fluxes and compute the likelihood). We therefore measure our performances in terms of likelihood computations per second, even though, for how the code is structured and given the simplicity of the likelihood of Eq. (61) and Eq. (66), this interval of time is obviously dominated by model computation. This is shown in Fig. A.2 as a function of the wavelength grid thinness for the least optimal model set-up: BC03 SSP libraries with full modelling from X-ray band to radio including nebular and synchrotron emission. As the Figure shows, the performance of the code decreases with wavelength grid size increasing. This is expected as, the thinner the wavelength grid, the larger the number of times the code has to compute, for instance: Eq. (A.1).
As a term of comparison, on a similar problem set-up the Prospector (Johnson et al. 2021) documentation17 declares 25 likelihoods per second, to be compared with our 200 ÷ 300 result shown in Fig. A.2. Additionally and differently from other libraries, the problem size seems not to affect too much the computation of likelihoods as we do not measure significant variations on performances when increasing the number of photometric bands, or when making the model more complex. This is mostly due to the highly optimised implementation of GalaPy. The execution time of most of the components is in fact negligible with respect to the computation of Eq. (A.1) whose scaling also affects how the likelihood-per-second execution time scales.
We point out that the measurements provided in this Section are obtained by running on a single core, as the parallelisation scheme of GalaPy is still under development and will be in its final form on future extensions focussed on boosting the performances. At current state, we exploit the parallel strategy already implemented in the samplers available in GalaPy (i.e. emcee and dynesty) by passing to the sampling algorithm a pool of processes obtained with the multiprocessing.Pool method of the Python standard library. This approach may prove not to be optimal in some cases and we will therefore explore different strategies in the future.
Appendix B Additional modelling information
Here, we provide an extension on the description of models reviewed in Sect. 2 with further details.
Appendix B.1 Difference between CSP emission assuming different SSP libraries
Stellar emission, as already explained in Sect. 2.2, is computed by assuming a SFH and integrating SSP emission. In GalaPy we provide the tabulated emission from 4 main SSP libraries: the classic Bruzual & Charlot (2003) libraries in both the low (bc03.basel) and high (bc03.stelib) resolution version, and two libraries, produced specifically for the publication of this package, obtained using the PARSEC code (Bressan et al. 2012; Chen et al. 2014). The latter are delivered in two flavours:
parsec22.nt contains SSP continuum emission including the non-thermal low energy contribution produced by SN synchrotron;
parsec22.ntl also accounts for the thermal and line emission produced in ionised nebular regions around young massive stars.
In Table B.1, we summarise the size of the aforementioned SSP tables along each of the 3 dimensions: wavelength, age and metallicity. In BC03 tables the time domain spans from 0 to 2 × 1010 yr while PARSEC22 tables go from 0 to 1.4 × 1010 yr. In both the libraries we have extended the wavelength domain from 1 to 1010 Å.
The emission predicted by the models tabulated in the 4 libraries do agree in general even though they show minor differences. To highlight how choosing one library over the other contributes differently to the panchromatic emission from a galaxy, we compute the total spectrum due to the composite stellar emission. Fig. B.1 shows the ratio between CSP emission predicted with the bc03.basel library (left panel) and with the parsec22.nt library (right panel) with respect to the parsec22.ntl library. To have a meaningful comparison, we also include the radio components in the plot, that therefore spans from 100 Å to 1010 Å. This means that, while CSPs built with parsec22.ntl self-consistently contain the contribution from nebular thermal emission and SN synchrotron non thermal emission, in the other two cases the latter components are added to the final CSP emission using models described in Sect. 2.4.1 and Sect. 2.4.2. Fig. B.1 shows how the parsec22.ntl library steals energy from the continuum at the shorter wavelengths (Optical to UV) and re-emits it in lines mainly in the IR region of the spectrum. This effect is more relevant for younger galaxies (blue and green solid lines) while becoming less important to irrelevant for older stellar populations (red solid line). In the radio bands the emission predicted by the models of Sect. 2.4.1 and Sect. 2.4.2 are in good agreement with the one obtained using the PARSEC library, even though it seems to deviate more for old stellar populations in the left panel, suggesting that the synchrotron emission might be slightly over-estimated with the model of Sect. 2.4.2. In general we suggest, whenever possible, to use the PARSEC22 libraries as it also provide the additional advantage of reducing the size of the parameter space.
For reference, we provide the values, entering Eq. (46), computed for the 7 metallicities available in the BC03 SSP libraries. The two metallicity-dependent parameters, R0 and R1, are tabulated in Table B.2.
 |
Fig. B.1 Logarithm of the ratio between CSPs obtained with different SSP libraries at fixed SFH and age. The left panel shows the ratio between PARSEC22 and BC03 while the right panel shows the ratio between PARSEC22 with and without lines. |
Main properties of the different SSP tables delivered with GalaPy.
Appendix B.2 Tunable parameters
In Table B.3 we provide a complete list of the parameters that can be tuned with GalaPy. All of the parameters are available from the galapy.Galaxy.GXY object (as well as from derived objects). We divided the table in sections describing which of the class-objects they model. The first column contains the API keyword used to access the parameter, the second column contains the symbol used in this manuscript to refer that parameter, in the third column we give a brief description of the parameter and the last column contains the eventual Eq.(s) where the parameter appears.
Each of the tunable parameters can be either fixed or set as free. In the latter case it will add a dimension to the parameter space explored by the sampler during SED-fitting. Always remember that, the larger the parameter space (both in terms of prior volume and dimensionality), the longer it will take for the sampler to converge. It is therefore always crucial to carefully select which parameters to sample and which to keep fixed. The volume, prior shape and fixed value used for each run depends on several considerations on the dataset that has to be fitted with GalaPy. The choice of these hyper-parameters is left to the user.
The parameters regulating the shape of the AGN template are not described in this manuscript and can be found in Fritz et al. (2006). Since in the current version of GalaPy we do not provide a template fitting interface yet, we discourage setting them as free, as it would imply sampling a discrete parameter space. Nonetheless, this custom behaviour can be achieved by modifying the likelihood in the sampling algorithm through the Python API of GalaPy.
Complete list of the tunable parameters available in GalaPy.
Appendix C Practical information
Appendix C.1 Installation and post-installation operations
GalaPy is available on the Python Package Index (PyPI) and can be installed by running
$ pip install galapy-fit
on a terminal18. Once the package has been installed, before the first usage run
$ galapy-download-database
to download on the file-system the database necessary for running. The database contains the formatted SSP libraries (Section 2.2), a collection of bandpass transmission filters (Sect. 2.6.3), the AGN templates (Sect. 2.5) and pre-computed tables for cosmological calculations (Sect. 2.6.1).
These two steps should be sufficient to obtain a working installation of GalaPy. For further details on how to install in developer mode and on the required dependencies of the library, the user can refer to the installation guide available in the documentation (galapy.readthedocs.io/en/latest/general/install_guide.html).
Appendix C.2 Running the automatised sampling script
We provide command-line tools for sampling the parameter space with our automatised set-up. The automatic fitting requires us to set up a parameter file that can be generated by calling
$ galapy-genparams [-n/--name NAME]
If the optional argument NAME is not provided, the generated file will be assigned the default name galapy_hyper_parameters.py. By modifying this self-explanatory file the user can set all the relevant information (e.g. free-parameters and priors, data-set, input/output files) required for running a sampling. The file is divided in four main sections:
Loading of the data-set: users can use their preferred method for loading the data-set (band-pass transmission filters, either from the data-base or custom, fluxes, errors and upper-limits). Since the parameter file is effectively a python script, external libraries (such as NumPy or Pandas) can be imported to ease the process. We also provide a function (i.e. galapy.internal.utils.cat_to_dict) for the conversion of ASCII catalogues19 to dictionaries.
Galaxy model set-up: here the user chooses their preferred models among those available in the package. Namely, the SFH model, the SSP library, whether to include an AGN, X-ray emission, radio support, cosmology and an eventual treatment of noise.
Sampling parameters: for choosing priors on the free parameters or fixing part of them to values different from their default values.
Sampler and output choices: choose the sampler and format for the sampling output file(s).
Once the parameter file has been set, by calling the command
$ galapy-fit galapy_hyper_parameters.py
the sampling starts on all the available parallel CPUs (see the documentation for further details on how to customize the parallel scheme or to run serially on a single CPU).
 |
Fig. C.1 Version 1.0.0 of the GalaPy logo. We encourage authors presenting results obtained with GalaPy to add their preferred version of the logo in public presentations. A variety of formats is available on the website and in the data-base. |
Besides this terminal entry-points, the GalaPy API is made available upon installation of the library. On a python script, shell or notebook the user can import modules, classes and functions from the galapy Python package. The entry-point themselves are made available for inspection and customisation on the sub-module galapy.sampling.Run. For more in-detail description, please inspect the API documentation20.
Appendix C.3 Acknowledging usage of the library
GalaPy relies on models and samplers that might require additional references along with this manuscript. We encourage authors to check the documentation for further instructions on how to acknowledge the relevant works.
Several data-formats for the GalaPy logo (Fig. C.1) are also available in the documentation. Even though we do not imprint the logo on the figures produced by our plotting API, we encourage authors in adding it to their presentations if presenting results obtained using GalaPy.
References
- Adams, N. J., Conselice, C. J., Ferreira, L., et al. 2023, MNRAS, 518, 4755 [Google Scholar]
- Amendola, L., Appleby, S., Avgoustidis, A., et al. 2018, Living Rev. Relativ., 21, 2 [NASA ADS] [CrossRef] [Google Scholar]
- Atek, H., Shuntov, M., Furtak, L. J., et al. 2023, MNRAS, 519, 1201 [Google Scholar]
- Battisti, A. J., da Cunha, E., Grasha, K., et al. 2019, ApJ, 882, 61 [NASA ADS] [CrossRef] [Google Scholar]
- Beckwith, S. V. W., Stiavelli, M., Koekemoer, A. M., et al. 2006, AJ, 132, 1729 [Google Scholar]
- Behiri, M., Talia, M., Cimatti, A., et al. 2023, ApJ, 957, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Bianchi, S., De Vis, P., Viaene, S., et al. 2018, A&A, 620, A112 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bischetti, M., Maiolino, R., Carniani, S., et al. 2019, A&A, 630, A59 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Blyth, S., van der Hulst, T. M., Verheijen, M. A. W., et al. 2015, in Advancing Astrophysics with the Square Kilometre Array (AASKA14), 128 [CrossRef] [Google Scholar]
- Booth, R. S., & Jonas, J. L. 2012, Afr. Skies, 16, 101 [NASA ADS] [Google Scholar]
- Boquien, Burgarella, D., Roehlly, Y., et al. 2019, A&A, 622, A103 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bressan, A., Chiosi, C., & Fagotto, F. 1994, ApJS, 94, 63 [NASA ADS] [CrossRef] [Google Scholar]
- Bressan, A., Granato, G. L., & Silva, L. 1998, A&A, 332, 135 [NASA ADS] [Google Scholar]
- Bressan, A., Silva, L., & Granato, G. L. 2002, A&A, 392, 377 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bressan, A., Marigo, P., Girardi, L., et al. 2012, MNRAS, 427, 127 [NASA ADS] [CrossRef] [Google Scholar]
- Brisbin, D., Miettinen, O., Aravena, M., et al. 2017, A&A, 608, A15 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Bruzual, G., & Charlot, S. 2003, MNRAS, 344, 1000 [NASA ADS] [CrossRef] [Google Scholar]
- Calzetti, D., Armus, L., Bohlin, R. C., et al. 2000, ApJ, 533, 682 [NASA ADS] [CrossRef] [Google Scholar]
- Camps, P., & Baes, M. 2020, Astron. Comput., 31, 100381 [NASA ADS] [CrossRef] [Google Scholar]
- Carnall, A. C., McLure, R. J., Dunlop, J. S., & Davé, R. 2018, MNRAS, 480, 4379 [Google Scholar]
- Casasola, V., Bianchi, S., De Vis, P., et al. 2020, A&A, 633, A100 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Casey, C. M., Kartaltepe, J. S., Drakos, N. E., et al. 2023, ApJ, 954, 31 [NASA ADS] [CrossRef] [Google Scholar]
- Castellano, M., Fontana, A., Treu, T., et al. 2022, ApJ, 938, L15 [NASA ADS] [CrossRef] [Google Scholar]
- Chabrier, G. 2003, PASP, 115, 763 [Google Scholar]
- Charlot, S., & Fall, S. M. 2000, ApJ, 539, 718 [Google Scholar]
- Chen, Y., Girardi, L., Bressan, A., et al. 2014, MNRAS, 444, 2525 [Google Scholar]
- Chen, Y., Bressan, A., Girardi, L., et al. 2015, MNRAS, 452, 1068 [Google Scholar]
- Chevallard, J., & Charlot, S. 2016, MNRAS, 462, 1415 [NASA ADS] [CrossRef] [Google Scholar]
- Cimatti, A., Fraternali, F., & Nipoti, C. 2020, Introduction to Galaxy Formation and Evolution: From Primordial Gas to Present-day Galaxies (Cambridge University Press) [Google Scholar]
- Clark, C. J. R., Verstocken, S., Bianchi, S., et al. 2018, A&A, 609, A37 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Collette, A., Kluyver, T., Caswell, T. A., et al. 2021, https://doi.org/18.5281/zenodo.5585380 [Google Scholar]
- Cropper, M., Pottinger, S., Niemi, S., et al. 2016, SPIE Conf. Ser., 9904, 99040Q [NASA ADS] [Google Scholar]
- Da Cunha, E., Charlot, S., & Elbaz, D. 2008, MNRAS, 388, 1595 [NASA ADS] [CrossRef] [Google Scholar]
- Davies, J. I., Baes, M., Bianchi, S., et al. 2017, PASP, 129, 044102 [NASA ADS] [CrossRef] [Google Scholar]
- De Vis, P., Jones, A., Viaene, S., et al. 2019, A&A, 623, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- DESI Collaboration 2016, arXiv e-prints [arXiv:1611.00036] [Google Scholar]
- Donevski, D., Damjanov, I., Nanni, A., et al. 2023, A&A, 678, A35 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Doore, K., Monson, E. B., Eufrasio, R. T., et al. 2023, ApJS, 266, 39 [NASA ADS] [CrossRef] [Google Scholar]
- Draine, B. T. 2011, Physics of the Interstellar and Intergalactic Medium (Princeton University Press) [Google Scholar]
- Draine, B. T., & Li, A. 2001, ApJ, 551, 807 [NASA ADS] [CrossRef] [Google Scholar]
- Draine, B. T., & Li, A. 2007, ApJ, 657, 810 [CrossRef] [Google Scholar]
- Dudzeviciute, U., Smail, I., Swinbank, A. M., et al. 2020, MNRAS, 494, 3828 [NASA ADS] [CrossRef] [Google Scholar]
- Dunlop, J. S., McLure, R. J., Biggs, A. D., et al. 2017, MNRAS, 466, 861 [Google Scholar]
- Duras, F., Bongiorno, A., Ricci, F., et al. 2020, A&A, 636, A73 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Eales, S., Dunne, L., Clements, D., et al. 2010, PASP, 122, 499 [NASA ADS] [CrossRef] [Google Scholar]
- Enia, A., Talia, M., Pozzi, F., et al. 2022, ApJ, 927, 204 [NASA ADS] [CrossRef] [Google Scholar]
- Fabbiano, G. 2006, ARA&A, 44, 323 [NASA ADS] [CrossRef] [Google Scholar]
- Ferland, G. J., Korista, K. T., Verner, D. A., et al. 1998, PASP, 110, 761 [Google Scholar]
- Ferland, G. J., Porter, R. L., van Hoof, P. A. M., et al. 2013, Rev. Mex. Astron. Astrofis., 49, 137 [Google Scholar]
- Ferland, G. J., Chatzikos, M., Guzmán, F., et al. 2017, Rev. Mex. Astron. Astrofis., 53, 385 [NASA ADS] [Google Scholar]
- Feroz, F., Hobson, M. P., & Bridges, M. 2009, MNRAS, 398, 1601 [NASA ADS] [CrossRef] [Google Scholar]
- Ferrara, A., Sommovigo, L., Dayal, P., et al. 2022, MNRAS, 512, 58 [NASA ADS] [CrossRef] [Google Scholar]
- Finkelstein, S. L., Bagley, M. B., Haro, P. A., et al. 2022, ApJ, 940, L55 [NASA ADS] [CrossRef] [Google Scholar]
- Finkelstein, S. L., Bagley, M. B., Ferguson, H. C., et al. 2023, ApJ, 946, L13 [NASA ADS] [CrossRef] [Google Scholar]
- Folk, M., Heber, G., Koziol, Q., Pourmal, E., & Robinson, D. 2011, in Proceedings of the EDBT/ICDT 2011 Workshop on Array Databases, 36 [CrossRef] [Google Scholar]
- Fontanot, F., La Barbera, F., De Lucia, G., Pasquali, A., & Vazdekis, A. 2018, MNRAS, 479, 5678 [NASA ADS] [CrossRef] [Google Scholar]
- Foreman-Mackey, D., Hogg, D. W., Lang, D., & Goodman, J. 2013, PASP, 125, 306 [Google Scholar]
- Förster Schreiber, N. M., & Wuyts, S. 2020, ARA&A, 58, 661 [Google Scholar]
- Fragos, T., Lehmer, B. D., Naoz, S., Zezas, A., & Basu-Zych, A. 2013, ApJ, 776, L31 [CrossRef] [Google Scholar]
- Franco, M., Elbaz, D., Béthermin, M., et al. 2018, A&A, 620, A152 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Fritz, J., Franceschini, A., & Hatziminaoglou, E. 2006, MNRAS, 366, 767 [Google Scholar]
- Fudamoto, Y., Oesch, P. A., Magnelli, B., et al. 2020, MNRAS, 491, 4724 [Google Scholar]
- Galliano, F. 2018, MNRAS, 476, 1445 [NASA ADS] [CrossRef] [Google Scholar]
- Giavalisco, M., Ferguson, H. C., Koekemoer, A. M., et al. 2004, ApJ, 600, L93 [NASA ADS] [CrossRef] [Google Scholar]
- Giulietti, M., Lapi, A., Massardi, M., et al. 2023, ApJ, 943, 151 [NASA ADS] [CrossRef] [Google Scholar]
- González-López, J., Bauer, F. E., Romero-Cañizales, C., et al. 2017, A&A, 597, A41 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Goodman, J., & Weare, J. 2010, Commun. Appl. Math. Comput. Sci., 5, 65 [Google Scholar]
- Gruppioni, C., Béthermin, M., Loiacono, F., et al. 2020, A&A, 643, A8 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hamed, M., Malek, K., Buat, V., et al. 2023, A&A, 674, A99 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Harikane, Y., Ouchi, M., Oguri, M., et al. 2023, ApJS, 265, 5 [NASA ADS] [CrossRef] [Google Scholar]
- Harris, A. I., Baker, A. J., Frayer, D. T., et al. 2012, ApJ, 752, 152 [NASA ADS] [CrossRef] [Google Scholar]
- Harris, C. R., Millman, K. J., Van Der Walt, S. J., et al. 2020, Nature, 585, 357 [NASA ADS] [CrossRef] [Google Scholar]
- Higson, E., Handley, W., Hobson, M., & Lasenby, A. 2019, Stat. Comput., 29, 891 [Google Scholar]
- Hodge, J. A., & da Cunha, E. 2020, Roy. Soc. Open Sci., 7, 200556 [NASA ADS] [CrossRef] [Google Scholar]
- Hopkins, P. F., Quataert, E., & Murray, N. 2012, MNRAS, 421, 3522 [Google Scholar]
- Hotan, A. W., Bunton, J. D., Chippendale, A. P., et al. 2021, PASA, 38, e009 [NASA ADS] [CrossRef] [Google Scholar]
- Hunt, L. K., De Looze, I., Boquien, M., et al. 2019, A&A, 621, A51 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Hunter, J. D. 2007, Comput. Sci. Eng., 9, 90 [NASA ADS] [CrossRef] [Google Scholar]
- Inoue, A. K., Shimizu, I., Iwata, I., & Tanaka, M. 2014, MNRAS, 442, 1805 [NASA ADS] [CrossRef] [Google Scholar]
- Isobe, T., & Feigelson, E. D. 1986, Bull. Inform. Centre Données Stellaires, 31, 209 [Google Scholar]
- Jakob, W., Rhinelander, J., & Moldovan, D. 2017, pybind11 - Seamless operabil-ity between C++11 and Python, https://github.com/pybind/pybind11 [Google Scholar]
- Jarvis, M., Taylor, R., Agudo, I., et al. 2016, in MeerKAT Science: On the Pathway to the SKA, 6 [Google Scholar]
- Jin, S., Daddi, E., Liu, D., et al. 2018, ApJ, 864, 56 [Google Scholar]
- Jin, S., Daddi, E., Magdis, G. E., et al. 2022, A&A, 665, A3 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Johnson, B. D., Leja, J., Conroy, C., & Speagle, J. S. 2021, ApJS, 254, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Johnston, S., Bailes, M., Bartel, N., et al. 2007, PASA, 24, 174 [NASA ADS] [CrossRef] [Google Scholar]
- Johnston, S., Taylor, R., Bailes, M., et al. 2008, Exp. Astron., 22, 151 [Google Scholar]
- Jonas, J., & MeerKAT Team 2016, in MeerKAT Science: On the Pathway to the SKA, 1 [Google Scholar]
- Kelly, B. C., Shetty, R., Stutz, A. M., et al. 2012, ApJ, 752, 55 [NASA ADS] [CrossRef] [Google Scholar]
- Koposov, S., Speagle, J., Barbary, K., et al. 2023, https://doi.org/18.5281/zenodo.7600689 [Google Scholar]
- Kroupa, P., Weidner, C., Pflamm-Altenburg, J., et al. 2013, in Planets, Stars and Stellar Systems, 5: Galactic Structure and Stellar Populations, eds. T. D. Oswalt, & G. Gilmore (Springer), 115 [CrossRef] [Google Scholar]
- Labbé, I., van Dokkum, P., Nelson, E., et al. 2023, Nature, 616, 266 [CrossRef] [Google Scholar]
- Lacey, C. G., Baugh, C. M., Frenk, C. S., et al. 2016, MNRAS, 462, 3854 [Google Scholar]
- Lapi, A., González-Nuevo, J., Fan, L., et al. 2011, ApJ, 742, 24 [NASA ADS] [CrossRef] [Google Scholar]
- Lapi, A., Pantoni, L., Zanisi, L., et al. 2018, ApJ, 857, 22 [NASA ADS] [CrossRef] [Google Scholar]
- Lapi, A., Pantoni, L., Boco, L., & Danese, L. 2020, ApJ, 897, 81 [NASA ADS] [CrossRef] [Google Scholar]
- Lewis, A. 2019, arXiv e-prints [arXiv:1910.13970] [Google Scholar]
- Liu, D., Lang, P., Magnelli, B., et al. 2019a, ApJS, 244, 40 [Google Scholar]
- Liu, D., Schinnerer, E., Groves, B., et al. 2019b, ApJ, 887, 235 [Google Scholar]
- LSST Science Collaboration 2009, arXiv e-prints [arXiv:0912.0201] [Google Scholar]
- Lutz, D., Poglitsch, A., Altieri, B., et al. 2011, A&A, 532, A90 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Mancuso, C., Lapi, A., Prandoni, I., et al. 2017, ApJ, 842, 95 [Google Scholar]
- Massardi, M., Stoehr, F., Bendo, G. J., et al. 2021, PASP, 133, 085001 [NASA ADS] [CrossRef] [Google Scholar]
- Mayya, Y. D., Bressan, A., Rodríguez, M., Valdes, J. R., & Chavez, M. 2004, ApJ, 600, 188 [NASA ADS] [CrossRef] [Google Scholar]
- McConnell, D., Allison, J. R., Bannister, K., et al. 2016, PASA, 33, e042 [NASA ADS] [CrossRef] [Google Scholar]
- Murphy, E. J., Bremseth, J., Mason, B. S., et al. 2012, ApJ, 761, 97 [Google Scholar]
- Nagao, T., Maiolino, R., & Marconi, A. 2006, A&A, 459, 85 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Naidu, R. P., Oesch, P. A., Setton, D. J., et al. 2022, ApJ, submitted [arXiv: 2208.02794] [Google Scholar]
- Negrello, M., Amber, S., Amvrosiadis, A., et al. 2016, MNRAS, 465, 3558 [Google Scholar]
- Noll, S., Burgarella, D., Giovannoli, E., et al. 2009, A&A, 507, 1793 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Norris, R. P., Marvil, J., Collier, J. D., et al. 2021, PASA, 38, e046 [NASA ADS] [CrossRef] [Google Scholar]
- Novak, M., Smolcic, V., Delhaize, J., et al. 2017, A&A, 602, A5 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Oliver, S. J., Bock, J., Altieri, B., et al. 2012, MNRAS, 424, 1614 [NASA ADS] [CrossRef] [Google Scholar]
- Pantoni, L., Lapi, A., Massardi, M., Goswami, S., & Danese, L. 2019, ApJ, 880, 129 [NASA ADS] [CrossRef] [Google Scholar]
- Pantoni, L., Lapi, A., Massardi, M., et al. 2021, MNRAS, 504, 928 [NASA ADS] [CrossRef] [Google Scholar]
- Pensabene, A., Carniani, S., Perna, M., et al. 2020, A&A, 637, A84 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Pensabene, A., Decarli, R., Bañados, E., et al. 2021, A&A, 652, A66 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Planck Collaboration VI. 2020, A&A, 641, A6 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Rodighiero, G., Bisigello, L., Iani, E., et al. 2022, MNRAS, 518, L19 [NASA ADS] [CrossRef] [Google Scholar]
- Salim, S., & Narayanan, D. 2020, ARA&A, 58, 529 [NASA ADS] [CrossRef] [Google Scholar]
- Sawicki, M. 2012, PASP, 124, 1208 [NASA ADS] [CrossRef] [Google Scholar]
- Schweitzer, M., Bender, R., Katterloher, R., et al. 2010, SPIE Conf. Ser., 7731, 77311K [NASA ADS] [Google Scholar]
- Scoville, N., Aussel, H., Brusa, M., et al. 2007, ApJS, 172, 1 [Google Scholar]
- Scoville, N., Lee, N., Bout, P. V., et al. 2017, ApJ, 837, 150 [NASA ADS] [CrossRef] [Google Scholar]
- Shapley, A. E. 2011, ARA&A, 49, 525 [NASA ADS] [CrossRef] [Google Scholar]
- Shirley, R., Roehlly, Y., Hurley, P. D., et al. 2019, MNRAS, 490, 634 [Google Scholar]
- Shirley, R., Duncan, K., Campos Varillas, M. C., et al. 2021, MNRAS, 507, 129 [NASA ADS] [CrossRef] [Google Scholar]
- Silva, L., Granato, G. L., Bressan, A., & Danese, L. 1998, ApJ, 509, 103 [Google Scholar]
- Simpson, J. M., Swinbank, A. M., Smail, I., et al. 2014, ApJ, 788, 125 [Google Scholar]
- Simpson, J. M., Smail, I., Swinbank, A. M., et al. 2017, ApJ, 839, 58 [NASA ADS] [CrossRef] [Google Scholar]
- Simpson, J. M., Smail, I., Dudzeviciute, U., et al. 2020, MNRAS, 495, 3409 [Google Scholar]
- Skilling, J. 2004, AIP Conf. Ser., 735 395 [Google Scholar]
- Skilling, J. 2006, Bayesian Anal., 1, 833 [Google Scholar]
- Smail, I., Dudzeviciute, U., Stach, S. M., et al. 2021, MNRAS, 502, 3426 [NASA ADS] [CrossRef] [Google Scholar]
- Smolcic, V., Delvecchio, I., Zamorani, G., et al. 2017, A&A, 602, A2 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Speagle, J. S. 2020, MNRAS, 493, 3132 [Google Scholar]
- Stroustrup, B. 2013, The C++ Programming Language (Pearson Education) [Google Scholar]
- Tacconi, L. J., Genzel, R., Saintonge, A., et al. 2018, ApJ, 853, 179 [Google Scholar]
- Tacconi, L. J., Genzel, R., & Sternberg, A. 2020, ARA&A, 58, 157 [NASA ADS] [CrossRef] [Google Scholar]
- Talia, M., Cimatti, A., Giulietti, M., et al. 2021, ApJ, 909, 23 [NASA ADS] [CrossRef] [Google Scholar]
- Targett, T. A., Dunlop, J. S., Cirasuolo, M., et al. 2013, MNRAS, 432, 2012 [NASA ADS] [CrossRef] [Google Scholar]
- Taylor, A. R., & Jarvis, M. 2017, in Materials Science and Engineering Conference Series, 198, 012014 [NASA ADS] [CrossRef] [Google Scholar]
- The Astropy Collaboration (Robitaille, T. P., et al.) 2013, A&A, 558, A33 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Van Rossum, G. 2007, in USENIX annual technical conference, Python Programming Language, 41, 1 [Google Scholar]
- Vega, O., Clemens, M. S., Bressan, A., et al. 2008, A&A, 484, 631 [NASA ADS] [CrossRef] [EDP Sciences] [Google Scholar]
- Vidal-García, A., Plat, A., Curtis-Lake, E., et al. 2024, MNRAS, 527, 7217 [Google Scholar]
- Virtanen, P., Gommers, R., Oliphant, T. E., et al. 2020, Nature Methods, 17, 261 [CrossRef] [Google Scholar]
- Walter, F., Decarli, R., Carilli, C., et al. 2012, Nature, 486, 233 [Google Scholar]
- Wang, T., Schreiber, C., Elbaz, D., et al. 2019, Nature, 572, 211 [Google Scholar]
- Yan, H., Ma, Z., Ling, C., Cheng, C., & Huang, J.-S. 2023, ApJ, 942, L9 [NASA ADS] [CrossRef] [Google Scholar]
- Yun, M. S., Scott, K. S., Guo, Y., et al. 2012, MNRAS, 420, 957 [NASA ADS] [CrossRef] [Google Scholar]
GalaPy can be installed from the Python Package Index: pypi.org/project/galapy-fit. The documentation is available at: galapy.readthedocs.io/en/latest/index.html
Detailed tutorials on customisation instructions are (and will be made) available in the project on-line documentation: galapy.readthedocs.io/en/latest/index.html
We also provide functionalities to convert eventual custom SSP libraries into the accepted format.
Even though we limit our discussion to the in situ SFH model, all the results can be also obtained using any other SFH model available in the library.
Specifically, when using PARSEC22 without nebular emission and radio-support is required, the system will automatically include the nebular free-free emission from Sect. 2.4.1 while, when using PAR-SEC22 with nebular emission and radio support is required, any source of stellar radio continuum is already present in the SSP and therefore the system will ignore the directive. Further details are given in Appendix B.1.
This choice is driven by the requirement to limit the number of external dependencies of GalaPy. See the online documentation for a complete list of available cosmological models and for instructions on how to use custom additional models not present in the database.
In case of energy counter detectors we make the replacement T(λ) → T(λ)/λ.
This hyper-parameters, including prior sizes, free model parameters and sampling strategy, can be set through the parameter-file generated calling the galapy-genparams command.
This argument also applies to the extreme case of a negative flux.
The prior bounds the algorithm to inspect only a finite region of the multidimensional parameters space, which would otherwise belong to RN, where N is the number of free parameters.
A value τquench ≥ 2 × 1010 Gyr is enough as it will always prove larger than the Age of the Universe at any epoch.
Besides the posterior/evidence split and stopping function mentioned in Sect. 3.2, we set a higher-bound stopping criterion corresponding to the maximum effective number of likelihood calls max(Neff) = 5 × 106. Our initial tolerance is set to 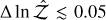 with an initial maximum number of iterations maxiter_init = 104. We then add iteratively 10 batches of new live-points with a maximum number of iterations per batch corresponding to maxiter_batch = 103. We use the multiple-ellipsoidal decomposition (Feroz et al. 2009) as bounding criterion.
with an initial maximum number of iterations maxiter_init = 104. We then add iteratively 10 batches of new live-points with a maximum number of iterations per batch corresponding to maxiter_batch = 103. We use the multiple-ellipsoidal decomposition (Feroz et al. 2009) as bounding criterion.
Available at dustpedia.astro.noa.gr. DustPedia is a collaborative focussed research project supported by the European Union under the Seventh Framework Programme (2007–2013) call (proposal no. 606847). The participating institutions are: Cardiff University, UK; National Observatory of Athens, Greece; Ghent University, Belgium; Université Paris Sud, France; National Institute for Astrophysics, Italy and CEA, France.
A truncated SFH that does not drop to zero after truncation allows to both assume an early stage bulk of star formation and a late time constant stellar mass growth. This would in turn be similar to the approach we propose for ETGs in Sect. 4.2.5, if after truncation a null SFR is assumed.
The same argument also applies to the other physical properties.
E.g. when assuming an interpolated SFH model, see Sect. 2.1.2.
Specifically at this link: prospect.readthedocs.io/faq section “How long will it take to fit my data” version v1.2.0.
GalaPy can also be installed from source by cloning the github repository: github.com/TommasoRonconi/galapy
Like those compiled with TopCat https://www.star.bris.ac.uk/mbt/topcat/
All Tables
All Figures
|
Fig. 1 Different models of star formation histories (SFH). Each coloured line shows the star formation rate ψ of a galaxy as a function of its age τ, according to empirical (constant SFR, Eq. (1), green; delayed exponential, Eq. (2) with κ = 1, red; log-normal, Eq. (3), yellow) and physically-motivated (In situ, Eq. (4): blue line) models. The vertical dotted line marks the age τquench of a possible abrupt quenching event; solid lines refer to the SFH of objects undergoing quenching, while dashed lines to the SFH of objects for which no quenching occurs. |
| In the text | |
|
Fig. 2 Evolution of the stellar mass M★ of a galaxy as a function of its age τ, for the SFH models shown in Fig. 1. |
| In the text | |
|
Fig. 3 Interpolated SFH model. Upper panel: SFR at different epochs as measured for a simulated galaxy (blue markers with errors) and our interpolated model (dashed grey line). Lower panel: evolution of the integrated stellar mass at different epochs (solid red line) resulting from the SFH interpolated from data in the upper panel. |
| In the text | |
|
Fig. 4 Evolution of various quantities according to the in situ SFH model. Left panel: stellar mass (Eqs. (4)–(5), red), gas mass (Eq. (10), blue) and dust mass (Eq. (11), green). Right panel: gas (blue) and stellar (green) metallicities (Eq. (14)). Linestyles as in Fig. 1. |
| In the text | |
|
Fig. 5 Comparison among the different simple stellar population libraries included in GalaPy: classic BC03 (blue), PARSEC22 without line emission (green), PARSEC22 with line emission (red). Linestyles refer to different metallicity as reported in legend. In all panels the approximate age of the stellar population is reported. In the top two panels we show SSPs from young stellar populations for whom the PARSEC22 models include the contribute of synchrotron (green models) as well as that of nebular emission (red models). |
| In the text | |
|
Fig. 6 Composite stellar populations as a function of the age, on assuming the in situ SFH (blue line of Fig. 1 with quenching at τ = 8 × 108 yr) and different single stellar population libraries (left: BC03; centre: PARSEC22 without nebular emission; right: PARSEC22 with nebular emission). |
| In the text | |
|
Fig. 7 Extinction laws adopted in GalaPy, normalised to the value in the V–band at 5500 Å, for diffuse dust (green) and dust in molecular clouds (blue). The extinction is modelled as a double powerlaw (see Eqs. (18)–(20)) with slope changing at around 100 μm (marked with a dotted line; the default values of the slopes are adopted in the plot (see Sect. 2.3 for details). |
| In the text | |
|
Fig. 8 Average fraction of stellar luminosity (see Eq. (27)) that is absorbed by MCs as a function of wavelength for galaxies of different age (colour-coded as in the legend). |
| In the text | |
|
Fig. 9 Overall attenuation curve at ages of 107 yr (dot-dashed, i.e. 0.5τesc), 5 × 108 yr (dashed, i.e. 10τesc), and 109 yr (solid, i.e. 20τesc), we include age effects and plot the value in units of the attenuation in the visible band (λV ≈ 5500 Å). We note that these values correspond to the blue, green and red lines of Fig. 8. Our attenuation curves are compared with Calzetti-like attenuation curves (dotted) for different values of the total-to-selective extinction ratio RV in the V–band (colour-coded). |
| In the text | |
|
Fig. 10 Impact of absorption from the two component dust models (molecular clouds, MC; diffuse dust, DD) implemented in GalaPy on the intrinsic stellar emission (dotted black line). Luminosity escaping from MCs is marked by a dashed black line, while the final stellar emission escaping MCs and DD is shown by a solid black line. The luminosity re-emitted in the IR bands is highlighted with a solid blue line for MCs and with a solid green line for the DD(+PAH) component. |
| In the text | |
|
Fig. 11 Behaviour of the two different dust components (molecular clouds, MC; diffuse dust, DD) as a function of galactic age in units of the characteristic escape time from molecular clouds τesc. We assume an in situ SFH as the blue line in Fig. 1 and set the characteristic escape time to 5 × 107 yr. Left panel: percentage of the intrinsic stellar luminosity absorbed by MC (blue), DD (green), and by both components (black). Right panel: temperature of the dust component computed from the age-dependent energy-conservation scheme implemented in GalaPy. The vertical dotted line marks the age, τquench = 8.8 × 108 yr, of a possible abrupt quenching event; solid lines refer to the evolution with quenching, dashed lines to that with no quenching. |
| In the text | |
|
Fig. 12 Additional stellar components contributing to the overall continuum emission in GalaPy: intrinsic (blue) and attenuated (green) free-free emission from nebular regions, synchrotron emission from SN (red), X-ray emission from high-mass and low-mass binary stars (yellow). For reference, the luminosity from attenuated stellar continuum and dust re-radiation, i.e. the sum of the solid lines in Fig. 11, is also reported (dashed black). |
| In the text | |
|
Fig. 13 Overall IGM transmission functions predicted by Inoue et al. (2014) for different values of redshift (colour-coded). |
| In the text | |
|
Fig. 14 Same as Fig. 15 for the mock observation of the passively evolving simulated galaxies of Sect. 4.1. |
| In the text | |
|
Fig. 15 Photometric system used to generate the mock observation for the actively star-forming simulated galaxies of Sect. 4.1. The lower x-axis shows the keyword name of the band-pass transmission while the upper x-axis shows the corresponding wavelength in angstroms. Transmissions are expressed in terms of photons and the dashed lines mark the position of the pivot wavelength for each band-pass filter. We note that this is just a possible set-up specific to the case of the mock galaxy of Sect. 4.1. It represents only a sub-set of the band-pass transmissions available in the GalaPy database. |
| In the text | |
|
Fig. 16 Distribution of the reduced χ2 for the best-fitting parameters of the two sets of sources (with and without spectroscopic redshift in dashed green and solid blue, respectively), as obtained by sampling the free-parameter space with dynesty. |
| In the text | |
|
Fig. 17 Results for some of the free and derived parameters obtained by fitting with GalaPy the mock observation set generated without spectroscopic redshift detection (see Sect. 4.1). The results are presented in terms of the ratio between the median value of the weighted samples collected by running the dynesty sampler. Errors are given in terms of the 16th and 84th percentiles, defining a 68% credible interval around the median, as detailed in Sect. 3.4. Blue circles, green upward triangles and red squares are actively star-forming sources modelled with an in situ, delayed exponential and constant SFH model, respectively. Violet crosses and yellow downward triangles are instead passively evolving sources modelled with an in situ and delayed exponential SFH model, respectively. |
| In the text | |
|
Fig. 18 Results of the parameters sampling for one of the mock observation of Sect. 4.1. Upper panel: best-fit SED (black solid line) and components (coloured lines) compared to the mock observation data (empty blue markers); 1-σ and 2-σ confidence around the mean of the samples is also shown with grey shaded areas. Lower panel: residuals with respect to the best-fit sample (black); mean and 1-/2-σ confidence regions are also shown with a grey solid line and shaded areas, respectively. |
| In the text | |
|
Fig. 19 Corner plot of the parameter posteriors obtained for the mock galaxy selected in Sect. 4.1.2, illustrating the one- and two-dimensional marginalised posteriors for a subset of the parameter space dimensions (for clarity and visualisation reasons). The shaded grey regions highlight (68%, 95%) confidence from darker to lighter, corresponding to (1-σ, 2-σ). The dashed black lines mark the position of the weighted median value of parameters while the values above the diagonal panels show the median and 68% percentile around the median (roughly corresponding to 1-σ confidence in a Gaussian approximation). As a term of comparison, we also show mark, with orange solid lines, the real value of each parameter. |
| In the text | |
 |
Fig. 20 Same as Fig. 19 for a sub-set of the derived parameters reported in Fig. 17. |
| In the text | |
|
Fig. 21 Results for the four dusty star forming galaxies of Sect. 4.2.1 Upper panels: GalaPy fits to the photometric data of four galaxies selected from the Pantoni et al. (2021) sample (blue markers with error-bars). Best-fitting model (black solid line), different components (colour-coded as in legend), and 1- and 2-σ confidence levels (grey shaded regions) around the mean of the samples are also shown. Lower panels: Standardised residuals with respect to the best-fitting galaxy models, and 1-/2-σ confidence intervals around the mean of the samples (grey shaded regions) are shown; the reduced χ2 of the fit is reported in each sub-panel. |
| In the text | |
|
Fig. 22 Average attenuation curves (black solid line) predicted by GalaPy in the best-fitting models for the 4 galaxies of P21, normalised to the average value of attenuation in the V–band (≈ 5500 Å). For reference, we also show Calzetti-like empirical attenuation curves for different values of the Rv parameter (colour-coded). |
| In the text | |
|
Fig. 23 Same as Fig. 21 for the Dustpedia sample of Sect. 4.2.2. |
| In the text | |
|
Fig. 24 Same as Fig. 21 for the J1135 lensed galaxy of Sect. 4.2.3. |
| In the text | |
|
Fig. 25 Same as Fig. 21 for the median of Sect. 4.2.4. |
| In the text | |
|
Fig. 26 Same as Fig. 21 for the quiescent sample of Sect. 4.2.5. |
| In the text | |
|
Fig. 27 Relative difference of photometric redshift estimated with GalaPy against the real spectroscopic values for the four dusty star-forming galaxies of the Pantoni et al. (2021) sample (green squares), the three quiescent galaxies of the Donevski et al. (2023) sample (blue circles), and the lensed galaxy with upper limits from (Giulietti et al. 2023, red triangle). Markers with error bars trace the median and 68% credible interval of the samples. |
| In the text | |
|
Fig. A.1 Dependency of SSP integration performances on the 3-dimensional matrix ordering. Different colours mark different orderings, as reported in the legend. Each panel shows how the integration time changes as a function of one of the three model parameters on which Eq. (A.1) depends. |
| In the text | |
|
Fig. A.2 Likelihoods generated per second with GalaPy as a function of the wavelength grid resolution. The dashed line marks the average over 1000 measurements and the shaded region highlights the 1-σ confidence intervals. |
| In the text | |
|
Fig. B.1 Logarithm of the ratio between CSPs obtained with different SSP libraries at fixed SFH and age. The left panel shows the ratio between PARSEC22 and BC03 while the right panel shows the ratio between PARSEC22 with and without lines. |
| In the text | |
|
Fig. C.1 Version 1.0.0 of the GalaPy logo. We encourage authors presenting results obtained with GalaPy to add their preferred version of the logo in public presentations. A variety of formats is available on the website and in the data-base. |
| In the text | |
Current usage metrics show cumulative count of Article Views (full-text article views including HTML views, PDF and ePub downloads, according to the available data) and Abstracts Views on Vision4Press platform.
Data correspond to usage on the plateform after 2015. The current usage metrics is available 48-96 hours after online publication and is updated daily on week days.
Initial download of the metrics may take a while.